Версия статьи с диаграммами под Flash 4
Казалось бы не так уж и давно вышел Pentium 4 2,8 ГГц, но неугомонная компания Intel видать настолько горда способностью своего нового процессорного ядра к постоянному «разгону», что не дает нам покоя анонсами все новых и новых процессоров :). Однако сегодняшний наш герой отличается от предыдущей топовой модели не только на 200 с небольшим мегагерц — то, о чем давно мечтали некоторые особо продвинутые пользователи, наконец-то свершилось: технология эмуляции двух процессоров на одном процессорном ядре, ранее бывшая достоянием лишь сверхдорогих Xeon, наконец-то «освобождена» и отправлена в «свободное десктопное плавание». Хотите двухпроцессорный домашний компьютер? Их есть у нас! Все последующие модели Pentium 4, начиная с рассматриваемой в этом материале, будут обладать поддержкой Hyper-Threading. Однако кто-то может вполне резонно поинтересоваться: «А зачем мне двухпроцессорная машина дома? У меня же не сервер какой-нибудь!». И действительно — зачем? Именно это мы и постарались объяснить ниже. Итак: Hyper-Threading — что это такое и зачем он может быть нужен в обычных персональных компьютерах?
SMP и Hyper-Threading: «галопом по европам»
Для начала, давайте сделаем вид, что начинаем «с чистого листа» т. е. механизмы функционирования многопроцессорных систем нам неизвестны. Мы не собираемся начинать данной статьей цикл монографий, посвященных этому вопросу :), поэтому сложных моментов, связанных, к примеру, с виртуализацией прерываний и прочими вещами, трогать не будем. Фактически, нам нужно просто представлять как работает классическая SMP(Symmetric Multi-Processor)-система с точки зрения обычной логики. Нужно это хотя бы потому, что не так уж велико количество пользователей, хорошо себе представляющих как работает SMP-система, и в каких случаях от использования двух процессоров вместо одного можно ожидать реального увеличения быстродействия, а в каких — нет. Честное слово, один из авторов этого материала как-то угробил часа полтора времени, доказывая своему, скажем так, «не бедному» другу, что Unreal Tournament у него на многопроцессорной машине будет работать ничуть не быстрее, чем на обычной :). Смешно? Уверяю вас — только со стороны. Итак, представим, что у нас есть, к примеру, два процессора (остановимся на этом, самом простом примере) вместо одного. Что это нам дает?
В общем-то… ничего. Потому что в дополнение к этому нам нужна еще и операционная система, умеющая эти два процессора задействовать. Система эта должна быть по определению многозадачной (иначе никакого смысла в наличии двух CPU просто быть не может), но кроме этого, ее ядро должно уметь распараллеливать вычисления на несколько CPU. Классическим примером многозадачной ОС, которая этого делать не умеет, являются все ОС от Microsoft, называемые обычно для краткости «Windows 9x» — 95, 95OSR2, 98, 98SE, Me. Они просто-напросто не могут определить наличие более чем одного процессора в системе… ну и, собственно, дальше объяснять уже нечего :). Поддержкой SMP обладают ОС этого же производителя, построенные на ядре NT: Windows NT 4, Windows 2000, Windows XP. Также в силу своих корней, этой поддержкой обладают все ОС, основанные на идеологии Unix — всевозможные Free- Net- BSD, коммерческие Unix (такие как Solaris, HP-UX, AIX), и многочисленные разновидности Linux. Да, к слову — MS DOS многопроцессорность в общем случае тоже «не понимает» :).
Если же два процессора все же определились системой, то дальнейший механизм их задействования в общем-то (на «логическом», подчеркнем, уровне!) довольно-таки прост. Если в данный момент времени исполняется одно приложение — то все ресурсы одного процессора будут отданы ему, второй же будет просто простаивать. Если приложений стало два — второе будет отдано на исполнение второму CPU, так что по идее скорость выполнения первого уменьшиться не должна вообще никак. Это в примитиве. Однако на самом деле все сложнее. Для начала: исполняемое пользовательское приложение у нас может быть запущено всего одно, но количество процессов (т. е. фрагментов машинного кода, предназначенных для выполнения некой задачи) в многозадачной ОС всегда намного больше. Начнем с того, что сама ОС — это тоже приложение… ну и не будем углубляться — логика понятна. Поэтому на самом деле второй CPU способен немного «помочь» даже одиночной задаче, взяв на себя обслуживание процессов, порожденных операционной системой. Опять-таки, к слову об упрощениях — именно так, идеально, разделить CPU между пользовательским приложением и ОС, конечно, все равно не получится, но, по крайней мере, процессор, занятый исполнением «полезной» задачи, будет меньше отвлекаться.
Кроме того, даже одно приложение может порождать потоки (threads), которые при наличии нескольких CPU могут исполняться на них по отдельности. Так, например, поступают почти все программы рендеринга — они специально писались с учетом возможности работы на многопроцессорных системах. Поэтому в случае использования потоков выигрыш от SMP иногда довольно весом даже в «однозадачной» ситуации. По сути, поток отличается от процесса только двумя вещами — он во-первых никогда не порождается пользователем (процесс может запустить как система, так и человек, в последнем случае процесс = приложение; появление потока инициируется исключительно запущенным процессом), и во-вторых — поток умирает вместе с родительским процессом независимо от своего желания — к примеру, если родительский процесс «глюкнул и упал» — все порожденные им потоки ОС считает бесхозными и «прибивает» уже сама, автоматически.
Также не стоит забывать, что в классической SMP-системе оба процессора работают каждый со своим кэшем и набором регистров, но память у них общая. Поэтому если две задачи одновременно работают с ОЗУ, мешать они друг другу будут все равно, даже если CPU у каждой «свой собственный». Ну и наконец последнее: в реальности мы имеем дело не с одним, не с двумя, и даже не с тремя процессами. На приведенном коллаже (это действительно коллаж, потому что со скриншота Task Manager были удалены все пользовательские процессы, т. е. приложения, запускаемые «для работы») хорошо видно, что «голая» Windows XP, сама по себе, не запустив еще ни одного приложения, уже породила 12 процессов, причем многие из них к тому же еще и многопоточные, и общее количество потоков достигает двухсот восьми штук (!!!).
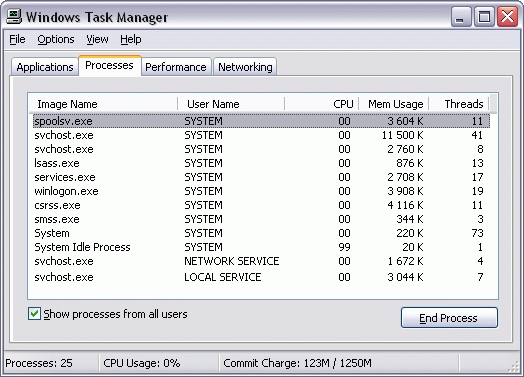
Поэтому рассчитывать на то, что нам удастся прийти к схеме «по собственному CPU на каждую задачу» совершенно не приходится, и переключаться между фрагментами кода процессоры будут все равно — и физические, и виртуальные, и будь они хоть виртуальные в квадрате и по 10 штук на каждое физическое ядро :). Впрочем, на самом деле все не так грустно — при грамотно написанном коде ничего в данный момент не делающий процесс (или поток) процессорного времени практически не занимает (это тоже видно на коллаже).
Теперь, разобравшись с «физической» многопроцессорностью, перейдем к Hyper-Threading. Фактически — это тоже многопроцессорность, только… виртуальная. Ибо процессор Pentium 4 на самом деле один — вот он, стоит в сокете, сверху кулер пришлепнут :). Второго сокета — нет. А процессоров ОС видит — два. Как это? В общем-то, очень просто. Смотрим на рисунок.
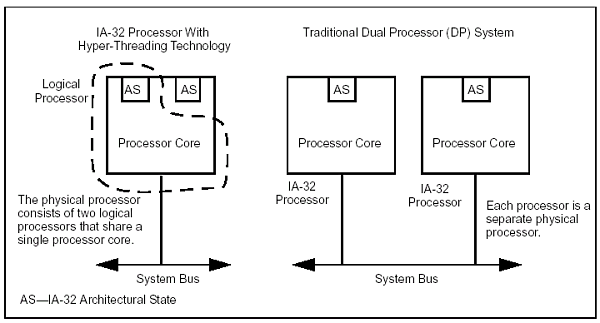
Здесь нам придется все-таки немного углубиться в технические детали, потому что иначе, увы, что-либо объяснить не получится. Впрочем, те, кому оные детали неинтересны, могут данный абзац просто пропустить. Итак, классическому «одноядерному» процессору в нашем случае добавили еще один блок AS — IA-32 Architectural State. Architectural State содержит состояние регистров (общего назначения, управляющих, APIC, служебных). Фактически, AS#1 плюс единственное физическое ядро (блоки предсказания ветвлений, ALU, FPU, SIMD-блоки и пр.) представляет из себя один логический процессор (LP1), а AS#2 плюс все то же физическое ядро — второй логический процессор (LP2). У каждого LP есть свой собственный контроллер прерываний (APIC — Advanced Programmable Interrupt Controller) и набор регистров. Для корректного использования регистров двумя LP существует специальная таблица — RAT (Register Alias Table), согласно данным в которой можно установить соответствие между регистрами общего назначения физического CPU. RAT у каждого LP своя. В результате мы получили схему, при которой на одном и том же ядре могут свободно выполняться два независимых фрагмента кода т. е. де-факто — многопроцессорную систему!
Hyper-Threading: совместимость
Кроме того, возвращаясь к вещам практическим и приземленным, хотелось бы затронуть еще один немаловажный аспект: не все ОС, даже поддерживающие многопроцессорность, могут работать с таким CPU как с двумя. Связано это с таким «тонким» моментом, как изначальное определение количества процессоров при инициализации операционной системы. Intel прямо говорит, что ОС без поддержки ACPI второй логический процессор увидеть не смогут. Кроме того, BIOS системной платы также должен уметь определять наличие процессора с поддержкой Hyper-Threading и соответствующим образом «рапортовать» системе. Фактически, применительно, к примеру, к Windows, это означает, что «в пролете» у нас оказывается не только линейка Windows 9x, но и Windows NT — последняя ввиду отсутствия поддержки ACPI не сможет работать с одним новым Pentium 4 как с двумя. А вот что приятно — это то, что несмотря на заблокированную возможность работы с двумя физическими процессорами, с двумя логическими, получаемыми с помощью Hyper-Threading, сможет работать Windows XP Home Edition. А Windows XP Professional, кстати, несмотря на ограничение количества физических процессоров до двух, при двух установленных CPU с поддержкой Hyper-Threading честно «видит» четыре :).
Теперь немного о «железе». То, что новые CPU с частотой более 3 ГГц могут потребовать замены системной платы, знают, наверное, уже все — земля (а точнее — Internet) слухами полнится уже давно. К сожалению, это на самом деле так. Даже при номинальном сохранении все того же процессорного разъема Socket 478 Intel не удалось оставить в неприкосновенности потребляемую мощность и тепловыделение новых процессоров — потребляют они больше, и греются, соответственно, тоже. Можно предположить (хоть это и не подтверждено официально), что увеличение потребления по току связано не только с ростом частоты, но и с тем, что из-за ожидаемого использования «виртуальной многопроцессорности» нагрузка на ядро в среднем вырастет, следовательно, возрастет и средняя потребляемая мощность. «Старые» системные платы в некоторых случаях могут быть совместимы с новыми CPU — но только если делались «с запасом». Грубо говоря, те производители, которые делали свои PCB в соответствии с рекомендациями самой Intel относительно потребляемой Pentium 4 мощности, оказались в проигрыше по отношению к тем, кто немного «перестраховался», поставив на плату VRM с запасом и соответствующим образом ее разведя. Но и это еще не все. Кроме ОС, BIOS и электроники платы, с технологией Hyper-Threading должен быть совместим еще и чипсет. Поэтому счастливыми обладателями двух процессоров по цене одного :) смогут стать только те, чья системная плата основана на одном из новых чипсетов с поддержкой 533 МГц FSB: i850E, i845E, i845PE/GE. Несколько особняком стоит i845G — первая ревизия этого набора микросхем Hyper-Threading не поддерживает, более поздняя — уже совместима.
Ну, вот, вроде бы с теорией и совместимостью разобрались. Но не будем спешить. ОК, у нас есть два «логических» процессора, у нас есть Hyper-Threading, вау! — это круто. Но как уже было сказано выше, физически у нас процессор как был один, так и остался. Зачем же тогда нужна такая сложная «эмуляционная» технология, отбрасывая то, что можно горделиво демонстрировать Task Manager с графиками загруженности двух CPU друзьям и знакомым?
Hyper-Threading: зачем она нужна?
Против обыкновения, в этой статье мы немного больше чем обычно уделим внимания рассуждениям т. е. не технической прозе (где все в общем-то довольно однозначно трактуется и на основании одних и тех же результатов совершенно независимые люди чаще всего делают тем не менее весьма похожие выводы), а «технической лирике» — т. е. попытке понять, что же такое нам предлагает Intel и как к этому следует относиться. Я уже неоднократно писал в «Колонке редактора» на нашем сайте, и повторю здесь, что эта компания, если внимательно посмотреть, никогда не отличалась абсолютным совершенством своих продуктов, более того — вариации на те же темы от других производителей подчас получались гораздо более интересными и концептуально стройными. Однако, как оказалось, абсолютно все делать совершенным и не нужно — главное чтобы чип олицетворял собой какую-то идею, и идея эта приходилась очень вовремя и к месту. И еще — чтобы ее просто не было у других.
Так было с Pentium, когда Intel противопоставила весьма шустрому в «целочисленке» AMD Am5x86 мощный FPU. Так было с Pentium II, который получил толстую шину и быстрый кэш второго уровня, благодаря чему за ним так и не смогли угнаться все процессоры Socket 7. Так было (ну, по крайней мере, я считаю это свершившимся фактом) и с Pentium 4, который противопоставил всем остальным наличие поддержки SSE2 и быстрый рост частоты — и тоже де-факто выиграл. Сейчас Intel предлагает нам Hyper-Threading. И мы отнюдь не призываем в священной истерике биться лбом о стенку и кричать «господи помилуй», «аллах велик» или «Intel rulez forever». Нет, мы просто предлагаем задуматься — почему производитель, известный грамотностью своих инженеров (ни слова про маркетологов! :)) и громадными суммами, которые он тратит на исследования, предлагает нам эту технологию.
Объявить Hyper-Threading «очередной маркетинговой штучкой», конечно, проще простого. Однако не стоит забывать, что это технология, она требует исследований, денег на разработку, времени, сил… Не проще ли было нанять за меньшую сумму еще одну сотню PR-менеджеров или сделать еще десяток красивых рекламных роликов? Видимо, не проще. А значит, «что-то в этом есть». Вот мы сейчас и попытаемся понять даже не то, что получилось в результате, а то, чем руководствовались разработчики IAG (Intel Architecture Group), когда принимали решение (а такое решение наверняка принималось!) — разрабатывать «эту интересную мысль» дальше, или отложить в сундук для идей забавных, но бесполезных.
Как ни странно, для того чтобы понять как функционирует Hyper-Threading, вполне достаточно понимать как работает… любая многозадачная операционная система. И действительно — ну ведь исполняет же каким-то образом один процессор сразу десятки задач? Этот «секрет» всем уже давно известен — на самом деле одновременно все равно выполняется только одна (на однопроцессорной системе), просто переключение между кусками кода разных задач выполняется настолько быстро, что создается иллюзия одновременной работы большого количества приложений.
По сути, Hyper-Threading предлагает нам то же самое, но реализована аппаратно, внутри самого CPU. Есть некоторое количество различных исполняющих блоков (ALU, MMU, FPU, SIMD), и есть два «одновременно» исполняемых фрагмента кода. Специальный блок отслеживает, какие команды из каждого фрагмента необходимо выполнить в данный момент, после чего проверяет, загружены ли работой все исполняющие блоки процессора. Если один из них простаивает, и именно он может исполнить эту команду — ему она и передается. Естественно, существует и механизм принудительного «посыла» команды на выполнение — в противном случае один процесс мог бы захватить весь процессор (все исполняющие блоки) и исполнение второго участка кода (исполняемого на втором «виртуальном CPU») было бы прервано. Насколько мы поняли, данный механизм (пока?) не является интеллектуальным т. е. не способен оперировать различными приоритетами, а просто чередует команды из двух разных цепочек в порядке живой очереди т. е. просто по принципу «я твою команду исполнил — теперь уступи место другому потоку». Если, конечно, не возникает ситуации, когда команды одной цепочки по исполняющим блокам нигде не конкурируют с командами другой. В этом случае мы получаем действительно на 100% параллельное исполнение двух фрагментов кода.
Теперь давайте подумаем, чем Hyper-Threading потенциально хороша, и чем — нет. Самое очевидное следствие ее применения — повышение коэффициента полезного действия процессора. Действительно — если одна из программ использует в основном целочисленную арифметику, а вторая — выполняет вычисления с плавающей точкой, то во время исполнения первой FPU просто ничего не делает, а во время исполнения второй — наоборот, ничего не делает ALU. Казалось бы, на этом можно закончить. Однако мы рассмотрели лишь идеальный (с точки зрения применения Hyper-Threading) вариант. Давайте теперь рассмотрим другой: обе программы задействуют одни и те же блоки процессора. Понятно, что ускорить выполнение в данном случае довольно сложно — ибо физическое количество исполняющих блоков от «виртуализации» не изменилось. А вот не замедлится ли оно? Давайте разберемся. В случае с процессором без Hyper-Threading мы имеем просто «честное» поочередное выполнение двух программ на одном ядре с арбитром в виде операционной системы (которая сама представляет собой еще одну программу), и общее время их работы определяется:
- временем выполнения кода программы №1
- временем выполнения кода программы №2
- временными издержками на переключение между фрагментами кода программ №1 и №2
Что мы имеем в случае с Hyper-Threading? Схема становится немного другой:
- время выполнения программы №1 на процессоре №1 (виртуальном)
- время выполнения программы №2 на процессоре №2 (виртуальном)
- время на переключение одного физического ядра (как набора требуемых обеим программам исполняющих блоков) между двумя эмулируемыми «виртуальными CPU»
Остается признать, что и тут Intel поступает вполне логично: конкурируют между собой по быстродействию у нас только пункты за номером три, и если в первом случае действие выполняется программно-аппаратно (ОС управляет переключением между потоками, задействуя для этого функции процессора), то во втором случае мы фактически имеем полностью аппаратное решение — процессор все делает сам. Теоретически, аппаратное решение всегда оказывается быстрее. Подчеркнем — теоретически. Практикум у нас еще впереди.
Но и это еще не все. Также одним из серьезнейших… нет, не недостатков, а скорее, неприятных моментов является то, что команды, увы, не исполняются в безвоздушном пространстве, но вместо этого Pentium 4 приходится иметь дело с классическим x86-кодом, в котором активно используется прямое адресование ячеек и даже целых массивов, находящихся за пределами процессора — в ОЗУ. Да и вообще, к слову, большинство обрабатываемых данных чаще всего находится там :). Поэтому «драться» между собой наши виртуальные CPU будут не только за регистры, но и за общую для обоих процессорную шину, минуя которую данные в CPU попасть просто не могут. Однако тут есть один тонкий момент: на сегодняшний день «честные» двухпроцессорные системы на Pentium III и Xeon находятся в точно такой же ситуации! Ибо наша старая добрая шина AGTL+, доставшаяся в наследство всем сегодняшним процессорам Intel от знаменитого Pentium Pro (в дальнейшем ее лишь подвергали модификациям, но идеологию практически не трогали) — ВСЕГДА ОДНА, сколько бы CPU ни было установлено в системе. Вот такой вот «процессорный коаксиал» :). Отойти от этой схемы на x86 попробовала только AMD со своим Athlon MP — у AMD 760MP/760MPX от каждого процессора к северному мосту чипсета идет отдельная шина. Впрочем, даже в таком «продвинутом» варианте мы все равно убегаем от проблем не очень далеко — ибо уж что-что, а шина памяти у нас точно одна — причем вот в этом случае уже везде (напоминаем, разговор идет про x86-системы).
Однако нет худа без добра, и даже из этого в общем-то не очень приятного момента Hyper-Threading может помочь извлечь какую-то пользу. Дело в том, что по идее мы должны будем наблюдать существенный прирост производительности не только в случае с несколькими задачами, использующими разные функциональные блоки процессора, но и в том случае, если задачи по-разному работают с данными, находящимися в ОЗУ. Возвращаясь к старому примеру в новом качестве — если одно приложение у нас что-то усиленно считает «внутри себя», другое же — постоянно подкачивает данные из ОЗУ, то общее время выполнения их в случае использования Hyper-Threading по идее должно уменьшиться даже если они используют одинаковые блоки исполнения инструкций — хотя бы потому, что команды на чтение данных из памяти смогут обрабатываться в то время, пока наше первое приложение будет что-то усиленно считать.
Итак, подведем итог: технология Hyper-Threading с теоретической точки зрения выглядит весьма неплохо и, мы бы сказали, «адекватно», т. е. соответствует реалиям сегодняшнего дня. Уже довольно редко можно застать пользователя с одним сиротливо открытым окном на экране — всем хочется одновременно и музыку слушать, и по Internet бродить, и диски с любимыми MP3 записывать, а может даже, и поиграть на этом фоне в какую-нибудь стрелялку или стратегию, которые, как известно, процессор «любят» ну просто со страшной силой :). С другой стороны, общеизвестно, что конкретная реализация способна иногда своей «кривизной» убить любую самую превосходную идею, и с этим мы тоже не раз встречались на практике. Поэтому закончив с теорией, перейдем к практике — тестам. Они-то и должны нам помочь ответить на второй главный вопрос: так ли хороша Hyper-Threading сейчас — и уже не в качестве идеи, а в качестве конкретной реализации этой идеи «в кремнии».
Тестирование
Тестовый стенд:
- Процессор: Intel Pentium 4 3,06 ГГц с поддержкой технологии Hyper-Threading, Socket 478


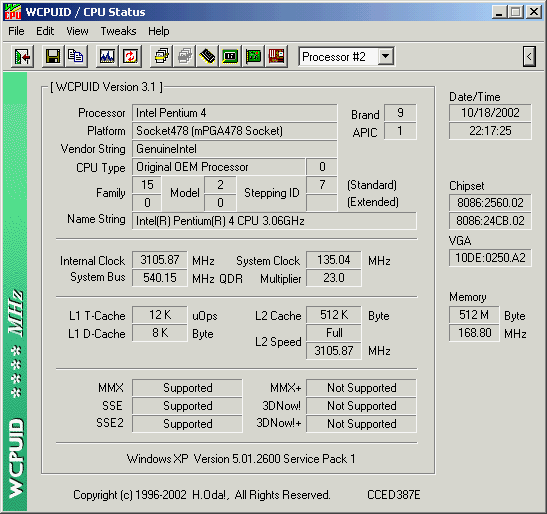
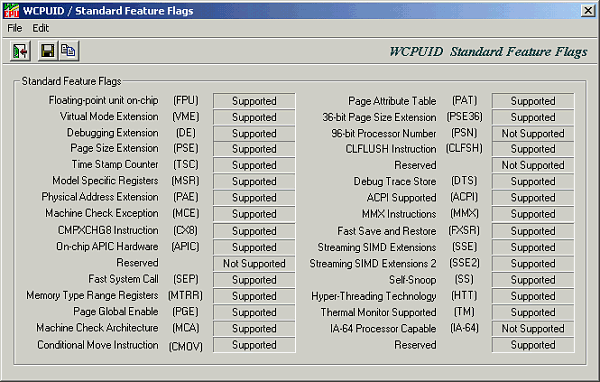
[ wcpuid p4 w/ht cpu1 ] [ wcpuid p4 w/ht cpu2 ] [ wcpuid p4 w/ht flags ]
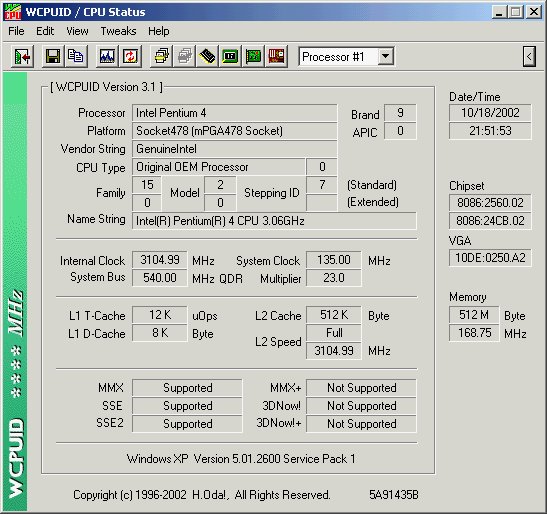
[ wcpuid p4 wo/ht ] [ wcpuid p4 wo/ht flags ]
- Материнская плата: Gigabyte 8PE667 Ultra (версия BIOS F3) на чипсете i845PE
- Память: 512 МБ PC2700(DDR333) DDR SDRAM DIMM Samsung, CL 2
- Видеокарта: Palit Daytona GeForce4 Ti 4600
- Жесткий диск: IBM IC35L040AVER07-0, 7200 об/мин
Программное обеспечение:
- OC и драйверы:
- Windows XP Professional SP1
- DirectX 8.1b
- Intel Chipset Software Installation Utility 4.04.1007
- Intel Application Accelerator 2.2.2
- Audiodrivers 3.32
- NVIDIA Detonator XP 40.72 (VSync=Off)
- Тестовые приложения:
- CPU RightMark 2002.B (с поддержкой мультипроцессорности и технологии Hyper-Threading)
- RazorLame 1.1.5.1342 + Lame codec 3.92
- VirtualDub 1.4.10 + DivX codec 5.02 Pro
- WinAce 2.2
- Discreet 3ds max 4.26
- BAPCo & MadOnion SYSmark 2002
- MadOnion 3DMark 2001 SE build 330
- Gray Matter Studios & Nerve Software Return to Castle Wolfenstein v1.1
- Croteam/GodGames Serious Sam: The Second Encounter v1.07
Вопреки обычаю, мы не будем сегодня тестировать производительность нового Pentium 4 3,06 ГГц в сопоставлении с предыдущими моделями или же с процессорами-конкурентами. Ибо это по большому счету бессмысленно. Тесты, составляющие нашу методику, не менялись уже довольно продолжительный период времени, и желающие провести необходимые сопоставления могут воспользоваться данными из предыдущих материалов, мы же сосредоточимся на основном моменте, не распыляясь на детали. А основным в этом материале, как, наверное, нетрудно догадаться, является исследование технологии Hyper-Threading и ее влияния на производительность… на производительность чего? Не столь уж и праздный вопрос, как оказывается. Впрочем, не будем забегать вперед. Начнем с традиционных тестов, через которые мы плавно подойдем (в контексте данного материала) к основным.
Кодирование WAV в MP3 (Lame)
Кодирование VideoCD в MPEG4 (DivX)
Архивация с помощью WinAce с 4-мегабайтным словарем
Хоть сколько-нибудь явного преимущества Hyper-Threading не продемонстрировала, но надо сказать, что мы и шансов-то особых данной технологии не дали — почти все приложения «однопроцессорные», одновременно исполняемых потоков не порождают (проверено!), и, стало быть, в этих случаях мы имеем дело с обычным Pentium 4, которому чуть-чуть подняли частоту. Говорить о каких-то тенденциях на фоне таких мизерных расхождений вряд ли уместно… хотя если все же высасывать их из пальца, то они даже немного в пользу Hyper-Threading.
3ds max 4.26
Классический тест, но в то же самое время — первое из приложений в этом обзоре, которое в явном виде поддерживает многопроцессорность. Конечно, колоссальным преимущество системы с включенной поддержкой Hyper-Threading не назовешь (оно составляет порядка 3%), однако не будем забывать, что в данном случае Hyper-Threading работала далеко не в самой лучшей для себя ситуации: 3ds max реализует поддержку SMP за счет порождения потоков, причем все они используются для одной и той же цели (рендеринг сцены) и, стало быть, содержат примерно одинаковые команды, а потому и работают тоже одинаково (по одной схеме). Мы уже писали, что Hyper-Threading лучше подходит для того случая, когда параллельно исполняются разные программы, задействующие разные блоки CPU. Тем более приятно, что даже в такой ситуации технология смогла «на ровном месте» обеспечить пусть и небольшой, но прирост быстродействия. Ходят слухи, что 3ds max 5.0 дает больший выигрыш при задействовании Hyper-Threading, и учитывая рвение, с которым Intel «проталкивает» свои технологии в области ведения производителей ПО, это как минимум следует проверить. Несомненно, так мы и сделаем, но уже в более поздних материалах на эту тему.
3DMark 2001SE
Результаты в общем-то вполне закономерные, и вряд ли могут вызвать у кого-то удивление. Быть может, лучше все-таки использовать бенчмарки для 3D именно для того, для чего они предназначены — тестирования скорости видеокарт, а не процессоров? Наверное, так оно и есть. Впрочем, результаты, как известно, лишними не бывают. Несколько настораживает чуть меньший балл у системы с задействованной Hyper-Threading. Впрочем, учитывая что разница составляет около 1%, мы бы не делали из этого далеко идущих выводов.
Return to Castle Wolfenstein,
Serious Sam: The Second Encounter
Примерно аналогичная ситуация. Впрочем, мы еще не подобрались даже близко к тестам, способным хоть как-то продемонстрировать плюсы (или минусы) Hyper-Threading. Иногда (на неощутимо малую величину) задействование «псевдо-многопроцессорности» дает отрицательный результат. Однако это не те сенсации, которых мы ждем, не так ли? :) Не слишком помогает даже тестирование со звуком, который, по идее, должен обсчитываться отдельным потоком и потому давать шанс проявить себя второму логическому процессору.
SYSmark 2002 (Office Productivity и Internet Content Creation)
А вот теперь так и хочется во весь голос крикнуть: «Ну, кто сомневался в том, что Hyper-Threading реально способна повысить быстродействие на реальных задачах?!». Результат: +16—20% — действительно ошеломляет. Причем что самое интересное — ведь SYSmark пытается эмулировать именно ту схему работы, которую Intel считает самой «удачной» для технологии Hyper-Threading — запуск различных приложений и одновременная работа с ними. Причем в процессе исполнения своего скрипта, SYSmark 2002 поступает вполне грамотно с точки зрения имитации работы пользователя, «отправляя в background» некоторые приложения, которые уже получили свое «долгосрочное задание». Так, например, кодирование видео происходит на фоне исполнения прочих приложений из скрипта Internet Content Creation, а в офисном подтесте действует вездесущее антивирусное ПО и декодирование речи в текст с помощью Dragon Naturally Speaking. По сути — первый тест, в котором созданы более или менее «вольготные» условия для технологии Hyper-Threading, и она тут же показала себя с наилучшей стороны! Впрочем, мы решили не полагаться во всем на тесты, написанные не нами, и провели «для закрепления эффекта» несколько показательных собственных экспериментов.
Экспериментируем с Hyper-Threading
Одновременное выполнение рендеринга в 3ds max и архивирования в WinAce
Вначале на фоне заведомо более длительного процесса архивирования была отрендерена стандартная тестовая сцена в 3ds max. Затем на фоне рендеринга специально растянутой сцены было выполнено стандартное тестовое архивирование файла в WinAce. Результат сравнивался со временем окончания последовательного выполнения тех же самых стандартных тестов. К полученным цифрам применялись два корректирующих коэффициента: для выравнивания времени исполнения заданий (мы полагаем, что эффект ускорения от параллельного выполнения двух приложений может быть корректно подсчитан только при условии одинаковой продолжительности выполняемых заданий) и для «снятия» эффекта от неравномерности выделяемых процессорных ресурсов для foreground-/background-приложений. В итоге мы «насчитали» положительный эффект ускорения на 17% от использования технологии Hyper-Threading.
Итак, впечатляющие результаты SYSmark получили подтверждение в тесте с соседством двух реальных программ. Конечно же, ускорение не двукратное, да и тесты в пару мы выбирали сами, исходя из наиболее благоприятной, по нашему мнению, ситуации для задействования Hyper-Threading. Но давайте задумаемся над этими результатами вот в каком разрезе: процессор, производительность которого мы сейчас исследуем — в общем-то, за исключением поддержки Hyper-Threading — просто давно привычный Pentium 4. Фактически, столбик «без Hyper-Threading» — это то, что мы могли бы видеть если бы эту технологию не стали переводить в десктопы. Несколько другое чувство сразу же возникает, правда? Давайте все-таки не будем жаловаться (по отечественной традиции) на то, что «все не так хорошо, как могло бы быть», а просто подумаем о том, что нам вместе с новым процессором дали еще один способ ускорить выполнение некоторых операций.
Фоновое архивирование в WinAce + проигрывание фильма
Рендеринг в 3ds max + фоновое проигрывание музыки
Методика выполнения теста совершенно тривиальна: в пару к просмотру фильма, сжатого предварительно в формат MPEG4 при помощи кодека DivX, фоном запускалось архивирование в WinAce (разумеется, в случае пропуска кадров и подтормаживания при просмотре, данный тест не имел бы практического смысла, но нареканий на качество просмотра не было). Аналогично, во время рендеринга обычной тестовой сцены в 3ds max фоном проигрывалась (через WinAmp) музыка из файла формата MP3 (и отслеживались не замеченные ни разу в итоге «заикания» звука). Обратите внимание на естественное распределение ролей «главное-фоновое» в каждой паре приложений. В качестве результата, как обычно, бралось время архивации и полного рендеринга сцены соответственно. Эффект от Hyper-Threading в цифрах: +13% и +8%.
Достаточно реальная ситуация, именно такие мы и старались воспроизвести. Вообще (и об этом будет сказано далее) Hyper-Threading не настолько очевидна, как кажется. Простой подход «в лоб» («у нас в ОС видны два процессора — давайте относиться к ним как к двум процессорам») не дает ощутимого эффекта, и возникает даже некоторое чувство обманутости. Однако, возвращаясь к вышесказанному, попробуем оценивать результаты с несколько других позиций: задачи, которые в обычной ситуации исполняются за одно время, в случае задействования Hyper-Threading, выполняются за меньшее время. Кто попробует возразить, что «нечто» хуже, чем «ничто»? В этом-то вся и суть — отнюдь не панацею нам предлагают, а «всего лишь» средство ускорить уже имеющееся процессорное ядро, кардинальных изменений не претерпевшее. Получается? Да. Ну и какие, по большому счету, могут быть еще вопросы? Конечно, до обещанных в пресс-релизе 30% в большинстве случаев оказывается далеко, однако не стоит делать вид, что в жизни случается, сопоставив пресс-релиз компании X с пресс-релизом компании Y, убедиться, что в первом обещаний меньше и они более «сбыточные». :)
Тестирование в CPU RightMark 2002B
Новая версия CPU RM поддерживает многопоточность (соответственно, и Hyper-Threading), и, естественно, мы не могли не воспользоваться возможностью протестировать новый процессор с помощью этого бенчмарка. Оговоримся, что пока это только первый «выход» CPU RM в тестах многопроцессорных систем, поэтому можно сказать что исследование было «обоюдосторонним» — мы тестировали Hyper-Threading как частный случай SMP на системе с Pentium 4 3,06 ГГц, а эта система, в свою очередь, тестировала наш бенчмарк :) на предмет валидности результатов, и, соответственно, правильной реализации в нем поддержки мультипоточности. Без преувеличения скажем, что результатами остались довольны обе стороны :). Несмотря на то, что пока CPU RM все еще «не полностью многопроцессорный» (несколько потоков создаются только в блоке рендеринга, Math Solving блок остается однопоточным), полученные нами результаты явственно свидетельсвуют о том, что поддержка SMP и Hyper-Threading присутствует, и польза от их наличия видна невооруженным глазом. Кстати, реализация многопоточности в блоке «решателя» в общем-то задача намного менее тривиальная, чем в блоке рендеринга, поэтому если у кого-то из читателей будут некие идеи по этому поводу — мы ждем ваших комментариев, идей, и предложений. Напоминаем, что проект CPU RightMark — это бенчмарк с открытыми исходными текстами, так что интересующиеся программированием могут не только воспользоваться им, но и вносить предложения по поводу усовершенствования кода.
Перед тем как перейти к диаграммам, остановимся поподробнее на методике. По подписям столбцов, легко заметить, что тестировалась производительность системы в целых двенадцати (!) вариантах. Однако ничего страшного в этом нет, и разобраться достаточно просто. Итак, изменяемыми были следующие факторы:
- Тесты проводились со включенной Hyper-Threading и с отключенной.
- Использовались установки CPU RM для количества создаваемых потоков: один, два, и четыре.
- Использовались установки CPU RM для используемого типа инструкций в расчетном модуле: SSE2 и «классические» x87 FPU.
Объясним последнее. Казалось бы, отказываться от использования SSE2 на Pentium 4 — полный, извините, бред (о чем мы уже неоднократно писали раньше). Однако в данном случае чисто теоретически это было неплохим шансом проверить функционирование и результативность технологии Hyper-Threading. Дело в том, что инструкции FPU использовались только в расчетном модуле, в модуле же рендеринга по-прежнему оставалась включенной поддержка SSE. Таким образом, те, кто внимательно читал теоретическую часть, наверняка уже поняли «где собака зарыта» — мы принудительно заставили разные части бенчмарка использовать разные вычислительные блоки CPU! По идее, в случае принудительного отказа от SSE2, Math Solving блок CPU RM должен был оставлять «нетронутым» блоки исполнения SSE/SSE2 инструкций, что давало возможность на полную катушку воспользоваться ими блоку рендеринга того же CPU RM. Вот теперь самое время перейти к результатам, и посмотреть насколько правильными оказались наши предположения. Также заметим, что с целью увеличения валидности и стабильности результатов, была изменена еще одна установка: количество фреймов (по умолчанию — 300) было увеличено до 2000.
Тут, собственно, комментировать практически нечего. Как мы уже говорили выше, блок «решателя» (Math Solving) остался нетронутым, поэтому на его производительность Hyper-Threading не оказывает никакого влияния. Однако в то же время отрадно… что не вредит! Ведь мы уже знаем, что теоретически возникновение ситуаций когда «виртуальная многопроцессорность» может мешать работе программ — возможно. Однако один факт советуем крепко запомнить: посмотрите, как сильно влияет на производительность блока «решателя» отказ от использования SSE2! Мы еще вернемся к этой теме чуть позже, и в весьма неожиданном ключе…
И вот — долгожданный триумф. Легко заметить, что как только количество потоков в блоке рендеринга становится больше одного (в последнем случае использовать возможности Hyper-Threading, мягко говоря, трудновато :) — сразу же это обеспечивает данной конфигурации одно из первых мест. Также заметно, что именно два потока являются оптимальными для систем с Hyper-Threading. Правда, быть может, кто-то вспомнит скриншот Task Manager, которым мы «стращали» вас выше, поэтому сделаем оговорку — два активно работающих потока. В общем-то, это очевидно и вполне логично — раз у нас два виртуальных CPU, то наиболее правильно создать ситуацию, когда и потоков тоже будет два. Четыре — уже «перебор», потому что за каждый из виртуальных CPU начинают «драться» по несколько потоков. Однако даже в этом случае системе со включенной Hyper-Threading удалось обогнать «однопроцессорного» конкурента.
Об удачах всегда принято говорить подробно и со вкусом, и естественно, еще подробнее и вкуснее о них говорить когда они — твои собственные. Констатируем, что «эксперимент с переходом на инструкции FPU» также безусловно удался. Казалось бы, отказ от SSE2 должен был сильнейшим образом ударить по производительности (быстренько вспоминаем разгромные результаты Math Solving Speed с применением инструкций FPU на первой диаграмме этого раздела). Однако что мы видим! — во второй строчке, на самом верху, среди чемпионов — именно такая конфигурация! Причины опять-таки понятны, и это очень радует, потому что их понятность позволяет сделать вывод о предсказуемости поведения систем с поддержкой технологии Hyper-Threading. «Минусовый» результат блока Math Solving на системе с включенной Hyper-Threading «компенсировал» своим вкладом в общую производительность блок рендеринга, которому полностью отдали на откуп исполняющие блоки SSE/SSE2. Причем компенсировал настолько хорошо, что по результатам такая система оказалась в первых рядах. Остается пожалуй только еще раз повторить то, о чем неоднократно шла речь выше: в полную силу возможности Hyper-Threading проявляются в тех ситуациях, когда активно работающие программы (или потоки) используют разные исполняющие блоки CPU. В данной ситуации эта особенность проявилась особенно сильно, поскольку мы имели дело с хорошо, тщательно оптимизированным кодом CPU RM. Однако главный вывод состоит в том, что в принципе Hyper-Threading работает — значит, будет работать и в других программах. Естественно, тем лучше, чем больше их разработчики будут уделять времени оптимизации кода.
Выводы
…В очередной раз, к радости всего прогрессивного человечества, Intel выпустила новый Pentium 4, производительность которого еще выше чем у предыдущего Pentium 4, но это еще не предел, и скоро мы увидим еще более быстрый Pentium 4… М-да… Не то что бы это неправда — действительно, так и есть. Однако мы уже договорились, что не будем рассматривать в данной статье производительность вышеуказанного Pentium 4 3,06 ГГц в связке с другими процессорами по той самой причине, что… см. выше по тексту. Нас, видите ли, интересует Hyper-Threading. Вот такие мы привередливые — не важны нам предсказуемые результаты повышения еще на 200 МГц частоты работы давно знакомого и предсказуемого процессорного ядра, подавай нам «свежатинку», ранее не рассматриваемую. И как уже наверное догадались прозорливые читатели, выводы наши будут посвящены опять-таки этой самой навязшей в зубах технологии и всему что с ней связано. Почему? Наверное, потому, что все остальное вы отлично знаете сами. Если, конечно, вовремя читаете iXBT.com [здесь затерялась длинная рекламная пауза] :).
И раз уж речь идет о Hyper-Threading, давайте для начала определим для себя главное: как к ней относиться? Что она из себя представляет? Не претендуя на истину в последней инстанции, сформулируем общее мнение, которое возникло у нас на основании результатов тестов: Hyper-Threading — это не SMP. «Ага!!!» — закричат поклонники альтернативы. «Мы так и знали!!!» — завопят они что есть мочи. «Hyper-Threading — это нечестный SMP!!!» — крики сии еще долго будут разноситься по бескрайним просторам Рунета… Мы же, как умудренные саксаулами аксакалы (или наоборот? :), возразим: «Ребята, а кто, собственно, обещал?». Кто произнес эту крамольную аббревиатуру? SMP, напомним — это Symmetric Multi-Processing, сиречь многопроцессорная архитектура. А у нас, пардон, процессор всего один. Да, он снабжен некой, простонародно выражаясь, «фичей», которая позволяет делать вид, что вроде бы оных процессоров два. Однако делает ли кто-то секрет из того, что на самом деле это не так? Вроде бы этого мы не заметили… Стало быть, мы имеем дело именно с «фичей», и не более того. И относиться к ней стоит именно таким образом, и никак иначе. Поэтому давайте не будем ниспровергать никем не возводимых идолов, и спокойно подумаем, имеет ли данная фича какой-то смысл.
Результаты тестов свидетельствуют, что в некоторых случаях — имеет. Фактически, то, о чем мы чисто теоретически рассуждали в первой части статьи, нашло свое практическое подтверждение — технология Hyper-Threading позволяет увеличить коэффициент полезного действия процессора в определенных ситуациях. В частности — в ситуациях, когда одновременно исполняются разнородные по характеру приложения. Зададим сами себе вопрос: «Это — плюс?». Наш ответ: «Да, это — плюс». Является ли он всеобъемлющим и глобальным? Похоже, что нет — ибо эффект от Hyper-Threading наблюдается исключительно в некоторых случаях. Однако так ли это важно если мы рассматриваем технологию в целом? Понятно, что появление CPU, способного в два раза быстрее делать все то, что делалось ранее — это громадный прорыв. Однако как говорили еще древние китайцы «упаси нас Господи жить в эпоху перемен». Intel не стал инициировать начало такой эпохи, просто добавив своему процессору возможность кое-что делать быстрее. Классический западный принцип, не очень хорошо воспринимаемый в нашем «шаролюбивом» обществе: «Вы можете получить нечто получше, если заплатите несколько больше».
Возвращаясь к практике: Hyper-Threading нельзя назвать «бумажной» технологией, ибо при определенных комбинациях она дает вполне ощутимый эффект. Добавим — даже намного больший эффект, чем иногда наблюдается при сравнении, к примеру, двух платформ с одним процессором на разных чипсетах. Однако следует четко понимать, что эффект этот наблюдается не всегда, и существенно зависит от… наверное, самым приемлемым термином будет «стиль». От стиля работы пользователя с компьютером. Причем именно здесь проявляется то, о чем мы сказали в самом начале: Hyper-Threading — это не SMP. «Классический SMP-стиль», где пользователь рассчитывает на реакцию столь же классической «честной» многопроцессорной системы, здесь не даст желаемого результата.
«Стиль Hyper-Threading» — это сочетание процессов, не побоимся этого слова, «развлекательных» или «служебных» с процессами «рабочими». Вы не получите существенного ускорения от CPU с поддержкой этой технологии в большинстве классических многопроцессорных задач, или если по привычке запускаете только одно приложение в один момент времени. Но вы скорее всего получите уменьшение времени исполнения многих фоновых задач, исполняемых в качестве «довеска» к обычной работе. Фактически, Intel просто еще раз напомнила всем нам, что операционные системы, в которых мы работаем — многозадачные. И предложила способ ускорения — но не столько одного какого-то процесса самого по себе, сколько комплекса выполняемых одновременно приложений. Это интересный подход, и, как нам кажется, достаточно востребованный. Теперь он обрел свое имя. Не мудрствуя лукаво, хочется сказать: просто хорошо, что эта оригинальная идея пришла кому-то в голову. Тем более неплохо, что он смог ее воплотить в конкретный продукт. В остальном, как и всегда — время покажет.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}