Часть 2 — Новые синтетические тесты для DX9

СОДЕРЖАНИЕ
- Общие сведения
- Идеология синтетических тестов
- Описания синтетических тестов набора RightMark 3D: Pixel Filling
- Описания синтетических тестов набора RightMark 3D: Geometry Processing Speed
- Описания синтетических тестов набора RightMark 3D: Hidden Surface Removal
- Описания синтетических тестов набора RightMark 3D: Pixel Shading
- Описания синтетических тестов набора RightMark 3D: Point Sprites
- Конфигурации тестовых стендов
- Результаты тестов: Pixel Filling
- Результаты тестов: Geometry Processing Speed
- Результаты тестов: Hidden Surface Removal
- Результаты тестов: Pixel Shading
- Результаты тестов: Point Sprites
- Выводы
Общие сведения
Как уже было неоднократно сказано ранее, выход нового API DirectX 9.0 не мог остаться незамеченным, тем более, что в продаже уже есть целая линейка видеокарт, поддерживающих DX9. Так что мы подготовили материал в 2-х частях. Первая часть, которая уже вышла в свет, целиком посвящена результатам тестирования всей линейки из пяти карт в большом количестве игровых тестов (разумеется, среди них пока нет ни одного, работающего под DX9, поэтому знакомство с обзором сводится к изучению линейки R9500-9700 в целом).
Кстати, очень рекомендуем ознакомиться с нашими уже вышедшими статьями, посвященными RADEON 9500-9700.
Теоретико-аналитические материалы и обзоры видеокарт, в которых рассматриваются функциональные особенности VPU
- Аналитический материал по особенностям архитектуры RADEON 9700 и Microsoft DirectX 9.0
- Базовый обзор ATI RADEON 9700 Pro 128MB
- Обзор Gigabyte MAYA II R9700Pro 128MB — производительность на новом стенде на базе Pentium 4 2.53 GHz, а также соперничество с новым драйвером 40.41 от NVIDIA
- Обзор Hercules 3D Prophet 9700 Pro 128MB — производительность нового драйвера CATALYST 2.3 в 3DMark2001 SE, бенчмарки Unreal Tournament 2003 DEMO final release
- Обзор PowerColor Evil Commando2 RADEON 9700 Pro 128MB — продолжение исследования производительности нового драйвера CATALYST 2.3 на базе игровых тестов, вопросы качества 3D-графики
- Обзор Sapphire Atlantis RADEON 9700 Pro 128MB — более детальное исследование анизотропной фильтрации у RADEON 9700
- Обзор ATI RADEON 9700, RADEON 9500 64MB и Gigabyte MAYA II RADEON 9500 64MB — базовый обзор новых продуктов ATI
- Обзор Sapphire Atlantis RADEON 9500 128MB — сенсационное открытие: RADEON 9500 cо 128 MB имеет 256-битную шину! Тестирование видеокарт в DOOM III
- Обзор HIS Excalibur RADEON 9700 PRO — Тестирование в DirectX 9.0 RC0
- Обзор ATI RADEON 9500 PRO — 128 bit шина обмена с памятью и сжатие буфера при АА (виртуальная 256 битная шина)
- Сводное тестирование ATI RADEON 9500 64MB, 9500 128MB, 9500 PRO, 9700 и 9700 PRO в DirectX 9.0: Часть 1 — Игровые тесты и 3DMark2001, а также Soft9700!
В данной статье читателей ждет очень интересный анализ тестирования этих плат в некоторых синтетических тестах из нового пакета RightMark3D, который вскоре выйдет для публичного ознакомления (фрагмент одной из игровых сцен представлен выше). Данный пакет целиком ориентирован на DX9-карты, хотя некоторые тесты могут работать и на DX81-платах.
Напомню, что по ценовым секторам линейка RADEON 9500-9700 распределена так:
- RADEON 9500 64MB (4 конвейера рендеринга, 128-битная шина памяти, частота 275/270 (540) МГц) — $120-140;
- RADEON 9500 128MB (4 конвейера рендеринга, 256-битная шина памяти, частота 275/270 (540) МГц) — $150-160;
- RADEON 9500 PRO 128MB (8 конвейеров рендеринга, 128-битная шина памяти, частота 275/270 (540) МГц) — $180-200;
- RADEON 9700 128MB (8 конвейеров рендеринга, 256-битная шина памяти, частота 275/270 (540) МГц) — $230-250;
- RADEON 9700 PRO 128MB (8 конвейеров рендеринга, 256-битная шина памяти, частота 325/310 (620) МГц) — $290-330.
Подробно все пять карт были описаны в первой части, поэтому здесь мы к этому не возвращаемся.
Новые синтетические тесты для DX9
В этой статье, мы представим вам подробные описания и первые результаты тестирования, полученные с помощью разрабатываемого нами набора конфигурируемых синтетических тестов для API DX9.
Набор синтетически из разрабатываемого нами тестового пакета RightMark 3D включает в себя (на данный момент) следующие тесты:
- Тест на закраску и фильтрацию текстур (Pixel Filling Test);
- Тест на производительность обработки геометрии (Geometry Processing Speed Test);
- Тест на производительность работы с отсечением невидимых точек и примитивов (Hidden Surface Removal Test);
- Тест на производительность сложных пиксельных шейдеров (Pixel Shader Test);
- Тест на производительность отрисовки, освещения и анимации спрайтов (Point Sprites Test);
- Тест на производительность драйверов и их взаимодействия с ускорителем (State Changes Test).
В этой статье мы представим вам первые пять тестов, а также всесторонне исследуем полученные с их помощью на ускорителях ATI и NVIDIA данные. Сразу отметим, что эта статья преследует две цели — исследовать поведение ускорителей под управлением API DX9 и исследовать поведение синтетических тестов RightMark 3D в различных ситуациях. Последний пункт видится нам крайне важным как для выявления степени применимости, повторяемости и, что самое главное, правдоподобности (обоснованности) результатов наших синтетических тестов, которые мы собираемся широко использовать в дальнейшем для тестирования различных DX9-ускорителей, а также планируем сделать доступными для свободного скачивания нашими читателями и всеми энтузиастами компьютерной графики. Но для начала, небольшое отступление, связанное с идеологическими вопросами тестирования:
Идеология синтетических тестов
Основная идея, стоящая за всеми нашими тестами — острая фокусировка на производительности той или иной конкретной подсистемы чипа. В отличие от реальных приложений, измеряющих эффективность работы ускорителя в том или ином практическом применении что называется «в комплексе», синтетические тесты пытаются вычленить отдельные аспекты производительности. Зачем, спросите вы? Дело в том, что между выходом новых ускорителей и приложений, эффективно и всесторонне использующих их возможности, зачастую проходит год или даже более. При этом, многие энтузиасты, которые желают находиться на переднем краю технологий, вынуждены принимать решение о покупке того или иного ускорителя практически вслепую — основываясь на результатах тестирования заведомо устаревшего программного обеспечения. Никто не может гарантировать им, что в будущем, в момент выхода столь ожидаемых ими игр, ситуация не поменяется кардинально. Кроме энтузиастов, которые добровольно идут на риск весьма дорогой лотереи по покупке только что появившихся продуктов, в непростую ситуацию попадает еще несколько категорий людей:
- Первая категория — покупающие себе компьютер, что называется «по максимуму» — на длительное время — и не желающие связываться с постоянными обновлениями железа. Для этих людей важно сделать правильный выбор, максимально увеличив срок пригодности их компьютера для приложений и применений, которые еще только будут появляться в будущем.
- Вторая категория — разработчики программного обеспечения, с первой минуты появления новых ускорителей вынужденные обращать пристальное внимание на их возможности и балансировку, дабы на основе этих данных грамотно спроектировать и сбалансировать не только движок (код), но и контент (уровни, модели) с учетом эффективного использования техники, которая получит распространение к моменту появления создаваемых ими приложений в продаже. Синтетические тесты помогут им сделать выводы, выбрав те или иные пути для реализации своих замыслов и, что ничуть не менее важно, разумно ограничив простор своей фантазии :-).
- И последняя категория людей — IT-аналитики (например, из крупных торгующих оптом фирм) и профессиональные авторы обзоров компьютерного железа — люди, которые по долгу их рода занятий зачастую вынуждены делать выводы о потенциале тех или иных изделий еще до их официального анонса.
Итак, синтетические тесты позволяют исследовать производительность и возможности отдельных подсистем ускорителей, тем самым позволяя заранее строить прогнозы о поведении ускорителя в тех или иных приложениях. Причем, как в уже существующих (обобщенная оценка пригодности и перспективности для целого класса применений) так и в еще разрабатываемых, разумеется, при условии наличия определенных характерных особенностей использования ускорителя под управлением этих приложений.
Описания синтетических тестов набора RightMark 3D
Pixel Filling
Данный тест выполняет целый ряд задач. В том числе:
- Измерение производительности закраски буфера кадров
- Измерение производительности различных режимов фильтрации текстур
- Измерение эффективности работы (кэширования) с текстурами различного объема
- Измерение эффективности работы (кэширования и компрессии) с текстурами различных форматов
- Измерение эффективности мультитекстурирования
- Наглядное сравнение качества реализации тех или иных режимов фильтрации текстур
Во время тестирования выводится пирамида, основание которой лежит точно в плоскости экрана, а вершина максимально удалена от наблюдателя:

Четыре стороны пирамиды состоят каждая из двух треугольников. Малое число треугольников позволяет устранить зависимость от геометрической производительности, не имеющей никакого отношения к исследуемым данным тестом вопросам. На каждую точку во время закраски накладывается от 1 до 8 текстур. При желании можно полностью отключить текстурирование (0 текстур) и измерять только скорость закраски с использованием константного значения цвета.
Во время тестирования вершина пирамиды равномерно перемещается по кругу, а само основание при этом вращается вокруг оси Z:
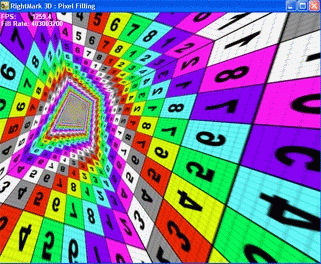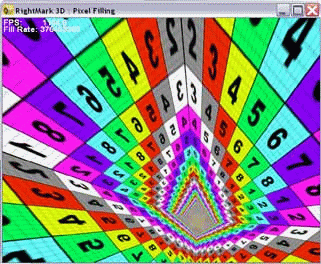
Таким образом, плоскости пирамиды поочередно принимают все возможные углы наклона в обеих плоскостях, а само число закрашиваемых точек не меняется — они один раз покрывают весь экран, при этом в наличии любые расстояния до точек, начиная от минимального и заканчивая максимально удаленными. От наклона закрашиваемой плоскости плоскости и расстояний до закрашиваемых точек зависят многие алгоритмы фильтрации, в том числе анизотропная фильтрация и различные современные реализации трилинейной фильтрации. Вращая пирамиду, мы ставим ускоритель во все условия, которые только могут встретиться в реальных применениях. Это позволяет нам не только визуально проверить качество фильтрации во всевозможных случаях, но и получить взвешенные результаты производительности.
Полезна возможность выбора режима работы теста — одни и те же действия могут быть выполнены шейдерами разных версий и фиксированными конвейерами, доставшимися в наследство от предыдущих поколений DX. Т.е. можно исследовать разницу в производительности в зависимости от используемой версии шейдеров.
Специальная текстура с различными цветами и цифрами облегчает исследование качественных аспектов фильтрации, а также ее взаимодействия с полноэкранным сглаживанием. При желании, также можно выделить различным цветом mip-уровни:
И сделать выводы об алгоритме их смешения и выбора.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Выделять ли цветом mip-уровни
- Режим работы (и максимальное число накладываемых на один пиксель текстур):
- Vertex Shaders 1.1 и Fixed Function Blend Stages (до 8 текстур)
- Vertex Shaders 2.0 и Fixed Function Blend Stages (до 8 текстур)
- Vertex Shaders 1.1 и Pixel Shaders 1.1 (до 4 текстур)
- Vertex Shaders 1.1 и Pixel Shaders 1.4 (до 6 текстур)
- Vertex Shaders 2.0 и Pixel Shaders 2.0 (до 8 текстур)
- Число текстур накладываемых на точку:
- 0 (только закраска)
- от 1 до 8
- Размер текстур:
- 128х128
- 256x256
- 512x512
- Формат текстур:
- A8R8G8B8
- X8R8G8B8
- A1R5G5B5
- X1R5G5B5
- DXT1
- DXT2
- DXT3
- DXT4
- DXT5
- Тип фильтрации:
- отсутствует
- билинейная
- трилинейная
- анизотропная
- анизотропная + трилинейная
Результат работы теста выдается в двух единицах — число кадров в секунду (FPS) и, что более удобно, число закрашенных в секунду пикселей (FillRate). Последнее число играет двойную роль. В режиме без текстур мы измеряем непосредственно скорость записи в буфер кадра. Таким образом, этот параметр означает число закрашенных в секунду точек экрана (Pixel FillRate). В режиме с использованием какого-либо числа текстур — число выбранных и отфильтрованных значений текстур в секунду (Texturing Rate, Texture Fill Rate).
Приведем пример пиксельного шейдера, используемого для закраски в ходе самого интенсивного варианта этого теста (PS/VS 2.0, 8 текстур):
ps_2_0
dcl t0
dcl t1
dcl t2
dcl t3
dcl t4
dcl t5
dcl t6
dcl t7
dcl_2d s0
dcl_2d s1
dcl_2d s2
dcl_2d s3
dcl_2d s4
dcl_2d s5
dcl_2d s6
dcl_2d s7
texld r0, t0, s0
texld r1, t1, s1
texld r2, t2, s2
texld r3, t3, s3
texld r4, t4, s4
texld r5, t5, s5
texld r6, t6, s6
texld r7, t7, s7
mov r11, r0
lrp r11, c0, r11, r1
lrp r11, c0, r11, r2
lrp r11, c0, r11, r3
lrp r11, c0, r11, r4
lrp r11, c0, r11, r5
lrp r11, c0, r11, r6
lrp r11, c0, r11, r7
mov oC0, r11
Geometry Processing Speed
Этот тест призван измерять скорость обработки геометрии в различных режимах. При его создании мы всячески стремились минимизировать влияние закраски и прочих подсистем ускорителя, и в тоже время, сделать саму геометрическую информацию, и ее обработку максимально приближенной к реальным моделям. Основная задача теста — измерение пиковой геометрической производительности на различных задачах трансформации и освещения. В данный момент, тест позволяет выбирать следующие моделей освещения (вычисляемые на уровне вершин):
- Ambient Lighting — простейшее константное освещение
- 1 Diffuse Light — один диффузный источник света
- 2 Diffuse Lights — два диффузных источника света
- 3 Diffuse Lights — три диффузных источника света
- 1 Diffuse + Specular Light — один диффузно-спекулярный источник
- 2 Diffuse + Specular Lights — два диффузно-спекулярных источника
- 3 Diffuse + Specular Lights — три диффузно-спекулярных источника
В ходе теста выводится несколько экземпляров одной и той же модели с большим числом полигонов. Каждый экземпляр модели имеет свои параметры геометрической трансформации и относительного расположения источников света. Размер модели выбран крайне малым (большинство полигонов сравнимы или меньше экранного пикселя):

и таким образом разрешение и закраска не оказывает влияния на результаты теста:
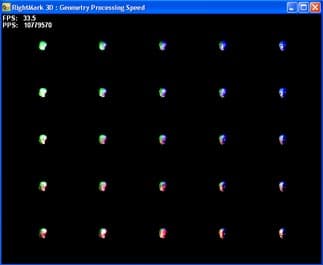
Источники света всячески перемещаются во время теста, дабы обеспечить равномерное разнообразие исходных расчетных параметров.
Допустимо выбирать три степени детализации сцены — они влияют на общее число полигонов, трансформируемых в одном кадре. Подобная возможность необходима для всесторонней проверки отсутствия зависимости результатов теста от сцены и числа кадров в секунду.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров и TCL
- Режим работы:
- Fixed Function TCL и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Pixel Shaders 1.1
- Vertex Shaders 1.1 и Pixel Shaders 1.4
- Vertex Shaders 2.0 и Pixel Shaders 2.0
- Детализация геометрии:
- 1 (низкая)
- 2 (средняя)
- 3 (высокая)
- Модель освещения (определяет сложность расчетов):
- Ambient Lighting — простейшее константное освещение
- 1 Diffuse Light — один диффузный источник света
- 2 Diffuse Lights — два диффузных источника света
- 3 Diffuse Lights — три диффузных источника света
- 1 (Diffuse + Specular) Light — один диффузно-спекулярный источник
- 2 (Diffuse + Specular) Lights — два диффузно-спекулярных источника
- 3 (Diffuse + Specular) Lights — три диффузно-спекулярных источника
Результат работы теста выдается в двух единицах — число кадров в секунду (FPS) и, что более удобно число трансформированных и освещенных за секунду треугольников (PPS — Polygons Per Second).
Приведем пример вершинного шейдера (VS 2.0), используемого для трансформации и расчета освещения от задаваемого извне числа диффузно-спекулярных источников в этом тесте:
vs_2_0
dcl_position v0
dcl_normal v3
//
// Position Setup
//
m4x4 oPos, v0, c16
//
// Lighting Setup
//
m4x4 r10, v0, c8 // transform position to world space
m3x3 r0.xyz, v3.xyz, c8 // transform normal to world space
nrm r7, r0 // normalize normal
add r0, -r10, c2 // get a vector toward the camera position
nrm r6, r0 // normalize eye vector
mov r4, c0 // set diffuse to 0,0,0,0
mov r2, c0 // setup diffuse,specular factors to 0,0
mov r2.w, c94.w // setup specular power
//
// Lighting
//
loop aL, i0
add r1, c[40+aL], -r10 // vertex to light direction
dp3 r0.w, r1, r1
rsq r1.w, r0.w
dst r9, r0.wwww, r1.wwww // (1, d, d*d, 1/d)
dp3 r0.w, r9, c[70+aL] // (a0 + a1*d + a2*d2)
rcp r8.w, r0.w // 1 / (a0 + a1*d + a2*d)
mul r1, r1, r1.w // normalize the vertex to the light vector
add r0, r6, r1 // calculate half-vector (light vector + eye vector)
nrm r11, r0 // normalize half-vector
dp3 r2.x, r7, r1 // N*L
dp3 r2.yz, r7, r11 // N*H
sge r3.x, c[80+aL].y, r9.y // (range > d) ? 1:0
mul r2.x, r2.x, r3.x
mul r2.y, r2.y, r3.x
lit r5, r2 // calculate the diffuse & specular factors
mul r5, r5, r8.w // scale by attenuation
mul r0, r5.y, c[30+aL] // calculate diffuse color
mad r4, r0, c90, r4 // add (diffuse color * material diffuse)
mul r0, r5.z, c[60+aL] // calculate specular color
mad r4, r0, c91, r4 // add (specular color * material specular)
endloop
mov oD0, r4 // final color
Hidden Surface Removal
Этот тест позволяет оценить наличие и эффективность техник, нацеленных на удаление невидимых точек и примитивов. Т.е эффективность работы с традиционным буфером глубины, а также эффективность и наличие раннего отсечения невидимых точек в том или ином виде. Тест генерирует псевдослучайную сцену из заданного числа треугольников:
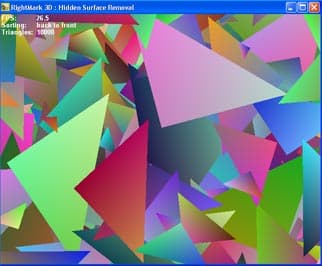
…которая будет затем выводиться в одном из трех выбранных режимов:
- Сортированные по удалению, от ближних к дальним (sorted, front to back order)
- Сортированные по удалению, от дальних к ближним (sorted, back to front order)
- Хаотически, без сортировки (unsorted)
Разумеется, что в случае 2 будут прорисованы последовательно все пиксели, в том числе и закрытые. Разумеется, если ускоритель основан на традиционной или гибридной архитектуре (в случае полностью тайлового ускорителя оптимизация возможна и тут, но не будем забывать что сортировка в итоге все равно будет присутствовать, пусть уже на уровне железа или драйвера).
В случае 1 в идеале может быть прорисовано только небольшое число видимых пикселей, остальные могут быть откинуты еще до закраски. В случае 3 мы имеем некую середину, похожую на то, с чем может встретиться механизм HSR чипа в реальной работе в не оптимизирующих последовательность вывода сцены на экран приложениях. Для того, чтобы получить представление о пиковой эффективности алгоритма HSR, необходимо соотнести результаты первого и второго режима (самого оптимального первого с самым неудобным вторым). Сравнение же оптимального режима с хаотическим (т.е. первого и третьего) даст нам приблизительную степень эффективности в реальных применениях.
Для того, чтобы максимально сгладить потенциальные особенности различных, как правило, основанных на разбиении буфера кадра на зоны, алгоритмов раннего HSR, сцена во время теста поворачивается вокруг оси Z. В итоге, треугольники и их границы принимают всевозможные положения.
Для проверки зависимости этого теста от прочих подсистем чипа и драйверов была добавлена возможность регулировать число выводимых треугольников. Разумеется, мы можем ожидать приближения результатов к идеальным по мере роста числа треугольников, но, с другой стороны, рост оправдан только до какого-то разумного предела, после чего степень влияния на тест сторонних подсистем снова может увеличиться. Поэтому и был введен этот параметр, необходимый для проверки добротности теста в плане зависимости от числа треугольников.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров и TCL
- Режим работы:
- Fixed Function TCL и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Число треугольников:
- От 1000 до 20000
- Режим сортировки выводимой сцены:
- Отсутствует;
- От дальних полигонов к ближним;
- От ближних полигонов к дальним
Pixel Shading
Данный тест призван исследовать производительность выполнения различных пиксельных шейдеров второй версии. Если в случае первой версии скорость выполнения шейдеров, транслировавшихся реально в настройки стадий, определялась по достаточно простым правилам, и для ее проверки было достаточно теста, схожего с Pixel Filling в режиме большого числа текстур, то в случае второй версии вершинных шейдеров все может существенно усложниться. Покомандное исполнение и новые форматы данных (плавающие числа) способны создать существенную разницу в производительности не только в случае разных архитектур ускорителей, но и даже на уровне сочетания отдельных команд и форматов данных внутри одного чипа. Мы решили применить к тестированию производительности пиксельных процессоров современных ускорителей подход, схожий с тестированием CPU. А именно, измерять производительность следующего набора пиксельных шейдеров, имеющих вполне распространенные реальные прототипы и применения:
- Расчет попиксельного освещения — 1 точечный источник (per-pixel diffuse lighting with per-pixel attenuation)
- Расчет попиксельного освещения — 2 точечных источника (per-pixel diffuse lighting with per-pixel attenuation)
- Расчет попиксельного освещения — 3 точечных источника (per-pixel diffuse lighting with per-pixel attenuation):
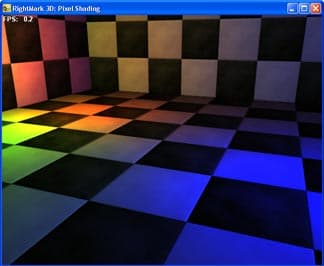
- Расчет попиксельного освещения — 1 точечный источник с бликом (per-pixel diffuse lighting + specular lighting with per-pixel attenuation)
- Расчет попиксельного освещения — 2 точечных источника с бликом (per-pixel diffuse lighting + specular lighting with per-pixel attenuation):
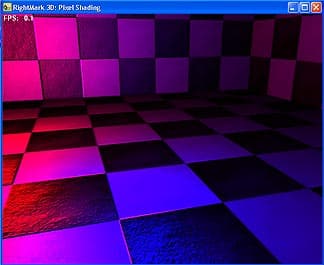
- Анимированная процедурная текстура мрамора (marble animated procedure texturing)
- Анимированная процедурная текстура огня (fire animated procedure texturing):

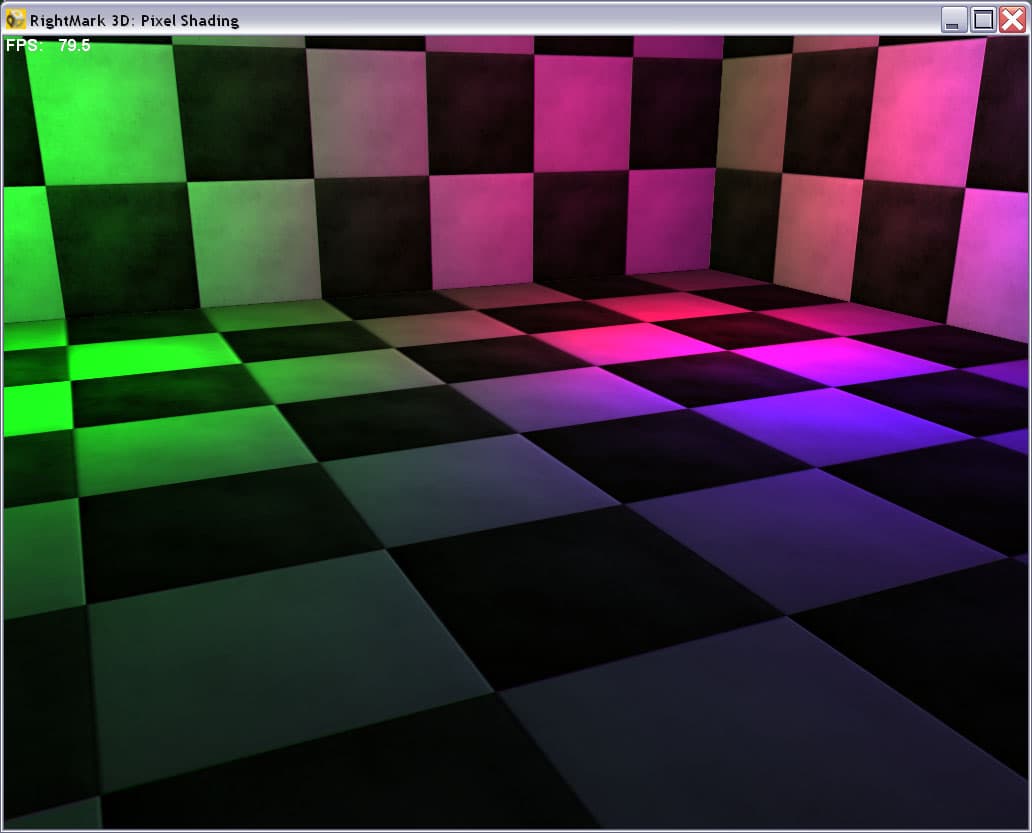
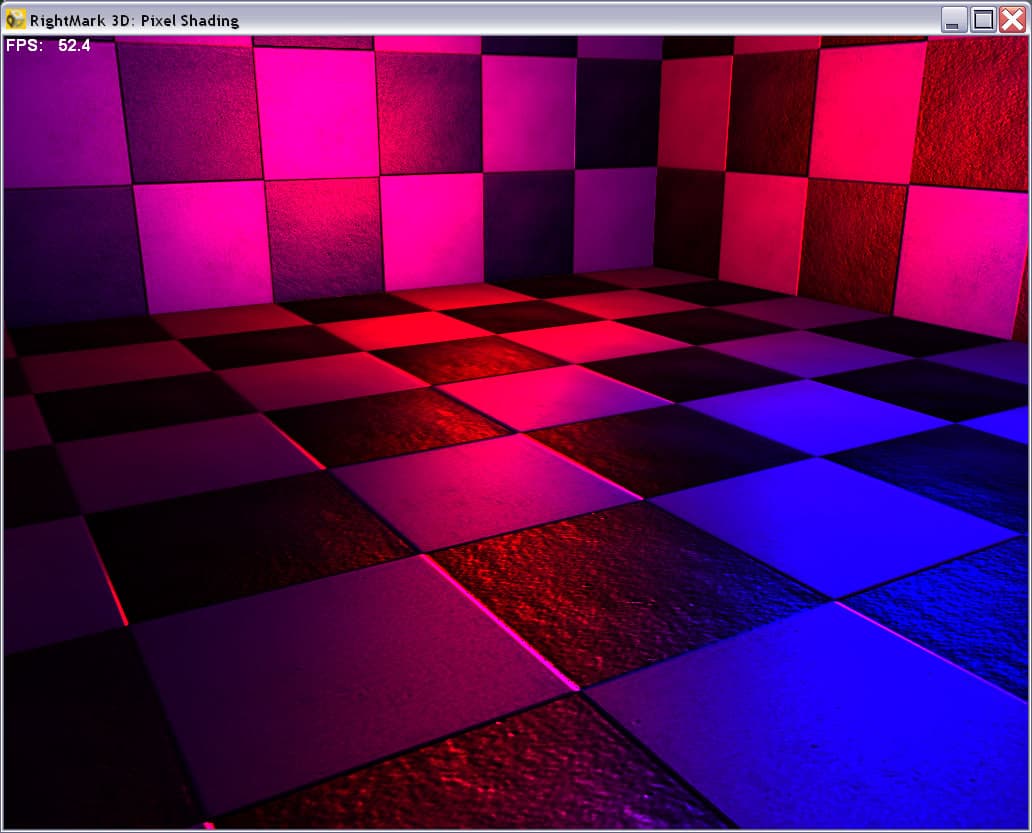

Два последних теста реализуют процедурные текстуры — значения цвета точек вычисляются в них по некой формуле — являющиеся приближенной математической моделью материала. Такие текстуры занимают очень мало памяти (хранятся только сравнительно небольшие таблицы для ускорения расчетов различных коэффициентов) и имеют при этом практически неограниченную детализацию! Кроме того, они легко анимируются простым изменением базовых параметров. Возможно, что по мере роста вычислительных возможностей ускорителей, в будущих приложениях будут задействованы такие методы текстурирования.
Геометрически тестовая сцена максимально упрощена, и таким образом, зависимость от геометрической производительности чипа практически нивелируется. Также отсутствует удаление невидимых поверхностей — все поверхности сцены видимы в любой момент времени. Нагрузка ложится только на плечи пиксельных конвейеров.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров
- Пиксельный шейдер:
- 1 point light ( per-pixel diffuse with per-pixel attenuation )
- 2 point lights ( per-pixel diffuse with per-pixel attenuation )
- 3 point lights ( per-pixel diffuse with per-pixel attenuation )
- 1 point light ( per-pixel diffuse + secular with per-pixel attenuation )
- 2 point lights ( per-pixel diffuse + secular with per-pixel attenuation )
- Procedure texturing (Marble)
- Procedure texturing (Fire)
Приведем коды некоторых шейдеров. Попиксельный расчет двух источников света с бликами:
ps_2_0
//
// Texture Coords
//
dcl t0 // Diffuse Map
dcl t1 // Normal Map
dcl t2 // Specular Map
dcl t3.xyzw // Position (World Space)
dcl t4.xyzw // Tangent
dcl t5.xyzw // Binormal
dcl t6.xyzw // Normal
//
// Samplers
//
dcl_2d s0 // Sampler for Base Texture
dcl_2d s1 // Sampler for Normal Map
dcl_2d s2 // Sampler for Specular Map
//
// Normal Map
//
texld r1, t1, s1
mad r1, r1, c29.x, c29.y
//
// Light 0
//
// Attenuation
add r3, -c0, t3 // LightPosition-PixelPosition
dp3 r4.x, r3, r3 // Distance^2
rsq r5, r4.x // 1 / Distance
mul r6.x, r5.x, c20.x // Attenuation / Distance
// Light Direction to Tangent Space
mul r3, r3, r5.x // Normalize light direction
dp3 r8.x, t4, -r3 // Transform light direction to tangent space
dp3 r8.y, t5, -r3
dp3 r8.z, t6, -r3
mov r8.w, c28.w
// Half Angle to Tangent Space
add r0, -t3, c25 // Get a vector toward the camera
nrm r11, r0
add r0, r11, -r3 // Get half angle
nrm r11, r0
dp3 r7.x, t4, r11 // Transform half angle to tangent space
dp3 r7.y, t5, r11
dp3 r7.z, t6, r11
mov r7.w, c28.w
// Diffuse
dp3 r2.x, r1, r8 // N * L
mul r9.x, r2.x, r6.x // * Attenuation / Distance
mul r9, c10, r9.x // * Light Color
// Specular
dp3 r2.x, r1, r7 // N * H
pow r2.x, r2.x, c26.x // ^ Specular Power
mul r10.x, r2.x, r6.x // * Attenuation / Distance
mul r10, c12, r10.x // * Light Color
//
// Light 2
//
// Attenuation
add r3, -c1, t3 // LightPosition-PixelPosition
dp3 r4.x, r3, r3 // Distance^2
rsq r5, r4.x // 1 / Distance
mul r6.x, r5.x, c21.x // Attenuation / Distance
// Light Direction to Tangent Space
mul r3, r3, r5.x // Normalize light direction
dp3 r8.x, t4, -r3 // Transform light direction to tangent space
dp3 r8.y, t5, -r3
dp3 r8.z, t6, -r3
mov r8.w, c28.w
// Half Angle to Tangent Space
add r0, -t3, c25 // Get a vector toward the camera
nrm r11, r0
add r0, r11, -r3 // Get half angle
nrm r11, r0
dp3 r7.x, t4, r11 // Transform half angle to tangent space
dp3 r7.y, t5, r11
dp3 r7.z, t6, r11
mov r7.w, c28.w
// Diffuse
dp3 r2.x, r1, r8 // N * L
mul r2.x, r2.x, r6.x // * Attenuation / Distance
mad r9, c11, r2.x, r9 // * Light Color
// Specular
dp3 r2.x, r1, r7 // N * H
pow r2.x, r2.x, c26.x // ^ Specular Power
mul r2.x, r2.x, r6.x // * Attenuation / Distance
mad r10, c13, r2.x, r10 // * Light Color
//
// Diffuse + Specular Maps
//
texld r0, t0, s0
texld r1, t2, s2
mul r9, r9, r0 // Diffuse Map
mad r9, r10, r1, r9 // Specular Map
// Finalize
mov oC0, r9
Процедурная текстура огня:
ps_2_0
def c3, -0.5, 0, 0, 1
def c4, 0.159155, 6.28319, -3.14159, 0.25
def c5, -2.52399e-007, -0.00138884, 0.0416666, 2.47609e-005
dcl v0
dcl t0.xyz
dcl t1.xyz
dcl t2.xyz
dcl t3.xyz
dcl_volume s0
dcl_2d s1
texld r0, t0, s0
mul r7.w, c0.x, r0.x
texld r2, t1, s0
mad r4.w, c0.y, r2.x, r7.w
texld r11, t2, s0
mad r1.w, c0.z, r11.x, r4.w
texld r8, t3, s0
mad r10.w, c0.w, r8.x, r1.w
mul r5.w, c2.x, r10.w
mad r7.w, c1.x, t0.x, r5.w
mad r9.w, r7.w, c4.x, c4.w
frc r4.w, r9.w
mad r6.w, r4.w, c4.y, c4.z
mul r1.w, r6.w, r6.w
mad r3.w, r1.w, c5.x, c5.w
mad r5.w, r1.w, r3.w, c5.y
mad r7.w, r1.w, r5.w, c5.z
mad r9.w, r1.w, r7.w, c3.x
mad r11.w, r1.w, r9.w, c3.w
mov r3.xy, r11.w
texld r6, r3, s1
mov oC0, r6
Point Sprites
Этот тест служит для выявления производительности одной единственной функции: вывода точечных спрайтов, предназначенных для создания систем частиц. В ходе теста выводится анимированная система частиц, в которой легко угадать горящую фигуру человека:
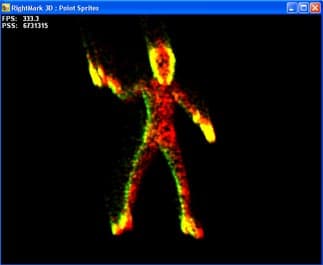
Мы можем регулировать размер частиц (который несомненно скажется на скорости их закраски), включать и выключать обработку освещения и анимацию. В случае систем частиц большую роль играет и обработка геометрической информации, именно поэтому мы не стали пытаться разделить два этих аспекта — закраска и геометрические вычисления (анимация и освещение), а предоставили возможность менять степень нагрузки на ту или иную часть теста за счет регулировки размера спрайтов и включения / выключения их анимации и освещения.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров
- Режим работы:
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Режим анимации:
- Отсутствует
- Проводится
- Режим освещения:
- Отсутствует
- Проводится
Оставайтесь с нами
В ближайшее время мы планируем завершить отладку и привести первые публичные результаты 7-го теста - теста измеряющего в первую очередь «добротность» драйверов и то, насколько эффективно построена передача данных и параметров ускорителю.
Кроме того, в скором времени во всех синтетических тестах появится возможность использовать не только ассемблерные версии шейдеров, но и компилируемые с языка высокого уровня, причем как родным компилятором Microsoft (HLSL) так и комплектом от NVIDIA — CG+CGFX.
А самым приятным фактом, несомненно, является планируемый в ближайшее время релиз первой тестовой (бета) версии пакета RightMark 3D. Пока, в первой бета-версии, для свободного использования будут доступны только синтетические тесты.
Практическое исследование
А теперь самое интересное. Приведем и прокомментируем различные данные, полученные нами на ускорителях двух «основных» в данный момент семейств — ATI RADEON 9500/9700 и NVIDIA GeForce 4 4200/4600.
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карт:
- Компьютер на базе Pentium 4 (Socket 478):
- процессор Intel Pentium 4 3066 МГц;
- системная плата ASUS P4GX8 (iE7205, HyperThreading ON);
- оперативная память 512 MB DDR SDRAM PC3200;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1;
- монитор
ViewSonic P817 (21").
При тестировании применялись драйверы от ATI версии 6.255 (CATALYST 3.0a) (использовался DirectX 9.0). VSync отключен в драйверах.
Для сравнительного анализа приведены результаты видеокарт:
- Albatron Medusa GeForce4 Ti 4600 (300/325 (650) МГц, 128 МБ, driver 42.01);
- ABIT Siluro GF4 Ti4200-8x (GeForce4 Ti 4200 with AGP 8x, 250/256 (512) МГц, 128 МБ, driver 42.01);
Pixel Filling
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом — выборка текстур не производится. Приведены результаты в миллионах пикселов в секунду для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
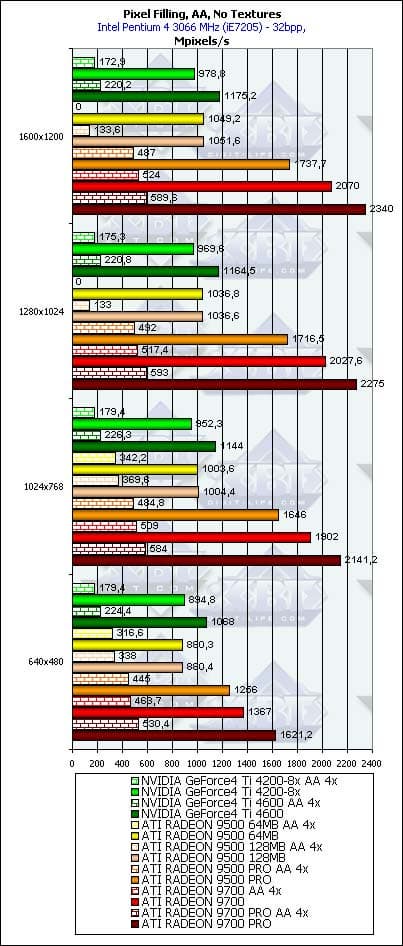
С ростом разрешения результаты старших карт RADEON, основанных на R300, растут, все ближе и ближе подступая к теоретическому пределу. А вот продукты на основе NV25 уже начиная с 1024х768 замирают на определенной черте, видимо продиктованной пропускной полосой памяти, а точнее, ее нехваткой. Потери на АА чуть менее трагичны у старших моделей RADEON, но у RADEON 9500 они заметнее, даже по сравнению с уже немолодыми продуктами NVIDIA. Интересно, что для режимов АА оптимум у продуктов ATI достигается в разрешении 1280х1024, дальше, видимо, сказывается гипертрофированный размер буфера кадра, который даже с учетом двукратного сжатия в режиме MSAA 4х будет занимать огромный объем.
- Тест на скорость закраски буфера кадров с одновременным текстурированием. Добавляется выборка одной простой билинейной текстуры — проверим, насколько наличие конкурентного потока чтения из памяти понизит эффективность закраски. Приведены результаты в миллионах пикселов в секунду, для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
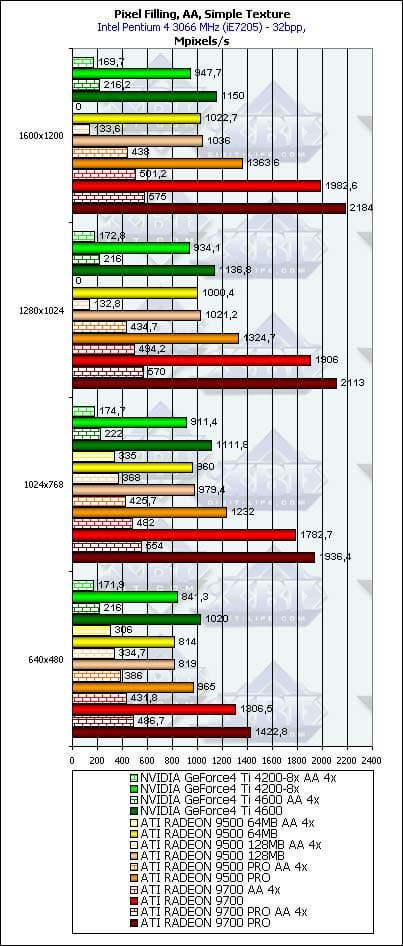
В общем и целом, картина практически та же, но пиковые значения несколько упали. Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум Измеренный максимум(без текстуры) Измеренный максимум(с одной текстурой) GeForce4 Ti 4200-8х 1000 978 947 GeForce4 Ti 4600 1200 1175 1150 RADEON 9500 128 1100 1051 1036 RADEON 9500 PRO 2200 (128 бит!) 1737 1363 RADEON 9700 2200 2070 1982 RADEON 9700 PRO 2600 2340 2184 Тест очень близко подобрался к предельным значениям, мы можем сделать вывод о его профпригодности в этом вопросе. Интересно, что у продуктов NVIDIA реальные данные заметно ближе к теоретическим, нежели у продуктов ATI. Сильнее всего ударило наличие конкурентного потока по RADEON 9500 PRO — сказывается недостаточная пропускная полоса памяти и присутствие только двух контроллеров — локальная шина начинает захлебываться. Лучше всего в этой проверке чувствует себя GeForce4 Ti 4600.
- Посмотрим на зависимость Texturing Rate (числа выбираемых и фильтруемых из текстур пикселей в секунду) от числа накладываемых за один проход текстур:
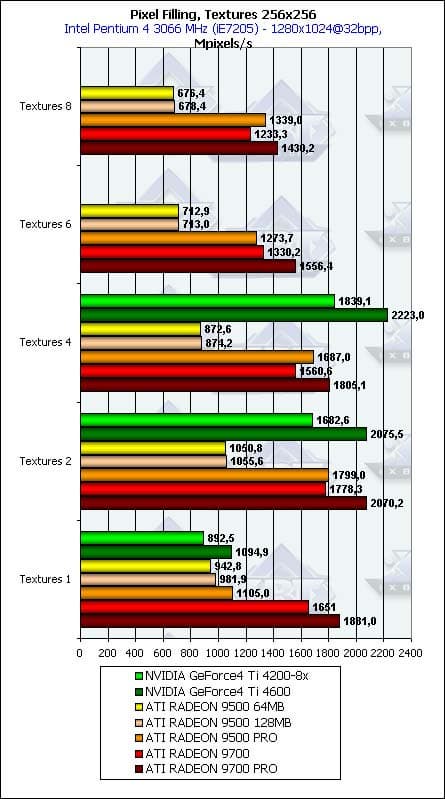
Если продукты NVIDIA прекрасно себя чувствуют в этом вопросе, по крайней мере, до 4 текстур, которые они умеют накладывать за один проход, то ATI выдает свойственное новому поколению небольшое, но заметное падение эффективности по мере увеличения числа текстур. Теперь нет стадий — есть пиксельный процессор. Следовательно, за каждую новую текстуру надо расплачиваться новой командой.
Продукт Теоретический максимум Измеренный максимум(2 текстуры) Измеренный максимум(макс. текстур) GeForce4 Ti 4200-8х 2000 1682 1839 GeForce4 Ti 4600 2400 2075 2223 RADEON 9500 128 1100 (4 TU!) 1055 678 RADEON 9500 PRO 2200 (128 бит!) 1799 1339 RADEON 9700 2200 1778 1233 RADEON 9700 PRO 2600 2070 1430 Хорошо видно, что при большом числе текстур (будущие приложения) ATI от памяти зависит мало (сравните последнюю колонку для 9500 PRO и 9700), а вот от числа конвейеров и тактовой частоты ядра — много; стимул включать конвейеры и разгонять ядро налицо.
- Исследуем зависимость от формата текстуры:
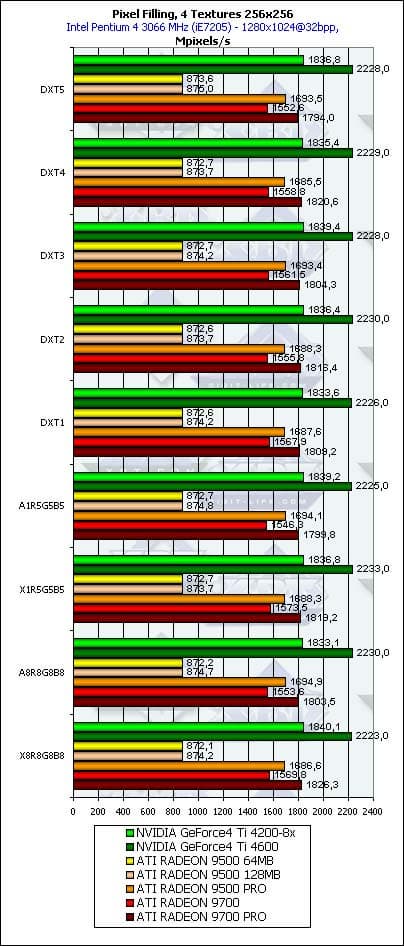
Результаты практически не меняются — все чипы давным-давно оптимизированы для 32-битных текстур и выполняют распаковку сжатых текстур без каких-либо задержек. Впрочем, в будущих обзорах, в том числе и обзоре GeForce FX, мы уделим внимание сравнительно новым плавающим форматам буфера рендеринга и текстур, и там, судя по всему, нас будут ждать сюрпризы (с точки зрения влияния формата на скорость обработки).
- Исследуем зависимость от типа фильтрации:
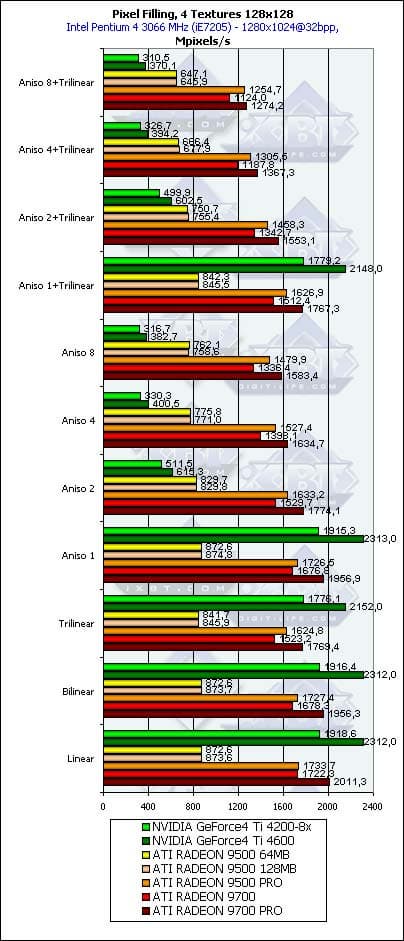
На более или менее существенных установках анизотропии продукты NVIDIA начинают катастрофически терять производительность. Этот факт подробно исследован в наших материалах ранее и не требует дополнительных комментариев. Все, что мы хотим отметить — наш тест показал вполне ожидаемые результаты, без каких-либо сюрпризов. Вскоре мы увидим, как обстоят дела с анизотропией у GeForce FX.
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей.
- Простейшее освещение — по сути, пиковая пропускная способность по треугольникам:
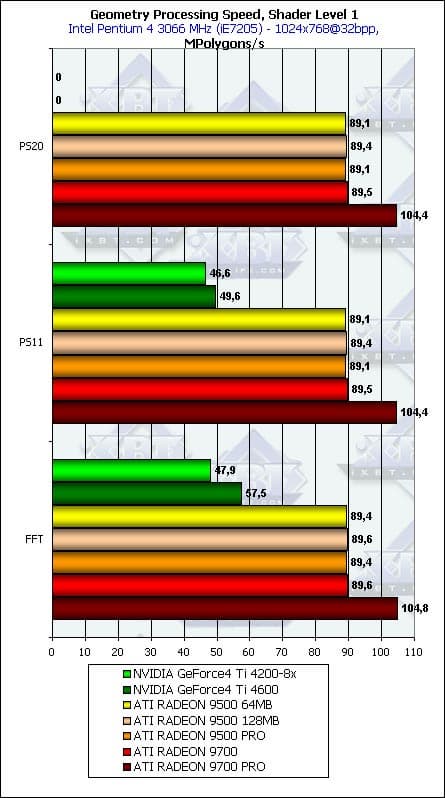
Чипы показывают хорошо повторимые, пиковые результаты производительности. Результаты ATI не зависят от версии шейдера (или аппаратной эмуляции T&L — на графике FFT — Fixed Function Transformation). 104 миллиона вершин в секунду — это не шутка. Приятно отметить, что это число хорошо согласуется с пиковым значением, приводимым ATI. Заметно, что результат зависит только от частоты ядра — следовательно, ни в одной из младших моделей на базе R300 производительность геометрических процессоров не занижена. Интересно, что аппаратная эмуляция T&L у продуктов NVIDIA чуть эффективнее аналогичного, микроскопического по сути (2 команды — умножение матриц 4х4 и одно копирование результата) вершинного шейдера. Отметим также, что продукты NVIDIA заметно проигрывают — сказывается наличие только двух вершинных процессоров против четырех у ATI. Итак, тест показал доселе невиданные результаты (по крайней мере, в исполнении 3D Mark 2001), существенно сократив разрыв между заявленной производителями и полученной на практике пиковой производительностью.
- Выберем более сложную модель освещения (рассчитываются два диффузных источника света):
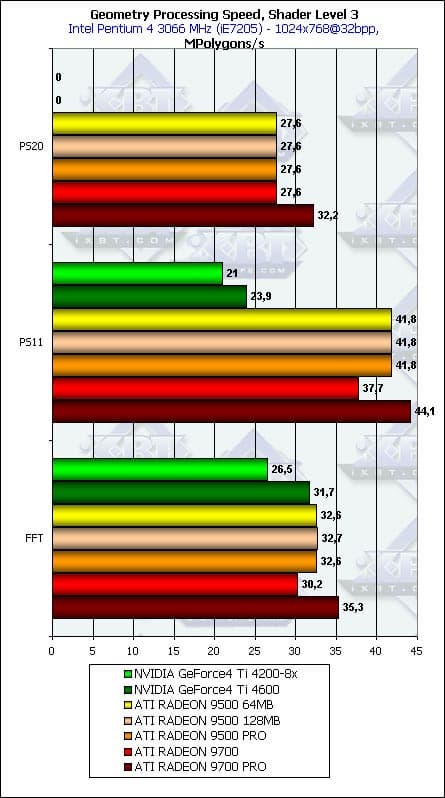
Теперь, аппаратная эмуляция T&L в исполнении ATI менее эффективна, чем вершинный шейдер версии 1.1. И сравнима по эффективности с вершинным шейдером 2.0. Как вы уже заметили, вторая версия далась нам небесплатно — использованные циклы стоят заметного падения производительности. Причем большего, чем мы могли ожидать от одной команды цикла на несколько десятков обычных команд. Странно. А если учесть, что, по некоторой информации, циклы на R300 разворачиваются в линейный код шейдера еще драйверами чипа, то тем более, подобные потери непонятны.
Вот и первый существенный вопрос к создателям драйверов ATI. Все ли в порядке, и если все — то в чем причина этого падения?
Непонятно также крайне небольшое, но постоянное отставание RADEON 9700 от всех вариантов 9500, но только в режимах эмуляции фиксированного T&L (FFT) и первой версии вершинных шейдеров.
Между тем, с ростом сложности шейдера, продукты NVIDIA начинают реабилитироваться. Особенно в режиме эмуляции аппаратного T&L (на графике FFT) — на старых и новых играх с его использованием годичной давности NVIDIA все еще способна показать класс.
- Еще два шейдера, в порядке увеличения сложности (один диффузно-спекулярный источник и три диффузно-спекулярных источника):
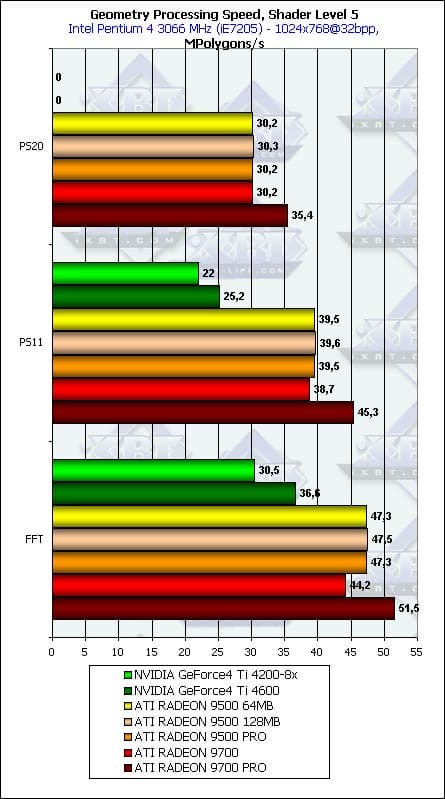
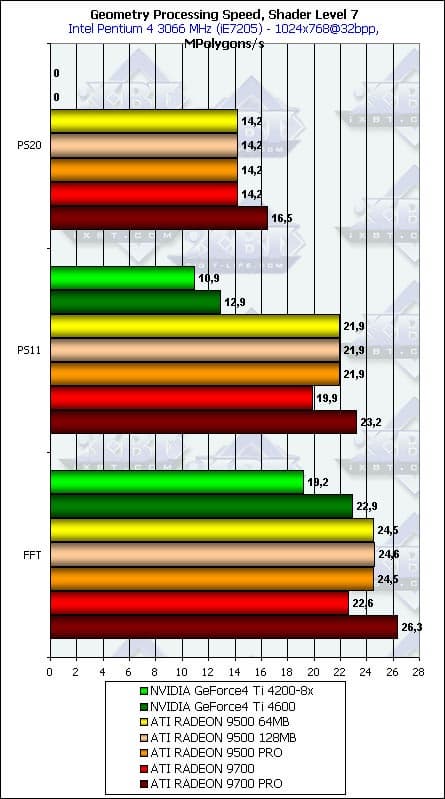
Картина повторяется, за исключением того, что здесь у обеих производителей FFT показывает себя чуть лучше вершинного шейдера. И вновь мы наблюдаем странное поведение RADEON 9700.
- Проверим зависимость от разрешения для разной степени сложности геометрических расчетов:
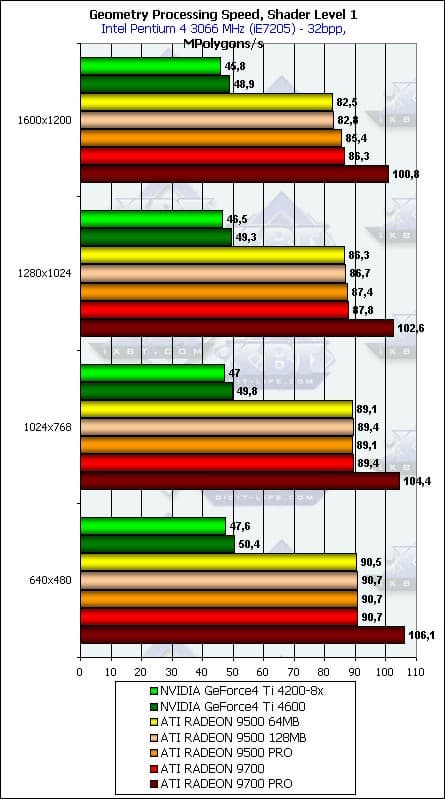
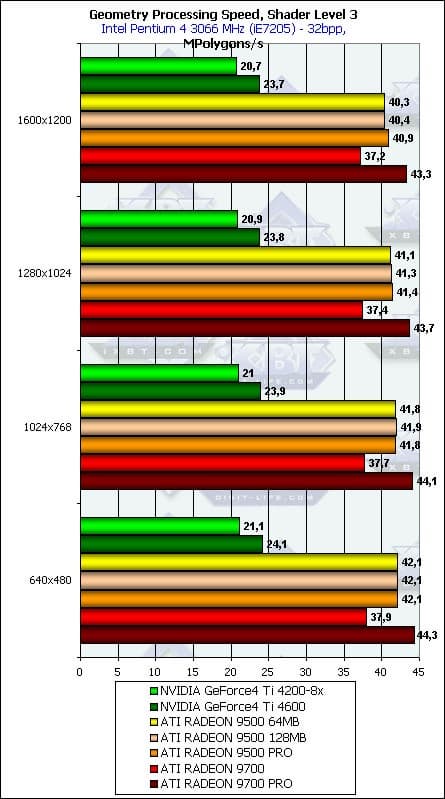
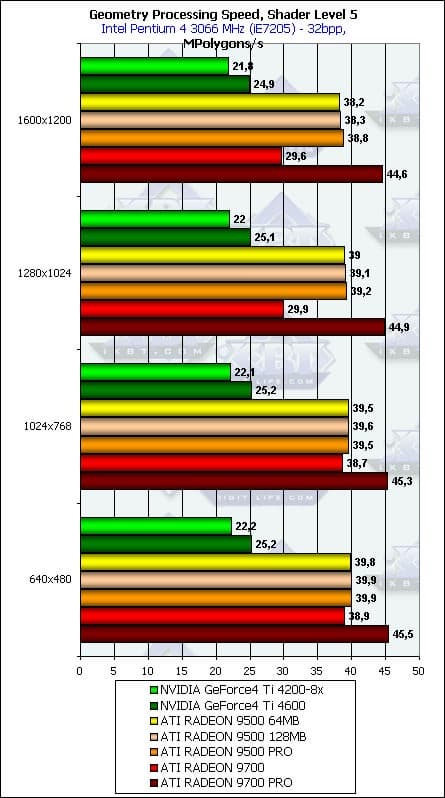
Зависимость практически отсутствует и более-менее заметна только на самой простой модели освещения, в самом большом разрешении. Итак, мы в очередной раз перепроверили желанный факт точной и узкой фокусировки описываемых синтетических тестов.
- Проверим зависимость от версии вершинных шейдеров с фиксированным конвейером закраски или совместного с ними используемых пиксельных шейдеров соответствующих версий:
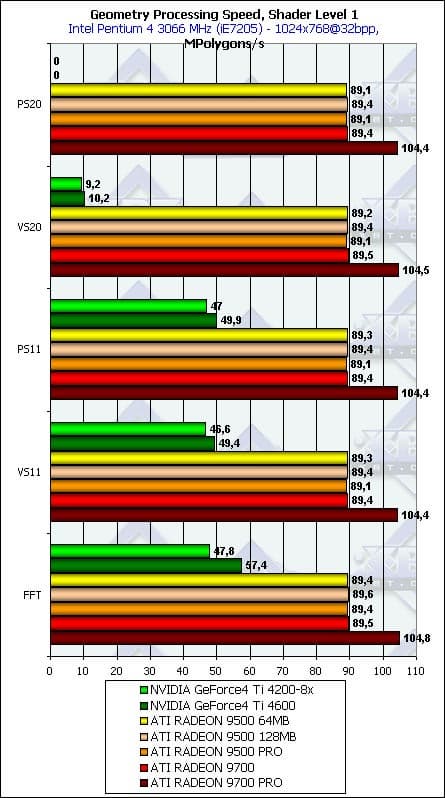
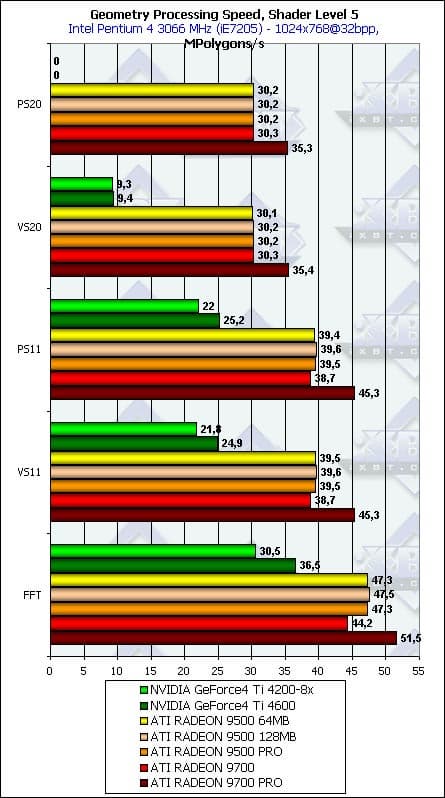
Hикаких аномалий, кроме вполне ожидаемого падения производительности во время программной эмуляции вершинных шейдеров второй версии на продуктах на базе NV25, которые, как известно, эту версию аппаратно не поддерживают.
- И последний тест — проверка зависимости от детализации модели:
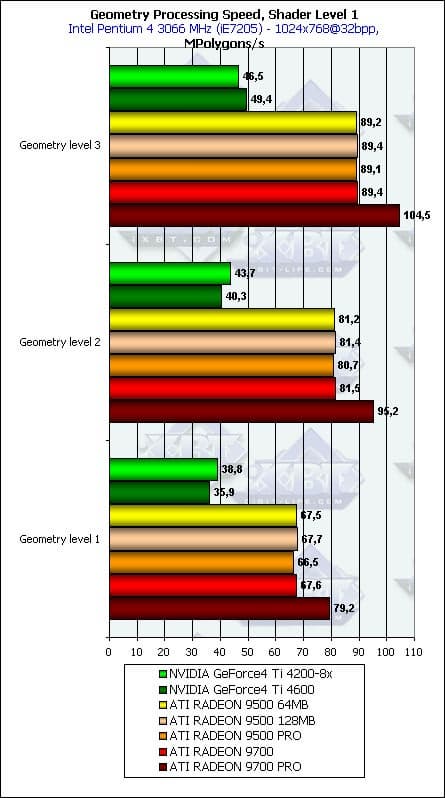
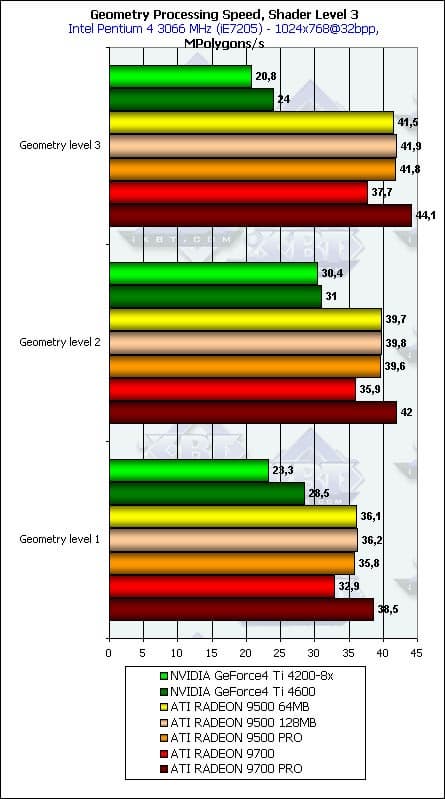
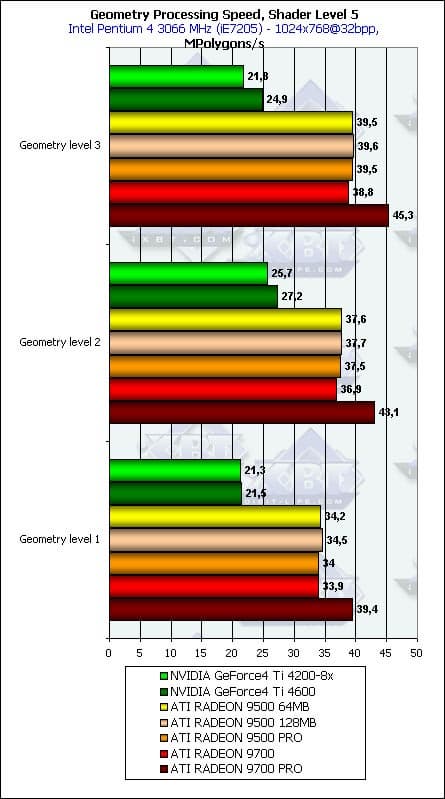
Все как и ожидалось — в общем и целом, чем больше полигонов в модели — тем выше результаты, но зависимость крайне слаба и начиная со второго уровня детализации ее можно положить достаточной. Интересно, что тем или иным образом (видимо, сказываются кэши вершин и прочие аспекты балансировки?) чипы NVIDIA достигают оптимума на средней детализации, в то время как продукты ATI продолжают расти и на высокой — они нацелены на более сложные сцены. Вполне логично — разница во времени проектирования дает себя знать, выражаясь в разном понимании «идеальной» сцены.
Hidden Surface Removal
- Проверим наличие и максимальную эффективность HSR в процентах (приведем сразу для разного числа треугольников):
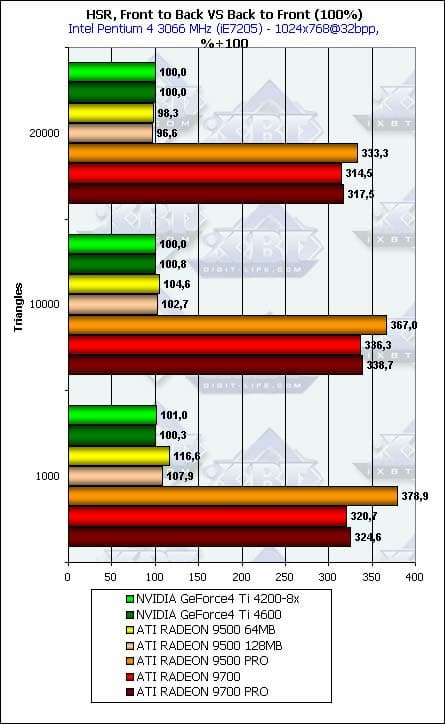
Вы еще не испытали шок? Налицо открытие — прокомментирую результаты:
- У обоих чипов NVIDIA HSR не функционирует! Он отключен драйверами (интересно, на NV20 он остается активированным, мы специально проверили этот факт). Ключ реестра, который позволял его включать или выключать, не действует — мы так и не смогли, на данный момент, активировать HSR на NV25. В чем дело? Ошибка в чипе, из-за которой пришлось раз и навсегда выключить эту возможность?
- У всех чипов RADEON семейства 9700 и RADEON 9500 PRO он присутствует (HyperZ) и демонстрирует прекрасную эффективность. Но, в противоположность этому, у всех чипов семейства RADEON 9500 он не функционирует! Вновь отключен, и, видимо, вновь на уровне драйверов. По какой причине? Может быть, для создания дополнительной разницы производительности в реальных приложениях, но, более вероятно, из-за брака у кристаллов в этом блоке, вследствие чего они и поступают для выпуска карт на базе RADEON 9500. Да, чтобы понизить производительность относительно RADEON 9500 PRO и 9700, у таких кристаллов еще и отключают половину конвейеров. В первой части мы уже обсуждали проблему «переделки RADEON 9500 в RADEON 9700 (9500 PRO)» при помощи RivaTuner, то есть, программно. События последующего времени нам показали, что не все так гладко, как хотелось бы. Прежде всего, обнаружилось, что не все R9500 после переделки работают без артефактов, около 28% по статистике имеют глюки, ярко свидетельствующие о неполадках в блоке HyperZ. А не этот ли блок, собственно, и отвечает за HSR? Полагаем, что, как и в случае с RADEON LE, компания ATI не утилизирует кристаллы с неисправным блоком HSR, а отключает его программным путем вместе с половиной конвейеров, и обкромсанные таким образом чипы поступают уже как RADEON 9500.
Итак, еще одна интересная тема для размышлений владельцев RADEON 9500, желающих увеличить программным путем производительность своих карт. Есть ли способ включить 4 конвейера, но не трогать при этом HSR? Пока ответа нет, мы работаем в этом направлении.
- Для полноты картины приведем эффективность по сравнению с несортированной сценой:
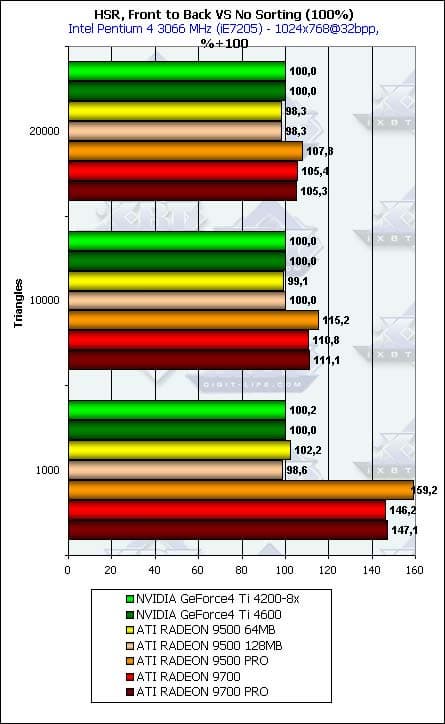
Даже в случае исходно хаотической сцены прирост есть, хотя и не столь высокий. Наиболее заметен он в случае небольшого числа полигонов. Вывод — если хотите воспользоваться благами HSR (к несчастью, у половины чипов, как только что выяснилось, отключенного) — сортируйте сцену перед выводом. Тогда и только тогда вам светит значительное, в несколько раз, преимущество. В случае же вывода неотсортированной сцены HSR сказывается, но не столь сильно — от единиц до десятка процентов. Впрочем, портальные приложения, так или иначе, сортируют сцену при выводе, а к ним относится подавляющее большинство современных FPS движков. Поэтому, игра с HSR стоит свеч, в первую очередь именно для этого класса игр.
Итак, как бы там ни было, мы снова обнаруживаем факт принудительного отключения HSR у большей половины ускорителей, принимающих участие в нашем обзоре. Получается, что когда вы покупаете RADEON 9500 и читаете в его спецификации о наличии HyperZ или покупаете GeForce4 Ti 4600 и читаете в ее спецификации о EarlyZ Cull — вы остаетесь обманутыми. Нехорошо.
- Проверим зависимость от разрешения:
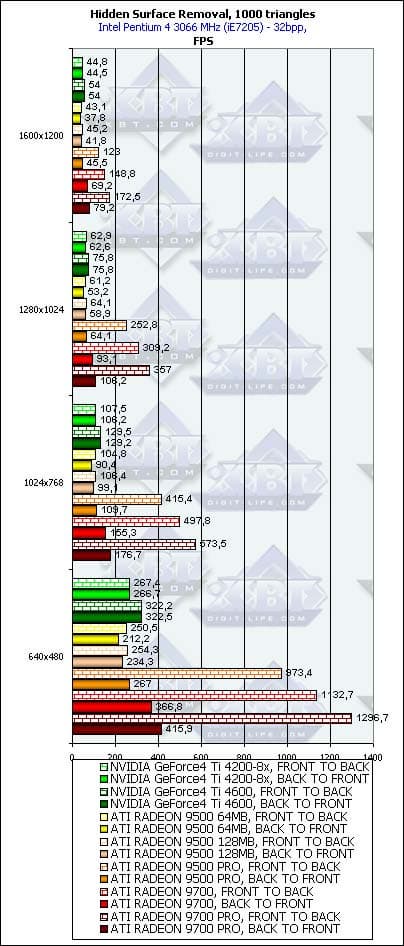
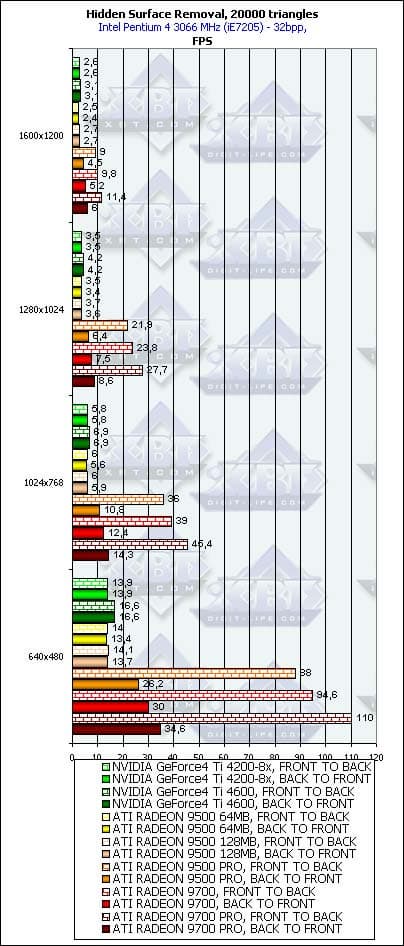
Вывод прост — там, где HSR работает, он больше всего любит небольшие разрешения. Объяснение вполне очевидно — отбрасываемые блоки, как правило, имеют фиксированный размер — скажем 8х8 — и при росте разрешения число блоков, которые необходимо отбросить для одного и того же полностью закрытого треугольника, растет, уменьшая эффективность HSR. Даже в случае иерархического буфера RADEON этот факт сказывается вполне заметно. В будущих версиях ускорителей их создателям есть о чем подумать — возможно, стоит использовать несколько базовых размеров блоков, переключая их в зависимости от разрешения или просто увеличить этот размер волевым решением, положив свершившимся фактом переход большинства покупателей новых ускорителей на ЖК-мониторы с разрешением как минимум 1280х1024.
- Для полноты картины, а также для наглядности сравнения FPS, приведем исходные данные, на которые мы опирались, вычисляя процентную эффективность в самом начале:
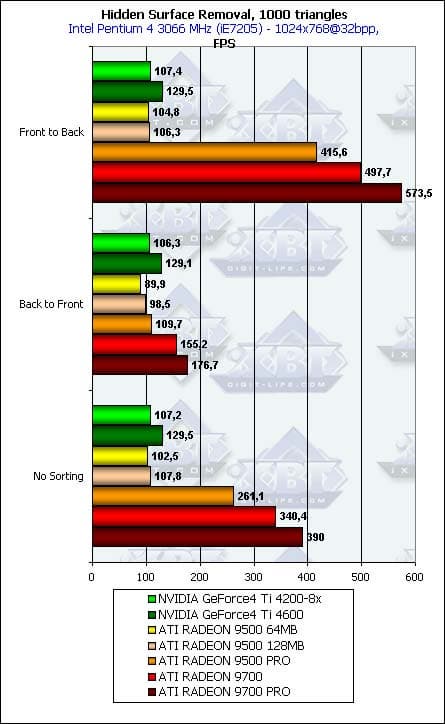
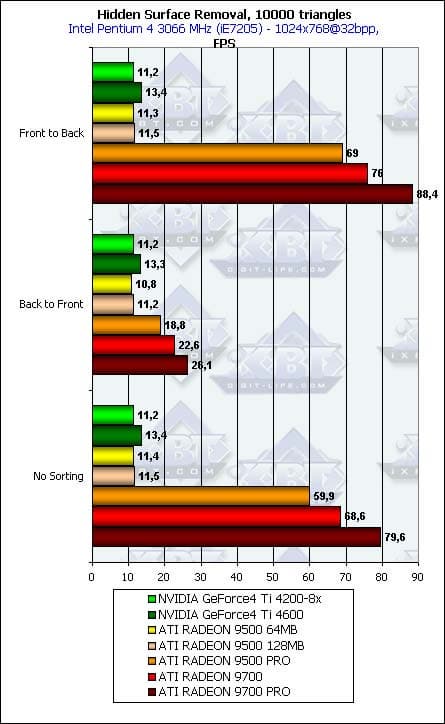
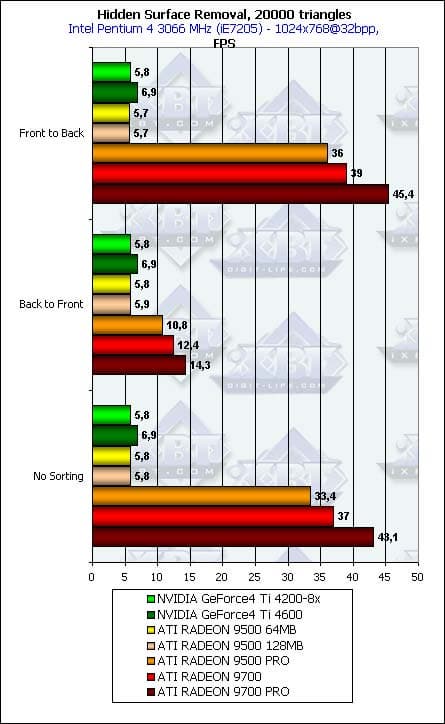
Pixel Shading
В данном тесте пока участвуют только продукты ATI — т.к. аппаратное исполнение второй версии пиксельных шейдеров является минимальным требованием для этого теста. Судите сами: на старой доброй GeForce4 Ti 4600 вкупе с 2 ГГц Pentium 4 программная эмуляция второй версии пиксельных шейдеров выдает порядка одного кадра в две секунды. И это — в маленьком окне.
- Сам тест:
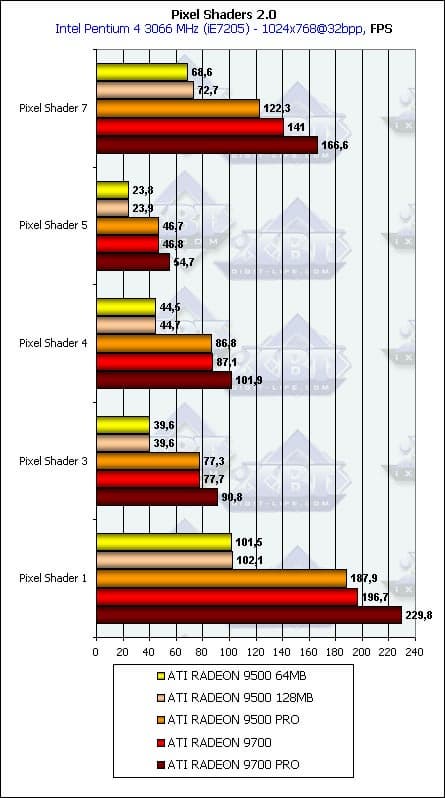
Ничего удивительного. На первом месте тактовая частота и количество конвейеров. Шина памяти сказывается несильно и только у некоторых шейдеров (первый и седьмой). 200 кадров по сравнению с 0.5 — сойдет за аргумент, по крайней мере, для использующих пиксельные шейдеры новой версии игр. Посмотрим, что нам принесет в этой области GeForce FX.
- Проверим зависимость от разрешения:
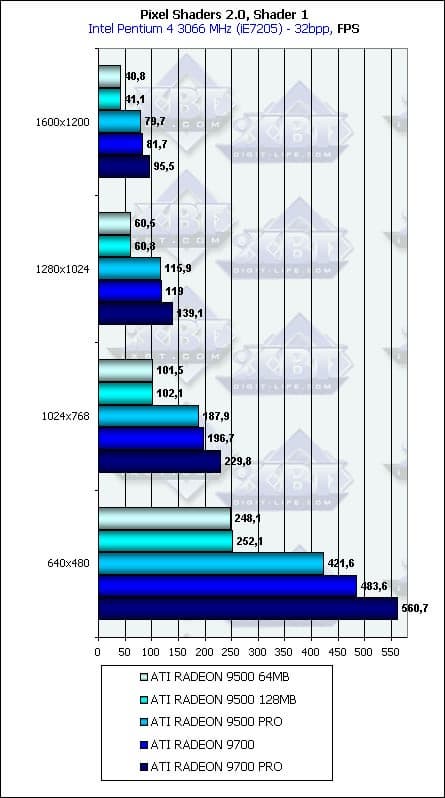
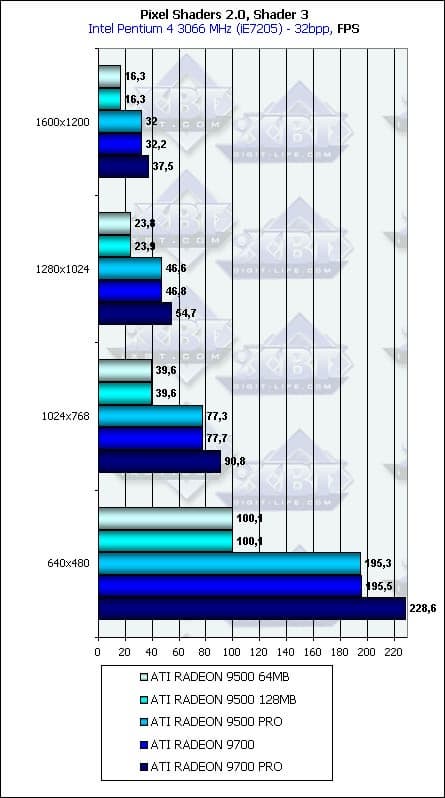
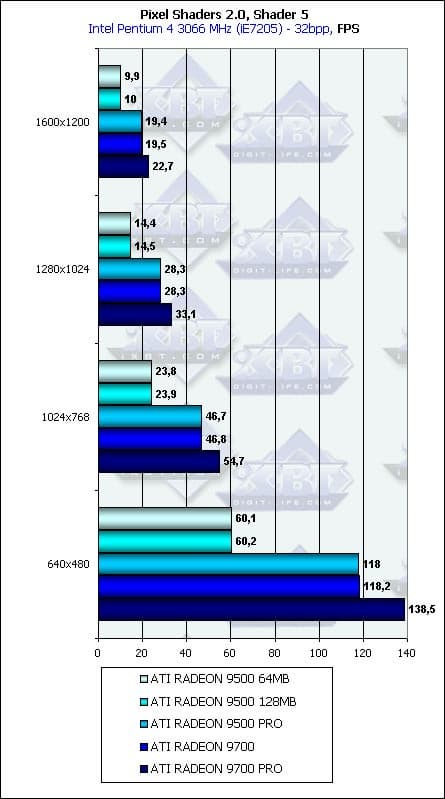
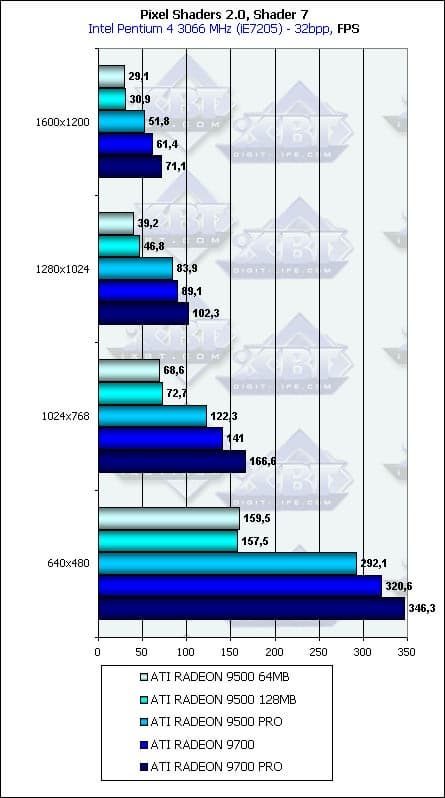
Ничего особенного. Вполне ожидаемая, хорошая зависимость. Влияние шины памяти почти незаметно, в силу уже озвученных выше причин — главные параметры для мало-мальски сложных пиксельных шейдеров — это частота ядра и число конвейеров. Налицо тот сдвиг от закраски к вычислениям, о котором нам столько говорят с приходом DX9.
Point Sprites
Итак, спрайты.
- С освещением и без, в зависимости от размеров:
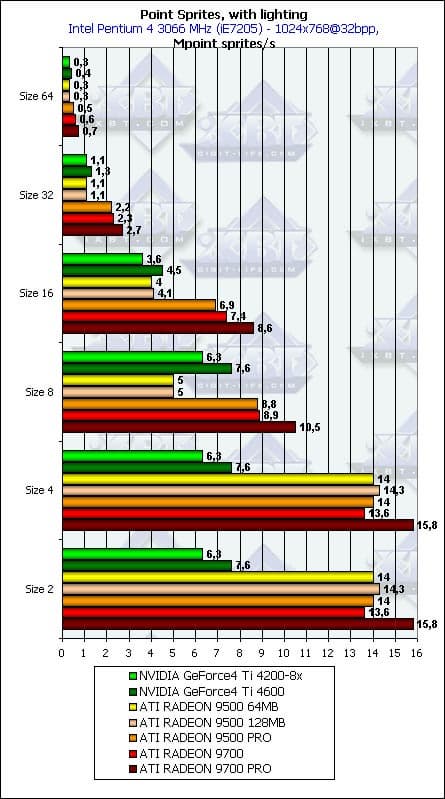
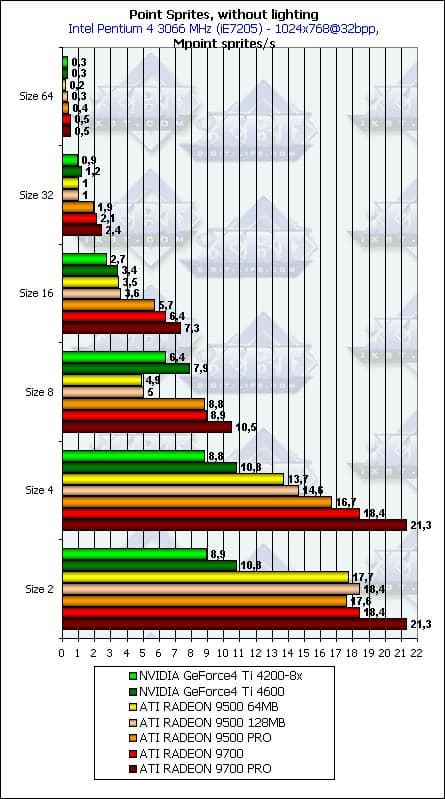
Как и ожидалось наличие или отсутствие освещения сказывается только на маленьких спрайтах, по мере роста размера все упирается в закраску. Происходит это при размере 8 и более. Итак, для вывода систем, состоящих из большого числа частиц, следует признать оптимальными размеры менее 8. Причем, NVIDIA показывает себя в плане зависимости от размера спрайтов гораздо лучше ATI — падение не столь заметно, а до размера 8 включительно можно считать его монотонным и не очень большим. ATI же теряет бодрость духа уже между 4 и 8 и делает это весьма резко. Пиковые значения достигаются, разумеется, без освещения, и составляют соответственно чуть более 20 миллионов спрайтов в секунду для RADEON 9700 PRO и чуть более 10 для GeForce4 Ti 4600.
Причем, при размерах 2 и 4 и ATI и NVIDIA упираются только в геометрическую производительность, а она, как известно, на несложных задачах должна быть вдвое выше у ATI. Что мы и наблюдаем.
Опять-таки отметим уже ранее озвученный вывод, что никакой особой панацеи точечные спрайты нам не приносят — цифры не сильно далеки от тех, что можно получить при помощи обычных полигонов. Впрочем, зачастую само использование точечных спрайтов с точки зрения программирования более удобно, и в первую очередь для всевозможных систем частиц.
- Посмотрим, какую роль сыграет наличие или отсутствие анимации:
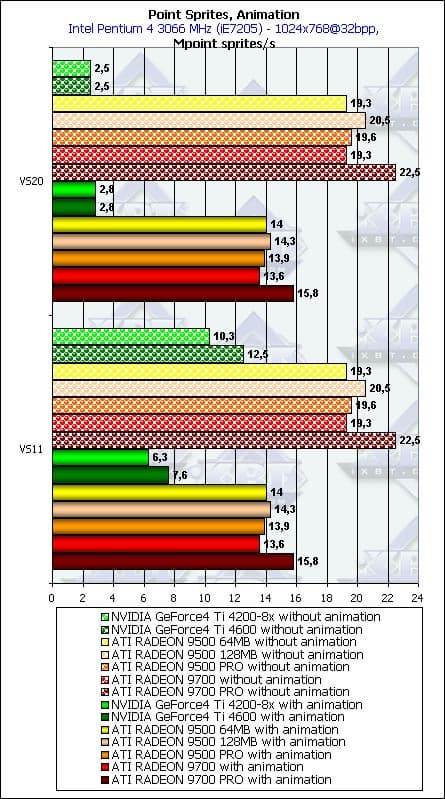
Итак, вклад анимации не столь велик, но заметен, причем вне зависимости от версии вершинных шейдеров.
- Напоследок приведем детальные графики зависимости от разрешения для трех размеров:
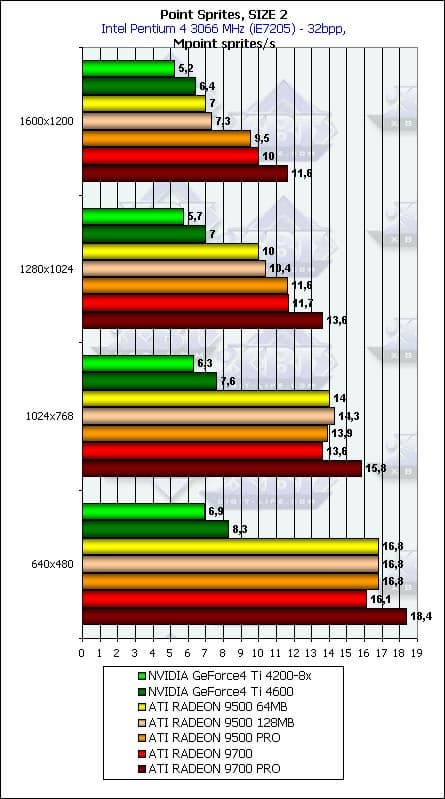
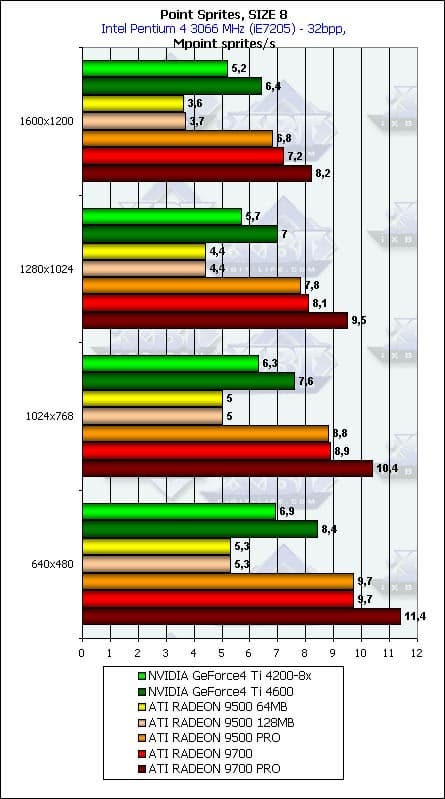
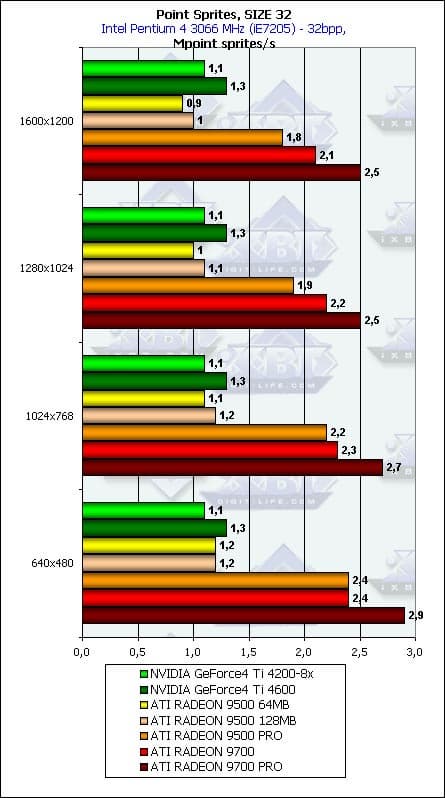
Все верно: зависимость невелика и значительна только для небольших размеров спрайтов.
На этом мы заканчиваем материал, посвященный первому широкому тестированию карт с использованием синтетических тестов для API DX9 из набора RightMark 3D.
Выводы
- Следует признать поведение тестов хорошо соответствующим их назначению. Результаты не только хорошо согласуются с теоретическими пиковыми порогами, но и практически не зависят от прочих подсистем ускорителей.
- Удивляет значительное падение производительности при использовании циклов в вершинных шейдерах второй версии при исполнении их на продуктах ATI.
- Можно признать открытием факт блокировки HSR у обеих карт из семейства GeForce4 Ti, а также у всех карт семейства RADEON 9500. Ранее этот вопрос никем не исследовался и не поднимался, но, как говорится в известной пословице, «тайное всегда становится явным».
- Отсутствие HSR у RADEON 9500, а также характер артефактов на некоторых переделанных в RADEON 9700 видеокарт ярко говорят о том, что на выпуск части плат RADEON 9500 идут кристаллы с битым блоком HSR. С одной стороны, это выгодно ATI (меньше отходов), с другой стороны, это обман пользователей, ибо во всех спецификациях карт RADEON 9500 присутствует технология HyperZ, собственно, и занимающаяся в т.ч. и HSR.
Ну что ж, мы будем еще возвращаться к вопросу тестирования RADEON 9500-9700 в DX9, если новые драйверы будут того заслуживать, а пока морально готовимся к…


Думаем, что все поняли, о чем идет речь :-)
за помощь по «взлому» некоторых RADEON 9500/9700 :-)
а также мы благодарим Филиппа Герасимова,
одного из авторов и главного программистаDirectX тестов пакета RightMark 3D


