И то, без сомнений и лени
Я шейдеры б выучил только за бамп,
И тем паче, за мягкие тени.
Да будь я канадских кровей инженер,
Да будь я китаец иль чукча,
Я сделал бы шейдеры только за то,
что Кармаки их уже учат! "
(Почти как у Маяковского)

СОДЕРЖАНИЕ
- Лекция первая, вводная
- Лекция вторая — ТТХ главного героя.
- Лекция третья — сравнение ключевых характеристик.
- Лекция четвертая — контроллер памяти.
- Лекция пятая — пиксельные конвейеры и текстурные блоки.
- Лекция шестая — вершинные конвейеры и языки высокого уровня.
- Лекция седьмая — сглаживание, видео возможности.
- Выводы.
Лекция первая: вводная
С радостью констатируем плавно состоявшееся открытие эпохи гибко программируемых графических ускорителей. Не будем скрывать, недостатки есть! Но они исправляются уже сейчас. В то же время, опасное головокружение от успехов старательно сдерживают программы реалистической графики, призванные продемонстрировать всю суету и мизерность возможностей даже последнего поколения ускорителей. Товарищи, дорога, по которой они идут, верна, и недалек тот день, когда на каждом столе будет стоять своя собственная окончательная фантазия — эпоха развитой реалистичной графики. Спасибо за внимание (продолжительные аплодисменты).
Основной темой данной статьи является предварительное исследование возможностей недавно анонсированного ATI чипа нового поколения, на которое, как на стержень, будут нанизаны различные рассуждения не только об этом ускорителе, но и о его основном конкуренте, еще не объявленном чипе NV30, а также перспективах аппаратного ускорения графики вообще.
Лекция вторая — ТТХ главного героя
Итак, ATI заранее анонсировала RADEON 9700, известный ранее нашим внимательным читателям под кодовым именем R300:
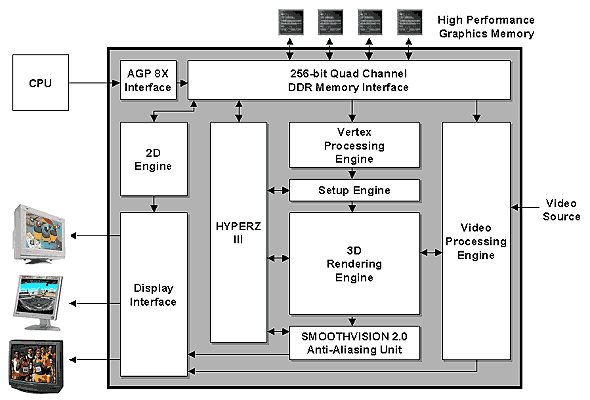
Без всяких сомнений, данный ускоритель открывает новое поколение графических архитектур ATI, исправно реализуя в железе последние тенденции, четко очерченные API DirectX 9. Ранее мы уже описывали ключевые требования, предъявляемые DX9 к ускорителям.
Приведем обещанные характеристики нового чипа и флагманской карты на его основе — RADEON 9700:
- Технология производства: 0.15 микрон;
- Число транзисторов: 107 миллионов;
- Тактовая частота ядра: 300 МГц (возможно выше, 315/325);
- Шина памяти: 256 бит DDR (позже, возможно DDR II);
- Максимальный объем локальной памяти: 256 Мб;
- Тактовая частота памяти: 300 DDR (600) МГц или более, пропускная способность около 20 Гб/сек;
- Интерфейсная шина: AGP 8x, пропускная способность 2 Гб/сек;
- Полная поддержка основных возможностей DX9:
- Плавающие 64 и 128 бит форматы данных для текстур и кадрового буфера (векторы из 4 компонент F16 или F32);
- Пиксельные конвейеры с плавающей арифметикой (формат вычислений 4*F32);
- Пиксельные шейдеры версии 2.0;
- Четыре независимых вершинных конвейера;
- Вершинные шейдеры версии 2.0;
- Аппаратная тесселяция N-Patches с картами смещения (Displacement Mapping) и, по желанию, адаптивным уровнем детализации;
- Восемь независимых пиксельных конвейеров
- Восемь текстурных блоков (по одному на пиксельный конвейер), способных производить трилинейную фильтрацию без потери скорости, а также (наконец) комбинировать анизотропную фильтрацию с трилинейной.
- Четырехканальный (4 канала по 64 бита) контроллер памяти, связанный с ядром ускорителя и AGP коммутатором "каждый-с-каждым";
- Технология экономии пропускной полосы памяти HyperZ III (Быстрая очистка и сжатие буфера глубины на основе блоков 8х8, иерархический Z-буфер для быстрого определения видимости);
- Ранний Z-тест (пиксельный шейдер выполняется только для видимых пикселей);
- Аппаратное ускорение распаковки и сжатия MPEG 1/2, возможность произвольно обрабатывать видеопоток с помощью пиксельных шейдеров (технология VIDEOSHADER);
- Два независимых CRTC;
- Два встроенных 10 бит 400 МГц RAMDAC с аппаратной гаммакоррекцией;
- Встроенный TV-Out;
- Встроенный DVI (TMDS трансмиттер) интерфейс, разрешение до 2043*1536.
- Встроенный цифровой интерфейс общего назначения для подключения внешнего RAMDAC или DVI трансмиттера, а также для сопряжения с TV тюнером.
- FC корпусовка (FlipChip — с перевернутым открытым кристаллом).
Итак, характеристики, несомненно, впечатляют. Далее мы подробно прокомментируем многие из этих пунктов, а в ближайшей части нашего повествования нас ждет:
Лекция третья — сравнение ключевых характеристик
Для сравнения выберем наиболее распространенные из ныне существующих игровых решений, а также главного будущего конкурента R300 — NV30.
Возможные спецификации NV30 не являются официальными либо точными — они процитированы автором по различным слухам, встречающимся в сети. Предположения о существенной части параметров строятся на основе открытых данных по новым кросс-АPI языкам высокого уровня С Graphics / Cine FX, предназначение которых — облегчить программирование столь гибких чипов. Кроме того, многие предположения относительно NV30 строились на основе требований DX 9:
| Ускоритель | R200 (RADEON 8500, 128MБ) | NV25(GeForce4 Ti 4600) | RV250 (RADEON 9000 PRO) | R300 (RADEON 9700) | NV30 |
|---|---|---|---|---|---|
| Технология, число транзисторов | 0.15 62 млн. | 0.15 68 млн. | 0.15 ~40 млн.(?) | 0.15 107 млн. | 0.13 120 млн. |
| AGP | 4x | 4x | 8х | 8x | 8x |
| Шина памяти, бит | 128 DDR | 128 DDR | 128 DDR | 256 DDR (II)(1) | 256 DDR II |
| Частота памяти, МГц | 275 | 325 | 275 | 300 (?) | 400+ (?) |
| Частота ядра, МГц | 275 | 300 | 275 | 300 (?) | 400 (?) |
| Пиксельных конвейеров | 4 | 4 | 4 | 8 | 8 |
| Текстурных блоков | 4x2 | 4x2 | 4x1 | 8x1 (2) | 8x2 (?) |
| Текстур за проход, до | 6 | 4 | 6 | 16 (3) | 16 (3)(?) |
| Вершинных конвейеров | 2 | 2 | 1 | 4 | 4 (?) |
| Фиксированный блок T&L | Да | Нет | Нет | Нет | Нет (?) |
| N-Patches | DX8 | Нет | DX8 (4) | DM (DX9) | DM (DX9) (?) |
| Вершинные шейдеры, версия | 1.1 | 1.1 | 1.1 | 2.0 | 2.0 (5)(?) |
| Пиксельные шейдеры, версия | 1.4 | 1.3 | 1.4 | 2.0 | 2.0 (5)(?) |
| Контроллер памяти | 2x64 | 4x32 | 1x128 | 4x64 | 4x64 (?) |
| Встроенные RAMDAC | 1x400 MHz | 2x360 MHz | 2x350 MHz | 2x400 MHz | 2x400 MHz (?) |
| Технологии экономии | Да (HyperZ II) | Да (LightSpeed II) | Да (HyperZ II ?) | Да (HyperZ III) | Да (LightSpeed III ?) |
Примечания:
- (1) Скорее всего, наравне с DDR будет поддерживаться и DDR II.
- (2) Каждый текстурный модуль способен самостоятельно делать трилинейную выборку.
- (3) Согласно требованиям DX9, за один проход может быть использовано до 16 различных текстур, с 8 предварительно вычисленными (интерполированными по поверхности треугольника) четырехмерными текстурными координатами. При этом, в пиксельном шейдере может быть сделано до 32 выборок конкретных значений из этих текстур.
- (4) Программная эмуляция.
- (5) Судя по всему, в железе будут реализованы возможности, превышающие требования DX для вершинных и особенно пиксельных шейдеров версии 2.0.
Какие общие выводы мы можем вынести для себя из этого сравнения?
- На данный момент R300 (если не принимать во внимание слухи о параметрах необъявленного NV30) является несомненным лидером среди игровых ускорителей. Причем как в архитектурном плане, так и с точки зрения "грубой производительности" которая может быть предположена исходя из спецификации и первых опубликованных в сети результатов ранних карт.
Впрочем, какие-либо выводы о его реальном рыночном положении можно будет сделать, только сравнив спецификации и производительность в приложениях окончательных версий R300 и NV30. Но, на данный момент R300 в продаже недоступен, его анонс является "бумажным". Раскрытие полного потенциала новых архитектур возможно только при участии DirectX 9, выход которого ожидается осенью. К оному событию, судя по всему, будет приурочен официальный выпуск NV30, и именно тогда состоится очередной раунд битвы гигантов. Таким образом, календарное преимущество более раннего анонса R300 пока не дает этому ускорителю каких-либо реальных козырей, кроме сомнительного приоритета в PR.
- Обратим внимание на свойственную предыдущему поколению ускорителей технологическую норму .15 микрон. С одной стороны, это позволяет быстрее поставить производство R300 на поток — по некоторым данным, промышленные объемы по технологии .13 микрон не будут доступны для ATI до самой зимы. Кроме того, технология .15 обкатана ATI на своих предыдущих продуктах, что, несомненно, позволит достичь более высокого процента выхода годных чипов в самом начале производства. С другой стороны, такое количество транзисторов при такой технологии само по себе может служить причиной низкого выхода годных чипов, высокого энергопотребления, и, что самое неприятное — большой себестоимости, что не оставит существенных резервов для ценовой конкуренции.
NVIDIA же, судя по всему, решила рискнуть — одной из первых получив доступ к .13 технологии, фирма находится в зеркальной по отношении к ATI ситуации. Новый техпроцесс грозит мучительной доводкой, возможным сдвигом выпуска в промышленных масштабах и низким начальным процентом выхода годных чипов. С другой стороны, по мере обкатки процесса NVIDIA будет получать все большее преимущество в себестоимости и, разумеется, тактовой частоте (изначально более высокочастотные архитектуры NVIDIA + более тонкая технология дают соотношение 400 против 300). Итак, время работает на NVIDIA, возможно, именно этот факт поторопил ATI с бумажным анонсом и (если это будет возможно по срокам) поторопит ее с выпуском карт в продажу еще до выхода DirectX 9.
Как бы там ни было, ставка на "почасовой калифат" — это рискованно.
- R300, несомненно, соответствует требованиям DX9 и является сознательным железным воплощением этого API. NV30 в свою очередь, по некоторым данным, готов предложить еще больше.
Вопрос в том, будут ли эти возможности NV30 так или иначе включены в DX (например, в виде некоего DX9.1, шейдеров 2.1 и т.д.) или останутся доступными только в виде расширений OpenGL.
- Нам предстоит насладиться серьезной конкуренцией двух близких по характеристикам продуктов, нацеленных на одну нишу и даже, судя по всему, выходящих в свет практически одновременно.
Лекция четвертая — контроллер памяти
Интересно, что в новом продукте ATI выбирает уже знакомый нам по продуктам NVIDIA подход к управлению памятью — четырехканальный контроллер памяти и внутренний коммутатор на чипе:
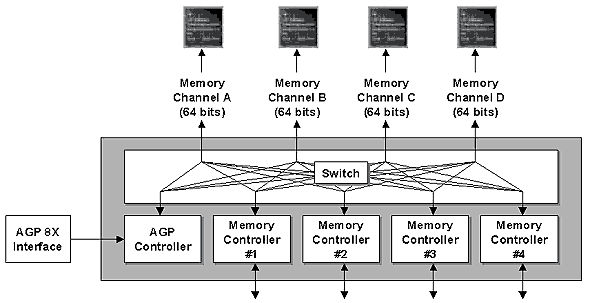
Согласитесь, картинка знакомая. Ранее ATI предпочитала двух- или одноканальные контроллеры, и, соответственно, пересылки данных крупными блоками, в то время как NVIDIA еще со времен NV20 строит кеширование и работе с памятью на более мелких блоках. У обоих подходов есть свои преимущества и недостатки, подход NVIDIA, например, сильнее нагревает память при работе и более критичен к ее параметрам и качеству. Как следствие этого — обеспечивает меньший частотный (разгонный) потенциал. Подход же ATI прекрасно дружит с памятью, но менее эффективен на сложных задачах, использующих множество потоков для доступа к памяти. По мере роста гибкости современных ускорителей, растет и число потоков, которые они считывают из памяти — тут и несколько потоков данных для вершинных шейдеров, и 4 или даже 6 текстур, накладываемых за один проход. Нет ничего удивительного в том, что подход NVIDIA становится все более и более эффективным на современных приложениях. Итак, с момента анонса R300 этот подход стал и подходом ATI :-).
Совокупность техник, применяемых для экономии пропускной полосы памяти, прибавила единичку в своем названии — теперь она называется HyperZ III. Суть осталась прежней — новых методик не реализовано, хотя, эффективность старых несомненно так или иначе повышена. В наличии сжатие и быстрая очистка буфера глубины на основе блоков 8х8, а также 3 уровня иерархического представления Z буфера для целей раннего определения видимости целых блоков полигонов. Давайте проиллюстрируем этот подход:
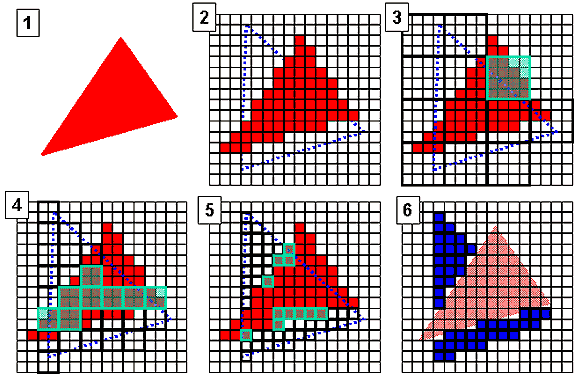
У нас есть уже закрашенный полигон (1), расположенный близко к наблюдателю. Мы хотим закрасить полигон (2), расположенный дальше и, соответственно, частично перекрытый. Вначале мы проводим поиск на самом верхнем уровне иерархического буфера глубины, на котором хранятся расстояния до самых больших блоков 4х4, и сразу выделяем блок, полностью принадлежащий верхнему треугольнику (3) и, следовательно, не нуждающийся в закраске. Таким образом, мы сразу отбрасываем необходимость закрашивать 16 точек. Затем мы переходим на более низкий уровень иерархии и отбрасываем еще 8 блоков 2х2. И на последнем уровне, детализированном до единичного пиксела, мы определяем еще несколько закрытых точек, которые не надо закрашивать. Разумеется, эта иллюстрация несколько схематична, но достаточна для понимания вычислительной выгоды и принципа работы иерархического буфера глубины.
Как и все современные ускорители, R300 снабжен технологией ранней проверки Z (Early Z Test). Суть ее проста — реальные значения цвета (а следовательно, и значения текстур и результаты работы) вычисляются только для видимых пикселей. Очевидно, что с появлением все более сложных шейдеров и методов текстурирования эта технология будет экономить все больше пропускной полосы памяти и вычислительных тактов ускорителя. На достаточно типичной сцене с коэффициентом перекрытия 2 она отбросит порядка четверти или трети пикселей. В предельном же случае (упорядоченного вывода сцены) — все 50%.
Интересно, NVIDIA назовет схожие технологии нового чипа LMA III или, в пику ATI, LMA 3? Как бы там ни было, никто не сомневается, что NVIDIA не будет сохранять прежнее название :-).
Лекция пятая — пиксельные конвейеры и текстурные блоки
С появлением DX9 требования к сложности пиксельных конвейеров чипа существенно возрастут. Основной катализатор требований — новая версия пиксельных шейдеров, 2.0, которую эти конвейеры обязаны исполнять:
| Версия | 1.1 | 1.4 | 2.0 |
|---|---|---|---|
| Текстур за проход, до | 4 | 6 | 16 |
| Команд выборки текстур, до | 4 | 6*2 | 32 |
| Вычислительных команд, до | 8 | 8*2 | 64 |
| Формат данных | I8[4] | I12[4] | F32[4] |
| Управление потоком команд | Нет | Нет | Нет |
| Вывод нескольких значений | Нет | Нет | До 4 значений |
| Доступ к Z буферу | Нет | Запись | Чтение и запись |
| Число константных регистров | 8 | 8 | 16 |
| Число общих регистров | 2 | 2 | 8 |
И это еще не все, описывая Cine FX — независимый от API аналог высокоуровневых эффект файлов DirectX 9, компилируемых как под последние версии OpenGL так и под DX9, NVIDIA упоминает о пиксельных шейдерах длиною до 1024 команд (!), исполняемых неразрывно за один проход. При этом в пиксельном шейдере может быть задействовано до 512 констант, каждая из которых при использовании засчитывается за одну команду. Судя по всему, в этом плане NV30 существенно опережает требования DX9. Поживем — увидим.
Ранее для исполнения пиксельных шейдеров применялись стадии — число текстурных стадий было равно максимальному числу используемых текстур, число вычислительных — максимальному числу команд. Каждая вычислительная стадия имела полноценное ALU и могла исполнять любую из команд шейдера. Стадии настраивались каждая на свою команду и объединялись цепочкой. В итоге, по мере обработки данные (конкретно — значения двух общих регистров) проходили через все стадии, и каждая выполняла над ними какую-либо операцию. Операция выполнялась за такт, и в итоге мы имели конвейер длиною до 8 стадий, в обработке на котором находились на разных стадиях до 8 различных точек. Конвейер выдавал по результату за такт:
| 1 такт | 2 такт | 3 такт | 4 такт | |
|---|---|---|---|---|
| 1 стадия (ADD) | 1 точка | 2 точка | 3 точка | 4 точка |
| 2 стадия (MUL) | - | 1 точка | 2 точка | 3 точка |
| 3 стадия (MUL) | - | - | 1 точка | 2 точка |
| Результат | - | - | - | 1 точка |
В действительности, создатели чипов не могли себе позволить иметь даже по 8 стадий на каждый конвейер — 32 полноценных ALU, даже целочисленного формата, заняли бы слишком много места на чипе. Обычно на каждый пиксельный конвейер делалось по 2 или 4 стадии (у Matrox Parhelia 512 — целых 5), а в случае более длинного шейдера стадии двух или даже четырех конвейеров объединялись в цепочку. Разумеется, количество закрашиваемых точек падало при таком объединении в два или в четыре раза.
По мере того, как шейдеры становятся все более сложными, подобный подход перестает оправдывать себя с любой точки зрения. Для реализации второй версии шейдеров при стадийном подходе необходимо как минимум 64 однотактовых ALU, что совершенно невыполнимо, особенно при плавающей точности представления данных. Кроме того, возрастает число временных регистров, значения которых надо хранить в каждом ALU и передавать от стадии к стадии на каждом такте. А что делать дальше, когда длина шейдеров вырастет еще больше?
Давайте посмотрим, как обстоят с этим дела на R300. В наличии 8 пиксельных конвейеров, каждый снабжен собственным процессором, исполняющим пиксельные шейдеры. Это не набор коммутируемых стадий с ALU, а именно процессор (RISC в классическом понимании) — он последовательно выполняет по команде за такт. Отсутствие управления потоком команд только упрощает дело. Да, чем длиннее шейдер, тем больше мы ждем результата. Но, с другой стороны, мы уже не столь жестко ограничены по сложности выполняемых за проход задач: теперь мы можем построить практически любую сцену за один или два прохода, и это гораздо выгоднее, чем несколько проходов более скоростных, но и более простых шейдеров. Ограничения по числу команд при новом подходе скорее символические — ничего не мешает тому же процессору исполнить последовательно 256 или 1024 команды — была бы только на чипе память для их хранения. Интересно, что для совместимости с первыми версиями шейдеров в пиксельном конвейере R300 и NV30 оставлена поддержка вычислений не только в плавающих форматах F32 и F16, но и в целочисленном формате I12. Без нее исполнение старых шейдеров могло бы натолкнуться на существенные трудности — эмуляция некоторых команд потребовала бы до 4 операций!

Примечание редактора: Почти портрет автора статьи.
Более того, для ускорения вычислений мы можем попытаться применить суперскалярный подход. Пусть и в самом примитивном варианте — как у первых суперскалярных RISC процессоров. Каждое ALU имеет в своем составе несколько функциональных блоков — блок для сложения и вычитания, блок для умножения, блок для деления, отдельное устройство отвечает за пересылки данных между регистрами. Не так сложно создать процессор, позволяющий параллельно выполнять команды, имеющие отношение к разным блокам, разумеется, при условии отсутствия зависимости между ними, т.е. когда следующая команда может исполняться, не дожидаясь результатов предыдущей. Вот почему создатели ускорителей и Microsoft рекомендуют при написании шейдеров обращать внимание на зависимость соседних команд и по возможности от нее избавляться.
С другой стороны, более продвинутое, спекулятивное исполнение с перестановкой и откатом инструкций и переименованием результатов для шейдерных процессоров пока не имеет смысла — оно очень дорого стоит с точки зрения неоправданного увеличения сложности каждого шейдерного процессора. Как всегда, в графике выгоднее распараллелить исполнение шейдеров на уровне объектов — вершин или пикселей, увеличив число параллельных процессоров исполняющих блоки, чем распараллеливать работу на уровне инструкций. И алгоритмы невелики, и соседние команды зачастую слишком тесно связаны. Именно по этому мы наблюдаем увеличенное вдвое число пиксельных и вершинных конвейеров (постепенно будем привыкать к слову "процессоров") по сравнению с R200.
Логично предположить что в скором будущем пиксельные процессоры станут полными двойниками (по набору возможностей) вершинных — тот же формат данных, те же арифметические команды, нет пока только управления порядком выполнения команд, но это поправимо. Фактически, грань между пиксельными и вершинными процессорами будет стираться. Через несколько поколений архитектур графический ускоритель превратится в набор одинаковых векторных процессоров общего назначения, между которыми будут находиться гибко конфигурируемые очереди для асинхронной передачи параметров. Роли процессоров будут на ходу распределяться в зависимости от используемого подхода к построению изображения баланса необходимой производительности на тех или иных задачах:

Интересно, что R300 построен по конфигурации 8х1 — к каждому пиксельному конвейеру привязан только один текстурный блок:
Один из восьми пиксельных конвейеров R300
Судя по всему, это вынужденная экономия, вызванная технологической нормой в .15 микрон. Можно придумать множество достаточно реалистичных ситуаций в пиксельном шейдере, когда ожидание результатов от единственного текстурного блока существенно снизит скорость исполнения шейдера! Причем можно прекрасно избежать этих простоев именно при наличии второго текстурного блока, повысив скорость выполнения пиксельного шейдера в полтора или даже два раза. Что ж, оставим это решение на совести ATI, радуясь тому что, несмотря на единственный текстурный блок, мы теперь можем выполнять с его помощью трилинейную фильтрацию без потери скорости. А также (исправлен известный недостаток R200) сочетать трилинейную и анизотропную фильтрацию.
При условии выполнения столь длинных шейдеров, вполне разумным видится несколько иной подход к организации текстурных блоков. Представьте себе, что блоки уже не привязаны намертво к конкретному пиксельному конвейеру, а обслуживают любой из них в порядке поступления запросов на выборку текстур. В таком случае, мы могли бы запускать шейдеры на разных конвейерах с некоторым временным сдвигом на несколько команд, компенсируя тем самым неравномерное чередование вычислений и доступа к текстурам. Вначале все блоки набрасывались бы на обслуживание тех конвейеров, которые ждут текстур, а другие конвейеры занимались бы вычислениями, потом ситуация менялась бы с точностью до наоборот. Таким образом, простой блоков существенно снизится, и можно будет говорить о том, что 8 общих блоков достаточны для 8 конвейеров. Вполне возможно, что ATI так и поступила, просто не желает разглашать детали реализации. Вполне возможно, что так поступит и NVIDIA в одном из своих будущих чипов — ведь эта идея уже как-то поднималась инженерами поглощенной ей 3dfx.
Лекция шестая — вершинные конвейеры и языки высокого уровня
Вершинные конвейеры не претерпели столь существенных изменений, как пиксельные, и в то же время совершили достаточно важный качественный скачок — появилась возможность управлять потоком команд. Теперь доступны подпрограммы, циклы, условные и безусловные переходы.
| Версия | 1.0 | 2.0 |
|---|---|---|
| Команд, до | 128 | 256 |
| Управление потоком команд | Нет | Да |
| Формат данных | F32[4] | F32[4] |
| Число константных регистров | 96 | 256 |
| Число общих регистров | 8 | 16 |
Впрочем, пока все решения по изменению потока команд принимаются на основании передаваемых в шейдер извне констант, что существенно ограничивает возможности оперативно принимать решения для каждой вершины в отдельности. Непонятны мотивы, по которым Microsoft остановился на таком половинчатом решении — судя по всему, ATI R300 (и NVIDIA NV30) не раскручивают циклы и подпрограммы в непрерывный ряд команд, а честно позволяют указателю следующей инструкции перемещаться по памяти команд внутри чипа. Что ж, в следующем поколении DX это ограничение будет снято, и мы сможем без оглядки называть вершинные конвейеры любого ускорителя вершинными процессорами. В отличии от R300, NV30 уже сейчас позволяет управлять порядком команд на основе данных из временных регистров — как и любой обычный процессор. С другой стороны, R300 позволяет исполнять шейдеры длинною до 1024 команд, NV30, по некоторым данным — только до 256 (с учетом раскрутки циклов и подпрограмм — до 65536 команд).
Все, что было сказано в предыдущей главе относительно суперскалярного исполнения может быть даже в большей мере отнесено и к вершинным шейдерам. Достаточно большие по длине шейдеры позволяют задуматься об оптимизации рассчитанной на успешное совместное выполнение команд.
Логично, что получив возможность исполнять шейдеры, состоящие из тысячи команд, создатели железа и API стали подумывать о создании языков высокого уровня. Гораздо приятнее иметь дело c диалектом С, чем с неким ассемблерным кодом, искусство программирования на котором было утрачено большинством программистов еще 8-10 лет назад. Что ж, железо, наконец, стало соответствовать, и если считать константы и команды все еще надо, то теперь счет идет на тысячи вместо сотен и на сотни вместо десятков. В скором времени сложность программ для ускорителя может сравниться со сложностью программ для обычных процессоров, по крайней мере, той их части, что отвечает за трехмерную графику.
Например, NVIDIA анонсировала свой диалект С Graphics ((CG), не путать с Computer Graphics :-)) поначалу жутко неудобный в вопросах использования, но, при всех своих недостатках, кросс API — можно компилировать код шейдеров как в OpenGL, так и, разумеется, в Direct3D среде. К компилятору прилагается роскошный набор готовых эффектов и примеров. Есть новая версия CG — для DX9. Эта версия более удобна с точки зрения привязки данных и использования, она по праву претендует на звание стандарта де факто.
Microsoft также не спит и постепенно отлаживает свой HLSL — фактически, тот же CG (можно было бы сказать и наоборот — разработка проводилась NVIDIA и Microsoft совместно), но действующий только в пределах DirectX. Кроме того, пока HLSL работает только с вершинными шейдерами.
ATI также не остается в стороне и объявляет какую-то графическую обезъяну (Render Monkey). Этот диалект имеет свои отличия. Наиболее удобными на данный момент следует признать CG и Cine FX от NVIDIA (аналог техник и эффектов из DX9, но, также как и CG, кросс API!). Хотя бы по наличию готовых экспортных плагинов для распространенных пакетов 3D моделирования и реалистичной графики.

Rendered Monkey :-)
Лекция седьмая — сглаживание, видео возможности
Интересно отметить отсутствие каких-либо прорывов в технике сглаживания — по сути, это все тот же SMOOTHVISION 2х, 4х и 6х, хотя и названный (а что вы ждали) SMOOTHVISION 2.0. Впрочем, несмотря на тот же подход к формированию псевдослучайных масок, сэмплы оных выбираются теперь методом мультисамплинга (MSAA), что должно несколько повысить производительность метода (несколько размыв текстуры) по сравнению с реализованным в R200 SSAA SMOOTHVISION. Впрочем, и первый был неплох. Cкорость MSAA, версии по предварительным данным, заметно возросла. Может быть, из-за более широкой шины, а может и из-за оптимизированного алгоритма. В практической части обзора R300 мы подробно исследуем вопросы падения производительности при включении FSAA и анизотропной фильтрации. Отметим также, что на прозрачных текстурах (с альфа каналом) чип переключается в SSAA режим, честно выбирая все семплы для каждой точки треугольника, а не только для его краев.
Интересно, что же предложит в своем новом чипе NVIDIA, различные гибриды на основе MSAA в исполнении которой смотрятся на фоне SMOOTHVISION несколько отстало?
Еще один существенный момент R300 — технология видеошейдеров. Ее суть в светлой идее использовать вычислительные возможности пиксельных конвейеров для перекладывания на их плечи части задач по кодированию и декодированию MPEG1/2 видеопотоков, а также по конверсии цветовых пространств, деинтерлейсингу, а также прочих задач обработки видео. На этой схеме мы видим, какие задачи переложены на пиксельные шейдеры, а какие по-прежнему выполняются выделенными аппаратными блоками:
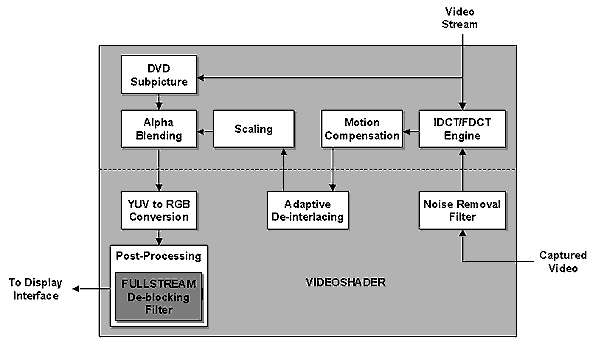
В ближайшем будущем гибкость и производительность шейдерных процессоров позволит им, судя по всему, аппаратно решать достаточно сложные задачи двуxмерного видео (вернее сказать, самые вычислительно интенсивные части сложных задач)- вплоть до распаковки MPEG4. Можно придумать и совсем сказочные применения — такие, как сжатие звука и распознавание речи! Почему бы не воспользоваться огромной вычислительной мощью, превратив ускоритель в сопроцессор общего назначения?

Выводы
Говорить о какой-либо победе ATI в лице R300 рано и нелепо — скорее можно назвать победой соотношение возможностей и цены младшего чипа 9000 линейки — RV250. Говорить о четком поражении R300 также рано и снова нелепо — налицо все задатки для здоровой конкуренции. Ждем карт, ждем DX9.
Если же попытаться формализовать интуитивные оценки на основе имеющейся сейчас информации и в отрыве от еще неизвестных цен, автор данной статьи расставил бы призовые места в следующем порядке: NV30, R300. Что поделать, дружба вновь проиграла.


