Часть 1-я
Оглавление
- «Крутой и холодный».
- Фронт конвейера: Предсказание переходов; Декодирование и IDQ; Стековый движок; Тайная жизнь нопов.
- Кэш мопов: Цели и предшественники; Устройство; Размеры; Ограничения; Работа.
- Диспетчер и планировщик: Переименование и размещение; Новый старый стиль.
- Исполнительная стадия: Тракты данных; Конфликты завершения; Межтрактные шлюзы; Вещественные денормалы; Частичный доступ к регистрам.
- AVX: Реализация; Подножка; Решение; Сохранение состояния; Динамические тайминги; Новые и отсутствующие команды.
- Тайминги команд.
- Кэши: L1D; LSU; Внеочерёдный доступ; STLF; Задержки чтения; TLB; Аппаратная предзагрузка.
- Hyper-Threading.
- Внеядро: Кэш L3; Кольцевая шина; Поддержка аппаратной отладки; Когерентность и «поддержка» OpenCL; Системный агент и ИКП.
- Turbo Boost 2.0.
- Экономия.
- Модели и чипсеты.
- Кристалл: Техпроцесс; Виды кристаллов; Устройство ГП; Устройство банка L3; 2-ядерные кристаллы.
- Производительность.
- Перспективы и итоги.
Читатель наверняка знаком с кратким описанием микроархитектуры Sandy Bridge и помнит, что для той статьи мы использовали лишь иллюстрации из презентаций Intel, снабдив их нашими комментариями. Очевидно, они рассказывают не всю историю, поэтому нужна детальная статья, где история рассказывается вся и уже из независимого источника. ;) Кроме того, т. к. в своё время мы не делали подробного описания предыдущей микроархитектуры Nehalem, восполним это тем, что детально опишем не только ныне добавленные и изменившиеся элементы, но и старые (притом, что они не обязательно появились в Nehalem — некоторые цифры и факты куда древнее). Также мы испытаем нововведение: специфические термины и сокращения будут особо выделены, а при наведении на них курсора покажется всплывающая подсказка-расшифровка со ссылкой на нашу «Энциклопедию процессорных терминов» (которая, кстати, обновляется перед выходом каждой статьи).
«Крутой и холодный»
Прежде всего, какой ЦП был нужен Intel после 2008 г., когда микроархитектурное превосходство первых Core i (Nehalem и, в 2009 г., Westmere) над ЦП соперника стало окончательным? Ситуация немного напоминает первый год после выхода Pentium II: почивая на лаврах и получая рекордную прибыль, хорошо бы сделать продолжение удачной архитектуры, не сильно изменив её название, добавив новые команды, использование которых значительно улучшит производительность, не забыв и о других новшествах, ускоряющих сегодняшние версии программ. Правда, в отличие от ситуации 10-летней давности, надо обратить внимание и на модную ныне тему энергоэффективности, обыгранную двусмысленным прилагательным Cool — «крутой» и «холодный», — и не менее модное стремление встроить в процессор всё, что пока ещё существует как отдельные микросхемы. Вот под таким соусом и подана новинка.

«Позавчера», «вчера» и «сегодня» процессоров Intel.
Интегрированный в кристалл ЦП графический процессор (ГП) мы детально рассмотрим в отдельной статье. Тут же исследуем результат работы израильского отделения Intel (Israel Development Center), которому в очередной раз поручили сделать ещё более экономную модификацию текущей (на 2008 г.) универсальной серверно-настольно-мобильной архитектуры (назовём её просто Nehalem). Правда, изначальное кодовое имя Gesher («мост» на иврите) по «политическим» причинам (была в Израиле такая партия, да сплыла…) пришлось изменить на Sandy Bridge — «песчаный мост» (сократим его до SB). Причина задержки не совсем ясна: следуя своей обычной практике выпуска каждый нечётный год нового техпроцесса («тик»), а каждый чётный — микроархитектуры («так»), SB должен был выйти в 2010 г. — тем более, что половина якобы новых добавленных в него идей уже были в предыдущих ЦП Intel. Тем не менее, учитывая состояние ЦП конкурента, нельзя сказать, что SB опоздал. Конечно, инженерам Intel надо бы поглядывать в сторону новых архитектур AMD, которые в ближайшем будущем (и опоздав гораздо больше, чем на год), кажется, чем-то грозят…
Технически задача стояла примерно так: на той же площади кристалла (т. е. при той же себестоимости) и том же 32 нм техпроцессе сделать ЦП, который на старых программах имел бы +10% скорости и −20% потребления одновременно, а на новых (где используются добавленные команды) — аж +100% пиковой скорости при том же TDP. Возможно, цифры были чуть другие, но почти так это выглядит по результатам. А вот какими методами — проще всего узнать, сравнивая SB с Nehalem (это относится к многочисленным прилагательным «больше», «быстрее», «экономней» и пр. далее в тексте). Напрашивается сравнение и с выходящей в середине 2011 г. архитектурой AMD Bulldozer, но оно будет после детального обзора её самой. Intel постепенно заместит архитектуру почти всех своих выпускаемых сегодня x86-ЦП (кроме Atom) с Nehalem на SB. Позиционирование против ЦП AMD пока точно не ясно, но один гол в ворота соперника уже забит: SB уже успела нещадно побить сегодняшние «Феномы», а обновлённые соперники выйдут на несколько месяцев позже — и не факт, что возьмут реванш.
Фронт конвейера
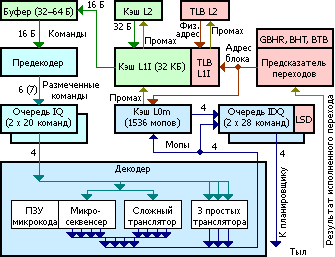
Фронт конвейера. Цвета показывают разные виды информации и обрабатывающих или хранящих её блоков.
Предсказание переходов
Начнём с заявления Intel о полностью переработанном предсказателе переходов (BPU). Как и в Nehalem, он каждый такт (и наперёд реального исполнения) предсказывает адрес следующей 32-байтовой порции кода в зависимости от предполагаемого поведения команд перехода в только что предсказанной порции — причём, судя по всему, вне всякой зависимости от числа и типа переходов. Точнее, если в текущей порции есть предположительно срабатывающий переход, выдаются его собственный и целевой адреса́, иначе — переход к следующей подряд порции. Сами предсказания стали ещё точней за счёт удвоения буфера целевых адресов (BTB), удлинения регистра глобальной истории переходов (GBHR) и оптимизации хэш-функции доступа к таблице шаблонов поведения (BHT). Правда, фактические тесты показали, что в некоторых случаях эффективность предсказания всё же чуть хуже, чем в Nehalem. Может быть, увеличение производительности с уменьшением потребления не совместимо с качественным предсказанием переходов? Попробуем разобраться.
В Nehalem (как и других современных архитектурах) BTB присутствует в виде двухуровневой иерархии — малый-«быстрый» L1 и большой-«медленный» L2. Происходит это по той же причине, почему существуют несколько уровней кэша: одноуровневое решение окажется слишком компромиссным по всем параметрам (размер, скорость срабатывания, потребление и пр.). Но в SB архитекторы решили поставить один уровень, причём размером вдвое больше, чем L2 BTB у Nehalem, т. е. наверняка не менее 4096 ячеек — именно столько их в Atom. (Следует учесть, что размер наиболее часто исполняемого кода медленно растёт и всё реже умещается в кэше L1I, размер которого совпадает у всех ЦП Intel с первых Pentium M.) По идее, при этом увеличится занимаемая BTB площадь, а т. к. общую площадь ядра менять не рекомендуется (таков один из начальных постулатов архитектуры) — у какой-то другой структуры что-то придётся забрать. Но остаётся ещё и скорость. Учитывая, что SB должен быть рассчитан на чуть большую скорость при том же техпроцессе, можно ожидать, что эта крупная структура будет бутылочным горлышком всего конвейера — если только не конвейеризировать и её (двух стадий уже хватит). Правда, общее число срабатывающих за такт транзисторов в BTB при этом удвоится, что совсем не способствует энергоэкономии. Опять тупик? На это Intel отвечает, что новый BTB хранит адреса в некоем сжатом состоянии, что позволяет иметь вдвое больше ячеек при похожих площади и потреблении. Но проверить это пока невозможно.
Смотрим с другой стороны. SB получил не новые алгоритмы предсказания, а оптимизированные старые: общий, для косвенных переходов, циклов и возвратов. Nehalem имеет 18-битный GBHR и BHT неизвестного размера. Впрочем, можно гарантировать, что число ячеек в таблице меньше, чем 218, иначе она бы заняла бо́льшую часть ядра. Поэтому существует специальная хэш-функция, сворачивающая 18 бит истории всех переходов и биты адреса команды в индекс меньшей длины. Причём, скорее всего, хэшей как минимум два — для всех битов GBHR и для тех, что отражают срабатывание наиболее трудных переходов. И вот эффективность хаотичного распределения индексами различных шаблонов поведения по номерам ячеек BHT определяет успешность предсказателя общего вида. Хотя явно это не сказано, но Intel наверняка улучшила хэши, что позволило использовать GBHR бо́льшей длины с не меньшей эффективностью заполнения. А вот о размере BHT по прежнему можно гадать — как и о том, как на самом деле изменилось потребление энергии предсказателем в целом… Что касается буфера адресов возвратов (RSB), он по-прежнему 16-адресный, но введено новое ограничение на сами вызовы — не более четырёх на 16 байт кода.
Пока мы не ушли далее, скажем о небольшом несоответствии декларируемой теории и наблюдаемой практики — а она показала, что предсказатель циклов в SB изъят, в результате чего предсказание финального перехода в начало цикла делается общим алгоритмом, т. е. хуже. Представитель Intel заверил нас, что ничего «хуже» быть не должно, однако…
Декодирование и IDQ
Предсказанные наперёд адреса исполняемых команд (попеременно для каждого потока — при включенной технологии Hyper-Threading) выдаются для проверки их наличия в кэшах команд (L1I) и мопов (L0m), но о последнем умолчим — опишем пока остальную часть фронта. Как ни странно, Intel сохранила размер считываемой из L1I порции команд в 16 байт (тут слово «порция» понимается согласно нашему определению). До сих пор это было препятствием для векторного кода, средний размер команд которого перерос 4 байта, а потому 4 команды, желательные для исполнения за такт, уже не уместятся в 16 байт. AMD решила эту проблему в архитектуре K10, расширив порцию команд до 32 байт — хотя её ЦП пока имеют не более чем 3-путный конвейер. В SB неравенство размеров приводит к побочному эффекту: предсказатель выдаёт очередной адрес выровненного 32-байтового блока, и если обнаружится (предположительно) срабатывающий переход в его первой половине, то считывать и декодировать вторую не надо — однако это будет сделано.
Из L1I порция попадает в буфер предекодера, а оттуда — в сам предекодер-длиномер (ILD), обрабатывающий до 7 или 6 команд/такт (с и без макрослияния; Nehalem умел максимум 6) в зависимости от их совокупной длины и сложности. Сразу после перехода обработка начинается с команды по целевому адресу, иначе — с того байта, перед которым предекодер остановился тактом ранее. Аналогично с финальной точкой: либо это (вероятно) срабатывающий переход, адрес последнего байта которого поступил от BTB, либо последний байт само́й порции — если только не достигнут предел в 7 команд/такт, или не встретилась «неудобная» команда. Скорее всего, буфер длиномера имеет всего 2–4 порции, однако длиномер может получить из него любые 16 подряд идущих байт. Например, если в начале порции опознаны 7 двухбайтовых команд, то в следующем такте можно обработать ещё 16 байт, начиная с 15-го.
Длиномер, помимо прочего, занимается обнаружением пар макросливаемых команд. О самих парах поговорим чуть позже, а пока заметим, что, как и в Nehalem, каждый такт может быть обнаружено не более одной такой пары, хотя максимум их можно было бы разметить 3 (и ещё одну одиночную команду). Однако измерение длин команд — процесс частично последовательный, так что определить несколько макросливаемых пар не удалось бы в течение такта.
Размеченные команды попадают в одну из двух очередей команд (IQ: instruction queue) — по одной на поток, на 20 команд каждая (что на 2 больше, чем у Nehalem). Декодер попеременно читает команды из очередей и переводит их в мопы. В нём есть 3 простых транслятора (переводят 1 команду в 1 моп, а с макрослиянием — 2 команды в 1 моп), сложный транслятор (1 команда в 1–4 мопа или 2 команды в 1 моп) и микросеквенсер для самых сложных команд, требующих 5 и более мопов из микрокода. Причём ПЗУ микрокода хранит только «хвосты» каждой последовательности, начиная с 5-го мопа, потому что первые 4 выдаются сложным транслятором. При этом если число мопов в микропрограмме не делится нацело на 4, то их последняя четвёрка будет неполной, но вставить ещё 1–3 мопа от трансляторов в этом же такте не получится. Результат декодирования поступает в кэш мопов и два буфера мопов (по одному на поток). Последние (официально именуемые IDQ — instruction decode queue, очередь декодированных команд) по-прежнему имеют по 28 мопов и возможность блокировки цикла, если его исполняемая часть там уместится.
Всё это (кроме кэша мопов) уже было в Nehalem. А в чём же различия? Прежде всего, что очевидно, декодер научили обрабатывать новые команды поднабора AVX. Поддержка наборов SSE со всеми цифрами уже никого не удивляет, а ускорение шифрования командами AES-NI (включая PCLMULQDQ) было добавлено в Westmere (32 нм версия Nehalem). В микрослияние подложили подводный камень: эта функция не срабатывает для команд, имеющих и константу, и RIP-относительную адресацию (RIP-relative, адрес относительно регистра-указателя команды — обычный способ обращения к данным в 64-битном коде). Такие команды требуют 2 мопа (отдельно загрузка и операция), а значит — декодер их обработает не более одной за такт, используя лишь сложный транслятор. Intel утверждает, что эти жертвы сделаны для экономии энергии, только не ясно, на чём: двухкратные размещение, исполнение и отставка мопов явно займут больше ресурсов, а значит — и потребят энергии, чем один.
Макрослияние оптимизировано — ранее в качестве первой сливаемой команды могло быть лишь арифметическое или логическое сравнение (CMP или TEST), теперь же допустимы простые арифметические команды сложения и вычитания (ADD, SUB, INC, DEC) и логического «И» (AND), также меняющие флаги для условного перехода (вторая команда пары). Это позволяет почти в любом цикле сократить последние 2 команды до 1 мопа. Разумеется, ограничения на сливаемые команды остались, но они некритичны, т. к. перечисленные ситуации для пары команд почти всегда исполняются:
- первый операнд первой команды должен быть регистром;
- если второй операнд первой команды находится в памяти, RIP-относительная адресация недопустима;
- вторая команда не может находиться в начале строки кэша или пересекать границу строк.
Правила для самого́ перехода такие:
- только TEST и AND совместимы с любым условием;
- сравнения на (не) равно и любые знаковые совместимы с любой разрешённой первой командой;
- сравнения на (не) перенос и любые беззнаковые не совместимы с INC и DEC;
- остальные сравнения (знак, переполнение, чётность и их отрицания) допустимы лишь для TEST и AND.
Главное изменение в очередях мопов — слитые мопы типа load-ex, обращение в память в которых требует чтения индексного регистра, (и ещё несколько редких видов) при записи в IDQ разделяются на пары. Даже если таких мопов попадётся 4, то в IDQ запишутся все 8 итоговых. Делается это потому, что в очередях мопов (IDQ), диспетчера (ROB) и резервации теперь применяется сокращённый формат мопа без 6-битного поля индекса (разумеется, для экономии при перемещении мопов). Предполагается, что такие случаи будут редки, а потому на скорость сильно влиять не будут.
Историю возникновения у этого буфера режима блокировки цикла мы расскажем ниже, а тут лишь укажем одну мелочь: переход на начало цикла ранее занимал 1 дополнительный такт, образуя «пузырь» между чтениями конца и начала цикла, а теперь его нет. Тем не менее, в четвёрке читаемых за такт мопов не могут оказаться последние из текущей итерации и первые из следующей, поэтому в идеале число мопов в цикле должно нацело делиться на 4. Ну а критерии для его блокировки почти не изменились:
- мопы цикла должны порождаться не более чем 8-ю 32-байтовыми порциями исходного кода;
- эти порции должны быть закэшированы в L0m (в Nehalem, разумеется, — в L1I);
- допускается до 8 безусловных переходов, предсказанных как срабатывающие (включая финальный);
- вызовы и возвраты недопустимы;
- недопустимы непарные обращения в стек (чаще всего при неравном числе команд PUSH и POP) — об этом ниже.
Стековый движок
Есть ещё один механизм, работу которого мы в прошлых статьях не рассматривали — стековый движок (stack pointer tracker, «следитель за указателем (на вершину) стека»), расположенный перед IDQ. Он появился ещё в Pentium M и до сих пор не изменился. Суть его в том, что модификация указателя стека (регистра ESP/RSP для 32/64-битного режима) командами для работы с ним (PUSH, POP, CALL и RET) делается отдельным сумматором, результат хранится в специальном регистре и возвращается в моп как константа — вместо того, чтобы модифицировать указатель в АЛУ после каждой команды, как это требует программная архитектура и как было в ЦП Intel до Pentium M.
Это происходит до тех пор, пока какая-то команда не обратится к указателю напрямую (и в некоторых других редких случаях) — стековый движок сравнивает теневой указатель с нулём и при ненулевом значении вставляет в поток мопов до вызывающей указатель команды синхронизирующий моп, записывающий в указатель актуальное значение из спецрегистра (а сам регистр сбрасывается). Поскольку требуется это редко, большинство обращений в стек, лишь неявно модифицирующих указатель, пользуются его теневой копией, изменяемой одновременно с остальными операциями. Т. е. с точки зрения блоков тыла конвейера такие команды кодируются единственным слитым мопом и ничем не отличаются от обычных обращений в память, не требуя обработки в АЛУ.
Внимательный Читатель (добрый день!) заметит связь: при зацикливании очереди мопов непарные обращения в стек недопустимы именно по причине того, что стековый движок в конвейере находится до IDQ — если после очередной итерации значение теневого указателя окажется ненулевым, в новой потребуется вставить синхромоп, а в циклическом режиме это невозможно (мопы только читаются из IDQ). Более того, стековый движок вообще при этом выключен для экономии энергии, как и все остальные части фронта.
Тайная жизнь нопов
Ещё одно изменение коснулось длиномера, но этот случай несколько выделяется. Сначала вспомним, что такое нопы и зачем они нужны. Когда-то в архитектуре x86 ноп был лишь 1-байтовый. Когда требовалось сместить код более чем на 1 байт или заменить команды длиной более 1-го байта, ноп просто вставляли несколько раз. Но несмотря на то, что эта команда ничего не делает, время на её декодирование всё-таки тратится, причём пропорционально числу нопов. Чтобы производительность «пропатченной» программы не просела, ноп можно удлинить префиксами. Однако в ЦП 90-х годов темп декодирования команд с числом префиксов выше определённой величины (которая куда меньше максимально допустимой длины x86-команды в 15 байт) резко падал. Кроме того, конкретно для нопа префикс применяется, как правило, одного вида, но многократно повторенный, что допускается лишь как нежелательное исключение, усложняющие длиномер.
Для разрешения указанных проблем начиная с Pentium Pro и Athlon процессоры понимают «длинный ноп» с байтом modR/M для «официального» удлинения команды с помощью регистров и адресного смещения. Естественно, никаких операций с памятью и регистрами не происходит, но при определении длины используются те же блоки длиномера, что и для обычных многобайтовых команд. Теперь использование длинных нопов официально рекомендуется учебниками по низкоуровневой программной оптимизации и от Intel, и от AMD. Кстати, предекодер SB вдвое (с 6 до 3 тактов) уменьшил штраф за префиксы 66 и 67, меняющие длину константы и адресного смещения — но, как и в Nehalem, штраф не накладывается на команды, где эти префиксы фактически не меняют длину (например, если префикс 66 применён к команде без непосредственного операнда) или являются частью списка переключателей опкодов (что сплошь и рядом используется в векторном коде).
Максимальная длина верно оформленного длинного нопа не превышает 9 байт для Intel и 11 для AMD. А потому для выравнивания на 16 или 32 байта нопов всё-таки может быть несколько. Однако т. к. команда эта простая, её декодирование и «исполнение» займёт ресурсов никак не больше обработки самых простых действующих команд. Поэтому уже много лет тестирование длинными нопами является стандартным методом определения параметров фронта конвейера, в частности — пропускной способности длиномера и декодера. И вот тут Sandy Bridge преподнёс очень странный сюрприз: тестирование производительности обычных программ не выявило никаких задержек и замедлений, а вот дежурная синтетическая проверка параметров декодера неожиданно показала, что его производительность равна одной команде за такт! При этом никаких официальных оповещений о таких радикальных изменениях в декодере Intel не давала.
Процедура замера отлично работала ещё на Nehalem и показывала верные 4 IPC. Можно свалить вину на новый и «чрезмерно» активный Turbo Boost 2.0, портящий замеряемые показатели тактов, но для тестов он был отключен. Перегрев с замедляющим частоту тротлингом тоже исключён. А когда, наконец, причина обнаружилась — стало ещё страннее: оказывается, длинные нопы на SB обрабатываются только первым простым транслятором, хотя 1-байтовые нопы с любым числом префиксов и аналогичные «по бездействию» команды (например, копирование регистра в себя) запросто принимаются всеми четыремя. Зачем так было делать — не ясно, однако как минимум один недостаток такого технического решения уже себя явно показал: на выяснение причин загадочной медлительности декодера нашей исследовательской командой было угрохано дней десять… В отместку просим яростных фанатов Противоположного Лагеря придумать какую-нибудь конспирологическую теорию о коварных планах некой компании I. по запутыванию наивных доблестных исследователей процессоров. :)
Кстати, как оказалось, «более равным» среди прочих транслятор №1 уже был. В Nehalem команды циклической прокрутки (ROL и ROR) с явным операндом-константой тоже декодировались только в первом трансляторе, причём в этом же такте отключался четвёртый, так что величина IPC падала до 3-х. Казалось бы — зачем приводить тут такой редкий пример? Но именно из-за этого подвоха, чтобы добиться пиковой скорости на алгоритмах хэширования вроде SHA-1, нужна была очень точная планировка команд, с которой компиляторы не справлялись. В SB же такие команды просто стали 2-мопными, так что, занимая сложный транслятор (который и так один), они ведут себя почти неотличимо для ЦП, но более предсказуемо для человека и компилятора. С нопами же получилось всё наоборот.
Кэш мопов
Цели и предшественники
Мы не зря отделили эту главу от остального описания фронта — добавление кэша мопов наглядно демонстрирует, какой путь выбрала Intel для всех своих процессоров, начиная с Core 2. В последний впервые (для Intel) был добавлен блок, который одновременно достигал две, казалось бы, противоречивые цели: увеличение скорости и экономия энергии. Речь идёт об очереди команд (IQ) между предекодером и декодером, хранившей тогда до 18 команд длиной до 64 байт в сумме. Если бы она только сглаживала разницу темпов подготовки и декодирования команд (как обычный буфер) — выгода была бы небольшая. Но в Intel догадались приделать к IQ небольшой блок LSD (вряд ли парни что-то «приняли», просто у них юмор такой) — Loop Stream Detector, «детектор циклического потока». При обнаружении цикла, умещающегося в 18 команд, LSD отключает все предыдущие стадии (предсказатель, кэш L1I и предекодер) и поставляет из очереди в декодер команды цикла, пока тот не завершится, либо пока не будет сделан переход за его пределы (вызовы и возвраты не допустимы). Таким образом экономится энергия за счёт отключения временно простаивающих блоков и увеличивается производительность за счёт гарантированного потока в 4 команды/такт для декодера, даже если они были «снабжены» самыми неудобными префиксами.
Intel явно понравилась эта идея, так что для Nehalem схема была оптимизирована: IQ продублирована (для двух потоков), а между декодером и диспетчером (т. е. аккурат на границе фронта и тыла) были поставлены две очереди IDQ на 28 мопов каждая, и блок LSD перенесли к ним. Теперь при блокировке цикла отключается ещё и декодер, а производительность поднялась в т. ч. за счёт гарантированного притока уже не 4-х команд, а 4-х мопов за такт, даже если их генерация производилась с минимальным (для Core 2/i) темпом в 2 мопа/такт. Яростные фанаты Противоположного Лагеря, на секунду оторвавшись от любимого занятия, тут же вставят шпильку: если LSD такая хорошая штука, почему же его не встроили в Atom? И шпилька справедлива — имея 32-моповую очередь после декодера, Atom не умеет блокировать в ней цикл, что как раз очень бы пригодилось для экономии драгоценных милливатт. Тем не менее, Intel не собиралась бросать идею и для новых ЦП подготовила обновление, да ещё какое!
Официальное внутреннее название кэша мопов — DSB (decode stream buffer: буфер потока декодирования), хотя он не так точно отражает суть, как рекомендуемый термин DIC (decoded instruction cache: кэш декодированных команд). Как ни странно, он не подменяет, а дополняет очереди IDQ, которые теперь соединяются с декодером или с кэшем мопов. При очередном предсказании перехода целевой адрес одновременно проверяется в кэшах команд и мопов. Если сработает последний — то далее считывание идёт из него, а остальной фронт отключается. Вот почему кэш мопов является кэшем нулевого уровня для мопов, т. е. L0m.
Интересно, что продолжить эту мысль можно, назвав IDQ кэшами «минус первого» уровня. :) Но не является ли такая сложная иерархия в рамках даже не всего ядра, а одного только фронта избыточной? Пускай Intel в качестве исключения не пожалела площадь, но принесёт ли пара IDQ существенную дополнительную экономию, учитывая, что при их работе теперь отключается лишь кэш мопов, т. к. остальной фронт (кроме предсказателя) и так спит? И ведь особой прибавки к скорости тоже не получишь, т. к. кэш мопов также настроен на генерацию 4 мопов/такт. Видимо, инженеры Intel решили, что 3-уровневая игра стоит милливаттовых свеч.
Кроме экономии, кэш мопов ускоряет производительность в т. ч. сокращением штрафа при фальш-предсказании перехода: в Nehalem при нахождении верного кода в L1I штраф был 17 тактов, в SB — 19, но если код нашёлся в L0m — то только 14. Причём это максимальные цифры: при внеочерёдном исполнении ложно предсказанного перехода планировщику надо ещё запустить и завершить предыдущие в программном порядке мопы, а за это время L0m может успеть подкачать верные мопы, чтобы планировщик успел их запустить сразу после отставки команд до перехода. В Nehalem такой приём работал с IDQ и фронтом, но в первом случае вероятность того, что верный целевой адрес тоже будет внутри 28-мопового цикла, весьма мал, а во втором медлительность фронта в большинстве случаев не позволяла снизить задержку до нуля. У SB такой шанс больше.
Устройство
Топологически L0m состоит из 32 наборов по 8 строк (8-путная ассоциативность). В каждой строке хранится 6 мопов (во всём кэше — 1536, т. е. «полтора киломопа»), причём за такт кэш может записать и считать по одной строке. Предсказатель выдаёт адреса 32-байтовых блоков, и именно этот размер является рабочим для L0m, поэтому далее под термином «порция» будем понимать выровненный и предсказанный как исполняющийся 32-байтовый блок кода (а не 16-байтовый, как для декодера). При декодировании контроллер L0m ждёт обработки порции до конца или до первого срабатывающего в ней перехода (разумеется, предположительно — тут и далее полагаем предсказания всегда верными), накапливая мопы одновременно с их отправкой в тыл. Затем он фиксирует точки входа в порцию и выхода из неё, согласно поведению переходов. Обычно точкой входа оказывается целевой адрес срабатывающего в предыдущей порции перехода (точнее, младшие 5 бит адреса), а точкой выхода — собственный адрес срабатывающего перехода в этой порции. В крайнем случае, если ни в предыдущей, ни в текущей порциях не сработает ни один переход (т. е. порции не только исполняются, но и хранятся подряд), то обе выполнятся целиком — вход в них будет на нулевом мопе и первом байте первой целиком уместившейся в этой порции команды, а выход — на последнем мопе последней целиком уместившейся команды и её начальном байте.
Если в порции оказалось более 18 мопов — она не кэшируется. Это задаёт минимум среднего (в пределах порции) размера команды в 1,8 байта, что не будет серьёзным ограничением в большинстве программ. Можно вспомнить второй пункт ограничений IDQ — если цикл уместится в порции, но займёт от 19 до 28 мопов, его не зафиксируют ни кэш L0m, ни очередь IDQ, хотя по размеру он бы везде уместился. Впрочем, в этом случае средняя длина команд должна быть 1,1–1,7 байта, что для двух десятков команд подряд крайне маловероятно.
Скорее всего, мопы порции одновременно записываются в кэш, занимая 1–3 строки одного набора, так что для L0m нарушается один из главных принципов работы наборно-ассоциативного кэша: при кэш-попадании обычно срабатывает одна строка набора. Тут же теги до трёх строк могут получить адрес одной и той же порции, отличаясь лишь порядковыми номерами. При попадании предсказанного адреса в L0m считывание происходит аналогично — срабатывают 1, 2 или 3 пути нужного набора. Правда, такая схема таит в себе недостаток.
Если исполняемая программа во всех порциях декодируется в 13–18 мопов, что займёт по 3 строки L0m для всех порций, обнаружится следующее: если текущий набор уже занят двумя 3-строчными порциями, и в него пытается записаться третья (которой не хватит одной строки), придётся вытеснить одну из старых, а с учётом её связности — все 3 старых. Таким образом больше двух порций «мелко-командного» кода в наборе не должно уместиться. При проверке этого предположения на практике получилось вот что: порции с крупными командами, требующие менее 7 мопов, упаковались в L0m числом в 255 (ещё одну занять почему-то не получилось), уместив почти 8 КБ кода. Средние порции (7–12 мопов) заняли все 128 возможных позиций (по 2 строки каждая), закэшировав ровно 4 КБ. Ну а мелкие команды уместились в 66-и порциях, что на две больше ожидаемого значения (2112 байт против 2048), что, видимо, объясняется граничными эффектами нашего тестового кода. Недостача на лицо — если бы 256 6-моповых строк могли быть заполнены полностью, их бы хватило на 85 полных троек с общим размером кода 2720 байт.
Возможно, Intel не рассчитывает, что в каком-то коде будет так много коротких и простых команд, что более 2/3 его придётся на 3-строчные порции, которые станут вытеснять друг друга из L0m раньше необходимого. А даже если такой код и встретится — учитывая простоту его декодирования, остальные блоки фронта запросто справятся с задачей поставки необходимых тылу 4 мопов/такт (правда, без обещанной экономии ватт и тактов штрафа при фальш-предсказании). Любопытно, что имей L0m 6 путей, проблемы бы не возникло. Intel же решила, что иметь размер кэша на треть больше именно за счёт ассоциативности — важнее…
Размеры
Вспомним, что идея кэшировать большое количество мопов вместо команд x86, не нова. Впервые она появилась в Pentium 4 в виде кэша моп-трасс — последовательностей мопов после развёртки циклов. Причём кэш трасс не дополнял, а заменял отсутствующий L1I — команды для декодера читались сразу из L2. Не смотря на забвение архитектуры NetBurst, разумно предположить, что инженеры Intel использовали прошлый опыт, хоть и без развёртки циклов и выделенного для кэша предсказателя. Сравним старое и новое решения (новые ЦП тут названы Core i 2, потому что номера почти всех моделей с архитектурой SB начинаются с двойки):
| Pentium 4 (Willamette, Northwood) | Pentium 4 (Prescott) | Core i 2 (Sandy Bridge) | |
| Объём, Кмопов | 12 | 12 | 1,5 |
| Организация, наборов·путей | 256·8 | 256·8 | 32·8 |
| Число мопов в строке | 6 | 6 | 6 |
| ПС, мопов/такт | 3 | 3 | 4 |
| Полный размер мопа, бит* | 119 | 138 | 139–147 |
| Сжатый размер мопа, бит* | 53 | 64 | 85 |
| Эквивалентный объём, КБ* | 80 | 96 | 16 |
* — предположительно
Тут нужны пояснения. Во-первых, пропускная способность для L0m указана с учётом общего ограничения ширины конвейера в 4 мопа. Выше мы предположили, что за такт L0m может прочесть и записать по 18 мопов. Однако при чтении все 18 (если их получилось именно столько при декодировании оригинальной порции) не могут быть отправлены за такт, и отправка происходит за несколько тактов.
Далее, размер мопа в битах вообще относится к очень деликатной информации, которую производители либо вообще не выдают, либо только при припирании к стенке (дескать, вы и так уже всё вычислили, так и быть — подтвердим). Для ЦП Intel последняя достоверно известная цифра — 118 бит для Pentium Pro. Ясно, что с тех пор размер увеличился, но с этого места начинаются догадки. 118 бит для 32-битного x86-ЦП может получиться, если в мопе есть поля для адреса породившей его команды (32 бита), непосредственного операнда (32 бита), адресного смещения (32 бита), регистровых операндов (3 по 3 бита + 2 бита на масштаб для индексного регистра) и опкода (11 бит, в которых закодирован конкретный вариант x86-команды с учётом префиксов). После добавления MMX, SSE и SSE2 поле опкода наверняка выросло на 1 бит, откуда и получена цифра 119.
После перехода на x86-64 (Prescott и далее), по идее, все 32-битные поля должны возрасти до 64-х бит. Но тут есть тонкости: 64-битные константы в x86-64 допускаются только по одной (т. е. более 8 байт обе константы в команде точно не займут), а виртуальная адресация и тогда, и сейчас пока обходится 48 битами. Так что увеличить размер мопа требуется всего на 16 бит адреса и 3 дополнительных бита номеров регистров (коих стало 16) — получаем (примерно) 138 бит. Ну а в SB моп, видимо, вырос ещё на 1 бит за счёт добавления очередных нескольких сотен команд со времён последних P4, и ещё на 8 — за счёт увеличения максимального числа явно указанных регистров в команде до 5 (при использовании AVX). Последнее, впрочем, сомнительно: со времён, представьте себе, аж i386 в архитектуру x86 не была добавлена ни одна новая команда, требующая хотя бы 4 байта константы (с единственным недавним и крайне незаметным исключением в SSE4.a от AMD, о котором даже большинство программистов не знает). А т. к. Intel AVX и AMD XOP обновили кодировку лишь векторных команд, биты номеров дополнительных регистров уместятся в старшей половине частично неиспользуемого (для этих команд) 32-битного поля непосредственного операнда. Тем более, что и в само́й x86-команде 4-й или 5-й регистр кодируется как раз четыремя битами константы.
Очевидно, что хранить и пересылать таких «монстров» в сколько-нибудь большом количестве — сильно затратно. Поэтому ещё для P4 Intel придумала сокращённый вариант мопа, в котором лишь одно поле для обеих констант, причём если они там не умещаются, то недостающие биты размещаются в этом же поле соседнего мопа. Однако если он уже хранит там свои константы, то в качестве соседа приходится вставлять ноп как донор-носитель дополнительных бит. Преемственность такой схемы наблюдается и в SB: лишние нопы не вставляются, но команды с 8-байтовыми константами (или с суммой размеров константы и адресного смещения в 5–8 байт) имеют в L0m двойной размер. Впрочем, учитывая длину таких команд, больше 4-х их в порции не уместится, так что ограничение по занимаемым мопам явно некритично. Тем не менее, констатируем: SB, в отличие от предыдущих ЦП, имеет аж 3 формата мопов — декодируемый (самый полный), хранимый в кэше мопов (с сокращением констант) и основной (без поля регистра индекса), используемый далее в конвейере. Впрочем, большинство мопов проходят нетронутыми от декодирования до отставки.
Ограничения
«Правила пользования кэшем» на спецформате мопов не заканчиваются. Очевидно, столь удобный блок как L0m никак не мог оказаться совсем без ограничений той или иной степени серьёзности, о которых нам не рассказали в рекламных материалах. :) Начнём с того, что все мопы транслируемой команды должны уместиться в одной строке, иначе они переносятся в следующую. Это объяснимо тем, что адреса мопов строки хранятся отдельно (для экономии 48 бит в каждом мопе), а все порождаемые командой мопы должны соответствовать адресу её первого байта, хранимому в теге только одной строки. Для восстановления оригинальных адресов в тегах хранятся длины породивших мопы команд. «Непереносимость» мопов несколько портит эффективность использования L0m, т. к. изредка встречающиеся команды, генерирующие несколько мопов, имеют существенный шанс не уместиться в очередной строке.
Более того, мопы самых сложных команд по-прежнему хранятся в ПЗУ с микрокодом, а в L0m попадают лишь первые 4 мопа последовательности, плюс ссылка на продолжение, так что всё вместе занимает целую строку. Из этого следует, что в порции могут встретиться не более трёх микрокодовых команд, а учитывая средний размер команды более вероятным пределом будут две. В реальности, впрочем, они попадаются куда реже.
Ещё один важный момент — L0m не имеет своего TLB. Вроде бы, это должно ускорять проверку адресов (которые тут только виртуальные) и уменьшить потребление энергии. Но всё гораздо интересней — не зря все современные кэши имеют физическую адресацию. Виртуальные адресные пространства исполняемых в ОС программ могут пересекаться, поэтому при переключении контекста задачи, чтобы по тем же адресам не считать старые данные или код, виртуально адресуемый кэш должен сбрасываться (именно так было с кэшем трасс у P4). Разумеется, его эффективность при этом будет низкой. В некоторых архитектурах применяются т. н. ASID (address space identifier, идентификатор адресного пространства) — уникальные числа, присваиваемые ОС каждому потоку. Однако x86 не поддерживает ASID за ненадобностью — учитывая наличие физических тегов для всех кэшей. Но вот пришёл L0m и нарушил картину. Более того, вспомним, что кэш мопов, как и большинство ресурсов ядра, разделяется между двумя потоками, так что в нём окажутся мопы разных программ. А если добавить переключение между виртуальными ОС в соответствующем режиме, то мопы двух программ могут совпасть по адресам. Что же делать?
Проблема с потоками решается просто — L0m просто делится пополам по наборам, так что номер потока даёт старший бит номера набора. Кроме того, L1I имеет включающую политику хранения относительно L0m. Поэтому при вытеснении кода из L1I происходит и удаление его мопов из L0m, что требует проверки двух смежных порций (размер строки всех кэшей современных ЦП, не считая самого́ L0m — 64 байта). Таким образом виртуальный адрес из тэгов закэшированных мопов всегда можно проверить в тегах L1I, используя его TLB. Выходит, что хоть L0m и имеет виртуальную адресацию, но заимствует физические теги для кода из L1I. Тем не менее, есть ситуация, при которой L0m целиком сбрасывается — промах и замещение в L1I TLB, а также его полный сброс (в т. ч. при переключении режимов работы ЦП). Кроме того, L0m совсем отключается, если базовый адрес селектора кода (CS) не равен нулю (что крайне маловероятно в современных ОС).
Работа
Главный секрет кэша мопов — алгоритм, подменяющий чтениями из L0m работу фронта по переработке команд в мопы. Начинается он с того, что при очередном переходе для выбора набора L0m использует биты 5–9 адреса цели перехода (или биты 5–8 плюс номер потока — при 2-поточности). В тегах набора указаны точка входа в порцию, мопы которой записаны в соответствующей тегу строке, и порядковый номер этой строки в пределах порции. Совпасть могут 1–3 строки, которые (скорее всего) одновременно считываются в 18-моповый буфер. Оттуда мопы четвёрками посылаются в IDQ, пока не будет достигнута точка выхода — и всё повторяется сначала. Причём когда в порции остаются неотправленными 1–3 последних мопа, они высылаются с 3–1 первыми мопами новой порции, в сумме составив обычную четвёрку. Т. е. с точки зрения принимающей мопы очереди IDQ все переходы сглажены в равномерный поток кода — как в P4, но без кэша трасс.
А теперь любопытный момент — в строке допускается не более двух переходов, причём если один из них — безусловный, то он окажется последним для строки. Наш Внимательный Читатель сообразит, что на всю порцию допустимо иметь до 6 условных переходов (каждый из которых может сработать, не будучи при этом точкой выхода), либо 5 условных и 1 безусловный, который будет последней командой порции. Предсказатель переходов в ЦП Intel устроен так, что он не замечает условный переход, пока он хотя бы раз не сработает, и только после этого его поведение будет предсказываться. Но даже «вечносрабатывающие» переходы тоже подпадают под ограничение. Фактически это значит, что завершить исполнение мопов порции допустимо и до точки её выхода.
А вот аналогичный трюк со множественным входом не пройдёт — если происходит переход в уже закэшированную порцию, но по другому смещению в ней (например, когда там более одного безусловного перехода), то L0m фиксирует промах, включает фронт и запишет поступившие мопы в новую порцию. Т. е. в кэше допустимы копии для порций с разными входами и одинаковым, точно известным выходом (помимо ещё нескольких возможных). А при вытеснении кода из L1I в L0m удаляются все строки, точки входа которых попадают в любой из 64-х байт двух порций. Кстати, в кэше трасс P4 тоже были возможны копии, причём они существенно уменьшали эффективность хранения кода…
Такие ограничения уменьшают доступность пространства L0m. Попробуем подсчитать, сколько же его остаётся для фактического использования. Средний размер команды x86-64 — 4 байта. Среднее число мопов на команду — 1,1. Т. е. на порцию скорее всего придётся 8–10 мопов, что составляет 2 строки. Как было ранее подсчитано, L0m сможет сохранить 128 таких пар, чего хватит на 4 КБ кода. Однако с учётом неидеального использования строк реальное число будет, видимо, 3–3,5 КБ. Интересно, как это вписывается в общий баланс объёмов кэшевой подсистемы?
- 1 банк L3 (фактически часть L3, в среднем приходящаяся на ядро) — 2 МБ;
- L2 — 256 КБ, в 8 раз меньше;
- оба L1 — по 32 КБ, в 8 раз меньше;
- кэшируемый объём в L0m — примерно в 10 раз меньше.
Любопытно, что если найти в ядре ещё одну структуру, хранящую много команд или мопов, то ей окажется очередь ROB диспетчера, в которой умещается 168 мопов, генерируемые примерно 650–700 байтами кода, что в 5 раз меньше эффективного эквивалентного объёма L0m (3–3,5 КБ) и в 9 раз меньше полного (6 КБ). Таким образом, кэш мопов дополняет стройную иерархию различных хранилищ кода с разными, но хорошо сбалансированными параметрами. Intel утверждает, что в среднем 80% обращений попадают в L0m. Это значительно ниже цифры в 98–99% для кэша L1I на 32 КБ, но всё равно — в четырёх случаях из пяти кэш мопов оправдывает своё присутствие.


