Часть 4-я
Оглавление
- «Крутой и холодный».
- Фронт конвейера: Предсказание переходов; Декодирование и IDQ; Стековый движок; Тайная жизнь нопов.
- Кэш мопов: Цели и предшественники; Устройство; Размеры; Ограничения; Работа.
- Диспетчер и планировщик: Переименование и размещение; Новый старый стиль.
- Исполнительная стадия: Тракты данных; Конфликты завершения; Межтрактные шлюзы; Вещественные денормалы; Частичный доступ к регистрам.
- AVX: Реализация; Подножка; Решение; Сохранение состояния; Динамические тайминги; Новые и отсутствующие команды.
- Тайминги команд.
- Кэши: L1D; LSU; Внеочерёдный доступ; STLF; Задержки чтения; TLB; Аппаратная предзагрузка.
- Hyper-Threading.
- Внеядро: Кэш L3; Кольцевая шина; Поддержка аппаратной отладки; Когерентность и «поддержка» OpenCL; Системный агент и ИКП.
- Turbo Boost 2.0.
- Экономия.
- Модели и чипсеты.
- Кристалл: Техпроцесс; Виды кристаллов; Устройство ГП; Устройство банка L3; 2-ядерные кристаллы.
- Производительность.
- Перспективы и итоги.
Экономия
Методы достижения энергоэффективности в архитектуре Nehalem почти совпадают с оными в ЦП Atom, что описано во 2-й части его детального обзора на нашем сайте (правда, поддержка состояния глубокого сна C6 и низковольтной памяти LV-DDR3 появилась только в Westmere). А что появилось в SB?
Во-первых — второй тип термодатчиков. Привычный термодиод, показания которого «видят» BIOS и утилиты, измеряет температуру для регулировки оборотов вентиляторов и защиты от перегрева (частотным троттлингом и, если не поможет, аварийным отключением ЦП). Однако его площадь весьма велика, потому их всего по одному в каждом ядре (включая ГП) и в системном агенте. К ним в каждом крупном блоке добавлено по нескольку компактных аналоговых МОП-схем с термотранзисторами. У них меньший рабочий диапазон измерений (80–100 °C), но они нужны для уточнения данных термодиода и построения точной карты нагрева кристалла, без чего нереализуемы новые функции TB 2.0. Более того, силовой контроллер может использовать даже внешний датчик, если производитель системной платы разместит и подключит его — хотя не совсем ясно, чем он поможет.
Добавлена функция перенумерации C-состояний, для чего отслеживается история переходов между ними для каждого ядра. Переход занимает время тем большее, чем больше «номер сна», в который ядро входит или из которого выходит. Контроллер определяет, имеет ли смысл усыплять ядро с учётом вероятности его «пробудки». Если таковая ожидается скоро, то вместо затребованного ОС состояния C6 или C3 ядро будет переведено в C3 или C1, соответственно, т. е. в более активное состояние, быстрее выходящее в рабочее. Как ни странно, несмотря на большее потребление энергии в таком сне, общая экономия может не пострадать, т. к. сокращаются оба переходных периода, в течение которых процессор совсем не спит.
Для мобильных моделей перевод всех ядер в C6 вызывает сброс и отключение кэша L3 общими для банков силовыми ключами. Это ещё сильнее снизит потребление при простое, но чревато дополнительной задержкой при пробуждении, т. к. ядрам придётся несколько сотен или тысяч раз промахнуться в L3, пока туда подкачаются нужные данные и код. Очевидно, в совокупности с предыдущей функцией это произойдёт, лишь если контроллер точно уверен, что ЦП засыпает надолго (по меркам процессорного времени).
Core i3/i5 прошлого поколения являлись своеобразными рекордсменами по требованиям к сложности системы питания ЦП на системной плате, требуя аж 6 напряжений — точнее, все 6 были и ранее, но не все вели в процессор. В SB силовые шины изменились не числом, а использованием:
- x86-ядра и L3 — 0,65–1,05 В (в Nehalem L3 отделён);
- ГП — аналогично (в Nehalem почти весь северный мост, который, напомним, являлся там вторым кристаллом ЦП, питается общей шиной);
- системный агент, у которого частота фиксирована, а напряжение — постоянное 0,8, 0,9 или 0,925 В (первые два варианта — для мобильных моделей), либо динамически регулируемое 0,879–0,971 В;
- умножители частоты — постоянное 1,8 В или регулируемое 1,71–1,89 В;
- драйвер шины памяти — 1,5 В или 1,425–1,575 В;
- драйвер PCIe — 1,05 В.
Регулируемые версии силовых шин используются в разблокированных видах SB с буквой K. В настольных моделях частота простоя x86-ядер повышена с 1,3 до 1,6 ГГц, судя по всему, без ущерба для экономии. При этом 4-ядерный ЦП при полном простое потребляет 3,5–4 Вт. Мобильные версии простаивают на 800 МГц и просят ещё меньше.
Модели и чипсеты
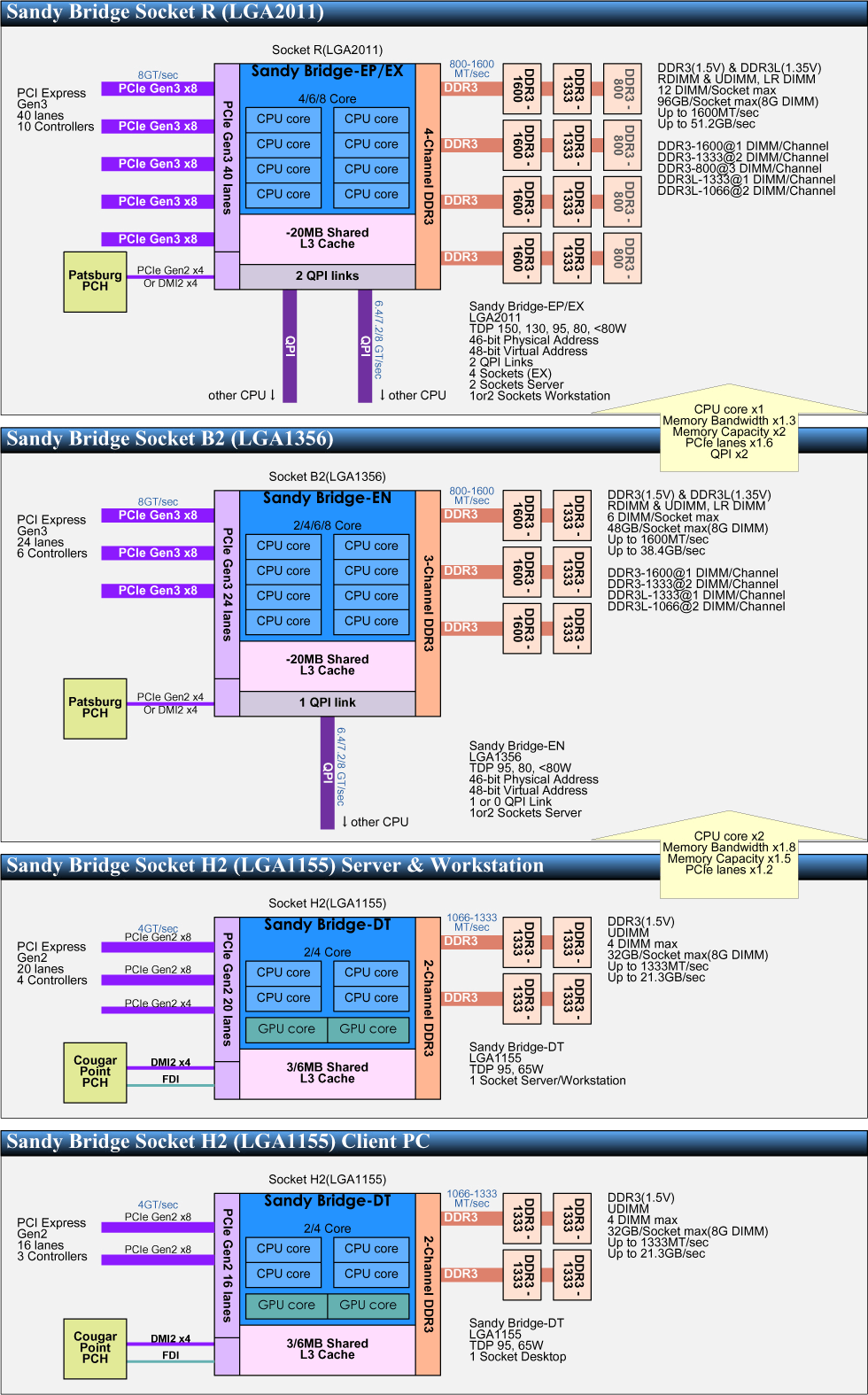 Серверные и настольные варианты SB для разных разъёмов. Обратите внимание на разную частоту работы ИКП в зависимости от числа подключенных модулей и их типа. Иллюстрация с pc.watch.impress.co.jp. |
Очередную смену разъёма для настольных линеек (с LGA1156 на LGA1155) обсуждать не будем — эта тема уже избита. :) По традиции укажем на список моделей в Википедии, хотя на момент сдачи этой статьи туда ещё не внесли несколько недавно анонсированных ЦП.
Традиционный для обоих производителей x86-ЦП модельный бардак начинается с самого мощного, «серверного» вида (без ГП, с 4-канальным ИКП и 40 полосами PCIe 3.0), также известного как SB-E — он попадёт и в десктопы под именем Core i7 Extreme и даже просто Core i7, «потеряв» 2–4 ядра, 8 полос PCIe и, возможно, 1 канал ИКП и снизив объём L3 с 20 МБ до 10–15. TDP «экстремалов», как и прежде, останется на 130 ваттах. Остальные анонсированные модели i7 — это «просто мощные» настольные ЦП, как и полагается. Среди i5 тоже есть исключения — они могут быть и 2-ядерными (с половинным размером L3). Среди i3 исключений нет, и на том спасибо.
Всё ещё живые Pentium и в очередной раз воскресшие Celeron лишены поддержки HT, AVX, AES-NI и TB для x86-ядер. Обе марки имеют три вида, обозначаемых буквой у номера модели — настольные G***, мобильные B*** или *** (только цифры) и встроенные ***E (с поддержкой ECC). Встроенные и часть мобильных ЦП используют корпус BGA1023, остальные мобильные — под разъём Socket G2. Celeron G440, B710, 787 и 827E — 1-ядерники, причём последний лишён даже ускорения 3D в ГП. Кэш L3 сократили до 1,5 МБ у 827E и 1 МБ (!) у B710 и 787. Pentium G имеют 3 МБ L3, а все остальные версии Pentium и Celeron — 2.
Мобильный ряд прежде всего удивляет моделью Core i7 Extreme 2920XM за $1096. Видимо, дверью ошиблась — это к модным нынче экономным серверам (где разблокированный множитель не пригодится), а не для портативных приборов с автономным питанием и слабеньким кулером. У мобильного i7 может быть разным размер L3 и число ядер (с буквой Q или X их 4, иначе — 2). i5 в этом отношении более стабильны, а у единственного пока i3 Turbo Boost работает только для ГП. Мобильные Core получат «старшую» графику (о различиях между ними — ниже), а вот Pentium и Celeron (даже настольные) помимо половины 3D-блоков лишены и технологий Clear Video HD (улучшение видеопотока «на лету») и QuickSync (аппаратный перекодировщик видео).
Номера моделей мало что скажут. Core i теперь 4-значные и начинаются с двойки; Pentium, наоборот, одну цифру потеряли (причём разница между 600-ми и 800-ми моделями — только в частоте и (не)поддержке памяти DDR3-1333). Если у настольной модели последняя цифра — 5, то у неё старший ГП, а если 0 — то младший. Однако для 2600K и 2500K это не работает: полноценная графика (вдобавок к разблокированному множителю) есть именно у них, а не у несуществующих 2605K и 2505K. У мобильных ЦП эта же пятёрка означает поддержку ECC-памяти и развилки шины PCIe. Ещё последней цифрой может быть 2, что означает включение этой модели в программу Processor Performance Upgrade — о ней мы расскажем в ближайшей статье.
Вдобавок, Внимательный Читатель нам напомнит, что с января 2011 г. выпускаются мобильные Celeron 763 и 925 на ядре Penryn 4-летней давности для пред-предыдущей архитектуры. А теперь сравним их (1 ядро, 1 МБ L2 и, разумеется, никакого ГП и L3) с готовящимися к выпуску мобильными же Celeron 787 и 857: 787 — 1-ядерник с 1 МБ L3, а 857 — 2-ядерник с 2 МБ; у 857 по сравнению с 787 базовая частота x86-ядер — меньше, базовая частота ГП — та же, а турбо-частота ГП — больше. А теперь попробуйте определить хотя бы что-то из этого только по номерам моделей…
Буквы S и T после номера означают «средне» и «очень» экономные модели, но сравнивать их частоты не получится: например, модель Core i5-2500 быстрее и прожорливей, чем 2500S, которая быстрее и прожорливей, чем 2500T, но вот насколько именно в каждом случае — без таблицы не ясно. Вдобавок, «очень» экономные Xeon обозначаются буквой L, а не T, а ещё есть не менее экономная встроенная модель i3-2340UE. Также известно, что настольные Pentium и Celeron моделей GxxxT дополнительно лишатся ускорения 3D в ГП, но вот Celeron G440 с тем же TDP в 35 Вт буквы T не имеет. У «просто» экономных мобильных и встроенных ЦП номера заканчиваются на 9, а у «самых» — на 7.
Удивительно, как Intel сама себе делает подножку: на сайте компании есть официальная и постоянно обновляемая база данных процессоров с почти полным списком характеристик старых и текущих моделей. В ней с удивлением можно обнаружить, что новый Pentium 957, оказывается, не имеет виртуализации, хотя все остальные источники (включая заявления самой Intel) говорят, что ни один ЦП новой архитектуры не лишится поддержки VT и x86-64.
Короче, бардак полный и, судя по всему, намеренный. Но один намёк на порядок всё же есть: если расположить модельные ряды как «Celeron-Pentium-i3-i5-i7», то в каждой линейке все ЦП окажутся дороже самого дорогого из предыдущей и дешевле самого дешёвого из следующей. Впрочем, уже сейчас (для текущих цен и пока анонсированных моделей) это работает лишь по отдельности для настольных и мобильных процессоров, ибо мобильный Celeron B810 сто́ит, как самый быстрый настольный Pentium. Но даже с этой поправкой нельзя твёрдо сказать, что Intel именует ЦП не по производительности, а по цене, ибо откуда тогда берутся сами цены? :)
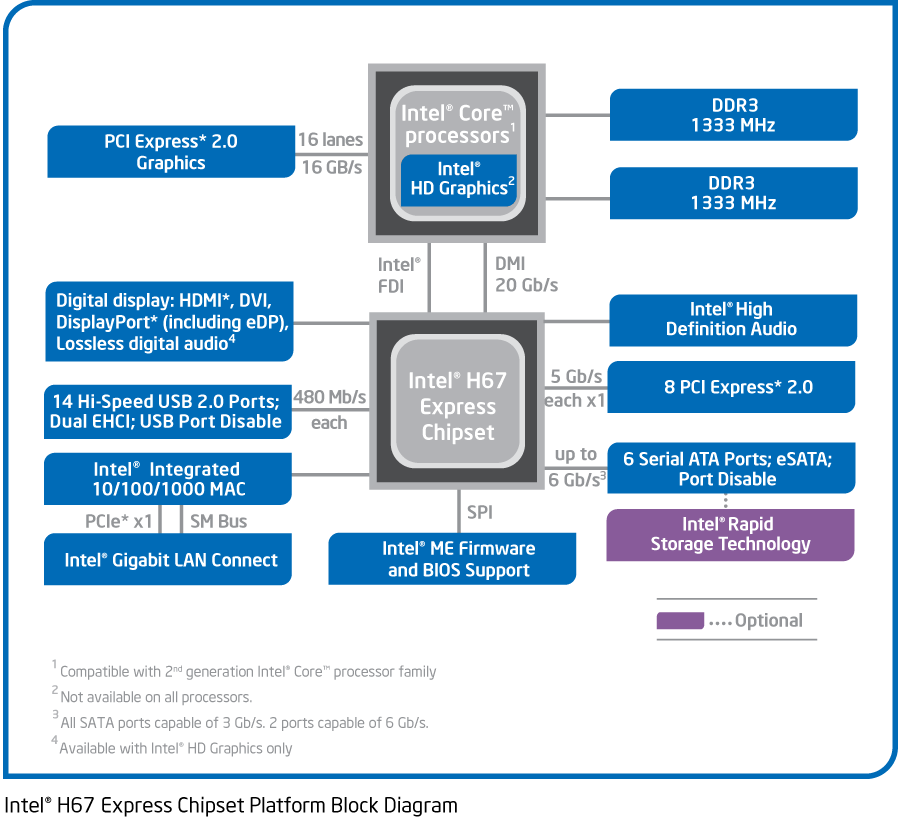
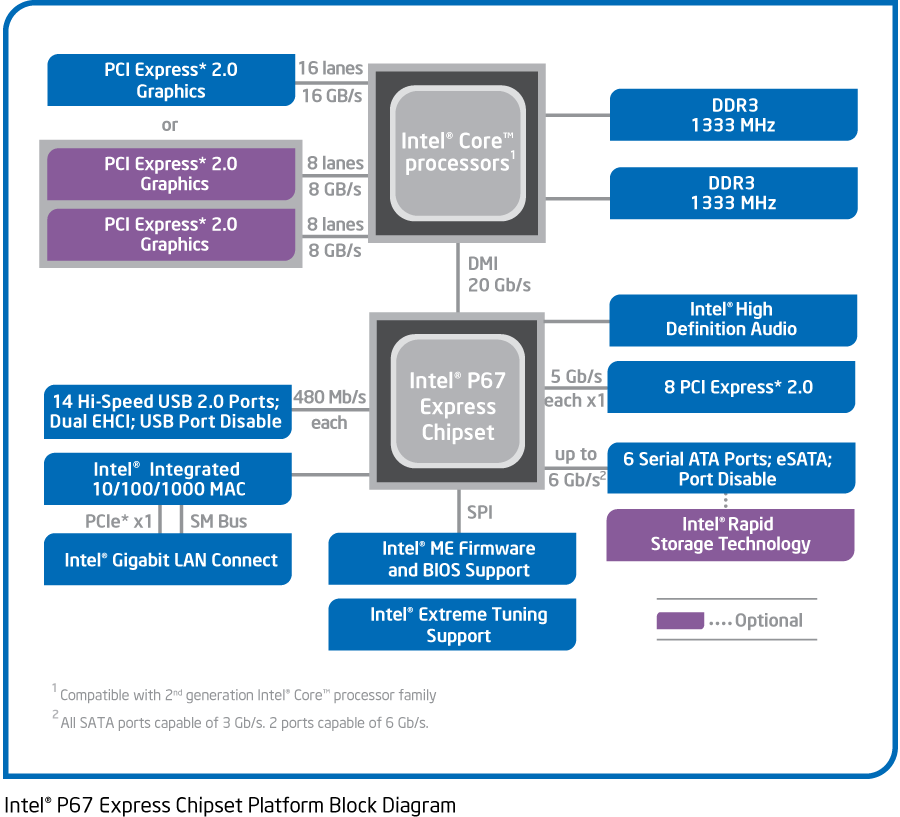
Чипсеты-близнецы H67 и P67.
Некоторые странности до сих пор имелись и среди чипсетов: долгое время можно было купить системную плату либо с поддержкой разгона (на чипсете P67), либо встроенного ГП (на H67). Пользователи, которые хотели и того, и другого, недоумевали, почему их поставили перед выбором «или-или». Ответ прост: чипсет Z68 с поддержкой «всего» вышел лишь в мае, на 4 месяца позже старта платформы. Причём физически это всё тот же P67/H67 (который суть один и тот же кристалл), только со всеми разблокированными функциями.

Чипсет Z68.
Помимо этого, для «бизнес-сектора» (малопонятный автору термин маркетологов) выпущены настольные Q67, Q65 и B65 — это H67 с поддержкой PCI; у последних двух только 1 (из 6) порт SATA — версии 3.0 (а не 2 из 6, как в остальных чипсетах), т. е. поддерживает скорость 6 Гбит/с, а у B65 нет RAID. Наиболее дешёвая модификация — H61, без PCI, RAID и SATA 3.0. Мобильных чипсетов набирается пять: стандартные QM67, QS67 и HM67 (с TDP около 3,9 Вт и размером микросхемы 25×25 мм) и экономные UM67 и HM65 (3,4 Вт и 22×22 мм). QM67 и QS67 допускают полный ручной разгон всех ядер (являясь по этой части мобильным аналогом P67); а ещё вся пятёрка имеет разную поддержку RAID — от никакой в HM65 и UM67 до уровней 0, 1, 5 и 10 в QM67 и HM67. Судя по всему, этот же южный мост применяется и в чипсетах C202, C204 и C206 для младших Xeon серий E3 (которые суть обычный 4-ядерный SB).
Проблему с поддерживаемыми функциями Intel уже продемонстрировала ошибкой в контроллере SATA во всех выпущенных в начале года чипсетах. Исправление и перевыпуск, как известно, влетели в миллиардную «копеечку», а репутационные издержки и вовсе трудновыразимы.
Кристалл
Техпроцесс
Физически техпроцесс 32 нм для SB мало отличается от такового для Westmere. Главное улучшение — в компенсации разброса параметров транзисторов, прежде всего утечки тока. Например, в Westmere в разных кристаллах на 300-миллиметровой пластине утечка могла иметь 4-кратную разницу, что особенно влияет на надёжность записи в кэши и РФ. Компенсация этого разброса для SB позволит достичь большего выхода годных кристаллов, лучшей экономии и более высоких частот. Как именно? В каждую линию шин записи в РФ и кэшах добавили программируемую «подтяжку» из трёх транзисторов разного размера, стабилизирующую уровень логической «1» в зависимости от утечки. Во время заводского тестирования утечка замеряется в разных местах кристалла, после чего «подтяжки» программируются на наиболее точную комбинацию транзисторов (из 8 возможных) для улучшения надёжности записи.
По некоторым данным, в кэшах Westmere использовалось не менее трёх видов ячеек СОЗУ. Для основных матриц L3 — средневольтная высокоплотная (площадью 0,171 квадратных микрон на бит), для тегов L3 — низковольтная скоростная (0,199 мк²/бит), а для L2 и L1 (включая теги) — 8-транзисторая ультранизковольтная скоростная (0,256 мк²/бит, но для L1 удельная площадь кэша примерно вчетверо больше за счёт многопортовости и встроенной в матрицу логики). Разнообразие видов СОЗУ показывает, что инженеры в каждом случае нашли свой баланс между скоростью срабатывания, площадью, потреблением и надёжностью хранения и работы. В частности, имея в L2 8-транзисторные ячейки, можно было устроить «бесплатный» порт записи — однако этот кэш не сделали 2-портовым, видимо, по причине усложнения управляющей логики, непропорционального получаемому ускорению.
Судя по всё ещё актуальной проблеме разброса параметров, для SB техпроцесс значительно оптимизировать не удалось. Тем не менее планки по частоте и экономии подняты — в частности, т. к. L3 теперь запитывается той же силовой шиной, что и x86-ядра, он должен быть рассчитан на работу при 0,65 В (при низкой нагрузке), что ниже минимального вольтажа для L3 в Westmere (0,8 В). Уменьшенного потребления удалось достичь без увеличения площади хранения бита, но со штрафом для надёжности — доля моделей SB с полным (не заблокированным частично) кэшем L3 пока оказывается меньше, чем у Nehalem и Westmere.
Виды кристаллов
4 вида кристалла для SB имеют такие физические показатели (для 8-ядерных — предполагаемые):
| Модели | Core i5/i3, Pentium, Celeron | Core i3, Core-М° i7/i5/i3 | Xeon, Core i7/i5 | Xeon, Core i7 Extreme |
| Число ядер x86 и ФУ ГП* | 2 + 6 | 2 + 12 | 4 + 12 | 8 + 0 |
| Объём кэша L3, МБ | 3 | 4 | 8 | 20 |
| Число транзисторов, млн. | 504 | 624 | 995 | ≈2200 |
| Площадь кристалла, мм² | 131 | 149 | 219 | ≈400 |
| Размер кристалла (Ш×В), мм | 13,803×9,507 | 14,554×10,256 | 21,078×10,256 | ≈20×20 |
° — мобильные варианты
* — под графическим ФУ понимается конечный исполнительный блок, иерархически эквивалентный «потоковому процессору» (SP) AMD и «CUDA-ядру» NVidia.
Помимо этих цифр также обнародовано, что старший 12-блочный ГП типа HD Graphics 3000 имеет 114 млн. транзисторов (обозначим эту меру как Мтр.), а 1 ядро x86 — 55 Мтр. (включая кэш L2). Из этих цифр можно подсчитать, что банк L3 на 2 MБ имеет 130,5 Мтр., а младший 6-блочный HD Graphics 2000 — 59 Мтр.
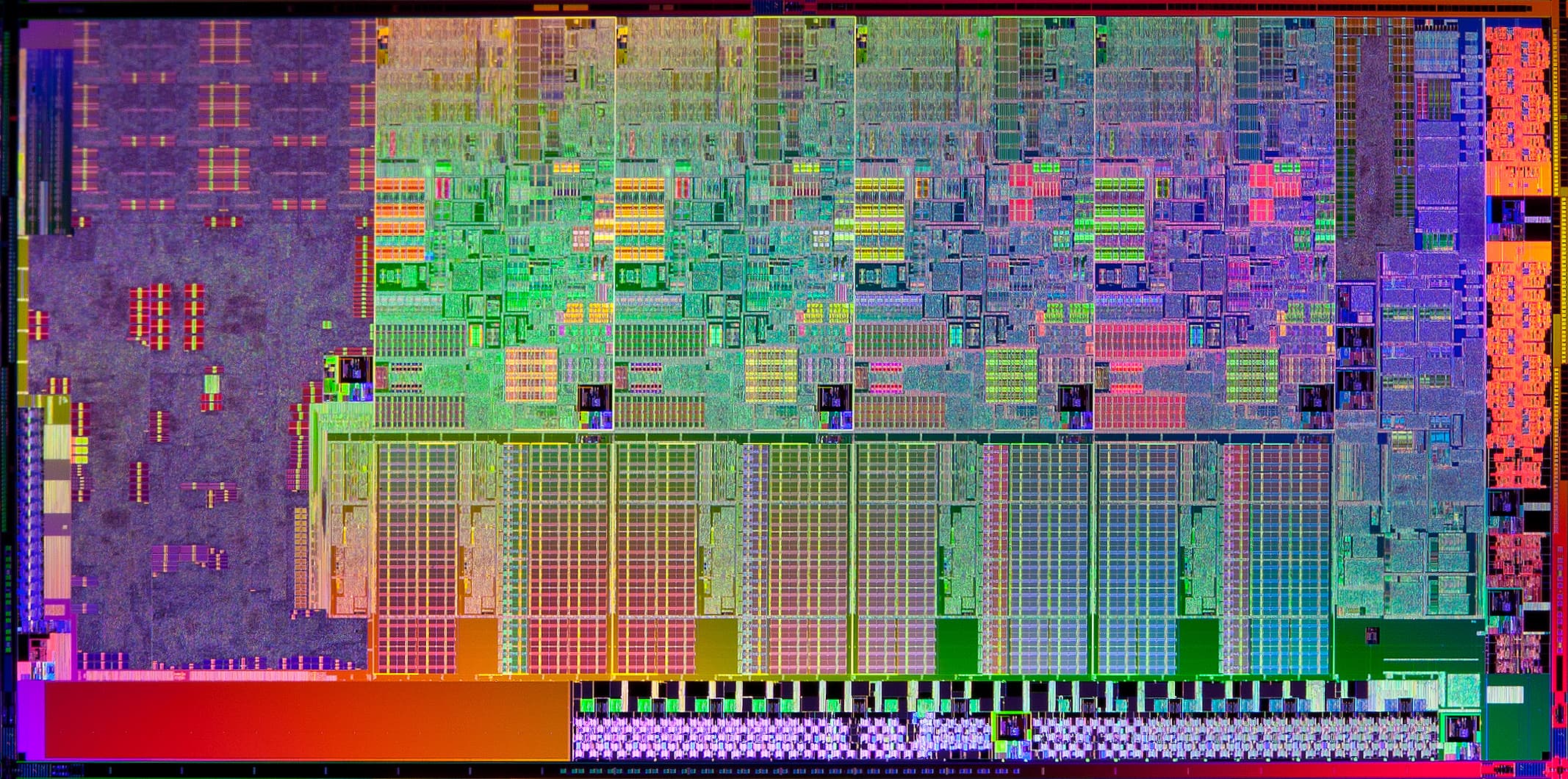
Кристалл 4-ядерного SB (по ссылке — очень детальное фото).
Посмотрим на кристалл — на примере 4-ядерного, фото которого — единственное доступное на сегодня. Как и в предыдущей архитектуре, Intel использовала модульную схему, позволяющую относительно легко получать новые модификации простым изменением числа блоков. В данном случае видны 4 модуля «ядро x86 и локальный банк L3», ГП (большой блок слева), системный агент со всеми контроллерами (справа) и физические интерфейсы (драйверы) шин: PCIe (вдоль правого края), FDI (в нижнем правом углу), памяти (внизу), GDXC (в нижнем левом углу) и DMI (в верхнем левом углу). Области с монотонным цветом общей площадью ≈12 мм² — пустые.
Устройство ГП
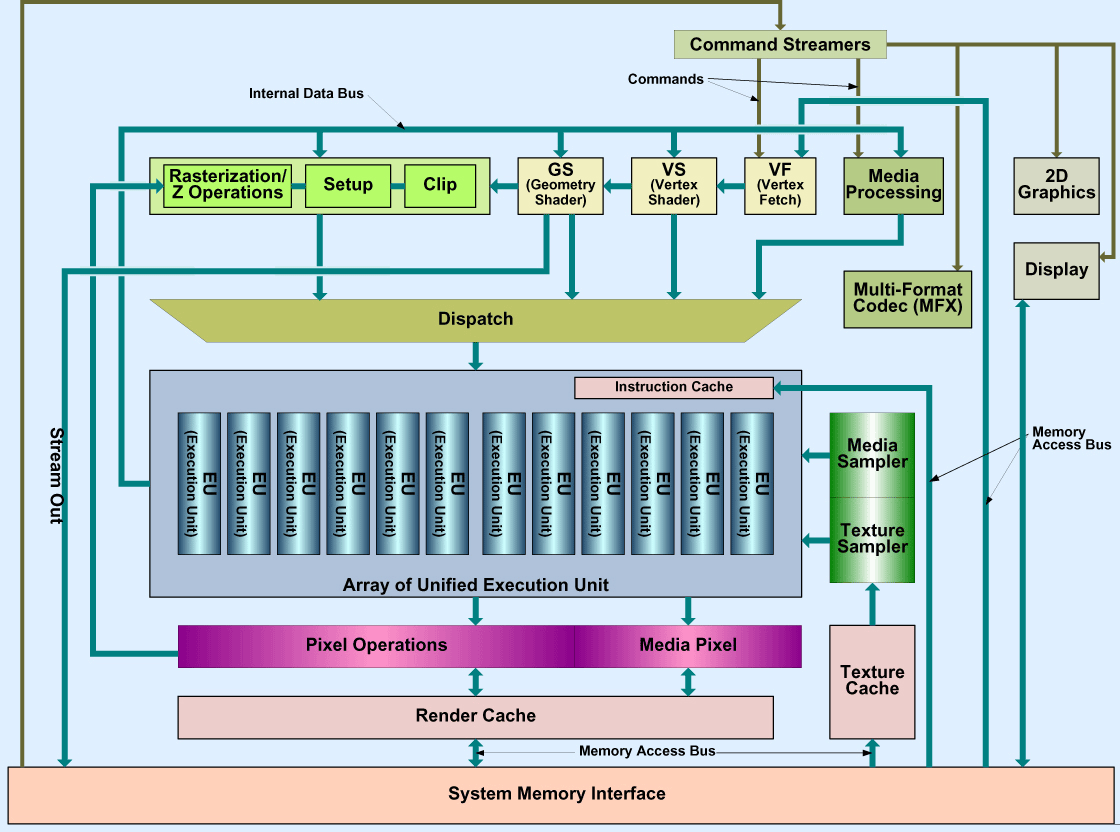 Блок-схема ГП в Sandy Bridge. Иллюстрация с pc.watch.impress.co.jp. |
Первое, что любопытно — его младшая версия получена не просто путём отсечения половины ФУ у старшей, но и последующим уменьшением размеров кристалла и по ширине, и по высоте. Этот факт мы исследуем позже, а тут обратимся ко второму моменту — если 59 Мтр. для HD Graphics 2000 верны, то всё, что остаётся после вычитания всех ФУ, занимает всего 3,4 Мтр. А ведь в ГП, помимо исполнительных блоков, есть много общих и не менее сложных ресурсов (площадь и сложность которых видна в центральной части ГП, а их количество — на блок-схеме): планировщик и кэш кода, процессор вершин, растеризатор, текстурный сэмплер и прочее.
Учитывая, что одно из рекламируемых преимуществ нового ГП Intel — это не только удвоенная (до 128 бит) разрядность ФУ (за счёт чего вся 3D-графика ускорилась «вдвое»), но и большее число аппаратных блоков — скорее всего общие части займут не намного меньше транзисторов, чем ФУ. Из чего надо сделать вывод, что цифра в 59 Мтр. занижена, а значит — из сокращённого 2-ядерного кристалла убрали что-то ещё, помимо половины ФУ в ГП. А т. к. все ядра и банки L3 мы уже посчитали, подозрения падают на системный агент — тем более, что именно в нём находится аппаратный перекодировщик QuickSync, отключенный в самых младших моделях, ГП которых из-за этого зовётся HD 1000. Чуть позже у нас окажется способ это проверить. Пока же заметим, что 4-ядерные модели с младшим ГП получены стандартным отключением 6 ФУ.
Устройство банка L3
В таблице не зря указаны именно физические параметры кэша L3 — фактически доступные размер и ассоциативность зависят от конкретной модели, ведь при заводском тестировании что-то могут отключить. А вот плотность в 7,8 транзистора/бит — общая для всех. Напомним, что стандартная ячейка применяемого в кэшах статического ОЗУ имеет 6 транзисторов, а экономная — 8 (с ущербом для площади, поэтому её размещают только в ядре, кэши которого относительно малы). Если из 130,5 Мтр. (для банка L3 на 2 МБ) вычесть положенные 100,7 Мтр. (при 6-транзисторных ячейках только для данных), останется 29,8 Мтр. Этого должно хватить на биты ECC (1 на байт) и теги (предположим, что это 50 бит на строку, включая свои биты ECC). Тогда контроллеру банка и агенту кольцевой шины останется 7,4 Мтр., что вполне вероятно.

Банк кэша L3 на 2 МБ. Вверху — агент кольцевой шины. В центре — контроллер банка. Справа от них — теги и ECC (вертикальный ряд). Остальные блоки — массивы данных. Нижние 4 пути могут отсутствовать.
Т. к. продвинутые методы ECC внедрены для защиты наиболее уязвимых, ультранизковольтных ячеек, в L3 они не применяются, поэтому выше мы посчитали число битов ECC как стандартный 1 на байт. Теперь посмотрим на фото банка. Видно, что каждый блок тегов состоит из двух матриц (бордового цвета). Размер большей из них составляет 10% от размера обслуживаемых матриц с данными (в которые, видимо, встроены и биты ECC), но с учётом меньшей плотности тут хранится примерно 8,5% информации от объёма строки и её ECC (576 бит) — и это почти соответствует вычисленному нами значению в 50 бит на строку. А вот что хранят малые матрицы тегов — сказать трудно…
2-ядерные кристаллы
Если кто думает, что в высокоинтеллектуальной аналитике процессорных архитектур нет места легкомысленным «фотожабам» — наслаждайтесь: попытаемся представить, как выглядят остальные два выпущенных кристалла для 2-ядерных моделей (возможно, Intel опубликует и их изображения, так что можно будет проверить). Со старшим вариантом проблем нет — удалив «лишние» 2 x86-ядра, сместим вправо ГП, водрузив его над левой третью ИКП.
Почти так должен выглядеть 2-ядерный SB с 4 МБ L3 и старшим ГП.
А вот с младшей версией всё интереснее. Сначала обратим внимание, что каждый банк L3 не зря имеет пусто́ты в нижней четверти — в некоторых 4-ядерных моделях отключена одна 4-путная четвертинка каждого банка, а в младшем 2-ядерном кристалле нижние четверти в обоих банках и вовсе физически отсутствуют. Управляющих цепей там нет, поэтому после урезания каждого банка сместим ИКП и ГП вверх.
Однако чтобы эта версия кристалла оказалась меньше и по высоте, ГП также придётся обрезать. Обратим внимание на его верхнюю часть с массивом блоков в 3 ряда и 4 колонки — это и есть 12 ФУ. Для образования необходимого сдвига достаточно отсечь верхний ряд, оставив 8 ФУ, из которых 2 будут выключены. Правда, при этом отсекается и верхний край драйвера шины DMI, а ниже (на место GDXC) его не переставить — слишком высокий.
Допустим, мы всё же как-то смогли сместить ГП вверх. Но тут нас ждёт ещё один сюрприз — локальный агент шины и контроллер L3 окажутся не на одной линии с остальными. Если в этом месте шине придётся сделать 2 поворота на 90°, это ограничит её максимальную частоту работы, а т. к. она должна совпадать с частотой x86-ядер — то и их. Значит, такое решение применяется только в недорогих ЦП, которым высокая частота не очень важна — но этот вывод нарушает наличие модели Core i5 2390T, которая имеет штатную частоту 2,7 ГГц, а авторазогнанную — до 3,5 ГГц. Правда, можно также предположить, что агент остался на месте, но небольшой кусочек логики «под» ним (в правом нижнем углу ГП) перемещён в положение «над». Но это замедлит уже сам ГП, а его скорость у вышеуказанной модели — до 1,1 ГГц (почти как в топовых моделях).
На этом трудности не заканчиваются — нам ещё придётся где-то «откусить» те же 3/4 миллиметра и по ширине. Хорошо бы подошёл контроллер PCIe, но лишать процессор со слабым встроенным ГП возможности подключения мощного внешнего — кощунство (хотя это очень удобно бы объяснило «подозреваемые на пропажу» транзисторы в системном агенте). А ещё справа расположен не менее важный контроллер FDI. Драйвер DMI слева также некуда девать, к тому же между ним и драйвером GDXC есть часть графической логики…
Всё это намекает на такой итог: у инженеров графического отдела было достаточно времени, чтобы подготовить сразу две версии раскладки блоков ГП — полную (на 12 ФУ) и компактную (на 6). Причём во второй версии некоторые общие блоки удалены (!), а остальные заметно переставлены, за счёт чего и нашлось место для сокращения и по длине, и по ширине. Таким образом, «обвинения» в пропаже транзисторов могут быть предъявлены не только системному агенту (где удалена как минимум мало кому нужная GDXC, а возможно — и блок QuickSync), но и ГП.
Проверить гипотезу можно двумя способами: дождавшись фото этого кристалла и/или детально исследовав, чем отличаются версии ГП в 2-ядерных моделях, помимо числа ФУ. С «гаданиями по чипу» на сегодня закончим, но заметим, что Intel вряд ли пошла бы на такие сложности, если бы не было очень серьёзного повода для экономии этих несчастных 18 мм² (всего 12% от площади старшего 2-ядерного кристалла), при том, что 12 мм² в 4-ядернике пропадают зря. Возможно, этот повод — минимизация стоимости наиболее популярных моделей, в т. ч. и для лучшего продвижения в мобильном сегменте. Посмотрим, как это отразится на ценах…
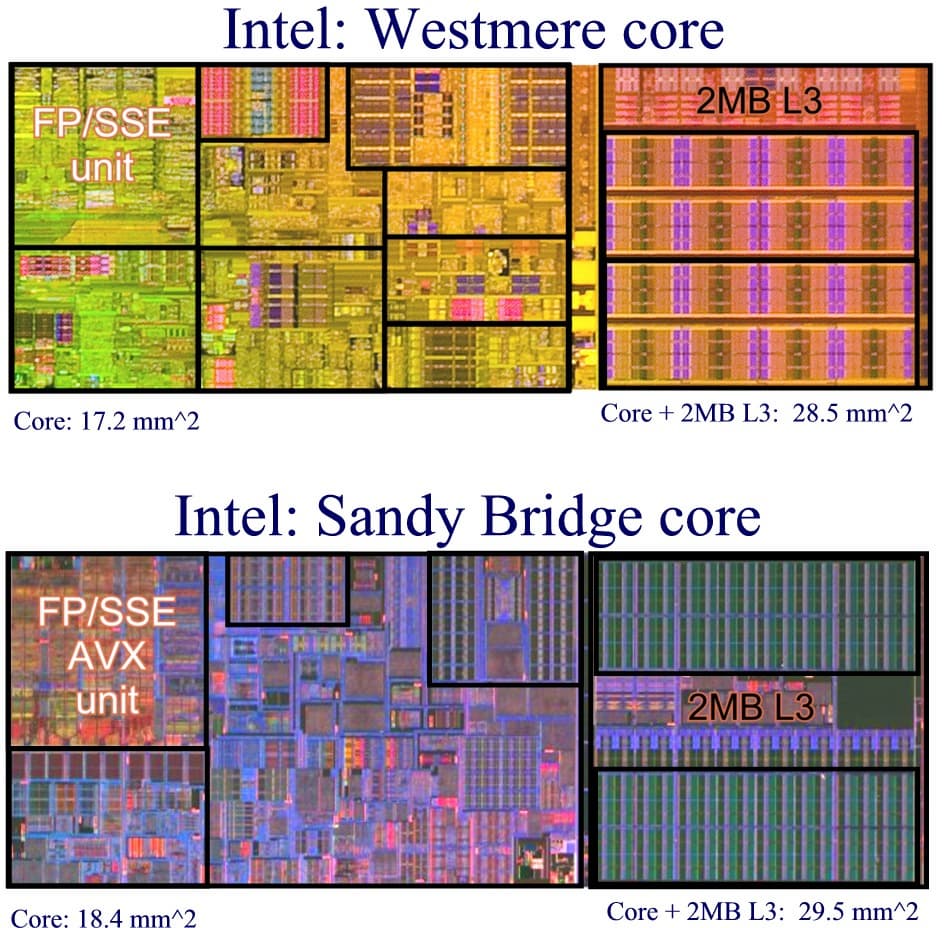
Ядро Westmere по сравнению с синтезированной моделью ядра SB (на 2010 г.). Как видно, разработчики уместили все новшества почти на той же площади. Иллюстрация с chip-architect.com.
Производительность
Что эта глава делает в теоретическом обзоре микроархитектуры? А то, что есть один общепризнанный тест, уже 20 лет (в разных версиях) использующийся для оценки не теоретической, а программно достижимой скорости компьютеров — SPEC CPU. Он может комплексно оценить производительность процессора, причём в наилучшем для него случае — когда исходный код тестов скомпилирован и оптимизирован для тестируемой системы (т. е. походя проверяется ещё и компилятор с библиотеками). Таким образом, полезные программы окажутся быстрее лишь с написанными вручную вставками на ассемблере, на что сегодня идут редкие смельчаки-программисты с большим запасом времени. SPEC можно отнести к полусинтетическим тестам, т. к. он и ничего полезного не вычисляет, и никаких конкретных цифр не даёт (IPC, флопсы, тайминги и пр.) — «попугаи» одного ЦП нужны только для сравнения с другими.
Обычно Intel предоставляет результаты для своих ЦП почти одновременно с их выпуском. Но с SB произошла непонятная 3-месячная задержка, а полученные в марте цифры всё ещё предварительны. Что именно их задерживает — неясно, однако это всё равно лучше, чем ситуация с AMD, вообще не выпустившей официальных результатов своих последних ЦП. Нижеуказанные цифры для Opteron даны производителями серверов, использовавшими компилятор Intel, так что эти результаты могут быть недооптимизированы: что программный инструментарий Intel может сделать с кодом, исполняемым на «чужом» ЦП, мы уже знаем. ;)
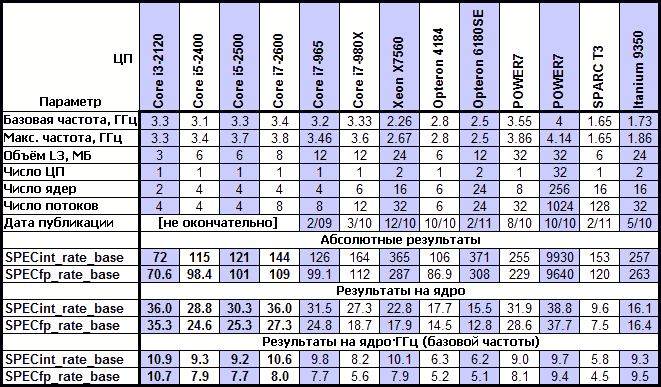
Сравнение систем в тестах SPEC CPU2006. Таблица составлена Дэвидом Кантером с realworldtech.com по данным на март'2011.
В сравнении с предыдущими ЦП SB показывает превосходные (в прямом смысле) результаты в абсолюте и вовсе рекордные на каждое ядро и гигагерц. Включение HT и добавление 2 МБ к L3 даёт +3% к вещественной скорости и +15% к целой. Однако самую высокую удельную скорость имеет 2-ядерная модель, и в этом — поучительное наблюдение: очевидно, Intel задействовала AVX, но т. к. целочисленного прироста пока получить нельзя, то можно ожидать резкое ускорение лишь вещественных показателей. Но и для них никакого скачка нет, что показывает сравнение 4-ядерных моделей — а результаты для i3-2120 раскрывают причину: имея те же 2 канала ИКП, каждое ядро получает вдвое бо́льшую ПСП, что отражается 34-процентным приростом удельной вещественной скорости. Видимо, кэш L3 на 6–8 МБ слишком мал, и масштабирование его собственной ПС за счёт кольцевой шины уже не спасает. Теперь ясно, зачем Intel планирует оснастить серверные Xeon 3- и даже 4-канальными ИКП. Только вот тамошним 8 ядрам уже и их не хватит, чтобы развернуться по полной…
Дополнение: В базе SPEC появились финальные результаты SB — цифры (ожидаемо) чуть подросли, но качественные выводы те же.
Перспективы и итоги
О выходящем весной 2012 г. 22-нанометровом преемнике Sandy Bridge под названием Ivy Bridge («плющевый мост») уже многое известно. Ядра общего назначения будут поддерживать чуть обновлённый поднабор AES-NI; вполне возможно и «бесплатное» копирование регистров на стадии переименования. Улучшений в Turbo Boost не предвидится, зато ГП (который, кстати, заработает на всех версиях чипсета) нарастит максимальное число ФУ до 16, станет поддерживать подключение не двух, а трёх экранов, наконец-то обретёт нормальную поддержку OpenCL 1.1 (вместе с DirectX 11 и OpenGL 3.1) и улучшит возможности по аппаратной обработке видео. Скорее всего, уже и в настольных и мобильных моделях ИКП станет поддерживать частоту 1600 МГц, а контроллер PCIe — версию шины 3.0. Главное технологическое новшество — в кэше L3 будут использоваться (впервые в массовом микроэлектронном производстве!) транзисторы с вертикально расположенным многосторонним затвором-ребром (FinFET), имеющие радикально улучшенные электрические характеристики (детали — в одной из ближайших статей). Ходят слухи, что версии с ГП снова станут многочиповыми, только на этот раз к процессору добавят один или несколько кристаллов быстрой видеопамяти.
Ivy Bridge будет подключаться к новым чипсетам (т. е. южным мостам) 70-й серии: Z77, Z75 и H77 для дома (заменят Z68/P67/H67) и Q77, Q75 и B75 для офиса (вместо Q67/Q65/B65). Она (т. е. физическая микросхема под разными именами) по-прежнему будет иметь не более двух портов SATA 3.0, а поддержка USB 3.0 наконец-то появится, но на год позже, чем у конкурента. Встроенная поддержка PCI исчезнет (после 19 лет шине пора на покой), зато контроллер дисковой подсистемы в Z77 и Q77 получит технологию Smart Response для увеличения производительности кэшированием дисков с помощью SSD. Впрочем, наиболее волнительная новость заключается в том, что несмотря на старую добрую традицию, настольные версии Ivy Bridge не просто будут размещаться в том же разъёме LGA1155, что и SB, но и будут обратно совместимы с ними — т. е. современные платы подойдут и новому ЦП.
Ну а для энтузиастов уже в 4-м квартале этого года будет готов куда более мощный чипсет X79 (к 4–8-ядерным SB-E для «серверно-экстремального» разъёма LGA2011). Он пока не будет иметь USB 3.0, зато портов SATA 3.0 будет уже 10 из 14 (плюс поддержка 4 видов RAID), а 4 из 8 полос PCIe могут соединяться с ЦП параллельно с DMI, удваивая ПС связи «ЦП—чипсет». К сожалению, X79 не подойдёт к 8-ядерным Ivy Bridge.
В качестве исключения (а может быть, и нового правила) список того, что бы хотелось улучшить и исправить в Sandy Bridge, приводить не будем. Уже очевидно, что любое изменение является сложным компромиссом — строго по закону сохранения вещества (в формулировке Ломоносова): если где-то что-то прибыло, то где-то столько же и убудет. Если бы Intel кидалась в каждой новой архитектуре исправлять ошибки старой, то число наломанных дров и полетевших щепок могло бы превысить выгоду от полученного. Поэтому вместо крайностей и недостижимого идеала экономически выгодней искать баланс между постоянно меняющимися и подчас противоположными требованиями.
Несмотря на некоторые пятна, новая архитектура должна не только ярко засветить (что, судя по тестам, она и делает), но и затмить все предыдущие — как свои, так и соперника. Объявленные цели по производительности и экономности достигнуты, за исключением оптимизации под набор AVX, которая вот-вот должна проявиться в новых версиях популярных программ. И тогда Гордон Мур ещё раз удивится своей прозорливости. Судя по всему, Intel во всеоружии подходит к Эпической Битве между архитектурами, которую мы увидим в этом году.
Благодарности выражаются:
- Максиму Локтюхину, тому самому «представителю Intel», сотруднику отдела программной и аппаратной оптимизации — за ответы на многочисленные уточняющие вопросы.
- Марку Бакстону, ведущему программному инженеру и главе отдела оптимизации — за его ответы, а также за саму возможность получить какую-то официальную реакцию.
- Агнеру Фогу, программисту и исследователю процессоров — за независимое низкоуровневое тестирование SB, обнаружившее массу нового и загадочного.
- Внимательному Читателю — за внимательность, стойкость и громкий храп.
- Яростным фанатам Противоположного Лагеря — до кучи.


