Часть 2: Память, Выдержка, Виды
Память Атома
Параметры кэшей Intel Atom таковы:
- L1I — 32 КБ, 8-путная ассоциативность, задержка (скорее всего) 3 такта;
- L1D — 24 КБ, 6-путная ассоциативность, задержка 3 такта;
- L2 — 512 КБ (+ ECC), 8-путная ассоциативность, задержка 19 тактов.
- шина «L2–ядро» — 256-битная, полноскоростная (хотя даже в синтетических тестах более 4,5 байт/такт не замечено).
Прежде всего удивляют странные параметры L1D, но о них мы поговорим особо. Сейчас же добавим, что у всех кэшей — 64-байтовые строки. Это также нетипично, т. к. за последние 20 лет вычислительная индустрия выработала наилучшее соотношение длины строки кэша к куску данных, обмениваемых с памятью за такт — 4:1. Т. е. 2×8×4=64 байта на строку — оптимально для 2-канального контроллера памяти с 8 байтами/такт на канал. Неужели Intel намекает на использование двух модулей памяти на дешёвых и компактных мобильных ПК? Но ведь таких чипсетов для Атома не было полтора года после его выпуска, пока не вышел NVIDIA Ion. Правда, как выяснилось, второй канал памяти даёт Атому лишь 5–6% прибавки к скорости…
L1D оснащён аппаратным предзагрузчиком (префетчером) из L2, а L2 — из памяти. Благодаря зарезервированным на доступ в L1D трём стадиям конвейера если операнд в памяти кэширован, то команда с ним скорее всего выполнится также быстро, как и с регистром. Наиболее частое исключение — когда доступ к памяти требует команда, исполняемая в порту 0, через который также происходят и обмены с памятью. Кроме того, доступ к памяти и кэшу замедляется на 3 такта (!), если используемые для вычисления адреса регистры недавно записывались.
Любопытно, что механизм STLF (Store-to-Load-Forwarding, перенаправление записи на чтение) работает только для целых чисел, но удивительно хорошо: мало того, что Atom может прочесть данные, отправленные на запись за такт до этого, хотя они ещё не попали в кэш. Другие процессоры могут их считать и в этом же такте, но там 2-портовый LSU (блок обмена данных с L1D). Зато тут это возможно, даже если размер данных для чтения превышает таковой для записи, либо при несовпадении начальных адресов. STLF не срабатывает лишь при пересечении границы строки кэша (как и везде). Но если пересечение произошло (в т. ч. и при обычном доступе) — это приводит к штрафу аж в 16 тактов, т. к. требует 4 доступа к кэшу (даже при чтении), хотя по идее достаточно и 2. Прочие случаи невыровненного доступа (когда адрес блока данных не делится нацело на свой размер), не выходящие за 64-байтовую границу, выполняются на полной скорости.

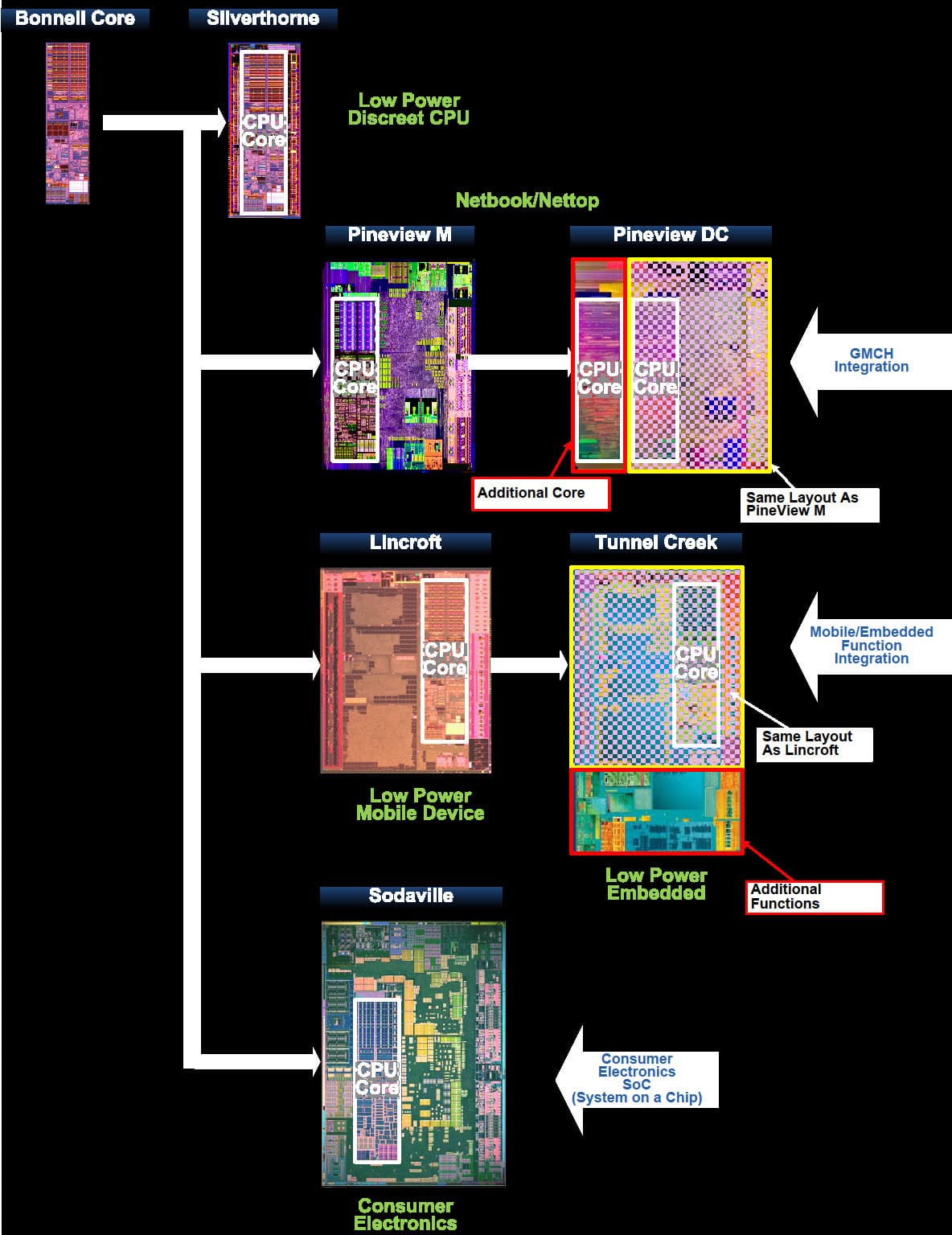
Чип Атома 400-х серий (Pineview) для платформы Pinetrail. Слева — ядро ЦП, справа — контроллер памяти, в центре — 3D/видеоядро, снизу — видеовыходы, сверху — остальные интерфейсы.
Надо полагать, что встраивание контроллера памяти (и вообще половины чипсета) в мобильный ЦП является очевидным шагом, особенно вспомнив первые подобные решения уже для 386-х процессоров. Однако Intel это сделала лишь почти через два года после выпуска первых Атомов, когда вышли модели Atom N450, N470, D410 и D510 (ядро Pineview). Подержка DDR3-1066 обещана с лета 2010 г. в моделях N455, N475 и N550, но контроллер памяти всё ещё одноканальный. Тесты показали, что особых преимуществ интеграция не принесла даже для программ, сильно зависящих от пропускной способности памяти: видимо, они и без ИКП упёрлись в слабое вычислительное ядро. Кстати, самый сложный 2-ядерный интегрированный Atom D510 имеет 176 млн. транзисторов, из которых 82 млн. потрачены на «северный мост». Сравните с цифрами для вычислительных ядер.
Выдержка Атома
Энергоэффективность — самое главное достоинство этого процессора. Хотя ЦП не всегда является самым активным потребителем электроэнергии в мобильном устройстве (при простое им оказывается подсветка ЖК-экрана или сам экран в случае применения OLED-матрицы), именно в нём применение энергосберегающих функций и технологий наиболее оправдано. Intel применила не только все накопленные до сих пор приёмы, но и добавила новые.
До Атома, когда дело доходило до анализа «энергоёмкости» нововведений, Intel применяла такое правило: при внедрении или изменении какого-либо блока, на каждые 1% ускорения ЦП должны приходиться не более чем 2% увеличения энергопотребления. Апофеоз сей недальновидной политики не заставил себя долго ждать: им стал Pentium 4. Аминь… Для Pentium M цифра энергоприбавки была уполовинена — не более 1% по ваттам. А для Атома (и, позже, в линейке Nehalem) — уполовинена снова.
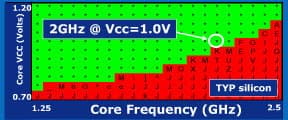 Результат неплох. По первоначальным предположениям младшим моделям для 1,3–1,5 ГГц хватит 0,8 В, для наиболее популярной частоты в 1,6 ГГц потребуется 0,85 В, а одного вольта хватило бы для 2,05 ГГц (если бы такая модель была). Цифры не такие уж и героические, ибо даже для настольных моделей куда более сложной архитектуры AMD K8 (при том, что она для экономии ватт совсем не предназначена), выполненных по последним степпингам предыдущего 65-нанометрового техпроцесса, отдельные чипы при 1 В питания работают на частоте 2,2–2,3 ГГц. Специально оптимизированная под энергосбережение версия 45-нанометрового техпроцесса могла бы дать простому Атому возможность повторить такое достижение в большинстве экземпляров. Но, в отличие от заявлений на слайдах, например, реальный Atom Z530 при частоте 1,6 ГГц питается от 1,213 В — и это специально отобранный для Z-подсерии особо экономный ЦП! «Настольная» модель 230 на той же частоте запитывается от 1,188 В… Atom N280, при простое снижая частоту с 1,66 до 1 ГГц, снижает напряжение до 1,063 В, а N450, интегрированный с северным мостом, — до 0,95.
Результат неплох. По первоначальным предположениям младшим моделям для 1,3–1,5 ГГц хватит 0,8 В, для наиболее популярной частоты в 1,6 ГГц потребуется 0,85 В, а одного вольта хватило бы для 2,05 ГГц (если бы такая модель была). Цифры не такие уж и героические, ибо даже для настольных моделей куда более сложной архитектуры AMD K8 (при том, что она для экономии ватт совсем не предназначена), выполненных по последним степпингам предыдущего 65-нанометрового техпроцесса, отдельные чипы при 1 В питания работают на частоте 2,2–2,3 ГГц. Специально оптимизированная под энергосбережение версия 45-нанометрового техпроцесса могла бы дать простому Атому возможность повторить такое достижение в большинстве экземпляров. Но, в отличие от заявлений на слайдах, например, реальный Atom Z530 при частоте 1,6 ГГц питается от 1,213 В — и это специально отобранный для Z-подсерии особо экономный ЦП! «Настольная» модель 230 на той же частоте запитывается от 1,188 В… Atom N280, при простое снижая частоту с 1,66 до 1 ГГц, снижает напряжение до 1,063 В, а N450, интегрированный с северным мостом, — до 0,95.
Спрашивается — за что боролись? А боролись не просто за экономию, а за дешёвую экономию, пусть и при не самых низких напряжениях. ULV Pentium M с TDP 3–5 Вт (при 1–1,3 ГГц и 90 нм) появился за 2,5 года до Атома, но стоил в 3–5 раз дороже. Впрочем, если бы его изготовили на 45 нм, он бы имел и площадь, и цену как раз вчетверо меньше…
В обычном ЦП для скорости при обращении в L1 одновременно запускаются три процесса — активация нужного банка с выборкой набора, трансляция физического адреса в виртуальный в TLB и выборка набора из массива тегов. Если произойдёт TLB-попадание, физический адрес сравнится с тут же считанными тегами, определяя номер пути, где произошло попадание в самом кэше. Далее из всего выбранного набора банк коммутирует для чтения или записи нужную строку. Если попадания нет ни в одном пути, регистрируется промах и запускается процесс заполнения данных из внешнего источника. В такой схеме множество операций делается наперёд и с явным избытком, в результате чего большая часть транзисторов, срабатывающих для обслуживания запроса, работают зря. Инженеры Intel модифицировали схему обращения так: операции происходят последовательно, причём только те, которые нужны, и только тогда, когда они нужны (подтверждаясь на предыдущем шаге). Т. е. сначала трансляция, потом считывание тегов, а потом доступ только к нужной строке из всего набора. Отказаться от трансляции в пользу виртуальной адресации L1 Интел не решилась — у такой идеи недостатки превышают преимущества по скорости и экономности.
Atom также динамически меняет включенную часть L2, следя за активностью доступа. Неиспользуемые банки «сливаются» (выгружают содержимое в память) и отключаются. Впрочем, главной деталью в экономных кэшах является вовсе не микроархитектурно реализованные алгоритмы экономии, а новый дизайн ячейки L1, который тесно связан с размером кэшей, точнее — с неравенством размеров. И снова оставим это на потом — не кэшем единым…
Главными потребителями джоулей в ЦП являются часто переключающиеся транзисторы ядра. И тут у Атома есть, чем похвастаться: помимо того, что этих транзисторов весьма немного за счёт сокращения специализированных блоков (например, есть только один умножитель-делитель и для целых, и для вещественных, и для скаляров, и для векторов), оставшиеся включаются только, тогда когда нужно. Выключен HT — его контроллер отключён от тактирования. Не используются 64 бита — старшая половина целочисленного тракта данных вместе с половинками регистров и ФУ также выключается. Долгое время не нужен FPU или векторный блок — отбой и ему.
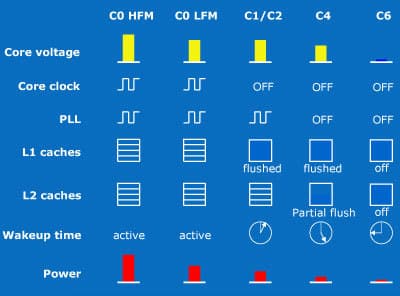
Всего у Атомов первого поколения 5 энергосостояний:
- высоко- и низкочастотный режимы C0 (HFM и LFM), отличаются только частотой (при LFM всегда 600 МГц) и напряжением ядра;
- C1 (он же C2) с нулевым тактированием и «слитыми» (но ещё запитываемыми) кэшами L1;
- C4 с отключенными умножителями частоты, «частично слитым» L2 и ещё больше сниженным напряжением;
- C6, при котором отключено и обесточено почти всё — даже из 203 выводов питания активны лишь 21, уменьшая утечки в 10 раз, а потребление — до 100 мВт (по некоторым данным в новых ЦП Z-серии — до 30 мВт).
В режиме C6 включенным остаётся лишь небольшой блок управления питанием, позволяющий проснуться в полноскоростной режим за 0,1 мс (из других режимов пробуждение намного быстрее). Блок оснащён массивом экономной статической памяти на 14 КБ (по ранним данным — 10,5), хранящим полное состояние ЦП, пока он выключен. C6 есть и у Penryn (мобильные Core 2 на 45 нм), но там о 0,1 Вт только мечтают. У Атома состояние C6, по утверждению Intel, занимает до 90% времени (предполагая, что устройство в основном «спит» в кармане или на столе), так что средняя мощность — всего 220 мВт. Т. к. в подсчёты включены и периоды «сна», здесь можно было бы написать любую цифру: проверить её всё равно почти нельзя :)

ИК-фотография ядра Lincroft на полной мощности и полном простое. В последнем случае единственное «горячее» пятнышко — блок управления питанием ядра.
Интегрированные модели Z6xx добавили ещё 4 режима:
- «форсаж» до частоты выше номинальной (C0 Burst Mode);
- ещё более экономный, чем LFM, сверхнизкочастотный режим ULFM C0 (у всех моделей — 200 МГц);
- S0i1 для простоя с быстрой готовностью — переход в S0i1 выполняется за 0,6 мс, а выход — за 1,2 мс (это дольше пробуждения из C6, но речь идёт не только о ядре, а обо всём чипе);
- S0i3 для длительного простоя — вход в него требует 0,45 мс, а выход — 3,1 мс.
В режиме S0i1 ядро находится в режиме C6, из остальных частей включен только блок управления питанием, его память и схема авторегенерации ОЗУ, потребляя в сумме 6 мВт. При S0i3 весь процессор физически отключается от питания, кроме авторегенератора с ничтожной 0,1 мВт. Также внедрён принцип «силовых островов» (power island) — функциональных блоков, оснащённых собственными ключами-коммутаторами питания, как в Core i (в Lincroft их 19). Теперь при простое блока можно снизить до нуля не только его частоту, но и питание, полностью отключив «остров» от всех подваваемых снаружи герц и вольт. Впрочем, т. к. ядро ЦП является одним из этих блоков, как и в Menlow, оно может отключаться лишь целиком — в режиме C6.
Ещё одно место экономии — сеть распределения тактирования. Дело в том, что синхронизационные сигналы (такты или «тики») необходимо доставлять во все места ядра строго одновременно. Частоты большие, фронты и спады неидеально резкие по времени — умножьте его на скорость света, и полученная цифра (2–5 см) уже вполне сравнима с размером ядра. Чтобы обеспечить одновременную доставку, сигнал распространяется по короткому пути от умножителя частоты до блоков и вентилей, что требует наличие всепокрывающей сети тактирования с огромной паразитной ёмкостью. В результате, скажем, у Pentium 4 на питание такой сети уходило до трети потребляемой мощности. Хотя никаких рекордов частоты Atom ставить не собирается, да и размеры ядра очень скромные — сеть ему не подходит. Сигнал с умножителей проходит по древообразной структуре делителей и усилителей, временные параметры которых подобраны так, чтобы после всех ветвлений приёмники получали такты одновременно. Это уменьшает затраты на тактирование до величины менее 10% от общих.
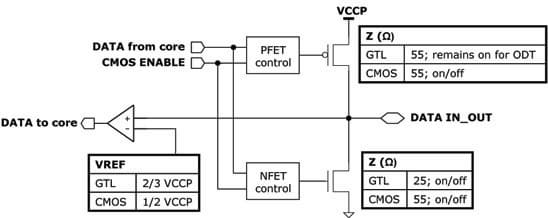
Атом экономит ватты не только внутри ЦП, но и снаружи. Речь идёт не о чипсете, а о 64-битной шине FSB до него. Экономия достигается за счёт настраиваемого режима терминаторов — оконечной нагрузки шины, которая предотвращает «звон» и другие паразитные явления, мешающие повышению частоты и стабильности. При изготовлении чипа однократным пережиганием перемычки выбирается стандартный режим (обычная GTL) или экономный (КМОП). GTL (Gunning Transceiver Logic, передаточная логика Ганнинга) переключается между 0,4 В и 1,2 В, что куда меньше размаха стандартных логических уровней, но требует симметричной терминации, потребляющей драгоценные милливатты на каждом бите шины. В режиме КМОП-шины терминаторы отключаются, а входные компараторы настраиваются на меньший уровень лог. «1» относительно напряжения питания. Т. к. скоростных рекордов ставить не надо, этого достаточно для частот 400 и 533 МГц (для последних моделей, где северный мост ещё внешний — даже 667).
Виды Атома
Вместо того, чтобы утопить читателя в длинной таблице-«простыне» с параметрами всех моделей Атомов, лучше дать ссылку на уже имеющуюся простыню в Википедии. :) Здесь же прокомментируем увиденное.

2-ядерный Diamondville против однокристального 2-ядерного Pineview со встроенным северным мостом
Атомы первого поколения делятся на версии Diamondville и Pineview для неттопов (компактных и дешёвых десктопов) и нетбуков (аналогичные эпитеты к ноутбуку), а также Silverthorne для MID-устройств платформы Menlow (ещё более мобильных «таблеток» и планшетов). Именно в таком порядке падает их потребляемая мощность и растёт цена — эти группы можно сравнить с аналогами «просто мобильных» ЦП, LV и ULV. Не удивительно, что 2-ядерные модели присутствуют только для неттопов, причём их цена не выше «нетбучной» серии N и меньше самых мобильных Z-вариантов. Модели N270 и N280, а также все из MID-подгруппы вышли с отключенной 64-битностью, а виртуализация волевым решением Intel и вовсе разрешена лишь старшим ЦП группы Z (вопрос о том, зачем она вообще там нужна, оставим на потом). Intel также оговаривается, что только в модели Z515 есть нечто под названием Burst Performance Technology (BPT), позволяющее динамически менять частоту между 0,8 и 1,2 ГГц в зависимости от вычислительных требований.

CoreExpress-Menlow — одна из первых плат на Атоме (внизу) и чипсете Poulsbo (в центре) размером 65×58 мм
Куда интересней разброс значений TDP при одинаковых или близких частотах и питающих напряжениях. Например, для частоты 1,6 ГГц — от 4 Вт для настольных моделей до 2 для «MID'овских». Причём указанные цифры даны для 1-поточной работы: для 2-поточной Intel мелким шрифтом на презентационных слайдах пишет цифру на 20% большую. Тем не менее, в сравнении с другими процессорами разница многократная. И если бы процессор был главным потребителем энергии в мобильных устройствах, Атомы наверняка имели бы шансы вытеснить другие архитектуры с этого рынка. Но не всё так просто — первые платы с Атомами использовали изначально не предназначенные для них чипсеты 945GSE (с TDP 6 Вт для северного моста и 3,3 Вт для южного) или даже 945GC (22 Вт). Для нетбуков и особенно MID-устройств Intel рекомендовала однокорпусные чипсеты UL11L или US15* (с разными буквами) с ТDP 2,3 Вт (вместе с Атомом они составляют платформу Poulsbo), но и это не блестящее решение — например, из-за ещё более низкой 3D-производительности, чем традиционно ожидается даже от интеловских чипсетов: ради экономии пришлось замедлить в 2–8 раз частоту GPU-ядра GMA 500 (оно же PowerVR SGX 535 производства Imagination Technologies — такое же, как и в iPhone 3GS и iPad): в US15* — 200 МГц (что позволяет ускорять видео с разрешением до 1366×768), в UL11L — 100 МГц (до 800×480). А ещё U*1** делаются по технологии аж 130 нм (так что размер его чипа втрое больше, чем у ЦП), поддерживают в разных версиях до 0,5–2 ГБ DDR2-533 в одном канале, и никаких SATA и USB 3.0. ИКП в Pineview «держит» уже 4 ГБ DDR2-800.
Также видно, что только для MID-устройств Intel приготовила особо компактные версии корпусов, а вообще для одного ЦП их небольшой зоопарк:
- BGA 437 для неттопов и нетбуков без встроенного северного моста, а также не очень мелких MID;
- micro-FCBGA8 559 для ЦП со встроенной «бижутерией»;
- BGA 441 для самых мелких устройств — всего 13×14 мм (первые два вида, а также чипсет — 22×22).
Для MID также наблюдается самый большой диапазон частот — от 0,8 до 2 ГГц. Из чего логично сделать вывод, что именно на эти применения Intel прежде всего и рассчитывает. Если только не смотреть на цены: самый дешёвый из выпускаемых в мире x86-процессоров — это Atom 230. А самый дешёвый из 2-ядерных — Atom 330. Причём он стоит почти те же $45 (рекомендованная цена), что и 1-ядерный Z500 с половиной частотой (зато TDP последнего в 12 раз меньше). Самый же крутой Z550 в 2,5 раза быстрее и в 3–4 раза дороже. Его точная цена неизвестна: некоторые Атомы продаются только в комплекте с чипсетом, но цена указана именно для ЦП — вокруг этой странности год назад NVIDIA даже поскандалила с Intel, пытаясь купить только процессоры без чипсетов для своей патформы Ion.
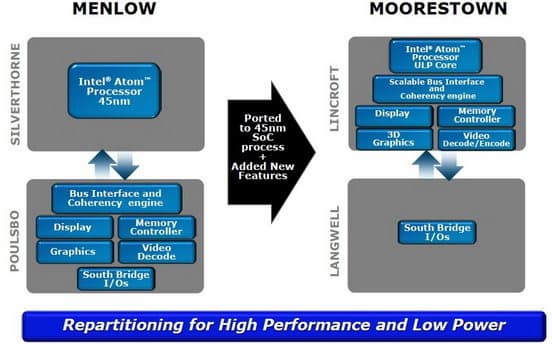
Moorestown в сравнении с Menlow
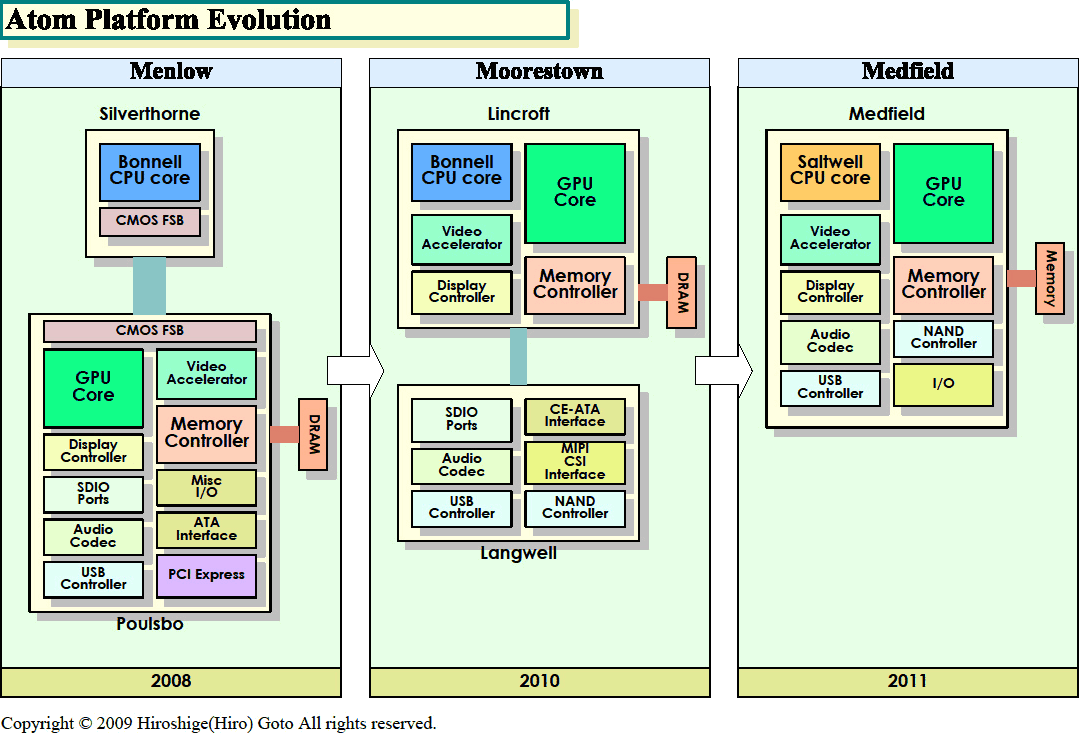
В мае 2010 г. анонсировано второе поколение и 4-й вид Атомов — 1-ядерный интегрированный Lincroft (модели Z6xx с пока ещё неизвестными номерами и макс. потреблением 1,2 Вт), являющийся частью платформы Moorestown для смартфонов, т. е. ещё более компактный и экономичный аналог Pineview. Разработка запоздала к началу массового производства на 32 нм, но 45-нанометровый техпроцесс обновлён — его SoC-версия (по сравнению с настольными 45 нм от Intel) обменивает потерю 6–8% максимума частоты на 2,5-кратное уменьшение тока утечки. Также новый чип получил:
- 32-битный контроллер памяти с увеличенной эффективностью и ПСП, причём собственно Lincroft будет поддерживать только особо экономную LPDDR1-400 (до 1 ГБ), а его пока не названные планшетные версии — только DDR2-800 (до 2 ГБ);
- обновлённое и ускоренное до 400 МГц GPU-ядро GMA 600 с поддержкой DirectX 9.L и OpenGL 2.1;
- новый аппаратный видеокодек, реализующий кодирование 720p30 H.264 и MPEG-4 и декодирование H.264, MPEG-4, WMV и VC-1 с разрешением 1080p30 для планшетов и 720p30 на смартфонах;
- поддержку более разнообразной и современной периферии, включая экраны с разрешением до 1366×768 через интерфейс LVDS для планшетов и 1024×600 через MIPI для смартфонов.
Таинственная BPT теперь на короткие интервалы сможет превышать номинальную частоту при отсутствии опасности перегрева, превратившись в аналог более знакомого TurboBoost для Core i. Базовые частоты для смартфонов обещаны 1,2–1,5 ГГц, а для планшетов — до 1,9; пиковые с BPT пока неизвестны. Теперь уже внутричиповая шина «ядро↔северный мост» ускорена до 800 МГц, что даёт 6,4 ГБ/с для чтения, но только 4,3 ГБ/с для записи. А новая технология Bus Turbo Mode даст дополнительный временный разгон главной шины, ИКП и шины памяти, когда их пропускной способности не хватает.
140 млн. транзисторов чипа умещаются на 65 мм² в корпусе размером 14×14×1 мм. Такой же компактный южный мост для Z6xx называется Langwell (он же «хаб-контроллер платформы» PCH MP20) и производится по 65-нанометровому техпроцессу, причём компанией TSMC. Взамен поддержки SATA обещают подключение флешевых SSD на скоростях до 80 МБ/с. Также есть DSP обработки изображений (со входом от камеры и выходом HDMI) и ещё один для звука с собственным буфером — последний может пробуждать контроллер памяти в ЦП и считывать в себя очередную порцию данных, не включая ядро, после чего ЦП снова засыпает. Управляется всё это невидимым для ОС системным контроллером на 32-битном RISC-ядре с собственным «BIOS».
Как ни странно, Langwell не включает в себя ещё один обязательный компонент, также производимый сторонними компаниями — Briertown (он же MSIC, микросхема смешанных сигналов), содержащий контроллер энергопотребления системы и зарядки аккумулятора, генератор питающих напряжений для остальных чипов, набор цифровых и аналоговых интерфейсов, ускоритель шифрования и часы. MSIC через прямую связь с ЦП и южным мостом настраивает их блоки управления питанием, выполняя встречные запросы настройки напряжений. Для оптимизации баланса скорости и потребления под конкретную задачу (в т. ч. управление «силовыми островами» и энергосостояниями ЦП) Briertown не угадывает вычислительную нагрузку, как аналогичный блок в Core i, а явно программируется профилями энергопотребления через интерфейс ACPI. За профили отвечает подсистема управления питанием ОС (OS Driven Power Management, OSPM), опрашивающая программы об их запросах ресурсов.
Время работы с батареей на 1,5 А·ч и 3,7 В обещано 45–50 ч при проигрывании звука и 4–6 ч с видео, сёрфингом или звонком по 3G. Экономия достигается тем, что в чипсетной части процессора обильно применяются те же методы экономии, что и в ядре. В состоянии S0i3 пара Lincroft + Langwell должна потреблять всего 3 мВт, а вся система — 20–25 мВт, что в 50 раз меньше, чем в платформе Menlow, и сравнимо с смартфонами на архитектуре ARM. Хотя по сравнению с Menlow обещано сокращение занимаемой площади вдвое, очень компактным Moorestown не будет, т. к. помимо вышеназванных трёх микросхем также нужен контроллер беспроводной связи и чип(ы) памяти — Intel не собирается умещать логику и память в один корпус, как в процессоре A4 для iPad.
Для Lincroft есть ещё один южный мост — Whitney Point, с которым в сумме получается платформа Oaktrail для неттопов. Места он занимает столько же, но энергии потребляет больше, т. к. дополнительно содержит контроллеры PCI и SATA. Можем предположить, что Langwell и Whitney Point это один и тот же чип, просто в смартфонной версии не все блоки включены — рыночная политика Интел.
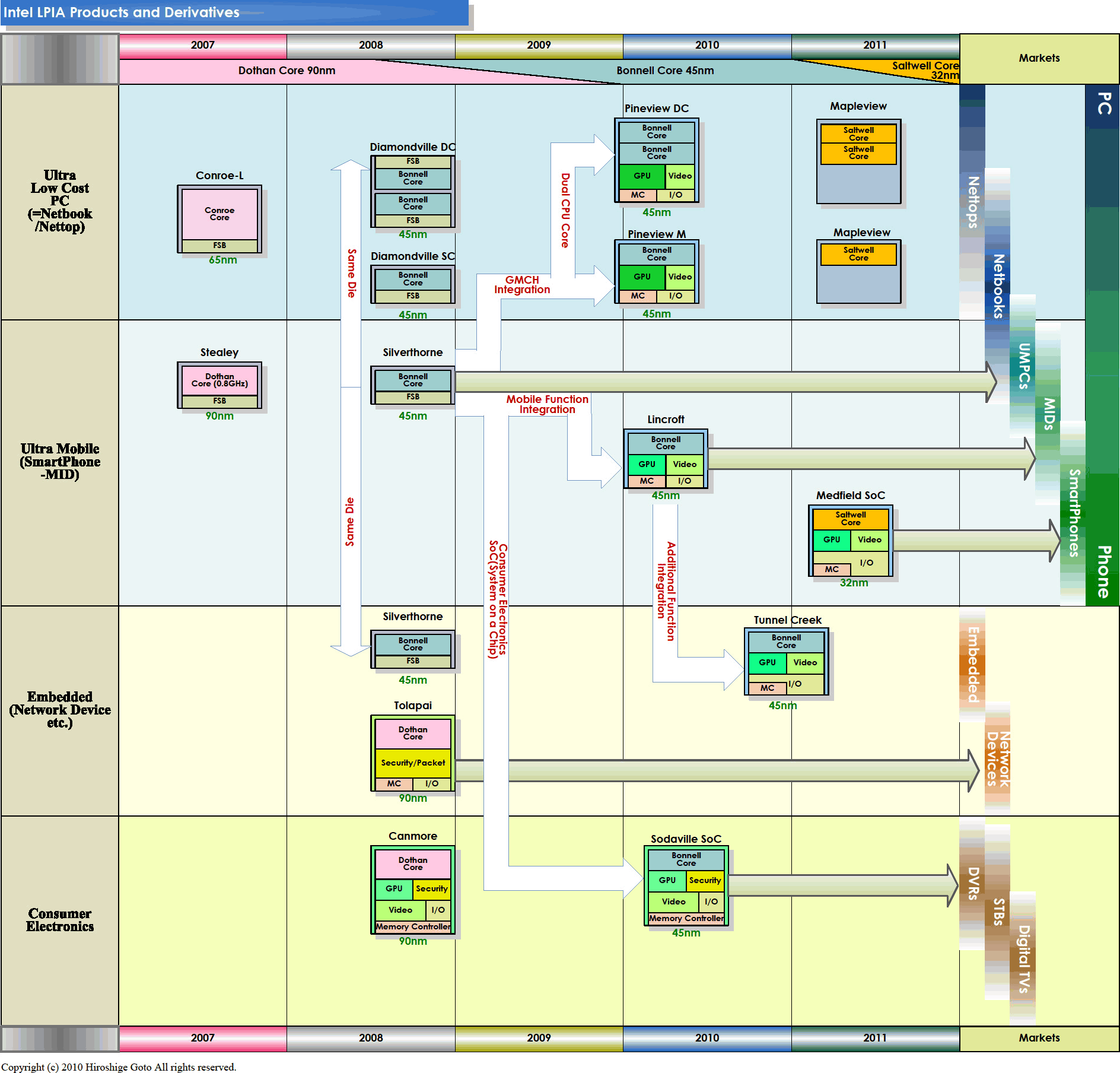
Если вы уже запутались в названиях и параметрах ядер и платформ — вот несколько шпаргалок, где также видно выходящее в 2011 г. третье 32-нанометровое поколение Атомов — Medfield с ядром ЦП Saltwell и встроенным южным мостом:
 |  |  |


