Часть 3: Неравенство, Загадки, Резвость, Соперники
Неравенство Атома
Странностей у этого процессора набирается столько, что кажется, будто разработчики Intel почувствовали себя авторами захватывающего детектива для будущих исследователей. И первое, что бросается в глаза — те самые 24 КБ в кэше L1D. Но вначале снова некоторая теория.
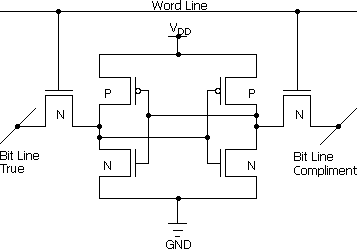
Десятилетия подряд стандартная ячейка КМОП СОЗУ (SRAM, статическая память с произвольным доступом) не менялась никак — хотя за это время появились (а некоторые — и исчезли) несколько семейств логики и десятки техпроцессов. Она состоит из 6 транзисторов, 2 из которых — коммутирующие (открываются для чтения или записи), а остальные двумя комплементарными парами (p- и n-канальное устройства) образуют кольцевой инвертор — простейший бистабильный логический элемент, хранящий 1 бит. При чтении ячейка выдаёт прямой и инверсный сигналы на двойную битовую шину. А вот при перезаписи (когда состояние должно смениться — либо 0→1, либо 1→0) заранее поданные на шину сигналы на мгновение приводят к двум коротким замыканиям в ячейке, которая выдаёт своё содержимое, противоположное записываемому значению. Только после переключения инверторов равенство состояния ячейки и подаваемого сигнала восстанавливается. В результате при перезаписи происходит частичное проседание напряжения на шине питания в районе записываемой строки или слова, что хоть и не сможет повредить хранящимся в округе данным, но явно ограничивает максимальную частоту срабатывания, не говоря уже об энергопотреблении. Кроме того, схема требует относительно высокого напряжения и при чтении, т. к. длинные (в масштабах чипа) битовые линии надо запитывать выходами инверторов, где ещё должно остаться достаточно энергии просто для сохранения значения, чтобы чтение не оказалось деструктивным (как в ДОЗУ — динамической оперативной памяти).
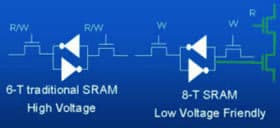 Решить проблему можно, добавив ещё пару транзисторов и превратив ячейку в 2-портовую. Теперь сигнал активации двойной шины подаётся лишь при записи. Так можно снизить требуемое напряжение питания за счёт того, что при чтении отдельная активационная линия (и её транзистор) подключает к одному из входов-выходов ячейки ещё один транзистор, работающий как усилитель для шины чтения. Теперь самой ячейке не надо «напрягаться» для смены целой пары линий со всеми их паразитными ёмкостями и прочими неидеальностями. Эта же схема впоследствии принята для L1 в архитектуре Nehalem, а недавно стало известно, что в мобильных чипах AMD Llano оба кэша L1 также будут использовать аналогичный подход. В Атоме так устроены все ячейки памяти ядра — кэши, регистры, буферы и очереди.
Решить проблему можно, добавив ещё пару транзисторов и превратив ячейку в 2-портовую. Теперь сигнал активации двойной шины подаётся лишь при записи. Так можно снизить требуемое напряжение питания за счёт того, что при чтении отдельная активационная линия (и её транзистор) подключает к одному из входов-выходов ячейки ещё один транзистор, работающий как усилитель для шины чтения. Теперь самой ячейке не надо «напрягаться» для смены целой пары линий со всеми их паразитными ёмкостями и прочими неидеальностями. Эта же схема впоследствии принята для L1 в архитектуре Nehalem, а недавно стало известно, что в мобильных чипах AMD Llano оба кэша L1 также будут использовать аналогичный подход. В Атоме так устроены все ячейки памяти ядра — кэши, регистры, буферы и очереди.
Инженеры, пойдя на такой шаг, не могли не знать, что кэши в современных ЦП занимают изрядную долю кристалла. Побочным эффектом внедрения большей по площади ячейки стало то, что этой самой площади просто не хватило для первоначально задуманного размера L1D — и из 32 КБ и 8-путной ассоциативности уместилось лишь 24 КБ и 6 путей. Однако минимальная разница в площади ячейки — 0,382 мк² для Атома и 0,346 мк² у Core 2 на тех же 45 нм — навевает подозрения, что официальная версия рассказывает нам не всё. Но прежде чем предложить свою, опять окунёмся в теорию — на этот раз мы вспомним, как разрабатываются сложные микросхемы.
Любой современный чип не един, а состоит из прямоугольных блоков. Внутри них транзисторы и проводящие дорожки размещаются по сетке с мелким шагом параллельно сторонам блока. При объединении элементов в простые схемы форма границы такого блока окажется неровной. Далее надо учесть, что все чипы разрабатываются с обильным применением специализированных САПР (CAD) — от моделирования концепции до просчёта топологии и подготовки масок слоёв. А для САПР нужна большая вычислительная мощность. Несмотря на имеющиеся у крупных компаний кластеры, выделенные для разработки чипов, их ресурсов всё равно не хватит, если вычисления будут вестись по идеальным и точным формулам.
Для ускорения просчёта сначала блоки по отдельности моделируются и оптимизируются, а затем из них, как из конструктора, собирается целый чип. При этом возникает проблема подгонки блоков друг к другу. Для упрощения они делаются прямоугольными: даже если внутри где-то останется свободное место, оно не обязательно будет заполнено при стыковке с другим блоком, т. к. у того в этом же месте тоже может оказаться «вмятина», а не «выпуклость». При подгонке пробуются разные варианты раскладки блока, пока не найдётся наиболее подходящая — напоминает игру «Пятнашки», только тут блоки можно ещё поворачивать и зеркально отражать. Выходит, логические блоки могли бы быть несколько плотнее, если бы оптимизация проводилась по всему кристаллу — но тогда их бы просчитывали годами. Блоки памяти имеют регулярную структуру, а потому там транзисторы размещены куда тесней.
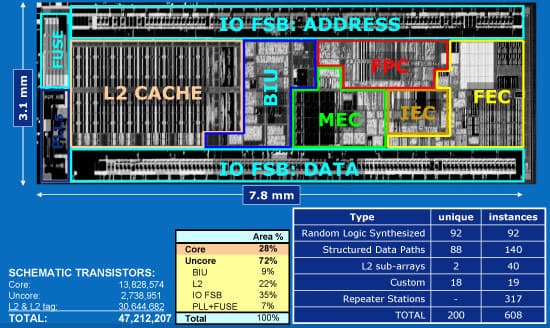
FEC — L1I + предсказатели + декодер;
IEC, FPC — целочисленный и векторно-вещественный исполнительные кластеры;
MEC — L1D + предзагрузчик;
BIU — контроллеры шины и L2; L2 Cache — он же;
IO FSB — драйверы шины (отдельно для адреса и данных);
Fuse — сменяемая часть микрокода; PLLs — умножители частоты
Вот как это сделано в Атоме — он представим в виде «моря FUB» (Functional Unit Block — блок функционального устройства). На фото чипа наложены границы 10 основных кластеров (как видно, не всегда прямоугольных), состоящих в сумме из 608 прямоугольных FUB двухсот разных видов. Причём большая часть FUB ядра уникальны (кэш L1 или ФУ тут считается как цельный FUB, хотя надо бы поделить), а в кэше L2 таких всего 2 — банк данных (используется 32 раза) и банк тегов (их 8). Любопытно, что самую большую долю площади занимает не ядро (28%) и даже не L2 (22%), а буферные драйверы FSB — аж 35%, что наверняка является рекордом для процессоров.
Но вернёмся к загадочному кэшу. Наша гипотеза такова: вначале группа инженеров, просчитав необходимую для целевой стоимости площадь, сообщила её архитектурщикам. Те стали разрабатывать блоки (или использовать уже готовые) и, тщательно подогнав их, сверяли с целевой площадью. После того, как всё сошлось, виртуальный чип стали подвергать моделированию. И тут выяснилось: в квадратные миллиметры «вписались», а в минимальные вольты — нет. Однако взяв новый тип ячейки кэшей, дизайнеры обнаружили несовместимость уже по площади — при том, что весь остальной чип почти готов.
Обычно в таких случаях разработчики собираются и обсуждают, где бы что из готовых блоков сократить в миллиметрах, вольтах или ваттах, чтобы перераспределить их данному (проблемному) блоку, не выйдя за рамки общего бюджета по всем параметрам. Такие дискуссии иногда похожи на перетягивание одеяла, т. к. каждый инженер считает, что именно его блок самый главный, и нечего делиться драгоценными ресурсами ради расточительства других. И тут настал ещё один пикантный момент — помня, что чип разрабатывается уже 3-й год, а также то, что предыдущий проект этой группы был отменён, инженеры (или руководство…) решили, что не гоже именитой фирме с огромным опытом растягивать разработку относительно простого процессора. Так что вместо долгой дискуссии, а затем перепланировки и переподгонки блоков приняли волевое решение просто сократить размер там, где режется быстрее всего, и, вроде бы, не сильно заметно для скорости. Хотя последнее спорно…
Внимательный читатель сразу задаст вопрос — а как же L2? Ведь его ради экономии площади не перевели на экономный тип ячеек, а питается он тем же напряжением, что и ядро с его низковольтными кэшами L1. А разница в том, что только L2 имеет биты обнаружения и коррекции ошибок (ECC). В редких случаях, когда проседание напряжения всё же приводит к ошибке при чтении, ECC спасает положение, исправляя наиболее частые 1-битные и обнаруживая 2-битные ошибки, что хоть и замедляет кэш, но всё же позволяет запитать L2 от низкого напряжения — вероятность появления неисправимой ошибки наверняка так мала, что за время работы чипа это скорее всего не произойдёт ни разу. Тут немедленно надо задать встречный вопрос — что же мешало инженерам встроить такой же ЕСС в кэши L1 (как это сделано во «взрослых» ЦП), понизить напряжение питания и не морочить себе головы переделкой типа ячеек? Возможным ответом будет то, что ECC-биты занимают лишние 12,5% площади матрицы кэша, добавляя 1 бит на каждый байт, и это даже чуть больше разницы площади двух типов ячеек. И вот тут возникает финальный вопрос — почему же тогда не перевести и L2 на низковольтовые ячейки без всяких ECC, чтобы сэкономить если не на площади матрицы, то хотя бы на логике проверки и коррекции, которая теперь не нужна (что также уменьшит время доступа)? И вот тут наша гипотеза обрывается… :)
И ещё: на фото чипа в блоке декодера есть непомеченный массив памяти рядом с L1I с нерегулярным устройством и площадью, близкой к L1D. Если это и есть буфер разметки предекодера — его размер в 24–28 КБ (т. е. 6–7 бит на 1 байт кода — по сравнению с тремя у AMD) навевает подозрения, что Intel явно просчиталась с распределением места между L1D (24 КБ) и L1I (≈60 КБ в сумме). Если же это вышеупомянутый «Ноев ковчег» состояния ядра для энергорежима C6, то и тут физический размер не соответствуют заявленному информационному — ещё одно неравенство…
Загадки Атома
Другие вопросы, остающиеся без ответа — зачем Атому понадобилась виртуализация, 64-битные вычисления и поддержка x87. Трудно представить себе, что на мобильном устройстве кто-то захочет запустить более одной ОС — даже сегодня и даже на десктопах это малоиспользуемая возможность. Впрочем, ради галочки виртуализацию вполне можно добавить, т. к. она не сильно увеличивает транзисторный бюджет, да и особой прыти при переключении между ОС тут никто не ждёт.
С 64-битностью вопрос сложней. Ясно, что в 2004–2007 гг., пока разрабатывалась архитектура, 8 ГБ ОЗУ никому не снилось не то что на дешёвом мобильном планшетике, но и на мощных компьютерах. Контроллеры памяти для Атома, напомним, физически поддерживают до 4 ГБ ОЗУ. Даже сейчас, когда это уже технически возможно и доступно по финансам, лишь профессиональные программы выиграют от более чем 4 ГБ памяти, для чего им и потребуется 64-битная адресация. Возможно, годику к 2012-му уже появится потребность в таком объёме и в карманно-мобильной технике, но к этому моменту Intel запросто могла бы доделать дизайн, если бы он с самого начала был 32-битный.
Есть два возможных ответа. Во-первых, коротышка Bonnell изначально разрабатывался для многоядерного чипа с целью получить большу́ю суммарную производительность, а значит — и большую потребность в памяти. Там 64 бита как раз пришлись бы. Ну а после расширения архитектуры на мобильные применения 64 бита решили на всякий случай не убирать ради унификации и ускорения разработки. Во-вторых, x86-64 даёт бо́льшую разрядность не только адресов, но и данных, а также удваивает число доступных регистров. Т. е. даже если вам не нужны 64 бита адреса, остальными добавками не помешает воспользоваться для ускорения вычислений.
А вот случай с поднабором x87 (а с ним — и MMX) объясним меньше всего. Прежде всего отметим, что регистры XMM, с которыми сегодня работают все ЦП при вещественных вычислениях, иногда называют векторными, что неточно. С их содержимым можно делать 3 вида операций: целочисленные векторные, вещественные векторные и вещественные скалярные. Целочисленные скалярные данные и адреса располагаются в регистрах общего назначения (РОНы), исторически появившиеся в ЦП первыми. Вторыми появились скалярные вещественные вычисления, и в x86-й архитектуре это было расширение x87. Если сравнить его с современными наборами SSE* и их регистрами XMM, то x87 имеет следующие достоинства:
- 80-битная внутренняя точность;
- команды для сложных функций (тригонометрия, логарифмы, BCD-преобразования);
- стек содержится отдельно от целочисленных данных;
- команды x87 короткие (чаще всего 2 байта) и не имеют префиксов.
А вот недостатки:
- набор команд x87 почти перестал развиваться;
- нет команд быстрых приближённых вычислений;
- 80-битная точность неудобна для хранения в памяти (10 байт не является целой степенью двойки) и подходит лишь для внутренних вычислений;
- даже в 64-битном режиме стек имеет 8, а не 16 регистров;
- стековая организация регистров менее удобна (особенно при автооптимизации компилятором), чем явное указание всех операндов, а значительная часть команд и вовсе работает лишь с регистром ST0;
- стек не может быстро обменяться данными с другими регистровыми файлами, т. к. «официально» это делается через память;
Глядя на второй список видно, что он малоисправим, так что имеет смысл подумать о том, являются ли преимущества x87 незаменимыми. Расширенная 80-битная точность (Extended precision, EP) для большинства вычислений избыточна — даже если где-то не хватит 53 бит мантиссы или ±300 степеней, модификацией алгоритма можно уменьшить накопление погрешности, а экспоненту считать отдельно. Почти все вещественные вычисления — от видеокарт до суперкомпьютеров — выполняются в одинарной или двойной точности (SP и DP, 32 и 64 бита).
Трансцендентные и BCD-функции редки и долгие для исполнения, а некоторые требуют не только микрокод, но и таблицы с константами — в отличие команд SSE, которые более популярны и выполняются за несколько тактов в конвейерных ФУ. Более того, современные компиляторы реализуют те же синусы и логарифмы векторами даже для скалярных операндов — т. к. они вычисляются через сумму рядов, что отлично подходит для SSE. В результате поддерживающий хотя бы SSE2 процессор может выполнить даже сложные скалярные операции в XMM-регистрах быстрее, чем микрокодом в x87.
Экономия регистров для скаляров и до x86-64 была не очень важна (в одном XMM-регистре умещается 2–4 вещественных элемента, которые можно перетасовать перед исполнением скалярной операции), а после удвоения числа регистров — и подавно. Что касается экономии кода и быстроты его дешифровки, это вполне полезно (современные команды раздуваются и усложняются с каждым очередным SSE), но многочисленные недостатки x87 затмить это не сможет.
Как видно, мы рассматривали x87 вообще, не задаваясь вопросом, как часто он нужен в мобильных применениях, где и с целочисленной скоростью иногда не всё хорошо. Профессиональные приложения, требующие большую точность и скорость, явно не для таких устройств. В настольных ЦП x87 оставляют лишь как дань прошлому — очередная «святая корова» совместимости, сто́ящая нескольких сотен тысяч или миллионов транзисторов, незаметных в цене и энергопотреблении обычных ЦП. Атому всё это не подходит — тогда зачем же там x87?
Может быть, дело в наборе MMX? Это первое векторное дополнение к IA-32 использует 64-битные порции стека x87 (адресуя их именно как регистры) для целочисленных векторных вычислений. Однако с выходом SSE2 и XMM-регистры вдвое большей разрядности стали принимать целочисленные данные. Как и x87, MMX давно перестал развиваться (имея ввиду команды специально для него), а 64-битные ОС запрещают использовать эти регистры в драйверах и ядре (в отличие от XMM). В крайнем случае Intel могла бы оставить Атому только набор MMX, учитывая, что микрокод там не нужен, а исполняется он в тех же ФУ, что и SSE* — потребовались бы только лишние 8 64-битных регистров. Окончательным гвоздём в гроб «мобильно-экономного x87» является то, что конкретно в Атоме эти команды исполняются медленно даже на фоне остальных. Кстати, о скорости…
Резвость Атома
Уже первые тесты 1-ядерных Атомов показали, что их производительность примерно соответствует Pentium M с половинной частотой (т. е. 600–900 МГц — сравните с частотами предков Атома). Надо полагать, что с архитектурной точки зрения 2-путный суперскаляр с упорядоченным исполнением команд и гиперпоточностью оказался за такт вдвое хуже 3-путного суперскаляра с перетасовкой команд и без гиперпоточности. Но на одинаковой частоте и при равной эффективности заполнения конвейеров он должен отстать лишь в полтора раза — по числу конвейеров. В чём дело? А дело в самой слабой части архитектуры Intel Atom — некачественном планировании и синхронизации команд и операндов.
Для начала напомним, что с точки зрения скорости исполнения каждая команда характеризуется двумя параметрами: задержка (latency) — сколько тактов надо ждать, пока запущенная в ФУ команда завершит исполнение, — и пропуск (reciprocal throughput, обратная пропускная способность) — как скоро после запуска этой команды можно в это же ФУ послать следующую (полагая, что она не конфликтует по данным с уже запущенными). Оба параметра чем меньше, тем лучше. Причём если задержка больше 1, то по пропуску можно определить, как эффективно работает ФУ. Если пропуск равен 1, то говорят, что ФУ полноконвейерно, т. е. может принимать очередную порцию данных каждый такт. Если 2 — ФУ полуконвейерное (например, обрабатывает операнды половинками, как это было долгое время со 128-битными XMM-регистрами). Если пропуск (почти) равен задержке — то ФУ неконвейерное и требует ждать (почти) полного окончания исполнения команды до запуска новой. Иногда пропуск даже превышает задержку, когда после выдачи результата надо доделать операции с неявными операндами. Если есть несколько одинаковых ФУ, умеющих исполнять данную команду (чаще всего это АЛУ), пропуск делится на их число, так что он может быть и нецелым.
А теперь сравним, что мы имеем у Атома и его хронологических предшественников и современников по самым частым командам. Ниже указаны пары «задержка/пропуск» для операций с регистрами; худшее значение строки, если оно одно, выделено красным:
| Домен | Действие | Команды | Atom | P MMX | P II(I) | P M | Core 2 | K6-2 | K7 | K8 |
| Скалярный целочисленный | Копирование | MOV | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,3 | 1/0,5 | 1/0,3 | 1/0,3 |
|---|---|---|---|---|---|---|---|---|---|---|
| Условное копирование | CMOV* | 2/2 | 1/1 | 2/1,5 | 2/1 | 1/0,3 | 1/0,3 | |||
| Обмен | XCHG | 6/6 | 3/3 | 3/1,5 | 2/1,5 | 2/2 | 3/3 | 2/1 | 2/1 | |
| Логические операции | AND, (X)OR, NOT, TEST | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,3 | 1/0,5 | 1/0,3 | 1/0,3 | |
| Простые сдвиги | SH*, SA*, RO* | 1/1 | 1/1 | 1/1 | 1/1 | 1/0,5-1 | 1-2/1-2 | 1/0,3 | 1/0,3 | |
| Сложение, вычитание | ADD, SUB | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,3 | 1/0,5 | 1/0,3 | 1/0,3 | |
| Умножение, 32×32=32 бита | IMUL | 5/2 | 9/9 | 4/1 | 4/1 | 3/1 | 3/3 | 4/2 | 3/1 | |
| Умножение, 32×32=64 бита | 6/6 | 9/9 | 5/5 | 5/5 | 5/1,5 | 3/3 | 6/4 | 3/3 | ||
| Скалярный вещественный (x87) | Копирование | FLD | 1/1 | 1/1 | 1/1 | 1/1 | 1/1 | 1/1 | 1/0,5 | 1/0,5 |
| Условное копирование | FCMOV* | 9/9 | 2/2 | 2/2 | 2/2 | 1-6/5 | 1-4/4 | |||
| Обмен | FXCH | 1/1¹ | 0-1/1 | 0/0,3 | 0/0,3 | 0/1 | 1/1¹ | 0/0,3 | 0/0,3 | |
| Сложение, вычитание | FADD, FSUB | 5/1 | 3/1 | 3/1 | 3/1 | 3/1 | 2/3 | 4/1 | 4/1 | |
| Умножение | FMUL | 5/2 | 3/2 | 5/2 | 5/2 | 5/2 | 2/3 | 4/1 | 4/1 | |
| Скалярный вещественный (SSE*) | Сложение, вычитание, SP | ADDSS, SUBSS | 5/1 | 3/1 | 3/1 | 3/1 | 4/1 | 4/1 | ||
| Сложение, вычитание, DP | ADDSD, SUBSD | 5/1 | 3/1 | 3/1 | 4/1 | |||||
| Умножение, SP | MULSS | 4/1 | 4/1 | 4/1 | 4/1 | 4/1 | 4/1 | |||
| Умножение, DP | MULSD | 5/2 | 5/2 | 5/1 | 4/1 | |||||
| Векторный целочисленный (MMX, SSE2+) | Копирование | MOVQ, MOVDQ* | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,3 | 1/0,5 | 2/0,5 | 2/0,5-1 |
| Логические операции | PAND(N), P(X)OR | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,3 | 1/0,5 | 2/0,5 | 2/0,5 | |
| Перепаковка | PACK*, PUNPCK*, PSHUF* | 1/1 | 1/1 | 1/1 | 1-2/1-2 | 1-3/1-2 | 1/0,5 | 2/0,5-2 | 2-3/0,5-2 | |
| Сложение, вычитание | PADD*, PSUB* | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 1/0,5 | 2/0,5 | 2/0,5 | |
| Умножение MMX | PMUL* | 4/1 | 3/1 | 3/1 | 3-4/1 | 3/1 | 2/1 | 3/1 | 3/1 | |
| Умножение SSE | 5/2 | 3-4/2 | 3-4/2 | 3/2 | ||||||
| Векторный вещественный (SSE*) | Копирование | MOVP* | 1/0,5 | 1/1 | 1/1 | 1/0,3 | 2/1 | 2/1 | ||
| Логические операции | AND(N)*, (X)OR* | 1/0,5 | 2/2 | 1/0,5 | 1/0,3 | 2/2 | 2/2 | |||
| Перепаковка | UNPCK*, SHUFP* | 1/1 | 2-3/2 | 1-4/1-2 | 1-3/1-2 | 3/3 | 3/2-3 | |||
| Сложение, вычитание, SP | ADDPS, SUBPS | 5/1 | 3/2² | 3/2 | 3/1 | 4/2 | 4/2 | |||
| Сложение, вычитание, DP | ADDPD, SUBPD | 6/6 | 3/2 | 3/1 | 4/2 | |||||
| Умножение, SP | MULPS | 5/2 | 4/2² | 4/2 | 4/1 | 4/2 | 4/2 | |||
| Умножение, DP | MULPD | 9/9 | 5/4 | 5/1 | 4/2 |
¹ — в отличие от др. ЦП, не спаривается с другими командами x87 ↑
² — только для P III ↑
Помимо сильных ограничений на одновременный запуск команд, погоня за тотальной экономией ваттов и вентилей привела к тому, что половина наиболее частых команд на Атоме выполняются медленнее, чем на ЦП прошлого века, включая даже первый Pentium. Например, удивляют огромные задержки команды XCHG и то, что вещественая FXCH, так нужная x87-му стеку, тратит на исполнение 1 такт (на всех остальных ЦП она «бесплатна», ибо разрешается при переименовании регистров и до ФУ не доходит) — это говорит о, мягко говоря, странностях при доступе к регистрам. Аналогично с флагами, что показывает вещественное условное копирование аж за 9 тактов. Но главные неприятности — с вещественными вычислениями.
Скалярные вещественные сложения полноконвейерны и занимают 5 тактов; векторные вещественные ведут себя так же с SP-числами (т. е. вещественный сумматор действительно 128-битный), но требуют 6 неконвейерных (!) тактов в случае двойной точности — а ведь даже от 64-битного сумматора надо ожидать показателя 6/2. Универсальный 64-битный умножитель на скалярных целочисленных данных ведёт себя как 32-битный, хотя 80-битное умножение (с 64-битной мантиссой) выполняет в полуконвейерном режиме с умеренной задержкой (5/2). С SP-умножением примерно так же: 4/1 для скаляра и 5/2 для вектора (всё в порядке), но замедление для упакованных DP-чисел ещё катастрофичней — 9 неконвейерных тактов, хотя хуже, чем 7/4, быть не должно. И ещё кое-что, что не попало в таблицу: если запустить пару MULPD и ADDPD так, чтобы вторая зависела по регистрам от первой, то, как и ожидается, пара выполнится последовательно за 15 тактов. А вот если регистры дать разные, чтобы была возможность одновременного исполнения, то мопы выполнятся не за 9 тактов, а за 13…
Таким образом, с вещественными скалярами Atom работает неплохо, а с SP-числами — даже и в векторном режиме, но комбинация DP и векторов необъяснимым образом рушит оба вещественных ФУ. Возможно, создатели понадеялись, что Атому придётся обрабатывать много вещественных лишь одинарной точности. Что тем более странно в свете сохранения x87-команд и добавки новейших на тот момент команд (S)SSE3. В результате, погнавшись за экономией и простотой, авторы новой архитектуры дискредитировали обе идеи, доведя их до абсурда.
Доказать чрезмерную экономию удалось коллегам с Tom’s Hardware Guide, рассчитавшим энергоэффективность двух систем с похожей конфигурацией — ПК с десктопным Core 2 Duo E7200 имеет в 2,5 раза больше производительности на каждый джоуль (т. е. 1 Вт·с), чем ПК с Атомом 230. Причём система на Core 2 потребляла в среднем всего на 13% больше энергии при нагрузке и почти столько же при простое. 2-ядерный интегрированный Atom D510 вдвое эффективней на ватт, чем Atom 230, но вдвое хуже, чем новый Core i3-530 (тоже 2-ядерный и интегрированный). И это приводит нас к заключительному сравнению.
Соперники Атома
Итак, чуть ли не главными соперниками мобильного процессора Atom стали другие процессоры той же Intel — Core 2 (как мобильный Penryn, так и настольный Conroe) и Core i3/i5. Скорости им не занимать, «врождённой юродивости» планировщика и прочих блоков нет, энергоэффективных внедрений не намного меньше, чем у Атома, а общая эффективность даже выше. Так что единственное, что не позволяет Атому распасться по транзисторам — это маркетологи Intel, не опускающие цену на мобильные Core 2 и Core i ULV-серий ниже $200, а Pentium/Celeron SU — ниже $100 (которые, впрочем, и дороже в производстве из-за большей площади). Кстати, в июле 2008 г. (через 3 месяца после начала продаж Атомов) глава Intel сказал, что Atom «имеет менее трети производительности Centrino. Вы имеете дело с тем, что большинство из нас не стало бы использовать». А чтобы не стало наверняка, Интел ввела искусственные ограничения на параметры устройств с чипсетами для Атома (по крайней мере, первого поколения) — на максимальное разрешение и размер экрана, наличие цифровых видеоинтерфейсов и объём ОЗУ и долговременной памяти. В результате многие производители перешли на более дорогой и специально не ограниченный чипсет NVIDIA Ion с аппаратным ускорением видео и интерфейсом HDMI.
В 2007 г. самая популярная в мобильном мире архитектура ARM пополнилась ядром Cortex A9. Этот 2-путный суперскаляр со 128-битными векторными операциями (поднабор NEON) и пиковой частотой в 2 ГГц потребляет 250 мВт при 1 ГГц (и это с перетасовкой команд!) и занимает 1,5 мм² (только ядро) при 65 нм (доступны варианты до 4 ядер). A9 используются в Nvidia Tegra 2, TI OMAP 4, Qualcomm Snapdragon и др. чипах. В год своего рождения Атом получил суровую конкуренцию, так что его единственное спасение — архитектура x86, которую Intel (а отчасти и AMD) 30 лет упорно проталкивает почти во все сферы применения компьютеров. Пока разнообразие программ под неё превышает таковое для других платформ, программисты будут чаще использовать x86, а пользователи — покупать то устройство, под которое написано больше софта, образуя замкнутый круг.
Впрочем, для мобильных устройств почти все нужные им программы уже есть и под архитектуру ARM, так что главную роль тут может сыграть банальная привычка и нежелание перестраиваться — ради знакомых окошек и менюшек многие потребители купят x86-модель, будь она вдвое медленней и/или жадней до питания. Возможно, поэтому Intel ещё в 2006 г. продала подразделение, занимавшееся разработкой основанных на архитектуре ARM процессоров StrongARM и XScale для PDA. А недавно опубликованное компанией сравнение скорости 1-ядерных ЦП показало: Atom N450 на 1,66 ГГц при веб-сёрфинге имеет 2–4-кратное превосходство над iPad с ЦП A4 (1 ядро Cortex A8 на 1 ГГц) и 3–5-кратное — над iPhone (оно же на 600 МГц). Что мы думаем про эти «замеры», напоминать не нужно :) А что касается привычек, для Moorestown Intel объявила о готовности программных платформ Android, MeeGo и Moblin, а вот Windows 7 без поддержки чипсетом шины PCI не пойдёт. Поддержка PCI будет лишь на более прожорливой платформе Oaktrail, которая будет готова только в начале 2011 г., т. к. этот чипсет готовится незапланированно и аврально.

На одной 300-миллиметровой пластине-«вафле» умещается около 2500 годных Атомов (1-го поколения), а пластины выходят круглосуточно со средним темпом одна в минуту…
AMD, извечный «второй номер» мирового процессоростроения для ПК, никак не могла остаться в стороне, видя, что потребители раскупают нетбуки с Атомами миллионами (всего на сегодня продано 50 млн. этих ЦП), и сначала решила победить Intel новой модификацией архитектуры K8 под названием Athlon Neo. У модели 2650e (в других корпусах это TF-20 и MV-40) при частоте 1,6 ГГц и 512 КБ L2 потребление — 15 Вт, а у 2-ядерных L310/L325/L335 на 1,2/1,5/1,6 ГГц — 13/18/18 Вт (9 Вт в простое при 800 МГц). Есть ещё Sempron 200U/210U на 1/1,5 ГГц с 256 КБ L2 и 8/15 ваттами. Хотя и 1 ГГц хватит для обгона 1-ядерного Атома на 1,6 ГГц — из 65 нм и старушки K8 меньше 8 Вт не выжмешь. Поэтому ещё в 2008 г. AMD объявила будущего убийцу Атома — Bobcat. За это время его успели несколько раз отсрочить и даже отменить и возродить, но уже не как сделанный с нуля дешёво-экономный ЦП, а как обрезок куда более мощной архитектуры Bulldozer, идущей на смену нынешним Athlon и Phenom в 2011 г. А пока ещё раз подивимся мыслям дизайнеров, придумавших такое имя: Bobcat это не только обитающая в Северной Америке рыжая рысь, но и марка юрких тракторчиков размером поменьше легковушки — такой Бобкэт уместится в ковше крупного многоядерного Бульдозера. :)
А пока это братство ещё не родилось, в качестве очередной полумеры 12 мая 2010 г. AMD анонсировала новые мобильные платформы, среди которых нас интересует сегмент ультратонких ноутбуков — компания специально отделяет их от нетбуков, намекая, что последние во всём слабее. 2-ядерный Athlon II Neo K325 (1,3 ГГц и 2×1 МБ L2) потребляет 12 Вт, как и 1-ядерный Athlon II Neo K125 на 1,7 ГГц. Главный же конкурент Атому по цене, но снова не по ваттам — V105 (лишённый даже приставки Sempron) на 1,2 ГГц, 512 КБ L2 и 9 Вт. Все эти чипы — 45-нанометровые, что почти не помогло им стать экономичнее, учитывая сложность ядра K10. Причём ядра урезанного, т. к. в отличие от других «коллег» по архитектуре, эта троица имеет лишь 64-битную ширину векторного блока — а ведь 128-битная обработка векторов считается одним из важнейших преимуществ K10 над K8. Самые экономные ЦП из новичков с полноценными векторами — Turion II Neo K665/K625 на 1,7/1,5 ГГц — греют воздух 15 ваттами. Кстати, последний питается напряжениями 0,987 и 0,812 В при нагрузке и простое, но и это не помогло снизить потребление…
Тайваньская VIA, давно купившая американских Centaur и Cyrix с их чипами, до 2008 г. выпускала лишь процессоры серии C7 и Eden. Это очень простые ЦП, чаще всего способные лишь на одну команду за такт и потребляющие 12–20 Вт прежде всего за счёт техпроцесса 90 нм. Но в 2008 г. компания представила новую архитектуру с названием Nano, которая должна быть и быстрее, и энергоэффективнее. Как это ей удалось, и стала ли она хотя бы косвенным конкурентом Атому — читайте в одной из ближайших статей.


