Эта справочная статья нужна, чтобы читатели не запутались в бесконечных терминах и сокращениях, переполняющих любую содержательную аналитику о процессорах и их архитектурах. Писать такие статьи без спецтерминов нельзя, иначе они превратятся в иносказательную кашу, из которой можно сделать какой угодно вывод, кроме правильного. Чтобы определиться, что именно автор имеет в виду под тем или иным специфическим словом или сокращением, не напоминая об этом каждый раз, и написана энциклопедия. Она также пригодится для изучения тематических иллюстраций, в изобилии встречающихся в процессорных статьях и презентациях и в большинстве случаев написанных на английском.
Заметим, что энциклопедия не заменяет, а дополняет другие статьи общего характера (например «Современные десктопные процессоры архитектуры x86: общие принципы работы») и аналитику по частным вопросам (например «О разрядности процессоров» и «Методы увеличения вычислительной производительности»). Тут приводятся лишь краткие описания, но не по отдельным терминам, а почти по всем, которые могут встретиться — кроме очень редких и устаревших.
| Оглавление |
|---|
По историческим причинам большинство этих терминов не только родилось в английском языке, но и, по большей части, так и не приобрело устоявшегося перевода. Если он всё же есть, то указан после оригинала — иначе даётся дословный перевод (в скобках) и авторская версия. Все термины снабжены одноимёнными локальными HTML-ссылками под значком ![]() , на которые можно ссылаться с других страниц.
, на которые можно ссылаться с других страниц.
Некоторые сокращения имеют несколько расшифровок и потому встречаются в нескольких разделах. Сами разделы имеют не алфавитную, а ассоциативную сортировку — например стадии конвейера перечислены в таком порядке, в котором реально встречаются в процессоре. Таким образом, в отличие от отсортированных по алфавиту справочников, эти словарные статьи можно также читать подряд.
Энциклопедия постоянно уточняется и пополняется (дата последнего обновления — в конце) и на данный момент содержит 234 термина (без учёта переводов и синонимов).
Общие положения и вычислительные парадигмы
![]() processor (обработчик), процессор — часть компьютера, обрабатывающая данные. Управляется программой или потоком — последовательностью закодированных команд. Физически представляет собой одну микросхему. Работает на определённой частоте, означающей количество тактов в секунду. За каждый такт процессор делает некоторую часть полезной работы. По умолчанию под процессором понимается центральный процессор.
processor (обработчик), процессор — часть компьютера, обрабатывающая данные. Управляется программой или потоком — последовательностью закодированных команд. Физически представляет собой одну микросхему. Работает на определённой частоте, означающей количество тактов в секунду. За каждый такт процессор делает некоторую часть полезной работы. По умолчанию под процессором понимается центральный процессор.
![]() CPU (central processing unit: «центральный блок обработки»), ЦП (центральный процессор) — главный и обязательно присутствующий процессор компьютера, обрабатывающий данные любого вида (в отличие от сопроцессоров).
CPU (central processing unit: «центральный блок обработки»), ЦП (центральный процессор) — главный и обязательно присутствующий процессор компьютера, обрабатывающий данные любого вида (в отличие от сопроцессоров).
![]() coprocessor, сопроцессор — специализированный процессор (например, вещественный или периферийный), обрабатывающий данные только какого-то одного вида, но быстрее, чем это смог бы сделать ЦП, за счёт оптимизированного устройства. Может быть как отдельной микросхемой, так и частью ЦП.
coprocessor, сопроцессор — специализированный процессор (например, вещественный или периферийный), обрабатывающий данные только какого-то одного вида, но быстрее, чем это смог бы сделать ЦП, за счёт оптимизированного устройства. Может быть как отдельной микросхемой, так и частью ЦП.
![]() core, ядро — в одноядерных ЦП: вычислительная часть процессора, остающаяся после вычета вспомогательных структур (контроллеров шин, кэшей и др.). В многоядерных ЦП: набор обрабатывающих блоков и смежных с ними кэшей, минимально необходимый для исполнения любых команд и имеющийся в нескольких экземплярах. Многоядерные ЦП могут иметь многоуровневое разделение ресурсов: например, ядра с отдельными кэшами L1 могут попарно объединяться, имея в каждой паре общий кэш L2, а пары объединяются в процессор с общим кэшем L3 и остальным блоками. AMD в новых микроархитектурах использует определение ядра, исполняющего лишь операции (не команды) общего назанчения.
core, ядро — в одноядерных ЦП: вычислительная часть процессора, остающаяся после вычета вспомогательных структур (контроллеров шин, кэшей и др.). В многоядерных ЦП: набор обрабатывающих блоков и смежных с ними кэшей, минимально необходимый для исполнения любых команд и имеющийся в нескольких экземплярах. Многоядерные ЦП могут иметь многоуровневое разделение ресурсов: например, ядра с отдельными кэшами L1 могут попарно объединяться, имея в каждой паре общий кэш L2, а пары объединяются в процессор с общим кэшем L3 и остальным блоками. AMD в новых микроархитектурах использует определение ядра, исполняющего лишь операции (не команды) общего назанчения.
![]() SMP (symmetric multiprocessing: симметричная многопроцессорность) — одновременное присутствие и работа в компьютере нескольких одинаковых процессоров и/или ядер.
SMP (symmetric multiprocessing: симметричная многопроцессорность) — одновременное присутствие и работа в компьютере нескольких одинаковых процессоров и/или ядер.
![]() uncore («внеядро») — термин Intel для обозначения части ЦП за пределами x86-ядра или ядер. Ресурсы внеядра (ГП, кэш L3 и системный агент) динамически разделяются между ядрами в зависимости от потребности.
uncore («внеядро») — термин Intel для обозначения части ЦП за пределами x86-ядра или ядер. Ресурсы внеядра (ГП, кэш L3 и системный агент) динамически разделяются между ядрами в зависимости от потребности.
![]() system agent (системный агент) — термин Intel для обозначения части ЦП за пределами всех ядер (включая специализированные — например, графическое) и кэша L3. Является частью внеядра.
system agent (системный агент) — термин Intel для обозначения части ЦП за пределами всех ядер (включая специализированные — например, графическое) и кэша L3. Является частью внеядра.
![]() word, слово — в общем случае — последовательность информации длиной 2N байт, где целое N>0. По содержимому может быть данными, адресом или командой. Иногда используется как мера разрядности (полуслово, двойное слово и т. п.) наряду с битами и байтами. В архитектуре x86 обозначает 2-байтовое целое данное.
word, слово — в общем случае — последовательность информации длиной 2N байт, где целое N>0. По содержимому может быть данными, адресом или командой. Иногда используется как мера разрядности (полуслово, двойное слово и т. п.) наряду с битами и байтами. В архитектуре x86 обозначает 2-байтовое целое данное.
![]() instruction, инструкция, команда — элементарная часть программы процессора. Команда задаёт операцию(и) над данными и/или адресами. Наиболее часто используемые команды делятся на такие виды:
instruction, инструкция, команда — элементарная часть программы процессора. Команда задаёт операцию(и) над данными и/или адресами. Наиболее часто используемые команды делятся на такие виды:
- копирование*;
- преобразование типа;
- перестановка элементов* (только для векторных);
- арифметика;
- логика* и сдвиги*;
- переходы.
Отмеченные звёздочками команды являются инвариантными по данным — они реализуют своё действие одинаковым алгоритмом вне зависимости от типа операндов. Команды, меняющие содержимое данных, являются вычислительными: чаще всего встречается простая арифметика и логика, затем умножения и сдвиги и, гораздо реже, — деления и преобразования.
![]() conditional, условная — команда или операция, исполняющаяся при совпадении требуемого условия с состоянием флагов.
conditional, условная — команда или операция, исполняющаяся при совпадении требуемого условия с состоянием флагов.
![]() operation, операция — задаваемое командой действие над своими аргументами — данными или (реже) адресом. Одна команда может задать несколько действий.
operation, операция — задаваемое командой действие над своими аргументами — данными или (реже) адресом. Одна команда может задать несколько действий.
![]() operand, операнд — параметр, обозначающий данные для операции или место, где они находятся. В команде может быть от нуля до нескольких операндов, большинство из которых явные (т. е. указаны в команде), но некоторые (скрытые) используются по умолчанию. Число даже явных операндов не всегда совпадает с числом аргументов выполняемой операции. Виды операндов:
operand, операнд — параметр, обозначающий данные для операции или место, где они находятся. В команде может быть от нуля до нескольких операндов, большинство из которых явные (т. е. указаны в команде), но некоторые (скрытые) используются по умолчанию. Число даже явных операндов не всегда совпадает с числом аргументов выполняемой операции. Виды операндов:
| По характеру доступа | Источник (хранит аргумент) | Приёмник (получает результат) | Модификанд (источник до операции и приёмник после) |
| По типу | Регистр (указан его номер) | Память (одно- или многобайтовое значение по указанному адресу) | Константа (непосредственное значение, записанное в самой команде; может быть только источником) |
![]() non-destructive, неразрушающий — формат операндов команды, при котором её результат не обязан перезаписывать какой-либо из аргументов, иначе формат называется разрушающим. Чтобы команда была неразрушающей, приёмник должен быть отдельным от всех источников (т. е. не должно быть модификандов, кроме случаев явного указания одинаковых приёмника и источника). Например, для элементарного сложения это потребует трёх операндов — приёмника и двух источников. В случае с двумя операндами сумма перезапишет одно из слагаемых.
non-destructive, неразрушающий — формат операндов команды, при котором её результат не обязан перезаписывать какой-либо из аргументов, иначе формат называется разрушающим. Чтобы команда была неразрушающей, приёмник должен быть отдельным от всех источников (т. е. не должно быть модификандов, кроме случаев явного указания одинаковых приёмника и источника). Например, для элементарного сложения это потребует трёх операндов — приёмника и двух источников. В случае с двумя операндами сумма перезапишет одно из слагаемых.
![]() integer, целый, целочисленный — относящийся к целым числам. Имеют разрядность 1, 2, 4 и 8 байт. Как правило, к ним также причисляют логический тип данных, описывающий набор бит. Обработка целых проще и быстрее, чем вещественных.
integer, целый, целочисленный — относящийся к целым числам. Имеют разрядность 1, 2, 4 и 8 байт. Как правило, к ним также причисляют логический тип данных, описывающий набор бит. Обработка целых проще и быстрее, чем вещественных.
![]() float («плавающий»), FP (floating point: плавающая точка), вещественный — относящийся к вещественным числам (точнее, к их рациональному подмножеству с плавающей запятой). Имеют точности HP, SP, DP и EP. Обработка вещественных труднее и дольше, чем целых.
float («плавающий»), FP (floating point: плавающая точка), вещественный — относящийся к вещественным числам (точнее, к их рациональному подмножеству с плавающей запятой). Имеют точности HP, SP, DP и EP. Обработка вещественных труднее и дольше, чем целых.
![]() register, регистр — ячейка, хранящая одно или несколько значений определённой разрядности и типа (например, целый векторный). Является наиболее частоиспользуемым типом операнда. Несколько однотипных регистров объединены в регистровый файл.
register, регистр — ячейка, хранящая одно или несколько значений определённой разрядности и типа (например, целый векторный). Является наиболее частоиспользуемым типом операнда. Несколько однотипных регистров объединены в регистровый файл.
![]() GPR (general purpose register), РОН (регистр общего назначения) — регистр для скалярных целых данных или адресов, используемый для наиболее частых команд.
GPR (general purpose register), РОН (регистр общего назначения) — регистр для скалярных целых данных или адресов, используемый для наиболее частых команд.
![]() ISA (instruction set architecture: архитектура набора команд) — описание процессора как математической модели, каковой он представляется программисту. Состоит из описаний всех исполняемых команд, имеющихся регистров, режимов и пр. структур и состояний, доступных программисту. Основывается на одной или более парадигмах. Без уточнения термин «архитектура» часто обозначает микроархитектуру.
ISA (instruction set architecture: архитектура набора команд) — описание процессора как математической модели, каковой он представляется программисту. Состоит из описаний всех исполняемых команд, имеющихся регистров, режимов и пр. структур и состояний, доступных программисту. Основывается на одной или более парадигмах. Без уточнения термин «архитектура» часто обозначает микроархитектуру.
![]() microarchitecture, микроархитектура — реализация ISA в виде блок-схемы процессора, каждый блок которой выполняет обособленную роль или функцию и состоит из массивов логических вентилей («экземпляров») и связывающих их линий. Для каждой ISA, как правило, есть несколько микроархитектур, отличающихся скоростью исполнения отдельных команд и всей программы, сложностью и ценой получаемого процессора, потребляемой энергией на каждую операцию и т. п. Большинство описываемых микроархитектурой блоков и состояний «прозрачны» для программиста (т. к. не указаны в ISA) и нужны для автоматического улучшения какой-либо численной характеристики — скорости, надёжности, потребления энергии и т. д. Часто обозначается термином «архитектура».
microarchitecture, микроархитектура — реализация ISA в виде блок-схемы процессора, каждый блок которой выполняет обособленную роль или функцию и состоит из массивов логических вентилей («экземпляров») и связывающих их линий. Для каждой ISA, как правило, есть несколько микроархитектур, отличающихся скоростью исполнения отдельных команд и всей программы, сложностью и ценой получаемого процессора, потребляемой энергией на каждую операцию и т. п. Большинство описываемых микроархитектурой блоков и состояний «прозрачны» для программиста (т. к. не указаны в ISA) и нужны для автоматического улучшения какой-либо численной характеристики — скорости, надёжности, потребления энергии и т. д. Часто обозначается термином «архитектура».
![]() paradigm, парадигма — тут: совокупность основополагающих правил и понятий, на основе которых строится конкретная программная архитектура или микроархитектура. Некоторые парадигмы взаимоисключающи, другие могут сочетаться.
paradigm, парадигма — тут: совокупность основополагающих правил и понятий, на основе которых строится конкретная программная архитектура или микроархитектура. Некоторые парадигмы взаимоисключающи, другие могут сочетаться.
![]() load/store (загрузка/сохранение — синонимы чтения и записи) — парадигма, при которой команды обработки работают только с регистрами, а загрузка констант и обмен данных между процессором и памятью производится отдельными командами и тоже через регистры. Это позволяет сильно упростить устройство и снизить себестоимость процессора, но усложняет программирование, замедляет скорость исполнения за такт и удлинняет программу. Большинство современных архитектур не используют парадигму load/store, допуская для большинства или всех команд обработку данных, находящихся и в регистрах, и в памяти, и в самой команде.
load/store (загрузка/сохранение — синонимы чтения и записи) — парадигма, при которой команды обработки работают только с регистрами, а загрузка констант и обмен данных между процессором и памятью производится отдельными командами и тоже через регистры. Это позволяет сильно упростить устройство и снизить себестоимость процессора, но усложняет программирование, замедляет скорость исполнения за такт и удлинняет программу. Большинство современных архитектур не используют парадигму load/store, допуская для большинства или всех команд обработку данных, находящихся и в регистрах, и в памяти, и в самой команде.
![]() RISC (reduced instruction set computer: вычислитель с сокращённым набором команд) — парадигма архитектуры, максимально удобной для физической реализации (в противоположность CISC): процессор имеет небольшое число команд (как правило, до 200), большая часть которых исполняет по одному простому действию (как правило, не сложнее умножения) со значительными ограничениями по разрядности, местоположению и типу аргументов (в частности, используется парадигма load/store). За счёт простоты почти каждая команда исполняется за одно действие, поэтому процессору не нужен микрокод. Чаще всего команды имеют одинаковую длину (как правило, 4 байта) и неразрушающую кодировку операндов.
RISC (reduced instruction set computer: вычислитель с сокращённым набором команд) — парадигма архитектуры, максимально удобной для физической реализации (в противоположность CISC): процессор имеет небольшое число команд (как правило, до 200), большая часть которых исполняет по одному простому действию (как правило, не сложнее умножения) со значительными ограничениями по разрядности, местоположению и типу аргументов (в частности, используется парадигма load/store). За счёт простоты почти каждая команда исполняется за одно действие, поэтому процессору не нужен микрокод. Чаще всего команды имеют одинаковую длину (как правило, 4 байта) и неразрушающую кодировку операндов.
![]() CISC (complex instruction set computer: вычислитель со сложным набором команд) — парадигма архитектуры, максимально удобной для эффективного (по числу OPC) программирования (в противоположность RISC): процессор имеет большое число команд (сотни), исполняющих в т. ч. сложные действия с аргументами разной разрядности, местоположения и типа. Сложные команды исполняются как последовательность простых, для чего процессору нужен декодер. Команды имеют переменную длину; по сравнению с RISC-ЦП код получается более компактным как по числу команд, так и по общей длине. За счёт разнообразия и сложности команд, меньшего числа архитектурных регистров и (часто) разрушающего формата операндов программирование CISC-ЦП для компилятора сложнее, чем RISC-ЦП, но для человека-программиста это не обязательно. CISC-ЦП для достижения производительности RISC-ЦП на одинаковой частоте должен быть сложнее.
CISC (complex instruction set computer: вычислитель со сложным набором команд) — парадигма архитектуры, максимально удобной для эффективного (по числу OPC) программирования (в противоположность RISC): процессор имеет большое число команд (сотни), исполняющих в т. ч. сложные действия с аргументами разной разрядности, местоположения и типа. Сложные команды исполняются как последовательность простых, для чего процессору нужен декодер. Команды имеют переменную длину; по сравнению с RISC-ЦП код получается более компактным как по числу команд, так и по общей длине. За счёт разнообразия и сложности команд, меньшего числа архитектурных регистров и (часто) разрушающего формата операндов программирование CISC-ЦП для компилятора сложнее, чем RISC-ЦП, но для человека-программиста это не обязательно. CISC-ЦП для достижения производительности RISC-ЦП на одинаковой частоте должен быть сложнее.
![]() SIMD (single instruction, multiple data: одна команда — много данных), векторность — парадигма параллелизма на уровне данных: помимо скалярных, имеются векторные команды для обработки аргументов-векторов, объединяющих несколько отдельных скалярных значений. Результат векторной команды — чаще всего также вектор. Применяется во всех современных архитектурах для удобной реализации высокоскоростной обработки, когда над большим объёмом данных требуется совершить одно действие. SIMD также подразумевает наличие команд тасовки элементов вектора без изменения их содержимого.
SIMD (single instruction, multiple data: одна команда — много данных), векторность — парадигма параллелизма на уровне данных: помимо скалярных, имеются векторные команды для обработки аргументов-векторов, объединяющих несколько отдельных скалярных значений. Результат векторной команды — чаще всего также вектор. Применяется во всех современных архитектурах для удобной реализации высокоскоростной обработки, когда над большим объёмом данных требуется совершить одно действие. SIMD также подразумевает наличие команд тасовки элементов вектора без изменения их содержимого.
![]() EPIC (explicitly parallel instruction computing: вычисление с явным параллелизмом команд) — парадигма, упрощающая суперскалярную микроархитектуру за счёт явного указания «связок» команд, которые могут одновременно отправиться на исполнение при готовности требуемых данных. Применяется только к RISC-архитектурам, хотя теоретически применима и к CISC. Для обработки данных общего назначения не подходит из-за относительно большого размера кода и сложности эффективного программирования и исполнения на любом алгоритме, поэтому для ЦП малопригодна, но применяется в некоторых DSP и GPU.
EPIC (explicitly parallel instruction computing: вычисление с явным параллелизмом команд) — парадигма, упрощающая суперскалярную микроархитектуру за счёт явного указания «связок» команд, которые могут одновременно отправиться на исполнение при готовности требуемых данных. Применяется только к RISC-архитектурам, хотя теоретически применима и к CISC. Для обработки данных общего назначения не подходит из-за относительно большого размера кода и сложности эффективного программирования и исполнения на любом алгоритме, поэтому для ЦП малопригодна, но применяется в некоторых DSP и GPU.
![]() DSP (digital signal processor: цифровой обработчик сигналов), цифровой сигнальный процессор — сопроцессор, оптимизированный для обработки потока данных, в т. ч. в реальном времени. Иногда встраивается в SoC.
DSP (digital signal processor: цифровой обработчик сигналов), цифровой сигнальный процессор — сопроцессор, оптимизированный для обработки потока данных, в т. ч. в реальном времени. Иногда встраивается в SoC.
![]() GPU (graphics processing unit: блок обработки графики), графический процессор (ГП) — сопроцессор, оптимизированный для обработки графики в реальном времени и некоторых неграфических задач. ГП иногда встраивается в микросхему ЦП.
GPU (graphics processing unit: блок обработки графики), графический процессор (ГП) — сопроцессор, оптимизированный для обработки графики в реальном времени и некоторых неграфических задач. ГП иногда встраивается в микросхему ЦП.
![]() GPGPU (general purpose GPU: вычисления общего назначения на ГП) — программы обработки неграфических данных, алгоритмы которых удобны для эффективного исполнения не только на ЦП, но и на ГП. Составление таких алгоритмов сложней из-за бо́льших ограничений ГП по сравнению с ЦП.
GPGPU (general purpose GPU: вычисления общего назначения на ГП) — программы обработки неграфических данных, алгоритмы которых удобны для эффективного исполнения не только на ЦП, но и на ГП. Составление таких алгоритмов сложней из-за бо́льших ограничений ГП по сравнению с ЦП.
![]() APU (accelerated processing unit: блок ускоренной обработки) — термин AMD для обозначения процессора с ядром или ядрами общего назначения архитектуры x86 и встроенным ГП, архитектура которого допускает относительно простую обработку неграфических данных с помощью GPGPU.
APU (accelerated processing unit: блок ускоренной обработки) — термин AMD для обозначения процессора с ядром или ядрами общего назначения архитектуры x86 и встроенным ГП, архитектура которого допускает относительно простую обработку неграфических данных с помощью GPGPU.
![]() SoC (system on chip: система на чипе) — микросхема, на единственном или основном кристалле которой находятся ядро или ядра ЦП, сопроцессоры и/или DSP и контроллеры памяти и ввода-вывода. (Остальные кристаллы в случае их присутствия являются памятью.) Используется вместо нескольких отдельных микросхем с похожей совокупной функциональностью для уменьшения массы, размеров, сложности монтажа, потребления энергии и цены конечного устройства.
SoC (system on chip: система на чипе) — микросхема, на единственном или основном кристалле которой находятся ядро или ядра ЦП, сопроцессоры и/или DSP и контроллеры памяти и ввода-вывода. (Остальные кристаллы в случае их присутствия являются памятью.) Используется вместо нескольких отдельных микросхем с похожей совокупной функциональностью для уменьшения массы, размеров, сложности монтажа, потребления энергии и цены конечного устройства.
![]() embedded, встроенный — относится к компьютерам и микросхемам, управляющим невычислительной аппаратурой (и часто физически встроенным в неё) и/или собирающим данные с датчиков. Встроенный компьютер может иметь человеко-машинный интерфейс, но с пользователем он общается гораздо реже, чем с другими устройствами. Для таких компьютеров требуется высокая надёжность в широком спектре физических воздействий (в т. ч. жёстких), часто в ущерб другим характеристикам (например, скорости).
embedded, встроенный — относится к компьютерам и микросхемам, управляющим невычислительной аппаратурой (и часто физически встроенным в неё) и/или собирающим данные с датчиков. Встроенный компьютер может иметь человеко-машинный интерфейс, но с пользователем он общается гораздо реже, чем с другими устройствами. Для таких компьютеров требуется высокая надёжность в широком спектре физических воздействий (в т. ч. жёстких), часто в ущерб другим характеристикам (например, скорости).
![]() ARM — RISC-архитектура, первая по распространённости в мире (вторая — x86). Применяется в мобильных компьютерах и производных от них устройствах (коммуникаторах, телефонах, планшетах и пр.) и в большинстве встроенных систем. Имеет неразрушающий формат операндов. Число доступных регистров в РФ — 16.
ARM — RISC-архитектура, первая по распространённости в мире (вторая — x86). Применяется в мобильных компьютерах и производных от них устройствах (коммуникаторах, телефонах, планшетах и пр.) и в большинстве встроенных систем. Имеет неразрушающий формат операндов. Число доступных регистров в РФ — 16.
![]() VM (virtual memory: виртуальная память) — технология, позволяющая каждой исполняемой программе в многозадачной среде использовать отдельное непрерывное адресное пространство, причём большего размера, чем имеется физической оперативной памяти, а также реализовать защищённое исполнение с изоляцией программ и их данных друг от друга. Виртуальная память физически размещается в ОЗУ и файле подкачки (своп-файле) на массовом носителе. В режиме работы с виртуальной памятью программы оперируют виртуальными адресами.
VM (virtual memory: виртуальная память) — технология, позволяющая каждой исполняемой программе в многозадачной среде использовать отдельное непрерывное адресное пространство, причём большего размера, чем имеется физической оперативной памяти, а также реализовать защищённое исполнение с изоляцией программ и их данных друг от друга. Виртуальная память физически размещается в ОЗУ и файле подкачки (своп-файле) на массовом носителе. В режиме работы с виртуальной памятью программы оперируют виртуальными адресами.
![]() VA (virtual address: виртуальный адрес) — адрес для виртуальной памяти, который до использования необходимо пересчитать (транслировать) в физический адрес в блоках TLB и PMH. Каждый виртуальный адрес попадает в какую-либо страницу, описываемую дескриптором («описателем») размером 4 (в 32-битном режиме ЦП) или 8 (в 64-битном) байт, содержащим физический адрес, тип и права доступа страницы или их группы. 512 или 1024 дескриптора формируют таблицу трансляции, а сами таблицы объединяются операционной системой в 2–4-ярусную древовидную структуру, уникальную для каждой задачи. Ссылка на корневую таблицу дерева передаётся в ЦП при переключении на новую задачу, каждая из которых таким образом получает отдельное виртуальное адресное пространство.
VA (virtual address: виртуальный адрес) — адрес для виртуальной памяти, который до использования необходимо пересчитать (транслировать) в физический адрес в блоках TLB и PMH. Каждый виртуальный адрес попадает в какую-либо страницу, описываемую дескриптором («описателем») размером 4 (в 32-битном режиме ЦП) или 8 (в 64-битном) байт, содержащим физический адрес, тип и права доступа страницы или их группы. 512 или 1024 дескриптора формируют таблицу трансляции, а сами таблицы объединяются операционной системой в 2–4-ярусную древовидную структуру, уникальную для каждой задачи. Ссылка на корневую таблицу дерева передаётся в ЦП при переключении на новую задачу, каждая из которых таким образом получает отдельное виртуальное адресное пространство.
![]() PA (physical address: физический адрес) — адрес, получаемый трансляцией из виртуального и необходимый для доступа в кэши и память.
PA (physical address: физический адрес) — адрес, получаемый трансляцией из виртуального и необходимый для доступа в кэши и память.
![]() page, страница — элементарный блок памяти при выделении виртуальной памяти программе. Младшие биты виртуального адреса обозначают смещение внутри страницы. Остальные биты задают начальный (базовый) адрес, который требуется транслировать. Для архитектуры x86 чаще всего используются страницы по 4 КБ, но также доступны «большие» страницы: для 32-битного режима — на 4 МБ, а для 64-битного — на 2 МБ и 1 ГБ.
page, страница — элементарный блок памяти при выделении виртуальной памяти программе. Младшие биты виртуального адреса обозначают смещение внутри страницы. Остальные биты задают начальный (базовый) адрес, который требуется транслировать. Для архитектуры x86 чаще всего используются страницы по 4 КБ, но также доступны «большие» страницы: для 32-битного режима — на 4 МБ, а для 64-битного — на 2 МБ и 1 ГБ.
Команды x86 и их наборы
![]() x86 — самая популярная архитектура для универсальных компьютеров. Изначально создана как 16-битная версия для процессоров Intel i8086 и i8088, применявшихся в первых IBM PC, значительно обновлена и расширена до 32-битной версии при выходе ЦП i80386, далее продолжала расширяться за счёт дополнительных поднаборов команд. Как правило, под x86 понимается наиболее современная её версия — x86-64. Учитывая все дополнения (чаще всего вводимые самой Intel), в x86 сейчас более 500 команд. Число регистров в РФ (включая РОНы) — 8 или 16. Длина одинарного слова данных — 2 байта.
x86 — самая популярная архитектура для универсальных компьютеров. Изначально создана как 16-битная версия для процессоров Intel i8086 и i8088, применявшихся в первых IBM PC, значительно обновлена и расширена до 32-битной версии при выходе ЦП i80386, далее продолжала расширяться за счёт дополнительных поднаборов команд. Как правило, под x86 понимается наиболее современная её версия — x86-64. Учитывая все дополнения (чаще всего вводимые самой Intel), в x86 сейчас более 500 команд. Число регистров в РФ (включая РОНы) — 8 или 16. Длина одинарного слова данных — 2 байта.
Состав команды x86:
- один или несколько префиксов;
- опкод;
- байт modR/M, кодирует типы операндов и регистровые операнды;
- байт SIB, кодирует регистры для доступа к памяти при сложных видах адресации;
- адрес или (чаще) адресное смещение (address displacement);
- непосредственный операнд (imm, immediate).
Обязателен только опкод, но в большинстве команд также есть несколько префиксов и байт modR/M. Оригинальная x86 кодирует операнды разрушающим образом.
![]() x86-64 — 64-битная расширение архитектуры x86. Основные изменения:
x86-64 — 64-битная расширение архитектуры x86. Основные изменения:
- расширена разрядность РОНов до 64 бит;
- удвоено до 16 число РОНов и регистров xmm (но не x87);
- отменены некоторые старые команды и режимы.
Если в 64-битной команде используется хотя бы один регистр из добавленных, ей требуется дополнительный REX-префикс, указывающий недостающие биты в кодах регистров.
![]() AMD64, EM64T, Intel 64 — коммерческие названия реализаций архитектуры x86-64, использованные AMD, Intel (раннее) и Intel (позднее). Практически идентичны.
AMD64, EM64T, Intel 64 — коммерческие названия реализаций архитектуры x86-64, использованные AMD, Intel (раннее) и Intel (позднее). Практически идентичны.
![]() prefix, префикс — часть команды, модифицирующая её исполнение или дополняющая опкод. В x86 бывает нескольких видов:
prefix, префикс — часть команды, модифицирующая её исполнение или дополняющая опкод. В x86 бывает нескольких видов:
- переключатели таблиц опкодов или режимов декодирования;
- указатели на половины требуемых команде регистровых файлов (REX-префиксы для 64-битного режима);
- указатели на один из сегментных регистров (устарели);
- блокировщик доступа к памяти (устарел);
- повторители команды (редко используются и доступны лишь для некоторых команд);
- модификаторы разрядности операнда и адреса (устарели).
Использование префиксов удлинняет команду и является следствием ранних попыток Intel укоротить наиболее частые команды x86, а позже — следствием добавления новых команд, сохраняя старые. Из-за префиксов трудно определить длину команды, что ограничивает скорость исполнения и требует сложной логики для длиномера и декодера. У каждого x86-ЦП есть ограничение на максимальное число префиксов в команде, при котором достижима пиковая скорость исполнения.
![]() opcode, опкод — главная часть команды, кодирующая операцию(и) и тип и разрядность операндов. В x86 кодируется одним байтом, чего хватает примерно для 100 команд, т. к. большинство из них имеют несколько вариантов типов и разрядностей операндов. Для увеличения числа команд применяются префиксы-переключатели таблиц опкодов. Чаще всего, в коде с векторной обработкой команды имеют по 2–3 переключателя.
opcode, опкод — главная часть команды, кодирующая операцию(и) и тип и разрядность операндов. В x86 кодируется одним байтом, чего хватает примерно для 100 команд, т. к. большинство из них имеют несколько вариантов типов и разрядностей операндов. Для увеличения числа команд применяются префиксы-переключатели таблиц опкодов. Чаще всего, в коде с векторной обработкой команды имеют по 2–3 переключателя.
![]() x87 — дополнение к архитектуре x86, описывающее команды для работы со скалярными вещественными числами, исполняемыми блоком FPU. Сейчас набор x87 мало востребован из-за возможности удобно и быстро исполнять скалярные вещественные вычисления в регистрах xmm.
x87 — дополнение к архитектуре x86, описывающее команды для работы со скалярными вещественными числами, исполняемыми блоком FPU. Сейчас набор x87 мало востребован из-за возможности удобно и быстро исполнять скалярные вещественные вычисления в регистрах xmm.
![]() F… (float: вещественный) — приставка к мнемонике команд x87 и к названиям вещественных ФУ (включая векторные).
F… (float: вещественный) — приставка к мнемонике команд x87 и к названиям вещественных ФУ (включая векторные).
![]() HP, SP, DP, EP (half-, single, double, extended precision: половинная, одинарная, двойная, расширенная точность) — форматы представления вещественного числа в большинстве ЦП и сопроцессоров.
HP, SP, DP, EP (half-, single, double, extended precision: половинная, одинарная, двойная, расширенная точность) — форматы представления вещественного числа в большинстве ЦП и сопроцессоров.
| Формат | HP | SP | DP | EP |
| Размер, байт* | 2 | 4 | 8 | 10 |
| Особенности | В ЦП доступен лишь как аргумент для преобразования в SP и обратно | В SSE-командах SP и DP сокращаются как S и D | Используется только в x87 и считается избыточным | |
| Как правило, для мультимедийных вычислений требуется HP и SP… | …а для научных — DP | |||
| Современные GPU могут использовать 100% ресурсов для вычислений с HP и SP… | …но не с DP | |||
* — больший размер позволяет иметь бо́льшую точность и диапазон степеней.
![]() CVT16, F16C — набор из двух команд для преобразования вещественных чисел из HP в SP и обратно.
CVT16, F16C — набор из двух команд для преобразования вещественных чисел из HP в SP и обратно.
![]() MMX (matrix math extension: расширения [для ISA добавлением] матричной математики; или multimedia extension: мультимедийные расширения) — первое применение парадигмы SIMD в x86: набор команд для работы с векторами длиной 8 байт, расположенными в стеке регистров FPU (mm-регистры) и содержащими 2, 4 или 8 целых элементов по 4, 2 или 1 байт, соответственно. Устарел после выхода поднабора SSE2.
MMX (matrix math extension: расширения [для ISA добавлением] матричной математики; или multimedia extension: мультимедийные расширения) — первое применение парадигмы SIMD в x86: набор команд для работы с векторами длиной 8 байт, расположенными в стеке регистров FPU (mm-регистры) и содержащими 2, 4 или 8 целых элементов по 4, 2 или 1 байт, соответственно. Устарел после выхода поднабора SSE2.
![]() EMMX (extended MMX: расширенное MMX) — расширения MMX введенные AMD и Cyrix. Были малопопулярны даже во время активного использования оригинального MMX.
EMMX (extended MMX: расширенное MMX) — расширения MMX введенные AMD и Cyrix. Были малопопулярны даже во время активного использования оригинального MMX.
![]() P… (packed: «упакованная») — приставка к мнемонике векторных целочисленных команд x86 и команд 3DNow.
P… (packed: «упакованная») — приставка к мнемонике векторных целочисленных команд x86 и команд 3DNow.
![]() 3DNow! — первое применение парадигмы SIMD для вещественных чисел в x86: набор команд для работы с векторами длиной 8 байт, расположенными в стеке регистров FPU и содержащими по два SP-элемента. Использовался только в процессорах AMD. Устарел после выхода поднабора SSE.
3DNow! — первое применение парадигмы SIMD для вещественных чисел в x86: набор команд для работы с векторами длиной 8 байт, расположенными в стеке регистров FPU и содержащими по два SP-элемента. Использовался только в процессорах AMD. Устарел после выхода поднабора SSE.
![]() SSE (streaming SIMD extensions: потоковые SIMD-расширения) — поднаборы SIMD-команд для векторов, хранящихся в отдельном регистровом файле с 16-байтовыми регистрами xmm. Оригинальный SSE работал только с SP-элементами. Далее дополнялся несколько раз: SSE2 — работа с целыми и DP-элементами; SSE3, SSSE3, SSE4.1, SSE4.2, SSE4.a — специфические команды для конкретных видов программ (медиа-кодирование, комплексные вычисления, работа с текстом и пр.). Вещественные SSE-операции могут быть и скалярными, используя только младший элемент вектора. Мнемоника вещественной SSE-команды состоит из:
SSE (streaming SIMD extensions: потоковые SIMD-расширения) — поднаборы SIMD-команд для векторов, хранящихся в отдельном регистровом файле с 16-байтовыми регистрами xmm. Оригинальный SSE работал только с SP-элементами. Далее дополнялся несколько раз: SSE2 — работа с целыми и DP-элементами; SSE3, SSSE3, SSE4.1, SSE4.2, SSE4.a — специфические команды для конкретных видов программ (медиа-кодирование, комплексные вычисления, работа с текстом и пр.). Вещественные SSE-операции могут быть и скалярными, используя только младший элемент вектора. Мнемоника вещественной SSE-команды состоит из:
- краткого названия операции (часто совпадает с названием исполняющего её ФУ);
- буквы S (scalar, скалярная) или P (packed, векторная, «упакованная»);
- буквы S (для SP) или D (для DP).
![]() xmm — общее название 16-байтового регистра для команд SSE.
xmm — общее название 16-байтового регистра для команд SSE.
![]() AVX (advanced vector extensions: продвинутые векторные расширения) — надстройки над обычным способом кодирования команд x86. AVX-код позволяет:
AVX (advanced vector extensions: продвинутые векторные расширения) — надстройки над обычным способом кодирования команд x86. AVX-код позволяет:
- обрабатывать 32-байтовые векторы в регистрах ymm (целочисленная арифметика и сдвиги — начиная с версии AVX2);
- использовать во всех векторных командах 3–4 операнда в неразрушающей форме;
- сэкономить на размере векторных команд заменой нескольких старых префиксов одним обязательным VEX-байтом.
Также добавлены новые векторные и скалярные (в AVX2) команды. Мнемоники команд AVX имеют приставку V.
![]() ymm — общее название 32-байтового регистра для команд AVX. Обратно совместим с регистром xmm с тем же номером, т. к. последний представляется младшей половиной первого.
ymm — общее название 32-байтового регистра для команд AVX. Обратно совместим с регистром xmm с тем же номером, т. к. последний представляется младшей половиной первого.
![]() XOP (extended operation: расширенная операция) — надстройка компании AMD, дополняющая набор AVX командами FMA и другими векторными. Имеет те же преимущества и ограничения (например, в текущей версии для целых доступна только 16-байтовая обработка), но отличается кодировкой (в частности, использует обязательный XOP-байт).
XOP (extended operation: расширенная операция) — надстройка компании AMD, дополняющая набор AVX командами FMA и другими векторными. Имеет те же преимущества и ограничения (например, в текущей версии для целых доступна только 16-байтовая обработка), но отличается кодировкой (в частности, использует обязательный XOP-байт).
![]() FMA (fused multiply-add: слитое умножение-сложение) — поднабор команд для слитых умножения-сложения и умножения-вычитания. Реализуется в блоке MADD двумя вариантами:
FMA (fused multiply-add: слитое умножение-сложение) — поднабор команд для слитых умножения-сложения и умножения-вычитания. Реализуется в блоке MADD двумя вариантами:
- общий, 4-операндный, неразрушающий FMA4 (D=±A×B±C);
- частный, 3-операндный, разрушающий FMA3 (A=±A×B±C или B=±A×B±C или C=±A×B±C).
FMA-команда отличается повышенной скоростью (слитая операция быстрее двух раздельных) и точностью (не происходит промежуточного округления произведения).
![]() AMD-V, VT (virtualization technology: технология виртуализации) — технологии аппаратной поддержки виртуализации в ЦП AMD и Intel. Практически идентичны. Виртуализация позволят одновременно запускать несколько программно изолированных ОС, разделяя между ними аппаратные ресурсы.
AMD-V, VT (virtualization technology: технология виртуализации) — технологии аппаратной поддержки виртуализации в ЦП AMD и Intel. Практически идентичны. Виртуализация позволят одновременно запускать несколько программно изолированных ОС, разделяя между ними аппаратные ресурсы.
![]() AES-NI (AES new instructions: новые команды [для] AES) — поднабор команд для ускорения операций (де)шифрования по стандарту AES. Сюда же можно отнести PCLMULQDQ — команду безпереносного умножения, ускоряющего алгоритмы шифрования. Используют векторные регистры xmm и ymm.
AES-NI (AES new instructions: новые команды [для] AES) — поднабор команд для ускорения операций (де)шифрования по стандарту AES. Сюда же можно отнести PCLMULQDQ — команду безпереносного умножения, ускоряющего алгоритмы шифрования. Используют векторные регистры xmm и ymm.
![]() PadLock — поднабор команд для ускорения операций (де)шифрования для всех популярных шифров, включая AES. Также включает аппаратный генератор случайных чисел, применяемый для криптографических программ. Применяется в ЦП VIA.
PadLock — поднабор команд для ускорения операций (де)шифрования для всех популярных шифров, включая AES. Также включает аппаратный генератор случайных чисел, применяемый для криптографических программ. Применяется в ЦП VIA.
![]() CPUID (CPU identify: идентификация ЦП) — команда выдачи «паспорта процессора» с перечислением всех основных качественных и количественных характеристик, включая поддерживаемые поднаборы команд.
CPUID (CPU identify: идентификация ЦП) — команда выдачи «паспорта процессора» с перечислением всех основных качественных и количественных характеристик, включая поддерживаемые поднаборы команд.
![]() MSR (model-specific register: специфический для модели регистр) — регистр специального назначения для аппаратной настройки какой-либо функции или режима ЦП. В x86-ЦП MSR-регистров несколько сотен, причём их количество и использование определяются микроархитектурой и не зависят от программной архитектуры ЦП. Для пользовательских программ чаще всего недоступны.
MSR (model-specific register: специфический для модели регистр) — регистр специального назначения для аппаратной настройки какой-либо функции или режима ЦП. В x86-ЦП MSR-регистров несколько сотен, причём их количество и использование определяются микроархитектурой и не зависят от программной архитектуры ЦП. Для пользовательских программ чаще всего недоступны.
![]() load-op, load-ex (загрузка-исполнение) — вариант команды, использующий данные в памяти как один из источников. Требует наличие в команде адреса операнда в памяти, либо указания адресных компонент в регистре(ах) и самой команде. В последнем случае арифметические операции с компонентами выполняются в AGU до загрузки операнда и исполнения основного действия.
load-op, load-ex (загрузка-исполнение) — вариант команды, использующий данные в памяти как один из источников. Требует наличие в команде адреса операнда в памяти, либо указания адресных компонент в регистре(ах) и самой команде. В последнем случае арифметические операции с компонентами выполняются в AGU до загрузки операнда и исполнения основного действия.
![]() load-op-store (загрузка-исполнение-сохранение) — вариант команды, использующий данные в памяти как модификанд. Помимо требований к командам типа load-op, также иногда нужен атомарный обмен с памятью: если между чтением аргумента и записью результата одним ядром к этому же значению обратится другое, то для обеспечения целостности данных второе обращение требуется блокировать, что в многоядерной системе весьма сложно.
load-op-store (загрузка-исполнение-сохранение) — вариант команды, использующий данные в памяти как модификанд. Помимо требований к командам типа load-op, также иногда нужен атомарный обмен с памятью: если между чтением аргумента и записью результата одним ядром к этому же значению обратится другое, то для обеспечения целостности данных второе обращение требуется блокировать, что в многоядерной системе весьма сложно.
![]() mov (move: «перемещение, движение») — команда копирования данных.
mov (move: «перемещение, движение») — команда копирования данных.
![]() cmov (conditional move: условное перемещение) — команда условного копирования. Использование cmov позволяет ускорить программу за счёт уменьшения числа труднопредсказуемых условных переходов.
cmov (conditional move: условное перемещение) — команда условного копирования. Использование cmov позволяет ускорить программу за счёт уменьшения числа труднопредсказуемых условных переходов.
![]() jmp (jump: прыжок), переход — команда передачи управления, указывающая адрес другой команды, исполняемой после перехода. Различные варианты переходов реализуют структурные конструкции программы. Виды переходов:
jmp (jump: прыжок), переход — команда передачи управления, указывающая адрес другой команды, исполняемой после перехода. Различные варианты переходов реализуют структурные конструкции программы. Виды переходов:
- безусловный — происходит всегда;
- условный;
- циклический — условный переход после модификации счётчика цикла и проверки условия выхода из него; редко применяется;
- вызов подпрограммы и возврат из неё;
- вызов прерывания и возврат из него.
Поведение переходов предсказывается заранее, чаще всего удачно.
![]() nop (no operation: нет операции), ноп — единственная команда, не кодирующая операцию. Чаще всего используется как «затычка» для заполнения места при отладке или выравнивании кода. В некоторых архитектурах (включая x86) ноп как отдельный опкод отсутствует, поэтому заменяется комбинацией простой команды и операндов, не меняющей состояние процессора (кроме указателя на исполняемую команду). В x86 имеет длину 1–15 байт.
nop (no operation: нет операции), ноп — единственная команда, не кодирующая операцию. Чаще всего используется как «затычка» для заполнения места при отладке или выравнивании кода. В некоторых архитектурах (включая x86) ноп как отдельный опкод отсутствует, поэтому заменяется комбинацией простой команды и операндов, не меняющей состояние процессора (кроме указателя на исполняемую команду). В x86 имеет длину 1–15 байт.
Общее устройство конвейера
![]() pipeline («трубопровод»), конвейер — в общем случае: организация выполнения операций одновременным исполнением работы на нескольких этапах (стадиях), каждый из которых выполняет часть действий, для увеличения общей производительности. В процессоре: основная часть ядра, исполняющая программу конвейерным принципом. Конвейер может быть простым (однопутным) и суперскалярным (многопутным).
pipeline («трубопровод»), конвейер — в общем случае: организация выполнения операций одновременным исполнением работы на нескольких этапах (стадиях), каждый из которых выполняет часть действий, для увеличения общей производительности. В процессоре: основная часть ядра, исполняющая программу конвейерным принципом. Конвейер может быть простым (однопутным) и суперскалярным (многопутным).
![]() stage, стадия — одна из нескольких частей конвейера. Как правило, каждый такт стадия выполняет одно или несколько простых действий в одном блоке, передаёт результат в следующую стадию и принимает результат предыдущей. При невозможности выполнить что-либо из этих действий впадает в ступор.
stage, стадия — одна из нескольких частей конвейера. Как правило, каждый такт стадия выполняет одно или несколько простых действий в одном блоке, передаёт результат в следующую стадию и принимает результат предыдущей. При невозможности выполнить что-либо из этих действий впадает в ступор.
![]() stall, ступор — останов работы конвейера или одной или нескольких его стадий из-за нехватки какого-либо ресурса. Ступор одной стадии в течение одного такта называется пузырь (bubble). Во избежание ступоров и приближения достижимой производительности к её теоретическому максимуму применяются многочисленные методы поддержания конвейера в максимально загруженном состоянии.
stall, ступор — останов работы конвейера или одной или нескольких его стадий из-за нехватки какого-либо ресурса. Ступор одной стадии в течение одного такта называется пузырь (bubble). Во избежание ступоров и приближения достижимой производительности к её теоретическому максимуму применяются многочисленные методы поддержания конвейера в максимально загруженном состоянии.
![]() way («путь») — в конвейере: магистраль для прохождения одного потока команд или мопов. Число путей применяется ко всему конвейеру и ограничивает максимальную величину суперскалярности, хотя между некоторыми смежными стадиями число путей может быть больше.
way («путь») — в конвейере: магистраль для прохождения одного потока команд или мопов. Число путей применяется ко всему конвейеру и ограничивает максимальную величину суперскалярности, хотя между некоторыми смежными стадиями число путей может быть больше.
![]() superscalar, суперскалярный — многопутный конвейер, обрабатывающий более одной команды за такт, или процессор, обладающий ядром(ами) с таким конвейером, или микроархитектура, описывающая такой конвейер.
superscalar, суперскалярный — многопутный конвейер, обрабатывающий более одной команды за такт, или процессор, обладающий ядром(ами) с таким конвейером, или микроархитектура, описывающая такой конвейер.
![]() front-end («передняя часть»), фронт конвейера — часть конвейера, читающая и обрабатывающая команды, подготавливая их для исполнения в тылу в виде мопов. Включает в себя стадии от предсказателя переходов до декодера или расположенных после него буфера и/или кэша мопов (в случае их присутствия). В терминах Intel буфер мопов отделяет фронт и тыл, так что запись в него является последней стадией фронта.
front-end («передняя часть»), фронт конвейера — часть конвейера, читающая и обрабатывающая команды, подготавливая их для исполнения в тылу в виде мопов. Включает в себя стадии от предсказателя переходов до декодера или расположенных после него буфера и/или кэша мопов (в случае их присутствия). В терминах Intel буфер мопов отделяет фронт и тыл, так что запись в него является последней стадией фронта.
![]() back-end («задняя часть»), тыл конвейера — часть конвейера, обрабатывающая данные исполнением мопов от фронта. Включает в себя стадии от чтения из буфера мопов и размещения мопов в планировщике(ах) до их отставки. Непосредственно обработка данных осуществляется только стадией исполнения, однако к тылу относят также остальные части исполнительного тракта, диспетчер и планировщик(и). Кэши, LSU и прочие блоки подсистемы памяти номинально не являются частью конвейера, несмотря на то, что при обработке доступов в память LSU должен сработать до отставки затребовавшей доступ команды.
back-end («задняя часть»), тыл конвейера — часть конвейера, обрабатывающая данные исполнением мопов от фронта. Включает в себя стадии от чтения из буфера мопов и размещения мопов в планировщике(ах) до их отставки. Непосредственно обработка данных осуществляется только стадией исполнения, однако к тылу относят также остальные части исполнительного тракта, диспетчер и планировщик(и). Кэши, LSU и прочие блоки подсистемы памяти номинально не являются частью конвейера, несмотря на то, что при обработке доступов в память LSU должен сработать до отставки затребовавшей доступ команды.
![]() µop, mop, микрооперация, моп — RISC-подобная команда (неверно названная операцией) во внутреннем формате ЦП, исполняющая одно или несколько элементарных действий. Команды CISC-ЦП переводятся в мопы в декодере, причём каждая простая команда генерирует один моп, а сложная — несколько. В RISC-ЦП декодер состоит лишь из простых блоков, выполняющих несложную подготовку команд для исполнения. Одна CISC-команда порождает в среднем более одного мопа, а число путей конвейера до и после декодера чаще всего одинаково, что создаёт дисбаланс нагрузок на стадии. Для его исправления применяются микрослияние и макрослияние.
µop, mop, микрооперация, моп — RISC-подобная команда (неверно названная операцией) во внутреннем формате ЦП, исполняющая одно или несколько элементарных действий. Команды CISC-ЦП переводятся в мопы в декодере, причём каждая простая команда генерирует один моп, а сложная — несколько. В RISC-ЦП декодер состоит лишь из простых блоков, выполняющих несложную подготовку команд для исполнения. Одна CISC-команда порождает в среднем более одного мопа, а число путей конвейера до и после декодера чаще всего одинаково, что создаёт дисбаланс нагрузок на стадии. Для его исправления применяются микрослияние и макрослияние.
![]() microfusion, микрослияние — возможность одним мопом закодировать две операции, чтобы уменьшить нагрузку на конвейер для некоторых относительно сложных команд. Чаще всего микрослитым мопом кодируется одна вычислительная операция и один связанный с ней доступ в память, включая вычисление адреса. Слитые мопы разделяются на два отдельных перед исполнением в тылу.
microfusion, микрослияние — возможность одним мопом закодировать две операции, чтобы уменьшить нагрузку на конвейер для некоторых относительно сложных команд. Чаще всего микрослитым мопом кодируется одна вычислительная операция и один связанный с ней доступ в память, включая вычисление адреса. Слитые мопы разделяются на два отдельных перед исполнением в тылу.
![]() macrofusion, макрослияние — надстройка над микрослиянием, позволяющая одним мопом закодировать две (редко больше) команды, чтобы увеличить значение IPC на 1 (более одного микрослияния за такт микроархитектуры x86-ЦП не допускают). Варианты сливаемых команд:
macrofusion, макрослияние — надстройка над микрослиянием, позволяющая одним мопом закодировать две (редко больше) команды, чтобы увеличить значение IPC на 1 (более одного микрослияния за такт микроархитектуры x86-ЦП не допускают). Варианты сливаемых команд:
- сравнение + условный переход;
- меняющая флаги арифметическая или логическая команда + условный переход (более общий вариант предыдущего пункта);
- любая команда, кроме нопа + ноп + (необязательно) любая команда, подходящая критериям выше;
- копирование «регистр-1 ← регистр-2» + вычислительная команда с регистром-1 как модификандом.
Из-за фиксированного размера мопа на операнды пары команд накладываются ограничения: не более одного доступа в память, не более одного непосредственного операнда (иногда не допускается вовсе) и т. п.
![]() in-order, поочерёдный — о последовательной обработке или исполнении команд и мопов в указанном программой порядке. Фронт конвейера всегда обрабатывает команды упорядоченно. Тыл обрабатывает данные поочерёдно или внеочерёдно.
in-order, поочерёдный — о последовательной обработке или исполнении команд и мопов в указанном программой порядке. Фронт конвейера всегда обрабатывает команды упорядоченно. Тыл обрабатывает данные поочерёдно или внеочерёдно.
![]() speculative (гипотетический), спекулятивный, упреждающий — следующий принципу упреждения: выполнение работы до подтверждения необходимости её результатов. В конвейерных процессорах — загрузка и/или исполнение наиболее вероятных команд и/или данных. Упреждение применяется, чтобы не ступорить часть конвейера в ожидании точного результата, когда данные или коды, нужные для работы текущей стадии, будут получены лишь через несколько тактов в одной из следующих. Проверка верности упреждения для команд происходит при отставке, а для данных возможна и ранее. Упреждение для команд применяется при предсказании ветвлений и внеочерёдном исполнении, а для данных — при предзагрузке и внеочерёдном доступе к памяти.
speculative (гипотетический), спекулятивный, упреждающий — следующий принципу упреждения: выполнение работы до подтверждения необходимости её результатов. В конвейерных процессорах — загрузка и/или исполнение наиболее вероятных команд и/или данных. Упреждение применяется, чтобы не ступорить часть конвейера в ожидании точного результата, когда данные или коды, нужные для работы текущей стадии, будут получены лишь через несколько тактов в одной из следующих. Проверка верности упреждения для команд происходит при отставке, а для данных возможна и ранее. Упреждение для команд применяется при предсказании ветвлений и внеочерёдном исполнении, а для данных — при предзагрузке и внеочерёдном доступе к памяти.
![]() OoO (out-of-order), внеочерёдность — упреждение для команд при обработке мопов: обработка в порядке, наиболее удобном ядру в данный момент. Применяется к тылу конвейера: отдельно к исполнительной части (OoOE) и доступу в память (memory disambiguation). Требует наличия аппаратной структуры, хранящей оригинальный порядок мопов (исходя из последовательности породивших их команд) для их поочерёдной отставки.
OoO (out-of-order), внеочерёдность — упреждение для команд при обработке мопов: обработка в порядке, наиболее удобном ядру в данный момент. Применяется к тылу конвейера: отдельно к исполнительной части (OoOE) и доступу в память (memory disambiguation). Требует наличия аппаратной структуры, хранящей оригинальный порядок мопов (исходя из последовательности породивших их команд) для их поочерёдной отставки.
![]() OoOE (out-of-order execution), внеочерёдное исполнение — концепция внеочерёдности, применяемая при исполнении мопов: моп запускается на выполнение, когда готовы все его операнды и целевое ФУ, даже если декодированные до него мопы ещё не исполнены. Является одним из видов упреждения для команд.
OoOE (out-of-order execution), внеочерёдное исполнение — концепция внеочерёдности, применяемая при исполнении мопов: моп запускается на выполнение, когда готовы все его операнды и целевое ФУ, даже если декодированные до него мопы ещё не исполнены. Является одним из видов упреждения для команд.
![]() SMT (simultaneous multithreading: одновременная многопоточность) — виртуальная многопроцессорность: одновременное исполнение конвейером одного ядра нескольких потоков для минимизации ступоров. При этом большинство ресурсов конвейера используется всеми потоками.
SMT (simultaneous multithreading: одновременная многопоточность) — виртуальная многопроцессорность: одновременное исполнение конвейером одного ядра нескольких потоков для минимизации ступоров. При этом большинство ресурсов конвейера используется всеми потоками.
![]() HT (Hyper-Threading), гиперпоточность — «тонкая» версия SMT в ЦП Intel: каждый такт каждая стадия конвейера или их группа выбирает один из двух или оба потока команд или мопов, исходя из готовности ресурсов для каждого из них.
HT (Hyper-Threading), гиперпоточность — «тонкая» версия SMT в ЦП Intel: каждый такт каждая стадия конвейера или их группа выбирает один из двух или оба потока команд или мопов, исходя из готовности ресурсов для каждого из них.
![]() MCMT (multicluster multithreading: многокластерная многопоточность) — ускоряющее производительность решение AMD, промежуточное между SMP и SMT: исполняющий два потока конвейер делится на параллельно работающие кластеры по несколько стадий каждый, причём одни кластеры разделяют свои ресурсы между потоками (как в SMP), а другие выделяются им монопольно (как в SMT).
MCMT (multicluster multithreading: многокластерная многопоточность) — ускоряющее производительность решение AMD, промежуточное между SMP и SMT: исполняющий два потока конвейер делится на параллельно работающие кластеры по несколько стадий каждый, причём одни кластеры разделяют свои ресурсы между потоками (как в SMP), а другие выделяются им монопольно (как в SMT).
![]() IPC (instructions per clock), команд (-а, -ы) за такт — мера производительности конвейера, его исполнительной стадии или отдельного ФУ. Пиковая величина IPC измеряется при выполнении потока команд или мопов, независимых друг от друга по данным, что позволяет по возможности осуществить их одновременное исполнение.
IPC (instructions per clock), команд (-а, -ы) за такт — мера производительности конвейера, его исполнительной стадии или отдельного ФУ. Пиковая величина IPC измеряется при выполнении потока команд или мопов, независимых друг от друга по данным, что позволяет по возможности осуществить их одновременное исполнение.
![]() CPI (clocks per instruction), такт (-а, -ов) на команду — величина, обратная IPC. Применяется для удобства, когда IPC<1.
CPI (clocks per instruction), такт (-а, -ов) на команду — величина, обратная IPC. Применяется для удобства, когда IPC<1.
![]() OPC (operations per clock), операция (-и, -й) за такт — величина, аналогичная IPC, но замеряющая операции исполняемых команд или мопов. При вычислении пиковой величины OPC конвейера, как правило, учитываются лишь вычислительные команды, и только над данными, а не адресами.
OPC (operations per clock), операция (-и, -й) за такт — величина, аналогичная IPC, но замеряющая операции исполняемых команд или мопов. При вычислении пиковой величины OPC конвейера, как правило, учитываются лишь вычислительные команды, и только над данными, а не адресами.
![]() FLOPC (float operations per clock: вещественные операции за такт), флоп (-а, -ов) за такт — величина OPC для вещественных вычислительных команд. Применяется к ядру, а при умножении на число ядер — ко всему процессору.
FLOPC (float operations per clock: вещественные операции за такт), флоп (-а, -ов) за такт — величина OPC для вещественных вычислительных команд. Применяется к ядру, а при умножении на число ядер — ко всему процессору.
![]() FLOPS (FLoat Operations Per Second: вещественные операции в секунду), флопс — произведение базовой частоты процессора на число флопов/такт. Применяется к ядру, а при умножении на число ядер — ко всему процессору, являясь в этом случае одной из его главных скоростных характеристик.
FLOPS (FLoat Operations Per Second: вещественные операции в секунду), флопс — произведение базовой частоты процессора на число флопов/такт. Применяется к ядру, а при умножении на число ядер — ко всему процессору, являясь в этом случае одной из его главных скоростных характеристик.
![]() latency, латентность, задержка — число тактов между подачей команды на исполнение и его завершением. Применяется для описания «хронологической длины» конвейера (близкой к числу стадий) и длительностей исполнения команды в ФУ или доступа в кэш или память. Большинство команд имеют постоянную задержку, почти не зависящую от содержимого обрабатываемых данных. Обращение к подсистеме кэшей и, особенно, к памяти имеют переменный характер задержки, поэтому для них указываются минимальная и средняя задержки.
latency, латентность, задержка — число тактов между подачей команды на исполнение и его завершением. Применяется для описания «хронологической длины» конвейера (близкой к числу стадий) и длительностей исполнения команды в ФУ или доступа в кэш или память. Большинство команд имеют постоянную задержку, почти не зависящую от содержимого обрабатываемых данных. Обращение к подсистеме кэшей и, особенно, к памяти имеют переменный характер задержки, поэтому для них указываются минимальная и средняя задержки.
![]() throughput, пропуск, темп, ПС (пропускная способность) — о командах: обратная пропускная способность — значение CPI при исполнении мопа(ов) данной команды для отдельного ФУ, либо всей исполнительной стадии конвейера. ФУ с пропуском в 1 CPI является полноконвейерным, т. е. принимающим на исполнение новый моп каждый такт, при том, что задержка может быть более 1 такта. ФУ с пропуском 2 является полуконвейерным, а с пропуском, (почти) равным задержке, — неконвейерным. Дробные значения пропуска команд получаются при суперскалярном исполнении. Например, 0,5 означает наличие либо двух одинаковых конвейерных (для исполнения данной команды) ФУ, либо четырёх полуконвейерных, а 1,5 — наличие двух одинаковых ФУ с CPI=3.
throughput, пропуск, темп, ПС (пропускная способность) — о командах: обратная пропускная способность — значение CPI при исполнении мопа(ов) данной команды для отдельного ФУ, либо всей исполнительной стадии конвейера. ФУ с пропуском в 1 CPI является полноконвейерным, т. е. принимающим на исполнение новый моп каждый такт, при том, что задержка может быть более 1 такта. ФУ с пропуском 2 является полуконвейерным, а с пропуском, (почти) равным задержке, — неконвейерным. Дробные значения пропуска команд получаются при суперскалярном исполнении. Например, 0,5 означает наличие либо двух одинаковых конвейерных (для исполнения данной команды) ФУ, либо четырёх полуконвейерных, а 1,5 — наличие двух одинаковых ФУ с CPI=3.
О других стадиях: значение IPC для стадии. Как правило, совпадает с числом путей конвейера в ней.
О кэше, памяти и соединяющих их с ядром шинах: прямая пропускная способность в байтах/такт или байтах/секунду. Пиковая ПС является произведением разрядности шины, числа передаваемых каждой линией битов/такт и (для Б/c) частоты. Фактическая ПС часто в 1,5–2 раза меньше пиковой. При указании приставок кратности (кило-, мега-, гига-, …) имеются в виду десятичные производные (103, 106, 109, …), а не двоичные (210=1,024·103, 220≈1,049·106, 230≈1,074·109, …). ПС памяти сокращается как ПСП, а кэша — ПСК.
![]() timing, временной параметр, тайминг — общее название пропуска и задержки. Чаще всего применяется к командам и доступу к подсистеме памяти.
timing, временной параметр, тайминг — общее название пропуска и задержки. Чаще всего применяется к командам и доступу к подсистеме памяти.
Стадии конвейера
![]() BPU (branch predictor unit: блок предсказания ветвлений), предсказатель переходов — начальная часть конвейера, реализующая один из видов упреждения команд. Прогнозирует поведение команд перехода (целевой адрес и предположение об исполнении), используя накопленную в специальных таблицах и регистрах статистику о дошедших до отставки переходах. Состоит из 1–2 стадий, работает отдельно от остального конвейера и раз в 2–3 такта выдаёт вероятный адрес следующей порции команд для исполнения. Для переходов разного типа применяет разные алгоритмы. Прогнозы даются на несколько переходов вперёд вне зависимости от темпа реального исполнения команд или даже их наличия в кэше L1I.
BPU (branch predictor unit: блок предсказания ветвлений), предсказатель переходов — начальная часть конвейера, реализующая один из видов упреждения команд. Прогнозирует поведение команд перехода (целевой адрес и предположение об исполнении), используя накопленную в специальных таблицах и регистрах статистику о дошедших до отставки переходах. Состоит из 1–2 стадий, работает отдельно от остального конвейера и раз в 2–3 такта выдаёт вероятный адрес следующей порции команд для исполнения. Для переходов разного типа применяет разные алгоритмы. Прогнозы даются на несколько переходов вперёд вне зависимости от темпа реального исполнения команд или даже их наличия в кэше L1I.
![]() IF (instruction fetch: загрузка команд) — несколько стадий (число которых совпадает с задержкой кэша L1I), тратящихся на загрузку порции команд из L1I в предекодер или декодер по предсказанному адресу.
IF (instruction fetch: загрузка команд) — несколько стадий (число которых совпадает с задержкой кэша L1I), тратящихся на загрузку порции команд из L1I в предекодер или декодер по предсказанному адресу.
![]() IChunk (instruction сhunk: «кусок команд»), порция команд — блок команд, загружаемый из L1I в предекодер или декодер. В x86 ЦП — 16 или 32 байта.
IChunk (instruction сhunk: «кусок команд»), порция команд — блок команд, загружаемый из L1I в предекодер или декодер. В x86 ЦП — 16 или 32 байта.
![]() predecoder, предекодер — предварительный декодер, разделяющий несколько CISC-команд из порции на отдельные элементы (см. x86), используя информацию от длиномера. Подготовка команд может происходить наперёд их дальнейшей обработки декодером, если до него есть буфер.
predecoder, предекодер — предварительный декодер, разделяющий несколько CISC-команд из порции на отдельные элементы (см. x86), используя информацию от длиномера. Подготовка команд может происходить наперёд их дальнейшей обработки декодером, если до него есть буфер.
![]() ILD (instruction length decoder: декодер длин команд), длиномер — определитель длин CISC-команд. В x86-ЦП анализирует их префиксы, опкоды и байты modR/M. В ЦП Intel длиномер является частью предекодера, измеряя длины «на лету». В большинстве ЦП AMD он работает с командами при их загрузке из L2 в L1I, сохраняя разметку байтов команд в дополнительных битах в L1I, считываемых предекодером при загрузке порции.
ILD (instruction length decoder: декодер длин команд), длиномер — определитель длин CISC-команд. В x86-ЦП анализирует их префиксы, опкоды и байты modR/M. В ЦП Intel длиномер является частью предекодера, измеряя длины «на лету». В большинстве ЦП AMD он работает с командами при их загрузке из L2 в L1I, сохраняя разметку байтов команд в дополнительных битах в L1I, считываемых предекодером при загрузке порции.
![]() ID (instruction decoder: декодер команд), decoder (декодер) — набор блоков, преобразующих команды в мопы. В x86-ЦП состоит из нескольких трансляторов и одного микросеквенсера (генератора последовательности мопов) с ПЗУ для микрокода. Осуществляет микрослияние и макрослияние.
ID (instruction decoder: декодер команд), decoder (декодер) — набор блоков, преобразующих команды в мопы. В x86-ЦП состоит из нескольких трансляторов и одного микросеквенсера (генератора последовательности мопов) с ПЗУ для микрокода. Осуществляет микрослияние и макрослияние.
![]() translator («переводчик»), транслятор — часть декодера, обрабатывающая простые и частые команды без использования микрокода. В x86-ЦП Intel есть 1–3 простых транслятора (на 1 меньше числа путей конвейера), каждый из которых переводит команду в 1 моп за такт, и 1 сложный транслятор, переводящий команду в 1–4 мопа/такт. Как правило, число генерируемых трансляторами мопов не больше числа путей. Большинство ЦП AMD имеют 3–4 транслятора, каждый из которых переводит команду в 1–2 мопа/такт. Макросливаемые команды обрабатываются парами любым транслятором, но не более одной пары за такт.
translator («переводчик»), транслятор — часть декодера, обрабатывающая простые и частые команды без использования микрокода. В x86-ЦП Intel есть 1–3 простых транслятора (на 1 меньше числа путей конвейера), каждый из которых переводит команду в 1 моп за такт, и 1 сложный транслятор, переводящий команду в 1–4 мопа/такт. Как правило, число генерируемых трансляторами мопов не больше числа путей. Большинство ЦП AMD имеют 3–4 транслятора, каждый из которых переводит команду в 1–2 мопа/такт. Макросливаемые команды обрабатываются парами любым транслятором, но не более одной пары за такт.
![]() µcode, microcode, микрокод — совокупность микропрограмм — последовательностей мопов (до нескольких сот длиной), задающих исполнение наиболее сложных команд, которые не могут быть обработаны трансляторами. Хранится в ПЗУ микропрограмм.
µcode, microcode, микрокод — совокупность микропрограмм — последовательностей мопов (до нескольких сот длиной), задающих исполнение наиболее сложных команд, которые не могут быть обработаны трансляторами. Хранится в ПЗУ микропрограмм.
![]() microsequencer, микросеквенсер — часть декодера, читающая микропрограммы из ПЗУ с ними.
microsequencer, микросеквенсер — часть декодера, читающая микропрограммы из ПЗУ с ними.
![]() mROM, µROM («микроПЗУ») — энергонезависимое хранилище для микрокода размером в несколько сотен килобит. Микросеквенсер декодера читает микропрограммы из микроПЗУ по несколько мопов за такт (согласно числу путей конвейера). Для исправления ошибок содержимое может корректироваться прямым программированием или перемычками.
mROM, µROM («микроПЗУ») — энергонезависимое хранилище для микрокода размером в несколько сотен килобит. Микросеквенсер декодера читает микропрограммы из микроПЗУ по несколько мопов за такт (согласно числу путей конвейера). Для исправления ошибок содержимое может корректироваться прямым программированием или перемычками.
![]() mop buffer, буфер мопов — последняя стадия фронта конвейера, принимающая мопы от декодера и/или кэша мопов и отправляющая их в диспетчер. По терминологии Intel называется IDQ (instruction decode queue: очередь декодирования команд). В ЦП Intel буфер мопов (как и кэш) может работать в режиме блокировки цикла, освобождая на время его исполнения остальные стадии фронта для простоя, накопления мопов команд после цикла или работы над другим потоком (в процессорах с SMT). Обнаружение и блокировка цикла в IDQ осуществляется блоком LSD (loop stream detector: детектор циклического потока).
mop buffer, буфер мопов — последняя стадия фронта конвейера, принимающая мопы от декодера и/или кэша мопов и отправляющая их в диспетчер. По терминологии Intel называется IDQ (instruction decode queue: очередь декодирования команд). В ЦП Intel буфер мопов (как и кэш) может работать в режиме блокировки цикла, освобождая на время его исполнения остальные стадии фронта для простоя, накопления мопов команд после цикла или работы над другим потоком (в процессорах с SMT). Обнаружение и блокировка цикла в IDQ осуществляется блоком LSD (loop stream detector: детектор циклического потока).
![]() dispatcher, диспетчер — блок конвейера, архитектурно занимающий бо́льшую часть тыла, включая его первую и последнюю стадии. Принимая мопы от декодера или буфера мопов, внеочерёдный диспетчер осуществляет переименование регистров, размещение мопов, приём сигналов о завершении исполнения мопов и отставку породивших их команд. Почерёдный диспетчер проще: он не делает переименование и размещение и заменяет собой планировщик.
dispatcher, диспетчер — блок конвейера, архитектурно занимающий бо́льшую часть тыла, включая его первую и последнюю стадии. Принимая мопы от декодера или буфера мопов, внеочерёдный диспетчер осуществляет переименование регистров, размещение мопов, приём сигналов о завершении исполнения мопов и отставку породивших их команд. Почерёдный диспетчер проще: он не делает переименование и размещение и заменяет собой планировщик.
![]() register rename, переименование регистров — поочерёдная привязка номера архитектурного регистра-приёмника, описываемого в ISA и указанного в мопе, к аппаратному регистру (должна точнее называться перенумерацией). Является первой стадией тыла конвейера и выполняется диспетчером перед размещением мопа. Аппаратных регистров в 4–10 раз больше, чем архитектурных того же типа, что позволяет реализовать одновременное исполнение мопов, до переименования ссылавшихся на один регистр, за счёт удаления ложных зависимостей по операндам. Не смотря на поочерёдность операции, суперскалярный диспетчер может не только переименовать несколько регистров за такт (учитывая, что в мопе приёмник максимум один, не считая регистра флагов), но и несколько раз за такт переименовать один и тот же архитектурный регистр. Часто также переименовываются 4–6 важнейших флагов и регистр управления вещественными вычислениями. Аппаратные векторные регистры иногда бывают вдвое меньше архитектурных — в этом случае переименование делается для старшей и младшей половин архитектурного. В продвинутых микроархитектурах мопы некоторых команд (обмен, копирование и обнуление) при работе только с регистрами исполняются уже на этой стадии и до размещения не доходят.
register rename, переименование регистров — поочерёдная привязка номера архитектурного регистра-приёмника, описываемого в ISA и указанного в мопе, к аппаратному регистру (должна точнее называться перенумерацией). Является первой стадией тыла конвейера и выполняется диспетчером перед размещением мопа. Аппаратных регистров в 4–10 раз больше, чем архитектурных того же типа, что позволяет реализовать одновременное исполнение мопов, до переименования ссылавшихся на один регистр, за счёт удаления ложных зависимостей по операндам. Не смотря на поочерёдность операции, суперскалярный диспетчер может не только переименовать несколько регистров за такт (учитывая, что в мопе приёмник максимум один, не считая регистра флагов), но и несколько раз за такт переименовать один и тот же архитектурный регистр. Часто также переименовываются 4–6 важнейших флагов и регистр управления вещественными вычислениями. Аппаратные векторные регистры иногда бывают вдвое меньше архитектурных — в этом случае переименование делается для старшей и младшей половин архитектурного. В продвинутых микроархитектурах мопы некоторых команд (обмен, копирование и обнуление) при работе только с регистрами исполняются уже на этой стадии и до размещения не доходят.
![]() allocator, разместитель — стадия внеочерёдного диспетчера, выполняющая размещение переименованных мопов в ROB и планировщике(ах). В некоторых микроархитектурах перед попаданием в планировщик(и) макро- и микрослитые мопы разделяются.
allocator, разместитель — стадия внеочерёдного диспетчера, выполняющая размещение переименованных мопов в ROB и планировщике(ах). В некоторых микроархитектурах перед попаданием в планировщик(и) макро- и микрослитые мопы разделяются.
![]() ROB (reorder buffer: «буфер переупорядочивания») — вопреки названию (термин Intel), хранит оригинальный (программный) порядок мопов, поэтому правильней называется RQ (retire(ment) queue: очередь отставки; термин AMD). Число мопов в ROB определяет т. н. OoO-окно — диапазон, внутри которого мопы могут исполняться вне программного порядка. Ячейка в ROB хранит урезанную версию мопа, в которой оставлены лишь необходимые планировщику поля. В частности, если диспетчер подключен к хранящему планировщику, то ROB после исполнения мопов хранит копии их результатов; если к ссылочному — то он хранит ссылки на результаты в физческом РФ; ни одна из версий не хранит опкод и другую информацию, нужную для исполнения мопа.
ROB (reorder buffer: «буфер переупорядочивания») — вопреки названию (термин Intel), хранит оригинальный (программный) порядок мопов, поэтому правильней называется RQ (retire(ment) queue: очередь отставки; термин AMD). Число мопов в ROB определяет т. н. OoO-окно — диапазон, внутри которого мопы могут исполняться вне программного порядка. Ячейка в ROB хранит урезанную версию мопа, в которой оставлены лишь необходимые планировщику поля. В частности, если диспетчер подключен к хранящему планировщику, то ROB после исполнения мопов хранит копии их результатов; если к ссылочному — то он хранит ссылки на результаты в физческом РФ; ни одна из версий не хранит опкод и другую информацию, нужную для исполнения мопа.
![]() SC, scheduler, планировщик — логический анализатор, принимающий мопы от диспетчера, планирующий и производящий их внеочерёдный запуск на исполнение и фиксирующий их завершение (указывая об этом диспетчеру для отставки породивших их команд). Планирование основано на определении зависимости мопов по операндам и отслеживании занятости ресурсов исполнительной стадии. Виды и свойства:
SC, scheduler, планировщик — логический анализатор, принимающий мопы от диспетчера, планирующий и производящий их внеочерёдный запуск на исполнение и фиксирующий их завершение (указывая об этом диспетчеру для отставки породивших их команд). Планирование основано на определении зависимости мопов по операндам и отслеживании занятости ресурсов исполнительной стадии. Виды и свойства:
| Ссылочный планировщик | Хранящий планировщик |
| Не хранит и не перемещает мопы и данные в резервации. | Хранит в резервации мопы и данные, сдвигая их при каждом запуске. |
| Манипулирует только мопами и номерами переименованных регистров, отслеживая архитектурные и упреждающие записи в таблице привязки. | Манипулирует мопами и уже известным (в т. ч. упреждающим) содержимым регистров, перехватывая результаты, возвращаемые исполненными мопами. |
| Имеет многопортовую резервацию, рассчитанную на все ФУ. | Имеет либо одну многопортовую резервацию, либо несколько однопортовых (с распределением ФУ между ними). |
| Размещаемые мопы привязаны номерами регистров к физическому РФ. | Размещаемые мопы привязаны номерами регистров к упреждающему РФ; разместитель записывает в резервацию уже известные значения их операндов из архитектурного РФ. |
| После исполнения мопа возвращает его диспетчеру со ссылкой на результат. | После исполнения мопа копирует в резервацию записанный им в упреждающий РФ результат и возвращает моп с результатом диспетчеру. |
![]() RS (reservation station: резервационная станция), резервация — в ссылочном планировщике: буфер готовящихся к исполнению мопов и ссылок на их операнды в физическом РФ. В хранящем планировщике: буфер готовящихся к исполнению мопов, накапливающий копии значений их операндов.
RS (reservation station: резервационная станция), резервация — в ссылочном планировщике: буфер готовящихся к исполнению мопов и ссылок на их операнды в физическом РФ. В хранящем планировщике: буфер готовящихся к исполнению мопов, накапливающий копии значений их операндов.
![]() issue («выпуск»), запуск — передача мопа из планировщика в исполнительный тракт для исполнения. Если планировщик допускает хранение в своей резервации микро- и макрослитых мопов (не требуя их разделения при размещении), то такие мопы запускаются по нескольку раз. Вычислительные мопы, читающие аргумент из памяти, сначала попадают в AGU, затем в LSU и, наконец, в нужное ФУ для обработки. Мопы, сохраняющие аргумент в памяти (и которые в х86 не бывают вычислительными), должны в любом порядке запуститься в AGU и LSU. Каждый получатель слитого мопа интерпретирует его по-своему, исполняя одну операцию. После выполнения последней из них моп удаляется из резервации, а планировщик сообщает диспетчеру о возможности отставки удалённого мопа.
issue («выпуск»), запуск — передача мопа из планировщика в исполнительный тракт для исполнения. Если планировщик допускает хранение в своей резервации микро- и макрослитых мопов (не требуя их разделения при размещении), то такие мопы запускаются по нескольку раз. Вычислительные мопы, читающие аргумент из памяти, сначала попадают в AGU, затем в LSU и, наконец, в нужное ФУ для обработки. Мопы, сохраняющие аргумент в памяти (и которые в х86 не бывают вычислительными), должны в любом порядке запуститься в AGU и LSU. Каждый получатель слитого мопа интерпретирует его по-своему, исполняя одну операцию. После выполнения последней из них моп удаляется из резервации, а планировщик сообщает диспетчеру о возможности отставки удалённого мопа.
![]() port, порт — для РФ: интерфейс для одной из шин исполнительного тракта, допускает либо чтения, либо записи. Для ФУ: интерфейс для приёма мопов или аргументов или отправки результатов. Для резервации: интерфейс для одного или нескольких ФУ, через который ему (им) передаются мопы или принимаются стоп-сигналы о завершении их исполнения.
port, порт — для РФ: интерфейс для одной из шин исполнительного тракта, допускает либо чтения, либо записи. Для ФУ: интерфейс для приёма мопов или аргументов или отправки результатов. Для резервации: интерфейс для одного или нескольких ФУ, через который ему (им) передаются мопы или принимаются стоп-сигналы о завершении их исполнения.
![]() RF (register file), РФ (регистровый файл) — набор одинаковых регистров, отличающихся лишь номером. С точки зрения архитектуры в ядре современного ЦП есть как минимум целочисленный РФ (набор РОНов для скалярных целых данных и адресов) и векторно-вещественный РФ (для остальных видов данных). Аппаратных РФ может быть больше, причём разрядность какого-либо них не обязательно совпадает с разрядностью архитектурных регистров, хранящих в данном РФ свои значения. Имеет по несколько портов чтения и записи, реализуя одновременный доступ, если нет конфликтов.
RF (register file), РФ (регистровый файл) — набор одинаковых регистров, отличающихся лишь номером. С точки зрения архитектуры в ядре современного ЦП есть как минимум целочисленный РФ (набор РОНов для скалярных целых данных и адресов) и векторно-вещественный РФ (для остальных видов данных). Аппаратных РФ может быть больше, причём разрядность какого-либо них не обязательно совпадает с разрядностью архитектурных регистров, хранящих в данном РФ свои значения. Имеет по несколько портов чтения и записи, реализуя одновременный доступ, если нет конфликтов.
![]() ARF (architectural RF), архитектурный РФ — в поочерёдных конвейерах: единственный вид РФ; хранящит текущее состояние описываемых архитектурой регистров и находится на исполнительном тракте. Во внеочерёдных конвейерах: РФ, хранящий последнее достоверно известное состояние архитектурных регистров, обновляемое при отставке мопов. Используется хранящим планировщиком. В ЦП с SMT на каждый поток есть либо по одному ARF, либо по одной таблице привязки регистров из физического РФ (в зависимости от вида планировщика). Иногда называется RRF (retired RF, «отставленный РФ»; не путать с renamed RF).
ARF (architectural RF), архитектурный РФ — в поочерёдных конвейерах: единственный вид РФ; хранящит текущее состояние описываемых архитектурой регистров и находится на исполнительном тракте. Во внеочерёдных конвейерах: РФ, хранящий последнее достоверно известное состояние архитектурных регистров, обновляемое при отставке мопов. Используется хранящим планировщиком. В ЦП с SMT на каждый поток есть либо по одному ARF, либо по одной таблице привязки регистров из физического РФ (в зависимости от вида планировщика). Иногда называется RRF (retired RF, «отставленный РФ»; не путать с renamed RF).
![]() FF (future file: «файл будущего»), RRF (renamed RF: переименованный РФ; не путать с retired RF), SRF (speculative RF: упреждающий РФ) — РФ, хранящий регистры с упреждёнными операндами и находящийся на исполнительном тракте. Используется хранящим планировщиком.
FF (future file: «файл будущего»), RRF (renamed RF: переименованный РФ; не путать с retired RF), SRF (speculative RF: упреждающий РФ) — РФ, хранящий регистры с упреждёнными операндами и находящийся на исполнительном тракте. Используется хранящим планировщиком.
![]() PRF (physical RF), физический РФ (ФРФ) — РФ, монопольно хранящий регистровые операнды мопов, замещая архитектурный и упреждающий РФ. Используется ссылочным планировщиком.
PRF (physical RF), физический РФ (ФРФ) — РФ, монопольно хранящий регистровые операнды мопов, замещая архитектурный и упреждающий РФ. Используется ссылочным планировщиком.
![]() EX (execution), исполнение — одна или несколько стадий исполнения мопов, содержащая все ФУ (при поочерёдном исполнении сюда не включены AGU). Фактическая длина этой стадии определяется для каждого мопа числом стадий обрабатывающего его ФУ.
EX (execution), исполнение — одна или несколько стадий исполнения мопов, содержащая все ФУ (при поочерёдном исполнении сюда не включены AGU). Фактическая длина этой стадии определяется для каждого мопа числом стадий обрабатывающего его ФУ.
![]() EU (execution unit: исполнительный блок), FU (functional unit: функциональный блок), ФУ, функциональное устройство — блок тыла, исполняющий мопы и обрабатывающий данные и адреса. Имеет порт управления для приёма мопов из резервации, 2–3 порта приёма аргументов и порт выдачи результата. Чаще всего именуется по названию исполняемой в нём команды или группы похожих команд. Физически находится в исполнительном тракте. Для наиболее частых команд исполнительная стадия может содержать более одного ФУ нужного типа. Производительность ФУ определяется таймингами исполняемых команд.
EU (execution unit: исполнительный блок), FU (functional unit: функциональный блок), ФУ, функциональное устройство — блок тыла, исполняющий мопы и обрабатывающий данные и адреса. Имеет порт управления для приёма мопов из резервации, 2–3 порта приёма аргументов и порт выдачи результата. Чаще всего именуется по названию исполняемой в нём команды или группы похожих команд. Физически находится в исполнительном тракте. Для наиболее частых команд исполнительная стадия может содержать более одного ФУ нужного типа. Производительность ФУ определяется таймингами исполняемых команд.
![]() datapath («путь данных»), исполнительный тракт — физическая структура процессора, реализующая обработку данных определённого типа. Включает один или несколько РФ, несколько ФУ и шлюзов. Почти все эти блоки расположены в ряд и связаны несколькими шинами, по максимальному числу портов в подключенных РФ. Шины чтения передают аргументы из РФ в ФУ и шлюзы, а шины записи возвращают результаты в шлюзы и РФ. Таким образом тракт реализует три стадии конвейера (а также все промежуточные между ними): чтение РФ, исполнение мопов и запись в РФ.
datapath («путь данных»), исполнительный тракт — физическая структура процессора, реализующая обработку данных определённого типа. Включает один или несколько РФ, несколько ФУ и шлюзов. Почти все эти блоки расположены в ряд и связаны несколькими шинами, по максимальному числу портов в подключенных РФ. Шины чтения передают аргументы из РФ в ФУ и шлюзы, а шины записи возвращают результаты в шлюзы и РФ. Таким образом тракт реализует три стадии конвейера (а также все промежуточные между ними): чтение РФ, исполнение мопов и запись в РФ.
![]() bypass («обход»), шунт, шлюз — коммутаторы и связанные с ними шины передачи данных внутри исполнительного тракта (шунт) или между ним и другими блоками (шлюз). Каждый шунт связывает одну из шин записи со всеми шинами чтения, позволяя использовать в следующем такте результат только что исполненного мопа — в обход записи в и чтения из РФ. Шлюзы на шинах записи ведут в другие тракты и LSU, а на шинах чтения — от них и от планировщика (для подачи констант, включая адреса и адресные смещения).
bypass («обход»), шунт, шлюз — коммутаторы и связанные с ними шины передачи данных внутри исполнительного тракта (шунт) или между ним и другими блоками (шлюз). Каждый шунт связывает одну из шин записи со всеми шинами чтения, позволяя использовать в следующем такте результат только что исполненного мопа — в обход записи в и чтения из РФ. Шлюзы на шинах записи ведут в другие тракты и LSU, а на шинах чтения — от них и от планировщика (для подачи констант, включая адреса и адресные смещения).
![]() AG (address generation: генерация адреса) — стадия арифметических действий с содержимым регистров и адресных смещений, необходимая для получения адреса аргумента в памяти. Выполняется в AGU. При внеочерёдном исполнении является частью стадии исполнения.
AG (address generation: генерация адреса) — стадия арифметических действий с содержимым регистров и адресных смещений, необходимая для получения адреса аргумента в памяти. Выполняется в AGU. При внеочерёдном исполнении является частью стадии исполнения.
![]() DCA (data cache access: доступ к кэшу данных) — одна или несколько стадий чтения аргумента из кэша или записи в кэш по вычисленному адресу под управлением LSU.
DCA (data cache access: доступ к кэшу данных) — одна или несколько стадий чтения аргумента из кэша или записи в кэш по вычисленному адресу под управлением LSU.
![]() WB (write-back: обратная запись) — стадия записи результатов из ФУ и/или чтений из памяти — в РФ и/или в ФУ (через шлюзы). Не путать с одноимённой политикой работы кэша.
WB (write-back: обратная запись) — стадия записи результатов из ФУ и/или чтений из памяти — в РФ и/или в ФУ (через шлюзы). Не путать с одноимённой политикой работы кэша.
![]() retire, отставка, commit («совершение») — последняя стадия конвейера и диспетчера, «легализующая» в программном порядке результаты команд, мопы которых находятся в ROB. Для этого диспетчер (в зависимости от типа планировщика) либо переносит результат мопа из ROB в архитектурный РФ, либо корректирует используемую для переименования регистров таблицу ссылок на физический РФ, чтобы записанный мопом архитектурный регистр указывал на верный физический. Т. к. во внеочерёдный диспетчер мопы возвращаются из планировщика не обязательно в программном порядке, в отставку заранее завершившийся моп может уйти, только если все предыдущие внесённые в ROB мопы уже отставлены или уходят в данном такте. Многомоповые команды могут отставиться только после отставки всех своих мопов. Отказ в отставке возможен в случае обнаружения:
retire, отставка, commit («совершение») — последняя стадия конвейера и диспетчера, «легализующая» в программном порядке результаты команд, мопы которых находятся в ROB. Для этого диспетчер (в зависимости от типа планировщика) либо переносит результат мопа из ROB в архитектурный РФ, либо корректирует используемую для переименования регистров таблицу ссылок на физический РФ, чтобы записанный мопом архитектурный регистр указывал на верный физический. Т. к. во внеочерёдный диспетчер мопы возвращаются из планировщика не обязательно в программном порядке, в отставку заранее завершившийся моп может уйти, только если все предыдущие внесённые в ROB мопы уже отставлены или уходят в данном такте. Многомоповые команды могут отставиться только после отставки всех своих мопов. Отказ в отставке возможен в случае обнаружения:
- исключения при исполнении мопа;
- для условных переходов — неверного предсказания перехода (поведения или адреса);
- для мопов, выполнивших упреждающие чтения из памяти — неверного предсказания адреса.
В последних двух случаях диспетчер возвращает конвейер в предыдущее точно известное состояние («сброс конвейера»), теряя все упреждающие результаты; успешная отставка обновляет это состояние. Отставка перехода вне зависимости от успешности предсказания пополняет статистику предсказателя.
![]() exception, исключение, исключительная ситуация — событие при обработке мопа, требующее аварийной реакции:
exception, исключение, исключительная ситуация — событие при обработке мопа, требующее аварийной реакции:
- ловушка — отладочный останов, системный вызов, переключение контекста программы и др. заранее запланированные и/или ожидаемые случаи;
- ошибка исполнения — отсутствие страницы в памяти, недопустимая команда, выход за допустимый диапазон аргумента или результата и пр.;
- внешнее прерывание процессора — аппаратный сбой, пропадание питания и пр.
При обнаружении исключения конвейер прекращает принимать новые команды и пытается довести до отставки все предыдущие (в программном порядке) мопы. Если при этом в них не обнаружено фальш-предсказание перехода, либо другое исключение, то далее ядро запускает обработку данного.
Блоки процессора
![]() taken («взят»), not taken («не взят», пропущен) — срабатывание и несрабатывание команды перехода при исполнении, а также соответствующее предсказание.
taken («взят»), not taken («не взят», пропущен) — срабатывание и несрабатывание команды перехода при исполнении, а также соответствующее предсказание.
![]() mispredict («фальш-предсказание») — ошибка предсказания поведения перехода. Обнаруживается при отставке перехода и вызывает сброс конвейера.
mispredict («фальш-предсказание») — ошибка предсказания поведения перехода. Обнаруживается при отставке перехода и вызывает сброс конвейера.
![]() BTB (branch target buffer: буфер целей ветвлений) — таблица адресов, на которые нацелены часто встречаемые команды переходов. Позволяет сделать предсказание, не читая сами команды. Пополняется (с вытеснением старых адресов) при исполнении нового или «забытого» перехода. (Однако в некоторых ЦП целевые адреса условных переходов попадают в BTB, только если переход «взят».)
BTB (branch target buffer: буфер целей ветвлений) — таблица адресов, на которые нацелены часто встречаемые команды переходов. Позволяет сделать предсказание, не читая сами команды. Пополняется (с вытеснением старых адресов) при исполнении нового или «забытого» перехода. (Однако в некоторых ЦП целевые адреса условных переходов попадают в BTB, только если переход «взят».)
![]() GBHR (global branch history register: регистр глобальной истории ветвлений) — регистр сдвига, хранящий поведение нескольких последних исполненных условных переходов. При исполнении перехода GBHR смещается, вытесняя самый «старый» бит и добавляя новый в зависимости от поведения перехода: 1 — «взят», 0 — «пропущен». Используется для индексации BHT.
GBHR (global branch history register: регистр глобальной истории ветвлений) — регистр сдвига, хранящий поведение нескольких последних исполненных условных переходов. При исполнении перехода GBHR смещается, вытесняя самый «старый» бит и добавляя новый в зависимости от поведения перехода: 1 — «взят», 0 — «пропущен». Используется для индексации BHT.
![]() BHT (branch history table: таблица истории ветвлений) — таблица 2-битных счётчиков, предсказывающих поведение переходов по 4-позиционной шкале (от «наверняка будет пропущен» до «наверняка будет взят»). Индексируется кодирующей хэш-функцией, использующей биты GBHR и адреса перехода.
BHT (branch history table: таблица истории ветвлений) — таблица 2-битных счётчиков, предсказывающих поведение переходов по 4-позиционной шкале (от «наверняка будет пропущен» до «наверняка будет взят»). Индексируется кодирующей хэш-функцией, использующей биты GBHR и адреса перехода.
![]() RSB (return stack buffer: буфер стека возврата) — часть BPU, буферизующая адреса возвратов из подпрограмм, вызванных последними. (Отдельного стека для адресов возврата в x86 нет — они находятся в общем стеке среди аргументов и результатов подпрограмм.) Для x86-ЦП имеет размер 12–24 адреса.
RSB (return stack buffer: буфер стека возврата) — часть BPU, буферизующая адреса возвратов из подпрограмм, вызванных последними. (Отдельного стека для адресов возврата в x86 нет — они находятся в общем стеке среди аргументов и результатов подпрограмм.) Для x86-ЦП имеет размер 12–24 адреса.
![]() flag, флаг — 1-битный индикатор состояния. В процессоре: часть регистра флагов, обновляющегося при исполнении некоторых команд (чаще всего скалярных целочисленных). 4 наиболее важных флага используются в командах условного исполнения (в т. ч. условных переходах).
flag, флаг — 1-битный индикатор состояния. В процессоре: часть регистра флагов, обновляющегося при исполнении некоторых команд (чаще всего скалярных целочисленных). 4 наиболее важных флага используются в командах условного исполнения (в т. ч. условных переходах).
![]() domain, домен — совокупность ФУ какого-либо исполнительного тракта, используемых для выполнения команд над операндами одного типа. Тракт может иметь один или несколько доменов. Если их несколько, то передача данных между ними вызывает задержку для срабатывания междоменных шлюзов.
domain, домен — совокупность ФУ какого-либо исполнительного тракта, используемых для выполнения команд над операндами одного типа. Тракт может иметь один или несколько доменов. Если их несколько, то передача данных между ними вызывает задержку для срабатывания междоменных шлюзов.
![]() ALU (arithmetic-logic unit), АЛУ, арифметико-логическое устройство — тесно связанный набор ФУ, исполняющий за 1 такт простые арифметические, логические и некоторые невычислительные команды над целочисленными операндами, являясь, таким образом, наиболее универсальным и часто используемым исполнительным блоком. Виды:
ALU (arithmetic-logic unit), АЛУ, арифметико-логическое устройство — тесно связанный набор ФУ, исполняющий за 1 такт простые арифметические, логические и некоторые невычислительные команды над целочисленными операндами, являясь, таким образом, наиболее универсальным и часто используемым исполнительным блоком. Виды:
![]() shifter («сдвигатель») — ФУ или блок для битового сдвига целых или логических операндов.
shifter («сдвигатель») — ФУ или блок для битового сдвига целых или логических операндов.
![]() AGU (address generation unit: блок генерации адреса) — арифметическое ФУ для адресных компонент из команды и регистров, фактически — целочисленный сумматор с простым сдвигателем.
AGU (address generation unit: блок генерации адреса) — арифметическое ФУ для адресных компонент из команды и регистров, фактически — целочисленный сумматор с простым сдвигателем.
![]() FPU (floating point unit: «устройство плавающей точки») — блок вещественных операций, состоящий из нескольких ФУ. Виды:
FPU (floating point unit: «устройство плавающей точки») — блок вещественных операций, состоящий из нескольких ФУ. Виды:
Иногда под FPU понимается весь векторно-вещественный домен.
![]() ADD (adder: сумматор) — относительно простое ФУ, выполняющее сложения, вычитания, сравнения и другие простые арифметические операции. Для вещественных является самостоятельным (FADD). Для целых — входит в состав ALU.
ADD (adder: сумматор) — относительно простое ФУ, выполняющее сложения, вычитания, сравнения и другие простые арифметические операции. Для вещественных является самостоятельным (FADD). Для целых — входит в состав ALU.
![]() MUL (multiplier: умножитель) — ФУ, выполняющее умножения. Является самым сложным и большим видом ФУ, поэтому иногда для экономии места (в ущерб скорости) делается половинной разрядности (относительно наибольших операндов).
MUL (multiplier: умножитель) — ФУ, выполняющее умножения. Является самым сложным и большим видом ФУ, поэтому иногда для экономии места (в ущерб скорости) делается половинной разрядности (относительно наибольших операндов).
![]() MAD, MADD (multiplier-adder: умножитель-сумматор) — тесно спаренные умножитель и сумматор, выполняющие слитое умножение-сложение и умножение-вычитание быстрее и точнее пары отдельных ФУ. Исполняет команды FMA, отдельное умножение и (иногда) отдельные сложение и вычитание.
MAD, MADD (multiplier-adder: умножитель-сумматор) — тесно спаренные умножитель и сумматор, выполняющие слитое умножение-сложение и умножение-вычитание быстрее и точнее пары отдельных ФУ. Исполняет команды FMA, отдельное умножение и (иногда) отдельные сложение и вычитание.
![]() MAC (multiplier-accumulator: умножитель-накопитель) — неверное название MADD. Аббревиатура «MAC» входит в мнемонику команд умножения-накопления, которые являются подвидом умножения-сложения.
MAC (multiplier-accumulator: умножитель-накопитель) — неверное название MADD. Аббревиатура «MAC» входит в мнемонику команд умножения-накопления, которые являются подвидом умножения-сложения.
![]() DIV (divider: делитель) — сложное неконвейерное ФУ для выполнения деления (а для вещественных чисел — и извлечения квадратного корня). Часто тесно связан с умножителем. Иногда для экономии вместо двух специализированных делителей имеется один универсальный — для целых и вещественных чисел.
DIV (divider: делитель) — сложное неконвейерное ФУ для выполнения деления (а для вещественных чисел — и извлечения квадратного корня). Часто тесно связан с умножителем. Иногда для экономии вместо двух специализированных делителей имеется один универсальный — для целых и вещественных чисел.
![]() pack (упаковать), unpack (распаковать), shuffle (тасовать, переставить) — векторные команды, исполняемые в тасовщике и меняющие расположение элементов вектора.
pack (упаковать), unpack (распаковать), shuffle (тасовать, переставить) — векторные команды, исполняемые в тасовщике и меняющие расположение элементов вектора.
![]() shuffler (тасовщик, перестановщик) — векторное ФУ, исполняющее команды перестановки элементов вектора.
shuffler (тасовщик, перестановщик) — векторное ФУ, исполняющее команды перестановки элементов вектора.
![]() PLL (phase-locked loop: фазовая синхронизация), умножитель частоты — аналого-цифровой блок процессора, генерирующий такты внутренней синхронизации для всей микросхемы или её части (ядра, общего кэша, ИКП и т. п.) умножением внешней частоты на задаваемый множитель. При изменении множителя умножителю требуется относительно много времени для стабилизации на новой частоте, во время чего тактируемые схемы простаивают.
PLL (phase-locked loop: фазовая синхронизация), умножитель частоты — аналого-цифровой блок процессора, генерирующий такты внутренней синхронизации для всей микросхемы или её части (ядра, общего кэша, ИКП и т. п.) умножением внешней частоты на задаваемый множитель. При изменении множителя умножителю требуется относительно много времени для стабилизации на новой частоте, во время чего тактируемые схемы простаивают.
![]() fuses, перемычки — матрица плавких перемычек для однократного программирования или коррекции работы некоторых блоков процессора (в частности, микрокода в декодере).
fuses, перемычки — матрица плавких перемычек для однократного программирования или коррекции работы некоторых блоков процессора (в частности, микрокода в декодере).
![]() driver, драйвер — в микроэлектронике: оконечное устройство внешней шины (до памяти, периферии или процессоров), выполняющее приём и передачу сигналов и физическую защиту от перенапряжения. Наборы драйверов расположены по краю кристалла.
driver, драйвер — в микроэлектронике: оконечное устройство внешней шины (до памяти, периферии или процессоров), выполняющее приём и передачу сигналов и физическую защиту от перенапряжения. Наборы драйверов расположены по краю кристалла.
Подсистема памяти
![]() cache, «$», кэш — программно недоступная буферная память, используемая процессором для ускорения обмена с оперативной памятью (улучшением таймингов) заменой обращений к ОЗУ обращениями к самому кэшу в случае кэш-попадания. В ЦП имеет 2–4-уровневую иерархию, причём оперативная память может считаться дополнительным (последним) уровнем. Как правило, каждый следующий уровень кэша относительно текущего (чаще всего начиная с L1) имеет…
cache, «$», кэш — программно недоступная буферная память, используемая процессором для ускорения обмена с оперативной памятью (улучшением таймингов) заменой обращений к ОЗУ обращениями к самому кэшу в случае кэш-попадания. В ЦП имеет 2–4-уровневую иерархию, причём оперативная память может считаться дополнительным (последним) уровнем. Как правило, каждый следующий уровень кэша относительно текущего (чаще всего начиная с L1) имеет…
| …бо́льшие: | …равные или меньшие: |
| информационный объём | влияние на общую производительность |
| занимаемую площадь | удельное потребление энергии (ватты на байт) |
| информационную плотность (байты на мм²) | технологическую плотность (транзисторы на бит) |
| ассоциативность | сложность реализации |
| задержку | пропуск |
| частоту попаданий | частоту работы |
В современных ЦП кэши (в сумме) часто занимают до половины места на кристалле и бо́льшую часть его транзисторов, но потребляют энергии значительно меньше прочих структур. В ЦП x86 все кэши имеют физическую адресацию, поэтому при обращении к L1 требуется преобразовать виртуальные адреса в TLB.
![]() mop cache (кэш мопов) — часть фронта конвейера, находящаяся перед стадией отправки. Кэширует декодированные из команд мопы, потому также называется кэшем 0-го уровня для мопов (L0m). В терминологии Intel называется DIC (decoded instruction cache: кэш декодированных команд) или DSB (decode stream buffer: буфер потока декодера).
mop cache (кэш мопов) — часть фронта конвейера, находящаяся перед стадией отправки. Кэширует декодированные из команд мопы, потому также называется кэшем 0-го уровня для мопов (L0m). В терминологии Intel называется DIC (decoded instruction cache: кэш декодированных команд) или DSB (decode stream buffer: буфер потока декодера).
![]() L1 (level 1: 1-й уровень) — общее название для первого уровня многоуровневой структуры: кэшей (L1I и L1D — без уточнения понимаются именно они), TLB и (иногда) BTB.
L1 (level 1: 1-й уровень) — общее название для первого уровня многоуровневой структуры: кэшей (L1I и L1D — без уточнения понимаются именно они), TLB и (иногда) BTB.
![]() L1I (level 1 for instructions: 1-й уровень для команд) — кэш для команд, подключенный к фронту конвейера. Записывается только со стороны L2, со стороны конвейера только читается. Почти всегда 1-портовый, разрядность порта совпадает с размером порции команд. Иногда освобождается от ECC в пользу чётности.
L1I (level 1 for instructions: 1-й уровень для команд) — кэш для команд, подключенный к фронту конвейера. Записывается только со стороны L2, со стороны конвейера только читается. Почти всегда 1-портовый, разрядность порта совпадает с размером порции команд. Иногда освобождается от ECC в пользу чётности.
![]() L1D (level 1 for data: 1-й уровень для данных) — кэш для данных, подключенный к тылу конвейера. Чаще всего 2–3-портовый. Разрядность порта либо равна, либо вдвое меньше наибольшего операнда команд. В ЦП с MCMT есть несколько L1D на модуль.
L1D (level 1 for data: 1-й уровень для данных) — кэш для данных, подключенный к тылу конвейера. Чаще всего 2–3-портовый. Разрядность порта либо равна, либо вдвое меньше наибольшего операнда команд. В ЦП с MCMT есть несколько L1D на модуль.
![]() L2 (level 2: 2-й уровень) — общее название для второго уровня многоуровневой структуры (кэша — по-умолчанию, TLB или BTB — при явном указании), используемого при промахе в первом уровне (L1). Кэш L2 почти всегда является общим для данных и команд. В 2-уровневой схеме он также является общим для ядер, в 3-уровневой — отдельным, в ЦП с MCMT — отдельным для каждого модуля и общим для его кластеров-«ядер». В ЦП x86 — 1-портовый.
L2 (level 2: 2-й уровень) — общее название для второго уровня многоуровневой структуры (кэша — по-умолчанию, TLB или BTB — при явном указании), используемого при промахе в первом уровне (L1). Кэш L2 почти всегда является общим для данных и команд. В 2-уровневой схеме он также является общим для ядер, в 3-уровневой — отдельным, в ЦП с MCMT — отдельным для каждого модуля и общим для его кластеров-«ядер». В ЦП x86 — 1-портовый.
![]() L3 (level 3: 3-й уровень) — кэш для данных и команд, используемый при промахе в L2 (других структур с тремя и более уровнями иерархии в процессорах нет). Иногда называется LLC (last level cache: кэш последнего уровня), имея ввиду, что после промаха в нём идёт обращение в память. Является общим для ядер (в ЦП с MCMT — модулей). Иногда работает на частоте, меньшей, чем у ядер. В ЦП x86 имеет по одному порту на банк, начиная от простого 1-банкового устройства.
L3 (level 3: 3-й уровень) — кэш для данных и команд, используемый при промахе в L2 (других структур с тремя и более уровнями иерархии в процессорах нет). Иногда называется LLC (last level cache: кэш последнего уровня), имея ввиду, что после промаха в нём идёт обращение в память. Является общим для ядер (в ЦП с MCMT — модулей). Иногда работает на частоте, меньшей, чем у ядер. В ЦП x86 имеет по одному порту на банк, начиная от простого 1-банкового устройства.
![]() hit, попадание — ситуация нахождения нужной информации при обращении в кэш. Антоним промаха.
hit, попадание — ситуация нахождения нужной информации при обращении в кэш. Антоним промаха.
![]() miss, промах — ситуация не нахождения нужной информации при обращении в кэш. Антоним попадания. Если текущий уровень кэша не последний — далее происходит обращение к следующему, иначе — к памяти. Возвращённые оттуда данные отдаются инициатору обращения и заполняют (fill) текущий уровень кэша, вытесняя (evict) из выбранного набора старую, наименее нужную информацию — причём если она пока больше нигде не записана, то её надо сохранить в следующем уровне. Почти все кэши являются неблокирующими (non-blocking), т. е. продолжают принимать запросы, пока обрабатываются промахи. Число удерживаемых промахов определяется размером специального буфера, при заполнении которого кэш блокирует обработку запросов.
miss, промах — ситуация не нахождения нужной информации при обращении в кэш. Антоним попадания. Если текущий уровень кэша не последний — далее происходит обращение к следующему, иначе — к памяти. Возвращённые оттуда данные отдаются инициатору обращения и заполняют (fill) текущий уровень кэша, вытесняя (evict) из выбранного набора старую, наименее нужную информацию — причём если она пока больше нигде не записана, то её надо сохранить в следующем уровне. Почти все кэши являются неблокирующими (non-blocking), т. е. продолжают принимать запросы, пока обрабатываются промахи. Число удерживаемых промахов определяется размером специального буфера, при заполнении которого кэш блокирует обработку запросов.
![]() line, строка — основная единица ёмкости кэша размером 32–128 байт. Обмен данными между разными уровнями кэша и между кэшем и памятью почти всегда происходит целыми строками.
line, строка — основная единица ёмкости кэша размером 32–128 байт. Обмен данными между разными уровнями кэша и между кэшем и памятью почти всегда происходит целыми строками.
![]() associativity, ассоциативность — индексируемость не адресом, а содержимым. Для наборно-ассоциативного кэша и TLB ассоциативность это показатель числа путей. При прочих равных, кэш/TLB с бо́льшей ассоциативностью имеет меньшую частоту промахов, но бо́льшие площадь тегов, потребление энергии (на байт) и (иногда) задержку. Полная ассоциативность означает, что кэш/TLB состоит из единственного набора (это также применимо к буферу). Может принимать значения, не равные целой степени двойки. Кэш с ассоциативностью 1 также называется кэшем с прямым отображением (direct-mapped).
associativity, ассоциативность — индексируемость не адресом, а содержимым. Для наборно-ассоциативного кэша и TLB ассоциативность это показатель числа путей. При прочих равных, кэш/TLB с бо́льшей ассоциативностью имеет меньшую частоту промахов, но бо́льшие площадь тегов, потребление энергии (на байт) и (иногда) задержку. Полная ассоциативность означает, что кэш/TLB состоит из единственного набора (это также применимо к буферу). Может принимать значения, не равные целой степени двойки. Кэш с ассоциативностью 1 также называется кэшем с прямым отображением (direct-mapped).
![]() way, путь — совокупность всех строк наборно-ассоциативного кэша с одинаковым номером во всех наборах.
way, путь — совокупность всех строк наборно-ассоциативного кэша с одинаковым номером во всех наборах.
![]() set, набор — совокупность из N строк кэша, одновременно проверяемых на наличие нужных данных при обращении, где N — показатель ассоциативности. При промахе одна из строк набора (как правило, с наименьшей популярностью) заменятся новой информацией.
set, набор — совокупность из N строк кэша, одновременно проверяемых на наличие нужных данных при обращении, где N — показатель ассоциативности. При промахе одна из строк набора (как правило, с наименьшей популярностью) заменятся новой информацией.
![]() port, порт — для кэша: интерфейс между кэшем и его контроллером, управляющим обменом данных. Истинная N-портовая структура позволяет одновременно осуществлять N обращений по разным адресам, однако это требует больших затрат транзисторов и применяется только в РФ. Для кэша используется более простая псевдомногопортовая схема: кэш делится на несколько банков, каждый из которых работает независимо, но обслуживает лишь свою часть адресов. Как правило, 2-портовому L1D для минимизации адресных конфликтов между портами достаточно 8 банков.
port, порт — для кэша: интерфейс между кэшем и его контроллером, управляющим обменом данных. Истинная N-портовая структура позволяет одновременно осуществлять N обращений по разным адресам, однако это требует больших затрат транзисторов и применяется только в РФ. Для кэша используется более простая псевдомногопортовая схема: кэш делится на несколько банков, каждый из которых работает независимо, но обслуживает лишь свою часть адресов. Как правило, 2-портовому L1D для минимизации адресных конфликтов между портами достаточно 8 банков.
![]() bank, банк — часть кэша, организованная как отдельный 1- или 2-портовый кэш, обслуживающий часть адресов. Многобанковая схема используется для создания псевдомногопортового кэша.
bank, банк — часть кэша, организованная как отдельный 1- или 2-портовый кэш, обслуживающий часть адресов. Многобанковая схема используется для создания псевдомногопортового кэша.
![]() tag («метка»), тэг — вспомогательное слово, хранящее адрес записанной в строке кэша информации, состояние строки (согласно протоколу когерентности) и её популярность (используется при вытеснении старых данных новыми после промаха). Физически все теги кэша хранятся в отдельном массиве и считываются либо одновременно с выборкой набора кэша, либо (для экономии энергии в ущерб скорости) до выборки. N-портовый кэш имеет N-портовый массив тегов или N 1-портовых массивов с одинаковым содержимым.
tag («метка»), тэг — вспомогательное слово, хранящее адрес записанной в строке кэша информации, состояние строки (согласно протоколу когерентности) и её популярность (используется при вытеснении старых данных новыми после промаха). Физически все теги кэша хранятся в отдельном массиве и считываются либо одновременно с выборкой набора кэша, либо (для экономии энергии в ущерб скорости) до выборки. N-портовый кэш имеет N-портовый массив тегов или N 1-портовых массивов с одинаковым содержимым.
![]() TLB (translation look-aside buffer: буфер-шпаргалка для трансляции) — кэш дескрипторов страниц виртуальной памяти, заменяющий трансляцию виртуальных адресов в физические более быстрым считыванием. Обращение в TLB нужно для обращения в физически адресуемый кэш (чаще всего — L1) и происходит либо одновременно с чтением тегов и выборкой набора этого кэша, либо (реже) — до. При попадании в TLB полученный физический адрес используется для проверки наличия нужной информации в выбранном теге кэша. Часто несколько TLB организуются в иерархию: TLB L1I и TLB L1D обслуживают запросы к кэшам L1I и L1D, при промахе обращаются во включающий(ие) TLB L2 бо́льшего размера (общий TLB L2 или отдельные TLB L2I и TLB L2D), а при промахе в нём (них) виртуальный адрес поступает в PMH. TLB L2 не обслуживают кэш L2, а только промахи в TLB L1: трансляция адресов нужна только для доступа к кэшам L1, а при промахе в них обращения в остальные кэши и память используют уже готовый физический адрес. Часто TLB делится на несколько массивов: самый большой — для страниц по 4 КБ, меньшие — для страниц по 2/4 МБ и 1 ГБ (может вовсе отсутствовать). TLB L1 часто полноассоциативны. N-портовому кэшу требуется N-портовый TLB или N 1-портовых TLB с одинаковым содержимым.
TLB (translation look-aside buffer: буфер-шпаргалка для трансляции) — кэш дескрипторов страниц виртуальной памяти, заменяющий трансляцию виртуальных адресов в физические более быстрым считыванием. Обращение в TLB нужно для обращения в физически адресуемый кэш (чаще всего — L1) и происходит либо одновременно с чтением тегов и выборкой набора этого кэша, либо (реже) — до. При попадании в TLB полученный физический адрес используется для проверки наличия нужной информации в выбранном теге кэша. Часто несколько TLB организуются в иерархию: TLB L1I и TLB L1D обслуживают запросы к кэшам L1I и L1D, при промахе обращаются во включающий(ие) TLB L2 бо́льшего размера (общий TLB L2 или отдельные TLB L2I и TLB L2D), а при промахе в нём (них) виртуальный адрес поступает в PMH. TLB L2 не обслуживают кэш L2, а только промахи в TLB L1: трансляция адресов нужна только для доступа к кэшам L1, а при промахе в них обращения в остальные кэши и память используют уже готовый физический адрес. Часто TLB делится на несколько массивов: самый большой — для страниц по 4 КБ, меньшие — для страниц по 2/4 МБ и 1 ГБ (может вовсе отсутствовать). TLB L1 часто полноассоциативны. N-портовому кэшу требуется N-портовый TLB или N 1-портовых TLB с одинаковым содержимым.
![]() PMH (page miss handler: обработчик промахов страниц) — транслятор виртуальных адресов в физические, также проверяющий и права доступа. Активируется при промахе в TLB последнего уровня, читает из кэша или памяти дескриптор нужной страницы, обновляет им TLB и возвращает физический адрес для обращения в кэш. Включает собственный небольшой буфер и предзагрузчик.
PMH (page miss handler: обработчик промахов страниц) — транслятор виртуальных адресов в физические, также проверяющий и права доступа. Активируется при промахе в TLB последнего уровня, читает из кэша или памяти дескриптор нужной страницы, обновляет им TLB и возвращает физический адрес для обращения в кэш. Включает собственный небольшой буфер и предзагрузчик.
![]() LSU (load-store unit: блок загрузки-сохранения), MEU (memory unit: блок памяти) — блок интерфейса между тылом конвейера и L1D. Содержит очереди чтений и записей с отслеживанием их зависимостей и функциями слияния записей, STLF и внеочерёдного доступа. Иногда неточно называется MOB (memory order buffer, «буфер порядка» [записей в] память), имея ввиду очередь программного порядка записей — часть LSU, аналогичную ROB для планировщика.
LSU (load-store unit: блок загрузки-сохранения), MEU (memory unit: блок памяти) — блок интерфейса между тылом конвейера и L1D. Содержит очереди чтений и записей с отслеживанием их зависимостей и функциями слияния записей, STLF и внеочерёдного доступа. Иногда неточно называется MOB (memory order buffer, «буфер порядка» [записей в] память), имея ввиду очередь программного порядка записей — часть LSU, аналогичную ROB для планировщика.
![]() STLF (store-to-load forwarding: перенаправление сохранения к загрузке) — функция очереди записи в LSU, позволяющая немедленно исполнить чтение (подставив данные из очереди вместо доступа к кэшу) в случае совпадения адреса чтения с адресом содержащейся в очереди предшествующей записи. Очередь продолжает хранить данные и после записи, поэтому STLF срабатывает вне зависимости от факта совершения записи читаемых данных.
STLF (store-to-load forwarding: перенаправление сохранения к загрузке) — функция очереди записи в LSU, позволяющая немедленно исполнить чтение (подставив данные из очереди вместо доступа к кэшу) в случае совпадения адреса чтения с адресом содержащейся в очереди предшествующей записи. Очередь продолжает хранить данные и после записи, поэтому STLF срабатывает вне зависимости от факта совершения записи читаемых данных.
![]() MD (memory disambiguation: устранение неопределённости памяти), внеочерёдный доступ — один из видов упреждения данных, механизм внеочерёдного доступа к кэшу, реализуемый в LSU. Позволяет переставлять порядок запросов, не нарушая целостность данных. Включает блок предсказания конфликтов адресов, аналогичный предсказателю переходов и предсказывающий наложение адресов — при предсказании отсутствия конфликта чтение исполняется до предшествующей в программном порядке записи, даже если адрес последней пока не известен. При наложении адреса уже выполненного чтения планировщик аннулирует результаты использовавших его мопов и перезапускает их с верными (перепрочитанными) данными.
MD (memory disambiguation: устранение неопределённости памяти), внеочерёдный доступ — один из видов упреждения данных, механизм внеочерёдного доступа к кэшу, реализуемый в LSU. Позволяет переставлять порядок запросов, не нарушая целостность данных. Включает блок предсказания конфликтов адресов, аналогичный предсказателю переходов и предсказывающий наложение адресов — при предсказании отсутствия конфликта чтение исполняется до предшествующей в программном порядке записи, даже если адрес последней пока не известен. При наложении адреса уже выполненного чтения планировщик аннулирует результаты использовавших его мопов и перезапускает их с верными (перепрочитанными) данными.
![]() flush (смыв) — процесс сохранения всего (пока не сохранённого) содержимого кэша данного уровня в следующем уровне иерархии. Происходит перед отключением кэша или при изменении в таблицах трансляции адресов.
flush (смыв) — процесс сохранения всего (пока не сохранённого) содержимого кэша данного уровня в следующем уровне иерархии. Происходит перед отключением кэша или при изменении в таблицах трансляции адресов.
![]() fetch (достать, принести) — операция загрузки из L1. Как правило, указывается с приставкой I для команд (из L1I) или D для данных (из L1D).
fetch (достать, принести) — операция загрузки из L1. Как правило, указывается с приставкой I для команд (из L1I) или D для данных (из L1D).
![]() prefetch («пред-доставка»), префетч, предзагрузка — операция предварительного чтения данных по упреждающему (предсказанному) адресу. Успешная предзагрузка скрывает задержку иерархии кэшей и памяти. Подключенный к кэшу предзагрузчик (prefetcher) отслеживает адреса чтений, записей и породивших их команд, предсказывает (на базе накопленной статистики) следующие адреса предположительно нужных данных и проверяет их наличие в кэше. При промахе запускается чтение данных из кэша следующего уровня. При попадании некоторые типы предзагрузчиков читают эти данные либо в собственный буфер, быстро их выдающий, если будет сделан запрос с совпавшим адресом, либо в очередь чтения в LSU.
prefetch («пред-доставка»), префетч, предзагрузка — операция предварительного чтения данных по упреждающему (предсказанному) адресу. Успешная предзагрузка скрывает задержку иерархии кэшей и памяти. Подключенный к кэшу предзагрузчик (prefetcher) отслеживает адреса чтений, записей и породивших их команд, предсказывает (на базе накопленной статистики) следующие адреса предположительно нужных данных и проверяет их наличие в кэше. При промахе запускается чтение данных из кэша следующего уровня. При попадании некоторые типы предзагрузчиков читают эти данные либо в собственный буфер, быстро их выдающий, если будет сделан запрос с совпавшим адресом, либо в очередь чтения в LSU.
Сложный предзагрузчик, как и предсказатель переходов, применяет разные алгоритмы и отслеживает собственную эффективность, отключая предзагрузку для труднопредсказуемых обращений во избежание помещения в кэш ненужных данных («загрязнение кэша»). Для борьбы с последним отсутствующие в кэше и подгруженные извне данные либо сначала сохраняются в буфере предзагрузчика и только в случае востребованности позже записываются в кэш, либо записываются сразу, но указанием наименьшей популярности. Современные ЦП имеют аппаратную предзагрузку почти во все кэши, а в их ISA есть команды программной предзагрузки по явно указанному адресу.
![]() align, выровнить — о размещении в памяти многобайтовой информации по адресу, нацело делящемуся на её размер, равный целой степени двойки. В CISC-ЦП команды имеют переменный размер и редко выравниваются. Данные для любых процессоров выравниваются почти всегда, хотя лишь для некоторых RISC-архитектур это обязательно. Выравнивание ускоряет доступ, исключая пересечение строки кэша, при котором требуется прочесть следующую строку и слить две части в одно слово.
align, выровнить — о размещении в памяти многобайтовой информации по адресу, нацело делящемуся на её размер, равный целой степени двойки. В CISC-ЦП команды имеют переменный размер и редко выравниваются. Данные для любых процессоров выравниваются почти всегда, хотя лишь для некоторых RISC-архитектур это обязательно. Выравнивание ускоряет доступ, исключая пересечение строки кэша, при котором требуется прочесть следующую строку и слить две части в одно слово.
![]() unaligned, misaligned, невыровненный — о данных, к которым не применено выравнивание. Некоторые x86-ЦП запрещают доступ к невыровненным данным для некоторых векторных команд. В некоторых других архитектурах невыровненный доступ запрещён полностью.
unaligned, misaligned, невыровненный — о данных, к которым не применено выравнивание. Некоторые x86-ЦП запрещают доступ к невыровненным данным для некоторых векторных команд. В некоторых других архитектурах невыровненный доступ запрещён полностью.
![]() inclusive, инклюзивная, включающая — политика работы кэша, в котором всегда хранятся копии всех кэшей меньших уровней.
inclusive, инклюзивная, включающая — политика работы кэша, в котором всегда хранятся копии всех кэшей меньших уровней.
![]() exclusive, эксклюзивная, исключающая — политика работы кэша, в котором никогда не хранятся копии всех кэшей меньших уровней.
exclusive, эксклюзивная, исключающая — политика работы кэша, в котором никогда не хранятся копии всех кэшей меньших уровней.
![]() non-exclusive («неисключающая»), mainly inclusive («в основном включающая»), свободная — комбинированная политика работы кэша, допускающая (необязательное) хранение копий некоторых строк кэшей меньших уровней.
non-exclusive («неисключающая»), mainly inclusive («в основном включающая»), свободная — комбинированная политика работы кэша, допускающая (необязательное) хранение копий некоторых строк кэшей меньших уровней.
![]() WT (write-through), сквозная запись — проведение записи в кэш следующего уровня или память сразу после записи в данный уровень. Упрощает взаимодействие кэшей (при большом темпе записей и отсутствии WCB — в ущерб производительности).
WT (write-through), сквозная запись — проведение записи в кэш следующего уровня или память сразу после записи в данный уровень. Упрощает взаимодействие кэшей (при большом темпе записей и отсутствии WCB — в ущерб производительности).
![]() WB (write-back: «обратная запись»), отложенная запись — проведение записи в кэш следующего уровня или память много позже записи в данный уровень (например, при вытеснении этой строки при промахе). Усложняет взаимодействие кэшей, но позволяет осуществить слияние записей. Не путать с одноимённой стадией конвейера.
WB (write-back: «обратная запись»), отложенная запись — проведение записи в кэш следующего уровня или память много позже записи в данный уровень (например, при вытеснении этой строки при промахе). Усложняет взаимодействие кэшей, но позволяет осуществить слияние записей. Не путать с одноимённой стадией конвейера.
![]() WC (write combine: слияние записи) — операция замены нескольких записей по одинаковому адресу последней из этих записей и/или замены нескольких записей по последовательным адресам одной записью совокупной длины. Выполняется в очереди записи LSU и отдельном WCB, увеличивая производительность при большом темпе записей.
WC (write combine: слияние записи) — операция замены нескольких записей по одинаковому адресу последней из этих записей и/или замены нескольких записей по последовательным адресам одной записью совокупной длины. Выполняется в очереди записи LSU и отдельном WCB, увеличивая производительность при большом темпе записей.
![]() WCB (write combine buffer: буфер слияния записи) — буфер для слияния записей, чаще всего — из L1D в L2.
WCB (write combine buffer: буфер слияния записи) — буфер для слияния записей, чаще всего — из L1D в L2.
![]() coherency, когерентность — согласование содержимого кэшей в многоядерной и/или многопроцессорной системе с помощью протокола когерентности. Разные протоколы описывают 4–5 состояний строки кэша, определяющих действия при её локальных и удалённых чтениях и записях, а также (по первым буквам состояний) название самого протокола (чаще всего — MESI, MOESI и MESIF). С числом ядер растут сложность соблюдения когерентности и синхронизирующий её снуп-трафик.
coherency, когерентность — согласование содержимого кэшей в многоядерной и/или многопроцессорной системе с помощью протокола когерентности. Разные протоколы описывают 4–5 состояний строки кэша, определяющих действия при её локальных и удалённых чтениях и записях, а также (по первым буквам состояний) название самого протокола (чаще всего — MESI, MOESI и MESIF). С числом ядер растут сложность соблюдения когерентности и синхронизирующий её снуп-трафик.
![]() snoop (подсматривание), снуп — проверка состояния строки с данным адресом в кэше другого ядра (относительно инициатора проверки). Используется для реализации когерентности. В многопроцессорных системах снуп-запросы могут занимать значительную долю всего межпроцессорного трафика, заметно снижая производительность.
snoop (подсматривание), снуп — проверка состояния строки с данным адресом в кэше другого ядра (относительно инициатора проверки). Используется для реализации когерентности. В многопроцессорных системах снуп-запросы могут занимать значительную долю всего межпроцессорного трафика, заметно снижая производительность.
![]() buffer, буфер — общее название структуры, разделяющей поток данных (в т. ч. между стадиями конвейера). Если буфер содержит более одного слова, то оформлен в виде очереди или полноассоциативной памяти и в таком виде позволяет сглаживать неравномерность поступления потока данных относительно его приёма.
buffer, буфер — общее название структуры, разделяющей поток данных (в т. ч. между стадиями конвейера). Если буфер содержит более одного слова, то оформлен в виде очереди или полноассоциативной памяти и в таком виде позволяет сглаживать неравномерность поступления потока данных относительно его приёма.
![]() FIFO (first-in, first-out: первым пришёл, первым вышел) — принцип работы буфера, при котором чтение слов происходят в порядке их записи.
FIFO (first-in, first-out: первым пришёл, первым вышел) — принцип работы буфера, при котором чтение слов происходят в порядке их записи.
![]() IO, I/O (input-output), ввод-вывод — общее название операций или блоков для обмена даннымимежду процессором и периферией.
IO, I/O (input-output), ввод-вывод — общее название операций или блоков для обмена даннымимежду процессором и периферией.
![]() BIU (bus interface unit: блок шинного интерфейса) — контроллер шины между процессором и северным мостом чипсета или межпроцессорной шины.
BIU (bus interface unit: блок шинного интерфейса) — контроллер шины между процессором и северным мостом чипсета или межпроцессорной шины.
![]() DDR (double data rate: двойной темп данных) — метод удвоения ПС шины передачей двух слов за такт — на фронте и спаде тактового импульса.
DDR (double data rate: двойной темп данных) — метод удвоения ПС шины передачей двух слов за такт — на фронте и спаде тактового импульса.
![]() QDR (quad data rate: четверной темп данных) — метод учетверения ПС шины передачей четырёх слов за такт — на фронтах и спадах тактовых импульсов двух линий тактирования, причём вторая смещена по фазе относительно первой на 90° (т. е. на половину длительности импульса).
QDR (quad data rate: четверной темп данных) — метод учетверения ПС шины передачей четырёх слов за такт — на фронтах и спадах тактовых импульсов двух линий тактирования, причём вторая смещена по фазе относительно первой на 90° (т. е. на половину длительности импульса).
![]() МT/s (megatransfers/second: «мегапередачи/секунду»), МП/с (миллионы передач в секунду), GT/s (gigatransfers/second: «гигапередачи/секунду»), ГП/с (миллиарды передач в секунду) — удельный темп передачи, мера производительности шины с переменной разрядностью. Равна произведению частоты, числа передаваемых каждой полосой битов/такт (1, 2 или 4), числа направлений (1 для полудуплексной шины, 2 для полнодуплексной) и плотности физического кодирования (как правило, 1 для полудуплексной шины и 0,8 для полнодуплексной). Для вычисления ПС шины (в битах/с) следует умножить темп передачи на число битовых полос в каждом направлении (1–40, обычно указывается после названия шины и символа «x»).
МT/s (megatransfers/second: «мегапередачи/секунду»), МП/с (миллионы передач в секунду), GT/s (gigatransfers/second: «гигапередачи/секунду»), ГП/с (миллиарды передач в секунду) — удельный темп передачи, мера производительности шины с переменной разрядностью. Равна произведению частоты, числа передаваемых каждой полосой битов/такт (1, 2 или 4), числа направлений (1 для полудуплексной шины, 2 для полнодуплексной) и плотности физического кодирования (как правило, 1 для полудуплексной шины и 0,8 для полнодуплексной). Для вычисления ПС шины (в битах/с) следует умножить темп передачи на число битовых полос в каждом направлении (1–40, обычно указывается после названия шины и символа «x»).
![]() FSB (front-side bus: «фронтовая шина») — общее название шины от x86-ЦП до северного моста чипсета. Чаще всего полудуплексная (с переключением направления передачи).
FSB (front-side bus: «фронтовая шина») — общее название шины от x86-ЦП до северного моста чипсета. Чаще всего полудуплексная (с переключением направления передачи).
![]() QPI (QuickPath Interconnect) — полнодуплексная (двунаправленная) межпроцессорная шина для ЦП Intel.
QPI (QuickPath Interconnect) — полнодуплексная (двунаправленная) межпроцессорная шина для ЦП Intel.
![]() HT (HyperTransport) — полнодуплексная (двунаправленная) межпроцессорная и чипсетная шина для ЦП AMD.
HT (HyperTransport) — полнодуплексная (двунаправленная) межпроцессорная и чипсетная шина для ЦП AMD.
![]() DMI (Direct Media Interface) — полнодуплексная (двунаправленная) шина от большинства современных ЦП Intel с ИКП до южного моста. Прежде, до интеграции функциональности северного моста в процессор, связывала северный и южный мосты чипсета.
DMI (Direct Media Interface) — полнодуплексная (двунаправленная) шина от большинства современных ЦП Intel с ИКП до южного моста. Прежде, до интеграции функциональности северного моста в процессор, связывала северный и южный мосты чипсета.
![]() IMC (integrated memory controller), ИКП, интегрированный (встроенный) контроллер памяти — контроллер памяти, встроенный в процессор. Встраивание улучшает тайминги доступа.
IMC (integrated memory controller), ИКП, интегрированный (встроенный) контроллер памяти — контроллер памяти, встроенный в процессор. Встраивание улучшает тайминги доступа.
![]() parity, чётность — простой способ обнаружения 1-битных ошибок. Применяется для защиты от ошибок чтения информации низкой важности, либо при низкой частоте возникновения ошибок, либо при возможности простого восстановления слова из внешнего источника. Применяется для кэша L1I и, иногда, L1D, а также некоторых шин. Как правило, требует 1 бит чётности на каждые 8–32 бита данных.
parity, чётность — простой способ обнаружения 1-битных ошибок. Применяется для защиты от ошибок чтения информации низкой важности, либо при низкой частоте возникновения ошибок, либо при возможности простого восстановления слова из внешнего источника. Применяется для кэша L1I и, иногда, L1D, а также некоторых шин. Как правило, требует 1 бит чётности на каждые 8–32 бита данных.
![]() ECC (error correction code), код коррекции ошибок — в процессоре и памяти: способ обнаружения и коррекции ошибок. Требует больше времени и энергии для генерации и проверки, чем чётность. В ЦП используется во всех кэшах, кроме L1I и, изредка, L1D. Чаще всего применяется в виде кода Хэмминга для 8-байтовых слов, занимая дополнительный ECC-байт на слово и давая возможность обнаружения 2-битных ошибок и коррекции 1-битных.
ECC (error correction code), код коррекции ошибок — в процессоре и памяти: способ обнаружения и коррекции ошибок. Требует больше времени и энергии для генерации и проверки, чем чётность. В ЦП используется во всех кэшах, кроме L1I и, изредка, L1D. Чаще всего применяется в виде кода Хэмминга для 8-байтовых слов, занимая дополнительный ECC-байт на слово и давая возможность обнаружения 2-битных ошибок и коррекции 1-битных.
Физическая реализация
![]() chip, чип, микросхема — интегральный полупроводниковый прибор, заменяющий тысячи и миллионы отдельных (дискретных) элементов. Состоит из корпуса и одного или нескольких размещённых внутри кристаллов. Чаще всего размещается на печатной плате — монтируется припаиванием или вставляется в разъём. Микросхемы являются главными и самыми сложными частями почти всех электронных приборов. Большинство микросхем — цифровые.
chip, чип, микросхема — интегральный полупроводниковый прибор, заменяющий тысячи и миллионы отдельных (дискретных) элементов. Состоит из корпуса и одного или нескольких размещённых внутри кристаллов. Чаще всего размещается на печатной плате — монтируется припаиванием или вставляется в разъём. Микросхемы являются главными и самыми сложными частями почти всех электронных приборов. Большинство микросхем — цифровые.
![]() socket, разъём — физический и электрический интерфейс для установки микросхемы на печатную плату с возможностью быстрой замены. Как правило, называется по типу подходящего для него корпуса и числа выводов. Часто имеет физическую защиту от неверной установки. При верной установке микросхемы особая деталь («ключ») в одном из её углов должна совпасть с ключом на разъёме.
socket, разъём — физический и электрический интерфейс для установки микросхемы на печатную плату с возможностью быстрой замены. Как правило, называется по типу подходящего для него корпуса и числа выводов. Часто имеет физическую защиту от неверной установки. При верной установке микросхемы особая деталь («ключ») в одном из её углов должна совпасть с ключом на разъёме.
![]() BGA (ball grid array: сеточный массив шаров) — корпус микросхемы с массивом выводов на нижней стороне в виде шариков припоя. Как правило, используется для припаивания на плату.
BGA (ball grid array: сеточный массив шаров) — корпус микросхемы с массивом выводов на нижней стороне в виде шариков припоя. Как правило, используется для припаивания на плату.
![]() LGA (land grid array: сеточный массив площадок) — корпус микросхемы с массивом выводов на нижней стороне в виде контактных площадок. Подходит только для установки в разъём.
LGA (land grid array: сеточный массив площадок) — корпус микросхемы с массивом выводов на нижней стороне в виде контактных площадок. Подходит только для установки в разъём.
![]() PGA (pin grid array: сеточный массив штырей) — корпус микросхемы с массивом выводов на нижней стороне в виде штырьков. Подходит для монтажа и установки в разъём.
PGA (pin grid array: сеточный массив штырей) — корпус микросхемы с массивом выводов на нижней стороне в виде штырьков. Подходит для монтажа и установки в разъём.
![]() die («кубик»), кристалл — главная часть микросхемы, тонкий прямоугольный кремниевый кристалл, на поверхности которого расположено большое множество интегральных элементов (чаще всего транзисторов) и межсоединений. Расположен в корпусе, с которым соединён чаще всего по принципу FC-BGA-монтажа. Иногда применяется бескорпусный монтаж кристалла на печатную плату, стекло или гибкую подложку. Чем больше площадь кристалла (и их число — для MCM), тем дороже микросхема. При производстве кристаллы получаются после разрезания кремниевой пластины.
die («кубик»), кристалл — главная часть микросхемы, тонкий прямоугольный кремниевый кристалл, на поверхности которого расположено большое множество интегральных элементов (чаще всего транзисторов) и межсоединений. Расположен в корпусе, с которым соединён чаще всего по принципу FC-BGA-монтажа. Иногда применяется бескорпусный монтаж кристалла на печатную плату, стекло или гибкую подложку. Чем больше площадь кристалла (и их число — для MCM), тем дороже микросхема. При производстве кристаллы получаются после разрезания кремниевой пластины.
![]() wafer («вафля»), пластина — круглая кремниевая пластина диаметром до 300 мм, используемая на микроэлектронной фабрике для производства микросхем. На пластине формируется регулярный массив «клеток», которые после разрезки пластины образуют кристаллы, устанавливаемые в корпусы.
wafer («вафля»), пластина — круглая кремниевая пластина диаметром до 300 мм, используемая на микроэлектронной фабрике для производства микросхем. На пластине формируется регулярный массив «клеток», которые после разрезки пластины образуют кристаллы, устанавливаемые в корпусы.
![]() MCM (multi-chip module: многочиповый модуль) — микросхема, в корпус которой установлено несколько кристаллов: как правило, друг на друге, реже (для сильногреющихся кристаллов) — на одном уровне. Кристаллы могут быть подключены не только к выводам, но и напрямую друг к другу. MCM чаще всего применяется для микросхем памяти и SoC, реже — для многоядерных ЦП.
MCM (multi-chip module: многочиповый модуль) — микросхема, в корпус которой установлено несколько кристаллов: как правило, друг на друге, реже (для сильногреющихся кристаллов) — на одном уровне. Кристаллы могут быть подключены не только к выводам, но и напрямую друг к другу. MCM чаще всего применяется для микросхем памяти и SoC, реже — для многоядерных ЦП.
![]() TSV (through silicon vias: «сквозькремниевые отверстия») — перспективный метод соединения нескольких кристаллов микросхемы, устанавливаемых друг на друга. Кристалл с TSV имеет дополнительные контакты на тыльной стороне для следующего кристалла. Без использования TSV кристаллы должны устанавливаться со сдвигом, чтобы не затенять контакты друг друга; при этом число самих контактов ограничено, т. к. они могут быть расположены лишь вдоль одной или двух сторон кристалла.
TSV (through silicon vias: «сквозькремниевые отверстия») — перспективный метод соединения нескольких кристаллов микросхемы, устанавливаемых друг на друга. Кристалл с TSV имеет дополнительные контакты на тыльной стороне для следующего кристалла. Без использования TSV кристаллы должны устанавливаться со сдвигом, чтобы не затенять контакты друг друга; при этом число самих контактов ограничено, т. к. они могут быть расположены лишь вдоль одной или двух сторон кристалла.
![]() FC (flip-chip: перевёрнутый кристалл) — метод установки кристалла в корпус транзисторами и контактами «вниз» (к плате). Применяется в большинстве современных микросхем, но без использования TSV не даёт возможность установить в MCM несколько кристаллов друг на друга.
FC (flip-chip: перевёрнутый кристалл) — метод установки кристалла в корпус транзисторами и контактами «вниз» (к плате). Применяется в большинстве современных микросхем, но без использования TSV не даёт возможность установить в MCM несколько кристаллов друг на друга.
![]() family, семейство — для x86-ЦП: совокупность моделей с общей микроархитектурой или несколькими похожими. В ответе на команду CPUID обозначается одной или двумя шестнадцатиричными цифрами.
family, семейство — для x86-ЦП: совокупность моделей с общей микроархитектурой или несколькими похожими. В ответе на команду CPUID обозначается одной или двумя шестнадцатиричными цифрами.
![]() model, модель — для x86-ЦП: линейка процессоров с несколько отличающимися деталями микроархитектуры и разным числом ядер, размеров кэшей, техпроцессом и другими характеристиками, влияющими на площадь и устройство кристалла. В ответе на команду CPUID обозначается одной или двумя шестнадцатиричными цифрами.
model, модель — для x86-ЦП: линейка процессоров с несколько отличающимися деталями микроархитектуры и разным числом ядер, размеров кэшей, техпроцессом и другими характеристиками, влияющими на площадь и устройство кристалла. В ответе на команду CPUID обозначается одной или двумя шестнадцатиричными цифрами.
![]() stepping, степпинг — для x86-ЦП: модификация модели, сделанная для улучшения второстепенных численных потребительских характеристик относительно предыдущего степпинга (например, увеличения частоты шины). В ответе на команду CPUID обозначается шестнадцатиричной цифрой.
stepping, степпинг — для x86-ЦП: модификация модели, сделанная для улучшения второстепенных численных потребительских характеристик относительно предыдущего степпинга (например, увеличения частоты шины). В ответе на команду CPUID обозначается шестнадцатиричной цифрой.
![]() revision, ревизия — версия микросхемы, сделанная для улучшения производственных характеристик относительно предыдущей ревизии (например, снижения себестоимости кристалла и исправления ошибок). В ответе на команду CPUID обозначается латинской буквой и десятичной цифрой. Первая ревизия (A0), как правило, является инженерным образцом. Для ЦП AMD ревизия либо даётся как 4-символьная комбинация, либо не указывается и считается равной степпингу.
revision, ревизия — версия микросхемы, сделанная для улучшения производственных характеристик относительно предыдущей ревизии (например, снижения себестоимости кристалла и исправления ошибок). В ответе на команду CPUID обозначается латинской буквой и десятичной цифрой. Первая ревизия (A0), как правило, является инженерным образцом. Для ЦП AMD ревизия либо даётся как 4-символьная комбинация, либо не указывается и считается равной степпингу.
![]() ES (engineering sample), инженерный образец — «бета-версия» микросхемы, не предназначенная для массового производства. Изготавливается малыми партиями для отладки и тестирования. Иногда содержит недокументированные режимы или функции, недоступные в массовых моделях.
ES (engineering sample), инженерный образец — «бета-версия» микросхемы, не предназначенная для массового производства. Изготавливается малыми партиями для отладки и тестирования. Иногда содержит недокументированные режимы или функции, недоступные в массовых моделях.
![]() MOS (metal-oxide-semiconductor: металл-оксид-полупроводник), МОП — слоистая структура, лежащая в основе интегральных полевых транзисторов для первых микросхем. В современных чипах управляющий затвор делается из поликремния (поликристаллического кремния), но в наиболее продвинутых снова применяется металлический затвор. Подзатворный диэлектрик также изготавливается не из диоксида кремния, а high-k-материалов. Часть кристалла, образующая канал с управляемой проводимостью между истоком и стоком, в современных микросхемах имеет механические напряжение. Идеальный МОП-транзистор имеет квадратичную зависимость потребления энергии от напряжения питания и линейную от частоты, причём максимум частоты линейно зависит от напряжения.
MOS (metal-oxide-semiconductor: металл-оксид-полупроводник), МОП — слоистая структура, лежащая в основе интегральных полевых транзисторов для первых микросхем. В современных чипах управляющий затвор делается из поликремния (поликристаллического кремния), но в наиболее продвинутых снова применяется металлический затвор. Подзатворный диэлектрик также изготавливается не из диоксида кремния, а high-k-материалов. Часть кристалла, образующая канал с управляемой проводимостью между истоком и стоком, в современных микросхемах имеет механические напряжение. Идеальный МОП-транзистор имеет квадратичную зависимость потребления энергии от напряжения питания и линейную от частоты, причём максимум частоты линейно зависит от напряжения.
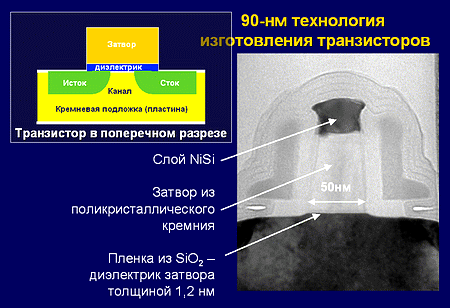
![]() process technology, техпроцесс — технологический процесс для массового производства микросхем. Характеризуется технормой, числом слоёв межсоединений, диаметром пластин, различными оптимизациями под скорость и/или энергоэффективность и пр. На передовых фабриках переход на новый техпроцесс происходит примерно каждые 2 года.
process technology, техпроцесс — технологический процесс для массового производства микросхем. Характеризуется технормой, числом слоёв межсоединений, диаметром пластин, различными оптимизациями под скорость и/или энергоэффективность и пр. На передовых фабриках переход на новый техпроцесс происходит примерно каждые 2 года.
![]() CD (тут — critical dimension: критический размер), технорма — главная характеристика техпроцесса. Измеряется в нанометрах (nm, нм; ранее — в микронах). Номинально равна минимальному полушагу линейно-регулярной структуры на кристалле, с некоторыми допущениями — удвоенной минимальной длине затвора транзистора и минимальной ширине дорожки. Однако начиная с 45 нм эти пропорции не соблюдаются, поэтому технорма приобретает всё более рекламное значение. Длина и ширина всего транзистора в несколько раз превышает технорму. Из-за особенностей современных техпроцессов при переходе на следующий (технорма которого, как правило, в 1,4 раза меньше текущего) площадь транзистора и всего кристалла уменьшается не в 2 (1,4²), а в 1,6–1,8 раза. Перевод микросхемы на меньшую технорму увеличивает массовость её производства и максимальную частоту, а также уменьшает себестоимость и энергопотребление. Оборудование для производства с меньшей технормой значительно дороже.
CD (тут — critical dimension: критический размер), технорма — главная характеристика техпроцесса. Измеряется в нанометрах (nm, нм; ранее — в микронах). Номинально равна минимальному полушагу линейно-регулярной структуры на кристалле, с некоторыми допущениями — удвоенной минимальной длине затвора транзистора и минимальной ширине дорожки. Однако начиная с 45 нм эти пропорции не соблюдаются, поэтому технорма приобретает всё более рекламное значение. Длина и ширина всего транзистора в несколько раз превышает технорму. Из-за особенностей современных техпроцессов при переходе на следующий (технорма которого, как правило, в 1,4 раза меньше текущего) площадь транзистора и всего кристалла уменьшается не в 2 (1,4²), а в 1,6–1,8 раза. Перевод микросхемы на меньшую технорму увеличивает массовость её производства и максимальную частоту, а также уменьшает себестоимость и энергопотребление. Оборудование для производства с меньшей технормой значительно дороже.
![]() CMOS (complementary MOS: комплементарный МОП), КМОП — первоначально: вид логики для цифровых микросхем, использующей в логических вентилях пары p- и n-канальных МОП-транзисторов. По сравнению с другими схемами такой вентиль занимает больше места и имеет меньшую предельную частоту, но потребляет значительно меньше энергии. Применяется в особо энергоэффективных схемах и редко — в процессорах. Сегодня под КМОП понимается технология для изготовления микросхем, содержащих оба вида МОП-транзисторов, и используется для всех цифровых чипов.
CMOS (complementary MOS: комплементарный МОП), КМОП — первоначально: вид логики для цифровых микросхем, использующей в логических вентилях пары p- и n-канальных МОП-транзисторов. По сравнению с другими схемами такой вентиль занимает больше места и имеет меньшую предельную частоту, но потребляет значительно меньше энергии. Применяется в особо энергоэффективных схемах и редко — в процессорах. Сегодня под КМОП понимается технология для изготовления микросхем, содержащих оба вида МОП-транзисторов, и используется для всех цифровых чипов.
![]() SRAM (static RAM: статическое ОЗУ), СОЗУ — энергозависимая полупроводниковая память, используемая в микросхемах в качестве кэшей, буферов и регистров. Среди остальных видов памяти является самой быстрой, энергопотребляющей и малоплотной. Элементарная ячейка СОЗУ, хранящая 1 бит, имеет 6 транзисторов для кэшей L2 и L3, 6 или 8 для L1 и 4+4W+R для РФ с W портами записи и R портами чтения.
SRAM (static RAM: статическое ОЗУ), СОЗУ — энергозависимая полупроводниковая память, используемая в микросхемах в качестве кэшей, буферов и регистров. Среди остальных видов памяти является самой быстрой, энергопотребляющей и малоплотной. Элементарная ячейка СОЗУ, хранящая 1 бит, имеет 6 транзисторов для кэшей L2 и L3, 6 или 8 для L1 и 4+4W+R для РФ с W портами записи и R портами чтения.
![]() МТр (миллионов транзисторов) — авторская мера количества транзисторов на кристалле или какой-либо его структуре.
МТр (миллионов транзисторов) — авторская мера количества транзисторов на кристалле или какой-либо его структуре.
![]() interconnect, межсоединения, дорожки — совокупность проводящих каналов (дорожек), соединяющих элементы микросхемы друг с другом, а также с её выводами. Расположены на 5–12 уровнях, причём самый нижний (на уровне транзисторов) изготовлен из поликремния, а остальные — из меди (в старых чипах — из алюминия). Верхний слой имеет контактные площадки для соединения кристалла с корпусом, следующий является силовым (поставляет питание), оставшиеся используются для синхронизации и переноса данных. Электрические контакты между слоями и до транзисторов образуются с помощью металлизированных отверстий (vias). Межслойный диэлектрик является high-k-соединением.
interconnect, межсоединения, дорожки — совокупность проводящих каналов (дорожек), соединяющих элементы микросхемы друг с другом, а также с её выводами. Расположены на 5–12 уровнях, причём самый нижний (на уровне транзисторов) изготовлен из поликремния, а остальные — из меди (в старых чипах — из алюминия). Верхний слой имеет контактные площадки для соединения кристалла с корпусом, следующий является силовым (поставляет питание), оставшиеся используются для синхронизации и переноса данных. Электрические контакты между слоями и до транзисторов образуются с помощью металлизированных отверстий (vias). Межслойный диэлектрик является high-k-соединением.
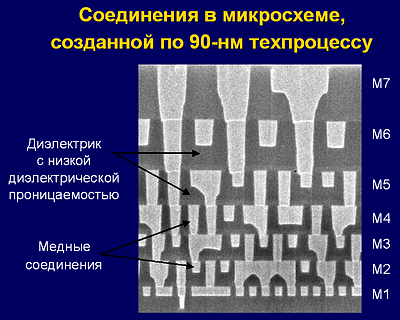
![]() k, диэлектрическая проницаемость — безразмерная физическая величина (часто называемая диэлектрической константой), характеризующая изолирующие свойства. По определению, k(вакуума)=1. До 2000 г. в микросхемах в качестве диэлектрика применялся диоксид кремния (SiO2) с k=3,9; материалы с большей k относятся к классу high-k, с меньшей — к low-k. В новых чипах используются оба вида.
k, диэлектрическая проницаемость — безразмерная физическая величина (часто называемая диэлектрической константой), характеризующая изолирующие свойства. По определению, k(вакуума)=1. До 2000 г. в микросхемах в качестве диэлектрика применялся диоксид кремния (SiO2) с k=3,9; материалы с большей k относятся к классу high-k, с меньшей — к low-k. В новых чипах используются оба вида.
![]() high-k (высокая «k») — о диэлектриках с показателем k больше, чем у SiO2. Диэлектрики на основе гафния (HfSiO или HfSiON с k≈25) применяются вместо SiO2 между затвором и каналом МОП-транзистора, уменьшая токи утечки, вызванные туннелированием электронов из-за малой толщины слоя — high-k-диэлектрик позволяет утолщить изолятор без замедления транзистора.
high-k (высокая «k») — о диэлектриках с показателем k больше, чем у SiO2. Диэлектрики на основе гафния (HfSiO или HfSiON с k≈25) применяются вместо SiO2 между затвором и каналом МОП-транзистора, уменьшая токи утечки, вызванные туннелированием электронов из-за малой толщины слоя — high-k-диэлектрик позволяет утолщить изолятор без замедления транзистора.
![]() low-k (низкая «k») — о диэлектриках с показателем k меньше, чем у SiO2. Легированный углеродом пористый SiO2 (с k≤3) применяется вместо обычного SiO2 как межслойный изолятор для межсоединений, уменьшая паразитную ёмкость. Это позволяет ускорить схему и уменьшить её потребление.
low-k (низкая «k») — о диэлектриках с показателем k меньше, чем у SiO2. Легированный углеродом пористый SiO2 (с k≤3) применяется вместо обычного SiO2 как межслойный изолятор для межсоединений, уменьшая паразитную ёмкость. Это позволяет ускорить схему и уменьшить её потребление.
![]() strained silicon, напряжённый кремний — техника ускорения переключения МОП-транзисторов, применяемая к области канала: для p-канальных транзисторы применяется сжатие шага кристаллической решётки вдоль канала, для n-канальных — растяжение.
strained silicon, напряжённый кремний — техника ускорения переключения МОП-транзисторов, применяемая к области канала: для p-канальных транзисторы применяется сжатие шага кристаллической решётки вдоль канала, для n-канальных — растяжение.
![]() SOI (silicon on insulator), кремний на изоляторе, КНИ — техника уменьшения токов утечки за счёт размещения под всеми транзисторами кристалла изолирующего слоя (как правило — диоксида кремния).
SOI (silicon on insulator), кремний на изоляторе, КНИ — техника уменьшения токов утечки за счёт размещения под всеми транзисторами кристалла изолирующего слоя (как правило — диоксида кремния).
![]() metal gate, металлический затвор — использование в качестве затвора МОП-транзистора металлокремниевого соединения или сплава металлов вместо поликремния для ускорения и уменьшения потребления энергии.
metal gate, металлический затвор — использование в качестве затвора МОП-транзистора металлокремниевого соединения или сплава металлов вместо поликремния для ускорения и уменьшения потребления энергии.
![]() TDP (thermal design power: мощность по термопроекту) — максимальная продолжительная теплорассеивающая способность, которую должна обеспечить микросхеме система охлаждения (в т. ч. для микросхем, не требующих использование радиатора). Равна практическому максимуму рассеиваемой (выделяемой в виде тепла) мощности при стабильной работе микросхемы на штатных частотах и напряжениях и максимально допустимой собственной температуре. Берётся чуть ниже достижимого на специальных тестах теоретического максимума и при продолжительной загрузке превышается лишь на небольшие промежутки времени. Для цифровых микросхем используется как приблизительный показатель потребления энергии (почти 100% её рассеивается), однако TDP процессоров «округляется» вверх до одного из стандартных значений (не обязательно ближайшего — в т. ч. по маркетинговым соображениям). TDP микросхем, требующих наличие радиатора, как правило, указывается только для тепловыделения через верхнюю крышку, которой касается радиатор, т. е. без учёта тепла, уходящего через печатную плату. В итоге TDP процессора может быть выше или ниже максимального продолжительного потребления энергии. Современные ЦП имеют программируемое значение TDP для подстройки под используемую систему охлаждения.
TDP (thermal design power: мощность по термопроекту) — максимальная продолжительная теплорассеивающая способность, которую должна обеспечить микросхеме система охлаждения (в т. ч. для микросхем, не требующих использование радиатора). Равна практическому максимуму рассеиваемой (выделяемой в виде тепла) мощности при стабильной работе микросхемы на штатных частотах и напряжениях и максимально допустимой собственной температуре. Берётся чуть ниже достижимого на специальных тестах теоретического максимума и при продолжительной загрузке превышается лишь на небольшие промежутки времени. Для цифровых микросхем используется как приблизительный показатель потребления энергии (почти 100% её рассеивается), однако TDP процессоров «округляется» вверх до одного из стандартных значений (не обязательно ближайшего — в т. ч. по маркетинговым соображениям). TDP микросхем, требующих наличие радиатора, как правило, указывается только для тепловыделения через верхнюю крышку, которой касается радиатор, т. е. без учёта тепла, уходящего через печатную плату. В итоге TDP процессора может быть выше или ниже максимального продолжительного потребления энергии. Современные ЦП имеют программируемое значение TDP для подстройки под используемую систему охлаждения.
![]() V-plane (voltage plane: слой напряжения) — силовая шина питания микросхемы. В простейшем случае имеется 1 слой питания для всего кристалла, но для сложных микросхем, включая процессоры, в целях улучшения энергоэффективности питание разных блоков может быть раздельным, чтобы была возможность независимой регулировки питающих напряжений. В большинстве ЦП есть 2–4 регулируемые шины и 1–3 фиксированные. Все они подключены к соответствующим каналам блока VRM.
V-plane (voltage plane: слой напряжения) — силовая шина питания микросхемы. В простейшем случае имеется 1 слой питания для всего кристалла, но для сложных микросхем, включая процессоры, в целях улучшения энергоэффективности питание разных блоков может быть раздельным, чтобы была возможность независимой регулировки питающих напряжений. В большинстве ЦП есть 2–4 регулируемые шины и 1–3 фиксированные. Все они подключены к соответствующим каналам блока VRM.
![]() VRM (voltage regulator module: модуль-регулятор напряжения) — блок питания для микросхем, поставляющий напряжения для их силовых шин. Чаще всего располагается на материнской плате. Каждый канал VRM является вольтодобавочным преобразователем, понижающим напряжение от 5 или (чаще) 12 В (получаемых из блока питания) до 0,5–3 В, причём эта величина может быть фиксированной, настраиваемой при загрузке системы или задаваемой в реальном времени (в этом случае она может меняться десятки раз в секунду). Большинство современных микросхем требуют 0,6–1,5 В. Наиболее сложные из них (в частности, почти все процессоры) сообщают обо всех необходимых в данный момент напряжениях с точностью 2,5 или 5 мВ через специальную последовательную шину, к которой подключен контроллер VRM. Через неё же VRM может сообщать процессору о своих возможностях, ограничениях и текущем состоянии.
VRM (voltage regulator module: модуль-регулятор напряжения) — блок питания для микросхем, поставляющий напряжения для их силовых шин. Чаще всего располагается на материнской плате. Каждый канал VRM является вольтодобавочным преобразователем, понижающим напряжение от 5 или (чаще) 12 В (получаемых из блока питания) до 0,5–3 В, причём эта величина может быть фиксированной, настраиваемой при загрузке системы или задаваемой в реальном времени (в этом случае она может меняться десятки раз в секунду). Большинство современных микросхем требуют 0,6–1,5 В. Наиболее сложные из них (в частности, почти все процессоры) сообщают обо всех необходимых в данный момент напряжениях с точностью 2,5 или 5 мВ через специальную последовательную шину, к которой подключен контроллер VRM. Через неё же VRM может сообщать процессору о своих возможностях, ограничениях и текущем состоянии.
![]() power gate (силовой затвор, ключ) — коммутатор (ключ) питания. Внешний ключ, как правило, основан на одном мощном транзисторе, а интегрированный в микросхему — на множестве слаботочных. Интегрированный ключ управляет подачей питания с какой-либо силовой шины или «земли» («минус» питания) на отдельные блоки. Отключение простаивающих блоков уменьшает общее потребление.
power gate (силовой затвор, ключ) — коммутатор (ключ) питания. Внешний ключ, как правило, основан на одном мощном транзисторе, а интегрированный в микросхему — на множестве слаботочных. Интегрированный ключ управляет подачей питания с какой-либо силовой шины или «земли» («минус» питания) на отдельные блоки. Отключение простаивающих блоков уменьшает общее потребление.
![]() C-state [точная расшифровка неизвестна], энергосостояние — состояние микросхемы с точки зрения потребления энергии. Для каждой силовой шины описывается его напряжение, а для каждого блока — состояние ключа питания (если есть), подача тактирования и активность. Каждая допустимая комбинация этих параметров обозначается буквой C и цифрой, причём C0 означает «всё включено», а бо́льшие цифры означают более глубокий сон при простое и большее время для пробуждения.
C-state [точная расшифровка неизвестна], энергосостояние — состояние микросхемы с точки зрения потребления энергии. Для каждой силовой шины описывается его напряжение, а для каждого блока — состояние ключа питания (если есть), подача тактирования и активность. Каждая допустимая комбинация этих параметров обозначается буквой C и цифрой, причём C0 означает «всё включено», а бо́льшие цифры означают более глубокий сон при простое и большее время для пробуждения.
![]() P-state (performance state: состояние производительности) — видимое для ОС состояние микросхемы с точки зрения баланса скорости и потребления энергии в энергосостоянии C0. Для каждой силовой шины описывает его напряжение, а каждого блока — частоту тактирования. Каждая такая комбинация обозначается отдельной цифрой, причём P0 обозначает максимальные скорость и потребление, а бо́льшие цифры означают их постепенное уменьшение. Для ЦП Intel P1 означает штатную частоту, а P0 — максимальную с учётом технологии Turbo Boost. Для ЦП AMD P0 означает максимальную возможную на данный момент частоту, меняющуюся при работе аналогичной технологии Turbo-Core.
P-state (performance state: состояние производительности) — видимое для ОС состояние микросхемы с точки зрения баланса скорости и потребления энергии в энергосостоянии C0. Для каждой силовой шины описывает его напряжение, а каждого блока — частоту тактирования. Каждая такая комбинация обозначается отдельной цифрой, причём P0 обозначает максимальные скорость и потребление, а бо́льшие цифры означают их постепенное уменьшение. Для ЦП Intel P1 означает штатную частоту, а P0 — максимальную с учётом технологии Turbo Boost. Для ЦП AMD P0 означает максимальную возможную на данный момент частоту, меняющуюся при работе аналогичной технологии Turbo-Core.
![]() SpeedStep, Cool’n’Quiet, PowerNow! — название фирменных технологий энергосбережения для ЦП Intel, AMD и VIA.
SpeedStep, Cool’n’Quiet, PowerNow! — название фирменных технологий энергосбережения для ЦП Intel, AMD и VIA.
![]() base frequency (базовая частота), штатная частота — максимальная частота продолжительной надёжной работы цифровой микросхемы при полной нагрузке и максимальной допустимой температуре кристалла. Является одной из основных характеристик цифровой микросхемы. Определяется во время пост-производственного теста вместе с необходимыми для её поддержания питающими напряжениями. В работе процессора частота может автоматически повышаться сверх штатной при наличии технологии авторазгона. Ручное повышение (обычный разгон), как правило, не рекомендуется, т. к. может привести к перегреву и выходу из строя чипа.
base frequency (базовая частота), штатная частота — максимальная частота продолжительной надёжной работы цифровой микросхемы при полной нагрузке и максимальной допустимой температуре кристалла. Является одной из основных характеристик цифровой микросхемы. Определяется во время пост-производственного теста вместе с необходимыми для её поддержания питающими напряжениями. В работе процессора частота может автоматически повышаться сверх штатной при наличии технологии авторазгона. Ручное повышение (обычный разгон), как правило, не рекомендуется, т. к. может привести к перегреву и выходу из строя чипа.
![]() Turbo Boost, Turbo Core — название фирменных технологий аппаратного (программно-независимого) авторазгона (повышения частоты свыше штатной) для ЦП Intel и AMD. Встроенный в ЦП контроллер питания учитывает следующие измеренные (или предсказанные им на основе ранее сделанных прямых или косвенных замеров) параметры:
Turbo Boost, Turbo Core — название фирменных технологий аппаратного (программно-независимого) авторазгона (повышения частоты свыше штатной) для ЦП Intel и AMD. Встроенный в ЦП контроллер питания учитывает следующие измеренные (или предсказанные им на основе ранее сделанных прямых или косвенных замеров) параметры:
- число загруженных ядер или модулей;
- средняя и/или максимальная (по всем датчикам) температура кристалла;
- сила тока для каждой силовой шины;
- потребляемая мощность (сумма произведений тока на напряжение для каждой силовой шины).
Если все требуемые для авторазгона параметры не превышают допустимые для данного ЦП пределы, то контроллер увеличивает множитель частоты (и, возможно, напряжение на соответствующей шине) полностью загруженным ядрам (иногда вместе с некоторыми простаивающими, но неотключаемыми), пока какой-либо из параметров не достигнет предела. Продвинутые версии авторазгона могут привести к выделению процессором энергии свыше значения TDP на время до минуты, пока остальные параметры (прежде всего температура) не достигли насыщения.
![]() frequency ceiling, частотный потолок — максимально достижимая на данный момент штатная частота микросхем данного типа при массовом производстве на данном оборудовании. Увеличивается при переходе на меньший техпроцесс, следующий степпинг и другую микроархитектуру с «простыми» (по метрике FO4) стадиями конвейера (для нового ЦП).
frequency ceiling, частотный потолок — максимально достижимая на данный момент штатная частота микросхем данного типа при массовом производстве на данном оборудовании. Увеличивается при переходе на меньший техпроцесс, следующий степпинг и другую микроархитектуру с «простыми» (по метрике FO4) стадиями конвейера (для нового ЦП).
![]() FO4 (fan-out of 4: коэффициент разветвления 4) — относительная метрика времени срабатывания логической схемы, не зависящая от используемого техпроцесса (в отличие от абсолютной, измеряемой в долях секунды). Равна времени срабатывания логического вентиля, нагруженного на выходе четырьмя другими того же размера. В процессорах применяется для измерения логической сложности стадии конвейера. Типичное её значение для современных x86-ЦП — 21–23 единицы FO4. Конвейер, разделённый на большее число стадий меньшей сложности, сможет работать на большей частоте, исполняя ту же совокупную работу, т. к. каждой стадии потребуется меньшее время для срабатывания. Реальная работа в стадии меньше, т. к. при замере «полной FO4-эквивалентной» задержки учитывается дрожание частоты (джиттер) и нечёткие срезы сигнала тактирования (≈2 FO4), а также задержки межстадийных буферов данных (≈3 FO4).
FO4 (fan-out of 4: коэффициент разветвления 4) — относительная метрика времени срабатывания логической схемы, не зависящая от используемого техпроцесса (в отличие от абсолютной, измеряемой в долях секунды). Равна времени срабатывания логического вентиля, нагруженного на выходе четырьмя другими того же размера. В процессорах применяется для измерения логической сложности стадии конвейера. Типичное её значение для современных x86-ЦП — 21–23 единицы FO4. Конвейер, разделённый на большее число стадий меньшей сложности, сможет работать на большей частоте, исполняя ту же совокупную работу, т. к. каждой стадии потребуется меньшее время для срабатывания. Реальная работа в стадии меньше, т. к. при замере «полной FO4-эквивалентной» задержки учитывается дрожание частоты (джиттер) и нечёткие срезы сигнала тактирования (≈2 FO4), а также задержки межстадийных буферов данных (≈3 FO4).


