общие принципы работы (x86 CPU digest 2.0)
Этот материал представляет собой обновлённую, существенно переработанную и дополненную версию статьи 2006 года, которая называлась «Современные десктопные процессоры архитектуры x86: общие принципы работы (x86 CPU FAQ 1.0)». Правда, чтобы не вводить потенциальных читателей в заблуждение словом «FAQ», мы решили назвать новый материал более правильным, как нам кажется, термином — «дайджест». Действительно, ведь большая его часть — это не ответы на конкретные вопросы, а разъяснения и краткие выжимки из чего угодно — от технической документации до истории развития микропроцессорной отрасли. Для кого предназначен данный материал? Нам видятся две группы потенциальных читателей.
Первая — это те, кто вдруг обнаружил, что ему действительно интересно узнать, как работает современный x86-процессор. Для них мы попытались сосредоточить в рамках статьи максимальное количество полезных сведений, которые позволяют получить более-менее полное представление об этом процессе, даже не имея до этого (почти) никаких специальных знаний: здесь объясняется значение основных терминов, устройство современных CPU, принципы взаимодействия различных их составляющих между собой, а также процессора с компьютерной системой в целом.
Вторая группа — это те, кто не найдёт в статье почти ничего нового для себя — но им попросту лень писать нечто похожее самостоятельно, чтобы сосредоточить разбросанные по мозгу знания в одном месте, «причесать» их, систематизировать, упорядочить, осовременить, и так далее. Мы сами отлично понимаем, как бывает лениво писать конспекты :) (а особенно — хорошие конспекты), поэтому если наш дайджест вас устраивает — мы с радостью дарим вам возможность им пользоваться.
Ну и традиционное предупреждение: если иное не указано явно, то слово «процессор» в данном материале обозначает «x86(-64) процессор, предназначенный для установки в десктопы или (намного реже) мобильные компьютеры». Серверные процессоры, специализированные процессоры с архитектурой x86, всевозможные embedded-варианты — всё это в рамках статьи не рассматривается.
Оглавление
- Введение
- Общие принципы взаимодействия процессора и ОЗУ
- Процессор: сведения общего характера
- Процессор: детальней
- Процессор: ещё детальней
- Приложение: генеалогическое древо x86-процессоров
- Заключение
Введение
Общее устройство вычислительной машины
Любой компьютер как универсальный инструмент для работы с информацией устроен очень просто. Все его части можно разделить на 3 вида: устройства обработки, хранения и обмена (ввода-вывода), причём последние могут осуществлять обмен данными как между компьютером и человеком, так и между другими компьютерами. С информационной точки зрения больше ничего там нет, хотя учитывая, что компьютер — устройство электрическое, ему нужен источник питания, кабели и т.п., но это общая часть всей электроники. При этом каждый элемент сам делится на компоненты вышеперечисленных трёх видов. Например, процессор относится к устройствам обработки, но внутри себя имеет блоки собственно вычислений, локальной памяти и обмена. Большая часть пока ещё непонятных терминов именует конкретные детали процессора или методы их взаимодействий.
Код и данные: основной принцип работы процессора
Если не пытаться изложить здесь «кратенько» курс информатики для средней школы, то единственное что хотелось бы напомнить — это то, что процессор (за редкими исключениями) исполняет не программы, написанные на каком-нибудь языке программирования (один из которых, вы, возможно, даже знаете), а так называемый машинный код. Т.е. командами для него являются последовательности байтов, находящихся в памяти компьютера, не имеющие ничего общего не только с каким-то человеческим языком, но и с языком программирования высокого уровня. Каждая команда занимает до нескольких байт, в среднем — 3-5. Там же, в основной памяти (ОЗУ, RAM) находятся и данные. Они могут находиться в отдельной области, а могут и быть перемешаны с кодом. Различие между кодом и данными состоит в том, что данные — это то, над чем процессор производит операции. А код — это команды, которые ему сообщают, какую именно операцию он должен произвести. Одновременно в памяти располагаются множество программ, необходимых им данных и некоторое свободное место.
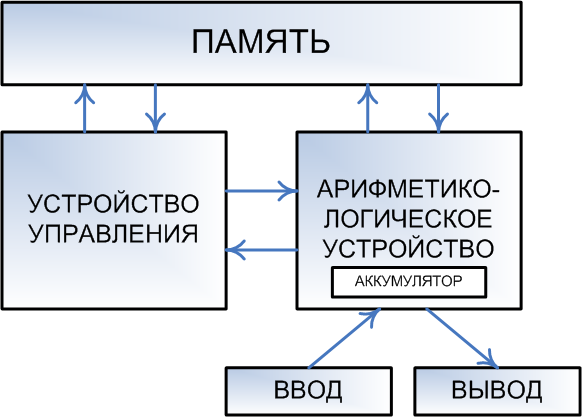
Чтобы исполнить команду, процессор должен прочитать её из памяти. Чтобы произвести операцию над данными (а этого требует почти каждая команда), процессор должен прочитать их из памяти, и, возможно, после произведения над ними определённого действия, записать их обратно в память в обновлённом (изменённом) виде. Команды и данные идентифицируются их адресом, который представляет собой порядковый номер байта в памяти, с которого эти данные начинаются (если они занимают несколько байт).
Общие принципы взаимодействия процессора и ОЗУ
Возможно, кого-то удивит, что достаточно большой раздел в «Дайджесте», посвящённом x86 CPU, выделен под объяснение особенностей функционирования памяти в современных системах, основанных на данном типе процессоров. Однако факты — упрямая вещь: сами x86-процессоры ныне содержат так много блоков, отвечающих именно за оптимизацию их работы с ОЗУ, что игнорировать эту тесную связь было бы совершенно нелепо. Можно сказать даже так: уж, коль решения, связанные с оптимизацией работы с памятью, стали неотъемлемой частью самих процессоров — то и саму память можно рассматривать в качестве некоего «придатка», функционирование которого оказывает непосредственное влияние на скорость работы CPU. Без понимания особенностей взаимодействия процессора с памятью, невозможно понять, за счёт чего тот или иной процессор (та или иная система) исполняет программы медленнее или быстрее.
Контроллер памяти
Итак, ранее выше мы уже говорили о том, что как команды, так и данные, попадают в процессор из оперативной памяти. На самом деле всё немного сложнее. Ещё недавно в большинстве x86-систем (т.е. компьютеров на базе x86-процессоров), процессор к памяти обращаться сам не мог, т.к. не имел в своём составе соответствующих узлов. Некоторые не самые новые, но ещё популярные линейки процессоров (Intel Core 2, Celeron и Pentium всех видов) используют такую классическую организацию и сейчас. В этой схеме процессор обращается к «промежуточному» специализированному устройству, называемому контроллером памяти, а уже тот, в свою очередь — к микросхемам ОЗУ, размещенным на модулях памяти. Модули вы наверняка видели — это такие длинные узкие текстолитовые «планочки» (фактически — небольшие платы) с несколькими микросхемами на них, вставляемые в специальные разъёмы на системной плате. Роль контроллера ОЗУ, таким образом, проста: он служит своего рода «мостом» между памятью и использующими её устройствами (а это не только процессор, но об этом — чуть позже).
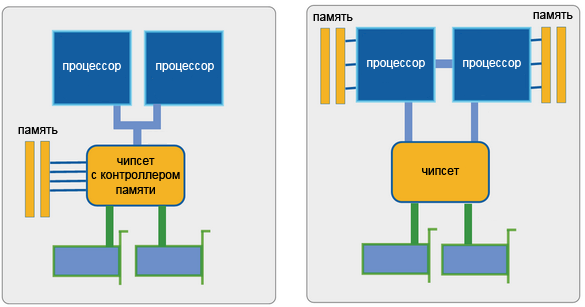
x86-система с внешним контроллером памяти (слева)
и с контроллером памяти, встроенным в процессор (справа)
В традиционной схеме, контроллер памяти входит в состав чипсета — набора микросхем, являющегося основой системной платы. От быстродействия контроллера во многом зависит скорость обмена данными между процессором и памятью, это один из важнейших компонентов, влияющих на общую производительность компьютера. По «новой» схеме (к ней относятся процессоры Intel Core с буквой «i», и все ныне выпускаемые CPU AMD), контроллер памяти входит в состав самого процессора — теперь никаких посредников между памятью и процессором нет, так что общаться им оказывается проще и быстрее. Однако многочисленным устройствам ввода-вывода жизнь несколько усложнилась — им путь до памяти стал на один шаг длиннее, т.к. чипсет никуда не исчез (а лишь лишился контроллера памяти), и теперь обращаться к памяти требуется через процессор, отвлекая его от выполнения программ. Тем не менее, новая схема является прогрессивной, потому что процессору важнее всего получить доступ к памяти как можно быстрее, даже ценой некоторого усложнения доступа для других устройств — именно он является главным потребителем и производителем той информации, которая записана в памяти.
Процессорная шина
Любой процессор обязательно оснащён как минимум одной процессорной шиной, которую в среде x86 CPU иногда по старинке называют FSB (Front Side Bus), хотя современные процессоры имеют для неё разные названия (QPI для Intel и HyperTransport для AMD). В многопроцессорных платах таких шин несколько, и связаны они с другими процессорами и чипсетом. В домашних компьютерах, где процессор, как правило, один, шина у него единственная (не считая шины памяти, если в процессор встроен её контроллер) и связывает его с чипсетом, а через него — со всеми остальными устройствами.
Оперативная память
Разрядность шины памяти, N-канальные контроллеры памяти
На сегодняшний день вся память, используемая в современных десктопных x86-системах, имеет шину шириной 64 бита. Это означает, что за один такт по данной шине одновременно может быть передано количество информации, кратное 8 байтам (8 байт для SDR-шин, 16 байт для DDR-шин). Особняком стоит только память типа RDRAM, применявшаяся в системах на базе процессоров Intel Pentium 4 на заре становления архитектуры NetBurst, но сейчас это направление признано тупиковым для x86-ПК (к слову — руку к этому приложила всё та же компания Intel, которая в своё время активно пропагандировала данный тип памяти). Некоторую неразбериху вносят лишь многоканальные контроллеры, обеспечивающие одновременную работу с несколькими отдельными друг от друга 64-битными шинами. Применительно к 2-канальным котроллерам некоторые производители заявляют о «128-битности». Однако арифметика на уровне 1-го класса в данном случае работает с оговоркой: 2x64 равно 128 только когда все каналы работают одновременно. Т.е. N-канальный контроллер памяти теоретически может увеличить скорость работы с данными в N раз, но при этом ширина каждой шины памяти во всех современных контроллерах, применяемых в x86-системах по-прежнему равна 64 битам. На данный момент времени, одноканальный контроллер памяти можно смело назвать анахронизмом: все современные x86-системы оснащены как минимум 2-канальными контроллерами памяти, а некоторые — даже 3-канальными.
Скорость чтения и записи
Скорость чтения и записи информации в память теоретически ограничивается исключительно пропускной способностью самой памяти. Так, например, двухканальный контроллер памяти стандарта DDR2-800 теоретически способен обеспечить скорость чтения и записи информации, равную 8 байт (ширина шины) * 2 (количество каналов) * 2 (протокол DDR, обеспечивающий передачу 2 пакетов данных за 1 такт) * 400'000'000 (фактическая частота работы шины памяти равная 400 МГц, т.е. 400 млн. тактов в секунду). Упомянем, что полученное произведение измеряется не в МБ/с (ГБ/с), а млн. (млрд.) байт/с, что несколько меньше честных двоичных «мега-» и «гига-». Даже с учётом этого, значения, получаемые в результате практических тестов, как правило, чуть ниже теоретических: сказывается «неидеальность» конструкции контроллера памяти, плюс накладки (задержки), вызванные работой подсистемы кэширования самого процессора (см. ниже раздел про процессорный кэш). Однако основной «подвох» содержится даже не в накладках, а в том, что скорость «линейного» чтения или записи является вовсе не единственной характеристикой, влияющей на фактическую скорость работы процессора с ОЗУ. Необходимо кроме линейной скорости считывания или записи учитывать ещё и такую характеристику, как латентность.
Латентность
Латентность (она же — задержка) является не менее важной характеристикой с точки зрения быстродействия подсистемы памяти, чем скорость «прокачки данных». Большая скорость обмена данными хороша тогда, когда их размер относительно велик, но если нам требуется «понемногу с разных адресов» — то на первый план выходит именно латентность. Что это такое? В общем случае — время, которое требуется для того, чтобы начать считывать информацию с определённого адреса. И действительно: с момента, когда процессор посылает контроллеру памяти команду на считывание (запись), и до момента, когда эта операция осуществляется, проходит определённое время. Причём оно вовсе не равно времени, которое требуется на пересылку данных. Приняв команду на чтение или запись от процессора, контроллер памяти «указывает» ей, с каким адресом он желает работать. Доступ к любому произвольно взятому адресу не может быть осуществлён мгновенно. Возникает задержка: адрес указан, но память не готова предоставить к нему доступ, особенно если он указывает на слишком далёкое от предыдущей операции место (по разнице адресов). В общем случае, эту задержку и принято называть латентностью. У разных типов памяти она разная. Так, например, память типа DDR3 имеет в среднем большие задержки, чем DDR2 (при одинаковой частоте передачи данных). В результате, если данные в программе расположены «хаотично» и «небольшими кусками», либо метод считывания или записи совсем не последовательный, то скорость обмена становится намного менее важной, чем скорость доступа к «началу куска», т.к. задержки при переходе на очередной адрес влияют на быстродействие системы намного сильнее, чем скорость считывания или записи.
«Соревнование» между скоростью чтения (записи) и латентностью — одна из основных головных болей разработчиков современных систем: к сожалению, рост скорости чтения (записи) почти всегда приводит к увеличению латентности. Так, например, память типа DDR обладает в среднем лучшей (меньшей) латентностью, чем DDR2. В свою очередь, у DDR3 латентность ещё выше (то есть хуже), чем у DDR2. Правда, здесь следует хорошо понимать, каким образом следует правильно сравнивать латентность. Если вы интересовались данным вопросом, вам наверняка хорошо знакома строчка вида «4-4-4-12», обозначающая как раз величину задержек при выполнении некоторых операций. Задержки в данном случае указаны в тактах частоты, на которой работает память. В то же время, если нас интересует латентность как единица измерения скорости, то считать её нужно не в тактах, а в секундах. Именно на этом часто «прокалываются» не очень хорошо разбирающиеся в вопросе пользователи, не понимающие, почему латентность, к примеру, в 6 тактов, может быть меньше, чем латентность в 4 такта. А всё очень просто: например, если модуль памяти с латентностью в 6 тактов, работает на частоте 800 МГц, а модуль памяти с латентностью 4 — на частоте 400 МГц — то совершенно очевидно, что 6 тактов на частоте 800 МГц займут меньше времени, чем 4 на частоте 400.
Также следует понимать, что «общая» латентность подсистемы памяти зависит не только от неё самой, но и от контроллера памяти и места его расположения — все эти факторы тоже влияют на задержку. Именно поэтому компания AMD в процессе разработки архитектуры AMD64 решила «одним махом» решить проблему высокой латентности, интегрировав контроллер прямо в процессор — чтобы максимально «сократить дистанцию» между процессорным ядром и модулями ОЗУ. Затея удалась, но с подвохом: теперь система на базе процессора AMD может работать только с той памятью, на которую рассчитан контроллер процессора. Наверное, поэтому компания Intel долго не решалась на такой кардинальный шаг, предпочитая действовать традиционными методами: усовершенствуя контроллер памяти в чипсете и механизм предзагрузки в процессоре (про него см. ниже) — пока всё-таки не согласилась, что идея AMD выгодней.
В завершение заметим, что понятия «скорость чтения / записи» и «латентность», в общем случае, применимы к любому типу памяти — в том числе не только к классическому ОЗУ (SDR, Rambus, DDR, DDR2, DDR3, …), но и к кэшу (см. ниже).
Процессор: сведения общего характера
Понятие архитектуры
Архитектура как совместимость с кодом
Наверняка вы часто встречались с термином «x86», или «Intel-совместимый процессор» (или «IBM PC compatible» — но это уже по отношению к компьютеру). Иногда также встречается термин «Pentium-совместимый» (почему именно Pentium — вы поймете сами чуть позже). Что скрывается за всеми этими названиями? На данный момент наиболее корректно с точки зрения авторов выглядит следующая простая формулировка: современный x86-процессор — это процессор, способный корректно исполнять машинный код архитектуры x86-64 (архитектура 32-битных процессоров Intel, дополненная 64-битными расширениями от AMD). В первом приближении современный x86 — это код, исполняемый процессором i80386 (известным в народе как «386-й»), окончательно же основной набор команд 32-битной архитектуры IA32 сформировался с выходом процессора Intel Pentium Pro (с очень незначительным дополнениями в следующих процессорах). Что означает «основной набор» и какие есть еще? Для начала ответим на первую часть. «Основной» в данном случае означает то, что с помощью исключительно этого набора команд может быть написана любая программа для процессора архитектуры x86.
Кроме того, у архитектуры IA32 существуют «официальные» расширения (дополнительные наборы команд) от разработчика самой архитектуры, компании Intel: MMX, многочисленные SSE (вплоть до 4.2) и AVX. Также существуют «неофициальные» (не от Intel) расширенные наборы команд: EMMX, 3DNow!, Extended 3DNow!, SSE4.a и XOP — их разработала компания AMD. Впрочем, «официальность» и «неофициальность» в данном случае понятие относительное — де-факто всё сводится к тому, что некоторые расширения набора команд Intel как разработчик изначального набора признаёт, а некоторые — нет, разработчики же программного обеспечения используют то, что им лучше всего подходит. В отношении расширенных наборов команд существует правило хорошего тона: прежде чем их использовать, программа должна проверить, поддерживает ли их процессор. Иногда отступления от этого правила встречаются (и могут приводить к неправильному функционированию программ), но объективно это является проблемой некорректно написанной программы, а не процессора.
Для чего предназначены дополнительные наборы команд? В первую очередь — для увеличения быстродействия при выполнении наиболее частых операций. Одна команда из дополнительного набора, как правило, выполняет действие, для которого понадобилась бы небольшая процедура, состоящая из команд основного набора, причём специальная команда выполняется процессором быстрее, чем заменяющая её последовательность. Однако в 99% случаев ничего такого, чего нельзя было бы сделать с помощью основных команд, команды из дополнительного набора также не делают. Таким образом, упомянутая выше программная проверка поддержки дополнительных наборов команд процессором должна выполнять очень простую функцию: если, например, процессор поддерживает SSE — значит, считать будем быстро и с помощью команд из набора SSE. Если нет — будем считать медленнее, с помощью команд из основного набора. Корректно написанная программа обязана действовать именно так. Впрочем, сейчас практически никто не проверяет у процессора наличие поддержки MMX, т.к. все CPU, вышедшие за последние 10 лет, этот набор поддерживают гарантированно. Для справки приведём табличку, на которой обобщена информация о поддержке различных расширенных наборов команд различными десктопными (предназначенными для настольных ПК) и некоторыми мобильными процессорами.
| Процессор | Год выпуска | x86-64 | PPro | MMX | Версия SSE | 3DNow! |
| Процессоры Intel | ||||||
| Pentium | 1993 | |||||
| Pentium Pro | 1995 | x | ||||
| Pentium MMX | 1997 | x | ||||
| Pentium II | x | x | ||||
| Celeron | 1998 | x | x | |||
| Pentium III | 1999 | x | x | 1 | ||
| Pentium 4 | 2000 | x | x | 2 | ||
| Celeron | x | x | 1 | |||
| Celeron | 2002 | x | x | 2 | ||
| Pentium M | 2003 | x | x | 2 | ||
| Pentium 4 | 2004 | x | x | x | 3 | |
| Celeron D | x | x | 3 | |||
| Pentium D, EE | 2005 | x | x | x | 3 | |
| Celeron D | ||||||
| Celeron | 2006 | x | x | x | 3S | |
| Celeron M | x | x | 3 | |||
| Core Solo, Duo | ||||||
| Core 2 | x | x | x | 3S | ||
| Core 2 | 2007 | x | x | x | 4.1 | |
| Celeron M | x | x | x | 3S | ||
| Pentium (DC) | ||||||
| Pentium (DC, M) | x | x | 3 | |||
| Atom | 2008 | x | x | x | 3S | |
| Celeron (DC) | ||||||
| Core i7 | x | x | x | 4.2 | ||
| Core i3, i5 | 2009 | x | x | x | 4.2 | |
| Core i9 | 2010 | x | x | x | 4.2 | |
| Процессоры AMD | ||||||
| K5 | 1996 | |||||
| K6 | 1997 | x | ||||
| K6-3D, K6-2+ | 1998 | x | x | |||
| K6-III | 1999 | x | x | |||
| Athlon | x | x | x | |||
| Duron | 2000 | x | x | x | ||
| Athlon XP | 2001 | x | x | 1 | x | |
| Athlon 4 (M) | ||||||
| Duron | ||||||
| Athlon 64 | 2003 | x | x | x | 2 | x |
| Sempron | 2004 | x | x | 1 (2) | x | |
| Athlon XP-M | 2005 | x | x | 2 | x | |
| Sempron | x | x | x | 2 (3) | x | |
| Athlon (64) X2 | x | x | x | 3 | x | |
| Turion (M) | ||||||
| Sempron (M) | x | x | 3 | x | ||
| Phenom | 2007 | x | x | x | 4.a | x |
| Athlon X2 | 2008 | x | x | x | 4.a | x |
| Athlon Neo | 2009 | x | x | x | 3 | x |
| Phenom II | x | x | x | 4.a | x | |
| Athlon II, X3, X4 | ||||||
Примечания:
PPro — означает наличие всех общих команд;
Версия SSE — номер последней поддерживаемой версии, подразумевая и все предыдущие;
Ряд SSE: SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2;
Для процессоров AMD наличие SSE4.a означает поддержку только SSE, SSE2, SSE3 и SSE4.a;
(M) — мобильная модель, даже если явно в имени не указано;
(DC) — двухядерный процессор, указано в индексе модели.
На данный момент всё популярное десктопное программное обеспечение (операционные системы Windows и Linux, офисные пакеты, компьютерные игры, и прочее) разрабатывается именно для x86-процессоров. Оно выполняется (за исключением «дурно воспитанных» программ) на любом x86-процессоре, независимо от того, кто его произвёл. Поэтому вместо ориентированных на разработчика изначальной архитектуры терминов «Intel-совместимый» или «Pentium-совместимый», стали употреблять нейтральное название: «x86-совместимый процессор», «процессор с архитектурой x86». В данном случае под «архитектурой» понимается архитектура системы команд (ISA, Instruction Set Architecture) — совместимость с определённым набором команд с точки зрения программиста. Есть и другая трактовка того же термина.
Архитектура как характеристика семейства процессоров
«Железячники» — люди, работающие в основном не с программным обеспечением, а с аппаратным — под «архитектурой» понимают несколько другое (правда, более корректно то, что они называют «архитектурой», называется «микроархитектурой», но приставку «микро» частенько опускают). Для них «архитектура CPU» — это некий набор свойств, присущий целому семейству процессоров, как правило, выпускаемому в течение многих лет (иначе говоря — их организация и «внутренняя конструкция»). Например, любой специалист по x86 CPU вам скажет, что процессор с ALU, работающими на удвоенной частоте, QDR-шиной, Trace cache, и, возможно, поддержкой технологии Hyper-Threading — это «процессор архитектуры NetBurst» (не пугайтесь незнакомых терминов — все нужные будут разъяснены чуть позже). Таким образом, понятие «архитектуры» применительно к процессорам двойственно: под ним может пониматься как совместимость с единым набором команд, так и совокупность аппаратных решений, присущих определённой достаточно широкой группе процессоров.
64-битные расширения классической x86 (IA32) архитектуры
В 2003 г. сначала AMD, а через год — и Intel, анонсировали практически идентичные технологии (впрочем, AMD предпочитает называть это архитектурой), благодаря которым классические x86 (IA32) CPU получили статус 64-битных. В случае с AMD данная технология получила наименование «AMD64», в случае с Intel — сначала «EM64T», а теперь Intel 64. Впрочем, сегодня часто указывают нейтральное «x86-64» — как общее обозначение всех 64-битных расширений архитектуры x86, не привязанное к зарегистрированным торговым маркам. Употребление одного из трёх приведённых наименований зависит больше от личных предпочтений употребляющего, чем от фактических различий — ибо различия между AMD64 и EM64T умещаются на кончике очень тонкой иглы. Так или иначе, всё сводится к следующему: все целочисленные регистры (общего назначения) стали вместо 32-битных 64-битными, число регистров (и общих, и векторных) удвоилось, 32-битные команды x86-кода получили свои 64-битные аналоги, а объём адресуемой памяти (и физической, и виртуальной) многократно увеличился (за счёт того, что логический адрес приобрёл вместо 32-битного 64-битный формат). Количество маркетинговых спекуляций на тему «64-битности» превысило все разумные пределы, поэтому следует рассмотреть достоинства данного нововведения.
Что не изменилось? В первую очередь — быстродействие процессоров. Вопиющей глупостью будет считать, что один и тот же процессор при переходе из привычного 32-битного в 64-битный режим (а 32-битный режим все нынешние x86 CPU поддерживают в обязательном порядке) станет работать вдвое быстрее. Разумеется, в некоторых случаях ускорение от использования 64-битной целочисленной арифметики может присутствовать — но количество этих случаев сильно ограничено, и большинства современного пользовательского программного обеспечения они никак не касаются. Кстати: а почему мы употребили термин «64-битная целочисленная арифметика»? А потому, что блоки операций с плавающей точкой (см. ниже) во всех x86-процессорах уже давным-давно не 32-битные. И даже не 64-битные. Классический вещественный вычислитель, окончательно ставший частью CPU ещё во времена старого доброго 32-битного Intel Pentium* — уже был 80-битным (и до сих пор таков). Векторные операнды команд SSE (с любой цифрой) — и вовсе 128-битные! В этом плане архитектура x86 достаточно парадоксальна: притом, что формально процессоры данной архитектуры достаточно долгое время оставались 32-битными — разрядность тех блоков, где «большая битность» была реально необходима — наращивалась совершенно независимо от остальных (более подробно о проблеме разрядности процессоров можно почитать в отдельном материале). Например, процессоры AMD Athlon XP и Intel Pentium 4 «Northwood» совмещали в себе блоки, работающие с 32-битными, 80-битными, и 128-битными операндами. 32-битными оставались лишь основной набор команд (унаследованный от первого процессора архитектуры IA32 — Intel 386) и адресация памяти (максимум 4 гигабайта, если не считать «эквилибристического выверта» от Intel — Physical Address Extension, позволявшего «32-битным» процессорам использовать 36(!)-битную адресацию).
* — первым x86 CPU, в который был интегрирован FPU (ранее он устанавливался на плату в качестве отдельного чипа), стал процессор предыдущего поколения — i486DX. Но в линейке i486 всё-таки присутствовал i486SX, в состав которого FPU не входил. Начиная с Pentium, Intel больше не выпускала x86 CPU без FPU, и эту моду быстро подхватили все остальные производители.
Таким образом, то, что процессоры AMD и Intel стали «формально 64-битными», на практике принесло нам лишь три усовершенствования: появление команд для работы с 64-битными целыми числами, увеличение количества и/или разрядности регистров, и увеличение максимального объёма адресуемой памяти. Заметим: реальной пользы этих нововведений (особенно третьего!) никто не отрицает. Равно как никто не отрицает заслуг компании AMD в продвижении идеи «осовременивания» (за счёт введения 64-битности) x86-процессоров. Мы лишь хотим предостеречь от чрезмерных ожиданий: не стоит надеяться на то, что компьютер, покупавшийся «в ценовом классе ВАЗа», от установки 64-битного программного обеспечения станет «лихим Мерседесом». Чудес на свете не бывает...
Процессорное ядро
О многоядерности (многопроцессорности) как концепции
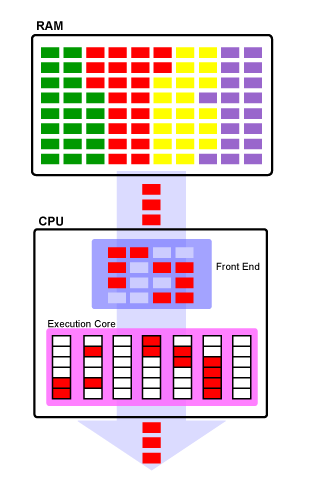
Классическая одноядерная (однопроцессорная) схема: в памяти находится код нескольких программ («кирпичики» разного цвета), но в один момент времени процессор выполняет код только одной из них
Прежде, чем мы начнём описывать особенности многоядерных систем, нужно вначале объяснить, зачем вообще они нужны, и как за счёт большего количества ядер и/или процессоров может достигаться положительный эффект. В данном случае мы для простоты считаем, что система, собранная на базе одного процессора с двумя ядрами, практически идентична по функционалу системе на базе двух процессоров с одним ядром — если ядра в обоих случаях идентичны*. Более подробное разъяснение можно прочитать в отдельном, более сложном материале, но хотя бы схематически описать ситуацию просто необходимо. Всё нижесказанное относится к концепции SMP (Symmetric Multiprocessing, cимметричная многопроцессорность), т.к. пока на x86 прижился именно этот вариант. Он требует, чтобы при любом числе процессоров (строго говоря — процессорных ядер) в системе они все были одинаковые, каждый может быть заменен любым другим, и все они осуществляют доступ к одному и тому же массиву памяти.
* — pаньше многоядерный процессор на массовом рынке был мечтой практически неосуществимой, поэтому в тех отраслях, где требовалась высокая производительность в специфических задачах, использовались системы не многоядерные, а многопроцессорные. Вместо того, чтобы интегрировать N ядер в один чип — на системную плату устанавливали N разъёмов, и в них — N одноядерных процессоров. Условно, современный десктоп на N-ядерном процессоре, можно приравнять к N-процессорной системе. Впрочем, многопроцессорные системы есть и сейчас — для тех, кого не устраивает максимально возможное количество ядер в одном CPU. Так, например, если вам нужна 16-процессорная (16-ядерная) система — то ввиду отсутствия 16-ядерных x86-процессоров (пока, на 2009 г.…), вам придётся согласиться на 4-процессорную систему, в которой у каждого процессора будет по 4 ядра.

4-процессорная системная плата, в каждый сокет которой можно установить
6-ядерный процессор. В результате мы получим 24-ядерную x86-систему.
Итак, наш главный вопрос: для чего всё это нужно? Каким образом за счёт увеличения количества ядер (процессоров) увеличивается быстродействие? Сразу расскажем, какой основной вопрос возникает при более детальном ознакомлении с многоядерными (многопроцессорными) системами: «Почему быстродействие увеличивается в разных случаях по-разному, а иногда не увеличивается вовсе?» Проще всего разъяснить это на примере простой и понятной аналогии с неким количеством работы, и неким количеством людей. Рассмотрим два самых распространённых варианта.
Вариант №1: несколько совершенно независимых друг от друга задач. Например, мы находимся в загородном доме, и нам необходимо наколоть дров и выкосить газон. Если у нас в распоряжении один человек — он будет вынужден сделать сначала одно дело, а потом другое, либо делать их параллельно, переключаясь между ними — но всё равно в один конкретный момент времени он будет занят чем-то одним. Если же есть два человека — то один может заняться колкой дров, а другой — косить газон. Заметьте: сами по себе задачи не стали выполняться быстрее — но мы экономим время за счёт того, что они выполняются параллельно. Продолжив аналогию, вы легко поймёте основной недостаток наращивания в данной ситуации количества людей до бесконечности (а они у нас олицетворяют процессорные ядра или одноядерные процессоры): рано или поздно для ещё одного человека просто не найдётся работы. Или ресурсов: например, колоть дрова можно и вдвоём — но что делать, если у нас всего один топор?
Вариант №2: одна частично или полностью распараллеливаемая задача. Почти идеально распараллеливаемая задача (при условии, как уже было упомянуто выше, наличия должного количества ресурсов) — это та же колка дров, или, например, мытьё полов. Каждому в руки по швабре и ведру, каждому свой участок пола — и вперёд! Вы, правда, наверняка заметите, на основании банального житейского опыта, что ещё и задача должна быть соответствующего масштаба: хорошо мыть полы вчетвером в большом доме, но совершенно бессмысленно — в одной комнатушке. В случае с многоядерностью всё совершенно аналогично: быстро выполняемая задача, даже если она хорошо параллелится, вызывает давно известный эффект: согласование действий между выполняющими работу начинает занимать время, сопоставимое с временем выполнения самой работы каждым исполнителем. Русская пословица «у семи нянек дитя без глаза» примерно характеризует данную ситуацию.
Более сложный случай — например, варка борща. Конечно, хозяйка может поручить кому-то почистить овощи, кому-то нарезать, и т.д., но всё равно на некотором этапе у нас начнётся достаточно длительный процесс (собственно варки), в котором участие более чем одного человека совершенно не требуется. Это и есть частично распараллеливаемая задача: некоторые её этапы могут выполняться параллельно, а некоторые — нет. Совершенно очевидно, что даже если выделить на выполнение этой задачи двух людей, в 2 раза её выполнение не ускорится (а если четырёх — то в случае с борщом, четвёртый может оказаться в большинстве случаев лишним). И у многоядерных процессоров на частично распараллеливаемой задаче не все ядра могут задействоваться одновременно всё время. А значит, некоторые из них как минимум иногда будут простаивать.
Подытожим: добавление ещё одного ядра не всегда приводит к ускорению, а даже если и приводит — то не всегда настолько, сколько можно было бы ожидать в идеальном случае. Фактически, всё зависит от решаемых задач (используемых программ). Некоторые задачи параллелятся хорошо, некоторые — не очень, некоторые не параллелятся вообще. Почти идеально в большинстве случаев параллелятся две независимых задачи, но… для этого нужно, чтобы у вас достаточно часто возникала потребность решать несколько независимых задач одновременно! Говоря конкретней, двухъядерный процессор на программах обычного пользователя в среднем получит ускорение примерно раза в полтора, а 4-ядерный — примерно в два по сравнению с одноядерным. А вот при запуске «профессиональных» программ кратность ускорения часто почти равна числу ядер.
Число ядер и технология Hyper-Threading
Первое, что надо сказать о ядрах — в одном процессоре их бывает много. В вашем их, скорее всего, не менее двух, а вообще их может быть от 1 до 6 (скоро — и больше). Все ядра одинаковые, но кроме них в процессоре есть и обслуживающие их общие блоки — общий кэш, контроллер памяти и шины обмена с другими процессорами и/или с чипсетом. В новейших процессорах к этому списку скоро добавятся и специализированные ядра, например, для 3D-графики и декодирования видео. Когда говорят об устройстве ядер, то имеют ввиду каждое ядро многоядерного процессора (даже если говорится «ядро» в единственном числе).
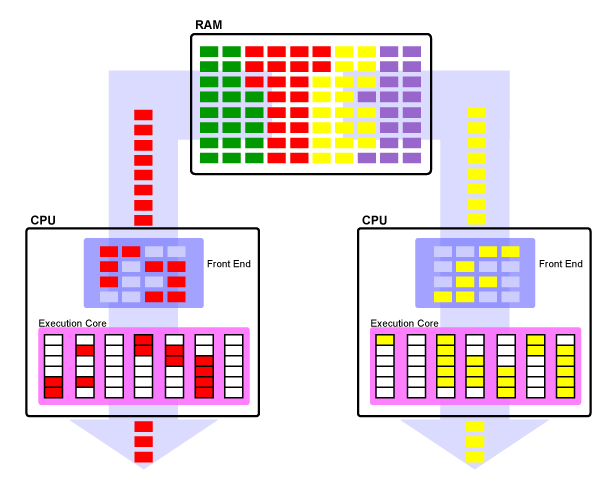
Многоядерная (многопроцессорная) система: благодаря наличию двух ядер (процессоров), можно одновременно исполнять код двух программ
Как было сказано, у многоядерности есть ограничения по увеличению производительности. Когда задачи или их части выполняются параллельно, ядра конкурируют за доступ к общим блокам. Например, если запустить две задачи, сильно зависящие от пропускной способности памяти, и которым не хватит объёма кэша каждого ядра, то производительности общего для ядер кэша, а также контроллера памяти может быть недостаточно, чтобы насытить сразу два ядра. В результате они оба будут простаивать до половины времени — реальное увеличение скорости по сравнению с однопоточным исполнением может быть околонулевым. Противоположная ситуация, когда программы оптимизированы под многоядерные процессоры и не перегружают разделяемые ресурсы, выглядит примерно так: процессор исполняет столько потоков, сколько у него ядер, причём каждый поток в основном использует блоки своего ядра, а общение ядер между собой, а также с памятью достаточно редко, чтобы даже исполнение нескольких потоков не перегружало общие элементы процессора и не приводило к задержкам работы ядер. Подобрать по такому критерию несколько разных программ весьма сложно, а вот оптимизировать одну — удаётся куда чаще. Именно в таких случаях и удаётся получить то, что называется линейным ростом производительности от числа потоков (фактически — ядер): 2 ядра работают вдвое быстрее одного, 4 — вдвое быстрее двух, и т.д.. Всё вышесказанное касается и многопроцессорных систем, где число ядер каждого CPU надо умножить на число последних.
Дополнительную сложность вносит поддержка некоторыми процессорами технологии Hyper-Threading (гиперпоточности). Она позволяет одному ядру работать за два — хотя и не так эффективно, как реально существующая пара ядер, зато куда дешевле. При этом операционная система сообщает о процессоре с вдвое большим числом ядер, поскольку видит число ядер логических (по максимальному количеству одновременно запускаемых программ), а не физических (по числу реально выполняемых). Изменение производительности может быть от почти незаметного замедления до внушительного (20-50 %) ускорения и сильно зависит от набора исполняемых программ, а в среднем же ускорение равно 10-15%. К сожалению, чем лучше программа оптимизирована под настоящую многоядерность, тем меньше она выиграет от «виртуальной» за счёт Hyper-Threading.
Процессор с поддержкой Hyper-Threading: на одном физическом ядре одновременно выполняется код двух приложений
Различия между ядрами одной микроархитектуры
«Процессорное ядро» (как правило, для краткости его называют просто «ядро») — это конкретное воплощение (микро)архитектуры (т.е. архитектуры в «аппаратном» смысле), являющееся стандартом для целой серии процессоров. Например, K10 — это микроархитектура, которая лежит в основе многих сегодняшних процессоров AMD: Athlon II, Phenom, Phenom II, Opteron. Микроархитектура задаёт общие принципы: «средний» по длине конвейер, исполнение до трёх команд за такт, предсказание переходов и внеочередное исполнение, и прочие «глобальные» особенности. Ядро — более конкретное воплощение. Например, процессоры микроархитектуры К10 с двумя ядрами, без поддержки многопроцессорности и кэша L3, с шиной HyperTransport частотой в 2 ГГц — это более-менее полное описание ядра Regor для Athlon II.
Можно сказать что «ядро» — это конкретное воплощение определённой микроархитектуры «в кремнии», обладающее (в отличие от самой микроархитектуры) набором строго обусловленных характеристик. Микроархитектура — аморфна, она описывает общие принципы построения процессора. Ядро — микроархитектура, «обросшая» всевозможными параметрами и характеристиками. Чрезвычайно редки случаи, когда процессоры сменяли микроархитектуру, сохраняя название. И, наоборот, практически любое наименование процессора хотя бы несколько раз за время своего существования «меняло» ядро. Например, общее название серии процессоров AMD — «Athlon 64» — это одна микроархитектура (K8), но целых 13 ядер — от Sledgehammer (2003 г.) до Huron (2009 г.). Разные ядра, построенные на одной микроархитектуре, могут иметь в том числе разное быстродействие.
Ревизии
Ревизия — одна из модификаций ядра, крайне незначительно отличающаяся от предыдущей, почему и не заслуживает звания «нового ядра». Как правило, из выпусков очередной ревизии производители процессоров не делают большого события, это происходит «в рабочем порядке». Так что даже если вы покупаете один и тот же процессор, с полностью аналогичным названием и характеристиками, но с интервалом где-то в полгода — вполне возможно, фактически он будет уже немного другой. Выпуск новой ревизии, как правило, связан с какими-то мелкими усовершенствованиями. Например, удалось чуть-чуть снизить энергопотребление, понизить напряжение питания, что-то оптимизировать, или была устранена пара мелких (иногда не очень…) ошибок. С точки зрения производительности была всего пара примеров, когда бы одна ревизия ядра отличалась от другой настолько существенно, чтобы об этом имело смысл говорить. Хотя чисто теоретически возможен и такой вариант — например, подвергся оптимизации один из блоков процессора, ответственный за исполнение нескольких команд. Подводя итог, можно сказать что «заморачиваться» ревизиями процессоров чаще всего не стоит: в очень редких случаях изменение ревизии вносит какие-то кардинальные изменения.
Частота работы ядра
Как правило, именно этот параметр в просторечии именуют «частотой процессора». Хотя в общем случае определение «частота работы ядра» всё же более корректно, так как совершенно не обязательно все составляющие CPU функционируют на той же частоте, что и ядро (наиболее частым примером обратного являлись старые «слотовые» x86 CPU — Intel Pentium II и Pentium III для Slot 1, AMD Athlon для Slot A — у них L2-кэш функционировал на 1/2, и даже иногда на 1/3 частоты работы ядра). Примерно также сегодня в большинстве процессоров работает кэш L3 — на своей отдельной частоте, меньшей, чем у каждого ядра. Ещё одним распространённым заблуждением является уверенность в том, что частота работы ядра однозначным образом определяет производительность. Это дважды не так.
Во-первых, каждое конкретное процессорное ядро (в зависимости от того, как оно спроектировано, сколько содержит исполняющих блоков различных типов, и т.д. и т.п.) может исполнять разное число команд за один такт, частота же — это всего лишь количество таких тактов в секунду. Таким образом (приведённое далее сравнение, разумеется, очень сильно упрощено) процессор, ядро которого исполняет 3 инструкции за такт, может иметь на треть меньшую частоту, чем процессор, исполняющий 2 инструкции за такт — и при этом обладать полностью аналогичным быстродействием.
Во-вторых, даже в рамках одного и того же ядра, увеличение частоты вовсе не всегда приводит к пропорциональному увеличению быстродействия. Здесь вам очень пригодятся знания, которые вы могли почерпнуть из раздела «Общие принципы взаимодействия процессора и ОЗУ». Дело в том, что скорость исполнения команд ядром процессора — это вовсе не единственный показатель, влияющий на скорость выполнения программы. Не менее важна скорость поступления команд и данных на CPU. Представим себе чисто теоретически такую систему: быстродействие процессора — 10'000 команд в секунду, скорость работы памяти — 1000 байт в секунду. Даже если принять, что одна команда занимает не более одного байта, а данных у нас нет совсем, с какой скоростью будет исполняться программа в такой системе? Не более 1000 команд в секунду, и производительность CPU тут совершенно ни при чём: мы будем ограничены не ей, а скоростью поступления команд в процессор. Таким образом, следует понимать: невозможно непрерывно наращивать одну только частоту ядра, не ускоряя одновременно подсистему памяти, так как в этом случае начиная с определённого этапа, увеличение частоты CPU перестанет сказываться на увеличении быстродействия системы в целом.
Наконец, у компании Intel есть технология TurboBoost, особенность которой в том, что процессоры с её поддержкой вообще не имеют никакой конкретной частоты чего-либо. Смысл TurboBoost — увеличивать частоту загруженных ядер в зависимости от числа простаивающих, а также от температуры и энергопотребления всего процессора. В результате «нормальная» частота (написанная на коробке процессора или в прайс-листе) реально почти всегда будет превышена на 133-666 МГц (в мобильных процессорах серии Core i7 возможен разгон на 1333 МГц, если работает только одно ядро), причём всё время меняясь. Грубо говоря, можно сказать, что TurboBoost даст примерно +10% к скорости «за просто так».
Виртуализация
Виртуализация в вычислительной технике — это возможность запускать несколько операционных систем (и программы из-под каждой из них) так, что они будут работать будто бы на своих отдельных компьютерах (т.е. подразумевается виртуализация «железа» по отношению к програмам). Впервые она появилась аж в 60-е годы на мейнфреймах IBM и до недавнего времени была полезна лишь для программирования и высокопроизводительных сетевых серверов. Однако новая ОС фирмы Microsoft Windows 7 уже требует аппаратную поддержку виртуализации в процессоре, если предполагается запускать 32-битные программы, написанные для Windows XP и более ранних версий (т.е. читай — всегда). Так зачем нужна эта аппаратная поддержка, если ранее и программной справлялись?
Аппаратная поддержка виртуализации в процессоре фактически означает наличие дополнительного поднабора команд, который позволяет инициировать, вызвать, завершать и переключать виртуальные ОС быстрее и с более надёжной изоляцией друг от друга (что важно для устойчивости и безопасности всей системы), чем программными средствами. Как обычно, оба главных производителя CPU стараются подчеркнуть преимущества своих реализаций, так что им даны разные имена: Intel Virtualization Technology (Intel VT) и AMD Virtualization (AMD-V). Причём между ними действительно есть небольшая разница, но, опять же, крайне незначительная и не приводящая к несовместимости. С точки зрения пользователя вердикт прост — поддержку виртуализации в процессоре лучше иметь, чем не иметь, т.к. даже если она не пригодится сейчас, то, возможно, пригодится через пару лет, а разница в стоимости у процессоров с и без неё почти незаметна. Более того — в новых CPU, виртуализацию поддерживают все модели, так что «хочешь, не хочешь»…
Особенности образования названий процессоров
Раньше, когда небо было голубее, пиво — вкуснее, а девушки — красивее (прим. ред.: мнение редакции не всегда совпадает с мнением авторов, особенно насчёт девушек), процессоры называли просто: имя производителя + название модельного ряда («линейки») + частота. Например: «AMD K6-2 450 MHz». В настоящее время оба основных производителя от этой традиции отошли и вместо частоты употребляют какие-то непонятные циферки, обозначающие невесть что. В первой версии статьи на этом месте было краткое объяснение того, что же эти циферки обозначают. Однако с тех пор (а прошло всего 3 года) оба основных производителя x86 CPU неоднократно меняли и дополняли эти правила, так что фактически уследить за ними в рамках даже регулярно обновляющегося цикла статей невозможно, да и не очень требуется. Есть способы лучше. Если вам нужно узнать основные характеристики какого-то процессора, проще всего просто набрать его полное имя в Гугле или Яндексе, и среди первой десятки результатов вы наверняка найдёте краткое описание его внутренностей. Если же требуется сравнить разные процессоры, названия которых вы не помните или не знаете, подойдёт Википедия: вот список всех процессоров AMD, а вот — процессоры Intel. Для любителей экзотики есть ещё процессоры VIA. Ссылки на детальные списки процессоров по линейкам (Celeron, Sempron, Core i7, Phenom, Nano и т.п.) см. в самом внизу страницы напротив слова Lists.
Что касается общего положения, то у обоих основных производителей ситуация примерно такая (с многочисленными исключениями, разумеется). Сначала указывается название линейки процессоров. Оно говорит об общей направленности применения: бюджетные, основные (mainstream), дешёвые и экономные (для нетбуков), основные и экономные (для ноутбуков), просто быстрые и быстрые с поддержкой многопроцессорности (для рабочих станций и серверов). После указывается номер поколения этой линейки — не обязательно порядковый, но чем больше — тем «круче». Затем, на том месте, где ранее была частота — 2-4-значное число «рейтинга» производительности, обозначающее сразу несколько методов её увеличения:
- число физических ядер (логических больше, если у процессора есть технология типа Hyper-Threading);
- их частота (при наличии технологии Turbo Boost или ей подобной — максимальная частота продолжительной надёжной работы всех ядер с их полной загрузкой, максимальной допустимой температурой корпуса процессора и «нормальным» напряжением питания);
- полный объём всех кэшей;
- число контроллеров и шин памяти и чипсета;
- частота этих шин;
- возможность частотного разгона разными способами;
- наличие дополнительных специализированных блоков и шин;
- разные мелочи.
Причём это число не является оценкой самой производительности, т.е. вы не только не сможете сказать, насколько модель 2300 быстрее модели 1200, но даже и какая из них быстрее в конкретной программе. Можно лишь утверждать, что с точки зрения производителя, модель 2300 сложнее в производстве, чем модель 1200 — у неё выше некоторые технические характеристики, больше ядер или кэша, и т.д. и т.п. При этом подразумевается, что раз уж модель с более высоким номером снабдили всеми этими «наворотами» — то она и работать будет быстрее (иначе зачем было снабжать?) Однако практика свидетельствует, что сбывается это предположение отнюдь не всегда.
Также иногда к «рейтингу» спереди или сзади добавляются 1-2 буквы для обозначения класса потребления энергии: для немобильных процессоров — просто «обычный» и «экономный», а для мобильных — более детальная градация.
Измерение скорости «в мегагерцах» — как это возможно?
Никак это не возможно, потому что скорость не измеряется в мегагерцах, как не измеряется расстояние в килограммах. Однако господа маркетологи давно уже поняли, что в словесном поединке между физиком и психологом побеждает всегда последний — причём независимо от того, кто на самом деле прав (прим. маркетологов: хотите об этом поговорить?) Поэтому мы и читаем про «сверхбыструю 1066-мегагерцевую шину», мучительно пытаясь понять, как скорость может измеряться с помощью частоты. На самом деле, раз уж прижилась такая извращённая тенденция, нужно просто чётко представлять себе, что имеется в виду. А имеется в виду следующее: если мы «закрепим» ширину шины на N битах — то её пропускная способность действительно будет зависеть от того, на какой частоте данная шина функционирует, и какое количество данных она способна передавать за такт. По обычной процессорной шине с «одинарной» скоростью (такая шина была, например, у процессора Intel Pentium III) за такт передаётся 64 бита, то есть 8 байт. Соответственно, если рабочая частота шины равна 100 МГц (100'000'000 тактов в секунду) — то скорость передачи данных будет равна 8 байт * 100'000'000 герц ≈ 763 мегабайта в секунду (а если считать в «десятичных мегабайтах», в которых принято считать потоки данных, то ещё красивее — 800 мегабайт в секунду). Соответственно, если на тех же 100 мегагерцах работает DDR-шина, способная передавать за один такт удвоенный объём данных — скорость вырастет ровно вдвое. Поэтому, согласно парадоксальной логике господ маркетологов, данную шину следует именовать «200-мегагерцевой». Хотя реальная частота работы у вышеописанных шин одинаковая — 100 мегагерц. Вот так «мегагерцы» и стали синонимом скорости.
Впрочем, независимые источники также указывают производительность шины не в герцах, а в транзакциях (т.е. актах передачи данных) в секунду — МТ/s или GТ/s (с приставками мега и гига). Это число надо умножить на ширину шины в байтах. Тем не менее, главное здесь — выучить наизусть один простой принцип: если уж мы занимаемся таким извращением, как сравнение скорости двух шин между собой «в мегагерцах» — то они обязательно должны быть одинаковой ширины и одного типа передачи за такт. Иначе получается как в одном форуме, где человек всерьёз доказывал, что пропускная способность AGP2X («133-мегагерцевая», но 32-битная шина) — выше, чем пропускная способность FSB у Pentium III 800 (реальная частота 100 МГц, ширина 64 бита).
О некоторых особенностях технологий DDR и шин НТ и QPI
Как уже было сказано, в режиме DDR по шине за один такт передаётся удвоенный объём информации. Правда, в документах, ориентированных больше на прославление достижений производителей, чем на объективное освещение реалий, почему-то не всегда указывают одно маленькое «но»: режимы удвоенной скорости включаются только при пакетной передаче данных, а она всегда включена не во всех типах шин. Т.е. если мы запросили из памяти парочку мегабайтов с адреса X по адрес Y — то да, эти два мегабайта будут переданы с удвоенной скоростью. А вот сам запрос на данные может быть передан по шине и с «одинарной» скоростью! Соответственно, если запросов у нас много, а размер пересылаемых данных не очень велик, то количество данных, которые «путешествуют» по шине с одинарной скоростью (а запрос — это тоже данные) будет почти равно количеству тех, которые передаются со скоростью удвоенной. Это касается шин доступа к памяти и старых шин связи с чипсетом, но новые шины включают пакетную передачу для любых видов информации. Новые — это HyperTransport (она же — НТ, но не путайте с HyperThreading) для процессоров AMD и QPI для Intel. У новичков есть четыре главных особенности, отличающие их от предыдущих решений: эти шины уже (как правило, 32 бита), в несколько раз быстрее по частоте, могут соединять только 2 устройства (на старые шины можно «повесить» и более) и, самое интересное, — они полнодуплексные. Т.е. фактически состоят из двух разнонаправленных половинок, позволяющих одновременно передавать данные в обе стороны. Так что для оценки скорости надо различать три цифры: частота работы шины (как правило, в спецификациях указывается именно она), количество передач данных в одном направлении (вдвое больше частоты за счёт DDR) и число совокупных передач данных в обоих направлениях (ещё вдвое больше). Теперь, если умножить второе или третье число на ширину шины в байтах, мы получим заветные гигабайты в секунду (точнее, млрд. байт/с) — в одном или двух направлениях.
Возможно, через несколько лет таким же изменениям подвергнется и шина между процессором и памятью — она станет узкой, сверхбыстрой и двухнаправленной. Однако возможность подключать несколько модулей памяти наверняка сохранится.
Внешние данные: корпус, разъём, охлаждение
У любого процессора есть не только интерьер, но и экстерьер — «одёжка», по которой его встречают. Не пользователи, конечно, а коллеги-компоненты по компьютеру. Чтобы процессор вообще заработал, требуется соблюсти несколько важных пунктов.
Во-первых, у процессора есть корпус определённого размера с определённым количеством выводов в определённом расположении — всё это должно точно подходить к разъёму для CPU на материнской плате (компактные процессоры для неттопов и нетбуков продаются вместе с мат. платами сразу запаянные в них). Тип разъёма (сокета) обозначается буквой или числом выводов. Для каждого процессора указывается тот разъём, который для него подходит. Причём «подходит» означает не только механическую совместимость (т.е. процессор физически умещается в разъёме в единственно верном положении, обозначенном специальной меткой-ключём), но и электрическую, силовую и интерфейсную. Последнее гарантирует, что выводы и контакты расположены в ожидаемом порядке, на выводы питания подаётся именно то напряжение и та сила тока, которая нужна, а к информационным выводам подключены нужные шины и линии управления чипсета и периферии. Впрочем, установка процессора нового поколения вместо старого даже при совпадении разъёма не всегда закончится удачно, потому что…
Во-вторых, BIOS (загрузочная программа, стартующая сразу после включения компьютера и записанная в микросхеме флеш-памяти на материнской плате) ожидает обнаружить лишь те виды процессоров, которые в него заложили разработчики системной платы. Но если ваш новый процессор вышел позже, то для поддержки всех его функций придётся обновить и сам BIOS, новую версию которого («прошивку») нужно загрузить с сайта производителя материнской платы, убедившись, что в ней есть поддержка новинки. Впрочем, иногда это не требуется — если новый CPU не сильно отличается от старого, то и обновление BIOS'а ему не нужно, но это должно быть явно сказано производителем процессора или системной платы.
В-третьих, даже если процессор точно заработал всеми своими наворотами и гигагерцами, есть ещё кое-что, без чего его работа может очень быстро закончится — охлаждение. При покупке стоит обратить внимание на то, сколько процессор выделяет энергии (эта величина почти равна её потреблению) — параметр TDP (Thermal Design Power), измеряемый в ваттах. Фактически это требование к системе охлаждения — именно столько тепла должен отводить кулер или радиатор, чтобы процессор не перегревался (для каждого процессора и вида корпуса есть своя максимально допустимая температура, гарантирующая продолжительную надёжную работу). Если перегрев всё-таки произойдёт, процессор сначала станет снижать фактическую частоту работы (причём различными программами-мониторами это не обязательно фиксируется), а затем может и вовсе подать сигнал аварийного отключения питания всего компьютера. Для этого в каждый современный CPU встроен датчик температуры, выдающий показания системной плате, а также собственным механизмам защиты, главная цель которых — не дать физически сжечь процессор (ценой потери производительности и даже данных).
Процессор: детальней
Кэш
Общее описание и принцип действия
Во всех современных процессорах есть кэш (cache). Это разновидность памяти (кардинальные отличия кэша от ОЗУ — скорость работы и меньшая задержка доступа), которая является своего рода «буфером» между контроллером памяти и процессором и служит для увеличения скорости работы с ОЗУ. Каким образом? Чтобы объяснить, сразу откажемся от попахивающих детским садом сравнений, которые частенько встречаются в популяризаторской литературе на процессорную тематику (бассейны, соединённые трубами разного диаметра, и т.д. и т.п.). Всё-таки человек, который дочитал статью до этого места и не заснул (прим. ред. — а ведь авторы так старались!), наверное, способен выдержать и «переварить» чисто техническое объяснение, без бассейнов, кошечек и одуванчиков.
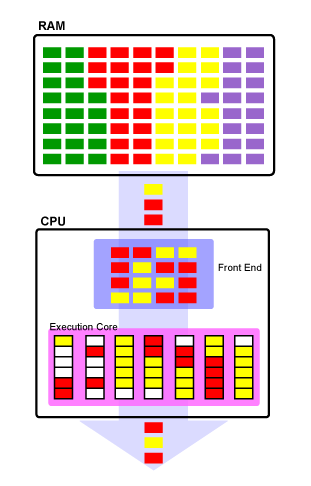
Итак, представим, что у нас есть много сравнительно медленной памяти (пусть это будет ОЗУ размером 1 мегабайт) и относительно мало очень быстрой (пусть это будет кэш размером всего 1 килобайт). Как нам с помощью этого несчастного килобайта увеличить скорость работы со всей памятью вообще? А вот здесь следует вспомнить, что данные в процессе работы программы, как правило, не бездумно перекидываются с места на место — они изменяются. Считали из памяти значение какой-то переменной, прибавили к нему какое-то число — записали обратно на то же место. Считали массив, отсортировали по возрастанию — опять-таки записали в память. Т.е. в каждый момент программа работает не со всей памятью, а, как правило, с относительно маленьким её фрагментом. Напрашивается решение — загрузить этот фрагмент в «быструю» память, обработать его там, а потом уже записать обратно в «медленную» (или просто удалить из кэша, если данные не изменялись). В общем случае, именно так и работает процессорный кэш: любая считываемая из памяти информация попадает не только в процессор, но и в кэш. И если эта же информация нужна снова, сначала процессор проверяет: нет ли её в кэше? Если есть (а современные кэши совершенны настолько, что это происходит в подавляющем большинстве случаев) — информация берётся оттуда, и обращения к памяти не происходит вовсе. Аналогично с записью: информация, если её объём влезает в кэш, пишется именно туда, и только потом, когда процессор закончил операцию записи, и занялся выполнением других команд, данные, записанные в кэш, параллельно с работой процессорного ядра «потихоньку» выгружаются в ОЗУ.
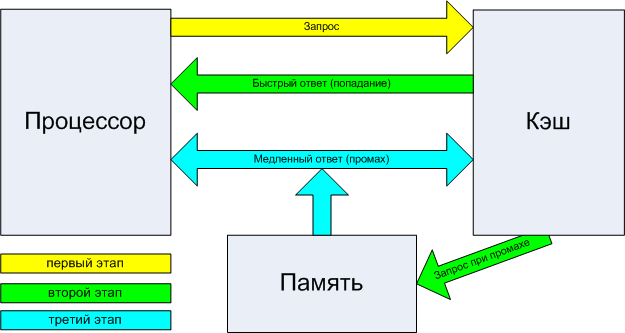
Основной принцип работы процессорного кэша. Второй этап предусматривает два различных варианта развития событий: быстрый ответ, либо передачу запроса дальше, в память. Третий этап в случае быстрого ответа отсутствует.
Говоря по-научному, кэш использует эффекты, которые называются временной и пространственной локальностью информации. Пространственная локальность означает, что несколько обращений к памяти подряд произойдут по адресам, скорее «близким» друг к другу, чем «далёким». Дело в том, что при чтении данных, которых не оказалось в кэше, процессор из памяти получает только их, а кэш дополнительно запрашивает себе ещё несколько десятков байт «вокруг». В результате, если первое обращение закэшировано, то, скорее всего, и для всех последующих также не потребуется обращаться к памяти. А временная локальность означает, что данные, к которым недавно обращались, скорее всего в течение ближайшего времени понадобятся ещё раз или много раз. Поэтому после удачного попадания в кэш (именно так это событие и называется — кэш-попадание, а отсутствие нужных данных в кэше — кэш-промах) информация там остаётся и даже получает больший «рейтинг популярности» (зачем — см. ниже).
Разумеется, объём данных, прочитанных и записанных за всё время работы программы — намного больше объёма кэша. Поэтому некоторые из них приходится время от времени удалять, чтобы в кэш могли поместиться новые, более актуальные. Самый простой из известных механизмов обеспечения данного процесса — отслеживание времени последнего обращения к данным, находящимся в кэше. Так, если нам необходимо поместить новые данные в кэш, а он уже «забит под завязку», контроллер, управляющий кэшем, смотрит: к какому фрагменту кэша не происходило обращения дольше всего (та самая «популярность»). Этот фрагмент и является первым кандидатом на «вылет», а на его место записываются новые данные, с которыми нужно работать сейчас.
Чтобы было понятно, насколько важен кэш, приведём простой пример: скорость обмена данными современного процессора с быстрейшим из своих кэшей (подробней — абзацем ниже) в 5-10 раз превосходит скорость его работы с памятью, а задержки меньше в 50 раз! Фактически, в полную силу современные процессоры способны работать только с кэшем: как только они сталкиваются с необходимостью прочитать данные из памяти — все их хвалёные гигагерцы просто простаивают. Опять-таки, простой пример: выполнение простейшей инструкции процессором происходит за 1 такт, т.е. за секунду он может выполнить такое количество простых инструкций, какова его частота (на самом деле еще больше, но это оставим на потом…). А вот время ожидания данных из памяти может в худшем случае составить более 200 тактов! Что делает процессор, пока ждёт нужные данные? А ничего не делает. Или, в лучшем случае, при наличии технологии гиперпоточности, переключается на другой поток команд, которому без кэша также плохо, как и этому.
Многоуровневое кэширование
Специфика конструирования современных процессорных ядер привела к тому, что систему кэширования в подавляющем большинстве CPU приходится делать многоуровневой. Кэш первого уровня (самый «близкий» к ядру) традиционно разделяется на две (как правило, равные) части: кэш инструкций (L1I) и кэш данных (L1D). Это разделение предусматривается так называемой «гарвардской архитектурой» процессора, которая по состоянию на сегодня является самой популярной теоретической основой для построения современных CPU. В L1I, соответственно, аккумулируются только команды (с ним работает декодер), а в L1D — только данные (они впоследствии, как правило, попадают во внутренние регистры процессора — обо всём этом см. ниже). Иерархически «над» L1 стоит кэш второго уровня — L2. Он, как правило, в 2-8 раз больше по объёму, примерно втрое медленнее, и является уже «смешанным» — там располагаются и команды, и данные. В первых многоядерных процессорах у каждого ядра были свои L1, но общий L2. Сегодня у каждого ядра есть свой L2, зато общим для всех ядер является L3 (кэш третьего уровня), который в 4-32 раза больше, чем L2, и ещё примерно втрое медленнее (но всё ещё быстрее памяти). Алгоритм работы с многоуровневым кэшем в общих чертах не отличается от алгоритма работы с одноуровневым, просто добавляются дополнительные итерации: сначала информация ищется в L1, если там промах — в L2, потом — в L3, и уже потом, если ни на одном уровне кэша она не найдена — идёт обращение к основной памяти (ОЗУ).
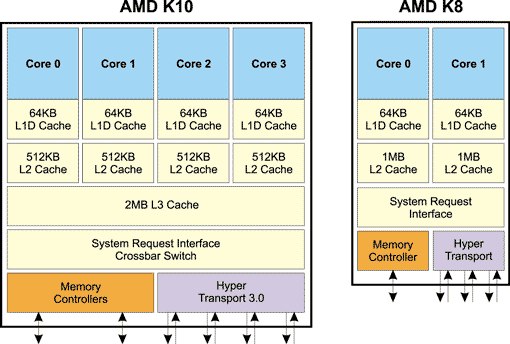
В новой архитектуре (К10) AMD использует общий для всех ядер кэш третьего уровня.
Раньше, в AMD К8, все ядра имели только свои собственные кэши 1 и 2 уровня.
Примерно так же выглядят новая и старая архитектуры Intel.
Декодер
На самом деле, исполнительные блоки всех современных десктопных x86-процессоров вовсе не работают с кодом в стандарте x86. У каждого процессора есть своя, «внутренняя» система команд, имеющая мало общего с теми командами (тем самым «кодом»), которые поступают извне. В общем случае, команды, исполняемые ядром — намного проще, «примитивнее», чем команды стандарта x86. Чтобы процессор с точки зрения программиста или пользователя «внешне выглядел» как x86 CPU, существует декодер: этот блок отвечает за преобразование «внешнего» x86-кода во «внутренние» команды, исполняемые ядром (при этом достаточно часто одна команда x86-кода преобразуется в несколько более простых «внутренних»). Декодер является важной частью современного процессора: от его быстродействия зависит то, насколько постоянным будет поток команд, поступающих на исполняющие блоки. Ведь они не способны работать с кодом x86, поэтому будут ли они что-то делать или простаивать — во многом зависит от эффективности работы декодера.
Регистры процессора
Регистры — по сути, те же ячейки памяти, но «территориально» они расположены прямо в процессорном ядре. Разумеется, скорость работы с регистрами намного больше не только скорости работы с ОЗУ, но и с кэшами любого уровня. Поэтому большинство команд архитектуры x86 предусматривают осуществление действий именно над содержимым регистров, а не над содержимым памяти. Однако общий объём регистров процессора, как правило, очень мал — он не сравним даже с объёмом кэшей первого уровня и составляет всего сотни байт. Поэтому код программы (не на языке высокого уровня, а именно машинный) обычно содержит примерно такую последовательность операций: загрузить в регистры процессора информацию из ОЗУ, произвести некое действие над содержимым этих регистров, поместив результат туда же, в регистры, а потом снова выгрузить результат в основную память. Т.к. работа с памятью куда медленнее, было бы неплохо, чтобы объём данных в регистрах был больше — тогда промежуточные результаты вычислений можно целиком (или почти…) хранить в ядре, не обращаясь даже в кэш, что резко ускорит работу процессора. Однако увеличить размер или число регистров значительно сложнее, чем увеличить кэш и, тем более, нарастить объём памяти (это вообще любой продвинутый пользователь сделает). Тем не менее, примерно раз в 5-10 лет к стандартному на этот момент набору регистров добавляется ещё столько же новых, либо сами регистры удваиваются (а при введении x86-64 с целочисленными регистрами произошло и то, и другое).
Функциональные устройства
Пройдя через все уровни кэша, декодер и некоторые подготовительные модули, команды наконец-то попадают в те блоки, ради которых вся эта катавасия и устраивалась: функциональные (исполняющие) устройства (ФУ). По сути, именно они и являются единственно необходимым элементом процессора. Можно обойтись без кэша — скорость снизится, но программы работать будут. Можно обойтись без декодера — исполняющие устройства станут сложнее, но работать процессор будет. Более того, у процессоров с системой команд концепции RISC (с точки зрения программиста, архитектура x86 к ней не отсносится, но для примера имеет смысл заметить) декодер отсутствует принципиально. А без функциональных устройств обойтись невозможно, ибо именно они исполняют операции над данными. Разных ФУ бывает много, но самые главные из них — арифметико-логические устройства (ALU), блоки вычислений с плавающей точкой (FPU), блоки векторной обработки (SIMD — таково общее название концепции векторных вычислений, означающее «одна команда, много данных») и блоки обмена данных с памятью. Каждое ФУ может исполнить только те команды, которые предназначены для него. Распределением команд, поступающих с декодера, по различным исполняющим устройствам занимается специальный блок-планировщик.
Арифметико-логические устройства
ALU (если не указано иное, то подразумевается именно целочисленный блок) традиционно отвечают за самые частые операции: простые арифметические действия (сложение, вычитание, сравнение) с целыми числами, логические операции («и», «или», «исключающее или» и «не»), копирование и простые преобразования чисел, а также битовые сдвиги. Блоков ALU в современных процессорах, как правило, 3. Для чего — вы поймёте позже, прочитав раздел «Суперскалярность и внеочередное исполнение команд». Внимательный читатель заметит, что выше не указаны ещё некоторые команды с целыми числами, которые, вроде бы должны быть исполнены в АЛУ. Например — умножение. Однако всё не так просто. Дело в том, что число и разнообразие функциональных устройств зависит от частоты встречи разных команд. Т.к. команды сложения, вычитания и копирования среди целых чисел наиболее «популярны», имеет смысл делать несколько АЛУ, исполняющих именно их, а вот целочисленное умножение, и, тем более, деление встречается куда реже, поэтому целочисленный умножитель почти во всех процессорах один (иногда — универсальный, в т.ч. и для вещественных чисел), а делителя нет вообще (эта операция делается в умножителе с использованием специальных таблиц констант для ускорения деления).
Блоки вычислений с плавающей запятой* и векторной обработки
FPU занимается выполнением команд, работающих с числами с плавающей запятой, кроме того, традиционно на него «вешают всех собак» в виде дополнительных наборов команд для работы с векторными данными (MMX и SSE с разными цифрами) — независимо от того, работают они с числами с плавающей запятой, или с целыми. Этих ФУ также 3-4, но тут расклад сил несколько иной — как правило, каждый блок умеет делать копирование данных, но только 2 или 3 исполняют простые команды (как у целочисленного АЛУ — их иногда называют SIMD ALU или SSE ALU), только один — умножение и деление, и ещё один — всё остальное (перетасовки элементов вектора, сложные преобразования форматов данных и пр.).
* — по традиции русской математической школы, мы называем FPU «блоком вычислений с плавающей запятой», хотя буквально его название (Floating Point Unit) переводится как «…с плавающей точкой» — согласно американскому стандарту написания таких чисел.
Блоки обмена данных с памятью
Тут есть 3 вида модулей — 2-3 так называемых AGU или устройства генерации адреса, подготавливающие адрес операции обмена, и по одному блоку загрузки и сохранения (выгрузки), соединённых с кэшем данных первого уровня. Тут всё просто — готовим адрес, а затем либо пишем данные из регистра в кэш, либо наоборот — читаем из кэша в регистр.
Энергосбережение
Помимо вычислительных «наворотов», у современных CPU есть ещё и различные технологии для уменьшения потребления энергии. Причём это касается процессоров не только для мобильных устройств, но и для настольных ПК, и даже серверов. Дело в том, что уменьшение потребления электроэнергии также приводит к уменьшению тепловыделения, которое за последние годы сильно выросло — ещё 10 лет назад было трудно себе представить, что средний процессор будет потреблять электричества и выделять тепла под 100 ватт, а то и больше. Системы охлаждения всё чаще становятся слишком дорогими и шумными, притом, что это один из самых ненадёжных узлов компьютера, требующий регулярного ухода. А если охлаждение не справится — процессор (или другой чувствительный компонент) перегреется. О перегреве и защите от него уже сказано выше, но с некоторых пор не помогает и это, нужны дополнительные меры. Такими мерами стали технологии регулировки потребления энергии в зависимости от требуемой загрузки процессора. Для Intel это называется SpeedStep, для AMD — Cool'n'Quiet и PowerNow! (плюс номер версии).
Анализируя загрузку различных блоков и шин, контроллер энергосбережения может снизить их частоту работы (для компонентов, которые могут работать несинхронно) или приостановить тактирование полностью, а также указать материнской плате понизить питающее напряжение (тоже — не всего процессора, а отдельного ядра или блока, хотя и не каждого). Регулировка напряжений особенно эффективна, т.к. от него потребляемая и выделяемая мощность зависит больше. Однако и частота (за редкими исключениями) и напряжение не могут упасть до нуля: реально частота падает в 2-3 раза относительно максимума, а напряжение — процентов на 20-30. Т.е. даже при полном простое (чего в многозадачных ОС не бывает никогда) процессор всё равно будет потреблять несколько ватт, а особо энергоэффективные CPU для ноутбуков — доли ватта. Тем не менее, это на порядок меньше, чем в случае отсутствия энергосберегающих технологий. Разумеется, во всех современных материнских платах и ОС энергосбережение процессора поддерживается и включено по умолчанию. Что касается эффективности, то считается, что технологии AMD чуть отстают от Intel, но реальная разница скорее всего окажется околонулевой, т.к. процессор — не единственная часть компьютера. В частности, современная видеокарта «налегает на ватты» посильнее многих серверных CPU, даже если она в корпусе одна; аналогично и для ноутбуков.
Также заметим, что переход на новый технологический процесс при изготовлении микросхем (грубо говоря, он измеряется в нанометрах и определяет минимальный размер элемента на чипе) помимо возможности размещения большего числа транзисторов и ускорения их срабатывания также приводит и к уменьшённому энергопотреблению. Так что, например, одинаковые по устройству и частоте процессоры, изготовленные по 65-нанометровой и 45-нанометровой технологии, будут потреблять разное количество энергии — у второго будет чуть меньшее питающее напряжение и потребляемый ток.
Процессор: ещё детальней
Особенности кэшей
Частота работы кэша и его шина
Во всех современных x86 CPU кэши L1 и L2 работают на той же частоте, что и процессорное ядро, но это вовсе не всегда было так (данный вопрос уже поднимался выше). Однако скорость работы с кэшем зависит не только от частоты, но и от ширины шины, с помощью которой он соединён с ядром. Как вы помните, скорость передачи данных является произведением частоты работы шины (количества тактов в секунду) на количество байт, которые передаются по шине за такт. Это количество можно увеличивать за счёт введения технологии DDR (Double Data Rate) и/или за счёт увеличения ширины шины. В случае с кэшем более популярен второй вариант — не в последнюю очередь из-за «пикантных особенностей» DDR, описанных выше. Более того, можно поставить сразу две параллельные шины, передающие данные в разные стороны — т.е. преобразовав шину в двунаправленную (полнодуплексную) удвоенной ширины. Споры о том, какой из подходов лучше (двунаправленная шина, но более узкая в каждом направлении, или однонаправленная широкая) — продолжаются до сих пор, как и множество других споров относительно технических решений, применяемых двумя основными конкурентами на рынке x86 CPU. Ранее под минимально разумной шириной шины кэша принималась разрядность внешней шины самого процессора, т.е. 64 бита. Теперь же большинство новых моделей имеют встроенный многоканальный контроллер памяти, общая эффективная ширина которого — 128 и более бит. Однако внутри процессора ширина шин между ядром и кэшем, а также самими кэшами может быть ещё шире: в большинстве случаев — 256 бит.
Эксклюзивный и не эксклюзивный кэш
Концепции эксклюзивного и не эксклюзивного кэширования очень просты: в случае не эксклюзивного кэша, информация на всех уровнях кэширования может дублироваться. Таким образом, L2 может содержать в себе данные, которые уже находятся в L1I и L1D, а L3 может содержать в себе полную копию всего содержимого L2 (и, соответственно, L1I и L1D). Эксклюзивный кэш, в отличие от не эксклюзивного, предусматривает чёткое разграничение: если информация содержится на каком-то уровне кэша — то на всех остальных она отсутствует. Плюс эксклюзивного кэша очевиден: общий размер кэшируемой информации равен суммарному объёму кэшей всех уровней — а у не эксклюзивного кэша размер кэшируемой информации (в худшем случае) равен объёму самого большого (по размеру и по номеру) уровня кэша. Минус эксклюзивного кэша менее очевиден, но он есть: необходим специальный механизм, который следит за собственно «эксклюзивностью» (например, «удаление» информации из L1 фактически инициирует процесс её копирования в L2).
Не эксклюзивный кэш традиционно использует компания Intel, эксклюзивный (с момента появления процессоров Athlon на ядре Thunderbird) — компания AMD. В целом, мы наблюдаем здесь классическое противостояние между объёмом и скоростью: за счёт эксклюзивности, при одинаковых объёмах L1/L2 у AMD общий размер кэшируемой информации получается больше — но за счёт неё же он работает медленней (задержки, вызванные наличием механизма обеспечения эксклюзивности). Следует заметить, что недостатки не эксклюзивного кэша Intel компенсирует просто, но весомо: наращивая его объёмы. Для топовых процессоров данной компании стал нормой L3-кэш объёмом 8 МБ — но AMD с её 512 КБ L2 на каждое из 2-6 ядер и максимум 6 МБ общего L3 также получает 7-9 МБ за счёт эксклюзивности.
Кроме того, увеличивать общий объём кэшируемой информации за счёт введения эксклюзивной архитектуры кэша имеет смысл только в том случае, когда выигрыш в объёме получается достаточно большим. Для AMD это актуально т.к. у её сегодняшних CPU суммарный объём L1D+L1I равен 128 КБ, а L2 — 512 КБ. Процессорам Intel, у которых оба числа вдвое меньше, введение эксклюзивной архитектуры дало бы намного меньше пользы.
А ещё есть распространённое заблуждение, что архитектура кэша у CPU компании Intel «инклюзивная». На самом деле — нет. Именно НЕ эксклюзивная. Инклюзивная архитектура предусматривает, что на «нижнем» уровне кэша не может находиться ничего, чего нет на более «верхнем». Не эксклюзивная архитектура всего лишь допускает дублирование данных на разных уровнях.
Суперскалярность и внеочередное исполнение команд
Основная черта всех современных процессоров состоит в том, что они способны запускать на исполнение не только ту команду, которую (согласно коду программы) следует исполнить в данный момент времени, но и другие «вблизи» неё. Приведём простой (канонический) пример. Пусть нам следует исполнить следующую последовательность команд:
- A = B + C
- Z = X + Y
- K = A + Z
Легко заметить, что команды (1) и (2) совершенно независимы друг от друга — они не пересекаются ни по исходным данным (переменные B и C в первом случае, X и Y во втором), ни по месту размещения результата (переменная A в первом случае и Z во втором). Стало быть, если на данный момент у нас есть свободные исполняющие блоки в количестве более одного, данные команды можно распределить по ним, и выполнить одновременно, а не последовательно*. Таким образом, если принять время исполнения каждой команды равным N тактов процессора, то в классическом случае исполнение всей последовательности заняло бы N*3 тактов, а в случае с параллельным исполнением — всего N*2 тактов (так как команду (3) нельзя выполнить, не дождавшись результата исполнения двух предыдущих).
* — разумеется, степень параллелизма не бесконечна: команды могут быть выполнены параллельно только в том случае, когда на данный момент времени есть в наличии соответствующее количество свободных от работы блоков (ФУ), причём именно таких, которые «понимают» рассматриваемые команды. Например, ALU физически неспособно исполнить инструкцию для FPU. Обратное также верно.
На самом деле, всё ещё сложнее. Так, если у нас имеется следующая последовательность:
- A = B + C
- K = A + M
- Z = X + Y
То очередь исполнения команд процессором будет изменена! Т.к. команды (1) и (3) независимы друг от друга ни по исходным данным, ни по месту размещения результата, они могут быть выполнены параллельно — и будут выполнены параллельно. А вот команда (2) будет выполнена после них (хронологически третьей) — поскольку для того, чтобы результат вычислений был корректен, необходимо, чтобы перед этим была выполнена команда (1). Именно поэтому обсуждаемый в данном разделе механизм и называется «внеочередным исполнением команд» (Out-of-Order Execution или «OoO»): в тех случаях, когда очерёдность выполнения никак не может сказаться на результате, команды отправляются на исполнение не в указанной в программе последовательности, а в той, которая позволяет достичь максимального быстродействия.
Теперь вам должно стать окончательно понятно, зачем современным CPU такое количество однотипных исполняющих блоков: они обеспечивают возможность параллельного выполнения нескольких одинаковых или близких по типу команд, которые в случае с «классическим» подходом к проектированию процессора пришлось бы выполнять так, как они содержатся в исходном коде, одну за другой.
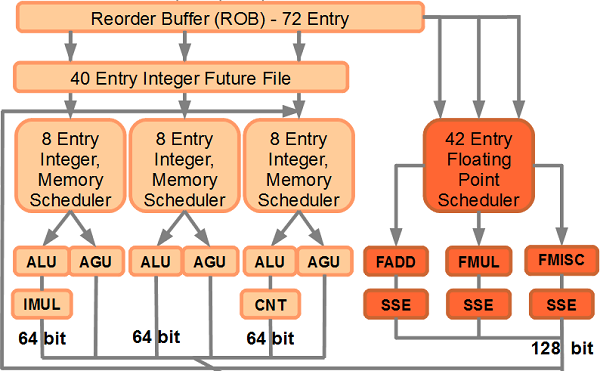
«Исполнительная» часть ядра AMD Deneb в качестве наглядной
иллюстрации возможностей параллельного выполнения команд
Процессоры, оснащённые механизмом параллельного исполнения нескольких подряд идущих команд, принято называть «суперскалярными». Однако не все суперскалярные процессоры поддерживают внеочередное исполнение. Так, в первом примере нам достаточно «простой суперскалярности» (выполнения двух последовательных команд одновременно) — а вот во втором примере без перестановки команд местами уже не обойтись, если мы хотим получить максимальное быстродействие. Все современные x86 CPU обладают обоими качествами: являются суперскалярными и поддерживают внеочередное исполнение команд — кроме процессора Intel Atom, который сделан с простой внутренней структурой, чтобы быть дешёвым и энергоэффективным одновременно. В то же время, были в истории x86 и «простые суперскаляры», OoO не поддерживающие. Например, классическим десктопным x86-суперскаляром без OoO был Intel Pentium (с или без MMX). Тот же Atom можно с натяжкой считать аналогом «Пентиума», хотя сильно продвинутым и по архитектуре, и по скорости.
Справедливости ради стоит заметить, что никаких заслуг в разработке концепций суперскалярности и OoO нет ни у Intel, ни у AMD, ни у какого-либо иного (в том числе из ныне почивших) производителя x86 CPU. Первый суперскалярный компьютер, поддерживающий OoO, был разработан Сеймуром Креем (Seymour Cray) ещё в 60-х годах XX века. Для сравнения: Intel свой первый суперскалярный процессор архитектуры x86 (Pentium) выпустила в 1993 г., первый суперскаляр с OoO (Pentium Pro) — в 1995 г.; первый суперскаляр с OoO от AMD (K5) увидел свет в 1996 г.. Комментарии, как говорится, излишни…
Предварительное (опережающее) декодирование и кэширование
Предсказание ветвлений
В любой более-менее сложной программе присутствуют команды условного перехода: «Если некое условие истинно — перейти к исполнению одного участка кода, если нет — другого». С точки зрения скорости выполнения кода программы современным процессором с большим числом подоготовительных стадий и собственно исполнением (так называемый исполнительный конвейер), любая команда условного перехода — воистину бич божий. Ведь до тех пор, пока не станет известно, какой участок кода после условного перехода окажется «актуальным» — его невозможно начать декодировать и исполнять. Для того чтобы как-то примирить концепцию «длинных» конвейеров с командами условного перехода, предназначается специальный блок: блок предсказания ветвлений. Занимается он, по сути, «пророчествами»: пытается предсказать, на какой участок кода укажет команда условного перехода, ещё до того, как она будет исполнена, и сработает ли переход вообще. В соответствии с указаниями «штатного внутриядерного пророка», процессором производятся вполне реальные действия: «напророченный» участок кода загружается в кэш (если он там отсутствует), и начинается декодирование и выполнение его команд. Причём среди выполняемых команд также могут содержаться инструкции условного перехода, и их результаты тоже предсказываются, что порождает целую цепочку из пока не проверенных предсказаний! Разумеется, если блок предсказания ветвлений ошибся, вся проделанная в соответствии с его предсказаниями работа просто аннулируется.
Алгоритмы, по которым работает блок предсказания ветвлений, вовсе не являются шедеврами искусственного интеллекта. Когда процессор впервые встречает условный переход, он пытается предсказать его поведение «по одёжке» — какого типа команда, куда происходит переход (вперёд по ходу исполнения программы или назад — это если он вообще произойдёт) и пр.. Точность такого предсказателя (он называется статическим) невелика. Самое интересное происходит, когда встречается уже знакомый переход. Чтобы его узнать, у предсказателя есть специальная таблица историй переходов, хранящая описание поведения нескольких сотен или тысяч последних обнаруженных в программе команд ветвления вместе с их адресами. Далее уже динамический предсказатель делает заключение о вероятном поведении команды не «по одёжке», а «по уму» — основываясь на детальной накопленной статистике поведения и этой команды перехода, и предыдущих её «коллег», исполненных до неё. Для поддержки этой статистики каждый раз, когда команда перехода доходит до исполнения, её результат попадает в предсказатель, чтобы тот скорректировал свою таблицу — перешли или нет, угадали или нет.
Несмотря на достаточно высокую эффективность алгоритмов, механизмы предсказания ветвлений в современных CPU всё равно постоянно совершенствуются и усложняются — но тут уже речь идёт о борьбе за единицы процентов: например, за то, чтобы повысить эффективность работы блока предсказания ветвлений с 95 процентов до 97, или даже с 97 до 99…
Предвыборка данных
Блок предвыборки данных (Prefetch) очень похож по принципу своего действия на блок предсказания ветвлений — но в данном случае речь идёт не о коде, а о данных. Общий принцип действия такой же: предзагрузчик (префетчер) анализирует запросы к данным, решает, что к некоему участку памяти, ещё не загруженному в кэш или ядро, скоро будет осуществлён доступ — и заранее даёт команду на загрузку данного участка ещё до того, как он понадобится программе. «Умно» (результативно) работающий блок предвыборки позволяет существенно сократить время доступа к нужным данным, и, соответственно, повысить скорость исполнения программы. Он хорошо компенсирует высокую латентность подсистемы памяти, подгружая нужные данные поближе к ядру или сразу в него, и тем самым, нивелируя задержки при доступе к ним, если бы они находились не в кэше, а в основном ОЗУ.
Разумеется, в случае предвыборки неизбежны негативные последствия: загружая ненужные (как позже окажется) данные в кэш, Prefetch вытесняет из него другие (быть может, как раз нужные). Кроме того, за счёт «предвосхищения» операции считывания, создаётся дополнительная нагрузка на контроллер памяти (причём в случае ошибки — совершенно бесполезная).
Алгоритмы Prefetch, как и алгоритмы блока предсказания ветвлений, тоже не блещут интеллектуальностью: как правило, данный блок стремится отследить, не считывается ли информация из памяти с определённым «шагом» (по адресам), и на основании этого анализа пытается предсказать, с какого адреса будут считываться данные далее. Как и в случае с блоком предсказания ветвлений, простота алгоритма вовсе не означает низкую эффективность: в среднем, блок предвыборки чаще «попадает», чем ошибается — это, как и в предыдущем случае, прежде всего связано с тем, что «массированное» чтение данных из памяти, как правило, происходит при исполнении различных циклов.
Приложение: генеалогия x86-процессоров от начала и до наших времён
Также, для справки, мы решили включить в данный материал своего рода «генеалогическое древо» всех десктопных x86-процессоров, т.к. оно позволяет проследить некоторые тенденции их развития, а заодно понять, насколько «взаимопроникающим» был процесс их разработки, особенно в самом начале. :)
«Доисторическая эпоха» — от Intel 8086 до Intel Pentium
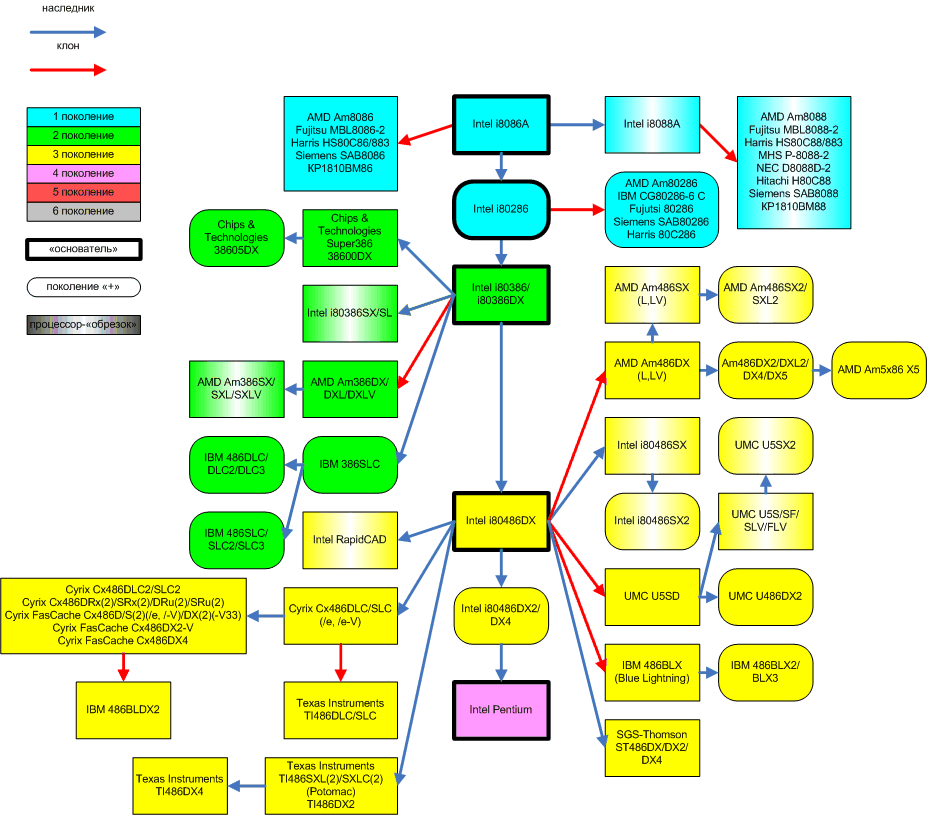
«Новейшая история» — от Intel Pentium до Intel Core i7 и AMD Phenom II
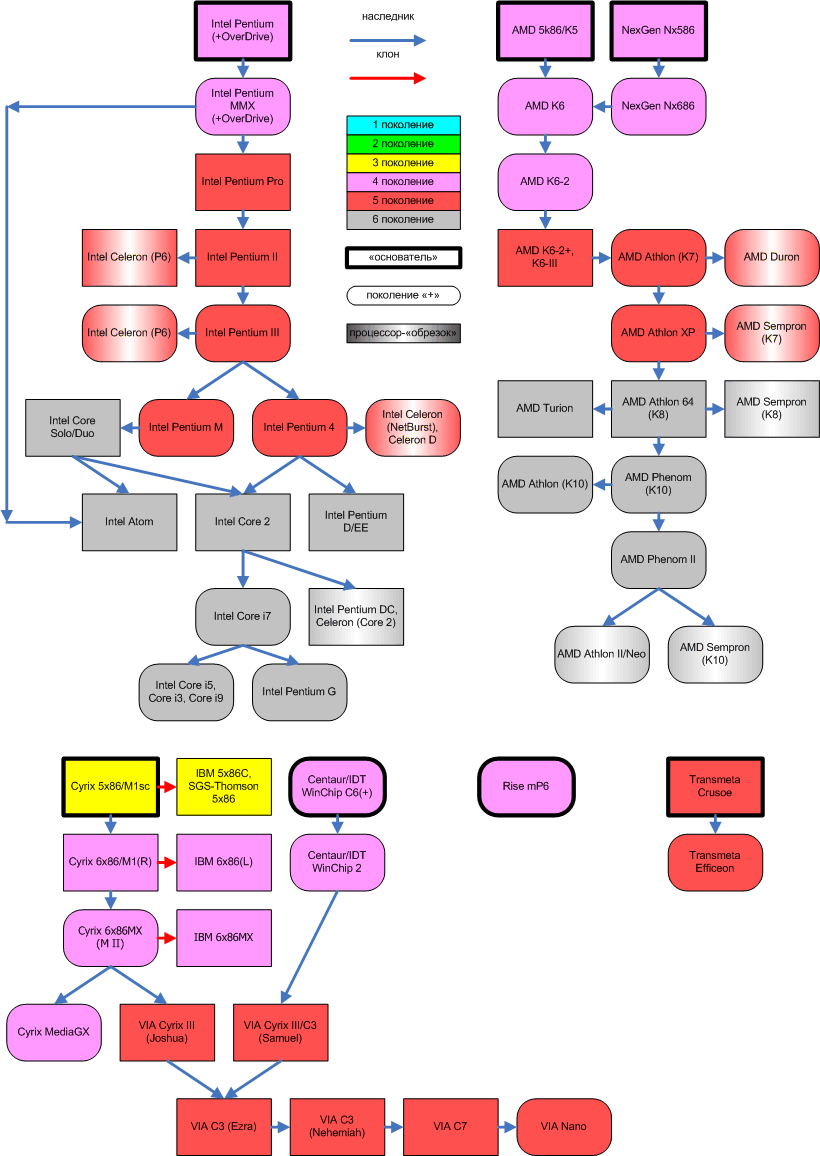
Заключение
не поймёт во всех деталях, как происходит процесс фотосинтеза!
(изложение личной позиции одним из близких знакомых автора)
Вполне возможно, чувства, которые у вас возникли после прочтения данной статьи, можно описать примерно так: «Вместо того, чтобы на пальцах объяснить, какой процессор лучше — взяли и загрузили мне мозги кучей специфической информации, в которой ещё разбираться и разбираться, и конца-края не видно!» Вполне нормальная реакция, мы вас хорошо понимаем. Скажем даже больше (и пусть с головы упадёт корона!): если вы думаете, что мы сами можем ответить на этот простецкий вопрос («какой процессор лучше?») — это не так. Не можем*. Для одних задач лучше один, для других — другой, а тут ещё цена разная, доступность, симпатии конкретного пользователя к определённым маркам… Не имеет задача однозначного решения. Если бы имела — наверняка кто-то бы его нашёл, и стал бы самым знаменитым обозревателем за всю историю независимых тестовых лабораторий.
* — примечание одного из авторов: «Лучший процессор — мой процессор!» :)
Хотелось бы подчеркнуть ещё раз: даже полностью усвоив и осмыслив всю информацию, изложенную в данном материале — вы по-прежнему не сможете предсказать, какой из двух процессоров будет быстрее в ваших задачах, глядя только на их характеристики. Во-первых — потому, что далеко не все характеристики процессоров здесь рассмотрены. Во-вторых — потому, что есть и такие параметры CPU, которые в числовом виде могут быть представлены только с очень большой «натяжкой». Так для кого же (и для чего) всё это написано? В основном — для тех самых «кроликов», которые непременно желают знать, что происходит внутри тех устройств, которыми они пользуются ежедневно. Зачем? Может, они просто лучше себя чувствуют, когда знают, что вокруг них происходит? :)
P.S. Захотелось ещё подробнее? Вам поможет «Обзор микроархитектур современных десктопных процессоров» от Олега Бессонова. Эта серия статей хоть и вышла в 2006 году, но в части теоретических сведений и углублённого описания принципов работы x86 CPU, не устарела до сих пор.


