Часть 1: общая организация, кэш инструкций и предсказание переходов, выборка и декодирование
За последние годы сформировалось несколько направлений, или семейств массовых высокопроизводительных микропроцессоров, конкурирующих друг с другом на рынке применений для десктопных компьютеров. Каждое семейство имеет свою микроархитектуру, или внутреннюю организацию процессорного ядра, разработанную на основе представлений её создателей о потребностях пользователей, критериях оценки производительности и прочих потребительских качеств, перспективах развития и рыночных тенденциях. Эти представления влияют на принятие разработчиками принципиальных решений о тех или иных ключевых архитектурных особенностях процессора и о различных компромиссах, заложенных в архитектуру. Несмотря на то, что общая организация суперскалярного процессора с внеочередным исполнением операций давно устоялась и воспроизводится в каждой современной архитектуре, имеется также большое количество принципиальных отличий между семействами. По существу, воспроизводится только общая структура процессора — а организация его отдельных подсистем различается весьма значительно.
В технической документации и статьях по архитектуре того или иного семейства процессоров можно найти более-менее обстоятельные описания его различных подсистем. Имеются также публикации по сравнительному анализу конкурирующих архитектур. Однако в связи с отсутствием единства в терминологии и различием в подходах разработчиков к представлению внутренней структуры своих процессоров возникают трудности в понимании их характеристик, особенностей и различий. Кроме того, процессоры развиваются, и их микроархитектуры претерпевают количественные и качественные изменения с этим развитием, что тоже затрудняет объективное сопоставление различных продуктов.
В настоящей статье делается попытка структурного и единообразного сравнения основных процессорных архитектур сегодняшнего дня. Будет рассматриваться организация наиболее важных подсистем для каждого процессора. Основной упор в изложении будет сделан на самых сложных элементах микроархитектуры — декодере машинных инструкций и подсистеме внеочередного исполнения операций (Out-of-Order execution, OoO). Эти элементы определяют индивидуальность каждого процессора и оказывают решающее влияние на его производительность. Все остальные подсистемы как бы обрамляют эти два элемента и играют подчинённую роль, хотя также могут оказывать значительное влияние на производительность.
Поскольку статья посвящена микроархитектурам, в ней не будут обсуждаться вопросы организации вычислительных систем на базе рассмотренных процессоров, а также вопросы комплексирования нескольких процессорных ядер на одном кристалле либо в одном корпусе. Несмотря на появление и распространение так называемых двухъядерных процессоров, микроархитектура каждого процессорного ядра не претерпела особых изменений. Поэтому в дальнейшем по тексту под процессором мы будем понимать отдельное процессорное ядро, исполняющее независимый поток инструкций.
Будут рассмотрены следующие основные семейства процессоров: Intel Pentium III, Intel Pentium 4, Intel Core, AMD Athlon 64 / Opteron и IBM PowerPC 970. Поскольку каждое из этих семейств претерпело определённое развитие, будут рассматриваться и отдельные представители этих семейств. Дадим краткие характеристики каждому из перечисленных семейств, а также конкретным процессорам, его представляющим (в скобках указывается сокращённое название каждого процессора в том виде, в каком оно будет употребляться по тексту):
- Intel Pentium III (P-III) — наиболее типичный представитель 6-го поколения процессорной архитектуры (P6) компании Intel. Будут также упоминаться процессоры, являющиеся развитием P-III — Pentium M (P-M) и Core Duo (P-M2). В связи с наличием серьёзных архитектурных усовершенствований процессоры P-M и P-M2 мы будем при необходимости выделять в отдельную подгруппу (P6+).
- Intel Pentium 4 (P-4) — представитель 7-го поколения процессоров (P7), эту архитектуру также называют NetBurst. Будет в основном рассматриваться первоначальный вариант микроархитектуры. Развитием семейства является процессор Prescott (P-4E), имеющий определённые микроархитектурные отличия и поддерживающий 64-битный режим целочисленной и адресной арифметики EM64T (x86-64).
- Intel Core (P8) — процессор новой микроархитектуры, выпуск намечен на III квартал 2006 г. В продажу поступит под названиями Core 2 Duo и Core 2 Extreme. Известен также под кодовым именем Conroe. Несмотря на то, что этот процессор базируется в основном на архитектурных принципах семейства P6, он имеет много принципиальных отличий количественного и качественного плана. По этой причине будем считать его представителем 8-го поколения процессорной архитектуры (P8) компании Intel.
- AMD Athlon 64 / Opteron (K8) — представитель единственной выпускаемой в настоящее время высокопроизводительной микроархитектуры компании AMD. Базируется на архитектурных принципах предыдущего семейства K7, отличается от него определёнными усовершенствованиями, поддержкой 64-битного режима AMD64 (x86-64) и наличием встроенного контроллера памяти.
- IBM PowerPC 970 (PPC970) — процессор RISC-архитектуры IBM Power, известен также под названием G5. Добавлен в рассмотрение к другим процессорам, относящимся к архитектуре x86, так как предназначен для недорогих платформ и достаточно распространён. До недавнего времени был основным процессором персональных компьютеров компании Apple (в настоящее время Apple постепенно переводит свои ПК на процессоры компании Intel). Основан на микроархитектуре серверного процессора Power4.
Настоящая статья основана на материалах компаний Intel, AMD, IBM и на других публикациях по рассматриваемым вопросам, а также на результатах экспериментального исследования микроархитектур. Некоторые выводы о структуре и количественных параметрах процессоров являются предположениями автора, основанными на результатах исследования и изучения литературы. Эти предположения могут оказаться не всегда верными, но в целом они удовлетворительно описывают большинство наблюдаемых эффектов и не противоречат доступным публикациям.
Общая организация современного микропроцессора
Большинство современных микропроцессоров относятся к классу конвейерных суперскалярных процессоров с внеочередным исполнением операций. Рассмотрим кратко каждую из этих трёх ключевых характеристик.
- Конвейерная организация процессора означает, что многие сложные действия разбиваются на этапы с небольшим временем выполнения. Каждый этап выполняется в отдельном устройстве (блоке). Максимальная длина этапа определяет время такта процессора. Требование снижения времени такта влечёт за собой необходимость увеличения числа этапов при выполнении сложных действий. Можно выделить два наиболее важных проявления конвейерной организации процессора — прохождение инструкции (операции) от момента считывания из кэша инструкций до полного завершения (отставки), и прохождение операции через функциональное устройство. Первое проявление обычно называют «конвейером процессора» либо «конвейером непредсказанного перехода» (что более правильно). Длина этого конвейера влияет на производительность только в случае неправильного предсказания перехода в программе, когда происходит отмена работы, выполненной во всех этапах, начиная с этого перехода (сброс конвейера). Длина конвейера функционального устройства, в свою очередь, определяет время ожидания результатов операции другой операцией, использующей эти результаты в качестве операндов. Такое старт-стопное время выполнения операции в функциональном устройстве называют латентностью. Обращение к кэшам всех уровней и к оперативной памяти также производится конвейерным образом. Большинство простых операций целочисленной арифметики и логики имеют латентность, равную единице — то есть они выполняются в функциональных устройствах синхронно, без конвейеризации.
- Суперскалярная организация означает, что на каждом этапе обрабатываются сразу несколько потоков инструкций (операций) в параллель — от выборки из кэша инструкций до полного завершения (отставки). Суперскалярность наряду с тактовой частотой является важнейшим показателем пропускной способности процессора. Уровень суперскалярности («ширина обработки», гарантированно обеспеченная на всех этапах) в современных производительных процессорах варьируется от 3 (P-III, P-4, K8) до 4-5 (P8, PPC970).
- Внеочередное исполнение операций означает, что операции не обязаны выполняться в функциональных устройствах строго в том порядке, который определён в программном коде. Более поздние (по коду) операции могут исполняться перед более ранними, если не зависят от порождаемых ими результатов. Процессор должен лишь гарантировать, чтобы результаты «внеочередного» выполнения программы совпадали с результатами «правильного» последовательного выполнения. Механизм внеочередного исполнения позволяет в значительной степени сгладить эффект от ожидания считывания данных из кэшей верхних уровней и из оперативной памяти, что может занимать десятки и сотни тактов. Также он позволяет оптимизировать выполнение смежных операций, особенно при наличии сложных зависимостей между ними в условиях высокой латентности исполнения в устройствах и недостаточного количества регистров.
Важной особенностью современных процессоров является также предварительное преобразование машинных инструкций в промежуточные операции (микрооперации), более удобные для обработки и исполнения. Иногда такие операции называют RISC-подобными, исходя из того, что архитектуры RISC (дословно «Компьютеры с сокращённым набором инструкций») разрабатывались как раз для того, чтобы обеспечить простоту, удобство и эффективность обработки машинных инструкций. Преобразование инструкций является необходимым для архитектуры x86 с её крайне нерегулярной и запутанной системой команд. Однако и для достаточно регулярной RISC-архитектуры PPC970 такое преобразование также производится — оно необходимо для разбиения некоторых сложных инструкций на простые операции.
В рассматриваемых процессорах эти промежуточные микрооперации обозначаются по-разному: uOP (Intel P-III, P-4, P8), MOP (AMD K8), IOP (IBM PPC970). Для унификации в дальнейшем во всех случаях будем называть эти микрооперации «МОПами» (либо просто «операциями»).
Итак, современный процессор состоит из различных блоков, или подсистем, работающих параллельно и независимо. Блоки могут являться конвейеризованными устройствами, работающими на тактовой частоте процессора (бывают также исключения, когда блок работает на половинной либо на удвоенной частоте). В процессоре имеется также большое количество очередей или буферов, которые необходимы в первую очередь для сглаживания задержек, возникающих при работе устройств. Конкретная операция может находиться в какой-либо очереди продолжительное время, ожидая готовности данных либо ресурсов для своего дальнейшего продвижения. Однако во многих случаях возможно и «гладкое» продвижения операции без ожиданий в очередях. Когда говорят о длине конвейера процессора, подразумевают как раз такой режим прохождения операции. Таким образом, длина конвейера — это минимальное время прохождения операции (в тактах) при условии, что нет никаких внешних причин для задержек.
Поскольку исходная программа подразумевает последовательную модель исполнения, машинные инструкции должны считываться также последовательно. Кроме того, есть такое понятие, как «отставка» инструкции, которое подразумевает, что данная инструкция выполнена вместе со всеми инструкциями, которые ей предшествовали в коде программы. Таким образом, операции (инструкции) уходят в отставку строго последовательно, именно в том порядке, который задаётся программой.
Понятия отставки является ключевым в отображении внеочередного исполнения инструкций внутри процессора в чисто последовательное исполнение в «модели процессора», как она представляется пользователю. Может оказаться, что какая-то операция уже выполнилась в своём функциональном устройстве — но при этом не должна была выполняться, так как было неправильно предсказано направление условного перехода либо были считаны данные с неправильного адреса. Такое выполнение называется спекулятивным. Когда будет правильно исполнена предшествующая ей операция перехода или чтения данных, такая неверная спекулятивная ветвь будет отменена, и при необходимости инструкция будет выполнена вновь (либо выполнится другая ветвь). Процедура отставки инструкции гарантирует, что она была выполнена «правильно». Любые прерывания процессора (по вводу-выводу либо аварийному событию) могут происходить только в момент отставки инструкции, к которой это прерывание относится.
Та часть процессора, в которую операции поступают строго последовательно, в соответствии с кодом программы, и из которой они выходят после выполнения тоже последовательно, называется подсистемой внеочередного исполнения. Внутри этой подсистемы обеспечивается асинхронная обработка операций, с учётом зависимостей между ними, готовности операндов и наличия требуемых ресурсов (устройств и очередей). Описанию этой подсистемы будет уделено особое внимание в данной статье.
Рассмотрим теперь общую структуру процессора и взаимодействие его элементов при прохождении машинной инструкции (и операций, в которые она была преобразована).
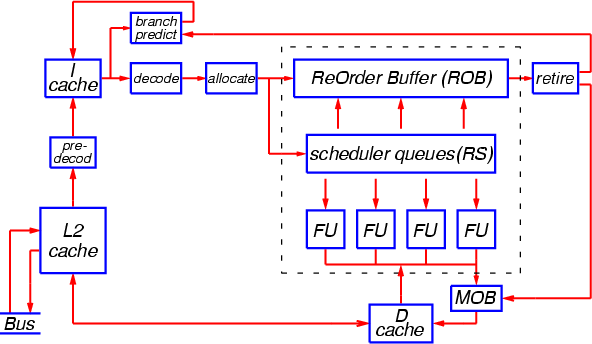
Рис. 1
Подмножество кода программы, наиболее «активно» исполняемое в данный отрезок времени, размещено в кэше инструкций (I-кэше). В зависимости от организации процессора, инструкции в этом кэше могут храниться в исходном неизменённом виде, либо в частично «предекодированном» виде, либо в полностью «декодированном» виде (то есть в виде готовых МОПов). В случае отсутствия в данном кэше нужных инструкций (исходных либо преобразованных) они считываются из кэша 2-го уровня (L2-кэша), при необходимости подвергаясь предварительному декодированию перед помещением в I-кэш.
Инструкции считываются из I-кэша блоками, с опережающей предвыборкой. Текущий блок инструкций отправляется сразу в два устройства — декодер инструкций и предсказатель переходов. Декодер преобразует исходные (либо частично декодированные) инструкции в микрооперации (МОПы), а предсказатель переходов определяет, есть ли в обрабатываемом блоке инструкции перехода, будут ли эти переходы совершены и по каким адресам. Если какой-либо переход предсказывается как «совершённый», то немедленно считывается блок инструкций, находящийся по предсказанному адресу.
Тем временем вновь порождённая декодером группа МОПов поступает в устройство переименования регистров и выделения ресурсов (Rename/Allocate). Переименование (или переназначение) регистров — это выделение данному МОПу нового экземпляра внутреннего регистра процессора, куда будут помещены результаты выполнения этого МОПа. Все дальнейшие операции, зависящие от результатов данного МОПа, будут использовать этот регистр в качестве операнда. «Переименованный» регистр ставится в соответствие регистру, который указан в машинной инструкции (так называемому «архитектурному регистру»). Необходимость в переназначении регистров связана с тем, что архитектурных регистров обычно очень мало, и при использовании столь ограниченного числа регистров невозможно эффективно исполнить поток операций — каждая новая операция, использующая определённый регистр, была бы вынуждена ждать завершения всех предыдущих операций, которые к нему обращаются (даже если ей не нужны результаты этих операций). Наличие большого числа машинных (физических) регистров и механизма переименования позволяет обойти эту проблему. Информация о соответствии регистров хранится в специальных таблицах. В момент отставки МОПа будет произведено обратное преобразование физического регистра в архитектурный.
После преобразования и подготовки регистров поступившая группа МОПов записывается в конец специальной очереди, носящей название «буфер переупорядочения» (ReOrder Buffer, ROB). Эта структура является ключевой в организации внеочередного исполнения операций. В ней хранятся все МОПы и необходимые вспомогательные данные от момента завершения декодирования и выделения ресурсов до момента отставки. Таким образом, длина буфера ROB ограничивает число операций, которые одновременно могут находиться в обрабатывающей части процессора (подсистеме внеочередного исполнения) — от самой «старой», которая ещё не завершена и поэтому не может «уйти в отставку», до самой «новой», которая только что поступила из декодера. В случае переполнения буфера переупорядочения, работа декодера приостанавливается до тех пор, пока не произойдёт отставка операций в начале очереди и освобождение места для новых МОПов.
Одновременно с попаданием в ROB новая группа МОПов передаётся в другую структуру данных, откуда МОПы будут отсылаться на исполнение непосредственно в функциональные устройства. Данная структура, известная под названием «пункт резервирования», «резервация» (Reservation Station, RS), представляет собой один или несколько буферов, к которым подсоединены эти функциональные устройства. В каждом такте в этих буферах производится поиск операций, которые готовы к исполнению (то есть аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания операции в функциональное устройство) вне зависимости от порядка, в котором они записывались в буфера. Устройство, которое осуществляет этот поиск и запуск на исполнение, обычно называют планировщиком, а сами буфера — очередями планировщика. Планировщик отслеживает зависимости между операциями по данным и прогнозирует готовность операций к исполнению в устройствах.
Таким образом, поиск МОПов для внеочередного исполнения всегда производится только в пределах такого буфера планировщика (единого для всех функциональных устройств, либо специфичного для каждой группы устройств), и этот буфер выглядит как «окно», в котором (при необходимости) происходит изменение порядка выполнения операций.
Очередь планировщика представляет собой полностью ассоциативный буфер, с точки зрения поиска операций для исполнения. Но с точки зрения помещения новых МОПов, она ведёт себя как обычная очередь. Все МОПы, находящиеся в какой-то момент в очередях планировщика, одновременно находятся и в буфере ROB. При запуске операции на исполнение в функциональном устройстве соответствующий ей МОП удаляется из очереди планировщика, а в момент завершения операции делается пометка в соответствующем элементе буфера ROB. Когда все МОПы, предшествующие данному, успешно выполнятся и отправятся в отставку, данный МОП также сможет быть отставлен и удалён из буфера ROB. Однако может оказаться, что МОП попал в ошибочную (спекулятивную) ветвь исполнения из-за неверного предсказания перехода — в этом случае вся ветвь будет удалена из буфера переупорядочения после правильного исполнения и отставки данной инструкции перехода.
Когда МОП, запущенный на исполнение в устройстве, удаляется из очереди планировщика, в ней освобождается место для приёма нового МОПа. Это означает, что эффективный размер окна для изменения порядка операций превышает длину данной очереди и ограничивается вместимостью буфера ROB.
К каждой очереди планировщика подсоединено одно или несколько специализированных функциональных устройств. Число операций, которые могут быть запущены на исполнение в каждом такте, обычно заметно превышает ширину остальных трактов процессора и варьируется от 5 (P-III) до 10 (PPC970), что позволяет сглаживать пиковую нагрузку и обеспечить высокую пропускную способность при неоднородной загрузке устройств.
Помимо арифметико-логических и адресных функциональных устройств, в каждом процессоре имеются также устройства загрузки и выгрузки (Load/Store), которые производят доступ к кэшам данных и к оперативной памяти. Эти устройства работают асинхронно от других, и их обычно не изображают на блок-схемах. Логически эти устройства связаны с устройствами вычисления адресов чтения/записи (AGU). Устройства загрузки и выгрузки конвейеризованы и могут одновременно обслуживать большое количество запросов. Эти устройства также осуществляют предварительную выборку из оперативной памяти (копирование в кэши тех данных, использование которых ожидается в ближайшее время). На Рис. 1 группа блоков процессора, образующих подсистему внеочередного исполнения, обведена пунктирной линией.
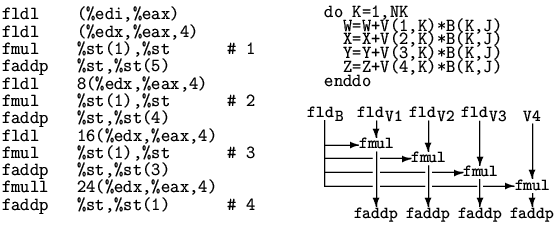
Рис. 2
На Рис. 2 показан фрагмент кода с глубоким внеочередным исполнением. Этот фрагмент представляет собой итерацию алгоритма перемножения матриц для процессора AMD Athlon [1]. Он состоит из 12 машинных инструкций и исполняется за 4 такта. Как видно из приведённой блок-схемы, алгоритм содержит 4 ветви, представляющие собой последовательности Load-Mul-Add (загрузка — умножение — сложение). Старт-стопное время исполнения каждой ветви составляет примерно 12 тактов, но благодаря внеочередному исполнению и переименованию регистров они обрабатываются параллельно, с глубоким перекрытием, обеспечивая темп выполнения 64-битных операций арифметики с плавающей точкой x87, близкий к предельному (две операции за такт).
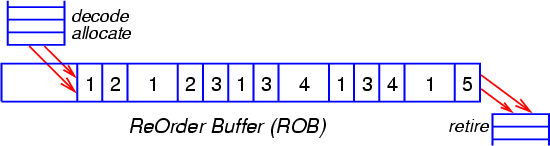
Рис. 3
На Рис. 3 показаны различные состояния, в которых могут находиться МОПы, помещённые в буфер переупорядочения. В хронологическом порядке, каждый МОП может проходить через следующие стадии:
- находится в очереди планировщика, но ещё не готов к исполнению;
- готов к исполнению (все аргументы операции вычислены);
- запущен на исполнение (диспетчеризован);
- исполнен и ждёт отставки либо отмены спекулятивной ветви;
- находится в процессе отставки.
Кроме того, в одной микроархитектуре (процессор P-4) перед попаданием в очереди планировщика, приписанные к группам функциональных устройств, все МОПы помещаются в предварительные очереди. Эти очереди выполняют амортизирующую роль, позволяя декодеру и аллокатору осуществлять опережающую подготовку операций.
Может оказаться, что буфер ROB не заполнен до конца — в этом случае в конце буфера (очереди) останется свободное место, куда могут в полном темпе поступать новые МОПы. Для этого необходимо, чтобы в очередях планировщика тоже оставалось свободное место для вновь поступающих МОПов.
Длина буфера переупорядочения в современных процессорах составляет несколько десятков элементов (от 40 в процессоре P-III до 126 в процессоре P-4). В случае если в начале очереди «застрянет» МОП, находящийся в процессе исполнения (например, ожидающий конца медленной операции или прихода данных из памяти), и новые МОПы будут поступать в полном темпе, буфер ROB заполнится за 20-40 тактов (P-III — за 13 тактов). На практике, средний темп выполнения операций находится на уровне 50% от предельного или несколько ниже. Взяв такой же темп поступления МОПов, получим время заполнения на уровне 40-80 тактов. Это существенно меньше, чем время ожидания данных из оперативной памяти (200-300 тактов и более). Приведённые цифры показывают, что при большом числе обращений к данным, которых нет в кэшах, и для которых не осуществляется эффективная предвыборка, буфер ROB будет, как правило, переполнен, и процессор будет простаивать в ожидании прихода данных из памяти. По существу, в каждый момент времени работу будет блокировать единственный МОП, находящийся в начале очереди и ожидающий загрузки данных. Размер буфера ROB в данном случае определяет, сколько МОПов, расположенных после этого, может быть помещено в ROB и исполнено (при условии, что они не зависят от загружаемых данных) до тех пор, пока процессор не остановится.
Следует отметить, что организация основных элементов микроархитектуры (подсистем декодера и внеочередного исполнения, кэшей, функциональных устройств) и её числовые характеристики (длины конвейеров, размеры очередей) зависят от базовых параметров, определённых разработчиками — и в первую очередь от целевой тактовой частоты, а также ширины и сложности трактов процессора. Например, базовым параметром архитектуры процессора P-4 является повышенная тактовая частота (в 1.4-1.5 раза по сравнению с классическими процессорами, исполненными по той же электронной технологии). Это влечёт за собой увеличение числа этапов конвейеров, а также, в ряде случаев, качественную переделку тех или иных подсистем, которые не могли бы быть реализованы для такой частоты традиционным образом. При сравнении длин конвейеров и времён выполнения различных действий нужно учитывать, что время такта в процессоре P-4 не превышает 0.7-0.75 от времени такта прочих процессоров, организованных более классическим способом. Поэтому в ряде случаев при оценках следует делать соответствующие поправки и выражать характеристики процессора P-4 в «нормализованных» тактах с учётом соотношения 1:1.4*.
* — Это соотношение получено эмпирическим путём, и, разумеется, не претендует на универсальность. В большинстве случаев его использование даёт вполне адекватные результаты при сравнении архитектуры P-4 (NetBurst) с микроархитектурами других процессоров.
Организация кэша инструкций и предсказание переходов
Кэш инструкций в традиционных процессорах
Во всех рассматриваемых микроархитектурах, за исключением процессора P-4, кэш инструкций (I-кэш) организован классическим образом. Рассмотрим для примера устройство такого кэша у процессоров P-M и P8 (кэш данных в этих процессорах устроен таким же образом).
Кэш 1-го уровня (L1-кэш) в указанных процессорах имеет размер 32 Кбайт и состоит из блоков по 64 байта, организованных в виде 64 наборов по 8 блоков. Для поиска требуемого элемента данных в кэше используется комбинированный алгоритм, сочетающий прямую адресацию по нескольким разрядам адреса с ассоциативным поиском. Младшие 6 разрядов адреса b5-0 указывают положение байта в 64-байтовом блоке и для поиска блока не используются. Следующие 6 разрядов адреса b11-6 указывают номер набора, а нахождение требуемого блока в наборе осуществляется сравнением самых старших разрядов адреса (ключа) с соответствующими разрядами адреса, хранящимися для каждого блока в наборе (тэгами). Таким образом, элемент данных по какому-либо адресу может располагаться в рассматриваемом кэше в одном из 8 блоков конкретного набора.
Если нужный блок данных не найден в L1-кэше, он ищется в кэше 2-го уровня (L2-кэше), и далее, если не найден и там, в оперативной памяти. Затем этот блок записывается в L1-кэш. Если все блоки в наборе уже заняты, то один из блоков удаляется (вытесняется). Как правило, для вытеснения используется алгоритм LRU (Least Recently Used — «наименее используемый в последнее время»).
Описанная организация кэша называется «наборно-ассоциативной» (set-associative). Число блоков в наборе (в данном случае 8) называется уровнем ассоциативности кэша. Оно определяет, сколько блоков данных, отстоящих друг от друга на расстоянии с определённой кратностью (в данном случае — кратном 4 Кбайт), может одновременно находиться в кэше. Данное ограничение называют проблемой алиасинга. Чем выше уровень ассоциативности, тем меньше вероятность, что различные блоки данных столкнутся с алиасингом. Например, у L1-кэшей процессора K8 уровень ассоциативности равен 2 при размере 64 Кбайт, а I-кэш процессора PPC970 имеет уровень ассоциативности, равный 1 при том же размере 64 Кбайт (такая организация называется прямым отображением), и состоит из блоков по 128 байтов.
Обычно поиск в кэшах осуществляется по физическому адресу элемента данных. Однако преобразование адреса из программного (логического) в физический требует определённого времени — для этого используется вспомогательная структура, похожая на небольшой кэш и называемая TLB (Translation Lookaside Buffer — «буфер преобразования адреса»). Поэтому для адресации набора L1-кэша, чтобы ускорить поиск, используют необходимые разряды программного адреса. В тех случаях, когда эти разряды адресуют не больше одной страницы памяти (размер которой, как правило, равен 4 Кбайт), они совпадают с соответствующими разрядами физического адреса. Например, в процессорах P-M и P8 для этого используются разряды b11-6, и данное условие соблюдается. Арифметически это условие можно выразить так: частное от деления размера кэша на уровень ассоциативности не должно превышать размера страницы. Легко видеть, что в процессорах K8 и PPC970 данное условие не соблюдается (64K/2=32K, 64K/1=64K).
В I-кэше процессора K8, помимо байтов инструкций, хранятся также так называемые биты предекодирования — по 3 разряда на байт. Их назначение будет описано в разделе про декодирование.
Инструкции считываются из I-кэша порциями (выровненными блоками), с опережающей предвыборкой, чтобы обеспечить бесперебойную работу декодера инструкций и ускорить предсказание переходов. Размер такого блока в процессорах P-III и K8 равен 16 байтам.
Предсказание адреса и направления переходов
Механизм предсказания переходов выполняет две основные функции — предсказание программного адреса инструкции, на которую производится переход (для всех инструкций перехода), и предсказание направления ветвления (для инструкций условного перехода). Оба предсказания должны быть выполнены заблаговременно — раньше, чем начнётся декодирование и обработка инструкции перехода — для того, чтобы выборка нового блока инструкций была произведена без потерь лишних тактов либо с минимальными потерями.
Необходимость предсказания адреса «целевой» инструкции вызвана тем, что этот адрес может быть извлечён из x86-инструкции перехода и вычислен только на финальной стадии декодирования, с большой задержкой. Более того, даже простое выделение инструкций переменной длины из считанного блока и поиск среди них инструкций перехода займёт какое-то время. Поэтому в процессорах архитектуры x86 предсказание производят по целому блоку, без разбиения его на составляющие инструкции.
В современных процессорах для предсказания адреса перехода обычно используют специальную таблицу адресов переходов BTB (Branch Target Buffer). Эта таблица устроена подобно кэшу и содержит адреса инструкций, на которые ранее производились переходы. Например, в процессоре P-III таблица BTB имеет размер 512 элементов и организована в виде 128 наборов с ассоциативностью 4. Для адресации набора используются младшие разряды адреса 16-байтового блока инструкций (b10-4). Если в этом блоке есть инструкции перехода, и если эти инструкции отрабатывали ранее, то алгоритм предсказания может очень быстро найти адрес целевой инструкции в таблице BTB и начать считывание блока, содержащего эту инструкцию. Адреса целевых инструкций помещаются в BTB в момент отставки соответствующих инструкций перехода.
В других современных процессорах размер таблицы BTB достигает 2048 элементов (K8) и 4096 элементов (P-4). Организация данной подсистемы в процессоре K8 несколько отличается от классической и основывается на предварительной разметке блоков инструкций в так называемых массивах селекторов перед помещением их в I-кэш. Эти селекторы привязаны к положению инструкций в I-кэше и при их вытеснении оттуда сохраняются в L2-кэше (в так называемых ECC-битах, предназначающихся для коррекции ошибок). Элементы таблицы BTB также привязаны к положению инструкций в I-кэше и теряются при их вытеснении. Это несколько снижает эффективность предсказания адресов переходов в процессоре K8.
Для предсказания направления условного перехода используется другой механизм, основанный на изучении поведения переходов в программе в процессе её выполнения (своего рода «сбор статистики»). Этот механизм учитывает как локальное поведение конкретной инструкции перехода (например, «как правило, переходит», «как правило, не переходит»), так и глобальные закономерности («чередуется по определённому закону» и т.п.). История поведения инструкций условного перехода записывается в специальных структурах, обычно называемых «таблицами истории переходов» (Branch History Table, BHT). Современные механизмы предсказания переходов обеспечивают правильное предсказание более чем в 90 процентах случаев.
В данной статье не будут рассматриваться конкретные алгоритмы предсказания переходов, тем более что информация о них в настоящее время обычно не разглашается разработчиками (см. статьи [2], [3]). Перечислим лишь некоторые механизмы, используемые в новом процессоре P8, имеющем наиболее совершенную систему предсказания переходов:
- сочетание локального и глобального механизмов для предсказания «обычных» инструкций перехода с учётом истории их поведения;
- статический предсказатель для инструкций, совершающих переход в первый раз, основанный на эмпирических закономерностях (например, «переход назад» обычно предсказывается как совершённый, так как может означать переход по циклу, а «переход вперёд» — как несовершённый);
- предсказатель коротких циклов, распознающий такие переходы и определяющий число итераций цикла (позволяет правильно предсказать момент выхода из цикла);
- предсказатель косвенных переходов, определяющий целевые адреса для различных исполнений инструкции перехода (с учётом возможного чередования этих адресов);
- предсказатель целевых адресов для инструкций выхода из подпрограммы, использующий небольшой аппаратный стек для запоминания адресов возврата (Return Address Stack) для эффективной отработки инструкций Call — Return.
В других процессорах компании Intel используется только часть перечисленных механизмов. Эти механизмы совершенствуются с каждым новым поколением процессоров.
В процессорах AMD K8 и IBM PPC970 используются более простые механизмы предсказания обычных переходов, и отсутствуют механизмы предсказания циклов и чередующихся косвенных переходов.
Механизм предсказания переходов работает одновременно с декодером инструкций и независимо от него. Благодаря эффективной реализации предсказания адреса перехода в процессорах P-III, P-M, P-M2, P8 и K8 при правильном предсказании теряется всего 1 такт. Это означает, что минимальное время, затрачиваемое на итерацию цикла (либо на один переход в цепочке переходов) составляет 2 такта. По существу, предсказатель переходов в таком цикле (или цепочке) работает в своём независимом цикле, состоящем из двух стадий — предсказания и считывания нового блока кэша — а декодер и прочие подсистемы процессора обрабатывают инструкции из вновь считываемых блоков. Поскольку предсказатель переходов «просматривает» целый блок, который может содержать большое число инструкций, то он может «опережать» декодер в своём просмотре. Благодаря этому переход может быть совершён раньше, чем исчерпаются инструкции в текущем блоке, и указанной потери такта не произойдёт — этот такт будет скрыт на фоне бесперебойной работы декодера.
В процессоре PPC970 предсказатель переходов работает менее эффективно — при правильном предсказании теряется 2 такта, а минимальное время итерации цикла составляет 3 такта. Хотя предсказатель просматривает инструкции с некоторым опережением, это может лишь частично скрыть потерю указанных двух тактов, и в результате эффективность исполнения перехода окажется ниже, чем в других процессорах.
Когда инструкция перехода попадёт в функциональное устройство для исполнения, будет выяснено, правильно предсказан этот переход, или нет. В момент её отставки при неправильном предсказании перехода все последующие инструкции будут отменены, и начнётся считывание инструкций из I-кэша по правильному адресу. Такую процедуру называют сбросом конвейера, а время (в тактах), которое было потрачено на выполнение инструкции перехода с момента её считывания из кэша, называют длиной конвейера непредсказанного перехода. Это время характеризует чистую потерю в идеальных условиях, когда инструкция проходила через все этапы «гладко» и нигде не задерживалась по внешним причинам. В реальных условиях потеря на неправильно предсказанный переход может оказаться выше.
Длина конвейера непредсказанного перехода не всегда указывается в документации и известна весьма приблизительно. Её довольно трудно замерить, так как современные предсказатели переходов работают достаточно эффективно и не позволяют добиться гарантированной доли неправильных предсказаний в тестах. Можно дать следующие примерные оценки длины конвейера: P-III — 11, P-M — 12, P-4 — 20, P-4E — 30, P8 — 14, K8 — 11, PPC970 — 13. Нужно учесть, что в процессорах P-4 и P-4E длина такта меньше, чем в других процессорах, и потеря на непредсказанный переход, выраженная в «нормализованных» тактах с учётом соотношения 1:1.4, составит соответственно 15 и 22.
Кэш трасс в процессоре Pentium 4 и особенности предсказания переходов
Кэш инструкций в процессоре P-4 очень сильно отличается от I-кэша в процессоре классической архитектуры. В нём преобразование исходных x86-инструкций в МОПы производится перед кэшем, а в кэш помещаются целые трассы, составленные из этих МОПов. Поэтому такой кэш в процессоре P-4 называется «кэш трасс» (Trace-cache, Т-кэш). Трассы формируются в соответствии с предполагаемым динамическим порядком исполнения инструкций. В момент декодирования производится первичное предсказание перехода, и если предсказывается совершённый переход, то целевая инструкция помещается в трассу вслед за инструкцией перехода. Трасса может содержать множество таких «запаянных» переходов.
Размещение кэша «после декодера» и хранение в нём сформированных МОПов позволяет избежать необходимости параллельно декодировать несколько инструкций в условиях повышенной тактовой частоты, а также сократить затраты (число этапов конвейера) на обработку операции после её выборки из кэша. Кроме того, «запаивание» предсказанных переходов в трассу позволяет существенно снизить потери на их выполнение — теперь в одном такте может быть выполнена операция, предшествующая переходу, сам переход и операция, следующая за ним. В классических процессорах такая последовательность могла бы занять три такта.
Принципиальной особенностью Т-кэша, которая определяет способ хранения МОПов и механизмы работы с ними, является отсутствие прямолинейного соответствия между адресом исходной инструкции и местоположением соответствующего МОПа (МОПов) в кэше в связи с тем, что x86-инструкция переменной длины преобразуется в один или несколько МОПов фиксированной длины. Кроме того, хранение МОПов в виде трасс в предполагаемом порядке исполнения операций нарушает монотонность и непрерывность соответствия между адресами инструкций и положением МОПов в кэше. И, наконец, возможность раскрутки циклов в Т-кэше (то есть размещения в нём нескольких итераций цикла) и построения пересекающихся трасс нарушает взаимную однозначность между x86-инструкциями и МОПами — теперь одной исходной инструкции могут соответствовать несколько МОПов в разных итерациях цикла либо в различных трассах.
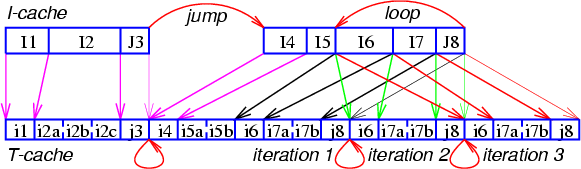
Рис. 4
На Рис. 4 показан пример подобного кода и соответствие между исходными инструкциями (в их естественном размещении) и МОПами в трассе (в предполагаемом порядке исполнения). В этом примере присутствует предсказанный переход и частичная раскрутка цикла. Буквами I и i обозначены обычные инструкции и МОПы, а буквами J и j — инструкции и МОПы перехода.
Механизм отображения адресов x86-инструкций в позиции МОПов необходим не для каждой инструкции, а только для тех, на которые производится переход — то есть для первого МОПа в каждой трассе. Все последующие МОПы располагаются в цепочке блоков кэша, непрерывно следующих друг за другом — до конца текущей трассы.
Т-кэш состоит из блоков размером в 6 ячеек. Обычно МОП занимает одну ячейку, однако в некоторых случаях может потребоваться дополнительное место для размещения недостающей информации. Темп последовательного чтения из Т-кэша составляет 1 блок за 2 такта, или 3 МОПа за такт — что находится в соответствии с темпом обработки и отставки МОПов.
Объём Т-кэша составляет 12K ячеек, или 2048 блоков, организованных в 256 наборов по 8 блоков. Для преобразования программного адреса первой x86-инструкции в каждой трассе (как правило, это инструкция, на которую производится переход) в положение первого блока трассы в кэше используется комбинированный алгоритм, сочетающий прямую адресацию по нескольким разрядам программного адреса инструкции с ассоциативным поиском. Разряды этого адреса b10-3 указывают номер набора, а нахождение требуемого блока в наборе осуществляется сравнением остальных разрядов адреса (ключа) с соответствующими разрядами адреса, хранящимися для каждого блока в наборе (тэгами).
При внешнем сходстве данной схемы адресации блоков в Т-кэше с аналогичной схемой для классических кэшей между ними есть принципиальное отличие. В классических кэшах по этой схеме адресуется каждый блок, в то время как в Т-кэше так отображается только первый блок в трассе. Использование нескольких внутренних разрядов адреса x86-инструкции для указания номера набора позволяет достаточно равномерно распределить заголовки трасс по наборам.
Последующие блоки в трассе располагаются в наборах с возрастающими номерами (после набора 255 следует набор 0). Все блоки в трассе связаны в двунаправленный список — в служебной информации каждого блока указаны номера (позиции) следующего и предыдущего блоков в соответствующих наборах. В случае если какой-то блок вытесняется из кэша, трасса «укорачивается» — то есть предыдущий блок трассы помечается как «последний».
Если инструкция, на которую производится переход, отсутствует в Т-кэше (то есть, в нём нет трассы с таким начальным адресом), начинается считывание x86-инструкций непосредственно из L2-кэша с их последующим декодированием и исполнением. Одновременно происходит формирование новой трассы МОПов и её размещение в Т-кэше. Если встречается инструкция условного перехода, то трасса, начиная с этой инструкции, строится в соответствии с результатом работы блока предсказания перехода декодера.
Декодер обрабатывает входной поток со скоростью не более одной x86-инструкции за такт, в зависимости от сложности формата инструкции и наличия префиксов. Если x86-инструкция не может быть преобразована в последовательность, состоящую из небольшого числа МОПов (до четырёх), она заменяется вызовом «микрокодовой подпрограммы», которая при работе будет генерировать МОПы и пересылать их на исполнение.
Имеется ряд ограничений, которые могут не позволить заполнить МОПами все 6 ячеек блока трассы и потребуют перейти к формированию следующего блока. Это требование размещения всех МОПов, составляющих x86-инструкцию, в одном блоке, и ограничение на число МОПов перехода — их может быть не более двух в блоке. Последнее ограничение связано с алгоритмом работы предсказателя переходов и согласовано с темпом, в котором может происходить отставка совершённых переходов — 1 операция за такт. В первом блоке трассы число МОПов перехода ограничено одним, что тоже связано с особенностями работы предсказателя переходов.
При появлении инструкции перехода построение трассы не прерывается, а продолжается в соответствии с предсказанным направлением этого перехода. Если переход будет предсказан как совершённый, непосредственно после МОПа перехода в трассе будет размещён МОП, на который происходит переход — причём оба этих МОПа могут оказаться в одном блоке и даже в одной «тройке», отсылаемой на исполнение. При предсказании перехода как не совершённого формирование трассы продолжится в натуральном порядке. Однако если при первом исполнении операции перехода выяснится, что переход был предсказан неправильно, формирование трассы прекратится, и она будет оборвана после этого МОПа. Также формирование трассы прекращается, если встречается инструкция косвенного перехода, вызова подпрограммы или возврата из подпрограммы. Максимальная длина трассы составляет 64 блока (384 ячейки для МОПов). При достижении этого предела формирование трассы также прекращается.
Может случиться, что правильно предсказанный совершённый переход является переходом по циклу. В таком случае появляется возможность «раскрутить» этот цикл и разместить в трассе несколько его итераций (Рис. 4), чтобы повысить скорость выборки и исполнения инструкций за счёт снижения затрат на переход по циклу. Существует механизм, ограничивающий раскрутку цикла разумными пределами.
При последующем выполнении кода МОПы считываются из Т-кэша последовательно, вплоть до завершения текущей трассы, в темпе 1 блок за 2 такта. Блоки считываются из наборов кэша с возрастающими номерами (после набора 255 следует набор 0). Если при исполнении трассы встречается операция условного перехода, то делается новое предсказание её направления и производятся следующие действия:
- если направление совпадает с тем, которое было предсказано при построении трассы — исполнение текущей трассы продолжается без перерыва и без потери тактов;
- если направление не совпадает с тем, которое было предсказано при построении трассы, и трасса по вновь предсказанному адресу найдена в кэше — начинает исполняться найденная трасса;
- если направление не совпадает с тем, которое было предсказано при построении трассы, и трасса по вновь предсказанному адресу не найдена — начинается формирование новой трассы с одновременным исполнением порождаемых МОПов.
При неправильном предсказании перехода (в тот момент, когда выяснится, что направление предсказано неверно) исполнение всех последующих МОПов прекращается, результаты их работы аннулируются, и производится поиск трассы по другому (правильному) адресу.
Первичное предсказание перехода при формировании трассы производится с помощью механизма, аналогичного такому механизму в классических процессорах, с использованием таблицы адресов переходов BTB размером 4096 элементов. Предсказание переходов при последующем исполнении трассы, считываемой из Т-кэша, производится по позиции МОПа перехода в Т-кэше с использованием вспомогательной таблицы адресов переходов TBTB (Trace-cache Branch Target Buffer), содержащей подмножество основной таблицы BTB и имеющей меньший размер (P-4 — 512 элементов, P-4E — 2048). Предсказание производится с опережением: в момент выборки и исполнения МОПов из текущего блока предсказывается поведение операций перехода, находящихся в следующем блоке. Для одного блока может быть предсказано до двух МОПов перехода (этим и вызвано ограничение на число таких МОПов в блоке).
Предсказатель переходов вычисляет лишь программный адрес целевой инструкции, а поиск трассы в Т-кэше по этому адресу осуществляется с помощью алгоритма, описанного выше. Поскольку предсказатель работает с опережением, пока запускаются МОПы из предыдущего блока, в случае принятия решения изменить порядок исполнения МОПов имеется достаточно времени, чтобы выбрать из кэша первый блок новой трассы и начать запускать МОПы из него без потери тактов.
Если операция перехода встретилась в первом блоке трассы, используется «стандартный» механизм предсказания переходов на базе основной таблицы BTB, так как механизм на базе таблицы TBTB в этот момент занят опережающей обработкой следующего блока. Стандартный механизм может обрабатывать не более одной операции перехода за раз, поэтому число МОПов перехода в первом блоке каждой трассы также ограничено одним.
Если при исполнении трассы произойдёт правильно предсказанный переход на начало другой трассы, то минимальное время, затрачиваемое на такой переход (в цикле либо в цепочке переходов) составит 4 такта. Благодаря опережающей работе предсказателя, это время может быть скрыто на фоне обработки МОПов и не представлять собой потерю. Однако если трасса (тело цикла) состоит только из одного блока, то время считывания МОПов из кэша в такой трассе составит лишь 2 такта, а время, затрачиваемое на переход — 4 такта (для процессора P-4E — 6 тактов).
Если направление перехода совпадает с тем, которое было предсказано при формировании трассы, то переход происходит без затрат времени. Имеется лишь ограничение на число МОПов перехода, уходящих в отставку — не более одного за такт. Это определяет минимальное время итерации развёрнутого цикла — 1 такт.
С учётом меньшей длины такта в процессоре P-4 время одной итерации цикла, выраженное в «нормализованных» тактах (с соотношением 1:1.4), составит всего 0.75 такта для цикла, «запаянного» в трассу, и 3 такта для цикла с переходом по трассе.
Эффективный размер Т-кэша, выраженный в байтах «эквивалентных x86-инструкций», можно оценить лишь приблизительно. При средней длине x86-инструкции в 3-4 байта и среднем числе МОПов (ячеек Т-кэша) в инструкции, равном 1.5, получаем среднюю «эффективную» длину МОПа на уровне 2-2.7 байта, что соответствовало бы эквивалентному размеру кэша инструкций 24-32 Кбайт. Однако в документации даётся оценка в 8-16 Кбайт, что, вероятно, как-то учитывает фрагментацию и потери на случаи многократного попадания одного и того же МОПа в кэш (при раскрутках циклов и в составе различных трасс).
Скорость работы Т-кэша (с учётом предсказания переходов) может варьироваться в очень широких пределах — от «идеальной» для алгоритмов, в которых все условные переходы были правильно предсказаны в момент формирования трассы, до довольно низкой при большом числе неправильных предсказаний. Вероятно, недостаточно высокая эффективность исполнения процессором P-4 сильно ветвящихся кодов, разработанных без надлежащего следования принципам оптимальной кодогенерации для суперскалярных конвейерных процессоров, связана именно с трудностью построения хорошо предсказанных трасс МОПов в Т-кэше, а также с потерями на работу механизма передачи управления для коротких трасс.
Более подробно устройство Т-кэша, механизм его функционирования и оценка эффективности работы описаны в статье [4].
Выборка и декодирование инструкций
Большинство процессоров, рассматриваемых в данной статье (за исключением RISC-процессора IBM PPC970) обрабатывают и исполняют инструкции архитектуры x86 (называемой также IA-32) и расширенной архитектуры x86-64 (называемой также AMD64 либо EM64T). Принципиальных различий по структуре машинной инструкции между архитектурами x86 и x86-64 нет, поэтому по тексту будем везде использовать общее наименование «x86-инструкции». Эти инструкции имеют очень сложный и нерегулярный формат и могут состоять из нескольких составных частей: одного или нескольких однобайтных префиксов, кода операции длиной от 1 до 3 байтов, описателя типа адресации операндов (ModR/M), указателя регистров базы, индекса и масштаба индексирования (SIB), поля смещения адреса и непосредственного операнда. Длина x86-инструкции может варьироваться от 1 до 15 байтов.
Для суперскалярной обработки необходимо в каждом такте извлекать из входного потока несколько инструкций переменной длины и отправлять каждую из них в отдельный блок декодирования для преобразования в микрооперации (МОПы). Эта задача представляется очень трудоёмкой, поэтому необходимо применение специальных средств, которые позволили бы её облегчить. В разных процессорах x86 используются различные приёмы и механизмы, обеспечивающие бесперебойную обработку инструкций. Лишь для процессора PPC970 не требуется никаких ухищрений, так как в RISC-архитектуре IBM Power машинные инструкции имеют фиксированную длину (4 байта) и регулярный формат. По типу используемых механизмов рассматриваемые процессоры можно разбить на четыре класса:
- PPC970: Не используется никакой механизм, так как инструкции имеют фиксированную длину и формат.
- P-III, P8: После выборки из I-кэша производится разметка инструкций (определение их границ и положения кода операции) в устройстве, называемом определителем длины инструкций (Instruction Length Decoder, ILD).
- K8: Перед помещением блоков инструкций в I-кэш производится предварительное декодирование (предекодирование) с аналогичной разметкой, информация о разметке записывается в дополнительные биты при каждом байте в I-кэше.
- P-4: Перед помещением в кэш производится полное декодирование инструкций, сформированные МОПы записываются в этот кэш (Т-кэш) в виде трасс.
В данном разделе будет рассмотрена работа устройств, выполняющих предварительную обработку инструкций перед помещением в кэш (если необходимо), выборку из кэша, декодирование с преобразованием в МОПы и подготовку к отправке сформированных групп МОПов в буфер переупорядочения и очереди планировщика для их последующего исполнения. Процессоры будут рассматриваться в указанном выше порядке — то есть в порядке усложнения механизма, обеспечивающего бесперебойную выборку инструкций.
IBM PowerPC 970
В процессоре PPC970 инструкции считываются из I-кэша блоками по 32 байта за такт, с опережающей предвыборкой. В связи с тем, что инструкции имеют фиксированную длину 4 байта, они немедленно отсылаются в декодер. Декодер может обрабатывать параллельно несколько инструкций и выдавать в каждом такте группу, содержащую до 4-5 МОПов.
Большинство машинных инструкций преобразуется в один МОП, однако имеются также «двойные» инструкции, разделяемые на два МОПа, и сложные инструкции, порождающие несколько МОПов. На два МОПа могут разделяться инструкции, имеющие более двух регистров-операндов или более одного регистра-результата (например, инструкция загрузки с автоинкрементом индекс-регистра). Оба МОПа от «двойной» инструкции обязательно помещаются в одну группу и могут соседствовать с МОПами от простых инструкций. МОПы, порождаемые из сложных инструкций, никогда не смешиваются с остальными МОПами — из них всегда формируются отдельные группы. Указанные ограничения могут привести к неполному заполнению групп.
Сформированная группа МОПов поступает в буфер переупорядочения и в дальнейшем отслеживается как единое целое. В блок отставки выполненные МОПы могут поступать также только в составе исходной группы. Помимо удобства отслеживания внеочередного исполнения и отставки, объединение МОПов в фиксированные группы имеет ещё одну цель: позиция МОПа в группе привязана к номеру очереди планировщика и функционального устройства, в которые этот МОП будет отправлен. Кроме того, МОП операции перехода может помещаться только в последнюю позицию в группе, а все прочие МОПы — только в первые четыре позиции. Порядок следования МОПов в группе соответствует исходному порядку инструкций, поэтому каждая операция перехода приводит к завершению текущей группы (с возможным неполным заполнением) и формированию новой группы, начиная со следующей инструкции.
Существуют и другие ограничения, требующие помещения какого-либо МОПа в определённую позицию в группе и приводящие к фрагментации. В основном эти ограничения связаны с тем, что для некоторых типов функциональных устройств имеются очереди планировщика, соответствующие только определённым позициям МОПа в группе. Например, операции для работы с регистрами условий декодер всегда помещает в позиции 0 или 1, операции целочисленного деления — в позиции 1 или 2, арифметические операции векторного блока VMX — в позиции 1 или 3, операции перестановок VMX — в позиции 0 или 2. В связи с этим в середине или конце группы могут остаться незанятые позиции.
Помимо перечисленных случаев, группа МОПов может оказаться не заполненной до конца, если прерывается входной поток инструкций — например, при отсутствии следующего блока инструкций в I-кэше, либо если инструкции считывались из кэша с недостаточным опережением.
Таким образом, декодер RISC-процессора PPC970 имеет высокую пропускную способность, но не обладает достаточной гибкостью при формировании групп МОПов. Это связано не с недостатками собственно декодера, а с особенностями организации подсистемы внеочередного исполнения и функциональных устройств процессора. Поэтому, несмотря на то, что «ширина обработки» входного потока инструкций и порождаемых МОПов формально равна 4-5, реальное число МОПов в группе составит в среднем, с учётом потерь на фрагментацию, не более 3.5. Это приводит к неполному заполнению буферов и снижению эффективной пропускной способности трактов процессора. Как будет показано в разделе про внеочередное исполнение, статическая привязка очередей и устройств к позициям МОПов может приводить также к неполной загрузке функциональных устройств.
При поступлении вновь сформированной группы МОПов в буфер переупорядочения и очереди планировщика производится переименование (переназначение) регистров результатов для этих МОПов. Имеется несколько групп внутренних (физических) регистров: 80 регистров общего назначения, 72 регистра для операций с плавающей точкой и некоторое количество регистров прочих типов.
Intel Pentium III, Pentium M и Core Duo
В процессорах семейства P6 инструкции считываются из I-кэша выровненными блоками по 16 байтов за такт. Выборка производится с опережением — у процессора есть два буфера, в которые помещаются два последних считанных блока. На вход подсистемы декодирования в каждом такте передаётся порция байтов, начинающаяся с того места, где была прекращена обработка в предыдущем такте. Длина этой порции ограничена также 16 байтами. Порция байтов поступает на вход определителя длины инструкций (ILD), который производит её разметку — нахождение границ и положения кода операции в каждой x86-инструкции.
Определитель длины инструкций должен быть обязательно реализован неконвейерным образом, с временем работы 1 такт — так как в следующем такте надо будет размечать новую порцию, начинающуюся после последней инструкции, размеченной в данном такте. Определитель содержит 16 одинаковых устройств, построенных на основе программируемых логических матриц (PLA). На вход каждого такого устройства подаётся фрагмент кода длиной 4 байта, начинающийся с одного из 16 байтов в обрабатываемой порции. Устройство (PLA) представляет собой примитивный декодер, который предполагает, что данный фрагмент является началом x86-инструкции (без префиксов), и пытается определить её длину. Кроме того, это устройство анализирует первый байт в фрагменте и определяет, не может ли он являться префиксом.
Результаты работы всех таких устройств собираются воедино с помощью цепочки схем быстрого переноса. По существу, эти схемы последовательно выстраивают список инструкций на основе данных о длинах и признаках наличия префиксов, начиная с первой инструкции в обрабатываемой порции байтов. По результатам этого выстраивания в специальных массивах делаются пометки о позициях кода операции и последнего байта в каждой инструкции. Эта информация используется в последующем такте для извлечения инструкций из буфера и передачи их на вход трёх каналов декодера.
В некоторых случаях определитель длины инструкций не может произвести разметку за один такт. Например, если встречается префикс, меняющий длину непосредственного операнда или смещения адреса в инструкции с 16 бит на 32 бита, либо наоборот, определитель переходит в «медленный» режим, размечая по 4 байта за такт. Однако такие случаи не часты и по существу представляют собой нарушение правил программирования. Кроме того, разметка замедляется, если в какой-то инструкции встречается два или более префиксов — в этом случае обработка каждого дополнительного префикса занимает один такт. На практике эта ситуация также очень редка.
После разметки три выделенные x86-инструкции передаются в основной декодер — точнее, в три параллельно работающих канала декодирования. Эти три канала не являются полностью симметричными — только первый из них может обработать любую инструкцию, а оставшиеся два имеют ограничения: инструкция должна иметь длину до 8 байтов и порождать только один МОП. У первого канала декодирования таких ограничений нет — он может породить до 4 МОПов в одном такте, параллельно с работой двух других каналов. Для обработки самых сложных инструкций (более 4 МОПов) требуются дополнительные такты, и в этом случае обработка ведётся последовательно.
Таким образом, схему работы декодера в процессоре P-III можно обозначить как «4-1-1 / >4»: он может обрабатывать в одном такте, либо три инструкции, порождающие до 6 МОПов (4+1+1), либо одну, порождающую более 4 МОПов. Порождаемые МОПы накапливаются в небольшой очереди перед отправкой (группами по три) в последующие тракты процессора. Схема «4-1-1» накладывает определённые ограничения на оптимальное размещение x86-инструкций в коде: сложные инструкции (в частности, инструкции типа Load-Op) должны чередоваться с простыми, а не следовать подряд друг за другом. Впрочем, даже при плотном размещении нескольких сложных инструкций всё равно в каждом такте будет порождаться как минимум 2 МОПа, а очередь МОПов после декодера позволит сглаживать возникающие неравномерности.
В процессоре P-III при декодировании инструкций загрузки из памяти с последующим исполнением (Load-Op) порождаются отдельные МОПы для загрузки и для выполнения. Аналогично, для инструкций выгрузки в память также порождаются два отдельных МОПа: для вычисления адреса, и для осуществления записи. В обоих случаях два МОПа обслуживаются в последующих трактах процессора по отдельности и занимают его ресурсы. Из-за частой встречаемости инструкций, содержащих загрузку из памяти и выгрузку в память, среднее число МОПов на одну x86-инструкцию может находиться в диапазоне от 1.3 до 1.5.
Начиная с процессора P-M, в декодере реализован механизм «слияния микроопераций» (micro-ops fusion), когда порождается единый МОП, содержащий два элементарных действия. Разделение на эти элементарные действия происходит при запуске МОПа на исполнение. Механизм слияния микроопераций похож на аналогичный механизм в процессорах AMD K7/K8. Этот механизм экономит ресурсы буферов и увеличивает эффективную пропускную способность трактов процессора. Благодаря такому механизму среднее число МОПов на одну x86-инструкцию значительно снижается и становится близким к единице. Кроме того, инструкции Load-Op могут теперь обрабатываться во всех трёх каналах декодера, что практически сводит на нет недостатки несимметричной схемы «4-1-1».
Правда, в декодере процессоров P-III и P-M имеется ещё одно ограничение, касающееся инструкций SSE. Эти инструкции могут обрабатываться только в первом канале декодера — причём данное ограничение относится не только к упакованным инструкциям SSE, расщепляемым на два МОПа, но и к скалярным инструкциям тоже. Кроме того, на инструкции SSE с загрузкой из памяти (Load-Op) не распространяется механизм слияния микроопераций. Таким образом, скалярная инструкция SSE типа Load-Op в процессоре P-M преобразуется в два МОПа, а упакованная — в четыре. Данные ограничения связаны, скорее всего, со сложностью реорганизации декодера для поддержки операций SSE.
В процессоре P-M2 (Core Duo) декодер x86-инструкций был радикально переделан. Теперь он поддерживает слияние микроопераций для инструкций Load-Op всех типов (включая различные SSE, за исключением инструкций упаковки/распаковки), а также обработку инструкций SSE (как скалярных, так и упакованных) во всех трёх каналах декодера. В результате число МОПов, порождаемых для скалярных инструкций SSE типа Load-Op, снизилось с двух до одного, а для упакованных — с четырёх до двух. Предельная пропускная способность декодера выросла в три раза — с одной инструкции SSE за такт до трёх.
Схему декодера процессора P-M2 можно обозначить как «4-2-2 / >2». По своей гибкости эта схема превосходит схему декодера процессора AMD K8 «2-2-2 / >2» благодаря обработке сложных инструкций в первом канале декодера одновременно с работой двух других каналов. Правда, декодер процессора K8 может порождать два МОПа также для некоторых других типов инструкций (не только SSE), но большинство таких инструкций в процессоре P-M2 являются простыми, с преобразованием в один МОП.
Таким образом, последний представитель семейства P6/P6+ — процессор P-M2 (Core Duo) — имеет гибкий трёхканальный декодер, эффективно работающий с подавляющим большинством x86-инструкций. Он в целом не уступает декодерам, реализованным с применением предекодирования перед помещением инструкций в I-кэш, и лишён некоторых их недостатков. Применённая в декодере схема потребовала введения сложного определителя длины инструкций и удлинения конвейера на один такт.
Несмотря на то, что МОПы выходят из декодера группами по три, в последующих трактах они обрабатываются и отслеживаются по отдельности. В частности, в буфере переупорядочения они размещаются плотно, без потери на фрагментацию, как это свойственно микроархитектурам, в которых МОПы собираются в фиксированные группы с привязкой позиции в группе к конкретным очередям и устройствам.
Одновременно с помещением новой группы МОПов в буфер переупорядочения и в очередь планировщика производится переименование (переназначение) регистров результатов для этих МОПов. Каждой позиции буфера переупорядочения приписан один внутренний (физический) регистр длиной 80 разрядов, который ставится в соответствие исходному (архитектурному) регистру. Обратное копирование содержимого физического регистра в соответствующий архитектурный будет произведено в момент отставки операции. Для хранения одного 128-битного регистра XMM используются два внутренних регистра.
Intel Core (P8)
Общая организация подсистемы декодирования инструкций в новом процессоре P8 напоминает организацию этой подсистемы в последнем представителе семейства P6/P6+ — процессоре P-M2 (Core Duo), и представляет собой её дальнейшее развитие. На данный момент пока что нет достаточно полной информации о новой микроархитектуре, однако на основе презентаций и замеров уже можно выявить её основные особенности.
Судя по представленным блок-схемам, в процессоре P8 по-прежнему используется схема с определителем длины инструкций. На этих схемах он назван предекодером и расположен после I-кэша. Предекодер может размечать до шести x86-инструкций за такт. После предекодера инструкции помещаются в небольшую очередь, откуда передаются в четыре параллельно работающие канала декодера. Перед попаданием в каналы декодера над одной парой инструкций может быть проведена операция объединения («макро-слияния», macro-fusion) в единую макроинструкцию: инструкция сравнения (CMP или TEST) может быть объединена с расположенной непосредственно после неё инструкцией условного перехода (Jcc). Такие пары инструкций очень часто встречаются в программах с большим числом ветвлений, содержащих конструкции If-Then-Else или Case. Объединённая макроинструкция (CMPJcc или TESTJcc) обрабатывается в одном канале декодера, преобразуется в один МОП и исполняется за один такт в соответствующем функциональном устройстве.
Таким образом, с учётом возможного объединения пары инструкций (макро-слияния), декодер процессора P8 способен принимать на вход до пяти x86-инструкций за такт. Это должно было потребовать увеличения размера порции байтов, обрабатываемой определителем длины инструкций (предекодером) за один раз. Определитель длины инструкций также должен был усложниться в связи с тем, что в инструкциях 64-битного режима EM64T (x86-64) появился дополнительный префикс REX, затрудняющий их разбор и определение длины. Кроме того, определитель теперь должен гарантированно размечать по четыре-пять x86-инструкций за такт, а не по три, как в предыдущих процессорах.
Предварительные замеры показали, что декодер процессора P8 может обрабатывать с полной скоростью инструкции, содержащие несколько префиксов (хотя пока ещё не ясно, относится ли это ко всем сочетаниям префиксов и инструкций). Данное свойство роднит его с декодером процессора AMD K8 (в котором инструкции NOP, содержащие 4 и более префиксов, обрабатываются даже медленнее, чем в P8), и отличает от предшествующего процессора P-M2 (в котором на обработку каждого префикса, начиная со второго, затрачивается дополнительный такт). По этим признакам можно было бы предположить, что информация о разметке инструкций запоминается в I-кэше для последующего использования — однако явного указания на такую организацию предекодирования в презентациях нет.
Также замеры показали, что определитель длины инструкций может обрабатывать более 16 байтов за такт. Однако длина блока, считываемого из I-кэша, не изменилась и составляет по-прежнему 16 байт. В совокупности ограничение на темп декодирования стало более мягким — теперь эта величина (16 байт/такт) ограничивает среднюю скорость декодирования потока инструкций, а не размер группы, декодируемой в каждом такте. Это также роднит новый декодер с декодером процессора K8.
Четыре параллельно работающих канала декодера организованы по несимметричной схеме (предположительно «4-1-1-1 / >4»): только первый канал может принимать сложные инструкции, порождающие более одного МОПа. Благодаря слиянию микроопераций, инструкции загрузки с исполнением (Load-Op) и выгрузки (Store) преобразуются в один МОП и не являются сложными. Все инструкции SSE (включая Load-Op) также преобразуются в один МОП. Упакованные инструкции SSE порождают «128-битные» МОПы, которые исполняются в 128-битном функциональном устройстве без расщепления и в полном темпе.
Несмотря на то, что в «простых» каналах декодера по-прежнему порождается всего один МОП, схему декодера процессора P8 было бы более правильно обозначить как «4-2-2-2 / >2», так как одна упакованная операция SSE соответствует двум МОПам в предшествующих процессорах (Intel P-III, P-M и AMD K8). Использование макро-слияния, слияния микроопераций и монолитных «128-битных» МОПов (для упакованных операций SSE) позволяет существенно уменьшить общее число порождаемых МОПов, что приводит к экономии ресурсов буферов и увеличению эффективной пропускной способности трактов процессора.
Таким образом, в процессе поэтапного эволюционного развития процессоров P-III —> P-M —> P-M2 —> P8, подсистема декодирования инструкций претерпела существенные количественные и качественные изменения. Смягчились ограничения на число префиксов и на размер инструкций, декодируемых в полном темпе. Добавился 64-битный режим целочисленной и адресной арифметики EM64T (x86-64). Число обрабатываемых за один такт x86-инструкций увеличилось с 3 до 4-5, а число порождаемых МОПов — с 3 до 4. Благодаря механизму слияния микроопераций все каналы декодера приобрели способность обрабатывать большинство машинных инструкций, и за счёт этого эффективная пропускная способность декодера и последующих трактов увеличилась дополнительно примерно в 1.3-1.5 раза. Кроме того, значительно увеличилась пропускная способность декодера для инструкций SSE, и вдвое уменьшилось число МОПов, порождаемых для упакованных операций. В результате совокупная эффективная пропускная способность декодера выросла в среднем не менее чем в два раза (в расчёте на такт), что находится в соответствии с повысившейся пропускной способностью функциональных устройств процессора (в полтора раза для логики и целочисленной арифметики, и в два-четыре раза для арифметики с плавающей точкой).
Как и в процессорах семейства P6/P6+, в новом процессоре МОПы после выхода из декодера обрабатываются и отслеживаются по отдельности. В частности, в буфере переупорядочения они размещаются плотно, без потери на фрагментацию. Для переназначения (переименования) регистров результатов используется набор внутренних (физических) регистров, общий для всех типов операций. По всей видимости, каждый физический регистр приписан к соответствующей позиции буфера переупорядочения (как и в процессорах семейства P6/P6+), и их количество равно размеру буфера. Регистры имеют длину 128 разрядов, и для хранения 128-битного регистра XMM используется один внутренний регистр.
AMD Athlon 64 / Opteron (K8)
В процессоре K8 применена схема с предварительным декодированием (предекодированием) x86-инструкций перед помещением их в I-кэш. Назначение этого предекодирования — определить границы и положение кода операции в каждой x86-инструкции, а также определить тип инструкции — простой или сложный. Простая инструкция будет преобразована в один или два МОПа в «простом» декодере (DirectPath, DP), сложная — в три или более МОПов в «сложном» декодере (VectorPath, VP). Для запоминания информации о разметке в I-кэше имеются дополнительные биты — по три бита на каждый байт инструкций. Таким образом, в дополнение к 64 Кбайтам для хранения исходных x86-инструкций в I-кэше имеется также 24 Кбайт для хранения информации о разметке. Предекодирование ведётся в небольшом темпе, не более 4 байтов за такт.
Из I-кэша инструкции считываются выровненными блоками по 16 байтов за такт, с опережающей предвыборкой. Благодаря наличию информации о разметке сразу после считывания блока происходит выделение инструкций из буфера и отсылка в соответствующие устройства декодирования — «простое» (DirectPath) или «сложное» (VectorPath). За один такт в простое устройство может быть отправлено до 6 инструкций — они накапливаются в небольшом входном буфере. Из этой очереди инструкции поступают в три параллельно работающих канала декодирования. Если во входном потоке есть сложная инструкция, то она направляется непосредственно в сложное устройство.
Таким образом, в каждом такте может быть начато декодирование трёх простых инструкций, либо одной сложной. Простые и сложные инструкции на дальнейших этапах декодирования не смешиваются — если на каком-то этапе обрабатывается сложная инструкция, то соответствующие этапы трёх каналов простого декодера не работают. На выходе из каждого канала простого декодера порождается один или два МОПа. Эти МОПы из трёх каналов попадают в небольшую очередь, на выходе из которой формируются группы по три МОПа. МОПы, порождаемые сложным устройством декодирования, также собираются группами по три.
В результате на выходе из декодера в каждом такте образуется одна группа, содержащая до трёх МОПов. Каждая такая группа содержит МОПы, произведённые либо простым, либо сложным устройством декодирования — то есть в одной группе МОПы из разных устройств не смешиваются. Это может привести к неполному заполнению последней группы МОПов, вышедшей из простого либо из сложного устройства. МОПы выходят из декодера в порядке, соответствующем порядку исходных x86-инструкций.
Сформированная группа МОПов поступает в буфер переупорядочения и в дальнейшем отслеживается как единое целое. В блок отставки выполненные МОПы могут поступать также только в составе исходной группы. Помимо удобства отслеживания внеочередного исполнения и отставки, объединение МОПов в фиксированные группы имеет ещё одну цель: позиция МОПа в группе привязана к номеру очереди планировщика и функционального устройства, в которые этот МОП будет отправлен. Это относится к целочисленным и адресным операциям (ALU/AGU). Для операций арифметики с плавающей точкой (FPU) такой привязки нет — группа, содержащая такие МОПы, просто копируется целиком в новый элемент очереди планировщика FPU. Статическая привязка позиции МОПа к номеру соответствующей очереди или устройства, в сочетании с отслеживанием инструкций в составе групп, позволяет упростить организацию подсистемы внеочередного исполнения.
К числу простых инструкций, порождающих два МОПа (DirectPath Double, DD), относятся все упакованные инструкции SSE, а также инструкции целочисленного умножения и некоторые другие. Для большинства таких инструкций нет ограничений по размещению в группах — например, два МОПа упакованной инструкции SSE могут оказаться в соседних группах. Однако МОПы инструкции целочисленного умножения должны обязательно размещаться в одной группе в двух первых позициях, так как они исполняются совместно в двух первых устройствах ALU. Подобное требование также может привести к неполному заполнению группы.
Для сложных инструкций (VectorPath) требуется, чтобы они обрабатывались в блоке отставки операций как единое целое, без смешивания с другими (простыми) инструкциями. Поэтому декодер не объединяет МОПы простых и сложных операций в одной группе, что приводит к потерям на фрагментацию. Правда, такие сложные инструкции в микроархитектуре K8 довольно редки.
Помимо перечисленных случаев, группа МОПов может оказаться не заполненной до конца, если прерывается входной поток инструкций. Это может произойти при отсутствии следующего блока инструкций в I-кэше, при неправильном предсказании условного перехода, при отсутствии адреса перехода в таблице BTB, а также и при правильном предсказании в случае, если инструкции считывались из кэша с недостаточным опережением.
Таким образом, схему работы декодера в процессоре K8 можно обозначить как «2-2-2 / >2». В сравнении с предшествующим процессором K7 декодер инструкций был значительно усовершенствован: в старом процессоре декодер работал по схеме «1-1-1 / >1» и обрабатывал только два класса инструкций — простые (DirectPath), порождающие один МОП, и сложные (VectorPath), порождающие два и более МОПов. К последним, в частности, относились все упакованные инструкции SSE, что приводило к заметному снижению эффективности работы декодера.
Важной особенностью процессора K8 (и его предшественника K7) является отход от принципа максимального упрощения МОПов, в которые преобразуются исходные x86-инструкции. Этот принцип предполагал, что МОПы должны быть RISC-подобными — в частности, что операции обработки должны отделяться от операций обращения в память. Следование данному принципу упрощало организацию процессора, но приводило к увеличению числа порождаемых и обрабатываемых МОПов примерно в 1.3-1.5 раза. В процессорах K7/K8 МОПы являются комбинированными и могут содержать два элементарных действия — арифметическое и адресное. Разделение на эти действия происходит при запуске МОПа на исполнение. Таким способом реализованы операции типов Load-Op, Op-Store и Load-Op-Store.
Данный подход был позднее заимствован и частично реализован в процессоре Intel P-M (и последующих) для операций типа Load-Op (под названием «слияние микроопераций»).
В связи с тем, что разметка x86-инструкций производится заранее, перед помещением в I-кэш, в декодере не накладывается никаких ограничений на их длину и структурную сложность. В частности, не ограничивается число префиксов в одной инструкции, что позволяет использовать фиктивные префиксы для выравнивания инструкций там, где это необходимо. Например, для бесперебойной работы декодера в максимальном темпе (три инструкции за такт) в процессоре K7 рекомендуется размещать по три x86-инструкции в выровненном блоке (бандле) длиной 8 байт. Для операций с плавающей точкой x87 можно использовать префикс REP, который не оказывает на них никакого влияния. Пример кода, в котором применение фиктивных префиксов могло бы оказаться необходимым, показан на Рис. 2 (правда, в данном примере инструкции уже выровнены правильным образом). В процессоре K8 рекомендация о размещении инструкции в 8-байтовых бандлах снята, однако могут потребоваться другие типы выравнивания.
Таким образом, процессор K8 имеет достаточно гибкий и эффективно реализованный трёхканальный декодер. Организация с предекодированием инструкций до помещения их в I-кэш позволяет уменьшить длину конвейера и снять ограничения на структурную сложность инструкций, декодируемых в полном темпе. Однако необходимость в предекодировании может снизить темп считывания потока инструкций из L2-кэша или памяти. Кроме того, предекодированию подвергаются только те участки кода, по которым проходит трасса исполнения. Поэтому участки, расположенные после «точек выхода» из этой трассы (то есть после совершённых инструкций перехода) или перед «точками входа» в трассу, могут оказаться неразмеченными либо неправильно размеченными. Последующее исполнение инструкций из этих участков кода потребует предекодирования «на ходу» с потерей темпа работы.
По завершении декодирования группа МОПов помещается в буфер переупорядочения и в очереди планировщика. Одновременно производится переименование (переназначение) регистров результатов для этих МОПов. Для этого используются отдельные наборы внутренних (физических) регистров для целочисленной/адресной арифметики ALU/AGU и для арифметики с плавающей точкой FPU. Физические регистры ALU/AGU приписаны соответствующим позициям буфера переупорядочения, и число таких регистров равно длине буфера (72 позиции). Также имеется определённое количество дополнительных регистров такого же типа, предназначенных для хранения последних значений результатов и используемых для ускорения доступа к данным. Для внутренних регистров FPU применяется более сложная динамическая схема переназначения, число таких регистров равно 120 (включая архитектурные). Для хранения одного 128-битного регистра XMM используются два внутренних регистра FPU.
Intel Pentium 4
В процессоре P-4 применена схема с полным декодированием x86-инструкций перед записью в кэш трасс (Т-кэш). Общая организация Т-кэша и специфика работы декодера x86-инструкций описаны в предыдущем разделе. Декодирование происходит в небольшом темпе, не более одной инструкции за такт. Инструкции помещаются в блоки Т-кэша длиной 6 ячеек в соответствии с предполагаемым порядком исполнения. Последовательность таких блоков образует трассу. Одновременно с декодированием вновь порождаемые МОПы отсылаются на исполнение.
При последующем исполнении трассы МОПы считываются из Т-кэша в темпе 1 блок за 2 такта — то есть по 3 МОПа за такт. Если исходная инструкция при декодировании не могла быть преобразована в короткую последовательность (до четырёх МОПов), она заменялась вызовом «микрокодовой подпрограммы». При исполнении трассы, содержащей такой вызов, недостающие МОПы выбираются из микропрограммной памяти по соответствующему адресу и отправляются на последующую обработку (также по 3 МОПа за такт).
Предельный темп считывания МОПов достигается только в том случае, если МОПы размещаются в Т-кэше плотно, без фрагментации. Имеется несколько причин, которые могут привести к неполному заполнению блоков кэша и снижению темпа считывания МОПов:
- необходимость размещения всех МОПов, составляющих x86-инструкцию, в одном блоке кэша;
- наличие в x86-инструкции литеральной константы или смещения адреса с длиной значимой части более 16 разрядов (в некоторых случаях это может потребовать выделения дополнительной ячейки Т-кэша);
- вызов «микрокодовой» подпрограммы для сложной инструкции;
- превышение ограничения на число операций перехода в блоке;
- завершение трассы по инструкции косвенного перехода, вызова подпрограммы или возврата из подпрограммы, по концу цикла, по достижению максимальной длины трассы.
В процессоре P-4 при декодировании инструкций загрузки из памяти с последующим исполнением (Load-Op) порождаются отдельные МОПы для загрузки и для выполнения. Для инструкций выгрузки в память в некоторых случаях также порождаются два отдельных МОПа: один для вычисления адреса, другой — для осуществления записи (МОП для вычисления адреса не нужен при применении простых схем адресации без использования байта SIB). Разделение таких инструкций на два МОПа также ведёт к снижению эффективного темпа обработки инструкций.
С другой стороны, упакованные операции SSE преобразуются в монолитные «128-битные» МОПы, что ведёт к снижению числа порождаемых МОПов (в сравнении с процессорами P-III и K8) и повышению эффективной плотности их потока. Это позволяет при активном использовании таких инструкций добиться высокого уровня загрузки функциональных устройств FPU (SSE), близкого к предельному.
Благодаря тому, что декодирование x86-инструкций производится заранее, перед помещением в T-кэш, в декодере не накладывается никаких ограничений на их длину и структурную сложность. В частности, скорость считывания и исполнения операций не зависит от числа префиксов в исходной инструкции.
Таким образом, специфика процессора P-4, работающего на повышенной частоте, привела к необходимости полного отделения процесса декодирования инструкций от их последующей обработки и исполнения. Это позволило исключить этапы конвейера, занимающиеся декодированием, из основного цикла выполнения программы (когда инструкции считываются из кэша), и благодаря этому сократить длину конвейера непредсказанного перехода.
Несмотря на то, что МОПы выходят из Т-кэша группами по три, в последующих трактах они обрабатываются и отслеживаются по отдельности. Также по отдельности МОПы отправляются в отставку — отставка производится в темпе до трёх МОПов за такт, без привязки к исходным группам, в составе которых они считывались из Т-кэша.
Для переназначения (переименования) регистров результатов используются раздельные наборы внутренних (физических) регистров для целочисленной арифметики и для арифметики с плавающей точкой FPU. Число регистров в каждом наборе соответствует размеру буфера переупорядочения и равно 128. В отличие от процессоров семейства P6/P6+, архитектурные регистры не хранятся отдельно от внутренних, и не производится копирование содержимого между этими наборами. Вместо этого используются дополнительные таблицы отображения номеров архитектурных регистров в номера физических регистров. Регистры FPU имеют длину 128 разрядов, и для хранения 128-битного регистра XMM используется один внутренний регистр.
Продолжение следует…
Список литературы
- O. Bessonov, D. Fougere, B. Roux. Development of efficient computational kernels and linear algebra routines for out-of-order superscalar processors. Future Generation Computer Systems, V.21, No.5, 2005, pp.743-748.
- A. Fog. How to optimize for the Pentium family of microprocessors. 2004.
- M. Milenkovic, A. Milenkovic, J. Kulick. Demystifying Intel Branch Predictors. Proceedings of the Workshop on Duplicating, Deconstructing and Debunking, 2002.
- О. Бессонов. Pentium 4: Мистический и загадочный Trace-кэш. Ф-Центр, 2005.
- Я. Керученько, Ю. Малич, В. Левченко. Replay: неизвестные особенности функционирования ядра Netburst. Ф-Центр, 2005.
- В. Картунов. Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Ф-Центр, 2005.
- О. Бессонов. Новое вино в старые мехи. Conroe: внук процессора Pentium III, племянник архитектуры NetBurst? iXBT.com, 2005.
- О. Бессонов. Двухъядерный процессор Yonah: уже не Pentium III, ещё не Conroe. iXBT.com, 2006.
- H.H. Sean Lee. P6 & NetBurst Microarchitecture. School of ECE, Georgia Institute of Technology, 2003.
- IA-32 Intel Architecture Optimization Reference Manual. Intel, 2006.
- IA-32 Intel Architecture Software Developer's Manual. Intel, 2006.
- Intel Architecture Optimization Reference Manual. Intel, 1999.
- J. Keshava, V. Pentkovski. Pentium III Processor Implementation Tradeoffs. Intel Technology Journal, V.3, Q2, 1999.
- G. Hinton et al. The Microarchitecture of the Pentium 4 Processor. Intel Technology Journal, V.5, Q1, 2001.
- S. Gochman et al. The Intel Pentium M Processor: Microarchitecture and Performance. Intel Technology Journal, V.7, Issue 2, 2003.
- S. Gochman et al. Introduction to Intel Core Duo Processor Architecture. Intel Technology Journal, V.10, Issue 2, 2006.
- D. Boggs et al. The Microarchitecture of the Intel Pentium 4 Processor on 90nm Technology. Intel Technology Journal, V.8, Issue 1, 2004.
- B. Valentine. Inside the Intel Core Microarchitecture. Intel Developer Forum, 2006.
- B. Inkley. Inside the Intel Core Microarchitecture. Intel Developer Forum, 2006.
- D. Kanter. Intel's Next Generation Microarchitecture Unveiled. Real World Technologies, 2006.
- Instruction length decoder for generating output length indicia to identity boundaries between variable length instructions. United State Patent 5,758,116, 1998.
- Software Optimization Guide for AMD64 Processors. AMD, 2005.
- В. Картунов. Детальное исследование архитектуры AMD64. iXBT.com, 2003.
- H. de Vries. Understanding the detailed Architecture of AMD's 64 bit Core. Chip-Architect, 2003.
- D. Kanter. AMD's K8L and 4x4 Preview. Real World Technologies, 2006.
- J. Tendler et al. POWER4 system microarchitecture. IBM Journal of Research and Development, V.46, No.1, 2002.
- Tom R. Halfhill. IBM Trims Power4, Adds ALTIVEC. 64-Bit PowerPC 970 Targets Entry-Level Servers and Desktops. Microprocessor Report, Oct.28, 2002.
- J. Stokes. Inside the PowerPC 970. Part II: The Execution Core. Ars Technica, 2003.
- С. Гарматюк. Современные десктопные процессоры архитектуры x86: общие принципы работы. iXBT.com, 2006.


