Второй концерт для Opteron'а с оркестром
Вместо предисловия
Ну что ж, до российских просторов добрались процессоры восьмого поколения от AMD — Opteron и Athlon 64. Причем, говоря откровенно, добрались они достаточно давно, и наверняка читатели сайта задавали один и тот же вопрос — ну что они тянут? Почему на iXBT все еще нет обзора? А не было их потому, что мы поставили перед собой гораздо более интересную (и более амбициозную) задачу — разобраться в деталях реализации микроархитектуры, в особенностях поведения, и создать на основе этого как можно более полное описание архитектуры поколения K8. Для начала, правда, попробуем реализовать все же несколько более скромную задачу: на первом этапе прояснить для себя некоторые нюансы работы нового поколения процессорной микроархитектуры. А тебе, читатель, решать, насколько удалось нам реализовать поставленную задачу.
Для начала напомним, что достаточно детальный обзор микроархитектуры К8 (настолько, насколько было возможно на тот момент) уже появлялся на нашем сайте полгода назад. Причем до сих мы не встречали более подробных описаний этой микроархитектуры. Так что искренне рекомендуем начать со статьи «Симфония Соль мажор для Opteron и Athlon 64», в которой весьма детально рассматривается архитектура процессоров семейства Hammer. Но, как мы помним, в той статье возникало некоторое количество вопросов и предположений, которые мы сейчас постараемся надлежащим образом прояснить и при необходимости прокомментировать.
Тестируемые платформы
Для начала перечислим тот набор «приборов и материалов», который понадобится нам для дальнейших исследований.
Платформа Opteron:
- Два процессора Opteron 240 (1400МГц)
- Материнская плата Rioworks HDAMA (AMD8131 + AMD8111)
- Материнская плата Asus SK8N for Opteron на базе чипсета nForce 3 Pro
- Материнская плата Soltek K8AV-R for Athlon 64 на базе VIA K8M400
- Два процессора Athlon 64 с частотами 1400МГц и 1600МГц
- Четыре модуля памяти Registered (!) DDR333 объемом 512МВ каждый, производства Transcend.
Платформа Pentium 4:
- Материнская плата на базе i875P Asus P4C800
- Pentium 4 3.0 GHz (15 x 200)
- TwinMos DDR400 (2 x 256MB, 2-2-2-5)
Что ж, парк оборудования не маленький…. Уже понятно, что из данного оборудования можно выяснить несколько вещей:
- Насколько отличается производительность Opteron от производительности Athlon 64 (не забывая о том, что память ECC Registered, вообще говоря, работает несколько медленнее «обычной»). Фактически, в этом сравнении мы попытаемся выяснить, насколько значителен прирост производительности от двухканальной памяти.
- Сравним, насколько хорошо масштабируется архитектура K8 с ростом частоты — это, по идее, должно быть небезынтересно (конечно, было бы неплохо посмотреть эту зависимость на нескольких коэффициентах умножения, тем более что частота памяти меняется с ростом частоты процессора; но будем пытаться обойтись тем, что есть).
- Сравним (куда уж деваться?! :-)) вышеуказанные процессоры по скорости в различных приложениях.
Но любое тестирование — это, прежде всего, методика. А потому вначале определимся именно с нею, с методикой нашего тестирования. Как правило, тестируя новую платформу, необходимо как можно раньше «прочувствовать» нюансы. Для этого воспользуемся синтетическими тестами, задача которых «проникнуть внутрь» микроархитектуры К8. Таким образом, план будет таков:
- При помощи синтетических тестов выяснить как можно больше подробностей про микроархитектуру Opteron и Athlon 64. Постараемся разрешить те вопросы, которые возникли у нас в предыдущем обзоре микроархитектуры Hammer.
- Затем сравнить между собой Opteron и Athlon 64, анализируя зависимость производительности системы от расширения шины памяти.
- Наконец, сравнить между собой системы двух главных конкурентов на рынке х86. От такого сравнения все равно никуда не деться — для обоснованного выбора платформы необходимо иметь на руках цифры соотношения скоростей в различных видах программ.
- Попытаемся сделать из всего этого вывод (даже, наверняка, не один)
Признаемся, что задача стоит достаточно нетривиальная. Дело в том, что к позиционированию тех или иных продуктов можно относиться совершенно различным образом. А посему не исключена такая ситуация, когда тот или иной продукт может выглядеть лучше или хуже просто за счет «выбора соперника». Дабы этого не произошло, постараемся максимально расширить перечень представленных тестов, а также выбрать соответствующих соперников, чтобы как можно полнее охватить ситуацию. И уж совсем не стоит забывать о наших читателях, которые наверняка читают этот обзор для того, чтобы понять — а стоит ли связываться с этой архитектурой? В каких приложениях она выгодна? Станет ли архитектура К8 прорывом, как это обещалось ранее корпорацией AMD? Подходит ли она для игр? Для видеокодирования? Можно ли делать серверы на ее основе? Годится ли она для рабочих станций?! Что насчет ее перспективности? Все это вопросы, на которые нам предстоит дать ответ — поэтому ответственность данного тестирования трудно переоценить.
Теперь позвольте представить команду, которая работала над этим обзором. Дело в том, что, задавшись целью привнести максимальную объективность в данный обзор, мы решили испробовать абсолютно новую для нас методику написания статей — коллективную работу. Нынешняя статья имеет не одного, не двух, и не трех авторов — нет, это в полной мере коллективная работа. Вам, дорогие читатели, судить, насколько удался этот творческий эксперимент; всем же его участникам он будет, безусловно, полезен. Как гласит высказанная Фридрихом Ницше мудрость: «все, что нас не убивает — делает нас сильнее». Имена, которые стали соавторами этой работы, знает практически любой посетитель раздела «Процессоры» конференции iXBT. Эти имена достаточно часто мелькают в практически любом обсуждении архитектур процессоров и систем на их основе, и сегодня мы постараемся беззастенчиво и в полной мере воспользоваться их глубокими знаниями по этому поводу. Итак, встречайте!
- Керученько Ян, известен как C@t
- Левченко Вадим, известен как VLev
- Бессонов Олег, известен как bess
- Малич Юрий, известен как Yury_Malich
- Павлов Игорь, известен как lkj
Кроме того, неоценимую помощь (как в области критических замечаний, так и по части постановки задачи) всем нам оказывали:
- Вайцман Илья, известен как Stranger_NN
- Лыков Андрей, известен как ISA_user
- Романов Сергей, известен как GReY
Таким образом, команда, согласитесь, выдалась преизрядная — переиначивая Владимира Ильича, «все сплошь матерые человечища!» :-). Но не будем забывать и про вторую, не менее важную, составляющую любого обзора, про «мерило любой теории» — про практику. Ею занималась команда тестеров iXBT, а именно:
- Кочетков Кирилл, он же Kirill Kochetkov
- Пикалов Сергей, он же Peek
- Майоров Дмитрий, он же Destrax
Таким образом, все участники являются отнюдь не новичками — с нашей точки зрения, это должно наилучшим образом сказаться на качестве материала. Осталась только одна небольшая роль, которую решил взять на себя Ваш покорный слуга, Картунов Виктор, aka matik. Так уж случилось, что именно моему «перу» принадлежит большинство предыдущих статей про Hammer на сайте iXBT. Соответственно, мне сегодня и «отдуваться» за данные ранее «обещания». Посмотрим, сумеет ли AMD выполнить то, что я «наобещал» ранее. :-) Итак, хорошо это, или плохо, роль «летописца» данной эпопеи — назвать ее тривиальным тестированием язык не поворачивается — досталась мне.
Однако, довольно дифирамбов — читатель уже наверняка потихоньку закипает: почему вместо тестов и пояснений продолжается какая-то «тягомотина» и раздача грамот? :spy: Долой расшаркивания, даешь статью! Вот теперь, читатель, ты можешь себе представить глубину чувств и долготерпения редакторов раздела, которые несколько месяцев (!) наблюдали за неспешным и несуетливым обсуждением особенностей микроархитектуры, и читали рассуждения о необходимости подробного обсуждения того или иного аспекта предполагаемой статьи. Равно, как теперь ты можешь оценить глубину терпения тестеров, раз за разом запускавших во всех возможных комбинациях тестовые программы, частенько отличающиеся от предыдущих вариантнов только парой байтов. Но не будем более испытывать еще и твое терпение, и приступим!
Модельный ряд Opteron
Теперь самое время напомнить, какие же процессоры объявила AMD 22 апреля (ничего не скажешь, знаменательная дата;:-) Более впечатляющей была бы только дата 7 ноября!). Как и предсказывалось в предыдущей статье, AMD начала штурм рынка на серверном направлении. 22 апреля были официально анонсированы процессоры Opteron. Причем примечательно то, что отныне AMD вообще отошла от указания частоты и/или рейтинга. Вместо этого все семейство Opteron разделено на три серии — 1хх, 2хх, и 8хх (другое название этих серий — 100, 200, и 800 серии соответственно). Отличаются они друг от друга тем, что Opteron 1хх работает только в однопроцессорных конфигурациях, Opteron 2xx работает не более чем в двухпроцессорных, а Opteron 8хх — до восьмипроцессорных включительно. Внутри каждой серии процессоры отличаются по номерам. Первыми были представлены процессоры только одной серии — 2хх, остальные серии (14х и 84х) были представлены в конце июня. Первоначально серия 2хх, состояла из следующих моделей: Opteron: 240 с частотой 1400МГц, 242 с частотой 1600МГц и 244 с частотой 1800МГц. 4 августа был представлен Opteron 246 — модель, тактовая частота которой составляет 2ГГц. Модели 146 и 846 с аналогичной частотой на подходе. Каждый процессор имеет 128 битную (+16 бит ЕСС) шину памяти, три интерфейса Hyper Transport, и 1024КВ L2 cache. Это максимальная конфигурация кэша, которую мы ожидали в предыдущей статье, и, насколько нам известно, предельная для текущего ядра.
В настоящий момент процессор поддерживает Registered DDR266 и DDR333 память с ECC или без неё. По-видимому, после принятия JEDEC стандарта ECC DDR400 мы «совершенно случайно» обнаружим поддержку этого типа в Opteron — основание так полагать нам дают результаты запуска процессора Athlon 64 с памятью DDR400, на которую он официально не рассчитан. Интересно, что Opteron способен работать даже с одним модулем памяти, что было для нас несколько неожиданно — памятуя о 128 битной шине памяти, мы опасались, что один модуль работать не будет. Естественно, использование одного модуля вдвое снижает пропускную способность памяти, и, возможно, изменяет латентность — чудес не бывает! Но радует возможность хотя бы запустить при необходимости систему, если один из двух модулей вышел из строя. Также достаточно ожидаемым для нас было то, что процессор не работает с нерегистровой памятью — как уже было сказано, Opteron предназначен для рынка серверов и рабочих станций, а там использование модулей Registered ECC практически обязательное условие.
Интересно, что можно поставить память только на один процессор — тогда второй в двухпроцессорной системе будет «пользоваться» при работе памятью первого. И это работает! :-) Что ж, вряд ли в реальной системе не поставят память на каждый процессор, но гибкость архитектуры вызывает уважение.
С одним процессором дуальная платформа также стартует и работает — собственно, ничего удивительного здесь нет, но убедиться следовало.
Подсистема кэша. Поиск и анализ изменений
Одним из важных слагаемых для результирующей производительности процессора является производительность подсистемы кэширования. Кэш-память призвана сгладить разницу в скоростях оперативной памяти и самого процессора, поэтому она находится на «переднем крае» борьбы с постоянным недостатком данных для процессора. Как известно, кэш в K7 имел несколько узких мест, в связи с чем было бы очень интересно узнать, что же, кроме объема, изменилось в организации кэша в К8 по сравнению с Athlon XP.
В общем случае, производительность кэша характеризуется несколькими параметрами: задержками (Latency), и темпом (throughput), а также некоторыми другими понятиями вроде типа ассоциативности (впрочем, о нем и других параметрах поговорим позднее). Первые два параметра влияют на производительность заметно больше, нежели остальные. Причем в общем случае эти задержки для произвольного и последовательного доступа могут отличаться (и отличаются, как мы ниже увидим). Соответственно, вначале опишем ситуацию с тем, как устроена подсистема кэш-памяти в Athlon XP, а затем сравним с K8 (в данном случае авторы считают вполне разумным применять именно данную аббревиатуру, поскольку в организации кэша разницы между Opteron-ом и Athlon-ом 64 попросту нет).
Взглянем на табличные данные задержки для кэшей L1 и L2 у Athlon XP и К8 соответственно:
| CPU | L1 latency, тактов | L2 latency, лучший случай | L2 latency, худший случай |
| Athlon XP | 3 | 11 | 20 |
| K8 | 3 | 11 | 16 |
Мы видим, что для кэша L2 опубликованы две цифры вместо одной. Какой смысл вложен в «лучший» и «худший» случаи? Для объяснения ситуации, припомним о такой особенности организации кэш-памяти процессоров AMD, как «эксклюзивность» (exclusive). Суть ее в том, что содержимое L1 не копируется в L2, а они друг друга дополняют. Таким образом, AMD говорит о суммарном объеме кэша как о L1 + L2.
Кстати, более строго было бы говорить о суммарном объеме как о L1 Data + L2, что в данном случае на 64КВ меньше. Дело в том, что, говоря о кэшировании данных, следовало бы для строгости отделять кэш команд.
Однако у такой организации кэшей есть несколько особенностей, которые необходимо знать. Прежде всего, заметим, что в Athlon XP ширина шины данных между кэшами L1 и L2 составляет 64 bit. Эти данные нам в дальнейшем понадобятся. Теперь рассмотрим на примере работы кэша у Athlon XP упомянутые особенности.
Особенность первая: поскольку в процессе работы затребованные или обработанные данные прежде всего «складываются» в кэш L1, то может возникнуть (и практически всегда возникает, кстати) нехватка места в L1. В этом случае кэш L1 должен сбросить самые «старые» или ненужные данные в L2, а уже затем принять новые данные (поскольку данные не дублируются в кэшах, мы не можем просто очистить строку кэша). Для того чтобы процесс «сбрасывания» данных происходил быстрее, в процессоре есть специальный буфер — Victim buffer, задача которого как раз и состоит в том, чтобы запомнить данные, которые будут сброшены в L2. Тем самым освобождается место в L1, которое займут свежие, только что поступившие данные. Собственно, необходимость в таком буфере возникает потому, что кэши L1 и L2 работают с разными задержками — в результате Victim buffer освобождает L1 cache от необходимости ожидать более медленный кэш L2.
Особенность вторая: Пусть, например, мы потребовали данных, которых нет в кэше L1, но они есть в кэше L2. Вполне жизненная ситуация, согласитесь! В этом случае задержки раскладываются следующим образом:
- На первом этапе процессор выполняет поиск данных в кэше L1, на это уходит три такта.
- На втором этапе необходимо освободить место в L1 для пересылки данных из L2. Соответственно, строка кэша в 64 байта сбрасывается в Victim buffer, освобождая место в L1. До окончания пересылки первого критического слова из L2 (после чего процессор уже может продолжать работу) необходимо еще 8 тактов.
Для читателей, обожающих подробности, укажем, что на самом деле на пересылку критического слова уходит 1 (один) такт, а оставшиеся 7 тактов уходят на собственно доступ к L2. То есть, проверке, действительно ли нужные данные лежат в кэше L2 — (L2 tag: 2 такта), и если да, то где именно — (L2 data: 2 такта), а также на доступ к шине (захват шины) — (Route/mux/ecc: 2 такта и write DC & forward: 1 такт).
Именно эти 8 + 3 такта и дают результирующую цифру в 11 тактов, которую мы и видим в таблице.
- Однако, все так просто и красиво только тогда, когда Victim buffer свободен (в нем у Athlon XP может одновременно находиться восемь строк кэша). Это и есть так называемый «лучший» сценарий. Если же Victim buffer полон, все становится гораздо печальнее. Теперь нам для начала операции очистки строки кэша в L1 необходимо вначале освободить место в Victim buffer-е. На это уходит 8 тактов (перенос строки в 64 байта по шине шириной 64 бита занимает как раз 8 тактов). Затем кэш L2 два такта «отдыхает», в это время обращение к нему невозможно (собственно, речь идет не об «отдыхе», а о «turnaround», переключении режимов записи/чтения). После этого на третьем этапе начинает копироваться строка из L2 в L1, это занимает еще 8 тактов. Одновременно с этим вытесняемая из L1 строка переносится в Victim buffer. Наконец, на этапе 4 кэш L2 опять «отдыхает» два такта (на самом деле, конечно, речь идет не об «отдыхе», а о переключении режимов чтения/записи, на которое и требуется два такта). Таким образом, в нашем случае одна операция загрузки строки из кэша L2 в L1 занимает 8 + 2 + 8 + 2 = 20 тактов. Те же 20 тактов возникают и в латентности, так как операция чтения на разделяемой шине L1-L2 не может начаться, пока не будет закончена операция записи из Victim buffer.
В реальной жизни кэш почти всегда, а Victim buffer частенько, заполнены данными. Соответственно, «под нагрузкой» латентность кэша второго уровня у Athlon XP скорее тяготеет к «худшему» варианту. И уж естественно, данные особенности необходимо учитывать, если мы стремимся добиться максимальной производительности от этой архитектуры. После этого вполне резонно может возникнуть вопрос — а зачем же AMD вообще связывалась такой технологией организации кэша, как exclusive? Тут напомним, что размер кэша L1 для Athlon XP составляет 128КВ, а L2 — 256КВ (позднее 512КВ). Соответственно, терять половину объема на тривиальное дублирование содержимого было бы крайне неразумно! Не говоря уже о том, что, по оценкам AMD, выгода от большого кэша L1 превышает убытки от более сложной организации взаимодействия между L1 и L2 cache. Кстати, именно такая организация кэш-памяти и позволила, например, выпустить процессор Duron, у которого L2 cache был 64КВ, то есть вдвое меньше L1. В случае традиционной inclusive архитектуры выпуск процессора с таким соотношением объемов был бы бессмысленным.
Соответственно, учитывая, что AMD по-прежнему является приверженцем exclusive архитектуры, достаточно разумным способом улучшить ситуацию «под нагрузкой» выглядит расширение шины данных между L1 и L2. Intel в ядре Coppermine сделала это, введя технологию ATC (Advanced Transfer Cache), одна из основных особенностей которой — 256 bit шина между L1 и L2. Отсюда понятен интерес, который мы проявляли к ширине шины еще в прошлой статье.
Кстати, небезынтересен следующий факт — из всех предыдущих рассуждений у читателя может сложиться впечатление, что «exclusive cache» это редкая гадость. Это не так — данная технология является особенностью, а не недостатком. В некотором смысле в этом впечатлении «виноваты» тесты, которые специально пишутся таким образом, чтобы создать большую нагрузку для шины L1-L2. AMD совершенно справедливо утверждает, что в реальных приложениях таких ситуаций, которые бы демонстрировали «несостоятельность» эксклюзивной технологии организации кэша, практически не возникает. Ну а то, что по теоретической пропускной способности кэш второго уровня у К7/К8 проигрывает кэшу Pentium 4, связано попросту с разной идеологией этих архитектур. Таким образом, не стоит поддаваться на «магию цифр», и делать преждевременные выводы.
И еще одно замечание — вообще говоря, варианты организации кэшей отнюдь не ограничиваются вариантами exclusive и inclusive. К примеру, данные в кэше первого и второго уровней могут обновляться по совершенно отличным друг от друга алгоритмам, что делает взаимодействие кэшей еще более сложным….
Однако вернемся к вопросу о ширине шины L1-L2. Перед тем, как мы рассмотрим результаты синтетических тестов, которые и дали нам ответ на этот вопрос, необходимо будет разобраться с такой характеристикой кэша, как степень ассоциативности. Как известно, кэш, вообще говоря, может различным образом отображать памяти. Можно выделить частично- и полно-ассоциативные, кэш «прямого отображения» — все эти разновидности кэша отличаются тем, каким именно образом кэш отображает содержимое памяти. Кроме того, при различной организации кэш обновляет свое содержимое, исходя из разных алгоритмов. Впрочем, к степени ассоциативности это отношения не имеет.
Наиболее распространенным в данный момент среди процессорных архитектур является частично-ассоциативный кэш («partial associative», иногда этот термин переводят как наборно-ассоциативный) с тем или иным количеством «каналов» (либо «областей», либо «наборов», достаточно трудно перевести английский термин «n-way»). Фактически, кэш со степенью ассоциативности n-way может отображать содержимое данной строки памяти на каждую из n своих строк. Этот вариант является разумным компромиссом между полностью ассоциативным («full associative») кэшем, и кэшем «прямого отображения». Первый может отображать содержимое любой области памяти в любой области кэша, но при этом крайне сложен в схемотехнике. Собственно, за всю историю, насколько нам известно, full associative cache применялся всего один (!) раз — в микропроцессоре Cyrix Cx686 в качестве L1 кэша для кода и его размер составлял всего 256 байт (8 строк!). Второй заметно проще, но и менее эффективен, так как данные из разных областей памяти могут конфликтовать из-за единственной строки кэша, где они только и могут быть размещены. В архитектурах К7 и К8 применяется 16-канальный частично-ассоциативный кэш второго уровня.
Теперь посмотрим, каким вообще образом можно было бы измерить ширину вышеупомянутой шины. Например, если начать чтение из L2 в L1, то это должно привести к тому, что вытесненные из L1 данные должны будут попасть в L2, поскольку размер L1 не бесконечен. Соответственно, в идеальном случае (пока не будем спорить, насколько он достижим) шина L1-L2 окажется загружена как востребованными нами данными, так и теми данными, которые выселяются из L1 в L2. Если предположить, что никаких потерь пропускной способности нет, то тогда максимальная скорость чтения/обмена, которую мы можем получить таким способом, должна равняться 64bit/2, то есть 4 байта за такт. Если нам удастся превзойти данный показатель, это может служить указателем на то, что данная шина шире, чем 64 bit. Правда, есть один нюанс — дело в том, что, если взаимодействие кэшей не полностью удовлетворяет условию эксклюзивности данных, то мы можем получить ситуацию, когда вытеснения данных происходить не будет. Такая ситуация требует дополнительного изучения, и при первой возможности оно будет проведено. Но показательным в любом случае будет скорость последовательного чтения массива размером больше L2, но меньше L2+L1Data (от 1024 до 1088 килобайт для K8). Если кэш работает неэксклюзивно, то часть данных будет вытеснена в оперативную память, и скорость чтения упадет. Если же высокая скорость чтения сохранится, это будет означать эксклюзивность работы кэша и пересылку удвоенного количества данных (как загружаемых в L2 из L1, так и возврат «выселенных» из L1 в L2). Именно на этом участке превышение средневзвешенной скорости над цифрой 4 байта за такт (то есть более 8 байт в обоих направлениях) будет означать более широкую, нежели 64 bit, шину!
С другой стороны, если у К8 более широкая, нежели 64 bit, шина, то тогда считывание одной строки кэша (64 байта) должно происходить за меньшее количество тактов. Естественно, имеет смысл делать ширину шины такой, чтобы прочитать строку кэша за целое число тактов — то есть 128 bit либо 256 bit (ясно, что более широкие варианты слишком нереальны, да и неэффективны, по правде говоря). Возможен еще смешанный вариант, когда у нас есть две шины по 64 bit (либо экзотические варианты, когда есть шина 128 bit в одну сторону, и 64 bit в другую). Фактически, нет особого смысла в ассиметричной шине — посему можно рассчитывать на следующие варианты:
- 64 bit, шина не изменилась
- 128 bit (либо 256 bit), ширина шины увеличена
- 64 bit + 64 bit, либо 128 bit + 128 bit, более широкие варианты маловероятны.
Следовательно, надо попробовать придумать методику, которая бы позволила отличить эти случаи между собой.
Для проверки варианта «имеет ли место быть там шина шириной 128 бит» начнем читать 64-байтную строку кэша «по кругу», с различных мест строки. Попутно будем замерять, какое количество тактов потребуется на загрузку каждого из составляющих ее 4-байтовых слов (естественно, не все так просто, есть большое количество факторов, которые приходится учитывать). Если считывание идет по 16 байт (шина 128 bit), то между загрузкой первого и последнего 4-байтного слова строки должно пройти 4 такта, кроме того, начиная читать строку, скажем, с третьего слова, мы бы получили начало строки сразу же или почти сразу же. Однако приходят они в конце «круга» на восьмом такте, как и положено при 64 битной шине! Если выразить это все более простым способом, то кэши обмениваются друг с другом кусками данных («словами»), равными ширине соединяющей их шины. Читая строку кэша с разных мест, «не по порядку», мы получаем разное время. Сдвигая начальную позицию, и сравнивая время прочтения всей строки, мы определяем размер слова этой шины. Тестирование по этому методу привело нас к выводу, что считываются «слова» размером 64 bit, то есть шина имеет ширину 64 bit.
Тем не менее, тест области между 1024 и 1088 килобайтами показал, что результирующая производительность превышает 8 байт/такт, что, вкупе с доказательством отсутствия 128 битной шины в любом ее виде, приведенном в предыдущем абзаце, фактически оставляет только вариант 3. Итак, можно констатировать, что в архитектуре К8 AMD модернизировала шину L1-L2 cache. Теперь вместо одной двунаправленной шины шириной 64 bit мы получили две встречных шины по 64 бита (64 + 64), что сильно снижает вероятность возникновения «затора» в этом месте. Неплохо! Кстати, это не замедлило сказаться на низкоуровневых тестах — скорость кэша второго уровня выросла как минимум на четверть при тех же частотах. Не менее важно то, что теперь снижены (собственно, практически полностью нивелированы) отрицательные эффекты от «перегруза» шины L1-L2, то есть теперь вероятность возникновения «худшего случая» сведена к минимуму, кроме того, заметно снижена латентность в «худшем случае».
Читателей, которые жаждут больших подробностей в методике измерения указанных нами величин, отсылаем к Приложению 1. В нем более подробно расписана методика и результаты исследований L2 cache. Мы же пойдем далее.
Декодеры и конвейеры. Идеология работы внутренних блоков
Как мы уже писали в предыдущей статье, одним из блоков, который подвергся кардинальной переработке в архитектуре К8, стал декодер х86-команд. Перед тем как рассматривать, что же конкретно изменилось, хотелось бы немного поговорить об «идеологии» архитектур. Впрочем, слово «идеология» слишком громкое — пожалуй, больше подойдет слово «концепция».
Дело в том, что уже давно не секрет, что внутренняя система команд у всех нынешних процессоров х86 кардинально отличается от внешней. И, если с внешней системой команд все ясно — она по определению «х86» с теми или иными расширениями — то вот с внутренней ситуация далеко не такая ясная. То есть, практически все интересующиеся этой темой знают, что внутри процессоров х86-команды «раскладываются на более простые» команды (кстати, упомянем, что, говоря о х86-инструкциях, мы подразумеваем и AMD64-инструкции, просто в дальнейшем не будем специально этого оговаривать). Но, оказывается, в этом направлении современные процессоры отличаются настолько сильно, что давно пришла пора упорядочить имеющуюся информацию. Вначале ознакомим читателя с сутью проблемы, из-за которой вообще возникла необходимость превращать «внешнюю» систему команд во внутреннюю. Так ли это необходимо? Судите сами!
Предваряя описание, укажем трудность, с которой мы столкнулись при описании. Концепции, на которых основана микроархитектура К7/К8, достаточно трудно описать так, чтобы это было просто и одновременно корректно. Поэтому неизбежно некоторые описания будут страдать излишней «литературностью» — а некоторые, напротив, излишней академичностью. Посему в данной главе (да и во всей статье) неизбежны «лирические отступления», которые призваны пояснить некоторые нюансы.
Вообще говоря, любая микропроцессорная архитектура имеет в качестве конечной объявленной цели максимальную производительность (речь в данный момент не идет о микропроцессорах «специального назначения», как, например, AMD Alchemy 1500 — рынок КПК менее чувствителен к такой потребительской характеристике, как производительность). В процессе достижения этой самой максимальной производительности неизбежны некоторые компромиссы. Соответственно, надо понимать, что многие «недостатки» тех или иных процессоров возникли не потому, что разработчики «сглупили» при проектировании, а потому, что вынуждены были пойти на компромисс, и, прежде всего, реализовать те вещи, которые показались им наиболее важными. Если вернуться к любимым «х86» процессорам, и поглядеть, то заметно, что Intel и AMD выбрали различные пути достижения максимальной производительности. Припомним, что производительность в упрощенном виде можно представить в виде произведения частоты на среднее число инструкций за такт. Соответственно, для увеличения произведения нам надо увеличивать один из множителей (либо оба, конечно). Соответственно, дальше дороги фирм разошлись — Intel склонилась скорее к увеличению частоты, AMD более привержена увеличению среднего числа исполняемых за такт инструкций.
Соответственно, все дальнейшие различия между микропроцессорными архитектурами этих фирм напрямую следуют из концепции, закладываемой в архитектуру. Не стали исключением и декодеры х86-инструкций в микропроцессорах Pentium 4, К7 и К8. Их особенности и отличия друг от друга связаны как раз с различием подходов к построению высокопроизводительных архитектур.
Кроме всего прочего, на конструкцию декодеров оказал влияние тот факт, что система х86-команд весьма неудобна для конструкторов микропроцессоров. Связано это с несколькими вещами:
- Инструкции «х86» имеют нерегулярную длину (вплоть до 15 байт (!))
- Кроме того, х86-инструкции еще и имеют нерегулярную структуру — к примеру, в первой команде первым стоит код операции, а во второй команде этот код находится на втором месте.
Все это привело к тому, что х86-инструкции оказалось выгоднее вначале «переводить» в некий внутренний набор регулярных команд заранее заданной структуры, которые затем и будут направлены в функциональные устройства микропроцессора. Кроме всего прочего, в такой внутренней команде можно предусмотреть дополнительные поля (например, облегчающие нахождение операндов). Если привести некую, достаточно условную, аналогию, представьте себе конвейер, на который беспорядочно свалены куски материалов и листики с инструкциями по сборке. Весь этот поток движется по конвейеру, а в результате должен получиться автомобиль. Не нравится?! То-то же! Вот и производителям не нравится. В результате они вынуждены некоторые усилия тратить на «разгребание» конвейера — данные (детали) отдельно, инструкции (листики с инструкциями по сборке) отдельно. И, только упорядочив это все, разложив по стадиям вдоль конвейера, можно продолжать сборку. Вроде бы понятно — для высокопроизводительной работы нужен порядок, с этим разобрались.
Теперь припомним, что уже довольно давно (с микропроцессора Pentium, если быть точнее), с 1993 года, х86-совместимые микропроцессоры стали «суперскалярными». То есть умеют исполнять более одной инструкции за такт. В нашем примере это равносильно существованию двух (трех, и так далее) сборочных конвейеров для автомобилей. Само по себе это усовершенствование подняло производительность микропроцессоров. Но и послужило источником новой проблемы.
Проблема оказалась связана с переменной длиной х86-команд. Это весьма крупное неудобство в плане суперскалярного исполнения. При этом сам перевод х86-инструкций во внутренние команды не вызывает особых трудностей. Неприятность же заключается в необходимости одновременной выборки сразу нескольких команд. Источник неприятности: местоположение второй команды можно определить только после анализа первой (в простейшем случае на это уйдет 1 такт или более, т.о. темп выдачи окажется неприемлемо низким — ~1 команда / такт вместо нескольких). Можно одновременно анализировать сразу байтовый набор в потоке инструкций, но отношение эффективность/затраты оказывается весьма неудовлетворительным. Поэтому используются комбинированные подходы к решению этой проблемы.
Вначале рассмотрим отличия идеологий в Pentium 4 и К7, а затем перейдем к «виновнику торжества» — архитектуре К8. На первом этапе и К7, и Pentium 4 используют довольно простой вариант одновременного анализа команд. А вот позднее пути этих архитектур расходятся.
Pentium 4: базовая концепция состоит в переводе х86-инструкций в более регулярные, «RISC-подобные» микрооперации фиксированной длины.
Выбирая х86-инструкции из куска кода, декодеры переводят х86-инструкции в микрооперации. Чтобы избежать потери времени при повторном просмотре этого же куска, выбирая вторую команду (как мы писали выше, здесь одна из основных трудностей в декодировании), Pentium 4 после перекодирования записывает полученную микрооперацию в Trace cache. Декодеры работают асинхронно (в данном случае имеется ввиду темп, а не частота работы) с исполнительными конвейерами. Все это следствие ключевой концепции микроархитектуры Pentium 4 — достичь как можно большей частоты. Естественно, что специальным образом подготовленные микроинструкции можно исполнять более эффективно и с большим темпом, нежели нерегулярные и весьма разнообразные по форме х86-инструкции. Таким образом, Pentium 4 старается держать как можно больше готовых «переведенных» команд для исполнения в Trace Cache. Да-да, в том самом, который может хранить до 12 000 микроопераций. Ну а поскольку одна х86-команда может превратиться в одну, две, или последовательность микроопераций, теперь бессмысленно оперировать такой привычной нам вещью, как «объем» кэша команд. Ведь в зависимости от того, какие команды нам встретились, количество х86-команд, уместившееся в Trace cache, будет от раза к разу совершенно различным. Таким образом, прямое сравнение «объема» кэша команд между Pentium 4 и его конкурентами становится попросту невозможным.
Правда, никто не мешает провести сравнение хотя бы по среднему количеству хранящихся инструкций, взяв широкий спектр задач; насколько нам известно, это мало кто делал — а от Intel мы подобных сравнений не дождемся, поскольку обычно по этому параметру Pentium 4 проигрывает в полтора-два раза конкурентам. Впрочем, это тема для отдельной статьи.
Другими словами, если подытожить, то Pentium 4 заранее превращает х86-инструкции в микрооперации, которые записываются в Trace Cache. Использование Trace Cache является, таким образом, одной из ключевых концепций в Pentium 4.
К7: этот микропроцессор поступает не так. Кэш команд (I-cache) по-прежнему выполняет свое главное назначение — хранит х86-инструкции. В конечном итоге х86-инструкции также превращаются во внутренние команды, но детали этого превращения у К7 отличаются. Выбрав и проанализировав инструкцию, К7(К8) записывает полученную информацию о её границах в специальный битовый массив, Decode Array; инструкция же подвергается дальнейшим преобразованиям во внутренний формат. После этого, при повторном просмотре участка кода, делать самую тяжелую работу по нахождению границ инструкций уже не нужно. Decode Array ассоциирован с I-cache, но физически, на кристалле, располагается отдельно. Каждому байту х86-инструкции (находящейся в I-cache) соответствуют три бита, хранящиеся в Decode Array. Эта запись содержит информацию о том, является ли данный байт первым (последним) байтом инструкции, является ли он префиксом, следует ли направлять инструкцию по особому пути декодирования (подробнее об этом дальше).
Таким образом, мы имеем два совершенно различных подхода: Pentium 4 сохраняет практически результат работы декодера (микрооперацию), в то время как K7/K8 — полезную информацию, существенно облегчающую повторное декодирование. Отсюда автоматически следует, что для того, чтобы система K7/K8 могла использовать все преимущества (и в первую очередь — высокую «емкость» I-кэша), она должна обладать самым совершенным аппаратом, позволяющим проводить повторное декодирование быстро и незаметно. Но мы пока отложим рассмотрение этих методов, так как сейчас нам надо взглянуть на те структурные единицы, которые в конечном итоге будут выданы декодером, и кратко проследить их дальнейшую судьбу.
Первоначальные х86-инструкции на завершающих этапах работы декодера К7/К8 «переводятся» в специальные внутренние команды — макрооперации, или mOP-ы. Большинству х86-инструкций соответствует одна макрооперация, некоторые инструкции преобразуются в два или три mOP-а, а наиболее сложные, например деление или тригонометрические, — в последовательность из нескольких десятков mOP-ов. Макрооперации имеют фиксированную длину и регулярную структуру. В то время как ROP, микрооперация, соответствует одной примитивной команде, посылаемой на исполнение функциональному устройству процессора, mOP соответствует двум командам, которые будут выполнены в двух «спаренных» функциональных устройствах. Очень условно можно считать что в определенный момент mOP может «расщепляться» на два ROP-a, или «выдавать» два ROP-a — по крайней мере, mOP содержит всю необходимую для запуска двух команд информацию, включая служебную. Откуда возникла идея использования более сложной, чем ROP, структурной единицы? Вспомним, что многие х86-инструкции производят сложные действия над значениями в памяти, — действия, включающие не только считывание или запись, но и изменение значения (например, увеличение значения переменной — счетчика, находящейся в памяти). После преобразования такой инструкции во внутренний формат можно либо сразу же дать ROP-ам относительную независимость в плане дальнейшего передвижения по блокам процессора, либо можно объединить всю содержащуюся в них информацию в одной «макрокоманде». В последнем случае мы получим выигрыш не только по количеству «перемещаемых» элементов и, соответственно, логики, отвечающей за такое «перемещение», но и выигрыш за счет того, что сможем существенно сократить число промежуточных операций записи/считывания результата. Наконец, кое-где мы сможем сократить даже число реально выполняемых команд — так, в нашем примере с переменной-счетчиком понадобится всего лишь одно вычисление адреса (вместо двух, как это было бы в случае «разъединенных» ROP-ов). Собственно, и в K7, и в K8 mOP содержит две команды — одну для ALU (или FPU), другую — для AGU (устройства вычисления адреса, Address Generation Unit). Если по каким либо причинам одной команды нет — например, инструкция не обращается к памяти и ей не требуется вычислять адрес — то соответствующие поля mOP-а будут содержать пустышку, NULL-ROP. Обратим внимание, что сошедший с декодера mOP в дальнейшем будет «путешествовать» по конвейеру процессора передвигаясь по своему «каналу» — в конце которого и доберется до пары функциональных устройств (естественно, ALU/FPU и AGU). Точнее, непосредственно перед этим знаменательным событием mOP окажется в очереди (reservation station), где и «выдаст» два нужных ROP-a. ROP-ы будут направляться на исполнение в том порядке, который окажется наиболее удобным, а не в том, какой задает жесткий текст выполняемой программы (конечно же, порядок отправки на исполнение не будет противоречить логике программы, а удобство будет определяться готовностью операндов и занятостью функциональных устройств, ФУ). Поэтому вполне допустимы ситуации, когда между выполнением ROP-ов, относящихся к одному mOP-у, будут выполняться и другие ROP-ы, порожденные совсем другими инструкциями — предшествующими нашей инструкции, или следующими за ней. И, наконец, заметим, что соотнесение 1mOP = ROP для ALU(FPU) + ROP для AGU — лишь частный случай более общей концепции: в последующих поколениях процессоров может быть добавлено, например, третье устройство на «канал» — и mOP уже будет иметь более сложную структуру.
Хорошо. Запуская mOP по «каналу» мы сможем в конечном итоге добиться одновременного запуска двух команд. Как достичь большего? Правильно — добавим параллельные каналы, и одновременно на каждый из них выдадим по макрооперации. Так поступила AMD в процессорах К7/К8. Каналов — три, они симметричны, каждый содержит свою очередь и свою пару функциональных устройств. В результате можно одновременно запускать команды сразу на шесть функциональных устройств (ФУ).
Мы говорим именно про отправку команд на исполнение, так как за счет конвейеризации возможны ситуации, когда одновременно в разных блоках процессора будут выполняться и два десятка команд. Также для полноты картины заметим, что и в К7, и в K8 имеется десять функциональных устройств — три ALU, три FPU, три AGU и отдельный блок умножения. Каждый канал разветвляется: в зависимости от того, какие значения обрабатывает инструкция, mOP пойдет либо по направлению к целочисленным блокам, либо — к блокам плавающей точки; блок же AGU останется общим.
Здесь мы подошли к фундаментальной концепции микроархитектуры К7/К8. Мы уже видели, что объединение двух отдельных микроопераций в одну макрооперацию даёт явные преимущества. Точно также дела обстоят и с самими макрооперациями — практически везде они выступают не в виде самостоятельных единиц, а в виде группы. Группу образуют как раз те 3 mOP-а, которые одновременно запускаются на параллельные каналы. Вся дальнейшая работа идет не с одиночными mOP-ами, а с «тройками» mOP-ов («line»). Такая тройка mOP-ов, «line», с точки зрения центрального управляющего блока процессора, ICU (Instruction Control Unit) воспринимается как единое целое: все основные действия выполняются именно над «line», в первую очередь — выделение внутренних ресурсов. Так, под «line» одним приемом выделяется группа из трех позиций в очередях (как мы помним, у каждого канала своя очередь). Здесь mOP-ы на короткое время приобретает независимость — точнее, самостоятельными оказываются ROP-ы, которые выбираются для запуска на ФУ в наилучшей последовательности. Когда окажутся запущенными составляющие всех трех mOP-ов, относящихся к «line», соответствующие позиции в очередях будут одновременно освобождены. Точно также, одновременно будет происходить и «отставка» — освобождение ресурсов после исполнения, сопровождающееся окончательной записью результатов в регистровый файл.
Этот дизайн сама AMD характеризует как «line-oriented», и он является предметом законной гордости корпорации. В нем каждый конвейер представляет собой один «канал» — кстати сказать, слово «канал» не является точной терминологией. Похоже, в этом случае жестко закрепленного термина вовсе не вводится, каждый раз, в зависимости от контекста, применяются термины «position», «issue position», «lane».
Итак, мы имеем три симметричных канала, работающих синхронно и параллельно. Макрооперации проходят конвейер, оставаясь прикрепленными к своим каналам — таким образом практически исключаются поздние стадии переброски и распределения команд по тем портам, к которым подсоединены специфические функциональные устройства, необходимые для исполнения конкретной команды (как правило — это самый «горячий» участок процессора). Далее, «line-oriented» подход позволяет кардинально снизить количество управляющей логики и количество «контролируемых элементов». Использование макроопераций, а не ROP-ов, в качестве элементов «line» позволяет увеличить её эффективную ширину, то есть, в конечном счете — количество команд, обрабатываемых за один такт. Наконец, количество параллельно обрабатываемых элементов в дальнейшем без особых сложностей может быть расширено просто за счет увеличения числа каналов (и, соответственно, количества ФУ). И, последнее: важно отметить, что хотя основные концепции и направлены на построение «широкого» эффективного конвейера, с равным успехом они могут быть применены к конвейерам самой разной длины.
И в этом моменте становится заметным ключевое отличие концепции К7 от концепции Pentium 4: если Pentium 4 спроектирован на достижение максимальной частоты, то К7 (да и К8, вообще говоря) в первую очередь рассчитан на исполнение максимального количества mOP-ов за такт (в конечном итоге, большее количество исполненных mOP-ов означает большее количество исполненных х86-команд, хотя зависимость здесь нелинейная).
Чтобы проиллюстрировать ситуацию, припомним наш конвейер. Представим себе, что мы для увеличения производительности сделали наш конвейер втрое более широким — то есть теперь на нем параллельно собирается три автомобиля. Соответственно, «листики с инструкциями» на конвейере лежат по три, равно как и «детали для сборки». Более того, «детали» теперь на каждое из трех мест можно класть по две! И, наконец, весь процесс укладки деталей производится одновременно одним механизмом, равно, как и готовые автомобили снимаются одновременно по три штуки.
Микроархитектуру Pentium 4 тогда очень условно можно представить как выстроенную в ряд последовательность из нескольких конвейеров разной ширины, между которыми «детали» и «полусобранные конструкции» перебрасываются специальными методами. Впрочем, не будем отвлекаться от основной задачи — тем более, что ситуация с Pentium 4 требует особого рассмотрения, да и не он является героем сегодняшнего рассказа.
Собственно, вот мы и пришли к идеологии микроархитектуры К7/К8. Надо отдать должное инженерам AMD, конструкция получилась элегантная и эффективная, при этом существенно расширена «параллельность» конвейера. Также весьма интересно, что концепция позволяет рост как «вширь», так и «вглубь».
Теперь понятно, что даже сходным образом звучащая фраза, справедливая для обеих архитектур — в современных процессорах х86-команды превращаются в «RISC-подобные» команды — означает в действительности совершенно разные вещи. Что же, согласитесь, это достаточно интересные сведения, на которых стоило остановиться!
Декодеры и конвейеры. Различие между К7 и К8
Ну а мы приступим к сравнению К7 и К8. Еще в прошлой статье мы указывали, что конвейер удлинился на несколько стадий. Но удлинился он, в основном, в области, связанной с декодерами, так что самое время поговорить именно о них. Тем более что именно с декодерами произошли наибольшие изменения, как количественные, так и качественные.
Для начала традиционно рассмотрим декодер К7 — так нам будет проще выявить изменения. Прежде всего определимся с терминологией; дело в том, что в архитектуре К7 термин «декодер» употребляется в нескольких контекстах, а именно:
- Предекодер (Predecoder) анализирует инструкции до их записи в I — cache, определяет адреса их начала и конца, местоположение префиксов и путь (способ) декодирования (DirectPath либо VectorPath). Вся эта информация записывается в специальные биты предекодирования (Decode Array) и помещается в L1-кэш. Одновременно производится распознавание инструкций перехода и подготовка специальных селекторов (branch selectors) для последующего быстрого предсказания и вычисления адресов переходов. Предекодирование осуществляется в темпе не более 4 байтов за такт. Здесь у нас возникли новые термины, DirectPath и VectorPath, значение которых будет пояснено ниже.
- Собственно декодер, который и занимается преобразованием х86-инструкций, считанных из I-кэша, выровненных и размеченных, в макрооперации. На выходе мы имеем сформированные тройки mOP-ов, которые движутся дальше по конвейеру
Мы видим, что уже в К7 декодирование представляет собой фактически целую совокупность операций. Эту совокупность мы будем обозначать термином «декодер», пока не вдаваясь в подробности. Теперь поясним два новых термина, DirectPath и VectorPath, которые мы ввели в пункте 1. Сам декодер в К7 может обрабатывать х86-инструкции двумя путями, DirectPath и VectorPath. Первый из них, DirectPath, занимается теми и только теми х86-инструкциями, которые превращаются ровно в одну mOP, и ни копейкой больше.
Все остальные инструкции в К7 обрабатываются VectorPath декодером, который превращает их в последовательность двух и более mOPs. Для таких х86-инструкций (включая самые сложные, например, целочисленное деление), используется устройство Microcode Engine («микрокодовое устройство»), которое, пользуясь встроенными таблицами, заменяет х86-инструкцию на целую последовательность mOPs.
Рассмотрим, как происходит работа декодера и конвейера в К7 (называя попутно этапы конвейера):
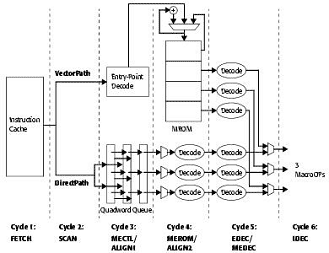
- 1. FETCH «выборка»: предекодер считывает 16 байт инструкций из I-cache, попутно определяя адрес следующего блока для выборки. Кстати, для К8 считывается также 16 байт. В определенных случаях (если размер одной х86 инструкции больше, чем 16/3 байт) эта стадия может стать ограничивающим фактором; правда, обычно средний размер х86-инструкции порядка 5 — 6 байт.
- 2. SCAN «сканирование»: на этом этапе при помощи записанных ранее битов предекодирования инструкции отделяются друг от друга, разделяются по пути декодирования (DirectPath или VectorPath). До 6 отделенных друг от друга инструкций отправляются на дальнейший этап DirectPath, и не более одной инструкции отправляется в VectorPath, в Microcode Engine.
- 3. ALIGN1 «выравнивание 1»: на этом этапе возможна буферизация до 9 DP инструкций (до 24 байт), три из которых каждый такт могут отсылаться дальше на исполнение в трех каналах исполнения. Номер этого канала 0/1/2 закрепляется за mOP-ом, в который трансформируется DP инструкция, на все последующие этапы, вплоть до «отставки» (retirement). Общая скорость исполнения на этой стадии для DP инструкций составляет 3 инструкции за такт. Инструкции типа VectorPath также проходят через этот этап для того, чтобы на выходе из декодера обеспечить порядок следования mOP-ов, соответствующий исходному порядку инструкций. VectorPath-инструкция занимает (блокирует) сразу все три канала декодирования и не может сочетаться с предшествующими DirectPath инструкциями. Если в предшествующем такте набралось меньше трех DirectPath-инструкций, то в оставшиеся каналы ничего не отсылается и они остаются незанятыми.
Здесь прервемся на секунду, и обратим внимание, что недостаток VectorPath инструкции состоит в том, что она «занимает» все три канала декодирования, не позволяя работать DP декодерам параллельно. Важно отметить, что сама по себе VectorPath инструкция не является «плохой» — Microcode Engine работает с той же скоростью «3 mOP-а в такт», что и DP декодеры, при этом полученные из VectorPath mOP-ы ничем не хуже полученных из DirectPath. Напротив, для сложных инструкций, дающих десятки команд (для деления, или для многих системных инструкций), VectorPath прекрасное решение! Проблема в VectorPath заключается в побочных эффектах, связанных с положением VP инструкции в «тройке». А именно:
- а) если VP инструкция — первая в тройке (имеет нулевую позицию), то она направляется на Microcode Engine, которая и генерирует последовательность mOP-ов (используя внутренние таблицы). mOP-ы выдаются тройками; если в последней тройке меньше трех mOP-ов, то в пустующие позиции проставляется NULL-ROP («пустышка»). Оставшиеся две инструкции из блока, содержащего обработанную VP-инструкцию, сдвигаются на одну позицию влево (т.е. в нулевую позицию) и дополняются до тройки следующей инструкцией.
- б) Если VP инструкция не является первой в тройке, то сперва декодируются предшествующие ей DP инструкции, причем недостающие позиции mOP-ов дополняются до тройки нужным числом NULL-ROP (одним или двумя). Далее — как в предыдущем пункте, то есть VP инструкция начинает обрабатываться со следующей «строки».
Нетрудно заметить, что, если, например, двух-mOP-овая VP-инструкция в потоке DP-инструкций занимает позицию #
- #0 — то будет пропущена одна позиция
- #1 — три
- #2 — две.
Таким образом, здесь, в среднем, будет теряться [(1 + 3 + 2)/3] / 2 == половина ресурсов «line»!
- 4. ALIGN2 «Выравнивание 2»: разбор (синтаксический анализ) инструкции в каждом из трех каналов с выделением префиксов, кода операции, байтов ModR/M и SIB и отсылка отсортированной информации на следующий этап для завершения раннего декодирования и генерации mOP-а. Инструкции типа VectorPath одновременно обрабатываются в своем устройстве декодирования. На этапах 3 (MECTL) и 4 (MEROM) происходит адресация и выборка «микрокода», необходимого для генерации mOP-ов на следующем этапе.
- 5. EDEC «Раннее декодирование»: окончательное декодирование и определение структуры x86-инструкции в каждом из трех каналов и генерация соответствующего mOP-а. Если на данном этапе обрабатывается VectorPath-инструкция (которая занимает все три канала декодирования), то соответствующие ей mOP-ы генерируются в Microcode Engine (этап 5 — MEDEC/MESEQ), и подставляются в выходной поток группами по три (собственно, детали мы описывали выше).
- 6. IDEC «Декодирование инструкций»: прием трех mOP-ов из предыдущего этапа (из трех каналов декодера DirectPath либо из Microcode Engine) и помещение их в очередь (reorder buffer) длиной 24 элемента по три mOP-а. Из этой очереди до трех mOP-ов могут быть пересланы на следующем этапе в блок целочисленной арифметики либо FPU для последующего запуска на выполнение. Информация обо всех mOP-ах остается в этой очереди (буфере) вплоть до их «отставки», которая должна происходить в исходном порядке следования инструкций. Устройство, которое управляет выполнением mOP-ов, начиная с их попадания в данный буфер и завершая их «отставкой», называется Instruction Control Unit (ICU).
Дальнейший путь по конвейеру отличается для целочисленных инструкций, и инструкций с плавающей точкой. Вначале приведем стадии для целочисленных инструкций:
- 7. SCHED «Планирование»: буферизация mOP-ов в очереди на исполнение (6 элементов по три mOP-а) и ожидание готовности операндов. По мере готовности, производится запуск ROP-ов типа IEU и/или AGU, на которые расщепляется mOP. ROP-ы запускаются в произвольном порядке и всегда выполняются в устройстве с номером, соответствующем номеру канала декодирования mOP-а (0/1/2).
- 8. EXEC «Исполнение»: исполнение целочисленного ROP-а. Если ROP требует обращения в L1-кэш, то в текущем и двух последующих этапах производится подготовка адреса и выборка данных. Таким образом, содержательная часть инструкции может быть выполнена на этапе EXEC с задержкой в три такта. При обращении к данным в L2-кэше либо в оперативной памяти задержка может составлять десятки и сотни тактов.
Теперь перечислим стадии для инструкций с плавающей точкой.
- 7. STKREN «Отображение стека»
- 8. REGREN «Переименование регистров»
Отображение стека x87-регистров на файл с плоской адресацией и последующее переименование (отображение номера) архитектурного регистра с плавающей точкой в аппаратный регистр для каждого из трех (максимум) mOP-ов.
- 9. SCHEDW
- 10. SCHED «Планирование» На этих стадиях происходит буферизация mOP-ов в очереди на исполнение (12 элементов по три mOP-а) и ожидание готовности исполнительных устройств и операндов. Для инструкций с плавающей точкой устройство выбирается уже не по номеру канала декодирования, а по требуемой функциональности (FADD/FMUL/FSTORE).
- 11. FREG «Чтение регистрового файла»: выборка данных, необходимых для выполнение запущенного MOP-а, из регистрового файла, и последующий запуск на исполнение в соответствующее функциональное устройство. Если mOP ожидает результатов выполнения предшествующей операции с плавающей точкой, то он запускается из предыдущей стадии SCHED на один такт раньше их ожидаемой готовности, и данные передаются на вход устройства в обход регистрового файла.
- 12-15. FEXEC1-4 «Исполнение FP»: конвейеризованное исполнение операции с плавающей запятой. Для операций с плавающей точкой, требующих обращения в память (кэш), происходит также обработка соответствующего mOP-а в блоке целочисленной арифметики для вычисления адреса и управления блоком загрузки-выгрузки (Load/Store Unit, LSU), который производит непосредственный доступ к данным.
Все эти стадии относятся к архитектуре К7, про архитектуру К8 известно значительно меньше подробностей. Стадии, не относящиеся к декодеру, формально не изменили своего назначения. Напротив, вместо первых шести стадий К7 в К8 мы видим следующие:
- FETCH1 (соответствует FETCH К7)
- FETCH2
- PICK
- DECODE1
- DECODE2
- PACK
- PACK/DECODE
- DISPATCH (соответствует IDEC К7)
В конечном итоге, на стадии 8 — К8 (и соответствующей ей стадии 6 — К7) декодером будет выдана тройка макроопераций. В этой статье, не строя предположений о том, что стоит за новыми стадиями, мы посмотрим на практический выигрыш от нововведений.
Вначале рассмотрим изменения качественные. Помимо двух путей декодирования, Direct Path (DP) и Vector Path (VP), уже знакомых нам по К7, в К8 мы видим новый тип — Direct Path Double (DD). Это действительно важное изменение: теперь большинство тех инструкций, которые раскладываются на 2 mOP-а и, следовательно, ранее направлялись по VectorPath, сейчас обрабатываются по-другому, как DirectPath Double. Как раз те самые «бывшие» VectorPath инструкции, которые ранее блокировали декодер, попусту «разбазаривая» часть его ресурсов. Теперь же они могут стартовать с любой позиции. Они дополняются до тройки как mOP-ами, полученными из DP-инструкций, так и отдельными mOP-ами из других DD. Последнее, но иными словами: эффективная скорость декодирования потока DD — 1.5 х86-инструкции в такт, соответствующая скорости выдачи 3 mOP-а в такт, то есть полностью заполненной «line». Замечательно! Среди DD-инструкций мы видим такие часто встречающиеся, как, к примеру, POP reg, RET, умножение (некоторые формы), а также packed-SSE2- и packed-SSE-инструкции. Отметим, что таким образом, K8 имеет существенные преимущества перед К7 при выполнении 128-разрядных SIMD-инструкций.
Теперь — изменения количественные. Скорость загрузки кода, находящегося в L2, но не в L1 I-Cache, заметна подросла — в К8 она увеличилась практически на две трети. Причины: как расширение интерфейса L2 — L1, так и появившаяся возможность сохранения битов предекодирования в L2.
И, наконец, скорость обработки последовательности DirectPath-инструкций. Алгоритм выравнивания инструкций, применявшийся в К7, не всегда обеспечивал 100%-ю эффективность (хотя, надо сказать, эффективность была достаточно высокой, в среднем выше 80-90%). Теперь, в К8, ситуация существенно изменилась. Из таблиц, приведенных в Приложении 2, видно, что для всех не слишком длинных инструкций (5 байт и менее) темп оказывается предельным. Для многих комбинаций из инструкций большего размера эффективность также 100%. В некоторых случаях, правда, стало немного хуже на длинных инструкциях. Но главное, что среднее число mOP-ов за такт заметно подросло! Браво инженерам АМД! И очень жаль, что все это пришлось выяснять в ходе многочисленных синтетических тестов, а не читать в документации — право, подобными достижениями можно и нужно гордиться!
Осталось добавить, что в декодере добавились этапы «переупаковки» и совместного анализа нескольких инструкций (Inter-instruction decoding). Эти этапы отвечают за переназначение потоков (lanes), в которых выполняются MOP-ы, с целью оптимизации использования функциональных устройств. Теперь за счет разнесения MOP-ов, не зависящих друг от друга, по разным потокам, удается повысить «КПД» использования исполнительных устройств. Также на этих этапах проводятся некоторые мелкие преобразования групп зависимых MOP-ов для уменьшения задержек при совместных обращениях к регистрам и к стеку.
Что ж, благодаря синтетическим тестам мы узнали много нового и интересного о «внутренностях» К8 архитектуры!
Контроллер памяти. Эффективность, характеристики
Еще в прошлой статье мы писали, что интегрированный контроллер памяти — это одна из «визитных карточек» микроархитектуры К8. По крайней мере, именно эта черта беспрестанно подчеркивалась в маркетинговых документах AMD, когда речь заходила о микроархитектуре К8. Настало время разобраться, так ли хорош интегрированный контроллер памяти? Достаточно ли он эффективен, действительно ли настолько снизились задержки при работе с памятью? Так ли все хорошо, как «обещалось» в предыдущей статье? В общем, пришло время контроллеру «сдавать экзамен».
Для начала напомним некоторые его особенности. В предыдущей статье мы уже указывали, что реальная частота памяти зависит от частоты процессора в силу того, что соотношение частот памяти и процессора может быть только целым. Повторим эту таблицу (в скобках укажем делитель):
| Частота CPU | DDR200, реальная частота | DDR266, реальная частота | DDR333, реальная частота | DDR400*, реальная частота |
|---|---|---|---|---|
| 1400МГц | 100МГц (14) | 127МГц (11) | 156МГц (9) | 200МГц (7) |
| 1600МГц | 100МГц (16) | 133МГц (12) | 160МГц (10) | 200МГц (8) |
| 1800МГц | 100МГц (18) | 129МГц (14) | 164МГц (11) | 200МГц (9) |
| 2000МГц | 100МГц (20) | 133МГц (15) | 166МГц (12) | 200МГц (10) |
* — напоминаем, что Opteron работает с памятью Registered DDR, а данная модификация для DDR400 пока не ратифицирована JEDEC. При этом память может быть как с ECC, так и без коррекции ошибок.
Красным цветом в нашей таблице выделены те частоты процессора и памяти, на которых память работает с номинальной частотой. Видно, что весьма выгодной выглядит частота 2000МГц, на которой любой тип памяти из поддерживаемых К8 работает на штатных частотах. Также видно, что «в полную мощь» контроллер памяти развернется тогда, когда будет официально объявлена память Registered ECC DDR400 — тогда мы сможем получить наиболее быстрый вариант подсистемы памяти. Забегая чуть вперед, заметим — Athlon64 прекрасно работает с памятью DDR400, невзирая на то, что сам продукт еще не был объявлен, а на момент выхода Opteron-а данная память еще не была стандартом.
Впрочем, пора переходить к делу — итак, какие же результаты демонстрирует нам подсистема памяти Athlon 64 и Opteron-а? В связи с принципиальной новизной микроархитектуры мы постарались сделать тесты как можно более разнообразными. Для начала поглядим на латентность подсистемы памяти — тем более что ранее именно в этой области мы обещали прорыв. Для наблюдения за латентностью воспользуемся утилитой Cache Burst 32:
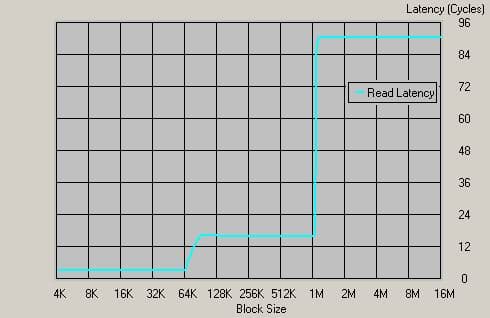
График для Athlon 64 1400МГц, DDR266
Давайте посчитаем величину латентности — примерно 90 тактов, что для процессора частотой 1400МГц составляет приблизительно 64 нс!!! Напоминаем, что это время по порядку величины сопоставимо с собственным временем доступа в динамическую ячейку памяти. И это время действительно намного меньше того, что демонстрируют классические чипсеты, с интегрированным в чипсет контроллером памяти! Однако это практически не актуальная сегодня память DDR266, что же покажут остальные типы памяти?!
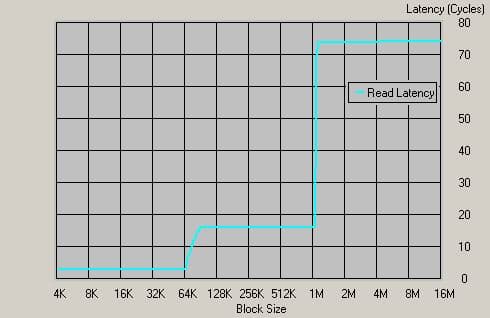
График для Athlon 64 1400МГц, DDR333
Мы видим 74 такта задержки, что соответствует приблизительно 45 нс!!! Это по-прежнему сравнимо со временем доступа к ячейке динамической памяти! Можно только выразить восхищение эффективностью такого решения, как встроенный контроллер памяти. Кстати, в текущей ситуации можно сравнить с задержками контроллера памяти процессора Opteron, который, как мы помним, использует Registered память (подчеркнем еще раз: наличие ECC при этом не обязательно!).
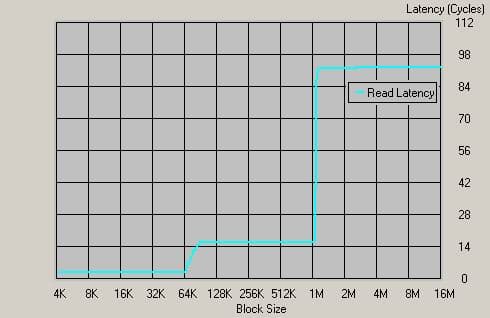
График для Opteron 1400МГц, Registered DDR333
Однако! Использование Registered памяти привело к тому, что вместо 74 тактов латентность составляет 94 такта. А это значит, что время доступа увеличилось до значения приблизительно 56 нс, то есть выросло на 20%. Что ж, и ранее нам было известно, что модули Registered память медленнее модулей обычной памяти. Теперь стало видно, насколько именно. В общем-то, буквально напрашивается желание измерить соотношение этих времен для разных видов памяти. Возможно, в одной из следующих статей мы вернемся к этой теме. Справедливости ради, отметим, что даже 56 нс — это восхитительно низкий результат на фоне классических чипсетов. Просто мы еще раз подтвердили тот факт, что за надежность серверных решений надо платить — в том числе скоростью.
Ну и «на сладкое» измерим задержки памяти для DDR400. Встречайте!
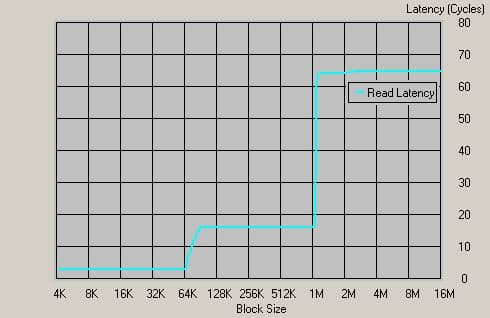
График для Athlon 64 1400МГц, DDR400
65 тактов!!! Соответственно, 33 нс!!! Что ж, конкуренты идут «нервно курить траву» — подобные задержки ни для каких контроллеров памяти, кроме интегрированных, нереальны. Похоже, в приложениях, зависящих от латентности (например, архиваторы, базы данных) микроархитектура К8 будет чувствовать себя весьма уверенно. Что ж, постараемся проверить! Ну а пока остается констатировать факт, что по величине латентности микроархитектура К8 абсолютный чемпион, и в ближайшее время недосягаема для любых конкурирующих архитектур (среди х86, конечно — мы не тестировали, к примеру, UltraSPARC IIIi с подобным контроллером). Для подтверждения этого факта приведем подобный график для Pentium 4 + i875P + Dual DDR400, самой быстрой комбинации для архитектуры конкурента:
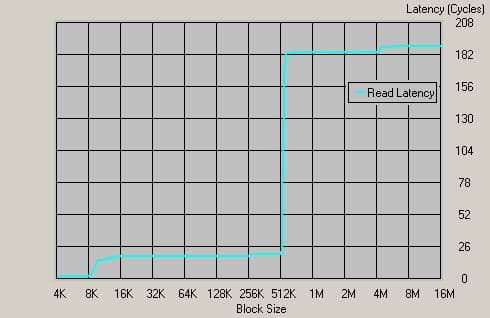
График для Pentium 4 3.0 ГГц, i875P + Dual DDR400
Видно, что у конкурента 63 нс. (189 тактов) — весьма неплохой результат, но, без сомнения, меркнущий на фоне результата интегрированного контроллера памяти.
Теперь перейдем к измерению пропускной способности подсистемы памяти. Ну а поскольку пока не очень понятно, какого рода тесты способны выжать максимум из подобного устройства контроллера памяти, дадим результаты измерения несколькими утилитами. Для начала Wstream -Pentium 4 3.0С (Asus P4C800, i875Р), Athlon 64 1400МГц, и Athlon 64 1600МГц. Заодно это позволит нам посмотреть на то, как масштабируется архитектура с частотой. Воспользуемся памятью DDR400 и, естественно, включим на Pentium 4 двухканальный режим работы с памятью.
Вот несколько диаграмм, из которых понятно соотношение скоростей при различных видах операций с памятью:
Что ж, видно, что Athlon 64, имеющий одноканальный контроллер памяти, не в состоянии конкурировать по пропускной способности с двухканальным контроллером памяти, расположенном в i875P. Также отметим, что процессоры Athlon 64 слегка увеличивают ПСП памяти с ростом частоты. Впрочем, это изменение невелико. Но бросается в глаза другое — а где отличия между Opteron-ом и Athlon 64?! Неужели вдвое более широкая шина памяти в Opteron ничего не дает?! По меньшей мере, это странно…. Или все же данный тест не в состоянии выжать максимум из новой и незнакомой для него микроархитектуры К8? А что покажут нам другие утилиты? Результаты оказались заметно другими. Взгляните в таблицу:
| Утилита | Pentium 4 + i875P + Dual DDR400 | Athlon 64 1400МГц + DDR333 | Athlon 64 1400МГц + DDR400 | Opteron 1400МГц + Reg. ECC DDR333 |
| Cache Burst 32 | 5526 MB/sec | 2282 MB/sec | 2934 MB/sec | 3912 MB/sec |
| Lram | 5494 MB/sec | - | - | 4478 MB/sec |
Вот это совсем другое дело — по крайней мере, похоже, что контроллер стал «шире». Кстати, отметим, что с ПСП у системы на базе Pentium 4 все хорошо. К сожалению, протестировать Athlon 64 при помощи Lram до их «исчезновения» мы не успели — как легко заметить, это наиболее эффективная утилита для замера скорости работы с памятью. Впрочем, и сама по себе скорость уже впечатляет. В данном случае Cache Burst 32 дает вполне показательное соотношение между двумя модификациями интегрированного контроллера — прирост от второго канала составляет 71%, при том что память ECC Registered на Opteron-е более медлительная. Результат можно считать вполне удовлетворительным. Судя по всему, Cache Burst 32 демонстрирует не самую большую ПСП — в частности, утилита Lram на Opteron-е сумела добиться заметно больших результатов. Это связано с особенностями алгоритмов — алгоритмы Cache Burst 32 заметно сильнее зависят от латентности. Таким образом, изыскания по способам достижения наибольшей пропускной способности необходимо продолжить — потенциал для роста явно есть.
Давайте прикинем эффективность встроенного контроллера памяти. Если поделить продемонстрированные цифры на теоретическую пропускную способность памяти, то получим для эффективности контроллера соответственно:
Замеренные данные по Cache Burst 32: для Athlon 64 эффективность достигает 91,6% от теоретической ПСП (на самом деле даже больше, поскольку память далеко не каждый такт отдает данные — есть неизбежные потери на refresh, например). Кстати, не будем забывать, что для процессора частотой 1400МГц память DDR333 работает фактически как память «DDR312» (если бы такой стандарт существовал), на частоте 156МГц. Для Opteron-а — эффективность приблизительно равна 77%. Тем не менее, измеряя результаты при помощи утилиты Lram, получаем пропускную способность заметно выше, и эффективность контроллера 88%, что заметно ближе продемонстрированному процессором Athlon 64. Что ж, вопрос с памятью требует дополнительного исследования на предмет того, каким именно методом можно получить наибольшую пропускную способность. Пока же можем констатировать тот факт, что и с ПСП у встроенного контроллера все великолепно — фактически, он демонстрирует ПСП 95% — 96% от возможной (с учетом того факта, что есть неизбежные потери на refresh памяти). Ситуация с Opteron-ом требует дополнительного уточнения — в более низкой эффективности виноват тот факт, что память Registered DDR имеет большие задержки, или же что-то еще? Не исключено также, что Opteron не смог продемонстрировать возможности своего контроллера памяти просто в силу относительно небольшой частоты — тогда с ростом частоты наблюдаемая эффективность (да и пропускная способность) контроллера будет расти.
В целом, эффективность встроенного контроллера можно охарактеризовать как великолепную! По-видимому, как только примут стандарт Registered ECC DDR400, Opteron сможет рассчитывать на эффективную ПСП в районе 5400MB/sec. Что ж, подождем стандарта и результатов!
Вместо послесловия
Попробуем подвести некоторые промежуточные итоги. Касающиеся как рассматриваемой микроархитектуры, так и данной статьи.
Прежде всего, надо сказать, что в процессе работы все мы еще раз почувствовали, на что именно мы «замахнулись». Ведь не секрет, что в русскоязычной части Интернета практически отсутствуют сколько-нибудь подробные и при этом достаточно понятные описания современных микроархитектур. И, естественно, одна статья, насколько подробной бы она ни была, ситуации в целом не изменит. Более того, стало ясно, что ответить на все поставленные вопросы в одной статье просто не получится. Соответственно, необходим цикл таких статей, которые бы смогли хотя бы на относительно элементарном уровне, но с соблюдением корректности изложения, познакомить читателя с современными достижениями построения производительных микроархитектур. Кроме того, до смерти надоело в случае выпуска новых продуктов попросту пересказывать маркетинговые документы фирм-производителей — как известно, наиболее ценен такой метод обработки информации, как ее анализ.
Также отметим, что в процессе обсуждения деталей всплыло огромное количество интересных нюансов, которые ранее нигде не обсуждались (например, тонкости работы кэша L2). Таким образом, выполненная работа послужила отправной точкой для того, чтобы задаться следующими, более «глубокими» вопросами. Что ж, это в определенной степени и есть показатель качества работы — в работе, сделанной на «скорую руку», эти нюансы наверняка бы прошли незамеченными.
Собственно, вернемся к теме статьи. Мы указали на некоторые интересные отличия микроархитектуры К8 от предшественников и конкурентов. Можно уверенно сказать, что инженерам AMD их работа удалась — в дальнейшем дело за технологами, которым необходимо «просто» наращивать частоту продукта. Эффективность же данной микроархитектуры и так весьма высока.
Также необходимо отметить, что выпуск статей-обзоров будет продолжен — одна статья, несмотря на ее немалый объем, не способна описать микропроцессор достаточно подробно. Думается, есть смысл затевать цикл статей, каждая из которых будет посвящена какому-нибудь аспекту микроархитектуры. Таким образом, эта статья — лишь одна из череды статей, в которых мы по мере сил и знаний будем постепенно обрисовывать нынешние горизонты процессорных архитектур.
Обратим внимание, что в данный момент мы оставили «за бортом» целый ряд вопросов, связанных с шиной Hyper Transport, межпроцессорным взаимодействием, и «серверным» применением микроархитектуры К8. Причины последнего весьма весомы — для полноценного исследования методику тестирования в серверных приложениях еще только предстоит разработать, и именно этим мы занимаемся в данный момент. Кроме того, есть еще ряд важной подготовительной работы, без которой полноценное «серверное» тестирование невозможно.
В ближайшем будущем выйдет следующая часть, которая будет содержать результаты «практической части» обзора микроархитектуры К8 — в том числе сравнение с конкурирующей архитектурой. Так что не теряйте бдительности!
P.S. «летописец» выражает персональную и огромную благодарность Филимоновой Валерии Евгеньевне и славному городу Питеру! Как минимум за то, что вышеупомянутая девушка самоотверженно пыталась привить «летописцу» правила орфографии и пунктуации. :-)


