Приложение 1. Методика и результаты тестирования латентности кэша L2 и пропускной способности его шины для архитектур K7/K8
Необходимость подобного исследования возникла из-за того, что данные моменты в документации AMD освящены неподробно и противоречиво. Соответствующие разделы переносятся из старой документации о первых реализациях Athlon с минимальными изменениями, а вопрос о ширине шины K8 и вовсе везде старательно обходится стороной.
Однако, Athlon-ы последних модификаций давно стоят у многих на столе, да и первые процессоры новой архитектуры K8 уже доступны. Так что мы можем проверить некоторые моменты непосредственным образом, то есть тестированием. Итак, начнем…
Исследование латентности кэша L2 в зависимой цепочке
Для этого в массиве (блоке) заданного размера, находящемся в оперативной памяти, создадим зависимую цепочку (в терминах C — однонаправленный список). Каждый элемент массива содержит адрес другого элемента (в терминах C — указатель на другой элемент), а цепочка адресов устроена так, что, начиная с первого элемента массива, перемещаясь по ней, мы обойдем все элементы массива строго по одному разу, и затем опять вернемся к первому.
Будем рассматривать два типа цепочек, отвечающим разным случаям обхода элементов массива:
- Последовательный доступ, обход элементов массива производится строго последовательно: первый, второй, третий, и т.д. до последнего, затем опять первый.

- Случайный доступ, обход производится в случайном порядке, однако условие выборки каждого элемента строго по одному разу за один обход сохраняется.

Когда зависимая цепочка создана и инициирована в соответствие с одним из вышеуказанных типов, адрес первого элемента загружен в регистр eax, ассемблерный код для обхода цепочки выглядит очень просто:
mov eax,[eax]
mov eax,[eax]
mov eax,[eax]
…
Теперь, если мы измерим время обхода всей цепочки и поделим его на количество элементов в цепочке, то получим среднюю латентность доступа (load-use latency) к элементу. Чтобы получить латентность доступа к кэшу процессора, размер элемента массива берут равным размеру строки кэша, то есть 64 байт (тогда доступ к одному элементу означает доступ к одной строке кэша), а размер самого массива — меньше или равным размеру кэша. Тогда, после нескольких первых обходов цепочки весь массив поместится в кэш, и далее, уже при точных измерениях времени, данные будут подгружаться только из кэша. Таким образом, для Opteron обход цепочки размером меньше 64 Kбайт даст латентность кэша L1, а обход цепочки размером от 96 до 1088 Kбайт — латентность кэша L2.
В таблице ниже приведены получившиеся результаты (в тактах) для архитектур K7/K8 и разных размеров массивов. При этом через дробь показаны результаты для последовательного и случайного обходов соответственно.
| 64K | 96K | 128K | 288K | 1088K | |
| K7, Thunderbird | 3/3 | 20/20 | 20/20 | 60/66 | - |
| K7, Palomino | 3/3 | 24/20 | 24/20 | 24/27 | - |
| K7, Thoroughbred | 3/3 | 24/20 | 24/20 | 24/38 | - |
| K8 | 3/3 | 16/16 | 16/16 | 16/16 | 17/43 |
Видно, что латентность кэша L1 составляет 3 такта, а латентность L2 в этой цепочке получилась больше указанных в документах AMD 11 тактов. Предположим, что увеличение латентности происходит из-за того, что стадии загрузки и сохранения (evict) строк кэша перекрываются и «мешают друг другу». В следующем тесте мы попытаемся исследовать этот вопрос поподробнее.
Бросается также в глаза, что латентность при последовательном обходе для Athlon-XP больше, чем при случайном, и, кстати, 24 такта больше, чем указано для максимальной летентности (20 тактов). Причина появления этих дополнительных 4 тактов заключается в накладных расходах на организацию алгоритма hardware prefetch, который начинает работать именно в случае последовательного доступа.
Чтобы не «засорять» результаты этими накладными расходами (которые проявляются в достаточно редком случае сильной загрузки шины), в дальнейшем чаще приводятся данные для случайного доступа (если противное не оговорено специально).
Тест латентности кэша L2 в зависимой цепочке с «nop»-ами
Чтобы стадии загрузки и сохранения строк кэша не мешали друг другу, добавим между соседними операциями доступа команды, не связанные с доступом в кэш, но приводящие к появлению фиксированного временного промежутка между окончанием предыдущей команды доступа и началом новой. Для краткости такие команды будем называть «nop-ами».
Теперь ассемблерный код в случае цепочек с разным числом nop-ов будет выглядеть (в регистре edx всегда лежит 0) так:
| 1 nop: | 2 nop: | 3 nop: | … nop |
mov eax,[eax] | mov eax,[eax] | mov eax,[eax] | mov eax,[eax] |
В архитектурах K7/K8 каждая из «nop» команд «add eax,edx» будет «тормозить» выполнение зависимой цепочки ровно на один такт, поэтому теперь, для получения корректного значения латентности, из среднего времени выполнения одного доступа будем вычитать количество вставленных nop-ов.
Результаты полученной латентности для K7/Palomino в зависимости от числа вставленных nop-ов для трех размеров массива (64Kбайт, 112Kбайт и 256Kбайт) показаны на графике:
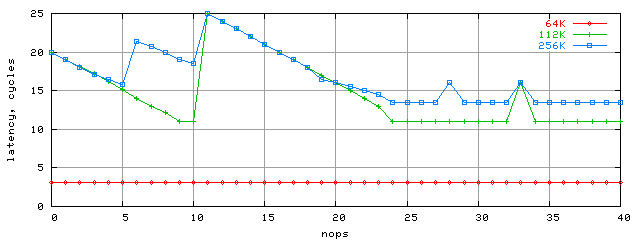
Латентность кэша L1 как была 3 такта, так и осталась. А вот для кэша L2 теперь мы наконец-то увидели и заявленную наименьшую латентность 11 тактов (для блока 112Kбайт, 9,10nop и более 24nop). Для больших блоков к минимальной латентности добавляется 2 такта, связанные с ограниченным размером кэша L1D TLB, которого «хватает» только на 128Kбайт случайного доступа (32 записи). В реальных программах, имеющих обычно более высокую степень локальности данных (внутри 4K страницы виртуальной памяти), этот эффект не будет проявляться столь сильно, потому поведение процессора на блоке размером 112K достаточно показательно.
Однако наиболее интересным результатом нам представляются само поведение графиков (регулярное, но с необъясненными пока скачками вплоть до 25 тактов латентности). Попытке объяснения этого поведения мы постараемся посвятить отдельное исследование в будущем.
Следует также заметить, что данные картины латентности несколько различаются для Athlon-ов с разными ядрами, что говорит о постоянном творческом поиске инженеров AMD (не нашедшем, к сожалению, достойного отражения в документации). В частности, латентность L2 для K7/Thoroughbred отличается (причем, в худшую сторону) от латентности K7/Palomino, что будет видно из следующего графика, где мы также покажем результаты и для K8 (размер блока, по указанной выше причине, 112Kбайт):
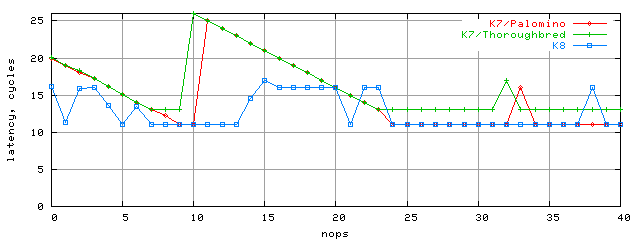
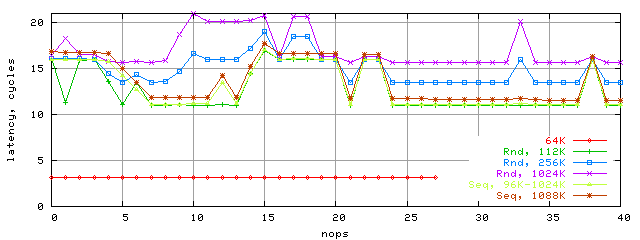
Ну что же, общая картина латентности сильно изменилась при переходе к новой архитектуре K8. Что приятно, латентность почти везде стала существенно ниже. Как мы предполагаем, повышение латентности кэша L2 K7 связано с ограничением пропускной способности шины L1-L2. Если это так, то можно сделать вывод, что пропускная способность шины увеличилась. Но об этом — в следующем разделе. А здесь напоследок приведем картину латентности кэша K8 в зависимой цепочке для разных размеров блоков и разных режимов доступа (Rnd — случайный, Seq — последовательный).
Тестирование пропускной способности (ПС) шины кэша L1-L2
Вначале воспользуемся полученными выше результатами для подсчета соответствующей им ПС шины L1-L2. При этом учтем, что каждый акт доступа в L2 (загрузка одной строки кэша L2 в L1) в эксклюзивной архитектуре кэша сопровождается дополнительно сбросом вытесненной строки из L1 в L2, то есть, один акт доступа вызывает пересылку 64+64=128байт по шине L1-L2. Пользуясь этим алгоритмом, пересчитаем латентность, показанную на рис. в соответствующую ПС:
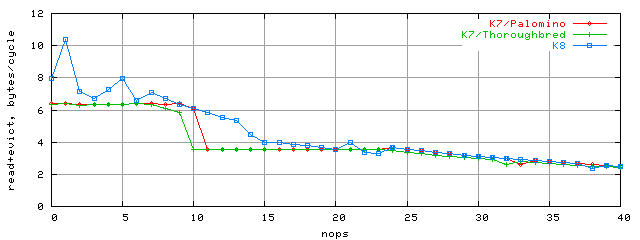
Из графика видно, что доступ в L2 кэш для K7 ограничен именно ПС L1-L2 6.4 байт/такт, в точности соответствующей ПС одной двунаправленной шине шириной 64бит (с учетом потерь на turnaround, 6.4=(64+64)/(8+2+8+2)). В то же время, для K8 этого ограничения нет, и в нашем случае зависимой цепочки достигается ПС более 10 байт/такт.
Еще раз заметим, что при подсчете ПС мы явно предполагали полную эксклюзивность работы кэша L1-L2 в нашем случае (вопрос о том, существуют ли вообще режимы доступа, в котором кэш K8 является не полностью эксклюзивным мы оставим на будущее). Самое время проверить этот тезис. Но вначале немного расширим описанную ранее методику. Вместо одной зависимой цепочки создадим несколько (одну, две, четыре или восемь) и будем обходить их параллельно. Соответствующий ассемблерный код для двух-nop-овых цепочек будет выглядеть так:
| 1 цепочка: | 2 цепочки: | 4 цепочки: |
mov eax,[eax] | mov eax,[eax] | mov eax,[eax] |
А теперь построим для последовательного доступа график зависимости ПС от размера блока для разного количества параллельных зависимых цепочек доступа:
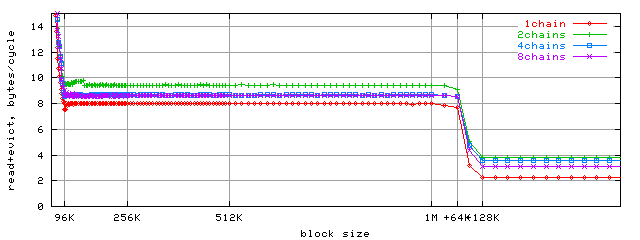
Поскольку ПС остается высокой вплоть до размера блока, равного L2+L1D (1088K=1M+64K), то, следовательно, эксклюзивность кэша можно в данном случае считать доказанной.
(В скобках и мелким шрифтом следует отметить, что для случайного доступа столь же показательной картины мы не увидим. Но причина этого кроется в недостаточной степени ассоциативности кэша L2 (да-да, 16 наборов ассоциативности уже оказывается недостаточно для кэша размером 1M). Возможно, в будущем мы попытаемся оценить некоторые другие эффекты, которые могут проистекать из этого факта).
А пока приведем график, на котором сравниваются пропускные способности шины при последовательном и случайном типах доступа, блок 96K:
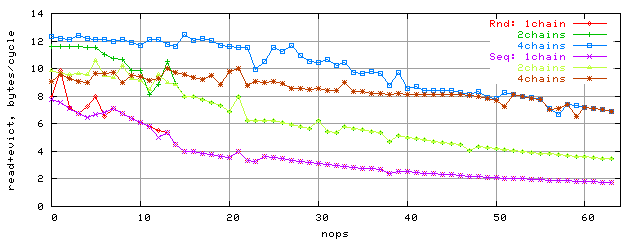
Нам остается попытаться получить максимальную ПС кэша L2, который должен наблюдаться при случайном доступе к блоку размером 96K. Для этого построим графики зависимости ПС от количества nop-ов в случае 2 и 4 зависимых потоков доступа:
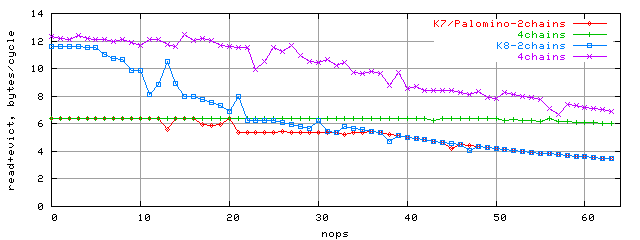
Именно здесь различия в шине L1-L2 архитектур K7/K8 особенно заметны. ПС выросла почти в 2 раза, до 12 байт/такт. Конечно, прокачать такое количество данных по старой 64бит шине за такт невозможно. Теперь ясно, что эффективная ширина этой шины в случае K8 составляет 128бит. А ее устройство изучим в следующем разделе.
Проверка гипотезы о 128бит «ширине» шины
Итак, эффективная ширина шины L1-L2 в K8 удвоилась по сравнению с K7 и составляет 128бит. Проверим, сохранилась ли ее архитектура (одна двунаправленная шина). Если это так, то каждую строку кэша можно загрузить за 4 такта (64байт/128бит=4такта), что можно проверить прямым тестированием. Если нет, то единственной разумной альтернативой устройства шины выглядят две однонаправленные шины, каждая шириной по 64бит. Изобразим эти варианты на схеме:
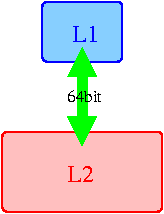

Для проверки [не]правильности варианта 128бит (изображенного посередине) вновь немного изменим нашу общую методику, основанную на зависимых цепочках доступа (в данном случае будем рассматривать снова только одну зависимую цепочку). Напомним, до сих пор, при каждом обходе цепочки доступ к каждому элементу массива (размер элемента равен 64байт — размеру строки кэша) происходил ровно один раз. При этом читалось 4байтное слово, имеющее смещение 0 относительно начала элемента.

Теперь же, во время этого доступа к каждому элементу мы будем читать вначале слово, имеющее смещение O1, а затем, внутри того же элемента, слово, имеющее смещение O2.

Не забудем как и раньше добавить фиксированные промежутки времени (nop-ы) перед загрузкой новой строки кэша (красные стрелочки на рис.), а также, дополнительно, фиксированные промежутки времени (будем назывыть их sync-nop-ы) между загрузками двух слов из одной и той же строки кэша (перед зелеными стрелочками). Данный прием позволит нам (при строго определенном количестве sync-nop-ов) избежать штрафа из-за преждевременного обращения к ещЈ не прибывшим данным и, (при достаточно большом количестве nop-ов) избежать взаимовлияния последовательных загрузок. В результате ассемблерный код станет таким (для примера, 2 sync-nop-а, 3 nop-а)
mov eax,[eax] ; первый доступ к строке кэша (красная стрелочка)
add eax,ebx ; sync-nop
add eax,ebx ; sync-nop
mov eax,[eax] ; второй доступ к строке кэша (зеленая стрелочка)
add eax,edx ; nop
add eax,edx ; nop
add eax,edx ; nop
…
Ну а теперь посмотрим на результаты латентностей загрузок двух слов, находящихся в одной строке в зависимости от их относительного смещения (offset=O2-O1) в этой строке. При этом количество nop-ов =64, а количество sync-nop-ов подбиралось так, чтобы средняя латентность была минимальной. На графике внизу нарисована латентность (в тактах) загрузки первого слова (1st word), второго слова (2nd word), а также относительная задержка (delay) между ними. Следует также отметить, что в этом тесте результаты для K7/Palomino и для K8 оказались идентичными, кроме этого, результаты также не зависят и от смещения O1 первого слова в строке (при этом относительное смещение берется конечно по модулю размера строки).
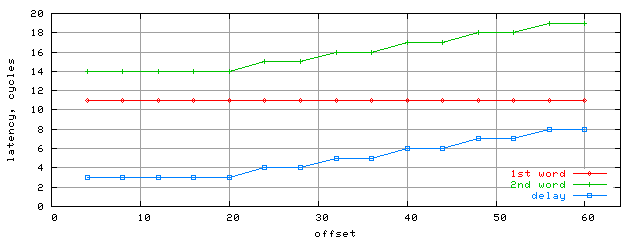
Результаты последнего теста доказывают, что ширина шины L1-L2 на чтение составляет 64бит, и, поскольку в предыдущем разделе также было доказано, что эффективная ширина всей шины L1-L2 K8 составляет 128бит, то это означает, что оставшиеся 64бит приходятся на часть шины L1-L2, отвечающую за запись (или точнее, evict). Итого, правильным оказывается вариант шины, показанный на рис. справа.
Итоги тестирования
В общем, можно сказать, что по сравнению с K7 архитектурой, изменения устройства доступа к кэшу L2 в архитектуре K8 есть, хотя являются непринципиальными и носят эволюционный характер, так как «расшивают» наиболее узкие места. А вот в оценке этого факта мнения участников данного тестирования разделились, потому приведем сразу два взаимоисключающих вывода.
- Архитектура K7/K8 имеет достаточно совершенную архитектуру кэша L1/L2, и потому рассмотренных выше изменений Opteron-у вполне достаточно для конкуренции с другими процессорами в ближайшие несколько лет.
- Отсутствие революционных изменений в организации доступа в кэш L2 во многом нивелирует выгоду от его значительного размера (1M), потому, возможно, в следующий ревизиях ядра AMD прийдется вносить сюда определенные изменения.


