Исполнять вдумчиво и размеренно
Для полного состава симфонического оркестра
© Б. Гребенщиков, «Орел, Телец и Лев».
- …хочешь, дружок, я расскажу тебе сказку?…
- …хочешь, дружок, я расскажу тебе сказку?…
- …хочешь, дружок, я расскажу тебе сказку?…
- …хочешь, дружок, я расскажу тебе сказку?…
- Хочу, хочу, ХОЧУ!!! — в истерике бился ребенок…
© старый, «добрый» анекдот
Вступление, или «песнь песней»
Внимательный читатель — это весьма интересный субъект. У него есть как достоинства, так и недостатки. К первым отнесем то, что внимательный читатель, как правило, догадывается, что хотели сказать авторы того или иного опуса. Но к недостаткам внимательного читателя надо отнести то же самое качество — иногда читатель догадывается о большем, нежели того хотелось бы авторам.
Техническая презентация — не менее странная вещь. С одной стороны, хочется рассказать о своем продукте как можно больше. С другой стороны, если рассказать все, что рассказывать потом, когда он выйдет? С третьей стороны, про продукт узнают конкуренты — и соответствующим образом скорректируют планы. Тоже нехорошо получается. Вот и мечется несчастный работник маркетинг-отдела в попытке «и рыбку съесть, и ушки не замочить».
Как уже наслышаны внимательные читатели, в течение некоторого времени AMD грозится выпустить процессоры нового поколения, основанные на ядре Hammer — Athlon 64 и Opteron. Первый предназначен для рынка десктопов, а второй — для рынка серверов. Дальнейший наш рассказ предназначен для упорядочивания и некоего осмысления той информации, которая на сегодняшний момент известна об этих процессорах.
Как мы помним, в новом процессоре от AMD несколько ключевых составляющих:
- архитектура х86-64
- ядро процессора
- интегрированный контроллер памяти
- шина ввода/вывода на основе Hyper Transport
Соответственно, попытаемся описать характерные особенности каждой из этих частей. Фотографии красавцев (слева направо — Opteron и Athlon 64):


Неожиданную «проблему» с процессорами Opteron (слева) нашли инженеры сервисного центра. Они задали вопрос, поражающий простотой: «а куда клеить гарантийные наклейки?» А действительно, куда? :-)
Архитектура х86-64
Вот уже достаточно долгое время архитектура х86 не претерпевала никаких принципиальных изменений — не считать же, в самом деле, принципиальным «подклеивание» новых наборов команд, впервые осуществленное Intel в Pentium MMX. Собственно, ключевые особенности адресации команд, сегментации памяти, сами х86 команды не менялись со времен i386 — это был последний революционный процессор. По-видимому, настало время перемен — и на сей раз знамя «революционной борьбы» решила поднять AMD. Для этого она сделала решительный шаг.
Впервые со времен i386 архитектура х86 подвергается расширению — подчеркиваем, не «подклеиванию» новых наборов команд, а полноценному расширению. Дело здесь даже не в том, что теперь на каждом рабочем столе может стоять 64-битовый компьютер — само по себе это не прибавляет производительности. Да и не так уж много у обычного потребителя задач, в которых это важно (разве что криптография, поскольку при переходе на 64 битовые вычисления она выигрывает едва ли не больше всех — ниже будет показано, насколько и почему). Дело в том, что теперь архитектуре х86 (обновленной) вновь есть, куда расти. Кроме того, данная архитектура исправляет некоторые огрехи, присущие х86 от рождения — например, в 64 битном режиме применяется «плоская» модель памяти, количество регистров общего назначения расширено до 16 (чуть дальше автор покажет, какие дивиденды это приносит). Так что самое время задаться вопросом — а кто же выиграет от подобного расширения архитектуры? Для начала перечислим группы пользователей, которым 64 адресация и 64 битовые вычисления нужны уже сейчас:
- пользователи CAD, систем проектирования, симуляторов уже давно нуждаются в объеме оперативной памяти больше 4 гигабайт. Хотя способы обходить это ограничение известны (к примеру, Intel PAE), за эти способы приходится расплачиваться производительностью. Действительно, процессоры Xeon поддерживают режим 36 битной адресации, в которой могут адресовать до 64GB оперативной памяти. Суть этой поддержки вкратце состоит в том, что оперативная память разбита на сегменты — и адрес состоит из номера сегмента и адреса ячейки внутри сегмента. Этот способ приводит к потере минимум 30% производительности при операциях с памятью. Да и программирование для «плоской» модели памяти в 64 разрядном адресном пространстве значительно проще и удобнее — благодаря большому адресному пространству ячейка имеет простой адрес, обрабатываемый за один раз. Не зря многие конструкторские бюро используют достаточно дорогие рабочие станции на RISC процессорах — там поддержка 64 битной адресации и большого объема памяти реализована давно.
- в подобной же ситуации находятся пользователи баз данных. Любое крупное предприятие имеет немаленькую базу данных, и расширение максимального объема памяти плюс возможность адресовать данные в базе данных напрямую для них дорогого стоят. Как уже говорилось выше, хотя в специальных режимах 32 битная архитектура IA32 и может адресовать до 64GB памяти — но переход на «плоскую» модель памяти в 64 битном пространстве гораздо выгоднее. Переход на 64 битовую адресацию выгоден и с точки зрения скорости, и с точки зрения удобства программирования.
- научные вычисления. Здесь ценен объем памяти, «плоская» модель памяти, и отсутствие ограничений на размер обрабатываемых данных. Кроме того, некоторые алгоритмы в 64 битном представлении имеют значительно более простой вид.
- есть область, которая очень выигрывает от 64 битных целочисленных вычислений. Это криптография и приложения, созданные для обеспечения безопасности. В этой области применение х86-64 способно привести если не к революции, то к огромному рывку вперед.
Таким образом, некоторый круг потенциальных потребителей новой архитектуры сложился уже сейчас. Тем же из покупателей, которым эти возможности не нужны, нет нужды использовать их в данный момент — для 32 битовых приложений ничего не меняется. Вообще ничего. Кроме того, вполне можно пользоваться 32 битными приложениями в 64 битной операционной системе — эдакие 64 бита «в рассрочку». Похоже, добавление этой технологии не так дорого — по заверениям AMD, данная технология увеличивает количество транзисторов на 2%-3%. Это связано в основном с расширением TLB (сокращение от Translation Lookaside Buffer — буфер быстрого преобразования адреса, представляющий собой специальную кэш-память; используется для ускорения страничного преобразования), а также всевозможных буферов всех видов и сортов, да расширение всех конвейеров и путей данных до 64 бит. Кстати, AMD слегка «хитрит» в этой оценке — по количеству транзисторов они, возможно, и правы (тем более что есть кэш, в котором транзисторов немало), но вот прирост площади кристалла будет явно больше.
Не будем таить греха — хороша х86, или нет, но именно эта архитектура является доминирующей по числу и инсталлированных систем, и существующего программного обеспечения. До сих пор, во многом с подачи Intel, бытовала точка зрения, что, дескать, х86 доживает последние дни (забавно, но такой точке зрения уже больше десяти лет — хоронили х86, хоронили, а она многие RISC процессоры пережила) — в дальнейшем все будем постепенно переезжать на новую архитектуру. В роли таковой, вполне естественно, прочили IA64. Однако AMD продемонстрировала, что «легким движением руки брюки превращаются…» — в общем, оказалось, что архитектуре х86 еще есть куда расти и развиваться, при этом сохраняя свое самое важное преимущество, инсталлированную базу программного обеспечения. Что ж, это хорошие новости — сомневаюсь, чтобы даже самый оптимистичный читатель пришел в восторг, узнав, что для перехода на новую, совершенно замечательную и прогрессивную архитектуру IA64 ему нужно выложить немаленькую сумму за оборудование и намного большую сумму за программное обеспечение. Так что эволюционный подход надо признать правильным и щадящим для пользователя. Не говоря уже о том, что такой подход дает возможность нацелить продукт сразу на несколько сегментов рынка, что явно выгоднее с финансовой точки зрения….
Автор, тщательно обдумав, пришел к выводу, что нет особого смысла в данной статье вдаваться в подробности относительно архитектуры х86-64. И вот по каким соображениям:
- Статья посвящена все-таки процессорам Athlon 64 и Opteron, а не описанию архитектуры х86-64.
- Полное описание этой архитектуры доступно на сайте www.amd.com и www.x86-64.org — и авторы не видят смысла его дублировать.
- При необходимости в подобном материале проще выпустить специализированный материал, чем пытаться уместить все известные данные в одной статье — и без того описание архитектуры процессоров занимает немало места.
С точки зрения автора, всей этой аргументации вполне достаточно. Единственно, некоторые важные уточнения по поводу SMP систем и программирования для них будут высказаны ниже — там, где они будут к месту. Пока же кратко остановимся на доступных режимах процессора.
Фактически, кроме стандартных и известных со времен i386 режимов, введен особый режим — Long mode. Когда он включен (бит LME выставлен в единицу), есть два «частных» режима работы процессора. В одном из них процессор находится в режиме совместимости, во втором — в «честном» 64 битном режиме. Для чего понадобилось делать 2 «частных» режима для 64 битного режима? Все очень просто — когда Вы используете 32 битную операционную систему, тогда пользоваться 64 битовым режимом нет никакого смысла. Но как только вы стали работать на 64 битной ОС, далее у вас два варианта — вы можете использовать старое, 32 битное программное обеспечение (и тогда и нужен режим совместимости), а можете использовать новое, 64 битное. Кроме того, переключения «частных» режимов Long mode происходят весьма быстро, в отличие от переключения режимов работы процессора. Таким образом, введение таких режимов становится целесообразным. По-видимому, есть смысл привести таблицу, поясняющую доступные программисту режимы процессора, и режим работы в них:
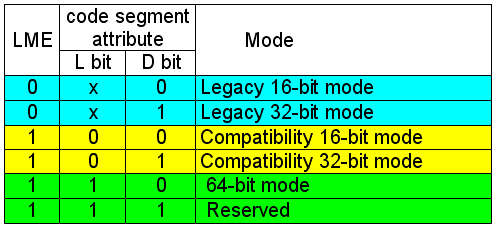
Символ «х» обозначает, что при выставленном бите LME в значение «0» значение бита L игнорируется.
Как видно, у процессора есть и 64 битный режимы работы, и 32 битный, и 16 битный — собственно, поддерживаются все предыдущие режимы. Это и есть условие совместимости, не так ли? Очень интересна надпись Reserved — чтобы это могло означать? На этот счет у автора нет никаких догадок — но, возможно, они появятся у читателей. Впрочем, одна совершенно сумасшедшая идея автору была подсказана одним из рецензентов — может быть, при этой комбинации процессор превращается в DSP-процессор? Естественно, не весь процессор — скорее, только некоторая его часть. Это действительно сумасшедшая идея — но если AMD ее воплотила, то в определенных видах операций этот процессор будет непревзойденным. :-) Естественно, вполне может быть, что все гораздо проще, и данная комбинация просто не нужна в данный момент — вот и зарезервирована на будущее.
Нельзя не отметить, что для того, чтобы пользователи смогли воспользоваться преимуществами х86-64, 8-ми дополнительными регистрами общего назначения, 8-ми дополнительными регистрами SSE2, и прочими программными «вкусностями» этих процессоров, необходим компилятор. И он — достаточно важная часть программы по продвижению этого процессора, и даже более важная для архитектуры х86-64! Ибо, если компилятора не будет — то мало кто начнет программировать под этот процессор вручную…. Если он будет, но будет неудобным — опять же, это скажется на количестве программистов, и, как следствие, на количестве пользователей (и финансовых показателях компании AMD). Таким образом, требования к компилятору достаточно высоки.
Надо отметить, что AMD хорошо это понимает — и работы над несколькими независимыми версиями компиляторов ведутся, вместе со всемирно известными компаниями-разработчиками программного обеспечения. Автор не уполномочен открывать их имена — при необходимости AMD сделает это сама. Нам же достаточно знать, что на момент выпуска этот процессор будет иметь необходимую поддержку в лице компиляторов, позволяющих задействовать его архитектурные преимущества. Естественно, выпуск процессора без компилятора так же возможен — благо, старый 32 битный код процессор исполняет «на ура». Но все же гораздо выгоднее со всех точек зрения запустить процессор в производство, снабдив его соответствующим компилятором.
Чтобы продемонстрировать полную совместимость своего детища, AMD проверила системы на новом процессоре в более чем 50 (!) операционных системах. Вот некоторые примеры систем, совместимость с которыми проверена:
- Windows (3.1, 9x, Me, 2000 Pro, 2000 Server, 2000 Advanced Server, WfW, XP)
- Windows NT (3.51 WS, server, 4.0 w/SP6, NT 4 Workstations)
- DOS (MSDOS 6.21, Novell DOS 7.0, PC DOS 6.1, 6.3, 7.0
- Linux (Mandrake 7.0, 7.1, Redhat 6.0, 6.1, 6.20, 7.0, Slackware 1.2, 2.0, SuSE 7.0)
- Unix (SCO, FreeBSD 3.0, Solaris 2.5, 2.6, 7, 8)
- Misc (OS/2 Warp3.0, 4.0, BeOS 4.5, 5.0, Netware 4.11, 4.2, 5.0, 5.1)
Ядро процессора
Для начала попробуем описать, какие изменения сделаны в ядре процессора и представим его блок-схему:
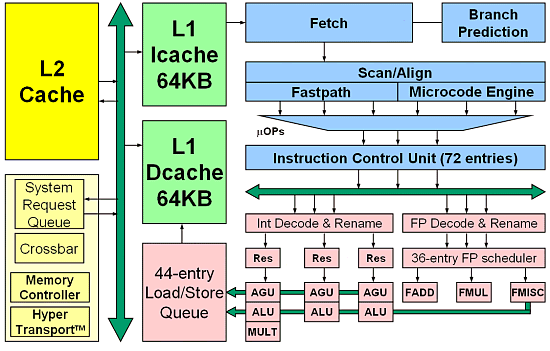
Начнем с I-cache, он же кэш инструкций. Его размер остался таким же, как и в Athlon — 64КВ. Он так и остался 2-х канальным частично-ассоциативным — таким образом, особых изменений по сравнению с Athlon в этом параметре нет. Размер блока — 64 байта. Наличествуют два набора тэгов — fetch port (порт выборки) и snoop (слежения). Содержимое защищено при помощи проверки четности.
D-cache, он же кэш данных, также 2-х канальный частично-ассоциативный. В текущей модификации поддерживается 40-битовый физический и 48-битовый линейный адрес — впрочем, при необходимости этот параметр можно увеличить. Размер блока данных также 64 байта. Из нововведений — MOESI протокол работы кэша первого уровня, ранее использовавшийся в чипсете AMD760MP(X). Поддерживает две 64-битовых операции чтения/записи каждый такт в различные банки! Три набора тэгов — port A, port B, snoop. Задержка выборки из этого кэша — 3 такта при выровненных обращениях, и плюс 1 такт, если данные не выровнены. Кстати, это достаточно низкое пенальти за то, что данные не выровнены — в Pentium 4, насколько известно автору, это пенальти значительно больше — по измерениям различных тестеров, цифры получаются от 6 до 10 тактов, в зависимости от методики. Сама Intel хранит гордое молчание на сей счет. Поддерживается hardware prefetch (блок предвыборки). Все данные защищены ECC.
Теперь перейдем к TLB — здесь есть некоторые разночтения. Одни источники утверждают, что TLB имеют емкость 40 входов, другие говорят о 32…. Но и те, и другие сходятся на том, что L1 TLB полностью ассоциативные, и поддерживают как 4К, так и 2М/4М страницы. Это должно особенно порадовать любителей «как следует посчитать» — в научных расчетах частенько используются страницы большого размера. Правда, остается открытым вопрос, одинакова ли емкость TLB для стандартных 4К страниц, и для 4М? Наверняка, нет, но точными сведениями авторы не обладают — только в одном из источников удалось найти, что для 4К страниц емкость 32 входа, а для 2М/4М — 8 входов. В отличие от TLB для L1 cache, L2 TLB поддерживает только 4К страницы — но зато емкость уже 512 входов с 4-х канальной ассоциативностью. Также автор видел указания на некий «кэш каталогов страниц» на 24 входа — его влияние пока непонятно. Надо уточнить, что речь идет скорее о разных уровнях одной и той же TLB для кэшей L1 и L2, а не о разных TLB. Кроме того, AMD утверждает, что, по сравнению с Athlon XP, емкость TLB выросла вдвое, а задержки уменьшились (!). Учитывая, что обычно рост объема сопровождается ростом задержек, ситуация заставляет задуматься — а как инженеры AMD сумели этого добиться? Может быть… Идея, конечно, сумасшедшая — но, возможно (подчеркиваю, только возможно), TLB работают на другой частоте, отличной от частоты ядра? Автор бы не удивился этому факту — заодно это бы многое объяснило. Наиболее простой вариант здесь — удвоенная частота…. Но, повторю, уверенности в этом нет.
Перейдем к L2 cache. Он, как и следовало ожидать, exclusive по отношению к L1. Сохранена 16-канальная частично-ассоциативная организация — по-видимому, AMD сочла бессмысленным дальнейшее увеличение этого параметра. Кроме того, он теперь использует pseudo-LRU схему, которая уменьшает вдвое количество LRU битов. Это скорее плохо, чем хорошо — но влияние этого параметра должно быть невелико. Зато, по-видимому, в таком случае удается ускорить предшествующую декодированию обработку этих битов — а вот это уже точно хорошо. :-) Кроме того, L2 cache содержит предварительно декодированные инструкции (термин непонятен — по-видимому, тем или иным образом предварительно «склеиваются» инструкции вместе с данными) и branch prediction bits (своего рода указатели, или просто «флаги» предсказания ветвления). Все это вместе составляет некоторый уникальный (по словам AMD) механизм, увеличивающий производительность процессора.
Интересно, что фактически декодирование (вернее, подготовка к нему) начинается прямо в L2 cache. Это означает, что при «выселении» данных из I-кэша эта информация перемещается в L2 cache, где для нее зарезервировано место. При этом повторно используются ECC биты для быстрой очистки/совместного использования страниц кэша — звучит, говоря откровенно, непонятно для автора — но грозно :-). Что AMD имеет в виду? Что для хранения дополнительной информации используются те биты, в которых хранилась информация ECC? Вряд ли это так — это привело бы к отсутствию защиты данных, на что никто не пойдет. Автор может только догадываться.
Вдвое увеличена скорость передачи данных из L2 в L1 кэш (по сравнению с Athlon XP) — это должно здорово помочь на многих операциях (интересно, кстати, каким образом — расширением шины или уменьшением задержек доступа?). Скорее всего, конечно, расширена шина — в пользу этого говорит то обстоятельство, что в 64 битном режиме для одновременной передачи и команды и операнда нам нужно, как минимум, 128 бит. Либо появилась возможность вести одновременно две операции по пересылке данных — например, запись и чтение — что равносильно тому же увеличению «эффективной» ширины шины. Кроме всего прочего, L2 cache поддерживает отложенные запросы — 8 отложенных запросов данных и 2 отложенных запроса инструкций. Как обычно, поддерживается несколько буферов: Victim буфер на 8 входов, такой же по величине буфер слежения, и буфер записи на 4 входа.
Но «самый главный» вопрос по поводу L2 cache для большинства читателей совсем другой — какого он будет размера? Если со старшими процессорами все более или менее понятно — Opteron будет содержать 1 MB L2 cache — то вот объем кэша у Athlon 64 совершеннейшая загадка. Существовали различные предположения о том, будет или нет объем равен 512 КВ. Автор считает, что будет два варианта — 256 КВ и 1 MB. Тому есть несколько соображений:
- Давайте припомним, для чего нам нужен кэш? Из-за того, что скорость процессоров растет намного быстрее, нежели скорость памяти, задержки при обращении в память сводят на «нет» все преимущества от скоростного процессора, ибо большую часть времени тот просто ждет. Именно поэтому и наращивают кэш в процессорах, чтобы сгладить этот эффект и дать процессору возможность продолжать работу над предварительно запасенными данными. Но ключевой особенностью архитектуры Hammer как раз и являются намного меньшие задержки памяти (автор продемонстрирует это ниже) по сравнению со всеми остальными архитектурами. Таким образом, именно Hammer меньше нуждается в кэше, нежели другие х86 архитектуры.
- Мы позволим себе привести один очень характерный график — там указан эффект от увеличения L2 cache с 256КВ до 1МВ. В диаграмме хорошо видно, что увеличение L2 cache до 1МБ приводит к 15% приросту производительности.
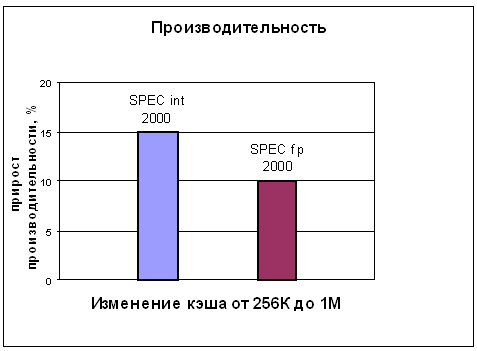
- Если попытаться интерполировать, то 512 КВ должны дать порядка 7-8% прироста в SPECint 2000. Теперь вспомним вот про что: площадь кристалла с 256 КВ кэшем L2 составляет приблизительно 104 мм2. А кристалла с 1 МВ — приблизительно 180 мм2 (по предварительным данным). Есть разница, не так ли? Соответственно, 512 КВ кэша L2 должны привести к площади порядка 140 мм2—150 мм2, что должно заметно сказаться на стоимости кристалла.
Именно поэтому я считаю, что вполне разумным вариантом будет выпуск настольного процессора Athlon 64 с 256 КВ кэша L2, и Opteron с 1МВ кэша L2. Справедливости ради, замечу также, что существует еще одна точка зрения, которая говорит, что наряду с обычным Athlon 64 будет выпущена модификация для двухпроцессорных станций с 512 КВ кэша L2. И в этом есть определенный смысл — если необходимо создать двухпроцессорную машину, то ставить Opteron будет явно дорого, а Athlon 64 в двухпроцессорной комбинации не работает. Посему действительно есть прямой смысл создать некоторую модификацию Athlon 64 (назовем ее условно Athlon DP), которая могла бы работать в двухпроцессорных комбинациях — и не более. Но, насколько известно автору, AMD остановилась на той точке зрения, что необходим десктопный вариант процессора с 256 КБ и серверный с 1 МБ кэша L2. А уже Opteron будет, если потребует рынок, иметь различные модификации.
Более того, появились данные о том, что, собственно, Opteron будет двух видов: один для двухпроцессорной конфигурации, другой — для четырех- и восьмипроцессорных систем. Обе модификации будут иметь по три шины Hyper Transport и по 1 MB кэша второго уровня. Необходимо заметить, что, в связи с разной архитектурой процессоров, становится все труднее и труднее сравнивать их между собой. В самом деле, поскольку методология работы с L2 cache у Pentium 4 и Hammer сильно отличаются, становится трудно или даже невозможно ответить на вопрос — что же лучше, 512 КВ кэша у одного, или 256 КВ у другого? Точный ответ на этот вопрос даст разве что эксперимент. :-)
Далее у нас блок предсказания переходов — он подвергся значительной переработке. Теперь он для увеличения точности ведет историю 16К (между прочим, это в 4 раза больше, нежели у Athlon XP) переходов, и также помнит 2К адресов назначения. Все это, вместе с 12-входовым стеком возврата адреса, позволяет AMD заявить о 5%—10% преимуществе в точности предсказаний по сравнению с предыдущим поколением процессоров. Это тем более важно, что из-за слегка удлинившегося конвейера (12 стадий вместо 10) процессор стал чуть более чувствителен к промахам предсказания переходов — правда, из-за значительно снизившейся задержки доступа в память пенальти в производительности, скорее всего, будет даже меньше, нежели у Athlon XP. Кстати, тут же надо указать, что улучшен и механизм prefetch — теперь программный prefetch не отключается при заполнении буферов, а аппаратный лучше работает в содружестве с программным.
Но вернемся к нашим данным. Далее наши данные попадают в декодер — ту часть, которая подверглась наибольшей переработке. Собственно, своим удлинением конвейер обязан именно декодеру — именно там добавились две дополнительные стадии. Что же такого там наворотили? Декодер превращает нерегулярные команды х86 (к тому же переменной длины) в µOPs (микрооперации) фиксированной длины. Причем за один такт каждый декодер может обработать инструкцию длиной до 16 байт (!) и отправить планировщику на исполнение µOPs, которые затем будут упакованы в группы по трое. Представим более подробный рисунок:
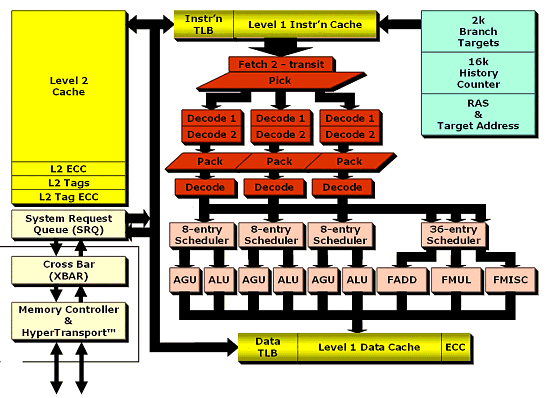
При этом инструкции могут быть превращены в µOPs двумя разными путями. Первый состоит в том, что при помощи блока Fastpath (быстрой обработки) инструкция х86 превращается в 1 или 2 µOPs, каковые затем (упакованные в блоки по три µOPs) направляются в планировщик. Второй — при помощи Microcode decoder инструкции х86 превращаются в последовательность из более чем двух µOPs (для сложных операций) каждая, при этом готовые последовательности загружаются из ROM (точнее сказать, из MIS — Microcode Instruction Sequencer, подобие ПЗУ, содержащее набор заранее запрограммированных последовательностей микроопераций). При этом в отличие от Athlon XP, заметно больше инструкций х86 используют более быстрый Fastpath декодер, имеющий меньшие задержки в тактах — 2 против 5. Кроме того, подобное устройство декодера приводит еще к нескольким следствиям:
- SSE инструкции в Athlon переводятся в µOPs при помощи Microcode decoder, а в Hammer — при помощи Fastpath decoder. Соответственно, мы вправе ожидать небольшого прироста производительности в данном наборе команд даже при прочих равных условиях.
- Также автору стали известны следующие данные:
- Hammer исполняет на 8% меньше микроопераций в наборе SPECint 2000.
- Hammer исполняет на 28% (!!!) меньше микроопераций в SPECfp 2000.
Здесь надо пояснить, что в данном случае не производительность процессора стала хуже, а просто изменение методики разбиения команд х86 на µOps привело к уменьшению общего количества µOPs, в которые превращается программа.
Думаю, читатель, теперь становится понятно, почему AMD изменяла прежде всего именно декодер — можно бороться за то, чтобы исполнять как можно больше работы за такт. А можно подумать и сделать так, чтобы было меньше работы вообще. Ничего не скажешь, интересная идея. По крайней мере, автору она импонирует — хотя бы в силу естественной лени. :-)
Ну а мы пойдем далее. Данные попадают на исполнительные устройства. А их у нас хватает: 3 целочисленных блока, 3 блока генерации адреса и загрузки, 3 суперскалярных FPU — тот же набор, что и у Athlon XP. Немало! Длина целочисленных конвейеров — 12 (10 у Athlon XP) стадий, FPU — 17 (столько же у Athlon XP). Теперь посмотрим поподробнее на целочисленные блоки:
- все данные могут быть 64-битовыми (в общем-то, очевидная ситуация, учитывая поддержку х86-64 технологии).
- три 8-ми входовые станции резервирования (все вместе они образуют 24-х входовый планировщик заданий — его емкость на треть больше, нежели у Athlon XP)
- исполнение за 1 такт (!) всех логических операций, кроме умножения.
- три такта на 32-битное умножение и пять тактов на 64-битное умножение (64 битное умножение может быть запущено каждый второй такт)
Собственно, эти данные удобно представить в виде таблицы:
| Задержка умножения, тактов | 8 bit, 16 bit | 32 bit | 64 bit |
|---|---|---|---|
| Athlon XP | 3 такта | 4 такта | N/A |
| «Hammer» | 3 такта | 3 такта | 5 тактов |
Добавим, что все операции можно запускать каждый такт, кроме 64 битного умножения, которое запускается каждый второй такт. Кстати, а новый 64 битный конвейерный умножитель тоже вместился в 2%-3% дополнительных транзисторов? Или используется некая схема со сдвигом наподобие той, которая работает в ALU Pentium 4?
Осталось сказать про FPU — полностью конвейеризированный блок, с внеочередным исполнением команд, с 36-х входовым буфером-планировщиком, к тому же умеющий исполнять некоторые (?!) DSP инструкции за 1 такт. По этому поводу, к сожалению, не удалось разыскать никаких дополнительных сведений, а жаль — некоторые предположения так и мелькают в голове.
Поддерживаемый набор инструкций — x87, MMX, 3DNow!, SSE и SSE2. При этом в 64 битовом режиме и FPU, и ALU поддерживают 16 регистров. Для чего это понадобилось? Здесь необходимо сделать некоторое лирическое отступление: то, что набор команд х86 считается «устаревшим», слышали многие. Но многие ли представляют себе, что является одним из основных «костылей», которые мешают наращивать производительность далее? Одним из главных «костылей» является тот факт, что архитектура х86 может иметь лишь 8 регистров общего назначения. При работе многих алгоритмов этого частенько не хватает — приходится тратить время и вычислительные ресурсы на то, чтобы «выкрутиться». Подчеркиваем, речь не идет о физических регистрах — со времен Р6 используется переименование регистров. Речь идет о том, что многие алгоритмы вынужденно усложнены в силу нехватки архитектурных 8 регистров общего назначения в х86. AMD предлагает возможность снизить остроту этой проблему, предоставляя дополнительных 8 регистров. Но поскольку совместимость с предыдущим программным обеспечением — обязательное требование для процессора общего назначения, то подобный подарок использовать в стандартном х86 не получится. Необходимо перейти на х86-64. Чтобы проиллюстрировать, что это дает, приведем эту гистограмму:
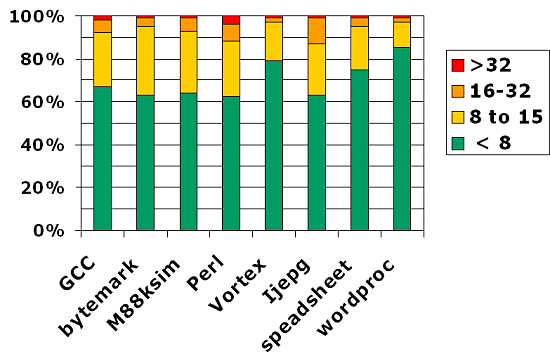
На ней обозначено, какой процент функций и алгоритмов в типовых приложениях использует то или иное количество регистров. Видно, что в Word больше 80% функций довольствуются 8 регистрами — а остальные функции вынуждены использовать «переименование регистров» и запоминать промежуточные данные. Соответственно, если регистров станет 16, то это устроит уже 96% встроенных функций Word. При этом понятно, что скорость исполнения вырастет, ибо не нужно прибегать к дорогостоящим (в смысле производительности) алгоритмическим методам, сохраняющим регистры. Для набора ByteMark, характерного тем, что используется большой перечень разнообразных алгоритмов, выигрыш будет еще значительнее. Наверняка наиболее благодарными потребителями дополнительных регистров будут всевозможные научные расчеты — их алгоритмы, как правило, весьма ресурсоемки.
Теперь посмотрим, на какую производительность FPU мы можем рассчитывать. Теоретически, в режиме х87 или SSE2, мы можем выполнять одно умножение и одно сложение за такт (1 Mul + 1 Add). На практике AMD удалось реализовать почти 1.9 FLOPs за такт (пиковая производительность в SSE2 scalar). На наш взгляд, это превосходно! В режимах SSE и 3DNow! теоретическая производительность составляет 2 умножения и 2 сложения за такт (но меньшей точности, чудес по-прежнему не бывает). Полученная практически производительность — чуть более 3.4 FLOPs за такт. При этом использовалась не последняя ревизия ядра Hammer — возможно, результаты удастся еще немного «подтянуть».
С ALU рекомендации все те же — использовать предварительно выровненные данные, пользоваться prefetch. Кстати, о префетче: есть несколько его видов — prefetchnta, prefetcht0, prefetcht1.
Отличаются они следующим:
- prefetchnta — перемещает данные прямо в L1 Data cache, минуя кэш L2. Когда данные записаны, в кэше L2 их нет. Кроме того, важно, что при этом данные не выселяются в L2, а помещаются только в «нулевую строку» кэша, сохраняя более «постоянные» данные, осевшие в первых линиях.
- prefetcht0 — перемещает данные в L1 cache и L2 cache.
- prefetcht1 — перемещает данные только в L2 cache.
Кроме этого, AMD вводит новый метод записи — так называемый Streaming Store, или non-temporal write. Отличительная его черта состоит в том, что при записи в память используется специальный Write буфер, и не используется ни L1 cache, ни L2 cache. Более того, нет необходимости выравнивать данные по длине линии кэша для достижения максимальной скорости. В результате не «загрязняется» кэш, что фактически означает, что его эффективный объем увеличился, а эффективная скорость записи в память возрастает почти вдвое (!).
Некоторые имеющиеся данные наводят на мысль, что Fastpath блоков два, а вот Microcode — только один. В принципе, данная ситуация возможна — если большинство операций проходят через Fastpath, то подобное «неравенство» вполне оправданно. Кристалл ведь не резиновый… Да и греться меньше будет. :-) Подчеркиваю, это всего лишь предположения автора.
Контроллер памяти
Всем уже давно понятно, что данный блок — один из ключевых в борьбе за производительность. Тем интересней, что же придумала AMD, чтобы добиться преимущества. Для начала припомним, что любая память с точки зрения скорости характеризуется, как минимум, несколькими параметрами — шириной шины данных, частотой синхронизации (или связанной с ней пропускной способностью), и задержками, которые возникают при ее работе. Соответственно, в идеале пропускная способность должна быть как можно больше, а задержки — как можно меньше. Что же у нас есть?
Припоминаем, что отличие Athlon 64 от Opteron состоит из нескольких пунктов — прежде всего, у Opteron двухканальный контроллер памяти, 128 бит вместо 64 бит. Также припомним большее число шин Hyper Transport, Socket 940 вместо Socket 754 у Athlon 64 (как раз следствие первых двух пунктов) и потенциально разный объем кэша. В данный момент нас интересует как раз первый пункт.
Итак, пропускная способность памяти характеризуется частотой ее работы (типом памяти) и шириной шины данных — соответственно, у нас поддерживается DDR память PC2100 и PC2700 (еще поддерживается память стандарта РС1600, но это для нас вряд ли интересно). Пропускная способность этой памяти составляет 2.1GB/s и 2.7GB/s (4.2GB/s и 5.4GB/s в случае двухканального контроллера Opteron). Таким образом, скорость памяти вполне «на уровне». Еще есть полуофициальный стандарт («де факто», но не «де юре») DDR400, ситуация с поддержкой которого неясна. С одной стороны, вряд ли сложно добавить поддержку еще и этого типа памяти — тем более что это практически не требует изменения процессора, нужно лишь немного изменить контроллер. С другой стороны, поскольку комитет JEDEC этого стандарта не принимал, сложно заявлять подобную поддержку официально. Видимо, придется дождаться конечного продукта, чтобы окончательно прояснить ситуацию с этим стандартом.
В последнее время вокруг DDR400 (либо РС3200, каковое название этот стандарт получит, если его утвердят) опять начались некие «телодвижения», связанные с тем, что Intel опубликовала планы его использования в своих будущих чипсетах. Правда, необходимо некоторое уточнение: дело в том, что контроллер памяти, по заверениям AMD, работает на частоте процессора… Но сама память на такой частоте работать не может — рабочая частота памяти намного меньше. Есть два варианта, каким образом можно организовать работу памяти — либо сделать часть чипа работающей на частоте памяти независимо от частоты остального процессора (что фактически означает асинхронность), либо ввести некоторые делители, и тогда скорость памяти будет зависеть от частоты ядра. Зная «любовь» AMD к асинхронным решениям, можно предположить, что более вероятно второе. И действительно, нам удалось разыскать такую пояснительную таблицу:
| Частота ядра, MHz | Тип памяти (скорость в MHz) | Соотношение частот | Делитель | Результирующая скорость памяти, MHz |
|---|---|---|---|---|
| 800 | 133 | 6,0 | 6 | 133 |
| 1000 | 133 | 7,5 | 8 | 125 |
Обратите внимание на выделенные цифры — по-видимому, в силу каких-то архитектурных ограничений делитель, отвечающий за скорость памяти, может быть только целым. Поэтому не все частоты процессора будут равнозначны — при некоторых частотах скорость памяти будет меньше номинальной. Наиболее вероятная гипотеза состоит в том, что данное ограничение связано с работой внутреннего коммутатора (X-bar в терминологии AMD), связывающего контроллер памяти и другие части процессора. Достаточно логично предположить, что очередность обращения к памяти различных блоков не может быть дробной — вернее, что обращаться к контроллеру памяти X-bar может только раз в целое число тактов процессора… Нам не удалось найти подтверждения или опровержения этой гипотезы — но она хорошо объясняет подобную особенность. Кстати, этот самый X-bar вообще-то произносится как «кросс-бар», но автор уж очень привык к старому названию. :-)
Однако вернемся к теме разговора — теперь понятно, что частота работы памяти отнюдь не такая тривиальная вещь, как мы думали раньше. Представим известную нам информацию графически:
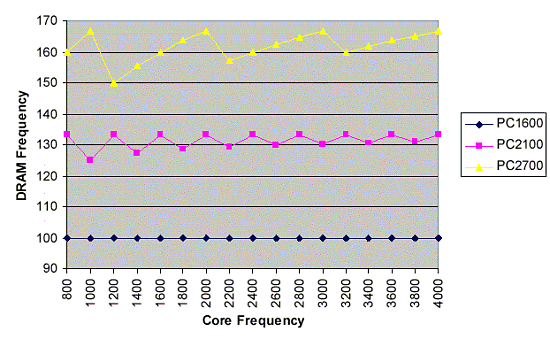
Зависимость скорости памяти от частоты ядра
Можно заметить несколько интересных вещей. Первое: скорость памяти РС1600 не зависит от частоты процессора — вполне понятно, ибо скорость процессора всегда кратна 200MHz, и для каждой частоты процессора находится свой целый делитель. Причем не очень понятно, этот делитель — только целый, или же он еще и кратен двойке? Первое лучше для эффективности — но намного сложнее в схемотехнике, нежели кратный двойке делитель. Частота памяти РС2100 совершает небольшие «затухающие колебания» недалеко от штатной частоты 133 (266) MHz. Частота памяти РС2700 ведет себя таким же образом. В результате на небольших частотах процессора (при небольших делителях) скорость памяти меняется сильно, а с ростом частоты ядра (и на некоторых частотах ядра изначально) частота работы памяти все ближе к номинальной частоте, или равна ей.
Второе: если этот делитель не будет зафиксирован жестко, то «оверклокеры» всех стран получат в руки новое оружие — теперь можно будет разгонять память, меняя данный делитель. При этом все остальные компоненты работают в штатном режиме. Занятно. :-)
Третье: если делитель должен быть не только целым, но и четным, то поддержка памяти DDR400 потребует нетривиальных мер — с ростом частоты ядра частота памяти будет меняться очень сильно, от штатных 200MHz до «разочаровывающих» 133MHz (при небольших частотах процессора). И только рост частоты ядра до 4 — 5 Гигагерц сделает эти колебания малозаметными. Либо, конечно, можно наращивать частоту по 200MHz — тогда мы сможем получить максимальную пропускную способность. Отсюда становится понятным осторожное отношение AMD к стандарту DDR400…. Правда, в случае, если делитель не обязательно кратен 2 — тогда понятно, что скорость DDR400 будет всегда максимальной…. Забегая вперед, скажем, что делитель, по всей видимости, не обязан быть кратным двойке.
Кстати, выбор частоты 200MHz в качестве опорной, с нашей точки зрения, легко объясним: дело в том, что по спецификации, старт шины Hyper Transport всегда происходит на частоте 200MHz — а уж потом выбирается необходимая частота для работы. Соответственно, раз уж у нас все равно будет 200MHz, почему бы не воспользоваться этой частотой еще и в качестве опорной для процессора?
Не знаю, как тебе, читатель, а автору все-таки интересно, какая же скорость памяти будет достигнута в подобной системе? Нам удалось разыскать некоторые данные (вероятнее всего, относящиеся к системе на базе Athlon 64 — Opteron должен был бы показать большее быстродействие), продемонстрированные на системе с памятью РС2100:
| Частота ядра, MHz | Copy32 — 64 bit | Copy64 — 64 bit | Copy32 — 128 bit | TRIAD — 128 bit | SCALE — 128 bit | ADD — 128 bit |
|---|---|---|---|---|---|---|
| 800 | 900 | 910 | 1040 | 1300 | 1300 | 1420 |
| 1000 | 900 | 942 | 1100 | 1400 | 1440 | 1550 |
| 1200 | 1050 | 1012 | 1240 | 1510 | 1590 | 1710 |
| 1400 | 950 | 1040 | 1240 (1150) | 1550 (1460) | 1610 (1280) | 1730 (1490) |
Синим цветом обозначены значения для системы Pentium 4 (неизвестной нам частоты) + Rambus.
И здесь трудно обойтись без комментариев. Во-первых, некоторые зависимости скорости памяти от частоты ведут себя странно — их характер отличен от других (к примеру, Copy32 — 64bit). Возможно, это связано с тем, что данные измерены для процессоров сравнительно небольшой частоты, и в полную силу работают эффекты, связанные с делителем частоты памяти. Хотя, говоря откровенно, данное объяснение автора не слишком устраивает — но, за неимением лучшего, пока будем пользоваться им. А в уме сделаем галочку при ближайшей возможности поинтересоваться этим моментом. Вторая особенность четко видна в таблице — указаны некоторые значения для системы Pentium 4 + RDRAM. С большой долей вероятности можно сказать, что наверняка имеется ввиду система на базе i850 — но не i850E. Впрочем, в данной ситуации трудно быть в чем-то уверенным. Как бы там ни было, даже если это РС800 RDRAM, ситуацию трудно переоценить — подобное устройство подсистемы памяти позволило обогнать на потоковых операциях память, имеющую в полтора раза большую теоретическую пропускную способность. А что будет на памяти РС2700? А на DDR400? Ну а третья особенность также заметна — пропускной способности памяти стандарта РС2100 хватает на процессор частотой 1200MHz — 1400MHz. При большей частоте, вероятно, наступает насыщение, и пропускная способность подсистемы памяти не меняется. По-видимому, насыщение пропускной способности памяти РС2700 должно наступить в районе 1800 MHz—2000 MHz (правда, надо помнить, что эта оценка, как и всякая экстраполяция, может оказаться неверной).
К сожалению, подобных данных для РС2700 разыскать не удалось…
Теперь перейдем к задержкам памяти. Здесь все сложнее. Гораздо сложнее… Прежде всего, потому, что вместе с ростом частоты памяти задержки увеличиваются — временные характеристики ячейки памяти ведь не изменились. Например, AMD в своих расчетах применяет РС2100 Cas 2, но РС2700 Cas 2.5 память. Приведем графики для обоих типов:
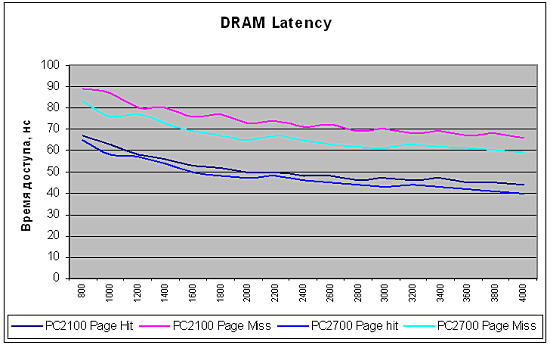
При этом автор обращает внимание читателей на тот факт, что эти данные получены на предварительной ревизии процессора (кстати, в данном случае неважен тип процессора, и у Athlon 64 и у Opteron скорость работы контроллера не отличается) — в финальном варианте они могут измениться. Кроме того, поскольку достоверность данных неизвестна — будем считать их всего лишь оценочным вариантом.
Видно, что абсолютные задержки памяти — в наносекундах — падают с ростом частоты памяти, и ростом частоты ядра. В пределе задержки стремятся ко времени доступа к ячейке. Естественно, также оно, это время, будет зависеть от того, открыта или закрыта «страница» памяти, случайный ли это адрес — и так далее. Из графика видно, что оно составляет величину порядка 40 наносекунд для обоих видов памяти. Можно так же предположить, что разница между задержками на частоте 800 MHz и 4000 MHz обусловлена работой контроллера памяти (вернее, его работой и работой X-bar). Интересно, что время работы контроллера порядка 25 наносекунд при частоте 800 MHz (по другим данным, порядка 40 нс). Это означает, что контроллер вовсе не обязательно работает на частоте ядра — его частота может быть и меньшей (но не менее 40 MHz, естественно). Соответственно, данная зависимость скорости памяти от делителя — еще один «рай» для оверклокеров.
В первых ревизиях ядра контроллер почти наверняка работает на частоте ядра — но в дальнейшем, при необходимости быстро наращивать скорость, AMD может еще вернуться к идее применить подобный делитель. Впрочем, это всего лишь домыслы автора, пусть и не лишенные некоторой целесообразности. Но, кроме всего прочего, у нас есть некоторые цифры задержек. Так хороши они или плохи? Посмотрим на график РС2100. К примеру, для частоты ядра в районе 1500 MHz задержки находятся в районе 55 наносекунд. Давайте сравним с задержками для чипсетов стандартной архитектуры:
| Чипсет | Величина задержек |
|---|---|
| VIA КТ266А | 115 |
| AMD760 | 160 |
| AMD760MP(X) | 200 |
| i850 | 170 |
Опять выясняются некоторые интересные цифры: так, например, чипсет VIA KT266A оказался весьма и весьма неплох по части временных характеристик. А вот сравнительно низкие показатели AMD760MP(X) связаны с использованием ECC Registered DDR памяти, которая имеет большие задержки при работе, нежели обычная Unbuffered — впрочем, даже с обычной памятью его предшественник, AMD760, работает не лучшим образом. По некоторым данным, работа контроллера памяти занимает 32 такта процессора. Плюс, естественно, время доступа к ячейке памяти — отсюда легко понятна зависимость производительности подсистемы памяти от частоты процессора. Кроме того, автору попалась на глаза цифра для систем SUN — порядка 180 нс для локальной памяти.
Теперь можно понять, что цифры задержек для Athlon 64 и Opteron не просто хороши! Они великолепны! А с ростом частоты процессора станут еще лучше. Надо отдать AMD должное — подобным ходом (интеграцией контроллера в процессор, и, как следствие, малыми задержками доступа) AMD сильно облегчила себе работу во всех ситуациях, связанных со случайным доступом в память — вернее, снизятся не задержки доступа к ячейке памяти (они зависят только от характеристик самой памяти и топологии системы), снизится общее время реакции подсистемы памяти. А вот случайный доступ к различным ячейкам частенько, например, встречается в базах данных. И здесь разница между «традиционными» чипсетами и конструкцией AMD будет, по-видимому, уже не на проценты, а в разы. Браво, AMD!
Но не будем спешить — интересно, что станет с этими цифрами в ситуации, когда система под нагрузкой. Да еще и в многопроцессорной системе, например. Нам удалось разыскать следующие данные:
| Количество процессоров | 1400 MHz лучшее / среднее / худшее | 2400 MHz лучшее / среднее / худшее | Улучшение, % |
|---|---|---|---|
| 1 | 64 / 64 / 64 | 56 / 56 / 56 | 14 / 14 / 14 |
| 2 | 83 / 98 / 113 | 60 / 78 / 96 | 38 / 26 / 18 |
| 4 | 122 / 133 / 153 | 94 / 106 / 132 | 30 / 25 / 16 |
Очевидно, что данные касаются системы на процессорах Opteron — никакие другие в 4-х процессорной конфигурации не работают. Заметим, что задержки, вначале достаточно большие (но при этом намного меньшие, нежели в других SMP архитектурах), но с ростом частоты процессоров сильно уменьшаются. Это тем более интересно, что до этого автор полагал, что наиболее значимым для величин задержек будет скорость межпроцессорных связей — той самой технологии Hyper Transport. По-видимому, ее задержки невелики, и попросту теряются на фоне задержек памяти и контроллера. Автор оценивает потери времени на одну передачу запроса к памяти другого процессора по шине Hyper Transport в 12-20 наносекунд, в зависимости от скорости процессоров. Впрочем, эта оценка может оказаться неверной.
Также интересно, как изменятся эти цифры под нагрузкой? Автор предполагает, что они увеличатся — но остается непонятным, насколько именно.
Впрочем, приведенная таблица говорит сама за себя — задержки по сравнению с другими многопроцессорными архитектурами очень низки. Это говорит о том, что эффект от перемещения контроллера памяти внутрь процессора скажется именно на многопроцессорном рынке. Рискнем сделать одно предположение: AMD направляет главный удар не столько на десктопный рынок, сколько на 2-х и особенно 4-х процессорный. За это предположение говорят как внимание, которое уделяется тщательному разъяснению устройства систем, так и категорическое отсутствие каких-либо подробностей о производительности многопроцессорных систем, даже самых невинных. Похоже, сами вопросы на эту тему нервируют AMD. :-)
В общем-то, эту идею автор считает здравой — тем более, что на десктопном рынке есть некоторое оружие: впереди Barton с его L2 кэшем 512 КБ и 333 MHz шиной FSB (а, возможно, шина достигнет и 400 MHz). Было бы расточительно не воспользоваться его потенциалом. Кроме того, похоже, не стоит ждать слишком многого от десктопного варианта, Athlon 64. Да, его ядро будет дополнено теми характеристиками, которых не хватает нынешнему Athlon XP. Да, появится поддержка SSE2. Да — и это главное отличие — появится поддержка х86-64. Но, повторим, похоже, основные «сюрпризы» AMD приготовила для многопроцессорного рынка.
Однако вернемся к теме задержек. С нашей точки зрения, величина этих задержек является вполне убедительным обоснованием, почему была выбрана именно такая архитектура — AMD удалось с блеском решить задачу сравнительно однородного доступа в память (сама AMD называет свою многопроцессорную архитектуру SUMO).
Очевидно, что с ростом количества процессоров в системе значения задержек увеличиваются. Впрочем, это достаточно понятно — ведь в многопроцессорной системе необходимо передавать еще и служебную информацию, обеспечивающую когерентность кэшей и памяти. Да и путь данных удлиняется.
Кроме всего прочего, по слухам, AMD добавила некоторые архитектурные ухищрения в работу с памятью. По непроверенным данным, контроллер памяти умеет держать до 16-ти открытых страниц памяти вместо 4-х (максимум для обычных чипсетов). Здесь надо сказать, что смысл, который в эту фразу вкладывает AMD, остался нам непонятым. Возможно, используется тот факт, что чип DDR SDRAM умеет держать до 8 страниц памяти открытыми. Если количество каналов памяти (два) маркетологи умножили на 8 — то вот и получилось «до 16 открытых страниц памяти». Также «поговаривают», будто бы специальный счетчик следит за тем, как долго открыта каждая страница, «обучаясь» на ходу. Правда, «глубина истории», по которой он обучается, автору неизвестна — характерная в подобных случаях глубина составляет 24 запроса.
Контроллер памяти с X-bar (ну а тот с ядром процессора) соединен шиной шириной 64 бита, работающей на частоте процессора — что дает на частоте 2 GHz скорость 16 GB/sec. Теперь смело можно добавлять поддержку любого типа памяти — узкого места при передаче из контроллера памяти в процессор не образуется. Естественно, подобная пропускная система избыточна для любых существующих видов памяти — но, по-видимому, сделать ее такой было проще схемотехнически, нежели придумывать специальную шину между X-bar и контроллером.
Также не будем забывать, что, кроме «простой» функции — работать с памятью — контроллер памяти содержит еще несколько функциональных блоков. В частности, достаточно много людей задавались таким вопросом: поскольку теперь контроллер памяти в процессоре, как именно будет происходить работа с памятью для, например, AGP видеоадаптера? Ведь теперь на его пути к памяти, кроме контроллера памяти (ранее встроенного в чипсет), теперь есть AGP 3.0 «туннель» AMD8151 (или подобные от других производителей), контроллер Hyper Transport, X-bar. Не приведет ли это к большим задержкам и к падению скорости для видео? «Масла в огонь» подлили некоторые слухи, согласно которым некоторые производители чипсетов стали делать свой собственный контролер памяти для видео — дабы нивелировать этот эффект. Теперь, думаю, можно дать ответ на этот вопрос: нет, не приведет. Во избежание подобной ситуации AMD внесла в контроллер, кроме всего, еще и Graphics Address Remapping Table (GART). Таким образом, есть дополнительная стадия передачи данных при помощи Hyper Transport от памяти к видеоадаптеру — но зато наиболее сложная и долгая работа по переименованию адресов памяти и размещению запросов происходит на гораздо более высокой скорости. В результате скорость скорее вырастет, чем упадет. Там же (в контроллере памяти) теперь и часть PCI-to-PCI bridge. В результате практически полный контроль над передачей данных в системе принимает на себя X-bar, внутренний коммутатор процессора — высвобождая ядро процессора для более интеллектуальной работы. Жаль, что мы так мало о нем знаем. Получается эдакая аналогия DMA, но на новом уровне. Чем-то неуловимо напоминает почившую в «бозе» I2O архитектуру (см. статью).
Впрочем, старый добрый DMA никуда не исчезает — он по-прежнему есть и поддерживается. Более того, подобная конструкция намного эффективнее (по данным AMD) освобождает процессор от участи в пересылке данных. Автор считает, что подобная конструкция должна значительно поднять производительность в области ввода/вывода, а это незамедлительно должно крайне благоприятным образом сказаться на скорости и удобстве работы в целом. Подчеркиваю, это личное мнение автора — AMD нигде об этом не упоминает.
Контроллер Hyper Transport
Вот так, незаметно, мы и подошли к следующему функциональному блоку — контроллеру Hyper Transport. Это достаточно важная часть системы — и тем более важная, что именно в этой области есть достаточное количество нововведений, ранее в архитектуре х86 не употреблявшихся. Здесь начитанный читатель может возразить — как это «ранее не употреблявшихся»? Ведь в чипсете nForce и nForce 2 применяется шина Hyper Transport — хоть и младший ее вариант…. Да, применяется. Но при этом не используются практически никакие специфические для Hyper Transport возможности — она работает в этом чипсете так же, как работала бы «очень быстрая» PCI.
Фактически, именно сейчас Hyper Transport должна «заиграть» в полную силу. Что ж, тем интереснее обсудить некоторые подробности ее работы.
Интересные данные можно предоставить о задержках во время работы подсистемы ввода/вывода, и их зависимости от нагрузки:
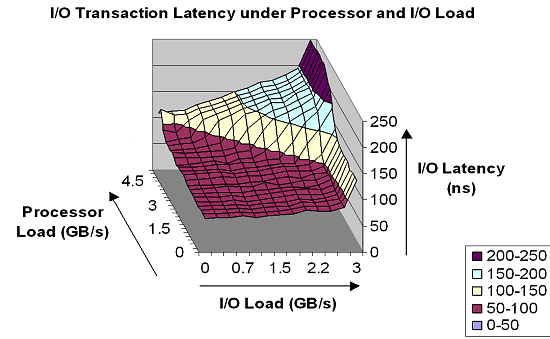
Видно, что только случай максимальной загрузки и процессора, и подсистемы ввода/вывода способен серьезно увеличить задержки. Здесь автор испытывает большое желание взять слово «серьезные» в кавычки — понятно, что задержка доступа в 250 наносекунд выглядит серьезной только на фоне задержки в 50 наносекунд. По сравнению же со всеми остальными традиционными подсистемами ввода/вывода все очень хорошо — у автора есть только некоторые цифры для других систем. Например, для SUN задержки даже в случае Fire Plane (а это, на минуточку, старший вариант шины с пропускной способностью 9.6 GB в секунду!) только на передачу уходит порядка 100 наносекунд. В общем случае эта цифра превышает характерное время для Hyper Transport. Кроме всего прочего, такой характер зависимости наводит на мысль (неизвестной степени достоверности) о том, что в подобном резком подъеме виновата не шина Hyper Transport, а внутренний коммутатор процессора — X-bar. Возможно, именно он становится «слабым звеном» при росте нагрузки. Тогда с ростом частоты процессора производительность X-bar тоже увеличится, и график при этих значениях должен приобрести значительно более пологий вид. К тому же это объясняет постоянные напоминания AMD о том, что с ростом частоты все станет «еще лучше».:-) Как говорится, практика покажет, была ли эта идея верной.
Надо напомнить, что ранее для величины задержки автор называл цифры 12-20 наносекунд. Налицо противоречие — здесь нет таких данных даже по порядку величины. Объяснение данного разногласия вот в чем — Hyper Transport может работать в двух режимах: когерентном и некогерентном. Для межпроцессорных связей используется когерентный режим, а для I/O — некогерентный. Так что никакого противоречия нет — задержки для них действительно разные.
Кроме того, раз уж мы заговорили о шине Hyper Transport, позволим себе напомнить уровень ее масштабируемости. Для этого приведем следующую диаграмму:
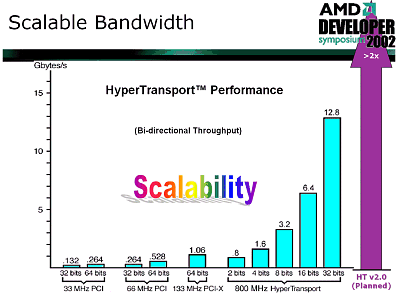
Согласитесь, диапазон скоростей, доступных для Hyper Transport, впечатляет. Вообще говоря, даже сама по себе эта шина — весьма сильная разработка. В ней достаточно хорошо сочетаются простота разводки, великолепные скоростные качества, низкие задержки, хорошая масштабируемость — и при всем при этом совместимость с давно изученной программной моделью PCI, что немаловажно для беспроблемного внедрения ее в промышленность.
Хочется также продемонстрировать, насколько разводка Hyper Transport проще, нежели разводка традиционных шин:
Легко заметить, какую площадь на печатной плате занимает шина AGP 8x с пропускной способностью 2 ГБ/секунду, а какую — шина Hyper Transport, прокачивающая до 6.4 ГБ/секунду. Думаем, комментарии излишни. Кстати, автору было достаточно интересно сравнить ее с другой перспективной разработкой — PCI Express, в девичестве 3GIO. В результате «раскопок» удалось найти следующие факты:
- и Hyper Transport, и PCI Express очень похожи — и та, и та сходны в концептуальной идее и многих деталях. В частности, это последовательные шины с похожим механизмом арбитража, и сходными возможностями по масштабируемости. Более того, у них одинаковый механизм формирования запроса, одинаковые методы контроля «на лету», обе поддерживают переключение трафика и передачу данных точка-точка, обе могут быть различной ширины и легко масштабируются.
- PCI Express создается как периферийная шина, может работать с картами расширения, разъемами, и короткими кабелями. Hyper Transport же создавалась как соединение точка-точка, но также может работать с картами расширения, разъемами, и короткими кабелями.
- PCI Express несовместима с текущей программной моделью PCI. Соответственно, ее внедрение потребует переработки BIOS и поддержки драйверами. Hyper Transport полностью совместима с текущей программной моделью PCI и не требует драйверов для работы. Она полностью прозрачна для приложений и ОС.
- PCI Express имеет большую стоимость в расчете на один проводник, но достигает при этом большей скорости, нежели Hyper Transport.
- Hyper Transport полностью готова к применению и является открытым стандартом. PCI Express находится в разработке и не может быть использована в текущий момент времени.
- Hyper Transport при необходимости может быть адаптирована к PCI 3.0, которая используется в PCI Express.
- Hyper Transport использует в текущей модификации 40 битный адрес, при необходимости может быть адаптирована к 64 битному адресу. Имеет длину команды 32/64 бита (96 бит при 64 битной адресации). PCI Express имеет 32/64 битный адрес, с длиной команды 96/128 бит.
- кроме того, длина пакета Hyper Transport составляет 64 байта, длина пакета у PCI Express — до 1 КВ, запросы — до 4 КВ.
- PCI Express имеет управляющие буферы размером 16 байт, а Hyper Transport — 64 байта. Легко заметить, что это равно размеру пакета — в связи с этим намного реже возникает ситуация нехватки буфера.
- PCI Express создается для больших серверов, что делает ее стоимость слишком высокой для обычных компьютеров. К тому же сервис по шифрованию трафика, например, требует дополнительных и крайне дорогостоящих надстроек. Hyper Transport стоит для конечного пользователя намного меньше и имеет встроенные возможности по шифрованию трафика.
- Hyper Transport поддерживает режим Masked Write, который необходим для работы AGP видеокарт. PCI Express этот режим не поддерживает — соответственно, создать видеокарту для PCI Express без переработки спецификаций (либо видеокарт, либо шины) невозможно. Кстати, а как Intel тогда собирается делать Serial AGP, о котором ходили слухи, как о следующем после AGP 8x стандарте?
Приведем график, который продемонстрирует скорость чтения:
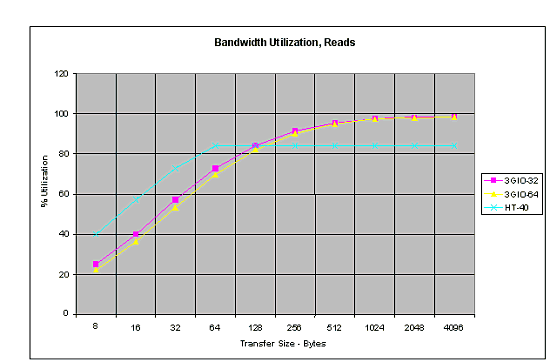
и записи:
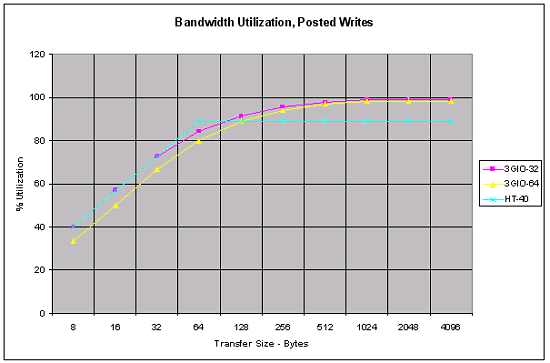
Видно, что вплоть до размера 64 байта (размер пакета) Hyper Transport равна или превосходит PCI Express, и лишь при большем размере пакета немного отстает по части эффективности — она утилизирует порядка 90% пропускной способности при отложенной записи, и порядка 85% при чтении. Вполне неплохо для шин, настолько отличающихся по времени создания. Тем интересней будет посмотреть на следующую версию Hyper Transport — что покажет она?
Вновь напомним, что шина Hyper Transport способна работать в двух режимах — когерентном, и некогерентном. Первый применяется для минимизации задержек, второй — для достижения максимальной пропускной способности и минимизации загрузки процессора. Теперь, на наш взгляд, самое время поговорить о следующей составной части систем на Athlon 64 и Opteron — пока же укажем, что, по мнению автора, подобная архитектура системы ввода/вывода и есть ключ к высокой производительности именно многопроцессорных вариантов.
Чипсет
Давно известно, что часто именно чипсет, как ближайшее окружение процессора, создает впечатление о производительности системы и ее преимуществах/недостатках. Тому масса примеров, и автор не видит смысла их приводить — при желании любой читатель сможет их отыскать самостоятельно. Так что вполне понятен интерес к тому, на каком же чипсете будут работать системы на Athlon 64 и Opteron.
Надо сказать, что и здесь AMD сумела найти нестандартный подход. Еще при объявлении компанией шины Hyper Transport было вполне логично предположить, что именно эта шина будет рано или поздно использоваться в новых системах на базе их очередного процессора. Но то, что предложила компания, выходит за рамки обычного чипсета — да и за рамки «необычного» чипсета выходит тоже. Судите сами: классический чипсет состоит, как правило, из двух (реже одной или трех) микросхем, в которых одна, содержащая контроллер памяти, AGP, и какую-либо вспомогательную шину (PCI либо любую другую) между микросхемами чипсета, обычно называется Northbridge. Соответственно, всевозможные контроллеры ввода/вывода, а в последнее время, как правило, и контроллер шины PCI, интегрируются в, так называемый, Southbridge. Так устроено подавляющее большинство чипсетов. Повторим — Northbridge и Southbridge соединяются той или иной шиной. Это может быть PCI, как в чипсетах ALi или старых чипсетах VIA, это может быть PCI64 «разных мастей», как в некоторых чипсетах Server Works или AMD760MP(X), это могут быть собственные шины, как в чипсетах SiS, Intel, или новых чипсетах VIA. В конце концов, это может быть Hyper Transport, как в чипсетах от NVIDIA. Угадайте, какой вариант выбрала AMD? :-) Правильно, Hyper Transport. Во-первых, потому что это шина ее собственной разработки. Во-вторых, потому что она имеет наибольшую скорость на сегодняшний момент из доступных на рынке шин. В-третьих, потому что ее разводка проста и позволяет создать недорогие материнские платы, что немаловажно при выборе платформы. Так что причины выбора вполне понятны. Но AMD пошла дальше, гораздо дальше.
Ведь что у нас осталось из функций чипсета? Контроллер памяти — в процессоре. AGP — частично там же, по крайней мере, наиболее сложная часть — GART. Контроллер шины Hyper Transport — и тот в процессоре. Остается часть AGP, контроллеры ввода/вывода, контроллер PCI… Собственно, все. Можно, конечно, все оставшиеся части интегрировать в одну микросхему (забегая вперед, скажем, что NVIDIA так и сделала). Но AMD нашла еще более красивое решение. Было создано три микросхемы (под объединяющей их серией AMD8000):

AMD8151, Hyper Transport — AGP tunnel

AMD8131, Hyper Transport — PCI-X контроллер

AMD8111, Hyper Transport — контроллер ввода/вывода, контроллер шины PCI, BIOS, и все оставшиеся функции, как-то IDE контроллер, USB 2.0, сеть, и прочее.
Что же дает такое разделение труда? Зачем три микросхемы, когда в принципе можно обойтись одной?
А дело здесь вот в чем — редкому пользователю нужны абсолютно все возможности, предоставляемые чипсетом. Обычно часть функций не используется, но пользователь все равно за них платит — и, в общем-то, все привыкли к тому, что это нормальное положение вещей. Но скажите, многим ли дома или в офисе нужен контроллер шины PCI-X, которая применяется отнюдь не в домашних машинах? А ведь добавление подобной шины ощутимо увеличивает цену конечной системы. В то же время вообще отказаться от этой шины нельзя, она активно используется в серверах. А многим ли серверам вообще нужно AGP? Да, по привычке мы ставим туда AGP видеокарту — но просто потому, что процесс перехода на AGP шину произошел слишком удачно, до практически полного исчезновения PCI видеокарт. Так вот, теперь не надо платить за ненужные вам функции — для построения системы обязательна только одна микросхема — AMD8111. Остальные две, вообще-то, могут отсутствовать. Конечно, нынешнюю машину без AGP разъема трудно себе представить — но, говоря откровенно, есть огромная область работ, в которой вполне справляется и интегрированное видео, а удешевление и уменьшение габаритов системы весьма желательны. Домашние, игровые компьютеры вполне разумно строить на комплекте AMD8151 + AMD8111 — есть все, что необходимо, и нет лишних функций. Сервер — извольте, рекомендуем AMD8131 (при необходимости можно несколько!) + AMD8111. Ниже будут представлены схемы, на которых эти идеи реализованы.
Обратите внимание: вместо одного чипсета для мейнстрим продуктов, одного для рабочих станций, одного или нескольких для серверов — мы получили один строительный набор из трех компонент, которые можно объединять практически в любой удобной для нас комбинации. Неожиданная, но интересная и здравая идея — не говоря уже о том, что она сильно сэкономит силы AMD в процессе технической поддержки. Ведь одно дело поддерживать один продукт, хоть и трехкомпонентный, а другое — десяток различных чипсетов. Так что и в этой области решение интересное и эффективное.
Несколько слов необходимо сказать также и о чипсетах других производителей. CrushK8 от NVIDIA нами уже упоминался — интересен тем, что это первое решение из одной микросхемы. У него будет вариант со встроенным видео — и в таком виде это будет очень интересное решение для, например, офисных компьютеров. А памятуя об очень неплохой производительности встроенного видеоадаптера в чипсетах NVIDIA, можно спокойно надеяться на то, что и поиграть тоже будет вполне комфортно.
Собственно, позвольте представить фрагмент слайда, который лучше всяких описаний представит планируемые чипсеты от других производителей:
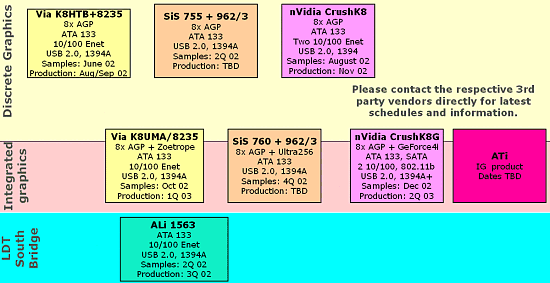
Впрочем, многие производители материнских плат уже демонстрировали свои продукты на базе некоторых чипсетов.
Другими словами, за рынок чипсетов под семейство Hammer можно не волноваться — процессоры еще официально не вышли, а уже анонсировано 8 (!) чипсетов, кроме, собственно, чипсета AMD8000. Кроме того, наверняка AMD будет придерживаться такой же стратегии, как и в чипсетах для Athlon MP — на рынке чипсетов для десктопов AMD уже не видно, там играют другие производители. А вот в двухпроцессорных системах работает чипсет AMD. С большой долей уверенности можно сказать, что AMD8000, скорее всего, на первом этапе будет играть роль эталонного чипсета для запуска семейства Hammer, а позднее — сместится в сектор многопроцессорных систем, где степень ответственности намного выше. В общем-то, на данный рынок никто из оставшихся производителей чипсетов, насколько нам известно, и не претендует — Server Works делает чипсеты под системы на базе процессоров Intel, а сама Intel чипсетов под процессоры конкурента делать, естественно, не собирается. Хотя автор с удовольствием бы на них взглянул! :-)
Системы на Athlon 64
Автору удалось добыть некоторые сведения (пока на уровне слухов — но автор мало в них сомневается) о модельном ряде процессоров Athlon 64. Как нам стало известно, стартует этот процессор приблизительно в конце первого — начале второго квартала, то есть март-апрель 2003 года. Стартует он с рейтингом 3100+, что соответствует реальной частоте в районе 1.8 GHz. В дальнейшем, видимо, модельный ряд будет следующим: 2800+ (1.6 GHz), 3100+ (1.8 GHz), 3400+ (2.2 GHz), 3700+ (2.4GHz), 4000+ (2.6 GHz) и 4300+ (2.8 GHz). Два последних, по слухам, выйдут спустя некоторое время, тогда как к выходу первых четырех все готово. Осталось наладить массовое производство — что, вообще говоря, не такое уж простое дело. Для этих процессоров известны уже все спецификации, как электрические, так и тепловые. Это говорит о том, что AMD имеет на руках, как минимум, рабочие образцы в кремнии. Видно, что в данный момент планируется продолжить использование рейтинга — сама AMD по этому поводу говорит следующее: «мы понимаем, что рейтинг — не лучший выход. Мы работаем вместе с индустрией над более корректной методикой измерения. Но до ее появления будет использоваться рейтинг». Ниже автор расскажет про наработки в этой области.
Как и сообщалось ранее, ядро Hammer будет производиться на Fab 30 в Дрездене, при помощи 0.13 мкм технологического процесса с применением SOI — «кремний на изоляторе».
Многопроцессорные системы. Opteron.
Очень интересная для нас ситуация сложилась с многопроцессорными системами на Opteron. С одной стороны, по распределению памяти — ну совершенно типичная NUMA архитектура (с неравномерным доступом к памяти), даже спорить не о чем. Ибо время доступа к памяти будет зависеть от того, локальная это память, или нет — а если не локальная, то какого именно процессора. С другой стороны, AMD буквально настаивает, что с точки зрения программной модели это SMP — и ничего более. Даже название придумала — SUMO. Как же разобраться в этом хитросплетении терминов?
Для начала давайте подумаем, чем же для программиста отличаются эти две программные модели? В общем случае, для того, чтобы программа исполнялась эффективно, необходимо следить за ее распределением в памяти в случае NUMA архитектуры, и нет такой необходимости в случае SMP архитектуры. Происходит это потому, что времена доступа к памяти различных иерархий в архитектуре NUMA обычно отличаются на порядки — и, соответственно, неправильное размещение программы в памяти приводит к падению производительности в десятки раз. Если же время доступа к памяти для разных процессоров одинаково, или отличается несущественно — то, с точки зрения программирования, мы имеем программную модель SMP. Она гораздо проще и практически весь софт для многопроцессорных архитектур х86 разработан именно для такой программной модели. Вот таким упрощенным образом можно вкратце описать различия между этими, подчеркиваем, программными моделями. Естественно, различия на этом не заканчиваются — просто мы позволим себе описание остальных различий оставить в качестве домашнего задания для энтузиастов :-). Или как тему для обсуждения в конференции.
Теперь, когда мы сформулировали критерий, надо каким-то образом добыть данные о временах доступа в многопроцессорных Opteron системах…. Кто-то уже давно сказал — кто ищет, тот всегда найдет. Нашли и мы. Для начала припомним графики задержек памяти, которые мы видели по тексту выше. Там были цифры для 2 hop-ов…. Припоминаете? Нарисуем, что такое hop, чтобы не путаться с терминами:
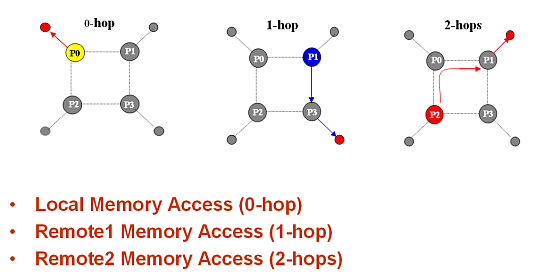
Видно, что обращение к памяти называется hop-ом. При этом обращение к своей локальной памяти — 0-hop. Обращение к памяти соседнего процессора, до которого надо путешествовать по шине Hyper Transport один раз — 1-hop. То же самое, но к процессору, до которого два путешествия по Hyper Transport — называется 2-hop.
А теперь посмотрим еще и на эти цифры (тестовая система — Opteron 2 GHz, 128 bit memory DDR333, CL 2.5, Hyper Transport 6.4 GB/sec).
Время доступа для:
- Однопроцессорной системы: порядка 45 нс
- Двухпроцессорной системы: 0-hop — 69 нс, 1-hop — 117 нс.
- 4-х процессорной системы: 0-hop — 100 нс, 1-hop — 118 нс, 2-hop — 136 нс.
Теперь видно, что в случае, когда процессоров 4, все времена доступа подтягиваются к среднему времени около 93 нс для двухпроцессорной системы и около 118 нс для 4-х процессорной. Последняя цифра, кстати, соответствует времени доступа хорошего однопроцессорного чипсета. Но здесь у нас общее время складывается из собственно времени доступа в память и времени передачи его по шине Hyper Transport (один или два раза)! Так что подобный результат можно признать вполне удовлетворительным. Кроме того, надо помнить, что все это справедливо для памяти CL 2.5 — при переходе на память CL 2 эти значения должны снизиться. Также для сравнения приведем цифры для 4-х процессорной системы SUN — порядка 207 наносекунд при доступе к «нелокальной» памяти удаленных процессоров. Данные взяты из статьи: http://www.ixbt.com/cpu/sun-solutions.shtml
Теперь вернемся к нашему предыдущему вопросу — так NUMA это, или SMP? Говоря формально, все-таки NUMA — 40% разницы не дают возможности назвать эту модель памяти SMP. А можно ли пользоваться моделью для SMP? Можно. Данная разница, хоть и заметна, под нагрузкой будет сглажена — у нас нет «твердых» цифр, но судя по некоторым данным, при нагрузке к этим временам надо добавить порядка 40 нс… Тогда эта разница превращается в 140 нс против 180 нс — а это уже другое соотношение. Таким образом, можно считать, что название SMP для данной системы вполне можно употреблять — и, соответственно, вполне можно программировать как для «классического SMP», без оглядки на действительную архитектуру системы (NUMA). Впрочем, мы не исключаем, что в дальнейшем ОС будут отслеживать распределение памяти в подобных системах — благодаря этому можно будет рассчитывать еще процентов на 10% прироста быстродействия. Почти наверняка найдется некоторое количество пользователей, которые привыкли выжимать всю производительность из систем. Опять — же, напомним, что сама AMD для наименования этой «переходной» архитектуры использует термин SUMO.
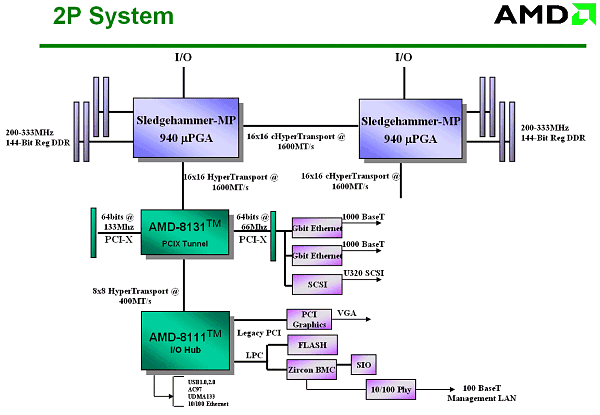
Теперь напомним вкратце, каково устройство многопроцессорных систем на архитектуре Hammer.
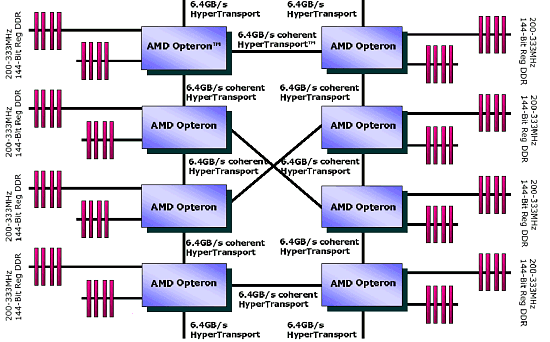
Система на 2 процессорах:
Система на 4-х процессорах:
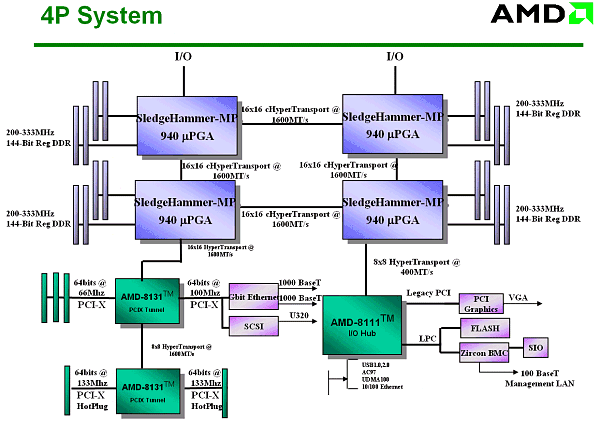
Внушительное зрелище, не так ли? :-) Заметим, что AGP здесь и не пахнет — он там попросту не нужен…. Собственно, слайд довольно старый — отсюда и отсутствие современного логотипа Opteron.
Кстати, если сделать не 4 канала ввода/вывода, а 2 — то две высвободившиеся связи Hyper Transport можно соединить друг с другом, вот так:
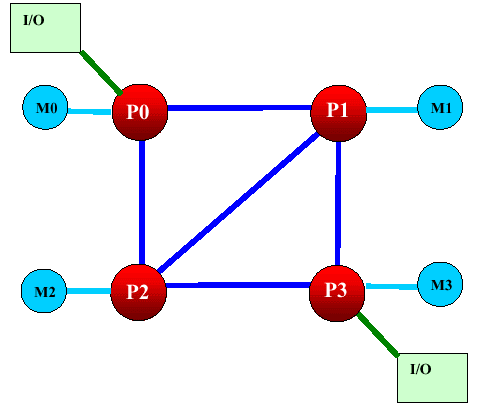
Тогда средневзвешенная скорость памяти составит 19,2 GB/sec вместо 12,8 GB/sec в классическом варианте, а средний «диаметр» системы (средняя длина пересылок данных в hop-ах) составит 1.17 hops, а не 1.33. В свою очередь, это приведет еще и к снижению задержек. Автору подобный вариант даже больше нравится, нежели классический симметричный — редко когда в действительности для ввода/вывода необходимо больше, чем 2 канала Hyper Transport суммарной производительностью более 12 гигабайт в секунду. А поэтому такой вариант будет даже более интересен.
Кроме всего прочего, архитектура Hammer позволяет строить и 8-ми процессорные системы. При этом у крайних 4-х процессоров по одной шине Hyper Transport отдано для ввода/вывода, а у центральных — все три задействованы в качестве межпроцессорных связей. Правда, надо отметить, что, по-видимому, задержки в такой системе сильно увеличатся — впрочем, поскольку точные данные у автора отсутствуют, все сказанное суть только наше предположение. «Классический» вариант такой системы выглядит так:
Теперь применим такую же идею — пару связей Hyper Transport, задействованных для ввода/вывода, соединим друг с другом. Задействуем диагональные крайние процессоры. Получаем средневзвешенную скорость памяти 32 GB/sec вместо 25,6 GB/sec в классическом варианте, а средний «диаметр» системы 1.64 hops, а не 1.71. Приятная прибавка, не правда ли?
Правда, есть некоторые сведения, что все три шины Hyper Transport не могут быть когерентными — только две. Если так, то в 4-х процессорной архитектуре несимметричный вариант невозможен, а в 8-ми процессорной не будет связей между центральными процессорами, что резко увеличит среднее число hop-ов между процессорами, и, как следствие, сильно увеличит латентность. Автор надеется, что этот пессимистический слух не оправдается — к тому же в других источниках прямо указано, что один из контроллеров может переключаться между режимами coherent и non-coherent Hyper Transport.
Нельзя не заметить, что 4-х и 8-ми процессорным архитектурам отчаянно не хватает пропускной способности именно межпроцессорных связей — и с ускорением шины Hyper Transport производительность многопроцессорных систем сделает новый рывок. Но это дело уже будущих модификаций Hammer — мы не испытываем ни малейшего сомнения, что данная архитектура еще неоднократно будет модифицироваться и улучшаться. Как очевидный вариант, к тому же косвенно подтвержденный AMD — следующая модификация ядра Hammer будет поддерживать память DDRII (это, кстати, по оценкам автора, должно дать довольно значительный прирост производительности). Так что есть твердая уверенность в том, что данная статья об ожидаемых процессорах AMD — не последняя :-). Теперь, когда многопроцессорная архитектура AMD озвучена, дело за рынком — дальше именно он решит успешность/неуспех архитектуры.
Интересно, а можно ли сделать больше, нежели 8 процессоров? Оказывается, можно! Правда, теперь не удастся обойтись средствами только процессоров, необходимы еще и коммутаторы Hyper Transport. При их помощи систему можно сделать поистине гигантской…. Впрочем, судите сами:
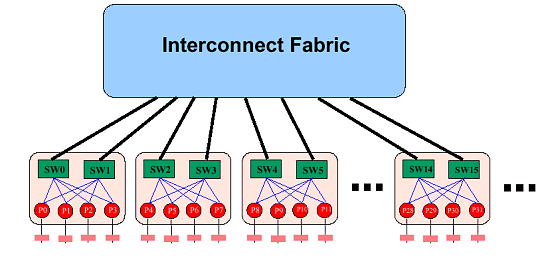
Гм… Подобные Hyper Transport switch уже существуют и доступны (на четыре шины). Объявлены также коммутаторы на 8 шин. Осталось понять, что это за Interconnect Fabric…. Но стоп — пора бы и остановиться :-). Тем более, что здесь самое время вспомнить, что не кто иная, как компания Cray объявила сравнительно недавно о том, что она будет строить суперкомпьютер производительностью порядка 36 TFlops на процессорах Opteron (с возможностью увеличения производительности до 54 TFlops позднее). Интересно, будет ли архитектура суперкомпьютера похожа на эту картинку? :-) Довольно долгое время мы сможем об этом только догадываться. Но возможности архитектуры действительно впечатляют. Кроме того, ходят слухи, которые автор не берется ни подтвердить, ни опровергнуть. Но слухи интересные: говорят, что для фирмы Cray AMD будет производить специальную версию Opteron — с 4-мя линками Hyper Transport. Процессоры вроде бы будут составлять трехмерную сеть. Собственно, принципиальных сложностей для добавления 4-го линка вроде бы нет — но тогда непонятно, в каком же форм-факторе будут производиться эти процессоры.
Думаем, в этом разделе будет уместно поместить фото 4-х процессорной материнской платы с Opteron-ами. Насколько нам известно, она еще нигде не публиковалась — хотя спорить на деньги в этом вопросе автор бы не стал :-) …

Ну а сейчас, когда мы обсудили практически все технические детали, самое время перейти к «сладкому» — показателям производительности. Показатели производительности — это некий итог тем идеям, которые заложены в архитектуре систем на Hammer. И, если можно так сказать, некая им оценка.
Производительность. Часть первая: «верхи не могут, низы не хотят»
Перед тем, как представить некоторые результаты замеров производительности, хочется как можно точнее определить, что же понимается под словом «производительность». С одной стороны, эта характеристика понятна интуитивно — чем «быстрее», тем лучше. Понятно также, что некое мерило эффективности системы действительно нужно и рынку, и индустрии — просто для того, чтобы были какие-то критерии для выбора. С другой стороны, после некоторого углубления в предмет, становится понятно меньше, чем было до изучения ситуации. Оказывается, не получается написать некоторое число, которое было бы производительностью системы. Вместо этого ситуация до боли напоминает бородатый анекдот:
- Петька, приборы!
- 20!
- Что двадцать?!
- А что приборы???!!!
Подобная ситуация сложилась и здесь — показатели производительности зависят от набора тестов, условий тестирования, а в последнее время обнаружилась и вовсе «модная» тенденция: в некоторых приложениях (например, Lightwave 7.0b) результаты частенько зависят от того, какую именно тестовую сцену (из нескольких входящих в комплект поставки) выбрать для тестирования. В одной из них обычно побеждает Athlon XP, в другой — Pentium 4. После этого ясно, что необходимо очень аккуратно следить за условиями экспериментов, и очень осторожно относиться к результатам любых тестов, условий проведения которых мы точно не знаем. Это в равной степени касается всех систем, а не только тех, о которых идет сегодняшний разговор.
К чему мы завели этот разговор? А к тому, что на сегодняшний момент сложилась, на взгляд автора, кризисная ситуация с тестированием различных платформ. Если тестирование какой-либо одной платформы есть сравнительно простая задача, слишком мало переменных меняется — то тестирование совершенно разных платформ частенько дает слишком странные, а то и просто некорректные результаты, на которые нет смысла опираться. Впрочем, такая ситуация сложилась уже давно — просто некоторое время она была незаметна для всех нас, поскольку ранее платформы х86 отличались между собой в основном разве что мелкими деталями. Но чем дальше — тем больше отличаются между собой различные платформы х86. И в результате показания тестов становятся все более невразумительными. Нет, по-прежнему тестеры ответственно и квалифицированно меряют количество кадров, время просчета, скорость выполнения скриптов…. Просто все больше и больше ситуаций, когда результаты тестов вызывают сомнения.
По-видимому, отчасти это закономерный процесс — идет время, становятся важными другие характеристики. Так «отслужили свое» синтетические тесты наподобие славного CHECKIT или SYSINFO — некоторые низкоуровневые тесты наподобие Cachemem по-прежнему используются для замера тех или иных характеристик, но скорость в SYSINFO давно уже не является показателем скорости процессора, не так ли?
Затем наступила эпоха «реальных» тестов — замеров скорости работы реально существующих приложений. Наступила эпоха Winstone. Долгое время этот тест был «лицом» Ziff-Devis Benchmark…. Все системы стремились набрать как можно больше баллов — а незапятнанное имя теста служило порукой тому, что результаты тестирования будут адекватно соотноситься с реальной скоростью систем. Но, к сожалению, с течением времени и ростом скорости систем, тест перестал вести себя адекватно. Нет, он не врал — просто результаты его перестали быть воспроизводимыми. Все чаще возникали странные ситуации, когда небольшое изменение тестовой конфигурации приводило к резким изменениям показателей производительности. И тестеры потеряли к нему доверие. Ведь к тестам, как и к людям, потерять доверие легко, а восстановить — ой, как сложно…. Если вообще возможно….
В какой-то степени, конечно, «спасают» тесты, давно ставшие промышленным стандартом де-факто для сравнения разных архитектур — автор имеет в виду тесты SPEC CPU2000 — вернее, фактически это набор тестов (см. статью). А уж каждый может выбрать те, которые важны именно для него. Но их применение весьма трудоемко, а результаты для неподготовленного пользователя попросту непонятны. В качестве «массового» и популярного бенчмарка эти тесты непригодны.
Подобная ситуация привела к тому, что возникла необходимость в новом тесте. К тому же, крайне желательно, чтобы он отображал не мифические «попугаи», которые непонятно как применять. Было бы гораздо лучше, чтобы его показатели соотносились со скоростью работы системы в реальных приложениях. Ну что ж, задача ясна. И она была выполнена. Вернее, была создана целая процедура тестирования. Получила эта процедура название True Performance Initiative.
Производительность. Часть вторая: TPI
Методика TPI состоит в измерении производительности в трех разделах: Productivity, Visual Computing, Gaming. Собственно, проще продемонстрировать слайд:

Здесь хорошо видно, какие именно приложения AMD считает вполне типичными приложениями для измерения производительности. Собственно, именно выбор приложений для тестирования — самое узкое место в составлении любого подобного теста, поскольку результат теста часто косвенно (а иногда и прямо) зависит от этого выбора. Причина, почему выбран тест SYSmark 2001, проста — AMD не согласна с изменением методики тестирования в тесте BAPCO SYSmark 2002. На эту тему уже были публикации — всех интересующихся подробностями мы отсылаем к документу под названием «SYSmark 2002 Analysis Presentation FINAL.pdf», который есть на сайте AMD. В области Visual Computing автору непонятно, зачем использовать Content Creation Winstone 2001 и 2002 одновременно — они во многом друг друга дублируют…. С набором игр, и особенно с их настройкой — также можно поспорить. Хотя основная идея понятна — выбрать некоторое количество типичных пользовательских программ, и протестировать системы на них. Соответственно, объявить средний результат показателем производительности. Также в плюсы этой идее можно прибавить то, что каждый из тестов, входящих в TPI, на сегодня достаточно актуален. Однако не совсем понятно, что делать, например, с Doom III — ясно ведь, что как только эта игра выйдет — она, как и все игры этой серии до нее, станет одним из самых популярных бенчмарков. Менять набор TPI? Но тогда где гарантия, что не произойдет ситуация, похожая на историю с SYSmark 2002? В общем-то, пока мы задаем эти вопросы скорее наперед. Не будем спешить — просто сделаем зарубку на память. :-)
Как уже упоминалось выше, на текущий момент AMD планирует использование рейтинга. Однако было бы неплохо представлять себе, как он был выставлен — если ничего не изменилось, то, скорее всего, выставлялся рейтинг на основе TPI.
Приведем некоторые графики (неизвестной степени достоверности) относительной производительности систем на Athlon 64 и Pentium 4 533FSB + RDRAM PC800:
Обратите внимание, что наклон кривой для Athlon 64 и для систем на AthlonXP или Pentium 4 разный. Производительность ядра Hammer меняется с ростом частоты гораздо быстрее — благодаря чему и выигрывает данная архитектура. Как видно, для того, чтобы получить текущую производительность Pentium 4 3.06 GHz, достаточно (согласно графику) частоты 1733 MHz. Однако выше автор уже писал, что Athlon 64, наиболее вероятно, выйдет с начальной частотой 1800 MHz — по-видимому, AMD желает иметь некоторый «запас прочности», чтобы будущая шина 800 MHz для Pentium 4 вместе с технологией Hyper Treading не привела к смене лидера. Впрочем, точно мы это узнаем только после выхода процессора и тестов готовых систем на его основе. Естественно, что данный график отражает производительность для систем, измеренный при помощи TPI — выше мы уже описывали методологию.
В случае же, если система на Pentium 4 будет использовать DDR память, график перемещается чуть ниже. В таком случае необходима даже меньшая частота Athlon 64, чтобы перегнать Pentium 4. Правда, AMD слегка «лукавит», применяя систему на i845D и память PC2100 — с более быстрой памятью показатели Pentium 4 будут выше — по-видимому, на уровне Pentium 4 533FSB + RDRAM. Ну что ж, возьмем «на заметку».
Заметим, что разница между процессорами Athlon 64 256 KB L2 cache и Athlon 64 1 MB L2 cache совсем не так велика, как можно было бы ожидать. По-видимому, в данном тестировании нет приложений, которые бы почувствовали эту разницу — возможно, более «тяжелые» приложения для рабочих станций покажут другой результат.
Кстати, теперь, благодаря нашим коллегам из немецкого журнала «c't», мы можем указать результаты еще одного сравнения:
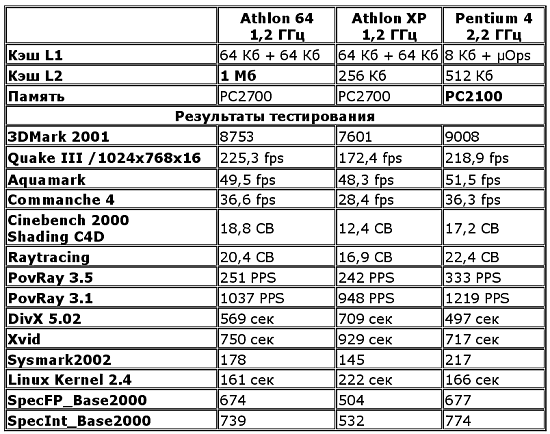
Надо сказать, что тестировался явно образец — и мы не знаем, будет ли он массово производиться. Также заметим, что тестировался образец частотой «всего» 1200 MHz — мы надеемся, что у AMD есть более высокочастотные модели. Впрочем, по слухам с Тайваня, уже есть образцы с частотой 1800 MHz. Кстати, AMD опять немного «слукавила» с памятью для Pentium 4.
Интересно было бы каким-то образом прикинуть эффект от внедрения на Pentium 4 шины 800 MHz и Hyper Treading — автор оценивает вклад в производительность как +15 — +20 единиц TPI. В этом случае процессор Athlon 64 с частотой 1800 MHz будет соперничать не с Pentium 4 3.06GHz, а с более скромным 2.53 GHz. В общем-то, и это очень неплохо.
А что у нас на фронте рабочих станций? Есть немного цифр и для них. Правда, для начала определимся со списком приложений, в которых это все будет тестироваться — понятно, что тестировать рабочие станции на приложениях и игрушках для десктопов бессмысленно. AMD считает, что достаточно репрезентативным будет такой набор тестов (данные, вероятно, неточны):
- SPEC CPU2000 (SPECint 2000, SPECfp 2000)
- SPECviewperf 7.0
- 3D Max 4.2(R3), Solidworks 2001,
- Pro/ENGINEER 2000i rev.2
- Pro/ENGINEER 2001
- Indy3D
- SOLIDbench 2002
- SoftImage XSI
- Maya Rendertest
- ScienceMark
- SreamD
- Linpack
На первый взгляд, возразить непросто — автору неизвестна степень распространенности этих приложений для рабочих станций среди других подобных программ, и аутентичность именно такой подборки тестов, поэтому просто примем пока ее на веру. Правда, уже можно заметить отсутствие LightWave 7.0B, очень «симпатизирующей» процессорам от Intel. Вернее, симпатизирующей им в одной из тестовых сцен. И посмотрим на график SPECint 2000 base (все дальнейшие графики относятся к процессору Opteron с L2 кэшем 1 MB):
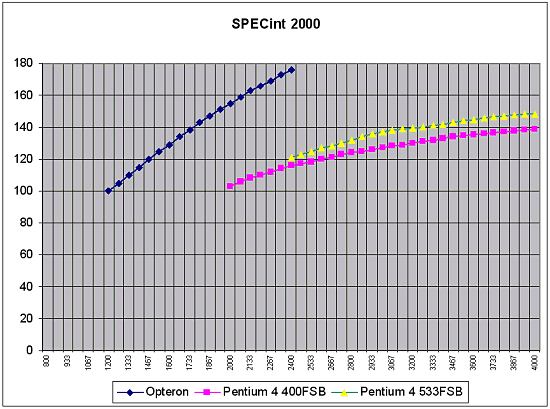
В этом графике нам не совсем понятно, какими «единицами» пользовался источник информации — посему приводим все данные в таком виде, в каком они были получены. Оставим на совести тестеров эти «единицы производительности». В принципе, можно попытаться отмасштабировать график по цифрам SPECint 2000 для Pentium 4 известных частот — тогда можно будет что-то понять. Можно попытаться также воспользоваться цифрами, приведенными несколько ранее — не забывая при этом, что ранее мы видели цифры для Athlon 64, а нынешний график — для Opteron. Насколько известно автору, разница в производительности между этими двумя разновидностями процессоров при прочих равных условиях составляет для SPECint 2000 приблизительно 2%. Фактически, эта разница обусловлена только тем фактом, что у Opteron шина памяти 128 бит. Самое интересное, что при подобной оценке сохраняется хорошее соответствие между результатами, полученными из различных источников. Отсюда же можно вычислить цену деления — 100 единиц данного графика приблизительно соответствуют 740 единицам SPECint_base 2000. Кстати, по некоторым предварительным данным неизвестной достоверности, прирост от 800 MHz FSB + Dual DDR400 составляет в SPECint 2000 порядка 10%. Если это правда, в этом тесте у Opteron вполне достаточный запас производительности для борьбы.
Интересно, что этот график относится к системе Opteron с памятью Registered 128 бит РС2100 Cas 2 — ибо применение памяти РС2700, но Cas 2.5 приводит к падению производительности. Видно, есть смысл дожидаться памяти PC2700 Cas 2 — тогда производительность системы на Opteron должна стать еще немного больше. Кроме того, видно, что, поскольку наклон кривых совершенно разный, на большое увеличение частоты Pentium 4 достаточно отвечать относительно небольшим ростом частоты Opteron. К примеру, на частоте 2 GHz Opteron обходит по производительности любую систему на Pentium 4 с шиной 533 и памятью РС800. Правда, как уже было сказано, большое влияние на этот график, по всей видимости, окажет применение шины 800 MHz, сдвоенного канала памяти DDR400 (это уже слухи, касающиеся Intel :-)), и технология Hyper Treading.
Надо сказать, рейтинг выходящих процессоров серии Opteron автору неизвестен. По слухам, он начнется с рейтинга порядка 3400+, затем продолжаясь выше — к примеру, вполне логичной выглядела бы система с рейтингом 3400+, 3700+, 4000+, и т.д. Правда, этот рейтинг, как уже было сказано, не совпадает с рейтингом производительности Athlon 64 — собственно, это понятно, ибо перечень задач совсем разный. Отрицательный же момент во всем этом в том, что введение еще одной системы измерений, по мнению автора, только запутает покупателей — посмотрим, что из этого выйдет. Какой реальной частоте соответствует этот рейтинг? Некоторые слухи дают основание полагать, что частота процессора Opteron с рейтингом 3400+ будет находиться в районе 1400 MHz—1600 MHz. Впрочем, к этой оценке необходимо подходить очень осторожно. Абсолютно точно об этом мы узнаем на стыке первого и второго кварталов, когда эта архитектура будет объявлена официально.
График для SPECfp 2000 base не менее интересен:
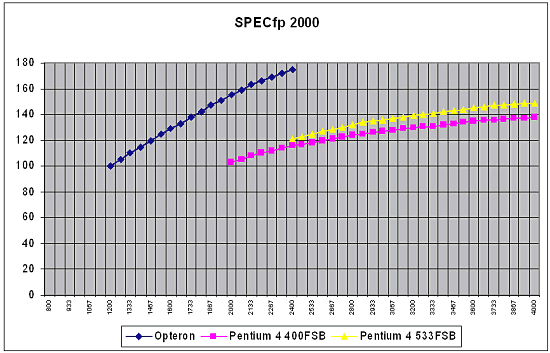
По приведенному графику видно, что и здесь 2 GHz Opteron достаточно для доминирования по производительности. Причем без особых усилий… Что ж, подождем — увидим. Тут же надо упомянуть, что, по некоторым «разведданным», прирост производительности у ядра Hammer от применения двухканальной памяти составляет для SPECfp 2000 величину порядка 8%-10%.
Естественно, некоторую (значительную?!) часть производительности в тесте SPECfp архитектуре Pentium 4 добавит новое ядро Prescott с L2 кэшем 1 MB и частотой шины 800 MHz — и на этом рынке, похоже, должна разгореться нешуточная «драка». Нам неизвестно, сколько производительности прибавит шина 800 MHz, но у Opteron много шансов достаточно долго оставаться лидером. Впрочем, некоторые слухи до автора дошли. По ним, прирост производительности при использовании шины FSB 800 MHz и сдвоенного контроллера памяти Dual DDR400 у систем на базе Pentium 4 составляет порядка 36% (!). Если это так, то AMD придется нелегко в этом тесте. Очень нелегко.
Достаточно интересно, что в области рабочих станций соотношение частот Opteron и сравнимого по производительности Pentium 4 даже меньше, чем для рынка десктопов, это заметно по вышеуказанным рейтингам и частотам — другими словами, для профессиональных приложений производительность памяти важнее роста по частоте. Ну что ж, ждем реальных систем — и ждем их соперника, Prescott. В данной ситуации Intel пригодятся те изменения (800 MHz FSB + Dual DDR400), которые она планирует сделать.
Посмотрим на производительность многопроцессорной Opteron-системы, и сравним ее с рабочей станцией на i850 + P4 400MHz bus. Данные, насколько нам известно, касаются систем на процессорах Opteron 1400 MHz revision A2 и Pentium 4 2800 MHz + RDRAM PC800:
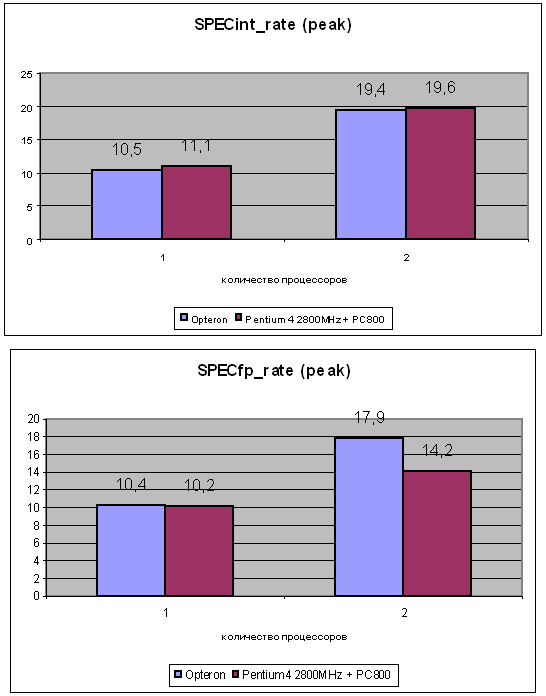
На наш скромный взгляд, вполне респектабельно — фактически, Opteron сумел догнать процессор с вдвое большей частотой. А кое в чем и обогнать….
Также небезынтересно посмотреть на предполагаемую производительность Opteron в SPEC CPU 2000 в сравнении с другими архитектурами:
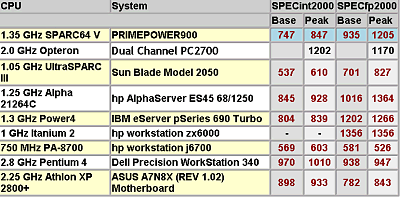
Естественно, цифры для 2 GHz Opteron — приближенные, они экстраполированы из производительности менее скоростной модели. Как видно, уровень производительности Opteron системы весьма хорош — в SPEC_fp 2000 выше только Power4 да Itanium 2, которые, вообще говоря, являются процессорами совсем другого уровня. Собственно, AMD и не предназначала Opteron в соперники Itanium 2 — просто поневоле хочется сравнить производительность двух 64 битных решений. В целочисленных же вычислениях практически никто не сможет его превзойти, включая Itanium 2 — по крайней мере, до появления комплекта Pentium 4 3400 MHz + 800 MHz FSB + Dual DDR400 + 1 MB L2 cache. В этом случае автор не берется угадывать результат. :-)
В подтверждение этого позвольте мне привести еще несколько интересных картинок. Как известно, в криптографии используется огромное количество целочисленных вычислений. Соответственно, данные в криптографии достаточно большой разрядности — например, 512 бит длины ключа совсем не редкость. Соответственно, достаточно большую роль для скорости работы криптографических программ будет иметь целочисленная производительность. Вначале посмотрим, насколько меньше вычислений можно делать, заменив стандартную х86 программу на х86-64 вариант:
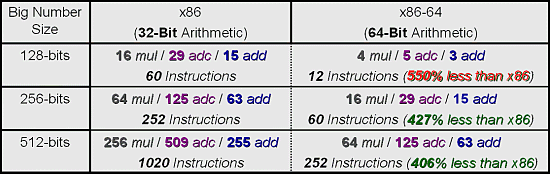
Естественно, такая разница в количестве исполняемых команд не проходит даром — правда, AMD здесь немного «увлеклась» маркетингом. Цифры посчитаны красиво — но не очень верно. В процентном соотношении количество команд уменьшилось на величину меньше 100%, естественно :-) — но пусть это останется на совести маркетингового отдела AMD. Производительность подобных систем также отличается:

И здесь наблюдается легкое «лукавство», ведь времена исполнения отличаются для 32 битных и 64 битных операндов, но в любом случае — для криптографии важность х86-64 трудно переоценить….
Ну что же — некоторые показатели производительности мы увидели. Естественно, это не отменяет «большого тестирования» систем на Athlon 64 и Opteron, как только те станут доступны. Автор же на этой оптимистической ноте хотел бы плавно перейти к окончанию повествования — и без того оно «слегка» затянулось.
Вместо заключения…
Автор долго размышлял, и, после некоторого раздумья, решил не делать выводов в стиле «лабораторной работы». Хотя бы потому, что, кроме всего прочего, случилось так, что полученные в процессе работы данные вызвали ожесточенные споры между автором и рецензентами. Это, с одной стороны, сделало работу над статьей более интересной — с другой стороны, сделало невозможным выводы в традиционном стиле. Просто потому, что выводы одного из рецензентов оптимистичны, другого — пессимистичны, а третий вообще отказывается, по его словам, «спекулировать» на эту тему. :-)
Вместо этого автор перечислит некоторое количество фактов, слухов, и соображений, чтобы закрепить пройденный материал.
Прежде всего, мы надеемся, что AMD сумеет вовремя начать поставки и будет успешна в выводе новой архитектуры на рынок — это ей сейчас крайне необходимо. Ну а нам было бы крайне интересно следить за той войной, которая разразится на рынке производительных систем с выходом архитектуры Opteron — не только интересно, но и крайне выгодно.
Кроме этого, автором владеет тайная надежда, что, благодаря небольшой стоимости разводки плат под двухпроцессорный вариант, появятся по настоящему недорогие и производительные двухпроцессорные системы, которые получат достаточное распространение. Это всего лишь надежда — посмотрим, как отреагирует рынок на эту архитектуру.
Надо так же отметить, что теперь у AMD есть для борьбы замечательный маркетинговый ход — теперь на каждом углу можно (и нужно!) трубить о том, что «у нас есть 64 битная архитектура, а у конкурента — нет». Вернее сказать, 64 битная архитектура у конкурента как раз есть, но на том рынке, куда она позиционируется, к подобным маркетинговым «ходам» прибегать не принято. :-) Тогда как на массовом рынке возможность рекламировать 64 битный процессор, доступный для всех — весьма заманчива.
Еще один интересный момент связан с тем, что для AMD, вообще говоря, гораздо интереснее в денежном плане начать с продаж систем на Opteron — ибо поначалу количество процессоров неизбежно будет ограниченным. В таких условиях выгоднее продать их подороже — а уже позднее, когда наладится производство, начать продажи Athlon 64. Автор, кстати, почти уверен, что так и случится — судя по всему, во втором квартале 2003 года производство начнется, но количество систем будет невелико.
Еще один интересный нюанс связан со слухами из Тайваня, согласно которым, AMD уже имеет на руках процессоры с частотой 2.4 GHz — напоминаем, что стартует эта архитектура, по всей видимости, с частоты 1.8 GHz (для Athlon 64). Таким образом, некоторый задел на будущее обеспечен.
Так же поговаривают, будто бы в «недрах» AMD «куют» новую ревизию, поддерживающую, кроме DDR SDRAM, еще и DDR II. Ну что же, хорошо бы — автор только «за».:-) Тем более, что данная архитектура действительно только выигрывает от ускорения памяти.
Достаточно интересным для нас был слух о процессорах Opteron с 4-мя шинами Hyper Transport — хотя эта идея и витала на поверхности. Правда, не исключено, что в свободную продажу эти процессоры так никогда и не попадут — а ведь с ними так мило можно было сделать 4-х, 8-ми, и «так далее» процессорные машины.
Свыше 400 систем на базе Athlon 64 находится в различных компаниях. Свыше 130 2-х и 4-х процессорных систем на базе Opteron испытываются представителями более чем 120 компаний. По крайней мере, это свидетельство того, что архитектура интересна — и того, что AMD не испытывает нужды с поставками образцов нового процессора.
Надо также сказать, что для успешного продвижения этой архитектуры на рынок AMD необходимо постараться постоянно держать некую дистанцию по производительности между своими системами, и системами конкурента — иначе нет особого стимула переходить на новую архитектуру.
Напомним также, что, по сложившемуся глубокому убеждению автора, не следует ожидать чудес от архитектуры Hammer на рынке десктопов — основной выигрыш, видимо, придется на рынок многопроцессорных систем. Для десктопов все преимущества в основном сведутся к поддержке x86-64, SSE2, и появлении более быстрых моделей. Впрочем, подобных «поводов» для покупки вполне может оказаться достаточно — особенно первого.
Ну и, кроме всего прочего — давненько ведь уже не было повода схлестнуться как следует, кто же сильнее, «слон» или «кит» :-) Так что ждем-с….
Автор должен сказать огромное спасибо людям, которые помогали создавать эту статью и рецензировали ее. В частности, эта статья была бы невозможной без:
- Андрея Лыкова, он же ISA_user
- Владимира Романченко, он же Lone
- Ильи Вайцмана, он же Stranger_NN
- Олега Бессонова, он же bess
- Максима Леня, он же C.A.R.C.A.S.S.
Ссылки по теме
Особо дотошные :-) читатели могут проверить выводы автора, самостоятельно собрав информацию по списку из нижеследующих адресов:
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- www.watch.impress.co.jp
- ascii24.com
- news.com.com
- ascii24.com
- akiba.ascii24.com
- ascii24.com
- www.hwextreme.com
- www.amdmb.com
- www.brave.cz
- www.theinquirer.net
- www.3dcenter.org
- zdnet.com.com
- www.amdboard.com — кстати, подборка заслуживает внимания!
- www.vanshardware.com
- www.aceshardware.com
- www.hardocp.com
- babelfish.altavista.com/
- www.aceshardware.com
- www.infosatellite.com
- active-hardware.com
- www.infosatellite.com
- www.hotchips.org
- www.analogzone.com
- www.hotchips.org
- www.hotchips.org
- www.theinquirer.net
- www.beareyes.com.cn
- www.computerbase.de
- ep.mailru.com
- ep.mailru.com
- www.heise.de



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}