Данной статьей автор хотел бы открыть цикл статей о высокопроизводительных вычислениях — теме, малознакомой массовому читателю, но приобретающей с каждым годом все большую актуальность.
Прежде всего, хочется сказать несколько слов о различных моделях вычислений. Все существующие на рынке системы можно условно поделить на системы с общей памятью (SMP) и системы с распределенной памятью (кластеры). Опять таки условно сферы их применения можно представить следующим образом:
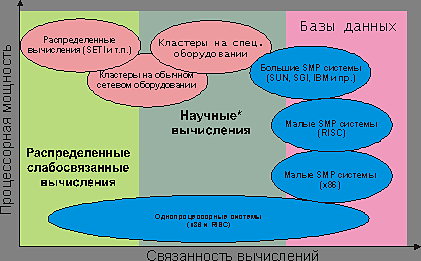
Рис.1 Области применения вычислительных систем (шкала условная, логарифмическая)
* — под «научными», понимается класс задач который требует степени связанности вычислений меньшей, нежели базы данных, но большей, чем распределенные слабосвязанные вычисления.
Затем надо развеять миф о непомерной цене RISC систем. На самом деле равная производительность стоит примерно одинаковых денег. Это принципиальный момент в понимании проблем высокопроизводительных вычислений. Типичным возражением обычно служит ссылка на дешевые (условно) PC-кластеры, однако их применение ограничено требованием минимизации межузлового трафика и весьма серьезными требования по локальности ввода/вывода. Таким образом, их применение для обработки больших БД (особенно с интенсивными изменениями, а не просто чтение) представляется мне проблематичной. Кроме того, даже лучшие из PC серверов представляют весьма скромные возможности по вводу/выводу данных. Следует отметить и тот факт, что масштабируемость (по производительности и вводу/выводу) у современных RISC машин многократно превосходят доступные сейчас для х86 систем. Впрочем, в последнее время появились новые продукты, которые значительно улучшают эти показатели для привычных х86 систем (в первую очередь я имею в виду процессоры семейства Hammer компании AMD).
Если представить графически позиционирование x86 и RISС систем то выглядеть это будет примерно так:
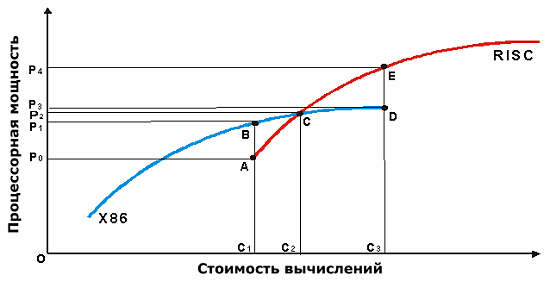
Рис.2 Соотношение цены и производительности x86 vs. RISC (шкала условная, логарифмическая)
Самым интересным для рассмотрения является отрезок «CD», на этом участке значительные вложения в х86 технику («С2С3») дают уже мизерную отдачу («Р2Р3»), а вложения в RISC системы, напротив, весьма эффективны («Р2Р4»). Напротив, если требования к производительности не достигают уровня «Р2», то вполне очевидно, что переплачивать за RISC системы не стоит. Но, если в процессе развития требования к производительности превысят уровень «Р2», то перед владельцем системы будет два пути — первый: до конца, не считаясь с эффективностью вложений поддерживать унаследованную х86 систему (до точки «D», суммарные расходы «ОС3») или второй: идти на замену системы на высокопроизводительное RISC решение. Затраты при этом (суммарные) составят «ОС2»+«ОС3». Что очень много. Напомню, шкала логарифмическая… Впрочем, если требования к производительности превысят уровень «Р3», то выбора у владельцев системы уже не будет (предполагается, естественно, что адекватность системы требованиям критически важна для бизнеса). Систему придется менять.
Поэтому те, кто планирует создание вычислительной системы масштаба предприятия должны весьма тщательно проанализировать как текущие, так и могущие возникнуть в планируемом будущем положение своих требований относительно точки «С». Если же переход через уровень «Р2» неизбежен — то может быть разумно будет строить систему сразу на RISC устройствах, даже если поначалу придется немного переплатить? Зато вы сразу окажетесь на перспективной тропинке, вам не придется мучаться над проблемой повторных вложений в вычислительную технику.
В рамках предполагаемого цикла статей хотелось бы рассмотреть как теоретические, так и практические аспекты построения высокопроизводительных систем, рассказать читателям о «параллельных мирах» — SUN, HP, SGI, IBM, mainframe и кластерных решениях.
Итак, перейдем к номеру первому в списке:
SUN Microsystems
Для понимания причин, по которым компания SUN сделала ставку на коммутируемые системы необходимо сделать краткий экскурс в историю внутрикомпьютерных коммуникаций.
На протяжении многих лет единственным массово применяемым способом соединения устройств в рамках вычислительных машин оставались те или иные шинные решения. Коммутируемые системы были известны, и их производительность была весьма велика (вспомните детища Сеймура Крэя) — но и цена их (а так же требования к условиям эксплуатации, типа цистерны с хладагентом, куда погружался компьютер) довольно долго оставались запредельными.
На раннем этапе (по разным технологическим причинам) шины были мультиплексированы, т.е., адрес и данные передавались по одним и тем же «проводам» с разделением по времени. Следующим шагом стало введение режима блочных передач — т.е., адрес выставлялся однократно, а потом по шине шел непрерывный блок данных. Соответственно, чем длиннее блок данных, тем меньшее время занимает передача адреса и тем выше эффективность использования шины. Эффективность такого решения можно оценивать по-разному — но ориентировочно выигрыш составляет примерно 50% относительно мультиплексированного для каждого адреса режима. Ярким примером такой работы можно назвать блочный режим работы, например, шины PCI. Дальнейшим шагом развития стало отделение шины данных от шины адреса. Но, естественно, при наличии на общей шине нескольких устройств эффективность ее использования заметно снижается из-за того, что появляется необходимость проведения арбитража устройств, претендующих на эту шину, определения приоритетов.
Но и такое решение не позволяло в достаточной мере реализовать потенциал процессоров и следующим шагом стал переход к конвейерным шинам с пакетами фиксированной длины.
Суть работы такой магистрали состоит в фиксации размера передаваемого блока данных (его выбирают равным размеру строки кэша микропроцессора) и четкой синхронизации циклов передачи адреса и данных (линии адреса и данных, естественно, разделены). Таким образом, процесс обмена данными разбивается на фазы, длительность и временные соотношения которых строго определены (после выставления адреса точно известно, в какой момент будет передан блок данных, и когда появится подтверждение правильности приема). Протокол обмена конвейерных магистралей позволяет осуществлять процедуры адресации и арбитража шины параллельно передаче данных предыдущего цикла. Это дает возможность поднять эффективность использования линий данных практически до 100%.
Такой режим, в свою очередь, позволил сделать следующий шаг — перейти от разделяемой шины к индивидуальным процессорным шинам с центральным коммутатором «развязывающим» узкие места в системе. Собственно, узким местом становится сам коммутатор — но высокопроизводительные коммутирующие матрицы известны уже давно и их конструкция не представляет из себя ничего уникального. А то, что передача адреса и арбитраж для пакета данных производятся параллельно с прохождением предыдущего пакета данных — позволяет производить передачу пакетов данных «на лету» без привнесения дополнительной задержки (на самом деле задержка присутствует, но она невелика).
Ключевой особенностью, отличающей решения компании SUN от решений конкурентов можно кратко обрисовать словом «коммутация». Ключевым элементом, на котором построены компьютеры SUN, является коммутатор UPA. Рассмотрим подробнее коммутатор UPA (ultra port architecture) (рис.1):
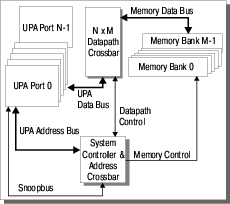
«UPA — это высокопроизводительная многопортовая масштабируемая архитектура, построенная на принципе одновременной пакетной коммутации нескольких портов и предназначенная для реализации широкого спектра вычислительных систем (от однопроцессорных рабочих станций до многопроцессорных серверов)»
архитектура опирается на многошинную организацию. Имеется три основных типа шин:
- шины адреса UPA-порта;
- шины данных UPA-порта;
- шины памяти
Принципиальной особенностью, которая отличает архитектуру UPA от ее конкурентов от HP, IBM и, например, SGI — это независимая коммутация адресов и данных. Такая особенность позволяет строить системы с произвольной шириной шин адресов и данных для каждого канала. Ниже подробно будут рассмотрены варианты построения систем на коммутаторе UPA.
При этом теоретически число портов UPA в системе не ограничено.
В системе, построенной в соответствии с концепцией Ultra Port применяются, в основном, соединения «точка-точка». Но, поскольку, число портов UPA в системе не ограничено только теоретически (на самом деле, очевидно, что создать чип, например, с 144*64=9216(!) «ногами» только для шин данных, мягко говоря, очень сложно (если не сказать — невозможно), поэтому в более чем 4 процессорных системах SUN применяется многоуровневая коммутация (коммутация четырехпроцессорных модулей через порт UPA). Такая архитектура позволяет строить максимально однородные системы в диапазоне 1-512 процессоров и обеспечивать высокие показатели в части отказоустойчивости и удобства эксплуатации систем.
Рабочие станции и «младшие» сервера строятся примерно одинаково — единственным различием можно признать (естественно, кроме видеосистем и устройств в/в) размер кэша процессора. У серверов он заметно (до 4 раз) больше, что связано с некоторыми особенностями функционирования серверов (множественные запросы + особенности алгоритмов обработки БД).
Рассмотрим подробнее архитектуру одной из младших моделей серверов SUN Enterprise:
SUN Ultra Enterprise 1 (150, 170, 170Е и 2)
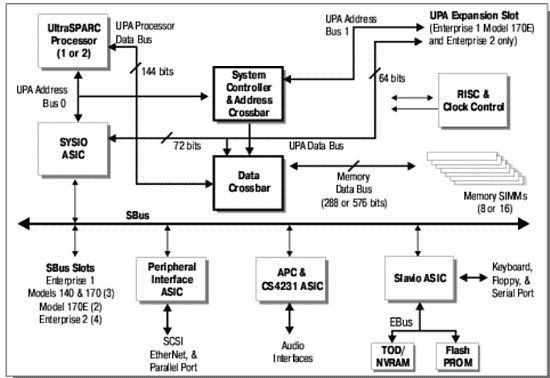
В качестве примера младших серверов SUN можно предложить читателю рассмотреть внимательно архитектуру сервера SUN Ultra Enterprise 170E или Ultra Enterprise 2 (машинки довольно старомодные, но интересующие нас особенности на их примере можно рассмотреть подробно). Главное, на что хотелось бы обратить внимание читателя — это ширина шин данных портов UPA, которыми процессоры присоединяются к системе (128 разрядов + ECC) и ширина шины памяти (256 или 512 бит + ECC). Такая организация в совокупности с индивидуальными каналами адресации и весьма продвинутой системой управления памяти с малыми задержками и большой шириной ШД (шины данных) позволяет организовать бесперебойное снабжение процессоров данными и обеспечение достаточной полосы пропускания для работы устройств ввода/вывода.
Пропускная способность шины данных порта UPA — 83,3MHz*16byte=1.333Gb/s, а памяти (общей для обоих процессоров и шины ввода/вывода, обратите внимание(!) 83,3MHz*16byte=2.6Gb/s или 5,2Gb/s. Т.о., как сказано выше пропускная способность памяти этих систем достаточна (и, даже, несколько избыточна) для нормальной работы двух процессоров и систем ввода/вывода с максимально возможной скоростью.
Поэтому, несмотря на скромные характеристики используемых в этих серверах процессоров, интегральные показатели производительности серверов при обработке разнообразных БД, например, в многопользовательском режиме весьма высоки. Так, например, двухпроцессорный сервер SUN 250 имеет производительность при работе с большими БД превосходящую таковую для четырехпроцессорного сервера Intel на процессорах P3 XEON 500. И это без учета его способности нормально адресовать память намного большую 4Gb.
Теперь давайте приглядимся поподробнее к несколько более мощной системе SUN.
SUN Ultra Enterprise 450
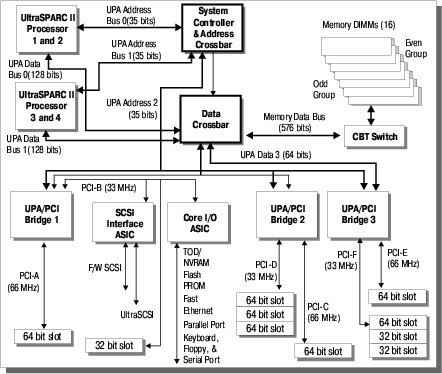
Принципиальным отличием этой модели от предыдущей являются:
1. Два процессора на каждом канале UPA, что, конечно, является отступлением от модели чистой коммутации, но, с другой стороны — всего два процессора с большими кэшами, да и шина все же 128bit… В общем, наверное это оправдано с экономической точки зрения. :-)
2. Самым интересным в этой структуре являются шины ввода-вывода. Обратите внимание, 6(!) шин PCI (правда, всего 5 независимых — PCI-B подключена через PCI-A), причем пропускной способности задействованных портов UPA более чем достаточно для обеспечения одновременной работы всех шин ввода/вывода на максимальной скорости. Что, как несложно подсчитать, много больше, чем может обеспечить даже самая «навороченная» Intel-based система.
Произведем несложный расчет — какова же пропускная способность системы ввода/вывода:
| Шина | Разрядность шины (bit/byte) | Частота (MHz) | Пиковая скорость (Mb/s) |
|---|---|---|---|
| PCI-A | 64/8 | 66 | 528 |
| PCI-C | 64/8 | 66 | 528 |
| PCI-D | 64/8 | 33 | 264 |
| PCI-E | 64/8 | 66 | 528 |
| PCI-F | 64/8 | 33 | 264 |
| Итого, ввод/вывод: | 2112 | ||
Итого — 2,1GB/s. Давайте сравним с тем, что может предоставить ServerSet HE — всего 1,056 GB/s, вдвое меньше… Да и то, если вспомнить, что шина памяти не может «прожевать» более 0,8 GB/s, то ситуация еще и усугубляется. Т.е., реально более 0,8 Gb/s все равно пропустить невозможно.
Внимательный читатель спросит (обязан!): «Как же так, а шина адреса всего 35 bit! Это что же значит? 64-разрядный процессор не работает «на всю катушку»?» И читатель в общем-то прав, процессоры могут адресовать 2^64, но реально используется всего 2^35… Мало? Да как сказать… 2^32 это, как все помнят 4Gb, 2^3=8, т.е., этот сервер в состоянии адресовать «всего» 32Gb памяти. А больше такому серверу и «не светит». Это далеко не самый мощный сервер из ассортимента компании SUN.
А вот теперь начинается самое «вкусное» — большие системы производства SUN Microsystems.
Сервера SUN серий Х000 и X500
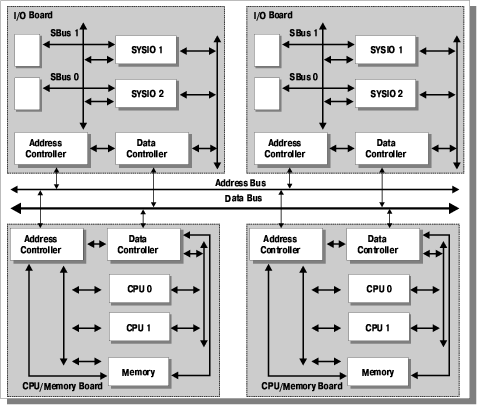
Все сервера этих серий фактически, представляют из себя (независимо от модели и назначения) сочетание различного количества т.н. «процессорных» плат, содержащих процессоры и память и плат ввода/вывода. Количество и соотношение этих плат и определяет мощность и назначение сервера. Процессорные модули практически повторяют архитектуру сервера SUN Enterprise 2, за единственным исключением — у них практически отсутствует интерфейсная часть. Вместо этого процессорные платы через порт UPA соединяются с объединительной шиной Gigaplane (не путать с коммутатором Gigaplane XB!). С этой же шиной соединяются и специализированные модули ввода/вывода. Существует 3 вида этих модулей — с шиной SBus, SBus+UPA порт, и, наконец, PCI. Причем, последний тип модулей устанавливается только в серверы серии Х500.
Модули ввода/вывода семейства Enterprise X000/X500
| Модуль ввода/вывода с шиной PCI | Модуль ввода/вывода с шиной SBus, сетевым и SCSI интерфейсом |
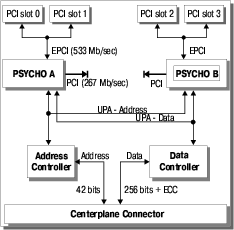 | 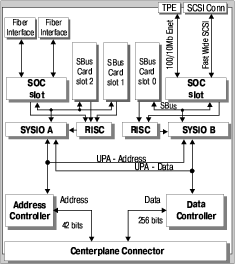 |
Шина Gigaplane представляет собой пакетно-конвейерную шину, шириной 256 разрядов и частотой 83,3MHz (Для серверов X500, 100MHz, за исключением сервера 6500 в максимальной конфигурации, для которой частота Gigaplane уменьшается до 83,3MHz) с раздельными шинам адреса и данных. Передача производится пакетами фиксированной длины 64 байта (2 такта шины). Адресное пространство шины — 42 разряда, что позволяет адресовать до 4,3TB памяти. Эффективность использования составляет до 95% от пиковой (3,2GB/s) и составляет, соответственно 3,04GB/s. Расходуется эта пропускная способность, к сожалению, не только для обеспечения потребностей ввода/вывода, но и для обращения процессоров к памяти «соседних» процессорных модулей. Однако, учитывая возможность установки в каждый модуль до 2GB оперативной памяти и некоторый избыток ее производительности (для своих процессоров) такая организация демонстрирует приемлемые показатели масштабирования. Однако, при числе процессоров до 4 я бы предпочел использовать модель 450, т.к., ее организация представляется мне предпочтительной, с т.з. организации работы процессоров с оперативной памятью.
…кстати, не в этом ли «собака зарыта»? Не поэтому ли, например, сидят на одной шине 2 процессора в модели 450? В смысле, чтобы двухпроцессорная система модели 450 уступала модели 280, например? А четырехпроцессорная Х000 так же уступала 450… Т.е., чтобы избежать внутрисемейной конкуренции… А?
В этом семействе серверов впервые появилась возможность «горячей» замены процессорных плат и плат ввода/вывода, что позволяет организовать (совокупно с отказоустойчивыми системами хранения) непрерывную эксплуатацию серверов семейства X000, что немаловажно ввиду постоянно возрастающего значения бесперебойной работы информационных систем в деятельности коммерческих структур. Стоимость простоя сервера определена (для компании с оборотом в несколько десятков миллионов долларов в год) в десятки тысяч долларов в час непосредственно упущенной прибыли, и в гораздо большие потери от авральной работы в период восстановления функционирования фирмы (при уже восстановленной работе информационной системы).
Другая новинка, логически вытекающая из первой и непосредственно с ней переплетенная — SyMON (системный монитор). Чем сложнее система, тем острее потребность в средствах слежения и управления ею. К таким средствам относится системный монитор SyMON. Он предназначен для мониторинга событий, происходящих в системе, оценки производительности, предсказания вероятных сбоев аппаратуры, а также для планирования загрузки системы. Монитор может помочь администратору системы в оценке степени ее загруженности и обнаружении «узких» мест, где теряется производительность, что позволяет правильно подобрать конфигурацию. В общем, представление о ней можно получить, посмотрев на системный монитор WinNT — но SyMON отличается от него, как «Мерседес» от «Жигуля». Хотя — что-то общее есть. :-)
Теперь перейдем к рассмотрению архитектуры самых мощных серверов компании SUN Microsystems на процессорах Ultra SPARC II — Ultra Enterprise 10000.
Архитектура узлов, из которых построены самые большие из предлагаемых компанией SUN серверов (Ultra Enterprise 10000) практически полностью воспроизводит архитектуру Ultra Enterprise 450 с той только разницей, что коммутаторы адреса и данных имеют по одному дополнительному порту, через который производится подключение платы к коммутатору второго уровня, а число коммутаторов адреса увеличено до четырех. Соответственно, и производительность этой платы мало отличается от производительности Ultra Enterprise 450. То есть каждая системная плата «десятитысячника» и по вычислительной мощности, и по интерфейсам представляет собой полноценный высокопроизводительный сервер.
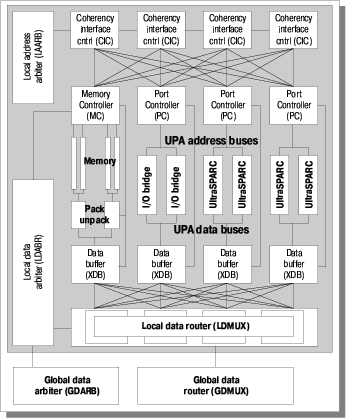
Следует обратить внимание, что в отличие от серверов серии Х000 вычислительные устройства (процессоры и память) объединены в рамках универсальных системных плат. С одной стороны — это позволяет обойтись использованием в системе всего одного типа плат, а с другой — в значительной степени снимает с системной магистрали нагрузку по передаче трафика ввода/вывода.
Большинство устройств системной платы знакомо из предыдущих рисунков, осталось пояснить назначение впервые введенных в этой системе узлов.
Буферы данных (XDB) обеспечивают бесконфликтное разрешение ситуаций, когда происходит одновременный доступ к одному и тому же порту со стороны нескольких устройств. В этом случае допускается проведение передачи только одного пакета, а остальные данные сохраняются в буферах передающих портов до завершения обмена. Благодаря фиксированной длине пакета (64 байта) максимальное время задержки до завершения передачи никогда не превышает постоянного значения (500 нс), а сама процедура разведения потоков данных легко прогнозируется.
Еще одной особенностью архитектуры платы, является наличие шины, связывающей коммутаторы адреса и данных. Это сделано для повышения живучести системы.
Для чего же введены дополнительные коммутаторы адреса? Подробнее это будет рассмотрено ниже.
Описанные выше системные платы (до 16) объединяются с помощью фирменной технологии Gigaplane-XB. Соответственно, число процессоров в системе может быть от 1 до 64 (16 плат по 4 процессора).
Коммутатор Gigaplane-XB предназначен для обеспечения соответствия пропускной способности каналов обмена данными в системе ее высокой производительности. Чтобы выполнить это требование, в основу данного коммутатора была положена архитектура UPA.
К числу особенностей реализации Gigaplane-XB относятся следующие:
- наличие раздельных шин адреса и данных, использующих соединения типа «точка-точка»;
- поддержка кодов контроля и коррекции (ECC-кодов) при передаче адреса и данных;
- обеспечение минимальной задержки передачи пакета данных, составляющей менее 500 нс.
В фирменной документации применительно к коммутатору адреса используется термин «шина», поскольку в нем, в отличие от коммутатора данных, адрес передается сразу всем устройствам, как в общих шинах, то есть реализуется принцип передачи «от одного всем». Такая организация адресных шин объясняется следующими причинами. Принцип передачи адреса по типу общей шины хорош тем, что он позволяет осуществлять мониторинг адресов для обеспечения когерентности кэш-памяти, однако общая шина имеет ограниченное быстродействие, которое снижается с увеличением длины шины и/или числа нагрузок на ней. Принцип коммутации информации обеспечивает высокое быстродействие, но не допускает мониторинга. В данном случае предпринята попытка объединить достоинства двух этих методов.
Внутренняя организация Gigaplane-XB интересна тем, что она содержит четыре адресных коммутатора. Число их соответствует числу модулей памяти на системных платах, и каждый модуль обычно выводится (коммутируется) на отдельную шину адреса. Таким образом может быть осуществлена одновременная адресация (но не передача данных!) ко всем модулям памяти платы. Большое число шин адреса необходимо для обеспечения высокой пропускной способности коммутатора данных. При меньшем их количестве коммутатор данных будет простаивать.
Gigaplane-XB реализован в виде двухплатной конструкции, где каждая плата содержит коммутатор данных половинной разрядности и две шины адреса. Такая организация позволяет сохранить работоспособность системы даже при выходе из строя одной из них (сервер необходимо перезапустить). Если же из строя выходят ВСЕ шины адреса (маловероятно, конечно), то предусмотрен вариант передачи адреса по шинам данных. Естественно, с катастрофическим падением производительности.
Наличие у каждой ячейки своего контроллера ввода/вывода, естественно, поднимает на весьма высокий уровень и общую пропускную способность сервера. Так, 16-процесорный сервер имеет 4 абсолютно независимых наборов шин PCI64*66 (2,1Gb/s всего), и например, при подключении к 2 ячейкам сетевых интерфейсов (2*1Gbit/s), а к двум остальным, например, RAID контроллеров (или контроллеров FC) можно получить весьма высокопроизводительное (4Gbit/s для соединений с сетью и 8Gbit/s (FC2) или 10,2Gbit/s (SCSI 320) для соединения с устройствами хранения). Впрочем, можно установить по одному контроллеру сетевого интерфейса и по одному контроллеру устройств хранения на каждый узел и получить тот же эффект. Даже пожалуй, так правильнее с т.з. распределения нагрузки на систему и отказоустойчивости.
Такой подход позволяет производить масштабирование системы без появления характерных для других архитектур узких мест, и добиться близкого к линейному уровня масштабирования (по числу процессоров) систем.
Теперь перейдем к рассмотрению современных систем компании SUN Microsystems построенных на процессорах последнего поколения — Ultra SPARC III. Для того, чтобы понять разницу давайте подробнее рассмотрим его отличия от Ultra SPARC II ( в общем-то весьма тривиального процессора, надо сказать…).
[ Оффтопик — «полуперсональные» системы SUN… ]
Микропроцессор Ultra SPARC III
Микропроцессор Ultra SPARC III является представителем последнего поколения микропроцессоров разработки компании SUN Microsystems и соответствует архитектуре SPARC v.9 (есть и другие производители, делающие процессоры, основанные на этой архитектуре). Давайте подробнее рассмотрим внутреннюю организацию этого процессора. Тем более, что для нас, привыкших, в основном, к архитектуре х86 совместимых процессоров в этом «камешке» есть немало интересного.
Итак:
64-разрядный микропроцессор Ultra SPARC III содержит:
| Функциональные устр-ва | 4 целочисленных, 2 плавающих |
| Конвейер | 14 стадий |
| L1 кэши | 4-канальный кэш данных — 64 КБ 4-канальный кэш команд — 32 КБ 4-канальный кэш предвыборки — 2 КБ 4-канальный кэш записи — 2 КБ |
| L2 кэши (внешние) | 1, 4 или 8 МБ, внешний, контролер интегрированный на кристалл, полноскоростной |
| Шины | Шина адреса (43bit * 150Mhz), шина L2 (256 bit * 200 Mhz), системная шина (128 bit * 150 Mhz) |
| SMP | До 4 на одной шине, в коммутируемой системе практически неограниченно (более 1000) |
Итак, пройдемся подробнее по этому процессору:
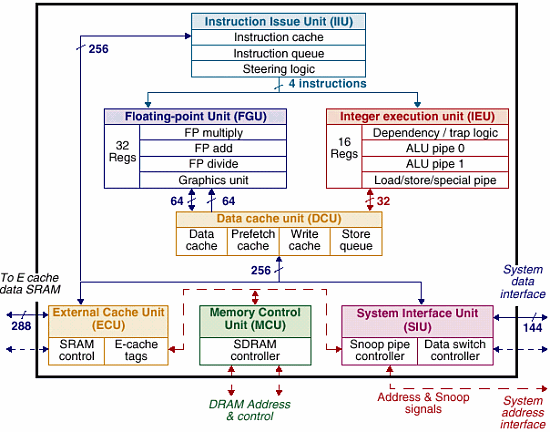
Внешняя шина, используемая для сношения процессора с внешним миром построена на вполне традиционных для SUN принципах — пакетно-конвейерная шина с раздельными линиями адреса и данных. Разрядность шины адрес 43 бита, что позволяет адресовать до 8ТБ памяти при работе в составе многопроцессорных систем,
Шина данных используемая в этом процессоре весьма тривиальна, правда, шириной 144 (128+ECC) разряда и частотой 150MHz, соответственно, пропускная способность ее составляет те же 2,4Gb/s.
Шина L2 шириной 288 разрядов (256+ECC) работает на частоте 200Mhz, что в пересчете на производительность составляет 6,4 Gb/s. На первый взгляд может показаться, что это очень мало, но кэш организован таким образом, что его шина используется практически на 100%, да и размер его несколько отличается от привычного — его размер составляет 4-8Mb. Подробнее его организацию мы рассмотрим ниже.
Конвейер процессора Ultra SPARC III
Конвейер этого процессора имеет длину 14 стадий, что является рекордной длиной для промышленных RISC процессоров (я помню про 20 + декодирование у P4, просто я веду речь о серверных процессорах, а на этом фронте Р4, так сказать, «не преуспел» :-)). Новейшие разработки на базе Р4 несмотря на все архитектурные «навороты» демонстрируют прирост производительности мягко говоря не очень адекватный приросту паспортных величин (частоты ядра, пропускной способности шин, введению громадного L4). Я склонен «списать» этот некоторый «пролет» именно на архитектурные особенности ядра процессора.
Ниже будут подробно рассмотрены способы, которыми компания SUN воспользовалась, чтобы избежать потерь производительности, связанных с проблемами прохождения ветвлений таким длинным конвейером.
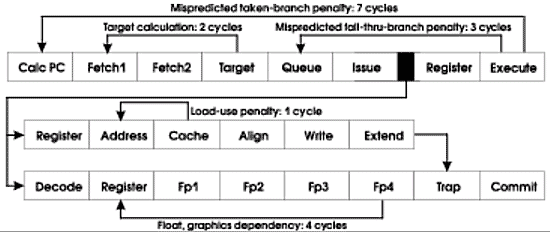
Исполнительная часть конвейера состоит из двух частей: целочисленной и плавающей. Обе части имеют одинаковую длину, что упрощает согласование их работы (позволяет выдавать результаты вычислений в порядке их запуска на исполнение).
Что интересно, исполнение целочисленных команд занимает реально 1 такт, а не 4, задержка введена для выравнивания времени исполнения, что нужно для сохранения последовательности следования результатов.
Особенностью работы процессора Ultra SPARC III является то, что в нем нет внеочередного исполнения! Команды запускаются в том порядке, в котором они перечислены в программе. Впрочем, при таком длинном конвейере внеочередное исполнение может породить столько проблем, что, пожалуй, так даже лучше. Да и архитектура процессора становится несколько проще. А учитывая то, что на кристалле расположены контроллеры памяти и весьма продвинутой внешней шины некоторая экономия транзисторов тоже смотрится разумно.
Однако, архитектура процессора позволяет запустить на исполнение до 6 команд одновременно, (4 целочисленных (2 arithmetic, logical, or shift, 1 load or store и 1 на BR pipeline) и две команды FP что много больше, чем в х86 процессорах и практически соответствует показателям «чемпиона» в этом деле — процессора HP PA-RISC 8x00. Естественно, что реальное количество одновременно исполняемых команд несколько меньше и составляет в среднем (на типичных приложениях) 4. Х86 имеют этот параметр несколько меньший, несмотря на большие предельные значения.
После выборки команды попадают в буфер (очередь) команд на 20 элементов (Instruction Queue), откуда группами направляются в соответствующие исполнительные устройства. Максимальное число команд в группе — 6. Все команды в группе получают идентификационный код, в соответствии с которым на выходе из конвейера будут распределены их результаты. Такой режим работы (пакетами команд) вполне эффективно загружает исполнительные устройства и при отсутствии режима внеочередного исполнения команд.
Интересной особенностью данного процессора является то, что результаты исполнения команд становятся доступны другим командам не после прохождения всего конвейера, а на следующей после получения результата стадии. Такая возможность возникает благодаря использованию дополнительного специального рабочего регистрового файла, с которым и производятся все манипуляции и откуда результаты переписываются (по завершении прохождения командой конвейера) в системный регистровый файл.
Если рассмотреть внимательно структуру конвейера микропроцессора Ultra SPARC III, то несложно заметить, что потери, при неправильно предсказанном направлении перехода составят 7 тактов. Не так много, как у Р4, но все же заметно. Так что же предпринято для снижения этих потерь?
Решение SUN, как и во всех остальных случаях отличаются, с одной стороны, простотой, а с другой — оригинальностью. Так, вместо двухуровневой (применяемой в Alpha 21264 и PA-RISC) схемы предсказания ветвления применена одноуровневая таблица истории переходов — но, на 16K значений… Есть и стек адресов возврата, на 8 значений (впрочем, это не «эксклюзив») и, внимание(!), специальная очередь команд емкостью 4 команды следующих за ветвлением, но из альтернативной предсказанной последовательности команд. Все это позволяет с одной стороны свести к минимуму ошибки предсказания, а с другой — минимизировать их отрицательное влияние на производительность процессора.
Теперь давайте перейдем к рассмотрению механизмов работы кэша L2, как и было обещано выше.
Контроллер L2 имеет работающую на полной частоте процессора (интегрированную на кристалл) таблицу тэгов вторичного кэша. Размер таблицы составляет 90 КБ, и этого достаточно для поддержания кэш-памяти объемом до 8 МБ. Такой размер кэша (у каждого процессора) и используется в высокопроизводительных системах компании SUN Microsystems.
Основным достоинством такого решения является то, что работа с таблицей осуществляется на частоте процессора, то есть результат обращения к кэшу становится известен гораздо раньше, чем в случае внешнего расположения таблицы тэгов. Соответственно, при непопадании в кэш процедура инициализации обращения к основной памяти начинается на несколько тактов раньше. Аналогично обстоит дело и с поддержкой когерентности кэшей в многопроцессорных системах.
Запись в L2 — как максимально эффективно распорядиться шиной
Канал записи состоит из трех основных частей: очереди на 8 слов (Store Queue), кэш-памяти данных первого уровня (L1 Data Cache) и кэш-памяти записи (Write Cache). Сразу же отметим, что кэши имеют различные механизмы обновления: L1 кэш данных — сквозной записи, а кэш записи — отложенный. Далее будет понятно, зачем это нужно.
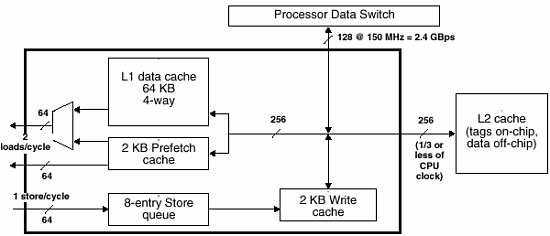
Сначала сохраняемая информация записывается в очередь. Это происходит во время выполнения команды сохранения.
Затем, после завершения команды, данные записываются в L1 кэш и, одновременно, в кэш записи.
При этом, если происходит непопадание в L1 кэш, то его содержимое не обновляется. В противном случае из-за сквозного режима обновления данной кэш-памяти происходило бы постоянное обращение к вторичному кэшу. Таким образом, кэш-память записи как бы дополняет и дублирует L1 кэш, но только в процессе записи. По утверждениям разработчиков, использование такой организации канала записи позволяет сократить трафик на шине вторичной кэш-памяти на 90% (чем-то мне это напоминает работу L2 у AMD…).
К сожалению, все эти ухищрения не могут перевесить того факта, что даже и предельная пропускная способность кэша второго уровня все же не превышает 6,4Gb/s — и несмотря на всё, скорость его по современным меркам мала. Хоть как-то приемлемым этот параметр (и то, только в сочетании с размером кэша) можно назвать только с т.з. алгоритмов обработки БД. Как показали измерения автора статьи (впрочем, весьма приблизительные), например 2*Р3 550 с внешним кэшем, емкостью 512kb и пиковой скоростью 2,2Gb/s при обработке БД под MS SQL несколько (в среднем) быстрее 2*Р3 550 с накристальным L2 емкостью 256Kb и пиковой скоростью 17,6Gb/s.
Для процессорно-интенсивных задач с хорошей организацией данных, (подобных задачам из набора SPEC) этот параметр (в совокупности с непривычно малым (для RISC систем) размером кэшей L1) совершенно неудовлетворителен. Так что, если нужен «числогрыз» — то US3 не лучший выбор.
Набор VIS — что это, и зачем
В рассказе о процессорах Ultra SPARС нельзя обойти стороной и мультимедиа-набор инструкций, впервые введенный в процессорах семейства Ultra SPARC — сравнительно простой набор инструкций для ускорения работы с видеопотоками.
Наиболее близким аналогом из мира х86 можно назвать, пожалуй, MMX, хотя VIS работает и с FP, что роднит его с SSE. Вот только VIS, как не странно — даже старше MMX, так что создатели первого мультимедийного набора инструкций наверняка о нем неплохо знали. Суть идеи проста — аппаратно выполнять часто встречающиеся при обработке видеопотоков процедуры.
Существует он в двух версиях, VIS v.1 для US1/2, и VIS v.2 для US3. Причем, оба «диалекта» существуют одновременно в 32- и 64- разрядных вариантах, что в полной мере соответствует концепции поддержки инвестиций пользователей*. Минимальными требованиями для создания такого приложения являются довольно старый компилятор С++ и Solaris 2.5.
* В отличие от, например, поведения HP… В одной знакомой организации стоит (простаивает) RISC сервер HP E45 — новые версии ПО требуют новейших версий ОС, а upgrade ОС — по цене сравним с покупкой х86 сервера (с ОС, естественно) аналогичной производительности. Как вы думаете, что они сделали? Купили х86 сервер и поставили freeBSD. :-)
C введением этого набора производительность компьютеров SUN на задачах обработки видеопотоков резко увеличилась и их использование в этих целях стало вполне реальным.
Компьютеры SUN на базе процессора Ultra SPARC III
SUN Blade 1000 (2000) — высокопроизводительная рабочая станция
Эта рабочая станция может иметь до 2 процессоров UltraSparc III c частотой 600, 750 или 900MHz (1050 для SB2000). 600MHz версии имеют по 4Mb кэша второго уровня у каждого процессора, а более высокочастотные модели оснащаются 8Mb L2.
Память этой системы может составлять от 0,5 до 8Gb, в системе может быть установлено до 2 UPA видеоадаптеров, они имеют достаточно широкий набор портов ввода/вывода.
Теперь перейдем к подробному рассмотрению этой системы (тем более, что у неё есть некоторые небезынтересные особенности). В частности, я хотел бы обратить внимание на организацию оперативной памяти в этой системе.
Память у этой двухпроцессорной системы — едина! Несмотря на два независимых контроллера памяти — память абсолютно равнодоступна (и с запасом для работы устройств ввода/вывода!) для обоих процессоров.
Обратите внимание на расположенный в центре рисунка коммутатор, к которому присоединены контроллеры ОЗУ обоих процессоров. Таким образом, обеспечена однородность памяти в рамках системы и исключены накладные расходы на бессмысленные пересылки из памяти в память.
Для обеспечения нормальной работы двух высокопроизводительных процессоров (а совокупная пропускная способность памяти у двух таких процессоров составляет 4,8Gb/s) и, одновременно, обслуживать высокопроизводительные устройства ввода/вывода система оснащается памятью с шириной шины 512bit (+ECC) и частотой 100MHz (6,4Gb/s).
Набор шин и портов ввода/вывода довольно традиционен:
- 2 UPA порта, к которым подключаются высокопроизводительные видеоакселераторы (как минимум один),
- Шина PCI 64*66 к которой присоединен встроенный FC-AL контроллер (и еще один слот свободен)
- Шина PCI 64*33 к которой присоединяются все остальные устройства (+3 свободных слота):
- Стандартный набор последовательных и параллельных портов
- Контроллер дисковода FD
- Ultra SCSI (40MB/s) контроллер
- Звуковая плата
- 4 USB порта
- 2 FireWire порта
- сетевой адаптер 100Base-T
Т.о., общая пропускная способность каналов ввода/вывода станции SUN Blade 1000 составляет (без учета видеоадаптеров) примерно 0,8Gb/s.
А вот если сопоставить все эти величины — то станет очевидно, что пропускная способность памяти (64byte*150MHz=9.6Gb/s) рассчитана вполне точно, посмотрите внимательно:
- Два процессора с шинами по 2,4Gb/s — 4,8Gb/s.
- Все устройства ввода вывода кроме видеоадаптера — 0,8Gb/s
- Канал UPA для видеоадаптера (8 byte*150Mhz) — 1,2Gb/s, до двух видеоадаптеров в системе — 2,4 Gb/s
Итого — максимум 8 Gb/s в системе.
Т.о., пропускная способность памяти рассчитана даже с некоторым запасом по отношению к максимально возможной нагрузке в системе. Зачем это превышение — подробнее станет понятно при рассмотрении построенной на аналогичной элементной базе сервера v880.
Если внимательно проанализировать вышесказанное то очевидным становится факт, что у этой системы практически нет узких мест. Система сбалансирована практически идеально. Но, к сожалению, есть несколько неочевидных моментов, которые омрачают радужную (казалось бы) картину.
Например, теоретически, латентность памяти у такой системы (с коммутатором) несколько больше, чем у системы без оного (при сравнении, например, с полностью синхронной системой с одним процессором и одним каналом памяти). Просто за счет дополнительных к обычным задержкам работы чипсета задержек коммутации. Т.е., алгоритмы, оперирующие небольшими порциями данных, но чувствительные к задержкам памяти будут недостаточно эффективны на такой архитектуре. С другой стороны, высокая пропускная способность памяти бывает востребована при обработке больших массивов данных. Подробнее этот вопрос будет рассмотрен ниже.
С другой стороны, свою роль играют и большие (многомегабайтовые) кэши процессоров, которые позволяют существенно сладить негативную роль задержек памяти в коммутируемой архитектуре.
Ну и, понятное дело стоит это все мощное оборудование немало…
Младшие модели серверов SUN на процессорах Ultra SPARC III
Оставив за рамками статьи ничем не примечательные серверы SUN Fire 280R (которые с т.з. архитектуры практически неотличимы от SUN Blade 1000, более того — это та же самая материнская плата, просто расположенная в другом, серверном, корпусе) перейдем к более интересным представителям семейства SUN Fire. И начнем с сервера SUN Fire V880.
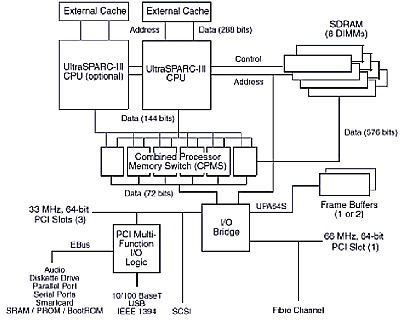
Что же мы видим на этой картинке?
- Четыре (1-4) платы, очень напоминающих с т.з. организации комплекса процессор-память рабочую станцию SUN Blade 1000.
- Высокопроизводительную системную шину SUN FirePlane производительностью 9,6Gb/s
- Два высокопроизводительных моста FirePlane-PCI
- I/O коммутатор для низкопроизводительных устройств, содержащий 2 контроллера шины PCI и контроллер шины Ebus.
- 2 контроллера шины Ebus используемых в процессе загрузки системы и её управления
Таким образом, совокупная производительность каналов ввода/вывода системы SUN Fire V880 составляет:
| Шина | Разрядность шины (bit/byte) | Частота (MHz) | Пиковая скорость (Mb/s) |
|---|---|---|---|
| PCI-A | 64/8 | 66 | 528 |
| PCI-B | 64/8 | 33 | 264 |
| PCI-C | 64/8 | 66 | 528 |
| PCI-D | 64/8 | 33 | 264 |
| Итого: | 1584 | ||
Вспомним, что и ServerSet III HE предоставит в распоряжение системы не более чем 0,8Gb/s — т.е., не более половины вышеприведенного значения.
Но и это не самое главное — совокупная пропускная способность памяти и суммарный объем кэшей составляет (в зависимости от числа процессоров):
| Число процессоров в системе (Шт.) | Объем кэшей в системе (Mb) | Пиковая скорость памяти, (GB/s) |
|---|---|---|
| 2 | 16 | 4,8 |
| 4 | 32 | 7,2 |
| 6 | 48 | 9,6 |
| 8 | 64 | 19,2 |
Что же, специалисты по обработке больших БД по достоинству оценят эти величины — тем более, что 8-процессорные x86 системы могут предоставить в их распоряжение всего лишь 16Mb кэшей и 1,6Gb/s скорость памяти (для восьмипроцессорных решений на базе Р3 XEON). Даже если обратить внимание на новейшие разработки IBM на базе процессоров Intel XEON MP — то картина все равно не очень радует. 4 процессора на шине с пропускной способностью 3,2Gb/s (т.е., 0,8Gb/s и 1Mb кэша в расчете на процессор). …Да, я сознательно не упомянул L4 кэш, размер которого составляет до 64Mb на каждые 4 процессора, но дело в том, что этот кэш находится архитектурно между шиной процессоров и памятью, т.е., одновременное обращение к L4 и к ОЗУ невозможно, этот кэш лишь повышает эффективность использования шины процессоров, но не пропускную способность системы в целом. Ну, даже если присовокупить сюда новейшие системы на двух (максимум) Р3 XEON, то их максимум — всего 4,2Gb/s на двоих и 0,5Mb кэша на процессор(но, там DDR, а это все же не SDRAM). Тоже пока не конкурент. Отмечу лишь, что, как и обещано, производительность памяти растет строго пропорционально количеству процессоров в системе. Примерно такой же эффект, я надеюсь, продемонстрируют нам 8-процессорные системы на базе процессоров AMD Hammer — но посмотрим. Кроме, того, v880 использует обычную SDRAM с минимально возможной латентностью (на частоте 150MHz), в отличие от DDR.
Теперь давайте перейдем к рассмотрению самого интересного семейства серверов SUN — SUN Fire x800
Семейство midframe/midrange серверов SUN Fire x800
Большие сервера — портреты крупным планом:
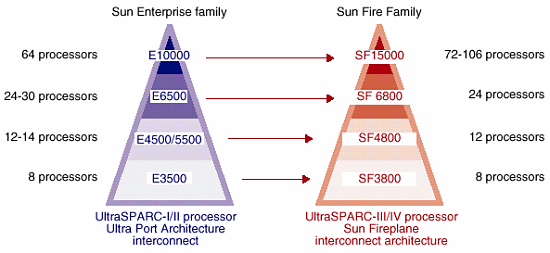
Примерно так выглядит позиционирование новых серверов по отношению к системам предыдущего поколения. При сравнимых (на момент анонса) ценах новые сервера предоставили пользователям качественно новый уровень производительности и управляемости. Подробнее это видно на следующем рисунке:
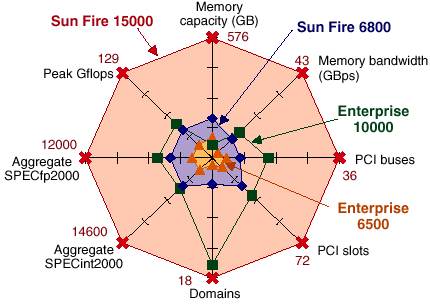
Семейство серверов SUN Fire x800 компании SUN Microsystems. Кубики, в которые играют инженеры.
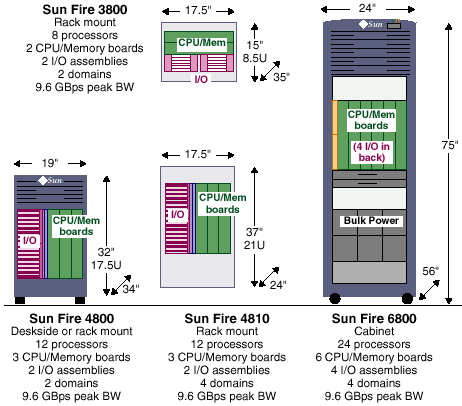
Принципиально важным моментом, отличающим серверные системы компании SUN от конкурирующих систем является модульный принцип построения — все эти сервера построены из одинаковых «кубиков». Состоят такие сервера как и их предшественники из процессорных плат и плат ввода/вывода и отличаются внутри семейства только количеством процессорных плат и плат ввода/вывода, подключаемых на общую высокопроизводительную шину.
В семейство серверов х800 входят модели с количеством процессоров от 8 до 24 (от 2 до 6 процессорных плат).
В отличие от рассмотренного выше варианта построения SMP систем сервера серии х800 используют и шинную, и коммутируемую (в рамках процессорной платы) архитектуру. В общих чертах архитектура этих машин повторяет архитектуру серверов SUN Enterprise X000/X500с той разницей, что вместо шины Gigaplane с пропускной способностью 6,4 Gb/s используется весьма похожая на неё шина Fireplane с пропускной способностью 9,6Gb/s, что позволяет одновременно производить операции с ней (вне пределов своей платы) четырем процессорам (4*2,4=9,6). Отдельный интерес представляет организация этой шины. Это, пожалуй, единственный известный мне случай реализации достаточно длинной шины с частотой 150MHz и шириной 512(!) разрядов (+ECC). Да еще и с несколькими нагрузками. Правда, и стоит такое решение солидных денег.
На предложенных рисунках приведены примеры конструктивов и некоторые характеристики различных серверов семейства х800.
Серверы SUN Fire x800:
| Модель сервера | Sun Fire 3800 | Sun Fire 4800/4810 | Sun Fire 6800 |
|---|---|---|---|
| Максимальное количество процессоров (шт.) | 8 | 12 | 24 |
| Максимальный объем памяти (Gb) | 64 | 96 | 192 |
| Пиковая пропускная способность памяти (Gb/s) | 19,2 | 28,8 | 57.6 |
| Установившаяся пропускная способность памяти (Gb/s) | 9,6 | 9,6 | 9,6 |
| Число модулей с 6 слотами сPCI (1584Mb/s на модуль) | 2 | - | - |
| Число модулей с 8 слотами PCI (2112Mb/s на модуль) | - | 2 | 4 |
| Число модулей с 4 слотами сPCI (1584Mb/s на модуль) | - | 2 | 4 |
| Максимальная пропускная способность ввода/вывода (Gb/s) | 3,2 | 7,4 | 14,8, но реально не более 9.6 (ограничивается пропускной способностью шины Fireplane) |
Эти сервера поддерживают технологию DSD и могут выделять в системе несколько независимых доменов для обеспечения бесперебойного функционирования системы.
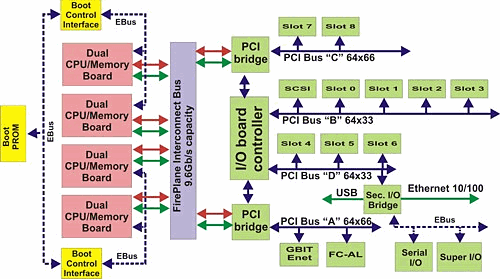
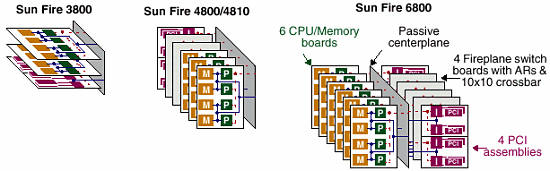
Давайте внимательно рассмотрим процессорную плату и плату ввода/вывода сервера семейства SUN Fire x800 (различия в рамках семейства ограничены только количеством тех или иных плат в системе)
Процессорная плата.
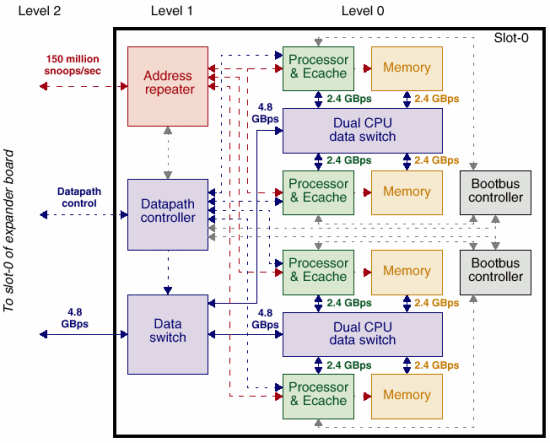
Что бросается в глаза при рассмотрении этой платы? В первую очередь внимание стоит обратить на количество каналов памяти (4), их пропускную способность (2,4Gb/s) и двухуровневую модель коммутации. Пары процессоров взаимодействуют между собой по каналам с пропускной способностью 4,8Gb/s, что позволяет работать с памятью соседней пары с весьма высокой скоростью, практически неотличимой от скорости работы со «своей» памятью.
Совокупная пропускная способность памяти для такой платы составляет, как несложно подсчитать, 9,6Gb/s.
Правда, как отмечено выше, латентность памяти превосходит таковую у х86 серверов — но и 8Mb L2 тоже не зря электричество в тепло переводят. :-)
Внимательный читатель наверное заметит, что пропускная способность внешнего интерфейса процессорной платы составляет всего 4,8Gb/s, что составляет половину от возможного (FirePlane имеет производительность 9,6Gb/s). В принципе, из всего спектра объяснений наиболее разумным мне кажется то, что это сделан для того, чтобы одна плата (пара плат) не захватила всей полосы пропускания FirePlane заблокировав этим работу остальных компонентов сервера. Хотя, с т.з. пиковой производительности это решение трудно назвать разумным — но если подойти к вопросу со стороны максимально возможной предсказуемости системы и ликвидации самой возможности «заторов» на шине, приводящих к «ступору» приложений и задержкам реакции, то это вполне может быть оправдано.
Кроме того, равенство пропускной способности памяти на плате и скорости внешнего интерфейса может привести к парадоксальной ситуации, когда память будет занята обслуживанием только внешних (расположенных на других платах) процессоров, оставив без внимания свои собственные процессоры. :-( :-)
Плата ввода/вывода тоже ничего уникального из себя не представляет:
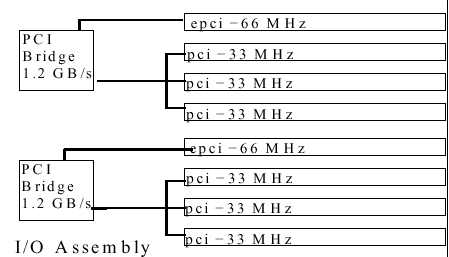
Плата с 8 слотами PCI (4800/4810 (2 в системе) и 6800 (4 в системе))
Соединение с шиной FirePlane, два контроллера PCI (64*66 + 64*33 bus) совокупной пропускной способностью 1584Mb/s
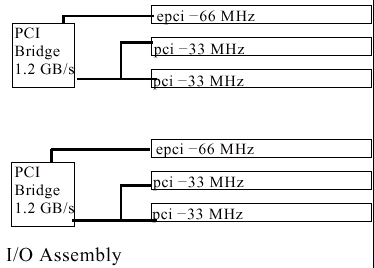
Плата в 6 слотами сPCI (3800, до 2 в системе)
Соединение с шиной FirePlane, два контроллера PCI (64*66 + 2*64*33 bus) совокупной пропускной способностью 2112Mb/s

Четырехпортовый контроллер cPCI с уменьшенным до 2 количеством разъемов PCI 33MHz, число таких контроллеров составляет в системе 4хх0 — 2, а в системе 6800 — 4 штуки…
Соединение с шиной FirePlane, два контроллера PCI (64*66 + 64*33 bus) совокупной пропускной способностью 1584Mb/s
Масштабируемость без компромиссов
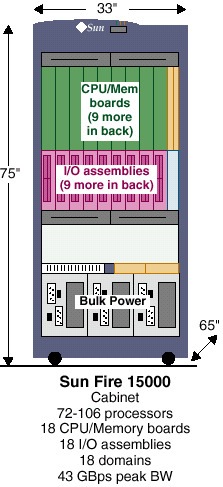
Сервера SUN Fire 15k, 106 процессоров, 576Gb памяти — как это сделано
Теперь давайте рассмотрим самый мощный из предлагаемых компанией SUN серверов — SUN Fire 15000
Двустороннее размещение плат позволяет сократить длину проводников шины FirePlane.
Однако, в отличие от серверов серии х800 процессорные платы и платы ввода/вывода подключаются не напрямую в разъем FirePlane, а через специальную промежуточную плату. Роль этой платы будет раскрыта ниже.
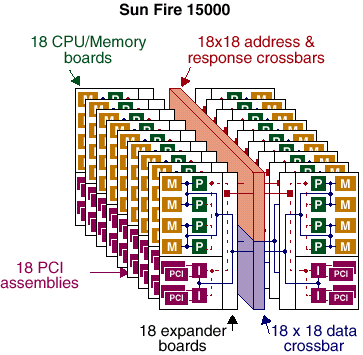
Как и ранее, в сервере SUN Enterprise 10000 фирма не стала «изобретать велосипед» и пошла на схожий шаг. Процессорные платы, применяемые в этих серверах полностью аналогичны таковым, примеряемым в серверах среднего уровня. Но, был создан коммутатор на 9 каналов Fireplane интегральной пропускной способностью 43,2Gb/s. Соответственно, к этому коммутатору присоединяются 18 процессорных плат, содержащих по 4 процессора Ultra SPARC III и 32Gb оперативной памяти каждая и 18 плат ввода/вывода, каждая из которых имеет 2 шины PCI 64*66 и 2 шины PCI 64*33 каждая. Общая пиковая пропускная способность памяти составит, как несложно подсчитать 172,8GB/s. Установленная пропускная способность памяти составляет более чем 43Gb/s. Что касается ввода вывода, то наличие в системе 18 модулей, пропускной способностью 2,1 (2.4 при использовании FO модулей)Gb/s на модуль позволяет достичь пиковой пропускной способности превышающей 38(43)Gb/s, или более 21Gb/s установленной пропускной способности ввода/вывода*. Сколько это все стоит я писать пока не буду… Много это стоит. Очень много…
* Представляете, ваш 40GB жесткий диск может быть «всосан» или «выплюнут» всего за 2 секунды!!! Или, если это недостаточно впечатляет, можете представить себе CD диски по 700MB каждый, вылетающие из некоторой «писалки», со скоростью 30 штук в секунду! И так непрерывно, сутками, месяцами и годами. Тем более, что применяемые шины PCI имеют способность замены плат «на ходу», т.н., hot plug PCI.
Давайте перейдем к более подробному рассмотрению узлов этой, без преувеличения, титанической системы.
Плата расширения — промежуточное звено. Зачем это надо?
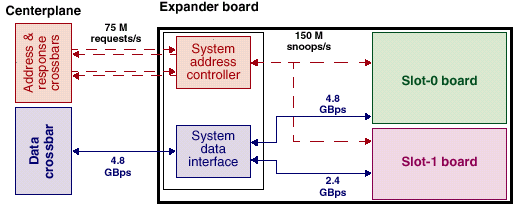
А просто для того, чтобы по возможности освободить системную шину FirePlane от трафика ввода/вывода. Кроме того, нашлось и еще одно интересное применение (см. ниже).
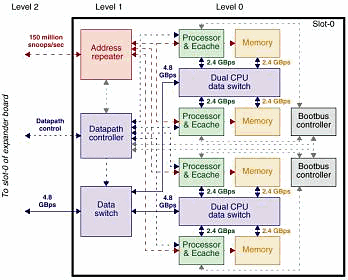
Что же, как и было сказано выше — «кирпичики» используемые в этой системе вполне привычны — по крайней мере плата процессоров/памяти практически идентична плате используемой в семействе серверов х800
Кроме того, я должен отметить, что, очевидно, и Dual CPU data switch — тоже не представляют из себя ничего уникального — в единственном числе они существуют, например в рабочих станциях Sun Blade 1000/2000
А вот и плата ввода/вывода.
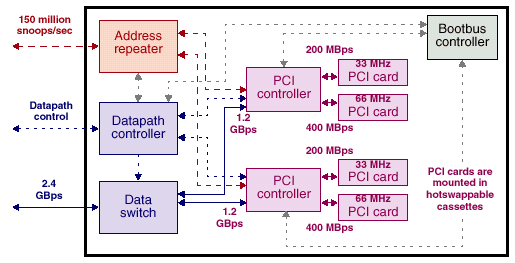
Четыре независимых шины ввода/вывода PCI шириной 64 разряда. Из них два — 66MHz, два — 33MHz.
Совокупная пропускная способность этих шин, как несложно подсчитать составляет чуть больше 1,5Gb/s.
С этой точки зрения кажется избыточной пропускная способность каналов, связывающих компоненты внутри платы и саму плату с системой — но, с другой стороны, это позволяет устройствам на шине PCI работать практически на предельно возможной скорости. Кроме того, есть еще один вариант платы ввода/вывода
Вот он, этот вариант.
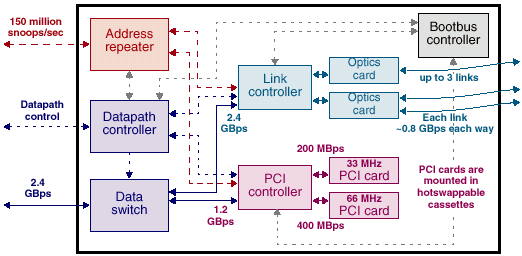
Три канала пропускной способностью 800Mb/s (пользовательских данных (т.е., 1Gbit/s интерфейсы)) могут быть использованы для соединения систем в рамках многомашинных кластеров или для связи с внешними устройствами хранения.
Внимательный читатель может спросить: «Так, нам обещали 106 процессоров, а 18*4 — всего 72! Где еще 34 процессора? Куда девали?» И читатель таки будет прав :-) … Вот и ответ:
MaxCPU Board
Плата содержащая 2 процессора Ultra SPARC III 900MHz c индивидуальными, как и положено, кэшами L2 по 8Mb но без оперативной памяти. Зачем такое? Приведем цитату из документации SUN: «…to replace PCI cards for the highest compute-intensive configurations when CPU power outweighs the for I/O connectivity.» Вот такими платами
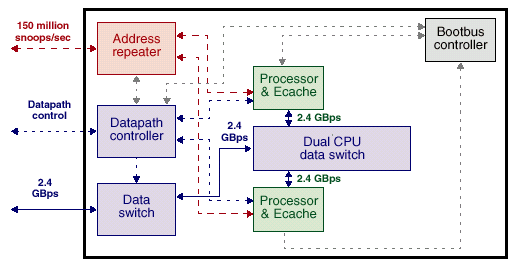
К сожалению, задержка обращения к оперативной памяти для этих процессоров, естественно, несколько больше, что приводит к снижению производительности этих процессоров по сравнению с процессорами, расположенными непосредственно на процессорных платах. Однако, ввиду высокой скорости соединений и большого объема кэша снижение это невелико и итоговая производительность системы вырастает при применении этих плат всё-таки заметно.
Соответственно, собранный модуль выглядит следующим образом:
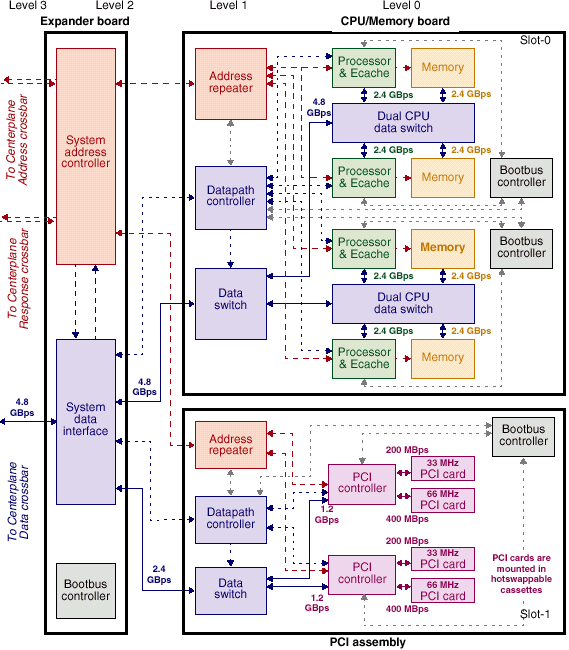
Что это напоминает? Да узел Sun Enterprise 10000! Практически законченный SMP компьютер с весьма серьезной производительностью и вполне адекватной системой ввода/вывода.
В системе их может быть 18 — как раз по числу разъемов FirePlane.
Впрочем возможен еще один вариант комплектации узла модулями, применяемый в системах с напряженным счетом, когда вместо платы ввода/вывода устанавливается дополнительный процессорный модуль. Вполне очевидно, что таких узлов в системе не может быть более 17 — ведь хотя бы один из узлов должен нести плату ввода вывода. :-)
Ну, а вот то, что получается при установке всех компонентов сервера в конструктив.
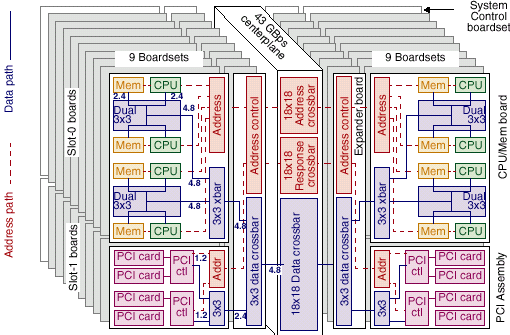
Напомню, как и раньше логически шина адреса едина во всей системе, что облегчает поддержание когерентности кэшей и зашиты памяти, а данные передаются по индивидуальным маршрутам, что обеспечивает максимально возможную производительность передачи данных.
Коммутатор памяти (крупно)
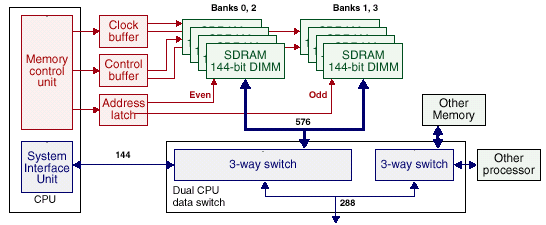
Обратите внимание, для работы в системе задействованы и контроллер памяти, и контроллер системного интерфейса.
Как это обычно для SUN адрес и данные передаются по независимым каналам, что позволяет максимально полно использовать пропускную способность памяти и сократить задержки выборки
Для обеспечения высочайшей отказоустойчивости системы SUN Fire обеспечены сквозной системой защиты аппаратной целостности данных, помимо общеизвестной ECC памяти включает в себя многоуровневую систему построения контрольных данных и проверки их состояния.
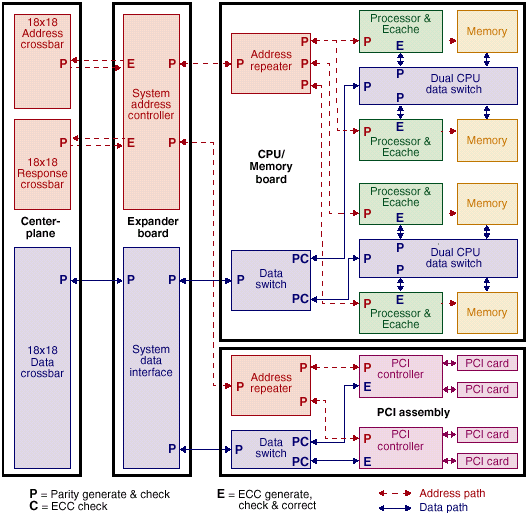
На рисунке вышк приведена обобщенная схема обеспечения достоверности данных в рамках одной из плат системы в составе сервера Fire 15k.
Кроме того, для обеспечения бесперебойной работы системы SUN Fire могут быть сконфигурированы таким образом, что продублированы будут ВСЕ мыслимые компоненты — процессоры, платы ввода вывода, шины и платы PCI, системный таймер, компоненты межпроцессорных коммуникаций и пр… Множественные же избыточные блоки питания и вентиляторы охлаждения — являются стандартными компонентами всех поставляемых серверов Sun Fire.
Теперь давайте рассмотрим семейство серверов SUN Fire, так сказать, с высоты птичьего полета для того чтобы составить общее представление о характеристиках этих систем.
Семейство серверов SUN Fire
| Sun Fire 280 | Sun Fire v880 | Sun Fire 3800 | Sun Fire 4800/4810 | Sun Fire 6800 | Sun Fire 15000 | |
|---|---|---|---|---|---|---|
| Количество процессорных плат (мах) | 1* | 4* | 2 | 3 | 6 | 18 |
| Количество процессоров (with MaxCPU board для Sun Fire 15k) | 2 | 8 | 8 | 12 | 24 | 72(106) |
| Количество разъемов памяти | 8 | 32 | 64 | 96 | 192 | 576 |
| Максимальная емкость памяти (1GB DIMM) | 8Gb | 32Gb | 64Gb | 96Gb | 192Gb | 576Gb |
| Количество доменов | n/a | n/a | 2 | 4 | 18 | |
| Пропускная способность памяти в пределах процессорной платы | 4.8 Gb/s | 9.6Gb/s | ||||
| Пропускная способность связи для каждой пары процессорных плат | n/a | 4.8Gb/s | ||||
| Суммарная пиковая пропускная способность памяти | 4.8 Gb/s | 19,2Gb/s | 28,8 Gb/s | 57,6 Gb/s | 172,8 Gb/s | |
| Суммарная установленная пропускная способность памяти в системе | 4.8 Gb/s | 9.6 Gb/s | 4.8 Gb/s | 9.6 Gb/s | 43 Gb/s | |
| Количество плат ввода/вывода (max) | n/a* | n/a* | 2 | 4 | 18 | |
| Тип разъемов PCI | PCI | hot-swap cPCI | PCI and hot-swap cPCI | hot-swap PCI | ||
| Количество шин PCI (maximum) | 2 | 4 | 8 | 12 | 12 | 72 |
| Количество разъемов PCI (maximum) | 4 | 9 | 12 | 16 | 32 | 72 |
| Пиковая пропускная способность ввода/вывода | 0.8Gb/s | 1,5Gb/s | 4.8 Gb/s | 9.6 Gb/s** | 43.2** Gb/s | |
| Установленная пропускная способность ввода/вывода | 0.8Gb/s | 1,5Gb/s | 4.8 Gb/s | 9.6 Gb/s** | 21 Gb/s | |
* — процессорные платы и платы I/O не унифицированы с семейством x800 и 15к
** — ограничено пропускной способностью Fireplane.
Определенный интерес представляет собой одновременное присутствие на рынке перекрывающихся моделей серверов v880 и 3800 — с одной стороны, 880-й демонстрирует большую пропускную способность памяти, а с другой — 3800 имеет гораздо большую пропускную способность ввода/вывода и может быть разделен на два независимых домена (что хорошо с т.з., например, отказоустойчивости). Что выбрать в каждом конкретном случае — надо решать исходя из предъявляемых к серверу требований.
Вопросом, который нельзя оставить без внимания можно назвать вопрос о том, чем приходится платить за такую многоуровневую структуру с абсолютно неоднородным доступом к памяти? Не слишком ли велики возникающие при этом задержки? Ответ прозвучит несколько парадоксальный: «И да, и нет, в зависимости от того, что вы хотите делать на этой системе». Рассмотрим подробнее как это выглядит:
Время выборки данных из памяти
| Расположение памяти по отношению к процессору | Sun Fire 3800 — 6800 | Sun Fire 15000 |
|---|---|---|
| Локальная память | 180ns | |
| 27 тактов | ||
| Память соседа в паре (на одном Dual-Processor Data Switch) | 193ns | |
| 29 тактов | ||
| Память процессоров из другой пары на той же процессорной плате | 207ns | |
| 31 такт | ||
| Память, расположенная на другой плате | 240ns | 333ns* |
| 50 тактов* | ||
| 36 тактов | 440ns** | |
| 66 тактов** | ||
* — данные есть в спец. буфере когерентности кэшей на объединительной плате.
** — данных нет в спец. буфере когерентности кэшей на объединительной плате.
Эта таблица описывает времена задержки при нахождении данных в различно расположенной относительно процессора памяти при отсутствии необходимости поддержания когерентности кэшей, т.е., затребованные данные не отображены в кэшах ни одного другого процессора. Если же требуется обеспечить когерентность кэшей в различных процессора, то в зависимости от их взаимного расположения задержка может составлять от 240ns (42 такта) до 553ns (83 такта).
Специалистам, привыкшим оценивать «задержку памяти» по частоте ее функционирования и считающим, что для PC133 задержка составляет 7,5ns и один такт системной шины такие параметры могут показаться чудовищными — но давайте разберемся, так ли это на самом деле?
Во первых, задержка выборки из хорошей SDRAM с таймингами 2-2 составляет, как нетрудно сосчитать, 4 такта. Еще не менее 4 тактов (примерно, точных данных найти не удалось) тратится на «перетаривание» (©, bess) данных из/в FSB в память и обратно. Ну, и примерно 1 такт на распространение сигнала. Итого, 9 тактов по 7,5ns — 67.5ns, и это в лучшем случае… Обычно — хуже (для таймингов памяти, например, 3-3 — 11 тактов и 82,5ns). Затем, следует вспомнить, что для большинства существующих архитектур к памяти может одновременно обратиться только один процессор (а насколько хорош Хаммер мы еще не знаем), в то время, как у SUN все процессоры могут одновременно обращаться к памяти (естественно, если они не пытаются обратиться к одному и тому же фрагменту). Т.е., для, например, двух Р3 на одной шине (да и для двух k7, память-то все равно одна) это время стоит, как минимум, удвоить, для 4 — учетверить (да и такт подлиннее — 10ns). Т.о., для 4 Р3 XEON время выборки (без учета проблем кэш-когерентности) составит в среднем 36 тактов по 10ns — 360ns, правда немало? И заметно больше, чем для 4 процессорного SUN. Если же обратиться к новейшим многопроцессорным системам на базе XEON MP — то время выборки из ОЗУ (не из L4) даже если не учитывать задержку поиска в L4 составит примерно те же 180ns в лучшем случае. При заметно меньшей общей пропускной способности.
Кроме того, не следует забывать, что шина данных процессора у систем SUN составляет 128 разрядов, что ровно вдвое больше, чем у существующих х86. Т.е., для выборки равного объема данных требуется вдвое меньшее число тактов системной шины. Так, что для корректного сравнения времени выборки при работе со значительными объемами данных данные SUN следует еще и поделить пополам.
Так что не все так плохо, как кажется на первый взгляд.
Из вышеприведенной таблицы видно, что и «цена» многоуровневой коммутации относительно невелика и разница во времени между лучшим и худшим расположением данных по отношению к затребовавшему их процессору составляет не более чем 2,5 раза.
Итак: В тех случаях, когда типичный объем выборки памяти составляет более чем 16 байт, а это типично для БД, больших CAD и т.п., то системы Ultra SPARC могут (и демонстрируют) впечатляющие показатели производительности (вполне приемлемое время выборки и впечатляющая производительность памяти), что позволяет без колебаний рекомендовать их для подобного применения. Напротив, если типичной задачей является высокопроизводительный счет с размером операнда 32 или 64 разряда, да еще и данные размазаны по памяти — то применение систем SUN не может считаться рациональным, так как типичное время выборки всё же больше, чем у х86 систем. Эти выводы полностью подтверждаются и результатами индустриальных тестов. Так, по данным тестирования на научных приложениях (тест SPEC) — системы SUN не блещут, а вот при тестировании БД — наоборот. Так, например, небезызвестная СУБД Oracle демонстрирует на технике SUN весьма впечатляющие характеристики.
Отдельного уважения заслуживает OS Solaris 8, которая способна всем этим управлять. Весьма достойная особа. :-)
Вывод: Как показано выше компания SUN предлагает потребителям полный спектр 64-разрядных решений — от недорогих персональных компьютеров (SUN Blade 100) ценой менее тысячи долларов, до высокопроизводительных корпоративных серверов с высочайшей производительностью (SUN Fire 15k) ценой в миллионы долларов. Отдельным «плюсом» следует признать сквозную программную совместимость всего спектра оборудования, единство операционной системы (Solaris 8) и, соответственно, абсолютное единство процедур управления для всего спектра техники.
Ну, а теперь беру большую ложку и начинаю сдабривать дегтем эту радужную картину:
1. К сожалению, SUN уделяет очень мало внимания внутренним системам хранения данных. Фактически, это внимание сводится к встроенным системным контроллерам, служащим для первоначальной загрузки системы. Всего 3 модели RAID контроллеров да и то, по несколько завышенной цене. Конечно, внутренние системы хранения не настолько уж актуальны для серверов с десятками процессоров, в конце-концов, внешние массивы не так уж и дороги, по сравнению со стоимостью серверов SUN, но, тем не менее… Для младших моделей хотелось бы и попроще что-нибудь. Хотя, должен отметить, что внешние накопители семейства Sun Storage очень хороши. Надо так же признать, что ввиду особенностей архитектуры компьютеры SUN практически не теряют производительности при работе с «софтовыми» RAID массивами.
2. Цена.. Как SUN устанавливает цены на свои системы — загадка. Нет, честно, насколько мне стало известно, цены на одинаковые системы могут различаться более чем в два раза. Поэтому, никаких цен кроме минимальных объявленных (а насколько они минимальны — вопрос отдельный) я старался не упоминать. Есть мнение, что эти цены обусловлены деятельностью антимонопольного комитета, не дающего фирме демпинговать — но при внимательном рассмотрении эта версия не выдерживает критики. Потому, что никто и никогда не заставит производителя держать цены настолько выше сопоставимых по цене альтернативных систем. Тут, скорее дело в том, что пока конкуренция на этом рынке недостаточно остра и SUN просто стрижёт купоны. Я надеюсь, что поддавленные снизу новыми х86 системами на базе Xeon MP и Hammer системы SUN начнут стремительно дешеветь. Или ускоряться при сохранении цены, что тоже неплохо.
3. Ну, и абсолютный уровень цен… Фактически, более-менее производительная система SUN стоит, как минимум несколько тысяч долларов… Поэтому, следует весьма тщательно проанализировать необходимость таких систем в вашей сети. На мой взгляд, такие цены не вполне оправданы, тем более, что с переходом на LINUX с SUN начинают впрямую конкурировать настольные х86 системы. К серверам, как не странно, это не относится — более-менее адекватный по производительности х86 сервер стоит сопоставимых денег (примерно $25k-$27k за сервер).
4. Очень странный, если не сказать больше, подход к поддержке систем… Например, установив в компьютер неоригинальный компонент (даже такой безобидный, как память или жесткий диск) владелец системы лишается фирменной гарантии на всю систему. Причем, означенный компонент может даже и поддерживаться самой OS — как например RAID контроллер от Mylex, результата это не изменит. А в сочетании с несколько завышенными ценами* на оборудование SUN это сильно похоже на банальный шантаж. Это, на мой взгляд, несколько неправильно.
* Так, стоимость жесткого диска ёмкостью 36Gb может составлять аж $1500! Да, в эти деньги входит полугодовое предпродажное тестирование — но учетверения цены это, на мой взгляд, не оправдывает.
Кое-что о конкурентах:
Надеюсь, читатель не забыл, что SPARC v.9 — является свободно распространяемой спецификацией? Компания FUJITSU-SIEMENS обладает, пожалуй, самым удачным клоном (хотя этот термин оспаривается — но никакого иного я придумать не смог) процессора ULTRA SPARC — SPARC64-GP. Более всего этот процессор похож на US II, но обладает и рядом отличий.
В частности, размер интегрированных на кристалл кэшей L2 (L1 в фирменной терминологии, кроме того процессор имеет 16kb кэш первого (нулевого) уровня) составляет 256Кб (D128+I128), таким образом off chip кэши (составляющие, как и у машин SUN до 8 Mb) становятся кэшами третьего уровня.
Интеграция L2 на кристалл позволила компании FUJITSU-SIEMENS поднять показатели производительности своих серверов серии PRIMEPOWER до высот, сравнимых с показателями современных серверов от SUN MICROSYSTEMS.
Свою роль сыграло и то, что пропускная способность применяемой системной шины несильно уступает пропускной способности шины FirePlane и значительно превосходит таковую у GigaPlane — эта шина имеет ширину 256 разрядов (против 512 у FirePlane) и частоту 225MHz против 150. Соответственно, ее пропускная способность составляет 7200 Mb/s на канал, что для архитектуры серверов серии 2000, весьма похожих на Enterprise 10000 дает (128 процессоров в 32 четырехпроцессорных платах) дает совокупную пропускную способность несколько даже превосходящую таковую у SUN Fire 15k.
Кроме того, в отличие от SUN, Fujitsu-Siemens не сажает более 2 плат по 4 процессора на один канал системной шины, в то время, как SUN в серверах 6800 допускает до 24 процессоров (6 плат) на одной шине FirePlane.
| Пропускная способность | Описание | Максимальная конфигурация | |||
|---|---|---|---|---|---|
| PRIMEPOWER 2000 | PRIMEPOWER 1000 | PRIMEPOWER 800 | |||
| Процессор | 1,8 Гбайт/с | Для 1-го порта процессора | 128 процессоров | 32 процессора | 16 процессоров |
| Память | 2,4 Гбайт/с | Производительность 1-го канала | 128-кратное чередование | 32-кратное чередование | 16-кратное чередование |
| Ввод/вывод | 0,9 Гбайт/с | В диапазоне от 2 до 4 PCI-шин | 192 PCI-шины | 48 PCI-шин | 24 PCI-шины |
| Коммутатор | Пиковая производительность | 57,6 Гбайт/с | 23,04 Гбайт/с | 11,52 Гбайт/с | |
Однако, несмотря на весьма интересные показатели производительности и стоимости (эти решения несколько дешевле аналогичных по производительности решений SUN) у серверов FUJITSU-SIEMENS есть и некоторые недостатки. Среди них:
- Меньшее количество системных доменов.
- Меньший максимальный объем памяти (не более 2Gb на процессор)
- Несколько меньшая наработка на отказ. И некоторая сложность в обслуживании «вот вывинтишь, эдак, болтов 40, чтобы плату расширения увидеть, и еще столько же, чтобы один упавший внутрь корпуса достать .... Все слова вспомнишь, даже и те которых не знал никогда!!!» — цитата из высказывания человека работавшего с F-S
- Некоторая несбалансированность архитектуры (на мой взгляд, несколько перекошено в сторону ввода/вывода)
В общем, если пользователь заинтересован в технике SPARC, предоставляющей высокие показатели производительности для БД, стабильности и управляемости Solaris 8 — то у него вполне есть выбор. Наличие внутреннего L2 емкостью 256kb выводит производительность SPARC64-GP на приемлемый уровень и в традиционных «счетных» задачах, крайне чувствительных к скорости кэшей, что позволяет рекомендовать эту систему и для «научного» применения.
Коллега matik, рецензируя эту статью, метко охарактеризовал эти сервера как «USII на стероидах», и мне кажется, что он недалек от истины. :-)
Кроме того, решения на процессорах SPARC (их клонах) весьма распространены в телекоммуникационных решениях, встраиваемых системах, комплексах промышленной автоматизации, военных системах, что вполне оправданно ввиду высочайшего качества проработки архитектуры, 100% предсказуемости (свободно распространяемая спецификация может быть проанализирована на предмет отсутствия «закладок» и непреднамеренных ошибок) и доступности качественного системного и инструментального ПО.
Что в будущем?
В октябре 2001 года SUN представила публике спецификации нового микропроцессора Ultra SPARC IIIi. Что же нового в этом камне?
1. L2 кэш «переедет» на кристалл и его частота сравняется с частотой ядра. Правда, при этом он похудеет до 1Mb, но внешний кэш, скорее всего, сохранится, став т.о., кэшем третьего уровня.
2. Будет совершен переход от SDRAM к DDR SDRAM — частота при этом, правда, несколько снизится, 133(266), но разрядность шины памяти останется прежней 128+ECC.
3. Объем поддерживаемой оперативной памяти будет увеличен с 8 до 16Gb на процессор.
4. Естественно, вырастет и частота. Стартовой будет частота в 1GHz.
5. Внутри процессора для связи всех его компонентов (ядро и кэши) будет применена шина JBUS пропускной способностью до 64Gb/s*.
6. Для связи процессоров (в рамках 4-way SMP ячейки?) будет применена шина та же JBUS, но с пропускной способностью ограниченной 16Gb/s**.
* — К сожалению, подробнее ничего об этой шине пока ничего сказать не могу…
** — Ориентировочно. Информация не подтверждена.
Эти изменения выглядят достаточно интересно с любой точки зрения, однако, к сожалению, пока сложно назвать момент выхода систем на этом микропроцессоре. Причем, этот момент, скорее всего, определяется не технологическими, а маркетинговыми соображениями — пока хорошо покупают процессоры и системы без «i» — то и нечего торопиться. :-(
Динамические системные домены — что это и зачем то нужно?
Представьте себя на месте администратора большой сети… У вас несколько (ну, давайте, 3 условно) крупных отделов, каждый из которых требует своего собственного сервера с гарантированной производительностью, общекорпоративная задача, которая должна работать безостановочно и разработчики, которые периодически могут «ронять» сервер в ходе своих экспериментов с ПО.
Малоприятное зрелище, не так ли? Оставаясь в классических рамках вам придется устанавливать не менее 6 серверов (три сервера отделов, 2 зеркальных для «главной задачи», и один для разработчиков)! Причем, скорее всего, разных, сообразно требованиям подразделений… А потом соотношение нагрузки изменится (например, в связи с опережающим развитием того или иного направления, или переписанная разработчиками задача «вдруг» захочет вдвое больше процессоров) и что? «Лыко-мочало», начинай замену серверов сначала?
Но не все так грустно. SUN может предложить администраторам таких систем весьма интересный вариант — выделение в рамках больших систем практически автономных доменов для решения тех или иных задач.
Технология DSD (Dynamic System Domain)
Двухуровневая модель коммутации позволяет получать интересные возможности. В частности, пользуясь тем, что каждая системная плата представляет из себя законченное с т.з. функциональности решение появилась возможность выделять в составе большого сервера самостоятельные вычислительные структуры.
В качестве доменов может выступать от одной до нескольких системных плат. Домен является полноценным SMP-компьютером, на котором можно производить все необходимые вычисления и пользоваться общесистемными ресурсами (дисками и т.п.).
Что же выигрывает (приобретает) пользователь от использования технологии DSD?
1. Критически важному приложению могут быть выделены некоторые фиксированные ресурсы, которые находятся в его исключительном распоряжении.
2. Появляется возможность выделять в рамках одного сервера «кусочки» предназначенные для тестирования и отладки нового ПО и(или) драйверов абсолютно безопасно для всей системы в целом.
3. В рамках большого сервера можно выделять сервера подразделений, например, по производительности, соответствующие их запросам.
Часто для краткости говорят о «сервере в сервере» или «системе в системе». Данное решение имеет следующие особенности:
- процессы создания (выделения) домена, равно как и его уничтожения, происходят параллельно с работой остальных ресурсов сервера, никак не влияя на них;
- нет никаких ограничений на то, какие именно ресурсы сервера можно включать в состав того или иного домена;
- количество доменов определяется лишь числом плат в системе (и, естественно, версией программного обеспечения), и не имеет теоретических ограничений.
Выглядит это примерно так:
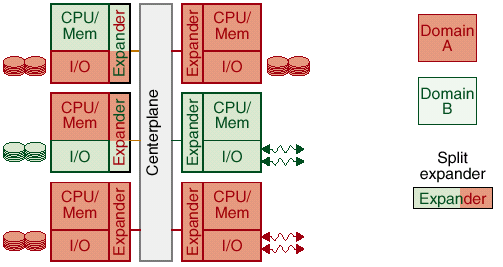
При этом оба системных домена практически независимы, задачи, выполняемые в рамках одного домена никоим образом не влияют на задачи другого домена.
Фактически, вы получаете в свое распоряжение несколько SMP серверов с достаточно произвольной конфигурацией соединенных между собой сверхбыстродействующей сетью. Как это сказывается на отказоустойчивости серверной системы понятно и без дополнительных объяснений. Да и управлять таким сервером с множеством виртуальных машин гораздо проще, чем набором из нескольких независимых серверов.
Вот пример конфигурирования сервера для поддержки трех независимых сервисов:
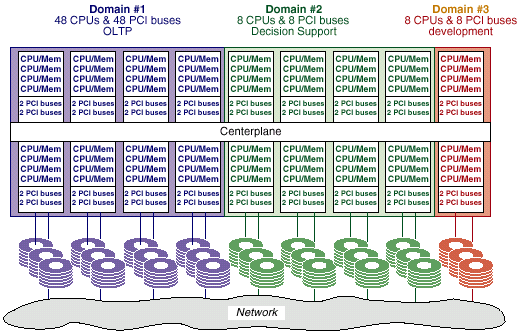
Впрочем, аналогичные способы есть и в распоряжении других производителей высокопроизводительной техники (Compaq (Alpha), SGI, HP и IBM).
От Советского Информбюро. В последний час
Пока статья готовилась к печати компания SUN выпустила новый сервер — SUN Fire 12000. Строго говоря, это ровно половинка от SUN Fire 15000 — так что у компании SUN есть некоторые проблемы с математикой… :-) Впрочем, маркетингЪ — дело хитрое…
Новый сервер должен занять место между SUN Fire 6800 и Fire 15000, соответственно, примерно посередине находятся и его технические характеристики.
Этот сервер имеет 9 разъемов для установки Expansion board и, соответственно, могут комплектоваться 36 процессорами (9*4), 288Gb оперативной памяти и 9 картами ввода/вывода (с максимальной пропускной способностью 2,1Gb/s на карту). Причем, точно так же, как и SUN Fire 15000 этот сервер может использовать и MAX CPU board — тогда максимальное число процессоров составит 36+8*2=52.
В остальном этот сервер полностью аналогичен системе fire 15000 и отличается от него (в равных комплектациях) только ценой.
Список литературы и источников:
- Архитектура процессора UltraSPARC III Андрей Шадский (НИИ системных исследований РАН) Copyright © 1993-2002, Jet Infosystems (http://www.jetinfo.ru/1999/7/1/article1.7.1999.html)
- Семейство компьютеров Ultra компании Sun Microsystems Андрей Шадский (НИИ системных исследований РАН) Copyright © 1993-2002, Jet Infosystems (http://www.jetinfo.ru/1997/23-24/1/article1.23-24.1997.html)
- http://docs.sun.com/
- http://www.solariscentral.org/
- http://www.sun.com
- http://sunsolve.Sun.COM
- http://www.sparc.org/standards.html
- http://www.primepower.ru
- http://www.elcom.spb.ru/
Благодарности:
Александру Лысенко aka «SUN tech nick», и компании Elcom Ltd. Datacenter System Reseller (С.-Пб) — за предоставленные материалы и консультации
Максиму Леню, aka «C.A.R.C.A.S.S.» — за помощь в разборе некоторых скользких моментов
Виктору Картунову aka «Matik» — за благожелательную критику и лит. придирки.


