Часть 2: внеочередное исполнение операций
Внеочередное исполнение операций, функциональные устройства
В предыдущем разделе было завершено рассмотрение подсистем процессора, выполняющих подготовку инструкций (операций) к исполнению в функциональных устройствах. Эта подготовка включает в себя выборку инструкций из кэша, их преобразование (декодирование) в промежуточные микрооперации (МОПы), формирование из них групп, содержащих от 3 до 4-5 операций. Включает в себя переназначение (переименование) регистров, выделение требуемых ресурсов и размещение сформированных групп МОПов в буфере переупорядочения, а также в очередях планировщика внеочередного исполнения. В рассмотренных подсистемах обработка операций ведётся в натуральном порядке — в котором инструкции следуют друг за другом при выполнении программы в последовательной модели вычисления. Эти подсистемы обычно объединяют под названием «Front End».
В свою очередь, подсистему внеочередного исполнения операций вместе с функциональными устройствами объединяют под названием «Back End», чтобы подчеркнуть её обособленность и самостоятельность. Внутри этой подсистемы обработка операций ведётся асинхронно, с учётом зависимостей между ними, готовности операндов и наличия требуемых ресурсов (устройств и очередей). При внеочередной обработке операций в этой подсистеме гарантируется, что результаты такого выполнения программы совпадут с результатами «правильного» последовательно выполнения.
Отставка выполненных машинных инструкций после их выхода из подсистемы внеочередного исполнения производится строго последовательно. Таким образом, восстанавливается натуральный порядок следования операций. Говорить о внешнем, или архитектурном состоянии программы можно только с позиции последней машинной инструкции, покинувшей блок отставки. При возникновении какого-либо прерывания все последующие инструкции будут считаться невыполненными, вне зависимости от действительного состояния их выполнения. При выходе из прерывания все эти инструкции будут повторно исполнены с самого начала.
В данном разделе будет рассмотрена организация подсистемы внеочередного исполнения операций и характеристики функциональных устройств, в которых эти операции выполняются. Структура этой подсистемы связана с устройством подсистемы декодирования инструкций, особенно для процессоров с фиксированной привязкой позиции МОПа в сформированной группе к номеру очереди планировщика и функционального устройства (AMD K8, IBM PPC970). Поэтому характеристики этих двух подсистем тесно переплетаются.
Процессоры будут рассматриваться по компаниям-производителям: сначала процессоры компании Intel в порядке следования поколений (Pentium III и его производные, Pentium 4 и новый процессор Intel Core), затем — процессоры компаний AMD (Athlon 64 / Opteron) и IBM (PowerPC 970).
Intel Pentium III, Pentium M и Core Duo
После выхода из декодера сформированные группы по три МОПа помещаются в буфер переупорядочения ROB, длина которого составляет 40 элементов (начиная с процессора P-M размер буфера ROB, по некоторым данным, увеличен до 60-80 элементов). Новая группа МОПов также копируется в очередь планировщика RS, из которой операции будут запускаться на исполнение. В процессоре P-III используется единая очередь планировщика размером в 20 элементов (начиная с процессоры P-M — 24 элемента), общая для всех типов операций. МОПы выбираются на исполнение из этой очереди во внеочередном порядке, по мере готовности аргументов операций (Рис. 5).
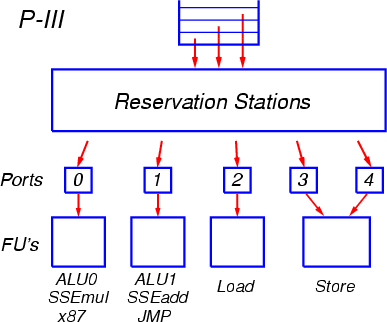
Рис. 5
МОПы отправляются на исполнение через так называемые порты запуска. Всего таких портов пять: два для арифметико-логических операций, и три — для операций вычисления адресов и для загрузки/выгрузки. К каждому из портов подсоединены соответствующие функциональные устройства.
Порт 0 обслуживает устройства целочисленной арифметики и логики, включая блоки для выполнения умножения и деления, а также устройства арифметики с плавающей точкой x87 и устройство умножения SSE. К порту 1 подсоединено другое устройство целочисленной арифметики и логики, частично дублирующее аналогичное на порту 0, устройство для выполнения переходов, а также устройства сложения и некоторых дополнительных операций SSE.
Начиная с процессора P-M, операции умножения и сложения с плавающей точкой x87 разнесены по разным портам (по аналогии с операциями SSE): умножение осталось на порту 0, а сложение переведено на порт 1. Также добавлены операции SSE2 с аналогичным распределением между портами.
К портам 2 и 3 подсоединены устройства вычисления адресов для операций загрузки из памяти и выгрузки в память, а к порту 4 — собственно устройство выгрузки, готовящее данные для отсылки в память.
В процессоре P-III при декодировании инструкций загрузки из памяти с последующим исполнением (Load-Op) порождаются отдельные МОПы для загрузки и для выполнения. Оба этих МОПа помещаются в буфер переупорядочения ROB и в очередь планировщика RS и обслуживаются по отдельности. Начиная с процессора P-M, в декодере реализован механизм «слияния микроопераций» (micro-ops fusion), когда порождается единый МОП, содержащий два элементарных действия. Разделение на эти элементарные действия, или микрооперации, происходит при их запуске на исполнение (диспетчеризации) из очереди планировщика. Сначала запускается микрооперация загрузки (через порт 2), а затем, в преддверии готовности операнда — функциональная микрооперация (через порт 0 или 1).
Аналогично операциям загрузки, для инструкций выгрузки в память в процессоре P-III также порождаются два отдельных МОПа: для вычисления адреса, и для осуществления записи. Эти МОПы запускаются (диспетчеризуются) по отдельности, соответственно через порты 3 и 4. Начиная с процессора P-M, для инструкций выгрузки порождается единый МОП, который разделяется на микрооперации при запуске на исполнение.
Механизм слияния микроопераций позволяет экономить ресурсы буферов внеочередного исполнения (ROB и RS), имеющих ограниченный размер, и увеличить эффективную пропускную способность трактов процессора. Этот механизм слияния похож на аналогичный механизм в процессорах AMD K7/K8, когда любой МОП может содержать в себе как операцию загрузки из памяти (выгрузки в память), так и функциональное действие.
Через каждый из пяти портов может отсылаться на исполнение по одной операции за такт. Таким образом, очередь планировщика представляет собой полностью ассоциативный буфер с довольно сложной организацией. В каждом такте может производиться поиск и извлечение до пяти элементов (МОПов) из этого буфера, и одновременно в него может быть помещено три новых МОПа. Для отправки на исполнение в буфере ищутся операции, аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания в функциональное устройство. Если для какого-то порта найдено несколько таких готовых операций, среди них выбирается одна по алгоритму «псевдо-FIFO» (First In, First Out). Этот алгоритм отдаёт предпочтение самым старым операциям, однако выполняет поиск не совсем строго и точно, что связано со сложностью реализации алгоритма с точным соблюдением старшинства. В результате может оказаться, что 100-процентная скорость выполнения потока инструкций не достигается даже при оптимальном потактовом планировании машинных инструкций программистом или транслятором из-за того, что не в каждом такте через порты 0 и 1 запускаются две операции.
Механизм внеочередного исполнения операций с единой очередью планировщика был разработан для первого процессора семейства P6 в 1995 году. Другие семейства процессоров с внеочередным исполнением (AMD K7/K8, Intel P-4, IBM PPC970) используют раздельные очереди планировщиков для различных групп функциональных устройств. В результате удаётся, как правило, избегать необходимости выбора сразу нескольких операций из очереди в одном такте. Как следствие, при оптимальном планировании машинных инструкций для всех этих процессоров удаётся добиться предельной скорости выполнения операций.
Латентность большинства операций целочисленной арифметики составляет 1 такт, а их суммарный темп исполнения — 2 операции за такт, по одной в устройствах, подсоединённых к портам 0 и 1. Некоторые операции (сложения/вычитания и копирования, а также логические) могут выполняться в устройствах на обоих портах. Также в каждом такте может быть произведено одно считывание из L1-кэша и одна запись в L1-кэш (64-разрядные).
Операции арифметики с плавающей точкой x87 выполняются в соответствующем устройстве на порту 0 (начиная с процессора P-M — в раздельных устройствах на портах 0 и 1). Операции сложения FADD могут стартовать в каждом такте, а операции умножения FMUL — с интервалом в 2 такта. Чередуя сложение и умножение, можно получить суммарный темп выполнения, равный одной операции за такт. Латентность операции сложения составляет 3 такта, умножения — 5 тактов.
Операции перестановки регистров x87 в стеке (FXCH) отрабатывают на стадии переименования регистров и поэтому не попадают в очереди планировщика и в функциональные устройства. Темп обработки таких операций равен трём за такт.
Скалярные операции SSE исполняются в полном темпе, упакованные операции — в половинном. Это связано с тем, что каждая упакованная инструкция SSE преобразуется в два МОПа. С учётом чередования сложения и умножения, суммарный темп выполнения составляет два МОПа за такт, что соответствует четырём 32-битным арифметическим операциям для упакованного режима. Латентность операций сложения и умножения SSE составляют соответственно 3 и 4 такта.
Операции сложения в 64-битном режиме SSE2 (начиная с процессора P-M) также выполняются в полном темпе с латентностью 3 такта, а операции умножения — в половинном темпе с латентностью 5 тактов. Таким образом, суммарный темп выполнения таких операций при чередовании сложения и умножения составляет один МОП за такт. Это в два раза ниже, чем в конкурирующих процессорах архитектуры x86 (P-4 и K8), и в четыре раза ниже, чем в процессоре PPC970 и новом процессоре Intel Core (P8). На практике на процессоре P-III удаётся добиться уровня в 0.9-0.95 арифметической операции SSE2 за такт.
Таким образом, в процессоре P-III имеется ряд недостатков, ограничивающих его производительность. Главным из них является слабость блока плавающей арифметики при работе в 64-битном и 80-битном режимах (SSE2 и x87). Другим недостатком являются ограничения в планировщике, которые не позволяют достичь полной скорости работы функциональных устройств. Некоторые ограничения микроархитектуры преодолёны в процессорах P-M и P-M2 (Core Duo).
Intel Pentium 4
После считывания из T-кэша группы по три МОПа помещаются в буфер переупорядочения ROB, длина которого составляет 126 элементов. Новая группа МОПов также копируется в очереди планировщика для последующей отправки на исполнение.
Очереди планировщика в процессоре P-4 выполнены в виде двухуровневой структуры. Сначала МОПы распределяются по двум предварительным очередям. В одну очередь помещаются МОПы операций загрузки и выгрузки, требующих вычисления адреса для обращения в память, в другую — обычные МОПы. Выборка МОПов из этих очередей и передача их на следующие этапы обработки может осуществляться с разной скоростью, что позволяет, например, начать обрабатывать МОПы обращения к памяти раньше, чем МОПы обычных операций. Таким образом, эти две очереди выполняют амортизирующую функцию перед помещением МОПов в очереди, которые привязаны к функциональным устройствам и из которых операции отсылаются на исполнение (Рис. 6).
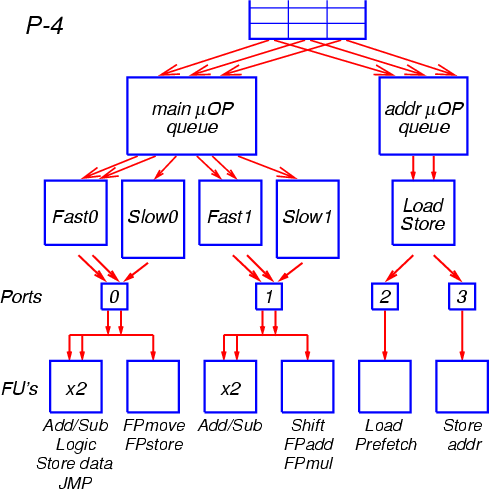
Рис. 6
Всего таких очередей пять: две очереди для операций, запускаемых в удвоенном темпе (Fast0 и Fast1), две очереди для операций, запускаемых в обычном темпе (Slow0 и Slow1), и очередь для операций загрузки и выгрузки. Первые четыре очереди соединены с предварительной (амортизирующей) очередью для обычных операций, последняя — с предварительной очередью для операций обращения к памяти.
По мере готовности операндов МОПы из этих очередей отправляются на исполнение в соответствующие функциональные устройства. Отправка операций происходит через так называемые порты запуска. К порту 0 подсоединены очереди Fast0 и Slow0, к порту 1 — очереди Fast1 и Slow1, к портам 2 и 3 — очередь для операций загрузки и выгрузки. Через порты 0 и 1 могут запускаться на исполнение по две операции в каждом такте (в начале такта — из очереди Slow либо Fast, в середине такта — только из очереди Fast). Таким образом, всего в каждом такте на исполнение может быть отправлено до шести операций. Это вдвое превышает темп поступления операций из T-кэша и темп отставки операций (по три МОПа за такт).
К порту 0 подсоединены функциональное устройство целочисленной арифметики и логики, работающее в удвоенном темпе, а также устройство, выполняющее операции пересылок и выгрузки в память для арифметики с плавающей точкой. Порт 1 обслуживает целочисленное устройство с удвоенным темпом работы, частично дублирующее аналогичное устройство на порту 0 и выполняющее операции сложения/вычитания и копирования, а также устройство сдвигов и основное устройство плавающей арифметики, выполняющее арифметические операции x87, MMX и SSE. К порту 2 подсоединено устройство загрузки из памяти, а к порту 3 — устройство вычисления адресов для операций выгрузки в память.
Организация системы внеочередного исполнения инструкций в виде многоуровневой структуры с раздельными очередями для разных групп функциональных устройств позволяет обеспечить работу процессора на повышенной тактовой частоте за счёт того, что на каждом этапе при работе с очередями и устройствами выполняются только простые действия. Например, для распределения трёх новых МОПов в амортизирующие очереди требуется просто скопировать каждый МОП в конец нужной очереди. Для перемещения МОПов из этих очередей в очереди (буфера) планировщика нужно выбрать соответствующую очередь по типу операции, а в случаях, когда подходят две очереди (Fast0 и Fast1 для сложения/вычитания и копирования) — принять решение, исходя из требования равномерной загрузки очередей. Для выбора инструкции, отсылаемой на исполнение, нужно просмотреть очереди, приписанные к данному порту, и найти в них МОП, готовый к исполнению (т.е. такой МОП, все операнды которого уже вычислены либо ожидаются к нужному моменту) с учётом готовности функциональных устройств. При наличии нескольких готовых МОПов выбирается самый старый. Эти действия проводятся независимо в каждом порту. Порты 0 и 1 работают на удвоенной частоте.
В связи с повышенной тактовой частотой, особенно с учётом работы двух портов на удвоенной частоте, в процессоре P-4 применён нестандартный подход для осуществления диспетчеризации (отсылки МОПа на исполнение).
Принятие решения о диспетчеризации в любом процессоре проводится за некоторое время до попадания операции в функциональное устройство. Это связано в первую очередь с тем, что операнды МОПа должны быть предварительно считаны из регистров (либо приняты из других функциональных устройств, от результатов работы которых зависит данная операция). Поэтому между моментами диспетчеризации и запуска на исполнение имеется один или несколько промежуточных этапов — обозначим их количество как N1. В свою очередь, продолжительность выполнения операции в функциональном устройстве может составлять один или несколько тактов — обозначим их число как N2. По завершении операции её результат может быть немедленно передан на вход другой операции, зависимой от этой, непосредственно перед началом её исполнения в функциональном устройстве. Непосредственно перед попаданием любой операции в функциональное устройство производится окончательная проверка готовности ожидаемых операндов. В случае их неготовности (например, из-за отсутствия считываемых данных в L1-кэше) операция помечается как недействительная, МОП этой операции не удаляется из очереди планировщика, и результаты её выполнения никуда не передаются.
Рассмотрим теперь следующий пример. Предположим, что некая операция поступает в функциональное устройство (ФУ), и результат её выполнения является операндом другой (зависимой) операции. Для наиболее эффективного исполнения потока операций необходимо, чтобы эта зависимая операция прошла диспетчеризацию через N2 тактов после первой и стартовала в функциональном устройстве тоже через N2 тактов после первой. В этом случае результаты первой операции будут готовы (на выходе из ФУ) как раз к тому моменту, когда вторая операция попадёт на вход в ФУ. Однако в силу того, что первая операция тоже могла зависеть от прихода каких-то других данных, вторая операция должна быть диспетчеризована не ранее, чем будет подтверждена готовность операндов для первой (чтобы гарантировать корректность её результатов, необходимых для исполнения второй операции). Так как между моментами диспетчеризации и проверки готовности (запуска) проходит N1 тактов, для соблюдения данного условия требуется выполнение неравенства N1<=N2. Например, в процессоре AMD K8 для операций ALU/AGU N1=N2=1, а для операций FPU N1=N2=2 (здесь указаны минимальные значения N2).
В процессоре P-4 время выполнения самых коротких операций составляет всего 0.5 такта (за счёт работы соответствующих ФУ на удвоенной частоте). За такое короткое время невозможно произвести все необходимые подготовительные действия перед запуском операции в ФУ. Поэтому неравенство N1<=N2 не выполняется, и диспетчеризация зависимой операции может быть проведена до подтверждения готовности операндов операции, от которой она зависит. Разумеется, перед попаданием в ФУ любая операция, не получившая операндов, будет помечена как недействительная. Однако подобный «холостой» запуск (с необходимостью повторного исполнения в будущем) будет произведён не только для первой операции, которая не успела своевременно получить свои операнды, но и для второй, которая от неё зависит (так как решение о её запуске уже принято), а также для всех последующих операций в «зависимой цепочке» — при условии, что они поступают в очередь планировщика плотным потоком, без достаточных временных интервалов.
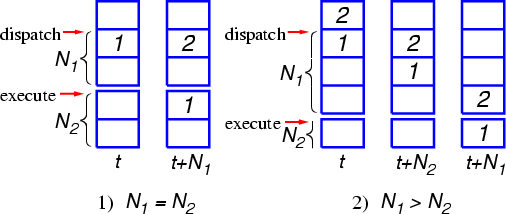
Рис. 7
На Рис. 7 показаны примеры для случаев N1=N2 (слева) и N1>N2 (справа). В первом случае диспетчеризация операции 2 производится корректно, в тот момент, когда операция 1 попадает в ФУ. Во втором случае диспетчеризация операции 2 производится в момент времени t+N2, то есть раньше, чем операция 1 попадёт в ФУ (это произойдёт позднее, в момент времени t+N1).
Точное значение числа промежуточных этапов конвейера в процессоре P-4 неизвестно, но для примера можно предположить, что оно равно трём для обычных операций (это согласуется со схемой конвейера, приведённой в документации по процессору), и шести — для операций, исполняемых на удвоенной частоте. Если сохранять все диспетчеризованные операции в очередях (буферах) планировщика, как это делается в традиционных процессорах, и удалять их оттуда только в момент успешного запуска на исполнение, то длину каждой очереди придётся увеличить как минимум на шесть (сверх нынешней длины, равной восьми для очередей Fast0 и Fast1).
Поскольку для порта запуска такая очередь является полностью ассоциативным буфером, поиск и извлечение нужного элемента из которого нужно осуществить всего за половину такта, подобное усложнение разработчики сочли неоправданным. Вместо этого они реализовали альтернативную схему. Суть её заключается в том, что в момент диспетчеризации МОП удаляется из очереди планировщика, но его копия помещается в другую очередь, представляющую собой линию задержки с продвижением МОПа вдоль неё в каждом такте (полутакте). Если к моменту прихода МОПа в ФУ подтверждается его корректность (то есть готовность всех операндов), то соответствующий ему элемент удаляется из линии задержки. В противном случае он продолжает продвижение по ней и через предусмотренное число тактов вновь поступает на вход функционального устройства для повторного исполнения. Поскольку основной причиной неготовности данных является их отсутствие в L1-кэше, то в большинстве случае достаточно задержать соответствующую инструкцию (а также все зависимые от неё) на промежуток времени, достаточный для считывания этих данных из L2-кэша. Поэтому и дополнительная длина линии задержки выбрана равной времени выборки из L2-кэша.
Механизму отсылки некорректных операций в линию задержки на фиксированный промежуток времени с их последующим безусловным запуском на исполнение разработчики дали название «реплей» (replay), а линии задержки назвали «петлями реплея». Этот механизм кажется простым и элегантным выходом из положения в ситуации, когда N1>N2. Он не избавляет от необходимости перевыполнять все операции в зависимой цепочке, однако экономит ресурсы и упрощает организацию системы внеочередного исполнения, позволяя тем самым обеспечить работу на повышенной тактовой частоте (и даже на удвоенной частоте). Однако работа этого механизма может привести к повторным попаданиям инструкции в петлю реплея в случаях, когда данные не оказались доступными после завершения первой петли. Например, при отсутствии требуемых данных в L2-кэше может потребоваться многократное прохождение петли реплея в ожидании их считывания из памяти. Несмотря на то, что повторные петли реплея выполняются с большим периодом, это может привести к неоправданному расходу ресурсов планировщика и ФУ (данная проблема частично снята в процессоре P-4E, где зависимые цепочки МОПов, ожидающих данных из памяти, перемещаются в отдельную асинхронную очередь). Другая неприятность связана с тем, что последующие МОПы в зависимой цепочке могут вовлекаться в реплей даже, несмотря на то, что начальные МОПы уже получили свои данные и корректно выполнились. Причиной этому является то обстоятельство, что каждый конкретный МОП зависит только от своего непосредственного предшественника в зависимой цепочке. Подобные эффекты многократного прохождения МОПов по петлям реплея получили в литературе название «торнадо».
Система реплея в процессоре P-4, а также все связанные с ней эффекты обстоятельно описаны в статье [5]. Согласно данным авторов этой статьи, число МОПов, попавших на повторное исполнение (однократное либо многократное), может достигать на реальных приложениях 35 процентов от общего числа операций в программе (этот пример соответствует программе-архиватору RAR, исполняемой на процессоре P-4 Northwood). В других программах этот показатель ниже. В программах с использованием плавающей арифметики реплей наблюдается намного реже. В процессоре P-4E (Prescott) проведён ряд серьёзных модификаций, позволивший во многих случаях заметно снизить попадания операций в петли реплея. Помимо основного эффекта от реплея, наблюдается и побочный в случаях двухпоточного исполнения процессов в режиме HyperThreading. В этом случае один процесс, подверженный частому реплею, может снижать производительность другого процесса из-за того, что он занимает функциональные устройства процессора.
Количественно оценить влияние данной реализации системы реплея на производительность довольно трудно. Процессор P-4 имеет избыточное количество функциональных устройств, позволяющих, например, выполнять по четыре целочисленные операции в каждом такте (при темпе работы трактов выборки и отставки инструкций, равном трём). Такая избыточность позволяет несколько сгладить отрицательные эффекты. Кроме того, исполнение петли реплея при отсутствии данных в L1-кэше может происходить в момент неизбежного простоя устройств процессора, что тоже несколько нейтрализует потери. Поэтому нельзя сделать однозначных выводов о масштабе снижения производительности. Наверное, как и для других подсистем процессора P-4, можно предположить, что данная система работает эффективно на оптимизированных программах, в которых упорядочены обращения к иерархиям памяти и аккуратно спланированы зависимые операции. А на программах, содержащих большое число плотных зависимых цепочек, косвенных ссылок, нерегулярных условных переходов и косвенных переходов по меняющимся адресам, может проявляться определённое снижение производительности, обусловленное реплеем и его следствиями.
Перейдём теперь к рассмотрению функциональных устройств.
В процессоре P-4 большинство операций целочисленной арифметики выполняется в устройствах, работающих на двойной частоте (Double Pumped ALU). Таких устройств два, они подсоединены к портам 0 и 1, и операции для них выбираются из очередей Fast0 и Fast1. Латентность этих операций (время выполнения в зависимых цепочках) составляет всего 0.5 такта. Для того чтобы обеспечить такую низкую латентность, каждое их этих двух 32-битных арифметико-логических устройств реализовано в виде двух отдельных 16-битных подустройств, обрабатывающих соответственно младшие и старшие 16 разрядов операндов. Из-за возможного переноса разрядов из младшей половины слова подустройство обработки старшей половины работает с временным сдвигом на полтакта. Таким образом, старт-стопное время выполнения операции составляет целый такт (два полутакта). Однако выполнение новой операции, зависящей от результатов текущей, начинается немедленно после получения младшей половины слова. Это правило распространяется также на логические операции, пересылки и чтение из памяти. Таким образом, операция обращения к памяти начинает выполняться, не дожидаясь готовности старших 16 разрядов адреса — поиск данных в L1-кэше начинается на основе младших 16 разрядов. Благодаря этому, полное время считывания данных из кэша составляет всего 2 такта.
Описанный единообразный подход к выполнению большинства простых операций обеспечивает латентность 0.5 такта при достижении темпа 4 операции за такт. Такой подход к реализации 32-битных устройств в виде двух отдельных 16-битных блоков можно назвать пространственно-временным параллелизмом. Этот подход применён в процессоре P-4 впервые. Новый подход дополняет практиковавшиеся ранее подходы пространственного параллелизма (использование двух одинаковых блоков для одновременной обработки операндов или симметричных частей операнда) и временного параллелизма (использование одного блока для их последовательной обработки). Отметим, что суммарная «ширина» результатов, получаемых из этих устройств в каждом такте, составляет 128 разрядов.
Операции сдвигов обрабатываются отдельно, в так называемом медленном устройстве. Их латентность составляет 4 такта, а темп выполнения — 1 операция за такт. Также в медленном устройстве исполняются целочисленные умножения, деления и другие редкие операции.
В процессоре P-4E (Prescott) организация устройств целочисленной арифметики претерпела определённые изменения. Они по-прежнему работают на удвоенной частоте и могут выполнять до 4 операций за такт, однако латентность 32-битных операций увеличилась до одного такта. Вероятно, каждое из двух устройств (Fast0 и Fast1) реализовано в виде двух отдельных 16-битных подустройств, обрабатывающих половины слова с двойной частотой, но результаты обработки младшей половины используются через полтакта только для вычислений в старшей половине и не передаются немедленно на следующую (зависимую) операцию, как в первоначальном процессоре P-4. Операции сдвигов в новом процессоре также обрабатываться в одном из быстрых устройств (Fast1), с латентностью 1 такт и темпом 2 операции за такт.
По поведению этих функциональных устройств можно было бы предположить, что каждое из них выполнено в виде двух отдельных монолитных 32-битных блоков, работающих на одинарной тактовой частоте и исполняющих операции со сдвигом на полтакта. Однако документация однозначно указывает на реализацию в виде 16-битных подустройств удвоенной частоты, не раскрывая деталей этой реализации. В любом случае, здесь разработчики отказались от пространственно-временного параллелизма в пользу чисто пространственного, когда результат передаётся из функционального устройства не по частям, со сдвигом на полтакта, а целиком и сразу.
В процессоре P-4E также увеличилось время доступа к L1-кэшу — до 4 тактов. Это связано с увеличением размера и уровня ассоциативности кэша и повышением разрядности мини-тэга, по которому производится быстрый поиск в кэше, а также с удлинением на 0.5 такта этапа подготовки адреса. С учётом меньшей длины такта время доступа к L1-кэшу, выраженное в «нормализованных» тактах (с соотношением 1:1.4), составит всего 1.5 такта для первоначального процессора P-4, и 3 такта для процессора P-4E.
Обработка 64-битных операций в режиме EM64T (x86-64) в процессоре P-4E производится по схеме, аналогичной описанной выше для 32-битных операций в процессоре P-4: каждое их двух 64-битных арифметико-логических устройств реализовано в виде двух отдельных 32-битных подустройств, обрабатывающих соответственно младшие и старшие 32 разряды операндов (с временным сдвигом на такт) и работающих на удвоенной частоте. Таким образом, эффективная латентность 64-битных операций также составляет 1 такт, а предельный темп запуска — 4 операции за такт. По такой же разнесённой схеме выполняются и операции сдвигов влево — перенос из младшей половины 64-разрядного слова принимается в старшую половину на следующем такте. Однако циклические сдвиги и сдвиги вправо уже не могут быть выполнены по этой схеме — из-за специфического способа переноса разрядов из старшей половины слова в младшую их латентность увеличилась до 7 тактов.
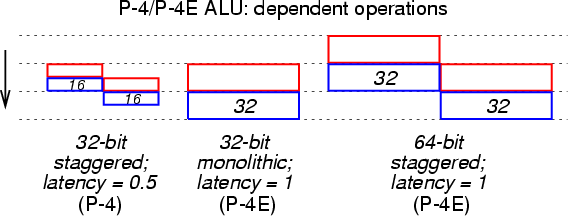
Рис. 8
На Рис. 8 показана схема разнесённого (со сдвигом на 0.5 такта) исполнения 32-битных операций в процессоре P-4, а также схемы монолитного исполнения 32-битных операций и разнесённого (со сдвигом на такт) исполнения 64-битных операций в процессоре P-4E.
Другие функциональные устройства в процессорах P-4 и P-4E реализованы по достаточно традиционной схеме. Операции SSE производятся над 128-разрядными регистрами XMM. Однотипные арифметические и логические операции SSE могут стартовать с интервалом в 2 такта. Чередуя операции сложения и умножения, можно получить суммарный темп выполнения, равный одному 128-битному результату за такт. Для упакованного 32-битного режима SSE это соответствует четырём арифметическим операциям за такт, для 64-битного режима SSE2 — двум операциям за такт, и для скалярных режимов — одной операции за такт. Латентность операций с плавающей точкой SSE/SSE2 составляет 4 такта для сложения и 6 тактов для умножения (в процессоре P-4E — на один такт больше). В режиме x87 операция умножения также выполняется в половинном темпе, а операция сложения — в полном.
В каждом такте может быть произведено одно 128-разрядное считывание из L1-кэша и одна 128-разрядная запись в L1-кэш. Благодаря этому темп работы FPU в упакованном режиме SSE2 в плотных циклах (например, при перемножении матриц) может приближаться к пиковому.
Длины очередей (буферов) планировщика составляют: 10 элементов для очереди Slow0 (пересылки и выгрузка в память для плавающей арифметики), 12 элементов для очереди Slow1 (основные операции плавающей арифметики, а также медленные целочисленные операции) и по 8 элементов для прочих очередей. В процессоре P-4E очереди Slow0 и Slow1 увеличены до 14 и 16 элементов, соответственно. Наиболее важной характеристикой является длина очереди для основных операций арифметики с плавающей точкой (Slow1). Замеры показывают, что эффективная вместимость этой очереди составляет 10 МОПов для процессора P-4, и 13-14 МОПов для P-4E. Отметим, что одна упакованная инструкция SSE отображается в один 128-битный МОП, а не в два 64-битных (как в процессорах P-III, P-M и K8), что повышает эффективную вместимость очередей при использовании упакованного режима.
Эффективный размер окна внеочередного исполнения в процессоре P-4 увеличивается также за счёт двух очередей МОПов, предшествующих основным очередям планировщика. Длина предварительной очереди арифметических МОПов составляет 32 элемента, очереди адресных МОПов — 16 элементов.
Таким образом, P-4 представляет собой высокопроизводительный процессор с глубоким внеочередным исполнением операций. Он работает на повышенной тактовой частоте (примерно в 1.4 раза выше, чем у других процессоров, исполненных по той же технологии) и имеет множество оригинальных микроархитектурных особенностей: удвоенную частоту работы целочисленных устройств, быстрый доступ к L1-кэшу, избыточность функциональных устройств, Т-кэш. Однако имеется ряд особенностей, которые снижают потенциал производительности процессора: выполнение скалярных операций арифметики с плавающей точкой (SSE и x87-FMUL) на половинной частоте, наличие аномалий при доступе к L1-кэшу (алиасинг), большие затраты на отработку подобных аномалий в системе реплея, длинный конвейер, большая схемная сложность и высокое энергопотребление, ограничивающее тактовую частоту. В результате процессор P-4 демонстрирует довольно высокую производительность на хорошо организованных кодах с регулярной структурой, но может уступать конкурентам (AMD K8) в менее оптимизированных приложениях.
Intel Core (P8)
Общая организация подсистемы внеочередного исполнения операций и функциональных устройств в новом процессоре P8 напоминает организацию этой подсистемы в процессорах семейства P6/P6+ (P-III, P-M, P-M2) и представляет собой её дальнейшее развитие. Главное отличие от последних представителей старого семейства (P-M и P-M2) состоит в расширении всех трактов обработки МОПов с трёх до четырёх, удлинении очередей и буферов, увеличении числа портов запуска и функциональных устройств и в существенном повышении скорости работы функциональных устройств плавающей арифметики SSE, а также в реализации 64-битного режима EM64T (x86-64) для целочисленной и адресной арифметики.
На данный момент пока что нет достаточно полной информации о микроархитектуре процессора P8, поэтому рассмотрим работу подсистемы внеочередного исполнения кратко, делая основной упор на её отличия от старой архитектуры.
После выхода из декодера сформированные группы по четыре МОПа помещаются в буфер переупорядочения ROB, длина которого составляет (по некоторым данным) 96 элементов. Новая группа МОПов также копируется в очередь планировщика RS, из которой операции будут запускаться на исполнение. В процессоре P8 используется единая очередь планировщика размером в 32 элемента, общая для всех типов операций. МОПы выбираются на исполнение из этой очереди во внеочередном порядке, по мере готовности аргументов операций (Рис. 9).
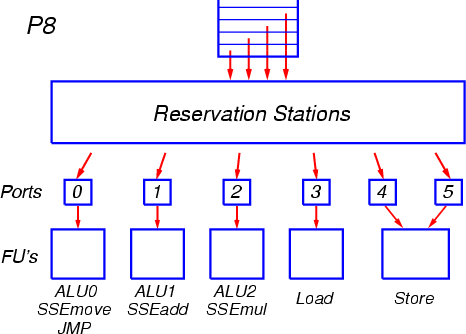
Рис. 9
МОПы отправляются на исполнение через порты запуска. Всего имеется три порта для арифметико-логических операций, и три — для операций вычисления адресов и для загрузки/выгрузки. Каждый из портов обслуживает соответствующие функциональные устройства и может запускать по одной операции за такт.
К каждому из трёх первых портов подсоединены устройства, выполняющие операции целочисленной арифметики и логики, а также некоторые операции MMX и SSE. Самые простые операции могут исполняться в устройствах на всех трёх портах, а операции сдвига и операции целочисленного сложения MMX и SSE — на двух портах. К указанным портам подсоединены также специфические функциональные устройства. На одном из портов находится устройство для выполнения операций перехода (включая объединённые операции сравнения и условного перехода), а также так называемое устройство пересылок для арифметики с плавающей точкой, на другом — устройство сложения с плавающей точкой, и на третьем — устройство умножения и деления с плавающей точкой. Некоторые менее частые арифметические и логические операции также исполняются в специализированных функциональных устройствах на соответствующих портах.
Увеличение числа универсальных устройств с двух до трёх (вместе с увеличением количества портов запуска) позволяет значительно повысить производительность процессора на целочисленных и логических операциях. В сочетании с выносом устройства для выполнения переходов на отдельный порт это позволяет выполнять операции SSE в полном темпе, по две упакованные арифметические операции за такт. При отсутствии дополнительного порта и устройств ALU функциональные устройства SSE простаивали бы в моменты запуска вспомогательных операций и операций перехода, и не достигался бы полный темп.
В новом процессоре активно используется механизм «слияния микроопераций» (micro-ops fusion), когда для инструкций загрузки из памяти с последующим исполнением (Load-Op) порождается единый МОП, содержащий два элементарных действия. Разделение на эти элементарные действия происходит при их запуске на исполнение (диспетчеризации) из очереди планировщика. Аналогичный механизм реализован и для инструкций выгрузки в память, когда порождается единый МОП для операции вычисления адреса и осуществления записи. Данный механизм был введён в процессоре P-M и похож на аналогичный механизм в процессорах AMD K7/K8.
Использование механизма слияния микроопераций снижает количество МОПов, порождаемых декодером. Если бы все обращения в память происходили в рамках инструкций загрузки с исполнением (Load-Op), то тогда пропускная способность процессора ограничивалась бы числом портов запуска арифметико-логических операций и соответствующих функциональных устройств — то есть тремя, и темп обработки МОПов, определяемый остальными трактами процессора и равный четырём, не достигался бы. Однако на практике в силу ограниченности системы команд x86 очень часто используются отдельные инструкции загрузки либо выгрузки, благодаря чему могут быть эффективно загружены все четыре канала обработки. Наличие четвёртого канала особенно важно для эффективного исполнения плотных кодов арифметики с плавающей точкой. Например, при реализации алгоритма перемножения матриц необходимо в каждом такте запускать одну операцию умножения, одну операцию сложения, одну операцию загрузки из памяти и ещё одну операцию (не в каждом такте) для работы с индексами, счётчиками и для организации цикла. Настоящая реализация позволяет организовать такой цикл и обеспечивает возможности для запуска дополнительных вспомогательных операций (например, предвыборки из памяти) без снижения полного темпа работы устройств арифметики с плавающей точкой.
В процессоре P8 имеется только одно устройство для операций перехода, что ограничивает средний темп выполнения переходов одной операцией за такт. По существу это ограничение относится только к несовершённым условным переходам, так как на выполнение одного совершённого перехода требуется в среднем 2 такта (в связи с необходимостью считывания из кэша нового блока инструкций по целевому адресу). Если на каком-то отрезке кода операции перехода встречаются с большей частотой, эти операции будут буферизоваться в очереди планировщика и могут выполняться с некоторой задержкой (по одной за такт). В случае правильного предсказания направления перехода такая задержка не повлияет на время выполнения программы. Это связано с тем, что решение не совершать переход было принято и отработано в момент предсказания, а последующее выполнение операции перехода в функциональном устройстве должно лишь подтвердить его правильность.
Данное ограничение может снизить скорость работы программы только в тех случаях, когда большое число операций перехода (составляющее более одной четверти от общего числа МОПов) встречается в продолжительных циклических участках кода, выполняющихся в полном темпе (4 операции за такт). Следует отметить, что наличие в процессоре только одного функционального устройства для операций перехода является осознанным решением разработчиков, а не принципиальным ограничением микроархитектуры.
Очередь планировщика в процессоре P8 представляет собой единый, полностью ассоциативный буфер с довольно сложной организацией. В каждом такте может производиться поиск и извлечение до шести элементов (МОПов) из этого буфера, и одновременно в него может быть помещено четыре новых МОПа. Для отправки на исполнение в буфере ищутся операции, аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания в функциональное устройство. В процессорах P-III, P-M, P-M2 выбор среди нескольких готовых операций производился по упрощённому алгоритму, в связи с чем предпочтение не всегда отдавалось самым старым операциям. Из-за этого снижалась эффективность выполнения кода даже при оптимальном потактовом планировании машинных инструкций программистом или транслятором. Детали реализации единой очереди планировщика в новом процессоре пока неизвестны. Можно предположить, что алгоритм выборки операций для запуска на исполнения усовершенствован с учётом накопленного опыта.
Выбор организации очереди планировщика в виде единого буфера, общего для всех типов операций, несмотря на сложность реализации, обладает рядом важных преимуществ. Он позволяет обеспечить более сбалансированную загрузку функциональных устройств и избегать ситуаций, когда в одной очереди имеются готовые к исполнению операции, и нет свободных (на данный момент) функциональных устройств, а в другой — нет готовых операций, но есть свободные устройства того же типа. Возможным компромиссом могла бы стать реализация отдельных очередей для арифметико-логических и адресных операций, но в этом случае перед помещением в такие очереди пришлось бы разъединять МОПы операций типа Load-Op, объединяющие два элементарных действия. Это потребовало бы увеличения суммарного размера очередей планировщика без существенного упрощения их структуры.
Латентность большинства операций целочисленной арифметики составляет 1 такт, а их суммарный темп исполнения — 3 операции за такт, по одной в устройствах, подсоединённых к трём первым портам. Латентность операций арифметики с плавающей точкой такая же, как у процессоров семейства P6/P6+: 3 такта для сложения, 4 такта для умножения SSE, и 5 тактов для умножения SSE2 и x87.
Самой важной особенностью процессора P8 является реализация арифметики с плавающей точкой в 128-битных устройствах SSE, работающих в полном темпе. Теперь в каждом такте может быть выполнена одна упакованная операция умножения, одна упакованная операция сложения и одна более простая упакованная операция. Таким образом, предельный темп выполнения арифметических операций FPU соответствует восьми 32-битным операциям за такт для упакованного режима SSE, четырём 64-битным операциям за такт для упакованного режима SSE2, и двум операциям за такт для скалярных режимов SSE (при чередовании умножения и сложения). Для упакованных режимов это вдвое превышает быстродействие конкурирующих процессоров архитектуры x86 (P-4 и K8) в пересчёте на такт, а для скалярных — соответствует процессору K8.
Единственным исключением является режим x87, в котором операции умножения исполняются по-прежнему в половинном темпе (это связано с тем, что все операции x87 имеют повышенную точность и являются 80-битными). По этой причине предельный темп в режиме x87 составит от одной операции за такт (при чередовании умножения и сложения) до полутора (при соотношении одно умножение на два сложения), против двух операций за такт у процессора K8.
Помимо арифметики с плавающей точкой, в новом процессоре очень эффективно реализованы упакованные операции целочисленной арифметики SSE2, также исполняемые в полном темпе. В каждом такте могут быть запущены две 128-битные операции сложения и одна 128-битная операция умножения; латентность этих операций составляет соответственно 1 и 3 такта. Также в каждом такте могут быть выполнены три 128-битные операции копирования регистров XMM с латентностью 1.
Для поддержки высокого темпа вычислений в упакованных режимах увеличена ширина доступа в память. Теперь в каждом такте может быть произведено одно 128-разрядное считывание из L1-кэша и одна 128-разрядная запись в L1-кэш. В целом одного считывания упакованного XMM-регистра за такт достаточно для обеспечения вычислений в режимах SSE/SSE2. Однако для целочисленных операций, а также для скалярных операций SSE темп в одно чтение из памяти за такт может ограничивать скорость выполнения кодов. При реализации плотных вычислительных циклов (например, в алгоритме перемножения матриц) такого темпа может оказаться недостаточно для достижения пиковой скорости работы FPU в упакованным режиме. Это связано с тем, что, помимо одной операции 128-битной загрузки на каждую пару операций умножения и сложения, раз в несколько тактов может потребоваться дополнительная операция загрузки. Данное требование может снизить предельно достижимый темп работы FPU до 85-90 процентов от пикового, либо может потребоваться более сложная схема раскрутки циклов для снижения числа обращений к памяти. Тем не менее, даже при неполной загрузке FPU процессор P8 становится лидером по пропускной способности в упакованных режимах SSE/SSE2 среди процессоров x86.
Таким образом, процессор новой архитектуры представляет собой достаточно сбалансированный продукт, имеющий высокую скорость исполнения инструкций для различных типов приложений, ориентированных как на операции целочисленной арифметики и логики, так и на арифметику с плавающей точкой.
AMD Athlon 64 / Opteron (K8)
После выхода из декодера сформированные группы по три МОПа помещаются в буфер переупорядочения ROB, который может содержать до 24 групп (72 МОПа). Новая группа МОПов также копируется в очереди планировщика, из которых операции будут запускаться на исполнение. В процессоре K8 имеется две очереди (буфера) планировщика: для целочисленных/адресных операций (ALU/AGU), и для операций арифметики с плавающей точкой (FPU). МОПы выбираются на исполнение из этих очередей во внеочередном порядке, по мере готовности аргументов операций (Рис. 10).
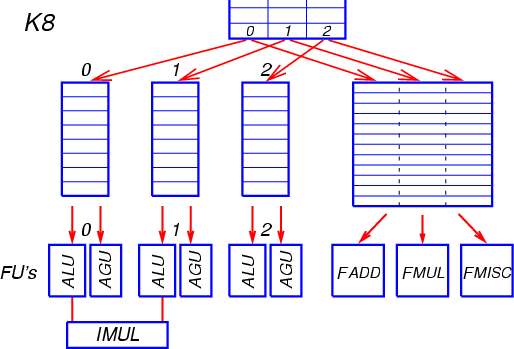
Рис. 10
Очередь (буфер) планировщика для целочисленных и адресных операций состоит из трёх независимых очередей, по одной очереди на каждую позицию МОПа в группе. Длина каждой очереди — 8 элементов. Элемент очереди может содержать 2 РОПа (редуцированные операции, микрооперации), на которые расщепляется МОП — один арифметический и один адресный. Простая целочисленная операция преобразуется только в арифметический РОП, операция типа Load-Op, Op-Store или Load-Op-Store — в арифметический и адресный РОПы, а операция загрузки (Load) или выгрузки (Store) — только в адресный РОП. Также выделяется элемент очереди для операции с плавающей точкой с загрузкой (Load) или выгрузкой (Store) — для неё тоже заполняется только адресный РОП.
Каждая из трёх очередей связана с двумя отдельными функциональными устройствами, приписанными к этой очереди — целочисленным (ALU) и адресным (AGU). По мере готовности операндов РОПы отсылаются на исполнение в соответствующее устройство. В каждом такте из каждой очереди может быть отправлен на исполнение один арифметический РОП и один адресный РОП (в общем случае из разных элементов очереди). После обработки адресного РОПа в AGU формируется запрос в устройство загрузки/выгрузки (Load/Store Unit) для последующего совершения операции доступа в память. В каждом такте может выполниться до двух операций 64-битной загрузки из L1-кэша либо одна загрузка и одна выгрузка.
МОПы операции целочисленного умножения всегда помещаются декодером в первые две позиции группы и выполняются совместно в двух соответствующих устройствах ALU. В остальном функциональные устройства для каждой из трёх очередей идентичны. Латентность большинства целочисленных операций составляет 1 такт.
Таким образом, позиция МОПа в группе, сформированной декодером, однозначно определяет номер очереди планировщика, в которую он будет помещён, и номер устройства ALU и/или AGU, в которое он будет отправлен на исполнение. Изменение порядка выполнения операций может производиться только в пределах каждой очереди. Жёсткая привязка МОПов к очередям может привести к тому, что готовый к выполнению МОП попадёт в такую очередь, где функциональные устройства заняты обработкой предшествующих операций, в то время как устройства на соседних очередях простаивают. Это приведёт к снижению производительности процессора из-за неполной загрузки устройств и возрастания времени выполнения операций.
Также возможна ситуация, когда одна из очередей переполнена МОПами, ожидающими результатов выполнения какой-то долгой операции — в этом случае новая группа из трёх МОПов не сможет быть размещена в очередях, несмотря на то, что остальные очереди свободны. Правда, вероятность такой ситуации не очень велика — для её появления необходимо, чтобы операции, зависимые друг от друга и образующие цепочку, попадающую в одну очередь, следовали в коде программы с шагом, равным трём. В принципе подобные проблемы могут легко решаться транслятором, который может разносить зависимые операции по разным позициям в формируемых группах МОПов и тем самым обеспечивать более сбалансированное распределение операций по очередям.
Буфер планировщика для операций плавающей арифметики устроен совершенно иначе. Он организован в виде отдельной очереди, состоящей из 12 элементов (строк). Каждая строка состоит из трёх позиций — по одной на каждую позицию МОПа в группе. Если вновь поступившая группа МОПов содержит хотя бы одну операцию с плавающей точкой, то для неё отводится новая строка в буфере. РОПы (микрооперации) плавающей арифметики помещаются в позиции строки, соответствующие позициям исходного МОПа в группе (остальные позиции остаются незанятыми). В отличие от очереди ALU/AGU, эти позиции не связаны с конкретными функциональными устройствами. Функциональных устройств FPU тоже три, но они разделяются по типам — FADD для операций сложения, FMUL для операций умножения, и FMISC — для пересылок и прочих вспомогательных операций.
МОПы плавающей арифметики, содержащие загрузку или выгрузку, попадают и в очередь планировщика ALU/AGU (адресный РОП), и в очередь планировщика FPU (арифметический РОП). Если операция является простой загрузкой и не содержит арифметической части, то в FPU она может выполняться в любом из трёх устройств. Однако это не относится к загрузкам XMM-регистров в режиме SSE — они всегда выполняются в устройстве FMISC. Из-за этого темп в две загрузки за такт в режиме SSE может быть достигнут лишь при чередовании операций простой загрузки (Load) с операциями загрузки с умножением или сложением (Load-Op).
РОПы отсылаются на исполнение в соответствующие функциональные устройства FPU по мере готовности операндов. В каждом такте в каждое устройство может быть отправлен один РОП. Некоторые РОПы могут исполняться в различных функциональных устройствах — в этом случае алгоритм выборки пытается сформировать оптимальный набор операций для запуска на исполнение в текущем такте. Однако в ряде случаев этот алгоритм не может совместить в одном такте две операции, если они могут претендовать на общее функциональное устройство. Например, если есть по одной операции для устройств FADD и FMUL, и три операции универсального типа FADD/FMUL/FMISC, то в одном такте алгоритм запустит операции FADD и FMUL, а в другом — все три универсальные операции, разнеся их по трём устройствам. Аналогично, если есть две операции целочисленного сложения MMX/SSE2 (могут исполняться в устройствах FADD и FMUL) и две операции умножения (только FMUL), то в одном такте запустятся обе операции сложения, а в двух последующих — по одной операции умножения (вместо того, чтобы совместить в двух тактах по одной операции сложения и умножения).
Когда все «непустые» РОПы из строки отправляются на исполнение, эта строка удаляется и очередь укорачивается, освобождая место для новой группы РОПов. Тем самым очередь планировщика FPU по своей организации напоминает игру «Тетрис» — только в ней удаление целой строки происходит при её опустошении (а не при заполнении, как в «Тетрисе»).
Эффективная вместимость очереди планировщика зависит от плотности размещения операций арифметики с плавающей точкой в коде. Для кода, состоящего исключительно из таких операций, формальная вместимость очереди составит 36 РОПов. Однако на практике такая плотность операций FPU недостижима, поскольку в любом алгоритме обязательно будут присутствовать вспомогательные операции для работы с индексами массивов и для организации циклов. Кроме того, часть очереди может быть занята РОПами, которые уже отправлены на исполнение, но ещё не проверены на предмет окончательной готовности операндов (между диспетчеризацией РОПа и его проверкой проходит 2-3 такта). С учётом резервирования одной строки для вновь поступающей группы операций эффективный размер очереди составляет приблизительно 8 элементов. Это соответствует 24 РОПам для идеализированного кода, состоящего из одних операций FPU, и 16 РОПам для более реалистичного кода, содержащего две операции FPU в каждой группе из трех МОПов. Для менее плотного кода вместимость очереди будет ещё ниже, однако в этом случае требования к буферу внеочередного исполнения снижаются. В целом очередь планировщика FPU выглядит как достаточно эффективно организованная «рыхлая» структура с ассоциативным доступом.
Каждое их двух основных устройств плавающей арифметики — сложения (FADD) и умножения (FMUL) — может выполнять одну операцию за такт с латентностью, равной четырём. С учётом того, что для упакованных режимов SSE одна машинная инструкция преобразуется декодером в два МОПа, предельный темп выполнения операций FPU для этого режима совпадает с темпом для скалярного режима и составляет два МОПа за такт (при чередовании операций сложения и умножения). Это соответствует четырём 32-битным арифметическим операциям за такт для упакованных режимов SSE и 3DNow!, и двум операциям за такт для прочих режимов — 64-битного упакованного SSE2 и всех скалярных (x87 и SSE/SSE2). Следует отметить, что на практике во внутреннем цикле возможно достижение уровня только в 1.8-1.9 арифметическую операцию за такт. Это связано с тем, что на каждую пару операций умножения-сложения необходима как минимум одна дополнительная операция загрузки из памяти, что не оставляет места в группах из трёх инструкций для операций организации циклов, предвыборки из памяти и прочих, а также может привести к определённым ограничениям скорости работы декодера.
Таким образом, подсистема внеочередного исполнения операций и набор функциональных устройств в процессоре AMD K8 организованы существенно несимметричным образом, с разделением на блок целочисленной/адресной арифметики ALU/AGU и блок арифметики с плавающей точкой FPU. Это отличает данный процессор от других, не имеющих такого явного разделения. В сочетании со «статическим» разбиением потока МОПов на группы по 3 элемента и с привязкой очередей и функциональных устройств ALU/AGU к позициям этих элементов, такая организация позволила упростить структуру процессора. В результате выделения обработки операций плавающей арифметики в отдельный блок сократилось число этапов конвейера целочисленной обработки, что критично для операций условного перехода (в случаях неправильного предсказания направления перехода). Обратной стороной такой организации является необходимость обеспечения избыточного количества идентичных универсальных функциональных устройств ALU/AGU, а также разнесения МОПов, ожидающих исполнения, на три короткие независимые очереди, что может привести к несбалансированной загрузке устройств и к снижению темпа исполнения операций.
IBM PowerPC 970
После выхода из декодера сформированные группы, содержащие до пяти МОПов каждая, помещаются в буфер переупорядочения. Размер буфера переупорядочения составляет 20 групп (до 100 МОПов). Новая группа МОПов также копируется в очереди планировщика, из которых операции будут запускаться на исполнение.
В процессоре PPC970 имеется большое количество очередей планировщика, специфичных для каждой группы функциональных устройств: 4 очереди для устройств арифметики с плавающей точкой (по 5 элементов каждая), 4 очереди для целочисленной арифметики и для адресных операций (по 9 элементов), 2 очереди для операций с регистрами условий (по 5 элементов), 1 очередь для операций перехода (12 элементов), 2 очереди для операций перестановок в векторном блоке VMX (по 8 элементов), и 2 очереди для арифметических операций VMX (по 10 элементов) (Рис. 11).
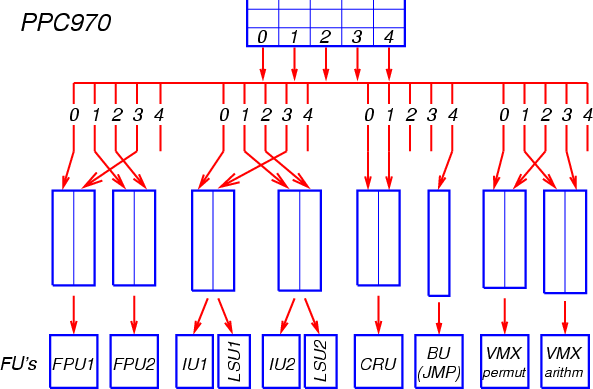
Рис. 11
Каждая из этих очередей соответствует определённой позиции МОПа в группе (от 0 до 4). В позицию 4 (последнюю в группе) декодер помещает только операции перехода. Операции арифметики с плавающей точкой, целочисленные и адресные операции могут располагаться в любой из оставшихся четырёх позиций — для каждой из них предназначена отдельная очередь. Операции с регистрами условий декодер всегда помещает в позиции 0 или 1, операции перестановок VMX — в позиции 0 или 2, арифметические операции VMX — в позиции 1 или 3, и операции целочисленного деления — в позиции 1 или 2. Порядок следования операций внутри группы сохраняется. При необходимости декодер оставляет промежуточные позиции в группе незанятыми, что ведёт к неполному заполнению группы. Таким образом, идея статической привязки МОПов к очередям планировщика и функциональным устройствам доведена в процессоре PPC970 до совершенства.
Все очереди планировщика (кроме единственной очереди для операций перехода) сгруппированы по две, и к каждой такой паре очередей подсоединено соответствующее функциональное устройство. Для запуска на исполнение в каждом такте из такой сдвоенной очереди выбирается самый старый из МОПов, аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания в функциональное устройство. Из каждой сдвоенной очереди для целочисленных и адресных операций на исполнение может быть отправлено два МОПа — по одному в соответствующее арифметическое (IU1/IU2) и адресное (LSU1/LSU2) устройства. Из каждой сдвоенной очереди FPU на исполнение отправляется один МОП — в соответствующее устройство FPU1/FPU2. По существу, каждая пара очередей проявляет себя как единая очередь двойного размера.
Очереди для устройств FPU и IU/LSU сгруппированы таким образом, что позиции МОПа в группе 0 и 3 соответствуют одному устройству, а позиции 1 и 2 — другому. Это сделано для того, чтобы МОПы по возможности равномерно распределялись между устройствами и обеспечивалась сбалансированная загрузка последних. Для избежания дисбаланса в загрузке устройств транслятор или программист должны придерживаться определённой дисциплины при генерации инструкций. Например, МОПы одного типа должны располагаться с дополнительным интервалом в одну позицию — в этом случае они попадут в разные пары очередей и, соответственно, в различные устройства. Если же допускать размещение МОПов одинакового типа по соседству, то может оказаться, что они оба попадут в одну очередь. В неудачном случае это может привести к половинной загрузке устройств одного типа, а при случайном распределении средняя загрузка составит 3/4 от оптимальной. Таким образом, правила генерации кода для процессора PPC970 напоминают правила для процессоров архитектуры с очень длинным машинным словом (VLIW), когда каждая позиция инструкции в машинном слове (бандле) привязана к определённому функциональному устройству (такова, например, организация процессоров архитектуры Intel IA-64).
Несбалансированная загрузка функциональных устройств, обусловленная жёсткой привязкой к позициям МОПов в группе, частично компенсируется избыточным количеством этих устройств, а также значительным суммарным размером очередей планировщика. Тем не менее, неплотное размещение МОПов в группах (и, как следствие, в буфере переупорядочения) в сочетании с неполным использованием устройств не позволяют рассматривать PPC970 как процессор, полноценно обрабатывающий по пять операций за такт в двух комплектах основных функциональных устройств. Тесты производительности подтверждают такую оценку.
Производительность процессора на целочисленных операциях ограничивается ещё из-за того, что латентность таких операций составляет 2 такта (а не 1 такт, как в большинстве конкурирующих процессоров). Функциональное устройство успевает выполнить операцию за один такт, но ещё один такт требуется для передачи результата на вход зависимой операции.
Каждое из двух устройств арифметики с плавающей точкой может выполнять одну комбинированную операцию 64-битного умножения со сложением (FMADD) за такт с латентностью 6 тактов. Операции умножения (FMUL) и сложения (FADD) представляют собой упрощённые варианты такой комбинированной операции. Предельный темп выполнения арифметических операций FPU соответствует, таким образом, четырём операциям за такт (при чередовании умножения и сложения). Это вдвое выше, чем у нынешних конкурирующих процессоров (P-4 и K8), и соответствует новому процессору Intel Core (P8). Однако подобный темп достижим только для определённых алгоритмов типа перемножения матриц. На обычной скалярной обработке в основном используются раздельные инструкции FMUL и FADD, поэтому добавочный эффект от комбинированных инструкций FMADD должен быть невелик, и потенциал FPU процессора PPC970 лишь немного превзойдёт аналогичную характеристику конкурентов с полночастотной реализацией скалярных операций (K8 и P8). В свою очередь, при использовании упакованного режима SSE2 процессор P8 будет иметь превосходство в производительности.
В каждом такте может быть произведено два 64-разрядных считывания из L1-кэша и одна 64-разрядная запись в L1-кэш. В целом такого темпа чтения из кэша достаточно для достижения полной производительности FPU. При реализации плотных вычислительных циклов (например, в алгоритме перемножения матриц) могут потребоваться дополнительные операции загрузки из кэша, однако наличие большого числа регистров FPU позволяет в ряде случаев обойти это требование. Поэтому в благоприятных случаях темп работы FPU может вплотную приближаться к пиковому.
Помимо обычного FPU, в процессоре PPC970 имеется отдельный блок векторных операций VMX, работающий со 128-битными регистрами, содержащими по четыре 32-битных числа с плавающей точкой. В этом блоке в каждом такте может стартовать одна комбинированная операция умножения со сложением, производящая действия над упакованными операндами. Предельный темп работы блока VMX составляет восемь 32-битных арифметических операций за такт, что соответствует процессору Intel Core (P8) для упакованного режима SSE. Блок VMX содержит также независимое устройство для операций перестановок, которое может повысить эффективность работы с упакованными операндами.
Таким образом, процессор PPC970 имеет хороший потенциал производительности, особенно для арифметики с плавающей точкой. Однако из-за статической привязки очередей и устройств к позициям МОПов он не очень хорошо сбалансирован. Поэтому эффективная загрузка функциональных устройств вызывает затруднения, а неплотное размещение МОПов в буферах уменьшает эффективный размер этих буферов и ограничивает возможности внеочередного исполнения. В результате реальная производительность процессора на приложениях с не очень регулярной структурой оказывается недостаточно высокой.
Продолжение следует…
Список литературы
- O. Bessonov, D. Fougere, B. Roux. Development of efficient computational kernels and linear algebra routines for out-of-order superscalar processors. Future Generation Computer Systems, V.21, No.5, 2005, pp.743-748.
- A. Fog. How to optimize for the Pentium family of microprocessors. 2004.
- M. Milenkovic, A. Milenkovic, J. Kulick. Demystifying Intel Branch Predictors. Proceedings of the Workshop on Duplicating, Deconstructing and Debunking, 2002.
- О. Бессонов. Pentium 4: Мистический и загадочный Trace-кэш. Ф-Центр, 2005.
- Я. Керученько, Ю. Малич, В. Левченко. Replay: неизвестные особенности функционирования ядра Netburst. Ф-Центр, 2005.
- В. Картунов. Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Ф-Центр, 2005.
- О. Бессонов. Новое вино в старые мехи. Conroe: внук процессора Pentium III, племянник архитектуры NetBurst? iXBT.com, 2005.
- О. Бессонов. Двухъядерный процессор Yonah: уже не Pentium III, ещё не Conroe. iXBT.com, 2006.
- H.H. Sean Lee. P6 & NetBurst Microarchitecture. School of ECE, Georgia Institute of Technology, 2003.
- IA-32 Intel Architecture Optimization Reference Manual. Intel, 2006.
- IA-32 Intel Architecture Software Developer's Manual. Intel, 2006.
- Intel Architecture Optimization Reference Manual. Intel, 1999.
- J. Keshava, V. Pentkovski. Pentium III Processor Implementation Tradeoffs. Intel Technology Journal, V.3, Q2, 1999.
- G. Hinton et al. The Microarchitecture of the Pentium 4 Processor. Intel Technology Journal, V.5, Q1, 2001.
- S. Gochman et al. The Intel Pentium M Processor: Microarchitecture and Performance. Intel Technology Journal, V.7, Issue 2, 2003.
- S. Gochman et al. Introduction to Intel Core Duo Processor Architecture. Intel Technology Journal, V.10, Issue 2, 2006.
- D. Boggs et al. The Microarchitecture of the Intel Pentium 4 Processor on 90nm Technology. Intel Technology Journal, V.8, Issue 1, 2004.
- B. Valentine. Inside the Intel Core Microarchitecture. Intel Developer Forum, 2006.
- B. Inkley. Inside the Intel Core Microarchitecture. Intel Developer Forum, 2006.
- D. Kanter. Intel's Next Generation Microarchitecture Unveiled. Real World Technologies, 2006.
- Instruction length decoder for generating output length indicia to identity boundaries between variable length instructions. United State Patent 5,758,116, 1998.
- Software Optimization Guide for AMD64 Processors. AMD, 2005.
- В. Картунов. Детальное исследование архитектуры AMD64. iXBT.com, 2003.
- H. de Vries. Understanding the detailed Architecture of AMD's 64 bit Core. Chip-Architect, 2003.
- D. Kanter. AMD's K8L and 4x4 Preview. Real World Technologies, 2006.
- J. Tendler et al. POWER4 system microarchitecture. IBM Journal of Research and Development, V.46, No.1, 2002.
- Tom R. Halfhill. IBM Trims Power4, Adds ALTIVEC. 64-Bit PowerPC 970 Targets Entry-Level Servers and Desktops. Microprocessor Report, Oct.28, 2002.
- J. Stokes. Inside the PowerPC 970. Part II: The Execution Core. Ars Technica, 2003.
- С. Гарматюк. Современные десктопные процессоры архитектуры x86: общие принципы работы. iXBT.com, 2006.


