Новое вино в старые мехи
Итак, на днях произошло давно ожидаемое событие — корпорация Intel объявила на форуме IDF о создании микроархитектуры процессоров IA-32 (x86) следующего поколения. Новая микроархитектура будет единой для всех трёх классов процессоров: мобильных, десктопных и серверных. Основными отличительными признаками новых процессоров является двухъядерность, поддержка 64-битового режима EM64T (x86-64), активное использование энергосберегающих технологий и внедрение «звёздных технологических расширений» (*Ts, Star Technologies), отработанных в последних версиях процессоров Pentium 4 и Pentium M. Первые варианты новых процессоров — мобильный Merom, десктопный Conroe и серверный Woodcrest — появятся в продаже во второй половине 2006 г.

Будучи приверженцем агрессивной рекламной политики, корпорация Intel постаралась представить характеристики своих новых процессоров в наиболее эффектной форме. На этот раз в качестве основного козыря была выбрана такая величина, как отношение производительности к потребляемой мощности (Performance/Watt) в сравнении с предыдущими моделями процессоров. Конечно, данная характеристика несколько сбивает читателя с толку — однако она всё же в состоянии дать общее представление о производительности процессора.
Что побудило Intel разработать новую архитектуру? Основные причины очевидны: это и чрезмерное повышение энергопотребления (и, как следствие, тепловыделения) процессоров семейства Pentium 4, и возникшая в этой связи мода на «экономичные» процессоры, и остановка эволюционного роста тактовых частот, вынудившая разработчиков приступить к созданию двухъядерных процессоров и к внедрению их сначала в общественное сознание, а затем и на массовый рынок. Вероятно, данный список можно дополнить ещё и таким неочевидным фактором, как нелюбовь (вполне оправданная экономически!) разработчиков матобеспечения к оптимизации своих программ для современных высокочастотных микропроцессоров, в связи с чем эти программы не получают ожидаемого выигрыша в производительности от ключевых архитектурных новшеств CPU (в первую очередь это относится к процессору Pentium 4).
На чём базируется новая архитектура? Это самый интересный вопрос, вызывающий множество субъективных толкований. Если посмотреть на соответствующий слайд из презентации, то можно увидеть, что новая архитектура якобы в равной степени основывается на двух предшествующих: NetBurst (Pentium 4), и Banias (Pentium M).
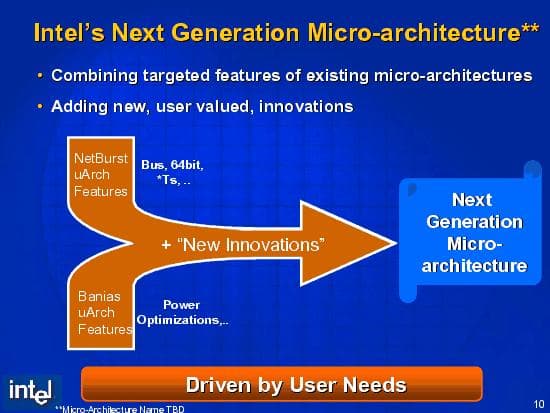
Однако приведённый на слайде список ключевых элементов, заимствованных из этих архитектур, крайне скромен. Он включает только такие позиции, как 64-битовость, «звёздные технологии», энергосбережение да шину, и не охватывает основные микроархитектурные черты. Поэтому определить истинного «предка» новой архитектуры вроде бы затруднительно. Однако достаточно понятно, что NetBurst (Pentium 4) непосредственным «папой» новых процессоров не является — иначе основные выигрышные характеристики этой архитектуры непременно были бы представлены и ярко выделены.
Отсюда возникает вопрос: является ли новая архитектура наследником старого доброго процессора Pentium III (из династии, которую ещё в далёком 1995 г. основал прадедушка Pentium Pro), либо это всё-таки новая архитектура, пусть и базирующаяся на основных принципах P-III? Является ли она шагом назад — или это всё же шаг вперёд? Чтобы ответить на этот неоднозначный вопрос, придётся рассмотреть под микроскопом те характеристики новых процессоров, которые были скупо представлены на презентациях, и проанализировать основные особенности, достоинства и недостатки предполагаемых предшественников — двух родственных процессоров Pentium III и Pentium M.
Конечно, не так важно, придём ли мы к выводу, что процессор Conroe является переделанным вариантом процессора Pentium M, или решим, что это совершенно новый процессор, который сконструировали с нуля, но во многом наполнили готовыми решениями из предшественника. Главное, чтобы стало понятно, на каких задачах новый процессор сможет выиграть у нынешних, а на каких — не сможет. Ну а придёт ли читатель к выводу, что был сделан «шаг назад, два шага вперёд», или он решит, что Intel топчется на месте — не так уж принципиально. Время всё равно рассудит.
Итак, сделаем предположение, что новая микроархитектура базируется в основном на процессоре Pentium M (и его непосредственном предке Pentium III), и не содержит таких принципиальных элементов архитектуры NetBurst (Pentium 4), как Trace-cache, Replay, форсированная тактовая частота, Hyper-Threading и прочее. Разумеется, многие допущения и выводы являются выражением субъективной точки зрения автора и потому могут оказаться неверными (особенно это касается количественных оценок).
Ниже по тексту процессор Pentium III везде будет обозначаться как P-III, а Pentium M — как P-M. В качестве процессора новой архитектуры будем рассматривать десктопный вариант Conroe как наиболее ориентированный на достижение предельной производительности для известных классов задач.
Основные характеристики новой микроархитектуры
Посмотрим теперь, что говорится о новой микроархитектуре в презентации на форуме IDF.

Говорится о ней совсем немногое, однако из представленных характеристик можно сделать важные выводы:
- «Ширина запуска» увеличена с трёх до четырёх — то есть теперь в каждом такте может декодироваться 4 инструкции x86, порождая до 4-х микроопераций (МОПов); аналогичным образом расширены все последующие тракты процессора, включая блок отставки инструкций (Retirement Unit). Данное расширение является самым важным и должно было потребовать полной переделки процессора (при возможном сохранении его общей идеологии и структуры).
- Эффективная длина конвейера увеличена до 14 стадий. Под этой величиной в документации компании обычно понимается «длина конвейера непредсказанного перехода». У процессора Pentium III она равна 10, Pentium M — 12, а (для сравнения) у процессоров Pentium 4 — от 20 до 30, в зависимости от модели. Как видим, новый процессор относится к классу «короткоконвейерных», что является косвенным подтверждением его родства с семейством P-III/P-M.
- Увеличен размер буферов, связанных с внеочередным исполнением инструкций (Out-of-Order execution, OoO), что обусловлено в первую очередь требованием повышения пропускной способности процессора из-за увеличения «ширины запуска».
- Реализован общий (для двух процессоров) кэш 2-го уровня (L2-кэш), увеличена его пропускная способность; обеспечена возможность прямого доступа к L1-кэшу соседнего процессора, что позволит повысить скорость межпроцессорных взаимодействий.
- Улучшена предвыборка данных из памяти (prefetch); усовершенствован механизм разрешения конфликтов по адресам между операциями записи в память и чтения из памяти (memory disambigution).
- Внедрены усовершенствованные технологии энергосбережения.
- Наконец, добавлен режим EM64T (x86-64), что должно было потребовать значительной переделки функциональных устройств целочисленной и адресной арифметики, а также увеличения разрядности регистров и ширины внутрипроцессорных шин.
Основные нововведения, влияющие на производительность процессора, будут рассмотрены ниже при анализе микроархитектуры P-III/P-M.
Процессор Pentium M — непосредственный предшественник Conroe
Общепризнанно, что процессор P-M является эволюционным развитием своего предшественника P-III. Однако он всё же обладает рядом отличительных признаков как количественного, так и качественного характера. Отметим эти признаки, а при дальнейшем рассмотрении будем считать, что все остальные характеристики процессора P-M унаследованы из P-III (и, соответственно, ограничимся в этой части рассмотрением собственно процессора P-III):
- Внедрены радикальные технологии энергосбережения (на них останавливаться не будем, так как нас в основном интересует производительность).
- Увеличены размер и ассоциативность кэшей инструкций и данных 1-го уровня (каждый до 32 Кбайт с ассоциативностью 8) и кэша 2-го уровня (до 2 Мбайт, и также ассоциативность 8).
- Существенно улучшен механизм предсказания переходов с учётом опыта реализации процессора Pentium 4.
- Введена шина процессора Pentium 4 (правда, пока с меньшей частотой — до 533 MHz).
- Добавлен набор инструкций SSE2, что сделало P-M программно совместимым с первыми поколениями процессора Pentium 4.
- Существенно ускорена работа с аппаратным стеком.
- Реализован механизм «слияния микроопераций» (micro-ops fusion) при декодировании машинных инструкций. Суть этого механизма заключается в том, что в ряде случаев вместо двух микроопераций (МОПов) порождается одна (называемая иногда «макрооперацией»), содержащая два элементарных действия. Макрооперация «расщепляется» на эти действия на финальных стадиях прохождения, перед запуском на исполнение в соответствующих функциональных устройствах. Механизм слияния реализован для двух классов инструкций: загрузки из памяти с последующим исполнением (Load-Op), когда одна макрооперация замещает МОПы чтения из памяти и выполнения операции; и выгрузки в память, когда замещаются МОПы вычисления адреса и непосредственной записи операнда в память. Основным положительным эффектом от введения данного механизма является повышение пропускной способности декодера инструкций в связи с тем, что он реализован в процессорах P-III/P-M по схеме «4-1-1»: из трёх параллельно декодируемых x86-инструкций только одна (в первом канале декодера) может порождать более одного МОПа (до четырёх). Слияние микроопераций для инструкций загрузки из памяти с исполнением и выгрузки в память позволяет перевести их в класс «простых» инструкций, обрабатываемых во всех каналах декодера, и тем самым увеличить объём полезной работы, выполняемой за такт, а также снизить число ситуаций, когда декодер работает не в полную силу. Данный механизм слияния похож на аналогичный механизм в процессорах AMD K7/K8, когда любая макрооперация может содержать в себе как операцию загрузки из памяти (выгрузки в память), так и функциональное действие.
Перечисленные усовершенствования позволили значительно повысить производительность процессора P-M в сравнении с P-III, что, наряду с резким снижением энергопотребления, обеспечило ему большой успех в классе мобильных компьютеров. Однако процессор P-M сохранил основные недостатки своего предшественника: невысокий потенциал роста тактовой частоты (по-видимому, более низкий, чем в процессорах AMD K8), и отсутствие 64-битового режима EM64T (x86-64), внедрение которого затруднительно без значительной переделки декодеров, всех трактов прохождения МОПов и функциональных устройств целоадресной арифметики.
В ближайшие месяцы ожидается появление последнего представителя семейства Pentium M двухъядерного процессора с кодовым наименованием Yonah, имеющего общий кэш 2-го уровня. Данная черта роднит его с будущими процессорами Merom/Conroe, но на этом сходство заканчивается. Таким образом, завершается эпоха процессоров семейства P-III/P-M в мобильном секторе. Однако для нас эти семейства становятся базой для анализа и сравнения с процессорами новой архитектуры. Давайте теперь перейдём к этому анализу.
Особенности, достоинства и недостатки процессоров P-III/P-M и соображения по новому процессору
Итак, проведём анализ архитектуры P-III/P-M, чтобы понять, какие изменения могли бы быть в неё внесены для повышения производительности и для реализации характеристик и возможностей новой архитектуры, представленных на форуме IDF.
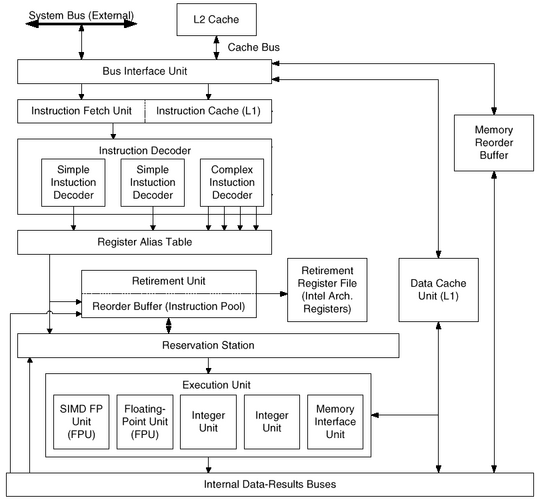
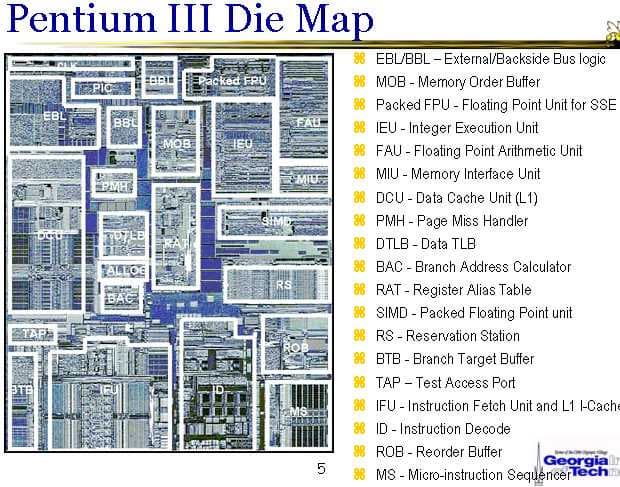
На приведенных выше иллюстрациях показана функциональная схема процессора P-III и карта размещения блоков и устройств на кристалле (для варианта процессора без кэша 2-го уровня). Рассмотрим некоторые подсистемы процессоров P-III и P-M, которые представляются наиболее критичными для повышения тактовой частоты, увеличения производительности и обеспечения новой функциональности.
Предвыборка инструкций и предсказание переходов
Механизм предсказания переходов выполняет две основные функции — предсказание программного адреса инструкции, на которую производится переход, и предсказание направления ветвления (для инструкций условного перехода). Оба предсказания должны быть выполнены заблаговременно — раньше, чем начнётся декодирование и обработка инструкции перехода — для того, чтобы выборка нового блока инструкций была произведена без потерь лишних тактов либо с минимальными потерями.
Оставим без рассмотрения конкретные алгоритмы предсказания направления переходов (здесь у компании Intel накоплен богатый опыт) и посмотрим на механизм предсказания адреса перехода и осуществления быстрой выборки. Необходимость такого предсказания вызвана тем, что этот адрес может быть извлечён из x86-инструкции и вычислен только на финальной стадии декодирования, с задержкой на несколько тактов.
Этот механизм реализован в процессоре P-III прямолинейно и основан на использовании таблицы адресов перехода (Branch Target Buffer, BTB) размером 512 элементов, организованной наподобие кэша в виде 128 наборов с ассоциативностью 4. Для адресации набора используются разряды b10-4 (предполагаемого) адреса инструкции перехода (точнее, её последнего байта). Видно, что элемент набора BTB соответствует одному выровненному 16-байтовому блоку инструкций — и именно блоками такого размера осуществляется предвыборка из I-кэша. Таким образом, для осуществления предсказания нет необходимости знать точный адрес инструкции перехода (к этому моменту её декодирование ещё не началось) — предсказание можно произвести по целому 16-байтовому блоку инструкций. В этой части механизм совпадает с тем, который был позднее реализован в процессоре AMD K7 (и ошибочно назван новаторским), только сделан он более алгоритмически просто, без использования предварительной разметки I-кэша и подготовки массива селекторов. Механизм имеет те же временные характеристики, что и в AMD K7/K8, и «теряет» на переходе всего 1 такт, который может быть легко скрыт даже на плотном потоке инструкций. Механизм обеспечивает возможность предсказания до 4-х потенциально совершаемых переходов в выровненном 16-байтовом блоке (в процессоре AMD K8 в блоке допускаются только 3 таких перехода).
Таким образом, существующий механизм можно признать вполне удовлетворительным. Возможный его минус заключается в большом количестве работы за такт (хотя здесь точные оценки сделать трудно). Также для нового процессора может понадобиться увеличение размера предвыборки до 32 байт, так как 16 байт может не хватить для комфортного размещения 4-х инструкций (с учётом возможного добавления префикса «REX» для новых 64-битовых инструкций и активного использования относительно длинных инструкций SSE). Желательно и увеличение размера BTB с 512 до 2048 или даже 4096 элементов (как в процессоре Pentium 4). Не исключено, что в процессоре P-M размер BTB уже был несколько увеличен.
Декодер
В процессоре реализован «прямой» декодер без использования предекодирования инструкций перед помещением их в I-кэш (как это сделано, например, в процессорах AMD K7/K8). Разметка (нахождение начальных и конечных байтов инструкций) осуществляется в динамике, в первом такте, сразу после выборки блока инструкций. Декодирование производится в трёх параллельно работающих каналах декодера (которые в дальнейшем для простоты будем называть просто «декодерами») по несимметричной схеме «4-1-1»: первый декодер может декодировать инструкции, порождающие до 4-х микроопераций (МОПов), а остальные два — только порождающие один МОП. Причём в полном темпе декодеры могут работать только с x86-инструкциями длиной не более 7-8 байтов. Данные ограничения могут снизить темп декодирования в ряде случаев до двух либо одной инструкции за такт.
Строго говоря, схему декодера следовало бы назвать «4-1-1 / >4», имея в виду, что при появлении инструкции, порождающей более 4-х МОПов, будет обрабатываться только одна эта инструкция. В таком понимании декодер процессора AMD K7 следовало бы обозначить как «1-1-1 / >1», так как он становится последовательным уже для двухМОПовой инструкции. Правда, тут необходимо уточнить: «1 МОП» в процессорах AMD K7/K8 может обозначать инструкцию «Load-Op». В процессоре AMD K8 декодер уже можно обозначить схемой «2-2-2 / >2», так как все упакованные инструкции SSE и некоторые другие, порождающие два МОПа, обратываются во всех каналах. В процессоре P-M «1 МОП» также может обозначать инструкцию «Load-Op» и некоторые другие, содержащие два элементарных действия благодаря «слиянию микроопераций» (micro-op fusion). Однако упакованная инструкция SSE порождает два МОПа и поэтому всегда должна обрабатываться первым декодером. Кроме того, инструкции SSE типа «Load-Op» по-прежнему расщепляются на отдельные МОПы «Load» и «Op», и тоже обрабатываются первым декодером (а упакованные инструкции SSE типа «Load-Op» расщепляются уже на 4 МОПа).
Таким образом, декодер в процессоре P-M, будучи в отдельных случаях более гибким, чем в процессоре AMD K8, имеет серьёзные ограничения в декодировании упакованных инструкций SSE и инструкций SSE с обращением к операнду в памяти. Кроме того, представляется, что он является очень сложным в реализации, что ведёт к удлинению такта и ограничению тактовой частоты процессора.
Самым сложным звеном в декодере P-M, принципиально отличающим его от декодера процессора AMD K8, является определитель длины x86-инструкций, который должен разметить три поступающие инструкции перед отправкой их в каналы декодирования. В связи с увеличением числа каналов в новом процессоре до четырёх, а также с появлением префикса 64-битовых операций «REX» и некоторым увеличением средней длины инструкции сложность такого определителя ещё более возрастает. Можно предположить, что в процессоре Conroe это звено будет разбито на несколько этапов конвейера, либо будет введена процедура предекодирования инструкций перед помещением их в I-кэш. Каждый из этих двух подходов имеет свои достоинства и недостатки.
Переделка декодера в части разметки инструкций позволила бы уменьшить объём работы, выполняемой в критических этапах конвейера, и соответственно повысить порог тактовой частоты.
Необходим ли новому процессору «симметричный» декодер «4-4-4-4» или хотя бы «2-2-2-2»? Это зависит от того, будут ли внесены изменения в схему декодирования инструкций SSE и в организацию порождаемых микро(макро)операций для этих инструкций, а также в темп работы функциональных устройств для SSE. Если существенных изменений в этой части сделано не будет, декодер необходимо будет расширить до «2-2-2-2» или «4-2-2-2» (а в идеале и до «4-4-4-4»), чтобы обеспечить возможность поставлять МОПы для SSE FPU в максимально возможном темпе (с учётом увеличенной до четырёх «ширины запуска»). Однако при сохранении нынешнего темпа работы функциональных устройств SSE и реализации слияния микроопераций SSE в той или иной форме (например, при появлении одного 128-битового МОПа для упакованных инструкций SSE вместо двух 64-битовых) потребность в создании сложного симметричного декодера снижается.
Можно предположить, что решение будет приниматься исходя из схемной сложности декодера и потребляемой им мощности. С точки зрения разметки инструкций и их взаимного расположения, особых проблем в реализации четырёх «сложных» декодеров по идее возникнуть не должно.
Плавающая арифметика (x87 и SSE)
В настоящее время x87-FPU в P-III/P-M реализован менее эффективно, чем в процессорах AMD K7/K8: инструкции «fmul» и «fadd» запускаются через один общий порт, и при этом «fmul» исполняется в половинном темпе (хотя в этом смысле x87-FPU сбалансирован по порту и темпу для равного числа операций сложения и умножения).
Скалярный режим SSE (32-битовый SSE1) в процессоре P-III реализован уже достаточно эффективно: инструкции «mulss» и «addss» являются полночастотными и запускаются через разные порты, что позволяет обеспечить суммарный темп выполнения таких инструкций, равный двум за такт. Вероятно, точно так же реализован и скалярный режим SSE2 (64-битовый) в процессоре P-M. Таким образом, непосредственно к FPU для скалярных режимов SSE претензий нет. Однако отсутствие слияния микроопераций для скалярных инструкций SSE типа «Load-Op», вносит ограничения на этапе декодирования и снижает плотность потока МОПов на других этапах. Ещё хуже дело обстоит с упакованными инструкциями SSE (см. предыдущий подраздел).
Таким образом, для повышения производительности SSE необходима по меньшей мере реализация укрупнения МОПов (соединения двух 64-битовых в один 128-битовый) для упакованных инструкций. При этом также желательна реализация слияния микроопераций загрузки и исполнения для инструкций «Load-Op», либо хотя бы расширение декодера до схемы «X-2-2-2», чтобы такие инструкции не снижали темп декодирования.
Радикальный прирост скорости можно было бы получить при реализации сдвоенного полночастотного 128-битового (2x64) FPU вместо нынешнего одинарного 64-битового. В этом случае все упакованные инструкции SSE сразу стали бы одноМОПовыми. Для данного варианта необходима также реализация 128-битовой операции загрузки XMM-регистра из памяти (кэша) — такая операция была бы полезна и при сохранении 64-битового FPU. Однако решение, наверное, опять будет приниматься исходя из схемной сложности и потребляемой мощности нового FPU.
Порты запуска и функциональные устройства
С учётом «четверного» декодирования инструкций и возможного «утяжеления» МОПов нынешнее количество портов (2 универсальных, 1 Load, 2 Store) и функциональных устройств представляется недостаточным
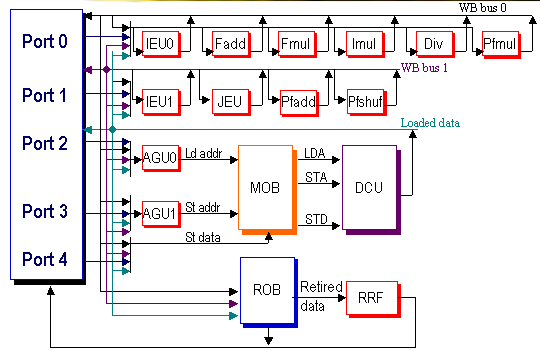
Для исполнения кодов, не содержащих плавающей арифметики, требуется добавление по крайней мере ещё одного целочисленного ФУ и соответствующего порта. В этом случае может быть достигнута полная (или почти полная) пропускная способность исходя из расклада «3 целочисленных инструкции + 1 загрузка из памяти».
Количество портов запуска для плавающей арифметики является достаточным как при сохранении нынешней пропускной способности FPU (2 порта по 64 бита для групп инструкций умножения и сложения, соответственно), так и при расширении FPU до 128 разрядов (при сохранении полночастотности ФУ FPU). Вариант с удвоением количества 64-битовых ФУ FPU (и увеличением числа портов FPU) представляется нерациональным.
Таким образом, вместо нынешних двух универсальных портов запуска в новом процессоре желательно иметь три или четыре порта с возможным разделением и/или пересечением функций. Можно предположить следующие варианты:
- 3 порта ALU, из них один совмещён с FPmul, и ещё один совмещён с FPadd;
- 3 порта ALU, из них один совмещён с FPmul, плюс 1 отдельный порт FPadd;
- 4 порта ALU, из них один совмещён с FPmul, и ещё один совмещён с FPadd.
Последний вариант представляется наиболее предпочтительным, однако потребует добавления ещё одного (четвёртого) ФУ целочисленной арифметики. Отметим, что целочисленная арифметика в новом процессоре 64-битовая, что означает большую сложность устройств в сравнении с процессорами P-III/P-M.
Возможно также добавление дополнительного порта 64-битовой загрузки из памяти, однако более простой альтернативой представляется расширение существующего порта до 128 разрядов (для загрузки XMM-регистров). Такое расширение необходимо при реализации сдвоенного полночастотного 128-битового (2x64) FPU вместо нынешнего одинарного 64-битового (в связи с удвоением потребности ФУ FPU в данных), однако может оказаться полезным и при сохранении нынешнего 64-битового FPU.
Кэши
Кэши инструкций и данных процессора P-M (каждый размером 32 Кбайт с ассоциативностью 8) представляются вполне эффективными и достаточными для нового процессора. Хотелось бы, конечно, увеличить размер кэша данных до 64 Кбайт. Однако это потребовало бы увеличения уровня ассоциативности до 16 (при сохранении требования индексирования набора кэша по логическому адресу), а реализовать такую схему эффективно может оказаться достаточно сложной задачей.
Для повышения темпа считывания данных (особенно при появлении полночастотного 128-битовго FPU) желательна реализация 128-битового чтения их кэша, то есть расширения порта чтения с 8 до 16 байтов. Вместо этого возможна реализация двухпортового чтения (по 8 байт), как это сделано в процессорах AMD K7/K8 — однако такой вариант представляется более сложным.
Кэш 2-го уровня процессора P-M также выглядит очень хорошо и по времени доступа, и по темпу, и по плотности физической организации. Нынешней предельной пропускной способности чтения из L2-кэша (32 байта за такт), в принципе, достаточно для того, чтобы снабжать данными оба L1-кэша в двухъядерной конфигурации (при надлежащей реализации конвейерного доступа). Предполагается, что в десктопном процессоре Conroe размер L2-кэша будет составлять 4 Мбайт.
Введение T-кэша для инструкций («кэша трасс», как это сделано в процессоре Pentium 4) не представляется эффективным и оправданным для относительно низкочастотной архитектуры, поскольку потребовалась бы полная переделка и значительное усложнение структуры ядра. Реализация предвыборки и предсказания переходов в процессорах Intel P-Pro/P-II/P-III/P-M, а также предекодирования в процессорах AMD K7/K8 показали, что в этой части у классических кэшей инструкций ещё есть резервы — особенно с учётом простоты реализации I-кэша, что важно для снижения энергопотребления.
Новый prefetch, быстрая FSB, память и доступ к соседним процессорам
Улучшенная предвыборка данных из памяти (prefetch) и усовершенствованный механизм разрешения конфликтов по адресам между операциями записи и чтения (memory disambigution), безусловно, позволят повысить темп считывания данных из иерархий памяти и увеличить скорость счёта «требовательных» программ. Этому будет также способствовать и увеличение частоты системной шины (у процессора Conroe предположительно до 1066 MHz).
Объединённый кэш 2-го уровня, а также наличие механизма быстрого доступа к L1-кэшу соседнего процессора позволят повысить эффективность исполнения взаимодействующих процессов. Это может дать толчок развитию методов распараллеливания прикладных программ для десктопного применения. Наличие таких черт в процессорах Merom/Conroe выгодно отличает их от нынешних двухъядерных вариантов процессоров AMD K8 X2.
Выводы
Итак, похоже, мы недооценивали микроархитектуру Intel P6 — особенно с учётом её развития в процессорах P-III и (в наибольшей степени) P-M. Конечно, она остаётся пока недостаточно совершенной для требований завтрашнего дня. Однако на её основе возможно создание новой или глубоко модифицированной архитектуры, которая позволила бы достичь неплохих показателей производительности при сохранении низкого энергопотребления.
Дополнение: немного слухов :)
Напоследок — удивительная информация из статьи «Intel Merom is designed from the ground up» («The Inquirer», 23.08.2005). Приведём несколько выдержек из статьи, касающихся нового процессора:
- «Each pipe is a full pipe versus the old P6 derived simple and complex pipe structures». Это можно расценивать как намёк на симметричный декодер (в варианте «4-4-4-4»).
- «The number of ALU ports are greatly increased also». А это — на добавление по меньшей мере двух новых портов запуска (т.е. на реализацию четырёх универсальных портов, два из которых предположительно разделяются с FPU).
- «In addition, Merom has Macro-Op fusion, the ability to gang x86 operations before decode. As an example, if you have a multiply followed by an add, Macro-Op fusion can turn that into a Multiply and Accumulate». Ну а это — самое невероятное. Подразумевается, что инструкции умножения и сложения, следующие друг за другом (предположительно инструкции SSE FPU) сливаются на стадии декодирования в макрооперацию FMA (FPmul+FPadd). Такое слияние может несколько повысить плотность МОПов в трактах процессора, однако основной выигрыш оно могло бы дать при наличии комбинированного функционального устройства FPU, обеспечивающего возможность запуска такой сдвоенной инструкции в каждом такте (подобные реализации были широко распространены среди RISC-процессоров — например, в IBM POWER 4/5 и Power PC 970, HP PA-RISC, Intel Itanium, etc).
В данном случае речь могла бы идти, например, о реализации двух 64-битовых полночастотных устройств FMA (по одному на каждый порт запуска инструкций FPU) с суммарной пиковой производительностью FPU, равной учетверённой тактовой частоте (против удвоенной тактовой частоты у процессоров P-III/P-M). Маловероятно, чтобы одновременно рассматривалось ещё и удвоение «ширины» полночастотного FPU до 128 бит, так как это вызвало бы чрезмерное усложнение и несбалансированность процессора.
Рассматриваемый вариант требует увеличения темпа считывания данных из L1-кэша — либо через реализацию двух 64-битовых портов чтения, либо через расширение существующего порта до 128 разрядов. В последнем случае хороший баланс между темпом загрузки данных и скоростью исполнения операций может быть достигнут только при использовании упакованных инструкций SSE.
В принципе, слияние инструкций умножения и сложения могло бы быть дополнено слиянием двух операций упакованной (макро)инструкции в один МОП и/или слиянием операций загрузки из памяти и исполнения для (макро)инструкции «Load-Op».
В целом, приведенная информация кажется не вполне правдоподобной, а реализация описанной схемы — маловероятной. Создание двух полночастотных 64-битовых устройств FMA вместо существующих раздельных устройств FPmul и FPadd потребует добавления схем сложения к первому устройству и схем умножения ко второму. Здесь наиболее затратным является блок умножения. Хотя, с другой стороны, такой вариант явился бы более простым и экономичным, чем реализация полночастотных сдвоенных (128-битовых) устройств FPmul и FPadd — и при этом позволил бы достичь такой же пиковой производительности FPU, не очень сильно уступая ему на «нерегулярных» операциях (а в ряде случаев и превосходя его — например, при использовании скалярных инструкций SSE).
При реализации слияния инструкций умножения и сложения в макрооперацию FMA, возникает ещё одна проблема. Обычно эту инструкцию реализуют таким образом, что после выполнения умножения получившийся результат с длинной мантиссой немедленно, без предварительного округления, складывается с операндом для операции сложения. Это позволяет выполнить комбинированную операцию максимально эффективно. К сожалению, в рассматриваемом случае такая оптимизация невозможна, так как нельзя полагаться на то, что в динамическом исполнении соседствующая пара инструкций умножения и сложения всегда будет слита в один МОП (этому могут помешать прерывания и другие обстоятельства). Так как отсутствие детерминизма в исполнении бинарного кода недопустимо, потребуется всегда производить округление результата операции умножения, что приведёт к потере как минимум одного такта. Впрочем, данное требование не препятствует достаточно эффективной реализации операции FMA в новом процессоре.
Подводя итог, можно сказать, что информация, озвученная в статье «The Inquirer», требует дополнительного подтверждения. Будем надеяться, что она подтвердится — но полагаться на неё пока не стоит...
Оценка производительности процессора Conroe
Рассмотренные архитектурные особенности нового процессора могут быть разбиты на две категории: те, которые позволяют поднять тактовую частоту, и те, которые непосредственно увеличивают производительность. Какие-либо количественные оценки по первой категории сделать трудно. Поэтому здесь мы можем лишь надеяться, что порог тактовой частоты процессора будет повышен (пусть не радикально), и полагаться на оценки, прозвучавшие в публикациях. Согласно этим оценкам, частота процессора Conroe, изготовленного по техпроцессу 65 нм, может достичь 3 GHz. С учётом информации о частоте шины 1066 MHz и размере L2-кэша в 4 Мбайта рассмотрим производительность процессора с нескольких сторон:
- Рекламная оценка компании Intel. Согласно презентациям на форуме IDF, производительность на ватт у Conroe приблизительно в 5 раз выше, чем у процессоров Northwood и Prescott, и в 3-3.5 раза выше, чем у двухъядерного процессора Smithfield. Отсюда можно сделать грубую оценку, что по абсолютной производительности превосходство составит соответственно 2.5 раза (два процессора против одного) и 1.5 раза (два против двух). То есть каждое процессорное ядро в составе Conroe (3 GHz) будет в 1.25-1.5 раза быстрее процессора Pentium 4 Prescott (3.2-3.8 GHz). Вероятно, приведенная оценка относится к наиболее выгодному для компании Intel тесту — т.е. к SPECint_base2000 (а не к SPECfp_base2000).
- Оценка производительности процессора Pentium M без учёта архитектурных новшеств. На данный момент производительность процессора Pentium M с частотой 2.26 GHz и 533 MHz FSB, при условии использования двухканального контроллера памяти DDR2-533, равна: SPECint_base2000 1812, SPECfp_base2000 1355. Таким образом, от гипотетического процессора Pentium M с частотой 3 GHz, 1066 MHz FSB, и L2-кэшем 2 Мбайта, можно ожидать (при грубой оценке) производительности в SPECint_base2000 около 2200-2300, а в SPECfp_base2000 около 1800-1900.
- Архитектурные расширения. Здесь оценить труднее всего. Эффект от некоторых новшеств может составить только доли процента. Вероятно, увеличение «ширины запуска» и усовершенствование декодера может дать определённый эффект для целочисленных приложений — около 10 процентов или несколько выше. Если будут сняты помехи для прохождения инструкций SSE (за счёт улучшения декодера и/или реализации слияния микроопераций «Load» и «Op»), то это может дать эффект для приложений с плавающей точкой в 5-10 процентов. При переходе в 64-битовый режим EM64T (x86-64) может быть получено ещё около 10 процентов. Таким образом, от одного процессорного ядра в составе Conroe с частотой 3 GHz, 1066 MHz FSB и L2-кэшем 2 Мбайта (по половине от 4 Мбайт на каждое ядро), можно ожидать производительности в SPECint_base2000 >2500, и в SPECfp_base2000 >2200. Дополнительный прирост производительности в плавающей арифметике может быть достигнут при реализации полночастотного 128-битового FPU либо двух 64-битовых комбинированных устройств FMA и слияния операций умножения и сложения. В этом случае можно говорить о SPECfp_base2000 на уровне 2400-2500. Приведённые оценки производительности в целочисленных приложениях дают прирост в сравнении с процессором Pentium 4 3.8 GHz приблизительно в 1.4 раза, что согласуется с рекламными оценками. Для приложений с плавающей арифметикой, производительность оценивается на уровне процессора Pentium 4 XE 3.73 GHz в случае, если FPU не будет расширен, и на 10-15 процентов выше в случае удвоения пиковой производительности FPU. Примерно в тех же соотношениях процессорное ядро Conroe (3 GHz) будет находиться с процессором AMD Athlon 64 FX 3 GHz (этот процессор должен появиться в течение ближайшего года).
- Пиковая производительность с плавающей точкой и бенчмарки класса «Linpack». При сохранении нынешней структуры FPU процессорное ядро Conroe (3 GHz) будет отставать от процессора Pentium 4 (3.8 GHz) в тесте «Linpack-1000» приблизительно на 10-15 процентов, и достигнет уровня 4 GFLOPS или чуть выше. При удвоении пиковой производительности FPU возможно значительное опережение в этом тесте — до полутора раз, с достижением уровня 7 GFLOPS. Отметим, однако, что данный тест не отражает производительность процессора на реальных задачах, и предназначен лишь для демонстрации его пикового потенциала.
Заключение
Итак, корпорация Intel, кажется, приняла вызов времени, наступила себе на горло, и сконструировала процессорную архитектуру, предназначенную не для хватания звёзд с небес, а для удовлетворения насущных потребностей пользователей. Причём именно в том виде, в каком сами пользователи (и Intel, глядя на них) себе это представляют. Теперь Intel и её процессоры трудно будет упрекать в потере производительности на тяжёлых играх, в высоком энергопотреблении и тепловыделении, в отсутствии конкурентоспособных двухъядерных решений, в неоправданном увлечении технологиями завтрашнего дня. Конечно, общественность быстро найдёт другие поводы для неконструктивной критики. Однако надо признать — Intel ответила своему конкуренту на его поле, и предложила изделия с неплохими характеристиками по всем «выигрышным» (для конкурента) направлениям. Более того: если результаты проведённого выше анализа окажутся верными, надо будет признать, что по большинству десктопных характеристик Intel получит превосходство (кроме, быть может, производительности на приложениях с плавающей арифметикой). Это означает, что конкурентная борьба должна обостриться, и AMD вынуждена будет выйти из «конструкторско-дизайнерской спячки», чтобы предложить достойные ответные решения. А это будет нам всем на руку.
Конечно, жаль, что через год NetBurst начнёт уходить из десктопных компьютеров. Эта архитектура обогнала своё время и, к сожалению, не была справедливо оценена. Если пользоваться привычными российскими аналогиями, то можно сказать, что, как всегда, подвели дороги. Но ведь дороги (точнее, в данном случае, матобеспечение) у нас не всегда будут такими плохими. Так что рано или поздно интерес к высокочастотным длинноконвейерным архитектурам всё равно возобновится. Да и не в первый раз уже мы видим борьбу «толстых низкочастотных» архитектур с «тонкими высокочастотными» вся история развития RISC-процессоров полна примерами такого рода.
Главное, что развитие архитектур не остановилось. После достижения в последние годы «порога тактовой частоты» сложилось впечатление, что конкуренты (Intel и AMD) вступили в картельный сговор, и решили больше не проводить серьёзных модификаций своих архитектур. Действительно, микропроцессорные технологии «перефорсированы», и вполне можно было бы приостановиться с их развитием. Хорошо, что этого не случилось — будем надеяться, что не случится и впредь. Тем более что есть ещё резервы (такие, например, как спекулятивное декодирование инструкций по нескольким направлениям). Да и кто знает — быть может, электронные технологии «прорвутся», и мы снова увидим определённый рост тактовых частот? Тогда жизнь станет ещё интереснее.
В общем, будем надеяться, что смелые и оптимистичные предположения, высказанные выше, подтвердятся, а несмелые и неоптимистичные — нет. И пожелаем успехов на этом поприще также и компании AMD. И в результате всем будет хорошо :).
Список литературы
- IA-32 Intel Architecture Optimization Reference Manual. Intel, 2005.
- IA-32 Intel Architecture Software Developer's Manual. Intel, 2005.
- S. Gochman et al. The Intel Pentium M Processor: Microarchitecture and Performance. Intel Technology Journal, V.7, Issue 2, 2003.
- J. Keshava, V. Pentkovski. Pentium III Processor Implementation Tradeoffs. Intel Technology Journal, V.3, Q2, 1999.
- Intel Architecture Optimization Reference Manual. Intel, 1999.
- M. Milenkovic, A. Milenkovic, J. Kulick. Demystifying Intel Branch Predictors. Proceedings of the Workshop on Duplicating, Deconstructing and Debunking, 2002.
- H.H. Sean Lee. P6 & NetBurst Microarchitecture. School of ECE, Georgia Institute of Technology, 2003.
- A. Fog. How to optimize for the Pentium family of microprocessors. 2004.
- О. Бессонов. Pentium 4: Мистический и загадочный Trace-кэш. 2005.
- S.L. Smith, D. Perlmutter. Intel Next Generation Multi-core Platforms. Intel Developer Forum, 2005.
- C. Demerjian. Intel Merom is designed from the ground up. The Inquirer, 23.08.2005.


