Вредный король
Жили-были две компании. Т. е. их, конкурентов, конечно, больше, но заклятые — именно Intel и AMD. Причём, так уж получилось: Intel, как правило, что-то новое придумывает и внедряет первой, а AMD внедряет второй, но дешевле, отбивая кусок рынка. Intel это не нравится, и она начинает действовать против конкурента не только обычными способами (выпуская очередной новый чип или снижая цены в свою очередь), но и другими, из-за которых потом AMD подаёт на Intel в суд по обвинению в нечестной конкуренции и нарушении антимонопольных законов. Нет необходимости описывать все перипетии этих дел, длящихся с переменным успехом для обеих сторон с середины 80-х (считая также и встречные иски). Однако среди арсенала Intel есть один приём, который нам особенно интересен.
Многие программисты считают компиляторы Intel лучшими в т. ч. за оптимизацию кода, используя их для требовательных к скорости программ. Intel также поставляет множество оптимизированных функциональных библиотек для различных профессиональных применений. Во многих случаях никаких сходных по скорости альтернатив им нет. Но те же программисты заметили, что компиляторы и библиотеки Intel работают зачастую подозрительно медленно на ЦП производства других компаний. Всё дело в том, что в генерируемом коде (в случае библиотек — в написанном вручную) есть несколько версий наиболее критичных участков, оптимизированных для конкретной архитектуры или набора команд (чаще всего из линейки SSEx). Также в коде есть функция определения типа ЦП (на котором запущен код), чтобы выбрать верную ветвь — диспетчер ЦП (не путать с планировщиком — частью конвейера, которую также иногда называют диспетчером). Суть проблемы в том, что интеловский диспетчер проверяет не только поддержку наборов команд, но и строку с названием процессора. И в случае, если производитель указан не как Intel, диспетчер выбирает код, обеспечивающий максимальную совместимость в ущерб скорости — даже если конкретный ЦП поддерживает все нужные команды.
Ситуация не нова и продолжается годами, но Intel ничего не меняет, хотя компиляторы фирмы не рекламируются как оптимально работающие только для её собственных ЦП. В результате программист и не подозревает, что зачастую пользователь «неправильных процессоров» недополучает производительности, но стоит только тому пересесть на одобренные свыше ЦП — как всё сразу ускоряется. Если бы об этом знали все программисты — возможно, некоторые из них стали бы оптимизировать свои программы вручную или перешли бы на использование других компиляторов и библиотек. Более того, Intel открыто пишет в документации, что если процессор возвращает название, не совпадающее с «Intel», то «не стоит полагаться на данную [в тексте] интерпретацию остальных полей», включая список поддерживаемых наборов команд. В выпущенной в январе 2010 г. официальной статье об использовании библиотеки Intel Performance Primitives для ЦП AMD отмечено, что последняя версия IPP честно оптимизирует код и тут — но не указано, что в нескольких других библиотеках это не происходит.
Intel специально ставит низкие (иногда даже нулевые) цены на свои инструменты для программирования, а поддержку им даёт на высоком уровне. Т. е. сама по себе продажа компиляторов, скорее всего, убыточна, но она улучшает продажи ЦП. Добавлять новые команды в процессор без поддержки на уровне компиляторов почти бессмысленно — кодируют на ассемблере сегодня крайне редко. Что касается AMD — она также делает свой компилятор Open64, но только для Linux.
У всех на слуху «полюбовное» соглашение между Intel и AMD в ноябре 2009 г., улаживающее иск последней, за что Intel выплатила круглую сумму. Менее известно, что AMD также потребовала подписать соглашение об урегулировании, где перечислены многие нечестные приёмы конкуренции, которые Intel обещает более не применять — среди них и «подмена ЦП». Документ обязывает Intel сменить код диспетчера на нейтральный — надо полагать, со следующей версии компилятора… Через месяц Федеральная Торговая Комиссия США (FTC) подала антимонопольную жалобу против Intel с резкими обвинениями на той же почве подмены путей кода, даже введя собственный термин «Defective compiler» для описания творения Intel. FTC требует, чтобы Intel бесплатно выпустила замену текущему компилятору или заплатку к его «дефектам», скомпенсировала стоимость перекомпиляции и распространения исправленных новым инструментом версий программ и объявила потребителям о замене старых версий на новые.
Пока шли прения, прошёл год, Intel выпустила новую версию своей популярной библиотеки MKL (Math Kernel Library) v10.3 — а диспетчер ЦП практически не поменялся. Скалярные, векторные и 64-битные версии функций всё ещё используют неоптимизированные пути на «некошерных» ЦП. Более того, многие функции теперь имеют новую ветку для грядущего набора AVX — и тоже только для Intel. Т. е. в процессорах Sandy Bridge такой код работать будет, а в AMD Bulldozer, выходящих в это же время и также готовых исполнять AVX, — нет. Впрочем, появилась новая ветвь специально для не-интеловских ЦП с SSE2 — и для многих функций она работает медленнее, чем SSE2-код для Intel. Причём эта ветвь существует лишь в 32-битных версиях MKL.
Смелый рыцарь
Читатель спросит — а откуда всё это известно? Тут на сцену выходит опытный программист и исследователь Агнер Фог (Agner Fog), известный в Сети своими учебниками по оптимизации и микроархитектурам, бесплатно выложенными на его сайте. В 2007 г. Фог ознакомил Intel с результатами своих исследований компиляторов с вышеуказанными выводами. Последовала долгая переписка, в которой компания отрицала наличие проблемы, хотя Фог продолжал аргументированно подтверждать её наличие. Другие специалисты также жаловались на те же проблемы и получили похожие ответы. Ситуация с компилятором не изменилась даже в версии 11.1.054, вышедшей сразу после подписания соглашения с AMD.
Как ни странно, Intel заявила в переписке, что намеренно оптимизирует не под наборы команд, а под конкретные архитектуры ЦП, чтобы оптимизация была лучше, что якобы отклоняет обвинения в нечестности (глупо требовать оптимизации под чужие ЦП). Но это также означает, что выход очередного нового ЦП само́й Intel, даже если он поддерживает те же команды, что и старый, потребует перекомпиляции программ новой версией компилятора, иначе старый диспетчер, запущенный на новом ЦП, не узна́ет даже родного производителя. Это если Intel не лукавит… Фог решил проверить и запустил программу, сделанную старой версией компилятора Intel, на новом, якобы неизвестном тому ЦП той же Intel. Как и следовало ожидать, всё заработало идеально. Причина — Intel хитро манипулирует цифрами «семейства» на новых ЦП так, чтобы они выглядели знакомо для старых программ, в частности, добавив «расширенное семейство» и «расширенную модель».
После того, как Intel отказалась как-либо решать проблему, Фог решил, что лучшая тактика — публичность. Но связавшись с несколькими IT-журналами, он никого не заинтересовал. Любители конспирологии, конечно, немедленно построят стройную теорию о том, как сами знаете кто подкупил сами знаете кого — но истина, возможно, куда банальнее: слишком уж узкоспециальная тема для среднестатистического читателя. Но то читатели, а вот почему AMD, коммерчески страдающая от этой ситуации больше всего, до сих пор молчит даже у себя на сайте? Может быть, она решила, что это как-то повредит утряске иска против Intel? А VIA/Centaur?..
Тем временем, Фог продолжал бомбить фактами (ссылки есть в его блоге). Например, согласно сайту CNET, Skype на некоторое время договорился с Intel ограничить функциональность своей программы на компьютерах с альтернативными ЦП, но позже ограничение было снято… В общем, кто виноват — ясно, теперь — что делать? Фог предлагает три варианта:
- Не использовать компилятор Intel. Компилятор GNU под Linux оптимизирует не хуже, чем Intel, но функциональная библиотека glibc несколько недоработана. Что касается инструментов для Windows — тут никаких альтернатив нет.
- Использовать компилятор Intel, вручную редактируя диспетчер. В учебнике по C++ Фог предоставил «честный» код и инструкции по встраиванию его в программы — однако данный способ завязан на недокументированных особенностях компиляторов Intel, которые меняются от версии к версии.
- Сменить в процессоре возвращаемую строку производителя с помощью команд виртуализации. Известно, что версия AMD этой технологии имеет такую возможность, что было продемонстрировано на небольшом примере — но до сих пор никто не взялся сделать полноценную программу для подмены. Этот способ хорош тем, что его могут использовать в т. ч. и конечные пользователи, не имеющие доступа к исходным кодам — а также журналисты, страстно желающие написать сенсационно-разгромную статью. :)
Тёмная лошадка
Как ни странно, раньше всех лопнуло терпение у VIA Technologies. Дело в том, что все 64-битные Windows (вплоть до Win 7 v6.1), а также FreeBSD загружаются только на ЦП известных им компаний. До поры до времени это были лишь AMD и Intel, и только начиная с Vista SP2 в список добавили и VIA. Но пока тайваньская фирма не была допущена в касту избранных (что, вообще говоря, есть повод для иска в суд с обвинением в картельном сговоре с «избранными»), в VIA не сидели сложа руки и решили, что если гора Microsoft не идёт к VIA, то VIA пойдёт к горе: в новый ЦП VIA Nano добавлена функция смены имени производителя, а заодно и других опознавательных цифр (как это выглядит — покажем ниже). Строго говоря, эта функция была тайком заявлена ещё для C3 (ядро Nehemiah, вышедшее как раз при появлении первых 64-битных ОС для ПК в 2003 г., что показывает запущенность проблемы), но то ли никто не удосужился проверить, то ли данные были неверны, но сенсации не получилось.
Впрочем, уже давно высказывались подозрения, что среди прочих программ пострадали от диспетчерской «закладки» и бенчмарки — а их замеры потом попадают в обзоры на сайтах, по которым потенциальные покупатели решают, что́ им купить. И вот один из доказанных примеров как раз ущемляет права VIA — Futuremark PCMark 2005 (предшественник PCMark Vantage) для теста производительности памяти использует оптимизации, основанные на названии компании-производителя ЦП, с разницей в скорости отдельных ветвей до полутора раз (при прочих равных условиях)!
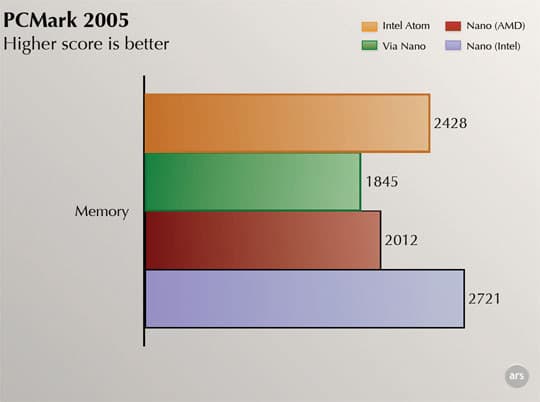
График с сайта ArsTechnica.com
Возможно, PCMark 2005 предполагает, что не-Intel ЦП не могут поддерживать SSE2 и его более свежие версии? Однако, будучи выпущенным в 2005 г., тест, по идее, должен был быть рассчитан в т. ч. и на только что выпущенные ЦП VIA C7 с поддержкой SSE2 и SSE3 — особенно учитывая, что в данном случае запускалась последняя версия теста (1.2.0), датированная 29 ноября 2006 г. Кроме того, значительна разница и между запусками «как AMD» и «как Intel». Futuremark могла бы оправдаться тем, что процессоры VIA не очень популярны и не продвигаются как конкуренты топам, но вот архитектура AMD K8 на тот момент не просто была, а как раз в 2005 г. получила поддержку SSE3.
Но всё это примеры из прошлого. Nano впервые позволил провести независимое исследование честности программ и тестов благодаря тому, что всё тот же Агнер Фог подобрал доступ к специальным регистрам для «перепрошивки» нужных значений и выпустил соответствующую утилиту (пока только для этого ЦП). Более того, мистер Фог любезно передал из своего далёкого Копенгагена в снежный Петербург плату с Nano, т. к. после упорных и продолжительных поисков оказалось, что в России продукцией VIA почти никто не занимается, а о Nano даже официальный дистрибьютор слышать не хочет. (Теперь-то, после тестирования, мы его хорошо понимаем…)
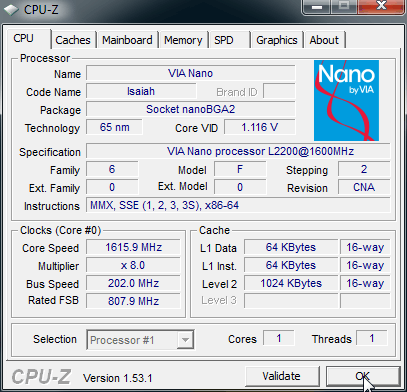
Итак, запустив для верности программу CPU-Z, мы увидим VIA Nano как он есть (на полной частоте):
А теперь, лёгким движением регистра, Nano превращается… превращается Nano…
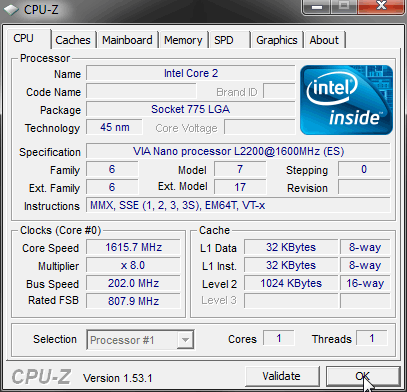
…В элегантный Intel Core 2! Бурные и продолжительные овации подчёркивают всю глубину трансформации — тут и добавление виртуализации, и уполовинивание обоих кэшей L1 (чтобы никто не догадался), и даже, на зависть всем, мгновенный переход на технологию 45 нм и другой разъём! Ладно, господа копперфильды, так где ж вы нас надули?
Ваши документы?
Прежде всего расскажем о том, что такое CPUID (CPU identification — (само)определение ЦП). Так называется команда процессора, возвращающая его «паспорт», впервые появившаяся в Пентиумах и старших 486-х. Её наличие обозначается возможностью перезаписи 21-го бита регистра флагов. У команды есть неявный аргумент — страница паспорта в регистре EAX, — а возвращает она 16 байт в регистрах EAX, EBX, ECX и EDX. Именно эта информация и нужна, чтобы программа определила наличие и численные параметры разных функций и возможностей ЦП. В реальности же встречаются исключения. Вот таблица возвращаемых значений с их описаниями на примере процессора Nano (для удобства просмотра эта же таблица вынесена на отдельную страницу):
| Страница (EAX) | EAX | EBX | ECX | EDX |
| 1-я часть | ||||
| Имя ЦП | Макс. номер страницы в 1-й части | Имя производителя (EBX-EDX-ECX, см. таблицу ниже) | ||
|---|---|---|---|---|
| 00 00 00 00 | 00 00 00 0A | 75 6E 65 47 | 6C 65 74 6E | 49 65 6E 69 |
| 10 | ’Cent’ | ’auls’ | ’aurH’ | |
| Основные функции и команды | Семейство; модель; степпинг | Брэнд; размер сброса строки кэша; число лог. ядер; номер 1-го контроллёра APIC | Флаги функций | |
| 00 00 00 01 | 00 00 06 F2 | 00 01 08 00 | 00 00 63 A9 | AF C9 FB FF |
| 6; F; 2 | Нет; 64 байта; 1; 0 | Почти всё, что есть у современного ЦП | ||
| Описатели кэшей и TLB (по байту) | 15 описателей (кроме AL, означающего число запросов этой страницы для получения всех описателей) | |||
| 00 00 00 02 | 02 B3 B0 01(←AL) | 00 00 00 00 | 00 00 00 00 | 2C 04 30 7D |
| 1 запрос; TLB-I для стр. по 4 МБ: 2 ячейки, 2 пути; TLB-I и -D для стр. по 4 КБ: по 128 ячеек, 4 пути | Нулевые описатели | L2: 2 МБ, 8 путей, 64 Б/стр.; TLB-D для стр. по 4 МБ: 8 ячеек, 4 пути; L1D и L1I: по 32 КБ, 8 путей, 64 Б/стр. | ||
| Серийный номер ЦП (если есть) | ||||
| 00 00 00 03 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Параметры кэшей (из-за ошибки в WinNT доступны, только если сброшен бит MISC_ENABLE.LCMV в регистре MSR 1A0) | ||||
| 00 00 00 04 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Параметры отладочных мониторов | Мин. размер строки монитора | Макс. размер строки монитора | Прерывания считаются остановами; учёт событий MWAIT | Число C-субсостояний энергосбережения для команды MWAIT |
| 00 00 00 05 | 00 00 00 40 | 00 00 00 40 | 00 00 00 03 | 00 02 22 20 |
| 64 байта | 64 байта | Да; да | 0 для C0, по 2 для C1–C4 | |
| Параметры управления питанием (при MISC_ENABLE.LCMV=0) | ||||
| 00 00 00 06 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Резерв | ||||
| 00 00 00 07 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 00 00 00 08 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Параметры DCA (Direct Cache Access, прямой доступ к кэшу) | ||||
| 00 00 00 09 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Параметры счётчиков производи- тельности | Ревизия; число и разрядность счётчиков; длина вектора в EBX | Параметры недоступности | Резерв | Число и разрядность счётчиков с фикс. привязкой |
| 00 00 00 0A | 06 28 03 02 | 00 00 00 00 | 00 00 00 00 | 00 00 05 03 |
| 2; 3; 40; 6 | Все события доступны | 3; 40 | ||
| 2-я часть | ||||
| Дополнительное имя | Макс. номер страницы во 2-й части | Имя производителя (для AMD и Transmeta) | ||
| 80 00 00 00 | 80 00 00 08 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 8 | Пусто | |||
| Дополнительные параметры | Семейство, модель, степпинг | Корпус и брэнд (для AMD) | Флаги функций | |
| 80 00 00 01 | 00 00 00 00 | 00 00 00 00 | 00 00 00 01 | 2A 10 08 00 |
| Нет дополнений | Пусто | Дополнительные флаги | ||
| Полное название процессора (иногда програмируется через MSR) | ||||
| 80 00 00 02 | 20 20 20 20 | 20 20 20 20 | 20 20 20 20 | 56 20 20 20 |
| 4 пробела | 4 пробела | 4 пробела | 3 пробела, ’V’ | |
| 80 00 00 03 | 4E 20 41 49 | 20 6F 6E 61 | 63 6F 72 70 | 6F 73 73 65 |
| ’IA N’ | ’ano ’ | ’proc’ | ’esso’ | |
| 80 00 00 04 | 32 4C 20 72 | 40 30 30 32 | 30 30 36 31 | 00 7A 48 4D |
| ’r L2’ | ’200@’ | ’1600’ | ’MHz’ | |
| Параметры L1 и основных TLB | TLB на 4 МБ для данных и кода (число путей и размер) | TLB на 4 КБ для данных и кода (число путей и размер) | L1D: размер; число путей и строк на тег; длина строки | L1I: размер; число путей и строк на тег; длина строки |
| 80 00 00 05 | 00 00 00 00 | 08 80 08 80 | 40 10 01 40 | 40 10 01 40 |
| Нет такого TLB | По 128 ячеек и 8 путей | 64 КБ; 16; 1; 64 Б | 64 КБ; 16; 1; 64 Б | |
| Параметры L2, L3 и TLB L2 | TLB L2 на 4 МБ для данных и кода (число путей и размер) | TLB L2 на 4 КБ для данных и кода (число путей и размер) | L2: размер; число путей и строк на тег; длина строки | L3: размер; число путей и строк на тег; длина строки |
| 80 00 00 06 | 00 00 00 00 | 00 00 00 00 | 04 00 81 40 | 00 00 00 00 |
| Нет такого TLB | Нет такого TLB | 1024 КБ; 16; 1; 64 Б | Нет L3 | |
| Параметры расширенного управления питанием | ||||
| 80 00 00 07 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| Другие параметры | Разрядность виртуальной и физической адресации | ? | Число ядер; разрядность номера ядра в APIC | ? |
| 80 00 00 08 | 00 00 30 24 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 48; 36 | ? | 1; 0 | ? | |
У процессоров VIA также доступна 3-я часть, начиная со страницы C0’00’00’00. Там описываются специфические для этих ЦП функции (набор команд PadLock) и содержится оригинал строки «Семейство, модель, степпинг». В наших тестах процессору, притворяющемуся Core 2, сменили имя производителя на «GenuineIntel», а положение в иерархии — на «6; 17; 0» (EAX=00’01’06’70, хотя ЦП со степпингом 0 обычно бывает лишь инженерным сэмплом — бета-версией чипа не для массового использования, что и указано буквами ES на втором скриншоте).
Нетрудно заметить, что далеко не вся поставляемая информация верна, даже если никакие строки не менялись. Параметры кэшей и TLB когда-то передавались описателями (дескрипторами) на стр. 2 1-й части. Но одного байта хватает далеко не на все комбинации чисел, поэтому во 2-й части кэши и TLB описываются точно, и именно туда и надо смотреть программам-детекторам. Например, среди описателей нет варианта для «L1D на 64 КБ, 2 пути и 64 Б/стр.» (как в современных процессорах AMD), но все программы верно показывают параметры кэшей для этих ЦП. Однако выше на примере CPU-Z мы видим, что для VIA Nano (и, скорее всего, вообще для всех ЦП) всё не так — судя по всему, параметры кэшей не читаются командой CPUID, а просто берутся из базы данных программы, основываясь на имени производителя и строке «Семейство, модель, степпинг». Происходит та же «подмена реальности», что и в диспетчерах программ, рождённых продуктами Intel.
Конечно, знающие программисты скажут «чья б корова мычала» — некоторые производители сами не всегда точно указывают данные в паспорте своих ЦП не только по причине отсутствия нужных кодов, но и из-за элементарной небрежности. Например, первые AMD Duron сообщали, что у них 1 КБ L2. Поэтому, чтобы верно отчитываться даже о первых вариантах ЦП, программы просто записывают «верные» показатели в собственные таблицы констант. Когда попадается действительно неизвестный процессор, имеет смысл читать буквально, через CPUID, но если это «оборотень в транзисторах» — обдурить можно не только исполняемые программы, но и пользователя.
Разоблачающие тесты
Плата VIA VB8001 на старом чипсете CN896 со впаянным Nano проделала долгий двухмесячный путь из Копенгагена в Санкт-Петербург (горячий привет Почте России!) не только ради снятия пары скриншотов. Тем более что наличие разъёма PCI-E x16 позволило установить туда стандартную видеокарту с нашего тестового стенда. Таким образом, не считая объёма ОЗУ (больше 4 ГБ в 2 слота установить не получится), соблюдены все стандартные условия, чтобы протестировать VIA Nano «по-взрослому», как настоящий 64-битный x86-процессор — благо, и новая методика образца 2010 года к тому времени была почти готова. Прежде всего нас интересовала производительность с «родным» (Native) и «подменённым» (на Core 2) CPUID как практическая проверка выводов Агнера Фога.
Но процесс тестирования иначе как «мучительным» назвать было сложно. Мы не можем судить о том, кто в этом виноват — недобросовестные производители ПО и/или компиляторов, конкретный экземпляр платы и/или процессора, — однако «мёртвые висы» (когда помогает лишь отключение питания или нажатие Reset) случались настолько часто, что тестеру даже пришлось протянуть от стенда к своему рабочему столу отдельный проводок c внешней кнопочкой сброса — уж очень напрягало постоянно вставать с кресла. :)
Вот полный список бенчмарков, в котором помечены тесты, удачно или неудачно пройденные VIA Nano в обоих режимах. Минус означает, что тест зависал или перезагружал компьютер сразу после запуска или в произвольном месте в процессе работы. Заметим, что «заминусованы» тесты, которые совсем не удалось выполнить: о таких сценариях, как «запустили — завис — перезапустили — завис — перезапустили — ура, прошёл!» мы даже не упоминаем.
|
|
* — Считается «условно пройденным»: по нашей тестовой методике каждый бенчмарк запускается 4 раза: один «разогревочный» прогон и 3 результирующих. В родном режиме VIA Nano ни разу не удавалось пройти весь тест Adobe Photoshop целиком: наилучшим достижением было 2 завершённых прогона, после чего на третьем система перезагружалась. ↑
Итого, из 54 тестов VIA Nano не смог пройти 15, т. е. больше четверти. Более чем ошеломляющая цифра для ЦП, который позиционируется как x86-64-совместимый. Как уже написано выше, мы не можем однозначно обвинять во всём именно процессор, но есть один наводящий на размышления нюанс: та же самая плата с VIA Nano сейчас работает дома у одного из авторов в качестве основы для домашнего NAS. Так вот: с набором ПО, сводящимся к 32-битной Windows XP Professional, медиасерверу, ftp- и http-серверу и антивирусу, она нормально функционировала в круглосуточном режиме на протяжении полутора месяцев без единого зависания…
Все возможные ошибки процессора могут быть исправлены в обновлённой линейке Nano 3xxx (ревизия CNB), но уточним: у нас нет никакой информации ни о сделанных исправлениях, ни о том, какие ошибки известны на данный момент самой VIA. Впрочем, глюки вполне могут оказаться вовсе не внутри процессора: из 15 проблемных программ 11 очень активно работают с видеоподсистемой, причём с задействованием возможностей аппаратного ускорения видеокарты. И здесь почва для фантазии весьма широка: от драйверов видеокарты до внутрисистемных драйверов контроллера PCI-E или его самого. Однако виновата скорее всего всё равно VIA. :)
Результаты сравнения родного режима с «эмуляцией» Intel Core 2
Посмотрим, насколько же ускоряются (в процентах) в «режиме Core 2» программы из тех, которым посчастливилось доработать до конца:
| Тест | Native | Core 2 | Δ% |
| Java | 10,55 | 10,67 | 1% |
| Архивация: 7-Zip | 0:18:25 | 0:18:20 | 0% |
| Архивация: WinRAR | 0:08:09 | 0:08:01 | 2% |
| Архивация: распаковка | 0:02:23 | 0:02:23 | 0% |
| Аудио: Apple Lossless | 20 | 21 | 5% |
| Аудио: FLAC | 25 | 25 | 0% |
| Аудио: Monkey's Audio | 19 | 19 | 0% |
| Аудио: MP3 (LAME) | 9 | 10 | 11% |
| Аудио: Nero AAC | 10 | 10 | 0% |
| Аудио: OGG Vorbis | 7 | 7 | 0% |
| Браузер: SunSpider/Chrome | 1357 | 1322 | 3% |
| Браузер: SunSpider/Firefox | 2259 | 2237 | 1% |
| Браузер: SunSpider/IE | 14875 | 15121 | −2% |
| Браузер: SunSpider/Opera | 863 | 859 | 0% |
| Браузер: SunSpider/Safari | 1245 | 1231 | 1% |
| Видео: DivX | 0:18:51 | 0:18:42 | 1% |
| Видео: Mainconcept | 0:56:32 | 0:56:31 | 0% |
| Видео: Premiere | 1:04:31 | 1:04:33 | 0% |
| Видео: x264 | 1:58:46 | 1:52:01 | 6% |
| Видео: XviD | 0:17:43 | 0:17:17 | 3% |
| Визуализация: Lightwave | 75,56 | 78,31 | −4% |
| Визуализация: UGS NX 6 | 0,74 | 0,73 | −1% |
| Графика: ACDSee | 0:21:59 | 0:21:43 | 1% |
| Графика: PaintShop | 0:38:01 | 0:37:58 | 0% |
| Графика: PhotoImpact | 0:33:10 | 0:32:53 | 1% |
| Графика: Photoshop | 0:31:47 | 0:31:27 | 1% |
| Игры: Borderlands | 11 | 11 | 0% |
| Игры: Far Cry 2 | 5,6 | 5,6 | 0% |
| Игры: Fritz Chess | 740 | 748 | 1% |
| Игры: Resident Evil 5 | 18,2 | 18,5 | 2% |
| Компиляция | 0:52:52 | 0:52:01 | 2% |
| Расчёты: MAPLE | 0,1211 | 0,1216 | 0% |
| Расчёты: Mathematica (int) | 0,804 | 0,891 | 11% |
| Расчёты: Mathematica (MMA) | 0,5269 | 0,4849 | −8% |
| Расчёты: MATLAB | 0,3421 | 0,2677 | 28% |
| Расчёты: UGS NX 6 | 1,47 | 1,47 | 0% |
| Рендеринг: 3ds max | 4:17:04 | 4:16:31 | 0% |
| Рендеринг: Lightwave | 1370,05 | 1428,26 | −4% |
Давайте разбираться. Сначала отсечём очевидное и привычное: как мы уже неоднократно писали, расхождение результатов на 1–2%, если оно не систематическое, не свидетельствует ни о чём, т. к. вполне укладывается в рамки погрешности измерений. Но в нашем случае оно как раз систематическое: +1/+2% встречается 11 раз, а −1/−2% — всего 2 раза. Таким образом, систематичность небольших выигрышей режима «притворства» процессором Intel Core 2, с одной стороны, подтверждает гипотезу о «нечестности» определения поддержки дополнительных наборов инструкций, с другой же — нивелирует любой вред до уровня несущественного.
Что с прочими тестами? С точки зрения проверки гипотезы Агнера Фога, наибольшего внимания заслуживают тесты в Lightwave, Apple Lossless, MP3 (LAME), SunSpider/Chrome, Mathematica, MATLAB, x264 и XviD. Соблюдём презумпцию невиновности ;) и выбросим из этого списка SunSpider/Chrome и XviD — где есть 1–2 процента, там изредка и 3 может встретиться, мало ли как бывает… Сложнее объяснить, почему придётся выкинуть и Apple Lossless с MP3 (LAME).
Дело в том, что наша методика, как и любой продукт, разрабатывавшийся для определённых целей, не может быть полностью универсальной. В частности, она неважно подходит для тестирования процессоров с очень маленькой производительностью. Одной из причин этого является использование бенчмарка dBpoweramp, выдающего целочисленные результаты: когда результат очень мал, разница между процессорами в одну измеряемую единицу может составлять «заметные» 5–10% в относительном исчислении. А на самом деле, быть может, это были не 9 и 10 баллов, а 9,4 и 9,6 — но этого мы никогда не узнаем, потому что округление произведено внутри бенчмарка.
Остаются Lightwave, Mathematica, MATLAB и x264. Казалось бы, не так уж много — но с нашей точки зрения, цель всё-таки достигнута: в этих случаях разницу в производительности не представляется возможным объяснить без привлечения гипотезы Агнера Фога. Правда, ориентацию на сигнатуры производителя разработчики MATLAB особенно и не скрывают, на тему чего мы даже сделали 2 года назад специальное исследование, — но касаемо других программ такая информация нам не известна. Дополнительно отметим, что крайне нестабильная работа Adobe Photoshop в родном режиме исправлена переходом в «поддельный», что выглядит куда наглядней жалкого процента прибавки к скорости. А вот Sony Vegas, наоборот, принципиально отказался работать на фальшивом Core 2.
В сухом остатке (из 38 тестов) мы имеем 6 случаев существенной разницы в производительности между родным и «обманным» режимами, причём в трёх из шести «притворство» процессором Intel привело к ускорению в среднем на 15%, а в других трёх — к замедлению в среднем на 5%. Выводы из этого можно сделать такие:
- Само наличие разницы в производительности ПО на одном и том же ЦП после замены его CPUID свидетельствует о том, что заявленная проблема влияния строки с именем производителя ЦП на скорость существует. Этот факт можно считать доказанным.
- Однозначно оценить данную проблему как приносящую процессорам не-Intel исключительно вред — не получается. Ну а подавляющее большинство тестов на смену CPUID либо вообще не прореагировало, либо прореагировало более чем вяло.
- Мы не утверждаем, что все подозрительные программы были собраны именно компилятором Intel (хотя именно от него ожидаются наблюдаемые эффекты), а прочие — какими-то другими. Не исключаем мы и возможности, что инструменты других фирм имеют похожие недостатки, тоже влияющие на производительность генерируемых программ.
О последнем косвенно свидетельствует присутствие в списке кодека x264, который относится к категории OSS (open source software), причем скомпилирован при помощи OSS-компилятора и таких же библиотек — т. е. никакого инструментария Intel в данном случае, по идее, использоваться не могло, а вот выигрыш от подмены CPUID на интеловский довольно существенный.
Если изложить вышесказанное в двух словах, то, да простит нас Смелый Рыцарь, наш вердикт будет таков: проблема существует, но переоценивать её влияние на производительность реального ПО не стоит.
Но раз у нас есть результаты VIA Nano…
…То почему бы не попытаться составить общее впечатление о его производительности? Разумеется, сравнивать этот процессор нужно в первую очередь с Intel Atom, но результатов его тестирования у нас ещё нет. А есть, например, результаты AMD Sempron 140. А что? Как и Nano, он одноядерный, с аналогичным устройством и объёмами кэшей, основан на современном OoO-ядре K10 с 3-путным суперскаляром и полноконвейерными ФУ. Почему бы не сравнить? Правда, у Sempron 140 существенно бо́льшая штатная частота (2,7 ГГц), но мы ведь сравниваем «прикидочно». Вполне подойдёт простая экстраполяция, предполагающая, что производительность Sempron линейно уменьшается пропорционально частоте. Учитывая, что его штатная частота и так не очень велика (применительно к границам, уже достигнутым ядром K10), а также то, что экстраполяция идёт в сторону уменьшения (поэтому, например, 2-канальный ИКП взамен чипсетного вроде бы ничего не даст) — предполагаемые значения, теоретически, должны быть весьма близки к истине.
И что у нас получилось?
| Тест | VIA Nano 1,6 ГГц (Native) | AMD Sempron 140 (пересчёт на 1,6 ГГц) | Δ% |
| Java | 10,55 | 15,9 | 51% |
| Архивация: 7-Zip | 0:18:25 | 0:11:40 | 58% |
| Архивация: WinRAR | 0:08:09 | 0:05:20 | 53% |
| Архивация: распаковка | 0:02:23 | 0:01:51 | 29% |
| Аудио: Apple Lossless | 20 | 26 | 30% |
| Аудио: FLAC | 25 | 31 | 24% |
| Аудио: Monkey's Audio | 19 | 23 | 21% |
| Аудио: MP3 (LAME) | 9 | 14 | 56% |
| Аудио: Nero AAC | 10 | 13 | 30% |
| Аудио: OGG Vorbis | 7 | 9 | 29% |
| Браузер: SunSpider/Chrome | 1357 | 959 | 42% |
| Браузер: SunSpider/Firefox | 2259 | 1612 | 40% |
| Браузер: SunSpider/IE | 14875 | 8884 | 67% |
| Браузер: SunSpider/Opera | 863 | 962 | −10% |
| Браузер: SunSpider/Safari | 1245 | 1498 | −17% |
| Видео: DivX | 0:18:51 | 0:12:52 | 47% |
| Видео: Mainconcept | 0:56:32 | 0:36:40 | 54% |
| Видео: Premiere | 1:04:31 | 0:33:32 | 92% |
| Видео: x264 | 1:58:46 | 1:00:42 | 96% |
| Видео: XviD | 0:17:43 | 0:11:27 | 55% |
| Визуализация: Lightwave | 75,56 | 40,46 | 87% |
| Визуализация: UGS NX 6 | 0,74 | 1,27 | 72% |
| Графика: ACDSee | 0:21:59 | 0:14:08 | 55% |
| Графика: PaintShop | 0:38:01 | 0:23:16 | 63% |
| Графика: PhotoImpact | 0:33:10 | 0:16:20 | 103% |
| Графика: Photoshop | 0:31:47 | 0:17:30 | 82% |
| Игры: Borderlands | 11 | 19,6 | 78% |
| Игры: Far Cry 2 | 5,6 | 9,2 | 64% |
| Игры: Fritz Chess | 740 | 950 | 28% |
| Игры: Resident Evil 5 | 18,2 | 31,4 | 73% |
| Компиляция | 0:52:52 | 0:33:01 | 60% |
| Расчёты: MAPLE | 0,1211 | 0,1741 | 44% |
| Расчёты: Mathematica (int) | 0,804 | 1,695 | 111% |
| Расчёты: Mathematica (MMA) | 0,5269 | 0,7766 | 47% |
| Расчёты: MATLAB | 0,3421 | 0,1664 | 106% |
| Расчёты: UGS NX 6 | 1,47 | 2,63 | 79% |
| Рендеринг: 3ds max | 4:17:04 | 0:47:53 | 437% |
| Рендеринг: Lightwave | 1370,05 | 878,93 | 56% |
Даже если убрать откровенно провальный результат Nano для рендеринга в 3ds max + V-Ray, то в среднем виртуальный одночастотный Sempron быстрее на 55%. Эффективность на ватт пока мы сравнить не можем, но на каждый потраченный транзистор — вполне. В Nano их 94 млн., а в Sempron (на ядре K10) — 234 млн., но если вспомнить, что последний суть 2-ядерный Athlon II X2 с одним отключенным ядром (которое иногда можно и разблокировать), то по приблизительному подсчёту числа транзисторов в кэшах и ядре K10 получается, что если бы на чипе физически было только одно ядро, то осталось бы 130 млн. транзисторов (включая отсутствующий у Nano 2-канальный ИКП, сложность которого мы оценим как незначительную). Т. е. большее на 38% число транзисторов дало Sempron превосходство в скорости в 55%.
Если результаты грубой прикидки не очень далеки от реальности, то КПД расхода транзисторного бюджета лишь подчёркивает наши рекомендации, данные в теоретическом обзоре микроархитектуры VIA Isaah. Но т. к. ничего идеального в мире нет, то как только нам удастся в аналогичных условиях протестировать Intel Atom (со своими особенностями), мы обязательно вернёмся к теме производительности VIA Nano.
На прошлой неделе пришла новость о том, что FTC и Intel заключили соглашение: FTC, даже имея доказательства в виде «неточных» результатов тестов типа PCMark 2005, не будет накладывать штрафные санкции, а за это Intel обещает (опять…):
- сообщить производителям ПО, что её компиляторы различают ЦП Intel и не-Intel и не всегда выдают для последних оптимальный код, — и возместить дополнительный расход любому производителю ПО, который по этой причине захочет переделать свою программу компилятором не от Intel (при том, что библиотеки Intel, исправлять которые соглашение не требует, можно использовать и с не-интеловскими компиляторами);
- не использовать подкупы, угрозы и т. п. стимулы для заключения эксклюзивных договоров с производителями ПК в обмен на их согласие не покупать ЦП конкурентов;
- как минимум 6 лет поддерживать шину PCI Express даже чипсетами или процессорами со встроенной графикой, чтобы можно было подключить GPU сторонних производителей;
- изменить условия лицензий так, чтобы предоставить бóльшую свободу конкурентам для сотрудничества и совместного развития технологий;
- продлить лицензионное соглашение с VIA Technologies для выпуска ЦП архитектуры x86 ещё на 5 лет — до 2018 г.
Победа?…
за предоставленную информацию, плату и программу,
а также Алексея АКА MoroseTroll,
который поднял тему, поддерживал её развитие
и оказывал технические консультации.


