Часть 1: Предыстория, Теория, Ядро, Сила
До Атома

Компания Intel давно стала обращать пристальное внимание на мобильный потребительский сектор и выпускать ориентированные на него продукты. Поначалу это были процессоры, подобранные по малому энергопотреблению при прочих равных параметрах (разве что частоты пониже, да корпус поменьше). Затем стали выпускать ЦП, специально доработанные для подобных применений. Историю можно начать с чипа i80386SL, у которого впервые появился SMM (System Management Mode — режим управления системой), динамическое ядро было заменено на статическое (т. е. для сохранения энергии частота может падать до нуля), и добавлены контроллеры кэша, памяти и шин ISA и PI (Peripheral Interface). Все эти изменения увеличили число транзисторов аж втрое (с 275 000 у обычного 386SX/DX до 855 000), но инженеры посчитали, что такой бюджет оправдан. Помимо этого также были версии i386CX и i386EX без встроенной периферии с тремя режимами энергосбережения.
Много воды утекло, каждый следующий ЦП (кроме серверных) выпускался как в обычном, так и в мобильном (иногда ещё и во встроенном) варианте, но все манипуляции в основном заключались в добавлении к ядру энергосберегающих режимов и отборе чипов, способных работать на пониженном напряжении при пониженных частотах. Между тем, конкуренция со стороны архитектур, разработанных специально для мобильных устройств, усилилась: 1990-е принесли появление PDA (начиная с Apple Newton MessagePad), а 2000-е дали коммуникаторы, интернет-планшеты (полузабытая аббревиатура MID) и ультрамобильные ПК (UMPC). В довесок ко всему оказалось, что основные задачи для пользователя таких устройств имеют небольшие вычислительные потребности, так что почти любой ЦП, выпущенный после 2000 г., уже обладал нужной мощностью для мобильного применения, кроме, разве что, современных игр (для которых как раз тогда появились мобильные консоли с 3D-графикой).
Назрела необходимость сделать специальную архитектуру для компактного мобильного устройства, где главное — не скорость, а энергоэффективность. В Intel такую задачу взяло на себя израильское отделение компании, создавшее до этого весьма удачное семейство мобильных процессоров Pentium M (ядра Banias и Dothan). В этих ЦП энергосберегающие принципы были поставлены во главу угла с самого начала разработки, так что динамическое отключение блоков в зависимости от их загрузки и плавное изменение напряжения и частоты стало залогом экономности серии. Особенно ярко Pentium M смотрелись на фоне выпускаемых тогда же Pentium 4, которые в сравнении с ними казались раскалёнными сковородками. Причём, работая на одной частоте, Pentium M выигрывали у «четвёрок» по производительности, что вообще впервые случилось в практике процессоростроения — обычно мобильный компьютер расплачивается за свою компактность всеми остальными характеристиками. Впрочем, и сами-то Pentium 4 были, скажем так, не очень хороши в роли универсального ЦП…
Успех платформы показал, что такая высокая скорость нужна не всем, а вот сэкономить ещё энергии было бы неплохо. На тот момент (середина 2007 г.) Intel выпустила «папу» наших сегодняшних героев — процессоры A100 и A110 (ядро Stealey). Это 1-ядерные 90-нанометровые Pentium M с четвертью кэша L2 (всего 512 КБ), сильно заниженными частотами (600 и 800 МГц) и потреблением 0,4–3 Вт. Для сравнения — стандартные Dothan при частотах 1400–2266 МГц имеют энергорасход 7,5–21 Вт, низковольтные (подсерия LV) — 1400–1600 МГц и 7,5–10 Вт, а впервые введённые ультранизковольтные (ULV) — 1000–1300 МГц и 3–5 Вт. Резонно полагая, что современный компьютер большую часть времени проводит в ожидании очередного нажатия клавиши или сдвига мыши ещё на один пиксель, главным отличием A100/A110 от подсерии ULV Intel сделала умение очень глубоко засыпать, когда считать не надо совсем, благодаря чему потребление при простое падает на порядок. А сильно сокращённый кэш (большой L2 на таких частотах не очень-то и нужен) помог уменьшить размер кристалла, что сделало его дешевле. Размер корпуса процессора уменьшился впятеро, а суммарная площадь ЦП и чипсета — втрое. Как мы увидим далее, такие приёмы были использованы и в серии Atom.

Несмотря на в принципе верное целеполагание, A100/A110 остались мало востребованы рынком. То ли 600–800 МГц оказалось всё же маловато даже для простенького интернет-планшета, то ли всего два чипа (что даже модельным рядом назвать трудно) с самого начала были экспериментальным продуктом для обкатки технологии, то ли процессор просто не раскрутили маркетологи, зная, что ему на смену идёт кое-что куда более продвинутое… Менее чем через полгода после выпуска A100/A110 26 октября 2007 г. Intel объявила о близком выпуске новых мобильных ЦП с кодовыми именами Silverthorne и Diamondville и ядром Bonnell — будущих Атомов. Кстати, название Bonnell произошло от имени холмика высотой 240 м в окрестностях г. Остин (штат Техас), где в местном центре разработки Intel располагалась малочисленная группа разработчиков Атома. «Как вы яхту назовёте, так она и поплывёт.» ©Капитан Врунгель
В 2004 г. эта группа, после отмены ведомого ею проекта Tejas (наследника Pentium 4), получила прямо противоположное задание — проект Snocone по разработке крайне малопотребляющего x86-ядра, десятки которых объединит в себе суперпроизводительный чип с потреблением 100–150 Вт (будущий Larrabee, недавно переведённый в статус «демонстрационного прототипа»). В группе оказалось несколько микроэлектронных архитекторов из других компаний, включая и «заклятого друга» AMD, а её глава Belli Kuttanna работал в Sun и Motorola. Инженеры быстро обнаружили, что различные варианты имеющихся архитектур не подходят их нуждам, а пока думали дальше, в конце года CEO Intel Пол Отеллини сообщил им, что этот же ЦП также будет и 1-2-ядерным для мобильных устройств. Тогда было тяжело предположить, как именно и с какими требованиями такой процессор будет применяться через отведённые на разработку 3 года — руководство с большой долей риска указало на наладонники и 0,5 Вт мощности. История показала, что почти всё было предсказано верно.
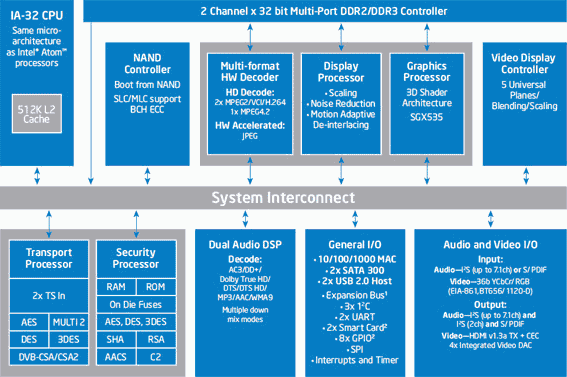
Устройство CE4100
Интересно, что уже вслед за Атомом летом 2008 г. был выпущен EP80579 (Tolapai) для встраиваемых применений с ядром Pentium М, 256 КБ L2, 64-битным каналом памяти, полным набором контроллеров периферии, частотами 600–1200 МГц и потреблением 11–21 Вт. А почти сразу после него — модель Media Processor CE3100 (Canmore) для цифрового дома и развлечений: архитектура Pentium М, частота 800 МГц, 256 КБ L2, три 32-битных канала контроллера памяти, 250 МГц RISC-видеосопроцессор и два 340 МГц ядра DSP (цифровой сигнальный процессор) для аудио. Как покупались эти штуки — не ясно, т. к. после анонса о них не было слышно ничего в т. ч. и от Intel. Видимо, не очень… Уже после расцвета Атома, в сентябре 2009-го, Intel повторила попытку и выпустила CE4100, CE4130 и CE4150 (Sodaville) уже на «атомном» ядре частотой 1200 МГц, двумя 32-битными каналами DDR3, обновлённой периферией и технормой 45 нм. И вновь с тех пор об этих высокоинтегрированных системах-на-чипе (SOC) мало слышно. Может быть, рынок не готов встретить героя?

Слева CE4100, справа — CE3100
Теория Атома
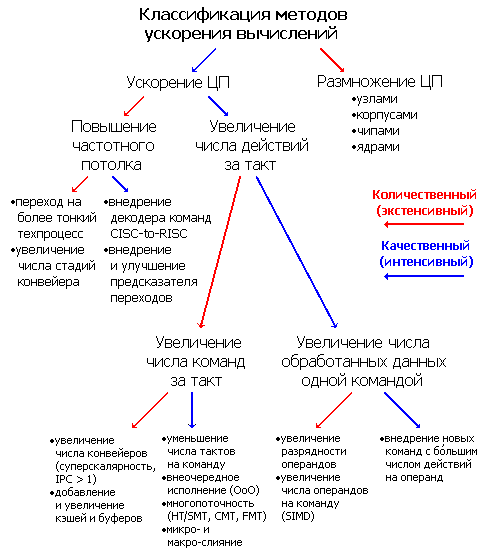
Для начала рассмотрим основные характеристики процессора с точки зрения потребителя. Их три: скорость, энергоэффективность, цена. (Правда, энергоэффективность — не очень-то «потребительская» характеристика, но, тем не менее, именно по ней проще всего судить о некоторых важных параметрах конечного устройства.) Далее вспомним, что у идеальной КМОП-микросхемы (по этой технологии изготавливаются все современные цифровые чипы) потребление энергии пропорционально частоте и квадрату напряжения питания, а пиковая частота линейно зависит от напряжения. В результате, уполовинив частоту, мы можем уполовинить напряжение, что в теории уменьшит потребление энергии в 8 раз (на практике — в 4–5 раз). Таким образом, мобильный процессор должен быть низкочастотным и низковольтным. Как же тогда он окажется быстрым? Для этого надо, чтобы за каждый такт он выполнял как можно больше команд, что чаще всего означает увеличение числа конвейеров (степени суперскалярности) и/или числа ядер. Но это ведёт к резкому росту транзисторного бюджета, что увеличивает площадь чипа, а значит и его стоимость.
 Таким образом, выиграть по всем трём пунктам не получится даже теоретически (чем и объясняется присутствие на рынке такого разнообразия процессорных архитектур). Поэтому где-то придётся сдать позиции. Исторический экскурс говорит, что сдать надо в скорости, что даст возможность сделать ядро ЦП максимально простым. Именно по этому пути и пошли инженеры из Остина. Обдумав варианты, они решили вернуться к архитектуре 15-летней давности, первый и последний раз (среди процессоров Intel) использовавшейся в первых Pentium. А именно: процессор остаётся суперскалярным (т. е. 2 команды за такт у нас будет — но не 3–4, как в современниках Атома), лишается механизма перетасовки команд перед исполнением (OoO), но приобретает то, чего у Pentium не было — технологию гиперпоточности (HyperThreading, HT), позволяющую на базе одного физического ядра эмулировать для ОС и ПО наличие двух логических. Чтобы объяснить, почему был сделан именно такой выбор, читателю рекомендуется сначала вспомнить все возможные способы увеличения производительности ЦП. А теперь оценим их с позиции потребления энергии и транзисторных затрат.
Таким образом, выиграть по всем трём пунктам не получится даже теоретически (чем и объясняется присутствие на рынке такого разнообразия процессорных архитектур). Поэтому где-то придётся сдать позиции. Исторический экскурс говорит, что сдать надо в скорости, что даст возможность сделать ядро ЦП максимально простым. Именно по этому пути и пошли инженеры из Остина. Обдумав варианты, они решили вернуться к архитектуре 15-летней давности, первый и последний раз (среди процессоров Intel) использовавшейся в первых Pentium. А именно: процессор остаётся суперскалярным (т. е. 2 команды за такт у нас будет — но не 3–4, как в современниках Атома), лишается механизма перетасовки команд перед исполнением (OoO), но приобретает то, чего у Pentium не было — технологию гиперпоточности (HyperThreading, HT), позволяющую на базе одного физического ядра эмулировать для ОС и ПО наличие двух логических. Чтобы объяснить, почему был сделан именно такой выбор, читателю рекомендуется сначала вспомнить все возможные способы увеличения производительности ЦП. А теперь оценим их с позиции потребления энергии и транзисторных затрат.
Использование многопроцессорной конфигурации в карманном или наколенном устройстве недопустимо, а вот многоядерность — вполне, если не хватает скорости одного ядра. Поначалу Intel сделала это тем же способом, что и в первых 2-ядерных Pentium 4 — поставив пару одинаковых 1-ядерных чипов на общую подложку и общую шину до чипсета. Из других разделяемых ресурсов есть лишь питающее напряжение, которое выбирается из максимума двух запросов. Т. е. ядра могут отдельно изменять свои частоты, но засыпают и пробуждаются синхронно. В декабре 2009 г. Intel выпустила первые интегрированные версии Атомов, где на одном кристалле есть 1–2 ядра и северный мост. На плате остался южный мост, соединённый с ЦП шиной DMI, что чуть быстрее и экономней предыдущей комбинации. Больше двух ядер нам скоро не предложат, так что основной скоростной упор сделан на их внутренности.
Вопрос повышения частотного потолка инженеров Intel на этом этапе тоже не очень волновал, хотя отказываться от принципа конвейерности и декодирования команд х86 во внутренние микрооперации (мопы) никто не собирался — это был бы слишком радикальный шаг назад. А вот предсказатели переходов, предзагрузчики данных и прочие вспомогательные системы заполнения конвейера стали очень важны, т. к. простаивающий конвейер, не умеющий исполнять другие команды в обход застрявшей, означает выкинутые насмарку драгоценные ватты — и у Атома все необходимые «подпорки» сделаны ненамного хуже, чем у Pentium M и более современных ему Core 2, разве что размеры буферов поменьше (опять же ради экономии). В итоге, основная битва разыгрывается вокруг производительности за такт.
Рассмотрев диаграмму вариантов ускорения ЦП, мы видим, что среди качественных способов увеличения производительности значится увеличение разрядности скалярных и векторных операций, а также усложнение системы команд разнообразными дополнениями со специализированными командами, выполняющими больше операций над аргументами. Всё это есть в Атоме — и самый последний на момент разработки набор команд SSSE3 и даже 64-битное расширение x86-64. Так что действий на команду выполняется достаточно. Вся суть Атома — в числе команд за такт, т. е. в показателе IPC.
Экстенсивным (количественным) путём было бы увеличение числа конвейеров и размеров разных кэшей и буферов. Очевидно, что начиная с определённого момента это слишком дорого обходится для транзисторного бюджета, принося всё меньше процентов ускорения от очередной добавки. Поэтому в Intel решили остановиться лишь на необходимом минимуме. А вот насчёт качественных мер вопрос посложней. Из возможных вариантов лишь обильное использование микрослияния мопов (mOP microfusion) не вызывает вопросов — необходимо, чтобы как можно меньшее число команд при декодировании генерировало более одного мопа, занимая оба конвейера и препятствуя исполнению двух команд за такт. Макрослияние не внедрено либо по причине его малой эффективности (если брать за пример реализацию в Core 2), либо из-за 50%-ного шанса на срабатывание (т. к. первая сливаемая команда должна попасть на первый декодер, а вторая на второй, и не иначе). С уменьшением числа тактов для исполнения команд мы ещё разберёмся.
Остались технологии максимизации заполнения конвейеров. Использовать их одновременно будет жирновато, так что придётся выбрать что-то одно — либо всем привычная за 15 лет перетасовка команд, либо более молодая HT, появившаяся у Intel лишь в последних моделях Pentium 4. Прежде всего следует сказать, что при использовании современных компиляторов (но без ручной оптимизации) число подряд идущих в программе команд, которые можно исполнить параллельно, колеблется около двух. Т. е. для 2-путного (2-way) конвейера перетасовка команд вроде бы не нужна. Кроме того, конвейер может быть частично заполнен или даже полностью остановлен не только невозможностью одновременного исполнения мопов, но и особо долгим кэш-промахом или неверно предсказанным переходом. Выходит, что вариант использования HT как альтернативы OoO выглядит разумно, хоть и непривычно для классических схем.
Добавим также, что так называемый «буфер переупорядочивания» и «резервационные станции» — довольно ресурсоёмкие блоки, которым приходится решать сложную задачу определения свободных ресурсов и взаимозависимостей в претендующих на исполнение командах. Единственный способ сделать это за 1 такт — разменять вычислительную сложность на избыточность. Для 3–4-путных конвейеров это делается с помощью сотен и тысяч компараторов, срабатывающих каждый такт и проверяющих все возможные комбинации запуска мопов. Что, разумеется, требует немалой площади и изрядного количества энергии. Гиперпоточность же требует лишь дополнительных буферов для хранения второго состояния конвейера (для «другого» потока), дубликата регистрового файла и относительно несложной логики, согласующей и переключающей потоки, а остальные ресурсы — общие.
Сразу возникает вопрос: если HT такая замечательная штука, почему её не внедряют повсеместно? Во-первых, для 3–4-поточного суперскаляра с OoO средняя загрузка конвейера такова, что второй поток команд поднимет скорость лишь процентов на 10. Ведь для его исполнения тоже нужны свободные ресурсы, а если обе программы спотыкаются об одно и то же (например, нехватку кэша), им ничто не поможет. Во-вторых, однопоточное приложение так не ускоришь, хотя общая отзывчивость системы улучшится. Т. е. общее ускорение будет сильно зависеть от подбора пары запущенных программ (тут везде мы предполагаем, что «гипер-» означает «двух-»). Однако за малую заплаченную цену в транзисторах это вполне неплохо. Intel, впрочем, приводит другие цифры, акцентируя на экономии: увеличивая потребление на 20%, включение HT даёт ускорение аж 30–50% (оставим эти цифры, особенно вторую, на совести заявителя).
Ядро Атома

Проведя необходимую теоретическую подготовку, мы наконец-то дошли до собственно архитектуры. Её сильное упрощение позволило сократить число транзисторов в ЦП до 47 млн. (из них на ядро, включая оба кэша L1 — 13,8 млн.), а площадь — до 26 мм² (используется 45-нанометровый техпроцесс с 9 слоями медных дорожек, металлическими затворами и подзатворными диэлектриками с высокой проницаемостью). Для сравнения — 90-нанометровые Pentium М занимали 84 мм², но там вчетверо больший кэш L2. Ядро Pentium М занимает примерно 35 млн. транзисторов, а Core 2 — 50 млн. Хотя, конечно, сравнения с первым Pentium (3,3 млн.) Атом не выдерживает — совсем уж простым его назвать тоже нельзя, что косвенно видно по размеру статьи. :)
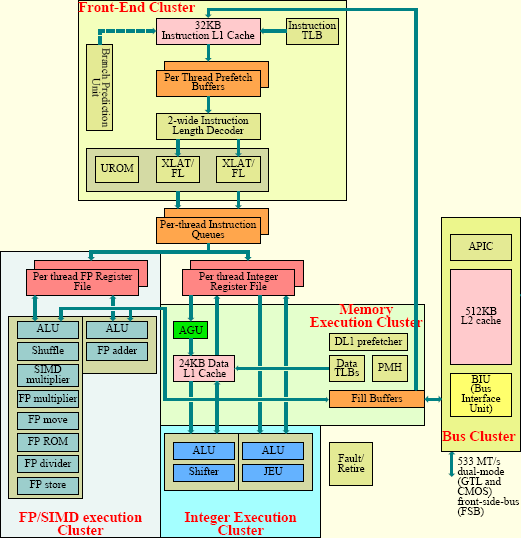
Atom проще всего описать как очень сильно модернизированный Pentium, но так можно сказать о почти любом современном процессоре. Больше всего с 15-летним старичком его роднит 2-путная суперскалярность и отсутствие OoO (первые наброски Атома и вовсе были 1-путными, как 486), зато отличает почти всё остальное. Прежде всего то, что «атомный конвейер» имеет аж 16 стадий. Для сравнения — у первого Pentium их 5 (8 у вещественной части), у Pentium M и Core Solo/Duo — 14, а у Core 2 — 16 (по замерам при сбросе конвейера). Зачем так много? Длинный конвейер позволяет поднять частотный потолок, но тут это совсем не надо. Есть 3 стадии для доступа к кэшу L1D, причём их проходят все команды, в т. ч. и не обращающиеся «наружу» — такое решение сильно упрощает управление конвейером и используется во всех «упорядоченных» (in-order) архитектурах. Также возможно более детальное отключение стадий при их простое для экономии энергии и «тонкое» переключение между потоками (при включенной HT) отдельными стадиями и их малыми группами. Однако полученную выгоду в ваттах и исполненных командах запросто нивелирует бо́льшая задержка при сбросе конвейера из-за неверно предсказанного перехода.
Конвейер Атома
| Стадия | IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Группа | Выборка из L1I (Instruction fetch) | Декодирование (Decode) | Планировка (Schedule) | Чтение регистрового файла (RF read) | Генерация адреса, доступ к L1D (Address generation, Data cache) | Исполнение (Execution) | Обработка исключений и гиперпоточности (Except/MT handle) | Отставка, запись результатов (Writeback, Data Commit) | ||||||||
Поэтому предсказатель переходов, с которого начинается конвейер, лишь немногим уступает «коллегам». Это 2-уровневый адаптивный предсказатель с таблицей глобальной истории переходов (GBHT) на 4096 ячеек и 12-битной индексацией. Буфер адресов переходов (BTB) имеет всего 128 ячеек, организованных как 32 4-путных набора (в десятки раз меньше, чем у современных десктопных и даже «классических» мобильных ЦП). Специального предсказателя для циклов или косвенных переходов нет. Как и у всех современных ядер, есть стек адресов возврата из подпрограмм на 8 ячеек (плюс 2 буферные ячейки в предсказателе). Таблицы сокращённого размера экономят место, но подставляют подножку на программах с большим числом переходов, даже хорошо предсказываемых или вовсе безусловных (включая вызовы подпрограмм). Причём переключение на второй поток может не помочь, т. к. оба потока разделяют эти буферы и таблицы. Предсказание происходит с темпом 1 раз за 2 такта, но если оно окажется неверным — штраф будет 13 тактов. Если предсказание поведения верное, но адрес уже вытеснен из крохотного BTB — ждать надо 7 тактов.
Команды загружаются 8-байтовыми кусками из кэша L1I в двойной буфер предекодера по 16 байт на поток, причём в 1-поточном режиме оба буфера могут обслуживать единственный поток при соблюдении правил выравнивания, достигая максимального темпа 10–11 байт/такт. Эта цифра несколько избыточна, ибо даже для своих 4-путных суперскаляров (да ещё и с макрослиянием, позволяющим изредка декодировать 5-ю команду) Intel до сих пор использует 16-байтовую загрузку — хотя средняя длина команды (особенно в 64-битном режиме и с обильным использованием разнообразных SSE) вот-вот перевалит за 4 байта.
Производители нафаршировали современные x86 ЦП громоздкой системой команд с чрезвычайно сложной схемой декодирования, поэтому декодеры вынуждены тратить большое число транзисторов и энергии даже на такую казалось бы элементарную операцию, как определение длины команды (точнее, этим занимается отдельная стадия — предекодер-длиномер или ILD), поскольку надо обрабатывать команды с несколькими префиксами. Для Атома число префиксов больше трёх вызовет серьёзную задержку. Т. е. на команды набора SSE2/3 (1–2 префикса) в 64-битном режиме (ещё 1) этого хватит, а вот для более свежего SSSE3 (или какого-то варианта SSE4, если Intel захочет добавить его в Атом) — уже нет.
Для ускорения замеров длин с L1I связан буфер тегов предекодирования, где хранится разметка границ команд. Такое решение оправдано для экономии энергии при исполнении уже встретившегося кода и похоже на используемое в ядрах AMD K7–K10, где работа ILD происходит при считывании из L2 в L1I — правда, там эта схема предназначена для ускорения основного декодирования. А вот в Атоме биты разметки определяются и отправляются в буфер лишь при первом исполнении закэшированного кода, что происходит со скоростью 3 такта/байт (у AMD — 4 байта/такт). Причина такой нерасторопности — очень простой последовательный длиномер. При этом стадию ILD все команды проходят всегда, просто ранее встретившиеся, считав готовую разметку, проходят её «навылет», не напрягая транзисторы — и снова экономия приводит к удлинению конвейера.
Декодирование команд происходит двумя простыми трансляторами и одним микросеквенсором. Это несколько отличается от обычной схемы, где один из трансляторов является сложным, т. к. генерирует более одного мопа за такт (как правило — 3–4, по числу конвейеров). Все трансляторы декодируют по одной команде за такт. Микросеквенсор выдаёт по нескольку мопов (для Атома, разумеется, не более двух), но в течение нескольких тактов и только для особо сложных команд, требующих микрокода. Однако по оценке Intel лишь 4% команд потребуют более 1 мопа — микрослиянию подвергается 16% команд, в т. ч. такие относительно сложные как Load-Op-Store (с модификатором в памяти), которым ранее требовалось 2–3 мопа (из других x86-архитектур так умеет лишь AMD K10). Т. е. для Атома микрослияние уменьшило число обращений в микрокод впятеро. Таким образом, стремление к разбиению команд на простые RISC-операции для ускорения исполнения, очевидное сегодня и 15 лет назад (этим от P5 отличался P6, он же Pentium Pro), в данном случае обратилось вспять — за неимением возможности перетасовать команды, крайне расточительно забивать весь конвейер мопами (тем более, что он и так очень узкий) — а скорости и без этого достаточно.
Выход декодера подключен к 32-моповой очереди, которая статически делится надвое при включенной HT. Весь front-end («голова конвейера» от предсказателя до очереди мопов) может работать в отрыве от back-end (исполнительного «хвоста») в случае задержек данных или исполнении долгой команды, наполняя очередь мопами про запас.
Сила Атома
Итак, как же Atom обрабатывает данные, чтобы было очень экономно, мало по транзисторам и не очень медленно? Исполнение начинается с того, что из очереди мопов 1–2 команды передаются в два исполнительных кластера — скалярный целочисленный (общего назначения) и векторно-вещественный (схема, больше похожая на устройство ядер AMD K7–K10). Обмен между кластерами (например, при преобразовании форматов) требует 4–5 тактов задержки. К общему кластеру подключен кэш L1D, так что общение с памятью для второго кластера дольше. Каждый кластер может исполнить две команды за такт, но не более двух в сумме, т. к. порты запуска кластеров тесно связаны.
Оба порта могут исполнить наиболее частые команды — копирование между регистрами одного типа и простые целочисленные операции в АЛУ (в т. ч. векторные). Но только порт 0 может выполнять обмен с памятью, сдвиги, перетасовки и перепаковки, умножения, деления и пр. сложную арифметику. Порту 1 эксклюзивно достались переходы и вещественные сложения (в т. ч. векторные). Помимо прочего, это означает, что ставший уже привычным 2-портовый доступ к L1D даже в сокращённом виде (запись + чтение) отсутствует — кэш строго однопортовый, что последний раз применялось в Intel 486.
Поскольку перетасовки команд перед исполнением нет, программистам (и компиляторам) придётся выучить правила спаривания команд. Впрочем, они существенно отличаются от имеющихся в Pentium:
- Запускаемая пара мопов всегда принадлежит одному потоку. Запустить один «свой» и один «чужой» не получится.
- Две команды должны идти в коде подряд — кроме допустимого случая, когда первая — это команда перехода, указывающая на вторую.
- Вторая (по ходу программы) команда не может читать регистр, модифицируемый первой — кроме условного перехода, который может быть вторым, т. к. сможет прочесть флаги, изменённые в этом же такте первым мопом.
- Команды не должны писать в один и тот же регистр (кроме флагов) — даже в случае его полной перезаписи.
- Команды должны использовать разные порты.
- Команды, загружающие функциональные устройства (ФУ) обоих портов, не спариваемы. Например, вещественное сложение с памятью использует порт 0 для вычисления адреса и доступа к памяти и порт 1 для самого сложения.
- Две скалярные вещественные команды для x87-стека мало того, что не спариваются (даже на разных портах), так ещё и дают дополнительную задержку в 1 такт — даже пара FNOP’ов, которые ничего не делают.
Из этого разгромного по сути списка запрещающих условий становится понятно, что суперскалярность у Атома не то чтобы номинальная, а даже «вычурно кривая». Вряд ли микроархитектурщики Intel резко поглупели, но погоня за крайней простотой и энергоэффективностью довела архитектуру до абсурда, когда один из двух конвейеров будет часто простаивать из-за слишком строгих правил спаривания. Некоторым облегчением является то, что запуск команд с разной длительностью исполнения не приводит к штрафам. Аналогично — обработка данных не своего типа (для векторных команд). Например, можно использовать команду MOVAPS для целых чисел.
Самым частым камнем преткновения для архитектур с упорядоченным исполнением является кэш-промах, на обслуживание которого может потребоваться 10–200 тактов. При промахе такой ЦП просто ждёт (в лучшем случае — приостановив тактирование для экономии), а архитектура с OoO — исполняет команды, накопленные в буфере перетасовки и независящие по данным от результата проблемной команды. Ситуация настолько частая, что совсем не иметь никакого механизма перетасовки показалось инженерам Intel неоправданным — и они придумали добавку под названием Safe Instruction Recognition (безопасное распознавание команд). Она всё же даёт процессору некоторую вольность в обращении с командами, позволяя исполнять их вне очереди, и по сути является OoO-механизмом, работающим в масштабе лишь двух команд, одна из которых должна быть вещественной, а вторая — целой. Если они друг другу не мешают, то первой может запуститься целочисленная команда, имеющая меньшую задержку (если только обе команды и так не планируются на спаривание).
Тем не менее, удаление полноценного OoO кажется катастрофическим, но, может быть, нам поможет спасительная гиперпоточность? Т. к. блоки ЦП разделяются между потоками (некоторые — статически, большая часть — динамически), может возникнуть ситуация, что при требовании одинакового ресурса обоими потоками процессор будет работать даже медленнее, чем в 1-поточном режиме. Что и наблюдается в некоторых тестах и вполне естественно для ситуации, когда потоки запущены одной и той же программой, параллельно что-то обрабатывающей одним алгоритмом. Кроме того, предсказатель ветвлений использует динамическое разделение ячеек BTB между потоками, даже если переходы в них общие и ссылаются на одинаковые адреса. Итог — стабильные 1,5–2 IPC без специфической оптимизации под Atom, мы, скорее всего, не получим даже с 2-поточным запуском.
После исполнения, но перед отставкой (т. е. «официальной» записью результатов операций в кэш и регистры) есть ещё 2 стадии для регистрации возможных исключений и «разбора полётов» в потоковом HT-движке. Как и остальные стадии, все мопы проходят и эти, даже при 1-поточном исполнении без исключений и прерываний.



{kind=link}