Часть 3-я
Оглавление
- «Крутой и холодный».
- Фронт конвейера: Предсказание переходов; Декодирование и IDQ; Стековый движок; Тайная жизнь нопов.
- Кэш мопов: Цели и предшественники; Устройство; Размеры; Ограничения; Работа.
- Диспетчер и планировщик: Переименование и размещение; Новый старый стиль.
- Исполнительная стадия: Тракты данных; Конфликты завершения; Межтрактные шлюзы; Вещественные денормалы; Частичный доступ к регистрам.
- AVX: Реализация; Подножка; Решение; Сохранение состояния; Динамические тайминги; Новые и отсутствующие команды.
- Тайминги команд.
- Кэши: L1D; LSU; Внеочерёдный доступ; STLF; Задержки чтения; TLB; Аппаратная предзагрузка.
- Hyper-Threading.
- Внеядро: Кэш L3; Кольцевая шина; Поддержка аппаратной отладки; Когерентность и «поддержка» OpenCL; Системный агент и ИКП.
- Turbo Boost 2.0.
- Экономия.
- Модели и чипсеты.
- Кристалл: Техпроцесс; Виды кристаллов; Устройство ГП; Устройство банка L3; 2-ядерные кристаллы.
- Производительность.
- Перспективы и итоги.
Кэши
В скобках указаны значения для Nehalem (если есть отличие).
| Кэш | L0m (новый) | L1I | L1D | L2 | L3 |
| Размер | 1536 мопов | 32 КБ | 256 КБ | 1–20 (2–30) МБ | |
| Ассоциативность | 8 | 8 (4) | 8 | 8 | 8, 12, 16, 20 (12, 16, 24) |
| Размер строки | 6 мопов | 64 байта | |||
| Задержка, тактов | 3? | 4 | 4–7 (4) | 11–12 (10) | ≈26–31 (≈35–40) |
| Число портов | 2 | 1 | 3 (2) | 1 | 1 на банк, 2–8 банков (2 на кэш, 1–10 банков) |
| Разрядность портов | 4 мопа | 16 байт | 64 байта | 64? (32) байта | |
| Частота (f — частота ядра) | f | f/2 | Максимум всех f (2,13–2,66 ГГц) | ||
| Политика работы | Включающая | Включающая | |||
| Свободная | |||||
| Только чтение | Отложенная запись | ||||
| Общий для … | Потоков ядра | Всех ядер, включая ГП | |||
L1D
Сразу скажем, что кэши L1I и L2 почти не изменились — у первого ассоциативность снова (как и до Nehalem) стала 8, а у второго чуть увеличилась задержка. Самое главное изменение в ядрах, касаемое кэшей, кроется в доступе к L1D, который теперь стал 3-портовым: к раздельным портам чтения и записи добавили ещё один для чтения. Кроме того, как уже было указано, в планировщике Nehalem 2-й порт вычисляет адрес чтения и исполняет само чтение, 3-й вычисляет адрес записи (только), а 4-й — исполняет саму запись. В SB же порты 2 и 3 могут и вычислить любой адрес, и исполнить чтение.
Внимательный Читатель сразу найдёт подвох: портов L1D — 3, а адресных генераторов — 2. При не более чем 16-байтовых обменах их устоявшийся максимальный темп составит 32 байта/такт (либо два чтения, либо чтение и запись). 32-байтовые операции каждым портом обслуживаются за два такта, причём вычисление адреса для конкретной команды происходит в течение первого из них. Так что для двух чтений и одной записи требуется три адреса в течение двух тактов — тогда при потоковых обменах один из трёх нужных адресов можно вычислить заранее в течение второго такта предыдущей 32-байтовой операции. Только так мы получим искомый максимум в 48 байт/такт.
Возникает довольно странный компромисс: три 16-байтовые операции за такт в потоке сделать нельзя. С другой стороны, за такт можно вычислить адреса для двух 32-байтовых обменов, но даже одно 32-байтовое чтение за такт не запустишь, потому что порты чтения не объединяются. Т. е. либо нам не будет хватать числа AGU (тех, что в портах 2 и 3), либо ширины портов, либо возможности их объединения.
Как мы знаем из теории, многопортовость в кэшах чаще всего делается не явная, а мнимая, с помощью многобанковости. Однако Nehalem нарушил это правило, внедрив 8-транзисторные битовые ячейки для всех кэшей ядра. Помимо большей экономии (об этом подробно рассказывалось в статье о микроархитектуре Intel Atom, который тоже применяет такую схему), это также даёт возможность получить истинную 2-портовость (чтение + запись), что и было использовано в L1D — никаких конфликтов по адресам в имеющихся 8 банках не было. В SB банков по-прежнему 8, а портов уже 3. Очевидно, конфликты неизбежны, но только среди адресов портов чтения.
Каждый банк L1D имеет ширину в 8 байт, вместе составляя строку, поэтому каждый из 16-байтовых портов использует 1–2 банка при выровненном доступе и 2–3 при невыровненном. Например, 8-байтовое чтение, пересекающее 8-байтовую границу, использует 2 банка, как и выровненное 16-байтовое. В SB конфликт происходит, если хоть один из банков, нужных одному чтению, также нужен и второму, причём для доступа к другой строке. Последнее означает, что если оба чтения требуют не только одинаковый(ые) банк(и), но и одинаковые номера строк в нём (них), то конфликта не будет, т. к. фактический доступ произойдёт один, и он обслужит оба обращения. В Nehalem, с его единственным чтением за такт, такого, очевидно, быть не могло.
Упомянув о невыровненном доступе, скажем и о более «грешных» делах — пересечении строки кэша, что обойдётся 5-тактным штрафом, и границы страницы виртуальной памяти (чаще всего — 4 КБ), что наказывается в среднем 24 тактами (ситуация требует сериализации конвейера). Причём последняя цифра малообъяснима, т. к. TLB, как мы увидим ниже, способны на одновременную обработку обеих смежных страниц — но даже при последовательном доступе двухзначной цифры получиться не может…
LSU
Изменений в LSU (контроллере L1D, который Intel упорно называет MOB) не меньше, чем в само́м кэше. Начнём с того, что очередь чтения удлинилась с 48 до 64 ячеек, а записи — с 32 до 36. Каждая ячейка привязана к одному мопу, а очередь записи хранит ещё и 32 байта данных (было 16). Очередь чтения хранит все команды считываний, но в каждый момент не более 32 могут обрабатываться на разных стадиях. Фактически, это отдельные диспетчер и планировщик, «ROB» которых хранит 64 мопа, а «резервация» — 32. Когда чтение завершено, моп удаляется из этой резервации, но остаётся в очереди чтения до отставки. Очередь записи хранит информацию до отставки предыдущих команд, когда ясно, что адрес, данные и сам факт исполнения команды верны, а значит её можно попытаться записать в кэш. Если попытка успешна — моп записи уходит в отставку, освобождая место и в очереди, и в ROB. При промахе или других проблемах запись задержится.
Как и все современные кэши, L1D является неблокирующим — после промаха он может принимать дальнейшие запросы одновременно с заполнением себя подгруженными данными. Кэш может выдержать даже 3 промаха/такт. Одновременно удерживается столько промахов, сколько имеется буферов заполнения. В SB, как и в его предшественнике, у L1D таковых 10, а у L2 — 16. Политика отложенной записи в L1D и L2 означает, что модифицированная строка остаётся в кэше до вытеснения, однако информация о факте её модификации (если до этого данные были «свежие») отправляется в теги соответствующей строки в L3.
Внеочерёдный доступ
Внеочерёдный движок получил любопытное дополнение: предсказание адресов, на основе которого порядок обращений в кэш может быть переставлен, делается не отдельными адресами, а целыми диапазонами — предсказывается верхнее и нижнее значения адреса, в пределах которых, как предполагается, произойдёт запись. Если точно известный адрес чтения не попадает ни в один диапазон ещё не исполненных записей — чтение можно запустить заранее. Такой вариант срабатывает чаще имевшегося ранее, который разрешал внеочерёдную загрузку, только если есть высокая вероятность несовпадения с конкретным адресом записи. Сама вероятность рассчитывается, как в предсказателе переходов — в LSU, видимо, есть некий аналог таблицы BHT со счётчиком вероятности в каждой ячейке. Когда адрес записи становится известен, счётчик увеличивается при несовпадении адресов и уменьшается при конфликте.
Однако предсказатель оперирует только выровненными на 16 байт чтениями размером до 16 байт, а также выровненными 32-байтовыми — остальные будут ждать вычисления адресов всех предыдущих записей. Ещё одна проблема нового движка в том, что он предсказывает лишь младшие 12 бит адресов: если у записи и чтения они равны (даже если они не предсказаны, а точно известны), то чтение считается зависимым от записи. Т. е. фактически предсказывается лишь 8 бит адреса — с 5-го по 12-й. Возможно, ложная зависимость обусловлена тем, что в ячейках таблицы счётчиков нет поля, хранящего старшую часть адреса.
STLF
…серьёзно улучшен. Описывать громоздкие старые правила для Nehalem мы не будем, укажем сразу новые:
- байты для чтения должны полностью содержаться в записи, вне зависимости от выровненности адресов и размеров операций; это эквивалентно следующему: W-байтовая запись по адресу A перенаправляется в R-байтовое чтение по адресу B, если A≤B и A+W≥B+R; далее указаны исключения:
- если запись 16- или 32-байтовая — 4- и 8-байтовые чтения обрабатываются в пределах её 8-байтовых порций;
- если запись 32-байтовая — все чтения, кроме 32-байтовых, обрабатываются в пределах её 16-байтовых половин;
Ясно, что STLF не может работать одновременно с внеочерёдной загрузкой: адреса записей должны быть известны точно, а не только 8 битами.
Задержки чтения
Видя такое благолепие, яростные фанаты Противоположного Лагеря немедленно требуют какого-нибудь негатива. К сожалению, и он нашёлся: во-первых, обещанные 11 тактов задержки при чтении L2 в наших тестах никак не получались меньше 12; аналогично с L3. Во-вторых (и это гораздо хуже), идеальные 4 такта задержки при чтении L1D доступны не всегда, потому что теперь надо смотреть не только в какой исполнительный домен загрузить данные, но и как вычисляется адрес. Напомним, что в x86 адрес обращения в память состоит из трёх компонент: регистр базы, регистр индекса (возможно, умноженный на масштаб 2, 4 или 8) и адресное смещение (явно указанное в команде). Сочетаться (сложением) они могут в любой комбинации. Как мы помним, в SB можно вычислить аж 3 команды LEA за такт (сложную и две простых), что втрое больше, чем ранее. :) А вот те адреса, что вычисляются в «правильных» AGU (в портах 2 и 3), дают уже втрое больше проблем, которых хватит аж на целую таблицу задержек чтения/записи (тут учтены и все межтрактные задержки на передачу данных):
| ↓ Свойства адреса Тип приёмника → | РОН | (x)mm | x87 | ymm |
| Смещение≥2048 ИЛИ есть индекс | 5 | 6 | 7 | 7 |
| Смещение<2048 И нет индекса | 4 | 5 | 6 | 7 |
Учитывая такое безобразие, удивительно, как SB не только не провалил ни один из наших тестов, но даже нигде не оказался медленнее, чем Nehalem с его почти честным 4-тактным L1D. Можно аккуратно предположить, что AGU в портах 2 и 3 настолько просты, что могут за такт сделать лишь одно сложение, да и то с неполной разрядностью одного из слагаемых — иначе оно затянется на второй такт, как и 3-компонентное. Если бы речь шла о 10-гигагерцовом ЦП с конвейером на сотню стадий, это ещё было бы простительно, но тут… Впрочем, есть другой вариант.
Сначала поясним, почему, вопреки тенденции, для ymm-пересылки цифры не указаны как 8 и 7. В одном из патентов Intel указан такой способ переноса «больших» данных из кэша в тракты: учитывая, что межтрактовая задержка в шлюзах равна 1 такту (для смежных трактов), надо в начале считать старшие 16 байт, которые уйдут на самый дальний тракт (2-й векторный), а через такт — младшие, которым надо на один тракт (и такт) ближе — тогда обе половины окажутся на местах синхронно. Вычисление адреса делается «впритык» к самому чтению (если ему ничего не мешает, например занятость портов или незавершённость записи по «подозрительному» адресу). Для этого AGU автоматически прибавляет к смещению 16, а возможно — вычисляет адреса обеих половин одновременно, что может объяснить медлительность при «сложной» адресации. В простом случае 32-байтовое чтение больше ничем не будет отличаться от 16-байтового, но если слово пересекает границу строки кэша, то теги читаются для двух строк, а если и границу страницы памяти — то и в TLB делается второе обращение. Тот же подход используется и при ymm-записях.
TLB
В скобках указаны значения для Nehalem (если есть отличие).
| Параметр | TLB L1I | TLB L1D | TLB L2 | |||
| Размер страницы | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ | 1 ГБ | 4 КБ |
| Размер | 128 | 8+8 (7+7) | 64 | 32 | 4 (0) | 512 |
| Ассоциативность | 4 | 8 (7) | 4 | 4 | 4 (–) | 4 |
| Задержка, тактов | 1, учтена в задержке к кэшу | 7 | ||||
| Число портов | 1 | 2 | 1 | |||
| Политика работы | Скорее всего, включающая (для 4 КБ) | |||||
| Общий для потоков? | Да | Нет | Да | |||
Изменения в подсистеме TLB небольшие: DTLB (так Intel называет TLB L1D) обзавёлся «честной» секцией для «сверхбольших» страниц по 1 ГБ. Впервые их поддержка появилась в AMD K10, а у Intel — в Westmere, однако в последнем они разбивались на множество «просто больших» страниц по 2 МБ и хранились в соответствующей секции TLB. ITLB (TLB L1I) получил две дополнительные ячейки для больших страниц, а STLB («shared TLB», т. е. разделяемый TLB L2) не изменился. Кстати, последний в Nehalem назывался UTLB (unified, единый), а вот для SB кэш L3 на большинстве слайдов переименовали в LLC (last level cache — кэш последнего уровня)… Кажется, кто-то в Intel обожает плодить сущности без необходимости. И кого ж они запутать хотят? :)
Суть странной записи «8+8» вместо «16» раскроется в главе о Hyper-Threading, а вот вопросы «Являются ли все или некоторые TLB неблокирующими?» и «Сколько промахов они могут удержать?» пока и вовсе останутся лишь с догадками «нет» и «нисколько». Зато известно, что при промахе в TLB L2 происходит обращение в адресный транслятор (PMH), на что уходит около 10 тактов. Это подозрительно мало, т. к. трансляция 64-битного виртуального адреса в физический (транслируются, правда, только биты с 13-го по 48-й) требует до 4 чтений из памяти или кэша. Столь быстрая реакция возможна, только если у PMH есть свой кэш. Его параметры и детали работы определить крайне трудно (уж очень тщательно скрыты задержки), но по известным примерам в предыдущих ЦП Intel предположим, что 32 ячейки наверняка найдутся. Точно известно только, что PMH может читать дескрипторы страниц откуда угодно — от L1D до памяти.
 Жёлтая структура слева — L1D, внизу-слева — TLB L2, остальное пространство — LSU. В центре видны два почти одинаковых вертикально вытянутых блока — видимо, это TLB L1D. |
Таблица выше является настоящим испытанием для Внимательного Читателя. Но подвох обнаруживается быстро — кэш L1D стал 3-портовым (надо полагать, вместе с тегами), а вот его TLB — почему-то нет, хотя было бы естественно. Ошибка? Нет, на фотографии ядра видно, что TLB (очевидно, 1-портовых) осталось 2, как у Nehalem. Видимо, причина в том, что на 2 AGU больше двух обменов/такт не получится, а при использовании команд AVX для достижения пика при потоковых операциях в среднем потребуется и вовсе 1,5 адреса/такт. Видимо, Intel посчитала, что ради экономии места третьи TLB и AGU пока лишние.
В Nehalem к битам TLB было добавлено поле VPID (идентификатор виртуального процесса), сравнение содержимого которого с текущим VPID позволяло определить, относится ли адрес в TLB в адресному пространству этой виртуальной машины или остался после переключения с соседней. Архитектура Westmere преобразовала это поле в более общий формат PCID (идентификатор контекста процесса), что позволило сохранять содержимое TLB не только при переключении виртуальных машин, но и при смене адресации в пределах одной ОС. Что к этому добавлено в SB (и добавлено ли…) — не известно.
Кстати, о виртуализации (раз уж мы пока нигде её не упомянули) — Westmere отличался от Nehalem в т. ч. наличием небольшого кэша на 3 так называемых VMCS (virtual machine control structure, структура управления виртуальной машиной), содержащих архитектурное состояние виртуальной ОС. Кэшировать их полезно для ускорения переключения между ОС. Надо полагать, в SB этот кэш как минимум сохранился, а то и увеличился.
Аппаратная предзагрузка
Для L1D предзагрузчик поддерживает до 4 явно заданных спецкомандами загрузок, но это не так интересно, как автозагрузки. Блок следит за числом ожидающих промахов в L1D, и когда оно мало, а ядро не исполняет потоковую операцию (типа загрузки или сохранения контекста или операций со «строками») — происходит загрузка по одному из предсказанных адресов. Обращения в TLB не нужны, т. к. физический адрес недавно сделанного чтения на некоторое время остаётся и в предзагрузчике, а предсказания никогда не пересекают границу в 4 КБ.
Используются два алгоритма. Первый (простой или потоковый) основан на возрастающих адресах читаемых всеми командами данных — убывающие адреса не обрабатываются, т. к. для этого алгоритма они редки. Второй (сложный или шаговый) имеет буфер предположительно на 256 ячеек — в каждой хранится собственный адрес недавней команды чтения (по его младшему байту ячейка индексируется, когда в очередь чтения LSU поступает новый моп), прошлый адрес её загрузки и шаг последовательности (полагая, что он регулярный и не превосходит ±2048). При каждом исполнении этого чтения предзагрузчик проверяет регулярность шага, и, при положительном исходе, загружает в кэш следующую порцию. Предзагрузка в L1I, как уже описывалось, основана на предсказаниях переходов.
Для L2 и L3 алгоритма также два, но они общие. Простой («пространственный») дополняет загруженную строку соседней, составляя выровненную 128-байтовую пару (предполагается пространственная локальность требуемых данных, откуда и имя). Сложный же (потоковый) следит за чтениями в кэши L1 (в т. ч. от их предзагрузчиков) из L2, ожидая последовательность адресов строк с одинаковым шагом. Этот предзагрузчик также не смеет пересечь страницу памяти. Оба алгоритма как минимум пишут в L3, а если локальный L2 свободен от обслуживания массы промахов в L1 — то и в него.
Интересно, что сложный алгоритм для L2 (а, возможно, и для L1D) имеет 2-битный насыщаемый счётчик, следящий за востребованностью данных: предположительно, если хотя бы 2 раза подряд предзагруженные данные были полезны, то даже если далее каждое третье обращение будет по «чужому» адресу, алгоритм не собьётся с найденного шага потока.
А теперь сюрприз — всё вышеописанное относится и к Nehalem. В SB же изменился только сложный алгоритм для L2, зато основательно:
- Теперь он может запустить уже две предзагрузки на каждое чтение этого потока, уходя вперёд максимум на 20 шагов;
- Вышеописанная функция работает только при достаточном простое L2: при его средней загрузке в него наперёд читается по одной строке, а при сильной — и вовсе ноль (точнее одна, но только в L3);
- Если шаг большой, то загрузка в L2 также отменяется (близкая локальность обеспечивается простым алгоритмом);
- Слежение производится за 32 потоками запросов: для каждой из 16 отслеживаемых страниц по 4 КБ допусти́м 1 восходящий и 1 нисходящий поток. Ранее было 12 восходящих потоков и 4 нисходящих, по одному на страницу.
Судя по всему (и к сожалению), у предзагрузчиков и SB, и его предшественников нет собственного буфера. Поэтому на оптимизированном коде, который учитывает размеры кэшей для деления обрабатываемых данных части, предзагрузчик может загрязнить кэш своими записями и сильно повысить частоту промахов при явных запросах. Intel не даёт никаких рекомендаций по устранению этой проблемы.
Hyper-Threading
Какие изменения в реализации этой технологии — также не было раскрыто, поэтому будем отталкиваться от того, что́ на этот счёт известно из описания Nehalem. Нас интересует, как разделяются между потоками блоки и стадии конвейера:
- Дублируются: TLB L1I для стр. по 2 МБ, IQ, RSB, IDQ, архитектурное состояние ядра, АРФ для старших половин ymm;
- Делятся пополам: TLB L1I для стр. по 4 КБ, L0m, ROB, обе очереди в LSU, буфер простого предзагрузчика в L1 (?);
- Делятся динамически: BTB, резервация, все ФУ, вся подсистема памяти (кроме её блоков, указанных выше);
- Чередуются по тактам (кроме случаев срыва одного из потоков): все стадии фронта, переименование, размещение мопов в планировщике и отставка.
Поясним, что такое «делятся динамически»: это значит, что блок не знает о существовании двух потоков и никак бы не изменился, если бы в ЦП не было многопоточности. Это особенно наглядно в случае диспетчера: ROB делится между потоками, т. к. надо соблюдать очерёдность размещений и отставок соответственно адресам каждого потока. Но когда мопы попадают в резервацию, адресов в них уже нет, а есть номера ячеек в ROB и ФРФ. Учитывая, что некий регистр-приёмник N при переименовании получит в одном потоке физический регистр X, а в другом — Y (что равносильно двум записям в N в одном потоке), то резервации всё равно, чьи мопы одновременно запускать, а для ФУ всё равно, чьи исполнять.
Наличие дублируемых и статически делящихся пополам ресурсов и чередование потоков по всей поочерёдной части конвейера говорит о том, что лучше всего Nehalem и SB чувствуют себя при исполнении пары почти одинаковых по объёму кода потоков. Причём если это 2 одинаковых потока, то обеспечить загрузку разных ФУ и прочих динамически разделяемых блоков будет трудно — общий алгоритм будет спотыкаться примерно в тех же местах, даже работая с разными данными. А подобрать две разные программы с примерно одинаковом темпом использования кода может оказаться ещё труднее — тем более, что это всецело зависит от ядра ОС, которая почти ничего не знает о внутренних событиях ЦП и загрузке его блоков.
Возможно, Intel не использовала динамическое разделение в TLB L1I (как в остальных TLB, особенно, учитывая, что сам кэш L1I разделяется так же), потому что его нет и у кэша мопов, а эти две структуры при вытеснении срабатывают одновременно. Впрочем, глядя на список пункта «Делятся пополам» (а в этих блоках, напомним, 3 цифры размеров из 4 в SB увеличились), можно сделать вывод, что ускорение от включения HT если не увеличится, то хотя бы с меньшей вероятностью станет отрицательным, что изредка бывало у Nehalem. Проверить это можно будущими тестами.
Внеядро
Кэш L3
Физически, кэш L3 по-прежнему разделён на банки по числу x86-ядер. В Nehalem была возможность сделать одну запись и одно чтение в/из L3 за такт, если они попадали в разные банки, т. к. использовался общий коммутатор и контроллер на весь кэш. Теперь организация банков другая: можно сделать запись или чтение, но в каждом банке по отдельности. А т. к. число включенных банков почти всегда равно числу ядер (исключения до сих пор встречались только у 6–10-ядерных серверных Xeon, где в некоторых моделях банков на 1 больше или меньше числа ядер), то это линейно увеличивает пиковую пропускную способность L3 с ростом числа ядер. Учитывая, что она разделяется между всеми ядрами и ГП, это очень полезно, т. к. пропуск, приходящийся на каждое ядро, до сих пор был главной проблемой любого разделяемого кэша.
Другое важное изменение в L3 — он стал работать на полной частоте ядра. Точнее, x86-ядер. Точнее, работающего(их) из них в данный момент, т. к. часть ядер могут спать. Помимо увеличения пропускной способности это ещё и уменьшает задержки, которые, разумеется, меряются тактами ядер на их частоте. И вот (см. таблицу с параметрами кэша) в SB они уменьшились на 30%. Это при том, что сама частота кэша вовсе не подросла на 30%. Причина в том, что когда поток данных пересекает силовые (по величине логических «0» и «1» в вольтах) и, особенно, частотные домены, происходит задержка в несколько тактов для преобразования уровней и совпадения фронтов тактовых сигналов. В SB такой проблемы нет, т. к. L3 работает на том же напряжении, что и работающие x86-ядра (не отключенные силовыми ключами), а частота у всех активно загруженных ядер всегда одинакова (включая применение технологии Turbo Boost) — и именно на неё и настроится частота L3.
Правда, всё может оказаться интересней. Внимательный Читатель успел заметить, что кэш L2 работает на половинной частоте, а потому, имея 64-байтовый порт, теряет половину ПС. Такое решение, видимо, связано с разумной достаточностью и 32 байт/такт, а потому можно применить более экономные транзисторы, которые, к тому же, будут работать при меньшей частоте. Про L3 такое достоверно не известно, но резонно предположить, что там ситуация та же: на высокой частоте работают только контроллеры портов кольцевой шины, обрабатывая по 32 байта/такт в каждом порту (детальней об этом ниже), а вот сам кэш работает целыми 64-байтовыми строками раз в 2 такта.
Как и в Nehalem, каждый банк L3 разделён на блоки по 512 КБ и 4 пути. В большинстве ЦП серий Core i в каждом банке таких блоков 3 или 4. Серверные ЦП Xeon с архитектурой Beckton и Westmere-EX имеют 6, 8 или 10 ядер и банков L3, но последние увеличены как по размеру (до 3 МБ), так и по ассоциативности (до 24), что в самых дорогих ЦП даёт аж 30 МБ. Для SB же пока обещаны «лишь» 8-ядерные Xeon с 20-путным L3 на 20 МБ.
Для любителей кунсткамеры добавим, что единственный представитель архитектуры Nehalem с одним работающим ядром (и одним банком L3 на 2 МБ) — это, как ни странно, не какой-то тихой сапой выпущенный сверхбюджетный Celeron, а Xeon LC3518, физически представляющий собой обычный 4-ядерный Nehalem с тремя (!) отключенными ядрами и их банками. Авторы SB также приготовили такие диковинки — это модели Celeron B и Pentium B, где на 2 ядра и ГП приходится не 4, не 3, а 2 МБ кэша с уполовиненной до 8 путей ассоциативностью.
Как и предшественник, ядра SB активней используют КМОП-логику по сравнению с динамической, что отразилось на частоте возникновения ошибок при работе. Это потребовало внедрить более мощные алгоритмы и коды обнаружения и коррекции ошибок (ECC) в кэшах ядер, способные в каждом байте обнаружить и исправить 2-битные ошибки и обнаружить (но не исправить) 3-битные. До сих пор ЦП умели обнаруживать до двух неверных бит и исправлять один, требуя в среднем 1 бит ECC на каждый защищаемый байт. Новый код, видимо, требует не менее 1,5 бит/байт — чуть позже мы сможем это проверить.
Кольцевая шина
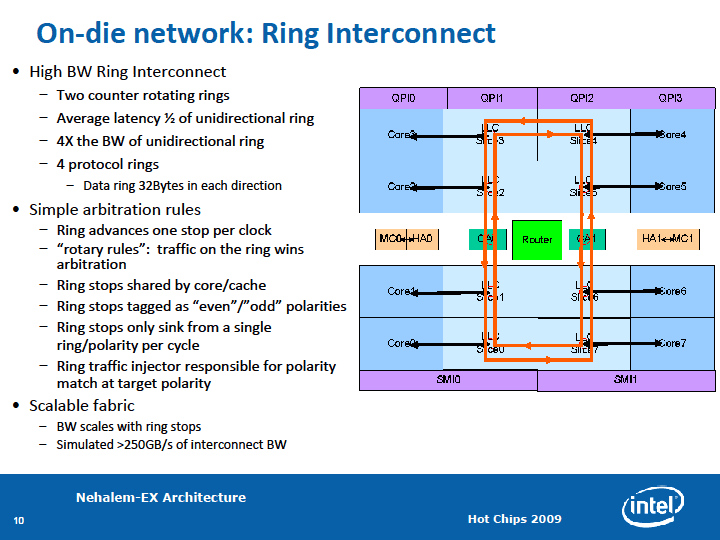  Вверху — слайд 2009 г. о кольцевой шине Nehalem-EX. Внизу — свежий о ней же в Sandy Bridge-EX. |
Не только наш Внимательный Читатель догадался, как надо связать L3 и ядра, чтобы ПС кэша росла пропорционально числу банков (а значит — и ядер). Однако эта кольцевая шина, вопреки утверждению Intel, в SB появилась не впервые. Если не считать различных специализированных процессоров (в частности, некоторых ГП), среди ЦП вообще она появилась в 9-ядерных Sony/IBM Cell BE (2007 г.). У ЦП Intel кольцевая шина была внедрена в 8-ядерных серверных Xeon серий Nehalem-EX (2010 г.), откуда с небольшими изменениями она попала SB. Её имеют и только что вышедшие серверные Westmere-EX (Xeon E7).
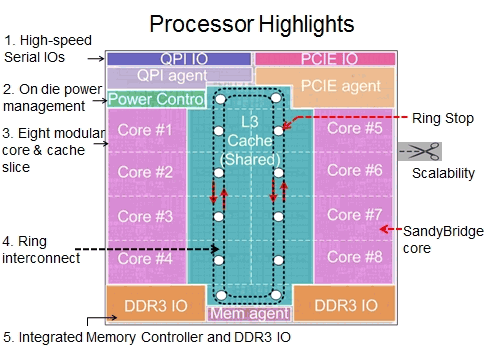
В каждом направлении протянуто 4 шины: запросов, подтверждений, снупов (для поддержки когерентности) и собственно данных (шириной 32 байта) — разумеется, всё защищено битами ECC. Протокол обмена является чуть переделанной и дополненной версией шины QPI, которую мы привыкли видеть как межпроцессорную шину типа «точка-точка», аналогичную HyperTransport в ЦП AMD. Внутри процессора связываемые «точки» являются агентами, каждый из которых имеет две пары шинных портов (приёмный и передающий в каждую сторону) и пару клиентских. К шинным подключены звенья шины, связывающие соседние агенты. К клиентским обычно подключены локальное x86-ядро и локальный банк L3. Однако в 2/4-ядерных SB один из крайних агентов подключен только к ГП, а второй — только к «системному агенту»; шинные порты также используются наполовину, т. к. в этих местах шина разворачивается на 180°, соединяя противонаправленные звенья. В 8-ядерном серверном SB будет 8 обычных агентов и 4 концевых, каждый из которых разворачивает направление обеих шин на 90°, задействуя все шинные порты, и обслуживает по одному клиенту-контроллеру: по 2 для памяти и для внешних шин (QPI и PCIe).
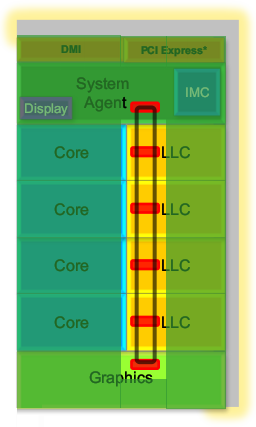 Агенты кольцевой шины показаны красным. |
При поступлении запроса локальный агент хэширует адрес для равномерного распределения данных по банкам, определяет направление передачи запроса (если только его не требуется обслужить тут же — во втором клиентском порту) и ожидает освобождения шины (текущий трафик имеет приоритет над новым). Каждый такт каждый агент мониторит приёмные порты обоих направлений и сравнивает в принятом сообщении целевой адрес с собственным: если он совпадёт, то сообщение передаётся в один из клиентских портов. Иначе оно передаётся на выходной порт, чтобы через такт попасть в соседний агент. Если в течение такта выходной порт оказался свободным, агент либо вставляет своё сообщение (если есть ожидающие для этого направления), либо посылает следующему агенту сигнал о свободной шине.
Таким образом, пиковая ПС шины равна полупроизведению числа используемых шинных портов всех агентов, 32 байт и частоты. «Полу-» — потому что требуется 2 порта для каждого звена. Учитывая, что кольцо, как и L3, работает на максимуме частот ядер, абсолютный максимум его ПС получается очень большим: для 4-ядерного ЦП на 3 ГГц — 960 млрд. байт/с (по «славной» традиции производителей винчестеров назовём это 960 ГБ/с :). Для сравнения — в Cell BE ко́льца также передают по 32 байта в каждую сторону, но на одну передачу требуется 2 такта, поэтому этот 9-ядерный ЦП наберёт на 3 ГГц примерно те же 960 ГБ/с.
Физически звенья шины проложены дорожками на самом высоком уровне, доступном для передачи сигналов — 7-м и 8-м слоях металлизации. Вышележащие слои используются только для питания и контактных площадок. Причём дорожки проходят поверх банков L3 и отдельного места не занимают. Такое устройство позволяет масштабировать шину простым копированием агентов и звеньев, что гораздо проще добавления дополнительных портов к центральному коммутатору. Впрочем, у последнего есть и преимущество — задержка прямой коммутации куда меньше, чем транзитной. Однако из-за более высокой частоты кэш L3 в SB оказался всё же с меньшей задержкой, чем в Nehalem.
Поддержка аппаратной отладки
Говоря о кольцевой шине, стоит упомянуть новую отладочную функцию — Generic Debug eXternal Connection (GDXC). Она позволяет мониторить трафик и синхрокоманды шины, перенаправляя их во внешний логический анализатор, подключаемый к спецпорту процессора. Ранее такие тонкие инструменты были доступны разве что производителям системных плат (разумеется, при полной секретности), да самим разработчикам. Но GDXC доступна и системным программистам, что, по идее, должно способствовать вылавливанию ошибок и оптимизации видеодрайверов. Что касается «обычных программистов», им наверняка пригодится увеличение (с 6 до 8) числа счётчиков производительности и событий в каждом ядре.
Когерентность и «поддержка» OpenCL
Nehalem был первым ЦП Intel со времён Pentium 4, в котором кэш последнего (т. е. 3-го) уровня стал включающим относительно остальных. Это означает, что в многопроцессорной системе процессорам будет проще отслеживать копии данных, раскиданных по разным кэшам, что требуется для поддержки их когерентности. Для этого теги каждой строки в L3 среди прочего хранят набор битов, обозначающих я́дра этого ЦП, в кэши которых эта строка была скопирована, а также номера других ЦП, в кэшах которых также есть её копия. Для Westmere-EX число таких битов наверняка не меньше 17 (10 ядер + 7 «остальных» ЦП). Кроме того, тогда же стандартный протокол когерентности MESI обновился до MESIF, включив в себя 5-е состояние Forward, разрешающее ответ на снуп-запрос от другого ЦП (в MESI ответить мог каждый ЦП, что увеличивало снуп-трафик). Соображением минимизации снуп-трафика руководствовалась и AMD, добавив для своих Opteron 5-е состояние Owned и получив протокол MOESI.
Когда при доступе в L3 из какого-либо ядра оказывается, что искомая строка закэширована другим ядром (для простоты предположим, что одним) и может быть им модифицирована, происходит обращение к его кэшам L1D и L2 для проверки её актуального состояния. Проверка называется «чистой», если данные оказались нетронутыми, и «грязной», если они модифицированы и требуют копирования в запрашивающее ядро и L3. В SB первый случай вызывает задержку в 43 такта, а второй — в 60. Эти указанные в документации цифры почему-то являются константами, хотя должны зависеть от топологического расстояния между ядрами на кольцевой шине. Да и разница в 17 тактов куда больше, чем положенные 2 для передачи 64 байт…
Новинкой в SB по части включающей политики L3 является то, что биты присутствия копий данных в кэшах ядер учитывают и ГП. Т. е. с точки зрения программы ГП можно использовать как векторный сопроцессор, работающий с общими данными в общем адресном пространстве. По идее, поддержка OpenCL 1.1 в ГП этому должна способствовать, что успел заявить Thomas Piazza, глава отдела графических архитектур Intel. Однако некоторые аналитики упорно писали, что OpenCL в SB не поддерживается. Ещё один детектив? Да, и он распутан.
Согласно заявлению другого представителя компании, поддержка физически есть, но из-за неготовности драйвера при его активации по-прежнему будут использоваться лишь ресурсы x86-ядер. Когда появится обновление, где всё заработает, — сказано не было. По менее официальным каналам получен намёк, что и до этого ГП как-то можно будет использовать в качестве сопроцессора. Но только после доделки нужного SDK (инструментального пакета для программистов) ГП будет доступен не «как-то», а по-человечески. :)
Для облегчения доступа к данным всё адресное пространство ЦП делится на 3 раздела: для x86-ядер, ГП и некогерентных данных. Раздел ГП использует «слабую» когерентность для ускорения проверок, осуществляемых программным путём через драйвер (в частности, данные пересылаются в раздел x86 синхронизационными процедурами, а не автоматически). Некогерентные данные также используются ГП для завершающих операций переноса готового кадра в память.
Каждый путь в L3 имеет 3 бита атрибутов, указывающих, что содержимое этих строк принадлежит вышеуказанным трём разделам в любой их комбинации. Но для минимизации затрат на поддержку когерентности между разделами протоколы и семантика связности (отличные в каждом из них) применяются, только когда это явно требуется — т. е. когда в одном пути кэшируется область, помеченная как общая для нескольких разделов.
Системный агент и ИКП
Системный агент — это та часть «внеядра», которая получается после вычета кэша L3 и ГП. Остаётся вот что:
- арбитр со своим портом кольцевой шины — коммутирует потоки данных между остальными частями агента;
- порт отладочной шины GDXC;
- контроллер шин QPI (1–2 соединения на 25,6, 28,8 или 32 ГБ/с) — очевидно, присутствует только в серверных моделях;
- контроллер шин PCIe 2.0 (на 1 ГП/с) или 3.0 (2 ГП/с, только для Xeon) — в зависимости от модели может быть 16-, 20-, 24- и 40-полосным и допускает различные схемы соединений по числу полос: для наиболее распространённых 20-полосных моделей это x16+x4 (для большинства мобильных SB доступен только этот вариант), x8+x8+x4 и x8+x4+x4+x4 (только для младших Xeon);
- контроллер шины DMI 2.0 — для соединения с PCH (чипсетом): фактически немного преобразованный 4-полосный канал PCIe, по сравнению с v1.0 (в Nehalem и Atom) удвоил ПС до 4 ГБ/с (сумма в оба направления);
- «гибкое межсоединение экранов» (Flexible Display Interconnect, FDI) — порт для соединения с контроллером физических интерфейсов экранов в составе чипсета, также переработанный из PCIe;
- ускоритель (де)кодирования видео;
- контроллер памяти;
- программируемый силовой контроллер (Power control unit, PCU) с собственной прошивкой.
Наиболее интересными тут оказываются 3 последних пункта. Однако видеоускоритель оставим для обзора графической части, тут же расскажем об ИКП. Он поддерживает 2–4 канала памяти вплоть до DDR3-1600 (с ПСП 12,8 ГБ/с на канал), но для настольных и мобильных ЦП — только 2 канала DDR3-1333. Каждый канал имеет отдельные ресурсы и независимо обслуживает запросы. ИКП имеет внеочерёдный планировщик операций (!), максимизирующий ПСП с минимизацией задержек. Кроме того, ещё в версиях Nehalem для Xeon появилась технология SMI (Scalable Memory Interconnect, масштабируемое межсоединение памяти) с использованием подключаемых SMB (масштабируемый буфер памяти, аналог буфера AMB из FB-DIMM, но находящийся не на модуле, а на системной плате). Буфер подключается скоростной последовательной шиной к каналу ИКП процессора и позволяет подключить к себе большее суммарное число модулей, чем напрямую к ЦП. Правда, от этого ухудшаются и задержки, и частота работы памяти.
В каждом канале есть 32-строковый буфер записи, причём запись считается завершённой, как только данные попадут в буфер. Как ни странно, слиянием записи этот буфер не занимается, в результате чего частичные записи (когда обновляется не вся строка) обрабатываются неэффективно, т. к. требуют чтения старой копии строки. Это странно, учитывая, что современные микросхемы памяти учитывают битовую маску записи не только для отдельных 8-байтовых слов (которых 8 на строку), но и байт в словах, потому комбинация неизменной и обновлённой частей строки производится внутри чипа памяти, а не в ИКП. Впрочем, в SB ИКП (как и кэши) может включать продвинутые методы ECC, и для этого даже частично обновляемую строку для пересчёта ECC надо начала считать целиком. Причём это правило работает даже при применении обычной памяти, а также в большинстве мобильных моделей, где ECC-память вовсе не поддерживается.
Turbo Boost 2.0
Силовой контроллер системного агента отвечает сразу за 3 функции — защита от перегрева, сохранение энергии и авторазгон (именно в таком порядке они добавлялись с эволюцией ЦП x86). Последний пункт в процессорах Intel известен как технология Turbo Boost (TB). Её обновлённая версия является одним из главных «гвоздей программы», т. к. для слабопараллелизуемых программ она может дать ускорение не меньшее, чем все архитектурные улучшения в ядрах.
Напомним, что TB следит за текущими частотами, напряжениями питания, силами тока и температурами разных частей кристалла, чтобы определить, можно ли повысить работающим ядрам частоту на очередной шаг множителя (отдельно для x86-ядер и ГП). При этом учитываются пределы по всем вышеуказанным параметрам. Главной новинкой 2-й версии TB является дополнительное повышение частот, происходящее сразу после периода простоя всех или большей части ядер и обусловленное температурной инерцией системы «ЦП + радиатор». Очевидно, что при включении нагрузки и всплеске выделения тепла температура кристалла достигнет некоего значения не мгновенно, а плавно и с замедлением. Так вот если текущая температура пока ещё не критическая, и по остальным параметрам также есть запас, то контроллер ещё чуть поднимет множитель, ещё чуть увеличив потребление и выделение энергии и ещё чуть увеличив скорость роста температуры. Кстати, Intel продемонстрировала стабильную работу 4-ядерного SB на частоте 4,9 ГГц с воздушным охлаждением…
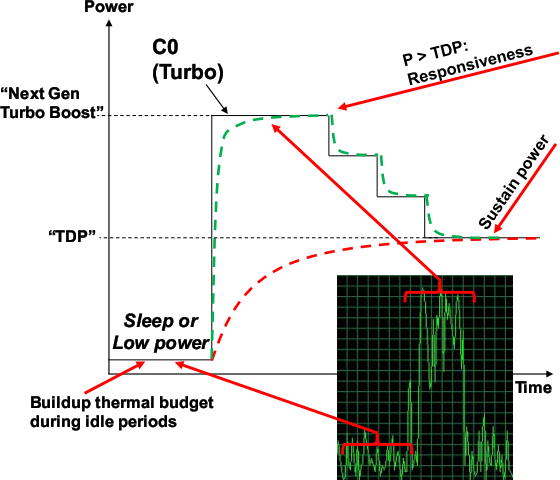
Зелёным пунктиром обозначена частота, а красным — температура. Во врезке — типичная нагрузка на ЦП домашнего ПК.
В зависимости от качества кулера и политики BIOS по регулировке оборотов вентилятора при разной температуре, первые 10–25 секунд после относительно длительного простоя процессор будет потреблять больше величины TDP, а занятые ядра теоретически должны работать на бо́льших частотах, чем у ЦП Westmere в тех же обстоятельствах. Как только температура поднимается до критической отметки, частота снизится к обычному «турбированному» значению — это снизит и выделение тепла до TDP, а температура расти перестанет. Выигрыш в том, что в течение нескольких секунд система будет работать чуть быстрее, чем с Turbo Boost 1.0. Т. е. вторая версия технологии является «турбонаддувом турбобуста». Отсюда ясно, на какие сценарии это рассчитано — периодический запуск малооптимизированных под многопоточность программ, быстро решающих свою задачу и снова погружающих систему в простой на несколько минут. При домашней и офисной работе — типичная ситуация.
Не стоит забывать, что теперь каждый шаг множителя для x86-ядер равен 100 МГц, а не 133, поэтому напрямую сравнивать «турбо-формулы» SB и Nehalem не получится. Для ГП шаг равен 50 МГц, а для ИКП — 266 (максимум — 2166, автоматически не разгоняется). Частота шины DMI принимается как базовая, от которой отталкиваются остальные часто́ты всей системы. Впрочем, ровно по этой причине её как раз надо оставить на стандартных 100 МГц, и если уж заниматься разгоном, то только через множители. Кстати, отдельный тактовый генератор теперь не обязателен и будет присутствовать лишь на дорогих «оверклокерских» платах, а остальные станут чуть дешевле и проще.
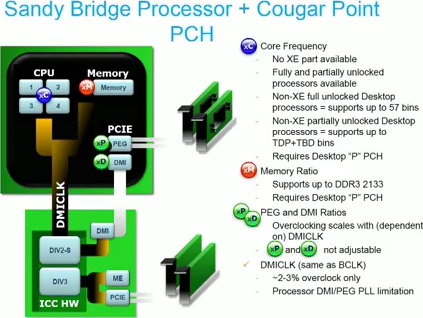
Обычно тактовый генератор южного моста подключен к нескольким делителям в самом мосту, а через шину DMI — и к ЦП с его разнообразными умножителями…
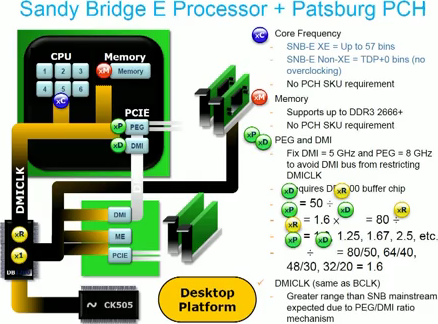
…Но в дорогих платах внешний генератор тактирует всё.


