Оглавление
- «Крутой и холодный».
- Фронт конвейера: Предсказание переходов; Декодирование и IDQ; Стековый движок; Тайная жизнь нопов.
- Кэш мопов: Цели и предшественники; Устройство; Размеры; Ограничения; Работа.
- Диспетчер и планировщик: Переименование и размещение; Новый старый стиль.
- Исполнительная стадия: Тракты данных; Конфликты завершения; Межтрактные шлюзы; Вещественные денормалы; Частичный доступ к регистрам.
- AVX: Реализация; Подножка; Решение; Сохранение состояния; Динамические тайминги; Новые и отсутствующие команды.
- Тайминги команд.
- Кэши: L1D; LSU; Внеочерёдный доступ; STLF; Задержки чтения; TLB; Аппаратная предзагрузка.
- Hyper-Threading.
- Внеядро: Кэш L3; Кольцевая шина; Поддержка аппаратной отладки; Когерентность и «поддержка» OpenCL; Системный агент и ИКП.
- Turbo Boost 2.0.
- Экономия.
- Модели и чипсеты.
- Кристалл: Техпроцесс; Виды кристаллов; Устройство ГП; Устройство банка L3; 2-ядерные кристаллы.
- Производительность.
- Перспективы и итоги.
Читатель наверняка знаком с кратким описанием микроархитектуры Sandy Bridge и помнит, что для той статьи мы использовали лишь иллюстрации из презентаций Intel, снабдив их нашими комментариями. Очевидно, они рассказывают не всю историю, поэтому нужна детальная статья, где история рассказывается вся и уже из независимого источника. ;) Кроме того, т. к. в своё время мы не делали подробного описания предыдущей микроархитектуры Nehalem, восполним это тем, что детально опишем не только ныне добавленные и изменившиеся элементы, но и старые (притом, что они не обязательно появились в Nehalem — некоторые цифры и факты куда древнее). Также мы испытаем нововведение: специфические термины и сокращения будут особо выделены, а при наведении на них курсора покажется всплывающая подсказка-расшифровка со ссылкой на нашу «Энциклопедию процессорных терминов» (которая, кстати, обновляется перед выходом каждой статьи).
«Крутой и холодный»
Прежде всего, какой ЦП был нужен Intel после 2008 г., когда микроархитектурное превосходство первых Core i (Nehalem и, в 2009 г., Westmere) над ЦП соперника стало окончательным? Ситуация немного напоминает первый год после выхода Pentium II: почивая на лаврах и получая рекордную прибыль, хорошо бы сделать продолжение удачной архитектуры, не сильно изменив её название, добавив новые команды, использование которых значительно улучшит производительность, не забыв и о других новшествах, ускоряющих сегодняшние версии программ. Правда, в отличие от ситуации 10-летней давности, надо обратить внимание и на модную ныне тему энергоэффективности, обыгранную двусмысленным прилагательным Cool — «крутой» и «холодный», — и не менее модное стремление встроить в процессор всё, что пока ещё существует как отдельные микросхемы. Вот под таким соусом и подана новинка.

«Позавчера», «вчера» и «сегодня» процессоров Intel.
Интегрированный в кристалл ЦП графический процессор (ГП) мы детально рассмотрим в отдельной статье. Тут же исследуем результат работы израильского отделения Intel (Israel Development Center), которому в очередной раз поручили сделать ещё более экономную модификацию текущей (на 2008 г.) универсальной серверно-настольно-мобильной архитектуры (назовём её просто Nehalem). Правда, изначальное кодовое имя Gesher («мост» на иврите) по «политическим» причинам (была в Израиле такая партия, да сплыла…) пришлось изменить на Sandy Bridge — «песчаный мост» (сократим его до SB). Причина задержки не совсем ясна: следуя своей обычной практике выпуска каждый нечётный год нового техпроцесса («тик»), а каждый чётный — микроархитектуры («так»), SB должен был выйти в 2010 г. — тем более, что половина якобы новых добавленных в него идей уже были в предыдущих ЦП Intel. Тем не менее, учитывая состояние ЦП конкурента, нельзя сказать, что SB опоздал. Конечно, инженерам Intel надо бы поглядывать в сторону новых архитектур AMD, которые в ближайшем будущем (и опоздав гораздо больше, чем на год), кажется, чем-то грозят…
Технически задача стояла примерно так: на той же площади кристалла (т. е. при той же себестоимости) и том же 32 нм техпроцессе сделать ЦП, который на старых программах имел бы +10% скорости и −20% потребления одновременно, а на новых (где используются добавленные команды) — аж +100% пиковой скорости при том же TDP. Возможно, цифры были чуть другие, но почти так это выглядит по результатам. А вот какими методами — проще всего узнать, сравнивая SB с Nehalem (это относится к многочисленным прилагательным «больше», «быстрее», «экономней» и пр. далее в тексте). Напрашивается сравнение и с выходящей в середине 2011 г. архитектурой AMD Bulldozer, но оно будет после детального обзора её самой. Intel постепенно заместит архитектуру почти всех своих выпускаемых сегодня x86-ЦП (кроме Atom) с Nehalem на SB. Позиционирование против ЦП AMD пока точно не ясно, но один гол в ворота соперника уже забит: SB уже успела нещадно побить сегодняшние «Феномы», а обновлённые соперники выйдут на несколько месяцев позже — и не факт, что возьмут реванш.
Фронт конвейера
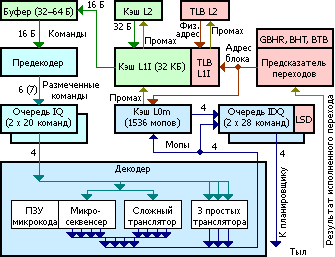
Фронт конвейера. Цвета показывают разные виды информации и обрабатывающих или хранящих её блоков.
Предсказание переходов
Начнём с заявления Intel о полностью переработанном предсказателе переходов (BPU). Как и в Nehalem, он каждый такт (и наперёд реального исполнения) предсказывает адрес следующей 32-байтовой порции кода в зависимости от предполагаемого поведения команд перехода в только что предсказанной порции — причём, судя по всему, вне всякой зависимости от числа и типа переходов. Точнее, если в текущей порции есть предположительно срабатывающий переход, выдаются его собственный и целевой адреса́, иначе — переход к следующей подряд порции. Сами предсказания стали ещё точней за счёт удвоения буфера целевых адресов (BTB), удлинения регистра глобальной истории переходов (GBHR) и оптимизации хэш-функции доступа к таблице шаблонов поведения (BHT). Правда, фактические тесты показали, что в некоторых случаях эффективность предсказания всё же чуть хуже, чем в Nehalem. Может быть, увеличение производительности с уменьшением потребления не совместимо с качественным предсказанием переходов? Попробуем разобраться.
В Nehalem (как и других современных архитектурах) BTB присутствует в виде двухуровневой иерархии — малый-«быстрый» L1 и большой-«медленный» L2. Происходит это по той же причине, почему существуют несколько уровней кэша: одноуровневое решение окажется слишком компромиссным по всем параметрам (размер, скорость срабатывания, потребление и пр.). Но в SB архитекторы решили поставить один уровень, причём размером вдвое больше, чем L2 BTB у Nehalem, т. е. наверняка не менее 4096 ячеек — именно столько их в Atom. (Следует учесть, что размер наиболее часто исполняемого кода медленно растёт и всё реже умещается в кэше L1I, размер которого совпадает у всех ЦП Intel с первых Pentium M.) По идее, при этом увеличится занимаемая BTB площадь, а т. к. общую площадь ядра менять не рекомендуется (таков один из начальных постулатов архитектуры) — у какой-то другой структуры что-то придётся забрать. Но остаётся ещё и скорость. Учитывая, что SB должен быть рассчитан на чуть большую скорость при том же техпроцессе, можно ожидать, что эта крупная структура будет бутылочным горлышком всего конвейера — если только не конвейеризировать и её (двух стадий уже хватит). Правда, общее число срабатывающих за такт транзисторов в BTB при этом удвоится, что совсем не способствует энергоэкономии. Опять тупик? На это Intel отвечает, что новый BTB хранит адреса в некоем сжатом состоянии, что позволяет иметь вдвое больше ячеек при похожих площади и потреблении. Но проверить это пока невозможно.
Смотрим с другой стороны. SB получил не новые алгоритмы предсказания, а оптимизированные старые: общий, для косвенных переходов, циклов и возвратов. Nehalem имеет 18-битный GBHR и BHT неизвестного размера. Впрочем, можно гарантировать, что число ячеек в таблице меньше, чем 218, иначе она бы заняла бо́льшую часть ядра. Поэтому существует специальная хэш-функция, сворачивающая 18 бит истории всех переходов и биты адреса команды в индекс меньшей длины. Причём, скорее всего, хэшей как минимум два — для всех битов GBHR и для тех, что отражают срабатывание наиболее трудных переходов. И вот эффективность хаотичного распределения индексами различных шаблонов поведения по номерам ячеек BHT определяет успешность предсказателя общего вида. Хотя явно это не сказано, но Intel наверняка улучшила хэши, что позволило использовать GBHR бо́льшей длины с не меньшей эффективностью заполнения. А вот о размере BHT по прежнему можно гадать — как и о том, как на самом деле изменилось потребление энергии предсказателем в целом… Что касается буфера адресов возвратов (RSB), он по-прежнему 16-адресный, но введено новое ограничение на сами вызовы — не более четырёх на 16 байт кода.
Пока мы не ушли далее, скажем о небольшом несоответствии декларируемой теории и наблюдаемой практики — а она показала, что предсказатель циклов в SB изъят, в результате чего предсказание финального перехода в начало цикла делается общим алгоритмом, т. е. хуже. Представитель Intel заверил нас, что ничего «хуже» быть не должно, однако…
Декодирование и IDQ
Предсказанные наперёд адреса исполняемых команд (попеременно для каждого потока — при включенной технологии Hyper-Threading) выдаются для проверки их наличия в кэшах команд (L1I) и мопов (L0m), но о последнем умолчим — опишем пока остальную часть фронта. Как ни странно, Intel сохранила размер считываемой из L1I порции команд в 16 байт (тут слово «порция» понимается согласно нашему определению). До сих пор это было препятствием для векторного кода, средний размер команд которого перерос 4 байта, а потому 4 команды, желательные для исполнения за такт, уже не уместятся в 16 байт. AMD решила эту проблему в архитектуре K10, расширив порцию команд до 32 байт — хотя её ЦП пока имеют не более чем 3-путный конвейер. В SB неравенство размеров приводит к побочному эффекту: предсказатель выдаёт очередной адрес выровненного 32-байтового блока, и если обнаружится (предположительно) срабатывающий переход в его первой половине, то считывать и декодировать вторую не надо — однако это будет сделано.
Из L1I порция попадает в буфер предекодера, а оттуда — в сам предекодер-длиномер (ILD), обрабатывающий до 7 или 6 команд/такт (с и без макрослияния; Nehalem умел максимум 6) в зависимости от их совокупной длины и сложности. Сразу после перехода обработка начинается с команды по целевому адресу, иначе — с того байта, перед которым предекодер остановился тактом ранее. Аналогично с финальной точкой: либо это (вероятно) срабатывающий переход, адрес последнего байта которого поступил от BTB, либо последний байт само́й порции — если только не достигнут предел в 7 команд/такт, или не встретилась «неудобная» команда. Скорее всего, буфер длиномера имеет всего 2–4 порции, однако длиномер может получить из него любые 16 подряд идущих байт. Например, если в начале порции опознаны 7 двухбайтовых команд, то в следующем такте можно обработать ещё 16 байт, начиная с 15-го.
Длиномер, помимо прочего, занимается обнаружением пар макросливаемых команд. О самих парах поговорим чуть позже, а пока заметим, что, как и в Nehalem, каждый такт может быть обнаружено не более одной такой пары, хотя максимум их можно было бы разметить 3 (и ещё одну одиночную команду). Однако измерение длин команд — процесс частично последовательный, так что определить несколько макросливаемых пар не удалось бы в течение такта.
Размеченные команды попадают в одну из двух очередей команд (IQ: instruction queue) — по одной на поток, на 20 команд каждая (что на 2 больше, чем у Nehalem). Декодер попеременно читает команды из очередей и переводит их в мопы. В нём есть 3 простых транслятора (переводят 1 команду в 1 моп, а с макрослиянием — 2 команды в 1 моп), сложный транслятор (1 команда в 1–4 мопа или 2 команды в 1 моп) и микросеквенсер для самых сложных команд, требующих 5 и более мопов из микрокода. Причём ПЗУ микрокода хранит только «хвосты» каждой последовательности, начиная с 5-го мопа, потому что первые 4 выдаются сложным транслятором. При этом если число мопов в микропрограмме не делится нацело на 4, то их последняя четвёрка будет неполной, но вставить ещё 1–3 мопа от трансляторов в этом же такте не получится. Результат декодирования поступает в кэш мопов и два буфера мопов (по одному на поток). Последние (официально именуемые IDQ — instruction decode queue, очередь декодированных команд) по-прежнему имеют по 28 мопов и возможность блокировки цикла, если его исполняемая часть там уместится.
Всё это (кроме кэша мопов) уже было в Nehalem. А в чём же различия? Прежде всего, что очевидно, декодер научили обрабатывать новые команды поднабора AVX. Поддержка наборов SSE со всеми цифрами уже никого не удивляет, а ускорение шифрования командами AES-NI (включая PCLMULQDQ) было добавлено в Westmere (32 нм версия Nehalem). В микрослияние подложили подводный камень: эта функция не срабатывает для команд, имеющих и константу, и RIP-относительную адресацию (RIP-relative, адрес относительно регистра-указателя команды — обычный способ обращения к данным в 64-битном коде). Такие команды требуют 2 мопа (отдельно загрузка и операция), а значит — декодер их обработает не более одной за такт, используя лишь сложный транслятор. Intel утверждает, что эти жертвы сделаны для экономии энергии, только не ясно, на чём: двухкратные размещение, исполнение и отставка мопов явно займут больше ресурсов, а значит — и потребят энергии, чем один.
Макрослияние оптимизировано — ранее в качестве первой сливаемой команды могло быть лишь арифметическое или логическое сравнение (CMP или TEST), теперь же допустимы простые арифметические команды сложения и вычитания (ADD, SUB, INC, DEC) и логического «И» (AND), также меняющие флаги для условного перехода (вторая команда пары). Это позволяет почти в любом цикле сократить последние 2 команды до 1 мопа. Разумеется, ограничения на сливаемые команды остались, но они некритичны, т. к. перечисленные ситуации для пары команд почти всегда исполняются:
- первый операнд первой команды должен быть регистром;
- если второй операнд первой команды находится в памяти, RIP-относительная адресация недопустима;
- вторая команда не может находиться в начале строки кэша или пересекать границу строк.
Правила для самого́ перехода такие:
- только TEST и AND совместимы с любым условием;
- сравнения на (не) равно и любые знаковые совместимы с любой разрешённой первой командой;
- сравнения на (не) перенос и любые беззнаковые не совместимы с INC и DEC;
- остальные сравнения (знак, переполнение, чётность и их отрицания) допустимы лишь для TEST и AND.
Главное изменение в очередях мопов — слитые мопы типа load-ex, обращение в память в которых требует чтения индексного регистра, (и ещё несколько редких видов) при записи в IDQ разделяются на пары. Даже если таких мопов попадётся 4, то в IDQ запишутся все 8 итоговых. Делается это потому, что в очередях мопов (IDQ), диспетчера (ROB) и резервации теперь применяется сокращённый формат мопа без 6-битного поля индекса (разумеется, для экономии при перемещении мопов). Предполагается, что такие случаи будут редки, а потому на скорость сильно влиять не будут.
Историю возникновения у этого буфера режима блокировки цикла мы расскажем ниже, а тут лишь укажем одну мелочь: переход на начало цикла ранее занимал 1 дополнительный такт, образуя «пузырь» между чтениями конца и начала цикла, а теперь его нет. Тем не менее, в четвёрке читаемых за такт мопов не могут оказаться последние из текущей итерации и первые из следующей, поэтому в идеале число мопов в цикле должно нацело делиться на 4. Ну а критерии для его блокировки почти не изменились:
- мопы цикла должны порождаться не более чем 8-ю 32-байтовыми порциями исходного кода;
- эти порции должны быть закэшированы в L0m (в Nehalem, разумеется, — в L1I);
- допускается до 8 безусловных переходов, предсказанных как срабатывающие (включая финальный);
- вызовы и возвраты недопустимы;
- недопустимы непарные обращения в стек (чаще всего при неравном числе команд PUSH и POP) — об этом ниже.
Стековый движок
Есть ещё один механизм, работу которого мы в прошлых статьях не рассматривали — стековый движок (stack pointer tracker, «следитель за указателем (на вершину) стека»), расположенный перед IDQ. Он появился ещё в Pentium M и до сих пор не изменился. Суть его в том, что модификация указателя стека (регистра ESP/RSP для 32/64-битного режима) командами для работы с ним (PUSH, POP, CALL и RET) делается отдельным сумматором, результат хранится в специальном регистре и возвращается в моп как константа — вместо того, чтобы модифицировать указатель в АЛУ после каждой команды, как это требует программная архитектура и как было в ЦП Intel до Pentium M.
Это происходит до тех пор, пока какая-то команда не обратится к указателю напрямую (и в некоторых других редких случаях) — стековый движок сравнивает теневой указатель с нулём и при ненулевом значении вставляет в поток мопов до вызывающей указатель команды синхронизирующий моп, записывающий в указатель актуальное значение из спецрегистра (а сам регистр сбрасывается). Поскольку требуется это редко, большинство обращений в стек, лишь неявно модифицирующих указатель, пользуются его теневой копией, изменяемой одновременно с остальными операциями. Т. е. с точки зрения блоков тыла конвейера такие команды кодируются единственным слитым мопом и ничем не отличаются от обычных обращений в память, не требуя обработки в АЛУ.
Внимательный Читатель (добрый день!) заметит связь: при зацикливании очереди мопов непарные обращения в стек недопустимы именно по причине того, что стековый движок в конвейере находится до IDQ — если после очередной итерации значение теневого указателя окажется ненулевым, в новой потребуется вставить синхромоп, а в циклическом режиме это невозможно (мопы только читаются из IDQ). Более того, стековый движок вообще при этом выключен для экономии энергии, как и все остальные части фронта.
Тайная жизнь нопов
Ещё одно изменение коснулось длиномера, но этот случай несколько выделяется. Сначала вспомним, что такое нопы и зачем они нужны. Когда-то в архитектуре x86 ноп был лишь 1-байтовый. Когда требовалось сместить код более чем на 1 байт или заменить команды длиной более 1-го байта, ноп просто вставляли несколько раз. Но несмотря на то, что эта команда ничего не делает, время на её декодирование всё-таки тратится, причём пропорционально числу нопов. Чтобы производительность «пропатченной» программы не просела, ноп можно удлинить префиксами. Однако в ЦП 90-х годов темп декодирования команд с числом префиксов выше определённой величины (которая куда меньше максимально допустимой длины x86-команды в 15 байт) резко падал. Кроме того, конкретно для нопа префикс применяется, как правило, одного вида, но многократно повторенный, что допускается лишь как нежелательное исключение, усложняющие длиномер.
Для разрешения указанных проблем начиная с Pentium Pro и Athlon процессоры понимают «длинный ноп» с байтом modR/M для «официального» удлинения команды с помощью регистров и адресного смещения. Естественно, никаких операций с памятью и регистрами не происходит, но при определении длины используются те же блоки длиномера, что и для обычных многобайтовых команд. Теперь использование длинных нопов официально рекомендуется учебниками по низкоуровневой программной оптимизации и от Intel, и от AMD. Кстати, предекодер SB вдвое (с 6 до 3 тактов) уменьшил штраф за префиксы 66 и 67, меняющие длину константы и адресного смещения — но, как и в Nehalem, штраф не накладывается на команды, где эти префиксы фактически не меняют длину (например, если префикс 66 применён к команде без непосредственного операнда) или являются частью списка переключателей опкодов (что сплошь и рядом используется в векторном коде).
Максимальная длина верно оформленного длинного нопа не превышает 9 байт для Intel и 11 для AMD. А потому для выравнивания на 16 или 32 байта нопов всё-таки может быть несколько. Однако т. к. команда эта простая, её декодирование и «исполнение» займёт ресурсов никак не больше обработки самых простых действующих команд. Поэтому уже много лет тестирование длинными нопами является стандартным методом определения параметров фронта конвейера, в частности — пропускной способности длиномера и декодера. И вот тут Sandy Bridge преподнёс очень странный сюрприз: тестирование производительности обычных программ не выявило никаких задержек и замедлений, а вот дежурная синтетическая проверка параметров декодера неожиданно показала, что его производительность равна одной команде за такт! При этом никаких официальных оповещений о таких радикальных изменениях в декодере Intel не давала.
Процедура замера отлично работала ещё на Nehalem и показывала верные 4 IPC. Можно свалить вину на новый и «чрезмерно» активный Turbo Boost 2.0, портящий замеряемые показатели тактов, но для тестов он был отключен. Перегрев с замедляющим частоту тротлингом тоже исключён. А когда, наконец, причина обнаружилась — стало ещё страннее: оказывается, длинные нопы на SB обрабатываются только первым простым транслятором, хотя 1-байтовые нопы с любым числом префиксов и аналогичные «по бездействию» команды (например, копирование регистра в себя) запросто принимаются всеми четыремя. Зачем так было делать — не ясно, однако как минимум один недостаток такого технического решения уже себя явно показал: на выяснение причин загадочной медлительности декодера нашей исследовательской командой было угрохано дней десять… В отместку просим яростных фанатов Противоположного Лагеря придумать какую-нибудь конспирологическую теорию о коварных планах некой компании I. по запутыванию наивных доблестных исследователей процессоров. :)
Кстати, как оказалось, «более равным» среди прочих транслятор №1 уже был. В Nehalem команды циклической прокрутки (ROL и ROR) с явным операндом-константой тоже декодировались только в первом трансляторе, причём в этом же такте отключался четвёртый, так что величина IPC падала до 3-х. Казалось бы — зачем приводить тут такой редкий пример? Но именно из-за этого подвоха, чтобы добиться пиковой скорости на алгоритмах хэширования вроде SHA-1, нужна была очень точная планировка команд, с которой компиляторы не справлялись. В SB же такие команды просто стали 2-мопными, так что, занимая сложный транслятор (который и так один), они ведут себя почти неотличимо для ЦП, но более предсказуемо для человека и компилятора. С нопами же получилось всё наоборот.
Кэш мопов
Цели и предшественники
Мы не зря отделили эту главу от остального описания фронта — добавление кэша мопов наглядно демонстрирует, какой путь выбрала Intel для всех своих процессоров, начиная с Core 2. В последний впервые (для Intel) был добавлен блок, который одновременно достигал две, казалось бы, противоречивые цели: увеличение скорости и экономия энергии. Речь идёт об очереди команд (IQ) между предекодером и декодером, хранившей тогда до 18 команд длиной до 64 байт в сумме. Если бы она только сглаживала разницу темпов подготовки и декодирования команд (как обычный буфер) — выгода была бы небольшая. Но в Intel догадались приделать к IQ небольшой блок LSD (вряд ли парни что-то «приняли», просто у них юмор такой) — Loop Stream Detector, «детектор циклического потока». При обнаружении цикла, умещающегося в 18 команд, LSD отключает все предыдущие стадии (предсказатель, кэш L1I и предекодер) и поставляет из очереди в декодер команды цикла, пока тот не завершится, либо пока не будет сделан переход за его пределы (вызовы и возвраты не допустимы). Таким образом экономится энергия за счёт отключения временно простаивающих блоков и увеличивается производительность за счёт гарантированного потока в 4 команды/такт для декодера, даже если они были «снабжены» самыми неудобными префиксами.
Intel явно понравилась эта идея, так что для Nehalem схема была оптимизирована: IQ продублирована (для двух потоков), а между декодером и диспетчером (т. е. аккурат на границе фронта и тыла) были поставлены две очереди IDQ на 28 мопов каждая, и блок LSD перенесли к ним. Теперь при блокировке цикла отключается ещё и декодер, а производительность поднялась в т. ч. за счёт гарантированного притока уже не 4-х команд, а 4-х мопов за такт, даже если их генерация производилась с минимальным (для Core 2/i) темпом в 2 мопа/такт. Яростные фанаты Противоположного Лагеря, на секунду оторвавшись от любимого занятия, тут же вставят шпильку: если LSD такая хорошая штука, почему же его не встроили в Atom? И шпилька справедлива — имея 32-моповую очередь после декодера, Atom не умеет блокировать в ней цикл, что как раз очень бы пригодилось для экономии драгоценных милливатт. Тем не менее, Intel не собиралась бросать идею и для новых ЦП подготовила обновление, да ещё какое!
Официальное внутреннее название кэша мопов — DSB (decode stream buffer: буфер потока декодирования), хотя он не так точно отражает суть, как рекомендуемый термин DIC (decoded instruction cache: кэш декодированных команд). Как ни странно, он не подменяет, а дополняет очереди IDQ, которые теперь соединяются с декодером или с кэшем мопов. При очередном предсказании перехода целевой адрес одновременно проверяется в кэшах команд и мопов. Если сработает последний — то далее считывание идёт из него, а остальной фронт отключается. Вот почему кэш мопов является кэшем нулевого уровня для мопов, т. е. L0m.
Интересно, что продолжить эту мысль можно, назвав IDQ кэшами «минус первого» уровня. :) Но не является ли такая сложная иерархия в рамках даже не всего ядра, а одного только фронта избыточной? Пускай Intel в качестве исключения не пожалела площадь, но принесёт ли пара IDQ существенную дополнительную экономию, учитывая, что при их работе теперь отключается лишь кэш мопов, т. к. остальной фронт (кроме предсказателя) и так спит? И ведь особой прибавки к скорости тоже не получишь, т. к. кэш мопов также настроен на генерацию 4 мопов/такт. Видимо, инженеры Intel решили, что 3-уровневая игра стоит милливаттовых свеч.
Кроме экономии, кэш мопов ускоряет производительность в т. ч. сокращением штрафа при фальш-предсказании перехода: в Nehalem при нахождении верного кода в L1I штраф был 17 тактов, в SB — 19, но если код нашёлся в L0m — то только 14. Причём это максимальные цифры: при внеочерёдном исполнении ложно предсказанного перехода планировщику надо ещё запустить и завершить предыдущие в программном порядке мопы, а за это время L0m может успеть подкачать верные мопы, чтобы планировщик успел их запустить сразу после отставки команд до перехода. В Nehalem такой приём работал с IDQ и фронтом, но в первом случае вероятность того, что верный целевой адрес тоже будет внутри 28-мопового цикла, весьма мал, а во втором медлительность фронта в большинстве случаев не позволяла снизить задержку до нуля. У SB такой шанс больше.
Устройство
Топологически L0m состоит из 32 наборов по 8 строк (8-путная ассоциативность). В каждой строке хранится 6 мопов (во всём кэше — 1536, т. е. «полтора киломопа»), причём за такт кэш может записать и считать по одной строке. Предсказатель выдаёт адреса 32-байтовых блоков, и именно этот размер является рабочим для L0m, поэтому далее под термином «порция» будем понимать выровненный и предсказанный как исполняющийся 32-байтовый блок кода (а не 16-байтовый, как для декодера). При декодировании контроллер L0m ждёт обработки порции до конца или до первого срабатывающего в ней перехода (разумеется, предположительно — тут и далее полагаем предсказания всегда верными), накапливая мопы одновременно с их отправкой в тыл. Затем он фиксирует точки входа в порцию и выхода из неё, согласно поведению переходов. Обычно точкой входа оказывается целевой адрес срабатывающего в предыдущей порции перехода (точнее, младшие 5 бит адреса), а точкой выхода — собственный адрес срабатывающего перехода в этой порции. В крайнем случае, если ни в предыдущей, ни в текущей порциях не сработает ни один переход (т. е. порции не только исполняются, но и хранятся подряд), то обе выполнятся целиком — вход в них будет на нулевом мопе и первом байте первой целиком уместившейся в этой порции команды, а выход — на последнем мопе последней целиком уместившейся команды и её начальном байте.
Если в порции оказалось более 18 мопов — она не кэшируется. Это задаёт минимум среднего (в пределах порции) размера команды в 1,8 байта, что не будет серьёзным ограничением в большинстве программ. Можно вспомнить второй пункт ограничений IDQ — если цикл уместится в порции, но займёт от 19 до 28 мопов, его не зафиксируют ни кэш L0m, ни очередь IDQ, хотя по размеру он бы везде уместился. Впрочем, в этом случае средняя длина команд должна быть 1,1–1,7 байта, что для двух десятков команд подряд крайне маловероятно.
Скорее всего, мопы порции одновременно записываются в кэш, занимая 1–3 строки одного набора, так что для L0m нарушается один из главных принципов работы наборно-ассоциативного кэша: при кэш-попадании обычно срабатывает одна строка набора. Тут же теги до трёх строк могут получить адрес одной и той же порции, отличаясь лишь порядковыми номерами. При попадании предсказанного адреса в L0m считывание происходит аналогично — срабатывают 1, 2 или 3 пути нужного набора. Правда, такая схема таит в себе недостаток.
Если исполняемая программа во всех порциях декодируется в 13–18 мопов, что займёт по 3 строки L0m для всех порций, обнаружится следующее: если текущий набор уже занят двумя 3-строчными порциями, и в него пытается записаться третья (которой не хватит одной строки), придётся вытеснить одну из старых, а с учётом её связности — все 3 старых. Таким образом больше двух порций «мелко-командного» кода в наборе не должно уместиться. При проверке этого предположения на практике получилось вот что: порции с крупными командами, требующие менее 7 мопов, упаковались в L0m числом в 255 (ещё одну занять почему-то не получилось), уместив почти 8 КБ кода. Средние порции (7–12 мопов) заняли все 128 возможных позиций (по 2 строки каждая), закэшировав ровно 4 КБ. Ну а мелкие команды уместились в 66-и порциях, что на две больше ожидаемого значения (2112 байт против 2048), что, видимо, объясняется граничными эффектами нашего тестового кода. Недостача на лицо — если бы 256 6-моповых строк могли быть заполнены полностью, их бы хватило на 85 полных троек с общим размером кода 2720 байт.
Возможно, Intel не рассчитывает, что в каком-то коде будет так много коротких и простых команд, что более 2/3 его придётся на 3-строчные порции, которые станут вытеснять друг друга из L0m раньше необходимого. А даже если такой код и встретится — учитывая простоту его декодирования, остальные блоки фронта запросто справятся с задачей поставки необходимых тылу 4 мопов/такт (правда, без обещанной экономии ватт и тактов штрафа при фальш-предсказании). Любопытно, что имей L0m 6 путей, проблемы бы не возникло. Intel же решила, что иметь размер кэша на треть больше именно за счёт ассоциативности — важнее…
Размеры
Вспомним, что идея кэшировать большое количество мопов вместо команд x86, не нова. Впервые она появилась в Pentium 4 в виде кэша моп-трасс — последовательностей мопов после развёртки циклов. Причём кэш трасс не дополнял, а заменял отсутствующий L1I — команды для декодера читались сразу из L2. Не смотря на забвение архитектуры NetBurst, разумно предположить, что инженеры Intel использовали прошлый опыт, хоть и без развёртки циклов и выделенного для кэша предсказателя. Сравним старое и новое решения (новые ЦП тут названы Core i 2, потому что номера почти всех моделей с архитектурой SB начинаются с двойки):
| Pentium 4 (Willamette, Northwood) | Pentium 4 (Prescott) | Core i 2 (Sandy Bridge) | |
| Объём, Кмопов | 12 | 12 | 1,5 |
| Организация, наборов⋅путей | 256⋅8 | 256⋅8 | 32⋅8 |
| Число мопов в строке | 6 | 6 | 6 |
| ПС, мопов/такт | 3 | 3 | 4 |
| Полный размер мопа, бит* | 119 | 138 | 139–147 |
| Сжатый размер мопа, бит* | 53 | 64 | 85 |
| Эквивалентный объём, КБ* | 80 | 96 | 16 |
* — предположительно
Тут нужны пояснения. Во-первых, пропускная способность для L0m указана с учётом общего ограничения ширины конвейера в 4 мопа. Выше мы предположили, что за такт L0m может прочесть и записать по 18 мопов. Однако при чтении все 18 (если их получилось именно столько при декодировании оригинальной порции) не могут быть отправлены за такт, и отправка происходит за несколько тактов.
Далее, размер мопа в битах вообще относится к очень деликатной информации, которую производители либо вообще не выдают, либо только при припирании к стенке (дескать, вы и так уже всё вычислили, так и быть — подтвердим). Для ЦП Intel последняя достоверно известная цифра — 118 бит для Pentium Pro. Ясно, что с тех пор размер увеличился, но с этого места начинаются догадки. 118 бит для 32-битного x86-ЦП может получиться, если в мопе есть поля для адреса породившей его команды (32 бита), непосредственного операнда (32 бита), адресного смещения (32 бита), регистровых операндов (3 по 3 бита + 2 бита на масштаб для индексного регистра) и опкода (11 бит, в которых закодирован конкретный вариант x86-команды с учётом префиксов). После добавления MMX, SSE и SSE2 поле опкода наверняка выросло на 1 бит, откуда и получена цифра 119.
После перехода на x86-64 (Prescott и далее), по идее, все 32-битные поля должны возрасти до 64-х бит. Но тут есть тонкости: 64-битные константы в x86-64 допускаются только по одной (т. е. более 8 байт обе константы в команде точно не займут), а виртуальная адресация и тогда, и сейчас пока обходится 48 битами. Так что увеличить размер мопа требуется всего на 16 бит адреса и 3 дополнительных бита номеров регистров (коих стало 16) — получаем (примерно) 138 бит. Ну а в SB моп, видимо, вырос ещё на 1 бит за счёт добавления очередных нескольких сотен команд со времён последних P4, и ещё на 8 — за счёт увеличения максимального числа явно указанных регистров в команде до 5 (при использовании AVX). Последнее, впрочем, сомнительно: со времён, представьте себе, аж i386 в архитектуру x86 не была добавлена ни одна новая команда, требующая хотя бы 4 байта константы (с единственным недавним и крайне незаметным исключением в SSE4.a от AMD, о котором даже большинство программистов не знает). А т. к. Intel AVX и AMD XOP обновили кодировку лишь векторных команд, биты номеров дополнительных регистров уместятся в старшей половине частично неиспользуемого (для этих команд) 32-битного поля непосредственного операнда. Тем более, что и в само́й x86-команде 4-й или 5-й регистр кодируется как раз четыремя битами константы.
Очевидно, что хранить и пересылать таких «монстров» в сколько-нибудь большом количестве — сильно затратно. Поэтому ещё для P4 Intel придумала сокращённый вариант мопа, в котором лишь одно поле для обеих констант, причём если они там не умещаются, то недостающие биты размещаются в этом же поле соседнего мопа. Однако если он уже хранит там свои константы, то в качестве соседа приходится вставлять ноп как донор-носитель дополнительных бит. Преемственность такой схемы наблюдается и в SB: лишние нопы не вставляются, но команды с 8-байтовыми константами (или с суммой размеров константы и адресного смещения в 5–8 байт) имеют в L0m двойной размер. Впрочем, учитывая длину таких команд, больше 4-х их в порции не уместится, так что ограничение по занимаемым мопам явно некритично. Тем не менее, констатируем: SB, в отличие от предыдущих ЦП, имеет аж 3 формата мопов — декодируемый (самый полный), хранимый в кэше мопов (с сокращением констант) и основной (без поля регистра индекса), используемый далее в конвейере. Впрочем, большинство мопов проходят нетронутыми от декодирования до отставки.
Ограничения
«Правила пользования кэшем» на спецформате мопов не заканчиваются. Очевидно, столь удобный блок как L0m никак не мог оказаться совсем без ограничений той или иной степени серьёзности, о которых нам не рассказали в рекламных материалах. :) Начнём с того, что все мопы транслируемой команды должны уместиться в одной строке, иначе они переносятся в следующую. Это объяснимо тем, что адреса мопов строки хранятся отдельно (для экономии 48 бит в каждом мопе), а все порождаемые командой мопы должны соответствовать адресу её первого байта, хранимому в теге только одной строки. Для восстановления оригинальных адресов в тегах хранятся длины породивших мопы команд. «Непереносимость» мопов несколько портит эффективность использования L0m, т. к. изредка встречающиеся команды, генерирующие несколько мопов, имеют существенный шанс не уместиться в очередной строке.
Более того, мопы самых сложных команд по-прежнему хранятся в ПЗУ с микрокодом, а в L0m попадают лишь первые 4 мопа последовательности, плюс ссылка на продолжение, так что всё вместе занимает целую строку. Из этого следует, что в порции могут встретиться не более трёх микрокодовых команд, а учитывая средний размер команды более вероятным пределом будут две. В реальности, впрочем, они попадаются куда реже.
Ещё один важный момент — L0m не имеет своего TLB. Вроде бы, это должно ускорять проверку адресов (которые тут только виртуальные) и уменьшить потребление энергии. Но всё гораздо интересней — не зря все современные кэши имеют физическую адресацию. Виртуальные адресные пространства исполняемых в ОС программ могут пересекаться, поэтому при переключении контекста задачи, чтобы по тем же адресам не считать старые данные или код, виртуально адресуемый кэш должен сбрасываться (именно так было с кэшем трасс у P4). Разумеется, его эффективность при этом будет низкой. В некоторых архитектурах применяются т. н. ASID (address space identifier, идентификатор адресного пространства) — уникальные числа, присваиваемые ОС каждому потоку. Однако x86 не поддерживает ASID за ненадобностью — учитывая наличие физических тегов для всех кэшей. Но вот пришёл L0m и нарушил картину. Более того, вспомним, что кэш мопов, как и большинство ресурсов ядра, разделяется между двумя потоками, так что в нём окажутся мопы разных программ. А если добавить переключение между виртуальными ОС в соответствующем режиме, то мопы двух программ могут совпасть по адресам. Что же делать?
Проблема с потоками решается просто — L0m просто делится пополам по наборам, так что номер потока даёт старший бит номера набора. Кроме того, L1I имеет включающую политику хранения относительно L0m. Поэтому при вытеснении кода из L1I происходит и удаление его мопов из L0m, что требует проверки двух смежных порций (размер строки всех кэшей современных ЦП, не считая самого́ L0m — 64 байта). Таким образом виртуальный адрес из тэгов закэшированных мопов всегда можно проверить в тегах L1I, используя его TLB. Выходит, что хоть L0m и имеет виртуальную адресацию, но заимствует физические теги для кода из L1I. Тем не менее, есть ситуация, при которой L0m целиком сбрасывается — промах и замещение в L1I TLB, а также его полный сброс (в т. ч. при переключении режимов работы ЦП). Кроме того, L0m совсем отключается, если базовый адрес селектора кода (CS) не равен нулю (что крайне маловероятно в современных ОС).
Работа
Главный секрет кэша мопов — алгоритм, подменяющий чтениями из L0m работу фронта по переработке команд в мопы. Начинается он с того, что при очередном переходе для выбора набора L0m использует биты 5–9 адреса цели перехода (или биты 5–8 плюс номер потока — при 2-поточности). В тегах набора указаны точка входа в порцию, мопы которой записаны в соответствующей тегу строке, и порядковый номер этой строки в пределах порции. Совпасть могут 1–3 строки, которые (скорее всего) одновременно считываются в 18-моповый буфер. Оттуда мопы четвёрками посылаются в IDQ, пока не будет достигнута точка выхода — и всё повторяется сначала. Причём когда в порции остаются неотправленными 1–3 последних мопа, они высылаются с 3–1 первыми мопами новой порции, в сумме составив обычную четвёрку. Т. е. с точки зрения принимающей мопы очереди IDQ все переходы сглажены в равномерный поток кода — как в P4, но без кэша трасс.
А теперь любопытный момент — в строке допускается не более двух переходов, причём если один из них — безусловный, то он окажется последним для строки. Наш Внимательный Читатель сообразит, что на всю порцию допустимо иметь до 6 условных переходов (каждый из которых может сработать, не будучи при этом точкой выхода), либо 5 условных и 1 безусловный, который будет последней командой порции. Предсказатель переходов в ЦП Intel устроен так, что он не замечает условный переход, пока он хотя бы раз не сработает, и только после этого его поведение будет предсказываться. Но даже «вечносрабатывающие» переходы тоже подпадают под ограничение. Фактически это значит, что завершить исполнение мопов порции допустимо и до точки её выхода.
А вот аналогичный трюк со множественным входом не пройдёт — если происходит переход в уже закэшированную порцию, но по другому смещению в ней (например, когда там более одного безусловного перехода), то L0m фиксирует промах, включает фронт и запишет поступившие мопы в новую порцию. Т. е. в кэше допустимы копии для порций с разными входами и одинаковым, точно известным выходом (помимо ещё нескольких возможных). А при вытеснении кода из L1I в L0m удаляются все строки, точки входа которых попадают в любой из 64-х байт двух порций. Кстати, в кэше трасс P4 тоже были возможны копии, причём они существенно уменьшали эффективность хранения кода…
Такие ограничения уменьшают доступность пространства L0m. Попробуем подсчитать, сколько же его остаётся для фактического использования. Средний размер команды x86-64 — 4 байта. Среднее число мопов на команду — 1,1. Т. е. на порцию скорее всего придётся 8–10 мопов, что составляет 2 строки. Как было ранее подсчитано, L0m сможет сохранить 128 таких пар, чего хватит на 4 КБ кода. Однако с учётом неидеального использования строк реальное число будет, видимо, 3–3,5 КБ. Интересно, как это вписывается в общий баланс объёмов кэшевой подсистемы?
- 1 банк L3 (фактически часть L3, в среднем приходящаяся на ядро) — 2 МБ;
- L2 — 256 КБ, в 8 раз меньше;
- оба L1 — по 32 КБ, в 8 раз меньше;
- кэшируемый объём в L0m — примерно в 10 раз меньше.
Любопытно, что если найти в ядре ещё одну структуру, хранящую много команд или мопов, то ей окажется очередь ROB диспетчера, в которой умещается 168 мопов, генерируемые примерно 650–700 байтами кода, что в 5 раз меньше эффективного эквивалентного объёма L0m (3–3,5 КБ) и в 9 раз меньше полного (6 КБ). Таким образом, кэш мопов дополняет стройную иерархию различных хранилищ кода с разными, но хорошо сбалансированными параметрами. Intel утверждает, что в среднем 80% обращений попадают в L0m. Это значительно ниже цифры в 98–99% для кэша L1I на 32 КБ, но всё равно — в четырёх случаях из пяти кэш мопов оправдывает своё присутствие.
Диспетчер и планировщик
Переименование и размещение
Переходим к тыловой части. Первое крупное изменение — новые диспетчер и планировщик. Как и любой представитель этой стадии, диспетчер выполняет переименование регистров, размещение мопов в очереди ROB и резервации, приём завершённых мопов и их отставку. Каждый такт диспетчер принимает до 4 мопов от IDQ, прописывает физические регистры, помещает мопы в ROB (тоже до 4), разделяет слитые мопы на простые и отправляет их (до 6) в резервацию, связав каждый с нужным портом запуска (которых тоже 6). Очевидно, что в четвёрке принимаемых мопов допустимо не более трёх микро- или макрослитых, чтобы после разделения их можно было обработать за такт. Мопам обмена с памятью также выделяют ячейки в очереди загрузки или сохранения в LSU.
Некоторые мопы сразу после (или даже вместо) переименования указываются как незапускаемые:
- любые нопы (до 4 за такт) — потому что они ничего не делают;
- FXCH (обмен местами регистров x87-стека, до 2 за такт) — их «исполнение» заключается в переименовании пары регистров (в предыдущих ЦП только эта команда удалялась при размещении);
- VZEROUPPER (1 за такт, потому что генерируются 4 неисполняемых мопа) — для обнуления старших половин всех регистров ymm (об этом позже);
- классы обнуляющих и единичных идиом (zeroing idioms, ones idioms; 4 и 2 за такт).
К обнуляющим относятся команды, действие которых при указанных операндах всегда сводится к обнулению регистра-приёмника, хотя сами они специально для этого не предназначены. К таким SB относит все виды команд *XOR* (исключающее ИЛИ), *SUB* (вычитание) и PCMPGT* (векторная целая проверка на «больше»), все аргументы которых являются одним регистром (звёздочками заменены переменные части мнемоник разных версий команд). Поскольку результат предопределён, то считается, что никаких источников команде читать не надо, а потому она эквивалентна простому помещению константы 0 в целевой регистр. Явное обнуление в x86 не используется из-за особенностей ISA: для РОНов такая команда окажется длиннее идиомы, а для векторных регистров этого варианта нет вообще.
Само обнуление происходит за счёт того, что архитектурный регистр-приёмник перенумеруется на свободный физический регистр, помечаемый как содержащий нули (хотя реально там наверняка что-то другое). Потому «исполнять» такие мопы можно по 4 за такт, тогда как обычные *XOR*, *SUB* и PCMPGT* запускаются максимум тройками. Как-бы-нулевой регистр не читается из РФ, а в ФУ просто посылается сигнал, что этот аргумент — константа 0. Правда, анализа на 0 результатов вычислений в ФУ и загрузок из кэша не происходит (хотя флаг Z после большинства операций в АЛУ показывает именно это), так что 0 в регистре может оказаться и после необнуляющих команд с последующим штатным чтением — диспетчер о нём просто не узнает.
К обнуляющим также относится команда CLC, сбрасывающая флаг переноса. Поскольку 4 основных флага (перенос, переполнение, ноль и знак) также переименовываются, CLC по нашим тестам также может «исполняться» 4 раза за такт, хоть это и бессмысленно. Впрочем, представитель Intel заявил, что к CLC заочное обнуление не относится… Ещё одна группа команд, сокращающаяся подобным образом — единичная идиома PCMPEQ* (векторная целая проверка на «равно»). По аналогии с обнуляющими, при одинаковых аргументах она всегда устанавливает все биты приёмника в «1». Однако, в отличие от «обнулятелей», такому мопу всё же надо исполниться в любом из двух портов, куда обычно попадают эти команды — удалённо отметить регистр как содержащий единицы диспетчер не может, их надо записать явно.
Новый старый стиль
Прежде чем рассказать о само́м планировщике, вспомним основные различия между ними в нашей Энциклопедии. Точнее, нас интересует «хранящий» вариант с несколькими РФ и «ссылочный» с одним (физическим). Первый более привычен, т. к. применялся во всех x86-ЦП с внеочерёдным исполнением, за исключением всех P4. А второй был в P4 — и вот сейчас вернулся в SB. Может быть, Intel что-то перепутала, внедрив в новую экономную архитектуру блок из старой Netburst, представители которой «прославились» тепловыделением? (Также его применяют во всех серверных ЦП IBM POWER, которые ещё выше по частоте и ещё жарче.) Однако планировщик к этому точно не был причастен, а очень даже наоборот — именно вариант с физическим регистровым файлом (ФРФ), как ни странно, оказывается самым экономным.
До сих пор все основные процессы в планировщике (от размещения до отставки) требовали перемещения мопов вместе с накопленными в них данными, что требовало довольно много энергии (вспомните длину мопа и добавьте биты регистров-операндов). Вариант с ФРФ копирует или меняет не сами значения, а только 8-битные (в данном случае) ссылки на тот регистр в ФРФ, где они хранятся. Ещё одно преимущество такой схемы в снятии ограничения на число чтений из РФ. Дело в том, что в старой схеме основным РФ в исполнительном тракте был спекулятивный (СРФ), а вторичным — архитектурный (АРФ). Размер СРФ должен быть достаточен, чтобы держать аргументы и результаты всех хранящихся в резервации(ях) мопов, а размер АРФ, разумеется, будет совпадать с числом регистров данного типа согласно ISA.
Проблема была в том, что у АРФ лишь 3 порта чтения (а в Pentium II и III — 2), и при переименовании регистров 3–4 размещаемых мопа могут за такт прочесть (и скопировать в свою ячейку ROB) лишь небольшое число регистров, которые достаточно давно не менялись, чтобы их значения уже успели попасть из СРФ в АРФ при отставке. Учитывая, что у каждой целочисленной и AVX-команды число читаемых регистров может достигать трёх, разместитель не справился бы за такт со сбором всех нужных данных для четвёрки мопов. При использовании единственного РФ число его портов достаточно большое (по нашим тестам, в SB — 10 чтений и 5 записей), чтобы за такт прочесть и записать всё необходимое.
Поскольку каждый моп теперь не накапливает содержимое регистров, обе очереди тыла (ROB для диспетчера и резервация для планировщика) могут при той же площади хранить большее число мопов: 128 и 36 ячеек в ROB и RS Nehalem подросли до 168 и 54 в SB. Это значит, что планировщик теперь может отслеживать зависимости команд в более длинном куске кода, получая возможность одновременно запустить даже далёкие друг от друга команды. Это особенно пригождается при исполнении двух потоков, делящих между собой большинство ресурсов, включая обе этих очереди (опишем потом, как именно). Размеры же ФРФ такие — 160 64-битных РОНов и 144 256-битных векторных регистра. Правда, на самом деле векторных РФ два, каждый из которых хранит 128-битные половины. Почему так?
Исполнительная стадия
Тракты данных
Для ответа на вопрос выше снова сделаем исторический экскурс. Давным-давно, в далёкой-далёкой… гм, эпохе 70-х и 80-х гг. процессоры обрабатывали лишь целые числа, а потому исполнительный тракт у них был один, на 8/16/32 бита. Затем добавился вещественный тракт на 64/80 бит (архитектуре x86 в этом смысле пришлось труднее, потому что расширенную 80-битную точность больше нигде не внедрили). Далее, рассматривая только ЦП Intel, последовал набор MMX, который архитектурно хоть и использовал стек x87, но физически имел не только отдельные ФУ, но и регистры. Потом добавлен SSE — хотя для программиста регистры xmm 128-битные, векторные РФ и ФУ до Core 2 были 64-битными и тоже отдельными. Правда, когда SSE2 расширил целочисленную обработку до 128 бит, для этих ФУ нового РФ не создали, а просто переделали блок MMX, чтобы его РФ и ФУ могли хранить и обрабатывать и половинки 128-битных регистров.
В Core 2 структура исполнительного блока окончательно приобрела нынешние очертания. 64-битный целочисленный тракт работает с командами общего назначения, первый 128-битный — с целочисленными векторами, а второй 128-битный — с вещественными векторами и скалярами (включая x87). Вспомним, что при исполнении SSE-кода переключаться между целым и вещественным режимом не надо (в отличие от режимов MMX и х87), и каждый регистр xmm может хранить и целые, и вещественные значения. Но т. к. физически они хранятся и обрабатываются в разных РФ и доменах, возникает вопрос о доступности нужных данных нужному ФУ, если они находятся в соседнем тракте. Чтобы перемещений между векторными трактами было как можно меньше, в каждом их них есть блоки для наиболее частых команд — в частности, логических и некоторых перестановок. Но т. к. ФУ отдельные, то и команды для них Intel тоже решила сделать отдельными — и вот в x86 появилась такая химера, как «вещественная логика». Как-нибудь мы поговорим об этом звере, а пока договоримся обозначать такие ФУ как FLOG. Аналогично, ФУ для «целочисленной логики» назовём ILOG.
Пересылки данных между векторными трактами весьма редки благодаря наличию большинства нужных ФУ на каждом из них. Схема исполнительной стадии в Nehalem (не считая ФУ, используемых некоторыми редкими командами) выглядит так:
| Тракт→ | 64 бита, целый1 | 128 бит №1, целый | 128 бит №2, вещественный |
| Порт 0 | АЛУ2 Сдвигатель | АЛУ Перестановщик | FMOV (x87) FMUL FDIV |
| Порт 1 | АЛУ IMUL AGU3 | MOV ILOG IMUL Сдвигатель | FADD Конвертер4 |
| Порт 5 | АЛУ Сдвигатель | АЛУ Перестановщик | FMOV (SSE)5 FLOG Перестановщик |
Не указаны порты: №2 для вычисления адреса чтения и самого чтения из памяти, №3 для вычисления адреса записи и №4 для самой записи.
1 — Не указан скалярный целочисленный делитель: он получает мопы со всех трёх портов при любом виде деления.
2 — Напомним, что АЛУ работают только с целыми числами и, помимо арифметики и логики, выполняют также копирования (MOV).
3 — Это ФУ исполняет только команду LEA: вычисление адреса как для операции чтения, но с помещением в приёмник самого́ адреса (иногда используется как замена некоторых арифметических команд). Аналогичный блок в порту 2 вычисляет адреса для «настоящих» чтений, выполняя дополнительные неарифметические операции.
4 — Преобразователь арифметических форматов (между двумя вещественными или вещественным и целым). Для некоторых команд использует один из вспомогательных ФУ, получающих мопы с других портов.
5 — «Вещественные копирования», ещё одна химера, когда речь идёт о векторном регистре целиком.
И тут на сцену выходит набор AVX и его 256-битные регистры ymm. Как их обрабатывать? Основных вариантов три:
- Не менять ФУ, обрабатывая регистры половинками, как это было с xmm до Core 2;
- Поставить отдельный тракт или расширить один из имеющихся, снабдив его необходимыми и «полноширными» ФУ;
- Снабдить недостающими ФУ оба нынешних тракта, чтобы они могли работать над регистром ymm одновременно.
Нетрудно догадаться, какой вариант был выбран, учитывая, что процессору надо и скорость вычислений поднять, и энергию (обязательно) с площадью (желательно) сэкономить. Правда, по причинам, описанным далее в главе об AVX, добавлен только вещественный домен в бывший целочисленный тракт, который мы теперь назовём смешанным. После добавки и перетасовки ФУ в SB получилось вот что:
 От центра вверх — 3 исполнительных тракта SB (в порядке, указанном в таблице). 5 структур ниже центра — 64-битные РФ (4 из них попарно объединены). Внизу — диспетчер и планировщик. |
| Тракт→ | 64 бита, целый1 | 128 бит №1, смешанный | 128 бит №2, вещественный |
| Порт 0 | АЛУ Сдвигатель | MOV ILOG IMUL+FMUL1 Сдвигатель | FMOV (x87, AVX) FMUL IDIV+FDIV2 |
| Порт 1 | АЛУ IMUL Сложное AGU | АЛУ FADD Конвертер Перестановщик | FADD Конвертер |
| Порт 5 | АЛУ Сдвигатель | АЛУ3 Сдвигатель Перестановщик | FMOV (SSE, AVX) FLOG Перестановщик |
Не указаны порты: №2 и №3 для вычисления адресов и чтения из памяти и №4 для записи. Жирным указаны добавленные ФУ, курсивом — перемещённые, подчёркнутым — спариваемые.
1 — Универсальный умножитель для векторных целых и всех вещественных.
2 — Универсальный делитель для скалярных целых и всех вещественных. (Деления векторных целых в x86 нет.)
3 — Спариваются блоки копирования и логики.
Обратим внимание, что в Nehalem до полноценного АЛУ порту 1 не хватало лишь сумматора — логика и копирование там и так исполнялись. В SB целочисленные блоки портов 0 и 1 целиком поменяли местами, потеряв только отдельный умножитель, но почему-то не добавив на его место сумматор. Также нужно пояснить, почему, начиная с Pentium Pro, мопы записи разбиваются отдельно на вычисление адреса и саму запись. Во-первых, в элементарном мопе (в отличие от слитого) нет места и для данных, и для компонент адреса. Во-вторых — это часто позволяет заранее вычислить адрес, что поможет как можно раньше определить возможные адресные конфликты с чтениями (подробней об этом — далее).
Конфликты завершения
Теперь на секунду вернёмся к планировщику. Иногда встречается такая ситуация: некая команда после запуска исполняется в течение X тактов, но через Y тактов (Y Теперь каждый из трёх вычислительных портов может за такт принять завершение до трёх мопов с разных трактов (правда, в сумме со всех портов — вряд ли больше 6). До сих пор такими параметрами могла похвастать лишь AMD, у которой раздельные 3-портовые планировщики для целочисленного и векторно-вещественного трактов запускают и принимают на пару 6 мопов/такт. Однако даже там не удалось обойти проблему переменной задержки некоторых команд — прежде всего это деление и вся трансцендентная арифметика. Время исполнения этих операций зависит от содержимого аргумента(ов) — например, для скалярного вещественного деления и извлечения корня в SB это 10–24 такта. В этих случаях в старых ЦП резервация просто блокировала порт с медлительным делителем, пока он не завершал работу. Затем ЦП обеих компаний научились принимать стоп-сигналы от всех ФУ (а не только от делителя-извлекателя), но только один за такт (если завершаемых мопов в данном порту больше — они становятся в очередь). И вот SB удалил возможную задержку, принимая 3 завершения за такт (очередь возможна лишь среди ФУ, совпадающих и по номеру порта, и по тракту). Правда, для этого ему пришлось приделать к некоторым командам временны́е балласты, но об этом — позже.
Межтрактные шлюзы
Пересылка данных между трактами обычно занимает заметное время (на Nehalem в большинстве случаев — 2 такта). Как с этим в SB? Оказывается, декодер для ряда команд вставляет специальные мопы, использующие некоторые ФУ как межтрактные шлюзы: с 64-битного тракта в любой 128-битный — через порт 0, обратно — через 5-й, а между 128-битными работают оба. «Настоящие» шлюзы, как и ранее, иногда вызывают задержку в 1 такт при переходе между целыми и вещественными SSE-операциями, хотя теперь они являются доменами одного тракта. Зато задержек в 2 такта уже почти нет. Судя по нашим тестам, передача между трактами обычно занимает 1 такт, но для шлюза в порту 0 может быть и бесплатна — возможно, он физически находится ближе к «своим» ФУ и успевает срабатывать вместе с ними.
Вспомним, что для AVX-кода доступен 256-битный перестановщик. Если исполняется команда, не требующая пересылки элементов между трактами, то её задержка такая же, как и для SSE-версии, т. к. использует 2 ФУ для половинок ymm. В противном случае используется полнодуплексный межтрактный перестановщик на 256 бит, причём его задержка в 1 такт присутствует, даже если фактически данные между трактами не передавались. Все шлюзы являются частью исполнительного конвейера — т. е. одновременно допускается использование ФУ и межтрактных пересылок.
Вещественные денормалы
Стандарт IEEE-754, который используют почти все современные процессоры для представления вещественных чисел, имеет такую особенность: когда экспонента E установлена в 0, а содержимое мантиссы M ненулевое, число интерпретируется не в нормальном виде (1,M⋅2E), а «денормальном» (0,M⋅2Emin, где Emin — минимальная «нормальная» экспонента). Обработка таких чисел (а также бесконечности и неопределённости) на ЦП Intel всегда была замедлена на сотни (!) тактов из-за микропрограммного получения результата. (Яростные фанаты Противоположного Лагеря могут гордиться своим кумиром — у AMD как минимум начиная с первых Athlon денормалы почти не замедляли вычисления, а бесконечности и неопределённости даже ускоряли.)
Проблема настолько велика, что для векторных вещественных вычислений Intel ввела в x86 специальный «облегчённый» режим DAZ ([assume] denormals are zero — считать денормалы нулями), идущий ради производительности несколько вразрез с мировым стандартом. В SB большинство подобных ситуаций разрешаются аппаратными механизмами, что кардинально повысило скорость обработки денормалов (и серьёзно уменьшило размер микрокода). Теперь лишь умножение изредка может вызвать небольшую дополнительную задержку. Это может значительно ускорить код, работающий с очень близкими к нулю числами — например, при вычислении знаменателей суммы ряда, что требуется для большинства трансцендентных функций.
Частичный доступ к регистрам
Очередная сложность, возникающая при разработке процессора — архитектурное допущение читать и менять часть какого-либо регистра. В x86 это применимо к РОНам, xmm и ymm — причём последний случай настолько особый, что этому посвящена целая глава. Тут же опишем проблему в целом на примере 64-битного РОНа.
Архитектурно программист может использовать регистр целиком, младшие 4 байта, младшие 2 байта и младший 1 байт. Для первых 4 РОНов есть ещё доступ ко второму байту, но для всех x86-ЦП уже давно рекомендуется настоятельно забыть эту возможность — трудностей хватает и без этого. При очередном архитектурном удвоении разрядности регистров у инженеров есть несколько вариантов реализации доступа к новым и старым регистрам как полностью, так и частично:
- Сделать отдельные архитектурные РФ для регистров нужной разрядности — как при переходе от 64-битных регистров mm (для MMX) к 128-битным xmm (которые, правда, не сразу можно было использовать для целых чисел, так что ФУ у них поначалу были разные). Выгода — нет зависимостей по данным (как если бы каждый xmm содержал бы в своей младшей половине mm с тем же номером). Минусов больше — требуются спецкоманды для перемещения данных между старым РФ и новым, а архитектурное состояние для сохранения вырастает не на 64, а на 128 байт (тогда регистров было ещё 8). Сегодня же, когда x87 и MMX уже устарели, их содержимое всё ещё надо сохранять (кроме случая с применением новой команды, как будет описано ниже).
- Сделать отдельные физические РФ для младших частей регистров — как во всех ЦП Intel от PPro до PM включительно (кроме P4). Правда, из-за дополнительных затрат это применяется лишь к младшим байтам РОНов — остальные части используют другие методы. Как и в случае выше, зависимостей нет — переименованный 8-битный регистр N хранится отдельно от 32-битного с тем же номером. Однако есть штраф, когда части регистра должны объединиться, чтобы быть обработанными другой командой.
Пример: команда-1 обработала младший байт 32-битного РОНа, а следующая команда-2 читает его целиком. Вроде бы всё решается просто — команда-1 записывает изменённый байт не в «байтовый», а в основной (полноразрядный) РФ, а затем этот регистр читается весь. Но при внеочерёдном исполнении состояние старших трёх байт читаемого архитектурного регистра достоверно известно лишь при отставке, когда спекулятивый РФ записывает в архитектурный результаты готовых мопов. А значит при частичном доступе команда-2 вынуждена ждать 5–7 тактов до отставки команды-1.
- То же, что и выше, но части регистра могут объединяться в шлюзе при ФУ — это используется для РОНов в ЦП Intel с Core (первых) по Nehalem. При этом разместитель диспетчера автоматически вставляет дополнительный синхромоп, встраивающий только что записанный байт из «байтового РФ» в младший байт соответствующего ему регистра «полного РФ». Штраф в такой ситуации — 2–3 такта, т. к. достаточно дождаться завершения (не отставки) лишь последней команды, пишущей в данный регистр.
- Хранить регистры в цельном РФ, но получать доступ отдельными частями: для 64-битного РОНа — 1+1+2+4 байта, для xmm — 4+4+8 (напомним, что в наборах SSE есть скалярные вещественные команды, обрабатывающие только младший SP- или DP-элемент вектора). Применяется в Intel Core (2) и Nehalem — только для xmm, а в ЦП AMD и Intel Pentium 4 — и для РОНов, и для xmm. Никаких штрафов при использовании и даже слиянии регистров нет (т. к. синхромопы не используются), но существует ложная зависимость, когда запись в часть архитектурного регистра всегда считается зависящей от предыдущих записей в этот регистр — частичных и даже полных, когда он целиком перезаписывается.
Пример: команда-1 частично или полностью использует регистр xmm1, команда-2 сохраняет его в память, а скалярная команда-3 — записывает в его же часть новое значение. Тут разместитель не сможет распознать, что команде-3 старшая часть регистра xmm1 не нужна, и не выделит ему отдельный физический регистр, чтобы выполнить эту команду одновременно с первыми двумя. Зато разместителю и резервации требуется менее сложная и более экономная логика для отслеживания зависимостей, т. к. она применяется к регистрам целиком.
- Как выше, но во избежание ложных зависимостей запись в часть регистра сбрасывает в 0 остальную часть — это применяется при 32-битных операциях с 64-битными РОНами на всех ЦП (чтобы не ставить отдельный РФ для 8-байтовых версий регистров в дополнение к 4- и 1-байтовым), а также (как мы увидим ниже) при 128-битных командах AVX с регистрами xmm, т. е. младшими половинами ymm. Оба решения, очевидно, являются архитектурными.
- Программист или компилятор явно удаляет зависимость частей регистра, обнуляя его целиком или частично до использования как приёмник. Этот способ также используется в AVX, причём с немалым подвохом.
Теперь, когда все варианты перечислены, — на чём же остановились авторы SB? Для РОНов теперь используется метод №4, как и для xmm/ymm — в Nehalem же при частичной обработке РОНов надо было ждать лишние 3 такта. Исключение составляют «старшие» байтовые регистры (от AH до DH), которые всё же могут отдельно переименовываться. Но, как подсказывает Внимательный Читатель, есть ещё один ресурс, который и переименовывается, и читается-пишется (причём частично — куда чаще, чем полностью): 4–6 самых используемых флагов.
До сих пор ЦП использовали к ним подход №2, но SB перешёл на модифицированный вариант №3: флаг переноса (C) переименовывается отдельно, а для остальных имеется сливающий моп. Что это даёт? Вот типичная ситуация: в конце цикла команда INC или DEC меняет его параметр, записывая флаги нуля и знака в поле флагов физического регистра (имеется только для РОНов). Затем условный переход проверяет флаг нуля или знака — никаких проблем, они только что изменились. Но если условный переход читает флаг переполнения, либо попалась команда сохранения всех флагов в стек — придётся ждать, пока команды, менявшие оставшиеся 2 флага, уйдут в отставку, чтобы выделить нужный бит или их все. И вот SB сократил этот штраф примерно вдвое. Если же читается флаг переноса — то штрафа нет вообще.
Т. к. остальные флаги всё ещё держатся вместе, это создаёт любопытные эффекты — например, для команд сдвига. Дело в том, что согласно ISA вытесняемые биты должны попадать во флаг переноса, причём если параметр сдвига более 1, то попадёт только последний бит. Так вот этот вариант до сих пор вызывал парадоксальную зависимость флага переноса от своего же старого значения — после такой команды чтение только что изменённого флага всё равно приводило к штрафу. В SB такого штрафа нет, зато синхромопы для слияния флагов теперь всегда вставляются после многобитных вращений. В результате задержка получения результата вращения в регистре-приёмнике — 1 такт, а во флагах — 2–3.
AVX
Реализация
Главным новшеством в исполнительной стадии является добавление недостававших ФУ, чтобы вкупе с уже имеющимися суметь исполнить любую операцию с региcтрами ymm (кроме деления и извлечения корня) в полноконвейерном варианте и одновременно над всем вектором. Но как же получается, что несколько ФУ, которые надо задействовать для исполнения операции, находятся в одном порту? Ведь, как мы знаем, каждый порт может за такт запустить 1 моп… И тут на помощь приходит второе новшество, без которого первое не имело бы смысла — впервые среди процессоров (именно процессоров вообще) запускаемый через порт резервации моп может активировать более одного ФУ: в данном случае — пару одинаковых, потому в таблице выше они и названы спариваемыми. Таким образом за такт можно исполнить 3 256-битные AVX-операции, активировав 6 ФУ!
Но где восклицание — там и половник дёгтя: т. к. AVX-моп один, использовать два ФУ из пары отдельно не получится. Запустить 128-битные SSE-команды (да и 128-битные AVX) тоже можно лишь 3 за такт, так что на имеющемся коде, не знающем ни про какой AVX, почти половина векторных ФУ нового ЦП будет простаивать (разумеется, в выключенном состоянии для экономии), не принеся никакого ускорения. Очевидно, Intel делает большую ставку на активное использование AVX в обновлённых версиях ПО. Но и тут безоблачного будущего не предвидится — и не только потому, что внедрение нового часто происходит медленно…
Подножка
Как мы помним из исторического экскурса выше, иногда содержимое xmm-регистров перемещается через шлюзы в соседний векторный тракт, где местное ФУ производит с ним некую операцию. Результат при этом почти всегда записывается в местный же РФ, так что если следующая операция, которую требовалось исполнить над этим вектором, снова должна использовать местное ФУ — данные уже на месте. А теперь представим себе, что в SSE-код программист-оптимизатор добавляет вручную написанную процедуру с использованием команд AVX и регистров ymm, младшие половины которых, как мы помним, совпадают с регистрами xmm с тем же номером. Поскольку при исполнении AVX-команд 1-й («смешанный») векторный тракт работает только с младшей половиной ymm, а 2-й — только со старшей, это может потребовать обмена местами неверно расположенных половин регистра, для чего перед каждой операцией придётся проверять, где они расположены. Intel решила проблему иначе.
Для SB схема использования двух трактов изменилась: теперь на 1-й тракт попадают всё регистры mm, xmm и младшие половины ymm, а на 2-й — стек х87 и старшие части ymm (причём в регистрах с теми же номерами, что и для младших половин). Таким образом все векторные команды, кроме 256-битных AVX, используют 1-й векторный РФ для хранения всех операндов и устройства 1-го тракта для исполнения (опять же, без делителя-извлекателя — это ФУ, видимо, просто не уместилось). При работе с командами MMX, SSE и 128-битных версий AVX 2-й РФ не используется, а только хранит своё содержимое. И вот с SSE есть сложность.
Команда SSE, записывающая в некий регистр xmm, сохраняет содержимое старшей половины соответствующего ему регистра ymm, а вот аналог этой команды из набора AVX, работающий с этим же регистром xmm, согласно ISA обнулит старшую часть своего ymm. Ситуация бы упростилась, если бы все программы использовали только 128-битные векторы или только 256-битные. Но всё хуже: 2-й РФ не просто хранит старшие половины ymm — он лишь отслеживает положение соответствующих им младших половин в 1-м РФ, но свои половины синхронно не перемещает. Пример: команда SSE «ADDPD xmm1, xmm2» складывает пару вещественных DP-элементов регистра xmm2 с аналогичной парой из xmm1 и записывает на место последнего результат. После переименования регистров моп команды приобретёт неразрушающий формат операндов и будет выглядеть, например, так: «ADDPD xmm78, xmm34, xmm56» — т. е. до его исполнения архитектурному регистру xmm1 соответствовал физический xmm34, xmm2 — xmm56, а после отставки xmm1 будет назначен на xmm78. А теперь вопрос на засыпку — что будет со старшей половиной регистра ymm1?
Решение
Если бы команда была «VADDPD xmm1, xmm2» (префикс V- используется во всех командах AVX, включая работающие с xmm), то ответ ясен — старшую половину архитектурного xmm1 надо обнулить, что делается разместителем даже без доступа в РФ. А вот для SSE-версии её надо сохранить, что для 2-го РФ означает копирование физического регистра №34 в №78. И это только для одной команды, а всего их может быть до 5 за такт (3 вычислительные и 2 загрузочные). Intel могла бы оснастить старший РФ 5-полосным шлюзом с портов чтения на порты записи, а переименователь — возможностью слежения за половинами ymm отдельно. Но для упрощения и/или экономии инженеры вместо этого внедрили небольшой «теневой» АРФ, хранящий 16 старших половин регистров ymm, когда они не используются SSE-кодом. (Возможно, поэтому для РОНов физических регистров 160, а для xmm/ymm — 144, хотя планировщик общий…) Причём, АРФ должно быть даже два — по одному на поток.
Теперь, допустим, надо исполнить 256-битную операцию с регистром ymm1. Вероятно, планировщик должен подать векторным РФ номера обеих половинок (старшую — из АРФ), считав их содержимое в пару ФУ… Но оказывается, что напрямую из АРФ читать мопам нельзя. Поэтому не будет SB исполнять 256-битную команду AVX сразу после SSE. Вместо этого грянет аж 70-тактовый штраф, в течение которого сначала должны исполниться уже запущенные в резервацию команды (сериализация конвейера), а затем специальная микропрограмма восстановит все 16 старших половин ymm. Более того, и 128-битную AVX-команду тоже ждёт штраф — в АРФ нельзя даже обнулить регистр без выгрузки в основной РФ. Тот же штраф будет при при обратном переходе — когда после AVX-кода встретится любая команда SSE, и старшие половины потребуется сохранить обратно в АРФ. Но если штраф будет происходит часто, программисты хором пошлют AVX на всякие другие буквы, возопив «Как жить дальше?!»
Ответ Intel — «надо чаще обнуляться». В составе набора AVX есть команда VZEROUPPER, сбрасывающая старшие половины всех регистров ymm всего за 1 такт. После этого все связи между половинами можно считать исправленными, т. к. для любого регистра xmmN старшая часть ymmN содержит 0. Переходы между 128-битным и 256-битным векторными кодами не вызовут штраф, т. к. в старших частях точно нули. На физическом уровне АРФ не сбрасывается, а помечается как целиком нулевой, так что его уже не надо грузить в основной РФ. Но произвести сериализацию всё же придётся…
Вспоминая программиста-оптимизатора, во избежании штрафа он должен поставить VZEROUPPER перед вызовом оптимизированной AVX-процедуры и после него. Если процедура находится в библиотеке, вызывать которую может как программа с кодом SSE, так и с AVX, то VZEROUPPER должна быть и в прологе, и в эпилоге каждой функции. Тут может быть полезна ещё одна команда VZEROALL, обнуляющая все регистры ymm целиком. Тем не менее, можно предсказать, что программисты наверняка часто будут забывать вставить команды VZERO* в свой ассемблерный код. Выловить же эти ошибки трудно, т. к. программа всё ещё будет работать, хоть и медленнее, но мало ли на то причин…
Кстати: само существование 128-битных команд AVX в дополнение к таким же, но 256-битным — тоже своего рода костыль. Только на этот раз не для нахождения очередного компромисса внутри процессора между сложностью, скоростью и площадью. Дело в довольно большом объёме кода драйверов и даже компонентов ядер разных ОС, которые используют xmm и точно не будут скоро переписаны под AVX. А значит и общаться с ними надо на «128-битном языке». Но т. к. соблазны AVX-кодировки велики (представитель Intel даже как-то сказал, что неразрушающий формат и компактизация кода в сумме дадут не меньший эффект, чем удлинение векторов), компания решила дать программистам шанс ускорить и 128-битный код, чтобы не переключаться каждый раз со штрафами между SSE и полноразрядным AVX. Впрочем, за счёт своей многочисленности сообщество программистов ядра Linux вполне быстро бы перевело эту ОС на новый формат (будь он обязательным). Поэтому можно сделать вывод, что в сложностях устройства AVX виновата … Microsoft! :)
Сохранение состояния
После удвоения разрядности векторных регистров размер полного описания архитектурного состояния ЦП стал больше на 256 байт — теперь в нём все регистры общего и специального назначений, стек x87 и набор ymm занимают 832 байта. При прерывании и переключении контекста задачи всё это надо как можно скорее записать в специальную область памяти, а при возврате восстановить. А т. к. задержка (особенно для прерываний) должна быть минимальной, объём пересылаемых данных оказывается тому препятствием. В SB регистры общего и специального назначений записываются всегда (впрочем, они и меняются всегда), но есть специальный блок, отслеживающий 3 остальных РФ — стек x87 с регистрами mm для MMX, и старшую и младшую половины регистров ymm для SSE и AVX. Сохраняться и восстанавливаться будут только РФ, модифицированные за текущий сеанс работы с задачей. Например, программа, работавшая лишь с РОНами, сохранит в статусе всего около 100 байт. Однако это произойдёт не автоматически, а при использовании добавленной команды XSAVEOPT, поддержка которой обозначается отдельным битом в CPUID.
Динамические тайминги
При тестировании задержек и пропусков команд (о чём мы детально поговорим далее) мы обнаружили у AVX-кода некую странность, которой «не может быть никогда». Точнее, речь идёт о векторном вещественном сложении (вычитании) и умножении. В идеале, они, как и почти все остальные команды, должны иметь фиксированные тайминги — однако в наших тестах (если, конечно, всё было замерено точно) получилось совсем не так. Судя по всему, в случае долгого неисполнения вещественного кода блоки FADD и FMUL переходят в некое «полувекторное» состояние, когда 256-битные команды обрабатываются каждый 2-й такт, а задержки — на 2 такта больше нормы. Через несколько сот исполненных вещественных команд задержка уменьшается на 1 такт, а ещё через несколько сот, вместе с пропуском, наконец, становится номинальной. 128-битные операции также затронуты — задержка изначально на такт больше, но хоть пропуск не страдает.
Сразу скажем, что представитель Intel заверил нас, что это ошибка в наших тестах. Да и здравый смысл подсказывает, что ничего подобного в ЦП быть не должно. Т. к. требуется экономить энергию, отключая неиспользуемые подолгу блоки (что используется ещё со времён Pentium-M), инженеры наверняка оптимизировали время их включения до 1–2 тактов. А то, что планировщику оказывается куда трудней управлять потоком мопов в «полусонные» ФУ — и вовсе удаляет последние остатки здравого смысла. С другой стороны — никаких ошибок в нашей методике совместными усилиями мы так и не нашли. Тем более, что по такой же схеме были получены и остальные сотни цифр, которые по большей части подтверждены. Однако, если бы мы стали перепроверять все версии, статья бы вышла лет через пять. Тем не менее, проверка будет, пока же при дальнейших обсуждениях таймингов проигнорируем этот странный момент…
Новые и отсутствующие команды
В AVX 1-й версии входят 256-битные команды вещественной арифметики, логики и перестановок, но целочисленную арифметику и сдвиги почему-то оставили 128-битными — до выхода AVX2. Пока что для обработки регистра ymm с целочисленными значениями надо сначала сохранить его старшую половину в младшей половине другого регистра, затем обработать младшие половины обоих (старшие при этом обнулятся) и снова собрать в 32-байтовый вектор. Зачем так сделано, официального объяснения нет, а неофициальное примерно такое — вещественной арифметике большие векторы сегодня нужней, а целочисленной их добавят «потом», и пока выгодней обходиться командами AVX с регистрами xmm. Но ещё раз посмотрим на таблицу ФУ в SB — дополнив 2-й тракт сумматором и подключив его к порту 5, где уже есть блок логики и копирований, мы получили бы в нём полноценное 128-битное АЛУ, которое могло бы работать со своим «собратом по порту» из 1-го тракта. Зачем же добавлять 32-байтовые целочисленные векторы лишь через два года в AVX2, если почти всё уже готово?…
В ГП разных компаний и экспериментальном процессоре Intel Larrabee есть команды с векторными адресами — scatter и gather (разброс и сбор): запись и чтение вектора по индивидуальным адресам или смещениям его элементов, составляющим другой вектор. AVX же эти полезные во многих алгоритмах команды получит лишь во 2-й версии, т. к. для эффективного (т. е. параллельного, а не поэлементного) исполнения требуется серьёзное дооснащение кэша сложными коммутаторами в буфере строки (всей 64-байтовой строки, а не 16-байтового порта кэша). Пока это малосовместимо с требованиями поднять скорость без ущерба для площади и экономии, а потому откладывается до следующей микроархитектуры Haswell.
Но и у 1-го AVX есть, чем заполнить лакуну — команды чтения и записи с байтовой маской. Тут интересно, что замаскированные байты не только не считываются или записываются, но даже и не проверяются на возможность доступа. Например, невыровненное чтение, пересекающее границу страницы памяти, может вызвать кучу неприятностей (промах в кэше или TLB, запрет доступа и пр.), однако если все байты «на той стороне» оказываются с нулями в маске, никаких проблем не будет, т. к. фактический доступ и все проверки для них будут отменены. В отличие от команд разброса и сбора, дополнительных аппаратных блоков тут вводить не нужно, по крайней мере для Intel — уже в Nehalem кэши обладали почти всем нужным для такого функционала, просто теперь он программно управляем. Ещё одна новинка — команда «широковещания» (broadcast), копирующая элемент во все позиции вектора-приёмника (почему-то только из памяти в регистр).
Тайминги команд
Нашу традиционную таблицу с задержками/пропусками на этот раз оформим картинкой — уж больно сложной она получается. Полный список таймингов всех команд доступен на сайте Агнера Фога.
Итак, к имеющимся командным группам добавлена ещё одна — для вещественных 256-битных команд AVX. За вре́менным неимением конкурентов (до выхода AMD Bulldozer) помечать синим эти клетки не будем. :) Сравнение SB по остальным командам прежде всего показывает увеличение общего IPC в каждой группе до рекордных 4, т. к. учитывались обнуляющие директивы, работающие в каждом домене (кроме x87, где вместо них — обмены регистров).
Если посмотреть на отдельные команды, то главные изменения по сравнению с Core i — умножения. Скалярное целочисленное стало полноконвейерным даже при получении полноразрядного результата, однако тут есть нюанс: указанные 3 такта (справедливые и для умножения 64⋅64=128 бит) это задержка перед получением младшей половины результата, отправляемой в регистр EAX (RAX); старшая, для регистра EDX (RDX), будет готова тактом позже. Это происходит потому, что целочисленный умножитель уникален наличием второго командного порта — основной (принимающий моп для записи EAX/RAX) подключен к 1-му порту резервации, а второй — сразу к двум остальным (0-му и 5-му), откуда он получает моп для записи старшей половины. Выходит, что умножитель как бы находится сразу на всех вычислительных портах. При этом приём мопов возможен парами каждый такт, так что в итоге умножение оказывается полноконвейерным.
Совсем другая картина наблюдается со вторым умножителем (который, напомним, является общим для векторных целых и всех вещественных) — он стал работать за 5 тактов, даже для целых элементов. Это значит, что некоторые коды с нечастыми векторными целыми умножениями, от результатов которых зависят дальнейшие вычисления (что не позволит использовать конвейерность), могут чуть замедлиться, если программу не спасут другие улучшения в ядре. Куда интересней проанализировать, почему это вообще произошло.
Дело в том, что в погоне за упрощением (в т. ч. и по причинам экономии) производители ЦП часто делают таблицу таймингов в резервации общей для целой группы команд, даже если нужные ФУ могут обработать некоторые команды быстрее. Например, все основные вещественные команды в архитектурах AMD K7–10 исполняются за 4 такта: скалярные и векторные, одинарной и двойной (не для K7) точности, сложения-вычитания и умножения — во всех восьми комбинациях, хотя в каждой паре второй вариант явно сложнее. Но планировщику проще считать, что все такие команды исполняются за одинаковое время.
Intel такой подход до сих пор использовала только в Pentium II/III/M для команд SSE, что также видно по таблице: для 64-битных ФУ векторные команды должны быть не только полуконвейерными (т. е. с пропуском 2), но и с на единицу большей задержкой, чего как раз нет. Планировщик в Core 2/i стал более разборчивым и даёт отдельные задержки для сложений и умножений, причём для последних — в зависимости от точности. SB же вернул «округлённые вверх» упрощения для всех умножений.
Вообще-то такая стандартизация задержек началась ещё в Nehalem. Его резервация устроена так, что порт 0 выпускает мопы с задержками либо 1 такт, либо 4 и больше, порт 1 — 1 или 3 такта, а порт 5 — только 1. Правда, есть 2-тактовые мопы, запускаемые через все 3 порта, но один такт из пары тратится на межтрактный шлюз. Порты 2, 3 и 4 монопольно используются операциями с памятью и адресами аж с Pentium Pro. В SB изменился лишь порт 0, который теперь выпускает мопы с задержками либо 1 такт, либо 5 и больше (мопов на 4 такта, кажется, уже нет).
Стандартизация задержек повлияла и на команду LEA. В таблице ФУ для SB блок AGU указан как сложный. Это потому, что в сложные зачислены команды LEA, у которых адрес или RIP-относительный, или 3-компонентный (плюс ещё два редких случая), остальные (простые) считаются в АЛУ других двух портов за такт. «Сложное AGU» считает свои адреса аж за 3 такта, хотя AGU в Nehalem справлялось со всеми видами операндов за такт. Возможная причина кроется в том, что никакого AGU в тракте нет, а сложные операции делаются в АЛУ порта 1, но с дополнительным функционалом. Этого бы хватило, чтобы вычислить адрес за 2 такта, но «ленивый» планировщик не поймёт такой моп, так что его задержка «для совместимости» с портом 1 искусственно увеличена до 3 тактов.
Впрочем, нашлись исключения и из стандартов. Оказывается, не все векторные умножения исполняются в порту 0 — несколько целочисленных перенесены в порт 1, но при этом они сохранили задержку в 5 тактов. Причём сами эти команды мало чем отличаются от других векторных целочисленных умножений, так что неясна причина выделения им отдельного специализированного умножителя, который затем расположили в соседнем порту… Ещё страннее ситуация с командами сравнения векторов с целыми элементами: для каждой из 4 разрядностей элемента (от 1 до 8 байт) есть сравнения на «равно» и на «больше». Так вот из этих 8 команд 7 исполняются за 1 такт в любом из двух векторных целочисленных АЛУ (как и ожидалось, ведь сравнение по сути есть вычитание). Но вот отдельно взятая PCMPGTQ (сравнение 8-байтовых элементов на «больше») исполняется только в порту 0 и за 5 (конвейерных) тактов, хотя сложность операции точно такая же. Есть исключения и среди команд преобразования форматов, задержки многих из которых стали на 2 такта больше… В общем, если именно таким образом обновлённый планировщик экономит энергию, на всякий случай напомним: иная простота — хуже. ;)
Из других изменений следует выделить улучшенные тайминги некоторых видов команд скалярного сдвига и вращения. Утверждается, что это сделано специально для ускорения криптоалгоритмов, которым спецкоманды AES-NI не подходят, т. к. они заточены конкретно под шифр AES. Всё бы хорошо, если бы другие виды тех же самых команд, не используемые в криптокоде, в результате не замедлились. Например, двойные сдвиги в Nehalem исполнялись за 4 конвейерных такта. Теперь те из них, что имеют фактор сдвига в виде константы, готовы уже через 1 такт, причём сразу в двух ФУ, зато те, у кого этот операнд — регистр, стали полуконвейерными. Такие же тайминги оказались и у обычных сдвигов (хотя они проще), видимо снова ради стандартизации. Таким образом, почти на каждое улучшение в пропуске или задержке «популярной» команды найдётся ухудшение в исполнении команд менее популярных.
Кэши
В скобках указаны значения для Nehalem (если есть отличие).
| Кэш | L0m (новый) | L1I | L1D | L2 | L3 |
| Размер | 1536 мопов | 32 КБ | 256 КБ | 1–20 (2–30) МБ | |
| Ассоциативность | 8 | 8 (4) | 8 | 8 | 8, 12, 16, 20 (12, 16, 24) |
| Размер строки | 6 мопов | 64 байта | |||
| Задержка, тактов | 3? | 4 | 4–7 (4) | 11–12 (10) | ≈26–31 (≈35–40) |
| Число портов | 2 | 1 | 3 (2) | 1 | 1 на банк, 2–8 банков (2 на кэш, 1–10 банков) |
| Разрядность портов | 4 мопа | 16 байт | 64 байта | 64? (32) байта | |
| Частота (f — частота ядра) | f | f/2 | Максимум всех f (2,13–2,66 ГГц) | ||
| Политика работы | Включающая | Включающая | |||
| Свободная | |||||
| Только чтение | Отложенная запись | ||||
| Общий для … | Потоков ядра | Всех ядер, включая ГП | |||
L1D
Сразу скажем, что кэши L1I и L2 почти не изменились — у первого ассоциативность снова (как и до Nehalem) стала 8, а у второго чуть увеличилась задержка. Самое главное изменение в ядрах, касаемое кэшей, кроется в доступе к L1D, который теперь стал 3-портовым: к раздельным портам чтения и записи добавили ещё один для чтения. Кроме того, как уже было указано, в планировщике Nehalem 2-й порт вычисляет адрес чтения и исполняет само чтение, 3-й вычисляет адрес записи (только), а 4-й — исполняет саму запись. В SB же порты 2 и 3 могут и вычислить любой адрес, и исполнить чтение.
Внимательный Читатель сразу найдёт подвох: портов L1D — 3, а адресных генераторов — 2. При не более чем 16-байтовых обменах их устоявшийся максимальный темп составит 32 байта/такт (либо два чтения, либо чтение и запись). 32-байтовые операции каждым портом обслуживаются за два такта, причём вычисление адреса для конкретной команды происходит в течение первого из них. Так что для двух чтений и одной записи требуется три адреса в течение двух тактов — тогда при потоковых обменах один из трёх нужных адресов можно вычислить заранее в течение второго такта предыдущей 32-байтовой операции. Только так мы получим искомый максимум в 48 байт/такт.
Возникает довольно странный компромисс: три 16-байтовые операции за такт в потоке сделать нельзя. С другой стороны, за такт можно вычислить адреса для двух 32-байтовых обменов, но даже одно 32-байтовое чтение за такт не запустишь, потому что порты чтения не объединяются. Т. е. либо нам не будет хватать числа AGU (тех, что в портах 2 и 3), либо ширины портов, либо возможности их объединения.
Как мы знаем из теории, многопортовость в кэшах чаще всего делается не явная, а мнимая, с помощью многобанковости. Однако Nehalem нарушил это правило, внедрив 8-транзисторные битовые ячейки для всех кэшей ядра. Помимо большей экономии (об этом подробно рассказывалось в статье о микроархитектуре Intel Atom, который тоже применяет такую схему), это также даёт возможность получить истинную 2-портовость (чтение + запись), что и было использовано в L1D — никаких конфликтов по адресам в имеющихся 8 банках не было. В SB банков по-прежнему 8, а портов уже 3. Очевидно, конфликты неизбежны, но только среди адресов портов чтения.
Каждый банк L1D имеет ширину в 8 байт, вместе составляя строку, поэтому каждый из 16-байтовых портов использует 1–2 банка при выровненном доступе и 2–3 при невыровненном. Например, 8-байтовое чтение, пересекающее 8-байтовую границу, использует 2 банка, как и выровненное 16-байтовое. В SB конфликт происходит, если хоть один из банков, нужных одному чтению, также нужен и второму, причём для доступа к другой строке. Последнее означает, что если оба чтения требуют не только одинаковый(ые) банк(и), но и одинаковые номера строк в нём (них), то конфликта не будет, т. к. фактический доступ произойдёт один, и он обслужит оба обращения. В Nehalem, с его единственным чтением за такт, такого, очевидно, быть не могло.
Упомянув о невыровненном доступе, скажем и о более «грешных» делах — пересечении строки кэша, что обойдётся 5-тактным штрафом, и границы страницы виртуальной памяти (чаще всего — 4 КБ), что наказывается в среднем 24 тактами (ситуация требует сериализации конвейера). Причём последняя цифра малообъяснима, т. к. TLB, как мы увидим ниже, способны на одновременную обработку обеих смежных страниц — но даже при последовательном доступе двухзначной цифры получиться не может…
LSU
Изменений в LSU (контроллере L1D, который Intel упорно называет MOB) не меньше, чем в само́м кэше. Начнём с того, что очередь чтения удлинилась с 48 до 64 ячеек, а записи — с 32 до 36. Каждая ячейка привязана к одному мопу, а очередь записи хранит ещё и 32 байта данных (было 16). Очередь чтения хранит все команды считываний, но в каждый момент не более 32 могут обрабатываться на разных стадиях. Фактически, это отдельные диспетчер и планировщик, «ROB» которых хранит 64 мопа, а «резервация» — 32. Когда чтение завершено, моп удаляется из этой резервации, но остаётся в очереди чтения до отставки. Очередь записи хранит информацию до отставки предыдущих команд, когда ясно, что адрес, данные и сам факт исполнения команды верны, а значит её можно попытаться записать в кэш. Если попытка успешна — моп записи уходит в отставку, освобождая место и в очереди, и в ROB. При промахе или других проблемах запись задержится.
Как и все современные кэши, L1D является неблокирующим — после промаха он может принимать дальнейшие запросы одновременно с заполнением себя подгруженными данными. Кэш может выдержать даже 3 промаха/такт. Одновременно удерживается столько промахов, сколько имеется буферов заполнения. В SB, как и в его предшественнике, у L1D таковых 10, а у L2 — 16. Политика отложенной записи в L1D и L2 означает, что модифицированная строка остаётся в кэше до вытеснения, однако информация о факте её модификации (если до этого данные были «свежие») отправляется в теги соответствующей строки в L3.
Внеочерёдный доступ
Внеочерёдный движок получил любопытное дополнение: предсказание адресов, на основе которого порядок обращений в кэш может быть переставлен, делается не отдельными адресами, а целыми диапазонами — предсказывается верхнее и нижнее значения адреса, в пределах которых, как предполагается, произойдёт запись. Если точно известный адрес чтения не попадает ни в один диапазон ещё не исполненных записей — чтение можно запустить заранее. Такой вариант срабатывает чаще имевшегося ранее, который разрешал внеочерёдную загрузку, только если есть высокая вероятность несовпадения с конкретным адресом записи. Сама вероятность рассчитывается, как в предсказателе переходов — в LSU, видимо, есть некий аналог таблицы BHT со счётчиком вероятности в каждой ячейке. Когда адрес записи становится известен, счётчик увеличивается при несовпадении адресов и уменьшается при конфликте.
Однако предсказатель оперирует только выровненными на 16 байт чтениями размером до 16 байт, а также выровненными 32-байтовыми — остальные будут ждать вычисления адресов всех предыдущих записей. Ещё одна проблема нового движка в том, что он предсказывает лишь младшие 12 бит адресов: если у записи и чтения они равны (даже если они не предсказаны, а точно известны), то чтение считается зависимым от записи. Т. е. фактически предсказывается лишь 8 бит адреса — с 5-го по 12-й. Возможно, ложная зависимость обусловлена тем, что в ячейках таблицы счётчиков нет поля, хранящего старшую часть адреса.
STLF
…серьёзно улучшен. Описывать громоздкие старые правила для Nehalem мы не будем, укажем сразу новые:
- байты для чтения должны полностью содержаться в записи, вне зависимости от выровненности адресов и размеров операций; это эквивалентно следующему: W-байтовая запись по адресу A перенаправляется в R-байтовое чтение по адресу B, если A≤B и A+W≥B+R; далее указаны исключения:
- если запись 16- или 32-байтовая — 4- и 8-байтовые чтения обрабатываются в пределах её 8-байтовых порций;
- если запись 32-байтовая — все чтения, кроме 32-байтовых, обрабатываются в пределах её 16-байтовых половин;
Ясно, что STLF не может работать одновременно с внеочерёдной загрузкой: адреса записей должны быть известны точно, а не только 8 битами.
Задержки чтения
Видя такое благолепие, яростные фанаты Противоположного Лагеря немедленно требуют какого-нибудь негатива. К сожалению, и он нашёлся: во-первых, обещанные 11 тактов задержки при чтении L2 в наших тестах никак не получались меньше 12; аналогично с L3. Во-вторых (и это гораздо хуже), идеальные 4 такта задержки при чтении L1D доступны не всегда, потому что теперь надо смотреть не только в какой исполнительный домен загрузить данные, но и как вычисляется адрес. Напомним, что в x86 адрес обращения в память состоит из трёх компонент: регистр базы, регистр индекса (возможно, умноженный на масштаб 2, 4 или 8) и адресное смещение (явно указанное в команде). Сочетаться (сложением) они могут в любой комбинации. Как мы помним, в SB можно вычислить аж 3 команды LEA за такт (сложную и две простых), что втрое больше, чем ранее. :) А вот те адреса, что вычисляются в «правильных» AGU (в портах 2 и 3), дают уже втрое больше проблем, которых хватит аж на целую таблицу задержек чтения/записи (тут учтены и все межтрактные задержки на передачу данных):
| ↓ Свойства адреса Тип приёмника → | РОН | (x)mm | x87 | ymm |
| Смещение≥2048 ИЛИ есть индекс | 5 | 6 | 7 | 7 |
| Смещение<2048 И нет индекса | 4 | 5 | 6 | 7 |
Учитывая такое безобразие, удивительно, как SB не только не провалил ни один из наших тестов, но даже нигде не оказался медленнее, чем Nehalem с его почти честным 4-тактным L1D. Можно аккуратно предположить, что AGU в портах 2 и 3 настолько просты, что могут за такт сделать лишь одно сложение, да и то с неполной разрядностью одного из слагаемых — иначе оно затянется на второй такт, как и 3-компонентное. Если бы речь шла о 10-гигагерцовом ЦП с конвейером на сотню стадий, это ещё было бы простительно, но тут… Впрочем, есть другой вариант.
Сначала поясним, почему, вопреки тенденции, для ymm-пересылки цифры не указаны как 8 и 7. В одном из патентов Intel указан такой способ переноса «больших» данных из кэша в тракты: учитывая, что межтрактовая задержка в шлюзах равна 1 такту (для смежных трактов), надо в начале считать старшие 16 байт, которые уйдут на самый дальний тракт (2-й векторный), а через такт — младшие, которым надо на один тракт (и такт) ближе — тогда обе половины окажутся на местах синхронно. Вычисление адреса делается «впритык» к самому чтению (если ему ничего не мешает, например занятость портов или незавершённость записи по «подозрительному» адресу). Для этого AGU автоматически прибавляет к смещению 16, а возможно — вычисляет адреса обеих половин одновременно, что может объяснить медлительность при «сложной» адресации. В простом случае 32-байтовое чтение больше ничем не будет отличаться от 16-байтового, но если слово пересекает границу строки кэша, то теги читаются для двух строк, а если и границу страницы памяти — то и в TLB делается второе обращение. Тот же подход используется и при ymm-записях.
TLB
В скобках указаны значения для Nehalem (если есть отличие).
| Параметр | TLB L1I | TLB L1D | TLB L2 | |||
| Размер страницы | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ | 1 ГБ | 4 КБ |
| Размер | 128 | 8+8 (7+7) | 64 | 32 | 4 (0) | 512 |
| Ассоциативность | 4 | 8 (7) | 4 | 4 | 4 (–) | 4 |
| Задержка, тактов | 1, учтена в задержке к кэшу | 7 | ||||
| Число портов | 1 | 2 | 1 | |||
| Политика работы | Скорее всего, включающая (для 4 КБ) | |||||
| Общий для потоков? | Да | Нет | Да | |||
Изменения в подсистеме TLB небольшие: DTLB (так Intel называет TLB L1D) обзавёлся «честной» секцией для «сверхбольших» страниц по 1 ГБ. Впервые их поддержка появилась в AMD K10, а у Intel — в Westmere, однако в последнем они разбивались на множество «просто больших» страниц по 2 МБ и хранились в соответствующей секции TLB. ITLB (TLB L1I) получил две дополнительные ячейки для больших страниц, а STLB («shared TLB», т. е. разделяемый TLB L2) не изменился. Кстати, последний в Nehalem назывался UTLB (unified, единый), а вот для SB кэш L3 на большинстве слайдов переименовали в LLC (last level cache — кэш последнего уровня)… Кажется, кто-то в Intel обожает плодить сущности без необходимости. И кого ж они запутать хотят? :)
Суть странной записи «8+8» вместо «16» раскроется в главе о Hyper-Threading, а вот вопросы «Являются ли все или некоторые TLB неблокирующими?» и «Сколько промахов они могут удержать?» пока и вовсе останутся лишь с догадками «нет» и «нисколько». Зато известно, что при промахе в TLB L2 происходит обращение в адресный транслятор (PMH), на что уходит около 10 тактов. Это подозрительно мало, т. к. трансляция 64-битного виртуального адреса в физический (транслируются, правда, только биты с 13-го по 48-й) требует до 4 чтений из памяти или кэша. Столь быстрая реакция возможна, только если у PMH есть свой кэш. Его параметры и детали работы определить крайне трудно (уж очень тщательно скрыты задержки), но по известным примерам в предыдущих ЦП Intel предположим, что 32 ячейки наверняка найдутся. Точно известно только, что PMH может читать дескрипторы страниц откуда угодно — от L1D до памяти.
 Жёлтая структура слева — L1D, внизу-слева — TLB L2, остальное пространство — LSU. В центре видны два почти одинаковых вертикально вытянутых блока — видимо, это TLB L1D. |
Таблица выше является настоящим испытанием для Внимательного Читателя. Но подвох обнаруживается быстро — кэш L1D стал 3-портовым (надо полагать, вместе с тегами), а вот его TLB — почему-то нет, хотя было бы естественно. Ошибка? Нет, на фотографии ядра видно, что TLB (очевидно, 1-портовых) осталось 2, как у Nehalem. Видимо, причина в том, что на 2 AGU больше двух обменов/такт не получится, а при использовании команд AVX для достижения пика при потоковых операциях в среднем потребуется и вовсе 1,5 адреса/такт. Видимо, Intel посчитала, что ради экономии места третьи TLB и AGU пока лишние.
В Nehalem к битам TLB было добавлено поле VPID (идентификатор виртуального процесса), сравнение содержимого которого с текущим VPID позволяло определить, относится ли адрес в TLB в адресному пространству этой виртуальной машины или остался после переключения с соседней. Архитектура Westmere преобразовала это поле в более общий формат PCID (идентификатор контекста процесса), что позволило сохранять содержимое TLB не только при переключении виртуальных машин, но и при смене адресации в пределах одной ОС. Что к этому добавлено в SB (и добавлено ли…) — не известно.
Кстати, о виртуализации (раз уж мы пока нигде её не упомянули) — Westmere отличался от Nehalem в т. ч. наличием небольшого кэша на 3 так называемых VMCS (virtual machine control structure, структура управления виртуальной машиной), содержащих архитектурное состояние виртуальной ОС. Кэшировать их полезно для ускорения переключения между ОС. Надо полагать, в SB этот кэш как минимум сохранился, а то и увеличился.
Аппаратная предзагрузка
Для L1D предзагрузчик поддерживает до 4 явно заданных спецкомандами загрузок, но это не так интересно, как автозагрузки. Блок следит за числом ожидающих промахов в L1D, и когда оно мало, а ядро не исполняет потоковую операцию (типа загрузки или сохранения контекста или операций со «строками») — происходит загрузка по одному из предсказанных адресов. Обращения в TLB не нужны, т. к. физический адрес недавно сделанного чтения на некоторое время остаётся и в предзагрузчике, а предсказания никогда не пересекают границу в 4 КБ.
Используются два алгоритма. Первый (простой или потоковый) основан на возрастающих адресах читаемых всеми командами данных — убывающие адреса не обрабатываются, т. к. для этого алгоритма они редки. Второй (сложный или шаговый) имеет буфер предположительно на 256 ячеек — в каждой хранится собственный адрес недавней команды чтения (по его младшему байту ячейка индексируется, когда в очередь чтения LSU поступает новый моп), прошлый адрес её загрузки и шаг последовательности (полагая, что он регулярный и не превосходит ±2048). При каждом исполнении этого чтения предзагрузчик проверяет регулярность шага, и, при положительном исходе, загружает в кэш следующую порцию. Предзагрузка в L1I, как уже описывалось, основана на предсказаниях переходов.
Для L2 и L3 алгоритма также два, но они общие. Простой («пространственный») дополняет загруженную строку соседней, составляя выровненную 128-байтовую пару (предполагается пространственная локальность требуемых данных, откуда и имя). Сложный же (потоковый) следит за чтениями в кэши L1 (в т. ч. от их предзагрузчиков) из L2, ожидая последовательность адресов строк с одинаковым шагом. Этот предзагрузчик также не смеет пересечь страницу памяти. Оба алгоритма как минимум пишут в L3, а если локальный L2 свободен от обслуживания массы промахов в L1 — то и в него.
Интересно, что сложный алгоритм для L2 (а, возможно, и для L1D) имеет 2-битный насыщаемый счётчик, следящий за востребованностью данных: предположительно, если хотя бы 2 раза подряд предзагруженные данные были полезны, то даже если далее каждое третье обращение будет по «чужому» адресу, алгоритм не собьётся с найденного шага потока.
А теперь сюрприз — всё вышеописанное относится и к Nehalem. В SB же изменился только сложный алгоритм для L2, зато основательно:
- Теперь он может запустить уже две предзагрузки на каждое чтение этого потока, уходя вперёд максимум на 20 шагов;
- Вышеописанная функция работает только при достаточном простое L2: при его средней загрузке в него наперёд читается по одной строке, а при сильной — и вовсе ноль (точнее одна, но только в L3);
- Если шаг большой, то загрузка в L2 также отменяется (близкая локальность обеспечивается простым алгоритмом);
- Слежение производится за 32 потоками запросов: для каждой из 16 отслеживаемых страниц по 4 КБ допусти́м 1 восходящий и 1 нисходящий поток. Ранее было 12 восходящих потоков и 4 нисходящих, по одному на страницу.
Судя по всему (и к сожалению), у предзагрузчиков и SB, и его предшественников нет собственного буфера. Поэтому на оптимизированном коде, который учитывает размеры кэшей для деления обрабатываемых данных части, предзагрузчик может загрязнить кэш своими записями и сильно повысить частоту промахов при явных запросах. Intel не даёт никаких рекомендаций по устранению этой проблемы.
Hyper-Threading
Какие изменения в реализации этой технологии — также не было раскрыто, поэтому будем отталкиваться от того, что́ на этот счёт известно из описания Nehalem. Нас интересует, как разделяются между потоками блоки и стадии конвейера:
- Дублируются: TLB L1I для стр. по 2 МБ, IQ, RSB, IDQ, архитектурное состояние ядра, АРФ для старших половин ymm;
- Делятся пополам: TLB L1I для стр. по 4 КБ, L0m, ROB, обе очереди в LSU, буфер простого предзагрузчика в L1 (?);
- Делятся динамически: BTB, резервация, все ФУ, вся подсистема памяти (кроме её блоков, указанных выше);
- Чередуются по тактам (кроме случаев срыва одного из потоков): все стадии фронта, переименование, размещение мопов в планировщике и отставка.
Поясним, что такое «делятся динамически»: это значит, что блок не знает о существовании двух потоков и никак бы не изменился, если бы в ЦП не было многопоточности. Это особенно наглядно в случае диспетчера: ROB делится между потоками, т. к. надо соблюдать очерёдность размещений и отставок соответственно адресам каждого потока. Но когда мопы попадают в резервацию, адресов в них уже нет, а есть номера ячеек в ROB и ФРФ. Учитывая, что некий регистр-приёмник N при переименовании получит в одном потоке физический регистр X, а в другом — Y (что равносильно двум записям в N в одном потоке), то резервации всё равно, чьи мопы одновременно запускать, а для ФУ всё равно, чьи исполнять.
Наличие дублируемых и статически делящихся пополам ресурсов и чередование потоков по всей поочерёдной части конвейера говорит о том, что лучше всего Nehalem и SB чувствуют себя при исполнении пары почти одинаковых по объёму кода потоков. Причём если это 2 одинаковых потока, то обеспечить загрузку разных ФУ и прочих динамически разделяемых блоков будет трудно — общий алгоритм будет спотыкаться примерно в тех же местах, даже работая с разными данными. А подобрать две разные программы с примерно одинаковом темпом использования кода может оказаться ещё труднее — тем более, что это всецело зависит от ядра ОС, которая почти ничего не знает о внутренних событиях ЦП и загрузке его блоков.
Возможно, Intel не использовала динамическое разделение в TLB L1I (как в остальных TLB, особенно, учитывая, что сам кэш L1I разделяется так же), потому что его нет и у кэша мопов, а эти две структуры при вытеснении срабатывают одновременно. Впрочем, глядя на список пункта «Делятся пополам» (а в этих блоках, напомним, 3 цифры размеров из 4 в SB увеличились), можно сделать вывод, что ускорение от включения HT если не увеличится, то хотя бы с меньшей вероятностью станет отрицательным, что изредка бывало у Nehalem. Проверить это можно будущими тестами.
Внеядро
Кэш L3
Физически, кэш L3 по-прежнему разделён на банки по числу x86-ядер. В Nehalem была возможность сделать одну запись и одно чтение в/из L3 за такт, если они попадали в разные банки, т. к. использовался общий коммутатор и контроллер на весь кэш. Теперь организация банков другая: можно сделать запись или чтение, но в каждом банке по отдельности. А т. к. число включенных банков почти всегда равно числу ядер (исключения до сих пор встречались только у 6–10-ядерных серверных Xeon, где в некоторых моделях банков на 1 больше или меньше числа ядер), то это линейно увеличивает пиковую пропускную способность L3 с ростом числа ядер. Учитывая, что она разделяется между всеми ядрами и ГП, это очень полезно, т. к. пропуск, приходящийся на каждое ядро, до сих пор был главной проблемой любого разделяемого кэша.
Другое важное изменение в L3 — он стал работать на полной частоте ядра. Точнее, x86-ядер. Точнее, работающего(их) из них в данный момент, т. к. часть ядер могут спать. Помимо увеличения пропускной способности это ещё и уменьшает задержки, которые, разумеется, меряются тактами ядер на их частоте. И вот (см. таблицу с параметрами кэша) в SB они уменьшились на 30%. Это при том, что сама частота кэша вовсе не подросла на 30%. Причина в том, что когда поток данных пересекает силовые (по величине логических «0» и «1» в вольтах) и, особенно, частотные домены, происходит задержка в несколько тактов для преобразования уровней и совпадения фронтов тактовых сигналов. В SB такой проблемы нет, т. к. L3 работает на том же напряжении, что и работающие x86-ядра (не отключенные силовыми ключами), а частота у всех активно загруженных ядер всегда одинакова (включая применение технологии Turbo Boost) — и именно на неё и настроится частота L3.
Правда, всё может оказаться интересней. Внимательный Читатель успел заметить, что кэш L2 работает на половинной частоте, а потому, имея 64-байтовый порт, теряет половину ПС. Такое решение, видимо, связано с разумной достаточностью и 32 байт/такт, а потому можно применить более экономные транзисторы, которые, к тому же, будут работать при меньшей частоте. Про L3 такое достоверно не известно, но резонно предположить, что там ситуация та же: на высокой частоте работают только контроллеры портов кольцевой шины, обрабатывая по 32 байта/такт в каждом порту (детальней об этом ниже), а вот сам кэш работает целыми 64-байтовыми строками раз в 2 такта.
Как и в Nehalem, каждый банк L3 разделён на блоки по 512 КБ и 4 пути. В большинстве ЦП серий Core i в каждом банке таких блоков 3 или 4. Серверные ЦП Xeon с архитектурой Beckton и Westmere-EX имеют 6, 8 или 10 ядер и банков L3, но последние увеличены как по размеру (до 3 МБ), так и по ассоциативности (до 24), что в самых дорогих ЦП даёт аж 30 МБ. Для SB же пока обещаны «лишь» 8-ядерные Xeon с 20-путным L3 на 20 МБ.
Для любителей кунсткамеры добавим, что единственный представитель архитектуры Nehalem с одним работающим ядром (и одним банком L3 на 2 МБ) — это, как ни странно, не какой-то тихой сапой выпущенный сверхбюджетный Celeron, а Xeon LC3518, физически представляющий собой обычный 4-ядерный Nehalem с тремя (!) отключенными ядрами и их банками. Авторы SB также приготовили такие диковинки — это модели Celeron B и Pentium B, где на 2 ядра и ГП приходится не 4, не 3, а 2 МБ кэша с уполовиненной до 8 путей ассоциативностью.
Как и предшественник, ядра SB активней используют КМОП-логику по сравнению с динамической, что отразилось на частоте возникновения ошибок при работе. Это потребовало внедрить более мощные алгоритмы и коды обнаружения и коррекции ошибок (ECC) в кэшах ядер, способные в каждом байте обнаружить и исправить 2-битные ошибки и обнаружить (но не исправить) 3-битные. До сих пор ЦП умели обнаруживать до двух неверных бит и исправлять один, требуя в среднем 1 бит ECC на каждый защищаемый байт. Новый код, видимо, требует не менее 1,5 бит/байт — чуть позже мы сможем это проверить.
Кольцевая шина
  Вверху — слайд 2009 г. о кольцевой шине Nehalem-EX. Внизу — свежий о ней же в Sandy Bridge-EX. |
Не только наш Внимательный Читатель догадался, как надо связать L3 и ядра, чтобы ПС кэша росла пропорционально числу банков (а значит — и ядер). Однако эта кольцевая шина, вопреки утверждению Intel, в SB появилась не впервые. Если не считать различных специализированных процессоров (в частности, некоторых ГП), среди ЦП вообще она появилась в 9-ядерных Sony/IBM Cell BE (2007 г.). У ЦП Intel кольцевая шина была внедрена в 8-ядерных серверных Xeon серий Nehalem-EX (2010 г.), откуда с небольшими изменениями она попала SB. Её имеют и только что вышедшие серверные Westmere-EX (Xeon E7).
В каждом направлении протянуто 4 шины: запросов, подтверждений, снупов (для поддержки когерентности) и собственно данных (шириной 32 байта) — разумеется, всё защищено битами ECC. Протокол обмена является чуть переделанной и дополненной версией шины QPI, которую мы привыкли видеть как межпроцессорную шину типа «точка-точка», аналогичную HyperTransport в ЦП AMD. Внутри процессора связываемые «точки» являются агентами, каждый из которых имеет две пары шинных портов (приёмный и передающий в каждую сторону) и пару клиентских. К шинным подключены звенья шины, связывающие соседние агенты. К клиентским обычно подключены локальное x86-ядро и локальный банк L3. Однако в 2/4-ядерных SB один из крайних агентов подключен только к ГП, а второй — только к «системному агенту»; шинные порты также используются наполовину, т. к. в этих местах шина разворачивается на 180°, соединяя противонаправленные звенья. В 8-ядерном серверном SB будет 8 обычных агентов и 4 концевых, каждый из которых разворачивает направление обеих шин на 90°, задействуя все шинные порты, и обслуживает по одному клиенту-контроллеру: по 2 для памяти и для внешних шин (QPI и PCIe).
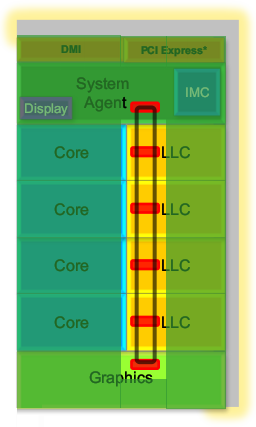 Агенты кольцевой шины показаны красным. |
При поступлении запроса локальный агент хэширует адрес для равномерного распределения данных по банкам, определяет направление передачи запроса (если только его не требуется обслужить тут же — во втором клиентском порту) и ожидает освобождения шины (текущий трафик имеет приоритет над новым). Каждый такт каждый агент мониторит приёмные порты обоих направлений и сравнивает в принятом сообщении целевой адрес с собственным: если он совпадёт, то сообщение передаётся в один из клиентских портов. Иначе оно передаётся на выходной порт, чтобы через такт попасть в соседний агент. Если в течение такта выходной порт оказался свободным, агент либо вставляет своё сообщение (если есть ожидающие для этого направления), либо посылает следующему агенту сигнал о свободной шине.
Таким образом, пиковая ПС шины равна полупроизведению числа используемых шинных портов всех агентов, 32 байт и частоты. «Полу-» — потому что требуется 2 порта для каждого звена. Учитывая, что кольцо, как и L3, работает на максимуме частот ядер, абсолютный максимум его ПС получается очень большим: для 4-ядерного ЦП на 3 ГГц — 960 млрд. байт/с (по «славной» традиции производителей винчестеров назовём это 960 ГБ/с :). Для сравнения — в Cell BE ко́льца также передают по 32 байта в каждую сторону, но на одну передачу требуется 2 такта, поэтому этот 9-ядерный ЦП наберёт на 3 ГГц примерно те же 960 ГБ/с.
Физически звенья шины проложены дорожками на самом высоком уровне, доступном для передачи сигналов — 7-м и 8-м слоях металлизации. Вышележащие слои используются только для питания и контактных площадок. Причём дорожки проходят поверх банков L3 и отдельного места не занимают. Такое устройство позволяет масштабировать шину простым копированием агентов и звеньев, что гораздо проще добавления дополнительных портов к центральному коммутатору. Впрочем, у последнего есть и преимущество — задержка прямой коммутации куда меньше, чем транзитной. Однако из-за более высокой частоты кэш L3 в SB оказался всё же с меньшей задержкой, чем в Nehalem.
Поддержка аппаратной отладки
Говоря о кольцевой шине, стоит упомянуть новую отладочную функцию — Generic Debug eXternal Connection (GDXC). Она позволяет мониторить трафик и синхрокоманды шины, перенаправляя их во внешний логический анализатор, подключаемый к спецпорту процессора. Ранее такие тонкие инструменты были доступны разве что производителям системных плат (разумеется, при полной секретности), да самим разработчикам. Но GDXC доступна и системным программистам, что, по идее, должно способствовать вылавливанию ошибок и оптимизации видеодрайверов. Что касается «обычных программистов», им наверняка пригодится увеличение (с 6 до 8) числа счётчиков производительности и событий в каждом ядре.
Когерентность и «поддержка» OpenCL
Nehalem был первым ЦП Intel со времён Pentium 4, в котором кэш последнего (т. е. 3-го) уровня стал включающим относительно остальных. Это означает, что в многопроцессорной системе процессорам будет проще отслеживать копии данных, раскиданных по разным кэшам, что требуется для поддержки их когерентности. Для этого теги каждой строки в L3 среди прочего хранят набор битов, обозначающих я́дра этого ЦП, в кэши которых эта строка была скопирована, а также номера других ЦП, в кэшах которых также есть её копия. Для Westmere-EX число таких битов наверняка не меньше 17 (10 ядер + 7 «остальных» ЦП). Кроме того, тогда же стандартный протокол когерентности MESI обновился до MESIF, включив в себя 5-е состояние Forward, разрешающее ответ на снуп-запрос от другого ЦП (в MESI ответить мог каждый ЦП, что увеличивало снуп-трафик). Соображением минимизации снуп-трафика руководствовалась и AMD, добавив для своих Opteron 5-е состояние Owned и получив протокол MOESI.
Когда при доступе в L3 из какого-либо ядра оказывается, что искомая строка закэширована другим ядром (для простоты предположим, что одним) и может быть им модифицирована, происходит обращение к его кэшам L1D и L2 для проверки её актуального состояния. Проверка называется «чистой», если данные оказались нетронутыми, и «грязной», если они модифицированы и требуют копирования в запрашивающее ядро и L3. В SB первый случай вызывает задержку в 43 такта, а второй — в 60. Эти указанные в документации цифры почему-то являются константами, хотя должны зависеть от топологического расстояния между ядрами на кольцевой шине. Да и разница в 17 тактов куда больше, чем положенные 2 для передачи 64 байт…
Новинкой в SB по части включающей политики L3 является то, что биты присутствия копий данных в кэшах ядер учитывают и ГП. Т. е. с точки зрения программы ГП можно использовать как векторный сопроцессор, работающий с общими данными в общем адресном пространстве. По идее, поддержка OpenCL 1.1 в ГП этому должна способствовать, что успел заявить Thomas Piazza, глава отдела графических архитектур Intel. Однако некоторые аналитики упорно писали, что OpenCL в SB не поддерживается. Ещё один детектив? Да, и он распутан.
Согласно заявлению другого представителя компании, поддержка физически есть, но из-за неготовности драйвера при его активации по-прежнему будут использоваться лишь ресурсы x86-ядер. Когда появится обновление, где всё заработает, — сказано не было. По менее официальным каналам получен намёк, что и до этого ГП как-то можно будет использовать в качестве сопроцессора. Но только после доделки нужного SDK (инструментального пакета для программистов) ГП будет доступен не «как-то», а по-человечески. :)
Для облегчения доступа к данным всё адресное пространство ЦП делится на 3 раздела: для x86-ядер, ГП и некогерентных данных. Раздел ГП использует «слабую» когерентность для ускорения проверок, осуществляемых программным путём через драйвер (в частности, данные пересылаются в раздел x86 синхронизационными процедурами, а не автоматически). Некогерентные данные также используются ГП для завершающих операций переноса готового кадра в память.
Каждый путь в L3 имеет 3 бита атрибутов, указывающих, что содержимое этих строк принадлежит вышеуказанным трём разделам в любой их комбинации. Но для минимизации затрат на поддержку когерентности между разделами протоколы и семантика связности (отличные в каждом из них) применяются, только когда это явно требуется — т. е. когда в одном пути кэшируется область, помеченная как общая для нескольких разделов.
Системный агент и ИКП
Системный агент — это та часть «внеядра», которая получается после вычета кэша L3 и ГП. Остаётся вот что:
- арбитр со своим портом кольцевой шины — коммутирует потоки данных между остальными частями агента;
- порт отладочной шины GDXC;
- контроллер шин QPI (1–2 соединения на 25,6, 28,8 или 32 ГБ/с) — очевидно, присутствует только в серверных моделях;
- контроллер шин PCIe 2.0 (на 1 ГП/с) или 3.0 (2 ГП/с, только для Xeon) — в зависимости от модели может быть 16-, 20-, 24- и 40-полосным и допускает различные схемы соединений по числу полос: для наиболее распространённых 20-полосных моделей это x16+x4 (для большинства мобильных SB доступен только этот вариант), x8+x8+x4 и x8+x4+x4+x4 (только для младших Xeon);
- контроллер шины DMI 2.0 — для соединения с PCH (чипсетом): фактически немного преобразованный 4-полосный канал PCIe, по сравнению с v1.0 (в Nehalem и Atom) удвоил ПС до 4 ГБ/с (сумма в оба направления);
- «гибкое межсоединение экранов» (Flexible Display Interconnect, FDI) — порт для соединения с контроллером физических интерфейсов экранов в составе чипсета, также переработанный из PCIe;
- ускоритель (де)кодирования видео;
- контроллер памяти;
- программируемый силовой контроллер (Power control unit, PCU) с собственной прошивкой.
Наиболее интересными тут оказываются 3 последних пункта. Однако видеоускоритель оставим для обзора графической части, тут же расскажем об ИКП. Он поддерживает 2–4 канала памяти вплоть до DDR3-1600 (с ПСП 12,8 ГБ/с на канал), но для настольных и мобильных ЦП — только 2 канала DDR3-1333. Каждый канал имеет отдельные ресурсы и независимо обслуживает запросы. ИКП имеет внеочерёдный планировщик операций (!), максимизирующий ПСП с минимизацией задержек. Кроме того, ещё в версиях Nehalem для Xeon появилась технология SMI (Scalable Memory Interconnect, масштабируемое межсоединение памяти) с использованием подключаемых SMB (масштабируемый буфер памяти, аналог буфера AMB из FB-DIMM, но находящийся не на модуле, а на системной плате). Буфер подключается скоростной последовательной шиной к каналу ИКП процессора и позволяет подключить к себе большее суммарное число модулей, чем напрямую к ЦП. Правда, от этого ухудшаются и задержки, и частота работы памяти.
В каждом канале есть 32-строковый буфер записи, причём запись считается завершённой, как только данные попадут в буфер. Как ни странно, слиянием записи этот буфер не занимается, в результате чего частичные записи (когда обновляется не вся строка) обрабатываются неэффективно, т. к. требуют чтения старой копии строки. Это странно, учитывая, что современные микросхемы памяти учитывают битовую маску записи не только для отдельных 8-байтовых слов (которых 8 на строку), но и байт в словах, потому комбинация неизменной и обновлённой частей строки производится внутри чипа памяти, а не в ИКП. Впрочем, в SB ИКП (как и кэши) может включать продвинутые методы ECC, и для этого даже частично обновляемую строку для пересчёта ECC надо начала считать целиком. Причём это правило работает даже при применении обычной памяти, а также в большинстве мобильных моделей, где ECC-память вовсе не поддерживается.
Turbo Boost 2.0
Силовой контроллер системного агента отвечает сразу за 3 функции — защита от перегрева, сохранение энергии и авторазгон (именно в таком порядке они добавлялись с эволюцией ЦП x86). Последний пункт в процессорах Intel известен как технология Turbo Boost (TB). Её обновлённая версия является одним из главных «гвоздей программы», т. к. для слабопараллелизуемых программ она может дать ускорение не меньшее, чем все архитектурные улучшения в ядрах.
Напомним, что TB следит за текущими частотами, напряжениями питания, силами тока и температурами разных частей кристалла, чтобы определить, можно ли повысить работающим ядрам частоту на очередной шаг множителя (отдельно для x86-ядер и ГП). При этом учитываются пределы по всем вышеуказанным параметрам. Главной новинкой 2-й версии TB является дополнительное повышение частот, происходящее сразу после периода простоя всех или большей части ядер и обусловленное температурной инерцией системы «ЦП + радиатор». Очевидно, что при включении нагрузки и всплеске выделения тепла температура кристалла достигнет некоего значения не мгновенно, а плавно и с замедлением. Так вот если текущая температура пока ещё не критическая, и по остальным параметрам также есть запас, то контроллер ещё чуть поднимет множитель, ещё чуть увеличив потребление и выделение энергии и ещё чуть увеличив скорость роста температуры. Кстати, Intel продемонстрировала стабильную работу 4-ядерного SB на частоте 4,9 ГГц с воздушным охлаждением…
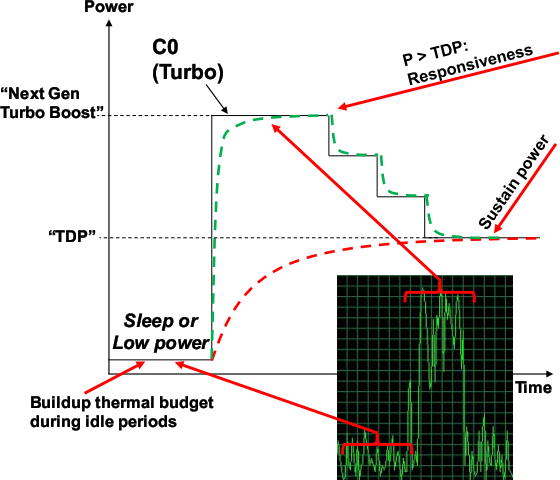
Зелёным пунктиром обозначена частота, а красным — температура. Во врезке — типичная нагрузка на ЦП домашнего ПК.
В зависимости от качества кулера и политики BIOS по регулировке оборотов вентилятора при разной температуре, первые 10–25 секунд после относительно длительного простоя процессор будет потреблять больше величины TDP, а занятые ядра теоретически должны работать на бо́льших частотах, чем у ЦП Westmere в тех же обстоятельствах. Как только температура поднимается до критической отметки, частота снизится к обычному «турбированному» значению — это снизит и выделение тепла до TDP, а температура расти перестанет. Выигрыш в том, что в течение нескольких секунд система будет работать чуть быстрее, чем с Turbo Boost 1.0. Т. е. вторая версия технологии является «турбонаддувом турбобуста». Отсюда ясно, на какие сценарии это рассчитано — периодический запуск малооптимизированных под многопоточность программ, быстро решающих свою задачу и снова погружающих систему в простой на несколько минут. При домашней и офисной работе — типичная ситуация.
Не стоит забывать, что теперь каждый шаг множителя для x86-ядер равен 100 МГц, а не 133, поэтому напрямую сравнивать «турбо-формулы» SB и Nehalem не получится. Для ГП шаг равен 50 МГц, а для ИКП — 266 (максимум — 2166, автоматически не разгоняется). Частота шины DMI принимается как базовая, от которой отталкиваются остальные часто́ты всей системы. Впрочем, ровно по этой причине её как раз надо оставить на стандартных 100 МГц, и если уж заниматься разгоном, то только через множители. Кстати, отдельный тактовый генератор теперь не обязателен и будет присутствовать лишь на дорогих «оверклокерских» платах, а остальные станут чуть дешевле и проще.
Обычно тактовый генератор южного моста подключен к нескольким делителям в самом мосту, а через шину DMI — и к ЦП с его разнообразными умножителями…
…Но в дорогих платах внешний генератор тактирует всё.
Экономия
Методы достижения энергоэффективности в архитектуре Nehalem почти совпадают с оными в ЦП Atom, что описано во 2-й части его детального обзора на нашем сайте (правда, поддержка состояния глубокого сна C6 и низковольтной памяти LV-DDR3 появилась только в Westmere). А что появилось в SB?
Во-первых — второй тип термодатчиков. Привычный термодиод, показания которого «видят» BIOS и утилиты, измеряет температуру для регулировки оборотов вентиляторов и защиты от перегрева (частотным троттлингом и, если не поможет, аварийным отключением ЦП). Однако его площадь весьма велика, потому их всего по одному в каждом ядре (включая ГП) и в системном агенте. К ним в каждом крупном блоке добавлено по нескольку компактных аналоговых МОП-схем с термотранзисторами. У них меньший рабочий диапазон измерений (80–100 °C), но они нужны для уточнения данных термодиода и построения точной карты нагрева кристалла, без чего нереализуемы новые функции TB 2.0. Более того, силовой контроллер может использовать даже внешний датчик, если производитель системной платы разместит и подключит его — хотя не совсем ясно, чем он поможет.
Добавлена функция перенумерации C-состояний, для чего отслеживается история переходов между ними для каждого ядра. Переход занимает время тем большее, чем больше «номер сна», в который ядро входит или из которого выходит. Контроллер определяет, имеет ли смысл усыплять ядро с учётом вероятности его «пробудки». Если таковая ожидается скоро, то вместо затребованного ОС состояния C6 или C3 ядро будет переведено в C3 или C1, соответственно, т. е. в более активное состояние, быстрее выходящее в рабочее. Как ни странно, несмотря на большее потребление энергии в таком сне, общая экономия может не пострадать, т. к. сокращаются оба переходных периода, в течение которых процессор совсем не спит.
Для мобильных моделей перевод всех ядер в C6 вызывает сброс и отключение кэша L3 общими для банков силовыми ключами. Это ещё сильнее снизит потребление при простое, но чревато дополнительной задержкой при пробуждении, т. к. ядрам придётся несколько сотен или тысяч раз промахнуться в L3, пока туда подкачаются нужные данные и код. Очевидно, в совокупности с предыдущей функцией это произойдёт, лишь если контроллер точно уверен, что ЦП засыпает надолго (по меркам процессорного времени).
Core i3/i5 прошлого поколения являлись своеобразными рекордсменами по требованиям к сложности системы питания ЦП на системной плате, требуя аж 6 напряжений — точнее, все 6 были и ранее, но не все вели в процессор. В SB силовые шины изменились не числом, а использованием:
- x86-ядра и L3 — 0,65–1,05 В (в Nehalem L3 отделён);
- ГП — аналогично (в Nehalem почти весь северный мост, который, напомним, являлся там вторым кристаллом ЦП, питается общей шиной);
- системный агент, у которого частота фиксирована, а напряжение — постоянное 0,8, 0,9 или 0,925 В (первые два варианта — для мобильных моделей), либо динамически регулируемое 0,879–0,971 В;
- умножители частоты — постоянное 1,8 В или регулируемое 1,71–1,89 В;
- драйвер шины памяти — 1,5 В или 1,425–1,575 В;
- драйвер PCIe — 1,05 В.
Регулируемые версии силовых шин используются в разблокированных видах SB с буквой K. В настольных моделях частота простоя x86-ядер повышена с 1,3 до 1,6 ГГц, судя по всему, без ущерба для экономии. При этом 4-ядерный ЦП при полном простое потребляет 3,5–4 Вт. Мобильные версии простаивают на 800 МГц и просят ещё меньше.
Модели и чипсеты
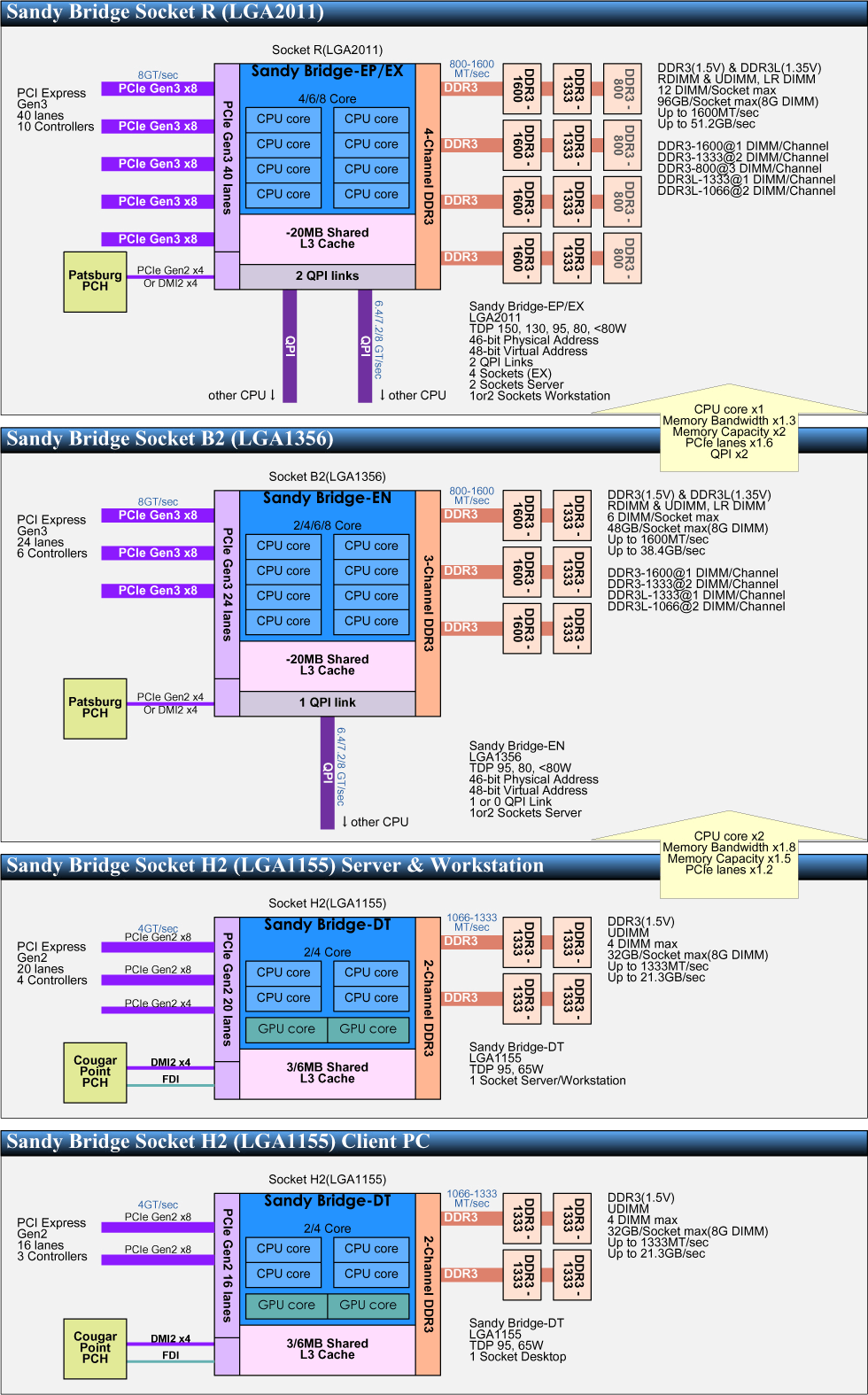 Серверные и настольные варианты SB для разных разъёмов. Обратите внимание на разную частоту работы ИКП в зависимости от числа подключенных модулей и их типа. Иллюстрация с pc.watch.impress.co.jp. |
Очередную смену разъёма для настольных линеек (с LGA1156 на LGA1155) обсуждать не будем — эта тема уже избита. :) По традиции укажем на список моделей в Википедии, хотя на момент сдачи этой статьи туда ещё не внесли несколько недавно анонсированных ЦП.
Традиционный для обоих производителей x86-ЦП модельный бардак начинается с самого мощного, «серверного» вида (без ГП, с 4-канальным ИКП и 40 полосами PCIe 3.0), также известного как SB-E — он попадёт и в десктопы под именем Core i7 Extreme и даже просто Core i7, «потеряв» 2–4 ядра, 8 полос PCIe и, возможно, 1 канал ИКП и снизив объём L3 с 20 МБ до 10–15. TDP «экстремалов», как и прежде, останется на 130 ваттах. Остальные анонсированные модели i7 — это «просто мощные» настольные ЦП, как и полагается. Среди i5 тоже есть исключения — они могут быть и 2-ядерными (с половинным размером L3). Среди i3 исключений нет, и на том спасибо.
Всё ещё живые Pentium и в очередной раз воскресшие Celeron лишены поддержки HT, AVX, AES-NI и TB для x86-ядер. Обе марки имеют три вида, обозначаемых буквой у номера модели — настольные G***, мобильные B*** или *** (только цифры) и встроенные ***E (с поддержкой ECC). Встроенные и часть мобильных ЦП используют корпус BGA1023, остальные мобильные — под разъём Socket G2. Celeron G440, B710, 787 и 827E — 1-ядерники, причём последний лишён даже ускорения 3D в ГП. Кэш L3 сократили до 1,5 МБ у 827E и 1 МБ (!) у B710 и 787. Pentium G имеют 3 МБ L3, а все остальные версии Pentium и Celeron — 2.
Мобильный ряд прежде всего удивляет моделью Core i7 Extreme 2920XM за $1096. Видимо, дверью ошиблась — это к модным нынче экономным серверам (где разблокированный множитель не пригодится), а не для портативных приборов с автономным питанием и слабеньким кулером. У мобильного i7 может быть разным размер L3 и число ядер (с буквой Q или X их 4, иначе — 2). i5 в этом отношении более стабильны, а у единственного пока i3 Turbo Boost работает только для ГП. Мобильные Core получат «старшую» графику (о различиях между ними — ниже), а вот Pentium и Celeron (даже настольные) помимо половины 3D-блоков лишены и технологий Clear Video HD (улучшение видеопотока «на лету») и QuickSync (аппаратный перекодировщик видео).
Номера моделей мало что скажут. Core i теперь 4-значные и начинаются с двойки; Pentium, наоборот, одну цифру потеряли (причём разница между 600-ми и 800-ми моделями — только в частоте и (не)поддержке памяти DDR3-1333). Если у настольной модели последняя цифра — 5, то у неё старший ГП, а если 0 — то младший. Однако для 2600K и 2500K это не работает: полноценная графика (вдобавок к разблокированному множителю) есть именно у них, а не у несуществующих 2605K и 2505K. У мобильных ЦП эта же пятёрка означает поддержку ECC-памяти и развилки шины PCIe. Ещё последней цифрой может быть 2, что означает включение этой модели в программу Processor Performance Upgrade — о ней мы расскажем в ближайшей статье.
Вдобавок, Внимательный Читатель нам напомнит, что с января 2011 г. выпускаются мобильные Celeron 763 и 925 на ядре Penryn 4-летней давности для пред-предыдущей архитектуры. А теперь сравним их (1 ядро, 1 МБ L2 и, разумеется, никакого ГП и L3) с готовящимися к выпуску мобильными же Celeron 787 и 857: 787 — 1-ядерник с 1 МБ L3, а 857 — 2-ядерник с 2 МБ; у 857 по сравнению с 787 базовая частота x86-ядер — меньше, базовая частота ГП — та же, а турбо-частота ГП — больше. А теперь попробуйте определить хотя бы что-то из этого только по номерам моделей…
Буквы S и T после номера означают «средне» и «очень» экономные модели, но сравнивать их частоты не получится: например, модель Core i5-2500 быстрее и прожорливей, чем 2500S, которая быстрее и прожорливей, чем 2500T, но вот насколько именно в каждом случае — без таблицы не ясно. Вдобавок, «очень» экономные Xeon обозначаются буквой L, а не T, а ещё есть не менее экономная встроенная модель i3-2340UE. Также известно, что настольные Pentium и Celeron моделей GxxxT дополнительно лишатся ускорения 3D в ГП, но вот Celeron G440 с тем же TDP в 35 Вт буквы T не имеет. У «просто» экономных мобильных и встроенных ЦП номера заканчиваются на 9, а у «самых» — на 7.
Удивительно, как Intel сама себе делает подножку: на сайте компании есть официальная и постоянно обновляемая база данных процессоров с почти полным списком характеристик старых и текущих моделей. В ней с удивлением можно обнаружить, что новый Pentium 957, оказывается, не имеет виртуализации, хотя все остальные источники (включая заявления самой Intel) говорят, что ни один ЦП новой архитектуры не лишится поддержки VT и x86-64.
Короче, бардак полный и, судя по всему, намеренный. Но один намёк на порядок всё же есть: если расположить модельные ряды как «Celeron-Pentium-i3-i5-i7», то в каждой линейке все ЦП окажутся дороже самого дорогого из предыдущей и дешевле самого дешёвого из следующей. Впрочем, уже сейчас (для текущих цен и пока анонсированных моделей) это работает лишь по отдельности для настольных и мобильных процессоров, ибо мобильный Celeron B810 сто́ит, как самый быстрый настольный Pentium. Но даже с этой поправкой нельзя твёрдо сказать, что Intel именует ЦП не по производительности, а по цене, ибо откуда тогда берутся сами цены? :)
Чипсеты-близнецы H67 и P67.
Некоторые странности до сих пор имелись и среди чипсетов: долгое время можно было купить системную плату либо с поддержкой разгона (на чипсете P67), либо встроенного ГП (на H67). Пользователи, которые хотели и того, и другого, недоумевали, почему их поставили перед выбором «или-или». Ответ прост: чипсет Z68 с поддержкой «всего» вышел лишь в мае, на 4 месяца позже старта платформы. Причём физически это всё тот же P67/H67 (который суть один и тот же кристалл), только со всеми разблокированными функциями.

Чипсет Z68.
Помимо этого, для «бизнес-сектора» (малопонятный автору термин маркетологов) выпущены настольные Q67, Q65 и B65 — это H67 с поддержкой PCI; у последних двух только 1 (из 6) порт SATA — версии 3.0 (а не 2 из 6, как в остальных чипсетах), т. е. поддерживает скорость 6 Гбит/с, а у B65 нет RAID. Наиболее дешёвая модификация — H61, без PCI, RAID и SATA 3.0. Мобильных чипсетов набирается пять: стандартные QM67, QS67 и HM67 (с TDP около 3,9 Вт и размером микросхемы 25×25 мм) и экономные UM67 и HM65 (3,4 Вт и 22×22 мм). QM67 и QS67 допускают полный ручной разгон всех ядер (являясь по этой части мобильным аналогом P67); а ещё вся пятёрка имеет разную поддержку RAID — от никакой в HM65 и UM67 до уровней 0, 1, 5 и 10 в QM67 и HM67. Судя по всему, этот же южный мост применяется и в чипсетах C202, C204 и C206 для младших Xeon серий E3 (которые суть обычный 4-ядерный SB).
Проблему с поддерживаемыми функциями Intel уже продемонстрировала ошибкой в контроллере SATA во всех выпущенных в начале года чипсетах. Исправление и перевыпуск, как известно, влетели в миллиардную «копеечку», а репутационные издержки и вовсе трудновыразимы.
Кристалл
Техпроцесс
Физически техпроцесс 32 нм для SB мало отличается от такового для Westmere. Главное улучшение — в компенсации разброса параметров транзисторов, прежде всего утечки тока. Например, в Westmere в разных кристаллах на 300-миллиметровой пластине утечка могла иметь 4-кратную разницу, что особенно влияет на надёжность записи в кэши и РФ. Компенсация этого разброса для SB позволит достичь большего выхода годных кристаллов, лучшей экономии и более высоких частот. Как именно? В каждую линию шин записи в РФ и кэшах добавили программируемую «подтяжку» из трёх транзисторов разного размера, стабилизирующую уровень логической «1» в зависимости от утечки. Во время заводского тестирования утечка замеряется в разных местах кристалла, после чего «подтяжки» программируются на наиболее точную комбинацию транзисторов (из 8 возможных) для улучшения надёжности записи.
По некоторым данным, в кэшах Westmere использовалось не менее трёх видов ячеек СОЗУ. Для основных матриц L3 — средневольтная высокоплотная (площадью 0,171 квадратных микрон на бит), для тегов L3 — низковольтная скоростная (0,199 мк²/бит), а для L2 и L1 (включая теги) — 8-транзисторая ультранизковольтная скоростная (0,256 мк²/бит, но для L1 удельная площадь кэша примерно вчетверо больше за счёт многопортовости и встроенной в матрицу логики). Разнообразие видов СОЗУ показывает, что инженеры в каждом случае нашли свой баланс между скоростью срабатывания, площадью, потреблением и надёжностью хранения и работы. В частности, имея в L2 8-транзисторные ячейки, можно было устроить «бесплатный» порт записи — однако этот кэш не сделали 2-портовым, видимо, по причине усложнения управляющей логики, непропорционального получаемому ускорению.
Судя по всё ещё актуальной проблеме разброса параметров, для SB техпроцесс значительно оптимизировать не удалось. Тем не менее планки по частоте и экономии подняты — в частности, т. к. L3 теперь запитывается той же силовой шиной, что и x86-ядра, он должен быть рассчитан на работу при 0,65 В (при низкой нагрузке), что ниже минимального вольтажа для L3 в Westmere (0,8 В). Уменьшенного потребления удалось достичь без увеличения площади хранения бита, но со штрафом для надёжности — доля моделей SB с полным (не заблокированным частично) кэшем L3 пока оказывается меньше, чем у Nehalem и Westmere.
Виды кристаллов
4 вида кристалла для SB имеют такие физические показатели (для 8-ядерных — предполагаемые):
| Модели | Core i5/i3, Pentium, Celeron | Core i3, Core-М° i7/i5/i3 | Xeon, Core i7/i5 | Xeon, Core i7 Extreme |
| Число ядер x86 и ФУ ГП* | 2 + 6 | 2 + 12 | 4 + 12 | 8 + 0 |
| Объём кэша L3, МБ | 3 | 4 | 8 | 20 |
| Число транзисторов, млн. | 504 | 624 | 995 | ≈2200 |
| Площадь кристалла, мм² | 131 | 149 | 219 | ≈400 |
| Размер кристалла (Ш×В), мм | 13,803×9,507 | 14,554×10,256 | 21,078×10,256 | ≈20×20 |
° — мобильные варианты
* — под графическим ФУ понимается конечный исполнительный блок, иерархически эквивалентный «потоковому процессору» (SP) AMD и «CUDA-ядру» NVidia.
Помимо этих цифр также обнародовано, что старший 12-блочный ГП типа HD Graphics 3000 имеет 114 млн. транзисторов (обозначим эту меру как Мтр.), а 1 ядро x86 — 55 Мтр. (включая кэш L2). Из этих цифр можно подсчитать, что банк L3 на 2 MБ имеет 130,5 Мтр., а младший 6-блочный HD Graphics 2000 — 59 Мтр.
Кристалл 4-ядерного SB (по ссылке — очень детальное фото).
Посмотрим на кристалл — на примере 4-ядерного, фото которого — единственное доступное на сегодня. Как и в предыдущей архитектуре, Intel использовала модульную схему, позволяющую относительно легко получать новые модификации простым изменением числа блоков. В данном случае видны 4 модуля «ядро x86 и локальный банк L3», ГП (большой блок слева), системный агент со всеми контроллерами (справа) и физические интерфейсы (драйверы) шин: PCIe (вдоль правого края), FDI (в нижнем правом углу), памяти (внизу), GDXC (в нижнем левом углу) и DMI (в верхнем левом углу). Области с монотонным цветом общей площадью ≈12 мм² — пустые.
Устройство ГП
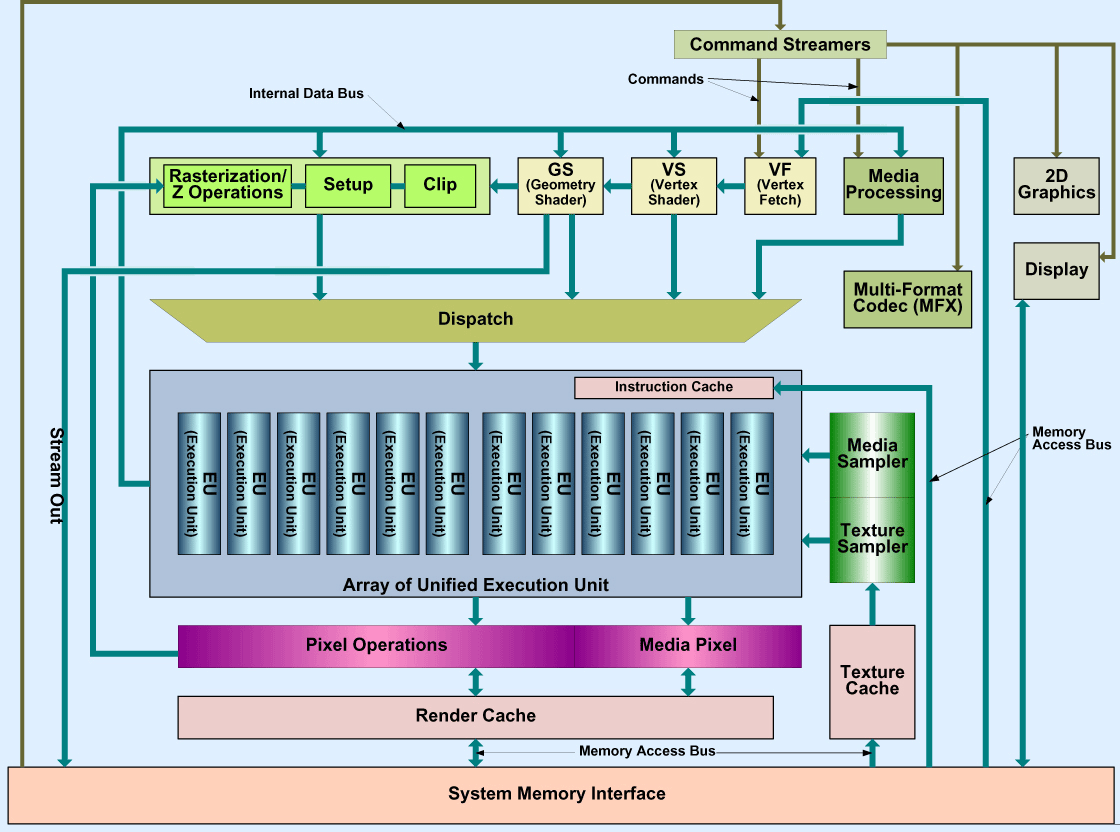 Блок-схема ГП в Sandy Bridge. Иллюстрация с pc.watch.impress.co.jp. |
Первое, что любопытно — его младшая версия получена не просто путём отсечения половины ФУ у старшей, но и последующим уменьшением размеров кристалла и по ширине, и по высоте. Этот факт мы исследуем позже, а тут обратимся ко второму моменту — если 59 Мтр. для HD Graphics 2000 верны, то всё, что остаётся после вычитания всех ФУ, занимает всего 3,4 Мтр. А ведь в ГП, помимо исполнительных блоков, есть много общих и не менее сложных ресурсов (площадь и сложность которых видна в центральной части ГП, а их количество — на блок-схеме): планировщик и кэш кода, процессор вершин, растеризатор, текстурный сэмплер и прочее.
Учитывая, что одно из рекламируемых преимуществ нового ГП Intel — это не только удвоенная (до 128 бит) разрядность ФУ (за счёт чего вся 3D-графика ускорилась «вдвое»), но и большее число аппаратных блоков — скорее всего общие части займут не намного меньше транзисторов, чем ФУ. Из чего надо сделать вывод, что цифра в 59 Мтр. занижена, а значит — из сокращённого 2-ядерного кристалла убрали что-то ещё, помимо половины ФУ в ГП. А т. к. все ядра и банки L3 мы уже посчитали, подозрения падают на системный агент — тем более, что именно в нём находится аппаратный перекодировщик QuickSync, отключенный в самых младших моделях, ГП которых из-за этого зовётся HD 1000. Чуть позже у нас окажется способ это проверить. Пока же заметим, что 4-ядерные модели с младшим ГП получены стандартным отключением 6 ФУ.
Устройство банка L3
В таблице не зря указаны именно физические параметры кэша L3 — фактически доступные размер и ассоциативность зависят от конкретной модели, ведь при заводском тестировании что-то могут отключить. А вот плотность в 7,8 транзистора/бит — общая для всех. Напомним, что стандартная ячейка применяемого в кэшах статического ОЗУ имеет 6 транзисторов, а экономная — 8 (с ущербом для площади, поэтому её размещают только в ядре, кэши которого относительно малы). Если из 130,5 Мтр. (для банка L3 на 2 МБ) вычесть положенные 100,7 Мтр. (при 6-транзисторных ячейках только для данных), останется 29,8 Мтр. Этого должно хватить на биты ECC (1 на байт) и теги (предположим, что это 50 бит на строку, включая свои биты ECC). Тогда контроллеру банка и агенту кольцевой шины останется 7,4 Мтр., что вполне вероятно.

Банк кэша L3 на 2 МБ. Вверху — агент кольцевой шины. В центре — контроллер банка. Справа от них — теги и ECC (вертикальный ряд). Остальные блоки — массивы данных. Нижние 4 пути могут отсутствовать.
Т. к. продвинутые методы ECC внедрены для защиты наиболее уязвимых, ультранизковольтных ячеек, в L3 они не применяются, поэтому выше мы посчитали число битов ECC как стандартный 1 на байт. Теперь посмотрим на фото банка. Видно, что каждый блок тегов состоит из двух матриц (бордового цвета). Размер большей из них составляет 10% от размера обслуживаемых матриц с данными (в которые, видимо, встроены и биты ECC), но с учётом меньшей плотности тут хранится примерно 8,5% информации от объёма строки и её ECC (576 бит) — и это почти соответствует вычисленному нами значению в 50 бит на строку. А вот что хранят малые матрицы тегов — сказать трудно…
2-ядерные кристаллы
Если кто думает, что в высокоинтеллектуальной аналитике процессорных архитектур нет места легкомысленным «фотожабам» — наслаждайтесь: попытаемся представить, как выглядят остальные два выпущенных кристалла для 2-ядерных моделей (возможно, Intel опубликует и их изображения, так что можно будет проверить). Со старшим вариантом проблем нет — удалив «лишние» 2 x86-ядра, сместим вправо ГП, водрузив его над левой третью ИКП.
Почти так должен выглядеть 2-ядерный SB с 4 МБ L3 и старшим ГП.
А вот с младшей версией всё интереснее. Сначала обратим внимание, что каждый банк L3 не зря имеет пусто́ты в нижней четверти — в некоторых 4-ядерных моделях отключена одна 4-путная четвертинка каждого банка, а в младшем 2-ядерном кристалле нижние четверти в обоих банках и вовсе физически отсутствуют. Управляющих цепей там нет, поэтому после урезания каждого банка сместим ИКП и ГП вверх.
Однако чтобы эта версия кристалла оказалась меньше и по высоте, ГП также придётся обрезать. Обратим внимание на его верхнюю часть с массивом блоков в 3 ряда и 4 колонки — это и есть 12 ФУ. Для образования необходимого сдвига достаточно отсечь верхний ряд, оставив 8 ФУ, из которых 2 будут выключены. Правда, при этом отсекается и верхний край драйвера шины DMI, а ниже (на место GDXC) его не переставить — слишком высокий.
Допустим, мы всё же как-то смогли сместить ГП вверх. Но тут нас ждёт ещё один сюрприз — локальный агент шины и контроллер L3 окажутся не на одной линии с остальными. Если в этом месте шине придётся сделать 2 поворота на 90°, это ограничит её максимальную частоту работы, а т. к. она должна совпадать с частотой x86-ядер — то и их. Значит, такое решение применяется только в недорогих ЦП, которым высокая частота не очень важна — но этот вывод нарушает наличие модели Core i5 2390T, которая имеет штатную частоту 2,7 ГГц, а авторазогнанную — до 3,5 ГГц. Правда, можно также предположить, что агент остался на месте, но небольшой кусочек логики «под» ним (в правом нижнем углу ГП) перемещён в положение «над». Но это замедлит уже сам ГП, а его скорость у вышеуказанной модели — до 1,1 ГГц (почти как в топовых моделях).
На этом трудности не заканчиваются — нам ещё придётся где-то «откусить» те же 3/4 миллиметра и по ширине. Хорошо бы подошёл контроллер PCIe, но лишать процессор со слабым встроенным ГП возможности подключения мощного внешнего — кощунство (хотя это очень удобно бы объяснило «подозреваемые на пропажу» транзисторы в системном агенте). А ещё справа расположен не менее важный контроллер FDI. Драйвер DMI слева также некуда девать, к тому же между ним и драйвером GDXC есть часть графической логики…
Всё это намекает на такой итог: у инженеров графического отдела было достаточно времени, чтобы подготовить сразу две версии раскладки блоков ГП — полную (на 12 ФУ) и компактную (на 6). Причём во второй версии некоторые общие блоки удалены (!), а остальные заметно переставлены, за счёт чего и нашлось место для сокращения и по длине, и по ширине. Таким образом, «обвинения» в пропаже транзисторов могут быть предъявлены не только системному агенту (где удалена как минимум мало кому нужная GDXC, а возможно — и блок QuickSync), но и ГП.
Проверить гипотезу можно двумя способами: дождавшись фото этого кристалла и/или детально исследовав, чем отличаются версии ГП в 2-ядерных моделях, помимо числа ФУ. С «гаданиями по чипу» на сегодня закончим, но заметим, что Intel вряд ли пошла бы на такие сложности, если бы не было очень серьёзного повода для экономии этих несчастных 18 мм² (всего 12% от площади старшего 2-ядерного кристалла), при том, что 12 мм² в 4-ядернике пропадают зря. Возможно, этот повод — минимизация стоимости наиболее популярных моделей, в т. ч. и для лучшего продвижения в мобильном сегменте. Посмотрим, как это отразится на ценах…
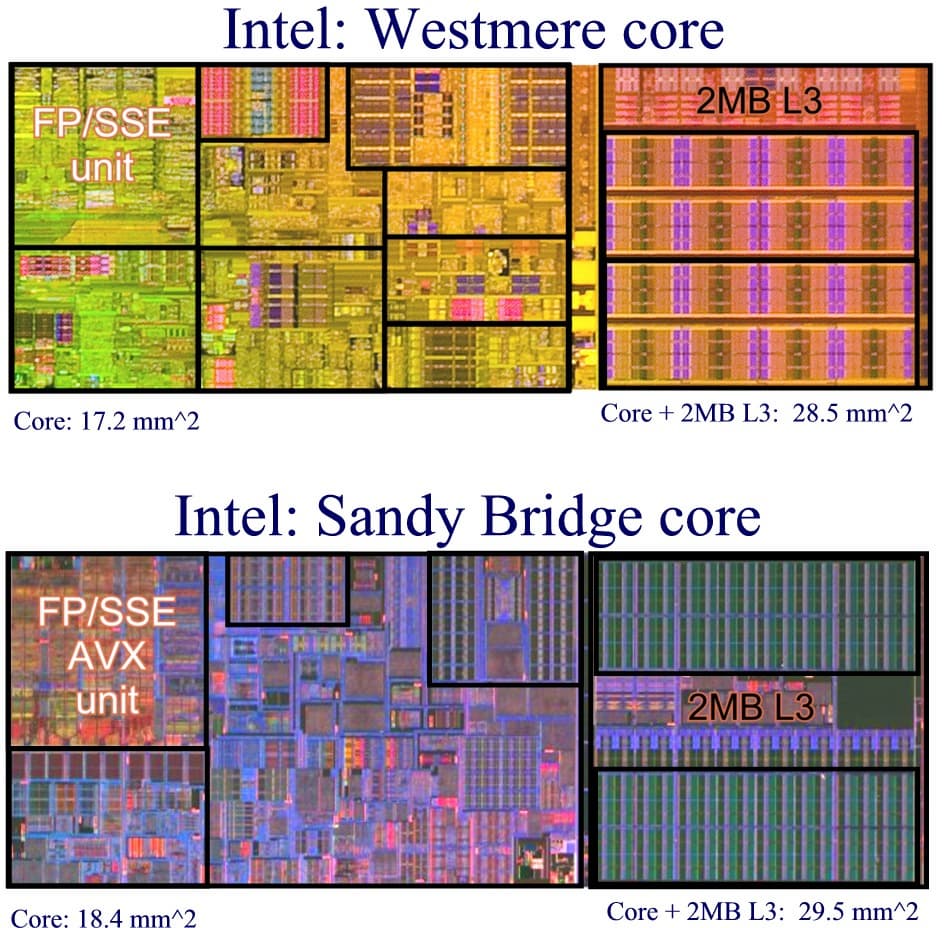
Ядро Westmere по сравнению с синтезированной моделью ядра SB (на 2010 г.). Как видно, разработчики уместили все новшества почти на той же площади. Иллюстрация с chip-architect.com.
Производительность
Что эта глава делает в теоретическом обзоре микроархитектуры? А то, что есть один общепризнанный тест, уже 20 лет (в разных версиях) использующийся для оценки не теоретической, а программно достижимой скорости компьютеров — SPEC CPU. Он может комплексно оценить производительность процессора, причём в наилучшем для него случае — когда исходный код тестов скомпилирован и оптимизирован для тестируемой системы (т. е. походя проверяется ещё и компилятор с библиотеками). Таким образом, полезные программы окажутся быстрее лишь с написанными вручную вставками на ассемблере, на что сегодня идут редкие смельчаки-программисты с большим запасом времени. SPEC можно отнести к полусинтетическим тестам, т. к. он и ничего полезного не вычисляет, и никаких конкретных цифр не даёт (IPC, флопсы, тайминги и пр.) — «попугаи» одного ЦП нужны только для сравнения с другими.
Обычно Intel предоставляет результаты для своих ЦП почти одновременно с их выпуском. Но с SB произошла непонятная 3-месячная задержка, а полученные в марте цифры всё ещё предварительны. Что именно их задерживает — неясно, однако это всё равно лучше, чем ситуация с AMD, вообще не выпустившей официальных результатов своих последних ЦП. Нижеуказанные цифры для Opteron даны производителями серверов, использовавшими компилятор Intel, так что эти результаты могут быть недооптимизированы: что программный инструментарий Intel может сделать с кодом, исполняемым на «чужом» ЦП, мы уже знаем. ;)
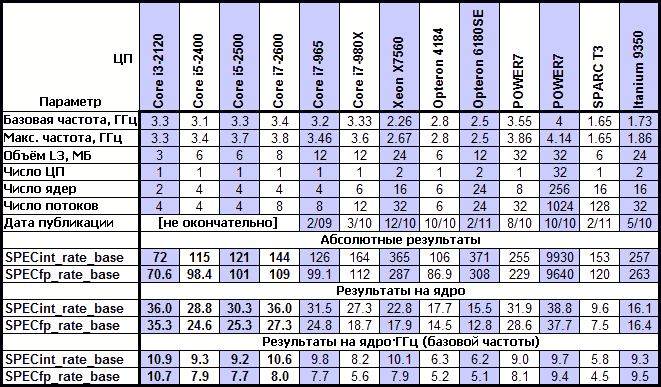
Сравнение систем в тестах SPEC CPU2006. Таблица составлена Дэвидом Кантером с realworldtech.com по данным на март'2011.
В сравнении с предыдущими ЦП SB показывает превосходные (в прямом смысле) результаты в абсолюте и вовсе рекордные на каждое ядро и гигагерц. Включение HT и добавление 2 МБ к L3 даёт +3% к вещественной скорости и +15% к целой. Однако самую высокую удельную скорость имеет 2-ядерная модель, и в этом — поучительное наблюдение: очевидно, Intel задействовала AVX, но т. к. целочисленного прироста пока получить нельзя, то можно ожидать резкое ускорение лишь вещественных показателей. Но и для них никакого скачка нет, что показывает сравнение 4-ядерных моделей — а результаты для i3-2120 раскрывают причину: имея те же 2 канала ИКП, каждое ядро получает вдвое бо́льшую ПСП, что отражается 34-процентным приростом удельной вещественной скорости. Видимо, кэш L3 на 6–8 МБ слишком мал, и масштабирование его собственной ПС за счёт кольцевой шины уже не спасает. Теперь ясно, зачем Intel планирует оснастить серверные Xeon 3- и даже 4-канальными ИКП. Только вот тамошним 8 ядрам уже и их не хватит, чтобы развернуться по полной…
Дополнение: В базе SPEC появились финальные результаты SB — цифры (ожидаемо) чуть подросли, но качественные выводы те же.
Перспективы и итоги
О выходящем весной 2012 г. 22-нанометровом преемнике Sandy Bridge под названием Ivy Bridge («плющевый мост») уже многое известно. Ядра общего назначения будут поддерживать чуть обновлённый поднабор AES-NI; вполне возможно и «бесплатное» копирование регистров на стадии переименования. Улучшений в Turbo Boost не предвидится, зато ГП (который, кстати, заработает на всех версиях чипсета) нарастит максимальное число ФУ до 16, станет поддерживать подключение не двух, а трёх экранов, наконец-то обретёт нормальную поддержку OpenCL 1.1 (вместе с DirectX 11 и OpenGL 3.1) и улучшит возможности по аппаратной обработке видео. Скорее всего, уже и в настольных и мобильных моделях ИКП станет поддерживать частоту 1600 МГц, а контроллер PCIe — версию шины 3.0. Главное технологическое новшество — в кэше L3 будут использоваться (впервые в массовом микроэлектронном производстве!) транзисторы с вертикально расположенным многосторонним затвором-ребром (FinFET), имеющие радикально улучшенные электрические характеристики (детали — в одной из ближайших статей). Ходят слухи, что версии с ГП снова станут многочиповыми, только на этот раз к процессору добавят один или несколько кристаллов быстрой видеопамяти.
Ivy Bridge будет подключаться к новым чипсетам (т. е. южным мостам) 70-й серии: Z77, Z75 и H77 для дома (заменят Z68/P67/H67) и Q77, Q75 и B75 для офиса (вместо Q67/Q65/B65). Она (т. е. физическая микросхема под разными именами) по-прежнему будет иметь не более двух портов SATA 3.0, а поддержка USB 3.0 наконец-то появится, но на год позже, чем у конкурента. Встроенная поддержка PCI исчезнет (после 19 лет шине пора на покой), зато контроллер дисковой подсистемы в Z77 и Q77 получит технологию Smart Response для увеличения производительности кэшированием дисков с помощью SSD. Впрочем, наиболее волнительная новость заключается в том, что несмотря на старую добрую традицию, настольные версии Ivy Bridge не просто будут размещаться в том же разъёме LGA1155, что и SB, но и будут обратно совместимы с ними — т. е. современные платы подойдут и новому ЦП.
Ну а для энтузиастов уже в 4-м квартале этого года будет готов куда более мощный чипсет X79 (к 4–8-ядерным SB-E для «серверно-экстремального» разъёма LGA2011). Он пока не будет иметь USB 3.0, зато портов SATA 3.0 будет уже 10 из 14 (плюс поддержка 4 видов RAID), а 4 из 8 полос PCIe могут соединяться с ЦП параллельно с DMI, удваивая ПС связи «ЦП—чипсет». К сожалению, X79 не подойдёт к 8-ядерным Ivy Bridge.
В качестве исключения (а может быть, и нового правила) список того, что бы хотелось улучшить и исправить в Sandy Bridge, приводить не будем. Уже очевидно, что любое изменение является сложным компромиссом — строго по закону сохранения вещества (в формулировке Ломоносова): если где-то что-то прибыло, то где-то столько же и убудет. Если бы Intel кидалась в каждой новой архитектуре исправлять ошибки старой, то число наломанных дров и полетевших щепок могло бы превысить выгоду от полученного. Поэтому вместо крайностей и недостижимого идеала экономически выгодней искать баланс между постоянно меняющимися и подчас противоположными требованиями.
Несмотря на некоторые пятна, новая архитектура должна не только ярко засветить (что, судя по тестам, она и делает), но и затмить все предыдущие — как свои, так и соперника. Объявленные цели по производительности и экономности достигнуты, за исключением оптимизации под набор AVX, которая вот-вот должна проявиться в новых версиях популярных программ. И тогда Гордон Мур ещё раз удивится своей прозорливости. Судя по всему, Intel во всеоружии подходит к Эпической Битве между архитектурами, которую мы увидим в этом году.
Благодарности выражаются:
- Максиму Локтюхину, тому самому «представителю Intel», сотруднику отдела программной и аппаратной оптимизации — за ответы на многочисленные уточняющие вопросы.
- Марку Бакстону, ведущему программному инженеру и главе отдела оптимизации — за его ответы, а также за саму возможность получить какую-то официальную реакцию.
- Агнеру Фогу, программисту и исследователю процессоров — за независимое низкоуровневое тестирование SB, обнаружившее массу нового и загадочного.
- Внимательному Читателю — за внимательность, стойкость и громкий храп.
- Яростным фанатам Противоположного Лагеря — до кучи.


