Справочная информация
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX/GM1XX
Справочная информация о семействе видеокарт GM2XX
Спецификации чипов семейства G8X/G9X
| кодовое имя | G80 | G84 | G86 | G92 | G94 | G96 |
| базовая статья | здесь | здесь | здесь | здесь | здесь | |
| технология (нм) | 90 | 80 | 65/55 | |||
| транзисторов (М) | 681 | 289 | 210 | 754 | 505 | 314 |
| универсальных процессоров | 128 | 32 | 16 | 128 | 64 | 32 |
| текстурных блоков | 32 | 16 | 8 | 64 | 32 | 16 |
| блоков блендинга | 24 | 8 | 16 | 8 | ||
| шина памяти | 384 (64х6) | 128 (64х2) | 256 (64х4) | 128 (64х2) | ||
| типы памяти | DDR, GDDR2, GDDR3, GDDR4 | |||||
| системная шина чипа | PCI-Express 16х | PCI-Express 2.0 16х | ||||
| RAMDAC | 2 х 400МГц | |||||
| интерфейсы | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link HDTV-Out | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link HDTV-Out HDMI | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link HDTV-Out HDMI DisplayPort | |||
| вершинные шейдеры | 4.0 | |||||
| пиксельные шейдеры | 4.0 | |||||
| точность пиксельных вычислений | FP32 | |||||
| точность вершинных вычислений | FP32 | |||||
| форматы текстур | FP32) FP16 I8 DXTC, S3TC 3Dc | |||||
| форматы рендеринга | FP32 FP16 I8 10 другие | |||||
| MRT | есть | |||||
| Антиалиасинг | TAA (AA прозрачных полигонов) CSAA 2x-16x | |||||
| генерация Z | 2х в режиме без цвета | |||||
| буфер шаблонов | двусторонний | |||||
| технологии теней | аппаратные карты теней оптимизации геометрических теней | |||||
Спецификации референсных карт на базе семейства G8X
| карта | чип шина | блоков ALU/TMU | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) | тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
| GeForce 8500 GT | G86 PEG16х | 16/8 | 450 | 400(800) | 256 DDR2 | 12.8 (128) | 3600 | |
| GeForce 8600 GT | G84 PEG16х | 32/16 | 540 | 700(1400) | 256 GDDR3 | 22.4 (128) | 8600 | 4300 |
| GeForce 8600 GTS | G84 PEG16х | 32/16 | 675 | 1000(2000) | 256 GDDR3 | 32.0 (128) | 10800 | 5400 |
| GeForce 8800 GTS 320MB | G80 PEG16х | 96/24 | 500 | 800(1600) | 320 GDDR3 | 64.0 (320) | 12000 | 10000 |
| GeForce 8800 GTS 640MB | G80 PEG16х | 96/24 | 500 | 800(1600) | 640 GDDR3 | 64.0 (320) | 12000 | 10000 |
| GeForce 8800 GTX | G80 PEG16х | 128/32> | 575 | 900(1800) | 768 GDDR3 | 86.4 (384) | 18400 | 13800 |
| GeForce 8800 Ultra | G80 PEG16х | 128/32 | 612 | 1080(2160) | 768 GDDR3 | 104.0 (384) | 19600 | 14700 |
| GeForce 8800 GT 256MB | G92 PEG16х | 112/56 | 600 | 700(1400) | 256 GDDR3 | 44.8 (256) | 33600 | 9600 |
| GeForce 8800 GT 512MB | G92 PEG16х | 112/56 | 600 | 900(1800) | 512 GDDR3 | 57.6 (256) | 33600 | 9600 |
| GeForce 8800 GTS 512MB | G92 PEG16х | 128/64 | 650 | 1000(2000) | 512 GDDR3 | 64.0 (256) | 41600 | 10400 |
| GeForce 8800 GS | G92 PEG16х | 96/48 | 550 | 800(1600) | 384 GDDR3 | 38.4 (192) | 26400 | 6600 |
| GeForce 9400 GT | G96 PEG16х | 16/8 | 550 | 800(1600) | 256/512 GDDR2 | 25.6 (128) | 4400 | 4400 |
| GeForce 9500 GT | G96 PEG16х | 32/16 | 550 | 800(1600) | 256/512 GDDR2/GDDR3 | 25.6 (128) | 8800 | 4400 |
| GeForce 9600 GSO | G92 PEG16х | 96/48 | 550 | 800(1600) | 384 GDDR3 | 38.4 (192) | 26400 | 6600 |
| GeForce 9600 GT | G94 PEG16х | 64/32 | 650 | 900(1800) | 512 GDDR3 | 57.6 (256) | 20800 | 10400 |
| GeForce 9800 GT | G92 PEG16х | 112/56 | 600 | 900(1800) | 512 GDDR3 | 57.6 (256) | 33600 | 9600 |
| GeForce 9800 GTX | G92 PEG16х | 128/64 | 675 | 1100(2200) | 512 GDDR3 | 70.4 (256) | 43200 | 10800 |
| GeForce 9800 GTX+ | G92 PEG16х | 128/64 | 738 | 1100(2200) | 512/1024 GDDR3 | 70.4 (256) | 47200 | 11800 |
| GeForce 9800 GX2 | 2xG92 PEG16х | 2x(128/64) | 600 | 1000(2000) | 2x512 GDDR3 | 2x64.0 (2x256) | 76800 | 19200 |
| GeForce GTS 250 | G92 PEG16х | 128/64 | 738 | 1100(2200) | 512/1024 GDDR3 | 70.4 (256) | 47200 | 11800 |
| карта | чип шина | блоков ALU/TMU | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) | тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
Подробности: G80, семейство GeForce 8800
Спецификации G80
- Официальное название чипа GeForce 8800
- Кодовое имя G80
- Технология 90 нм
- 681 миллион транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других возможных видов данных
- Аппаратная поддержка последних новшеств DirectX 10, в том числе и новой шейдерной модели - Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 384 бит шина памяти, 6 независимых контроллеров шириной 64 бита, поддержка GDDR4
- Частота ядра 575 ГГц (GeForce 8800 GTX)
- 128 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- ALU работают на более чем удвоенной частоте (1.35 ГГц для 8800 GTX)
- 32 текстурных блока, поддержка FP16 и FP32 компонент в текстурах
- 64 блока билинейной фильтрации (т.е. возможна бесплатная честная трилинейная фильтрация, а также вдвое более эффективная по скорости анизотропная фильтрация)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах - размер блока планирования - 8х4 (32) пикселя.
- 6 широких блоков ROP (24 пикселя) c поддержкой режимов антиалиасинга до 16 семплов на пиксель в том числе при FP16 или FP32 формате буфера кадра (т.е. возможны HDR+AA). Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравниение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 96 MSAA отсчетов (+ 96 Z) за такт, в режиме без цвета (Z only) - 192 отсчета за такт.
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы вынесены на внешний дополнительный чип NVIO (2 RAMDAC, 2 Dual DVI, HDMI, HDTV)
- Очень хорошая масштабируемость архитектуры, можно по одному блокировать или убирать контроллеры памяти и ROP (всего 6), шейдерные блоки (всего 8 блоков TMU+ALU)
Спецификации референсной карты GeForce 8800 GTX
- Частота ядра 575 МГц
- Частота универсальных процессоров 1350 МГц
- Количество универсальных процессоров 128
- Количество текстурных блоков - 32, блоков блендинга - 24
- Эффективная частота памяти 1.8 ГГц (2*900 МГц)
- Тип памяти GDDR3, 1.1 нс (штатная частота 2*900 МГц)
- Объем памяти 768 мегабайт
- Пропускная способность памяти 86.4 гигабайта в сек.
- Теоретическая максимальная скорость закраски 13.8 гигапикселя в сек.
- Теоретическая скорость выборки текстур 18.4 гигатекселя в сек.
- Два DVI-I разъема (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $599
Спецификации референсной карты GeForce 8800 GTS
- Частота ядра 500 МГц
- Частота универсальных процессоров 1200 МГц
- Количество универсальных процессоров 96
- Количество текстурных блоков - 24, блоков блендинга - 20
- Эффективная частота памяти 1.6 ГГц (2*800 МГц)
- Тип памяти GDDR3, 1.1 нс (штатная частота 2*900 МГц)
- Объем памяти 640 мегабайт
- Пропускная способность памяти 64.0 гигабайта в сек.
- Теоретическая максимальная скорость закраски 10.0 гигапикселя в сек.
- Теоретическая скорость выборки текстур 12.0 гигатекселя в сек.
- Два DVI-I разъема (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $449
Архитектура
Перехода на унифицированные графические архитектуры мы ждали долго. Теперь можно констатировать факт - с появлением GeForce 8800 этот переход случился, и критическая вершина уже пройдена. Дальше последует постепенный спуск подобных архитектур в средний и бюджетный сегменты и их дальнейшее развитие, вплоть до слияния с многоядерными процессорными архитектурами в дальней перспективе. Итак, знакомимся с первой унифицированной архитектурой от NVIDIA:
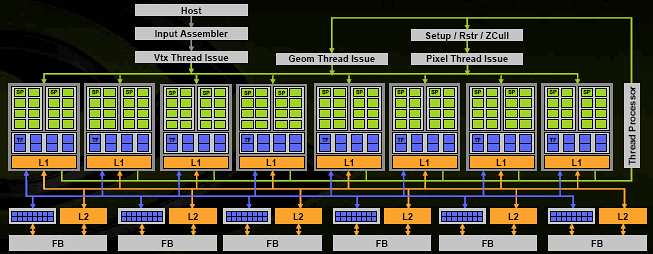
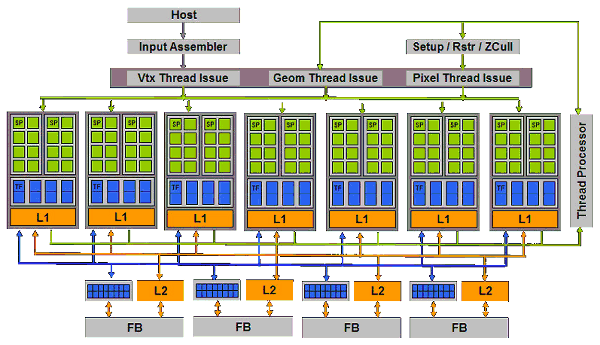
Перед нами вся диаграмма чипа. Чип состоит из 8 универсальных вычислительных блоков (шейдерных процессоров) и хотя NVIDIA говорит о 128 процессорах, заявляя, что каждое ALU является таковым, это несколько неверно - единица исполнения команд - такой вот процессорный блок, в котором сгруппированы 4 TMU и 16 ALU. Всего, таким образом, мы имеем 128 ALU и 32 TMU, но гранулярность исполнения составляет 8 блоков, каждый из которых в один момент может заниматься своим делом, например, исполнять часть вершинного, или пиксельного, или геометрического шейдера над блоком из 32 пикселей (или блоком из соответствующего числа вершин и иных примитивов). Все ветвления, переходы, условия и т.д. применяются целиком к одному блоку и таким образом логичнее всего, его и называть шейдерным процессором, пускай и очень широким.
Каждый такой процессор снабжен собственным кэшем первого уровня, в котором теперь хранятся не только текстуры, но и другие данные, которые могут быть запрошены шейдерным процессором. Важно понимать, что основной поток данных, например пиксели или вершины, которые и проходят обработку, двигаясь по кругу под управлением серого кардинала (блока, помеченного на схеме Thread Processor) - не кэшируются, а идут потоком, в чем и состоит основная прелесть сегодняшних графических архитектур - отсутствие полностью случайного доступа на уровне обрабатываемых примитивов.
Кроме управляющего блока и 8 вычислительных шейдерных процессоров в наличии 6 блоков ROP, исполняющих определение видимости, запись в буфер кадра и MSAA (синие, рядом с блоками кэша L2) сгруппированные с контроллерами памяти, очередями записи и кэшем второго уровня.
Таким образом, мы получили очень широкую (8 блоков, обрабатывающих порции по 32 пикселя каждый) архитектуру способную плавно масштабироваться в обе стороны. Добавление или удаление контроллеров памяти и шейдерных процессоров, будет соответствующим образом масштабировать пропускную способность всей системы, не нарушая баланса и не создавая узких мест. Это логичное и красивое решение, реализующее основной плюс унифицированной архитектуры - автоматический баланс и высокий КПД использования имеющихся ресурсов.
Кроме шейдерных блоков и ROP в наличии набор управляющих и административных блоков:
- Блоки, запускающие на исполнение данные тех или иных форматов (Vertex, Geometry и Pixel Thread Issue) - своеобразные привратники, подготавливающие данные для числодробилки в шейдерных процессорах в соответствии с форматом данных, текущим шейдером и его состоянием, условиями ветвлений и т.д.
- Setup/Raster/ZCull - блок, превращающий вершины в пиксели - здесь выполняется установка, растеризация треугольника на блоки по 32 пикселя, предварительный блочный HSR.
- Input Assembler - блок, выбирающий геометрические и прочие исходные данные из памяти системы или локальной памяти, собирающий из потоков исходные структуры данных, которые пойдут извне на вход нашей «карусели». А на выходе, после многих кругов под управлением вершинного, геометрического, пиксельного шейдера и настроек блендинга, мы получим готовые (и сглаженные, если нужно) пиксели из ROP блоков.
Кстати, небольшое отступление: хорошо видно, что в будущем эти блоки приобретут более общий характер и не будут так завязаны на конкретные виды шейдеров. Т.е. превратятся просто в универсальные блоки, осуществляющие запуск данных на вычисление и конверсию форматов - например, от одного шейдера к другому, от вершинного к пиксельному и т.д. Никаких принципиальных изменений в архитектуру это уже не внесет, диаграмма будет выглядеть и работать практически также, за исключением меньшего числа специальных «серых» блоков. Уже сейчас все три блока Thread Issue являются, скорее всего (реально) одним блоком с общей функциональностью и контекстными дополнениями:

Шейдерный процессор и его TMU/ALU

Итак, в каждом из 8 шейдерных блоков в наличии 16 скалярных ALU. Что, опять таки дает нам потенциальную возможность увеличить КПД их нагрузки вплоть до 100%, вне зависимости от кода шейдера. ALU работают на удвоенной частоте и таким образом соответствуют или превосходят (в зависимости от операций в шейдере) 8 четырехкомпонентных векторных ALU старого образца (G70) на равной базовой частоте ядра. NVIDIA приводит такой расчет пиковой производительности:

Однако он действителен для самого невыгодного для других варианта, когда имеют место два умножения. В реальной жизни стоит поделить это преимущество в полтора раза или около того. Но, в любом случае, эти скалярные ALU за счет более высокой тактовой частоты и их числа обгонят все ранее существовавшие чипы. За исключением, может быть, SLI конфигурации G71, в случае не самых выгодных для новой архитектуры шейдеров.
Интересно, что точность всех ALU составляет FP32 и, с учетом новой архитектуры, мы не предвидим никакого преимущества для FP16 шейдеров с пониженной точностью. Еще один интересный момент - поддержка вычислений в целочисленном формате. Этот пункт необходим для реализации SM4. При реализации арифметики соблюден стандарт IEEE 754, что делает ее пригодной для серьезных неигровых вычислений - научных, статистических, экономических и др.
Теперь о взаимодействии текстурных блоков и ALU в рамках одного шейдерного блока:

Операция выборки и фильтрации текстур не требует ресурсов ALU и может теперь производиться полностью параллельно математическим вычислениям. Генерация же текстурных координат (на схеме - А) по прежнему отнимает часть времени ALU. Это логично, если мы хотим использовать транзисторы чипа на все 100%, ведь генерация текстурных координат требует стандартных плавающих операций и заводить для нее отдельные ALU было бы непредусмотрительно.
Сами по себе текстурные модули имеют следующую конфигурацию:
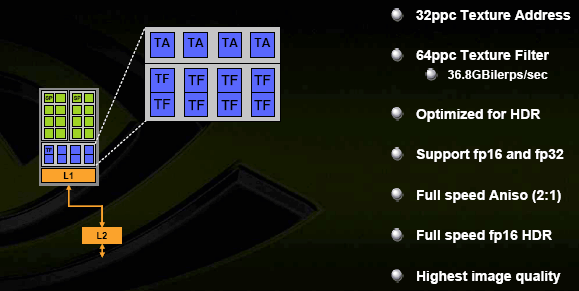
В наличии 4 модуля для адресации текстур TA (определения по координатам точного адреса для выборки) и вдвое больше модулей для билинейной фильтрации TF. Почему так? Это позволяет при умеренном расходовании транзисторов обеспечить бесплатную честную трилинейную фильтрацию или вдвое понизить падение скорости при анизотропной фильтрации. Скорость на обычных разрешениях, в обычной фильтрации и без АА давно не имеет смысла - и предыдущее поколение ускорителей прекрасно справляется в таких условиях. Новым чипом поддерживаются и FP16/FP32 форматы текстур, а также SRGB гамма коррекция на входе (TMU) и выходе (ROP).
Приведем спецификации шейдерной модели новых процессоров, соответствующей требованиям SM4:
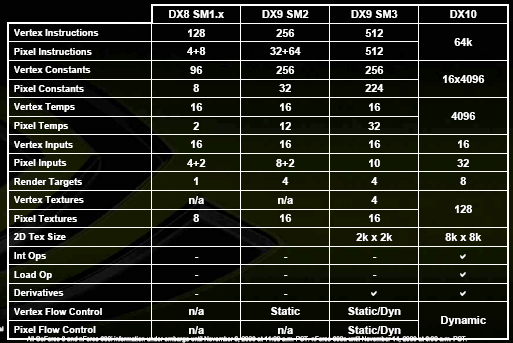
Налицо значительные количественные и качественные перемены - все меньше и меньше ограничений для шейдеров, все больше и больше общего с CPU. Пока что без особого произвольного доступа (такая операция появилась в SM4, - пункт Load Op на диаграмме, но ее эффективность для общих целей пока сомнительна, особенно в первых реализациях), но нет сомнений, что в скором времени и этот аспект будет развит, как была развита за эти 5 лет поддержка FP форматов - от первых проб в NV30 до тотального, сквозного FP32 конвейера во всех режимах сейчас - в G80.
Блоки ROP, запись в буфер кадра, сглаживание
Как мы помним, кроме 8 шейдерных блоков, в наличии 6 блоков ROP:

На диаграмме показаны два отдельных пути для Z и C однако реально это просто один набор ALU, которые делятся на две группы при обработке пикселей с цветом, либо действуют как одна группа при обработке в режиме Z-Only, увеличивая таким образом пропускную способность вдвое. В наше время нет смысла считать отдельные пиксели - их и так достаточно, важнее посчитать сколько MSAA сэмплов может быть обработано за такт. Соответственно, при MSAA 16х чип может выдавать 6 полноценных пикселей за такт, при 8х - 12 и т.д. Интересно, что масштабируемость работы с буфером кадров на высоте - как мы помним, каждый блок ROP работает с собственным контроллером памяти и не мешает соседним.
И наконец-то есть полноценная поддержка FP32 и FP16 форматов буфера кадров вместе с антиалиасингом, теперь нет никаких ограничений для фантазии разработчиков, и HDR на протяжении всего конвейера не требует изменения общей последовательности построения кадра даже в AA режиме.
CSAA
Появился и новый метод сглаживания - CSAA. Скоро на сайте будет его подробное исследование, а пока отметим, что этот метод во многом похож на подход ATI и также имеет дело с псевдостохастическими паттернами и распространением отсчетов на соседние геометрические зоны (происходит размазывание пикселя, пиксели не имеют резкой границы, а как бы переходят один в другой с т.з. AA, покрывая некую зону). Причем цвета отсчетов и глубина хранятся отдельно от информации об их местоположении и таким образом на один пиксель может приходиться 16 отсчетов но, например, всего 8 вычисленных значений глубины - что дополнительно экономит пропускную способность и такты.
Известно, что классический MSAA в режимах, больших чем 4х, становится очень требователен с точки зрения памяти, в то время как качество растет все меньше и меньше. Новый метод корректирует это, позволяя получать 16х режим сглаживания, заметно более качественный чем MSAA 16х, с вычислительными затратами, сравнимыми с 4х MSAA.
NVIO
Еще одно новшество в G80 - вынесенные за предел основного чипа ускорителя интерфейсы. За них теперь отвечает отдельный чип под названием NVIO:

В этом чипе интегрированы:
- 2 * 400 МГц RAMDAC
- 2 * Dual Link DVI (или LVDS)
- HDTV-Out
Подсистема вывода выглядит так:
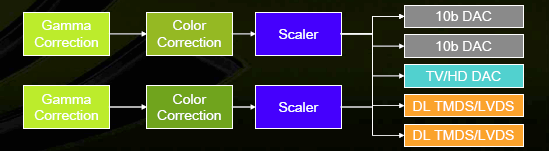
Точность при этом всегда составляет 10 бит на компоненту. Разумеется, в среднем сегменте и тем более в бюджетных решениях отдельный внешний чип может не сохраниться, но для дорогих карт в таком решении больше плюсов, чем минусов. Интерфейсы занимают значительную площадь чипа, сильно зависят от помех, требуют особого питания. Устранив все эти проблемы при помощи внешнего чипа, можно выиграть в качестве выходных сигналов и гибкости конфигурации, а также не усложнять разработку и так сложного чипа учетом оптимальных режимов для встроенных RAMDAC.
Подробности: G84/G86, семейства GeForce 8600 и 8500
Спецификации G84
- Официальное название чипа GeForce 8600
- Кодовое имя G84
- Технология 80 нм
- 289 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе и новой шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 128-бит шина памяти, два независимых контроллера шириной 64 бита
- Частота ядра до 675 МГц (GeForce 8600 GTS)
- ALU работают на более чем удвоенной частоте (1.45 ГГц для GeForce 8600 GTS)
- 32 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- 16 текстурных блоков, поддержка FP16 и FP32 компонент в текстурах
- 16 блоков билинейной фильтрации (по сравнению с G80 нет возможности бесплатной трилинейной фильтрации и более эффективной по скорости анизотропной фильтрации)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 2 широких блока ROP (8 пикселей) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 32 MSAA отсчетов (+ 32 Z) за такт, в режиме без цвета (Z only) — 64 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы (два RAMDAC, два Dual DVI, HDMI, HDTV) интегрированы на чип (в отличие от вынесенных на внешний дополнительный чип NVIO у GeForce 8800)
Спецификации референсной карты GeForce 8600 GTS
- Частота ядра 675 МГц
- Частота универсальных процессоров 1450 МГц
- Количество универсальных процессоров 32
- Количество текстурных блоков — 16 (см. синтетику), блоков блендинга — 8
- Эффективная частота памяти 2.0 ГГц (2*1000 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 32.0 гигабайта в сек.
- Теоретическая максимальная скорость закраски 5.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур 10.8 гигатекселя в сек.
- Энергопотребление до 71 Вт
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600)
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $199-229
Спецификации референсной карты GeForce 8600 GT
- Частота ядра 540 МГц
- Частота универсальных процессоров 1180 МГц
- Количество универсальных процессоров 32
- Количество текстурных блоков — 16 (см. синтетику), блоков блендинга — 8
- Эффективная частота памяти 1.4 ГГц (2*700 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 22.4 гигабайта в сек.
- Теоретическая максимальная скорость закраски 4.3 гигапикселя в сек.
- Теоретическая скорость выборки текстур 8.6 гигатекселя в сек.
- Энергопотребление до 43 Вт
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600)
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, опциональная поддержка HDCP
- Рекомендуемая цена $149-159
Спецификации G86
- Официальное название чипа GeForce 8500
- Кодовое имя G86
- Технология 80 нм
- 210 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе и новой шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 128-бит шина памяти, два независимых контроллера шириной 64 бита
- Частота ядра до 450 МГц (GeForce 8500 GT)
- ALU работают на удвоенной частоте (900 МГц для GeForce 8500 GT)
- 16 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- 8 текстурных блоков, поддержка FP16 и FP32 компонент в текстурах
- 8 блоков билинейной фильтрации (по сравнению с G80, нет возможности бесплатной трилинейной фильтрации и более эффективной по скорости анизотропной фильтрации)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 2 широких блока ROP (8 пикселей) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 32 MSAA отсчетов (+ 32 Z) за такт, в режиме без цвета (Z only) — 64 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы (два RAMDAC, два Dual DVI, HDMI, HDTV) интегрированы на чип (в отличие от вынесенных на внешний дополнительный чип NVIO у GeForce 8800)
Спецификации референсной карты GeForce 8500 GT
- Частота ядра 450 МГц
- Частота универсальных процессоров 900 МГц
- Количество универсальных процессоров 16
- Количество текстурных блоков — 8, блоков блендинга — 8
- Эффективная частота памяти 800 МГц (2*400 МГц)
- Тип памяти DDR2
- Объем памяти 256/512 мегабайт
- Пропускная способность памяти 12.8 гигабайта в сек.
- Теоретическая максимальная скорость закраски 3.6 гигапикселя в сек.
- Теоретическая скорость выборки текстур 3.6 гигатекселя в сек.
- Энергопотребление до 40 Вт
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600)
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, опциональная поддержка HDCP
- Рекомендуемая цена $89-129
Архитектура G84 и G86
Уже по спецификациям видно, что G84 — это что-то среднее между одной четвертой и одной третьей частей флагмана линейки G80. С точки зрения количества универсальных процессоров получается четверть, а с точки зрения количества блоков ROP и контроллера памяти — треть. С текстурниками сложнее, это вроде бы не четверть, но и не половина, об этом мы поговорим ниже. G86, в свою очередь, вообще нечто интересное — по вычислительной мощности всего лишь 1/8 от G80, а по ROP — всё та же 1/3. Явно NVIDIA не торопится спускать в low-end чипы, быстрые вычислительно.
Основной вопрос тут — а достаточно ли будет этой самой четвертинки и 1/8 для того, чтобы составить достойную конкуренцию нынешним решениям и будущим чипам AMD? Не слишком ли сильно урезали в NVIDIA количество блоков? Причем, не сказать, чтобы по количеству транзисторов оба чипа были слишком маленькие... В G84 почти половина транзисторов G80, в G86 — почти треть. Похоже, что решение компромиссное, если бы они оставляли половину блоков G80, то чип был бы слишком дорогим в производстве, да и составлял бы успешную конкуренцию своим же GeForce 8800 GTS.
В ближайшем будущем, скорее всего, на основе технологии 65 нм можно будет сделать более производительные чипы для среднего и нижнего ценовых диапазонов, а сейчас пока что получилось так. Мы рассмотрим вопрос производительности новых чипов в синтетических и игровых тестах, но уже сейчас можно сказать, что G84 и G86 могут быть не слишком быстрыми из-за малого количества ALU, они, скорее всего, будут примерно наравне с текущими решениями схожей с ними цены.
На архитектуре G84 и G86 мы не будем останавливаться слишком подробно, изменений по сравнению с G80 тут немного, в силе остается всё сказанное в обзоре GeForce 8800, с поправкой на количественные характеристики. Но все же опишем основные моменты, которые стоят нашего внимания и приведем несколько слайдов, посвященных архитектурным спецификациям новых чипов.
G80 состоит из восьми универсальных вычислительных блоков (шейдерных процессоров), NVIDIA предпочитает говорить о 128 процессорах. Единица исполнения команд, судя по всему, это такой процессорный блок целиком, в котором сгруппированы 4 TMU и 16 ALU. Каждый из блоков в один момент может исполнять часть вершинного, пиксельного или геометрического шейдера над блоком из 32 пикселей, вершин или иных примитивов, также может заниматься физическими расчетами. У каждого процессора есть свой кэш первого уровня, в котором хранятся текстуры и другие данные. Кроме управляющего блока и вычислительных шейдерных процессоров присутствует шесть блоков ROP, исполняющих определение видимости, запись в буфер кадра и MSAA, сгруппированные c контроллерами памяти, очередями записи и кэшем второго уровня.
Эта архитектура способна масштабироваться в обе стороны, что и было сделано в новых решениях. Мы уже упоминали об этом красивом решении, реализующем основной плюс унифицированной архитектуры — автоматический баланс и высокий КПД использования имеющихся ресурсов в статье по GeForce 8800. Там же предполагалось, что решение среднего уровня будет состоять из половины вычислительных блоков, а решение на основе двух шейдерных процессоров и одного ROP станет бюджетным. К сожалению, если в GeForce 8800 было восемь процессоров, составляющих 32 TMU и 128 ALU, в новых чипах их количество урезали сильнее, чем мы предполагали изначально. Судя по всему, схема G84 выглядит так:
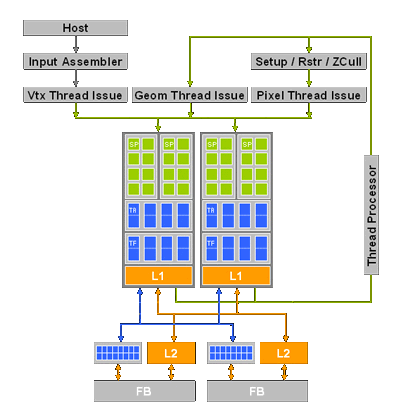
То есть, всё осталось неизменным, кроме количества блоков и контроллеров памяти. Есть небольшие изменения, связанные с текстурными блоками и заметные на этом рисунке, но об этом мы поговорим далее. Любопытно, куда ушло столько транзисторов, если всего лишь 32 процессора в G84 оставили? В G84 чуть ли не половина транзисторов, по сравнению с G80, при значительно сниженном числе каналов памяти, ROP и шейдерных процессоров. Да и у G86 транзисторов очень много, при всего лишь 16-ти процессорах...
Интересно также, насколько качественно в реальных приложениях будет балансироваться нагрузка между исполнением вершинных, пиксельных и геометрических шейдеров, ведь число универсальных исполнительных блоков стало теперь значительно меньше. Тем более, что сама по себе унифицированная архитектура ставит новые задачи перед разработчиками, при её использовании придётся думать о том, как эффективно использовать общую мощность между вершинными, пиксельными и геометрическими шейдерами. Приведем простой пример — упор в пиксельные расчёты. В этом случае увеличение нагрузки на вершинные блоки в традиционной архитектуре не приведет к падению производительности, а в унифицированной — вызовет изменение баланса и уменьшение количества ресурсов для пиксельных расчетов. Мы обязательно рассмотрим вопрос производительности, а сейчас продолжим исследование изменений в архитектуре G84 и G86.
Шейдерный процессор и TMU/ALU
Схема шейдерных блоков и оценка их пиковой вычислительной производительности G80 приводилась в соответствующей статье, для G84 и G86 схема не изменилась, а их производительность пересчитать несложно. ALU в чипах также работают на удвоенной частоте и они скалярные, что позволяет добиться высокого КПД. Никаких отличий нет и по функциональности, точность всех ALU составляет FP32, есть поддержка вычислений в целочисленном формате, а при реализации соблюден стандарт IEEE 754, важный для научных, статистических, экономических и других вычислений.
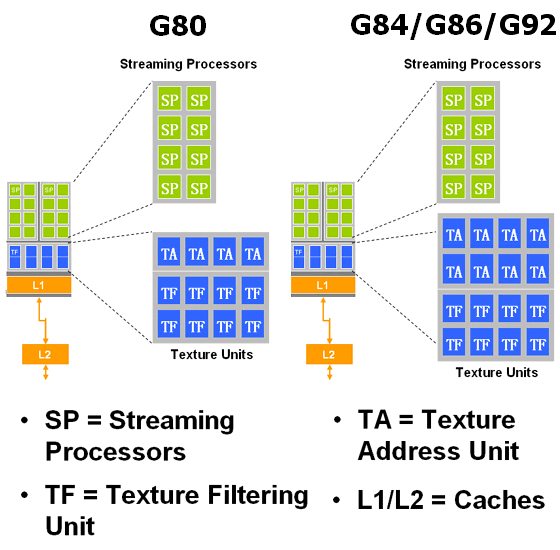
А вот текстурные модули по сравнению с примененными в G80 изменились, NVIDIA уверяет, что в новых чипах были сделаны архитектурные изменения для увеличения производительности унифицированных процессоров. В G80 каждый текстурник мог вычислять четыре текстурных адреса и выполнять восемь операций текстурной фильтрации за такт. Утверждается, что в новых чипах первое число было увеличено вдвое, и он способен на большее в два раза количество текстурных выборок. То есть, текстурные модули G84 и G86 имеют следующую конфигурацию (для сравнения слева приведена схема блока G80):
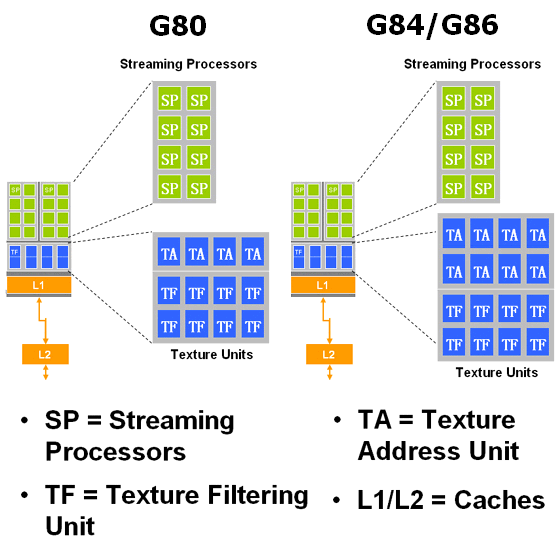
По словам NVIDIA, теперь каждый из блоков имеет восемь модулей адресации текстур (определения по координатам точного адреса для выборки) TA и ровно такое же количество модулей билинейной фильтрации (TF). У G80 было четыре модуля TA и восемь TF, что позволяло при сниженном расходе транзисторов обеспечить «бесплатную» трилинейную фильтрацию или вдвое снизить падение скорости при анизотропной фильтрации, что полезно именно для ускорителей верхнего уровня, где анизотропная фильтрации используется пользователями почти всегда. Мы проверим правильность этой информации в практической части, обязательно посмотрите анализ соответствующих синтетических тестов, так как они противоречат этим данным.
Вся остальная функциональность текстурных блоков одинакова, поддерживаются форматы текстур FP16/FP32 и др. Только если на G80 фильтрация FP16 текстур также была на полной скорости из-за удвоенного количества блоков фильтрации, в решениях среднего и нижнего уровней такого уже нет (опять же, при условии, если вышеуказанные изменения действительно имеются).
Блоки ROP, запись в буфер кадра, сглаживание
Блоки ROP, которых в G80 было шесть штук, а в новых чипах стало по два, не изменились:
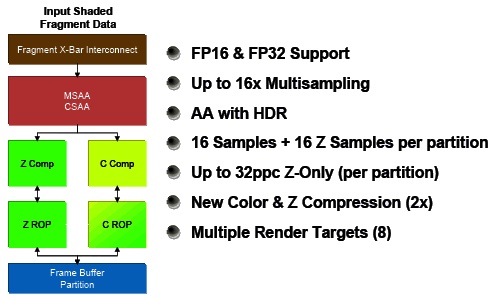
Каждый из блоков обрабатывает по четыре пикселя (16 субпикселей), всего получается 8 пикселей за такт для цвета и Z. В режиме только Z обрабатывается в два раза большее количество сэмплов за один такт. При MSAA 16х чип может выдавать два пикселя за такт, при 4х — 8 и т.д. Как и в G80, есть полноценная поддержка FP32 и FP16 форматов буфера кадров совместно с антиалиасингом.
Поддерживается известный по GeForce 8800 новый метод сглаживания — Coverage Sampled Antialiasing (CSAA), который был подробно описан в соответствующем материале:
- [15.12.06] Детальное исследование Coverage Sampling Antialiasing, реализованного в серии GPU GeForce 8800
Вкратце, суть метода такова, что цвета отсчетов и глубина хранятся отдельно от информации об их местоположении, на один пиксель может приходиться по 16 отсчетов и всего 8 вычисленных значений глубины, что экономит пропускную способность и такты. CSAA позволяет обойтись передачей и хранением одного значения цвета или Z на каждый субпиксель, уточняя усредненное значение экранного пикселя за счёт более подробной информации о том, как этот пиксель перекрывает края треугольников. В итоге, новый метод позволяет получать режим сглаживания 16х, заметно более качественный чем MSAA 4х, с вычислительными затратами, сравнимыми с ним. А в редких случаях, в которых метод CSAA не работает, получается обычный MSAA меньшей степени, а не полное отсутствие антиалиасинга.
PureVideo HD
Переходим к наиболее интересным изменениям. Оказывается, в G84 и G86 есть нововведения, выгодно отличающие их даже от G80! Это касается встроенного видеопроцессора, который в новых чипах получил расширенную поддержку PureVideo HD. Заявлено, что эти чипы полностью разгружают центральный процессор системы при декодировании всех типов распространенных видеоданных, в том числе наиболее «тяжелого» формата H.264.
В G84 и G86 используется новая модель программируемого PureVideo HD видеопроцессора, более мощная, по сравнению с примененной в G80, и включающая так называемый BSP движок. Новый процессор поддерживает декодирование H.264, VC-1 и MPEG-2 форматов с разрешением до 1920x1080 и битрейтом до 30-40 Мбит/с, он выполняет всю работу по декодированию CABAC и CAVLC данных аппаратно, что позволяет воспроизводить все существующие HD-DVD и Blu-ray диски даже на средних по мощности одноядерных ПК.
Видеопроцессор в G84/G86 состоит из нескольких частей: сам Video Processor второго поколения (VP2), выполняющий задачи IDCT, компенсации движения и удаления артефактов блочности для MPEG2, VC-1 и H.264 форматов, поддерживающий аппаратное декодирование второго потока; поточный процессор (BSP), выполняющий задачи статистического декодирования CABAC и CAVLC для формата H.264, а это одни из самых трудоёмких расчетов; движок декодирования защищенных данных AES128, предназначение которого понятно из его названия — он занимается расшифровкой видеоданных, используемых в защите от копирования на Blu-ray и HD-DVD дисках. Вот так выглядят различия в степени аппаратной поддержки декодирования видео на разных видеочипах:
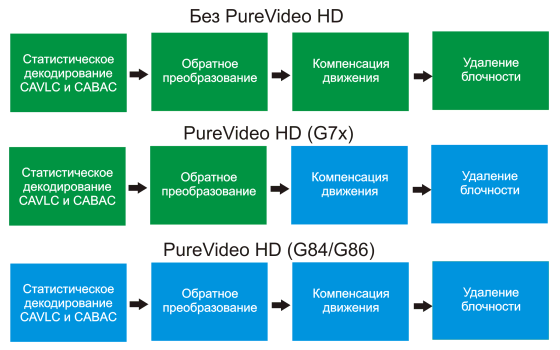
Голубым цветом выделены задачи, выполняемые видеочипом, а зелёным — центральным процессором. Как видите, если предыдущее поколение помогало процессору только в части задач, то новый видеопроцессор, применяемый в последних чипах, делает все задачи сам. Эффективность решений мы проверим в будущих материалах по исследованию эффективности аппаратного декодирования видео, NVIDIA же приводит в материалах такие цифры: при использовании современного двухъядерного процессора и программного декодирования данных, воспроизведение дисков Blu-ray и HD-DVD съедает до 90-100% процессорного времени, при аппаратном декодировании на видеочипе прошлого поколения на той же системе — до 60-70%, а с новым движком, который они разработали для G84 и G86 — всего лишь 20%. Это, конечно, не похоже на заявленное полностью аппаратное декодирование, но все же на очень и очень эффективное.
На момент анонса, новые возможности, появившиеся в PureVideo HD, работают лишь в 32-битной версии Windows Vista, а поддержка PureVideo HD в Windows XP появится только летом. Что касается качества воспроизведения видео, постобработки, деинтерлейсинга и т.п., то с этим у NVIDIA дела улучшились еще в GeForce 8800, а новые чипы ничем особенно не отличаются в этом плане.
CUDA, неигровые и физические расчеты
В статье по GeForce 8800 упоминалось, что увеличившаяся пиковая производительность плавающей арифметики у новых ускорителей и гибкость унифицированной шейдерной архитектуры, стали достаточны для расчета физики в игровых приложениях и даже более серьезных задач: математического и физического моделирования, экономических и статистических моделей и расчетов, распознавания образов, обработки изображений, научной графики и многого другого. Для этого был выпущен специальный API, ориентированный на вычисления, который удобен для адаптации и разработки программ, перекладывающих вычисления на GPU — CUDA (Compute Unified Device Architecture).
Подробнее о CUDA написано в статье о G80, мы остановимся на еще одном модном направлении в последнее время — поддержке физических расчетов на GPU. NVIDIA называет подобную свою технологию Quantum Effects. Декларируется, что все видеочипы нового поколения, включая рассматриваемые сегодня G84 и G86, неплохо подходят для расчетов подобного рода, позволяя перенести часть нагрузки с CPU на GPU. В качестве конкретных примеров приводятся симуляции дыма, огня, взрывов, динамики волос и одежды, шерсти и жидкостей, и многого другого. Но пока что больше хочется написать о другом. О том, что пока нам показывают только картинки из тестовых приложений с большим количеством рассчитываемых видеочипами физических объектов, а играми с такой поддержкой даже пока и не пахнет.

Поддержка внешних интерфейсов
Как мы помним, в GeForce 8800 нас несколько удивило еще одно неожиданное новшество — дополнительный чип, поддерживающий вынесенные за пределы основного внешние интерфейсы. В случае топовых видеокарт этими задачами занимается отдельный чип под названием NVIO, в котором интегрированы: два 400 МГц RAMDAC, два Dual Link DVI (или LVDS), HDTV-Out. Уже тогда мы предполагали, что в среднем и нижнем сегментах отдельный внешний чип вряд ли сохранится, так и получилось на самом деле. В G84 и G86 поддержка всех указанных интерфейсов встроена в сам чип.
На GeForce 8600 GTS устанавливаются два Dual Link DVI-I выхода с поддержкой HDCP, это первая видеокарта на рынке с подобными возможностями (HDCP и Dual Link совместно). Что касается HDMI, поддержка этого разъема аппаратно реализована полностью и может быть выполнена производителями на картах специального дизайна. А вот у GeForce 8600 GT и 8500 GT поддержка HDCP и HDMI опциональная, но они вполне могут быть реализованы отдельными производителями в своей продукции.
Подробности: G92, семейство GeForce 8800
Спецификации G92
- Кодовое имя чипа G92
- Технология 65 нм
- 754 миллиона транзисторов (больше, чем у G80)
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 256-бит шина памяти, четыре независимых контроллера шириной по 64 бита
- Частота ядра 600 МГц (GeForce 8800 GT)
- ALU работают на более чем удвоенной частоте (1.5 ГГц для GeForce 8800 GT)
- 112 (это у для GeForce 8800 GT, а всего, вероятно, 128) скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- 56 (64) блоков текстурной адресации с поддержкой FP16 и FP32 компонент в текстурах (пояснения см. ниже)
- 56 (64) блоков билинейной фильтрации (как и в G84 и G86, нет бесплатной трилинейной фильтрации и более эффективной анизотропной фильтрации)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 4 широких блока ROP (16 пикселей) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 64 MSAA отсчетов (+ 64 Z) за такт, в режиме без цвета (Z only) — 128 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы (два RAMDAC, два Dual DVI, HDMI, HDTV) интегрированы на чип (в отличие от вынесенных на внешний дополнительный чип NVIO у GeForce 8800)
Спецификации референсной карты GeForce 8800 GT 512MB
- Частота ядра 600 МГц
- Частота универсальных процессоров 1500 МГц
- Количество универсальных процессоров 112
- Количество текстурных блоков — 56, блоков блендинга — 16
- Эффективная частота памяти 1.8 ГГц (2*900 МГц)
- Тип памяти GDDR3
- Объем памяти 512 мегабайт
- Пропускная способность памяти 57.6 гигабайта в сек.
- Теоретическая максимальная скорость закраски 9.6 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 33.6 гигатекселя в сек.
- Энергопотребление до 110 Вт
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $249
Спецификации референсной карты GeForce 8800 GT 256MB
- Частота ядра 600 МГц
- Частота универсальных процессоров 1500 МГц
- Количество универсальных процессоров 112
- Количество текстурных блоков — 56, блоков блендинга — 16
- Эффективная частота памяти 1.4 ГГц (2*700 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 44.8 гигабайта в сек.
- Теоретическая максимальная скорость закраски 9.6 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 33.6 гигатекселя в сек.
- Энергопотребление до 110 Вт
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $199
Спецификации референсной карты GeForce 8800 GTS 512MB
- Частота ядра 650 МГц
- Частота универсальных процессоров 1625 МГц
- Количество универсальных процессоров 128
- Количество текстурных блоков — 64, блоков блендинга — 16
- Эффективная частота памяти 2.0 ГГц (2*1000 МГц)
- Тип памяти GDDR3
- Объем памяти 512 мегабайт
- Пропускная способность памяти 64.0 гигабайта в сек.
- Теоретическая максимальная скорость закраски 10.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 41.6 гигатекселя в сек.
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDCP
- Рекомендуемая цена $349-399
Архитектура чипа G92
Архитектурно G92 от G80 отличается не сильно. По тому, что нам известно, можно сказать, что G92 — это флагман линейки (G80), переведенный на новый техпроцесс, с небольшими изменениями. NVIDIA указывает в своих материалах, что чип имеет 7 больших шейдерных блоков и, соответственно, 56 текстурных блоков, а также по четыре широких ROP, число транзисторов в чипе вызывает подозрения о том, что они что-то не договаривают. В анонсированных изначально решениях задействованы не все блоки, существующие в чипе физически, их количество в G92 больше, чем активных в GeForce 8800 GT. Хотя увеличенная сложность чипа объясняется включением в его состав ранее отдельного чипа NVIO, а также видеопроцессора нового поколения. Кроме того, на количество транзисторов повлияли и усложненные блоки TMU. Также, вполне вероятно, были увеличены кэши для увеличения эффективности использования 256-битной шины памяти.
В этот раз, чтобы составить достойную конкуренцию соответствующим чипам AMD, в NVIDIA решили оставить в mid-end чипе довольно большое количество блоков. Подтвердилось наше предположение из обзора G84 и G86, что на основе технологии 65 нм выпустят гораздо более производительные чипы для среднего ценового диапазона. Архитектурных изменений в чипе G92 немного, и мы не будем на этом останавливаться подробно. Всё сказанное выше про решения из серии GeForce 8 остаётся в силе, мы повторим только некоторые основные моменты, посвященных архитектурным спецификациям нового чипа.
Для нового решения NVIDIA в своих документах приводит такую схему:
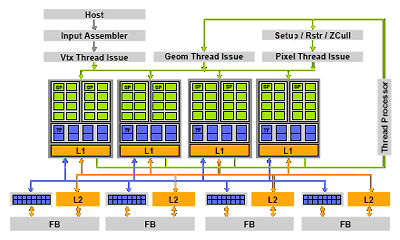
То есть из всех изменений — только уменьшенное количество блоков и некоторые изменения в TMU, о которых написано далее. Как выше указано, есть сомнения в том, что физически это так и есть, но даём описание, исходя из того, что пишет NVIDIA. G92 состоит из семи универсальных вычислительных блоков (шейдерных процессоров), NVIDIA традиционно говорит о 112 процессорах (по крайней мере, в первых решениях GeForce 8800 GT). Каждый из блоков, в котором сгруппированы 8 TMU и 16 ALU, может исполнять часть вершинного, пиксельного или геометрического шейдера над блоком из 32 пикселей, вершин или иных примитивов, может заниматься и другими (неграфическими) расчетами. У каждого процессора есть свой кэш первого уровня, в котором хранятся текстуры и другие данные. Кроме управляющего блока и вычислительных шейдерных процессоров присутствует четыре блока ROP, исполняющих определение видимости, запись в буфер кадра и MSAA, сгруппированные c контроллерами памяти, очередями записи и кэшем второго уровня.
Универсальные процессоры и TMU
Схема шейдерных блоков и оценка их пиковой вычислительной производительности G80 приводилась в соответствующей статье, для G92 она не изменилась, их производительность пересчитать несложно, исходя из изменений в тактовой частоте. ALU в чипах работают на более чем удвоенной частоте, они скалярные, что позволяет добиться высокого КПД. Про функциональные отличия пока что неизвестно, доступна ли точность расчетов FP64 в этом чипе или нет. Точно есть поддержка вычислений в целочисленном формате, а при реализации всех вычислений соблюден стандарт IEEE 754, важный для научных, статистических, экономических и других расчетов.
Текстурные модули в G92 не такие, как в G80, они повторяют решение TMU в G84 и G86, в которых были сделаны архитектурные изменения для увеличения производительности. Напомним, что в G80 каждый текстурник мог вычислять по четыре текстурных адреса и выполнять по восемь операций текстурной фильтрации за такт, а в G84/G86 TMU способны на большее в два раза количество текстурных выборок. То есть, каждый из блоков имеет восемь модулей адресации текстур (определения по координатам точного адреса для выборки) TA и ровно такое же количество модулей билинейной фильтрации (TF):
Не стоит думать, что 56 блоков GeForce 8800 GT в реальных применениях будут сильнее 32 блоков в GeForce 8800 GTX. При включенной трилинейной и/или анизотропной фильтрации последние будут быстрее, так как они смогут выполнит чуть больше работы по фильтрации текстурных выборок. Мы проверим эту информацию в практической части, сделав анализ результатов соответствующих синтетических тестов. Вся остальная функциональность текстурных блоков не изменилась, поддерживаются форматы текстур FP16, FP32 и другие.
Блоки ROP, запись в буфер кадра, сглаживание
Блоки ROP сами по себе также не изменились, но их количество стало другим. В G80 было шесть ROP, а в новом решении их стало четыре, для снижения себестоимости производства чипов и PCB видеокарт. Также это урезание может быть связано с тем, чтобы не создавать слишком сильную конкуренцию существующим решениям верхнего уровня.
Каждый из блоков обрабатывает по четыре пикселя или 16 субпикселей, и всего получается 16 пикселей за такт для цвета и Z. В режиме только Z обрабатывается в два раза большее количество сэмплов за один такт. При MSAA 16х чип может выдавать два пикселя за такт, при 4х — 8 и т.д. Как и в G80, полноценно поддерживаются форматы буфера кадров FP32 и FP16 совместно с антиалиасингом.
Поддерживается известный по предыдущим чипам серии новый метод сглаживания — Coverage Sampled Antialiasing (CSAA). А ещё одним нововведением стало то, что в GeForce 8800 GT был обновлен алгоритм антиалиасинга полупрозрачных поверхностей (transparency antialiasing). На выбор пользователя предлагались два варианта: мультисэмплинг (TRMS) и суперсэмплинг (TRSS), первый отличался очень хорошей производительностью, но эффективно работал далеко не во всех играх, а второй был качественным, но медленным. В GeForce 8800 GT декларируется новый метод мультисэмплинга полупрозрачных поверхностей, улучшающий его качество и производительность. Этот алгоритм даёт почти такое же улучшение качества, как и суперсэмплинг, но отличается высокой производительностью — лишь на несколько процентов хуже для режима без включенного антиалиасинга полупрозрачных поверхностей.
PureVideo HD
Одним из ожидаемых изменений в G92 стал встроенный видеопроцессор второго поколения, известный по G84 и G86, получивший расширенную поддержку PureVideo HD. Уже известно, что этот вариант видеопроцессора почти полностью разгружает CPU при декодировании всех типов видеоданных, в том числе «тяжелых» форматов H.264 и VC-1.
Как и в G84/G86, в G92 используется новая модель программируемого PureVideo HD видеопроцессора, включающая так называемый BSP движок. Новый процессор поддерживает декодирование H.264, VC-1 и MPEG-2 форматов с разрешением до 1920x1080 и битрейтом до 30-40 Мбит/с, выполняя работу по декодированию CABAC и CAVLC данных аппаратно, что позволяет воспроизводить все существующие HD-DVD и Blu-ray диски даже на средних по мощности одноядерных ПК. Декодирование VC-1 не такое эффективное, как H.264, но оно всё же поддерживается новым процессором.
Подробнее о видеопроцессоре второго поколения можно прочитать в части, посвященной чипам G84 и G86. Работа современных видеорешений была частично проверена в последнем материале по исследованию эффективности аппаратного декодирования видеоданных.
PCI Express 2.0
Из настоящих нововведений в G92 можно выделить поддержку шины PCI Express 2.0. Вторая версия PCI Express увеличивает стандартную пропускную способность в два раза, с 2.5 Гбит/с до 5 Гбит/с, в результате, по разъему x16 можно передавать данные на скорости до 8 ГБ/с в каждом направлении, в отличие от 4 ГБ/с для версии 1.x. При этом очень важно, что PCI Express 2.0 совместим с PCI Express 1.1, и старые видеокарты будут работать в новых системных платах, и новые видеокарты с поддержкой второй версии останутся работоспособными в платах без его поддержки. При условии достаточности внешнего питания и без увеличения пропускной способности интерфейса, естественно.
Для обеспечения обратной совместимости с существующими PCI Express 1.0 и 1.1 решениями, спецификация 2.0 поддерживает как 2.5 Гбит/с, так и 5 Гбит/с скорости передачи. Обратная совместимость PCI Express 2.0 позволяет использовать прошлые решения с 2.5 Гбит/с в 5.0 Гбит/с слотах, которые будут работать на меньшей скорости, а устройство, разработанное по спецификациям версии 2.0, может поддерживать и 2.5 Гбит/с и 5 Гбит/с скорости. В теории с совместимостью всё хорошо, а вот на практике с некоторыми сочетаниями системных плат и карт расширения возможно возникновение проблем.
Поддержка внешних интерфейсов
Как и следовало ожидать, имеющийся на платах GeForce 8800 дополнительный чип NVIO, поддерживающий вынесенные за пределы основного внешние интерфейсы (два 400 МГц RAMDAC, два Dual Link DVI (или LVDS), HDTV-Out), в данном случае был включен в состав самого чипа, поддержка всех указанных интерфейсов встроена в сам G92.
На видеокартах GeForce 8800 GT обычно устанавливают два Dual Link DVI-I выхода с поддержкой HDCP. Что касается HDMI, поддержка этого разъема реализована полностью, она может быть выполнена производителями на картах специального дизайна, которые могут быть выпущены несколько позже. Хотя наличие разъема HDMI на видеокарте совершенно необязательно, его с успехом заменит переходник с DVI на HDMI, который прилагается в комплекте большинства современных видеокарт.
В отличие от видеокарт серии RADEON HD 2000 компании AMD, GeForce 8800 GT не содержит встроенный аудиочип, необходимый для поддержки передачи звука по DVI при помощи переходника на HDMI. Подобная возможность передачи видео- и аудиосигнала по одному разъему востребована, прежде всего, на картах среднего и низшего уровней, которые устанавливаются в маленькие корпусы медиацентров, а GeForce 8800 GT вряд ли подходит на эту роль.
Подробности: G94, семейство GeForce 9600
Спецификации G94
- Кодовое имя чипа G94
- Технология 65 нм
- 505 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 256-бит шина памяти, четыре независимых контроллера шириной по 64 бита
- Частота ядра 650 МГц (GeForce 9600 GT)
- ALU работают на более чем удвоенной частоте (1.625 ГГц у GeForce 9600 GT)
- 64 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- 32 блока текстурной адресации с поддержкой FP16 и FP32 компонент в текстурах
- 32 блока билинейной фильтрации (как и в G84 и G92, это даёт увеличенное количество билинейных выборок, но без бесплатной трилинейной фильтрации и эффективной анизотропной фильтрации)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 4 широких блока ROP (16 пикселей) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 64 MSAA отсчетов (+ 64 Z) за такт, в режиме без цвета (Z only) — 128 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы (два RAMDAC, два Dual DVI, HDMI, DisplayPort) интегрированы на чип
Спецификации референсной карты GeForce 9600 GT
- Частота ядра 650 МГц
- Частота универсальных процессоров 1625 МГц
- Количество универсальных процессоров 64
- Количество текстурных блоков — 32, блоков блендинга — 16
- Эффективная частота памяти 1.8 ГГц (2*900 МГц)
- Тип памяти GDDR3
- Объем памяти 512 мегабайт
- Пропускная способность памяти 57.6 гигабайта в сек.
- Теоретическая максимальная скорость закраски 10.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 20.8 гигатекселя в сек.
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDMI и DisplayPort с HDCP
- Энергопотребление до 95 Вт
- Рекомендуемая цена $169-189
Архитектура G94
С архитектурной точки зрения G94 отличается от G92 только количественными характеристиками, у него меньшее число исполнительных блоков: ALU и TMU. Да и от G8x отличий не так много. Как было написано в предыдущих материалах, линейка чипов G9x является слегка модифицированной линейкой G8x, переведенной на новый техпроцесс с небольшими архитектурными изменениями. Новый mid-end чип имеет 4 больших шейдерных блока (всего 64 ALU) и 32 текстурных блока, а также четыре широких ROP.
Итак, архитектурных изменений в чипе немного, почти обо всех написано выше, и всё ранее сказанное для предыдущих решений остаётся в силе. А здесь приведём только основную диаграмму чипа G94:
Текстурные блоки в G94 точно такие же, что и в G84/G86 и G92, они умеют выбирать вдвое больше билинейно отфильтрованных выборок из текстур, по сравнению с G80. Но 32 текстурных блока GeForce 9600 GT в реальных приложения не будут работать быстрее, чем 32 блока у GeForce 8800 GTX лишь из-за большей рабочей частоты GPU. Такое может наблюдаться только при выключенной трилинейной и анизотропной фильтрации, что бывает крайне редко, только в тех алгоритмах, где применяются неотфильтрованные выборки, к примеру, в parallax mapping.
Ещё одним из преимуществ G9x и GeForce 9600 GT в частности, компания NVIDIA считает некую новую технологию сжатия, реализованную в блоках ROP, которая, по их оценке, работает на 15% эффективнее той, что использовалась в предыдущих чипах. Видимо, это как раз те самые архитектурные модификации в G9x, предназначенные для обеспечения большей эффективности работы 256-битной шины памяти, по сравнению с 320/384-битной, о которых мы писали ранее. Естественно, в реальных приложениях такой большой разницы не будет, даже по данным самой NVIDIA прирост от нововведений в ROP чаще всего составляет лишь около 5%.
Несмотря на все изменения в архитектуре G9x, добавляющие сложности чипу, о которых мы ещё поговорим ниже, число транзисторов в чипе довольно велико. Вероятно, такая сложность GPU объясняется включением в его состав ранее отдельного чипа NVIO, видеопроцессора нового поколения, усложнение блоков TMU и ROP, а также другие скрытые модификации: изменение размеров кэшей и т.п.
PureVideo HD
В G94 встроен всё тот же видеопроцессор второго поколения, известный по G84/G86 и G92, отличающийся улучшенной поддержкой PureVideo HD. Он почти полностью разгружает CPU при декодировании большинства распространенных типов видеоданных, в том числе H.264, VC-1 и MPEG-2, с разрешением до 1920x1080 и битрейтом до 30-40 Мбит/с, выполняя работу по декодированию полностью аппаратно. И хотя декодирование VC-1 у решений NVIDIA не такое эффективное, как H.264, небольшая часть процесса использует мощности центрального процессора, но это всё равно позволяет воспроизводить все существующие HD DVD и Blu-Ray диски даже на средних по мощности компьютерах. Подробнее о видеопроцессоре второго поколения можно прочитать в наших обзорах G84/G86 и G92, ссылки на которые приведены в начале статьи.
Ну а мы отметим программные улучшения PureVideo HD, которые были приурочены к выходу GeForce 9600 GT. Из последних нововведений PureVideo HD можно отметить двухпоточное декодирование, динамическое изменение контрастности и цветовой насыщенности. Эти изменения не исключительны для GeForce 9600 GT, и в новых версиях драйверов, начиная с ForceWare 174, они введены для всех чипов, поддерживающих полное аппаратное ускорение при помощи PureVideo HD. Помимо рассматриваемой сегодня видеокарты, в этот список входят: GeForce 8600 GT/GTS, GeForce 8800 GT и GeForce 8800 GTS 512.
Динамическое улучшение контрастности довольно часто используется в бытовой технике, в телевизорах и видеоплеерах, оно может улучшить изображение с неоптимальной экспозицией (сочетание выдержки и диафрагмы). Для этого, после декодирования каждого кадра, анализируется его гистограмма, и если у кадра неудачная контрастность, гистограмма пересчитывается и применяется к изображению. Вот пример (слева - начальное изображение, справа - обработанное):

Примерно то же самое относится и к появившемуся в PureVideo HD динамическому улучшению цветовой насыщенности. Бытовая техника также очень давно применяет некоторые улучшающие изображение алгоритмы, в отличие от компьютерных мониторов, которые воспроизводят всё как есть, что во многих случаях может вызывать слишком тусклую и неживую картинку. Автоматический баланс компонент цвета в видеоданных, рассчитываемый также каждый новый кадр, улучшает восприятие картинки человеком, немного скорректировав насыщенность её цветов:

Двухпоточное декодирование позволяет ускорять декодирование и постобработку двух разных потоков видеоданных одновременно. Это может быть полезно при выводе в таких режимах, как «картинка-в-картинке», которые используются в некоторых Blu-Ray и HD DVD дисках (к примеру, второе изображение может показывать режиссёра фильма, дающего свои комментарии к показываемым в основном окне сценам), такими возможностями снабжены издания фильмов WAR и Resident Evil: Extinction.
Ещё одним полезным нововведением последней версии PureVideo HD стала возможность одновременной работы оболочки Aero в операционной системе Windows Vista во время проигрывания аппаратно ускоренного видео в оконном режиме, что ранее не было возможно. Не сказать, чтобы это очень сильно волновало пользователей, но возможность приятная.
Поддержка внешних интерфейсов
Поддержка внешних интерфейсов у GeForce 9600 GT аналогична GeForce 8800 GT, за исключением появившейся интегрированной поддержки DisplayPort, разве что. Имеющийся на платах GeForce 8800 дополнительный чип NVIO, поддерживающий вынесенные за пределы основного внешние интерфейсы в G94 также был включен в состав самого чипа.

На референсных видеокартах GeForce 9600 GT установлены два Dual Link DVI выхода с поддержкой HDCP. Поддержка HDMI и DisplayPort реализована аппаратно в чипе, и эти порты могут быть выполнены партнёрами NVIDIA на картах специального дизайна. Причём, как уверяет NVIDIA, в отличие от G92, поддержка DisplayPort теперь встроена в чип и внешние трансмиттеры не требуются. Вообще, разъемы HDMI и DisplayPort на видеокарте необязательны, их могут заменить простые переходники с DVI на HDMI или DisplayPort, которые иногда попадаются в комплекте с современными видеокартами.
Подробности: G96, семейства GeForce 9400 и 9500
Спецификации G96
- Кодовое имя чипа G96
- Технология 65 нм
- 314 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 128-бит шина памяти, два независимых контроллера шириной по 64 бита
- Частота ядра 550 МГц
- ALU работают на более чем удвоенной частоте (1.4 ГГц)
- 32 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит точности в рамках стандарта IEEE 754, MAD+MUL без потери тактов)
- 16 блоков текстурной адресации с поддержкой FP16 и FP32 компонент в текстурах
- 16 блоков билинейной фильтрации (как и для G92, это даёт увеличенное количество билинейных выборок, но без бесплатной трилинейной фильтрации и эффективной анизотропной фильтрации)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 2 широких блока ROP (8 пикселей) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 32 MSAA отсчетов (+ 32 Z) за такт, в режиме без цвета (Z only) — 64 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы (два RAMDAC, два Dual DVI, HDMI, DisplayPort) интегрированы на чип
Спецификации референсной карты GeForce 9500 GT
- Частота ядра 550 МГц
- Частота универсальных процессоров 1400 МГц
- Количество универсальных процессоров 32
- Количество текстурных блоков — 16, блоков блендинга — 8
- Эффективная частота памяти 1.6 ГГц (2*800 МГц)
- Тип памяти GDDR2/GDDR3
- Объем памяти 256/512/1024 мегабайт
- Пропускная способность памяти 25.6 гигабайта в сек.
- Теоретическая максимальная скорость закраски 4.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 8.8 гигатекселей в сек.
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDMI и DisplayPort с HDCP
Спецификации референсной карты GeForce 9400 GT
- Частота ядра 550 МГц
- Частота универсальных процессоров 1400 МГц
- Количество универсальных процессоров 16
- Количество текстурных блоков — 8, блоков блендинга — 8
- Эффективная частота памяти 1.6 ГГц (2*800 МГц)
- Тип памяти GDDR2
- Объем памяти 256/512 мегабайт
- Пропускная способность памяти 25.6 гигабайта в сек.
- Теоретическая максимальная скорость закраски 4.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур до 4.4 гигатекселей в сек.
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDMI и DisplayPort с HDCP
Архитектура G96
Архитектурно G96 — ровно половина чипа G94, который, в свою очередь, отличается от G92 только количественными характеристиками. У G96 вдвое меньшее число всех исполнительных блоков: ALU, TMU и ROP. Новый видеочип предназначен для решений самого низкого ценового диапазона, и имеет два больших шейдерных блока (всего 32 ALU) и 16 текстурных блоков, а также восемь ROP. Ещё у него урезана шина памяти, с 256-битной до 128-битной, если сравнивать с G94 и G92. Все аппаратные возможности остались неизменными, отличия только в производительности.
Подробности: G92b, семейство GeForce GTS 200
Спецификации референсной видеокарты GeForce GTS 250
- Частота ядра 738 МГц
- Частота универсальных процессоров 1836 МГц
- Количество универсальных процессоров 128
- Количество текстурных блоков — 64, блоков блендинга — 16
- Эффективная частота памяти 2200 (2*1100) МГц
- Тип памяти GDDR3
- Объем памяти 512/1024/2048 мегабайт
- Пропускная способность памяти 70.4 ГБ/с
- Теоретическая максимальная скорость закраски 11.8 гигапикселей в сек.
- Теоретическая скорость выборки текстур до 47.2 гигатекселей в сек.
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- Двойной SLI разъем
- Шина PCI Express 2.0
- TV-Out, HDTV-Out, поддержка HDCP, HDMI, DisplayPort
- Энергопотребление до 150 Вт (один 6-штырьковый разъём)
- Двухслотовое исполнение
- Рекомендуемая цена $129/$149/$169
В общем-то, эта «новая» видеокарта на основе 55 нм чипа G92 не отличается от GeForce 9800 GTX+ ничем. Выход новой модели может быть частично оправдан установкой на неё не 512 мегабайт видеопамяти, как у 9800 GTX+, а гигабайта, что сильно влияет на производительность в тяжёлых режимах с максимальными настройками качества, высокими разрешениями с включенным полноэкранным сглаживанием. А есть ещё двухгигабайтные варианты, но это уже больше маркетинговое преимущество, чем реальное.
В таких условиях старшие версии GeForce GTS 250 действительно должна быть ощутимо быстрее GeForce 9800 GTX+ из-за увеличенного объёма памяти. А некоторые наиболее современные игры получат преимущество даже не в самых высоких разрешениях. Всё бы ничего, да только ведь некоторые производители карт выпустили GeForce 9800 GTX+ с гигабайтом памяти ещё раньше...
Производство видеочипов G92b по 55 нм технологическим нормам и заметное упрощёние дизайна PCB позволило компании NVIDIA сделать решение, аналогичное GeForce 9800 GTX по характеристикам, но с меньшей ценой и сниженными потреблением энергии и тепловыделением. И теперь, чтобы обеспечить GeForce GTS 250 электропитанием, на плате установлен лишь один 6-штырьковый PCI-E разъём питания. Вот и все основные отличия от 9800 GTX+.
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX


