Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX/GM1XX
Справочная информация о семействе видеокарт GM2XX
Спецификации чипов семейства GK1XX/GM1XX
| кодовое имя | GK110 | GK104 | GK106 | GK107 | GM107 |
| базовая статья | здесь | здесь | здесь | здесь | здесь |
| технология, нм | 28 | ||||
| транзисторов, млрд | 7,1 | 3,5 | 2,5 | 1,3 | 1,9 |
| универсальных процессоров | 2880 | 1536 | 960 | 384 | 640 |
| текстурных блоков | 240 | 128 | 80 | 32 | 40 |
| блоков блендинга | 48 | 32 | 24 | 16 | |
| шина памяти | 384 | 256 | 192 | 128 | |
| типы памяти | DDR3, GDDR5 | ||||
| системная шина | PCI Express 3.0 | ||||
| интерфейсы | DVI Dual Link HDMI DisplayPort | ||||
| вершинные шейдеры | 5.0 | ||||
| пиксельные шейдеры | 5.0 | ||||
| точность вычислений | FP32/FP64 | ||||
| Сглаживание | MSAA CSAA FXAA TXAA | ||||
Спецификации референсных карт на базе семейства GK1XX/GM1XX
| карта | чип | блоков ALU/TMU/ROP | частота ядра, МГц | частота памяти, МГц | объем памяти, ГБ | ПСП, ГБ/c (бит) | текстури- рование, Гтекс | филлрейт, Гпикс | TDP, Вт |
| GeForce GTX Titan Z | 2xGK110 | 2x(2880/240/48) | 705(876) | 1750(7000) | 2×6 GDDR5 | 2×336,4 (2×384) | 2×169 | 2×33,8 | 375 |
| GeForce GTX Titan Black | GK110 | 2880/240/48 | 889(980) | 1750(7000) | 6 GDDR5 | 336,4 (384) | 213 | 42,7 | 250 |
| GeForce GTX Titan | GK110 | 2688/224/48 | 836(876) | 1500(6000) | 6 GDDR5 | 288,4 (384) | 187,3 | 40,1 | 250 |
| GeForce GTX 780 Ti | GK110 | 2880/240/48 | 875(928) | 1750(7000) | 3 GDDR5 | 336 (384) | 210 | 42 | 250 |
| GeForce GTX 780 | GK110 | 2304/192/48 | 863(900) | 1500(6000) | 3 GDDR5 | 288,4 (384) | 165,7 | 41,4 | 250 |
| GeForce GTX 770 | GK104 | 1536/128/32 | 1046(1085) | 1750(7000) | 2-4 GDDR5 | 224,3 (256) | 133,9 | 33,5 | 230 |
| GeForce GTX 760 Ti | GK104 | 1344/112/32 | 915(980) | 1500(6000) | 2 GDDR5 | 192,3 (256) | 102,5 | 29,3 | 170 |
| GeForce GTX 760 | GK104 | 1152/96/32 | 980(1033) | 1500(6000) | 2 GDDR5 | 192,3 (256) | 94,1 | 31,4 | 170 |
| GeForce GTX 750 Ti | GM107 | 640/40/16 | 1020(1085) | 1350(5400) | 2-4 GDDR5 | 88 (128) | 40,8 | 16,3 | 60 |
| GeForce GTX 750 | GM107 | 512/32/16 | 1020(1085) | 1250(5000) | 1-2 GDDR5 | 80 (128) | 32,6 | 16,3 | 55 |
| GeForce GTX 740 | GK107 | 384/32/16 | 993 | 1250(5000) | 1-2 GDDR5 | 80,1 (128) | 31,8 | 7,9 | 64 |
| GeForce GTX 690 | 2xGK104 | 2x(1536/128/32) | 915(1019) | 1502(6008) | 2×2 GDDR5 | 384,6 (2×256) | 234,2 | 58,6 | 300 |
| GeForce GTX 680 | GK104 | 1536/128/32 | 1006(1058) | 1502(6008) | 2 GDDR5 | 192,3 (256) | 128,8 | 32,2 | 195 |
| GeForce GTX 670 | GK104 | 1344/112/32 | 915(980) | 1502(6008) | 2 GDDR5 | 192,3 (256) | 102,5 | 29,3 | 170 |
| GeForce GTX 660 Ti | GK104 | 1344/112/24 | 915(980) | 1502(6008) | 2 GDDR5 | 144,2 (192) | 102,5 | 22,0 | 150 |
| GeForce GTX 660 | GK106 | 960/80/24 | 980(1033) | 1502(6008) | 2 GDDR5 | 144,2 (192) | 78,4 | 23,5 | 140 |
| GeForce GTX 650 Ti | GK106 | 768/64/16 | 925 | 1350(5400) | 1-2 GDDR5 | 86,4 (128) | 59,2 | 14,8 | 110 |
| GeForce GTX 650 | GK107 | 384/32/16 | 1058 | 1250(5000) | 1-2 GDDR5 | 80,0 (128) | 33,9 | 16,9 | 64 |
| GeForce GT 640 | GK107 | 384/32/16 | 900 | 900(1800) | 2 DDR3 | 28,5 (128) | 28,8 | 14,4 | 65 |
Подробности: семейство GeForce GTX 600
Спецификации GK104
- Кодовое имя чипа GK104;
- Технология производства 28 нм;
- 3.54 миллиардов транзисторов;
- Площадь ядра 294 мм²;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 256-битная шина памяти, четыре независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Базовая частота ядра 1006 МГц;
- Средняя турбо-частота ядра 1058 МГц;
- 8 потоковых мультипроцессоров, включающих 1536 скалярных ALU для расчётов с плавающей запятой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 128 блоков текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 4 широких блока ROP (32 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2
- Поддержка шины PCI Express 3.0
Спецификации референсной видеокарты GeForce GTX 690
- Базовая частота ядра 915 МГц;
- Средняя турбо-частота 1019 МГц;
- Количество универсальных процессоров 2×1536;
- Количество текстурных блоков — 2×128, блоков блендинга — 2×32;
- Эффективная частота памяти 6008 (1502×4) МГц;
- Тип памяти GDDR5, 2×256-бит шина памяти;
- Объем памяти 2×2 ГБ;
- Пропускная способность памяти 2×192.3 ГБ/с;
- Теоретическая максимальная скорость закраски 58.6 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 234.2 гигатекселей в секунду;
- Три Dual Link DVI-I разъема, один DisplayPort;
- Одинарный SLI-разъем;
- Шина PCI Express 3.0;
- Энергопотребление до 300 Вт;
- Два 8-контактных разъёма питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $999 (для России — 35999 руб)
Спецификации референсной видеокарты GeForce GTX 680
- Базовая частота ядра 1006 МГц;
- Средняя турбо-частота 1058 МГц;
- Количество универсальных процессоров 1536;
- Количество текстурных блоков — 128, блоков блендинга — 32;
- Эффективная частота памяти 6008 (1502*4) МГц;
- Тип памяти GDDR5, 256-бит шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 192.3 ГБ/с;
- Теоретическая максимальная скорость закраски 32.2 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 128.8 гигатекселей в секунду;
- Два Dual Link DVI-I разъема, один HDMI, один DisplayPort;
- Двойной SLI разъем;
- Энергопотребление до 195 Вт (два 6-контактных разъёма);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $499 (для России — 17999 руб).
Спецификации референсной видеокарты GeForce GTX 670
- Базовая частота ядра 915 МГц;
- Средняя турбо-частота 980 МГц;
- Количество универсальных процессоров 1344;
- Количество текстурных блоков — 112, блоков блендинга — 32;
- Эффективная частота памяти 6008 (1502×4) МГц;
- Тип памяти GDDR5, 256-бит шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 192,3 ГБ/с;
- Теоретическая максимальная скорость закраски 29,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 102,5 гигатекселей в секунду;
- Два Dual Link DVI-I разъема, один HDMI, один DisplayPort;
- Двойной SLI разъем;
- Шина PCI Express 3.0;
- Энергопотребление до 170 Вт;
- Два 6-контактных разъёма питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $399 (для России — 13999 руб).
Первой видеокартой на основе графического процессора GK104 стала GeForce GTX 680. Она заменила переставший выпускаться GTX 580 на базе GF110. С одной стороны, принцип наименования видеокарт NVIDIA вроде бы не изменился, топовая модель получила изменение первой цифры индекса. С другой — даже судя по кодовому имени чипа GK104, он изначально вряд ли планировался в роли именно топового решения.
Вполне вероятно, изначально это должна была быть GTX 670 (приставка Ti по вкусу) или что-то в этом роде, но потом решили повременить с настоящим топовым чипом, раз у TSMC с новым техпроцессом до сих пор дела неидеальны, и выпустить в качестве верхней модели менее мощный чип. Впрочем, мы не раз говорили о том, что наименование видеокарт всегда является маркетинговым решением, которое не особенно влияет на технические характеристики.
Правда, оно сильно влияет на розничную цену решений. По всем внешним признакам (сложность чипа, сложность печатной платы, энергопотребление, да и себестоимость, скорее всего), GTX 680 больше похожа на решение из верхнего среднего диапазона. На это же намекают и кодовые имена чипов: GF104 — GK104. Впрочем, после выхода видеоплат AMD по высоким ценам, которые не слишком сильно обогнали GeForce GTX 580, у NVIDIA появился большой соблазн поднять GK104 в верхний ценовой диапазон, заработав самим и давая заработать своим партнёрам по выпуску видеокарт.
Дело хозяйское, и рекомендуемая рыночная цена в $499 для североамериканского рынка на момент выхода стала весьма выгодной (с российской ценой чуть похуже, Radeon HD 7970 продавался у нас дешевле). Сначала на основе чипа GK104 выпущена лишь одна модель видеокарты — GeForce GTX 680, которая в будущем дополнилась более интересным для масс решением с урезанными возможностями и двухчиповой платой. Потенциальные покупатели с ещё большим удовольствием выберут GTX 670 с меньшей ценой и не слишком зарезанной производительностью, как это всегда и бывает. Но сначала NVIDIA вступила в более дорогой сектор, ведь оставшиеся GTX 570 и GTX 580 им нужно было сначала распродать.
В отличие от предшественниц на базе Fermi, новая модель платы имеет 256-битную шину памяти и соответствующий объём видеопамяти, равный 2 ГБ. Конечно, это гораздо лучше, чем 1.5 ГБ, но в современных условиях уже хуже, чем 3 ГБ, имеющиеся у некоторых моделей GTX 580 и у всех Radeon HD 7900. К сожалению, 2 ГБ — по сути, единственно возможное значение, так как 1 ГБ — это слишком мало, а 4 ГБ быстрейшей GDDR5 памяти — чересчур дорого даже для 500-долларовой видеокарты. Так что тут у конкурента есть небольшое преимущество, которое может сказаться в тяжёлых режимах и сверхвысоких разрешениях вроде 2560×1600.
Глядя на плату, сразу же отмечаешь изменившийся дизайн разъёмов дополнительного питания и то, что их два 6-контактных, что весьма удивительно для топовой модели. Изменение разъемов и их ориентации сделано для экономии места на PCB, освободившееся место заняли другие полезные элементы и кожух кулера. К слову, о полезных элементах — GPU питается от четырёх фаз, а от дополнительных двух запитана GDDR5 память. Чего вполне хватает для нетребовательной к питанию GTX 680, и даже оставляет некоторый (но, вероятно, всё же не слишком большой для любителей экстремального разгона) запас для разгона.
Кроме того, что GeForce GTX 680 отличается высокой производительностью и сравнительно низким потреблением энергии, новая видеокарта имеет новую систему охлаждения. Понятно, что менее греющийся чип не требует столь продвинутых кулеров, как топовые решения предыдущих поколений, поэтому система охлаждения у GTX 680 в целом стала тише. Да и в конструкции используется специальный акустический материал, снижающий уровень шума.

В подошву радиатора встроены три тепловые трубки, которые отводят основное тепло от GPU. Которое далее рассеивается двухслотовым алюминиевым радиатором с рёбрами изменённого дизайна, для лучшего его продувания вентилятором. Укороченный (по сравнению с предыдущими решениями) радиатор позволяет добиться более эффективного воздухообмена, а также сэкономить лишнюю пару баксов. Ну а для чего ещё нужны энергоэффективные решения? В том числе и для этого.
В результате, по оценкам компании NVIDIA, GeForce GTX 680 тише своего прямого конкурента (понятно, что речь о Radeon HD 7970) на 5 дБ — 46 дБ вместо 52 дБ в одинаковых условиях..
Архитектура и нововведения в Kepler
GeForce GTX 680 основана на первом графическом процессоре компании NVIDIA, имеющем новейшую архитектуру Kepler. Основы архитектуры были заложены ещё в вышедшем в 2010 году Fermi (GeForce GTX 480), а некоторые детали даже ещё раньше, но, несмотря на все сходства, в целом Kepler вполне можно назвать полностью переработанной архитектурой, продолжающей тенденции оптимизации эффективного исполнения сложных вычислительных задач, а также имеющей очень быструю обработку геометрии и тесселяции.
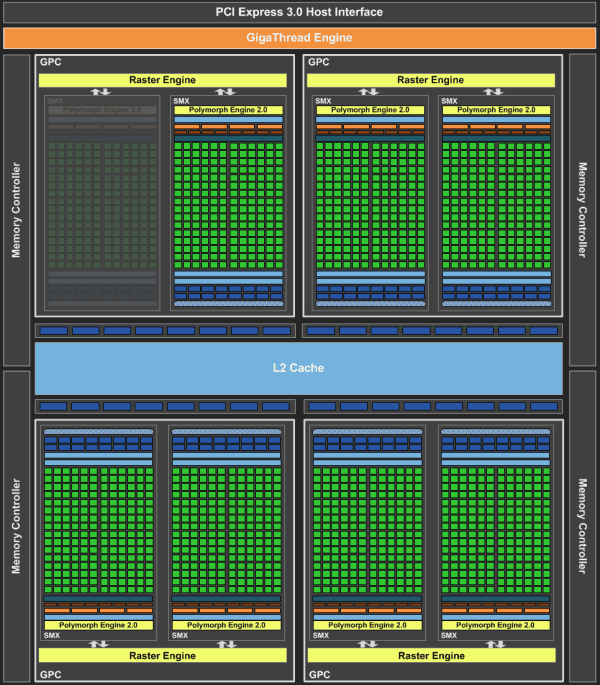
Как и в случае с Fermi, новый GPU имеет в своём составе несколько блоков GPC (кластеры графической обработки — Graphics Processing Clusters), которые являются независимыми устройствами в составе видеочипа, способными работать сами как отдельные устройства, так как в их составе есть все необходимые собственные ресурсы: растеризаторы, геометрические движки и текстурные модули. То есть, большинство функционала выполняется внутри блоков GPC. Блок-схема GK104 выглядит так:

Новый GPU имеет четыре блока GPC, как и предыдущий топовый чип GF100/GF110, но в отличие от них, каждый из этих блоков содержит по два потоковых мультипроцессора, отличающихся от того, что мы видели во всех предыдущих чипов NVIDIA. Новое решение использует следующее поколение потоковых мультипроцессоров (Streaming Multiprocessor), которые теперь называются SMX, в отличие от SM в предыдущих чипах. Сразу скажем, что название с приставкой буквы «X» — весьма условное, она не означает ничего определённого, кроме указания на то, что эти блоки в Kepler изменились по структуре. Давайте рассмотрим SMX, потому что важнейшие изменения произошли именно в них:
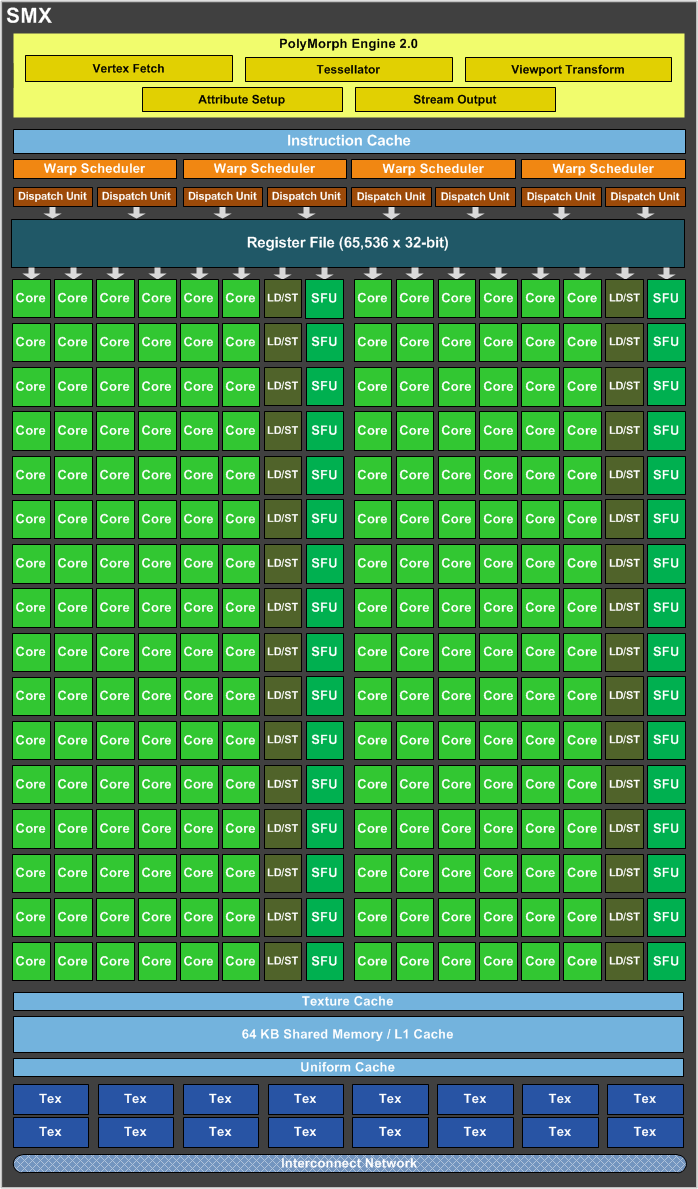
Мультипроцессоры — это основная составная часть GPU компании NVIDIA, и именно они претерпели больше всего изменений в Kepler. По сравнению с предыдущими SM, новые SMX обеспечивают более высокую производительность, что видно по количеству функциональных устройств в составе SMX, но при этом потребляют значительно меньше энергии. А уменьшенное количество мультипроцессоров на GPU (8 в отличие от 16 в GF100/GF110) было продиктовано установленными рамками по площади ядра.
Большая часть ключевых блоков GPU включена в состав SMX: потоковые процессоры (CUDA Cores) выполняют все математические операции над пикселями, вершинами и занимаются неграфическими вычислениями, текстурные модули (TMU) фильтруют текстурные данные, загружают и записывают их из/в видеопамять, блоки специальных функций (Special Function Units, SFU) выполняют сложные операции (вычисление синуса, косинуса, квадратного корня и т.п.) и интерполяции графических атрибутов. Ну а движок PolyMorph обеспечивает выборку вершин, занимается тесселяцией, преобразованием в экранные координаты, установкой атрибутов и потоковым выводом (stream output).
Как вы можете видеть на схеме SMX, количество блоков загрузки-сохранения (Load-Store Unit — LSU) в GK104 в расчёте на каждые шесть потоковых блоков снизилось. Блоки LSU используются для передачи данных из/в кэш и разделяемую память, что может негативно сказаться на задачах GPU вычислений. Впрочем, это уменьшение количества LSU не должно значительно повлиять на производительность в графических применениях, но очень похоже, что GK104 всё же немного упростили в смысле оптимальности для GPGPU задач.
Темп FP64 вычислений в GK104 даже ниже, чем у предыдущих чипов, так как в SMX организация потоковых процессоров изменилась. В остальном, GK104 по балансу очень похож на предыдущий чип аналогичного класса — GF104, кроме уже указанных изменений и ожидаемо увеличенного количества памяти для регистров и некоторых других модификаций.
На схеме выше видно, что каждый блок SMX содержит 192 потоковых вычислительных ядра, и это в шесть раз больше, чем в SM у Fermi. Поэтому, по сравнению с аналогичными блоками мультипроцессоров в Fermi, SMX обеспечивает значительно большую мощность по обработке пикселей, текстур и геометрии. Даже с учётом того, что предыдущие чипы имели удвоенную частоту работы для потоковых ядер (CUDA cores).
Увеличенная вдвое частота ALU требует и вдвое большее число стадий конвейера, который работает на вдвое большей частоте, потребляя в целом вчетверо больше энергии. И эта увеличенная частота для потоковых процессоров в Fermi привела к вдвое большим затратам энергии, чем они могли бы быть бы при вдвое большем количестве ALU, но работающих на обычной, не удвоенной частоте. Но решение о применении так называемого «hotclock» в Tesla и Fermi было принято исключительно из-за невозможности засунуть требуемое число ALU, работающих на обычной частоте, в определённую площадь чипа.
В Fermi (и ещё раньше, в Tesla) такое решение позволило обеспечить относительно высокую производительность GPU при сравнительно небольшом расходе площади ядра на CUDA cores, что было крайне важным при менее совершенных техпроцессах. Ну а негативным побочным эффектом этого решения было серьёзно завышенное энергопотребление. В Kepler уже не нужно было экономить площадь по понятным причинам, ведь из-за 28 нм технологии чип и так очень маленький — менее 300 мм², и оказалось эффективнее отказаться от удвоенной тактовой частоты, разместив больше потоковых процессоров на каждый мультипроцессор. Что в результате позволило добиться минимизации накладных расходов, меньшего энергопотребления и лучшей энергоэффективности.
Но это ещё далеко не все изменения. Чтобы «прокормить» данными вычислительные блоки SMX, каждый из них содержит по четыре блока планировщика варпов (warp scheduler), каждый из которых, в свою очередь, обрабатывает по две инструкции за такт на один варп. Интересно, что по сравнению с SM в Fermi, в новой архитектуре SMX уменьшено количество управляющей логики в чипе. Именно уменьшено, а не увеличено! Получается, что NVIDIA в Fermi логику усложнила, затем в Kepler упростила, а их конкурент AMD усложнил логику в GCN, по сравнению с предыдущей архитектурой. Поэтому, можно сказать, что последние архитектуры этих компаний сблизились ещё плотнее (мы об этом немного рассказывали в обзоре Radeon HD 7970).
Функциональность блоков управления в Kepler была переработана в угоду большей энергоэффективности. Хотя и Kepler и Fermi содержат схожие аппаратные блоки, занимающиеся управлением загрузкой данных и варпов, управлением потоками команд, но планировщик Fermi также содержит ещё и сложную аппаратную стадию, служащую для предотвращения конфликтов доступа к данным. Специальная таблица регистров (multi-port register scoreboard) отслеживает регистры, данные в которых ещё не готовы, а блок проверки зависимостей (dependency check) анализирует их использование, проверяя зависимости команд.
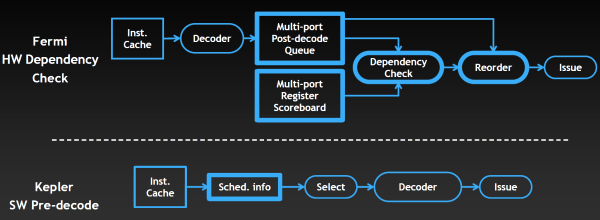
Но раз информация о задержках при доступе известна заранее и они не меняются, то подобный анализ можно провести ещё в компиляторе. И в Kepler часть управляющей логики решили перенести из GPU в компилятор, который частично занимается планированием. Как видно на схеме выше, проверка зависимостей и упорядочивание команд на Fermi осуществляется аппаратно, внутри GPU, а в случае Kepler эти задачи выполняет компилятор. И как тут снова не вспомнить конкурента, у которого в GPU так и было — программные решения вместо аппаратной логики. То есть, снова мы видим подтверждение сближения архитектур AMD и NVIDIA.
Конечно, упрощающие начиповую логику нововведения наверняка снизили эффективность обработки потоковых данных в некоторых задачах. Но, что интересно, по данным NVIDIA, в большинстве задач она мало отличается от эффективности Fermi. Зато принятое решение позволило убрать сложные и весьма энергоёмкие блоки, заменив их простыми, которые просто берут предопределённые данные о задержках от компилятора и используют их при планировании.
Предполагаем, что для графических применений такой подход вполне имеет смысл, ведь GK104 — это чип, предназначенный скорее для игр, чем для глобальных вычислений на GPU в составе больших серверов. Скорее всего, для GPGPU задач в обозримом будущем выйдет ещё более сложный графический процессор на базе архитектуры Kepler. Для настольных же систем важно то, что по данным NVIDIA, радикально изменённая архитектура мультипроцессоров SMX позволила вдвое улучшить энергоэффективность, по сравнению с решениями на базе архитектуры Fermi. Причём, имеется в виду не первенец GeForce GTX 480, основанный на чипе GF100, а более удачная по этим параметрам модель GTX 580, созданная на основе чипа GF110.
Изменения в Kepler коснулись далеко не только блоков потоковой обработки и мультипроцессоров SMX. Кроме этого, первый GPU архитектуры Kepler получил совершенно новый интерфейс памяти. Как вы помните, семейства GTX 400 и GTX 500 имели сравнительно широкие шины памяти, но сами микросхемы памяти на них работали на относительно низкой частоте. Полностью переработанная подсистема памяти в GK104 позволила значительно увеличить рабочие частоты GDDR5 видеопамяти, повысив их сразу в полтора раза — до 1500(6000) МГц!
Для использования такой быстрой памяти пришлось внести массу изменений в контроллеры памяти, их логический и физический дизайн. В результате, GeForce GTX 680 на момент выхода имеет быстрейшую видеопамять. Впрочем, желание получить максимально быструю память могло быть вызвано другой характеристикой чипа — шириной шины памяти. Вероятно, исходя из планируемого размера GPU, при его проектировании было решено оснастить чип лишь четырьмя 64-битными каналами памяти. Это вполне привычное решение для чипов NVIDIA из среднего ценового диапазона, таких как GF104, но топовые видеокарты компании уже давно имеют более широкую ширину памяти.
Да и объём той же кэш-памяти второго уровня «привязан» к числу контроллеров памяти (по 128 КБ на канал), и поэтому её тут столько же, сколько и у GF1x4 — 512 КБ. Правда, параметры пропускной способности этого L2 кэша в Kepler заметно улучшились, чтобы поддержать увеличенную скорость математических вычислений. Так, полоса пропускания кэш-памяти второго уровня выросла на 73% (из-за возросшей частоты и ширины доступа — 512 байт за такт, вместо 384 байт), а для атомарных операций так и вовсе в несколько раз.
Всё же, мы считаем весьма вероятным то, что GK104 изначально проектировался как видеочип для среднего ценового диапазона, поэтому и был оснащён лишь 256-битной шиной, но потом, когда топовое решение задержалось, а конкурент выпустил не такой уж быстрый GPU, было решено быстренько изменить рыночную стратегию, выпустив mid-end GPU в качестве high-end решения. И по соответствующей цене. В общем-то, смену стратегии нам подтвердили и представители NVIDIA, вопрос лишь в том, а не временная ли эта смена, пока не вышло более мощное решение?
Впрочем, мы сейчас рассматриваем не вопросы рыночного позиционирования, а архитектуру нового GPU. И ширина шины памяти и сложность/размер чипа — это всегда некий компромисс, на который приходится идти его создателям. Видимо, в случае GK104 поставить больше каналов памяти не позволил размер и/или целевая сложность чипа. Тем более, если изначально планировали и выход более мощного решения.
Некоторые изменения в новом графическом процессоре коснулись и блоков обработки геометрии. Обновленный движок PolyMorph получил версию 2.0, но единственным изменением в нём стала увеличенная вдвое скорость обработки геометрических примитивов. То есть, по сравнению с Fermi, каждый из блоков PolyMorph способен обрабатывать вдвое больше данных за такт. Собственно, это стало необходимым уже только потому, что таких блоков в GK104 стало вдвое меньше, чем в GF100/GF110.

Но из-за значительно возросшей тактовой частоты GPU, задачи тесселяции выполняются на первом из Kepler заметно быстрее и по сравнению с GeForce GTX 580, и до четырёх раз быстрее, чем на быстрейшем решении конкурента — Radeon HD 7970. Это справедливо для синтетических тестов, вроде примера SubD11 из Microsoft DirectX 11 SDK, в котором NVIDIA и намеряла четыре раза, а в реальных приложениях скорость не упирается в скорость обработки геометрии.
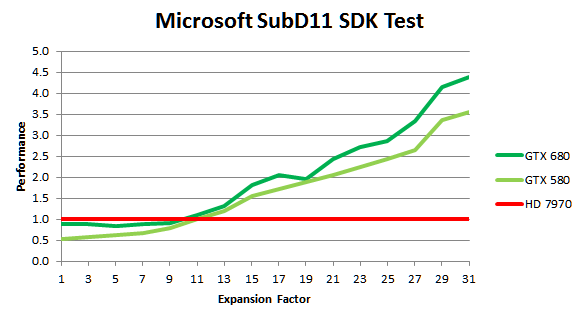
Как видите, даже в геометрической синтетике при малом количестве обрабатываемой геометрии (малых степенях разбиения примитивов) решение AMD оказывается быстрее по тем или иным причинам — в таких случаях скорость упирается в другие блоки. Но уж когда геометрии обрабатывается много, то тут новому GK104 конкурентов быть просто не может — он быстрее не только конкурента, но опережает даже GF110, правда не в разы.
Помимо блоков PolyMorph, отметим изменения в балансе между количеством ROP и движков растеризации — в Kepler их количество равное и обеспечивается 1:1 баланс между растеризацией и работой блоков ROP. У GF100 и GF110 было четыре блока растеризации и шесть ROP, а у GF114 их соотношение и вовсе было 2:4, а у GeForce GTX 680 четыре блока растеризации и четыре же блока ROP.
NVIDIA считает, что такая архитектура сбалансированнее и блоки в GK104 будут использоваться эффективнее. Ведь растеризатор вычисляет, какие пиксели для каждого треугольника закрашивать, а ROP непосредственно записывает данные в память, и за одно и то же время они выполняют равное количество работы. И теперь эти блоки не простаивают, так как могут обработать равное количество данных, а для полной загрузки ROP не обязательно нужно использовать блендинг.
По некоторым данным, в Kepler применяется изменённый алгоритм сжатия для передачи данных между памятью и ROP, повышающий эффективность использования имеющейся полосы пропускания. Есть у нас сведения и об ускорении темпа скорости заполнения и блендинга для буферов формата R11G11B10, иногда используемого для экономии ПСП вместо полноценного 16-битного.
Ещё одним изменением, связанным с графической архитектурой Kepler, можно назвать поддержку «bindless» текстур. В предыдущих графических процессорах модели привязки текстур обеспечивают поддержку одновременной работы лишь с 128 текстурами, которым выделялся свой фиксированный слот в таблице привязки. В Kepler же внедрили так называемые «не привязанные» текстуры, и шейдерная программа может обращаться к текстурам напрямую, без использования таблицы привязки.

Это решение увеличивает одновременное количество обрабатываемых текстур в одной шейдерной программе более чем до 1 миллиона. Может быть это покажется не слишком большим изменением, но оно позволит увеличить количество уникальных текстур и материалов в одной сцене (что может использоваться в техниках, аналогичных известной MegaTexture, применяемой в движке id Software, например), а также теоретически поможет снизить загрузку CPU при рендеринге.
К сожалению, у этой возможности пока что нет широкой программной поддержки. Пока что bindless текстурирование можно использовать только в OpenGL, а её добавление в самый популярный графический API DirectX планируется в будущих версиях или при помощи специального интерфейса NVAPI. Будем ждать, сама по себе возможность многообещающая.
Теоретическая оценка производительности GeForce GTX 680
Хотя изменения в Kepler коснулись множества исполнительных блоков, всё же корни архитектуры явно имеют под собой основу в виде Fermi. Основная архитектура чипа почти не изменилась, он всё так же состоит из крупных блоков GPC, содержащих мультипроцессоры SM, имеющих почти всё необходимое для независимой работы. Блоки обработки геометрии такие же, только вдвое быстрее (но их и вдвое меньше), текстурные модули и ROP остались почти без изменений, разве что количество первых увеличилось вдвое.
Наверное, это и правильно — зачем что-то менять, когда оно и так работает хорошо? Да и новых версий графических API не появилось, не считать же большим обновлением DirectX 11.1, некоторые из возможностей которого, кстати, Kepler поддерживает, но скорее всего не все. Нужно было просто улучшить все блоки, подтянув имеющиеся слабые места, укрепив сильные. С чем, похоже, в NVIDIA отлично справились. Тем интереснее сравнить теоретические показатели нового решения NVIDIA с предыдущим топовым GeForce GTX 580 и Radeon HD 7970 от их конкурента — какие у GTX 680 есть слабости?
| Видеокарта | Radeon HD 7970 | GeForce GTX 580 | GeForce GTX 680 |
|---|---|---|---|
| Графический процессор | Tahiti XT | Fermi (GF110) | Kepler (GK104) |
| Сложность чипа, млрд.транз. | 4,3 | 3,0 | 3,5 |
| Потоковых ядер, шт | 2048 | 512 | 1536 |
| Текстурных модулей (TMU), шт | 128 | 64 | 128 |
| Блоков ROP, шт | 32 | 48 | 32 |
| Шина памяти, бит | 384 | 384 | 256 |
| Частота GPU, МГц | 925 | 772/1544 | 1006(1058) |
| Частота видеопамяти, МГц | 5500 | 4000 | 6000 |
| Пропускная способность, ГБ/с | 264 | 192 | 192 |
| Производительность ALU, терафлопс | 3.79 | 1.58 | 3.09 |
| Скорость заполнения, ГП/с | 29,6 | 37,1 | 32,2 |
| Скорость выборки текстур, ГТ/с | 118,4 | 49,4 | 128,8 |
| Макс. энергопотребление | 250 | 244 | 195 |
В NVIDIA решили убрать многие недостатки своего предыдущего решения, серьёзно увеличив математическую и текстурную производительность, но оставив при этом производительность блоков ROP и ПСП примерно той же, что и у GeForce GTX 580. Увеличив вдвое количество блоков текстурирования и втрое — математических (правда, тут надо помнить об удвоенной частоте ALU в Fermi), инженеры компании этим самым оставили хорошую заявку на высочайшую производительность.
Сначала о том, что у GeForce GTX 680 отлично или очень хорошо. Во-первых, текстурирование. По этому параметру (по крайней мере, в теории) они превзошли даже быстрейшую видеокарту AMD, а их решения всегда отличались большим количеством блоков выборки и фильтрации текстур. Но особенно мощно достижение выглядит на фоне GTX 580 — текстурирование ускорилось в 2,6 раза и оно точно не будет ограничивающим производительность фактором!
Второй параметр, на который мы обращаем особое внимание — вычислительные возможности. Хотя лучшая видеокарта AMD всё ещё быстрее решения NVIDIA, но разрыв значительно сократился, 22% — это уже не несколько раз в предыдущих поколениях. Тем более, что чип имеет примерно на столько же меньше транзисторов. Сравнение с GF110 и вовсе опустим, по причине слишком лёгкой победы нового решения по этой пиковой теоретической характеристике.
Рассмотрим скорость заполнения (филлрейт), которая до сих пор зачастую является одним из ограничителей производительности в играх, особенно старых. Если сравнивать GeForce GTX 680 с конкурентом, то тут наблюдаем небольшой выигрыш, а если с предшествующей моделью — то не слишком большой проигрыш. Но почему в NVIDIA не увеличили количество блоков ROP? Во-первых, потому, что они «привязаны» к контроллерам памяти, которых в GK104 лишь четыре. Во-вторых, инженеры NVIDIA увеличили эффективность использования ресурсов ROP (см. выше), поэтому этой скорости должно быть достаточно.
Итак, переходим к самой неоднозначной характеристике нового решения — ширине шины памяти, её частоте и, соответственно, пропускной способности. С частотой памяти всё хорошо, мы писали выше, а вот её ПСП может быть главным ограничителем производительности для GeForce GTX 680! Это отлично видно из сравнения теоретических показателей в табличке. И пусть своей предшественнице новая модель не проигрывает (но она имеет значительно меньшую производительность и не упирается в ПСП), но конкурент впереди по одному из важнейших показателей аж на 37.5%!
Мы уж не повторяемся, что из-за 256-битной шины на карту установлено лишь 2 ГБ памяти, чего может не хватать в высоких разрешениях и степенях полноэкранного сглаживания, ради которых и покупаются топовые видеоплаты. В общем, если где-то в играх будут отставания от Radeon HD 7970, то можете быть уверены почти на 100%, что дело либо в объёме памяти, либо в её пропускной способности. В случае отсутствия явных багов в драйверах, конечно.
Несмотря на эти недостатки, многочисленные положительные улучшения в GPU не могли не сказаться и на практической производительности новой видеокарты компании NVIDIA — и на день своего выхода, она скорее всего станет быстрейшим одночиповым решением на рынке. Ну и GTX 680 является наименее требовательным к электропитанию, то есть — весьма и весьма энергоэффективным. В то время как конкурирующее решение схожей производительности имеет набор из одного 8-контактного и одного 6-контактного разъёмов дополнительного питания, что стало фактическим стандартом для высокопроизводительных видеокарт, GeForce GTX 680 имеет лишь два 6-контактных разъёма и установленное максимальное энергопотребление в 195 Вт, что явно ниже максимальных 250 Вт у главного конкурента.
GPU Boost
Одной из наиболее интересных особенностей первенца архитектуры Kepler является технология GPU Boost. Уже по названию понятно, что она неким образом должна ускорять производительность. Это комбинированная программно-аппаратная технология, появившаяся в GeForce GTX 680, которая динамически изменяет частоту GPU, исходя из условий его работы и некоторых характеристик.

Специализированный аппаратный блок в чипе постоянно отслеживает потребление энергии видеокартой и некоторые другие параметры, такие как температура, и автоматически изменяет частоту графического процессора, повышая её для получения максимально возможной производительности в пределах установленного пакета теплопотребления.
Но каким образом принимается решение о повышении частоты? Не секрет, что в большинстве игровых приложений GPU работают с потреблением энергии, далёким от максимально возможного для видеоплаты. Так, GeForce GTX 680 на базовой частоте в 1 ГГц в играх потребляет в среднем лишь около 170 Вт, хотя в принципе может использовать 195 Вт и даже больше. То есть, никто не мешает поднять частоту и напряжение GPU и повысить производительность, при этом, не выйдя за рамки TDP. Что, собственно, уже давно делают и на CPU и GPU.
Отличие GPU Boost от предыдущих, значительно менее продвинутых методов ограничения теплопотребления от компании NVIDIA, в том, что новая технология основана на работе преимущественно аппаратного блока и работает независимо от программных профилей в драйвере и не требует никаких действий от пользователя, обеспечивая «бесплатный» прирост производительности. При этом на изменение частоты уходит лишь 100 мс, т.е. оно почти мгновенное с точки зрения человека.
И теперь в спецификациях GPU производства NVIDIA будет как базовая частота (base clock), так и турбо-частота (boost clock). Для GeForce GTX 680 базовая частота равна 1006 МГц, и это — гарантированная частота работы во всех 3D приложениях, даже нетипичных — тех, которые максимально загружают работой GPU. А турбо-частота — это средняя частота, которая достигается в типичных приложениях, требующих меньшего энергопотребления. Мы не зря выделили слово «средняя», так как в реальности частота скачет не только от приложения к приложению, но и запросто может изменяться в пределах одной игры, в зависимости от нагрузки на видеоплату.
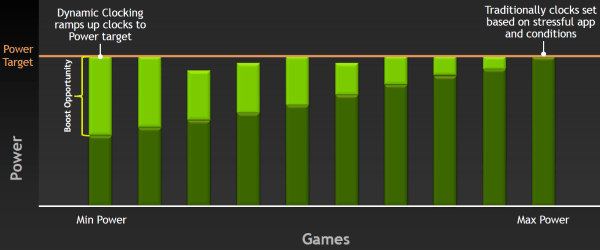
И в среднем, турбо-частота в играх составляет как раз около 1058 МГц, что даёт прирост скорости порядка 5%. Можно подумать, что игра не стоит свеч, ибо прирост в среднем небольшой. Но в некоторых играх есть ещё больший запас по потреблению, и турбо-частота GeForce GTX 680 вырастает и до 1100 МГц. GPU Boost повышает частоту, пока не достигается выбранный предел потребления, и для многих игр частота будет близка именно к верхнему пределу. Понятно, что вместе с частотой растёт и напряжение, подаваемое на GPU, причём оно изменяется плавно, как и рабочая частота.
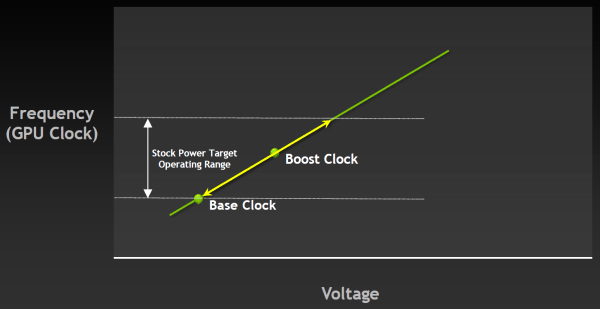
Например, 3DMark 11 является весьма требовательным к мощности GPU приложением, при работе в котором GeForce GTX 680 часто упирается в предел TDP даже при базовой частоте в 1 ГГц. Но потребление GK104 в реальных играх ниже, к примеру, в игре Crysis 2 чип способен работать на частоте в 1.05 ГГц, а в Battlefield 3 так и вовсе на 1.1 ГГц. Почему бы не воспользоваться этим «бесплатным» ускорением, решили в NVIDIA.
В отличие от аналогичной технологии компании-конкурента на графическом рынке, GPU Boost может не только снижать частоту при превышении TDP, но и увеличивать её — для этого и задана boost clock. Хотя, надо сказать, что в целом все подобные технологии схожи и отличие между разными реализациями весьма небольшое. Главное — что теперь у NVIDIA тоже есть весьма продвинутая технология по управлению частотами в зависимости от потребления, и она реально работает.
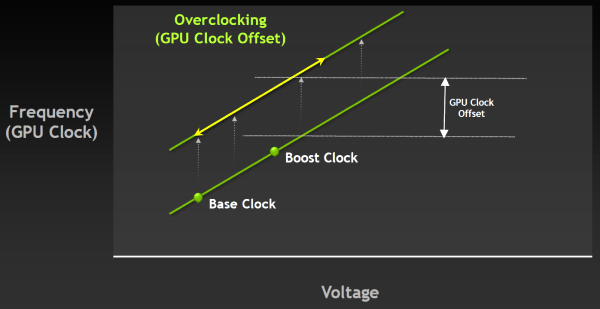
Кстати, сама по себе технология не мешает дальнейшему разгону, а работает вместе с ним. При разгоне меняется только базовая частота, а турбо-частота выбирается самим GPU в зависимости от достижения установленного уровня TDP. Который, кстати, теперь также можно регулировать, в том числе из утилит вроде EVGA Precision, использующих NVAPI. Правда, из-за более «умного» мониторинга и постоянного изменения частоты GPU под нагрузкой, подход к экстремальному разгону придётся менять в каких-то деталях, привыкая к новому принципу работы. Зато массовому пользователю подход NVIDIA с турбо-частотой будет вполне удобен.
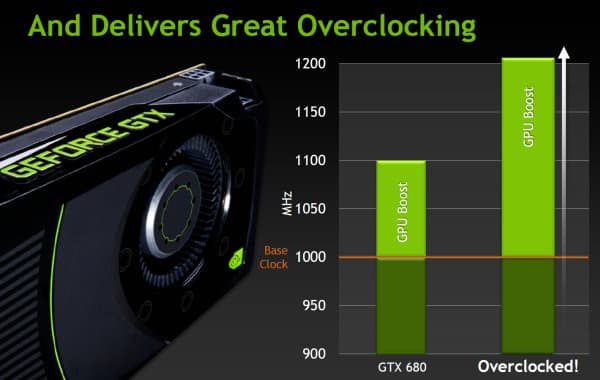
Правда, к сожалению, динамическое изменение частоты GPU Boost нельзя ни отключить, ни отрегулировать разность между частотами. То есть, при разгоне изменяется только базовая частота, а прирост от GPU Boost будет постоянным. Было бы значительно удобнее, если бы можно было бы изменять верхний предел или среднюю турбо-частоту, а то и вовсе отключать технологию. Особенно это было бы удобно для нас, тестеров.
Полноэкранное сглаживание методами FXAA и TXAA
Очень интересно наблюдать за развитием полноэкранного сглаживания на протяжении нескольких лет. На смену суперсэмплингу (SSAA), который первым появился в игровых видеокартах и является наиболее качественным, но весьма требовательным к ресурсам, пришёл мультисэмплинг (MSAA), более быстрый метод, но имеющий свои недостатки в плане качества. А теперь и его потихоньку вытесняют более современные методы сглаживания, основанные на постобработке отрендеренного кадра.
Один из таких методов сглаживания — FXAA, он известен уже какое-то время и появился в нескольких современных играх. Этот алгоритм использует мощность потоковых процессоров при постфильтрации и производится совместно с другими фильтрами, вроде размытия в движении (motion blur), bloom и другими аналогичными.
Использование методов вроде FXAA и схожего метода от конкурента — MLAA, особенно актуально для игровых движков, использующих отложенное затенение (deferred shading), так как они снижают требования к объёму видеопамяти и менее затратны по вычислительной мощности, по сравнению с более привычным для нас мультисэмплингом (MSAA). Кроме того, применение MSAA сглаживания при HDR рендеринге может приводить к появлению видимых артефактов, когда разность между значениями яркостей соседних участков изображения слишком велика. Так как FXAA выполняется в конце процесса рендеринга, уже в виде постфильтра, то он лишён многих проблем.
Метод FXAA также менее требователен, по сравнению с MSAA — по оценке компании NVIDIA примерно на 60%. Новый вид сглаживания впервые появился в 2011 году в игре Age of Conan и затем использовался в 15 проектах. А теперь, начиная с видеодрайверов NVIDIA версии 300, метод сглаживания FXAA можно будет форсировать из панели управления драйвера для сотен игровых приложений.
В качестве демонстрации эффективности FXAA по сравнению с MSAA, NVIDIA совместно с Epic показала на Kepler Editor's Day (и на выставке игровых разработчиков GDC 2012, которая проходила рядом в то же время) уже известную демонстрационную программу Samaritan, показывающую как может выглядеть игра с поддержкой возможностей DirectX 11. Эта демо-программа использует тесселяцию и карты смещения (displacement mapping), подповерхностное рассеивание (subsurface scattering), эффект имитации глубины резкости (depth of field), динамические отражения, тени и многие другие эффекты, и она очень сложна с точки зрения вычислительной мощи GPU.
Так вот, в отличие от GDC 2011, когда впервые показанное демо Samaritan использовало MSAA и было запущено на системе из трёх GeForce GTX 580, работающих в SLI связке, в этом году Epic показывала демку на системе с одной видеокартой GeForce GTX 680. Естественно, это не говорит о том, что новинка такая же по мощности, как три GTX 580. Есть сразу несколько объяснений этому: а) SLI не обеспечивает 100% эффективности, особенно на системе из трёх GPU; б) вместо MSAA в 2012 году использовался менее затратный метод FXAA; в) GTX 680 — это действительно очень мощная видеокарта!
Вы спросите, а что там с качеством? Наверняка же оно было хуже при FXAA и на одной GTX 680. Да, скорее всего, оно было хуже. Вот только настолько ли хуже стало итоговое качество, насколько MSAA требовательнее к GPU? В этом как раз основная польза метода FXAA — оно обеспечивает значительно лучшую скорость при примерно таком же качестве сглаживания, что и у MSAA. Вы можете оценить разницу на скриншотах:

И то же самое, но в статическом полноразмерном виде:



Важно понимать, что есть разница между несколькими типами FXAA, включаемыми в играх и из панели драйвера NVIDIA. Первоначальная версия FXAA (FXAA 1), внедрённая в такие игры, как Age of Conan, F.E.A.R. 3 и Duke Nukem Forever, обеспечивает высокое качество ценой несколько большего падения производительности. А более новый метод FXAA, вроде FXAA 3 в Battlefield 3, обеспечивает оптимальный компромисс между качеством и падением производительности, и для него можно регулировать качество, производительность и резкость, что и делается создателями игр на стадии разработки.
Включаемая из панели настроек драйвера версия FXAA — это нечто среднее между методами FXAA 1 и FXAA 3 с некоторыми изменениями, которые улучшают восприятие таких элементов, как сглаженный текст. По сравнению с FXAA 3, внедрённым в игры, «драйверный» метод сглаживания обеспечивает лучшее качество на всём, кроме текста и других элементов интерфейса, так как постфильтр в этом случае применяется уже к картинке целиком, когда она полностью готова, а игровые разработчики обычно накладывают текстовые элементы уже после всей постфильтрации. Ну и по понятной причине этот метод несколько медленнее внедрённого в игры FXAA 3.
Но одним FXAA дело не заканчивается. Как известно, нет предела совершенству. Не то, чтобы FXAA был к нему близок, ведь совершеннее всего по качеству сглаживания примитивный суперсэмплинг (SSAA), но он и самый требовательный — слишком требовательный. Чтобы улучшить качество сглаживания, почти не повысив ресурсоёмкость, в NVIDIA был разработан ещё один метод — TXAA. Кстати, на мероприятии для прессы об этом методе рассказывал русскоязычный сотрудник компании Юрий Уральский.
Основная цель TXAA в том, чтобы добиться качества сглаживания, максимально близкого к тому, что делается в пререндеренной графике (полнометражные мультфильмы и эффекты в кино). Так вот, TXAA — это ещё один метод сглаживания, разработанный сотрудниками компании, который становится весьма актуальным, в том числе из-за высокой текстурной производительности Kepler. TXAA также использует постобработку, но не только её, ведь в том и отличие, что это — гибридный метод, которые включает как использование аппаратных MSAA мультисэмплов, так и специальный качественный сглаживающий постфильтр и даже опциональную временную (temporal) компоненту.

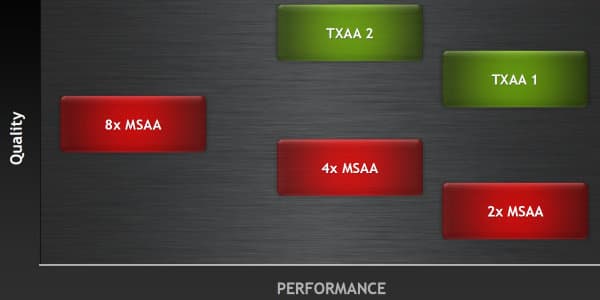
Метод сглаживания TXAA доступен в двух режимах: TXAA 1 и TXAA 2. Первый режим предлагает качество сглаживания, аналогичное методу 8x MSAA, но с производительностью, идентичной 2x MSAA, а второй обеспечивает ещё лучшее качество, но с производительностью, примерно соответствующей 4x MSAA. Соответственно, они используют 2 или 4 аппаратных мультисэмпла. Мы обязательно исследуем все эти методы в отдельном материале, сравнив их в том числе и с тем, что предлагает конкурент — компания AMD.
Временная (temporal) компонента в данном случае позволяет увеличить качество сглаживания за счёт небольших смещений субпикселей каждый кадр (так называемый jitter). Такой метод уже применялся ранее компанией ATI — в этом случае расположение субсэмплов внутри пикселя не является фиксированным и меняется каждый кадр. И так как устройства вывода и человеческое зрение инерционны, то человеческий мозг просто не успевает увидеть каждый кадр отдельно и объединяет информацию из соседних. И если при рендеринге каждого кадра немного изменять положение субпикселей, то субъективное восприятие качества сглаживания будет лучше — как будто субпикселей больше, чем их есть на самом деле.
Будет проще понять, если пояснить на примере. Допустим, если использовать 2х сглаживание, но в чётных и нечётных кадрах использовать два сэмпла на разных позициях (по диагонали: то слева-снизу и справа-сверху, то слева-сверху и справа-снизу), то при достаточно высокой частоте кадров человеческий глаз увидит, а мозг усреднит эти кадры и получится как будто 4х сглаживание с четырьмя субпикселями, а не двумя. Конечно, если число субпикселей слишком мало, то это будет заметно на глаз, но в случае TXAA всё должно быть хорошо.
Как и метод сглаживания FXAA, новый алгоритм будет внедряться в выходящие игровые приложения, начиная уже с этого года — для этого все заинтересованные игровые разработчики, среди которых мы можем отметить Crytek, Epic, Bitsquid и многих других, уже получили исходный код, так что мы надеемся, что появление TXAA не заставит себя ждать. Отдельной радостной новостью для владельцев видеокарт NVIDIA на основе архитектуры Fermi будет то, что TXAA будет работать в том числе и на их системах. А вот форсировать TXAA в драйвере не удастся, придётся ждать появления игр с его поддержкой.
Вопросы субъективной оценки качества сглаживания у таких методов вроде: «Да оно же всё замыливает!» мы пока что оставим в стороне, до подробного исследования качества сглаживания на видеокартах NVIDIA и AMD. А пока же поясним, что полностью убрать алиасинг полностью без некоторого снижения чёткости физически невозможно. Тем более тот, который видно только в динамике. На статических скриншотах всё может быть прекрасно, но в движении проявится алиасинг. И как раз TXAA отлично справляется в таких случаях и призван приблизить качество сглаженной картинки к тому, что мы видим в кино.
Адаптивная вертикальная синхронизация (Adaptive VSync)
Это — ещё одна программная технология, поддержка которой появилась в новейших драйверах компании NVIDIA. Пусть она и не относится напрямую к GeForce GTX 680, но совершенно точно направлена на улучшение комфортности при игре на видеокартах компании.

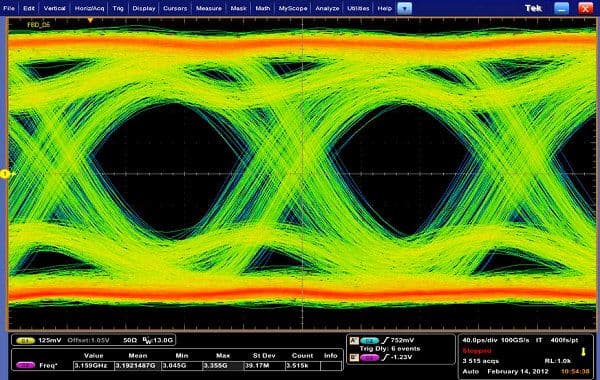
Напомним, что вертикальная синхронизация (VSync) придумана и используется для того, чтобы минимизировать артефакты изображения в виде разрывов кадра (tearing), заметные тогда, когда FPS в игре вырастает выше частоты обновления монитора. Такие артефакты видны и в случае, когда FPS ниже, но заметнее они именно при очень высоком FPS. На следующем графике указан момент, когда возникают разрывы изображения:
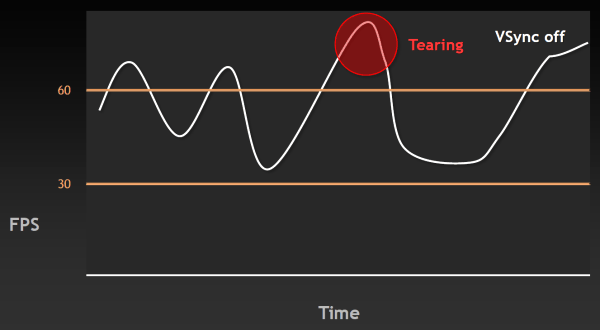
Естественно, такие вещи раздражают пользователя — казалось бы, частота кадров у системы высокая, а плавности нет. Поэтому была придумана вертикальная синхронизация, ограничивающая FPS сверху, привязывая её к частоте обновления монитора. Но при включении этой синхронизации появляется другая известная проблема — рывки или скачки в частоте кадров (stutter). Они случаются, когда частота кадров падает ниже 60 FPS, вызывая резкое двукратное падение частоты кадров до 30 Гц и ниже (20 Гц, 15 Гц) в случае включенной синхронизации. Естественно, это также не улучшает восприятия видеоряда в играх.
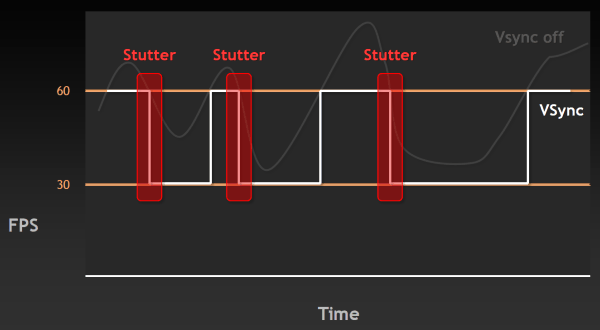
Чтобы решить обе эти проблемы и приблизиться к идеальной плавности в частоте кадров, инженеры NVIDIA сделали в драйверах то, что давно делается на игровых консолях — изменили работу алгоритма вертикальной синхронизации так, чтобы избавиться от разрывов кадра и одновременно минимизировать скачки FPS. Разработанную технологию назвали адаптивной вертикальной синхронизацией (Adaptive VSync), она динамически включает и выключает VSync так, чтобы приблизиться к идеальной плавности и постоянной частоте смены кадров. Проще всего это продемонстрировать на графиках — лучше один раз увидеть, чем сто раз прочитать.
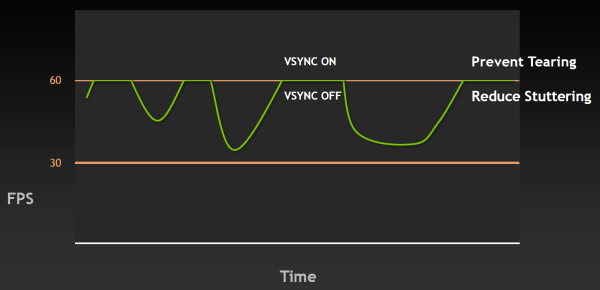
При частоте кадров выше 60 FPS в случае адаптивной синхронизации будет работать обычный VSync, но когда FPS падает ниже отметки 60 (или другого значения частоты обновления экрана), то адаптивная вертикальная синхронизация временно отключает VSync, позволяя частоте кадров достигнуть своего обычного значения, не «придушенного» синхронизацией до половины частоты обновления. А уже после того, как FPS возвращается к отметке выше 60, VSync снова автоматически включается, чтобы не появились разрывы в изображении.
Таким образом, эта технология значительно увеличивает плавность вывода движущейся картинки на экран, приближая её к плавности консольных игр. Начиная с версии 300, в видеодрайверах NVIDIA появилась поддержка этой технологии. Она включается из панели настроек драйвера, причём можно включить синхронизацию и на половинной частоте обновления экрана, что также может быть полезно в случаях, когда производительность в игре скорее ближе к 30 FPS, чем к 60 FPS (ведь обычный VSync в таких случаях просто не будет работать):
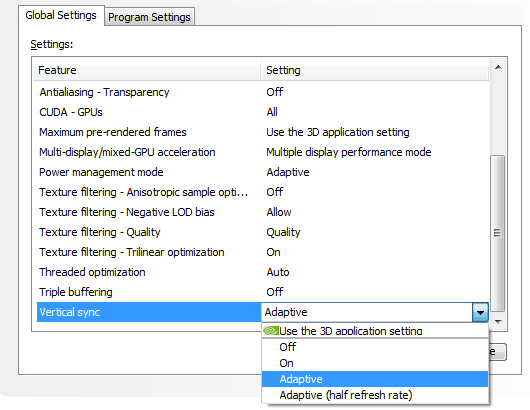
К слову, у NVIDIA есть и ещё одна программная возможность — ограничение количества FPS сверху так, чтобы частота GPU динамически снижалась в случае избытка производительности. Например, вы играете в старую игру, в которой с лёгкостью получаете 200-300 FPS. Зачем вам столько, если их всё равно не видно? И зачем гонять видеочип на частоте в 1 ГГц, если игре более чем достаточно и половины от этого значения?

К сожалению, эта возможность (пока?) недоступна из драйверов, но есть в NVAPI. И при помощи утилиты EVGA Precision 3.0 (а в дальнейшем эта настройка появится и в панели управления видеодрайвера) в играх, использующих DirectX или OpenGL, вы можете ограничить потолок FPS, к примеру, на уровне 60 кадров в секунду и получить при этом идеальную плавность и достаточно высокую производительность, да ещё и сниженную частоту GPU и меньшее напряжение, а значит и потребление энергии. Все они будут ровно такими, которые потребуются для достижения 60 FPS в игре.
Возможно, эти программные технологии не так эффектны, как некоторые аппаратные усовершенствования, появившиеся в Kepler, но нам кажется, что вместе с Adaptive VSync это очень интересные программные возможности, значительно улучшающие комфортность игры и энергоэффективность системы. И для некоторых пользователей эти технологии могут оказаться даже более важными, чем некоторые из аппаратных изменений.
Аппаратное кодирование видео — NVENC
NVIDIA не могла пройти мимо современных тенденций на рынке GPU и CPU, связанных с включением в производимые чипы специализированных блоков для аппаратного кодирования видеоданных. Аналогично последним продуктам конкурентов, производящих CPU и GPU, все видеочипы архитектуры Kepler получат аппаратный блок кодирования видео в формате H.264 — NVENC.
Вы, конечно же, помните, как все предыдущие годы нам долго и упорно рассказывали об ускорении видеокодирования на GPU, но это дело толком так и не пошло. По разным причинам, тут и сложности переноса эффективного кода на GPU и недостатки в качестве картинки закодированного таким образом видео, а главное, что энергопотребление топовых чипов при такой загрузке отнюдь не низкое и ресурсы тратятся расточительно. В общем, если раньше ПО для кодирования видео на GPU использовало потоковые процессоры видеочипов, то теперь этим делом будет заниматься выделенный аппаратный блок.
Кодировщик видеоданных NVENC почти вчетверо быстрее предыдущих методов, основанных на использовании CUDA, и это — при гораздо меньшем потреблении энергии (буквально менее 10 Вт). Вот что значит специализированное «железо», в отличие от универсального! Стоило ли городить огород с CUDA-кодированием — большой вопрос. Но зато теперь пользовательские приложения могут использовать возможности NVENC и CUDA-кодирования параллельно, если это кому понадобится.
Блок NVENC, имеющийся в GeForce GTX 680, способен кодировать видео в полном FullHD (1920×1080 пикселей) разрешении со скоростью в 4-8 раз быстрее реального времени. То есть, в высокопроизводительном режиме 16-минутное видео в формате 1080p при 30 FPS закодируется за две минуты. Аппаратным кодировщиком NVIDIA поддерживаются разрешения вплоть до 4096×4096 и следующие версии формата H.264: Base, Main и High Profile Level 4.1 (стандарт Blu-ray), в том числе и многоканальное кодирование MVC (Multiview Video Coding) для стереоскопического видео.
Кроме задач перекодирования видео, NVENC будет полезен и в других близких задачах, вроде программ видеомонтажа, беспроводной передачи изображения и при проведении видеоконференций. Прямо со дня анонса GeForce GTX 680, блок аппаратного видеокодирования будет поддерживаться в Cyberlink MediaEspresso, а в ближайшем будущем ожидается поддержка в Cyberlink PowerDirector, Arcsoft MediaConverter и других программах.
А для разработчиков NVIDIA выпустила специальный SDK, в котором раскрываются возможности API для видеокодирования при помощи NVENC. Вскоре CUDA-программисты получат возможность и одновременного использования NVENC и CUDA в своём ПО, что может быть очень полезно в задачах обработки и монтажа видео. К примеру, видеоданные будут обрабатываться на потоковых ядрах, и затем посылаться на кодирование в NVENC, и всё это будет работать одновременно и без лишних пересылок данных туда-сюда.
Расширенная поддержка многомониторного вывода
Довольно длительное время у NVIDIA не было ответа на конкурирующую технологию (а по сути — просто одну из технических характеристик) AMD Eyefinity, которая позволяет выводить изображение более чем на два монитора. И вот теперь, начиная с GeForce GTX 680, аналогичное решение поддерживается и видеокартами NVIDIA. Новая плата поддерживает до четырёх устройств вывода одновременно, в отличие от двух в предыдущих моделях.

Причём, новая видеокарта в одиночку способна выводить стереоизображение на три монитора одновременно, что называется 3D Vision Surround и ранее было доступно лишь на двухчиповых системах, и даже использовать четвёртый монитор для вывода какой-то другой информации, вроде окна с браузером, электронной почтой или Skype. Для подключения самых современных устройств вывода изображения, обновленный движок вывода в GK104 поддерживает DisplayPort 1.2, HDMI 1.4a, мониторы высокого разрешения (3840×2160, так называемые «4K») и многопоточный вывод звука, для чего имеет все необходимые разъёмы:

Было сделано и несколько чисто программных изменений: теперь панель задач Windows можно расположить на центральном мониторе, разворачивать окно лишь на текущий монитор, задавать собственные разрешения экрана, а также использовать «горячие клавиши» для управления корректировкой экранных рамок — ведь этот функционал может мешать в некоторых играх, закрывая важные элементы интерфейса.
Кстати, по поводу поддержки нескольких мониторов одновременно. Многие из наших читателей знают, что подключение второго монитора с другими характеристиками (разрешение, частота обновления) на видеокартах семейства Fermi вызывало одновременный переход GPU в режим большего энергопотребления, по сравнению со стандартным режимом простоя при подключении одного устройства вывода. Так вот, в Kepler эта досадная оплошность была устранена и теперь GPU всегда работает в стандартном режиме питания при скольки угодно подключенных мониторах (речь о 2D режиме, естественно).
Особенности модели GeForce GTX 670
Следующей после GTX 680 вышла видеокарта GeForce GTX 670, основанная на всё том же графическом процессоре архитектуры Kepler, известном нам под кодовым именем GK104. Установленный на GeForce GTX 670 графический процессор GK104 состоит из четырёх кластеров графической обработки Graphics Processing Clusters, и отличается от GPU, который мы рассматривали в обзоре GTX 680, только количеством активных блоков:
Чтобы обеспечить достаточно высокую производительность для успешной конкуренции с ускорителями компании AMD, в GeForce GTX 670 было решено использовать графический процессор GK104 с одним из восьми отключенных мультипроцессоров SMX. То есть, один из блоков SMX в чипе отключен аппаратно, и GTX 670 предлагает мощь 1344 вычислительных CUDA ядер, собранных в 7 мультипроцессоров.
Базовая тактовая частота чипа в GeForce GTX 670 равна 915 МГц, что на 10% ниже, чем у топовой GTX 680. Но средняя турбо-частота GPU Boost равна 980 МГц, что уже лишь на 8% меньше. Напомним, что GPU Boost позволяет графическим процессорам архитектуры Kepler автоматически увеличивать частоту GPU для достижения максимально возможной производительности. Об этой технологии можно подробно прочитать в базовом обзоре GeForce GTX 680. Реальная турбо-частота GK104 в случае GTX 670 зависит от конкретного 3D-приложения, и чаще всего составляет значение даже выше, чем 1 ГГц. Она обеспечивается в большом количестве игр и других приложений, использующих мощности GPU, хотя реальная турбо-частота для каждого приложения своя.
А вот подсистема памяти GeForce GTX 670 полностью идентична той, что мы видели в модели GTX 680, да и в двухчиповой GeForce GTX 690 тоже. Как и в случае этих моделей, работу графического процессора обеспечивает четыре 64-битных канала и контроллера памяти, что в сумме превращается в 256-битную шину памяти с достаточно высокой пропускной способностью, учитывая высокую тактовую частоту чипов видеопамяти. Её объём также остался неизменным — на плате установлено два гигабайта памяти GDDR5, работающей на той же высокой частоте в 6008 МГц.
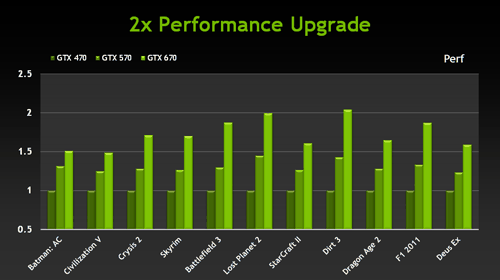
Как и следовало ожидать, производительность GeForce GTX 670 получилась довольно высокой. По тестам NVIDIA, во многих популярных игровых приложениях новинка догоняет по скорости даже Radeon HD 7970. И для тех активных игроков, кто планирует скорый апгрейд графической подсистемы, GeForce GTX 670 может стать неплохим вариантом. По сравнению с GeForce GTX 570 из предыдущего поколения, новая модель на Kepler обеспечивает 30-40% преимущества по скорости в самых требовательных играх, не говоря уже о более старых видеокартах, вроде GeForce GTX 470:
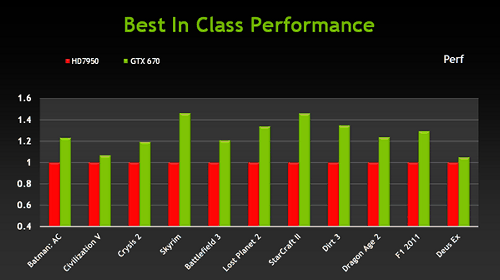
Но не только со своими предыдущими решениями сравнивает NVIDIA выпущенную сегодня модель GeForce GTX 670. Аналогичное сравнение по скорости GeForce GTX 670 проведено и с Radeon HD 7950 в играх вроде Elder Scrolls V: Skyrim и StarCraft 2, а также таких требовательных DirectX 11 приложениях, как Battlefield 3 и Crysis 2:
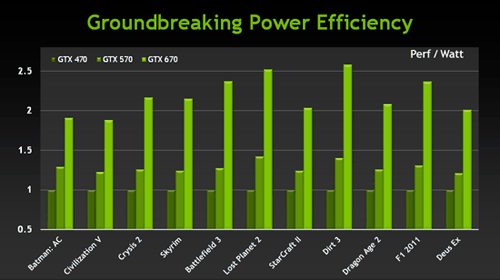
Как обычно в случае решений на базе архитектуры NVIDIA Kepler, более высокая частота кадров у GeForce GTX 670 дополняется улучшенной функциональностью (стереорендеринг и поддержка четырёх мониторов одной видеокартой) и отличными потребительскими свойствами в виде меньшего энергопотребления, а значит и шума от системы охлаждения. NVIDIA сравнивает энергоэффективность новинки с показателем GeForce GTX 470, получая почти 2,5-кратное преимущество:
Как и её более производительная сестра, новая модель GeForce GTX 670 поддерживает все технологии компании NVIDIA, в том числе Adaptive VSync, PhysX и 3D Vision Surround. И это не пустые слова, ведь скорости мощного чипа GK104 должно хватать даже для тяжёлых приложений с включением физических эффектов и стереорендеринга, кроме тех условий, когда рекомендуется применение выделенного GPU для PhysX-эффектов.
Дизайн и охлаждение платы
Референсная плата GeForce GTX 670 имеет длину 24 см (сравните с 25,5 см у GTX 680), но сама по себе печатная плата весьма короткая. Чтобы GeForce GTX 670 была совместимой с большинством систем, в PCB эталонного дизайна были внесены некоторые модификации. Из-за сниженных требований по питанию GK104, силовая часть была перемещена на другую сторону платы, ближе к видеоразъёмам. Сам графический процессор был повёрнут вокруг оси, часть элементов перенесены на заднюю часть платы, и схема питания теперь расположена к GPU гораздо ближе, чем обычно.
Такое решение в плате GeForce GTX 670 референсного дизайна позволило облегчить правую сторону печатной платы настолько, что появилась возможность значительно её укоротить. Но это касается лишь самой PCB, а кулер остался такой же, что и у GeForce GTX 680. Так как чип применён тот же GK104, да и его мощность отличается в GTX 670 не более чем на четверть, поэтому и система охлаждения применяется такая же.
О кулере этой модели подробно написано в выше GeForce GTX 680, в подошву радиатора встроены тепловые трубки, отводящие тепло от GPU, а в конструкции вентилятора используются специальные звукопоглощающие материалы, минимизирующие наиболее раздражающие слух частоты в шуме системы охлаждения. Вентилятор GTX 670 выдувает нагретый воздух из системного блока, что улучшает общее охлаждение системы и особенно важно для сравнительно небольших корпусов.
Но небольшой физический размер эталонной платы GeForce GTX 670 и её невысокое потребление энергии не значит, что она медленная. Новая модель предоставляет отличную производительность, так как основана на лишь незначительно «урезанном» чипе GK104, турбо-частота которого зачастую превышает 1 ГГц в большом количестве приложений, в среднем составляя 980 МГц. Кроме этого, обещается ещё и приличный разгон до частот выше 1,1 ГГц.
GeForce GTX 670 обеспечивает высочайшую производительность, ожидаемую от платы высокопроизводительного рыночного сегмента. По сравнению с решениями предыдущего поколения (GeForce GTX 580 и GTX 570) новинка не только быстрее, но и потребляет значительно меньше энергии — типичное потребление энергии в играх в среднем равно 141 Вт. Это значение справедливо для стандартных настроек, а при разгоне можно изменить параметр «power target» со 100% до +122%, получив улучшение разгонного потенциала и прирост типичного потребления до 173 Вт в среднем.
Применение эффективного кулера обеспечивает невысокий нагрев и тишину, а из-за нового дизайна PCB, видеокарта занимает меньше места в системном блоке. Кроме того, что производители готовых систем смогут создавать на основе GeForce GTX 670 компактные игровые системы высокой мощности, ожидается появление видеокарт оригинального дизайна с уменьшенными физическими габаритами, в том числе даже и с однослотовой системой охлаждения.
В случае с видеокартой модели GeForce GTX 670, партнёры компании NVIDIA получили возможность разработать платы собственного дизайна прямо с самого начала продаж. Поэтому, начиная с сегодняшнего дня, в рознице должны появиться различные модели GeForce GTX 670 от разных компаний, имеющие оригинальный дизайн печатных плат, систем питания и охлаждения, а также увеличенные частоты.
Такие решения появились у большинства партнёров калифорнийской компании, в том числе: ASUS, EVGA, Gainward, Galaxy, Gigabyte, MSI, Zotac и других. В качестве примера приведём две наиболее мощные модели. ASUS GeForce GTX 670 DirectCU II TOP имеет GPU, работающий на базовой частоте в 1058 МГц со средней турбо-частотой в 1137 МГц.

А ещё производительнее Zotac GeForce GTX 670 AMP! Edition, графический процессор в котором разогнан до 1098 МГц, турбо-частота равна 1176 МГц, и память также работает на увеличенной частоте в 6608 МГц. Пожалуй, это — один из наиболее мощных вариантов, способных догнать и GeForce GTX 680, работающие на эталонных частотах.

Многие из подобных моделей имеют усиленные системы питания с 8- и 6-контактными разъёмами дополнительного питания, увеличенным числом фаз и т.п. То же самое касается и систем охлаждения. Фабрично разогнанные варианты GeForce GTX 670 имеют ещё более эффективные кулеры с увеличенным количеством вентиляторов большого диаметра, что позволяет дополнительно улучшить эффективность охлаждения.
Всё остальное в GeForce GTX 670 мало чем отличается от того, что мы уже видели в предыдущей видеокарте GeForce GTX 680. Для вывода изображения GeForce GTX 670, как и старшая модель, имеет два выхода Dual Link DVI, один HDMI и один DisplayPort. Также отметим, что это решение позволяет вывести стереоизображение сразу на несколько мониторов при помощи технологии 3D Vision Surround, что ранее было доступно лишь в SLI-конфигурации.
Особенности модели GeForce GTX 690
Видеокарта на базе двух графических процессоров GK104 стала верхней моделью линейки GeForce GTX 600 и расположилась над быстрейшей одночиповой GeForce GTX 680. Что касается сравнения с конкурентом, то аналога по мощности и цене компания AMD так и не выпустила. Топовая плата GeForce на базе двух быстрейших GPU имеет название, отличающееся от аналогичной одночиповой модели лишь средней цифрой (680→690). Рекомендованная розничная цена решения для североамериканского рынка равна $999. Для нашей розницы цена ещё выше. Впрочем, подобные имиджевые решения в небольших количествах покупаются энтузиастами за любые деньги, и их цена не является определяющим фактором для покупки.
Так как двухчиповая модель имеет сдвоенную 256-битную шину памяти, то общий объём установленной на неё видеопамяти равен 2×2 ГБ. Это вполне достаточный объём, а 4 ГБ на чип — это было бы слишком много по разным причинам. Двух гигабайт на GPU должно хватать в большинстве режимов, и разве что в сверхвысоких разрешениях со стереорендерингом и/или сглаживанием может потребоваться больший объём.
Систему охлаждения и дизайн GeForce GTX 690 мы рассмотрим далее, а тут отметим, что плата двухслотовая, на неё установлено два 8-контактных разъёма питания, а также три выхода Dual-Link DVI и один mini-DisplayPort. Двухчиповая плата и не имеет HDMI выходов, в отличие от одночиповой GeForce GTX 680.
Имеющиеся на GeForce GTX 690 графические процессоры GK104 используют одинаковую конфигурацию мультипроцессоров, эти чипы состоят из четырёх кластеров графической обработки Graphics Processing Clusters каждый, и не отличаются от тех, что мы рассматривали в случае одночипового аналога.
Подсистема памяти двухчиповой GeForce GTX 690 также аналогична той, что мы видели в GeForce GTX 680, просто удвоенная — на каждый GPU приходится по четыре 64-битных канала памяти (256-бит на чип), и всего на плате установлено два набора по 2 ГБ быстрой GDDR5 видеопамяти. Причём её частота не отличается от частоты памяти в GTX 680 (то есть, 6008 МГц эффективной частоты) и это — правильное решение, так как нехватка пропускной способности видеопамяти в одночиповой модели иногда проявлялась.
Базовая (основная) частота графических процессоров в GTX 690 составляет 915 МГц, что на 10% ниже частоты GK104, установленного в одночиповой GTX 680. Но GK104 поддерживает технологию GPU Boost, которая позволяет GeForce GTX 690 автоматически увеличивать частоту GPU для достижения максимально возможной производительности. Об этой технологии можно подробно прочитать в базовом обзоре Kepler, а средняя турбо-частота для GeForce GTX 690 равна 1019 МГц, что лишь на 4% меньше, чем у одночипового варианта.
Высокая рабочая частота не отменяет её дальнейший возможный рост в рамках разгона. Наоборот, судя по всему, GeForce GTX 690 спроектирована для достижения максимальной производительности в том числе и в режиме разгона. Так, типичное потребление энергии в играх в среднем равно лишь 263 Вт, но плата оснащена двумя 8-контактными разъёмами дополнительного питания, которые вместе с PCI Express интерфейсом дают в сумме до 375 Вт доступной энергии. И даже с учётом максимального потребления в 300 Вт, у GTX 690 явно остаётся определённый запас по питанию. Вероятно, у энтузиастов разгона получится увеличить рабочую частоту GPU до 1,2 ГГц и даже выше.
Это важно, так как на предыдущих двухчиповых видеокартах компании NVIDIA важнейшим фактором ограничения производительности было высокое энергопотребление. К примеру, на GeForce GTX 295 и GTX 590 устанавливались видеочипы, работающие на значительно сниженных частотах, по сравнению с их одночиповыми собратьями GTX 285 и GTX 580. В случае GeForce GTX 690 удалось снизить влияние этого фактора, так как архитектура Kepler отличается весьма высокой энергоэффективностью.
Поэтому графические процессоры GK104, на которых основана новая модель GeForce GTX 690, имеют турбо-частоту, мало отличающуюся от той, что имеет GPU одночиповой GeForce GTX 680. При этом чипы GK104 и там и там идентичны и не имеют отключенных исполнительных блоков. Частоты и шины памяти также абсолютно одинаковы, и пропускная способность видеопамяти не пострадала. В результате, GeForce GTX 690 обеспечивает уровень производительности, сравнимый с тем, который даёт пара видеокарт GeForce GTX 680, работающих в SLI-режиме.
Но у GeForce GTX 690 есть и преимущества перед двумя одночиповыми платами. Во-первых, эта модель нуждается лишь в одном полноразмерном слоте PCI Express. Во-вторых, GeForce GTX 690 потребляет значительно меньше энергии, чем две платы GTX 680, и выделяет тепла меньше, что даёт меньший уровень шума от системы охлаждения. И, в-третьих, две GeForce GTX 690 можно объединить в ещё более производительную монструозную систему Quad SLI.

Кстати, о производительности. Понятно, что GeForce GTX 690 обеспечивает высочайшую скорость рендеринга в 3D приложениях. На момент выхода это быстрейшая видеокарта на рынке, и по данным компании NVIDIA, она в среднем на 45% быстрее, чем предыдущий двухчиповый вариант — GeForce GTX 590, хотя такой разрыв в скорости между ними наблюдается не везде:
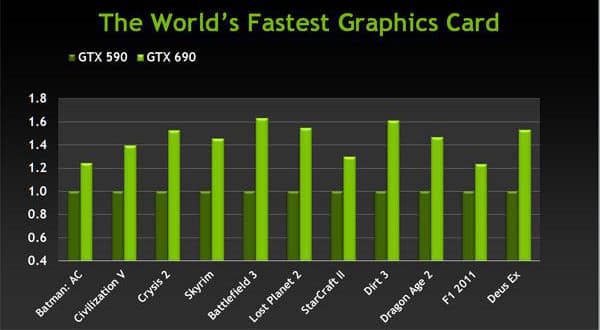
Но не только производительность важна в современных условиях. Сейчас всё чаще упирают на показатель энергоэффективности, который становится всё более важным, особенно в случае таких мощных двухчиповых решений как GeForce GTX 690. По сравнению с той же двухчиповой GeForce GTX 590, новая плата обеспечивает до двух раз более высокую энергоэффективность (в среднем — 70-75%):
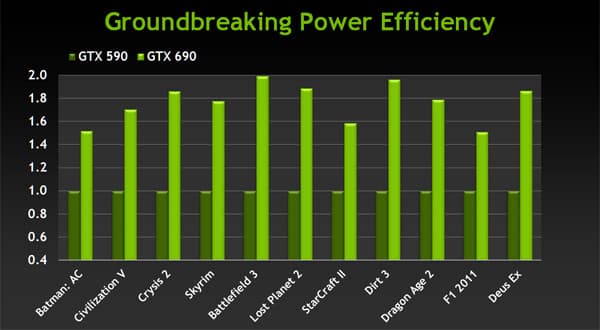
Как и её младшая сестра, новая двухчиповая модель GeForce GTX 690 поддерживает все технологии компании, в том числе Adaptive VSync, PhysX и 3D Vision Surround. Причём, некоторые технологии, такие как PhysX и 3D Vision Surround, в случае этой модели имеют даже больше смысла, так как GeForce GTX 690 обеспечивает более высокую производительность, которая никогда не помешает в тяжёлых приложениях, особенно с включением тяжёлых физических эффектов и стереорендеринга.
Например, в некоторых играх для оптимальной производительности в высоких разрешениях с максимальными настройками качества, NVIDIA рекомендует применение выделенного GPU для PhysX-эффектов. А GeForce GTX 690 уже содержит два графических процессора на борту, что позволяет выделить один из них под физические расчёты при такой необходимости. То же самое касается и стереорежима, особенно в высоких разрешениях на несколько экранов — GeForce GTX 690 обеспечивает достаточно производительности, чтобы насладиться высокой частотой кадров в таких условиях.
Но самой любопытной новой функциональностью в вышедшей двухчиповой видеокарте NVIDIA нам видится аппаратное измерение частоты кадров, позволяющее минимизировать проблемы мультичиповых решений, такие как небольшие, но неприятные скачки частоты кадров, более известные как micro-stuttering.
В режиме SLI современные видеочипы работают в режиме AFR-рендеринга, когда каждый графический процессор занимается своими кадрами: один чётными, другой — нечётными. И из-за того, что нагрузка на GPU в разных кадрах может отличаться, видеочипы справляются с работой за разное время, а при выводе отрендеренных кадров на экран возникает нестабильность FPS. В GeForce GTX 690 появился механизм аппаратного измерения FPS и регулирования потока кадров. Он постоянно отслеживает частоту кадров и сглаживает пики FPS, возникающие по причине разности во времени обработки кадров, и в результате смена кадров происходит плавнее, по сравнению с предыдущими SLI-системами.
Дизайн и охлаждение платы
Рассматриваемая двухчиповая плата компании NVIDIA имеет необычный даже для топовых плат дизайн, отражающий её непревзойдённую игровую производительность и цену. Так, каждый GPU двухчиповой видеокарты имеет свой отдельный радиатор — они видны в прозрачных пластиковых окошках на плате. А для любителей прозрачных корпусов и светодиодов на торце платы есть светящийся логотип GeForce GTX.
Кожух системы охлаждения новой видеокарты сделан из покрытого хромом алюминия, а кожух вентилятора выполнен из магниевого сплава — лёгкого материала с хорошей теплопроводностью — эти же характеристики и послужили причиной его применения в GeForce GTX 690. Эти необычные решения явно придают видеокарте солидный вид, что важно для топового сегмента. Ведь если пользователь заплатил за видеокарту столько денег, то ему явно хотелось бы, чтобы она и выглядела дорого.
Как всегда, создание двухчиповой видеокарты экстремальной мощности — не самое простое занятие. В процессе её проектирования возникает масса интересных и сложных задач, в числе которых питание двух GPU от одного источника (а сейчас цепи питания даже на одночиповых картах довольно сложны) и достаточно эффективное охлаждение графических процессоров, расположенных близко друг к другу на одной печатной плате.
Больше всего ограничивает полёт фантазии конструкторов физически доступное пространство — ведь помимо двух GPU, на печатной плате нужно расположить два комплекта видеопамяти с собственной шиной, а также коммутатор, обеспечивающий работу двух чипов с одним слотом PCI Express. Несмотря на это, для обеспечения более широкой совместимости с игровыми системами, в NVIDIA решили ограничить длину двухчиповой платы 11 дюймами (28 см). Можете сравнить её с 25,5-сантиметровой GeForce GTX 680, имеющей вдвое меньшее кол-во микросхем памяти и самих GPU.
Сюда же относятся и трудности с обеспечением приемлемого охлаждения. Та же GeForce GTX 680 имеет чуть меньшую PCB, зато большой кулер с тепловыми трубками и крупными радиатором и вентилятором. В случае двух графических чипов на почти такой же площади охладить их заметно сложнее. Чтобы решить эту задачу, инженеры компании NVIDIA постарались использовать площадь и объём платы максимально эффективно. Печатная плата десятислойная (у GTX 590 было 12 слоёв, но там две 384-битные шины памяти), а в слоях питания применяется много меди, что обеспечивает высокую надёжность и эффективность, а также улучшает тепловые характеристики.
Для достижения лучшей эффективности охлаждения в столь сложных условиях недостатка места на плате, каждый GPU имеет свой выделенный радиатор, основанный на медной испарительной камере и рёбрах радиатора двухслотовой высоты. А для лучшего охлаждения задней стороны платы и установленных на неё компонентов, используется дополнительная алюминиевая пластина.

Кулер оснащен низкоскоростным вентилятором с крыльчаткой большого диаметра. Для увеличения эффективности охлаждения и снижения шума от вентилятора был проработан кожух системы охлаждения — прямо под вентилятором спроектированы специальные каналы низкого профиля для направления потока воздуха на радиаторы. Также инженеры NVIDIA улучшили управляющую логику вентилятора, скорость его вращения изменяется плавно, а не пошагово.
В результате всех оптимизаций, уровень шума не просто снизился, а были приглушены отчётливо слышимые высокочастотные звуки, вызывающие наибольшие нарекания. Ну а об общем уровне шума можно судить по цифрам для GeForce GTX 690 и пары GeForce GTX 680 в режиме SLI. Если вентиляторы двух одночиповых карт шумят на 51 децибел (дБА), то новая GeForce GTX 690 лишь на 47 дБА — приличная разница.
Выше написано, что графический процессор GK104 обладает поддержкой PCI Express 3.0. Эта версия обладает скоростью передачи 8 гигатранзакций в секунду вместо 5 ГТ/с для версии 2.0, и его пропускная способность выросла вдвое, по сравнению со стандартом предыдущей версии. Поэтому старый чип-коммутатор NF200, который применялся ещё со времён GeForce GTX 295, в данном случае не подходит, так как не рассчитан на шину PCI Express 3.0.
Компания AMD использовала в своих двухчиповых видеокартах решения компании PLX Technology (пусть и со своей маркировкой) ещё давно, а NVIDIA ранее применяла собственные давние разработки. Но NF200 тут не подходит, а новый коммутатор они решили не разрабатывать, используя коммутатор PEX 8747 от PLX Technology. Микросхема коммутатора обеспечивает независимый доступ двух GPU к PCI Express 3.0 x16 интерфейсу, разделяя пропускную способность одного слота на два графических процессора.

PLX Technology — хорошо известный разработчик подобных решений, их микросхемы встречаются на видеокартах, системных платах и разнообразных контроллерах и адаптерах. Интересно, что на днях появилось сообщение о покупке PLX Technology компанией Integrated Device Technology (IDT), который близки по специализации.
Коммутатор PEX 8747 — 48-канальный и пятипортовый, он поддерживает третье поколение PCI Express. В конфигурации двухчиповой видеокарты коммутатор раздаёт каждому GPU по 16 каналов PCI-E, но с вдвое меньшей пропускной способностью (ведь один x16 слот делится на два чипа). PEX 8747 оптимизирован для использования в высокопроизводительных графических задачах и обеспечивает высокую скорость и малые задержки. К слову, данный чип-коммутатор производится по 40 нм технологическому процессу и потребляет до 8 Вт энергии, что также необходимо учитывать при конструировании двухчиповой платы и её системы охлаждения.
Всё остальное в GeForce GTX 690 мало чем отличается от систем из двух видеокарт GeForce GTX 680, объединённых в режиме SLI. Например, для повышения качества изображения можно использовать специфичные для SLI-конфигураций режимы с большим количеством выборок. Для вывода изображения GeForce GTX 690 имеет три разъёма Dual Link DVI и один mini DisplayPort. Это решение позволяет вывести стереоизображение на несколько мониторов при помощи технологии 3D Vision Surround.
Особенности модели GeForce GTX 660 Ti
- Базовая частота ядра 915 МГц;
- Средняя турбо-частота 980 МГц;
- Количество универсальных процессоров 1344;
- Количество текстурных блоков — 112, блоков блендинга — 24;
- Эффективная частота памяти 6008 (1502×4) МГц;
- Тип памяти GDDR5, 192-битная шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 144,2 ГБ/с;
- Теоретическая максимальная скорость закраски 22,0 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 102,5 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один HDMI, один DisplayPort;
- Двойной SLI-разъем;
- Шина PCI Express 3.0;
- Энергопотребление до 150 Вт;
- Два 6-контактных разъёма питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для России 11 999 руб.
В линейке решений компании NVIDIA модель GeForce GTX 660 Ti занимает место между старшей GeForce GTX 670 и младшей GeForce GTX 660, замещая топовые платы предыдущего поколения, вроде GeForce GTX 570 и GTX 580, предлагаемые до выхода решений на базе архитектуры Kepler среднего уровня. Принцип наименования видеокарт NVIDIA сохранился, модель в шаге от более старших получила изменение средней цифры индекса, а также суффикс «Ti», означающий то, что существует ещё и GTX 660 без этой приставки, как в линейке предыдущего поколения.
Интересно, что до выхода ожидаемого чипа GK106 и видеокарт среднего уровня на его основе, было принято решение выпустить ещё более урезанную модель на базе GK104. Вероятно, и с производством на TSMC получше стало, и бракованные GK104 уже накопились, да и запас топовых видеокарт серии GTX 500 потихоньку иссякает. Кроме того — надо уже конкурировать с Radeon HD 7870 чем-то более современным. Кстати, ещё одним конкурентом для GTX 660 Ti стала модель Radeon HD 7950, с ними и нужно сравнивать новинку. Рекомендуемая рыночная цена GeForce GTX 660 Ti для российского рынка на старте продаж была установлена равной 11 999 руб.
В отличие от топовых моделей серии GTX 600, новая видеокарта имеет 192-битную шину памяти, хотя объём видеопамяти (по крайней мере, для референсной платы) остался равным 2 ГБ. О подробностях такого сочетания читайте далее. В условиях современных приложений и максимальных настроек качества этого объёма может иногда не хватать, и тут GTX 660 Ti может даже иметь некоторое преимущество перед GTX 670 и GTX 680, так как 192-битная шина позволяет легко и просто установить на неё 3 ГБ памяти, чем уже воспользовались некоторые партнёры NVIDIA, выпустив соответствующие модели.
Архитектура
Видеокарта GeForce GTX 660 Ti основана на графическом процессоре архитектуры Kepler, известном нам под кодовым именем GK104, поэтому всё уже было очень подробно рассказано выше, а сейчас мы лишь остановимся на отличиях конкретной модификации GTX 660 Ti. Установленный на GeForce GTX 660 Ti графический процессор GK104 состоит из четырёх кластеров графической обработки Graphics Processing Clusters, и отличается от GPU, который мы рассматривали в разделах GTX 680 и GTX 670, только количеством активных блоков (заблокированные блоки выделены цветом):
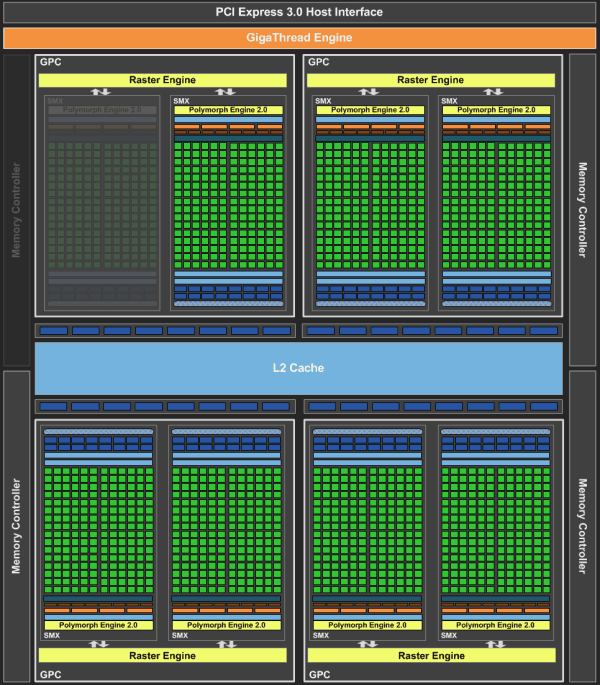
Как видите на схеме, видеочип в модели GeForce GTX 660 Ti имеет 7 активных мультипроцессоров SMX, состоящих из 1344 вычислительных CUDA ядер, точно как и GeForce GTX 670. То есть, лишь один из блоков SMX в чипе отключен аппаратно. А вот подсистема памяти у GeForce GTX 660 Ti отличается от той, что имеет GTX 670 — активными оставлены лишь три из четырёх 64-битных контроллеров видеопамяти. Но при этом её объём у референсной платы составляет 2 ГБ, а вовсе не 1,5 или 3 ГБ, как можно было бы предположить, исходя из разрядности шины.
Мы знаем, что контроллер памяти, встроенный в графические процессоры NVIDIA, поддерживает использование чипов памяти смешанной ёмкости, что и позволяло ранее использовать буфер в 2 ГБ в той же GeForce GTX 550, например. Но тогда именно чипы памяти были разные, а в некоторых образцах GTX 660 Ti объём в 2 ГБ набран при помощи 8-ми микросхем, а не 12-ти. При этом два из трёх 64-битных контроллеров памяти используют по два 32-битных чипа, а третий — четыре чипа 32-битной же памяти, но к каждой из них доступ у GPU лишь 16-битный. Видимо, такое решение помогает сэкономить на себестоимости чипов памяти. К слову, ничто не мешает производителям ставить на свои варианты GTX 660 Ti по 3 ГБ памяти, и такие варианты появятся в продаже сразу же. Ну а рабочая частота GDDR5-видеопамяти в новой модели идентична значению частоты, на которой она работает в GTX 670 и GTX 680 — 6008 МГц.
Что касается частот видеочипа, то в GTX 660 Ti они также полностью соответствуют значениям, установленным для GTX 670. Базовая тактовая частота чипа в GeForce GTX 660 Ti равна 915 МГц, а средняя турбо-частота GPU Boost равна 980 МГц, что лишь на 8% меньше, чем в топовой GTX 680. Напомним, что GPU Boost позволяет графическим процессорам архитектуры Kepler автоматически увеличивать частоту GPU для достижения максимально возможной производительности в случае наличия запаса по энергопотреблению. Реальная турбо-частота GK104 в случае модели GTX 660 Ti зависит от конкретного 3D-приложения, и чаще всего составляет значение выше 1 ГГц.
Новый метод сглаживания TXAA
Долгие годы под полноэкранным сглаживанием чаще всего подразумевался метод мультисэмплинга (MSAA — MultiSample Anti-Aliasing). Он стал стандартным для сглаживания краёв полигонов ещё несколько лет назад, но с увеличением популярности отложенного (deferred) затенения, ресурсоёмкость MSAA возросла. Да и по качеству к мультисэмплингу всегда были претензии, для чего даже пришлось вводить гибридные методы сглаживания, вроде MSAA+SSAA. Ведь MSAA не способен качественно сглаживать мелкую геометрию и полупрозрачные текстуры, и особенно это заметно при движении, когда начинают появляться артефакты, вроде «ползущих» и «мерцающих» пикселей.
Позднее появились методы сглаживания, использующие постобработку изображения, вроде MLAA и FXAA. Эти техники отличаются очень малой ресурсоёмкостью и поддерживаются во многих современных играх. Так, поддержка FXAA есть в Batman: Arkham City и The Elder Scrolls V: Skyrim, а также его можно включить в панели настроек драйвера NVIDIA и для других игр. В этих методах для постобработки используется пиксельный шейдер, который повышает время отрисовки кадра (и снижает FPS, соответственно) лишь на 3-7%, по сравнению с 30-50% потери производительности от включения MSAA.
Но у этих методов есть свои недостатки — отсутствие временного (temporal) сглаживания и пропуск при обработке некоторых граней треугольников, которые нуждаются в сглаживании. Иными словами, качество FXAA иногда даже несколько хуже, чем у MSAA, а отдельные недостатки присущи обоим указанным методам.
Чтобы улучшить качество сглаживания, почти не повысив его ресурсоёмкость, в NVIDIA был разработан ещё один метод — TXAA. Этот метод сглаживания также использует постобработку, но не только её, это — гибридный метод, которые включает использование аппаратных MSAA мультисэмплов и специального сглаживающего постфильтра с опциональной временной компонентой. TXAA был специально разработан для того, чтобы снизить артефакты временного алиасинга — «мерцающие» и «ползущие» пиксели, которые хорошо заметны при движении.
Для сглаживания пикселей в TXAA используется выборка субпикселей как внутри так и снаружи пикселя, да ещё в сочетании со значениями из предыдущих кадров (опциональная временная компонента), что обеспечивает отличное качество фильтрации. В сценах с движением камеры, при помощи TXAA достигается качество сглаживания, аналогичное тому, что мы видим при оффлайновом рендеринге, например, в 3D-мультфильмах. Сглаживающий фильтр методом TXAA работает качественнее, чем MSAA, и особенно это заметно на растительности и прочих подобных объектах. К сожалению, есть и небольшой недостаток — TXAA-фильтрация многим пользователям покажется слишком «замыливающей» изображение — оно немного теряет в резкости из-за того, что берутся сэмплы вне пикселя, а также из предыдущих кадров. Но это — дело вкуса.
Метод сглаживания TXAA существует в двух вариантах. Первый предлагает качество сглаживания, аналогичное методу 8x MSAA, но с производительностью, идентичной 2x MSAA, а второй обеспечивает ещё лучшее качество, но с производительностью, примерно соответствующей 4x MSAA. Соответственно, они используют 2 или 4 аппаратных мультисэмпла. Влияние метода TXAA на общую производительность в разных играх отличается и в основном зависит от скорости MSAA, так как использует и мультисэмплинг.
Можно сказать, что если FXAA обеспечивает максимальную производительность при неплохом качестве, то TXAA обеспечивает максимальное качество при небольшом снижении скорости рендеринга. Новый алгоритм уже внедряется в игровые приложения — все заинтересованные игровые разработчики, среди которых есть такие компании как Crytek, Epic, Bitsquid, уже получили соответствующий исходный код, так что появление TXAA не заставит себя долго ждать. К сожалению, TXAA не будет работать на видеокартах архитектуры Fermi и более ранних, метод поддерживается лишь на новых Kepler и требует применения видеокарт серии GTX 600. Да и форсировать TXAA из драйвера не удастся.
Игра Secret World стала первой, в которой используется метод TXAA, доступный для Kepler, а для владельцев других DX11-видеокарт есть и FXAA — более простой метод сглаживания. Всего в Secret World предлагается четыре уровня фильтрации: No AA, FXAA, FXAA HQ, TXAA 2x и TXAA 4x. Без включения сглаживания вовсе, на экране будет наблюдаться несглаженная геометрия и артефакты, которые мы описали выше. При включении же TXAA, картинка получается полностью сглаженной — все треугольники и отдельные объекты не имеют рваных граней. Лучше всего это заметно по следующему видеоролику (к сожалению, в нём показано сравнение только несглаженного и сглаженного методом TXAA кадра, а сравнения разных методов нет):
Вопросы субъективной оценки качества сглаживания у таких методов мы пока что оставим до подробного исследования качества сглаживания на видеокартах NVIDIA и AMD. Но ещё раз поясним, что полностью убрать алиасинг без некоторого снижения чёткости просто невозможно. Тем более это касается артефактов, видимых только в динамике. На статических скриншотах всё может быть прекрасно и чётко, но в движении недостатки проявятся. И TXAA отлично справляется именно в таких случаях и призван в очередной раз улучшить качество сглаженной картинки. Вот ещё один пример, но уже статический:

Сглаживание TXAA действительно качественно работает, хотя у любителей чёткой и резкой картинки могут появиться вопросы к излишнему «замыливанию». Оно возникает из-за самого принципа сглаживания методом постобработки, и никуда от него не деться.
Плата GeForce GTX 660 Ti и модификации
Референсная плата GeForce GTX 660 Ti повторяет модель GTX 670. Сама по себе печатная плата весьма короткая и для неё возможно применение сравнительно компактных кулеров. PCB эталонного дизайна упрощена по сравнению с GTX 680, а из-за сниженных требований по питанию, силовая часть перемещена на другую сторону платы. Графический процессор повёрнут вокруг оси, часть элементов перенесена на заднюю часть платы, и схема питания расположена к GPU ближе, чем обычно. Ровно как у GTX 670, только микросхемы питания размещены иначе.
Несмотря на и так не самые низкие тактовые частоты GPU (применение технологии GPU Boost приводит к тому, что GeForce GTX 660 Ti в играх часто работает на частоте, близкой к 1 ГГц), представленная модель GeForce GTX 660 Ti вполне может обеспечить любителям разгона неплохие возможности по дальнейшему поднятию частот.
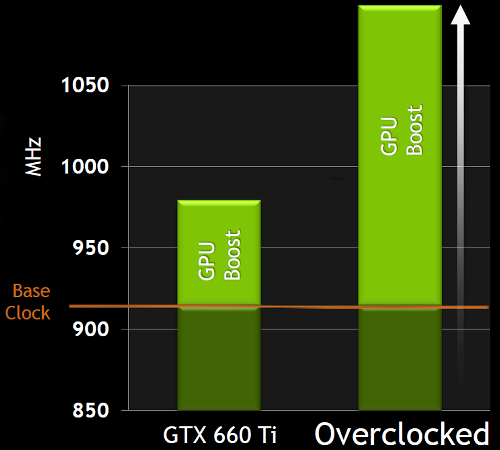
Ведь даже при большой нагрузке, GeForce GTX 660 Ti с референсными частотами потребляет порядка 134 Вт энергии в игровых приложениях, что не превышает официального предела TDP, установленного в 150 Вт. А если изменить настройку «power target» в драйвере, увеличив её с 100% до +123%, что обычно рекомендуется при разгоне, плата в целом будет потреблять лишь до 165 Вт в таких приложениях, что совсем немного — очевидно, что у GTX 660 Ti имеется неплохой запас по разгону. А косвенно приличный разгонный потенциал может подтвердить факт единовременного выхода разогнанных вариантов GTX 660 Ti от партнёров компании.
В случае с представленной сегодня видеокартой, партнёры компании NVIDIA получили возможность разработать платы собственного дизайна и продавать их прямо с самого начала продаж. И, начиная с сегодняшнего дня, в рознице появятся различные модели GeForce GTX 660 Ti от разных производителей, имеющие оригинальный дизайн печатных плат, систем питания и охлаждения, а также повышенные тактовые частоты.
Такие решения появятся у большинства партнёров калифорнийской компании — производители видеокарт уже в день анонса предлагают различные модели GeForce GTX 660 Ti, как обычные с референсными характеристиками и частотами, так и специальные фабрично разогнанные варианты, отличающиеся повышенными частотами для GPU и видеопамяти, а также собственным дизайном печатных плат и систем охлаждения.
Приведём лишь несколько моделей, отличающихся от стандартных: ASUS GTX 660 Ti DirectCU II Top, видеочип которой работает на частоте 1072(1137) МГц, Gigabyte GV-N66TOC-2GD и Zotac GeForce GTX 660 Ti AMP! Edition, графический процессор которых имеет 1033(1111) МГц частоту, и MSI N660Ti-Power Edition 2GD5/OC, видеочип которой работает на 1019(1097) МГц.
Вероятно, некоторые из подобных моделей имеют усиленные системы питания с 8- и 6-контактными разъёмами дополнительного питания, увеличенным числом фаз и т.п. То же самое касается и систем охлаждения — как видите на фото, даже разогнанные варианты GeForce GTX 660 Ti имеют короткие, но эффективные кулеры с увеличенным количеством вентиляторов большого диаметра, что позволяет улучшить эффективность охлаждения.
Всё остальное в GeForce GTX 660 Ti повторяет то, что мы уже видели в видеокарте модели GeForce GTX 670. Для вывода изображения на референсной плате имеется два выхода Dual Link DVI, один HDMI и один DisplayPort. Такое решение позволяет вывести стереоизображение сразу на несколько мониторов при помощи технологии 3D Vision Surround, что ранее было доступно лишь в SLI-конфигурации. Понятно, что новая модель поддерживает и все остальные технологии компании NVIDIA, в том числе Adaptive VSync и PhysX.
Подробности: семейство GeForce GTX 660
Спецификации GK106
- Кодовое имя чипа GK106;
- Технология производства 28 нм;
- 2,54 миллиардов транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 192-битная шина памяти, три независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5-памяти;
- Базовая частота ядра 980 МГц;
- Средняя турбо-частота ядра 1033 МГц;
- 5 потоковых мультипроцессоров, включающих 960 скалярных ALU для расчётов с плавающей запятой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32- и FP64-точностью в рамках стандарта IEEE 754-2008);
- 80 блоков текстурной адресации и фильтрации с поддержкой FP16- и FP32-компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 3 широких блока ROP (24 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16- или FP32-формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort;
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2;
- Поддержка шины PCI Express 3.0.
Спецификации референсной видеокарты GeForce GTX 660
- Базовая частота ядра 980 МГц;
- Средняя турбо-частота 1033 МГц;
- Количество универсальных процессоров 960;
- Количество текстурных блоков — 80, блоков блендинга — 24;
- Эффективная частота памяти 6008 (1502×4) МГц;
- Тип памяти GDDR5, 192-битная шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 144,2 ГБ/с;
- Теоретическая максимальная скорость закраски 23,5 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 78,4 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один HDMI, один DisplayPort;
- Двойной SLI-разъем;
- Шина PCI Express 3.0;
- Энергопотребление до 140 Вт;
- Один 6-контактный разъём питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для России 8 499 руб. (для рынка США — $229)
Модель GeForce GTX 660 в линейке решений компании NVIDIA заняла место между старшей GeForce GTX 660 Ti и младшей GeForce GTX 650, анонсированной одновременно с GTX 660. Она замещает платы предыдущего поколения среднего уровня, вроде GeForce GTX 560 (Ti), предлагаемые до выхода решений на базе архитектуры Kepler. Среднеценовая модель получила цифру «6» в середине индекса, но без суффикса «Ti», который остался за платой на урезанном GK104, выпущенной чуть раньше.
Выпуск долгожданного чипа GK106 был сигналом того, что с производством на TSMC дела налажены, да и старые решения серии GTX 500 стало стыдно продавать, в то время как серия Radeon HD 7800 от конкурента присутствует на рынке уже почти полгода. Именно две модели этой серии AMD и стали главными конкурентами для GTX 660. Её рекомендованная цена уложилась ровно посередине между ценами моделей Radeon HD 7850 и HD 7870, с ними двумя мы и сравниваем новинку.
Как и самая слабая видеокарта на базе чипа GK104, новая модель имеет 192-битную шину памяти, но объём видеопамяти остался равным 2 ГБ. Для платы такого уровня это — оптимальный объём локальной памяти, лишь в условиях самых современных приложений и максимальных настроек качества с полноэкранным сглаживанием высокого уровня его может иногда не хватить. Впрочем, партнёры могут выпустить и модификации с 3 ГБ памяти, так как 192-битная шина позволяет сделать это легко и просто.
Архитектура GK106
В отличие от предыдущих видеокарт семейства GeForce GTX 600, модель GTX 660 основана на базе нового видеочипа среднего уровня, получившего название GK106. Этот GPU поддерживает все возможности, появившиеся в топовом GK104, на котором основана видеокарта GeForce GTX 680 и все особенности архитектуры Kepler относятся к нему в полной мере, включая организацию мультипроцессоров SMX и технологию повышения частоты GPU Boost. Архитектура Kepler давно нам известна и её особенности мы уже рассматривали.
Интересно, что хотя модель GeForce GTX 660 основана на полной (не урезанной) версии чипа GK106, она включает пять мультипроцессоров SMX, состоящих из 960 потоковых вычислительных ядер и 80 текстурных модулей. Причём, эти пять SMX собраны в три кластера графической обработки Graphics Processing Clusters (GPC), как в этом можно убедиться на диаграмме, предоставленной компанией NVIDIA:
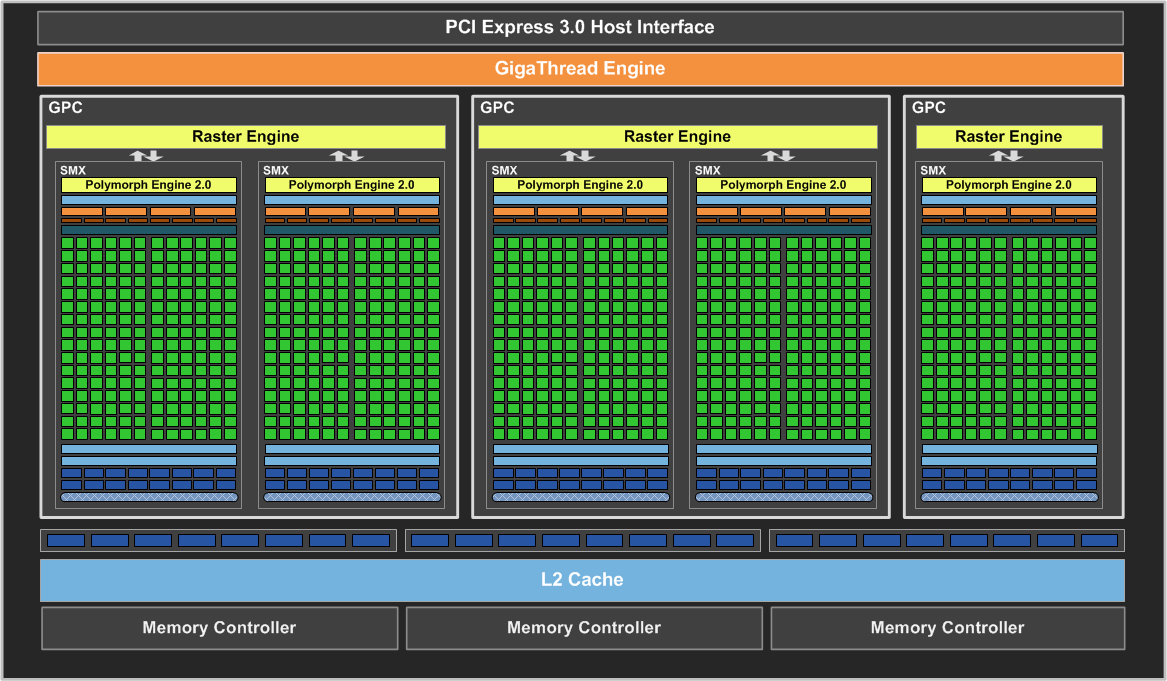
Мало того, что это решение с нечётным количеством блоков, так оно ещё и несимметричное. Любому взглянувшему на диаграмму выше сразу станет понятно, что намного логичнее было бы использование пусть тех же трёх GPC, но с шестью мультипроцессорами SMX — по два на каждый кластер GPC. С другой стороны, технически ничто не мешало NVIDIA сделать так, как показано на диаграмме — и вполне возможно, что аппаратно так оно и есть, благо, что похожий пример мы уже видели на диаграмме следующего топового чипа GK110, который также состоит из нечётного количества мультипроцессоров SMX (15 штук).
Впрочем, пользователю от этого не жарко и не холодно — ну пять их, так и ладно! А нам интересны причины, побудившие NVIDIA поступить настолько нелогично. То ли шестой SMX не входил в запланированный размер кристалла или потребление чипа среднего уровня, то ли производительность GK106 с шестью SMX была бы слишком близкой к той же GeForce GTX 660 Ti, основанной на урезанном GK104. Нам кажется, что дело как раз в этом.
Как и указанное выше решение, GeForce GTX 660 имеет три 64-битных контроллера памяти, что в сумме составляет 192-битный доступ к локальной видеопамяти. Так как блоки растровых операций ROP «привязаны» к контроллерам, то их количество также не изменилось с GTX 660 Ti и составляет 24 блоков. Как и в случае со старшим решением на базе GK104, контроллер памяти GeForce GTX 660 умеет работать с чипами памяти смешанной ёмкости. Именно это решение позволило сделать объём памяти не 1.5 или 3 ГБ, а 2 ГБ, при использовании 192-битного доступа.
Мы уже писали о том, как это сделано технически. Контроллеры памяти используют восемь чипов памяти, первый 64-битный контроллер получает четыре микросхемы общим объёмом 1 ГБ и 16-битным режимом доступа к каждой их них, а остальные два контролера управляют двумя чипами памяти каждый, и они имеют 32-битный доступ и ёмкость по 512 МБ на чип. Тонкости решения NVIDIA не раскрывает, но схематически это работает так — три контроллера распределяют память на три фрагмента объёмом в 512 МБ (общий размер этого фреймбуфера получается 1.5 ГБ), а к оставшимся 512 МБ памяти доступ осуществляется по 64-битной шине одного из контроллеров.
Таким образом, появляется возможность использовать все 2 ГБ памяти, хотя некоторые потери в производительности по сравнению с полноценным решением вполне возможны. Хотя ничто не может помешать производителям видеокарт ставить на свои варианты GeForce GTX 660 по 3 ГБ GDDR5 памяти — такие варианты вполне возможны. Рабочая частота GDDR5-видеопамяти в новой модели идентична значению частоты, на которой она работает во всех топовых платах компании — (1502)6008 МГц.
Неудивительно, что GeForce GTX 660 поддерживает такую технологию, как GPU Boost. Базовая частота GK106 в составе GeForce GTX 660 равна 980 МГц — это минимальная и гарантированная частота для работы 3D приложений, даже с учётом специализированных стресс-тестов, нагружающих систему питания видеокарт настолько, насколько это возможно. Среди характеристик последних видеокарт NVIDIA есть и «турбо-частота» (Boost Clock) — это средняя частота, на которой GPU работает в реальных 3D-приложениях и играх, требующих меньшей энергии. Средняя турбо-частота для GeForce GTX 660 равна 1033 МГц, что на 5% выше базовой — это лишь типичный прирост, получаемый пользователем, но зачастую GPU работает и на более высокой частоте.
Особенности
Печатная плата GeForce GTX 660 весьма короткая и для неё возможно применение сравнительно компактных кулеров. PCB эталонного дизайна заметно упрощена по сравнению с топовыми решениями, в том числе из-за других требований по питанию. Длина эталонной платы GeForce GTX 660 составляет 24 см, для дополнительного питания используется лишь один 6-контактный разъём питания.
Выше мы писали о том, что GPU Boost обеспечивает высокую тактовую частоту графического процессора. И типичная частота GK106 в играх в номинальном режиме составляет 1033 МГц, но это не максимальное значение. Во многих случаях видеочип платы GeForce GTX 660 будет работать на ещё большей частоте, чем 1033 МГц. И для рассматриваемой видеокарты вполне типичны частоты порядка 1084 МГц и даже выше.
Это вполне объяснимо, так как GeForce GTX 660 при типичной игровой нагрузке потребляет лишь 115 Вт энергии. Такое значение достигается при установке настройки «power target» на 100% (значение по умолчанию). При разгоне же GeForce GTX 660 потребуется поднять это значение. К примеру, при значении +110% плата будет потреблять уже до 127 Вт в тех же самых условиях. Несмотря на довольно высокую тактовую частоту GPU, представленная модель вполне может обеспечить любителям разгона неплохие возможности по дальнейшему поднятию частот.
Как часто получается в последнее время у NVIDIA, сразу после анонса в продаже появятся фабрично разогнанные варианты GeForce GTX 660 от партнёров компании, так как они получили возможность разработать платы собственного дизайна и продавать их с начала продаж. Различные модели GeForce GTX 660 могут иметь оригинальный дизайн печатных плат, систем питания и охлаждения, а также повышенные тактовые частоты. Подобные решения появятся у многих партнёров NVIDIA, некоторые из указанных моделей имеют усиленные системы питания, с увеличенным числом фаз и т.п. То же самое касается и систем охлаждения — многие из разогнанных вариантов GeForce GTX 660 довольно компактны и имеют эффективные кулеры с увеличенным количеством вентиляторов большого диаметра, что позволяет улучшить эффективность охлаждения.
В остальном, GeForce GTX 660 похожа на предыдущие модели видеокарт NVIDIA. Для вывода изображения на референсной плате имеется два выхода Dual Link DVI и по одному полноразмерному HDMI и DisplayPort, как и в старших модификациях линейки. Такое решение позволяет вывести стереоизображение сразу на несколько мониторов при помощи технологии 3D Vision Surround, что ранее было доступно лишь в SLI-конфигурации. Модель поддерживает и все остальные технологии компании NVIDIA, в том числе Adaptive VSync и PhysX.
Модель GeForce GTX 660 предлагает все современные возможности а также уровень производительности, который немногим уступает старшей модели GTX 660 Ti, созданной на базе урезанного GK104. При этом новая видеоплата предлагается по более привлекательной цене и может стать одной из наиболее массовых видеокарт на рынке ПК.
Особенности модели GeForce GTX 650 Ti
- Частота ядра 925 МГц;
- Количество универсальных процессоров 768;
- Количество текстурных блоков — 64, блоков блендинга — 16;
- Эффективная частота памяти 5400 (1350×4) МГц;
- Тип памяти GDDR5, 128-битная шина памяти;
- Объем памяти 1 или 2 ГБ;
- Пропускная способность памяти 86,4 ГБ/с;
- Теоретическая максимальная скорость закраски 14,8 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 59,2 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI;
- Шина PCI Express 3.0;
- Энергопотребление до 110 Вт;
- Один 6-контактный разъём питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $149
Логично, что GeForce GTX 650 Ti расположилась в продуктовой линейке компании NVIDIA между моделями GeForce GTX 660 и GTX 650. Она замещает платы предыдущего поколения среднего уровня, вроде GeForce GTX 560 и GTX 550 Ti. Принцип наименования видеокарт NVIDIA всё тот же, бюджетная модель получила цифру «5» в середине индекса, но так как это быстрейшая из двух бюджетных GTX 650, то к наименованию прикрепили и суффикс «Ti», который и отличает новинку от GTX 650 на базе GK107, о которой написано ниже.
Выпуск видеокарты на базе урезанного чипа GK106 говорит о том, что на производстве уже скопился кое-какой брак от чипов, не прошедших GTX 660, но который можно пустить на GTX 650 Ti. Что касается решений конкурирующей компании AMD, то новая GTX 650 Ti не имеет прямого соперника. Рекомендованная цена новинки уложилась между ценами моделей Radeon HD 7770 и HD 7850, но всё же гораздо ближе к первой.
В отличие от видеокарты на базе полноценного чипа GK106, новая модель имеет лишь 128-битную шину памяти, и объём установленной на неё видеопамяти равен 1 или 2 ГБ. Для платы такого уровня даже 1 ГБ — это вполне нормальное значение, и лишь в условиях наиболее требовательных приложений и максимальных настроек качества с полноэкранным сглаживанием высокого уровня его может не хватить. Впрочем, производители уже предлагают и 2-гигабайтные варианты, так что выбор у покупателя будет.
Архитектура
Модель GeForce GTX 650 Ti основана на базе рассмотренного выше видеочипа среднего уровня, получившего название GK106. Этот GPU поддерживает все возможности, появившиеся в топовом GK104 (GeForce GTX 680) и все особенности архитектуры Kepler относятся к нему в полной мере. Хотя эта модель основана на полной версии чипа GK106, но она включает пять мультипроцессоров SMX, а не шесть, как было бы логичнее. И эти пять SMX собраны в три кластера графической обработки Graphics Processing Clusters (GPC). Что же урезали в нём при создании GTX 650 Ti? Рассмотрим диаграммы чипа:
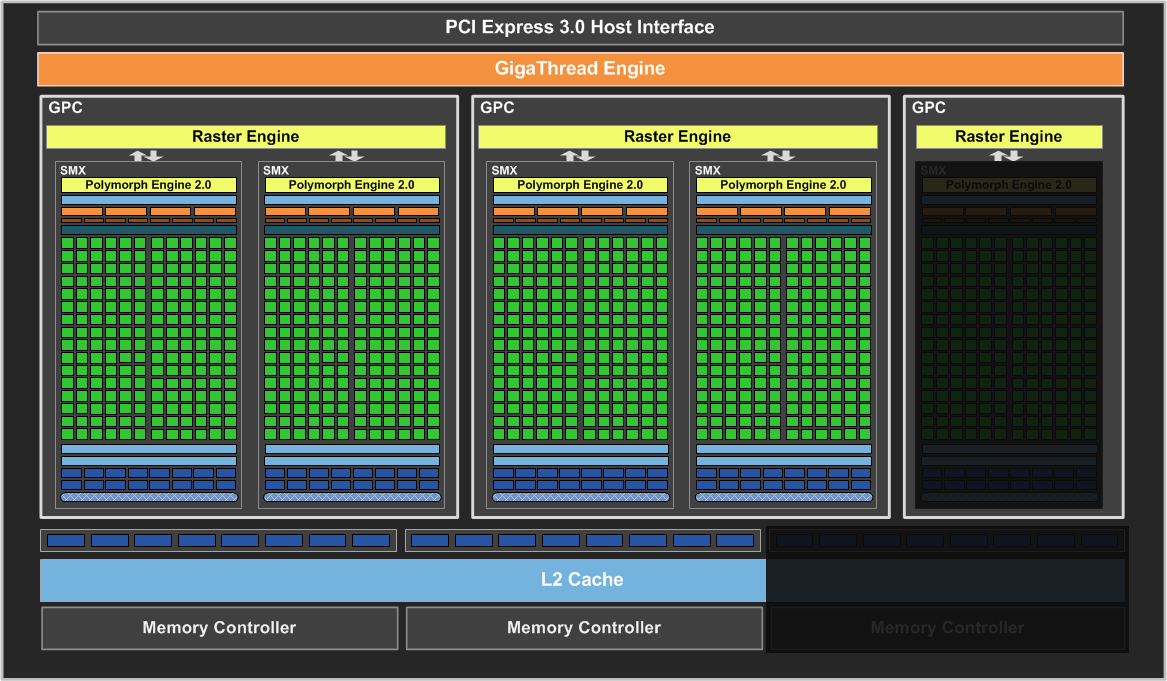
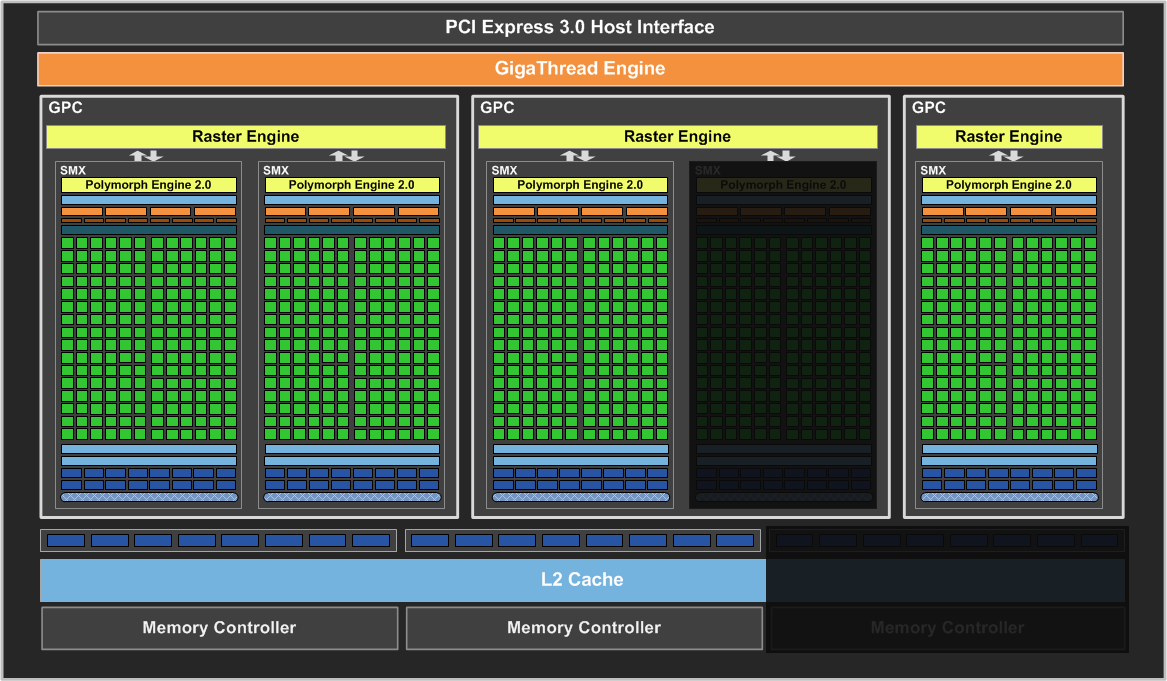
Вы спросите, почему диаграмма не одна, а две? Всё объясняется несимметричностью GPU. В нём есть три GPC, два их которых включают по два мультипроцессора SMX, и один из GPC содержит лишь один SMX. Поэтому при отключении SMX в таком GPC, отключится он весь целиком. То есть, в GTX 650 Ti идут чипы, содержащие по четыре активных блока SMX, но собранные в два или три кластера GPC — как повезёт. На что это может повлиять? Теоретически, в «неудачном» GPU с двумя активными GPC, будут работать два блока растеризации Raster Engine, а не три, как в «удачном». То есть, в некоторых случаях возможна даже разная производительность у разных GTX 650 Ti, особенно в специфических задачах. Впрочем, потребителей бюджетных чипов такие мелочи не должны волновать, да и не волнуют.
Итак, в случае модели GeForce GTX 650 Ti, в чипе GK106 активны четыре из пяти имеющихся физически блоков SMX, что в целом составляет 768 потоковых процессоров и 64 текстурных модуля. В отличие от GeForce GTX 660, имеющего все три 64-битных контроллера памяти активными, подсистема памяти GeForce GTX 650 Ti задействует лишь два 64-битных контроллера из имеющихся на чипе трёх, что в сумме составляет лишь 128-битную шину. А частота видеопамяти была уменьшена с 6000 до 5400 МГц. В итоге, получившейся пропускной способности в 86.4 ГБ/с может быть маловато, учитывая мощность GK106 и высокие требования к ПСП у современных игр, особенно с включением полноэкранного сглаживания. Так как блоки растровых операций ROP «привязаны» к контроллерам памяти, то их количество также изменилось по сравнению с GTX 660 и в нашем случае равно 16 активных блоков.
GeForce GTX 650 Ti также не поддерживает технологию GPU Boost. Данная технология обеспечивает работу на максимально возможных частотах в рамках выбранного теплопакета и работает независимо от драйверов или иного ПО. Но в NVIDIA решили, что нечего баловать «бюджетников» такими сложнейшими технологиями, и так уже должны быть счастливы уже при виде Kepler за $149. В общем, номинальная (и единственная) тактовая частота видеочипа GK106, применённого в GeForce GTX 650 Ti, равна 925 МГц и она фиксированная, в отличие от более мощных решений.
Другие особенности
Печатная плата GeForce GTX 650 Ti меньше платы GTX 660, она очень и очень короткая и для неё возможно применение компактных кулеров, хотя и всё равно двухслотового размера. PCB эталонного дизайна заметно упрощена по сравнению с более дорогими решениями, длина платы GeForce GTX 650 Ti составляет лишь 145 мм, а для дополнительного питания используется один 6-контактный разъём, как и на GTX 660.
Как получается в последнее время у NVIDIA почти каждый раз, сразу же после анонса новых решений, в продаже появляются фабрично разогнанные варианты с оригинальными системами охлаждения и т.п. Вот и для GeForce GTX 650 Ti производители разрабатывали собственный дизайн и продают такие решения с самого начала продаж. Различные модели GTX 650 Ti могут иметь свой дизайн печатных плат, систем питания и охлаждения, а также повышенные тактовые частоты. Подобные решения выпустили многие партнёры NVIDIA, и вот лишь малая их часть:
Некоторые из подобных моделей имеют усиленные системы питания, с увеличенным числом фаз, собственные системы охлаждения, которые могут оказаться более эффективными. Многие из разогнанных вариантов GeForce GTX 650 Ti или весьма компактны или имеют эффективные кулеры с увеличенным количеством вентиляторов большого диаметра, что позволяет улучшить эффективность охлаждения и даёт возможность выбора.
Плата в целом двухслотовая и требует подключения дополнительного питания по одному 6-контактному PCIe разъёму. Для вывода изображения на референсной плате имеются следующие разъёмы: два dual-link DVI и один mini-HDMI. И хотя референсный дизайн обеспечивает вывод изображения лишь на три устройства, все GeForce GTX 650 Ti поддерживают четыре дисплея, и некоторые из партнёров NVIDIA такую возможность предлагают. Решение позволяет вывести стереоизображение сразу на несколько мониторов при помощи технологии 3D Vision Surround, что ранее было доступно лишь в SLI-конфигурации.
Естественно, новая модель поддерживает и все остальные технологии компании NVIDIA, о которых мы ранее писали, в том числе Adaptive VSync и PhysX. В качестве дополнения упомянем то, что покупатели GeForce GTX 650 Ti во всём мире получили бесплатные копии игры Assassin’s Creed III — одного из долгожданных игровых экшн-проектов, вышедших осенью 2012 года. Это один из самых популярных игровых сериалов, ПК-версия которого отличается улучшенной графикой с поддержкой технологий DirectX 11. Производители видеокарт прикладывают соответствующие купоны в комплект поставки, и игра стала доступна для покупателей в конце ноября.
Спецификации GK107
- Кодовое имя чипа GK107;
- Технология производства 28 нм;
- 1,3 миллиардов транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 128-битная шина памяти, два независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5-памяти;
- Частота ядра до 1058 МГц;
- 2 потоковых мультипроцессора, включающих 384 скалярных ALU для расчётов с плавающей запятой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32- и FP64-точностью в рамках стандарта IEEE 754-2008);
- 32 блоков текстурной адресации и фильтрации с поддержкой FP16- и FP32-компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 2 широких блока ROP (16 пикселей) с поддержкой режимов сглаживания до 32 выборок на пиксель, в том числе при FP16- или FP32-формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort;
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2;
- Поддержка шины PCI Express 3.0
Спецификации референсной видеокарты GeForce GT 640
- Частота ядра 900 МГц;
- Количество универсальных процессоров 384;
- Количество текстурных блоков — 32, блоков блендинга — 16;
- Эффективная частота памяти 1800 (900*2) МГц;
- Тип памяти GDDR3, 128-бит шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 28,5 ГБ/с;
- Теоретическая максимальная скорость закраски 14,4 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 28,8 гигатекселей в секунду;
- Поддержка Dual Link DVI-I, HDMI, DisplayPort;
- Энергопотребление до 65 Вт;
- Двухслотовое исполнение;
В описании чипа GK104 и решений на его основе мы убедились, что видеочипы архитектуры Kepler весьма энергоэффективны — они весьма мощны при сравнительно низком потреблении энергии. Именно поэтому новая архитектура просто идеально подходит для высокопроизводительных ноутбуков, а также недорогих настольных решений. Так, компанией Acer был выпущен ультрабук Aspire Timeline Ultra M3, основанный на NVIDIA GeForce GT 640M и изначально чип GK107 вышел именно в мобильной версии.
Для того, чтобы вместить такой мощный GPU в жёсткие "ноутбучные" рамки по размеру и весу, их мощностью обычно приходилось поступаться и предыдущие модели ультрабуков имели лишь интегрированные GPU, которые весьма слабы в 3D-графике. Но компания NVIDIA предложила использование выделенного видеоядра GeForce в дополнение к интегрированному в CPU. Видеоядра энергоэффективного настолько, чтобы ультрабук оставался и ультралёгким и ультратонким.

Чтобы ультрабук был ещё и высокопроизводительным, NVIDIA предложила новейшие видеоядра семейства GeForce 600M, которые можно применять в тонких и лёгких ноутбуках. На основе новой архитектуры Kepler производится несколько моделей мобильных графических процессоров: GT 640M, GT 650M и GTX 660M. Тот же самый чип лежит и в основе настольной видеокарты GeForce GT 640.
Все эти модели основаны на графическом процессоре, известном под кодовым именем GK107 (где буква «K» означает архитектуру Kepler), имеющем в своём составе один кластер графической обработки (Graphics Processing Cluster — GPC), который являются минимальным неделимым устройством в составе видеочипов данной архитектуры. В настольном GK104 (на котором основана модель GeForce GTX 680) таких кластеров четыре штуки, а в GK107 лишь один. В состав GPC входят растеризаторы, геометрические движки и текстурные модули. Приведём блок-схему мобильного чипа GK107:

Блок GPC содержит два потоковых мультипроцессора нового поколения — SMX. По сравнению с предыдущими мультипроцессорами SM, новые SMX обеспечивают более высокую производительность, но при этом потребляют значительно меньше энергии, что особенно важно для мобильных решений вроде GK107. На схеме GPU видно, что каждый из блоков SMX содержит по 192 потоковых вычислительных ядра, что в шесть раз больше, чем в блоках SM чипов архитектуры Fermi. Более подробно все изменения и нововведения Kepler расписаны выше.
Общее количество вычислительных CUDA ядер в GK107 равно 384 штукам, блоков выборки и фильтрации текстур 32 штуки, а блоков ROP — 16. Номинальная частота GPU в мобильном GT 640M равна 625 МГц, а в настольном — 900 МГц. Но так как чип поддерживает технологию GPU Boost, появившуюся в Kepler, реальная частота в большинстве 3D-приложений может превышать эти значения.
GK107 имеет два 64-битных канала памяти, что в целом даёт 128-битную шину. Вместе с поддержкой до 2 гигабайт памяти стандартов DDR3 и GDDR5, общая пропускная способность может составлять до 64 гигабит/с, что очень неплохо для решений средней мощности. К сожалению, в ноутбуках чаще устанавливается более дешёвая DDR3 память, да и настольная видеокарта с памятью GDDR5 пока ещё не вышла, и меньшая ПСП может негативно сказаться на производительности.
В целом характеристики GeForce GT 640M и GT 640 весьма неплохие, особенно в расчёте на применение первой модели даже в ультрабуках, а второй — в домашних и игровых системах нетребовательных пользователей. Ведь предыдущие ультракомпактные ноутбуки, имеющие лишь интегрированные видеоядра, по 3D-производительности весьма слабы, и назвать их "игровыми" не получится — большая часть современных игр на них просто неиграбельны (обеспечивают менее 20 FPS) при любых настройках, даже минимальных, или вовсе не запускаются.
Что касается дискретной модели GeForce GT 640, то она имеет простой дизайн печатной платы и охлаждения, потребляет мало энергии, стоит недорого и обеспечивает неплохую для своего класса производительность 3D-рендеринга. Из явных же недостатков решения стоит отметить существование лишь DDR3 версии этой модели, ПСП которой явно служит ограничивающим производительность фактором.
Особенности модели GeForce GTX 650
- Частота ядра 1058 МГц;
- Количество универсальных процессоров 384;
- Количество текстурных блоков — 32, блоков блендинга — 16;
- Эффективная частота памяти 5000 (1250×4) МГц;
- Тип памяти GDDR5, 128-битная шина памяти;
- Объем памяти 1 или 2 ГБ;
- Пропускная способность памяти 80,0 ГБ/с;
- Теоретическая максимальная скорость закраски 16,9 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 33,9 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI;
- Шина PCI Express 3.0;
- Энергопотребление до 64 Вт;
- Один 6-контактный разъём питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $109 (для России — 3999 руб)
Модель GeForce GTX 650 в продуктовой линейке компании NVIDIA расположилась между GeForce GTX 650 Ti и GeForce GT 640. Она заменила бюджетные платы предыдущего поколения, вроде GeForce GTS 450 и ниже, предлагаемые до выхода решений на базе архитектуры Kepler. Принцип наименования видеокарт NVIDIA не изменился, бюджетная модель получила цифру «5» в середине индекса, и так как это более медленная из двух модификаций GTX 650, то в её наименовании нет суффикса «Ti», что отличает новинку от GTX 650 Ti, созданную на базе чипа GK106.
Что касается решений конкурента — компании AMD — то новая GeForce GTX 650 не имеет прямого соперника в линейке Radeon HD 7000, как это получается со многими моделями. Рекомендованная цена новинки NVIDIA уложилась между ценами моделей Radeon HD 7750 и HD 7770, поэтому и сравнивать плату калифорнийской компании нужно и с той и с другой моделью от AMD.
Точно как и одноимённая видеокарта с суффиксом Ti, сделанная на базе урезанного чипа GK106, новая модель имеет 128-битную шину памяти, и объём установленной на неё видеопамяти может быть равен 1 или 2 ГБ. Для бюджетной платы и 1 ГБ можно считать вполне достаточным объёмом, ведь только в условиях самых требовательных приложений и максимальных настроек качества с полноэкранным сглаживанием высокого уровня памяти может не хватать. Но, как всегда, производители предлагают и 2-гигабайтные варианты, так что выбор у покупателя есть.
Архитектура GPU и особенности платы
Модель GeForce GTX 650 основана на базе бюджетного видеочипа, получившего название GK107, на котором базируются некоторые мобильные решения, а также настольная видеокарта GeForce GT 640. Этот GPU поддерживает все возможности, появившиеся в топовом GK104 (GeForce GTX 680) и все особенности архитектуры Kepler относятся к нему в полной мере, включая организацию мультипроцессоров SMX. Графический процессор GK107 в модификации GeForce GTX 650 имеет в своём составе один кластер графической обработки Graphics Processing Cluster (GPC), состоящий из двух мультипроцессоров SMX.
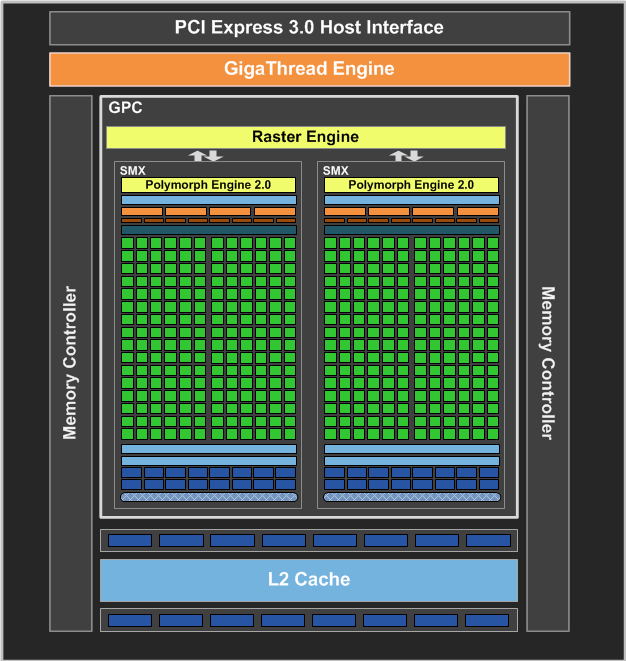
Соответственно, объём GDDR5 памяти для референсных моделей GTX 650 составляет 1 или 2 ГБ локальной видеопамяти. Которая работает на эффективной частоте в 5000 МГц, сниженной относительно более дорогих моделей на базе Kepler. В итоге, пропускной способности в 80 ГБ/с будет вполне достаточно для такого бюджетного решения — ведь это почти столько же, что и у заметно более мощной GTX 650 Ti.
Как старшая модель GeForce GTX 650 Ti и другие платы на базе чипа GK107, новинка не поддерживает технологию GPU Boost — комбинацию программно-аппаратных решений, позволяющую автоматически увеличивать рабочие частоты GPU, в зависимости от его энергопотребления для достижения максимальной производительности. Технология обеспечивает работу на максимально возможных частотах в рамках выбранного теплопакета, но в NVIDIA решили, что бюджетные видеокарты обойдутся без подобных технологий. Поэтому, номинальная тактовая частота видеочипа GK107, применённого в GeForce GTX 650, равна 1058 МГц и эта частота фиксированная, в отличие от более мощных решений.
Печатная плата GeForce GTX 650 очень короткая и для неё возможно применение компактных кулеров, хотя и всё равно двухслотового размера. PCB эталонного дизайна заметно упрощена по сравнению с более дорогими решениями, и длина платы GeForce GTX 650 составляет лишь 145 мм. Для дополнительного питания используется один 6-контактный разъём, как и на GTX 660. Для вывода изображения на референсной плате есть следующие разъёмы: два dual-link DVI и один mini-HDMI. Хотя такой дизайн обеспечивает вывод изображения лишь на три устройства, все GeForce GTX 650 аппаратно поддерживают до четырёх дисплеев.
Понятно, что с графическим процессором GK107, применяемым в том числе в мобильных устройствах, уровень потребления энергии у GeForce GTX 650 весьма низок даже с учётом высоких рабочих частот. Энергопотребление GeForce GTX 650 в режиме простоя составляет примерно 5 Вт, а при проигрывании видео в высоком разрешении — лишь 13 Вт, что является одними из лучших показателей в классе. В более тяжёлых задачах новая модель потребляет до 64 Вт энергии, и рассеивает столь же мало тепла. Но по некоторым причинам, инженеры решили оставить один 6-контактный разъём питания на плате референсного дизайна. Это дополнительное питание обеспечивает лучшие возможности в режиме разгона, да и стабильность системы в таком варианте явно выше.
Впрочем, некоторые из партнёров NVIDIA по выпуску видеокарт предлагают модели GeForce GTX 650 и без необходимости дополнительного питания. А если пользователя интересуют более мощные решения, то многие компании выпускают и фабрично разогнанные решения прямо с момента анонса, как это принято у NVIDIA в последнее время. Многие из плат GeForce GTX 650 от партнёров, имеют рабочую частоту GPU, превышающую 1100 МГц, и способны разогнаться до частот выше 1200 МГц. Некоторые из таких моделей имеют усиленные системы питания, собственные системы охлаждения, которые могут оказаться более эффективными.
GeForce GTX 650 поддерживает все остальные технологии компании NVIDIA, о которых мы выше писали, в том числе Adaptive VSync и PhysX. Так как GeForce GTX 650 имеет в своей основе графический процессор GK107 на основе архитектуры Kepler, то новая видеокарта предлагает все современные возможности в виде DirectX 11, PhysX, TXAA, адаптивного VSync и других технологий. Владельцы устаревших игровых систем, имеющих DirectX 10-совместимое аппаратное обеспечение, в лице GTX 650 получили ещё один вариант для апгрейда своей видеосистемы за сравнительно небольшие деньги.
Спецификации GK110
- Кодовое имя чипа GK110;
- Технология производства 28 нм;
- 7,1 миллиардов транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 384-битная шина памяти, шесть независимых контроллеров шириной по 64 бита каждый, с поддержкой GDDR5-памяти;
- Частота ядра 836 (турбо-частота — 876) МГц;
- 15 потоковых мультипроцессоров, включающих 2880 скалярных ALU для расчётов с плавающей запятой одинарной точности (FP32) и 960 скалярных ALU для расчётов двойной точности (FP64) в рамках стандарта IEEE 754-2008;
- 240 блоков текстурной адресации и фильтрации с поддержкой FP16- и FP32-компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 6 широких блоков ROP (48 пикселей) с поддержкой режимов сглаживания до 32 выборок на пиксель, в том числе при FP16- или FP32-формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort;
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2;
- Поддержка шины PCI Express 3.0.
Спецификации референсной видеокарты GeForce GTX Titan
- Частота ядра 836 (876) МГц;
- Количество универсальных процессоров 2688;
- Количество текстурных блоков — 224, блоков блендинга — 48;
- Эффективная частота памяти 6000 (1500×4) МГц;
- Тип памяти GDDR5, 384-битная шина памяти;
- Объем памяти 6 ГБ;
- Пропускная способность памяти 288,4 ГБ/с;
- Вычислительная производительность (FP32/FP64) 4.5/1.3 терафлопс;
- Теоретическая максимальная скорость закраски 40,1 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 187,3 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2;
- Шина PCI Express 3.0;
- Энергопотребление до 250 Вт;
- Один 8-контактный и один 6-контактный разъёмы питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $999 (для России — 34990 руб).
NVIDIA отошла от своего принципа наименования видеокарт для TITAN, но в подобной эксклюзивной модели вполне можно пойти на такой шаг. Единственная исключительная модель получила слово, а не цифры в конце названия, что отличает новинку от всех видеокарт линейки GeForce GTX 600. Ускоритель вычислений NVIDIA Tesla K20X также основан на наиболее мощном чипе семейства Kepler, содержащем 2688 вычислительных CUDA-ядер, и вообще — это почти что близнец вышедшей игровой карты на этом же GPU, который применяется в быстрейшем суперкомпьютере мира под названием TITAN. Поэтому неудивительно, что NVIDIA решила назвать свою игровую карту GeForce GTX TITAN, чтобы рынок ассоциировал их игровые решения с успешными суперкомпьютерными.
На рынке GeForce GTX TITAN не заменил никакую модель видеокарты в линейке компании NVIDIA, а будет сосуществовать с двухчиповой GeForce GTX 690 в самых верхних её строчках. Модель GTX 690 будет продолжать производиться и продаваться, так как эти две видеокарты друг другу ничуть не мешают — они очень разные. GeForce GTX 690 лучше подходит для одних целей, когда важен максимальный FPS, несмотря на объективные недостатки мультичипового AFR-рендеринга, а TITAN лучше подойдёт в качестве универсального решения с большим объёмом локальной памяти и быстрым к ней доступом, что скажется в сверхвысоких разрешениях. Кроме того, TITAN компактнее и требует меньше энергии, поэтому подойдёт для большего количества систем, а ещё он тише и предлагает дополнительные возможности вроде GPU Boost 2.0 и полноскоростных вычислений с двойной точностью.
Что касается решений конкурента — компании AMD — то вполне понятно, что новая GeForce GTX TITAN осталась без прямого соперника. У AMD просто нет чипов такой сложности, да и официальная двухчиповая плата на менее сложных появилась уже после выхода TITAN, хотя партнёры AMD предлагали подобные модели и ранее, в т.ч. совсем уж экстремальные варианты, вроде ASUS ARES II с тремя 8-контактными (!!!) разъёмами питания. Прямого же одночипового соперника для TITAN в линейке Radeon HD 7000 можно и не ждать.
В отличие от предыдущих быстрейших видеокарт на базе одного GPU от NVIDIA последнего поколения, TITAN сделан на базе чипа GK110 и имеет 384-битную шину памяти. Поэтому объём установленной на неё видеопамяти теоретически мог быть равен 3 или 6 ГБ. В случае столь дорогой и элитной модели установка 6 ГБ памяти совершенно оправдана, хотя из практических соображений было бы вполне достаточно и 3 ГБ. Но ведь это ровно как у лучших моделей конкурента, ставить с которыми TITAN на одну полку NVIDIA явно не хочет. Ну и для серьёзных вычислений объём в 6 ГБ может быть вполне актуальным. Так что, даже в условиях самых требовательных приложений и максимальных настроек качества с полноэкранным сглаживанием любого уровня видеопамяти у TITAN всегда хватит.
Конструкция платы и системы охлаждения
Длина платы GeForce GTX TITAN равна 10.5 дюймов (267 мм), для питания она использует один 8-контактный и один 6-контактный разъёмы от блока питания. Для вывода изображения используется стандартный набор из двух разъёмов Dual-Link DVI, одного HDMI и одного DisplayPort разъёма.

Дизайн корпуса GeForce GTX TITAN схож с дизайном другой топовой видеокарты NVIDIA — GeForce GTX 690. Выглядит плата в целом очень солидно, и качество сборки и материалов соответствующее. Понятно, что для премиум-сегмента принято использовать соответствующие материалы, и инженеры NVIDIA решили накрыть конструкцию «Титана» алюминиевой крышкой. В центре крышки есть прозрачное пластиковое окно, открывающее пытливому взору чудесный вид на испарительную камеру и двухслотовый алюминиевый радиатор, участвующий в охлаждении чипа GK110.
Логотип GeForce GTX на боковом торце видеокарты имеет светодиодную подсветку. Она служит также индикатором включения, а интенсивность подсветки светодиодами можно отрегулировать вручную, используя специальное ПО от партнёров NVIDIA. Можно даже настроить светодиоды так, чтобы интенсивность их свечения изменялась в зависимости от нагрузки на GPU.
Так как GeForce GTX TITAN спроектирован и предназначен для энтузиастов и любителей выжать из системы всё до последнего, это не могло не сказаться на некоторых технических решениях, применённых в конструкции. Сам чип GK110 снабжает энергией 6-фазная схема питания с защитой от перенапряжения, а дополнительная схема с двумя фазами используется для питания GDDR5 видеопамяти. 6+2-фазная схема обеспечивает плату питанием даже с учётом возможного разгона, процесс которого стал ещё легче благодаря возможности повышения напряжения (читайте об этом ниже). К слову, сама NVIDIA уверяет, что при стандартном охлаждении для графического процессора возможно достижение тактовой частоты выше 1 ГГц.
Для своей новой видеокарты высшего класса, инженеры NVIDIA разработали новую систему охлаждения, которая отличается высокой эффективностью. В кулере используется технология испарительной камеры, которая отлично рассеивает тепло, были увеличены рёбра радиатора, а также в очередной раз улучшена схема управления вентилятором, изменяющая рабочее напряжение и частоту его вращения для достижения оптимального сочетания акустического и температурного режимов.

Медная испарительная камера в кулере GeForce GTX TITAN работает как тепловая трубка, но она более мощная и эффективная. Кроме того, для улучшения работы камеры используется новый материал термоинтерфейса от компании Shin-Etsu, который обеспечивает двукратное преимущество перед тем, что применялся ранее в GeForce GTX 680. В результате, новая испарительная камера и термоинтерфейс позволяют отводить больше тепла от GK110, давая возможность работы на более высокой тактовой частоте.
Тепло от испарительной камеры отводится при помощи большого двухслотового радиатора из алюминиевого сплава. По сравнению с предыдущими решениями линейки GeForce GTX 600, в кулере TITAN применяются удлинённые рёбра радиатора, что увеличивает площадь рассеивания и повышает её эффективность. На GeForce GTX TITAN также установлена алюминиевая пластина с обратной стороны, которая дополнительно охлаждает печатную плату и компоненты на ней. В конструкции вентилятора используются те же демпфирующие материалы, что и в GeForce GTX 680 — они служат для снижения уровня шума.
К слову о шуме. NVIDIA приводит цифры собственных акустических замеров, но не для одночиповых видеосистем, а для экстремальных многочиповых — чтобы разница была ощутимей. Так вот, при запуске бенчмарка Unigine Heaven в разрешении 1920×1080 с полноэкранным сглаживанием и экстремальным уровнем тесселяции, различные системы на базе трёх видеокарт показали следующий уровень шума:
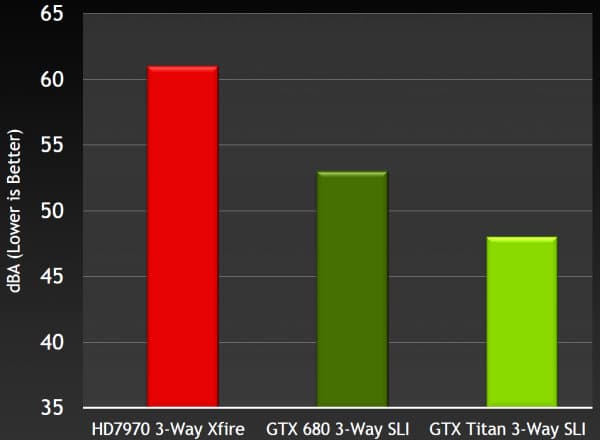
Как видите, кулер GeForce GTX TITAN справляется с работой просто отлично. Мало того, что работа трёх GK110 должна обеспечивать заметно более высокую производительность (об это читайте далее), так эти три видеокарты GTX TITAN ещё и тише работают, по сравнению как с тремя GTX 680, так и с тремя Radeon HD 7970. Причём, если замеры корректны, разница в шуме между лучшими решениями AMD и NVIDIA должна быть просто колоссальной!
Графическая архитектура
Новая модель GeForce GTX TITAN основана на базе самого сложного видеочипа NVIDIA, да и вообще. Интересно, что первое практическое применение процессор GK110 впервые получил в суперкомпьютере Окриджской национальной лаборатории, который получил имя собственное — TITAN. Ещё в ноябре 2012 года этот суперкомпьютер был включён в «суперкомпьютерный» список TOP500 как самое быстрое подобное устройство. Всего в конструкции TITAN используется 18668 профессиональных вычислительных систем NVIDIA Tesla K20X, что позволило суперкомпьютеру показать рекордный результат в 17.59 петафлопс (речь о вычислениях двойной точности) в общепризнанном тесте LINPACK.
Топовый GPU компании поддерживает все возможности, появившиеся в GK104 (GeForce GTX 680), и все особенности архитектуры Kepler относятся и к нему, включая организацию мультипроцессоров SMX, хотя есть и явные отличия. Графический процессор GK110 имеет в своём составе один пять (нечётное число, что необычно) кластеров графической обработки Graphics Processing Cluster (GPC), состоящих из трёх (снова нечётное!) мультипроцессоров SMX каждый, то есть, схема 5×3, в отличие от схемы 4×2 для GK104. Видимо, при схеме 8×2 чип получался слишком сложным. Для наглядности рассмотрим диаграмму топового чипа:

Кроме нечётных чисел вроде бы всё почти привычно для Kepler — примерно те же мультипроцессоры SMX, но есть отличия. Как и GK104, GK110 состоит из мультипроцессоров SMX, содержащих по 192 вычислительных блока (самые маленькие зелёные квадратики), но что это за оранжевые блоки в количестве 64 штуки на каждый SMX? Таким образом NVIDIA выделяет ALU, способные вычислять с двойной точностью (FP64), в отличие от FP32-точности «зелёных». Это основное отличие устройства SMX в GK110 от всех других чипов.
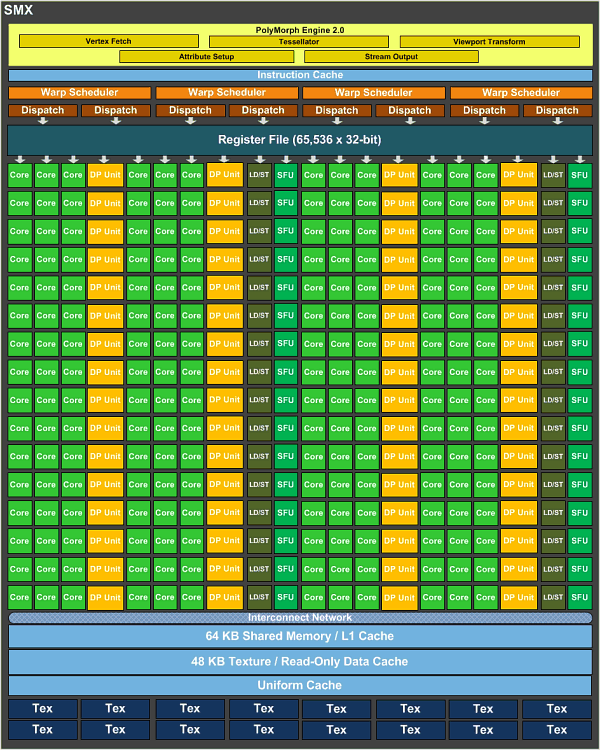
В остальном, всё ровно так же, что и в GK104, каждый SMX имеет по движку PolyMorph Engine, 64 КБ общей памяти, 48 КБ текстурной кэш-памяти и по 16 блоков текстурной фильтрации (всего 240 TMU в чипе физически). Подсистема памяти GK110, лежащего в основе GeForce GTX TITAN, содержит шесть 64-битных каналов памяти, что в сумме даёт 384-битный доступ к ней. И так как блоки растровых операций ROP «привязаны» к контроллерам памяти, то их количество в данном GPU равно 48 блокам. Объём кэш-памяти второго уровня на весь чип составляет 1.5 МБ.
Как мы уже писали, объём локальной GDDR5 видеопамяти для TITAN равен 6 ГБ. Столь огромный даже по нынешним меркам объём памяти явно предназначен для энтузиастов. Компания NVIDIA неоднократно получала запросы об увеличенном объёме памяти от пользователей — они хотят ещё более высокой производительности в высоких разрешениях с применением нескольких мониторов в современных играх и проектах будущего. Пожалуй, в случае продукта премиум-класса и такой объём памяти вполне оправдан. А практически он может понадобиться разве что в расчётных GPGPU-задачах, да при появлении первых мультиплатформенных игр, предназначенных для будущего поколения консолей, которые будут иметь довольно большой объём памяти. И 6 ГБ памяти с 384-битным интерфейсом должны дать GeForce GTX TITAN всё необходимое для достижения высокой частоты кадров во всех возможных играх и условиях, даже в ближайшие годы.
Как и другие старшие модели, GeForce GTX TITAN поддерживает фирменную технологию GPU Boost, теперь уже второй версии (подробнее см. ниже). Это комбинация программно-аппаратных решений, позволяющая автоматически увеличивать рабочие частоты GPU в зависимости от его энергопотребления для достижения максимальной производительности. Базовая тактовая частота графического процессора GK110 в GeForce GTX TITAN равна 836 МГц, а средняя турбо-частота (Boost Clock) равна 876 МГц, что немногим больше. Как и в случае предыдущих решений, это лишь средняя частота, которая изменяется в зависимости от игры и нагрузки, а реальные частоты GPU в играх могут быть и выше. Частота GDDR5 памяти в GeForce GTX TITAN составляет традиционные 6008 МГц, как и в предыдущей топовой плате компании. Результирующей пропускной способности в 187 ГБ/с должно быть достаточно даже для такого мощного решения, но в некоторых случаях её может и не хватить.
Технология GPU Boost 2.0
В GeForce GTX TITAN внедрена поддержка второй версии технологии GPU Boost. Она включает все возможности GPU Boost 1.0 и служит для того же самого — автоматически увеличивает рабочую частоту GPU в зависимости от нагрузки, потребления и температуры. Технология GPU Boost впервые появилась в GeForce GTX 680 и она динамически управляет частотой в зависимости от условий работы видеочипа, а главной целью является достижение максимально возможной производительности в рамках определённого потребления (и выделения) энергии. К примеру, частота GPU в GTX 680 автоматически повышается, если уровень потребления не превышает 170 Вт.
Но в TITAN инженеры пошли дальше. Они определили, что уровень потребления GPU не всегда ограничивает производительность при низких рабочих температурах видеочипа. И во второй версии GPU Boost ограничителем для роста частоты служит уже не уровень потребления, а рабочая температура GPU, установленная для TITAN на 80 градусов.
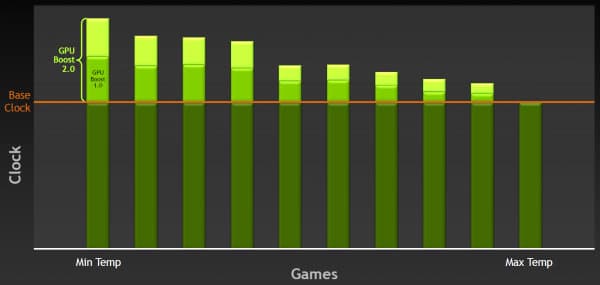
В случае модели GeForce GTX TITAN, частота видеочипа автоматически увеличивается, пока температура ядра остаётся равной или ниже 80 градусов. И сам GPU отслеживает температуру, изменяя частоту и напряжение так, чтобы поддерживать этот уровень нагрева. Такое изменение в GPU Boost 2.0 сказывается и на уровне шума от вентилятора системы охлаждения — при выборе целевой температуры, её проще контролировать, и частота вращения вентилятора изменяется в меньших пределах, что снижает общий уровень шума.
В дополнение к переходу от контроля потребления к температурному пределу, NVIDIA дала энтузиастам широкие возможности по настройке работы GPU Boost. При использовании программного обеспечения, разработанного партнёрами NVIDIA, счастливые пользователи видеокарт TITAN могут изменять целевую температуру GPU на свой вкус. К примеру, если пользователь хочет достичь большей производительности от GeForce GTX TITAN, то он может изменить температурный предел с 80 до 85 градусов. Тогда у GPU будет больше возможностей для поднятия частоты и напряжения, пока им не достигнута изменённая целевая температура.
Из-за этих изменений в логике работы GPU Boost 2.0, целевой уровень потребления (power target) уже не показывает типичное потребление в среднем, а является максимально возможным значением для данной модели видеокарты. При установке целевого потребления в 100%, максимальное потребление будет ограничено значением в 250 Вт, а максимально возможное значение в 106% установит этот уровень на планке в 265 Вт. Типичный же уровень потребления видеокартой будет изменяться в зависимости от температуры среды.
К слову, поэтому GPU Boost 2.0 хорошо подходит для экстремального разгона с применением водяного охлаждения, ведь оно обеспечивает температуру ядра GPU значительно ниже целевой, что в результате должно привести к возможности достижения более высоких частот и напряжений. Иными словами, если раньше некоторые энтузиасты разгона ругались на то, что GPU Boost 1.0 им мешает, то теперь они будут недовольны чуть меньше, как минимум. Более того, для них есть ещё одна хорошая новость, связанная с возможностью повышения напряжения.
Пользователям GeForce GTX TITAN доступна ещё одна новая настройка GPU Boost 2.0 — управление перенапряжением (overvoltage). Так как в TITAN турбо-частота и уровень напряжения теперь зависят от рабочей температуры GPU, то теперь нет причин ограничивать напряжение видеочипа слишком строго. А возможность повышения напряжения серьёзно упрощает достижение высоких тактовых частот. По умолчанию, напряжение графического процессора TITAN ограничено рамками, установленными в NVIDIA. Этот предел напряжения нужен для того, чтобы предотвратить необратимые повреждения кристалла, обеспечив работоспособность и надёжную работу видеокарты. Ведь подача слишком высокого напряжения на GPU может привести к быстрой деградации чипа и вызвать поломку.
Но экстремальных энтузиастов разгона это не страшит, они всегда хотят получить максимальные возможности по повышению напряжения. И GPU Boost 2.0 даёт им эту возможность, открывая настройку «перенапряжения». Естественно, она отключена по умолчанию и при попытке включения покажет устрашающее предупреждение о риске повреждения видеокарты. Полной демократии нет и тут, каждый из производителей видеокарт может ограничивать возможности по повышению напряжения для моделей, вышедших под их маркой. Да и в целом поддержка этой возможности необязательна и может быть заблокирована производителем в BIOS видеокарты.
Естественно, что при повышенном напряжении GeForce GTX TITAN сможет достичь ещё более высоких частот, особенно при условии соответствующего экстремального охлаждения. Да и в некоторых случаях простое повышение предела частоты GPU не вызывает роста реальной частоты, что случается тогда, когда прирост ограничен недостатком питания. Именно в этих случаях повышение предела напряжения для GPU поможет достичь более высокой частоты работы.
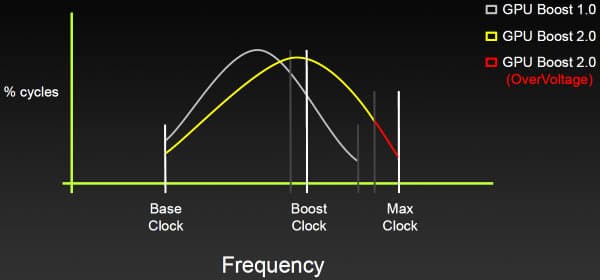
Нововведения GPU Boost 2.0 позволили NVIDIA достичь более высокой производительности и в типичных условиях без пользовательского разгона, позволяя выставить более высокое напряжение и частоту GPU. При включении возможности превышения стандартного напряжения GPU, появляется дополнительная возможность увеличить производительность, но повышается и риск повреждения GPU и выхода его из строя.
Ещё одним интересным нововведением GPU Boost 2.0 можно назвать «разгон дисплея», как его называет сама NVIDIA. Многим игрокам нравится играть с включенной вертикальной синхронизацией (VSync), потому что это позволяет избежать артефактов вроде разрыва картинки, когда VSync выключен. Но при включении вертикальной синхронизации, частота кадров ограничивается сверху частотой обновления монитора, обычно равной 60 Гц для всех современных устройств вывода изображения. В результате, производительность игры ограничена на уровне 60 FPS, несмотря на то, что видеочип может рендерить сцену и на более высокой скорости.

И только увеличение частоты обновления экрана соответственно скажется и на итоговой частоте кадров в секунду. Скажем, если GPU может отрендерить 90 FPS, то при включенном VSync монитор сможет показать лишь 60 FPS, но если повысить частоту обновления до 80 Гц, то GPU получит возможность работать быстрее — на 80 FPS при том же отсутствии артефактов разрыва картинки.
В GPU Boost 2.0 была добавлена возможность «разгона дисплея». При помощи соответствующих утилит от производителей видеокарт, пользователь GeForce GTX TITAN получает возможность увеличения частоты следования пикселей (pixel clock) для вашего дисплея, что позволяет добиться более высокой частоты обновления экрана, а соответственно и увеличения итоговой частоты кадров. Естественно, не все мониторы поддерживают такой разгон, так что тут у пользователей есть богатое поле для экспериментов.
Вычисления с двойной точностью на GeForce GTX TITAN
Интересно, что NVIDIA решила сделать из GeForce GTX TITAN первую игровую видеокарту серии GeForce, которая обеспечивает неграфические вычисления двойной точности с полной скоростью, предусмотренной архитектурой графического процессора, да ещё и не ограниченную программно. Не секрет, что предыдущие видеокарты GeForce, имеют весьма низкую скорость вычислений с двойной точностью (double-precision, DP). К примеру, каждый мультипроцессор в GK104, применяемом в GeForce GTX 680, имеет по 192 потоковых ядра для вычислений с одинарной точностью (single-precision, SP) и лишь 8 ядер для DP-вычислений. Поэтому скорость вычислений с двойной точностью была равна лишь 1/24 от скорости SP-вычислений. В случае чипа GK110, который лежит в основе GeForce GTX TITAN, на каждый SMX приходится по 64 ядер, способных на вычисления с двойной точностью (и те же 192 SP-ядра), так что производительность в DP-вычислениях составляет 1/3 от SP-скорости, что заметно выше.
Ещё до выхода TITAN в Сети появились слухи о том, что в GeForce на основе чипа GK110 скорость вычислений с двойной точностью будет искусственно ограничена, чтобы не создавать конкуренцию с линейкой Tesla. К счастью, слухи остались лишь слухами и NVIDIA решила оставить производительность DP-вычислений на полноценном уровне, чтобы обеспечить разработчиков ПО, инженеров и студентов недорогим аппаратным обеспечением, которое способно обеспечить производительность выше 1 терафлопса при DP-вычислениях. Вероятно, компания рассчитывает, что распространение сравнительно недорогого (по меркам профессиональных решений) GeForce GTX TITAN в среде разработчиков, использующих неграфические вычисления на GPU, позволит им разрабатывать и оптимизировать свои приложения под процессоры NVIDIA, что увеличит распространение GPGPU задач, столь желанное компанией.
Включение возможности полноскоростных DP-вычислений на GeForce GTX TITAN возможно из настроек драйвера. По умолчанию, GeForce GTX TITAN запускает DP-вычисления лишь на 1/24 от скорости вычислений с одинарной точностью (количество соответствующих мультипроцессоров SMX меньше втрое, но они ещё и работают в 8 раз медленнее), аналогично GeForce GTX 680. Чтобы включить возможность полноскоростных вычислений, нужно открыть панель управления NVIDIA и в панели «Управление параметрами 3D» («Manage 3D Settings») найти настройку «CUDA — Double Precision» и пометить галочку напротив строки «GeForce GTX TITAN». При включении настройки, она будет применена сразу же, без необходимости перезагрузки. Причём, записывается в BIOS видеокарты и не требует постоянного включения после каждой перезагрузки.
Зачем нужны столь сложные телодвижения, не лучше ли было просто включить быстрые DP-вычисления на постоянной основе? Секрет кроется в том, что при полноскоростной работе DP-ядер, графический процессор GK110 потребляет больше энергии и не может работать на частоте, выбранной для «игрового» режима GeForce. NVIDIA обошла проблему очень просто — при включении этой настройки, видеочип GeForce GTX TITAN будет всегда работать на пониженной частоте и при меньшем напряжении.
Соответственно, если вы не используете никаких специфических GPGPU-приложений, использующих расчёты с двойной точностью, то в настройке нет никакого смысла — она только снизит производительность в игровых приложениях и других 3D-задачах. Игр, использующих такие вычисления, просто не существует (да и не факт, что они появятся в обозримом будущем). Поэтому, чтобы отключить полноскоростные DP-вычисления, нужно проделать обратное действие, сняв «галочку» в настройке «CUDA — Double Precision» в панели управления NVIDIA.
GeForce GTX TITAN — это экстремальная видеокарта для тех энтузиастов компьютерных игр и любителей разгона, кто совсем не стеснён в средствах. Перед двухчиповыми решениями вроде GTX 690 у неё есть важное преимущество в том, что некоторые игры предпочитают одночиповые решения, да и в целом игры работают на одном GPU лучше, чем на двух и более (проблемы AFR-рендеринга и их причины мы не раз называли в своих материалах). Кроме того, таких карт в ПК можно установить три штуки, и это будет очень быстрая система, а вот двухчиповых три уже не поставить.
Естественно, что TITAN поддерживает все современные технологии компании NVIDIA, о которых мы ранее неоднократно писали, в том числе Adaptive VSync и PhysX. Обо всех этих технологиях подробно написано в базовом обзоре GeForce GTX 680 — первой видеокарты семейства Kepler. И так как GeForce GTX TITAN имеет в своей основе топовый графический процессор GK110 на основе этой архитектуры, то новая модель предлагает все современные возможности в виде DirectX 11, PhysX, TXAA, адаптивного VSync и других технологий.
Особенности модели GeForce GTX 780
- Частота ядра 863 (900) МГц;
- Количество универсальных процессоров 2304;
- Количество текстурных блоков — 192, блоков блендинга — 48;
- Эффективная частота памяти 6000 (1500×4) МГц;
- Тип памяти GDDR5, 384-битная шина памяти;
- Объем памяти 3 ГБ;
- Пропускная способность памяти 288,4 ГБ/с;
- Вычислительная производительность (FP32) 4,0 терафлопс;
- Теоретическая максимальная скорость закраски 41,4 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 165,7 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2;
- Шина PCI Express 3.0;
- Энергопотребление до 250 Вт;
- Один 8-контактный и один 6-контактный разъёмы питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $649 (для России — 23999 руб).
Так как эта видеокарта выпущена уже в рамках следующего семейства — GeForce GTX 700, то NVIDIA вернулась к своему принципу наименования видеокарт (в отличие от эксклюзивной модели GTX Titan). Номинально это уже следующее поколение, и решение топовое, поэтому изменилась первая цифра в начале суффикса. Понятно, что в линейке компании новая модель GeForce GTX 780 заменила видеокарту GTX 680, а GTX Titan продолжает существовать в виде эксклюзивной модели, вместе с двухчиповой GeForce GTX 690.
Что касается решений компании AMD, которые становятся конкурентами для представленной сегодня GTX 780, то прямого соперника для новой GeForce GTX 780 у них также нет. Как мы уже писали, AMD вообще не делает чипов такой сложности и размера, и настоящего соперника для GTX 780 из линейки Radeon HD 7000 назвать не получится. Топовая одночиповая плата Radeon HD 7970 заметно медленнее и стоит дешевле, а двухчиповая модель Radeon HD 7990 и быстрее и дороже новинки NVIDIA.
Объём видеопамяти, по сравнению с GTX Titan, пришлось урезать — всё-таки нужно было на чём-то сэкономить. Поэтому, модель GTX 780 имеет 3 ГБ видеопамяти, а не 6 ГБ, как у Titan. На сегодняшний день эта разница почти ничего не даёт (кроме сверхвысоких разрешений сразу на трёх мониторах, да ещё со стереорендерингом, разве что), но в будущем, с распространением игр для следующего поколения консолей, такой объём может пригодиться, а 3 ГБ может не хватить. Но это — дело довольно далёкого будущего, ещё минимум с полгода-год можно даже не беспокоиться. Кроме того, в будущем возможен выход моделей GTX 780 также с 6 ГБ видеопамяти, если это позволит сделать NVIDIA.
Печатная плата референсного варианта GeForce GTX 780 от NVIDIA имеет длину в 10.5 дюймов (267 мм), для вывода изображения на ней установлены два разъёма Dual-Link DVI, один HDMI и один DisplayPort 1.2 порт. Дополнительное питание на карту подаётся при помощи одного 8-контактного и одного 6-контактного PCI-E разъёмов. Дизайн корпуса аналогичен плате GTX Titan и схож с дизайном двухчиповой видеокарты NVIDIA — GeForce GTX 690. Видеокарта появилась на рынке почти со дня анонса — с конца мая 2013 года.
Графическая архитектура
Модель GeForce GTX 780 основана на самом сложном графическом процессоре, который получил первое практическое применение в суперкомпьютере Окриджской национальной лаборатории в качестве универсального вычислительного устройства. Топовый GPU компании поддерживает все возможности, известные со времён GK104 (GeForce GTX 680), и все особенности архитектуры Kepler относятся и к нем в полной мере. Полная версия графического процессора GK110 имеет в своём составе пять кластеров графической обработки Graphics Processing Cluster (GPC), каждый из которых состоит из трёх мультипроцессоров SMX, но в случае GeForce GTX 780 отключена часть исполнительных устройств:
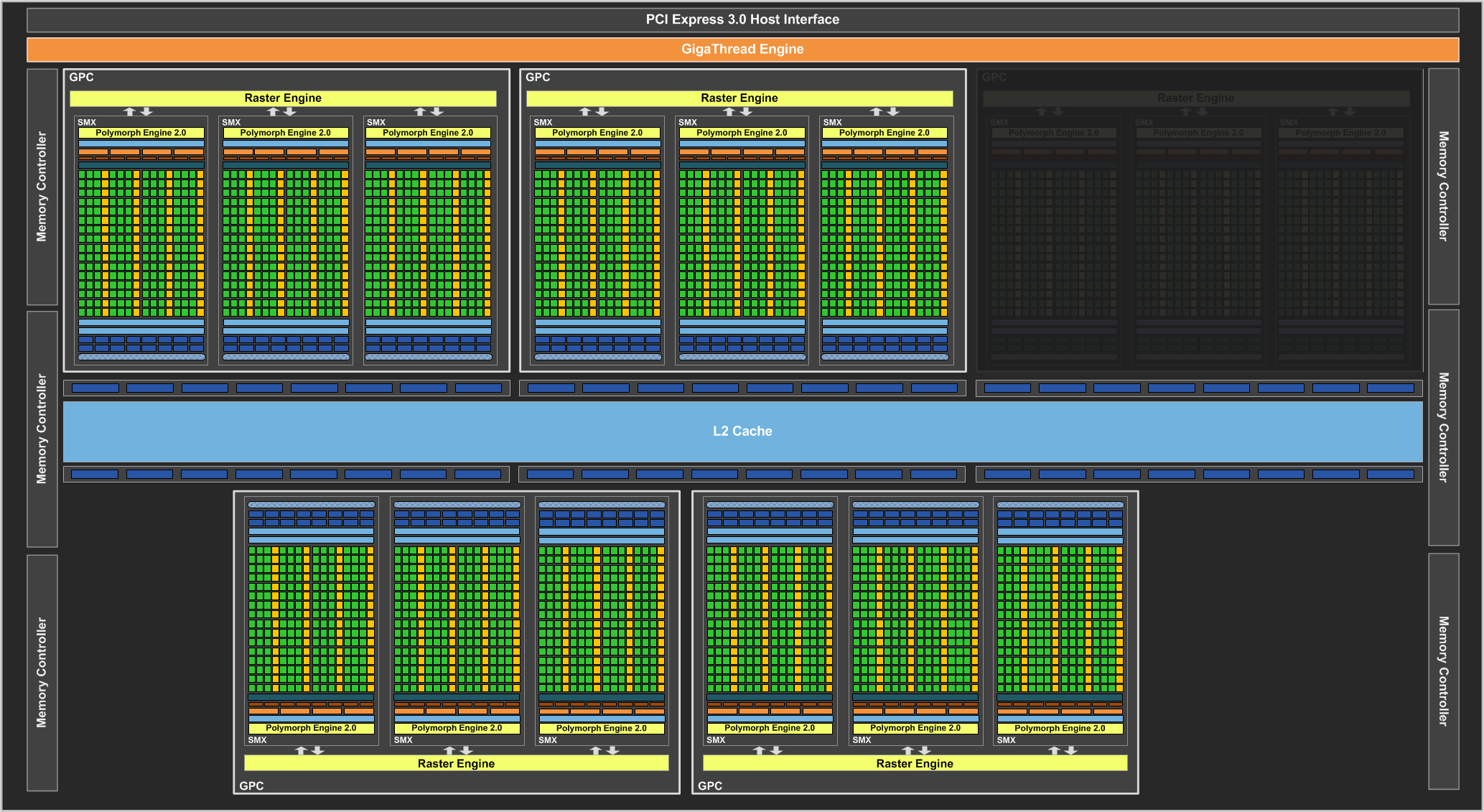
GK110 состоит из 15 мультипроцессоров SMX, содержащих по 192 вычислительных блока. Каждый мультипроцессор имеет по движку PolyMorph Engine и по 16 блоков текстурной фильтрации. Подсистема памяти GK110, лежащего в основе GeForce GTX 780, содержит шесть 64-битных каналов памяти, что в сумме даёт 384-битный доступ к ней. И так как блоки растровых операций ROP «привязаны» к контроллерам памяти, то их количество в данном GPU равно 48 блокам. Объём кэш-памяти второго уровня на весь чип составляет 1.5 МБ.
Так как в основе GeForce GTX 780 лежит урезанная версия графического чипа GK110, то не все из блоков физически включены и работают. Так, GPU в этой модели содержит лишь 12 активных SMX блоков, что в целом даёт нам 2304 потоковых вычислительных ядра. А уж какие конкретно блоки SMX отключены — неизвестно. Поэтому количество активных кластеров GPC (а вместе с ними и количество движков растеризации) может быть или 4 или 5, в зависимости от того, в одном кластере находятся отключённые три мультипроцессора SMX, или нет.
Количество активных текстурных блоков TMU в данной версии чипа равно 192 штуки, а вот по блокам ROP никаких ограничений нет — работают все 48. Подсистема памяти по сравнению с GTX Titan также не урезана — в видеочипе GeForce GTX 780 все шесть 64-битных контроллеров памяти активны, что в итоге составляет 384-битную шину памяти. И даже частоту видеопамяти не снизили, в GeForce GTX 780 чипы памяти работают на той же эффективной частоте в 6 ГГц.
Базовая же тактовая частота самого GPU, лежащего в основе GeForce GTX 780, равна 863 МГц, что несколько выше, чем у Titan. Как вы помните, у всех современных решений NVIDIA графический процессор почти всегда работает на более высокой частоте — Boost Clock. Турбо-частота для GTX 780 равна 900 МГц — это средняя частота видеочипа GTX 780, достигаемая в большом количестве игр и других 3D-приложений, а реальная частота может быть ещё выше и зависит от многих условий: температуры, загрузки GPU работой и т.п.
Интересно, что по поводу полноскоростных неграфических вычислений с двойной точности, которые обеспечивает GTX Titan, компания NVIDIA молчит. Это, скорее всего, означает то, что производительность таких вычислений ограничена программно, и скорость вычислений с двойной точностью (double-precision, DP) будет низкой — лишь 1/24 от скорости SP-вычислений, несмотря на то, что чип GK110, который лежит в основе GeForce GTX 780, способен на большее (1/3 от SP-скорости). Но надо же оставить какие-то преимущества для Titan, вот и оставили 6 гигабайт памяти и полноскоростные DP-вычисления. Что вполне разумно.
Разгон и охлаждение
Серия GeForce GTX 700 поддерживает второе поколение технологии GPU Boost, когда частота и производительность видеокарт зависит от температуры графического процессора — чем лучше охлаждение GPU, тем большую частоту работы он обеспечивает. Это особенно полезно при экстремальном охлаждении. Технология GPU Boost 2.0 также даёт пользователям больше возможностей по разгону — энтузиасты этого дела могут установить повышенную целевую температуру, а также повысить напряжение на GPU, не прибегая к сложным методам с применением паяльника.
Мы уже несколько раз писали о технологии NVIDIA GPU Boost, в том числе и о её второй версии. Главное изменение второй версии GPU Boost заключается в том, что повышение частоты GPU основывается не только на ограничителе потребления, но и на температурном пределе для видеочипа, по умолчанию равном 80 градусов. И если она ниже, то частота GPU автоматически повышается. Причём, пользователь может сам повысить целевую температуру.
А для экстремальных оверклокеров GPU Boost 2.0 предлагает возможность повышения рабочего напряжения GPU. Поддержка этой возможности опциональная и может быть заблокирована производителями, так как существует риск необратимого повреждения видеочипа при подаче слишком высокого напряжения. Однако при соответствующем охлаждении и питании это помогает достичь высоких тактовых частот при разгоне.
В референсном дизайне GeForce GTX 780 используется тот же самый высокопроизводительный кулер, что применяется в топовой плате GeForce GTX Titan. Эта система охлаждения содержит медную испарительную камеру и массивный двухслотовый радиатор из алюминиевого сплава, дополненные эффективным вентилятором. Поэтому в работе кулер GTX 780 такой же тихий, что и в случае GTX Titan — он значительно тише предыдущих топовых решений серий GTX 600 и GTX 500:
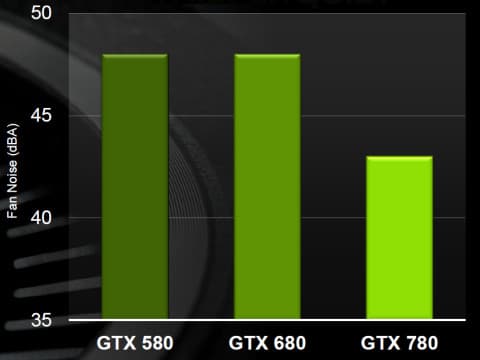
Измерение шума производилось компанией NVIDIA в условиях запущенного бенчмарка Unigine Heaven 4.0 в разрешении 1920×1080 с применением полноэкранного сглаживания, максимальных настроек теста и экстремального уровня тесселяции. Вклад в снизившийся шум от кулера внес и новый адаптивный алгоритм управления вентилятором, который обеспечивает более стабильную скорость вращения, без резких рывков и завываний от изменения частоты вращения.
Диаграмма показывает скорость вращения вентилятора в бенчмарке Unigine Heaven 4.0 в разрешении 1920×1080 с полноэкранным сглаживанием и максимальными настройками, при помощи двух разных алгоритмов управлением вентилятором — старого и нового. Так как технология Boost 2.0 динамически изменяет частоту вращения вентилятора, чтобы поддерживать целевую температуру, то если не фильтровать входные значения температуры, получаются довольно ощутимые скачки частоты вращения от 2980 до 3100 об/мин, а это вызывает повышенный уровень шума. Новый же алгоритм, который применили в GeForce GTX 780, использует адаптивный фильтр температуры, чтобы избежать слишком частого изменения частоты вращения и понизить итоговый уровень шума.
Добавим, что GeForce GTX 780 поддерживает все современные технологии компании NVIDIA, о которых мы ранее писали. Обо всех этих технологиях подробно написано в базовом обзоре GeForce GTX 680 — первой видеокарты семейства Kepler. И так как GeForce GTX 780 имеет в своей основе топовый графический процессор GK110 на основе той же архитектуры, то новая модель предлагает все современные возможности в виде DirectX 11, PhysX, TXAA, адаптивного VSync и других технологий.
Особенности модели GeForce GTX 770
- Частота ядра 1046 (1085) МГц;
- Количество универсальных процессоров 1536;
- Количество текстурных блоков — 128, блоков блендинга — 32;
- Эффективная частота памяти 7000 (1750×4) МГц;
- Тип памяти GDDR5, 256-бит шина памяти;
- Объем памяти 2 или 4 ГБ;
- Пропускная способность памяти 224,3 ГБ/с;
- Вычислительная производительность (FP32) 3,2 терафлопс;
- Теоретическая максимальная скорость закраски 33,5 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 133,9 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2;
- Шина PCI Express 3.0;
- Двойной SLI разъем;
- Энергопотребление до 230 Вт;
- Один 8-контактный и один 6-контактный разъёмы питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $399 (для России — 14490 руб).
Эта видеокарта стала второй в новом семействе GeForce GTX 700, и она имеет традиционное наименование для NVIDIA, с отличающейся от топовой карты средней цифрой суффикса. По сравнению с GTX 670 изменилась и первая цифра, так как номинально это уже следующее поколение, хотя физически чип тот же самый. Естественно, что как и следует из наименования новинки, модель GeForce GTX 770 заменяет в линейке компании видеокарту GeForce GTX 670. С платами компании AMD, которые могут стать соперниками представленной сегодня GeForce GTX 770, всё очень просто — прямым соперником для новой модели является самая производительная одночиповая видеокарта — Radeon HD 7970 GHz Edition. Топовая одночиповая плата Radeon и стоит примерно столько же, да и по производительности они должны быть весьма близки.
GeForce GTX 770 будет поставляться на рынок в двух вариантах: с 2 и 4 гигабайтами видеопамяти. Первая конфигурация идеально подойдёт для пользователей, имеющих дисплеи с FullHD (1920×1080 и 1920×1200 пикселей) разрешением, а 4-гигабайтная модель оправдана для мониторов с ещё большим разрешением или систем с многомониторными конфигурациями. На сегодняшний день объём в 2 ГБ ещё можно считать достаточным, хотя с распространением мультиплатформенных игр, спроектированных в т.ч. и для следующего поколения консолей, может пригодиться и 4 ГБ, а то и больше.
Печатная плата референсного варианта GeForce GTX 770 имеет длину в 10.5 дюймов (267 мм), для вывода изображения на ней установлены два разъёма Dual-Link DVI, один HDMI и один DisplayPort 1.2 порт. Дополнительное питание на карту подаётся при помощи одного 8-контактного и одного 6-контактного PCI-E разъёмов. Дизайн корпуса аналогичен плате модели GeForce GTX 780.
Как и вышедшая на неделю раньше GTX 780, референсная плата модели GTX 770 использует то же самое устройство охлаждения, известное ещё по Titan и хорошо зарекомендовавшее себя. Этот кулер основан на принципе испарительной камеры, дополненной массивным двухслотовым радиатором из алюминиевого сплава и эффективным вентилятором, который обеспечивает очень тихую работу даже при значительной нагрузке в течение продолжительного времени (бенчмарк Unigine Heaven 4.0 в разрешении 1920×1080 с полноэкранным сглаживанием, максимальными настройками, в т.ч. тесселяции):
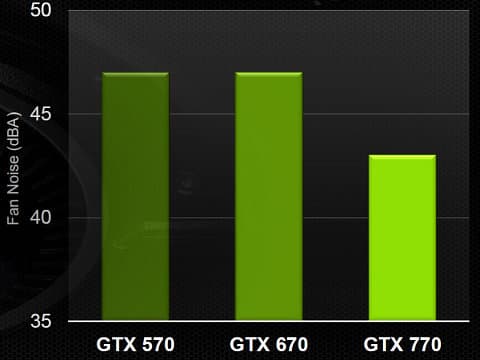
Если кулеры на предыдущих платах этого уровня обеспечивали уровень шума порядка 47 дБА, то кулер GeForce GTX 770 работает на 4 дБА тише, что весьма ощутимо. Вклад в снизившийся шум от кулера внес и новый адаптивный алгоритм управления вентилятором, который обеспечивает более стабильную скорость вращения. Впрочем, это касается лишь референсного кулера NVIDIA, а на рынке будут продаваться видеокарты GeForce GTX 770 от разных производителей, в том числе с собственным дизайном печатной платы и системами охлаждения.
В продажу видеокарта GeForce GTX 770 от NVIDIA поступила в конце мая, и сразу же стали доступными как референсные варианты, так и платы собственного дизайна от партнёров компании, с уникальными кулерами, печатными платами и более высокими штатными частотами — так называемым фабричным разгоном.
Графическая архитектура
Модель GeForce GTX 770 основана на давно известном нам графическом процессоре GK104, который получил первое практическое применение ещё в GeForce GTX 680, выпущенном больше года тому назад. Полная версия графического процессора GK104 имеет в своём составе четыре кластера графической обработки Graphics Processing Cluster (GPC), каждый из которых состоит из двух мультипроцессоров SMX, и в случае GeForce GTX 770 все исполнительные устройства активны:
Графический чип GK104, на котором основана модель GeForce GTX 770, имеет 8 активных мультипроцессоров SMX — то есть все физически существующие в GPU блоки рабочие. В общем это даёт 1536 потоковых вычислительных ядер, ровно как и у топовой платы предыдущего поколения — GeForce GTX 680. Каждый мультипроцессор имеет по движку PolyMorph Engine и по 16 блоков текстурной фильтрации. Общее количество активных текстурных блоков TMU в чипе равно 128 штукам, а блоков ROP в GK104 всего 32, и все они в GeForce GTX 770 рабочие.
Подсистема памяти также полностью повторяет ту, что была у GTX 680 — четыре 64-битных контроллера видеопамяти дают совместную 256-битную шину. Казалось бы — неужели по сравнению с GTX 680 не будет никаких изменений и новинка теоретически может быть ограничена пропускной способностью памяти, как бывшая топовая модель? Но нет, NVIDIA решила поднять тактовую частоту памяти у GeForce GTX 770 до значения в 7010 МГц, поэтому пиковая ПСП у новинки стала равна 224,3 ГБ/с, то есть более чем на 15% выше, по сравнению с GTX 680.
Базовая частота графического процессора в GeForce GTX 770 для референсной платы составляет 1046 МГц, а средняя турбо-частота (Boost Clock) равна 1085 МГц. Впрочем, турбо-частота отражает лишь среднее её значение в некотором наборе приложений и игр, а реальная частота будет зависеть от множества условий: приложения, его настроек, а также температуры и потребления GPU. И не зря мы упомянули о том, что это лишь референсные частоты, так как многие из партнёров NVIDIA предложили варианты GTX 770, работающие на более высокой рабочей частоте.
Особенности модели GeForce GTX 760
- Частота ядра 980 (1033) МГц;
- Количество универсальных процессоров 1152;
- Количество текстурных блоков — 96, блоков блендинга — 32;
- Эффективная частота памяти 6000 (1500×4) МГц;
- Тип памяти GDDR5, 256-бит шина памяти;
- Объем памяти 2 или 4 ГБ;
- Пропускная способность памяти 192,3 ГБ/с;
- Вычислительная производительность (FP32) 2,3 терафлопс;
- Теоретическая максимальная скорость закраски 31,4 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 94,1 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2;
- Шина PCI Express 3.0;
- SLI разъем;
- Энергопотребление до 170 Вт;
- Два 6-контактных разъёма питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $249 (для России — 8990 руб).
Видеокарта стала третьей в номинально новом семействе GeForce GTX 700, она имеет традиционное наименование для NVIDIA, с привычно отличающейся от топовых плат средней цифрой номера модели. По сравнению с GTX 660 Ti решили убрать и суффикс. Кстати, именно модель GTX 660 Ti в линейке компании NVIDIA новая GeForce GTX 760 и заменяет, а вот GTX 660 и GTX 650 остаются в производстве, ведь они медленнее и дешевле новинки. Равно как и GTX 690 и GTX Titan остаются в линейке и предназначаются для небольшой прослойки энтузиастов.
Конкурента среди плат компании AMD, который может стать соперником представленной сегодня GeForce, в этот раз подобрать не слишком просто — самым близким соперником для новой модели NVIDIA является видеокарта Radeon HD 7950, которая и стоит почти столько же, и по производительности где-то близко должна быть. Но, вполне возможно, что GTX 760 будет стоять посередине между HD 7950 и HD 7870, и сравнивать нужно с обеими.
Как и GTX 770, новинка будет продаваться в двух вариантах: с 2 и 4 гигабайтами видеопамяти. Первая конфигурация лучше подойдёт для пользователей, имеющих дисплеи с FullHD (1920×1080 и 1920×1200 пикселей) разрешением, а 4-гигабайтная модель предназначена для мониторов с ещё большим разрешением или систем с многомониторными конфигурациями. Мы уже писали, что на сегодняшний день объём в 2 ГБ ещё можно считать достаточным, но всё чаще в современных играх пригождается и 3-4 ГБ.
Печатная плата референсного варианта GeForce GTX 760 имеет длину в 9.5 дюймов (около 24 см), типичное энергопотребление составляет 170 Вт, для дополнительного питания используются два 6-контактных разъема, а из разъёмов вывода изображения на ней установлены два выхода Dual Link DVI, один HDMI и один DisplayPort 1.2 порт.

Как и в двух предыдущих моделях новой серии GeForce GTX 700, в новинке применяется улучшенный адаптивный контроллер вентилятора, обеспечивающий более плавную и стабильную частоту его вращения и, соответственно, меньший шум. Впрочем, вряд ли мы увидим в продаже много вариантов GeForce GTX 760 с референсными кулерами, партнёры NVIDIA выпустили модели с таким GPU, имеющие печатные платы и кулеры собственного дизайна, а также с увеличенными частотами (фабричным разгоном). Большинство из них будет иметь 2 ГБ видеопамяти, но для желающих большего будут и четырёхгигабайтные варианты.
Графическая архитектура
Видеокарта модели GeForce GTX 760 основана на графическом процессоре GK104, на котором основано множество видеокарт NVIDIA, начиная с GTX 660 Ti и заканчивая GTX 770. Полная версия графического процессора GK104 имеет в своём составе четыре кластера графической обработки Graphics Processing Cluster (GPC), каждый из которых состоит из двух мультипроцессоров SMX, но в случае GeForce GTX 760 не все исполнительные устройства активны:
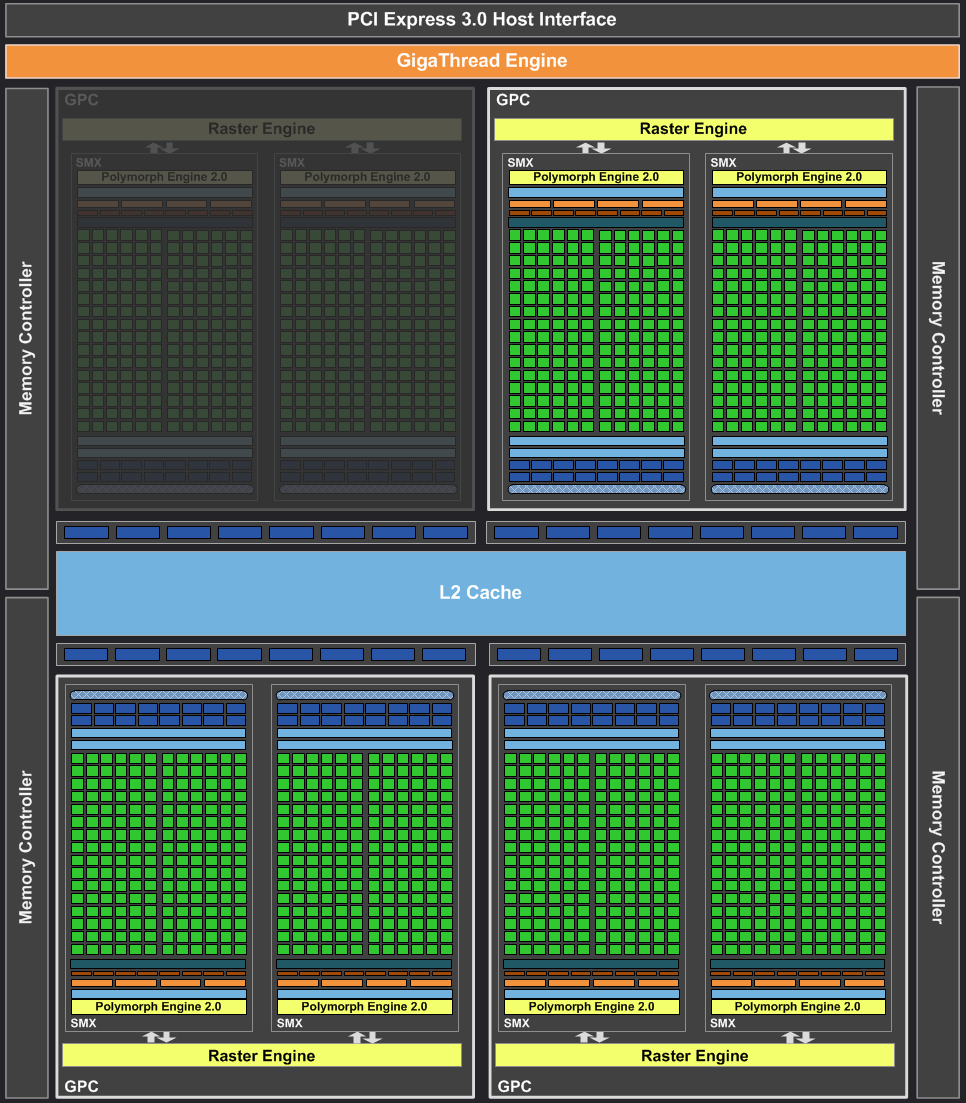
Конкретная модификация графического чипа GK104, на котором основана модель GeForce GTX 760, имеет лишь 6 активных мультипроцессоров SMX — что в общем даёт 1152 потоковых вычислительных ядра из 1536 имеющихся в чипе физически. То есть, меньше, чем даже в GTX 660 Ti, не говоря об остальных модификациях. Важно, что активных кластеров GPC может быть 3 или 4, в зависимости от этого будет меняться и количество движков растеризации. Зато движков тесселяции всегда шесть, соответственно количеству SMX, так как каждый мультипроцессор имеет по движку PolyMorph Engine. И по 16 блоков текстурной фильтрации, поэтому общее количество активных текстурных блоков TMU в этом чипе равно 96 штукам, а вот блоки ROP разблокированы все, и их в GK104 всего 32.
А вот подсистема памяти полностью повторяет ту, что была у GTX 680 и шина памяти у GTX 760 не урезана, в отличие от GTX 660 Ti. Чип имеет четыре 64-битных контроллера видеопамяти, которые дают полноценную 256-битную шину. NVIDIA решила оставить и тактовую частоту памяти у GeForce GTX 760 такой же, что была и у GTX 680 — микросхемы памяти работают на частоте в 6 ГГц, и итоговая ПСП новинки заметно выше, чем у GTX 660 Ti.
Базовая рабочая частота графического процессора модели GeForce GTX 760 равна 980 МГц, но в случае всех современных видеокарт NVIDIA ещё важнее турбо-частота (Boost Clock), показывающая среднее значение частоты в некотором наборе игр, и для GTX 760 она равна 1033 МГц. Реальная тактовая частота GPU в GeForce GTX 760 зависит от множества показателей, таких как потребление и температура, а также нагрузки на видеочип. Как и другие карты серии, GeForce GTX 700 поддерживает вторую версию GPU Boost 2.0, которая обеспечивает лучшие возможности для разгона и аппаратного мониторинга.
Понятно, что GeForce GTX 760 поддерживает и все остальные современные технологии компании NVIDIA. Игроки, которые решатся на апгрейд видеокарты уровня GeForce GTX 560, дополнительно получат следующие возможности графических решений поколения Kepler: поддержку до четырёх дисплеев, возможность одновременного стереорендеринга на несколько мониторов, поддержку полноэкранного сглаживания при помощи метода TXAA, и т.д.
Подробности: семейство GeForce GTX 750
Спецификации GM107
- Кодовое имя чипа GM107;
- Технология производства 28 нм;
- 1,87 миллиардов транзисторов;
- Площадь ядра 148 мм²;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 128-битная шина памяти: два независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Базовая частота ядра 1020 МГц;
- Средняя турбо-частота ядра 1085 МГц;
- 5 (4 активных у GTX 750) мультипроцессоров, включающих 640 (512 активных у GTX 750) скалярных ALU для расчётов с плавающей запятой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 40 (32 активных у GTX 750) блоков текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 2 широких блока ROP (16 пикселей) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка портов Dual Link DVI, HDMI и DisplayPort.
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2
- Поддержка шины PCI Express 3.0
Спецификации референсной видеокарты GeForce GTX 750 Ti
- Частота ядра 1020 (1085) МГц;
- Количество универсальных процессоров 640;
- Количество текстурных блоков — 40, блоков блендинга — 16;
- Эффективная частота памяти 5400 (1350×4) МГц;
- Тип памяти GDDR5, 128-бит шина памяти;
- Объем памяти 1 или 2 ГБ;
- Пропускная способность памяти 86,4 ГБ/с;
- Вычислительная производительность (FP32) 1,31 терафлопс;
- Теоретическая максимальная скорость закраски 16,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 40,8 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2 (опционально);
- Шина PCI Express 3.0;
- Энергопотребление до 60 Вт;
- Дополнительное питание не требуется;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $149 (для России — 5490 руб).
Спецификации референсной видеокарты GeForce GTX 750
- Частота ядра 1020 (1085) МГц;
- Количество универсальных процессоров 512;
- Количество текстурных блоков — 32, блоков блендинга — 16;
- Эффективная частота памяти 5000 (1250×4) МГц;
- Тип памяти GDDR5, 128-бит шина памяти;
- Объем памяти 1 ГБ;
- Пропускная способность памяти 80,0 ГБ/с;
- Вычислительная производительность (FP32) 1,04 терафлопс;
- Теоретическая максимальная скорость закраски 16,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 32,6 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один mini HDMI, один DisplayPort 1.2 (опционально);
- Шина PCI Express 3.0;
- Энергопотребление до 55 Вт;
- Дополнительное питание не требуется;
- Двухслотовое исполнение;
- Рекомендуемая цена для рынка США — $119 (для России — 4490 руб).

Представленные модели видеокарт на базе нового чипа имеют традиционное наименование для семейства NVIDIA GeForce GTX 700 и отличаются друг от друга наличием суффикса «Ti» у старшей. GeForce GTX 750 Ti и GTX 750 заменяют в линейке компании NVIDIA выпущенную ранее GeForce GTX 650 Ti (в том числе Boost-вариант), а видеокарты GTX 660 и GTX 650 будут продолжать производиться и продаваться, как и ранее. Самыми близкими соперниками для новых моделей NVIDIA серии GTX 750 являются видеокарты Radeon R7 260, 260X и 265, которые и стоят почти столько же, и по производительности где-то близко должны быть. Вполне возможно, что новинкам от NVIDIA придётся разместиться по скорости и/или цене посередине между представленными моделями от AMD и конкурировать сразу с несколькими, как это часто бывает.
Старшая модель продаётся в двух вариантах: с 1 и 2 гигабайтами видеопамяти. Естественно, что конфигурация с меньшим объёмом не очень подойдёт для пользователей, имеющих дисплеи с FullHD (1920×1080 и 1920×1200 пикселей) разрешением, а вот 2-гигабайтная модель вполне справится с таким разрешением, а никто и не будет ставить GTX 750 Ti в игровую систему с многомониторной конфигурацией или стереорендерингом. На сегодняшний день объём в 2 ГБ для бюджетных решений можно считать вполне достаточным, а вот 1 ГБ в некоторых условиях будет откровенно мало. Впрочем, в том числе за счёт этого цена модели GTX 750 оказалась ощутимо ниже. А вот приоритетное использование 2 ГБ памяти в GeForce GTX 750 Ti вполне логично, однако, партнёры компании могут выпустить и чуть менее дорогие варианты карты с 1 ГБ памяти, если пользователям покажется ощутимой такая экономия «на спичках», но советовать их покупку мы точно не станем.
Печатные платы GeForce GTX 750 Ti и GTX 750 референсного дизайна очень компактны и имеют длину менее 15 см, (5.75 дюймов) а типичное их энергопотребление составляет 60 и 55 Вт, соответственно, поэтому дополнительного питания новым решениям NVIDIA попросту не требуется. Это делает их отлично подходящими для применения в ПК компактного размера новых форм-факторов, получивших популярность в последнее время. Для таких систем очень важны малый размер платы, низкое потребление энергии, небольшое тепловыделение и шумность системы охлаждения. И так как длина плат невелика, а уровень потребления менее 75 Вт, получаемых по PCI Express слоту, то данная видеокарта является идеальным вариантом для таких ПК. Из разъёмов вывода изображения на референсном варианте установлены два выхода Dual Link DVI, один mini-HDMI и опционально может быть установлен и DisplayPort 1.2 порт.
В дополнение к моделям GeForce GTX 750 Ti и GTX 750 с референсными частотами, большинство партнёров NVIDIA также предлагают и разогнанные модели этих видеокарт с повышенными частотами и собственным дизайном плат, отличающимся от дизайна NVIDIA. Это и неудивительно, ведь видеокарты на чипе GM107 имеют достаточно высокий потенциал для разгона, ограниченный скорее максимально возможным потреблением плат, ведь дополнительного питания они не получают. Тем не менее, разгонный потенциал у них неплохой, многие тестеры достигают частот для GPU порядка 1270-1300 МГц и даже выше.
Архитектурные изменения в Maxwell и GM107
Видеокарты семейства GeForce GTX 750 основаны на совершенно новом графическом процессоре GM107. В самом по себе чипе архитектуры Maxwell первого поколения по сравнению с Kepler не слишком много новых возможностей, связанных с 3D-графикой, которые открыты и полезны прямо сейчас. Вполне естественно, что при выходе GPU новой архитектуры не из топового сегмента, компания-производитель рассказывает не обо всех архитектурных нововведениях. Кроме этого, в мобильном GM107 части задуманной в Maxwell функциональности просто нет, она появится лишь в будущих GPU более высокого уровня.
Первый же чип архитектуры Maxwell выглядит скорее эволюцией Kepler, который был эволюцией Fermi, и все они ограничены функциональностью DirectX 11. С графической точки зрения между первым Maxwell и Kepler нет разницы, GM107 остаётся Direct3D 11.0-совместимым чипом, поддерживающим базовую функциональность плюс почти все возможности Direct3D 11.1 и 11.2, но всё же не все, поэтому называться D3D11.2-совместимым он всё же не может, как и Kepler. Собственно, это не так уж важно, потому что разработчики могут пользоваться большинством возможностей D3D 11.2 и на Kepler/Maxwell.
Итак, с точки зрения графических возможностей API, в первом поколении Maxwell нет никаких изменений по сравнению с Kepler, вся функциональность осталась такой же. Зато в процессе переноса архитектуры Kepler из GPU, предназначенных для настольных ПК, серверов и суперкомпьютеров в мобильный чип Tegra K1, инженеры NVIDIA поняли очень многое о том, как можно снизить потребление энергии GPU и получить большую производительность из архитектуры при имеющихся ограничениях по потреблению. И всё, что они узнали в процессе проектирования Tegra, было внедрено в первый чип архитектуры Maxwell.
Хотя первый GPU архитектуры Maxwell не выглядит радикально новым на фоне Kepler по своим возможностям, внутри он очень сильно переработан. Инженеры NVIDIA проделали очень большую работу для увеличения эффективности всех внутренних блоков Maxwell и GM107, в частности. Большая энергоэффективность новой архитектуры достигается при помощи лучшей загрузки имеющихся вычислительных возможностей. В Maxwell было сделано достаточно большое количество изменений, чтобы назваться полностью новой архитектурой, и это ещё с учётом того, что пока далеко не все её возможности раскрыты публично.
Но не только энергетическая эффективность важна, но и рациональное использование площади кристалла, ведь она сказывается на себестоимости продукта, а высокая плотность размещения транзисторов для Maxwell важна ещё и потому, что количество функциональных блоков при том же энергопотреблении было увеличено и их нужно как-то разместить в чипе, не слишком повышая себестоимость. Забегая вперёд, можно утверждать, что именно большая энергоэффективность и более «плотный» дизайн GPU дали возможность NVIDIA достичь производительности уровня GK106 у графического процессора GM107 меньшей площади. Рассмотрим диаграмму нового чипа:
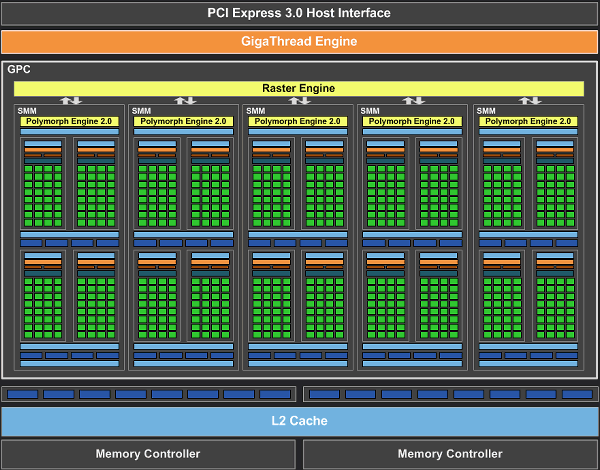
Полная версия графического процессора GM107 имеет в своём составе один кластер графической обработки Graphics Processing Cluster (GPC), который состоит из пяти мультипроцессоров SMM. Также он имеет два 64-битных контроллера памяти, дающих совместную 128-битную шину обмена данными с видеопамятью. На диаграмме указан полноценный чип, на котором основана модель GeForce GTX 750 Ti, а в случае GTX 750 отключена часть исполнительных блоков — полностью отключен один мультипроцессор SMM.
Как видите, с аппаратной точки зрения по диаграмме огромных изменений в архитектуре Maxwell нет. Как и в предыдущих чипах, в состав вычислительного кластера (Graphics Processing Cluster — GPC) входит несколько мультипроцессоров, каждый из которых содержит движки обработки геометрии Polymorph Engine и текстурные модули TMU. Блоки растеризации ROP относятся к кластеру GPC и они всё так же «привязаны» к кэш-памяти второго уровня и 64-битным контроллерам памяти. Впрочем, NVIDIA утверждает, что все связи между блоками были переработаны полностью, а потоки данных оптимизированы, что также снизило потребление энергии.
Одним из самых интересных изменений в архитектуре Maxwell стали абсолютно новые потоковые мультипроцессоры (Streaming Multiprocessor — SM), которые имеют как лучшую энергоэффективность, так и производительность по отношению к площади чипа. Даже несмотря на то, что дизайн мультипроцессоров SMX в Kepler и так был достаточно эффективным, при разработке нового GPU архитекторы увидели возможности для улучшения и серьёзно модифицировали мультипроцессоры в Maxwell, дав им название SMM. Было улучшено многое, в том числе блоки управления и планирования, распределение загрузки между блоками, количество выдаваемых на исполнение инструкций за такт и многое другое. Оптимизированная архитектура Maxwell позволила увеличить количество мультипроцессоров в GM107 до пяти, по сравнению с двумя в GK107, при увеличении площади чипа лишь на четверть.

Организация мультипроцессоров изменилась очень серьёзно. В то время как мультипроцессор SMX в Kepler является довольно большим блоком, в GM107 каждый мультипроцессор разделён ещё на четыре отдельных логических вычислительных раздела, каждый из которых имеет свой буфер инструкций, планировщик варпов и состоит из 32 вычислительных ядер. Подход архитектуры Kepler с числом потоковых ядер, не кратным степени двойки, был упразднён, а такое разбиение SMM на вычислительные разделы схоже с тем, что было в Fermi (GF100), что ещё раз подтверждает истину о том, что новое — это хорошо забытое старое. Разделение вычислительных блоков упростило общий дизайн и управляющую логику чипа, снизило задержки, площадь чипа и потребляемую им энергию.
В чипах Kepler, каждый мультипроцессор SMX содержит управляющую логику, которая распределяет и планирует работу и обмен данными для 192 вычислительных ядер, поэтому управляющий блок довольно сложен сам по себе. В архитектуре Maxwell было принято решение разделить мультипроцессор SMM на четыре вычислительных блока, каждый из которых содержит собственный блок управления, обслуживающий лишь 32 ядра и намного более простой. Таким образом проектировщики Maxwell добились разделения одной сложной задачи планирования и управления на несколько заметно более простых, а часть управляющей блоками работы при этом делается программно, при помощи компилятора.
Количество ALU на планировщик, кратное степени двойки, упрощает планирование, так как каждый из планировщиков варпов отправляет инструкции на исполнение выделенному набору ALU, равному размеру варпа (32). Каждый планировщик варпов также умеет выдавать по две инструкции, вроде отправки на исполнение математической операции в ALU и операции с памятью в блок load/store unit (LSU) за один такт — dual-issue. Впрочем, даже отправка одной команды достаточна для полной загрузки работой всех вычислительных ядер, в отличие от Kepler, где использование вычислительных ресурсов при одинарной точности вычислений было недостаточно эффективным из-за некоторых ограничений в блоках планирования.
Общими в SMM остались лишь текстурные модули и FP64-блоки, а FP32-блоки, блоки специальных инструкций (special function unit — SFU) и блоки загрузки-сохранения (load/store unit — LSU) выделены для каждого раздела. Такое решение хорошо с точки зрения эффективности, ведь общие ресурсы хороши только тогда, когда они загружены работой, а при её (частичном) отсутствии они просто занимают место на чипе и потребляют энергию. Не говоря о том, что соединения между ними также дорого обходятся с точки зрения площади чипа и потребления, так как требуется дополнительная работа по планированию и координации работы всех блоков.
Хотя из-за перехода с общих ресурсов к выделенным новая архитектура NVIDIA потеряла некоторые преимущества в производительности, но зато выиграла в потреблении и площади чипа. Более того, по данным NVIDIA эффективность SMM такова, что один новый мультипроцессор с 128 вычислительными ядрами показывает 90% от производительности мультипроцессоров SMX с 192 ядрами при значительно меньшем размере.
Четыре вычислительных раздела в составе SMM попарно делят между собой по четыре текстурных модуля и текстурную кэш-память, равно как и кэш-память первого уровня (для вычислительных задач), скомбинированные в единый блок. А вот общая (shared) память объёмом в 64 КБ на мультипроцессор выделена в отдельный блок, который делится между всеми четырьмя вычислительными блоками.
Самое важное, что новый дизайн мультипроцессоров обеспечил значительно меньший размер, занимаемый блоком на кристалле, при достижении около 90% производительности мультипроцессора архитектуры Kepler. А меньшая площадь мультипроцессора означает, что на тот же размер чипа можно поместить большее количество мультипроцессоров. Если сравнивать схожие по позиционированию чипы GK107 и GM107, то общее количество мультипроцессоров в GM107 равно пяти, в отличие от двух SM в Kepler. Если говорить о теоретической производительности, то это означает на четверть большую текстурную производительность, в 1.7 раз большее количество вычислительных ядер и примерно в 2.3 раза большую вычислительную производительность по оценке NVIDIA.
Чтобы повысить производительность GM107 при сохранении той же шины памяти, что и у GK107, было сделано несколько изменений и в подсистеме памяти. Так как производительность GM107 близка к скорости GK106, а ширина шины у новинки меньше: 128-бит против 192-бит, то для обеспечения достаточной производительности подсистемы памяти NVIDIA добавила большой объём кэш-памяти второго уровня. Хотя они могли разместить на её месте ещё больше исполнительных блоков, но тогда их было бы нечем «прокормить» — ведь ALU и TMU нуждаются в данных, которые нужно брать из видеопамяти. Похоже, что инженеры NVIDIA нашли некий баланс между количеством исполнительных устройств и объёмом L2-кэша.
Также была увеличена пропускная способность внутренних межчиповых связей, а чтобы возросшая требовательность к ПСП не ограничивала общую производительность, был значительно увеличен объём кэш-памяти второго уровня. Он вырос с 256 КБ в GK107 до 2048 КБ в GM107 — в 8 раз! С кэш-памятью большего объёма потребуется меньше запросов к гораздо более медленной видеопамяти, что снижает как потребление энергии, так и улучшает общую 3D-производительность.
В дополнение к указанным выше улучшениям, инженеры компании NVIDIA серьёзно модифицировали каждый из блоков первого чипа Maxwell на уровне транзисторов, что также позволило повысить энергоэффективность. Всё вместе это привело к тому, что GM107 имеет практически вдвое лучшую энергоэффективность по сравнению с аналогичными чипами Kepler, и это — при использовании всё того же 28 нм техпроцесса!
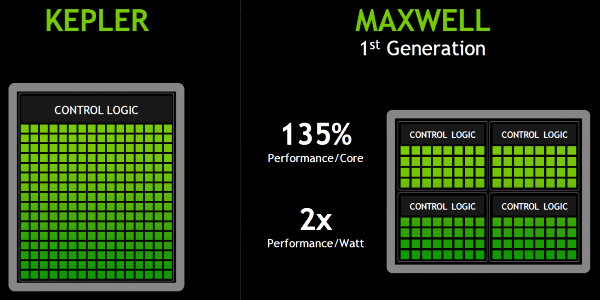
Неудивительно, что GeForce GTX 750 и GTX 750 Ti обеспечивают одни из лучших показателей производительности в своём классе при том, что они потребляют заметно меньше энергии, по сравнению с решениями конкурента и предыдущими поколениями плат компании NVIDIA. Значительное упрощение аппаратных блоков GPU, более эффективное использование имеющихся ресурсов и глубокая модернизация привели к тому, что пиковая производительность на ядро выросла на 35% по сравнению с чипами архитектуры Kepler.
Большая эффективность означает меньшее потребление энергии, то есть лучшую энергоэффективность (соотношение производительности и потребления энергии) у первого чипа архитектуры Maxwell, и модель GeForce GTX 750 Ti по этому параметру вдвое лучше GTX 650 Ti и до четырёх раз обгоняет по энергоэффективности модель GTX 550 Ti, основанную на видеочипе семейства Fermi и выпущенную четыре года назад. Иными словами, если верить цифрам NVIDIA, то они дважды удвоили энергоэффективность своих недорогих решений за прошедшие четыре года. Но самое впечатляющее в том, что они смогли добиться двукратного прироста в эффективности без смены техпроцесса.
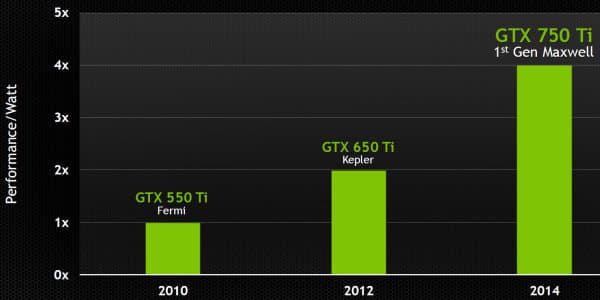
Модель GeForce GTX 750 Ti основана на полноценном видеочипе GM107, имеющем 640 вычислительных ядер, подсистема памяти состоит из двух 64-битных контроллеров памяти (всего 128-бит) объёмом 1 или 2 гигабайта. Применяется GDDR5-память с эффективной частотой для микросхем памяти равной 5.4 ГГц. Младшая модель имеет 512 вычислительных ядра и 32 TMU, но 16 блоков ROP и 128-битная шина остались на месте. Её отличие от старшей в подсистеме памяти в том, что она довольствуется 1 ГБ GDDR5-памяти с частотой в 5.0 ГГц.
Естественно, что GM107 поддерживает технологию динамического изменения тактовой частоты и напряжения GPU Boost 2.0, обеспечивающую максимально возможную 3D-производительность в определённых условиях (напряжение, температура, потребление) при сохранении минимального уровня частоты, который гарантируется при любых номинальных условиях. Базовая тактовая частота для видеочипа в моделях GeForce GTX 750 Ti и GTX 750 равна 1020 МГц, а турбо-частота (средняя повышенная частота в нескольких играх и приложениях) — 1085 МГц. Естественно, по природе своей турбо-частота в каждой игре и при разных условиях может отличаться, есть лишь некое среднее значение.
Обе платы семейства GeForce GTX 750 поддерживают и все остальные современные технологии компании NVIDIA, известные ещё по графическим решениям поколения Kepler и о которых мы ранее неоднократно писали: поддержка до четырёх дисплеев, возможность одновременного стереорендеринга на несколько мониторов, поддержка полноэкранного сглаживания при помощи метода TXAA, технологии G-Sync, NVENC, ShadowPlay и другие. С точки зрения подключения дисплеев также нет ничего нового — есть привычная поддержка уже известных стандартов DisplayPort 1.2 и HDMI 1.4, так как более новых версий этих разъемов ждать ещё слишком рано.
Улучшение вычислительных возможностей
Но это ещё не все изменения в Maxwell, некоторые связаны именно с вычислительными возможностями. Судя по некоторым данным, сами вычислительные ядра (ALU) также были переработаны, исправлены проблемы, имеющиеся в Kepler, а также изменена длина конвейера исполнительных устройств — количество тактов на исполнение некоторых зависимых арифметических инструкций было снижено, по сравнению с Kepler, что также улучшает эффективность использования вычислительных блоков. Были серьёзно ускорены и атомарные операции с памятью, которые теперь выполняются напрямую, в отличие от Fermi и Kepler, где эффективность таких операций в некоторых случаях была не слишком велика.
В целом, с точки зрения CUDA-программ, мультипроцессор SMM очень похож на SMX архитектуры Kepler, а ключевые улучшения ориентированы на повышение эффективности исполнения кода. Размер регистрового файла и максимальное количество запущенных варпов на SMM остались неизменными: 64k 32-битных регистров и 64 варпа, как и максимальное количество регистров на поток — 255. А вот максимальное количество активных блоков потоков (thread blocks) на мультипроцессор было удвоено до 32 штук, что улучшает эффективность использования вычислительных ресурсов для некоторых задач с маленькими блоками потоков.
Важным нововведением в мультипроцессорах Maxwell стало то, что они имеют по 64 КБ выделенной разделяемой (shared) памяти на мультипроцессор, в отличие от Fermi и Kepler, которые делят 64 КБ памяти между кэш-памятью первого уровня и разделяемой памятью. Каждый поток может использовать не больше 48 КБ и в Maxwell, но общее увеличение разделяемой памяти также ведёт к улучшению эффективности использования ресурсов. Выделение shared-памяти в отдельный блок в Maxwell стало возможным из-за объединения функциональности кэш-памяти первого уровня и текстурного кэша в одном блоке. Их объединение, к слову, привело ещё и к уменьшению занимаемой ими площади на кристалле. В общем, возможности и эффективность кэширования и использования локальной памяти в Maxwell заметно изменились, и это ещё предстоит раскрыть с программной стороны.
Ещё одна новая архитектурная возможность GM107 — поддержка динамического параллелизма. Она впервые появилась в топовом чипе GK110 и позволяет GPU создавать дополнительную работу для самого себя. Динамический параллелизм появился в CUDA 5.0 и позволяет потокам CUDA-программ запускать дополнительные кернелы (kernels) на том же GPU. Архитектура Maxwell принесла поддержку динамического параллелизма в бюджетный сегмент, даже в такой маленький и недорогой чип, как GM107, а чуть позже принесёт и во всю линейку решений NVIDIA.
Из того, что не вошло в официальные документы NVIDIA об изменениях в Maxwell, можно особо выделить запланированное появление поддержки унифицированной (виртуальной) памяти — unified memory. Это — технология виртуального объединения оперативной и видеопамяти, когда CPU и GPU могут использовать общую память совместно, получая доступ к тем же самым данным, без необходимости предварительной их пересылки, что требуется сейчас. На данный момент, перед выполнением любых расчётных задач на GPU требуется сначала перенести необходимые данные из оперативной памяти CPU в локальную видеопамять, к которой имеет доступ GPU. А поддержка унифицированной памяти упростит задачу. Впрочем, речь лишь об упрощении для программиста, так как передача данных всё равно будет происходить по всё той же шине PCI Express, которая не отличается слишком высокой скоростью и будет узким местом во многих случаях. Тем не менее, определённые улучшения возможны, но лишь после того, как эта возможность будет поддержана разработчиками.
Для этого компания NVIDIA уже выпустила новую версию CUDA 6 Release Candidate, которая должна облегчить задачу параллельного программирования. С учётом появления в продаже GeForce GTX 750 Ti, основанных на новой архитектуре Maxwell, разработчики ПО вероятно уже могут разрабатывать программное обеспечение, используя такую новую функциональность, как унифицированную память, описанную выше. Также, в состав CUDA 6 вошло улучшенное масштабирование многочиповых конфигураций и подменяемые библиотеки, которые способны автоматически ускорить ПО, использующее библиотеки BLAS и FFTW, заменяя привычные CPU-библиотеки их GPU-ускоренными версиями.
NVIDIA ни слова не упоминает о производительности расчётов с двойной точностью на новом графическом процессоре, что легко объяснить тем, что чип с потреблением в 60 Вт предназначается для мобильных решений и компактных ПК. Но мы знаем, что эта скорость для GM107 составляет 1/32 от скорости расчётов с одинарной точностью — то есть, возможность хоть и есть, но её практическое применение ничем не оправдано.
Понятно, что NVIDIA не особенно много рассказывает об улучшениях в GM107, если в будущем планируется выпуск куда более мощных и функциональных графических процессоров большей сложности. Предполагаем, что очень многое в Maxwell, особенно касающееся функциональности по работе с 3D-графикой, пока что осталось «за кадром», равно как и некоторые нововведения, связанные с вычислительными возможностями. Впрочем, совсем скоро начнётся очередная конференция GTC 2014, на которой компания NVIDIA вполне может раскрыть некоторые подробности о вычислительных возможностях Maxwell и о других новинках.
Ускорение кодирования и декодирования видеоданных
Одним из нововведений графических чипов семейства Kepler по сравнению с предыдущими поколениями GeForce, был аппаратный кодировщик видеоданных в формате H.264 — NVENC. Выделенный аппаратный блок для кодирования видеоданных принёс значительное увеличение производительности кодирования и снижение энергозатрат на эту задачу. Одним из интересных применений NVENC стало внедрение функции записи игрового процесса ShadowPlay, не требующее особых ресурсов центрального процессора и получившее достаточно высокую популярность.
Для дальнейшего улучшения производительности кодирования данных, в первом чипе архитектуры Maxwell блок кодирования NVENC был улучшен и он теперь обеспечивает сжатие видеоданных в формате H.264 в 6-8 раз быстрее реального времени, что в полтора-два раза превосходит показатели Kepler. Увеличение производительности кодирования видео в семействе Maxwell в реальности пока что скажется не так уж сильно. На данный момент NVENC чаще всего используется в приложениях вроде ShadowPlay, где хватало и мощности этого блока предыдущего поколения. Ну разве что задержки при кодировании и влияние на общую производительность будет ещё меньше. Большую пользу можно получить при перекодировании видео из формата в формат (если это кем-то до сих пор используется), ведь в таком случае перекодирование займёт вдвое меньше времени.
Увеличение эффективности кодирования важно скорее для мобильной версии Maxwell, используемой в ноутбуках. Ведь новый блок NVENC отличается не только производительностью, но и меньшим потреблением энергии и при кодировании, так что ноутбук на основе GM107 в таких задачах должен проработать в автономном режиме ещё дольше. Тем более это касается будущих смартфонно-планшетных решений с видеоядром архитектуры Maxwell, где низкое потребление в видеозадачах ещё важнее.
Не только блок кодирования видеоданных получил усовершенствования в новом чипе, но и блок декодирования. Увы, блок декодирования в Maxwell не имеет поддержки полностью аппаратного декодирования формата H.265 (HEVC), на что многие надеялись. NVIDIA планирует предложить лишь программно-аппаратную реализацию для декодирования этого нового видеоформата. Вероятно, они хотят задействовать вычислительные блоки GPU, как это было ранее с CUDA-ускоренным декодированием H.264. Впрочем, зато декодирование этого «старого» формата у нового чипа NVIDIA ускорилось. NVIDIA утверждает, что благодаря изменениям в блоке декодирования видеоданных, появлению локального кэша и увеличению эффективности обмена данными с памятью, декодирование H.264 видеопотока стало в 8-10 раз быстрее, при меньшем потреблении энергии.
Ну а из дополнительных новых возможностей Maxwell, связанных с декодированием видеоданных, можно отметить новое состояние питания графического процессора — GC5, предназначенное специально для случаев очень слабой загрузки GPU работой, вроде декодирования и проигрывания видеоданных. Режим питания GC5 обеспечивает сравнительно низкое потребление энергии в таких задачах по сравнению с графическими чипами предыдущих поколений и будет особенно полезен в ноутбуках и других мобильных устройствах.
Оценка производительности
Давайте оценим производительность новых решений, исходя из теоретических данных и тестирования, проведённого в NVIDIA. Модели GeForce GTX 750 и GTX 750 Ti основаны на новом GPU с разным количеством активных исполнительных блоков, но оценивать производительность новинки, исходя из теории, проще по старшему решению. Судя по теоретическим цифрам, GeForce GTX 750 должна уступать своей старшей сестре примерно 10-15%, в зависимости от нагрузки на различные исполнительные блоки GPU или видеопамять (в случае, если 1 ГБ в младшей модели достаточно, конечно). Для начала рассмотрим пиковые теоретические показатели первого графического процессора архитектуры Maxwell по сравнению с аналогичным чипом поколения Kepler — GK107:
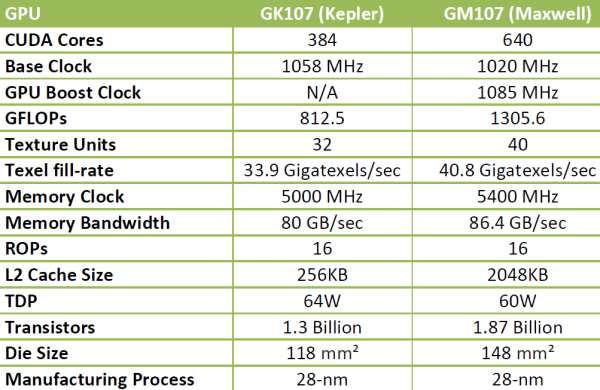
Если сравнивать GM107 с GK107 по топовым решениям, как это делает NVIDIA, то хорошо видно, что у чипа архитектуры Maxwell аж на 60% выше математическая производительность за счёт выросшего количества ALU, на 20% выросла скорость текстурных выборок и фильтрации. Зато пропускная способность видеопамяти повысилась лишь на 10% (86.4 ГБ/с против 80 ГБ/с), а производительность блоков ROP так и вовсе стала немного ниже, за счёт меньшей базовой тактовой частоты и одинакового количества соответствующих блоков, что может сказаться в некоторых условиях.
Иными словами, GTX 750 Ti будет иметь явное преимущество в играх, которым важна высокая скорость текстурирования и математическая производительность (а это — большинство игр), а в случае, если упор будет в ПСП или блоки ROP, то преимущества почти не будет или новинка даже будет немного проигрывать своему предшественнику. Давайте сначала посмотрим, что получилось в тестах у самой NVIDIA.
С какими из своих видеокарт сама NVIDIA сравнивает новинку? Основываясь на последних данных базы Steam Hardware Survey, одной из самых популярных у пользователей является модель GeForce GTX 550 Ti, выпущенная несколько лет назад и достаточно распространённая. Естественно, что NVIDIA удобно сравнить GeForce GTX 750 Ti с ней, ведь новинка обеспечивает более чем двукратный (+120% в среднем, по данным компании) прирост в производительности при почти вдвое меньшем потреблении энергии: 60 Вт против 116 Вт.
Далее, NVIDIA уверяет, что GeForce GTX 750 Ti обеспечит компактные системы мощным видеоядром, достаточным для игры в разрешении 1920×1080. Это делает новинку и весьма удачным бюджетным вариантом для апгрейда видеоподсистемы для устаревших ПК, не имеющих возможности обеспечения дополнительного питания и обходящейся 300-ваттным БП. Также выпущенная недавно модель GeForce GTX 750 Ti должна отлично подходить для мультимедийных центров и домашних кинотеатров, имеющих жёсткие ограничения по потреблению энергии.
Вероятно, именно поэтому они сравнивают свою новую видеокарту с интегрированной графикой от Intel и собственной платой GeForce GT 640, основанной на аналогичном чипе GK107 предыдущего поколения. Посмотрим, что может дать энергоэффективная версия Maxwell в условиях современной игры, где важна мощность графического процессора — Call of Duty Ghosts. Разрешение равно 1920×1080, включено полноэкранное сглаживание уровня 4x и средние настройки качества, использовалась система на базе процессора Intel Core i5 «Haswell» со встроенным видеоядром Intel HD Graphics 4600:
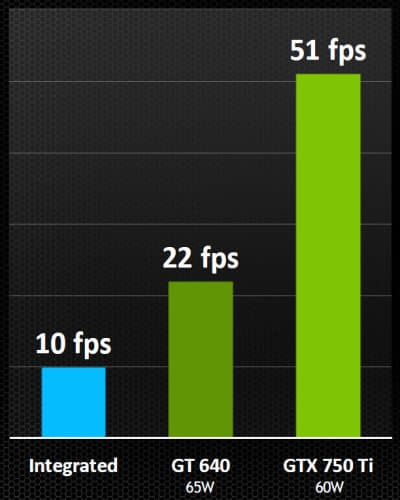
Как видно на диаграмме, GeForce GTX 750 Ti показывает более чем пятикратный прирост производительности, по сравнению с интегрированным в CPU графическим ядром от Intel в этой игре и более чем двукратное превосходство по отношению к модели на базе схожего по сложности и потреблению энергии чипа NVIDIA предыдущего поколения. Посмотрим, что с производительностью новинки будет в одной из популярных и требовательных игр современности — Batman: Arkham Origins.
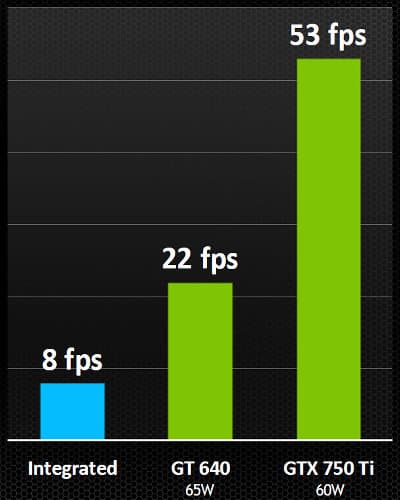
Те же самые решения сравнивались на той же системе в игре Batman: Arkham Origins при разрешении 1920×1080, также с использованием полноэкранного сглаживания уровня 4x и средних настройках качества. В этой игре новая модель GeForce GTX 750 Ti показала более чем 6-кратное превосходство над интегрированной графикой Intel и была на 140% быстрее предшественницы в лице GeForce GT 640, потребляющей даже чуть больше энергии. Так что можно точно сказать, что GeForce GTX 750 Ti — действительно очень неплохой вариант для включения в конфигурацию компактных систем с низким потреблением энергии. Даже при сравнительно невысокой цене решения, вместе с GeForce GTX 750 Ti компактные системы легко могут стать достаточно мощными даже для требовательных игр.
Но хватит сравнивать новинку со старой моделью прошлого поколения и интегрированной графикой, ведь на рынке противостоять новой модели будут совершенно другие решения. NVIDIA уверяет, что даже при сравнении с ними всё для новинки прекрасно и она является лучшей в своём классе. Вероятно, если сравнивать их по энергоэффективности, то так оно и будет, ведь по потреблению энергии GM107 действительно рекордсмен. А что с чистой производительностью, без оглядки на класс и потребление? NVIDIA сравнивает новинку с Radeon R7 260X, которая действительно и является одним из её главных конкурентов:
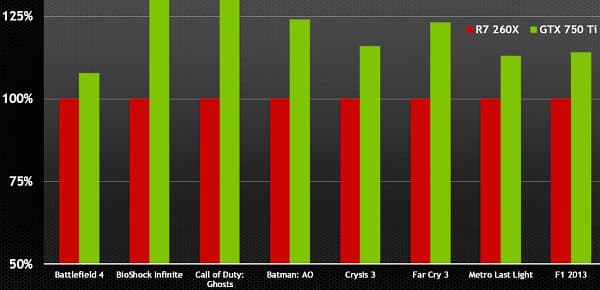
Все тесты проводились на системе с Intel Core i7-4770K, в разрешении 1920×1080 пикселей и при средних настройках. В таких условиях, по данным NVIDIA, их GeForce GTX 750 Ti в большинстве современных игр действительно обеспечивает на 10-15% большую производительность, чем плата конкурента, даже без скидки на меньшее энергопотребление (не забываем, что эти данные — от заинтересованной стороны). Ну а если рассматривать соотношение скорости рендеринга и потребления энергии, то GTX 750 Ti абсолютно точно станет победителем, ведь GeForce GTX 750 Ti потребляет 60 Вт, а Radeon R7 260X — 115 Вт, что почти вдвое больше. Впрочем, зато плата NVIDIA имеет более высокую цену, а у AMD есть ещё одна новая модель — Radeon R7 265, а с ней NVIDIA сравнить новинку не успела.
Рассмотрим и прикидки производительности GeForce GTX 750 — младшей модели на базе GM107. Эта плата предназначена для того же ценового диапазона, только располагается в линейке компании чуть ниже GTX 750 Ti. Из названия понятно, что она имеет сниженную производительность из-за частично отключенных исполнительных блоков. Так, активными в GeForce GTX 750 являются лишь 512 потоковых вычислительных ядер из 640 — то есть, один из пяти его мультипроцессоров отключен. А вот частота GPU осталась на том же уровне: 1020 МГц базовой частоты и 1085 МГц средней турбо-частоты. Подсистема памяти младшей модели отличается от GTX 750 Ti тем, что она содержит лишь 1 ГБ памяти, работающей на частоте 5.0 ГГц.
Итак, с чем сравнивать GeForce GTX 750? NVIDIA начинает со старенькой GeForce GTS 450 на базе GF106. Вполне естественно, что новая плата показывает трёхкратное превосходство по производительности, а потребляет при этом лишь 55 Вт, в отличие от 106 Вт у старой модели позапрошлого архитектурного поколения. Но такое сравнение не слишком серьёзно, поэтому переходим к уже виденному нами сравнению с интегрированным графическим ядром Intel и моделью архитектуры Kepler. Причём, сделаем это в одной из самых популярных онлайновых игр:
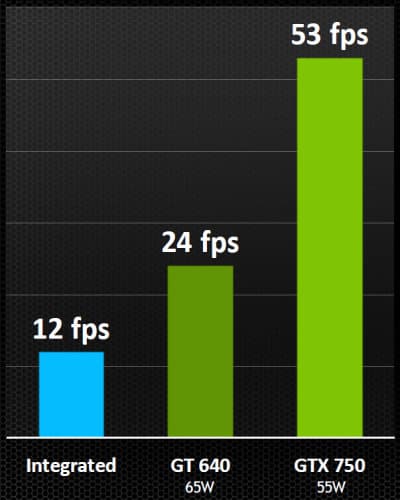
Сравнение в игре World of Tanks при разрешении 1920×1080 и высоких настройках показывает, что GeForce GTX 750 более чем вдвое быстрее предшественницы GeForce GT 640, и при этом потребляет заметно меньше энергии. Сравнение с Intel HD Graphics 4600 особого смысла не имеет, интегрированная графика по скорости рендеринга в этой игре уступает новинке более чем вчетверо. Неудивительно, что младшая модель, ровно как и GeForce GTX 750 Ti, отлично подойдёт для компактных ПК, так как она имеет такой же размер платы и потребляет даже чуть меньше энергии. Сравним её с парой отстающих ещё в одной популярной игре — Elder Scrolls Skyrim.
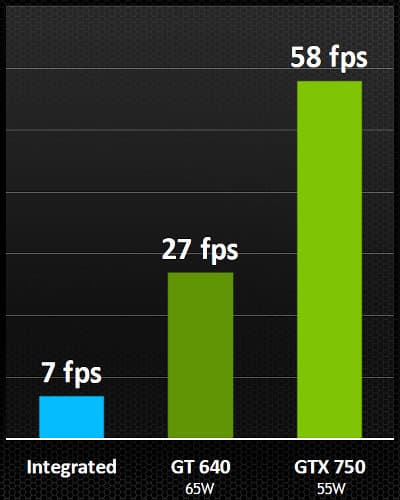
Настройки рендеринга в Elder Scrolls Skyrim были такие: разрешение 1920×1080, средние игровые настройки качества, сглаживание отключено. Новая модель GeForce GTX 750 более чем в 8 раз быстрее интегрированного видеоядра от Intel в этой игре и вдвое быстрее GeForce GT 640, основанной на чипе GK107 предыдущего поколения Kepler и имеющей чуть большее энергопотребление. Но снова — главным соперником новинки будет не GT 640, а Radeon R7 260, например. Посмотрим, справляется ли с конкурентом вторая новинка:
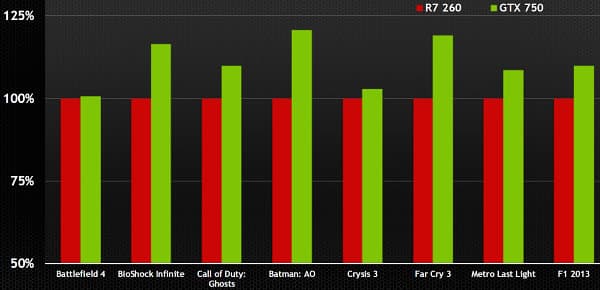
Эти тесты проводились на системе с процессором Intel Core i7-3960X в разрешении 1920×1080 пикселей при средних настройках качества. Но даже в этом случае получилось, что GeForce GTX 750 или на уровне конкурента или чуть быстрее его, и всё это — при почти вдвое меньшем энергопотреблении: 55 Вт против 95 Вт у Radeon. И снова мы видим очень хорошие цифры по энергоэффективности, а вот цена на младшую плату семейства GeForce GTX 750 также кажется слегка завышенной.
Рыночное позиционирование семейства GeForce GTX 750
Хотя графический процессор GM107 близок по характеристикам и позиционированию к GK107, имея те же 16 блоков ROP и 128-битную шину памяти, но из-за архитектурных улучшений в Maxwell, GM107 имеет заметно большее количество потоковых ядер. Видимо, поэтому новый GPU стал основой не только для модели GeForce GTX 750, но и для GTX 750 Ti. И эта серия расширяет и так уже довольно широкую линейку видеокарт NVIDIA.
GeForce GTX 750 Ti недостаточно быстра для того, чтобы заменить GeForce GTX 660, но она намного быстрее обычной GTX 650 (не Ti), поэтому новинки замещают решения GTX 650 Ti, в том числе и модификацию Boost, выполненные на урезанных GK106. Таким образом NVIDIA значительно снизила себестоимость данных продуктов, ведь новые платы серии GTX 750 обещают быть не хуже тех, которые они заменяют, при гораздо меньшей сложности GPU и печатных плат.

С одной стороны, потребление в 60 Вт и мощь на уровне GTX 650 Ti (Boost) делает линейку GTX 750 лучшими среди видеокарт с низким потреблением без необходимости подключения дополнительного питания. А во многих развивающихся странах именно такие решения и имеют рыночный успех, продаваясь очень массово. С другой, цена на GTX 750 Ti в $149 и $119 для модели GTX 750 означает, что эти модели не дают рынку никакого прироста в производительности за эти деньги, ведь они заменили линейку GTX 650 Ti аналогичной стоимости.
Конкурентами для новинок серии GTX 750 со стороны компании AMD являются видеокарты семейства Radeon R7: 260, 260X и недавний вариант — R7 265. С точки зрения соотношения производительности и цены, особенно с учётом недавнего снижения цен на продукцию AMD, у последних есть небольшое преимущество по этому параметру, а NVIDIA в очередной раз выставила слегка завышенную цену на свои новинки, чтобы заработать для себя больше денег, и это — их полное право. Себестоимость новых плат значительно ниже, чем у тех же Radeon R7 26x, поэтому прибыль долго ждать себя не заставит. Бизнес есть бизнес.
Если смотреть на результаты тестов, то обе платы NVIDIA показали очень хороший результат, если оглядываться на мизерное потребление ими энергии и не смотреть на установленную компанией цену. Именно цена и выбранное ценовое позиционирование не позволяют нам полностью и бесповоротно восторгаться решениями калифорнийской компании, которые технически весьма хороши. Проблема в том, что GeForce GTX 750 Ti по скорости вряд ли заметно превзойдёт GeForce GTX 650 Ti (и тем более — Boost), при том, что она заменяет эту модель на рынке.
То есть, пользователь должен довольствоваться тем, что его новая плата потребляет вдвое меньше энергии, а вот сэкономить у него вряд ли получится. А ведь раньше видеокарты новых поколений, меняющие первую цифру в индексе, всегда были производительнее предыдущей модели с теми же остальными цифрами: GTX 650 Ti превосходила по скорости GTX 550 Ti и т.п. В случае с нынешними новинками этого не получилось, и это нас слегка печалит.
С архитектурной точки зрения, новый GPU первого поколения архитектуры Maxwell хоть и является последователем Kepler, но с весьма значительными модификациями, направленными на повышение энергоэффективности и снижения себестоимости. К сожалению, функциональных изменений в первом поколении (это уточнение важно) Maxwell не произошло, и GM107 в этом смысле полностью идентичен чипам GK1xx. К примеру, полной поддержки Direct3D 11.1 и 11.2 в нём не появилось, хотя она могла бы быть полезной, с учётом распространения в ближайшем будущем мультиплатформенных игр, ведь все современные игровые консоли такую поддержку имеют.
Впрочем, это касается лишь графических возможностей (возможно также, что некоторые способности Maxwell в GM107 пока что не раскрыты за ненадобностью), а с вычислительной точки зрения некоторые изменения в архитектуре есть. По CUDA-возможностям новое бюджетное решение соответствует уровню топового GK110, оно поддерживает такие техники как динамический параллелизм и HyperQ. Кроме этого, увеличилось и количество одновременно исполняемых команд, количество доступных регистров на поток, были серьёзно модифицированы блоки планировщиков, появилась отдельная общая память в мультипроцессорах SMM и т.д.
Да и в остальном на низком уровне изменений в Maxwell очень много уже сейчас, даже в сравнительно маломощном GM107. По общей эффективности новый чип намного лучше предыдущих, и это касается как энергетической эффективности, так и плотности размещения транзисторов на чипе и вычислительной эффективности. При помощи глубокой модернизации блоков предыдущих архитектур и других изменений, NVIDIA добилась удвоения показателя соотношения производительности к потреблению энергии, и это достижение невозможно переоценить в век главенства энергоэффективности.
При всё усложняющемся внедрении более совершенных техпроцессов на фабриках, производящих микрочипы, очень важным является умение выжимать все соки из имеющихся возможностей. И при разработке архитектуры Maxwell, а также графического процессора GM107 в частности, инженеры NVIDIA сделали очень важное и полезное дело, найдя множество возможностей по увеличению производительности в рамках уже освоенных технологий производства. Простое увеличение количества функциональных блоков в таком случае бы не сработало, так как размер чипа и его энергопотребление стали бы слишком большими. А глобальные улучшения энергоэффективности к Maxwell позволили добиться значительно лучшего соотношения производительности и потребления в новом GeForce GTX 750 Ti.
Для того, чтобы повысить производительность при сокращении затрат энергии, был серьёзно изменён дизайн мультипроцессоров SMM в составе нового графического процессора GM107. В мультипроцессорах были выделены четыре вычислительных раздела, имеющие собственные выделенные блоки планирования и управления, также были изменены и планировщики в самих мультипроцессорах и связи между всеми блоками. Все эти изменения в GPU позволили обеспечить более эффективное использование возможностей аппаратных блоков чипа, что повысило его энергоэффективность. Так, новая модель GeForce GTX 750 Ti обеспечивает более чем 1.7-кратную производительность чипа GK107 из предыдущего поколения, при даже чуть меньшем потреблении энергии в рамках 60 Вт!
Чтобы повысить эффективность работы с видеопамятью, шина которой осталась лишь 128-битной, был значительно увеличен объём кэш-памяти второго уровня (до 2 МБ, что в восемь раз больше, чем в GK107 и даже больше, чем в GK110!), которая обеспечивает дополнительную буферизацию различных данных: текстурных, атомарных операций и т.п. Большая кэш-память снижает требования к ПСП, что позволяет обеспечить высокую производительность при сравнительно узкой шине к видеопамяти.
В итоге, первое решение на базе графического чипа архитектуры Maxwell стало лучшим по энергоэффективности среди видеокарт NVIDIA и вообще. Неудивительно, что самой впечатляющей характеристикой новинок является их энергопотребление. Все описанные в статье оптимизации в Maxwell привели к тому, что при производительности решения на базе GM107, близкой к лучшим моделям на GK106, GeForce GTX 750 Ti потребляет лишь 60 Вт (55 Вт для GTX 750), что значительно меньше, чем GeForce GTX 650 Ti, и даже чуть меньше, чем GTX 650 и GT 640! При этом, GeForce GTX 750 Ti почти вдвое быстрее GeForce GTX 650 и втрое производительнее GeForce GT 640, что явно можно считать важной победой для NVIDIA. Так что по энергоэффективности новинки абсолютно точно являются лучшими видеокартами на рынке.
Что касается соотношения производительности и площади чипов, то тут NVIDIA тоже есть чем гордиться. Если GK107 имел площадь чипа в 118 мм² при сложности в 1.3 млрд. транзисторов, то GM107 имеет площадь 148 мм² при сложности в 1.87 млрд. транзисторов. По сути, NVIDIA «упаковала» на 44% больше транзисторов в на 25% больший по площади GPU, то есть, плотность размещения транзисторов была также значительно улучшена — за что также можно благодарить описанные выше оптимизации.
В общем, новые модели видеокарт NVIDIA на чипах архитектуры Maxwell отлично подойдут для применения в домашних ПК, домашних кинотеатров и компактных ПК, требующих низкого энергопотребления и тепловыделения — для них производительность серии GeForce GTX 750 будет просто великолепной. То же самое можно сказать и про тех, кто хочет сделать модернизацию своего ПК, но не имеет возможности установить мощную видеокарту, требующую дополнительного питания. Правда, цены на новинки NVIDIA низкими назвать не получится, ведь конкурент предлагает лучшее соотношение цены и производительности, даже серьёзно проигрывая по себестоимости и энергоэффективности.
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX/GM1XX
Справочная информация о семействе видеокарт GM2XX


