Новый однопроцессорный лидер 3D-графики
Содержание
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Часть 3 — Результаты игровых тестов (производительность)
Да-да, по сути точно такой же заголовок, какой был у статьи по Radeon HD 7970 в конце прошлого года. Потому что суть осталась той же: с выходом Geforce GTX 680 мы получили нового короля 3D-графики, если не считать прошлогодних двухпроцессорных решений, которые еще пока остаются в половине тестов самыми производительными в абсолютном исчислении, однако у них цены намного выше, и вообще эти изделия - более имиджевые, нежели имеющие реальные хоть какие массовые применения.
Поэтому мы поздравляем компанию Nvidia с долгожданным выпуском архитектуры Kepler, погрузимся в процесс изучения новшеств, обзорную лекцию по которым проведет Алексей Берилло.
Часть 1: Теория и архитектура
Наконец-то настал этот день! Прошло без малого два долгих года с момента выхода Geforce GTX 480, основанного на чипе новейшей тогда архитектуры Fermi. Позади все проблемы с 40 нм техпроцессом, а также с изделиями на его основе, которые категорически не хотели быть энергоэффективными, хотя быстрыми они, несомненно, были.
К сожалению, темпы освоения технологических процессов заметно снизились, по крайней мере это точно можно сказать про фабрики тайваньской TSMC, и нам пришлось очень долго ждать нового поколения GPU, произведённых на более тонком техпроцессе, чем 40 нм. И всё же конкурент Nvidia в очередной раз опередил их, выпустив своё 28 нм топовое решение ещё в конце прошлого года. А калифорнийская компания в то время ещё тихо работала над своим новым детищем.
И вот, настал тот день, когда все ожидания закончились. Сегодня мы предлагаем вашему вниманию новейшую архитектуру компании Nvidia, получившую название в честь очередного физика — Kepler. О названии новой архитектуры мы знали уже несколько лет, президент компании Дженсен Хуанг объявил об этом ещё на GTC 2010. Ещё тогда стало понятно, что наибольшее внимание при её разработке будет направлено на повышение эффективности, в частности — энергетической.
Собственно, почему именно так, стало понятно позднее — Fermi оказалась быстрой, но и весьма прожорливой и горячей. Ведь основной задачей при разработке архитектуры Fermi было значительное увеличение производительности, по сравнению с Tesla, с особенным упором на ускорение обработки геометрии, тесселяцию и универсальные вычислительные возможности. Энергопотребление хоть и тогда было важным фактором, но всё же производительность и функциональность были важнее.
А в случае с Kepler основной задачей стала именно максимальная энергоэффективность. На основе полученных знаний при проектировании Fermi, инженеры Nvidia сделали новую архитектуру высокоэффективной. Конечно, новый 28 нм техпроцесс сыграл важнейшую роль в снижении требований к электропитанию, но также на эффективность повлияли и архитектурные изменения в Kepler — все исполнительные блоки нового графического процессора были полностью переработаны.
Первый чип архитектуры, выпущенный на рынок, получил кодовое имя GK104, а выпущенная на нём плата — Geforce GTX 680. Как видно по названию — это продолжатель дела GTX 480 и GTX 580, только более производительный и эффективный, при этом обладающий меньшим энергопотреблением. Применение 28 нм техпроцесса позволило выпустить сравнительно небольшой чип с довольно высокой производительностью. Но ещё больше повлияла полная архитектурная переработка нового GPU с целью оптимизации энергопотребления.

Nvidia сравнивает своё новое решение с гибридными автомобилями, имеющими как бензиновые двигатели, так и электромоторы, вроде концепт-кара BMW i8. Нет, это не значит, что в GK104 есть два разных ядра (хотя было бы интересно, опыт у Nvidia по той же Tegra 3 есть). Просто GTX 680 может работать в максимально производительном режиме, потребляя при этом минимум энергии. Nvidia не без причин считает новый чип не только самым быстрым в своей истории, но и наиболее энергоэффективным решением, но об этом — далее.
Ах, эта энергоэффективность! В последнее время ей прожужжали все уши и на каждом углу. Впрочем, в случае GPU она вполне имеет определённый смысл, ведь зачастую производительность видеочипов сейчас ограничена именно энергопотреблением. Кулер можно поставить более производительный (вплоть до жидкостного охлаждения), а вот питания подать больше, чем позволяет PCI-E интерфейс и дополнительные разъёмы, просто не получится. Именно поэтому энергоэффективность в общем-то тождественна производительности в случае топовых решений и больших чипов.
Теоретическая часть статьи частично перекликается с предыдущими, так как новое решение во многом повторяет предыдущие из линеек GTX 400 и GTX 500. Частично новый чип похож на топовые GF100 и GF110, а больше всего — на GF104 и GF114, на которых основаны Geforce GTX 460 и GTX 560 Ti, соответственно. Большинство технических данных об архитектуре «Fermi» было раскрыто нами ещё давно, в специальном обзоре архитектуры GF100 и обзоре Geforce GTX 470 и GTX 480, которые весьма полезно прочитать перед знакомством с новым GPU. А также стоит ознакомиться и с другими материалами по графическим архитектурам компании Nvidia:
- [25.01.11] Nvidia Geforce GTX 560 Ti: чуть слабее Geforce GTX 570/580, но и дешевле
- [09.11.10] Nvidia Geforce GTX 580: новый король 3D-графики на закате 2010 года
- [12.07.10] Nvidia Geforce GTX 460: распространение новой архитектуры GF1xx на средний ценовой диапазон
- [27.03.10] Nvidia Geforce GTX 480 архитектура нового графического процессора изнутри; как реализована поддержка DirectX 11
Будем считать, что с предыдущими архитектурами видеочипов компании Nvidia читатели уже знакомы, и рассмотрим подробные характеристики нового графического процессора от этой компании, а также новой модели видеокарты Geforce GTX 680, основанной на чипе GK104.
Графический ускоритель серии Geforce GTX 680
- Кодовое имя чипа GK104;
- Технология производства 28 нм;
- 3.54 миллиардов транзисторов (чуть больше, чем у GF100 и GF110);
- Площадь ядра 294 мм2 (гораздо меньше, чем GF110 и даже меньше GF114!);
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических и вычислительных шейдеров, а также тесселяции;
- 256-битная шина памяти, четыре независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Базовая частота ядра 1006 МГц;
- Средняя турбо-частота ядра 1058 МГц (читайте об этом ниже);
- 8 потоковых мультипроцессоров, включающих 1536 скалярных ALU для расчётов с плавающей запятой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 128 блоков текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 4 широких блока ROP (32 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
- Интегрированная поддержка четырёх мониторов, включая два порта Dual Link DVI, а также HDMI 1.4a и DisplayPort 1.2
- Поддержка шины PCI Express 3.0
Спецификации референсной видеокарты Geforce GTX 680
- Базовая частота ядра 1006 МГц;
- Средняя турбо-частота 1058 МГц;
- Количество универсальных процессоров 1536;
- Количество текстурных блоков 128, блоков блендинга 32;
- Эффективная частота памяти 6008 (1502*4) МГц;
- Тип памяти GDDR5, 256-бит шина памяти;
- Объем памяти 2 ГБ;
- Пропускная способность памяти 192.3 ГБ/с;
- Теоретическая максимальная скорость закраски 32.2 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 128.8 гигатекселей в секунду;
- Два Dual Link DVI-I разъема, один HDMI, один DisplayPort;
- Двойной SLI разъем;
- Энергопотребление до 195 Вт (два 6-контактных разъёма);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $499 (для России 17999 руб).
Новый графический процессор GK104, и видеокарта Geforce GTX 680 на его основе, призваны заменить переставший выпускаться GTX 580 на базе GF110. С одной стороны, принцип наименования видеокарт Nvidia вроде бы не изменился, топовая модель получила изменение первой цифры индекса. С другой — даже судя по кодовому имени чипа GK104, он изначально вряд ли планировался в роли именно топового решения.
Вполне вероятно, изначально это должна была быть GTX 670 (приставка Ti по вкусу) или что-то в этом роде, но потом решили повременить с настоящим топовым чипом, раз у TSMC с новым техпроцессом до сих пор дела неидеальны, и выпустить в качестве верхней модели менее мощный чип. Впрочем, мы не раз говорили о том, что наименование видеокарт — всегда маркетинговое решение, которое не особенно влияет на технические характеристики.
Правда, оно сильно влияет на розничную цену решений. По всем внешним признакам (сложность чипа, сложность печатной платы, энергопотребление, да и себестоимость, скорее всего), GTX 680 больше похожа на решение из верхнего среднего диапазона. На это же намекают и кодовые имена чипов: GF104 — GK104. Впрочем, после выхода видеоплат AMD по высоким ценам, которые не слишком сильно обогнали Geforce GTX 580, у Nvidia появился большой соблазн поднять GK104 в верхний ценовой диапазон, заработав самим и давая заработать своим партнёрам по выпуску видеокарт.
Дело то хозяйское, и рекомендуемая рыночная цена в $499 для североамериканского рынка сейчас весьма выгодна (с российской ценой чуть похуже, Radeon HD 7970 уже сейчас продаются дешевле). Впрочем, теперь ожидается ответный ход конкурента, и вполне вероятно, что он не только снизит цены на свою топовую линейку, но и сможет выпустить несколько новых моделей, в том числе разогнанный вариант HD 7970, а также двухчиповую плату на основе пары Tahiti. Вот как выпустит, так и будем сравнивать.
Пока что на основе чипа GK104 выпущена лишь одна модель видеокарты Geforce GTX 680, которая в будущем вполне может дополниться гораздо более интересным для масс решением с урезанными возможностями. Предполагаем, что потенциальные покупатели с ещё большим удовольствием возьмут какой-нибудь GTX 670 Ti с меньшей ценой и не слишком зарезанной производительностью, как это всегда и бывает. И как раз такое решение, при условии отсутствия проблем с производством, сможет повторить успех таких плат как Geforce 8800 GT и GTX 460. Ну а пока что Nvidia вступила в более дорогой сектор, ведь оставшиеся GTX 570 и GTX 580 надо распродать.
В отличие от предшественниц на базе Fermi, новая модель имеет 256-битную шину памяти и соответствующий объём видеопамяти, равный 2 ГБ. Конечно, это гораздо лучше, чем 1.5 ГБ, но в современных условиях уже хуже, чем 3 ГБ, имеющиеся у некоторых моделей GTX 580 и у всех Radeon HD 7900. К сожалению, 2 ГБ — по сути, единственно возможное значение, так как 1 ГБ это слишком мало, а 4 ГБ быстрейшей GDDR5 памяти чересчур дорого даже для 500-долларовой видеокарты. Так что тут у конкурента есть небольшое преимущество, которое может сказаться в тяжёлых режимах и сверхвысоких разрешениях вроде 2560x1600.
Глядя на плату, сразу же отмечаешь изменившийся дизайн разъёмов дополнительного питания и то, что их два 6-контактных, что весьма удивительно для топовой модели. Изменение разъемов и их ориентации сделано для экономии места на PCB, освободившееся место заняли другие полезные элементы и кожух кулера. К слову, о полезных элементах — GPU питается от четырёх фаз, а от дополнительных двух запитана GDDR5 память. Чего вполне хватает для нетребовательной к питанию GTX 680, и даже оставляет некоторый (но, вероятно, всё же не слишком большой для любителей экстремального разгона) запас для разгона.
Кроме того, что Geforce GTX 680 отличается высокой производительностью и сравнительно низким потреблением энергии, новая видеокарта имеет новую систему охлаждения. Понятно, что менее греющийся чип не требует столь продвинутых кулеров, как топовые решения предыдущих поколений, поэтому система охлаждения у GTX 680 в целом стала тише. Да и в конструкции используется специальный акустический материал, снижающий уровень шума.

В подошву радиатора встроены три тепловые трубки, которые отводят основное тепло от GPU. Которое далее рассеивается двухслотовым алюминиевым радиатором с рёбрами изменённого дизайна, для лучшего его продувания вентилятором. Укороченный (по сравнению с предыдущими решениями) радиатор позволяет добиться более эффективного воздухообмена, а также сэкономить лишнюю пару баксов. Ну а для чего ещё нужны энергоэффективные решения? В том числе и для этого.
В результате, по оценкам компании Nvidia, Geforce GTX 680 тише своего прямого конкурента (понятно, что речь о Radeon HD 7970) на 5 дБ — 46 дБ вместо 52 дБ в одинаковых условиях. Конечно же, это сравнение заинтересованной стороны, а о наших субъективных ощущениях читайте в следующем разделе.
Архитектура и нововведения в Kepler
Анонсированная сегодня модель Geforce GTX 680 основана на первом графическом процессоре компании Nvidia, имеющем новейшую архитектуру Kepler. Основы архитектуры были заложены ещё в вышедшем в 2010 году Fermi (Geforce GTX 480), а некоторые детали даже ещё раньше, но, несмотря на все сходства, в целом Kepler вполне можно назвать полностью переработанной архитектурой, продолжающей тенденции оптимизации эффективного исполнения сложных вычислительных задач, а также имеющей очень быструю обработку геометрии и тесселяции.
Как и в случае с Fermi, новый GPU имеет в своём составе несколько блоков GPC (кластеры графической обработки — Graphics Processing Clusters), которые являются независимыми устройствами в составе видеочипа, способными работать сами как отдельные устройства, так как в их составе есть все необходимые собственные ресурсы: растеризаторы, геометрические движки и текстурные модули. То есть, большинство функционала выполняется внутри блоков GPC. Блок-схема GK104 выглядит так:

Новый GPU имеет четыре блока GPC, как и предыдущий топовый чип GF100/GF110, но в отличие от них, каждый из этих блоков содержит по два потоковых мультипроцессора, отличающихся от того, что мы видели во всех предыдущих чипов Nvidia. Новое решение использует следующее поколение потоковых мультипроцессоров (Streaming Multiprocessor), которые теперь называются SMX, в отличие от SM в предыдущих чипах. Сразу скажем, что название с приставкой буквы «X» — весьма условное, она не означает ничего определённого, кроме указания на то, что эти блоки в Kepler изменились по структуре. Давайте рассмотрим SMX, потому что важнейшие изменения произошли именно в них:
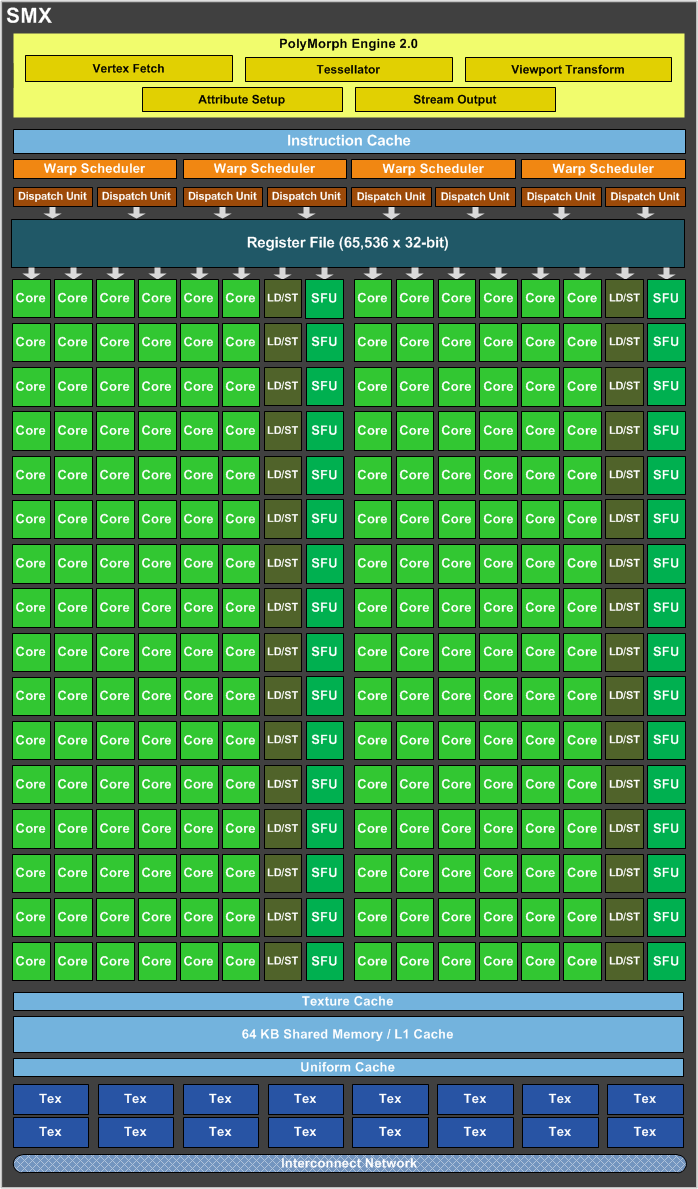
Мультипроцессоры — это основная составная часть GPU компании Nvidia, и именно они претерпели больше всего изменений в Kepler. По сравнению с предыдущими SM, новые SMX обеспечивают более высокую производительность, что видно по количеству функциональных устройств в составе SMX, но при этом потребляют значительно меньше энергии. А уменьшенное количество мультипроцессоров на GPU (8 в отличие от 16 в GF100/GF110) было продиктовано установленными рамками по площади ядра.
Большая часть ключевых блоков GPU включена в состав SMX: потоковые процессоры (CUDA Cores) выполняют все математические операции над пикселями, вершинами и занимаются неграфическими вычислениями, текстурные модули (TMU) фильтруют текстурные данные, загружают и записывают их из/в видеопамять, блоки специальных функций (Special Function Units, SFU) выполняют сложные операции (вычисление синуса, косинуса, квадратного корня и т.п.) и интерполяции графических атрибутов. Ну а движок PolyMorph обеспечивает выборку вершин, занимается тесселяцией, преобразованием в экранные координаты, установкой атрибутов и потоковым выводом (stream output).
Как вы можете видеть на схеме SMX, количество блоков загрузки-сохранения (Load-Store Unit — LSU) в GK104 в расчёте на каждые шесть потоковых блоков снизилось. Блоки LSU используются для передачи данных из/в кэш и разделяемую память, что может негативно сказаться на задачах GPU вычислений. Впрочем, это уменьшение количества LSU не должно значительно повлиять на производительность в графических применениях, но очень похоже, что GK104 всё же немного упростили в смысле оптимальности для GPGPU задач.
К сожалению, мы смогли узнали не все подробности об архитектуре нового чипа Nvidia. Обо всём, что касается CUDA-вычислений, в том числе и поддержке 64-битных вычислений, а может и новых более мощных решениях, будет рассказано на GTC 2012 уже в мае. Так что ждём подробностей от Nvidia, а пока рассматриваем то, что известно и делаем предположения.
Точных данных у нас нет, но скорее всего, темп FP64 вычислений в GK104 даже ниже, чем у предыдущих чипов, так как в SMX организация потоковых процессоров изменилась. В остальном, GK104 по балансу очень похож на предыдущий чип аналогичного класса — GF104, кроме уже указанных изменений и ожидаемо увеличенного количества памяти для регистров и некоторых других модификаций.
На схеме выше видно, что каждый блок SMX содержит 192 потоковых вычислительных ядра, и это в шесть раз больше, чем в SM у Fermi. Поэтому, по сравнению с аналогичными блоками мультипроцессоров в Fermi, SMX обеспечивает значительно большую мощность по обработке пикселей, текстур и геометрии. Даже с учётом того, что предыдущие чипы имели удвоенную частоту работы для потоковых ядер (CUDA cores).
Увеличенная вдвое частота ALU требует и вдвое большее число стадий конвейера, который работает на вдвое большей частоте, потребляя в целом вчетверо больше энергии. И эта увеличенная частота для потоковых процессоров в Fermi привела к вдвое большим затратам энергии, чем они могли бы быть бы при вдвое большем количестве ALU, но работающих на обычной, не удвоенной частоте. Но решение о применении так называемого «hotclock» в Tesla и Fermi было принято исключительно из-за невозможности засунуть требуемое число ALU, работающих на обычной частоте, в определённую площадь чипа.
В Fermi (и ещё раньше, в Tesla) такое решение позволило обеспечить относительно высокую производительность GPU при сравнительно небольшом расходе площади ядра на CUDA cores, что было крайне важным при менее совершенных техпроцессах. Ну а негативным побочным эффектом этого решения было серьёзно завышенное энергопотребление. В Kepler уже не нужно было экономить площадь по понятным причинам, ведь из-за 28 нм технологии чип и так очень маленький — менее 300 мм2, и оказалось эффективнее отказаться от удвоенной тактовой частоты, разместив больше потоковых процессоров на каждый мультипроцессор. Что в результате позволило добиться минимизации накладных расходов, меньшего энергопотребления и лучшей энергоэффективности.
Но это ещё далеко не все изменения. Чтобы «прокормить» данными вычислительные блоки SMX, каждый из них содержит по четыре блока планировщика варпов (warp scheduler), каждый из которых, в свою очередь, обрабатывает по две инструкции за такт на один варп. Интересно, что по сравнению с SM в Fermi, в новой архитектуре SMX уменьшено количество управляющей логики в чипе. Именно уменьшено, а не увеличено! Получается, что Nvidia в Fermi логику усложнила, затем в Kepler упростила, а их конкурент AMD усложнил логику в GCN, по сравнению с предыдущей архитектурой. Поэтому, можно сказать, что последние архитектуры этих компаний сблизились ещё плотнее (мы об этом немного рассказывали в обзоре Radeon HD 7970).
Функциональность блоков управления в Kepler была переработана в угоду большей энергоэффективности. Хотя и Kepler и Fermi содержат схожие аппаратные блоки, занимающиеся управлением загрузкой данных и варпов, управлением потоками команд, но планировщик Fermi также содержит ещё и сложную аппаратную стадию, служащую для предотвращения конфликтов доступа к данным. Специальная таблица регистров (multi-port register scoreboard) отслеживает регистры, данные в которых ещё не готовы, а блок проверки зависимостей (dependency check) анализирует их использование, проверяя зависимости команд.
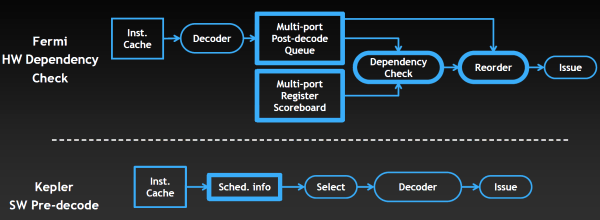
Но раз информация о задержках при доступе известна заранее и они не меняются, то подобный анализ можно провести ещё в компиляторе. И в Kepler часть управляющей логики решили перенести из GPU в компилятор, который частично занимается планированием. Как видно на схеме выше, проверка зависимостей и упорядочивание команд на Fermi осуществляется аппаратно, внутри GPU, а в случае Kepler эти задачи выполняет компилятор. И как тут снова не вспомнить конкурента, у которого в GPU так и было — программные решения вместо аппаратной логики. То есть, снова мы видим подтверждение сближения архитектур AMD и Nvidia.
Конечно, упрощающие начиповую логику нововведения наверняка снизили эффективность обработки потоковых данных в некоторых задачах. Но, что интересно, по данным Nvidia, в большинстве задач она мало отличается от эффективности Fermi. Зато принятое решение позволило убрать сложные и весьма энергоёмкие блоки, заменив их простыми, которые просто берут предопределённые данные о задержках от компилятора и используют их при планировании.
Предполагаем, что для графических применений такой подход вполне имеет смысл, ведь GK104 — это чип, предназначенный скорее для игр, чем для глобальных вычислений на GPU в составе больших серверов. Скорее всего, для GPGPU задач в обозримом будущем выйдет ещё более сложный графический процессор на базе архитектуры Kepler. Возможно, какую-то информацию о нём мы узнаем уже на конференции GTC 2012, которая пройдёт в мае в США.
Для настольных же систем важнее то, что по данным Nvidia, радикально изменённая архитектура мультипроцессоров SMX позволила вдвое улучшить энергоэффективность, по сравнению с решениями на базе архитектуры Fermi. Причём, имеется в виду не первенец Geforce GTX 480, основанный на чипе GF100, а более удачная по этим параметрам модель GTX 580, созданная на основе чипа GF110.
Но изменения в Kepler коснулись далеко не только блоков потоковой обработки и мультипроцессоров SMX. Кроме этого, первый GPU архитектуры Kepler получил совершенно новый интерфейс памяти. Как вы помните, семейства GTX 400 и GTX 500 имели сравнительно широкие шины памяти, но сами микросхемы памяти на них работали на относительно низкой частоте. Полностью переработанная подсистема памяти в GK104 позволила значительно увеличить рабочие частоты GDDR5 видеопамяти, повысив их сразу в полтора раза — до 1500(6000) МГц!
Для использования такой быстрой памяти пришлось внести массу изменений в контроллеры памяти, их логический и физический дизайн. В результате, Geforce GTX 680 на момент выхода имеет быстрейшую видеопамять. Впрочем, желание получить максимально быструю память могло быть вызвано другой характеристикой чипа — шириной шины памяти. Вероятно, исходя из планируемого размера GPU, при его проектировании было решено оснастить чип лишь четырьмя 64-битными каналами памяти. Это вполне привычное решение для чипов Nvidia из среднего ценового диапазона, таких как GF104, но топовые видеокарты компании уже давно имеют более широкую ширину памяти.
Да и объём той же кэш-памяти второго уровня «привязан» к числу контроллеров памяти (по 128 КБ на канал), и поэтому её тут столько же, сколько и у GF1x4 — 512 КБ. Правда, параметры пропускной способности этого L2 кэша в Kepler заметно улучшились, чтобы поддержать увеличенную скорость математических вычислений. Так, полоса пропускания кэш-памяти второго уровня выросла на 73% (из-за возросшей частоты и ширины доступа — 512 байт за такт, вместо 384 байт), а для атомарных операций так и вовсе в несколько раз.
Всё же, мы считаем весьма вероятным то, что GK104 изначально проектировался как видеочип для среднего ценового диапазона, поэтому и был оснащён лишь 256-битной шиной, но потом, когда топовое решение задержалось, а конкурент выпустил не такой уж быстрый GPU, было решено быстренько изменить рыночную стратегию, выпустив mid-end GPU в качестве high-end решения. И по соответствующей цене. В общем-то, смену стратегии нам подтвердили и представители Nvidia, вопрос лишь в том, а не временная ли эта смена, пока не вышло более мощное решение?
Впрочем, в этом разделе мы рассматриваем не вопросы рыночного позиционирования, а архитектуру нового GPU. И ширина шины памяти и сложность/размер чипа — это всегда некий компромисс, на который приходится идти его создателям. Видимо, в случае GK104 поставить больше каналов памяти не позволил размер и/или целевая сложность чипа. Тем более, если изначально планировали и выход более мощного решения.
Некоторые изменения в новом графическом процессоре коснулись и блоков обработки геометрии. Обновленный движок PolyMorph получил версию 2.0, но единственным изменением в нём стала увеличенная вдвое скорость обработки геометрических примитивов. То есть, по сравнению с Fermi, каждый из блоков PolyMorph способен обрабатывать вдвое больше данных за такт. Собственно, это стало необходимым уже только потому, что таких блоков в GK104 стало вдвое меньше, чем в GF100/GF110.

Но из-за значительно возросшей тактовой частоты GPU, задачи тесселяции выполняются на первом из Kepler заметно быстрее и по сравнению с Geforce GTX 580, и до четырёх раз быстрее, чем на быстрейшем решении конкурента — Radeon HD 7970. Это справедливо для синтетических тестов, вроде примера SubD11 из Microsoft DirectX 11 SDK, в котором Nvidia и намеряла четыре раза, а в реальных приложениях скорость не упирается в скорость обработки геометрии.
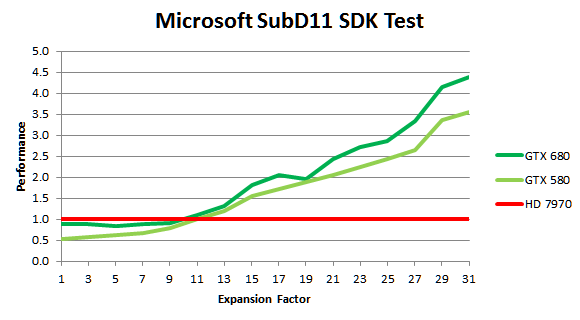
Как видите, даже в геометрической синтетике при малом количестве обрабатываемой геометрии (малых степенях разбиения примитивов) решение AMD оказывается быстрее по тем или иным причинам — в таких случаях скорость упирается в другие блоки. Но уж когда геометрии обрабатывается много, то тут новому GK104 конкурентов быть просто не может — он быстрее не только конкурента, но опережает даже GF110, правда не в разы.
Помимо блоков PolyMorph, отметим изменения в балансе между количеством ROP и движков растеризации — в Kepler их количество равное и обеспечивается 1:1 баланс между растеризацией и работой блоков ROP. У GF100 и GF110 было четыре блока растеризации и шесть ROP, а у GF114 их соотношение и вовсе было 2:4, а у Geforce GTX 680 четыре блока растеризации и четыре же блока ROP.
Nvidia считает, что такая архитектура сбалансированнее и блоки в GK104 будут использоваться эффективнее. Ведь растеризатор вычисляет, какие пиксели для каждого треугольника закрашивать, а ROP непосредственно записывает данные в память, и за одно и то же время они выполняют равное количество работы. И теперь эти блоки не простаивают, так как могут обработать равное количество данных, а для полной загрузки ROP не обязательно нужно использовать блендинг.
По некоторым данным, в Kepler применяется изменённый алгоритм сжатия для передачи данных между памятью и ROP, повышающий эффективность использования имеющейся полосы пропускания. Есть у нас сведения и об ускорении темпа скорости заполнения и блендинга для буферов формата R11G11B10, иногда используемого для экономии ПСП вместо полноценного 16-битного.
Ещё одним изменением, связанным с графической архитектурой Kepler, можно назвать поддержку «bindless» текстур. В предыдущих графических процессорах модели привязки текстур обеспечивают поддержку одновременной работы лишь с 128 текстурами, которым выделялся свой фиксированный слот в таблице привязки. В Kepler же внедрили так называемые «не привязанные» текстуры, и шейдерная программа может обращаться к текстурам напрямую, без использования таблицы привязки.

Это решение увеличивает одновременное количество обрабатываемых текстур в одной шейдерной программе более чем до 1 миллиона. Может быть это покажется не слишком большим изменением, но оно позволит увеличить количество уникальных текстур и материалов в одной сцене (что может использоваться в техниках, аналогичных известной MegaTexture, применяемой в движке id Software, например), а также теоретически поможет снизить загрузку CPU при рендеринге.
К сожалению, у этой возможности пока что нет широкой программной поддержки. Пока что bindless текстурирование можно использовать только в OpenGL, а её добавление в самый популярный графический API DirectX планируется в будущих версиях или при помощи специального интерфейса NVAPI. Будем ждать, сама по себе возможность многообещающая.
Теоретическая оценка производительности Geforce GTX 680
Хотя изменения в Kepler коснулись множества исполнительных блоков, всё же корни архитектуры явно имеют под собой основу в виде Fermi. Основная архитектура чипа почти не изменилась, он всё так же состоит из крупных блоков GPC, содержащих мультипроцессоры SM, имеющих почти всё необходимое для независимой работы. Блоки обработки геометрии такие же, только вдвое быстрее (но их и вдвое меньше), текстурные модули и ROP остались почти без изменений, разве что количество первых увеличилось вдвое.
Наверное, это и правильно — зачем что-то менять, когда оно и так работает хорошо? Да и новых версий графических API не появилось, не считать же большим обновлением DirectX 11.1, некоторые из возможностей которого, кстати, Kepler поддерживает, но скорее всего не все. Нужно было просто улучшить все блоки, подтянув имеющиеся слабые места, укрепив сильные. С чем, похоже, в Nvidia отлично справились. Тем интереснее сравнить теоретические показатели нового решения Nvidia с предыдущим топовым Geforce GTX 580 и Radeon HD 7970 от их конкурента — какие у GTX 680 есть слабости?
| Видеокарта | Radeon HD 7970 | Geforce GTX 580 | Geforce GTX 680 |
|---|---|---|---|
| Графический процессор | Tahiti XT | Fermi (GF110) | Kepler (GK104) |
| Сложность чипа, млрд.транз. | 4,3 | 3,0 | 3,5 |
| Потоковых ядер, шт | 2048 | 512 | 1536 |
| Текстурных модулей (TMU), шт | 128 | 64 | 128 |
| Блоков ROP, шт | 32 | 48 | 32 |
| Шина памяти, бит | 384 | 384 | 256 |
| Частота GPU, МГц | 925 | 772/1544 | 1006(1058) |
| Частота видеопамяти, МГц | 5500 | 4000 | 6000 |
| Пропускная способность, ГБ/с | 264 | 192 | 192 |
| Производительность ALU, терафлопс | 3.79 | 1.58 | 3.09 |
| Скорость заполнения, ГП/с | 29,6 | 37,1 | 32,2 |
| Скорость выборки текстур, ГТ/с | 118,4 | 49,4 | 128,8 |
| Макс. энергопотребление | 250 | 244 | 195 |
Похоже, в Nvidia решили убрать многие недостатки своего предыдущего решения, серьёзно увеличив математическую и текстурную производительность, но оставив при этом производительность блоков ROP и ПСП примерно той же, что и у Geforce GTX 580. Увеличив вдвое количество блоков текстурирования и втрое — математических (правда, тут надо помнить об удвоенной частоте ALU в Fermi), инженеры компании этим самым оставили хорошую заявку на высочайшую производительность.
Сначала о том, что у Geforce GTX 680 отлично или очень хорошо. Во-первых, текстурирование. По этому параметру (по крайней мере, в теории) они превзошли даже быстрейшую видеокарту AMD, а их решения всегда отличались большим количеством блоков выборки и фильтрации текстур. Но особенно мощно достижение выглядит на фоне GTX 580 — текстурирование ускорилось в 2,6 раза и оно точно не будет ограничивающим производительность фактором!
Второй параметр, на который мы обращаем особое внимание — вычислительные возможности. Хотя лучшая видеокарта AMD всё ещё быстрее решения Nvidia, но разрыв значительно сократился, 22% — это уже не несколько раз в предыдущих поколениях. Тем более, что чип имеет примерно на столько же меньше транзисторов. Сравнение с GF110 и вовсе опустим, по причине слишком лёгкой победы нового решения по этой пиковой теоретической характеристике.
Рассмотрим скорость заполнения (филлрейт), которая до сих пор зачастую является одним из ограничителей производительности в играх, особенно старых. Если сравнивать Geforce GTX 680 с конкурентом, то тут наблюдаем небольшой выигрыш, а если с предшествующей моделью — то не слишком большой проигрыш. Но почему в Nvidia не увеличили количество блоков ROP? Во-первых, потому, что они «привязаны» к контроллерам памяти, которых в GK104 лишь четыре. Во-вторых, инженеры Nvidia увеличили эффективность использования ресурсов ROP (см. выше), поэтому этой скорости должно быть достаточно.
Итак, переходим к самой неоднозначной характеристике нового решения — ширине шины памяти, её частоте и, соответственно, пропускной способности. С частотой памяти всё хорошо, мы писали выше, а вот её ПСП может быть главным ограничителем производительности для Geforce GTX 680! Это отлично видно из сравнения теоретических показателей в табличке. И пусть своей предшественнице новая модель не проигрывает (но она имеет значительно меньшую производительность и не упирается в ПСП), но конкурент впереди по одному из важнейших показателей аж на 37.5%!
Мы уж не повторяемся, что из-за 256-битной шины на карту установлено лишь 2 ГБ памяти, чего может не хватать в высоких разрешениях и степенях полноэкранного сглаживания, ради которых и покупаются топовые видеоплаты. В общем, если где-то в играх будут отставания от Radeon HD 7970, то можете быть уверены почти на 100%, что дело либо в объёме памяти, либо в её пропускной способности. В случае отсутствия явных багов в драйверах, конечно.
Несмотря на эти недостатки, многочисленные положительные улучшения в GPU не могли не сказаться и на практической производительности новой видеокарты компании Nvidia — и на день своего выхода, она скорее всего станет быстрейшим одночиповым решением на рынке. По оценке специалистов самой компании, Geforce GTX 680 быстрее своего главного конкурента — Radeon HD 7970 — на величину от 15 до 30%, в зависимости от приложения. Конечно же, в реальности цифры должны быть несколько ниже, но они наверняка положительные.
Мы обязательно проверим цифры в дальнейших разделах статьи, а тут ещё раз отметим, что GTX 680 совершенно точно является наименее требовательным к электропитанию, то есть — весьма и весьма энергоэффективным. В то время как конкурирующее решение схожей производительности имеет набор из одного 8-контактного и одного 6-контактного разъёмов дополнительного питания, что стало фактическим стандартом для высокопроизводительных видеокарт, Geforce GTX 680 имеет лишь два 6-контактных разъёма и установленное максимальное энергопотребление в 195 Вт, что явно ниже максимальных 250 Вт у конкурента.
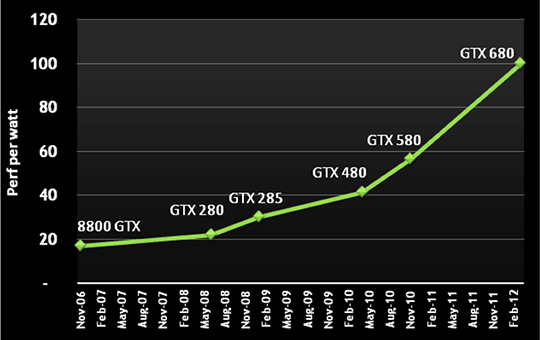
Впрочем, эти данные также ещё нужно проверять на практике, так как установленные значения TDP не всегда совпадают с реальными. В любом случае, Geforce GTX 680 имеет лишь два 6-контактных разъёма питания и в принципе обязана потреблять меньше энергии. А если новая модель ещё и производительнее конкурента, то естественно и энергоэффективнее. Очень любопытно сравнение всех решений Nvidia по этому показателю (производительность измерялась в 3DMark Vantage):
GPU Boost
Одной из наиболее интересных особенностей первенца архитектуры Kepler является технология GPU Boost. Уже по названию понятно, что она неким образом должна ускорять производительность. Это комбинированная программно-аппаратная технология, появившаяся в Geforce GTX 680, которая динамически изменяет частоту GPU, исходя из условий его работы и некоторых характеристик.

Специализированный аппаратный блок в чипе постоянно отслеживает потребление энергии видеокартой и некоторые другие параметры, такие как температура, и автоматически изменяет частоту графического процессора, повышая её для получения максимально возможной производительности в пределах установленного пакета теплопотребления.
Но каким образом принимается решение о повышении частоты? Не секрет, что в большинстве игровых приложений GPU работают с потреблением энергии, далёким от максимально возможного для видеоплаты. Так, Geforce GTX 680 на базовой частоте в 1 ГГц в играх потребляет в среднем лишь около 170 Вт, хотя в принципе может использовать 195 Вт и даже больше. То есть, никто не мешает поднять частоту и напряжение GPU и повысить производительность, при этом, не выйдя за рамки TDP. Что, собственно, уже давно делают и на CPU и GPU.
Отличие GPU Boost от предыдущих, значительно менее продвинутых методов ограничения теплопотребления от компании Nvidia, в том, что новая технология основана на работе преимущественно аппаратного блока и работает независимо от программных профилей в драйвере и не требует никаких действий от пользователя, обеспечивая «бесплатный» прирост производительности. При этом на изменение частоты уходит лишь 100 мс, т.е. оно почти мгновенное с точки зрения человека.
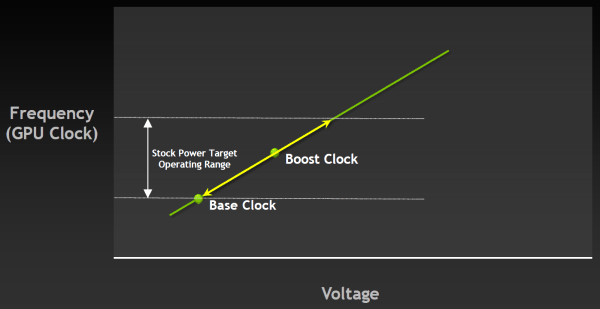
И теперь в спецификациях GPU производства Nvidia будет как базовая частота (base clock), так и турбо-частота (boost clock). Для Geforce GTX 680 базовая частота равна 1006 МГц, и это — гарантированная частота работы во всех 3D приложениях, даже нетипичных — тех, которые максимально загружают работой GPU. А турбо-частота — это средняя частота, которая достигается в типичных приложениях, требующих меньшего энергопотребления. Мы не зря выделили слово «средняя», так как в реальности частота скачет не только от приложения к приложению, но и запросто может изменяться в пределах одной игры, в зависимости от нагрузки на видеоплату.
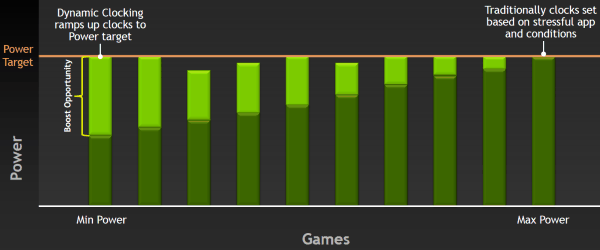
И в среднем, турбо-частота в играх составляет как раз около 1058 МГц, что даёт прирост скорости порядка 5%. Можно подумать, что игра не стоит свеч, ибо прирост в среднем небольшой. Но в некоторых играх есть ещё больший запас по потреблению, и турбо-частота Geforce GTX 680 вырастает и до 1100 МГц. GPU Boost повышает частоту, пока не достигается выбранный предел потребления, и для многих игр частота будет близка именно к верхнему пределу. Понятно, что вместе с частотой растёт и напряжение, подаваемое на GPU, причём оно изменяется плавно, как и рабочая частота.
Например, 3DMark 11 является весьма требовательным к мощности GPU приложением, при работе в котором Geforce GTX 680 часто упирается в предел TDP даже при базовой частоте в 1 ГГц. Но потребление GK104 в реальных играх ниже, к примеру, в игре Crysis 2 чип способен работать на частоте в 1.05 ГГц, а в Battlefield 3 так и вовсе на 1.1 ГГц. Почему бы не воспользоваться этим «бесплатным» ускорением, решили в Nvidia.
В отличие от аналогичной технологии компании-конкурента на графическом рынке, GPU Boost может не только снижать частоту при превышении TDP, но и увеличивать её — для этого и задана boost clock. Хотя, надо сказать, что в целом все подобные технологии схожи и отличие между разными реализациями весьма небольшое. Главное — что теперь у Nvidia тоже есть весьма продвинутая технология по управлению частотами в зависимости от потребления, и она реально работает.
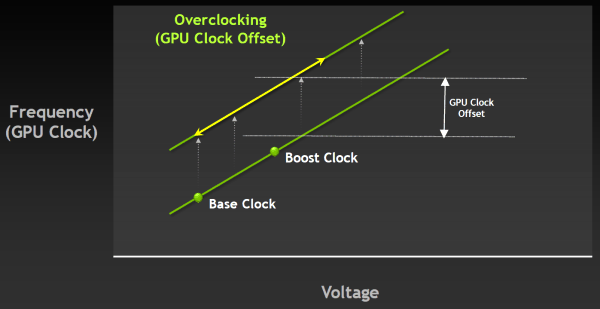
Кстати, сама по себе технология не мешает дальнейшему разгону, а работает вместе с ним. При разгоне меняется только базовая частота, а турбо-частота выбирается самим GPU в зависимости от достижения установленного уровня TDP. Который, кстати, теперь также можно регулировать, в том числе из утилит вроде EVGA Precision, использующих NVAPI. Правда, из-за более «умного» мониторинга и постоянного изменения частоты GPU под нагрузкой, подход к экстремальному разгону придётся менять в каких-то деталях, привыкая к новому принципу работы. Зато массовому пользователю подход Nvidia с турбо-частотой будет вполне удобен.
Правда, к сожалению, динамическое изменение частоты GPU Boost нельзя ни отключить, ни отрегулировать разность между частотами. То есть, при разгоне изменяется только базовая частота, а прирост от GPU Boost будет постоянным. Было бы значительно удобнее, если бы можно было бы изменять верхний предел или среднюю турбо-частоту, а то и вовсе отключать технологию. Особенно это было бы удобно для нас, тестеров.
Полноэкранное сглаживание методами FXAA и TXAA
Очень интересно наблюдать за развитием полноэкранного сглаживания на протяжении нескольких лет. На смену суперсэмплингу (SSAA), который первым появился в игровых видеокартах и является наиболее качественным, но весьма требовательным к ресурсам, пришёл мультисэмплинг (MSAA), более быстрый метод, но имеющий свои недостатки в плане качества. А теперь и его потихоньку вытесняют более современные методы сглаживания, основанные на постобработке отрендеренного кадра.
Один из таких методов сглаживания — FXAA, он известен уже какое-то время и появился в нескольких современных играх. Этот алгоритм использует мощность потоковых процессоров при постфильтрации и производится совместно с другими фильтрами, вроде размытия в движении (motion blur), bloom и другими аналогичными.
Использование методов вроде FXAA и схожего метода от конкурента — MLAA, особенно актуально для игровых движков, использующих отложенное затенение (deferred shading), так как они снижают требования к объёму видеопамяти и менее затратны по вычислительной мощности, по сравнению с более привычным для нас мультисэмплингом (MSAA). Кроме того, применение MSAA сглаживания при HDR рендеринге может приводить к появлению видимых артефактов, когда разность между значениями яркостей соседних участков изображения слишком велика. Так как FXAA выполняется в конце процесса рендеринга, уже в виде постфильтра, то он лишён многих проблем.
Метод FXAA также менее требователен, по сравнению с MSAA — по оценке компании Nvidia примерно на 60%. Новый вид сглаживания впервые появился в 2011 году в игре Age of Conan и затем использовался в 15 проектах. А теперь, начиная с видеодрайверов Nvidia версии 300, метод сглаживания FXAA можно будет форсировать из панели управления драйвера для сотен игровых приложений.
В качестве демонстрации эффективности FXAA по сравнению с MSAA, Nvidia совместно с Epic показала на Kepler Editor's Day (и на выставке игровых разработчиков GDC 2012, которая проходила рядом в то же время) уже известную демонстрационную программу Samaritan, показывающую как может выглядеть игра с поддержкой возможностей DirectX 11. Эта демо-программа использует тесселяцию и карты смещения (displacement mapping), подповерхностное рассеивание (subsurface scattering), эффект имитации глубины резкости (depth of field), динамические отражения, тени и многие другие эффекты, и она очень сложна с точки зрения вычислительной мощи GPU.
Так вот, в отличие от GDC 2011, когда впервые показанное демо Samaritan использовало MSAA и было запущено на системе из трёх Geforce GTX 580, работающих в SLI связке, в этом году Epic показывала демку на системе с одной видеокартой Geforce GTX 680. Естественно, это не говорит о том, что новинка такая же по мощности, как три GTX 580. Есть сразу несколько объяснений этому: а) SLI не обеспечивает 100% эффективности, особенно на системе из трёх GPU; б) вместо MSAA в 2012 году использовался менее затратный метод FXAA; в) GTX 680 — это действительно очень мощная видеокарта!
Вы спросите, а что там с качеством? Наверняка же оно было хуже при FXAA и на одной GTX 680. Да, скорее всего, оно было хуже. Вот только настолько ли хуже стало итоговое качество, насколько MSAA требовательнее к GPU? В этом как раз основная польза метода FXAA — оно обеспечивает значительно лучшую скорость при примерно таком же качестве сглаживания, что и у MSAA. Вы можете оценить разницу на скриншотах:

И то же самое, но в статическом полноразмерном виде:



Важно понимать, что есть разница между несколькими типами FXAA, включаемыми в играх и из панели драйвера Nvidia. Первоначальная версия FXAA (FXAA 1), внедрённая в такие игры, как Age of Conan, F.E.A.R. 3 и Duke Nukem Forever, обеспечивает высокое качество ценой несколько большего падения производительности. А более новый метод FXAA, вроде FXAA 3 в Battlefield 3, обеспечивает оптимальный компромисс между качеством и падением производительности, и для него можно регулировать качество, производительность и резкость, что и делается создателями игр на стадии разработки.
Включаемая из панели настроек драйвера версия FXAA — это нечто среднее между методами FXAA 1 и FXAA 3 с некоторыми изменениями, которые улучшают восприятие таких элементов, как сглаженный текст. По сравнению с FXAA 3, внедрённым в игры, «драйверный» метод сглаживания обеспечивает лучшее качество на всём, кроме текста и других элементов интерфейса, так как постфильтр в этом случае применяется уже к картинке целиком, когда она полностью готова, а игровые разработчики обычно накладывают текстовые элементы уже после всей постфильтрации. Ну и по понятной причине этот метод несколько медленнее внедрённого в игры FXAA 3.
Но одним FXAA дело не заканчивается. Как известно, нет предела совершенству. Не то, чтобы FXAA был к нему близок, ведь совершеннее всего по качеству сглаживания примитивный суперсэмплинг (SSAA), но он и самый требовательный — слишком требовательный. Чтобы улучшить качество сглаживания, почти не повысив ресурсоёмкость, в Nvidia был разработан ещё один метод — TXAA. Кстати, на мероприятии для прессы об этом методе рассказывал русскоязычный сотрудник компании Юрий Уральский.
Основная цель TXAA в том, чтобы добиться качества сглаживания, максимально близкого к тому, что делается в пререндеренной графике (полнометражные мультфильмы и эффекты в кино). Так вот, TXAA — это ещё один метод сглаживания, разработанный сотрудниками компании, который становится весьма актуальным, в том числе из-за высокой текстурной производительности Kepler. TXAA также использует постобработку, но не только её, ведь в том и отличие, что это — гибридный метод, которые включает как использование аппаратных MSAA мультисэмплов, так и специальный качественный сглаживающий постфильтр и даже опциональную временную (temporal) компоненту.

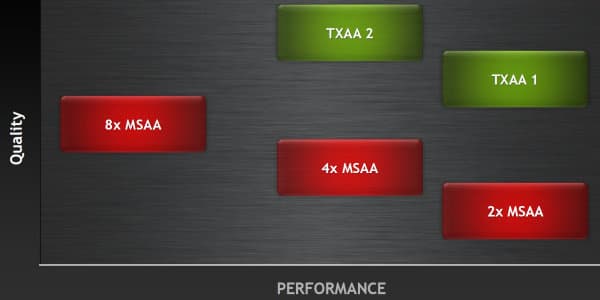
Метод сглаживания TXAA доступен в двух режимах: TXAA 1 и TXAA 2. Первый режим предлагает качество сглаживания, аналогичное методу 8x MSAA, но с производительностью, идентичной 2x MSAA, а второй обеспечивает ещё лучшее качество, но с производительностью, примерно соответствующей 4x MSAA. Соответственно, они используют 2 или 4 аппаратных мультисэмпла. Мы обязательно исследуем все эти методы в отдельном материале, сравнив их в том числе и с тем, что предлагает конкурент — компания AMD.
Временная (temporal) компонента в данном случае позволяет увеличить качество сглаживания за счёт небольших смещений субпикселей каждый кадр (так называемый jitter). Такой метод уже применялся ранее компанией ATI — в этом случае расположение субсэмплов внутри пикселя не является фиксированным и меняется каждый кадр. И так как устройства вывода и человеческое зрение инерционны, то человеческий мозг просто не успевает увидеть каждый кадр отдельно и объединяет информацию из соседних. И если при рендеринге каждого кадра немного изменять положение субпикселей, то субъективное восприятие качества сглаживания будет лучше — как будто субпикселей больше, чем их есть на самом деле.
Будет проще понять, если пояснить на примере. Допустим, если использовать 2х сглаживание, но в чётных и нечётных кадрах использовать два сэмпла на разных позициях (по диагонали: то слева-снизу и справа-сверху, то слева-сверху и справа-снизу), то при достаточно высокой частоте кадров человеческий глаз увидит, а мозг усреднит эти кадры и получится как будто 4х сглаживание с четырьмя субпикселями, а не двумя. Конечно, если число субпикселей слишком мало, то это будет заметно на глаз, но в случае TXAA всё должно быть хорошо.
Как и метод сглаживания FXAA, новый алгоритм будет внедряться в выходящие игровые приложения, начиная уже с этого года — для этого все заинтересованные игровые разработчики, среди которых мы можем отметить Crytek, Epic, Bitsquid и многих других, уже получили исходный код, так что мы надеемся, что появление TXAA не заставит себя ждать. Отдельной радостной новостью для владельцев видеокарт Nvidia на основе архитектуры Fermi будет то, что TXAA будет работать в том числе и на их системах. А вот форсировать TXAA в драйвере не удастся, придётся ждать появления игр с его поддержкой.
Вопросы субъективной оценки качества сглаживания у таких методов вроде: «Да оно же всё замыливает!» мы пока что оставим в стороне, до подробного исследования качества сглаживания на видеокартах Nvidia и AMD. А пока же поясним, что полностью убрать алиасинг полностью без некоторого снижения чёткости физически невозможно. Тем более тот, который видно только в динамике. На статических скриншотах всё может быть прекрасно, но в движении проявится алиасинг. И как раз TXAA отлично справляется в таких случаях и призван приблизить качество сглаженной картинки к тому, что мы видим в кино.
Адаптивная вертикальная синхронизация (Adaptive VSync)
Это — ещё одна программная технология, поддержка которой появилась в новейших драйверах компании Nvidia. Пусть она и не относится напрямую к Geforce GTX 680, но совершенно точно направлена на улучшение комфортности при игре на видеокартах компании.

Напомним, что вертикальная синхронизация (VSync) придумана и используется для того, чтобы минимизировать артефакты изображения в виде разрывов кадра (tearing), заметные тогда, когда FPS в игре вырастает выше частоты обновления монитора. Такие артефакты видны и в случае, когда FPS ниже, но заметнее они именно при очень высоком FPS. На следующем графике указан момент, когда возникают разрывы изображения:
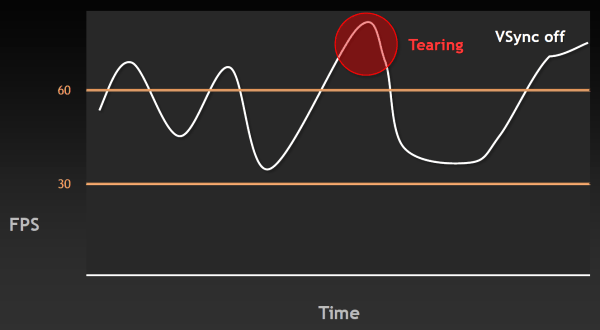
Естественно, такие вещи раздражают пользователя — казалось бы, частота кадров у системы высокая, а плавности нет. Поэтому была придумана вертикальная синхронизация, ограничивающая FPS сверху, привязывая её к частоте обновления монитора. Но при включении этой синхронизации появляется другая известная проблема — рывки или скачки в частоте кадров (stutter). Они случаются, когда частота кадров падает ниже 60 FPS, вызывая резкое двукратное падение частоты кадров до 30 Гц и ниже (20 Гц, 15 Гц) в случае включенной синхронизации. Естественно, это также не улучшает восприятия видеоряда в играх.
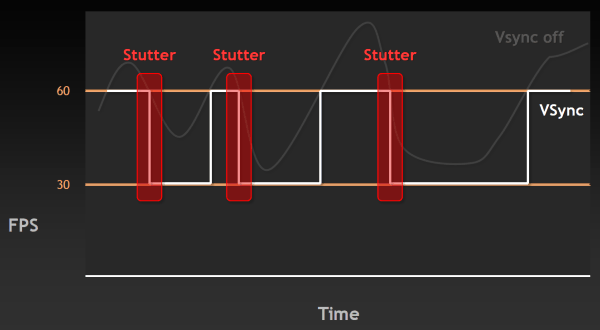
Чтобы решить обе эти проблемы и приблизиться к идеальной плавности в частоте кадров, инженеры Nvidia сделали в драйверах то, что давно делается на игровых консолях — изменили работу алгоритма вертикальной синхронизации так, чтобы избавиться от разрывов кадра и одновременно минимизировать скачки FPS. Разработанную технологию назвали адаптивной вертикальной синхронизацией (Adaptive VSync), она динамически включает и выключает VSync так, чтобы приблизиться к идеальной плавности и постоянной частоте смены кадров. Проще всего это продемонстрировать на графиках — лучше один раз увидеть, чем сто раз прочитать.
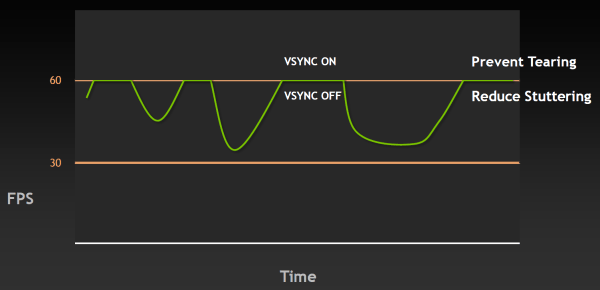
При частоте кадров выше 60 FPS в случае адаптивной синхронизации будет работать обычный VSync, но когда FPS падает ниже отметки 60 (или другого значения частоты обновления экрана), то адаптивная вертикальная синхронизация временно отключает VSync, позволяя частоте кадров достигнуть своего обычного значения, не «придушенного» синхронизацией до половины частоты обновления. А уже после того, как FPS возвращается к отметке выше 60, VSync снова автоматически включается, чтобы не появились разрывы в изображении.
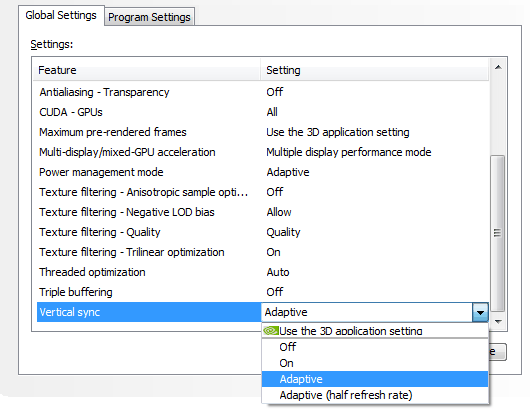
Таким образом, эта технология значительно увеличивает плавность вывода движущейся картинки на экран, приближая её к плавности консольных игр. Начиная с версии 300, в видеодрайверах Nvidia появилась поддержка этой технологии. Она включается из панели настроек драйвера, причём можно включить синхронизацию и на половинной частоте обновления экрана, что также может быть полезно в случаях, когда производительность в игре скорее ближе к 30 FPS, чем к 60 FPS (ведь обычный VSync в таких случаях просто не будет работать):
К слову, у Nvidia есть и ещё одна программная возможность — ограничение количества FPS сверху так, чтобы частота GPU динамически снижалась в случае избытка производительности. Например, вы играете в старую игру, в которой с лёгкостью получаете 200-300 FPS. Зачем вам столько, если их всё равно не видно? И зачем гонять видеочип на частоте в 1 ГГц, если игре более чем достаточно и половины от этого значения?

К сожалению, эта возможность (пока?) недоступна из драйверов, но есть в NVAPI. И при помощи утилиты EVGA Precision 3.0 (а в дальнейшем эта настройка появится и в панели управления видеодрайвера) в играх, использующих DirectX или OpenGL, вы можете ограничить потолок FPS, к примеру, на уровне 60 кадров в секунду и получить при этом идеальную плавность и достаточно высокую производительность, да ещё и сниженную частоту GPU и меньшее напряжение, а значит и потребление энергии. Все они будут ровно такими, которые потребуются для достижения 60 FPS в игре.
Возможно, эти программные технологии не так эффектны, как некоторые аппаратные усовершенствования, появившиеся в Kepler, но нам кажется, что вместе с Adaptive VSync это очень интересные программные возможности, значительно улучшающие комфортность игры и энергоэффективность системы. И для некоторых пользователей эти технологии могут оказаться даже более важными, чем некоторые из аппаратных изменений.
Технология Nvidia PhysX и новые игры
Собственно, ничего нового в поддержке технологии ускорения физических эффектов на GPU, в Kepler не появилось. Все его возможности остались теми же, а архитектурные изменения по сравнению с Fermi влияют на производительность. Но из-за значительно увеличенной мощности нового графического процессора, вполне логично, что у него останется больше ресурсов на неграфические вычисления, такие как физические спецэффекты.
Поэтому в будущих играх с поддержкой GPU PhysX мы вправе ожидать настроек и профилей, предназначенных для таких мощных решений, как Geforce GTX 680, более требовательных к вычислительным возможностям. Игр с поддержкой GPU PhysX выходит не так много, но на мероприятии Nvidia для прессы, посвящённом анонсу Geforce GTX 680 (Kepler Editor's Day), Рэнди Питчфорд, основатель и президент компании Gearbox, показал игру Borderlands 2, работавшую на новой видеокарте семейства Kepler.

Эта игра, по крайней мере в своей ПК версии, будет использовать технологию PhysX (в т.ч. и аппаратное ускорение физических эффектов на GPU), для имитации тканей и жидкости, а также сложных эффектов частиц. К сожалению, видеозапись и фотографирование показанного игрового процесса были запрещены, поэтому вы можете поверить нам на слово — выглядит игра очень неплохо.
Но не только FPS и RPG с видом от первого лица используют возможности PhysX. На том же мероприятии была показана широко известная в узких азиатских кругах игра под названием QQ Dance 2. Не смейтесь, это — очень популярная многопользовательская «танцевальная» (что бы это ни значило) игра для ПК. Первая часть игры входит в тройку наиболее продаваемых игр в Китае (видимо, в основном потому, что НЕ многопользовательские игры там НЕ покупаются, а просто скачиваются), и в неё одновременно играют до двух миллионов китайцев (вы только представьте себе ЭТО!), а зарегистрированы 100 млн. учётных записей.

Так вот, вторая часть игры создаётся компанией-разработчиком H3D, она основана на собственном игровом движке, который использует возможности всего лишь DirectX 9, зато в нём применяется PhysX для имитации тканей и других объектов, вроде физически корректного поведения трясущихся волос и украшений (правда, в показанной демке используется не так уж много физически взаимодействующих вершин — до 50000 штук). Игра выйдет в открытое бета-тестирование в конце текущего года. Для китайцев, естественно. А нам остаётся лишь обиженно облизываться, кусать локти и ждать гораздо менее интересных игр с поддержкой GPU PhysX в 2012 году.
Кроме игр, Nvidia показывала и пару демонстрационных программ, в которых применяются некоторые из новых физических эффектов: Fur и Fracture. Пока что эти возможности не входят в состав PhysX SDK, но зато это — будущее физических эффектов, рассчитываемых на графических процессорах.
Первая демонстрационная программа под названием Fracture показывает реалистичные разрушения объектов в реальном времени. То есть, не по заранее предусмотренным линиям и кускам, как это делается сейчас, а совершенно произвольно. Сейчас разрушаемые объекты заранее создаются по кускам, и разрушаются именно так, как это задумано создателями игры на стадии разработки.
В новой же демке Nvidia показана возможность расчёта разрушений в реальном времени, когда у объектов нет заранее смоделированных кусков и их можно разбить на сколько угодно кусков в произвольных местах. В программе используется GPU-ускорение физики твёрдых тел (rigid bodies), и даже на видеокартах предыдущего поколения обеспечивается приемлемая частота кадров порядка 40-50 FPS.
В дополнение к новой реалистичной системе разрушений, была показана система симуляции шерсти и волос. Вторая демонстрационная программа носит такое же говорящее название — Fur, и в ней забавный «шерстяной» персонаж составлен из 840 тысяч частиц, физически имитирующих примерно 100 тысяч отдельных волосков шерсти. В демке используется совершенно новый алгоритм и все расчеты полностью производятся на GPU.
Также, на мероприятии Nvidia для прессы, представитель Rockstar Games Саймон Рэмси (Simon Ramsey), показал довольно длинный ролик с игровыми сценами из долгожданной многими игры Max Payne 3. Игра выглядит очень неплохо, и в ней явно видно влияние предыдущих версий, так полюбившихся игрокам.


К сожалению, видеозапись и во время этой демонстрации также была запрещена и мы можем показать лишь пару выданных скриншотов. Правда, не очень понятно, каким образом игра Max Payne 3 относится к Nvidia, кроме понятных сотрудничества в плане помощи в разработке. Вроде бы, никаких особых технологий компании (CUDA, PhysX) в игре не поддерживается...
Аппаратное кодирование видео — NVENC
Nvidia не могла пройти мимо современных тенденций на рынке GPU и CPU, связанных с включением в производимые чипы специализированных блоков для аппаратного кодирования видеоданных. Аналогично последним продуктам конкурентов, производящих CPU и GPU, все видеочипы архитектуры Kepler получат аппаратный блок кодирования видео в формате H.264 — NVENC.
Вы, конечно же, помните, как все предыдущие годы нам долго и упорно рассказывали об ускорении видеокодирования на GPU, но это дело толком так и не пошло. По разным причинам, тут и сложности переноса эффективного кода на GPU и недостатки в качестве картинки закодированного таким образом видео, а главное, что энергопотребление топовых чипов при такой загрузке отнюдь не низкое и ресурсы тратятся расточительно. В общем, если раньше ПО для кодирования видео на GPU использовало потоковые процессоры видеочипов, то теперь этим делом будет заниматься выделенный аппаратный блок.
Кодировщик видеоданных NVENC почти вчетверо быстрее предыдущих методов, основанных на использовании CUDA, и это — при гораздо меньшем потреблении энергии (буквально менее 10 Вт). Вот что значит специализированное «железо», в отличие от универсального! Стоило ли городить огород с CUDA-кодированием — большой вопрос. Но зато теперь пользовательские приложения могут использовать возможности NVENC и CUDA-кодирования параллельно, если это кому понадобится.
Блок NVENC, имеющийся в Geforce GTX 680, способен кодировать видео в полном FullHD (1920x1080 пикселей) разрешении со скоростью в 4-8 раз быстрее реального времени. То есть, в высокопроизводительном режиме 16-минутное видео в формате 1080p при 30 FPS закодируется за две минуты. Аппаратным кодировщиком Nvidia поддерживаются разрешения вплоть до 4096x4096 и следующие версии формата H.264: Base, Main и High Profile Level 4.1 (стандарт Blu-ray), в том числе и многоканальное кодирование MVC (Multiview Video Coding) для стереоскопического видео.
Кроме задач перекодирования видео, NVENC будет полезен и в других близких задачах, вроде программ видеомонтажа, беспроводной передачи изображения и при проведении видеоконференций. Прямо со дня анонса Geforce GTX 680, блок аппаратного видеокодирования будет поддерживаться в Cyberlink MediaEspresso, а в ближайшем будущем ожидается поддержка в Cyberlink PowerDirector, Arcsoft MediaConverter и других программах.
А для разработчиков Nvidia выпустила специальный SDK, в котором раскрываются возможности API для видеокодирования при помощи NVENC. Вскоре CUDA-программисты получат возможность и одновременного использования NVENC и CUDA в своём ПО, что может быть очень полезно в задачах обработки и монтажа видео. К примеру, видеоданные будут обрабатываться на потоковых ядрах, и затем посылаться на кодирование в NVENC, и всё это будет работать одновременно и без лишних пересылок данных туда-сюда.
Расширенная поддержка многомониторного вывода
Довольно длительное время у Nvidia не было ответа на конкурирующую технологию (а по сути — просто одну из технических характеристик) AMD Eyefinity, которая позволяет выводить изображение более чем на два монитора. И вот теперь, начиная с Geforce GTX 680, аналогичное решение поддерживается и видеокартами Nvidia. Новая плата поддерживает до четырёх устройств вывода одновременно, в отличие от двух в предыдущих моделях.

Причём, новая видеокарта в одиночку способна выводить стереоизображение на три монитора одновременно, что называется 3D Vision Surround и ранее было доступно лишь на двухчиповых системах, и даже использовать четвёртый монитор для вывода какой-то другой информации, вроде окна с браузером, электронной почтой или Skype. Для подключения самых современных устройств вывода изображения, обновленный движок вывода в GK104 поддерживает DisplayPort 1.2, HDMI 1.4a, мониторы высокого разрешения (3840x2160, так называемые «4K») и многопоточный вывод звука, для чего имеет все необходимые разъёмы:

Было сделано и несколько чисто программных изменений: теперь панель задач Windows можно расположить на центральном мониторе, разворачивать окно лишь на текущий монитор, задавать собственные разрешения экрана, а также использовать «горячие клавиши» для управления корректировкой экранных рамок — ведь этот функционал может мешать в некоторых играх, закрывая важные элементы интерфейса.
Кстати, по поводу поддержки нескольких мониторов одновременно. Многие из наших читателей знают, что подключение второго монитора с другими характеристиками (разрешение, частота обновления) на видеокартах семейства Fermi вызывало одновременный переход GPU в режим большего энергопотребления, по сравнению со стандартным режимом простоя при подключении одного устройства вывода. Так вот, в Kepler эта досадная оплошность была устранена и теперь GPU всегда работает в стандартном режиме питания при скольки угодно подключенных мониторах (речь о 2D режиме, естественно).
Теоретические выводы
Очевидно, что первенец семейства Kepler получился весьма интересным. Он основан не просто на улучшенной предыдущей архитектуре, но с совершенно иным подходом — со ставкой на энергоэффективность и другим балансом между ориентацией на графические и универсальные вычисления. В целом, новый GPU верхнего ценового диапазона весьма отличается от предшествующих решений сразу по многим параметрам: увеличено количество большинства исполнительных блоков, особенно математических и текстурных, значительно повышена рабочая частота чипа, внесены некоторые архитектурные изменения. Но главное в том, что энергопотребление (а соответственно и тепловыделение) при этом значительно снижено.
В графическом процессоре новой архитектуры остались все преимущества Fermi, но почти все даже потенциально слабые места были доработаны. Nvidia сделала всё, чтобы повысить производительность своего нового GPU. Так, по сравнению с предыдущим топовым решением в виде Geforce GTX 580, нынешняя видеокарта имеет втрое больше вычислительных ядер! Значительно увеличилась не только математическая мощь, но и производительность обработки геометрии и скорость текстурных выборок, что давно было одним из слабых мест видеокарт Nvidia.
Из потенциальных слабостей новой модели Geforce GTX 680 мы можем отметить возможный недостаток видеопамяти для экстремальных условий и сверхвысоких разрешений, а также — не увеличившуюся со времён GTX 580 пропускную способность памяти и меньшую скорость заполнения. К сожалению, эти параметры вполне могут стать главными ограничителями производительности новинки и в синтетических тестах и в играх, и если проигрыши где-то будут, то во многом из-за этого.
Но не только производительность важна в новой видеокарте. Ведь зачем нужны пользователю 100-150 FPS, которые нередки для мультиплатформенных игр на топовых решениях? А вот качество и комфортность всегда есть куда улучшить, пусть даже и экстенсивными способами, вроде усовершенствования полноэкранного сглаживания. И вместе с выходом нового решения Nvidia внедряет новый метод антиалиасинга TXAA, который в будущих играх должен обеспечить высокое качество при небольшом падении производительности.
Кроме этого, вместе с выходом Geforce GTX 680 у Nvidia появились программные и аппаратные технологии, такие как специализированный блок кодирования видеоданных NVENC и адаптивная синхронизация Adaptive VSync, которая улучшает комфортность и плавность рендеринга, динамически включая и выключая вертикальную синхронизацию, сглаживая так называемые разрывы изображения (tearing) и резкие скачки частоты кадров (stutter). Кроме того, с оглядкой на возможности конкурента, в GTX 680 наконец-то появилась возможность вывода изображения сразу на четыре экрана — причём, на три даже в стереорежиме. В общем, новых возможностей у платы на базе GK104 довольно много.
Исходя из теоретических данных, Geforce GTX 680 можно считать неплохой заменой для GTX 580. Во многом на характеристиках новой видеокарты сказалась смена техпроцесса на более тонкий, но, тем не менее, смена приоритетов и проведённые архитектурные модификации сказались не менее сильно. С точки зрения пользователя важна не только улучшенная производительность, но и новые технологии, а также сниженные потребности в энергии и меньшие тепловыделение с шумностью системы охлаждения.
Как всегда, в первой части нашего материала мы познакомились лишь с теоретическими особенностями нового решения, а также с пока единственной моделью видеокарты на его основе. Следующая часть статьи посвящена практической части исследования в синтетических тестах, в которой мы сравним производительность новой видеокарты Geforce GTX 680 со скоростью предшествующего топового решения компании, а также конкурирующей видеокарты от компании AMD.
Nvidia Geforce GTX 680 — Часть 2: видеоплата и синтетические тесты →



