
На протяжении нескольких лет компания Nvidia активно развивала свои решения, предназначенные для рынка аппаратной 3D-графики реального времени. Достаточно вспомнить основные архитектуры последнего десятилетия: появление аппаратного расчёта трансформации и освещения (T&L) в Geforce 256 (NV10) в 1999 году, программируемую попиксельную обработку на Geforce 3 (NV20) в 2001 году, в дальнейшем усовершенствованную в Geforce FX (NV30).
Следующим действительно большим шагом стал выпуск Geforce 8 (G80) в 2006 году, в этом GPU появились унифицированные шейдеры и скалярная архитектура потоковых процессоров. Каждый из вышеперечисленных чипов представлял новую архитектуру, и все они были в самом деле важными шагами в развитии игровой и профессиональной 3D-графики.
Так как создание действительно новой архитектуры GPU занимает сейчас 3-4 года, то немудрено, что после выхода Geforce 8800 GTX на основе G80 нам пришлось ждать обновления базовой архитектуры так долго. У каждой компании свои сроки и организация работы, у Nvidia между обновлениями проходит несколько лет, и вот это время для представления новой архитектуры как раз и подошло.
Сегодня мы наконец-то расскажем об архитектурных подробностях наиболее современного GPU компании Nvidia, который имеет кодовое обозначение GF100. «GF» в данном случае означает графический («Graphics») чип, основанный на вычислительной архитектуре «Fermi», а число «100» принятое для продуктов Nvidia наименование первого из чипов архитектуры, нацеленного на верхний ценовой диапазон рынка. Позднее должны появиться и менее мощные чипы семейства, предназначенные для других секторов рынка.
Сразу же остановимся на том, о чём мы сегодня НЕ расскажем: о конкретных моделях карт на базе GF100, их характеристиках (количество блоков, тактовые частоты), ценах и энергопотреблении. Ну и о производительности в существующих приложениях пока что есть совсем немного информации. Впрочем, до реального выхода продукции на рынок ещё есть время, и в следующий раз мы вам обо всём обязательно расскажем.
Итак, GF100 это первый видеопроцессор, основанный на архитектуре Fermi. Он поддерживает все нововведения современного DirectX 11 API, такие как аппаратная тесселяция и вычислительные возможности DirectCompute. Более того, архитектура GF100 спроектирована с учётом будущих возможностей API и потребностей графических приложений, таких как трассировка лучей (raytracing) и мощные физические эффекты.
Естественно, как это всегда было принято у Nvidia, топовый чип GF100 должен стать самым производительным решением на рынке. В отличие от стратегии конкурента, в этой компании любыми средствами всегда стараются выпустить максимально производительное одночиповое решение. Плохо это или хорошо вопрос отдельный, но успешность компании говорит сама за себя.
Видеочип GF100 использует уже третье поколение потоковых мультипроцессоров (Streaming Multiprocessor) и более чем удваивает количество вычислительных ядер (CUDA cores), по сравнению с предыдущей архитектурой. Это является заметным усилением, с учётом значительно усложнившихся исполнительных устройств. В отличие от существующих DX11 решений конкурента, которые являются скорее доводкой GPU предыдущего поколения.
Количество и производительность других исполнительных блоков также были увеличены в GF100, но это не главное. С точки зрения 3D-графики, наиболее важным изменением архитектуры нам видится то, что геометрический конвейер в новом GPU впервые за многое время подвергся весьма значительной переработке. Для того чтобы соответствовать новым возможностям DirectX 11 и современных графических приложений, в этом GPU значительно увеличена пиковая производительность обработки геометрии, геометрических шейдеров и stream out.
Тут необходимо сделать небольшое отступление... Посмотрите на существующие игры. Попиксельная обработка в них достигла довольно приличного уровня, и пиксельные эффекты достаточно сложны, в то время как геометрическая сложность даже в самых лучших играх и приложениях заметно отстаёт. В кадре игровых проектов обрабатывается максимум до 1-2 миллионов полигонов, что несравнимо с сотнями миллионов в анимационных проектах, к которым стремится качество графики реального времени.
Это положение объясняется тем, что аппаратная и программная поддержка в аппаратной 3D-графике длительное время росла в сторону усиления именно пиксельных шейдеров. А блоки обработки геометрии на протяжении многих лет оставались без особых изменений и их работа не была распараллелена. Что сильно повлияло на разницу в росте возможностей пиксельной и вершинной обработки за эти годы. Так, Geforce GTX 285 более чем в 100 раз мощнее Geforce FX по пиксельной обработке, но всего лишь менее чем в три раза быстрее по обработке геометрии!
На помощь приходят широко известные техники, давно используемые в индустрии 3D-графики, появившиеся задолго до аппаратных решений. Так, в киноиндустрии давно используют разбиение примитивов (tessellation, тесселяция) и наложение карт смещения (displacement mapping). В своих материалах мы уже рассказывали об этих возможностях, например, в FAQ по 3D графике образца 2005 года.
Тесселяцией большие треугольники разбиваются на мелкие, и затем при помощи карт смещения displacement maps координаты вершин смещаются так, чтобы придать геометрии более детализированный вид. Комплексное применение этих двух техник рендеринга даёт возможность получения геометрически сложных моделей из относительно простого описания.

К сожалению, ранние API не содержали возможностей по подобному увеличению геометрической сложности сцен. В D3D9 и даже D3D10 приложениях невозможно создавать такое количество геометрии на GPU, хотя некие зачаточные функции в D3D10 и существуют. Да и предыдущие аппаратные архитектуры к активному применению тесселяции подготовлены очень плохо. Так, простое добавление возможности тесселяции к GT200 создало бы сильное ограничение в геометрической производительности.
А вот новый графический конвейер GF100 спроектирован с учётом этих возможностей, он способен обеспечить действительно высокую производительность для тесселяции и обработки геометрии. В новом GPU архитектура традиционной геометрической обработки уступила место новой архитектуре, использующей несколько так называемых полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно, по сравнению с одним подобным блоком во всех предыдущих поколениях GPU.
Обо всём этом мы очень подробно расскажем далее. Также в плюс быстрой обработке геометрии играет и новая архитектура памяти. Кэши первого и второго уровней обеспечивают высокоскоростной доступ к геометрическим атрибутам для потоковых процессоров и блоков тесселяции.
И несмотря на то, что в GF100 достаточно других нововведений, направленных на увеличение производительности и гибкости, главным изменением с точки зрения влияния на индустрию аппаратной 3D-графики мы считаем именно высокоскоростную обработку геометрии.
Но у GF100 есть и другие сильные стороны, раскрывающие возможности архитектуры Fermi. Хотя в графических расчётах потоки зачастую работают независимо друг от друга и обеспечивают высокую локальность доступа к памяти, в последнее время большое значение имеют неграфические вычисления на GPU, предъявляющие несколько иные требования к аппаратной части. Такие вычислительные потоки нуждаются в обмене данными друг с другом, их алгоритмы значительно более разнообразны и им нужен доступ к чтению и записи в различные области памяти.
Основными изменениями в GF100, связанными с повышением эффективности вычислительных алгоритмов, являются: быстрое переключение контекста между графическими и неграфическими расчётами (например, PhysX), конкурентное исполнение вычислительных программ и улучшенная архитектура кэширования, эффективная для таких задач, как трассировка лучей и искусственный интеллект.
Для быстрого одновременного исполнения различных алгоритмов в GF100 было снижено время переключения контекста, что должно увеличить производительность в целом. Так, игровое приложение может использовать Direct3D 11 для отрисовки сцены, затем переключиться на CUDA для трассировки лучей при гибридном рендеринге, далее вызвать DirectCompute программу для постобработки изображения и выполнить расчёты для физических эффектов PhysX. И всё это в пределах одного кадра, то есть нескольких миллисекунд.
Из других нововведений можно также отметить улучшенную производительность атомарных операций (atomic operations), что ускоряет такие алгоритмы, как рендеринг полупрозрачных поверхностей без предварительной сортировки (order independent transparency). Но далее мы на всём остановимся очень подробно...
А пока остановимся на интересном вопросе тактовых частот чипа. Похоже, что тут тоже есть интересные изменения, по сравнению с GT200. Теперь главной стала не базовая частота чипа, а частота шейдерного домена. А другие блоки работают на частоте, пониженной на определённый делитель, относительно шейдерной. Блоки ROP и кэш L2 всегда работают на своей частоте, как было и ранее, а потоковые процессоры и кэш L1 на частоте шейдерного домена. А текстурные модули и оставшиеся блоки чипа (PolyMorph и Raster) работают на половинной частоте от частоты шейдерного домена. Не сказать, чтобы это что-то сильно меняло, просто любопытное изменение потоковые процессоры теперь главнее.
Тесселяция и наложение карт смещения
Перед тем, как приступить к рассказу об архитектуре GF100, нужно уделить время объяснению работы тесселяции и наложения карт смещения. Хотя эти техники рендеринга не являются новыми, до сих пор в 3D-графике реального времени они практически не использовались. Даже несмотря на теоретическую возможность их применения в прошлом и аппаратную поддержку со стороны некоторых производителей (Matrox Parhelia и AMD RADEON).
Лишь с появлением специальных ступеней графического конвейера в DirectX 11 разработчики могут начать действительно широкое применение этих техник в играх. Но какие преимущества может дать применение тесселяции и карт смещения в 3D-графике реального времени, и почему это было невозможно ранее?
Программные пакеты по созданию цифрового контента (ZBrush, 3D Studio Max, Maya, SoftImage и др.) содержат в себе средства, позволяющие использовать эти возможности. Но в нынешних условиях моделлер должен вручную создавать полигональные модели с несколькими уровнями детализации для применения LOD level of detail.
Эти модели в виде вершин и треугольников, а также ассоциированных с ними текстур, передаются каждый кадр в GPU по интерфейсу PCI Express. Поэтому игровые разработчики вынуждены использовать сравнительно простые модели из-за ограниченной пропускной способности этой шины, равно как и не особенно высокой геометрической производительности имеющихся GPU.
Даже в лучших игровых приложениях на моделях и окружении мы видим множество рубленых линий и углов, вызванных ограничениями предыдущих графических API и существующих видеочипов. Разработчикам приходится идти на компромисс, повышая детализацию моделей персонажей, заметно меньше внимания обращая на окружение. Мы уж не говорим о том, что часть не особенно мелкой геометрии разработчикам приходится имитировать при помощи пиксельных эффектов, а реалистичные волосы у людей в играх заменяются текстурами, головными уборами и короткими причёсками.
Всё это может измениться с применением тесселяции и современных видеочипов. В GPU посылается несложная геометрически модель отрисовываемого объекта, а аппаратный тесселятор разбивает её на большее количество геометрических примитивов, необходимое для текущей сцены. Затем эти вершины смещаются на необходимое расстояние для добавления детализации.
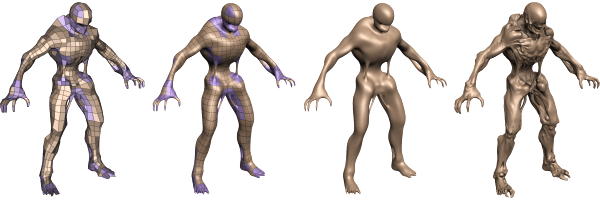
Мы уже рассматривали в статье по ссылке выше, как это делается. Посмотрите на рисунок, слева изображена упрощённая модель, использующая четырёхугольные примитивы. Она весьма несложная, по сравнению с нынешними моделями персонажей, используемыми в играх. Далее идёт изображение, полученное при помощи тесселяции. Оно очень сглаженное и с отсутствующими острыми углами.
Но сама по себе тесселяция не добавляет деталей, а только сглаживает модель. Поэтому к ней нужно ещё применить карту смещения высот (displacement map). В итоге справа мы видим весьма реалистично выглядящую модель персонажа с множеством геометрических деталей.
Преимуществ у такого подхода предостаточно. Исходная модель геометрически простая, что означает высокую эффективность хранения и передачи по шине. Требования по пропускной способности для отсылки модели в GPU получаются весьма низкие, а так как анимация рассчитывается для простенькой исходной модели, то возможно применение более сложных анимационных алгоритмов.
Другим важным преимуществом является возможность гибкого изменения результирующей геометрической сложности, то есть динамический уровень детализации (LOD). Так как все данные для тесселяции хранятся на чипе, передача нескольких моделей с разными уровнями детализации не требуется. Также, можно обойтись одной и той же моделью и картой смещения для разных игровых платформ, задавая уровень детализации при помощи разбиения на различное количество примитивов.
Важным отличием тесселяции и карт смещения от попиксельных эффектов вроде карт нормалей и parallax mapping является воздействие именно на вершины, а не пиксели. То есть, при описанном выше методе без проблем получатся чёткие тени, самозатенение и детальные силуэты объектов.
Причём карты смещения могут легко сочетаться с пиксельными техниками. Так, displacement mapping можно использовать для имитации крупных неровностей модели, а для normal mapping оставить такие мелкие детали, как царапины и поры кожи.
Ещё одной из интереснейших возможностей, предоставляемых тесселяцией и картами смещения, является возможность динамического изменения геометрии «на лету». Например, выстрел из автомата по кирпичной стене вызовет реальное изменение геометрии и появление в стене дырки, а не просто отметки («decal»), обозначающей место попадания, как это повсеместно делается сейчас.
Графическая архитектура GF100
А вот теперь самое время перейти к рассмотрению архитектуры. Как и предыдущие чипы разработки Nvidia, GF100 имеет в своей основе несколько кластеров, но теперь это кластеры графической обработки (Graphics Processing Clusters), каждый из которых состоит из нескольких потоковых мультипроцессоров (Streaming Multiprocessors), которые, в свою очередь, содержат массивы потоковых процессоров.
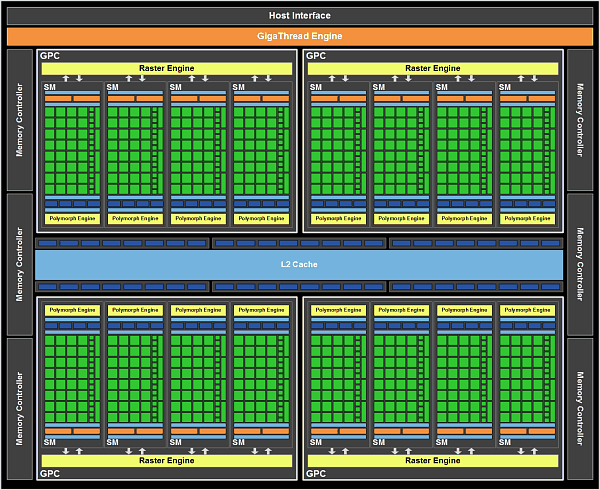
GF100 содержит четыре кластера GPC, шестнадцать мультипроцессоров SM и шесть 64-битных контроллеров памяти. Как обычно, Nvidia планирует запуск нескольких моделей графических решений на основе GF100, с разным количеством активных блоков GPC и контроллеров памяти. Это логично и с точки зрения удешевления производства, так как техпроцесс TSMC всё ещё недостаточно отработан, и полностью годных чипов не очень много, так и с рыночной политикой, когда в разные ценовые диапазоны направляются чипы с разными количественными характеристиками.
Итак, новый GPU в своем полном представлении содержит внешний PCI Express интерфейс, движок GigaThread, четыре GPC, шесть контроллеров памяти, шесть укрупненных блоков ROP, а также 768 КБ кэш-памяти второго уровня, присоединённые к блокам ROP.
GPU получает команды по Host Interface, движок GigaThread запрашивает нужные данные из системной памяти и копирует их в локальную память. В отличие от предыдущего чипа, имеющего восемь контроллеров памяти по 64-бита, GF100 имеет шесть таких контроллеров, но обладающих поддержкой GDDR5 памяти, которой не было у решений на основе GT200. В итоге, применение GDDR5 памяти и 384-битного доступа к ней даёт довольно высокую пропускную способность.
Диспетчер GigaThread является центром чипа, он создаёт и распределяет блоки потоков по разным мультипроцессорам, а мультипроцессоры распределяют варпы (warps, группы из 32 потоков) среди потоковых процессоров (CUDA cores) и других исполнительных блоков.
Всего в состав GF100 входит 512 потоковых процессоров, так называемых CUDA cores, собранных в 16 мультипроцессоров по 32 штуки в каждом. Каждый SM поддерживает одновременное выполнение до 48 варпов, а CUDA core может выполнять все типы программ: вершинные, пиксельные, геометрические, вычислительные.
GF100 содержит 48 блоков ROP, которые выполняют работу по блендингу и сглаживанию пикселей, а также отвечают за атомарные операции с памятью. Блоки ROP в новом чипе Nvidia сгруппированы в шесть групп по восемь модулей. Каждая группа обслуживается своим 64-битным контроллером памяти.
Архитектура Graphics Processing Clusters
Как написано выше, графическая архитектура чипа GF100 основана на четырёх кластерах Graphics Processing Clusters, каждый из которых содержит по четыре мультипроцессора и по своему отдельному движку растеризации (Raster Engine).
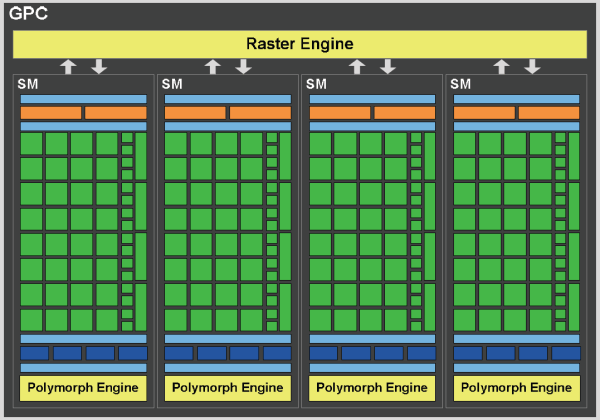
В новом GPC видны две ключевые инновации. Во-первых, появился масштабируемый движок растеризации, выполняющий установку треугольников (triangle setup), растеризацию и отбрасывание невидимых поверхностей (z-cull). А во-вторых, GPC также содержит и отдельные движки PolyMorph, выполняющие выборку вершинных атрибутов и тесселяцию. Причём движок растеризации Raster Engine принадлежит к GPC, а PolyMorph к каждому из мультипроцессоров SM в кластере.
Кластер GPC включает все основные графические блоки GPU, за исключением блоков ROP. Получается, что это почти отдельный видеочип, и их в GF100 четыре штуки. В предыдущих чипах Nvidia, мультипроцессоры и текстурные блоки были сгруппированы в кластеры текстурной обработки (Texture Processing Clusters). А в GF100 каждый из мультипроцессоров SM имеет по четыре выделенных текстурных блока. Но об этом далее.
Третье поколение потоковых мультипроцессоров
В третьем поколении потоковых мультипроцессоров Nvidia мы видим несколько усовершенствований и нововведений, направленных как на увеличение производительности, так и на улучшения в программируемости и гибкости их использования.
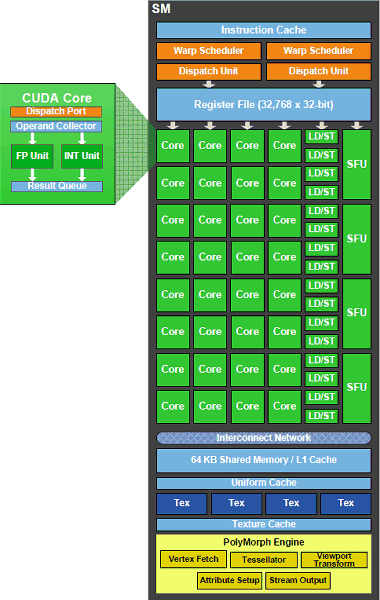
Итак, каждый из мультипроцессоров SM содержит по 32 потоковых CUDA ядра, что вчетверо больше, чем в GT200 (тут нужно учитывать снизившееся общее число мультипроцессоров в чипе). Они остались скалярными, как и ранее, что даёт хороший КПД для любых приложений, а не только обладающих специальной оптимизацией. Например, операции с Z-буфером (1D) и доступ к текстурам (2D) способны полностью загрузить работой исполнительные блоки GPU, в отличие от суперскалярных архитектур.
Потоковые процессоры имеют в своём составе исполнительное устройство для целочисленных вычислений (ALU) и исполнительное устройство для вычислений с плавающей запятой (FPU). Вычисления GF100 соответствуют новому стандарту IEEE 754-2008 по вычислениям с плавающей запятой, а также предоставляют возможность выполнения совмещенных операций умножения-сложения (fused multiply-add, или FMA) для вычислений одинарной и двойной точности.
FMA, в отличие от инструкции умножения-сложения (multiply-add, MAD), выполняет эти две операции лишь с одним округлением. Такой подход обеспечивает отсутствие потерь точности при сложении и минимизирует ошибки рендеринга в некоторых случаях. Например, при близких перекрывающихся треугольниках.
Новый целочисленный блок ALU, появившийся в GF100, поддерживает полную 32-битную точность для всех инструкций, как этого требуют языки программирования. Помимо этого, целочисленный ALU с высокой эффективностью исполняет 64-битные операции. Каждый из мультипроцессоров имеет 16 блоков загрузки и сохранения данных (load/store unit, LD/ST или LSU), позволяющих вычислять адреса источника и назначения для 16 потоков за такт.
Четыре исполнительных блока специальных функций (Special Function Units, SFU) выполняют сложные операции, такие как вычисление синуса, косинуса, квадратного корня и т.п. Кроме того, эти блоки используются для интерполяции графических атрибутов. Каждый блок SFU выполняет одну инструкцию на поток за один такт, то есть варп из 32 потоков будет выполняться за 8 тактов. Конвейер SFU отделён от блока диспетчера, что позволяет последнему обращаться к другим исполнительным устройствам в то время, когда SFU занят.
Двойной планировщик варпов
Итак, мультипроцессор выполняет потоки группами по 32 штуки, такие группы называются варпами. Каждый мультипроцессор содержит два планировщика варпов (Warp Scheduler) и два диспетчера инструкций (Instruction Dispatch Unit), что позволяет одновременно выполнять по два варпа на каждом из SM.
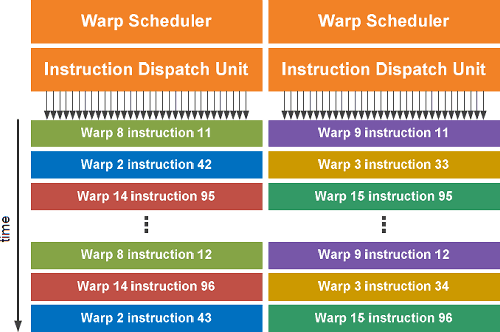
Двойной планировщик варпов в GF100 выбирает два варпа и запускает на выполнение по одной инструкции из каждого из них на группе из 16 вычислительных ядер, 16 блоков LSU или четырёх SFU. Так как варпы исполняются независимо друг от друга, планировщик GPU не должен проверять поток инструкций на зависимые команды. Использование такой модели одновременного исполнения двух команд (dual-issue) за такт позволяет достичь высокой производительности, близкой к пиковым теоретическим значениям.
Большинство инструкций может выполняться одновременно по две штуки: две целочисленные инструкции, две инструкции с плавающей запятой, или сочетание целочисленной, инструкции с плавающей запятой, загрузки данных, сохранения данных, специальных инструкций SFU. Но это относится только к инструкциям одинарной точности. Команды двойной точности не могут исполняться одновременно с любой другой инструкцией.
Текстурные модули
Раз уж речь идёт о графическом чипе, то очень важно количество текстурных модулей в GPU и их возможности. Как видно на схеме мультипроцессора выше, в каждом из них есть по четыре текстурных блока. Каждый из которых вычисляет адрес и выбирает данные для четырёх текстурных выборок за такт. Результат может быть выдан как в неотфильтрованном виде (для Gather4), так и с билинейной, трилинейной или анизотропной фильтрацией. Естественно, с потерей темпа.
По описанию не очень понятно, что изменилось в GF100 по сравнению с предыдущими архитектурами чипов. Но Nvidia утверждает, что основной задачей текстурников в GF100 было увеличение эффективности выполнения текстурных выборок. Причём в качестве положительных изменений отмечен перенос текстурных модулей в мультипроцессоры, а также улучшение эффективности кэширования и увеличение тактовых частот TMU.
Остановимся на этом подробнее. В предыдущем чипе GT200 до трёх мультипроцессоров использовали один укрупнённый текстурный блок, содержащий восемь текстурных модулей. В новой архитектуре GF100 каждый из мультипроцессоров имеет свои выделенные текстурные модули и текстурный кэш. Что, по идее, должно положительно сказаться на эффективности, но мы проверим это в следующий раз.
Были сделаны и другие улучшения в текстурных модулях, и результирующий прирост скорости текстурирования Nvidia оценивает положительно. Особенно, когда дело касается наложения карт теней (shadow mapping) и алгоритмов вроде screen space ambient occlusion. В обеих техниках используется стандартная возможность Gather4 из DirectX, которая позволяет выполнить одновременную выборку четырех значений за такт. Причём заявлено 2-3-кратное преимущество в производительности таких выборок, по сравнению с конкурирующим решением от AMD.
Что ещё важнее, GF100 имеет более эффективную выделенную кэш-память первого уровня. И вместе с унифицированным кэшем второго уровня это даёт втрое больший объём доступной кэш-памяти для текстур, по сравнению с GT200.
И даже с учётом того, что у GT200 больше блоков текстурирования, чем у GF100, новый чип обеспечивает большую производительность текстурирования в реальных приложениях. Посмотрим, как этот прирост оценивает сама Nvidia.
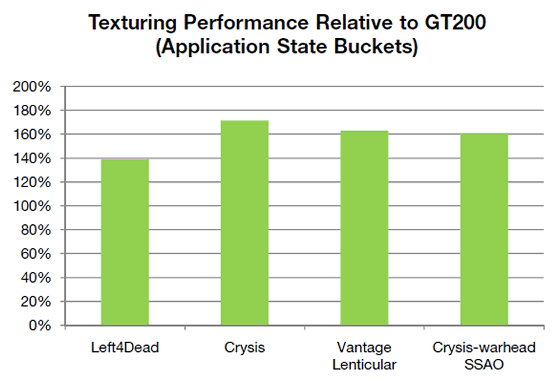
Понятно, что это не средняя частота кадров в приложении, а скорость выполнения нескольких вызовов функций отрисовки, ограниченная скоростью текстурирования. С учётом меньшего количества текстурников, результаты GF100 можно считать хорошими чип справляется с выборками в среднем в 1.6 раза быстрее, чем GT200.
Из других функциональных изменений в TMU отметим то, что текстурники GF100 получили поддержку новых форматов сжатия BC6H и BC7, появившихся в DirectX 11 и предназначенных для текстур и внеэкранных буферов (render target) в HDR формате.
Параллельная обработка геометрии
Теперь очень подробно расскажем о самых важных нововведениях в GF100. Все предыдущие поколения GPU используют единый блок для выборки, установки и растеризации треугольников. Такой конвейер обеспечивает фиксированную производительность и зачастую является ограничителем общей производительности рендеринга.
В этой ситуации также была виновата и сложность распараллеливания растеризации при отсутствии соответствующих изменений в программном интерфейсе (API). И если раньше такой подход к одиночному блоку растеризации работал сносно, то при увеличении сложности и массовости геометрических расчётов растеризация стала главным ограничителем на пути увеличения сложности геометрии в 3D сценах.
Активное использование тесселяции полностью меняет баланс загрузки различных блоков GPU. С тесселяцией плотность треугольников вырастает на порядки, что сильно нагружает такие ранее последовательные участки графического конвейера, как установка треугольников (triangle setup) и растеризация. Для обеспечения высокой производительности тесселяции необходимо было решить эту проблему изменениями архитектуры, перебалансировав весь графический конвейер GPU.
Чтобы добиться высокой скорости обсчёта геометрии, компания Nvidia разработала масштабируемый блок обработки геометрии с названием PolyMorph Engine. Каждый из 16-ти блоков PolyMorph, имеющихся в GF100, содержит собственный модуль по выборке вершин (vertex fetch unit) и тесселятор, что значительно увеличивает производительность геометрических вычислений.
Вдобавок к этому, в GF100 были включены четыре блока растеризации Raster Engine, работающие параллельно и позволяющие выполнять установку до четырёх треугольников за такт. Вместе эти блоки обеспечивают приличный рост производительности обработки треугольников, тесселяции и растеризации.
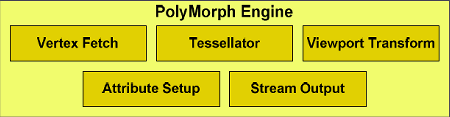
PolyMorph Engine содержит пять стадий: выборка вершин (Vertex Fetch), тесселяция, преобразование в экранные координаты (Viewport Transform), установка атрибутов (Attribute Setup), и потоковый вывод (Stream Output). Результаты, вычисленные в каждой стадии, передаются в мультипроцессор SM. Последний выполняет шейдерную программу, возвращая данные к следующей стадии PolyMorph Engine. После прохождения всех стадий результаты направляются в движки растеризации Raster Engine.
Первая стадия начинается с выборки вершин из глобального вершинного буфера. Выбранные вершины посылаются в мультипроцессор для вершинного затенения (vertex shading и hull shading). В этих двух стадиях вершины преобразуются из координат объектного пространства (object space) в мировое (world space), и вычисляются параметры, необходимые для тесселяции, такие как коэффициент разбиения (tessellation factor). Эти параметры затем пересылаются в тесселятор.
Во второй стадии модуль PolyMorph считывает эти параметры тесселяции и разбивает патч (гладкая поверхность, определенная контрольными точками), выводя результирующую сетку (mesh). Эти новые вершины посылаются в мультипроцессор, где выполняется доменный и геометрический шейдеры.
Доменный шейдер вычисляет итоговое положение каждой вершины на основе данных от поверхностного шейдера (Hull Shader) и тесселятора. На этой стадии обычно применяется карта смещения (displacement map), добавляющая патчу детализации. Геометрический шейдер проводит дополнительную обработку, добавляя или удаляя вершины или примитивы, если необходимо.
В последней стадии PolyMorph Engine производит преобразование в экранные координаты (viewport transformation) и коррекцию перспективы. Далее следует установка атрибутов, а вершины могут быть выведены при помощи stream output в память для дальнейшей обработки.
В предыдущих архитектурах подобные аппаратно зашитые (fixed function) операции выполнялись лишь одним конвейером. При выполнении на GF100 и fixed function, и программируемые операции будут распараллелены, что должно вызвать прирост производительности в случае ограничения производительности этими операциями.
Блок растеризации
После того, как примитивы обработаны блоком PolyMorph, они отсылаются в блок растеризации Raster Engine. Которых в чипе также установлено несколько штук четыре в случае GF100. Они тоже работают параллельно, и в результате достигается высокая производительность обработки геометрии.

Движок растеризации выполняет три стадии конвейера. В стадии установки граней (edge setup) производится выборка положения вершин и вычисляются проекции граней треугольника. Треугольники, обращённые к экрану обратной стороной, отбрасываются как невидимые (back face culling). Каждый из блоков установки граней обрабатывает по одной точке, линии или треугольника за такт.
Растеризатор использует проекции граней для каждого примитива и вычисляет покрытие пикселей. Если включено сглаживание, то вычисляется покрытие для каждой выборки цвета и выборки покрытия. Каждый из четырёх растеризаторов на выходе выдаёт по восемь пикселей за такт, то есть всего получается 32 прошедших растеризацию пикселя за такт для всего GPU.
Пиксели из растеризатора посылаются в блок отбрасывания невидимых поверхностей Z-cull. Этот блок сравнивает глубину (depth) пикселей из тайла с глубиной существующих пикселей в экранном буфере и отбрасывает те из них, которые лежат за пикселями в экранном буфере. Это называется раннее отбрасывание невидимых поверхностей, которое экономит ресурсы, убирая необходимость проведения лишних попиксельных вычислений.
Такую архитектуру кластеров GPC можно считать наиболее важным нововведением в геометрическом конвейере GF100. Ведь при тесселяции требуется значительно большая производительность блоков установки треугольников и их растеризации. Шестнадцать блоков PolyMorph Engine значительно увеличивают производительность выборки треугольников, тесселяции и потокового вывода Stream Out, а четыре блока Raster Engine обеспечивают высокую скорость установки треугольников и их растеризации.
Красивой теории написано много, а где же хотя бы примерные цифры производительности? По оценке Nvidia, наличие выделенных тесселяторов в каждом из мультипроцессоров и блоков растеризации в каждом кластере GPC даёт прирост геометрической производительности GF100 вплоть до восьмикратного, по сравнению с GT200. Посмотрим, что получается на практике, при сравнении уже с лучшим из конкурентов RADEON HD 5870:
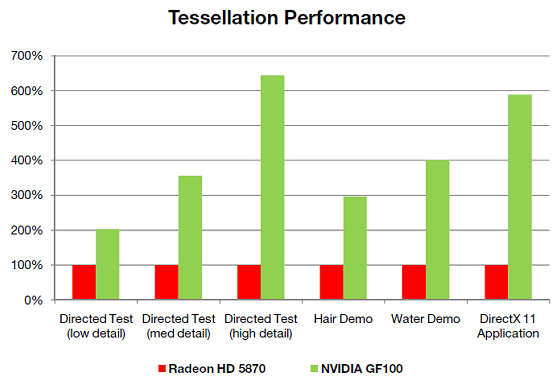
Первые три столбца показывают чисто синтетическую производительность тесселяции с разной степенью детализации. И с её увеличением мы видим, как сильно растёт производительность GF100 относительно топовой одночиповой видеокарты конкурента (если верить результатам, полученным в лаборатории Nvidia, разумеется, мы проведем собственные тесты, когда появится техническая возможность, то есть будут доступны сами карты).
Следующие два теста Nvidia называются Hair и Water, они содержат не только чисто синтетический код тесселяции, но и пиксельные и вычислительные шейдеры, поэтому разница в скорости получилась меньше. Выглядят они вот так:


Ну а последний столбик диаграммы показывает относительную производительность набора вызовов функций отрисовки (state bucket) в пределах одного кадра, взятую из неназванного DirectX 11 приложения. Вполне возможно, что это приложение Heaven Benchmark от Unigine.
Нужно заметить, что шестикратная разница в этих столбиках не означает такой же разницы даже в мгновенной частоте кадров. Это производительность лишь части вызовов функций отрисовки, скорость в которых ограничена именно скоростью тесселяции.
Впрочем, у нас есть некоторые данные и по нескольким секундам этого бенчмарка. Nvidia измерила среднюю частоту кадров в Unigine Heaven на протяжении 60 секунд, при этом использовались сцены с колючим драконом и каменной тропинкой.
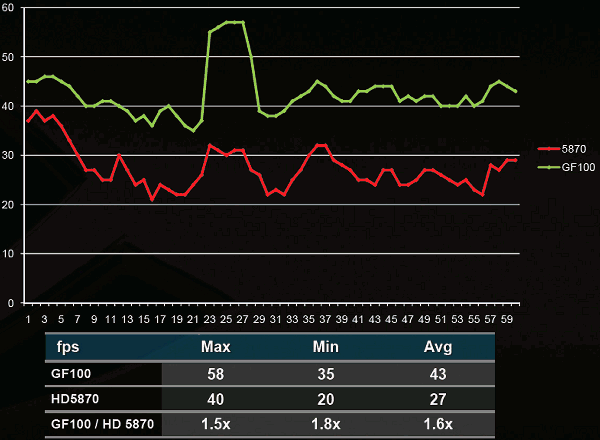
Судя по графикам FPS, с тесселяцией GF100 справляется действительно заметно лучше быстрейшей одночиповой продукции конкурента. И пусть средняя частота кадров выше лишь в 1,6 раза (хотя это тоже совсем неплохо), разница в минимальных показателях получается ещё больше.
Подсистема памяти
Эффективная организация подсистемы памяти очень важна для современного GPU. Тем более, когда всё больше и больше внимания уделяется неграфическим вычислениям. Ещё в первом поколении CUDA-архитектуры компания Nvidia воплотила конфигурируемую общую память и разделяемый кэш первого уровня. Обмен данными между вычислительными потоками очень важен, и общая память теперь широко используется в неграфических задачах на GPU.
В своём новом чипе компания Nvidia снова усовершенствовала модель памяти. Теперь GF100 содержит выделенный кэш первого уровня в каждом мультипроцессоре (SM). Эта кэш-память работает совместно с разделяемой (общей) памятью мультипроцессора и дополняет её. Общая память улучшает скорость доступа к памяти для алгоритмов с предсказуемым доступом к памяти, а кэш-память L1 ускоряет доступ из нерегулярных алгоритмов, в которых адреса запрашиваемых данных заранее неизвестны.
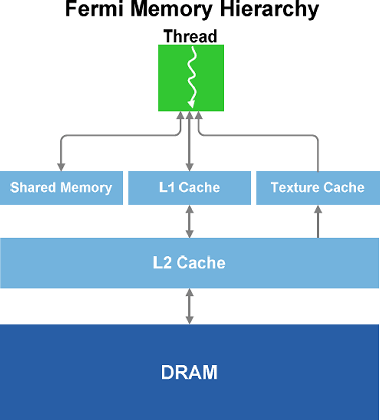
Каждый мультипроцессор в GF100 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, и наоборот 16 КБ общей памяти и 48 КБ кэша.
Для графических программ GF100 использует вариант с 16 КБ кэша, он работает как регистровый буфер. В вычислительных программах кэш и общая память позволяет потокам одного блока обмениваться данными, работая вместе, что снижает требования к пропускной способности памяти. Кроме того, общая память сама по себе позволяет эффективно использовать на GPU многие вычислительные алгоритмы.
Кроме того, GF100 имеет 768 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки. Кэш второго уровня обеспечивает эффективный и высокоскоростной обмен данными для всего GPU. И вычислительные алгоритмы, запросы данных в которых непредсказуемы (физические расчёты, трассировка лучей и др.), получат значительный прирост скорости от аппаратной кэш-памяти. А фильтры постобработки, в которых несколько мультипроцессоров читают одни и те же данные, получат ускорение из-за меньшего количества вызовов данных из внешней памяти.
Унифицированная кэш-память более эффективна, чем отдельные кэши для разных целей. При выделенных кэшах может сложиться положение, когда один из них используется полностью, но воспользоваться простаивающими объёмами других типов кэш-памяти при этом невозможно. И эффективность кэширования будет ниже теоретически возможной. А унифицированный L2 кэш в GF100 динамически выделяет пространство под разные запросы, что позволяет добиться высокой эффективности.
В общем, теперь один L2 кэш замещает собой текстурный L2 кэш, кэш ROP и начиповые буферы GPU предыдущих поколений. Кэш второго уровня в GF100 используется для записи и чтения данных, и является полностью последовательным (когерентным). Сравните с L2 кэшем в GT200, используемым только для чтения. Итоговая таблица сравнения систем кэшей GF100 и GT200 выглядит так:
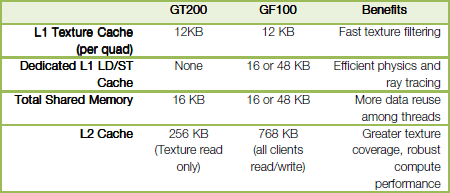
В целом, как вы можете убедиться, архитектура кэш-памяти в GF100 значительно улучшена по сравнению с предыдущими чипами. Новый GPU обеспечивает более эффективный обмен данными между стадиями конвейера и способен значительно сэкономить пропускную способность внешней памяти, повысив эффективность использования исполнительных блоков видеочипа.
Новые блоки ROP и улучшенное сглаживание
Блоки ROP и вся подсистема блендинга и сглаживания в GF100 также претерпела значительные изменения, направленные на всё то же увеличение эффективности их работы. Один раздел ROP в GF100 содержит восемь блоков ROP, то есть вдвое больше, чем в предыдущих поколениях. Каждый блок ROP способен выводить 32-битное целочисленное значение за такт, пиксель формата FP16 за два такта или FP32 пиксель за четыре такта.
Самым большим недостатком предыдущих чипов, связанным с ROP, можно считать низкую эффективность сглаживания методом мультисэмплинга MSAA 8x. Nvidia заявляет, что значительно улучшила производительность этого режима в GF100, подняв эффективность сжатия буфера, а также эффективность блоков ROP при рендеринге небольших примитивов, которые невозможно сжать. Последнее изменение важно и потому, что тесселяция увеличивает количество мелких примитивов, и требования к производительности блоков ROP при этом растут.
Предыдущие поколения архитектур Nvidia отличаются большим падением производительности рендеринга при включенных режимах сглаживания с восемью мультисэмплинговыми выборками. Так, в игре Tom Clancy’s HAWX, средний FPS у GTX 285 в режиме MSAA 8x получается на 60% ниже, чем при MSAA 4x. С GF100 ситуация совсем иная, производительность в режиме 8x лишь на 10% ниже, чем при 4x. См. диаграмму:
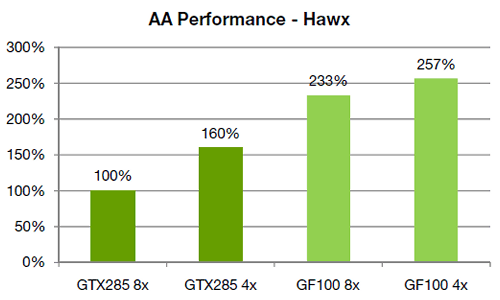
В итоге в режиме 4x новая карта на чипе GF100 в 1.6 раза быстрее, чем GTX 285 на основе GT200, зато при MSAA 8x новая карта опережает старую в 2,3 раза! Очень хорошая цифра, и приличное достижение. Похоже, что в режиме 8x MSAA новые решения будут более чем вдвое опережать старые. А вот в менее сложных условиях разница в скорости будет явно меньше.
Но не только скорость сглаживания интересует потенциальных покупателей GF100, но и качество изображения. В своих новых решениях Nvidia вводит новый алгоритм сглаживания, названный 32x CSAA (Coverage Sampling Antialiasing), обеспечивающий высочайшее качество сглаживания как геометрии, так и текстур при использовании режима alpha-to-coverage. Число 32 в данном случае расшифровывается как 8 честных мультисэмплинговых выборок и 24 выборки покрытия пикселя (pixel coverage).
Существующие игры ограничены возможностями API и мощностью GPU по обработке геометрии, поэтому во многих случаях вместо реальной геометрии используют полупрозрачные альфа-текстуры и метод их сглаживания alpha-to-coverage. И качество сглаживания их граней зависит от количества coverage выборок. В предыдущих поколениях использовалось 4 или 8 выборок, что не обеспечивало полного избавления от алиасинга, а также добавляло бандинг (см. скриншот ниже). Теперь, с режимом 32x CSAA, новый GPU использует 32 coverage выборок, минимизирующих артефакты алиасинга.
Полупрозрачное сглаживание методом мультисэмплинга (Transparency Multisampling, или TMAA) теперь также получает преимущество от улучшенного метода CSAA. TMAA обычно используется в старых DirectX 9 приложениях, которые не используют метод alpha-to-coverage, недоступный для этого API. В этом случае используется техника альфа-теста, при которой полупрозрачные текстуры имеют резкие края. При помощи TMAA старый код переводится в alpha-to-coverage, который в случае GF100 использует все возможности улучшенного метода CSAA.

Изображение слева показывает сглаживание методом TMAA, использующим режим 16xQ с 8 мультисэмплами и 8 coverage выборками, который максимален для GT200. А на правой картинке изображен антиалиасинг методом TMAA, использующий метод 32x CSAA, с 8 мультисэмплами и 24 coverage выборками, появившийся в GF100. Как видите, разница в качестве ощутимая.
Причём из-за того, что использование coverage выборок не слишком сильно повышает требования к пропускной способности памяти и её объёму, производительность нового метода 32x CSAA незначительно отличается от обычного 8x MSAA на GF100. В среднем разница между производительностью 32x CSAA и 8x MSAA составляет всего лишь 7%. Учитывая небольшую разницу между 4x и 8x, показанную нами выше, остаётся ли смысл в методах менее чем 32x CSAA на таких мощных решениях, как GF100? Это мы обязательно проверим на практике, сразу же когда такая возможность нам представится.
Вычислительные задачи на GPU
В последние годы значительно увеличилась реалистичность отрисовываемой в реальном времени картинке. И в основном эти улучшения были обусловлены стремительным развитием программируемых пиксельных шейдеров. Но компьютерная графика это не только растеризация, есть ещё трассировка лучей и Reyes, например. У каждого из путей есть свои сильные и слабые стороны, и разные методы можно использовать для решения различных задач.
До сих пор GPU создавались с расчётом на применение растеризации. Но постепенно появляется возможность применения и других методов в графических движках, и GPU должны подстраиваться под эти требования, расширяя свои возможности. Некоторые из указанных графических алгоритмов можно применять уже сейчас, используя расчётные API вроде CUDA, DirectCompute или OpenCL.
Архитектура чипа GF100 была спроектирована для эффективного исполнения различных алгоритмов и решения множества задач, поддающихся распараллеливанию. Таким алгоритмам, как трассировка лучей, физические расчёты и искусственный интеллект, общая память бесполезна, и в этом случае поможет кэш-память, имеющаяся в GF100. 48 килобайт кэша первого уровня на каждый из мультипроцессоров и использование глобального кэша второго уровня повысит производительность многих алгоритмов.
Ещё одним важным изменением в GF100 стал улучшенный планировщик. G80 и GT200 выполняют большие программы со сравнительно большим временем переключения контекста между различными задачами. Для чисто вычислительных задач с большими объёмами данных это нормально, но игровые приложения используют несколько различных задач одновременно: имитация тканей, физика жидкостей, постобработка и т.п. И на GF100 эти задачи могут эффективно выполняться параллельно, обеспечивая максимальный КПД для вычислительных устройств.
Так, в играх с использованием вычислительных шейдеров, переключение контекста происходит каждый кадр, и высокая скорость этого переключения критична для поддержания высокой частоты кадров. В GF100 значительно снизили время переключения контекста (до 20 микросекунд), что сделало возможным быстрое и неоднократное переключение между потоками в пределах одного кадра.
Вычислительные алгоритмы могут использоваться для решения большого количества задач различного плана в игровых приложениях. Например, это новые гибридные алгоритмы рендеринга, когда трассировка лучей применяется для отрисовки корректных отражений и преломлений. Или воксельный рендеринг для правдоподобной имитации объёмных данных.
Это может быть и сложная постобработка изображений: продвинутый HDR рендеринг, сложные фильтры для сглаживания и имитации оптических эффектов, вроде имитации зоны нерезкости и боке (bokeh). А в играх уже сейчас используются физические эффекты, которые можно ещё усложнить, добавить динамику жидкостей, турбулентность для эффектов с системами частиц, вроде дыма или жидкостей, и т.п.
Есть ещё множество возможностей, например, выполнение искусственного интеллекта на GPU, для того, чтобы AI управлял большим количеством персонажей с применением сложных поведенческих схем.
Трассировка лучей
Метод трассировки лучей часто используется в 3D-графике, но он слишком трудоёмок, чтобы использовать его в графике реального времени. Поэтому в будущих приложениях возможно применение трассировки совместно с растеризацией. Похоже, что именно GF100 является тем GPU, с которым возможна качественная трассировка лучей в реальном времени.
Трассировку непросто выполнить эффективно на GPU, ведь просчитываемые лучи имеют непредсказуемые направления, и их просчёт требует доступа к памяти по случайным адресам, в то время как GPU обычно получают данные из памяти линейными блоками.
Но архитектура GF100 отличается от предыдущих именно тем, что при её проектировании учитывались требования в том числе и алгоритмов трассировки лучей. Это первый видеочип, поддерживающий аппаратную рекурсию, что делает возможным эффективное выполнение подобных задач. Да и двухуровневая архитектура кэширования значительно увеличивает эффективность рейтрейсинга, увеличивая скорость запросов данных из памяти. L1 кэш улучшает «локальность» памяти для соседних лучей, а L2 кэш увеличивает пропускную способность доступа к видеопамяти.
Также GF100 способен эффективно выполнять и продвинутые алгоритмы просчёта глобального освещения, такие как трассировка пути (path tracing). Этот метод схож с трассировкой лучей, в нём используется большое количество лучей для сбора данных о непрямом освещении сцены. По оценкам Nvidia, в данном алгоритме производительность GF100 до четырёх раз выше, по сравнению с GT200.
Но всё же эти методы слишком сложны, чтобы применять их в играх. Разработчики могут использовать одновременно и растеризацию, и трассировку лучей, что называется гибридным рендерингом. Например, растеризация может использоваться в первом проходе рендеринга, а для части пикселей в следующем проходе при помощи трассировки лучей просчитается отражение. Такие гибридные модели отличный способ получения высокой производительности при весьма высококачественном результате.

Чтобы не быть голословными, приводим в пример демонстрационную программу Nvidia, где при рендеринге моделей автомобилей рассчитывается глобальное освещение при помощи технологии Nvidia OptiX. В будущем вполне возможна интеграция OptiX в игровой движок гоночной игры, и игроки смогут получать очень качественные скриншоты своих любимых автомобилей в режимах «photo mode» или «gallery mode», которые есть в подобных играх.

Рассмотрим некоторые из вычислительных эффектов, которые появятся в играх ближайшего времени. Например, в игре Metro 2033, которая должна выйти в марте этого года, реализована качественная постфильтрация с имитацией эффекта глубины резкости (depth of field).
Для имитации этого оптического эффекта используются возможности DirectCompute вычислительные шейдеры DirectX 11. Применение стандартной техники постобработки даёт сравнительно низкое качество постфильтрации, а использование пиксельных шейдеров для техник DOF кинематографического качества вызывает слишком большие потери производительности.
Поэтому игровые разработчики проекта Metro 2033 совместно с Nvidia разработали технику, использующую возможности DirectCompute для реализации сложной постобработки. Результат мы должны вживую увидеть в марте, а пока что ограничимся скриншотом, эффект DOF на котором смотрится довольно неплохо.

А вот ещё одна игра, которая вот-вот появится на прилавках магазинов Dark Void. Она разрабатывается с осени 2008 года, и наиболее интересной её частью для нас является применение весьма интересных продвинутых PhysX эффектов.
Как и в случае с предыдущей игрой, разработчики совместно с Nvidia поработали над включением в проект интересных физических эффектов, предлагаемых новым модулем APEX Turbulence из комплекта возможностей PhysX. Эту самую турбулентность можно увидеть в эффекте дыма от реактивного ранца (jetpack) и некоторых видов оружия (disintegrator).

Также в Dark Void можно увидеть множество различных физических эффектов, созданных на основе систем частиц. Обычно их хорошо видно при выстрелах из разнообразного оружия и при попадании этих выстрелов в поверхности. Как на этом скриншоте:

Демонстрация возможностей физических эффектов Supersonic Sled
Ну и в качестве наиболее эффектной демонстрации возможностей нового GPU по физическим эффектам компания Nvidia предлагает демку Supersonic Sled. Приложение использует множество возможностей PhysX, но также использует и продвинутые техники рендеринга (взять ту же тесселяцию и постобработку) и выглядит в целом очень неплохо.

В демке можно наблюдать за множеством физических эффектов и симуляций. Например, модель самого «транспортного средства» Sled также физически корректно рассчитывается при помощи PhysX. Правда, на CPU, так как состоит из слишком малого количества деталей, чтобы переносить это на GPU.
Физическая модель Sled состоит из 200 твёрдых тел и 200 осевых шарниров. И вся физика этих объектов при помощи PhysX рассчитывается на CPU. И ragdoll модель пилота также считается на PhysX. Из всех анимаций в демке заранее просчитанной является только лицевая анимация пилота. Всё остальное рассчитывается в реальном времени.
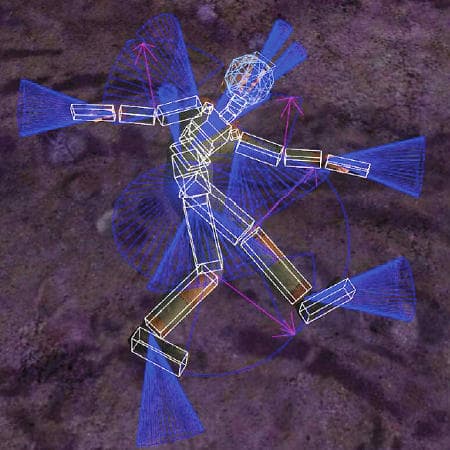
На видеочип возложены наиболее требовательные физические эффекты: имитация поведения дыма, пыли и осколков. Системы частиц на GPU: дым от ракетного двигателя, пыль от ракеты, взрывы, дымные следы от отвалившихся деталей.

Наиболее впечатляюще выглядят разрушения объектов. Например, мост может разрушаться на заранее заданное количество твёрдых тел, вплоть до миллиона! При этом GF100 обеспечивает интерактивную частоту кадров, и смотрится это очень эффектно.

Из графических технологий, применённых в Supersonic Sled, не связанных с физическими эффектами, можно отметить качественную постобработку размытие в движении и применение тесселяции для поверхности земли. Причём, как вы можете видеть на скриншоте выше, тесселяция используется адаптивная.
Технология Nvidia 3D Vision Surround
Естественно, что после анонса главным конкурентом технологии, позволяющей выводить изображение сразу на три монитора, как-то ответить было бы очень желательно. И Nvidia пошла даже ещё дальше, предложив возможность вывода изображения на три устройства в стереорежиме.
Читателям хорошо известна технология Nvidia 3D Vision, которая использует активные беспроводные затворные очки и стереодрайверы Nvidia с поддержкой нескольких сотен игр в стереорежиме. Так вот, на двух видеокартах Nvidia GF100, работающих в конфигурации SLI, при помощи технологии 3D Vision Surround можно будет получить стереоизображение высокого разрешения сразу на трёх устройствах вывода.

Жаль, что поддержка 3D Vision Surround доступна лишь с двумя или более GPU, объединёнными в систему SLI, и с одной видеокартой этот режим не работает. Вообще, решение ведь явно программное, и оно будет работать в том числе и на SLI системах на основе старых видеокарт. Но это абсолютно точно будет игровой режим максимально возможного на сегодня качества. Ведь поддерживается три монитора в разрешении 1920x1080 в стереорежиме, или в разрешении 2560x1600 в обычном 2D.
Плюс ко всему, 3D Vision Surround включает возможность компенсации изображения, скрытого за рамками мониторов. С включенной функцией та часть изображения, которая скрыта за рамками мониторов, не показывается пользователю. В результате получается более целостная картинка, что особенно важно для стереорежима, когда малейшее несоответствие разрушает эффект от стереоизображения. А так получается, как будто рамки мониторов это части кокпита самолёта, вертолёта или гоночного болида.
Выводы
С появлением подробных данных о новой архитектуре Nvidia стало понятно, что эта компания всё так же находится на переднем крае 3D-технологий и продвигает их на рынке ПК. Возможно кого-то пугает, что GPU сейчас становятся всё более похожими на CPU и даже могут составить им конкуренцию в некоторых применениях в высокопроизводительных вычислениях. Но всё же GF100 это в первую очередь именно видеочип.
В состав нового GPU входит шестнадцать движков тесселяции и четыре блока растеризации. И они нужны именно для 3D-графики, скорее даже для будущей 3D-графики. Именно тесселяция и наложение карт смещения могут принести то улучшение качества картинки в игровых приложениях, которое ждут пользователи. И именно в GF100 сделано всё для того, чтобы разработчики могли использовать тесселяцию с максимальным удобством для себя и высокой производительностью для игроков.
Но не только тесселяция и изменившаяся организация обработки геометрических данных привлекает в новой графической архитектуре Nvidia. Возможности неграфических расчётов на GPU сейчас становятся очень важными. И GF100 предлагает максимум возможностей на данный момент. Это первый GPU с поддержкой C++, рекурсии и возможностью кэширования и записи и чтения данных. Эти нововведения совместно дают разработчикам возможности для решения множества проблем и задач, включая трассировку лучей, глобальное освещение, сложные физические эффекты, искусственный интеллект.
Возможно, кому-то кажется несколько странным возлагать на GPU задачи, которыми всегда занимался CPU. Но похоже, что это именно тот путь, по которому движется вся индустрия. И пусть большинство нынешних игровых приложений являются мультиплатформенными, и они ограничены слабостями консолей, на ПК уже сейчас можно добиться намного большего, и нам остаётся надеяться на то, что разработчики будут этим пользоваться. В любом случае, когда-нибудь придёт следующее поколение консолей, и оно совершенно точно будет архитектурно больше похоже на GF100, чем на предыдущие поколения GPU.
В остальном, заочно познакомившись с архитектурой GF100, можно отметить, что в ней, помимо того, что появилось много нового, были устранены и некоторые недостатки предыдущих GPU. Например, значительно усилены блоки ROP и ускорено полноэкранное сглаживание. Которое также получило усовершенствования и по качеству.
К сожалению, пока что нам мало что известно о производительности нового GPU в широком наборе приложений. Мы можем основываться лишь на данных, полученных от Nvidia, и то только для малого круга задач и лишь при определённых настройках. Но если всё обещанное они выполнят, то похоже, что GF100 действительно станет наиболее производительным решением среди всех имеющихся на рынке. Не говоря уже о тех исключительных возможностях, предоставляемых этим GPU для разработчиков.
Это действительно совершенно новая архитектура с множеством интересных изменений. И в ней сходу видно лишь одно потенциально узкое место производительность текстурных модулей. Хотя сама Nvidia говорит о 1,6-кратном приросте скорости блоков TMU, вполне возможны ситуации, когда GF100 будет наравне или даже уступать по скорости текстурирования конкурирующим решениям, особенно в устаревших приложениях, не использующих Gather4 и SSAO. Ведь количество текстурных модулей по сравнению с GT200 даже снизилось.
А в целом, как обычно, рыночный успех новых решений Nvidia будет зависеть от финальных тактовых частот. На бумаге почти всё в новой архитектуре выглядит неплохо, но всё это может быть испорчено низкими частотами конкретных решений, если проблемы с производством на TSMC действительно так велики, как об этом говорят некоторые источники. Будем ждать появления видеокарт на основе новой архитектуры и обязательно расскажем вам о них!


