архитектура нового графического процессора изнутри; как реализована поддержка DirectX 11

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Этого мы ждали если не два года, то год точно... Однако проблемы с производством и иные факторы все откладывали и откладывали выпуск нового продукта Nvidia на базе уже широко всем известной архитектуры Fermi. И вот наконец-то все, что говорила Nvidia на конференциях в октябре 2009 и в январе 2010, стало реальностью. И наша задача изучить новый продукт калифорнийской компании и рассказать о нем. Слово берет Алексей Берилло. Он бывал на всех упомянутых форумах, ему и карты в руки.
Часть 1: Теория и архитектура
Ну вот и дошло дело до практического знакомства с новой графической архитектурой компании Nvidia и первым решением на её основе — Geforce GTX 480. Думаем, что не будет преувеличением сказать, что сегодняшнего анонса заждались все: и поклонники компании, и просто интересующиеся 3D-видеокартами, и даже пользователи продукции конкурента. Первым нужно было подтверждение способностей любимой компании, вторым и третьим — сильная конкуренция и широкий выбор на рынке видеокарт для ПК.
Самой Nvidia также уже очень желательно было обновить графическую архитектуру, ведь предыдущие чипы поддерживают только возможности DirectX 10 и DirectX 10.1, а главный конкурент ещё с осени предлагает всем желающим решения с поддержкой DirectX 11, и игры с использованием возможностей последней версии этого API уже давно начали и продолжают появляться.
Хотя с момента появления первых данных о новой архитектуре прошло не так уж много времени, может показаться, что ждать пришлось слишком долго. Эта ситуация объясняется психологическим фактором, ведь вычислительную архитектуру «Fermi» анонсировали ещё осенью прошлого года, а почти все подробные технические данные были рассказаны ещё в январе. Мы даже выпустили тогда специальный обзор архитектуры GF100, который во многом повторяет первая часть сегодняшнего материала.
Именно поэтому многим читателям кажется, что задержка с выпуском была слишком большая, что-то около полугода. На самом деле перенос был всего лишь один — трёхмесячный. Изначально планировался выход новых решений в последнем квартале 2009 года, который затем был передвинут на квартал вперёд.
Причина долгого ожидания выхода новых решений на рынок довольно проста, и не всё тут зависело от Nvidia. Понятно, что выпуск настолько мощного и большого GPU (более чем три миллиарда транзисторов) был возможен только при помощи нового 40-нм технологического процесса фабрик TSMC. Вот с ним как раз и возникли проблемы. Длительное и мучительное освоение техпроцесса начиналось с мобильных графических чипов AMD и настольного RV740 (он оказался не очень удачным), а также — с мобильных решений архитектуры GT21x компании Nvidia.
Конкурент справился с выпуском новых чипов на этом техпроцессе несколько быстрее, так как его топовый RV870 всё же значительно проще с точки зрения количества транзисторов и потому, что это — доработанная предыдущая архитектура, а не полностью новая, как GF100. В дальнейшем вышли и другие чипы, предназначенные для среднего и нижнего ценовых диапазонов, но и после этого проблемы с производством никуда не испарились, той же AMD продолжает не хватать 40-нм чипов, чтобы удовлетворить требования рынка.
Понятно, что с недостаточно отлаженным и проблемным производством, столь сложный чип GF100 не мог появиться быстро. И вообще — ему было очень непросто появиться таким, каким он был запланирован изначально. Мы не зря упоминали в выводах теоретической статьи о том, что многое решат частоты и параметры конкретных моделей на основе GF100. И вот какими они оказались, и что решили — мы и узнаем в сегодняшней статье.
Для начала будет полезно прочитать предыдущие материалы, если вы ещё не знакомы с архитектурой Geforce GTX 200 (GT200). Все подробности о ней можно прочитать в базовом обзоре на нашем сайте. Это дальнейшее развитие архитектуры G8x/G9x, в которую были внесены некоторые изменения. Вот ссылки и на другие статьи по теме:
- [17.06.08] Nvidia Geforce GTX 280 — 240 калифорнийских стрелков: Смогут ли одолеть предыдущее войско в виде 9800 GX2?
- [29.10.07] Nvidia Geforce 8800 GT (G92) — Уже 112 быстрых калифорнийских стрелков...
- [08.11.06] Nvidia Geforce 8800 GTX (G80) — новый монстр в 3D-графике и первый DX10-ускоритель
Итак, с предыдущими архитектурами видеочипов Nvidia читатели хорошо знакомы, а теперь мы рассмотрим подробные характеристики нового графического процессора этой компании и двух новых моделей видеокарт серии Geforce GTX 400, основанных на этом GPU, выполненном с применением многострадального 40-нм техпроцесса.
Графические ускорители серии Geforce GTX 400
- Кодовое имя чипа GF100;
- Технология производства 40 нм;
- Более 3 миллиардов транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 384-битная шина памяти, шесть независимых контроллеров шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Частота ядра до 700 МГц;
- Удвоенная частота ALU до 1401 МГц;
- 16 потоковых мультипроцессоров, включающих 512 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 6 широких блоков ROP (48 пикселей) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты Geforce GTX 480
- Частота ядра 700 МГц;
- Частота универсальных процессоров 1401 МГц;
- Количество универсальных процессоров 480;
- Количество текстурных блоков — 60, блоков блендинга — 48;
- Эффективная частота памяти 3696 (924*4) МГц;
- Тип памяти GDDR5, 384-бит шина памяти;
- Объем памяти 1536 МБ;
- Пропускная способность памяти 177,4 ГБ/с;
- Теоретическая максимальная скорость закраски 33,6 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 42 гигатекселя в секунду;
- Два Dual Link DVI-I разъема, один Mini HDMI, поддерживается вывод в разрешениях до 2560х1600;
- Двойной SLI разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 250 Вт (8-штырьковый + 6-штырьковый разъёмы);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $499 (в России — 18999 руб).
Спецификации референсной видеокарты Geforce GTX 470
- Частота ядра 607 МГц;
- Частота универсальных процессоров 1215 МГц;
- Количество универсальных процессоров 448;
- Количество текстурных блоков — 56, блоков блендинга — 40;
- Эффективная частота памяти 3348 (837*4) МГц;
- Тип памяти GDDR5, 320-бит шина памяти;
- Объем памяти 1280 МБ;
- Пропускная способность памяти 133,9 ГБ/с;
- Теоретическая максимальная скорость закраски 24,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 34 гигатекселя в секунду;
- Два Dual Link DVI-I разъема, один Mini HDMI, поддерживается вывод в разрешениях до 2560х1600;
- Двойной SLI разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 215 Вт (два 6-штырьковых разъёма);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $349 (в России — 14999 руб).
Производство графических процессоров GF100 по 40-нм технологическим нормам позволило компании Nvidia выпустить такой мощный GPU, который состоит из 3 млрд. транзисторов. Это самый сложный видеочип за всё время. Он обладает массой новых возможностей, о которых мы расскажем далее, а сейчас остановимся на названиях моделей.
Принцип наименования видеокарт Nvidia остался тем же, что и раньше. По сравнению с предыдущими топовыми картами поменялась первая цифра. Причём она скакнула сразу с «2» до «4», пропустив «3». Сделано это потому, что в третьей серии в линейке компании ранее уже появились карты, основанные на старых GPU и предназначенные для OEM-сборщиков.
Новые модели GTX 470 и GTX 480, по всей видимости, должны сместить GTX 275 и GTX 285 по цене ещё ниже, а GTX 295 вряд ли будет выпускаться вообще. Пока остаются проблемы с производством чипов GF100 по новому техпроцессу, многие из карт предыдущего поколения останутся в производстве и продаже, просто их цена снизится ещё немного.
Две модели из серии, как обычно бывает в случае видеокарт Nvidia, отличаются тактовыми частотами видеочипа и памяти, а также разным количеством отключенных исполнительных блоков. GTX 480 имеет 480 потоковых процессоров, 60 TMU и 48 блоков ROP, а модель GTX 470 отличается ещё меньшим количеством активных исполнительных блоков: 448 потоковых процессоров, 56 текстурных блоков и 40 блоков ROP.
Именно так, решений с полностью рабочим GPU пока что не существует, обе модели урезаны так или иначе. Разница в производительности между моделями должна получиться около 20-25%, и неработоспособные на частоте 700/1400 и с 480 включенными процессорами чипы можно будет пустить на GTX 470.
На обе модели устанавливают память типа GDDR5, чтобы не было ограничения производительности полосой пропускания, но ширина шины памяти и её объём у решений отличаются. Старшая модель использует полноценную 384-бит шину памяти, а у младшей отключён один из шести 64-битных контроллеров, поэтому ей остаётся довольствоваться 320-битной шиной.
Соответственно, это влияет и на объём видеопамяти. С 384-битной шиной можно установить 768, 1536 МБ или 3 ГБ, а с 320-битной — 640, 1280 или 2560 МБ. Естественно, что в Nvidia выбрали 1536 и 1280 МБ, так как 640-768 — это слишком мало, а в 3 ГБ нет смысла. Причём объём в 1280 и 1536 МБ мы считаем довольно удачным, так как даже если в редчайших случаях приложениям и не хватает одного гигабайта, то полутора им точно хватит.
Также старшее и младшее решение отличаются разным дизайном печатной платы, и референсные кулеры у них разные — на GTX 470 стоит кулер попроще. Но он всё равно двухслотовый, да и энергопотребление карты хоть и ниже, чем у GTX 480, но незначительно, разница между 215 и 250 Вт невелика.
Основные архитектурные особенности GF100
Как мы уже писали в теоретической статье, кодовое обозначение GF100 расшифровывается так: «GF» в данном случае означает графический («Graphics») чип, основанный на вычислительной архитектуре «Fermi», а число «100» — принятое для продуктов Nvidia наименование первого из чипов архитектуры, нацеленного на верхний ценовой диапазон рынка.
Архитектура GF100 поддерживает все нововведения современного DirectX 11 API, такие как аппаратная тесселяция и вычислительные возможности DirectCompute. Более того, архитектура GF100 спроектирована с учётом будущих возможностей API и потребностей графических приложений, таких как трассировка лучей и физические эффекты.
В GF100 используется третье поколение потоковых мультипроцессоров (Streaming Multiprocessor) с более чем удвоенным количеством вычислительных ядер (CUDA cores), по сравнению с предыдущей архитектурой. Количество и производительность других исполнительных блоков также были увеличены в GF100, но наиболее важным изменением архитектуры является то, что геометрический конвейер в новом GPU впервые за многое время подвергся весьма значительной переработке.
Для того, чтобы соответствовать новым возможностям DirectX 11 и современных графических приложений, в этом GPU значительно увеличена пиковая производительность обработки геометрии, геометрических шейдеров и stream out. И, что особенно важно, этот GPU очень быстр в тесселяции, самом важном нововведении DirectX 11.
Графический конвейер GF100 специально спроектирован с учётом этих возможностей, он способен обеспечить действительно высокую производительность для тесселяции и обработки геометрии. В новом GPU архитектура традиционной геометрической обработки уступила место новой архитектуре, использующей несколько так называемых полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно, по сравнению с одним таким блоком во всех предыдущих поколениях GPU.
В плюс возможностям графического процессора идёт и новая архитектура подсистемы памяти. Полноценные кэши первого и второго уровней обеспечивают быстрый доступ к геометрическим атрибутам для потоковых процессоров и блоков тесселяции.
Есть у GF100 и другие сильные стороны, раскрывающие возможности архитектуры Fermi. В последнее время большое значение имеют неграфические вычисления на GPU, предъявляющие специфические требования к аппаратной части. И основными изменениями в GF100, связанными с повышением эффективности вычислительных алгоритмов, являются быстрое переключение контекста между графическими и неграфическими расчётами, конкурентное исполнение вычислительных программ и улучшенная архитектура кэширования, эффективная для таких задач, как трассировка лучей и искусственный интеллект.
Из других нововведений можно также отметить улучшенную производительность атомарных операций (atomic operations), что ускоряет такие алгоритмы, как рендеринг полупрозрачных поверхностей без предварительной сортировки (order independent transparency). Но давайте перейдём уже к архитектурным подробностям.
Архитектура графического процессора GF100
Как и предыдущие чипы разработки Nvidia, GF100 имеет в своей основе несколько кластеров, теперь они называются кластерами графической обработки (Graphics Processing Clusters), каждый из которых состоит из нескольких потоковых мультипроцессоров (Streaming Multiprocessors), которые, в свою очередь, содержат массивы потоковых процессоров.
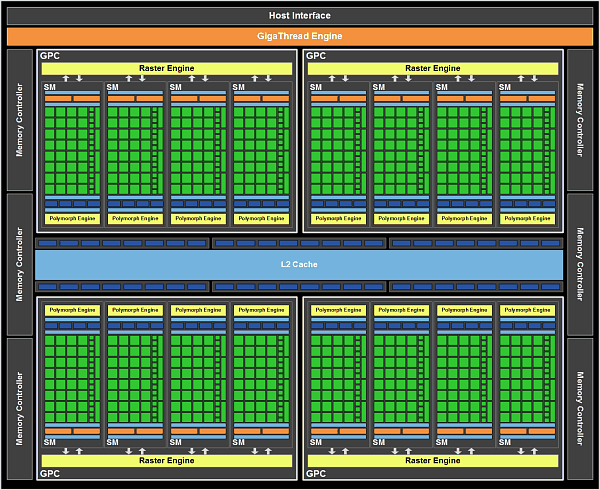
GF100 содержит четыре кластера GPC, шестнадцать мультипроцессоров SM и шесть 64-битных контроллеров памяти. Пока что Nvidia выпустила две модели видеокарт на основе GF100, с разным количеством активных блоков GPC и контроллеров памяти: GTX 470 и GTX 480. Это логично с точки зрения производства, техпроцесс TSMC всё ещё не позволяет выпускать полностью годные чипы в массовых количествах. Такой подход соответствует и рыночной политике, в разные ценовые диапазоны направляются чипы с разными характеристиками.
Итак, новый GPU в своем полном представлении содержит внешний интерфейс PCI Express, движок GigaThread, четыре GPC, шесть контроллеров памяти, шесть укрупненных блоков ROP, а также 768 КБ кэш-памяти второго уровня, присоединённые к блокам ROP.
GPU получает команды по Host Interface, движок GigaThread запрашивает нужные данные из системной памяти и копирует их в локальную память. В отличие от предыдущего чипа, имеющего восемь контроллеров памяти по 64 бита, GF100 имеет шесть таких контроллеров, но обладающих поддержкой GDDR5 памяти, которой не было у решений на основе GT200. В итоге применение GDDR5 памяти и 384-битного доступа к ней даёт достаточно высокую пропускную способность.
Диспетчер GigaThread является центром чипа, он создаёт и распределяет блоки потоков по разным мультипроцессорам, а мультипроцессоры распределяют варпы (warps, группы из 32 потоков) среди потоковых процессоров (CUDA cores) и других исполнительных блоков.
Всего в состав GF100 входит 512 потоковых процессоров, собранных в 16 мультипроцессоров по 32 штуки в каждом. В выпущенных моделях их количество уменьшено до 448 и 480 для GTX 470 и GTX 480 в составе 14 и 15 мультипроцессоров для GTX 470 и GTX 480, соответственно. Каждый SM поддерживает одновременное выполнение до 48 варпов, а CUDA core может выполнять все типы программ: вершинные, пиксельные, геометрические, вычислительные.
Чип GF100 содержит 48 блоков ROP, которые выполняют работу по блендингу и сглаживанию пикселей, а также отвечают за атомарные операции с памятью. Блоки ROP в новом чипе Nvidia сгруппированы в шесть групп по восемь модулей. Каждая группа обслуживается своим 64-битным контроллером памяти. Младшая модель серии GTX 400 отличается одним отключенным укрупнённым блоком ROP, поэтому имеет 320-битную шину памяти и 40 блоков ROP.
Архитектура Graphics Processing Clusters
Итак, графическая архитектура чипа GF100 состоит из четырёх кластеров Graphics Processing Clusters, каждый из которых содержит по четыре мультипроцессора и по своему отдельному движку растеризации (Raster Engine).
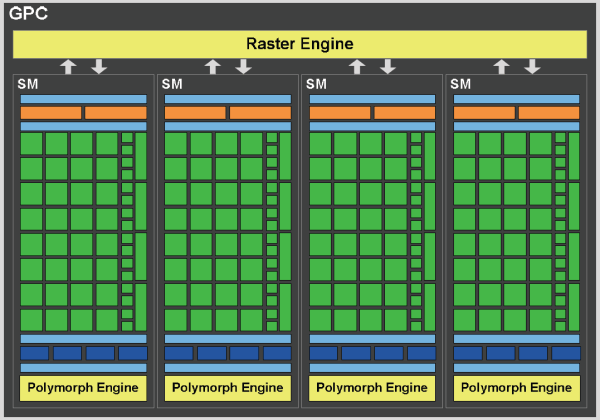
В новом GPC видны два ключевых изменения. Во-первых, появился свой масштабируемый движок растеризации, выполняющий установку треугольников (triangle setup), растеризацию и отбрасывание невидимых поверхностей (z-cull). А во-вторых, GPC теперь содержит и отдельные движки PolyMorph, выполняющие выборку вершинных атрибутов и тесселяцию. Причём движок растеризации Raster Engine принадлежит к GPC, а PolyMorph — к каждому из мультипроцессоров SM в кластере.
Кластер GPC включает все основные графические блоки GPU, за исключением блоков ROP. Фактически, его можно расценивать как отдельный видеочип, и таких в GF100 четыре штуки. В предыдущих GPU Nvidia мультипроцессоры и текстурные блоки были сгруппированы в кластеры текстурной обработки (Texture Processing Clusters), а в GF100 каждый из мультипроцессоров SM имеет по четыре выделенных текстурных блока. Далее об этом написано подробно.
Потоковые мультипроцессоры
В третьем поколении потоковых мультипроцессоров Nvidia мы видим несколько усовершенствований и нововведений, направленных как на увеличение производительности, так и на улучшение программируемости и гибкости их использования.
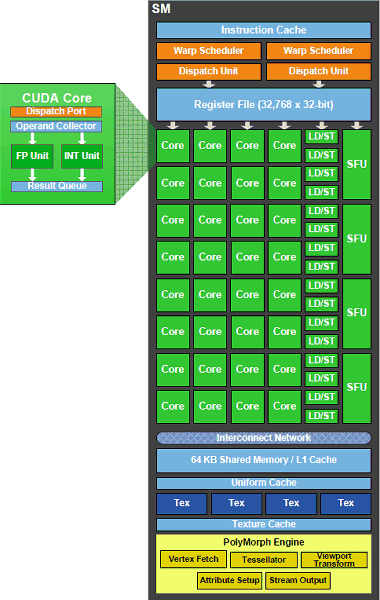
Каждый из мультипроцессоров SM содержит по 32 потоковых CUDA ядра, что вчетверо больше, чем в GT200 (хотя тут нужно учитывать снизившееся общее число мультипроцессоров в чипе). Они остались скалярными, как и ранее, что даёт высокий КПД для любых приложений, а не только специально оптимизированных. Например, операции с Z-буфером (1D) и доступ к текстурам (2D) могут полностью загрузить работой исполнительные блоки GPU, в отличие от ALU суперскалярных архитектур, где КПД будет ниже.
Потоковые процессоры имеют в своём составе исполнительное устройство для целочисленных вычислений (ALU) и исполнительное устройство для вычислений с плавающей запятой (FPU). Вычисления GF100 соответствуют новому стандарту IEEE 754-2008 по вычислениям с плавающей запятой, а также предоставляют возможность выполнения совмещенных операций умножения-сложения (fused multiply-add, или FMA) для вычислений одинарной и двойной точности.
FMA, в отличие от инструкции умножения-сложения (multiply-add, MAD), выполняет эти две операции лишь с одним округлением. Такой подход обеспечивает отсутствие потерь точности при сложении и минимизирует ошибки рендеринга в некоторых случаях. Например, при близких перекрывающихся треугольниках.
Новый целочисленный блок ALU, появившийся в GF100, поддерживает полную 32-битную точность для всех инструкций, как этого требуют языки программирования. Помимо этого, целочисленный ALU с высокой эффективностью исполняет 64-битные операции. Каждый из мультипроцессоров имеет 16 блоков загрузки и сохранения данных (load/store unit, LD/ST или LSU), позволяющих вычислять адреса источника и назначения для 16 потоков за такт.
Четыре исполнительных блока специальных функций (Special Function Units, SFU) выполняют сложные операции, такие как вычисление синуса, косинуса, квадратного корня и т.п. Кроме того, эти блоки используются и для интерполяции графических атрибутов. Каждый блок SFU выполняет одну инструкцию на поток за один такт, то есть варп из 32 потоков будет выполняться за восемь тактов. Конвейер SFU отделён от блока диспетчера, что позволяет последнему обращаться к другим исполнительным устройствам в то время, когда SFU занят.
Важно отметить, что несмотря на значительно ускоренные вычисления с двойной точностью, на которые способна архитектура Fermi, игровые решения на базе чипа GF100 намеренно приторможены и исполняют такие расчёты медленнее, чем теоретически могут. Производительность 64-битных вычислений в Geforce GTX 480 искусственно снижена вчетверо. В случае GTX 480 — до 168 гигафлоп вместо возможных 672.
Собственно, такое решение логично, ведь вычисления с двойной точностью не особенно сильно нужны графическим решениям. Зато это позволит обеспечить хорошие продажи соответствующих решений Tesla на архитектуре Fermi. А картам Geforce не нужна ни очень высокая производительность 64-битных вычислений, ни коррекция ошибок памяти ECC. Всё это будет там, где это востребовано — в Tesla.
Двойной планировщик варпов
Как написано выше, мультипроцессоры выполняют потоки группами по 32 штуки, такие группы называются варпами. Каждый мультипроцессор содержит по два планировщика варпов (Warp Scheduler) и по два диспетчера инструкций (Instruction Dispatch Unit), что позволяет одновременно выполнять по два варпа на каждом из SM.
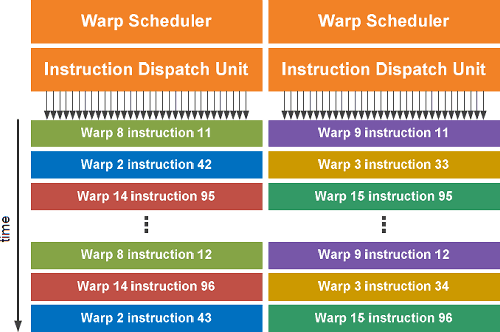
Двойной планировщик варпов в GF100 выбирает два варпа и запускает на выполнение по одной инструкции из каждого из них на группе из 16 вычислительных ядер, 16 блоков LSU или четырёх SFU. Так как варпы исполняются независимо друг от друга, планировщик GPU не должен проверять поток инструкций на зависимые команды. Использование такой модели одновременного исполнения двух команд (dual-issue) за такт позволяет достичь высокой производительности, близкой к пиковым теоретическим значениям.
Большинство инструкций может выполняться одновременно по две: пара целочисленных инструкций, две инструкции с плавающей запятой, или сочетание целочисленной, инструкции с плавающей запятой, загрузки данных, сохранения данных, специальных инструкций SFU. Но это относится только к инструкциям одинарной точности, а команды двойной точности не могут исполняться одновременно с любой другой инструкцией.
Текстурные модули
Для любого графического чипа очень важно количество текстурных модулей в GPU и их возможности. Как видно на схеме мультипроцессора, в каждом из них есть по четыре текстурных блока. Каждый из которых вычисляет адрес и выбирает данные для четырёх текстурных выборок за такт. Результат может быть выдан как в неотфильтрованном виде (для Gather4), так и с билинейной, трилинейной или анизотропной фильтрацией. При фильтрации — с соответствующей потерей темпа.
Кардинально в TMU GF100 ничего не изменилось, по сравнению с предыдущими архитектурами чипов. Nvidia утверждает, что основной задачей текстурников в GF100 было увеличение эффективности выполнения текстурных выборок. В качестве положительных изменений отмечен перенос текстурных модулей в мультипроцессоры, а также улучшение эффективности кэширования и увеличение тактовых частот TMU.
В предыдущем чипе GT200 до трёх мультипроцессоров использовали один укрупнённый текстурный блок, содержащий восемь текстурных модулей. В новой архитектуре GF100 каждый из мультипроцессоров имеет свои выделенные текстурные модули и текстурный кэш. Что теоретически должно положительно сказаться на эффективности, а как дело обстоит на практике — мы проверим в следующей части статьи.
Особенно большой прирост скорости текстурирования Nvidia обещает, когда дело касается наложения карт теней (shadow mapping) и алгоритмов вроде screen space ambient occlusion. В обеих техниках используется стандартная возможность Gather4 из DirectX, которая позволяет выполнить одновременную выборку четырех значений за такт.
Что даже ещё важнее, GF100 имеет более эффективную выделенную кэш-память первого уровня. И вместе с унифицированным кэшем второго уровня это даёт втрое больший объём доступной кэш-памяти для текстур, по сравнению с GT200. Но GT200 имеет всё же банально больше блоков текстурирования количественно, и мы ещё проверим, обеспечивает ли новый чип высокую производительность текстурирования в реальных приложениях или нет.
Из других функциональных изменений в TMU отметим то, что текстурники GF100 получили поддержку новых форматов сжатия BC6H и BC7, появившихся в DirectX 11 и предназначенных для текстур и внеэкранных буферов (render target) в HDR-формате.
Параллельная обработка геометрии
Вернёмся к самым важным нововведениям в GF100. Все предыдущие поколения GPU используют один блок для выборки, установки и растеризации треугольников. Этот привычный вид графического конвейера обеспечивает фиксированную производительность и зачастую может являться ограничителем общей производительности.
В этом также виновата и сложность распараллеливания обработки при отсутствии соответствующих изменений в программном интерфейсе (API). И если ранее такой конвейер с одним блоком растеризации работал приемлемо, при увеличении сложности и массовости геометрических расчётов, растеризация стала главным ограничителем на пути увеличения сложности геометрии в 3D-сценах.
Так, активное использование тесселяции полностью меняет баланс загрузки различных блоков GPU. С тесселяцией плотность треугольников вырастает на порядки, что сильно нагружает такие ранее последовательные участки графического конвейера, как установка треугольников (triangle setup) и растеризация. Для обеспечения высокой производительности тесселяции необходимо было решить эту проблему изменениями архитектуры, перебалансировав весь графический конвейер GPU.
Чтобы добиться высокой скорости обсчёта геометрии, компания Nvidia разработала масштабируемый блок обработки геометрии с названием PolyMorph Engine. Каждый из 16-ти блоков PolyMorph, имеющихся в GF100, содержит собственный модуль по выборке вершин (vertex fetch unit) и тесселятор, что значительно увеличивает производительность геометрических вычислений.
Вдобавок к этому, в GF100 были включены четыре блока растеризации Raster Engine, работающие параллельно и позволяющие выполнять установку до четырёх треугольников за такт. Вместе эти блоки обеспечивают приличный рост производительности обработки треугольников, тесселяции и растеризации.
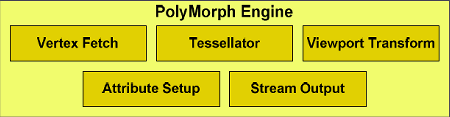
PolyMorph Engine содержит пять стадий: выборка вершин (Vertex Fetch), тесселяция, преобразование в экранные координаты (Viewport Transform), установка атрибутов (Attribute Setup) и потоковый вывод (Stream Output). Результаты, вычисленные в каждой стадии, передаются в мультипроцессор SM. Последний выполняет шейдерную программу, возвращая данные к следующей стадии PolyMorph Engine. После прохождения всех стадий результаты направляются в движки растеризации Raster Engine.
Первая стадия начинается с выборки вершин из глобального вершинного буфера. Выбранные вершины посылаются в мультипроцессор для вершинного затенения (vertex shading и hull shading). В этих двух стадиях вершины преобразуются из координат объектного пространства (object space) в мировое (world space) и вычисляются параметры, необходимые для тесселяции, такие как коэффициент разбиения (tessellation factor). Эти параметры затем пересылаются в тесселятор.
Во второй стадии модуль PolyMorph считывает эти параметры тесселяции и разбивает патч (гладкая поверхность, определенная контрольными точками), выводя результирующую сетку (mesh). Эти новые вершины посылаются в мультипроцессор, где выполняется доменный и геометрический шейдеры.
Доменный шейдер вычисляет итоговое положение каждой вершины на основе данных от поверхностного шейдера (Hull Shader) и тесселятора. На этой стадии обычно применяется карта смещения (displacement map), добавляющая патчу детализации. Геометрический шейдер проводит дополнительную обработку, добавляя или удаляя вершины или примитивы, если необходимо.
В последней стадии PolyMorph Engine производит преобразование в экранные координаты (viewport transformation) и коррекцию перспективы. Далее следует установка атрибутов, а вершины могут быть выведены при помощи stream output в память для дальнейшей обработки.
В предыдущих архитектурах подобные fixed function операции выполнялись лишь одним конвейером. Теоретически при выполнении на GF100 и fixed function, и программируемые операции должны быть распараллелены, что, в свою очередь, должно вызвать прирост производительности в случае ограничения производительности такими операциями.
Блок растеризации
После того, как примитивы обработаны блоком PolyMorph, они отсылаются в блок растеризации Raster Engine. Которых в чипе также установлено несколько штук — четыре в случае GF100. Они тоже работают параллельно, и в результате достигается высокая производительность обработки геометрии.

Движок растеризации выполняет три стадии конвейера. В стадии установки граней (edge setup) производится выборка положения вершин и вычисляются проекции граней треугольника. Треугольники, обращённые к экрану обратной стороной, отбрасываются как невидимые (back face culling). Каждый из блоков установки граней обрабатывает по одной точке, линии или треугольника за такт.
Растеризатор использует проекции граней для каждого примитива и вычисляет покрытие пикселей. Если включено сглаживание, то вычисляется покрытие для каждой выборки цвета и выборки покрытия. Каждый из четырёх растеризаторов на выходе выдаёт по восемь пикселей за такт, то есть всего получается 32 прошедших растеризацию пикселя за такт для всего GPU.
Пиксели из растеризатора посылаются в блок отбрасывания невидимых поверхностей Z-cull. Этот блок сравнивает глубину (depth) пикселей из тайла с глубиной существующих пикселей в экранном буфере и отбрасывает те из них, которые лежат за пикселями в экранном буфере. Это называется раннее отбрасывание невидимых поверхностей, которое экономит ресурсы, убирая необходимость проведения лишних попиксельных вычислений.
Новую архитектуру кластеров GPC мы считаем наиболее важным нововведением в геометрическом конвейере GF100. Ведь при тесселяции требуется значительно большая производительность блоков установки треугольников и их растеризации. Шестнадцать блоков PolyMorph Engine значительно увеличивают производительность выборки треугольников, тесселяции и потокового вывода Stream Out, а четыре блока Raster Engine обеспечивают высокую скорость установки треугольников и их растеризации.
В следующей части статьи мы обязательно проверим те предварительные оценки производительности тесселяции, что мы давали в теоретическом описании архитектуры GF100. Наличие выделенных тесселяторов в каждом из мультипроцессоров и блоков растеризации в каждом кластере GPC должно давать прирост геометрической производительности вплоть до восьмикратного, по сравнению с GT200. Вот это мы скоро и проверим.
Подсистема памяти
Для современного GPU очень важна и эффективная организация подсистемы памяти. Тем более, когда всё больше и больше внимания уделяется неграфическим вычислениям. В своём новом чипе компания Nvidia ещё раз усовершенствовала модель памяти. GF100 содержит выделенный кэш первого уровня в каждом мультипроцессоре (SM).
Кэш-память работает совместно с разделяемой (общей) памятью мультипроцессора и дополняет её. Общая память улучшает скорость доступа к памяти для алгоритмов с предсказуемым доступом к памяти, а кэш-память L1 ускоряет доступ из нерегулярных алгоритмов, в которых адреса запрашиваемых данных заранее неизвестны.
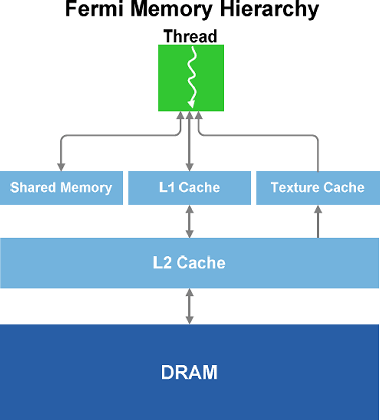
Каждый мультипроцессор в GF100 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, и наоборот — 16 КБ общей памяти и 48 КБ кэша.
Для графических программ GF100 использует вариант с 16 КБ кэша, он работает как регистровый буфер. В вычислительных программах кэш и общая память позволяет потокам одного блока обмениваться данными, работая вместе, что снижает требования к пропускной способности памяти. Кроме того, общая память сама по себе позволяет эффективно использовать на GPU многие вычислительные алгоритмы.
Кроме того, GF100 имеет 768 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки. Кэш второго уровня обеспечивает эффективный и высокоскоростной обмен данными для всего GPU. И вычислительные алгоритмы, запросы данных в которых непредсказуемы (физические расчёты, трассировка лучей и др.), получат значительный прирост скорости от аппаратной кэш-памяти. А фильтры постобработки, в которых несколько мультипроцессоров читают одни и те же данные, получат ускорение из-за меньшего количества вызовов данных из внешней памяти.
Унифицированная кэш-память более эффективна, чем отдельные кэши для разных целей. При выделенных кэшах может сложиться положение, когда один из них используется полностью, но воспользоваться простаивающими объёмами других типов кэш-памяти при этом невозможно. И эффективность кэширования будет ниже теоретически возможной. А унифицированный L2 кэш в GF100 динамически выделяет пространство под разные запросы, что позволяет добиться высокой эффективности.
В общем, теперь один L2 кэш замещает собой текстурный L2 кэш, кэш ROP и начиповые буферы GPU предыдущих поколений. Кэш второго уровня в GF100 используется для записи и чтения данных, и является полностью последовательным (когерентным). Сравните с L2 кэшем в GT200, используемым только для чтения.
В целом, новый GPU обеспечивает более эффективный обмен данными между стадиями конвейера и способен значительно сэкономить пропускную способность внешней памяти, повысив эффективность использования исполнительных блоков видеочипа.
Новые блоки ROP и улучшенное сглаживание
Блоки ROP и подсистема блендинга и сглаживания в GF100 также претерпела значительные изменения, направленные на увеличение эффективности их работы. Один раздел ROP в GF100 содержит восемь блоков ROP, то есть вдвое больше, чем в предыдущих поколениях. Каждый блок ROP способен выводить 32-битное целочисленное значение за такт, пиксель формата FP16 за два такта или FP32 пиксель за четыре такта.
Самым большим недостатком предыдущих чипов, связанным с ROP, считается низкая эффективность сглаживания методом мультисемплинга MSAA 8x. Nvidia значительно улучшила производительность этого режима в GF100, повысив эффективность сжатия буфера, а также эффективность работы блоков ROP при рендеринге небольших примитивов. Последнее изменение важно и потому, что тесселяция увеличивает количество мелких треугольников, и требования к производительности блоков ROP при этом возрастают.
Но не только скорость сглаживания нам интересна, но и качество изображения. В своих новых решениях серии GTX 400, Nvidia вводит новый алгоритм сглаживания, названный 32x CSAA (Coverage Sampling Antialiasing), обеспечивающий высочайшее качество сглаживания как геометрии, так и полупрозрачных текстур, использующих alpha-to-coverage. Число 32 в данном случае расшифровывается как восемь честных мультисемплинговых выборок плюс 24 выборки покрытия пикселя (pixel coverage).
В предыдущих поколениях использовалось четыре или восемь выборок, что не обеспечивает полного избавления от алиасинга, но вызывает бандинг. А новый режим 32x CSAA использует 32 coverage выборки, минимизирующих все артефакты алиасинга.
Полупрозрачное сглаживание методом мультисемплинга (Transparency Multisampling, или TMAA) также получает преимущество от улучшенного метода CSAA. TMAA обычно используется в старых DirectX 9 приложениях, которые не используют метод alpha-to-coverage, недоступный для этого API. В этом случае используется техника альфа-теста, при которой полупрозрачные текстуры имеют резкие края.

Изображение слева показывает сглаживание методом TMAA, использующим режим 16xQ с восемью мультисемплинговыми и восемью coverage выборками, максимально возможный для GT200. А с правой стороны показан антиалиасинг TMAA на GF100, использующий метод 32x CSAA, с восемью мультисемплинговыми и 24 coverage выборками.
Использование coverage выборок не очень сильно повышает требования к пропускной способности памяти и её объёму, производительность нового метода 32x CSAA незначительно отличается от обычного 8x MSAA на GF100, лишь на десяток процентов в худшем случае. А, учитывая небольшую разницу между 4x и 8x, самым лучшим методом по соотношению производительности и качества будет как раз 32x CSAA, особенно на таких мощных решениях, как GTX 470 и GTX 480.
Вычислительные задачи на GPU
До сих пор GPU создавались с расчётом на применение растеризации, а другие применения были лишь побочной возможностью. Но постепенно появляются и другие применения, новые алгоритмы в игровых движках, так как GPU расширяют свои возможности, поддерживая расчётные API вроде CUDA, DirectCompute и OpenCL.
Архитектура чипа GF100 была спроектирована для эффективного исполнения различных алгоритмов и решения множества неграфических задач, поддающихся распараллеливанию. Например, в трассировке лучей, физических расчётах и алгоритмах искусственного интеллекта, использование общей памяти бесполезно, но в этом случае поможет кэш-память, которая как раз появилась в GF100. 48 килобайт кэша первого уровня на каждый из мультипроцессоров и использование глобального кэша второго уровня может повысить производительность многих алгоритмов.
Другим важным изменением в GF100 стал улучшенный планировщик. G80 и GT200 выполняют большие программы со сравнительно большим временем переключения контекста между различными задачами. Для чисто вычислительных задач с большими объёмами данных это подходит, но игровые приложения используют несколько различных задач одновременно: имитация тканей, физика жидкостей, постобработка и т.п. И на GF100 эти задачи могут эффективно выполняться параллельно, обеспечивая максимальный КПД для вычислительных устройств.
В играх с использованием вычислительных шейдеров, переключение контекста происходит каждый кадр, и высокая скорость этого переключения критична для поддержания высокой частоты кадров. В GF100 значительно снизили время переключения контекста (до 20 микросекунд), что сделало возможным быстрое и неоднократное переключение между потоками в пределах одного кадра.
Вычислительные алгоритмы могут использоваться для решения большого количества задач различного плана в игровых приложениях. Например, это новые гибридные алгоритмы рендеринга, когда трассировка лучей применяется для отрисовки корректных отражений и преломлений. Или воксельный рендеринг для правдоподобной имитации объёмных данных.
Это может быть и сложная постобработка изображений: продвинутый HDR-рендеринг, сложные фильтры для сглаживания и имитации оптических эффектов, вроде имитации зоны нерезкости и боке (bokeh). А в играх уже сейчас используются физические эффекты, которые можно ещё усложнить, добавить динамику жидкостей, турбулентность для эффектов с системами частиц, вроде дыма или жидкостей, и т.п.
Из конкретных примеров можно привести многие современные игры. Так, для создания реалистичной водной поверхности в совсем новой игре Just Cause 2 при помощи CUDA используются возможности чипов Nvidia. Мы уж не говорим о DirectCompute, который применяется для постобработки в Aliens vs Predator, Metro 2033 и DiRT 2.
Для раскрытия всех вычислительных способностей новых решений, Nvidia выпустила CUDA Toolkit 3.0, в котором появилась поддержка основанных на графическом процессоре GF100 продуктов, вместе с обещанной поддержкой C++, ECC, а также библиотек линейной алгебры (BLAS и LAPACK), дебаггера CUDA-GDB и профайлера Visual Profiler.
Также Nvidia выпускает удобный набор для 3D-разработчиков — Parallel Nsight, также известный как Nexus. Этот набор помогает в удобной разработке приложений, использующих GPU в среде Visual Studio 2008. В него входят утилиты для отлова ошибок, профилирования, анализа кода для GPU и его производительности. Всё это интегрировано прямо в Visual Studio и весьма удобно. Поддерживается CUDA C, OpenCL, DirectCompute, Direct3D, и OpenGL. Мы уверены, что разработчики оценят богатые возможности нового ПО Nvidia и возьмут его на вооружение.
Трассировка лучей
Метод трассировки лучей часто используется в 3D-графике, но он слишком трудоёмок, чтобы использовать его в графике реального времени. Поэтому в будущих приложениях возможно применение трассировки совместно с растеризацией. Трассировку непросто выполнить эффективно на GPU, ведь просчитываемые лучи имеют непредсказуемые направления, и их просчёт требует доступа к памяти по случайным адресам, в то время как GPU обычно получают данные из памяти линейными блоками.
Архитектура GF100 как раз отличается от предыдущих тем, что при её проектировании учитывались требования в том числе и алгоритмов трассировки лучей. Это первый видеочип, поддерживающий аппаратную рекурсию, что делает возможным эффективное выполнение подобных задач. Да и двухуровневая архитектура кэширования значительно увеличивает эффективность рейтрейсинга, увеличивая скорость запросов данных из памяти. L1 кэш улучшает «локальность» памяти для соседних лучей, а L2 кэш увеличивает пропускную способность доступа к видеопамяти.
GF100 способен эффективно выполнять и продвинутые алгоритмы просчёта глобального освещения, такие как трассировка пути (path tracing). Этот метод схож с трассировкой лучей, в нём используется большое количество лучей для сбора данных о непрямом освещении сцены. В данном алгоритме производительность GF100 до 3,5-4 раз выше по сравнению с GT200.
Но всё же эти методы слишком сложны, чтобы применять их в играх. Разработчики могут использовать одновременно и растеризацию, и трассировку лучей, что называется гибридным рендерингом. Например, растеризация может использоваться в первом проходе рендеринга, а для части пикселей в следующем проходе при помощи трассировки лучей просчитается отражение. Такие гибридные модели — отличный способ получения высокой производительности при весьма высококачественном результате.
Для демонстрации возможностей своих решений Nvidia создала специальную демонстрационную программу Design Garage, в которой при рендеринге моделей автомобилей в настраиваемой сцене при помощи технологии Nvidia OptiX рассчитывается глобальное освещение. Эта программа будет доступна для всех владельцев видеокарт Nvidia, но на решениях вышедших до GTX 470 и GTX 480, она довольно сильно тормозит.

В качестве пожелания к игровым разработчикам — нам бы очень хотелось увидеть интеграцию подобной возможности в игровой движок какой-нибудь гоночной игры. С её помощью игроки смогли бы получить очень качественные изображения своих любимых автомобилей в режимах «photo mode» или «gallery mode», уже существующих в подобных играх, но весьма далёких по качеству от представленного выше.
Технология Nvidia 3D Vision Surround
С выходом решений линейки GTX 400 компания Nvidia предложила технологию, позволяющую выводить стереоизображение сразу на три монитора (понятно, что сподвигла их на это вышедшая ранее технология Eyefinity от заклятого конкурента).
Технология использует активные беспроводные затворные очки и стереодрайверы Nvidia из комплекта 3D Vision. На двух видеокартах GTX 400, работающих в конфигурации SLI, при помощи технологии 3D Vision Surround можно получить стереоизображение высокого разрешения сразу на трёх устройствах вывода.

Поддерживается три монитора в разрешении 1920x1080 в стереорежиме или в разрешении 2560x1600 в обычном 2D. Также, 3D Vision Surround включает возможность компенсации изображения, скрытого за рамками мониторов. С включенной функцией та часть изображения, которая скрыта за рамками мониторов, не показывается пользователю. В результате получается более целостная картинка, что особенно важно для стереорежима, когда малейшее несоответствие картинки на разных мониторах может разрушить эффект объёма.
Отметим, что 3D Vision Surround — это чисто программное решение, и оно работает лишь с двумя или более GPU, объединёнными в систему SLI, а с одной видеокартой такой возможности нет — количество активных выходов всё равно не может быть более двух на каждую карту. Зато эта технология будет работать в том числе и на SLI системах на основе старых видеокарт серии GTX 200. Поддержка 3D Vision Surround должна появиться в драйверах в следующем месяце.
Выводы по архитектуре
Из написанного выше очевидно, что GF100 — это абсолютно новая архитектура Nvidia, а не доработанная старая. Новый GPU отличается значительно улучшенными возможностями по графическим и неграфическим расчётам. Можно сказать, что по своей универсальности он стал ближе к CPU и должен в ближайшем будущем составить им конкуренцию в высокопроизводительных вычислениях.
С точки зрения графического конвейера в GF100 были сделаны очень важные изменения. В состав нового GPU входит шестнадцать движков тесселяции и четыре блока растеризации, которые весьма полезны для 3D-графики в играх DirectX 11. Тесселяция и наложение карт смещения являются самым важным нововведением этой версии API и приносят заметное улучшение качества картинки, и GTX 470 и GTX 480 должны обеспечивать высокую производительность при обработке геометрии.
Не только изменениями в графическом конвейере может похвастать новая графическая архитектура Nvidia. Новые решения предлагают максимальные возможности для неграфических расчётов на GPU. Это первые графические решения с поддержкой C++, рекурсии и возможностью кэширования и записи и чтения данных. Нововведения дают разработчикам возможности для решения множества задач, включая трассировку лучей, глобальное освещение, сложные физические эффекты, искусственный интеллект и т.п.
В новой архитектуре были устранены и некоторые недостатки предыдущих GPU. Например, блоки ROP в GF100 значительно усилены, а полноэкранное сглаживание получило улучшения и по качеству и по производительности.
По сравнению с предыдущим чипом, в GF100 компания Nvidia удвоила число потоковых процессоров, немного увеличила пропускную способность памяти за счёт поддержки GDDR5 (но шина памяти сузилась с 512-бит до 384-бит). И всё бы хорошо, но при сравнении характеристик GF100 и GT200 видно, что слабым местом нового решения может стать количество текстурных модулей — их в GF100 стало даже меньше, чем было в GT200.
И вполне возможны ситуации, когда GTX 480 будет наравне или даже уступать по скорости текстурирования предыдущим решениям Nvidia и конкурирующим, особенно в устаревших приложениях, не использующих Gather4 и SSAO. Такому решению Nvidia мы видим два возможных объяснения. Или разработчики намеренно усилили вычислительные способности чипа, несколько ослабив при этом графические, предполагая дальнейшее изменение баланса в играх в сторону вычислений, или же изначально частота работы текстурных блоков планировалась большей, чем получилось в итоге в моделях, поступивших в продажу.
Как мы знаем, у Nvidia разные части чипа способны работать на разных частотах, производных от других. И есть такое предположение, что TMU должны были работать быстрее, и этим объясняется их меньшее количество, по сравнению с GT200. Возможно, что из-за проблем с техпроцессом TSMC, частоту текстурных модулей не удалось поднять до проектной, и в итоге пиковая производительность текстурирования не просто не выросла, а даже снизилась.
Если решение об усилении математических способностей в ущерб текстурированию было принято намеренно, будет ли оно оправданным при том, что в последние годы выходят в основном мультиплатформенные игры, а требовательные ПК-игры можно пересчитать по пальцам? Впрочем, возможно, что в реальных игровых приложениях недостаток компенсируется улучшенной архитектурой кэширования, которая сгладит его.
Ещё одним недостатком новых видеокарт Nvidia, на наш взгляд, можно назвать отключение части потоковых ядер из-за проблем с производством столь сложного чипа на 40 нм техпроцессе TSMC. Все первые модели на GF100 имеют отключенные исполнительные блоки: в GTX 480 и GTX 470 активны не 512 потоковых процессоров, которые физически есть в чипе, а лишь 480 и 448 процессоров, соответственно. Вместе с не слишком высокими частотами это объясняется необходимостью улучшения выхода годных продуктов. В результате, очень хорошо выглядящая на бумаге архитектура может показать не самые впечатляющие результаты в некоторых приложениях.
Но об этом мы точно узнаем в следующих частях статьи. В первой части мы познакомились с теоретическими особенностями нового чипа GF100 и новых моделей видеокарт на его основе от компании Nvidia, а следующая часть статьи посвящена практической части исследования в синтетических тестах, в которой мы сравним производительность новых решений на основе чипа GF100 со скоростью предыдущих решений компании и конкурирующих видеокарт AMD.


