240 калифорнийских стрелков: Смогут ли одолеть предыдущее войско в виде 9800 GX2?

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Часть 1: Теория и архитектура
Все интересующиеся 3D-графикой долго ждали настоящего обновления архитектуры G80. Разнообразных слухов о следующем поколении чипов хватало всегда, некоторые из них в дальнейшем подтвердились, но в 2007 году мы дождались лишь минорного архитектурного обновления в виде решений на основе чипов G92. Все выпущенные на их основе видеокарты — неплохие для своих секторов рынка, эти чипы позволили снизить стоимость мощных решений, сделав их менее требовательными к питанию и охлаждению, но энтузиасты ждали полноценного обновления.
И пока мы его ждали, Nvidia успевала запутывать всех кодовыми именами, изменениями названий и т.п. Будущие карты и/или чипы в разное время ожидались под именами G100, G200, GT200 и D10U. Естественно, речь об утечках информации, и вполне возможно, что намеренная путаница — это один из методов борьбы с ними. Хотя есть вероятность, что причины этого в том же, что и в путанице с названиями, который мы видим в линейке компании.
В итоге, были анонсированы два решения на базе видеочипа с кодовым наименованием G100 или GT200 (в разных источниках они именуются по-разному), что только затрудняет понимание. Хотя Nvidia традиционно именует чипы по названиям карт — Geforce GTX 260 и Geforce GTX 280. В своем материале мы будем называть видеочип GT200, а готовые решения — так, как называет карты сама Nvidia.
Очень радостно, что наконец-то теоретическая часть по новым продуктам в этот раз будет полноценной, архитектурные изменения в чипе есть, пусть и не такие большие, как при выходе G80. Перед прочтением данного материала мы рекомендуем внимательно ознакомиться с базовыми теоретическими материалами DX Current, DX Next и Longhorn, описывающими различные аспекты современных аппаратных ускорителей графики и архитектурные особенности продукции Nvidia и AMD.
- [06.06.05] Longhorn — ускорители и шейдеры для DirectX 10
- [01.03.05] DirectX.Update — Ускорители 3D-графики: полшага вперед
- [09.04.04] DX.Next: ближайшее и ближнее будущее аппаратного ускорения 3D-графики
Эти материалы достаточно точно спрогнозировали текущую ситуацию с архитектурами видеочипов, оправдались многие предположения о будущих решениях. А подробную информацию об унифицированной архитектуре Nvidia G8x/G9x на примере предыдущих чипов можно найти в следующих статьях:
- [11.12.07] Nvidia Geforce 8800 GTS 512MB (G92) — Снова 128 более сильных калифорнийских стрелков, но с урезанными копьями
- [29.10.07] Nvidia Geforce 8800 GT (G92) — Уже 112 быстрых калифорнийских стрелков…
- [17.04.07] Nvidia Geforce 8600 GTS (G84) — 32 калифорнийских стрелка в действии
- [08.11.06] Nvidia Geforce 8800 GTX (G80) — новый монстр в 3D-графике и первый DX10-ускоритель
Архитектурно GT200 во многом перекликается с G8x/G9x, новый чип взял у них всё лучшее и был дополнен многочисленными улучшениями. И сейчас мы переходим к рассмотрению особенностей новых решений, и начинаем с теоретических данных об обновленной архитектуре.
Графический ускоритель Geforce GTX 280
- кодовое имя чипа GT200;
- технология 65 нм;
- 1,4 миллиарда (!) транзисторов;
- унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных;
- аппаратная поддержка DirectX 10, в том числе шейдерной модели — Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output);
- 512-битная шина памяти, восемь независимых контроллеров шириной по 64 бита;
- частота ядра 602 МГц (Geforce GTX 280);
- ALU работают на более чем удвоенной частоте 1,296 ГГц (Geforce GTX 280);
- 240 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит и 64-бит точности в рамках стандарта IEEE 754(R), выполнение двух операций MAD+MUL за такт — подробности см. далее);
- 80 блоков текстурной адресации и фильтрации (как и в G84/G86 и G92) с поддержкой FP16 и FP32 компонент в текстурах;
- возможность динамических ветвлений в пиксельных и вершинных шейдерах;
- 8 широких блоков ROP (32 пикселя) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 128 MSAA отсчетов (+ 128 Z) за такт, в режиме без цвета (Z only) — 256 отсчетов за такт;
- запись результатов до 8 буферов кадра одновременно (MRT);
- все интерфейсы (два RAMDAC, два Dual DVI, HDMI, DisplayPort, HDTV) интегрированы на отдельный чип.
Спецификации референсной видеокарты Geforce GTX 280
- частота ядра 602 МГц;
- частота универсальных процессоров 1296 МГц;
- количество универсальных процессоров 240;
- количество текстурных блоков — 80, блоков блендинга — 32;
- эффективная частота памяти 2,2 ГГц (2*1100 МГц);
- тип памяти GDDR3;
- объем памяти 1024 МБ;
- пропускная способность памяти 141,7 ГБ/с;
- теоретическая максимальная скорость закраски 19.3 гигапикселей в с;
- теоретическая скорость выборки текстур до 48.2 гигатекселя в с;
- два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600;
- двойной SLI разъем;
- шина PCI Express 2.0;
- TV-Out, HDTV-Out, DisplayPort (опционально);
- энергопотребление до 236 Вт;
- двухслотовое исполнение;
- рекомендуемая цена $649.
Спецификации референсной видеокарты Geforce GTX 260
- частота ядра 576 МГц;
- частота универсальных процессоров 1242 МГц;
- количество универсальных процессоров 192;
- количество текстурных блоков — 64, блоков блендинга — 28;
- эффективная частота памяти 2,0 ГГц (2*1000 МГц);
- тип памяти GDDR3;
- объем памяти 896 МБ;
- пропускная способность памяти 111,9 ГБ/с;
- теоретическая максимальная скорость закраски 16,1 гигапикселей в с;
- теоретическая скорость выборки текстур до 36,9 гигатекселя в с;
- два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600;
- двойной SLI-разъем;
- шина PCI Express 2.0;
- TV-Out, HDTV-Out, DisplayPort (опционально);
- энергопотребление до 182 Вт;
- двухслотовое исполнение;
- рекомендуемая цена $399;
Первое, что привлекает внимание — огромная сложность GPU. Как вы понимаете, 1,4 миллиард транзисторов делает видеочип GT200 наиболее сложным видеочипом в истории. Естественно, будучи изготовленным всё по той же технологии производства 65 нм, что и чипы G9x, новый GPU имеет довольно большую площадь, а также потребление энергии и тепловыделение. И рабочие частоты были явно понижены по сравнению с предыдущими решениями. Будем ждать перевода производства на технологию 55 нм, которая позволит снизить себестоимость производства. А на данный момент, соответствующие мощности TSMC, видимо, заняты производством других чипов.
Количественных и качественных архитектурных изменений в GT200 довольно много. Видеочип, применённый в видеокартах серии Geforce GTX 200, включает в себя большое количество улучшений и модификаций, по сравнению с предыдущими GPU.
При разработке нового чипа перед инженерами компании Nvidia стояли определенные задачи, некоторые из них:
- создать GPU с производительностью до двух раз превосходящей скорость предыдущего топового решения (имеется в виду Geforce 8800 GTX на основе G80);
- перебалансировать архитектуру под будущие 3D-приложения, использующие более сложные шейдеры (усилить математику и увеличить внутричиповые кэши);
- увеличить эффективность архитектуры, её производительность на ватт и квадратный миллиметр площади чипа;
- устранить некоторые узкие места предыдущих чипов, обнаруженные при исполнении алгоритмов с участием геометрических шейдеров и stream out;
- значительно усилить вычислительные возможности GPU для приложений CUDA и расчёта физики, дополнив это расширением функциональности (FP64);
- снизить потребление энергии во время простоя видеочипа.
И такая работа была успешно проведена, в GT200, по сравнению с G8x/G9x, были сделаны соответствующие изменения. Перечислим основные архитектурные улучшения нового видеочипа, по сравнению с первым чипом первого поколения унифицированных архитектур Nvidia (G80):
- почти вдвое большее количество потоковых процессоров;
- в 2,5 раза большее количество одновременно выполняемых вычислительных потоков;
- возможность одновременного исполнения двух инструкций (dual issue) потоковыми процессорами;
- поддержка вычислений с плавающей точкой двойной точности, по стандарту IEEE 754R;
- обновленная управляющая логика с увеличенной эффективностью;
- удвоенный размер файла регистров, увеличивающий скорость исполнения сложных шейдеров;
- архитектурные улучшения, ускоряющие stream out и исполнение геометрических шейдеров;
- гигабайтный буфер экрана и 512-битная шина памяти;
- полноскоростной блендинг блоками ROP (против половинной скорости у G80);
- улучшенные технологии компрессии и z-cull, большая эффективность использования пропускной способности памяти, улучшенные алгоритмы сжатия;
- аппаратная поддержка 10-битного вывода по DisplayPort.
Архитектура
Ещё первое поколение унифицированных чипов Nvidia (серии Geforce 8 и 9) имело в своей основе масштабируемый массив процессоров. Второе поколение унифицированной архитектуры, которое мы сегодня рассматриваем, также имеет подобную основу, но улучшенную и переработанную. Массив содержит определённое количество блоков TPC (Texture Processing Clusters), каждый из которых включает несколько потоковых мультипроцессоров (streaming multiprocessors — SM). А каждый из SM, в свою очередь, состоит из нескольких потоковых процессоров (SP), которые чаще всего считаются и сравниваются в маркетинговых материалах. Потоковые мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических задачах, так и в некоторых расчётных.
Новое поколение архитектуры графических чипов Nvidia увеличило свою вычислительную производительность по сравнению с предыдущими чипами G80 и G92. Во-первых, число потоковых мультипроцессоров SM на каждый блок TPC возросло и стало равным трём, в отличие от двух в предыдущем поколении. Во-вторых, число блоков TPC в чипе было увеличено с 8 штук до 10. В итоге мы получили 10 * 3 * 8 = 240 потоковых процессоров в одном GPU. Приведём основную диаграмму чипа GT200:
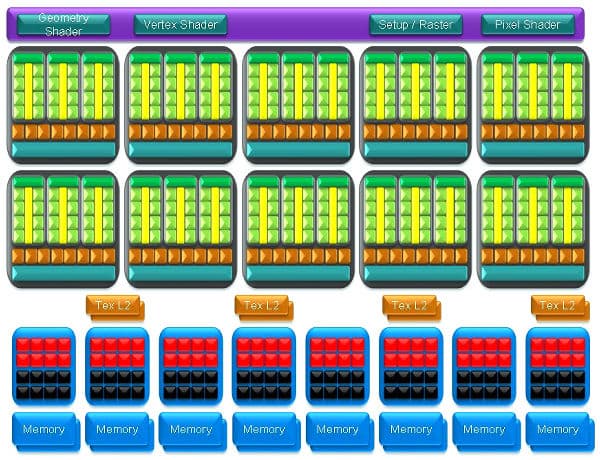
Всё то же, что и у G80, особенных изменений нет, разве что диаграмма ярче стала. В верхней части диаграммы виден диспетчер — логика, которая управляет выполнением многочисленных шейдеров. Также там расположены и блоки triangle setup, и другие. Далее, идут уже десять блоков TPC, каждый из которых включает по 24 потоковых процессора и по 8 блоков текстурной выборки, и фильтрации. Блоки ROP, связанные с интерфейсом обмена с памятью, расположены в нижней части диаграммы. А подробная диаграмма блока TCP:

Ничего особенно нового, очевидны только количественные изменения и добавленный FP64. К слову, каждый TCP содержит локальную память объёмом 16 Кб, которая разделяется между всеми потоковыми процессорами в блоке.
Чтобы было понятнее, какую часть чипа занимают те или иные блоки в GPU, приведем фотографию чипа GT200 с указанными площадями соответствующих исполнительных блоков.
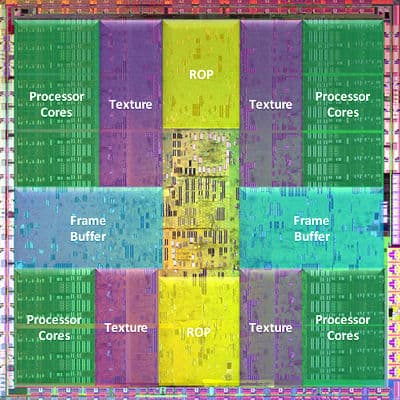
В центре, вероятно, расположена управляющая логика. Кэши в видеочипах небольшие, по сравнению с процессорными, и на схеме они отдельно не выделены, хотя они там есть. Как видите, больше всего места занимают потоковые процессоры, но довольно велики и блоки TMU и ROP, первые мало уступают по занимаемой площади шейдерным процессорам. Понятно, почему транзисторный бюджет и общая площадь чипа так сильно выросли, ведь в GT200, по сравнению с G80 и G92 выросло количество всех блоков, без исключения.
В результате всех количественных и качественных изменений, эффективность новой архитектуры значительно увеличена, по сравнению с предыдущим поколением. Сейчас мы подробно остановимся на каждой модификации в новом поколении GPU. Увеличенное количество одновременно исполняющихся потоков
Одной из важнейших отличительных особенностей GT200 является поддержка более чем 30000 потоков. Управляющая потоками логика следит за тем, чтобы все потоковые процессоры были заняты работой на 100%, чтобы их мощности не простаивали. Каждым блоком SM поддерживается одновременное выполнение до 1024 потоков, что для 30 подобных блоков на чип составляет целых 30720 потоков, одновременно исполняемых GT200. Сравните с 768 потоками на SM и 12288 потоков на GPU для предыдущих решений на основе чипов G80 и G92.
Это изменение должно вызвать прирост производительности и гибкости, как параллельных вычислений, так и сложных графических расчётов. К сожалению, Nvidia не приводит статистики, поэтому судить о реальных приростах сложно. Увеличенный размер файла регистров
По сравнению с G80 и G92, был удвоен размер локального регистрового файла в каждом блоке SM. Предыдущие решения иногда сталкивались с ситуациями, когда сложные и длинные шейдеры упирались в нехватку места для регистров, и их значения перебрасывались в память, что снижало производительность. Увеличенный размер файла регистров на GT200 позволяет осуществлять выполнение сложных и длинных шейдеров с большей эффективностью и производительностью.
Конечно, это вызвало определённое усложнение чипа и увеличение его площади, но регистровый файл занимает незначительную часть площади блоков SM. Зато увеличивающаяся сложность шейдеров в играх и приложениях приведет к увеличению производительности в случаях, когда им требуется много регистров. Так, по данным самой Nvidia, увеличенный вдвое регистровый файл даёт прирост скорости в 3DMark Vantage на 10-15%. Это очень хорошая цифра для подобной экстенсивной модификации в чипе. Улучшенные возможности по одновременному исполнению двух инструкций (Dual Issue)
Dual Issue — это способность выполнения сразу двух инструкций за такт в одном шейдере (MAD+MUL в данном случае). В каждом блоке SM содержатся специальные исполнительные блоки (special function unit — SFU), они вычисляют сложные функции, интерполируют атрибуты, а также выполняют операции умножения (MUL). С их помощью каждый потоковый процессор чипа GT200 способен исполнять не только одну операцию умножения со сложением (multiply-add — MAD), но одновременно ещё и MUL.
Для выполнения MAD используются возможности самих потоковых процессоров, а SFU в то же время выполняет ещё одну операцию умножения. Специально оптимизированные тесты используют эту возможность с близкой к 100% эффективностью, и именно благодаря этой особенности, анонсированные компанией Nvidia видеокарты достигают пиковой теоретической производительности почти в гигафлоп для вычислений с плавающей точкой одинарной точности. Поддержка вычислений двойной точности
Но не одной одинарной точностью может похвалиться рассматриваемый видеочип. Очень важным для вычислительных задач (CUDA и т.п.) добавлением в GT200 является поддержка вычислений с плавающей точкой двойной точности (64-бит). Это необходимо для целого ряда научных, инженерных и финансовых задач, требующих очень высокой точности расчётов. Для этих расчётов каждый SM содержит блок для математических вычислений с двойной точностью, и всего в чипе получается 30 таких блоков.
Каждый из этих блоков выполняет операцию MAD с более высокой точностью, в соответствии со спецификациями стандарта IEEE 754R. Общая производительность вычислений с двойной точностью у всех десяти блоков TPC в Geforce GTX 200 доходит до 90 гигафлопс в пике, что примерно равно мощности восьмиядерного центрального процессора Xeon. Увеличенная скорость текстурирования
Предыдущий топовый чип Nvidia, известный под кодовым названием G80, содержал восемь блоков TPC, в каждом из которых было по восемь блоков текстурной фильтрации (64 пикселя за такт) и по четыре блока текстурной адресации (32 пикселя за такт). Они могли выбирать 32 пикселя 8-битных значений за такт, в том числе 2x анизотропно отфильтрованные, или столько же билинейно отфильтрованных 8-битных или 16-битных значений.
В G92 баланс был изменён в сторону большего количества блоков адресации, этот чип может выбирать и билинейно фильтровать 64 пикселя за такт для текстур с 8 бит на канал и 32 пикселя 16-битных значений с плавающей точкой. Новый чип также содержит аналогичное количество блоков адресации и фильтрации на один TPC. Каждый из них включает восемь текстурных блоков, способных выбирать и фильтровать восемь пикселей за такт или четыре с анизотропной фильтрацией, или четыре в формате FP16.
Для GT200 получается 80 или 40 пикселей за такт, соответственно. Так что, по сути, эффективность текстурирования со времени G92 увеличилась только из-за большего количества соответствующих блоков. Но Nvidia говорит о том, что GT200 содержит более эффективную управляющую логику, которая позволяет добиться практической скорости выборок более близкой к теоретической, чем предыдущие чипы (имеется в виду G92, у которого с этим были некоторые проблемы, отмечаемые в наших статьях). По их собственным измерениям, новый чип на 22% эффективнее в текстурировании, по сравнению с G92, мы проверим это в следующей части статьи. Изменённое соотношение количества исполнительных блоков
Это лишь следствие внесённых в архитектуру изменений. Количество текстурных блоков увеличилось в меньшее количество раз, по сравнению с ростом числа вычислительных блоков, и их соотношение изменилось. Это стало полезным, так как игры и другие приложения используют всё более сложные и длинные шейдеры, и больший упор идёт в вычисления, а не в текстурные выборки. Поэтому в Geforce GTX 200 сдвинули баланс к большему соотношению числа SP и TMU.
К каждому TPC добавили по одному SM, оставив неизменным количество блоков адресации и фильтрации текстурных данных, поэтому это соотношение выросло в полтора раза по сравнению с G92. Такое решение было принято на основе анализа производительности современных игр и приложений ближайшего будущего (ведь Nvidia тесно работает с разработчиками игр). Улучшения в блоках ROP
Предыдущее поколение чипов G80 использовало новые на то время блоки ROP с улучшенными возможностями, а в GT200 подсистема ROP была дополнительно переработана. Все базовые возможности остались прежними, но производительность блоков увеличилась за счет экстенсивного роста. Теперь поддерживается вывод до 32 пикселей за такт, по 4 пикселя на каждый широкий блок ROP (всего их восемь).
То же и с одновременной записью цвета и значения Z — до 32 пикселей. Пиксели, использующие 8-битный формат, могут быть выведены с использованием блендинга на удвоенной частоте по сравнению с предыдущим поколением чипов. Старые GPU имеют по шесть широких блоков ROP и могут выводить 24 пикселя за такт и блендить 12 пикселей. GT200 в этих условиях способен выводить 32 пикселя за такт с блендингом. Модифицированные блоки геометрических шейдеров и потокового вывода (stream out)
Предыдущие поколения унифицированных чипов Nvidia в некоторых условиях показывали слабую производительность геометрических шейдеров и stream out. В частности, это было видно в одном из тестов геометрических шейдеров во второй версии нашего синтетического теста RightMark.
Чтобы исправить ситуацию, внутренние буферы чипа GT200 были значительно увеличены — в несколько раз, по сравнению с G80 и G92. Это позволяет новому чипу показывать значительный прирост скорости в таких задачах с активным использованием геометрических шейдеров и stream out. По данным Nvidia, в нашем RightMark 3D 2.0 их новая видеокарта Geforce GTX 280 показывает результат в несколько раз выше, чем у Geforce 9800 GTX и оказывается быстрее некоторые из конкурирующих продуктов. Проверим и это. Другие усовершенствования в архитектуре
Судя по данным компании, были сделаны и другие изменения для увеличения производительности и эффективности новой архитектуры. Так, был оптимизирован интерфейс памяти между блоком data assembler и блоками по работе с буфером кадра, что позволило GT200 получить более быстрый доступ к проиндексированным примитивам. В таких условиях у предыдущего поколения были некоторые проблемы.
Был увеличен и размер кэшей, что снизило количество простоев конвейера и ускорило связь между его геометрической и вершинной стадиями с viewport clip и cull. Также увеличилась производительность Z-Culling, что должно быть особенно хорошо заметно по скорости в высоких разрешениях рендеринга. А про улучшения в блоках ROP мы написали выше.
Были проведены некоторые модификации и улучшения в микроархитектуре, связанные с регистрами, логикой управления потоками и инструкциями. Видеочип GT200, по сравнению со старыми чипами, эффективнее «кормит» данными разнообразные исполнительные блоки. Эти изменения, в том числе, позволили реализовать возможность одновременного исполнения двух операций за один такт шейдерными блоками, о которой мы писали чуть выше. Объём видеопамяти — 1 гигабайт
Строго говоря, это не совсем улучшения видеочипа, ведь и на предыдущие решения можно было установить 1 ГБ памяти, и даже более. Но, тем не менее, чем современнее игра, тем более требовательна она к объему установленной видеопамяти. И геометрии больше используют, и текстуры с картами нормалей более высокого разрешения, карты теней и карты среды в 16-битных форматах, и по несколько буферов высокого разрешения (для постобработки и отложенного рендеринга, например)…
Многие современные техники требовательны к объёмам видеопамяти и пропускной её способности. Не говоря о мультисэмплинге, который также сильно влияет на соответствующие требования. Новые видеокарты Geforce GTX 280 поддерживают объём памяти в 1 ГБ, что позволяет увеличить производительность в условиях нехватки видеопамяти, в высоких разрешениях с включенным антиалиасингом. 512-битная шина видеопамяти
А это — очевидное улучшение по сравнению и с G80 и с G92. В GT200 используется 512-битный доступ к локальной памяти, в отличие от 384-битного у G80 и 256-битного у G92. Как и в предыдущих чипах, применяются 64-битные блоки обмена с памятью, только теперь их не четыре и не шесть, а восемь. Соответственно увеличилась ширина шины и пропускная способность памяти.
Изменилась в лучшую сторону в новых решениях и эффективность использования видеопамяти. Блоки по работе с фреймбуфером были переработаны с учётом более высокой частоты памяти, внесены изменения в алгоритмы кэширования и доступа к банкам памяти. А технологии сжатия информации в GT200 получили дальнейшие усовершенствования со времён G92, что усилило позиции решения в тяжёлых режимах. Отсутствие поддержки DirectX 10.1
Несмотря на ожидания некоторых пользователей, новейшим видеочипом GT200 не поддерживаются все возможности DirectX 10.1. Отсутствие этой поддержки Nvidia объясняет тем, что эта версия API включает некритичное дополнение DirectX 10, некоторые из его возможностей доступны и на картах Geforce, начиная с восьмой серии, например, чтение данных из мультисэмплингового буфера.
По словам компании, их консультации с разработчиками программного обеспечения показали, что поддержка DirectX 10.1 для последних не так важна, поэтому компания решила не вносить изменений в свои чипы, а сосредоточиться на скорости имеющихся возможностей и увеличения эффективности существующих блоков. Подход нельзя назвать приемлемым во всех случаях, но он полностью объясняет позицию Nvidia по данному вопросу.
CUDA
Видеочип GT200 разрабатывался с прицелом на его активное использование в вычислительных задачах при помощи технологии CUDA. В так называемом расчётном режиме, новый видеочип можно представить как программируемый мультипроцессор с 240 вычислительными ядрами, встроенной памятью, возможностью случайной записи и чтения и гигабайтом выделенной памяти с большой ПСП. Как говорят в Nvidia, в таком режиме Geforce GTX 280 превращает обычный ПК в маленький суперкомпьютер, обеспечивающий скорость почти в терафлоп, что полезно для многочисленных научных и прикладных задач.
Несколько ключевых факторов делают Geforce GTX 200 отличным параллельным процессором. Во-первых, это CUDA. Ведь важнейшей частью параллельных вычислений всегда является программное обеспечение. А CUDA — это простой и мощный метод для переноса вычислений с CPU на GPU. Также очень важно, что GT200 проектировался специально с учётом его использования для неграфических вычислений, в него добавили такие возможности, как общая память и поддержка вычислений двойной точности.
В итоге, Geforce GTX 280, со своими 240 ядрами, работающими на частоте 1.3 ГГц, является одним из наиболее мощных процессоров по расчётам с плавающей точкой. В этом ему помогает и очень высокая пропускная способность доступа к памяти, которая обеспечивается 512-битной шиной обмена с локальной памятью и быстрая GDDR3 видеопамять.
Довольно большое количество наиболее требовательных задач могут быть перенесены с CPU на GPU при помощи CUDA, и при этом получить прирост производительности при переносе части расчётов на видеочип. На картинке показаны примеры применения CUDA в реальных задачах, приведены цифры, показывающие кратность прироста производительности GPU по сравнению с CPU.
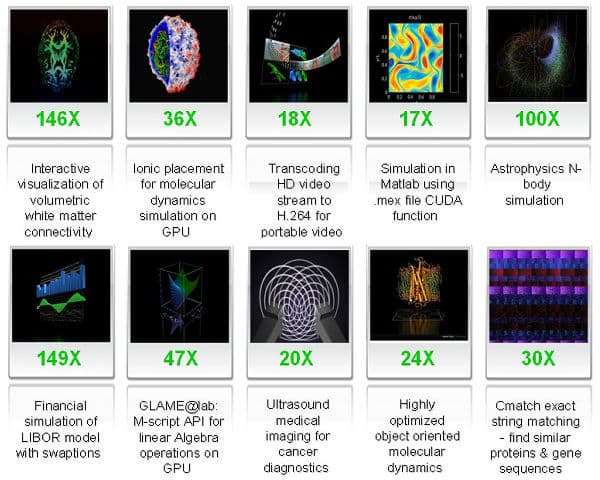
Как видите, задачи самые разнообразные: перекодирование видеоданных, молекулярная динамика, астрофизические симуляции, финансовые симуляции, обработка изображений в медицине и т.п. Причём, приросты от переноса расчётов на видеочип получились порядка 20-140-кратных. Таким образом, новый видеочип поможет ускорить множество разных алгоритмов, если их перенести на CUDA.
Одним из бытовых применений расчётов на GPU можно считать перекодирование видеороликов из одного формата в другой, а также кодирование видеоданных в соответствующих приложениях по их редактированию. Компания Elemental выполнила задачу переноса кодирования на GPU в своём приложении RapidHD, получив следующие цифры:
Мощнейший GPU Geforce GTX 280 отлично показывает себя в этой задаче, прирост скорости по сравнению с быстрейшим центральным процессором составляет более 10 раз. Кодирование двухминутного видеоролика заняло 231 секунду на CPU и всего лишь 21 секунду на GT200. Важно, что применение GPU позволило добиться выполнения данной задачи не просто в реальном времени, но даже и ещё быстрее!
Ещё одной задачей, в которой уже сейчас можно получить огромный прирост производительности, является Folding@Home — распределённые вычисления по симуляции свёртывания молекул белка, целью которого является получение лучшего понимания причин возникновения некоторых болезней, вызываемых дефектными белками. Процесс таких вычислений идёт на видеочипах в десятки и даже сотни раз быстрее, чем на CPU.
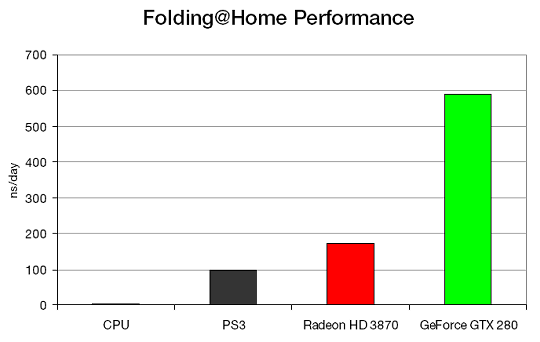
Скорость симуляции измеряется в наносекундах в день, число показывает, сколько наносекунд жизни протеина может быть имитировано за один день компьютерных расчётов. Если центральный процессор может симулировать лишь 4 нс/день, PlayStation 3 — около 100 нс/день, то производительность Geforce GTX 280 достигает 590 нс/день, что более чем в сотню раз быстрее, чем CPU, и в три раза быстрее топового одночипового решения конкурента.
Ещё одним важным фактом для подобных распределённых вычислений является то, что в мире есть более 70 миллионов видеокарт Nvidia с поддержкой CUDA, со средней производительностью около 100 гигафлопс каждая. А теперь представьте, если хотя бы 1% из этих видеокарт будет использоваться в той Folding@Home, это добавит сразу 70 петафлопов потенциальной производительности к проекту! Мощности видеочипов открывают поистине потрясающие возможности, дело лишь в их раскрытии…
По теме CUDA у нас на сайте планируется выход отдельного материала, более подробно раскрывающего аспекты его использования и описание примеров реального применения в различных задачах. А одним из примеров применения, которые полезен для всех пользователей сейчас, служит ускорение физических расчётов на GPU.
Nvidia PhysX
В современных играх грамотно реализованные физические взаимодействия играют важную роль, они делают игры более интересными. Почти все физические расчёты требовательны к производительности, и соответствующие алгоритмы требуют больших объемов вычислений. До определённого времени эти расчёты выполнялись только на центральных процессорах, потом появились физические ускорители компании Ageia, которые хоть и не получили широкого распространения, но заметно оживили активность на этом рынке.
Производители видеочипов всерьёз взялись за перенос выполнения физических расчётов на GPU. Но изначально они больше работали с Havok, которую затем купила компания Intel. В последующем, Nvidia пришлось приобрести другую компанию — Ageia, у которой для них был интересен больше всего сам по себе PhysX SDK, а не аппаратные физические ускорители, роль которых теперь отдана видеокартам.
Итак, Nvidia PhysX является мощным физическим движком реального времени, который используется в большом количестве известных игровых приложений на ПК и игровых консолях. Список игр с поддержкой PhysX содержит более 150 игр, которые выпущены или разрабатываются для нескольких платформ: персонального компьютера, Sony Playstation 3, Microsoft Xbox 360 и Nintendo Wii.
PhysX API изначально использовал возможности центральных процессоров и специализированных ускорителей физики Ageia, но после его портирования на CUDA, расчёты ускоряются на любой видеокарте компании Nvidia с поддержкой CUDA. То есть, начиная с Geforce 8 и заканчивая свежими Geforce GTX 260 и 280. То есть, все 70 миллионов видеокарт Geforce 8 и 9 серий в скором времени получат поддержку PhysX, в том числе и в ранее вышедших проектах.
При работе с мощным видеочипом, PhysX может предложить много новых эффектов, таких как: динамические эффекты дыма и пыли, симуляция тканей, симуляция жидкостей и газов, погодные эффекты и т.п. Но это всё принципиально возможно и на CPU. Что даёт игрокам перенос физических расчётов на GPU? Nvidia даёт такую диаграмму, показывающую относительную производительность наиболее распространенных физических алгоритмов на PhysX.
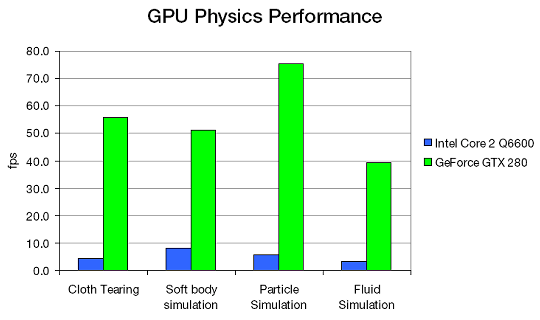
Это такие типы задач, как имитация тканей, частиц, жидкостей и гибких (мягких) тел. В среднем, видеочип оказывается в 11 раз быстрее, чем четырехъядерный центральный процессор, пусть и не самый быстрый. Неплохо, если перенос физики на GPU не снизит общую производительность в случае её упора в возможности видеокарты.
Улучшенная технология управления питанием
Новый видеочип использует улучшенное управление питанием, по сравнению с предыдущим поколением чипов Nvidia. Он динамически изменяет частоты и напряжения блоков GPU, основываясь на величине их загрузки, и способен частично отключать некоторые из блоков. В итоге, GT200 значительно снижает энергопотребление в моменты простоя, потребляя около 25 ватт, что очень мало для GPU такого уровня. Решение поддерживает четыре режима работы:
- режим простоя или 2D (около 25 ватт);
- режим просмотра HD/DVD видео (около 35 ватт);
- полноценный 3D режим (до 236 ватт);
- режим HybridPower (около 0 ватт);
Для определения загрузки, в GT200 используются специальные блоки, анализирующие потоки данных внутри GPU. На основе данных от них, драйвер динамически устанавливает подходящий режим производительности, выбирает частоту и напряжение. Это оптимизирует потребление электроэнергии и тепловыделение от карты.
Есть возможность частичного отключения некоторых из блоков GPU, которые не используются в данный момент, что ещё эффективнее работает в целях улучшения энергетической эффективности. Всё это обеспечивает почти 10-кратную разницу в потреблении между режимом простоя и 3D-режимом (25 ватт и 236 ватт, соответственно).
Поддерживается технология HybridPower, о которой мы рассказывали в предыдущих материалах, так что видеочип в Geforce GTX 280 может быть и отключен, если в качестве платформы используется системная плата на основе интегрированного чипсета nForce, обладающая соответствующей поддержкой (например, nForce 780a и nForce 750a). А в случае запуска требовательных 3D-приложений, драйвер переключает использование интегрированного ядра на внешнюю видеокарту.
Другие особенности нового решения Nvidia
Не обошлось без поддержки технологии Nvidia SLI. Geforce GTX 280 поддерживает как обычный SLI режим из двух видеокарт, который увеличивает производительность на 50-80%, и так называемый 3-way SLI, который увеличивает скорость ещё, что позволяет использовать самые высокие разрешения и максимальные настройки качества во всех приложениях. Конечно же, для этого нужна соответствующая системная плата на основе чипсета nForce. Для поддержки этих возможностей на каждой видеокарте установлено по два SLI-разъёма, при помощи которых карты соединяются между собой специальной планкой.

Но мы не устаем напоминать о недостатках мультичипового режима рендеринга AFR. О задержках, не уменьшаемых при видимом росте FPS режимом AFR, когда рендеринг вроде бы становится плавней, чем на одночиповой системе, но играть почти так некомфортно, как и в случае одиночной видеокарты.
Как и все видеокарты на чипах G9x, Geforce GTX 280 поддерживает и второе поколение PureVideo HD, которое мы знаем по предыдущим чипам серии Geforce 8 и 9. Поддерживаются следующие возможности: аппаратное декодирование видео форматов H.264, VC-1 и MPEG2, улучшенная постобработка, динамическая подстройка контраста и цветовых тонов, двухпоточное декодирование HD видео, одновременная работа интерфейса Windows Vista Aero и декодирование HD видео.
На референсных видеокартах Geforce GTX 260 и 280 установлены по два Dual Link DVI выхода с поддержкой HDCP, а также один HDTV выход. HDMI и DisplayPort выводы можно реализовать при помощи переходников с DVI на HDMI или DisplayPort, также вероятен выпуск видеокарт от партнёров компании Nvidia с установленными на них соответствующими разъемами.
Мы рассмотрели теоретические особенности решений серии Geforce GTX 200, основанных на видеочипе GT200, представляющем второе поколение унифицированной архитектуры Nvidia. Далее следует практическая часть исследования с синтетическими тестами, в которой мы пронаблюдаем внесённые архитектурными улучшениями изменения в производительности, определим слабые и сильные стороны видеокарт, а также узнаем, как соотносится производительность новой топовой видеокарты Nvidia с другими моделями.


