Nvidia Geforce GTX 280 1024MB PCI-E
240 калифорнийских стрелков: Смогут ли одолеть предыдущее войско в виде 9800 GX2?

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Nvidia Geforce GTX 280 (GT200): Часть 1: Теоретические сведения
На улице лето, за окном гроза, дует теплый влажный ветер, под боком в стенде стоит новая печка-грелка, извергающая на меня горячий воздух после снятия жара с 280-ти Ватт выделенного тепла, все одно к одному.
Мне нравятся Hi-End ускорители тем, что если его снять с компа сразу после работы (с руганью и дуя на обожженные пальцы), положить во всевозможные предохранительные пакеты, спасающие чудо технику прецизионного качества от повреждений, то даже после перевозки в течение часа — изделие будет теплым, как будто сейчас только что с фабрики или хлебопекарни. И даже иногда горячим. Так что все эти сотни Ватт — это вам не лампочку вывернуть и в кармане донести.
Мы внутри раздела в силу работы и служебных нужд иногда передаем друг другу видеокарты для тестов и прочих исследований, и подчас принимаешь ускоритель, а он внутри почти горячий еще… За время перевозки в машине не успел остыть… :)
Так вот, играм все нужно больше FPS, людям нужно больше красивой графики, а ускорителям нужно больше кушать, и потому компании-производители кулеров будут еще долго при делах, придумывая новые изощренные способы снять жар с огнедышащих драконов квадратной формы и вывести его за пределы корпуса (иногда и просто в корпус, чтобы там все спеклось). Скоро на видеокарты будем надевать такие же огромные 24-пиновые коннекторы, какими подрубаем питание к материнским платам. Уже пойдет речь о трехслотовых видеокартах, которым наверно потребуется уже особое крепление в корпусе. Да, вроде бы техпроцесс все уменьшается, но размеры видеокарт все растут и растут, ибо от них хотят все больше и больше.
Бедная Nvidia сделала очередного монстра, как в 2006 году — G80, чип очень дорогой — это видно по всем параметрам, судя по первой информации — карт в продажу после анонса пойдет очень мало, что говорит о невысоком проценте выхода годных. При этом, чтобы сбить спрос — цену на GTX 280 подняли до небес. Почему бедная? — ну потому что есть разница в ситуации в 2006 году и сейчас. Если тогда реально была нужда в новых супермощных картах, и G80 показал тогда реально революционный прорыв, то теперь это очередные плюс двадцать-тридцать процентов к… 9800 GTX. Да, даже не к 9800 GX2. Ниже мы все покажем детально. Хотя есть и тесты, где GTX 280 является полный лидером. И если ранее реально G80 (8800 GTX) — разбирался как горячие пирожки зимой, то теперь спрос явно будет не таким высоким. Хотя с учетом того, что в начале продаж карт вообще будет очень мало, Nvidia боится и такого спроса, потому цены подняты до 650 долларов США, что явно нелогично, ибо даже 9800 GX2 стоит дешевле.
Ну чтобы интригу разбавить практикой, мы перейдем к изучению карты. Теоретическую часть читатели уже изучили, поняли, что внутри одного такого квадратика со стороной в 3 см находится воплощение суперидей инженеров Nvidia, для которых потребовалось аж почти полтора миллиарда транзисторов, теперь посмотрим на то, а как он выглядит.
Платы
| Reference Nvidia Geforce GTX 280 1024MB PCI-E | |
|---|---|
|

|
| Reference Nvidia Geforce GTX 280 1024MB PCI-E | |
|---|---|
|
Карта имеет 1024 МБ памяти GDDR3 SDRAM,
размещенной в 16 микросхемах (по 8 на каждой стороне PCB)
Микросхемы памяти Hynix (GDDR3). Микросхемы расчитаны на максимальную частоту работы в 1200 (2400) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| Reference Nvidia Geforce GTX 280 1024MB PCI-E | Reference card Nvidia Geforce 9800 GTX |

|

|

|
|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| Reference Nvidia Geforce GTX 280 1024MB PCI-E | Reference card Nvidia Geforce 9800 GTX |

|

|

|
|
Очевидно, что перед нами совершенно новый дизайн, не похожий ни на что ранее вапускаемое Nvidia, поскольку PCB несет в себе 512-битную шину обмена с памятью. Это заставляет размещать на текстолите 16 микросхем памяти, поэтому потребовался дизайн с двухсторонним монтажом микросхем (по 8 штук на каждой стороне). Поэтому длина карты осталась большой, да и PCB весьма дорогая. Не забываем, что Nvidia снова прибегла к способу разделения блоков GPU, и вынесла все блоки, отвечающие за вывод информации, в отдельную микросхему NVIO, как это было в случае G80 (8800 GTX/Ultra).


Выше показаны GPU и тот самый NVIO. Понятно, что размеры кристалла у GPU намного меньше — он закрыт крышкой, однако можно себе представить площадь ядра, вмещающего в себя почти 1,5 миллиарда транзисторов.
Теперь о кулере. Система охлаждения принципиально не отличается от того варианта, что мы видели еще на Geforce 8800 GTS 512. Да и форма кулера та же самая. Просто выросла длина радиатора в соответствии с размерами самой карты, ну и сзади установлена пластина для охлаждения микросхем памяти на обороте карты. Все устройство собрано так, что создает единый общий большой радиатор из крышек (задняя и передняя крышки защелкиваются, поэтому при разборе видеокарты и снятии кулера есть определенные сложности и нужен некий опыт, чтобы обнажить саму карту, не нанеся повреждений). Опыт создания 9800 GX2 с такими же защелками понравился инженерам.



Напоминаем еще раз важный момент: длина ускорителя — 270 мм, как у 8800 GTX/Ultra, поэтому в корпусе должно быть достаточно места для установки такой конструкции. А также обратим внимание на ширину кожуха, которая неизменна вдоль всей длины, а следовательно на материнской плате за PCI-E x16 разъемом не должно быть никаких портов и высоких конденсаторов, причем на ширину 30 мм (то есть не только за самим слотом PCI-E, но за соседним с ним не должно быть никаких высоких частей на системной плате).
Видеокарты этой серии оснащены гнездом для подключения звукового потока с аудио-карты для передачи его затем на HDMI (с помощью переходника DVI-to-HDMI), то есть сама видеокарта не оснащена аудио-кодеком, но осуществляет прием сигнала от внешней звуковой карты. Поэтому, если кому эта функция важна, следите за тем, чтобы в комплекте поставки видеокарты был аудио-шнурок для этих целей.
Также отметим, что питание ускорителя осуществляется с помощью ДВУХ разъемом, причем 6-пинового и 8-пинового. Поэтому также следует обращать внимание на наличие в комплекте поставки переходника питания на 8-пин.
У карты имеется гнездо TV-выхода, которое уникально по разъему, и для вывода изображения на ТВ как через S-Video, так и по RCA, требуются специальные адаптеры-переходники, поставляемые вместе с картой. Более подробно о ТВ-выходе можно почитать здесь.
Подключение к аналоговым мониторам с d-Sub (VGA) производится через специальные адаптеры-переходники DVI-to-d-Sub. Также поставляются переходники DVI-to-HDMI (мы помним, что данные ускорители поддерживают полноценную передачу видео и звука на HDMI-приемник), поэтому проблем с такими мониторами также не должно быть.
Максимальные разрешения и частоты:
- 240 Hz Max Refresh Rate
- 2048 × 1536 × 32bit x85Hz Max — по аналоговому интерфейсу
- 2560 × 1600 @ 60Hz Max — по цифровому интерфейсу (все DVI-гнезда с Dual-Link)
Что касается возможностей видеокарт по проигрыванию MPEG2 (DVD-Video), то еще в 2002 году мы изучали этот вопрос, с тех пор мало что поменялось. В зависимости от фильма загрузка CPU при проигрывании на современных видеокартах не поднимается выше 25%.
По поводу HDTV. Одно из исследований также проведено, и с ним можно ознакомиться здесь.
Мы провели исследование температурного режима с помощью утилиты RivaTuner (автор А.Николайчук AKA Unwinder) и получили следующие результаты:
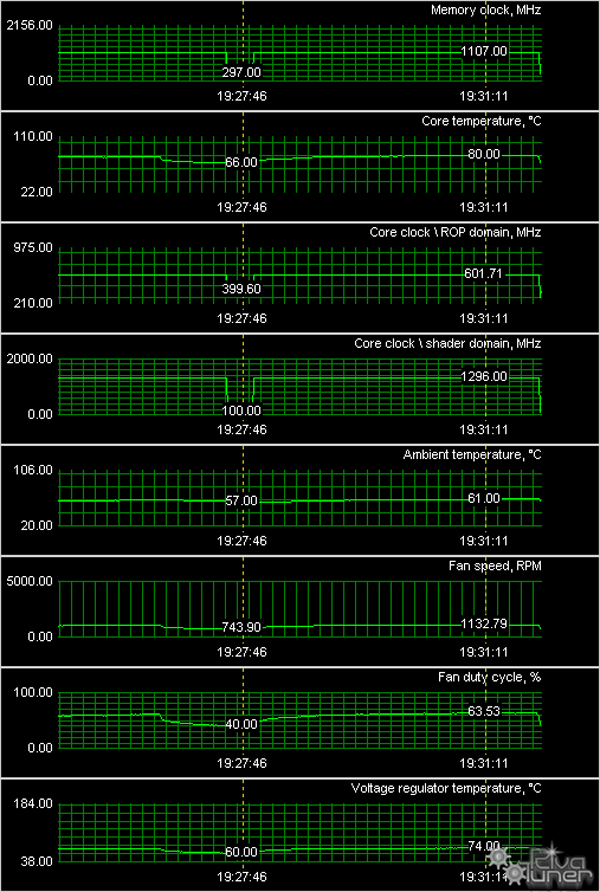
Стоит особо обратить внимание на то, на сколько снижаются частоты при работе в 2D (левый маркер на скриншоте) — до 100(!) МГц по шейдерному блоку и по памяти! Это реально снижает потребление карты до 110 Вт. Когда как в 3D при полной нагрузке ускоритель ест все 280 Вт! И при этом нагрев ядра достигает 80 градусов, что укладывается в норму, особенно если учесть, что кулер остается тихим. В этом плане карта безупречна, только лишь нужен очень мощный блок питания. Полагаем, что всем понятно, что ниже 700Вт даже нет смысла пробовать.
Поскольку карта поставляется в ОЕМ-виде как сэмпл, то о комплекте поставки речь не идет.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core2 (775 Socket)
- процессор Intel Core2 Extreme QX9650 (3000 MHz);
- системная плата Zotac 790i Ultra а чипсете Nvidia nForce 790i Ultra;
- оперативная память 2 GB DDR3 SDRAM Corsair 2000MHz (CAS (tCL)=5; RAS to CAS delay (tRCD)=5; Row Precharge (tRP)=5; tRAS=15);
- жесткий диск WD Caviar SE WD1600JD 160GB SATA.
- блок питания Tagan TG900-BZ 900W.
- операционная система Windows Vista 32bit SP1; DirectX 10.1;
- монитор
Dell 3007WFP (30"). - драйверы ATI версии CATALYST 8.5; Nvidia версии 175.16 (9ххх серия) и 177.34 (GTX 280).
VSync отключен.
Синтетические тесты
Используемые нами пакеты синтетических тестов можно скачать здесь:
- D3D RightMark Beta 4 (1050) с описанием на сайте 3d.rightmark.org
- D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3 — тесты пиксельных шейдеров версий 2.0 и 3.0 ссылка.
- RightMark3D 2.0 с кратким описанием: ссылка
Для работы RightMark3D 2.0 требуется установленный пакет MS Visual Studio 2005 runtime, а также последнее обновление DirectX runtime.
Синтетические тесты проводились на следующих видеокартах:
- Nvidia Geforce GTX 280 со стандартными параметрами (далее GFGTX280)
- Nvidia Geforce 9800 GX2 со стандартными параметрами (далее GF9800GX2)
- Nvidia Geforce 9800 GTX со стандартными параметрами (далее GF9800GTX)
- Nvidia Geforce 8800 Ultra со стандартными параметрами (далее GF8800U)
- RADEON HD 3870 X2 со стандартными параметрами (далее HD3870X2)
- RADEON HD 3870 со стандартными параметрами (далее HD3870)
Для сравнения результатов Geforce GTX 280 были выбраны именно эти модели видеокарт по следующим причинам: с Geforce 9800 GX2 её будет интересно сравнить, как с быстрейшей двухчиповой картой на GPU предыдущего поколения, с Geforce 9800 GTX — как с одночиповой, со старой моделью Geforce 8800 Ultra сравниваем для того, чтобы посмотреть разницу в пропускной способности, оценить влияние улучшений архитектуры. Ну а с RADEON HD 3870 и HD 3870 X2 сравнение интересно потому, что это быстрейшие одночиповое и двухчиповое решение от AMD на данный момент.
Direct3D 9: Тесты Pixel Filling
В тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:

Как обычно — не у всех видеокарт получаются значения, близкие к теоретическим. Чаще всего, результаты синтетики не дотягивают до теории, ближе всего к ним подбираются видеокарты на основе G80 и RV670, они не добирают до теории лишь 10-15%. А вот для видеокарт Nvidia, отличающихся улучшенными TMU, в нашем старом тесте теоретический максимум не достигается. Причём, не видно никаких улучшений в GT200, что G92 в нашем тесте выбирает лишь около 32 текселей за один такт из 32-битных текстур при билинейной фильтрации, что GT200 не дотягивает до теоретических способностей. Впрочем, возможно, виноват наш устаревший тест.
Тем не менее, Geforce GTX 280 слишком близок к Geforce 9800 GTX, а с одной текстурой он вообще проигрывает даже Geforce 8800 Ultra, несмотря на большую ПСП! А ведь в таких случаях карты ограничены пропускной способностью видеопамяти… В случае с большим количеством текстур на пиксель, способности блоков ROP раскрываются полнее, и в более тяжелых условиях карта на GT200 становится быстрейшей (если учесть некорректный результат теста двухчиповой видеокарты Nvidia). Двухчиповую же карту от AMD новинка опережает во всех протестированных режимах. Посмотрим на результаты в тесте филлрейта:
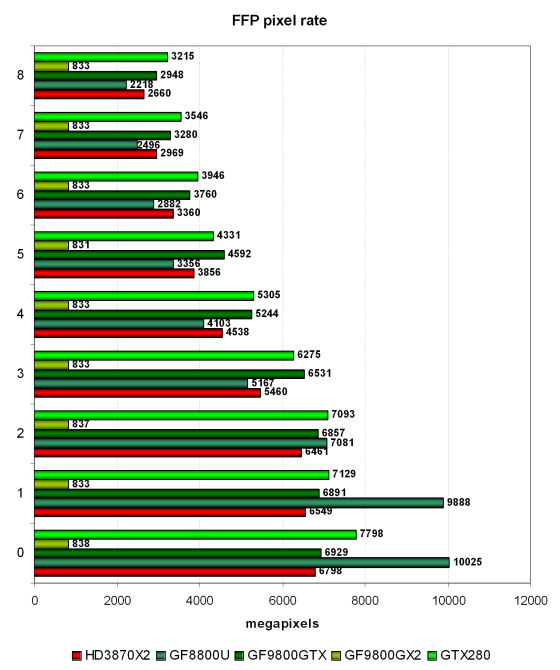
Второй синтетический тест измеряет скорость заполнения, и в нём мы видим ту же самую ситуацию, но уже с учетом количества записанных в буфер кадра пикселей. Странно, что в случаях с 0 и 1 накладываемыми текстурами у Geforce GTX 280 получился такой низкий результат, обычно в таких режимах производительность ограничена ПСП, а также количеством и рабочей частотой блоков ROP. А с этим у нового решения всё в порядке…
Но получается всё так же, как и в предыдущем тесте — лишь в ситуациях с большим количеством текстур на пиксель, Geforce GTX 280 немного выигрывает у ближайших конкурентов, хотя должен бы отрываться сильнее.
Direct3D 9: Тесты Geometry Processing Speed
Рассмотрим пару предельных геометрических тестов, и первым у нас будет самый простой вершинный шейдер, показывающий максимальную пропускную способность по треугольникам:
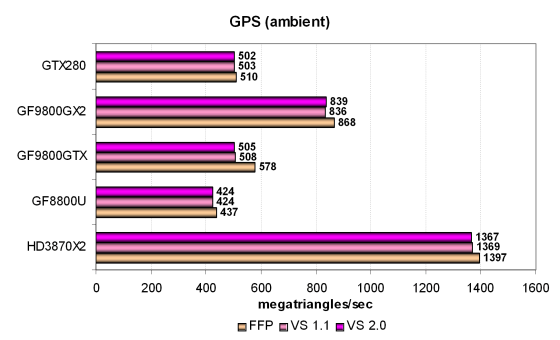
Все современные чипы основаны на унифицированных архитектурах, их универсальные исполнительные блоки в этом тесте заняты только геометрической работой, и решения показывают высокие результаты, явно упирающиеся не в пиковую производительность унифицированных блоков, а в производительность других блоков, например, triangle setup.
Собственно, результаты в очередной раз подтверждают то, что чипы AMD быстрее обрабатывают геометрию, по сравнению с чипами Nvidia, а двухчиповые решения в AFR режиме эффективно удваивают частоту кадров. Geforce GTX 280 проигрывает двухчиповым картам, опережает решение на G80 и находится на одном уровне с быстрейшей из одночиповых карт на основе G92. Получается, что этот тест зависит исключительно от тактовой частоты GPU. Что интересно, эффективность выполнения теста в разных режимах у GT200 больше походит на ту, что показывает G80, но не G92.
Мы убрали из рассмотрения промежуточные тесты на скорость обработки геометрии с одним источником освещения, и сразу же переходим к рассмотрению самой сложной геометрической задачи с тремя источниками света, включающей статические и динамические переходы:
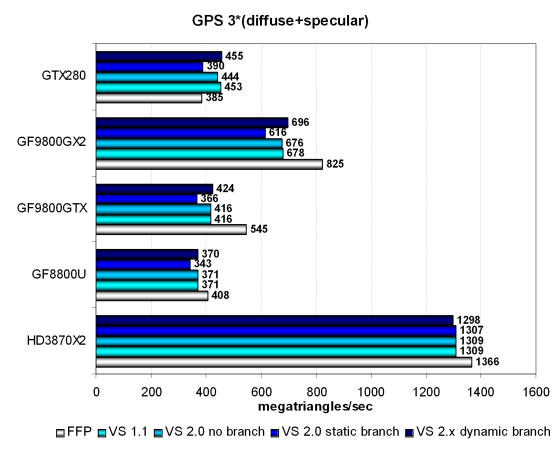
В этом варианте разница между решениями AMD и Nvidia видна лучше, разрыв немного увеличился. Geforce GTX 280 показывает лучший результат из карт Nvidia, чуть-чуть опережая Geforce 9800 GTX и 8800 Ultra, кроме FFP теста, который сейчас уже никого не интересует. В целом, новый чип неплохо проявляет себя в данных геометрических тестах. Но в реальных приложениях универсальные шейдерные процессоры заняты в основном пиксельными расчетами, к исследованию производительности которых мы и переходим.
Direct3D 9: Тесты Pixel Shaders
Первая группа пиксельных шейдеров, которую мы рассматриваем, является очень простой для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0.
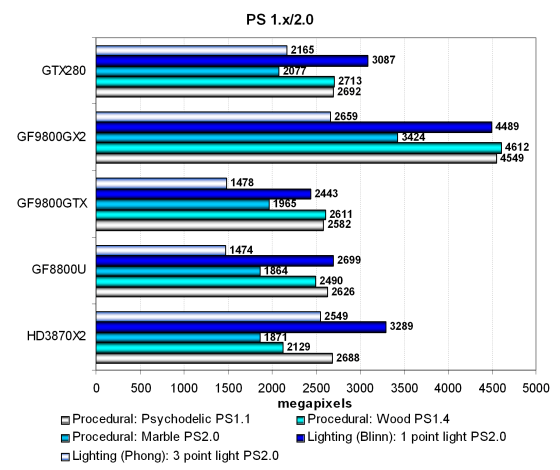
Тесты слишком просты для современных архитектур и не показывают их истинную силу. Это хорошо видно по первым двум тестам (Wood и Psychodelic), результаты которых почти на всех решениях одинаковые. Кроме того, в простых тестах производительность ограничена скоростью текстурных выборок, что видно по слабым результатам RADEON HD 3870 X2, показавшем результат на уровне одночиповых решений Nvidia.
В более сложных тестах Geforce GTX 280 показывает неплохие результаты, опережая и топовую карту на G92, и карту на G80. Причём, с увеличением сложности задачи, отрыв GT200 от предыдущих чипов явно растёт. Хотя двухчипового 9800 GX2 карта не догоняет ни в одном из тестов. Посмотрим на результаты тестов более сложных пиксельных программ промежуточных версий:
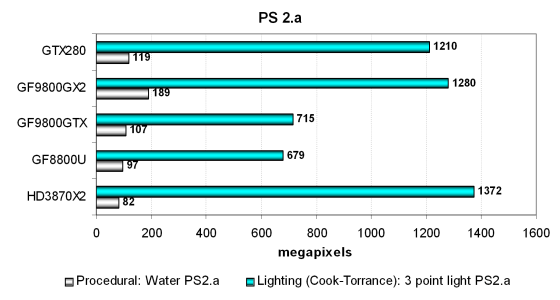
В сильно зависящем от скорости текстурирования тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, поэтому карты расположились строго по скорости текстурирования, как было на самом первом графике. Единственный RADEON, даже будучи двухчиповым, отстаёт от всех решений на основе G92, G80 и GT200. Ну а рассматриваемая сегодня видеокарта проигрывает только двухчиповой 9800 GX2, опережая одночиповых собратьев, точно по теории.
Второй тест, более интенсивный вычислительно, явно лучше подходит для архитектуры R6xx и GT200, обладающих большим количеством вычислительных блоков. В этом тесте решение AMD показывает лучший результат, далее следует также двухчиповая карта, но от Nvidia. Но самое приятное в том, что Geforce GTX 280 проигрывает им совсем чуть-чуть! Неплохой результат, GT200 быстрее одного G92 в этом тесте в 1.7 раза, как Nvidia и писала в своих презентациях. А вот эффективности SLI для 9800 GX2 явно не достаёт.
Direct3D 9: Тесты пиксельных шейдеров New Pixel Shaders
Эти тесты пиксельных шейдеров DirectX 9 ещё сложнее, они делятся на две категории. Начнем с более простых шейдеров версии 2.0:
- Parallax Mapping — знакомый по большинству современных игр метод наложения текстур, подробно описанный в статье Современная терминология 3D графики
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами
Существует два варианта этих шейдеров: с ориентацией на математические вычисления, и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:
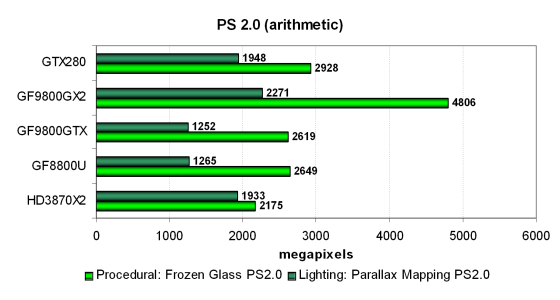
Положение видеокарт в тесте «Frozen Glass» отличается от результатов предыдущих тестов. Несмотря на то, что это математические тесты, зависящие от частоты шейдерных блоков, Geforce GTX 280 выигрывает у 9800 GTX совсем немного, а двухчиповый 9800 GX2 далеко впереди них обоих. Видимо, производительность ограничена не только математикой, но и скоростью текстурных выборок. RADEON HD 3870 X2 показывает самый слабый результат.
Зато во втором тесте «Parallax Mapping» решение AMD заметно сильнее, хоть и снова позади лучших карт Nvidia. Но в этот раз оно проигрывает только новой видеокарте и двухчиповому решению. Улучшения в TMU и внутричиповых кэшах сказались на результате GTX 280, она обогнала двухчиповый RADEON и немного отстаёт от аналогичного решения на двух G92. Рассмотрим эти тесты в модификации с предпочтением выборок из текстур математическим вычислениям, там видеокарты на основе G92 должны показать более высокие относительные результаты:
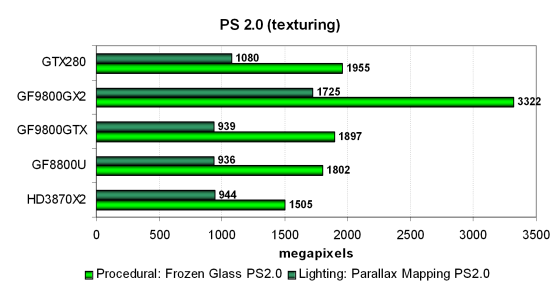
Положение немного изменилось, мы видим явный упор производительности в скорость текстурных блоков. Geforce GTX 280 во всех тестах прилично опережает решение AMD и немного — всех одночиповых собратьев. А вот впереди всех — двухчиповый Geforce 9800 GX2. Надо заметить, что для всех решений варианты шейдеров с большим количеством математических вычислений работают быстрее в 1.5-2 раза, по сравнению с их «текстурными» вариантами.
Рассмотрим результаты ещё двух тестов пиксельных шейдеров — версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9. Тесты отличаются тем, что сильно нагружают и ALU и текстурные модули, обе шейдерные программы сложные, длинные, включают большое количество ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, также описанная в статье Современная терминология 3D графики
- Fur — процедурный шейдер, визуализирующий мех
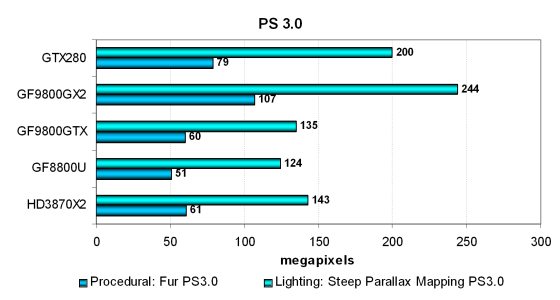
Хотя решения AMD обеспечивают эффективное исполнение сложных пиксельных шейдеров версии 3.0 с большим количеством ветвлений, Geforce 9800 GTX показывает результат на одном уровне с двухчиповой картой на базе RV670. Это можно объяснить ускоренными билинейными текстурными выборками в архитектуре G9x и большей эффективностью использования имеющихся ресурсов, обусловленную разницей между скалярной и суперскалярной архитектурами.
Двухчиповый Geforce 9800 GX2 почти удваивает производительность, являясь лидером в обоих тестах, ну а рассматриваемый сегодня Geforce GTX 280 логично расположился посередине между этими решениями. Хотелось бы большей разницы между скоростью GT200 и G92, конечно… Хотя бы в 1.6-1.7 раз.
Direct3D 10: Тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)
В новую версию RightMark3D 2.0 вошли два знакомых PS 3.0 теста под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два полностью новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсэмплинга, что дополнительно увеличивает нагрузку на видеочипы.
Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами, при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель!) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере.
Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40-80, включение «шейдерного» суперсэмплинга — до 60-120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот.
Проверим сначала режимы без включенного суперсэмплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым.
Результаты в «High» получились почти в полтора раза ниже, чем в «Low». В остальном — Direct3D 10 тесты процедурной визуализации меха с большим количеством текстурных выборок снова показывают огромное преимущество решений Nvidia над AMD. Производительность в этом тесте зависит не только от количества и скорости блоков TMU, но и от филлрейта и ПСП. Сравнение результатов Geforce 9800 GTX и 8800 Ultra указывает на это.
У героя обзора Geforce GTX 280 очень хорошие результаты в этом тесте, он лишь чуть-чуть отстал от двухчипового Geforce 9800 GX2, обогнав одночиповое решение на G92 на 60-70%. Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсэмплингом, увеличивающим работу в четыре раза, возможно в такой ситуации что-то изменится, и ПСП с филлрейтом будут влиять меньше:
Включение суперсэмплинга теоретически увеличивает нагрузку в четыре раза, но на видеокартах Nvidia скорость снижается чуть сильнее, чем на AMD, за счет чего отрыв между ними сокращается, и HD 3870 вместе с X2 вариантом совсем немного подтягиваются вверх. Но преимущество карт Nvidia никуда не делось, оно подавляющее.
В остальном, с увеличением сложности шейдера и нагрузки на видеочип, разница между Geforce GTX 280 и всеми остальными картами Nvidia очень сильно растёт. Теперь новый GTX опережает старый в 2.5 раза! Вот что значит архитектура, переработанная для исполнения сложнейших шейдеров. Даже двухчиповый 9800 GX2 повержен с большим преимуществом.
Второй тест, измеряющий производительность выполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением, число выборок возрастает в два раза, а суперсэмплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсэмплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше, по сравнению с простым режимом. Проверяем сначала простые варианты без суперсэмплинга:
Этот тест даже интереснее с практической точки зрения, ведь разновидности parallax mapping давно применяются в играх, а тяжелые варианты, вроде нашего steep parallax mapping используются в некоторых проектах, например, в Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсэмплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип примерно в два раза, такой режим называется «High».
Повторилась ситуация предыдущего теста. Хотя решения AMD ранее были сильны в Direct3D 9 тестах parallax mapping, в обновленном D3D10 варианте без суперсэмплинга они не могут справиться с нашей задачей на уровне видеокарт Geforce. Кроме того, включение самозатенения вызывает на продукции AMD большее падение производительности, по сравнению с разницей для решений Nvidia.
Рассматриваемый нами сегодня Geforce GTX 280 уже без включения суперсэмплинга начинает опережать всех, включая Geforce 9800 GX2, обгоняя 9800 GTX и 8800 Ultra в тяжелом режиме более чем в два раза. Посмотрим, что изменит включение суперсэмплинга, в прошлом тесте он вызывал большее падение скорости на картах Nvidia.
При включении суперсэмплинга и самозатенения задача получается более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая большое падение производительности. Разница между скоростью разных видеокарт уже несколько другая. Включение суперсэмплинга сказывается как и в предыдущем случае — карты производства AMD улучшают свои показатели относительно решений Nvidia. HD 3870 продолжает отставать от всех Geforce, зато двухчиповый X2 почти на одном уровне с 8800 Ultra и 9800 GTX.
Что касается сравнения Geforce GTX 280 с предыдущими топами на базе одного чипа G80 или G92, они оба повержены с 2-3 кратным преимуществом! А в High режиме новая видеокарта намного быстрее и двухчиповой на G92. Снова просто отличный результат, показывающий, насколько хорошо GT200 разбирается с такими сложнейшими задачами.
Direct3D 10: Тесты пиксельных шейдеров PS 4.0 (вычисления)
Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере.
Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos.
Ранее, при анализе результатов наших синтетических тестов, мы не раз отмечали, что в вычислительно сложных задачах современная архитектура AMD показывает себя зачастую лучше конкурирующей от Nvidia. Но время идёт, и ситуация меняется, теперь в соперничестве RADEON HD 3870 и любого из Geforce, решение AMD уступает. Зато двухчиповый HD 3870 X2 хорош (спасибо AFR), почти на одном уровне с двухчиповым же Geforce 9800 GX2.
Но нас с вами сегодня интересует производительность Geforce GTX 280. И она просто отличная, видеокарта на основе нового чипа GT200 почти догоняет двухчиповые карты прошлого поколения, опережая «старую» Geforce 8800 Ultra и «почти новую» Geforce 9800 GTX на 60-70%, что примерно соответствует разнице в чистой мощности шейдерных блоков, их количеству и тактовой частоте.
Второй тест шейдерных вычислений носит название Fire, и он ещё более тяжёл для ALU. В нём текстурная выборка только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки:
В общем, в данном тесте скорость рендеринга явно ограничена производительностью шейдерных блоков. Со времени выхода RADEON HD 3870 X2 ошибка в драйверах AMD была исправлена, результат их решений AMD стал подобающим теории, и теперь RADEON HD 3870 в этом тесте показывает скорость даже выше, чем у всех Geforce 8800 и 9800.
Но не Geforce GTX 280, опережающий одночиповых предшественников от Nvidia более чем в 1.5 раза, что также близко к теоретической разнице в шейдерной производительности. Лидером же является двухчиповый RADEON HD 3870 X2. И вероятно, что с появлением новых решений AMD, пальма первенства в математических тестах перейдёт к ним.
Direct3D 10: Тесты геометрических шейдеров
В пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующих частицу. Аналогичные алгоритмы должны получить широкое использование в будущих DirectX 10 играх.
Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково.
Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности:
Начинается самое интересное, ведь в Nvidia пообещали увеличение эффективности исполнения геометрических шейдеров. Впрочем, график показывает, что первый тест слабо использует эти возможности, и нам придётся подождать второго. Соотношение скоростей при разной геометрической сложности сцен примерно одинаковое. Производительность соответствует количеству точек, с каждым шагом падение FPS составляет около двух раз. Задача для современных видеокарт не очень сложная и ограничение скорости мощностью потоковых процессоров в тесте не явное, задача ограничена также и ПСП и филлрейтом, хотя и в меньшей степени.
Geforce GTX 280 показывает результат на уровне двухчиповой RADEON HD 3870 X2, что более чем в два раза быстрее одиночной HD 3870. По скорости среди собратьев от Nvidia, результат анонсированной карты лёг точно между одиночной картой на базе чипа G92 и двухчиповой версией. В целом — не так плохо, хотя хотелось бы достижения производительности 9800 GX2. Возможно, при переносе части вычислений в геометрический шейдер ситуация изменится, посмотрим:
Разница между рассмотренными вариантами теста невелика, существенных изменений не произошло. Все видеокарты Nvidia показывают почти те же результаты при изменении параметра GS load, отвечающем за перенос части вычислений в геометрический шейдер. Зато результаты обеих видеоплат AMD немного выросли, и RADEON HD 3870 отстаёт уже меньше, а двухчиповая HD 3870 X2 даже немного впереди Geforce GTX 280. Посмотрим, что изменится в следующем тесте, который предполагает большую нагрузку именно на геометрические шейдеры…
«Hyperlight» — это второй тест геометрических шейдеров, демонстрирующий использование сразу нескольких техник: instancing, stream output, buffer load. В нем используется динамическое создание геометрии при помощи отрисовки в два буфера, а также новая возможность Direct3D 10 — stream output. Первый шейдер генерирует направление лучей, скорость и направление их роста, эти данные помещаются в буфер, который используется вторым шейдером для отрисовки. По каждой точке луча строятся 14 вершин по кругу, всего до миллиона выходных точек.
Новый тип шейдерных программ используется для генерации «лучей», а с параметром «GS load», выставленном в «Heavy» — ещё и для их отрисовки. То есть, в режиме «Balanced» геометрические шейдеры используются только для создания и «роста» лучей, вывод осуществляется при помощи «instancing», а в режиме «Heavy» выводом также занимается геометрический шейдер. Сначала рассматриваем лёгкий режим:
Относительные результаты в разных режимах соответствуют нагрузке: во всех случаях производительность неплохо масштабируется и близка к теоретическим параметрам, по которым каждый следующий уровень «Polygon count» должен быть в два раза медленней. Производительность Geforce 9800 GX2 в этот раз провалилась куда-то глубоко-глубоко, возможно, на новых драйверах ситуация будет иной. Обе карты производства AMD также отстают от всех решений Nvidia.
Если сравнивать все платы на G80, G92 и GT200, наглядно видно, что упор в тесте получается во что-то отличное от ПСП, филлрейта и вычислительной мощности — все карты практически равны. Хотя и несколько удивительно, что в тяжелом режиме GT200 немного проигрывает G92… Цифры могут измениться на следующей диаграмме, в тесте с более активным использованием геометрических шейдеров. Также будет интересно сравнить друг с другом результаты, полученные в «Balanced» и «Heavy» режимах.
Ну вот, дождались! Впервые в геометрических тестах, соотношение скоростей между GT200 и всеми остальными изменилось так, как было задумано инженерами Nvidia, когда они устраняли недостатки предыдущих архитектур. Geforce GTX 280 более чем в два раза быстрее и Geforce 9800 GTX и 8800 Ultra. Мало того, он опережает и двухчиповый RADEON HD 3870 X2. Вероятно, выиграл бы и у 9800 GX2 по-честному, даже без помощи драйверных проблем последнего в этом тесте.
Что касается сравнения результатов в разных режимах, тут всё как всегда, в конкурентной борьбе одночиповой видеоплате AMD не помогает и то, что при переходе от использования «instancing» к геометрическому шейдеру при выводе, видеокарты Nvidia (кроме новой на GT200) теряют в производительности. У всех карт Geforce на основе чипов G92 и G80 скорость в «Balanced» режиме получается выше, чем в «Heavy» у RADEON HD 3870. При этом, получаемая в разных режимах картинка не отличается визуально.
Много интереснее поведение Geforce GTX 280 в «Balanced» и «Heavy». Это — первая видеокарта Nvidia, получившая прирост производительности от переноса части вычислений в геометрический шейдер в данном тесте. Снова налицо работа над ошибками у Nvidia, как это было ранее уже не раз! Кое-кому надо бы поучиться у них, а не продолжать наступать на одни и те же грабли уже которое поколение…
Direct3D 10: Скорость выборки текстур из вершинных шейдеров
В тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути и соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет.
Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»:
Судя по предыдущим исследованиям, на результаты этого теста сильно влияет пропускная способность памяти, и чем проще режим, тем большее влияние на скорость она оказывает. Это хорошо заметно по сравнительным результатам Geforce 9800 GTX и Geforce 8800 Ultra, если в простом режиме вторая выигрывает за явным преимуществом в ПСП, в среднем результаты сближаются, а в самом сложном они уже почти равны.
Двухчиповая 9800 GX2 не особо вырывается вперёд, хотя HD 3870 X2 показывает двукратный прирост по сравнению с HD 3870. Вероятно, недостатки драйверов, точнее — режима AFR. Тем не менее, даже Geforce 8800 Ultra показывает результат лучше, чем HD 3870 X2, а за рассматриваемой сегодня Geforce GTX 280 можно закрепить формальное лидерство. Посмотрим на результаты этого же теста с увеличенным количеством текстурных выборок:
Ситуация изменилась не слишком сильно, в лёгком режиме продолжает лидировать GTX 280, но в сложном 9800 GX2 уже выходит вперёд. Впрочем, Geforce GTX 280 всё равно быстрее обоих конкурентов от AMD и немного впереди одночиповых собратьев линеек Geforce 8 и 9. Как и в прошлый раз, по мере усложнения задачи, результаты карт уплотняются.
Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту.
А вот тест «Waves» благосклоннее к продукции AMD, одночиповая модель семейства RADEON HD 3800 смотрится неплохо, опережая решение на базе G92 в лёгком режиме, немного уступая в тяжёлом. Ясно видно, что в этом тесте скорость зависит не столько от мощности TMU, сколько от ПСП и филлрейта, так как даже двухчиповая карта на двух G92 показала результат на уровне решения предпредыдущего поколения — Geforce 8800 Ultra. Наш герой Geforce GTX 280 впереди всех в легчайшем режиме, но в остальных двух уступает двухчиповому RADEON. Рассмотрим второй вариант этого же теста:
Изменений немного, но с увеличением сложности теста результаты видеоплат серии RADEON HD 3800 стали ещё чуть лучше относительно скорости карт Nvidia. Последние потеряли в скорости несколько больше. Все остальные выводы также остаются в силе — скорость более всего ограничивается ПСП, в лёгком режиме сильнее, а в тяжёлых большую роль начинают играть блоки TMU и «двухчиповость», поэтому 9800 GX2 догоняет GTX 280, а HD 3870 X2 и вовсе опережает. В тестах VTF положение плат AMD серьёзно улучшилось, если ранее мы замечали, что решения Nvidia лучше справляются с тестами текстурных выборок из вершинных шейдеров, теперь ситуация иная.
Выводы по синтетическим тестам
На основе результатов синтетических тестов Geforce GTX 280, а также других моделей видеокарт обоих основных производителей видеочипов, мы можем сделать вывод, что новое решение Nvidia получилось очень мощным. В синтетических тестах оно значительно опережает по скорости одночиповые варианты предыдущего поколения, иногда до двух раз и даже более, часто борется на равных с двухчиповыми продуктами. Это стало возможным благодаря улучшенной архитектуре GT200 с увеличенным количеством исполнительных блоков ALU, TMU и ROP. Все модификации и улучшения позволяют рассмотренной видеокарте показывать отличные результаты во всех синтетических тестах.
Совсем не только увеличенное количество исполнительных блоков повлияло на рост скорости, но и улучшенная по сравнению с G8x и G9x архитектура, отличающаяся более высокой эффективностью, вычислительной производительностью, важной для современных и будущих приложений с большим количеством сложных шейдеров всех типов. В архитектуру GT200 были внесены изменения почти во все блоки, мощнее стали и шейдерные процессоры, и текстурные и блоки ROP, и многое другое.
Кроме модификаций, направленных на дальнейшее увеличение производительности, Nvidia уделила внимание и устранению досадных недостатков в G8x/G9x. Благодаря этому, видеоплаты на основе чипа GT200 показывают лучшие результаты в условиях очень сложных шейдеров, и особенно — сложных геометрических шейдеров с созданием геометрии «на лету». Это первый видеочип от Nvidia, который получил прирост производительности от переноса части вычислений в геометрический шейдер в одном из наших синтетических тестов. И тем более приятно, что сама компания использует наш тест для внутренних целей.
В целом, новая видеокарта Geforce GTX 280 отлично сбалансирована, особенно для будущих приложений, более требовательных к шейдерной производительности. Она обладает большим количеством всех исполнительных блоков, очень широкой шиной обмена с памятью, а следовательно, и высокой ПСП, на ней установлено оптимальное для high-end решения количество локальной видеопамяти. Технических недостатков у решения не так много, единственное, чего хотелось бы — слегка большей рабочей частоты для видеочипа в целом и шейдерных блоков в частности. Но это — вопрос скорее к технологическому процессу…
Следующая часть нашей статьи содержит тесты нового решения компании Nvidia в современных игровых приложениях. Эти результаты должны примерно соответствовать выводам, сделанным при анализе результатов синтетических тестов, с поправкой на большее влияние филлрейта и ПСП. Скорость рендеринга в играх сильнее зависит от скорости текстурирования и филлрейта, чем от мощности ALU и блоков обработки геометрии. И, судя по результатам в синтетике, можно предположить, что скорость Geforce GTX 280 в играх будет где-то между Geforce 9800 GTX и 9800 GX2, но ближе к последнему. То есть, в среднем, GT200 должен быть быстрее G92 на 60-80%.
Nvidia Geforce GTX 280 (GT200) — Часть 3: Игровые тесты (производительность)
Монитор Dell 3007WFP для тестовых стендов предоставлен компанией Nvidia
| 17 июня 2008 г. |
|
|