DirectX 10 все еще на подходе, и уже 96 калифорнийских стрелков в действии:
Часть 1: Теория и архитектура
- Унификация! Унификация!
Становится общей спецификация
- Унификация! Унификация!
В пику процессорам выйдет формация
Привычных порядков переориентация
Ставит NVIDIA, игра начинается.
Сможет ли Intel за нею угнаться?
(рэп)

Поздняя осень, промозглость, а то и уже морозы с гололедами и прочими прелестями. Однако эта мрачная по календарю пора традиционно расцвечена приготовлениями к рождественским продажам на Западе, и к радостным предновогодним хлопотам у нас.
Не менее традиционно перед таким, самым главным в году, действом, когда некоторые компании за эти 2 месяца получают 90% всей годовой прибыли, ряд фирм из IT-индустрии спешат выпустить свои новинки, чтобы очарованные ими покупатели смогли перед Рождеством купить их. Обычно такие анонсы звучат в октябре, чтобы было время для наполнения складов и начала продаж. Однако на сей раз о новинке от NVIDIA мы услышим только 8 ноября, тем не менее, анонс сделан таким образом, что поставки готовых карт уже были начаты недели 2 назад, и к началу ноября новинки можно было купить. Разумеется, не по заявленным для позиционирования ценам, а много выше.
Впрочем, рынок всегда цены расставляет так, как того требует спрос. Если последний будет ажиотажным, то и цены будут соответствующими. К сожалению, это немного не касается нашего рынка, где есть свои специфичные законы. Благодаря славной таможне с ее, мягко говоря, странной политикой, а также благодаря ряду торговых организаций, которые не думают о будущем, а сразу накручивают цены так, что мало кто купит (а потом они мучаются — как сбыть даже по входящим ценам). Слава Богу, что таких становится все меньше, и хоть и медленно, но мы движемся к цивилизованному рынку (если бы не происки, опять же, таможни, которая только по ей ведомым мотивам может что-то пропустить, а что-то арестовать или задержать). Хотелось бы отметить опыт Чехии, которая в свое время (после бархатных революций) отменила таможенные пошлины на IT-продукцию, поскольку сама все равно не производила таковую (а спрос был). А у нас — если и сами не умеем, так и не даем зеленый свет импорту и развитию и насыщению рынка высокотехнологичными товарами («собака на сене»).
Вернемся к новинке. У многих опытных пользователей трехмерной графики в играх уже на устах навязло сочетание DirectX 10. Новый, можно сказать, принципиально новый API, который будет внедрен только в MS Windows Vista, дает разработчикам, как игр, так и аппаратного обеспечения, большие широты и гибкость. Впрочем, эти лозунги звучали и ранее, когда каждая новая версия DX сопровождалась громким пиаром с подобной темой. Но видимо, все же недостаточно гибкости и свобод давали те версии, раз потребовалось выйти на уровень универсальных процессоров и шейдеров, ими исполняемых. Но об этом подробнее расскажет далее Александр Медведев, матерый и испытанный суровыми ветрами шейдерных вычислений, волк и гуру в 3D.
Понятно всем, что трехмерная графика, ее скорость и возможности начинаются с графического процессора — GPU. А сегодня в его роли будет выступать GeForce 8800 GTX (ранее известный под кодовым именем G80, а еще ранее — NV50).

Так выглядит пластина с этими кристаллами. Надо сказать, что опытному глазу уже становится видно, что размеры у последних очень велики. Да, новое ядро состоит из 681 миллиона транзисторов! Это даже намного больше, чем имеет самый суперсовременный четырехядерный процессор от Intel!
-А у меня около 700! (показывает язык)
-Ну и дура, зато у меня они крупнее!"
(разговор двух блондинок из GPU-народности)
Понятно, что если бы предыдущие чипы имели ядра такого же размера, то первая блондинка была бы права: транзисторы были бы крупнее :)
Впрочем, возможно, что какие-нибудь GeForce256 и имели кристалл такого же размера, но при этом техпроцесс был сильно толще, да и число транзисторов на порядок было меньшим. Хотя, вспоминая в памяти размеры корпусов тех GPU, слабо верится в то, что размеры ядра были бы столь велики. При изучении карты мы вернемся к вопросу о размере чипа в целом.
Итак, новый продукт NVIDIA внес революционность в уже несколько застоявшийся порядок в 3D несколькими моментами: новая шина обмена с памятью в 384 бита (промежуточный вариант между 256 и 512 бит); поэтому и новый объем локальной памяти — 768 мегабайт; поддержка универсальной шейдерной архитектуры (больше нет разделений на вершинные и пиксельные шейдерные блоки), что наиболее ярко покажет себя в DX10-приложениях, которых, понятно, еще нет (сама MS Windows Vista еще не вышла официально). Остальные нюансы мы изучим по мере ознакомления с новинкой.

Передаем слово Александру Медведеву, он расскажет обо всех новшествах в архитектуре:
Переход на унифицированные графические архитектуры мы ждали долго. Теперь можно констатировать факт — с появлением GeForce 8800 (далее мы будем использовать кодовое название G80) переход случился, и критическая вершина уже пройдена. Дальше — постепенный спуск подобных архитектур в средний и бюджетный сегменты и их дальнейшее развитие, вплоть до слияния с многоядерными процессорными архитектурами в более далекой перспективе.
Итак, для начала — несколько ссылок на теоретические материалы, которые полезно прочесть (или освежить) в качестве разминки, перед чтением теоретической части долгожданного обзора G80:
- [06.06.05] Longhorn — ускорители и шейдеры для DirectX 10
- [01.03.05] DirectX.Update — Ускорители 3D-графики: полшага вперед
- [09.04.04] DX.Next: ближайшее и ближнее будущее аппаратного ускорения 3D-графики
Строго рекомендуем обратить внимание на фундаментальный труд:
- [22.09.03] Аппаратная графическая подсистема будущего
Достаточно точно спрогнозировавший текущую архитектурную ситуацию, да, по большому счету, и будущую ситуацию на ближайшие несколько лет.
А теперь, поехали!

Графический ускоритель GeForce 8800
- Официальное название чипа GeForce 8800
- Кодовое имя G80
- Технология 90 нм
- 681 миллион транзисторов (!)
- Унифицированная архитектура (массив общих процессоров для потоковой обработки вершин и пикселей, а также других возможных видов данных)
- Аппаратная поддержка последних новшеств DirectX 10, в том числе и новая шейдерная модель — SM4, генерация геометрии и запись промежуточных данных из шейдеров.
- 384 бит шина памяти, 6 независимых контроллеров шириной 64 бита, поддержка GDDR4 (1,8 ГГц)
- Частота ядра 575 МГц (GeForce 8800 GTX)
- 128 скалярных (не векторных, внимание!) ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32бит точности в рамках стандарта IEE 754, MAD+MUL без потери тактов)
- ALU работают на удвоенной частоте (1.35ГГц для 8800GTX)
- 32 текстурных блока, поддержка FP16 и FP32 компонент в текстурах
- 64 блока билинейной фильтрации (то есть, возможна честная бесплатная трилинейная фильтрация, а также вдвое более эффективная по скорости анизотропная фильтрация)
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах — размер блока планирования — 8х4 (32) пикселя.
- 6 широких блоков ROP (24 пикселя) c поддержкой AA до 16 семплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра (то есть, возможны HDR+AA). Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 96 MSAA отсчетов (+ 96 Z) за такт, в режиме без цвета (Z only) — 192 отсчета за такт.
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Все интерфейсы вынесены на внешний дополнительный чип NVIO (2 RAMDAC, 2 Dual DVI, HDMI, HDTV)
- Очень хорошая масштабируемость архитектуры, можно по одному блокировать или убирать контроллеры памяти и ROP (Всего 6), шейдерные блоки (Всего 8 блоков TMU+ALU)
- Очень большой размер кристалла.
Первые карты на базе GeForce 8800
- NVIDIA GeForce 8800 GTX 768MB GDDR3, 575/1350/1800 MHz, 128 unified processors/32 TMUs/24 ROPs — $599;
- NVIDIA GeForce 8800 GTS 640MB GDDR3, 500/1200/1600 MHz, 96 unified processors/24 TMUs/20 ROPs — $449;
Архитектура
Итак, здравствуй, первая унифицированная архитектура от NVIDIA:
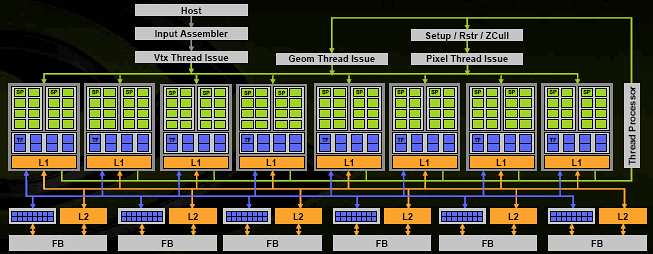
Перед нами вся диаграмма чипа. Чип состоит из 8 универсальных вычислительных блоков (шейдерных процессоров), и хотя NVIDIA говорит о 128 процессорах, заявляя, что каждое ALU является таковым, это несколько неверно - единица исполнения команд — такой процессорный блок, в котором сгруппированы 4 TMU и 16 ALU. Всего, таким образом, мы имеем 128 ALU и 32 TMU, но гранулярность исполнения составляет 8 блоков, каждый из которых в один момент может заниматься своим делом, например, исполнять часть вершинного, или пиксельного, или геометрического шейдера над блоком из 32 пикселей (или блоком из соответствующего числа вершин и иных примитивов). Все ветвления, переходы, условия и т.д. применяются целиком к одному блоку и таким образом, логичнее всего, его и называть шейдерным процессором, пускай и очень широким.
Каждый такой процессор снабжен собственным КЭШем первого уровня, в котором теперь хранятся не только текстуры, как ранее, но и другие данные, которые могут быть запрошены шейдерным процессором. Важно понимать, что основной поток данных, например, пиксели или вершины, которые и проходят обработку, двигаясь по кругу под управлением серого кардинала (блока помеченного на схеме как Thread Processor), — не кэшируются, а идут потоком. В этом и состоит основная прелесть сегодняшних графических архитектур — отсутствие полностью случайного доступа на уровне обрабатываемых примитивов. Однако в будущем картина может измениться, но об этом немного позже.
Кроме управляющего блока и 8 вычислительных шейдерных процессоров в наличии 6 блоков ROP, исполняющих определение видимости, запись в буфер кадра и MSAA (синие, рядом с блоками КЭШа L2), сгруппированные c контроллерами памяти, очередями записи и КЭШем второго уровня.
Таким образом, мы получили очень широкую (8 блоков обрабатывающих порции по 32 пикселя каждый) архитектуру, способную плавно масштабироваться в обе стороны. Добавление или удаление контроллеров памяти и шейдерных процессоров будет соответствующим образом масштабировать пропускную способность ВСЕЙ системы, не нарушая баланса (вспомним основную проблему среднего класса ATI) и, не создавая узких мест. Логичное красивое решение, реализующее основной плюс унифицированной архитектуры — автоматический баланс и высокий КПД использования имеющихся ресурсов. Уберем мысленно половину блоков — и вот, решение среднего уровня. Оставим только два шейдерных процессора и один ROP — и вот, самое бюджетное решение, в том числе для встраивания в системные чипсеты.
Кроме шейдерных блоков и ROP в наличии набор управляющих и административных блоков:
- Блоки, запускающие на исполнение данные тех или иных форматов (Vertex, Geometry и Pixel Thread Issue), — своеобразные привратники, подготавливающие данные для числодробилки в шейдерных процессорах в соответствии с форматом данных, текущим шейдером и его состоянием, условиями ветвлений и т.д.
- Setup/Raster/ZCull — блок, превращающий вершины в пиксели, — здесь выполняется установка, растеризация треугольника на блоки по 32 пикселя, предварительный блочный HSR.
- Input Assembler — блок, выбирающий геометрические и прочие исходные данные из памяти системы или локальной памяти, собирающий из потоков исходные структуры данных, которые пойдут извне на вход нашей «карусели». А на выходе в итоге, после многих кругов под управлением сперва вершинного, потом геометрического (см. статью по DX 10) и затем пиксельного шейдера и настроек блендинга, мы получим готовые, сглаженные, если надо, пикселы из ROP блоков.
Кстати, небольшое отступление: хорошо видно, что в будущем эти блоки приобретут более общий характер и не будут так завязаны на конкретные виды шейдеров. То есть превратятся в универсальные блоки, осуществляющие запуск данных на вычисление и конверсию форматов – например, от одного шейдера к другому, от вершинного к пиксельному и т.д. Никаких принципиальных изменений в архитектуру это уже не внесет, диаграмма будет выглядеть и работать практически также, за исключением меньшего числа специальных «серых» блоков. Уже сейчас все три блока Thread Issue являются, скорее всего (реально), одним блоком с общей функциональностью и контекстными дополнениями:

Прелести унификации — дорога к полностью универсальному потоковому процессору открыта уже сейчас, и вопрос можно считать практически решенным. Кстати, об этом снова далее ;-)
Пока посмотрим ближе на
Шейдерный процессор и его TMU/ALU

Итак, в каждом из 8 шейдерных блоков в наличии 16 скалярных ALU. Что, опять таки, дает нам потенциальную возможность увеличить КПД их нагрузки вплоть до 100% вне зависимости от кода шейдера. ALU работают на удвоенной частоте и таким образом, соответствуют или превосходят (в зависимости от операций в шейдере) 8 четырехкомпонентных векторных ALU старого «образца» (G70) на равной базовой частоте ядра. NVIDIA приводит такой расчет пиковой производительности:

Однако он действителен для самого невыгодного для других варианта, когда имеют место два умножения. В реальной жизни стоит поделить это преимущество в полтора раза или около того. Но, в любом случае, эти скалярные ALU за счет более высокой тактовой частоты и их числа обгонят все ранее существовавшие чипы. За исключением, может быть, SLI конфигурации G7X в случае не самых выгодных для новой архитектуры шейдеров. Это предположение мы проверим далее, в синтетических и игровых тестах.
Интересно, что точность всех ALU составляет FP32 и, с учетом новой архитектуры, мы не предвидим никакого преимущества для FP16 шейдеров с пониженной точность. Как и в случае последних чипов ATI об этом компромиссе можно, наконец-то, забыть. Еще один интересный момент — поддержка вычислений в целочисленном формате. Этот пункт необходим для реализации SM4. При реализации арифметики соблюден стандарт IEE 754, что делает ее пригодной для серьезных, неигровых вычислений — например, научных, статистических или экономических. Об этом — чуть далее ;-)
Теперь о взаимодействии текстурных блоков и ALU в рамках одного шейдерного блока:

Операция выборки и фильтрации текстур не требует ресурсов ALU и может теперь производиться полностью параллельно математическим вычислениям. Генерация текстурных координат (на схеме — А) по-прежнему отнимает часть времени ALU. Это снова логично, если мы хотим использовать транзисторы чипа на все 100%, ведь генерация текстурных координат требует стандартных плавающих операций, и заводить для нее отдельные ALU было бы непредусмотрительно.
Сами по себе текстурные модули имеют следующую конфигурацию:
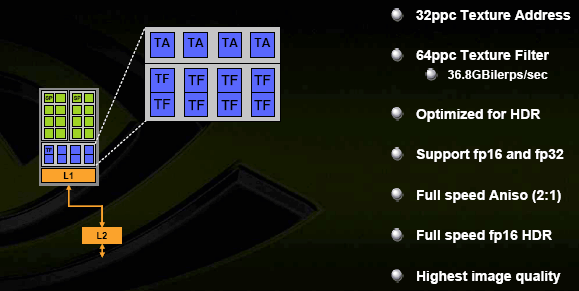
В наличии 4 модуля для адресации текстур TA (определения по координатам точного адреса для выборки) и вдвое больше модулей для билинейной фильтрации TF. Почему так? Это позволяет при умеренном расходовании транзисторов обеспечить честную бесплатную трилинейную фильтрацию или вдвое понизить падение скорости при анизотропной фильтрации. И то, и то — вполне характерно для сегодняшнего использования ускорителей, когда анизотропия становится самым популярным методом фильтрации среди игроков, покупающих карты хайенд сегмента. Скорость на обычных разрешениях, в обычной фильтрации и без АА давно не имеет смысла — и предыдущее поколение ускорителей прекрасно справляется в таких условиях даже с самыми последними играми на самых больших мониторах. Сегодняшние чипы можно по праву назвать AF+AA+HDR чипами. Кстати, про HDR — поддерживаются, в том числе и FP16/FP32 форматы текстур. А также SRGB гамма-коррекция на входе (TMU) и выходе (ROP).
Обещано также значительное улучшение КАЧЕСТВА анизотропии, которое должно теперь сравниться или даже обогнать последние продукты ATI в режиме высокого качества AF. Забегая вперед, отметим, что мы проверили это заявление, и оно соответствует действительности! NVIDIA реально устранила еще одно слабое место своих чипов — и теперь мы имеем прекрасную по качеству анизотропию с очень слабым падением скорости (конкретные результаты исследования далее, в игровом разделе статьи).
Напоследок, приведем спецификации шейдерной модели новых процессоров, соответствующей требованиям SM4:
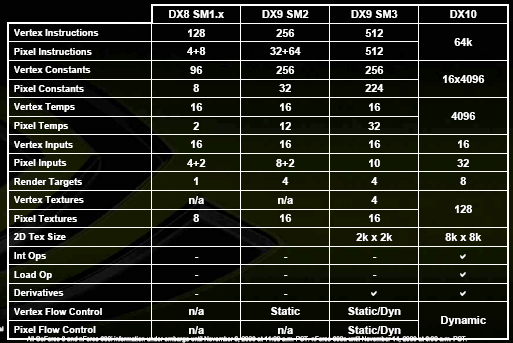
Налицо значительные количественные и качественные перемены — все меньше и меньше ограничений для шейдеров, все больше и больше общего с CPU. Пока без особого произвольного доступа (такая операция появилась в SM4, — пункт Load Op на диаграмме, но ее эффективность для общих целей пока сомнительна, особенно в первых реализациях), но нет сомнений, что в скором времени и этот аспект будет развит, как была развита за эти 5 лет поддержка FP форматов — от первых проб в NV30 до тотального, сквозного FP32 конвейера во всех режимах сейчас — в G80.
Блоки ROP, запись в буфер кадра, сглаживание
Как мы помним, кроме 8 шейдерных блоков, в наличии 6 блоков ROP такого содержания:

На диаграмме показаны два отдельных пути для Z и C, однако реально это один набор ALU, которые делятся на две группы при обработке пикселей с цветом, либо действуют как одна группа при обработке в режиме Z-Only, увеличивая, таким образом, пропускную способность вдвое. В наше время нет смысла считать отдельные пиксели — их и так достаточно, важнее посчитать, сколько MSAA сэмплов может быть обработано за такт — эти данные и приведены. Соответственно, при MSAA 16х чип может выдавать 6 полноценных пикселей за такт, при 8х — 12 и т.д. Интересно, что масштабируемость работы с буфером кадров на высоте — как мы помним, каждый блок ROP работает с собственным контроллером памяти и не мешает соседним.
Наконец-то есть полноценная поддержка FP32 и FP16 форматов буфера кадров ВМЕСТЕ с АA — теперь никаких ограничений для фантазии разработчиков — HDR на протяжении всего конвейера не требует изменения общей последовательности построения, кадра, даже в AA режиме — все шейдеры останутся, по сути, прежними, надо будет только изменить формат данных.
CSAA
Появился и новый метод сглаживания — CSAA. Мы исследуем его подробно в следующей статье, которая планируется к выходу в скором времени. Пока отметим, что этот метод во многом похож на подход ATI и также имеет дело с псевдостохастическими паттернами и распространением отсчетов на соседние геометрические зоны (происходит размазывание пиксела, пикселы не имеют резкой границы, а как бы переходят один в другой, с точки зрения AA, покрывая некую зону). Цвета отсчетов и глубина хранятся отдельно от информации об их местоположении, и таким образом, на один пиксель может приходиться 16 отсчетов но, например, всего 8 вычисленных значений глубины — что дополнительно экономит ПСП и такты.
Известно, что классический MSAA в режиме большем чем 4х становится очень прожорливым, с точки зрения памяти, в то время как качество растет все меньше и меньше. Новый метод корректирует это поведение, позволяя получать 16х режим сглаживания, заметно более качественный, чем MSAA 16х с вычислительными затратами, сравнимыми с 4х MSAA. Пока суммируем, что и здесь NVIDIA подтянула свои слабые (ранее), по сравнению с ATI, места.
NVIO
Еще одно новшество — вынесенные за предел основного чипа ускорителя интерфейсы. За них теперь отвечает отдельный чип под названием NVIO:

В нем интегрированы:
- 2 * 400 МГц RAMDAC
- 2 * Dual Link DVI (или LVDS)
- HDTV-Out
Подсистема вывода, таким образом, выглядит так:
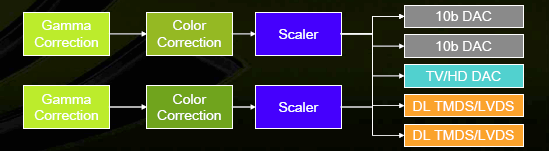
Точность при этом составляет 10 бит на компоненту на всем ее протяжении.
Разумеется, в среднем сегменте и тем более в бюджетных решениях отдельный внешний чип может не сохраниться, но для дорогих карт здесь больше плюсов, чем минусов. Интерфейсы занимают значительную площадь чипа, сильно зависят от помех, требуют особого питания. Устранив все эти моменты с помощью внешнего чипа можно выиграть в качестве выходных сигналов и в гибкости конфигурации, а также не усложнять разработку и так сложного ускорителя учетом оптимальных режимов для встроенных RAMDAC.
Конвейер с точки зрения API DirectX 10
Напомним нашим читателям ключевые особенности DX10, которые станут доступны нам позже, с окончательным выходом новой OS и нового API:
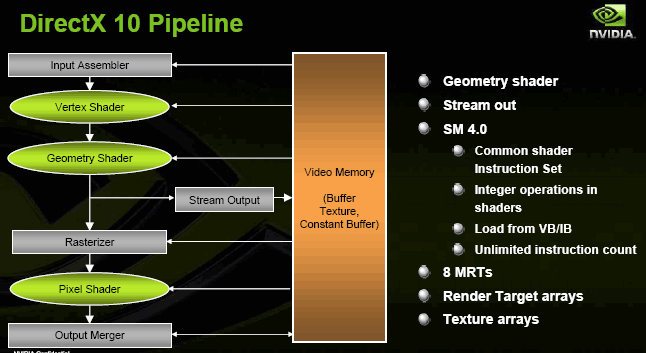
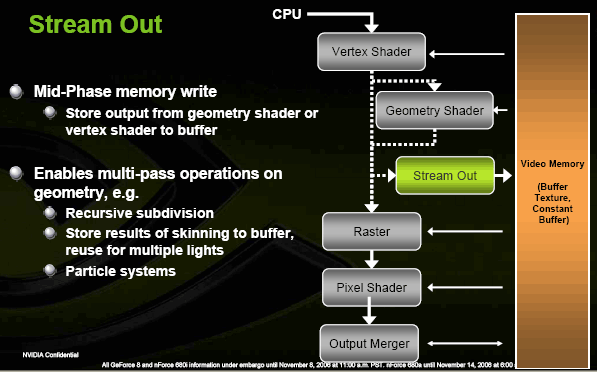
Это SM4, массивы текстур и буферов кадра, генерация геометрии в геометрических шейдерах (новый тип шейдеров) и запись промежуточных геометрических данных обратно в буфер кадра. В сумме эти новшества делают возможным полностью аппаратную реализацию шейдерами ранее недоступных алгоритмов, таких как гладкие поверхности с рекурсивным разбиением, сложные системы частиц, взаимодействующих друг с другом и с окружением и т.д.
Здесь, как мы видим, все хорошо соответствует нашим прогнозам из статьи DX.Next (ближайшее и ближнее будущее аппаратного ускорения 3D-графики)
Также в наличии средства для снижения стоимости вызова API и виртуализации ресурсов — оценить которые (их эффективность в реальных приложениях) мы сможем только с выходом Vista и первых игр для нее.
Важно понимать, что архитектура, с точки зрения API и с точки зрения железной его реализации, может быть различной. Так и здесь, несмотря на эту достаточно жесткую схему, сам чип потенциально может иметь дело и с другими разновидностями шейдеров — все зависит от того, как представить в API. Например, ничего не мешает геометрическому шейдеру быть до вершинного, а не после и т.д. Об этом и дальнейших перспективах мы уже говорили в статье Аппаратная графическая подсистема будущего.
G80 как ваш персональный суперкомпьютер
А теперь самое интересное. Пиковая производительность плавающей арифметики нового ускорителя превышает любой из доступных сейчас настольных процессоров. Вычисления производятся в стандарте IEE 754. Унифицированная шейдерная архитектура обладает гибкостью, достаточной для расчета не только физики в игровых приложениях, но и более серьезных задач — математического и физического моделирования, экономических и статистических моделей и расчетов. Распознавания образов, обработки изображений, научной графики, да мало ли какие еще задачи можно решить с помощью хорошего потокового процессора, с возможностью динамических ветвлений?
Что для этого надо? Поддержка со стороны приложений. А что надо для эффективной поддержки со стороны приложений? Правильно, удобный, ориентированный на вычисления API, который проживет дольше одного или двух поколений ускорителей и будет достаточно удобен для быстрой адаптации и разработки программ, перекладывающих вычисления на GPU.
Итак, фанфары! Теперь, с выходом G80, появился и такой API для чипов NVIDIA!
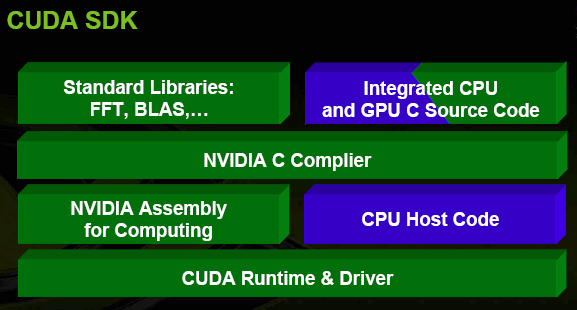
CUDA (Compute Unified Device Architecture) — унифицированная вычислительная архитектура для различных задач, реализованная специальный SDK, API и компилятор С, а также как небольшие аппаратные закладки в G80 (некий специальный вычислительный режим, в котором данные обрабатываются по основному кругу диспетчер <-> шейдерный блок <-> кэш, без разделения их на классы пикселей, вершин и т.д.), судя по всему не потребовавшие практически никаких существенных изменений в архитектуре и коснувшиеся только некоторых «обходных» путей для данных в ускорителе.
Теперь, можно разрабатывать приложения, которые будут использовать (при наличии оного) подходящее аппаратное ускорение в лице G80 и последующих преемников, для различных интенсивных потоковых и векторных вычислений. В будущем мы попробуем коснуться этого вопроса в отдельной статье и измерить реальную производительность этого решения на типовых задачах. А пока отметим, что NVIDIA приводит цифры от 10х прироста (начиная!) и до нескольких сотен раз в зависимости от задачи при сравнении G80 c двухядерным Core2 duo на частоте 2.66 ГГц.
Основная прелесть такого решения — независимость от DX и от оборудования — программистам будет достаточно действовать в рамках SDK, не вдаваясь в детали реализации и компиляции. Им не придется учить шейдерную модель и писать отдельные графические шейдеры для своих вычислительных задач. А значит, это решение вполне может стать стандартом де-факто.
И да, прощайте отдельные физические ускорители от всяких третьих фирм ;-)

Общие тенденции
Сейчас очевидно, что борьба между процессорными и графическими лидерами началась. AMD приобрел ATI, чтобы выступить единым лицом на будущем ландшафте унифицированных графическо-вычислительных процессоров. А NVIDIA, видимо, пока чувствует в себе силы оставаться в одиночке, качая мышцы на рынке чипсетов, где она получает все более и более заметную долю с каждой новинкой, и, поглядывая в сторону CPU, — сложность которых уже не напугает эту фирму, а лицензии на общепринятые шины у NVIDIA есть, как от Intel, так и от AMD. Конечно, они не будут в ближайший год или два выпускать настольный процессор для конкуренции с титанами этого рынка, но, вполне возможно, что в скором времени мы увидим какую-нибудь экзотическую пробу пера в области мобильных процессоров для КПК и смартфонов или еще где-нибудь с краешку рынка.
Нет сомнений, что через 5-10 лет графические ускорители, идущие по пути все большей универсальности и гибкости и центральные процессоры, идущие по пути все большего параллелизма, сойдутся в едином продукте. Один чип будет содержать в себе набор, возможно, разнокалиберных ядер, как выделенных вычислительных или графических, так и общего назначения. На его борту примостится и все вчерашнее северного моста (что мы уже наблюдаем у AMD и в некоторых серверных архитектурах) — контроллеры памяти, межпроцессорные шины, и системные шины общего назначения.
Мы с вами увидим это великое слияние, которое вполне может оказаться и великим переделом сложившегося Wintel рынка. Свой шанс могут получить как новые игроки по типу NVIDIA, так и новые OS. Разумеется, шанс может быть упущен — и гораздо спокойнее было бы уйти под крыло процессорной и платформенной компании, как это сделала ATI. Спокойнее, но победа никогда не дается спокойствием. NVIDIA сейчас, как никогда на подъеме и ощущает в себе силы стать как минимум еще одним локомотивом индустрии, роль которого столько лет подряд исполнял чуть запыхавшийся в последнее время Intel.
Моя любимая присказка — поживем, увидим ;-)
Хайтек — то самое место, где она как никогда уместна.
А теперь перейдем к практической части!


