Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX/GM1XX
Справочная информация о семействе видеокарт GM2XX
Спецификации чипов семейства GF1XX
| кодовое имя | GF100 | GF104 | GF110 | GF114 | GF106 | GF116 | GF108 | GF119 |
| базовая статья | здесь | здесь | здесь | здесь | здесь | здесь | - | |
| технология, нм | 40 | |||||||
| транзисторов, млрд | 3,0 | 1,95 | 3,0 | 1,95 | 1,17 | 1,17 | 0,59 | ? |
| универсальных процессоров | 512 | 384 | 512 | 384 | 192 | 192 | 96 | 48 |
| текстурных блоков | 64 | 32 | 16 | 8 | ||||
| блоков блендинга | 48 | 32 | 48 | 32 | 24 | 16 | 4 | |
| шина памяти | 384 | 256 | 384 | 256 | 192 | 128 | 64 | |
| типы памяти | GDDR3, GDDR5 | |||||||
| системная шина чипа | PCI Express 2.0 16х | |||||||
| RAMDAC | 2×400МГц | |||||||
| интерфейсы | 2×DVI Dual Link HDMI DisplayPort | |||||||
| вершинные шейдеры | 5.0 | |||||||
| пиксельные шейдеры | 5.0 | |||||||
| точность вычислений | FP32/FP64 | |||||||
| форматы текстур | FP32 FP16 I8 DXTC, S3TC 3Dc другие | |||||||
| форматы рендеринга | FP32 FP16 I8 I10 (RGBA 10:10:10:2) другие | |||||||
| MRT | есть | |||||||
| Антиалиасинг | MSAA 2х-8х CSAA до 32x | |||||||
Спецификации референсных карт на базе семейства GF1XX
| карта | чип | блоков ALU/TMU/ROP | частота ядра, МГц | частота памяти, МГц | объем памяти, МБ | ПСП, ГБ/c (бит) | текстури- рование, Гтекс | филлрейт, Гпикс | TDP, Вт |
| GeForce GT 630 | GF108 PEG16x | 96/16/16 | 810/1620 | 900(1800)/800(3200) | 1024 DDR3/512 GDDR5 | 28,8—51,2 (128) | 13,0 | 13,0 | 65 |
| GeForce GT 620 | GF108 PEG16х | 96/16/16 | 700/1400 | 800(3200) | 1024 GDDR5 | 51,2 (128) | 11,2 | 11,2 | 65 |
| GeForce GT 610 | GF119 PEG16х | 48/8/4 | 810/1620 | 900 (1800) | 1024 DDR3 | 14,4 (64) | 6,5 | 3,2 | 29 |
| GeForce GTX 590 | 2xGF110 PEG16х | 2x(512/64/48) | 607/1215 | 854(3414) | 2x1536 GDDR5 | 328 (2x384) | 78 | 58 | 365 |
| GeForce GTX 580 | GF110 PEG16х | 512/64/48 | 772/1544 | 1002(4008) | 1536 GDDR5 | 192,4 (384) | 49,4 | 37,0 | 244 |
| GeForce GTX 570 | GF110 PEG16х | 480/60/40 | 732/1464 | 950(3800) | 1280 GDDR5 | 152,0 (320) | 43,9 | 29,3 | 219 |
| GeForce GTX 560 Ti 448 | GF110 PEG16х | 448/56/40 | 750/1500 | 950(3800) | 1280 GDDR5 | 152,0 (320) | 42,0 | 30,0 | 219 |
| GeForce GTX 560 Ti | GF114 PEG16х | 384/64/32 | 822/1644 | 1002(4008) | 1024 GDDR5 | 128,0 (256) | 52,6 | 26,3 | 170 |
| GeForce GTX 560 | GF114 PEG16х | 336/56/32 | 810/1620 | 1000(4000) | 1024 GDDR5 | 128,0 (256) | 45,3 | 25,9 | 150 |
| GeForce GTX 560 SE | GF114 PEG16х | 288/48/24 | 736/1472 | 960(3840) | 1024 GDDR5 | 92,2 (192) | 35,4 | 17,7 | 150 |
| GeForce GTX 550 Ti | GF116 PEG16х | 192/32/24 | 900/1800 | 1026(4104) | 1024 GDDR5 | 98,5 (192) | 28,8 | 21,6 | 116 |
| GeForce GT 520 | GF119 PEG16х | 48/8/4 | 810/1620 | 900 (1800) | 512/1024 DDR3 | 14,4 (64) | 6,5 | 3,2 | 29 |
| GeForce GTX 480 | GF100 PEG16х | 480/60/48 | 700/1401 | 924(3696) | 1536 GDDR5 | 177,4 (384) | 42,0 | 33,6 | 250 |
| GeForce GTX 470 | GF100 PEG16х | 448/56/40 | 607/1215 | 837(3348) | 1280 GDDR5 | 133,9 (320) | 34,0 | 24,3 | 215 |
| GeForce GTX 465 | GF100 PEG16х | 352/44/32 | 607/1215 | 802(3208) | 1024 GDDR5 | 102,6 (256) | 26,7 | 19,4 | 200 |
| GeForce GTX 460 1 ГБ | GF104 PEG16х | 336/56/32 | 675/1350 | 900(3600) | 1024 GDDR5 | 115,2 (256) | 37,8 | 21,6 | 160 |
| GeForce GTX 460 768 МБ | GF104 PEG16х | 336/56/24 | 675/1350 | 900(3600) | 768 GDDR5 | 86,4 (192) | 37,8 | 16,2 | 150 |
| GeForce GTX 460 SE | GF104 PEG16х | 288/48/24 | 675/1350 | 850(3400) | 1024 GDDR5 | 108,8 (256) | 32,4 | 21,6 | 140 |
| GeForce GTS 450 | GF106 PEG16х | 192/32/16 | 783/1566 | 900(3600) | 1024 GDDR5 | 57,7 (128) | 25,1 | 12,5 | 106 |
| GeForce GT 440 | GF108 PEG16х | 96/16/16 | 810/1620 | 900(1800)/800(3200) | 1024 DDR3/512 GDDR5 | 28,8—51,2 (128) | 13,0 | 13,0 | 65 |
| GeForce GT 430 | GF108 PEG16х | 96/16/16 | 700/1400 | 900 (1800) | 1024 DDR3 | 28,8 (128) | 11,2 | 11,2 | 49 |
Подробности: GF100, семейство GeForce GTX 400
Спецификации GF100
- Кодовое имя чипа GF100
- Технология производства 40 нм
- Более 3 миллиардов транзисторов
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции
- 384-битная шина памяти, шесть независимых контроллеров шириной по 64 бита каждый, с поддержкой памяти GDDR5
- Частота ядра до 700 МГц
- Удвоенная частота ALU до 1401 МГц
- 16 потоковых мультипроцессоров, включающих 512 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008)
- 64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- 6 широких блоков ROP (48 пикселей) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort
Спецификации референсной видеокарты GeForce GTX 480
- Частота ядра 700 МГц
- Частота универсальных процессоров 1401 МГц
- Количество универсальных процессоров — 480
- Количество текстурных блоков — 60, блоков блендинга — 48
- Эффективная частота памяти 3696 (924×4) МГц
- Тип памяти GDDR5, 384-битная шина памяти
- Объем памяти 1536 МБ
- Пропускная способность памяти 177,4 ГБ/с
- Теоретическая максимальная скорость закраски 33,6 гигапикселей в секунду
- Теоретическая скорость выборки текстур 42,0 гигатекселя в секунду
- Два разъема Dual Link DVI-I, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600
- Двойной SLI-разъем
- Шина PCI Express 2.0
- Поддержка HDCP, HDMI, DisplayPort
- Энергопотребление до 250 Вт (8-штырьковый + 6-штырьковый разъёмы)
- Двухслотовое исполнение
- Рекомендуемая цена для американского рынка $499
Спецификации референсной видеокарты GeForce GTX 470
- Частота ядра 607 МГц
- Частота универсальных процессоров 1215 МГц
- Количество универсальных процессоров — 448
- Количество текстурных блоков — 56, блоков блендинга — 40
- Эффективная частота памяти 3348 (837×4) МГц
- Тип памяти GDDR5, 320-битная шина памяти
- Объем памяти 1280 МБ
- Пропускная способность памяти 133,9 ГБ/с
- Теоретическая максимальная скорость закраски 24,3 гигапикселей в секунду
- Теоретическая скорость выборки текстур 34,0 гигатекселя в секунду
- Два разъема Dual Link DVI-I, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600
- Двойной SLI-разъем
- Шина PCI Express 2.0
- Поддержка HDCP, HDMI, DisplayPort
- Энергопотребление до 215 Вт (два 6-штырьковых разъёма)
- Двухслотовое исполнение
- Рекомендуемая цена для американского рынка $349
Принцип наименования видеокарт NVIDIA остался тем же, что и раньше. По сравнению с предыдущими топовыми картами, поменялась первая цифра. Причём она скакнула сразу с «2» до «4», пропустив «3». Сделано это потому, что в третьей серии в линейке компании ранее уже появились карты, основанные на старых GPU и предназначенные для OEM-сборщиков.
Модели серии, как обычно бывает в случае видеокарт NVIDIA, отличаются тактовыми частотами видеочипа и памяти, а также разным количеством отключенных исполнительных блоков. GTX 480 имеет 480 потоковых процессоров, 60 TMU и 48 блоков ROP, а модель GTX 470 отличается ещё меньшим количеством активных исполнительных блоков: 448 потоковых процессоров, 56 текстурных блоков и 40 блоков ROP.
На обе модели устанавливается память типа GDDR5, чтобы не было ограничения производительности полосой пропускания, но ширина шины памяти и её объём у решений отличаются. Старшая модель использует полноценную 384-битную шину памяти, а у младшей отключён один из шести 64-битных контроллеров, поэтому ей остаётся довольствоваться 320-битной шиной.
Соответственно, это влияет и на объём видеопамяти. С 384-битной шиной можно установить 768, 1536 МБ или 3 ГБ, а с 320-битной — 640, 1280 или 2560 МБ. Естественно, что в NVIDIA выбрали 1536 и 1280 МБ, так как 640–768 — это слишком мало, а в 3 ГБ нет смысла. Причём объём в 1280 и 1536 МБ мы считаем довольно удачным, так как даже если в редчайших случаях приложениям и не хватает одного гигабайта, то полутора им точно хватит.
Также старшее и младшее решение отличаются разным дизайном печатной платы, и референсные кулеры у них разные — на GTX 470 стоит кулер попроще. Но он всё равно двухслотовый, да и энергопотребление карты хоть и ниже, чем у GTX 480, но незначительно, разница между 215 и 250 Вт невелика.
Основные архитектурные особенности GF100
Кодовое обозначение GF100 расшифровывается так: «GF» в данном случае означает графический («Graphics») чип, основанный на вычислительной архитектуре «Fermi», а число «100» — принятое для продуктов NVIDIA наименование первого из чипов архитектуры, нацеленного на верхний ценовой диапазон рынка.
Архитектура GF100 поддерживает все нововведения современного DirectX 11 API, такие как аппаратная тесселяция и вычислительные возможности DirectCompute. Более того, архитектура GF100 спроектирована с учётом будущих возможностей API и потребностей графических приложений, таких как трассировка лучей и физические эффекты.
В GF100 используется третье поколение потоковых мультипроцессоров (Streaming Multiprocessor) с более чем удвоенным количеством вычислительных ядер (CUDA cores), по сравнению с предыдущей архитектурой. Количество и производительность других исполнительных блоков также были увеличены в GF100, но наиболее важным изменением архитектуры является то, что геометрический конвейер в новом GPU впервые за многое время подвергся весьма значительной переработке.
Для того чтобы соответствовать новым возможностям DirectX 11 и современных графических приложений, в этом GPU значительно увеличена пиковая производительность обработки геометрии, геометрических шейдеров и stream out. И, что особенно важно, этот GPU очень быстр в тесселяции, самом важном нововведении DirectX 11.
Графический конвейер GF100 специально спроектирован с учётом этих возможностей, он способен обеспечить действительно высокую производительность для тесселяции и обработки геометрии. В новом GPU архитектура традиционной геометрической обработки уступила место новой архитектуре, использующей несколько так называемых полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно, по сравнению с одним таким блоком во всех предыдущих поколениях GPU.
В плюс возможностям графического процессора идёт и новая архитектура подсистемы памяти. Полноценные кэши первого и второго уровней обеспечивают быстрый доступ к геометрическим атрибутам для потоковых процессоров и блоков тесселяции.
Есть у GF100 и другие сильные стороны, раскрывающие возможности архитектуры Fermi. В последнее время большое значение имеют неграфические вычисления на GPU, предъявляющие специфические требования к аппаратной части. И основными изменениями в GF100, связанными с повышением эффективности вычислительных алгоритмов, являются быстрое переключение контекста между графическими и неграфическими расчётами, конкурентное исполнение вычислительных программ и улучшенная архитектура кэширования, эффективная для таких задач, как трассировка лучей и искусственный интеллект.
Из других нововведений можно также отметить улучшенную производительность атомарных операций (atomic operations), что ускоряет такие алгоритмы, как рендеринг полупрозрачных поверхностей без предварительной сортировки (order independent transparency). Но давайте перейдём уже к архитектурным подробностям.
Архитектура графического процессора GF100
Как и предыдущие чипы разработки NVIDIA, GF100 имеет в своей основе несколько кластеров (теперь они называются кластерами графической обработки, Graphics Processing Clusters), каждый из которых состоит из нескольких потоковых мультипроцессоров (Streaming Multiprocessors), которые, в свою очередь, содержат массивы потоковых процессоров.
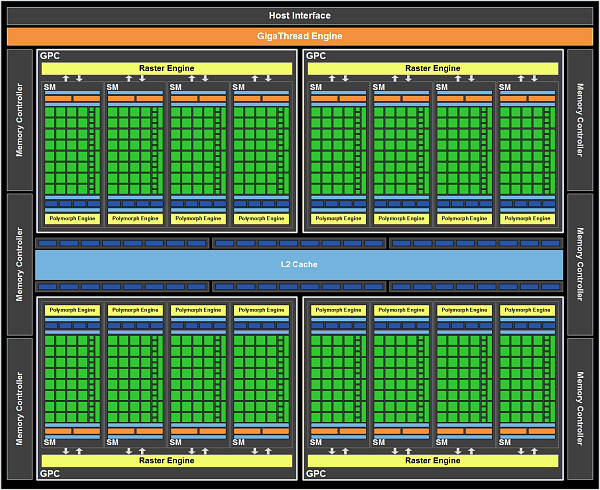
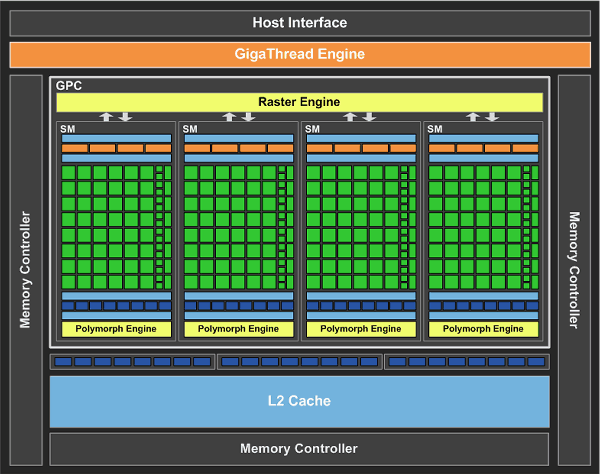
GF100 содержит четыре кластера GPC, шестнадцать мультипроцессоров SM и шесть 64-битных контроллеров памяти. Пока что NVIDIA выпустила две модели видеокарт на основе GF100, с разным количеством активных блоков GPC и контроллеров памяти: GTX 470 и GTX 480. Это логично с точки зрения производства, техпроцесс TSMC всё ещё не позволяет выпускать полностью годные чипы в массовых количествах. Такой подход соответствует и рыночной политике, в разные ценовые диапазоны направляются чипы с разными характеристиками.
Итак, новый GPU в своем полном представлении содержит внешний PCI Express интерфейс, движок GigaThread, четыре GPC, шесть контроллеров памяти, шесть укрупненных блоков ROP, а также 768 КБ кэш-памяти второго уровня, присоединённые к блокам ROP.
GPU получает команды по Host Interface, движок GigaThread запрашивает нужные данные из системной памяти и копирует их в локальную память. В отличие от предыдущего чипа, имеющего восемь контроллеров памяти по 64 бита, GF100 имеет шесть таких контроллеров, но обладающих поддержкой GDDR5 памяти, которой не было у решений на основе GT200. В итоге применение памяти GDDR5 и 384-битного доступа к ней даёт достаточно высокую пропускную способность.
Диспетчер GigaThread является центром чипа, он создаёт и распределяет блоки потоков по разным мультипроцессорам, а мультипроцессоры распределяют варпы (warps, группы из 32 потоков) среди потоковых процессоров (CUDA cores) и других исполнительных блоков.
Всего в состав GF100 входит 512 потоковых процессоров, собранных в 16 мультипроцессоров по 32 штуки в каждом. В выпущенных моделях их количество уменьшено до 448 и 480 для GTX 470 и GTX 480 в составе 14 и 15 мультипроцессоров для GTX 470 и GTX 480, соответственно. Каждый SM поддерживает одновременное выполнение до 48 варпов, а CUDA core может выполнять все типы программ: вершинные, пиксельные, геометрические, вычислительные.
Чип GF100 содержит 48 блоков ROP, которые выполняют работу по блендингу и сглаживанию пикселей, а также отвечают за атомарные операции с памятью. Блоки ROP в новом чипе NVIDIA сгруппированы в шесть групп по восемь модулей. Каждая группа обслуживается своим 64-битным контроллером памяти. Младшая модель серии GTX 400 отличается одним отключенным укрупнённым блоком ROP, поэтому имеет 320-битную шину памяти и 40 блоков ROP.
Архитектура Graphics Processing Clusters
Итак, графическая архитектура чипа GF100 состоит из четырёх кластеров Graphics Processing Clusters, каждый из которых содержит по четыре мультипроцессора и по своему отдельному движку растеризации (Raster Engine).
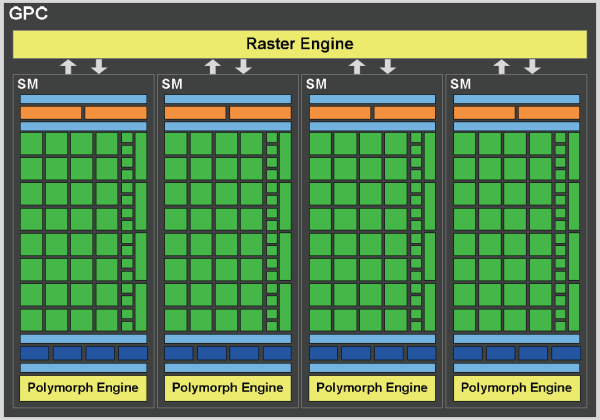
В новом GPC видны два ключевых изменения. Во-первых, появился свой масштабируемый движок растеризации, выполняющий установку треугольников (triangle setup), растеризацию и отбрасывание невидимых поверхностей (z-cull). А во-вторых, GPC теперь содержит и отдельные движки PolyMorph, выполняющие выборку вершинных атрибутов и тесселяцию. Причём движок растеризации Raster Engine принадлежит к GPC, а PolyMorph — к каждому из мультипроцессоров SM в кластере.
Кластер GPC включает все основные графические блоки GPU, за исключением блоков ROP. Фактически, его можно расценивать как отдельный видеочип, и таких в GF100 четыре штуки. В предыдущих GPU NVIDIA мультипроцессоры и текстурные блоки были сгруппированы в кластеры текстурной обработки (Texture Processing Clusters), а в GF100 каждый из мультипроцессоров SM имеет по четыре выделенных текстурных блока. Далее об этом написано подробно.
Потоковые мультипроцессоры
В третьем поколении потоковых мультипроцессоров NVIDIA мы видим несколько усовершенствований и нововведений, направленных как на увеличение производительности, так и на улучшение программируемости и гибкости их использования.
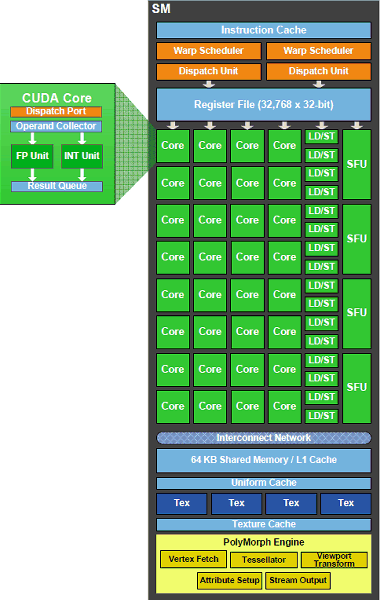
Каждый из мультипроцессоров SM содержит по 32 потоковых CUDA-ядра, что вчетверо больше, чем в GT200 (хотя тут нужно учитывать снизившееся общее число мультипроцессоров в чипе). Они остались скалярными, как и ранее, что даёт высокий КПД для любых приложений, а не только специально оптимизированных. Например, операции с Z-буфером (1D) и доступ к текстурам (2D) могут полностью загрузить работой исполнительные блоки GPU, в отличие от ALU суперскалярных архитектур, где КПД будет ниже.
Потоковые процессоры имеют в своём составе исполнительное устройство для целочисленных вычислений (ALU) и исполнительное устройство для вычислений с плавающей запятой (FPU). Вычисления GF100 соответствуют новому стандарту IEEE 754-2008 по вычислениям с плавающей запятой, а также предоставляют возможность выполнения совмещенных операций умножения-сложения (fused multiply-add, или FMA) для вычислений одинарной и двойной точности.
FMA, в отличие от инструкции умножения-сложения (multiply-add, MAD), выполняет эти две операции лишь с одним округлением. Такой подход обеспечивает отсутствие потерь точности при сложении и минимизирует ошибки рендеринга в некоторых случаях. Например, при близких перекрывающихся треугольниках.
Новый целочисленный блок ALU, появившийся в GF100, поддерживает полную 32-битную точность для всех инструкций, как этого требуют языки программирования. Помимо этого, целочисленный ALU с высокой эффективностью исполняет 64-битные операции. Каждый из мультипроцессоров имеет 16 блоков загрузки и сохранения данных (load/store unit, LD/ST или LSU), позволяющих вычислять адреса источника и назначения для 16 потоков за такт.
Четыре исполнительных блока специальных функций (Special Function Units, SFU) выполняют сложные операции, такие как вычисление синуса, косинуса, квадратного корня и т. п. Кроме того, эти блоки используются и для интерполяции графических атрибутов. Каждый блок SFU выполняет одну инструкцию на поток за один такт, то есть варп из 32 потоков будет выполняться за восемь тактов. Конвейер SFU отделён от блока диспетчера, что позволяет последнему обращаться к другим исполнительным устройствам в то время, когда SFU занят.
Важно отметить, что несмотря на значительно ускоренные вычисления с двойной точностью, на которые способна архитектура Fermi, игровые решения на базе чипа GF100 намеренно приторможены и исполняют такие расчёты медленнее, чем теоретически могут. Производительность 64-битных вычислений в GeForce GTX 480 искусственно снижена вчетверо. В случае GTX 480 — до 168 гигафлоп вместо теоретически возможных 672.
Собственно, такое решение логично, ведь вычисления с двойной точностью не особенно сильно нужны графическим решениям. Зато это позволит обеспечить хорошие продажи соответствующих решений Tesla на архитектуре Fermi. А картам GeForce не нужна ни очень высокая производительность 64-битных вычислений, ни коррекция ошибок памяти ECC. Всё это будет там, где это востребовано, — в Tesla.
Двойной планировщик варпов
Как написано выше, мультипроцессоры выполняют потоки группами по 32 штуки, такие группы называются варпами. Каждый мультипроцессор содержит по два планировщика варпов (Warp Scheduler) и по два диспетчера инструкций (Instruction Dispatch Unit), что позволяет одновременно выполнять по два варпа на каждом из SM.
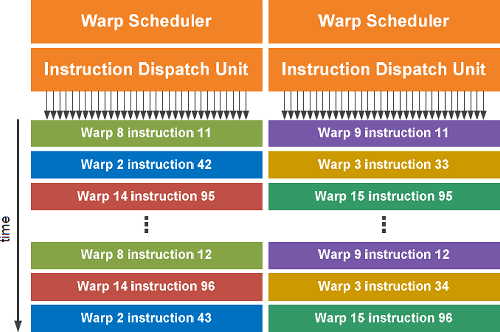
Двойной планировщик варпов в GF100 выбирает два варпа и запускает на выполнение по одной инструкции из каждого из них на группе из 16 вычислительных ядер, 16 блоков LSU или четырёх SFU. Так как варпы исполняются независимо друг от друга, планировщик GPU не должен проверять поток инструкций на зависимые команды. Использование такой модели одновременного исполнения двух команд (dual-issue) за такт позволяет достичь высокой производительности, близкой к пиковым теоретическим значениям.
Большинство инструкций может выполняться одновременно по две: пара целочисленных инструкций, две инструкции с плавающей запятой или сочетание целочисленной, инструкции с плавающей запятой, загрузки данных, сохранения данных, специальных инструкций SFU. Но это относится только к инструкциям одинарной точности, а команды двойной точности не могут исполняться одновременно с любой другой инструкцией.
Текстурные модули
Для любого графического чипа очень важно количество текстурных модулей в GPU и их возможности. Как видно на схеме мультипроцессора, в каждом из них есть по четыре текстурных блока. Каждый из которых вычисляет адрес и выбирает данные для четырёх текстурных выборок за такт. Результат может быть выдан как в неотфильтрованном виде (для Gather4), так и с билинейной, трилинейной или анизотропной фильтрацией. При фильтрации — с соответствующей потерей темпа.
Кардинально в TMU GF100 ничего не изменилось, по сравнению с предыдущими архитектурами чипов. NVIDIA утверждает, что основной задачей текстурников в GF100 было увеличение эффективности выполнения текстурных выборок. В качестве положительных изменений отмечен перенос текстурных модулей в мультипроцессоры, а также улучшение эффективности кэширования и увеличение тактовых частот TMU.
В предыдущем чипе GT200 до трёх мультипроцессоров использовали один укрупнённый текстурный блок, содержащий восемь текстурных модулей. В новой архитектуре GF100 каждый из мультипроцессоров имеет свои выделенные текстурные модули и текстурный кэш. Что теоретически должно положительно сказаться на эффективности, а как дело обстоит на практике — мы проверим в следующей части статьи.
Особенно большой прирост скорости текстурирования NVIDIA обещает, когда дело касается наложения карт теней (shadow mapping) и алгоритмов вроде screen space ambient occlusion. В обеих техниках используется стандартная возможность Gather4 из DirectX, которая позволяет выполнить одновременную выборку четырех значений за такт.
Что даже ещё важнее, GF100 имеет более эффективную выделенную кэш-память первого уровня. И вместе с унифицированным кэшем второго уровня это даёт втрое больший объём доступной кэш-памяти для текстур, по сравнению с GT200. Но GT200 имеет всё же банально больше блоков текстурирования количественно, и мы ещё проверим, обеспечивает ли новый чип высокую производительность текстурирования в реальных приложениях или нет.
Из других функциональных изменений в TMU отметим то, что текстурники GF100 получили поддержку новых форматов сжатия BC6H и BC7, появившихся в DirectX 11 и предназначенных для текстур и внеэкранных буферов (render target) в HDR-формате.
Параллельная обработка геометрии
Вернёмся к самым важным нововведениям в GF100. Все предыдущие поколения GPU используют один блок для выборки, установки и растеризации треугольников. Этот привычный вид графического конвейера обеспечивает фиксированную производительность и зачастую может являться ограничителем общей производительности.
В этом также виновата и сложность распараллеливания обработки при отсутствии соответствующих изменений в программном интерфейсе (API). И если ранее такой конвейер с одним блоком растеризации работал приемлемо, при увеличении сложности и массовости геометрических расчётов растеризация стала главным ограничителем на пути увеличения сложности геометрии в 3D-сценах.
Так, активное использование тесселяции полностью меняет баланс загрузки различных блоков GPU. С тесселяцией плотность треугольников вырастает на порядки, что сильно нагружает такие ранее последовательные участки графического конвейера, как установка треугольников (triangle setup) и растеризация. Для обеспечения высокой производительности тесселяции необходимо было решить эту проблему изменениями архитектуры, перебалансировав весь графический конвейер GPU.
Чтобы добиться высокой скорости обсчёта геометрии, компания NVIDIA разработала масштабируемый блок обработки геометрии с названием PolyMorph Engine. Каждый из 16 блоков PolyMorph, имеющихся в GF100, содержит собственный модуль по выборке вершин (vertex fetch unit) и тесселятор, что значительно увеличивает производительность геометрических вычислений.
Вдобавок к этому, в GF100 были включены четыре блока растеризации Raster Engine, работающие параллельно и позволяющие выполнять установку до четырёх треугольников за такт. Вместе эти блоки обеспечивают приличный рост производительности обработки треугольников, тесселяции и растеризации.
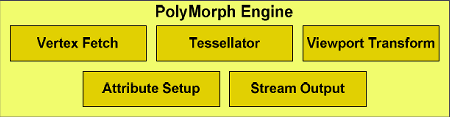
PolyMorph Engine содержит пять стадий: выборка вершин (Vertex Fetch), тесселяция, преобразование в экранные координаты (Viewport Transform), установка атрибутов (Attribute Setup) и потоковый вывод (Stream Output). Результаты, вычисленные в каждой стадии, передаются в мультипроцессор SM. Последний выполняет шейдерную программу, возвращая данные к следующей стадии PolyMorph Engine. После прохождения всех стадий результаты направляются в движки растеризации Raster Engine.
Первая стадия начинается с выборки вершин из глобального вершинного буфера. Выбранные вершины посылаются в мультипроцессор для вершинного затенения (vertex shading и hull shading). В этих двух стадиях вершины преобразуются из координат объектного пространства (object space) в мировое (world space), и вычисляются параметры, необходимые для тесселяции, такие как коэффициент разбиения (tessellation factor). Эти параметры затем пересылаются в тесселятор.
Во второй стадии модуль PolyMorph считывает эти параметры тесселяции и разбивает патч (гладкая поверхность, определенная контрольными точками), выводя результирующую сетку (mesh). Эти новые вершины посылаются в мультипроцессор, где выполняется доменный и геометрический шейдеры.
Доменный шейдер вычисляет итоговое положение каждой вершины на основе данных от поверхностного шейдера (Hull Shader) и тесселятора. На этой стадии обычно применяется карта смещения (displacement map), добавляющая патчу детализации. Геометрический шейдер проводит дополнительную обработку, добавляя или удаляя вершины или примитивы, если необходимо.
В последней стадии PolyMorph Engine производит преобразование в экранные координаты (viewport transformation) и коррекцию перспективы. Далее следует установка атрибутов, а вершины могут быть выведены при помощи stream output в память для дальнейшей обработки.
В предыдущих архитектурах подобные fixed function операции выполнялись лишь одним конвейером. При выполнении на GF100 теоретически все операции (и fixed function, и программируемые) должны быть распараллелены, что, в свою очередь, должно вызвать прирост производительности в случае ограничения производительности такими операциями.
Блок растеризации
После того, как примитивы обработаны блоком PolyMorph, они отсылаются в блок растеризации Raster Engine. Которых в чипе также установлено несколько штук — четыре в случае GF100. Они тоже работают параллельно, и в результате достигается высокая производительность обработки геометрии.

Движок растеризации выполняет три стадии конвейера. В стадии установки граней (edge setup) производится выборка положения вершин и вычисляются проекции граней треугольника. Треугольники, обращённые к экрану обратной стороной, отбрасываются как невидимые (back face culling). Каждый из блоков установки граней обрабатывает по одной точке, линии или треугольника за такт.
Растеризатор использует проекции граней для каждого примитива и вычисляет покрытие пикселей. Если включено сглаживание, то вычисляется покрытие для каждой выборки цвета и выборки покрытия. Каждый из четырёх растеризаторов на выходе выдаёт по восемь пикселей за такт, то есть всего получается 32 прошедших растеризацию пикселя за такт для всего GPU.
Пиксели из растеризатора посылаются в блок отбрасывания невидимых поверхностей Z-cull. Этот блок сравнивает глубину (depth) пикселей из тайла с глубиной существующих пикселей в экранном буфере и отбрасывает те из них, которые лежат за пикселями в экранном буфере. Это называется раннее отбрасывание невидимых поверхностей, которое экономит ресурсы, убирая необходимость проведения лишних попиксельных вычислений.
Новую архитектуру кластеров GPC мы считаем наиболее важным нововведением в геометрическом конвейере GF100. Ведь при тесселяции требуется значительно большая производительность блоков установки треугольников и их растеризации. Шестнадцать блоков PolyMorph Engine значительно увеличивают производительность выборки треугольников, тесселяции и потокового вывода Stream Out, а четыре блока Raster Engine обеспечивают высокую скорость установки треугольников и их растеризации.
В следующей части статьи мы обязательно проверим те предварительные оценки производительности тесселяции, что мы давали в теоретическом описании архитектуры GF100. Наличие выделенных тесселяторов в каждом из мультипроцессоров и блоков растеризации в каждом кластере GPC должно давать прирост геометрической производительности вплоть до восьмикратного, по сравнению с GT200. Вот это мы скоро и проверим.
Подсистема памяти
Для современного GPU очень важна и эффективная организация подсистемы памяти. Тем более, когда всё больше и больше внимания уделяется неграфическим вычислениям. В своём новом чипе компания NVIDIA ещё раз усовершенствовала модель памяти. GF100 содержит выделенный кэш первого уровня в каждом мультипроцессоре (SM).
Кэш-память работает совместно с разделяемой (общей) памятью мультипроцессора и дополняет её. Общая память улучшает скорость доступа к памяти для алгоритмов с предсказуемым доступом к памяти, а кэш-память L1 ускоряет доступ из нерегулярных алгоритмов, в которых адреса запрашиваемых данных заранее неизвестны.
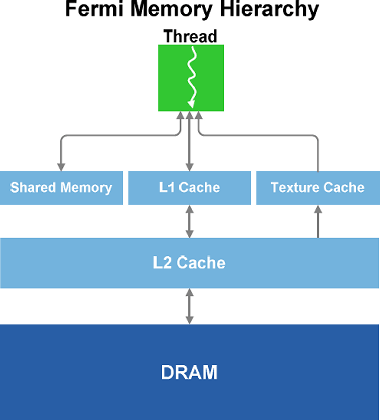
Каждый мультипроцессор в GF100 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, и наоборот — 16 КБ общей памяти и 48 КБ кэша.
Для графических программ GF100 использует вариант с 16 КБ кэша, он работает как регистровый буфер. В вычислительных программах кэш и общая память позволяет потокам одного блока обмениваться данными, работая вместе, что снижает требования к пропускной способности памяти. Кроме того, общая память сама по себе позволяет эффективно использовать на GPU многие вычислительные алгоритмы.
Кроме того, GF100 имеет 768 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки. Кэш второго уровня обеспечивает эффективный и высокоскоростной обмен данными для всего GPU. И вычислительные алгоритмы, запросы данных в которых непредсказуемы (физические расчёты, трассировка лучей и др.), получат значительный прирост скорости от аппаратной кэш-памяти. А фильтры постобработки, в которых несколько мультипроцессоров читают одни и те же данные, получат ускорение из-за меньшего количества вызовов данных из внешней памяти.
Унифицированная кэш-память более эффективна, чем отдельные кэши для разных целей. При выделенных кэшах может сложиться положение, когда один из них используется полностью, но воспользоваться простаивающими объёмами других типов кэш-памяти при этом невозможно. И эффективность кэширования будет ниже теоретически возможной. А унифицированный L2 кэш в GF100 динамически выделяет пространство под разные запросы, что позволяет добиться высокой эффективности.
В общем, теперь один L2 кэш замещает собой текстурный L2 кэш, кэш ROP и начиповые буферы GPU предыдущих поколений. Кэш второго уровня в GF100 используется для записи и чтения данных, и является полностью последовательным (когерентным). Сравните с L2 кэшем в GT200, используемым только для чтения.
В целом, новый GPU обеспечивает более эффективный обмен данными между стадиями конвейера и способен значительно сэкономить пропускную способность внешней памяти, повысив эффективность использования исполнительных блоков видеочипа.
Новые блоки ROP и улучшенное сглаживание
Блоки ROP и подсистема блендинга и сглаживания в GF100 также претерпела значительные изменения, направленные на увеличение эффективности их работы. Один раздел ROP в GF100 содержит восемь блоков ROP, то есть вдвое больше, чем в предыдущих поколениях. Каждый блок ROP способен выводить 32-битное целочисленное значение за такт, пиксель формата FP16 за два такта или FP32 пиксель за четыре такта.
Самым большим недостатком предыдущих чипов, связанным с ROP, считается низкая эффективность сглаживания методом мультисемплинга MSAA 8x. NVIDIA значительно улучшила производительность этого режима в GF100, повысив эффективность сжатия буфера, а также эффективность работы блоков ROP при рендеринге небольших примитивов. Последнее изменение важно и потому, что тесселяция увеличивает количество мелких треугольников, и требования к производительности блоков ROP при этом возрастают.
Но не только скорость сглаживания нам интересна, но и качество изображения. В своих новых решениях серии GTX 400, NVIDIA вводит новый алгоритм сглаживания, названный 32x CSAA (Coverage Sampling Antialiasing), обеспечивающий высочайшее качество сглаживания как геометрии, так и полупрозрачных текстур, использующих alpha-to-coverage. Число 32 в данном случае расшифровывается как 8 честных мультисемплинговых выборок плюс 24 выборки покрытия пикселя (pixel coverage).
В предыдущих поколениях использовалось 4 или 8 выборок, что не обеспечивает полного избавления от алиасинга, но вызывает бандинг. А новый режим 32x CSAA использует 32 coverage-выборки, минимизирующих все артефакты алиасинга.
Полупрозрачное сглаживание методом мультисемплинга (Transparency Multisampling, или TMAA) также получает преимущество от улучшенного метода CSAA. TMAA обычно используется в старых DirectX 9 приложениях, которые не используют метод alpha-to-coverage, недоступный для этого API. В этом случае используется техника альфа-теста, при которой полупрозрачные текстуры имеют резкие края.

Изображение слева показывает сглаживание методом TMAA, использующим режим 16xQ с 8 мультисемплинговыми и 8 coverage-выборками, максимально возможный для GT200. А с правой стороны показан антиалиасинг TMAA на GF100, использующий метод 32x CSAA, с 8 мультисемплинговыми и 24 coverage-выборками.
Использование coverage-выборок не очень сильно повышает требования к пропускной способности памяти и её объёму, производительность нового метода 32x CSAA незначительно отличается от обычного 8x MSAA на GF100, лишь на десяток процентов в худшем случае. А, учитывая небольшую разницу между 4x и 8x, самым лучшим методом по соотношению производительности и качества будет как раз 32x CSAA, особенно на таких мощных решениях, как GTX 470 и GTX 480.
Вычислительные задачи на GPU
До сих пор GPU создавались с расчётом на применение растеризации, а другие применения были лишь побочной возможностью. Но постепенно появляются и другие применения, новые алгоритмы в игровых движках, так как GPU расширяют свои возможности, поддерживая расчётные API вроде CUDA, DirectCompute и OpenCL.
Архитектура чипа GF100 была спроектирована для эффективного исполнения различных алгоритмов и решения множества неграфических задач, поддающихся распараллеливанию. Например, в трассировке лучей, физических расчётах и алгоритмах искусственного интеллекта, использование общей памяти бесполезно, но в этом случае поможет кэш-память, которая как раз появилась в GF100. 48 килобайт кэша первого уровня на каждый из мультипроцессоров и использование глобального кэша второго уровня может повысить производительность многих алгоритмов.
Другим важным изменением в GF100 стал улучшенный планировщик. G80 и GT200 выполняют большие программы со сравнительно большим временем переключения контекста между различными задачами. Для чисто вычислительных задач с большими объёмами данных это подходит, но игровые приложения используют несколько различных задач одновременно: имитация тканей, физика жидкостей, постобработка и т. п. И на GF100 эти задачи могут эффективно выполняться параллельно, обеспечивая максимальный КПД для вычислительных устройств.
В играх с использованием вычислительных шейдеров, переключение контекста происходит каждый кадр, и высокая скорость этого переключения критична для поддержания высокой частоты кадров. В GF100 значительно снизили время переключения контекста (до 20 микросекунд), что сделало возможным быстрое и неоднократное переключение между потоками в пределах одного кадра.
Вычислительные алгоритмы могут использоваться для решения большого количества задач различного плана в игровых приложениях. Например, это новые гибридные алгоритмы рендеринга, когда трассировка лучей применяется для отрисовки корректных отражений и преломлений. Или воксельный рендеринг для правдоподобной имитации объёмных данных.
Это может быть и сложная постобработка изображений: продвинутый HDR-рендеринг, сложные фильтры для сглаживания и имитации оптических эффектов, вроде имитации зоны нерезкости и боке (bokeh). А в играх уже сейчас используются физические эффекты, которые можно ещё усложнить, добавить динамику жидкостей, турбулентность для эффектов с системами частиц, вроде дыма или жидкостей и т. п.
Из конкретных примеров можно привести многие современные игры. Так, для создания реалистичной водной поверхности и в алгоритме постобработки изображения в совсем новой игре Just Cause 2 при помощи CUDA используются возможности чипов NVIDIA. Мы уж не говорим о DirectCompute, который применяется для постобработки в Aliens vs Predator, Metro 2033 и DiRT 2.
Для раскрытия всех вычислительных способностей новых решений, NVIDIA выпустила CUDA Toolkit 3.0, в котором появилась поддержка основанных на графическом процессоре GF100 продуктов, вместе с обещанной поддержкой C++, ECC, а также библиотек линейной алгебры (BLAS и LAPACK), дебаггера CUDA-GDB и профайлера Visual Profiler.
Также NVIDIA выпускает удобный набор для 3D-разработчиков — Parallel Nsight, также известный как Nexus. Этот набор помогает в удобной разработке приложений, использующих GPU в среде Visual Studio 2008. В него входят утилиты для отлова ошибок, профилирования, анализа кода для GPU и его производительности. Всё это интегрировано прямо в Visual Studio и весьма удобно. Поддерживается CUDA C, OpenCL, DirectCompute, Direct3D и OpenGL. Мы уверены, что разработчики оценят богатые возможности нового ПО NVIDIA и возьмут его на вооружение.
Технология NVIDIA 3D Vision Surround
С выходом решений линейки GTX 400 компания NVIDIA предложила технологию, позволяющую выводить стереоизображение сразу на три монитора (понятно, что сподвигла их на это вышедшая ранее технология Eyefinity от заклятого конкурента).
Технология использует активные беспроводные затворные очки и стереодрайверы NVIDIA из комплекта 3D Vision. На двух видеокартах GTX 400, работающих в конфигурации SLI, при помощи технологии 3D Vision Surround можно получить стереоизображение высокого разрешения сразу на трёх устройствах вывода.

Поддерживается три монитора в разрешении 1920×1080 в стереорежиме или в разрешении 2560×1600 в обычном 2D. Также 3D Vision Surround включает возможность компенсации изображения, скрытого за рамками мониторов. С включенной функцией та часть изображения, которая скрыта за рамками мониторов, не показывается пользователю. В результате получается более целостная картинка, что особенно важно для стереорежима, когда малейшее несоответствие картинки на разных мониторах может разрушить эффект объёма.
Отметим, что 3D Vision Surround — это чисто программное решение, и оно работает лишь с двумя или более GPU, объединёнными в систему SLI, а с одной видеокартой такой возможности нет — количество активных выходов всё равно не может быть более двух на каждую карту. Зато эта технология будет работать в том числе и на SLI-системах на основе старых видеокарт серии GTX 200.
Подробности: GF104, семейство GeForce GTX 460
Спецификации GF104
- Кодовое имя чипа GF104;
- Технология производства 40 нм;
- 1,95 миллиарда транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 256-битная шина памяти, четыре независимых контроллера шириной по 64 бита каждый, с поддержкой памяти GDDR5;
- Частота ядра 675 МГц;
- Удвоенная частота ALU 1350 МГц;
- 8 потоковых мультипроцессоров, включающих 384 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 4 широких блока ROP (32 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTX 460
- Частота ядра 675 МГц;
- Частота универсальных процессоров 1350 МГц;
- Количество универсальных процессоров — 336;
- Количество текстурных блоков — 64, блоков блендинга — 24/32;
- Эффективная частота памяти 3600 (900×4) МГц;
- Тип памяти GDDR5, 192/256-битная шина памяти;
- Объем памяти 768/1024 МБ;
- Пропускная способность памяти 86,4/115,2 ГБ/с;
- Теоретическая максимальная скорость закраски 16,2/21,6 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 37,8 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600;
- Двойной SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 150/160 Вт (два 6-штырьковых разъёма);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $199/229 (в России — 7999/8999 руб).
Новый графический процессор GF104, предназначенный для среднего ценового диапазона, также выполнен по 40-нанометровым технологическим нормам, как и предшествующий ему топовый видеочип. Только на основе таких технологий и можно выпустить столь мощный GPU, состоящий почти из 2 млрд. транзисторов, при цене готового решения около $200.
Принцип наименования видеокарт NVIDIA не изменился, по сравнению с верхними моделями поменялась лишь средняя цифра в индексе. Новое решение получило наименование GTX 460, то есть, это тот же уровень, что и GTX 260 из предыдущего поколения. О пропущенном поколении «3» мы уже писали в прошлый раз, в линейке компании под именем третьей серии ранее появились карты, основанные ещё на старых GPU, предназначенные для OEM-сборщиков.
На основе GF104 пока что была выпущена только одна модель — GeForce GTX 460, которая приходит на смену всех решений от GTX 260 до GTX 285. Впрочем, как хорошо видно по приведённым выше характеристикам, реально под именем GTX 460 будут выпускаться две разные модели видеокарт. На первый взгляд, они отличаются только объёмом видеопамяти, а остальные характеристики у них идентичны, но это не совсем так.
Модели с разным объёмом памяти, хоть и не отличаются тактовыми частотами видеочипа и памяти, и имеют равное количество исполнительных блоков ALU и TMU, но GTX 460 с 768 МБ памяти имеет 192-битную шину памяти, 24 блока ROP и 384 КБ кэш-памяти второго уровня, а модель с 1024 МБ памяти отличается 256-битной шиной, 32 блоками ROP и 512 КБ кэша. Соответственно различна и пропускная способность видеопамяти.
Все эти отличия связаны с количеством активных 64-битных каналов памяти. У 768-мегабайтной версии их три, а у 1024-мегабайтной — четыре. Соответственно, отличается и количество установленных на PCB микросхем памяти. Не совсем понятно, зачем в NVIDIA решили сделать две модели под одним и тем же названием, отличающиеся таким образом. К слову, немного отличается и потребление энергии: 150 Вт у младшей версии и 160 Вт — у старшей.
В остальном, кроме указанных отличий, решения одинаковы. Обе модели с разным объёмом памяти имеют по 336 активных вычислительных процессоров (из 384 ALU, физически присутствующих в GPU) и по 56 TMU (из 64 в чипе). И снова мы видим, что решений с полностью рабочим чипом (пока?) не существует, обе GTX 460 урезаны, одна чуть больше, другая чуть меньше. Разница в производительности между моделями вряд ли составит более чем 10—15%, если не брать случаи с нехваткой 768 МБ видеопамяти, но для одного наименования и это слишком много, на наш взгляд.
По мере улучшения выхода годных чипов GF104 и продажи запасов видеокарт GeForce GTX 470, весьма вероятен выход как минимум ещё одной модели видеокарты на основе этого графического процессора. Можно предположить, что это будет некая замена для GTX 465 или даже GTX 470 со всеми активными 384 ALU и 64 TMU, а также более высокими частотами работы как GPU, так и GDDR5 видеопамяти. Скажем, если GPU будет работать на частоте 750 МГц, а видеопамять на 1200(4800) МГц, то такое решение уже вполне способно будет поспорить по производительности и с GeForce GTX 470. Тем более что NVIDIA уже сейчас заявляет об отличном разгонном потенциале чипа GF104.
Архитектура графического процессора GF104
Кодовое обозначение GF104 означает, что это графический чип, основанный на вычислительной архитектуре «Fermi», а число «104» — принятое для продуктов NVIDIA наименование видеочипа архитектуры, нацеленного на средний ценовой диапазон рынка. Напомним, что новая архитектура NVIDIA поддерживает все нововведения современного DirectX 11 API, такие как аппаратная тесселяция и вычислительные возможности DirectCompute. В целом, GF104 очень похож на GF100, и отличия в основном количественные.
В GF104 используются такие же потоковые мультипроцессоры (Streaming Multiprocessor) с ещё большим количеством вычислительных ядер (CUDA cores) в каждом, по сравнению с предыдущей архитектурой и даже топовым GF100. Хотя наиболее важным отличием архитектуры является значительная переработка геометрического конвейера во всех новых GPU. Чтобы соответствовать новым возможностям DirectX 11, в современной архитектуре NVIDIA значительно увеличена пиковая производительность обработки геометрии.
Графический конвейер GF104 способен обеспечить высокую производительность в приложениях с использованием тесселяции и обработки больших объёмов геометрических данных. Новая архитектура геометрической обработки использует несколько полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно. Также никуда не делась и новая архитектура подсистемы памяти в виде полноценных кэшей первого и второго уровней, которые обеспечивают быстрый доступ к данным.
Как и вышедший ранее топовый чип, GF104 состоит из кластеров графической обработки (Graphics Processing Clusters), каждый из которых содержит несколько потоковых мультипроцессоров (Streaming Multiprocessors), которые, в свою очередь, имеют в своём составе по несколько потоковых процессоров.

GF104 содержит два кластера GPC, восемь мультипроцессоров SM и четыре 64-битных контроллера памяти, сблокированных с кэш-памятью второго уровня и 8 блоками ROP в каждом. Пока что NVIDIA выпустила только одну модель видеокарты на основе GF104, но с разным количеством активных контроллеров памяти и её объёмов: GTX 460 с 768 МБ и 1024 МБ.
Всего в состав GF104 входит 384 потоковых процессора, собранных в 8 мультипроцессоров по 48 штук в каждом. В выпущенной на данный момент модели GTX 460 их количество снижено до 336, то есть один из мультипроцессоров отключен. На схеме чипа он выделен цветом сниженной насыщенности.
Новый GPU в своем полном представлении (которое пока что не вышло на рынок, т. к. GTX 460 урезан по количеству ALU и TMU) содержит внешний интерфейс PCI Express, движок GigaThread, два GPC, по четыре контроллера памяти и укрупненных блоков ROP, а также 384 или 512 КБ (в зависимости от ширины шины и объёма видеопамяти) кэш-памяти второго уровня, присоединённые к блокам ROP.
В отличие от топового чипа, имеющего шесть контроллеров памяти по 64 бита, в составе GF104 есть лишь четыре таких контроллеров, что в сумме составляет 256 бит. Но применение памяти GDDR5 даёт достаточно высокую пропускную способность для решения такого уровня. Младшая модель GTX 460 с 768 МБ памяти отличается одним отключенным укрупнённым блоком ROP и имеет лишь 192-битную шину памяти и 24 блока ROP, которые объединены с контроллерами.
Оба кластера Graphics Processing Clusters содержат по четыре мультипроцессора и по отдельному движку растеризации (Raster Engine). В каждом из GPC есть свой масштабируемый движок растеризации, выполняющий установку треугольников, растеризацию и отбрасывание невидимых поверхностей. Также, оба GPC содержат и отдельные движки PolyMorph, выполняющие выборку вершинных атрибутов и тесселяцию, привязанные к каждому из мультипроцессоров SM в кластере. Всего движков PolyMorph в чипе GF104 — восемь штук, но активных в вариантах GTX 460 — лишь семь, по количеству мультипроцессоров.
Каждый из мультипроцессоров SM теперь содержит по 48 потоковых CUDA-ядер, что в полтора раза больше, чем в GF100. Потоковые процессоры имеют в своём составе исполнительное устройство для целочисленных вычислений (INT) и исполнительное устройство для вычислений с плавающей запятой (FPU). Каждый из мультипроцессоров имеет 16 блоков загрузки и сохранения данных (load/store unit, LD/ST или LSU), позволяющих вычислять адреса источника и назначения для 16 потоков за такт.
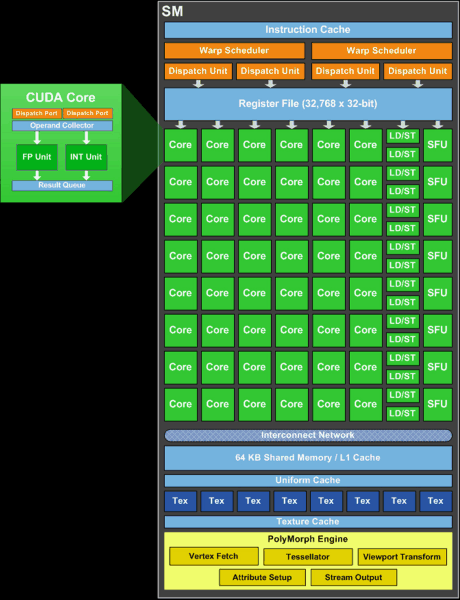
Изменилось в большую сторону и количество блоков для выполнения специальных функций (Special Function Units, SFU), которые вычисляют сложные операции, такие как синус, косинус, квадратный корень и т. п. Их в GF104 стало восемь, а не четыре, как было в GF100, что теоретически может повысить производительность в некоторых случаях.
Чтобы «прокормить» данными увеличенное количество потоковых процессоров, для каждого мультипроцессора было удвоено количество управляющих блоков — диспетчеров (Dispatch Unit). Каждый мультипроцессор содержит по два планировщика варпов (Warp Scheduler), но по четыре диспетчера инструкций. Это решение позволяет на каждом из SM одновременно запускать по две инструкции за такт на каждый из двух варпов, а всего на SM — по четыре инструкции за такт. Это решение теоретически должно повысить эффективность использования потоковых процессоров (повысить их КПД).
Для графического чипа чуть ли не важнее всего количество и эффективность текстурных модулей. Как видно на схеме мультипроцессора, в каждый из SM поместили уже по восемь текстурных блоков, в отличие от четырёх TMU, имеющихся в каждом мультипроцессоре GF100. Каждый из этих блоков вычисляет адрес и выбирает данные для четырёх текстурных выборок за такт.
В остальном, в TMU по сравнению с GF100 ничего не изменилось, но их общее количество осталось тем же, что и в топовом чипе, при меньшем числе других блоков. Это говорит об ином балансе чипа и вполне вероятно не совсем верном решении NVIDIA по включению в состав GF100 лишь 64 TMU. Далее мы проверим, как скажется на результатах GTX 460 такое количество текстурных блоков.
Подсистема памяти в целом осталась той же, как и ожидалось. Каждый мультипроцессор в GF104 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, и наоборот — 16 КБ общей памяти и 48 КБ кэша. Кроме этого, GF104 имеет 512 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки.
Другие нововведения в GF104
Расскажем кратко и об остальных изменениях в новом GeForce GTX 460. По заявлениям NVIDIA, их новый чип среднего уровня поддерживает битстриминг аудиопотоков форматов Dolby True HD и DTS-HD при передаче сигнала по HDMI на внешние ресиверы, что может быть полезно для HTPC-применений. То есть, инженеры NVIDIA наконец-то устранили один из недостатков, за которые некоторые пользователи ругали предыдущие чипы, сравнивая их с конкурирующими.
Из наиболее важных изменений для пользователей изменений можно отметить улучшенное управление питанием power gating, позволяющее отключать неиспользуемые функциональные устройства. Никаких дополнительных подробностей пока что неизвестно, но мы уверены, что в этом смысле у GF104 всё сделано лучше, чем у GF100. Решения на основе нового чипа потребляют энергии гораздо меньше.
Ну и последнюю технологию, которую можно упомянуть в этом разделе — это 3D Vision Surround. Ничего нового в GF104 в этом смысле нет, он ровно так же программно поддерживает данную технологию при помощи драйверов, просто ранее вышедший драйвер с поддержкой этой технологии существовал лишь в виде бета-версии, а с момента анонса GeForce GTX 460 был выпущен полноценный релиз.
Подробности: GF106, семейство GeForce GTS 450
Спецификации GF106
- Кодовое имя чипа GF106;
- Технология производства 40 нм;
- 1,17 миллиарда транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 192-битная шина памяти, три независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Частота ядра 783 МГц (для GTS 450);
- Удвоенная частота ALU 1566 МГц (для GTS 450);
- 4 потоковых мультипроцессора, включающих 192 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 1 блок растеризации с четырьмя движками PolyMorph;
- 32 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 3 широких блока ROP (24 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTS 450
- Частота ядра 783 МГц;
- Частота универсальных процессоров 1566 МГц;
- Количество универсальных процессоров 192;
- Количество текстурных блоков — 32, блоков блендинга — 16;
- Эффективная частота памяти 3608 (902×4) МГц;
- Тип памяти GDDR5, 128-бит шина памяти;
- Объем памяти 1024 МБ;
- Пропускная способность памяти 57.7 ГБ/с;
- Теоретическая максимальная скорость закраски 12.5 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 25.1 гигатекселей в секунду;
- Два Dual Link DVI-I разъема, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600;
- Одинарный SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 106 Вт (один 6-штырьковый разъём);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $129 (в России — 4999 руб).
Графический процессор GF106, предназначенный для нижнего-среднего ценового диапазона, также выполнен по 40 нм технологическим нормам, как и остальные видеочипы линейки. Для данного рыночного сектора новый GPU довольно мощный и сложный, он состоит из заметно более чем 1 млрд. транзисторов, а цена готового решения GeForce GTS 450 лишь немногим превысила $100 на старте продаж.
Принцип наименования видеокарт NVIDIA остался прежним. В случае рассматриваемой видеокарты, по сравнению с более мощными моделями, поменялась не только средняя цифра в индексе. Новое решение получило наименование GTS 460, и буква «S» в названии указывает на средний уровень в линейке ниже, чем у серии GTX. Изменилось и цифровое обозначение, 450 это меньше, чем более мощная 460, что вполне логично.
На базе чипа GF106 пока что анонсирована только одна модель — GeForce GTS 450, которая приходит на смену решению GTS 250 (как видите, изменилась только цифра поколения, с 2 на 4). Как видно по характеристикам чипа GF106 и видеокарты GTS 450, аппаратно имеется поддержка 192-битной шины памяти и 24 блока ROP, но выпущенная видеокарта имеет лишь 128-битную шину и 16 активных блоков ROP (а также 256 КБ кэша вместо имеющихся 384 КБ).
Логично ожидать выхода и полноценного решения на основе данного GPU. Тем более что аналогично чипу GF104, новый GPU также отличается приличным разгонным потенциалом. По данным NVIDIA, большинство видеокарт GeForce GTS 450 способны обеспечить работу GPU на частоте до 900 МГц и даже выше, а многие из партнёров компании планируют предложить фабрично разогнанные варианты таких карт.
Поэтому, со временем весьма вероятен выход как минимум ещё одной модели видеокарты на основе этого графического процессора. Можно предположить, что он будет медленнее 460, но быстрее 450, и иметь GPU со всеми активными каналами памяти, а также более высокими частотами работы. Есть и ещё один вариант — установка на карту 1,5 ГБ более дешёвой памяти типа GDDR3. Ну а если и GDDR5, то даже 768 МБ для такой платы вполне хватит.
Архитектура графического процессора GF106
Новый чип получил кодовое имя GF106, и оно означает, что это графический чип, основанный на вычислительной архитектуре «Fermi», а числовое значение с окончанием на «6» — принято для видеочипов архитектуры NVIDIA, нацеленных на нижний-средний ценовой диапазон рынка. Понятно, что эта архитектура поддерживает все нововведения современного DirectX 11 API, такие как аппаратная тесселяция и вычислительные возможности DirectCompute, и отличается от старших GPU в основном количественно.
GF106 очень похож на GF104, и, глядя на их сравнительные характеристики, поначалу кажется, что это ровно половинка от GF104. На деле отличий больше, и в GF106 скорее 0,6 или даже 0,7 от GF104. В новом GPU содержится ровно вдвое меньше потоковые мультипроцессоров (Streaming Multiprocessor), а соответственно и вычислительных процессоров, но количество каналов памяти, а вместе с этим и блоков ROP и L2 кэша, отличается менее чем в два раза.
Известно, что наиболее важным отличием текущей архитектуры NVIDIA является значительная переработка геометрического конвейера. Чтобы соответствовать новым возможностям DirectX 11, в современных GPU от NVIDIA была значительно увеличена пиковая производительность обработки геометрии. Новая архитектура геометрической обработки использует несколько полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно.
Аналогично предыдущим чипам линейки, в основе GF106 лежит кластере графической обработки (Graphics Processing Cluster), в данном случае он один и содержит четыре потоковых мультипроцессора (Streaming Multiprocessors), которые, в свою очередь, имеют в своём составе по 48 потоковых процессоров, как и у GF104.
Учитывая эти данные, получается, что в целом чип имеет 192 потоковых процессора и 32 текстурных модуля. А также три (в отличие от четырёх у GF104) 64-битных контроллера памяти, сблокированных с кэш-памятью второго уровня (384 КБ) и восемью блоками ROP (всего 24 штуки, в отличие от 32-х у GF104).
Но, как указано выше, пока что компания NVIDIA выпустила только одну модель видеокарты на базе GF106, и один из контроллеров памяти в нём отключен. Зато количество активных потоковых процессоров соответствует их физическому количеству в GPU, в отличие от всех ранее выпущенных чипов новой архитектуры. Итого, шина памяти у выпущенного GeForce GTS 450 получается 128-битная, хотя аппаратно в чипе есть три контроллера по 64-бит и в будущем вполне возможен выход 192-битного варианта на основе GF106.
За исключением количественных отличий, GF106 идентичен GF104. Кластер Graphics Processing Cluster содержит лишь один движок растеризации (Raster Engine), выполняющий установку треугольников, растеризацию и отбрасывание невидимых поверхностей, и четыре движка PolyMorph, выполняющих выборку вершинных атрибутов и тесселяцию, привязанные к каждому из мультипроцессоров SM в кластере. Другими словами, по сравнению с GF104 и GF100, у сегодняшнего чипа производительность обработки геометрии и тесселяции не будет такой высокой, что несколько нивелирует преимущества новой архитектуры.
По устройству мультипроцессоры SM в GF106 такие же, как и в GF104, они содержат по 48 потоковых CUDA ядер, что в полтора раза больше, чем в GF100. Потоковые процессоры имеют в своём составе исполнительное устройство для целочисленных вычислений (INT) и исполнительное устройство для вычислений с плавающей запятой (FPU).
Каждый из мультипроцессоров имеет 16 блоков загрузки и сохранения данных (load/store unit, LD/ST или LSU), позволяющих вычислять адреса источника и назначения для 16 потоков за такт. А также удвоенное количество блоков для выполнения специальных функций (Special Function Units, SFU) и диспетчеров (Dispatch Unit) — то есть, никаких изменений по сравнению с GF104 тут нет.
Каждый из мультипроцессоров имеет восемь текстурных блоков, в отличие от четырёх TMU в GF100, и всего получается 32 TMU. Кроме их количества на SM, никаких изменений по сравнению с GF100 нет. Да и подсистема памяти осталась той же: каждый мультипроцессор в GF106 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, и наоборот — 16 КБ общей памяти и 48 КБ кэша. Кроме этого, новый GPU имеет 384 КБ унифицированной кэш-памяти второго уровня, которая обслуживает запросы по загрузке и сохранению данных, а также текстурные выборки.
Другие особенности GeForce GTS 450
Похоже, что GeForce GTS 450 неплохо подойдёт для сборки высокопроизводительных HTPC. Хотя видеокарта довольно крупная по размеру, она занимает в корпусе два слота и требует дополнительного питания, но также отличается и неплохой 3D производительностью, что в некоторых случаях важно и для HTPC, являющихся одновременно и домашними ПК.
А новый GPU, как и его старший брат GF104, поддерживает битстриминг аудиопотоков форматов Dolby True HD и DTS-HD Master Audio при передаче сигнала по HDMI на внешние ресиверы. Немаловажно отметить и полную поддержку декодирования Blu-ray-фильмов, в том числе и в стереоформате, который набирает популярность в последнее время.
Новое решение NVIDIA поддерживает и технологию 3D Vision Surround, позволяющую выводить стереоизображение сразу на три монитора. Но это снова относится лишь к мультичиповым конфигурациям, технология поддерживается программно в драйверах, и для поддержки вывода на три монитора потребуются две видеокарты в SLI-режиме.
Специально к выходу нового решения, NVIDIA подготовила и новую версию драйверов. Основным, важнейшим для пользователей изменением, является оптимизация производительности для всей новой линейки видеокарт: GTX 480/470/465, GTX 460 и GTS 450. Пользователям решений новой линейки обещано по 7—13% прироста на видеокартах серии GeForce 400 во многих современных играх, а в отдельных случаях и вовсе до 20%.
Подробности: GF110, семейство GeForce GTX 500
Спецификации GF110
- Кодовое имя чипа GF110;
- Технология производства 40 нм;
- Около 3 миллиардов транзисторов (примерно столько же, что и у GF100);
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 384-битная шина памяти, шесть независимых контроллеров шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Частота ядра 772 МГц;
- Удвоенная частота ALU 1544 МГц;
- 16 потоковых мультипроцессоров, включающих 512 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 6 широких блоков ROP (48 пикселей) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTX 580
- Частота ядра 772 МГц;
- Частота универсальных процессоров 1544 МГц;
- Количество универсальных процессоров 512;
- Количество текстурных блоков — 64, блоков блендинга — 48;
- Эффективная частота памяти 4008 (1002×4) МГц;
- Тип памяти GDDR5, 384-бит шина памяти;
- Объем памяти 1536 МБ;
- Пропускная способность памяти 192,4 ГБ/с;
- Теоретическая максимальная скорость закраски 37,1 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 49,4 гигатекселей в секунду;
- Два Dual Link DVI-I разъема, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600;
- Двойной SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 244 Вт (один 6-штырьковый и один 8-штырьковый разъёмы);
- Двухслотовое исполнение;
- Рекомендуемая цена для американского рынка $499 (для России — 17999 руб).
Спецификации референсной видеокарты GeForce GTX 570
- Частота ядра 732 МГц;
- Частота универсальных процессоров 1464 МГц;
- Количество универсальных процессоров 480;
- Количество текстурных блоков — 60, блоков блендинга — 40;
- Эффективная частота памяти 3800 (950×4) МГц;
- Тип памяти GDDR5, 320-битная шина памяти;
- Объем памяти 1280 МБ;
- Пропускная способность памяти 152 ГБ/с;
- Теоретическая максимальная скорость закраски 29,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 43,9 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600;
- Двойной SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 219 Вт (два 6-штырьковых разъёма);
- Двухслотовое исполнение;
- Рекомендованная цена для России — 14999 руб.
Новый графический процессор GF110 и видеокарты GeForce GTX 580 и GTX 570 на его основе призваны со временем полностью заместить GTX 480 на базе GF100. Новый GPU также выполнен по технологическим нормам 40 нм, как и предшествующий топовый видеочип. Ранние слухи присваивают ему наименование GF100B, что из-за немногочисленных модификаций вполне похоже на правду, но чипу всё же дали новый индекс — GF110.
Принцип наименования видеокарт NVIDIA вроде бы не изменился, но свежему топу зачем-то дали цифру нового поколения. Иначе говоря, судя по индексу, это должны быть тоже топовые карты, но уже нового поколения. Хотя, на наш взгляд, намного логичнее было бы название GTX 485 и GTX 475 (по аналогии с GTX 285), ведь в GF110 нет никаких радикальных архитектурных изменений. Хотя это действительно полностью переработанный чип, но по сравнению с GF100 функциональных изменений в нём явно недостаточно для отнесения к новому поколению. Впрочем, наименование видеокарт — всегда штука маркетинговая и на реальные технические характеристики не влияющая.
На основе чипа GF110 сначала была выпущена одна модель видеокарты — GeForce GTX 580, а затем последовала и GTX 570 (видимо, после того, как были распроданы остатки GTX 470 и GTX 480). Старшая модель, как и её предшественница GTX 480, имеет 384-битную шину памяти и соответствующий объём видеопамяти, равный 1536 МБ. Значение это единственно возможное, по сути, так как 768 МБ — это слишком мало, а 3 ГБ — уже чересчур много (хотя такие варианты тоже появились в продаже).
В отличие от топовой, модель GTX 570 имеет лишь 320-битную шину памяти с одним отключенным 64-битным контроллером и соответствующий объём видеопамяти, равный 1280 МБ, как и у её предшественницы GTX 470. Вероятно, в будущем какие-то из партнёров NVIDIA выпустят и варианты с 2.5 ГБ на борту, чтобы получить дополнительное преимущество. В основном маркетинговое, так как 1.25 ГБ будет недоставать лишь в редких очень тяжёлых режимах.
Архитектура графического процессора GF110
Для увеличения эффективности GPU в терминах отношения производительности и потребления, чип GF110 был полностью переработан инженерами. Каждый блок GPU был модифицирован в той или иной мере для того, чтобы снизить утечки и оптимизировать чип целиком. Естественно, что NVIDIA не будет называть конкретных изменений, но они утверждают, что большая часть транзисторов данного GPU подверглась переработке.
В GF110 используются точно такие же потоковые мультипроцессоры (Streaming Multiprocessor) с тем же количеством вычислительных ядер (CUDA cores) в каждом, что и в GF100. Архитектурно новый чип, используемый в GeForce GTX 580 и GTX 570, не очень сильно отличается от GF100, на котором основана модель GTX 480. Этот новый GPU использует ровно ту же конфигурацию мультипроцессоров, что и GF100, он состоит из кластеров графической обработки (Graphics Processing Clusters), каждый из которых содержит несколько потоковых мультипроцессоров (Streaming Multiprocessors), которые, в свою очередь, имеют в своём составе по несколько потоковых процессоров.
GF110 содержит восемь кластеров GPC, шестнадцать мультипроцессоров SM и шесть 64-битных контроллеров памяти, соединённых с кэш-памятью второго уровня и имеющих по 8 блоков ROP в каждом. Итого, в состав чипа входит 512 потоковых процессоров, собранных в 16 мультипроцессоров по 32 штук в каждом. В отличие от GF100, в выпущенной на данный момент модели GTX 580 их количество не занижено искусственно, как это сделано в GTX 480, и все мультипроцессоры активны.
Подсистема памяти осталась без изменений. Каждый мультипроцессор в GF110 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, или наоборот — 16 КБ общей памяти и 48 КБ кэша. Кроме этого, GF110 имеет 768 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки.
Но есть в GF110 и небольшие архитектурные изменения. Изначально в Интернете появились слухи о том, что в GF110 будет удвоено количество текстурных модулей, но это не соответствует истине — в чипе их ровно столько же (64 TMU). Но есть один показатель производительности, связанный с обработкой текстур, который действительно вырос вдвое. И те читатели, которые следили за модификациями архитектуры Fermi в GF104, вероятно уже догадались, о чём пойдёт речь. Как и предшествующий чип среднего ценового диапазона, GF110 умеет обрабатывать (включая билинейную фильтрацию) текстурные данные всех форматов вплоть до FP16 на полной скорости, без потери тактов.
Напомним, что GF100 не умеет этого, и теоретический темп по обработке FP16 текстур, часто используемых в современных 3D играх, у первого Fermi чипа вдвое ниже, чем у GF104 и GF110. Это архитектурное улучшение способно помочь увеличить производительность рендеринга во многих приложениях, использующих подобные внеэкранные буферы (например, для HDR рендеринга). Данная модификация объясняет и ранние слухи о 128 TMU в GF110. Видимо, удвоенную скорость обработки FP16 данных кто-то принял за удвоенное количество текстурных модулей.
Но это ещё не всё, есть и второе архитектурное отличие GF110 от GF100, хотя и несколько меньшее по значению и влиянию — в новом GPU была увеличена эффективность алгоритма z-cull, для чего были введены новые форматы тайлов. Это изменение может помочь увеличить производительность в некоторых случаях, и мы проверим это в синтетических тестах.
В целом, одни только архитектурные изменения в GF110 привели к росту производительности рендеринга примерно на 5—10%, согласно внутренним тестам компании NVIDIA. А в некоторых приложениях (DiRT 2, 3DMark Vantage) — до 15%.
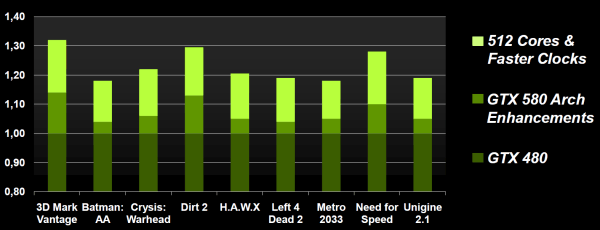
Нельзя не отметить и увеличение количества активных исполнительных блоков по сравнению с GF100, к тому же — работающих на более высокой частоте при меньшем потреблении энергии! Это добавляет ещё 10—15% производительности, и в итоге у GTX 580 получается средний прирост производительности рендеринга в реальных приложениях около 20%, по отношению к GTX 480. Это очень неплохой итоговый результат с учётом малого количества архитектурных изменений. Впрочем, мы его ещё проверим в практических разделах нашего материала.
Тесселяция, тесселяция, тесселяция…
Как давно известно, одним из основных архитектурных преимуществ семейства Fermi, и новых топовых решений GeForce GTX 580/570 в частности, является весьма высокая производительность тесселяции — пожалуй, самого важного нововведения DirectX 11. Архитектура распараллеленной обработки геометрии, применяемая во всех современных решениях NVIDIA, очень эффективна при тесселяции с высокими уровнями разбиения примитивов, когда треугольников становится очень много. Это и понятно, ведь примитивы обрабатываются одновременно 16-ю движками PolyMorph, в отличие от одного (пусть и более мощного) блока у лучших чипов конкурента на данный момент.
Мы уже писали о том, что компания AMD критикует слишком мелкие треугольники в некоторых бенчмарках (Heaven, HAWX 2), считая тесселяцию такого уровня неэффективной. Это в какой-то мере верно, но лишь для предыдущих архитектур, в которых геометрический конвейер выполнен в традиционном стиле, с возможностью обработки лишь одного треугольника за такт.
В случае же архитектуры Fermi, и особенно — топовых чипов вроде GF110, такая тесселяция выполняется вполне эффективно, что мы и видим в соответствующих тестах производительности. Сетовать же на слишком мелкие треугольники вообще довольно странно, достаточно посмотреть на то, к чему стремится 3D-графика реального времени — на современные рендеренные мультфильмы, например. И уж там то этих треугольников ещё на порядки больше.
Понятно, что для игр пока что такое качество недостижимо, но индустрия явно идёт в этом направлении. И весьма вероятно, что и GPU в следующем поколении игровых консолей будут обладать возможностями по обработке геометрии, близкими к тем, что умеет Fermi, и это — правильный путь, хотя он и может казаться несколько преждевременным. Но всегда кому-то приходится быть первыми, и в случае с тесселяцией это, как ни странно (вспоминая многочисленные поколения тесселяторов у AMD), оказалась компания NVIDIA.
Для демонстрации возможностей своих видеочипов, NVIDIA выпустила две специальные демопрограммы: Endless City и Alien vs. Triangles. Они отличаются прогрессивным использованием тесселяции с высоким уровнем разбиения и показывают всю геометрическую мощь решений компании. Так, в Endless City обрабатывается до 600 млн. треугольников в секунду!

В этой демке рендерится одна из наиболее сложных геометрических сцен из отрисовывающихся в реальном времени. Причём, здания в этом городе процедурно генерируются на GPU, составляясь из набора заранее сконструированных объектов.
Тесселяция обеспечивает невиданную ранее детализацию на близких к камере объектах, а дальние объекты разбиваются на меньшее количество примитивов (адаптивная тесселяция). В демке используются трёхмерные карты смещения, в отличие от обычных карт высот, а для освещения сцены используется около 500000 источников света и применяется алгоритм имитации глобального освещения screen-space ambient occlusion.
Вторая демонстрационная программа с применением тесселяции называется Alien vs. Triangles. Тесселяция в ней используется для добавления геометрических деталей к фигуре инопланетного персонажа, для чего применяется сразу несколько различных карт смещений. Самая главная отличительная особенность демки заключается в использовании тесселяции для имитации реалистичных повреждений.

В демке используется сразу три различные карты смещения для персонажа (Normal, Spike и Fungus). Ещё четыре карты смещения используются в качестве карт повреждений, и при попадании в инопланетянина из бластера, они процедурно модифицируются в реальном времени для имитации повреждений.
Но разве только в демонстрационных программах можно увидеть активное применение тесселяции? Кроме уже давно известных игр, вроде DiRT 2 и Metro 2033, можно отметить и недавно вышедшую демонстрационную версию игры HAWX 2, в которой также применяется довольно агрессивная тесселяция при рендеринге поверхности земли.

Как хорошо видно, применяется адаптивная тесселяция ландшафта. Причём, средний размер треугольника, по данным NVIDIA, в этой игре не превышает 18 пикселей. Это можно назвать средним значением, и уж точно не слишком снижающим эффективность современных DX11 видеочипов. Будет интересно посмотреть на сравнение производительности различных решений в этом бенчмарке, когда (и если) мы введём его в свой набор тестов.
Остальные изменения
Нововведения в новых моделях не ограничиваются лишь 3D функциями чипа. Несмотря на то, что разница между указанным компанией NVIDIA потреблением для GTX 480 и GTX 580 составляет лишь 6 Вт (250 и 244 Вт, соответственно), замеры в реальных условиях дают несколько большую цифру — 20—30 Вт разницы. В пользу GTX 580, естественно. То есть, при потенциальном увеличении производительности на 20% (это мы проверим в следующих разделах материала) GTX 580 потребляет энергии где-то на 10% меньше. То же самое относится и к GTX 570, она заметно эффективнее карт предыдущей серии.
Пониженное энергопотребление и модифицированный кулер, работающий более эффективно, должны привести к снижению шума. Новая система охлаждения использует технологию испарительной камеры, известную по оригинальным системам охлаждения некоторых производителей. Медная испарительная камера отбирает тепло у GPU, которое затем рассеивается при помощи большого двухслотового радиатора. В конструкции применяется вентилятор турбинного типа, он засасывает прохладный воздух изнутри корпуса и выбрасывает нагретый наружу.
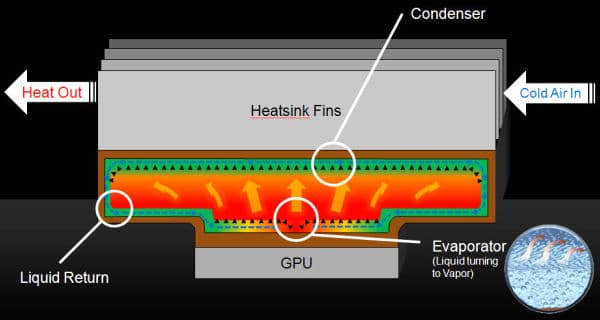
Что также немаловажно, заявлено применение вентилятора с уменьшенной вибрацией и шумом, а новые алгоритмы управления частотой вращения «смягчают» раскрутку вентилятора при работе GPU с большой нагрузкой. По измерениям самой NVIDIA, новый кулер GeForce GTX 580 тише чем даже система охлаждения у GTX 285, не говоря уж про довольно шумную GTX 480.
Были внесены некоторые изменения и в систему мониторинга питания и нагрева. Если ранее видеокарты защищались от выхода из строя исключительно при помощи недопущения работы GPU при превышении критической температуре, то теперь проводится наблюдение и за энергопотреблением всей системы.

Новые элементы аппаратного мониторинга наблюдают за силой тока и напряжением на 12-вольтных линиях питания (PCI-E, 8- и 6-штырьковые дополнительные разъемы). Драйвер опрашивает значения этих параметров и может снизить тактовую частоту GPU при условии запущенных требовательных тестов стабильности, вроде Furmark и OCCT, если уровень питания превышает максимально возможный.
Это ограничение справедливо только в случае таких, заранее предопределённых в драйвере приложений, но не в играх. На сегодняшний день ограничение работает исключительно в случае запуска приложения Furmark и при превышении возможностей линий питания. В таком случае драйвер вдвое понизит рабочие тактовые частоты GPU.
Подробности: GF114, семейство GeForce GTX 500 Ti
Спецификации GF114
- Кодовое имя чипа GF114;
- Технология производства 40 нм;
- 1,95 миллиарда транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 256-битная шина памяти, четыре независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Частота ядра 822 МГц;
- Удвоенная частота ALU 1644 МГц;
- 8 потоковых мультипроцессоров, включающих 384 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 4 широких блока ROP (32 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTX 560 Ti
- Частота ядра 822 МГц;
- Частота универсальных процессоров 1644 МГц;
- Количество универсальных процессоров 384;
- Количество текстурных блоков — 64, блоков блендинга — 32;
- Эффективная частота памяти 4008 (1002×4) МГц;
- Тип памяти GDDR5, 256-битная шина памяти;
- Объем памяти 1024 МБ;
- Пропускная способность памяти 128 ГБ/с;
- Теоретическая максимальная скорость закраски 26,3 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 52,6 гигатекселей в секунду;
- Два разъема Dual Link DVI-I, один Mini HDMI, поддерживается вывод в разрешениях до 2560×1600;
- Один SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 170 Вт (два 6-штырьковых разъёма);
- Двухслотовое исполнение;
- Рекомендованная цена для России — 9999 руб (для США — $249).
Видеокарта GeForce GTX 560 Ti, выполненная на основе нового графического процессора GF114, заменила на рынке модель GTX 470. Новый GPU выполнен по всё тем же 40-нанометровым технологическим нормам, как и все предшествующие видеочипы этого поколения, и улучшение его характеристик стало возможным из-за отладки техпроцесса 40 нм и глубокой переработки GPU, аналогичной той, что была сделана и в GF110, о котором написано выше.
Принцип наименования видеокарт NVIDIA новой серии уже известен с GTX 580, когда всем обновленным видеокартам была дана цифра нового поколения, указывающая на улучшения в переработанных GPU при отсутствии функциональных изменений. По сравнению с GTX 460 поменялась не только первая цифра в индексе, новое решение получило суффикс Ti, о котором мы уже говорили выше.
На основе GF114 пока что выпущена только одна модель, которая отличается от GeForce GTX 460 1GB только изменённым количеством исполнительных блоков и тактовыми частотами. Новая видеокарта имеет 384 активных вычислительных процессора и 64 TMU, а также 256-битную шину памяти, 32 блока ROP и 512 КБ кэш-памяти второго уровня. Объём памяти у референсной видеокарты равен 1 ГБ, и это — оптимальный объём для современной видеокарты среднего уровня. Хотя для маркетинговой конкуренции с Radeon HD 6950 некоторые вендоры могут выпустить и 2 ГБ варианты, и мы думаем, что ждать их долго не придётся.
Архитектура графического процессора GF114
Аналогично вышедшим ранее моделям серии GeForce GTX 500, GTX 560 Ti использует улучшенный графический процессор, знакомый нам по предыдущей серии GTX 400, но модифицированный для лучшего соотношения производительности и энергопотребления. Для увеличения энергоэффективности GF114 был модифицирован так, чтобы снизить утечки и оптимизировать чип. GTX 560 Ti — это последователь дела GTX 460, имеющий уже 384 потоковых процессора и 8 движков PolyMorph, вместо 336 и 7 у аналогичной модели прошлого поколения. В остальном, GF114 очень похож на GF104, и отличия только в количестве разблокированных функциональных устройств.
GeForce GTX 560 Ti использует ту же конфигурацию мультипроцессоров Streaming Multiprocessor, что и GTX 460. В применённом GF114 используются потоковые мультипроцессоры с увеличенным количеством вычислительных ядер (CUDA cores) в каждом, по сравнению с топовыми чипами текущей архитектуры. В общем, каждый SM имеет 48 потоковых процессоров, четыре диспетчера и восемь блоков TMU.
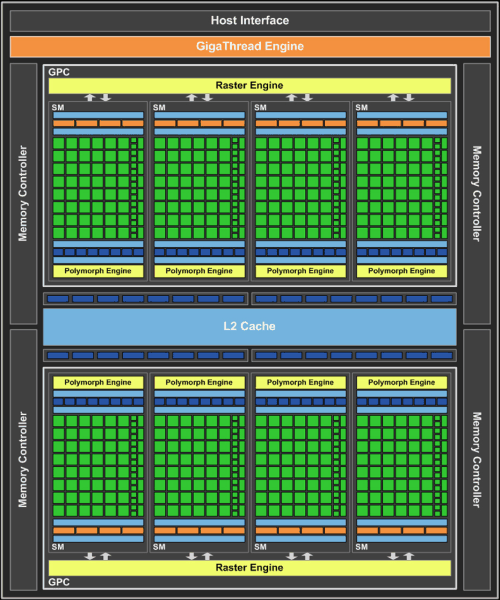
GF114 содержит два кластера GPC, восемь мультипроцессоров SM и четыре 64-битных контроллера памяти, сблокированных с кэш-памятью второго уровня и 8 блоками ROP в каждом. Итого, в состав нового GPU входит 384 потоковых процессора, собранных в 8 мультипроцессоров по 48 штук в каждом. Более подробная информация об архитектурных изменениях мультипроцессоров дана в обзоре GeForce GTX 460.
Подсистема памяти GF114 осталась той же — каждый мультипроцессор имеет 64 килобайта начиповой памяти, а GPU в целом содержит 512 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных. В отличие от топового чипа GF110, имеющего шесть контроллеров памяти по 64 бита, в состав GF114 включено четыре таких контроллера, что в сумме составляет 256-битную шину. По сравнению с GTX 460 пришлось ещё увеличить тактовую частоту примененной GDDR5 памяти, чтобы обеспечить достаточную пропускную способность.
Как и все остальные графические процессоры архитектуры Fermi, GF114 имеет очень сильные позиции по геометрической производительности и скорости рендеринга в приложениях, активно использующих тесселяцию. Среди таких можно назвать следующие DirectX 11 игры: H.A.W.X. 2, Lost Planet 2, Metro 2033 и Civilization V.
Новая архитектура NVIDIA использует несколько полиморфных движков (PolyMorph Engines) и блоков растеризации (Raster Engines), работающих параллельно. И сравнительно большое количество движков PolyMorph в GF114 обеспечивает высокую производительность тесселяции, а несколько растеризаторов быстро выполняют свою задачу по отбросу невидимых поверхностей и растеризации. Графический процессор, лежащий в основе GeForce GTX 560 Ti, имеет восемь движков PolyMorph и два растеризатора. А конкурирующий с ним Radeon HD 6870 имеет лишь один тесселятор и растеризатор, хотя и более эффективные, если их сравнивать один к одному.
Более интересно сравнение с Radeon HD 6950, имеющим уже по два тесселятора и растеризатора. И тут уже преимущество кого-либо по скорости обработки геометрии и тесселяции не столь очевидно. Всё решится в тестах производительности, например в бенчмарке Heaven, результаты которого вы увидите в третьей части нашего материала. В любом случае, GTX 560 Ti должен обеспечивать достаточно высокую производительность обработки геометрии, даже по сравнению со свежим топовым чипом AMD.
Ещё одно важное изменение GTX 560 Ti состоит в серьёзном повышении тактовых частот при одновременном снижении токов утечек. В отличие от референсной частоты GTX 460, равной 675/1350 МГц, для GTX 560 Ti её повысили до 822/1644 МГц, что на 22% выше. И вместе с увеличенным количеством активных исполнительных устройств, теоретический прирост производительности по сравнению с GTX 460 составляет почти 40%! Это должно вызвать приросты FPS в игровых тестах от 30% и выше, что мы обязательно проверим далее.
При этом возможности разгона GPU также остались довольно высокими, и ожидается выход фабрично разогнанных моделей от партнёров с частотами GPU выше 900 МГц. Но самой важной задачей последнего времени является оптимизация по энергетической эффективности — то есть, одновременное повышение производительности и удержание приемлемого потребления. По данным NVIDIA, GeForce GTX 560 Ti в реальных тестах обеспечивает более чем на 20% лучшее соотношение производительности и потребления, по сравнению с GTX 460 1 ГБ.
Кстати, в обзоре GTX 460 мы предполагали будущий выход видеокарт на чипе GF104 со всеми активными 384 ALU и 64 TMU, и более высокими частотами работы как GPU, так и видеопамяти. Вот GTX 560 Ti как раз и стал этим решением, хотя его частота даже превысила наши ожидания. Сильные стороны нового решения понятны — достаточная математическая производительность, очень высокая (самая высокая для видеокарт NVIDIA) текстурная производительность, да и все остальные теоретические параметры неплохие. Среди возможных минусов решения — недостаток пропускной способности видеопамяти, который может ограничивать производительность нового решения в некоторых случаях.
Другие изменения
В этом разделе изменений минимум, и ничего особенного написать не получится, ведь новый GeForce GTX 560 Ti весьма похож на GTX 460. Как и GF104, новый чип среднего ценового диапазона поддерживает битстриминг аудиопотоков форматов Dolby True HD и DTS-HD при передаче сигнала по HDMI на внешние ресиверы, что может быть полезно для HTPC-применений.
Специально для работы на повышенных по сравнению с GTX 460 тактовых частотах, была изменена референсная плата, усилены цепи питания и улучшено устройство охлаждения видеокарты. В новом кулере применяется дополнительная медная тепловая трубка и большие по размеру радиатор и вентилятор. При этом кулер охлаждает не только сам графический процессор, но и микросхемы памяти и элементы в цепи питания.
Для защиты видеокарты и всей системы от повреждений, связанных с превышением возможностей линий питания, референсная видеокарта GeForce GTX 560 Ti использует уже знакомые нам технологии мониторинга, введённые в GeForce GTX 580. Эти элементы аппаратного мониторинга наблюдают за силой тока и напряжением на 12-вольтных линиях питания (PCI-E и 6-штырьковые дополнительные разъемы), драйвер опрашивает значения параметров и может снизить тактовую частоту GPU.
Напомним, что эта система ограничения питания работает исключительно для приложений, тестирующих стабильность системы (Furmark, OCCT), и не работает в случае игр, даже с учётом разгона. В этом её отличие от более сложной системы AMD, которая может снижать частоты и в играх. Кроме того, в случае NVIDIA эта система мониторинга опциональна, и может не применяться на видеокартах, произведённых некоторыми партнёрами компании, если они так решат.
Подробности: двухчиповая видеокарта GeForce GTX 590
- Кодовое имя чипов — GF110;
- Технология производства 40 нм;
- 2 чипа по 3 миллиарда транзисторов каждый;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11, в том числе и новой шейдерной модели — Shader Model 5.0;
- Двойная 384-битная шина памяти: дважды по шесть независимых контроллеров шириной по 64 бита каждый, с поддержкой GDDR5 памяти;
- Частота ядра 607 МГц;
- Удвоенная частота ALU 1215 МГц;
- 2x16 потоковых мультипроцессоров, включающих в общем 1024 скалярных ALU для расчётов с плавающей точкой (целочисленные и плавающие форматы, поддержка точности FP32 и FP64 в рамках стандарта IEEE 754-2008);
- 2x64 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 2x6 широких блоков ROP (всего 96 пикселей) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Для каждого GPU интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTX 590
- Частота ядра 607 МГц;
- Частота универсальных процессоров 1215 МГц;
- Количество универсальных процессоров 2x512;
- Количество текстурных блоков — 2x64, блоков блендинга — 2x48;
- Эффективная частота памяти 3414 (854*4) МГц;
- Тип памяти GDDR5, двойная 384-битная шина памяти;
- Объём памяти 2x1536 МБ;
- Пропускная способность памяти 2x164 гигабайт в секунду;
- Теоретическая максимальная скорость закраски 58 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 78 гигатекселей в секунду;
- Одинарный SLI разъем;
- Шина PCI-Express 2.0;
- Разъёмы: три Dual Link DVI, один mini DisplayPort
- Максимальное энергопотребление до 365 Вт;
- Два 8-штырьковых разъёма питания;
- Двухслотовое исполнение;
- Рекомендуемая цена для России — 25999 руб., для США — $699.
Анонсированная видеокарта на базе двух графических процессоров GF110 стала на самую верхнюю ступень в линейке NVIDIA, прямо над быстрейшей одночиповой GeForce GTX 580. Что касается сравнения с конкурентом, то и по цене (по крайней мере — для западного рынка) и по производительности им становится AMD Radeon HD 6990. Как мы уже писали, производителям графических чипов сейчас приходится выжимать все соки из всё того же 40 нм техпроцесса, и сделать это можно разве что выпуском двухчиповых карт.
Принцип наименования видеокарт NVIDIA немного изменился со времени предыдущей двухчиповой GeForce GTX 295. Теперь топовая карта на двух GPU имеет название, отличающееся от быстрейшей одночиповой модели средней цифрой (580->590). Естественно, что выпущена лишь одна двухчиповая модель, так как это решение максимальной производительности.
Предположительная рыночная цена новой модели для североамериканских магазинов равна $699, что соответствует цене конкурирующего решения, а вот российская рекомендуемая цена снова заметно выше. Остаётся надеяться, что в продаже она появится по цене ближе к $699 по официальному курсу, чем по 25999 руб. Впрочем, видеоплата имиджевая, её купят и за столько.
Так как двухчиповая модель имеет сдвоенную 384-битную шину памяти, то соответствующий объём установленной на неё видеопамяти равен 2x1.5 ГБ. 3 ГБ на чип разумно решили не устанавливать, и полутора гигабайт должно хватать почти во всех режимах. Хотя в сверхвысоких разрешениях со стереорендерингом и сглаживанием этого может уже не хватать.
Система охлаждения GeForce GTX 590 двухслотовая, а энергопотребление карты с двумя GPU на борту весьма высоко по вполне понятным причинам. Как и в случае недавно вышедшего решения от конкурента, на GTX 590 установлено два 8-штырьковых разъёма питания, чего ранее в своих референсных образцах оба производителя GPU не делали. Теоретически, судя по заявленным цифрам, GTX 590 должна потреблять меньше своего конкурента, но в бескомпромиссных решениях нас больше беспокоит низкая частота GPU.
Архитектура
Так как видеокарта GeForce GTX 590 основана на двух GPU модели GF110, то расписывать в этом разделе особо нечего — всё уже рассказано ранее. А тут мы лишь вкратце повторим лишь самое основное. Главной задачей инженеров NVIDIA при разработке GF110 было улучшение энергетической эффективности. Чип был полностью переработан для того, чтобы снизить утечки и оптимизировать его потребление.
Архитектурно чипы GF110, используемые в GeForce GTX 590, не очень отличаются от GF100, на котором основана первая модель линейки Fermi — GTX 480. Оба GPU использует одинаковую конфигурацию мультипроцессоров, эти чипы состоят из четырёх кластеров графической обработки Graphics Processing Clusters.
Каждый из двух GF110 содержит четыре кластера GPC, шестнадцать мультипроцессоров SM и шесть 64-битных контроллеров памяти, соединённых с кэш-памятью второго уровня и имеющих по 8 блоков ROP в каждом. Итого, в состав каждого чипа входит 512 потоковых процессоров, собранных в 16 мультипроцессоров по 32 штук в каждом. И в выпущенной двухчиповой модели GTX 590 их количество не занижено искусственно, все мультипроцессоры активны.
Каждый мультипроцессор в GF110 имеет 64 килобайта начиповой памяти, которая может быть сконфигурирована в двух разных вариантах: 48 килобайт общей памяти и 16 килобайт L1 кэш-памяти, или наоборот — 16 КБ общей памяти и 48 КБ кэша. Кроме этого, GF110 имеет 768 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки.
Интересно, что в NVIDIA для двухчипового решения решили оставить все исполнительные блоки GF110 активными, но при этом сильно снизили тактовую частоту применяемых GPU. Причём, очень похоже, что ограничивает частоту максимально возможное энергопотребление видеокарты, даже с её двумя 8-штырьковыми разъёмами питания. Интересно, а не лучше ли было сделать подобную двухчиповую карту на базе двух графических процессоров GF114, имеющими меньше исполнительных блоков, но с сильно повышенными частотами?
Питание и охлаждение
Надо сказать, что проектирование такого решения с двумя мощнейшими GPU на одной плате и их серьёзными требованиями по питанию — это весьма непростая инженерная задача. В GeForce GTX 590 используется 12-слойная печатная плата, а для лучшего отведения тепла в слоях питания применяется много меди, что также продляет и срок её службы. Питание двух GPU обеспечивается при помощи 10-фазной системы с цифровым контроллером, а ещё два двухфазных контроллера питают GDDR5 видеопамять.
Возможности слота PCI-Express 2.0 x16 по максимальной пропускной способности (до 8 гигабайт в секунду) делятся на два GPU при помощи специального чипа — PCI-Express коммутатора NF200, который применялся ещё со времён GeForce GTX 295. Этот коммутатор даёт каждому GPU по 16 каналов PCI-E, но уже с вдвое меньшей пропускной способностью. В отличие от AMD, использующей решения PLX со своей маркировкой, NVIDIA применяет собственные давние разработки.

Эффективное охлаждение столь горячего двухчипового решения — это даже ещё более сложная задача. И NVIDIA отлично с ней справилась! Важным преимуществом GeForce GTX 590, которое особенно выделяет компания, является низкий уровень шума от устройства её охлаждения. На плату установлен высокоэффективный кулер с двумя испарительными камерами на каждый GPU и низкоскоростным вентилятором с крыльчаткой большого диаметра (90 мм).
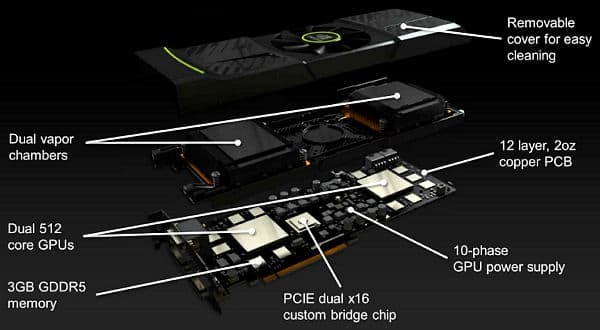
Для достижения максимальной эффективности, система охлаждения GeForce GTX 590 содержит два раздельных радиатора (по одному на каждый GPU), использующих технологии испарительных камер. А для лучшего охлаждения задней стороны платы и установленных на неё компонентов, используются дополнительные алюминиевые пластины. Ну а для некоторых пользователей главным нововведением кожуха кулера может стать светящийся логотип GeForce.
Новый кулер обладает заметно лучшей эффективностью, по сравнению с другими мощными системами охлаждения. В итоге, именно GeForce GTX 590 стала самой тихой двухчиповой видеокартой, и не только в этом поколении. По оценкам NVIDIA, новое решение тише GeForce GTX 295 и GeForce 9800 GX2, не говоря уже о конкурирующем Radeon HD 6990, который весьма сильно шумит при большой нагрузке. Впрочем, у него может быть преимущество в скорости, о чём мы узнаем в следующих частях статьи.
Всё остальное в модели GeForce GTX 590 мало чем отличается от систем из двух видеокарт GTX 570 или GTX 580, объединённых в SLI. Для повышения качества изображения можно использовать специфичные для SLI-конфигураций режимы с количеством выборок вплоть до 64x, а на Quad SLI системе и вовсе до 128x. Для вывода изображения каждая GTX 590 имеет по три разъёма Dual Link DVI и один mini DisplayPort. Это решение позволяет вывести стереоизображение сразу на три монитора при помощи технологии 3D Vision Surround:

Естественно, что требования по питанию у двух- и четырёхчиповых видеосистем весьма серьёзные. Рекомендуется применение блока питания, обеспечивающего минимум 700 Вт, так как только сама видеокарта может потреблять до 365 Вт (а на деле — даже больше). Что уж говорить о двух таких монстрах в одном корпусе! Тут уже нужен не только мощный БП, но и правильное охлаждение в корпусе. Поэтому компания NVIDIA, вместе со своими партнёрами, решила сделать сертификацию подобных решений, пригодных для создания Quad SLI систем.

Так, одним из базовых требований является системная плата с достаточным расстоянием между слотами PCI-Express x16 — две платы должны быть установлены минимум через один слот расширения. Естественно, речь о референсном воздушном кулере, водяное охлаждение лишнего слота не потребует. Вполне логично, что в список сертифицированных системных плат уже вошли топовые модели для энтузиастов от известных производителей.
Требования по питанию также довольно жёсткие по понятным причинам. Блок питания в системе с Quad SLI должен иметь четыре 8-штырьковых PCI-E разъёма, обеспечивая подачу до 150 Вт на каждый из них. Пока что список проверенных вариантов БП невелик, и в него входят блоки мощностью 1100-1500 Вт. Есть определённые требования для создания Quad SLI систем и к корпусам. Корпус должен обеспечивать достаточное охлаждение для внутренних компонентов системы с прямым потоком воздуха в районе расположения видеокарт.
Подробности: GF116, семейство GeForce GTX 550 Ti
- Кодовое имя чипа GF116;
- Технология производства 40 нм;
- 1.17 миллиарда транзисторов;
- Унифицированная архитектура с массивом процессоров для потоковой обработки различных видов данных: вершин, пикселей и др.;
- Аппаратная поддержка DirectX 11 API, в том числе шейдерной модели Shader Model 5.0, геометрических (geometry) и вычислительных (compute) шейдеров, а также тесселяции;
- 192-битная шина памяти, три независимых контроллера шириной по 64 бита каждый, с поддержкой GDDR5 памяти в микросхемах смешанной плотности;
- Частота ядра 900 МГц;
- Удвоенная частота ALU 1800 МГц;
- 4 потоковых мультипроцессора, включающих 192 скалярных ALU для расчётов с плавающей точкой (поддержка вычислений в целочисленном формате, с плавающей запятой, с FP32 и FP64 точностью в рамках стандарта IEEE 754-2008);
- 32 блока текстурной адресации и фильтрации с поддержкой FP16 и FP32 компонент в текстурах и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов;
- 3 широких блока ROP (24 пикселя) с поддержкой режимов антиалиасинга до 32 выборок на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг;
- Запись результатов до 8 буферов кадра одновременно (MRT);
- Интегрированная поддержка RAMDAC, двух портов Dual Link DVI, а также HDMI и DisplayPort.
Спецификации референсной видеокарты GeForce GTX 550 Ti
- Частота ядра 900 МГц;
- Частота универсальных процессоров 1800 МГц;
- Количество универсальных процессоров 192;
- Количество текстурных блоков — 32, блоков блендинга — 24;
- Эффективная частота памяти 4104 (1026×4) МГц;
- Тип памяти GDDR5, 192-битная шина памяти;
- Объем памяти 1024 МБ;
- Пропускная способность памяти 98,5 ГБ/с;
- Теоретическая максимальная скорость закраски 21,6 гигапикселей в секунду;
- Теоретическая скорость выборки текстур 28,8 гигатекселей в секунду;
- Два разъема Dual Link DVI-I и один Mini HDMI
- Один SLI-разъем;
- Шина PCI Express 2.0;
- Поддержка HDCP, HDMI, DisplayPort;
- Энергопотребление до 116 Вт (один 6-штырьковый разъём);
- Двухслотовое исполнение;
- Рекомендованная цена для России — 5999 руб (для США — $149).
Модель GeForce GTX 550 Ti, выполненная на основе улучшенного графического процессора GF116, не заменяет на рынке видеокарту GeForce GTS 450. В начале своего пути эти две модели будут сосуществовать в линейке компании вместе. Обновленный GPU выполнен по всё тем же 40 нм технологическим нормам, как и другие видеочипы этого поколения, а улучшение его характеристик стало возможным из-за отладки 40 нм техпроцесса и глубокой переработки GPU.
Принцип наименования видеокарты снова немного изменился. Обновленная модель теперь не просто принадлежит к новому 5-му поколению, и по сравнению с GTS 450 добавился не только суффикс Ti. По какой-то причине NVIDIA решила перевести выпущенное решение на основе чипа GF116 в более высокий класс GTX, по сравнению с предшествующей аналогичной картой, относящейся к классу GTS. Неужели 192-битной шины достаточно для этого?
На базе видеочипа GF116 была выпущена единственная модель — GTX 550 Ti, и продавать её будут на североамериканском рынке по ценам от $149. Конкурентами данной платы одновременно являются и Radeon HD 5770 и Radeon HD 6850. Компания AMD предусмотрительно снизила рекомендованные цены перед анонсом конкурирующего решения, и теперь новая цена для HD 5770 равна $129, а для HD 6850 — $149. Что как раз чуть меньше или равно цене плат GTX 550 Ti со стандартными частотами. Российская рекомендованная цена для видеокарты от NVIDIA ещё выше, хотя уже с момента анонса они будут продаваться дешевле.
Архитектура и аппаратные изменения
Как и в вышедших ранее моделях серии GeForce GTX 500, в анонсированном GTX 550 Ti используется улучшенный графический процессор, уже знакомый нам по предыдущей серии, и лишь слегка модифицированный для того, чтобы поднять производительность и улучшить энергетическую эффективность.
Модификации в GF116 направлены на то, чтобы снизить утечки и повысить выход годных чипов на высоких частотах, по сравнению с GF106. В результате, GTX 550 Ti имеет лучшие характеристики, работая при этом на частоте, почти на 120 МГц большей, чем графический процессор GTS 450. При этом он потребляет лишь на 10% больше энергии.
Подробная информация обо всех архитектурных особенностях Fermi дана в базовых обзорах линеек GeForce GTX 400 и 500, здесь мы лишь повторим основное. GeForce GTX 550 Ti использует ту же конфигурацию мультипроцессоров, что и GTS 450. GF116 содержит один кластер GPC, четыре мультипроцессора SM и три 64-битных контроллера памяти, сблокированных с кэш-памятью второго уровня и 8 блоками ROP в каждом. Итого, в состав нового GPU входит 192 потоковых процессора, собранных в 4 мультипроцессора по 48 штук в каждом.
А вот подсистема памяти GF116 всё же претерпела некоторые изменения. Каждый мультипроцессор имеет всё те же 64 килобайта начиповой памяти, и GPU в целом содержит 384 КБ унифицированной кэш-памяти второго уровня, которая обслуживает все запросы по загрузке и сохранению данных. Зато в составе GTX 550 Ti активны уже три контроллера памяти, а не два, как было в GTS 450, что в сумме составляет 192-битную шину.
Но даже это ещё не всё. В GF116 изменились не только частоты и ширина шины. Как вы помните из технических характеристик решения, при 192-битной шине памяти GTX 550 Ti каким-то образом содержит ровно 1 гигабайт видеопамяти, хотя обычно в таких случаях должно получаться 768 или 1536 МБ. Если использовать одинаковые микросхемы GDDR5, конечно.
Так вот контроллер памяти нового GPU поддерживает использование чипов памяти смешанной плотности. Что и позволяет набрать ровно 1024 мегабайт, используя 192-битный интерфейс. Применяется четыре чипа одной плотности (32Mx32) общим объёмом 512 мегабайт, и ещё два чипа вдвое большей плотности (64Mx32), которые вместе также составляют 512 МБ. И в сумме как раз и получается 1 гигабайт.

Интересно, каким образом решены некоторые трудности, и не возникнет ли проблем с производительностью в определённых условиях? Но решение любопытное и, видимо, имеет больше смысла для более дорогих чипов. Ведь если бы тот же GF110 поддерживал такую возможность, на него можно было бы поставить не 3 ГБ памяти, что пока явно излишне, а 2 ГБ, получив ту же производительность при меньшей себестоимости. Посмотрим, получит ли продолжение поддержка микросхем памяти смешанной плотности в будущих решениях NVIDIA.
Как и все остальные графические процессоры архитектуры Fermi, GF116 использует несколько полиморфных движков (PolyMorph Engines), работающих параллельно, но лишь один блок растеризации (Raster Engine). Сравнительно большое количество движков PolyMorph в этом GPU способно обеспечить высокую производительность тесселяции, а вот единственный растеризатор, скорее всего, не будет настолько же эффективно выполнять задачи по растеризации, как у старших чипов NVIDIA.
Графический процессор, лежащий в основе GeForce GTX 550 Ti, имеет лишь один растеризатор, как и конкурирующие с ним Radeon HD 6850 и HD 5770, но у чипов AMD растеризатор обычно работает эффективнее. Конечно, GTX 550 Ti в любом случае обеспечит достаточную производительность обработки геометрии, но вот преимущества перед своими конкурентами, которое имеют старшие чипы NVIDIA, у него уже не будет.
Зато скорость самой тесселяции у нового чипа должна быть всё же выше, чем у того же Radeon HD 5770 (а возможно и HD 6850), ведь эта работа распределяется между четырьмя движками PolyMorph, в отличие от одного выделенного блока тесселяции (хотя и более производительного) у конкурентов. Это может сказаться в таких новых DirectX 11 играх с поддержкой тесселяции, как HAWX 2.
Важнейшее изменение GTX 550 Ti, с точки зрения производительности, состоит в значительном повышении тактовых частот GPU и памяти, а также расширение её шины. В отличие от референсной частоты чипа GTS 450, равной 783/1566 МГц, в GTX 550 Ti её повысили до 900/1800 МГц, что на 15% выше. С видеопамятью ещё лучше, её частота повышена с 3608 МГц до 4104 МГц, то есть на 14%, да ещё шина расширилась в полтора раза. В итоге, общее увеличение пропускной способности GTX 550 Ti по сравнению с GTS 450 превышает 70%!
Подобное повышение теоретических характеристик вызывает рост практической производительности рендеринга в играх, особенно в случаях, когда скорость ограничена ПСП видеопамяти. Судя по тестам самой NVIDIA, при типичных для GTX 550 Ti настройках (1680x1050 и MSAA 4x), одно только расширение шины до 192-бит даёт порядка 14% в среднем, а в случае некоторых игр даже выше (StarCraft II — 31%, Aliens vs Predator — 23%, Batman: Arkham Asylum — 21%).
Среднее ускорение от роста частот с 783/1566 до 900/1800 МГц составляет ещё примерно столько же (около 13-14%), а в некоторых современных играх, таких как Just Cause 2 и Battlefield Bad Company 2, оно и вовсе равно теоретическому приросту в частотах. Ну а в среднем, по набору игровых тестов у NVIDIA для GeForce GTX 550 Ti получились приросты FPS порядка 28%.
Как обычно для линейки GeForce GTX 500, заметно повышенные частоты и характеристики не вызвали такого же прироста в энергопотреблении. По данным компании, благодаря аппаратным модификациям, направленным на снижение потребления, GTX 550 Ti получилась в среднем на 20% энергоэффективнее, по сравнению со своей предшественницей.
При всём этом, новый GPU имеет отличные возможности по разгону. Похоже, что без необходимости каких-либо модификаций, большинство плат GTX 550 Ti будет работать на частоте выше 1 ГГц. И для этого даже не нужно повышать напряжения и частоту вращения вентилятора референсной системы охлаждения. Поэтому, как и в случае со многими другими платами на чипах NVIDIA, одновременно с видеокартами, имеющими стандартные частоты (900/1800/4100 МГц) на рынок выходят и фабрично разогнанные модели от партнёров компании.
Эти видеокарты имеют повышенные до 950-975-1000-1050 МГц частоты для GPU, что даст дополнительные 5-10% производительности в случаях отсутствия явной зависимости скорости рендеринга от пропускной способности памяти. И такие решения точно не будут редкими в продаже, так как уже все основные партнёры NVIDIA объявили о планах по их выпуску. И на примере той же GeForce GTX 560 Ti мы видим, что зачастую сложнее найти решение с референсными частотами, нежели разогнанное фабрично.
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX


