Расклад сил
Год назад мы уже рассказывали о новом APU в кратком обзоре «Процессорное трио AMD». (Кстати, применять аббревиатуру APU мы тут не будем, используя более знакомый термин ЦП.) Рассматривать Llano отдельно от остальных двух новинок этого года от AMD было бы неверно, ибо компания весьма точно разделила потребителей на сегменты, покрыв новыми процессорами почти всё, что до 2011 г. было отдано на откуп Феномам, Атлонам и Семпронам. Главной идеей создания гибридных ЦП было помещение графического процессора (ГП) на кристалл центрального, названное маркетологами «слиянием» (Fusion). Ранее интегрированная графика у AMD существовала лишь в северном мосте чипсета (у Intel её в 2010 г. переместили в микросхему ЦП, но оставили отдельным кристаллом, причём изготовленным по худшей технорме). А какая вообще графика требуется пользователям?

- Простая: для интернета, офиса, фильмов и старых игр — только это до сих пор и могла обеспечить «интеграшка»;
- Быстрая: в т. ч. для современных игр — такой уровень и сейчас под силу только отдельным видеокартам, цена которых чаще всего больше, чем у ЦП;
- Средняя: в т. ч. для игр, но либо не самых современных, либо не с самыми крутыми настройками, а главное — в компактном и тихом корпусе и за весьма ограниченный бюджет.
Именно для таких среднячков и сделан Llano. Он точно не поставит рекорды ни в одной категории, которой обычно сравнивают процессоры — ни по скорости (причём и в графической, и в вычислительной частях), ни по экономии, ни по цене. Его цель — занять золотую середину между всеми крайностями. Хотя нельзя сказать, что новизны нет совсем: гибридный ЦП впервые позволил сделать систему одновременно компактную (даже северный мост не нужен), пригодную для большинства игр и доступную почти всем игрокам. Например, всё более популярный форм-фактор «всё-в-одном» (монитор и системный блок в одном корпусе) теперь получит достойную 3D-графику.
Помимо того, что хотят массы, AMD должна была учесть и собственные возможности, которые сильно рассеяны из-за внедрения в течение года трёх архитектур, причём каждая — по новому для фирмы техпроцессу (совершенно немыслимая для конкурента ситуация — с их известной стратегией «тик-так»). Поэтому в данном случае (из трёх) ради минимизации рисков и экономии денег и времени решили не делать новую x86-архитектуру, а в очередной (но последний) раз обновить и дополнить старую. Так получились ядра K12, пришедшие на смену K10.
Впрочем, весь процессор мог «получиться» куда раньше. Дело в том, что впервые идея об APU была заявлена из уст представителей AMD ещё в 2006 г., почти одновременно с покупкой ATI. Уже через год планов было громадье: сначала готовилась интеграция двух кристаллов в корпусе (как сделала Intel), затем — на одном кристалле, но со слабым взаимодействием (видимо, с отдельным КП для графической памяти), потом — с разделяемыми ресурсами, и, наконец, с полным «сплавом» вычислительных блоков общего и графического назначений. Причём шаг №1 должен был произойти уже в 2008 или 2009 г. Ясно, что многое пошло не так, а сложная финансовая ситуация заставила AMD даже выделить производственные мощности в виде отдельной компании Global Foundries (GF). Потерянное время пришлось навёрстывать авралом, так что первый вышедший APU оказался сразу третьим шагом вышеозначенного плана.
Если кратко перечислить суть Llano, то получится вот что:
- 2–4 ядра K12, суть — улучшенные K10;
- по 0,5 или 1 МБ L2 на ядро, без L3;
- накристальный ГП класса HD 5000;
- более скоростной ИКП, чем у K10, но лишённый за ненадобностью поддержки ECC;
- контроллер шины PCIe 2.0, в т. ч. для подключения внешней видеокарты или двух;
- более агрессивный авторазгон Turbo Core 2.0 (TC), но только для x86-ядер;
- силовые ключи шин питания x86-ядер, ГП и блока UVD;
- кристалл изготовлен по 32 нм технорме.
K10++ = K12
Ядро K10 уже настолько устарело, что обновлять его надо либо кардинально, либо никак, потому что всё равно через пару лет спишут. AMD выбрала второй путь, но хотя бы косметический ремонт старикану надо бы сделать, благо он не потребует полной переделки блочного расклада. Итак, что изменилось:
- Диспетчер и планировщик:
- Размер очереди ROB увеличился с 72 до 84 мопов (точнее, 28 троек, пришедших от декодеров, включая «пузыри»);
- Размер трёх (по числу портов) резерваций для команд общего назначения увеличился с 8 до 10 мопов (в каждой). Общая векторно-вещественная резервация осталась на уровне 36 (это число не изменилось за 12 лет со времён первых Атлонов);
- Векторные команды, модифицирующие младшую часть регистра xmm и обнуляющие старшую, не вызывают ложную зависимость от содержимого старшей части. (Подробней о сложностях частичного доступа к регистрам в разных процессорах рассказано в одной из глав описания микроархитектуры Sandy Bridge.)
- Тайминги команд:
- В порт 2 добавлен целочисленный делитель, что сократило число тактов деления в 2–8 раз (в зависимости от числа значащих бит аргументов). Ранее целые деления исполнялись на единственном универсальном делителе, находящимся в FPU (так AMD традиционно называет векторно-вещественный блок), который теперь выполняет только вещественное деление (с той же скоростью). Как и умножитель (в порту 0), целый делитель возвращает старшую часть результата в порт 1;
- Возможно (пока не проверено), копирование регистров xmm вещественными командами исполняется с пропуском в 3 IPC, а целыми — 2 (в обоих случаях было в среднем 2,5);
- Ещё более мелкие изменения в некоторых командах.
- Подсистема памяти:
- Две общие очереди чтения-записи в LSU удвоились до 88 ячеек (24 для первичного обращения и 64 для вторичного — при промахе в L1D);
- Какие-то изменения в STLF, чуть изменившие (в разные стороны) пропуски некоторых команд;
- L2D TLB удвоился до 1024 адресов (но остался 4-путным); улучшилась резидентность при переключении виртуальных машин (видимо, реже происходит смыв TLB);
- Новый предзагрузчик L1D (в дополнение к старому) отслеживает запросы отдельных команд (описание аналога от Intel см. тут);
- Задержка L2 увеличилась с 9 до 10 тактов, а задержки при чтении из памяти — с 150 до 180;
- Переход между когерентными состояниями строк кэша ускорились;
- ИКП больше не поддерживает DDR2, зато улучшил собственный предзагрузчик, который отслеживает до 8 потоков с разным шагом (гранулярность шагов — ±64 байта, т. е. размер строки кэша). При этом (как и в K10) предзагруженные строки хранятся в отдельном буфере и отдаются только при явном запросе с совпавшим адресом — т. е. скрываются задержки только самой памяти, но не пересылки по шинам внутри ЦП. Кроме того, каналы памяти полностью независимы (ungangaed mode), включая возможность исполнения разных команд;
- Декларируется увеличение скорости заполнения памяти, однако команда копирования строки из памяти в память по результатам тестов наоборот, замедлилась с 15 до 9,2 байт/такт.
Даже сама AMD не скрывает, что всего этого хватит не более чем на «6% ускорения» (включая добавку от удвоенного L2), а судя по нашим тестам, эти «6%» на деле чаще оказываются в районе погрешности измерения. Не удивительно, что в сравнении с обновлёнными в этом же году процессорами соперника новые Llano смотрятся в отношении «два ядра K12 ≈ одному ядру SB» (особенно со включенной гиперпоточностью у последнего).
Наш постоянный Внимательный читатель сделает любопытное наблюдение: впервые у AMD вышли 4-ядерные процессоры с 1 МБ L2. При выходе K10 (в 2007 г., на 65 нм) первые Феномы имели по 0,5 МБ на ядро, но дополненные 2 МБ L3, чем AMD сильно гордилась — её первый настольный x86-ЦП с L3! (Ещё в 2002 г. серверные Intel Xeon архитектуры Foster MP на свои 180 нм получили 0,5–1 МБ L3, за что потребителям пришлось платить умопомрачительную цену в несколько тысяч долларов. Через год эти модели были перевыпущены на 130 нм в т.ч. как настольные Pentium 4 Extreme Edition с 2 МБ L3.) Через 2 года, при выпуске 4-ядерных Athlon X4, решили обойтись без L3, не увеличив при этом L2. Его объём удвоили до 1 МБ только у 1- и 2-ядерных моделей, хотя по нашим тестам оказалось, что зря — лучше бы площадь сэкономили, ибо такому ядру лишние 0,5 МБ почти не помогают.
И вот прошла ещё пара лет, выпускаются чуть ускоренные «К10++», дополненные чуть ускоренным же ИКП (что даже немного ослабляет требования к подсистеме кэшей). И вместо наиболее очевидного варианта «4 по 0,5» мы видим «4 по 1». Зачем?.. L3 такому ЦП не нужен, т. к. ГП использовать его не может, а обмен данными для x86-ядер будет прежде всего полезен для высокопроизводительных программ, которые устаревшей архитектуре и так не светят (тем более на фоне своего же более мощного ядра Bulldozer). Возможный ответ заключается в том, что с учётом компоновки кристалла на нём осталось много свободного места, которое было соблазнительно наскоро заполнить чем-то хоть полезным без побочных эффектов. Позже мы это обсудим.
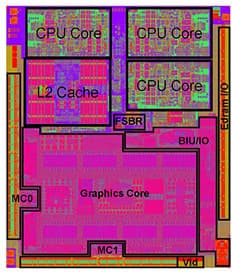
Графика
Если кратко, то в наиболее полной версии ГП имеется:
- 400 универсальных «шейдерных процессоров» (SP, но далее назовём их по-честному — ФУ);
- 20 текстуризаторов (TMU);
- 8 рендер-блоков (ROP) по 4 значения глубины или шаблона (Z/stencil) на пиксель;
- 2 цифровых видеовыхода — eDP, LDVS (эти оба — для встроенного ЖКД), HDMI, DVI или DisplayPort 1.1; RAMDAC (цифроаналоговый преобразователь для VGA) находится в южном мосте;
- поддержка DirectX 11, OpenGL 4.1 и OpenCL 1.1;
- связь с x86-ядрами с доступом к их адресному пространству и поддержкой когерентности памяти;
- Dual Graphics (ранее это называлось Hybrid CrossFireX) — спаривание с одним или двумя внешним(и) ГП 6000-й серии для совместной работы и увеличения числа подключаемых мониторов.
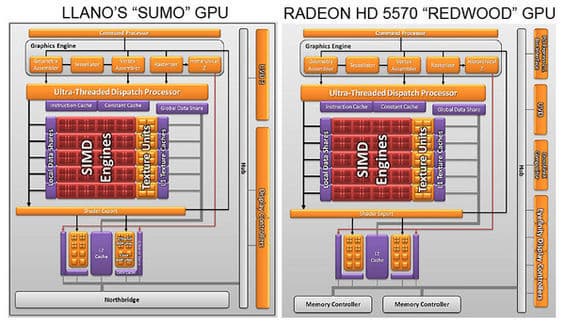
Сравнение старшего ГП Llano (в зависимости от частоты это HD 6550D или HD 6620G) с Radeon HD 5570
Этот вид ГП совпадает с дискретным Radeon HD 5570 «Redwood PRO» архитектуры Evergreen, хотя производительность встроенного в Llano собрата будет хуже из-за меньшей ПСП и её разделения с x86-ядрами. Всего имеется 4 вида ГП, но это не считая разных частот для настольных и мобильных версий (обозначаются буквами D и G). Все версии в деталях описаны по ссылкам выше, но следует добавить, что версия с 160 ФУ является сокращённым вариантом модели 6480G с 240 ФУ, а вариант на 320 ФУ — это обрезок от самой полной на 400 ФУ.
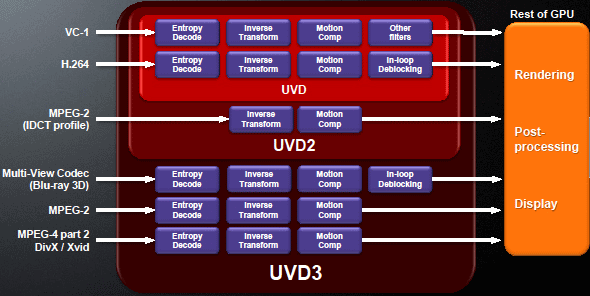
Устройство UVD 3.0
Главное отличие видеочасти Llano от 5000-й серии внешних ГП — обновление аппаратного видеодекодера UVD с версии 2.2 до 3.0, которая встречается у HD 6000. Теперь есть поддержка воспроизведения H.264, VC-1, MPEG-2 и MPEG-4, DivX, Xvid и MVC (для Blu-ray 3D), но до сих пор нет аппаратного кодирования. Intel со своей технологией QuickSync до сих пор впереди.

AMD особо гордится гибкими возможностями подключения мониторов и/или устройств PCIe (включая видеокарту/ы) ко встроенным контроллерам на 32 полосы (в сумме). Из них 4 выделяются для связи с южным мостом (шина UMI), ещё 4 — для 1–4 неграфических устройств (GPP), 8 — для подключения только мониторов (DVI и DDI — цифровой интерфейс дисплея) и ещё 16 — для мониторов и/или видеокарт (dGPU) и/или периферии (почти во всех комбинациях). Всего можно подключить до 6 мониторов, но разных картинок на них будет не более двух, т. к. именно столько на кристалле «головных контроллеров».
Тайное оружие AMD — GPGPU, т. е. вычисления общего назначения на ресурсах ГП. Поддержка OpenCL 1.1 даёт возможность получить 480+96 гигафлопсов пиковой производительности (от ГП и x86, соответственно) — правда, только на SP-числах. Такие цифры заткнут за пояс любой процессор соперника: даже с учётом грядущей в Ivy Bridge нормальной поддержки OpenCL его немощный (даром, что обновлённый) ГП мало поможет против сотен ФУ в Radeon. Однако, несмотря на активные усилия AMD по продвижению гибридных вычислений, «вундерваффе» станет массово применяться, возможно, уже когда Llano понадобится разве что гробовщик. Ну что ж, герою-первопроходцу споют песню, ведь все следующие ЦП AMD для всех платформ будут гибридными. Многоядерность тоже когда-то появилась впервые…
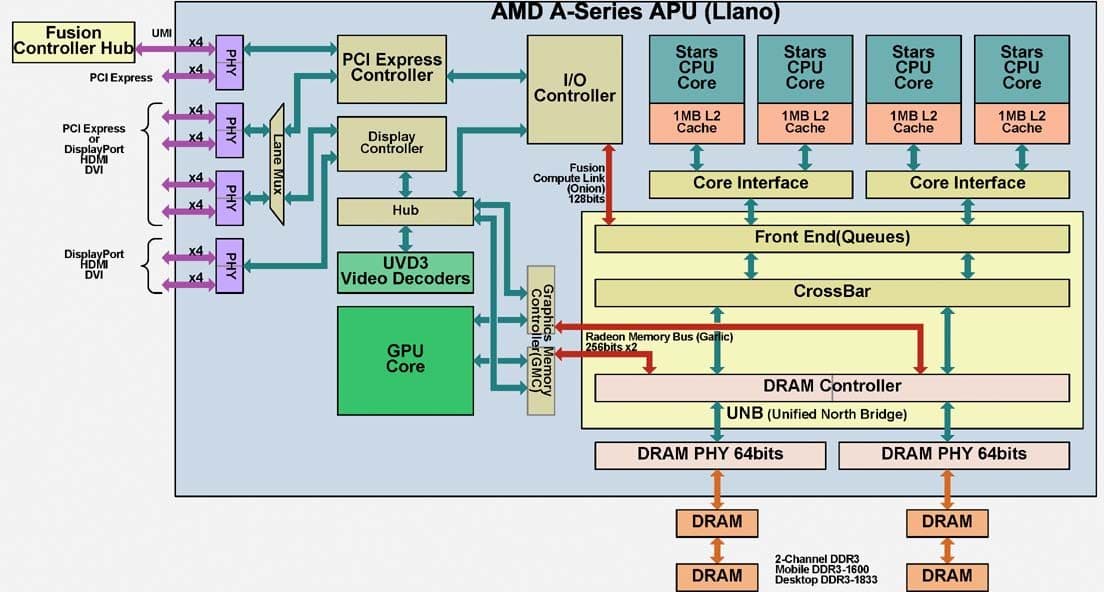
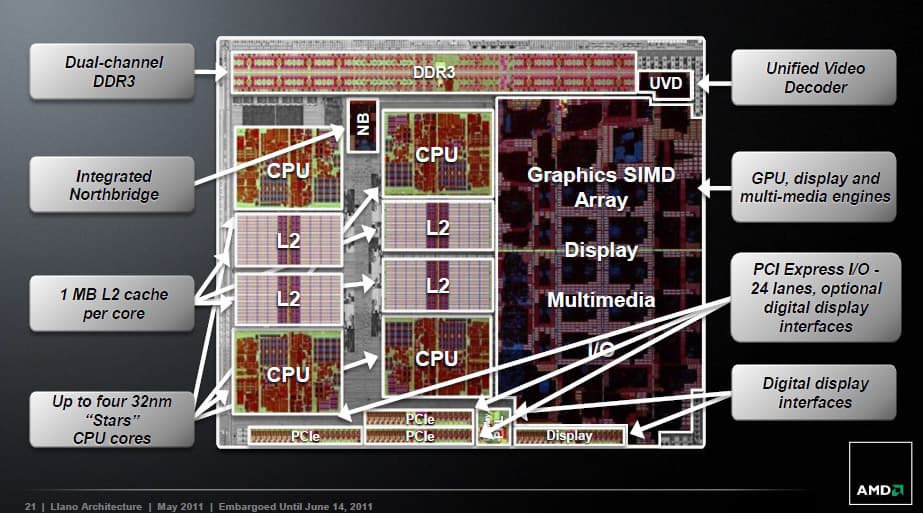
Внеядро
Официально оно зовётся то CNB (Common NorthBridge), то UNB (Unified NorthBridge) — т. е. общий-единый северный мост (назовём его просто СМ). (У AMD вообще случился полный бардак с названиями, кодовыми именами и сокращениями — они часто дублируются, самопротиворечат, меняются как перчатки до выхода продуктов и слабо систематизированы. Например, ядро Llano имеет второе название Husky, а встроенный ГП исходя из архитектуры должен иметь 5000-е номера моделей.) Для нас тут любопытны три момента. Начнём с ИКП: настольные варианты поддерживают скорости до 1866 МГц для одного модуля на канал и 1600 для двух. Мобильные же 1866 МГц не тянут, зато работают и с низковольтовыми LV-DIMM на частоте до 1333 МГц и по одному на канал.
Интересно рассмотреть и умножители частоты (PLL). AMD их также относит к СМ, хотя на любых современных ЦП они получают питание по отдельной шине (которую даже не упоминают в списке прочих). В процессор из южного моста поступает две опорные частоты — 100 и 133 МГц. Первую используют PLL для x86-ядер, умножая её на коэффициенты начиная от 8 (800 МГц — частота простоя, как и у K10). Вторая используется для ИКП и контроллеров шин (минимальный множитель тут также 8). Но самое интересное — умножитель для ГП. Если внимательно изучить часто́ты графики в разных моделях (из таблиц по ссылкам выше), то окажется, что они вовсе не кратны какой-то большой цифре. Судя по всему, этот PLL является вовсе не умножителем, а синтезатором частоты — т. е. честным тактовым генератором, частота которого настраивается с точностью до 1 МГц. Именно так это устроено во всех дискретных ГП, а вот во встроенном у Intel стоит умножитель.
А теперь — немного мистики. Где-то на техасщине есть селенье Llano на 3000 ковбоев и доярок. (Кстати, это испанское слово правильно произносится как «Лья́но», но название села и процессора — «Ллэ́но».) Говорят, там изредка вспоминают старую забаву сжигания ведьм и охоты на вампиров… Иначе как объяснить, что скучные технари из расположенного неподалёку Остина (а этот город, как мы знаем, вобрал в себя процессорные команды и AMD, и Intel, и даже VIA) решили не только назвать в его честь процессор, но и обозначить в нём шины кодовыми именами Onion и Garlic — лук и чеснок. Что там ещё против нечисти помогает?..
Разумеется, у них есть и удобоваримые названия. Fusion compute link (FCL, «связь слитых вычислений», она же — «лук») соединяет ГП с x86-ядрами, обеспечивая минимальную задержку чтения в обход кэшей, в т. ч. при случайном доступе. Её напарница, Radeon memory bus (RMB, «шина памяти Radeon», она же — «чеснок»), связывает ИКП с ГП и оптимизирована под максимальный пропуск (в т. ч. и для записи) для потоковых данных. Ещё одна шина CCI (видимо, Common/Coherent Core Interface — «общий/когерентный интерфейс ядер» или ещё какой-то «хрен») нужна для связи ИКП с x86-ядрами. Очевидно, что цели у шин до памяти противоположные. Ясно, что кому-то чего-то не хватит, но чтобы это происходило как можно реже, AMD решила снабдить ГП своим собственным ИКП (GMC), который соединяется с парой шин до модулей ОЗУ конкурентно с x86-ИКП. Контроллеры имеют разные буферы, таблицы и алгоритмы.
Отличия «флоры» на этом не заканчиваются. «Лук» — это полнодуплексная шина шириной 2×128 бит с регулируемой в зависимости от нагрузки частотой (совпадающей, видимо, с максимумом частот ядер на данный момент). ГП может её использовать под управлением видеодрайвера, когда требуется иметь доступ к общему адресному пространству, что влечёт программную проверку когерентности с трансляцией адресов и даже подкачкой страниц из свопа (если потребуется). Она же используется, если x86-ядрам надо получить доступ к кадровому буферу (тут снуп-проверка не нужна).
«Чеснок» же имеет разрядность 2×256 бит, работает с частотой СМ (а не самого ГП) и только с некогерентными адресным пространством (выделенным в BIOS для ГП), зато с более высоким приоритетом использования шины, чем «лук». Больший приоритет для ГП означает снижение задержек без выигрыша ПСП, но в ущерб задержкам для x86-ядер — вот откуда лишние 30 тактов и, похоже, единственное разумное обоснование для увеличения L2.
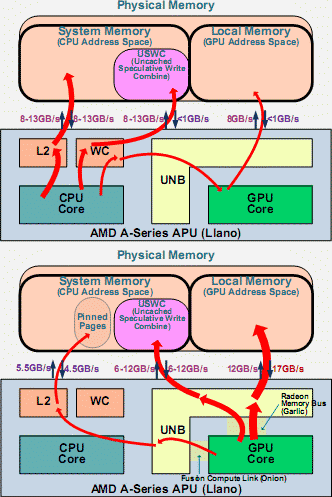 ПСП при доступе от x86-ядер и ГП. «X–Y GB/s» означает X ГБ/с для одно- и Y для многопоточного доступа. Схема Hiroshige Goto с PC watch |
Интересно, что AMD ради высокой производительности GPGPU и некоторых других вычислений (в т. ч. перекодировании видео) сделала оптимизацию случая, когда графические и x86-ядра работают над общими данными — при этом их не требуется копировать из общей (когерентной) памяти в графическую и обратно. Интерфейс OpenCL даёт сразу несколько способов это сделать. Например, область памяти типа USWC (некэшируемая, упреждающая, со слиянием записей) обычно используется под кадровый буфер, но графические и x86-ядра могут получать к ней доступ поочерёдно. Также можно объявить некоторые страницы «фиксированными» (pinned), виртуальные адреса которых накладываются на физические непрерывно (для облегчения трансляции) — тогда любые ядра могут одновременно получать в них доступ, хотя для ГП так будет медленней.
Впрочем, эта оптимизация меркнет при рассмотрении пропусков разных видов обменов. На схемах видно, что максимум ПСП для одно- и многопоточного обменов между памятью и x86-ядрами — всего 8 и 13 ГБ/с, т. е. 27% и 43% от теоретического пика. Цифры для ГП — 40% и 57%. Тут, правда, не ясно, допустимо ли сложение чтений и записей — если да, то ситуация несколько лучше: одновременно читая и записывая, только x86-ядра могут в многопотоке загрузить 87% ПСП, а только графические — 97%. Тем не менее, странно, почему для каждого случая мы не можем получить 100%. Возможно, дело как раз в том самом приоритете для ГП, который понижает ПСП и для себя (когда простаивают x86-часть), и для x86 (когда молчит уже ГП).
Ещё меньше пропуски при обменах с чужими адресными пространствами, но тут объяснения есть: где-то нет кэширования в L2, а только буферы слияния записи (WC, по 4 на ядро); где-то нужны снуп-проверка и трансляция адресов. В любом случае, AMD ещё надо хорошо поработать, чтобы нагрузить на полную широкие внутренние шины и внешнюю память. Для сравнения, ещё более широкая кольцевая шина в Sandy Bridge сразу даёт весь свой теоретический максимум, т. к. подключена к кэшу L3.
Наконец-то 32!
Тут GF явно в догоняющих. Её 32-нанометровый техпроцесс на частично обеднённых КНИ-пластинах (PD-SOI) использует HKMG-транзисторы с напряжённым кремнием, изготовленные по методу «затвор первым» (детали обо всех этих технологий см. в нашем описании современных достижений микроэлектроники). По утверждению GF, на кристалле могут присутствовать транзисторы, настроенные под три разных напряжения срабатывания — от 0,8 до 1,3 В (какие из них фактически используются в Llano — не ясно). Поверх них — 11-слойная медная металлизация с низкопроницаемыми диэлектриками; шаг затвора с учётом его контакта до одного из нижних трёх слоёв дорожек — 104 нм (для сравнения параметры Intel: 9 металлов и 112,5 нм — детально значение этих цифр исследовано в наших «разборах нанометров»). Есть несколько разных видов ячеек СОЗУ с разным сочетанием площади, потребления и скорости. Также допустимы сквозькремниевые соединения кристаллов (TSV), хотя на практике их в AMD пока никто не показал. В общем, всё примерно как у Intel, но в массовом производстве — на год позже.
Из тонких особенностей выделяются специальные транзисторы, корректирующие фронты сигналов для борьбы с утечками и выравнивания параметров всего массива транзисторов на многобитных шинах. Причём такая мера является «костылём», вызванным тем, что без него переведённое с 45 на 32 нм ядро заработало бы не так хорошо. При этом присутствуют и некоторые штатные средства экономии, в полном наборе имеющиеся в ядрах Bulldozer, изначально сделанных под 32 нм — детально поговорим о них в грядущей статье об этой архитектуре.
Разумеется, никак не обойти замену 6-транзисторных ячеек СОЗУ в кэшах L1 на 8-транзисторные; зачем это надо — описано в примере для Atom. (Кстати, впервые Intel применила такой приём экономии в Pentium 4 при переходе на 65 нм — разумеется, не для того, чтобы сделать его ультрамобильным, а т. к. иначе даже на новом техпроцессе не укладывались в предел по TDP.) Но тут есть любопытный момент: замена почему-то почти не отразилась на площади кэшей. Чтобы разобраться с хитростями 32 нанометров у AMD, самое время заняться любимым делом процессорных аналитиков — подсчётом транзисторов :)

Кристалл 4-ядерного Llano
Итак, 4-ядерный Llano (с текущими степпингами и частотами потребляющий 35–100 Вт) имеет площадь 228 мм², на которых расположились 1450 млн. транзисторов (как обычно, сократим эту меру до «Мтр»). При этом на рекламном слайде AMD утверждает, что на x86-ядра и ГП ушло по 35%, а на СМ — 30%. Звучит крайне сомнительно: по расчётам, внеядро K10 (за вычетом контроллера и драйвера(ов) шины HyperTransport) занимает ≈16 Мтр, а присутствующие тут блок UVD и контроллер PCIe никак не тянут на 419 Мтр. Возможно, речь шла о соотношении потраченной площади, что близко к реальности, но совсем не показательно, поэтому вернёмся к транзисторам. 2-ядерная версия кристалла (неизвестной пока площади) получит 758 Мтр и ГП на 240 «ядер».
Каждое ядро x86 занимает 9,69 мм² без учёта L2 и 17,7 мм² с L2. Транзисторов в нём «более 35» Мтр (у K10 было 30) + 1,38 на силовые ключи, а вместе с L2 — 110 Мтр. Предположим, что «более 35» означает «меньше 35,5», и получим ≈73,5 Мтр на мегабайт L2. Вычисленное значение для K10 — 76,25. Разница небольшая, но меньше это число точно стать не должно. Выходит, что либо ранее мы недооценивали сложность ядра K10 (где должно быть примерно на 3 Мтр больше), либо AMD (как уже многажды бывало) снова «намудрила» с цифрами. Проверим выкладки так: в «лишние» 5 Мтр должны уложится по 2 тр./бит в 128 КБ обоих L1 (это 2,1 Мтр), дополнительные 512 72-битных (скорее всего, тоже 8-транзисторных) ячеек для L2D TLB (+ 0,3 Мтр), а почти всё остальное — добавленная логика (в частности, целочисленный делитель — штука весьма немалая). Вроде всё совпадает. Видимо, «110» были округлены вниз примерно на 3 Мтр. Тем не менее, примем данное число.
Подсчитаем транзисторный бюджет большого и малого ГП + UVD + СМ: 1450−4×110=1010 и 758−2×110=538 Мтр. А теперь заглянем в таблицу дискретных ГП AMD той же архитектуры (изготавливаются на 40-нанометровом техпроцессе компании TSMC) и обнаружим вышеупомянутый Redwood с такими же параметрами, что и у старшего ГП Llano, но с транзисторным бюджетом лишь в 627 Мтр (включая контроллеры двух шин). А в наши 1010 Мтр уместится почти целый Juniper, который вдвое круче по всем параметрам! Далее, можно вычесть цифры Juniper из Redwood, т. к. эти ГП прежде всего отличаются формулой графических ядер и спаренных с ними спецблоков. Получаем 413 Мтр на 400 ФУ, 20 TMU и 8 ROP. Если же аналогично вычесть старший ГП Llano из младшего, то получится 472 Мтр на 160 ФУ, 8 TMU и 4 ROP!

Корпус (с варварски содранной крышкой) и основной кристалл XCGPU
Можно зайти с другой стороны — год назад был представлен чип, имеющий полное право называться первым массовым APU — XCGPU, процессор для нового поколения приставки Xbox моделей S. Предыдущие версии имели ЦП и ГП отдельно, тут же 45-нанометровое изделие GF умещает:
- 3 ядра ЦП (чуть модифицированные версии миниядер PPE из ЦП IBM Cell), работающие на частоте 3,2 ГГц;
- 1 МБ общего для них кэша L2, работающего с половинной частотой и подключенного к 256-битной шине;
- 500 МГц ГП AMD Xenos на 240 ФУ с пиковой производительностью в 240 Гфлопс;
- на втором чипе, связанном 500-мегагерцовой 512-битной шиной — 8 ROP и кадровый буфер на 10 МБ с архитектурой eDRAM (встроенное динамическое ОЗУ с 1-транзисторными ячейками).
Один корпус вместо двух (у прошлого ГП кадровый буфер также сидел рядом вторым кристаллом) сэкономил 60% TDP и 50% площади. На 10 МБ ОЗУ + ROP ушло 105 Мтр, т. е. для 8 ROP остаётся всего ≈10 Мтр. Но главное для нас то, что у основного чипа — 372 Мтр, из которых 165 ушло на ЦП + L2, а 232 — на ГП. И вот эта последняя цифра совсем не вяжется с похожим (в т. ч. по пиковой скорости) младшим ГП в Llano, которому, как мы подсчитали по не менее официальным цифрам, выпало 538 Мтр. В общем, веселуха с транзисторами продолжается — видимо, на техасщине это тоже популярная забава :)
Кристалл со странностями
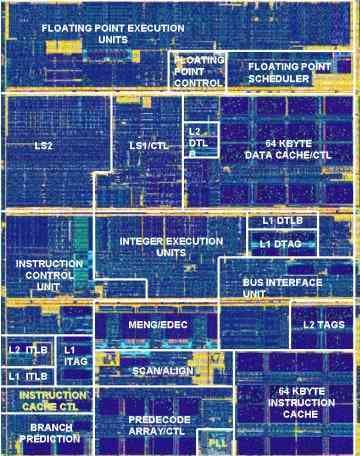
Теперь вернёмся к x86-ядрам. Тут полезно сделать небольшую ретроспективу. Давным-давно жила-была компания DEC — один из мировых лидеров по производству мэйнфреймов, миникомпьютеров и рабочих станций. И была в ней группа талантливых разработчиков микроархитектур, из-под руки которых вышли всемирно известные PDP-11, VAX и Alpha. О последней стоит сказать особо: её первая версия, Alpha 21064 или EV4 (1992 г.), это первый КМОП-процессор, частота которого превысила самые быстрые доселе компьютеры на ЭСЛ-логике. Второе поколение (21164 или EV5 — 1995 г.) — первый ЦП со встроенным L2 (который, правда, убрали из ЦП следующей версии). 21264 (EV6, 1998 г.) — второй (после AMD K5) 4-путный ЦП с внеочередным исполнением (и с рекордными для логики 15,2 Мтр). 21364 (EV7, 2003 г.) — первый ЦП с высокоскоростным ИКП и сетевой межпроцессорной шиной. Планировавшийся на 2004 г. 21464 (EV8) должен был стать первым суперскаляром на 8 IPC и с 4-путной SMT.
Но из-за просчётов руководства (и неожиданного для всех скачка производительности у x86 с выходом Pentium Pro) компьютеры с ЦП Alpha становились всё менее популярны, DEC терпела убытки, пока не была куплена компанией Compaq в 1998 г. Последняя свои микросхемы не разрабатывала и не производила (являясь активным покупателем ЦП Intel), так что судьба инженеров, продолжавших дорабатывать Альфы, была весьма печальна. В 2001 г. все наработки по Alpha (включая исследования по SMT, которые позже вырастут в технологию HyperThreading) Compaq продала в Intel, а та пригласила технарей работать над будущим Itanium (совместно с HP). (Говорят, большинство из перешедших 300 с чем-то инженеров до сих пор работают над новыми версиями этих ЦП.) Но часть персонала ушла ещё при кончине DEC…
…И ушла в AMD! Более того, Дэррик «Дёрк» Мэер, один из создателей Альфы, перешёл в AMD ещё в 1996 г. Возглавив группу, во многом состоящую из своих бывших коллег, он стал работать над новым ЦП. И уже в 1999 г. вышел первый Athlon. ЦП, разумеется, сделан с нуля, но в нём использовалась системная шина с технологией DDR, первоначально разработанная для Alpha 21264. А в первых Opteron применили ИКП и шину HyperTransport, также от наработок для Alpha. Атлоны позволили в первый (и, пока, в последний) раз на равных соревноваться с Intel, пока та соображала, что бы такого сделать с Pentium 4… В общем, без команды архитектурщиков и инженеров из DEC об AMD сейчас бы вспоминали не чаще, чем о VIA. Но самое интересное для нас тут — как выглядели ядра Атлонов с первого по последний, и, для сравнения, Llano (по ссылкам — крупные версии):
| K7, 250 нм, 1999 г. | K7, 180 нм, 2001 г. | K8, 130 и 90 нм, 2003 и 2004 гг. |
 | ||
| K8, 65 нм, 2006 г. | K10, 65 и 45 нм, 2007 и 2009 гг. | K12, 32 нм, 2011 г. |
 Карта блоков ядра авторства Hans de Vries с chip-architect.com. Зелёным обозначены расширенные блоки, красным — добавленные. Впрочем, в именовании последних Ханс ошибся: в LSU никаких дополнительных «стадий декодирования и упаковки» нет, как и ФУ для AVX в FPU. Что не разъясняет природу новообнаруженных на этих местах блоков… |
Ясно, что любое сделанное с нуля ядро будет иметь совершенно новую раскладку блоков, с учётом архитектуры, техпроцесса и прочих параметров. Однако лицо Атлонов словно застряло во времени: за 12 лет на семи поколениях техпроцессов взаимное расположение и даже относительный размер основных блоков почти не изменились! Для сравнения, за это время Intel сделала с нуля P4, P-M, Core 2, Nehalem и Atom (не считая тех же Itanium и других не x86-ЦП), каждый их которых имеет совершенно отличный расклад ядра. Нельзя сказать, что в AMD сидят лентяи — просто либо первоначальный расклад оказался исключительно удачным, либо (что куда более вероятно) в AMD не хватило людских ресурсов, чтобы разработать совершенно новую микроархитектуру ранее 2011 г. Поэтому каждый раз ограничивались такими обновлениями существующей, чтобы они не повлекли полной переделки ядра.
Впрочем, кое-какие сдвиги в K12 всё же достойны комментария. Из-за удлинившегося целочисленного тракта (включающего в себя и резервации) контроллер L2 «вылез» дальше остальных блоков, так что по обе стороны от него есть полосы свободного места. Особенно его много у L1I — настолько, что, немного потеснившись в логике фронта, его можно было бы увеличить на 50%. В других местах тоже стало посвободней — прежде всего из-за чуть более широких кэшей. Однако не смотря на их перевод с 6- на 8-транзисторную ячейку, относительная длина у них почти та же, что и у K10. Тем не менее, инженеры могли бы сократить несколько долей миллиметра по длине, пересобрав некоторую мешающую этому логику. Но не сделали это либо из-за недостатка времени, либо за ненадобностью.
Ладно там независимые аналитики из интернетов — но как AMD умудрилась ошибиться в разрисовке своего же кристалла, проведя границу блока UVD по его середине?..
А причина ненадобности может оказаться весьма проста — по ширине 4-ядерный кристалл ограничен длиной ГП. В результате парам x86-ядер не тесно даже с мегабайтовыми кэшами L2 — вокруг них полно свободного места. А ведь можно было ограничиться половиной L2 и развернуть ядра и СМ на 90° — сверху от них (по фото) освободится пространство, где можно разместить половину драйверов шин памяти, а вторую — вдоль левого края (ничего страшного, у Athlon II X2 эта полоска имеет аж два излома). В результате чип станет чуть длиннее (на ширину драйверов ОЗУ), но куда у́же.
Рассмотрим теперь ГП. Сразу можно сделать наблюдение: каждый большой прямоугольный блок устроен по принципу «массивы — по периметру, логика — по центру». Массивы — это мелкие горизонтальные прямоугольнички, устройство которых удивительно похоже по всему ГП. Зато логика, наоборот, совершенно хаотична. Такая комбинация может быть, только если и логику, и массивы оптимизировали по площади (и, во вторую очередь, экономии) в ущерб частоте. Но тут она и не нужна — выше 850 МГц не поднимаются даже дискретные ГП этой архитектуры. Тем не менее, линейная регулярность в логике должна быть, но тут она видна только на крупноблочном уровне: можно сказать точно, что 5 столбцов одинаковых блоков по 5 строк — это те самые 400 ФУ и 20 TMU. Число ROP (8) не делится на 5, и т. к. вряд ли одна пара рендер-блоков отключена даже в старшем ГП — их среди регулярных столбцов, видимо, нет…

Одна из пяти строчек с (предположительно) 80 графическими ФУ в ГП Llano
Резонно предположить, что вычислительные тракты займут наибольшую часть места, и это будут два похожих столбца по центру. Однако неясно, почему они хоть немного, но отличаются, и почему в каждом из них должно быть по 8 пятёрок 32-битных ФУ, но визуально ничего подобного не наблюдается… Выходит, либо AMD играет с Фотошопом (как это до сих пор продолжается с изображениями кристалла 4-модульного Bulldozer — скоро увидите), либо инженеры бывшей ATI намудрили что-то такое, что распознать это не могут даже видавшие всякого аналитики :)
Впрочем, кое-что всё же видно: по периметру каждой половины блока есть 64 одинаковых регулярных массива. При этом в вычислительную часть SIMD-блока (помимо 80 SP) входят 16 регистровых файлов (РФ) по 1024 128-битных регистра. Плотность этих РФ в битах/мм² оказывается лишь чуть меньше плотности кэша L2 для x86-ядер и примерно в 20 раз лучше, чем у векторно-вещественного РФ там же. И это при обязательной многопортовости! Вот какие транзисторные оптимизации доступны при низких целевых частотах.
Теперь сообразим, как выглядит 2-ядерный кристалл с младшим ГП на 240 ФУ и половиной ROP. Все уже заметили «трещину» посреди ГП? Очевидно, это и есть «линия разреза», остаться после которого суждено только нижней части — вместе с нижней парой x86-ядер. Но постойте, ведь в верхней половине ГП есть ещё куча нужной логики и блок UVD — где будут они? Допустим, что их уместят встык к ФУ и TMU, но тогда придётся подвинутся драйверам ОЗУ, которые должны быть расположены либо углом, либо в 4 ряда (а не в 2, как сейчас: по числу каналов).
Не меньший вопрос — насчёт «потерянных» двух ROP. По 4 этих блока должны оказаться по разные стороны «трещины» (у всех старших ГП их 8, а у младших — 4). Но не считая вышеуказанных пяти «вычислительных столбцов», все остальные блоки и сверху и снизу разные. Если кто-то из читателей сможет аргументированно привязать хоть что-то из них к схеме ГП — добро пожаловать в комментарии на форуме. Стоит добавить, что при сравнении с не менее качественным фото ядра APU Zacate (с ГП на 80 ФУ той же архитектуры) ничего похожего на структуры из Llano не видно…
Экономия
Первый пункт — цифровое предсказание потребления в модуле управления питанием (Digital APM). До сих пор APM работал примерно так: собирая аналоговые данные с термодиодов и датчиков тока, модуль их оцифровывал и делал выводы об общем потреблении. Цифровой APM таким методом только подтверждает ранее сделанное предсказание, основанное на сборе статистики по загрузке отдельных блоков. Зная её и зависимость потребления этого конкретного блока от его прошлой и текущей нагрузок, можно вычислить, сколько через мгновение должен потреблять весь чип, исходя из его математической модели. Смысл этого в том, что предсказание делается куда быстрее реальных измерений, причём его не надо предварительно калибровать под особенности конкретного кристалла, как того требуют аналоговые датчики. Цифровой APM, замеряя 95 сигналов и ошибаясь менее чем на 2%, обеспечивает более быстрые подстройки частот и напряжений при колебаниях нагрузки — ещё до того, как кристалл среагирует изменением температуры.
Любопытная хитрость, позволяющая цифровой модели там мало отклоняться от реальности, заключается в том, что APM учитывает теплопроводность отдельных участков кристалла, зная их расположение, площадь и локальную температуру. Поток тепла перераспределяется из работающих блоков в соседние, которые, возможно, простаивают, оттягивая на себя часть тепла. Учитывая, что тепло отводится через всю поверхность чипа, но имеет ограничение по потоку (≈50 Вт/см²) — чем с большей площади идёт охлаждение, тем лучше. Таким образом, горячее место на кристалле, если оно окружено простаивающими блоками, будет охлаждаться не только над собой, но и немножко сбоку, что и учитывает модель APM. Ей надо также учесть, что технология кремния-на-изоляторе (КНИ), при всех её технических преимуществах, имеет и недостаток: слой диоксида кремния работает в качестве не только электро-, но и термоизолятора. При прочих равных КНИ-кристалл имеет больше шансов перегреться. Но AMD с этим знакома уже давно и наверняка что-то придумала :)
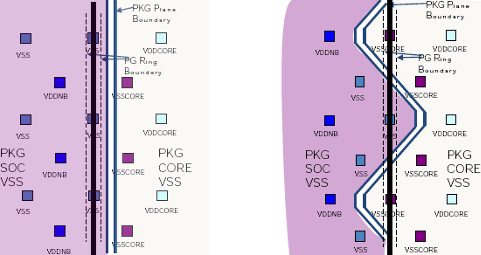
Пилообразная граница между доменами питания у Llano удлиняет периметр, позволяя разместить над двойным набором ключей (вертикальные пунктиры) силовые контакты (квадраты) смежных доменов для экономии места под ключи. Иллюстрация с доклада для конференции ISSCC
Второй момент — силовые ключи, подключающие «землю» к ядрам (шины питания тут всегда включены). Используются n-канальные транзисторы, эффективность которых в качестве ключей (особо низкое сопротивление во включенном режиме и особо высокое в выключенном) оказывается лучше, чем у p-канальных — что является следствием применения КНИ. Intel использует p-канальную коммутацию шин питания — т. к. у неё техпроцесс на цельном кремнии. AMD утверждает, что n-канальные транзисторы меньше и быстрее при тех же электрических параметрах. В результате утечка тока у отключенного ядра уменьшена в 10 раз. Фактические тесты действительно подтверждают резкое сокращение потребления ЦП при частичной или нулевой загрузке.

Карта утечек тока Llano (красный — больше, синий — меньше) при нулевом тактировании, полученная с помощью «meridian photon recombination». При этом никакого другого упоминания этой фразы в сети больше нет — что же это за загадочный метод? И почему часть ГП странно замазана?..
AMD также показала карту утечек тока в трёх случаях: когда цепи включены, когда выключен блок UVD и когда выключена вся графика. x86-ядра, разумеется, могут отключаться по отдельности в энергосостоянии C6. При усыплении всех ядер напряжение на шине их питания снижается, чтобы уменьшить даже эту мизерную утечку. При этом APM позволяет усыпить ядро как по его просьбе (т. е. от исполняющейся на нём программе), так и по команде ОС (которая исполняется в другом ядре). Усыпление ГП происходит после неактивности в течение заданного времени. Усыпление UVD и контроллера PCIe — программное, через драйверы и BIOS соответственно.
| Засыпание ↓ | Пробуждение ↑ |
| Ядро активно | |
| Смыв кэшей | |
| Сохранение состояния в ОЗУ | Загрузка состояния из ОЗУ |
| Инициализация кэшей | |
| Запуск загрузочного микрокода (как после сброса) | |
| Подключение перемычек с коррекцией микрокода | |
| Понижение частоты | Повышение частоты |
| Отключение PLL | |
| Отключение шин до СМ | Подключение шин до СМ |
| Отключение силовой шины | Подключение силовой шины |
| Включение и калибровка PLL | |
| Ядро спит | |
В этой таблице указаны процедуры засыпания в состояние C6 и пробуждения из него. Последнее занимает 30 мкс для одного ядра и 100 мкс для всего ЦП (включая пробуждение модулей памяти), причём AMD обещает даже эти достойные цифры ещё улучшить. (Можете их сравнить с Intel Atom моделей Z6xx.) При этом в спящем ЦП всё равно работает APIC — программируемый контроллер прерываний, реагирующий на внешние события, включая регулярные пробуждения по таймеру. В отличие от того же «Атома», AMD не стала внедрять специальное буферное СОЗУ для хранения состояния ядра на кристалле, разумно полагая, что пока будут выполняться остальные процедуры, ИКП успеет подкачать нужные несколько сот байт.
Заметим, что шин питания у SB — три, у Llano — две: для x86-ядер и всего остального, включая ГП (кроме умножителей, для которых есть отдельная слаботочная шина). Это чуть удешевляет плату, но не приводит к неоптимальному потреблению энергии. Второе напряжение является максимумом из потребностей СМ (включая ИКП), ГП, UVD и контроллера PCIe. При декодировании видео ГП простаивает, но запитывается полными вольтами — однако они не доходят до потребления, остановленные силовыми ключами. Похоже, что AMD нашла оптимум между ценой и экономией.
Наконец, третья добавка — разряжённая сеть тактирования. Через неё умножитель частоты передаёт потребителям тактовые импульсы нужной им частоты. Требуется, чтобы все импульсы дошли строго одновременно до всех частей потребителей, что вынуждает строить разветвлённое дерево дорожек, высчитывая их длину так, чтобы задержка распространения сигнала до любой конечной ветки была одинакова. Учитывая затухание сигнала, приходится регулярно ставить усилители, вносящие собственную задержку. В результате на полной частоте вся эта сеть потребляет значительную энергию, даже если никакой полезной работы не выполняется. Например, у Pentium 4 на её питание уходило до трети потребляемой мощности.
|
В AMD поступили так же, как и создатели Atom: сократили число буферов и усилителей вдвое, а число ветвей — впятеро, удалив ненужные с учётом нагрузки. Теперь при полной выкладке Llano тактирует всего 32% блоков (только фактически работающие), а при простое (без отключения блоков) — лишь 12%. Так получилось уменьшить на 54% потребляемую сетью мощность. Опять же — всё со слов AMD. В таблице рядом показаны результаты моделирования максимального потребления при питании 1 В.
Ещё три технологии касаются конкретно ГП. Во-первых, адаптивная модуляция подсветки (adaptive backlight modulation, ABM) плавно затемняет лампы или светодиоды подсветки при выводе «тёмной» картинки — при этом выводимые пиксели пропорционально осветляются, чтобы воспринимаемое изображение имело верную яркость. Во-вторых, сжатие кадрового буфера позволяет выводить только изменённые части кадра относительно предыдущего — с сильной экономией трафика шины (много ли пикселей меняется от кадра к кадру при перемещении курсора?). В-третьих, внешний ГП при простое спит, потребляя всего 0,2 Вт (с готовностью проснуться за 0,15 с), хотя это больше заслуга его устройства, а не процессора.
Что всё это даст потребителю? А то, что впервые со времён мобильных Pentium 4 AMD предложила платформу, достаточно экономную, чтобы если не выиграть, то хотя бы на равных соревноваться с соперником (при одинаковой скорости и ёмкости батарей). При этом вариант AMD стоит дешевле, если систему на базе Intel оснастить дискретным ГП, сравнимым со встроенным в Llano.
Turbo Core 2.0
Экономия ватт даст больше шансов разогнать работающие ядра, что будет посильнее призрачных «6%», когда вычислительная производительность нужна во что бы то ни стало. Поможет в этом новый (по сравнению с внедрённым в Phenom II X6) алгоритм Turbo Core 2.0. Он работает во всех мобильных моделях, разгоняя их на 400-900 МГц, но не во всех настольных, где разгон — всего на 300 МГц. Причём для конкретного ЦП разгон либо включен, либо нет — никакой регулировки типа «от 100 до 500 МГц» нет. Если сравнить это с возможностями Turbo Boost, то видно, что AMD есть к чему стремиться.
Как и с Turbo Boost 2.0, теперь можно ненадолго превысить предел TDP, если температура ещё не подошла к своему лимиту. В версии 1.0 ускорение делалось на базе активности половины ядер, а не каждого по отдельности. Т. е. формула ускорения (приращение множителей при простое от N−1 до 0 ядер) для 6-ядерного Фенома выглядела так: x-x-x-0-0-0. Однако у Llano авторазгон присутствует и у 3-ядерного A6-3500 (т. е. с нечётным числом ядер), из чего можно сделать осторожный вывод, что TC 2.0, видимо, наконец-то научился работать с поядерной дискретностью. Проверить это, как ни странно, весьма трудно, т. к. AMD до сих пор не даёт возможность считать реальную частоту ядер. Кроме того, как уже сказано, не может ускоряться ГП. Пока…
Модели, чипсеты и платформы
Как обычно, дадим ссылки на описания настольных и мобильных моделей в Википедии и прокомментируем увиденное. Во-первых, не доверяйте всему, что там пишут над таблицами ;) Во-вторых, знакомые имена ушли в прошлое, оставив лишь буквы и цифры. С буквами после номера модели просто: M — мобильная модель на 35 Вт, MX — на 45, K — настольная со свободным множителем. А вот их комбинации с цифрами уже возвращают нас в привычный бардак. В таблице указаны общие характеристики первых выпущенных видов Llano.
| Ряд | Число ядер | Объём L2, МБ | ГП | Turbo Core | Память | TDP, Вт |
| E2 | 2 | 0,5×2 | 6370D | нет | DDR3-1600 | 65 |
| E2-M | 6380G | у всех | DDR3-1333 | 35 | ||
| A4 | 2 | 0,5×2 | 6410D | нет | DDR3-1600 | 65 |
| A4-M | 1×2 | 6480G | у всех | DDR3-1333 | 35 | |
| A4-MX | 45 | |||||
| A6 | 3/4 | 1×3/4 | 6530D | иногда | DDR3-1866 | 65/100 |
| A6-M | 4 | 1×4 | 6520G | у всех | DDR3-1333 | 35 |
| A6-MX | DDR3-1600 | 45 | ||||
| A8 | 4 | 1×4 | 6550D | иногда | DDR3-1866 | 65/100 |
| A8-M | 6620G | у всех | DDR3-1333 | 35 | ||
| A8-MX | DDR3-1600 | 45 |
Казалось бы, куда логично назвать все 4-ядерные модели — A8, а отличия в ГП оставить лишь в номерах. Не менее разумно оснастить все A4 полными кэшами L2, а все MX-версии — памятью на 1600 МГц (иначе не ясно, почему на +200 МГц базовой частоты x86-ядер модели A4-3310MX в сравнении с A4-3300M угрохали лишние 10 Вт). Из номеров моделей пока можно узнать, что первая цифра — 3, последняя — 0, а две средние — чем больше, тем лучше. При всём идиотизме такого описания — это всё, что можно сказать, чтобы не пускаться в исключения.
Занятно, что TС отсутствует у 100-ваттовых ЦП, хотя, казалось бы, у них-то точно потолок разгона высокий… Куда хуже то, что, несмотря на все ухищрения, меньше 65 Вт у настольных моделей нет. Разумеется, надо отдать должное неслабому ГП (даже у A4 и E2), но как минимум с маркетинговой точки зрения (по сравнению с модельным рядом Intel) смотрится плохо.
С тех пор уже объявлены новые модели, описание которых показывает, куда расширяется модельный ряд:
- Помимо A8-3870K, планируется ещё одна разблокированная модель — A6-3670K на 2,7 ГГц (также без авторазгона) и ГП 6530D на 443 МГц. Таким образом, даже скромный игрок сможет быть разгонщиком;
- Готовятся 4-ядерные Athlon II X4 моделей 631, 641 и 651 на 2,6, 2,8 и 3 ГГц, 100 Вт TDP, без TC и даже без ГП. К ним присоединятся и 2-ядерные Sempron X2 198 на 2,5 ГГц и Athlon II X2 221 на 2,8 (оба — с 0,5 МБ L2 и TDP на 65 Вт). Все они уже не APU — потому, видимо, их и назвали старыми именами. Возможно, эти модели придут, когда современные ЦП на 45 нм уже уйдут на покой, а новые ещё не появятся;
- Модель A4-3305M отличается от A4-3300M тем, что имеет половинные кэши L2 и самый слабый ГП, зато последний работает на частоте 593 МГц (быстрее любого другого мобильного Llano). Таким образом, внезапная пятёрка внесла очередное исключение: по большинству характеристик 3305M относится к линейке E2;
- Планируемые модели ноутбуков HP Pavilion в списке доступных ЦП имеют и другие модели Llano, которые вносят ещё больший бардак (например, больший номер может означать меньшую частоту, а буква M — 45 Вт TDP). Впрочем, эти номера запросто могут бесследно исчезнуть…
Настольные модели используют PGA-корпус для разъёма Socket FM1 на 905 выводов, а мобильные — FS1 на 722. В будущем возможны мобильные модели в BGA-корпусе для распайки на плате, хотя для них почему-то также указывается разъём — FP1. Интересно, что для этих ЦП TDP указан как 20 или 26 Вт для 2-ядерных и 30 Вт для 4-ядерных — нижняя граница вплотную подходит к чипам Zacate с ядрами Bobcat…
От чипсетов остались лишь южные мосты, потому что северный уже весь «сынтегрирован» — и это вдвойне хорошо, т. к. уже известно, что они смогут работать как минимум с некоторыми ЦП из второго поколения APU, выходящего в 2012 г. Официально чипсет называется Fusion Controller Hub («узел управления слиянием», смех в зале), а неофициально — Hudson. Изготавливается по технорме 65 нм в корпусе FCBGA-605 размером 23×23 мм. FCH для Llano делятся на два класса — мобильные M с TDP 2,7–4,7 Вт и настольные D на 5 Вт.
- Все версии имеют: 6 портов SATA 3.0 (на 6 Гбит/с), RAID 0/1, 4 порта PCIe 2.0 x1 и 3 PCI, VGA (аналоговая часть), звук HD Audio, 14 портов USB 2.0, гигабитный Ethernet, контроллер карт SD (до 32 ГБ и 25 МБ/с), встроенный тактовый генератор и поддержка UEFI (новый «BIOS»);
- M2 (он же — A60M, предназначен для платформы Sabine): стандартная модель;
- M3 (A70M, для Sabine): как M2, но 4 порта USB обновлены до версии 3.0;
- D1 (A45, для Value Lynx): отсутствуют Ethernet, RAID, SD и VGA; все порты SATA — только версии 2.0; + 1 порт PCI;
- D2 (A55, для Lynx и Carina): как M2, но с поддержкой RAID 10 и FIS-based switching (возможность подключения к порту SATA до 15 устройств через хаб-разветвитель);
- D3 (A75, для Lynx и Carina): как D2, но 4 порта USB обновлены до версии 3.0.
Платформа Sabine — для «обычных» ноутбуков, Value Lynx — дешёвые домашние ПК, Lynx — «просто» домашние ПК, а Carina — офисные ПК. Чем отличаются последние два — неясно.
Итого
В теории всё выглядит хорошо: AMD малыми усилиями сделала ЦП, некоторые характеристики которых можно с полным правом назвать передовыми и даже уникальными, что и обеспечит им продажи. Заменив старые Атлоны и добавив к ним графику за меньшие деньги и ватты, можно почувствовать, что прогресс есть даже у ЦП с 12-летней микроархитектурой. Но всему приходит конец — выходящее весной 2012 г. второе поколение APU Trinity уже будет использовать новые ядра Piledriver («улучшенный Бульдозер») и новый разъём Socket FM2 на 904 вывода (специально несовместимый с нынешним). В Trinity обещают ГП с новой архитектурой VLIW4 (используется пока только в чипе Cayman, он же Radeon HD 69x0), аппаратный видеокодер (VCE), подключение до трёх мониторов, наличие TC версии 3.0 (с разгоном ГП), поддержку DDR3-2133 и PCIe 3.0, 65–125 Вт TDP и обновлённые чипсеты.
А в следующих поколениях встроенных ГП на базе архитектуры «Southern Islands» появятся: лучшая поддержка языков высокого уровня для GPGPU (с использованием более привычной парадигмы суперскалярных RISC-ядер вместо EPIC), общее адресное пространство с x86, 64-битная виртуальная адресация с подкачкой страниц, переключение контекста (для многозадачности) и протокол когерентности для PCIe (чтобы всё вышеперечисленное было возможно и для внешнего ГП).

На радостях от выпуска новых ЦП в AMD даже считать разучились, заявив в одном из слайдов, что «APU знаменуют самый большой сдвиг в технологии ПК с момента изобретения x86-ЦП более 40 лет назад». Изобретения? Более 40 лет назад? Ну, пока кто-то в AMD открывает для себя непознанные страницы истории (или арифметики) — отдадим дань окончательно уходящим на покой Атлонам. Из них выжали всё, и этого хватило надолго.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}