Старшая и младшая модификации AMD Kabini в сравнении с предшественниками и прямыми конкурентами
Спустя два с небольшим года после появления платформы AMD Brazos, пережившей за это время лишь небольшие косметические доработки, компания вывела на рынок нечто принципиально новое, а именно SoC Temash и Kabini. Необходимость в таком шаге, в общем-то, назрела уже давно — Zacate и Ontario порядком устарели. Нет, конечно, первое время они более чем успешно могли конкурировать с Intel Atom, но «замахивалась»-то компания совсем на другой уровень — Celeron и Pentium, причем и цены готовых продуктов, соответственно, оказывались очень близкими к ноутбукам/нетбукам на указанных процессорах. А вот с такой конкуренцией все сразу пошло не так. Во-первых, быстро выяснилось, что процессорная производительность Zacate (т.е. Е-серии APU) ниже, чем даже у более старых Celeron. Во-вторых, преимущества в графической составляющей, на которые AMD изначально активно упирала, тоже быстро рассосались. Точнее, в 2011 году они еще были, но в 2012 Intel перевела CULV-процессоры на архитектуру Ivy Bridge, с существенно «допиленным» GPU, по своим формальных характеристикам уже не уступающим Radeon HD. Попытка парировать удар при помощи Trinity удалась лишь частично — настольные APU и часть ноутбучных были конкурентоспособны, но вот при необходимости «уложить» это семейство в TDP <20 Вт приходилось слишком уж уменьшать тактовые частоты, да и выход годных чипов оставлял желать лучшего. Не говоря уже о том, что кристалл Trinity/Richland по площади в полтора раза превосходил даже четырехъядерные Ivi Bridge Core i7-QM, не оставляя AMD простора для ценового маневра. Был, конечно, и изначально одномодульный дизайн, но именно что одномодульный и с усеченной графикой, так что снижение себестоимости его не слишком спасало. А Intel как раз после освоения техпроцесса 22 нм начал «давить» на экономичность, предлагая заинтересованным производителям CULV-процессоры в таких количествах, что их начало хватать не только на ноутбуки, мини-ПК и моноблоки, но даже и на системные платы для розничного рынка.
AMD же, повторимся, занималась косметическими доработками Brazos. Впрочем, не по своей воле — на самом деле замена платформы ожидалась еще в прошлом году однако то ли ее саму до ума довести не успели из-за нехватки ресурсов (которые требовались и для разработки других продуктов), то ли проблемы с освоением техпроцесса 28 нм помешали, то ли руководство пришло к выводу, что «перестановка кроватей» делу не поможет... В общем, платформа Deccan (до четырех ядер архитектуры Bobcat, унаследованных от Brazos, графика VLIW4 и южный мост, упакованные в SoC) была официально отменена в пользу своей преемницы Kerala, что и привело к такой вот неприятной паузе, поскольку эта платформа (равно как и ее планшетная модификация Samara) была запланирована на 2013 год. К счастью, это событие произошло вовремя, в отличие от многих других планов компании. Впрочем, необходимость маневрировать ресурсами до добра не доводит, так что мы не удивились бы, узнав, что Kaveri (наследники Richland/Trinity) появится в следующем году, а не в этом именно из-за необходимости в срок выпустить Temash и Kabini, однако могло быть и хуже. В любом случае, отставание в самом экономичном и недорогом сегменте, который интересен многим пользователям (хотя бы потому, что и «нетбучные»-то платформы уже справляются со многими актуальными «бытовыми» нагрузками) было куда более сильным, чем в массовом десктопном сегменте, еще и постепенно становящемся все менее массовым, так что можно считать, что все сделано более-менее вовремя. А сегодня мы посмотрим — что именно сделано.
От Zacate к Kabini вкратце
Архитектурных изменений в новом семействе APU много, так что со временем мы надеемся представить вашему вниманию подробную статью, посвященную этому вопросу. Ну а пока кратко пробежимся по наиболее интересным моментам — это позволит понять, чего от новых устройств можно ожидать, а чего не стоит.
Итак, для начала вспомним — что собой представляли APU для платформы Brazos (Zacate и Ontario). Несмотря на то, что AMD неоднократно утверждала, что эта архитектура разработана «с нуля», с потребительской точки зрения все выглядело чуть иначе: взяли старый добрый Radeon HD 5450, да «навесили» на него пару ядер Athlon (разумеется, со всеми доработками, существующими к 2011 году), снабдив заодно контроллером PCIe. Посмотрели на результат, и... Начали обрезать и ужимать, что можно и что нельзя, дабы уложиться в жесткие рамки TDP с использованием несколько устаревшего уже к тому моменту техпроцесса 40 нм. В частности, процессоры семейства К8 имели двухканальный контроллер памяти, еще более актуальный для APU — не вмещается по контактам (микросхема должна быть компактной) и энергопотреблению: оставляем один канал. Еще со времен К7 кэш-память процессора имела емкость 128К (по 64К на инструкции и данные) — слишком много транзисторов, поэтому возвращаемся к схеме 32/32 как в К6. 256К интегрированного полноскоростного L2 появились еще в К6-III, исчезли в первых К7, но позднее вернулись на место, да и емкость на ядро быстро росла вплоть до 1 МиБ в старших К8 — тоже много и неэкономично: в Bobcat осталось 512К кэш-памяти второго уровня, но на половинной тактовой частоте. Точнее, дважды по 512 — по числу ядер: классическая схема первых двухъядерных процессоров (Athlon 64 X2 и Pentium D) без общей кэш-памяти, поскольку L3, естественно, в эти «малютки» никак не вмещался. 64-разрядный FPU тоже наследие К8 — во «взрослых» процессорах (начиная с К10) он был уже 128-разрядным. Контроллер PCIe ограничили восемью линиями, из которых четыре 2.0 можно было использовать для подключения дискретных GPU, а еще четыре 1.0 уходили на создание линка UMI к южному мосту. Да и графическое ядро тоже в немалой степени оказалось жертвой оптимизаций. Формально оно относилось к 6000-й (а в Brazos 2.0 — к 7000-й) серии, но 3D-часть содержала лишь два SIMD-блока (80 ГП, из-за архитектурных особенностей VLIW5 обычно загружаемых работой лишь на 4/5), как в Radeon HD 4450/5450, а не четыре, что было минимумом для Radeon HD 64x0. Аналогичным образом поглумились и над блоком декодирования видео — хоть его официально и именовали UVD3, аппаратной поддержки Blu-ray 3D (основное отличие UVD3 от UVD2) обнаружить на месте никому не удалось. В общем, в конечном итоге получился такой вот любопытный продукт, по производительности процессорной части уступающий Athlon 64 X2 (а в однопоточных приложениях — даже Sempron с той же частотой) и с графикой медленнее, чем Radeon HD 5450. Зато относительно экономичный и недорогой в производстве, благодаря кристаллу площадью лишь 75 мм².
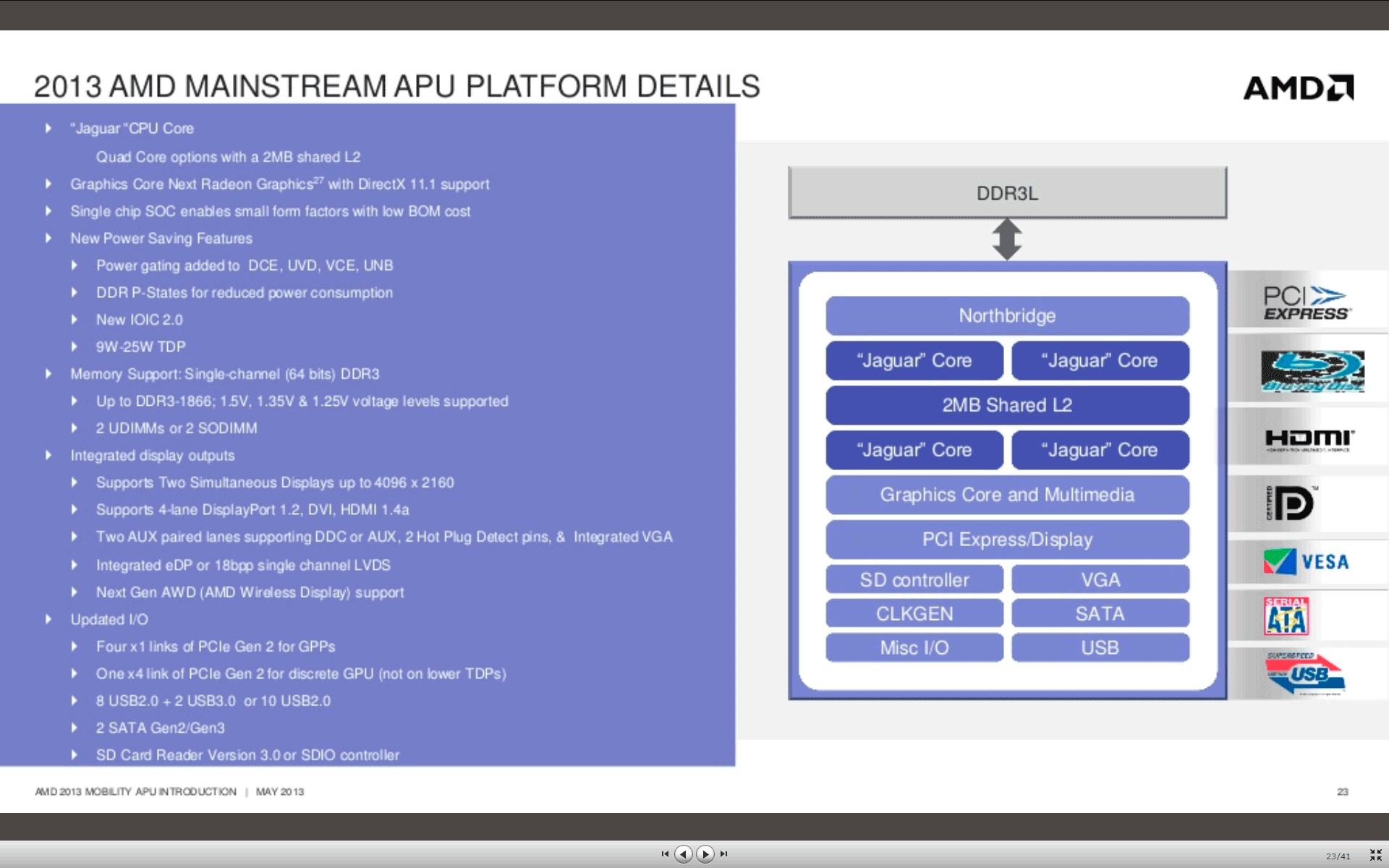
А теперь переходим к Kabini и обнаруживаем, что новый APU очень мало похож на старый. Во-первых, это SoC, причем первый SoC такого уровня — Intel в аналогичном исполнении предлагает лишь Atom, а полноценные Core, несмотря на использование техпроцесса 22 нм — лишь SiP: это тоже позволяет обойтись одним прибором на плате, однако дороже в производстве. Впрочем, CULV-Haswell функциональнее в плане периферии, однако для компактных систем вполне достаточно и пары SATA600, равно как десятка USB-портов, два из которых поддерживают USB 3.0. Ну а возможности по подключению дискретной графики у этих двух конкурентов вообще одинаковые — PCIe 2.0 x4. Хотя желающих использовать ее совместно с Kabini наверняка будет меньше, чем во времена Brazos — новое видеоядро содержит уже 128 ГП архитектуры GCN (причем разные модификации отличаются только тактовой частотой) и полнофункциональный видеодекодер. Но самые заметные изменения произошли в процессорной части, поскольку вместо двух ядер Bobcat теперь используется два или даже четыре ядра Jaguar, в которых компания вернула на место многое из того, что ранее пришлось «резать» — в частности 128-разрядный FPU. И кэш-память «перелопатили» как надо: фактически, Kabini — это первые продукты AMD с единым L2 емкостью 1 или 2 МиБ, работающим синхронно с процессорными ядрами.
Стоит, правда, отметить, что ничего не дается даром — несмотря на компактность самих ядер Jaguar и использование техпроцесса 28 нм, результирующий размер кристалла Kabini оказался равным 107 мм², в то время, как Brazos вмещался в 75 мм². Однако вспоминаем о том, что это уже SoC, т.е. в отличие от конкурирующих разработок или более ранних продуктов самой компании для создания законченной платформы требуется ровно один чип. Периферийные же ее возможности выглядят намного более сбалансированными, чем то, что предлагалось в рамках Brazos. Кое-что ненужное отброшено: в отличие от чипсета А50М, Kabini не содержит сетевой контроллер (которым практически никто из производителей не пользовался — всего-то 100 Мбит/с при наличии на рынке копеечных гигабитных микросхем с PCIe-интерфейсом), снабжен лишь двумя, а не шестью портами SATA600 (без комментариев) и портов USB 2.0 осталось восемь, а не 14, а пара USB 1.1 которую AMD с достойным лучшего применения упорством «пихала» во многие чипсеты, канула в лету. Зато большинство модификаций APU получили пару портов USB 3.0, что в наше время излишеством не является. Кроме того, четыре линии PCIe для подключения дополнительных контроллеров модернизированы до версии 2.0, что может тоже пригодиться. Заодно и видеовыходы модернизировали: их по-прежнему три, но пара цифровых теперь поддерживает разрешение до 4К, да и для реализации eDP/LVDS дополнительные трансмиттеры уже не нужны. В общем, несмотря на площадь кристалла где-то между 116 мм² (Ivy Bridge DС GT2, т.е. Core i3 и выше) и 94 мм² (Celeron/Pentium на основе IBDC-GT1) запас «ценовой прочности» у Kabini при нормальном выходе годных кристаллов крайне высок — процессорам Intel требуется чипсет. А переход на Haswell добавляет не только производительности, но и площади основного кристалла при сохранившемся дополнительном для реализации периферийной составляющей, так что положение дел не изменится: в принципе старшие модели младшего семейства APU оставляют AMD некоторую свободу ценового маневра даже несмотря на отставание по техпроцессу.
А теперь добавим в эту бочку меда традиционную ложку, или даже скорее ведерко дегтя — контроллер памяти остался одноканальным! Собственно, как нам кажется, это самый большой недостаток Kabini — четыре процессорных ядра и неплохое видеоядро (128 ГП — это уровень настольных А4; только там еще и VLIW4, а не GCN) вынуждены довольствоваться 64-разрядной шиной. И пусть даже частоту памяти повысили официально до 1600 МГц в старших моделях (неофициально — и вовсе до 1866 МГц), положение дел это не слишком меняет: для GPU одного канала мало. Производительность последнего в результате оказывается куда более низкой, чем могла бы, в чем мы уже убедились. Теперь же настало время познакомиться с другим компонентом APU и сравнить его с конкурентами.
Конфигурация тестовых стендов
| Процессор | AMD C-60 | AMD E1-2100 | AMD E2-1800 | AMD A6-5200 | Celeron 1007U | Intel Core i3-3217U |
| Название ядра | Ontario | Kabini | Zacate | Kabini | Ivy Bridge DC | Ivy Bridge DC |
| Технология пр-ва | 40 нм | 28 нм | 40 нм | 28 нм | 22 нм | 22 нм |
| Частота ядра std/max, ГГц | 1,0/1,3 | 1,0 | 1,75 | 2,0 | 1,5 | 1,8 |
| Кол-во ядер/потоков вычисления | 2/2 | 2/2 | 2/2 | 4/4 | 2/2 | 2/4 |
| Кэш L1 (сумм.), I/D, КБ | 64/64 | 64/64 | 64/64 | 128/128 | 64/64 | 64/64 |
| Кэш L2, КБ | 2×512 | 1024 | 2×512 | 2048 | 2×256 | 2×256 |
| Кэш L3, МиБ | — | — | — | — | 2 | 3 |
| Графика | Radeon HD 6290 | Radeon HD 8210 | Radeon HD 7340 | Radeon HD 8400 | HDG | HDG 4000 |
| Кол-во ГП | 80 | 128 | 80 | 128 | 24 | 64 |
| Частота std/max, МГц | 276/400 | 300 | 523/680 | 600 | 350/1000 | 350/1050 |
| Оперативная память | 1×DDR3-1066 | 1×DDR3-1333 | 1×DDR3-1333 | 1×DDR3-1333 | 2×DDR3-1600 | 2×DDR3-1333 |
| Платформа | Acer Aspire One 722-C68 | ECS KBN-I/2100 | Foxconn NanoPC nT-A3800 | ECS KBN-I/5200 | Gigabyte C1007UN-D | Intel NUC |
На тестирование нам достались платы с двумя модификациями Kabini — самой старшей и самой младшей. Как видим, общего между ними — только количество ГП в видеоядре, но частота последних различается вдвое. Такое же соотношение и у частоты процессорных ядер, и у их количества, и у емкости кэш-памяти. Жаль вот только число каналов памяти вдвое не отличается. Только ее тактовая частота незначительно, но получить 1600 МГц на ECS KBN-I/5200 нам так и не удалось, о чем мы уже писали. Поэтому всю четверку APU AMD мы тестировали с DDR3-1333. Откуда четверка? Е2-1800 был почти самым быстрым представителем семейства Brazos (выше только Е2-2000, но отличие лишь в 3% тактовой частоты), а C-60 — самый медленный из протестированных нами. Хотя для сравнения с Е1-2100 больше подошел бы «стартовый» С-50, более близкий по ТТХ, но мы его не тестировали. Да и так даже интереснее — посмотрим: смогут ли архитектурные усовершенствования скомпенсировать в однопоточном ПО отсутствие поддержки Turbo Core.
И две модели Intel — давно уже протестированный Core i3-3217U (на конкуренцию с этим семейством A6-5200 и рассчитан) и более дешевый Celeron 1007U. Заметим, что разница между ними куда меньше, нежели между A6-5200 и E1-2100, что логично — у Intel есть еще и Atom, с которым по позиционированию пересекаются Е1. А вот Е2 должны, по замыслу AMD, конкурировать как раз с Celeron. Но посмотрим, насколько это удается хотя бы А6-5200, благо в прошлый раз мы уже установили, что с производительностью GPU у последнего не все гладко. У Celeron же графическая часть пусть и слабенькая, но поддержка двухканальной памяти есть, что вполне может сказаться. Заметим, кстати, что заставить его работать с DDR3-1600 тоже удалось не сразу (похоже, у мини-плат избирательность к модулям памяти — общая беда), но удалось. Так что ПСП получилась повыше, чем даже у Core i3 — при его тестировании мы были ограничены имеющимися в наличии модулями SO-DIMM. И еще один немаловажный фактор — разные версии видеодрайверов: 9.17.10.2932 и 6.16.00.3112 соответственно. Как будет показано далее, различия между ними весьма заметны — программисты Intel свершили очередной подвиг (предыдущий был зимой и относился к профессиональному ПО), радикально повысив производительность в режиме минимальной графической нагрузки. Правда, возникло ощущение, что и качество картинки несколько снизилось, хотя точно ответить на этот вопрос сложно — оно там и без того никакое, так что вопрос стоит лишь так: можно ли поиграть хоть как-то или вообще нельзя?
Тестирование
Традиционно, мы разбиваем все тесты на некоторое количество групп и приводим на диаграммах средний результат по группе тестов/приложений (детально с полной методикой тестирования вы можете ознакомиться в отдельной статье). Результаты на диаграммах приведены в баллах, за 100 баллов принята производительность референсной тестовой системы iXBT.com образца 2011 года для тестирования микросистем. Основывается она на процессоре AMD E-350 с использованием встроенного видеоядра. Объем памяти для всех систем — 4 ГБ. Тем, кто интересуется более подробной информацией, опять-таки традиционно предлагается скачать таблицу в формате Microsoft Excel, в которой все результаты приведены как в преобразованном в баллы, так и в «натуральном» виде.
Интерактивная работа в трехмерных пакетах
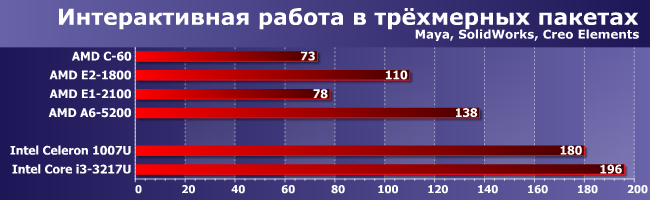
Celeron по вполне понятным причинам отстает от Core i3 — меньше тактовая частота и емкость кэш-памяти, но радикально превосходит любые APU «своего» сегмента. Увы, но производительность на поток AMD удалось поднять лишь примерно на 20% и относится это только к старшей модели, благо в ней и частота процессорных ядер выше, чем получалось добиться от Brazos. Младшая же «болтается» на том же уровне, что и старые С, превосходя их, впрочем, в компактности и экономичности.
Финальный рендеринг трехмерных сцен
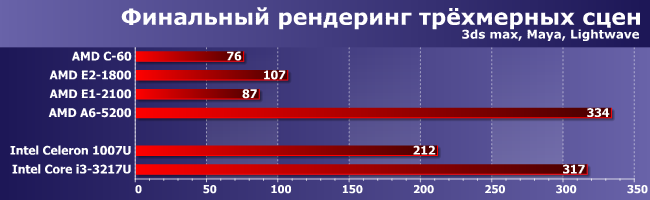
«Настоящих» четырехъядерных процессоров в этом классе всего два — A6-5200 и его чуть более медленный родственник A4-5400, так что ничего удивительного нет в том, что первый из них способен при серьезной нагрузке обогнать и младший Core i3 U-серии. Понятно, что на рекорд это не тянет, поскольку даже младшие же Core i7 в полтора раза быстрее, однако они и дороже. Да и на фоне разгрома Е2-1800 от руки Celeron это безусловное достижение. Правда, достигнутое при помощи четырех ядер с довольно высокой тактовой частотой, так что и новые Е2 поскромнее куда будут, но архитектурный прогресс тоже есть. И хорошо заметен если сравнить Е1-2100 с С-60 — почти 15%: лишь немногим меньше, чем прирост Haswell над Ivy Bridge.
Упаковка и распаковка
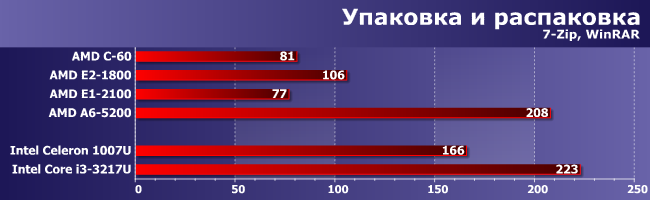
А вот здесь Е1-2100 даже до С-60 не дотянулся, причем на «турбонадув» тут ничего не спишешь — максимальный проигрыш вовсе не в однопоточных подтестах (коих тут два из четырех). Зато А6-5200 оказался хорош, выйдя на второе место. Будь у него двухканальный контроллер памяти (что для этих программ важно) — мог бы и победить. Да и в более новых версиях WinRar, где вопрос с поддержкой многопоточности сдвинулся с мертвой точки, его показатели будут более высокими.
Кодирование аудио
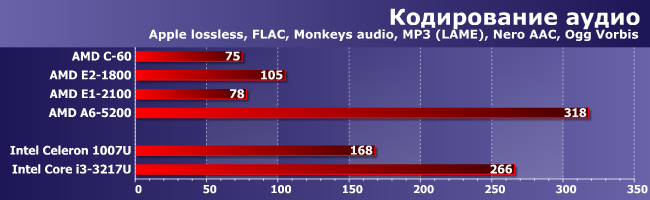
Вот и снова первое место, причем с большим отрывом от преследователей. Что легко объяснимо — производительность системы памяти здесь не важна, а при запуске четырех одинаковых потоков кода два ядра с Hyper-Threading ни в коей мере не конкурент четырем «настоящим».
Компиляция
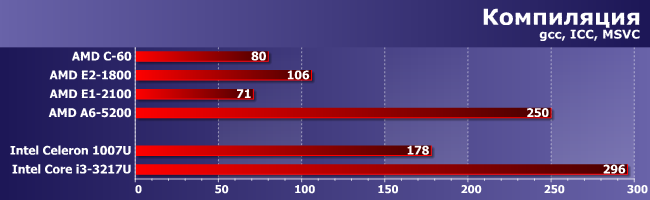
Но когда наоборот (если код разный, а ПСП важна), тогда все возвращается на круги своя: догнать Core i3 (даже самый слабый и уже устаревший) не выходит. С другой стороны, это все равно огромный рывок — лучшее, что предлагала AMD в этом сегменте ранее и с Celeron-то конкурировать уже не могло. Причем не обязательно с современным — старшие модели Brazos с трудом «доползли» лишь до уровня Celeron SU2300 четырехлетней давности. Ну а современные модели Celeron, естественно, в полтора и более раз быстрее со всеми вытекающими, однако до А6-5200 им остается еще полтора. Е1-2100, напротив, в очередной раз нас разочаровал — при такой нагрузке он должен быть быстрее С-60. Тем более что у него не только процессорные ядра быстрее, но и кэш-память, да и частота оперативной выше. Возможно, конечно, есть какие-то особенности у конкретного продукта (а такое бывает — мы уже видели, как можно затормозить С-70), но пока никаких эталонов для сравнения у нас нет. Да и других продуктов на этом APU вообще на рынке поискать еще :) Поэтому просто констатируем факт, что младшая модель в линейке вовсе не обязательно будет выигрывать у Ontario в производительности, к чему нужно быть готовым каждому покупателю. C другой стороны, те, кому и правда важна производительность, как нам кажется, на этот сегмент внимания и не обращают.
Математические и инженерные расчеты
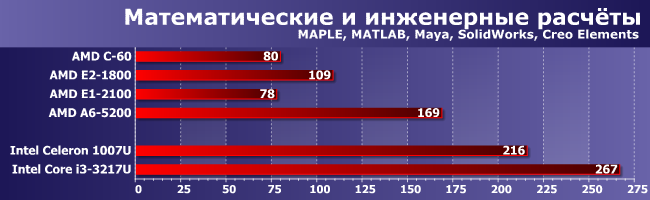
Что уже стало привычным, «малопоточное» ПО стабильно выводит на первые места процессоры Intel. Конкретно в этой группе им некогда мешала «кривизна» видеодрайверов, однако ее исправили еще в начале года — теперь ничего не мешает. В результате в этом классе конкурировать с Celeron могут только Pentium и выше, но не APU AMD. C другой стороны, если лучшие представители семейства Brazos отставали от Celeron вдвое, а Kabini — лишь на треть, уже есть чему порадоваться: их хотя бы можно сравнивать, а не как раньше :)
Растровая графика
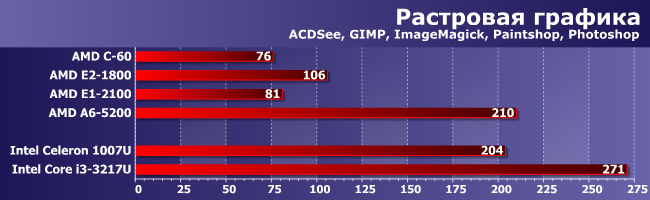
А это более смешанная по характеру нагрузки группа, так что тут уже A6-5200 может иногда воспользоваться своим преимуществом в количестве ядер, хотя бы обгоняя Celeron. Опять же — это немало, поскольку Е2-1800 и тут от оного отставал почти вдвое.
Векторная графика
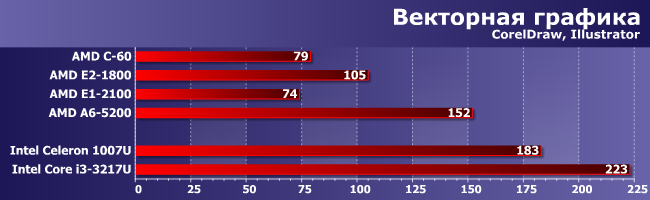
Что касается этих программ, то положение двоякое: все-таки новые Celeron быстрее, но по сравнению с Zacate — огромный шаг вперед. Причем, заметим, почти на пустом месте — двух ядер более чем достаточно. Т.е. «выстрелили» другие преимущества новой архитектуры — в первую очередь быстрый и единый L2, что роднит Kabini с Core 2, а именно под это программы векторной графики до сих пор и оптимизированы в первую очередь. И именно поэтому Е2-1800 тут медленнее, чем даже Celeron SU2000/U3000 многолетней давности, а вот A6-5200 уже быстрее, нежели многие CULV-процессоры линейки Sandy Bridge. Но, конечно, не Ivy Bridge, где к усовершенствованиям архитектуры добавились и более высокие тактовые частоты.
Кодирование видео
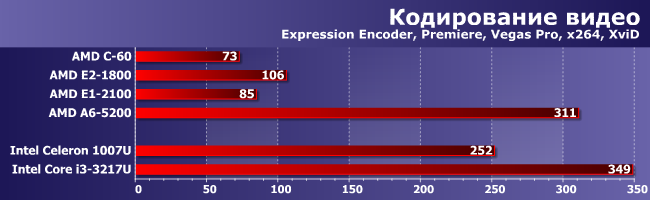
Увы, но даже четыре высокочастотных ядра не позволили A6-5200 выйти на первое место — любой «ивиковый» Core i3 быстрее. С другой стороны, «сэндик» на 1,6 ГГц работал медленнее, а уж про трехкратное (!) преимущество над Brazos и говорить нечего. С практической точки зрения можно констатировать качественную, а не количественную разницу — старая платформа AMD не позволяла даже задумываться о таких задачах, а вот на новой их можно решать. Не слишком быстро, но можно. Было время, и «взрослые» ноутбуки работали куда медленнее. И не такие уж доисторические — любой ноутбучный Core 2 Duo подойдет, а ведь устройства на них до сих пор встречаются в продаже.
Офисное ПО
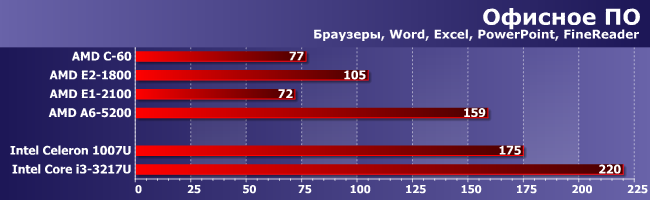
Опять же — прогресс заметен, правда конкурентов догнать ни удалось: ни формального (коим AMD считает Core i3), ни реального (мы все более склоняемся к мысли, что таковыми являются в большей степени Celeron или Pentium как максимум). Но разница с последними будет в большинстве случаев малозаметной, в отличие от Brazos, работать на котором можно было лишь в виде наказания :)
Java
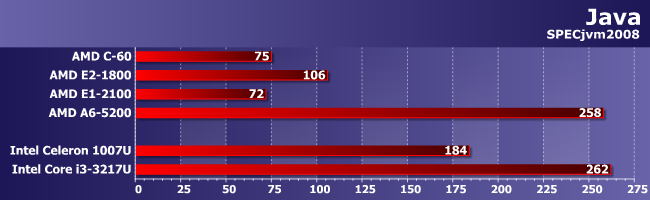
Почти первое место. Можно даже сказать, что оно тут первое одно на двоих. В общем, решение AMD дистанцировать А6-5200 и А4-5000 (на данный момент единственные четырехъядерные Kabini) от разнообразных E1/E2 является правильным — это продукты разного уровня. Причем сравнение результатов E1-2100 и C-60 показывает, что слишком многого только лишь от новой процессорной архитектуры ждать не стоит, так что, опять же, сохранение для двухъядерных Kabini принадлежности к указанным линейкам тоже верно.
Игры
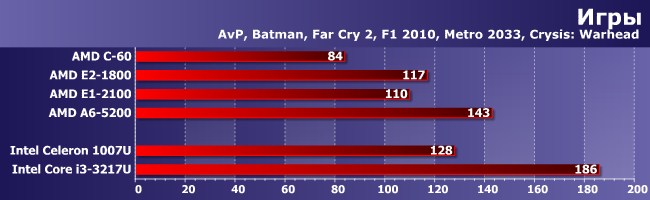
Графика — то, что радикально отличает Е1-2100 от разработок предыдущего поколения: несмотря на изначально «задавленные» ТТХ, он все равно держится на уровне старших представителей Brazos. А А6-5200 как мы уже выяснили в специальном подробном исследовании сильно мешает одноканальный режим работы памяти. Впрочем, в нем же мы установили, что такие настройки все еще слишком тяжелы для процессоров этого сегмента, так что результаты их использования имеют лишь теоретическое значение.
Игры: низкое качество
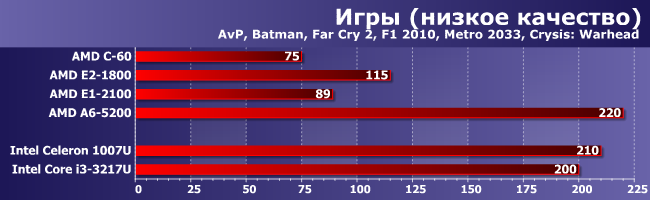
А вот в более практически значимом режиме положение дел меняется — А6-5200 становится лучшим среди всех, зато Е1-2100 быстро «проваливается» на свое место. Впрочем, это для нас уже не новость. Что новость, так это результаты Celeron, который умудрился обогнать Core i3! Мы склонны «благодарить» за такой внезапный успех программистов компании — драйверы разные, причем 1007U тестировался с заметно более свежим. С другой стороны, в режиме максимальной загрузки видеочасти это ему как-то не помогло, так что возможно и другое объяснение — потребление GPU сильно «давит» на процессорную составляющую. И пусть в данной группе нагрузка на графическое ядро не максимальная, однако 16 конвееров при попытке их использования (а процессор «не знает», что часть можно бы и отключить) потребляют больше энергии, нежели 6. Настолько больше, что частоту процессорных ядер приходится даже снижать ниже номинала, что и дает фору Celeron. Так это или нет — покажут дальнейшие исследования. На данный момент нам важнее, то, что и такое бывает. А еще важнее то, что в подобных случаях А6-5200 полностью оправдывает свое позиционирование: он действительно работает на уровне Core i3. И пусть ни один, ни другой для игрового ноутбука, строго говоря, непригодны, но немного поиграть на APU AMD удастся с чуть большим успехом.
Многозадачное окружение
Как правило мы не используем результаты этого экспериментального теста для процессоров нижнего сегмента производительности (да и вообще его на последних не «прогоняем»), но сегодня решили сделать исключение из данного правила. Хотя бы потому, что, как уже не раз было показано выше, A6-5200 принципиально отличается от суррогатов предыдущего поколения, так что может применяться и в высоконагруженных (относительно) системах. Напомним, в чем заключается тест: пять бенчмарков запускаются практически одновременно (с паузой в 15 секунд), при этом всем задачам присваивается «фоновый» статус (ни одно окно не является активным). Результатом является среднее геометрическое времён выполнения всех тестов, которое мы приведем на диаграмме «в чистом виде» (поскольку база для нормирования отсутствует), т.е. в данном случае меньший результат — лучше.
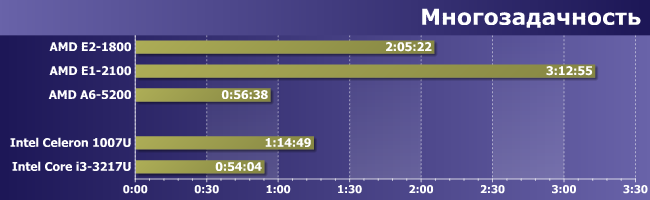
Итак, что мы наблюдаем? Очевидно, что так нагружать суррогаты с TDP 9 Вт (E1-2100 или C-серию) не стоит — можно не дождаться результатов :) Более трех часов среднего времени выполнения тестов говорят сами за себя. «Полноценные» представители семейств Brazos и Kabini (двухъядерные модели) быстрее примерно в полтора раза, что тоже, впрочем, не слишком меняет дело. И даже час времени — много, так что если «тяжелая» нагрузка актуальна, не стоит перебарщивать с экономичностью: лучше уж «посмотреть» в сторону Core i5/i7, уменьшающих время до 20-30 минут. Но, в принципе, как CULV-модификации i3, так и четырехъядерные Kabini способны демонстрировать результаты на уровне Core 2 Duo E6600 или Athlon 64 X2 6000+, что для низкопотребляющих процессоров в общем-то неплохо. Не идеально, поскольку упомянутые модели лишь двухъядерные и очень старые, но ведь некогда они были как бы не самыми быстрыми среди массовых (и то — относительно массовых: E6600 на старте продаж стоил дороже, чем ныне Core i7) :) Также это уровень «35 Вт Celeron» (мобильных и настольных экономичных), а более «зажатые» теплопакетом линейки последних еще медленнее.
В общем, как и ожидалось, четыре ядра при действительно многопоточной нагрузке позволяют добиться неплохих результатов. Но, конечно, не являются какой-то панацеей — архитектура Small Cores сама по себе достаточно слаба. Экономична, технологична и все такое прочее, но не слишком производительна. В итоге способна конкурировать либо со старыми, либо с низкочастотными современными, но в обоих случаях двухъядерными процессорами Intel. Да и со «своими» тоже — одномодульный A6-5400K и двухъядерный A4-3400 быстрее, чем четырехъядерный A6-5200 в этом тесте.
OpenCL
Мы решили поэкспериментировать и с такой нагрузкой, благо AMD делает настолько явный упор на гетерогенные вычисления, что даже придумала для своих процессоров специальное название :) Intel ничем таким не занималась, однако медленно, но верно довела функциональность собственных IGP до того же уровня — начиная с Ivy Bridge, OpenCL-код выполняется и на графических ядрах. Правда вот у нас возникла некоторая заминка с участниками — большую часть основных сегодняшних героев мы при помощи Basemark CL не тестировали. Ну что ж — приведем результаты тех, кого тестировали, а для пущего эффекта добавим на диаграмму и то, чего достигают «взрослые» модели как AMD, так и Intel.
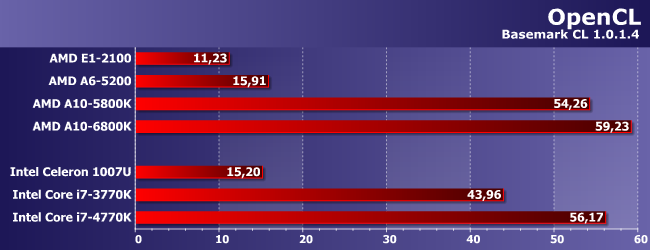
Итак, как видим, OpenCL не панацея: медленные процессоры остаются медленными, а быстрые — быстрыми: даже Core i7-3770K в три-четыре раза производительнее бюджетных ULV-процессоров обоих компаний, а ведь это далеко не предел возможного. Особенно для настольной системы, где OCL-код может выполняться дискретным GPU (а то и не одним): как показало наше недавнее исследование, система с Radeon HD 7970 в этом тесте набирает почти 350 баллов. Такой метод повышения производительности компактным системам, естественно, недоступен.
С другой стороны игнорировать OCL программистам тоже не стоит — Core i7-990X (безусловно, процессор старый, но мощный — шесть ядер с частотой выше 3 ГГц, способных выполнять 12 потоков вычисления) «в одиночку» (без поддержки со стороны GPU) имеет результат 19 баллов, что тоже показало упомянутое исследование. Наши же низкопотребляющие герои... В целом медленнее, конечно, но «приварок» от графических процессоров позволяет им справляться с подобным кодом не слишком медленно. Даже Е1-2100 «набил» 11 баллов — почти вдвое меньше, чем i7-990X, но ведь процессорную составляющую этих устройств и сравнивать-то напрямую нет смысла! Ни по вычислительной, ни по рассеиваемой мощности — это два вообще никак непересекающихся мира. Однако GPGPU позволяет им в некоторых классах задач различаться уже только количественно, но не качественно.
Что же касается лобового столкновения «одноклассников», то А6-5200, честно говоря, нас несколько разочаровал — да, он быстрее, чем Celeron 1007U, но лишь немного быстрее. Что-то «съели» более быстрые процессорные ядра (пусть и в меньшем количестве), что-то нужно списать на эффект от памяти (а Basemark CL к ОЗУ неравнодушен, в чем мы уже убеждались на примере А10-6800К), но важен конечный результат. А он такой, какой есть — даже А6-5200 при такой нагрузке эквивалентен лишь Celeron. Сравнивать с Core i3 нет смысла — там и НТ есть, и, что еще более важно, графических процессоров втрое больше.
Понятно, что один тест — не истина в последней инстанции. Тем более что есть в его поведении некоторые странности — GPU от NVIDIA он явно на дух не переносит, так что оптимизации под разные архитектуры явно отличаются. Однако в свое оправдание заметим, что ранее Basemark CL входил в список приложений, которые сама AMD рекомендовала использовать при тестировании процессоров. По вполне понятным причинам: во времена Sandy Bridge (IGP которых не умел выполнять OCL-код) разница между APU AMD и процессорами Intel была радикальной. А после появления Ivy Bridge и Haswell картина стала диаметрально противоположной — забавно наблюдать, как 26 (2 центральных и 24 графических) «решателя» Intel в массивно-параллельном коде демонстрируют тот же уровень производительности, что и 132 (4+128) коллеги от AMD :) В общем, по-видимому, скоро отношение последней компании к данному бенчмарку тоже изменится на противоположное.
Итого
Среди военных распространена одна (достаточно злая) поговорка: Генералы всегда готовятся к прошедшей войне. Последние несколько лет складывается ощущение, что в руководстве AMD эти самые генералы и «окопались»: мы уже не первый раз сталкиваемся с прекрасными (не побоимся этого слова — с точки зрения технической оригинальности разработки этой компании очень часто интереснее, чем у конкурентов) продуктами, которые... опаздывают на рынок на год-два. В самом деле — что было бы, появись тот же А6-5200 во времена господства Sandy Bridge? Фурор был бы — этот процессор действительно способен конкурировать с Core i3 (тогдашними), причем не только с низкопотребляющими модификациями: пусть процессорная составляющая «регулярных» моделей мощнее, но и теплопакет выше, а графика намного слабее (и по производительности, и по функциональности). Но вот убедительной победы (да и вообще победы) над Ivy Bridge не получается, хотя Kabini вышел на рынок одновременно с Haswell. В результате новые Core i3 по теплопакету соответствуют уже А4-5000, а по производительности превосходят А6-5200 — ведь последний, как видим, в лучшем случае сравним с прошлогодними Core i3 (а в худшем — и от Celeron того времени отстает). Аналогичное замечание относится и к Temash, благо производительность некоторых представителей данного семейства предсказуема — ТТХ А4-1250 и протестированного сегодня E1-2100 идентичны во всем, кроме TDP: это прекрасный конкурент Clover Trail, но ведь уже продвигается Bay Trail. И реально продвигается — анонсы продуктов множатся как гробы после вождя. А как крупные производители отреагировали на Kabini и Temash? Несколько странным образом — на первом они зачем-то выпускают «полноразмерные» ноутубки (массой 2,5 кг), а второй используют не в планшетах, а в компактных ноутбуках, где как раз хорошо смотрелся бы А4-5000, но уж никак не А4-1200.
В общем, остается только надеяться на то, что по мере увеличения выпуска APU этих линеек ассортимент использующих их конечных продуктов будет расширяться «в правильном направлении». Есть только опасения, что времени на это не слишком много — так и до Broadwell дотянуть можно со всеми вытекающими. Но не будем сейчас о наболевшем. Тем более, не касающемся технических вопросов. С этой же стороны все по-прежнему неплохо. Не настолько хорошо, как могло бы быть, появись процессоры в прошлом году, но пока еще неплохо. Во всяком случае, с Celeron и Pentium конкурировать представители линейки Kabini могут, в отличие от Brazos, неспособного даже на это. Понятно, что AMD как обычно переоценила свою разработку, «замахнувшись» на уровень Core i3, однако иногда тот же A6-5200 и на такое способен — главное, чтоб с ценами и характеристиками тех же ноутбуков все было хорошо. А дополнительная свобода выбора покупателям еще никогда не вредила. Во всяком случае тем, кто умеет ей пользоваться :)
за помощь в комплектации тестовых стендов



