Обзор существующих бенчмарков
Содержание
- Введение
- Конфигурация тестовой системы
- Basemark CL
- CLBenchmark
- Folding@Home Benchmark
- FLACCL
- GPU Caps Viewer
- LuxMark
- Futuremark PCMark
- ratGPU OpenCL Benchmark
- SiSoftware Sandra
- SVPmark
- Выводы
Введение
История вычислений общего назначения на графических процессорах началась довольно давно. Многоядерные процессоры, созданные для параллельных векторных вычислений, используемых в 3D-графике, имеют в определенных задачах весьма высокую производительность. Технологии неграфических расчетов общего назначения GPGPU (General-Purpose computation on GPUs) появились несколько лет назад, и последние поколения GPU обладают гибкой архитектурой, способной выполнять не только примитивные графические задачи прошлого, но и более сложные универсальные. С развитием высокоуровневых языков программирования, моделей программирования и программных платформ, помогающих распараллелить вычисления, возможности универсальных вычислений на GPU раскрываются все полнее.
Соответственно, возникла и потребность в измерении производительности GPGPU-вычислений, которую могут обеспечить различные графические процессоры. В свое время основные производители видеочипов, Nvidia и AMD, разработали соответствующие платформы под названием CUDA (Compute Unified Device Architecture) и CTM (Close To Metal, или AMD Stream Computing), которые не совместимы между собой и не подходят для описанной выше задачи. На всеобщее счастье, в дальнейшем была разработана открытая программная платформа OpenCL, которая предназначена для параллельных вычислений на различных типах процессоров (GPU, CPU, FPGA и т. п.) и поддержана большинством заинтересованных компаний, среди которых Nvidia, AMD, Intel, IBM и многие другие.
Открытые стандарты, подобные OpenCL, являются наиболее универсальными для нашей задачи, так как они позволяют использовать один и тот же код (или почти один и тот же, с небольшими оптимизациями, специфическими для конкретных решений — но тут уже нужно быть крайне осторожным) на процессорах разных производителей. Хотя у таких методов есть и недостатки, вроде меньшей гибкости и ограниченности в использовании неким общим набором возможностей, которые предлагает большинство поддерживаемых процессоров, но измерить GPGPU-производительность можно лишь таким методом, и OpenCL-тесты для этого отлично подходят.
Найти подходящие OpenCL-бенчмарки не так просто, как может показаться. Некоторые тесты не работают на GPU одной из компаний (к примеру, FlopsCL не заработал на Geforce GTX 670), другие слишком сложны в использовании или не дают повторяемых результатов. А есть бенчмарки, в которых OpenCL применяется, но не для тестирования производительности. Например, в свежих версиях популярного пакета тестов AIDA64 существует стресс-тест, использующий OpenCL, но нет бенчмарков, позволяющих оценить скорость таких вычислений.
Причем у разработчиков есть планы по GPGPU-тестам на базе OpenCL, и работа идет, но они ссылаются на задержки и сложности при разработке OpenCL-тестов, вызванные несовершенством соответствующих компиляторов. По мнению разработчиков AIDA64, у двух из трех основных производителей GPU (каких именно из набора AMD, Nvidia и Intel — догадаться несложно) имеющиеся OpenCL-компиляторы не соответствуют предъявляемым требованиям и просто не могут корректно откомпилировать их код. Разработчики надеются все-таки выпустить бенчмарк(и) до конца нынешнего года, а пока что его нет.
Да и в других тестах есть определенные проблемы и со скоростью, и с корректностью результатов. Об этом мы поговорим далее, в разделах статьи, посвященных конкретным OpenCL-бенчмаркам. Хотя выбор не слишком велик, нам все же удалось набрать некоторое количество таких приложений, хотя и не все они подходят для сравнения вычислительной производительности GPU и CPU. Мы постарались найти именно специализированные бенчмарки, но в материал попало и просто программное обеспечение, использующее возможности OpenCL, при помощи которого можно выполнить эту задачу.
Мы постараемся рассмотреть в материале наиболее известные и адекватные тесты GPGPU-производительности. К примеру, тестов рендеринга при помощи просчета лучей (raytracing) у нас будет два — потому что они весьма сильно отличаются по оптимизации. Один из этих тестов работает заметно быстрее на видеочипах одной компании, а вот во втором ситуация обратная — там оказываются несколько сильнее уже видеокарты другого производителя.
Конфигурация тестовой системы
- Центральный процессор Intel Core i7-990X (6 ядер; 3,46 ГГц);
- Система охлаждения Corsair H80;
- Системная плата Intel DX58SO2 на базе чипсета Intel X58;
- Оперативная память 12 ГБ DDR3-1600 Crucial (1600 МГц);
- Твердотельный накопитель Crucial M4 64 ГБ, SATA 3.0;
- Накопитель на жестких дисках WD Caviar Green WD20EARX 2 TБ, SATA 3.0;
- Блок питания FSP Epsilon FX700-GLN (700 Вт);
- Операционная система Microsoft Windows 7 Ultimate, 64-битная.
Пусть комплектующие в виде системной платы и CPU и не самые современные, но тестовая система получилась достаточно производительная, так как она в свое время предназначалась для экстремальных пользователей. Из ее явных недостатков можно отметить разве что отсутствие поддержки PCI Express версии 3.0, но это вряд ли сильно помешает нам сегодня.
Видеокарты для исследования мы взяли следующие:
- AMD Radeon HD 6950
- AMD Radeon HD 7970
- Nvidia Geforce GTX 670
Geforce GTX 670 и Radeon HD 7970 близки друг к другу по цене и игровой производительности, а две модели Radeon из разных поколений будут интересны с точки зрения архитектурных изменений. Использовались видеодрайверы AMD Catalyst версии 13.8 beta и Nvidia версии 326.19. Все их настройки были выставлены по умолчанию.
Basemark CL 1.0.1-4
http://www.rightware.com/category/products/basemark-cl

Тест Basemark CL компании Rightware — один из специализированных OpenCL-бенчмарков, содержащий синтетические тесты, разделенные на несколько категорий. В отличие от тех тестов, которые нацелены на чисто графические задачи, Basemark CL содержит и задачи других типов, вроде физических симуляций. Но и тестирование производительности в тестах обработки изображений и видеоданных в этом пакете есть. К сожалению, данный бенчмарк на настоящий момент в публичном доступе отсутствует, и это явный его недостаток.
При запуске Basemark CL предлагает выбрать OpenCL-платформу и профиль, которые будут в дальнейшем использоваться при тестировании, причем доступны и CPU-профили. Поэтому мы протестировали не только три графических процессора обоих основных производителей GPU, но и центральный процессор системы — достаточно мощный шестиядерник. К сожалению, это процессор еще позапрошлого поколения, не имеющий встроенного видеоядра с поддержкой GPGPU-вычислений. Рассмотрим сначала общий счет и отдельный по разделам:
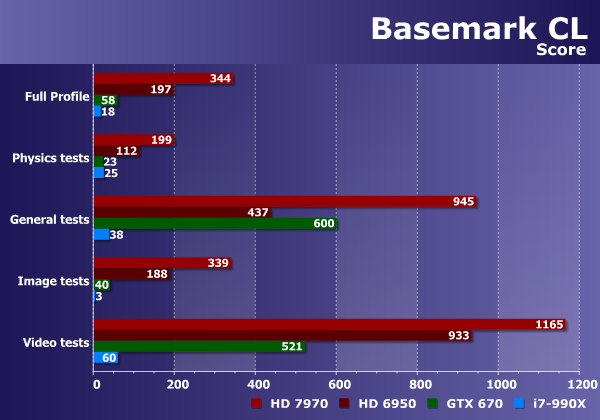
Общий счет в Basemark CL показывает, насколько хорошо справился тот или иной процессор как в целом, так и отдельно по наборам задач: физические тесты, общие тесты, обработка изображений и обработка видеоданных. На первый взгляд, у CPU есть преимущество перед видеочипом Nvidia лишь в физических тестах, но их мы рассмотрим подробно дальше — есть вероятность какой-то ошибки. В остальных случаях GPU далеко впереди.
При сравнении графических процессоров AMD и Nvidia в этом бенчмарке явно выигрывают платы Radeon, причем даже предыдущего поколения! Кроме одного («General») набора подтестов, даже Radeon HD 6950 оказался быстрее, чем Geforce GTX 670. Что уж говорить о Radeon HD 7970, который обогнал конкурента минимум в два раза. Похоже, что тесты в данном бенчмарке лучше оптимизированы для графических архитектур компании AMD. Рассмотрим набор общих и физических тестов по отдельности:
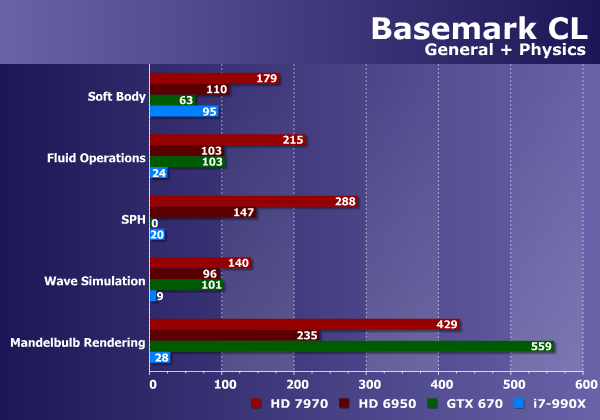
Мы объединили физические тесты и общие на одной диаграмме. Из всех них только физический подтест Soft Body неплохо работает на универсальных ядрах CPU, так что Core i7 опережает видеокарту Nvidia Geforce GTX 670 и подбирается к Radeon HD 6950. Все остальные тесты хорошо распараллеливаются и получают мощное ускорение при работе на GPU.
В первых двух тестах Radeon HD 7970 далеко впереди, а в случае теста SPH наблюдались явные проблемы с исполнением OpenCL-кода на Geforce GTX 670 (даже визуально было видно, что расчет частиц производится неверно), так что этот тест из сравнения можно исключить, как некорректный.
Симуляция волн на поверхности работает на Geforce чуть хуже, чем на Radeon, а единственный подтест, где видеокарта на базе графического процессора Nvidia побеждает — рендеринг фрактала Mandelbulb. Единственной Geforce не могут противостоять в этом тесте оба решения на базе видеочипов AMD, не говоря уже об универсальном центральном процессоре.
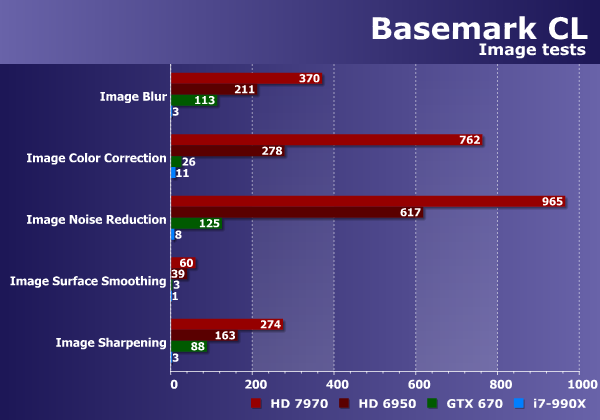
Подтесты раздела обработки изображений, включенные в состав Basemark CL, являются довольно простыми фильтрами постобработки, знакомыми нам по популярному ПО для работы с фотографиями и другими изображениями: смазывание в движении, шумоподавление, увеличение резкости, сглаживание, цветокоррекция и т. п. Из-за схожих алгоритмов, используемых в этих фильтрах и в реальных программах, данный синтетический бенчмарк может быть вполне показательным.
Очень сложно сравнивать мощнейшие GPU с явно не подходящим для таких задач универсальным процессором на одной диаграмме — столбики CPU на ней просто не видны. Графические же чипы при обработке изображений чувствуют себя как рыба в воде, а лучший из них (Radeon HD 7970) опережает универсальный вычислитель в сотню раз!
Что касается сравнения различных GPU, то тут можно отметить явный проигрыш единственного представленного решения Nvidia. Geforce GTX 670 в одном из тестов показывает результат на уровне CPU, да и в остальных в разы отстает даже от устаревшей модели Radeon HD 6950. Естественно, что Radeon HD 7970 оказывается лидером тестов обработки изображения.
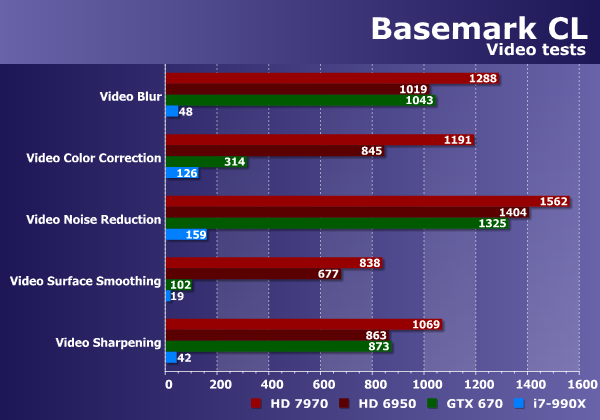
Раздел обработки видеоизображения почти полностью повторяет предыдущий. Оно и понятно, ведь видеоданные — не что иное, как множество статичных изображений. Так что, аналогично обработке изображений из предыдущего раздела, тесты видеообработки в Basemark CL должны более-менее отражать ту производительность, что мы можем увидеть в случае реального ПО по обработке видеоданных.
Собственно, выводы остаются теми же, что и в предыдущем разделе. Разницы между обработкой видео и статичных картинок в алгоритмическом смысле практически нет. Разве что производительность мощных GPU AMD теперь ограничена какими-то дополнительными факторами, и Geforce в трех из пяти задач идет наравне хотя бы с Radeon HD 6950.
В целом, применять Basemark CL для определения OpenCL-производительности вполне можно, но это не лучший подобный тест, и без оговорок тут не обойтись. К примеру, в некоторых подтестах наблюдаются проблемы совместимости, а то и явные «баги», не позволяющие выполнить честное сравнение. По тем же тестам, которые подходят, можно сделать вывод о том, что даже мощный CPU сильно отстает по производительности от GPU, а видеочипы AMD оказываются значительно быстрее конкурирующих графических процессоров Nvidia в этих конкретных задачах.
CLBenchmark 1.1.3
Второй рассматриваемый нами сегодня пакет — CLBenchmark компании Kishonti Informatics, известной по мобильному графическому бенчмарку GFXBench, ранее выходившему под именами GLBenchmark и DXBenchmark. Это еще один тестовый пакет для определения вычислительной производительности разных OpenCL-платформ, позволяющий протестировать различные CPU и GPU в вычислительных задачах.
Версия пакета «Desktop Edition» доступна для бесплатного скачивания и частного использования. В официальных требованиях этой версии — интернет-соединение для сбора информации о протестированных OpenCL-процессорах. Для нас очень важно, что тесты в составе CLBenchmark помогают оценить и слабые, и сильные стороны отдельных решений и даже архитектур, лучше подходящих под разные задачи. К примеру, отличие между предпочтениями CPU и GPU в CLBenchmark четко заметно, и сейчас вы в этом убедитесь:
На первой диаграмме мы собрали почти все тесты рендеринга обработки изображений, представленные в CLBenchmark. Почему почти все? Да потому, что два из физических тестов (SPH Fluid Simulation и Optical Flow: Feature Matching) просто не работают на видеокартах AMD. Это к слову о зрелости OpenCL — данная платформа довольно молода и еще не слишком хорошо развита.
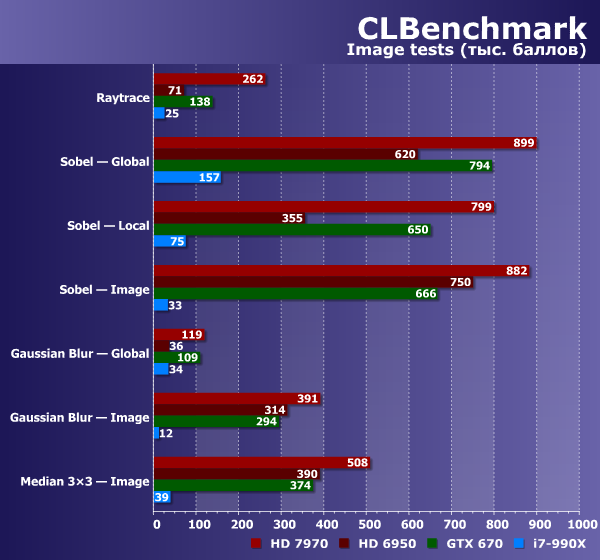
Первый тест осуществляет замер производительности рендеринга при помощи трассировки лучей. Применяется традиционный алгоритм рейтрейсинга с поддержкой отражений, мягких теней и расчетом глобального освещения. Применяемая сцена содержит 600 тысяч треугольников и отрисовывается в разрешении 2048×1024.
В тесте рейтрейсинга в Basemark CL получились очень интересные результаты, похожие на то, что должно быть, исходя из теории. Шестиядерный CPU хоть и отстал от всех GPU, но он лишь втрое медленнее видеокарты предыдущего поколения — Radeon HD 6950. Которая, в свою очередь, очень сильно уступает Radeon HD 7970 из нынешней линейки компании AMD. Ну а Nvidia Geforce GTX 670 по скорости в данном тесте находится между двумя Radeon.
Все остальные тесты на первой диаграмме связаны с обработкой изображений. Они в целом аналогичны тем, что мы видели в предыдущем бенчмарке (сглаживание, определение границ, шумоподавление…), но тут и фильтры отличаются, и результаты совсем иные. Фильтры с почти одинаковым названием (в первой его части) используют разные алгоритмы для того, чтобы определить все возможности тестируемого аппаратного обеспечения. Так, фильтр Sobel существует аж в трех вариантах, использующих разные особенности вычислительных устройств.
И вот тут мы уже видим что-то похожее на настоящие синтетические тесты. Так, CPU показывает в Sobel лучший результат при использовании глобальной памяти, а GPU ведут себя по-разному. Если Radeon HD 7970 и Geforce GTX 670 близки по скорости в трех вариантах теста, то у Radeon HD 6950 мы видим сильное падение производительности в варианте с использованием локальной памяти — в архитектуре GCN были проведены соответствующие оптимизации. Видеокарта на чипе Nvidia хоть и показывает результат, близкий к скорости Radeon HD 7970, но все же отстает.
В тестах Gaussian Blur и Median 3×3 выводы почти такие же, разве что Intel Core i7 отстал от всех GPU еще больше — кроме варианта с использованием глобальной памяти, в котором CPU силен и находится на уровне Radeon HD 6950, имеющего явные проблемы при таком исполнении задачи.
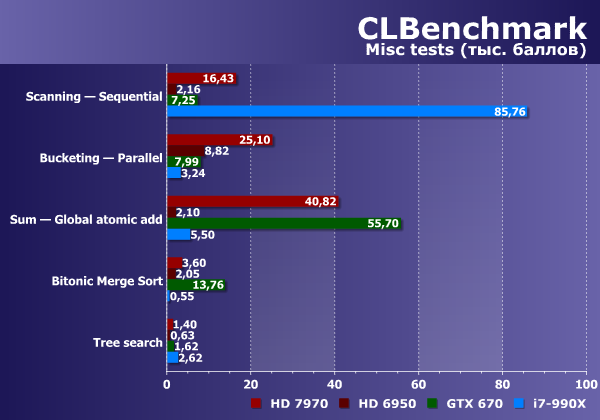
Создатели CLBenchmark постарались обеспечить свой бенчмарк подтестами, отражающими потребности реальных приложений, вроде рейтресинга и постфильтров для изображений, но добавили и чисто синтетические подтесты, объединенные в группу «Принципы программирования» («Programming Principles»). Эти тесты также содержат разные реализации и алгоритмы, используемые в реальных приложениях в виде суммирования, сортировки, поиска данных и т. д. Причем есть два теста сканирования: последовательное и параллельное. Нетрудно догадаться, что в первом с большим превосходством побеждает CPU, а во втором — GPU.
Но это не единственный тест, где CPU силен. В подтесте древовидного поиска наш Intel Core i7 также показывает лучший результат. Соответственно, эти две задачи можно признать лучше подходящими для выполнения на универсальных вычислительных устройствах. Однако и новые графические процессоры, как Nvidia, так и AMD, справляются с ними довольно неплохо.
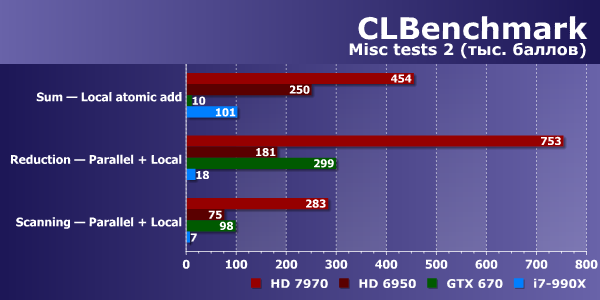
Оставшиеся тесты нужно рассматривать по отдельности. В основном, графические чипы в них выглядят сильнее, чем универсальный CPU, но есть нюансы. Так, при суммировании с использованием атомарных операций в глобальной памяти Geforce GTX 670 заметно быстрее всех остальных решений, в том числе и Radeon HD 7970 (а HD 6950 в этом тесте провалился ниже уровня CPU), зато в алгоритме с использованием локальной памяти ситуация меняется на обратную, и GPU Nvidia проваливается далеко вниз, до 10 раз уступая даже универсальному процессору. Надо отметить, что Radeon HD 7970 в обоих вариантах смотрится очень неплохо.
Вот вам и тонкости реализации алгоритма, показывающие, как именно можно оптимизировать код под то или иное устройство. В этих чисто синтетических тестах хорошо видны недостатки тех или иных решений. Например, в тесте битонной сортировки (Bitonic Merge Sort) графический процессор Geforce одержал победу и над GPU AMD и над CPU, зато в тесте распараллеленного сканирования с использованием локальной памяти он показал почти втрое худший результат по сравнению с Radeon HD 7970.
Так что можно сделать вывод о том, что бенчмарк CLBenchmark очень хорошо подходит в качестве пиковых теоретических тестов (обработка изображений и принципы программирования), с объяснениям того, почему получилось именно так. Как набор синтетических тестов CLBenchmark очень неплох, ну а для прямого сравнения мощности различных решений подходит разве что тест рейтрейсинга, да и то — с оговорками в виде различной оптимизации для разных решений.
Folding@Home Benchmark 1.2.0
http://proteneer.com/blog/?page_id=1671
FAHBench — это официальный тест производительности проекта распределенных вычислений, известного под именем Folding@Home. Проект распределенных вычислений Folding@Home предназначен для проведения компьютерного моделирования свертывания молекул белка, он стартовал больше десятка лет назад и является крупнейшим подобным проектом по мощности и числу участников. Целью проекта является исследование причин возникновения болезней, вызываемых дефектными белками (болезни Альцгеймера и Паркинсона, диабет второго типа, коровье бешенство, склероз и некоторые формы онкологических заболеваний).
Бенчмарк FAHBench предназначен для измерения производительности графических процессоров в столь сложной вычислительной задаче, он позволяет сравнить производительность CPU и GPU, причем для видеокарт компании Nvidia доступны два метода: OpenCL и CUDA. К сожалению, с CUDA-вариантом возникли какие-то проблемы, и тестирование просто не запускалось, поэтому пришлось ограничиться OpenCL-версией. К слову, FAHBench также не работает и на старых встроенных видеоядрах Intel по причине отсутствия поддержки ими вычислений с двойной точностью.
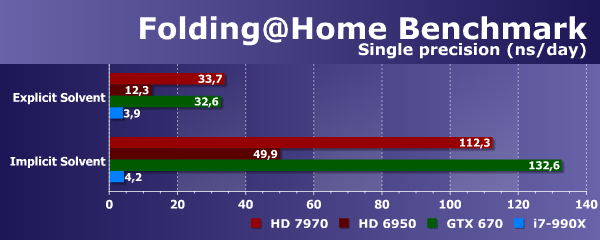
Если до этого мы рассматривали целые тестовые пакеты, содержащие множество различных задач, то FAHBench очень прост — он измеряет производительность в единственной узкоспециализированной задаче. Интересны цифры нашего тестового CPU: при explicit- и implicit-методах моделирования результаты почти одинаковы, разница не превышает 10%.
Все совсем иначе в случае графических процессоров. Все три видеокарты значительно быстрее работают при методе моделирования implicit, обеспечивая в 3-4 раза большую производительность, чем при методе explicit. Лучший GPU в 8 раз быстрее CPU в первом варианте и более чем в 30 раз быстрее во втором.
Любопытно, что устаревший Radeon HD 6950 показал скорость вдвое-втрое ниже, чем видеокарты нынешнего поколения. В сравнении же Geforce GTX 670 и Radeon HD 7970 явного лидера нет, эти модели видеокарт весьма близки друг к другу по производительности в этой задаче, но в implicit-варианте плата Nvidia все же чуть быстрее.
FLACCL 0.3
http://www.cuetools.net/wiki/FLACCL
Программное обеспечение FLACCL (ранее известное как FlaCuda) не является тестом производительности как таковым — это решение для кодирования аудиоданных в формат FLAC (Free Lossless Audio Codec). FLAC — популярный свободный кодек, предназначенный для сжатия аудиоданных без потерь, в отличие от форматов сжатия с потерями, вроде MP3, AAC и Ogg Vorbis. FLAC, как и другие кодеки сжатия без потерь, часто используется меломанами и подходит для прослушивания музыки на высококачественной аппаратуре.
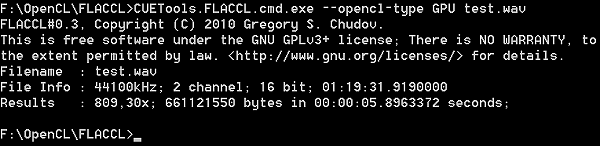
FLACCL — это первый FLAC-кодировщик, использующий CUDA, а затем перешедший на OpenCL, что позволило добавить поддержку графических решений AMD. К сожалению, проект больше не развивается, и текущая версия была выпущена еще осенью 2010 года — однако она поддерживает все видеокарты, начиная от Nvidia Geforce GTX 200 и AMD Radeon HD 5000. FLACCL реализован в виде утилиты командной строки без графического интерфейса, поэтому для тестирования мы просто кодировали аудиозапись в несжатом формате WAV длительностью 1 час 19 минут.

Так как это не специализированный бенчмарк, а просто ПО, которое можно использовать в том числе и для тестирования производительности, то есть определенные тонкости. К примеру, нужно обязательно делать замер скорости при вторичном запуске, так как результат получается в разы лучше. Видимо, это связано с неэффективным кодом чтения данных с диска, и если данные находятся уже в кэше (в оперативной памяти), то сжатие происходит гораздо быстрее, и тогда уже ограничение общей производительности определяется именно скоростью вычислений.
Цифры на графике показывают, во сколько раз быстрее реального времени происходит кодирование аудиофайла. В случае исполнения кода на CPU (причем это такой же OpenCL-код, а не C++-оптимизированный для x86-архитектуры) скорость кодирования не слишком-то ниже той, что получается на GPU, так что с этой реальной задачей наш универсальный процессор справляется отлично.
Если же сравнивать различные графические процессоры между собой, то модели Radeon HD 6950 и HD 7970 показали очень близкую скорость, что говорит о том, что более новый GPU ограничивает какой-то дополнительный фактор. Geforce GTX 670 отстает от обеих плат AMD в тесте FLAC-кодирования, хотя разница не слишком велика. В целом, для тестирования OpenCL-производительности это ПО применять можно, но оно не слишком подходит для тестирования GPU по причине недостаточной эффективности распараллеливания.
GPU Caps Viewer 1.18.1
http://www.ozone3d.net/gpu_caps_viewer
GPU Caps Viewer компании Geeks3D — это бесплатная информационная утилита, предоставляющая пользователю информацию об аппаратных решениях ПК, в основном предназначенная для получения различной информации о функциональности установленного графического процессора. В ней дается полная информация о возможностях графической подсистемы, включая данные о типе GPU, объеме и скорости видеопамяти, поддержке программных возможностей DirectX, OpenGL, OpenCL и CUDA.
Также утилита содержит несколько демонстрационных программ, использующих возможности OpenGL 3.2 и OpenCL, а вот как таковых тестов производительности OpenCL в ней (пока что?) нет. Но это не беда, можно просто использовать число кадров в секунду, получаемое при рендеринге в демонстрационных программах, использующих OpenCL-вычисления. В состав GPU Caps Viewer входят четыре такие «демки»: объемный (в трех измерениях) фрактал множества Julia, использующий трассировку лучей; объемная система частиц, состоящая из одного миллиона штук; сложная объемная поверхность, деформируемая при помощи OpenCL; и довольно простой эффект постобработки.
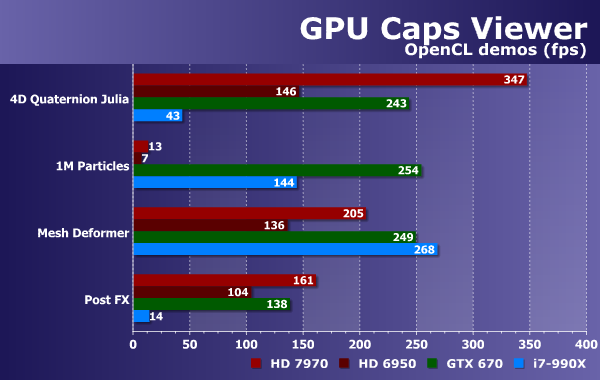
Демо-программы этого ПО сочетают использование OpenGL и OpenCL, и некоторые из них довольно известны. Так, код подтеста PostFX был взят из Nvidia SDK и модифицирован, но он выполняется быстро не только на графических процессорах этой компании, но и на GPU конкурента, основанных на базе современной графической архитектуры GCN. А вот CPU в данном подтесте явно подкачал — отстает от видеочипов до 8-10 раз.
В тесте отрисовки фрактала 4D Quaternion Julia получаемый FPS был крайне нестабилен, так что тест плохо подходит для постоянного использования. Тем не менее, видеоплата Radeon HD 7970 оказалась явным лидером, она вдвое быстрее решения из предшествующего поколения. Ну а карта Geforce в который уже раз оказалась ровно между двумя Radeon.
Тест деформации объемной поверхности очень быстро выполняется на CPU — в нем Core i7-990X показал лучший результат. Сразу за ним следует решение Nvidia, с небольшим отставанием идет Radeon HD 7970, ну а GPU из предыдущего поколения AMD остался последним.
Тест с миллионом обрабатываемых частиц лучше всего выполняет Geforce GTX 670, а вот оба Radeon его провалили — налицо какая-то ошибка, то ли драйвера, то ли OpenCL-компилятора, из-за которой ими был показан аномально низкий результат. Так что если GPU Caps Viewer и можно использовать при OpenCL-тестировании, то лишь некоторые из демо-программ, и с оговорками.
LuxMark 2.0
http://www.luxrender.net/wiki/LuxMark
LuxMark — один из двух OpenCL-тестов, рассмотренных в нашем материале, в котором вычислительные способности процессоров используются для реалистичного рендеринга методом трассировки лучей. Идея выпустить бенчмарк родилась в 2009 году, он был выпущен в рекламных целях поддержки движка рендеринга LuxRender. LuxRender имитирует распространение света в реальности при помощи специальных алгоритмов и существует в версиях для следующего специализированного ПО: Blender, 3dsmax, SketchUp, C4D, XSI, Poser и др.
Первой версией тестового пакета OpenCL была простенькая графическая оболочка для SmallLuxGPU (как ранее назывался рендерер), измеряющая производительность рендеринга. Затем бенчмарк начали использовать многие сайты, тестирующие видеокарты, LuxMark 1.0 получил широкое распространение и даже был отмечен компанией AMD (вам очень скоро станет понятно, почему).
Текущая версия LuxMark использует движок рендеринга SLG2, который большинство вычислений перекладывает на OpenCL-устройства, поддерживаются разные платформы и профили. LuxMark 2.0 содержит три сцены и пять вариантов тестов различной сложности (262 тыс. треугольников, 488 тыс. треугольников и 2 млн. треугольников), а результат выдается в виде количества выборок, рассчитанных в секунду в среднем.

Самый простой подтест из трех — сцена LuxBall HDR, содержащая 262 000 треугольников. Первая же диаграмма наводит на мысли о крайне специфических оптимизациях кода данного рендерера. В задаче, которая теоретически должна очень неплохо распараллеливаться, шестиядерный CPU опережает один из GPU и лишь втрое медленнее самого быстрого Radeon HD 7970. Разница между решениями AMD из разных поколений также довольно велика.

Второй тест — средней сложности, он использует сцену Sala, в которой почти полмиллиона графических примитивов. Ситуация изменилась минимально, Core i7-990X теперь почти догнал уже и Radeon HD 6950. Старшая модель из текущей линейки Radeon HD 7900 остается лидером, далеко опережающим соперников.
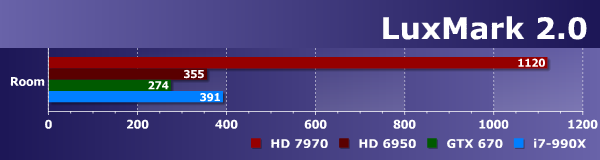
Ну и самая сложная сцена LuxMark — Room, которая содержит более 2 млн. треугольников. Рендеринг этой сцены возможен исключительно при запуске 64-битной версии бенчмарка — настолько сложна эта задача. Да и не все бюджетные GPU способны с ней справиться. Хотя представленные в сравнении видеочипы не относятся к недорогим, два из них справились с задачей даже хуже CPU, что явно говорит о недостаточной оптимизации кода под GPU.
В данном бенчмарке явно есть некая специфическая оптимизация под графические процессоры компании AMD. И особенно заметно выделяется по результатам тестов современная графическая архитектура GCN, которая отлично подходит для выполнения подобных OpenCL-задач. Да и универсальный процессор Intel неплохо себя показал в этом бенчмарке, всегда обгоняя Geforce GTX 670, а иногда и Radeon HD 6950. Видимо, код распараллелен не слишком эффективно или используются какие-то возможности OpenCL, которые плохо работают на некоторых GPU. Ниже мы сравним полученные результаты с другим тестом, также использующим трассировку лучей и сложные 3D-сцены. На наш взгляд, если и использовать LuxMark, то только как один из OpenCL-тестов, но явно не единственный.
Futuremark PCMark 8
http://www.futuremark.com/benchmarks/pcmark8
Пакет тестов PCMark 8 компании Futuremark является последней версией широко распространенного бенчмарка для измерения общей производительности ПК. PCMark 8 можно назвать одним из наиболее полных тестов производительности, включающим разнообразные подтесты. Пакет обеспечивает режимы нагрузок, отражающие типичные задачи пользователей домашнего компьютера, такие как просмотр веб-страниц, редактирование текстов, игры, редактирование изображений, а также видеочаты. Раздел «Creative» данного пакета содержит уже более сложные задачи для продвинутых пользователей, которые дополнены сложным редактированием фотографий и видеоданных, включая их перекодирование из формата в формат, а также групповым видеочатом.
К сожалению, публичные версии пакета тестов PCMark 8 пока что недоступны, но журналисты уже имеют доступ к этому пакету. И для нас самое главное то, что в текущей версии PCMark появилась поддержка OpenCL. PCMark 8 использует возможности OpenCL 1.1 в тестах видеочата и группового видеочата, которые включены в разделы «Home» и «Creative», причем можно выбрать OpenCL-устройство из нескольких присутствующих в системе. Более продвинутые возможности OpenCL 1.2 применены в задаче редактирования видеоданных («Video Edit») в разделе «Creative». К сожалению, не все из поддерживающих OpenCL устройств имеют поддержку версии 1.2, и поэтому GPU Nvidia не получил преимущества в этих подтестах.
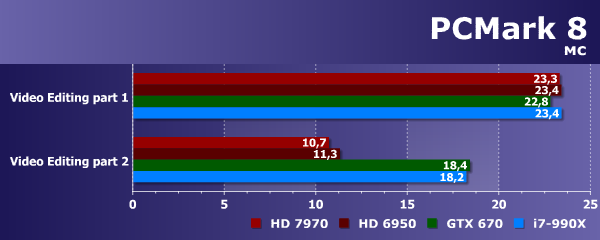
Это как раз видно на диаграмме — налицо отставание Geforce GTX 670 от остальных графических процессоров во второй части тестов. Эти 70% преимущества у решений AMD объясняются тем, что Nvidia пока что не выпустила драйверов с поддержкой OpenCL 1.2. А результаты первой части тестов редактирования видео вообще не отличаются на всех конфигурациях нашей тестовой системы.
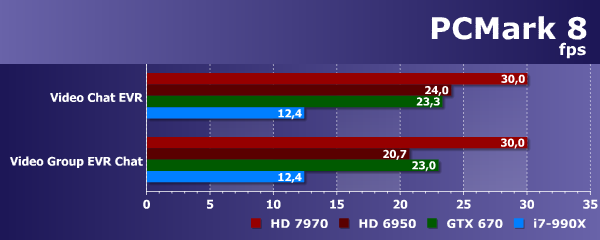
В подтестах видеочата разница в скорости больше похожа на правду, и тут не используется OpenCL 1.2, поэтому сравнение честное. Все графические процессоры в 2-2,5 раза быстрее универсального процессора Intel Core i7-990X, но Radeon HD 7970 явно мощнее всех — только этот GPU обеспечил 30 FPS в обоих подтестах. Оставшиеся Radeon HD 6950 и Geforce GTX 670 весьма близки друг к другу в этом бенчмарке, но они не дотягивают до 30 FPS.
Хотя положение разных видеокарт на второй диаграмме похоже на то, что должно получаться в реальных задачах, использовать универсальный пакет PCMark 8 в качестве узкоспециализированного OpenCL-бенчмарка не имеет особенного смысла. Во-первых, для этой цели пригодны лишь пара тестов из всего набора, а во-вторых — налицо ограничение в 30 FPS, выше которого не прыгнешь.
ratGPU OpenCL Benchmark 0.5.8
ratGPU OpenCL Benchmark — это второй тест в нашем исследовании, использующий рендеринг методом просчета лучей (рейтрейсинг), и он сильно отличается от ранее рассмотренного LuxMark. Что схоже в этих двух бенчмарках — так это то, что оба они основаны на бесплатных движках рендеринга, использующих OpenCL. Текущая версия ratGPU доступна в вариантах для 3dsmax и Maya, она также включает в себя и отдельное приложение для тестирования OpenCL-производительности.
Пакет теоретически должен работать на любой видеокарте Nvidia, начиная с серии Geforce 8, и на любом Radeon компании AMD, начиная с серии Radeon HD 5000, имеющих как минимум 512 мегабайт локальной видеопамяти. Естественно, крайне рекомендуется использовать самые свежие драйверы: для Radeon — минимум Catalyst 12, для Nvidia — версию 290 и выше. ratGPU позволяет запускать бенчмарк в трех режимах с разной сложностью расчетов и качеством рендеринга: low, medium и high quality, а результат выдается в виде времени, затраченного на суммарную отрисовку всех четырех сцен, входящих в пакет тестов. Поэтому чем число на диаграмме меньше, тем быстрее данный процессор:

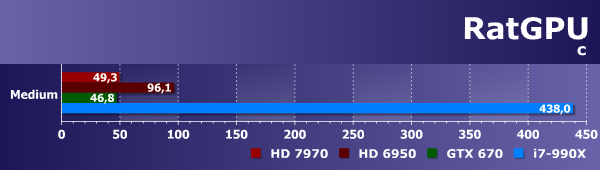
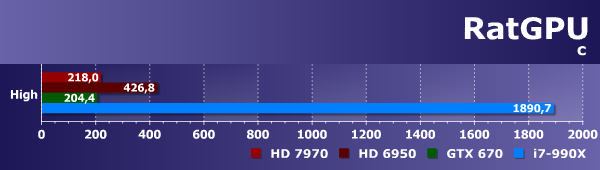
Результаты бенчмарка ratGPU любопытны уже тем, что они весьма сильно отличаются от виденных нами ранее в LuxMark, хотя задача трассировки лучей одна и та же. Похоже, что ratGPU-рендерер имеет лучше распараллеленный и оптимизированный для GPU код, который выполняется на видеопроцессорах в разы быстрее. Также ratGPU по-другому, по сравнению с тем же LuxRender, использует аппаратные возможности различных графических процессоров, и видеокарты AMD в случае этого теста уже проигрывают решению Nvidia.
Интересна и разница между GPU разных поколений компании AMD. Новая видеокарта Radeon HD 7970, основанная на базе чипа, имеющего архитектуру GCN, в этом бенчмарке также гораздо быстрее, чем старая видеокарта Radeon HD 6950, как и в LuxMark. Понятно, что универсальный процессор в этом тесте уступает всем видеопроцессорам, причем разница достигает 9-10 раз, что гораздо больше, чем было в LuxMark.
Нас больше всего интересует сравнение пары современных GPU AMD и Nvidia, и тут можно сказать, что они очень близки друг к другу, и лишь небольшое преимущество, около 5-10%, есть у Geforce GTX 670. Такая странность в кардинально отличающихся результатах ratGPU и LuxMark приводит к выводу о том, что эти два теста OpenCL-рейтрейсинга нужно использовать только совместно, чтобы увидеть общую картину — и в таком случае их использовать вполне возможно.
SiSoftware Sandra 2013
Еще одним крупным и универсальным пакетом тестов является SiSoftware Sandra 2013. Последняя версия этой популярной утилиты включает функции анализа, тестирования и диагностики ПК, поддерживает все актуальные операционные системы Windows. SiSoftware довольно часто обновляет свой пакет тестов Sandra, и в версии 2013 года многие из них появились или были доработаны. Еще в Sandra 2009 были включены тесты GPGPU с поддержкой AMD Stream и Nvidia CUDA, а годом позднее появился набор GPGPU-тестов, портированный на платформы OpenCL и DirectCompute (DirectX 11 Compute Shader).
Сейчас эталонные GPGPU-тесты в составе SiSoftware Sandra 2013 включают одновременную поддержку всех трех популярных платформ GPGPU: OpenCL, DirectCompute и CUDA. Иными словами, в одних и тех же GPGPU-тестах для видеокарт на графических процессорах Nvidia можно использовать три разные платформы, а на чипах AMD — две (исключая CUDA естественно).
Важно, что многие из OpenCL-тестов в Sandra приближены к потребностям пользователей. К примеру, некоторые финансовые расчеты и криптографические задачи отлично распараллеливаются и ускоряются на графических процессорах, и этот пакет тестов позволяет понять, какую скорость в этих задачах способны обеспечить различные вычислительные устройства с поддержкой OpenCL.
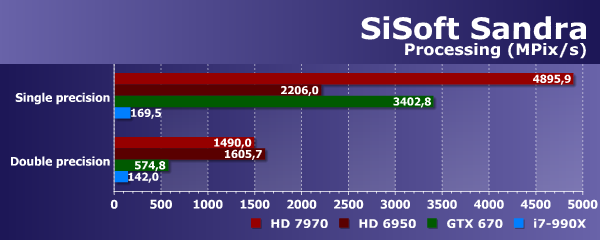
Сначала мы рассмотрим тест на выполнение простых математических расчетов — так называемую пиковую производительность. Этот OpenCL-тест аналогичен мультимедийному тесту CPU в Sandra, известному уже много лет. В тесте рассчитываются фракталы Мандельброта, и использование одинаковой нагрузки теоретически позволяет оценить прирост производительности от GPGPU, но в нашем случае это не так интересно: ведь мы сравниваем CPU и GPU в едином OpenCL-тесте.
Даже шестиядерный CPU заметно проигрывает нетоповым GPU в параллельных вычислениях. Впрочем, при двойной точности вычислений Core i7-990X показал лишь вчетверо худший результат, чем Geforce GTX 670, но более чем в 10 раз уступил графическим процессорам AMD. Если для CPU небольшая разница в производительности вычислений разной точности нормальна, то в случае графических процессоров она обычно больше, и лишь Radeon HD 6950 ведет себя в этом тесте подобно универсальному процессору.
Если же сравнивать по производительности GPU друг с другом, то тут любопытны несколько закономерностей. Во-первых, вычисления с двойной точностью значительно медленнее на Geforce по сравнению с обеими платами Radeon. Во-вторых, при одинарной точности явным лидером сравнения является Radeon HD 7970, а видеочип Nvidia уступает ему почти в полтора раза. Ну и, в-третьих, при двойной точности более современная плата Radeon уступает нетоповой модели из предыдущего поколения — видимо, сказывается архитектурная разница.
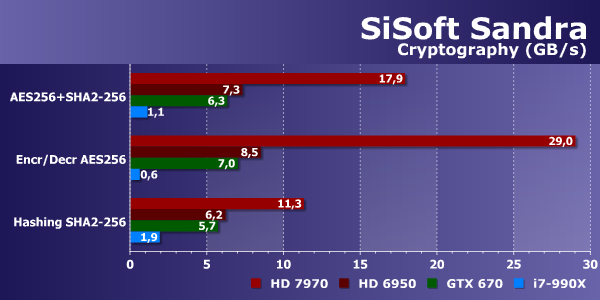
От пиковой синтетики переходим к тестам, приближенным к реальности. Первым таким тестом в Sandra является определение скорости криптографических расчетов — кодирования и декодирования данных. В таких задачах GPU всегда показывают себя с лучшей стороны, и особенно это касается современного решения компании AMD — Radeon HD 7970. Графические процессоры архитектуры GCN наиболее производительны в задачах со множеством целочисленных расчетов.
Любопытно, но Geforce GTX 670 показал результат лишь на уровне Radeon HD 6950. Более свежая же видеокарта AMD более чем вдвое быстрее этой парочки. Ну а универсальный процессор тестовой системы, даже такой достаточно мощный шестиядерник, как Intel Core i7-990X, очень сильно уступил даже решению Nvidia, не говоря уже о лучшем GPU этого теста — Radeon HD 7970.
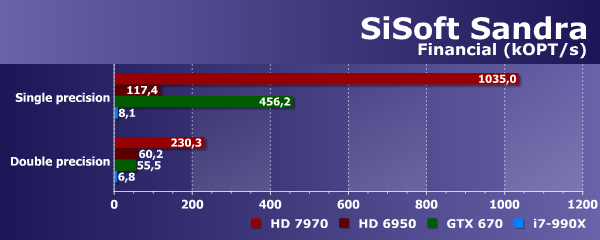
Еще одним типом задач, где применение OpenCL (и GPGPU в целом) весьма оправданно, является финансовый анализ. Многие такие алгоритмы прекрасно распараллеливаются и получают огромное ускорение при работе на GPU, хотя там есть свои сложности — к примеру, никто не будет доверять важные расчеты, связанные с финансами, графическим процессорам без поддержки памяти с ECC и без двойной точности. Неудивительно, что уже существуют профессиональные аппаратные решения, специально предназначенные для данного рынка.
С самого начала тестирования в Sandra можно было предположить, что лидером во всех этих задачах станет Radeon HD 7970. Так и получилось: результат видеокарты Geforce GTX 670 оказался хоть и заметно лучше, чем у старой Radeon HD 6950 при расчетах одинарной точности, но и она более двух раз уступила топовой плате AMD. А уж при двойной точности расчетов проигрыш платы Nvidia и вовсе стал плачевным — разница составила более четырех раз, и ее слегка обогнала даже Radeon HD 6950. Давно известно, что игровые видеокарты Nvidia не слишком хороши при FP64-расчетах, если это не GTX Titan, конечно.
Небезынтересно было понаблюдать и за скоростью CPU в этой задаче. Разница между FP32 и FP64 и в этом тесте из пакета Sandra оказалась очень небольшой. Судя по соотношению скоростей CPU и GPU, можно предположить, что при двойной точности расчетов мощный универсальный процессор вполне сможет конкурировать с бюджетными GPU даже в таких условиях, которые лучше подходят графическим процессорам.
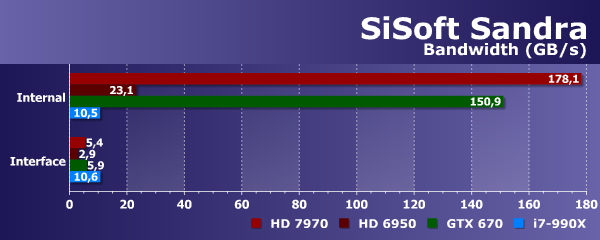
Интересен в Sandra и бенчмарк, измеряющий пиковую пропускную способность как локальной памяти (видеопамяти в случае видеокарт), так и внешнего интерфейса (PCI Express в случае видеокарт). Понятно, что для нашего тестового CPU эти цифры одинаковы, так как он имеет только один тип памяти — DDR3. А вот ПСП видеокарт сильно отличается. Особенно это касается устаревшей уже Radeon HD 6950, видеопамять которой показала в этом тесте аномально низкую полосу пропускания — результат явно некорректный. Да и по PCI-E Radeon HD 6950 работает совсем не так эффективно, как современные видеокарты.
Которые, к слову, для внешней памяти (PCI-E) показали схожие результаты, а вот реальная ПСП локальной памяти у Radeon HD 7970 выше, чем у Geforce GTX 670. В тесте Sandra получилось 178 ГБ/с против 151 ГБ/с (при теоретических 264 и 192 ГБ/с соответственно), то есть у платы Nvidia эффективность использования шины памяти несколько выше. Логично, что скорость системной DDR3-памяти тестового ПК оказалась почти вдвое больше, чем скорость интерфейса, по которому подключены графические процессоры — в данном случае у CPU есть явное преимущество. Впрочем, как раз тут нам бы помогла поддержка PCI-E 3.0, которой у тестовой системы нет.
Надо сказать, что Sandra 2013 вполне подходит в качестве одного из тестовых OpenCL-пакетов для реального применения. Более того, возможность измерения CUDA- и DirectCompute-производительности также может быть весьма полезной. Хотя сегодня мы рассматриваем исключительно OpenCL-бенчмарки, мы обратили внимание на производительность графических решений, отобранных для этого материала, и в DirectCompute- и CUDA-вариантах (эти данные мы в статье не приводим).
Интересно, что в большинстве тестов решения AMD показывают близкие результаты в OpenCL и DirectCompute, а иногда их скорость в OpenCL-тесте оказывается чуть выше. В случае видеоплаты Nvidia все обстоит совершенно иначе: зачастую Geforce GTX 670 намного быстрее в CUDA- или DirectCompute-вариантах этих же тестов. Что говорит об очевидном — решения AMD лучше оптимизированы для OpenCL, а чипы Nvidia значительно лучше исполняют код CUDA и Compute Shader.
SVPmark 3.0.3a
http://svp-team.com/wiki/SVPmark/ru
Ну и последним тестом OpenCL-производительности у нас будет SVPmark. Он позволяет оценить скорость вычислений при использовании алгоритмов, применяющихся в пакете SmoothVideo Project (SVP). SVP позволяет просматривать видеоданные на ПК с увеличением плавности видеоряда, которая обеспечивается добавлением в него кадров, содержащих интерполированную информацию о промежуточных положениях объектов.
Подобные технологии широко используются в современных LCD-телевизорах (наверняка все видели на ТВ-коробках красивые цифры с сотнями герц, вроде «200 Hz» или «400 Hz» и т. п. — вот это оно и есть), но и на ПК использование SVP имеет смысл, так как пакет абсолютно бесплатен, дает бо́льшую плавность воспроизведения и имеет гибкие настройки, позволяющие подстроить изображение так, как нужно пользователю, в большинстве популярных программных медиапроигрывателей.
Нас интересует то, что пакет SVP использует вычислительные способности современных графических процессоров, поддерживающих OpenCL — они применяются для снижения нагрузки на CPU и повышения качества итоговой картинки. Тестовый пакет SVPmark позволяет определить, нужно ли использовать в работе ускорение на GPU или нет, и включает следующие группы тестов: синтетические тесты для CPU (четыре теста) и GPU (три теста), реальные тесты в виде сценариев Avisynth на тестовых видеофрагментах заданного разрешения и измерение времени их исполнения. Естественно, мы использовали максимально возможное разрешение Full HD и OpenCL-ускорение:
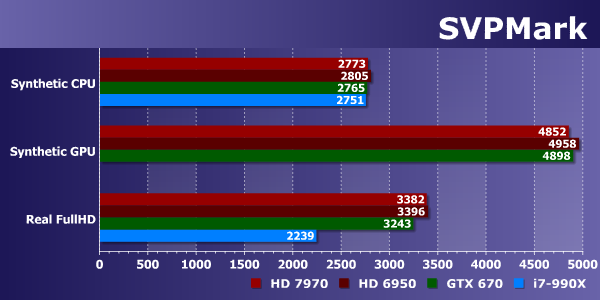
Судя по цифрам, этот тест довольно прост для всех наших OpenCL-устройств. Даже Core i7-990X справляется с задачей очень хорошо, и в реальных тестах при обработке видеоданных в Full HD-разрешении он отстает от графических процессоров лишь в полтора раза. Понятно, что цифры первого подтеста (синтетический тест CPU) практически не отличаются во всех трех случаях (так как центральный процессор во всех сравниваемых системах один и тот же).
Смотрим, что можно сказать по сравнению различных графических процессоров в этом бенчмарке. Разница крайне невелика. В синтетических тестах ее фактически нет, разница между результатами лишь 2%, то есть она лежит в пределах погрешности, да и в реальном тесте видеообработки даже до 5% разницы не дотянули. Так что, на наш взгляд, SVPMark вряд ли подходит для задачи тестирования OpenCL-производительности графических процессоров.
Выводы
После многочисленных тестов можно смело утверждать, что как сама платформа OpenCL, так и соответствующие бенчмарки и драйверы еще недостаточно «зрелые». Во многих тестовых пакетах находились какие-то странности с производительностью некоторых решений, а то и вовсе фатальные ошибки, не позволяющие запустить тест в нормальном режиме и получить итоговый результат.
Примеров такой «сырости» в нашем материале было отмечено предостаточно: несколько тестов пакета Basemark CL некорректно работают на Geforce, пара тестов из CLBenchmark вовсе не запускаются на Radeon, наблюдаются явные проблемы с одной из демо-программ в GPU Caps Viewer на чипах AMD, а также можно выделить неравное сравнение в PCMark, вызванное отсутствием поддержки OpenCL 1.2 в драйверах Nvidia.
Вторым по важности пунктом в наших выводах следует явная предрасположенность некоторых тестовых пакетов к решениям разных производителей и даже поколений их продуктов. Сплошь и рядом встречаются сильно отличающиеся оптимизации, из-за которых впереди то графические процессоры AMD, то чипы компании Nvidia (необходимо отметить, что последнее случалось намного реже). Нет, мы вовсе не обвиняем авторов тестов в «любви» к тем или иным решениям, все объясняется объективными причинами. Ведь даже в одинаковых, казалось бы, задачах можно использовать разные возможности OpenCL, которые на одних чипах работают быстрее, а на других — медленнее.
И в качестве примеров таких оптимизаций можно указать на бенчмарки LuxMark и ratGPU. Оба этих теста измеряют GPGPU-производительность в одной и той же задаче — при рендеринге 3D-изображения при помощи трассировки лучей (рейтрейсинг), но их результаты отличаются радикально! Похоже, что эти OpenCL-бенчмарки имеют различные оптимизации, предназначенные для определенных GPU. Тест LuxMark заметно быстрее работает на графических процессорах AMD Radeon, чем на чипах Nvidia Geforce, а в ratGPU ситуация обратная — видеокарта компании Nvidia в нем несколько сильнее конкурирующей, схожей по позиционированию и цене.
И что же в итоге: можно ли применять OpenCL-бенчмарки для тестирования графических процессоров? Конечно можно. Вот только очень осторожно. Во-первых, нужно четко отмечать те тесты, в которых наблюдалась явно аномальная производительность того или иного решения, и учитывать это в своих выводах. Во-вторых, если наблюдаются явные предпочтения по производителю вычислительного устройства, то следует попытаться найти аналогичные тесты, использующие ту же задачу в качестве вычислительной нагрузки, и применять не один из тестов, а сразу несколько.
Ну и последнее: по вышеуказанным причинам, для оценки OpenCL-производительности нельзя делать далеко идущие выводы лишь по одному-двум бенчмаркам, желательно провести сравнение сразу в нескольких OpenCL-тестах и сделать общие выводы. Например, если бы мы сейчас оценивали примерно равные по цене и позиционированию графические процессоры Geforce GTX 670 и Radeon HD 7970 в OpenCL-тестах, то вывод был бы таким: решение компании AMD значительно производительнее видеокарты Nvidia в большинстве выбранных нами GPGPU-задач.
Что касается использования OpenCL-бенчмарков в материалах раздела «3D-видео», то мы постараемся включить некоторые из представленных в материале тестов, доказавших свою актуальность и применимость, в наши базовые материалы, посвященные выходу новых моделей видеокарт разных производителей.


