
Со времени выхода нашего первого бенчмарка для тестирования ноутбуков (iXBT Notebook Benchmark v.1.0) прошло уже более года, и все используемые в бенчмарке приложения успели обновиться. А потому мы решили обновить и сам бенчмарк, а заодно и расширить набор используемых для тестирования приложений. Учитывая, что данный тестовый пакет мы будем использовать для тестирования не только ноутбуков, но и готовых решений (моноблоков, десктопов) и процессоров, мы также изменили название бенчмарка на iXBT Application Benchmark 2015. Этим названием мы хотим подчеркнуть тот факт, что речь идет о тестовом пакете на основе реальных приложений. Собственно, идеология, положенная в основу бенчмарка iXBT Application Benchmark 2015, осталась прежней — как в бенчмарке iXBT Notebook Benchmark v.1.0. Изменились лишь версии используемых приложений и расширился набор самих приложений. И если ранее в нашем пакете iXBT Notebook Benchmark v.1.0 использовалось девять различных приложений, на основе которых было создано девять отдельных тестов, то теперь используется тринадцать приложений, на основе которых создано шестнадцать различных тестов.

Производительность виртуальной машины всегда ниже, чем реальной, хотя в последнее время эти потери удалось серьезно сократить благодаря совершенствованию аппаратной и программной поддержки. В этом материале мы посмотрим, как уменьшилась производительность реальных приложений в виртуальной машине относительно реальной. В качестве хост-ОС и гостевой ОС используется Windows 7.
Тестировать рабочие станции (в том числе, и графические) нам приходится не так часто, как, скажем, ноутбуки, моноблоки или обычные домашние компьютеры. Однако и использовать для этого методику, которую мы применяем для тестирования ноутбуков и моноблоков, было бы некорректно, а потому мы решили разработать отдельную методику тестирования рабочих (графических) станций. Под термином «рабочая станция», как правило, понимают высокопроизводительный компьютер, который предназначен для таких специализированных задач, как обработка изображений, видео и звука, решения различных инженерных и архитектурных задач, задач САПР, инженерно-технических и научных вычислений и пр. Мы подобрали 12 различных тестов, включая как нашу автоматизацию процесса работы в приложениях, так и признанные отраслевые бенчмарки. Была подобрана и протестирована референсная система, с которой мы в дальнейшем будем сравнивать все новые решения.


В наступившем 2014 году первым анонсом для компании AMD стало представление очередного семейства APU, известного под кодовым именем Kaveri. Именно в этом поколении APU наконец-то стало видно, для чего компания несколько лет назад купила ATI, известную своими графическими решениями — для полноценного слияния вычислительных CPU- и GPU-ядер. В Kaveri объединилось множество технологий, предназначенных именно для универсальных вычислений: унифицированная графическая архитектура, общий доступ к памяти и прочие возможности архитектуры HSA. И глобальная цель Kaveri — не просто выпуск очередных решений со встроенной графикой для наиболее массового ценового сегмента, но значительно более важная задача, к которой AMD идет и о которой мы поговорим в обзоре.


Одним из самых интересных нововведений платформы Intel Haswell стала графическая часть. Для новой линейки представлено несколько вариантов интегрированного графического ядра, от младшего сегмента и до самой мощной версии Iris Pro 5200 с собственной памятью, играющей также роль высокоскоростного общего кэша. В этом материале речь пойдет о технических особенностях новых интегрированных графических адаптеров Intel и строении модельной линейки.

Архитектура процессорной части платформы Intel Haswell: основные новшества и преимущества в отдельных блоках по сравнению с предыдущим поколением архитектуры Intel Sandy Bridge и предыдущим поколением 22-нанометровых процессоров Ivy Bridge.

Новые команды и ускорение старых, защита реальная и мнимая, секреты экономии и авторазгона, бардак с названиями и кристаллами, реализация 22-нанометровых транзисторов, срам на презентации и, конечно же, — мировой заговор.

Новые команды и ускорение старых, защита реальная и мнимая, секреты экономии и авторазгона, бардак с названиями и кристаллами, реализация 22-нанометровых транзисторов, срам на презентации и, конечно же, — мировой заговор. Во второй части обзора описаны: энергоэффективность и авторазгон, модели, кристаллы и то, что сверху, детали о транзисторах.

Новые команды и ускорение старых, защита реальная и мнимая, секреты экономии и авторазгона, бардак с названиями и кристаллами, реализация 22-нанометровых транзисторов, срам на презентации и, конечно же, — мировой заговор. В первой части обзора описаны: ядро, режим SMEP, цифровой ГСЧ и Большой Брат, внеядро и ГП.

Данное небольшое тестирование можно считать практической проверкой известного всем предположения, что падение скорости вычислений от виртуализации — незначительно.

AMD запоздало ответила на Intel Atom, выпустив процессор, разработанный с нуля специально для массовых мобильных устройств. Что получилось и что нет, как могло быть и как планируется продолжить — подробно в нашем обзоре.

AMD запоздало ответила на Intel Atom, выпустив процессор, разработанный с нуля специально для массовых мобильных устройств. Что получилось и что нет, как могло быть и как планируется продолжить — подробно в нашем обзоре.

AMD запоздало ответила на Intel Atom, выпустив процессор, разработанный с нуля специально для массовых мобильных устройств. Что получилось и что нет, как могло быть и как планируется продолжить — подробно в нашем обзоре.
Разумеется, игры бывают разными, а мы тестировали только шесть из них. С другой стороны, примерно одинаковое положение во всех шести позволяет с высокой долей уверенности утверждать, что и в других картина вряд ли будет сильно отличаться. Так какой будет итоговая оценка? Миф о радикальном влиянии версии драйверов можно считать опровергнутым. Миф о неограниченной процессорозависимости видеокарт, растущей по мере роста мощности последних, тоже можно считать опровергнутым как минимум в рамках, в которые укладываются протестированные процессоры. Миф о радикальной разнице между платформами в плане поддержки конфигураций PCIe тоже можно считать опровергнутым в рамках тестирования. Миф о том, что важнейшим компонентом игрового компьютера является видео… А это, собственно, и не миф, что было очевидно изначально. Мы просто в очередной раз подтвердили данный постулат.

Перед окончанием действия методики 2011 года мы решили провести эксперимент: сформировать на ее основе сокращенный вариант, сделанный по принципу отбрасывания всех игровых и профессиональных приложений и предназначенный специально для тестирования офисных и мини-ПК, и выпустить серию сравнений на базе этой новой методики. Кроме того, мы выполнили серию тестов с целью получить ответ на вопрос: сколько памяти нужно устанавливать в офисный или домашний неигровой миникомпьютер, не предназначенный для решения сложных профессиональных задач?

Данная статья сводит воедино все выпущенные за прошлый год статьи процессорного раздела: от будничных тестирований новых моделей и расширенного исследования новых архитектур — до аналитики и эссе на процессорные и околопроцессорные темы. Статьи представлены в списке в хронологическом порядке, а выпущенные в рамках специальных серий — еще и перечислены отдельно в рамках этих «сериалов». Кроме того, путеводитель позволяет быстро найти все материалы, в которых приведены результаты тестовых испытаний определенной модели процессора, для чего приведен отдельный список протестированных за год процессоров. Ссылки на статьи сопровождаются краткой аннотацией.

Обзор микроархитектуры процессоров AMD Llano: позиционирование, отличия от предыдущих ЦП, встроенная графика и методы её интеграции, новый для AMD 32-нанометровый техпроцесс, кристалл и его странности, энергоэффективность, авторазгон, модели, чипсеты, платформы, перспективы и итоги.

История, наши дни и будущее микроэлектроники. Даны описания современных и будущих технологических процессов разных фирм, а также раскрыты некоторые любопытные и важные тайны, о которых за пределами отрасли чипостроения знают весьма мало.

История, наши дни и будущее микроэлектроники. Даны описания современных и будущих технологических процессов разных фирм, а также раскрыты некоторые любопытные и важные тайны, о которых за пределами отрасли чипостроения знают весьма мало.

История, наши дни и будущее микроэлектроники. Даны описания современных и будущих технологических процессов разных фирм, а также раскрыты некоторые любопытные и важные тайны, о которых за пределами отрасли чипостроения знают весьма мало.

История, наши дни и будущее микроэлектроники. Даны описания современных и будущих технологических процессов разных фирм, а также раскрыты некоторые любопытные и важные тайны, о которых за пределами отрасли чипостроения знают весьма мало.
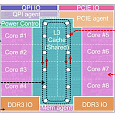
В этом цикле статей мы выполним детальный обзор микроархитектуры процессоров Intel Sandy Bridge. При этом мы опишем не только ныне добавленные и изменившиеся элементы, но и старые. В первой части цикла раскрывается подход к новой микроархитектуре «крутой и холодный», обсуждаются фронт конвейера (предсказание переходов, декодирование и IDQ, стековый движок, тайная жизнь нопов) и кэш мопов (цели и предшественники, устройство, размеры, ограничения, работа). Во второй части цикла рассматриваются планировщик (размещение и переименование, новый старый стиль), исполнительная стадия (тракты данных, конфликты завершения, межтрактные шлюзы, вещественные денормалы, частичный доступ к регистрам), AVX (реализация, подножка, решение, сохранение состояния, динамические тайминги, новые и отсутствующие команды) и тайминги команд. В третьей части цикла рассматриваются кэши (L1D, LSU, внеочередной доступ, STLF, задержки чтения, TLB, аппаратная предзагрузка), Hyper-Threading, внеядро (кэш L3, кольцевая шина, поддержка аппаратной отладки, когерентность и «поддержка» OpenCL, системный агент и ИКП) и Turbo Boost 2.0. В четвертой, заключительной части цикла рассматриваются экономия, модели и чипсеты, кристалл (техпроцесс, виды кристаллов, устройство ГП, устройство банка L3, 2-ядерные кристаллы), производительность, а также перспективы и итоги.
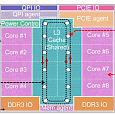
В этом цикле статей мы выполним детальный обзор микроархитектуры процессоров Intel Sandy Bridge. При этом мы опишем не только ныне добавленные и изменившиеся элементы, но и старые. В четвертой, заключительной части цикла рассматриваются экономия, модели и чипсеты, кристалл (техпроцесс, виды кристаллов, устройство ГП, устройство банка L3, 2-ядерные кристаллы), производительность, а также перспективы и итоги.
В этом цикле статей мы выполним детальный обзор микроархитектуры процессоров Intel Sandy Bridge. При этом мы опишем не только ныне добавленные и изменившиеся элементы, но и старые. В третьей части цикла рассматриваются кэши (L1D, LSU, внеочередной доступ, STLF, задержки чтения, TLB, аппаратная предзагрузка), Hyper-Threading, внеядро (кэш L3, кольцевая шина, поддержка аппаратной отладки, когерентность и «поддержка» OpenCL, системный агент и ИКП) и Turbo Boost 2.0.
В этом цикле статей мы выполним детальный обзор микроархитектуры процессоров Intel Sandy Bridge. При этом мы опишем не только ныне добавленные и изменившиеся элементы, но и старые. Во второй части цикла рассматриваются планировщик (размещение и переименование, новый старый стиль), исполнительная стадия (тракты данных, конфликты завершения, межтрактные шлюзы, вещественные денормалы, частичный доступ к регистрам), AVX (реализация, подножка, решение, сохранение состояния, динамические тайминги, новые и отсутствующие команды) и тайминги команд.

В этом цикле статей мы выполним детальный обзор микроархитектуры процессоров Intel Sandy Bridge. При этом мы опишем не только ныне добавленные и изменившиеся элементы, но и старые. В первой части цикла раскрывается подход к новой микроархитектуре «крутой и холодный», обсуждаются фронт конвейера (предсказание переходов, декодирование и IDQ, стековый движок, тайная жизнь нопов) и кэш мопов (цели и предшественники, устройство, размеры, ограничения, работа).

Основная группа и подгруппы, в неё входящие, обеспечивают достижение главной цели методики тестирования: подробное исследование производительности тестируемой системы с помощью основных наборов бенчмарков и выведение среднего балла, который в рамках рассматриваемой методики является универсальной обобщённой характеристикой производительности.

Несложно заметить, что история разгона процессоров на платформах Intel (да и AMD, в общем-то, тоже), как и вообще вся человеческая история, соткана из регулярных взлетов и падений. Бывают периоды, когда что-либо разгонять сложно (если вообще возможно), причем это требует высокой квалификации. Но они сменяются моментами, когда разгон становится делом простым и элементарным. Правила игры, как водится, определяет производитель. Иногда, правда, некоторым пользователям кажется, что они самые умные и способны обмануть кого угодно, однако на поверку оказывается, что любой «аттракцион неслыханной щедрости» проводится в заранее определенных рамках.
TSMC начнёт выпуск 1,6-нм чипов в 2026 году
25 апреля 2024 г.
Чем на это будет отвечать Intel? В Сети засветились 55-ваттный мобильный APU AMD Strix Halo с огромным iGPU и 12-ядерный Strix Point
25 апреля 2024 г.
Нет, новая SoC Kirin 9010 не выглядит хорошо даже на фоне старых платформ Qualcomm. Это примерно уровень Snapdragon 888 из 2020 года
24 апреля 2024 г.
