Часть 2-я
Оглавление
- «Крутой и холодный».
- Фронт конвейера: Предсказание переходов; Декодирование и IDQ; Стековый движок; Тайная жизнь нопов.
- Кэш мопов: Цели и предшественники; Устройство; Размеры; Ограничения; Работа.
- Диспетчер и планировщик: Переименование и размещение; Новый старый стиль.
- Исполнительная стадия: Тракты данных; Конфликты завершения; Межтрактные шлюзы; Вещественные денормалы; Частичный доступ к регистрам.
- AVX: Реализация; Подножка; Решение; Сохранение состояния; Динамические тайминги; Новые и отсутствующие команды.
- Тайминги команд.
- Кэши: L1D; LSU; Внеочерёдный доступ; STLF; Задержки чтения; TLB; Аппаратная предзагрузка.
- Hyper-Threading.
- Внеядро: Кэш L3; Кольцевая шина; Поддержка аппаратной отладки; Когерентность и «поддержка» OpenCL; Системный агент и ИКП.
- Turbo Boost 2.0.
- Экономия.
- Модели и чипсеты.
- Кристалл: Техпроцесс; Виды кристаллов; Устройство ГП; Устройство банка L3; 2-ядерные кристаллы.
- Производительность.
- Перспективы и итоги.
Диспетчер и планировщик
Переименование и размещение
Переходим к тыловой части. Первое крупное изменение — новые диспетчер и планировщик. Как и любой представитель этой стадии, диспетчер выполняет переименование регистров, размещение мопов в очереди ROB и резервации, приём завершённых мопов и их отставку. Каждый такт диспетчер принимает до 4 мопов от IDQ, прописывает физические регистры, помещает мопы в ROB (тоже до 4), разделяет слитые мопы на простые и отправляет их (до 6) в резервацию, связав каждый с нужным портом запуска (которых тоже 6). Очевидно, что в четвёрке принимаемых мопов допустимо не более трёх микро- или макрослитых, чтобы после разделения их можно было обработать за такт. Мопам обмена с памятью также выделяют ячейки в очереди загрузки или сохранения в LSU.
Некоторые мопы сразу после (или даже вместо) переименования указываются как незапускаемые:
- любые нопы (до 4 за такт) — потому что они ничего не делают;
- FXCH (обмен местами регистров x87-стека, до 2 за такт) — их «исполнение» заключается в переименовании пары регистров (в предыдущих ЦП только эта команда удалялась при размещении);
- VZEROUPPER (1 за такт, потому что генерируются 4 неисполняемых мопа) — для обнуления старших половин всех регистров ymm (об этом позже);
- классы обнуляющих и единичных идиом (zeroing idioms, ones idioms; 4 и 2 за такт).
К обнуляющим относятся команды, действие которых при указанных операндах всегда сводится к обнулению регистра-приёмника, хотя сами они специально для этого не предназначены. К таким SB относит все виды команд *XOR* (исключающее ИЛИ), *SUB* (вычитание) и PCMPGT* (векторная целая проверка на «больше»), все аргументы которых являются одним регистром (звёздочками заменены переменные части мнемоник разных версий команд). Поскольку результат предопределён, то считается, что никаких источников команде читать не надо, а потому она эквивалентна простому помещению константы 0 в целевой регистр. Явное обнуление в x86 не используется из-за особенностей ISA: для РОНов такая команда окажется длиннее идиомы, а для векторных регистров этого варианта нет вообще.
Само обнуление происходит за счёт того, что архитектурный регистр-приёмник перенумеруется на свободный физический регистр, помечаемый как содержащий нули (хотя реально там наверняка что-то другое). Потому «исполнять» такие мопы можно по 4 за такт, тогда как обычные *XOR*, *SUB* и PCMPGT* запускаются максимум тройками. Как-бы-нулевой регистр не читается из РФ, а в ФУ просто посылается сигнал, что этот аргумент — константа 0. Правда, анализа на 0 результатов вычислений в ФУ и загрузок из кэша не происходит (хотя флаг Z после большинства операций в АЛУ показывает именно это), так что 0 в регистре может оказаться и после необнуляющих команд с последующим штатным чтением — диспетчер о нём просто не узнает.
К обнуляющим также относится команда CLC, сбрасывающая флаг переноса. Поскольку 4 основных флага (перенос, переполнение, ноль и знак) также переименовываются, CLC по нашим тестам также может «исполняться» 4 раза за такт, хоть это и бессмысленно. Впрочем, представитель Intel заявил, что к CLC заочное обнуление не относится… Ещё одна группа команд, сокращающаяся подобным образом — единичная идиома PCMPEQ* (векторная целая проверка на «равно»). По аналогии с обнуляющими, при одинаковых аргументах она всегда устанавливает все биты приёмника в «1». Однако, в отличие от «обнулятелей», такому мопу всё же надо исполниться в любом из двух портов, куда обычно попадают эти команды — удалённо отметить регистр как содержащий единицы диспетчер не может, их надо записать явно.
Новый старый стиль
Прежде чем рассказать о само́м планировщике, вспомним основные различия между ними в нашей Энциклопедии. Точнее, нас интересует «хранящий» вариант с несколькими РФ и «ссылочный» с одним (физическим). Первый более привычен, т. к. применялся во всех x86-ЦП с внеочерёдным исполнением, за исключением всех P4. А второй был в P4 — и вот сейчас вернулся в SB. Может быть, Intel что-то перепутала, внедрив в новую экономную архитектуру блок из старой Netburst, представители которой «прославились» тепловыделением? (Также его применяют во всех серверных ЦП IBM POWER, которые ещё выше по частоте и ещё жарче.) Однако планировщик к этому точно не был причастен, а очень даже наоборот — именно вариант с физическим регистровым файлом (ФРФ), как ни странно, оказывается самым экономным.
До сих пор все основные процессы в планировщике (от размещения до отставки) требовали перемещения мопов вместе с накопленными в них данными, что требовало довольно много энергии (вспомните длину мопа и добавьте биты регистров-операндов). Вариант с ФРФ копирует или меняет не сами значения, а только 8-битные (в данном случае) ссылки на тот регистр в ФРФ, где они хранятся. Ещё одно преимущество такой схемы в снятии ограничения на число чтений из РФ. Дело в том, что в старой схеме основным РФ в исполнительном тракте был спекулятивный (СРФ), а вторичным — архитектурный (АРФ). Размер СРФ должен быть достаточен, чтобы держать аргументы и результаты всех хранящихся в резервации(ях) мопов, а размер АРФ, разумеется, будет совпадать с числом регистров данного типа согласно ISA.
Проблема была в том, что у АРФ лишь 3 порта чтения (а в Pentium II и III — 2), и при переименовании регистров 3–4 размещаемых мопа могут за такт прочесть (и скопировать в свою ячейку ROB) лишь небольшое число регистров, которые достаточно давно не менялись, чтобы их значения уже успели попасть из СРФ в АРФ при отставке. Учитывая, что у каждой целочисленной и AVX-команды число читаемых регистров может достигать трёх, разместитель не справился бы за такт со сбором всех нужных данных для четвёрки мопов. При использовании единственного РФ число его портов достаточно большое (по нашим тестам, в SB — 10 чтений и 5 записей), чтобы за такт прочесть и записать всё необходимое.
Поскольку каждый моп теперь не накапливает содержимое регистров, обе очереди тыла (ROB для диспетчера и резервация для планировщика) могут при той же площади хранить большее число мопов: 128 и 36 ячеек в ROB и RS Nehalem подросли до 168 и 54 в SB. Это значит, что планировщик теперь может отслеживать зависимости команд в более длинном куске кода, получая возможность одновременно запустить даже далёкие друг от друга команды. Это особенно пригождается при исполнении двух потоков, делящих между собой большинство ресурсов, включая обе этих очереди (опишем потом, как именно). Размеры же ФРФ такие — 160 64-битных РОНов и 144 256-битных векторных регистра. Правда, на самом деле векторных РФ два, каждый из которых хранит 128-битные половины. Почему так?
Исполнительная стадия
Тракты данных
Для ответа на вопрос выше снова сделаем исторический экскурс. Давным-давно, в далёкой-далёкой… гм, эпохе 70-х и 80-х гг. процессоры обрабатывали лишь целые числа, а потому исполнительный тракт у них был один, на 8/16/32 бита. Затем добавился вещественный тракт на 64/80 бит (архитектуре x86 в этом смысле пришлось труднее, потому что расширенную 80-битную точность больше нигде не внедрили). Далее, рассматривая только ЦП Intel, последовал набор MMX, который архитектурно хоть и использовал стек x87, но физически имел не только отдельные ФУ, но и регистры. Потом добавлен SSE — хотя для программиста регистры xmm 128-битные, векторные РФ и ФУ до Core 2 были 64-битными и тоже отдельными. Правда, когда SSE2 расширил целочисленную обработку до 128 бит, для этих ФУ нового РФ не создали, а просто переделали блок MMX, чтобы его РФ и ФУ могли хранить и обрабатывать и половинки 128-битных регистров.
В Core 2 структура исполнительного блока окончательно приобрела нынешние очертания. 64-битный целочисленный тракт работает с командами общего назначения, первый 128-битный — с целочисленными векторами, а второй 128-битный — с вещественными векторами и скалярами (включая x87). Вспомним, что при исполнении SSE-кода переключаться между целым и вещественным режимом не надо (в отличие от режимов MMX и х87), и каждый регистр xmm может хранить и целые, и вещественные значения. Но т. к. физически они хранятся и обрабатываются в разных РФ и доменах, возникает вопрос о доступности нужных данных нужному ФУ, если они находятся в соседнем тракте. Чтобы перемещений между векторными трактами было как можно меньше, в каждом их них есть блоки для наиболее частых команд — в частности, логических и некоторых перестановок. Но т. к. ФУ отдельные, то и команды для них Intel тоже решила сделать отдельными — и вот в x86 появилась такая химера, как «вещественная логика». Как-нибудь мы поговорим об этом звере, а пока договоримся обозначать такие ФУ как FLOG. Аналогично, ФУ для «целочисленной логики» назовём ILOG.
Пересылки данных между векторными трактами весьма редки благодаря наличию большинства нужных ФУ на каждом из них. Схема исполнительной стадии в Nehalem (не считая ФУ, используемых некоторыми редкими командами) выглядит так:
| Тракт→ | 64 бита, целый1 | 128 бит №1, целый | 128 бит №2, вещественный |
| Порт 0 | АЛУ2 Сдвигатель | АЛУ Перестановщик | FMOV (x87) FMUL FDIV |
| Порт 1 | АЛУ IMUL AGU3 | MOV ILOG IMUL Сдвигатель | FADD Конвертер4 |
| Порт 5 | АЛУ Сдвигатель | АЛУ Перестановщик | FMOV (SSE)5 FLOG Перестановщик |
Не указаны порты: №2 для вычисления адреса чтения и самого чтения из памяти, №3 для вычисления адреса записи и №4 для самой записи.
1 — Не указан скалярный целочисленный делитель: он получает мопы со всех трёх портов при любом виде деления.
2 — Напомним, что АЛУ работают только с целыми числами и, помимо арифметики и логики, выполняют также копирования (MOV).
3 — Это ФУ исполняет только команду LEA: вычисление адреса как для операции чтения, но с помещением в приёмник самого́ адреса (иногда используется как замена некоторых арифметических команд). Аналогичный блок в порту 2 вычисляет адреса для «настоящих» чтений, выполняя дополнительные неарифметические операции.
4 — Преобразователь арифметических форматов (между двумя вещественными или вещественным и целым). Для некоторых команд использует один из вспомогательных ФУ, получающих мопы с других портов.
5 — «Вещественные копирования», ещё одна химера, когда речь идёт о векторном регистре целиком.
И тут на сцену выходит набор AVX и его 256-битные регистры ymm. Как их обрабатывать? Основных вариантов три:
- Не менять ФУ, обрабатывая регистры половинками, как это было с xmm до Core 2;
- Поставить отдельный тракт или расширить один из имеющихся, снабдив его необходимыми и «полноширными» ФУ;
- Снабдить недостающими ФУ оба нынешних тракта, чтобы они могли работать над регистром ymm одновременно.
Нетрудно догадаться, какой вариант был выбран, учитывая, что процессору надо и скорость вычислений поднять, и энергию (обязательно) с площадью (желательно) сэкономить. Правда, по причинам, описанным далее в главе об AVX, добавлен только вещественный домен в бывший целочисленный тракт, который мы теперь назовём смешанным. После добавки и перетасовки ФУ в SB получилось вот что:
 От центра вверх — 3 исполнительных тракта SB (в порядке, указанном в таблице). 5 структур ниже центра — 64-битные РФ (4 из них попарно объединены). Внизу — диспетчер и планировщик. |
| Тракт→ | 64 бита, целый1 | 128 бит №1, смешанный | 128 бит №2, вещественный |
| Порт 0 | АЛУ Сдвигатель | MOV ILOG IMUL+FMUL1 Сдвигатель | FMOV (x87, AVX) FMUL IDIV+FDIV2 |
| Порт 1 | АЛУ IMUL Сложное AGU | АЛУ FADD Конвертер Перестановщик | FADD Конвертер |
| Порт 5 | АЛУ Сдвигатель | АЛУ3 Сдвигатель Перестановщик | FMOV (SSE, AVX) FLOG Перестановщик |
Не указаны порты: №2 и №3 для вычисления адресов и чтения из памяти и №4 для записи. Жирным указаны добавленные ФУ, курсивом — перемещённые, подчёркнутым — спариваемые.
1 — Универсальный умножитель для векторных целых и всех вещественных.
2 — Универсальный делитель для скалярных целых и всех вещественных. (Деления векторных целых в x86 нет.)
3 — Спариваются блоки копирования и логики.
Обратим внимание, что в Nehalem до полноценного АЛУ порту 1 не хватало лишь сумматора — логика и копирование там и так исполнялись. В SB целочисленные блоки портов 0 и 1 целиком поменяли местами, потеряв только отдельный умножитель, но почему-то не добавив на его место сумматор. Также нужно пояснить, почему, начиная с Pentium Pro, мопы записи разбиваются отдельно на вычисление адреса и саму запись. Во-первых, в элементарном мопе (в отличие от слитого) нет места и для данных, и для компонент адреса. Во-вторых — это часто позволяет заранее вычислить адрес, что поможет как можно раньше определить возможные адресные конфликты с чтениями (подробней об этом — далее).
Конфликты завершения
Теперь на секунду вернёмся к планировщику. Иногда встречается такая ситуация: некая команда после запуска исполняется в течение X тактов, но через Y тактов (Y Теперь каждый из трёх вычислительных портов может за такт принять завершение до трёх мопов с разных трактов (правда, в сумме со всех портов — вряд ли больше 6). До сих пор такими параметрами могла похвастать лишь AMD, у которой раздельные 3-портовые планировщики для целочисленного и векторно-вещественного трактов запускают и принимают на пару 6 мопов/такт. Однако даже там не удалось обойти проблему переменной задержки некоторых команд — прежде всего это деление и вся трансцендентная арифметика. Время исполнения этих операций зависит от содержимого аргумента(ов) — например, для скалярного вещественного деления и извлечения корня в SB это 10–24 такта. В этих случаях в старых ЦП резервация просто блокировала порт с медлительным делителем, пока он не завершал работу. Затем ЦП обеих компаний научились принимать стоп-сигналы от всех ФУ (а не только от делителя-извлекателя), но только один за такт (если завершаемых мопов в данном порту больше — они становятся в очередь). И вот SB удалил возможную задержку, принимая 3 завершения за такт (очередь возможна лишь среди ФУ, совпадающих и по номеру порта, и по тракту). Правда, для этого ему пришлось приделать к некоторым командам временны́е балласты, но об этом — позже.
Межтрактные шлюзы
Пересылка данных между трактами обычно занимает заметное время (на Nehalem в большинстве случаев — 2 такта). Как с этим в SB? Оказывается, декодер для ряда команд вставляет специальные мопы, использующие некоторые ФУ как межтрактные шлюзы: с 64-битного тракта в любой 128-битный — через порт 0, обратно — через 5-й, а между 128-битными работают оба. «Настоящие» шлюзы, как и ранее, иногда вызывают задержку в 1 такт при переходе между целыми и вещественными SSE-операциями, хотя теперь они являются доменами одного тракта. Зато задержек в 2 такта уже почти нет. Судя по нашим тестам, передача между трактами обычно занимает 1 такт, но для шлюза в порту 0 может быть и бесплатна — возможно, он физически находится ближе к «своим» ФУ и успевает срабатывать вместе с ними.
Вспомним, что для AVX-кода доступен 256-битный перестановщик. Если исполняется команда, не требующая пересылки элементов между трактами, то её задержка такая же, как и для SSE-версии, т. к. использует 2 ФУ для половинок ymm. В противном случае используется полнодуплексный межтрактный перестановщик на 256 бит, причём его задержка в 1 такт присутствует, даже если фактически данные между трактами не передавались. Все шлюзы являются частью исполнительного конвейера — т. е. одновременно допускается использование ФУ и межтрактных пересылок.
Вещественные денормалы
Стандарт IEEE-754, который используют почти все современные процессоры для представления вещественных чисел, имеет такую особенность: когда экспонента E установлена в 0, а содержимое мантиссы M ненулевое, число интерпретируется не в нормальном виде (1,M·2E), а «денормальном» (0,M·2Emin, где Emin — минимальная «нормальная» экспонента). Обработка таких чисел (а также бесконечности и неопределённости) на ЦП Intel всегда была замедлена на сотни (!) тактов из-за микропрограммного получения результата. (Яростные фанаты Противоположного Лагеря могут гордиться своим кумиром — у AMD как минимум начиная с первых Athlon денормалы почти не замедляли вычисления, а бесконечности и неопределённости даже ускоряли.)
Проблема настолько велика, что для векторных вещественных вычислений Intel ввела в x86 специальный «облегчённый» режим DAZ ([assume] denormals are zero — считать денормалы нулями), идущий ради производительности несколько вразрез с мировым стандартом. В SB большинство подобных ситуаций разрешаются аппаратными механизмами, что кардинально повысило скорость обработки денормалов (и серьёзно уменьшило размер микрокода). Теперь лишь умножение изредка может вызвать небольшую дополнительную задержку. Это может значительно ускорить код, работающий с очень близкими к нулю числами — например, при вычислении знаменателей суммы ряда, что требуется для большинства трансцендентных функций.
Частичный доступ к регистрам
Очередная сложность, возникающая при разработке процессора — архитектурное допущение читать и менять часть какого-либо регистра. В x86 это применимо к РОНам, xmm и ymm — причём последний случай настолько особый, что этому посвящена целая глава. Тут же опишем проблему в целом на примере 64-битного РОНа.
Архитектурно программист может использовать регистр целиком, младшие 4 байта, младшие 2 байта и младший 1 байт. Для первых 4 РОНов есть ещё доступ ко второму байту, но для всех x86-ЦП уже давно рекомендуется настоятельно забыть эту возможность — трудностей хватает и без этого. При очередном архитектурном удвоении разрядности регистров у инженеров есть несколько вариантов реализации доступа к новым и старым регистрам как полностью, так и частично:
- Сделать отдельные архитектурные РФ для регистров нужной разрядности — как при переходе от 64-битных регистров mm (для MMX) к 128-битным xmm (которые, правда, не сразу можно было использовать для целых чисел, так что ФУ у них поначалу были разные). Выгода — нет зависимостей по данным (как если бы каждый xmm содержал бы в своей младшей половине mm с тем же номером). Минусов больше — требуются спецкоманды для перемещения данных между старым РФ и новым, а архитектурное состояние для сохранения вырастает не на 64, а на 128 байт (тогда регистров было ещё 8). Сегодня же, когда x87 и MMX уже устарели, их содержимое всё ещё надо сохранять (кроме случая с применением новой команды, как будет описано ниже).
- Сделать отдельные физические РФ для младших частей регистров — как во всех ЦП Intel от PPro до PM включительно (кроме P4). Правда, из-за дополнительных затрат это применяется лишь к младшим байтам РОНов — остальные части используют другие методы. Как и в случае выше, зависимостей нет — переименованный 8-битный регистр N хранится отдельно от 32-битного с тем же номером. Однако есть штраф, когда части регистра должны объединиться, чтобы быть обработанными другой командой.
Пример: команда-1 обработала младший байт 32-битного РОНа, а следующая команда-2 читает его целиком. Вроде бы всё решается просто — команда-1 записывает изменённый байт не в «байтовый», а в основной (полноразрядный) РФ, а затем этот регистр читается весь. Но при внеочерёдном исполнении состояние старших трёх байт читаемого архитектурного регистра достоверно известно лишь при отставке, когда спекулятивый РФ записывает в архитектурный результаты готовых мопов. А значит при частичном доступе команда-2 вынуждена ждать 5–7 тактов до отставки команды-1.
- То же, что и выше, но части регистра могут объединяться в шлюзе при ФУ — это используется для РОНов в ЦП Intel с Core (первых) по Nehalem. При этом разместитель диспетчера автоматически вставляет дополнительный синхромоп, встраивающий только что записанный байт из «байтового РФ» в младший байт соответствующего ему регистра «полного РФ». Штраф в такой ситуации — 2–3 такта, т. к. достаточно дождаться завершения (не отставки) лишь последней команды, пишущей в данный регистр.
- Хранить регистры в цельном РФ, но получать доступ отдельными частями: для 64-битного РОНа — 1+1+2+4 байта, для xmm — 4+4+8 (напомним, что в наборах SSE есть скалярные вещественные команды, обрабатывающие только младший SP- или DP-элемент вектора). Применяется в Intel Core (2) и Nehalem — только для xmm, а в ЦП AMD и Intel Pentium 4 — и для РОНов, и для xmm. Никаких штрафов при использовании и даже слиянии регистров нет (т. к. синхромопы не используются), но существует ложная зависимость, когда запись в часть архитектурного регистра всегда считается зависящей от предыдущих записей в этот регистр — частичных и даже полных, когда он целиком перезаписывается.
Пример: команда-1 частично или полностью использует регистр xmm1, команда-2 сохраняет его в память, а скалярная команда-3 — записывает в его же часть новое значение. Тут разместитель не сможет распознать, что команде-3 старшая часть регистра xmm1 не нужна, и не выделит ему отдельный физический регистр, чтобы выполнить эту команду одновременно с первыми двумя. Зато разместителю и резервации требуется менее сложная и более экономная логика для отслеживания зависимостей, т. к. она применяется к регистрам целиком.
- Как выше, но во избежание ложных зависимостей запись в часть регистра сбрасывает в 0 остальную часть — это применяется при 32-битных операциях с 64-битными РОНами на всех ЦП (чтобы не ставить отдельный РФ для 8-байтовых версий регистров в дополнение к 4- и 1-байтовым), а также (как мы увидим ниже) при 128-битных командах AVX с регистрами xmm, т. е. младшими половинами ymm. Оба решения, очевидно, являются архитектурными.
- Программист или компилятор явно удаляет зависимость частей регистра, обнуляя его целиком или частично до использования как приёмник. Этот способ также используется в AVX, причём с немалым подвохом.
Теперь, когда все варианты перечислены, — на чём же остановились авторы SB? Для РОНов теперь используется метод №4, как и для xmm/ymm — в Nehalem же при частичной обработке РОНов надо было ждать лишние 3 такта. Исключение составляют «старшие» байтовые регистры (от AH до DH), которые всё же могут отдельно переименовываться. Но, как подсказывает Внимательный Читатель, есть ещё один ресурс, который и переименовывается, и читается-пишется (причём частично — куда чаще, чем полностью): 4–6 самых используемых флагов.
До сих пор ЦП использовали к ним подход №2, но SB перешёл на модифицированный вариант №3: флаг переноса (C) переименовывается отдельно, а для остальных имеется сливающий моп. Что это даёт? Вот типичная ситуация: в конце цикла команда INC или DEC меняет его параметр, записывая флаги нуля и знака в поле флагов физического регистра (имеется только для РОНов). Затем условный переход проверяет флаг нуля или знака — никаких проблем, они только что изменились. Но если условный переход читает флаг переполнения, либо попалась команда сохранения всех флагов в стек — придётся ждать, пока команды, менявшие оставшиеся 2 флага, уйдут в отставку, чтобы выделить нужный бит или их все. И вот SB сократил этот штраф примерно вдвое. Если же читается флаг переноса — то штрафа нет вообще.
Т. к. остальные флаги всё ещё держатся вместе, это создаёт любопытные эффекты — например, для команд сдвига. Дело в том, что согласно ISA вытесняемые биты должны попадать во флаг переноса, причём если параметр сдвига более 1, то попадёт только последний бит. Так вот этот вариант до сих пор вызывал парадоксальную зависимость флага переноса от своего же старого значения — после такой команды чтение только что изменённого флага всё равно приводило к штрафу. В SB такого штрафа нет, зато синхромопы для слияния флагов теперь всегда вставляются после многобитных вращений. В результате задержка получения результата вращения в регистре-приёмнике — 1 такт, а во флагах — 2–3.
AVX
Реализация
Главным новшеством в исполнительной стадии является добавление недостававших ФУ, чтобы вкупе с уже имеющимися суметь исполнить любую операцию с региcтрами ymm (кроме деления и извлечения корня) в полноконвейерном варианте и одновременно над всем вектором. Но как же получается, что несколько ФУ, которые надо задействовать для исполнения операции, находятся в одном порту? Ведь, как мы знаем, каждый порт может за такт запустить 1 моп… И тут на помощь приходит второе новшество, без которого первое не имело бы смысла — впервые среди процессоров (именно процессоров вообще) запускаемый через порт резервации моп может активировать более одного ФУ: в данном случае — пару одинаковых, потому в таблице выше они и названы спариваемыми. Таким образом за такт можно исполнить 3 256-битные AVX-операции, активировав 6 ФУ!
Но где восклицание — там и половник дёгтя: т. к. AVX-моп один, использовать два ФУ из пары отдельно не получится. Запустить 128-битные SSE-команды (да и 128-битные AVX) тоже можно лишь 3 за такт, так что на имеющемся коде, не знающем ни про какой AVX, почти половина векторных ФУ нового ЦП будет простаивать (разумеется, в выключенном состоянии для экономии), не принеся никакого ускорения. Очевидно, Intel делает большую ставку на активное использование AVX в обновлённых версиях ПО. Но и тут безоблачного будущего не предвидится — и не только потому, что внедрение нового часто происходит медленно…
Подножка
Как мы помним из исторического экскурса выше, иногда содержимое xmm-регистров перемещается через шлюзы в соседний векторный тракт, где местное ФУ производит с ним некую операцию. Результат при этом почти всегда записывается в местный же РФ, так что если следующая операция, которую требовалось исполнить над этим вектором, снова должна использовать местное ФУ — данные уже на месте. А теперь представим себе, что в SSE-код программист-оптимизатор добавляет вручную написанную процедуру с использованием команд AVX и регистров ymm, младшие половины которых, как мы помним, совпадают с регистрами xmm с тем же номером. Поскольку при исполнении AVX-команд 1-й («смешанный») векторный тракт работает только с младшей половиной ymm, а 2-й — только со старшей, это может потребовать обмена местами неверно расположенных половин регистра, для чего перед каждой операцией придётся проверять, где они расположены. Intel решила проблему иначе.
Для SB схема использования двух трактов изменилась: теперь на 1-й тракт попадают всё регистры mm, xmm и младшие половины ymm, а на 2-й — стек х87 и старшие части ymm (причём в регистрах с теми же номерами, что и для младших половин). Таким образом все векторные команды, кроме 256-битных AVX, используют 1-й векторный РФ для хранения всех операндов и устройства 1-го тракта для исполнения (опять же, без делителя-извлекателя — это ФУ, видимо, просто не уместилось). При работе с командами MMX, SSE и 128-битных версий AVX 2-й РФ не используется, а только хранит своё содержимое. И вот с SSE есть сложность.
Команда SSE, записывающая в некий регистр xmm, сохраняет содержимое старшей половины соответствующего ему регистра ymm, а вот аналог этой команды из набора AVX, работающий с этим же регистром xmm, согласно ISA обнулит старшую часть своего ymm. Ситуация бы упростилась, если бы все программы использовали только 128-битные векторы или только 256-битные. Но всё хуже: 2-й РФ не просто хранит старшие половины ymm — он лишь отслеживает положение соответствующих им младших половин в 1-м РФ, но свои половины синхронно не перемещает. Пример: команда SSE «ADDPD xmm1, xmm2» складывает пару вещественных DP-элементов регистра xmm2 с аналогичной парой из xmm1 и записывает на место последнего результат. После переименования регистров моп команды приобретёт неразрушающий формат операндов и будет выглядеть, например, так: «ADDPD xmm78, xmm34, xmm56» — т. е. до его исполнения архитектурному регистру xmm1 соответствовал физический xmm34, xmm2 — xmm56, а после отставки xmm1 будет назначен на xmm78. А теперь вопрос на засыпку — что будет со старшей половиной регистра ymm1?
Решение
Если бы команда была «VADDPD xmm1, xmm2» (префикс V- используется во всех командах AVX, включая работающие с xmm), то ответ ясен — старшую половину архитектурного xmm1 надо обнулить, что делается разместителем даже без доступа в РФ. А вот для SSE-версии её надо сохранить, что для 2-го РФ означает копирование физического регистра №34 в №78. И это только для одной команды, а всего их может быть до 5 за такт (3 вычислительные и 2 загрузочные). Intel могла бы оснастить старший РФ 5-полосным шлюзом с портов чтения на порты записи, а переименователь — возможностью слежения за половинами ymm отдельно. Но для упрощения и/или экономии инженеры вместо этого внедрили небольшой «теневой» АРФ, хранящий 16 старших половин регистров ymm, когда они не используются SSE-кодом. (Возможно, поэтому для РОНов физических регистров 160, а для xmm/ymm — 144, хотя планировщик обший…) Причём, АРФ должно быть даже два — по одному на поток.
Теперь, допустим, надо исполнить 256-битную операцию с регистром ymm1. Вероятно, планировщик должен подать векторным РФ номера обеих половинок (старшую — из АРФ), считав их содержимое в пару ФУ… Но оказывается, что напрямую из АРФ читать мопам нельзя. Поэтому не будет SB исполнять 256-битную команду AVX сразу после SSE. Вместо этого грянет аж 70-тактовый штраф, в течение которого сначала должны исполниться уже запущенные в резервацию команды (сериализация конвейера), а затем специальная микропрограмма восстановит все 16 старших половин ymm. Более того, и 128-битную AVX-команду тоже ждёт штраф — в АРФ нельзя даже обнулить регистр без выгрузки в основной РФ. Тот же штраф будет при при обратном переходе — когда после AVX-кода встретится любая команда SSE, и старшие половины потребуется сохранить обратно в АРФ. Но если штраф будет происходит часто, программисты хором пошлют AVX на всякие другие буквы, возопив «Как жить дальше?!»
Ответ Intel — «надо чаще обнуляться». В составе набора AVX есть команда VZEROUPPER, сбрасывающая старшие половины всех регистров ymm всего за 1 такт. После этого все связи между половинами можно считать исправленными, т. к. для любого регистра xmmN старшая часть ymmN содержит 0. Переходы между 128-битным и 256-битным векторными кодами не вызовут штраф, т. к. в старших частях точно нули. На физическом уровне АРФ не сбрасывается, а помечается как целиком нулевой, так что его уже не надо грузить в основной РФ. Но произвести сериализацию всё же придётся…
Вспоминая программиста-оптимизатора, во избежании штрафа он должен поставить VZEROUPPER перед вызовом оптимизированной AVX-процедуры и после него. Если процедура находится в библиотеке, вызывать которую может как программа с кодом SSE, так и с AVX, то VZEROUPPER должна быть и в прологе, и в эпилоге каждой функции. Тут может быть полезна ещё одна команда VZEROALL, обнуляющая все регистры ymm целиком. Тем не менее, можно предсказать, что программисты наверняка часто будут забывать вставить команды VZERO* в свой ассемблерный код. Выловить же эти ошибки трудно, т. к. программа всё ещё будет работать, хоть и медленнее, но мало ли на то причин…
Кстати: само существование 128-битных команд AVX в дополнение к таким же, но 256-битным — тоже своего рода костыль. Только на этот раз не для нахождения очередного компромисса внутри процессора между сложностью, скоростью и площадью. Дело в довольно большом объёме кода драйверов и даже компонентов ядер разных ОС, которые используют xmm и точно не будут скоро переписаны под AVX. А значит и общаться с ними надо на «128-битном языке». Но т. к. соблазны AVX-кодировки велики (представитель Intel даже как-то сказал, что неразрушающий формат и компактизация кода в сумме дадут не меньший эффект, чем удлинение векторов), компания решила дать программистам шанс ускорить и 128-битный код, чтобы не переключаться каждый раз со штрафами между SSE и полноразрядным AVX. Впрочем, за счёт своей многочисленности сообщество программистов ядра Linux вполне быстро бы перевело эту ОС на новый формат (будь он обязательным). Поэтому можно сделать вывод, что в сложностях устройства AVX виновата … Microsoft! :)
Сохранение состояния
После удвоения разрядности векторных регистров размер полного описания архитектурного состояния ЦП стал больше на 256 байт — теперь в нём все регистры общего и специального назначений, стек x87 и набор ymm занимают 832 байта. При прерывании и переключении контекста задачи всё это надо как можно скорее записать в специальную область памяти, а при возврате восстановить. А т. к. задержка (особенно для прерываний) должна быть минимальной, объём пересылаемых данных оказывается тому препятствием. В SB регистры общего и специального назначений записываются всегда (впрочем, они и меняются всегда), но есть специальный блок, отслеживающий 3 остальных РФ — стек x87 с регистрами mm для MMX, и старшую и младшую половины регистров ymm для SSE и AVX. Сохраняться и восстанавливаться будут только РФ, модифицированные за текущий сеанс работы с задачей. Например, программа, работавшая лишь с РОНами, сохранит в статусе всего около 100 байт. Однако это произойдёт не автоматически, а при использовании добавленной команды XSAVEOPT, поддержка которой обозначается отдельным битом в CPUID.
Динамические тайминги
При тестировании задержек и пропусков команд (о чём мы детально поговорим далее) мы обнаружили у AVX-кода некую странность, которой «не может быть никогда». Точнее, речь идёт о векторном вещественном сложении (вычитании) и умножении. В идеале, они, как и почти все остальные команды, должны иметь фиксированные тайминги — однако в наших тестах (если, конечно, всё было замерено точно) получилось совсем не так. Судя по всему, в случае долгого неисполнения вещественного кода блоки FADD и FMUL переходят в некое «полувекторное» состояние, когда 256-битные команды обрабатываются каждый 2-й такт, а задержки — на 2 такта больше нормы. Через несколько сот исполненных вещественных команд задержка уменьшается на 1 такт, а ещё через несколько сот, вместе с пропуском, наконец, становится номинальной. 128-битные операции также затронуты — задержка изначально на такт больше, но хоть пропуск не страдает.
Сразу скажем, что представитель Intel заверил нас, что это ошибка в наших тестах. Да и здравый смысл подсказывает, что ничего подобного в ЦП быть не должно. Т. к. требуется экономить энергию, отключая неиспользуемые подолгу блоки (что используется ещё со времён Pentium-M), инженеры наверняка оптимизировали время их включения до 1–2 тактов. А то, что планировщику оказывается куда трудней управлять потоком мопов в «полусонные» ФУ — и вовсе удаляет последние остатки здравого смысла. С другой стороны — никаких ошибок в нашей методике совместными усилиями мы так и не нашли. Тем более, что по такой же схеме были получены и остальные сотни цифр, которые по большей части подтверждены. Однако, если бы мы стали перепроверять все версии, статья бы вышла лет через пять. Тем не менее, проверка будет, пока же при дальнейших обсуждениях таймингов проигнорируем этот странный момент…
Новые и отсутствующие команды
В AVX 1-й версии входят 256-битные команды вещественной арифметики, логики и перестановок, но целочисленную арифметику и сдвиги почему-то оставили 128-битными — до выхода AVX2. Пока что для обработки регистра ymm с целочисленными значениями надо сначала сохранить его старшую половину в младшей половине другого регистра, затем обработать младшие половины обоих (старшие при этом обнулятся) и снова собрать в 32-байтовый вектор. Зачем так сделано, официального объяснения нет, а неофициальное примерно такое — вещественной арифметике большие векторы сегодня нужней, а целочисленной их добавят «потом», и пока выгодней обходиться командами AVX с регистрами xmm. Но ещё раз посмотрим на таблицу ФУ в SB — дополнив 2-й тракт сумматором и подключив его к порту 5, где уже есть блок логики и копирований, мы получили бы в нём полноценное 128-битное АЛУ, которое могло бы работать со своим «собратом по порту» из 1-го тракта. Зачем же добавлять 32-байтовые целочисленные векторы лишь через два года в AVX2, если почти всё уже готово?…
В ГП разных компаний и экспериментальном процессоре Intel Larrabee есть команды с векторными адресами — scatter и gather (разброс и сбор): запись и чтение вектора по индивидуальным адресам или смещениям его элементов, составляющим другой вектор. AVX же эти полезные во многих алгоритмах команды получит лишь во 2-й версии, т. к. для эффективного (т. е. параллельного, а не поэлементного) исполнения требуется серьёзное дооснащение кэша сложными коммутаторами в буфере строки (всей 64-байтовой строки, а не 16-байтового порта кэша). Пока это малосовместимо с требованиями поднять скорость без ущерба для площади и экономии, а потому откладывается до следующей микроархитектуры Haswell.
Но и у 1-го AVX есть, чем заполнить лакуну — команды чтения и записи с байтовой маской. Тут интересно, что замаскированные байты не только не считываются или записываются, но даже и не проверяются на возможность доступа. Например, невыровненное чтение, пересекающее границу страницы памяти, может вызвать кучу неприятностей (промах в кэше или TLB, запрет доступа и пр.), однако если все байты «на той стороне» оказываются с нулями в маске, никаких проблем не будет, т. к. фактический доступ и все проверки для них будут отменены. В отличие от команд разброса и сбора, дополнительных аппаратных блоков тут вводить не нужно, по крайней мере для Intel — уже в Nehalem кэши обладали почти всем нужным для такого функционала, просто теперь он программно управляем. Ещё одна новинка — команда «широковещания» (broadcast), копирующая элемент во все позиции вектора-приёмника (почему-то только из памяти в регистр).
Тайминги команд
Нашу традиционную таблицу с задержками/пропусками на этот раз оформим картинкой — уж больно сложной она получается. Полный список таймингов всех команд доступен на сайте Агнера Фога.
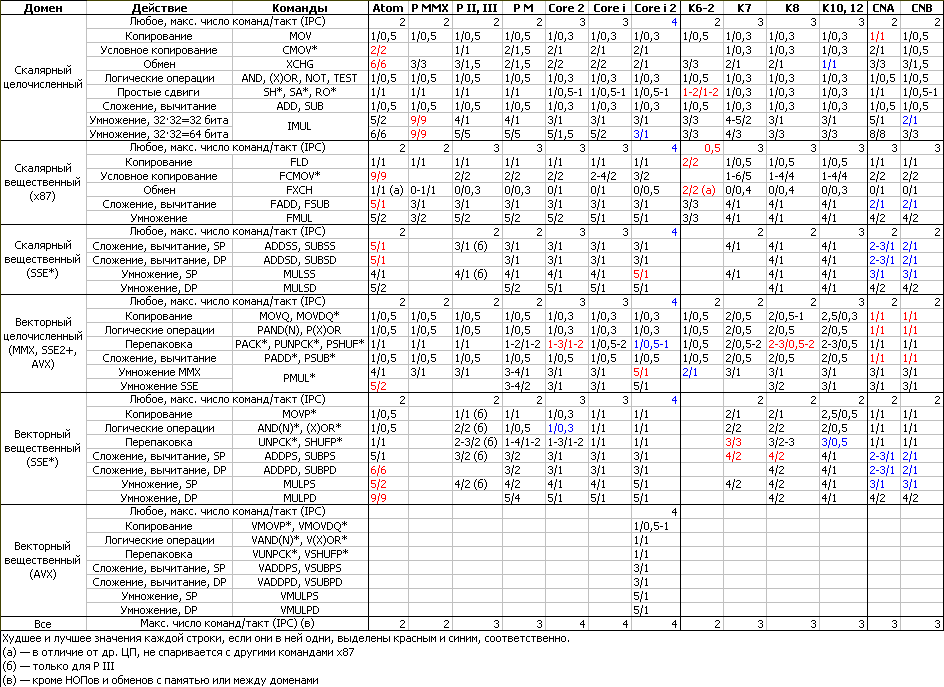
Итак, к имеющимся командным группам добавлена ещё одна — для вещественных 256-битных команд AVX. За вре́менным неимением конкурентов (до выхода AMD Bulldozer) помечать синим эти клетки не будем. :) Сравнение SB по остальным командам прежде всего показывает увеличение общего IPC в каждой группе до рекордных 4, т. к. учитывались обнуляющие директивы, работающие в каждом домене (кроме x87, где вместо них — обмены регистров).
Если посмотреть на отдельные команды, то главные изменения по сравнению с Core i — умножения. Скалярное целочисленное стало полноконвейерным даже при получении полноразрядного результата, однако тут есть нюанс: указанные 3 такта (справедливые и для умножения 64·64=128 бит) это задержка перед получением младшей половины результата, отправляемой в регистр EAX (RAX); старшая, для регистра EDX (RDX), будет готова тактом позже. Это происходит потому, что целочисленный умножитель уникален наличием второго командного порта — основной (принимающий моп для записи EAX/RAX) подключен к 1-му порту резервации, а второй — сразу к двум остальным (0-му и 5-му), откуда он получает моп для записи старшей половины. Выходит, что умножитель как бы находится сразу на всех вычислительных портах. При этом приём мопов возможен парами каждый такт, так что в итоге умножение оказывается полноконвейерным.
Совсем другая картина наблюдается со вторым умножителем (который, напомним, является общим для векторных целых и всех вещественных) — он стал работать за 5 тактов, даже для целых элементов. Это значит, что некоторые коды с нечастыми векторными целыми умножениями, от результатов которых зависят дальнейшие вычисления (что не позволит использовать конвейерность), могут чуть замедлиться, если программу не спасут другие улучшения в ядре. Куда интересней проанализировать, почему это вообще произошло.
Дело в том, что в погоне за упрощением (в т. ч. и по причинам экономии) производители ЦП часто делают таблицу таймингов в резервации общей для целой группы команд, даже если нужные ФУ могут обработать некоторые команды быстрее. Например, все основные вещественные команды в архитектурах AMD K7–10 исполняются за 4 такта: скалярные и векторные, одинарной и двойной (не для K7) точности, сложения-вычитания и умножения — во всех восьми комбинациях, хотя в каждой паре второй вариант явно сложнее. Но планировщику проще считать, что все такие команды исполняются за одинаковое время.
Intel такой подход до сих пор использовала только в Pentium II/III/M для команд SSE, что также видно по таблице: для 64-битных ФУ векторные команды должны быть не только полуконвейерными (т. е. с пропуском 2), но и с на единицу большей задержкой, чего как раз нет. Планировщик в Core 2/i стал более разборчивым и даёт отдельные задержки для сложений и умножений, причём для последних — в зависимости от точности. SB же вернул «округлённые вверх» упрощения для всех умножений.
Вообще-то такая стандартизация задержек началась ещё в Nehalem. Его резервация устроена так, что порт 0 выпускает мопы с задержками либо 1 такт, либо 4 и больше, порт 1 — 1 или 3 такта, а порт 5 — только 1. Правда, есть 2-тактовые мопы, запускаемые через все 3 порта, но один такт из пары тратится на межтрактный шлюз. Порты 2, 3 и 4 монопольно используются операциями с памятью и адресами аж с Pentium Pro. В SB изменился лишь порт 0, который теперь выпускает мопы с задержками либо 1 такт, либо 5 и больше (мопов на 4 такта, кажется, уже нет).
Стандартизация задержек повлияла и на команду LEA. В таблице ФУ для SB блок AGU указан как сложный. Это потому, что в сложные зачислены команды LEA, у которых адрес или RIP-относительный, или 3-компонентный (плюс ещё два редких случая), остальные (простые) считаются в АЛУ других двух портов за такт. «Сложное AGU» считает свои адреса аж за 3 такта, хотя AGU в Nehalem справлялось со всеми видами операндов за такт. Возможная причина кроется в том, что никакого AGU в тракте нет, а сложные операции делаются в АЛУ порта 1, но с дополнительным функционалом. Этого бы хватило, чтобы вычислить адрес за 2 такта, но «ленивый» планировщик не поймёт такой моп, так что его задержка «для совместимости» с портом 1 искусственно увеличена до 3 тактов.
Впрочем, нашлись исключения и из стандартов. Оказывается, не все векторные умножения исполняются в порту 0 — несколько целочисленных перенесены в порт 1, но при этом они сохранили задержку в 5 тактов. Причём сами эти команды мало чем отличаются от других векторных целочисленных умножений, так что неясна причина выделения им отдельного специализированного умножителя, который затем расположили в соседнем порту… Ещё страннее ситуация с командами сравнения векторов с целыми элементами: для каждой из 4 разрядностей элемента (от 1 до 8 байт) есть сравнения на «равно» и на «больше». Так вот из этих 8 команд 7 исполняются за 1 такт в любом из двух векторных целочисленных АЛУ (как и ожидалось, ведь сравнение по сути есть вычитание). Но вот отдельно взятая PCMPGTQ (сравнение 8-байтовых элементов на «больше») исполняется только в порту 0 и за 5 (конвейерных) тактов, хотя сложность операции точно такая же. Есть исключения и среди команд преобразования форматов, задержки многих из которых стали на 2 такта больше… В общем, если именно таким образом обновлённый планировщик экономит энергию, на всякий случай напомним: иная простота — хуже. ;)
Из других изменений следует выделить улучшенные тайминги некоторых видов команд скалярного сдвига и вращения. Утверждается, что это сделано специально для ускорения криптоалгоритмов, которым спецкоманды AES-NI не подходят, т. к. они заточены конкретно под шифр AES. Всё бы хорошо, если бы другие виды тех же самых команд, не используемые в криптокоде, в результате не замедлились. Например, двойные сдвиги в Nehalem исполнялись за 4 конвейерных такта. Теперь те из них, что имеют фактор сдвига в виде константы, готовы уже через 1 такт, причём сразу в двух ФУ, зато те, у кого этот операнд — регистр, стали полуконвейерными. Такие же тайминги оказались и у обычных сдвигов (хотя они проще), видимо снова ради стандартизации. Таким образом, почти на каждое улучшение в пропуске или задержке «популярной» команды найдётся ухудшение в исполнении команд менее популярных.
Комментарии