
Действующие лица и исполнители:
- Главный герой NV30 в роли GPU нового поколения GeForce FX
- Главный герой второго плана R300 в роли RADEON 9700 PRO
- 128-битная память DDR II на частоте 1 ГГц в роли главного злодея
- Шейдеры DirectX 9.0 и кинематографические эффекты в роли аргументов
- Прогрессивные технологии экономии пропускной полосы памяти и полноэкранного сглаживания в научно-фантастической роли защитников главного героя
Также в фильме принимают участие популярные синтетические актеры уже снятых и еще только планируемых полнометражных 3D-фильмов.
Мы к сценарию и самому фильму вернемся немного позже, а сейчас в качестве пролога или, так сказать, увертюры, предлагаем Вашему вниманию светскую кинохронику…
Светская кинохроника
25 ноября 2002 года, в пять часов вечера, в Московском кинотеатре "Пять Звезд" прошла официальная Российская презентация нового продукта NVIDIA GeForce FX.
Утро. Главный редактор видеораздела Андрей Воробьев в ожидании начала презентации:

5:00pm Кинотеатр "Пять звезд". Прибывающих журналистов встречает персонал презентации в веселых техногенных париках:

Оформление кинотеатра как нельзя лучше сочетается с привычными нам FPS. Знакомые элементы, узкие многоярусные навесы и коридоры. Диффузные, точечные и спекулярные источники света работают в точном соответствии с законами трехмерной компьютерной графики:

В наличии не только классический вентилятор, из множества игр, включая Doom III:

Но и обязательные монстры, без которых не обходится ни одна стрелялка:

Обратите внимание на использование попиксельного освещения, карт рельефа и окружающей среды. А в этом закутке разместились два монстра с кинематографическим качеством рендеринга: у первого присутствует сложная процедурная текстура, а на втором мы видим потрясающую анимированную шейдерную шерсть:

Эти светящиеся буквы напомнят нам, зачем же мы пришли:

Что ж, пора начинать презентацию. Выступает Европейский маркетинг-директор NVIDIA Алан Тике:

Он рассказывает о своем виденье будущего ПК, о роли отдельных и интегрированных графических решений. А также, разумеется, о росте занимаемой NVIDIA доле рынка. Затем выступает главный специалист по связям с разработчиками Джон Спитцер:

Его презентация посвящена непосредственно GeForce FX. Он не только рассказывает о характеристиках нового GPU но и демонстрирует карту на его основе, а также ее работу в составе демонстрационной системы. Все присутствующие с удовольствием наслаждаются демонстрационными программами NVIDIA и технологическими демками будущих игр. STALKER погружает зал в тишину зрители неотрывно смотрят на экран, с удивлением узнавая привычные элементы. Поверьте, на большом киноэкране игра с таким уровнем детализации выглядит ничуть не менее "кинематографично", чем Final Fantasy! Все затаив дыхание наблюдают за фантастически реальным (если так можно выразится) пейзажем заброшенного советского завода (или НИИ) из демонстрационного пролета в тестовой версии движка STALKER. Заметно, что обилие геометрии заставляет порой притормаживать даже GeForce FX. По субъективным ощущениям средняя скорость 15…30 кадров в секунду. Отметим что на GeForce4 MX440 эта игра идет со скоростью около одного или двух кадров, причем с артефактами. На GeForce4 Ti 4600 около 8..12 кадров. Что ж, эта игра будет серьезным аргументом за покупку нового ускорителя.
Далее разговор заходит о средствах моделирования, разработки и CG:

И напоследок Джон отмечает что продукты NVIDIA стали для разработчиков и тестеров стандартом дефакто, и это в свою очередь позволяет им становится все более и более надежными. Вот он смысл девиза "play it's meant to be played" играй так как это было задумано:

Карта в наших руках!

Между тем, наступило время задать вопросы и получить на них ответы. Выясняется, что со дня на день ожидается вторая ревизия чипа, которая и пойдет в массовое производство. Что дополнительное питание GeForce FX может быть не задействовано но тогда карта будет работать медленнее. Что карта сама регулирует скорость вращения вентилятора, основываясь на информации со встроенных в чип датчиков активности. Что новый GPU потребляет почти вдвое больше энергии, чем предыдущий. Несмотря на новую технологию сказывается существенно возросшие частота и число транзисторов. Что громоздкое решение использованное для охлаждения референсных карт может быть заменено производителем на более стандартное, но в случае его недостаточной эффективности скорость работы карты придется снизить. И много, других архитектурных подробностей, которые нашли отражение в новой версии нашей статьи.
Между тем, всем участникам презентации предоставилась возможность пообщаться в неформальной обстановке принять участие в различных конкурсах и перекусить. Автор не долго думая, решил поучаствовать в конкурсе фотопроб, близком к одному из его хобби и к своему удивлению занял первое место :-) В этом ему помогали симпатичные бабочки сошедшие прямо с экрана соответствующей демки NVIDIA:

Впрочем, что это такое? Мы забыли вернуть на место движок цветности из набора кинематографических эффектов! Вот теперь рендеринг удался:

Полученный приз отличная соковыжималка "Тефаль" заставил автора задуматься о логике организаторов розыгрыша. Судя по всему, она не основывается на классической двоичной системе :-). Больше всего внимания привлек конкурс в котором было необходимо создать свой собственный кинообраз. Справедливо отметить, что его участники потратили и больше всего труда, конструируя одежду и аксессуары:

Победил загадочный принц Гамлет, с ананасовым черепом в руках:

Несомненно, этот образ был самым сильным, законченным и трагическим. На этом все. Тестам время, а презентациям час. Вовращаемся к нашему фильму…
Кратко суммируем дополнения и уточнения внесенные в изначальный текст статьи:
Вокруг сценария: «Беги, Индустрия, беги!»

18 ноября 2002 года состоялся официальный анонс долгожданного и одного из самых спорных GPU от NVIDIA, известного специалистам под кодовым именем NV30. Вместе с ним было объявлено новое маркетинговое имя: GeForce FX. Ранее, считалось, что для выделения особой стати и значимости нового решения NVIDIA сменит давно присутствующую на рынке марку на что-то новое, но в итоге решено было этого не делать. Опросы общественного мнения показывают, что бренд GeForce известен существенно большему числу людей, чем название фирмы NVIDIA. Что ж, аналогичная ситуация уже случалась вспомним Pentium. Параллель с Intel признанным локомотивом IT индустрии уместна вдвойне, так как в данный момент NVIDIA, несомненно, является локомотивом на рынке 3D-графики, таким же, каким в свое время была 3dfx создатель первого действительно успешного аппаратного 3D-решения. Символичен тот факт, что во время разработки и проектирования NV30 было использовано множество идей и наработок из так и не осуществленного проекта 3dfx под кодовым именем Mojo. ![]()
Ни для кого не секрет, что GeForce FX являет собой воплощение так называемой гибко программируемой графической архитектуры т.е. графического процессора. Самое время назвать этот чип GPU, однако, с другой стороны, этот термин уже использовался ранее, для обозначения менее гибких решений, представляющих предыдущее поколение ускорителей (будем называть его поколением DX8: NV2x, R200 и пр.). Давайте отойдем подальше и окинем взглядом весь процесс перехода от фиксированных к гибко программируемым архитектурам:
- DX7/NV1x/R100 появление конфигурируемых пиксельных стадий.
- DX8/NV2x/R200 появление вершинных шейдеров и ограниченных пиксельных шейдеров на основе все тех же стадий.
- DX9/NV3x/R300 появление полноценных вершинных шейдеров с управлением потоком команд, появление программно управляемых пиксельных шейдеров с произвольным расположением команд.
Итак, налицо эволюционно происходящая революция (да будет прощена мне эта вольная фраза), причем все еще не завершенная на текущем этапе. В будущем нас ожидает еще один или даже несколько вероятных этапов:
- DX9.1/NV4x/R400 появление вершинных и пиксельных шейдеров с полым управляемым потоком команд и без каких-либо существенных ограничений на размер.
- DX10 появление возможности генерации новых вершин в шейдере и заметный рост возможностей системы шейдерных комманд.
- Появление полностью симметричной схемы программируемого GPU как массива полнофункциональных шейдерных процессоров, без какого-либо заранее заданного архитектурного разделения на пиксельные или вершинные шейдеры, тесселирующие или выбирающие текстуры блоки.
Как говорится, поживем увидим. Согласитесь, что три последних, вполне логичных шага, намеченных нами, могут растянуться на куда как большее число версий DX, как по вине Microsoft, так и по коварному умыслу разработчиков графических чипов.
С другой стороны, если с высоты подобной эволюционной схемы текущий этап и выглядит вполне рядовым, то для многих пользователей и программистов он может оказаться революционным, спровоцировав переход на использование возможностей гибкого программирования ускорителей. Большие и гибкие пиксельные шейдеры, даже без управления потоком команд, или с упрощенным управлением на уровне предикатов, способны принести на PC ранее недоступный визуальный уровень, совершив скачок существенно более заметный, нежели первые потуги прошлого поколения, зажатого в рамки неудобного ассемблерного кода шейдеров и крайне жестких ограничений считанным числом пиксельных стадий. Количество вполне может в этот раз перейти в качество, и эпоха DX9-ускорителей станет такой же заметной вехой, как появление 3dfx Voodoo. Вспомним Voodoo также не был первым в концептуальном плане. Но именно он спровоцировал количественный скачок распространения ускорителей, перешедший в качественный скачок написания поддерживающих их игр. Будем надеяться, что и в этот раз индустрия получит мощный толчок, вызванный возможностью писать сложные вершинные и пиксельные шейдеры на языках высокого уровня.
Пока же вопрос о революционности DX9-решений, о которой только и говорят специалисты по продажам соответствующих компаний, оставим в стороне, предоставив времени право разрешить его в ту или иную сторону. Отметим только, что если революционность всего решения в целом требует подтверждения и признания, то революционность отдельных технологий, заложенных в GeForce FX, не вызывает никаких сомнений уже сейчас. Но об этом чуть далее.
Следует отметить постепенное приближение ускорителей к обычным процессорам общего назначения, проходящее сразу на нескольких фронтах:
- Существенное повышение тактовых частот
- Постепенная замена и вытеснение грубой силы различными оптимизационными алгоритмами и подходами
- Выдвижение на первое место вычислительного аспекта
- Появление развитой системы команд «общеграфического» назначения.
- Поддержка нескольких универсальных форматов (видов) данных.
- Вероятное появление суперскалярного и спекулятивного исполнения.
- Постепенное снятие ограничений на сложность и гибкость программ.

Как мы видим, ускорители семимильными шагами движутся в сторону CPU, уже сейчас опережая «средние» модели процессоров общего назначения по числу транзисторов или пиковой вычислительной мощности. Вопрос конвергенции зависит только от времени и гибкости. CPU идут навстречу, со своей стороны все более увеличивая производительность, особенно на векторных операциях, и в скором времени будут способны выполнять вчерашние задачи графического ускорения. Более того, растет степень силового параллелизма CPU вспомните появление HT или многоядерных CPU. До прямой конфронтации еще очень далеко, но помяните мои слова через пять-десять лет она будет. Не столько между классами устройств ясно, что то, что останется в результате этой борьбы, будет называться CPU (или CGPU :) ), а между фирмами законодателями мод в той и другой области. Борьба же за кошельки покупателей происходит уже сейчас, и, судя по всему, графика в этой области нисколько не проигрывает CPU, а как минимум идет на равных.
Перед прочтением дальнейшего материала настоятельно рекомендуем читателю ознакомиться (если это еще не было сделано) со следующими ключевыми теоретическими материалами:
- 3dfx Tribute
- Matrox Parhelia 512 и DirectX 9
- 3Dlabs P10 и OpenGL 2.0
- ATI RADEON 9700 и DirectX 9
- ATI RADEON 9700 PRO
На этом, закончим наше обзорное отступление и обратимся к главному герою статьи GeForce FX.
GeForce FX: главная роль крупным планом


Ключевые спецификации нового GPU:
- Технологическая норма 0.13 микрон, медные соединения
- 125 миллионов транзисторов
- 3 геометрических процессора (превышают спецификации DX9 VS 2.0)
- 8 пиксельных процессоров (значительно превышают спецификации DX9 PS 2.0)
- Гибко конфигурируемый массив из 8 конвейеризированных фильтрующих текстуры блоков вычисляет до 8 выбранных и отфильтрованных результатов за такт.
- системный интерфейс AGP 3.0 (8х)
- 128-битный (!) интерфейс локальной памяти DDR2
- Эффективный четырехканальный контроллер памяти с коммутатором
- Развитые техники экономии пропускной полосы локальной памяти: полное сжатие буфера кадра, включая информацию о цвете (впервые, коэффициент сжатия до 4:1, только в режимах MSAA), и глубине (сжатие Z буфера)
- Тайловые оптимизации: кэширования, сжатия и раннего отсечения невидимых поверхностей (Early HSR)
- Поддержка точных целочисленных форматов (10/16 бит на компоненту) и точных плавающих форматов (16 и 32 бита на компоненту) для буфера кадра и текстур.
- Сквозная точность всех операций 32-бит плавающей арифметики (поддержка т.н. 128 бит глубины цвета)
- Новый алгоритм оптимизированной анизотропной фильтрации будучи активирован пользователем снижает падение производительности (читай величины fps) без особенного падения качества
- Качество анизотропии вплоть до 8х от обычной билинейной фильтрации, т.е. до 128 дискретных отсчетов на одну выборку из текстуры
- Новые гибридные режимы АА 8х (DirectX и OpenGL) и 6xS (только DirectX)
- Сжатие буфера кадра позволяет существенно снизить падение производительности при активации FSАА
- Два встроенных RAMDAC 400 МГц
- Встроенный интерфейс для внешнего TV-Out чипа
- Встроенные в чип три TMDS канала для внешних интерфейсных DVI чипов
- Потребляемый чипом GeForce FX, сделанным по технологии 0.13 мкм, ток сравним с требованиями, заложенными в спецификацию AGP 3.0. Таким образом, потенциально возможно создание карт на базе GeForce FX без использования внешнего питания.
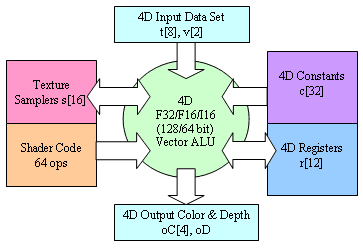
А теперь приведем блок-схему GeForce FX:
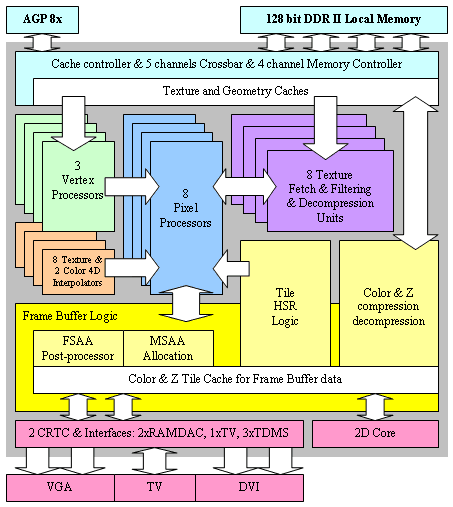
И поясним назначение блоков:
- Cache controller, Memory controller, Crossbar блок, отвечающий за обмен и кэширование данных, поступающих из локальной памяти GPU и системной шины AGP.
- Vertex Processors геометрические (вершинные) процессоры, исполняют вершинные шейдеры и эмулируют фиксированный T&L. Осуществляют геометрические преобразования и подготовку параметров для закраски и пиксельных процессоров.
- Pixel Processors пиксельные процессоры, исполняют пиксельные шейдеры и эмулируют пиксельные стадии. Осуществляют закраску пикселей и формируют запросы к блокам выборки текстур.
- Texture Fetch & Filtering & Decompression Units блоки выборки, распаковки, и фильтрации текстур. Осуществляют выборку конкретных значений конкретных текстур по запросам из пиксельных процессоров.
- Texture & Color Interpolators интерполяторы текстурных координат и значений цвета, рассчитываемых, как выходные параметры в вершинном процессоре. Эти блоки вычисляют для каждого пиксельного процессора его уникальные значения входных параметров исходя из положения закрашиваемой им точки.
- Frame Buffer Logic блок, отвечающий за работу с буфером кадра, включая сжатие буфера кадра (Frame Buffer Compression & Decompression), кэширование, раннее отсечение невидимых блоков и точек (Tile HSR Logic так называемый Early Cull HSR), а также размещение сэмплов при полноэкранном сглаживании (MSAA Allocation) и их постобработку итоговую фильтрацию в FSAA-режимах (FSAA post-processor)
- Ядро двухмерной графики (2D Core)
- Два контроллера дисплея, два RAMDAC и богатый набор интерфейсов включая три встроенных DVI и один встроенный TV-Out
Давайте подробно прогуляемся по основным блокам нового чипа, примерно в той же последовательности, в которой через них проходит обычный поток данных. По дороге мы будем комментировать назначение, архитектуру (как базовую, с точки зрения DirectX 9.0, так и дополнительные возможности GeForce FX), и отклоняться на различные лирические отступления.
Системный интерфейс
Очевидно, что данные, с которыми работает чип, программы и команды, которые он выполняет, не появляются из ниоткуда изначально их формирует CPU под управлением драйверов, а затем они попадают в графический чип через системный интерфейс, роль которого выполняет специальная графическая шина (AGP). Посмотрим на этот процесс поближе:
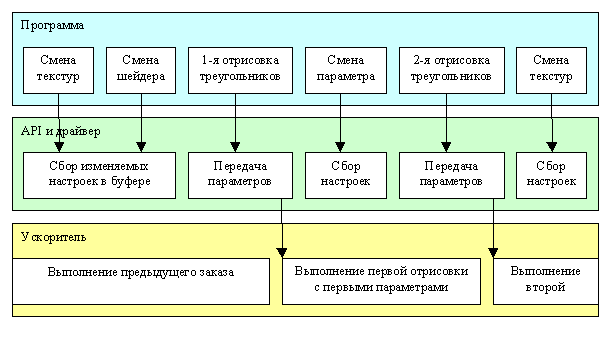
Как мы видим на схеме программа достаточно часто вызывает API, меняя различные параметры (у современных приложений смена параметров сводится в основном к назначению новых текстур и шейдеров), а затем посылает на отрисовку буфер с геометрической информацией, которую и должен воспроизвести ускоритель с участием ранее заданных шейдеров и текстур. Однако каждый вызов API не передается современным ускорителям напрямую это было бы слишком расточительно. Различные настройки накапливаются драйвером в специальном буфере в системной памяти, и только когда наступает время рисовать что-либо с их использованием, ускорителю передается указатель на этот буфер с сохраненными там для него настройками (командами), кодом шейдеров и ссылками на геометрические данные которые надо нарисовать. Начиная с этого момента, ускоритель самостоятельно интерпретирует буфер, настраивая свои внутренние блоки, и самостоятельно выводит на экран фигуры по переданным ему геометрическим данным, так же постепенно выбирая геометрические данные из локально и/или системной памяти через системный интерфейс (часто геометрия находится в его локальной памяти, полностью или частично). Драйверы, разумеется, не ждут, пока ускоритель закончит эту работу, а сразу возвращают управление программе и продолжают собирать настройки и команды в новом буфере. Ожидание включается только в том случае, если новый запрос на отрисовку придет раньше, чем ускоритель успеет закончить предыдущий.
Кстати, геометрические данные могут иметь достаточно гибкий, задаваемый из программы формат записи для каждой вершины. Запись состоит из некоего набора базовых типов данных, таких как плавающие и целые числа и векторы, значение цвета и т.д. То, как эти параметры будут интерпретированы, какие из них определят геометрические координаты точки в пространстве, какие номера комбинируемых текстур, а какие - текстурные координаты, значения цвета или еще какие либо параметры пиксельных шейдеров, решает только код вершинного шейдера, т.е. программист. Фактически, вы просто описываете ваши внутренние форматы представления объектов и программируете ускоритель так, чтобы он мог их верно интерпретировать. Налицо тот самый перенос функций ранее традиционно выполняемых CPU на плечи гибко программируемого процессора.
Но мы несколько забежали вперед. Вернемся на землю. В GeForce FX роль системного интерфейса играет хорошо знакомая нам шина AGP, а конкретно ее третья версия.
Для справки кратко суммируем отличия и новшества стандарта AGP 3.0, известного также как AGP 8x по сравнению с AGP 4х:
- Удвоена пропускная способность. Теперь она составляет 2.1 Гбайта в секунду, а эффективная тактовая частота соответственно равняется 533 МГц:
AGP 4X AGP 8X Bytes per transfer 4 (32 bits) 4 (32 bits) Clock rate 266.67 MHz 533.33 MHz Bus bandwidth 1.1 GB/sec 2.1 GB/sec - Добавлены новые возможности изохронной передачи данных (т.е. непрерывной передачи потоковых данных с гарантированным временем задержки), позволяющие ускорителю точно знать, что необходимые ему параметры будут доставлены вовремя, не заставляя его проводить время в холостых циклах.
- Шина полностью (прямо и обратно) совместима с картами предыдущей версии (AGP 2.0) и может работать в режимах 2х и 4х по стандарту 2.0 и в режимах 4х и 8х по расширенному стандарту 3.0. Таким образом, новые, полностью соответствующие спецификации AGP 8х карты будут совместимы со всеми материнскими платами с AGP 2x, 4x и 8х, а новые платы AGP 8х будут поддерживать карты с 2х и 4х, если они соответствуют спецификациям AGP 2.0 или 3.0.
- Внесены оптимизации для более производительного AGP-текстурирования.
- Исключены некоторые редкие и непопулярные возможности 2.0 (их можно удалить без потери совместимости).

Сформулируем каверзный вопрос: принесет ли AGP 3.0 какие-либо преимущества ускорителям последнего поколения? Ответ на этот вопрос зависит в первую очередь от программ. Фактически, появление сложных пиксельных шейдеров и нетривиальных моделей закраски и освещения, разумеется, увеличивает не только число используемых текстур и их объем, но и число передаваемых с каждой вершиной параметров, описывающих, так или иначе, свойства рисуемых материалов. Кроме того, геометрическая производительность нового чипа заметно выросла по сравнению с предыдущим поколением это тоже добавит требований к пропускной полосе системной шины. Но насколько велики эти требования? Исследования показывают, что большинство современных приложений ориентируется на сцены умеренной сложности, текстуры для которых целиком помещаются в локальной памяти ускорителя, а геометрическая информация не отнимает и трети пропускной полосы AGP 4x.

Приход кинематографической реалистичности, о которой так много говорится в связи с GeForce FX, разумеется, должен увеличить требования к системной шине столь детализированные сцены могут занимать гигабайты. Вопрос лишь в том, насколько быстро состоится ее реальный приход. Скорее всего, сменится не одно поколение ускорителей, прежде чем мы действительно увидим в приложениях сцену сравнимого с популярными синтетическими фильмами нашего времени качества и объема, исполняемую в железе. Как бы там ни было, поддержка AGP 8х необходима даже при минимальной вероятности того, что пропускной способности AGP 4х будет недостаточно. Нужна она и для того, чтобы просто соответствовать современным стандартам и (самое главное) для снижения задержек обращения к ускорителю, ставших для нынешнего поколения ощутимым врагом.
Переживать нечего на век GeForce FX новой версии AGP хватит. Возможно, что она станет последней классической AGP в ее нынешним виде следующая графическая шина общего назначения будет базироваться на последовательных технологиях, разработанных в рамках проекта 3GIO.
Контроллер памяти и локальный буфер
Неожиданное решение NVIDIA использовать 128-битную шину памяти вкупе с совместно разработанной с SAMSUNG высокоскоростной памятью DDR2 вызвало множество споров и непонимания. С одной стороны:- Это резко снижает стоимость и сложность печатных плат.
- Это снижает стоимость и габариты корпуса GPU
- Память DDR2 имеет более совершенный интерфейс, менее капризный и более защищенный от помех
- Память DDR2 имеет существенно меньшие характерные задержки и время доступа, что заметно сказывается при сложных сценариях доступа. Кроме того, хронологическая кривая развития параметров памяти DDR2 выглядит более оптимистично:
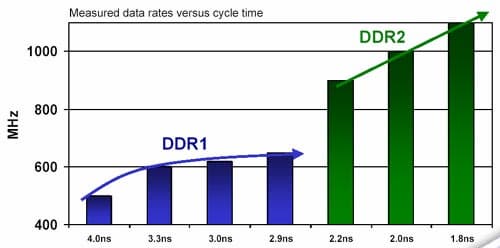
- Есть простор для роста в следующем чипе: даже при использовании той же памяти можно увеличить шину до 256 бит.
Но с другой стороны:
- 1 ГГц 128-битная память DDR2, имеет меньшую пиковую физическую пропускную способность (16 Гбайт в секунду), чем используемая в других DX9-ускорителях 256-битная DDR-память с частотой 600 и более МГц (около 20 Гбайт за секунду для RADEON 9700 PRO).
- Графические задачи предполагают достаточно последовательный характер доступа к памяти, что делает их не столь чувствительным к ее задержкам.
- 1 ГГц память DDR2, возможно, будет по началу более дефицитна и дорога, чем уже привычная классическая DDR.

Как бы там ни было, не вызывает сомнения, что специалисты из NVIDIA тщательно взвесили все аргументы «за» и «против» прежде чем принять это решение. В отличие от нас, перед их глазами наверняка были какие-то конкретные цифры, полученные во время эмуляции или использования тестовых чипов.
Самый сильный аргумент «за», несомненно, лежит в области технологий экономии пропускной полосы памяти. Обладая грамотным контроллером и хорошими технологиями, можно взять вершину производительности, не применяя грубой силы добиться эффективной пропускной полосы памяти, сравнимой или даже превосходящей оную для 256-битных решений. Что ж, далее мы вернемся к этому вопросу подробнее.
Контроллер памяти построен по уже привычной для продуктов NVIDIA четырехканальной схеме (4х32), отличным образом зарекомендовавшей себя на чипах предыдущего поколения. Внутренние кэши чипа связаны с четырьмя каналами памяти и системной шиной коммутатором «каждый с каждым» вновь, как и в случае предыдущего поколения.

Во время работы чипа возникает четыре основных потока данных три на считывание (текстуры, буфер кадра, геометрическая информация) и один на запись (буфер кадра). Кроме того, часть или вся геометрическая информация может поступать снаружи по системной шине. Четырехканальный контроллер памяти наилучшим образом соответствует такому сценарию использования в случае двух каналов производительность заметно упадет, а в случае большего числа каналов ее почти не прибавится, число же выводов чипа и сложность платы возрастут заметно. В этом плане интересен пример RADEON 9500 с 64 Мбайтами памяти в такой конфигурации у R300 работают только два канала контроллера памяти, и, возможно, этот фактор оказывает весомый вклад в общее падение производительности. В случае более дешевых вариантов GeForce FX можно будет ограничиться менее скоростной памятью, сохранив уже присутствующие в 128-битной конфигурации четыре канала.
Из системного интерфейса и интерфейса локальной памяти данные попадают во внутренние кэши чипа кэш геометрии, кэш буфера кадра и кэш текстур. Далее их пути расходятся по соответствующим блокам. Мы начнем с геометрии:
Вершинные процессоры
GeForce FX снабжен тремя (!) независимыми вершинными процессорами, полностью соответствующими (и превышающими) спецификации DX9 на вершинные шейдеры версии 2.0. Даже на существующих приложениях геометрическая производительность подобной упряжки должна в 2 3 раза превышать геометрический блок NV25 не только из-за увеличенного числа процессоров, но и из-за более высокой тактовой частоты ядра и более соврешенной конструкции исполнительных блоков. Однако это не все.
Вот так выглядит обобщенная схема вершинного процессора DX9:
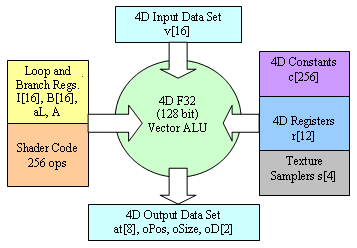
Итак, вся обработка и хранение промежуточных результатов происходят в плавающем формате F32. На входе программы-шейдера до 16 четырехмерных векторов те самые исходные «геометрические» данные, о которых мы уже говорили. На выходе позиция вершины в экранных координатах, размер точки в случае использования спрайтов, 8 векторов текстурных координат и два вектора значений цвета, интерполируемые затем (во время закраски треугольника) для каждого пикселя. После интерполяции значения этих векторов попадут в пиксельный шейдер как входные параметры. Кроме того, в наличии 256 константных векторов, задаваемых извне, и 12 временных регистров общего назначения, используемых для хранения промежуточных результатов. Присутствуют четыре специальных регистра сэмплеры, позволяющие вершинному шейдеру выбирать значения из текстур. Это нужно для использования текстур в качестве карт смещения и других подобных эффектов.

С этой точки зрения вершинный процессор напоминает любой другой процессор общего назначения. Но как обстоят дела с программируемостью? Шейдер представляет собою программу, которая управляет векторным ALU, обрабатывающим четырехмерные векторы. Длина программы шейдера до 256 операций, однако в ней могут присутствовать циклы и переходы. Для организации циклов служат 16 целочисленных регистров-счетчиков «I», которые доступны из шейдера только на чтение т.е. являются константами, задаваемыми снаружи из приложения. Для организации условных переходов служат 16 логических (однобитовых) регистров«B». И вновь, их нельзя изменить из шейдера. В итоге, все переходы и циклы являются заранее предопределенными и могут управляться только «снаружи», из приложения. Еще раз напомню, что это базовая модель, декларируемая DX9.
Кроме того, существует ограничение на суммарное число инструкций, которые могут быть исполнены в рамках шейдера с учетом всех циклов и ветвлений / переходов. Это число 65536. Зачем такие строгие ограничения? Вообще-то, для соответствия подобным требованиям чип может вообще не включать какой-либо логики, ответственной за исполнение циклов или переходов. Достаточно обеспечить последовательное выполнение шейдеров длиной до 65536 команд и «раскручивать» все условия и циклы заранее в драйвере. Фактически, нам придется каждый раз, как только в программе будут сменены константы, отвечающие за параметры циклов и переходов, загружать в чип новый шейдер. Именно такой подход реализован в R300. Именно такой подход позволяет иметь всего один набор управляющей логики и копию вершинной программы, разделяемые всеми вершинными процессорами. И именно такой подход не дает нам считать вершинный процессор полноценным мы не можем принимать решения на лету, уникальные для каждой вершины, основываясь на вычисленных прямо в шейдере критериях. Более того, можно опасаться, что подобная раскрутка переходов и циклов делает процесс смены шейдера или его параметров, отвечающих за переходы, достаточно емким с точки зрения ресурсов CPU. Недаром ATI рекомендует программистам как можно реже менять вершинные шейдеры цена такой смены сравнима со сменой активной текстуры.

Теперь самое интересное. NVIDIA пошла на шаг дальше, сделав вершинные процессоры действительно динамически управляемыми. Каждый вершинный процессор GeForce FX имеет собственный указатель текущей команды и набор контрольной логики, отвечающей за реализацию переходов и циклов. В результате, такой процессор более сложен в реализации, но более гибок в программировании. Мы можем не задумываясь использовать в циклах и условиях в качестве определяющих параметров результаты только что проведенных вычислений, так как это делается в обычных языках программирования для привычных CPU общего назначения. Можно сказать, что вершинные процессоры GeForce FX проповедуют индивидуальный подход к каждой вершине :-)
Подобное решение делает чип сложнее, но позволяет программистам проще реализовывать различные задумки. Например, не надо разбивать исходную модель на части во время ее загрузки или во время моделирования для обработки ее различных частей различными методами можно сделать необходимую селекцию уже внутри вершинного шейдера и обойтись одним шейдером вместо трех-четырех различных. Вполне состоятельный пример такого случая приводит NVIDIA в своей документации для разработчиков. А ведь помимо всего прочего, смена вершинного шейдера занимает заметное время не только из-за проверки и компиляции, но и из-за существенной латентности системной шины AGP. Вполне вероятен вариант, когда использовать большой шейдер, содержащий в себе несколько динамически переключаемых алгоритмов, будет гораздо выгоднее, чем постоянно менять небольшие и узкоспециализированные шейдеры.

Кроме того, можно запрограммировать различные оптимизации скажем, рассчитывать освещение от источника вблизи и издалека по разным алгоритмам, что также сэкономит нам производительность. Можно прервать выполнение шейдера в любом месте, например, по какому-либо условию, что также позволяет оптимизировать вычисления.
Интересно, что в GeForce FX вершинных процессора не четыре, как в продукте ATI, а три как раз по числу точек в треугольнике. Кроме того, шейдеры при условии динамического исполнения могут выполняться для разных вершин разное число тактов, но запуск новых вершин происходит синхронно, т.е. уже выполнившие шейдер блоки будут ждать завершения работы еще не выполнивших, чтобы потом всем вместе начать обработку следующей тройки вершин. Ясно, что динамические переходы стоили NVIDIA дополнительных транзисторов. Три процессора могут быть как слабым местом, так и вполне достаточным сбалансированным решением пока мы не знаем ничего о производительности отдельно взятого вершинного процессора на единицу тактовой частоты. Как и в случае обычных CPU, она может существенно отличаться в различных разработках. Предыдущие тестирования синтетическими тестами показывают, что NVIDIA прекрасно балансирует свои продукты. Кроме того, частота ядра GeForce FX заметно превосходит RADEON 9700 PRO. При практическом тестировании мы внимательно исследуем баланс нового чипа и придирчиво сравним его с творениями ATI.
Пока же давайте посмотрим на сравнительную таблицу возможностей вершинных процессоров:
| 1.1 base | 2.0 base | 2.0 (R300) | 2.0 (NV30) | |
|---|---|---|---|---|
| Входных векторов | 16 | 16 | 16 | 16 |
| Выходных векторов и 4D интерполяторов | 4+2 | 8+2 | 8+2 | 8+2 |
| Временных регистров | 12 | 12 | 12 | 16 |
| Констант | 96 | 256 | 256 | 256 |
| Число циклов, до | нет | 16 | 16 | 256 |
| Переходы и циклы | нет | заранее | заранее | динамически |
| Статических инструкций, до | 128 | 256 | 256 | 256 |
| Исполненных инструкций, до | 128 | 65536 | 65536 | 65536 |
Выделенные жирным шрифтом параметры и позволяют NVIDIA говорить о поддержке шейдеров на уровне «2.0+».
Конечно, возможность динамического исполнения не просто хороша, она логична и желанна. Рано или поздно все шейдеры, как пиксельные, так и вершинные получат такую возможность как обязательное требование. Но сейчас, в рамках этого поколения ускорителей и API, совершенно не ясно, насколько широко она будет поддержана программистами. Вдруг (как это уже было с пиксельными шейдерами 1.4) программисты станут в своих разработках ориентироваться только на наименьший общий знаменатель, т.е. на базовую версию 2.0. Скорее всего, в ближайшее время так и будет в этом отношении я питаю сдержанный пессимизм. Однако в случае OpenGL это новшество NVIDIA может найти более широкую поддержку там царят собственные расширения, и программистам все равно приходится зачастую писать два варианта кода.
Кроме того, напомним, что набор команд вершинных шейдеров в DX9 был расширен по сравнению с DX8, в том числе, добавлены полноценные тригонометрические функции и команды записи по условию и перестановки элементов векторов. Интересно, что реализация тригонометрических функций в GeForce FX крайне оперативна вычисление SIN или COS занимает всего один такт (!). Для этого используются специальные таблицы констант, по которым проводится двуступенчатая интерполяция.
Приведем набор команд, поддерживаемых вершинными процессорами GeForce FX:
- Add and multiply (ADD, DP3, DP4, DPH, MAD, MOV, SUB)
- Math (ABS, COS, EX2, EXP, FLR, FRC, LG2, LOG, RCP, RSQ, SIN)
- Set On (SEQ, SFL, SGR, SGT, SLE, SLT, SNE, STR)
- Branching (BRA, CAL, NOP)
- Address Registers (ARL, ARR)
- Graphics-oriented (DST, LIT)
- Minimum/maximum (MAX, MIN)
По последним данным, GeForce FX не будет поддерживать карты смещений (Displacement Maps) и не будет выполнять аппаратной тесселяции N-Patches. Т.е. с большой долей вероятности, технологию DM ожидает та же участь, что постигла N-Patches номинальная поддержка в приложениях, но отстутствие моделей изначально разработанных с ее учетом. Разработчики зачастую ориентируются на наибольший общий знаменатель и если продукты NVIDIA не будут поддерживать DM количество потенциально использующих его приложений может существенно сократится. На данный момент наличие N-Patches и DM не является обязательным требованием для совместимости с DX9.
Глобальная тенденция в области поверхностей высшего порядка и аппаратной тесселяции вполне очевидна в будущих версиях DX в той или иной форме станет доступна запись вычисленных данных из вершинного шейдера в память ускорителя. Вплоть до возможности генерации произвольного числа новых вершин, необходимой для поддержки произвольных HOS на уровне шейдеров.
Пиксельные процессоры и текстурные блоки
Для начала, приведем логическую схему пиксельного процессора в понимании базовых требований к PS 2.0 DX9:
Итак, на входе у нас 8 интерполированных по поверхности треугольников текстурных координат (с перспективной коррекцией) и два интерполированных цветовых вектора. Изначально эти векторы были рассчитаны для каждой вершины треугольника, но чтобы получить их значения для каждой из закрашиваемых пиксельным шейдером точек, мы должны их интерполировать в зависимости от положения этой точки относительно вершин. С точки зрения программиста эти векторы могут содержать что угодно, не только координаты текстуры и цвет. Как их использовать, определит пиксельный шейдер.
На выходе у нас до 4 различных значений цвета (каждое из них 4D-вектор), записываемых в разные выходные буферы кадра, и одно значение глубины, которое мы при желании также можем изменить и записать самостоятельно. Нам доступны 32 константных вектора и 12 временных векторных регистров. Именно так, в соответствии с буквой спецификации DX9, и реализованы пиксельные шейдеры в R300, за исключением одного расширения, присутствующего и в R300, и в NV30, но почему-то пока не отраженного в документации по DX9 мы можем использовать в шейдере вычисленное значение буфера глубины и исходное значение цвета в этой точке для реализации какого-либо собственного смешения (блендинга) или принятия тех или иных решений.
В ходе выполнения шейдера мы можем осуществлять выборку текстур, нам доступны до 16 различных текстур (глубина вложенности зависимых выборок не должна превышать 4). Для выборки значений из текстуры служит специальная команда, в которой указывается, куда помещать результат, из какой текстуры (ее олицетворяет один из 16 регистров сэмплеров) и по каким координатам выбирать данные. В отличие от предыдущего поколения, эта команда является полноценной командой шейдера и может использоваться в любом месте и в произвольном порядке. Однако есть ограничение на число команд выборки несмотря на то, что общая длина шейдера может быть 64 команды, число обращений к текстурам не должно превышать 32.
Т.к. мы имеем только 8 интерполированных по треугольнику координат, назвать эти 16 текстур полноценными в принятом для старых ускорителей смысле нельзя. Если ранее под TMU понимался некий блок, включающий в себя как механизм фильтрации и выборки значений из текстуры, так и интерполятор текстурных координат, то теперь TMU в таком понимании не существует. Он распался на два отдельных блока набор интерполяторов и набор блоков, осуществляющих саму выборку данных из текстуры по запросу из шейдера. Множество эффектов требует доступа к разным текстурам по одинаковым координатам или, например, многократных выборок из одной текстуры, на основе динамически вычисляемых координат, поэтому такой подход видится оправданным.
В отличие от вершинного процессора, который всегда работает с форматом данных F32, пиксельный процессор (как в R300, так и в NV30) поддерживает три формата F32, F16 и целочисленный формат I16 (R300) / I12 (NV30). Последние два не только полезны для реализации совместимости со старыми шейдерами версий 1.х, но и обеспечивают преимущество в скорости вычислений.
В DX9 система команд пиксельного процессора во многом аналогична системе команд вершинного:
- Add and multiply (ADD, LRP, DP3, DP4, LRP, MAD, MOV, SUB)
- Texturing (TEX, TXD, TXP)
- Partial Derivatives (DDX, DDY)
- Math (ABS, COS, EX2, EXP, FLR, FRC, LG2, LOG, NRM, POW, RCP,RSQ, SIN)
- Set On (SEQ, SFL, SGR, SGT, SLE, SLT, SNE, STR)
- Graphics-oriented (DST, LIT, RFL)
- Minimum/maximum (MAX, MIN)
- Macros (SINCOS, CRS)
- Pack (PK2H, PK2US, PK4B, PK4UB, PK4UBG, PK16)
- Unpack (UP2H, UP2US, UP4B, UP4UB, UP4UBG, UP16)
- Kill (KIL)
Выделяются команды доступа к текстурам (выборки) и команды упаковки/распаковки данных позволяющие хранить в стандартных форматах текстур и буфера кадра собственные нестандартные наборы скалярных и плавающих переменных. Эта возможность желанный путь к экономии при реализации сложных эффектов пропускной полосы памяти и занимаемого исходными данными или результатами шейдеров места.
Имеет смысл отметить одну тонкость. Использование записи (модификации) значений глубины сразу же делает несостоятельными все HSR-оптимизации и попытки раннего определения видимости, которые столь существенно увеличивают производительность современных ускорителей. Т.е. если вы используете или модифицируете в шейдере информацию о глубине аппаратный ранний HSR будет отключен и итоговая эффективность закраски снизится.
В GeForce FX алгоритм HSR не претерпел никаих изменений по сравнению с NV25 его эффективность осталась на прежнем, справедливо отметить, достаточно выском уровне.
Теперь вновь самое интересное. И в области пиксельных шейдеров GeForce FX преподносит нам сюрприз требования DX9 вновь превышены, на сей раз весьма кардинально:
| 1.1 base | 2.0 base | 2.0 (R300) | 2.0 (NV30) | |
|---|---|---|---|---|
| Входных векторов | 4+2 | 8+2 | 8+2 | 8+2 |
| Выходных векторов | 1 | 4+Z | 4+Z | 4+Z |
| Временных регистров | 2 | 12 | 12 | 16/32* |
| Констант | 8 | 32 | 32 | До 1024/512** |
| Переходы и циклы | нет | нет | нет | нет |
| Предикаты (условия) | нет | 12 | 12 | 64 |
| Вложенность выборок, до | 4 | 4 | 4 | неограниченна |
| Текстур, до | 4 | 16 | 16 | 16 |
| Статических инструкций, до | 4+8 | 32+64 | 32+64 | До 1024** |
* 16 регистров F32 или 32 регистра F16
** Каждая использованная F32-константа стоит нам (занимает место) двух команд, т.е. в сумме число констант * 2 + число команд не превышает 1024. Каждая использованная F16 или I12 константа стоит нам одной команды.
Несомненно, повышенная гибкость GeForce FX в этом вопросе налицо. Но будет ли она востребована программистами чего-либо, кроме демонстрационных программ NVIDIA (см. рассуждения в конце предыдущей главы)?
Впрочем, именно на пиксельных шейдерах начинаются многочисленные «но». Во-первых, производительность команд при обработке плавающих данных падает как минимум вдвое по сравнению с целочисленными (это чисто вычислительная производительность, без учета потерь на повысившийся объем передаваемых данных). Пиксельный процессор GeForce FX способен исполнять до двух целочисленных или одной плавающей команды или двух операций доступа к текстурам за такт т.е. на целочисленных операциях и получении выбранных значений текстур из текстурных блоков он является суперскалярным процессором. Именно это позволяет сохранять высокую скорость исполнения DX8 приложений с пиксельными шейдерами (один пиксельный процессор GeForce FX тратит на эмуляцию шейдера первой версии сравнимое с GeForce 4 число тактов).
Во вторых, плавающие текстуры вообще не фильтруются (!). Т.е. если мы хотим выбрать би- или три- линейно фильтрованное значение из текстуры хранимой в плавающем формате мы должны сами запрограммировать фильтрацию в пиксельном шейдере, потратив на нее 4 или 8 выборок текстур и десяток вычислительных команд. Согласитесь, это резко охладит наш энтузиазм по поводу повышенной точности хранения (с вычислениями падение всего двукратное). Опять мы наблюдаем знакомую картину, нововведения формально есть, реально надо ждать следующей редакции чипа (NV35) а то и следующего поколения (NV40) для того чтобы их можно было продуктивно и без оглядки их использовать.
Интересно, что NVIDIA сумела реализовать в пиксельном процессоре команды выборки текстур без каких либо задержек. Даже зависимые выборки следующие друг за другом выполняются каждый такт. Этот факт способен дать GeForce FX существенное преимущество над R300 на некоторых сложных шейдерах. Физически, в чипе присутствует пул из 8 текстурных блоков осуществляющих распаковку, выборку и фильтрацию текстур. Хотя за такт может быть выполнена две команды выборки данных из текстуры в каждом пиксельном процессоре, но сами значения текстур вычисляются только 8 блоками, соответственно максимум 8 значений за такт. Второе передаваемое значение значение могло быть выбрано и вычисленно заранее, пока пиксельный процессор выполнял другие комманды. Для этого оно сохраняется в специальном регистре. Каждый блок способен выбирать 8 дискретных отсчетов за такт, т.е. производить трилинейную фильтрацию без потери скорости (так же как в R300). В простых же случаях мы получаем совершенно аналогичную картину:
| R300 | NV30 | |
|---|---|---|
| Билинейная фильтрация | 8 текстур за такт | 8 текстур за такт |
| Трилинейная фильтрация | 8 текстур за такт | 8 текстур за такт |
| Минимальная установка анизотропии | 8 текстур за такт | 8 текстур за такт |
Впрочем, справедливо отметить что тактовая частота GeForce FX выше. Но, пока мы говорим только о потенциальной возможности реальная эффективность балансировки и производительности чипа в этом вопросе подлежит придирчивому исследованию в наших последующих материалах.
Алгоритмы фильтрации трилинейной и анизотропной, претерпели в GeForce FX некоторые изменения. Теперь пользователь может выбирать из нескольких градаций между классическими алгоритмами, привычными нам по предыдущим чипам и их оптимизированными вариантами, более производительными но в некоторых ситуациях менее качественными (утверждается, что визуальное отличие минимально оптимизации учитывают особенности восприятия и ориентации полигонов). Фактически, пользователю предоставляется возможность плавно выбирать между качеством и скоростью фильтрации, остановившись на оптимальном для него соотношении. Подобный подход мы считаем более правильным, нежели молчаливое внедрение оптимизаций, без предоставления возможностей их отключить.
Интересно, что при работе с традиционными целочисленными текстурами (8 бит на компоненту) происходит автоматическая обработка значений экспоненциальной функцией (так называемая гамма-коррекция). Значение экспоненты соответствует общепринятому стандарту sRGB. Это позволяет, несмотря на 8 битное представление данных, сохранить и корректно обработать изображение с большим динамическим диапазоном. Такая возможность является обязательно для DX9 чипов и заложена как в R300, так и в NV30. Приведем наглядный пример (из материалов ATI :-)) использования подобной гамма коррекции при построении изображения:

На всякий случай поясню на картинке справа изображено то, что более точно соответствует типичному освещению в соборе. Как раз эта картинка и рассчитывалась с использование гамма коррекции.
Для современных чипов крайне важен скоростной аспект анизотропной фильтрации. NVIDIA не ввела никаких радикальных новшеств в этой области NV30 по прежнему использует адаптивные алгоритмы традиционной анизотропии, известные нам еще по NV25. По заявлениям разработчиков в них были внесены некоторые оптимизации, которые могут быть включены в настройках драйвера, и дают умеренный прирост без заметных потерь визуального качества. Столь аккуратные формулировки наводят на мысль, что о какой либо революции в этой области речь не идет. Как бы там ни было 8 производительных текстурных модулей способных выбирать по 8 отсчетов за такт и высокая тактовая частота ядра должны сказать свое веское слово в вопросе производительность. Посмотрим, насколько веским это слово будет в сравнении с продуктамиATI традиционно обладающих производительной анизотропией.
Подход к реализации анизотропии, проповедуемый NVIDIA зависит в первую очередь от вычислительных ресурсов чипа и лишь потом от полосы пропускания памяти. ATI наборот, перекладывает основную нагрузку на память, используя базирующийся на RIP картах алгоритм. Подобный расклад, судя по всему, был еще одним аргументом за 256 битную шину для ATI и за 128 битную при более высокой тактовой частоте чипа для NVIDIA.
Полноэкранное сглаживание и сжатие буфера кадра
Самая интересная для сегодняшних применений особенность GeForce FX сжатие буфера кадров. Сжимаются не только значения глубины, но и значения цвета. По заявлениям NVIDIA алгоритм сжатия работает без потерь. Он основан на том факте, что в MSAA режимах большинство блоков сглаживания в буфере кадра не находится на границах треугольников и поэтому содержать одинаковые значения цвета.
Само по себе сжатие буфера кадра несет множество плюсов:
- Возможность быстрой очистки буфера кадра, так же как это было возможно ранее для буфера глубины.
- Существенная экономия пропускной полосы памяти, особенно вкупе с использованием сжатых текстур.
- В высоких разрешениях и особенно при использовании тройной буферизации кадра будет крайне ощутима экономия свободного места в локальной памяти, в которое смогут поместится дополнительные текстуры и геометрические данные, существенно разгрузив таким образом AGP шину и следовательно скачкообразно увеличив производительность.
- И, наконец, практически вдвое увеличит эффективность использования доступной полосы локальной памяти, став, таким образом, основным аргументом за использование 128 бит шины памяти без риска разгромного проигрыша конкурирующим 256 бит решениям.
Кстати, по некоторой информации R300 также включает техники сжатия цветовой информации в буфере кадра, но видимо не столь эффективные.
Вспомним, как выполняется уже привычный нам MSAA. Никаких дополнительных вычислений не надо все отсчеты в пределах блока сглаживания формируются из одного вычисленного пиксельным шейдером результата. Единственная причина падения производительности необходимость пересылать увеличенный в разы (согласно установке сглаживания при 4х буфер кадра будет вчетверо больше при 2х вдвое) буфер кадра туда и обратно. Но, при этом в том же режиме 4х в подавляющем большинстве блоков сглаживания присутствуют два или чаще одно (!) уникальное значение цвета. Блоки, в которых три или четыре значения уникальны надо еще поискать. Грех не воспользоваться подвернувшейся возможностью и не закодировать информацию такого MSAA буфера эффективно записав только реально присутствующие отличные цвета.
Таким образом, мы практически полностью (останутся считанные проценты дополнительных данных) компенсируем увеличение буфера при включении MSAA. Итак, мы можем прогнозировать практически бесплатные умеренные режимы MSAA (например 2х и Quincunx) и очень дешевые средние установки (4х) в случае GeForce FX. Это преимущество может быть столь значительным, что с лихвой скомпенсирует традиционное отставание анизотропии от продуктов ATI в совмещенных режимах (FSAA+Aniso), представляющих сейчас наибольший интерес для текущих и ближайших приложений.
GeForce FX включает новый гибридный режим MSAA названный 8х и новый гибридный MSAA режим 6xS (последний доступен только в DirectX). Впрочем, эти режимы являются комбинацией SS и MS сглаживания за основу по прежнему, как и в NV25 берутся два типа базовых 2х2 блоков MSAA 2х с диагональным расположением семлов и 4х, отсчеты из которых затем усредняются по с использованием того или иного паттерна, так же как и в предыдущем поколении. Т.е. чип как и NV25 может записывать до 4 MSAA семплов из одного вычисленного пиксельным шейдером значения. Отсюда и приводимый коэффицент сжатия 4:1. Как вы уже догадались для режимов FSAA имеющих в своей основе MSAA 2х блоки этот коэффицент будет 1:2.
Итак, главная надежда создателей GeForce FX возложена на сжатие буферов глубины и кадра, особенно в FSAA режимах. Факт принятия на вооружение 128 битной шины может служить косвенным показателям того, что эта надежда была оправдана.
Герой в костюме: референсная карта на основе GeForce FX
Вот так выглядит «образцовый» дизайн карты на основе GeForce FX:

(нажав на изображение можно открыть большой вариант картинки)
В наличии разъем для внешнего дополнительного питания, один DVI, один TV-Out и один VGA разъем. Два чипа Silicon Image отвечают за двуканальный (до 2048х1536) DVI интерфейс, чип Phillips за TV-Out. В GeForce FX и на этой карте использованы уже опробованое решение на базе внешних интерфейсных чипов это характерно для топовых продуктов NVIDIA. В последующих продуктах для ниши Mainstream TV-Out и DVI интерфейсы скорее всего будут интегрированны в чип. В наличии 8 микросхем DDR2 памяти SAMSUNG 128 Мбайт 128 бит, 1 ГГц эффективной частоты передачи данных. Интересно что микросхемы памяти расположены достаточно далеко от чипа видимо 128 бит шина и улучшенные интерфейсные характеристики DDR2 позволили сделать разводку более простой. Официальная тактовая частота чипа 500 МГц, в будущем вероятно появление разных (возможно и более быстрых) вариантов карт на основе GeForce FX. Как вариант может быть использовано решение с наружным забором или отводом воздуха, наподобие разработанной компанией Abit технологии:

Интересно что в чип встроены термальные датчики и схема для регулировки скорости вентилятора в зависимости от режима работы чипа и активности исполнительных блоков. Т.е. при работе в неинтенсивных 3D или 2D приложениях вентилятор будет существенно снижать уровень издаваемого шума.
Прокат и кассовые сборы: заключение кинокритика
Лично нам не терпится дождаться финальной «боевой» сцены нашего фильма, где лицом к лицу столкнуться лицу RADEON 9700 PRO и NVIDIA GeForce FX. Бой, несомненно, будет происходить как на арене синтетических (DX9) так и практических (DX8/DX9/OpenGL) тестов. Самым интересным, «финальным» кадром, нам видится противостояние этих карт в еще не готовой, но уже чрезвычайно популярной игре Doom III. Эта знаковая игра вполне способна решающим образом повлиять на судьбу нескольких поколений видеокарт в пользу того или иного лагеря. На стороне NVIDIA традиционно сильные OpenGL драйверы и высокая тактовая частота чипа, на стороне ATI широкая шина памяти и линейка продуктов, стартующая с заметным опережением по времени. Впрочем, предварительные данные говорят за «вычислительный» баланс игры, который, потенциально на руку более высокочастотному продукту NVIDIA.
А вот некоторые цифры:
| Карта | RADEON 9700 PRO | GeForce FX 5800 Ultra |
|---|---|---|
| Частота ядра | 325 МГц | 500 МГц |
| Эффективная частота памяти | 620 МГц | 1000 МГц |
| Ширина шины памяти | 256 бит | 128 бит |
| Пикселей в секунду, максимум | 2.6 Гигапикселей | 4 Гигапикселя |
| Текселей в секунду, максимум | 2.6 Гигатекселя | 4 Гигатекселя |
| Пропускная полоса памяти | 20 Гигабайт/сек | 16 Гигабайт/сек |
| Заявленная эффективная полоса | 60 Гигабайт/сек | 48 Гигабайт/сек |
| Вершинных операций в секунду | 1.3 Гигаопераций | 1.5 Гигаопераций |
| Пиксельных операций в секунду | 5.2 Гигаопераций | 8 Гигаопераций |
Интересно, что никто не сможет измерить эффективность техник экономии полосы памяти точно в драйверах отключение техник экономии пропускной полосы заблокировано. Впрочем мы склоняемся к более скромным оценкам эффективность этих техник как приблизительно 1.5 раза для ATI и 2.0 раза для NVIDIA в типичных сценариях использования. В итоге, эффективная полоса ATI лежит где то в области 28 Гигабайт в секунду а NVIDIA в районе 32 Гигабайт, что заметно больше и принимая во внимания более высокую частоту ядра может обеспечить ей как минимум 20..30% преимущество на типичных задачах.
Зная эти цифры ATI не спит и планирует в первой половине 2003 года начать производство чипа с частотой ядра 400..500 МГц на сей раз более доступного по цене, но по прежнему производительного GPU (RV350) а во второй половине 2003 года мы увидим .13 чип с частотой 500-600 МГц (R400) который должен в будущем составить конкуренцию оптимизированному варианту NV30 (назовем его NV35). Со стороны NVIDIA, в первой половине 2003 года также будут введены два новых игрока NV31 и NV34 приблизительную нишу которых, опытные читатели определят исходя из цифр. Особых проблем с запуском этих чипов не предвидится они будут базироваться на уже обкатанном .13 технологическом процессе и повторно использовать уже разработанные для NV30 блоки. Кроме того, со временем вполне вероятно появление вариантов NV30 работающих на более высокой частоте ядра 550 или даже 600 МГц в лаборатории NVIDIA даже некоторые из первых чипов успешно функционировали на таких частотах.
С точки зрения выбора пользователя серьезную конкуренцию продуктам NVIDIA способен составить RADEON 9700 без индекса PRO он несет привлекательное соотношение цены и производительности для еще не окончательно оторванного от окружающей жизни любителя игр. Отдельный вопрос составляет ниша средних и бюджетных DX9 ускорителей RADEON 9500/9500 PRO. Особенно выгодное отношение цена-производительность у моделей RADEON 9500 PRO с 128 Мбайтами памяти и "недекларированной" 256 бит шиной. Пока что NVIDIA нечего противопоставить на этом рынке, позже, месяца через три, подтянется уже упомянутый NV31.
Несомненно, положительную роль в быстром появлении продуктов поддерживающих новые технологии сыграет наличие языка высокого уровня для шейдеров в DX9. Многие программисты не решались браться за шейдеры именно по причине неудобств в разработке и отладке ассемблерного кода. Внесет свою лепту и инициативна NVIDIA по созданию и поддержки открытого компилятора языка высокого уровня для шейдеров CG и интерпретатора файлов схожих с эффектами DX9 CG FX. Оба этих продукта не только доступны с исходными текстами, но и поддерживают сразу оба API и DirectX и OpenGL что, несомненно, упростит разработку многим OpenGL программистам. Доступны плагины для популярных пакетов трехмерной графики, экспортирующие модели и материалы в понятном для CG FX виде.
Первые образцы карт на базе GeForce FX будут доступны в декабре, массовые поставки чипов производителям начнутся в январе, и, соответственно, в феврале карты станут широко доступны для покупателей. Стартовая цена еще не определена точно, но в первые недели она будет находится в диапазоне от $399 для модели FX 5800 и $499 для модели FX5800 Ultra параметры которой и фигурировали в нашей сравнительной таблице. Несомненно, что цена будет зависить от процента выхода годных чипов, ситуации на рынке памяти, и даже региона где продается карта.
Занимаем места в кинозале блокбастер обещает быть захватывающим! Более того, можно предположить, что элемент неизвестности и неожиданности сохранится в этом фильме до последней минуты…
Интересно, когда мы увидим на своем экране такую графику в реальном времени?


