Пословица.
В этой статье мы помянем добрым словом так и не увидевшие свет продукты компании 3dfx, которая скоропостижно сошла со сцены рынка 3D графики. В первую очередь, речь пойдет о многострадальном Rampage, тем более, что это имя появилось на просторах сети очень давно. Всем незавершенным разработкам 3dfx выпала печальная судьба: умереть, так и не попав на рынок. Тем не менее, у нас есть шанс (очень небольшой, в первую очередь, по соображениям престижа) увидеть в отголоски идей 3dfx в будущих продуктах NVIDIA, т.к. все наследсво 3dfx было куплено именно NVIDIA Corp. Впрочем, последние разработки 3dfx, несомненно, достойны и нашего внимания.
На момент покупки товарных знаков и интеллектуальной собственности компанией NVIDIA, в 3dfx разрабатывались (в порядке планируемого выхода в свет) следующие продукты:
- Spectre (растеризатор Rampage и геометрический процессор Sage)
- Fear (растеризатор Fusion и геометрический процессор Sage2)
- Mojo (совмещенные растеризатор и геометрический процессор, тайловая архитектура)
Навечно предварительные
Обратимся к связке Rampage+Sage. Об этих чипах у нас есть максимальное количество информации, к тому же они (на момент продажи 3dfx) уже были реализованы в кремнии. Фактически, Spectre был готов к финальному тестированию, а затем и к массовому производству.
Много нас, а он один…
С упорством, достойным занесения в анналы 3dfx придерживается многочиповой архитектуры. Мало того, что скорость закраски ускорителей масштабируется, путем увеличения числа чипов растеризаторов. На сей раз, еще и геометрический процессор реализован в виде отдельного чипа. Последнее, с моей точки зрения вполне логично:
- Каждому растеризатору свой процессор геометрии не нужен, проще обойтись общим.
- На геометрический процессор можно возложить почетный труд полноценного AGP 4x моста, дабы обеспечить работу двух или четырех чипов одновременно, с полноценной поддержкой всех возможнойстей AGP. С его помощью, можно легко решить прочие "задачи дирижера" оркестром, состоящего из нескольких чипов растеризаторов.
Применение чипов растеризаторов с собственными шинами памяти увеличит ее эффективную пропускную способность. Но у любого плюса, разумеется, есть и свои минусы. В первую очередь мы сталкиваемся с высокой ценой многочипового ускорителя. Во вторую, мы вынуждены дублировать текстуры в локальной памяти чипа. Это уже хорошо известные аспекты. А вот и новый — нам не ясно где мы будем хранить геометрию. Делать еще один локальный геометрический буфер для Sage слишком расточительно. Значит надо:
- Либо хранить всю геометрическую информацию в системной памяти, обращаться к ней через AGP и, возможно, кэшировать ее значительное количество прямо на чипе.
- Можно также записывать ее в локальные буфера памяти (через растеризаторы) и через них же принимать обратно.
Последнее труднее реализуется, и несколько портит "малину" растеризаторам, сбивая их с толку и отнимая у них часть объема и снижая эффективность полосы пропускания локальной памяти. Достоверно неизвестно, как было организовано кэширование, но мы точно знаем, что основной объем геометрии хранится в системной памяти и доступ к нему осуществляется через AGP.
Буфер кадра распределен между локальными буферами растеризаторов, каждый отвечает за свой набор горизонтальных сегментов (как и у VSA-100) — это позволяет более продуктивно кэшировать обращения к памяти, нежели в случае разделения по единичным линиям развертки (оригинальная технология SLI в Voodoo1/2).
Итак, перед нами схема взаимодействия:
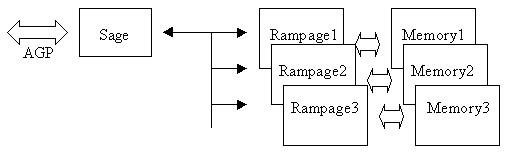
До 4 чипов могут обединяться и работать вместе без какого либо дополнительного моста, и даже без применения Sage
Физическая организация работы чипов rampage с памятью:
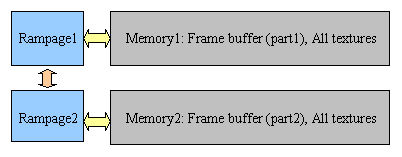
Между собой чипы общаются по специальной AGP подобной шине, в результате чего логическая организация работы с памятью выглядит следующим образом:
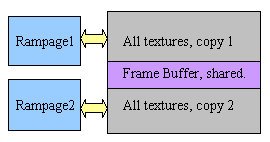
Но, со вдвое увеличенной пропускной полосой. За которую и приходится расплачиваться необходимостью дважды хранить текстуры.
Текстурный компьютер
Теперь посмотрим на базовые спецификации:
| Rampage | GeForce3 (NV20) | |
|---|---|---|
| Пиксельных конвейеров | 4 | 4 |
| Текстурных модулей на конвейер | 1 | 2 |
| Текстур на пиксель | 1..8 | 1..4 |
| Пиксельный fillrate | 800 млн. (200 MHz) до 1000? | 800 млн. (200 MHz) |
| Тексельный fillrate | 800 млн. | 1600 млн. |
| Интерфейс памяти | 128 бит DDR (каждый чип) | 128 бит DDR |
| DX8 шейдеры | 1.0 (+доп. возможности) | 1.1 (+доп. возможности) |
| Сжатие текстур | DXT1..5; FXT1 | DXT1..5; S3TC |
| Кубические карты среды | Да | Да |
| YUV форматы текстур | Да | Да |
| EMBM и DOT3 BM | Да | Да |
| Overbright lighting | Да | Нет |
| T-Buffer AA | Да | Нет |
| Multisampling Effects/AA | Да | Да |
Снова, как и у GeForce3, четыре пиксельных конвейера обеспечивают закраску до четырех точек треугольника за такт. Впрочем, у Rampage в наличии только один текстурный блок у каждого конвейера. Но не будем спешить с выводами. Дело в том, что текстурный блок текстурному блоку рознь, и если один TMU обеспечивает полноценную трилинейную фильтрацию за такт, требуемая ему пропускная полоса памяти сравняется с двумя билинейными. А модули Rampage способны фильтровать трилинейную текстуру за один такт. Также, они способны применять более изощренные виды фильтрации (вплоть до адаптивной 128 точечной анизотропной) разумеется, расплачиваясь за это падением производительности:
- Линейная и трилинейная — 1 значение за такт.
- Адаптивная анизотропная — множество установок качества, а именно до 8 точек за такт; до 16 точек (до 2х тактов); … до 128 точек за 8 тактов максимум.
Подход к комбинированию текстур оригинален (в GeForce3, впрочем, тоже заметны зачатки подобного подхода, но все же сохранены два парраллельных блока текстурирования, дабы получить преимущество в случае билинейной фильтрации). Текстуры в Rampage могут вычисляться последовательно, до 8 раз, каждая с использованием собственного типа фильтрации (от примитивной точечной, до адаптивной анизотропной с верхним порогом в 128 точек). Разумеется, присутствует гибкий механизм комбинации вычисленных значений. Фактически, вычисляются и сохраняются до 8 значений RGBASTW (цвет, прозрачность, 3 текстурные координаты). При этом результирующий цвет точки можно вычислять, используя все эти параметры, с помощью некой гибко задаваемой схемы (программы). Но и это еще не все. До 4 раз подряд можно использовать значения предыдущей текстуры для определения смещенных или абсолютных координат текстур, вычисляемых далее, на последующих стадиях. В результате, можно реализовывать различные эффекты основанные на смещении (например, EMBM ) и многие другие, и даже использовать так называемое процедурное текстурирование, когда текстура задается некой формулой, по которой может быть рассчитано ее значение в различных точках. Смещение может быть масштабировано на величину в степени двойки:
TextureCoord=CalculatedCoord+Displacement<
Сложность вычисляемого за 8 комбинационных стадий выражения весьма велика — допускаеся до 8 различных операций между 8 текстурами и интерполированными значениями аттрибутов из вершин закрашиваемого треугольника. Например, можно запрограммировать такую формулу:
Pixel=(((A+B)*(C+D))*E+F)*(G*H)/2
Вы, наверное, заметили, наблюдая за последними разработками в области 3D графики, что налицо повсеместная тенденция перехода от параллельного расчета (несколькими текстурными блоками), с последующей фиксированной комбинацией, выдающей по результату за такт, к последовательному расчету произвольного числа текстур одним блоком, с гибко программируемой комбинацией на основе программы (шейдера). Rampage не только поддерживает пиксельные шейдеры версии 1.0, но и кроме того, обеспечивает различные дополнительные возможности, выходящие за их рамки. Причем выходящие очень существенно — гибкость его текстурных статий значительно выше, нежели у GeForce3. Как мы уже говорили, сохранение значений текстурных координат и глубины, и возможность привлечения их к расчету окончательного значения точки позволяет реализовывать процедурные и комбинированные текстуры, вычисляемые на основе некоего, пока достаточно ограниченного, математического выражения. Скажем:
Alpha=(CS+CT)*Const
Pixel=ARGB*Alpha + BRGB*(1-Alpha)
Здесь S и T — координаты на поверхности текстуры. Везде можно использовать сами значения и их модификации (X, -X, 1-X, X-0.5). Более того, есть возможность условного выбора, например, так:
Pixel=(AA+ВA)?СRGB:DRGB
Поддерживается и "межцветовое" комбинирование (R+G+B) необходимое для вычисления скалярного произведения векторов или произведения вектора на матрицу (DotProduct). Они используются в различных моделях попиксельного освещения, столь хорошо демонстрируемого нам различными технологическими демо программами для GeForce3.
Но и это еще не все. Все промежуточные значения цвета и прозрачности не только вычисляются, но и сохраняются с точностью 13 бит (12 бит значения со знаком). Что позволяет избежать слишком темных сцен, благодаря более широкому динамическому диапазону, и получить качественное результирующее изображение даже в случае комбинации 8 текстур. Благодаря подобной точности хранения и обработки промежуточных значений цвета (56 бит на цвет), яркость освещения вершины, получаемая как сумма по всем источникам света, может лежать в диапазоне 0-16.0, а не 0-1.0 (в целочисленном представлении 0..4095 вместо 0..255). Что позволяет реализовывать так называемый OverBright Lighting. Сцены с различными яркими источниками света, под открытым небом, особенно с солнцем, выглядят значительно правдоподобнее. На каждом шаге можно умножить значения на любую степень двойки (сдвиг на произвольное число бит) без потери производительности:
Pixel=(ARGB<<2)* (BRGB<<3)
Поддерживается ключевые значения в текстурах (texture chroma keying), позволяющая решать какие значения текстуры учитывать, а какие считать несуществующими (полностью прозрачными). Причем, допустимо определить как конкретное ключевое значение (скажем 0, 13 или 255) так и диапазон. По большому счету эта возможность всегда может быть реализована (так или иначе) через текстуры с прозрачностью, но подобный подход экономит нам память и позволяет более естественно программировать некоторые эффекты. Т.е. существенно экономит команды шейдера, число которых ограничено. Со значениями, попавшими под ключевое условие возможно проделать три вещи. Заменить на черный (0-е значение), заменить на любую заданную константу или взять от них некий фиксированный процент (масштабировать).
Главный вопрос, возникающий при первом взгляде на параметры растеризатора — зачем столько текстур. Ответ прост — подобные числа позволят реализовывать более точные физические модели освещения поверхности, причем рассчитывая точные значения для каждой точки, а не аппроксимируя их по поверхности треугольника. Например, мы можем легко посчитать аппаратно следующую (достаточно физически справедливую) модель (в том или ином виде зачастую применяемую в програмных рендерах реалистичной 3D графики), с пиксельной точностью: Pixel=AmbientK*AmbientLightColor*AmbientTextureColor + DiffuseK* DiffuseTextureColor*Sum(DiffuseLightmapTextureColor[n], n) + SpecularK*SpecularTextureColor*Sum(SpecularLightmapTextureColor[n] <
В случае 3-х источников освещения мы можем почитать это все за один проход! Что даст нам качество поверхности на картинке, сравнимое с программным рендерингом средней сложности, в реальном времени. Если мы учтем только 2 позиционных источника света — мы сможем использовать еще пару освободившихся текстур, например, для карт отражения. Добавить в эту поверхность рельеф/преломление (возможно различное для диффузной и бликовой составляющих) или применить карту преломления (эта область еще не развита, но у меня есть подозрение, что в скором времени в аппаратной 3D графике появится и такое понятие).
Да, ближайшие годы несомненно пройдут под знаком повышения реалистичности изображений. Об этом говорят и создатели Doom3, и спецификации новых чипов.
С T-Buffer — все как и раньше, его поддержка полностью соответствует VSA-100. Но есть и новости — пара слов про multisampling. Rampage поддерживает так называемый M-Buffer и экономящий текстурное время режим MultiSampling AA. А именно, в нем, так же как и в GeForce3 одно цветовое значение текстуры используется для эффективного краевого сглаживания два или четыре раза в различных позициях.
Геометрия с общественной нагрузкой
Итак, теперь мы обратим свой взгляд на геометрический процессор, и по совместительству, полноценный AGP мост — Sage. Функциональность моста позволит использовать двух и четырех чиповые карты на его базе в AGP режиме (даже под Windows 2000). Внешний геометрический процессор штука весьма противоречивая. Мы уже касались покрытого мраком вопроса о том, как Sage кэширует геометрию. Но возникает еще один вопрос — правда ли, что он обеспечивает полную AGP функциональность или растеризаторы вновь не способны осуществлять AGP текстурирование? Хотя, используется оно, если честно, ныне нечасто…
Еще одна маленькая нестыковка возникает, когда мы обращаемся к цифрам. Пропускная способность блока установки Rampage — 20 млн. треугольников. Ну, максимум 25 млн., с учетом повышенной до 250 МГц тактовой частоты. А Sage по спецификации способен обработать максимум 50 млн. треугольников. Да, некоторые из них будут отброшены (back-face ориентированные треугольники) в процессе обработки и не переданы на Rampage. Но на среднестатистической игровой сцене их число явно меньше 50%. Поэтому, геометрическая мощность ускорителей на базе этой парочки ограничена в первую очередь чипами растеризаторов. Впрочем, эти 20-30 миллионов теоретических треугольников Sage очень хорошо перекликаются с практической производительностью GeForce3. А раздельная реализация 3dfx и ее давнее добротное отношение к декларируемым цифрам позволяли бы надеяться на сравнимую геометрическую производительность в реальных тестах и приложениях. Sage поддерживает вершинный шейдеры 1.0 версии (насколько он производителен в этом плане — неизвестно), обеспечивает весь джентльменский набор по расчету освещения и генерации текстурных координат.
Sage (как и GeForce3) способен аппаратно тесселировать прямоугольные и треугольные патчи (гладкие поверхности). 50 (20 без учета отброшенных) млн. треугольников — вполне достаточное значение, вопрос в том, насколько к нему приблизится Sage в реальных тестах. Кстати, в случае использования гладких поверхностей, число отбрасываемых треугольников увеличивается. И может быть соотношение 50 к 25 вполне обосновано.
Карты, деньги, два ствола…
На базе парочки чипов Rampage и Sage планировалось для начала три карты.
1 Rampage
Недорогая карта. Здесь геометрия обрабатывается программно. Эта карта сравнима с "полноценной" GeForce2, но медленнее GeForce3, особенно в современных играх. Но не следует забывать, что отсутствие HW T&L могло здорово изменить эту картину в некоторых будущих играх в худшую сторону. Впрочем, как бы там ни было, это бюджетная карта.
1 Rampage + 1 Sage
Массовый вариант. Быстрее GeForce2, возможно, несколько медленнее GeForce3. Но, в случае комбинирования числа текстур, превышающего четыре, способна существенно вырваться вперед (пока GeForce3 будет осуществлять еще проход).
2 Rampage + 1 Sage
Дорогой вариант, превосходящий GeForce3 по производительности и, почти наверняка, по цене. Единственное место, где он может отступить — предельные тесты на пропускную способность по треугольникам, но это не так страшно. За время жизни этой карты игры с 50 млн. полигонов в секунду вряд ли появятся и получат широкое распространение. Эта цифра, все еще прерогатива синтетических тестов.
Все карты выпускались бы с названиями Spectre (плюс номер модели). Цена неизвестна — она сильно зависит от стоимости памяти и процента выхода годных чипов.
Что дальше
Дальше должны были появится еще два продукта. Дальнейшее продолжение Spectre — линейка Fear. Здесь, практически тот же Sage, с увеличенной производительностью и более продвинутый в количественном плане вариант Rampage (Fusion). Технологически ничего особенно нового, просто эволюционное развитие, выше частота, больше конвейеров.
Зато еще позднее должен был появится Mojo — принципиально новое, тайловое решение. Не зря же 3dfx купила технологии Gigapixel. У Mojo ожидалось кардинальное новшество — реализация некой разновидности аппаратной сортировки, когда каждый тайл экранного буфера хранит не только цвета точек, но и информацию о задевающих его примитивах (binning архитектура). Т.е, подаваемые на ускоритель треугольники аппаратно сортировались бы прямо на лету, за счет определения принадлежащих им тайлов. Кроме того — в Mojo планировался 16 битный, плавающий формат для вычисления и хранения цветовых компонент. Нас ждала очень точная передача цвета (64 бит плавающий цвет) и его рассчеты,а также широчайший динамический диапазон. А возможно, и еще что-то, кто теперь знает… За тайловыми архитектуроми вполне вероятно будущее, и следующие продукты от NVIDIA (30-40 серий) несомненно вберут в себя некоторые ключевые концепции из Mojo.
Реквием
На этом все. Давайте сыграем минутку-другую в Quake1, в память о 3dfx, открывшей нам дорогу к повсеместному железному 3D.


