или "Наглядный процессор"
(А.Л. Гуртовцев, В.С. Гудыменко — "Программы для микропроцессоров", с.3.)

СОДЕРЖАНИЕ
- Общие сведения о P10 и позиционирование
- Линейка продуктов
- Спецификации P10
- Архитектура P10
- Особенности видеокарты 3Dlabs Wildcat VP870 128MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D и предельные тесты из DirectX 8.1 SDK
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Результаты тестов: Игровые тесты 3DMark2001 SE
- Качество 3D в играх
- Результаты тестов: Профессиональные тесты: SPECviewperf 7.0
- Результаты тестов: Профессиональные тесты: Discreet 3DS MAX 4.26
- Выводы
Р10 можно по праву приоритета считать основателем крепнущего племени гибко программируемых GPU. При ближайшем рассмотрении становится ясно, что этот чип занимает особенное положение. P10 — ничто иное, как железное воплощение проекта стандарта API OpenGL 2.0. В том понимании, в котором этот API видится 3Dlabs. Мы уже подробно писали о проекте OpenGL 2.0 и не раз уделяли внимание возможностям DirectX 9 (в аналитических материалах по Matrox Parhelia-512 и ATI RADEON 9700). Внимательный читатель заметил: несмотря на общность идей, связанную с возможностью гибко программировать работу графического ускорителя, можно легко найти отличия в реализации этих идей, даже на уровне API. Теперь, с появлением в нашей лаборатории карты на базе 3Dlabs P10, мы сделаем выводы об отличиях на уровне железа.
Позиционирование
Ни в коей мере не следует напрямую сравнивать эту карту (на уровне спецификаций, частот или скорости в игровых тестах и приложениях) с новейшими игровыми решениями — чип разрабатывался как профессиональный ускоритель OpenGL приложений, со всеми вытекающими отсюда последствиями. Известно, что игровые приложения, в своей основной массе, по-прежнему, нуждаются в скорости закраски и текстурирования, в то время как профессиональные — в скорости трансформации и освещения. Кроме того, игровые приложения (не будем пока вспоминать о будущих, завязанных на шейдеры играх, например, на основе движка Next Doom) пока не требуют какого-либо выдающегося набора дополнительных возможностей. Тем паче не идет разговор о краевом сглаживании или экзотических методах качественного мультисамплинга и AA. Даже максимальные установки анизотропной фильтрации редко задействуются обычными игроками.
Профессиональный ускоритель — таково позиционирование этого чипа разработчиками. Само собой разумеется, что Creative, купивший 3Dlabs, обращает свое внимание в первую очередь на массовый и, следовательно, игровой рынок (вспомните, что в свое время произошло с также приобретенным Creative разработчиком профессиональных звуковых решений EMU и его творениями). Очевидно, что чуть позже Р10 также будет выпущен на игровое поле, возможно, с некоторыми аппаратными модификациями (с архитектурной точки зрения этот GPU является очень легко масштабируемым в любом направлении — как в сторону увеличения fillrate, так и в любую другую). Возможно, что Creative на первых порах ограничится и просто заточенными под игры драйверами. С нашей точки зрения, подобный сценарий позволителен только при условии невысокой цены игровых решений на базе P10 — по некоторым причинам (мы вернемся к ним далее), конкурировать на игровом поле с будущими топовыми решениями NVIDIA и ATI им не под силу. Вне зависимости от степени оптимизации драйверов.
А теперь давайте посмотрим, как позиционируются карты на основе P10 внутри семейства профессиональных ускорителей 3Dlabs:
Линейка продуктов
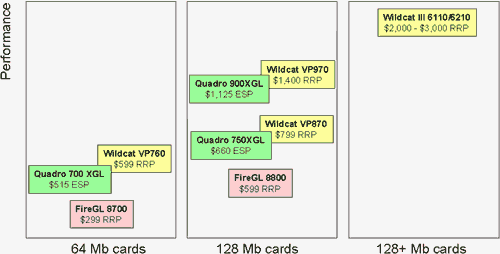
- Wildcat VP970: 128 MB of 256-bit DDR SDRAM; 225M Vertices/Sec; 42G AA Samples/Sec; Решение предназначено для тяжелых процессов отрисовки в CAD/DCC приложениях всех видов.
- Wildcat VP870: 128 MB of 256-bit DDR SDRAM; 188M Vertices/Sec; 35G AA Samples/Sec; Решение также предназначено для CAD/DCC приложений (но более легкого плана).
- Wildcat VP760: 64 MB of 256-bit DDR SDRAM; 165M Vertices/Sec; 23G AA Samples/Sec; Это решение также позиционируется для CAD приложений и являет собою разумный компромисс между ценой и мощностью.
Вся линейка расположена в середине большой пирамиды, символизирующей охват различных секторов профессионального рынка продуктами от 3Dlabs.
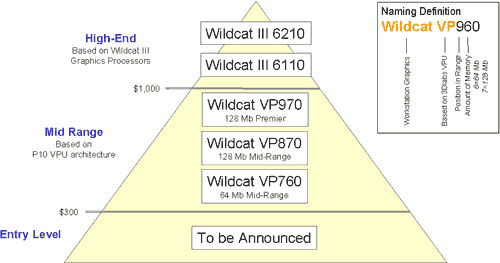
Как мы видим, несмотря на революционность нового изделия, это не High-End, в отличие от всех новинок от NVIDIA или ATI. Наверху сегмента по-прежнему тяжеловесы семейства Wildcat III, настоящие "львы" рынка профессиональной 3D-графики. Вместе с тем, как мы убедимся далее, даже "середнячок из середины" — Wildcat VP870 — способен соперничать с High-End продуктом от NVIDIA — Quadro4 900XGL. Хотя и позиционируется самой 3Dlabs, как конкурент Quadro4 750XGL.
Ну а теперь приступим к рассмотрению характеристик P10.
Спецификации
Приведем уже традиционные ТТХ ускорителя и карты на его основе — VP870:
- Технология производства: 0.15 микрон;
- Число транзисторов: более 76 миллионов;
- Тактовая частота ядра: неизвестна (предположительно 200-250 МГц);
- Шина памяти: 256 бит DDR;
- Максимальный объем локальной памяти: 256 Мб;
- Объем локальной памяти на тестируемой карте: 128 Мб;
- Тактовая частота памяти: неизвестна (предположительно 250-300 DDR МГц), пропускная способность около 17-20 Гб/сек;
- Интерфейсная шина: AGP 4x, пропускная способность 1 Гб/сек;
- Полная поддержка всех возможностей проекта стандарта OpenGL 2.0 от 3Dlabs ;
- Оптимизированные для профессиональных приложений драйверы;
- 16 скалярных плавающих (F32) гибко конфигурируемых вершинных процессоров (более гибкий аналог четырех векторных 4D процессоров R300 или NV30);
- 64 плавающих (F32) процессора для генерации текстурных координат;
- 64 непрограммируемых блока для выборки и фильтрации значений текстур
- Поддержка трилинейной и анизотропной фильтрации;
- 64 целочисленных (фиксированная точка) процессора для исполнения пиксельных шейдеров;
- Возможность произвольно программировать (!) последние ступени пиксельного конвейера, отвечающие за чтение и запись значений в кадровый буфер, сглаживание и мултисамплинг;
- В буфер кадра может быть выведено (без учета мултисамплинга) не более 4 полностью рассчитанных пикселей за такт.
- Неполная (!) поддержка возможностей DX9 (пиксельные конвейеры на шейдерной стадии оперируют только с целочисленной арифметикой):
- Пиксельные шейдеры версии 1.4;
- Вершинные шейдеры версии 2.0 (?);
- Мультисамплинг до 8x включительно;
- Аппаратная тесселяция N-Patches с картами смещения (Displacement Mapping) и, по желанию, адаптивным уровнем детализации;
- Возможность многопоточного исполнения команд — построение изображения параллельно для нескольких приложений и окон с аппаратным менеджментом потоков команд;
- Технология экономии пропускной полосы памяти на основе поблочной закраски треугольников (блоки 8х8);
- HSR — возможность раннего отбрасывания невидимых блоков 8х8 и ранний Z тест на пиксельном уровне;
- Два независимых CRTC;
- Два встроенных 10 бит 400 МГц RAMDAC с аппаратной гамма коррекцией;
- Встроенный (два?) DVI (TMDS трансмиттер) интерфейс.
- Встроенный цифровой интерфейсный видео порт общего назначения.
| Ускоритель | R200(128 MB) | NV25(Ti 4600) | R300 | NV30 (1) | Parhelia 512 | P10(VP870) |
|---|---|---|---|---|---|---|
| Технология; число транзисторов, млн | 0.15; 62 | 0.15; 68 | 0.15; 107 | 0.13; 120 | 0.15; 96 | 0.15; 72 |
| AGP | 4x | 4x | 8x | 8x | 4х | 4х |
| Шина памяти, бит | 128 DDR | 128 DDR | 256 DDR (II) (2) | 256 DDR II | 256 DDR | 256 DDR |
| Частота памяти, МГц | 275 | 325 | >300 | >400 | 275 | 250…300 (?) |
| Частота ядра, МГц | 275 | 300 | 300 | 400 | 220 | 200…250 (?) |
| Пиксельных конвейеров | 4 | 4 | 8 | 8 | 4 | 64 (9) |
| Текстурных модулей | 4х2 | 4х2 | 8х1 (3) | 8х2 | 4х4 | 64 (10) |
| Текстур за проход | 6 | 4 | 16 (4) | 16 (4) | 4 | 8 (5) |
| Вершинных конвейеров | 2 | 2 | 4 | 4 | 4 | 16 (7) |
| Фиксированный блок T&L | Да | Нет | Нет | Нет | Нет | Нет |
| N-Patches | DX8 | Нет | DM (DX9) | DM (DX9) | DM (DX9) | DM (DX9) |
| Вершинные шейдеры | 1.1 | 1.1 | 2.0 | 2.0 (6) | 2.0 (?) | 2.0 (?) |
| Пиксельные шейдеры | 1.4 | 1.3 | 2.0 | 2.0 (6) | 1.3 | 1.2 (?) |
| Контроллер памяти | 2х64 | 4х32 | 4х64 | 4х64 | 1х256 | ? |
| RAMDAC, МГц | 400 | 400 | 2*400 | 2*400 (?) | 2*400 | 2*400 |
| Технологии экономии | Да(HyperZ II) | Да(LightSpeed II) | Да(HyperZ III) | Да (LightSpeed 3 ?) | Только ранний Z тест | Блоки 8х8 (8) |
Примечание:
- (1) Компиляция на основе официальных данных и слухов
- (2) Скорее всего, наравне с DDR будет поддерживаться и DDR II.
- (3) Каждый текстурный модуль способен самостоятельно делать трилинейную выборку.
- (4) Согласно требованиям DX9, за один проход может быть использовано до 16 различных текстур с 8 предварительно вычисленными (интерполированными по поверхности треугольника) полными 4D текстурными координатами. При этом, в пиксельном шейдере может быть сделано до 32 выборок конкретных значений из этих текстур.
- (5) Может быть использовано до 8 текстур с предварительно вычисленными или интерполированными полными текстурными координатами. В пиксельном шейдере может быть сделано до 16 выборок конкретных значений из этих текстур.
- (6) Судя по всему, в железе будут реализованы возможности, превышающие требования DX для вершинных и пиксельных шейдеров версии 2.0.
- (7) 16 скалярных плавающих процессоров объединяются по 2, 3 или 4 для обработки векторных величин. Т.е. полные 4D векторные команды выполняются по 4 за такт, так же, как и на R300 или NV30, а скалярные и 2D/3D векторные команды исполняются в большем числе, в зависимости от комбинации команд ждущих выполнения.
- (8) Закраска треугольников по блокам 8х8 для оптимизации кеширования и предварительного HSR на блочном и пиксельном уровне.
- (9) Число параллельных 32 бит целочисленных процессоров для обработки пиксельных шейдеров. Процессоры могут быть гибко переконфигурированы для поддержки того или иного формата вычислений, например, целочисленных форматов R10G10B10A2 или R16G16B16 . Во втором случае число параллельно обрабатываемых пикселей снизится вдвое (будут задействованы по два процессора на один пиксель). Кроме того, есть важное ограничение — чипом может быть записано в буфер кадра (т.е. физически закрашено) максимум 4 точки за такт. Из-за существенного числа процессоров и ограничений технологии .15 3Dlabs не смогли поддержать формат с плавающей точкой, однако планируют сделать это в будущих чипах.
- (10) Судя по всему, реальное число полноценных текстурных блоков ниже — 16 или даже 8.
Архитектура P10
P10 обладает очень специфической архитектурой — фиксированные блоки много раз чередуются с программируемыми, причем программируемые, как правило, организованы в виде широких массивов простых процессоров, гибко конфигурируемых для исполнения тех или иных задач в группы.
Приведем крупномасштабную блочную схему P10:
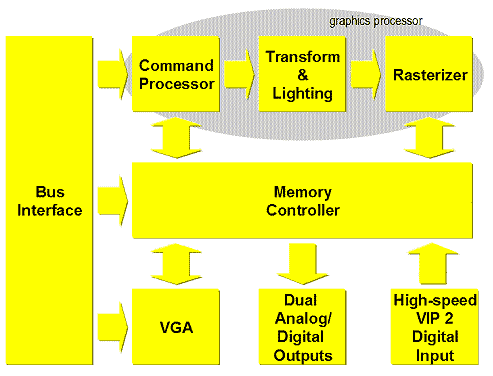
В наличии VGA совместимое графическое ядро, два CRTC, а также специальный цифровой интерфейс для импорта (захвата) видеоданных.
Интересной чертой, полезной для профессионального применения является способность P10 одновременно исполнять параллельные потоки команд от разных приложений. За эту возможность отвечает командный процессор:
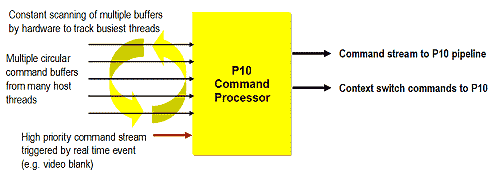
который не только дирижирует 3D конвейером, организуя некий графический аналог "многозадачности" (на основе переключения контекстов), распространенной в современных CPU, но и выполняет приоритетные команды, требующие немедленной реакции "вне очереди", такие, как переключение видеостраниц и пр.
P10 поддерживает так называемое виртуальное текстурирование, самостоятельно управляя блочным кешированием больших текстур в локальной памяти ускорителя:
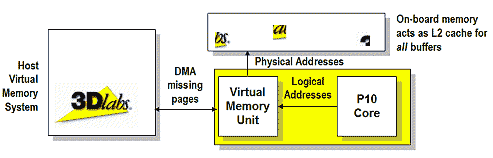
и вновь налицо четкая аналогия с современными CPU, снабженными MMU с поддержкой виртуальной памяти на основе страниц. Здесь роль страниц играют прямоугольные блоки текстур, кешируемые в локальной памяти ускорителя. Подкачка текстур через AGP DIME или PCI DMA осуществляется чипом автоматически, по мере надобности. Таким образом, мы получаем не только эффективное кеширование больших наборов текстур, но и важную для профессиональной графики возможность работать с отдельными текстурами, размер которых может превышать объем локальной памяти ускорителя (!).
Теперь, давайте посмотрим на полную схему трехмерного графического конвейера P10, отвечающего за построение трехмерных изображений:
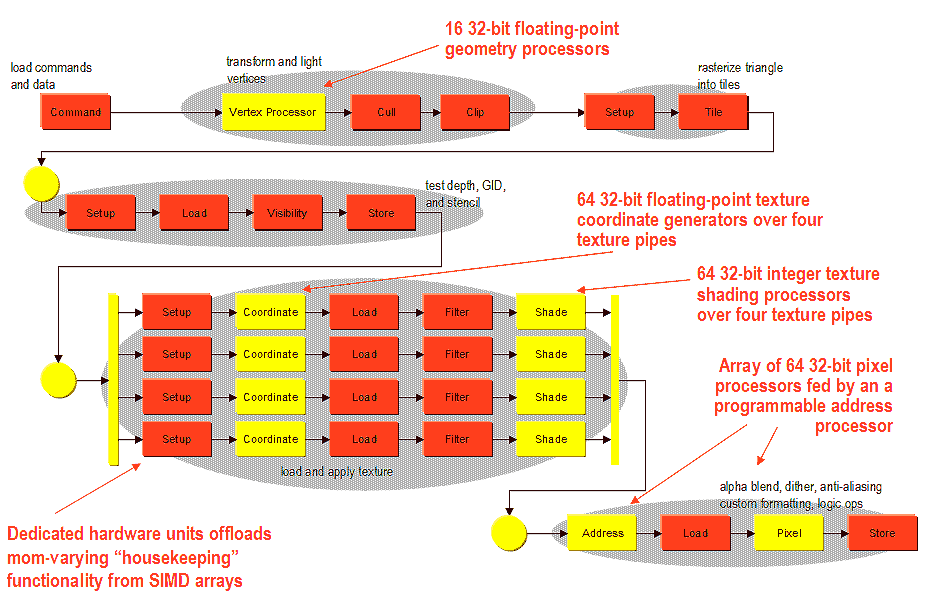
Как обычно в трехмерной графике, наблюдается четкая последовательность поточного прохождения данных через функциональные блоки ускорителя.
Вначале команды попадают в вершинный процессор:
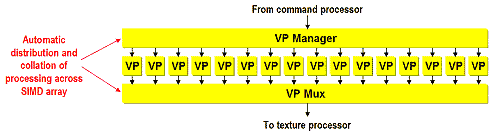
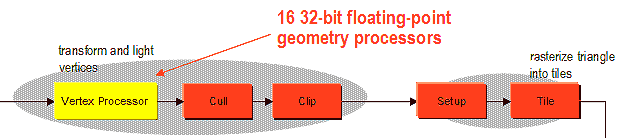
Способный, в отличие от прочих распространных ныне программируемых чипов, не только считывать, но и записывать в память обработанные параметры вершин. Подобная гибкость позволяет запрограммировать практически любые алгоритмы тесселяции сплайновых поверхностей или других представлений HOS и SS (Subdivision Surfaces), включая N-Patches. Интересно, что вершинный процессор способен считывать не только значения вершин и их атрибутов, но и значения текстур, что позволяет реализовать различные алгоритмы пертурбации и генерации геометрии на основе текстурных карт высот, нормалей и других считываемых из текстур значений. Характерный пример подобных алгоритмов — уже не раз описанный нами DM (Displacement Mapping). В этом плане совместимость P10 с DX9 беспокойства не вызывает. Интересно, что в отличие от NVIDIA, MATROX и ATI, в наличии не 4 векторных процессора, а 16 скалярных. Специальный блок (VP Manager) дирижирует этими процессорами на основе команд вершинного шейдера, объединяя их при необходимости для векторной обработки двух, трех или четырехмерных значений. По сравнению с общепринятыми четырьмя векторными процессорами, подобное решение гарантирует равную или превосходящую производительность. Разумеется, при условии одинаковой частоты и сходной производительности выполняющих атомарные операции АЛУ.
Далее полученные в результате работы массива вершинных процессоров координаты вершин и их атрибуты отправляются на закраску. Вначале выделенные аппаратные блоки отбрасывают обратные грани и выходящие за пределы области видимости треугольники (см. также общую схему, блоки Cull и Clip):
После отбрасывания треугольников, они попадают на установку (Setup) и разбиваются на тайлы 8х8 для последующей растеризации. За это вновь отвечают выделенные аппаратные блоки — подобным подходом разумного чередования программируемых и фиксированных блоков пропитан весь P10.
После разбиения на регионы (тайлы) закраска каждого тайла будет проходить по следующему сценарию:
Вначале проверяется видимость региона в целом и его отдельных пикселов, затем выполняется выборка необходимых значений текстур, затем вычисляются результирующие значения пикселей. Давайте посмотрим на этот процесс более подробно.
Вот так происходит раннее определение необходимости закрашивать блоки и отдельные пикселы (см. также общую схему):

Желтым кружочком обозначена очередь тайлов (фрагментов) 8х8, направляемых на растеризацию. В наличии специальные аппаратные блоки, которые определяют видимость — вначале каждого тайла, а затем и отдельных его пикселов, считывая значения глубины и буфера шаблонов и проводя необходимые сравнения. Далее, уже отдельные видимые пикселы отправляются в очередь на закраску.
Закраска выполняется параллельно для 64 пикселов, т.е. вплоть до целого блока 8х8 (!). Каждый из 64 пикселов проходит следующий путь через фиксированные и программируемые аппаратные блоки:
Программируемыми являются плавающий процессор для генерации координат (Coordinate) и целочисленный пиксельный процессор (Shader). Выбирающие и фильтрующие текстуры блоки Load и Filter реализованы аппаратно и способны выполнять билинейную и трилинейную фильтрацию. Но при необходимости их результаты могут возвращаться в процессор генерации координат, видимо, в том числе и для организации анизотропной фильтрации или более сложных методов выборки текстур. Разумеется, имея программируемый процессор для генерации текстурных координат, мы можем, в том числе, работать и с объемными текстурами и с кубическими или сферическими картами среды. Напомним, что, к сожалению, пиксельный процессор является целочисленным, и это не позволяет ему быть совместимым с пиксельными шейдерами версии 2.0 из DX9.
И наконец, после вычисления финального значения, как результата пиксельного шейдера, оно отправляется в один из специальных программируемых конвейеров:
Которые позволяют реализовывать произвольные методы заполнения буфера кадров, в том числе и различные методы AA и мультисамплинга, а также запись результатов рендеринга сразу в несколько буферов.
Напоследок, прежде чем приступить к тестам производительности, приведем список поддерживаемых текущими драйверами возможностей DirectX 8:
- Размер текстур — до 2048x2048, возможны неквадратные текстуры
- Максимальная степень анизотропии — 8
- Максимальное число источников света — 16
- Максимальное число текстур за один проход — 8
- Число плоскостей отсечения — 6
- Максимальный размер спрайтов — 127
- Максимальное число примитивов за один вызов — 1073741823 (много)
- Размер вершинного буфера — 65536
- Максимальное число потоков вершин — 8
- Версия вершинных шейдеров — 1.1
- Число констант вершинного шейдера — 128
- Версия пиксельных шейдеров — 1.2
- Максимальное значение пиксельного шейдера — 8
- Режимы мултисамплинга: нет, 2, 4, 8 сэмплов
- Форматы итогового буфера:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- Форматы буфера глубины:
- D3DFMT_D32
- D3DFMT_D24S8
- D3DFMT_D16
- D3DFMT_D24X8
- Форматы текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_V8U8
- D3DFMT_L6V5U5
- D3DFMT_X8L8V8U8
- D3DFMT_Q8W8V8U8
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Форматы кубических текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Форматы объемных текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Режимы фильтрации обычных текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MINFANISOTROPIC
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- D3DPTFILTERCAPS_MAGFANISOTROPIC
- Режимы фильтрации кубических текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- Режимы фильтрации объемных текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MAGFPOINT
В общем и целом — все на уровне, возможность использовать до 16 источников света и 8 текстур за проход выглядит привлекательно. Разумеется, поддерживается полный спектр операций с буфером шаблонов и полный набор режимов проверки глубины. Удивляет только отсутствие какой-либо (даже билинейной) фильтрации объемных текстур, но, возможно, это вопрос драйверов. Как бы там ни было, в пределах DX8 реализованы все необходимые базовые возможности, в том числе превышающие NV25. Ясно что с DX9 ситуация будет не столь безоблачна, хотя бы из-за пиксельных шейдеров, однако сказать что-либо точно можно будет только с выходом DX9 драйверов для P10.
Напоследок приведем список поддерживаемых на данный момент OpenGL расширений:
| Matrox, ICD for Parhelia version 1.2 | NVIDIA, GeForce4 Ti 4400/AGP/SSE2, version 1.3.1 | 3Dlabs, Wildcat VP870, version: 1.2.0 |
|---|---|---|
| GL_ARB_multitexture | GL_ARB_imaging | GL_ARB_multitexture |
| GL_ARB_point_parameters | GL_ARB_multisample | GL_ARB_texture_env_add |
| GL_ARB_texture_compression | GL_ARB_multitexture | GL_ARB_texture_env_combine |
| GL_ARB_texture_cube_map | GL_ARB_texture_border_clamp | GL_ARB_texture_env_crossbar |
| GL_ARB_texture_env_add | GL_ARB_texture_compression | GL_ARB_texture_border_clamp |
| GL_ARB_texture_env_combine | GL_ARB_texture_cube_map | GL_ARB_texture_cube_map |
| GL_ARB_texture_env_dot3 | GL_ARB_texture_env_add | GL_ARB_texture_env_dot3 |
| GL_ARB_transpose_matrix | GL_ARB_texture_env_combine | GL_EXT_bgra |
| GL_S3_s3tc | GL_ARB_texture_env_dot3 | GL_EXT_blend_subtract |
| GL_ATI_element_array | GL_ARB_transpose_matrix | GL_EXT_blend_minmax |
| GL_ATI_vertex_array_object | GL_S3_s3tc | GL_EXT_compiled_vertex_array |
| GL_EXT_bgra | GL_EXT_abgr | GL_EXT_polygon_offset |
| GL_EXT_blend_color | GL_EXT_bgra | GL_EXT_rescale_normal |
| GL_EXT_blend_func_separate | GL_EXT_blend_color | GL_EXT_separate_specular_color |
| GL_EXT_blend_logic_op | GL_EXT_blend_minmax | GL_EXT_secondary_color |
| GL_EXT_blend_minmax | GL_EXT_blend_subtract | GL_EXT_texture3D |
| GL_EXT_blend_subtract | GL_EXT_compiled_vertex_array | GL_EXT_texture_object |
| GL_EXT_secondary_color | GL_EXT_separate_specular_color | GL_EXT_texture_edge_clamp |
| GL_EXT_compiled_vertex_array | GL_EXT_fog_coord | GL_EXT_texture_env_add |
| GL_EXT_draw_range_elements | GL_EXT_multi_draw_arrays | GL_EXT_texture_env_combine |
| GL_EXT_element_array | GL_EXT_packed_pixels | GL_EXT_texture_env_dot3 |
| GL_EXT_fog_coord | GL_EXT_paletted_texture | GL_EXT_texture_cube_map |
| GL_EXT_multi_draw_arrays | GL_EXT_point_parameters | GL_EXT_texture_filter_anisotropic |
| GL_EXT_packed_pixels | GL_EXT_rescale_normal | GL_EXT_multi_draw_arrays |
| GL_EXT_point_parameters | GL_EXT_clip_volume_hint | GL_SGIS_multitexture |
| GL_EXT_rescale_normal | GL_EXT_draw_range_elements | GL_SGIS_texture_border_clamp |
| GL_EXT_secondary_color | GL_EXT_shared_texture_palette | GL_SGIS_texture_lod |
| GL_EXT_separate_specular_color | GL_EXT_stencil_wrap | GL_NV_register_combiners |
| GL_EXT_stencil_wrap | GL_EXT_texture3D | GL_NV_vertex_program |
| GL_EXT_subtexture | GL_EXT_texture_compression_s3tc | GL_NV_texgen_reflection |
| GL_EXT_texture3D | GL_EXT_texture_edge_clamp | GL_WIN_swap_hint |
| GL_EXT_texture_compression_s3tc | GL_EXT_texture_env_add | GL_KTX_buffer_region |
| GL_EXT_texture_cube_map | GL_EXT_texture_env_combine | - |
| GL_EXT_texture_edge_clamp | GL_EXT_texture_env_dot3 | - |
| GL_EXT_texture_env_add | GL_EXT_texture_cube_map | - |
| GL_EXT_texture_filter_anisotropic | GL_EXT_texture_filter_anisotropic | - |
| GL_EXT_texture_lod_bias | GL_EXT_texture_lod | - |
| GL_EXT_vertex_array | GL_EXT_texture_lod_bias | - |
| GL_EXT_vertex_array_object | GL_EXT_texture_object | - |
| GL_EXT_vertex_shader | GL_EXT_vertex_array | - |
| GL_EXT_texture_env_combine | GL_EXT_vertex_weighting | - |
| GL_EXT_texture_env_dot3 | GL_HP_occlusion_test | - |
| GL_KTX_buffer_region | GL_IBM_texture_mirrored_repeat | - |
| GL_MTX_fragment_shader | GL_KTX_buffer_region | - |
| GL_NV_texgen_reflection | GL_NV_blend_square | - |
| GL_SGIS_multitexture | GL_NV_copy_depth_to_color | - |
| GL_SGIS_texture_lod | GL_NV_evaluators | - |
| WGL_EXT_swap_control | GL_NV_fence | - |
| - | GL_NV_fog_distance | - |
| - | GL_NV_light_max_exponent | - |
| - | GL_NV_multisample_filter_hint | - |
| - | GL_NV_occlusion_query | - |
| - | GL_NV_packed_depth_stencil | - |
| - | GL_NV_point_sprite | - |
| - | GL_NV_register_combiners | - |
| - | GL_NV_register_combiners2 | - |
| - | GL_NV_texgen_reflection | - |
| - | GL_NV_texture_compression_vtc | - |
| - | GL_NV_texture_env_combine4 | - |
| - | GL_NV_texture_rectangle | - |
| - | GL_NV_texture_shader | - |
| - | GL_NV_texture_shader2 | - |
| - | GL_NV_texture_shader3 | - |
| - | GL_NV_vertex_array_range | - |
| - | GL_NV_vertex_array_range2 | - |
| - | GL_NV_vertex_program | - |
| - | GL_NV_vertex_program1_1 | - |
| - | GL_SGIS_generate_mipmap | - |
| - | GL_SGIS_multitexture | - |
| - | GL_SGIS_texture_lod | - |
| - | GL_SGIX_depth_texture | - |
| - | GL_SGIX_shadow | - |
| - | GL_WIN_swap_hint | - |
| - | WGL_EXT_swap_control | - |


