Трудно определить жанр настоящего труда. Формально — это обзор современного положения дел в компьютерной графике. Ежели трактовать по Аристотелю, то сей труд имеет:
- в качестве формальной причины — светлую дату — десятилетие появления на свет интерфейса OpenGL. И двадцатилетие IRIS GL. Король умер — да здравствует король! Интересный десятилетний цикл, однако.
- первоначальные наброски {drafts} интерфейса OpenGL 2.0 в качестве субстрата и основы.
- мое недовольство современной полигональной трехмерной графикой как движущую причину и начало движения.
- тяжелее определить самое главное, цель — то, ради чего эта статья написана. Ведь не может она всего лишь выражать недовольство и не иметь благородной цели? Основная задача — выделение объективных проблем трехмерной графики, которые остаются нерешенными в течение десятилетий.
Отсчет десятилетий
Десять лет тому назад, летом 1992 года, корпорация SGI (тогда еще Silicon Graphics) явила миру спецификацию OpenGL 1.0. Этот программный интерфейс был во многом основан на проприетарной библиотеке IRIS GL, поддерживаемой с 1982 года. Для развития нового интерфейса был организован консорциум The OpenGL Architecture Review Board {ARB}. Так что в текущем году вполне можно отпраздновать десятилетие "стандартного графического конвейера с открытым лицом" и двадцатилетие интерфейсов компьютерной графики реального времени от SGI. Конечно, можно было бы копать глубже, вспомнив Ivan Sutherland, а то и Гаспара Монжа вместе с Евклидом. Впрочем, это было бы слишком глубоко, подобная ретроспекция не входит в число скромных целей этой статьи.
Сначала про стандартный конвейер {pipeline} от Silicon Graphics. Классическая библиотека трехмерной графики представляет собой черный ящик, который снабжен одним лотком для подачи треугольников, массой тумблеров (вкл. — выкл.) и ручек настройки. Что происходит с треугольником внутри ящика? [Ну, на самом деле не только с треугольником. В число примитивов входят точки, отрезки прямых, и выпуклые полигоны не обязательно о трех вершинах. Но мы будем следить только за судьбой треугольника.] Координата и нормаль каждой вершины треугольника преобразуются с помощью модельной матрицы {MODELVIEW}. [В OpenGL есть несколько матричных стеков. Очень удобный подход.]
Исходя из этих геометрических свойств вершины, свойств материала и положения источников света, при включенном расчете освещенности генерируется цветовая характеристика (если цвет был явно указан, то его значение переписывается). При включенной генерации текстурных координат они также изменяются, а после трансформируются с помощью текстурной матрицы. Эта так называемая геометрическая стадия.
Далее к каждой вершине треугольника применяется матрица трехмерного проективного преобразования {PROJECTION}. Полученная четверка проективных координат {x,y,z,w} нормализуется: {x/w,y/w,z/w,1}. Такое преобразование перегоняет пирамиду видимости в единичный куб. Часть треугольника, которая не попадает в пирамиду видимости {frustrum}, отсекается {clip}. Визуально это соответствует тому, что рисуется только часть треугольника, видимая в окне, и вдобавок та, которая ближе к наблюдателю, чем дальняя плоскость отсечения, и дальше, чем ближняя. Также к треугольнику применяются клиентские плоскости отсечения {client clip planes}. Первые две компоненты в тройке нормализованных координат используются для позиционирования проекции треугольника в окне. Третья компонента после используется для выполнения Z теста {Z test~depth test}. Треугольник, спроецированный на плоскость, может быть ориентирован "по часовой стрелке" и в обратном направлении. Можно указать "правильную" ориентацию, рисуются только треугольники, таковой обладающие {face cull}.
Следующий этап — растеризация. Все атрибуты с учетом проективной коррекции интерполируются на пиксели, принадлежащие треугольнику. Для всех текстурных стадий вычисляются текстурные координаты, выбранные из текстур значения последовательно смешиваются, формируя одно цветовое значение. Рассчитывается также stencil значение и значение Z в данном пикселе. Эта троица называется мудреным словом "фрагмент" {fragment}. Для фрагмента выполняется ряд тестов {depth, alpha, stencil}. При отрисовке в случае успешного выполнения тестов новый цвет смешивается со старым с помощью текущей моды смешения {blend}, обновляется stencil и Z-значение.
Вся виртуальная машина OpenGL управляется набором булевых переменных, которые включают ту или иную ветвь конвейера (расчет освещенности, текстурных координат, пиксельные тесты и так далее) и числовых значений, связанных с данной стадией. Конвейер является "переводом" английского слова "pipeline", что значит "трубопровод". Так что поток данных в стандартном конвейере можно весьма натуралистично представлять как течение жидкости в трубе с множеством задвижек, змеевиков, холодильников и нагревательных элементов.
Это стандартный графический конвейер. [ Исключительно в части обработки полигонов. OpenGL имеет высокоуровневые сплайновые примитивы и встроенные средства обработки картинок — массивов пикселей.]
Известная сентенция гласит, что ничто не вечно под луной. А Гегель утверждает, что развитие идет по спирали. Отсюда с неизбежностью следует, что ошибки предшественников уступают место более совершенным ошибкам последователей.
Стандартный конвейер и геометрия
Объекты в 3D графике состоят из треугольников. Для вершин треугольников определяются геометрические, цветовые и текстурные характеристики. Обычно треугольники имеют общие вершины, так что неразумно дублировать информацию. Стандартным способом описания является определение двух массивов — массива вершин {Vertex Buffer, VB}, в котором сохранены геометрические, цветовые и текстурные характеристики вершин, и массива индексов {Index Buffer, IB}, в котором три последовательных индекса формируют отдельный треугольник. Еще массивы индексов можно структурировать не как набор отдельных треугольников, а как одну полоску {strip} или веер {fan} из треугольников.
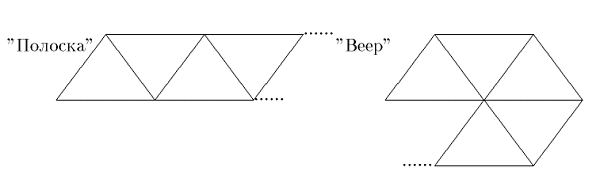
Это более экономные способы индексации геометрии. Весьма удобный на первый взгляд подход на практике оборачивается настоящим кошмаром.
Для произвольной полигональной модели соотношение V/T="число вершин/число треугольников" приблизительно равно 0.5 — на каждые два треугольника приходится одна новая вершина. Каждый желающий может убедиться в этом, использовав формулу Эйлера.
У набора треугольников это соотношение равно 3.0, для полосок и вееров из треугольников соотношение стремится с ростом длины к единице, оставаясь больше. Разбить произвольную модель, заданную как набор треугольников, на полоски и веера довольно сложно. Алгоритмы некрасивые и медленные. Для склейки коротких полосок используется такой чудовищный прием, как вставка вырожденных треугольников. Но в любом случае соотношение V/T остается в два раза хуже оптимального. Отмечу, что у современных чипов скорость геометрической трансформации зачастую является одним из узких мест. Так что за скорость надо бороться.
У проблемы организации геометрии есть еще одно лицо — это архитектура железа. И способ снижения V/T, который называется кэшированием обработанных вершин. Индексу соответствует уникальная вершина, обработанные вершины кладутся в LILO очередь. Для каждой вершины треугольника по индексу, как по ключу, в очереди ищется уже обработанная копия. Если таковая находится, то обработка вершины повторно не производится. Подобная организация геометрии снижает отношение V/T. В случае достаточно длинной очереди (в реальности порядка 100 — 1000 вершин) и правильного упорядочения треугольников соотношение становится близким к оптимальному значению 0.5, так что хотелось бы законодательно утвердить подобный порядок. А именно, указать достаточно длинный, 256 элементов, по крайней мере, буфер обработанных вершин в качестве необходимого ингредиента правильного видеоускорителя. Никаких полосок и вееров, одни треугольники. Заполнение статического индексного буфера могло бы выглядеть примерно так:
BeginStaticTriangleBuffer(TriangleBufferHandle);
…
/*новая вершина, N-тый элемент массива.*/
ReadVertexFromArray(N);
/*кладем ее в кэш по адресу M */
WriteToCache(M);
…
/*читаем вершину из кэша по адресу M. Вот заранее обработанная вершина нам и пригодилась */
ReadVertexFromCache(M);
…
EndTriangleBuffer();
Каждая тройка команд Read* формирует один треугольник. Конечно, мне могут возразить, что явное использование кэш памяти в интерфейсе является дурным тоном. Что я могу ответить? Не согласен. Если внутренняя структура чипов такова, что при оптимальном программировании возможен прирост скорости в разы, то она однозначно должна быть учтена. Большую головную боль представляет собой необходимость оптимизировать приложение для чипов, о внутренней структуре которых нет никаких четких данных. Тем более, что размер кэша в современных чипах различается в разы. Оптимизация под современные видеоускорители — это ловля черной кошки в темной комнате, причем непонятно, то ли это действительно кошка, то ли какая-нибудь пантера.
Проблема носит явный геометрический характер — треугольники имеют общие вершины. Кэш надо рассматривать именно с этой точки зрения — как хороший способ указывать локальные правила склейки геометрии. Обобщение полосок и вееров, если угодно. Полоска - это ведь тоже неявный способ кэширования (сохраняются две вершины последнего треугольника). Я бы был согласен, если бы из интерфейса удалили полоски и веера, предоставив новую возможность — отрисовку набора треугольников с явным указанием кэширования. [ Замечу кстати, что статический индексный буфер, полученный в результате приведенной выше процедуры, может быть легко сжат, так как большая часть операций происходит с индексами в кэше, а эти индексы являются заведомо небольшими числами.]
Первый метод приспособлен для статической геометрии. И остается старый способ отрисовки набора треугольников без явного указания последовательности кэширования, но с его использованием. В принципе, можно было бы этим и ограничиться, если бы быть уверенными, что производители железа последуют рекомендации делать аппаратный кэш указанного типа (LILO или LRU) и длины. А уж при использовании первого метода никуда им, голубчикам, не деться…
Теперь про процедурные поверхности и тесселяцию. Стандартные сплайны (и рациональные функции) плохи тем, что добиться непрерывности нормали чрезвычайно сложно (фактически, автор не знает ни одного работающего алгоритма склейки сплайнов на неравномерных сетках).
Предлагается другой подход. Первая часть подхода состоит в том, что для треугольника (или четырехугольника) для каждого ребра указывается уровень тесселяции. Библиотека тесселирует заплатку (пока абстрактно, не создавая геометрической информации, только топологическую) соответственно с тесселяцией ребер. Удобно тесселяцию делать плавающей (как в OpenGL расширении gl_nv_evaluators). Там новые вершины "зарождаются" в серединах ребер:
Теперь основным вопросом является генерация координат (и прочих атрибутов) для вершин. Как это делать? Наверное, с помощью текстур. Рассмотрим равномерную (в смысле топологии) сетку, в узлах которой заданы атрибуты — нормаль, координата, цвет и т.д. Набор текстур. [ Интересно, что треугольные текстуры необычны в графике, тогда как их четырехугольные собратья очень популярны. Между тем операции фильтрации здесь ненамного сложнее, быть может, даже проще. Нетривиальным фактом является то, что в качестве координаты здесь удобнее использовать тройку чисел u,v,w с соотношением u+v+w=1. Такие текстуры удобнее использовать для отдельных треугольников, скажем, как карты освещенности. В этом случае их легче сшивать. Так что еще одно требование — даешь треугольные текстуры!]
Абстрактно полученные вершины тесселированной заплатки имеют u,v текстурные координаты для четырехугольных заплаток и тройку барицентрических координат u,v,w:u+v+w=1 в треугольном случае. Библиотека сэмплирует текстуру по данному адресу для каждой вершины. Стандартная билинейная интерполяция неплоха, но в этом случае нет смысла использовать тесселяцию большую, чем разрешение текстуры. Более приемлема сплайновая интерполяция на каждом текселе (скажем, аналог pn_triangles aka TrueForm).
Теперь перейдем к способу подачи вершинных массивов. Сейчас стандартным является представление каждой компоненты векторов (координата, нормаль, текстурные координаты) как ANSI 32bit float. Зачастую такая точность оказывается излишней, так для нормали вполне достаточно 16 бит на компоненту. Многие объекты хорошо локализованы (модели монстров, скажем), для координаты здесь также вполне достаточно 16 бит на компоненту. Да и у текстурных координат обычно можно без заметной потери качества снизить точность. Так что разумной является поддержка сжатых форматов для вершинных атрибутов. Такая возможность существовала и в классическом интерфейсе OpenGL, но там пользователь сам выбирал формат, и он никак не мог надеяться, что декодировка будет достаточно быстрой. Что формировало замкнутый круг — программисты не были уверены в том, что формат низкой точности поддерживается, вендоры не поддерживали форматы с низкой точностью якобы из-за отсутствия спроса. На мой взгляд, правильной методикой является подача статических массивов в унифицированном формате (float) и сжатие их на стороне API, причем API сам предоставляет список доступных форматов. Ситуация мне кажется схожей с использованием сжатых текстур. Обычная методология состоит в том, что в оперативную память загружается несжатая копия текстуры. API сжимает ее, сохраняя в видеопамяти. Оригинал удаляется из памяти. Стоит ли мелочиться со сжатием? Если двукратный выигрыш в требуемом объеме памяти не кажется серьезным, то не стоит.
Вопрос: Как проблемы геометрии решены в OpenGL 2.0?
Ответ: никак не решены. Массивы являются объектами. К ним возможен прямой доступ, ни о каком сжатии и оптимизации индексов, равно как и о кэшировании, речь идти не может. Сжатые форматы — да, можно использовать байты и короткие слова {GL_SHORT, 16 бит}. Но опять нет никакой уверенности, что эти форматы будут обрабатываться достаточно быстро. О тесселяции обмолвились примерно в том смысле, что: "Никто не знает, что это такое, потому добавлять в интерфейс мы это не будем, но работаем напряженно". В качестве специальной возможности добавлены раздельные индексные массивы для разных вершинных атрибутов. Якобы это помогает программисту в разрешении коллизий, когда вершины разделяют одни атрибуты (скажем, координату) и не разделяют другие (скажем, цвет). Базовый пример — куб с разным цветом граней. Очень спорная возможность.
Определение видимости на стандартном конвейере
Стандартным определением видимости (а точнее сказать "невидимости") служит иерархическое подразделение экранной плоскости. Если куски геометрии пообъектно отсортированы от ближнего к дальнему (тут сортировка не обязана быть точной), то оказывается возможным в реальном времени довольно быстро строить структуру данных, которая будет нам говорить о потенциальной невидимости объема, ограничивающего данный кусок геометрии. Уже сейчас вендоры (NVIDIA в частности) поддерживают раннее определение видимости на стороне 3D API. Таким целям служит расширение HP_occlusion_test.
В наброске OpenGL 2.0 нет никаких упоминаний об определении видимости. А жаль.
Если бы спросили меня, я в качестве одного из возможных подходов предложил бы следующую стратегию поддержки портального рендеринга. Вводится новый объект — CSG стек полигонов. Каждый элемент стека представляет собой набор сканлайнов, ограничивающий область на экране. В частности, это маска для рендеринга. В стек можно положить полигон P, пересекая область, ограниченную текущим элементом на вершине стека, и проекцию P. Пользователь может узнать о том, что верхний элемент стека пуст, и откатиться на шаг назад. С помощью такого стека полигонов можно было бы определять видимость отдельных частей сцены с помощью портальных алгоритмов, комбинируя процесс отрисовки с определением видимости. Особенно хорошо алгоритм работал бы на сценах, сходных с обычными уровнями в шутере, обеспечивая нулевой коэффициент перекрытия {overdraw}. В этом алгоритме полигоны могут использоваться по несколько раз. Очень хотелось бы иметь небольшой кэш, куда можно было бы класть преобразованные треугольники.
Стандартный конвейер, полупрозрачность и объемные эффекты
Хотелось бы видеть полупрозрачные объекты, и это желание естественно. Визуально мы вполне можем разделить ситуацию, когда полупрозрачный объект A находится впереди объекта B и противоположное положение вещей. На уровне треугольников это означает, что программист должен отсортировать полупрозрачные треугольники от дальнего к ближнему относительно наблюдателя и рисовать их в именно таком порядке. Весьма странно возлагать обязанность сортировки именно на программиста, хотя трансформацию вершинных координат мы возлагаем на железо. Проблему усугубляют пересекающиеся треугольники, про которые нельзя сказать, какой из них ближе. Еще страшнее. Треугольники A,B,C могут не пересекаться, треугольник A может быть ближе треугольника B, который ближе треугольника C, который ближе треугольника A. Это значит, что для правильной сортировки нужно подразделять треугольники (скажем, с помощью BSP дерева). А BSP дерево ой как недешево… Сортировка треугольников — неприемлемое решение данной проблемы.
Так что сортировка должна проводиться на пиксельном уровне. Известный мне неплохой алгоритм может быть назван "попиксельной сортировкой с помощью Z буфера". Подобно тому, как с помощью Z буфера мы выделяем самый близкий непрозрачный пиксель, мы можем выделить сначала "самый далекий полупрозрачный", потом тот, который первый по близости после "самого далекого" и так далее. Записанный в псевдокоде, алгоритм выглядит примерно так:
Переменные: Zmin, Zminmax
Для всех точек полигонов, висящих над данным пикселем:
Вычисляем Z.
Если Z==Zmin, то выполняем blend операцию.
Если Z Конец цикла по точкам.
Используем Z minmax в качестве Zmin для следующего прохода.
Подобный процесс может быть осуществлен на современном оборудовании (скажем, см. демонстрационную программку "Прозрачность, не зависящая от порядка" на сайте NVIDIA). Однако эта реализация просто чудовищно неэффективная. Замечу, что для осуществления процесса мы должны собрать в кучу все полупрозрачные треугольники. Шаг алгоритма заключается в отрисовке всех этих треугольников. Дополнительно используется еще один Z буфер. Если число перекрытия равно N, то мы должны прогнать алгоритм N раз.
Процесс можно существенно ускорить, если на каждом шаге выкидывать из списка полупрозрачных треугольников те, у которых все пиксели легли на отведенные им места. Тогда общее число проходов алгоритма снижается примерно в два раза. Скажем, при числе перекрытия, равном 4, над пикселем надо пройтись 4 раза. Предложенный алгоритм будет делать в среднем 10 операций, всего в два с половиной раза больше. Кроме того, существует ряд оптимизаций, позволяющих правильно рисовать полупрозрачные объекты с небольшими накладными расходами. Эти оптимизации делятся на те, которые можно проводить на стороне API (разбиение набора полупрозрачных полигонов плоскостью на два поднабора и сортировка внутри каждого, использование Z буфера со многими слоями), и на оптимизации на стороне программиста (сортировка прозрачных непересекающихся объектов по удаленности).
Так или иначе, данная функциональность кажется мне абсолютно необходимой. Можно ли ее реализовать на OpenGL 2.0? При помощи пиксельных шейдеров это можно сделать с оговорками и не очень эффективно. Потому как никакого обратного потока данных (хотя бы подобного гистограммам) со стадии растеризации здесь нет.
Теперь — объемная прозрачность. Говорить много по этому поводу мне не хочется. Моя мечта — возможность рассмотрения трехмерной текстуры как массива вокселей. Добавить к стандартным примитивам объемные — скажем, тетраэдр. К каждой вершине привязаны соответствующие координаты в трехмерной текстуре. Способ рендеринга — трассировка луча от значения в Z буфере к наблюдателю через объект. Однако такой явный способ введения полупрозрачных объемных объектов "напрямую" наталкивается на значительные сложности а части корректного рендеринга перекрывающихся объектов.
Читатель может спросить, почему я такое внимание уделяю теме прозрачности (в том числе и объемной). Отвечу. Посмотрите результаты NV Shader Contest. Топовые позиции так или иначе связаны с эффектами типа прозрачности.
Объекты трехмерной графики. Синхронизация
О времена, о нравы! И в OpenGL просочились объекты…
Что является объектами трехмерной графики? Разработчики OpenGL 2.0 считают, что основными объектами трехмерной графики являются:
- Image Objects
- Texture Objects
- Cube Map Objects
- Vertex Array Objects
- Display List Objects
- Shader Objects
- Frame Buffer Objects
- Buffer Objects
- Program Objects
Все объекты OpenGL 2.0 хранятся на стороне API. При создании объекта необходимо указывать приоритет и политику {policy} его использования. Такой подход призван упорядочить поток данных, располагая наиболее важные данные в более быстрой памяти. Также решается вопрос синхронизации OpenGL вызовов за счет введения асинхронных команд и способов определения, завершилось исполнение данной команды, или нет. Такие нововведения кажутся весьма полезными. Но слишком уж они очевидны. Нет здесь никакой интриги…
Вершинные массивы являются прямой калькой с DX-овых VB и IB, так что обсуждать здесь особенно нечего, а экранные списки остались со стародавних времен. Шейдерные объекты соответствуют вершинным и пиксельным шейдерам. Правда, последние правильнее называть фрагментными шейдерами {Fragment Shader}. Однако я постоянно буду сбиваться на более привычное именование. Шейдеры двух типов, собранные в единое целое, называются "программным объектом" {Program Object }.
А в части хранения пиксельных структур фантазия разработчиков разыгралась… Наличие Текстур, Картинок, Буферов и Экранных Буферов в качестве независимых сущностей может поставить в тупик даже искушенного читателя. Так или иначе, вся функциональность в этой области может быть довольно просто описана. Есть понятие конфигурируемого буфера, куда происходит отрисовка {render target}. Есть один предопределенный буфер такого сорта — это экранный буфер. Пользователь также может создавать несколько внеэкранных буферов отрисовки. Такие буферы отрисовки можно представить как папку для бумаг, куда можно подшить несколько листков — поверхностей, таких как цветовой буфер {color}, Z буфер, буфер шаблонов {stencil}, буфер вспомогательных данных {aux data}, буфер накопления {accumulation} и пр. Любую отдельную поверхность (ну, почти любую — из экранного буфера нельзя выдрать цветовую составляющую) можно удалить из буфера отрисовки и прикрепить к произвольной текстуре, осуществляя таким образом отрисовку в текстуру {render to texture}. Так что текстуры и буферы отрисовки представляют собой объекты, содержащие соответственно одну или несколько ссылок собственно на пиксельные данные. Возникает неясность — могут ли одновременно существовать несколько активных буферов отрисовки? Это было бы очень неплохо, так как зачастую требуется рисовать одни и те же данные в текстуру(ы) и в экранный буфер. Текущая версия API не содержит намеков на то, что так можно делать. Также весьма хотелось бы иметь возможность конфигурировать шесть одновременно активных буферов отрисовки таким образом, чтобы отрисовка треугольника в кубическую текстуру окружения производилась не шесть, а всего лишь один раз. Это мечты.
Нельзя не упомянуть про буферы вспомогательных данных. Такой буфер содержит до четырех чисел типа float на пиксел. Утверждается, что подобные буферы будут весьма полезны в реализации многопроходных алгоритмов рендеринга. Оно может быть и так, но существуют алгоритмы типа многослойного буфера шаблонов, где не требуется столь высокая точность. Иногда несколько байт лучше, чем один float. Конечно, такой буфер служит дальнейшим развитием буферов накопления {accumulation}, которые, тем не менее, представлены в набросках интерфейса. Хотя функциональность буферов дополнительных данных несравнимо шире за счет доступа в шейдере на чтение и запись. Возможно организовать второй буфер шаблонов или вспомогательный Z буфер для правильной отрисовки полупрозрачных полигонов. При реализации многопроходного рендеринга можно попиксельно сохранять заранее рассчитанные значения, скажем, нормали.
В документации упоминаются F LILO буферы, предназначенные для сохранения обработанных фрагментов. Инженеры OpenGL 2.0 побоялись представить их в текущей документации, хотя и очень хотели. И правильно сделали. Очень модная штука, и очень бессмысленная.
Несколько слов о потоковой обработке массивов пикселей. OpenGL 2.0 предоставляет довольно мощные инструменты для чтения клиентских данных и преобразования их во внутренний формат (pack-unpack шейдеры). Но мне это не инстересно. Мне интереснее фильтры, которые были вымараны из спецификации OpenGL.
Многого мне не надо. Размытие по Гауссу. Оператор Лапласа. Фильтры, которые размывают в зависимости от значений Z буфера, или от степени линейности Z буфера — очень полезная штука для реализации фокуса камеры или для качественного размытия теней, полученных с помощью буфера шаблонов {stencil buffer}.
С самими фильтрами {convolution filters} интересные вещи творятся. Возможность применять к картинке фильтр закреплена в стандарте OpenGL 1.2, однако немногие из производителей железа реализуют эту возможность, хотя, казалось бы — чего проще. Более того, наметилась нездоровая тенденция (причесывая все под одну гребенку пиксельных шейдеров) реализовывать convolution filters с помощью многократного сэмплирования одной текстуры. Подобного развития событий нельзя допускать. Стоимость свертки фильтра 4x4 с пикселями картинки просто несравнима со стоимостью шестнадцати сэмплирований текстуры. Тем более, что операции свертки являются потоковыми с весьма предсказуемым обращением с памятью и хорошей возможностью оптимизации на самом низком уровне.
Что же OpenGL 2.0? В документации всячески пропагандируется реализация фильтров с помощью многократного чтения из текстуры в пиксельном шейдере. Так делать можно, но сам подход мне не нравится. Видимо, одним из лучших решений является введение явно указанного фильтра как способа интерполяции текстуры. Я обсужу этот подход в части, посвященной шейдерам.
Так или иначе, но настоящая документация в части хранения и использования пиксельных данных кажется весьма сырой. Остается надеяться, что в будущем она приобретет более регулярный и удобопонимаемый вид.
Снова о геометрии
Возвращаемся к этому вопросу, но на качественно новом уровне. Как я уже упоминал, идеальным мне кажется представление статической [Статическая в смысле топологии и возможно постоянства вершинных атрибутов. Однако такая геометрия вполне может давать различные картинки, скажем, при использовании матричного скиннинга и анимации палитры матриц]
геометрии в виде вершинных массивов {VB} и буфера отдельных треугольников с явным указанием способа кэширования.
В полигональной графике есть, по крайней мере, два хорошо известных алгоритма, учитывающие топологию модели в степени, которая плохо обеспечивается указанием набора VB+TB.
Первый алгоритм — это расчет нормалей с помощью усреднения по треугольникам. Сначала для всех вершин считается координата в модельном пространстве. Потом для каждого треугольника ищется нормаль. Для каждой вершины нормаль является усреднением нормалей треугольников, имеющих данную вершину. Кроме нормалей, так можно считать и локальную систему координат, весьма важный объект в поточечном освещении {per pixel lighting}. Вы можете спросить меня, а зачем искать нормаль к статической геометрии? Отвечу. При матричном скиннинге обычным является расчет нормали с помощью взвешенного действия тех же матриц (а эстеты используют обратные транспонированные), которыми преобразуется координата. Что почти всегда дает неправильный результат. Оказывается, что усреднение нормали — единственный приемлемый способ ее расчета. Что уж говорить про шейдерные варианты деформируемой геометрии. Метод был бы достаточно быстр. Если бы не одно "НО". Требуется очень массивное число записей в память. Так что простой по числу операций алгоритм оказывается провальным в плане скорости.
Так вот, локальность геометрии, обеспеченная явным указанием способа кэширования, также обеспечивает и возможность очень хорошей реализации данного метода (большая часть операций записи в память элиминируется).
Второй алгоритм — это расчет теневых объемов для теней, изготовленных с помощью буфера шаблонов. Этот алгоритм использует более слабую топологическую информацию и с успехом может быть аппаратно ускорен. Опять-таки, при наличии небольшого кэша. Но на сей раз кэша обработанных треугольников или их ребер.
Как мне кажется, эти два метода являются желательным ингредиентом хорошего API полигональной графики, равно как и геометрические операции, подобные subdivision surfaces. В OpenGL 2.0 подобную функциональность нельзя реализовать. Нет никаких способов нетривиально обрабатывать геометрию с помощью не шейдерных процедур. Стандартный конвейер в целом сохранен, и только две стадии — обработка вершин (то, что во введении названо геометрической стадией) и растеризация фрагментов (но не конвенциональные тесты и смешение цветов) реализованы с помощью программируемого языка шейдеров.
Пиксельные и вершинные эффекты
Здесь пойдет речь о шейдерном языке OpenGL 2.0. Как говорят, лучше один раз увидеть, чем сто раз услышать. Ну так смотрите.
Вершинный шейдер:
const ubyte *phongVertex = "
void main (void)
{
varying vec3 normal; // output to fragment shader
// Transform vertex to clip space and output. Note gl_Position
// is predefined and must be written to.
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// Transform, normalize and output normal.
normal = normalize (gl_NormalMatrix * gl_Normal);
}";
Пиксельный шейдер
const ubyte *phongFragment = "
void main (void)
{
varying vec3 normal; // input from vertex shader
// Material state
uniform vec3 ambientColor;
uniform vec3 materialDiffuseColor;
uniform vec3 materialSpecularColor;
uniform float materialShininess;
// Light state
uniform vec3 diffuseIntensity;
uniform vec3 specularIntensity;
uniform vec3 position;
uniform vec3 halfVector;
float normalDotVP, normalDotHalfVector, powerFactor;
vec3 color, diffuseLight, specularLight;
normalDotVP = min (0, dot (normal, position));
normalDotHalfVector = min (0, dot (normal, halfVector);
if (normalDotVP == 0.0)
powerFactor = 0.0;
else
powerFactor = pow (normalDotHalfVector, materialShininess);
diffuseLight = diffuseIntensity * normalDotVP;
specularLight = specularIntensity * powerFactor;
color = ambientColor + diffuseLight * materialDiffuseColor +specularLight * materialSpecularColor;
gl_FragColor = vec4 (color, 1.0);
}";
Заметим, во-первых, что язык базируется на C. Заметим, во-вторых, что входными данными вершинного шейдера являются предопределенные переменные gl_Vertex, gl_Normal. Эти данные определяются повершинно. Результат работы вершинного шейдера сохраняется в переменной varying vec3 normal. Ключевое слово {varying} означает, что данная переменная будет интерполироваться по треугольнику. Эта переменная, наряду со статическими данными diffuseIntensity, specularIntensity etc. становится доступной в пиксельном шейдере. То есть пиксельные и вершинные шейдеры нуждаются во взаимной стыковке {linking}.Типы данных, допустимые в шейдерах обоих типов — это действительные числа float, вектора из действительных чисел длиной 2,3,4; матрицы 2 x 2, 3 x 3, 4 x 4 и числа типа int. Также допустимы массивы из таких данных и структуры. Векторный язык весьма удобен за счет наличия операторов *,+ и возможности маскирования: vec4 dup = pos.xxyy;
Данные могут быть константами, определенными на стадии компиляции, Read Only константами, устанавливаемыми через вызовы API, локальными переменными шейдера, и varying переменными, осуществляющими связь вершинного и пиксельного шейдеров.
Имеются директивы препроцессора, конструкции {if-else, for, do-while} и процедуры вызова подпрограмм. Встроенные функции включают тригонометрические, геометрические функции, функции типа {max-min-fract-clamp etc.}, матричное умножение, очень важная функция шума (noise). В пиксельных шейдерах доступно сэмплирование текстуры (с явным указанием уровня детализации), для переменных доступны их частные производные в оконных координатах, что весьма удобно.
Жалко, что в языке пиксельных шейдеров не присутствуют фильтры (как способ сэмплирования текстуры). Коэффициенты такого фильтра могут определяться или статическим образом, или динамически. В качестве хорошего примера динамического фильтра мог бы выступать фильтр Гаусса с попиксельно определяемым радиусом размытия. Или анизотропный фильтр, который задается как эллипс в пространстве текстуры. Типичным применением явной фильтр-интерполяции текстуры был бы следующий nearest-convolution фильтр. U-V координаты преобразуются к ближайшему текселю в пространстве текстуры, выбирается матрица значений, окружающих этот тексель и сворачивается со статическим фильтром. Куда удобнее, чем:
tex = TexCoord0;
finalColor = texture (SRC_IMAGE, tex) * kernel[4];
tex.s += Xdelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[5];
tex.t += Ydelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[8];
tex.s -= Xdelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[7];
tex.s -= Xdelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[6];
tex.t -= Ydelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[3];
tex.t -= Ydelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[0];
tex.s += Xdelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[1];
tex.s += Xdelta;
finalColor += texture (SRC_IMAGE, tex) * kernel[2];
// Convert the RGB color to RGBA
newColor = vec4 (finalColor, 1.0);
Досадно отсутствие в вершинных шейдерах операции сэмплирования текстуры. Многие функции удобнее представлять не в аналитическом в виде, а как массив значений. Еще более обидно то, что в шейдерах недоступна операция свободного адресного чтения из OpenGL вершинных массивов. Да и писать в память в шейдере, конечно же, нельзя.
Касательно общего стиля шейдерной презентации. Довольно мрачно. Но от версии к версии улучшения заметны. Местами. Скажем, есть такой оператор индексации массива []. В такой форме записи массив можно индексировать целым числом. Но есть еще функция element(a, float i), вызов которой эквивалентен a[(int)i]. Когда я написал в службу поддержки, почему нельзя писать a[(int)i], мне ответили, что язык не допускает приведение типов, нельзя привести float к int — каково? Однако инженеры одумались. Теперь float можно-таки привести к int. Но функция element осталась. Важное улучшение касается чтения из буферов. Ранее этой цели служила функция lookup, которой я посвятил целый гневный абзац. Однако этот абзац мне пришлось вытереть (нет функции — нет проблемы). Теперь доступ к старым значениям цвета, Z буфера и буфера шаблонов осуществляется как надо, чтением из RO переменных:
vec4 gl_FBColor;
float gl_FBDepth;
float gl_FBStencil;
vec4 gl_FBDatan;
Странно, что архитекторы OpenGL так привязаны к классическим тестам и операциям смешения {blend}. Скажем, классическая настройка функции смешения как (GL_ONE,GL_ONE) соответствует такой немудреной приставке в конце шейдера:
gl_FragColor=gl_FBColor+calculated_color;
Утверждается, что воплощение с помощью шейдеров будет из-за "экстремально глубокой конвейеризации и введения дополнительных зависимостей" медленнее, чем стандартное. Я не верю. Единственный тест, который имело хоть какой-то смысл оставить непрограммируемым, это Z-тест. Потому как современные чипы строят иерархические структуры данных для Z. Так почему не ввести в язык такие ограничения, которые бы позволяли эффективно использовать иерархические структуры для предварительного тайл-теста? Потому как иерархия неплоха и для других типов данных, скажем, для буфера шаблонов.
Заметьте, что в этом разделе я не предворяю описание OpenGL 2.0 своими размышлениями на тему. Мои размышления на эту тему очень просты. А именно — зачем затевать язык, который так похож на язык высокого уровня, и который таковым не является?
Немного расширив правила, можно получить язык, компилируемый на стороне API, который полностью заменяет стандартный C. А именно, можно ввести в язык операцию отрисовки треугольника. Процедуры такого языка не вызываются при обработке вершин. Пользователь непосредственно вызывает (через вызов API) такие процедуры, передавая в качестве параметров числа и OpenGL массивы. Обычно внутри этой процедуры вершины в цикле будут преобразовываться с помощью шейдерной подпрограммы, формируя отдельные треугольники, подаваемые на стадию растеризации. Всего лишь надо добавить команду растеризации треугольника с тремя заданными вершинами и их {varying} характеристиками. В таком языке вполне могут существовать встроенные функции, скажем, для тесселяции заплаток. Неплохи были бы встроенные кэши. [что-то типа LRU_map Cache. Функциональность — кэш держит фиксированное, скажем, 256 число пар объект-ключ, положенных последними. Можно удалять объекты по ключу, можно определить наличие объекта с данным ключом, можно положить пару объект-ключ.]
Если мы хотим сохранить возможность параллельного выполнения шейдерных процедур, то мы можем ввести операцию потоковой обработки массива с помощью функции, которая может модифицировать только текущий элемент массива и не использует в своей работе другие элементы того же массива. В любом случае, вся мыслимая функциональность конвейера реализуется в программном коде на специализованном языке.
О высоком и низком
В конце предыдущего раздела было выяснено, что с помощью незначительного расширения синтаксиса шейдеров можно создать язык, удовлетворяющий всем мыслимым потребностям, которые возникают или возникнут у программистов трехмерной графики. Все в руках программиста — это одновременно сильная и слабая сторона такого подхода.
Язык будет довольно удобен (уже удобнее C за счет поддержки векторных типов), но все же каждую мелочь надо будет реализовывать "руками" (гм, весьма мозолистыми…).
Второй путь развития графики — целиком высокоуровневый подход, описание сцены "в целом".
Мои мысли о высокоуровневом подходе довольно тривиальны. Сцена описывается как набор геометрических объектов и эффектов, действующих на них. Каждый объект локализован в пространстве, то есть API знает объем (сфера, куб, пирамида и т.д), ограничивающий объект. Эффекты (позиционированный источник света, область тумана и пр.) также локализованы в пространстве, для каждого эффекта указан код (вот тут неплох шейдерный язык), который модифицирует вершинные характеристики, а также код, который работает на пиксельном уровне. Для эффектов указана последовательность их применения. Библиотека трехмерной графики сама должна для каждого объекта определить набор действующих эффектов и скомпилировать результирующий эффект. Сцена перед отрисовкой целиком описывается, библиотека сама (скажем, исходя из грубой портальной структуры) определяет видимость, сортирует объекты по удаленности и управляет отрисовкой полупрозрачных объектов.
Какой подход более перспективен? Высокоуровневый подход казался бы весьма перспективным, если бы не объективные сложности с определением видимости для произвольных сцен. Целиком низкоуровневый подход кажется относительно сложным для реализации как на уровне написания драйверов, так и на уровне программирования. Те же сложности с определением видимости остаются.
Впрочем, ситуация выбора вполне аналогична той, которая встала перед Алисой в стране Чудес. Когда та спросила:
– A куда мне идти?
Чеширский Кот ответил:
– Неважно, куда, главное — это не останавливаться! Куда-нибудь, да придешь.
Вместо заключения
Как можно охарактеризовать презентации OpenGL 2.0 в целом?
Пункт 0. Введение объектов как сущностей трехмерной графики. Идея политик и приоритетов. Довольно закономерный шаг.
1. Геометрические объекты. Как мне кажется, серьезная недоработка инженеров. Отсутствие возможности сжатия на стороне API и следование старой концепции структурирования геометрии мне категорически не нравится.
2. Текстурно-буферно-пиксельные объекты. Документация довольно тяжеловесная, но вроде интерфейс содержит все необходимое.
3. Шейдерные объекты вкупе с очень перспективным языком, которому нет равных по мощи и удобству (но и по степени удаленности от современного железа). Однако множество неприятных мелочей в спецификации языка портят довольно благоприятную картину. Я уж не говорю о том, что неразумно ограничивать встроенный аналог C только компиляцией вершинных и пиксельных эффектов.
Однако. По сравнению с прошлогодней версией заметны значительные улучшения. Так что постепенно вырисовываются контуры удобного и надежного интерфейса, традиционного в хорошем смысле этого слова.
Ах да, благодарности…
Джону Шимпфу (John Schimpf), инженеру OpenGL 2.0, за внимание и постоянную готовность отвечать на вопросы.
Константину Мироновичу за то, что он взялся рецензировать мою статью. Его замечания были неизменно ценны, а энциклопедические знания позволили устранить множество ошибок и неточностей.
Участникам конференции "Форум Разработчиков Компьютерных Игр" на iXBT.com за ценные обсуждения.


