В предыдущей статье мы с вами познакомились с новым бенчмарком 3DMark Vantage от компании Futuremark Corporation, который был выпущен в конце апреля этого года. Обновление популярной серии бенчмарков 3DMark хоть и традиционно вызвало споры о его полезности в виде теста, красотах демонстрируемой картинки и поддержке последних технологий, но оно в любом случае станет индустриальным стандартом в измерении производительности игровых компьютеров, хочет этого кто-то или нет. Ведь пользователям нужен простой тест, где производительность системы оценивалась бы единственной цифрой. Хотя цифр этих сейчас стало больше, а пакет работает только в операционной системе MS Windows Vista и предлагает значительно меньше возможностей без оплаты лицензии…
Мы уже писали о ценовой политике и системных требованиях пакета тестов, а теперь — пара слов об отсутствии поддержки прогрессивнейшего Direct3D 10.1. Компания Futuremark решила не включать её в текущую версию Vantage, хотя видеокарты производства AMD довольно давно обладают поддержкой этой версии API, начиная от модели RADEON HD 3450 и заканчивая HD 3870 X2. Некоторые пользователи тут же увидели за этим решением могучую руку Nvidia, решения которой не поддерживают Direct3D 10.1. На что представители Futuremark отвечают тем, что DirectX 10.1 стал доступен слишком поздно для включения его возможностей в процесс разработки теста. Это и понятно, учитывая то, сколько времени пакет делался.
Возможно, когда-то позднее появится Special Edition новой версии бенчмарка, вроде того, что мы видели в виде далёкого уже 3DMark 2001 SE, и она будет содержать в себе какой-нибудь Direct3D 10.1 тест. Причём, скорее всего, не влияющий на финальный счёт в 3DMark. В любом случае, можно точно сказать, что и AMD и Nvidia принимали равное участие в обсуждении возможностей 3DMark Vantage, а о каждом изменении в спецификациях разработчики теста рассказывали всем участникам программы разработки. И компания AMD в данном случае была в одинаковых условиях с другими участниками, той же Nvidia.
Но это всё скорее политика и разборки конкурентов, толком тут никто ничего не расскажет. А мы с вами сегодня лучше подробнее рассмотрим технологические особенности нового тестового пакета от Futuremark. Тестовая система в этот раз будет одна и все опыты мы провели на ней.
Конфигурация и настройки тестовой системы
В данном исследовании использовалась следующая программно-аппаратная конфигурация:
- Процессор: Intel Core 2 Quad Q6600
- Системная плата: Foxconn X38A (Intel X38)
- Оперативная память: 2 GB DDR2 SDRAM Patriot 800MHz
- Видеокарта: Nvidia Geforce 8800 GT 512MB
- Жесткий диск: Seagate Barracuda 7200.7 120GB SATA
- Операционная система: Microsoft Windows Vista 32-bit
- Видеодрайверы: Nvidia ForceWare 175.12
- Дополнительное ПО: Nvidia PerfKit 6 Beta 2, Microsoft PIX for Windows
Использовалось тестовое разрешение 1280x1024, с включенными мультисэмплингом с четырьмя выборками (MSAA 4x) и анизотропной фильтрацией максимально возможного уровня — 16x (только для графических «игровых» тестов). Все возможности включались из настроек теста, в конфигурационной панели видеодрайверов ничего не изменялось.
Наборы предустановок (preset)
Как мы уже упоминали, одним из важнейших нововведений в 3DMark Vantage стали наборы предустановок. Это комбинации настроек теста, таких как разрешение, уровень антиалиасинга, текстурной фильтрации и т.п., предназначенные для видеокарт разного уровня, от интегрированных до топовых, с разной нагрузкой на видеочип.
При запуске определенного набора настроек, в результате выдаётся цифра количества очков для этого конкретного набора. В прошлых версиях 3DMark был один такой пресет — настройки по умолчанию, а теперь есть Entry, Performance, High и Extreme. Мы свели все особенности наборов в табличку:
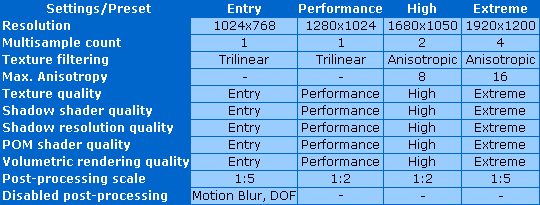
Как вы понимаете, пресет Entry предназначен для сравнения производительности интегрированных в чипсеты видеоядер и видеокарт самого низкого уровня с 128 мегабайтами видеопамяти. Performance нацелен на видеорешения среднего уровня с 256 мегабайтами видеопамяти, а наборы настроек ещё более высокого уровня требуют 512 мегабайт видеопамяти и предназначены для наиболее мощных видеокарт.
Всё устроено довольно логично. Экранные разрешения впервые выбраны с учётом распространённости LCD мониторов, особенно широкоформатных. А применение полноэкранного сглаживания и анизотропной фильтрации также сделано с учётом уровня пресета. Единственное, что непонятно — соотношение разрешений эффектов постобработки и экрана, которые равны для самого низкого и самого высокого уровней.
Итоговое количество очков отражает общую производительность системы, учитывается мощность видеокарты и центрального процессора. Есть и отдельные показатели: GPU Score и CPU Score. Первая цифра содержит в себе значения FPS графических тестов, а вторая — двух тестов для CPU. Интересно, что общие очки 3DMark рассчитываются для каждого набора настроек по-разному, значение GPU Score оказывает наибольшее влияние на них в наборе Extreme, и наименьшее — в Entry. Эти наборы настроек влияют исключительно на два графических теста: Jane Nash и Calico, все остальные тесты, включая процессорные и feature тесты, от этих настроек не зависят.
Для того чтобы было понятно, как зависят результаты теста от пресетов, мы провели тесты во всех режимах и собрали их в сводную таблицу:

Хорошо заметно, что общее количество очков сильно зависит от выбранного набора настроек (пресета). Но изменяется только FPS в первых двух графических тестах, CPU Marks и соответствующие показатели FPS остаются практически неизменными. То же самое касается и feature тестов, которые не зависят от настроек пресетов.
Графические тесты
«Professional» и «Advanced» версии пакета содержат два графических теста, два теста центральных процессоров, и шесть так называемых feature тестов. Оба графических теста продвинуты технологически, и поддерживают массу новых возможностей, доступных на видеокартах с поддержкой Direct3D 10. Два теста CPU также разработаны «с нуля» и отличаются близкими к реальным игровым алгоритмами расчета физики и искусственного интеллекта. Причем, второй («физический») тест CPU может использовать аппаратный ускоритель физики Ageia PhysX.

Оба игровых теста используют один и тот же графический движок и большинство используемых возможностей, таких как эффекты постобработки. Однако между тестами есть и некоторые отличия, если в первом тесте отрисовывается большая indoor сцена с многочисленными сложными статическими и динамическими объектами, физическими расчётами на видеочипе, симуляцией тканей и динамическими волнами, вместе с множеством источников света, то во второй сцене мы видим открытую 3D сцену в космосе, с огромным количеством сравнительно простых объектов и более сложной постобработкой.
Графический движок 3DMark Vantage поддерживает все современные технологии, и даже больше — то, что в играх пока что не применяется. Можно особо отметить следующее: расчет многочисленных источников освещения за проход, несколько моделей освещения, сложные пиксельные, вершинные и геометрические шейдеры, использование возможностей видеочипа в физических расчетах, HDR рендеринг, карты теней методом Variance Shadow Maps и отфильтрованные Cascaded Shadow Maps, многочисленные методы постобработки (bloom, streaks & flare, halo, depth of field, motion blur, depth fog, volumetric fog, tone-mapping), системы «мягких» частиц. Рассмотрим всё это несколько подробнее.
Движок Vantage осуществляет следующие проходы рендеринга каждый кадр:
- Проход обновления GPU симуляций (вода, имитация тканей, и т.п.)
- Рендеринг карт теней
- Предварительный depth рендеринг некоторых материалов для оптимизации производительности
- Отрисовка непрозрачных поверхностей, а также рендеринг отражений и преломлений
- Отрисовка полупрозрачных поверхностей
- Постобработка
Все используемые карты теней генерируются до процесса основного рендеринга сцены, который состоит из шагов 3, 4 и 5. В качестве алгоритмов наложения теней используются Variance Shadow Maps и PCF-отфильтрованные Cascaded Shadow Maps. Алгоритмом имитируется полутень, а качество рендеринга регулируется при помощи изменения количества сэмплов для фильтрации. К сожалению, теней в графических сценах почти не видно, а обычному пользователю важны не умные слова, а визуальные впечатления.
Предварительный depth проход выполняется только для избранных материалов со сложными шейдерами для снижения overdraw в основном проходе. Эффекты постобработки выполняются в отдельном шаге после основного рендеринга сцены, они используют выходное изображение сцены, к которому применяются фильтры и эффекты. Некоторые из видов постобработки требуют дополнительных проходов рендеринга, например, эффект смазывания в движении motion blur нуждается в так называемом velocity проходе.
Движок бенчмарка рендерит всё в повышенном динамическом диапазоне (HDR), используя для этого буфер формата R16G16B16A16. Который в дальнейшем подвергается дополнительной обработке несколькими постфильтрами и при помощи tone mapping выводится на дисплей. В бенчмарке используются кубические карты в HDR формате, но обычные 2D текстуры довольствуются стандартными форматами с 8-бит на каждый цветовой канал.
Используемые в сценах шейдеры состоят из трёх типов: шейдеры материалов, шейдеры освещения и шейдеры трансформации. Шейдеры материалов описывают, как поверхность отражает и поглощает свет, шейдеры освещения описывают, как световые лучи взаимодействуют с поверхностью материала, а шейдеры трансформации выполняют вершинные операции. Вот два примера технологически сложных материалов, кожа и одежда девушки из первого теста и поверхность космического корабля из второго:


Шейдеры материалов и освещения хранятся в виде HLSL фрагментов. При рендеринге поверхности, которую освещает один или более источников света, движок комбинирует соответствующий шейдер материала со всеми необходимыми шейдерами освещения, а затем компилирует шейдер. Используемые комбинации шейдеров предварительно генерируются и кэшируются для быстрого доступа в процессе рендеринга. Скомбинированный шейдер проходит все влияющие источники света и вызывает функцию затенения поверхности для того, чтобы рассчитать интенсивность света для каждого источника. Таким образом, многочисленные источники света разных типов рассчитываются за один проход.
В игровых сценах движком используется большое количество известных нам методов постобработки: bloom, streaks, flares, halo, depth of field, motion blur, depth fog, volumetric fog, tone mapping. Все они уже применяются в игровых приложениях в той или иной мере, но в случае Vantage постэффекты ещё более впечатляющи, вот лишь пара примеров:


Для физических симуляций на GPU применяются два метода: текстурный и вершинный. В текстурных симуляциях отрисовывается один или несколько буферов, все расчеты делаются попиксельно в пиксельных шейдерах. Вершинные симуляции используют stream out для передачи данных в следующие проходы симуляции. Примерами таких симуляций является водная поверхность и имитация тканей в первом тесте.


Рендеринг систем частиц также отличается технологичностью. Кроме того, что видеочипом просчитывается физика их поведения, используется алгоритм смягчения краёв частиц, известный нам ещё со времён игры Call of Duty 2. И, аналогично нашим тестам из RightMark 2.0, для разворачивания вершин в прямоугольные частицы используется геометрический шейдер. Примеры использования систем частиц в Vantage:


Graphics Test 1: Jane Nash
Тестовая сцена Jane Nash показывает довольно большое внутреннее помещение со сложными динамическими объектами, многочисленными источниками света, сложной моделью освещения и физическими симуляциями на GPU. Рендеринг сцены использует несколько проходов, включая проходы для отрисовки отражений и преломлений на водной поверхности, а также рендеринг карты столкновений. Сцена отличается большим количеством статических и динамических объектов, расчётом теней при помощи метода Cascaded Shadow Maps с PCF-фильтрацией границ, отсутствием в алгоритмах просчета лучей, имитацией тканей, математически сложными анизотропными материалами, рендерингом поверхности воды с отражениями и преломлениями, а также каустикой.


И вот теперь мы займёмся самым интересным — анализом статистики, полученной при помощи Nvidia PerfKit. Мы запускали Vantage из Microsoft PIX for Windows, собирая статистику со счётчиков PerfKit, а также делая анализ рендеринга кадров при помощи PIX. Первый графический тест содержит 11 геометрических шейдеров, все довольно простые, но один из них очень сложный, состоящий из 327 инструкций с условиями и циклами. В этом тесте используются также 86 вершинных (максимум 114 инструкций) и 85 пиксельных шейдеров. Пиксельные значительно сложнее, есть несколько программ с 600, 700, 800, 900 инструкциями, максимум — 1063 команд с кучей вложенных циклов и условных переходов.
Судя по этим цифрам, Jane Nash должен очень сильно загружать работой блоки, исполняющие шейдеры, достаточно много в шейдерах и текстурных выборок, что тоже обязано повлиять на загрузку блоков видеочипа. Рассмотрим статистику со счётчиков PerfKit и стандартных счётчиков производительности Windows и PIX.

Проанализируем все полученные данные по порядку. На частоту кадров можно не обращать особого внимания, под PIX она довольно сильно отличается от того, что получается в реальных условиях. Средняя загрузка всех четырёх ядер центрального процессора выше нуля, в среднем по процессору целиком она не превысила 11% — неплохой результат для сложного теста с большим количеством полигонов и вызовов функций отрисовки.
Среднее число вызовов функций отрисовки (draw calls) на кадр — 740, при максимальном под 2000. Судя по этим цифрам, сцена неплохо оптимизирована. Количество полигонов, рассчитываемых за кадр (не путать с количеством геометрии в кадре) — 1.3 миллионов в среднем, а максимальное — 3.6 млн. Не сказать, что это рекордное число, но довольно большое даже по современным меркам. В тестовых условиях используется чуть менее 400 мегабайт видеопамяти, то есть, даже нестандартных 384-мегабайтных видеокарт должно хватать, ну а уж 512 — точно. Это всё для разрешения 1280x1024, в стандартном для пресета Extreme 1920x1200 цифра будет другой.
Счетчики производительности PerfKit показали, что нагрузка на видеочип очень велика. GPU практически постоянно загружен полностью, данные показывают всего лишь 0.1% его простоя. Основная нагрузка лежит на шейдерных блоках и TMU, их средняя загрузка достигла почти 80% и 25% соответственно. Причём шейдерные блоки в некоторых случаях были загружены на все 100%. Достаточно тяжелая работа в этом тесте и для input assembler, а вот блоки геометрии и ROP загружены незначительно. В GPU симуляциях применяется stream out, и его использование подтверждается соответствующим счётчиком.
Graphics Test 2: New Calico
Вторая графическая сцена New Calico показывает открытое космическое пространство с огромным количеством движущихся твердых объектов: планет, космических кораблей и астероидов. Сцена отличается тем, что большинство объектов динамические, но среди них нет объектов, к которым применяется скиннинг, активно используется instancing, в сцене применяются алгоритмы с просчётом лучей (Parallax Occlusion Mapping, True Impostors и объемный туман), а алгоритм теней в данном случае — Variance Shadow Mapping.
True Impostors — это метод рендеринга многочисленных сложных объектов, снижающий нагрузку на видеочип. Он позволяет добиться точной имитации 3D объектов при помощи расчёта специальных 2D изображений (подобно спрайтам). Метод основывается на алгоритме Relief Mapping и отличается от предыдущих аналогичных методов тем, что у него нет ограничений по углу обзора и анимации. В данном случае метод применяется для отрисовки огромного количества астероидов (см. второй скриншот). Если бы это были трехмерные объекты, скорость рендеринга была бы значительно ниже.


К большому сожалению, этот тест Vantage из-под PIX с анализом построения кадра запускаться отказался, при загрузке текстур его работа аварийно завершалась. Поэтому анализа используемых шейдеров, к сожалению, в этот раз не будет. Но показания счётчиков производительности мы сняли:
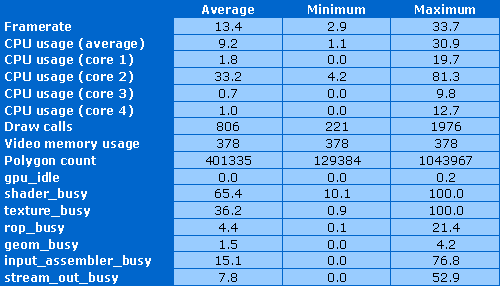
Средняя загрузка ядер центрального процессора в этот раз получилась иной, больше всего тест грузил второе ядро, в среднем на треть, все остальные были загружены незначительно или не всё время тестирования. Средняя загрузка CPU целиком — менее 10%, что довольно неплохо для теста с огромным количеством динамических объектов и, соответственно, вызовов функций отрисовки.
Среднее число вызовов draw calls на кадр в этот раз чуть больше 800, а максимальное так же под 2000 вызовов. Сцена очень хорошо оптимизирована, основной вклад в это сделали instancing и true impostors. Среднее количество полигонов, рассчитываемых за рендеринг одного кадра, получилось равным около 400 тысяч треугольников, максимальное — чуть более одного миллиона. Именно из-за хорошей оптимизации и получилось такое малое количество геометрии, в сцене много попиксельного освещения и сложного parallax mapping. В выбранном разрешении используется снова менее 400 мегабайт видеопамяти, требования к её объёму остаются теми же (для стандартного разрешения пресета Extreme значение вырастет).
Нагрузка на GPU снова такая же — то есть, максимальная. Чип постоянно загружен на 100% практически без простоя. Большая часть нагрузки снова на шейдерные и текстурные блоки — 65% и 36% соответственно. И те и другие иногда загружены на все 100%, но в этот раз нагрузка несколько смещена в сторону текстурных выборок. Загружен работой и input assembler, а блоки геометрии, ROP и stream out заняты работой менее чем на 10% в среднем, хотя последний используется весьма активно.
Тесты центрального процессора
Тесты процессора должны по возможности отражать реальную игровую ситуацию, и при этом должны быть интересны пользователям визуально. Оба теста CPU также используют одинаковый графический движок, который используется в тестах GPU, но для снижения влияния мощности видеочипов, количество используемых эффектов максимально снижено, выключена вся постобработка, за исключением необходимого для HDR рендерера tone mapping. Также применяются значительно более простые шейдеры, используемые геометрические модели максимально упрощены, а рендеринг теней отключён. Первый процессорный тест использует имитацию искусственного интеллекта (AI), а второй — физические расчёты.
Тест AI содержит алгоритмы нахождения пути (pathfinding) и совместного маневрирования, в данном случае — самолётов. Каждый самолёт летит по определенному маршруту через несколько ворот, избегая столкновений друг с другом и поверхностью земли. Нагрузка на CPU распараллелена полностью, тест может использовать любое количество процессорных ядер. Более быстрые процессоры могут рассчитывать путь более точно и маршруты самолётов будут интеллектуальнее. Алгоритм поиска пути основан на трёх принципах: прохождении ворот в определённом порядке, имитации физической модели самолёта и ухода от столкновений с другими самолётами.
CPU Test 1: AI

В первом тесте CPU не используется геометрических шейдеров вовсе, а вершинных и пиксельных — по пять штук каждого типа. Вершинные шейдеры все простые, кроме одного на 50 инструкций. Пиксельные также просты, в основном всего лишь 3-6 инструкций, но один из них на 25 команд, да ещё и с циклом. Несколько удивляет на фоне того, что нагрузка на GPU должна быть минимальной. Также не совсем понятно, для чего на каждом мелком самолётике в CPU тесте применена атласная текстура с разрешением 512х512 пикселей. Можно было бы обойтись и вовсе без текстур…
Производительность данного теста измеряется в количестве операций в секунду. Число операций равно числу путей, рассчитанных для самолётов во время тестирования. Затем это число делится на время тестирования. Рассмотрим результаты счётчиков производительности PerfKit:
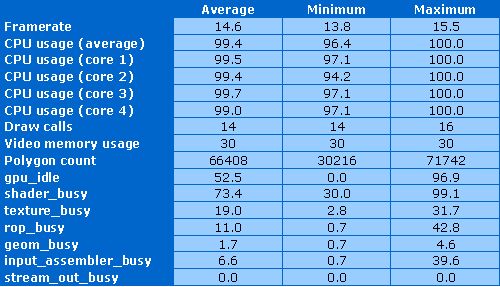
Как видите, загрузка всех ядер процессора идентичная и практически максимальная — в среднем 99.4%, и менее 97% не опускалась. То есть, тест полностью ограничен скоростью CPU, как и должно быть. Количество вызовов функций отрисовки весьма невелико — всего лишь 14-16 вызовов, это не создаёт значительной нагрузки на процессор. Количество полигонов и используемый объем видеопамяти весьма малы по современным меркам — 65 тысяч треугольников и 30 мегабайт, соответственно. Это также нормально для процессорного теста.
Хотя и видеочипу досталась не самая лёгкая работа, судя по счётчикам производительности. Не самый слабый тестовый GPU простаивал чуть больше половины времени, а загрузка шейдерных блоков достигала почти 100%, в среднем составляя 73%. TMU и ROP тоже не отдыхают в тесте, загружены на 19% и 11% в среднем. Несколько необычно для CPU теста, но в общем, судя по цифрам CPU, всё нормально.
CPU Test 2: Physics
Физический тест CPU очень сильно нагружает процессор сложными физическими расчётами, которые появятся в будущих играх. Сцена снова основана на самолётах, но задачи и цели у них другие. Самолёты выпускают дым, взаимодействующий с различными объектами, вроде ворот, гибких колец и земли.
Данный тест содержит несколько самолётов, которые одновременно пролетают через гоночные ворота, в результате получается большое количество столкновений и физических взаимодействий. Самолёты состоят из 12 целых частей, соединённых в 11 разрушаемых точках. Все разрушения при столкновениях рассчитываются в реальном времени без скриптов. Самолеты летят по определённым законам, которые имитируют реалистичное поведение. Также за каждой моделью самолёта выпускается цветной дым, использующий симуляцию жидкостей и газов библиотеки PhysX. В сцене расположены два типа ворот: пончикообразные летающие и ворота из двух стоек. Первые имитируют поверхность натянутой ткани, а вторые — эластичное тело, используя физические имитации ткани и мягких тел в PhysX.

В данном случае для нас больше всего интересно то, что тест физических расчётов использует библиотеку AGEIA PhysX с поддержкой соответствующего ускорителя physics processing unit (PPU). По умолчанию, бенчмарк будет использовать физический ускоритель, но его использование можно отключить в настройках. Возможности видеочипов по физическим расчётам в данном тесте не используются, так как подобные задачи возложены на видеочип в обоих графических тестах.
Если в системе нет PPU, тогда на каждое доступное ядро CPU выделяется по одной паре ворот. В случае с физическим ускорителем на каждое процессорное ядро, за исключением одного, выделяется по двое ворот, а на PPU — четыре пары. Одно ядро CPU отнимается потому, что имитация жёстких объектов выполняется на CPU, а всё остальное — на PPU. Каждые двое или четверо ворот рассчитываются отдельно от других, они не синхронизируются друг с другом, и разные устройства (ядра CPU и PPU) могут показывать различную скорость симуляции.
В этом процессорном тесте в алгоритме системы частиц используется один довольно сложный геометрический шейдер на 103 инструкции, служащий для генерации частиц из вершин. Вершинных и пиксельных шейдеров по шесть каждого типа. Вершинные шейдеры относительно простые, по 10-25 инструкций, а пиксельные — до 23 инструкций. С текстурами всё те же вопросы — в сцене используется несколько текстур по 512х512 и одна 1024х1024, что на low-end видеокартах может несколько ограничивать общую производительность. Посмотрим, что покажут цифры:
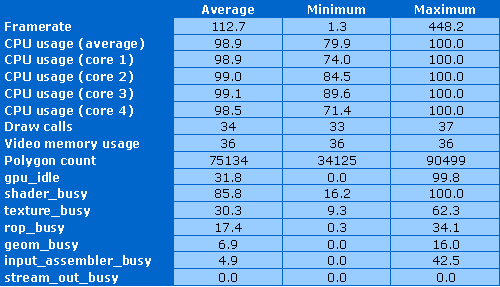
В этот раз загрузка ядер процессора несколько меньше, хотя тоже близка к максимальной — в среднем 98.9%, хотя в середине теста было и меньше 80%, но весьма короткое время. Тест всё равно полностью ограничен скоростью CPU. Количество вызовов функций отрисовки чуть больше предыдущего случая, так как тут более сложная сцена — более 30 вызовов, но это также крайне мало и не грузит процессор лишней работой. Количество полигонов и используемый объем видеопамяти очень небольшое — 75 тысяч треугольников и 36 мегабайт, соответственно.
Видеочипу в этот раз ещё тяжелее, что немудрено — вторая сцена сложнее. Тестовый G92 простаивал в среднем лишь треть всего времени. Загрузка шейдерных блоков в среднем составляла 85%, достигая 100%. Текстурные блоки загружены почти на треть, а блоки растеризации — на 17%, остальные незначительно. Непонятно, зачем в CPU тесте задавать не самую простую работу для видеокарты. Хотели приблизить тест к реальной игровой ситуации?
Для того, чтобы рассмотреть возможное влияние различных видеокарт на средний FPS, а также узнать разброс результатов на разных системах, рассмотрим результаты CPU тестов на одной и той же тестовой системе, использованной в предыдущей статье, но с разными видеокартами:
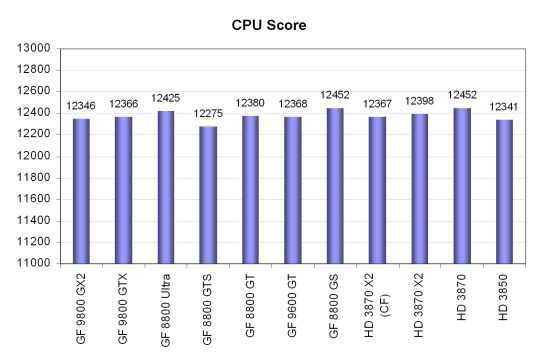
Видно, что разница если и есть, то она не зависит от мощности видеокарты, а скорее просто показывает погрешность теста, разброс его показателей. Максимальное полученное значение — 12452 очков, а минимальное — 12275, то есть, меньше 1.5% разницы, что является вполне допустимой цифрой погрешности.
Мощность CPU, в свою очередь, также влияет исключительно на тесты центрального процессора. Для того, чтобы убедиться в этом, мы изменяли количество доступных для процесса 3DMark Vantage ядер тестового четырёхъядерного процессора и получили следующие результаты:

Как видите, полученные цифры GPU Marks не зависят от количества ядер нашего процессора, результаты графических тестов почти идентичны и отличаются не более чем на величину погрешности измерения. А вот CPU Marks и результаты первого и второго процессорных тестов зависят от числа доступных им ядер целиком. Виртуальный двухъядерный процессор показал в этих тестах почти ровно вдвое больший результат, по сравнению с одноядерником. Трёхъядерный — втрое больший, четырёхъядерный — чуть более, чем в четыре раза. К слову, Feature тесты также показали полностью идентичные цифры во всех случаях, мощность CPU на них не оказывает видимого влияния.
«Feature» тесты
3DMark Vantage традиционно предлагает и так называемые feature тесты, всего их шесть в этот раз. Каждый из этих тестов предназначен для изучения производительности конкретных блоков видеокарты, и использует их возможности по максимуму. В отличие от основных графических тестов, с многочисленными эффектами и техниками, выполняемыми одновременно, эти тесты выделяют производительность специфичных возможностей видеочипов. Вот список feature тестов в Vantage:

Feature Test 1: Texture Fill

Первый тест — тест скорости текстурных выборок. Используется заполнение прямоугольника значениями, считываемыми из маленькой текстуры размером 2x2 пикселя. Используется по три вершинных и пиксельных шейдера не очень большой сложности — максимум около 60 инструкций. Шейдеры простые по сути — мультитекстурирование из 16 слоёв. Геометрических шейдеров нет. Смотрим, что покажут счётчики производительности:
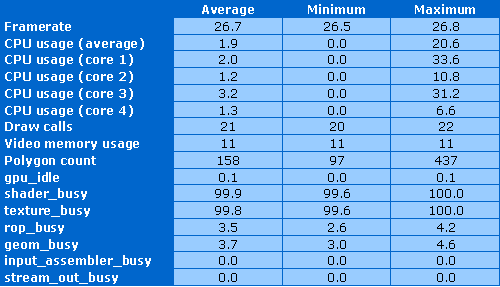
Частота кадров довольно ровная, в отличие от предыдущих графических тестов. Использование ресурсов центрального процессора сведено к минимуму, максимальные цифры загрузки встречаются только в начале, потом всё приходит в норму — около 2% от возможностей тестового четырехъядерника. Количество вызовов функций отрисовки незначительно превышает 20 штук, видеопамяти используется всего лишь 11 мегабайт, а количество полигонов в сцене — менее двух сотен (и те, в основном, из-за отрисовки интерфейса).
Видеочип загружен работой на полную — работает абсолютно без простоев. Причём, что интересно, нагрузка почти 100%-ная и на текстурные блоки и на шейдерные, видимо, из-за того, что выборки текстурные вызываются из шейдера. Но скорость рендеринга ограничена текстурной производительностью. Нагрузка на блоки геометрии и растеризации совсем невелика, не говоря уже про простаивающие в этом тесте input assembler и stream out. Всё, как и должно быть в подобном теоретическом тесте, придраться не к чему.
Feature Test 2: Color Fill

Второй тест — скорости заполнения. Используются очень простые пиксельные и вершинные шейдеры (по четыре штуки каждого типа), не ограничивающие производительность рендеринга, лишь по 2-6 инструкций в каждом. Геометрические шейдеры отсутствуют. Рассчитанное значение записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется внеэкранный буфер формата R16G16B16A16, наиболее часто используемый в играх, применяющих HDR рендеринг.
Мы уже отмечали, что показания теста соответствуют нашим в RightMark, с поправкой на использование 16-битного буфера и говорят скорее о пропускной способности памяти, зависящей прежде всего от ширины шины памяти и её частоты, чем о других показателях. Посмотрим на цифры:
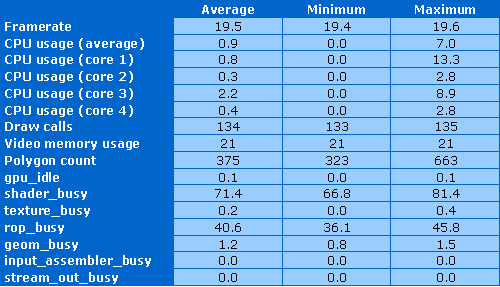
FPS снова стабилен, а загрузка CPU даже меньше, чем в предыдущем случае — менее 1%. Количество вызовов draw calls больше, чем в предыдущем тесте — около 135, видеопамяти используется 21 мегабайт, а количество рассчитываемых за время построения кадра полигонов — от 300 до 600, в среднем 375.
Чип G92 загружен работой полностью и является единственным ограничителем производительности. Он простаивает лишь 0.1% времени теста. А вот дальше — интересное. Шейдерные процессоры загружены работой на 70-80%, а блоки ROP — на 35-45%. Все остальные находятся почти что в состоянии полного покоя.
Вот с ROP получилось интересно. Получается, что доступная полоса пропускания памяти на Geforce 8800 GT лишь наполовину обеспечивает работой имеющиеся блоки ROP, и при росте частоты памяти наблюдается соответствующий прирост результатов. Так, при частоте памяти 600(1200) МГц результат этого теста на Geforce 8800 GT равен 1.82 ГПикс/с, а при вдвое больших 1200(2400)МГц — 3.58 ГПикс/с, что в 1.97 раза больше. То есть, наблюдается линейная зависимость результата теста от ПСП и подтверждается указанное ограничение.
Feature Test 3: Parallax Occlusion Mapping

Один из самых интересных feature тестов, подобные применяемому алгоритму используются в играх, хотя там они проще. В сцене рисуется всего один четырехугольник (два треугольника), с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются ресурсоёмкие операции по трассировке лучей и карта высот высокого разрешения — 4096х4096 точек. Поверхность затеняется при помощи сложного алгоритма освещения по Strauss.
Это тест с очень сложным и тяжелым для видеочипа пиксельным шейдером, содержащим многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss. Для освещения используется четыре точечных и три направленных источника света с самозатенением, которые рассчитываются за один проход. К сожалению, как и второй графический тест, он не запустился под PIX для анализа построения кадра, поэтому о сложности и количестве шейдеров мы ничего сказать не можем. Зато можем посмотреть статистику использования блоков видеочипа, и не только её:
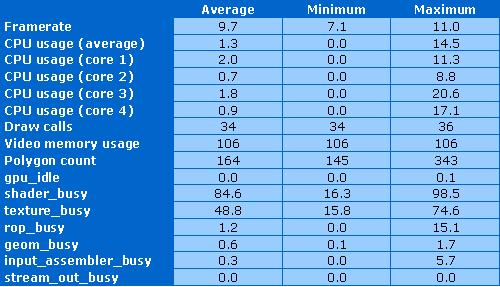
Центральный процессор почти не используется во время тестирования, его загрузка оказалась лишь чуть больше 1%. Количество вызовов функций отрисовки равно 34-36, используется более 100 мегабайт видеопамяти для большой текстуры и буферов. А вот количество полигонов в сцене подтверждает несложную геометрию с попиксельными расчётами.
Видеочип всегда полностью загружен работой, не простаивает вообще. Вопрос — какой работой? Больше всего тест зависит от шейдерной мощности и эффективности исполнения ветвлений — в среднем шейдерные блоки загружены работой на 85%, а порой значение достигает и максимума. Но не только в шейдерную производительность упирается тест, он зависит и от скорости текстурных выборок. Посмотрите, блоки TMU заняты работой в среднем наполовину, а иногда работают и на 3/4 своих возможностей. Все остальные блоки отдыхают. Теория из прошлой статьи подтверждается.
Feature Test 4: GPU Cloth

Этот тест отрисовывает 12 развевающихся флагов, анимация которых рассчитывается полностью на GPU. Вычисления делаются в вершинных и геометрических шейдерах, а результаты выводятся при помощи stream out. Каждый флаг смоделирован как сетка связанных вершин, каждая из которых соединена с соседними. На ткань флагов влияют силы гравитации и ветра.
Тест интересен тем, что рассчитывает физические взаимодействия по имитации ткани, используя силы видеочипа. Используется вершинная симуляция при помощи комбинированной работы вершинного и геометрического шейдеров, а также блок stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров, но также и скорость stream out.
Всего в тесте применяется 72 геометрических шейдера, в том числе очень сложные — до 327 инструкций с циклами! Также в наличии 46 вершинных (совсем не тяжелые — до 45 инструкций) и 11 пиксельных (тоже все простые — до 60 инструкций, но один — 165 инструкций с циклами). Не совсем понятно, что относительно сложный пиксельный шейдер делает в тесте физики на GPU? Разработчикам виднее, давайте проанализируем показания счётчиков:
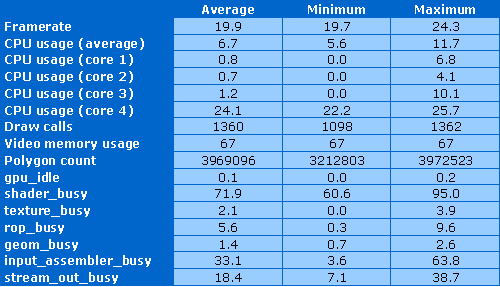
Интересно, что тест грузит работой именно четвёртое ядро CPU. В среднем процессор загружен работой менее чем на 7%, но одно ядро — почти на четверть. Вызовов draw calls достаточно много — в среднем 1360 штук, что подтверждается и числом полигонов — около четырёх миллионов рассчитываемых треугольников в кадре! Видеопамять загружена в основном геометрией, используется до 70 мегабайт видеоОЗУ.
Чип снова полностью занят вычислениями, почти не простаивает. Наибольшая нагрузка лежит, естественно, на шейдерных процессорах, они работают почти на 3/4 своих сил, а иногда и на 95%. Геометрические, текстурные и блоки ROP в этом feature тесте работают мало, чего не скажешь о блоках input assembler и stream out. Первый загружен очень большим количеством геометрических данных и занят на 33% (максимум до 64%), а второй используется в алгоритме физических расчетов и загружен на 7-39%. Возможно, другие видеочипы показали бы иные цифры.
Feature Test 5: GPU Particles

Это — тест физической симуляции эффектов на базе систем частиц, движение которых рассчитывается мощностями GPU. В этот раз также используется вершинная симуляция, где каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот, отображающей невидимый объект. Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующих частицу.
В процессе теста исполняется три геометрических шейдера, сложностью до 120 инструкций, по 8 вершинных (до 70 инструкций) и пиксельных шейдеров (около 20 инструкций). Судя по этим цифрам, тест должен больше всего загружать шейдерные блоки вершинными и геометрическими расчётами, а также блок stream out.
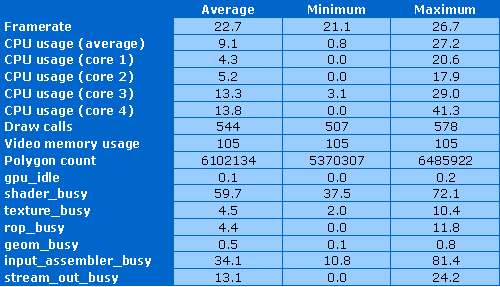
Частота кадров стабильная, процессор загружен на 9% в среднем, но нагрузка распределена между разными ядрами. Количество вызовов функций отрисовки превышает 500, загрузка видеопамяти невелика — чуть больше 100 мегабайт. А вот количество рассчитываемых примитивов в сцене — более 6 миллионов!
Видеочип не простаивает ни секунды, он постоянно занят работой. Наибольшая нагрузка, как и предполагалось, лежит на шейдерных блоках, которые загружены от 38% до 72%, а в среднем на 60%. Также очень сложная работа для input assembler, уж очень много вершинных данных он раздаёт остальным блокам. Нагрузка на блок stream out не так велика, как предполагалось, да и остальные блоки загружены не слишком сильно.
Feature Test 6: Perlin Noise

Этот feature тест можно считать математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Это стандартный алгоритм, часто используемый в процедурном текстурировании, он очень сложен математически. А для большей нагрузки на видеочип каждый цветовой канал использует собственную функцию шума.
В тестовой сцене используется три простеньких вершинных шейдера сложностью в 3-12 инструкций, и вообще нет геометрических шейдеров. Пиксельных шейдеров в тесте три, два очень простых и один сложнейший аж на 2630 инструкций! И математических и текстурных. Немудрено, если основная нагрузка ляжет на шейдерные процессоры, но достанется и текстурникам. Смотрим:
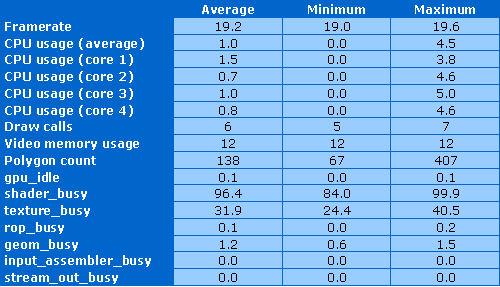
Загрузка CPU этим тестом совсем невелика, в среднем лишь 1%, да и каждое из ядер никогда не загружено даже более чем на 5%. Количество вызовов draw calls составляет лишь 5-7 штук, количество полигонов немногим превышает 400, со средним значением 138 треугольников. Используется всего лишь 12 мегабайт видеопамяти.
Чип и в этот раз загружен работой полностью, все синтетические тесты показали полную загрузку тестового GPU. И действительно, как нами и предполагалось, нагрузка на шейдерные блоки получилась огромной, больше всех остальных тестов — в среднем более 96%, с минимумом в 84% и максимумом в 100%! Но и блоки текстурных выборок заняты работой примерно на треть в среднем, что тоже немало. А вот остальные блоки GPU не заняты почти совсем. Так что этот тест также вполне отвечает своим задачам.
Настройки 3DMark Vantage
Основные настройки теста предоставляют множество возможностей по контролю над движком бенчмарка, пользователю даётся возможность отключения и изменения почти всего, что можно. Перечислим все настройки с кратким описанием:
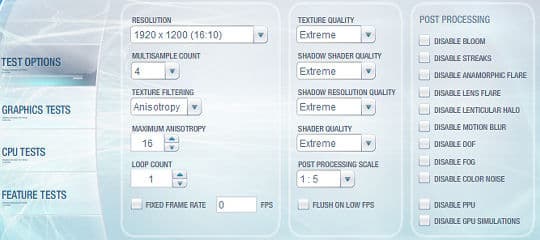
- Resolution — выбор тестового разрешения. Поддерживаются все имеющиеся разрешения, которые видеокарта рапортует Direct3D 10.
- Multisample count — выбор уровня сглаживания методом мультисэмплинга. Возможен выбор всех поддерживаемых установленной видеокартой уровней MSAA для соответствующего тестового разрешения.
- Texture filtering — выбор метода текстурной фильтрации: optimal и anisotropic. Первый вариант предполагает использование трилинейной фильтрации, второй — анизотропной.
- Maximum anisotropy — выбор степени анизотропной фильтрации в случае, если выбрана анизотропная в предыдущем пункте. Доступны все возможные для видеокарт значения, в большинстве случаев — до 16.
- Loop count — количество циклов, которые будет выполнять бенчмарк. Полезно скорее для определения стабильности системы в случае разгона.
- Fixed frame rate — выбор фиксированного значения частоты кадров в секунду, на которых будет выполняться тест.
- Texture quality — выбор качества текстур для графических тестов. Регулируется разрешение текстур, более низкие значения означают меньшее разрешение и качество рендеринга.
- Shadow shader quality — выбор качества фильтрации теней из нескольких значений. Выбранный уровень влияет на количество сэмплов, которые выбираются в алгоритмах наложения теней при их фильтрации.
- Shadow resolution quality — выбор разрешения для карт теней. Напрямую влияет на качество и производительность.
- Shader quality — одна из основных настроек теста. Настройка качества шейдера влияет на используемые в тестах техники шейдерных расчётов, алгоритмы и их качество.
- Post processing scale — отношение разрешения эффектов постобработки к разрешению экрана. Определяет качество таких эффектов, как bloom, DOF, flare и т.п.
- Flush on low FPS — самое необычное значение для бенчмарков, которое может пригодиться в определённых ситуациях, когда производительность теста на некоторых аппаратных конфигурациях настолько мала, что операционная система вызывает ошибку Timeout Detection and Recovery error (TDR), прерывающую тест. Ошибка случается при частоте кадров 2 FPS или ниже. Данная настройка позволяет избежать подобных проблем и позволить тесту пройти до конца. Но включать её нужно только в случае возникновения указанной ошибки, в противном случае тест не будет отражать реальную производительность.
- Disable (bloom, streaks, anamorphic flare, lens flare, lenticular halo, motion blur, DOF, fog, color noise) — настройки для отключения эффектов постобработки отдельно друг от друга. Возможно отключение всех постэффектов, за исключением tone mapping, необходимого для HDR рендеринга.
- Disable PPU — возможность отключения использования PPU во втором процессорном тесте. На системах с наличием физического ускорителя, по умолчанию он используется в этом тесте, но чтобы сравнить системы с PPU и без него в равных условиях, можно отключить использование аппаратного ускорителя физики.
- Disable GPU simulations — настройка, отключающая расчет симуляций, рассчитываемых видеокартой в графических тестах. К ним относится вода, имитация тканей и др.
Изменение любой из этих опций, кроме «Disable PPU», при выбранном наборе настроек, вызовет смену пресета на «Custom». Эта возможность используется для более глубокого анализа производительности, изменением тех или иных настроек можно добиться дополнительных данных о производительности системы. Но сравнивать придётся только результаты по конкретным тестам, так как общее количество очков при «Custom» настройках не рассчитывается. Рассмотрим влияние всех опций на производительность в виде общего числа очков GPU Marks, и отдельно по графическим тестам (в процентах указан относительный прирост):
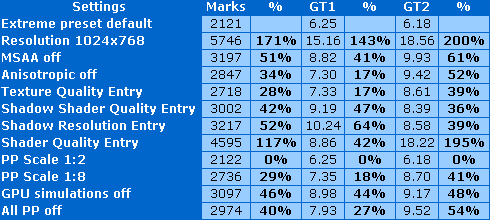
Очень сильно на производительности сказывается тестовое разрешение. Это и немудрено, работы блокам пиксельных шейдеров, которые в Vantage важнее всего, в таком случае значительно меньше. И особенно важно разрешение для второго теста, где скорость увеличилась втрое! Также очень сильно увеличивает производительность и изменение параметра Shader Quality, что обусловлено тем же самым. Отключение полноэкранного сглаживания повышает скорость в полтора раза, отсутствие анизотропной фильтрации — на треть. И снова это больше влияет на второй графический тест, особенно анизотропка. Понятно, что и пониженное текстурное разрешение сильнее сказывается на New Calico…
Довольно сильно влияют на скорость рендеринга в Vantage и параметры, связанные с рендерингом теней. Снижение разрешения карт теней и уменьшение качества их фильтрации вызывает рост производительности почти в полтора раза в каждом случае. И тут наблюдается обратная показанной выше ситуация, так как во втором тесте тех же источников света значительно меньше, чем в первом. Отключенные физические симуляции увеличивают FPS почти в полтора раза в обоих случаях. Изменение опций, связанных с постобработкой, сильнее влияет на скорость второго теста, но вот разницы между postprocessing scale, равным 1:2 и 1:5 (декларируемое значение по умолчанию) нет никакой.
Выводы
Ранее сделанные выводы относительно 3DMark Vantage не изменились, а слегка дополнились. Их можно лишь повторить: с точки зрения современных технологий 3D графики и тестирования, новый пакет тестов хорошо справляется со своей работой. В тестах применяются многочисленные новые техники и алгоритмы: очень сложные шейдеры всех типов, с большим количеством математических и текстурных операций и циклами, симуляция физики на GPU для имитации тканей и водной поверхности, продвинутые системы частиц, поддержка многоядерных центральных процессоров и физических ускорителей, многочисленные эффекты постобработки, массовое применение instancing и stream out, продвинутые методы parallax mapping и многое другое.
Графические и feature тесты загружают именно те блоки видеочипа, что и должны. Их производительность полностью ограничена мощностью видеочипа G92 и видеокарты в целом (рабочая частота и пропускная способность видеопамяти), и GPU занят работой всё время. А процессорные тесты, в свою очередь, отлично нагружают работой все ядра многоядерных CPU. Feature тесты показывают хорошее определение производительности именно тех блоков, тестирование которых они декларируют. Используемые шейдеры достаточно сложны для того, чтобы назвать их будущим игрового 3D. В итоге — применение всех тестов бенчмарка объективно оправдано.


