Часть 12: Процессоры VIA C7/C7-M
Новое поколение десктопных/мобильных процессоров VIA C7/C7-M было представлено компанией VIA Technologies сравнительно давно в конце мая-начале июня 2005 года. Тем не менее, в виде готовых решений (ноутбуков, а также платформ pc1000/pc1500) эти процессоры стали доступны значительно позже. Техническая документация на эти процессоры (в отличие от предыдущей модели VIA C3) по-прежнему отсутствует, основная официальная информация о них представлена лишь на страницах web-сайта произодителя.
Итак, новое поколение процессоров VIA C7/C7-M (а отличаются они, по большей части, только названием и максимальными тактовыми частотами) основано на ядре под кодовым названием «Esther», выполненном в рамках архитектуры VIA CoolStream(tm). Философия этой архитектуры основывается на трех составляющих безопасности («Secure by Design»), низкого энергопотребления («Low Power by Design») и производительности («Performance by Design»).
Первая составляющая обеспечивается встроенным в ядро и уже традиционным для VIA модулем безопасности VIA PadLock, который был доработан в этих процессорах добавлением хэширования по алгоритмам SHA-1 и SHA-256 и аппаратной поддержки умножителя Montgomery, применяемого в алгоритме шифрования RSA, а также технологии NX (No Execute) bit.
Вторая составляющая концепции CoolStream достигается применением 90-нм технологического процесса IBM «кремний на изоляторе» (SOI). В связи с этим, энергопотребление процессоров C7/C7-M составляет всего 12-20 Ватт (в зависимости от тактовой частоты от 1.5 до 2.0 ГГц, соответственно).
Третья составляющая «производительность» обеспечивается еще одной технологией VIA StepAhead(tm), суть которой заключается в использовании шины VIA V4 (аналога P4 Quad-Pumped bus) с частотой до 200 МГц (800 МГц quad-pumped), 16-стадийного конвейера, полноскоростного 128-КБ эксклюзивного L2-кэша, и уже типичного для процессоров VIA улучшенного предсказателя ветвлений. Вторым важным фактором третьей составляющей является технология VIA TwinTurbo(tm), позволяющая процессору переключаться между режимом полной производительности и энергосберегающим режимом за один(!) такт процессора благодаря наличию в процессоре двух блоков PLL. Увидеть последнюю в действии (а точнее, технологию энергосбережения VIA PowerSaver в целом) пользователям платформ на базе VIA C7/C7-M на данный момент не представляется возможным производитель до сих пор не предоставил официальный драйвер процессора, который позволял бы операционной системе управлять режимами энергопотребления этих процессоров. К счастью, экспериментальным путем нами было установлено, что реализация этой технологии, в отличие от ее раннего варианта, встречающегося в VIA C3, сделана намного разумнее в полном соответствии с хорошо знакомой, можно сказать стандартной технологией Enhanced Intel SpeedStep.
Тем не менее, настоящая статья посвящена изучению не этих технологий, а основных низкоуровневых характеристик нового ядра Esther с помощью тестового пакета RightMark Memory Analyzer. Эти характеристики мы сопоставим с ранее полученными на платформе VIA Antaur (мобильный вариант «второго поколения» процессоров VIA C3 с ядром Nehemiah, в котором впервые появилась поддержка инструкций SSE).
Конфигурации тестовых стендов
Тестовый стенд №1 (ноутбук ВЕРСИЯ MarcoPolo43T)
- Процессор: VIA Antaur (ядро Nehemiah, 1,0 ГГц)
- Чипсет: VIA CLE266/VT8622
- Память: 256 МБ Hyundai DDR-266, тайминги 2.5-3-3-7
Тестовый стенд №2 (ноутбук MaxSelect Optima C4)
- Процессор: VIA C7-M (ядро Esther, 1,5 ГГц)
- Чипсет: VIA CN700 (PM880/VT8235)
- Память: 512 MB Hyundai DDR-400 в режиме DDR-333, тайминги 3-3-3-7
- Видео: VIA/S3 Graphics UniChrome Pro IGP, размер UMA-буфера 64MB
- Версия BIOS: 4.06CJ15, 10/31/2005
Характеристики CPUID
Рассмотрение ядра Esther на примере 1,5-ГГц процессора VIA C7-M начнем с анализа основных характеристик CPUID процессора.
Таблица 1. VIA Antaur (Nehemiah) CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 698h | Семейство 6, модель 9, степпинг 8 |
| Характеристики кэшей и TLB | 40040120h 40040120h 00408120h 0880h 0880h | L1-D кэш: 64 КБ, 4-асс., 32-байтн. строка L1-I кэш: 64 КБ, 4-асс., 32-байтн. строка L2-кэш: 64 КБ, 16-асс., 32-байтн. строка D-TLB: 4-КБ стр., 8-асс., 128 записей I-TLB: 4-КБ стр., 8-асс., 128 записей |
| Basic Features, EDX (избранные характеристики) | 0381B93Fh | Bit 23: Поддержка MMX Bit 25: Поддержка SSE |
| Basic Features, ECX | 00000000h | - |
| Extended Features, EDX | 00000000h | - |
Таблица 2. VIA C7-M (Esther) CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 6A9h | Семейство 6, модель 10, степпинг 9 |
| Характеристики кэшей и TLB | 40040140h 40040140h 0080A140h 0880h 0880h | L1-D кэш: 64 КБ, 4-асс., 64-байтн. строка L1-I кэш: 64 КБ, 4-асс., 64-байтн. строка L2-кэш: 128 КБ, 32-асс., 64-байтн. строка D-TLB: 4-КБ стр., 8-асс., 128 записей I-TLB: 4-КБ стр., 8-асс., 128 записей |
| Basic Features, EDX (избранные характеристики) | A7C9BBFFh | Bit 23: Поддержка MMX Bit 25: Поддержка SSE Bit 26: Поддержка SSE2 Bit 29: Поддержка TM1 |
| Basic Features, ECX | 00000181h | Bit 0: Поддержка SSE3 Bit 7: Поддержка EIST Bit 8: Поддержка TM2 |
| Extended Features, EDX | 00100000h | Bit 20: Поддержка NX bit |
По основному идентификационному коду сигнатуре процессора отличия ядра Esther от Nehemiah весьма скромные: номер семейства остался тем же (6), увеличился лишь номер модели, да и то всего на единицу (с 9 на 10). Изменение номера степпинга не стоит воспринимать в серьез, т.к. вполне возможны различные варианты моделей, отличающихся по этому параметру в большую или меньшую сторону. Впрочем, серьезных отличий в номере семейства (например, перехода от «Pentium II/III/M-подобного» семейства 6 к «Pentium 4-подобному» семейству 15) ожидать и не стоило Esther можно считать дальнейшим эволюционным развитием ядра Nehemiah, также, скажем, как и ядро Yonah эволюционным развитием ядра Dothan. Напомним, что в том случае наблюдалась прямая аналогия: номер семейства остался тем же (6), а номер модели увеличился на единицу (с 13 до 14), даже несмотря на «двухъядерность» Yonah.
В то же время, изменения в основных низкоуровневых характеристиках Esther весьма серьезные. Прежде всего, это касается L1-D/L1-I и L2-кэшей процессора наряду с увеличением объема L2 до 128 КБ, его ассоциативность возросла до 32(!), а длина строк всех уровней кэша увеличена до 64 байт. Прочие изменения включают в себя реализацию в новом ядре наборов инструкций SSE2 и SSE3 (последних без специфических инструкций MONITOR и MWAIT, которые встречаются и актуальны только для процессоров Intel с технологией Hyper-Threading и/или многоядерностью), а также технологий Thermal Monitor 1 (TM1), Thermal Monitor 2 (TM2) и Enhanced Intel SpeedStep (EIST). Последняя, как мы уже говорили, соответствует «EIST-подобной» реализации фирменной технологии VIA PowerSaver. Наконец, в CPUID C7/C7-M прописана поддержка технологии NX bit, о которой говорилось выше, при описании усовершенствований модуля безопасности процессора VIA PadLock.
Реальная пропускная способность кэша данных/памяти
Приступим к рассмотрению результатов тестов. Как обычно, начнем его с тестов реальной пропускной способности L1/L2-кэша данных процессора и оперативной памяти.
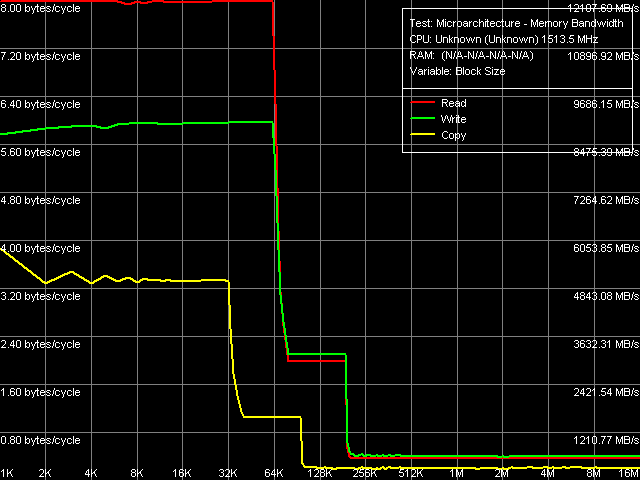
Рис. 1. Реальная пропускная способность L1/L2-кэша данных и оперативной памяти
Кривые зависимости пропускной способности от размера блока данных (рис. 1) имеют вполне типичный вид. По ним можно сказать, что ядро Esther характеризуется эксклюзивной организацией L1/L2 кэша, объем первого уровня кэша составляет 64 КБ (первый перегиб на кривых чтения и записи), а объединенный объем L1+L2 кэша данных 192 КБ (второй перегиб).
Таблица 3
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 4.89 7.98 5.80 7.08 | 7.79 8.00 4.32 5.98 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 1.28 1.28 1.25 1.28 | 1.84 1.99 2.07 2.11 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 439 МБ/с 433 МБ/с 151 МБ/с 201 МБ/с | 525 МБ/с 564 МБ/с 625 МБ/с 622 МБ/с |
Количественные оценки пропускной способности всех трех уровней памяти приведены в таблице 3. По сравнению с предыдущим решением от VIA ядром Nehemiah, однозначных преимуществ реализации L1-кэша данных в Esther не наблюдается. Его эффективность при считывании данных в MMX-регистры возросла, но, в то же время, эффективность операций записи данных как из MMX-, так и из SSE-регистров несколько снизилась. Зато стала более эффективной реализация шины данных L1-L2 (мы изучим ее отдельно ниже), что проявило себя в виде увеличения эффективности L2-кэша как при операциях чтения, так и записи (причем в последнем случае пропускная способность этого уровня кэша даже несколько выше, чем при чтении, что встречается довольно редко).
Несмотря на использование более скоростной, 100-МГц (400-МГц Quad-Pumped) системной шины V4, обладающей теоретической пропускной способностью 3.2 ГБ/с, а также более скоростной памяти DDR-333 с предельной пропускной способностью 2.67 ГБ/с, реальная пропускная способность памяти при тотальном чтении данных (без оптимизации) осталась на весьма скромном уровне порядка 0.56 ГБ/с. В то же время, приятно отметить, что в этой платформе значительно возросла пропускная способность памяти при операциях записи данных в последнюю до величин порядка 0.62 ГБ/с, что в 3-4 раза выше по сравнению с ранней платформой с процессором VIA Antaur.
Предельная реальная пропускная способность памяти
Оценим максимально достижимые величины предельной реальной пропускной способности памяти с помощью различных методов оптимизации. Прежде всего, рассмотрим метод программной предвыборки данных (software prefetch), хорошо подходящий для оптимизации чтения из памяти для большинства современных процессоров.
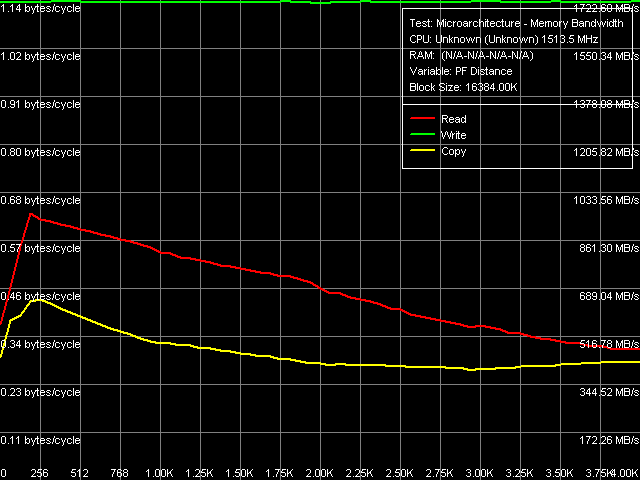
Рис. 2. Предельная реальная пропускная способность памяти, Software Prefetch / Non-Temporal Store
Внешний вид кривых зависимости ПСП от дистанции предвыборки (рис. 2) на C7-M заметно отличается от кривых, полученных ранее на VIA C3/Antaur. А именно, кривые характеризуются четким максимумом эффективности предвыборки при ее дистанции в 192 байта (т.е. опережающего запроса данных, расположенных на 3 строки кэша впереди относительно текущих данных), в то время как программная предвыборка на C3/Antaur не отличалась особой эффективностью, и ПСП плавно спадала по мере увеличения дистанции предвыборки.
Достигнутое этим методом значение максимума реальной ПСП в 962 МБ/с является и абсолютным максимумом как видно из данных таблицы 4, остальные методы оптимизации не отличаются столь же высокой эффективностью. По этому показателю также наблюдается расхождение с предыдущим поколением процессоров на ядре Nehemiah в том случае максимальная реальная ПСП достигалась лишь в несколько «нечестном» методе считывания целых строк кэша («нечестность» которого заключается в том, что таким методом невозможно действительно считать все требуемые данные из памяти, хотя их пересылка по системной шине процессора, несомненно, идет в полном объеме).
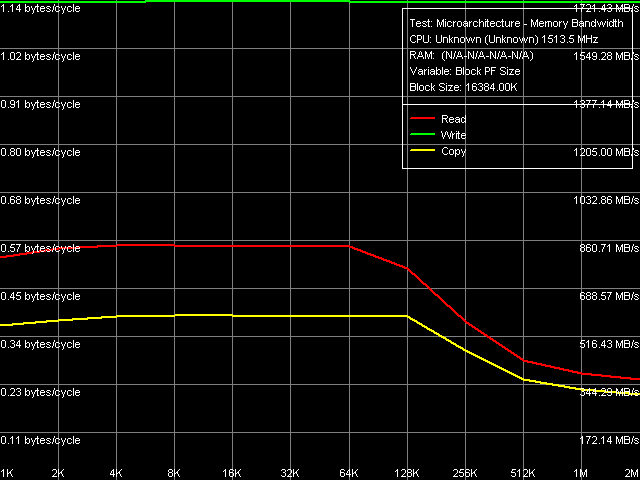
Рис. 3. Предельная реальная пропускная способность памяти, Block Prefetch 1 / Non-Temporal Store
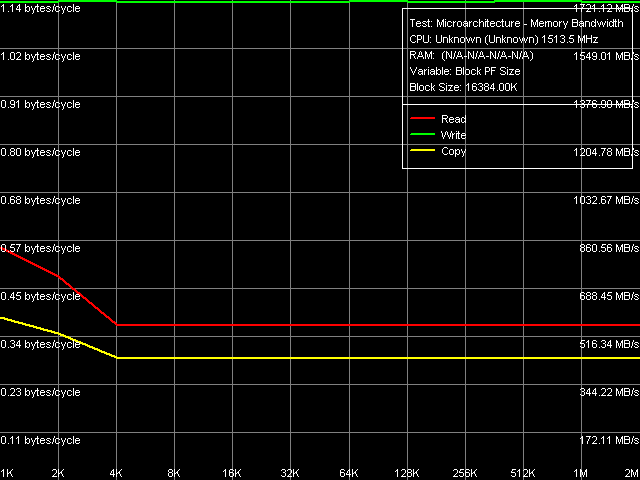
Рис. 4. Предельная реальная пропускная способность памяти, Block Prefetch 2 / Non-Temporal Store
Что касается методов Block Prefetch 1 и Block Prefetch 2, первый из которых изначально рассчитан для достижения максимума ПСП на процессорах AMD K7, а второй для AMD K8, их поведение на VIA C7-M (рис. 2 и 3, соответственно) оказывается похожим на то, что мы наблюдали ранее на VIA C3/Antaur. Максимум эффективности первого метода достигается при размере «предвыборочного блока» в 64 КБ, второго 1 КБ (т.е. можно сказать, что второй метод практически не работает). Наконец, метод чтения целых строк кэша, который, как мы уже упоминали выше, давал наилучший результат на VIA Antaur, в случае C7-M также оказывается весьма эффективным (достигаемое значение ПСП 910-920 МБ/с), но все же его эффективность несколько ниже по сравнению с методом программной предвыборки данных. Такая «расстановка сил» оказывается исключительно в пользу нового ядра Esther, т.к. Software Prefetch является наиболее часто употребляемым, практически универсальным методом оптимизации чтения данных из памяти.
Таблица 4
| Режим доступа | Предельная реальная ПСП на чтение, МБ/с* | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 439 (20.6 %) 433 (20.3 %) 334 (15.7 %) 485 (22.7 %) 524 (24.6 %) 537 (25.2 %) 539 (25.3 %) 609 (28.6 %) 660 (31.0 %) 660 (31.0 %) | 525 (19.7 %) 564 (21.1 %) 911 (34.2 %) 962 (36.1 %) 843 (31.6 %) 844 (31.6 %) 785 (29.4 %) 839 (31.5 %) 920 (34.5 %) 910 (34.1 %) |
*в скобках указаны значения относительно максимально возможного предела для данного типа памяти
Что касается методов оптимизации записи данных в память, реальное практическое значение имеет всего один метод метод прямого сохранения данных непосредственно из MMX/SSE-регистров в память через буферы объединения записи (Write-Combining Buffers), минуя всю иерархию кэшей процессора. Он же оказывается бесспорным лидером как на ранней платформе Nehemiah, так и на новой Esther на последней достигается величина ПСП порядка 1.72 ГБ/с (табл. 5), т.е. почти 65% от теоретического максимума. Метод записи целых строк кэша, который отличался несколько большей ПСП на Nehemiah, здесь преподносит неожиданный сюрприз его эффективность оказывается ниже, чем у простой, тотальной записи данных через всю иерархию кэшей процессора. Такое поведение не очень понятно, но, тем не менее, оно не имеет большого практического значения, т.к. данный метод носит чисто синтетический характер и непригоден для реальной записи данных в память.
Таблица 5
| Режим доступа | Предельная реальная ПСП на запись, МБ/с* | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 151 (7.1 %) 201 (9.4 %) 1046 (49.1 %) 1046 (49.1 %) 200.4 (9.4 %) 200.4 (9.4 %) | 625 (23.4 %) 622 (23.3 %) 1721 (64.5 %) 1722 (64.5 %) 576 (21.6 %) 576 (21.6 %) |
*в скобках указаны значения относительно максимально возможного предела для данного типа памяти
Средняя латентность кэша данных/памяти
Прежде чем перейти к рассмотрению латентности различных уровней памяти, напомним, что наиболее значимым изменением кэша данных и инструкций в новых процессорах C7/C7-M с ядром Esther стало увеличение длины их строки с 32 до 64 байт. Поскольку именно это значение фигурирует во всех тестах латентности и определяется автоматически при запуске RMMA на новом, еще неизвестном процессоре, посмотрим для начала на вид кривых, полученных в тестах определения длины строки L1- и L2-кэшей данных.
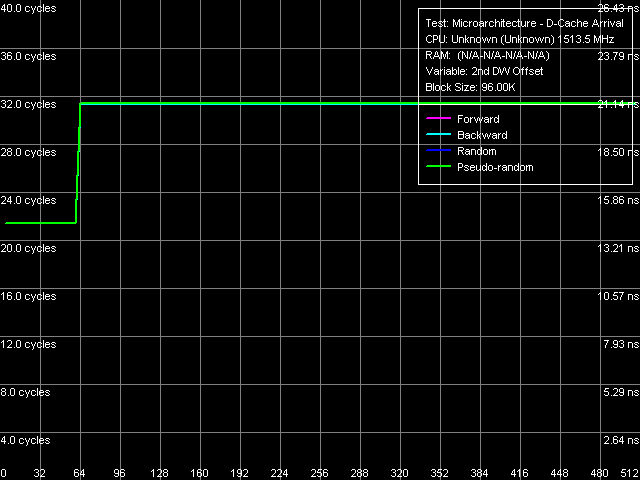
Рис. 5. Определение длины строки L1-кэша данных
Итак, длина строки L1-кэша данных (рис. 5) не вызывает сомнений во всех режимах обхода максимальное возрастание латентности доступа в этом тесте, представляющем собой модификацию теста прибытия данных, наблюдается при считывании соседнего элемента, отстоящего от главного на 64 и более байт. Следовательно, длина строки L1-кэша данных действительно равна 64 байтам.
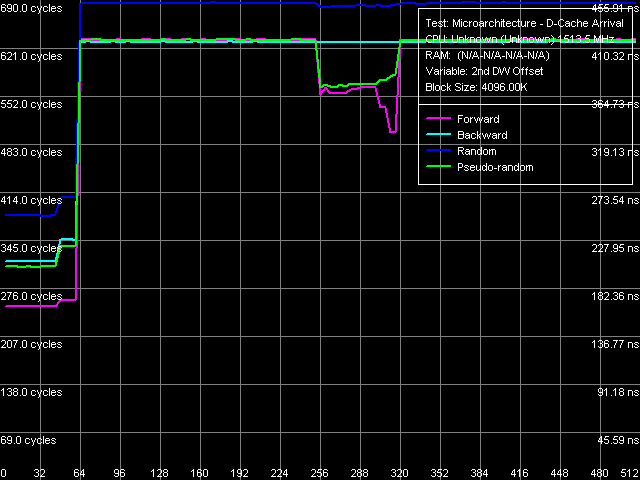
Рис. 6. Определение длины строки L2-кэша данных
Достаточно четкая картина, но с некоторым вмешательством аппаратной предвыборки (да-да, реализованной впервые в процессорах VIA, ее мы подробнее увидим ниже) наблюдается и во втором тесте прибытия данных по шине L2-RAM. По этим кривым можно заключить, что во всех случаях пересылка данных из памяти в L2-кэш осуществляется на уровне целых строк L2-кэша, длина которой также составляет 64 байта.
Перейдем теперь к изучению латентностей L1/L2-кэша данных и памяти как таковых.
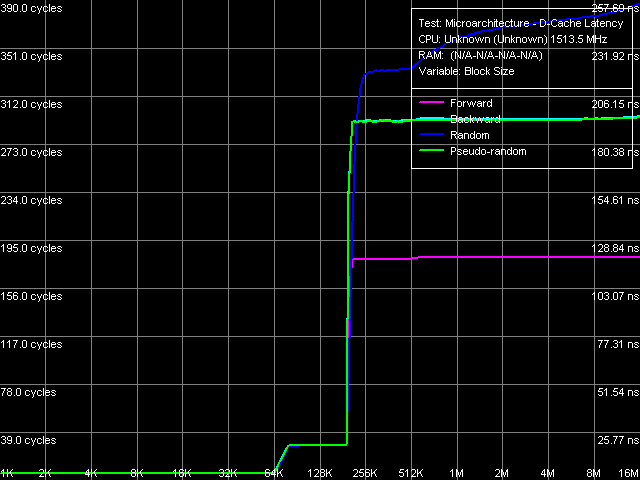
Рис. 7. Латентность L1/L2-кэша данных и оперативной памяти
Общий вид кривых (рис. 7) выглядит типично для процессоров с эксклюзивной иерархией кэша. Наиболее значимым отличием Esther от Nehemiah, которое мы уже могли увидеть и выше, является реализация (впервые для процессоров VIA) аппаратной предвыборки данных, которая эффективно работает в случае прямого последовательного обхода памяти. Аналогичную картину можно было наблюдать, к примеру, на процессорах AMD K7.
Таблица 6
| Уровень, доступ | Средняя латентность, тактов | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| L1, прямой L1, обратный L1, псевдослучайный L1, случайный | 6 6 - 6 | 6 6 6 6 |
| L2, прямой L2, обратный L2, псевдослучайный L2, случайный | 25 25 - 25 | 29 29 29 29 |
| RAM, прямой RAM, обратный RAM, псевдослучайный* RAM, случайный* | 126 (126 нс) 126 (126 нс) - 195 (195 нс) | 181 (120 нс) 294 (194 нс) 294 (194 нс) 379 (250 нс) |
*Размер блока 4 МБ
Количественные оценки латентностей L1-, L2-кэша и оперативной памяти приведены в табл. 6. Латентность первого уровня кэша в новом ядре Esther осталась на уровне 6 тактов, впервые встретившимся в ядре Nehemiah (напомним, что предыдущее поколение процессоров VIA C3 с ядрами Ezra/Samuel имело «4-тактный» L1-кэш). Таким образом, процессоры VIA по-прежнему остаются процессорами, обладающими самой высокой латентностью доступа в L1-кэш данных.
В новом ядре Esther возросла и «средняя» латентность (т.е. латентность, наблюдаемая в нормальных условиях, без разгрузки шины) L2-кэша данных по сравнению с Nehemiah она увеличилась на 4 такта. Что ж, изменения нельзя назвать неожиданными, учитывая значительное изменение самой структуры кэша в виде увеличения его длины строки до более привычного ныне значения в 64 байта.
Латентность оперативной памяти в рассматриваемой платформе оказывается весьма высокой она даже выше по сравнению с ранее исследованной платформой с процессором VIA Antaur. Отчасти поправляет это положение лишь аппаратная предвыборка данных при прямом последовательном доступе к памяти, снижая ее латентность до 120 нс, истинная же ее латентность наблюдается при обратном и псевдослучайном обходе и составляет 194 нс. Дальнейшее увеличение латентности при случайном обходе связано, как мы неоднократно писали, с исчерпанием объема D-TLB, который в данном случае способен вмещать лишь 128 страниц, т.е. «покрывать» область не более 512 КБ.
Минимальная латентность L2 кэша данных/памяти
Оценим минимальную латентность L2-кэша данных процессора VIA C7-M с помощью разгрузки шины L1-L2 вставкой пустых операций (рис. 8).
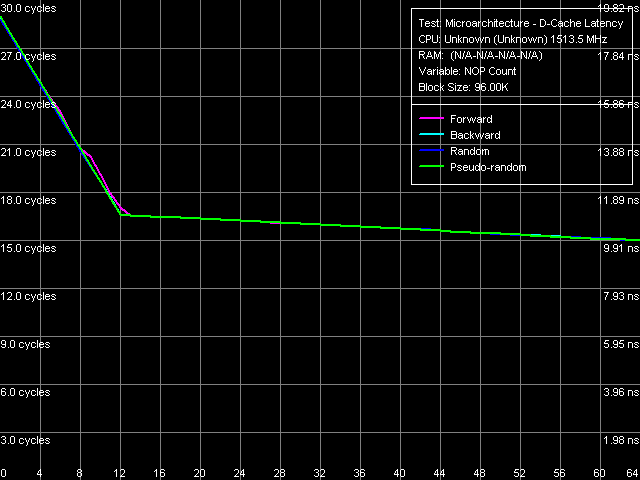
Рис. 8. Минимальная латентность L2-кэша данных
По непонятным причинам, что, однако, случается на всех процессорах VIA, предварительный тест измерения времени исполнения одной инструкции NOP дает несколько завышенное значение (в данном случае порядка 1.03 тактов процессора вместо 1.00), что приводит к занижению базовой линии по мере увеличения количества пустых операций, вставленных между соседними обращениями к кэшу. Тем не менее, в данном случае эта погрешность сравнительно невелика и позволяет увидеть, что минимальная латентность во всех случаях достигается при вставке 12 NOP-ов и составляет 17 тактов. Такое же значение (при вставке 8 NOP-ов и более) наблюдалось и на процессоре VIA Antaur (см. табл. 7).
Таблица 7
| Уровень, доступ | Минимальная латентность, тактов | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| L2, прямой L2, обратный L2, псевдослучайный L2, случайный | 17 17 - 17 | 17 17 17 17 |
| RAM, прямой RAM, обратный RAM, псевдослучайный* RAM, случайный* | 126 (126 нс) 126 (126 нс) - 192 (192 нс) | 142 (94 нс) 291 (192 нс) 289 (191 нс) 373 (246 нс) |
*Размер блока 4 МБ
Минимальную латентность памяти оценим аналогичным тестом, увеличив размер обходимого блока данных до 4 МБ.
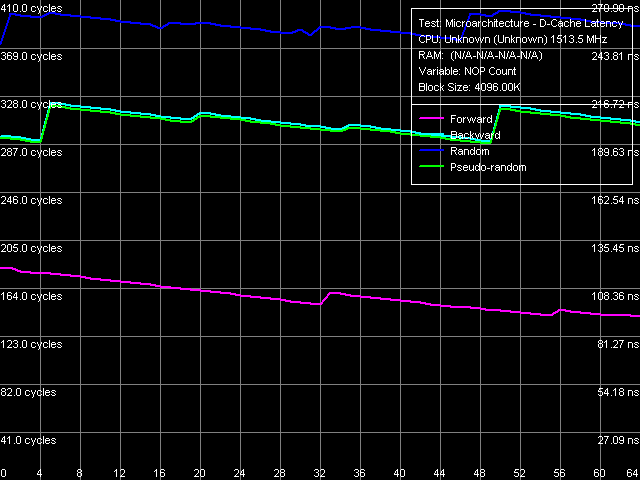
Рис. 9. Минимальная латентность оперативной памяти
Картина разгрузки шины L2-RAM (рис. 9) напоминает таковую для процессоров семейства AMD K7, в которых аппаратная предвыборка данных также реализована только для прямого последовательного обхода и обладает сравнительно малой эффективностью «разгрузочная кривая» спадает очень плавно и не достигает своего минимума даже при вставке 64 NOP-ов. Минимальное значение латентности оперативной памяти в этой точке составляет 94 нс. В случае обратного, псевдослучайного и случайного обхода кривые имеют типичный «зубчатый» вид с шагом в 15 NOP-ов, соответствующих коэффициенту умножения частоты системной шины процессора (100 МГц x 15 = 1.5 ГГц). Как это обычно и бывает, минимальные латентности в этих режимах не сильно отличаются от своих «средних» значений.
Ассоциативность кэша данных
Весьма интересной особенностью L2-кэша нового ядра Esther является очень высокая степень его ассоциативности, равная 32 на данный момент, процессоры VIA C7/C7-M являются первыми процессорами, обладающие столь «высокоассоциативным» кэшем (правда, не совсем понятно, для чего учитывая его сравнительно малый объем в 128 КБ).
Попробуем оценить ассоциативность L1/L2-кэша данных рассматриваемого процессора, воспользовавшись стандартным тестом (рис. 10).
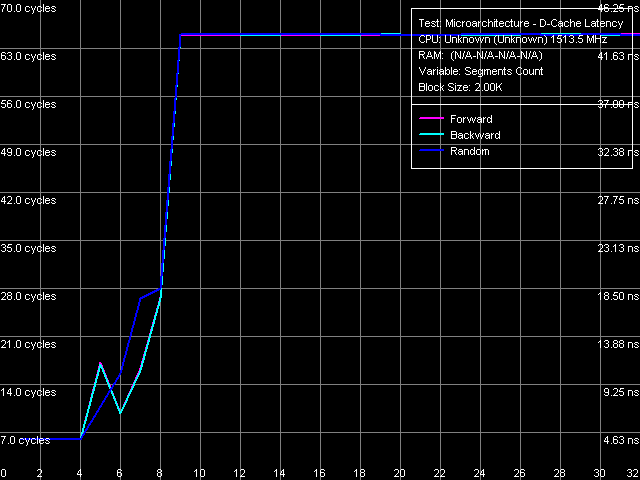
Рис. 10. Ассоциативность L1/L2-кэша данных
К сожалению, этот тест не дает однозначной картины по его результатам можно говорить об ассоциативности L1-кэша, равной четырем (область первого перегиба на графике), в то время как по мере дальнейшего увеличения числа сегментов достаточно четкой картины не наблюдается. Впрочем, это неудивительно ведь максимальное их количество в данном тесте ограничено 32 (при разработке теста никак не предполагалось появление процессоров с таким кэшем), тогда как вторая область перегиба в данном случае (эксклюзивная организация) должна наблюдаться при количестве сегментов, равному «суммарной ассоциативности» L1+L2 кэшей, т.е. 36. Что ж, нам пока остается лишь поверить в 32-way ассоциативность L2-кэша процессоров C7/C7-M, а в дальнейшем расширить функциональность нашего тестового пакета.
Реальная пропускная способность шины L1-L2
Учитывая эксклюзивную организацию L1-L2 кэшей данных в процессорах Antaur и C7/C7-M, при которой каждое обращение к L2-кэшу, наряду с пересылкой данных из L2 в L1, сопровождается вытеснением строки-«жертвы» из L1 в L2, значения реальной пропускной способности шины L1-L2, полученные в соответствующем подтесте RMMA, были удвоены (табл. 8).
Таблица 8
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт* | |
|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 2.56 2.56 2.56 2.56 | 4.32 4.32 4.40 4.40 |
*с учетом эксклюзивности кэша
Как известно по данным нашего прошлого исследования процессоров VIA, шина данных L1-L2 в процессоре VIA Antaur характеризуется сравнительно низкой пропускной способностью всего 2.56 байт/такт, что могло бы предполагать всего лишь 32-битную ее организацию. Тем не менее, тест прибытия данных, проведенный в том исследовании, показал, что разрядность этой шины на самом деле составляет 64 бита, поскольку чтение смежных элементов одной 32-байтной строки кэша не сопровождалось дополнительными задержками.
В новом ядре Esther скоростные показатели шины L1-L2 заметно возросли до значений порядка 4.4 байт/такт (несколько выше в случае записи, нежели чтения напомним, что такую же картину мы наблюдали в самом первом тесте, при изучении пропускной способности L2-кэша на чтение/запись). Весьма неплохо, учитывая возросшие требования к ПС этой шины, налагаемые увеличением длины строки кэша до 64 байт. В то же время, разрядность этой шины по-прежнему осталась на уровне 64 бит, что, на самом деле, не так уж плохо. Такой же расклад (64-разрядная шина, 64-байтные строки) имеет место, к примеру, в архитектуре AMD K7.
Для подтверждения нашего предположения о 64-разрядности шины L1-L2 кэша воспользуемся тестом прибытия данных (рис. 11).
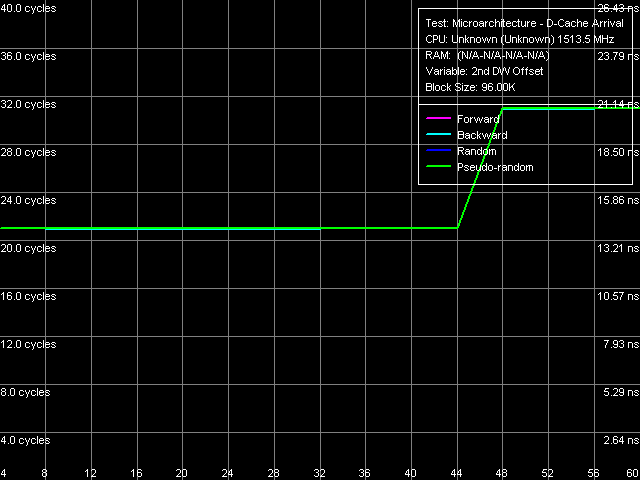
Рис. 11. Прибытие данных по шине L1-L2, тест 1
Напомним, что в этом тесте происходит считывание двух элементов из одной и той же строки кэша, второй элемент отстоит от первого (начала строки) на заданную величину (от 4 до 60 байт). Данный тест показывает, что за 6 тактов доступа в L1-кэш, из L2-кэша процессора успевают прибыть лишь первые 48 байт (с 0-го по 47-й включительно), в то время как запрос последующего 48-го байта сопровождается ощутимым увеличением задержек. Это означает, что скорость передачи данных действительно составляет 48/6 = 8 байт/такт, т.е. разрядность шины равна 64 бит.
Кроме того, вторая разновидность теста прибытия данных (рис. 12) позволяет узнать дополнительные подробности о порядке поступления данных из L2 в L1.
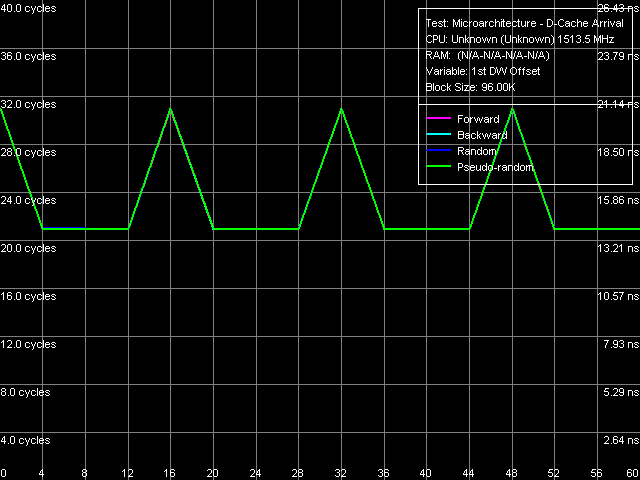
Рис. 11. Прибытие данных по шине L1-L2, тест 2
В этом тесте переменной является смещение первого запрашиваемого элемента относительно начала строки (от 0 до 60 байт), в то время как второй запрашиваемый элемент всегда смещен относительно первого на -4 байта (за исключением начальной точки, когда смещение оказывается равным -4 + 64 = +60 байт, вследствие необходимости соблюдения условия попадания обоих элементов в одну и ту же строку кэша).
По виду полученных кривых (рис. 12) можно заключить, что считывание данных из L2-кэша процессоров VIA C7/C7-M осуществляется 16-байтными блоками, причем оно может начинаться с любой позиции, кратной 16 (которым отвечают точки максимума на кривых):
1) 0-15, 16-31, 32-47, 48-63
2) 16-31, 32-47, 48-63, 0-15
3) 32-47, 48-63, 0-15, 16-31
4) 48-63, 0-15, 16-31, 32-47
Напомним, что аналогичная картина, но с 8-байтным «гранулированием», наблюдается в архитектуре AMD K7/K8, т.е. организация кэшей данных процессоров VIA приобретает все больше и больше сходства с таковой в процессорах AMD.
Кэш инструкций, эффективность декодирования/исполнения
Для начала, приведем картину декодирования/исполнения простейших инструкций NOP, потому как она достаточно сильно отличается от типично наблюдаемой (рис. 13).
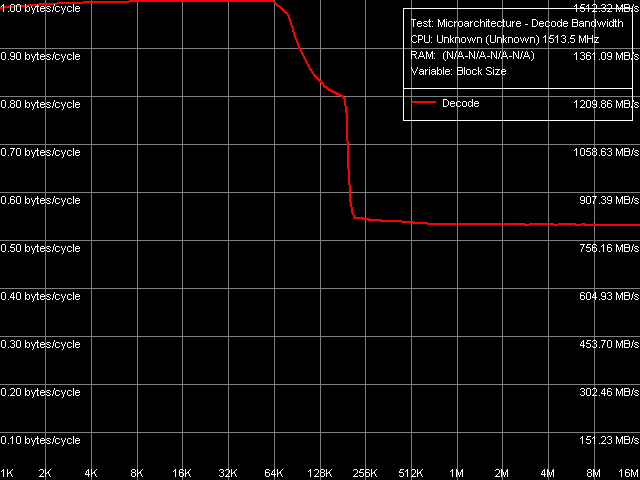
Рис. 13. Эффективность декодирования/исполнения, инструкции NOP
А именно, здесь отсутствует четкая область, соответствующая исполнению инструкций из L2-кэша. Это не значит, что L2-кэш этого процессора «не работает» на случай кэширования кода (вместо данных), т.к. скорость декодирования/исполнения в области 64-192 КБ все-таки отличается от таковой при выходе за пределы суммарного объема L1I и L2-кэша.
В то же время, картина, получаемая при декодировании/исполнении прочих инструкций, например, 6-байтных операций сравнения вида cmp eax, xxxxxxxxh (CMP 3-6), выглядит более типично (рис. 14).
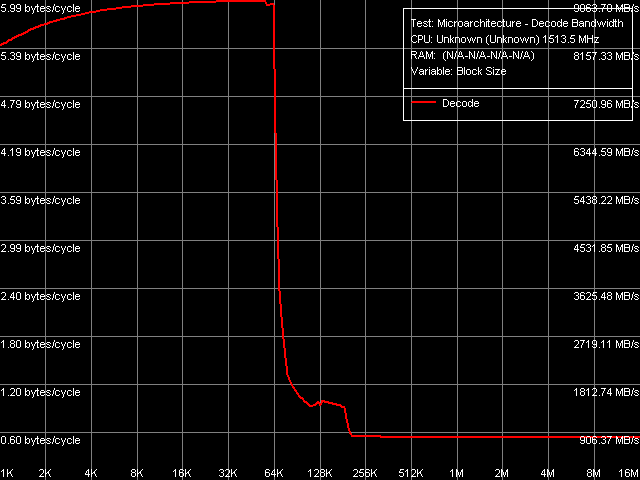
Рис. 14. Эффективность декодирования/исполнения, инструкции CMP
Перейдем к количественным оценкам скорости декодирования/исполнения, представленным в табл. 9.
Таблица 9
| Тип инструкций (размер, байт) | Эффективность декодирования/исполнения, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| VIA Antaur (Nehemiah) | VIA C7-M (Esther) | |||
| L1-I кэш | L2 кэш | L1-I кэш | L2 кэш | |
| NOP (1) | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) | ~0.84 (0.84) |
| SUB (2) | 2.00 (1.00) | 1.14 (0.57) | 2.00 (1.00) | 0.93 (0.46) |
| XOR (2) | 2.00 (1.00) | 1.14 (0.57) | 2.00 (1.00) | 0.93 (0.46) |
| TEST (2) | 2.00 (1.00) | 1.14 (0.57) | 2.00 (1.00) | 0.93 (0.46) |
| XOR/ADD (2) | 2.00 (1.00) | 1.14 (0.57) | 2.00 (1.00) | 0.93 (0.46) |
| CMP 1 (2) | 2.00 (1.00) | 1.14 (0.57) | 2.00 (1.00) | 0.93 (0.46) |
| CMP 2 (4) | 2.00 (0.50) | 1.14 (0.28) | 2.00 (0.50) | 0.93 (0.23) |
| CMP 3-6 (6) | 5.99 (1.00) | 1.14 (0.19) | 5.99 (1.00) | 1.00 (0.16) |
| Prefixed CMP 1-4 (8) | 2.67 (0.33) | 1.14 (0.14) | 2.67 (0.33) | 0.96 (0.12) |
Что касается декодирования/исполнения простейших ALU-операций (как независимых, так и псевдозависимых) из L1-кэша, здесь не наблюдается изменений еще со времен первых VIA C3 (а возможно и более ранних процессоров VIA/Centaur). Предельный темп декодирования/исполнения этих инструкций остается на уровне 1 инструкции/такт, что на сегодняшний день выглядит весьма слабо.
Скорость декодирования/исполнения инструкций типа CMP 2 (cmp ax, 0000h) и Prefixed CMP 1-4 ([rep][addrovr]cmp eax, xxxxxxxxh) по-прежнему оказывается меньшей по сравнению с остальными инструкциями. Замедление их исполнения происходит ровно во столько раз, сколько префиксов они содержат в сумме с основной операцией. Так, темп исполнения CMP 2 снижен в 2 раза (1 префикс + 1 операция), а префиксных CMP в 3 раза (2 префикса + 1 операция). А это значит, что процессоры с ядром Esther, как и все предыдущие процессоры VIA, по-прежнему расходуют свои исполнительные устройства на «исполнение» каждого префикса.
Это подтверждает и отдельный подтест Prefixed NOP Decode Efficiency, в котором осуществляется декодирование/исполнение инструкций вида [66h]nNOP, n = 0..14 (рис. 15).
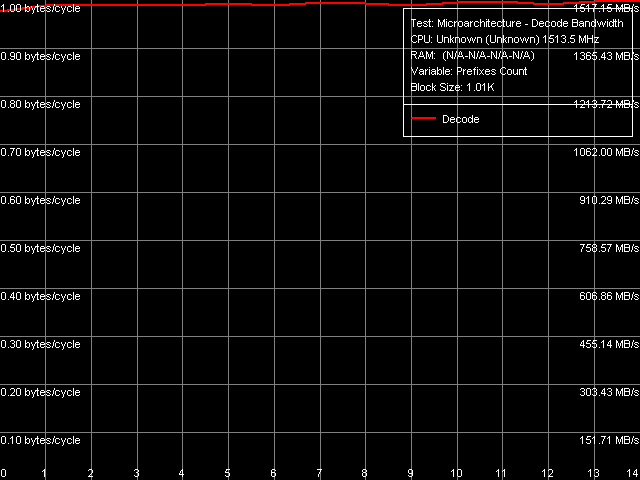
Рис. 15. Эффективность декодирования/исполнения префиксных инструкций NOP
Скорость декодирования/исполнения таких инструкций, выраженная в байтах/такт, не зависит от количества префиксов и всегда составляет ровно 1 байт/такт. Это значит, что время исполнения одной инструкции, выраженное в тактах процессора, действительно линейно растет по мере увеличения количества содержащейся в ней префиксов. Весьма неэффективный подход, если учесть, что префиксы встречаются в потоке x86-кода не так уж и редко (особенно если учесть SSE/SSE2/SSE3-инструкции, для которых была реализована поддержка в ядре Esther).
Ассоциативность кэша инструкций
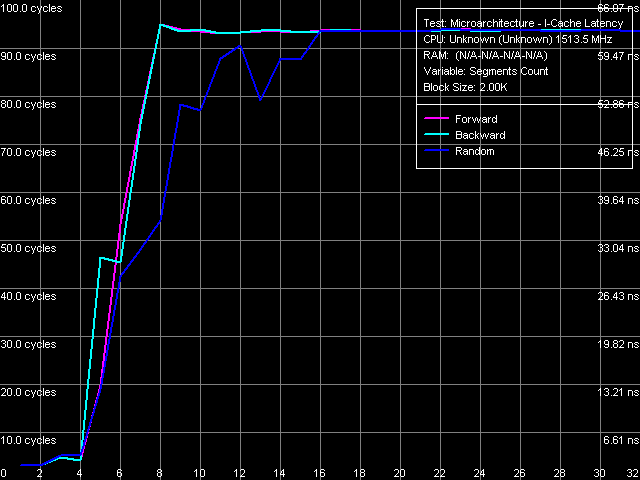
Рис. 16. Ассоциативность кэша инструкций
Как и в случае ассоциативности L1/L2-кэша данных, тест ассоциативности кэша инструкций (рис. 16) позволяет увидеть лишь заявленную ассоциативность L1-I кэша, равную четырем. Область второго перегиба, соответствующая суммарной ассоциативности L1-кэша инструкций и объединенного L2-кэша инструкций/данных (36), на данном графике попросту «не помещается». Будем надеяться, что мы сможем увидеть ее в будущем, с выпуском новой версии тестового пакета RMMA.
Буфер переупорядочивания инструкций (I-ROB)
Весьма интересную картину ядро Esther показывает в тесте буфера переупорядочивания инструкций (рис. 17), принцип работы которого следующий: запускается одна простая, но долго исполняемая инструкция операция зависимой загрузки последующей строки данных из памяти, mov eax, [eax], а сразу вслед за ней серия очень простых, не зависящих от нее операций (nop). В идеализированном случае, как только время исполнения такой связки начинает зависеть от количества NOP-ов, можно считать, что объем буфера I-ROB исчерпан.
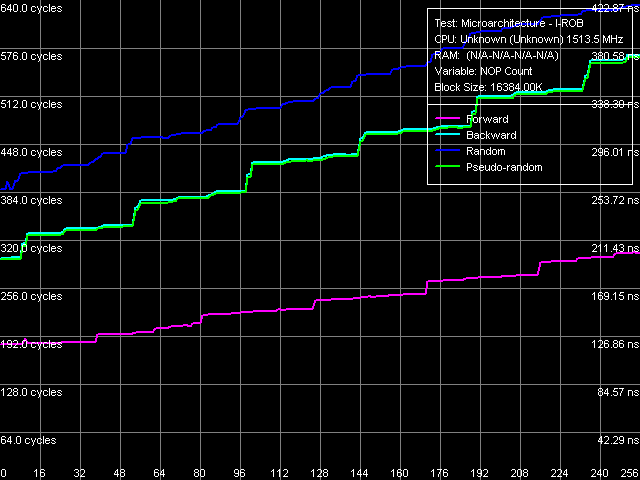
Рис. 17. Объем буфера переупорядочивания инструкций
«Интересность» этой картины заключается в том, что время исполнения такой связки практически сразу начинает зависеть от количества NOP-ов. А это означает лишь одно буфер переупорядочивания инструкций у процессоров VIA C7/C7-M отсутствует, т.е. о внеочередном исполнении кода на этих процессорах говорить не приходится. Впрочем, отсутствие I-ROB хорошо вписывается в общую картины предельной простоты реализации микроархитектуры процессора, вроде рассмотренных выше декодера и исполнительных устройств.
Характеристики TLB
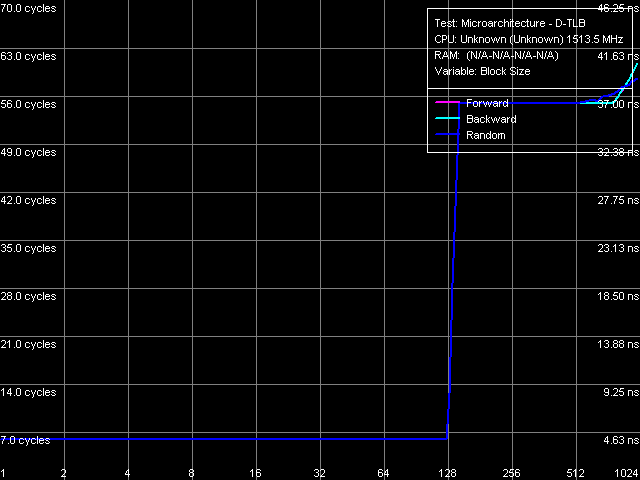
Рис. 18. Размер D-TLB
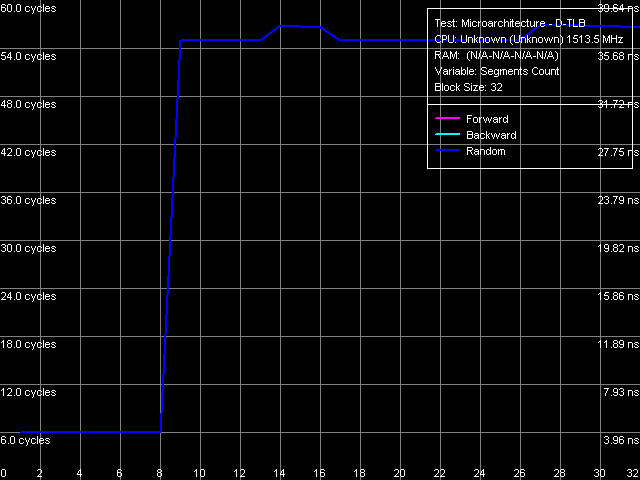
Рис. 19. Ассоциативность D-TLB
Тесты определения размера (рис. 18) и ассоциативности D-TLB (рис. 19), как и в случае ядра Nehemiah, и в отличие от более ранних моделей, не преподносят каких-либо сюрпризов. Размер D-TLB действительно равен 128 записям (что мы увидели как в характеристиках CPUID, так и в тесте латентности L1/L2/RAM), штраф промаха (выхода за пределы его объема) весьма велик порядка 49 тактов процессора. Степень ассоциативности 8, «промах по ассоциативности» сопровождается примерно таким же штрафом.
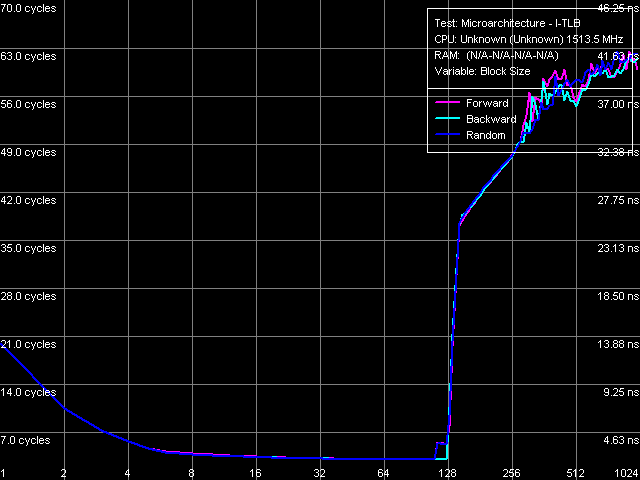
Рис. 20. Размер I-TLB
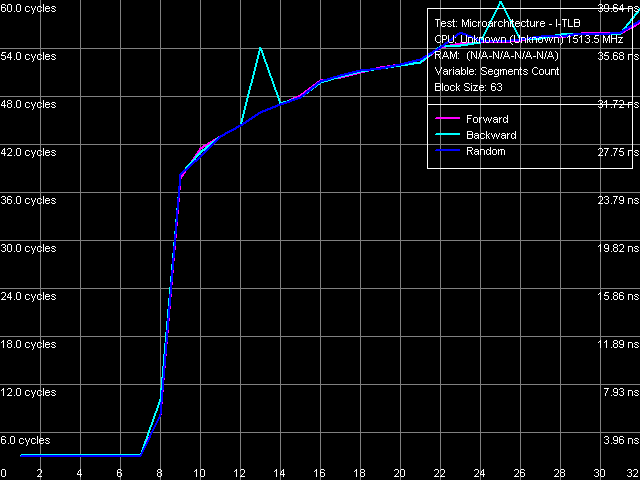
Рис. 21. Ассоциативность I-TLB
Сказанное выше с равным успехом относится и к тестам I-TLB размера (рис. 20) и ассоциативности (рис. 21). Размер I-TLB также составляет 128 записей, а степень его ассоциативности равна 8. Кроме того, начальная область теста размера I-TLB позволяет определить «латентность L1-кэша инструкций», т.е. время исполнения одной операции ближнего безусловного перехода, которое оказывается равным 3 тактам. Штраф промаха I-TLB оценить сложнее вследствие постоянного возрастания латентности по мере увеличения количества обходимых страниц памяти. Однако в обоих случаях («промаха по размеру» и «промаха по ассоциативности») можно обозначить начальную область, в которой латентность возрастает до величины порядка 38-39 тактов, т.е. минимальный штраф промаха I-TLB составляет 35-36 тактов процессора.
Заключение
Новое процессорное ядро Esther процессоров VIA C7/C7-M в микроархитектурном плане нельзя назвать прорывом, чем-то кардинально новым. Во многом оно является просто доработкой предыдущего ядра Nehemiah ядра десктопных процессоров VIA C3 «второго поколения» и мобильных процессоров VIA Antaur. Наиболее важные отличия C7/C7-M от C3/Antaur, видные невооруженным глазом, заключаются в поддержке наборов SIMD-инструкций SSE2 и SSE3, расширении L2-кэша до 128 КБ с одновременным увеличением степени его ассоциативности аж до 32, а также (что менее очевидно для простого пользователя) в увеличении длины строки всех кэшей процессора до 64 байт. И если изменения подсистемы памяти процессора можно признать вполне удачными увеличилась пропускная способность шины L1-L2 и L2-кэша, что, в свою очередь, позволило достичь большую пропускную способность оперативной памяти и оправдало применение в новых процессорах более скоростной системной шины V4 (аналога Pentium 4 Quad-Pumped bus), то увы, то же самое нельзя сказать о вычислительных блоках процессоров. VIA C7/C7-M по-прежнему имеют весьма посредственный декодер, не способный эффективно обрабатывать инструкции с префиксами каковыми, в частности, являются все без исключения SIMD-инструкции. Судя по всему, не увеличилось и количество исполнительных блоков процессора по крайней мере, даже простейшие ALU-операции по прежнему исполняются со скоростью всего в одну операцию за такт процессора. Таким образом, от новых процессоров VIA C7/C7-M вряд ли стоит ждать особо высокой производительности. И даже если верить рекламным заявлениям VIA о том, что эти процессоры характеризуются наилучшим соотношением производительности на Ватт мощности по сравнению со всеми остальными процессорами, становится понятно, что достигается оно исключительно за счет малой мощности, но никак не высокой производительности. В общем, область применения процессоров VIA по-прежнему остается ограниченной решениями, возможно, обладающими сверхмалым энергопотреблением, но уж никак не высокой производительностью.


