Часть 4: Платформы VIA C3
Наше очередное исследование низкоуровневых характеристик платформ посвящено изучению платформ на базе процессоров VIA C3, которые мы что-то давно не рассматривали. Дабы восполнить этот пробел, мы решили провести сравнительное тестирование десктопного варианта VIA C3 Ezra и нового мобильного ядра VIA C3 Antaur. Что можно сказать об этих процессорах? О производительности говорить вряд ли стоит — с результатами соответствующих тестов можно ознакомиться в отдельном исследовании. Лучше проанализируем основные характеристики этих процессоров, которые заявлены в документации VIA, и попытаемся увидеть их на практике. Сразу отметим, что имеющаяся документация на C3 Ezra гораздо более подробная, нежели документация Antaur.
Представим основные характеристики VIA C3 Ezra.
- Полная программная совместимость с существующими x86-приложениями
- Набор MMX-совместимых инструкций
- Набор AMD 3DNow!-совместимых инструкций
- Два больших (64 КБ, 4-way) L1 кэша для инструкций и данных, соответственно
- 64-КБ (4-way) L2 виктим-кэш (эксклюзивная архитектура L1-L2)
- Два больших TLB (128 записей, 8-way) с двумя PDC (Page Directory Caches)
- Уникальные и сложные механизмы предсказания ветвлений
- Частота системной шины 100/133 МГц
- Малый размер ядра (52 мм2 в TSMC 0.13u исполнении)
- Очень низкая рассеиваемая мощность (для которой, однако, требуется активное охлаждение)
Итак, VIA заявляет, что C3 Ezra характеризуется наличием больших кэшей и TLB — причем настолько, что они якобы больше, чем у любого другого x86 процессора (что, конечно же, не так — взять, например, хотя бы рассмотренные ранее платформы AMD K7/K8). Дополнительные подробности реализации этого уровня микроархитектуры Ezra — это наличие буферов STLF (store-to-load forwarding) и WC (write-combining), каждый размером по четыре 8-байтных записи (32 байта). Наконец, отмечается наличие скрытой спекулятивной предвыборки данных (prefetch) в D-Cache, и «агрессивной», но так же скрытой предвыборки инструкций в I-Cache. Ниже мы увидим, проявляют ли они себя в действительности.
А пока рассмотрим спецификации нового VIA Antaur. В принципе, он почти не отличается от Ezra:
- Полная программная совместимость с существующими x86-приложениями
- Набор MMX-совместимых инструкций
- Набор SSE-совместимых инструкций
- Два больших (64 КБ, 4-way) L1 кэша инструкций и данных
- 64-КБ (16-way) L2 виктим-кэш (эксклюзивная архитектура L1-L2)
- Два больших TLB (128 записей, 8-way) с двумя PDC
- Кэш адресов ветвлений (Branch Target Address Cache) размером в 1024 записи, каждая из которых идентифицирует два ветвления
- Уникальные и сложные механизмы предсказания ветвлений :)
- Частота системной шины 133 МГц
- Малый размер ядра (52 мм2 в TSMC 0.13u исполнении)
- Очень низкая рассеиваемая мощность (но активное охлаждение ему так же требуется)
Вот, собственно, и все, что говорит VIA о своем новом процессоре. Основные отличия от Ezra можно перечислить по пальцам. Прежде всего, это «замена» AMD 3DNow! на Intel SSE — разумное решение, учитывая, что ПО, оптимизированного под SSE, куда больше, нежели под 3DNow! Во-вторых, это увеличенная ассоциативность (с 4 до 16) все столь же малого 64-КБ L2-кэша — этот шаг, надо сказать, не очень понятен. Наконец, мы видим дальнейшие усовершенствования традиционных для VIA «уникальных и сложных механизмов предсказания ветвлений» добавлением в ядро процессора BTA-кэша. На этом, пожалуй, закончим с анализом документации и приступим, наконец, к тестированию.
Конфигурации тестовых стендов и ПО
Тестовый стенд №1
- Процессор: VIA C3 ядро Ezra, 866 МГц (6.5x133 МГц)
- Материнская плата: Asus CUSC rev1.5
- Чипсет: SIS630E
- Память: JetRam PC-133 SDRAM, 133 МГц
Тестовый стенд №2 (ноутбук ВЕРСИЯ MarcoPolo43T)
- Процессор: VIA C3 ядро Antaur, 1 ГГц (7.5x133 МГц)
- Чипсет: VIA CLE266 + VT8622
- Память: Hyundai PC2100 DDR SDRAM, 266 МГц (тайминги 2.5-3-3)
Программное обеспечение
- Windows XP Professional SP1
- RightMark Memory Analyzer 2.4
Реальная пропускная способность кэша данных/памяти
По традиции, начнем тестирование низкоуровневых параметров платформ VIA C3 с оценки реальной пропускной способности кэша процессоров и оперативной памяти. Для этого будем использовать первый тест RMMA, Memory Bandwidth. Как мы видели выше, единственными доступными расширениями процессора VIA C3 Ezra являются MMX (точнее, есть еще и 3DNow!, но с точки зрения тестирования пропускной способности памяти они нас не особо интересуют). В связи с этим, ПС L1/L2 кэша и RAM на этой платформе можно оценить с помощью одного- единственного теста — D-Cache/RAM Bandwidth, MMX Registers. Его результаты мы и представляем вашему вниманию.
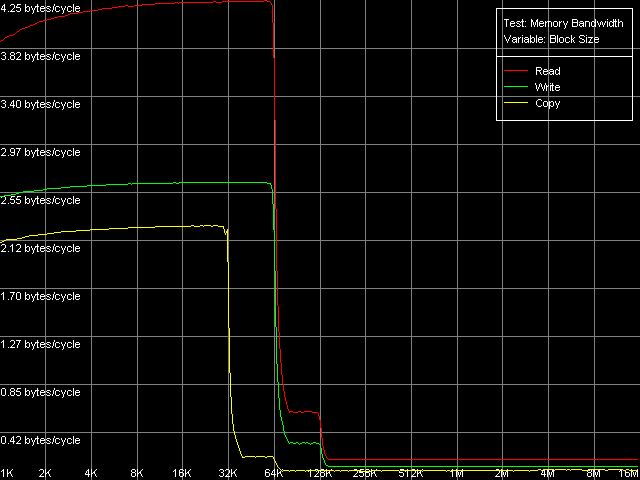
VIA C3 Ezra 733 МГц
В то же время, в VIA C3 Antaur появились расширения SSE, в связи с чем мы можем оценить пропускную способность кэша данных и памяти в двух режимах доступа — используя MMX- и SSE-регистры.
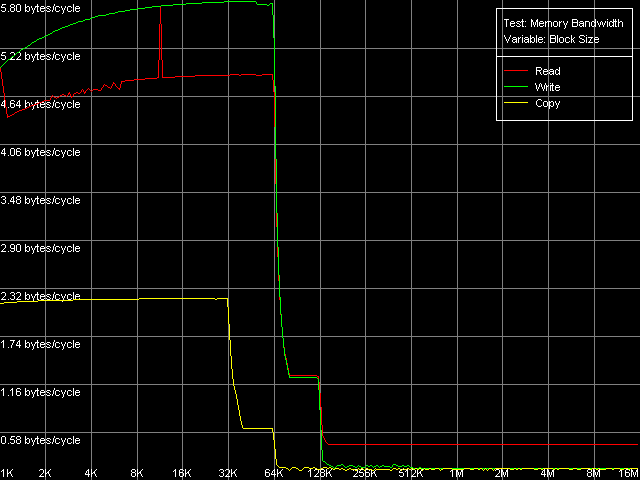
VIA C3 Antaur 1 ГГц, MMX
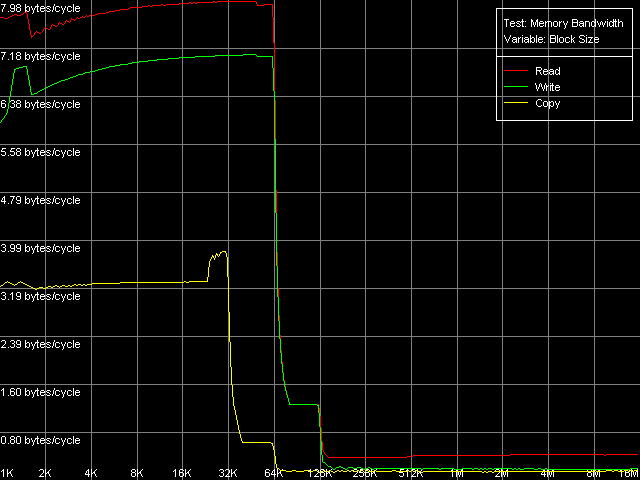
VIA C3 Antaur 1 ГГц, SSE
Сначала оценим качественный вид полученных кривых. По нему можно заключить, что оба процессора имеют кэш первого уровня (L1) размером 64 КБ, в то время как эффективный размер второго уровня кэша (L2) составляет 128 КБ. По данным именно этого, пока что единственного теста нельзя сказать, является ли L2 128-килобайтным инклюзивным кэшем, или же 64-килобайтным эксклюзивным. Однако представленный выше анализ документации VIA, да и результаты последующих тестов, которые мы обсудим ниже, позволяют сделать выбор в пользу второго — VIA (точнее — Centaur) пошла по пути AMD, что является вполне оправданным шагом. А вот расходовать половину объема L2 для дублирования данных L1 кэша, как это было бы, если бы правильным оказалось первое предположение (128-килобайтный инклюзивный кэш), было бы, наоборот, очень неразумной политикой.
Представим теперь результаты нашего первого измерения в числах.
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 4.25 - 2.64 - | 4.89 7.98 5.80 7.08 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 0.61 - 0.34 - | 1.28 1.28 1.25 1.28 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 161.6 МБ/с - 111.0 МБ/с - | 439.0 МБ/с 433.4 МБ/с 151.1 МБ/с 200.8 МБ/с |
Мы начнем их рассмотрение с оценки реальной ПС первого уровня кэша. Величины ПС связки L1-регистры у ранней модели Ezra составляют 4.25 байт/такт на чтение и 2.64 байт/такт на запись. Согласно имеющейся документации VIA, этот процессор умеет исполнять ровно одну MMX-инструкцию за такт, т.е. теоретическое ограничение ПС связки L1-регистры по конвейеру должно составлять 8 байт (64 бита)/такт. Реальная же ПСП оказывается заниженной — эффективность L1 на чтение 53%, на запись и того ниже — всего 33%. Новое ядро Antaur в этом тесте показывает довольно интересную картину — эффективность L1 на чтение MMX-операндов лишь немного возросла (4.89 байт/такт, 61% от теоретического предела), а на запись — весьма значительно (до 5.80 байт/такт, т.е. 72.5% от предельного значения). Причем, что весьма любопытно, запись MMX-значений оказывается эффективнее их чтения — подобную картину можно встретить довольно редко. Использование SSE-регистров значительно улучшает показатели ПС первого уровня кэша — они возрастают до 7.98 байт/такт на чтение и 7.08 байт/такт на запись. К сожалению, в документации VIA Antaur ничего не сказано о скорости исполнения SSE-инструкций, но вполне разумно предполагать, что одна простая SSE-инструкция исполняется за 2 такта. Что и дает нам такой же, как и в случае MMX, теоретический предел доступа в L1 — 8 байт/такт (пересылка половины SSE-операнда за такт).
Пропускная способность второго уровня кэша, как это обычно и бывает, гораздо ниже. Ezra имеет совсем никудышные показатели — 0.61 байт/такт на чтение и 0.34 байт/такт на запись. Что незамедлительно сказывается и на реальной пропускной способности памяти — 161.6 МБ/с на чтение (15.2% от теоретического максимума) и 111.0 МБ/с на запись (10.4% от предельного значения). Причем «слабым звеном», судя по всему, является именно шина L1-L2 кэша данных. Действительно, ее пропускная способность при тотальном чтении данных, в пересчете в МБ/с, составляет всего 528 МБ/с на чтение и 294 МБ/с на запись, что гораздо ниже, чем теоретическая ПСП используемого типа памяти (1067 МБ/с). На фоне столь низкой реальной ПС связки L1-L2 в условиях тотального чтения/записи данных смешно говорить о различных «фичах» процессора, призванных минимизировать простои системной шины и столь гордо разрекламированных VIA.
Что приятно, в новом ядре Antaur этот показатель был значительно улучшен — эффективная ПС L2-кэша при тотальном чтении данных, а также при их записи, возросла до 1.28 байт/такт (1280 МБ/с). Что, впрочем, все равно мало, учитывая, что используемый в этой платформе чипсет работает с памятью PC2100 DDR, теоретическая ПС которой — 2133 МБ/с. По сравнению с Ezra реальная ПС L2 выросла на 110% при осуществлении чтения данных и на 276% при записи. Разумеется, это отразилось и на величинах средней/минимальной латентности L2 кэша и реальной ПС шины L1-L2 в операциях чтения/записи строк кэша, которые мы рассмотрим ниже. Наконец, нельзя не отметить и возросшую реальную ПС оперативной памяти — она увеличилась до 433-439 МБ/с при операциях чтения (более чем в 2 раза, что нельзя списать на счет использования памяти типа DDR вместо SDRAM) и 151-200 МБ/с при операциях записи, причем более высокие значения последней достигаются при использовании SSE-регистров.
Предельная реальная пропускная способность памяти
Оценка предельной реальной ПСП на Ezra — довольно нетривиальная задача. Действительно, ведь у этого процессора отсутствуют необходимые расширения (MMX Extensions), которые используются в методах оптимизации чтения/записи данных из/в RAM. В связи с чем, единственно возможным методом измерения является метод чтения/записи строк кэша (из L2 в RAM и наоборот) — несколько «нечестный» метод с точки зрения оптимизации доступа в память, поскольку соответствующие значения ПСП нельзя достичь при тотальном чтении/записи данных. Но вполне правомерный для оценки предельной реальной ПСП, поскольку, напомним, обращение к памяти осуществляется на уровне целых строк L2-кэша, размер которой у процессоров VIA C3 равен 32 байтам. Сразу скажем о значениях, полученных этим методом на Ezra, после чего детально рассмотрим различные варианты оптимизации на Antaur. Итак, реальная ПСП на чтение при использовании этого метода на Ezra возрастает до 227 МБ/с (всего 21.3% от теоретического предела, но на 40.5% выше, чем при тотальном чтении). Реальная ПСП на запись строк кэша не сильно уступает — 205 МБ/с, что также весьма немного (19.2% от теоретического максимума), но на 84.8% выше, чем при тотальной записи данных из MMX-регистров процессора. Вот, собственно, и все, что можно сказать о максимальной реальной ПСП на этой платформе. Несмотря на то, что, согласно документации VIA, процессоры C3 Ezra имеют буферы объединения записи (по протоколу write-combining), скорость такого обращения мы оценить не можем ввиду отсутствия необходимых инструкций «прямой» записи данных из регистров процессора в память.
В то же время, процессор Antaur благодаря наличию SSE имеет все необходимое, чтобы оценить варианты оптимизации доступа в память по полной программе. Поскольку результаты тестирований в MMX- и SSE-режимах доступа на качественном уровне не отличаются, мы представим лишь картинки, полученные при использовании SSE-регистров.
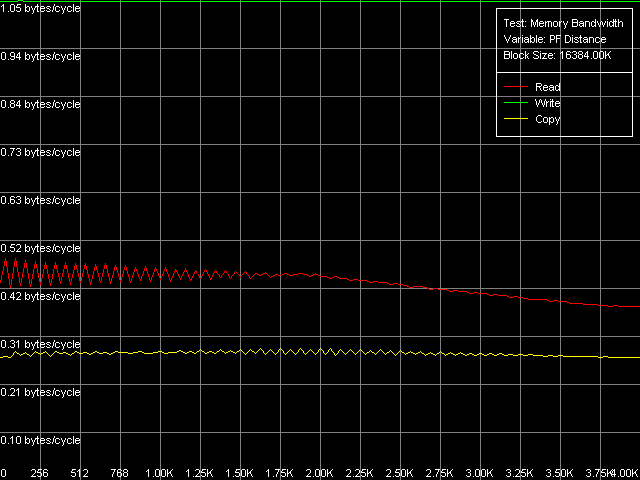
VIA C3 Antaur 1 ГГц, SSE, Software Prefetch
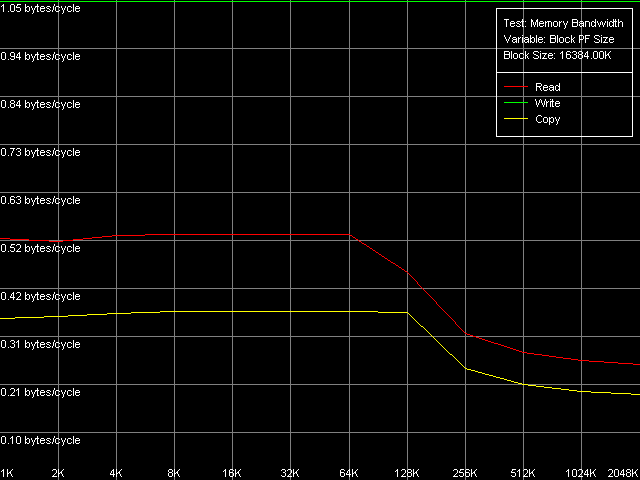
VIA C3 Antaur 1 ГГц, SSE, Block Prefetch 1
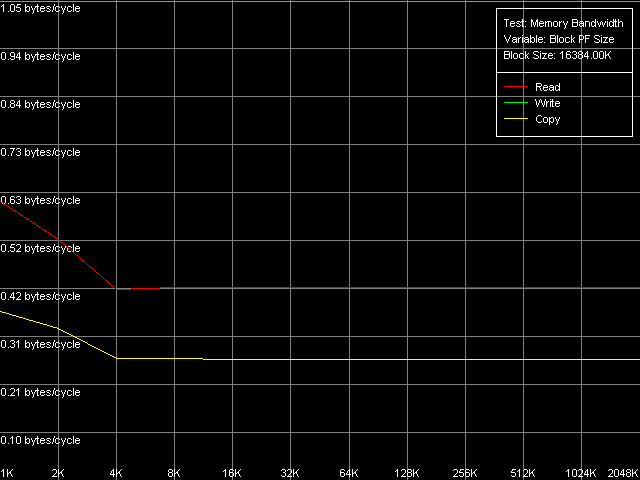
VIA C3 Antaur 1 ГГц, SSE, Block Prefetch 2
| Режим доступа | Предельная реальная ПСП на чтение, МБ/с* | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэш, прямое Чтение строк кэш, обратное | 161.6 (15.2 %) - - - - - - - 227.0 (21.3 %) 227.1 (21.3 %) | 439.0 (20.6 %) 433.4 (20.3 %) 334.1 (15.7 %) 484.7 (22.7 %) 524.1 (24.6 %) 537.3 (25.2 %) 539.3 (25.3 %) 609.0 (28.6 %) 660.4 (31.0 %) 660.3 (31.0 %) |
*в скобках указаны значения относительно максимально возможного предела для данного типа памяти.
В ряду исследованных оптимизаций на чтение мы получили лишь одно аномальное значение — в методе Maximal RAM Bandwidth, Software Prefetch, MMX Registers. 334.1 МБ/с — это даже ниже, чем значение средней ПСП на чтение (439.0 МБ/с). Далеко идущие выводы из этого вряд ли стоит делать — тестирование ноутбуков сопряжено с рядом трудностей и, по всей видимости, просто сработал режим энергосбережения. Учитывая, что метод Maximal RAM Bandwidth, Software Prefetch, SSE Registers показал весьма достойный результат — 484.7 МБ/с (22.7% от теоретического максимума, на 11.8% выше средней ПСП). Но, в то же время, далеко не максимальный. Действительно, легко увидеть, что методы Block Prefetch позволяют достичь больших значений максимальной реальной ПСП — так же, как это было у процессоров AMD K7. Т.е. наблюдается определенное сходство процессоров VIA и AMD, которое, возможно, связано с одинаковой организацией иерархии кэша данных у процессоров этих производителей. Относительно эффективности Block Prefetch можно сказать следующее: она выше при использовании Block Prefetch 2 (специфичного для K8) по сравнению с Block Prefetch 1 (специфичного для K7), а также при использовании SSE-регистров по сравнению с MMX-регистрами. Поэтому максимальное значение реальной ПСП достигается в методе Maximal RAM Bandwidth, Block Prefetch 2, SSE Registers, и составляет оно 609.0 МБ/с (28.6% от теоретического максимума). Тем не менее, и это значение не является абсолютным пределом. Последний достигается в методах чтения строк кэша (тест D-Cache Bandwidth, пресет L2 Cache-RAM Bus Bandwidth) и равен 660.4 МБ/с (31.0% от теоретического предельного значения). Надо отметить, что полученные на платформе Antaur максимальные значения ПСП на чтение во всех случаях получились весьма далеки от теоретической ПСП (реально достигаемый максимум — лишь 1/3 пропускной способности этого типа памяти).
| Режим доступа | Предельная реальная ПСП на запись, МБ/с* | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэш, прямая Запись строк кэш, обратная | 111.0 (10.4 %) - - - 205.2 (19.2 %) 204.7 (19.2 %) | 151.1 (7.1 %) 200.8 (9.4 %) 1046.3 (49.1 %) 1046.3 (49.1 %) 200.4 (9.4 %) 200.4 (9.4 %) |
*в скобках указаны значения относительно максимально возможного предела для данного типа памяти.
Посмотрим, как обстоит дело с методами оптимизации записи в память. Максимум (1046.3 МБ/с — эффективность 49.1%) достигается при включении прямого сохранения данных (Non-Temporal store), что мы наблюдали и раньше при тестировании AMD K7/K8, Intel Pentium 4 и Intel Pentium III/Pentium M. В то же время, метод записи строк кэша не дает особого выигрыша в скорости доступа в память, ибо полученные значения 200.4 МБ/с в точности соответствуют среднему значению, полученному при тотальной записи данных из SSE-регистров процессора Antaur (200.8 МБ/с). Тем не менее, нельзя не вернуться к теме весьма низких показателей реальной ПСП в целом, для DDR выглядящих весьма и весьма сомнительно. Если низкие показатели максимальной реальной ПСП на чтение можно объяснить наличием в системе «узкого горлышка» в виде шины L1-L2, реальная ПС которой в операциях тотального чтения данных не превышает 50% теоретической ПСП DDR, то с записью данных методом прямого сохранения далеко не так все ясно. Получается, что называемый VIA «ultra efficient DDR memory controller» чипсета CLE266 не так уж и хорош при работе с DDR? Вполне возможно — причем даже так, что в нашем случае реально он работает с этим типом памяти так, как если бы это была обычная SDRAM! (отметим, что контроллер памяти этого чипсета, согласно документации, умеет работать как с DDR, так и с SDRAM)
Средняя латентность кэша данных/памяти
Представим сначала общую картину латентности различных уровней подсистемы памяти для обоих процессоров Ezra и Antaur (тест D-Cache Latency, пресет D-Cache/RAM Latency).
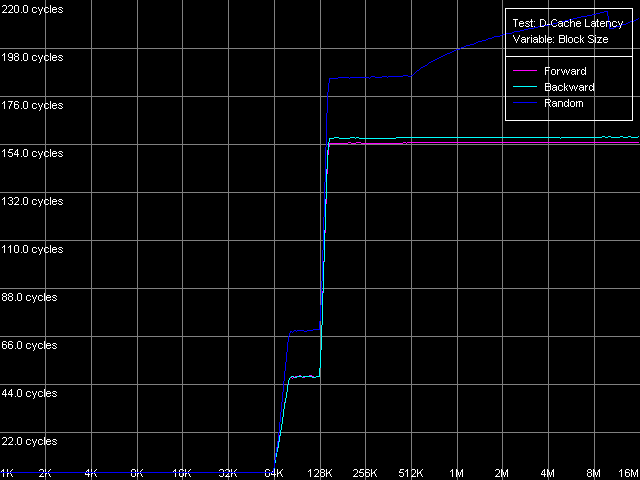
VIA C3 Ezra 866 МГц
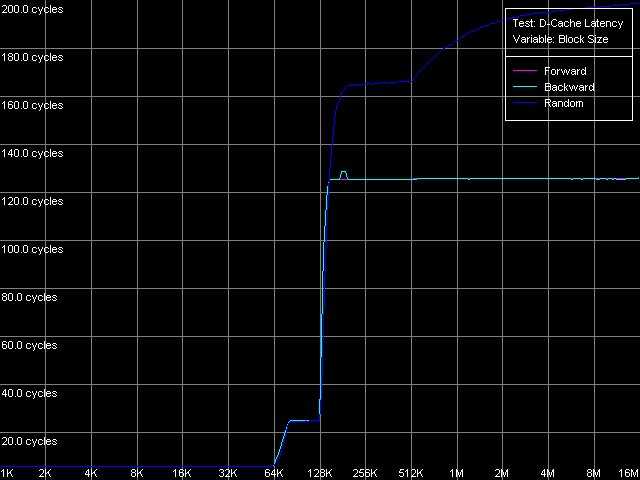
VIA C3 Antaur 1 ГГц
Отметим характерную особенность полученных кривых — плавный рост латентности случайного доступа к памяти при пересечении границы 512 КБ. Причина такого роста, как уже отмечалось в серии предыдущих исследований, заключается в исчерпании ресурсов буфера трансляции адресов виртуальных страниц памяти в физические адреса (D-TLB), размер которого, согласно этому тесту, должен быть равен 128 записям (512 КБ / 4 КБ). Приступим теперь к количественным оценкам латентности.
| Уровень, доступ | Средняя латентность, тактов | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| L1, прямой L1, обратный L1, случайный | 4 4 4 | 6 6 6 |
| L2, прямой L2, обратный L2, случайный | 48 48 69 | 25 25 25 |
| RAM, прямой RAM, обратный RAM, случайный* | 155 (179 нс) 157 (181 нс) 209 (241 нс) | 126 (126 нс) 126 (126 нс) 195 (195 нс) |
*Размер блока 4 МБ
Латентность доступа к первому уровню кэша у Ezra довольно высока — 4 такта процессора во всех режимах обхода. Подобную латентность мы видели только при тестировании процессора Intel Pentium 4 Prescott. Что удивляет — так это еще большая латентность L1 кэша данных у Antaur — она возросла до 6 тактов(!) — а это выше, чем у любого процессора, известного нам по предыдущим исследованиям. И это — учитывая возросшую пропускную способность этого уровня кэша у Antaur, как было показано выше.
Напротив, данные по средней латентности доступа в L2 оказываются явно на пользу Antaur. Собственно, именно это является ожидаемым фактом, ибо, как мы уже видели выше, и еще увидим ниже, шина данных L1-L2 у Antaur по сравнению с Ezra была улучшена. Более высокое значение латентности случайного доступа у Ezra (69 тактов против 48 для прямого/обратного) также является довольно интересным фактом. Что означает, что его шина L1-L2 работает оптимально лишь при последовательных обращениях (как в прямую, так и обратную сторону), а случайные обращения приводят к возникновению дополнительных задержек. По всей видимости, виновата довольно «непродуманная» организация вытеснения строки (evict) из L1 в L2 при загрузке новой строки из L2 в L1. Тем не менее, у Antaur этот момент был явно доработан, поскольку латентность доступа в L2 во всех режимах доступа составляет 25 тактов процессора.
Архитектурные улучшения Antaur положительно сказываются и на латентности доступа в оперативную память (126 нс) — по сравнению с Ezra (180 нс) она снизилась на 30%. Здесь, конечно, можно было возразить, что в этих платформах используются разные типы оперативной памяти, но, как мы видели выше, используемая в платформе Antaur память DDR что-то не очень-то себя проявляет. Средняя латентность случайного доступа в память, измеренная при 4-мегабайтном размере блока последней, конечно, оказывается гораздо выше — 241 нс у Ezra и 195 нс у Antaur (уменьшение — порядка 20%). Отчасти это связано с исчерпанием D-TLB, но отметим, что латентность случайного доступа у обоих процессоров в области 128-512 КБ также выше по сравнению с латентностью прямого/обратного доступа.
Минимальная латентность L2 кэша данных/памяти
Для начала определим минимальную латентность L2 кэша данных, используя метод разгрузки соответствующей шины данных вставкой «пустых» операций с помощью пресета Minimal L2 Latency, Method 1. Заметим, что автоматическая процедура определения длительности одной «пустой» операции на этих процессорах почему-то выдала завышенные значения (1.03 такта на Antaur, 1.10 тактов на Ezra, против положенных 1.00 тактов), в связи с чем, потребовалась некоторая коррекция графиков, результат которой мы и представляем вашему вниманию.
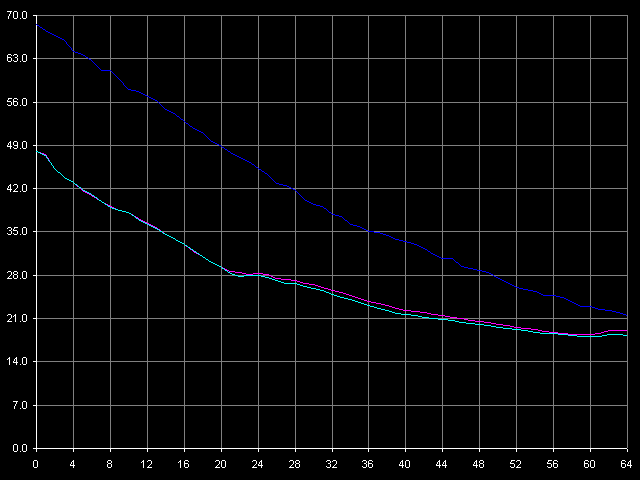
VIA C3 Ezra 866 МГц
VIA C3 Antaur 1 ГГц
Мы видим, что латентность доступа в L2 у Ezra плавно спадает от своих «средних» значений до минимальных, которые составляют 17 тактов во всех режимах доступа (для случайного доступа это значение достигается при количестве «NOP»-ов, явно большем 64-х). У Antaur наблюдается принципиально иная картина — минимальная латентность достигается довольно «резко», уже при 8 «NOP»-ах, и составляет точно такое значение — 17 тактов. Обнаруженные ранее различия в реализациях шины L1-L2 у процессоров Ezra и Antaur отлично проявляют себя и в этом тесте. Хотя минимальные значения латентности у обоих процессоров получились одинаковыми, они явно достигаются «разной ценой». Так, Ezra предпочитает очень редкие обращения к L2 кэшу (когда два последующих обращения разделены во времени 60-70 тактами процессора) — только в этом случае достигается минимальная латентность этого уровня кэша. В то же время, при очень частых обращениях (когда два последующих обращения идут подряд, одно за другим), как мы видели выше, Ezra уступает Antaur почти в 2 раза.
| Уровень, доступ | Минимальная латентность, тактов | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| L2, прямой L2, обратный L2, случайный | 17 17 17 | 17 17 17 |
| RAM, прямой RAM, обратный RAM, случайный* | 143 (165 нс) 145 (168 нс) 205 (236 нс) | 126 (126 нс) 126 (126 нс) 192 (192 нс) |
*Размер блока 4 МБ
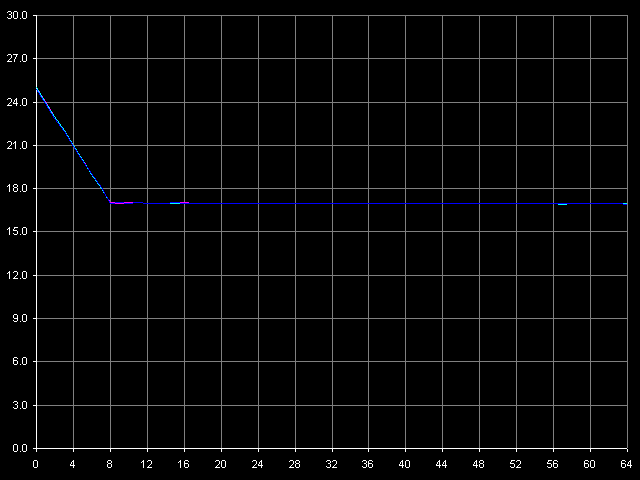
Вслед за латентностью L2, измерим минимальную латентность RAM при 4-мегабайтном размере блока, выбрав пресет Minimal RAM Latency, 4 MB Block. Представляемые графики также скорректированы с учетом погрешности измерений длительности одного «NOP»-а.
VIA C3 Ezra 866 МГц
VIA C3 Antaur 1 ГГц
Согласно этому тесту, важной особенностью обоих процессоров C3 является отсутствие(!) алгоритма Hardware Prefetch — вопреки заявленной в документации «скрытой спекулятивной загрузке данных», поскольку разгрузка шины L2-RAM не приводит к уменьшению латентности доступа в память, даже при прямом последовательном обходе. Вместо этого наблюдается наличие характерных «зубчатых» кривых во всех режимах доступа. Расстояния между «зубчиками» у Ezra равны 6-7 тактам, что соответствует коэффициенту умножения 6.5 (866.6 / 133.3 = 6.5). У Antaur это значение ровно на один такт выше (7-8 тактов), поскольку на такт системной шины у этого процессора приходится 7.5 тактов процессора (1000.0 / 133.3 = 7.5).
Минимальная латентность доступа к памяти у Ezra в среднем равна 166 нс (прямой/обратный последовательный обход), что примерно на 7.8% ниже средней величины (180 нс). Минимальная латентность случайного доступа в тех же условиях — 236 нс — лишь на 2% ниже среднего значения (241 нс). В то же время, разгрузка шины L2-RAM у Antaur практически ни к чему не приводит — минимальная латентность прямого/обратного обхода памяти равна средней величине (126 нс), а случайного — на 4 такта меньше среднего значения (192 нс). Что означает, что BIU у Antaur, как и его шина L1-L2, также работает эффективнее, чем у Ezra, даже при «плотных» обращениях к памяти.
Ассоциативность кэша данных
Мы добрались до измерений ассоциативности кэша данных, где нас ждут первые неожиданные результаты тестирования. Для этого достаточно взглянуть на полученные картинки.
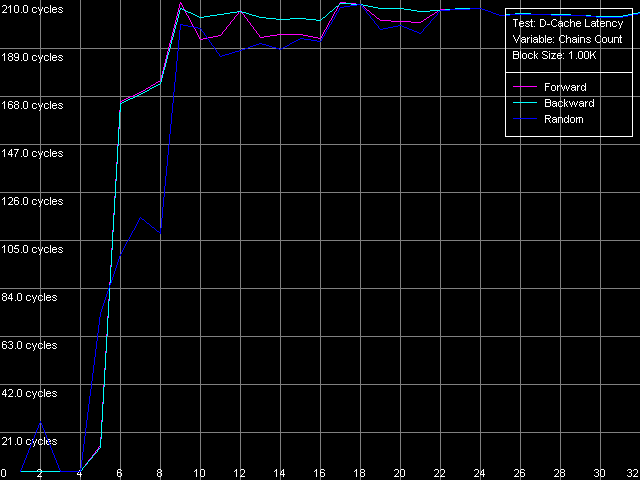
VIA C3 Ezra 866 МГц
Странность Ezra заключается в том, что его L2 кэш не проявляет свою заявленную ассоциативность, равную четырем. По соответствующим кривым можно выявить область 1-4 цепочек, соответствующую документированной ассоциативности L1-кэша. В то же время, второй перегиб на кривой, который для эксклюзивной архитектуры кэша должен наблюдаться в области «суммарной» ассоциативности обоих уровней кэша (в данном случае — восьми) как бы отсутствует вовсе. Ну, или присутствует, но лишь при 5 цепочках, т.е. L2 кэш получается как бы одноассоциативным («кэшем с прямым отображением»).
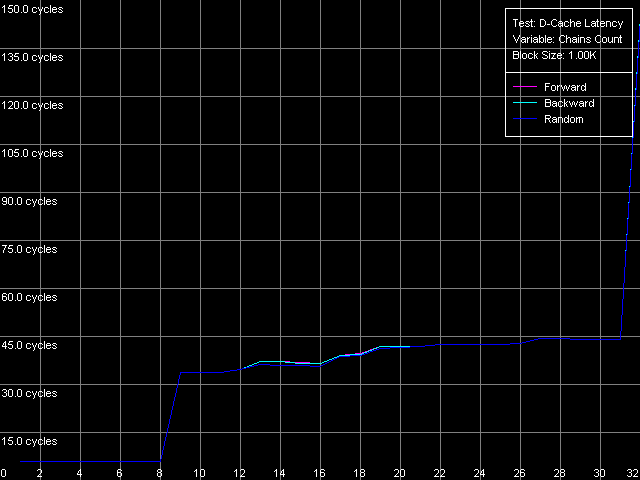
VIA C3 Antaur 1 ГГц
Antaur демонстрирует другую странность, можно сказать — в точности наоборот. Ассоциативность L1 у этого процессора оказывается завышенной в 2 раза (8-way, против документированного значения 4-way), в то время как заявленная 16-way ассоциативность L2 не проявляется вовсе. По этому поводу можно сказать лишь одно — организация алгоритма замещения строк кэша (pseudo-LRU) явно отличается от таковой в процессорах семейств Intel/AMD, где мы получали более (AMD) или менее (Intel) четкие и вполне интерпретируемые кривые ассоциативности.
Реальная пропускная способность шины L1-L2
О шине L1-L2 кэша процессоров VIA C3 мы уже говорили неоднократно — самое время определить ее реальную пропускную способность специальным тестом (D-Cache Bandwidth, пресет L1-L2 Cache Bus Bandwidth).
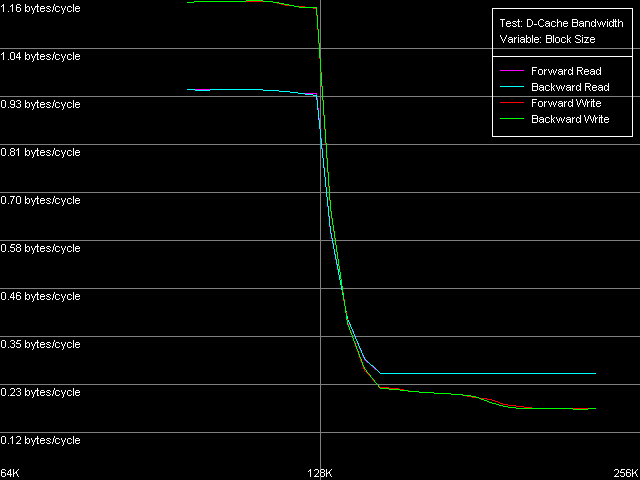
VIA C3 Ezra 866 МГц
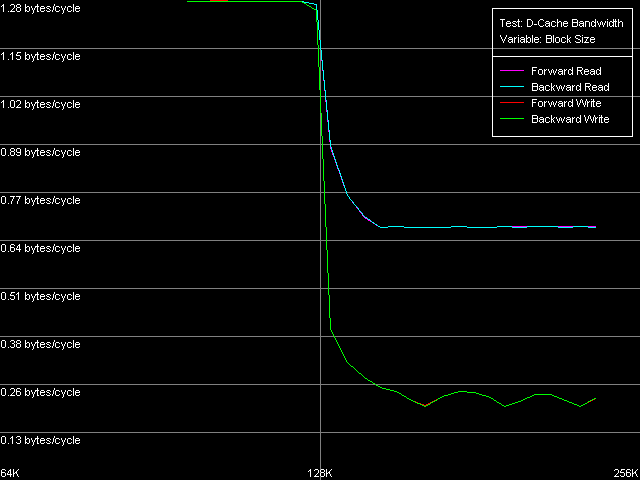
VIA C3 Antaur 1 ГГц
Поскольку процессоры VIA C3 имеют эксклюзивную организацию кэша, полученные в этом тесте значения реальной ПС шины L1-L2 в области 64-128 КБ необходимо удвоить, поскольку один акт обращения к L2 кэшу процессора приводит к пересылке одной строки кэша (32 байт) из L2 в L1 с одновременным сбросом строки-«жертвы» (victim) из L1 в L2.
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт* | |
|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 1.88 1.88 2.32 2.32 | 2.56 2.56 2.56 2.56 |
*с учетом эксклюзивности кэша
Скоростные показатели этой шины у Ezra, как мы и предполагали ранее, действительно весьма низкие — всего 1.88 байт/такт на чтение и 2.32 байт/такт на запись. И вновь мы видим довольно нетипичную картину, когда скорость записи оказывается выше скорости чтения. У Antaur, напротив, эти показатели весьма ровные — 2.56 байт/такт во всех случаях, что, кстати, действительно выше, чем у Ezra (на 36% при чтении и 10% при записи строк кэша). Столь низкие абсолютные значения реальной ПС шины L1-L2 могли бы позволить нам сказать, что соответствующая шина имеет очень низкую разрядность — скажем, всего 32 бита (пересылка до 4.0 байт/такт, включительно). Тем не менее, как мы увидим ниже, это не так — разрядность шины, по крайней мере, на чтение, должна быть не меньше 64 бит. Чтобы показать, что это действительно так, воспользуемся тестом D-Cache Arrival, выбрав пресет L1-L2 Cache Bus Data Arrival Test 1, 32 bytes.
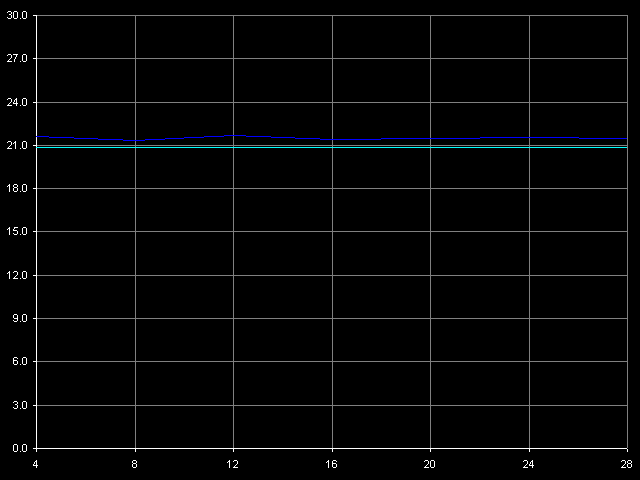
VIA C3 Ezra 866 МГц
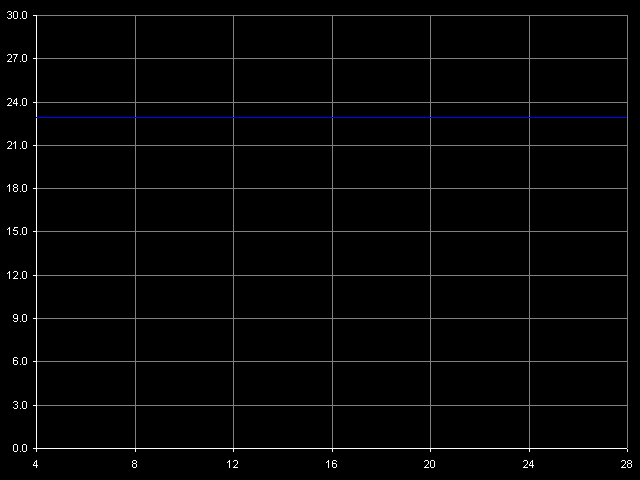
VIA C3 Antaur 1 ГГц
В этом тесте осуществляются два обращения к одной и той же строке кэша с переменным смещением второго элемента строки (4-28 байт) относительно первого, который всегда расположен в начале строки. Из представленных рисунков видно, что суммарная латентность двух обращений к одной и той же строке кэша во всех случаях доступа у обоих Ezra и Antaur не зависит от смещения второго элемента относительно первого (до 28 байт включительно). Общая латентность такого обращения к кэшу равна 21 тактам процессора у Ezra и 23 тактам у Antaur, что в точности соответствует сумме латентностей доступа в L2 и L1 кэш (17+4 и 17+6 тактов, соответственно). Отсутствие задержек при доступе к любому элементу запрашиваемой строки означает, что за 4 такта доступа в L1 у Ezra, и за 6 тактов доступа в L1 у Antaur из L2 успевает прибыть целая строка кэша, равная 32 байтам. В свою очередь, это означает, что теоретическая величина ПС шины L1-L2 должна быть не меньше 32/4 = 8 байт/такт у Ezra и 32/6 = 5.33 байт/такт у Antaur. В обоих случаях эти величины соответствуют 64-битной шине обмена данными между L1 и L2 кэшем процессоров VIA C3.
Кэш инструкций, эффективность декодирования
Как обычно, представим здесь наиболее показательные кривые, полученные в тесте I-Cache с использованием пресета L1i Size / Decode Bandwidth, CMP Instructions 3, в котором декодируются и исполняются простейшие 6-байтные инструкции cmp eax, 0x00000000.
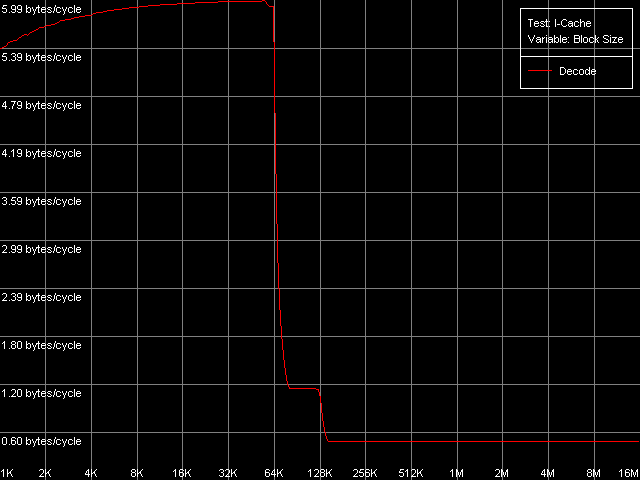
VIA C3 Ezra 866 МГц
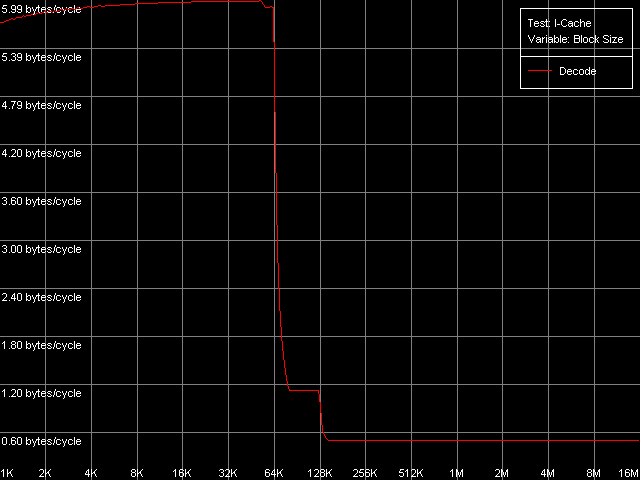
VIA C3 Antaur 1 ГГц
Отметим, что именно в этом случае нам удалось достичь максимальную скорость декодирования/исполнения x86 ALU инструкций процессорами VIA C3 (в пересчете на количество байт) — 6.0 байт/такт, что соответствует исполнению ровно одной инструкции за один такт процессора. По этим кривым также отметим, что размер L1 кэша инструкций равен 64 КБ, а L2 кэш является унифицированным кэшем данных/инструкций, размер которого, с учетом эксклюзивной организации, также составляет 64 КБ. Полученные результаты в точности соответствуют заявленным в документации VIA значениям.
Посмотрим теперь на результаты тестов декодирования/исполнения остальных простейших x86 ALU инструкций.
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| VIA C3 Ezra | VIA C3 Antaur | |||
| L1i кэш | L2 кэш | L1i кэш | L2 кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 1.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (0.50) 5.99 (1.00) 2.66 (0.33) | 0.97 (0.97) 1.15 (0.58) 1.15 (0.58) 1.15 (0.58) 1.15 (0.58) 1.15 (0.58) 1.15 (0.29) 1.15 (0.19) 1.15 (0.14) | 1.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 5.99 (1.00) 2.66 (0.33) | 1.00 (1.00) 1.14 (0.57) 1.14 (0.57) 1.14 (0.57) 1.14 (0.57) 1.14 (0.57) 1.14 (0.28) 1.14 (0.19) 1.14 (0.14) |
Первое, что можно увидеть при изучении полученных данных — это практически полная идентичность значений скорости декодирования инструкций у обоих процессоров, как из L1i, так и из L2 кэша. В свою очередь это позволяет предположить, что декодер ALU-инструкций в Antaur не претерпел каких-либо изменений по сравнению с более ранней моделью этого процессора (Ezra). Что касается собственно эффективности декодирования, легко увидеть, что ее реальный предел — одна инструкция/такт, который, очевидно, задается устройством конвейера и исполнительных блоков Ezra/Antaur. Действительно, анализ документации Ezra показывает наличие лишь одного исполнительного блока Integer ALU.
Отдельного внимания заслуживают инструкции CMP 2 (cmp ax, 0x00) и Prefixed CMP 1-4 ([rep][addrovr]cmp eax, value), поскольку скорость их исполнения оказывается ниже. Сопоставляя количество используемых этими инструкциями префиксов и скорости их исполнения, можно заключить, что процессоры VIA C3 рассматривают каждый префикс как отдельную инструкцию! Действительно, в первом случае (CMP 2) используется один префикс (operand-size override, 0x66), т.е. такая инструкция представляется декодером C3 как две операции. В связи с чем, темп ее исполнения вдвое ниже (1 инструкция/2 такта). Во втором случае (Prefixed CMP 1-4) наряду с инструкцией cmp декодеру «поставляются» целых два префикса — поэтому темп исполнения такой «сложной» операции оказывается втрое ниже (1 инструкция / 3 такта). Дабы окончательно убедиться в справедливости сделанного предложения, представим результаты специального теста Prefixed NOP Decode Efficiency.
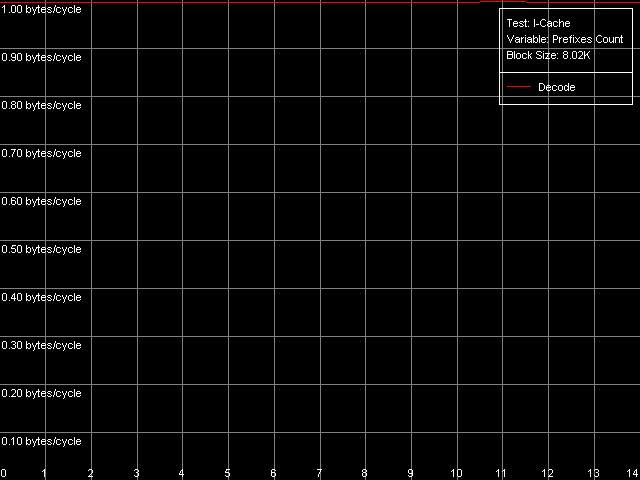
VIA C3 Ezra 866 МГц
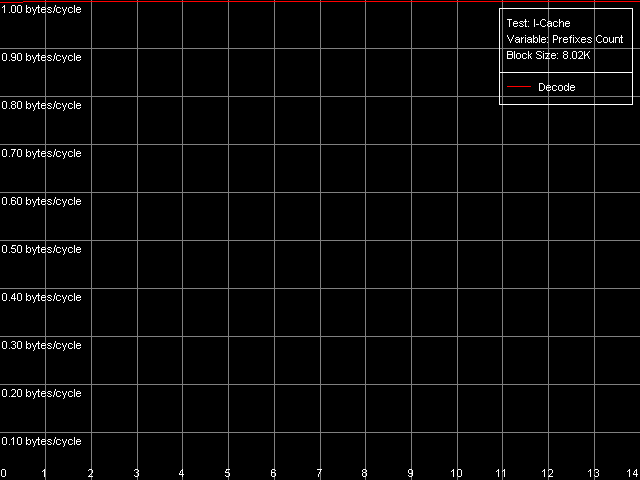
VIA C3 Antaur 1 ГГц
Итак, скорость исполнения инструкций вида [0x66]nNOP (в пересчете на байт/такт) не зависит от количества префиксов (n = 0-14), а это значит, что каждый префикс (в т.ч. идущие подряд одинаковые префиксы) действительно «исполняется» процессором как отдельная инструкция. Что ж, VIA/Centaur подошли к проблеме префиксов предельно просто — никаким «отсечением», столь заметным на процессорах семейства Intel Pentium 4, здесь и не пахнет.
Вернемся к значениям эффективности декодирования инструкций в представленной выше таблице, и рассмотрим теперь значения в области L2 кэша. За исключением простейшей однобайтной NOP (скорость декодирования/исполнения которой ограничена конвейером процессора), эффективность декодирования инструкций из L2 составляет 1.15 байт/такт (0.58 инструкций/такт и ниже), что, очевидно, лимитируется скоростью «закачки» инструкций из L2 в L1, которая, как мы помним, осуществляется «агрессивным» скрытым образом :). Кстати, у Ezra это выглядит не столь уж иронично — действительно, 1.15 байт/такт — это куда выше, чем загрузка данных из L2 в L1, которая, как мы видели по результатам первого теста, осуществляется со скоростью 0.61 байт/такт. У Antaur картина выглядит в точности наоборот — загрузка данных (1.28 байт/такт) осуществляется быстрее «подкачки» инструкций из этого же кэша в L1i.
Ассоциативность кэша инструкций
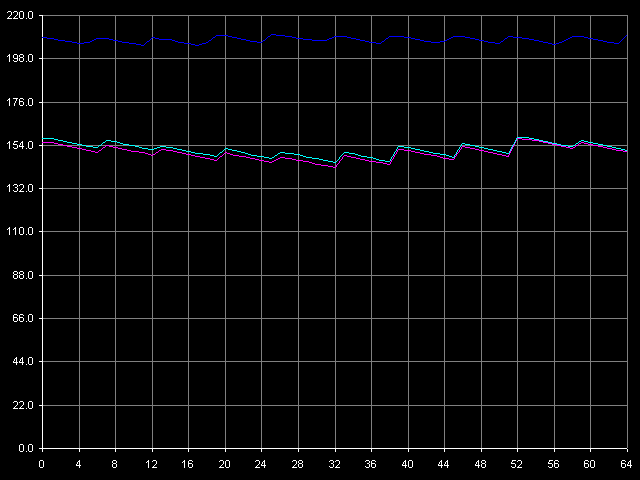
Как мы видели выше, попытка измерения ассоциативности кэша данных процессоров Ezra/Antaur ни к чему хорошему не привела — вразумительных значений получить не удалось. Посмотрим, как отнесется к подобному тесту кэш инструкций рассматриваемых процессоров. Для этого используем пресет I-Cache Associativity.
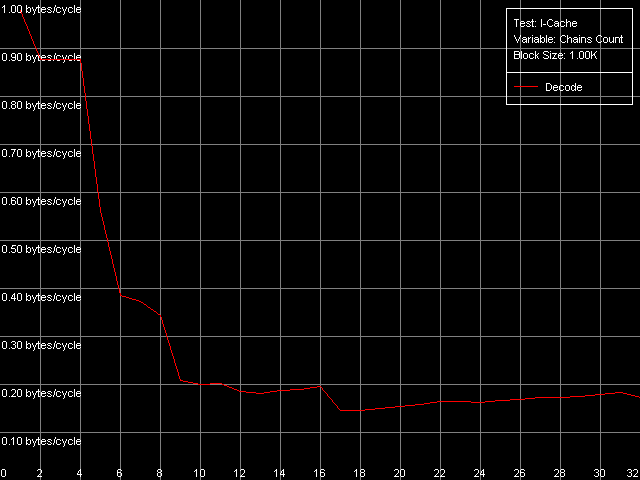
VIA C3 Ezra 866 МГц
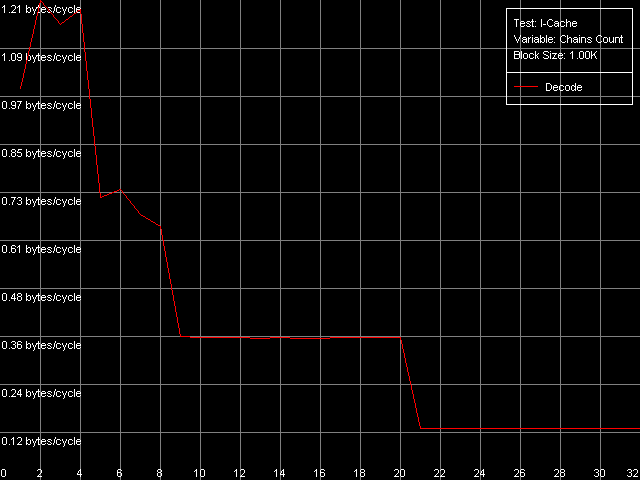
VIA C3 Antaur 1 ГГц
Как видно из представленных рисунков, кэш инструкций Ezra/Antaur дает вполне адекватную картину ассоциативности. У обоих процессоров можно выделить область 1-4 цепочек, соответствующую кэшу L1i, имеющему степень ассоциативности, равную четырем. Вторая область у Ezra наблюдается при 5-8 цепочках, как и положено, и соответствует она «общей» ассоциативности L1i+L2, равной восьми, поскольку оба кэша имеют степень ассоциативности 4. Соответствующая область у Antaur — 5-20 цепочек, поскольку ассоциативность L2 у этого процессора была увеличена до 16, и «общая» ассоциативность L1i+L2, таким образом, равна 20. Что ж, остается непонятной причина странного поведения унифицированного L2 кэша при тестировании ассоциативности кэша данных, и вполне адекватного — при тестировании ассоциативности кэша инструкций.
Характеристики D-TLB
Напоследок измерим характеристики TLB подопытных процессоров VIA C3. И сразу скажем, что здесь нас ждет еще один сюрприз — на этот раз только от Ezra. Для ответа на вопрос, какой именно, просто взглянем на картинки, полученные в тесте D-TLB, пресет D-TLB Size.
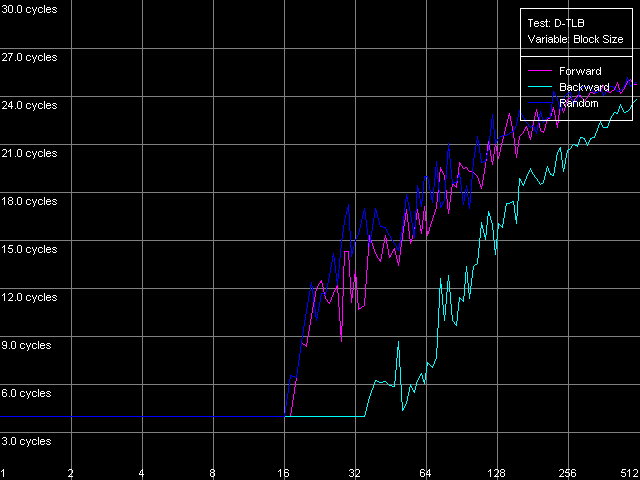
VIA C3 Ezra 866 МГц
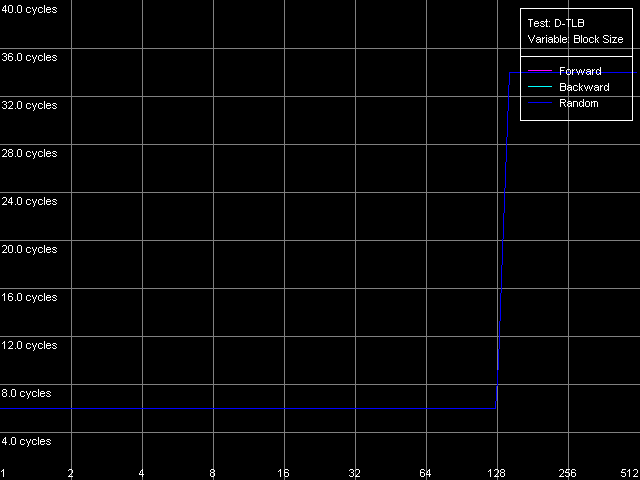
VIA C3 Antaur 1 ГГц
Как мы уже говорили в самом начале, размер D-TLB у обоих процессоров должен составлять 128 записей. Что и наблюдается у Antaur. Но какие красивые кривые рисует нам Ezra! По ним, в целом, можно сказать, что размер D-TLB у последнего — якобы всего 16 записей. Что еще можно сказать по данным этого теста? Главное, что промах D-TLB обходится для Antaur весьма «дорого» — латентность доступа в L1 возрастает до 34 тактов. У Ezra, если, конечно, верить такому виду кривых, промах обходится менее «дорого» — латентность L1 увеличивается до 24 тактов.
Измерим также ассоциативность D-TLB у рассматриваемых процессоров. Для Ezra мы выбрали пресет D-TLB Associativity, 16 Entries, после чего уменьшили их количество до восьми, и вот что получилось.
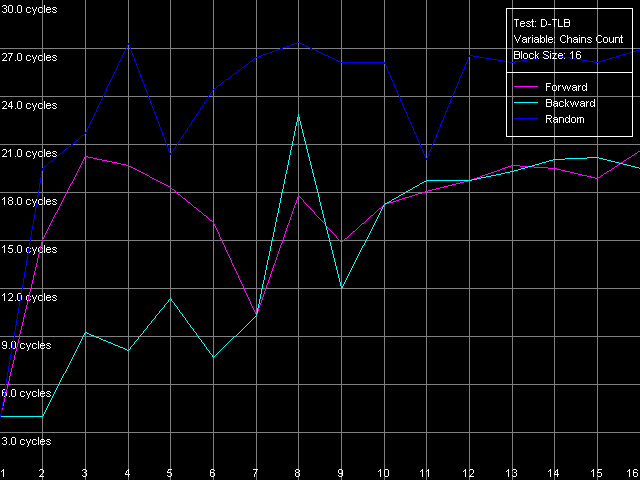
VIA C3 Ezra 866 МГц
Путем анализа этого безобразия можно заключить, что «дефектный» D-TLB процессора Ezra содержит не только 16 записей, но и имеет степень ассоциативности, равную единице! Документированные значения этих параметров — 128 записей страниц, а степень ассоциативности — восемь. Первое действительно проявляет себя, как мы видели выше, в тесте латентности, а вот реальная оценка второго косвенными методами не представляется возможной.
В то же время, вид кривых на Antaur, полученных в пресете D-TLB Associativity, 64 Entries, представляется куда более разумным.
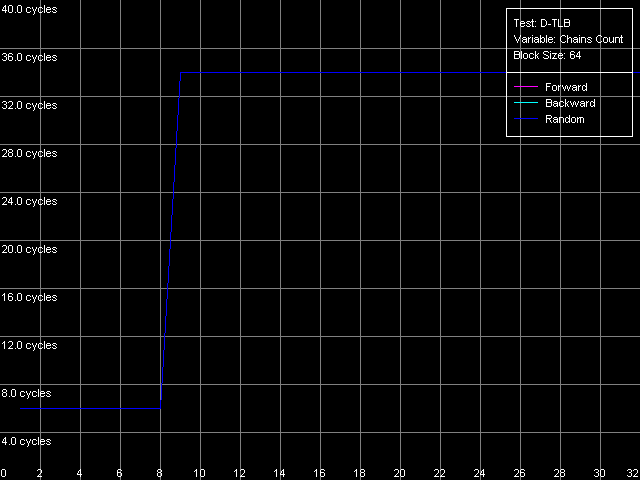
VIA C3 Antaur 1 ГГц
Они не только совпадают одна с другой (т.е. все режимы обхода D-TLB дают одинаковые результаты), но и позволяют правильно определить ассоциативность D-TLB, которая, как и положено, оказывается равной восьми. Кроме того, промах D-TLB за счет «пробоя» его ассоциативности сопровождается таким же увеличением латентности доступа в L1 — до 34 тактов, как и просто выход за пределы этого буфера.
Характеристики I-TLB
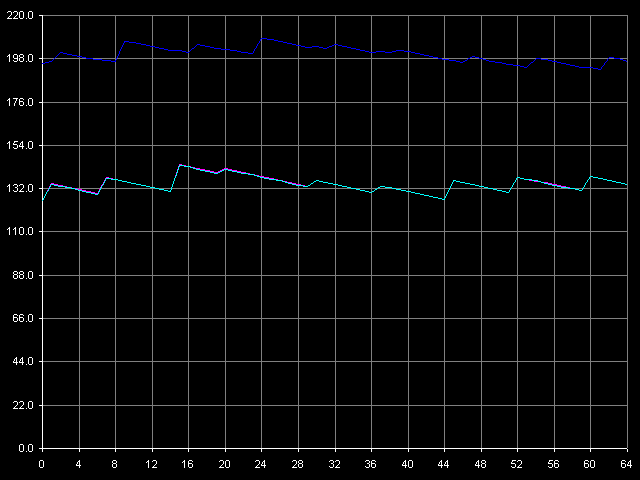
Как ни странно, тесты I-TLB никаких сюрпризов нам не преподнесли. Все выглядит вполне предсказуемо, к тому же, вскрываются некоторые дополнительные особенности реализации микроархитектуры процессоров Ezra/Antaur. Итак, для начала посмотрим на вид кривых, полученных в тесте I-TLB, пресет I-TLB Size.
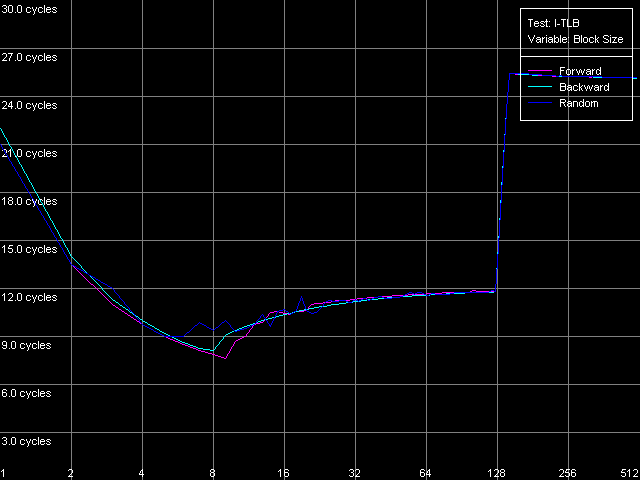
VIA C3 Ezra 866 МГц
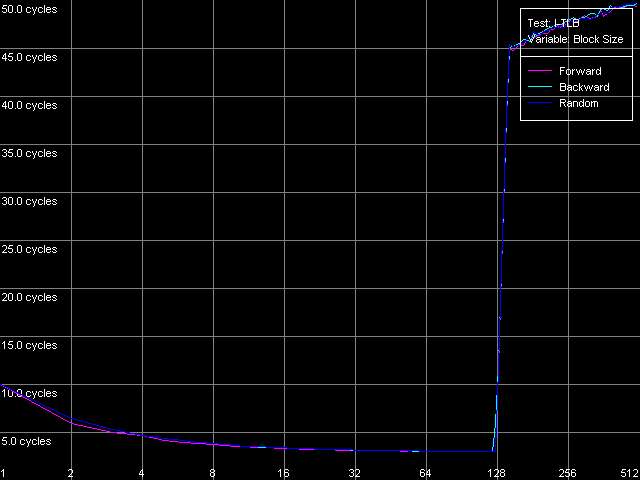
VIA C3 Antaur 1 ГГц
Размер I-TLB у обоих процессоров определяется вполне четко — он равен 128 записям. Теперь поговорим об отличиях. Для этого напомним, что, фактически, в этом тесте измеряется латентность исполнения последовательности операций безусловных переходов (mov ecx, addr_val; jmp ecx). В области малого количества страниц, для которой размер I-TLB оказывается достаточным, явно лидирует Antaur — латентность исполнения такой связки команд находится в пределах 3-5 тактов процессора, против 9-12 у Ezra. Таким образом, различия в алгоритме предсказания ветвлений у Ezra и Antaur действительно имеются — в пользу последнего (возможно, сказывается наличие BTA-кэша). Но в то же время, промах I-TLB гораздо «дороже» обходится для Antaur (латентность 45-50 тактов), нежели Ezra (латентность порядка 25-26 тактов).
Что касается тестов ассоциативности I-TLB, здесь все так же достаточно четко. Чтобы убедиться в этом, взглянем на кривые, полученные в пресете I-TLB Associativity, 64 Entries.
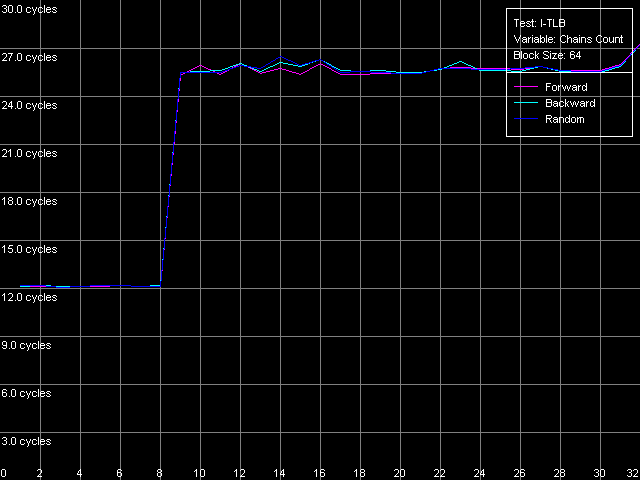
VIA C3 Ezra 866 МГц
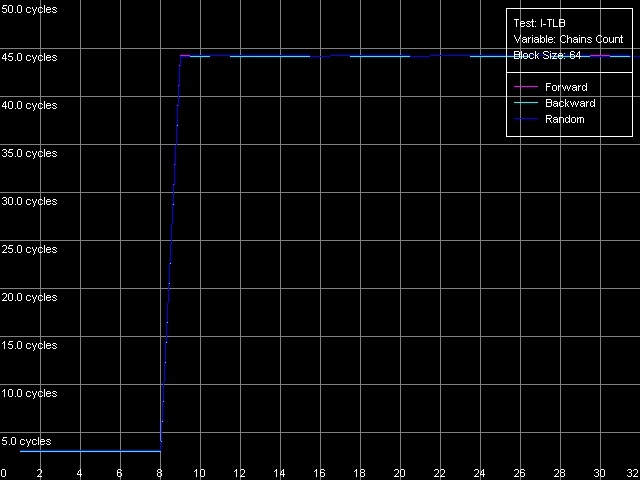
VIA C3 Antaur 1 ГГц
В обоих случаях ассоциативность I-TLB получилась равной восьми (как и сказано в документации VIA), а ее «пробой» приводит к такому же возрастанию латентности исполнения «прыжков» по памяти (до 25-26 тактов у Ezra и примерно до 44 тактов у Antaur), как и выход за пределы размера этого буфера.
Заключение
Представленные вашему вниманию результаты низкоуровневого тестирования платформ VIA C3 Ezra/Antaur позволяют сказать, прежде всего, что эти процессоры действительно являются «полностью x86 программно-совместимыми». Никакого транскодинга инструкций здесь не наблюдается — по результатам тестов I-Cache можно заявить, что все исполняется «честно». Трудно сказать, как именно была произведена «подмена» 3DNow! в Ezra на SSE в Antaur. Не исключено, что исполнительные блоки процессора остались такими же, а SSE-команды поставляются тому же «3DNow!»-блоку, поэтому исполняются как минимум за 2 такта (быть может, именно поэтому устройство конвейера этого процессора так тщательно скрывается?). Во-вторых, важно отметить, пожалуй, главное улучшение микроархитектуры процессора VIA Antaur — значительную доработку шины эксклюзивного L1-L2 кэша, которая положительно сказалась на величинах реальной пропускной способности этой шины и латентности кэша L2 — которые были весьма узким местом у более ранней модели VIA C3 Ezra. Ну и, конечно же, нельзя не отметить ряд сюрпризов, которые преподнесли нам эти процессоры — это странности в измерении ассоциативности кэша данных у обоих процессоров и в тестах объема/ассоциативности D-TLB у Ezra.


