Часть 2: Платформы Intel Pentium 4
Мы продолжаем цикл низкоуровневого исследования важнейших характеристик платформ с помощью универсального тестового пакета RightMark Memory Analyzer. На этот раз мы представляем вашему вниманию результаты сравнительного тестирования платформ Intel Pentium 4, которое, как вы, наверное, догадываетесь, приурочено к выпуску нового 90-нм процессора Prescott. Это исследование позволит нам выявить важнейшие изменения, которые были внесены в микроархитектуру NetBurst с выпуском нового процессора. Для нашего тестирования мы выбрали три модели процессоров Intel Pentium 4 (Northwood, Gallatin и Prescott) с одной и той же частотой ядра (3,2 ГГц), что позволило провести их сравнительное тестирование в одинаковых условиях (одни и те же частота ядра, чипсет и тип памяти).
Конфигурации тестового стенда и ПО
Тестовый стенд:
- Процессоры:
- Intel Pentium 4 3,2 ГГц (ядро Northwood, FSB 800/HT, 512 КБ L2)
- Intel Pentium 4 Extreme Edition 3.2 ГГц (ядро Gallatin, FSB 800/HT, 512 КБ L2, 2 МБ L3)
- Intel Pentium 4 3,2 ГГц (ядро Prescott, FSB 800/HT, 1 МБ L2)
- Материнская плата: ASUS P4C800 Deluxe (версия BIOS 1014) на чипсете Intel 875P
- Память: 2x512 МБ PC3200 DDR SDRAM DIMM TwinMOS (тайминги 2-2-2-5)
Системное ПО и драйверы устройств:
- Windows XP Professional SP1
- DirectX 9.0b
- Intel Chipset Installation Utility 5.0.2.1003
- ATI Catalyst 3.9
Реальная пропускная способность кэша данных/памяти
Начнем сравнительное тестирование платформ Intel Pentium 4 с оценки средней реальной пропускной способности кэша данных и памяти. Будем исследовать эту характеристику в двух режимах доступа — используя для этой цели MMX- и SSE/SSE2-регистры. Для этого воспользуемся тестом Memory Bandwidth, выбрав настройки D-Cache/RAM Bandwidth, MMX Registers; SSE Registers; SSE2 Registers. Использование SSE/SSE2-регистров позволяет достичь больших значений реальной ПС кэша данных/памяти, причем результаты SSE и SSE2 оказываются идентичными. Приведем здесь общую картину реальной ПС в случае использования SSE-регистров.
Средняя реальная ПСП, Intel Pentium 4 Northwood
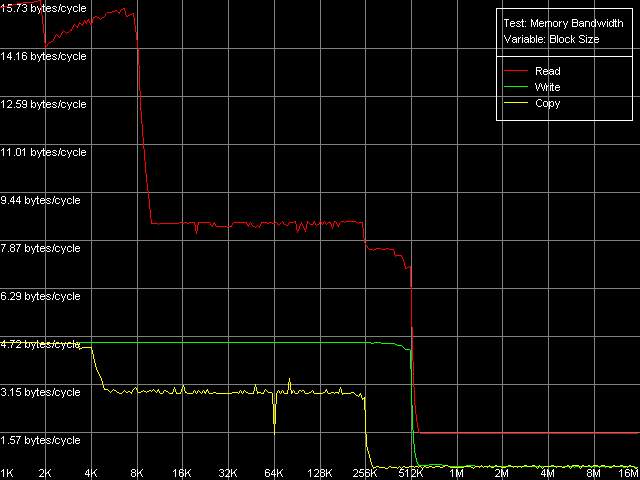
Средняя реальная ПСП, Intel Pentium 4 XE Gallatin
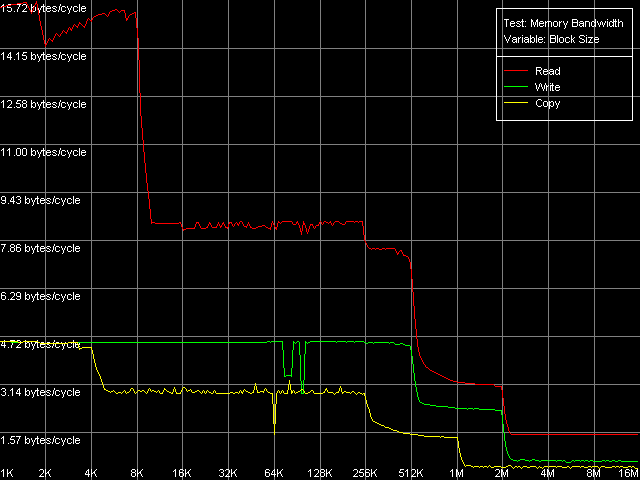
Средняя реальная ПСП, Intel Pentium 4 Prescott
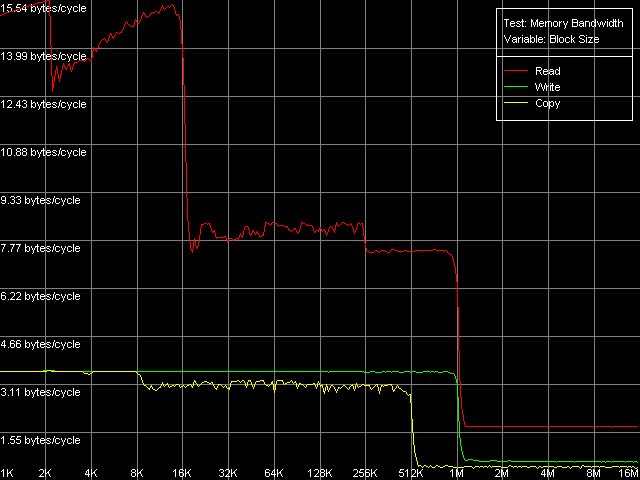
На всех трех процессорах мы получили достаточно очевидную картину. Из нее четко видно наличие двух уровней кэша данных (L1 и L2), размеры которых соответствуют заявленным в документации (8/8/16 КБ L1, 512/512/1024 КБ L2 для Northwood/Gallatin/Prescott, соответственно). Действительно, объем обоих уровней кэша данных в новом 90нм процессоре Prescott был удвоен по сравнению с его предшественниками (Northwood и Gallatin). Pentium 4 XE, как и следовало ожидать, характеризуется наличием еще одного уровня кэша данных (L3) объемом 2 МБ. Во всех случаях интересно отметить некоторое снижение эффективной ПС кэша L2 на чтение при пересечении границы 256 КБ. Причина этого, по всей видимости, связана с исчерпыванием D-TLB (который, как мы увидим дальше, на всех процессорах может содержать всего 64 записи, что в точности соответствует адресации 256 КБ виртуальной памяти). Наконец, последней особенностью полученных нами кривых можно считать наличие перегибов, четко соответствующих размерам L1, L2 (и L3) кэша данных, что говорит об инклюзивной организации последнего (как мы видели в предыдущем исследовании, эксклюзивный кэш данных процессоров семейства AMD K7/K8 проявляет себя в этом тесте принципиально иным образом).
Приступим к рассмотрению самих значений средней реальной ПС L1, L2 (L3) кэша данных и памяти на исследуемых платформах.
| Уровень | Средняя реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.83 15.73 3.52 4.56 | 7.84 15.72 3.51 4.56 | 7.82 15.54 2.90 3.56 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.25 8.50 3.54 4.55 | 4.25 8.50 3.54 4.55 | 4.55 8.38 2.90 3.54 |
| L3, чтение, MMX L3, чтение, SSE L3, запись, MMX L3, запись, SSE | - - - - | 2.13 3.31 2.30 2.42 | - - - - |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 1.21 (3915.8 МБ/с) 1.55 (5011.0 МБ/с) 0.47 (1533.3 МБ/с) 0.47 (1533.5 МБ/с) | 1.21 (3900.4 МБ/с) 1.53 (4959.2 МБ/с) 0.66 (2130.0 МБ/с) 0.66 (2122.9 МБ/с) | 1.55 (5003.9 МБ/с) 1.75 (5664.3 МБ/с) 0.63 (2029.6 МБ/с) 0.63 (2030.3 МБ/с) |
Как видно из этой таблицы, исследуемые процессоры семейства Intel Pentium 4 имеют и много общего, и ряд отличий. Так, эффективная ПС связки L1-регистры во всех случаях оказывается близкой к 8 байтам/такт (MMX) и 16 байтам/такт (SSE), что говорит о возможности пересылки всего одного значения из памяти (64- и 128-битного, соответственно) в MMX- и SSE/SSE2-регистры за один такт процессора. Напомним, что в процессорах семейства AMD K7/K8 мы видели противоположную картину: реальная ПС L1-LSU-registers достигала своего максимального значения (13-15 байт/такт) именно в случае MMX-регистров (пересылка двух значений за такт), в то время как эффективная ПС снижалась вдвое при переходе к SSE-регистрам (пересылка одного операнда за два такта процессора). Эффективность L1 на запись не претерпела каких-либо изменений при переходе от Northwood к Gallatin, а вот на Prescott она несколько упала (на 20-28%).
Кэша L2 работает на чтение одинаково эффективно как у Northwood, так и у Gallatin. А вот Prescott с его увеличенными объемами L1 и L2 привносит в эту картину некоторые отличия: эффективность чтения в MMX-регистры процессора чуть возросла (на 7%), а в SSE — немножко упала (на 1%). Об эффективности влияния на запись этого уровня кэша можно сказать то же самое, что и об L1 кэше: переход к новой микроархитектуре Prescott привел к ее снижению на те же 20-28%.
Посмотрим, наконец, какие различия имеются в ряду исследуемых процессоров относительно операций доступа в оперативную память. Ее средняя реальная ПС на чтение оказывается очень близкой как на Northwood, так и на Gallatin, т.е. наличие третьего уровня кэша у последнего здесь никак не сказывается. В то же время, новый 90-нм процессор демонстрирует значительное улучшение этого параметра (на 13-27%), особенно при использовании MMX-регистров. Это наталкивает на мысль, что алгоритм Hardware Prefetch в новой микроархитектуре Prescott был несколько улучшен. Мы коснемся этого факта несколько позже, при изучении картины латентности доступа в оперативную память. Что касается реальной ПСП на запись, видно, что она возросла еще со времен Gallatin (в среднем, на 39% по сравнению с Northwood) и практически не изменилась при переходе к новой микроархитектуре (точнее, даже несколько упала, примерно на 5%).
Таким образом, новый процессор Prescott демонстрирует довольно смешанную картину. Из ключевых моментов можно отметить снижение эффективности обоих уровней кэша данных на запись и возросшую среднюю реальную пропускную способность памяти на чтение.
Максимальная реальная пропускная способность памяти
Как и прежде, попытаемся «выжать максимум» из подсистемы памяти, то есть — достичь максимальных значений реальной ПСП в операциях чтения и записи. Для этого будем использовать следующие доступные методы достижения максимальной действительной ПСП на чтение:
- Software Prefetch
- Block Prefetch 1
- Block Prefetch 2
- Чтение строк кэша (прямое/обратное)
И вот такие — для оценки максимальной реальной ПСП на запись:
- Non-Temporal store
- Запись строк кэша (прямая/обратная)
Во всех случаях, где это возможно, будем использовать как MMX-, так и SSE/SSE2-регистры. Напомним, что методы Prefetch/Non-Temporal store реализованы в тесте Memory Bandwidth, а методы чтения/записи строк кэша — в тесте D-Cache Bandwidth.
Для наглядности продемонстрируем кривые, полученные с использованием Software Prefetch и SSE-регистров процессора.
Максимальная реальная ПСП, Intel Pentium 4 Northwood
Максимальная реальная ПСП, Intel Pentium 4 XE Gallatin
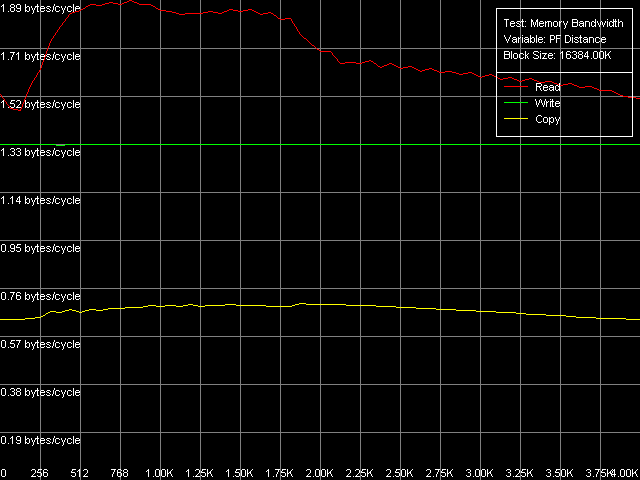
Максимальная реальная ПСП, Intel Pentium 4 Prescott
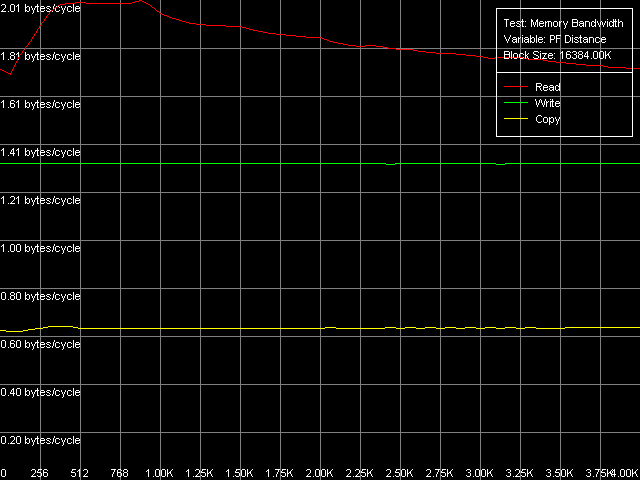
| Режим доступа | Максимальная реальная ПСП на чтение, МБ/с | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэш, прямое Чтение строк кэш, обратное | 3915.8 (78.1 %) 5011.0 (100.0 %) 5345.3 (106.7 %) 5802.4 (115.8 %) 4332.2 (86.5 %) 4811.5 (96.0 %) 3716.2 (74.2 %) 4798.3 (95.8 %) 5943.0 (118.6 %) 5950.4 (118.7 %) | 3900.4 (78.6 %) 4959.2 (100.0 %) 5472.0 (110.3 %) 6124.1 (123.5 %) 4317.8 (87.1 %) 4725.8 (95.3 %) 3836.8 (77.4 %) 4787.1 (96.5 %) 5903.5 (119.0 %) 5904.0 (119.1 %) | 5003.9 (88.3 %) 5664.3 (100.0 %) 6484.1 (114.5 %) 6493.4 (114.6 %) 4700.5 (83.0 %) 5164.5 (91.2 %) 4952.5 (87.4 %) 5562.9 (98.2 %) 5762.2 (101.7 %) 5767.6 (101.8 %) |
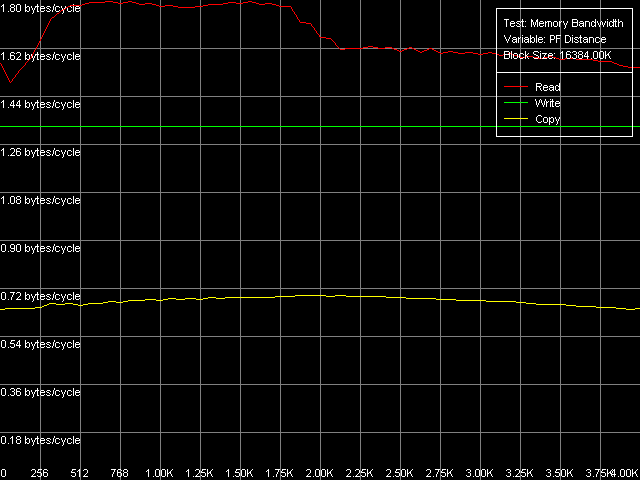
Легко видеть, что в тестах максимальной действительной ПСП на чтение использование MMX как на Northwood, так и на Gallatin во всех случаях проигрывает SSE/SSE2 (результаты последних, как и ранее, — идентичны). Использование Software Prefetch дает ощутимый выигрыш в скорости на всех трех типах процессоров. При этом на Gallatin и Prescott достигаются максимально возможные значения ПСП, равные 6124.1 МБ/с и 6493.4 МБ/с, соответственно. Достижение большей величины реальной ПСП на Gallatin по сравнению с Northwood, по-видимому, можно отнести к наличию у первого сравнительно большого дополнительного уровня кэша данных L3 объемом 2 МБ. Интересно, что эффективность чтения памяти в методе Software Prefetch как с помощью MMX-, так и SSE/SSE2-регистров на Prescott оказывается практически одинаковой, что говорит о весьма большом потенциале Software Prefetch в процессорах Prescott.
Можно сказать, что Software Prefetch в новом поколении процессоров Prescott претерпел значительные улучшения, позволяющие достичь, фактически, 100% эффективности двухканальной памяти DDR на чтение. Что приятно, соответствующие моменты отражены и в документации Prescott. Так, отмечается, что в новой ревизии микроархитектуры NetBurst инструкции Software Prefetch могут инициировать не только загрузку данных с новой страницы памяти (чего не было в предыдущих реализациях Pentium 4), но и загрузку соответствующего дескриптора страницы в D-TLB. Вторым значимым улучшением является кэширование инструкций Software Prefetch Trace-кэшем процессора, позволяющее значительно снизить затраты на их исполнение.
Методы Block Prefetch являются специфичными для процессоров AMD, поэтому мы приводим их результаты исключительно для того, чтобы убедиться, что для рассматриваемого семейства Intel Pentium 4 они совершенно не годятся. Во всех случаях они не только не улучшают картину реальной ПСП, но даже ухудшают ее по сравнению со средними значениями реальной ПСП, полученными без применения каких-либо оптимизаций.
Методы чтения строк кэш показывают весьма интересную картину. Они выдают довольно близкие значения на Northwood и Gallatin, которые примерно на 19% выше по сравнению со средней величиной реальной ПСП на чтение на этих процессорах. Кстати, значение 5950.4 МБ/с, достигаемое этими методами на Northwood, является для него абсолютным пределом, недостижимым при использовании Software Prefetch ввиду посредственной реализации последнего. В то же время, чтение строк кэш на Prescott дает довольно неожиданный результат, который оказывается немногим (не более чем на 2%) лучше, чем при обычном полном чтении данных с использованием SSE/SSE2-регистров.
| Режим доступа | Максимальная реальная ПСП на запись, МБ/с | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэш, прямая Запись строк кэш, обратная | 1533.3 (100.0 %) 1533.5 (100.0 %) 4290.5 (279.8 %) 4290.6 (279.8 %) 2541.5 (165.7 %) 2545.7 (166.0 %) | 2130.0 (100.3 %) 2122.9 (100.0 %) 4289.7 (202.1 %) 4290.0 (202.1 %) 2676.1 (126.1 %) 2676.2 (126.1 %) | 2029.6 (100.0 %) 2030.3 (100.0 %) 4290.3 (211.3 %) 4290.1 (211.3 %) 2997.0 (147.6 %) 2979.1 (146.7 %) |
Что касается максимальных значений реальной ПСП на запись, здесь все получается довольно четко. Во всех трех случаях максимальная величина реальной ПСП составляет 4290 МБ/с, что соответствует 67% от теоретически возможной максимальной ПСП двухканальной DDR. Она достигается при использовании метода прямого сохранения данных по протоколу объединения записи (write-combining). Наличие большего количества буферов сохранения и объединения записи у Prescott здесь никак себя не проявляет — видимо, предельная величина реальной ПСП жестко задается типом используемого чипсета, т.е. именно последний является лимитирующим фактором. Что касается метода записи строк кэша, то результат вновь оказывается довольно неожиданным. В то время как эффективность шины L2-RAM на чтение, как было показано, у Prescott несколько ниже (на 2-3%), чем у Northwood/Gallatin, ее эффективность на запись оказывается наивысшей именно у Prescott (на 12-17% выше). Тем не менее, значения реальной ПСП, достигаемые в этом методе, хотя и выше средних (на 26-66%, в зависимости от модели процессора), но весьма далеки от предельных значений, достигаемых в методе прямого сохранения данных (минуя кэш данных процессора).
Латентность кэша данных/памяти
Перейдем к изучению средней латентности уровней кэша данных и памяти, т.к. именно здесь нас ждут самые неожиданные открытия касательно новой микроархитектуры NetBurst 90-нм процессоров Prescott. Для получения общей картины воспользуемся тестом D-Cache Latency, выбрав пресет D-Cache/RAM Latency.
Средняя латентность, Intel Pentium 4 Northwood
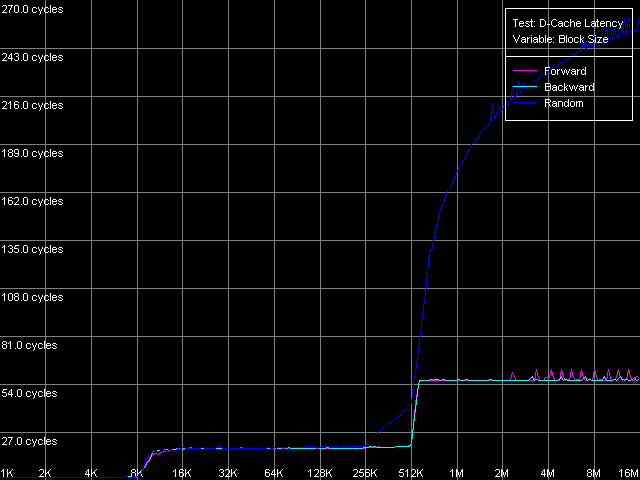
Средняя латентность, Intel Pentium 4 XE Gallatin
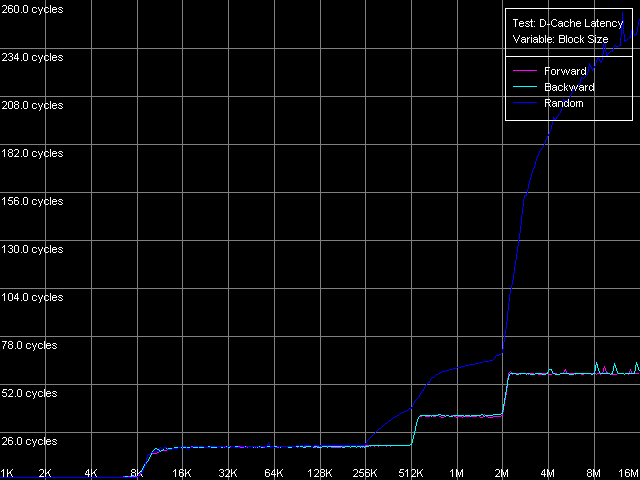
Средняя латентность, Intel Pentium 4 Prescott
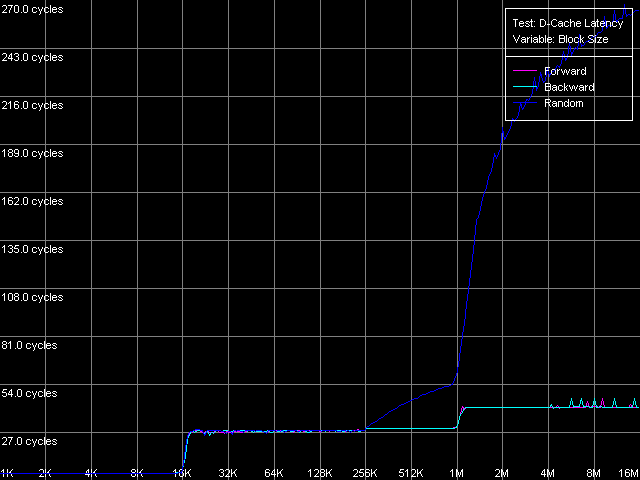
Общая картина латентности на всех трех «подопытных» на качественном уровне очевидна. На кривых можно четко выделить области, соответствующие латентности кэша L1 (размер блока до 8 КБ, Northwood/Gallatin и до 16 КБ включительно, Prescott) и L2 (размер блока до 512 КБ, Northwood/Gallatin и до 1 МБ, Prescott). Pentium 4 XE, как и следовало ожидать, и в этом тесте отлично проявляет свой кэш данных третьего уровня, при размере блока до 2 МБ включительно. Наличие перегибов на кривых в точках, строго соответствующих областям L1, L2 (L3) вновь подтверждает инклюзивную организацию уровней кэша данных в рассматриваемых процессорах, включая L3 процессора Pentium 4 XE. Заметим, что дублирование целых 512 КБ кэша L2 в двухмегабайтном кэше L3, что составляет 25% его объема, является весьма и весьма серьезной платой за простоту организации шины кэша (L1-L2 и L2-L3). Тогда, как известно, что AMD в своих процессорах семейства K7/K8 реализует более сложную, эксклюзивную организацию уровней L1-L2, исключая возможность «засорения» ненужными данными даже 6.25% (Opteron, Athlon 64), не говоря уж о 25% (Athlon XP/MP) кэша данных второго уровня.
Особенностью кривых латентности случайного доступа на всех трех типах Pentium 4 является ее плавное увеличение при размерах блока 256 КБ и выше. Напомним, что нечто похожее мы наблюдали и в нашем первом тесте средней реальной ПС кэша L2, и связано это с тем, что размер D-TLB у этого типа процессоров весьма небольшой и может обеспечивать эффективную адресацию лишь 256 КБ (64 страниц) виртуальной памяти. Столь небольшой размер D-TLB при относительно большом объеме кэша (1 МБ L2, Prescott и 2 МБ L3, Gallatin) можно считать существенным недостатком архитектуры NetBurst процессоров Pentium 4. Удивительно, что в новой ее ревизии (Prescott) инженеры Intel не позаботились об увеличении размера D-TLB или введения двухуровневой системы D-TLB, присущей процессорам семейства AMD K7/K8. В связи с этим, точная оценка латентности случайного доступа в L3 (Gallatin) и RAM оказывается затруднена; здесь и далее мы оперируем значениями, полученными при размерах блока 1 МБ (L3) и 4 МБ (RAM).
Перейдем к количественной оценке средней латентности различных уровней кэша/памяти при различных режимах доступа.
| Уровень, доступ | Средняя латентность, тактов | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, прямой L1, обратный L1, случайный | 2.0 2.0 2.0 | 2.0 2.0 2.0 | 4.0 4.0 4.0 |
| L2, прямой L2, обратный L2, случайный | 18.5 18.5 18.5 | 18.5 18.5 18.5 | 28.5 28.5 28.5 |
| L3, прямой L3, обратный L3, случайный* | - - - | 35.5 35.5 61.0 | - - - |
| RAM, прямой RAM, обратный RAM, случайный** | 57.0 (17.6 нс) 57.0 (17.6 нс) 229.0 (71.0 нс) | 58.0 (18.0 нс) 58.0 (18.0 нс) 185.0 (57.0 нс) | 41.0 (12.7 нс) 41.0 (12.7 нс) 225.5 (69.8 нс) |
*Размер блока 1 МБ
**Размер блока 4 МБ
Как видно из этой таблицы, серьезных различий между Northwood и Gallatin в плане латентности не наблюдается. Латентность L1 во всех случаях доступа составляет ровно 2 такта, латентность L2 — в среднем 18.5 тактов. Латентность кэша L3 процессора Pentium 4 XE при прямом и обратном доступе почти в два раза выше, чем латентность L2 — она составляет 35.5 тактов (а при случайном доступе — и того выше, 61 такт процессора, правда, с упомянутой выше оговоркой, что точное измерение последней не представляется возможным ввиду исчерпания D-TLB процессора). Наконец, латентность последнего уровня — оперативной памяти — характеризуется величинами 57-58 тактов (17.6-18.0 нс) при прямом/обратном доступе, что говорит о наличии хорошего алгоритма Hardware Prefetch, работающего в этих режимах обхода. Латентность случайного доступа в RAM (с той же оговоркой) существенно выше, она составляет 229 тактов (71.0 нс) на Northwood и 185 тактов (57.0 нс) на Gallatin. Меньшую величину латентности памяти на последнем можно отнести разве что к наличию кэша данных третьего уровня, объем которого позволяет покрыть до 50% обращений к памяти в рассматриваемом случае.
Самые неожиданные результаты, как вы, возможно, догадались, конечно же ждут нас в новой архитектуре Prescott. Итак, латентность L1 во всех случаях доступа возросла до 4(!) тактов (выше, чем во всех известных на сегодняшний день современных процессорах), латентность L2 — до 28.5 тактов. Изменения, надо сказать, просто поразительные, и явно не в пользу нового 90-нм процессора. Хотя есть и одно утешение: алгоритм Hardware Prefetch, как мы уже предполагали, и вправду улучшен в новой архитектуре 90-нм процессора Pentium 4. Действительно, латентность прямого/обратного обхода памяти уменьшилась до 41 такта процессора (12.7 нс), т.е. почти на 39% по сравнению с предыдущими моделями Pentium 4. В то же время, латентность случайного доступа осталась на уровне Northwood — она составляет 225.5 тактов процессора (69.8 нс).
Минимальная латентность L2/L3 кэша данных/памяти
Посмотрим теперь, каких минимальных значений латентности каждого из уровней (L2, L3, RAM) можно достичь на каждой из моделей процессоров Pentium 4. Для этого будем использовать метод разгрузки шины кэша процессора вставкой «пустых» операций. Приведем здесь кривые, полученные в тесте D-Cache Latency с пресетом Minimal L2 Cache Latency, Method 1.
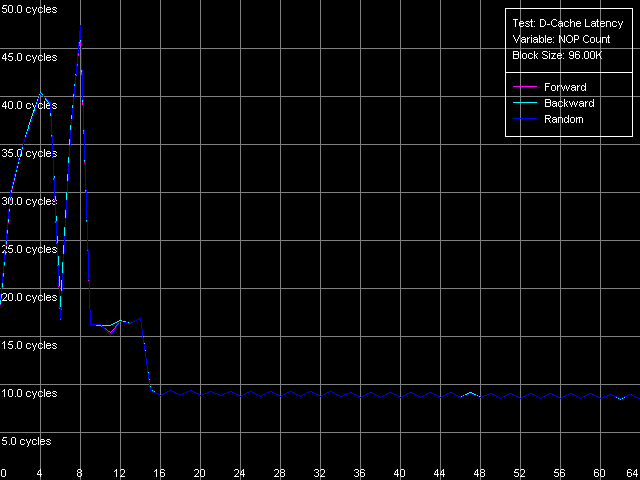
Минимальная латентность L2, Intel Pentium 4 Northwood
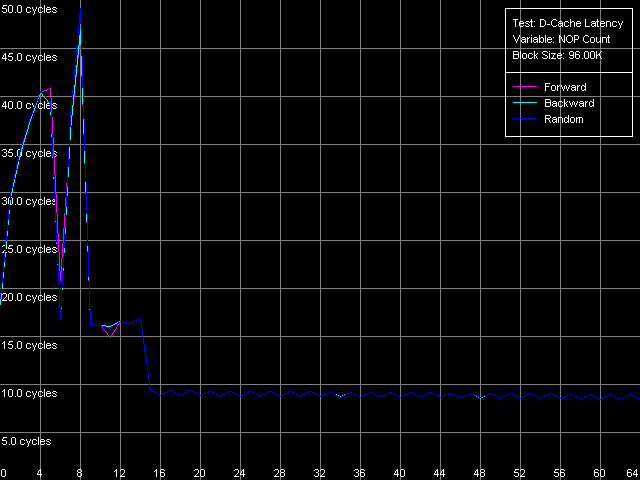
Минимальная латентность L2, Intel Pentium 4 XE Gallatin
Минимальная латентность L2, Intel Pentium 4 Prescott
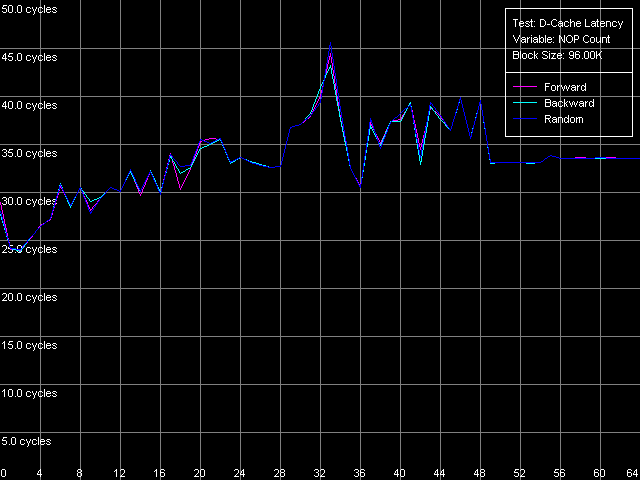
С Northwood и Gallatin все в порядке — при вставке уже 15 пустых операций (OR EAX, EDX, время исполнения которой — 0.5 такта процессора) достигается минимальная величина латентности L2, равная 9 тактам. Картина на Prescott получается фантастической! Сколько ни вставляй таких пустых операций (время исполнения которых, что немаловажно, возросло в два раза — оно составляет ровно один такт процессора), разгрузка шины не наблюдается, и минимальная латентность — тоже. Тем не менее, все-таки можно наметить некий минимум, наблюдающийся при двух «NOP»-ах, который составляет 24 такта (все же немного меньше, чем средняя латентность). Серьезные изменения микроархитектуры NetBurst налицо, причем, в очередной раз — далеко не в пользу Prescott. Остается только попытаться использовать другой метод разгрузки шины, специально разработанный для процессоров, которые могут осуществлять спекулятивную загрузку данных (которая в случае измерения латентности ни к чему хорошему, кроме штрафов, конечно не приведет). Взглянем на ее результаты на всех трех исследуемых процессорах.
Минимальная латентность L2, метод 2, Intel Pentium 4 Northwood
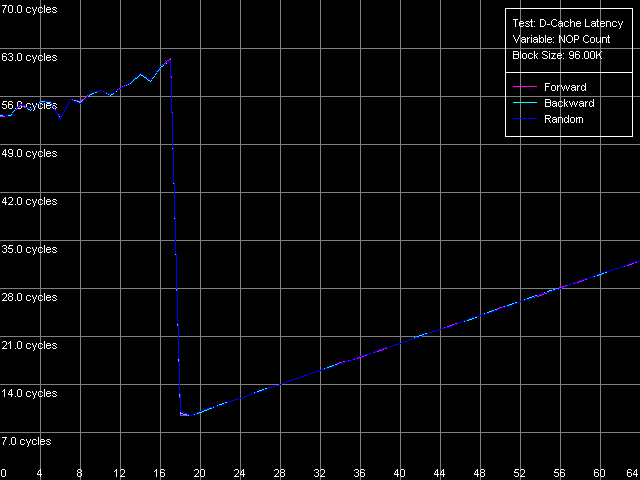
Минимальная латентность L2, метод 2, Intel Pentium 4 XE Gallatin
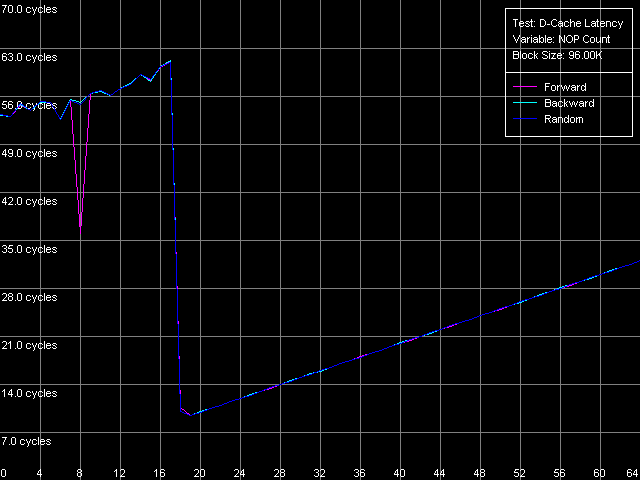
Минимальная латентность L2, метод 2, Intel Pentium 4 Prescott
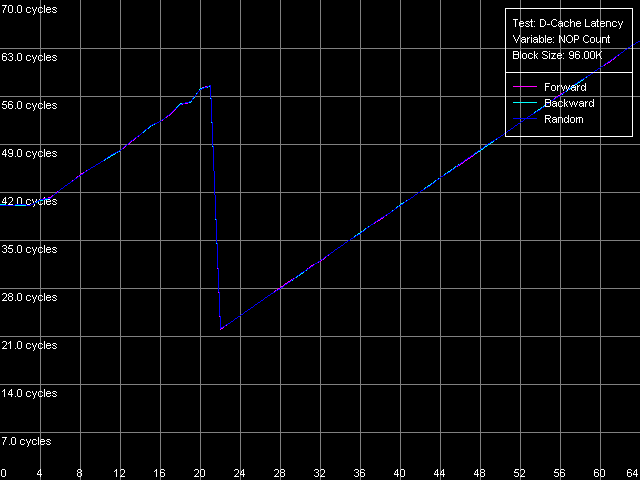
И снова Northwood и Gallatin ведут себя вполне адекватно. Минимальная латентность L2 — 9 тактов, как и положено, и наблюдается она при вставке 18 «NOP»-ов (что в точности соответствует 9 тактам процессора, как и положено в данной методике тестирования). Картина на Prescott, хотя и не принципиально, но иная. Минимум составляет 22 такта, и наблюдается он при 22 «NOP»-ах (а поскольку каждый из них отнимает 1 такт процессора, значит, 22 такта и получается). Так и запишем — минимальная латентность L2 у Prescott — 22 такта, и ничего больше не скажешь.
Поскольку у одного из наших «подопытных» есть кэш данных третьего уровня, почему бы нам не оценить минимальную латентность и этого уровня? Для этого возьмем за основу те же пресеты Minimal L2 Cache Latency (Method 1, 2), и увеличим размер блока до 1024 КБ.
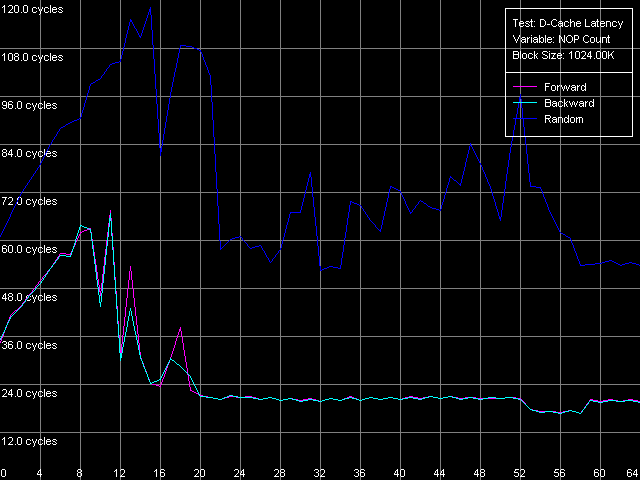
Минимальная латентность L3 при прямом и обратном последовательном доступе достигается столь же легко, уже при вставке 20 «пустых» операций, и составляет 20 тактов процессора (некоторое ее снижение до 17 тактов при вставке 53-58 «NOP»-ов остается не очень понятным). Минимальная латентность случайного доступа в L3 намного больше (причина этого уже обсуждалась выше) — в нашем тесте она составила 52.7 тактов, что все же меньше, чем ее среднее значение.
Оценим минимальную латентность последнего, общего для всех процессоров «уровня» — оперативной памяти. Здесь имеются различия между рассматриваемыми типами процессоров, несмотря на то, что используется один и тот же чипсет и тип памяти.
Минимальная латентность RAM, Intel Pentium 4 Northwood
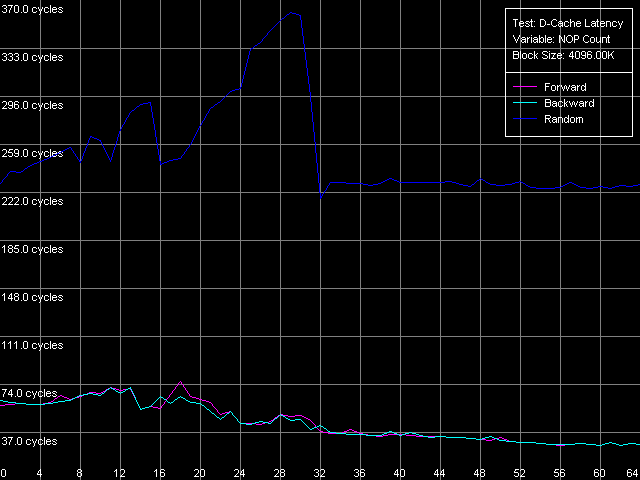
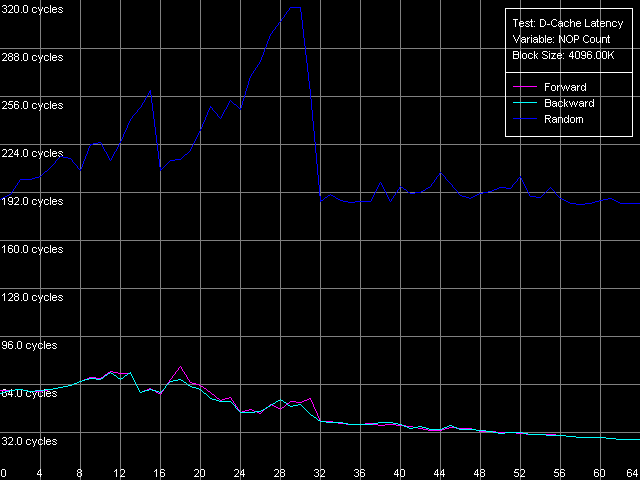
Минимальная латентность RAM, Intel Pentium 4 XE Gallatin
Минимальная латентность RAM, Intel Pentium 4 Prescott
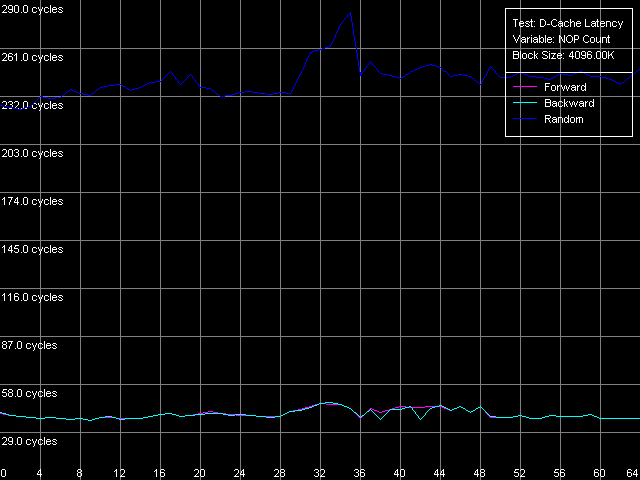
Первые два типа процессоров вновь ведут себя аналогично. Достигаемое минимальное значение латентности памяти при прямом/обратном доступе составляет 27.3-27.6 тактов (8.4-8.5 нс). Минимальная латентность случайного доступа в память +почти на порядок выше — 218 тактов (67.4 нс) на Northwood и 184 такта (57.0 нс) на Gallatin. На последнем она почти не отличается от средней величины (185 тактов). Prescott, как всегда, проявляет себя неожиданным образом. Во-первых, минимальная латентность при прямом/обратном обходе памяти составляет целых 36 тактов процессора (11.2 нс), что на 31% выше по сравнению с предыдущими моделями. Получается, что расхваленный нами Hardware Prefetch далеко не так хорош? По-видимому, все же нет, просто можно сказать, что он специально оптимизирован для «плотных» обращений к памяти, идущих подряд без каких-либо пропусков. В то время как Hardware Prefetch на более ранних Pentium 4 любит такие пропуски, точнее — вставки «пустых» операций между двумя соседними обращениями к памяти. Кроме того, возможно, что в Prescott что-то не так с процедурой разгрузки шины «пустыми» операциями. Хотя бы потому, что этим методом нельзя достичь минимальную латентность RAM при случайном доступе — в нашем тесте она составляет 224 такта (69.3 нс), тогда как средняя величина — 225.5 тактов, т.е. всего на 1.5 такта выше.
| Уровень, доступ | Минимальная латентность, тактов | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, прямой L1, обратный L1, случайный | 2.0 2.0 2.0 | 2.0 2.0 2.0 | 4.0 4.0 4.0 |
| L2, прямой* L2, обратный* L2, случайный* | 9.0 (9.0) 9.0 (9.0) 9.0 (9.0) | 9.0 (9.0) 9.0 (9.0) 9.0 (9.0) | 24.0 (22.0) 24.0 (22.0) 24.0 (22.0) |
| L3, прямой L3, обратный L3, случайный** | - - - | 20.0 20.0 52.7 | - - - |
| RAM, прямой RAM, обратный RAM, случайный*** | 27.4 (8.4 нс) 27.3 (8.4 нс) 218.0 (67.4 нс) | 27.6 (8.5 нс) 27.6 (8.5 нс) 184.0 (57.0 нс) | 36.0 (11.2 нс) 36.0 (11.2 нс) 224.0 (69.3 нс) |
* В скобках указаны значения, полученные методом 2.
** Размер блока 1 МБ
*** Размер блока 4 МБ
Ассоциативность кэша данных
Ассоциативность кэша данных — не менее важная его характеристика, чем его объем или латентность. И здесь, как всегда, нас ждут интересные сюрпризы, причем на этот раз — в большей степени даже от Northwood и Gallatin, нежели Prescott. Для получения качественной картины воспользуемся пресетом D-Cache Associativity в тесте D-Cache Latency.
Ассоциативность кэша, Intel Pentium 4 Northwood
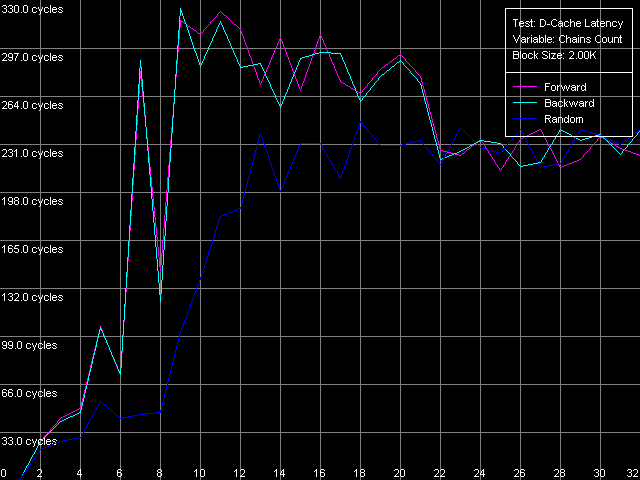
Ассоциативность кэша, Intel Pentium 4 XE Gallatin
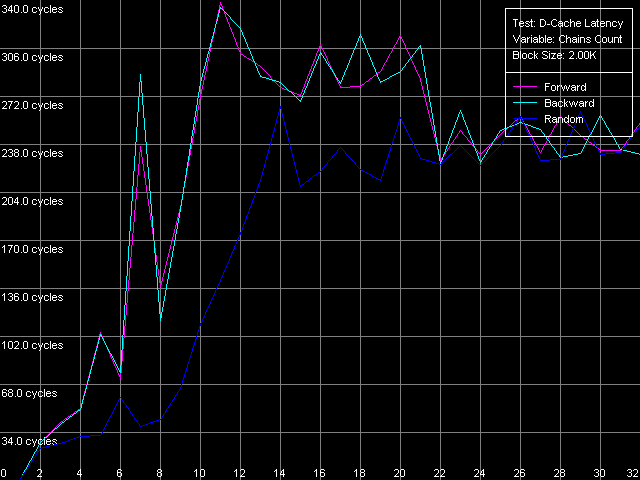
Ассоциативность кэша, Intel Pentium 4 Prescott
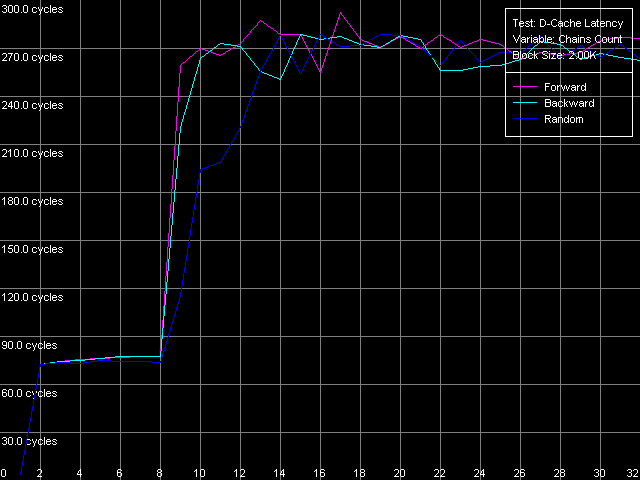
Результаты весьма интересные и трудно интерпретируемые (чего не скажешь об AMD K7/K8 — там все выглядело замечательно!). Тем не менее, при большом желании у всех трех Pentium 4 можно выявить две области, особенно различимые по кривым случайного доступа. Первая из них — это начальная точка, соответствующая L1 кэшу, который в нашем тесте получился одноассоциативным. Вторая область — до 8 цепочек включительно, что соответствует заявленной ассоциативности кэша L2, равной восьми.
То, что ассоциативность L1 в нашем тесте получилась равной единице, является неожиданным результатом. Напомним, что RightMark Memory Analyzer измеряет ассоциативность путем считывания строк кэша с «нехороших» адресов памяти, имеющих смещения друг относительно друга 1 МБ и выше. Это означает, что кэш L1 у всех трех моделей Pentium 4 не может эффективно ассоциироваться более чем с одной из строк памяти, расположенных по таким адресам. Что позволяет нам с полным правом считать, что его реальная, или эффективная ассоциативность действительно равна единице. Причем этот результат нельзя считать недостатком метода, ибо заметим, что кэш L2 в этом же самом методе проявляет свою истинную ассоциативность (8-way set associative).
Остается лишь отметить, что заявленную (именно такую, ибо по честному ее нельзя назвать «истинной» характеристикой) ассоциативность L1, равную четырем (Northwood, Gallatin) или восьми (Prescott) можно достичь, но в особых условиях доступа. А именно, L1 кэш процессоров проявляет свою заявленную ассоциативность только в пределах своего собственного объема (так, каждая строка L1 кэша процессора Prescott объемом 16 КБ способна ассоциироваться с восемью строками памяти, имеющими смещения друг относительно друга 16/8 = 2 КБ).
Реальная пропускная способность шины L1-L2 и L2-L3
Предмет гордости процессоров семейства Pentium 4 — это наличие очень широкой, 256-битной шины обмена данными между L1 и L2 кэшем данных. Так почему нам не посмотреть, насколько эффективной она является в реальности, и не претерпела ли она изменений при модификациях архитектуры NetBurst? Для ответа на поставленный вопрос воспользуемся тестом D-Cache Bandwidth, выбрав пресет L1-L2 Cache Bus Bandwidth.
Реальная ПС шины L1-L2, Intel Pentium 4 Northwood
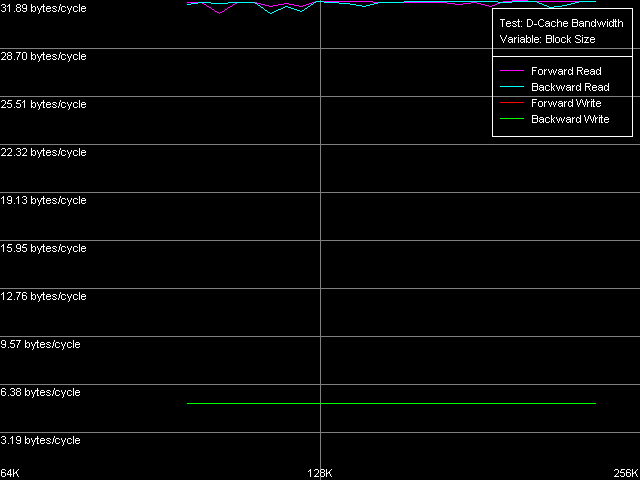
Реальная ПС шины L1-L2, Intel Pentium 4 XE Gallatin
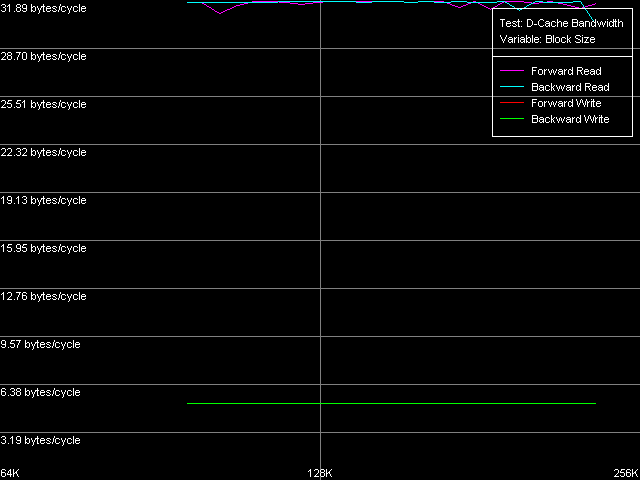
Реальная ПС шины L1-L2, Intel Pentium 4 Prescott
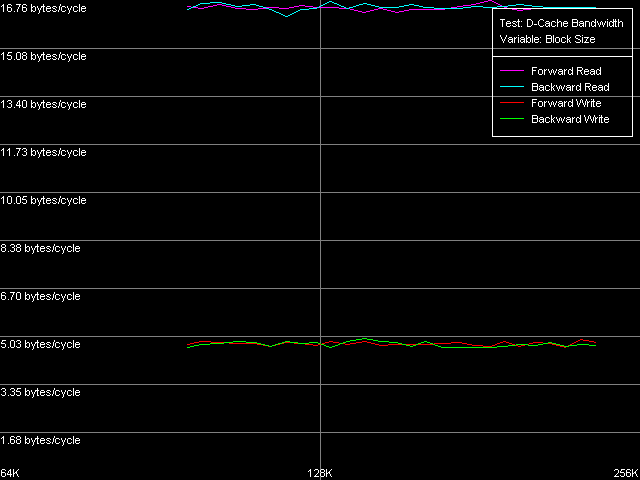
Эффективность этой шины у Northwood и Gallatin на чтение действительно очень высока — величина 31.89 байт/такт является нешуточной, т.к. составляет 99.6% от теоретического максимума. По этому показателю микроархитектуре NetBurst действительно есть чем похвастаться. В то же время, эффективность такой шины на запись куда ниже — всего 5.16 байт/такт, а это лишь 16% от теоретического максимума (можно даже предположить, что ее реальная ширина на запись — всего 64 бита).
Но как всегда, нас не перестает удивлять новый, улучшенный 90-нм процессор Pentium 4 Prescott! Эффективность его шины L1-L2 упала почти в два раза по сравнению с предыдущими моделями — до 16.76 байт/такт (эффективность — 52.3%). Поскольку эта величина превышает 16.0 байт/такт, мы все же не можем говорить о том, что шина L1-L2 была «урезана» вдвое, до 128 бит. Нет, скорее имеет место некое умышленное замедление работы той же самой, 256-битной шины. К сожалению, специально разработанный тест прибытия данных (D-Cache Arrival), позволяющий оценивать различные тонкости организации шины данных, в данном случае оказывается бессмысленным — за целых 4 такта латентности доступа в кэш L1 из кэша L2 вполне успеют прибыть все 64 байта данных (целая строка) даже в случае использования 128-битной шины. Резюмируя, можно сказать, что путем замедления латентности доступа в кэш L1 в два раза Intel хитро замаскировала и другие «тормоза» своего нового процессора Prescott, в частности, эффективную ПС шины L1-L2.
Что касается эффективной пропускной способности шины L1-L2 на запись, в новом Prescott она также несколько упала, но не столь кардинально, как ее ПС на чтение. Действительно, 4.92-4.97 байт/такт — это всего на 4-5% меньше, чем в предыдущих моделях Pentium 4, и так же неэффективно. Как мы уже отмечали в нашей предыдущей статье, процессоры семейства AMD K7/K8, имеющие эксклюзивную организацию L1-L2, характеризуются куда более эффективными значениями ПС L1-L2 на запись строк кэша.
Поскольку в нашем распоряжении имеется процессор Pentium 4 XE с присутствующим в нем кэшем данных третьего уровня, почему бы нам не оценить эффективную ПС соответствующей шины, L2-L3? Для этого возьмем за основу тот же пресет L1-L2 Cache Bus Bandwidth и немного модифицируем параметры теста таким образом:
- Minimal Block Size = 1024KB;
- Maximal Block Size = 2048KB;
- Minimal Stride Size = 128 bytes (да-да, строки кэша из L2 в L3 и, далее, в RAM передаются именно так, в удвоенном объеме).
Полученный результат очень нагляден — шина L2-L3 в процессоре Pentium 4 XE является 64-разрядной. Ее эффективность на чтение — 6.05 байт/такт (75.6%), на запись — в среднем 4.67 байт/такт (58.4%).
| Шина данных, режим доступа | Реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1-L2, чтение (прямое) L1-L2, чтение (обратное) L1-L2, запись (прямая) L1-L2, запись (обратная) | 31.89 31.88 5.16 5.16 | 31.89 31.88 5.16 5.16 | 16.76 16.73 4.92 4.97 |
| L2-L3, чтение (прямое) L2-L3, чтение (обратное) L2-L3, запись (прямая) L2-L3, запись (обратная) | - - - - | 6.05 6.05 4.66 4.68 | - - - - |
Trace Cache, эффективность декодирования
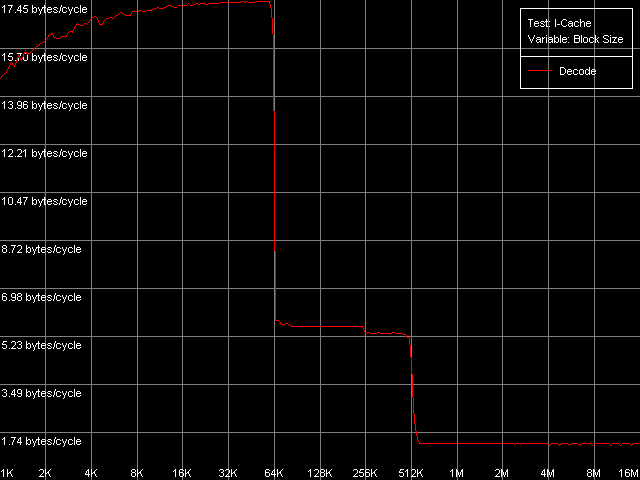
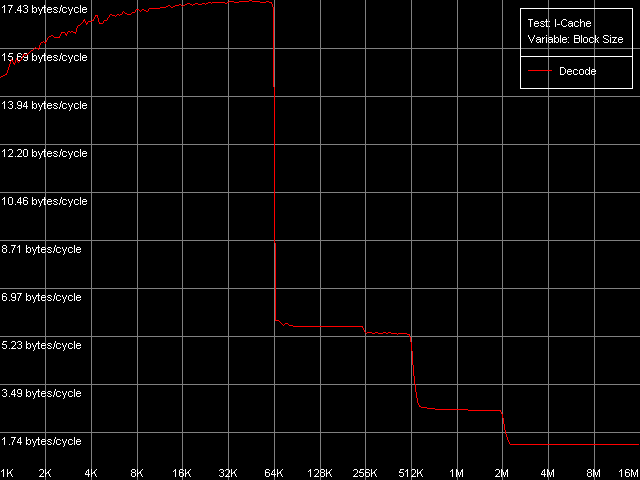
Одним из наиболее занимательных элементов микроархитектуры Intel NetBurst является, конечно же, особый кэш инструкций процессора, называемый Trace Cache. Этот кэш хранит результат работы декодера инструкций в форме микроопераций (до 12000 uop включительно), а не индивидуальные байты, составляющие x86-инструкции, как это делается в традиционных моделях L1i кэша, и имеет ряд других преимуществ. Основным следствием такой особенности реализации кэша инструкций является наличие зависимости объема такого кэша от типа используемых инструкций. Для наглядности мы возьмем наиболее показательный пример, позволяющий достичь практически максимального эффективного объема Trace Cache, а также высокой скорости декодирования команд. С этой целью воспользуемся тестом I-Cache, выбрав пресет L1i Size / Decode Bandwidth, CMP Instructions 3.
Декодирование команд, Intel Pentium 4 Northwood
Декодирование команд, Intel Pentium 4 XE Gallatin
Декодирование команд, Intel Pentium 4 Prescott
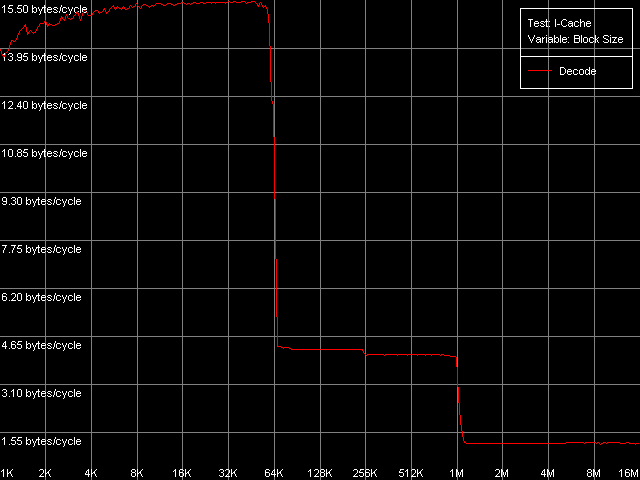
Видно, что на всех трех моделях процессоров достигается значительный эффективный объем Trace Cache, составляющий 63 КБ (10.5 тысяч микроопераций). При превышении этого объема четко прослеживается «подкачка» кода из унифицированного кэша L2, способного кэшировать как данные, так и код. Точно такой же характеристикой обладает кэш L3 процессора Pentium 4 XE. Легко заметить некоторое снижение скорости исполнения кода при размере блока кода 256 КБ и выше. Именно таким образом проявляет себя сравнительно малый объем TLB, на этот раз — TLB инструкций (I-TLB), который, как мы увидим ниже, имеет такой же размер (64 записи, адресация 256 КБ виртуальной памяти). Наконец, инклюзивная организация уровней кэша проявляет себя и в этом случае, т.е. в случае кэширования кода вместо данных.
Для более детального исследования характеристик Trace Cache и декодера процессоров рассматриваемого семейства мы провели ряд дополнительных тестов, использующих как независимые, так и зависимые ALU-операции. Результаты этих тестов для каждого из «подопытных» процессоров представлены в виде отдельных таблиц.
Эффективность декодирования, Pentium 4 Northwood
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP | 10.0 (10.0) | 2.89 (2.89) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 11.61 (2.90) | 3.98 (0.99) |
| CMP 3 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 4 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 5 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 6* | 32.0 (10.6) | 8.75 (1.46) | 5.52 (0.92) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.69 (1.46) | 3.99 (0.50) |
| Зависимые | |||
| LEA | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| MOV | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| ADD | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| OR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| SHL | - | 0.75 (0.25) | 0.75 (0.25) |
| ROL | - | 0.75 (0.25) | 0.75 (0.25) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Эффективность декодирования, Pentium 4 XE Gallatin
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | ||
|---|---|---|---|---|
| Trace Cache | L2 Cache | L3 Cache | ||
| Независимые | ||||
| NOP | 10.0 (10.0) | 2.89 (2.89) | 0.99 (0.99) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 11.62 (2.90) | 3.98 (0.99) | 2.64 (0.66) |
| CMP 3 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 4 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 5 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 6* | 32.0 (10.6) | 8.75 (1.46) | 5.53 (0.92) | 2.60 (0.43) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 23.22 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.69 (1.46) | 3.99 (0.50) | 2.64 (0.33) |
| Зависимые | ||||
| LEA | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| MOV | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| ADD | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| OR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| SHL | - | 0.75 (0.25) | 0.75 (0.25) | 0.75 (0.25) |
| ROL | - | 0.75 (0.25) | 0.75 (0.25) | 0.75 (0.25) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Как обычно, начнем с рассмотрения процессоров Pentium 4 нынешнего поколения — Northwood и Gallatin, а затем перейдем к новому процессору Prescott. Тем более что первые два практически не отличаются друг от друга, а последний, как всегда, вносит определенную сумятицу.
Легко заметить, что объем Trace Cache во всех случаях, в пересчете на количество микроопераций, реально не превышает величину 11000 uop, что позволяет предположить наличие некоторого резерва в одну тысячу микроопераций, отводящегося под служебные нужды. Максимальная скорость исполнения простых команд из Trace Cache достигает 2.9 операций/такт. При этом видно, что она лимитируется именно исполнительным блоком процессора (предельная скорость работы которого — 3 микрооперации/такт), а не скоростью «подкачки» инструкций из Trace Cache, в пересчете на размер x86 команд (скорость исполнения достигает 17.44 байт/такт и выше). По этому показателю процессоры семейства Pentium 4 выгодно отличаются от рассмотренных нами ранее AMD K7/K8, где скорость исполнения больших x86 команд лимитировалась именно скоростью «подкачки» инструкций из L1i в исполнительный блок процессора (не более 16 байт/такт).
Среди независимых инструкций неожиданный результат наблюдается в случае XOR и TEST, предельная скорость исполнения которых оказывается равной всего двум операциям за такт процессора, в точности так же, как и зависимых LEA/MOV/ADD/OR. Причина этого кроется, по всей видимости, в возможности исполнения указанных инструкций только в одном из двух блоков FastALU. Действительно, как нетрудно видеть, «разбавка» команды XOR операцией ADD (XOR/ADD) приводит к увеличению скорости исполнения такого кода до предельного значения 2.9 байт/такт.
Отдельного внимания заслуживает код CMP 6, представляющий собой повторяющиеся инструкции CMP EAX, 0x7FFFFFFF. Такая операция, как видно по результатам нашего тестирования, представляет собой две микрооперации, в отличие от всех других рассмотренных случаев. В связи с этим, эффективная скорость ее исполнения, в пересчете на количество x86 операций в два раза ниже (1.46 байт/такт).
Не менее интересными и важными являются результаты тестирования кода, содержащего CMP-инструкции с двумя «бессмысленными» префиксами. Увеличение скорости его исполнения до 23.2 байт/такт, а также кажущееся уменьшение эффективного объема Trace Cache при декодировании таких операций позволяют предположить, что «бессмысленные» префиксы отсекаются еще декодером x86-инструкций до помещения соответствующей микрооперации в Trace Cache. В таком предположении эффективный объем Trace Cache оказывается не меньшим, чем при хранении CMP-инструкций (10.5 тысяч микроопераций). В то же время, использование кода Prefixed CMP 4 ([0xF3][0x67]CMP EAX, 0x7FFFFFFF) вносит определенные недоразумения в сделанное нами предположения. Действительно, если считать, что префиксы отсекаются еще до помещения в Trace Cache, а собственно 32-битная инструкция CMP разбивается на 2 микрооперации, эффективный объем Trace Cache получается равным 14.7 тысячам микроопераций, что больше заявленного значения в документации значения в 12 тысяч. Таким образом, реальное положение дел, по-видимому, обстоит намного сложнее, нежели в сделанном нами простом предположении.
Что касается подкачки команд из унифицированного L2 кэша кода/данных, тут все сильно зависит от типа самих команд. А подкачиваются они, как можно заметить, с темпом примерно 1 инструкция/такт, независимо от того, сколько реально позволяет L2 кэш. И только инструкции типа Prefixed CMP, по каким-то причинам, закачиваются из L2 с меньшим темпом — всего половина инструкции/такт. Как видно из второй таблицы, подкачка кода может идти и из третьего уровня кэша процессора Pentium 4 XE (Gallatin). В этом случае, похоже, скорость исполнения кода лимитируется уже скоростными показателями этого уровня кэша, ибо все упирается в некое загадочное значение 2.64 байт/такт (для инструкций размером 4-8 байт).
Эффективность декодирования, Pentium 4 Prescott
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP | 10.0 (10.0) | 2.85 (2.85) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.97 (1.98) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.97 (1.98) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 10.29 (2.57) | 3.98 (0.99) |
| CMP 3 | 63.0 (10.5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 4 | 63.0 (10.5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 5 | 63.0 (10.5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 6* | 32.0 (10.6) | 8.62 (1.44) | 4.25 (0.71) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.53 (1.44) | 4.40 (0.55) |
| Зависимые | |||
| LEA | - | 1.99 (0.99) | 1.99 (0.99) |
| MOV | - | 1.99 (0.99) | 1.99 (0.99) |
| ADD | - | 1.99 (0.99) | 1.99 (0.99) |
| OR | - | 1.99 (0.99) | 1.99 (0.99) |
| SHL | - | 3.00 (1.00) | 3.00 (1.00) |
| ROL | - | 3.00 (1.00) | 3.00 (1.00) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Посмотрим теперь, какие сюрпризы нам приготовила новая, улучшенная архитектура NetBurst процессоров Pentium 4 Prescott. Что касается независимых операций, серьезных изменений не наблюдается. По крайней мере, Trace Cache остался в точности таким же. Уменьшилась лишь скорость исполнения команд (микроопераций), но это уже претензии к исполнительному блоку процессора (увеличенная длина конвейера, конечно же, в этом тесте проявляет себя незамедлительно). Падение производительности составляет от 1.7 (простейшие операции вроде NOP и SUB) до 12.4% (длинные CMP и Prefixed CMP). XOR и TEST здесь ведут себя аналогично — для достижения пиковой скорости им необходима «разбавка» другими ALU-операциями. Значит, и организация ALU осталась более-менее такой же.
Без сюрпризов со стороны Prescott нам, конечно, не обойтись. На этот раз это обработка зависимых команд, вроде LEA/MOV/ADD/OR. Как видно из таблицы, они ведут себя одинаково и исполняются со скоростью всего-навсего 1 операция/такт (кстати, напомним, что то, что OR ведет себя именно так, мы выяснили еще в тесте минимальной латентности L2/RAM). Именно поэтому здесь мы даже не смогли оценить эффективную границу Trace Cache, ибо их скорость исполнения как из L1i, так и из L2 одинакова — 2 байта/такт.
Но есть и приятный сюрприз — это обещанное улучшение поддержки операций Shift и Rotate. В этом отношении заметен ощутимый прогресс — латентность исполнения таких команд на Prescott уменьшилась до 1 такта, против 4 тактов у предыдущего поколения процессоров Pentium 4.
Вернемся к затронутому выше вопросу об отсечении префиксов, тем более что в RightMark Memory Analyzer есть специальный тест, позволяющий оценить эффективность декодирования/исполнения x86-команды NOP с произвольным количеством префиксов [0x66]. Для этого выберем пресет Prefixed NOP Decode Efficiency. Результаты теста на всех трех процессорах сведены в следующую таблицу.
| Количество префиксов | Эффективность декодирования, байт/такт (инструкций/такт) | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| 0 | 2.89 (2.89) | 2.89 (2.89) | 2.84 (2.84) |
| 1 | 5.78 (2.89) | 5.75 (2.88) | 5.68 (2.84) |
| 2 | 8.59 (2.86) | 8.59 (2.86) | 8.52 (2.84) |
| 3 | 11.44 (2.86) | 11.41 (2.85) | 11.34 (2.84) |
| 4 | 14.25 (2.85) | 14.25 (2.85) | 14.09 (2.82) |
| 5 | 17.11 (2.85) | 17.10 (2.85) | 16.89 (2.82) |
| 6 | 19.73 (2.82) | 19.75 (2.82) | 19.51 (2.79) |
| 7 | 22.57 (2.82) | 22.55 (2.82) | 22.30 (2.79) |
| 8 | 25.20 (2.80) | 25.18 (2.80) | 24.87 (2.76) |
| 9 | 27.94 (2.79) | 27.92 (2.79) | 27.54 (2.75) |
| 10 | 30.88 (2.81) | 30.88 (2.81) | 30.76 (2.80) |
| 11 | 33.39 (2.78) | 33.39 (2.78) | 33.24 (2.77) |
| 12 | 36.02 (2.77) | 36.00 (2.77) | 35.86 (2.76) |
| 13 | 38.38 (2.74) | 38.38 (2.74) | 38.18 (2.73) |
| 14 | 41.06 (2.74) | 41.07 (2.74) | 40.85 (2.72) |
Получается очевидная картина. При увеличении количества «бессмысленных» префиксов на всех трех процессорах наблюдается линейный рост скорости исполнения такой x86-команды, в результате чего достигаются воистину фантастические скорости выполнения, в пересчете на количество байт — до 41 байт/такт. В то же время, если пересчитать полученные значения на реальное количество исполняемых операций (NOP), мы получим типичные значения скорости исполнения команды NOP (2.7-2.9 операций/такт, значения в скобках), лишь незначительно уменьшающиеся при увеличении количества префиксов. А это означает, что декодер NetBurst, по всей видимости, действительно умеет отделять бессмысленные префиксы еще на стадии генерирования микроопераций, непосредственно перед помещением последних в Trace Cache процессора.
Напоследок нам остается оценить ассоциативность кэша L1 инструкций (Trace Cache) и кэша L2 при исполнении кода из последнего. Для этого используем пресет I-Cache Associativity.
Ассоциативность кэша инструкций, Intel Pentium 4 Northwood
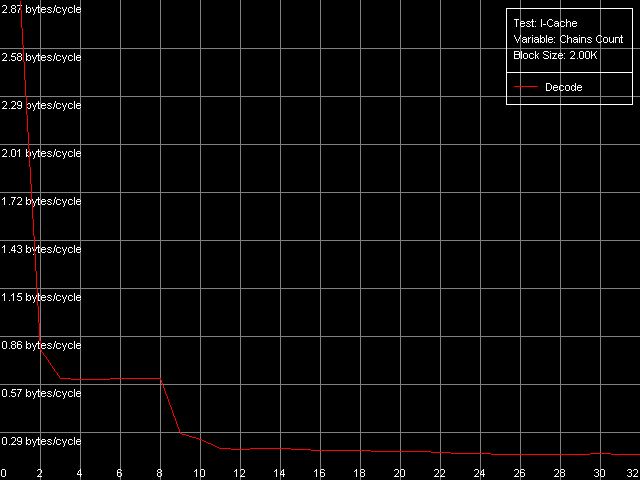
Ассоциативность кэша инструкций, Intel Pentium 4 XE Gallatin
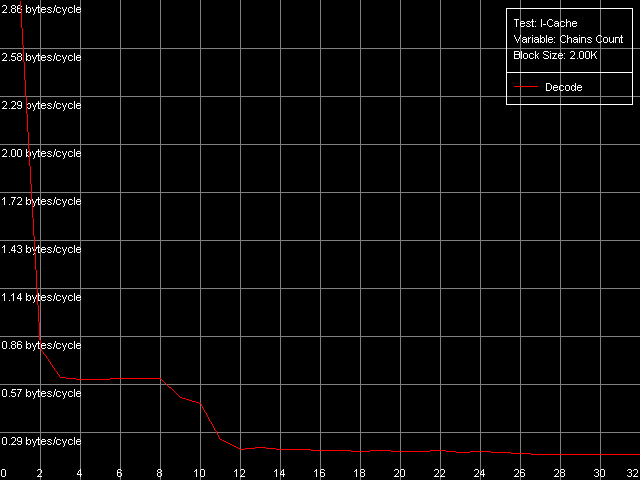
Ассоциативность кэша инструкций, Intel Pentium 4 Prescott
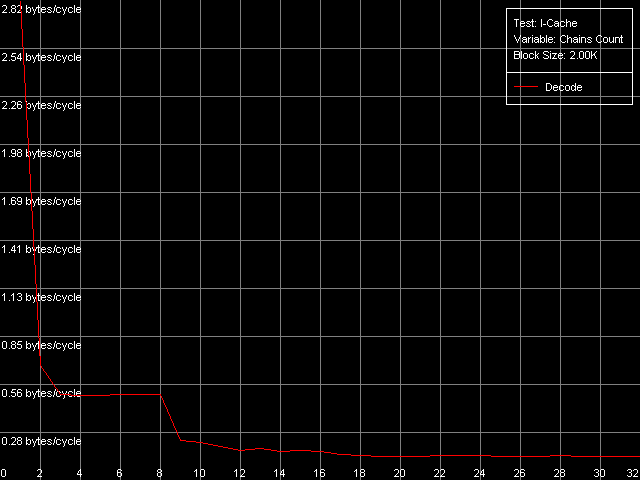
Northwood и Prescott дают довольно четкую картину, по которой можно судить, что ассоциативность Trace Cache равна единице, в то время как объединенный L2 кэш инструкций/данных имеет ассоциативность, равную восьми (именно такое значение было получено нами ранее при исследовании ассоциативности кэша данных). Картина на Gallatin оказывается несколько более размытой ввиду наличия дополнительного уровня кэша, ассоциативность которого, по крайней мере, не превышает ассоциативность L2 кэша.
Характеристики D-TLB
О D-TLB мы уже говорили довольно много, настало время наконец исследовать его характеристики специализированным тестом (D-TLB). Для начала оценим его размер, который, согласно неоднократно сделанным выводам, должен составлять всего 64 записи. Используем с этой целью пресет D-TLB Size.
Размер D-TLB, Intel Pentium 4 Northwood
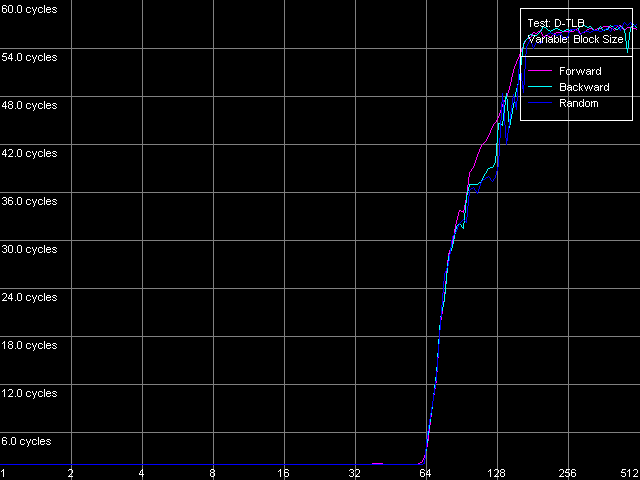
Размер D-TLB, Intel Pentium 4 XE Gallatin
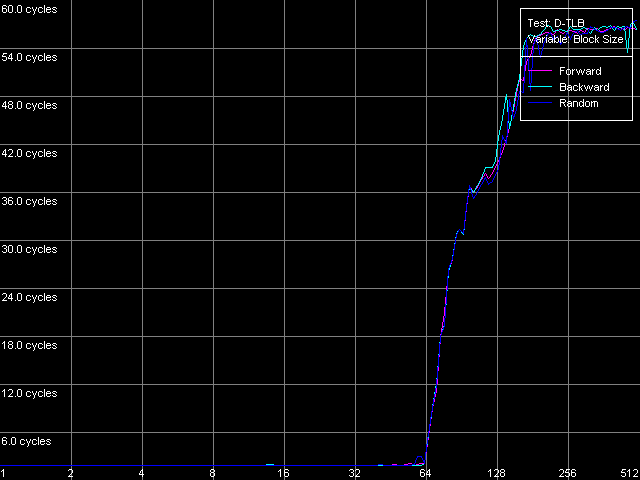
Размер D-TLB, Intel Pentium 4 Prescott
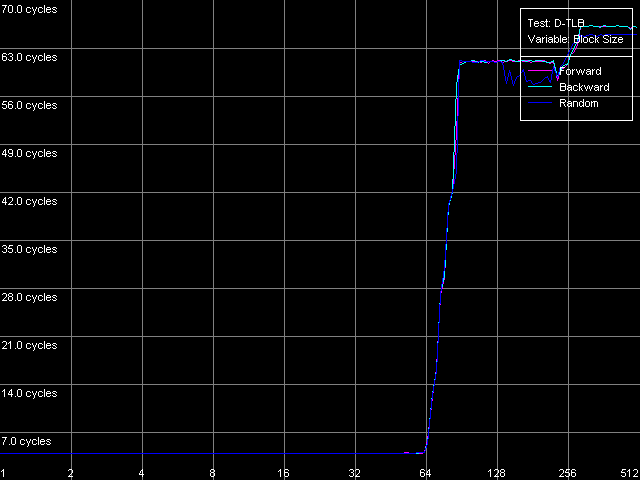
Наше предположение относительно размера и структуры D-TLB подтверждается для всех трех процессоров: он одноуровневый, и размер этого единственного уровня D-TLB равен 64 записям (дескрипторам страниц памяти). Что является более потрясающим фактом, так это то, насколько же дорого обходится (с точки зрения количества тактов процессора) промах D-TLB. Действительно, латентность доступа в L1 кэш в условиях промаха D-TLB составляет порядка 57 тактов (Northwood, Gallatin) и 60-67 тактов на Prescott. Аналогичная картина на процессорах семейства AMD K7/K8, даже в случае промаха L2 D-TLB, куда лучше — латентность доступа в L1 в этих условиях не превышает 30-36 тактов процессора.
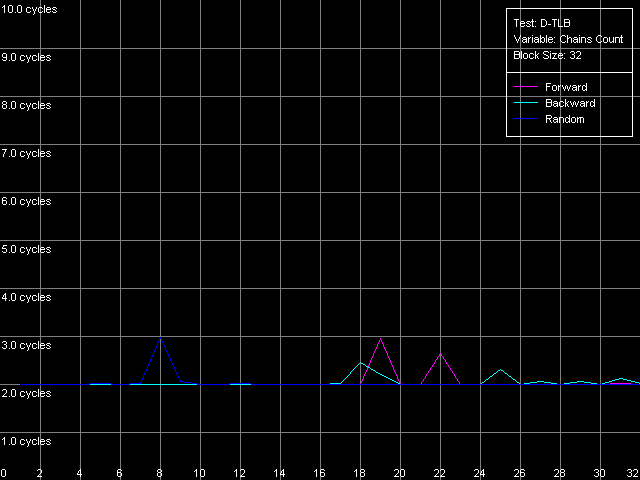
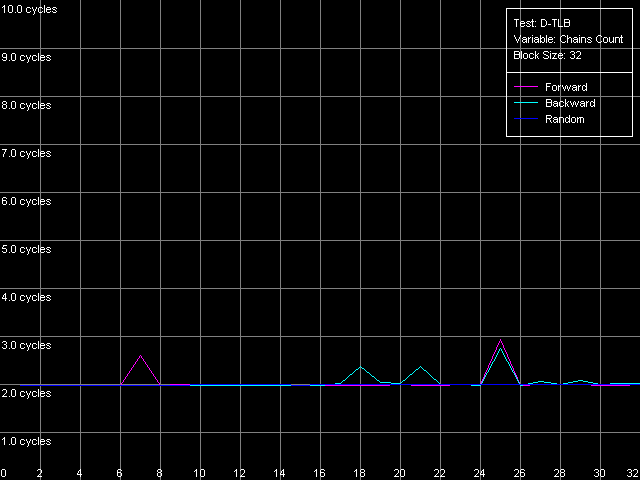
Попытаемся теперь оценить ассоциативность D-TLB. Для этого используем пресет D-TLB Associativity, 32 Entries.
Ассоциативность D-TLB, Intel Pentium 4 Northwood
Ассоциативность D-TLB, Intel Pentium 4 XE Gallatin
Ассоциативность D-TLB, Intel Pentium 4 Prescott
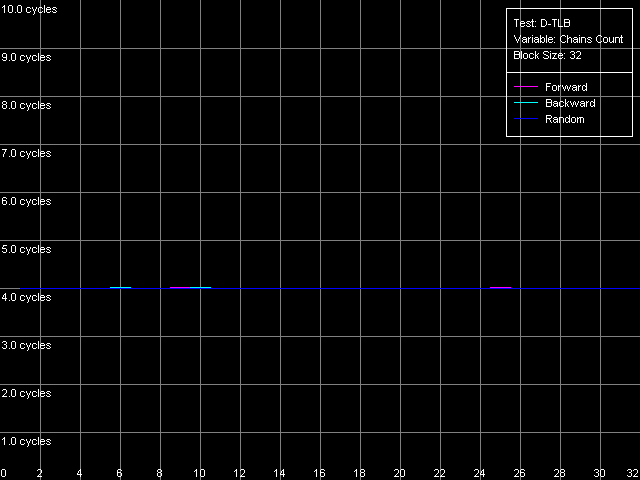
Интерпретация результатов предельно проста — во всех трех моделях процессоров Pentium 4 первый и единственный уровень D-TLB является полноассоциативным.
Характеристики I-TLB
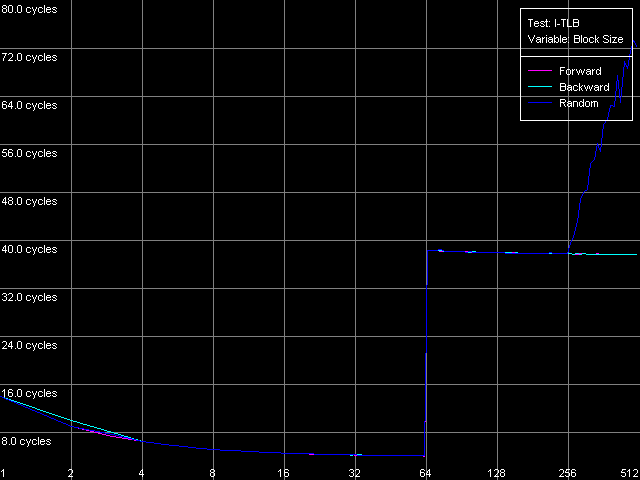
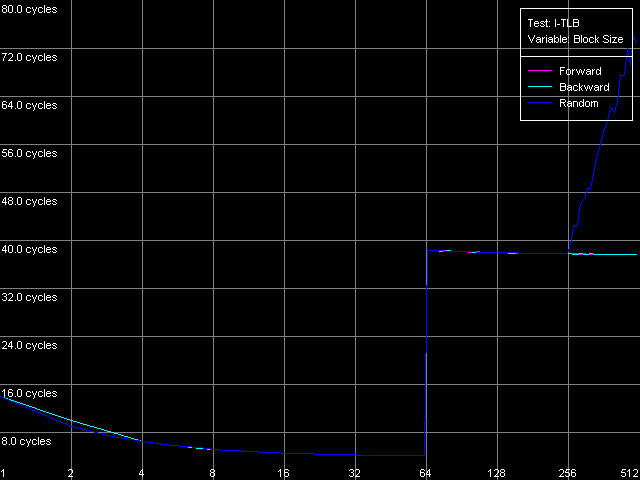
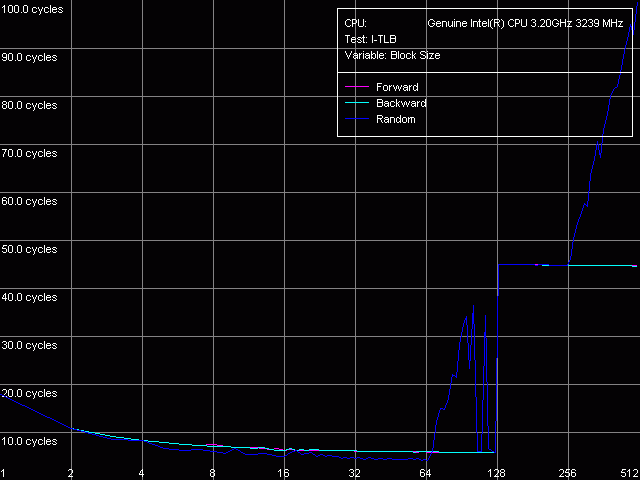
Измерим характеристики TLB инструкций по аналогии с тем, как мы тестировали D-TLB. Вопрос о размере I-TLB также уже частично затрагивался в разделе, посвященном тестированию Trace Cache, где мы увидели, что эффективность декодирования несколько снижается при превышении величины размера блока кода 256 КБ. Это позволило нам предположить, что I-TLB в процессорах семейства Pentium 4 также содержит всего 64 записи для адресации 4-килобайтовых страниц виртуальной памяти. Проверим это предположение с помощью теста I-TLB, пресет I-TLB Size.
Размер I-TLB, Intel Pentium 4 Northwood
Размер I-TLB, Intel Pentium 4 XE Gallatin
Размер I-TLB, Intel Pentium 4 Prescott
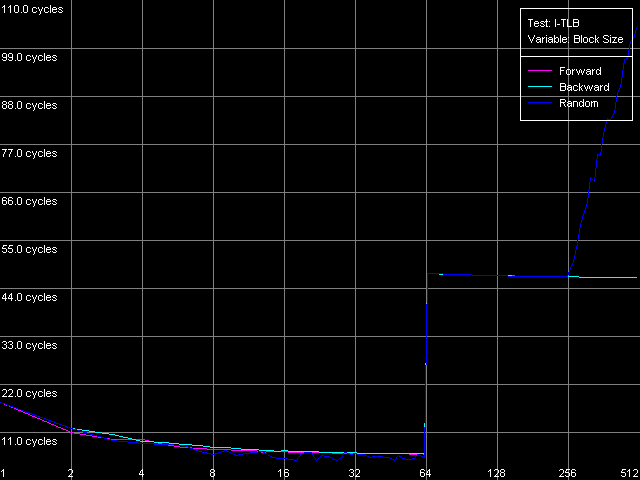
Итак, размер I-TLB у всех трех процессоров действительно соответствует 64 записям дескрипторов страниц (256 КБ) виртуальной памяти. Промах I-TLB обходится не менее серьезно, чем D-TLB — латентность исполнения кода, соответствующего «прыжкам» по страницам виртуальной памяти, возрастает примерно на порядок (до 36 тактов, Northwood/Gallatin и 44 тактов, Prescott) при выходе за границы объема I-TLB.
Нам остается определить ассоциативность I-TLB, воспользовавшись пресетом I-TLB Associativity, 32 Entries.
Ассоциативность I-TLB, Intel Pentium 4 Northwood
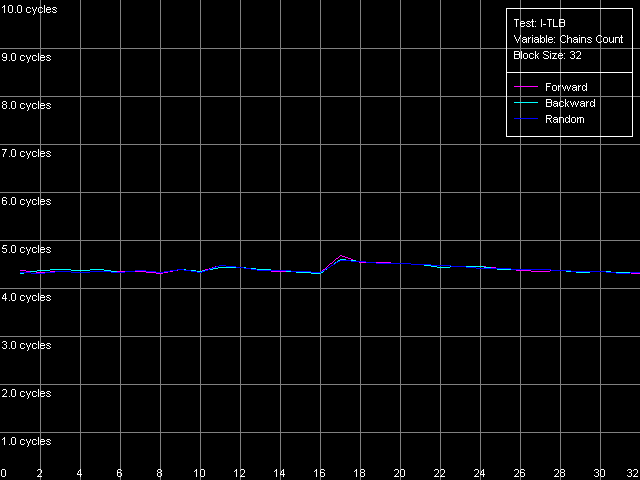
Ассоциативность I-TLB, Intel Pentium 4 XE Gallatin
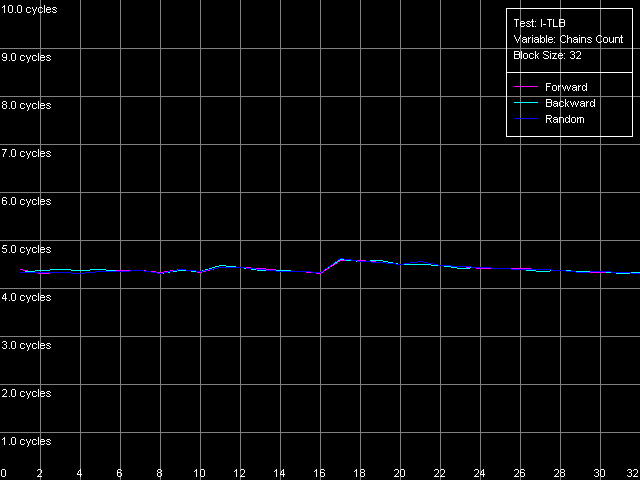
Ассоциативность I-TLB, Intel Pentium 4 Prescott
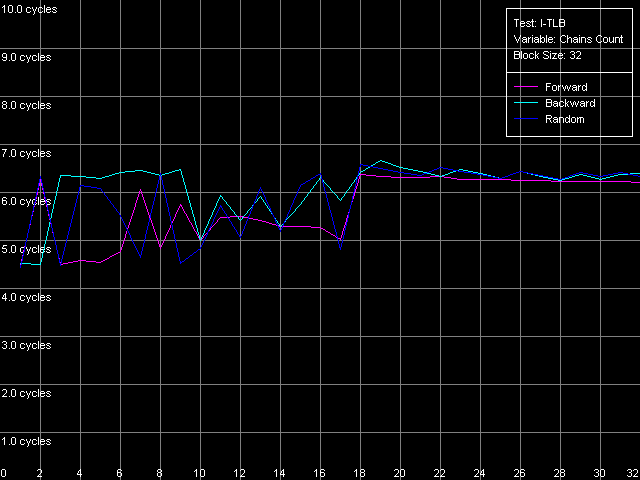
Результат нашего последнего теста показывает, что I-TLB, как и D-TLB в рассматриваемых процессорах, является полностью ассоциативным. В заключение отметим, что со структурной точки зрения ни D-TLB, ни I-TLB не претерпели каких-либо изменений при переходе к новой микроархитектуре NetBurst, реализованной в 90-нм процессорах Pentium 4 Prescott.
Заключение
Настало время подвести итог. Надо сказать, что новая микроархитектура Prescott произвела на нас весьма неоднозначное впечатление. С одной стороны — это улучшенная поддержка Hardware и Software Prefetch, позволяющая достичь больших значений максимальной действительной пропускной способности памяти. Тем не менее, похоже, что на этом положительные моменты новой микроархитектуры заканчиваются. Нет, конечно, есть ряд других приятных моментов — снижение латентности исполнения инструкций Shift и Rotate с четырех до одного такта, ну и, конечно, введение нового набора SIMD-инструкций SSE3, которые мы подробно рассмотрим в отдельной статье. А в остальном остается сплошное разочарование. Увеличение латентности доступа в L1/L2 кэш, снижение эффективной пропускной способности шины между этими уровнями кэша почти в два раза, увеличение латентности исполнения ряда инструкций — можно ли назвать такие моменты «улучшениями» микроархитектуры NetBurst? Скорее, нет, имеет место умышленное сдерживание ее потенциала. Например, для того, чтобы будущие процессоры Pentium 4 с ядром Tejas выглядели на фоне Prescott значительно лучше. Ведь с выпуском последних Intel наверняка уберет все эти сдерживающие моменты, и будет демонстрировать всем свое новое «чудо техники». Впрочем, настанет время, и мы обязательно доберемся до низкоуровневого тестирования и Tejas, вскрывая тем самым все ключевые изменения микроархитектуры NetBurst, в точности так же, как мы поступили в этой статье с Prescott.
Приложение 1: Влияние технологии Hyper-Threading
В предлагаемом вашему вниманию небольшом приложении мы попытались оценить, сказывается ли наличие/отсутствие технологии Hyper-Threading (точнее, ее включение или отключение в BIOS) на величины каких-либо низкоуровневых параметров платформ Intel Pentium 4, и если да, то как именно. Поводом к этому исследованию явились обнаруженные экспериментально различия в значениях дескрипторов кэша/TLB, выдаваемых функцией CPUID (EAX = 2) процессоров семейства Intel Pentium 4. Собственно, различия были обнаружены лишь в одном дескрипторе, отвечающем за размер I-TLB.
| Модель процессора | Значение | Описание |
|---|---|---|
| P4 Northwood 2.4 ГГц, без Hyper-Threading | 50h | Instruction TLB: 4K, 2M or 4M pages, fully associative, 64 entries |
| P4 Northwood 3.06 ГГц, с Hyper-Threading | 51h | Instruction TLB: 4K, 2M or 4M pages, fully associative, 128 entries |
Мы решили проверить, так ли это на самом деле, для чего запустили реализованный в RMMA v2.5 тест I-TLB (пресет I-TLB Size). Результаты теста на Northwood и Prescott оказались одинаковыми — ниже мы приводим картинки, полученные на последнем.
Размер I-TLB, Intel Pentium 4 Prescott, HT on
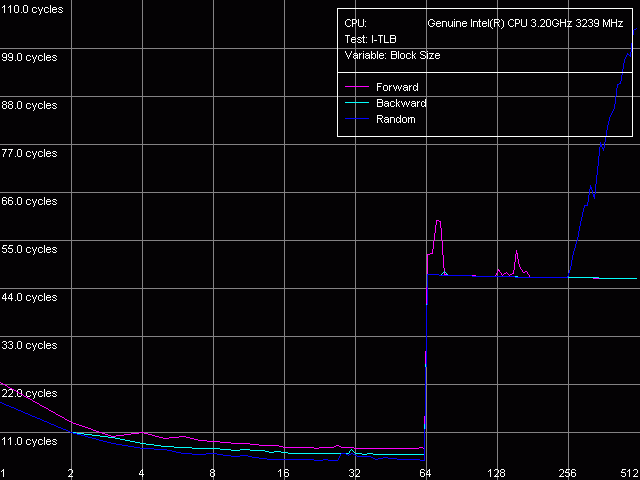
Размер I-TLB, Intel Pentium 4 Prescott, HT off
Что ж, размер I-TLB при включении технологии Hyper-Threading действительно уменьшается вдвое, но его промах в обоих случаях обходится процессору одинаково (латентность возрастает на порядок). Таким образом, можно сказать, что включение Hyper-Threading как бы приводит к разделению этого буфера на две части — каждому логическому процессору достается своя половина. В связи с чем, используя терминологию Intel, I-TLB можно отнести к «разделяемому» (partitioned) типу ресурсов процессора. Таковыми, согласно документации Intel, является большинство различных буферов, реализованных в микроархитектуре NetBurst — в качестве примера приводятся буферы очередей микроопераций (находящиеся после Trace Cache), переименованных регистров (естественно, каждому логическому процессору необходим как бы отдельный набор регистров), буфер переупорядочивания микроопераций (reorder buffer), а также буферы загрузки-сохранения данных (load-store buffers). Интересно, что I-TLB, разделение которого видно невооруженным глазом, никак не упоминается. Разделение таких буферов, как отмечает Intel, призвано минимизировать простои одного логического процессора в случае, если второй логический процессор «застрял» в результате какого-либо промаха (промаха кэша, неправильно предсказанного ветвления, зависимости инструкций и т.п.).
В то же время, анализ дескрипторов кэша, да и проведенные тесты D-TLB (пресет D-TLB Size) не показали каких-либо различий в размере этого буфера при включении и выключении Hyper-Threading — он остается равным 64 записям в обоих случаях, т.е. при включении Hyper-Threading становится общим для обоих логических процессоров (в терминологии Intel — «обобщенный» (shared) ресурс процессора). Обобщенными ресурсами при задействовании Hyper-Threading становится большинство ресурсов процессора — целью этого является повышение эффективности динамической утилизации соответствующего ресурса. К ним относятся кэши процессора и все исполнительные ресурсы. Касательно D-TLB, который, как мы обнаружили, действительно является обобщенным ресурсом, в документации отмечается, что его записи в этом случае содержат идентификатор логического процессора.
В заключение отметим, что результаты всех остальных тестов RMMA не показали каких-либо значимых различий в остальных важнейших низкоуровневых параметрах процессоров при включении/отключении технологии Hyper-Threading. Разумеется, с той оговоркой, отмеченной в документации RMMA, что тестирование процессоров Pentium 4 в режиме Hyper-Threading проводилось в строго «однопоточном» режиме, т.е. в условиях минимальной загрузки системы посторонними процессами.


