Часть 1: Платформы AMD K7/K8
В предыдущей статье, посвященной разработанному нами тестовому пакету RightMark Memory Analyzer, мы рассмотрели основные возможности программы и принципы работы реализованных в ней тестов важнейших характеристик платформы (если говорить более точно, подсистемы процессор/чипсет/память). Теперь настало время, так сказать, проверить теорию на практике. А именно проверить применимость заложенных в разработанном нами тестовом пакете принципов для объективного измерения низкоуровневых характеристик различных существующих на сегодняшний день платформ. Мы открываем цикл статей по измерению характеристик платформ рассмотрением платформ семейства AMD K7 (процессор Athlon XP, ядро Palomino) и K8 (процессор Opteron 244).
Конфигурации стендов и ПО
- Тестовый стенд №1
- Процессоры: AMD Athlon XP 1800+ (1533 МГц, 256 КБ L2) в режиме SMP
- Материнская плата: ASUS A7M266-D (версия BIOS 1010) на чипсете AMD 760MPX
- Память: 2x256 МБ PC2100 DDR SDRAM, 133 МГц (тайминги 2-2-2-6)
- Программное обеспечение
- Windows XP Professional SP1
- AMD PCI Bus Master IDE Driver 1.43c
- AMD AGP Driver 5.33
- RightMark Memory Analyzer 2.4 (использовалась опция ThreadLock, позволяющая получать более надежные результаты на SMP платформах).
- Тестовый стенд №2
- Процессор: AMD Opteron 244 (1800 МГц = 200x9, 1 МБ L2)
- Материнская плата: ASUS SK8N на чипсете nForce3
- Память: 4x512 МБ PC2700 DDR, 166 МГц (тайминги 2.5-3-3-7)
- Программное обеспечение
- Windows XP Professional SP1
- RightMark Memory Analyzer 2.4
Реальная пропускная способность кэша данных/памяти
Для оценки средних величин реальной пропускной способности кэша данных и оперативной памяти, а также размеров уровней кэша данных, воспользуемся первым реализованным в RMMA тестом (Memory Bandwidth), выбрав пресет D-Cache/RAM Bandwidth, MMX Registers.
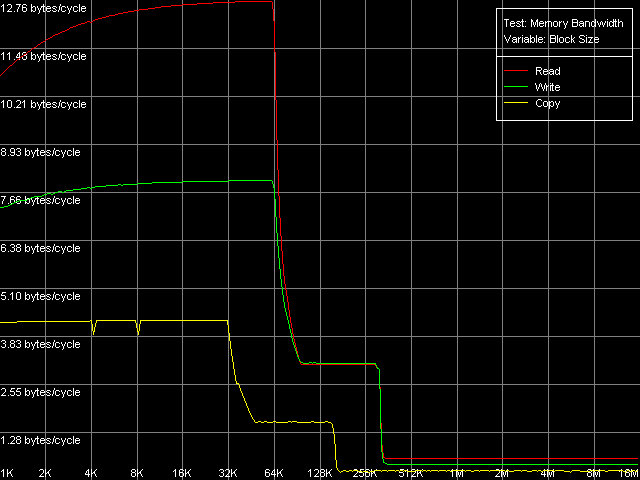
AMD Athlon XP 1800+
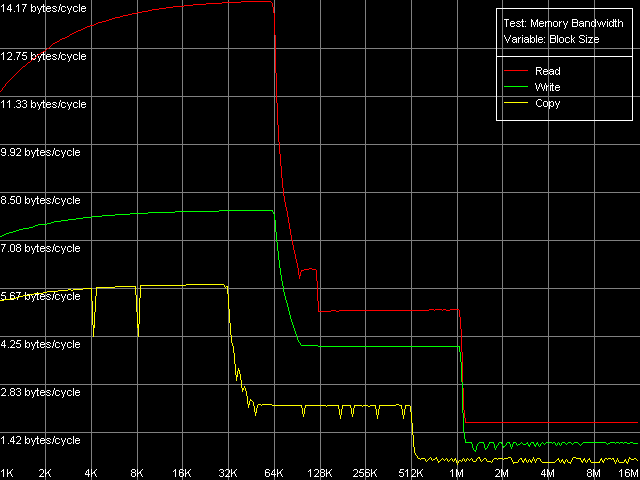
AMD Opteron 244
Мы видим, что оба процессора имеют кэш данных первого уровня размером 64 КБ (первый перегиб на кривых Read и Write). Интересной особенностью кривых в обоих случаях является наличие второго перегиба в области, соответствующей суммарному размеру L1+L2 кэшей данных (320 КБ и 1088 КБ, соответственно). Такая особенность является весьма характерным признаком эксклюзивной архитектуры кэша данных процессора (каковой она и является в процессорах семейства AMD K7/K8), в то время как кривые на процессорах с инклюзивной архитектурой (как мы увидим далее) имеют перегибы в областях, соответствующих размерам L1 и L2 (а также L3) кэша.
Средняя реальная пропускная способность кэша L1, точнее, связки L1-LSU, на чтение в обоих случаях (12.8 байт/такт, K7 и 14.2 байт/такт, K8) немного не дотягивает до теоретического максимума 16 байт/такт. Последний соответствует 128-битной шине данных между L1 и LSU (Load-Store Unit), заявленной в документации AMD (два 64-битных порта). Эффективность L1 на запись гораздо (а именно, в два раза) ниже, что позволяет предположить использование лишь одного такого порта при операциях записи данных.
В рассматриваемой системе K7 значения средней реальной пропускной способности памяти (реальной ПСП) составили 900 МБ/с на чтение и 690 МБ/с на запись. Соответствующие цифры на K8 3100 МБ/с и 2025 МБ/с. В обоих случаях эти величины получились намного меньше предельной теоретической ПСП. Это не удивительно, поскольку в данном тесте не используются какие-либо оптимизации, направленные на достижение максимально возможных значений реальной ПСП. Мы попытаемся достичь этих значений в следующих тестах. Но сначала рассмотрим ту же картину, но используя регистры SSE вместо MMX (пресет D-Cache/RAM Bandwidth, SSE Registers).
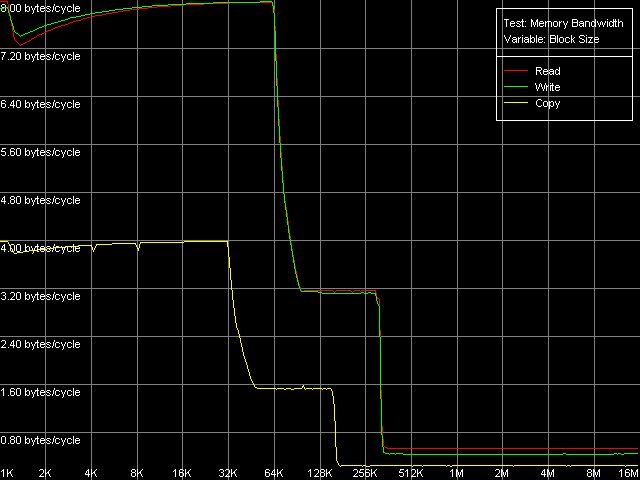
AMD Athlon XP 1800+
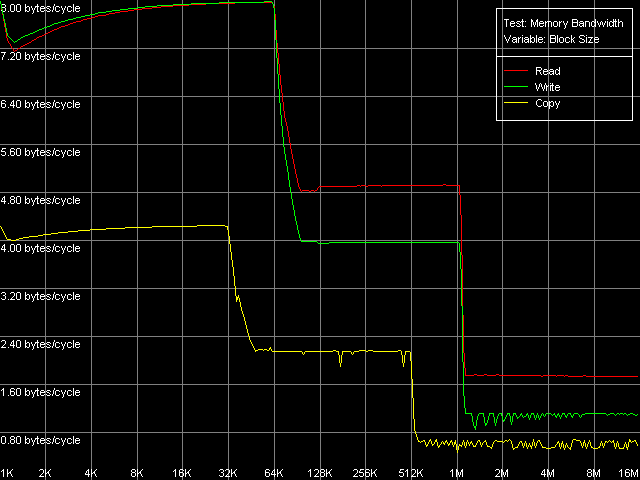
AMD Opteron 244
Полученную картину можно назвать одновременно и ожидаемой (K7) и довольно неожиданной (K8). То, что эффективность работы процессоров AMD K7 с регистрами SSE ниже, чем у конкурентов, наверное, не удивит никого. В частности, высказывались предположения (не лишенные оснований), что Athlon XP/MP не имеет самостоятельного блока SSE, а его функциональность эмулируется посредством 3DNow! Но сейчас мы отметим лишь то, что предельная реальная ПС связки L1-LSU в случае пересылки 128-битных значений составляет величину 8 байт (64 бита)/такт. Иными словами, за один такт передается лишь половина операнда, хранящегося в XMM-регистре. И это несмотря на 128-разрядность соответствующей шины. Удивляет, однако, что в архитектуре K8 (со времен K7) в этом отношении ничего не изменилось, т.е. инженеры AMD явно не позаботились об улучшении передачи 128-разрядных данных по шине L1-LSU. Эффективность последней на запись в этом случае составляет точно такое же значение (8 байт/такт, которое получается и в случае использования MMX-регистров).
Предельная реальная пропускная способность памяти
Попытаемся оценить предельную реальную ПСП в операциях чтения/записи данных. При этом будем использовать регистры MMX, поскольку в обоих случаях лучшие результаты у нас получились именно с ними. Для начала будем использовать метод Software Prefetch для чтения, включив режим прямой записи в память, минуя кэш данных процессора (Non-Temporal store). Для этого выберем пресет Maximal RAM Bandwidth, Software Prefetch, MMX Registers.
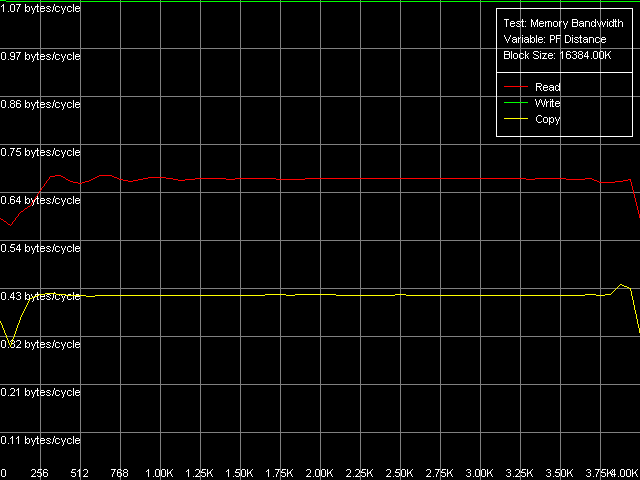
AMD Athlon XP 1800+
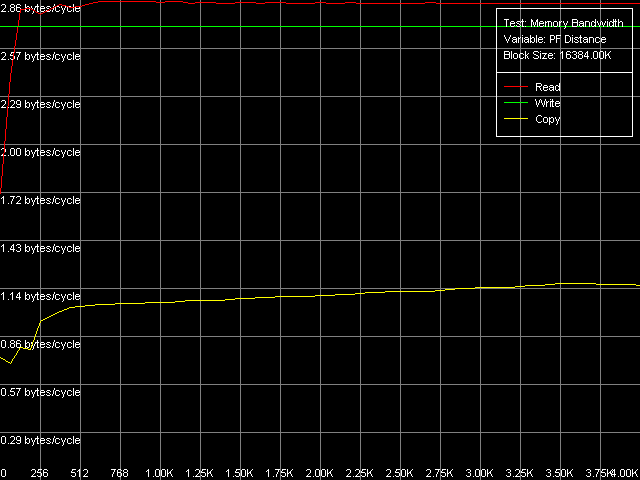
AMD Opteron 244
Различия между архитектурами K7/K8 оказываются весьма существенными. Software Prefetch для K7 явно слабоват. Максимальная реальная ПСП на чтение в нашем тесте составляет 1047 МБ/с (при длине префетча 320 байт и выше), что всего лишь в 1.16 раз выше среднего значения. В то же время, выигрыш от использования Software Prefetch на K8 весьма значителен: реальная ПСП на чтение достигает 5150 МБ/с (длина префетча 640 байт и выше), а это в 1.66 раз выше, чем при обычном чтении данных. За столь хорошую реализацию Software Prefetch инженеров AMD остается только похвалить.
Посмотрим теперь, как сказывается включение режима Non-Temporal store на величинах реальной ПСП записи данных. Они составляют 1647 МБ/с для Athlon XP (в 2.38 раз выше по сравнению со средней) и 4880 МБ/с для Opteron (в 2.41 раза выше). Таким образом, выигрыш оказывается весьма значительным и сопоставимым на обоих платформах. Более того, полученные в этом тесте значения реальной ПСП на запись в обоих случаях оказываются действительно предельными, недостижимыми другими методами (как будет показано ниже).
Итак, поскольку реальная ПСП на чтение на нашей первой тестовой системе (Athlon XP) получилась явно не максимально возможной, попробуем другими методами выжать из этой системы максимум. А заодно посмотрим, насколько хорошо они подходят для нашей второй тестовой системы (Opteron). Выберем метод Block Prefetch 1, который как раз рекомендуется AMD для достижения максимальной действительной пропускной способности чтения на системах класса K7 (пресет Maximal RAM Bandwidth, Block Prefetch 1, MMX Registers).
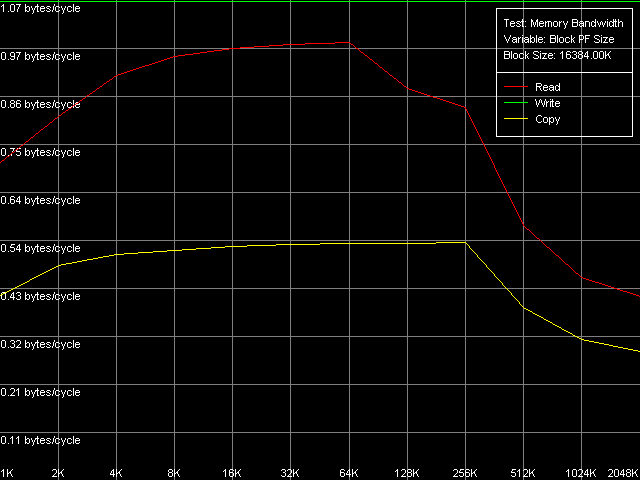
AMD Athlon XP 1800+
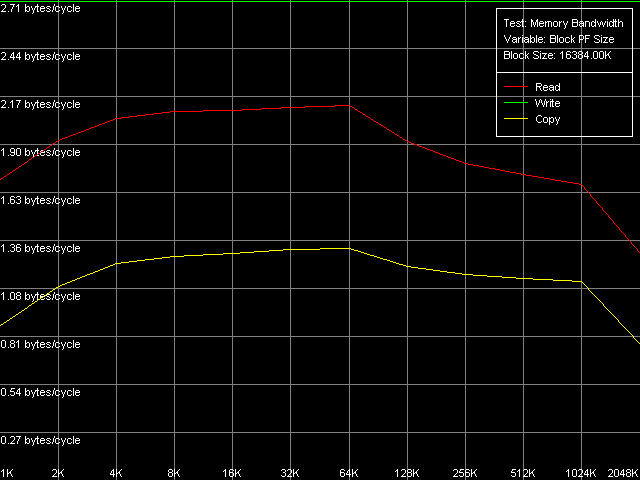
AMD Opteron 244
Поскольку методы Software Prefetch / Block Prefetch касаются лишь чтения данных, реальная ПСП на запись на обоих платформах, естественно, какой была, такой и осталась. Зато в этом тесте мы достигли максимального значения реальной ПСП на чтение для платформы K7, равное 1505 МБ/с (в 1.67 раз быстрее по сравнению со средней реальной ПСП) при размере префетч-блока 64 КБ, соответствующем размеру L1 кэша данных. Она несколько уменьшается при дальнейшем увеличении размера префетч-блока (т.е., при достижении области L2), затем резко падает (при размере префетч-блока 256 КБ на Athlon XP и 1 МБ на Opteron). Интересно отметить, что поведение кривых чтения данных более-менее одинаково на обоих платформах, но максимальная действительная ПСП на чтение на Opteron в этом случае не достигается (она составляет всего 3813 МБ/с, т.е. 123% от средней величины). В то же время, вновь наблюдаются определенные различия между этими двумя платформами AMD. Так, максимальная действительная ПСП, при осуществлении операции копирования на Athlon XP, наблюдается при размере префетч-блока, равного объему L2 (256 КБ), в то время как на Opteron ее профиль полностью повторяет профиль чтения, имея два перегиба при 64 (L1) и 1024 КБ (L2). Это связано, по-видимому, с различным способом утилизации кэша данных этих процессоров при осуществлении операции копирования с использованием прямого (Non-Temporal) сохранения данных.
Рассмотрим несколько иной метод предварительного кэширования данных Block Prefetch 2 (напомним, что отличия методов Block Prefetch между собой мы рассматривали в нашей первой статье). Именно этот метод рекомендуется в руководстве по оптимизации 64-битного ПО для платформы AMD K8 при осуществлении чтения/копирования крупных блоков данных (относительно его применимости касательно 32-битных программ почему-то умалчивается). Посмотрим, насколько хорошо он подходит для рассматриваемых нами платформ (пресет Maximal RAM Bandwidth, Block Prefetch 2, MMX Registers).
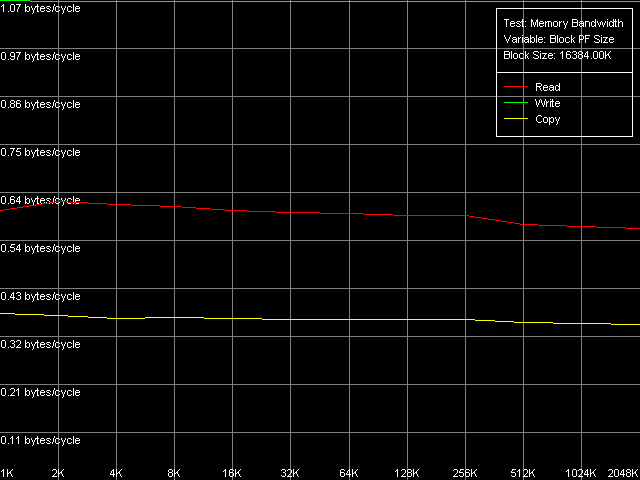
AMD Athlon XP 1800+
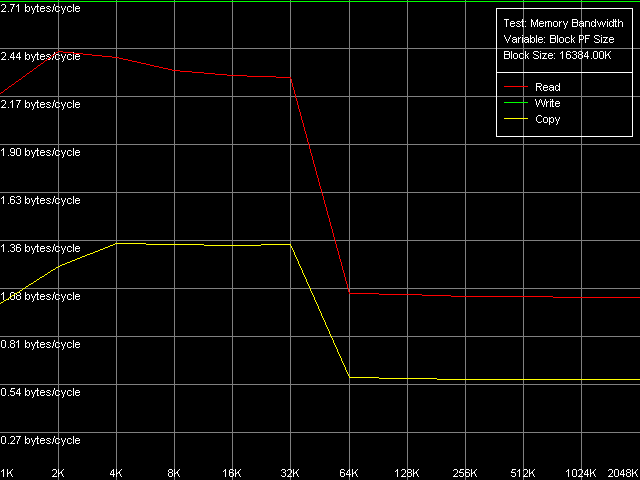
AMD Opteron 244
Мы видим, что для Athlon XP этот метод совершенно никуда не годится, хотя некий выигрыш в скорости все же есть (957 МБ/с против среднего значения 900 МБ/с, т.е. в 1.06 раз выше). Что касается платформы Opteron результат, надо сказать, неожиданный. Увеличение реальной ПСП, конечно, имеет место быть (4366 МБ/с против 3100 МБ/с, выигрыш в 1.41 раз). Но все же не такое весомое, как при использовании самого обычного Software Prefetch (1.66 раз). Что же получается этот метод и впрямь годится только для 64-битного кода? Что-то не особо верится, но будем надеяться, что это можно будет проверить в не столь отдаленном будущем.
Картина максимальной реальной ПСП на чтение/запись была бы неполной без рассмотрения еще одного метода чтения/записи не отдельных 64- (или 128-) битных значений в регистры процессора, а сразу целых строк кэш (размер которой у наших процессоров составляет 64 байта) из памяти в кэш процессора (чтение), или, наоборот, из кэша в память (запись). Для этого перейдем сразу в третий подтест RMMA (D-Cache Bandwidth) и выберем там пресет L2 Cache-RAM Bus Bandwidth.
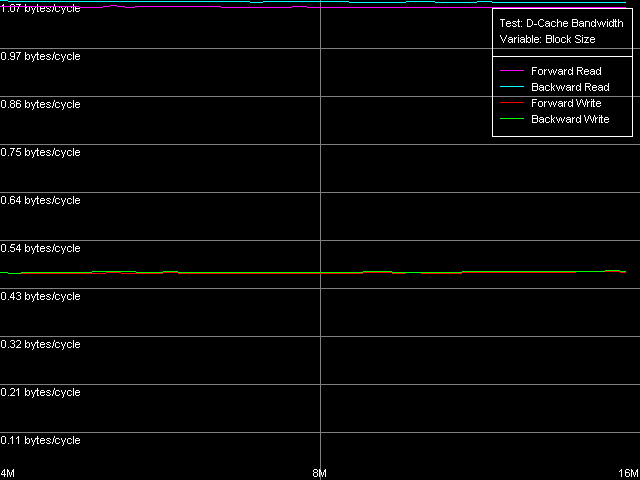
AMD Athlon XP 1800+
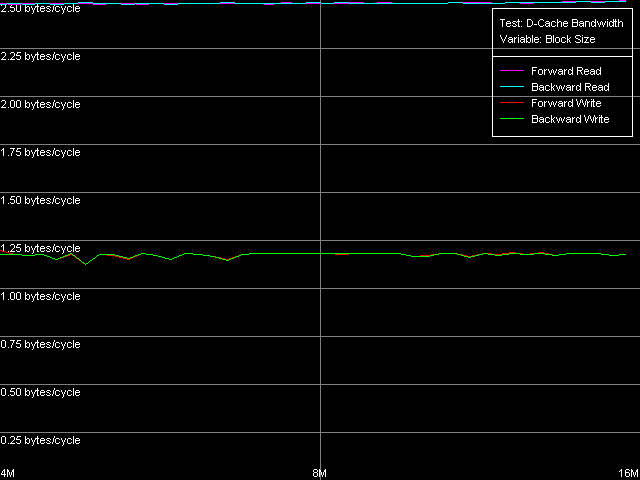
AMD Opteron 244
Есть чему порадоваться в этом тесте мы наконец-то достигли максимальную величину реальной ПСП на чтение для Athlon XP (1630-1647 МБ/с, что в 1.81-1.83 раз выше средней реальной ПСП). Которая, кстати, равняется максимальной действительной ПСП на запись, полученной методом прямого сохранения данных (1647 МБ/с). Таким образом, данную цифру можно действительно считать предельной величиной для данной конкретной системы (на ее значение, конечно, влияет не только тип используемого процессора, но также чипсета и собственно памяти). А вот система на Opteron в этом тесте демонстрирует далеко не лучший результат (4490 МБ/с, что в 1.45 раз выше среднего), вполне сопоставимый с полученным нами ранее методом Block Prefetch 2.
С записью целых строк кэш на обоих системах дела обстоят немногим лучше, чем с тотальной записью данных различия в величинах реальной ПСП оказываются минимальными (реальная ПСП в операциях записи строк всего в 1.04-1.07 раз выше, чем при тотальной записи).
| Метод | Реальная пропускная способность памяти на чтение | |
|---|---|---|
| AMD K7 | AMD K8 | |
| Тотальное чтение | 900 МБ/с (100 %) | 3100 МБ/с (100 %) |
| Тотальное чтение, Software Prefetch | 1047 МБ/с (116 %) | 5150 МБ/с (166 %) |
| Тотальное чтение, Block Prefetch 1 | 1505 МБ/с (167 %) | 3813 МБ/с (123 %) |
| Тотальное чтение, Block Prefetch 2 | 957 МБ/с (106 %) | 4366 МБ/с (141 %) |
| Чтение строк кэш, прямое | 1630 МБ/с (181 %) | 4492 МБ/с (145 %) |
| Чтение строк кэш, обратное | 1647 МБ/с (183 %) | 4490 МБ/с (145 %) |
| Метод | Реальная пропускная способность памяти на запись | |
|---|---|---|
| AMD K7 | AMD K8 | |
| Тотальная запись | 690 МБ/с (100 %) | 2025 МБ/с (100 %) |
| Тотальная запись, Non-Temporal | 1647 МБ/с (238 %) | 4880 МБ/с (241 %) |
| Запись строк кэш, прямая | 718 МБ/с (104 %) | 2161 МБ/с (107 %) |
| Запись строк кэш, обратная | 721 МБ/с (104 %) | 2133 МБ/с (105 %) |
Резюмируя все вышесказанное, можно сказать, что максимальная действительная ПСП на чтение/запись для рассматриваемой платформы K7 составляет 1647 МБ/с (77% от теоретического максимума 2133 МБ/с). Предельная реальная ПСП на чтение на Opteron равна 5150 МБ/с (98% от теоретического максимума, равного 5250 МБ/с), а на запись несколько ниже, 4880 МБ/с (93% от теоретического максимума).
Латентность кэша данных/памяти
Для оценки средней латентности каждого из уровней кэша данных/памяти воспользуемся вторым тестом, выбрав пресет D-Cache/RAM Latency.
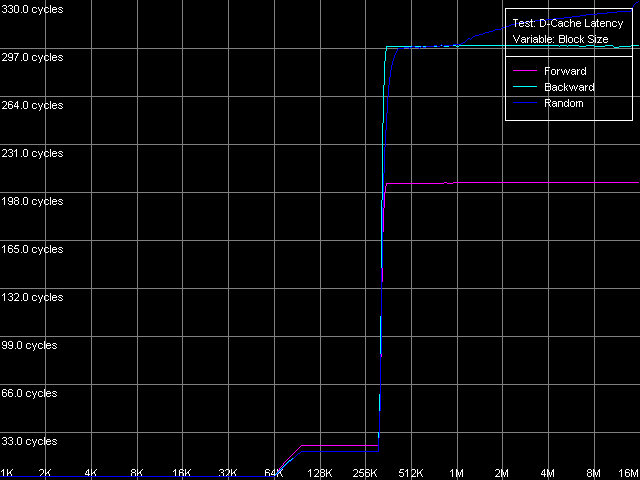
AMD Athlon XP 1800+
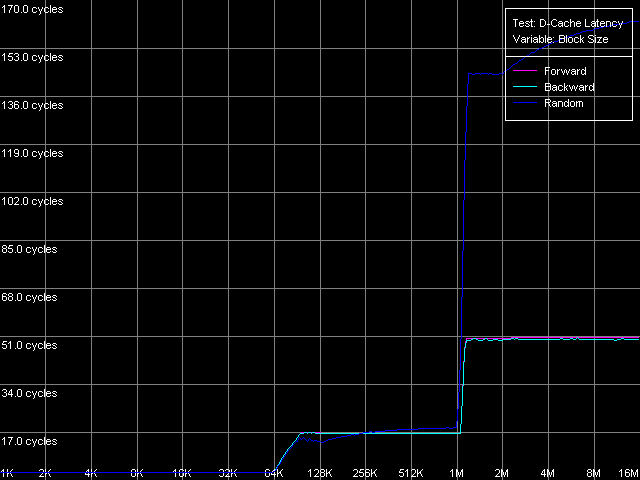
AMD Opteron 244
Латентность кэша L1 для обоих платформ составляет 3 такта во всех случаях доступа (прямой, обратный, случайный). В то же время, латентность кэша L2 процессора Athlon XP составляет 24 такта при прямом доступе (причина этого связана с появлением накладных расходов на организацию алгоритма Hardware Prefetch) и 20 тактов при обратном/случайном доступе. Соответствующие величины на Opteron составляют в среднем 17 тактов (во всех случаях доступа). В обоих случаях она оказывается несколько выше, чем заявленная в документации величина минимальной латентности. Ее мы попытаемся достичь в следующем тесте. А сейчас рассмотрим среднюю латентность доступа к памяти. На платформе K7 она составляет величину порядка 205 тактов (133 нс) при прямом доступе и примерно 300 тактов (195 нс) при обратном/случайном доступе, что говорит о наличии относительно хорошего механизма Hardware Prefetch, работающего в случае прямого последовательного обращения к памяти. Тем не менее, картина латентности памяти на K8 куда лучше. Первое, что бросается в глаза это наличие превосходного алгоритма Hardware Prefetch, причем работающего как при прямом, так и при обратном обходе (величины латентности памяти составляют всего 50 тактов, т.е. 28 нс!). Латентность при случайном доступе несколько выше 144 такта (80 нс). Плавное увеличение последней в обоих случаях (при размере блока 1 МБ и выше на K7, 2 МБ и выше на K8) связано с увеличением количества промахов L2 D-TLB, размер которого может обеспечить эффективную случайную адресацию именно таких объемов данных, но не более.
| Уровень | Средняя латентность (прямой/обратный/случайный доступ), AMD K7 | Средняя латентность (прямой/обратный/случайный доступ), AMD K8 |
|---|---|---|
| L1 кэш | 3/3/3 | 3/3/3 |
| L2 кэш | 24/20/20 | 17/17/17 |
| RAM | 205/300/300 (133/195/195 нс) | 50/50/144 (28/28/80 нс) |
Минимальная латентность L2 кэша данных/памяти
Для оценки минимальной латентности L2 воспользуемся пресетом с очевидным названием Minimal L2 Cache Latency.
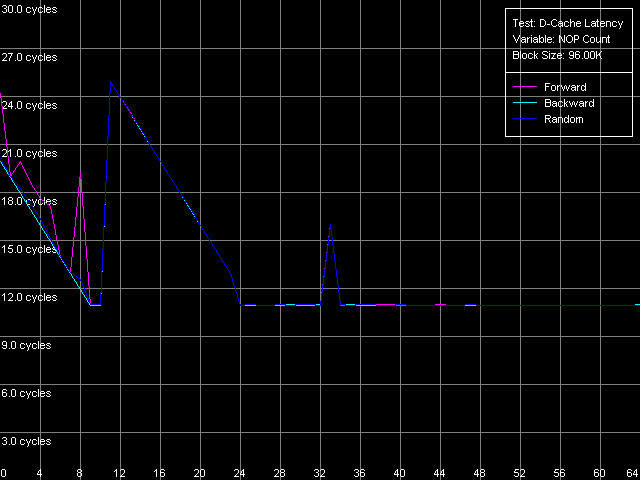
AMD Athlon XP 1800+
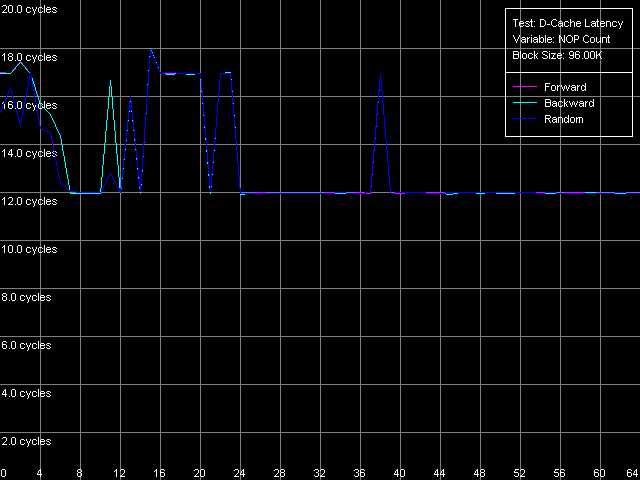
AMD Opteron 244
Интересно отметить, что в обоих случаях минимальная латентность L2 (11 тактов, AMD K7; 12 тактов, AMD K8), во всех режимах доступа, наблюдается при вставке 24-х «NOP»-ов. Поскольку каждый «NOP» = or eax, edx на процессорах AMD K7/K8 исполняется ровно один такт, это соответствует 24-тактной разгрузке шины L1-L2 между каждыми последующими обращениями к ней. Довольно интересные «скачки» в области 33 (K7) и 38 (K8) «NOP»-ов, а также особенности ее «разгрузки» в области до 24-х «NOP»-ов пока что остаются необъяснимыми.
Оценим минимальную латентность памяти. Для этого за основу возьмем пресет Minimal RAM Latency, 4M Block. Далее, учитывая полученную выше картину латентности, уменьшим размер блока до 1 МБ для системы K7 и до 2 МБ для K8. Это позволит минимизировать потери, связанные с промахом L2 TLB.
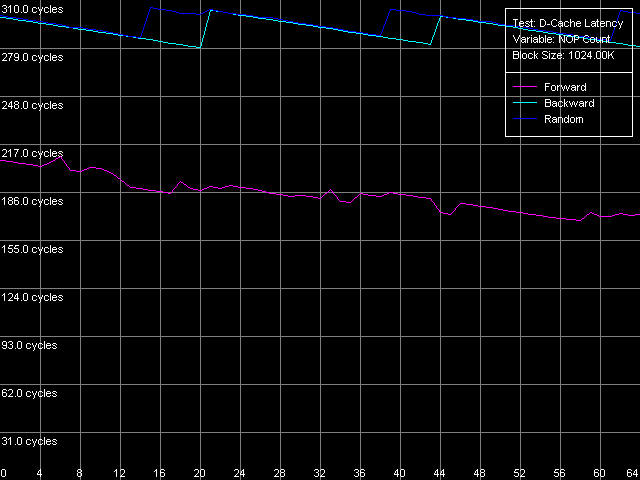
AMD Athlon XP 1800+
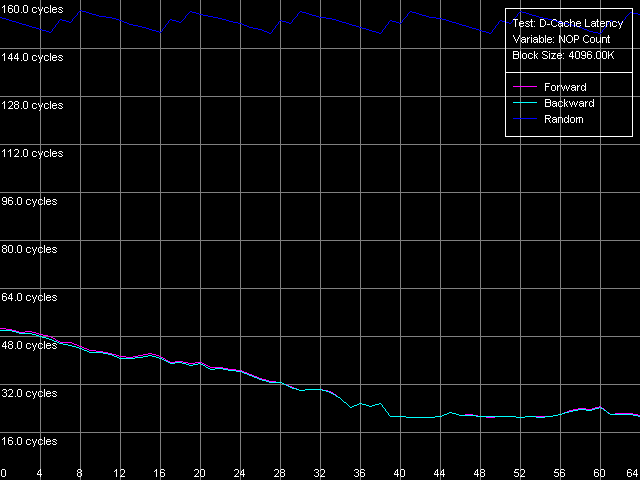
AMD Opteron 244
Рассмотрим вид кривых на платформе K7. Увеличение разгрузки шины L2-RAM ведет к плавному уменьшению величины латентности прямого последовательного доступа к памяти. По результатам данного теста нельзя сказать о достижении минимальной величины. Тем не менее, отдельный тест показывает, что она достигается при вставке порядка 380 «NOP»-ов между каждыми последующими обращениями и составляет величину 25-26 тактов процессора. В то же время, кривые обратного последовательного и случайного доступа имеют принципиально иной вид они характеризуются наличием «зубчиков» со вполне определенной периодичностью. Латентность обратного доступа к памяти находится в интервале 280 304 такта (183 198 нс), а латентность случайного доступа оказывается лишь незначительно выше (284 305 тактов, 185 199 нс), поскольку, как было сказано выше, мы измеряли ее в условиях практически полного отсутствия промахов L2 TLB.
Заслуживает внимания вид кривых обратного и случайного доступа. Возникновение «зубчиков» связано с тем, что новый цикл обмена с памятью может стартовать/заканчиваться только на целом числе тактов системной шины. Как можно видеть, в данном случае «зубчики» расположены с интервалом в 23 «NOP»-а. Это означает, что цикл обмена с памятью в рассматриваемой системе (с коэффициентом умножения, равным 1533.3/133.3 = 11.5) может осуществляться только на каждом четном (либо нечетном) такте шины памяти. Причина такого поведения некоторых платформ AMD K7 пока что остается невыясненной. Отметим лишь, что это не связано с двухпроцессорной конфигурацией тестируемой системы, а также не зависит от типа используемой памяти (DDR или SDRAM) и является, по всей видимости, особенностью реализации того или иного чипсета.
Картина минимальной латентности памяти на Opteron существенно отличается. Прежде всего следует упомянуть достижение минимального значения латентности прямого/обратного последовательного доступа уже при 39 «NOP»-ах (что почти в 10 раз меньше по сравнению с Athlon XP), которая составляет всего 21 такт процессора (11.7 нс). Латентность случайного доступа оказывается гораздо выше (по-видимому, именно ее следует считать объективной характеристикой латентности памяти в системах, где реализован алгоритм Hardware Prefetch). Она находится в интервале 139 148 тактов (77 82 нс) и характеризуется в точности такой же «зубчатой» кривой с периодичностью в 11 «NOP»-ов, что соответствует возможности осуществления цикла обмена с памятью на каждом такте ее 166 МГц шины.
| Минимальная латентность (прямой/обратный/случайный доступ), AMD K7 | Минимальная латентность (прямой/обратный/случайный доступ), AMD K8 | |
|---|---|---|
| L1 | 3/3/3 | 3/3/3 |
| L2 | 11/11/11 | 12/12/12 |
| RAM | 25/280/284 (16.3/183/185 нс) | 21/21/139 (11.7/11.7/77 нс) |
Ассоциативность кэша данных
Для определения ассоциативности кэша данных используем пресет D-Cache Associativity.
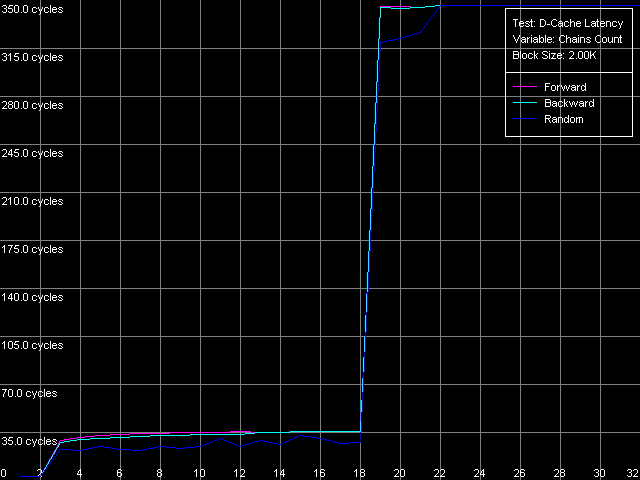
AMD Athlon XP 1800+
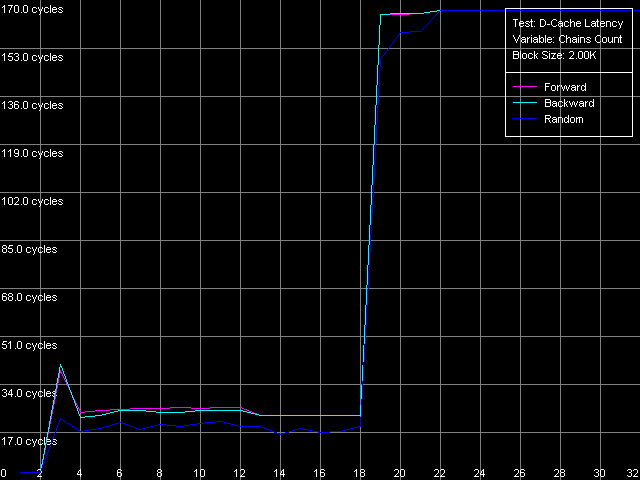
AMD Opteron 244
Оба процессора AMD Athlon XP и Opteron характеризуется очень четкими кривыми, на которых можно выделить область, соответствующую двухнаборно-ассоциативному L1 кэшу (при кол-ве цепочек 1-2), латентность которого так и остается равной 3 тактам во всех случаях доступа. Область 3-18 цепочек соответствует ассоциативности кэша L2, которая в нашем случае получилась как бы завышенной (18, против документированной степени ассоцитивности L2, равной 16). Причина этого явления связана с эксклюзивной архитектурой кэша процессоров семейства AMD K7/K8. Поскольку такая архитектура кэша не предполагает дублирование данных, содержащихся в кэше L1 кэшем L2, величина 18 соответствует как бы «суммарной» ассоциативности L1+L2 кэшей данных. Процессоры с инклюзивной архитектурой кэша, как мы увидим в последующих исследованиях, характеризуются иным видом кривых, перегибы на которых строго соответствуют ассоциативности L1 и L2 кэшей.
Обратим внимание на то, что величина латентности L2 и RAM в обоих случаях получилась несколько завышенной в этом тесте, особенно при последовательном режиме доступа. Такое увеличение латентности, по всей видимости, связано с возрастанием накладных расходов на постоянную переассоциацию строк кэша со строками памяти по схеме LRU (Least Recently Used), что позволяет «удерживать» в иерархии кэшей процессора все данные, считываемые с «нехороших» адресов с точки зрения организации кэша данных процессора.
Реальная пропускная способность шины L1-L2
Для определения этой величины вновь воспользуемся третьим тестом (D-Cache Bandwidth), но выберем пресет L1-L2 Cache Bus Bandwidth.

AMD Athlon XP 1800+
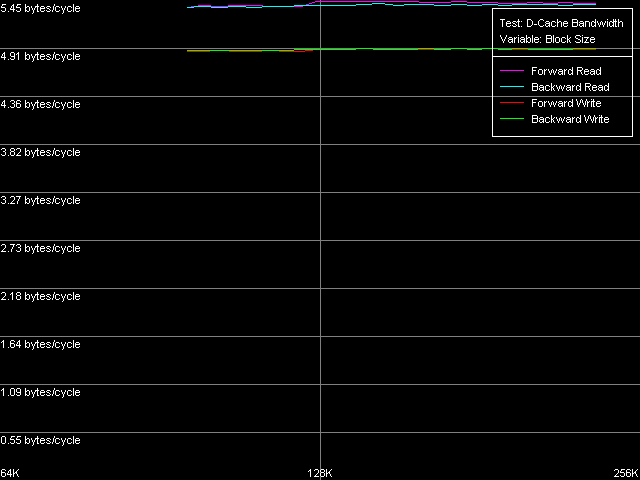
AMD Opteron 244
На первой системе (Athlon XP) мы получили величину реальной ПС шины L1-L2, равную 3.2 байт/такт во всех случаях доступа. Напомним, что каждый акт доступа в L2 (загрузка одной строки кэша L2 в кэш L1) в эксклюзивной архитектуре кэша сопровождается дополнительным сбросом вытесненной строки из L1 в L2, то есть, один акт доступа вызывает пересылку удвоенного объема данных по шине L1-L2. В связи с этим, эффективная ПС шины L1-L2 составляет, в нашем случае, величину 6.4 байт/такт, что в соответствует 64-битной шине данных между L1 и L2 кэшем процессора. На второй тестовой системе (Opteron) реальная пропускная способность шины L1-L2 гораздо выше (10.9 байт/такт с учетом эксклюзивности), что соответствует заявленной в документации AMD 128-битной шине обмена между L1 и L2 кэшем. Отметим и другую интересную особенность эксклюзивной архитектуры кэша, которая проявляется в том, что эффективность шины L1-L2 на запись оказывается не хуже ее эффективности на чтение строк кэш из L2 в L1. Это особенно заметно в архитектуре AMD K7 (реальная ПС шины L1-L2 как на чтение, так и на запись составляет 3.2 (6.4) байт/такт), в то время как AMD K8 характеризуется несколько меньшей эффективностью шины L1-L2 на запись, соответствующая величина реальной ПС которой составляет 4.9 (9.8) байт/такт.
Попытаемся получить некоторые дополнительные характеристики шины L1-L2 кэша, воспользовавшись специально разработанным для этой цели тестом прибытия данных (D-Cache Arrival), измеряющим суммарную латентность двух обращений к одной и той же строке кэша данных. В нашем случае будем использовать пресет L1-L2 Bus Data Arrival, 64 bytes.
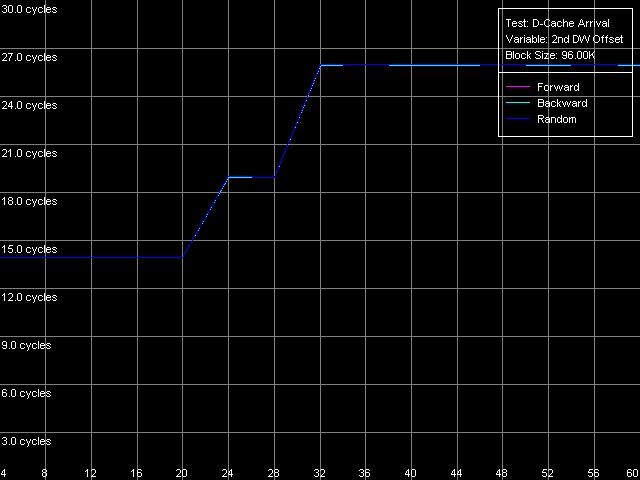
AMD Athlon XP 1800+
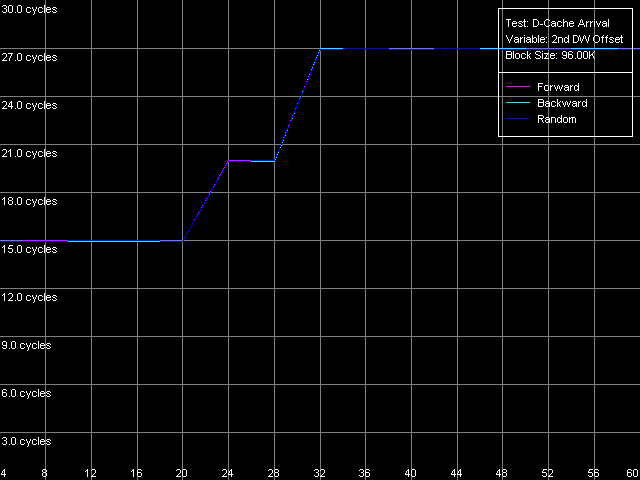
AMD Opteron 244
На рисунках изображена зависимость суммарной латентности двойного обращения от смещения второго обращения (в байтах) относительно первого. Видно, что в данном случае (при достаточной разгрузке шины введением 64 «NOP»-ов между двумя последующими обращениями к соседним строкам кэша) кривые последовательного прямого, обратного и случайного доступа оказываются вырожденными. При смещениях 2-го элемента строки в пределах 4-20 байт относительно первого суммарная латентность двух обращений составляет 14/15 тактов (для K7/K8, соответственно), что в точности соответствует доступу в L2 кэш (11/12 тактов) с последующим доступом в L1 кэш (3 такта). В то же время, возрастание общей латентности при величине смещения 24 байт и выше, связано с тем, что предельная теоретическая пропускная способность двунаправленной 64-битной шины L1-L2 процессора AMD Athlon XP на чтение, составляет величину 8 байт/такт (за 3 такта обращения, связанных с доступом в L1, из L2 может прибыть не более, чем 8x3 = 24 байт данных). Довольно неожиданным является такое же поведение процессора Opteron, означающее, что эффективная разрядность шины L1-L2 на чтение составляет всего 64 бита. Более подробно это рассматривалось в приложении 1 к статье, посвященной детальному исследованию архитектуры AMD64.
Легко показать, что введение дополнительной задержки величиной в 1 такт между последующими обращениями к одной и той же строке кэша (путем увеличения количества SyncNOP на единицу) приводит к «сдвигу» границы, наблюдаемой на графике, на величину 8 байт. При количестве SyncNOP-ов больше пяти эта граница исчезает, поскольку за 3 (L1) + 5 (SyncNOPs) = 8 тактов обращения к кэшу L2 по шине L1-L2 успевает прибыть 8x8 = 64 байта, что соответствует целой строке кэша.
Наконец, попытаемся оценить, как именно осуществляется считывание строки из кэша L2 в кэш L1 (с ее начала, независимо от смещения первого элемента, или же с запрашиваемой позиции, оборачиваясь на конце строки). Для этого воспользуемся возможностью построения графика суммарной латентности от смещения первого слова относительно начала строки кэша, задав такие пользовательские (Custom) параметры теста D-Cache Arrival:
- Variable Parameter = 1st DW Offset;
- Minimal Block Size = 96 KB;
- Minimal NOP Count = 64;
- Minimal SyncNOP Count = 0;
- Stride Size = 64 bytes;
- Minimal 1st Dword Offset = 0;
- Maximal 1st Dword Offset = 60;
- Minimal 2nd Dword Offset = 60;
- Selected Tests = Forward, Backward, Random.
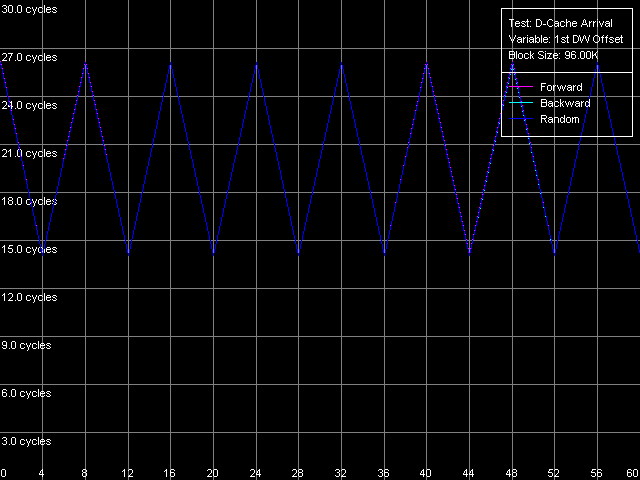
AMD Athlon XP 1800+
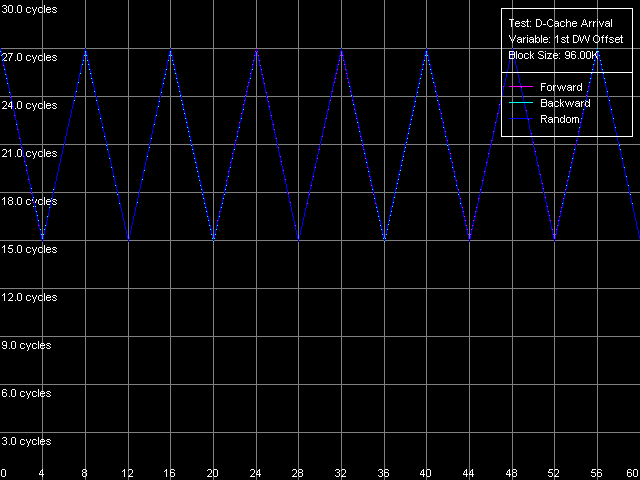
AMD Opteron 244
Отметим, что использование смещения второго слова относительно первого, равного 60 байтам, фактически означает, что его реальное смещение составит -4 байта (за исключением начальной точки, когда смещение действительно равно 60 байтам), т.е. второе слово будет располагаться в строке кэша на одну позицию «левее» первого. Теперь рассмотрим сами рисунки. Прежде всего, опровергнем гипотезу о том, что данные всегда считываются с начала строки, независимо от расположения первого элемента. В этом случае, поскольку считывание 2-го элемента в данном тесте осуществляется в таком порядке: (60, 0, 4, ..., 56), мы имели бы вид кривых, идентичный полученному выше, но со смещением всей картины на 4 байта влево. Таким образом, в рассматриваемых архитектурах (K7 и K8) считывание строки кэша может начинаться с некоторой ненулевой позиции, зависящей от расположения первого элемента. Для ответа на вопрос, как именно связаны эти две величины, рассмотрим сам вид полученных кривых. Легко заметить, что они характеризуется всего двумя значениями суммарной латентности максимумом, равным 26/27 тактам (при смещениях первого слова, кратных восьми, назовем их «четными») и минимумом, равным 14/15 тактам (при «нечетных» смещениях). Иными словами, это означает, что в случае «нечетных» смещений первого слова данные, прибывающие из кэша L2, оказываются в кэше L1 сразу, в то время как считывание данных с «четных» смещений приводит к максимальной задержке прибытия второго слова, отстоящего от первого на -4 байта. На основании полученных результатов сделаем предположение, что считывание строки кэша из L2 в L1 в процессорах семейства AMD K7/K8 может осуществляться с любого смещения, кратного 8 байтам. Далее считывание идет вперед, оборачиваясь на конце строки пока вся строка не считается полностью. Для проверки этого предположения мысленно рассмотрим два примера. Пусть в первом из них данные запрашиваются с «четного» смещения, равного 24 байтам. Тогда считывание данных из L2 в L1, на каждом такте, будет осуществляться в такой последовательности: (24-31, 32-39, 40-47, 48-55, 56-63, 0-7, 8-15, 16-23). Это объясняет, почему задержка чтения второго слова, имеющего фактическое смещение 24 4 = 20 байт, оказывается максимальной (26/27 тактов). Рассмотрим теперь другой случай, когда смещение первого слова оказывается «нечетным», к примеру, 44 байт. Считывание данных, согласно нашему предположению, будет осуществляться так: (40-47, 48-55, 56-63, 0-7, 8-15, 16-23, 24-31, 32-39). Что и объясняет, почему суммарная латентность обращения к элементам, имеющим смещения 44 и 40 байт, соответственно, получилась минимальной (14/15 тактов). А это, в свою очередь, доказывает сделанное выше предположение.
Кэш инструкций, эффективность декодирования
Для начала оценим характеристики уровней кэша инструкций (напомним, что L2 кэш обычно может кэшировать как данные, так и исполняемый код) и эффективность декодирования простой 6-байтной команды cmp eax, 0x00000000, которая позволяет достичь максимальной скорости декодирования. С этой целью воспользуемся тестом I-Cache, выбрав пресет L1i Size / Decode Bandwidth, CMP Instructions 3.
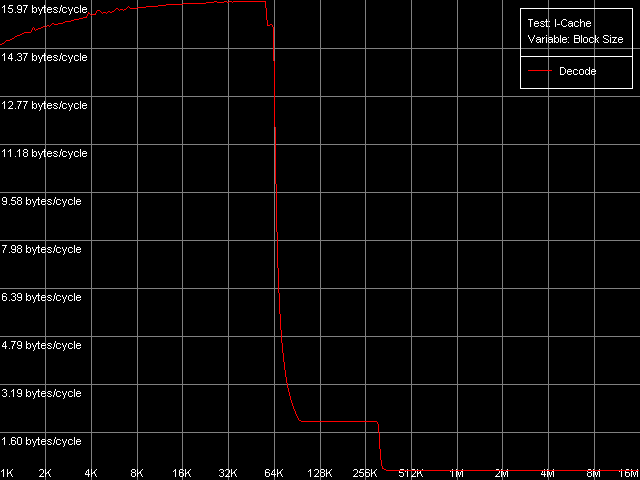
AMD Athlon XP 1800+
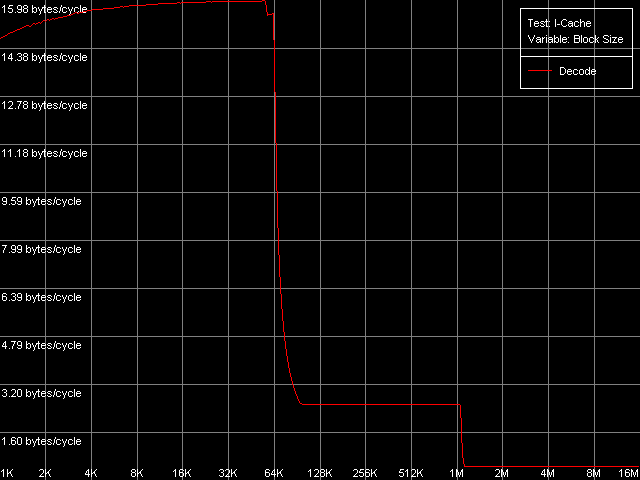
AMD Opteron 244
Размер первого уровня кэша инструкций (L1i), как и ожидалось, составляет ровно 64 КБ как для K7, так и для K8. Неизменной остается и эксклюзивная организация иерархии L1-L2, которая распространяется и на случай кэширования кода. Действительно, кривые скорости декодирования имеют второй перегиб при 320 КБ (64+256) на K7 и 1088 КБ (64+1024) на K8. Эффективность декодирования/исполнения кода, находящегося в L1i кэше, достигает почти предельного для данных архитектур значения 16 байт/такт, о котором мы говорили выше при рассмотрении реальной ПС L1 кэша данных. Эффективность кэширования этого типа инструкций кэшем L2 намного ниже. Посмотрим, как обстоят дела со скоростью исполнения других типов инструкций из L1i/L2 кэша.
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт), AMD K7 | Эффективность декодирования, байт/такт (инструкций/такт), AMD K8 | ||
|---|---|---|---|---|
| L1i кэш | L2 кэш | L1i кэш | L2 кэш | |
| NOP (1) | 3.00 (3.00) | 1.97 (1.97) | 3.00 (3.00) | 2.56 (2.56) |
| SUB (2) | 5.33 (2.67) | 1.97 (0.98) | 6.00 (3.00) | 2.56 (1.28) |
| XOR (2) | 5.33 (2.67) | 1.97 (0.98) | 6.00 (3.00) | 2.56 (1.28) |
| TEST (2) | 5.33 (2.67) | 1.97 (0.98) | 6.00 (3.00) | 2.56 (1.28) |
| XOR/ADD (2) | 5.33 (2.67) | 1.97 (0.98) | 6.00 (3.00) | 2.56 (1.28) |
| CMP 1 (2) | 5.33 (2.67) | 1.97 (0.98) | 6.00 (3.00) | 2.56 (1.28) |
| CMP 2 (4) | 11.98 (3.00) | 1.97 (0.49) | 11.98 (3.00) | 2.56 (0.64) |
| CMP 3 (6) | 15.97 (2.66) | 1.97 (0.33) | 15.98 (2.66) | 2.56 (0.43) |
| CMP 4 (6) | 15.97 (2.66) | 1.97 (0.33) | 15.98 (2.66) | 2.56 (0.43) |
| CMP 5 (6) | 15.97 (2.66) | 1.97 (0.33) | 15.98 (2.66) | 2.56 (0.43) |
| CMP 6 (6) | 15.97 (2.66) | 1.97 (0.33) | 15.98 (2.66) | 2.56 (0.43) |
| Prefixed CMP 1 (8) | 15.97 (2.00) | 1.97 (0.25) | 15.98 (2.00) | 2.56 (0.32) |
| Prefixed CMP 2 (8) | 15.97 (2.00) | 1.97 (0.25) | 15.98 (2.00) | 2.56 (0.32) |
| Prefixed CMP 3 (8) | 15.97 (2.00) | 1.97 (0.25) | 15.98 (2.00) | 2.56 (0.32) |
| Prefixed CMP 4 (8) | 15.97 (2.00) | 1.97 (0.25) | 15.98 (2.00) | 2.56 (0.32) |
Первое, что бросается в глаза это полная независимость скорости исполнения инструкций из L2 от их типа, в случае обоих архитектур K7 (1.97 байт/такт) и K8 (2.56 байт/такт). Во втором случае эффективность исполнения кода из L2, конечно, несколько возросла (почти на 30%), но оба значения явно далеки от теоретического предела для 64-разрядности шины L1-L2 на чтение. Что касается L1i кэша, видно, что декодирование «крупных» инструкций (вроде 6- и 8-байтных cmp) явно лимитируется предельной пропускной способностью L1 16 байт/такт (2.66 инструкций/такт и ниже). А вот на сравнительно «мелких» (одно-, двух- и четырехбайтных) независимых инструкциях можно достигнуть предельной скорости декодирования/исполнения, которая в архитектуре K7/K8 составляет величину 3 инструкции/такт. Легко увидеть, что в декодер K8 введен ряд улучшений, касающихся декодирования простых операций ALU, позволяющих достичь предельную скорость их исполнения, по сравнению с декодером K7.
Попытаемся оценить ассоциативность L1 кэша инструкций и объединенного L2 кэша кода/данных (ассоциативность последнего, естественно, должна равняться полученной нами ранее при анализе ассоциативности L1/L2 кэша данных). Для этого используем пресет I-Cache Associativity.
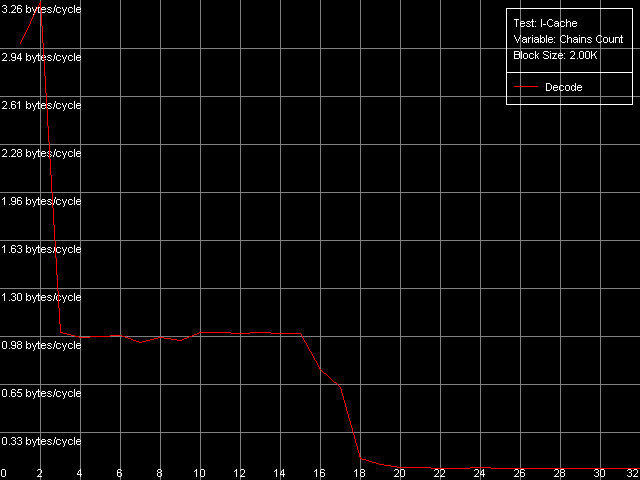
AMD Athlon XP 1800+
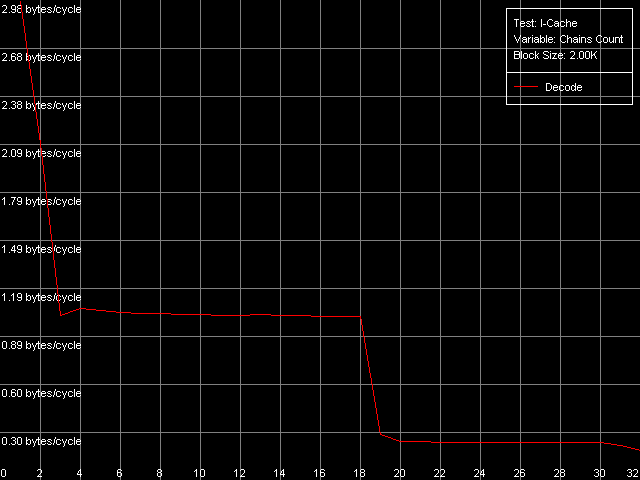
AMD Opteron 244
Результаты тестирования достаточно четкие, в особенности на платформе Opteron. В обоих случаях видно, что ассоциативность L1 кэша инструкций равна двум, а «общая» ассоциативность L1i+L2 равна 18, что еще раз подтверждает эксклюзивную организацию иерархии уровней кэша в рассматриваемых архитектурах процессоров.
Посмотрим, наконец, насколько эффективно эти процессоры умеют «расправляться» с большим количеством (по сути, бессмысленных) префиксов, предшествующих одной-единственной осмысленной x86 инструкции. Для этого воспользуемся специальным пресетом Prefixed NOP Decode Efficiency.
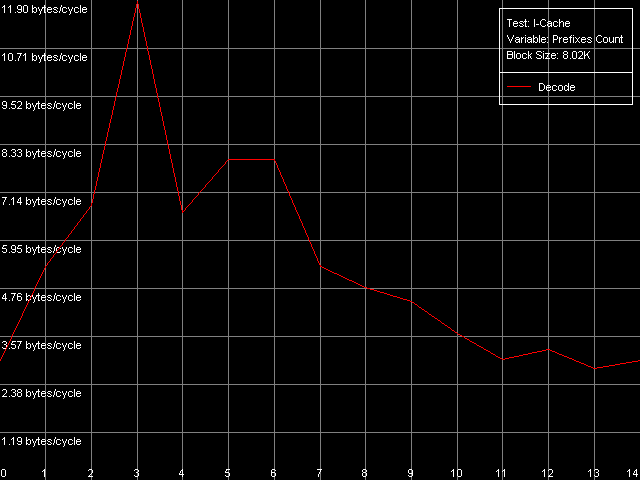
AMD Athlon XP 1800+
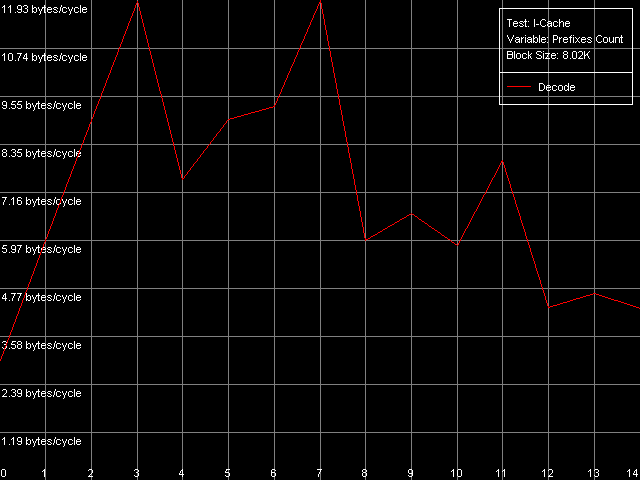
AMD Opteron 244
Кривая зависимости на K7 характеризуется максимумом при количестве префиксов, равном трем (11.2 байт/такт / 4 = 2.8 операций/такт), а при увеличении количества префиксов эффективность декодирования (в пересчете на количество операций) сильно снижается. У K8 с «отсечением» префиксов дела обстоят несколько лучше, хотя все равно не так хорошо, как хотелось. Вид кривой несколько изменился, имеются дополнительные максимумы, которые, однако, не являются таковыми при пересчете на количество исполняемых операций. А ведь именно такие команды [0x66]nNOP рекомендует AMD в своем руководстве по оптимизации ПО для процессоров семейства K8 в качестве «нейтрального» кода, использующегося например, для выравнивания границы начала цикла.
Характеристики уровней D-TLB
Для начала получим общую картину уровней TLB данных, присутствующих в каждом из рассматриваемых процессоров. Для этого выберем тест D-TLB и воспользуемся пресетом D-TLB Size для системы на Athlon XP. Для второй системы (Opteron) мы выбрали ручные настройки теста, увеличив максимальное кол-во измеряемых записей D-TLB до 1024, т.к. размер L2 D-TLB у этого процессора оказался явно больше 512.
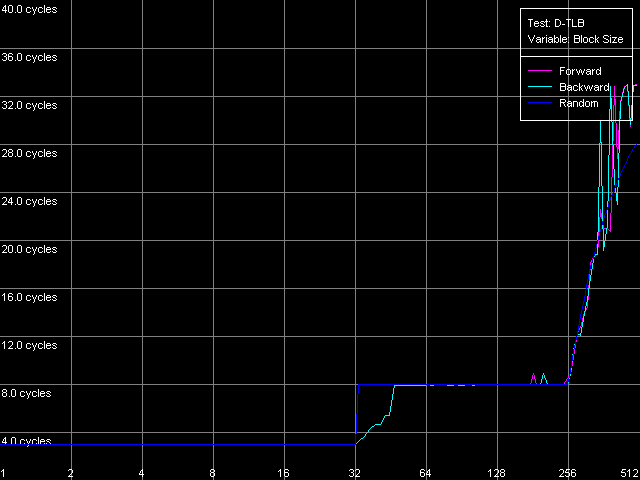
AMD Athlon XP 1800+
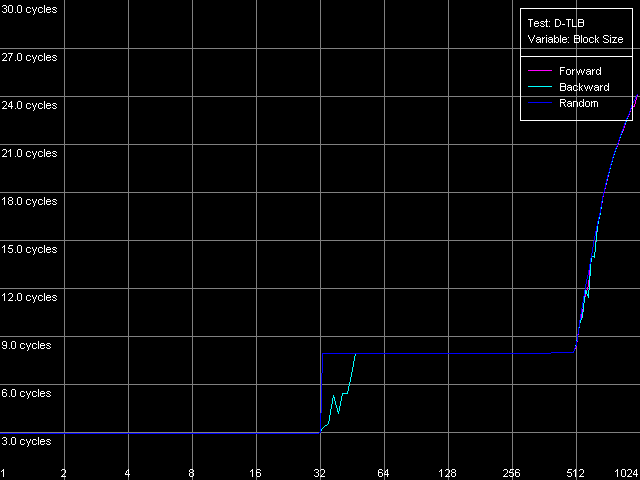
AMD Opteron 244
Мы видим, что оба рассматриваемых процессора имеют двухуровневую систему D-TLB, с размером L1 D-TLB, равным 32 записям. Размер L2 D-TLB у Athlon XP составляет 256 записей, а в Opteron его увеличили ровно в 2 раза (512 записей). Поскольку второй скачок наблюдается в области, соответствующей размеру L2 D-TLB, а не общему объему L1+L2 D-TLB, можно предположить, что структура D-TLB обоих процессоров имеет «инклюзивную» организацию (к сожалению, обычно детали организации уровней TLB при наличии нескольких таких уровней никак не отражаются в документации). В обоих случаях, промах L1 D-TLB сопровождается увеличением латентности доступа в L1 кэш до 8 тактов. Промах L2 D-TLB сказывается существенно сильнее по мере увеличения количества промахов латентность доступа в L1 кэш плавно возрастает до значений, явно превышающих латентность L2 кэша.
Согласно документации AMD, L1 D-TLB в процессорах семейства K7/K8 является полностью ассоциативным (fully associative). Самое время проверить это утверждение. Для этого выберем пресет D-TLB Associativity, 16 Entries, которые заведомо поместятся в L1 D-TLB.
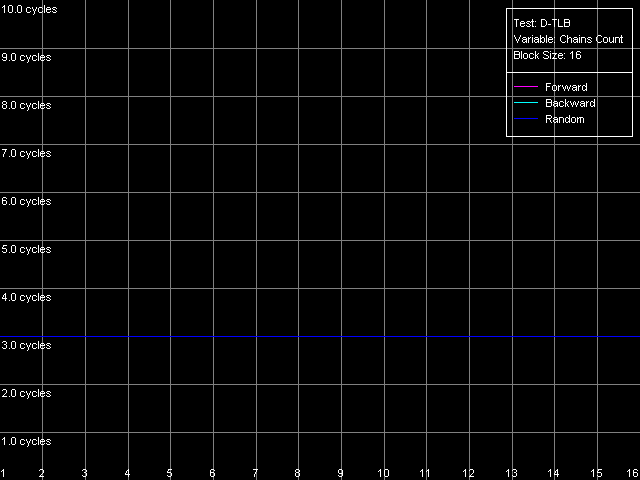
AMD Athlon XP 1800+
AMD Opteron 244
Проверка подтверждает: латентность доступа в L1 кэш при обращении к 16 страницам памяти у обоих процессоров остается равной 3 тактам при любом количестве зависимых цепочек доступа. Такой же вид кривых можно получить и при максимальном количестве цепочек, равным 32. Это означает, что L1 TLB является полностью ассоциативным (поскольку степень его ассоциативности оказывается не меньшей, чем его собственный размер).
Попробуем оценить степень ассоциативности L2 D-TLB. Для этого возьмем такое количество страниц, которое заведомо выше, чем количество записей в L1 TLB, но ниже, чем в L2 TLB (пресет D-TLB Associativity, 64 Entries для K7; D-TLB Associativity, 128 Entries для K8).
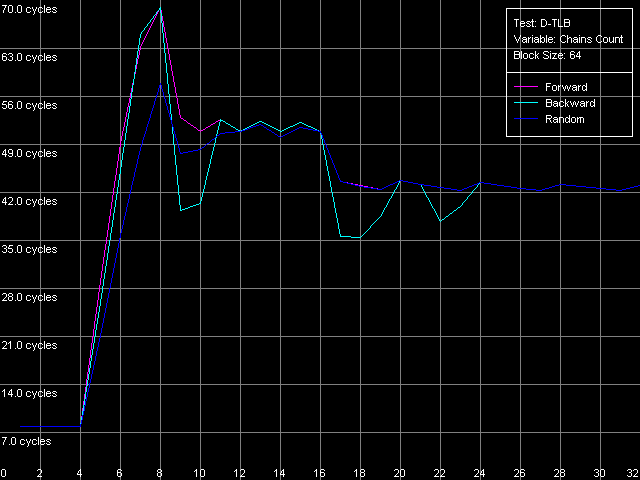
AMD Athlon XP 1800+
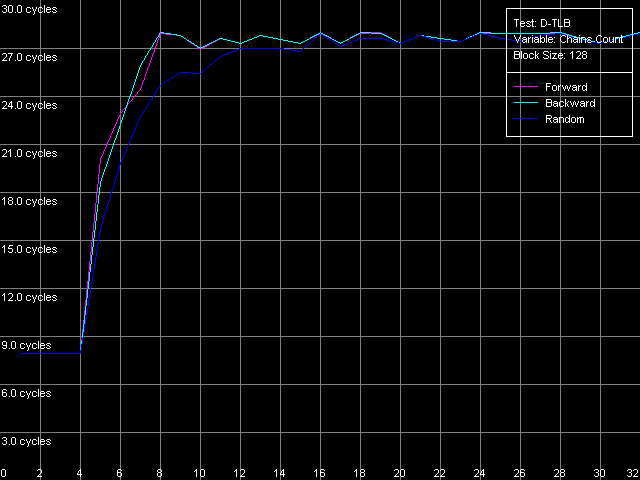
AMD Opteron 244
Видно, что латентность доступа в L1 кэш в условиях промаха L1 D-TLB (т.е. использования только L2 D-TLB) резко возрастает при количестве цепочек, большем четырех. Это означает, что L2 D-TLB в рассматриваемых процессорах является четырехнаборно-ассоциативным.
Характеристики уровней I-TLB
Измерим характеристики I-TLB точно так же, как и D-TLB. Для определения размеры (структуры уровней) I-TLB воспользуемся пресетом I-TLB Size в тесте I-TLB.
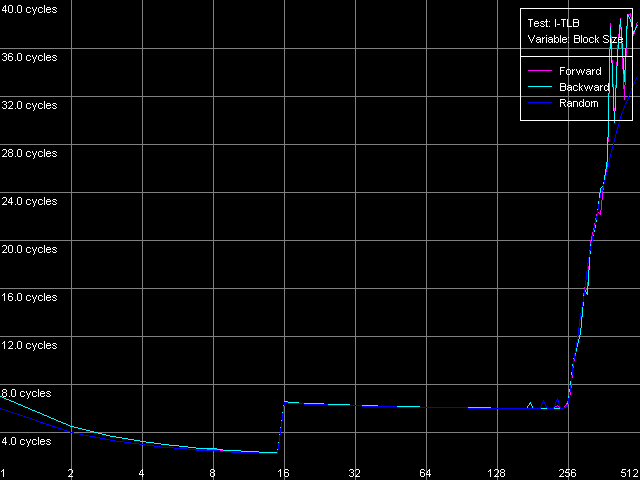
AMD Athlon XP 1800+
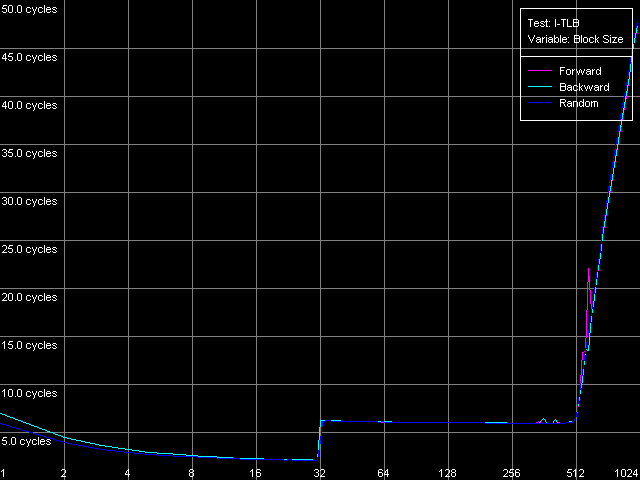
AMD Opteron 244
Для платформы Opteron мы вновь немного модифицировали стандартный пресет, увеличив максимальное количество TLB Entries до 1024. Оба процессора, по результатам теста, имеют два уровня I-TLB. Мы видим, что первый уровень (L1 I-TLB) в архитектуре AMD K8 был увеличен вдвое (до 32 записей) по сравнению с архитектурой предыдущего поколения K7. Такие же изменения коснулись и второго уровня L2 I-TLB, размер которого в новой архитектуре был расширен до 512 записей. Тем не менее, оба процессора имеют одинаковую организацию взаимодействия уровней I-TLB, которую, как и в случае с D-TLB, мы условно называем «инклюзивной».
Оценим ассоциативность каждого из уровней I-TLB. За основу возьмем пресет I-TLB Associativity, 16 Entries. При тестировании платформы AMD K7 уменьшим число используемых записей I-TLB до 15, чтобы избежать выход за пределы L1 I-TLB (поскольку одна его запись в нашем случае будет «занята» адресацией страницы собственно тестового кода).
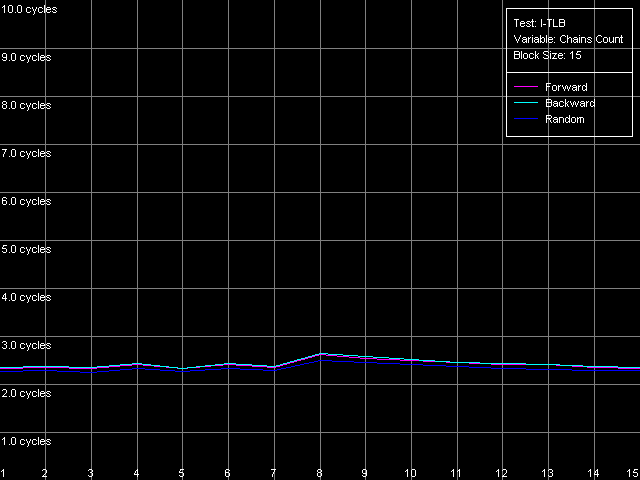
AMD Athlon XP 1800+
AMD Opteron 244
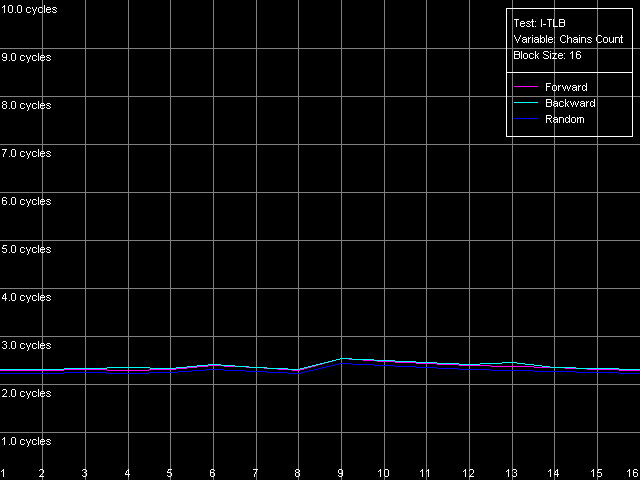
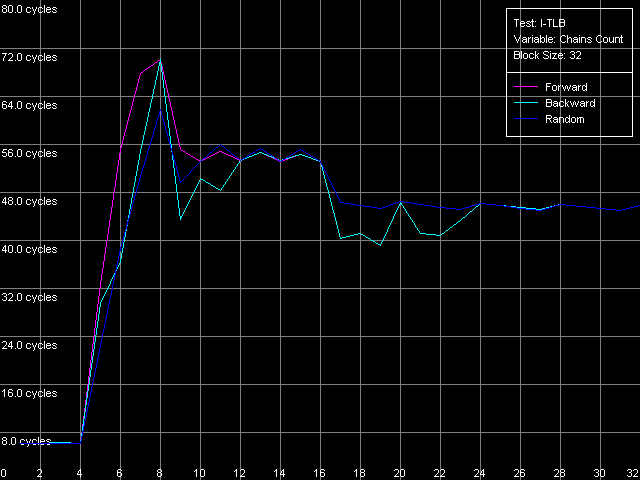
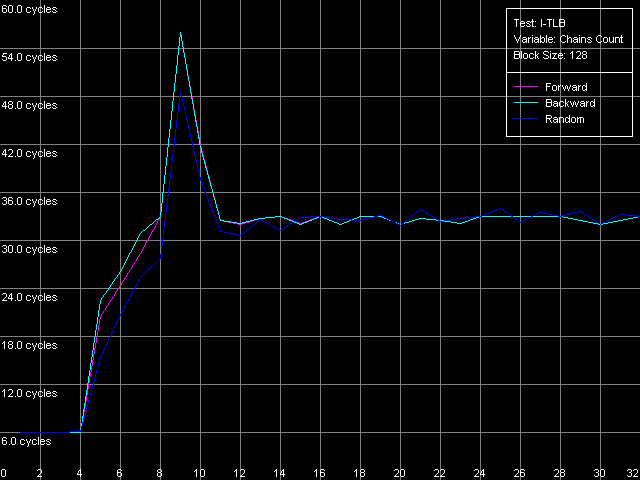
Интерпретация результатов весьма очевидна L1 I-TLB в обоих случаях является полноассоциативным. Нам остается определить ассоциативность второго уровня TLB инструкций. Для этого используем пресет I-TLB Associativity, 32 Entries для K7 и I-TLB Associativity, 128 Entries для K8.
AMD Athlon XP 1800+
AMD Opteron 244
В обоих случаях имеем весьма четкую картину, соответствующую заявленной ассоциативности L2 I-TLB, равной четырем.
Заключение
В этой статье мы представили вашему вниманию результаты нашего первого серьезного исследования платформ (на примере платформ AMD K7/K8) на низком уровне с использованием единого универсального тестового пакета RightMark Memory Analyzer. Полученные результаты позволяют сделать вывод о том, что разработанный нами тестовый пакет можно успешно применять для исследования основных важнейших низкоуровневых характеристик платформ. В нашей следующей статье мы продолжим начатые исследования, перейдя к сравнительному тестированию платформ Intel Pentium 4.


