Часть 3: Платформы Intel Pentium III и Pentium M (Banias)
Продолжается наш цикл исследования платформ с помощью универсального тестового пакета RightMark Memory Analyzer. На сей раз мы остановились на рассмотрении платформ Intel Pentium III. Рассмотрение ранних поколений процессоров этого класса, которым исполнилось уже немало лет, конечно, было бы не столь интересным. Поэтому мы решили включить в наше сравнительное тестирование только самые последние его модели, а именно — мобильное решение Pentium III-M (Geyserville), серверный вариант Pentium III-S (Tualatin), а также принципиально новую его разновидность (которую и к классу Pentium III можно отнести весьма условно, потому что больше некуда) — ключевой компонент Intel Centrino Mobile Technology, процессор Pentium M (Banias). Последняя, как известно, состоит из трех компонентов — самого процессора, чипсета семейства Intel 855, а также интегрированного модуля беспроводной LAN (Intel PRO/Wireless 2100). Процессор Pentium M, согласно заявлениям Intel, имеет улучшенную архитектуру с низким энергопотреблением, ключевыми инновационными моментами которой являются «энергооптимизированная» 400 МГц системная шина, удвоенные объемы кэша инструкций и данных, улучшенные алгоритмы предсказания ветвлений и предварительной выборки данных (prefetch), поддержка расширений SSE2, технологий Enhanced Intel SpeedStep и Thermal Monitor. Имеются также и микроархитектурные изменения ядра процессора, включающие в себя Micro-Ops Fusion (слияние микроопераций, представляющих одну макрооперацию) и улучшенное управление стеком (уменьшение количества микроопераций, отвечающих за изменения стека, за счет отслеживания последних на локальном уровне). В общем, на словах все это выглядит замечательно, но посмотрим, каким оно является на самом деле.
Конфигурации тестовых стендов и ПО
Тестовый стенд №1 (ноутбук Compaq Presario 2700)
- Процессор: Intel Pentium III-M (ядро Geyserville, 1000 МГц)
- Чипсет: Intel 830MP
- Память: 256МБ PC-133 SDRAM, 133 МГц
Тестовый стенд №2
- Процессор: Intel Pentium III-S (ядро Tualatin, 1400 МГц) в режиме SMP
- Материнская плата: SuperMicro P3TDLE (версия BIOS 3DL1101)
- Чипсет: ServerWorks Serveset III LE
- Память: 2x256МБ Kingston PC-133 Registered SDRAM, 133 МГц (тайминги 2-2-2-5)
Тестовый стенд №3 (ноутбук MaxSelect TravelBook Z4)
- Процессор: Intel Pentium-M (ядро Banias, 1300 МГц)
- Чипсет: Intel 855PM (Montara)
- Память: 512МБ PC2100 DDR, 266 МГц
- Интегрированная видеосистема
Программное обеспечение
- Windows XP Professional SP1
- RightMark Memory Analyzer 2.4
Реальная пропускная способность кэша данных/памяти
Как и прежде, начнем наше исследование с оценки реальной пропускной способности различных уровней подсистемы памяти, для чего воспользуемся тестом Memory Bandwidth во всех режимах доступа к памяти (пресеты D-Cache/RAM Bandwidth, MMX Registers; SSE Registers; SSE2 Registers). Для примера представим здесь кривые, полученные при использовании первого набора инструкций — MMX.
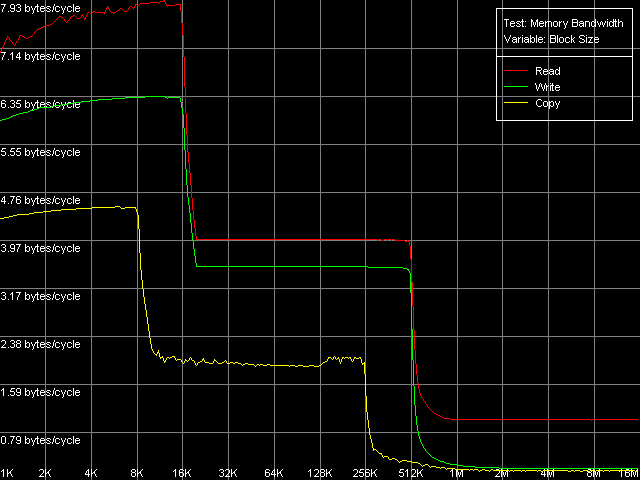
Pentium III-M
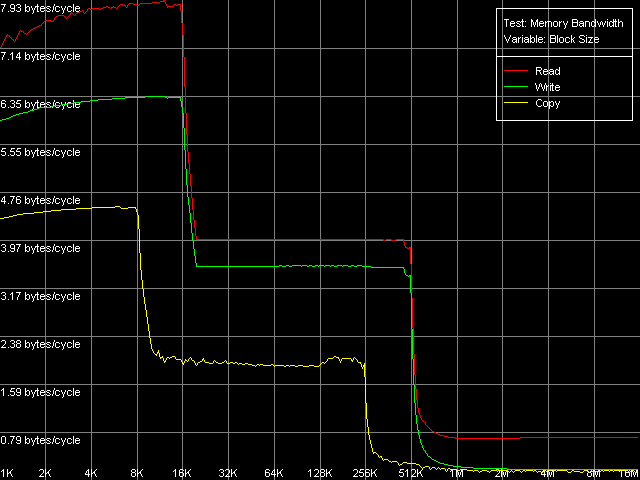
Pentium III-S
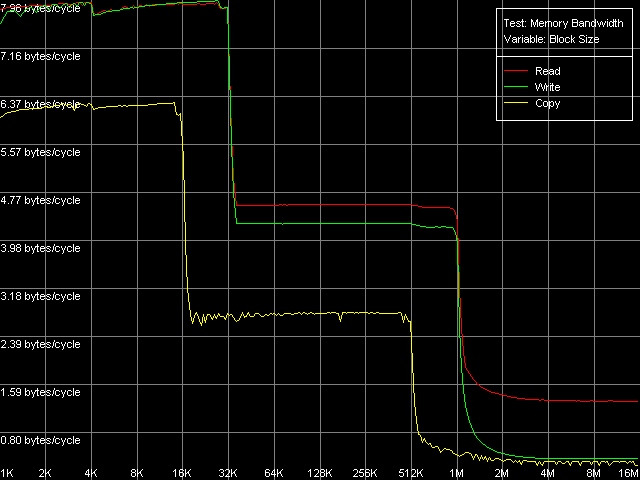
Pentium M
Отметим, что расширения SSE2 доступны только у третьей из рассматриваемых платформ. Результаты тестирования Pentium M с этим набором инструкций оказались идентичными результатам, полученным при использовании расширений SSE. Подобную картину мы видели и при сравнительном тестировании платформ Intel Pentium 4.
Полученные кривые на всех трех процессорах выглядят вполне очевидно. По ним можно сказать, что эти процессоры имеют двухуровневую систему кэша данных с инклюзивной организацией, которая «выдает» себя наличием четких перегибов, соответствующих размерам L1 и L2 кэша. У первых двух процессоров, Pentium III-M и Pentium III-S, эти размеры составляют 16 и 512 КБ, соответственно, а у Pentium M в этом плане имеется значительное улучшение — размеры обоих уровней кэша действительно были удвоены. Тем не менее, здесь нельзя не отметить еще одно важное обстоятельство, которое сразу проявляет себя (еще при запуске тестового приложения) — размер строки кэша у последнего также был удвоен, и составляет теперь 64 байта, против 32 байт у процессоров семейства Pentium III. Иными словами, можно говорить, что размеры наборов кэшей (т.е. количество линий) у Pentium M, по сути, остались теми же, изменился лишь размер самой линии.
| Уровень | Средняя реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.93 7.93 6.36 6.58 | 7.93 7.93 6.36 6.58 | 7.94 7.98 7.96 7.52 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.00 4.00 3.55 3.55 | 4.00 4.00 3.55 3.55 | 4.58 4.58 4.27 4.27 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 739.4 МБ/с 739.4 МБ/с 157.2 МБ/с 157.2 МБ/с | 994.4 МБ/с 994.9 МБ/с 273.6 МБ/с 273.6 МБ/с | 1740.3 МБ/с 1737.4 МБ/с 482.5 МБ/с 477.4 МБ/с |
Приступим к количественной оценке скоростных показателей уровней кэша данных. Для начала сопоставим между собой две платформы на базе процессоров Pentium III, а именно, его мобильный (Pentium III-M) и серверный (Pentium III-S) варианты. Первое, что бросается в глаза, это реальная пропускная способность L1 и L2 кэша данных на чтение — у обоих процессоров она получилась одинаковой при использовании MMX- и SSE-регистров. Эффективность L1 на чтение составляет 7.93 байт/такт, на запись — несколько ниже (6.36 байт/такт, MMX-регистры; 6.58 байт/такт, SSE-регистры), что позволяет говорить о пересылке не более чем одного 64-битного значения (целого MMX-регистра или половины SSE-регистра) за один акт обращения к L1 кэшу. L2 кэш, как и следовало ожидать, характеризуется меньшей реальной пропускной способностью, которая не зависит от типа используемых регистров — 4.00 байт/такт на чтение и 3.55 байт/такт на запись (т.е. реально за один акт обращения к этому уровню кэша в операциях тотального чтения/записи пересылается не более чем одно 32-разрядное значение). Итак, по скоростным характеристикам кэша данных мы не увидели каких-либо различий между мобильным и серверным вариантами Pentium III. Посмотрим, как они проявляют себя в операциях чтения/записи «последнего уровня» подсистемы памяти — т.е. собственно оперативной памяти. По этому показателю мобильная платформа явно проигрывает серверной (739.4 МБ/с против 994.4 МБ/с на чтение, 157.2 МБ/с против 273.6 МБ/с на запись). Тем не менее, это вполне может быть связано с типом используемых чипсетов, а не процессоров, которые, как мы видели выше, не различаются между собой при обращении к «собственной» подсистеме памяти, т.е. кэшу данных. В обоих случаях довольно сильно удивляют очень низкие показатели реальной пропускной способности памяти на запись — они составляют всего 14.7% (в случае Pentium III-M) и 25.6% (в случае Pentium III-S) от теоретического максимума, равного 1066 МБ/с.
Посмотрим, какие отличия по показателям пропускной способности кэша данных/памяти имеются у Pentium M. Эффективность L1 на чтение, можно сказать, практически не изменилась (7.94-7.98 байт/такт против 7.93), а вот на запись — значительно возросла, причем в большей степени при использовании MMX (7.96 байт/такт против 6.36, что на 25% выше), нежели SSE-регистров (7.52 байт/такт против 6.58, т.е. прирост составляет 14%). Возросла и эффективность второго уровня кэша, которая вновь оказалась одинаковой при использовании MMX и SSE-регистров. Выигрыш в скорости, по сравнению с Pentium III, при операциях чтения из L2 составляет 14%, а при записи — даже несколько выше (20%). Что касается реальной пропускной способности памяти, прямое сопоставление абсолютных значений здесь, конечно, не представляется возможным ввиду использования разных типов памяти. Тем не менее, нам ничего не мешает сопоставить относительные значения реальной ПСП. Эффективность чтения из DDR на платформе Pentium M составляет 81.6% от теоретического максимума (2133 МБ/с), что в целом сопоставимо со значениями, достигаемыми на платформах Pentium III (69.3% на Pentium III-M и 93.2% на Pentium III-S). А вот эффективность записи и здесь намного ниже — всего 22.6%, что вновь немногим отличается от значений, полученных на платформах Pentium III (14.7% и 25.6% на мобильном и серверном варианте, соответственно).
Предельная реальная пропускная способность памяти
Далее мы попытаемся оценить максимальные значения реальной ПСП, которые можно достичь на этих платформах, используя различные методы оптимизации. В случае операции чтения, как и ранее, будем использовать следующие доступные методы:
- Software Prefetch (тест Memory Bandwidth, пресеты Maximal RAM Bandwidth, Software Prefetch, MMX/SSE Registers);
- Block Prefetch 1 (тест Memory Bandwidth, пресеты Maximal RAM Bandwidth, Block Prefetch 1, MMX/SSE Registers);
- Block Prefetch 2 (тест Memory Bandwidth, пресеты Maximal RAM Bandwidth, Block Prefetch 2, MMX/SSE Registers);
- Чтение строк кэша (тест D-Cache Bandwidth, пресет L2 Cache-RAM Bus Bandwidth).
Для возможности сопоставления результатов между собой приведем значения, рассчитанные относительно значений предельной ПСП рассматриваемых типов памяти (1066 МБ/с, PC-133 SDRAM; 2133 МБ/с, PC2100 DDR).
| Режим доступа | Максимальная реальная ПСП на чтение, МБ/с* | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 739.4 (69.3 %) 739.4 (69.3 %) 1022.4 (95.9 %) 1022.7 (95.9 %) 845.3 (79.2 %) 846.4 (79.4 %) 925.6 (86.8 %) 907.2 (85.1 %) 757.2 (71.0 %) 757.0 (71.0 %) | 994.4 (93.2 %) 994.9 (93.3 %) 1025.7 (96.2 %) 1023.7 (96.0 %) 949.4 (89.0 %) 949.8 (89.0 %) 1023.9 (96.0 %) 1012.4 (94.9 %) 1050.4 (98.5 %) 1044.5 (97.9 %) | 1740.3 (81.6 %) 1737.4 (81.4 %) 1881.4 (88.2 %) 1883.7 (88.3 %) 1515.4 (71.0 %) 1517.5 (71.1 %) 1795.0 (84.1 %) 1800.3 (84.4 %) 1791.0 (84.0 %) 1786.9 (83.8 %) |
*в скобках указаны значения, рассчитанные относительно значений предельной (теоретической) пропускной способности данного типа памяти
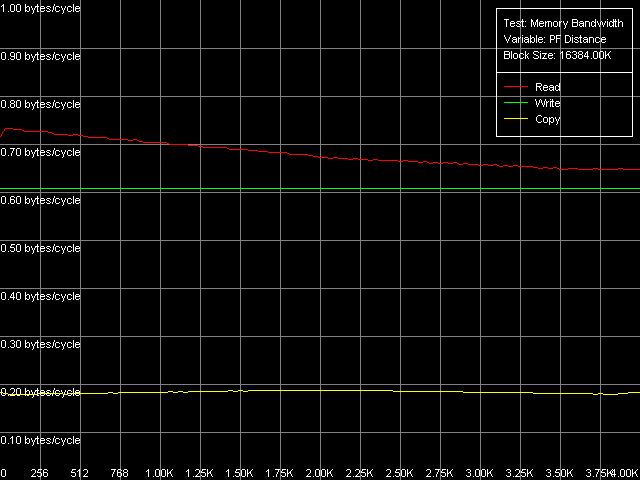
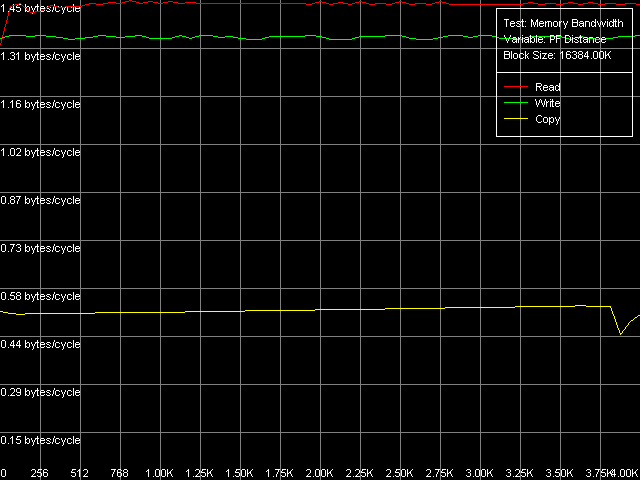
Как видно на этой таблице, все три процессора одинаково хорошо выигрывают в скорости чтения из памяти при использовании стандартного метода Software Prefetch, результаты которого мы и приводим на рисунках.
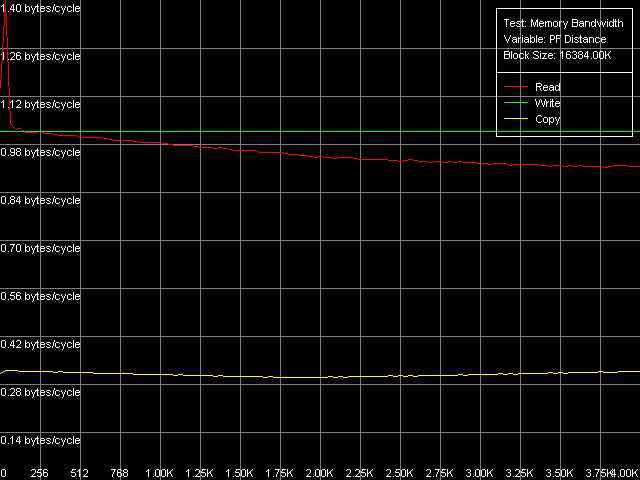
Pentium III-M
Pentium III-S
Pentium M
Весьма интересной особенностью реализации Software Prefetch у процессоров семейства Pentium III является резкое увеличение реальной ПСП при минимальной длине префетча (32 байта, что особенно заметно на Pentium III-M), а при ее увеличении эффективность Software Prefetch падает. В то же время у Pentium M эффективность Software Prefetch сохраняется более-менее постоянной, начиная от минимальной длины префетча (64 байта) и вплоть до границы страницы памяти (4096 байт). На количественном уровне, использование метода Software Prefetch при операциях чтения на процессорах Pentium III позволяет достичь 96% от максимальной теоретической ПСП, в то время как у Pentium M его эффективность несколько ниже — достигается лишь 88% от предельной ПСП. В то же время отметим, что значения, полученные этим методом, для Pentium M являются максимальными.
Методы Block Prefetch, в особенности первый из них, вновь демонстрируют свою неприменимость по отношению к процессорам Intel. Тем не менее, выигрыш при их использовании все-таки имеется, но только в случае Pentium III-M, в то время как на других процессорах достигаемые максимальные значения ПСП оказываются либо ниже средних (Block Prefetch 1, Pentium III-S и Pentium M), либо сопоставимыми с ними (Block Prefetch 2, Pentium III-S и Pentium M).
Наконец, методы чтения строк кэша демонстрируют явные различия между тремя «подопытными» процессорами. На Pentium III-M они приводят к результатам, почти не отличающимся от значений средней реальной ПСП, на Pentium M заметно некоторое увеличение реальной ПСП (до 84% от теоретического предела), а вот Pentium III-S здесь демонстрирует лучший результат! (до 98.5% от предельной ПСП). Таким образом, можно сказать, что различия между мобильной платформой Pentium III-M и серверной Pentium III-S, по всей видимости, все же имеются не только на уровне используемых чипсетов, но и процессоров.
Вслед за чтением, попытаемся достичь максимальных значений реальной ПСП и на запись, тем более что средние значения последней получились совсем не оптимальными. Для этого используем два доступных нам метода — прямого сохранения данных (Non-Temporal Store, тест Memory Bandwidth, любой из пресетов Maximal RAM Bandwidth) и записи строк кэша (тест D-Cache Bandwidth, пресет L2 Cache-RAM Bus Bandwidth).
| Режим доступа | Максимальная реальная ПСП на запись, МБ/с* | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 157.2 (14.7 %) 157.2 (14.7 %) 744.4 (69.8 %) 744.5 (69.8 %) 154.4 (14.5 %) 152.8 (14.3 %) | 273.6 (25.7 %) 273.6 (25.7 %) 850.3 (79.7 %) 850.3 (79.7 %) 273.7 (25.7 %) 273.8 (25.7 %) | 482.5 (22.6 %) 477.4 (22.4 %) 1746.2 (81.9 %) 1746.3 (81.9 %) 491.5 (23.0 %) 484.6 (22.7 %) |
*в скобках указаны значения, рассчитанные относительно значений предельной ПСП
Метод прямого сохранения (Non-Temporal Store) на всех рассматриваемых платформах дает существенный выигрыш в скорости. По сравнению со средними значениями он особенно заметен на Pentium III-M (выигрыш в 4.7 раз), но если рассматривать абсолютные значения, то лидерами выступают Pentium III-S (79.7%) и особенно Pentium M (81.9%). В то же время, метода записи строк кэша не дает какого-либо увеличения реальной ПСП по сравнению со средними значениями на любом из процессоров.
Средняя латентность кэша данных/памяти
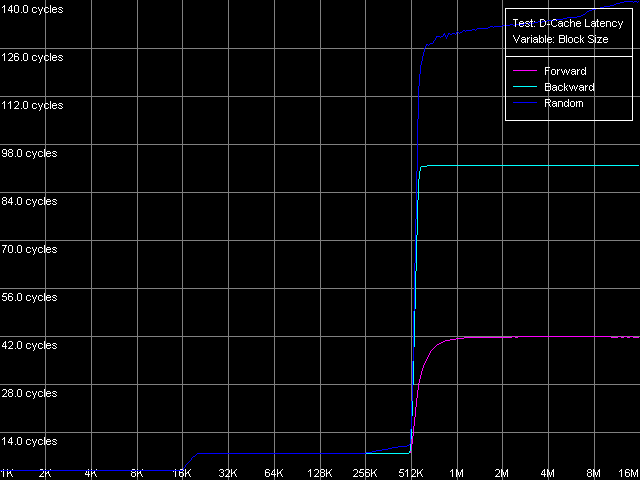
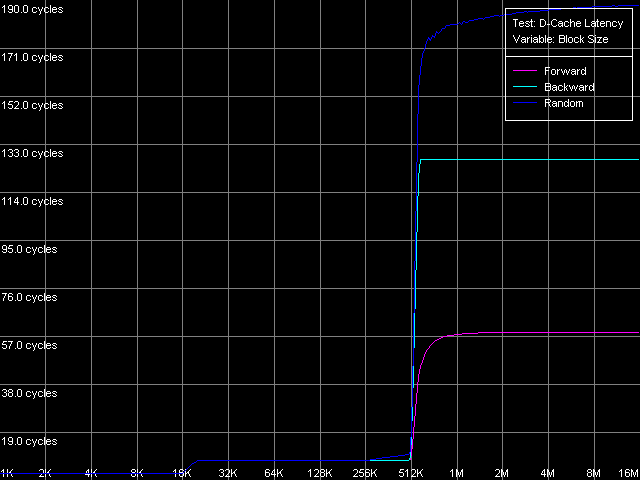
Разумеется, важной характеристикой подсистемы памяти является не только ее реальная пропускная способность, но и латентность. Измерим ее с помощью теста D-Cache Latency, выбрав стандартный пресет D-Cache/RAM Latency. Результат этого теста приведен на рисунках.
Pentium III-M
Pentium III-S
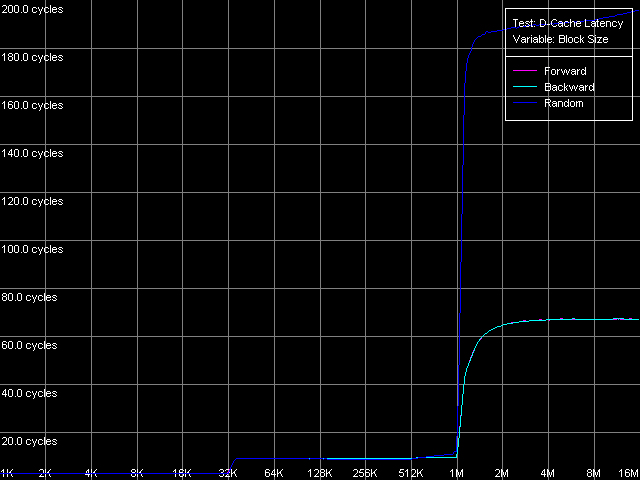 Pentium M
Pentium M Так же, как и кривые реальной пропускной способности, кривые латентности имеют довольно четкие перегибы в точках, соответствующих размерам L1/L2 кэша данных процессоров. Во всех случаях на кривых латентности случайного доступа можно заметить ее плавное возрастание при размерах блока 256 КБ и выше (Pentium III-M/S) и 512 КБ и выше (Pentium M). Причина этого, как уже отмечалось в нашем предыдущем исследовании, связана с исчерпанием ресурса D-TLB процессоров. Кстати, уже по результатам этого теста можно сказать, что размер D-TLB у Pentium M, как и размер его кэша данных, также был удвоен по сравнению с процессорами Pentium III-M/S. Тем не менее, как всегда, исследования D-TLB будут представлены ниже в отдельном разделе. А сейчас приступим к количественным оценкам средней латентности уровней кэша данных/памяти.
| Уровень, доступ | Средняя латентность, тактов | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| L1, прямой L1, обратный L1, случайный | 3.0 3.0 3.0 | 3.0 3.0 3.0 | 3.0 3.0 3.0 |
| L2, прямой L2, обратный L2, случайный | 8.0 8.0 8.0 | 8.0 8.0 8.0 | 9.5 9.5 9.5 |
| RAM, прямой RAM, обратный RAM, случайный* | 42.0 (57.5 нс) 92.0 (125.8 нс) 134.2 (183.5 нс) | 58.7 (42.0 нс) 127.2 (91.2 нс) 186.4 (133.5 нс) | 66.5 (51.2 нс) 66.5 (51.2 нс) 190.3 (146.7 нс) |
*Размер блока 4 МБ
С латентностью L1 кэша все достаточно очевидно — она составляет 3 такта у всех рассматриваемых процессоров во всех режимах доступа. То же самое можно сказать о латентности второго уровня (L2) — во всех случаях на процессорах Pentium III она составляет 8 тактов, а вот у Pentium M она несколько возросла — средняя величина получилась равной 9.5 тактам процессора.
Посмотрим, как обстоят дела с задержками, возникающими при различных режимах обхода памяти. Оба процессора Pentium III в этом отношении ведут себя одинаково: прямой последовательный обход дает наименьшие значения (57.5 нс на Pentium III-M, 42.0 нс на Pentium III-S), а обратный последовательный обход приводит к два с лишним раза большим задержкам (125.8 нс, Pentium III-M; 91.2 нс, Pentium III-S). Наконец, наибольшая латентность памяти проявляется при случайном обходе цепочки размером 4 МБ (183.5 нс, Pentium III-M; 133.5 нс, Pentium III-S). Отметим, что во всех режимах обхода, значения латентности памяти на серверной платформе Pentium III-S примерно в 1.37 раз меньше, чем на мобильной Pentium III-M.
У Pentium M по отношению к доступу к памяти, как нетрудно видеть, имеются серьезные изменения. Главным образом, это улучшение алгоритма предварительной загрузки данных (data prefetch logic), который теперь работает как при прямом, так и при обратном обходе. Значение латентности памяти в этих случаях составляет 51.2 нс, что занимает промежуточное положение между Pentium III-M и Pentium III-S. Латентность случайного доступа к памяти на этой платформе составляет 146.7 нс, что вновь занимает промежуточное положение между мобильной и серверной платформами Pentium III.
Минимальная латентность L2 кэша данных/памяти
Посмотрим, что будет происходить с латентностью доступа в L2 кэш при последовательном увеличении количества «пустых» операций, вставленных между операциями обращениями к этому уровню кэша данных. Для этого взглянем на рисунки, полученные в тесте D-Cache Latency с использованием настроек Minimal L2 Cache Latency, Method 1.
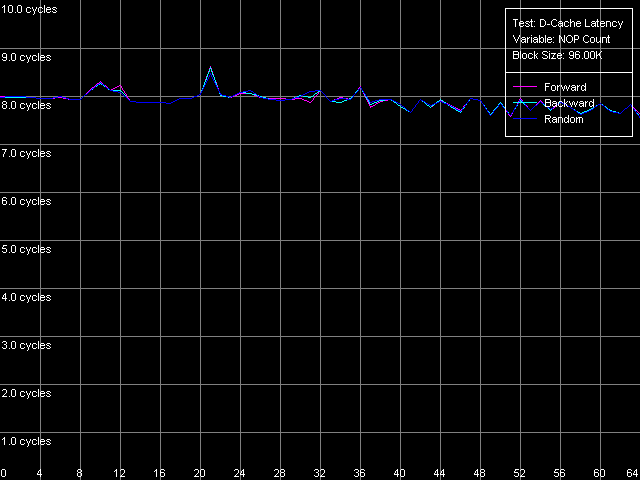
Pentium III-M
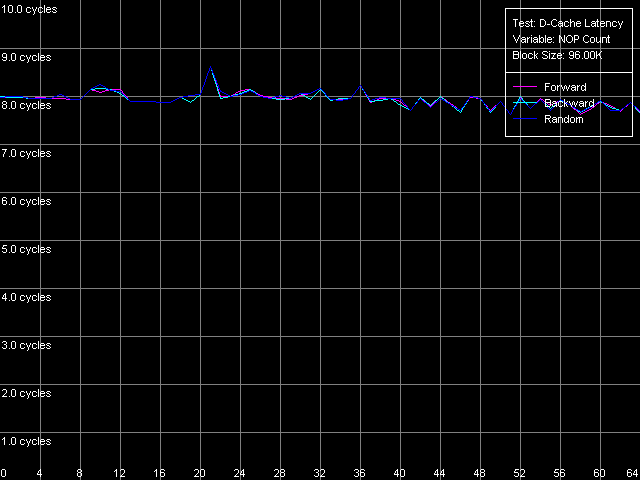
Pentium III-S
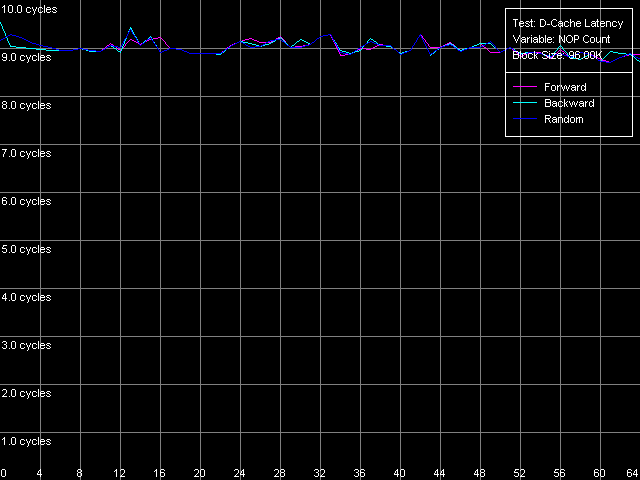
Pentium M
И увидим, что на Pentium III-M/S таким методом не достигается ровным счетом ничего — латентность доступа в L2 при любом из режимов обхода остается равной 8 тактам процессора. На Pentium M же имеются некоторые изменения — при вставке даже одной «пустой» операции (исполнение которой занимает один такт процессора) латентность L2 достигает своего минимального (заявленного) значения, равного 9 тактам.
Отметим, что мы исследовали латентность кэша L2 и другим заложенным в RMMA методом (Minimal L2 Cache Latency, Method 2). Результаты этого теста мы не приводим на рисунках, но скажем, что они получились довольно неожиданными — латентность L2 во всех случаях оказалась ровно на один такт меньшей по сравнению с ее значениями, полученными первым методом (7 тактов на Pentium III-M/S, 8 тактов на Pentium M).
Оценим теперь и минимальные значения латентности памяти, которые достигаются в этом же тесте при использовании пресета Minimal RAM Latency, 4MB Block.
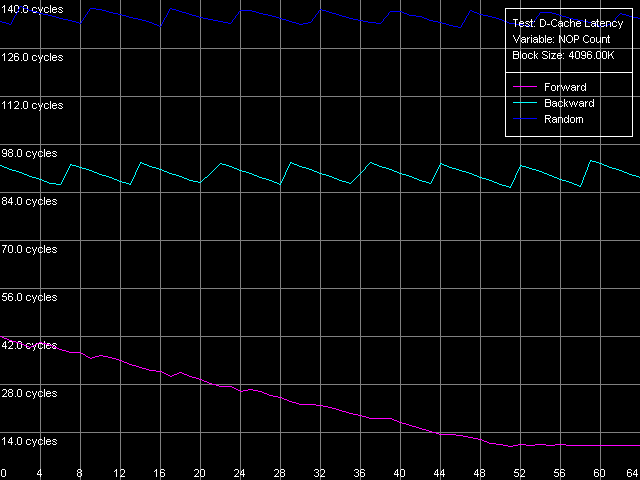
Pentium III-M
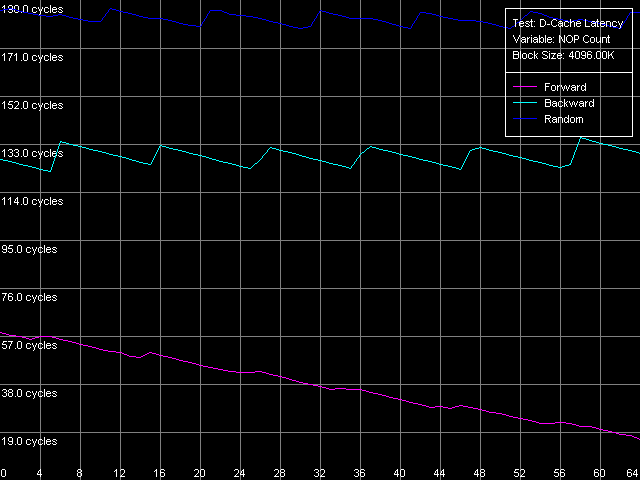
Pentium III-S
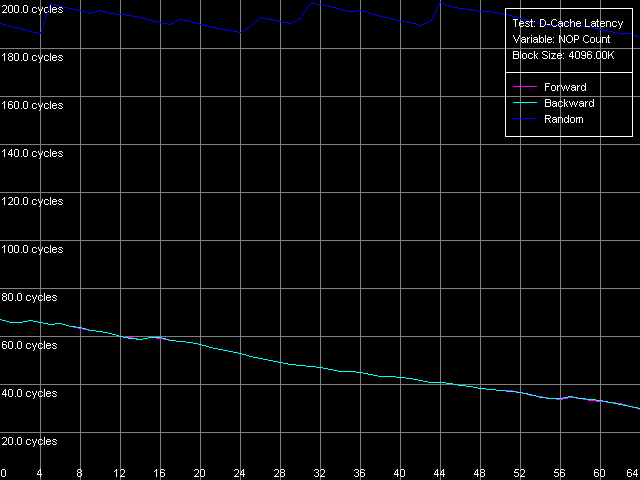
Pentium M
Кривые прямого последовательного доступа на Pentium III-M и Pentium III-S ведут себя несколько по-разному, что, однако, можно снова отнести как к различиям в реализации используемых чипсетов, так и к различиям в организации алгоритма Hardware Prefetch у этих процессоров. А именно, минимальная латентность памяти в этом режиме обхода на Pentium III-M достигается уже при вставке 50 «пустых» операций и составляет 10.2 такта (14.0 нс). В то же время, минимум на Pentium III-S достигается при количестве «NOP»-ов, большем чем 64, а достигнутое в этом тесте минимальное значение составляет 16.5 тактов (11.8 нс, что, впрочем, все равно ниже, чем у Pentium III-M). Обратный последовательный и случайный режимы обхода характеризуются уже знакомым по исследованиям платформ K7/K8 видом кривых с «зубчиками», шаг между которыми равен коэффициенту соотношения между частотой процессора и частотой его системной шины. Минимальные значения латентности памяти при обратном обходе составляют 117.0 нс на Pentium III-M и 87.8 нс на Pentium III-S. Минимальная латентность случайного доступа вновь гораздо выше — 181.0 нс и 128.2 нс на мобильной и серверной платформах Pentium III, соответственно.
Соответствующие зависимости латентности памяти от количества вставленных «пустых» операций на Pentium M внешне очень похожи на те, которые мы видели при тестировании платформы Opteron в ходе сравнительного тестирования платформ K7/K8. Тем не менее, минимальная латентность прямого/обратного последовательного обхода здесь не достигается даже при 64 «NOP»-ах, и полученные в этом тесте минимальные значения составляют 30 тактов процессора (23.1 нс). Кривая латентности случайного доступа вновь имеет весьма характерный «зубчатый» вид, по ней можно судить, что обращение к памяти у рассматриваемой платформы может идти на каждом такте 100 МГц quad-pumped системной шины процессора. Само значение минимальной латентности случайного доступа оказывается равным 142.5 нс. Точно так же, как и среднее значение латентности случайного доступа к памяти, оно оказывается меньшим, чем у Pentium III-M, но большим, чем у Pentium III-S. Можно предположить, что несколько большие значения средней и минимальной латентности случайного доступа к памяти на платформе Pentium M по сравнению с серверной платформой Pentium III-S связаны с асинхронным режимом работы памяти на первой платформе, в то время как последняя имеет синхронный режим доступа.
| Уровень, доступ | Минимальная латентность, тактов | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| L1, прямой L1, обратный L1, случайный | 3.0 3.0 3.0 | 3.0 3.0 3.0 | 3.0 3.0 3.0 |
| L2, прямой* L2, обратный* L2, случайный* | 8.0 (7.0) 8.0 (7.0) 8.0 (7.0) | 8.0 (7.0) 8.0 (7.0) 8.0 (7.0) | 9.0 (8.0) 9.0 (8.0) 9.0 (8.0) |
| RAM, прямой RAM, обратный RAM, случайный** | 10.2 (14.0 нс) 85.5 (117.0 нс) 132.3 (181.0 нс) | 16.5 (11.8 нс) 122.5 (87.8 нс) 179.0 (128.2 нс) | 30.0 (23.1 нс) 30.2 (23.3 нс) 184.7 (142.5 нс) |
* В скобках указаны значения, полученные методом 2
**Размер блока 4 МБ
Ассоциативность кэша данных
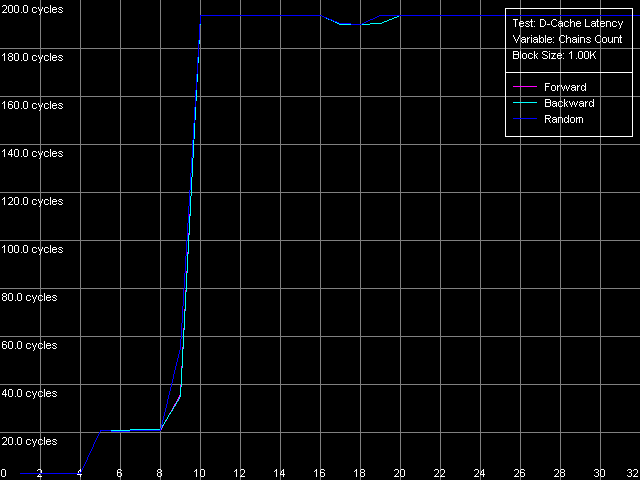
Приступим к изучению следующей характеристики кэша данных рассматриваемых процессоров — его ассоциативности. Для этого воспользуемся тестом D-Cache Latency, выбрав пресет D-Cache Associativity.
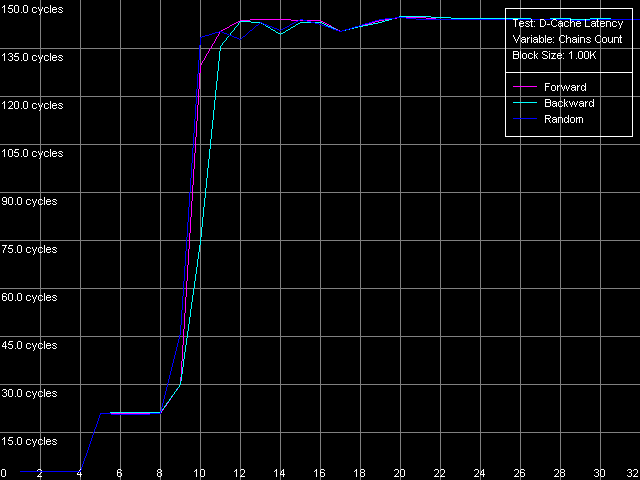
Pentium III-M
Pentium III-S
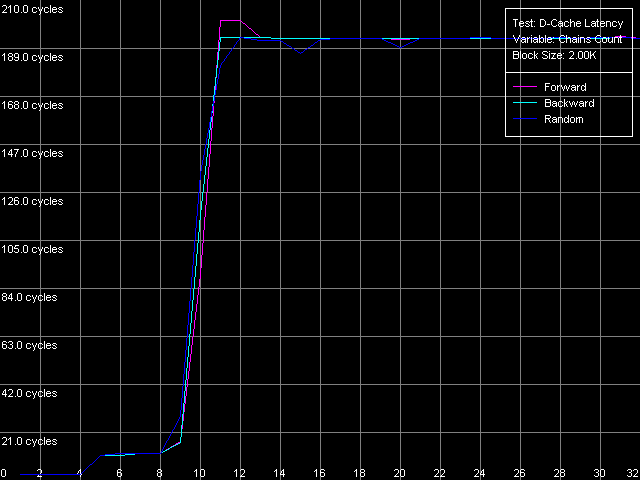
Pentium M
Полученные картинки ассоциативности (т.е. зависимости латентности доступа в кэш от количества обходимых зависимых цепочек доступа) получились очень четкими. В этом отношении платформы Intel Pentium III не сильно отстают от платформ AMD K7/K8, чего не скажешь об еще одном рассмотренном нами классе платформ Intel Pentium 4. А именно, у всех трех процессоров в этом тесте можно выделить три четких области. В первой из них (до 4 цепочек включительно) латентность доступа к кэшу процессора во всех режимах обхода сохраняется равной 3 тактам (латентности L1), а это значит, что первый уровень кэша данных рассматриваемых процессоров имеет степень ассоциативности, равную четырем.
Вторая область — от 5 до 8 цепочек, включительно, характеризуется значениями латентности порядка 20 тактов (платформы Pentium III-M/S) и 11 тактов (Pentium M). Она соответствует латентности кэша второго уровня (L2), ассоциативность которого в нашем тесте получилась равной восьми, в точности, как это и заявлено в документации. Нетрудно заметить, что на платформах семейства Pentium III латентность второго уровня кэша в этих, более жестких условиях тестирования получилась примерно в 2.5 раза завышенной, в точности так же, как это наблюдалось при тестировании платформ K7/K8. Причина этого, согласно сделанному в той статье предположению, связана с увеличением накладных расходов на постоянную переассоциацию строк кэша со строками памяти. В то же время, нельзя не отметить, что «многосегментный» вариант обхода цепочки на Pentium M сопровождается пренебрежимо малым увеличением латентности (с 9.5 до 11 тактов), что говорит о серьезном улучшении алгоритма работы наборно-ассоциативного кэша данных этого процессора (традиционно осуществляемого по принципу LRU).
Наконец, третья область, от 9 до 32 цепочек доступа включительно, соответствует «пробою» ассоциативности обоих уровней кэша данных процессора, а соответствующие величины латентности соответствуют максимальным величинам латентности памяти во всех режимах обхода (разумеется, ни о каком Hardware Prefetch при прямом/обратном обходе здесь и речи быть не может!).
Реальная пропускная способность шины L1-L2
Согласно заявлениям Intel, процессор Pentium M имеет «Advanced Data Transfer Cache». Проверим, насколько серьезно это заявление, в смысле, имеются ли на самом деле какие-нибудь различия в реализации шины L1-L2 кэша данных у рассматриваемых процессоров. Для этого сначала используем тест D-Cache Bandwidth, пресет L1-L2 Cache Bus Bandwidth.
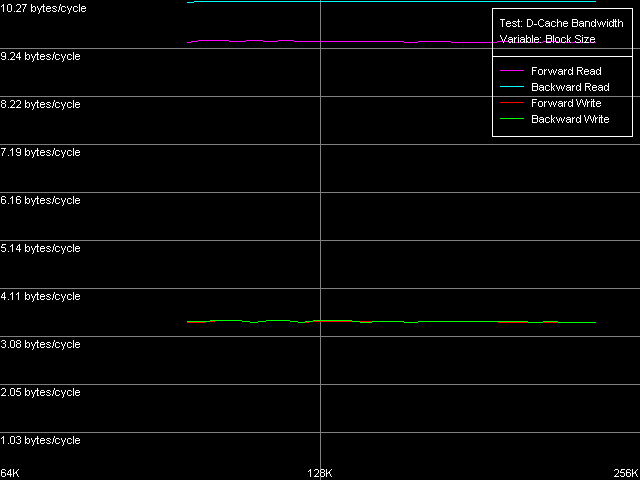
Pentium III-M
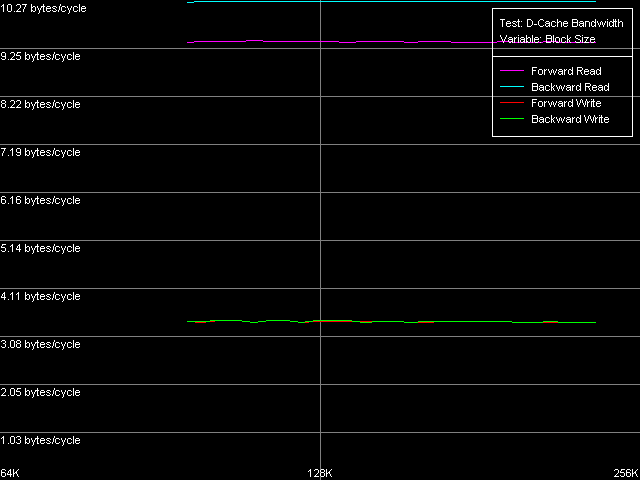
Pentium III-S
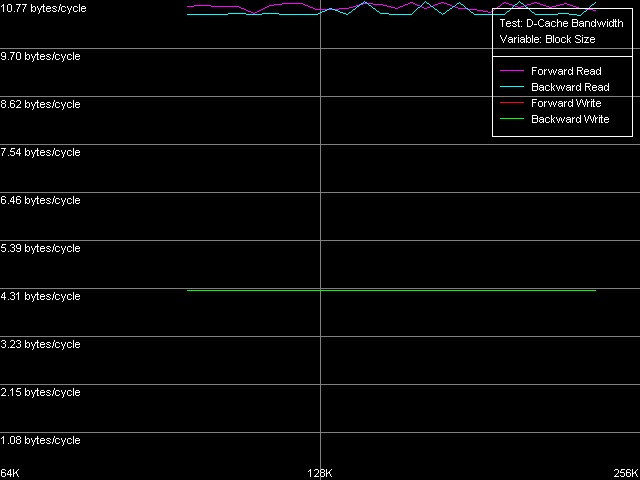
Pentium M
Невооруженным взглядом видно, что эффективная ширина шины обмена даными между двумя уровнями кэша данных у всех трех процессоров составляет 128 бит, причем максимальные значения реальной пропускной способности этой шины весьма далеки от теоретического предела, равного 16.0 байт/такт.
| Шина данных, режим доступа | Реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | |
| L1-L2, чтение (прямое) L1-L2, чтение (обратное) L1-L2, запись (прямая) L1-L2, запись (обратная) | 9.44 10.27 3.43 3.44 | 9.42 10.27 3.44 3.44 | 10.75 10.77 4.27 4.27 |
Количественная оценка реальной ПС шины L1-L2 показывает, что, во-первых, ее эффективность оказывается одинаковой как у Pentium III-M, так и Pentium III-S. У этих процессоров максимальная реальная ПС шины L1-L2 наблюдается при обратном чтении данных, и составляет 10.27 байт/такт (64.2% от теоретического максимума). В то же время, эффективность этой шины на запись намного ниже, как это обычно и бывает у процессоров с инклюзивной организацией уровней кэша данных, и составляет величину 3.44 байт/такт (21.5% от теоретического предела). Pentium M, хотя и имеет некоторые улучшения скоростных показателей этой шины (эффективность на чтение возросла до 67.3%, на запись — до 26.7%), но все же не столь значительные, чтобы называть кэш данных этого процессора «Advanced Data Transfer Cache». То ли дело шина L1-L2 процессоров Pentium 4 Northwood/Gallatin, где достигается почти 100% эффективность утилизации 256-битной шины данных при операциях пересылки строк кэша из L2 в L1, такую шину действительно не стыдно так называть.
Кстати, то, что эффективная ширина шины кэша данных у Pentium M осталась 128-разрядной, а реальный размер строки кэша увеличился вдвое, является довольно спорным моментом, далеко не лучшим образом характеризующим этот процессор. Действительно, для пересылки 64 байт данных даже с предельной скоростью 16 байт/такт потребовалось бы целых 4 такта процессора. В то же время, латентность первого уровня кэша осталась равной трем тактам, так что запрашиваемая строка даже в идеальных условиях была бы доступной не сразу, а с задержкой в один такт минимум. Собственно, а почему бы нам не проверить эти рассуждения на практике? Ведь для этого в RMMA существует специальный тест прибытия данных (D-Cache Arrival). Результаты этого теста на Pentium M мы и представим вашему вниманию.
Для начала посмотрим, как зависит суммарная латентность двух обращений к одной и той же строке кэша при увеличении расстояния между этими обращениями от 4 до 60 байт. Для этого используем пресет L1-L2 Cache Bus Data Arrival Test 1, 64 bytes.
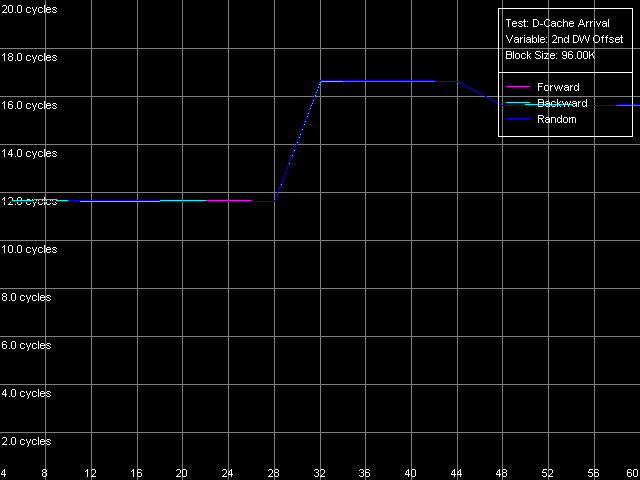
Pentium M
Результат довольно интересной — латентность двух обращений остается минимальной (12 = 3 + 9 тактов) при смещениях второго элемента до 28 байт включительно, после чего она возрастает на 5 тактов. Ее снижение на 1 такт при дальнейшем увеличении смещения (от 48 байт и выше) пока что остается непонятным. Тем не менее, полученный результат означает, что запрашиваемая 64-байтная строка действительно оказывается доступной кэшу L1 не сразу. Как именно прибывают данные из L2 в L1, ответить весьма затруднительно. Отметим лишь, что беспрепятственное прибытие количества байт, меньшего 32 за 3 такта процессора в среднем соответствует измеренной в предыдущем тесте реальной ПС шины данных L1-L2 этого процессора.
Далее посмотрим, с каких позиций возможно считывание строки из L2 в L1 — только ли с ее начала, или откуда-нибудь еще? (как это было в случае процессоров AMD K7/K8, где, напомним, считывание оказывается возможным с любой позиции строки кэша, кратной 8 байтам). Для этого воспользуемся пресетом L1-L2 Cache Bus Data Arrival Test 2, 64 bytes.
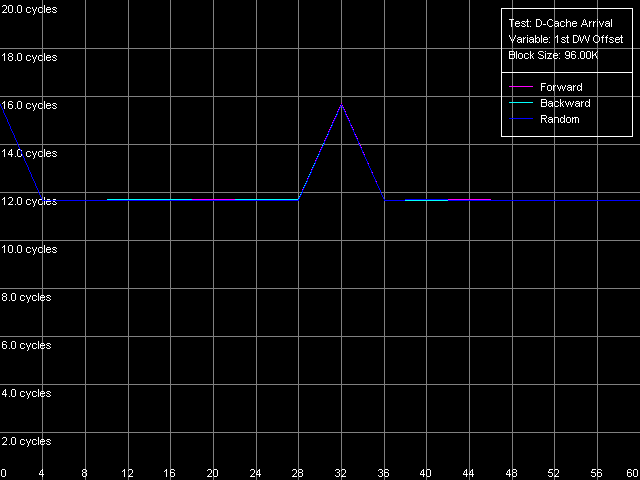
Pentium M
Как мы уже писали, в этом тесте осуществляется чтение второго элемента строки кэша со смещением, равным 60 байтам относительно смещения первого элемента, которое является переменной величиной. Таким образом, начальная точка (0 байт) соответствует действительному запросу второго элемента со смещением 60 байт, в то время как все последующие — запросу второго элемента, отстоящего от первого на 4 байта влево.
(для наглядности, запишем это утверждение математически:
((N + 60) % 64) = (N — 4), при N >= 4)
Вернемся к самим результатам теста. Увеличение латентности с 12 до 16 тактов в начальной точке означает, как мы уже видели выше, что запрос последнего элемента строки кэша действительно связан с возникновением задержек. Второй максимум наблюдается при смещении первого элемента, равного 32 байтам, а это означает, что запрос (32 — 4) = 28-го байта строки оказывается связан с возникновением точно такой же задержки. Таким образом, результат этого теста показывает, что считывание строки кэша может начинаться не только с ее нулевого элемента (с ее начала), но и с ее середины (т.е. со смещения, равного 32 байтам). При этом в первом случае считывание строки идет в такой последовательности: 0-31, 32-63, а во втором — наоборот: 32-63, 0-31. Именно поэтому в первом случае задержки возникают при чтении 60-го элемента, а во втором — 28-го, которые в обоих случаях являются последними из запрашиваемых элементов строки.
Полученные в этом тесте результаты указывают на то, что, по всей видимости, шина данных L1-L2 кэша данных у процессора Pentium M все-таки является 256-разрядной (теоретический предел пропускной способности — 32 байта/такт, что совпадает с нашими наблюдениями), однако пересылка данных происходит лишь на каждом втором такте, что и дает полученную выше «эффективную» ширину этой шины, равную 128 битам.
Кэш инструкций, эффективность декодирования/исполнения
Приступим к оценке основных характеристик кэша инструкций, декодера и исполнительных ресурсов рассматриваемых процессоров. С этой целью используем тест I-Cache, и представим здесь, как и прежде, наиболее показательные кривые, полученные в пресете L1i Size / Decode Bandwidth, CMP Instructions 3 (соответствующий код представляет собой последовательность 6-байтных операций cmp eax, 0x00000000).
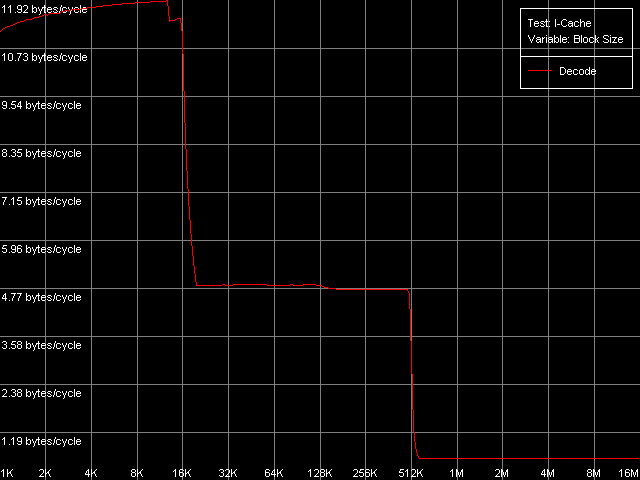
Pentium III-M
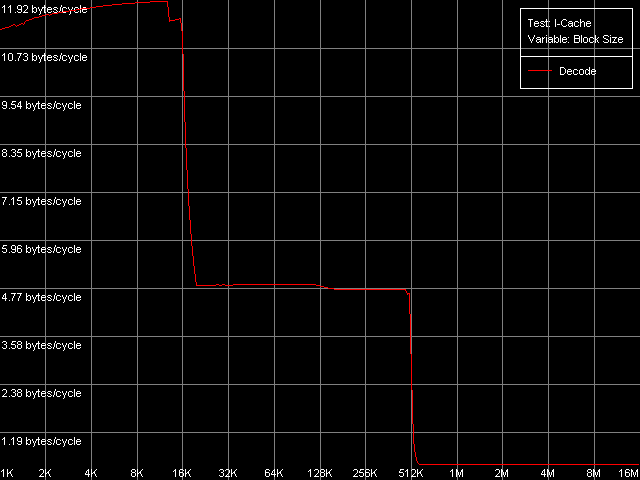
Pentium III-S
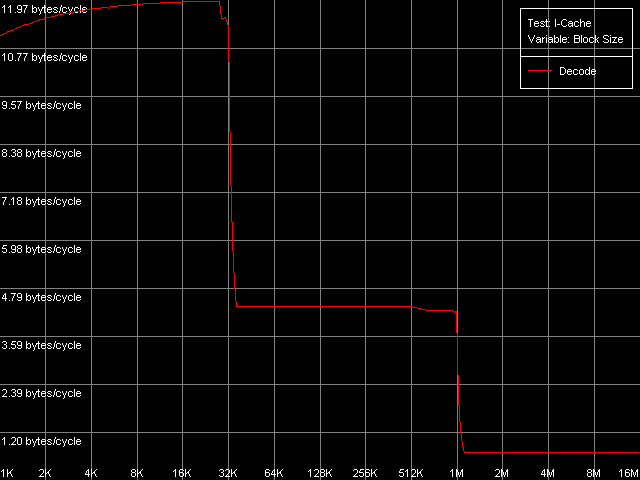
Pentium M
Об L1 кэше инструкций процессора Pentium M можно сказать, что его размер действительно удвоился по сравнению с размером L1-I кэша процессоров семейства Pentium III и составляет 32 КБ. Область 16 — 256 КБ на процессорах Pentium III и 32 — 512 КБ на процессоре Pentium M соответствует L2 кэшу, который у данных процессоров (как и во всех рассмотренных ранее случаях AMD K7/K8 и Intel Pentium 4) является унифицированным кэшем кода/данных. При этом вполне естественно, что инклюзивная организация уровней кэша распространяется и на случай кэширования кода. Кстати, именно в этой области можно разглядеть едва заметное уменьшение скорости исполнения блока кода, если его размер превышает 128 КБ (Pentium III-M/S) или 512 КБ (Pentium M). Ту же картину мы видели при тестировании платформ Intel Pentium 4 и справедливо отнесли это на счет исчерпания ресурсов I-TLB. В нашем случае можно сказать, что I-TLB процессоров Pentium III-M/S содержит всего 32 записи (128 КБ / 4 КБ), в то время как его размер у Pentium M стал в четыре раза больше (до 128 дескрипторов страниц, 512 КБ / 4 КБ).
Тем не менее, вернемся к оценке эффективности L1-I/L2 кэша, декодера и исполнительных устройств процессора. Для этого рассмотрим данные, полученные в остальных подтестах теста I-Cache.
| Тип инструкций (размер инструкции, байт) | Эффективность декодирования, байт/такт | |||||
|---|---|---|---|---|---|---|
| Pentium III-M | Pentium III-S | Pentium M | ||||
| L1-I | L2 | L1-I | L2 | L1-I | L2 | |
| Независимые/условно зависимые | ||||||
| NOP (1) | 2.00 | 1.69 | 2.00 | 1.69 | 2.00 | 1.94 |
| SUB (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| XOR (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| TEST (2) | 3.99 | 2.72 | 3.99 | 2.72 | 3.99 | 3.65 |
| XOR/ADD (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| CMP 1 (2) | 3.99 | 2.72 | 3.99 | 2.72 | 3.99 | 3.65 |
| CMP 2 (4) | 7.96 | 4.87 | 7.96 | 4.88 | 7.98 | 4.12 |
| CMP 3-6 (6) | 11.92 | 4.88 | 11.92 | 4.88 | 11.97 | 4.36 |
| Prefixed CMP 1-4 (8) | 2.28 | 2.13 | 2.28 | 2.13 | 2.00 | 1.78 |
| Зависимые | ||||||
| LEA (2) | 2.00 | 1.65 | 2.00 | 1.65 | 2.01 | 1.94 |
| MOV (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| ADD (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| OR (2) | 2.00 | 1.68 | 2.00 | 1.68 | 2.02 | 1.98 |
| SHL (3) | 3.03 | 2.29 | 3.03 | 2.29 | 3.03 | 2.86 |
| ROL (3) | 3.00 | 2.78 | 3.00 | 2.79 | 3.00 | 2.70 |
Для начала рассмотрим наиболее благоприятный случай — декодирование/исполнение блоков кода небольших размеров, помещающихся в L1-I кэш процессоров. Видно, что максимальная скорость декодирования/исполнения простейших ALU-инструкций у всех трех процессоров составляет 2 инструкции/такт, она достигается в случае простейших независимых операций вроде NOP, TEST, CMP 1, CMP 2 и CMP 3-6. Кстати, насчет последних нужно сказать, что скорость их исполнения не зависит от размера значения поля immediate (0, 8, 16 или 32 бита), точно так же, как и у процессоров AMD K7/K8, но не Intel Pentium 4. Что неудивительно, поскольку устройство декодера Pentium III куда ближе к K7/K8, нежели принципиально иного Pentium 4.
Скорость исполнения этих операций на Pentium M если и стала выше, то крайне незначительно (увеличение скорости составляет доли процента), что вряд ли позволяет говорить о серьезных изменениях микроархитектуры процессора на уровне декодера и исполнительных устройств.
Темп исполнения «условно зависимых» операций SUB, XOR и XOR/ADD, содержащих ложные зависимости по регистру EAX, составляет всего лишь одну операцию за такт. Что это — нехватка исполнительных ресурсов или неумение разрешать подобные зависимости? Очевидно, имеет место быть именно второе. Подтвердим наше предположение следующими фактами, известными из документации Intel.
- Процессоры Pentium III имеют два блока ALU (порты 0 и 1), способных исполнять одну операцию за такт каждый. Именно такой темп (2 операции/такт) мы и получили выше, при рассмотрении элементарных независимых ALU-операций вроде NOP, TEST и CMP.
- Исполнение простейших операций SUB, XOR и XOR/ADD не связано с доступом к блоку генерации адресов AGU (порт 0) или блоку загрузки/сохранения данных LSU (порты 2, 3, 4). Таким образом, их исполнение не должно лимитироваться данными факторами.
Жаль, что у Pentium M в этом отношении не имеется каких-либо улучшений, тогда как процессоры AMD K7/K8 давно умеют разрешать условные зависимости подобного рода.
С зависимыми операциями все намного понятнее — их темп исполнения на всех трех процессорах составляет ровно одну операцию в такт, что означает исполнение одной операции в любом из блоков ALU за один такт процессора.
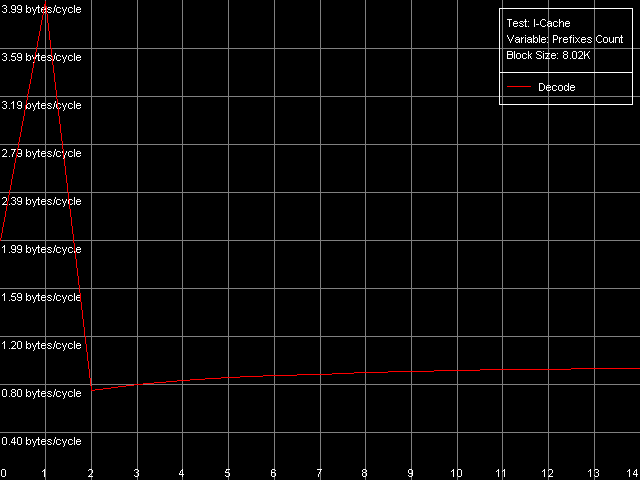
Особым случаем являются простейшие инструкции CMP, содержащие два «бессмысленных» префикса, REP и Address Override (Prefixed CMP 1-4). Их темп исполнения оказывается крайне низким, в особенности — на Pentium M (одна такая операция исполняется за четыре такта процессора!), так что с «отсечением» префиксов дела у Pentium III/Pentium M обстоят явно плохо. Впрочем, как именно — легко узнать, используя специальный подтест Prefixed NOP Decode Efficiency.
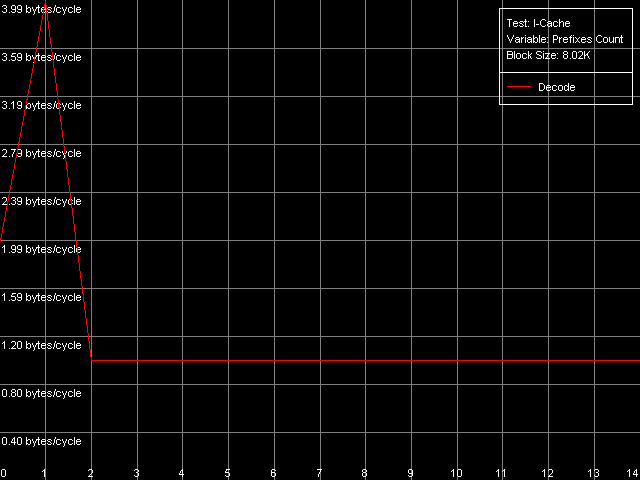
Pentium III-M
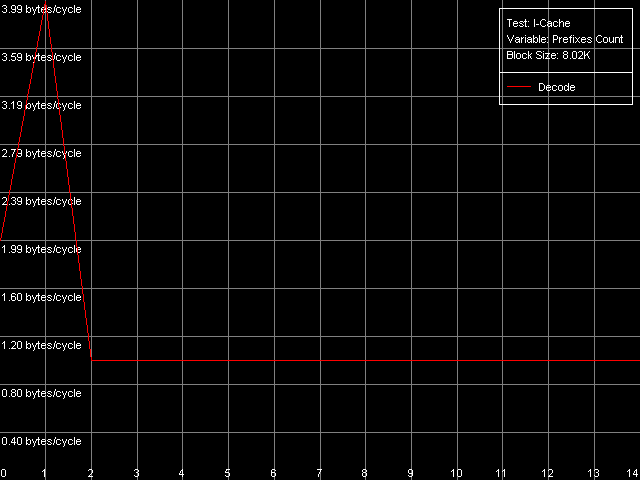
Pentium III-S
Pentium M
По результатам этого теста сразу видно, что эффективное исполнение инструкций с префиксами возможно лишь при количестве последних, равным всего-навсего одному, после чего наблюдается очень серьезное падение производительности. Причем и в этом тесте результаты явно не в пользу Pentium M.
Тем не менее, одно приятное улучшение в Pentium M все же имеется — это значительно возросшая скорость декодирования/исполнения инструкций из унифицированного L2 кэша. В большинстве случаев (как независимых, так и зависимых инструкций) прирост в скорости составляет 18%, а для простейших TEST и CMP 1 — и того выше (34%). Но вот с «крупными» CMP 2 и CMP 3-6 и здесь имеется разочарование: скорость исполнения последних из L2 упала на 15 и 10%, соответственно. Про Prefixed CMP, у которых дела и так обстоят весьма посредственно, можно сказать то же самое — эффективность их исполнения из L2 снизилась на 16%.
Ассоциативность кэша инструкций
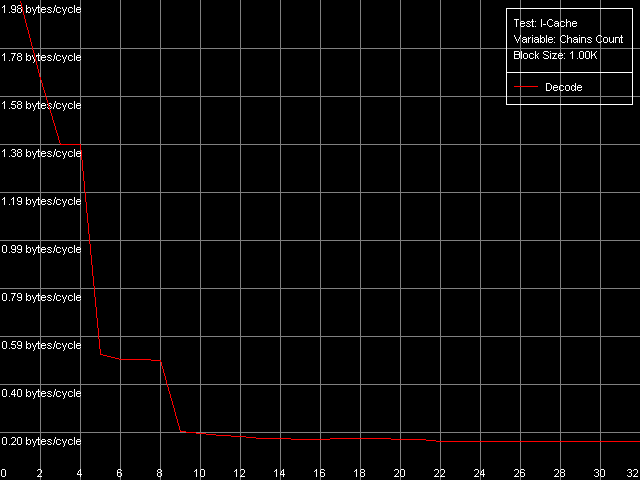
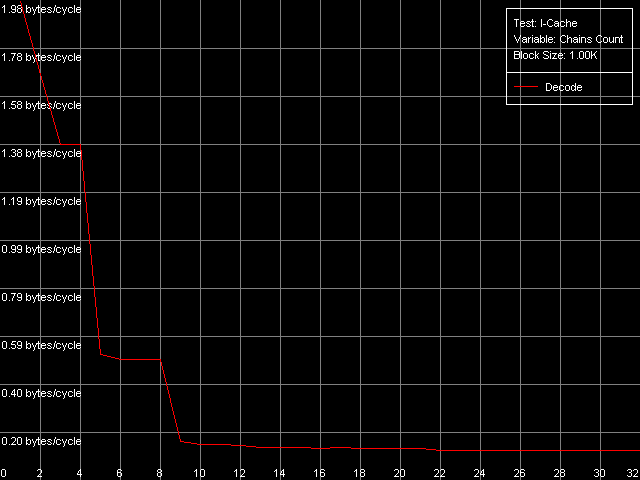
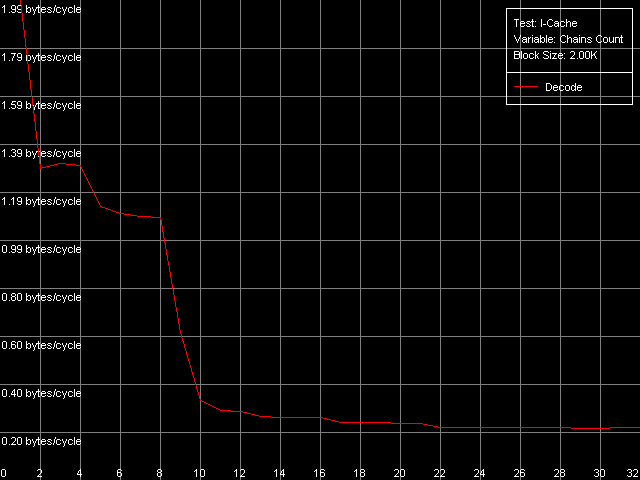
Для измерения ассоциативности L1-I/L2 кэша воспользуемся подтестом I-Cache Associativity, в котором исполняются простейшие инструкции NOP, расположенные линейно не в одном большом блоке, а по различным адресам памяти, имеющим «плохие» смещения друг относительно друга с точки зрения кэша процессоров.
Pentium III-M
Pentium III-S
Pentium M
Кривые на мобильном Pentium III-M и серверном Pentium III-S оказались абсолютно идентичными, а вот вид кривой на Pentium M несколько иной. Главным образом за счет того, что скорость исполнения из L2 (область 5-8 цепочек) на этом процессоре серьезно возросла. Но общая картина сохраняется довольно четкой: ассоциативность кэша L1-I равна четырем, а объединенного L2 — восьми (такое же значение мы получили и в тесте ассоциативности кэша данных, как тому и положено быть для унифицированного кэша кода/данных).
Характеристики D-TLB
Вот мы добрались и до традиционных заключительных тестов буферов трансляции виртуальных адресов страниц памяти в физические адреса (D-TLB/I-TLB). Для начала измерим размер буфера TLB данных, используя тест D-TLB, настройки D-TLB Size.
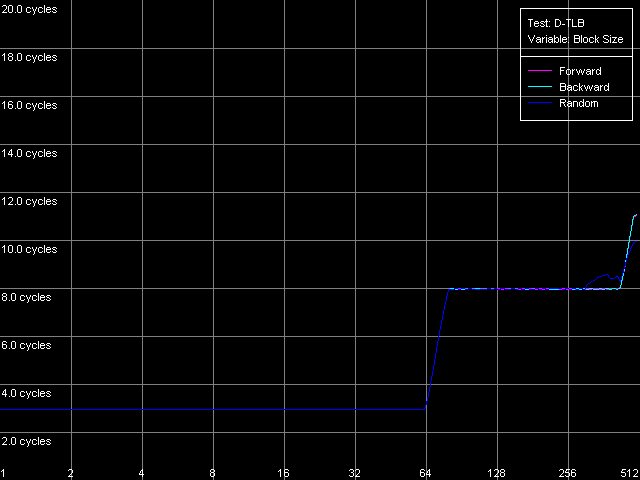
Pentium III-M
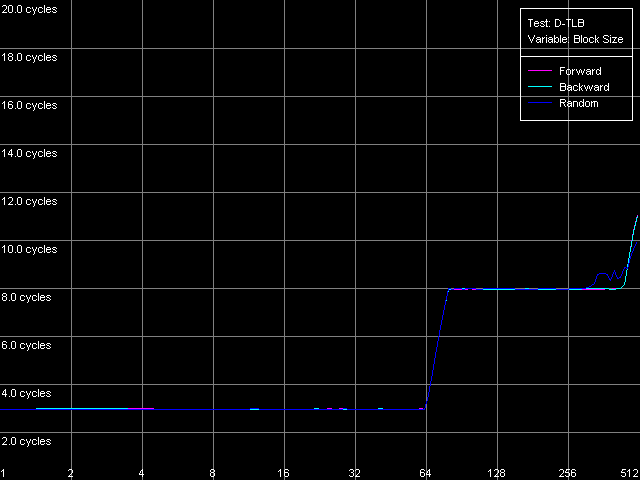
Pentium III-S
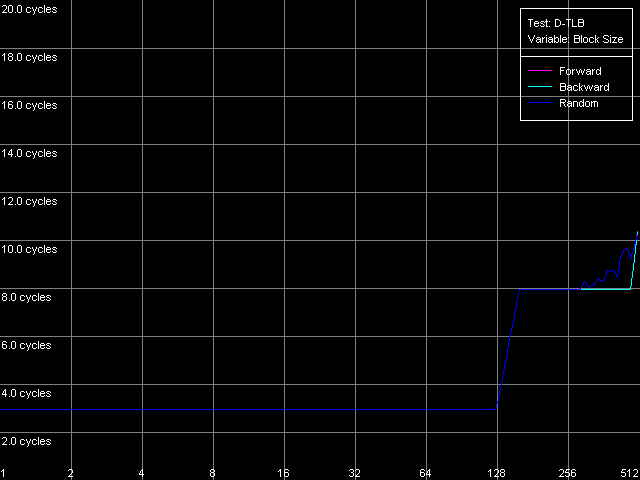 Pentium M
Pentium MСделанное еще в первом разделе предположение касательно размера D-TLB подтверждается: у процессоров Pentium III-M/S он может содержать 64 записи, а у Pentium M он действительно расширен до 128 записей. Организация D-TLB является традиционной для процессоров Intel — одноуровневой. Наконец, здесь нельзя не отметить, что промах D-TLB весьма легко сказывается на латентности доступа в L1 — у всех процессоров в условиях промаха она возрастает всего до 8 тактов, в точности, как у AMD K7/K8, и далеко не так катастрофически, как это выглядит у Intel Pentium 4.
Измерим теперь и ассоциативность первого и единственного уровня D-TLB данного семейства процессоров. Для этого используем пресет D-TLB Associativity, 32 Entries — именно такое количество последних вполне «влезет» в D-TLB каждого из процессоров.
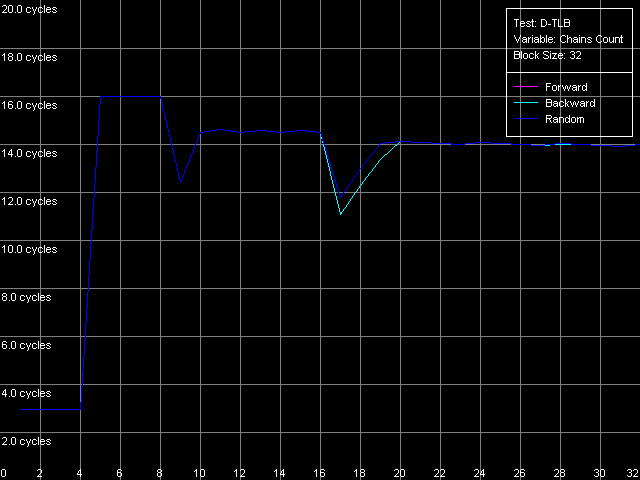
Pentium III-M
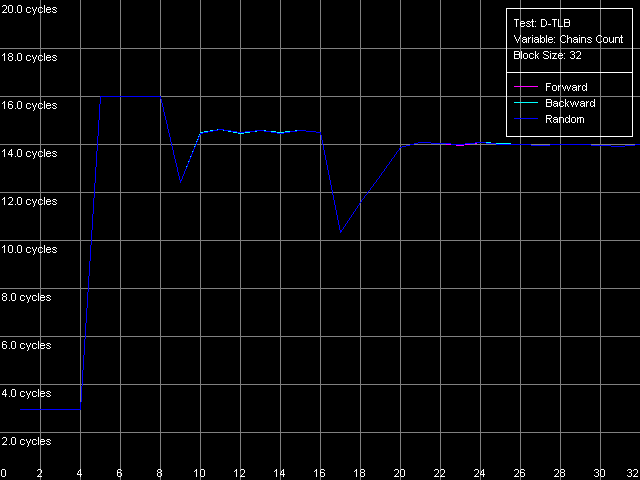
Pentium III-S
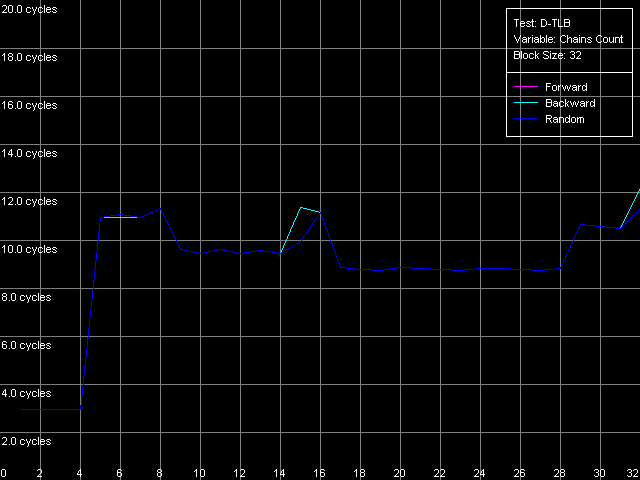
Pentium M
И вновь кривые на Pentium III-M и Pentium III-S оказались одинаковыми. Ассоциативность D-TLB равна четырем, а ее «провал» приводит к увеличению латентности доступа в L1 кэш в среднем до 14 тактов. В то же время, у Pentium M с этим дело обстоит куда лучше. Ассоциативность D-TLB этого процессора также равна четырем, но средняя латентность при ее исчерпании уменьшилась до 9 тактов, что определенно является положительным моментом.
Характеристики I-TLB
Посмотрим, что же мы можем сказать о TLB инструкций у рассматриваемых процессоров. Для начала измерим их размер (тест I-TLB, пресет I-TLB Size).
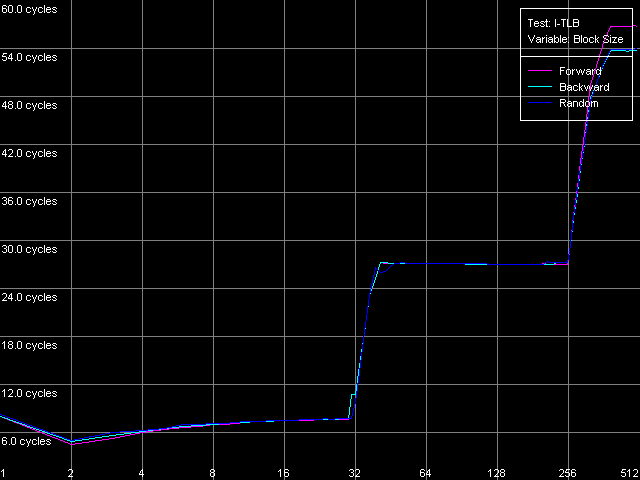
Pentium III-M
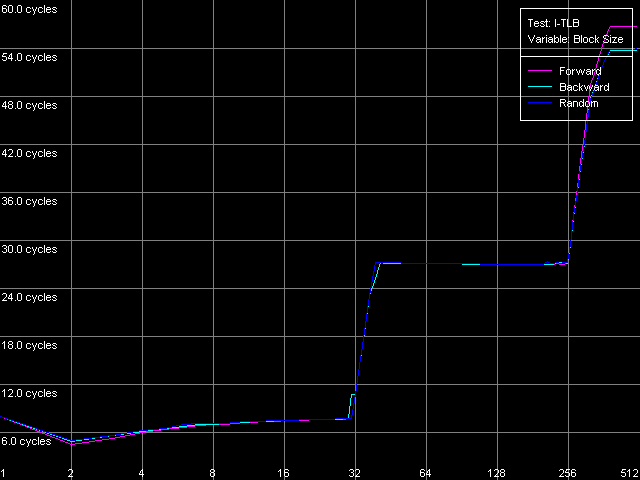
Pentium III-S
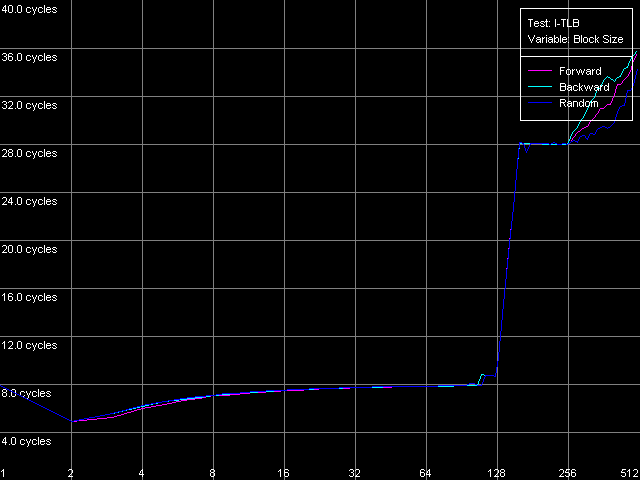
Pentium M
И увидим, что сделанное нами чуть ранее предположение подтвердилось — I-TLB процессора Pentium M увеличился в четыре раза (до 128 записей) по сравнению с процессорами Pentium III-M/S. Промах I-TLB сказывается на латентности исполнения последовательности безусловных переходов куда сильнее (она возрастает до 27-28 тактов), чем промах D-TLB на латентности доступа в L1 кэш данных. Наличие резкого скачка при 256 страницах на кривых Pentium III-M/S связано с исчерпанием размера L1-I кэша у этих процессоров и попаданием в область объединенного L2 кэша кода/данных.
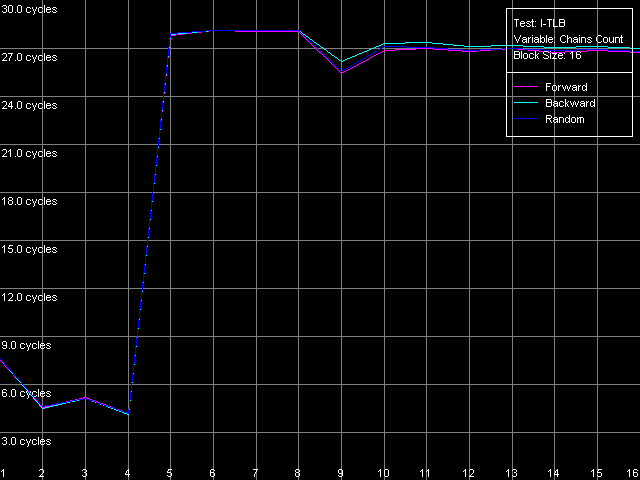
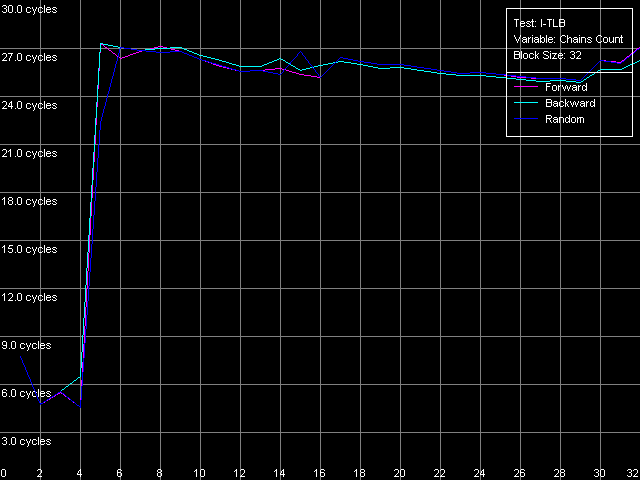
Напоследок оценим ассоциативность I-TLB у наших процессоров. Для Pentium III-M/S с относительно малым размером этого буфера используем пресет I-TLB Associativity, 16 Entries, а для Pentium M ничего не мешает взять и больше — I-TLB Associativity, 32 Entries.
Pentium III-M
Pentium III-S
Pentium M
Результат этого теста весьма очевидный: у всех трех процессоров ассоциативность I-TLB равна четырем, причем выход за ее пределы сопровождается таким же возрастанием латентности исполнения «прыжков» (до 27 тактов), как и выход за пределы размера I-TLB.
Заключение
Сделаем выводы относительно «нового поколения» процессоров семейства Pentium III, ключевого компонента Intel Centrino Mobile Technology — процессора Intel Pentium M. Для этого рассмотрим два основных момента, заявленных Intel, и сопоставим их с тем, что мы получили в представленном вашему вниманию исследованию низкоуровневых характеристик процессоров Intel Pentium III.
Первым серьезным отличием, согласно Intel, является удвоение объемов кэша инструкций и данных. Это действительно почти так, поскольку, как мы уже отмечали, удвоился и размер строки кэша, а значит, размер кэша с точки зрения количества линий остался тем же самым. Что действительно увеличилось — так это размеры D-TLB и I-TLB, что определенно идет на пользу Pentium M. Еще один плюс — улучшение показателей латентности как кэша данных, так и TLB в условиях «исчерпания» их ассоциативности. Но нельзя не упомянуть и негативные моменты. Прежде всего, это увеличение латентности L2 кэша, хотя и незначительное — всего на один такт. Которая, конечно же, возросла из-за того, что ширина шины обмена данными между L1 и L2 кэшами так и осталась 128-битной, и для прибытия целой 64-байтной строки кэша теперь требуется введение дополнительных задержек.
Второй момент, о котором заявляет Intel — микроархитектурные изменения ядра процессора. Честно говоря, реальное тестирование декодера и исполнительных блоков процессора не позволяет говорить о наличии серьезных изменений на этом уровне. Действительно, предельная скорость исполнения кода осталась такой же, да и с разрешением зависимостей и отсечением префиксов у этого процессора дела обстоят не лучше, чем у Pentium III. Бесспорно, есть и положительный момент — это увеличение скорости выборки инструкций из L2 кэша. Что на самом деле не столь актуально, поскольку трудно себе представить программу, исполняющую непрерывный блок кода размером 512 КБ.


