Семейства видеокарт NVIDIA GeForce Справочная информация
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX
Спецификации чипов семейства NV4X
| кодовое имя | NV45 | NV40 | NV42 | NV41(M) | NV43 | NV44A | NV44 | |
| базовая статья | здесь | здесь | здесь | |||||
| технология (нм) | 130 | 110 | 130 | 110 | ||||
| транзисторов (М) | 222 | 190 | 143 | 77 | ||||
| пиксельных процессоров | 16 | 12 | 8 | 4 | ||||
| текстурных блоков | 16 | 12 | 8 | 4 | ||||
| блоков блендинга | 16 | 12 | 4 | 2 | ||||
| вершинных процессоров | 6 | 3 | ||||||
| шина памяти | 256 (64х4) | 128 (64х2) | 64 (32х2) | |||||
| типы памяти | DDR, GDDR2, GDDR3 | |||||||
| системная шина чипа | PEG 16х | AGP 8х | PEG 16х | AGP 8х | PEG 16х | |||
| RAMDAC | 2 х 400МГц | |||||||
| интерфейсы | TV-Out TV-In (нужен чип захвата) 2 x DVI (нужны внешние интерфейсные чипы) | |||||||
| вершинные шейдеры | 3.0 | |||||||
| пиксельные шейдеры | 3.0 | |||||||
| точность пиксельных вычислений | FP16 FP32 | |||||||
| точность вершинных вычислений | FP32 | |||||||
| форматы компонент текстур | FP32 (без фильтрации) FP16 I8 DXTC*, S3TC 3Dc (эмуляция) | |||||||
| форматы рендеринга | FP32 (без блендинга и MSAA) FP16 (без MSАА, на NV44 нет блендинга) I8 | |||||||
| MRT | есть | |||||||
| Антиалиасинг | 2х и 4x RGMS SS (в гибридных режимах) | |||||||
| генерация Z | 2х в режиме без цвета | |||||||
| буфер шаблонов | двусторонний | |||||||
| технологии теней | аппаратные карты теней оптимизации геометрических теней | |||||||
Спецификации референсных карт на базе семейств NV4X
| карта | чип шина | блоков PS/TMU/VS | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) | тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
| GeForce 6800 Ultra | NV40 AGP | 16/16/6 | 400 | 550(1100) | 256 GDDR3 | 35.2 (256) | 6400 | |
| GeForce 6800 | NV40 AGP | 12/12/5 | 325 | 350(700) | 128 DDR | 22.4 (256) | 3900 | |
| GeForce 6800 GT | NV40 AGP | 16/16/6 | 350 | 500(1000) | 256 GDDR3 | 32.0 (256) | 5600 | |
| GeForce 6800 LE | NV40 AGP | 8/8/4 | 320 | 350(700) | 128 DDR | 22.4 (256) | 2560 | |
| GeForce 6600 | NV43 PEG16х | 8/8/3 | 300 | 350(700) | 128 DDR | 11.2 (128) | 2400 | 1200 |
| GeForce 6600 GT | NV43 PEG16х | 8/8/3 | 500 | 500(1000) | 128 GDDR3 | 16.0 (128) | 4000 | 2000 |
| GeForce 6800 GTO | NV45 PEG16х | 12/12/5 | 350 | 450(900) | 256 GDDR3 | 28.8 (256) | 4200 | |
| GeForce Go 6800 | NV41M PEG16х | 12/12/5 | 275 | 300(600) | 256 GDDR3 | 19.2 (256) | 3300 | |
| GeForce 6800 | NV41 PEG16х | 12/12/5 | 325 | 350(700) | 128 DDR | 22.4 (256) | 3900 | |
| GeForce 6600 GT | NV43 AGP | 8/8/3 | 500 | 450(900) | 128 GDDR3 | 14.4 (128) | 4000 | 2000 |
| GeForce 6800 GT | NV45 PEG16х | 16/16/6 | 350 | 500(1000) | 256 GDDR3 | 32.0 (256) | 5600 | |
| GeForce 6800 Ultra | NV45 PEG16х | 16/16/6 | 400 | 550(1100) | 256 GDDR3 | 35.2 (256) | 6400 | |
| GeForce 6200 32TC | NV44 PEG16х | 4/4/3 | 350 | 350(700) | 32 GDDR | 2.8 (32) | 1400 | 700 |
| GeForce 6200 64TC | NV44 PEG16х | 4/4/3 | 350 | 350(700) | 64 GDDR | 5.6 (64) | 1400 | 700 |
| GeForce Go 6200 | NV44 PEG16х | 4/4/3 | 300 | 300(600) | 16 GDDR | 2.4 (32) | 1200 | 600 |
| GeForce 6800 LE | NV41 PEG16х | 8/8/4 | 325 | 350(700) | 128 DDR | 19.2 (256) | 2600 | |
| GeForce 6600 | NV43 AGP | 8/8/3 | 300 | 275(550) | 128 DDR | 8.8 (128) | 2400 | 1200 |
| GeForce 6600 LE | NV43 AGP | 4/4/3 | 300 | 250(500) | 128 DDR | 8.0 (128) | 1200 | |
| GeForce 6200 | NV43 PEG16х | 4/4/3 | 300 | 275(550) | 128 DDR | 4.4 (64) | 1200 | |
| GeForce Go 6600 | NV43 PEG16х | 8/8/3 | 375 | 350(700) | 128 DDR | 11.2 (128) | 3000 | 1500 |
| GeForce Go 6800 Ultra | NV42 PEG16х | 12/12/5 | 450 | 530(1060) | 256 GDDR3 | 33.9 (256) | 5400 | |
| GeForce 6800 Ultra | NV45 PEG16х | 16/16/6 | 400 | 525(1050) | 512 GDDR3 | 33.6 (256) | 6400 | |
| GeForce 6200 A | NV44A AGP | 4/4/3 | 350 | 250(500) | 128 GDDR | 4.0 (64) | 1400 | 700 |
| GeForce Go 6800 | NV42 PEG16х | 12/12/5 | 450 | 550(1100) | 128 GDDR3 | 35.2 (256) | 5400 | |
| карта | чип шина | блоков PS/TMU/VS | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) | тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
Подробности: NV40/NV45, семейство GeForce 6800
Спецификации NV40/NV45
- Кодовое имя чипа NV40/NV45
- Технология 130нм FSG (IBM)
- 222 миллиона транзисторов
- FС корпус (flip chip, перевернутый чип, без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта DDR/DDR2/GDDR3 памяти
- AGP 3.0 8x шинный интерфейс у NV40, PCI Express 16х у NV45 (в корпус интегрирован второй чип — HSI мост)
- Специальный режим работы AGP 16х (в обе стороны), для PCI-Express моста HSI
- 16 Пиксельных процессоров, по одному текстурному блоку на каждом с произвольной фильтрацией целочисленных и плавающих текстур (анизотропия степени до 16х включительно).
- 6 Вершинных процессоров, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка)
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 32 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка «двустороннего» буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов (так называемая технология Ultra Shadow II)
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выборку значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате
- Поддерживается буфер кадра в плавающем формате (включая операции блендинга)
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2x RAMDAC 400 МГц
- 2x DVI интерфейса (требуются внешние чипы)
- TV-Out и TV-In интерфейс (требуются отдельные чипы)
- Программируемый потоковый видеопроцессор (для задач компрессии, декомпрессии и постобработки видео)
- 2D ускоритель с поддержкой всех функций GDI+
Спецификации референсной карты GeForce 6800 Ultra AGP
- Частота ядра 400 МГц
- Эффективная частота памяти 1.1 ГГц (2*550 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 35.2 гигабайта в сек.
- Теоретическая скорость закраски 6.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур 6.4 гигатекселя в сек.
- Два DVI-I разъема
- TV-Out
- Потребляет до 120 Ватт энергии (на карте два разъема дополнительного питания, рекомендуются источники питания суммарной мощностью 480 и более Ватт)
Архитектура чипа
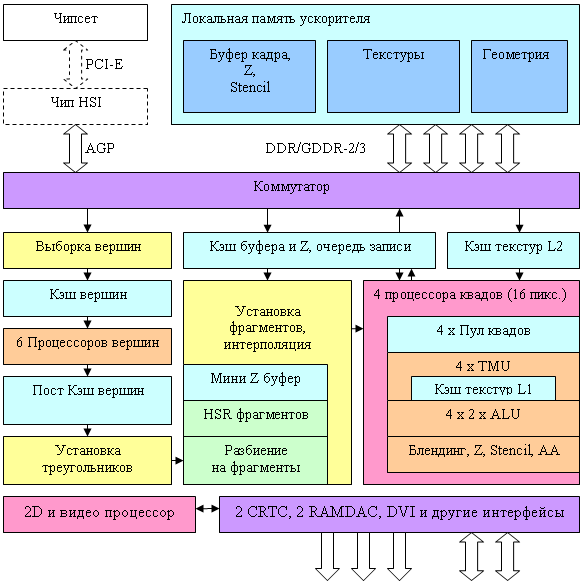
Приведем блок схему вершинного процессора NV40:
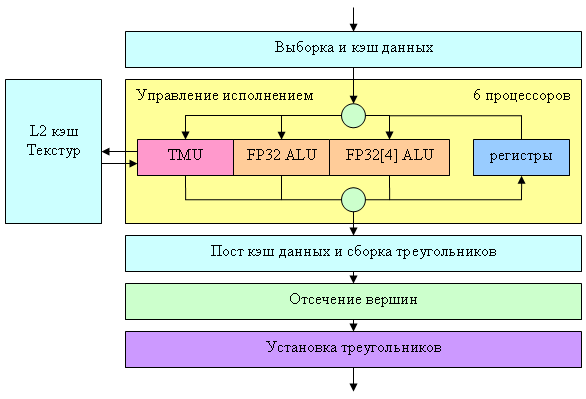
Собственно сам процессор на схеме обозначен желтым прямоугольником, остальные окружающие его блоки показаны для более полной картины. Заявлено, что NV40 содержит 6 независимых процессоров (мысленно скопируем желтый блок 6 раз), каждый из которых исполняет свои команды и имеет собственную контрольную логику (то есть разные процессоры могут одновременно исполнять различные ветки условий над разными вершинами). За один такт вершинный процессор NV40 может выполнить одну векторную операцию (до четырех компонент FP32) одну скалярную FP32 операцию и осуществить один доступ к текстуре. Поддерживаются целочисленные и плавающие форматы текстур и мип-маппинг. В одном вершинном шейдере может быть задействовано до четырех различных текстур. Однако фильтрация не производится – возможен только самый простой, дискретный доступ к ближайшему значению по заданным координатам.
Так выглядит сводная табличка параметров вершинного процессора NV40 с точки зрения вершинных шейдеров DX9 в сравнении с семействами R3XX и NV3X:
Версия вершинных шейдеров | 2.0 (R 3 XX) | 2. a (NV 3 X) | 3.0 (NV40) |
Число инструкций в коде шейдера | 256 | 256 | 512 и более |
Число исполняемых инструкций | 65535 | 65535 | 65535 и более |
Предикаты | Нет | Есть | Есть |
Временных регистров | 12 | 13 | 32 |
Константных регистров | 256 и более | 256 и более | 256 и более |
Статические переходы | Да | Да | Да |
Динамические переходы | Нет | Да | Да |
Глубина вложенности динамических переходов | Нет | 24 | 24 |
Выбор значений текстур | Нет | Нет | Да (4) |
Рассмотрим пиксельную архитектуру NV40 в порядке следования данных:
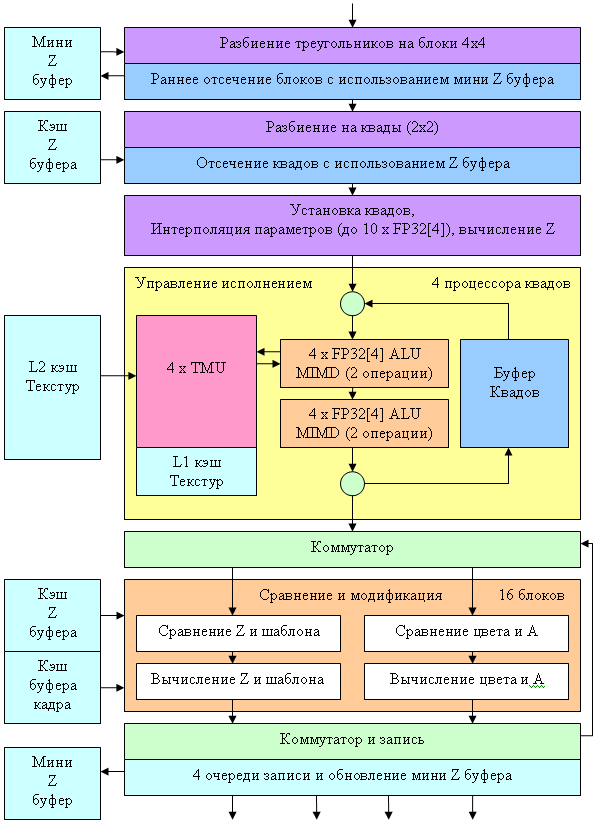
Остановимся на самых интересных фактах. Во-первых, если ранее в NV3X был лишь один процессор квадов, обрабатывающий за такт блок из четырех пикселей (2х2), то теперь таких процессоров стало четыре. Они полностью независимы и каждый из них может исключаться из работы (например, для создания облегченной версии чипа с тремя процессорами при наличии брака в одном из них). По-прежнему сохранилась очередь для «карусели» квадов (см. DX Current), своя в каждом процессоре. Соответственно, сохранился и схожий с NV3X подход на исполнение пиксельных шейдеров: прогон через одну настройку (операцию) более чем сотни квадов и последующей смены настройки в соответствии с кодом шейдера. Но есть и заметные отличия. В первую очередь – это число TMU – теперь у нас только по одному TMU на каждый пиксель квада. Всего у нас 4 процессора квадов, в каждом по 4 TMU, таким образом, всего их 16.
Новые TMU поддерживают анизотропную фильтрацию с соотношением сторон до 16:1 включительно (так называемые 16х, у NV3X было до 8х) и, наконец-то, научились выполнять все виды фильтрации с плавающими форматами текстур. Правда, при условии 16 битной точности компонент (FP16). Для FP32 фильтрация по-прежнему недоступна, однако и FP16 можно считать заметным прогрессом – теперь плавающие текстуры станут «полноправной» альтернативой целочисленным в любых применениях, тем более что сама фильтрация FP16 текстур происходит без снижения скорости (впрочем, повышенный поток данных может и должен сказаться на производительности реальных приложений).
Отметим двухуровневую организацию кэширования текстур – каждый процессор квада имеет свой собственный кэш текстур первого уровня. Необходимость наличия оного вызвана двумя фактами – четырехкратным увеличением числа обрабатываемых одновременно квадов (очередь квадов в одном процессоре не выросла, но процессоров теперь четыре) и наличием конкурентного доступа к кэшу текстур из вершинных процессоров.
На каждый пиксель приходится по два ALU, причем каждое из них может выполнить две различные(!) операции над разным числом произвольно выбираемых компонент вектора (до 4х). То есть, возможны схемы 4, 1+1, 2+1, 3+1 (как в R3XX), и новая конфигурация 2+2, ранее недоступная. Подробнее об этом вопросе см. DX Current. Поддерживается произвольное маскирование и перестановка компонент после операции. Кроме того, ALU способно выполнять нормализацию вектора как одну операцию, что может существенно сказаться на производительности некоторых алгоритмов. Аппаратное вычисление значений SIN и COS было изъято из новой архитектуры NVIDIA – опыт показал, что израсходованные на эту возможность транзисторы были потрачены зря – все равно доступ по простейшей таблице (1D текстуре) способен дать лучшие результаты с точки зрения скорости, тем более, учитывая отсутствие такой поддержки у ATI.
Таким образом, в зависимости от кода, может быть выполнено от одной до четырех различных FP32 операций за такт, над векторами и скалярами. На схеме видно, что первое ALU задействуется для служебных операций во время выборки значений текстур, таким образом, за один такт мы можем либо выбрать одно значение текстуры и задействовать второе ALU для одной или двух операций, либо задействовать оба ALU, если мы не выбираем текстуру в этот заход. Производительность такой связки напрямую зависит от компилятора и кода, но очевидно, что мы имеем
Минимум: одну выборку текстуры за такт
Минимум: две операции за такт без выборки текстуры
Максимум: четыре операции за такт без выборки текстуры
Максимум: одну выборку текстуры и две операции за такт
По некоторым данным, число временных регистров для каждого квада было увеличено вдвое, то есть теперь мы имеем 4 временных FP32 регистра на пиксель или 8 временных FP16 регистров. Этот факт должен существенно увеличить производительность сложных шейдеров. Кроме того, сняты какие-либо аппаратные ограничения на длину пиксельных шейдеров и число выборок текстур – теперь все будет зависеть только от API. Самое главное усовершенствование – поддержка динамического управления исполнением.
А теперь – сводная таблица возможностей:
Версия пиксельного шейдера | 2.0 (R3XX) | 2.a (NV3X) | 2.b (R420) | 3.0 (NV40) |
Вложенность выборок текстур до | 4 | Без ограничений | 4 | Без ограничений |
Выборок значений текстур до | 32 | Без ограничений | Без ограничений | Без ограничений |
Длина кода шейдера | 32 + 64 | 512 | 512 | 512 и более |
Исполняемых инструкций шейдера | 32 + 64 | 512 | 512 | 65535 и более |
Интерполяторы | 2 + 8 | 2 + 8 | 2 + 8 | 10 |
Предикаты | нет | да | нет | да |
Временных регистров | 12 | 22 | 32 | 32 |
Константных регистров | 32 | 32 | 32 | 224 |
Произвольная перестановка компонент | нет | да | нет | да |
Инструкции градиента (D D X/ D DY) | нет | да | нет | да |
Глубина вложенности динамических переходов | нет | нет | нет | 24 |
А теперь вернемся к нашей схеме и обратим внимание на ее нижнюю часть. Там расположен блок, отвечающий за сравнение и модификацию значений цвета, прозрачности, глубины и буфера шаблонов. Всего у нас 16 таких блоков. Ввиду достаточной однотипности задачи сравнения и модификации, мы можем использовать этот блок в двух режимах:
Стандартный (за один такт производится):
- Сравнение и модификация значения глубины
- Сравнение и модификация значения буфера шаблона
- Сравнение и модификация значения компоненты прозрачности и цвета (блендинг)
Турбо режим (за один такт производится):
- Сравнение и модификация двух значений глубины
- Сравнение и модификация двух значений буфера шаблона
Разумеется, что последний режим возможен только в случае отсутствия вычисленного и записываемого значения цвета. Вот откуда в спецификации указано, что в случае отсутствия цвета чип может закрасить (точнее заполнить) 32 пикселя за один такт, причем рассчитывается как значение глубины, так и значение буфера шаблонов. Подобный «турбо» режим полезен в первую очередь для ускорения построения теней на основе буфера шаблонов (алгоритм, принятый в Doom III), и для предварительного прохода рендеринга, в котором рассчитывается только Z буфер (зачастую такая техника позволяет сэкономить время на длинных шейдерах, так как фактор перекрытия будет гарантированно уменьшен до единицы).
Наконец-то исправлено досадное упущение с отсутствием в семействе NV3X поддержки MRT (Multiple Render Targets – рендеринг в несколько буферов) – то есть возможности расчета и записи в одном пиксельном шейдере до четырех различных значений цвета, которые будут затем помещены в разные буфера (одинакового размера). Отсутствие такой функции у NV3X было серьезным аргументом в пользу R3XX для разработчиков. Теперь, в NV40, эта возможность появилась. Еще одно важное отличие от предыдущих поколений – интенсивная поддержка этим блоком плавающей арифметики. Все операции по сравнению, блендингу и записи цвета могут проходить в формате компонент FP16. Наконец-то мы имеем, что называется, полную (ортогональную) поддержку операций с 16 битной плавающей точкой – как в плане фильтрации и выборки текстур, так и в плане работы с буфером кадра. На очереди FP32, но, видимо, это вопрос следующего поколения.
Еще один интересный факт – поддержка MSAA. Как и его предшественники (NV 2Х и NV 3 X), NV40 может осуществлять 2 x MSAA без потери скорости (генерируется и сравнивается два значения глубины на один пиксель) а в случае 4 x MSAA необходимо добавить один штрафной такт (впрочем, на практике нет необходимости вычислять все четыре значения за такт – все равно будет проблематично записать в буфер глубины и кадра столько информации за один такт – полоса пропускания памяти достаточно ограничена). Более 4х MSAA не поддерживается – как и в предыдущем семействе, все более сложные режимы гибриды между 4х MSAA и последующим SSAA того или иного размера. Но теперь, наконец-то, поддерживается RGMS (повернутая решетка отсчетов MSAA):
Вот такой отдельный программируемый блок NV40 берет на себя задачи обработки видеопотоков:
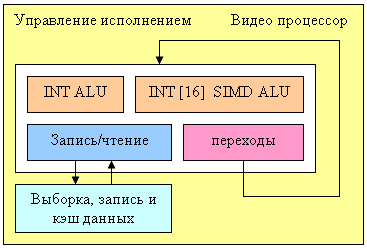
Процессор содержит четыре функциональных блока (целочисленное ALU, векторное целочисленное ALU с 16 компонентами, блок загрузки и выгрузки данных и блок управления переходами и условиями) и может таким образом выполнять до четырех различных операций за такт. Формат данных – целые числа, видимо, 16 битной или 32 битной точности (точно неизвестно, но для некоторых алгоритмов 8 бит было бы недостаточно). Для удобства процессор включает специальные возможности выборки, коммутации и записи потоков данных. Классические задачи декодирования и кодирования видео (IDCT, деинтерлейсинг, преобразование цветовых моделей и т.д.) могут быть выполнены без участия CPU. Однако управление со стороны центрального процессора все равно требуется – подготовку данных и выбор параметров преобразований надо выполнять на CPU, особенно в случае достаточно сложных алгоритмов сжатия, включающих в себя распаковку как один из промежуточных шагов.
Такой процессор способен существенно разгрузить CPU, особенно в случае больших разрешений видео, таких, как все более набирающие популярность форматы HDTV. Неизвестно, используются ли возможности этого процессора для ускорения 2D графики, особенно некоторых достаточно сложных функций GDI+ — было бы логично задействовать его на этом поприще, но точной информации об этом аспекте у нас нет. Как бы там ни было, NV40 соответствует высочайшим требованиям к аппаратному ускорению 2D – все необходимые вычислительно интенсивные функции GDI и GDI+ выполняются аппаратно.
Подробности: NV43, GeForce 6600[GT]
Спецификации NV43
- Кодовое имя чипа NV43
- Технология 110нм (TSMC)
- 146 миллионов транзисторов
- FС корпус (перевернутый чип, без металлической крышки)
- 128 бит интерфейс памяти
- До 256 мегабайт DDR/DDR2/GDDR3 памяти
- Встроенный в чип PCI-Express 16х шинный интерфейс
- Возможность трансляции интерфейса в AGP 8х с помощью двустороннего PCI Express<->AGP моста HSI
- 8 Пиксельных процессоров, по одному текстурному блоку на каждом с произвольной фильтрацией целочисленных и плавающих текстур (анизотропия степени до 16х включительно).
- 3 Вершинных процессора, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка)
- Вычисление, блендинг и запись до 4 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 8 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка "двустороннего" буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов (так называемая технология Ultra Shadow II) в частности широко используемых в движке Doom III
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выборку значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате
- Поддерживается буфер кадра в плавающем формате (включая операции блендинга)
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса (требуются интерфейсные чипы)
- TV-Out и TV-In интерфейс (требуются интерфейсные чипы)
- Программируемый потоковый видеопроцессор (для задач компрессии, декомпрессии и постобработки видео)
- 2D ускоритель с поддержкой всех функций GDI+
Спецификации референсной карты GeForce 6600 GT
- Частота ядра 500 МГц
- Эффективная частота памяти 1 ГГц (2*500 МГц)
- Шина памяти 128 бит
- Тип памяти GDDR3
- Объем памяти 128 мегабайт
- Пропускная способность памяти 16 гигабайт в сек.
- Теоретическая скорость закраски 2 гигапикселя в сек.
- Теоретическая скорость выборки текстур 4 гигатекселя в сек.
- Один VGA (D-Sub) и один DVI-I разъем
- TV-Out
- Потребляет до 70 Ватт энергии (то есть на PCI-Express карте разъем для дополнительного питания не нужен, рекомендован источник питания суммарной мощностью 300 или более Ватт)
Архитектура чипа NV43
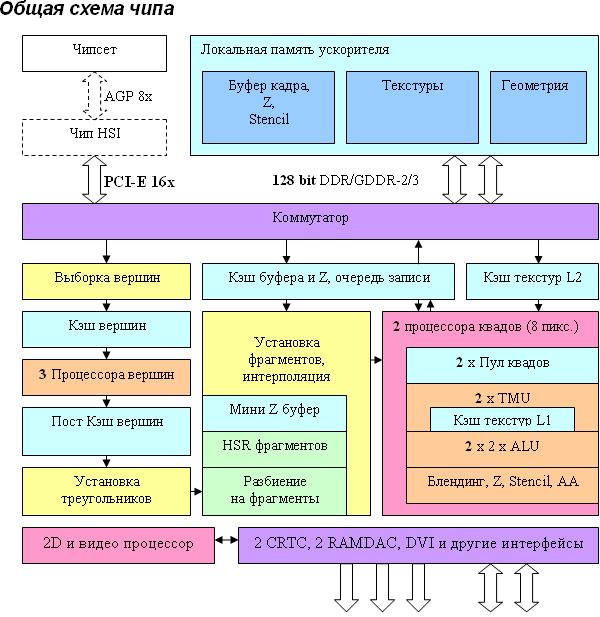
Особых архитектурных отличий от NV40 нет, что, впрочем, не удивительно – NV43 является масштабированным (путем уменьшения числа вершинных и пиксельных процессоров и каналов контроллера памяти) решением, основанным на архитектуре NV40. Отличия количественные (на схеме выделены жирным), а не качественные – с точки зрения архитектуры чип практически не изменился.
Итак, в наличии три (было шесть) вершинных процессоров, и два (было четыре) независимых пиксельных процессора, каждый из которых работает с одним квадом (фрагментом 2х2 пикселя). Интересно, что на сей раз поддержка шинного интерфейса PCI-Express стала «родной» (то есть реализованной в чипе), а AGP 8х платы будут содержать дополнительный двусторонний мост PCI-Ex <-> AGP (показан пунктиром), подробно описанный нами ранее. Кроме того, отметим очень важный ограничивающий момент – двухканальный контроллер и 128 битную шину памяти – этот факт подробно рассмотрен в обзоре.
Архитектура вершинных и пиксельных процессоров осталась прежней – эти элементы были детально описаны выше в секции NV40/NV45. Вершинные и пиксельные процессоры в NV43 остались неизменными, а вот внутренние кэши могли быть уменьшены пропорционально числу конвейеров. Впрочем, число транзисторов не дает особых поводов для беспокойства — учитывая не столь большие размеры кэшей, было бы разумнее оставить их такими же, как у NV40, скомпенсировав тем самым заметный недостаток пропускной полосы памяти. Довольно крупный по размеру и транзисторам массив ALU, осуществляющий постобработку, проверку, генерацию Z и блендинг пикселей для записи результатов в буфер кадра также был уменьшен на каждом конвейере по сравнению с NV40 — все равно уменьшенная полоса памяти не позволит записать 4 полных гигапикселя в секунду, и потенциал закраски (8 конвейеров на 500 МГц) может быть полноценно использован только на более-менее сложных шейдерах, с более чем двумя текстурами и сопутствующими математическими вычислениями.
Подробности: NV44, семейство GeForce 6200
Спецификации NV44
- Кодовое имя чипа NV44
- Технология 110 нм (TSMC)
- 77 миллионов транзисторов
- FС корпус (перевернутый чип, без металлической крышки)
- 64 бит двуканальный интерфейс памяти
- До 64 мегабайт DDR/DDR2/GDDR3 памяти
- Встроенный в чип PCI-Express 16х шинный интерфейс
- Расширенные возможности использования системной памяти, адресуемой через PCI Express для хранения буферов кадра, текстур и другой информации, традиционно располагаемой в локальной памяти
- 4 Пиксельных процессора, по одному текстурному блоку на каждом с произвольной фильтрацией целочисленных и плавающих текстур (анизотропия степени до 16х включительно).
- 3 Вершинных процессора, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка)
- Вычисление, блендинг и запись до 2 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 4 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка «двустороннего» буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов (так называемая технология Ultra Shadow II) в частности широко используемых в движке Doom III
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выборку значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате
- Поддерживается буфер кадра в плавающем формате и не поддерживается операция FP16 блендинга, в отличие от остальных чипов семейства
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса (требуются интерфейсные чипы)
- TV-Out и TV-In интерфейс (требуются интерфейсные чипы)
- Программируемый потоковый видеопроцессор (для задач компрессии, декомпрессии и постобработки видео)
- 2D ускоритель с поддержкой всех функций GDI+
Спецификации референсных карт GeForce 6200 TC-16/TC-32
- Частота ядра 350 МГц
- Эффективная частота памяти 700 МГц (2*350 МГц)
- Шина памяти 32 бит/64 бит
- Тип памяти DDR2
- Объем памяти 16 мегабайт/32 мегабайта
- Пропускная способность памяти 2.8 гигабайта в сек./5.6 гигабайта в сек.
- Теоретическая скорость закраски 700 мегапикселей в сек.
- Теоретическая скорость выборки текстур 1.4 гигатекселя в сек.
- Один VGA (D-Sub) и один DVI-I разъем
- TV-Out
- На PCI-Express карте разъем для дополнительного питания не нужен
Архитектура чипа NV44
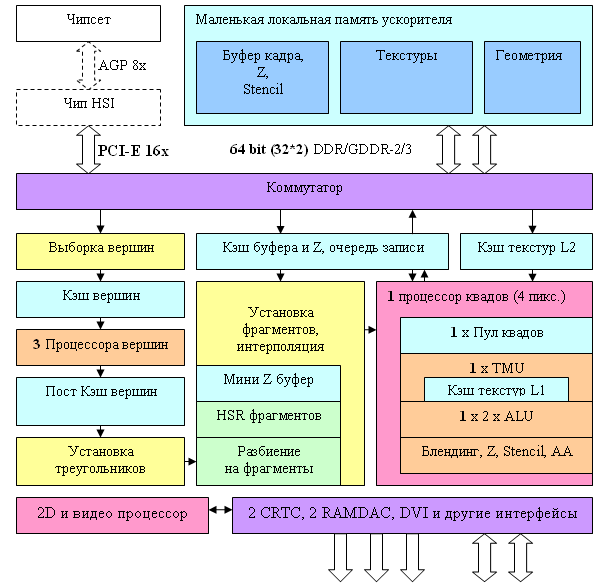
Какие-либо глобальные архитектурные отличия от NV40 и NV43 отсутствуют, есть некоторые новшества в пиксельном конвейере, нацеленные на более эффективную работу с системной памятью в качестве буфера кадра. В общем же NV44 является масштабированным (путем уменьшения числа вершинных и пиксельных процессоров и каналов контроллера памяти) решением, основанным на архитектуре NV40. Отличия количественные (на схеме выделены жирным), а не качественные — с точки зрения архитектуры чип практически не изменился, если не считать единственное исключение — отсутствие FP16 блендинга.
В наличии три вершинных процессора, как у NV43, и один (было два) независимый пиксельный процессор, работающий с одним квадом (фрагментом 2х2 пикселя). PCI-Express стал «родным», реализованным на чипе, как и в случае NV43, AGP 8х плат с этим чипом, в варианте TC (TurboCache), не производятся, так как сама идея эффективного использования системной памяти для рендеринга требует адекватной пропускной способности графической шины в обе стороны.
Очень важным ограничивающим моментом является двухканальный контроллер с 64-битной шиной памяти, его ограничения подробно рассмотрены в обзорных статьях. Причем, судя по корпусу чипа и числу выводов, 64 бит это аппаратный предел для NV44 и 128 битных карт на его основе быть не может, в семействе 6200 они реализованы на NV43.
Архитектура вершинных и пиксельных процессоров, а также видеопроцессора осталась прежней — эти элементы были детально описаны нами выше. Если не считать декларируемых доработок для эффективной адресации системной памяти из блоков текстурирования и блендинга. Однако это то, что озвучивается — реально есть причины считать, что все эти возможности, не такие принципиальные, и реализуемые скорее на уровне менеджера общего кэша и кроссбара, изначально были заложены в семейство NV4X. Просто нет смысла использовать их на уровне драйверов у старших карт с более скоростной и емкой локальной памятью. Также нет смысла в такой технологии у карт с AGP интерфейсом, который станет узким местом, так как скажется низкая скорость записи в системную память, сравнимая со скоростью PCI.
Вот так поясняет эти различия NVIDIA в своих материалах:
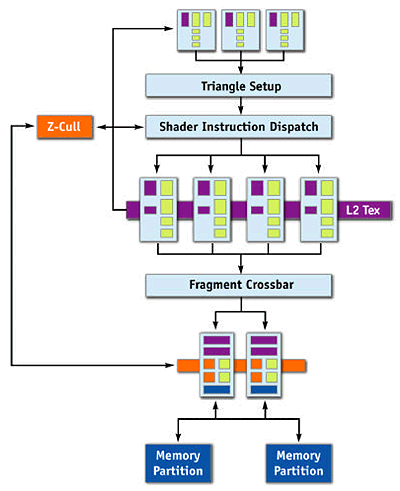
… обычная схема и NV44 с TurboCache:
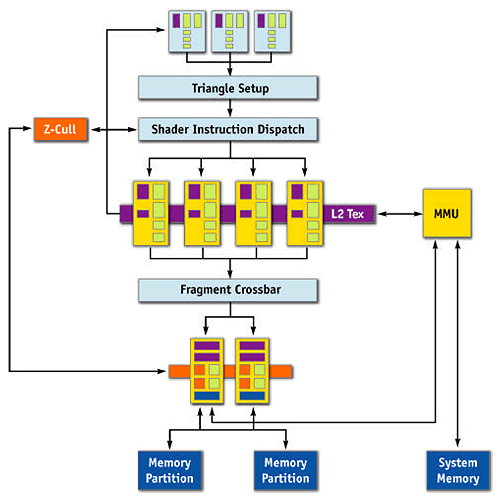
Очевидна разница, связанная с подачей данных для текстур и дополнительным путем для записи данных кадра (блендинга) в системную память. Однако исходная схема чипа с кроссбаром, трактующим графическую шину практически как пятый канал контроллера памяти, может быть изначально способна на такое (начиная с NV40 и даже ранее). И сложно сказать, действительно ли в NV44 есть архитектурные изменения в плане работы с записью и чтением данных или эти возможности просто задействуются на уровне драйвера.
С другой стороны, не будем отрицать, что оптимальным было бы некое страничное MMU и динамическая подкачка данных из системной памяти в локальную, которая трактовалась бы как кэш третьего уровня. Если реализована такая схема — все становится на свои места. И эффективность будет заметно выше дискретного размещения объектов там или там, и наличие небольших аппаратных переделок оправдано. Тем более что, обкатав этот страничный блок подкачки, можно будет задействовать его в будущих архитектурах, которые, судя по всему, будут в обязательном порядке снабжены такими блоками.
Справочная информация о семействе видеокарт NV4X
Справочная информация о семействе видеокарт G7X
Справочная информация о семействе видеокарт G8X/G9X
Справочная информация о семействе видеокарт GT2XX
Справочная информация о семействе видеокарт GF1XX
Справочная информация о семействе видеокарт GK1XX
Комментарии