Обзор видеоускорителя AMD Radeon RX 7900 XT (20 ГБ) на основе карты XFX Radeon RX 7900 XT

Наконец-то до нас добралось долгожданное новое поколение графической архитектуры AMD — пока что не топовая модель Radeon RX 7900 XTX, а ее младшая сестра Radeon RX 7900 XT. Еще в декабре прошлого года компания AMD выпустила в продажу две модели видеокарт, и до нас они ехали несколько дольше обычного. Новые видеокарты основаны на GPU уже третьего поколения графической архитектуры RDNA (RDNA3), который стал первым графическим процессором, основанным на чиплетах — нескольких кристаллах на одной подложке — аналогично процессорам Ryzen той же AMD. Это должно помочь получить максимальную эффективность и снизить себестоимость по сравнению с привычным подходом в виде одного большого кристалла.
Компания AMD решила использовать чиплетную конфигурацию в Navi 31 (кодовое имя графических процессоров серии Radeon RX 7900) для того, чтобы достичь лучшей производительности при сохранении относительно невысокой сложности кристаллов (а значит, и меньшей себестоимости) — этот подход отличается от больших GPU, которые делает Nvidia. Инженеры AMD отделили некоторые участки, которые вполне можно перенести на более проверенный и менее дорогой техпроцесс, такие как кэш-память третьего уровня Infinity Cache и контроллеры GDDR6-памяти, и перенесли их с большого основного кристалла на шесть маленьких — memory cache die (MCD), что можно увидеть на схематическом изображении GPU.

Эти кристаллы производятся при помощи техпроцесса 6 нм, а основная часть GPU — graphics compute die (GCD) — при помощи более совершенного процесса 5 нм. И так как соединение кэшей и GPU должно быть высокоскоростным, то эти кристаллы соединяются друг с другом при помощи очень быстрого соединения, обеспечивающего пропускную способность более 5 ТБ/с между GCD и всеми MCD.
Архитектура RDNA3 обещает около 50% прироста энергоэффективности по сравнению с RDNA2, и это неплохая заявка на высокую конкурентоспособность, ведь решения на основе RDNA2 уже неплохо соперничали с видеокартами Nvidia. Новая архитектура приносит множество улучшений в вычислительных возможностях, подсистеме памяти и выводе информации на дисплеи, а также пытается устранить некоторые недоработки предыдущей архитектуры — RDNA3 обладает специализированными блоками ускорения искусственного интеллекта и улучшенными блоками аппаратной трассировки лучей, которые являлись главной ахиллесовой пятой предыдущего поколения.
Архитектура RDNA3 вводит новые вычислительные блоки с удвоенным темпом вычислений и оптимизацией, направленной на улучшение использования имеющихся ресурсов SIMD, а также новыми блоками ускорения ИИ, которые используются для выполнения матричных вычислений. По данным AMD, все улучшения должны дать рост производительности на такт на 17% по сравнению с RDNA2. Добавим к этому большее количество потоковых процессоров в чипе и повышенную тактовую частоту — и получим серьезный рост производительности по сравнению с предыдущим поколением. При этом типичное энергопотребление топовой модели RX 7900 XTX составляет всего 355 Вт, а для рассматриваемой сегодня RX 7900 XT — и вовсе лишь 300 Вт, что позволяет обходиться двумя 8-контактными разъемами дополнительного питания и кулерами меньшего размера по сравнению с решениями конкурента.

По данным AMD, новый флагман компании — Radeon RX 7900 XTX — обеспечивает до 70% преимущества в 4K-разрешении по сравнению с предыдущей топовой моделью RX 6950 XT. Это связано как с архитектурными преимуществами новой версии RDNA, так и с повышенной тактовой частотой и бо́льшим количеством исполнительных блоков, за что спасибо чиплетной конфигурации и продвинутым техпроцессам TSMC. Но сегодня мы рассмотрим модель Radeon RX 7900 XT, основанную на урезанной версии графического процессора Navi 31. Она также предназначена для требовательных игроков, выбирающих исключительно 4K-разрешение и максимальные настройки качества, а главным конкурентом для RX 7900 XT на рынке является Nvidia GeForce RTX 4070 Ti, имеющая чуть меньшую цену.
Основой рассматриваемой сегодня модели видеокарты Radeon RX 7900 XT является новый графический процессор Navi 31, базирующийся на архитектуре RDNA третьего поколения, которая очень похожа и тесно связана с архитектурами RDNA предыдущих версий, так что перед прочтением статьи будет полезно ознакомиться с нашими предыдущими материалами по видеокартам компании AMD:
- [02.08.22] AMD Radeon RX 6950 XT: новый флагман AMD против Nvidia GeForce RTX 3090 Ti
- [16.12.21] AMD Radeon RX 6900 XT: удалось ли компании догнать топовый GeForce RTX 3090 конкурента?
- [23.11.20] AMD Radeon RX 6800: серьезный конкурент для Nvidia GeForce RTX 3070
- [21.11.20] AMD Radeon RX 6800 XT: компании AMD удается догнать флагманские решения конкурента, но не во всем

| Графические ускорители серии Radeon RX 7900 | |
|---|---|
| Кодовое имя чипа | Navi 31 |
| Технология производства | 5 нм и 6 нм (N5 и N6 TSMC) |
| Количество транзисторов | 57,7 млрд (26,8 млрд у Navi 21) |
| Площадь ядра | 522 мм² (520 мм² у Navi 21) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 384-битная: 6 независимых 64-битных контроллера памяти с поддержкой GDDR6 |
| Частота графического процессора | до 2500 МГц |
| Вычислительные блоки | 96 вычислительных блоков CU, состоящих в целом из 6144 (или 12288, смотря как считать) ALU для целочисленных расчетов и расчетов с плавающей запятой (поддерживаются форматы INT4, INT8, INT16, FP16, FP32 и FP64) |
| Блоки трассировки лучей | 96 блоков Ray Accelerator для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 384 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 24 широких блока ROP на 192 пикселя с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка интерфейсов HDMI 2.1b и DisplayPort 2.1 |
| Спецификации референсной видеокарты Radeon RX 7900 XT | |
|---|---|
| Частота ядра (игровая/турбо) | 2025/2400 МГц |
| Количество универсальных процессоров | 5376 (10752) |
| Количество текстурных блоков | 336 |
| Количество блоков блендинга | 192 |
| Эффективная частота памяти | 20 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 320 бит |
| Объем памяти | 20 ГБ |
| Пропускная способность памяти | 800 ГБ/с |
| Вычислительная производительность (FP32) | до 51,6 терафлопс |
| Теоретическая максимальная скорость закраски | 460 гигапикселей/с |
| Теоретическая скорость выборки текстур | 804 гигатекселя/с |
| Шина | PCI Express 4.0 x16 |
| Разъемы | один HDMI 2.1b, два DisplayPort 2.1 и один USB Type C |
| Энергопотребление | до 300 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2,5 |
| Рекомендуемая цена | $899 |
Наименование новой модели видеокарты соответствует принятому несколько лет назад принципу названий для решений компании AMD: по сравнению с Radeon RX 6900 XT поменялась первая цифра поколения. Суффикс XT остался, но теперь это не топовая модель: новинка стоит на шаг ниже флагмана семейства, которым является Radeon RX 7900 XTX, который мы также очень скоро подробно разберем.
Цены на пару видеокарт Radeon RX 7900 решили установить... несколько более высокие, чем мы привыкли, но это объясняется общей ситуацией на мировых рынках. Нас больше беспокоит очень малая разница в цене между XT и XTX — всего лишь $100 на североамериканском рынке. Мы еще не раз остановимся на этом вопросе, но даже поверхностный взгляд на характеристики двух видеокарт говорит о том, что разница в производительности между ними получилась больше разницы в цене.

Впрочем, сравнивать цены правильнее с решениями конкурента, и с этим всё более-менее нормально: главным конкурентом RX 7900 XT является младшая из трех вышедших старших видеокарт нового семейства GeForce — RTX 4070 Ti. Интереснее всего, что в этом поколении не видеокарта AMD сто́ит дешевле конкурирующей, а решение Nvidia. Хотя всегда можно сказать, что у них есть еще более дорогая RTX 4080, но по скорости RX 7900 XT ближе все-таки к RTX 4070 Ti.
По объему видеопамяти для рассматриваемой сегодня видеокарты AMD в соответствии с шириной шины особого выбора не было: можно было поставить или 10, или 20 ГБ. Понятно, что объема в 10 ГБ не хватает уже сейчас, и для RX 7900 XT можно считать второй вариант не просто приемлемым и достаточным на данный момент, но и перспективным. Пока что наличие 20 ГБ видеопамяти против 12 ГБ у RTX 4070 Ti не принесет преимущества RX 7900 XT, но эту разницу можно считать потенциальным недостатком решения Nvidia, что может негативно сказаться в ближайшие годы.
Референсный дизайн у моделей Radeon RX 7900 XT и RX 7900 XTX схожий, но рассматриваемая сегодня младшая модель в целом чуть меньше по всем размерам и не имеет RGB-подсветки, в отличие от старшей. Обе видеокарты значительно меньше соответствующих по цене видеокарт компании Nvidia. Для вывода изображения используются два стандартных разъема DisplayPort 2.1 и один HDMI 2.1, также есть разъем USB-C с поддержкой вывода DisplayPort — для использования с VR-шлемами.

Для дополнительного питания AMD использует два привычных 8-контактных разъема, что в теории дает до 375 Вт при долговременной нагрузке. Nvidia применяет спорный новый 16-контактный разъем 12VHPWR, который, впрочем, дает возможность подать до 600 Вт питания. То есть, с одной стороны, видеокарты AMD куда проще установить в любую систему, не имеющую новых (и довольно редких пока) блоков питания, зато два 8-контактных разъема ограничивают максимальную мощность, подаваемую на видеокарту. Неудивительно, что некоторые розничные варианты видеокарт серии RX 7900 имеют по три 8-контактных разъема — особенно предназначенные для любителей разгона.
Новый дизайн референсных видеокарт нового поколения довольно строг — четкие линии, матовый черный цвет, отсутствие лишних украшательств. Вид у референсных карт простой и элегантный, а для желающих более цветастого внешнего вида партнеры AMD выпустили большое количество моделей с собственными дизайном, размерами, подсветкой и системами охлаждения, некоторые из них фабрично разогнаны и имеют повышенные уровни энергопотребления и производительности.
Одним из самых важных отличий Navi 31 является переход на чиплетную компоновку. В теории, чиплеты отлично подходят для конфигурации GPU, так как позволяют разбивать огромные монолитные кристаллы на несколько более мелких — это позволяет как улучшать масштабируемость (набирать топовые модели из большего количества кристаллов, а средние и младшие — из меньшего количества точно таких же) и применять кристаллы, произведенные при помощи разных техпроцессов, что может быть полезно для снижения себестоимости. А основная сложность в чиплетной компоновке GPU — линии связи между чиплетами, которые должны быть очень быстрыми и при этом не слишком большими по площади и потреблению энергии, иначе это съест всю пользу от разделения на чиплеты.
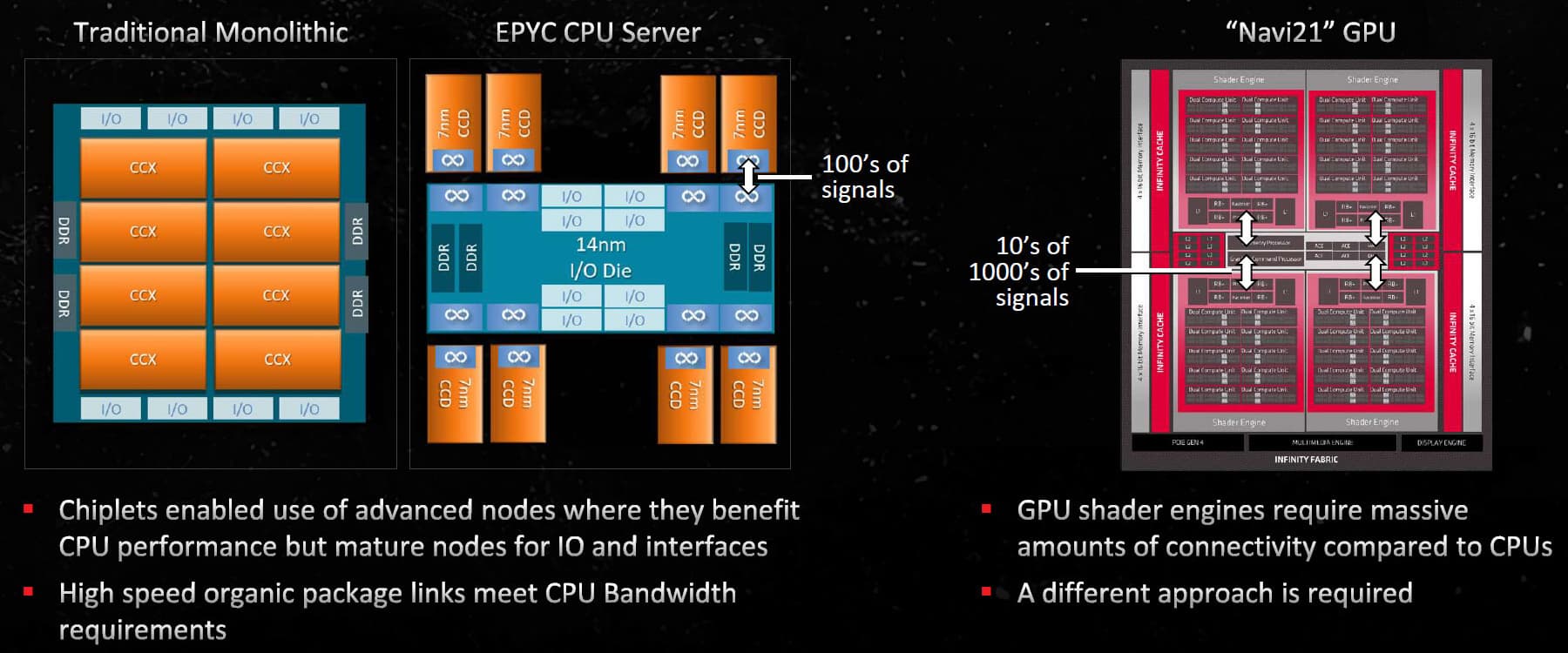
Чиплетная организация Navi 31 состоит из одного основного кристалла Graphics Compute Die (GCD) и нескольких чиплетов с кэшем и контроллерами памяти — Memory Cache Die (MCD) и отличается от организации центральных процессоров Zen последних поколений. В Zen 2 и более поздних используется отдельный чиплет ввода-вывода Input/Output Die (IOD), содержащий все внешние интерфейсы вроде PCIe и USB, а в последних добавили и функциональность обработки видеоданных и встроенного графического ядра целиком. Чиплет IOD соединен с одним или двумя вычислительными чиплетами — Core Compute Die/Core Complex Die (CCD), содержащим вычислительные ядра, кэш-память и остальное, при помощи быстрого соединения.
Типичные вычислительные алгоритмы, работающие на ядрах CPU, в основном помещаются в кэш-память разных уровней, а каналов к внешней памяти у настольных Zen всего два 64-битных, и в этом заключается важное отличие CPU от GPU. CCD-чиплеты Ryzen имеют небольшую площадь, порядка 70 мм² для Ryzen 7000, а IOD может иметь площадь лишь 122 мм² — также в серии Ryzen 7000. Графические процессоры совершенно иные, им нужна очень большая пропускная способность памяти для того, чтобы обеспечить работой все вычислительные ядра GPU — до 1 ТБ/с и больше. Да и требования к скорости связей внутри основной части GPU выше, высокие межкристальные задержки при разделении на много мелких кристаллов не подходят. Поэтому решение из Ryzen тут не сработало бы, а оптимально чуть ли не противоположное — размещение контроллеров памяти и кэш-памяти на нескольких небольших кристаллах, тогда как основные вычислительные блоки расположены в едином центральном чиплете GCD.

Основной чиплет содержит почти всё: вычислительные блоки CU и все основные функциональные блоки, кроме контроллеров памяти и кэш-памяти третьего уровня. Чиплеты с контроллерами памяти и L3-кэшем — Memory Cache Die (MCD) — содержат довольно большие блоки кэш-памяти Infinity Cache и физический интерфейс памяти GDDR6, плюс линки Infinity Link для подключения к основному чиплету GCD.
Главный чиплет содержит 45,7 млрд транзисторов в кристалле площадью 300 мм², который производится на TSMC с использованием современного техпроцесса 5 нм, а чиплеты MCD содержат лишь по 2,05 млрд транзисторов каждый и имеют площадь всего 37 мм² — они производятся по техпроцессу 6 нм. Кэш-память и внешние интерфейсы памяти масштабируются хуже всего, и плотность транзисторов в этом случае получается заметно ниже, чем для основного чиплета — 55,4 млн транзисторов на мм², тогда как у GCD почти втрое плотнее — 152,3 млн/мм².
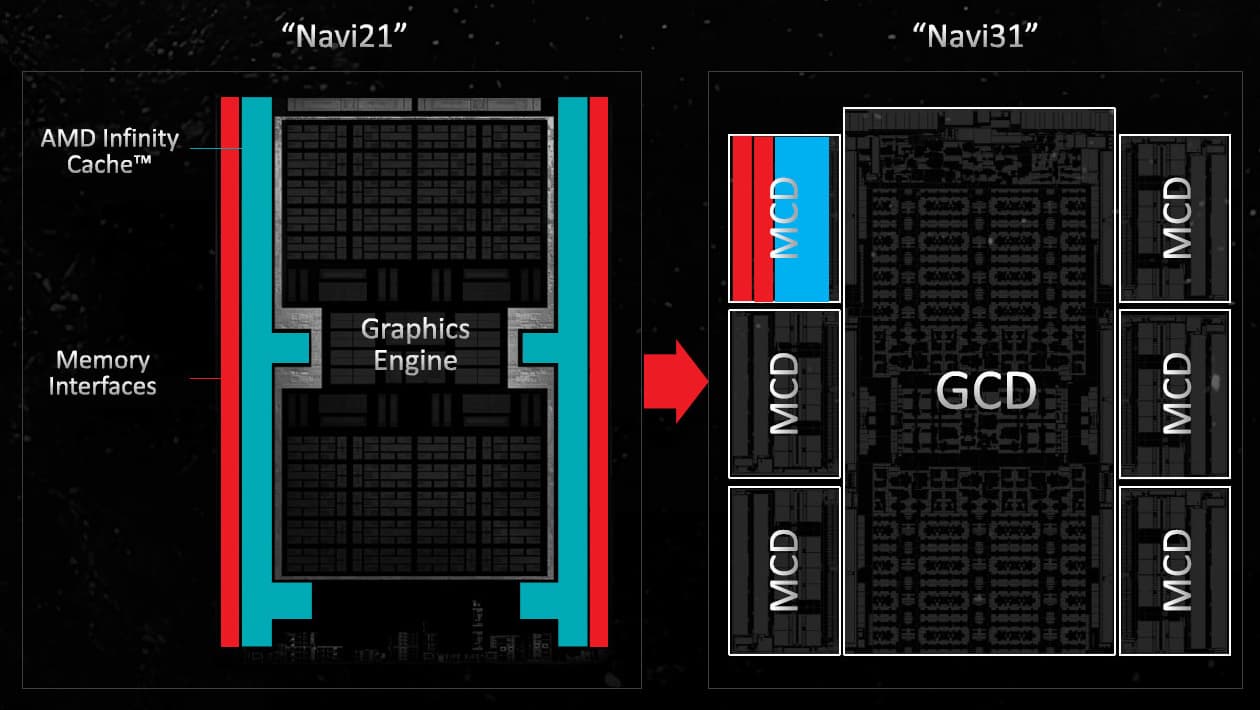
Отделение контроллеров памяти и кэш-памяти третьего уровня от остальных функциональных блоков графического процессора помогает снизить себестоимость производства, что потенциально может позволить AMD выпускать решения с лучшими характеристиками при схожей цене. Пока что не очень понятно, дает ли текущее разделение на чиплеты достаточное снижение себестоимости производства кристаллов, чтобы покрыть накладные расходы на сборку этих чиплетов на одной подложке и их дополнительное тестирование. Вероятно, пока что это компромиссное решение на начальной стадии, но потенциал у него немалый.
Кроме того, у чиплетов есть и явные недостатки — в виде дополнительных накладных расходов и задержек, связанных с использованием связи чиплетов между собой, которая явно менее производительна, чем соответствующие линии в одном кристалле. Но это лишь начало — чиплеты Zen 2 тоже не были идеальными, а скорее не слишком эффективными, но зато в чиплетной организации Zen 3 и Zen 4 компания уже добилась ожидаемого преимущества. Вероятно, так же будет и с графическими процессорами.
И не надо путать чиплетный графический процессор Navi 31 с многочиповым модулем Vega 10, в котором просто используется HBM2-память в отдельных кристаллах, но на той же подложке. В чиплетном GPU различные блоки помещены в разные кристаллы, и один основной чиплет GCD просто не может работать самостоятельно — без L3-кэшей и контроллеров памяти, находящихся в отдельных MCD-чиплетах. Канал связи между чиплетами кэша-памяти и графическим чиплетом называется Infinity Link — он отвечает за маршрутизацию Infinity Fabric между кристаллами GPU, и совокупная пропускная способность между чиплетами составляет 5,3 ТБ/с, а пропускная способность между отдельными чиплетами составляет 900 ГБ/с, что больше ПСП для Radeon RX 6950 XT.

Одной из возможных проблем чиплетной организации может быть дополнительное энергопотребление всех каналов Infinity Link — естественно, что внешние каналы потребляют больше энергии, чем внутренние. Но в AMD отдельно работали над оптимизацией связей между чиплетами GPU, и в итоге получили высокопроизводительное разветвленное соединение, упакованное куда более плотно по сравнению с тем, что используется в Ryzen. Это значительно снизило требования к энергопотреблению, и в итоге получилось, что все соединения Infinity Fanout, обеспечивающие высокую пропускную способность, потребляют менее 5% общего энергопотребления всего GPU, а это не так уж и много.

Еще один момент, связанный с логикой Infinity Link на чиплетах GCD и MCD — немалая площадь, которую она занимает на кристаллах. На GCD все шесть интерфейсов занимают до 10% площади, а на MCD и вовсе около 15% от общей площади чиплета. Так что однокристальный GPU такой сложности был бы не слишком большим — явно менее 425 мм². Правда, с учетом новизны и относительной дороговизны производства по техпроцессу 5 нм, чиплетная организация может быть вполне обоснована даже на начальной стадии, если себестоимость производства разных чиплетов и сборка их на одной подложке, а также дополнительное тестирование, обходятся дешевле производства одного большего кристалла.
Чиплетная компоновка — просто более удобный формат физической организации большого чипа, а интересные архитектурные изменения RDNA3 скрыты внутри основного чиплета — в исполнительных блоках. Рассмотрим базовые блоки любого современного чипа AMD — вычислительные блоки Compute Unit (CU), каждый из которых имеет собственное локальное хранилище для обмена данными или расширения локального регистрового стека, а также кэш-память и полноценный текстурный конвейер с блоками выборки и фильтрации текстур. Каждый из таких вычислительных блоков самостоятельно занимается планированием и распределением работы, и в RDNA3 с ними произошли некоторые изменения, на которых мы подробно остановимся в дальнейшем. А пока что рассмотрим блок-схему полной версии графического процессора Navi 31:
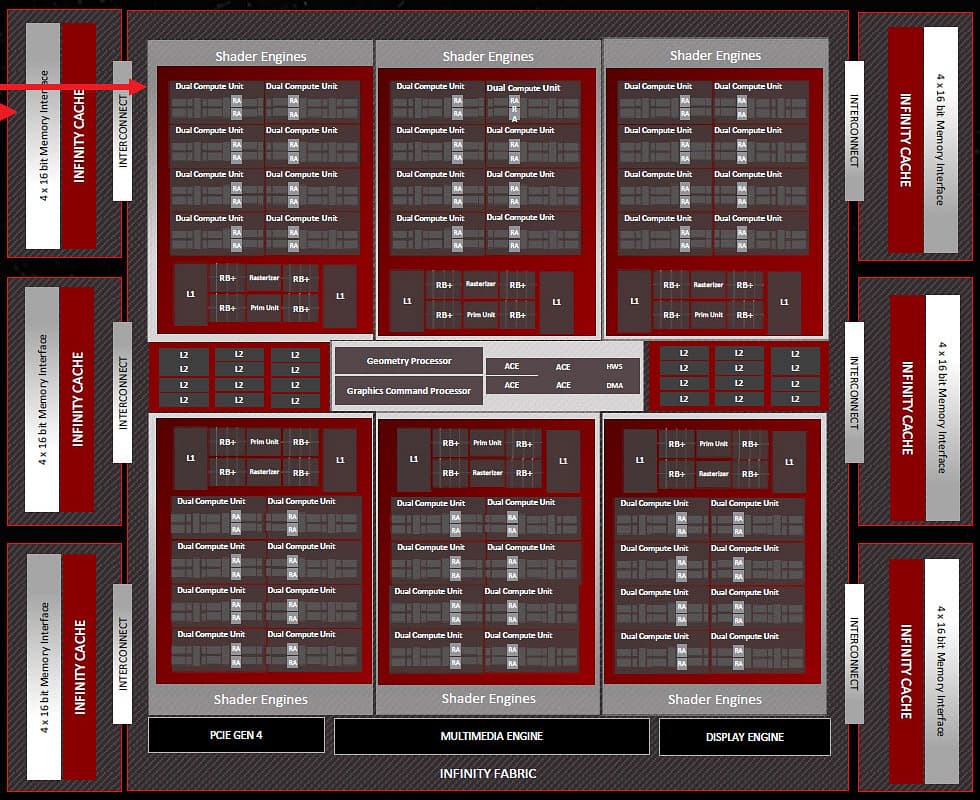
Основной чиплет GCD содержит шесть шейдерных движков Shader Engines, каждый из которых состоит из 16 вычислительных блоков (или восьми двойных вычислительных блоков RDNA3), имеющих по 1024 потоковых процессора. То есть, всего в чипе содержится 6144 потоковых процессора, 96 ускорителей трассировки лучей и 96 ИИ-ускорителей. Navi 31 имеет 384 текстурных блока TMU и аж 192 блоков ROP — вполовину больше, чем Navi 21.
Топовая модель Radeon RX 7900 XTX основана на полном чипе Navi 31 и включает все 96 CU, а младшая видеокарта из пары использует основной чиплет с несколькими отключенными блоками — число потоковых процессоров снижено с 6144 до 5376 (активны 84 вычислительных блока из 96), 84 ускорителей трассировки лучей, 336 текстурных модуля и все 192 блока ROP. Это не единственное изменение RX 7900 XT: из шести MCD-чиплетов с 96 МБ L3-кэша модель XT использует только пять кристаллов, что ограничивает объем L3-кэша на уровне 80 МБ, ширина шины памяти становится 320-битной (один 64-битный контроллер находится в неактивном MCD — точнее, два 32-битных) и ее объем урезается до 20 ГБ по сравнению с 24 ГБ у топовой модели. Чипы GDDR6-памяти работают на эффективной скорости 20 Гбит/с, что в итоге дает неплохую пропускную способность в 800 ГБ/с.
Что касается физического воплощения, то все шесть чиплетов MCD на подложке RX 7900 XT присутствуют, конечно же — в том числе чтобы не нарушать прижим радиатора охлаждения, но один из них электрически отключен от основного чиплета — и в теории, этот отключенный кристалл чиплета MCD может быть бракованным и нерабочим, а уж как дело обстоит на деле — доподлинно неизвестно.
Итак, архитектура RDNA3 — это улучшенная и расширенная RDNA2 с некоторыми новыми возможностями. Для увеличения пропускной способности в ней была серьезно изменена подсистема кэширования на всех уровнях, а соответствующее увеличение вычислительной производительности достигается не просто добавлением большего количества вычислительных блоков, но реализацией возможности двойного запуска команд на исполнение.
AMD утверждает, что они смогли улучшить использование исполнительных блоков на 20% — если в графических процессорах RDNA2 функциональные блоки относительно часто простаивали, то в RDNA3 над этим поработали. Самые большие изменения внутри основного чиплета произошли в вычислительных блоках CU и процессорах — увеличенный объем кэш-памяти всех уровней, увеличенный регистровый файл, а также более широкие и производительные интерфейсы между блоками. Самих блоков CU в Navi 31 больше, чем в Navi 21, и они работают быстрее на 17,4% за такт и на более высокой частоте, что вместе дает значительное повышение производительности GPU нового поколения.
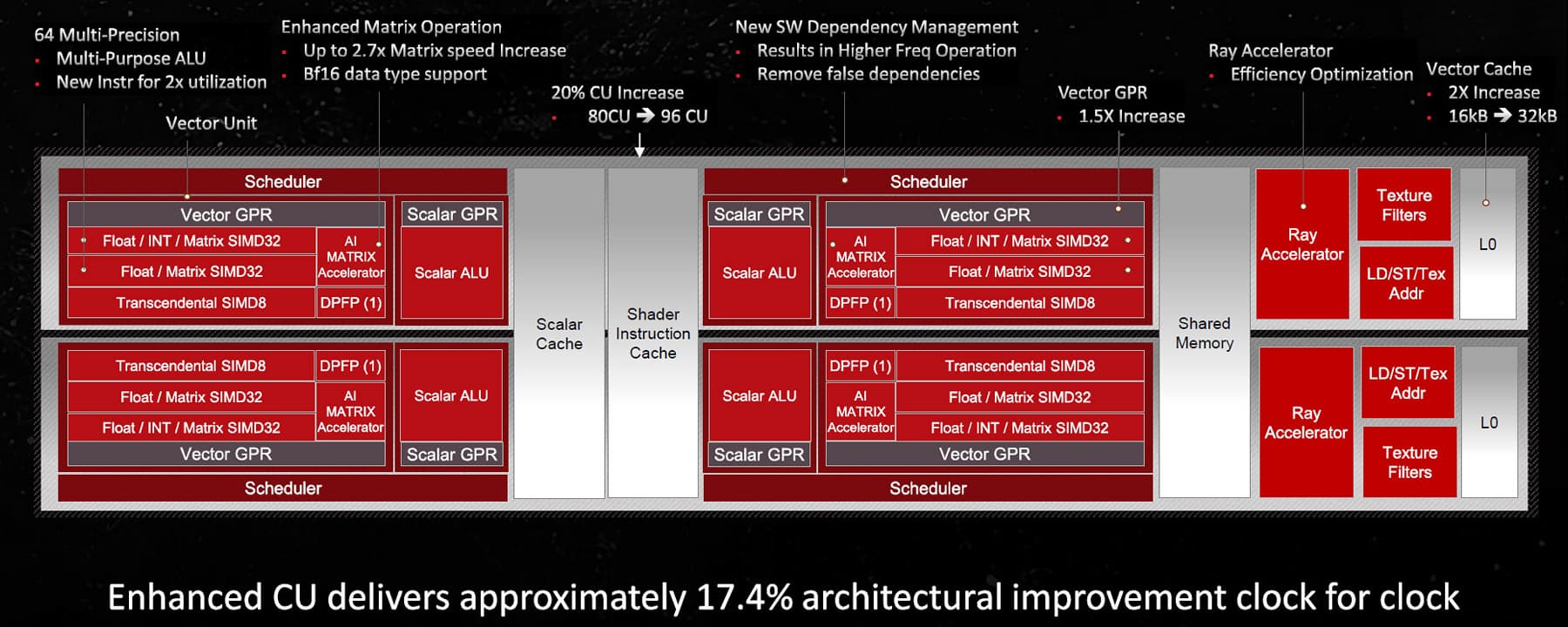
Navi 31 имеет больше вычислительных блоков по сравнению с Navi 21, и каждый из них имеет более высокую вычислительную производительность, поэтому для сохранения эффективности должна быть усилена подсистема памяти. И в RDNA3 получили значительное увеличение пропускной способности на каждом уровне подсистемы памяти, а особенно ускорились кэши первого и второго уровней. Как и прошлое поколение RDNA, третье имеет четырехканальный скалярный кэш объемом 16 КБ, задержка загрузки и использования для которого несколько снижена благодаря повышенной тактовой частоте. L0-кэш увеличен до 32 КБ (вдвое больше, чем в RDNA 2), также была увеличена емкость кэшей среднего уровня — L1 и L2 — для того, чтобы лучше справляться с повышенной пропускной способностью более мощного графического процессора. RDNA2 имела 16-канальный L1-кэш объемом в 128 КБ, совместно используемый массивом шейдерных блоков, а в RDNA3 его емкость удвоили до 256 КБ, сохраняя 16-канальность. Емкость L2-кэша также увеличена до 6 МБ по сравнению с 4 МБ в RDNA2 при сохранении той же 16-канальности. При этом, несмотря на увеличение пропускной способности, в RDNA3 обеспечивается снижение задержек для L1 и L2.
Канал между основными вычислительными блоками и L1-кэшем стал в полтора раза шире — 6144 байта за такт, как и канал между L1- и L2-кэшем — 3072 байта за такт. L3-кэш, также известный как Infinity Cache, в Navi 31 по сравнению с Navi 21 даже уменьшился в объеме — он составляет 96 МБ (для старшей модели RX 7900 XTX) против 128 МБ, зато связь между L3 и L2 стала в 2,25 раза шире — 2304 байта за такт, и пропускная способность его повысилась до 5,3 ТБ/с, что в 2,7 раз больше, чем пиковая пропускная способность интерфейса у RX 6950 XT. Всё это справедливо лишь для топовой RX 7900 XTX, а младшая RX 7900 XT имеет лишь пять активных MCD и уже 1920 байт/такт до 80 МБ кэша Infinity Cache.
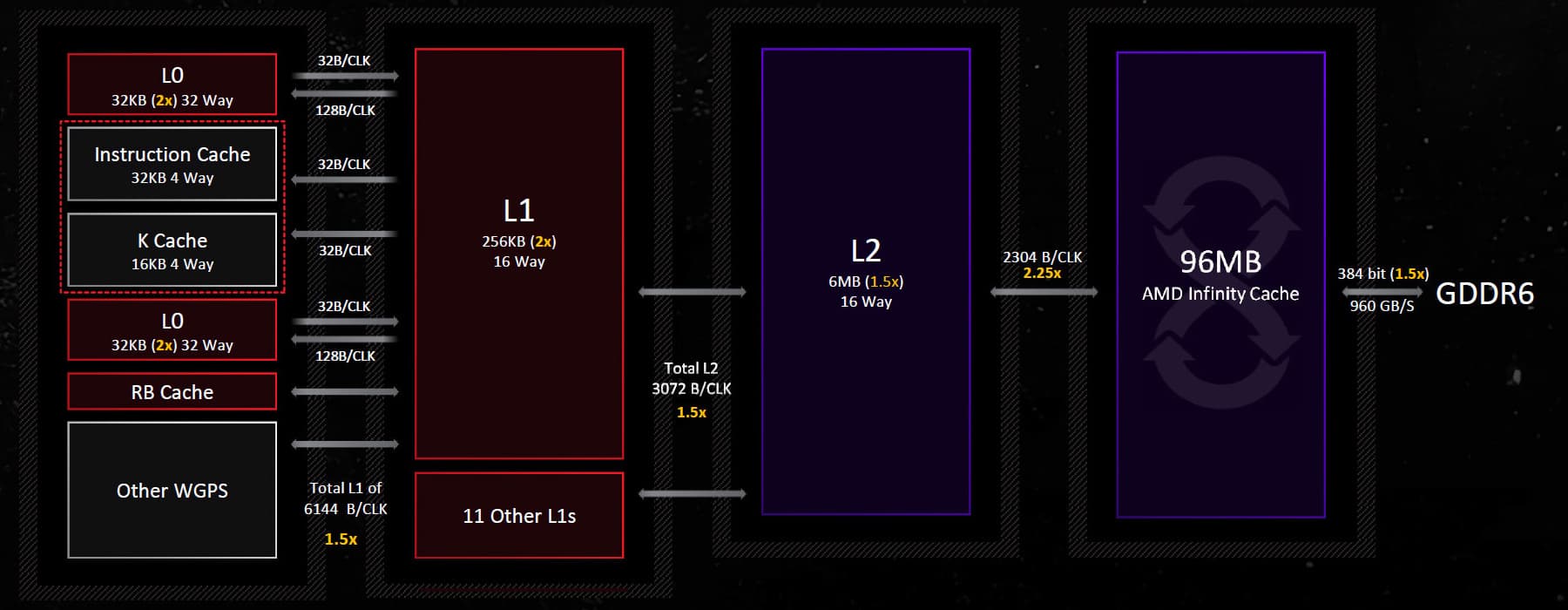
Другие ухудшения в подсистеме кэширования в виде повышенных задержек L3-кэша неудивительны — Infinity Cache теперь реализован в виде отдельных чиплетных кристаллов с контроллерами памяти и L3-кэшем. Возможно, RDNA3 сможет справиться с этим, обслуживая большее количество обращений к памяти при помощи более быстрого и объемного L2-кэша, и количество обращений к Infinity Cache в целом снизится.
Что касается ПСП видеопамяти, шесть 64-битных каналов дают 384-битную шину GDDR6-памяти, которая работает на скорости 20 Гбит/с — по сравнению с 16 Гбит/с у 6900 XT и 18 Гбит/с у RX 6950 XT. Так что пропускная способность возросла до 960 ГБ/с (для RX 7900 XTX), и это лишь на 5% меньше, чем 1008 ГБ/с у GeForce RTX 4090, хотя в прошлом поколении разрыв был чуть ли не двукратным — 512 ГБ/с и 936 ГБ/с для RX 6900 XT и RTX 3090, соответственно. Этот прирост будет весьма полезным в современных играх, особенно в 4K-разрешении. Да и ПСП у RX 7900 XT также достаточно велика, хоть от него и отрезали один из шести контроллеров памяти. Это должно сохранить относительно высокую производительность и при сниженном объеме L3-кэша.
Что касается сравнения с конкурирующими GPU, то компания Nvidia для уменьшения требований к пропускной способности внешней памяти в разы увеличила объем L2-кэша вместо добавления третьего уровня кэш-памяти — это увеличило задержку доступа к L2-кэшу по сравнению с графическими процессорами AMD, но зато дало графическим процессорам архитектуры Ada Lovelace преимущество по задержке. И объем L2-кэша в чипах семейства GeForce RTX 40 чуть ли не равен объему Infinity Cache в чипах AMD. Кроме этого, задержка доступа к видеопамяти в RDNA3 чуть выше по сравнению с Ada Lovelace — отчасти потому, что решения AMD проверяют дополнительный уровень кэш-памяти.
Рассматриваемая модель Radeon RX 7900 XT имеет 20 ГБ локальной памяти, и этот объем можно считать более чем достаточным — а если вдруг нужно больше, то существует старшая модель RX 7900 XTX с 24 ГБ памяти, которая продается чуть дороже. Хотя игры становятся всё более требовательными и используют всё больше и больше ресурсов (та же аппаратная трассировка лучей предъявляет дополнительные требования к объему памяти) и некоторые современные игры уже занимают более 12 ГБ памяти при максимальных графических настройках, на данный момент даже 12 ГБ локальной видеопамяти (как у RTX 4070 Ti) всё еще достаточно, но 20 ГБ можно считать приличным запасом на будущее, да и сейчас нехватка 12 ГБ может сказаться, хоть и в редких случаях.
В дополнение к обычной иерархии глобальной памяти, графические процессоры имеют и быструю оперативную память — локальной память GPU. В графических процессорах компании AMD это называется Local Data Share (LDS), а графические процессоры Nvidia называют это общей (или разделяемой) памятью. Как и в предыдущих поколениях RDNA, в каждом укрупненном вычислительном блоке новой архитектуры RDNA3 есть LDS объемом в 128 КБ, состоящей из двух блоков по 64 КБ, каждый из которых связан с одним из CU. Похоже, что в RDNA3 были улучшены задержки доступа к LDS благодаря архитектурным улучшениям и высокой тактовой частоте, а низкая задержка доступа к LDS может быть полезна в том числе и при трассировке лучей, так как эта память используется для хранения информации о BVH.
Одними из самых важных изменений в графической архитектуре RDNA3 стали вычислительные блоки с одновременным запуском двух инструкций на исполнение (dual issue), специальные оптимизации для более полного использования имеющихся ресурсов, поддержка новых математических форматов, а также ускорение ИИ-вычислений при помощи перераспределения ресурсов SIMD для исполнения матричных функций. Все вместе эти оптимизации должны дать повышение производительности на такт порядка 17% по сравнению с вычислительными блоками архитектуры RDNA2.
RDNA3 имеет большое преимущество в вычислительной производительности — не только потому, что у него больше укрупненных блоков WGP самих по себе, но и благодаря архитектурному изменению. SIMD-блоки получили ограниченную возможность одновременного выполнения двух инструкций — некоторые операции могут быть упакованы в одну инструкцию VOPD (vector operation, dual — векторная операция, двойная) в режиме Wave32. В режиме Wave64 SIMD-блоки начинают выполнение вейвфронта шириной 64 за один цикл. Wave64 может использовать ALU в режиме удвоенного темпа при исполнении соответствующего кода, а в режиме Wave32 компилятор выполняет переупорядочивание и упаковку инструкций в VOPD.
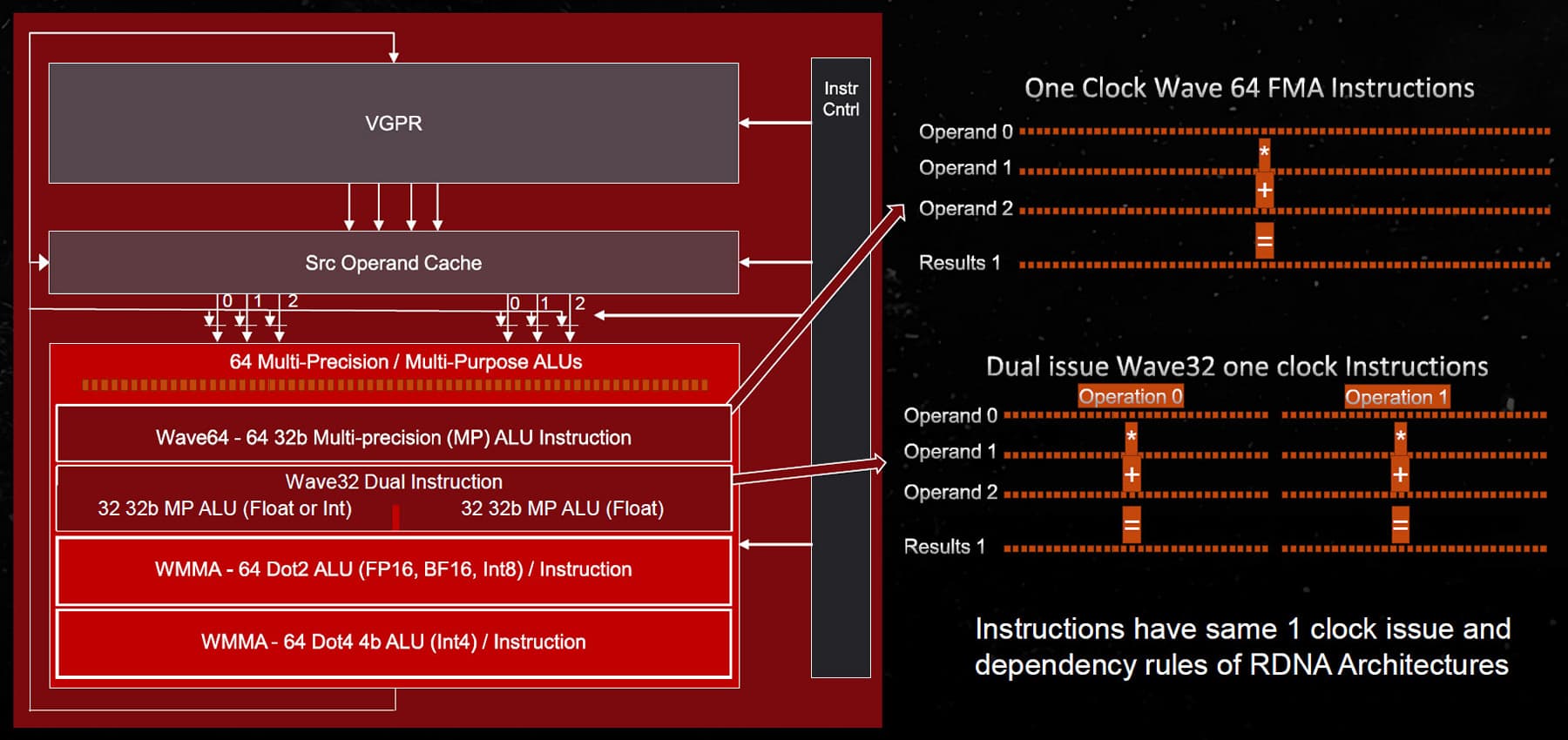
К сожалению, пока что прирост производительности от этого нововведения невелик — тестовая сцена с трассировкой лучей и использованием VOPD обеспечила лишь 4% прирост в количестве кадров в секунду за счет устранения узкого места ALU. Возможно, в будущем мы увидим некоторые улучшения по мере оптимизации компилятора и развития использования сложных шейдеров и трассировки лучей. Теоретически эта возможность удваивает вычислительные возможности FP32 при небольших накладных расходах (кроме самих дополнительных исполнительных блоков), но уж слишком это зависит от возможностей компилятора шейдеров. В теории, со временем AMD может помочь разработчикам лучше оптимизировать игровой код, заменив скомпилированные автоматически шейдеры оптимизированными вручную.
Каждый SIMD-блок способен запускать до двух инструкций за такт, но они могут выдать вторую инструкцию только когда аппаратное и программное обеспечение AMD способно извлечь ее из текущего вейвфронта — если следующая инструкция не может быть выполнена параллельно с текущей, то дополнительные ALU не будут использоваться. Это означает, что в RDNA3 стало сложнее добиться вычислительной производительности, близкой к пиковой, а ведь RDNA первого поколения избавилась от похожей зависимости в GCN, когда реальная производительность была далека от теоретической. Посмотрим, что получилось у них в этот раз.
Двойной запуск команд является сравнительно дешевым способом увеличить производительность, если достаточно большую долю времени дополнительные блоки будут заняты работой при двойном запуске на исполнение. Но эффективность использования ALU в RDNA3, скорее всего, будет ниже, чем в RDNA2.
Мы видели недавно на примере видеокарт Intel, к чему приводит недостаточная эффективность использования имеющихся исполнительных блоков — теоретически они должны быть гораздо производительнее, чем получается на практике. Так и тут — в теории RX 7900 XTX/XT потенциально могут выдавать более чем вдвое больше терафлопов по сравнению с RX 6950 XT, а на практике преимущество будет куда меньше — ведь даже по заявлениям AMD оно не превышает 70%.
Соответственно, и количество потоковых процессоров в новых GPU теперь можно считать несколько иначе. AMD говорит, что в нем содержатся все те же 64 потоковых процессора (Streaming Processor — SP) на вычислительный блок CU, но теперь на один CU приходится четыре SIMD32 векторных блока, два из которых могут обрабатывать только операции с плавающей запятой FP32 или матричные, но не целочисленные INT32. Нечто схожее сделала компания Nvidia в Ampere (и это продолжилось в Ada), и получается некоторая нестыковка между подсчетом, принятым ранее и тем, что получается в RDNA3.
Потенциальную производительность FP32-вычислений для всего GPU повысили вдвое, не изменяя целочисленные возможности. То есть по сравнению с CU предыдущего поколения RDNA2 каждый CU теперь имеет 128 аналогичных потоковых процессоров и 12288 ALU на весь чип, или 64 потоковых процессоров (и 6144 потоковых процессоров на GPU) с удвоенной пропускной способностью только для FP32-вычислений. Собственные данные AMD говорят о 6144 потоковых процессорах и 96 блоках CU для RX 7900 XTX и 84 CU с 5376 ALU для RX 7900 XT, так же будем считать и мы. Но с учетом того, что пиковая производительность FP32-вычислений удвоилась — хотя бы теоретически. Это похоже на то, что есть у Nvidia в Ampere и Ada — 128 блоков FP32 и 64 блока INT32 на каждый CU.
Кроме удвоенной производительности FP32-вычислений, была повышена и производительность матричных вычислений, которые часто используются в задачах искусственного интеллекта. Общее увеличение производительности матричных вычислений указывается до 2,7 раз, но это учитывает все улучшения, включая частоту и увеличенное количество блоков.
Блоки ИИ-ускорения, появившиеся в архитектуре RDNA3, переназначают SIMD32 модули для выполнения матричных вычислений вместо обычных FP32/FP16-операций. Вместе с FP16 поддерживаются форматы BF16 и INT8, и все три имеют одинаковую пиковую производительность, превышающую вдвое производительность при одинарной точности с плавающей запятой — FP32. Потоковые процессоры RDNA2 и так умели исполнять операции половинной точности FP16 в двойном темпе, но в RDNA3 были сделаны некие оптимизации по пропускной способности и улучшению энергоэффективности, включая новые инструкции, поддерживаемые именно в режиме матричных вычислений.
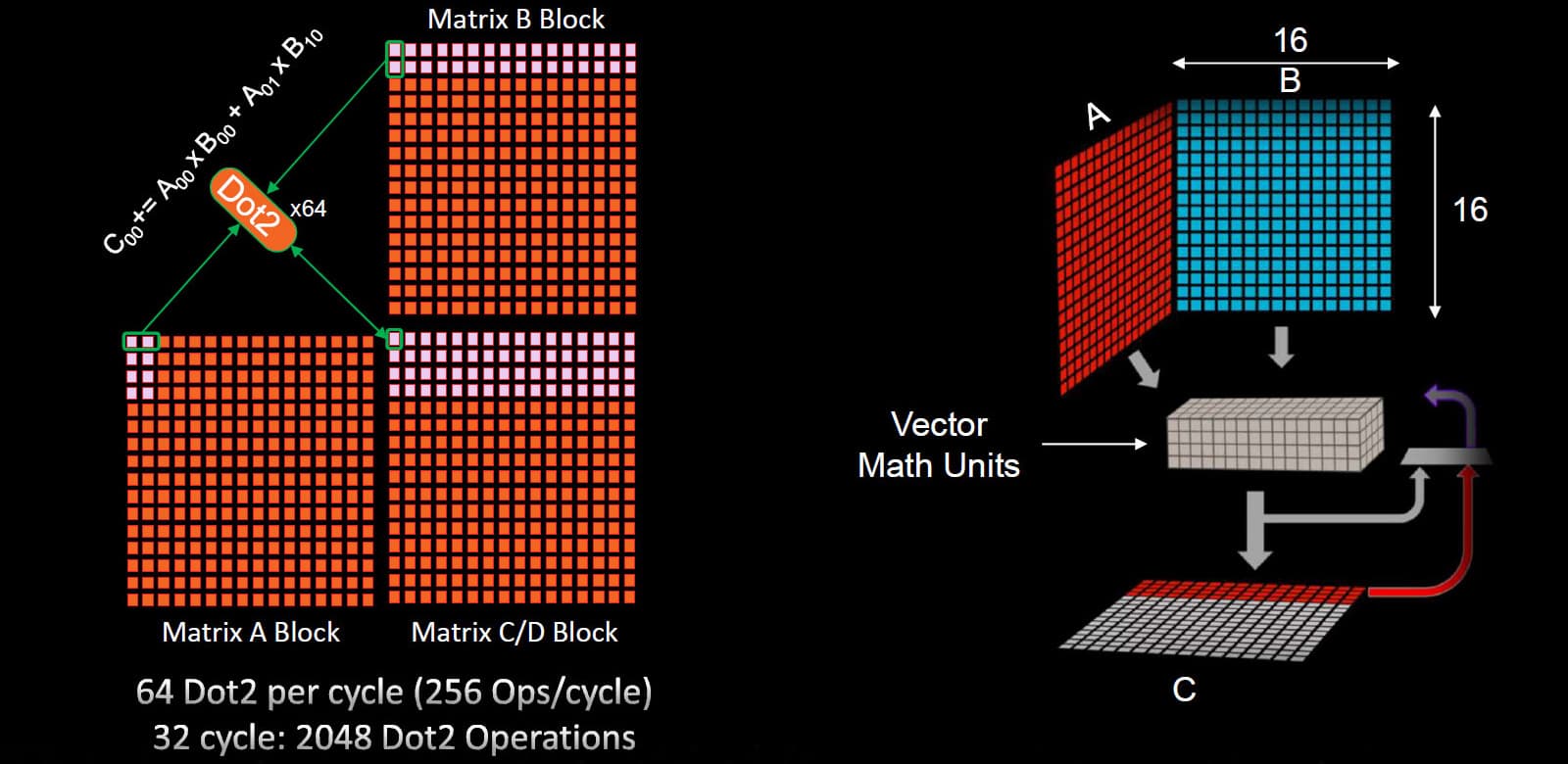
Вычислительный блок, содержащий SIMD-блоки, может работать в виде матричного ускорителя, выполняя соответствующие вычисления — AI Matrix Accelerator, что повышает производительность матричного умножения в 2,7 раза. Графический процессор Navi 31 ускоряет матричные вычисления, распространенные в задачах искусственного интеллекта, аналогично тензорным ядрам Nvidia и векторным ядрам Intel XMX. Для игровых GPU это важно для возможного будущего использования в технологии масштабирования FSR 3.0 — ведь теперь аппаратно ускоренный ИИ есть у всех трех главных компаний, производящих графические процессоры.
Пока что не совсем понятно, как сравнивать возможности GPU разных производителей по производительности матричных/векторных/тензорных вычислений, но похоже, что пиковые возможности Navi 31 всё же ощутимо ниже, чем у конкурирующих видеокарт Nvidia. И всё же, много важнее эффективная производительность в реальных задачах, и ее мы сможем сравнить лишь когда появится ПО, использующее AI Accelerator в AMD и аналогичные блоки в других GPU.
Невозможно не упомянуть улучшения в аппаратных блоках трассировки лучей, которые были сделаны в новой архитектуре RDNA3. Ray Accelerator первого поколения, которые мы видели в RDNA2, были явно спроектированы впопыхах, в попытках догнать по функциональности конкурента. Но графические процессоры Nvidia содержат продвинутые аппаратные блоки с фиксированными функциями расчета пересечения лучей, что разгружает SIMD-блоки и значительно ускоряет обработку. Было очевидно, что в RDNA3 компания AMD должна улучшить Ray Accelerator, и по их заявлению было достигнуто повышение производительности трассировки лучей в среднем на 80% по сравнению с RDNA2, если учесть все факторы (количество блоков, тактовую частоту и программно-аппаратные оптимизации).
Трассировка лучей в графических процессорах RDNA3 лишь догоняет конкурентов. В соответствующих аппаратных блоках RDNA2, которые занимаются трассировкой лучей, нет фиксированной логики для обхода структуры Bounding Volume Hierarchy (BVH), часть работы выполняется универсальными блоками и это выливается в их сравнительно низкую производительность в задачах с трассировкой. Блоки Ray Accelerator в RDNA2 могут выполнять до четырех пересечений луча с ограничивающим объемом за такт или одно пересечение луча с треугольником, хотя первое же поколение аппаратных блоков трассировки в Intel Arc выполняет до 12 пересечений лучей с ограничивающими объемами за такт, а Nvidia Ada — до четырех пересечений луча и треугольников за такт.
Что касается оптимизаций блоков аппаратной трассировки, то RDNA3 получило второе их поколение, где были внедрены специализированные режимы сортировки и сокращения итераций обхода дерева сортировки. Все оптимизации принесли снижение количества циклов на луч, производительность блоков трассировки увеличилась на 50%. Также AMD внесла несколько изменений в геометрический и пиксельный конвейер, что может снизить нагрузку на CPU при помощи сбора и анализа потоков множественной отрисовки. Благодаря раннему этапу отбрасывания, блоки трассировки Navi 31 аппаратно поддерживают расчет 12 примитивов за такт по сравнению с восемью примитивами за такт в RDNA2, а общая конфигурация обеспечивает на 50% более высокую производительность за такт.

В RDNA3 сосредоточились на увеличении эффективности трассировки — уменьшении работы над нахождением пересечений лучей с ограничивающими объемами и треугольниками, а не над улучшением пиковых значений. Утверждается, что RDNA3 имеет улучшенный обход структур BVH, что в теории повышает производительность трассировки лучей. RDNA3 также имеет в 1,5 раза больший по объему векторный регистровый файл VGPR, что позволяет обсчитывать больше лучей одновременно. Применяются и другие оптимизации для снижения количества вычислений при обходе BVH, специализированные алгоритмы сортировки для повышения эффективности и т.д.
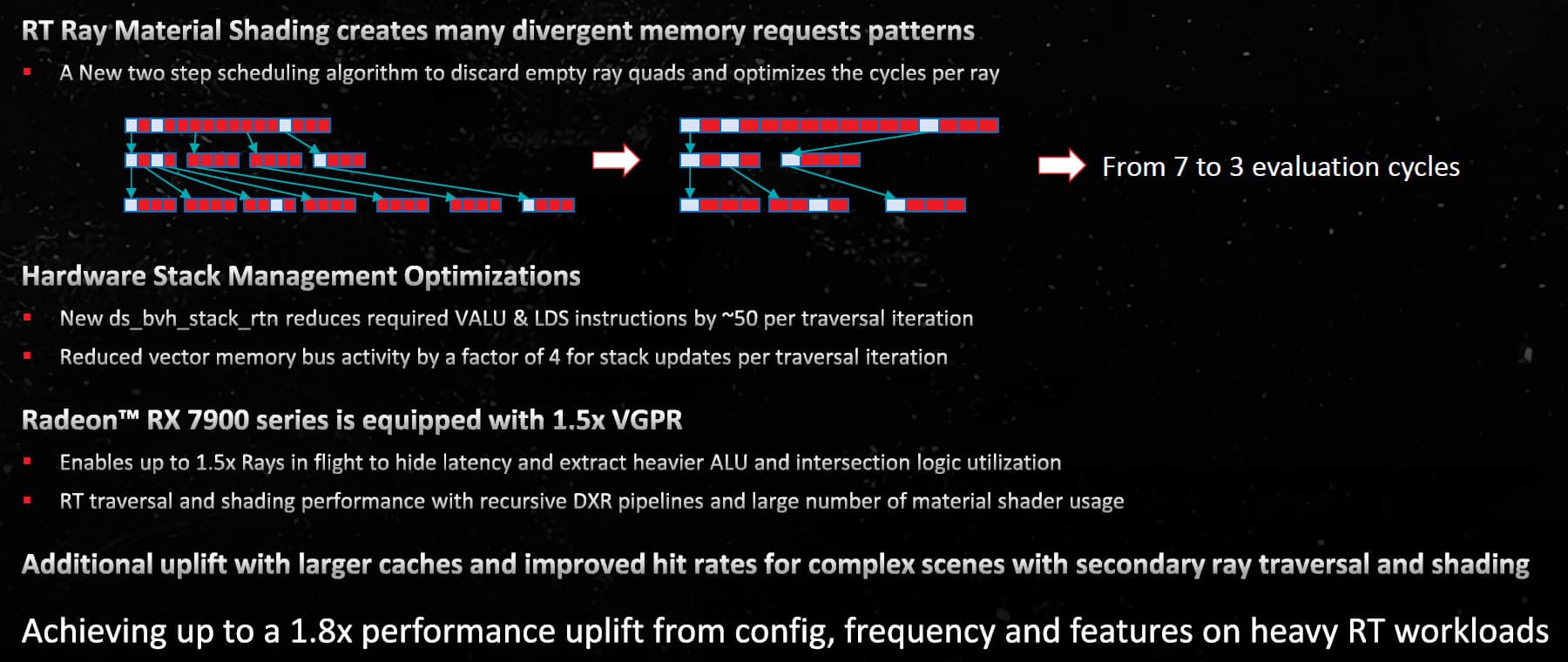
Благодаря новым оптимизациям, повышенной тактовой частоте и увеличенному количеству блоков ускорения трассировки лучей, в RDNA3 обеспечивается повышение производительности при трассировке лучей до 1,8 раза по сравнению с RDNA2. Вряд ли Navi 31 догонят топовые решения Nvidia Ampere даже при подобных реальных приростах, а ведь в Ada Lovelace производительность трассировки увеличилась еще сильнее — сильно сомневаемся, что у RX 7900 XTX/XT получится догнать RTX 4070 Ti/4080 при активном применении трассировки лучей, но ситуация точно должна улучшиться для AMD. Это видно и по их же сравнительным тестам, в которых RX 7900 XTX обеспечивает значительно бо́льшую частоту кадров, чем RX 6950 XT:
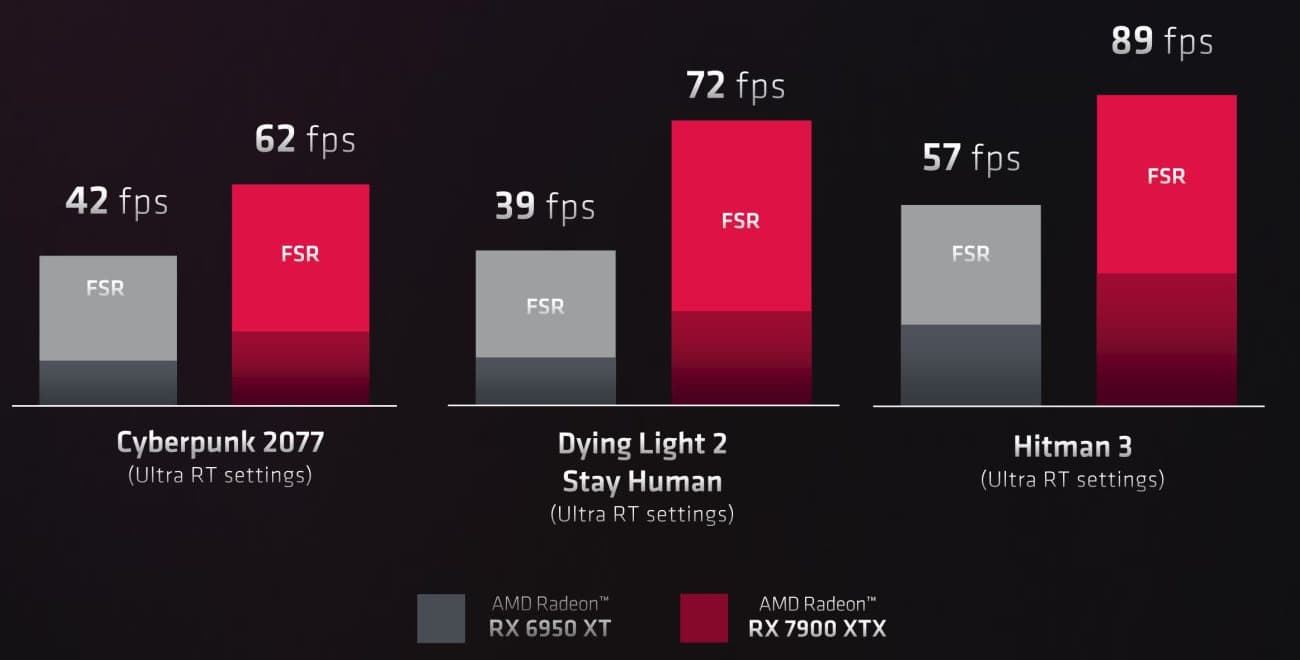
Из других улучшений в RDNA3, связанных именно с 3D-графикой, можно отметить изменения командного процессора, геометрического и пиксельного конвейера. Первое должно повысить производительность при определенных рабочих нагрузках и снизить простой вычислительных блоков, а аппаратное отсечение невидимой геометрии увеличит производительность в соответствующих задачах, также увеличивается и количество растеризованных пикселей — вероятно, речь о росте количества блоков ROP с 128 в Navi 21 до 192 в Navi 31. Последнее изменение логично — ширина шины памяти увеличилась на 50%, и это можно и нужно использовать.
Для многих пользователей важно, что AMD в своих новых графических процессорах серьезно модифицировала и блоки обработки видеоданных и вывода информации на дисплеи. Так, Navi 31 способен кодировать и декодировать видеоданные в формате AV1 при помощи пары независимых блоков кодирования-декодирования, которые могут обрабатывать два независимых видеопотока или объединять возможности при работе с одним потоком с удвоенной производительностью — видеодвижки в Navi 31 на 80% быстрее предшественников из RDNA2 и позволяют одновременно работать с парой видеопотоков в форматах H.264 и H.265.
Также новый GPU способен кодировать и декодировать видеопоток формата AV1 при 8K-разрешении с частотой кадров в 60 FPS — это примерно те же возможности, что уже есть у конкурентов. В этом поколении AMD также представляет Smart Access Video — функцию, которая позволяет драйверу AMD использовать аппаратные кодировщики видео из процессоров Ryzen 7000 для настольных ПК — для повышения общей производительности кодирования.
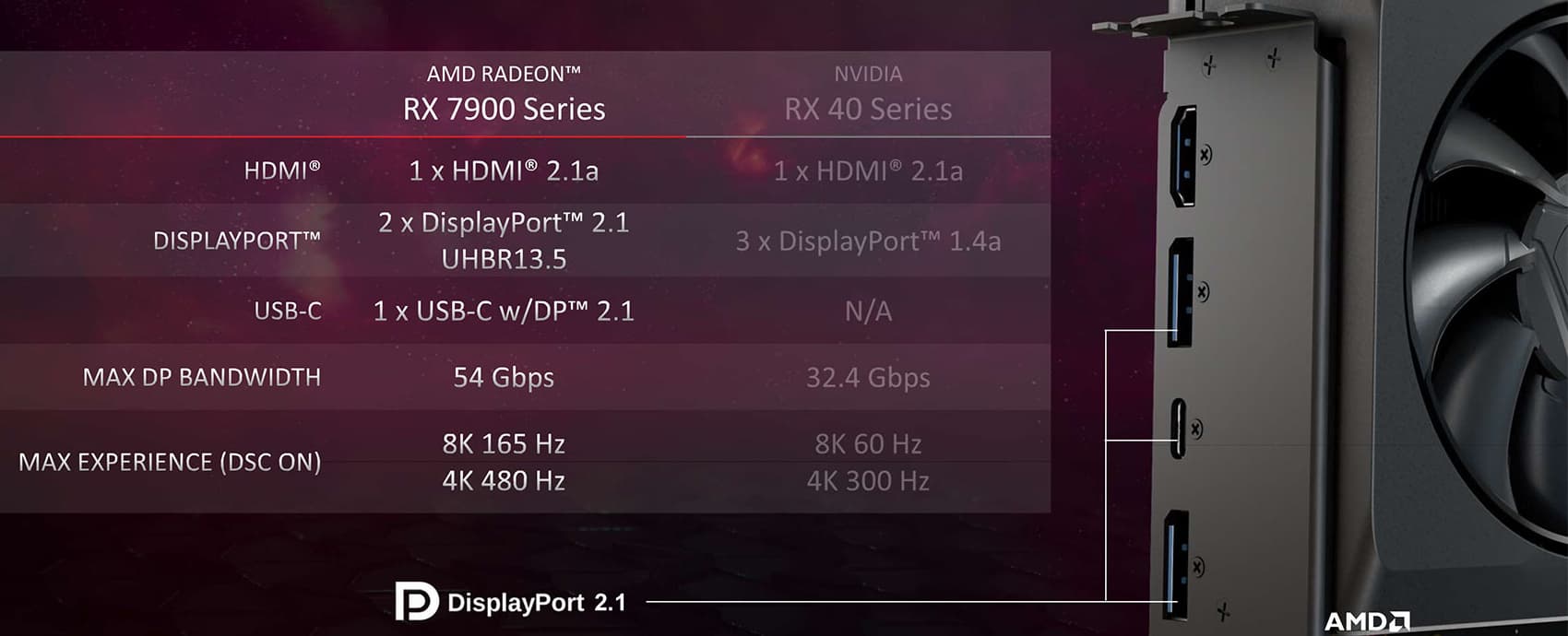
В Navi 31 был улучшен и движок поддержки дисплеев по сравнению с предыдущим поколением. Новый Radiance Display Engine поддерживает разъемы DisplayPort 2.1 со скоростями передачи данных UHBR 10 и UHBR 13.5, что вдвое больше, чем у DisplayPort 1.4. Хотя у видеокарт Intel также есть поддержка DisplayPort 2.1, но максимальная пропускная способность у Arc ограничена значением 40 Гбит/с (UHBR 10), а для Radeon RX 7900 это уже 54 Гбит/с (UHBR 13.5).
Поддержка такой пропускной способности означает возможность подключения 4K-дисплея одним кабелем — с частотой обновления до 240 Гц без использования сжатия видеопотока, а со сжатием Display Stream Compression можно использовать 4K при 480 Гц или 8K при 165 Гц. Это относится к обеим выпущенным видеокартам серии RX 7900, и если говорить о референсных вариантах, то обе они имеют по два полноразмерных разъема DisplayPort 2.1, а также по одному HDMI 2.1b и USB-C (поддерживается вывод по DisplayPort).
Итак, с архитектурными изменениями RDNA3 и Navi 31 мы познакомились, теперь рассмотрим характеристики выпущенных недавно видеокарт двух моделей в сравнении с лучшим решением предыдущего поколения, а также — всеми тремя моделями видеокарт поколения RTX 40 конкурента. Да, с топовой GeForce RTX 4090 новинки компании AMD не соперничают на рынке, но будет любопытно прикинуть, насколько они должны отставать от топовой модели соперника по теоретическим характеристикам.
| Radeon RX 7900 XTX | Radeon RX 7900 XT | Radeon RX 6950 XT | GeForce RTX 4090 | GeForce RTX 4080 | GeForce RTX 4070 Ti | |
|---|---|---|---|---|---|---|
| Модель GPU | Navi 31 | Navi 31 | Navi 21 | AD102 | AD103 | AD104 |
| Техпроцесс, нм | 5/6 | 5/6 | 7 | 5 | 5 | 5 |
| Кол-во транзисторов, млрд | 57,7 | 55,6 | 26,8 | 76,3 | 45,9 | 35,8 |
| Площадь, мм² | 522 | 485 | 519 | 608 | 379 | 295 |
| Потоковые процессоры | 6144 (12288) | 5376 (10752) | 5120 | 16384 | 9728 | 7680 |
| Блоки TMU | 384 | 336 | 320 | 512 | 304 | 240 |
| Блоки ROP | 192 | 192 | 128 | 176 | 112 | 80 |
| RT-ядра | 96 | 84 | 80 | 128 | 76 | 60 |
| Турбо-частота, ГГц | 2,5 | 2,4 | 2,3 | 2,5 | 2,5 | 2,6 |
| Объем видеопамяти, ГБ | 24 | 20 | 16 | 24 | 16 | 12 |
| Частота видеопамяти, ГГц | 20 | 20 | 18 | 21 | 22,4 | 21 |
| Ширина шины, бит | 384 | 320 | 256 | 384 | 256 | 192 |
| L2/L3-кэш, МБ | 96+6 | 80+6 | 128+4 | 76 | 64 | 48 |
| ПСП, ГБ/с | 960 | 800 | 576 | 1008 | 717 | 504 |
| Производительность FP32, Тфлопс | 61,4 | 51,6 | 23,7 | 82,6 | 48,7 | 40,1 |
| Текстурирование, Гтекс/с | 960 | 804 | 739 | 1290 | 762 | 626 |
| Скорость заполнения, Гпикс/с | 480 | 460 | 296 | 444 | 281 | 209 |
| Потребление, Вт | 355 | 300 | 335 | 450 | 320 | 285 |
| Рекомендованная цена, $ | 999 | 899 | 1099 | 1599 | 1199 | 799 |
Первое же, что бросается в глаза — значительное отставание Radeon RX 7900 XTX/XT почти по всем характеристикам от флагмана Nvidia — GeForce RTX 4090. Оно и понятно, это решение совсем другого ценового уровня, но слишком уж велика разница вообще по всем параметрам, кроме пропускной способности памяти и скорости заполнения, ведь у Radeon RX 7900 XTX/XT теперь широкая шина памяти и большое количество блоков ROP — вероятно, в том числе и благодаря чиплетной конфигурации, которая позволила разместить больше контроллеров памяти, чем на монолитном кристалле схожей площади.
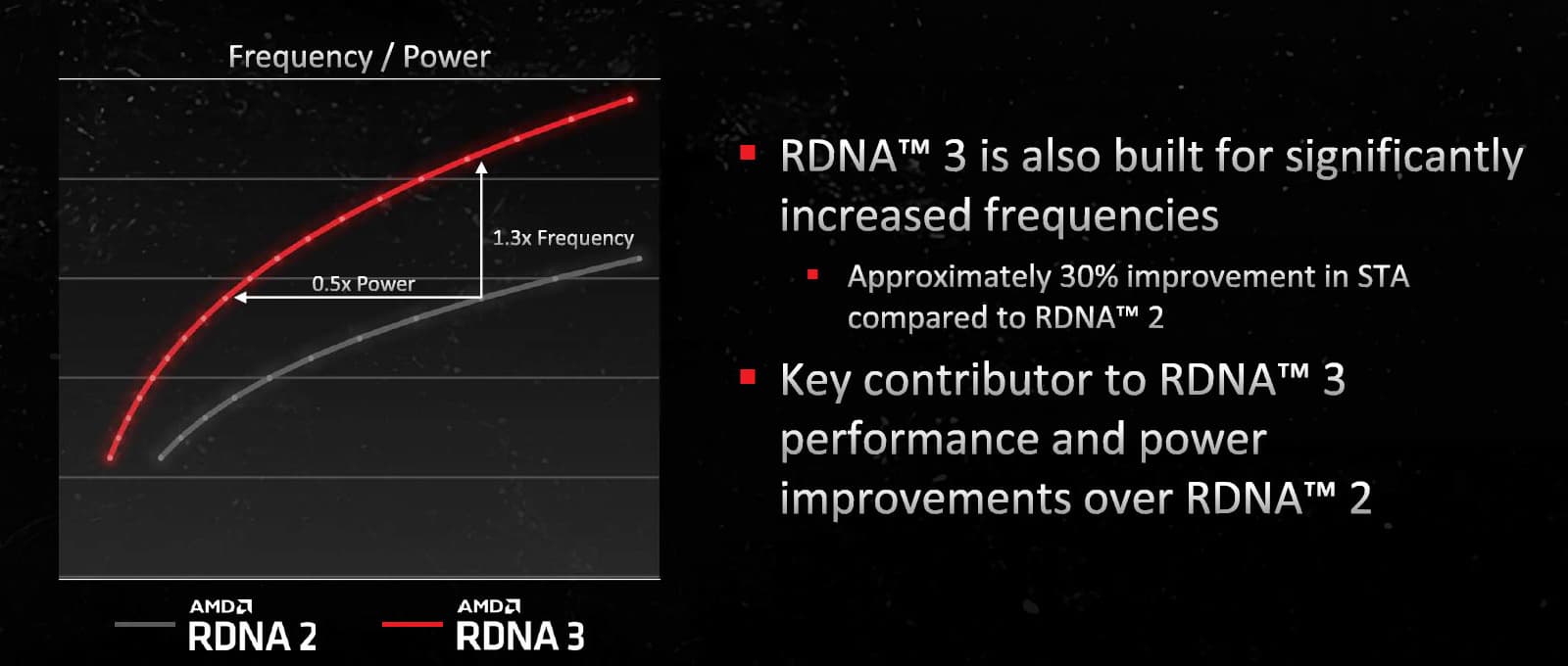
Также сразу заметны очень близкие тактовые частоты вообще для всех GPU в таблице — около 2,5 ГГц в турбо-режиме. И по спецификациям кажется, что AMD просто не смогли увеличить тактовые частоты по сравнению с RDNA2, хотя и собирались, да и смена техпроцесса явно должна была помочь. AMD утверждает, что графические процессоры RDNA3 превзойдут официальные тактовые частоты, указанные в виде «игровых» — к слову, теперь указывается еще и «турбо»-частота, которая выше «игровой».
Хотя представители компании заявляли ранее, что RDNA3 рассчитана на 3 ГГц, официальные тактовые частоты RX 7900 XTX/XT значительно ниже этого значения, хотя реальные частоты могут быть и выше. Зато, по данным AMD, графические процессоры Navi 31 могут работать на той же частоте, что и аналогичные графические процессоры RDNA2, используя вдвое меньше энергии, или в 1,3 раза быстрее при том же потреблении. Так что в итоге AMD остановилась на некоем балансе частоты и потребления, утвердив турбо-частоту в 2,5 ГГц для старшей модели.
Что касается других характеристик, то по пропускной способности памяти у Nvidia теперь преимущества нет — из-за широкой шины памяти, Navi 31 практически догнала конкурента, несмотря на разный тип памяти, а удвоение количества FP32-блоков сделало RDNA3 более похожей на Ampere и Ada по вычислительной производительности, и если эффективность использования вычислительных блоков у Navi 31 будет не слишком хуже, чем у конкурента, то вполне можно оценивать их реальную производительность по пиковым значениям.
Повышенная пропускная способность важна для обеспечения эффективной работы более производительного графического процессора, и AMD не просто расширила шину памяти, но увеличила пропускная способность кэш-памяти на всех уровнях, увеличив емкость кэш-памяти и на основном кристалле — чтобы не тратить большее количество энергии на доступ к L3-кэшу вне кристалла. AMD также увеличила и объем регистрового файла, что должно помочь улучшить использования блоков, и сократила задержку LDS, что должно сказаться при трассировке лучей. А вот небольшое снижение объема L3-кэша по сравнению с предыдущим поколением не так уж важно, так как применяется 384-битная шина памяти и более скоростная GDDR6-память.
Чиплетная организация GPU позволила ограничить площадь основного кристалла за счет перемещения L3-кэша и контроллеров памяти на отдельные чиплеты — это также помогает получить более широкую общую шину памяти и более высокую пропускную способность при использовании основного кристалла меньшей площади, на котором просто физически не нашлось бы места для подключения 384-битной шины. В результате, Radeon RX 7900 XTX получился очень близким по производительности к GeForce RTX 4080, а Radeon RX 7900 XT — к RTX 4070 Ti.
Что касается количества транзисторов и размеров кристаллов, то Nvidia выпустила монолитные кристаллы AD102, AD103 и AD104. Крупнейший из них имеет 76,3 млрд транзисторов в чипе размером 608 мм², второй — AD103, используемый в RTX 4080, имеет 45,9 млрд транзисторов и 369 мм², а AD104 (RTX 4070 Ti) — 35,8 млрд транзисторов и 295 мм². Если бы Navi 31 конкурировал с RTX 4090, то у AMD было бы явное преимущество по этим параметрам, но RX 7900 XTX соответствует скорее RTX 4080, а RX 7900 XT — RTX 4070 Ti, и тут уже всё не так однозначно с привлекательностью чиплетов — гипотетический монолитный чип с 58 млрд транзисторов и площадью 522 мм² — это явно многовато. Похоже, что чиплетная организация также отличается и немалыми накладными расходами — часть площади и транзисторов расходуются на то, что прямо не влияет на производительность. И что касается ближайшего будущего, если для гипотетического среднеценового Navi 32 и имеет смысл использовать те же MCD и меньший по размеру GCD, то еще менее дорогой Navi 33 нет смысла делать чиплетным, по всей вероятности.
Тем более, что производительность сейчас — это не просто пиковые значения, но и такие технологии, как DLSS3 (тензорные ядра и ускоритель оптического потока), а также продвинутые блоки трассировки лучей. AMD хоть и старается догонять конкурента по этим возможностям, но, похоже, это происходит не так активно, как нам хотелось бы — они явно приняли решение отказаться от значительного повышения производительности блоков аппаратной трассировки лучей, считая это не самым главным, вероятно. Также у AMD до сих пор нет полноценного ответа даже на DLSS2, не говоря о DLSS3. Пока что не совсем понятно, правильную ли они выбрали стратегию, и кто в итоге выиграет.

Что касается прикидок по сравнительной производительности по данным AMD — если не учитывать трассировку лучей, то Radeon RX 7900 XT явно быстрее RX 6950 XT и находится примерно на уровне GeForce RTX 3090 Ti и чуть выше RTX 4070 Ti, а старшая модель Radeon RX 7900 XTX быстрее их где-то на 20%. RTX 4080 также быстрее, но чуть меньше. При такой разнице в рекомендованных ценах, XTX смотрится несколько предпочтительнее, особенно для 4K. Но и RX 7900 XT отлично выступает в таких условиях — обеспечивая комфортную игру в 4K при максимальных настройках с не менее чем 60 FPS практически во всех играх. Ну а для игровых мониторов с разрешением 2560x1440 будет возможность получения очень высокой частоты кадров.
Если же включить аппаратную трассировку лучей в играх, то конкуренты RX 7900 XT из стана Nvidia получают явное преимущество. RTX 3090 Ti и RTX 4070 Ti будут уже явно производительнее, и это тем более важно, что трассировка лучей появляется во всё большем количестве игр и нагрузка на соответствующие аппаратные блоки со временем лишь увеличивается. Мы ожидали улучшения ситуации с поддержкой трассировки в RDNA3 и она действительно случилась, но... явно не настолько, чтобы догнать даже предыдущее поколение конкурента — Ampere. И если для вас важны эти возможности современных GPU, то в таком случае стоит присмотреться к RTX 4070 Ti или RTX 4080, а вот если трассировка лучей кажется вам каким-то необязательным и слабо заметным эффектом (что не так), который наносит слишком сильный удар по производительности (а вот это уже правда), то Radeon RX 7900 XT будет очень неплохим вариантом за свои деньги. Он точно справляется с трассировкой лучше GPU предыдущего поколения:
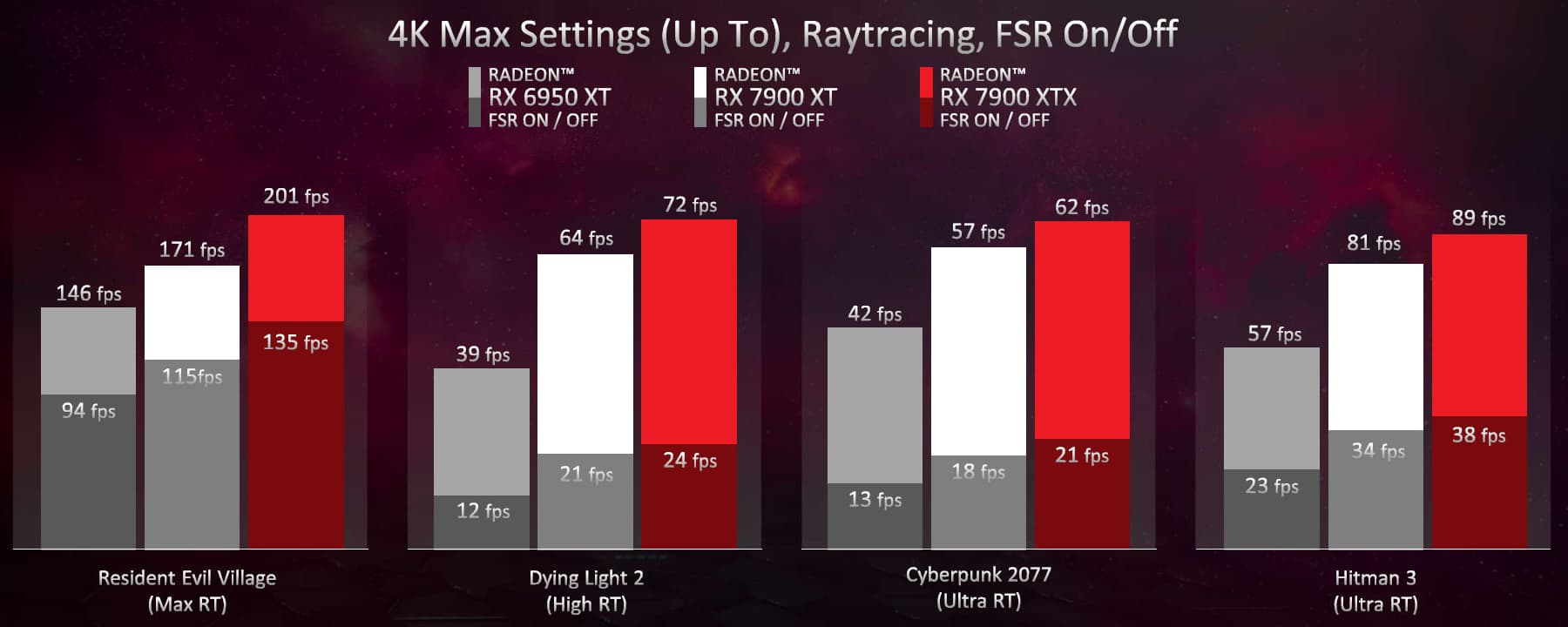
Энергоэффективность Radeon RX 7900 XT находится на очень высоком уровне — она гораздо лучше, чем у и так неплохих аналогов по этому показателю из предыдущей линейки, не говоря про поколение Ampere у Nvidia. Правда, у новых моделей линейки GeForce RTX 40 она еще выше, но вполне возможно, что в будущем AMD сможет повысить эффективность исполнения существующего кода на новых вычислительных блоках с двойным темпом, требующим специальной оптимизации. Конечно, никакого удвоения производительности не произойдет, но в новых приложениях и играх относительная производительность новых GPU может несколько вырасти — правда, может потребоваться время для ручной оптимизации и улучшения шейдерного компилятора.
Интересно, что AMD и Nvidia пришли к примерно одному уровню производительности разными путями. Чиплетная организация помогает AMD использовать меньшую площадь основного кристалла при сохранении широкой шины памяти, но это же и является более дорогим решением из-за упаковки всех кристаллов на одну подложку, и накладывает определенные требования и ограничения на пропускную способность и задержки связей между чиплетами графического процессора. Nvidia же размещает всё на единых больших кристаллах, и RTX 4080 и RTX 4070 Ti получились с меньшей пропускной способностью и меньшим объемом кэш-памяти по сравнению с RX 7900 XTX и RX 7900 XT соответственно.
При этом решения двух компаний очень близки во многих играх — исключая те, в которых активно используется трассировка лучей, и хотя Nvidia всё же имеет некоторое лидерство по максимальной производительности в RTX 4090, но AMD отвечает выгодными GPU с точки зрения соотношения цены и производительности. Правда, в последнем поколении цены получились не слишком низкими у обеих компаний, и мы очень надеемся, что в будущем их соперничество всё же приведет к снижению цен на видеокарты, а не только к появлению новых технологий с обеих сторон. Уж слишком стали отставать выходящие игры от потенциальных возможностей топовых GPU — платить за это сейчас готовы лишь очень редкие энтузиасты.
Что касается сравнения с учетом цен, то анонсированная рекомендованная цена в $899 для Radeon RX 7900 XT уж слишком близка к цене RX 7900 XTX, которая лишь на сотню долларов дороже. Покупка старшей модели даст +15%-17% к производительности при +10% разницы в цене, что кажется явно несбалансированным соотношением. То есть, как RTX 4090 является более выгодной видеокартой по сравнению с RTX 4080, так и RX 7900 XTX смотрится выгоднее, чем RX 7900 XT. А ведь в прошлом поколении видеокарт AMD и Nvidia, топовые модели стоили заметно дороже и давали сравнительно небольшой прирост производительности. В текущем же поколении GPU обе компании изменили свой подход. Возможно, AMD стоило отойти от округленных до сотен цен, назначив для RX 7900 XT цену хотя бы $850 (а лучше еще меньше), тогда и с GeForce RTX 4070 Ti было бы проще конкурировать.
На этой мысли мы заканчиваем с теоретической частью и переходим к рассмотрению практических особенностей видеокарты Radeon RX 7900 XT в исполнении компании XFX.
Сведения о производителе: Компания ATI Technologies (торговая марка ATI) основана в 1985 году в Канаде как Array Technology Inc. В том же году была переименована в ATI Technologies. Штаб-квартира в г. Маркхам (Торонто). C 1987 года компания сконцентрировалась на выпуске графических решений для ПК. Начиная с 2000 года основным брендом графических решений ATI становится Radeon, под которым выпускаются GPU как для настольных ПК, так и для ноутбуков. В 2006 году компанию ATI Technologies покупает компания AMD, в которой образуется подразделение AMD Graphics Products Group (AMD GPG). C 2010 года AMD отказывается от бренда ATI, оставив лишь Radeon. Штаб-квартира AMD в Саннивейл (Калифорния), а у AMD GPG остается главным офисом бывший офис AMD в Маркхаме (Канада). Своего производства нет. Общая численность сотрудников AMD GPG (включая региональные офисы) — около 2000 человек.
Объект исследования: серийно выпускаемый ускоритель трехмерной графики (видеокарта) XFX Radeon RX 7900 XT 20 ГБ 320-битной GDDR6


| XFX Radeon RX 7900 XT 20 ГБ 320-битной GDDR6 | ||
|---|---|---|
| Параметр | Значение | Номинальное значение (референс) |
| GPU | Radeon RX 7900 XT (Navi31) | |
| Интерфейс | PCI Express x16 4.0 | |
| Частота работы GPU (ROPs), МГц | 2400(Boost)—2900(Max) | 2400(Boost)—2900(Max) |
| Частота работы памяти (физическая (эффективная)), МГц | 2500 (20000) | 2500 (20000) |
| Ширина шины обмена с памятью, бит | 320 | |
| Число вычислительных блоков в GPU | 84 | |
| Число операций (ALU/CUDA) в блоке | 64 | |
| Суммарное количество блоков ALU/CUDA | 5376 | |
| Число блоков текстурирования (BLF/TLF/ANIS) | 336 | |
| Число блоков растеризации (ROP) | 192 | |
| Число блоков Ray Tracing | 84 | |
| Число тензорных блоков | - | |
| Размеры, мм | 280×115×58 | 280×115×58 |
| Количество слотов в системном блоке, занимаемые видеокартой | 3 | 3 |
| Цвет текстолита | черный | черный |
| Энергопотребление пиковое в 3D, Вт | 315 | 315 |
| Энергопотребление в режиме 2D, Вт | 25 | 25 |
| Энергопотребление в режиме «сна», Вт | 7 | 7 |
| Уровень шума в 3D (максимальная нагрузка), дБА (BIOS P/BIOS S) | 36,6 | 36,6 |
| Уровень шума в 2D (просмотр видео), дБА | 18,0 | 18,0 |
| Уровень шума в 2D (в простое), дБА | 18,0 | 18,0 |
| Видеовыходы | 1×HDMI 2.1, 2×DisplayPort 2.1, Type-C (DP 2.1) | 1×HDMI 2.1, 2×DisplayPort 2.1, Type-C (DP 2.1) |
| Поддержка многопроцессорной работы | нет | |
| Максимальное количество приемников/мониторов для одновременного вывода изображения | 4 | 4 |
| Питание: 8-контактные разъемы | 2 | 2 |
| Питание: 6-контактные разъемы | 0 | 0 |
| Питание: 16-контактные разъемы | 0 | 0 |
| Вес карты с комплектом поставки (брутто), кг | 1,9 | 1,9 |
| Вес карты чистый (нетто), кг | 1,6 | 1,6 |
| Максимальное разрешение/частота, DisplayPort | 3840×2160@480 Гц, 7680×4320@165 Гц | |
| Максимальное разрешение/частота, HDMI | 3840×2160@144 Гц, 7680×4320@60 Гц | |
| Средняя цена карты XFX | около 90 тысяч рублей на момент подготовки обзора | |

Карта имеет 20 ГБ памяти GDDR6 SDRAM, размещенной в 10 микросхемах по 16 Гбит на лицевой стороне PCB. Микросхемы памяти SK hynix (GDDR6, H56G42AS8D-X014) рассчитаны на номинальную частоту работы в 2500 (20000) МГц.
| XFX Radeon RX 7900 XT (20 ГБ) | AMD Radeon RX 6900 XT (16 ГБ) |
|---|---|
| вид спереди | |
 |  |
| вид сзади | |
 |  |
Мы логично сравниваем новую карту с предшественницей. Хотя формально модель, которую мы купили, выпущена под брендом XFX, это в чистом виде референсная карта, на которой нет даже наклеек компании XFX (обычно партнеры AMD, пакуя эталонные карты в свои коробки, стараются хоть как-то заявить о своей причастности к этому продукту). Именно поэтому выше в сведениях о производителе приведена информация об AMD (ибо фактически это их карта).
Так вот, если сравнивать референс-карты двух поколений, то прекрасно видно, что размеры PCB у них практически одинаковые, однако теперь на таком же куске текстолита надо развести шину обмена с памятью в 384 бит (а ранее — 256 бит). Да, фактическая ширина шины у данного ускорителя — 320 бит, но физически на карте разводится 384 бит, просто не установлены две микросхемы памяти (такой же прием использовала Nvidia на картах GeForce RTX 3080 10 ГБ и GeForce RTX 3080 12 ГБ). Понятно, что для карты на базе Radeon RX 7900 XTX (с 24 ГБ и шириной шины 384 бит) может использоваться та же самая PCB.

AMD никогда не маркирует свои GPU понятным образом (как это делает Nvidia, где по маркировке с кодовым названием поколения сразу можно понять, какое ядро перед нами), всё зашифровано в цифровой код. Дата выпуска — 39-я неделя 2022 года (октябрь). Стоит напомнить, что теперь по крайней мере топовые графические ядра AMD имеют чиплетную структуру (а не в виде одного цельного кристалла), и действительно мы видим 7 кристаллов в одной упаковке: 6 небольших кристаллов MCD, в которых размещены Infinity Cache (в каждом MCD по 16 МБ такой кеш-памяти) и контроллеры памяти (каждый MCD имеет 64-битный контроллер) и 1 большой кристалл GCD, в котором размещены потоковые процессоры, шейдерные движки и так далее. В Radeon RX 7900 XT работают только 5 из 6 MCD, поэтому объем Infinity Cache сокращен до 80 МБ, а контроллеры памяти образуют шину только 320 бит. В большом чиплете GCD также отключены 12 вычислительных блоков (из 96), так что их стало 84, остальные блоки урезаны соразмерно.
Суммарное количество фаз питания у карты XFX Radeon RX 7900 XT (20 ГБ) — 17, а у ее предшественницы Radeon RX 6900 XT — 16. При этом распределение фаз такое: у референс-карты Radeon RX 6900 XT — 13 фаз на ядро и 3 на микросхемы памяти, у карты XFX Radeon RX 7900 XT (20 ГБ) — 14 + 3.

Зеленым цветом отмечена схема питания ядра, красным — памяти. 14 фаз питания ядра управляются двумя ШИМ-контроллерами MP2856 (Monolithic Power Systems), расположенными на оборотной стороне PCB. Каждый такой контроллер рассчитан максимум на 9 фаз.


Тремя фазами питания микросхем памяти управляет ШИМ-контроллер MP2857 (тоже MPS), он также расположен на тыльной стороне карты.
В преобразователе питания, традиционно для всех топовых видеокарт, используются транзисторные сборки DrMOS — в данном случае MP87997 (Monolithic Power Systems), каждая из которых рассчитана максимально на 70 А.

Отдельного контроллера, отвечающего за мониторинг карты (отслеживание напряжений и температуры), нет, эти функции AMD традиционно возлагает на сам GPU.
Энергопотребление карты XFX в тестах доходило до 315 Вт. Питание на карту подается через два традиционных 8-контактных разъема питания.

Отметим габариты данной карты, ставшие уже стандартными для средних и топовых видеокарт: длина 28 см, высота более 11 см, толщина около 5 см. В результате видеокарта занимает 3 слота в системном блоке.

Мы визуально сравнили Radeon RX 7900 XT (нижняя карта) c предшественником. Несмотря на небольшие различия по размерам, просматривается единая концепция, в том числе в плане использования испарительной камеры в СО. Жалко лишь, что теперь AMD отказалась от симпатичных и броских наклеек с лого семейства Radeon на вентиляторах, в целом дизайн стал мрачным и почти черным.

Карта имеет стандартный для AMD и нестандартный для большинства видеокарт набор видеовыходов: два DP, один USB Type-C и один HDMI. Поменялись только версии поддерживаемых стандартов, теперь это HDMI 2.1 и DisplayPort 2.1. Разъем USB Type-C используется в качестве третьего вывода DP 2.1, конвертация происходит через контроллер Cypress.


Основой кулера является многосекционный пластинчатый радиатор, имеющий в своей основе огромную испарительную камеру. Микросхемы памяти охлаждаются с помощью этой же камеры (через термопрокладки). А для охлаждения преобразователей питания VRM имеются свои подошвы на большой жесткой раме, прикрученной к радиатору и служащей также для усиления жесткости конструкции.

Задняя пластина не участвует в охлаждении оборотной стороны платы, а просто служит элементом защиты PCB. Поверх радиатора установлен кожух, покрывающий три вентилятора ∅95 мм.
Остановка вентиляторов при малой нагрузке видеокарты происходит, если температура GPU опускается ниже 50 градусов. При запуске ПК вентиляторы работают, однако после загрузки видеодрайвера идет опрос рабочей температуры, и они выключаются.
Мониторинг температурного режима с помощью MSI Afterburner:
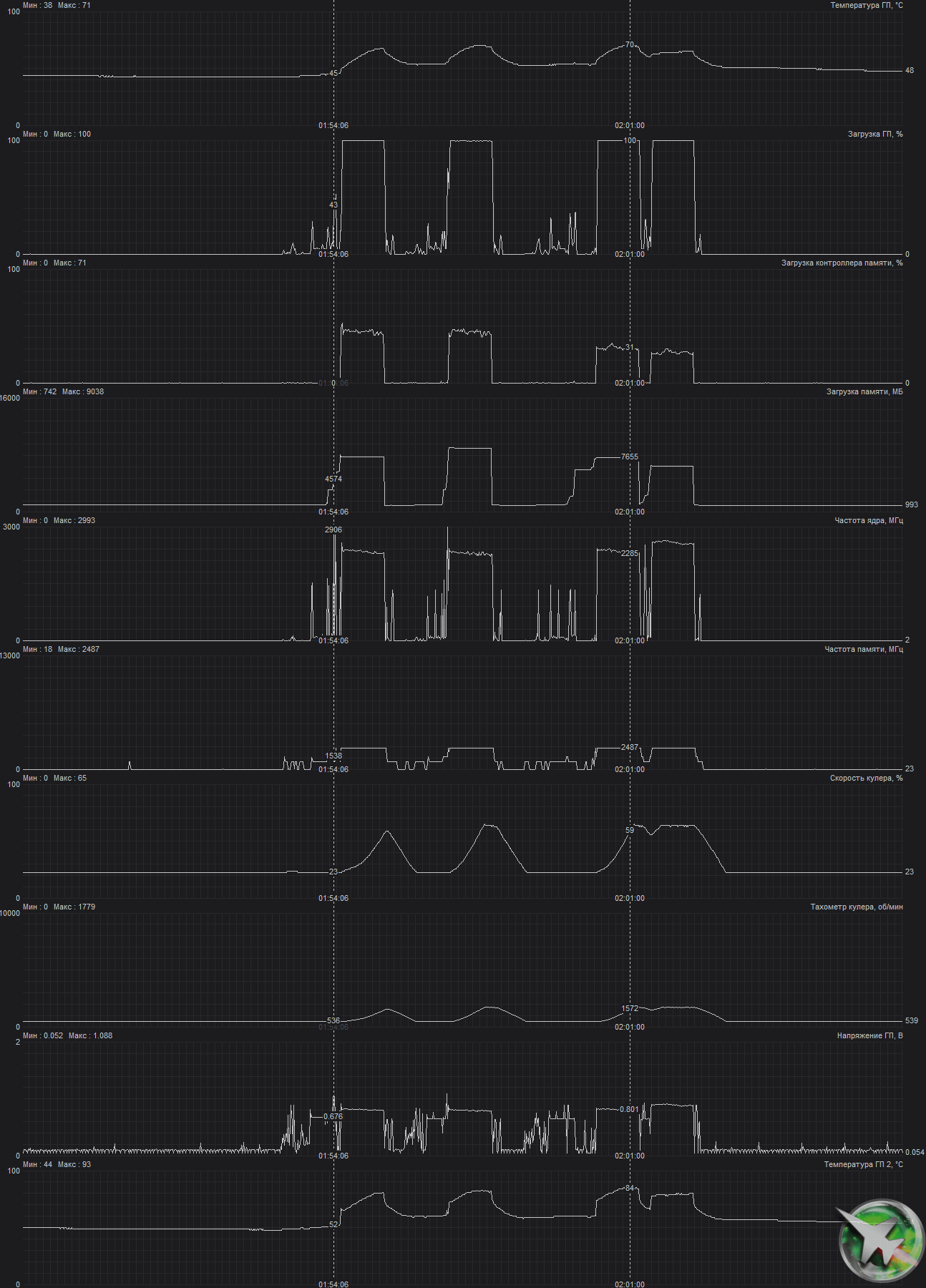
После 2-часового прогона под нагрузкой максимальная температура ядра не превысила 70 градусов, что является нормальным результатом для видеокарт такого уровня. Энергопотребление карты доходило до 315 Вт.


Максимальный нагрев наблюдался около блока VRM и микросхем памяти.
Методика измерения шума подразумевает, что помещение шумоизолировано и заглушено, снижены реверберации. Системный блок, в котором исследуется шум видеокарт, не имеет вентиляторов, не является источником механического шума. Фоновый уровень 18 дБА — это уровень шума в комнате и уровень шумов собственно шумомера. Измерения проводятся с расстояния 50 см от видеокарты на уровне системы охлаждения.
Режимы измерения:
- Режим простоя в 2D: загружен интернет-браузер с сайтом iXBT.com, окно Microsoft Word, ряд интернет-коммуникаторов
- Режим 2D с просмотром фильмов: используется SmoothVideo Project (SVP) — аппаратное декодирование со вставкой промежуточных кадров
- Режим 3D с максимальной нагрузкой на ускоритель: используется тест FurMark
Оценка градаций уровня шума следующая:
- менее 20 дБА: условно бесшумно
- от 20 до 25 дБА: очень тихо
- от 25 до 30 дБА: тихо
- от 30 до 35 дБА: отчетливо слышно
- от 35 до 40 дБА: громко, но терпимо
- выше 40 дБА: очень громко
В режиме простоя в 2D температура была не выше 40 °C, вентиляторы не работали, уровень шума был равен фоновому — 18 дБА.
При просмотре фильма с аппаратным декодированием ничего не менялось.
В режиме максимальной нагрузки в 3D температура достигала 70 °C (ядро). Вентиляторы при этом раскручивались до 1870 оборотов в минуту, шум вырастал до 36,6 дБА: это громко, но еще терпимо.
Карта XFX (она же референс-карта) не имеет подсветки.

В комплекте поставки кроме самой карты и большой листовки непонятного предназначения ничего больше нет.



Мы провели тестирование новой модели видеокарты AMD со стандартными частотами в нашем наборе синтетических тестов. Он продолжает меняться, иногда добавляются новые тесты, а устаревшие постепенно убираются. Мы бы хотели добавить еще больше примеров с вычислениями, но с этим есть определенные сложности. Мы постоянно стараемся расширять и улучшать набор синтетических тестов, и если у вас есть четкие и обоснованные предложения — напишите их в комментариях к статье или отправьте авторам.
Из более-менее новых бенчмарков мы начали использовать несколько дополнительных тестов для измерения производительности трассировки лучей и, а также технологий масштабирования разрешения и увеличения производительности: DLSS и XeSS. В качестве полусинтетических тестов у нас также используется набор подтестов из довольно популярного пакета 3DMark: Time Spy, Port Royal, DX Raytracing, Speed Way и др. А вот примеры приложений DirectX 11 и 12, входящие в различные SDK, пришлось убрать — последнее время они всё чаще давали некорректные результаты.
Синтетические тесты проводились на следующих видеокартах:
- Radeon RX 7900 XT со стандартными параметрами (RX 7900 XT)
- Radeon RX 6950 XT со стандартными параметрами (RX 6950 XT)
- GeForce RTX 4080 со стандартными параметрами (RTX 4080)
- GeForce RTX 4070 Ti со стандартными параметрами (RTX 4070 Ti)
- GeForce RTX 3090 Ti со стандартными параметрами (RTX 3090 Ti)
Для анализа производительности новой видеокарты Radeon RX 7900 XT мы взяли топовую модель Radeon RX 6950 XT из предыдущего поколения на основе архитектуры RDNA2 — ее показатели нужны для того, чтобы понять, насколько графический процессор архитектуры RDNA3 стал быстрее, хотя эта модель и не является прямым последователем для новинки: RX 6950 XT — просто лучшая из прошлого поколения, вот и всё.
Прямого соперника для новинки компании AMD нет, по цене рассматриваемая сегодня видеокарта расположилась между RTX 4080 и RTX 4070 Ti, но всё же заметно ближе к последней. Именно поэтому мы и взяли обе эти видеокарты в тесты, хотя старшая из них соперничает уже скорее с RX 7900 XTX (которую мы также скоро рассмотрим, к слову). А для некоторых тестов использовали еще и RTX 3090 Ti — чтобы понять, насколько хорошо новинка AMD справится с лучшим решением Nvidia из прошлого поколения.
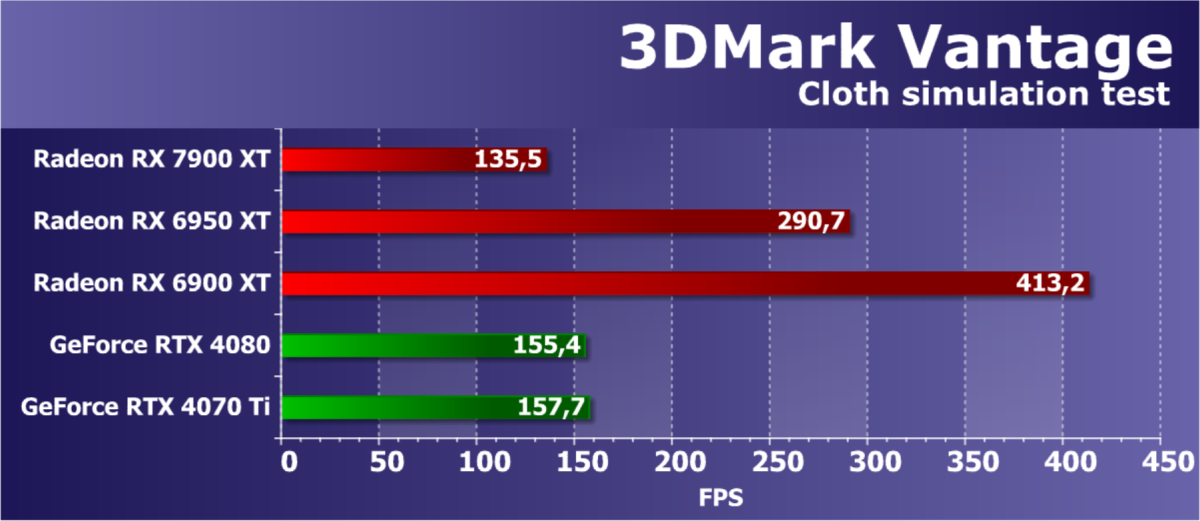
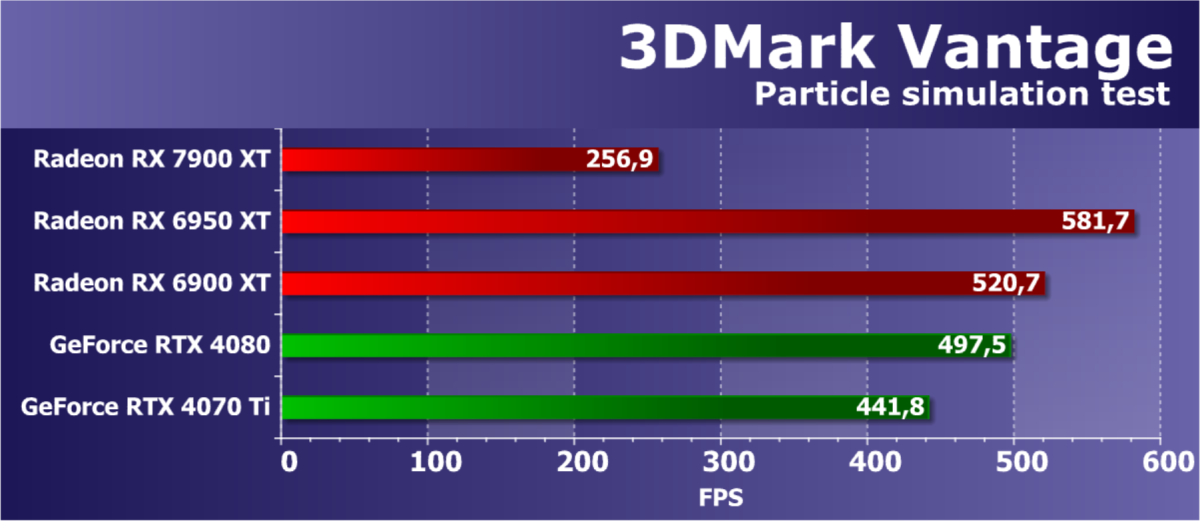
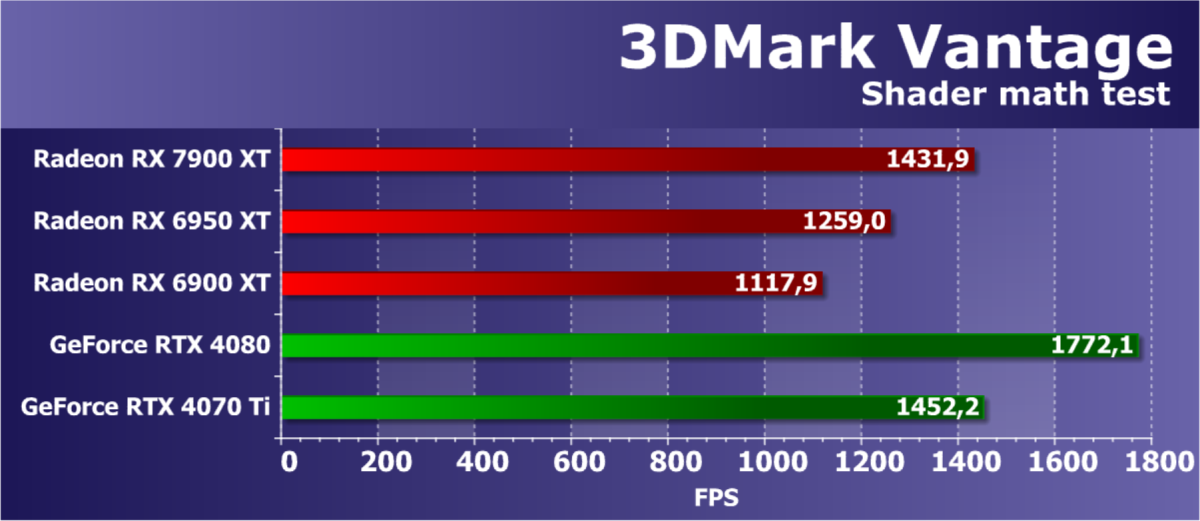
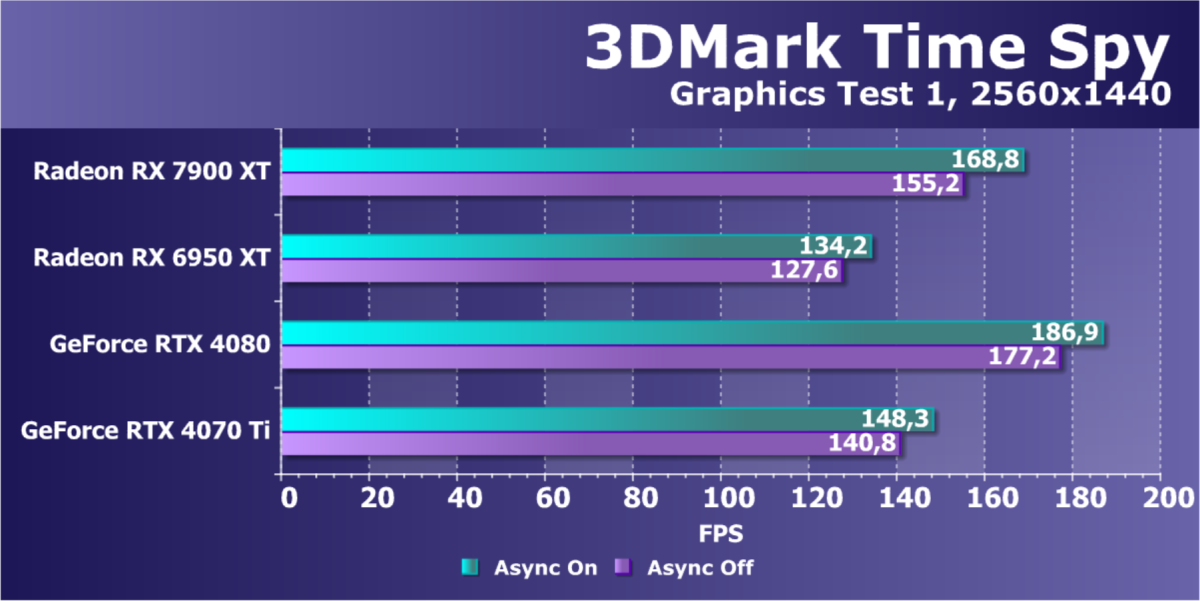
- Компьютер на базе процессора Intel Core i9-12900K (Socket LGA1700):
- Платформа:
- процессор Intel Core i9-12900K (разгон до 5,1 ГГц по всем ядрам);
- ЖСО Asus ROG Ryujin II 360;
- системная плата Asus ROG Maximus Z690 Extreme на чипсете Intel Z690;
- оперативная память Kingston Fury (KF552C40BBK2-32) 32 ГБ (2×16) DDR5 4800 МГц (XMP 5200 МГц);
- SSD Intel 760p NVMe 1 ТБ PCI-E;
- жесткий диск Seagate Barracuda 7200.14 3 ТБ SATA3;
- блок питания Gigabyte UD1000GM PG5 (1000 Вт);
- корпус Thermaltake Level20 XT;
- операционная система Windows 11 Pro 64-битная;
- телевизор LG 55Nano956 (55″ 8K HDR, HDMI 2.1);
- драйверы AMD версии 22.12.1;
- драйверы Nvidia версии 527.56/527.62;
- VSync отключен.
- Платформа:
Во всех игровых тестах использовалось максимальное качество графики в настройках.
- Marvel’s Spider-Man Miles Morales (Insomniac Games/Sony Interactive)
- Cyberpunk 2077 (Софтклаб/CD Projekt RED), патч 1.4 (версия 1.5 еще не тестировалась)
- God of War (Sony IE/Sony IE)
- Call of Duty: Modern Warfare II (Infinity Ward/Activision)
- Marvel’s Guardians of the Galaxy (Eldos/Square Enix)
- The Medium (Bloober/Bloober)
- A Plague Tale: Requiem (Asobo Studio/Focus Entertainment)
- Resident Evil Village (Capcom/Capcom)
- Far Cry 6 (Ubisoft/Ubisoft)
- Battlefield 2042 (DICE/EA)
Перед демонстрацией детальных тестов мы приводим краткие сведения о производительности семейства, к которому относится конкретный исследуемый ускоритель, а также его соперников. Всё это нами субъективно оценивается по шкале из пяти градаций.
Игры без использования трассировки лучей (классическая растеризация):
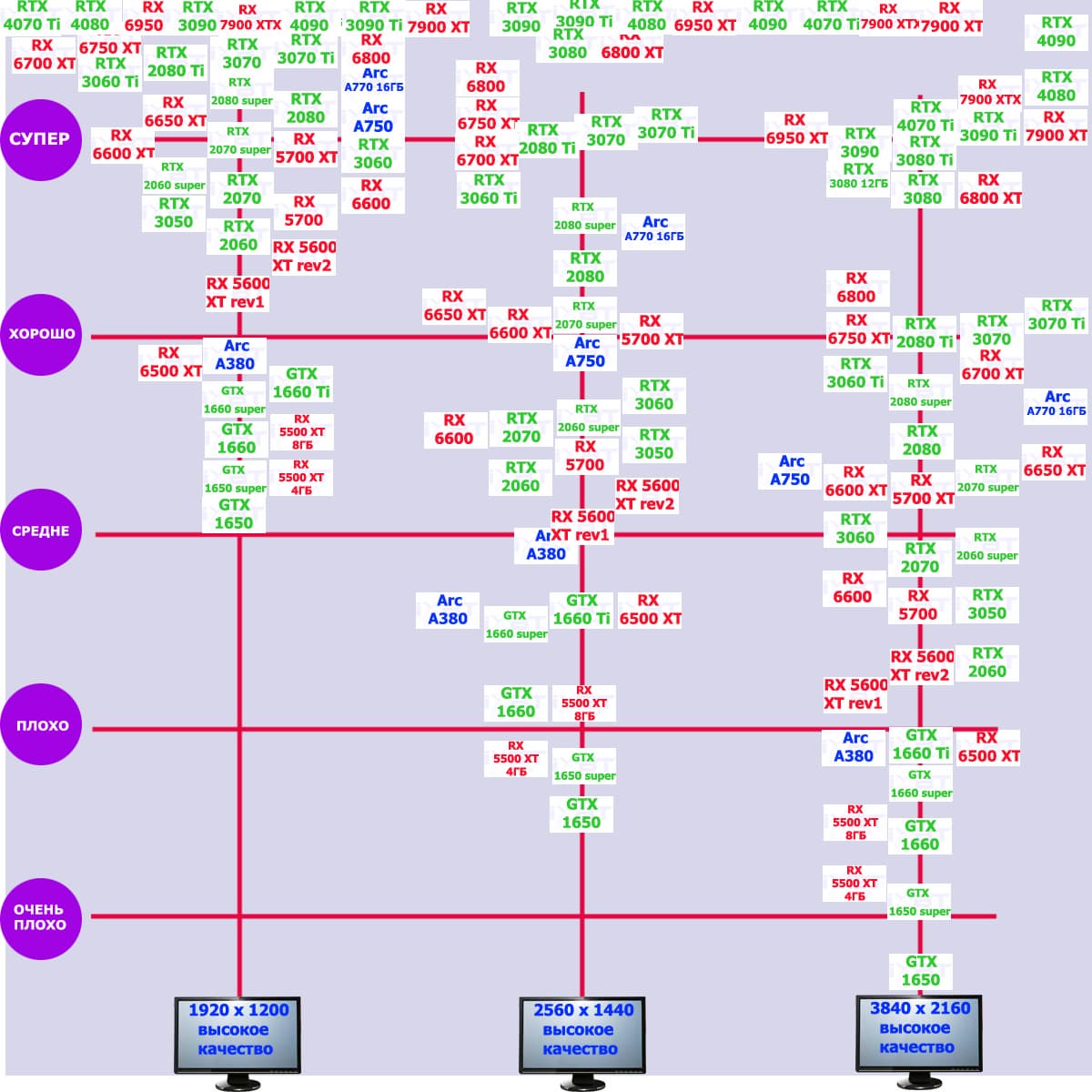
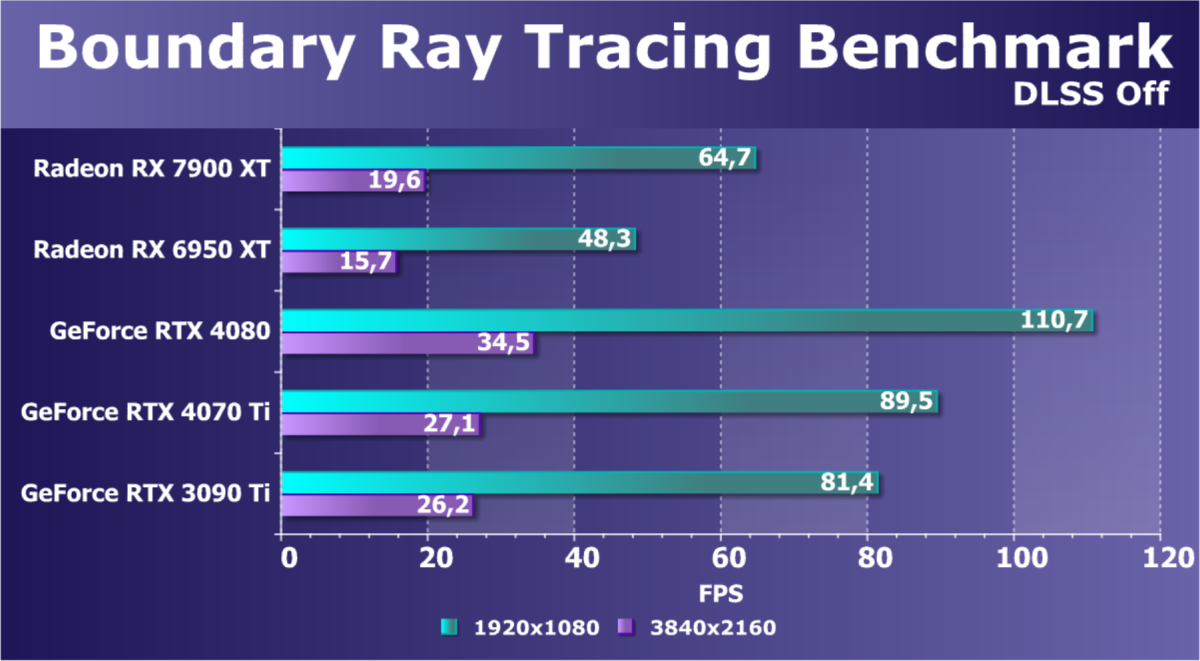
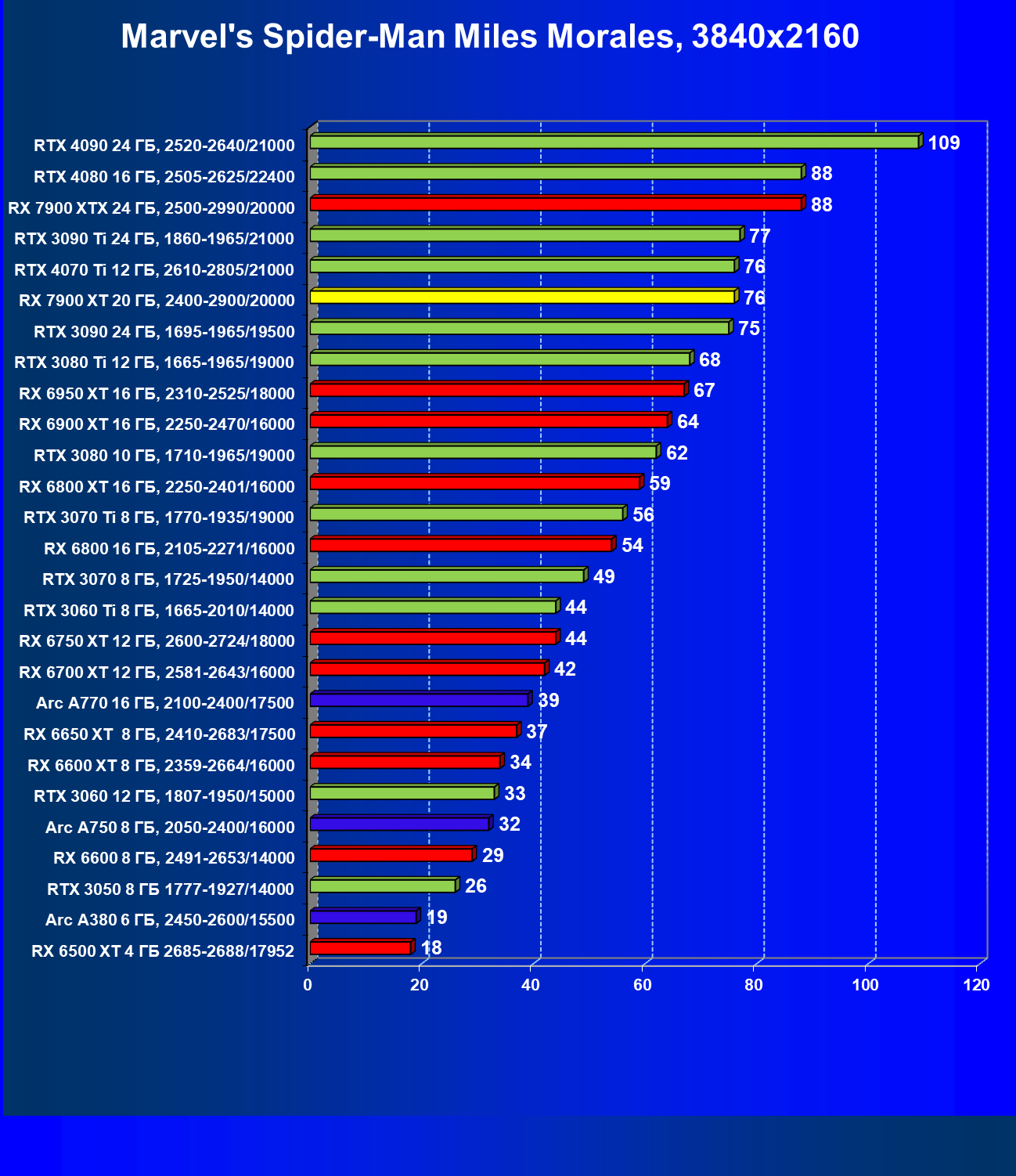
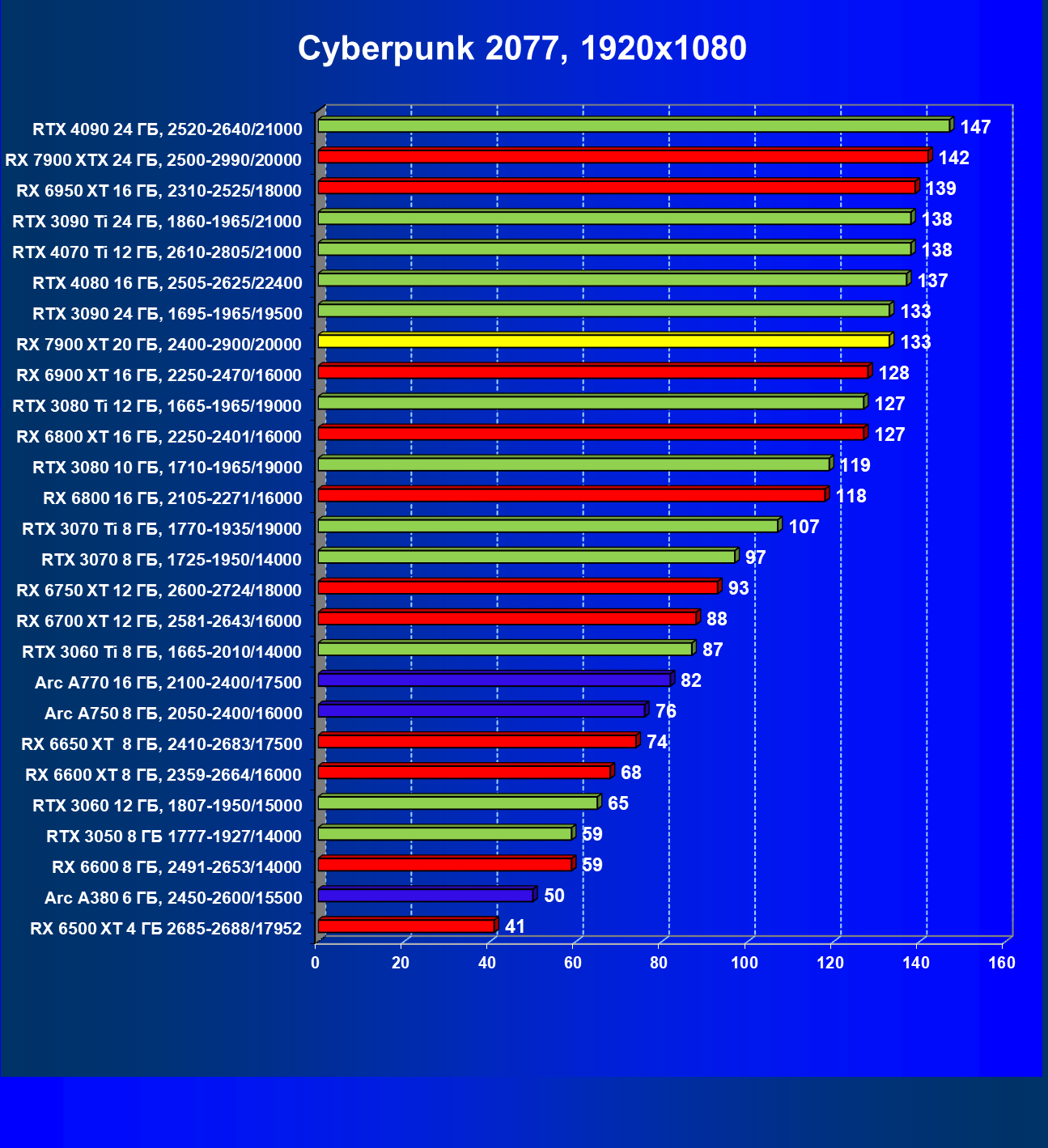
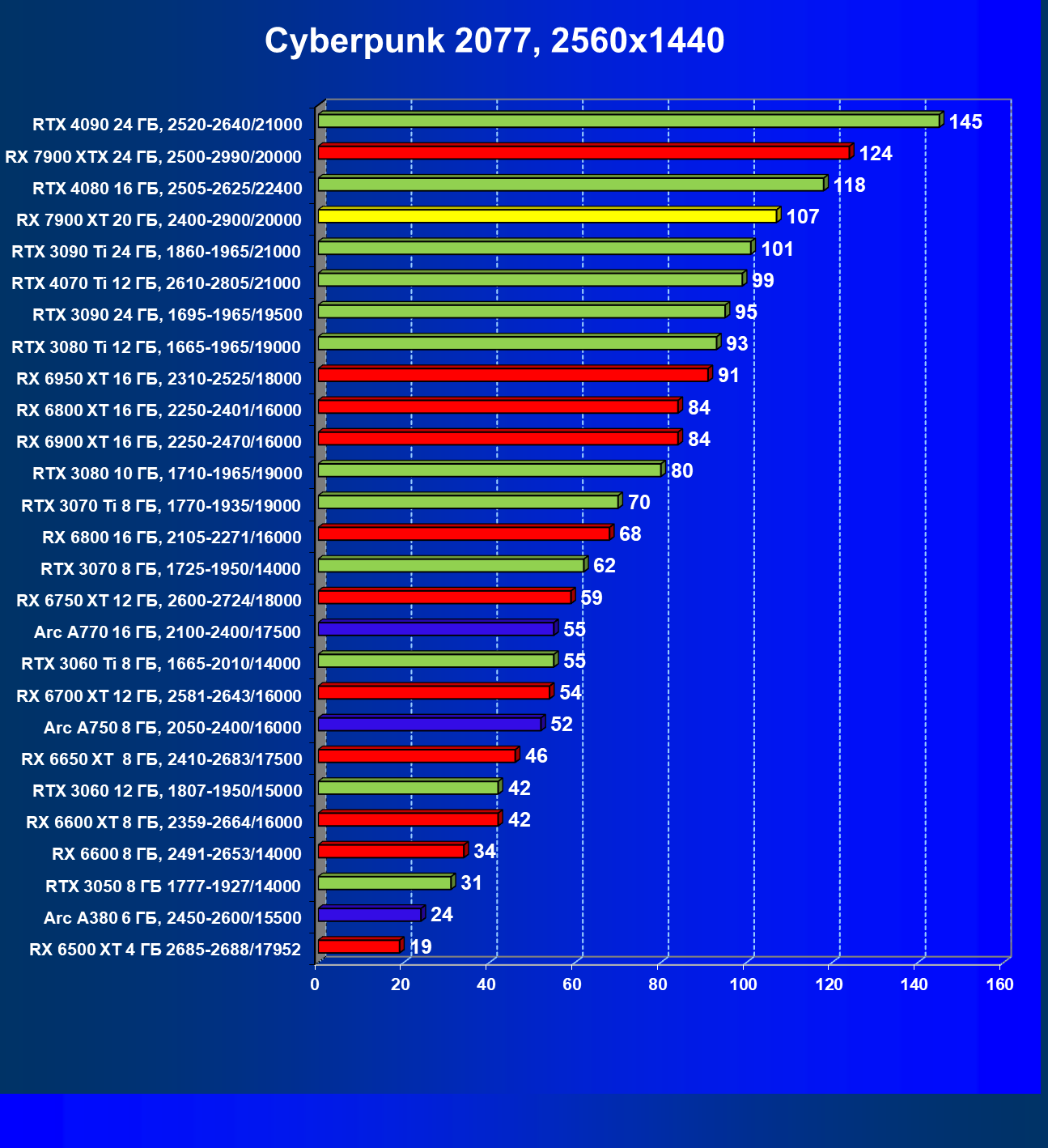
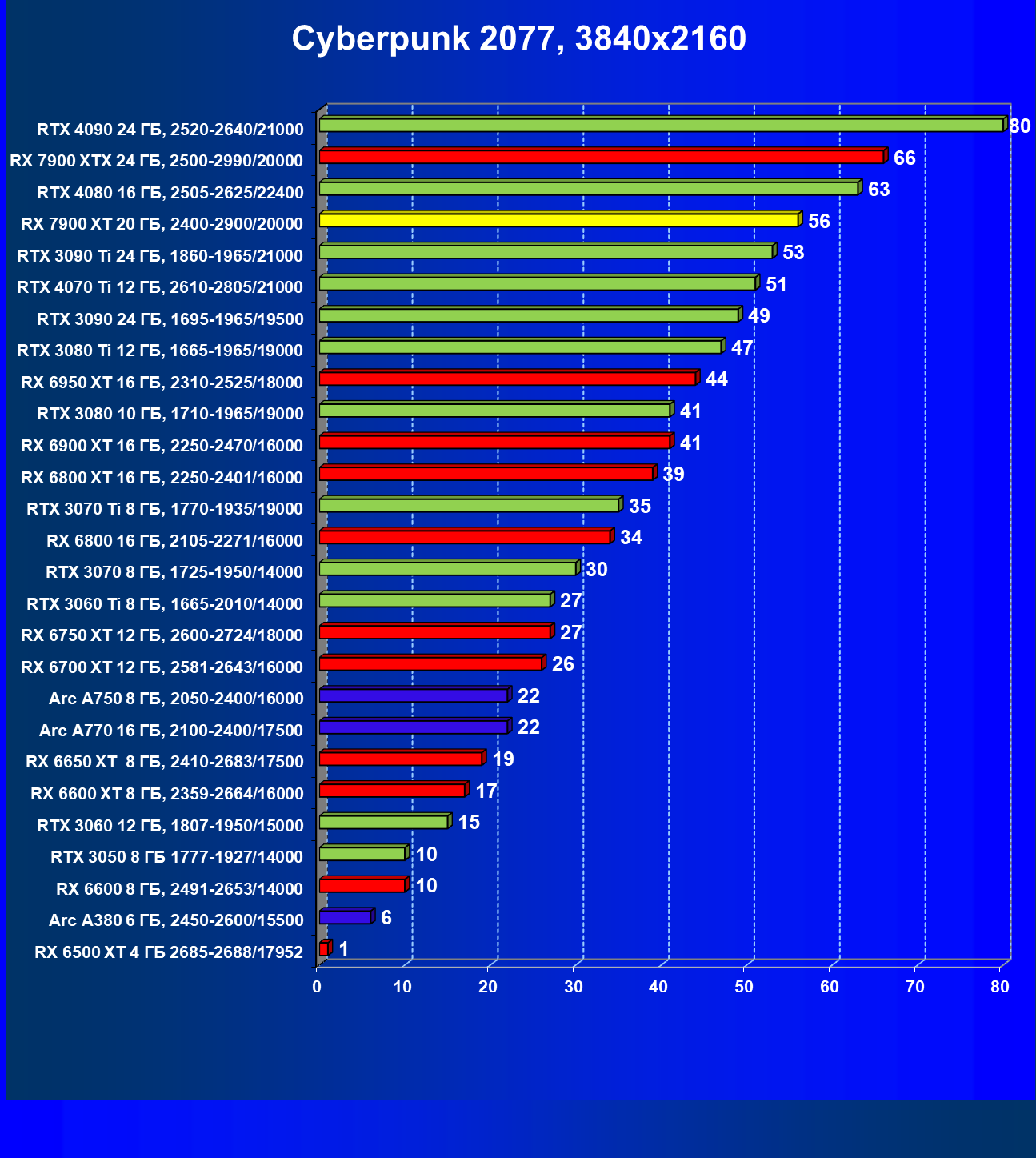
Здесь всё понятно: в разрешениях 1080p (Full HD) и 1440p (2.5K) новинка AMD выступает на уровне флагманов последних поколений и обеспечивает полный комфорт в играх с максимальными настройками графики. В 2160p (4K) Radeon RX 7900 XT близок по производительности к GeForce RTX 3090 Ti и GeForce RTX 4070 Ti.
Игры с использованием трассировки лучей и DLSS/FSR:
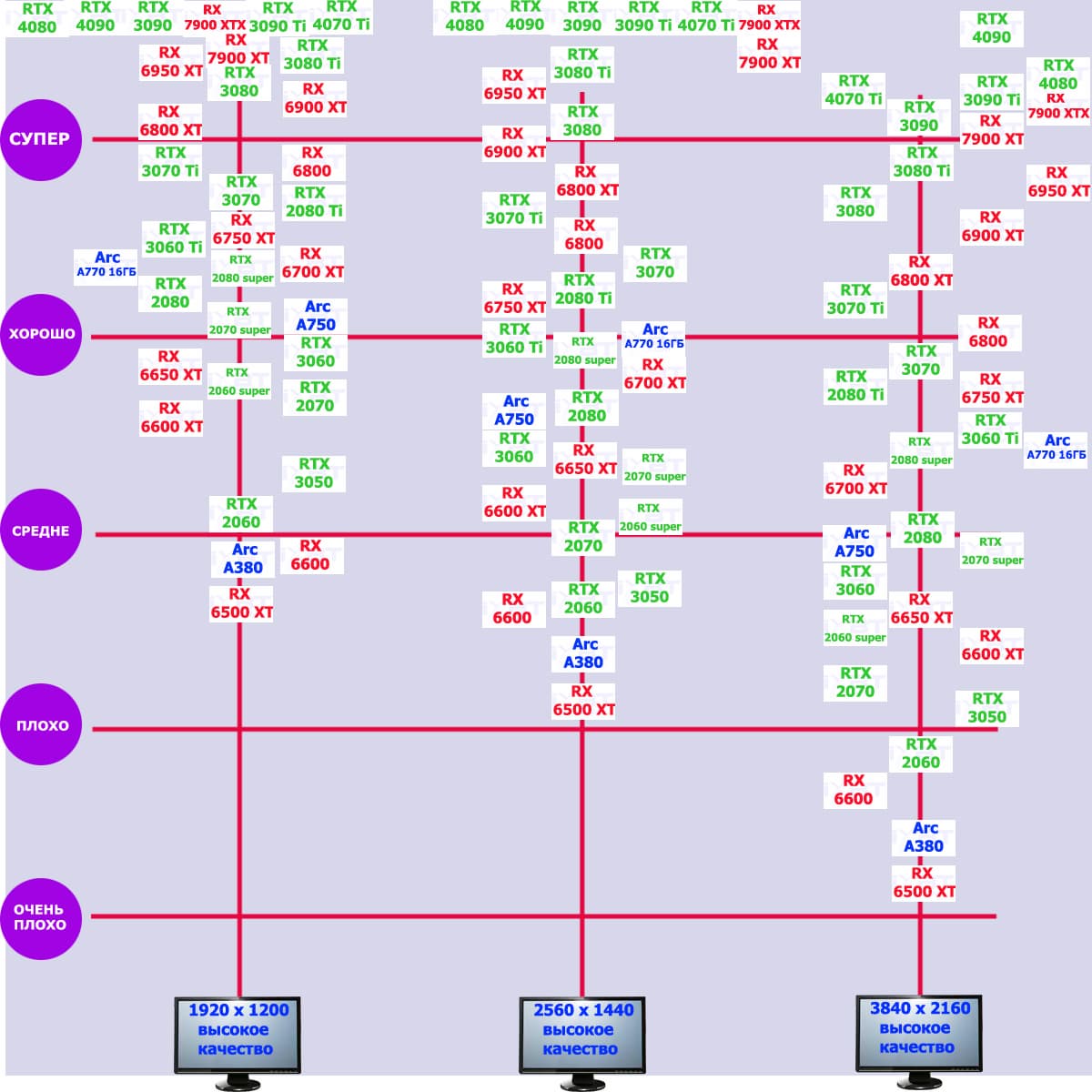
Технология трассировки лучей весьма затратна в плане производительности, однако если игра поддерживает еще и технологии Nvidia DLSS или AMD FSR, то падение FPS уже не столь значительное, подчас оно даже компенсируется указанными технологиями рендеринга в сниженном разрешении.
И если раньше семейству Radeon RX 6000 даже поддержка FSR не сильно помогала поднять производительность при включении RT, то у Radeon RX 7000 в этом плане всё намного лучше. Да, пока падение FPS всё же более сильное, чем у Nvidia GeForce RTX, однако Radeon RX 7900 XT даже в 4K может выдавать очень хорошие показатели производительности при использовании трассировки лучей и FSR.
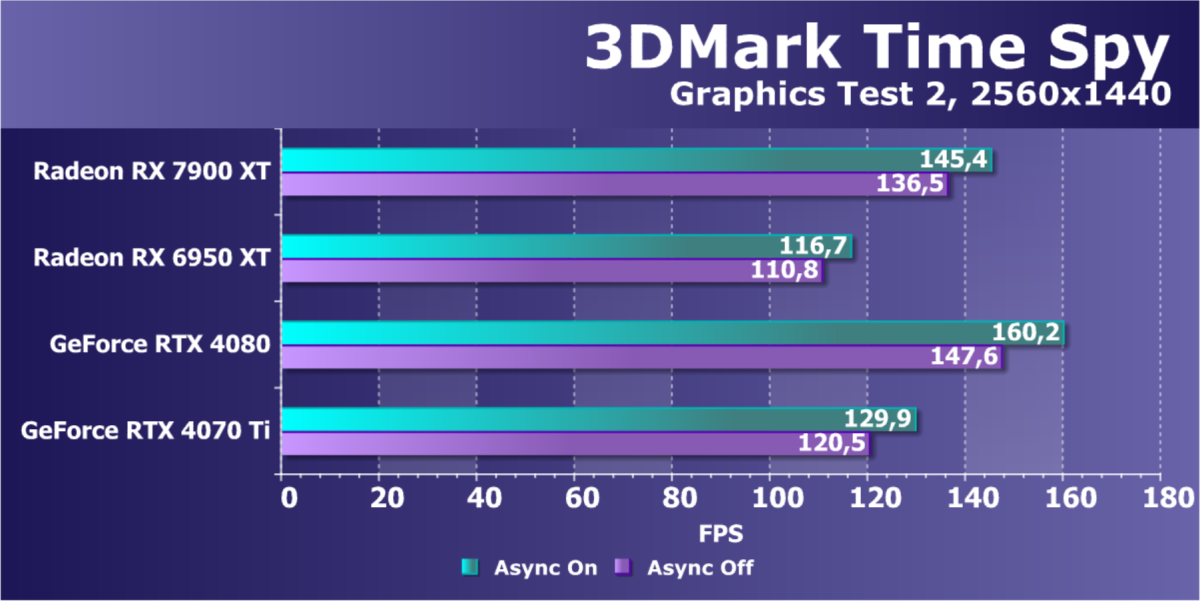
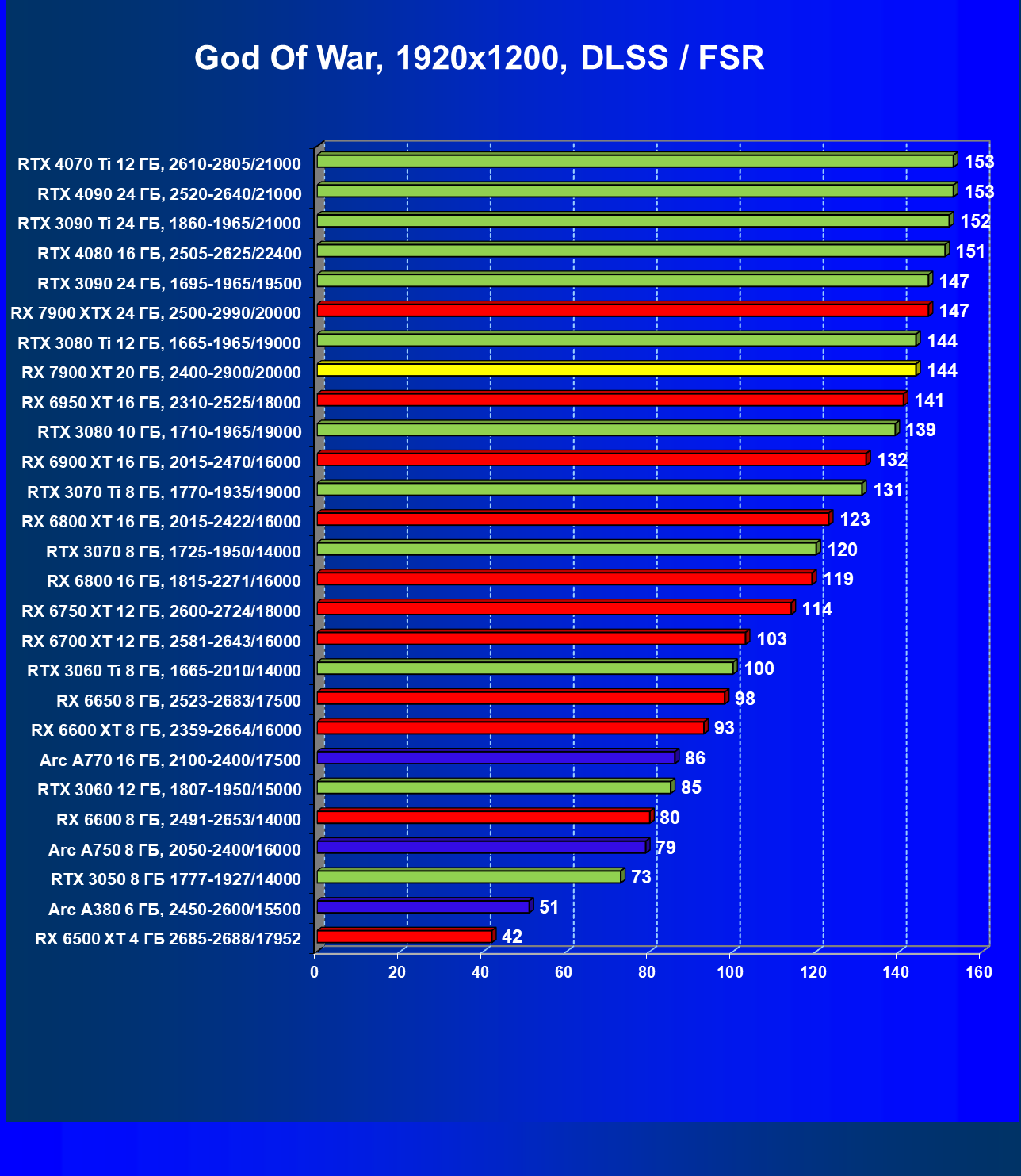
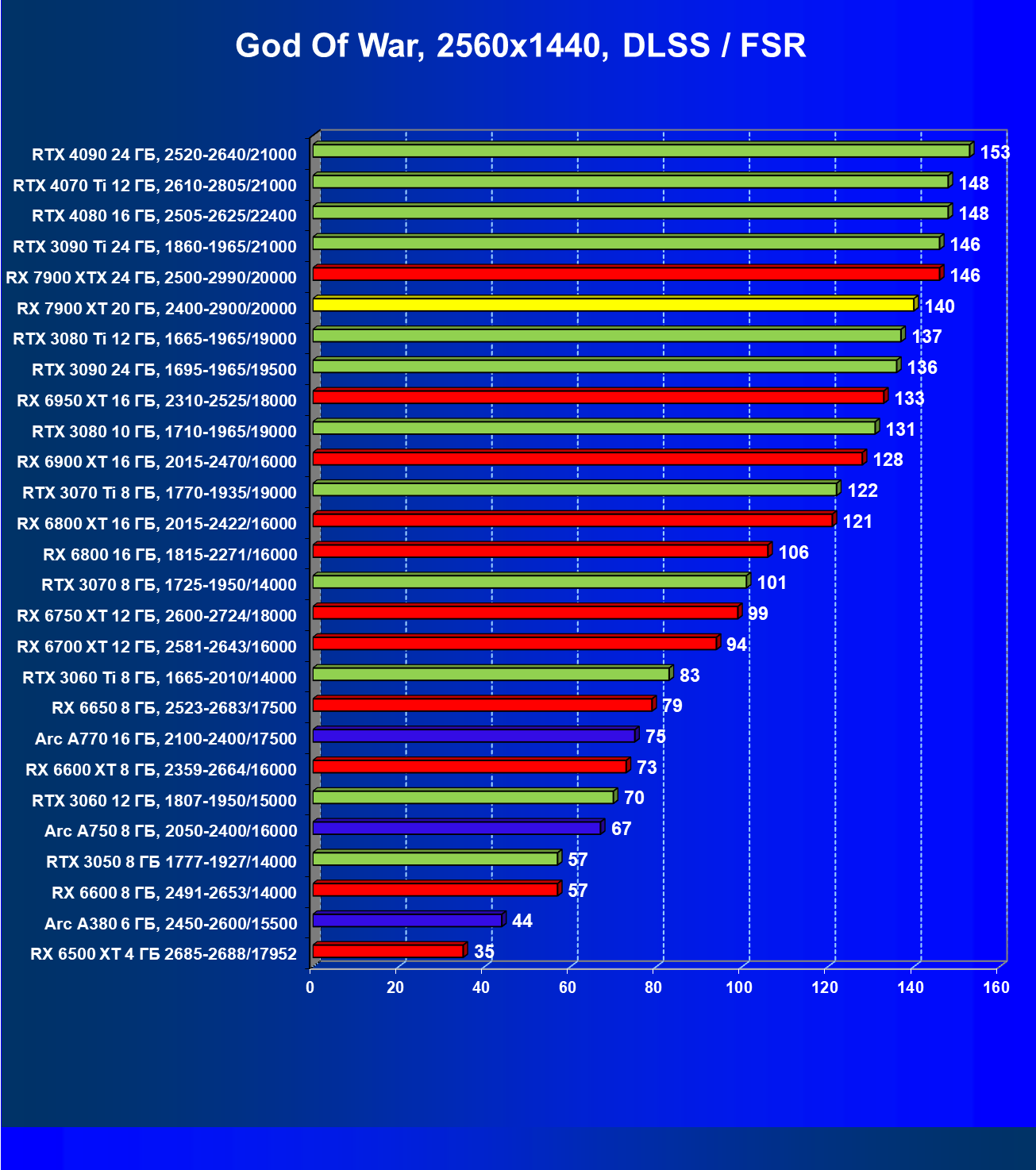
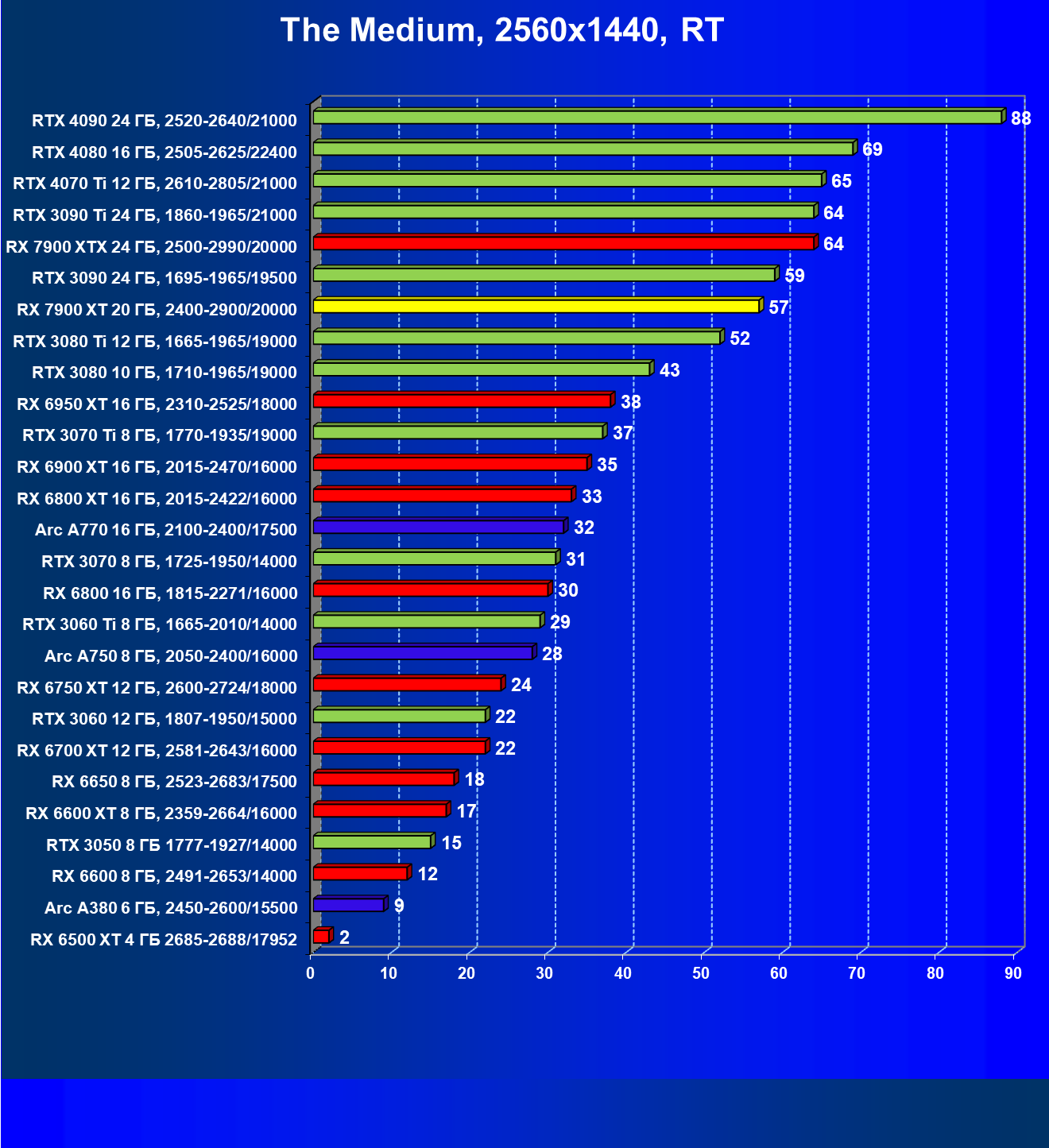
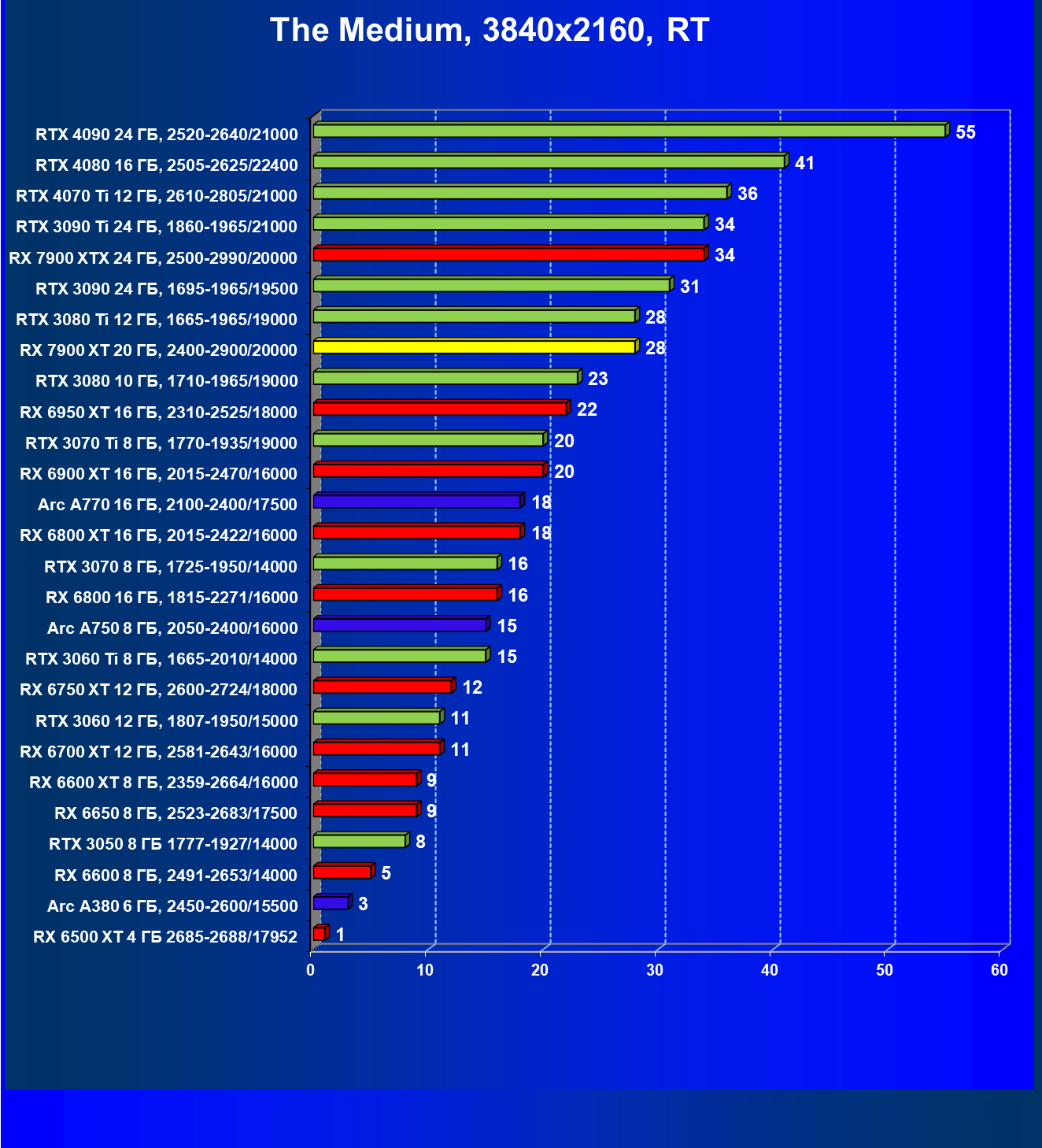
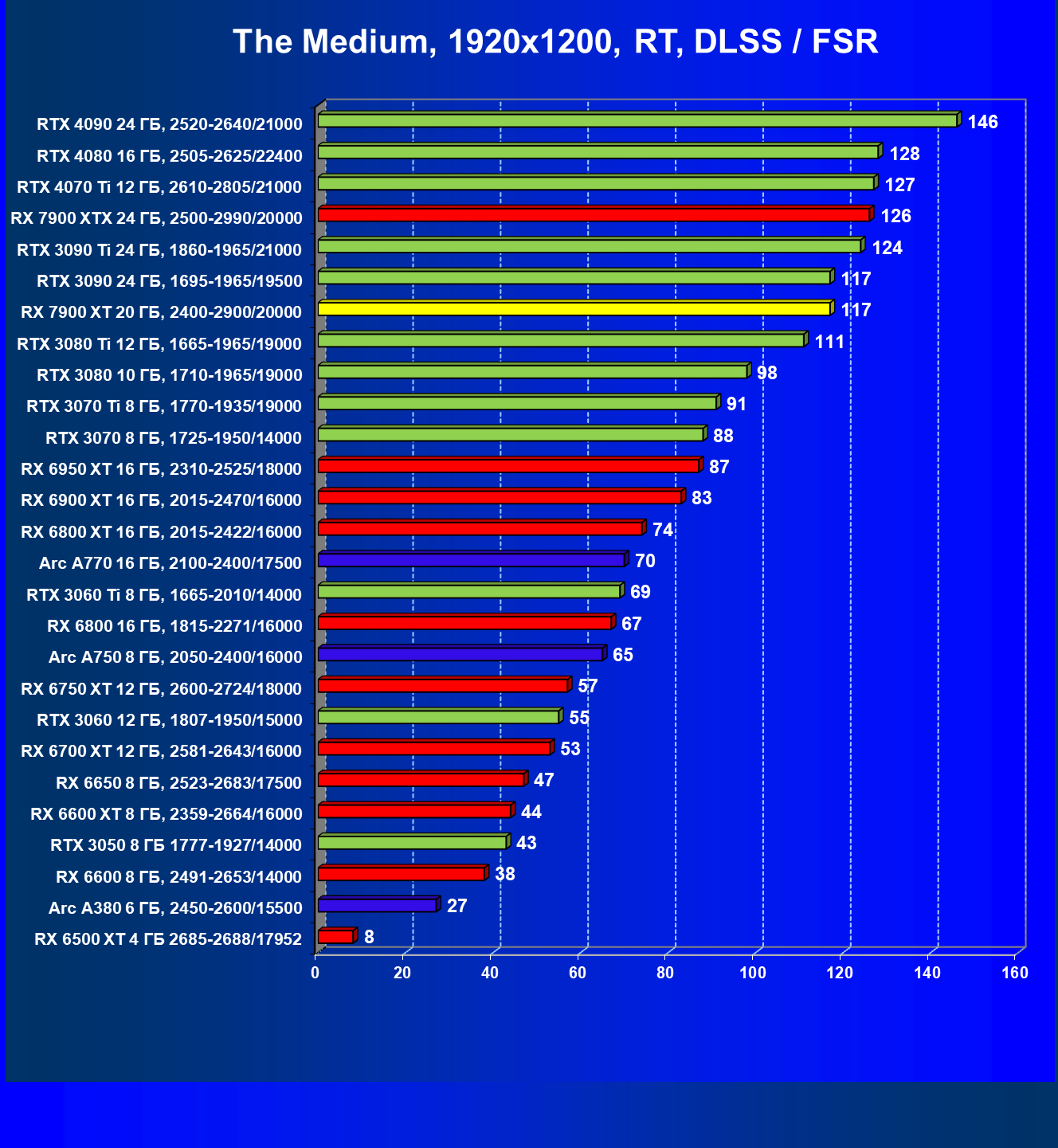
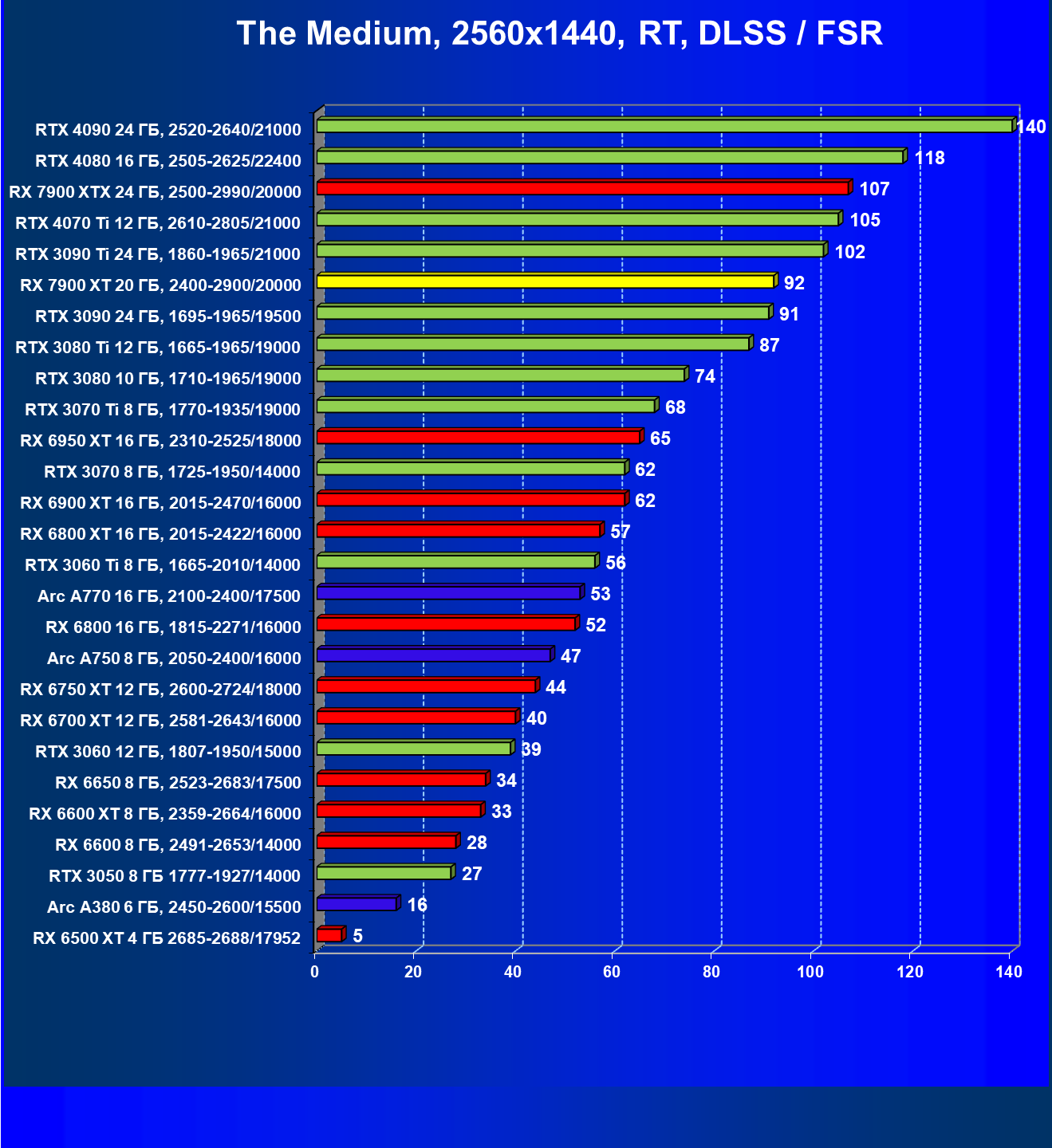
Стандартные результаты тестов без использования аппаратной трассировки лучей в разрешениях 1920×1200, 2560×1440 и 3840×2160
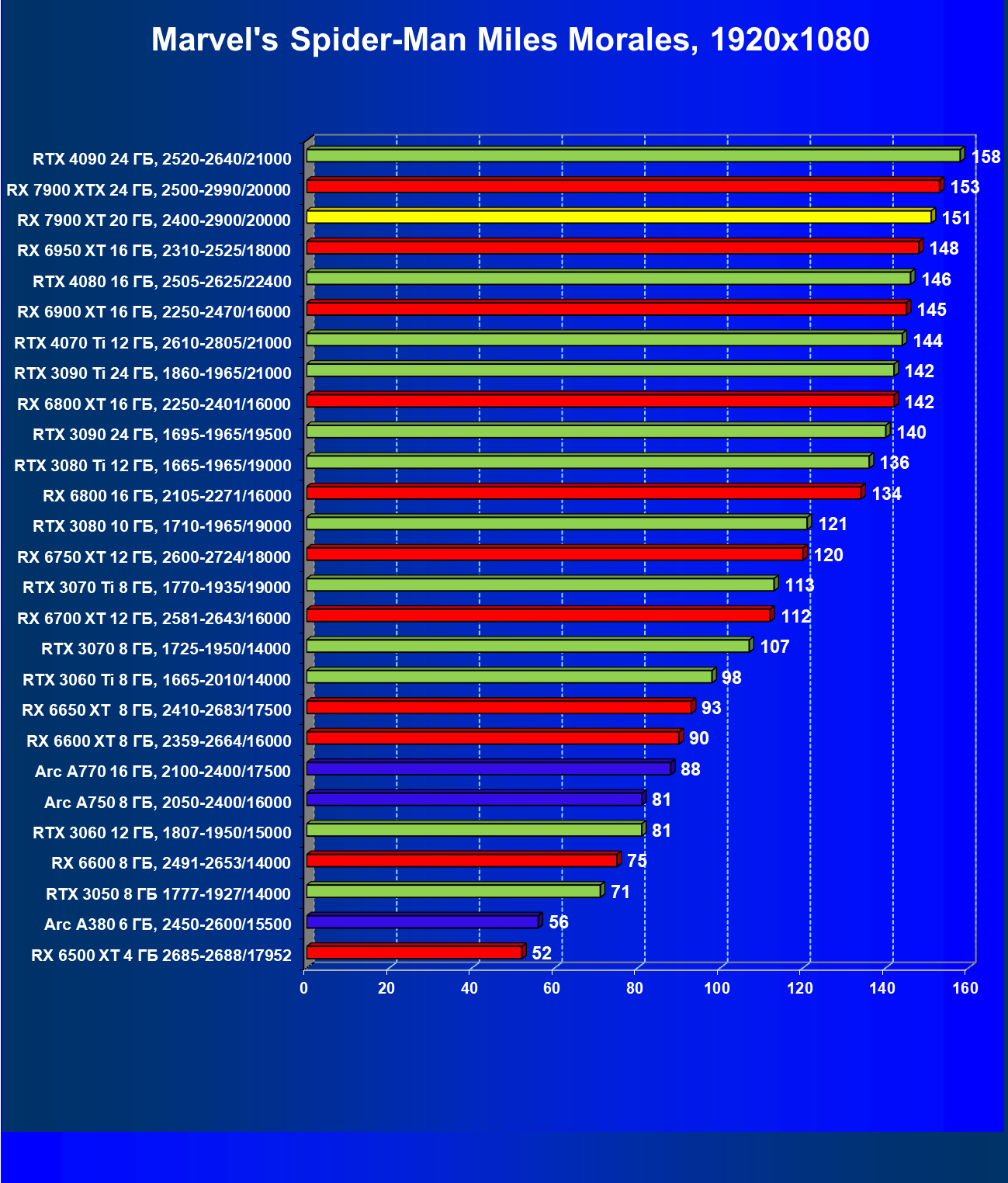
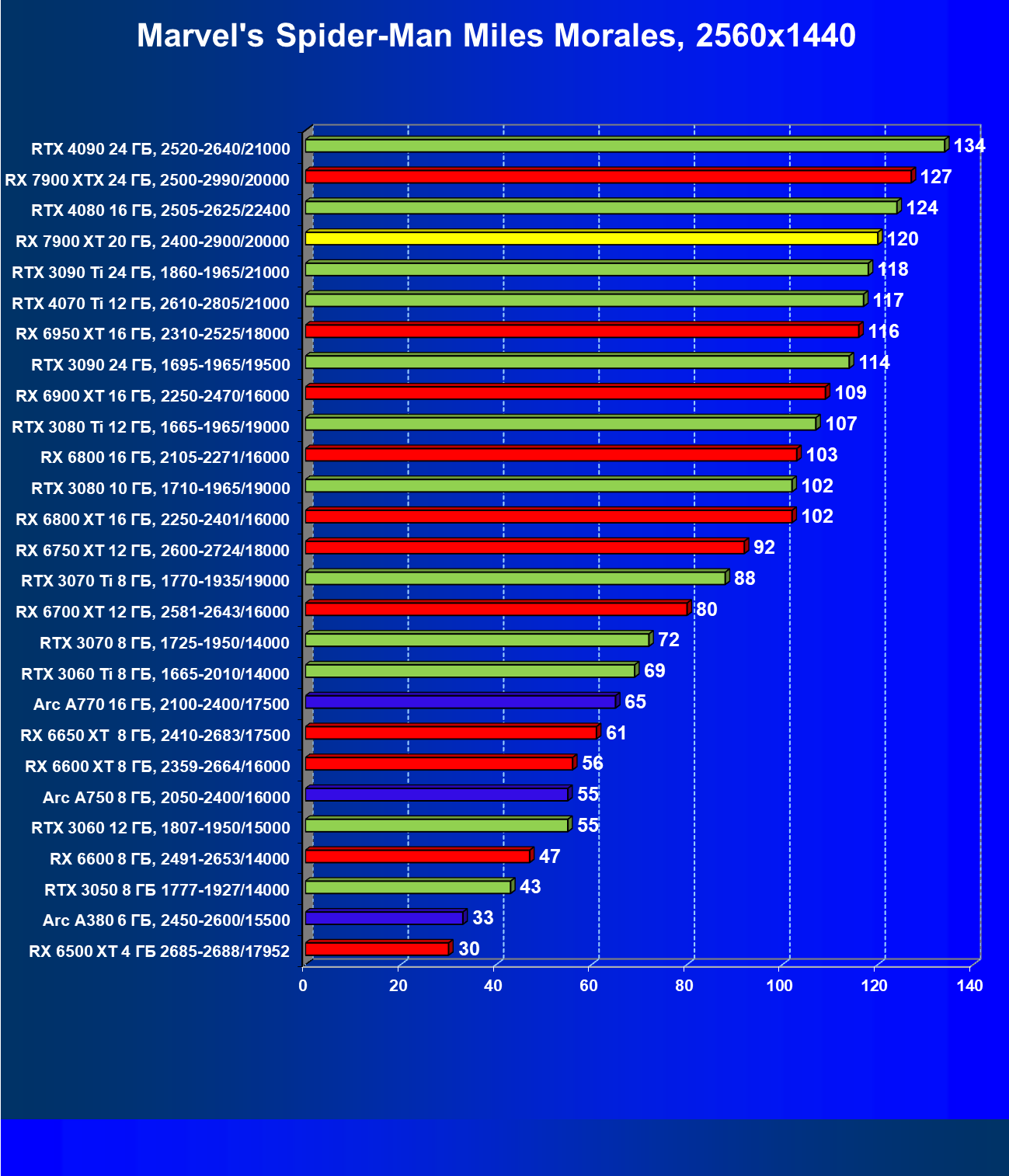
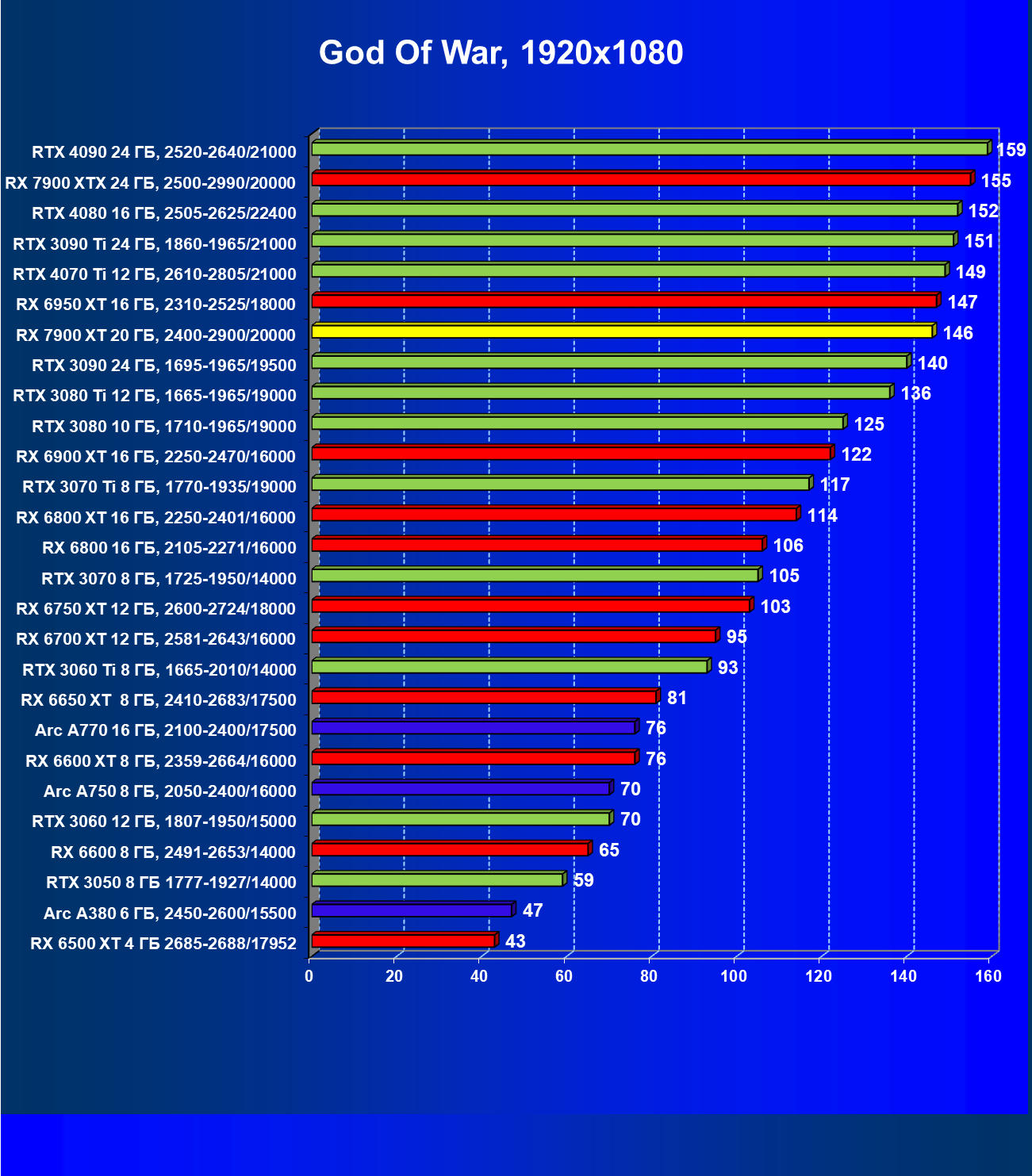
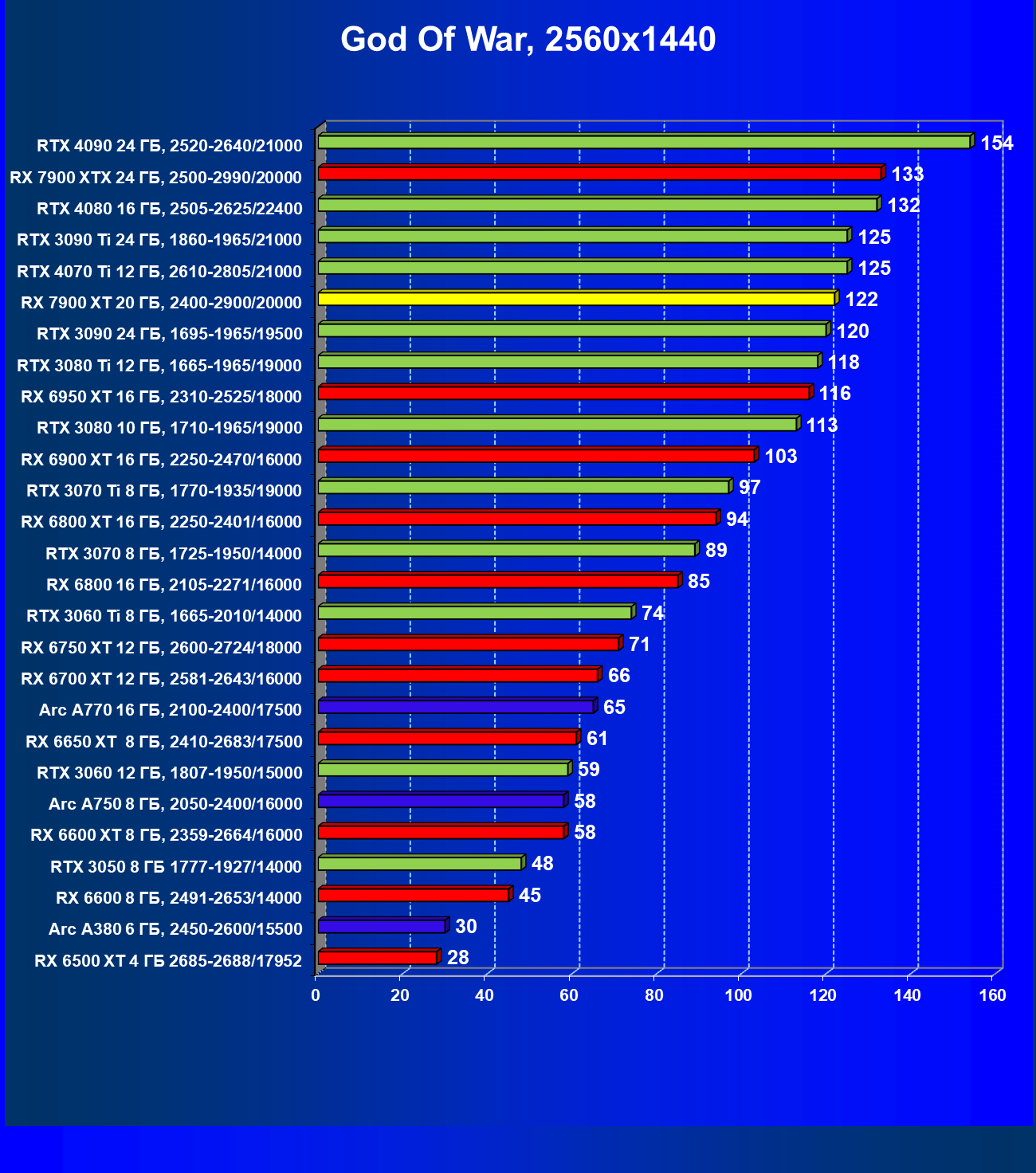
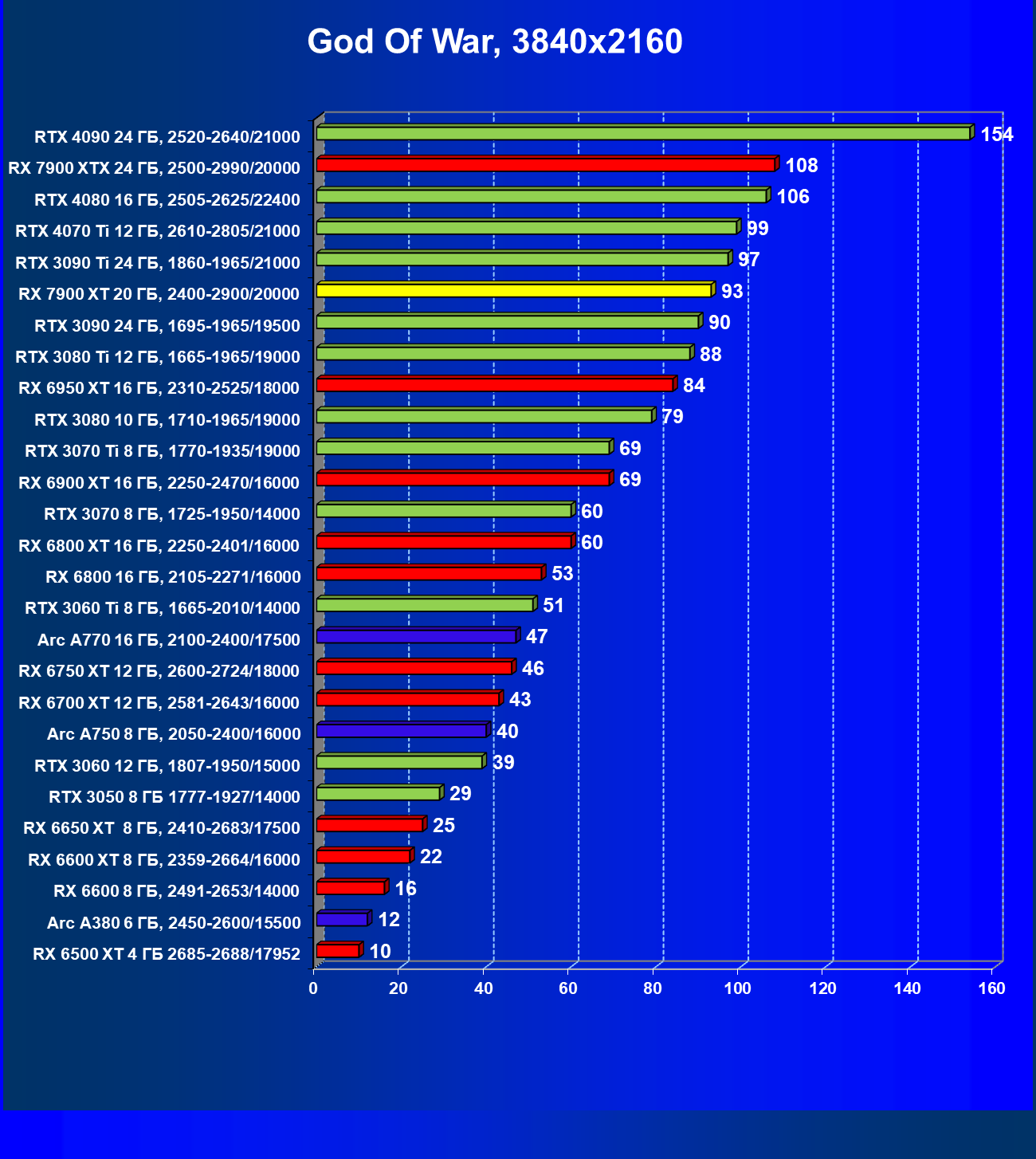
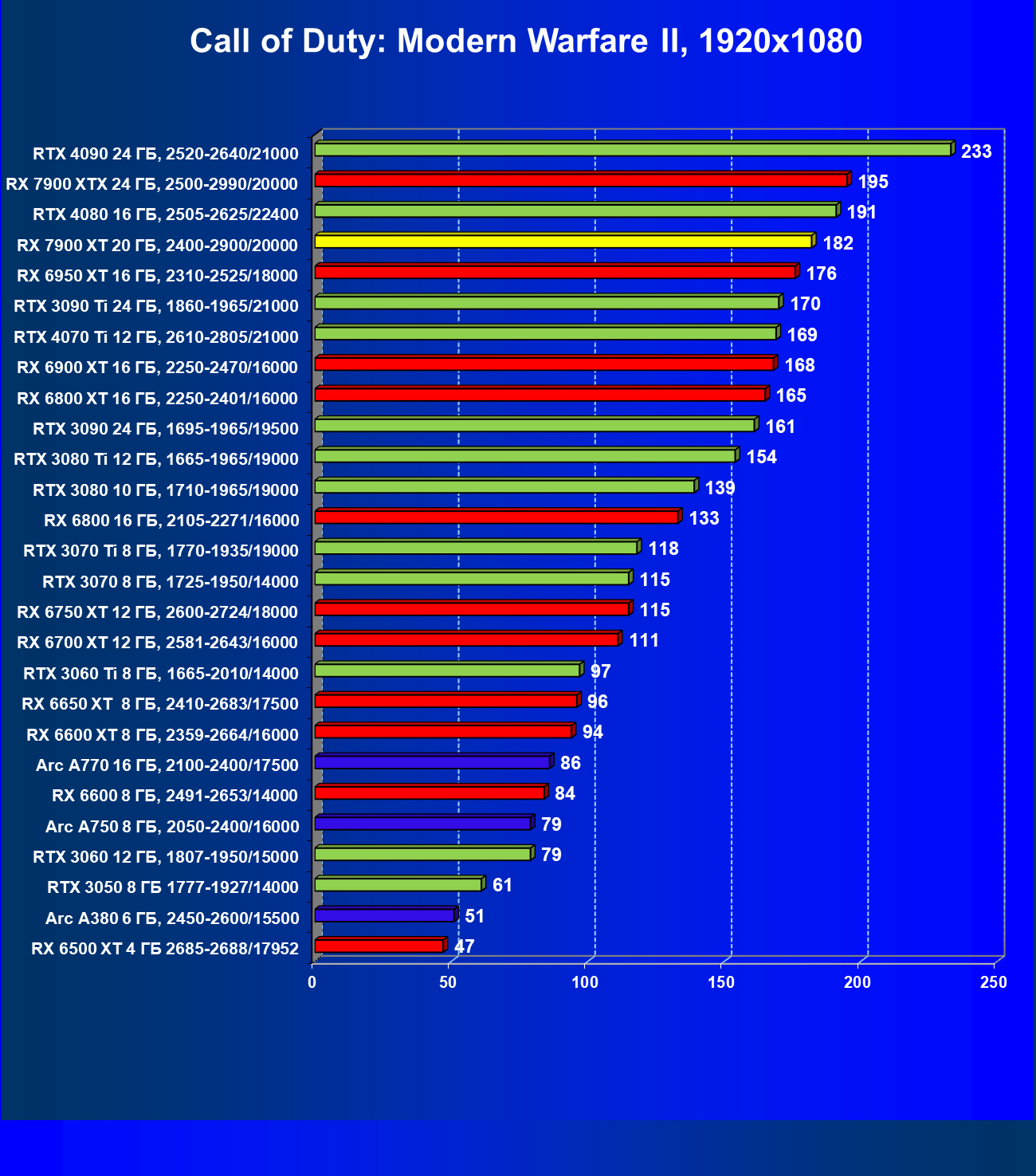
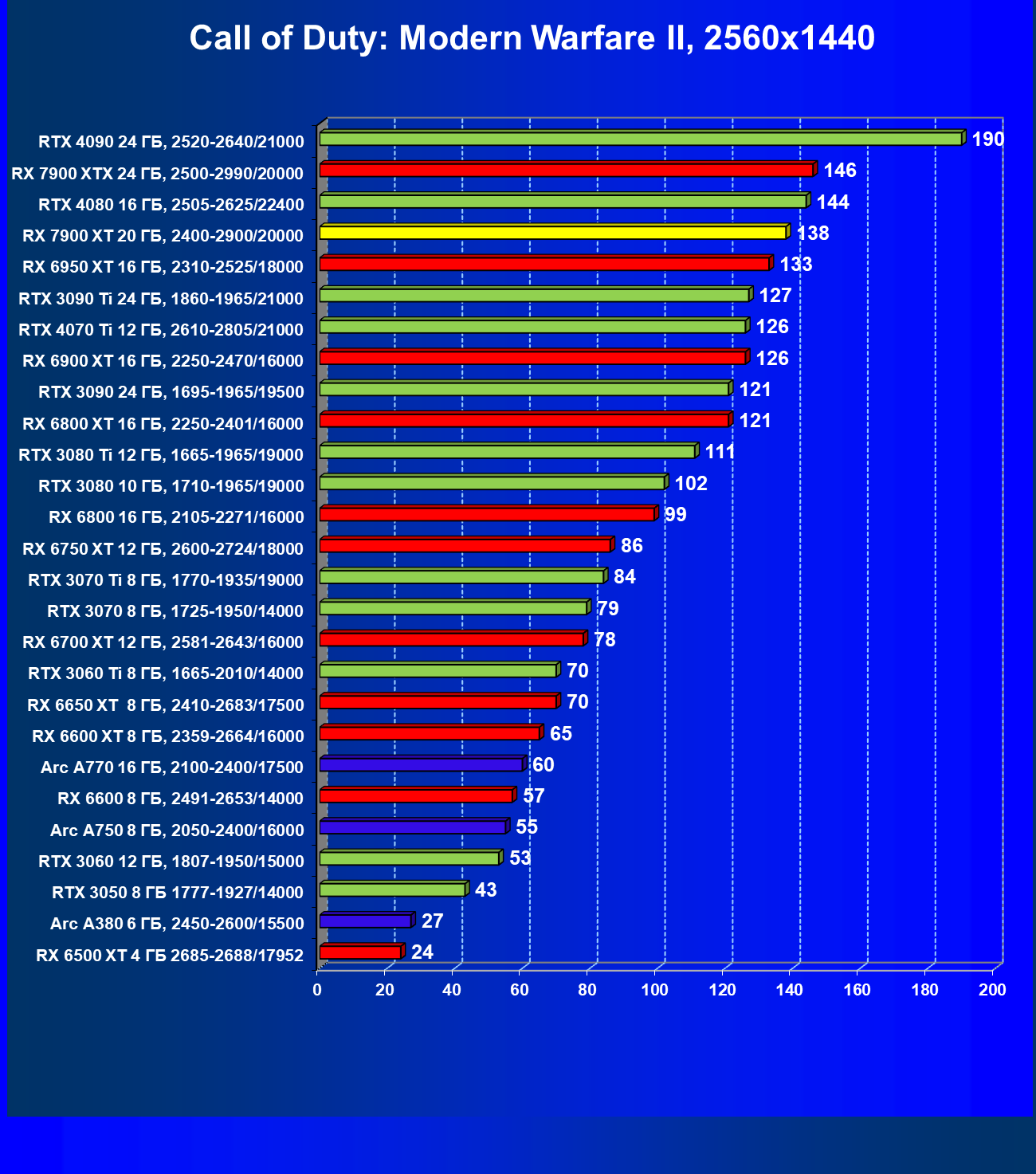
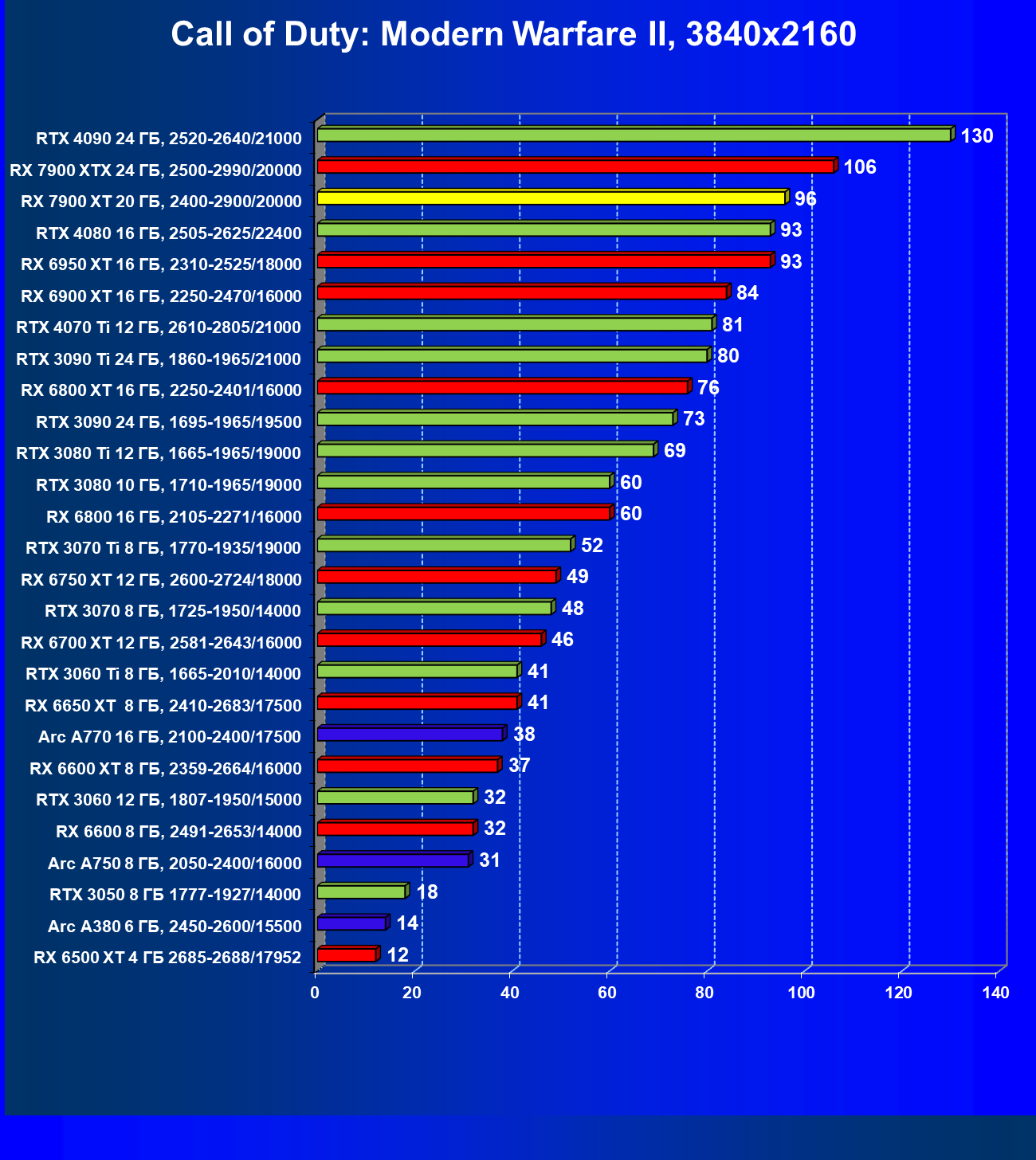
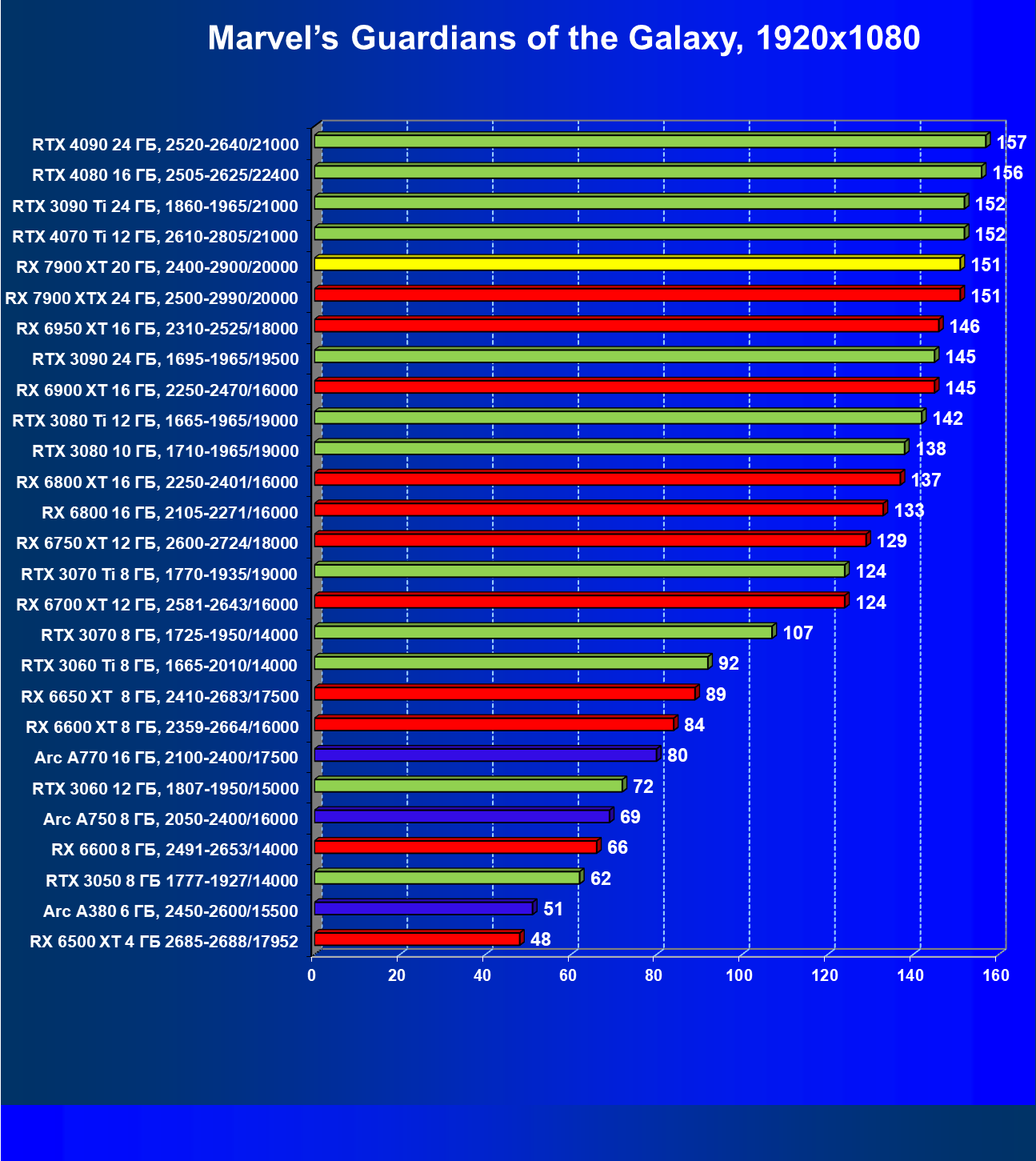
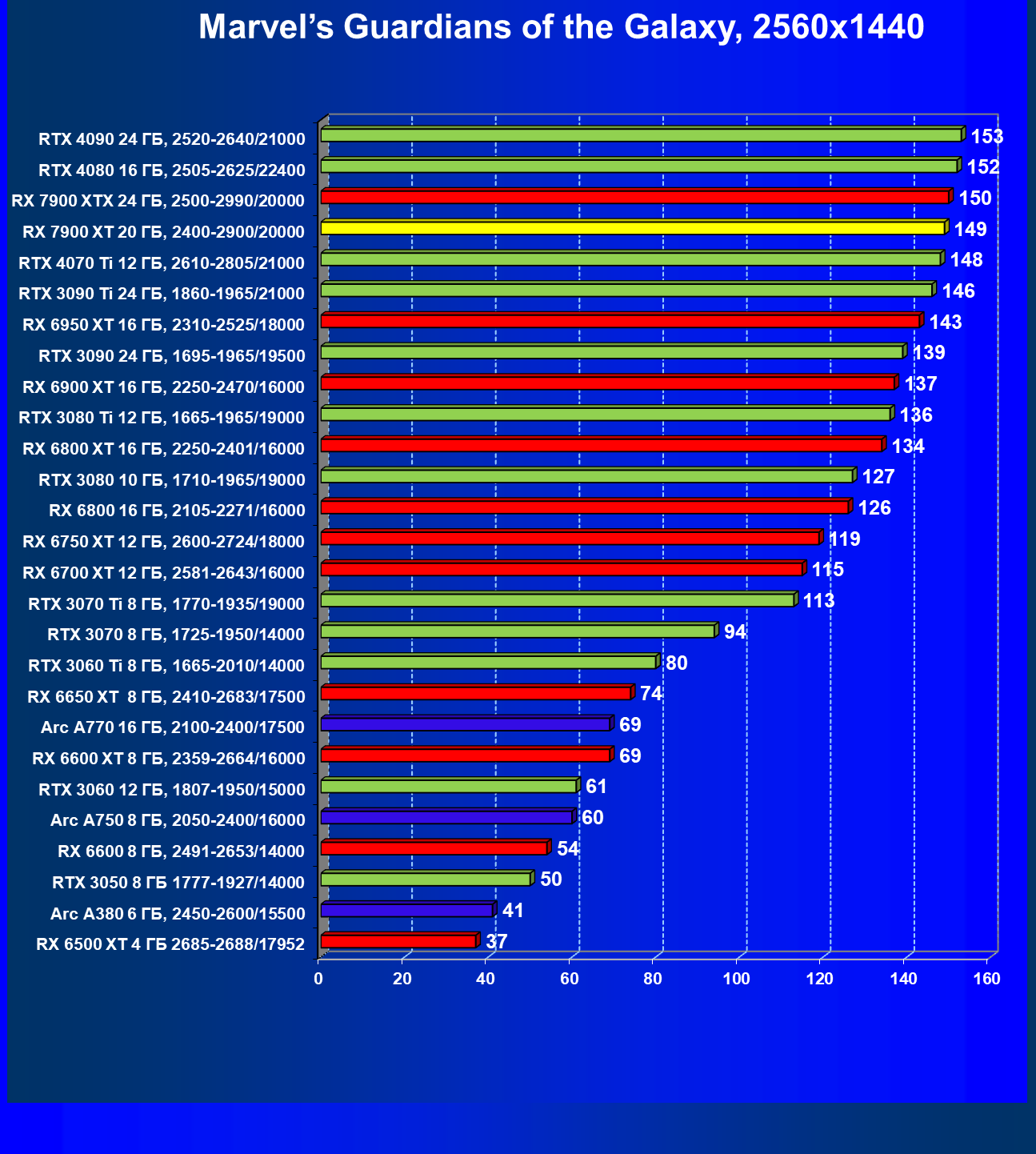
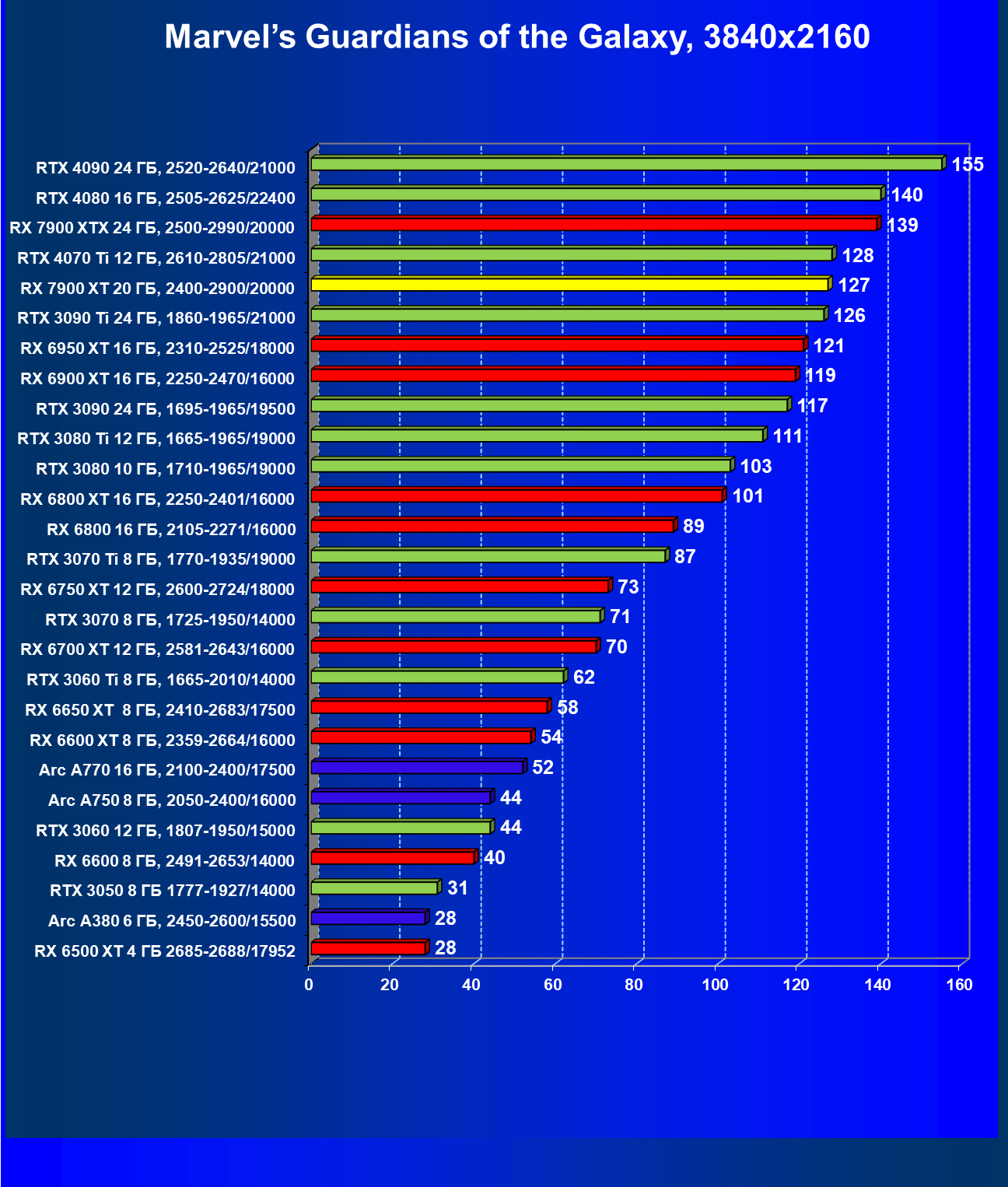
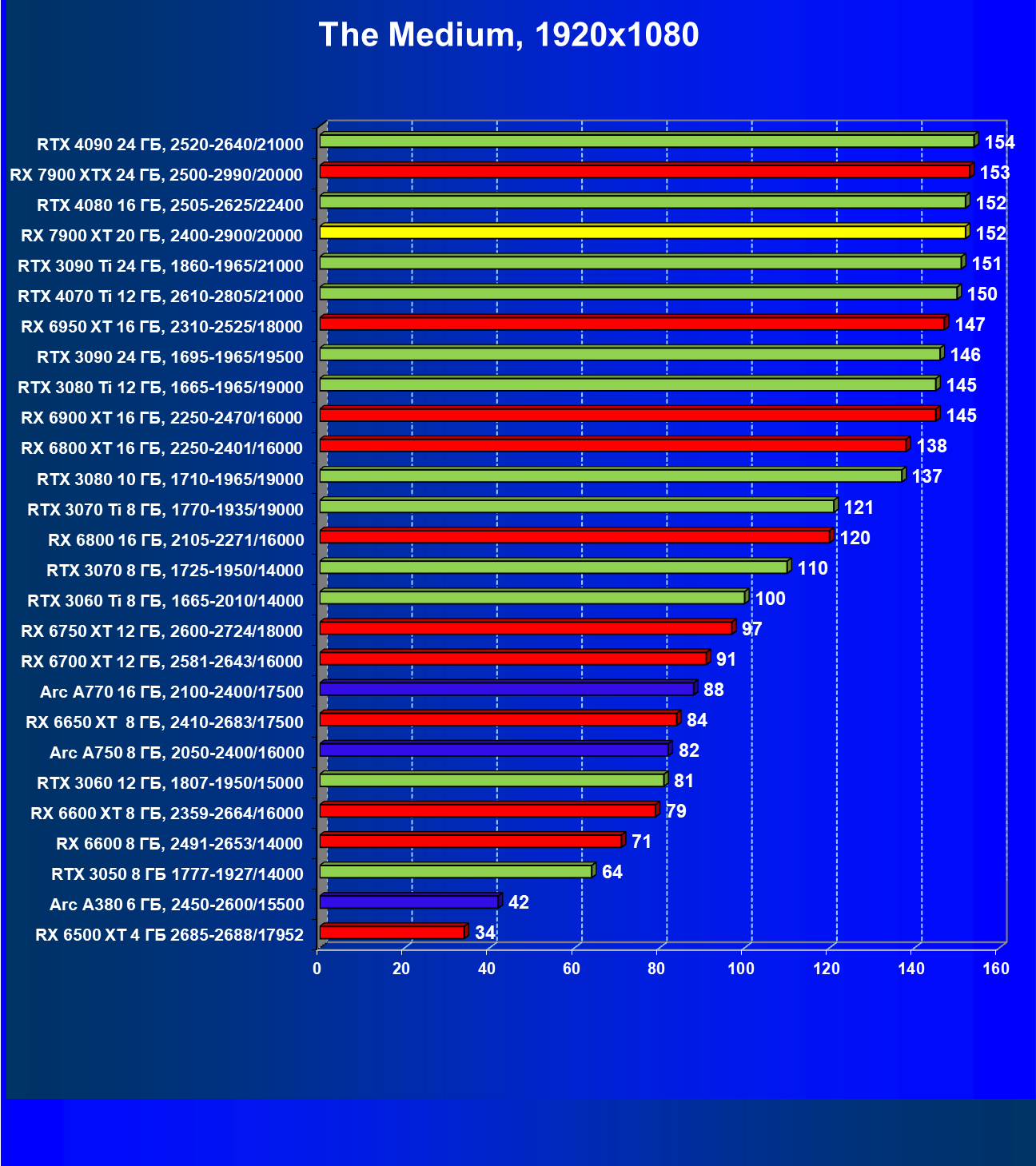
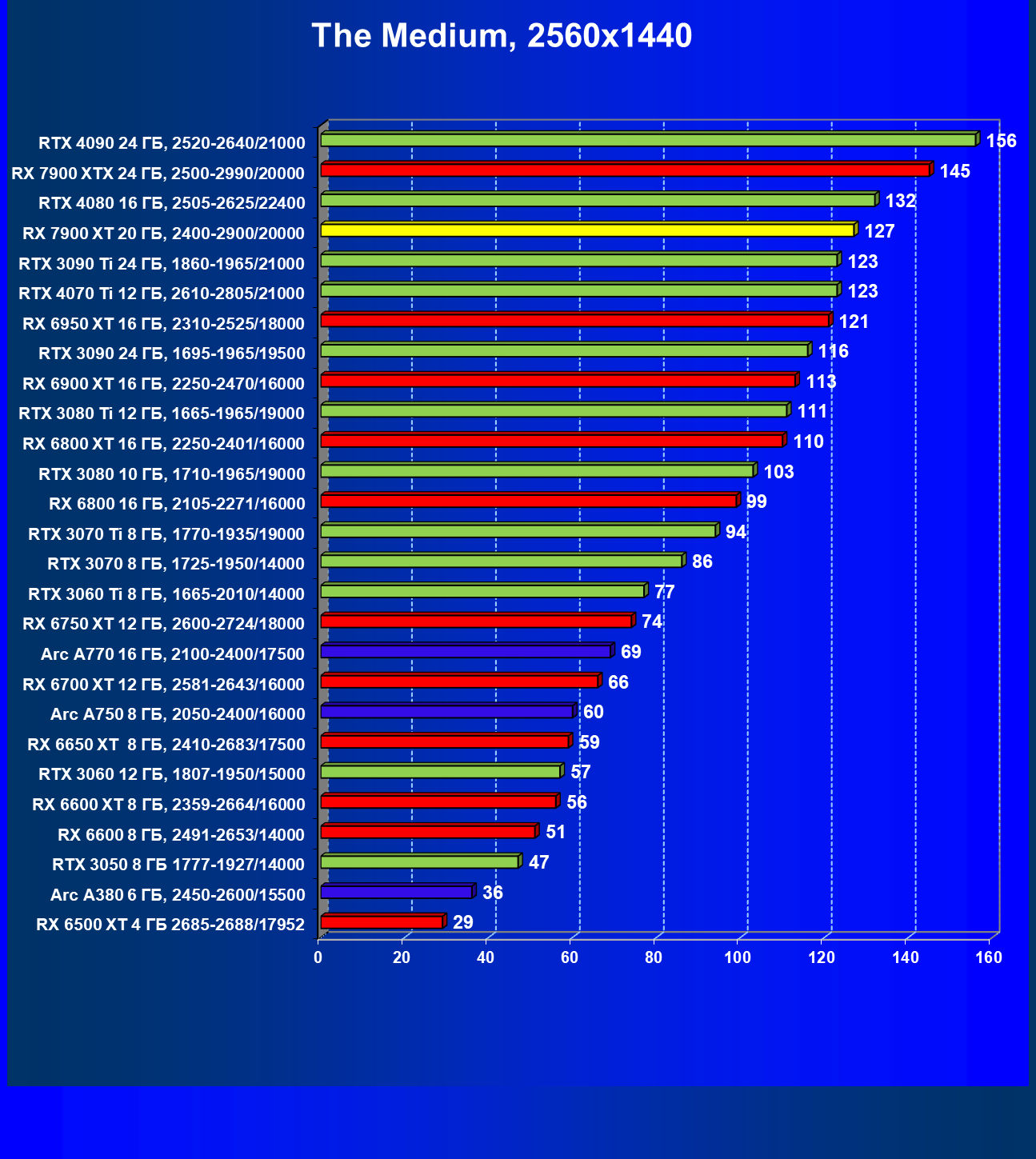
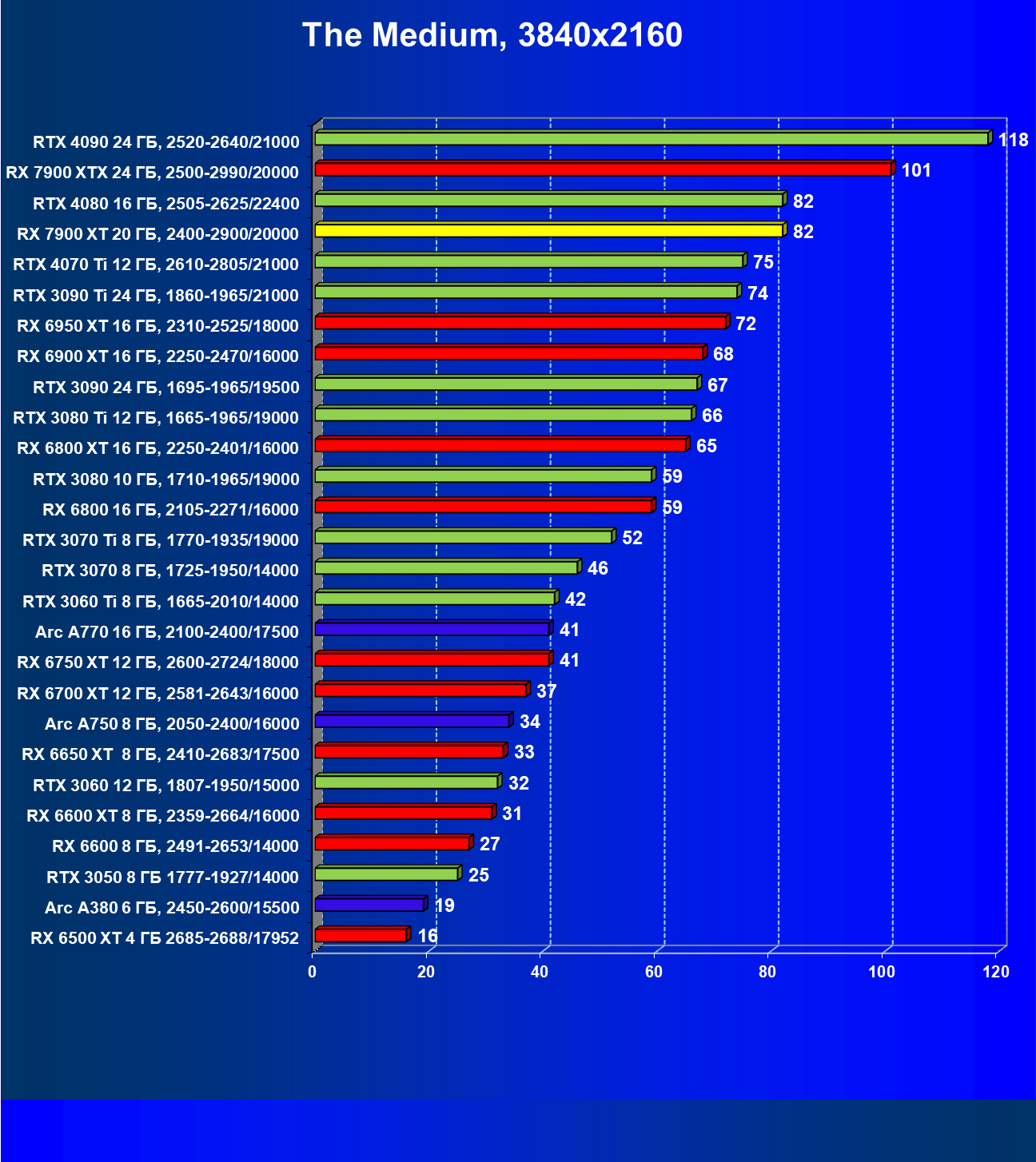
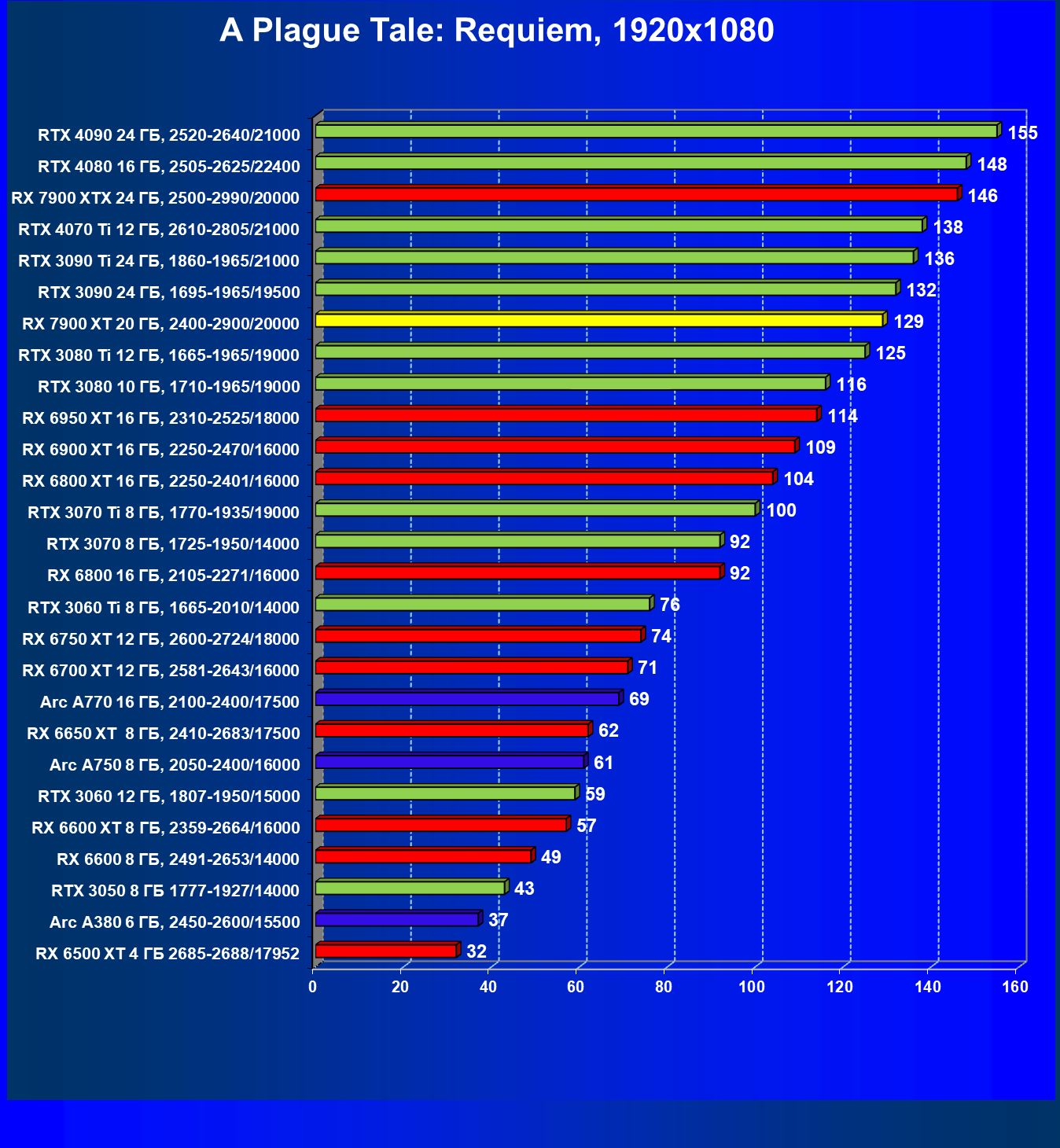
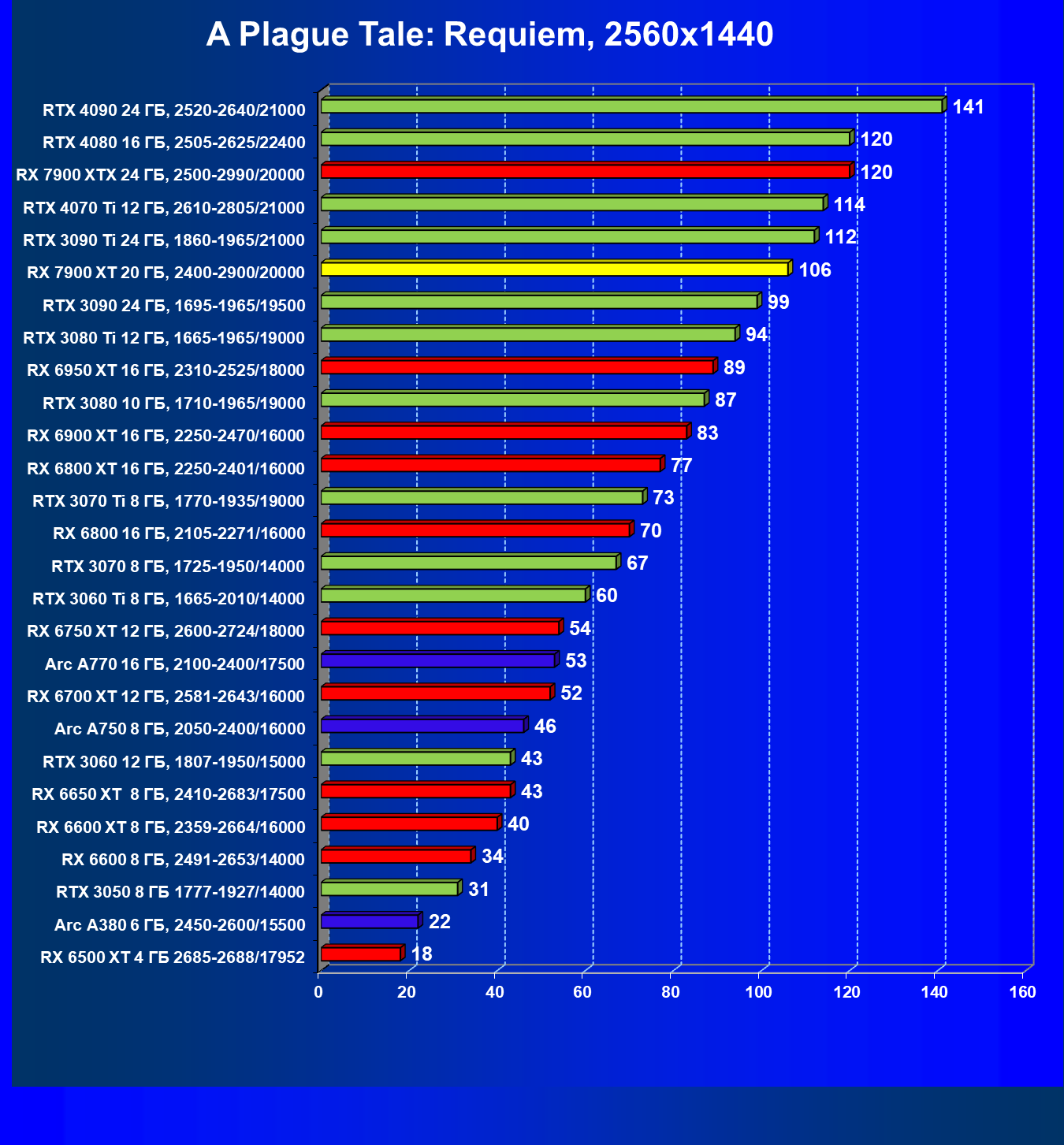
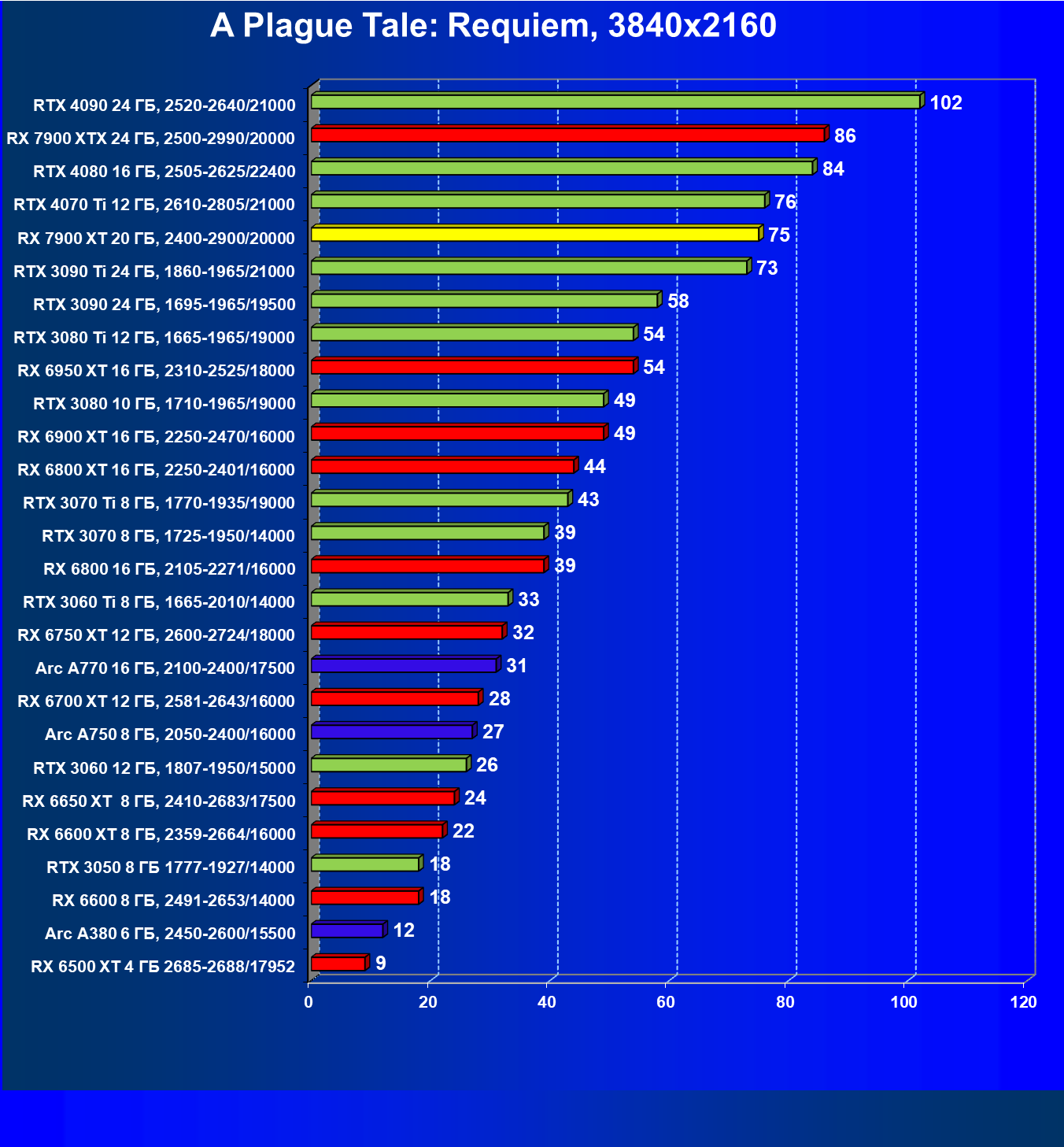
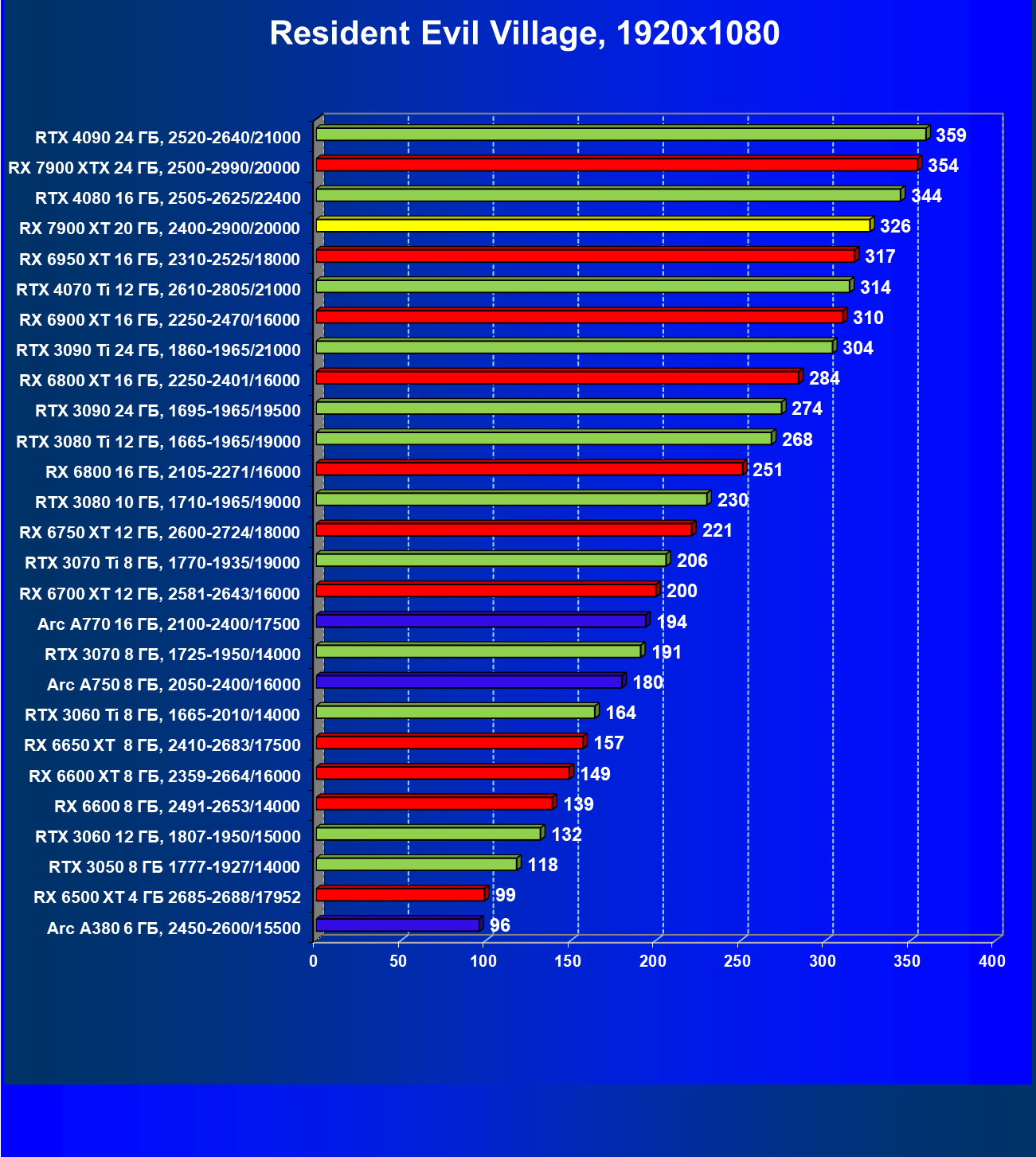
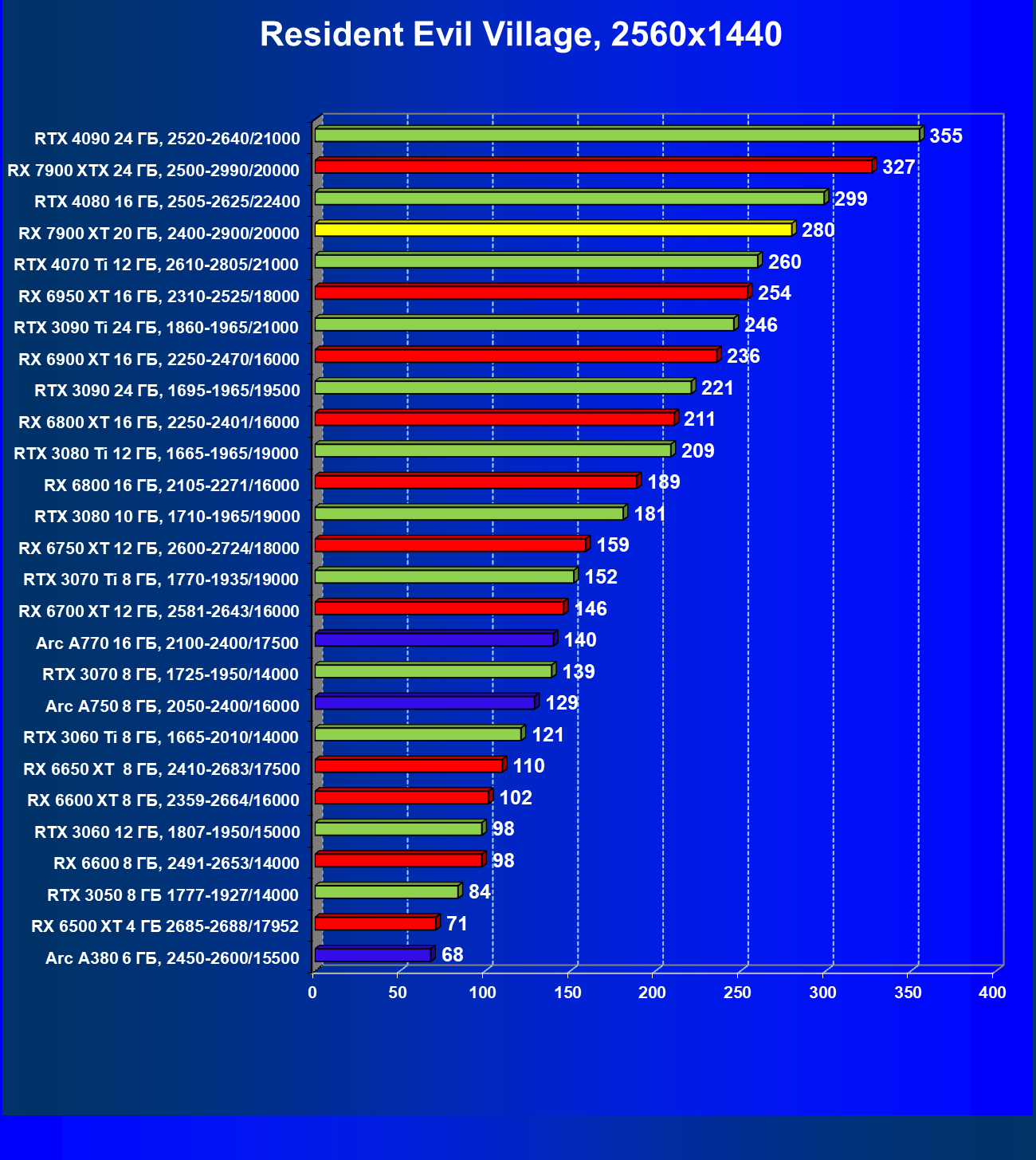
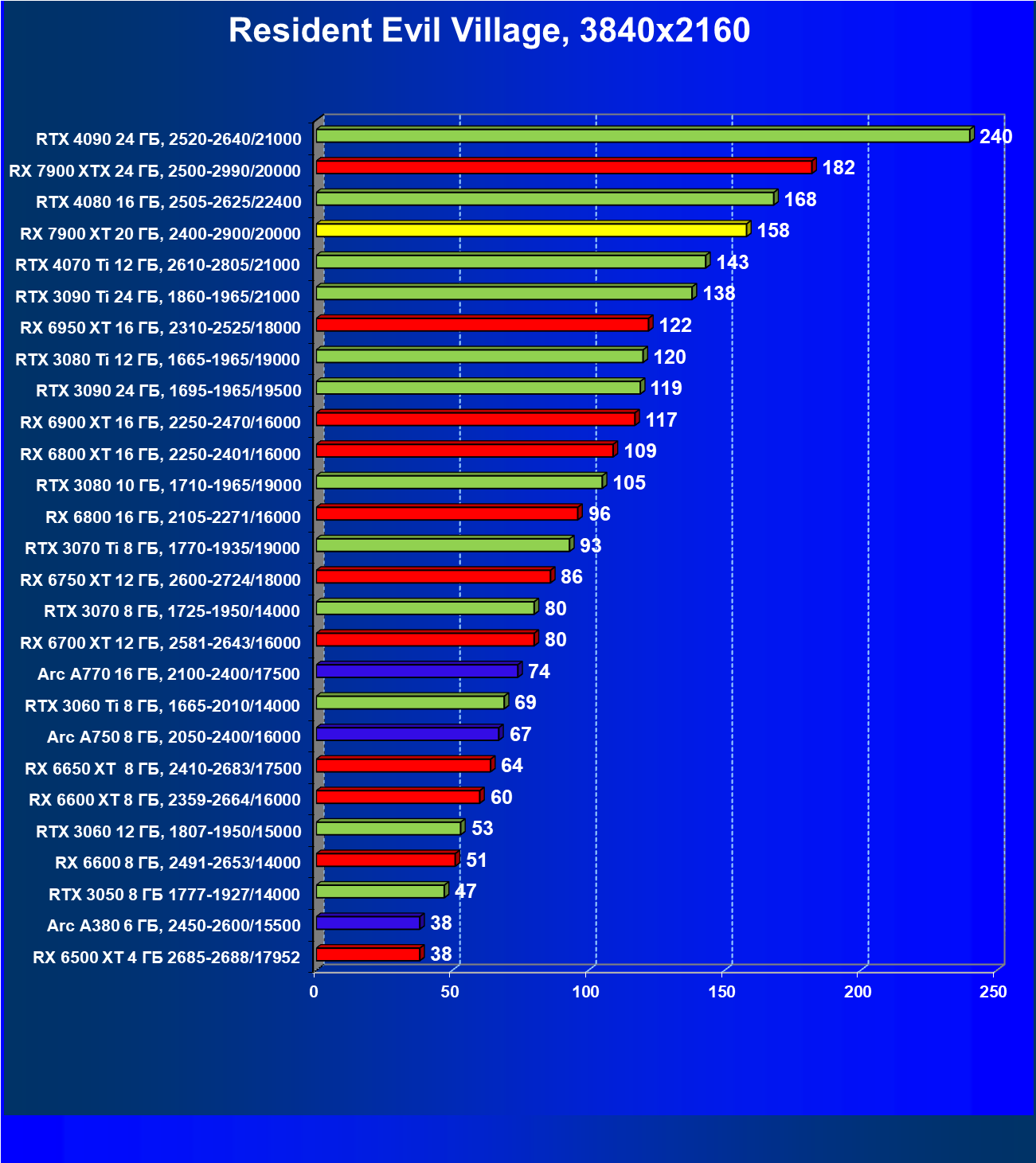
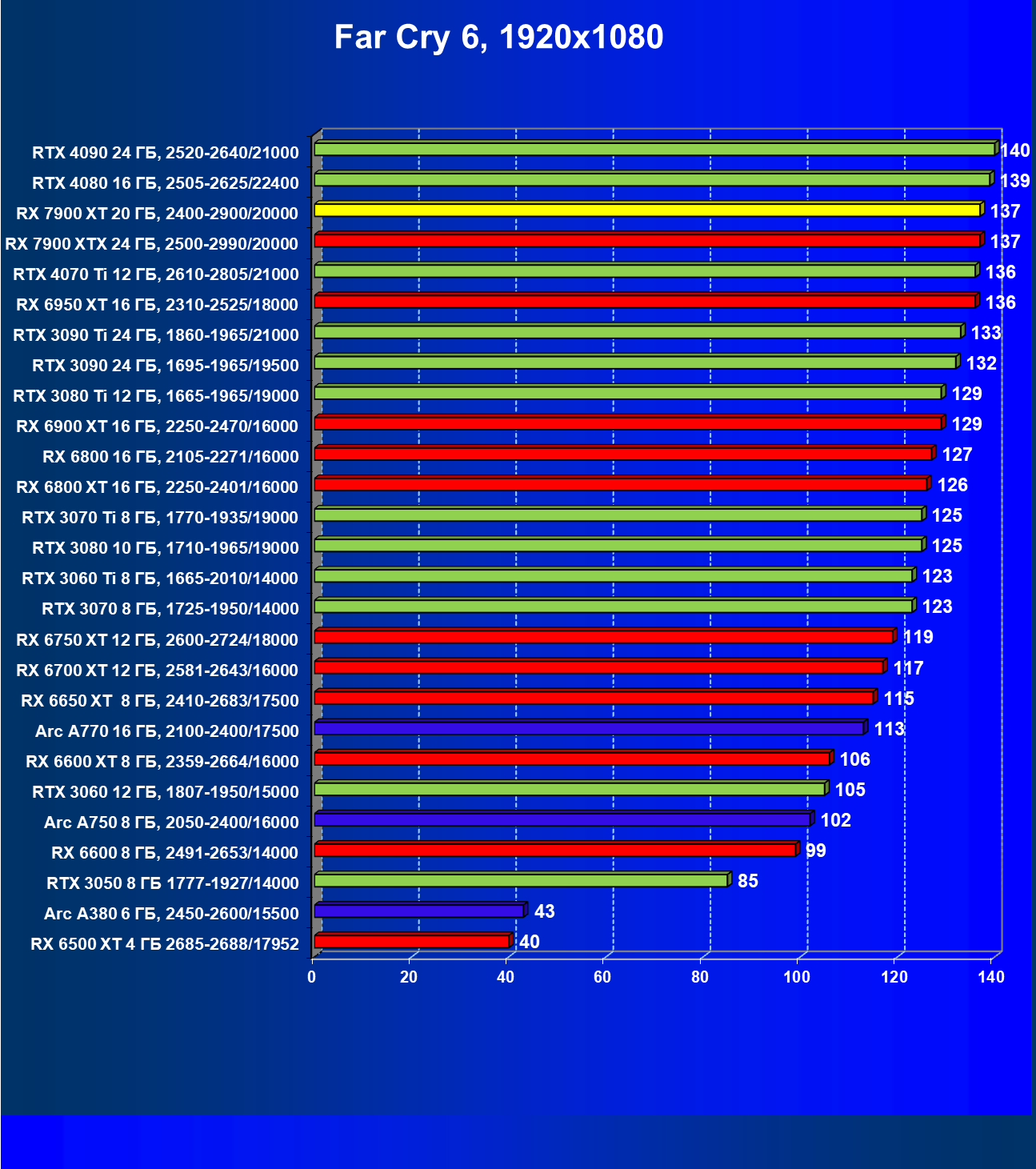
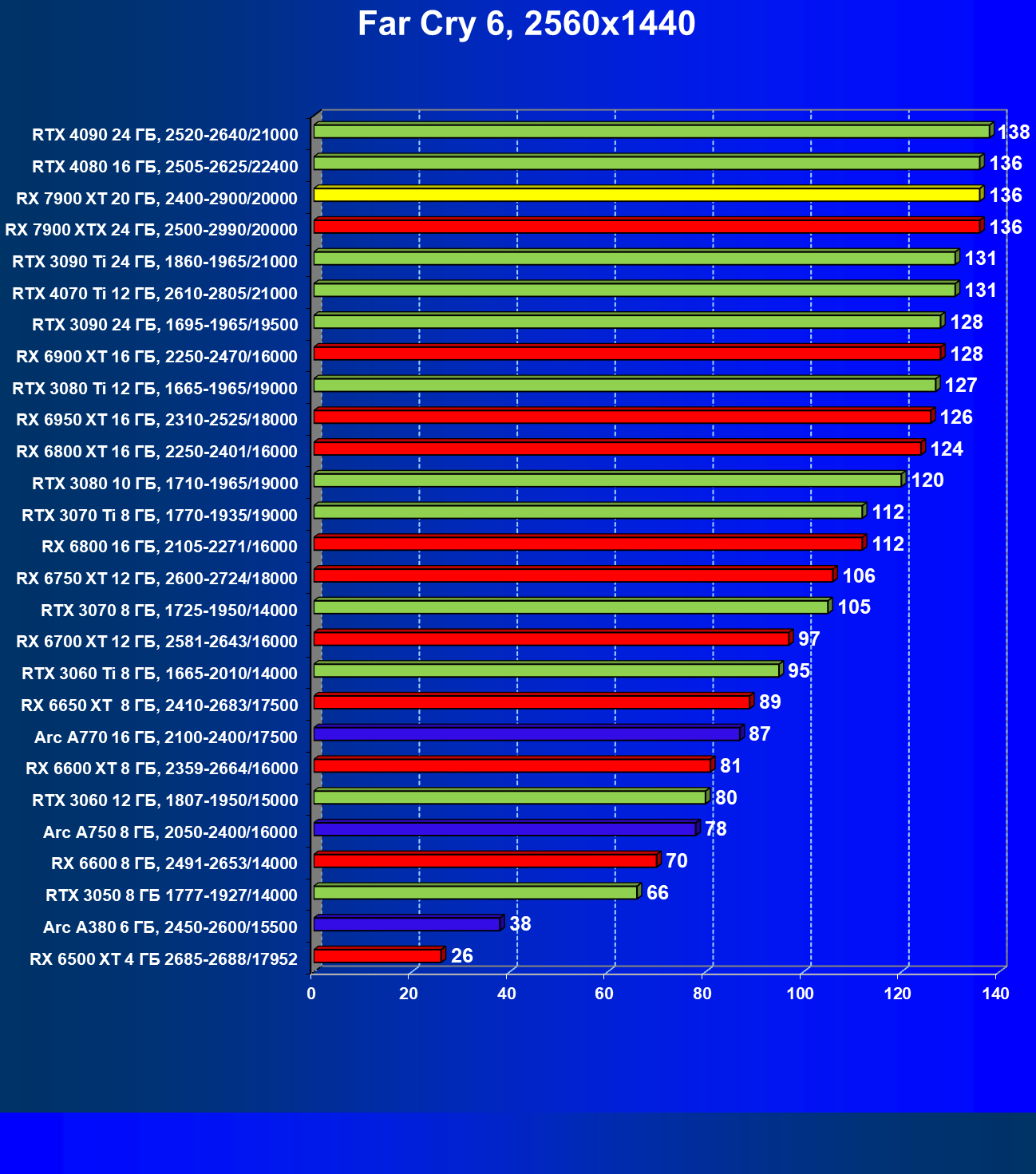
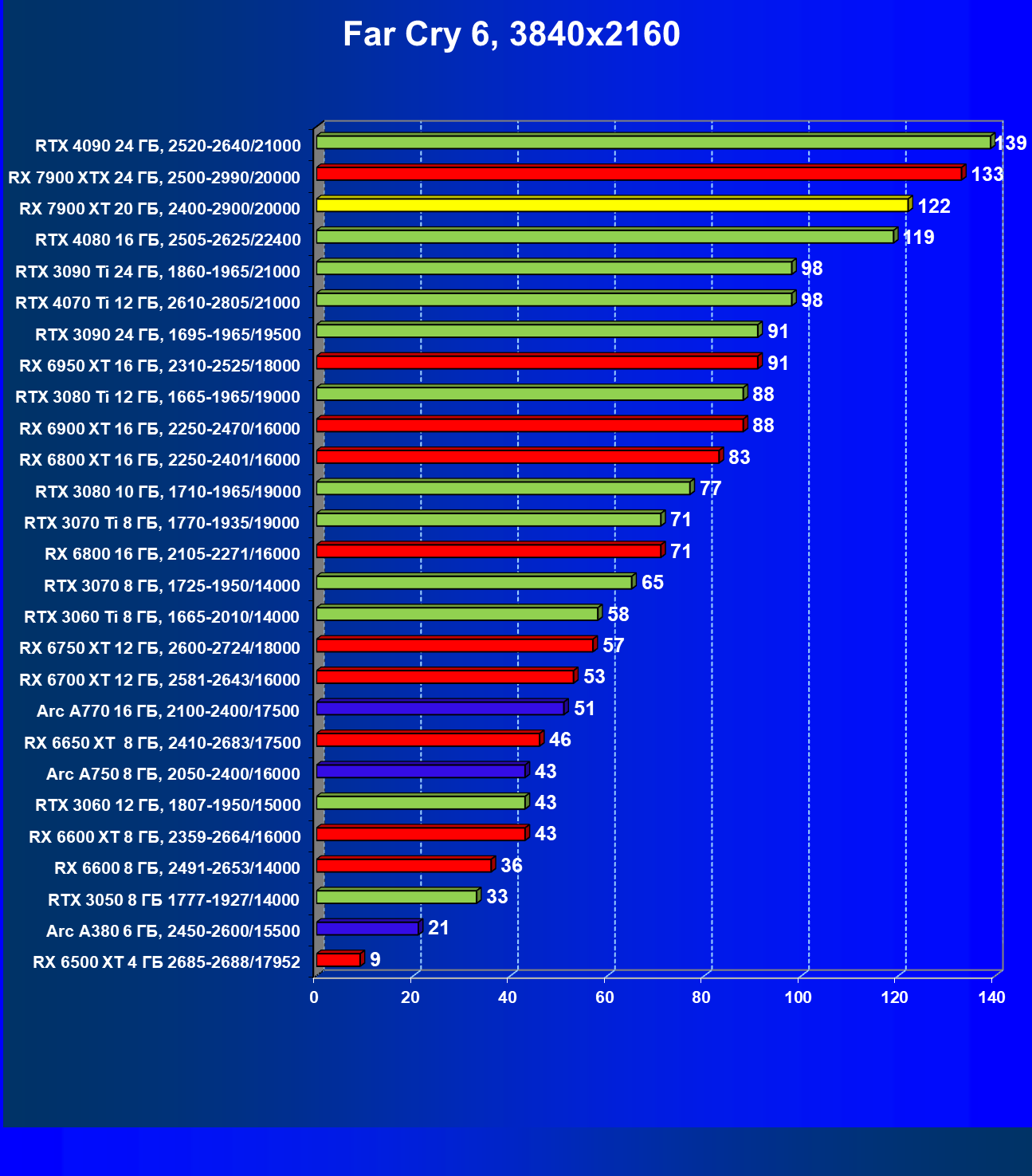
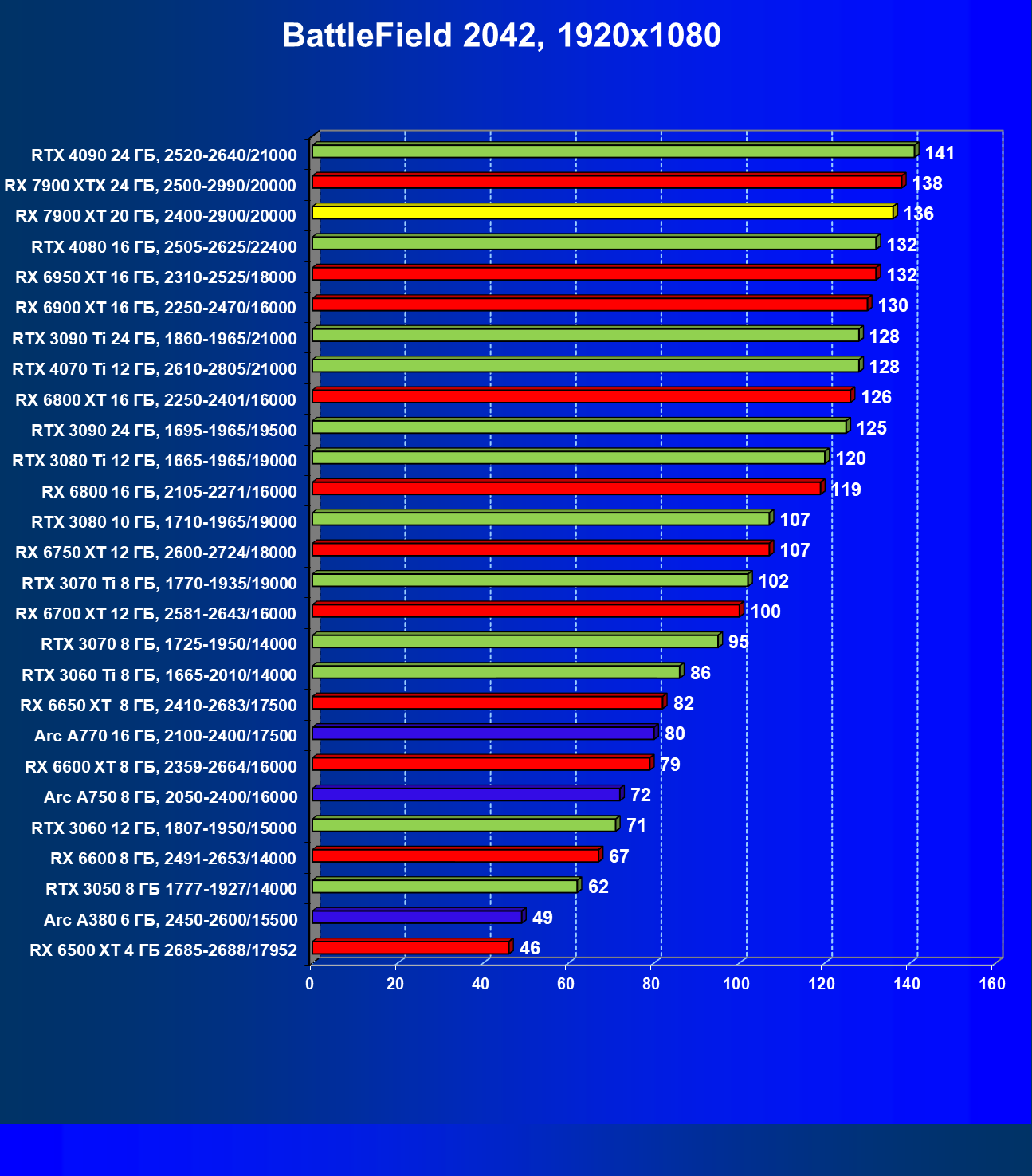
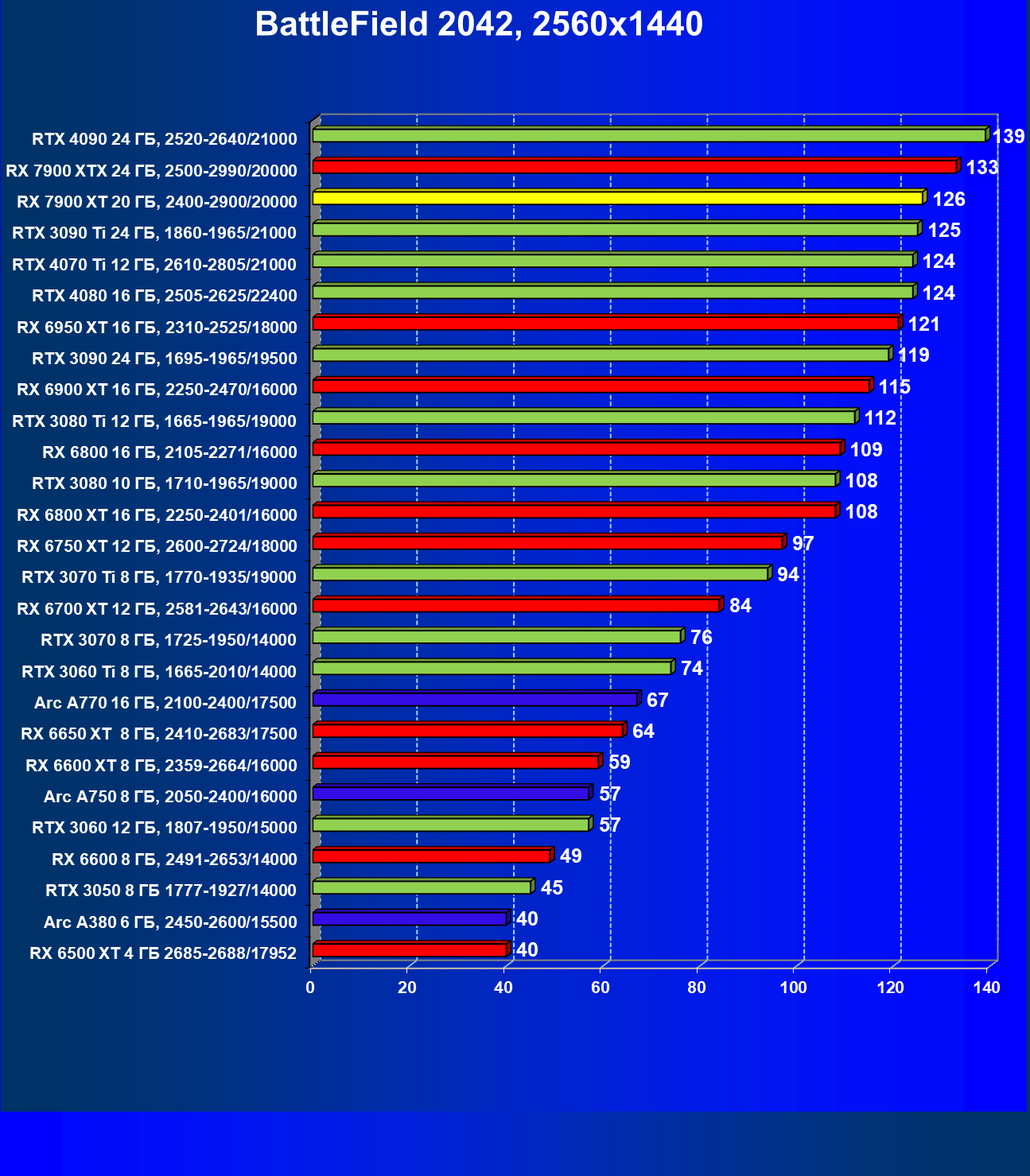
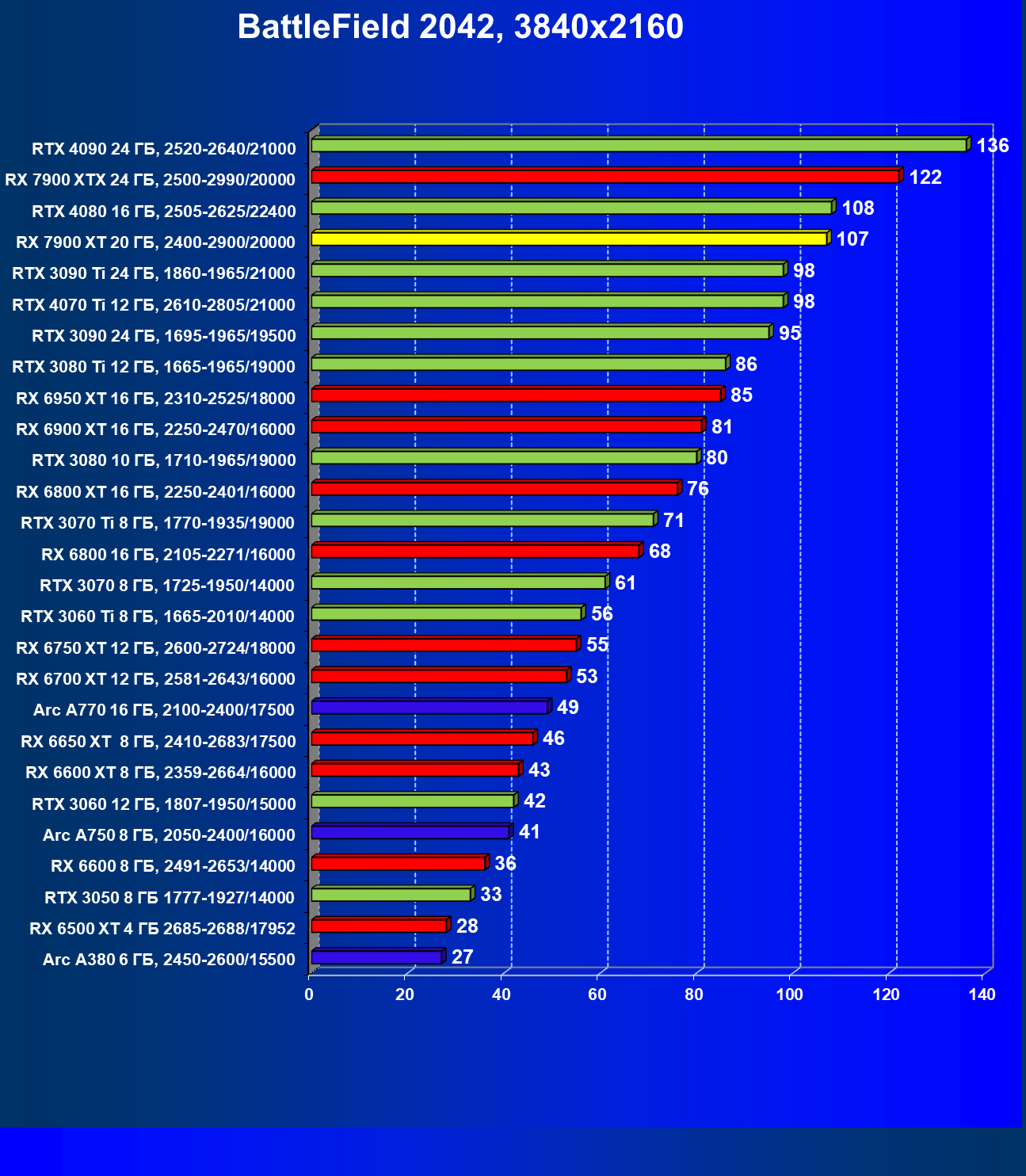
Все регулярно тестируемые нами видеокарты сейчас поддерживают технологию RT, поэтому мы проводим тесты не только с использованием обычных методов растеризации, но и с включением RT и DLSS/FSR.
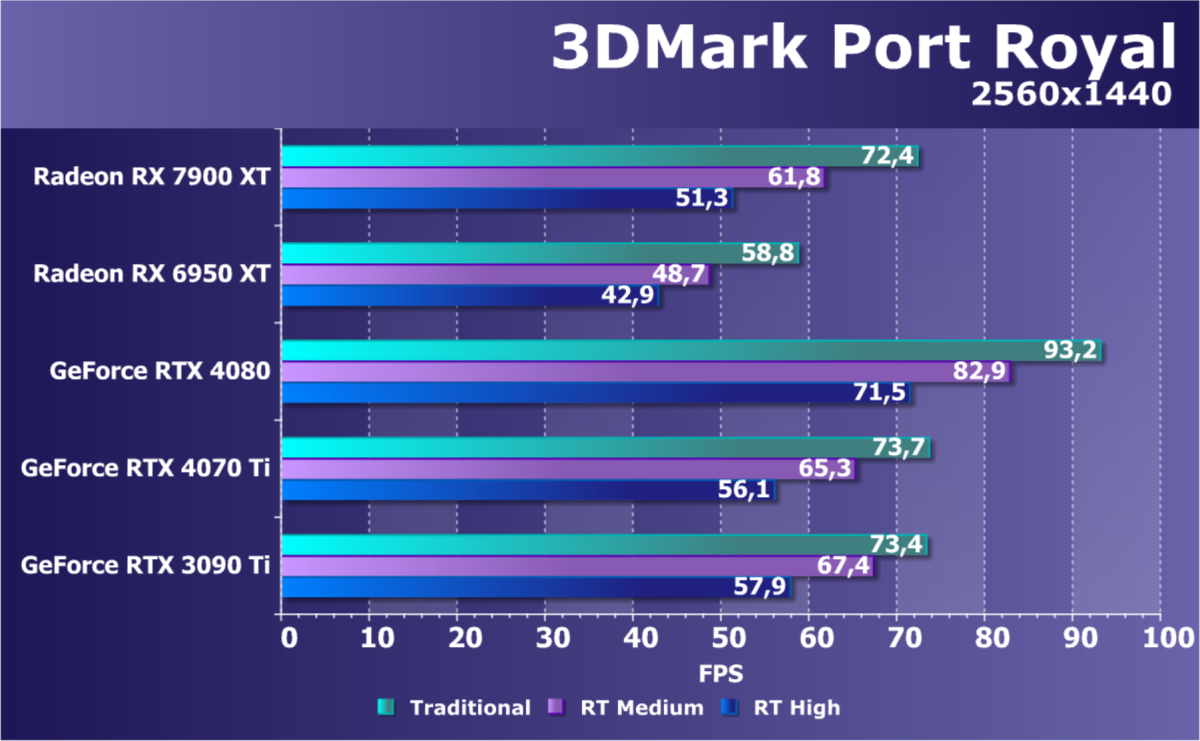
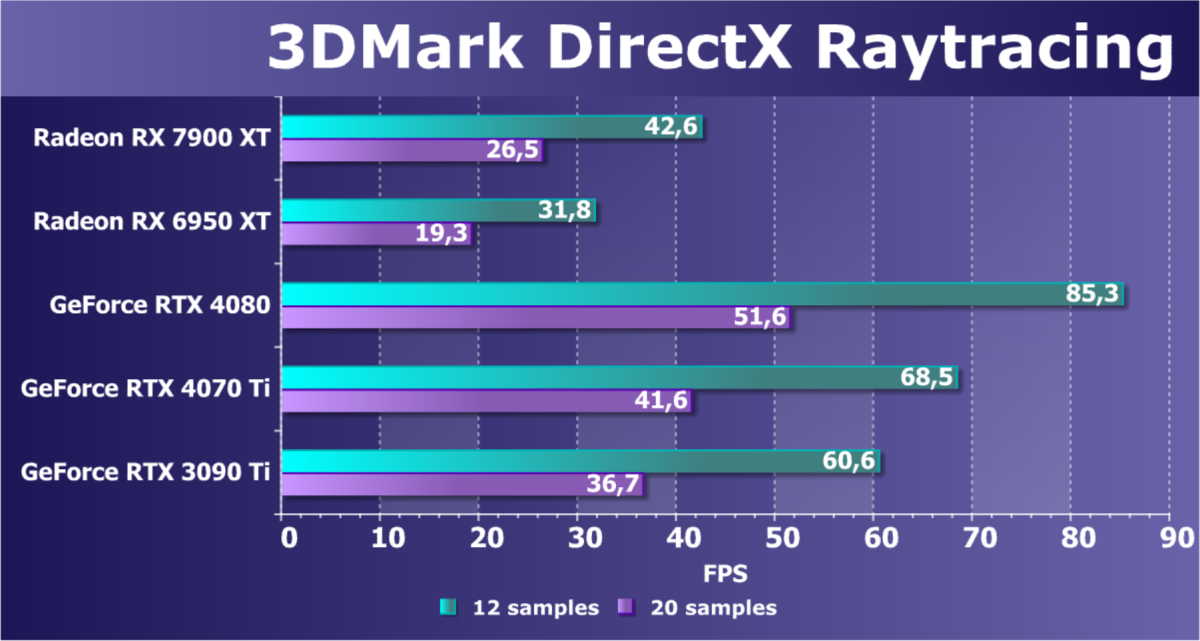
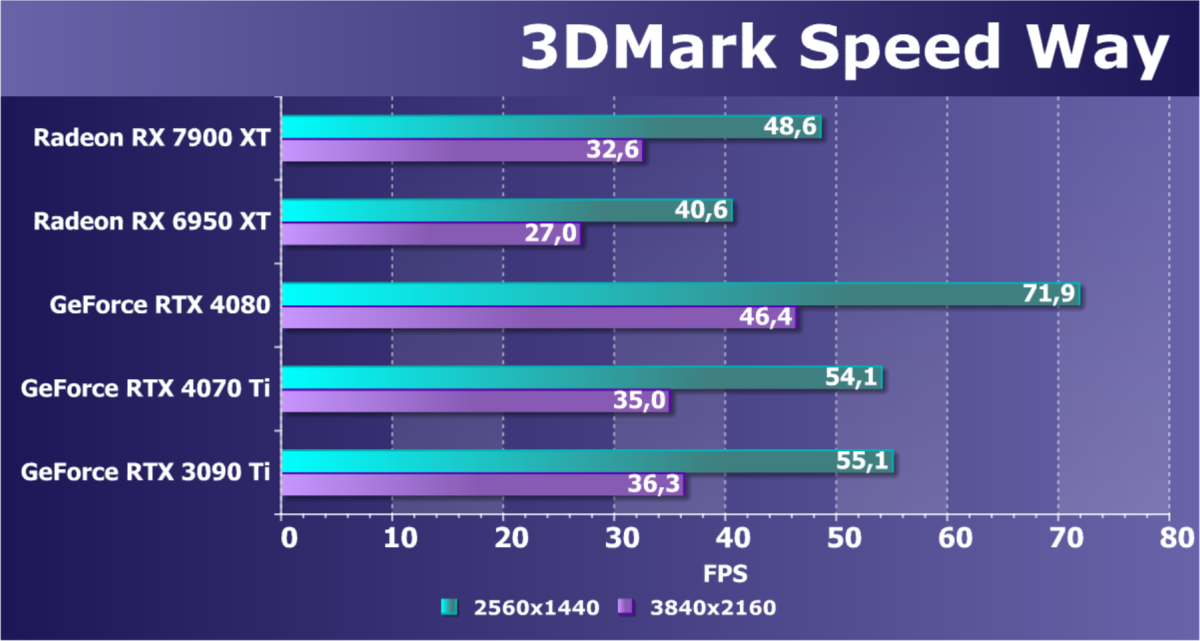
Результаты тестов со включенной аппаратной трассировкой лучей и/или DLSS/FSR в разрешениях 1920×1200, 2560×1440 и 3840×2160
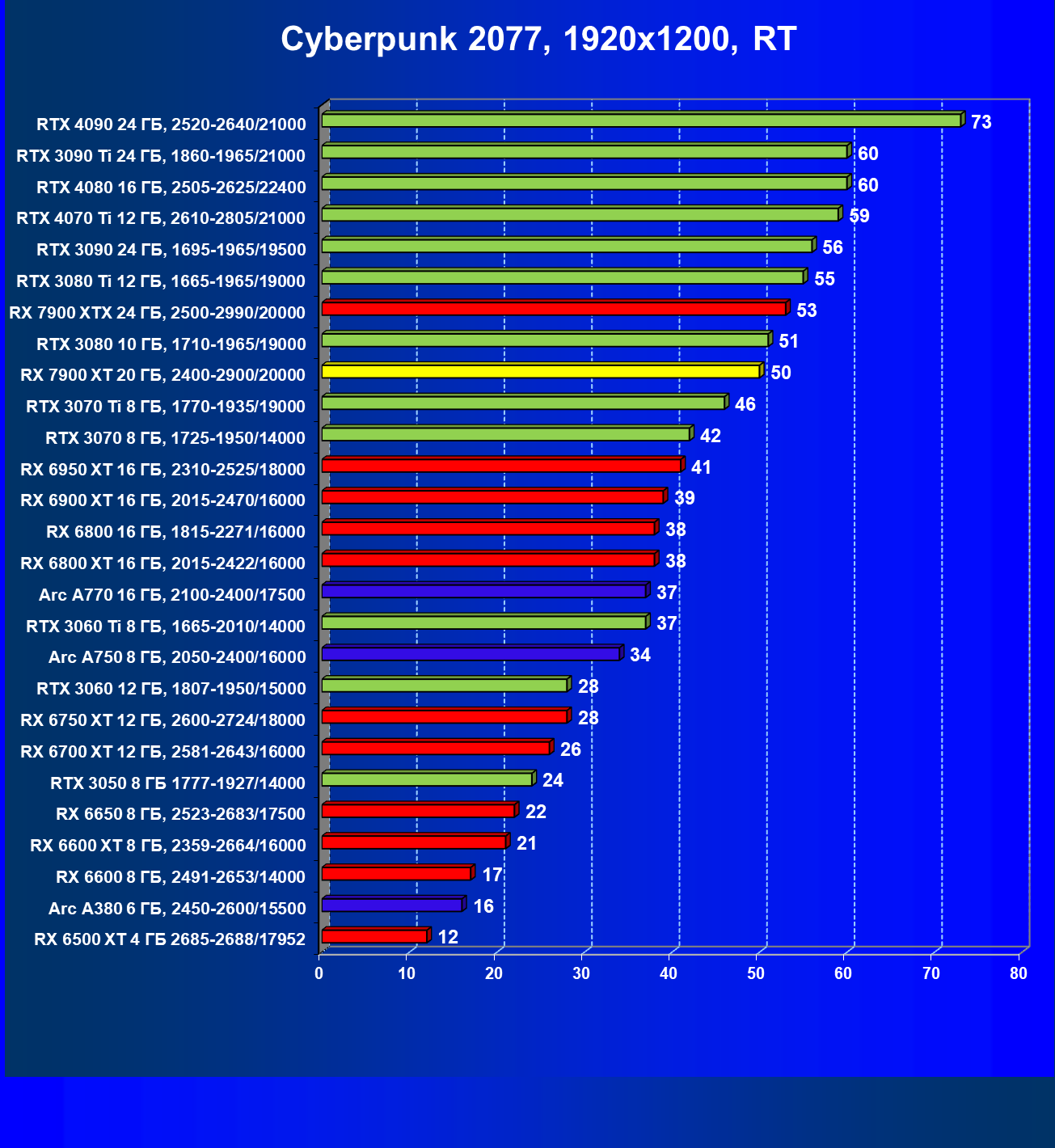
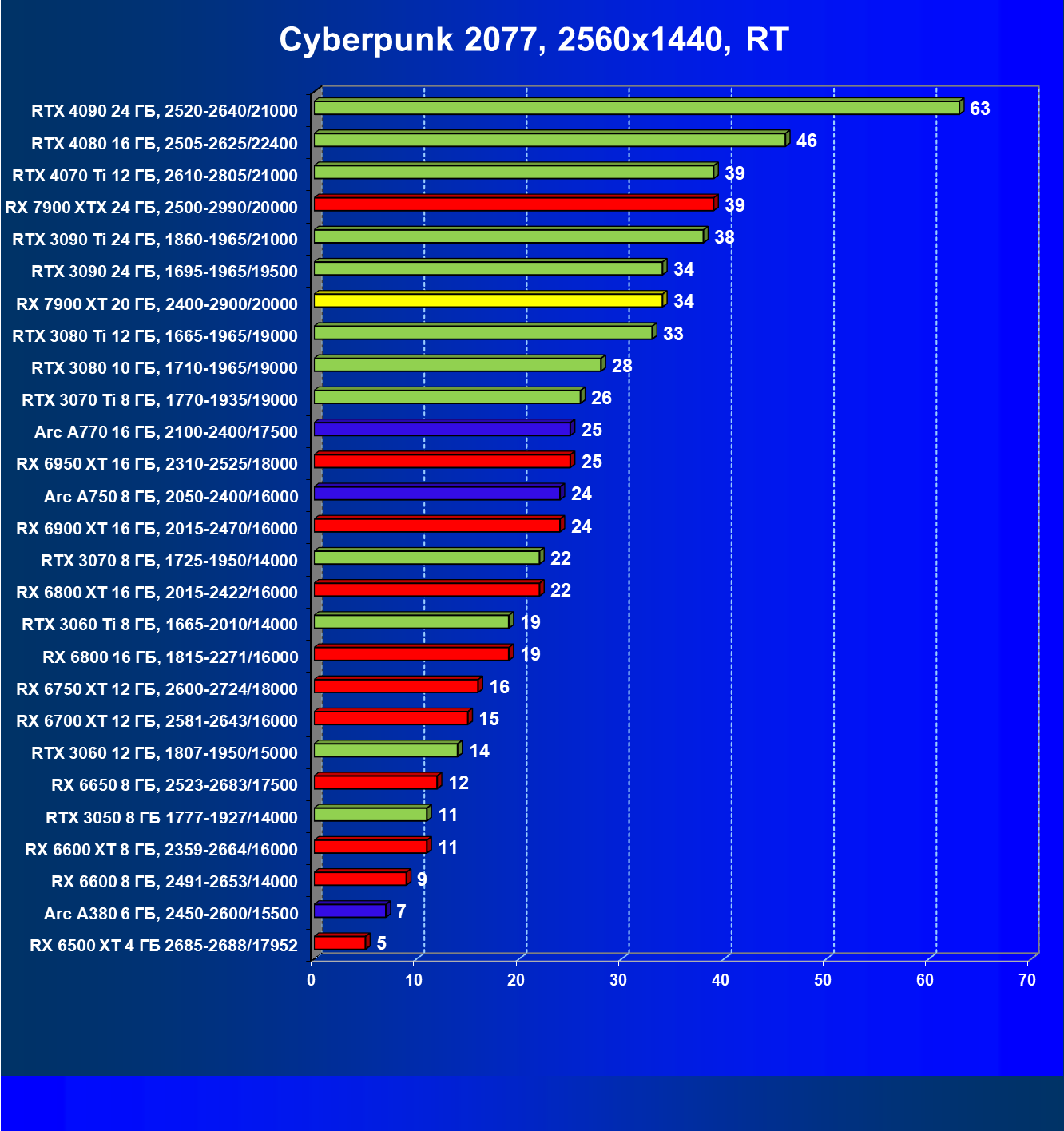
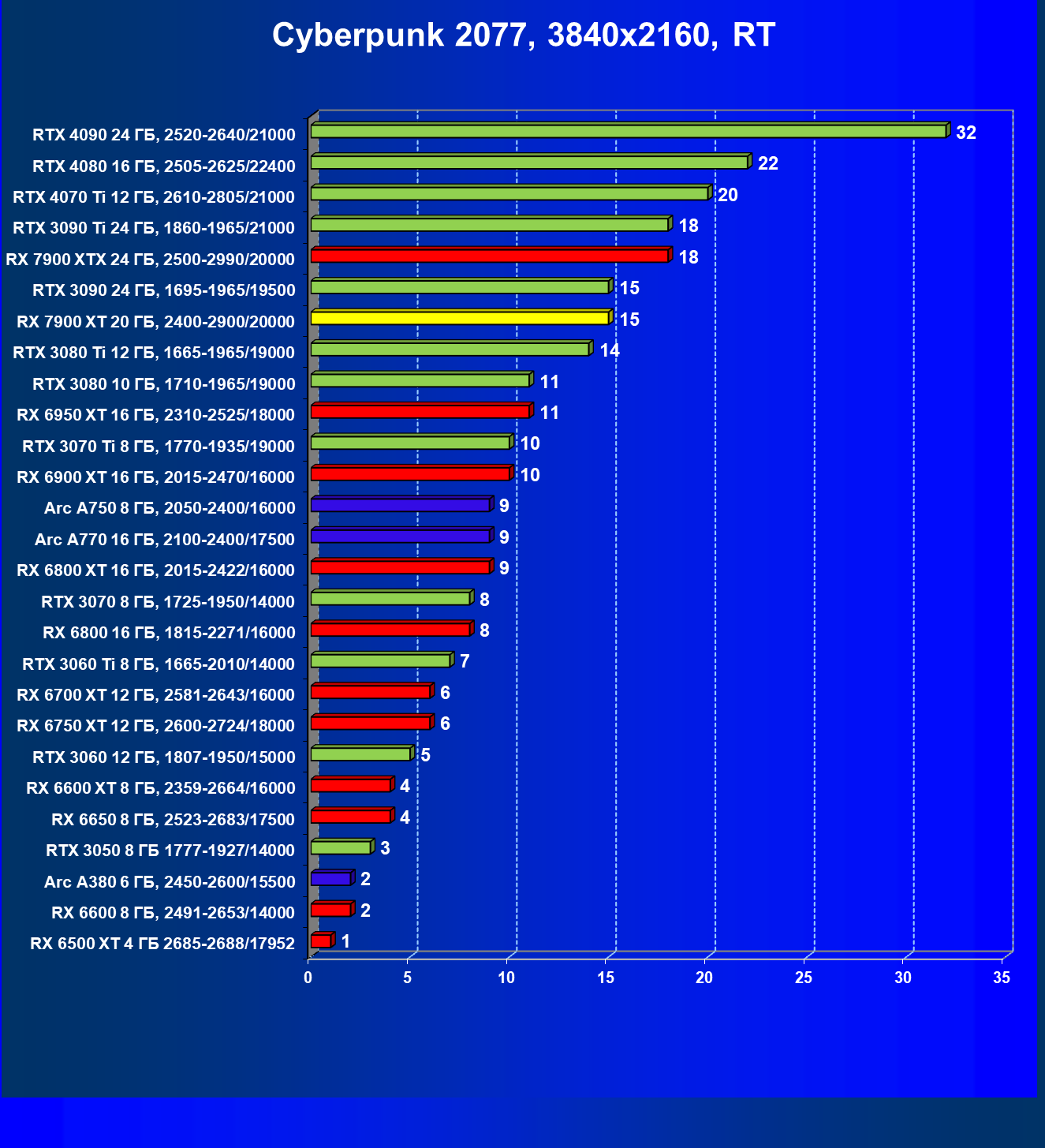
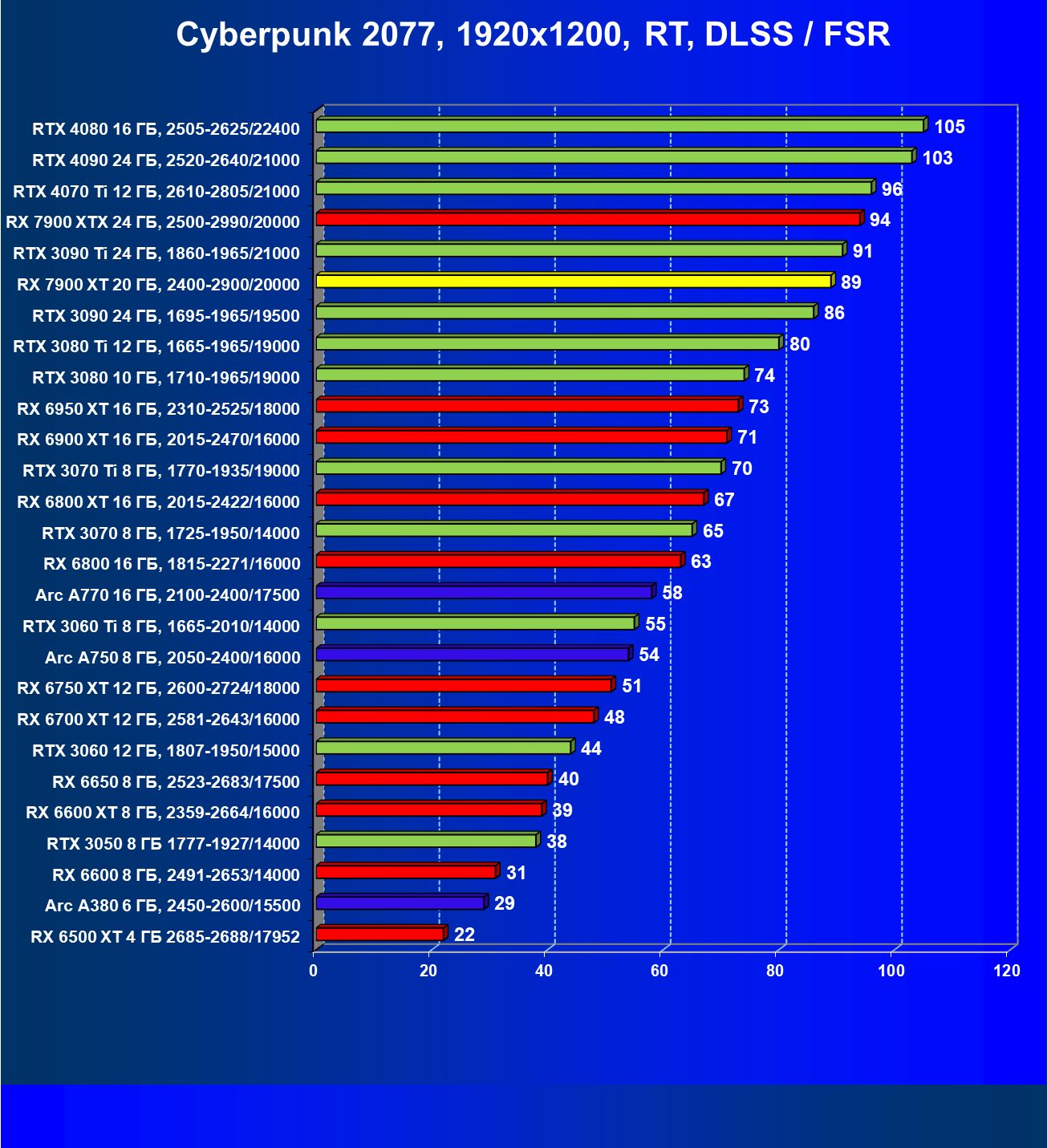
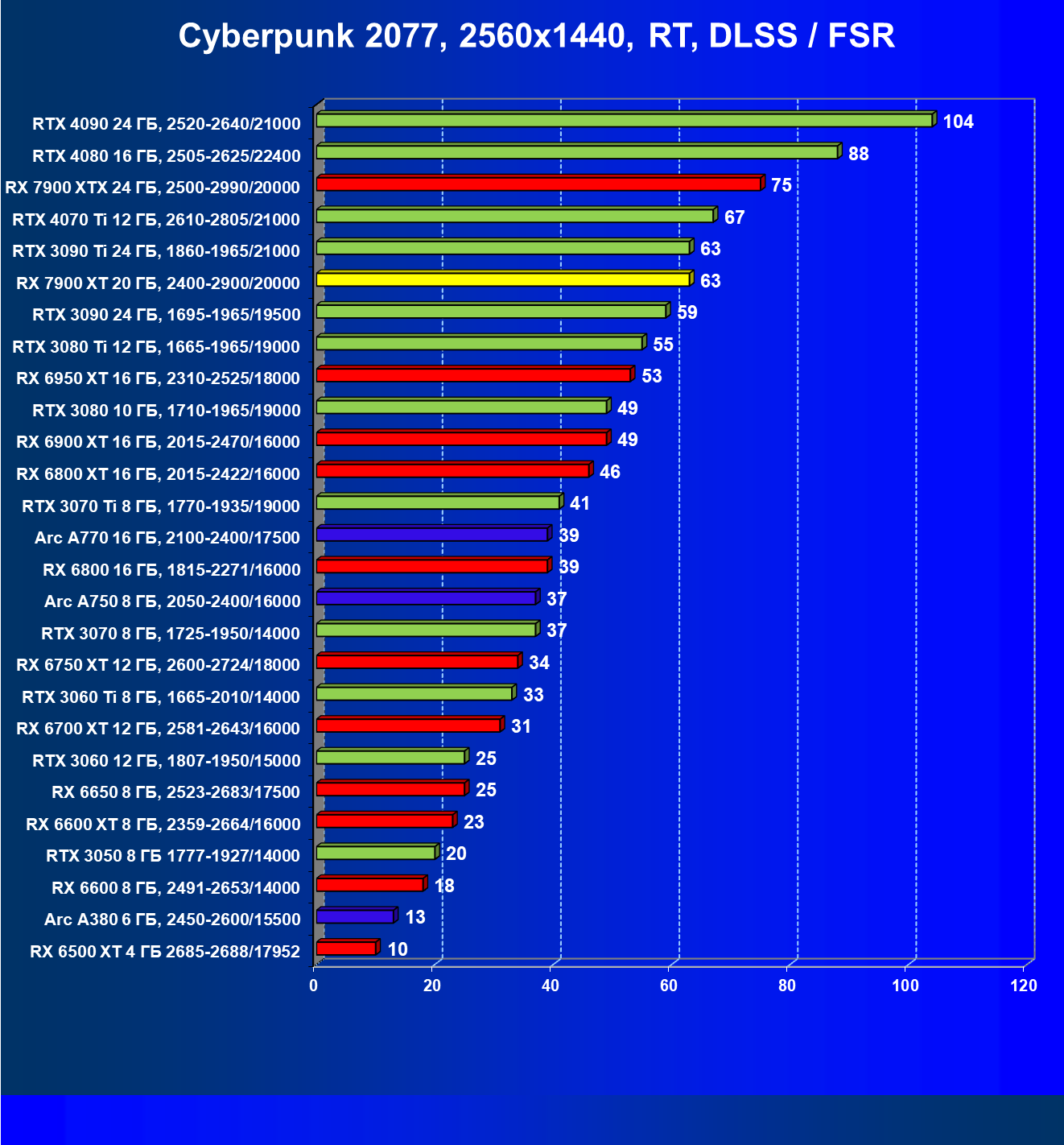
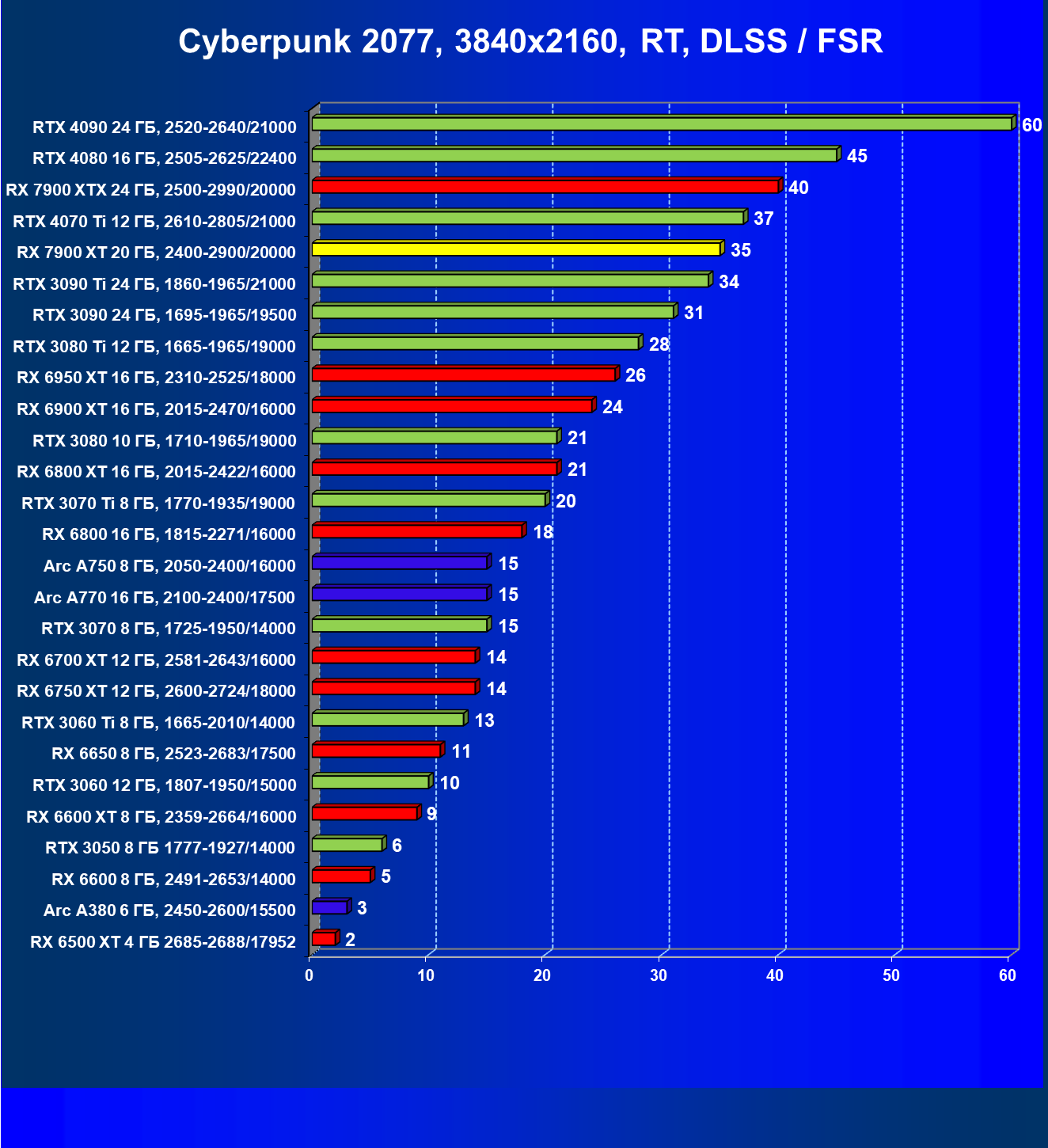
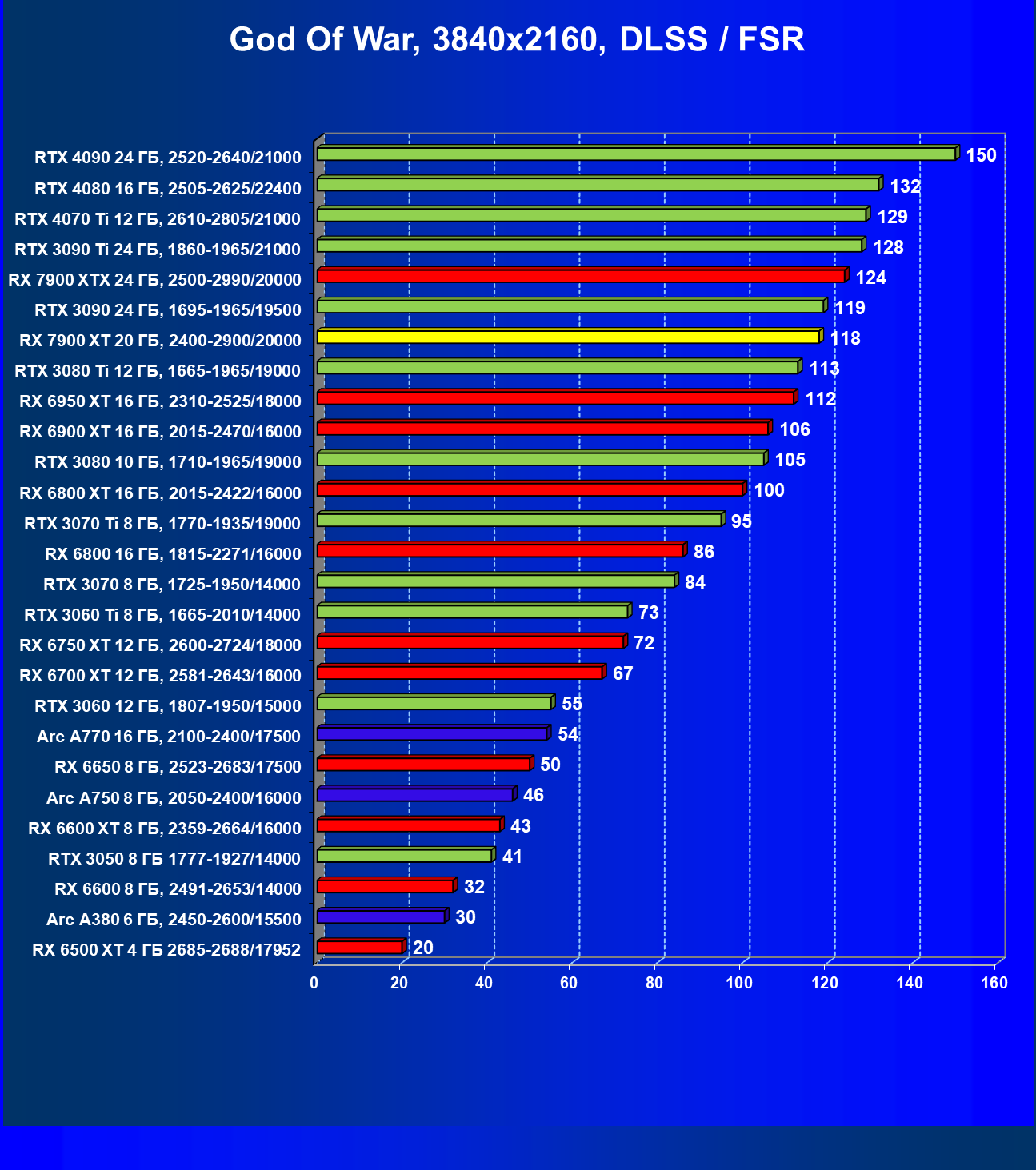
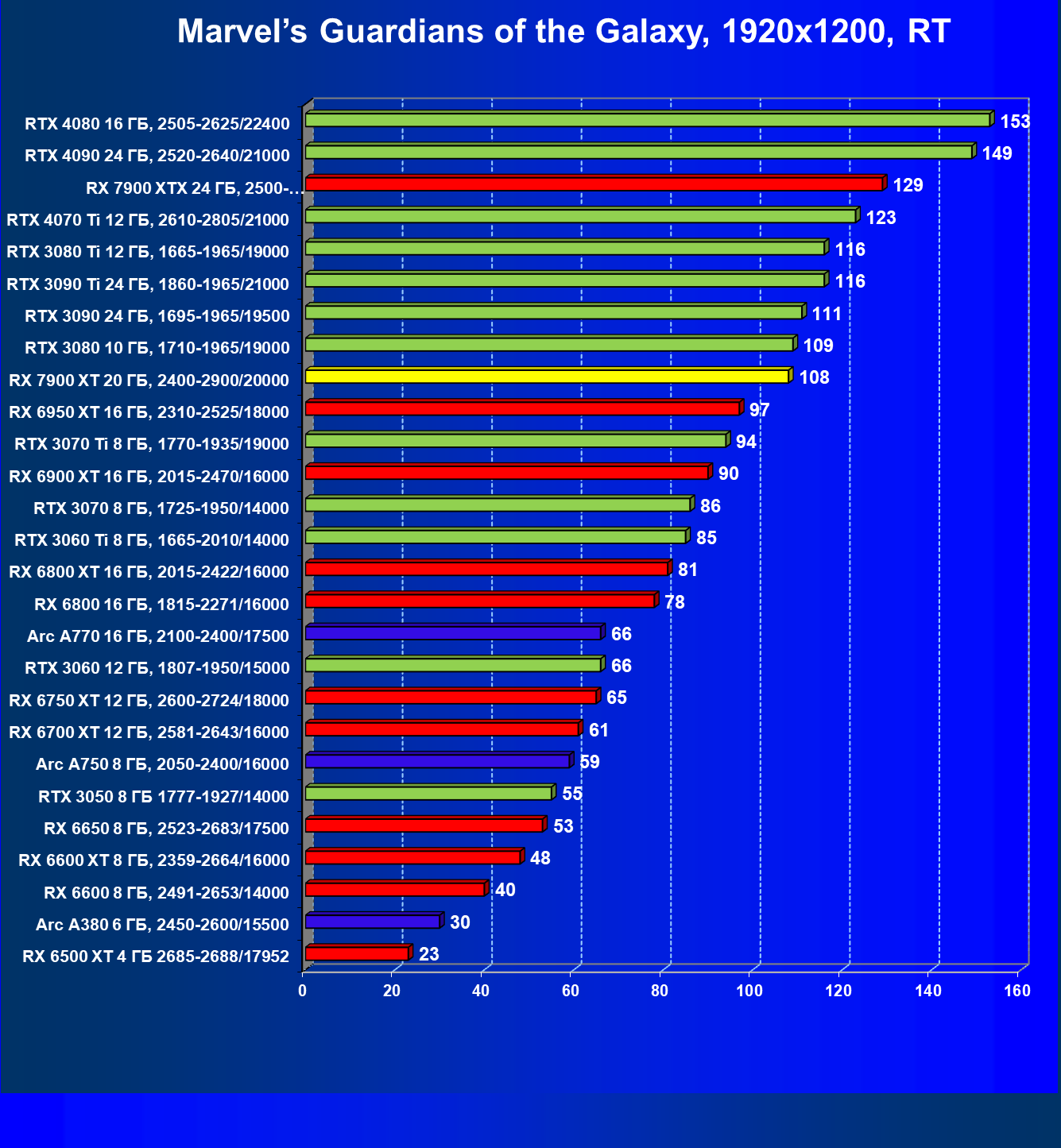
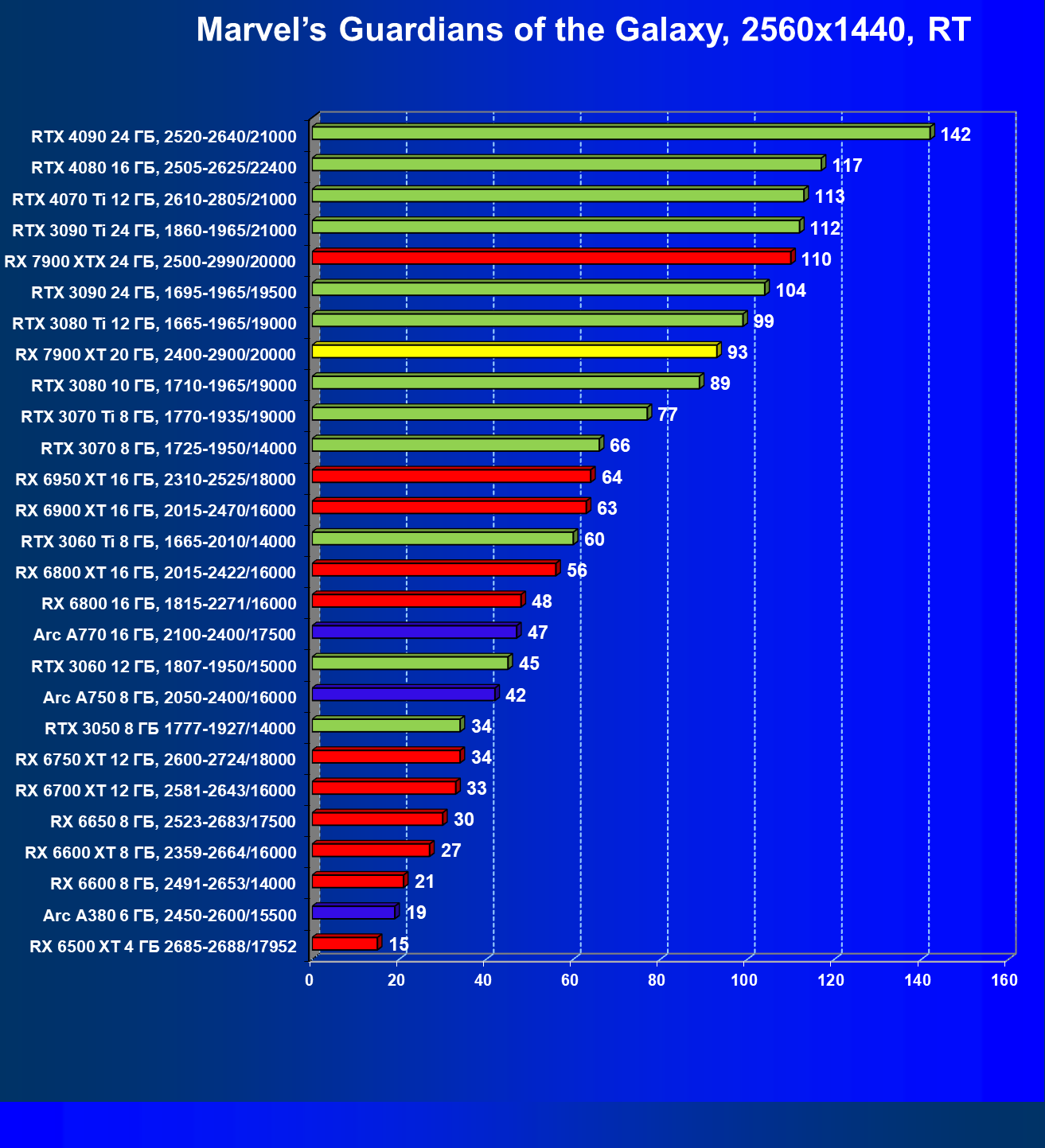
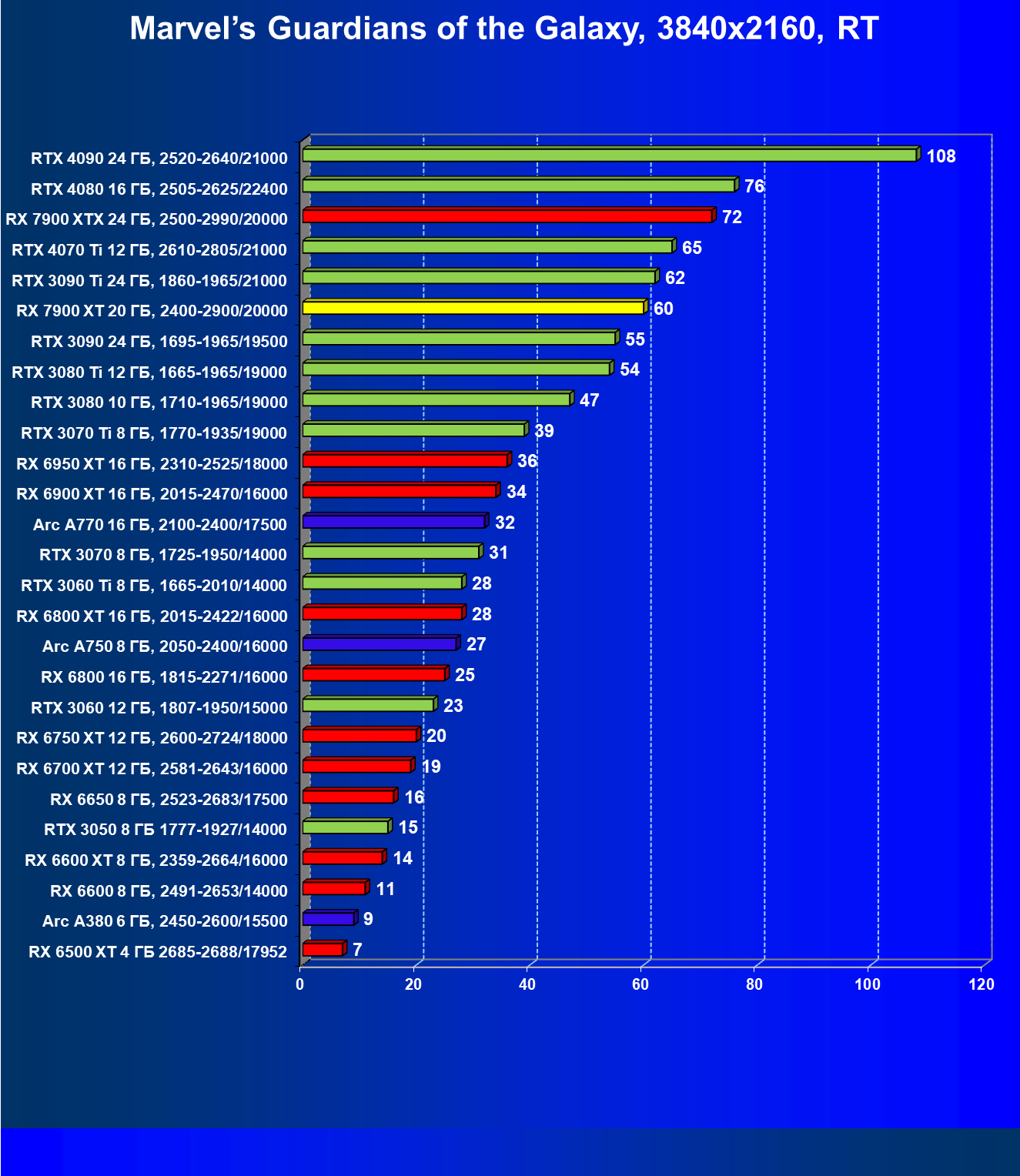
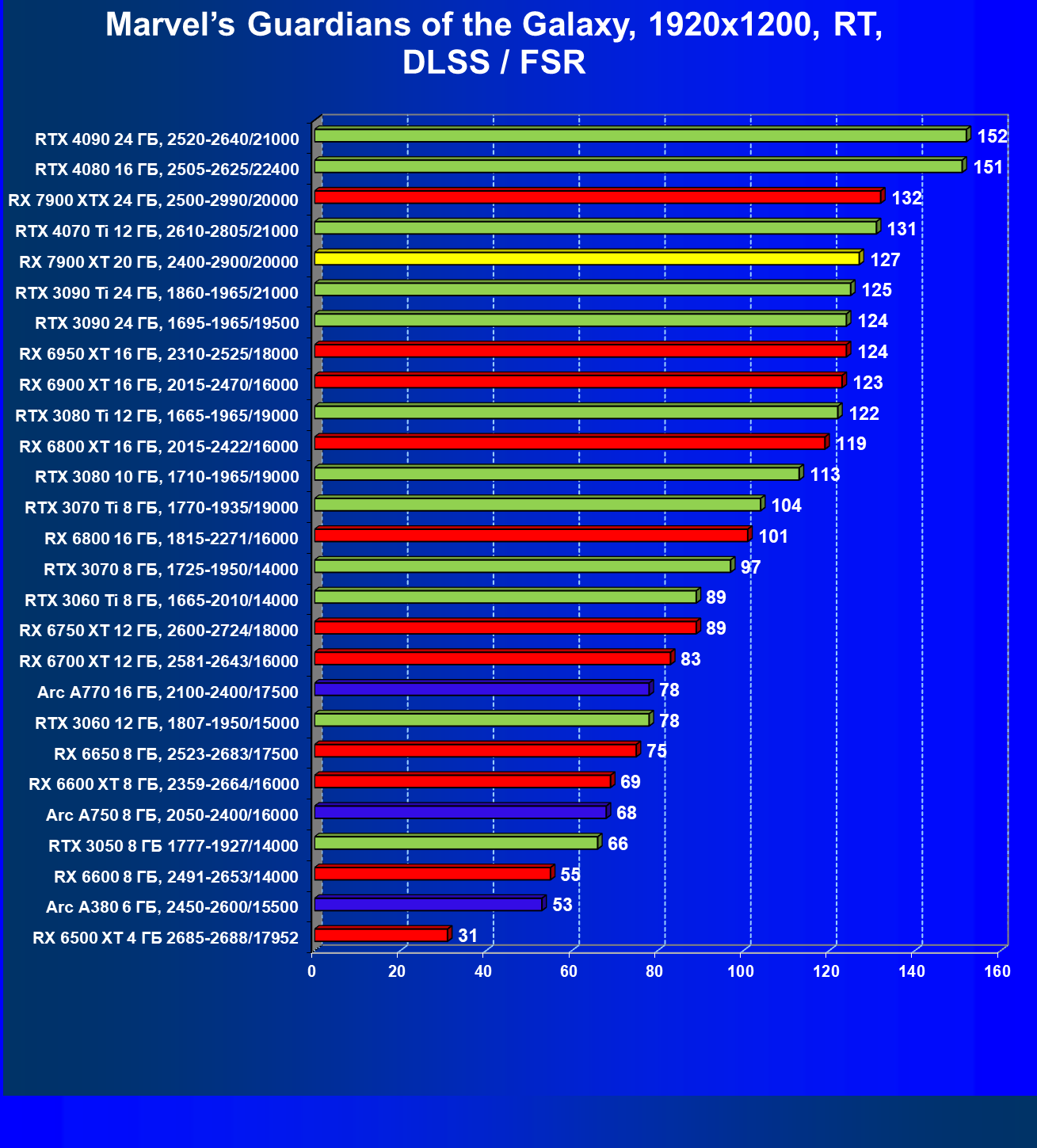
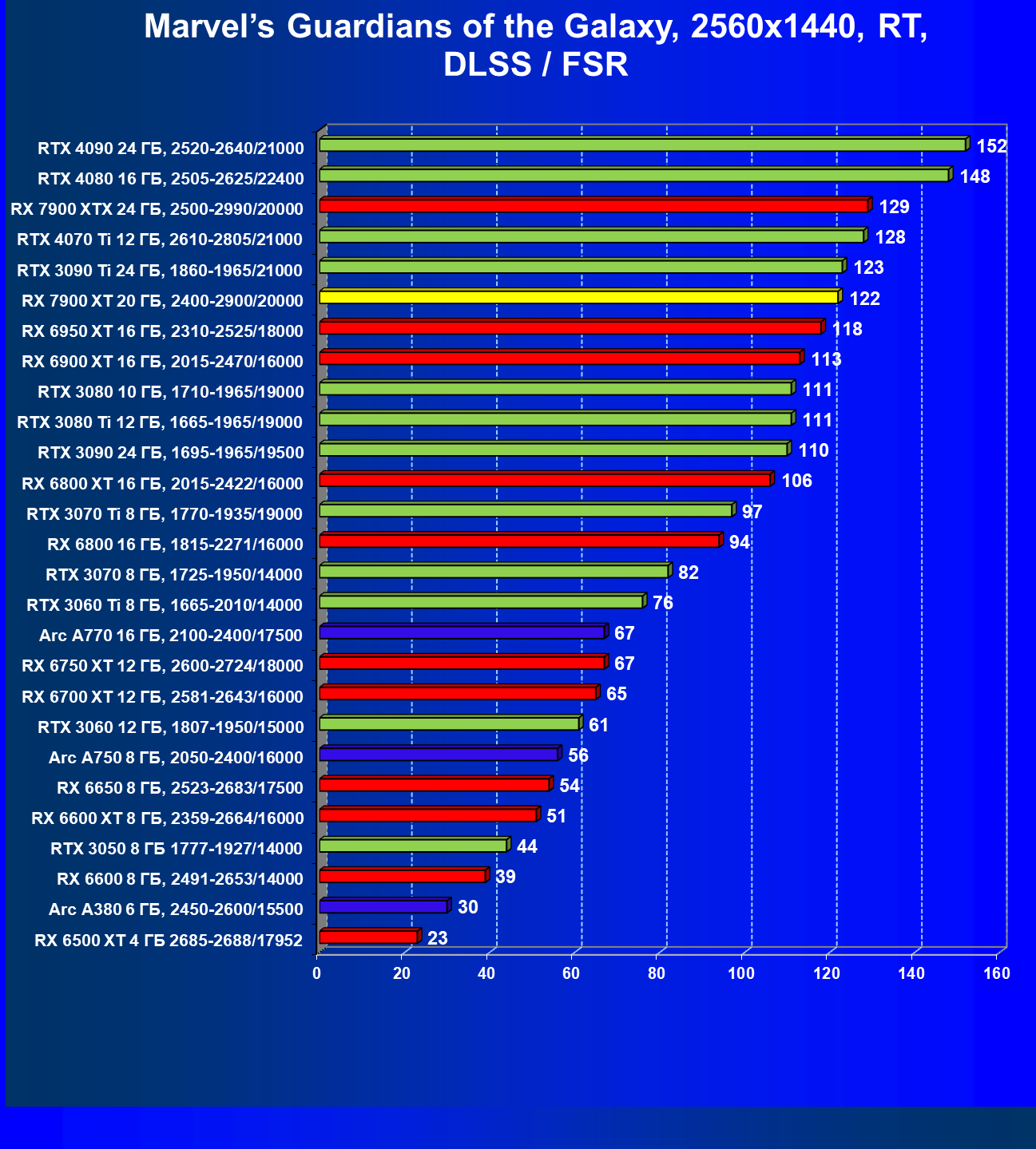
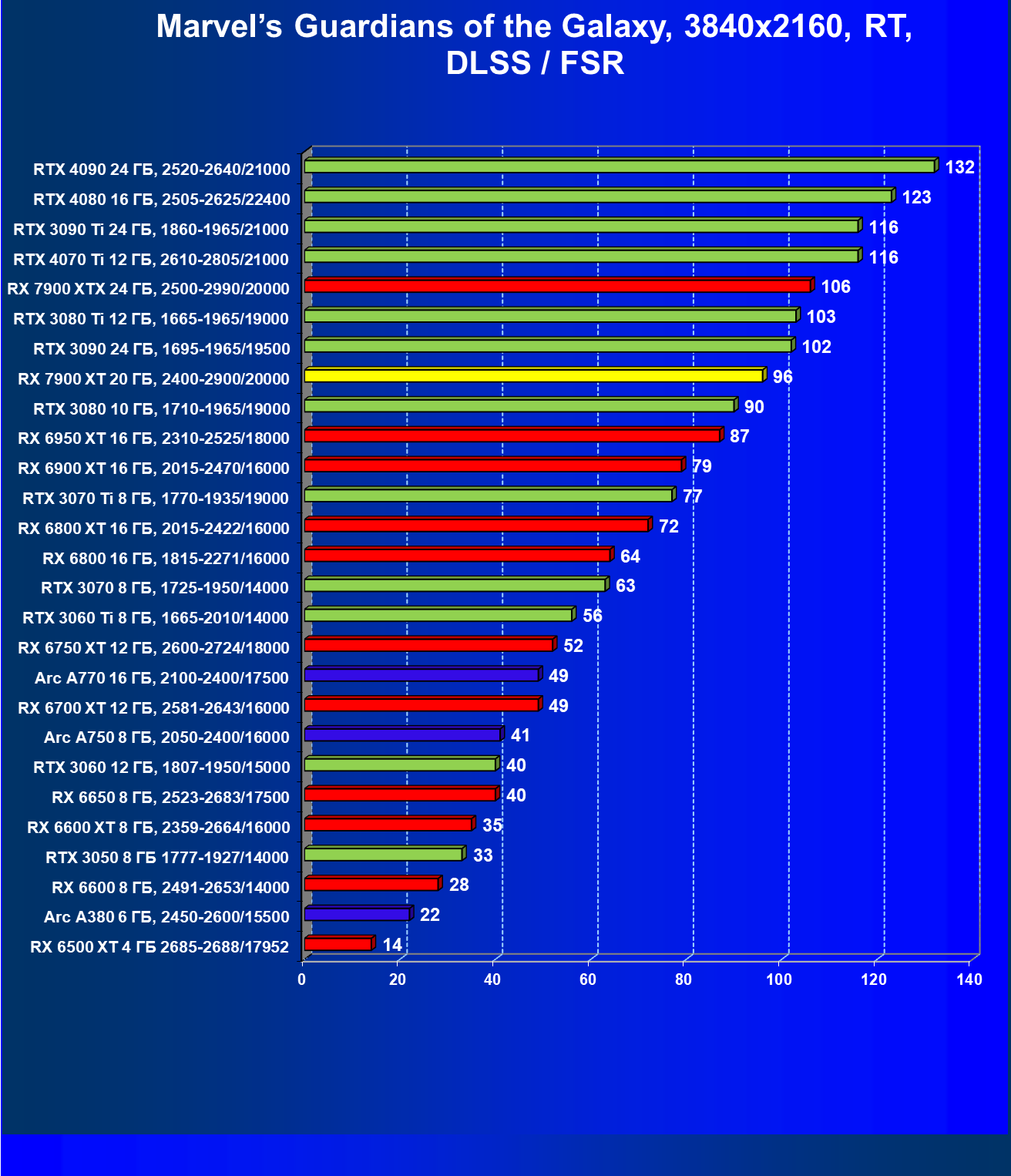
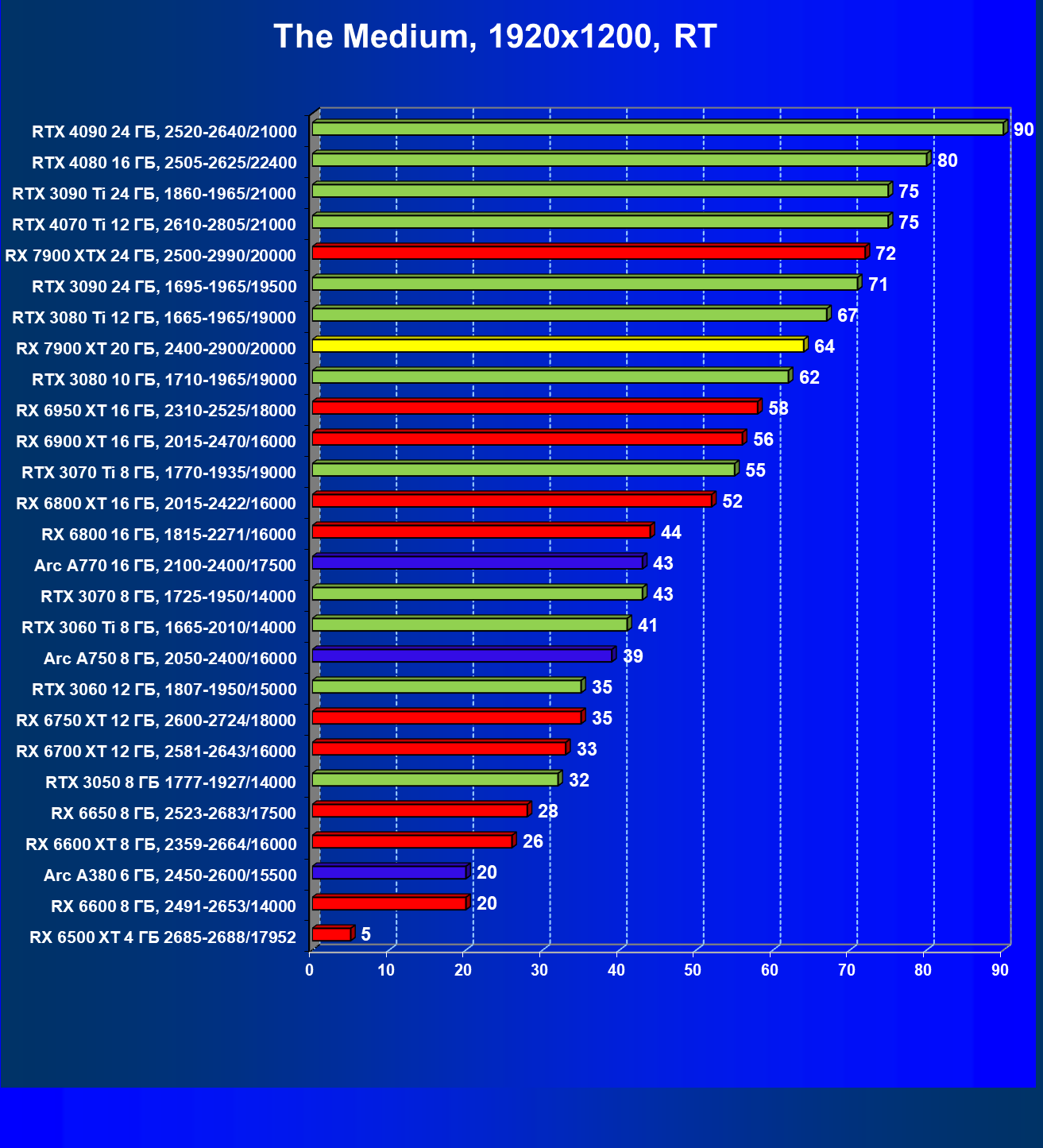
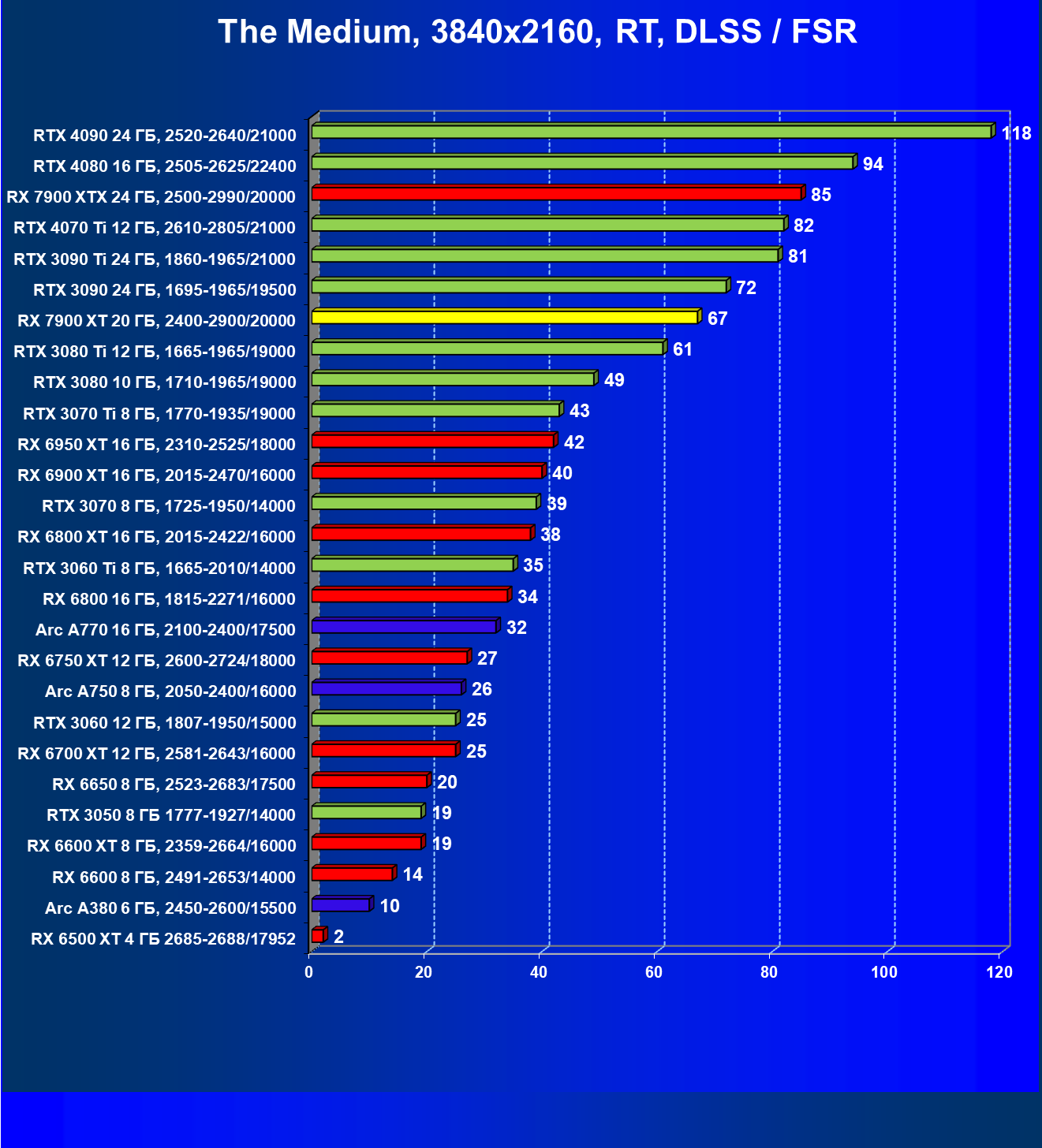
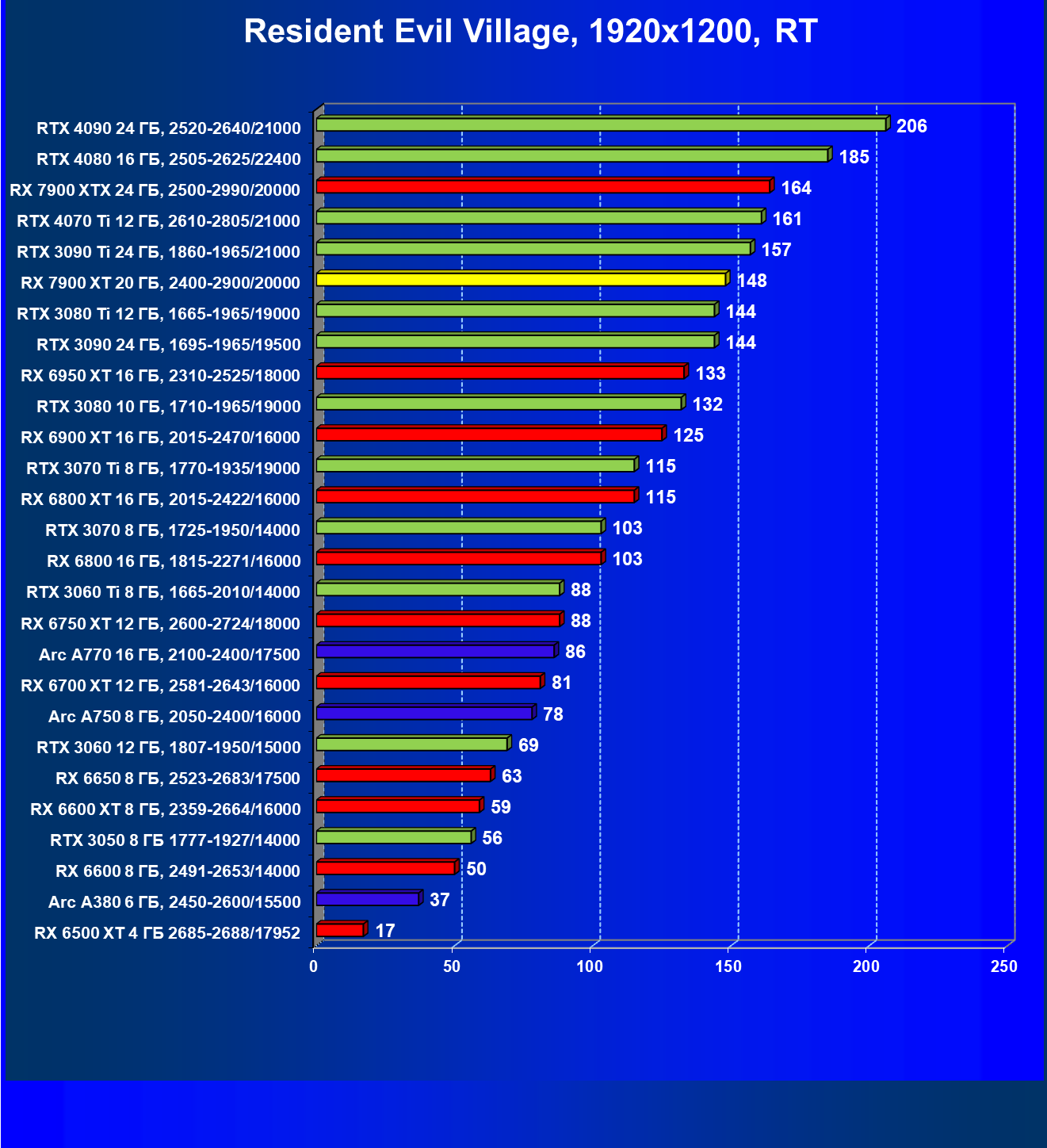
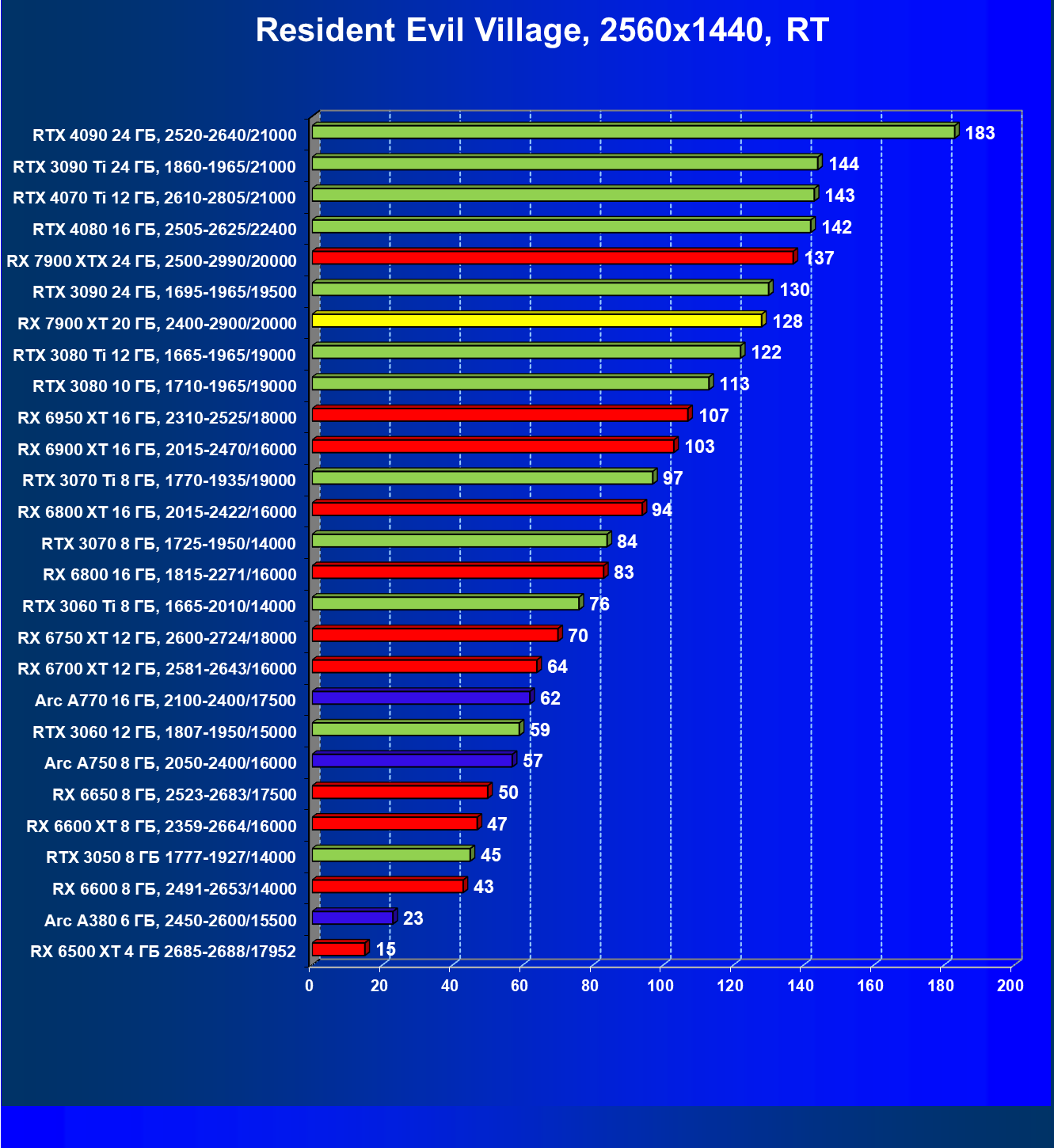
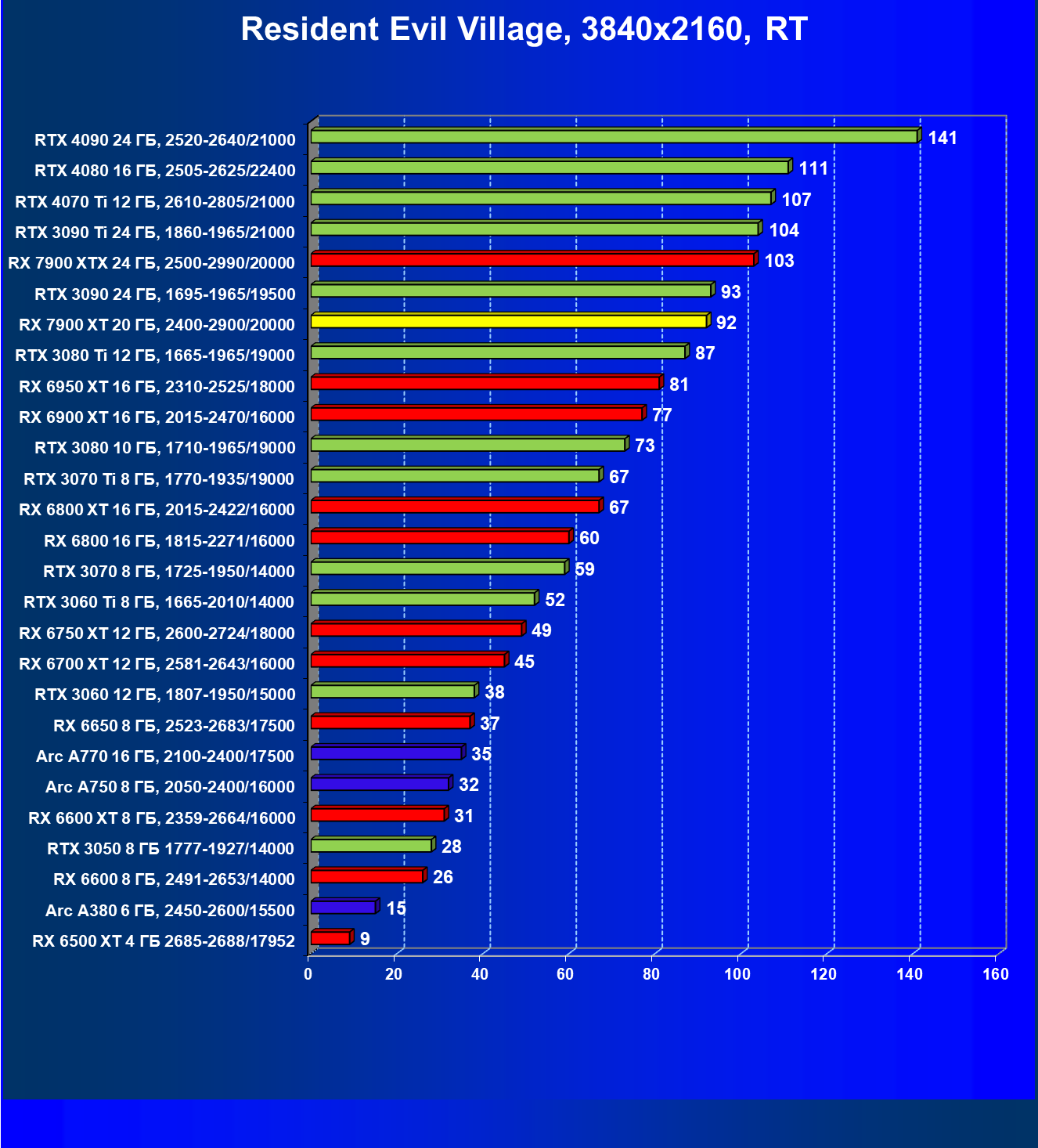
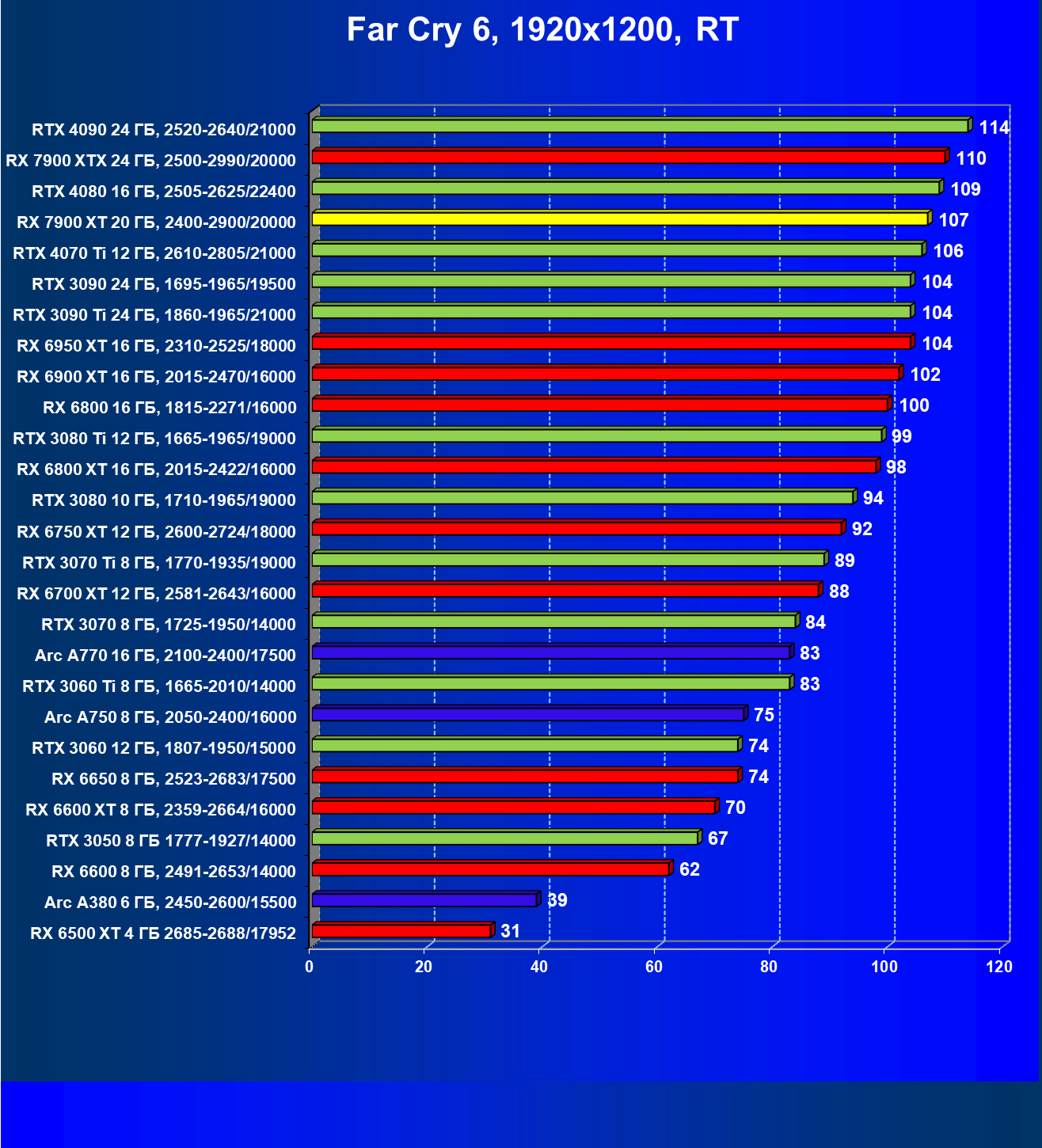
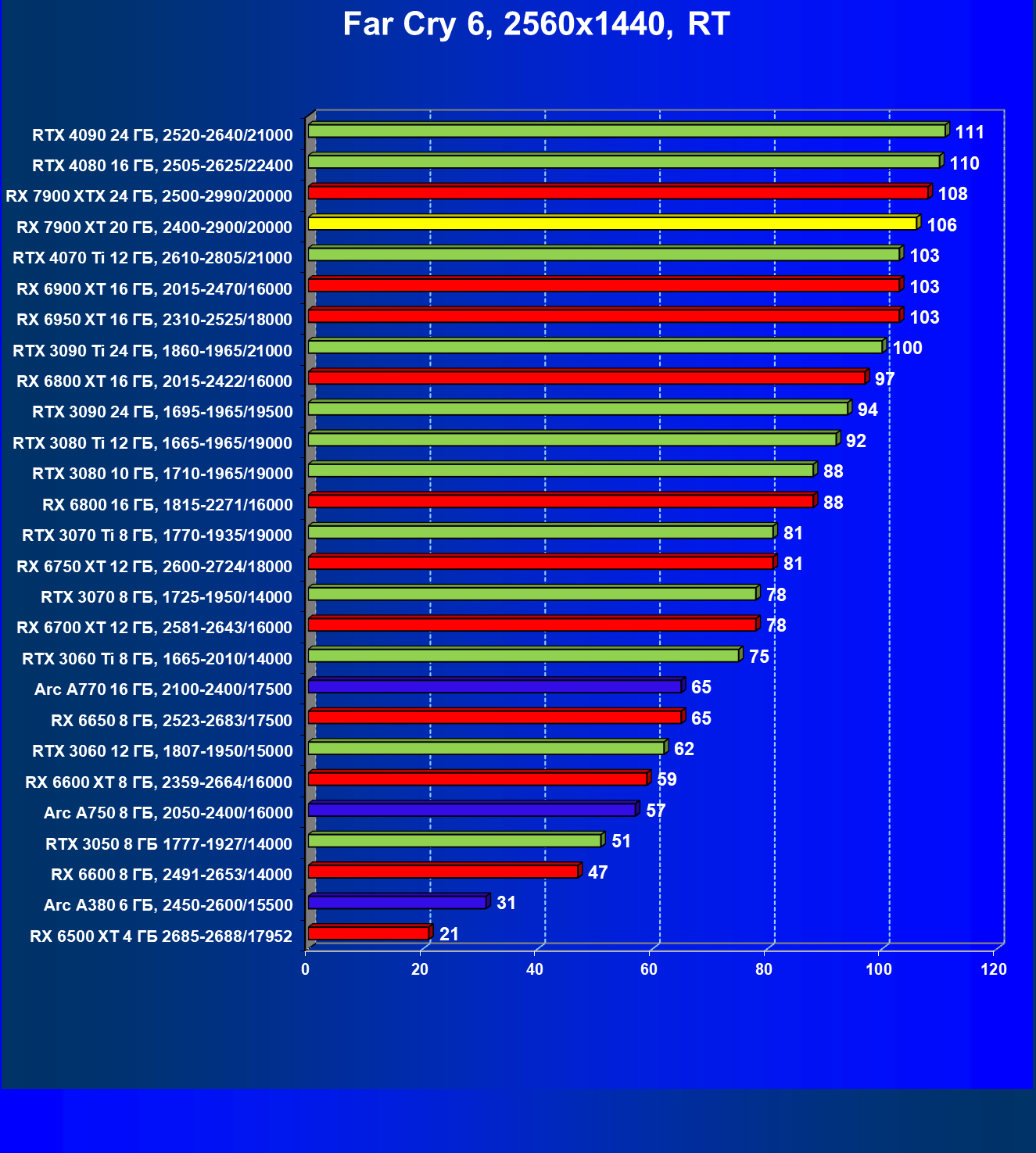
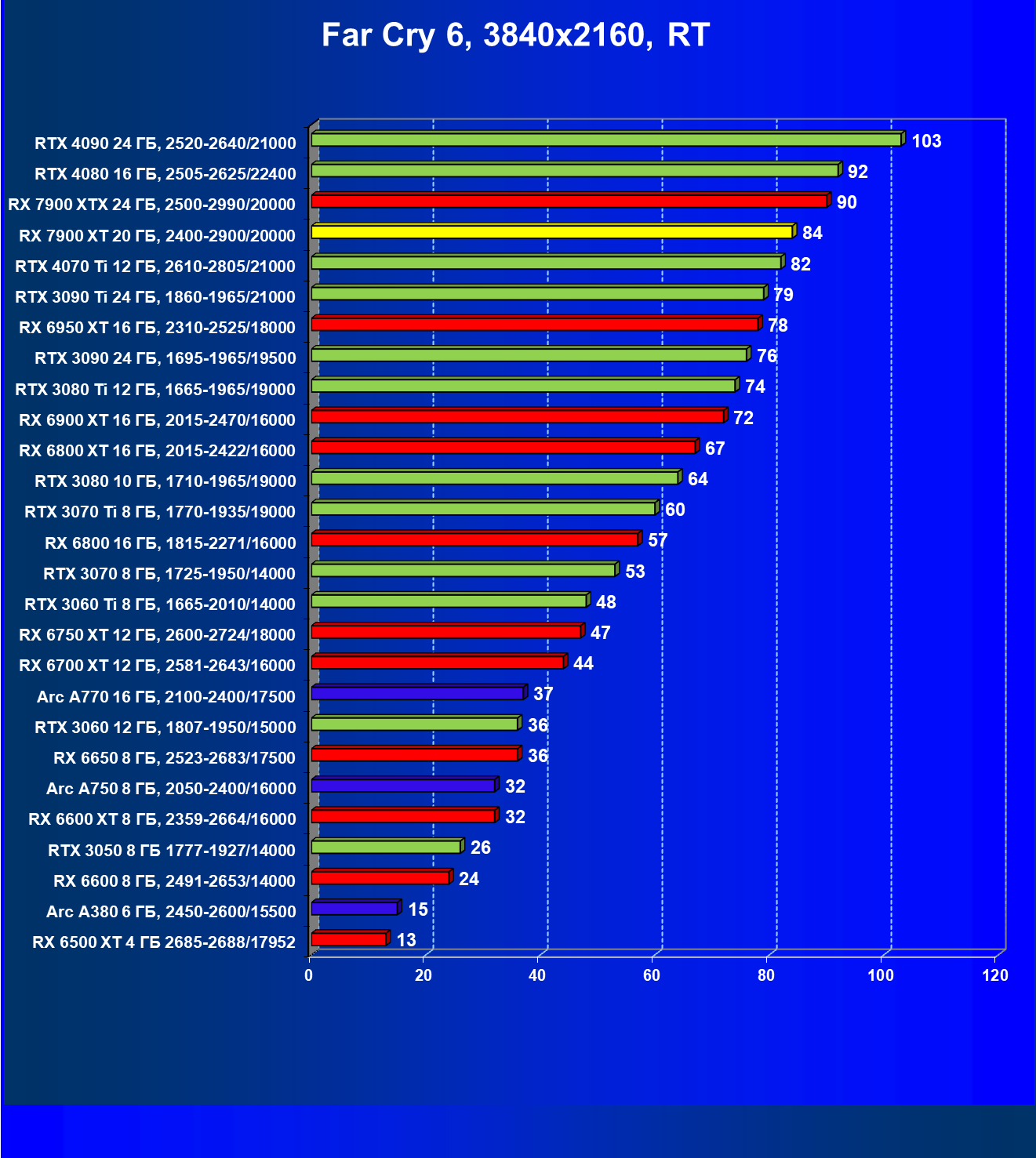
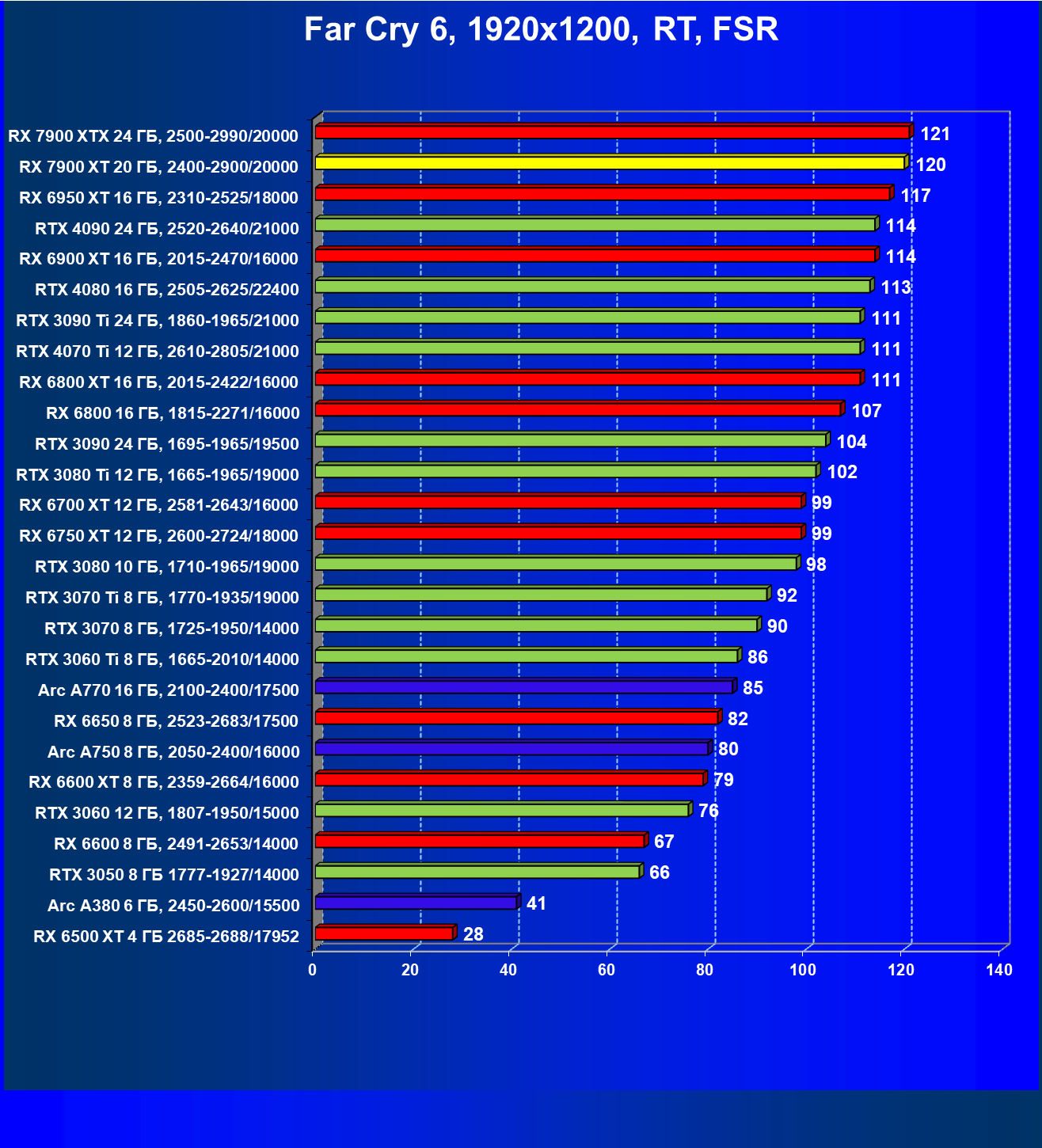
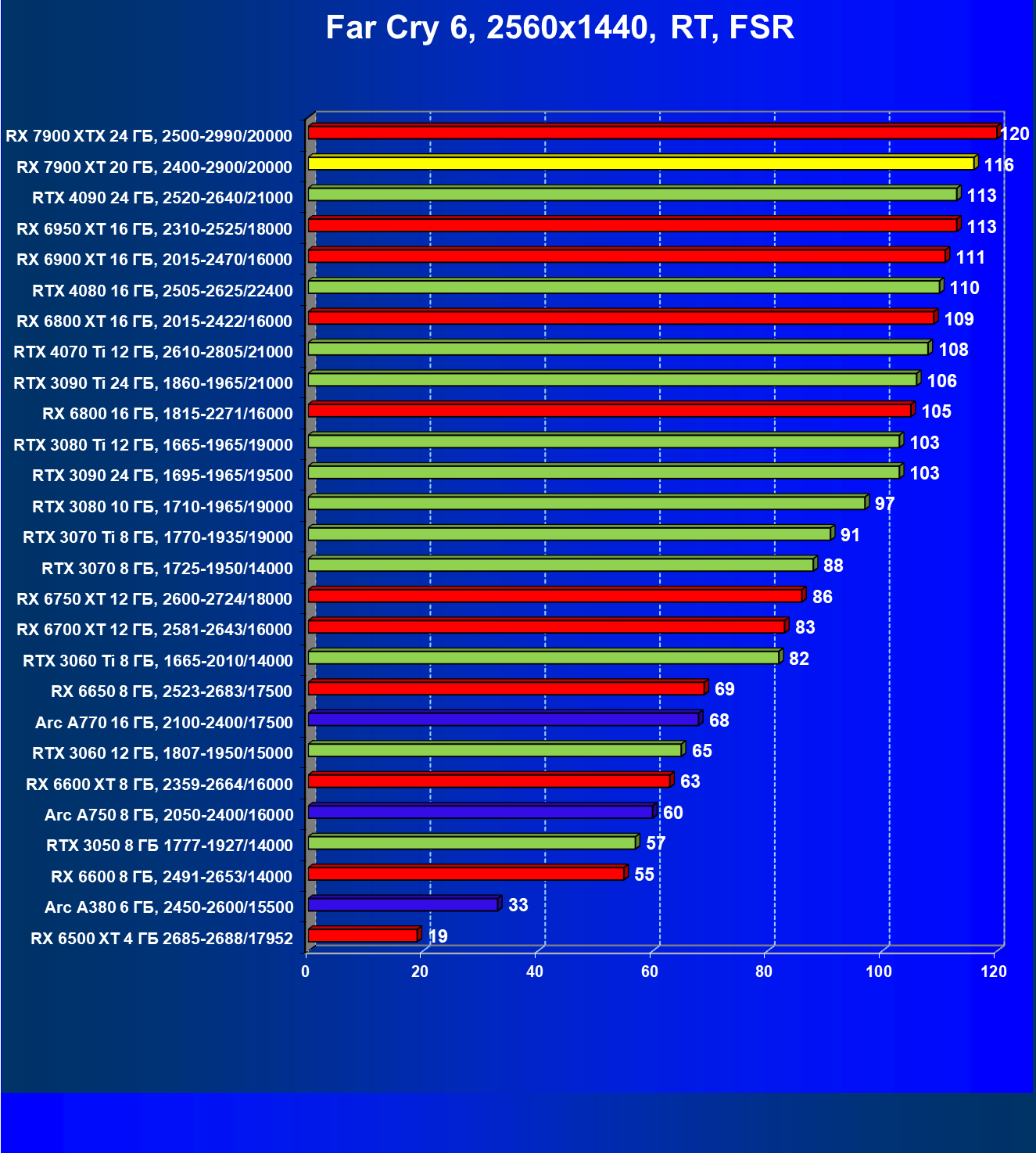
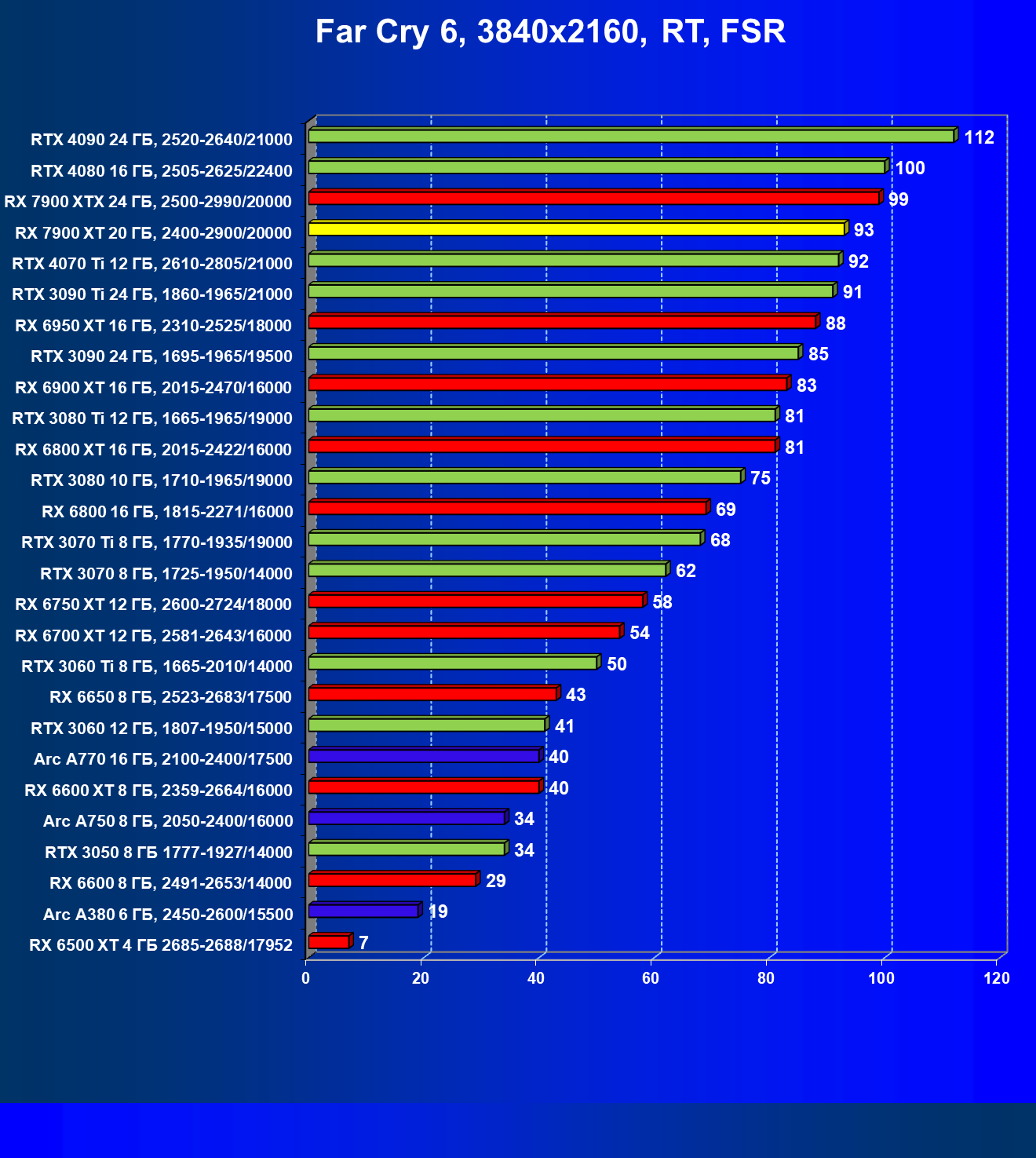
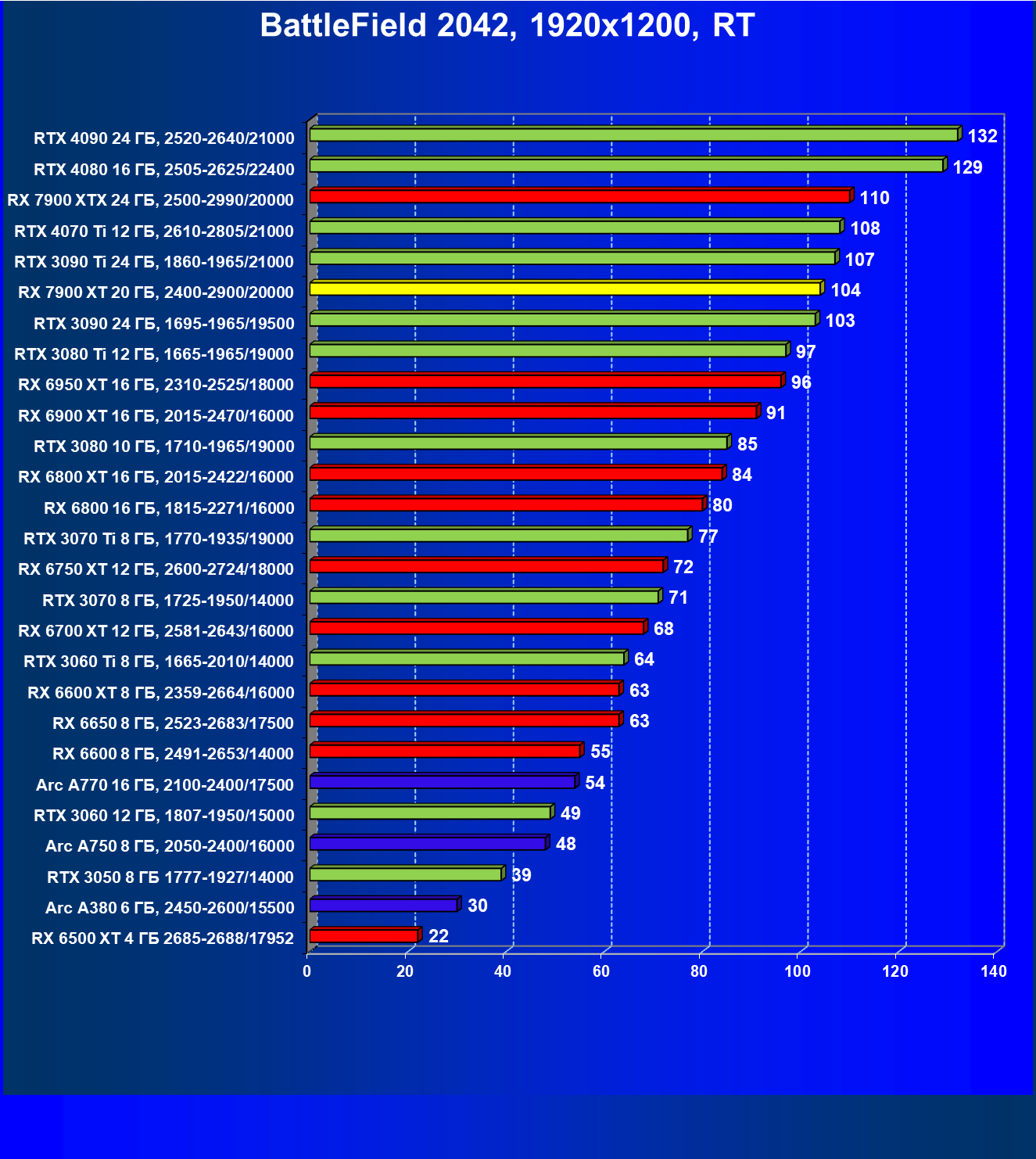
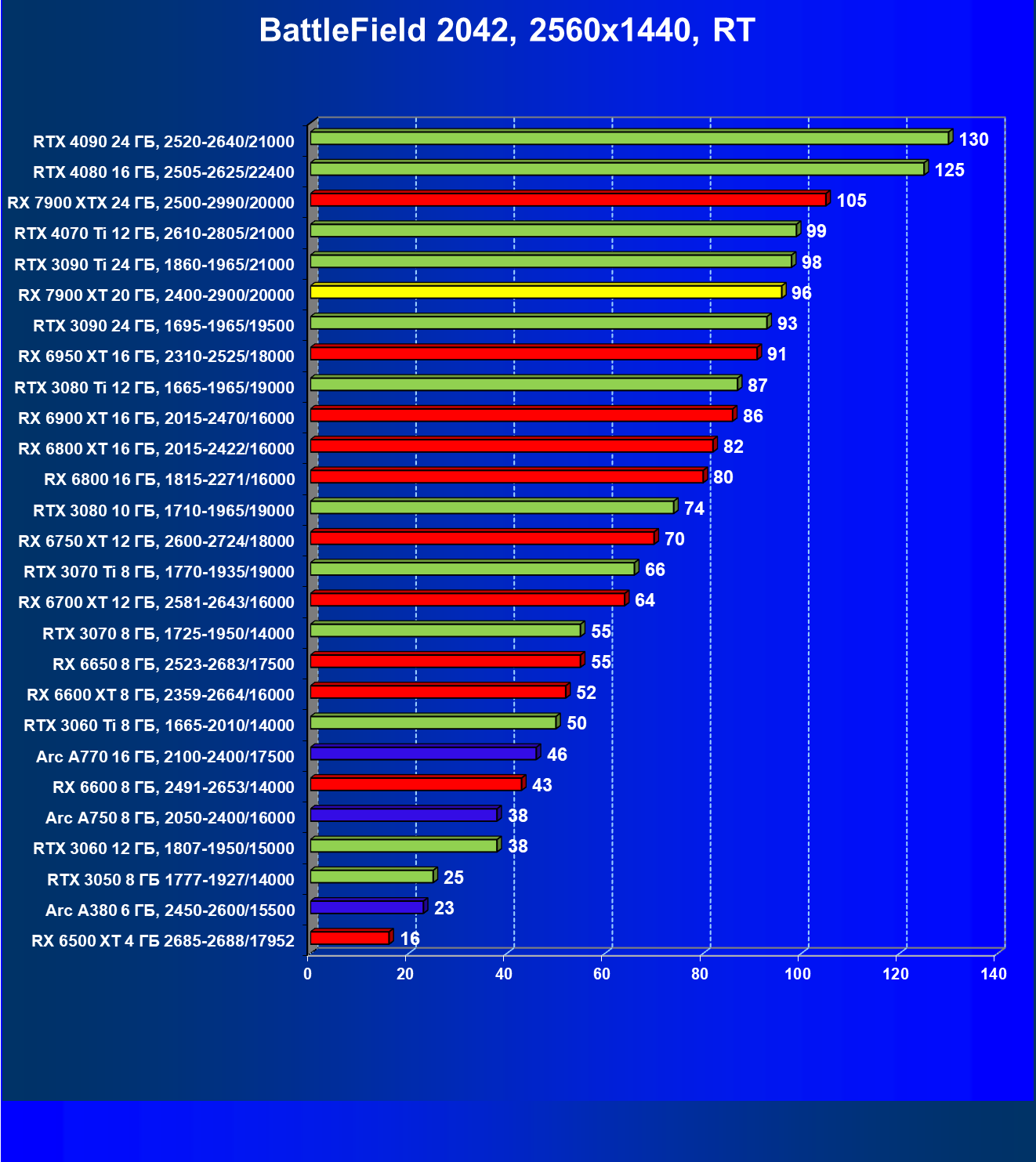
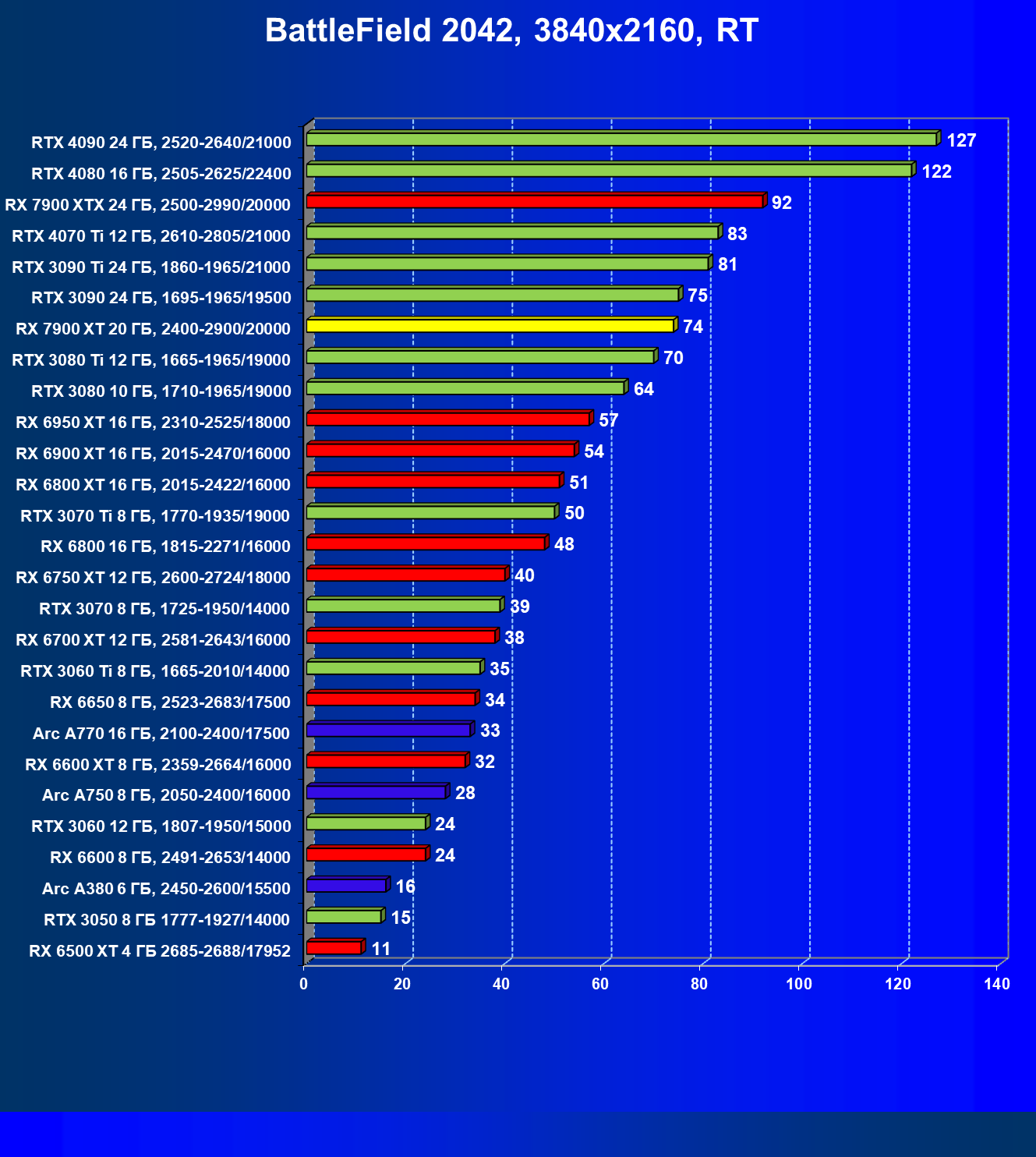
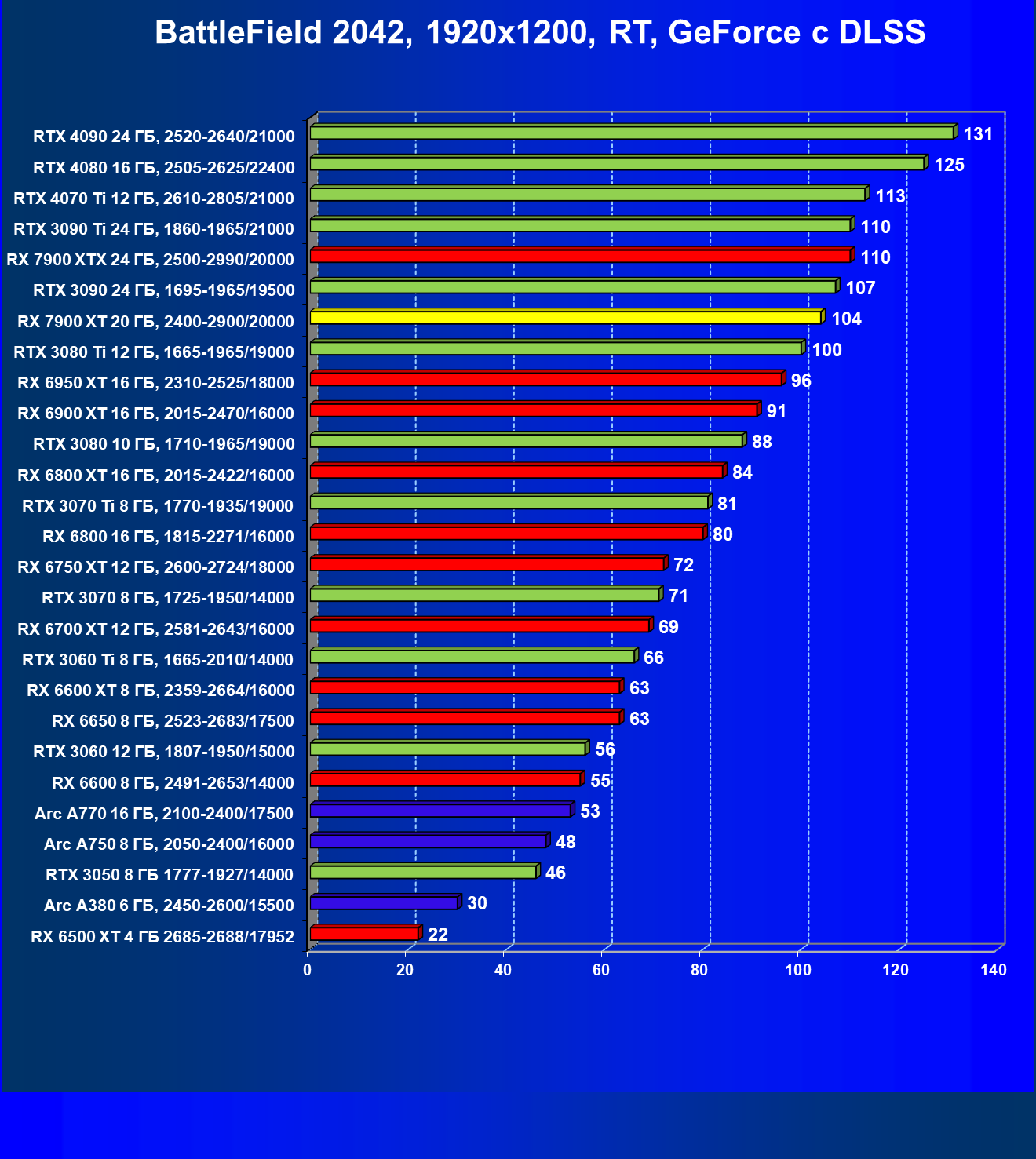
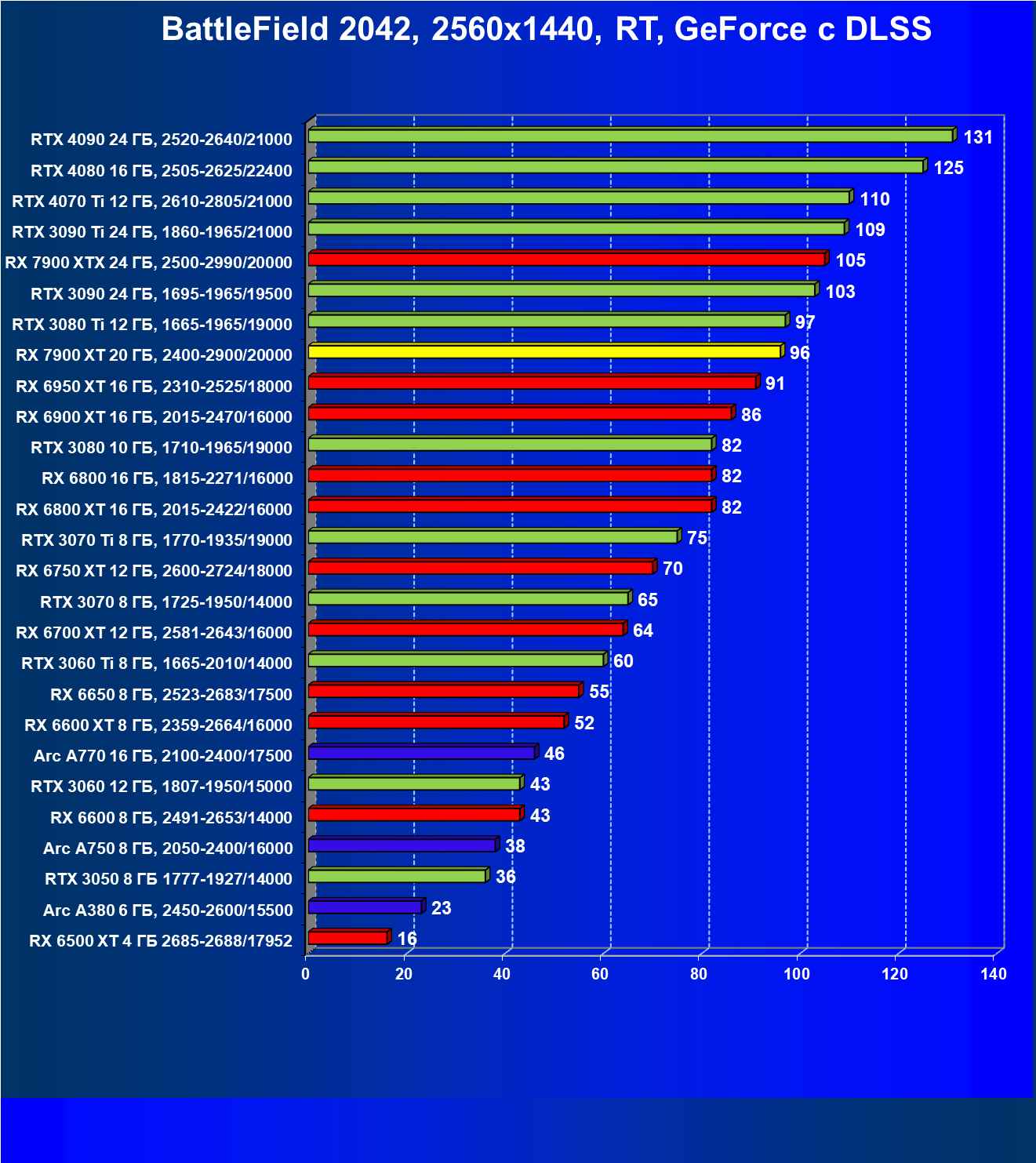
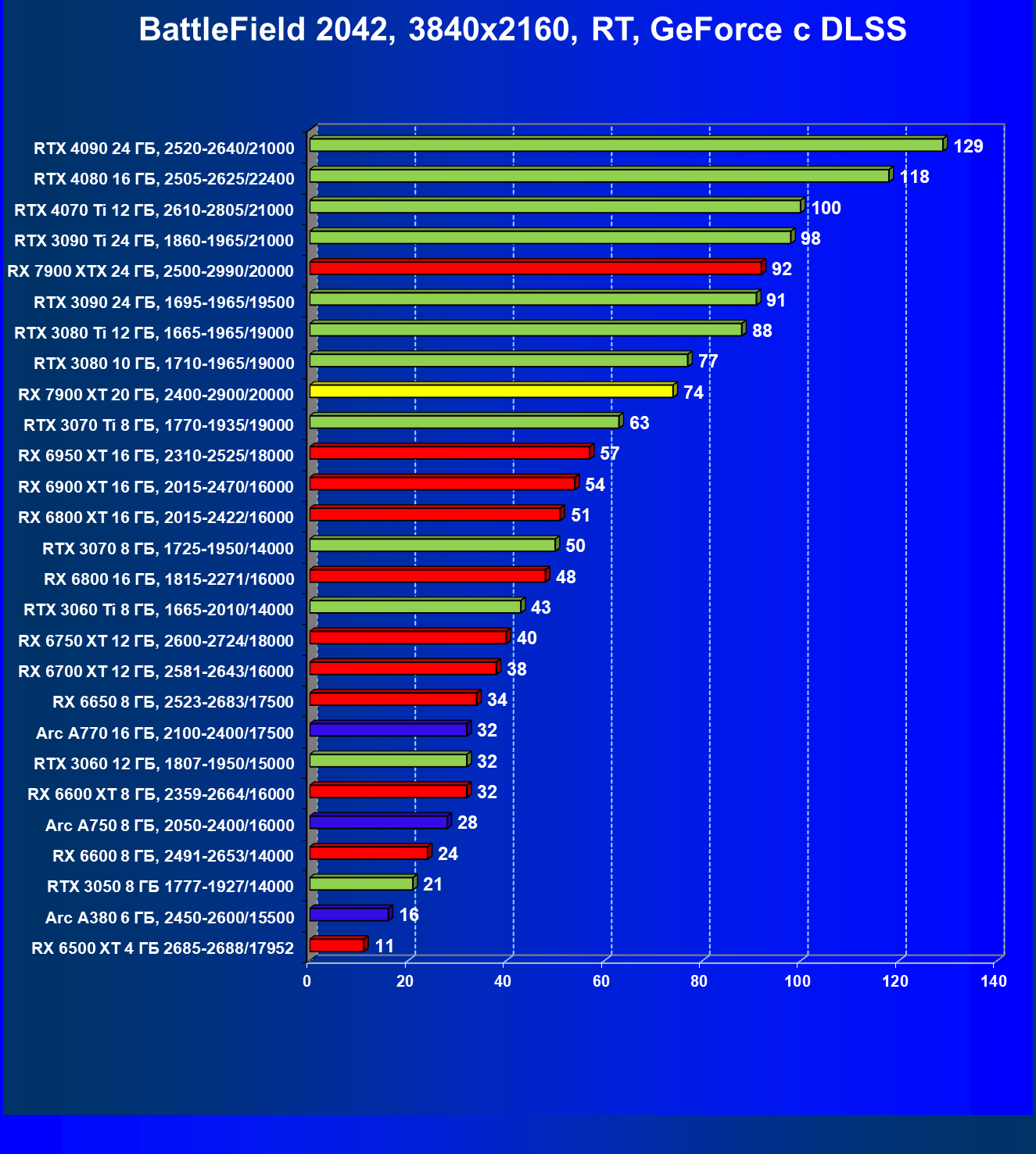
Результаты тестов с включенной аппаратной трассировкой лучей и DLSS/FSR в разрешении 7680×4320 (8К)
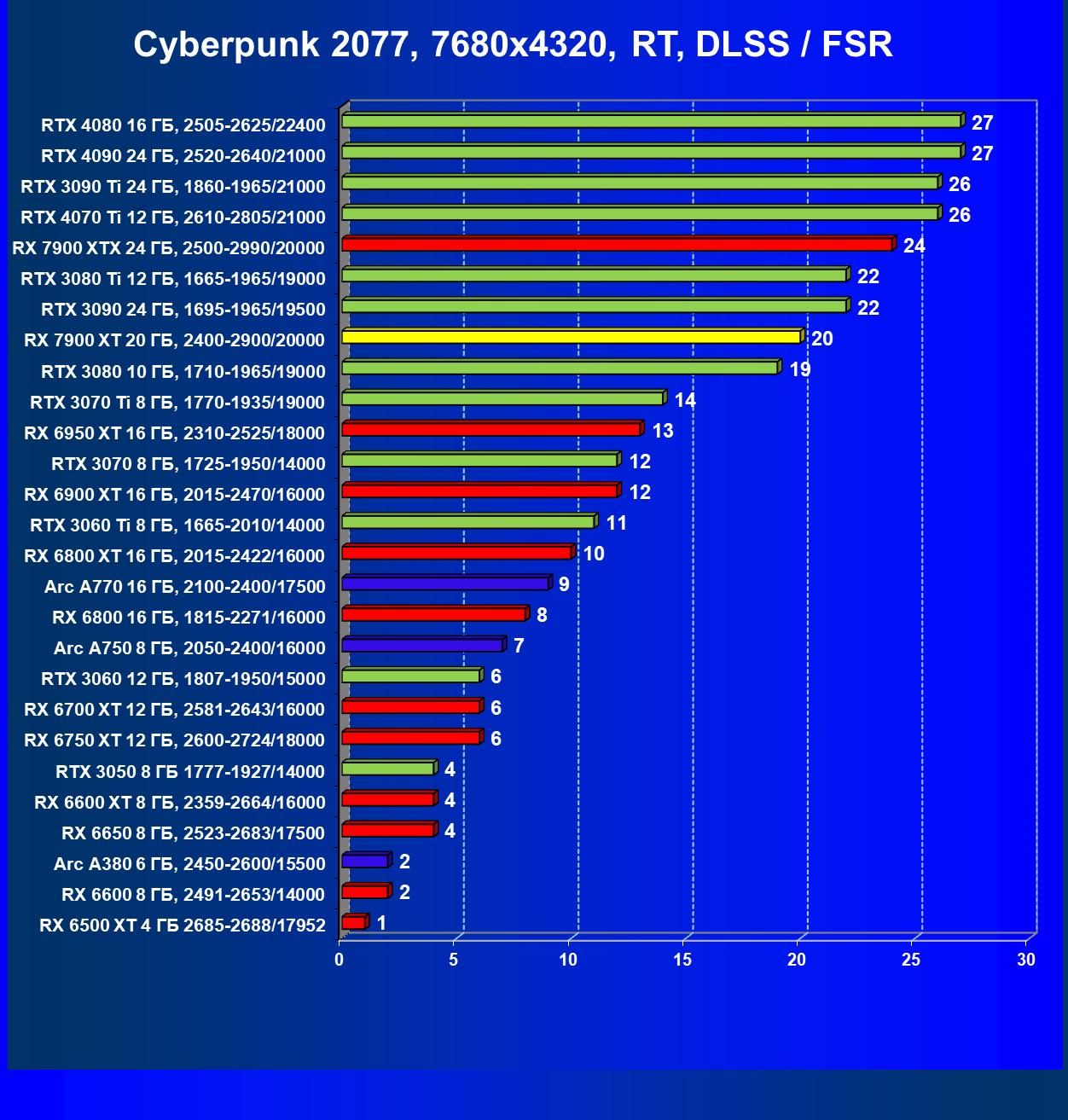
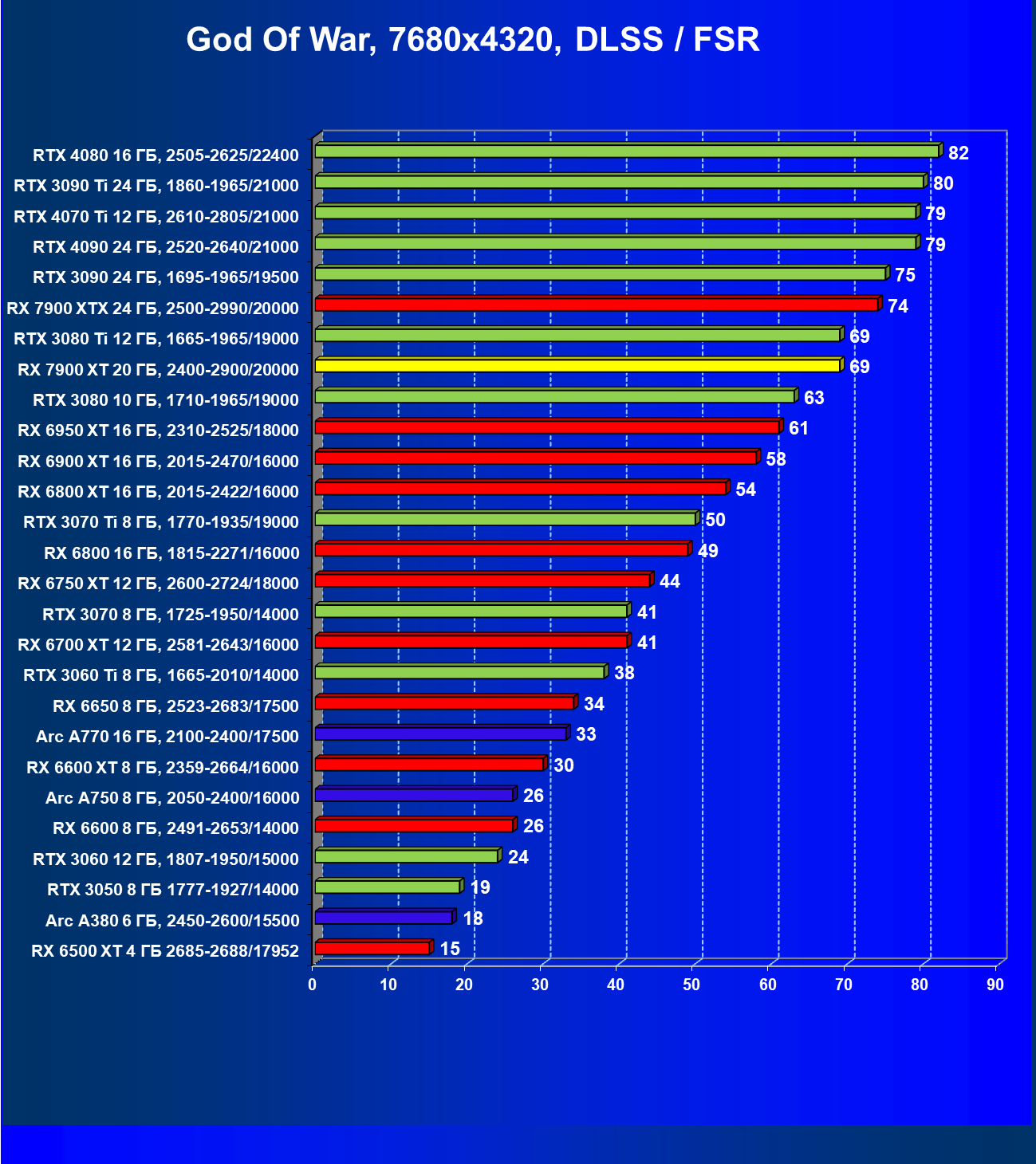
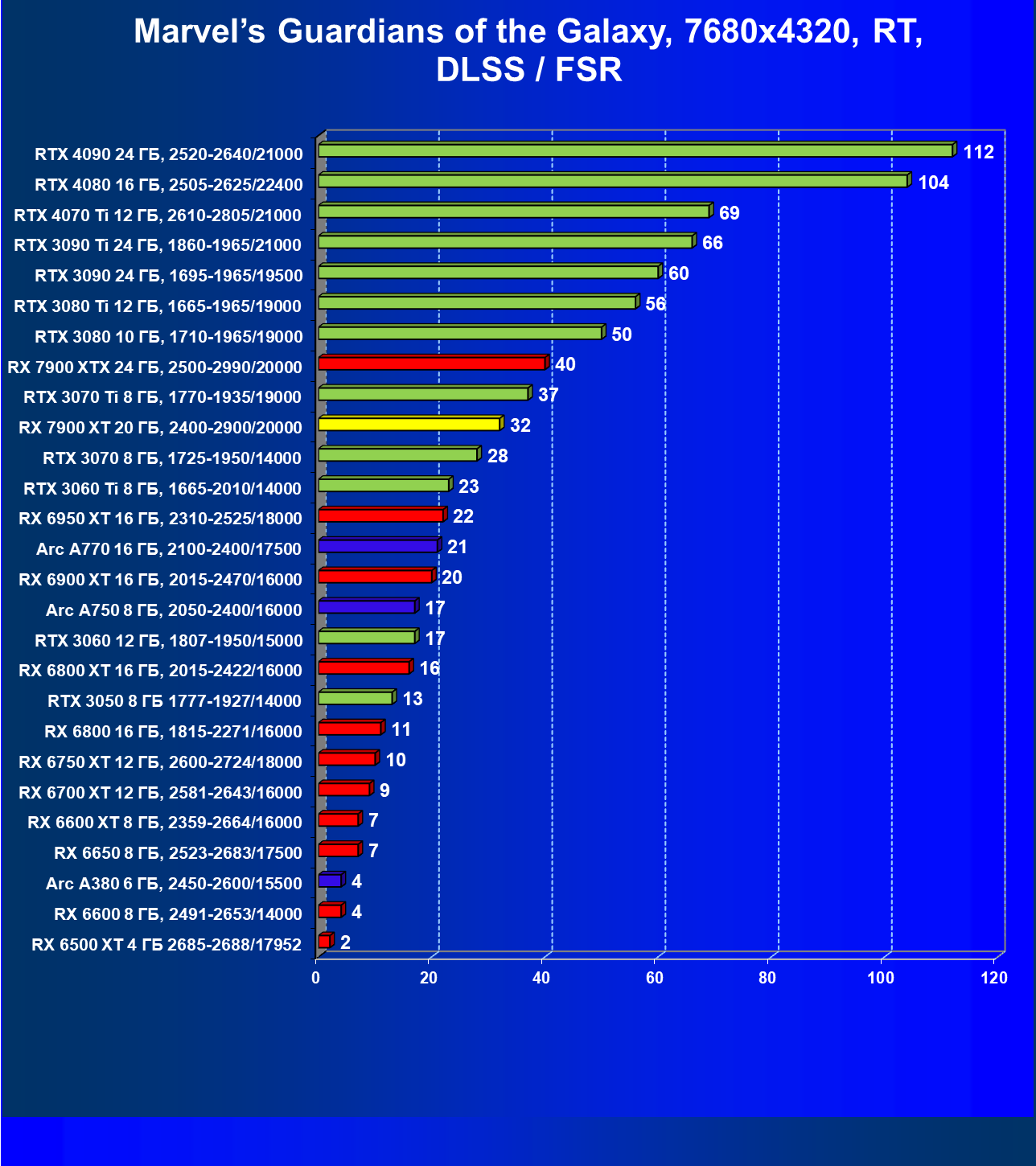
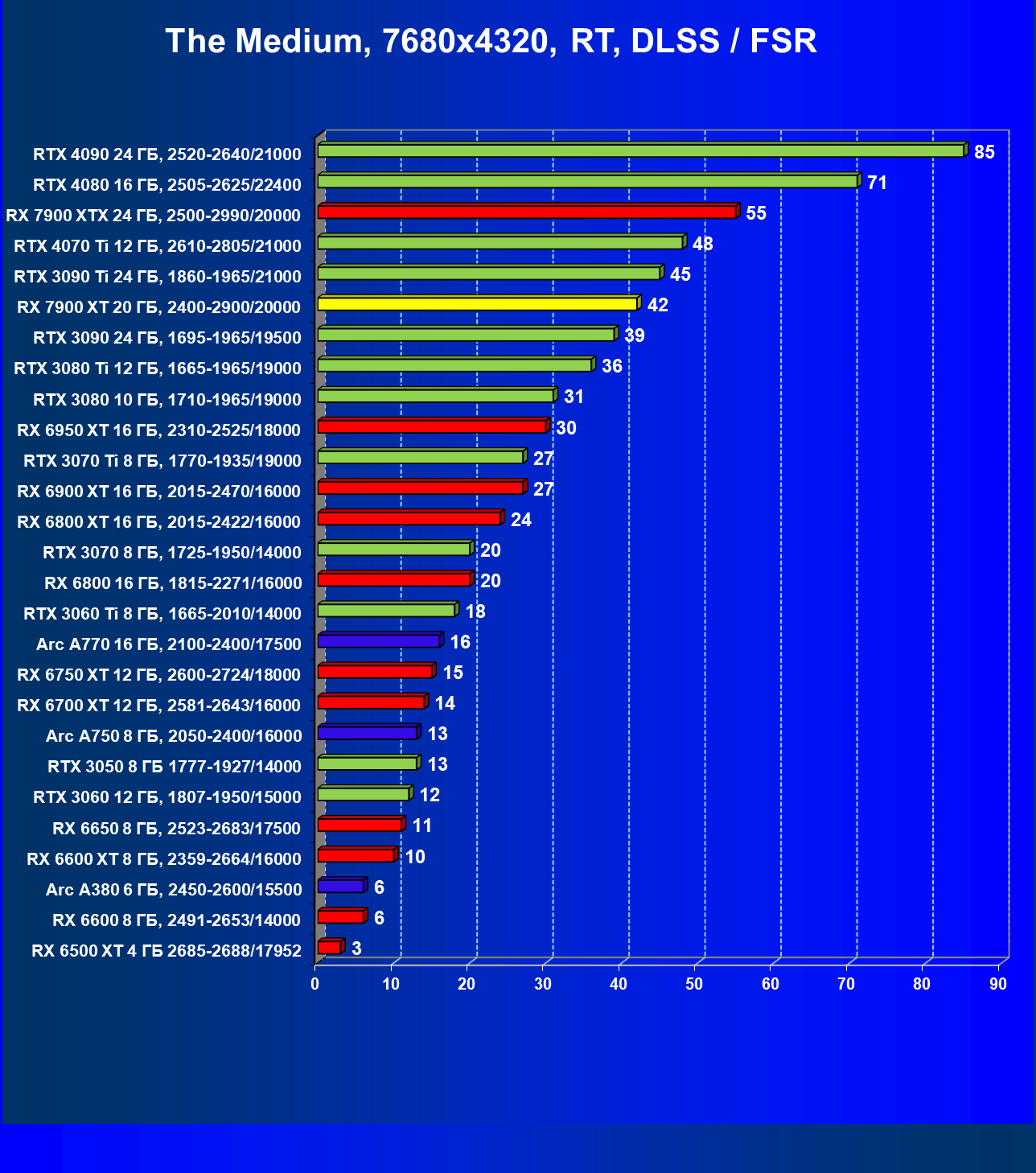
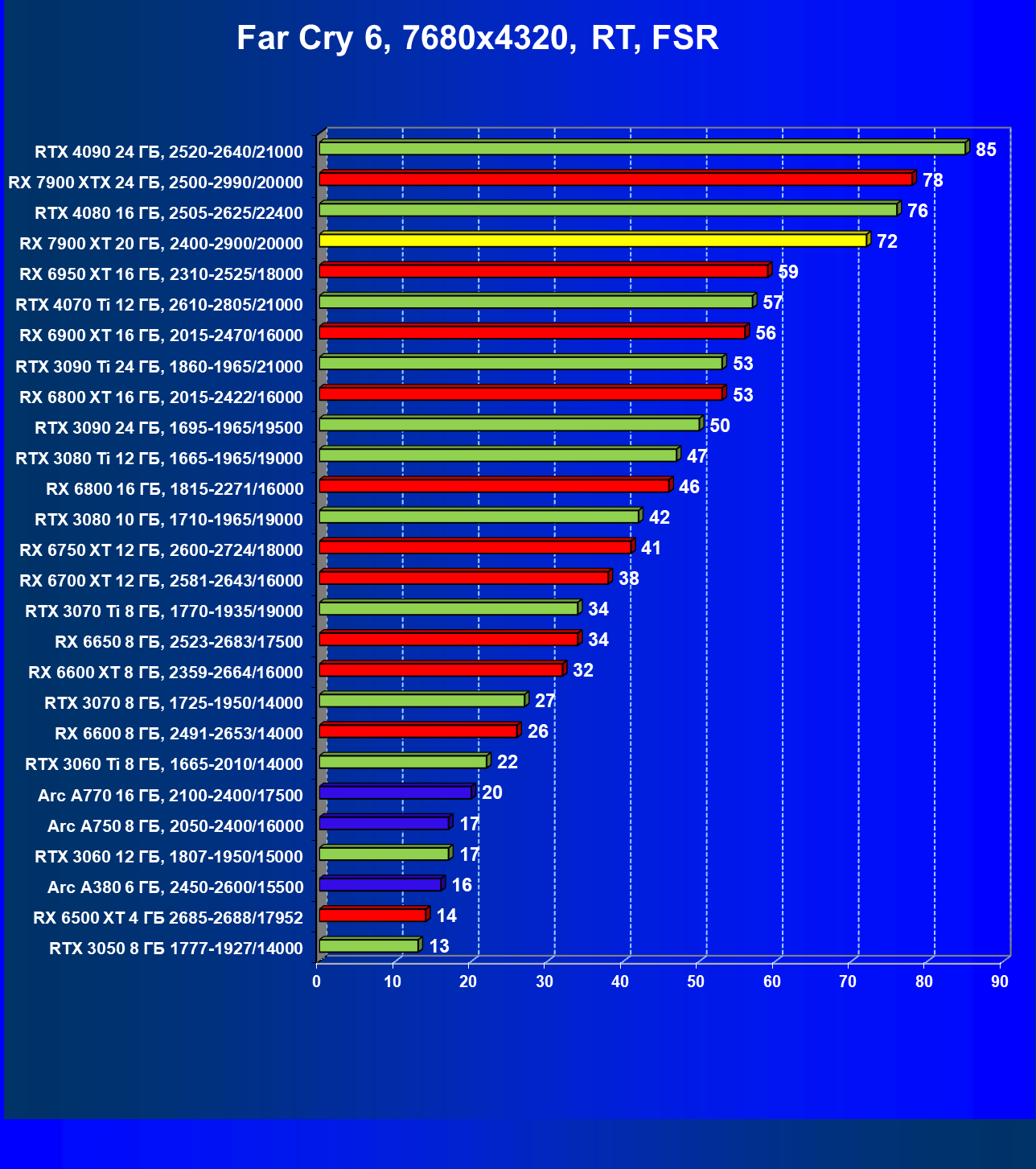
Сегодня нормально поиграть в таком разрешении можно только на самых флагманских и дорогих видеокартах, да и то для приемлемого комфорта требуется обязательное использование DLSS (или FSR). В итоге поиграть в таком разрешении всё же можно, хотя и далеко не во все игры.

Рейтинг ускорителей iXBT.com демонстрирует нам функциональность видеокарт друг относительно друга и представлен в двух вариантах:
- Вариант рейтинга iXBT.com без включения RT
Рейтинг составлен по всем тестам без использования технологий трассировки лучей. Этот рейтинг нормирован по наиболее слабому ускорителю из группы карт — Radeon RX 6500 XT (то есть сочетание скорости и функций Radeon RX 6500 XT приняты за 100%). Рейтинги ведутся по 27 ежемесячно исследуемым нами акселераторам в рамках проекта Лучшая видеокарта месяца. В данном случае из общего списка выбрана группа карт для анализа, в которую входят Radeon RX 7900 XT и его конкуренты.
Рейтинг приведен суммарно для всех трех разрешений.
| № | Модель ускорителя | Рейтинг iXBT.com | Рейтинг полезности | Цена, руб. |
|---|---|---|---|---|
| 03 | RTX 4080 16 ГБ, 2505—2625/22400 | 518 | 53 | 98 000 |
| 04 | RX 7900 XT 20 ГБ, 2400—2900/20000 | 494 | 55 | 90 000 |
| 05 | RTX 4070 Ti 12 ГБ, 2610—2805/21000 | 477 | 56 | 85 000 |
| 06 | RTX 3090 Ti 24 ГБ, 1860—1965/21000 | 474 | 48 | 99 500 |
| 07 | RX 6950 XT 16 ГБ, 2310—2525/18000 | 450 | 54 | 83 100 |
В целом по всем тестам и разрешениям Radeon RX 7900 XT опережает конкурента в лице GeForce RTX 4070 Ti на 3,5%, однако он и чуть дороже. А вот предыдущий флагман AMD — Radeon RX 6950 XT — отстал от Radeon RX 7900 XT уже почти на 10% (при этом Radeon RX 7900 XT в новом поколении — не самый топовый продукт). Еще более дорогой GeForce RTX 4080 логично оказывается выше всех в этом рейтинге.
- Вариант рейтинга iXBT.com с включением RT/DLSS/FSR
Рейтинг составлен по 9 тестам, в которых используется технология трассировки лучей и одновременно технология Nvidia DLSS, AMD FSR или Intel XeSS. Этот рейтинг нормирован по самому слабому ускорителю в данной группе — Radeon RX 6500 XT (то есть сочетание скорости и функций Radeon RX 6500 XT приняты за 100%).
Рейтинг приведен суммарно для всех трех разрешений.
| № | Модель ускорителя | Рейтинг iXBT.com | Рейтинг полезности | Цена, руб. |
|---|---|---|---|---|
| 04 | RTX 4070 Ti 12 ГБ, 2610—2805/21000 | 805 | 95 | 85 000 |
| 05 | RTX 3090 Ti 24 ГБ, 1860—1965/21000 | 786 | 79 | 99 500 |
| 06 | RX 7900 XT 20 ГБ, 2400—2900/20000 | 751 | 83 | 90 000 |
| 07 | RTX 3090 24 ГБ, 1695—1965/19500 | 730 | 78 | 93 000 |
| 09 | RX 6950 XT 16 ГБ, 2310—2525/18000 | 652 | 78 | 83 100 |
Видно, что в поколении Radeon RX 7000 специалисты AMD немного улучшили положение дел с падением производительности при включении трассировки лучей. В частности, в тестах без RT наш сегодняшний испытуемый опережал Radeon RX 6950 XT на 10%, а при включении RT и FSR оказывается быстрее уже на 15%. Однако падение производительности все-таки есть, и оно сильнее, чем у видеокарт семейства GeForce RTX. Поэтому в данном случае ускоритель Radeon RX 7900 XT на 7% отстает от GeForce RTX 4070 Ti, а также уступает флагману Nvidia предыдущего поколения — GeForce RTX 3090 Ti.
Рейтинг полезности тех же карт получается, если показатель предыдущего рейтинга разделить на цены соответствующих ускорителей. Для расчета рейтинга полезности использованы розничные цены на январь 2023 года. Учитывая нацеленность RX 7900 XT на разрешение 4К, мы привели рейтинг, подсчитанный только при использовании разрешения 3840×2160. Поэтому цифры отличаются от рейтинга iXBT.com.
- Вариант рейтинга полезности без включения RT
| № | Модель ускорителя | Рейтинг полезности | Рейтинг iXBT.com | Цена, руб. |
|---|---|---|---|---|
| 13 | RX 7900 XT 20 ГБ, 2400—2900/20000 | 86 | 770 | 90 000 |
| 16 | RTX 4070 Ti 12 ГБ, 2610—2805/21000 | 85 | 720 | 85 000 |
| 23 | RX 6950 XT 16 ГБ, 2310—2525/18000 | 77 | 644 | 83 100 |
| 25 | RTX 3090 Ti 24 ГБ, 1860—1965/21000 | 72 | 714 | 99 500 |
| 26 | RTX 3090 24 ГБ, 1695—1965/19500 | 70 | 650 | 93 000 |
Удивительно, но факт: даже с завышенной ценой Radeon RX 7900 XT оказался лидером группы. Поясним, что стоимость таких карт пока чрезмерно высока, поскольку они почти не представлены на отечественном рынке: официальные поставки «универсальных» производителей (Asus/MSI/Gigabyte) очень скромные, а партнеры самой AMD (Sapphire, PowerColor) вообще держат паузу, официальных поставок нет вовсе. Поэтому пока Radeon RX 7000 можно купить в основном только на маркетплейсах типа Ozon и Avito, где ценники высоки из-за малого количества товара.
- Вариант рейтинга полезности с включением RT
| № | Модель ускорителя | Рейтинг полезности | Рейтинг iXBT.com | Цена, руб. |
|---|---|---|---|---|
| 06 | RTX 4070 Ti 12 ГБ, 2610—2805/21000 | 149 | 1270 | 85 000 |
| 17 | RX 7900 XT 20 ГБ, 2400—2900/20000 | 124 | 1112 | 90 000 |
| 18 | RTX 3090 Ti 24 ГБ, 1860—1965/21000 | 123 | 1228 | 99 500 |
| 21 | RTX 3090 24 ГБ, 1695—1965/19500 | 119 | 1110 | 93 000 |
| 25 | RX 6950 XT 16 ГБ, 2310—2525/18000 | 107 | 892 | 83 100 |
В рейтинге полезности с учетом игр с трассировкой лучей ситуация для карт AMD похуже, и хотя Radeon RX 7900 XT удалось опередить флагмана предыдущего поколения Nvidia, новый GeForce RTX 4070 Ti выглядит существенно привлекательнее.
AMD Radeon RX 7900 XT (20 ГБ) — второй по старшинству ускоритель в топовом сегменте нового поколения AMD Radeon RX 7000, примерно соответствующий по скорости ускорителю GeForce RTX 4070 Ti от Nvidia.
Ранее мы уже видели графические чипы с несколькими кристаллами, но это были очень дорогие решения, где GPU упаковывались в один чип вместе с памятью HBM. Теперь же мы впервые видим сам GPU с чиплетной компоновкой, состоящий из нескольких кристаллов (ранее AMD выпустила чиплетные центральные процессоры).

Такая компоновка усложнила процесс формирования чипов из кристаллов, однако позволила AMD получать более высокий процент годных кристаллов (каждый из них не столь сложен, как ранее, когда весь GPU размещался в едином кристалле), а также повысить частотные показатели работы ядер.
Графическая архитектура RDNA3 войдет в историю уже только из-за того, что именно на ней основан первый GPU, использующий чиплетную компоновку. Это важный шаг, к которому шли уже несколько лет, так как производство очень больших однокристальных чипов стоит дорого, а разделение на несколько более мелких помогает снизить себестоимость. Кроме того, становится возможно сочетать в одном чипе несколько кристаллов, произведенных при использовании различных техпроцессов. Компания AMD сделала подобный шаг в процессорах еще несколько лет назад, выпустив Ryzen на основе чиплетной компоновки, и это принесло им определенный успех. Теперь они сделали почти то же самое и с GPU, что должно позволить им сэкономить на производстве.
При помощи RDNA3 компания AMD планирует развить успех RDNA2, добавив архитектурные улучшения и оптимизации, направленные на повышение производительности и эффективности, помимо увеличения количества исполнительных блоков и роста тактовой частоты. В последнем им помогла физическая реализация: AMD перешла на современный техпроцесс TSMC, обеспечивший высокую плотность транзисторов и увеличенное количество исполнительных блоков при той же площади на кристалле. Также вычислительные блоки получили увеличенный объем регистрового файла и возможность двойного выпуска инструкций, хоть и ограниченную, но зато при небольших накладных расходах. А из улучшений функциональности отметим модернизированные блоки трассировки лучей, а также возможность организации вычислительных блоков для более эффективных матричных вычислений. Также в Navi 31 улучшились возможности по обработке видеоданных и выводу информации на дисплеи — и сейчас этот графический процессор имеет лучшие характеристики среди всех GPU на рынке.
Radeon RX 7900 XT стал отличным конкурентом для GeForce RTX 4070 Ti, в играх с растеризацией обходя соперника, а в играх с RT немного отставая от него. В целом можно сказать, что они примерно равны. Пока цены новинок AMD на нашем рынке высоковаты из-за запоздалого появления этих карт, но рано или поздно они должны придти в норму, и тогда Radeon RX 7900 XT должен оказаться примерно равен GeForce RTX 4070 Ti и по цене. При этом Radeon RX 7900 XT обладает 20 ГБ памяти против 12 ГБ у соперника, хотя это скорее неустранимая особенность логической организации чипа, чем осмысленное решение. Ведь даже в разрешении 4K двенадцати гигабайт локальной памяти хватит всем играм на 2-3 года вперед, так что больший объем памяти у продукта AMD не становится реальным конкурентным преимуществом.
Ранее в случаях с GeForce RTX 4080/4090 изюминкой нового ускорителя мы называли поддержку разрешения 8К, поскольку даже GeForce RTX 4080 уже обладает достаточной производительностью, чтобы некоторые игры с использованием DLSS обеспечивали игроку нормальный комфорт на максимальных настройках графики в 8К (а когда в игры массово внедрят поддержку DLSS 3, комфорт станет еще выше). В принципе, GeForce RTX 4070 Ti и Radeon RX 7900 XT всё еще могут условно входить в число ускорителей, обеспечивающих приемлемый FPS в таком разрешении, но таких игр уже наберется немного. И как раз широкое внедрение DLSS 3 поможет GeForce RTX 4070 Ti сильно выиграть у соперника. Правда, пока внедрение DLSS 3 продвигается весьма медленно.

Конкретная протестированная нами видеокарта XFX Radeon RX 7900 XT (20 ГБ) является, по сути, референсной картой, поэтому долго обсуждать ее не имеет смысла: такие модели обычно можно купить только в первых партиях, затем они пропадают из продажи и уступают место картам собственного дизайна каждого из производителей, в том числе XFX. Кратко можно сказать, что СО здесь весьма мощная, нагрев ядра при длительной стрессовой нагрузке не превышает 70 градусов, но и работает СО с отчетливо слышным шумом. Размеры карты стандартны, их нельзя назвать большими в сравнении с аналогами того же уровня производительности. Карта может потреблять до 315-320 Вт, она требует использовать два 8-контактных разъема питания.
Отметим еще раз, что Radeon RX 7900 XT отлично подходит для классических игр (без трассировки лучей) в разрешении 4К с максимальным качеством графики, а также для игр с трассировкой лучей в том же разрешении, но обязательно совместно с FSR. Также отметим поддержку стандарта DisplayPort 2.1.
Справочные материалы:
Комментарии