Поскольку процессоры в плане производительности ушли далеко вперед, ребром встал вопрос о создании архитектуры памяти, способной обеспечить требуемый уровень пропускной способности, чтобы не сдерживать основную подсистему (процессор). Ключевыми моментами при разработке новой архитектуры памяти стали повышение частоты передачи данных, обеспечение минимальных задержек, создание максимально гибкой и масштабируемой архитектуры и обеспечение доступной цены.
На протяжении почти двадцати лет развития компьютерной индустрии сменилось только девять поколений динамического ОЗУ (DRAM Dynamic Random Access Memory). Производительность самого ядра ДОЗУ в последнее время изменяется крайне слабо из-за технологических "узких мест", а альтернативы нынешнему строительному элементу ячейки (ключ с емкостью) в ближайшем будущем не предвидится. Единственная возможность несколько улучшить производительность ядра использовать более совершенные проектные нормы изготовления кристалла (уменьшение занимаемой площади) и улучшать фрагментацию матрицы массива (увеличение плотности размещения строительных элементов и оптимизация внутренней схемотехники). Поэтому разработчики современных типов динамической памяти сосредоточили внимание на внутренней логике, что постоянно подталкивает их к совершенствованию как внутреннего, так и внешнего интерфейса это и использование многобанковой архитектуры, и введение новых питающих протоколов, и использование всевозможных внутренних блоков контроля состояния, и переход на новые разновидности упаковки микросхем, и т.д. все уже известные приемы.
Как известно, основным решением для увеличения пропускной способности любого интерфейса является увеличение частоты функционирования и/или ширины шины в виде зависимости: BW = MHz x Bit. Однако при нынешнем технологическом уровне невозможно сколь угодно расширять шину и увеличивать частоту, поскольку в определенной "точке" увеличения начинают достаточно сильно проявляться паразитные индуктивности (влияет сильнее, чем паразитная емкость), ВЧ-шумы и электромагнитная интерференция, и теперь разработчики уже вынуждены искать альтернативные варианты варьирования этих двух составляющих. Так, например, архитектура и структура стандартного синхронного ДОЗУ (SDRAM) при нынешней технологии себя практически исчерпала уже на коммутациях чуть более 200MHz, и с уменьшением нормы производства кристалла значительно поднять частоту уже не удается сказываются влияния тех факторов, речь о которых шла выше.
На сегодняшний день ЦП содержит 16-128 KB чрезвычайно высокоскоростной кэш-памяти первого уровня (L1) с очень маленькой задержкой, предназначенной для инструкций и данных (если придерживаться "гарвардской" архитектуры), которая работает на полной частоте процессора это дает вероятность более 90%, что процессор будет постоянно получать необходимые данные и не будет тратить время на ожидание. Внутренняя или внешняя 64/128/256 bit шина соединяет кристалл процессора со вторичным кэшем (L2), обычно работающим на полной частоте или на половине частоты функционирования ядра ЦП, и имеющим объем 64-2048 KB. Опять же, вторичный кэш способствует обеспечению доставки данных, если произошел промах в L1, таким образом, компенсируя возможные "потери".
Современное синхронное ДОЗУ соединяется с процессором посредством 16/64 bit интерфейса через специальное коммуникационное логическое устройство мостового или хабового типа (компонент чипсета, отвечающий, в частности, за связанное функционирование основной подсистемы и подсистемы памяти объединенный контроллер основных подсистем), содержащее помимо контроллера памяти еще и другие логические блоки. Если не принимать во внимание "первые шаги" интерфейсов памяти, то вообще ДОЗУ эволюционировало от асинхронной EDO DRAM, проходя несколько усовершенствованный этап пакетного асинхронного BEDO DRAM, перевоплотясь в 66-, 100- и, наконец, 133MHz синхронное DRAM, до синхронного ДОЗУ с удвоенной частотой передачи данных DDR (Double Data Rate) SDRAM. Сигнальные протоколы, используемые в этих типах памяти менялись реже: от уже почти забытой "тяжелой" 5V транзисторно-транзисторной логики (TTL Transistor-Transistor Logic), через более ее низкоуровневый 3.3V усовершенствованный вариант (LVTTL Low-Voltage Transistor-Transistor Logic), до сегодняшней 2.5V терминируемой логики (SSTL Stub Series Terminated Logic) с маленькой разностью (Swing, именуемый также "размахом") между логическими уровнями.
Сегодня, благодаря высокой степени иерархии уровней (L1/L2/L3) подсистемы кэш-памяти, основное ДОЗУ может функционировать на частоте, значительно меньше результирующей (мультиплицированная частота основного интерфейса) частоты процессора без особых последствий для производительности системы. Несмотря на постоянное увеличение частоты функционирования ЦП, частота работы шины также должна увеличиваться реально, а не за счет умножения, поднимая производительность других подсистем. Архитектуры памяти следующего поколения пересматривают устоявшиеся традиционные методы упаковки микросхем, топологию и нормы производства монтажных печатных плат, и, наконец, культуру производства, потенциально сдерживающие до настоящего момента рост производительности подсистемы DRAM, выводя их на абсолютно новый уровень.
В настоящее время назрела необходимость в кардинальном пересмотре стратегии современной внешней и внутренней архитектуры ДОЗУ, принимая во внимание приводимую ранее зависимость и варьируя две составляющие в поиске оптимального соотношения, учитывая также уровень современной технологии. Естественно, что это совсем не главная (но явно стимулирующая) причина, по которой необходимо увеличивать производительность подсистемы памяти, поскольку основная это обеспечение постоянной доставки данных процессору, чтобы последний не простаивал в ожидании поступления информации на обработку. Отчетливо осознавая это, разработчики архитектур динамической памяти еще в начале 90-х годов конца прошлого тысячелетия разбились на два лагеря: одни пошли по пути увеличения частоты в ущерб ширине шины (RDRAM, RLDRAM и SLDRAM), другие наоборот (SDRAM, ESDRAM, HSDRAM, VCSDRAM, DDR SDRAM). Через некоторое время стало ясно, что вторые испытывают технологические затруднения, поскольку архитектура, которая легла в основу конечных продуктов, очень близко подошла к своему пределу стало крайне сильно сдерживать растущее влияние паразитных факторов, причем эффективность и загрузка протокола даже в настоящее время не могут подняться выше 70%. Кардинально противоположно ситуация складывается с первыми (точнее сказать, массовым продуктом пока стал только RDRAM, а остальные два до сих пор не выпускаются): уровень технологии того времени не давал возможности сделать продукты широкодоступными, однако эффективность и загрузка канала, благодаря сверхвысоким частотам (на настоящий момент синхронизация до 533MHz), достигает 98-100 %. Обратной же стороной медали является значительно более узкая шина данных (16/18 bit), чем у вторых. Однако, учитывая уровень современной технологии, после небольшой доработки текущей архитектуры, появилась реальная возможность в разы увеличить пропускную способность переходом на новую сигнальную логику, небольшим увеличением частоты синхронизации, а главное расширением шины данных в 2/4 раза (32/64 bit) по сравнению с настоящей 16 bit. Очевидно, что именно первые и определяют стратегию развития передовых технологий современной ДОЗУ тем более, что нынешние достижения в технологии уже позволяют реально говорить о 32bit (и даже о 64bit) интерфейсе DRDRAM.
Память SLDRAM (Synchronous-Link DRAM) и DRDRAM (Direct Rambus DRAM) являются архитектурами ДОЗУ следующего поколения, в основе которых изначально лежит концепция "канальной" иерархии расширение шины данных путем увеличения количества однородных параллельных каналов, именуемое параллелизмом, который частично (есть определенные конкретные сдерживающие факторы увеличения числа каналов) решает проблему узкой шины данных. Несмотря на то, что DRDRAM существует в настоящее время, а SLDRAM (с 1999 года консорциум SLDRAM принял решение закрыть проекта, и в дальнейшем взять за основу в разработке технологии DDRII именно модель SLDRAM) не является коммерческим продуктом, оба ДОЗУ уникальны. Эти две архитектуры объединяют три самых главных фактора: высокая и сверхвысокая частота синхронизации, узкая ширина шины данных, и передача информации по фронту и срезу синхросигнала (технология DDR), а все остальное, исключая уникальные архитектурные решения, это средства для максимального приближения реальной пропускной способности (эффективность) к теоретическому пределу и стабилизации функционирования на конкретной частоте. Еще одной, но уже менее важной особенностью, являются разделенные командно-адресный интерфейс и шина данных, что позволяет значительно уменьшить количество сигнальных выводов, требуемых для контроля и адресации, и упрощает конвейеризирование запросов. Тем не менее, схемы коммуникаций с разделенными каналами (SLC Shared-Link Communication) в этих двух архитектурах также отличаются: если в SLDRAM передача команд и адреса происходит по одной и той же шине пакетами (полностью 100% конвейеризированный пакетный протокол), то в DRDRAM команды (делятся на группы со своей шиной каждая), адрес строки и адрес столбца передаются по разным шинам.
| Сравнительная таблица архитектур DRDRAM и SLDRAM | ||||
| Параметр | DRDRAM800 | SLDRAM400 | SLDRAM800 | |
| Частота синхронизации (SYNC Frequency) | 400MHz | 200MHz | 400MHz | |
| Ширина шины данных канала (Channel Bus Width) | 16/18 bit | 16/18 bit | 16/18 bit | |
| Пропускная способность канала (Channel BW) | 1600MBps | 800MBps | 1600MBps | |
| Максимальное число каналов (Parallelism) | 4 | 4 | 4 | |
| Используемый сигнальный протокол (Signal Logic) | 1.8V RSL | 2.5V SSTL_2 | 2.5V SSTL_2 | |
| Количество используемых чипов памяти на один канал | 32 | 8/64 buffered | 8/48 buffered | |
| Общий объем на один канал при 64Mb технологии | 256MB | 512MB | 384MB | |
| Количество сигнальных выводов на один канал | 31 | 36 | 36 | |
| Количество выводов (H/S pins) на четыре канала | 124 | 102 | 102 | |
| Минимальная длинна пакета данных (Minimum BL) | 8bit | 4bit | 8bit | |
| Интервал между пакетами (Gap Between Burst) | 5-10 ns | 5ns | 2.5ns | |
| Режимы, использующиеся для уникальной адресации | Нет | Multicast/ Broadcast | Multicast/ Broadcast | |
| Пустые модули (Dummy Modules) | D-RIMM-CONT | Нет* | Нет* | |
| Тип упаковки микросхем (Package Type) | CSP | TSOP/VSMP | TSOP/VSMP | |
| Суммарная рассеиваемая мощность по всем каналам | 1300mW | 270mW | 270mW | |
| Примечание *: | сквозная цепочка инициализации (SI/SO-DC SelectIn/SelectOut Daisy Chain) является шинной электрической структурой и не относится к модульной конфигурации | |||
Так, SLDRAM Consortium определяет свой Sync-Link DRAM интерфейс (шина SLBus) первых четырех генераций, как 16/18 bit шину данных с интерфейсом DDR, поддерживающую до восьми нагрузок (в данном случае понятие "нагрузка" определяет либо одну микросхему памяти, либо один буферизированный модуль памяти, поскольку модуль, содержащий более двух микросхем, по правилам SLDRAM должен буферизироваться) на один канал (до четырех каналов максимум со схемами построения иерархии на основе режимов многоабонентской доставки (Multicast) и/или ретрансляции (Broadcast), обусловленными уникальной системой адресации) и синхронизирующихся частотой 200/300/400/600 MHz при линейной пропускной способности 400/600/800/1200 Mbps/p соответственно. Используя буферизированные модули, можно объединять до 64 микросхем памяти восемь буферизированных модулей, содержащих по восемь микросхем памяти каждый. Тем не менее, поколения 400/600 MHz имеют некоторые особенности структуры шины, которые консорциум не раскрывает. Это определяется растущими в зависимости от увеличения частоты функционирования паразитными влияниями, эффективной защиты от которых по большому счету в SLDRAM не предусмотрено, в отличие от DRDRAM, где механизмы компенсации от такого рода факторов введены изначально.
Rambus Incorporated в своей памяти Direct RDRAM использует 16/18 bit внешний DDR-интерфейс (структура RAMBus), поддерживая максимум до 32 микросхем памяти на один канал (максимум до четырех каналов на один контроллер). Конфигурация канала DRDRAM ограничивается максимум тремя модулями памяти в состав одного может входить от 1 до 16 (реально обычно 8 или 16) микросхем, в зависимости от используемой конфигурации и монтажа. Настоящий стандарт DRDRAM определяет генерации приборов памяти, синхронизирующихся на частоте 300/355/400/533 MHz, соответственно обеспечивая линейную пропускную способность 600/711/800/1066 Mbps/p. Первые поколения 600/711 MHz не являются "прямой" генерацией DRDRAM, а перекочевали из предыдущего стандарта CRDRAM (Concurrent RDRAM).
Естественно, что первичная задача всей иерархии памяти сводится к нахождению баланса между производительностью и стоимостью, куда в данном случае не входит так называемая "цена за мегабайт", которая, вообще говоря, является не менее важной.
Теория исследуемых эффектов и описание модели
В рамках этой статьи мы рассмотрим модели структур шины памяти, приближающеся к реальным интерфейсам DRDRAM и SLDRAM, что даст не только достаточно глубокое представление о самих подсистемах и о базовой концепции конструирования высокоскоростных интерфейсов (не только памяти, а шин вообще), но и поможет понять трудности, с которыми приходится сталкиваться разработчикам в проектировании и создании современных цифровых СВЧ-схем и устройств. Данное изучение фокусируется на моделировании структур RAMBus (шина Direct RDRAM) и SLBus (шина Sync-Link DRAM) при помощи средств программного пакета HSPICE от Meta-Software в окружении UNIX, которое было проведено в начале 1999 года специальной исследовательской группой компании MOSAID Technologies. Целью проводимого моделирования является сравнение эффективности двух рассматриваемых структур, их помехозащищенность, а также выявление "узких мест", на которые следует обратить особое внимание. Однако в рамках настоящей статьи мы ограничимся лишь сравнительным анализом полученных результатов моделирования непосредственно внешних шин DRDRAM и SLDRAM и не будем рассматривать эффективность используемых сигнальных протоколов, сравнивать потребляемую мощность и сложность устройств, а также принимать во внимание конечную цену.
Подсистема SLDRAM использует в качестве "рабочего материала" уже ставшие стандартом средства упаковки микросхем (корпус TSOP и VSMP аналог TSOP для вертикального монтажа), более совершенный сигнальный протокол, модуль памяти и расположение компонент на системной плате очередной шаг по пути более полной "обратной совместимости" с уже существующими решениями. Совершенно другим представляется стандарт DRDRAM, в котором воплотились самые передовые идеи, начиная от внутренней архитектуры, и заканчивая интерфейсными схемами и средствами упаковки чипов. Собственно, единственное, что действительно объединяет текущих лидеров это единичный строительный элемент массива ДОЗУ, который остался абсолютно нетронутым как уже говорилось ранее, ячейка ядра представляет собой транзистор с конденсатором. Именно потому, что производительность ячейки не подвергается такой модернизации, как остальные "окружающие" компоненты, далее будет рассматриваться, по большому счету, исключительно эффективность интерфейсных схем.
Для данного исследования использовалась упрощенная репродукция (модель) двух рассматриваемых структур и максимально точное их моделирование, при применении номинальных сигнальных протоколов, рекомендуемой геометрии и топологии шин, а также точного соблюдения нагрузочных характеристик, устанавливаемых требованиями спецификаций каждой из структур они достаточно детально описаны в соответствующих документах, список которых приводится в конце.
Операции чтения/записи моделировались исходя из частоты синхронизации каждой из структур: 200MHz (400Mbps/p) для SLDRAM и 400MHz (800Mbps/p) для DRDRAM как видно, последний обладает двукратным преимуществом перед SLDRAM в плане пиковой пропускной способности. Для исходных данных использовались специальные схемы модели, предназначенные для максимизации реализма воздействия эффектов межсимвольной интерференции (ISI InterSymbol Interference) и взаимного влияния соседних линий (Crosstalk), возникающих и сильно выраженных на сверхвысоких частотах (СВЧ) и определяющих соответственно временные искажения и искажения формы сигнала. Несмотря на то, что на первый взгляд эффекты связанных линий (Crosstalk-effect) и межсимвольной интерференции (ISI-effect) кажутся взаимосвязанными, на самом деле они могут существовать независимо и дополнять друг друга в плане негативных эффектов. Рассмотрим подробнее данные воздействия, поскольку они представляют первостепенный интерес в моделировании высокоскоростных схем, так как являются, пожалуй, наиглавнейшим "сдерживающим" фактором.
Так, возникновение эффекта связанных линий (или перекрестных помех) обуславливается близким расположением друг от друга сигнальных проводников, в результате чего возникают взаимные паразитные наводки. Можно сказать, что данный эффект является прямым следствием электромагнитной связи и зависит от частоты функционирования тракта и величины тока в проводнике. С физической точки зрения Crosstalk объясняется непосредственно наведением токов в проводнике: каждый из проводников с переменным электрическим полем имеет свое магнитное поле, которое наводят в близлежащих линиях переменные ЭДС. Результирующие же токи будут продуктом собственных токов и токов взаимной индукции.
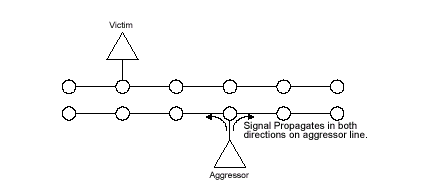
Перекрестные помехи (такая интерпретация Crosstalk больше подходит для описания эффектов в цифровых схемах) возникают из-за наличия емкостных и индуктивных связей между линиями и проявляются в наведении в линии-"жертве" (Victim) сигналов от линий-"агрессоров" (Aggressor) последствия этого негативного воздействия могут быть самыми разными. Справедливости ради необходимо заметить, что в реальной шине каждая линия может являться как "жертвой", так и "агрессором" (или "возбудителем") друг относительно друга. Так, существует несколько видов взаимного влияния соседних линий:
- Обратные перекрестные помехи (Backward Crosstalk) представляют собой наведение сигнала в линии-"жертве", распространяющегося в направлении, противоположном направлению распространения сигнала в линии-"агрессоре";
- Прямые перекрестные помехи (Forward Crosstalk) определяют наведение сигнала в линии-"жертве", распространяющегося в том же направлении, что и сигнал в линии-"агрессоре";
- "Четные" перекрестные помехи (Even Mode Crosstalk) являются случаем, когда сигнал-"агрессор" переключается в том же направлении, что и сигнал-"жертва";
- "Нечетные" перекрестные помехи (Odd Mode Crosstalk) описывают ситуацию, когда сигнал-"агрессор" переключается в противоположном направлении сигналу-"жертве".
В большинстве питающих протоколов источник сигнала необязательно находится в начале линии (предельный случай), так что в линии-"возбудителе" сигнал может распространяться в обоих направлениях. Дополнительные линии-"агрессоры" могут находиться в соседних слоях платы, если проводники в них оказываются расположенными топологически не перпендикулярно по отношению к линии-"жертве". Поскольку величина связи быстро убывает с расстоянием, достаточно рассмотреть только те линии-"агрессоры", которые расположены в пределах пяти ширин проводников, начиная от линии-"жертвы" (так называемое правило взаимосвязи S>4w, использующееся при расчете высокоскоростных СВЧ схем). Кроме того, существуют внутренние перекрестные помехи в корпусах микросхем, которые также оказывают влияние на форму сигнала.
Обратные перекрестные помехи существуют как в симметричных, так и в несимметричных (микрополосковых) линиях. Амплитуда этих помех пропорциональна коэффициенту связи, амплитуде сигнала-"агрессора" и длине участка связи (аналогично случаю с направленным ответвителем). Обратные помехи достигают максимума и остаются постоянными, когда время распространения по связанным линиям превышает половину времени нарастания сигнала-"агрессора". В предположении, что сигнал-"агрессор" идеален и связанная линия ненагружена, получено следующее выражение: LMBC=1/2*(tR/LBD), где LMBC (Length for Max Backward Crosstalk) длина линии при максимальном значении обратной помехи, tR (Rise Time) длительность фронта или время нарастания, LBD (Board Delay per Unit Length) задержка распространения сигнала на единицу длины или погонная задержка.
Как уже упоминалось, источник сигнала в шине необязательно находится в начале линии, и сигнал в таком случае распространяется в обоих направлениях это приводит к тому, что обратные перекрестные помехи распространяются в обе стороны от точки включения источника. Распространяясь в разные стороны друг от друга, данные импульсы будут встречаться и "складываться" в определенные моменты времени и в определенном месте линии, что может привести к удвоению амплитуды помехи. Ниже в таблице приводятся примеры значений коэффициентов связи (Coupling Factor) и соответствующие им величины помех для проводников с различной геометрией.
| Примеры значений коэффициента связи при обратных помехах | |||
| Длина:ширина:толщина линии | Степень связи | Максимальное значение перекрестной помехи | |
| 24:4:8 | 0.65% | 9.8mV | |
| 20:4:8 | 1.3% | 19.5mV | |
| 16:4:8 | 1.75% | 26.2mV | |
| 14:4:8 | 2.5% | 37.5mV | |
| 12:4:8 | 3.4% | 51.0mV | |
| 8:4:8 | 6.55% | 98.2mV | |
| 4:4:8 | 13.5% | 202.5mV | |
| Примечание: | er=4.5, VOH_MAX=1.5V, Zo=65 Ом | ||
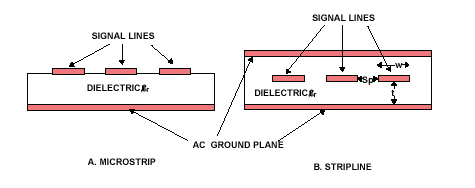
Следует учесть, что скорость спада ограничена максимально возможной длиной участка связи, а также то, что несколько параллельных линий увеличивают общий уровень шумов. Например, прямые перекрестные помехи отсутствуют в симметричных полосковых линиях (СПЛ), но имеются в МПЛ (несимметричных полосковых или микрополосковых линиях) это справедливо лишь для идеального случая при постоянной диэлектрической проницаемости. В реальных платах прямые перекрестные помехи практически отсутствуют в СПЛ, но значительны в МПЛ. Уровень помех прямо пропорционален коэффициенту связи между линиями, длине их связи и скорости нарастания/спада сигнала (крутизне фронта/среза, Slew=dU/dt).
Уровень прямых перекрестных помех также зависит от геометрии проводников. В отличие от обратных, прямые перекрестные помехи сигнала-"жертвы" продолжают нарастать по длине участка связи, пока сигнал-"агрессор" не будет поглощен нагрузкой (терминатором), т.е. вдоль всего маршрута прохождения сигнала. Рассмотрим несколько способов минимизации эффекта взаимного влияния соседних линий:
- Проводники в соседних слоях необходимо стараться планарно ориентировать перпендикулярно друг к другу;
- Минимизировать отклонения полного сопротивления линий;
- Стараться минимизировать номинальное волновое сопротивление проводников на плате, что дает уменьшение отношения ширина/длина линии (например, в ПЛ-структурах чем меньше волновое сопротивление тем шире проводник) и снижает уровни прямых и обратных перекрестных помех;
- Для изготовления печатной платы использовать материалы с малой диэлектрической проницаемостью;
- Учитывать возможность удвоения сигнала на приемнике из-за сложения обратных помех с сигналом от источника;
- Минимизировать расстояния, на которых проводники оказываются близко расположенными увеличивать взаимную отдаленность;
- Создавать линиям синхросигналов, управляющих синхронизацией компонент различных групп, разные маршруты распространения для минимизации перекрестных помех между этими группами особенно актуально для устройств, обладающих расщепленной шиной (несколько независимых шин, каждая из которых управляется отдельным агентом). Подобное разделение помогает снизить влияние эффекта связанных линий.
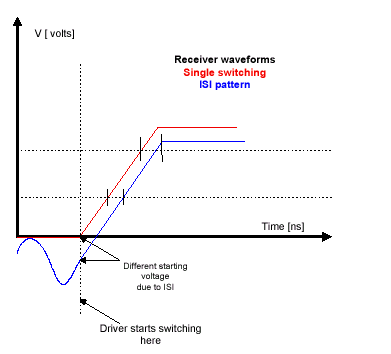
Межсимвольная интерференция (сокращенно МСИ или ISI) характеризуется проникновением сигнала, распространяющегося по одной сигнальной трассе, в соседнюю линию иными словами, речь идет о воздействии на полезный сигнал ВЧ-шумов (сигналы более высокого порядка) из соседней линии, которые способны искривить четко установленный временной протокол (проявление эффекта растягивания и/или запаздывания сигнала). В результате для конечного устройства (контроллера или подчиненного, микросхемы памяти) будет достаточно сложно связать (возникает некий эффект асинхронности) приходящие по соседним линиям данные относительно синхросигнала. С физической точки зрения ISI-effect объясняется влиянием на форму сигнала высших типов колебаний, которые могут возникнуть в линии передачи при неудачном выборе геометрии. Например, изгиб проводника или какое-либо уширение сильнее начинают проявлять себя с увеличением частоты, и уже на коммутациях от 300MHz даже контактная площадка для резистора может быть скачком волнового сопротивления. Все это может порождать временные задержки, в связи с чем приход данных по отдельному проводнику может запаздывать относительно данных в остальных линиях шины.
Также межсимвольная интерференция это эффект, возникающий при отражении переданного сигнала от приемника и последующем воздействии отраженного сигнала на следующую посылку. Проявление этого эффекта зависит от частоты передачи посылок, времени задержки линии передачи и коэффициентов отражения источника и приемника (или генератора и нагрузки).
В момент прихода сигнала от источника из-за межсимвольной интерференции в линии еще присутствует небольшое отрицательное напряжение. Поэтому результирующий логический уровень окажется заниженным и четко установится с некоторой временной задержкой. Таким образом, межсимвольная интерференция является одной из основный проблем при разработке высокоскоростных схем, в которых период следования сигнала меньше времени задержки в линии передачи.
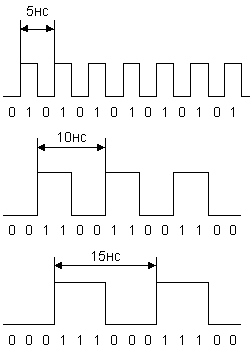
Для оценки наибольших временных искажений, связанных с межсимвольной интерференцией, выполняется вариация параметров на наименьшем тактовом периоде, на удвоенном и на утроенном наименьшем тактовом периодах. Например, если максимальная частота функционирования шины (предельный случай) составляет результирующих 400MHz (при синхросигнале 200MHz и использовании DDR), то длительность импульса, передающего 1bit информации, составляет 2.5ns (5ns период). При этом шаблон данных (случайная, псевдослучайная или заранее четко определенная последовательность логических "0" и "1") должен повториться с длительностью импульса 5ns и 7.5ns (10ns и 15ns периоды соответственно) для результирующей частоты 200MHz и 100MHz (соответственно 100/50 MHz задающая).
Результаты наихудшего случая для каждого из этих трех периодов могут быть использованы для определения множества решений первого этапа. Максимальная разница в сдвигах по времени между этими наборами данных даст первое приближение оценки влияния межсимвольной интерференции, а конечное множество решений должно удовлетворять всем комбинациям ISI оно может быть получено проведением моделирования на границах множества решений второго этапа при передаче по линии длинного псевдослучайного набора. Если временные искажения или искажения формы сигнала не превышают заданную величину, то множество решений второго этапа удовлетворяет исходным условиям. Если же искажения превышают заданную величину, то необходимо минимизировать коэффициенты отражения в линии и тем самым сократить величину межсимвольной интерференции. Как правило, наилучшим способом уменьшить коэффициенты отражения является минимизация изменения волнового сопротивления по длине линии, тщательное согласование и т.д. Наихудший же случай МСИ может быть определен с помощью следующих процедур:
- Моделируется самая длинная линия в шине с использованием псевдослучайной последовательности для самого короткого и самого длинного периодов.
- Полученные результаты моделирования ISI считаются начальными.
- Определяются задержки нарастания и спада для каждого случая передачи набора данных.
- Вычитание минимальной и максимальной задержек из соответствующих начальных даст разности наихудшего случая.
- Находится минимальная отрицательная и наибольшая положительная разность, что и будет являться наихудшим случаем с учетом влияния межсимвольной интерференции.
Программа HSPICE в данном случае была выбрана не случайно эта среда моделирования предназначена специально для проведения электромагнитного анализа (огромная масса громоздких вычислений с решением уравнений Максвелла основы теории электромагнитных полей) и расчета СВЧ схем во временной области (в отличии от Microwave Office и Serenade, которые считают в частотной). Иными словами, HSPICE удобен для анализа именно переходных процессов (задержки, искажения сигналов и т.д.) в ВЧ-линиях. Если говорить конкретно, то отличие HSPICE от классического Berkeley SPICE заключаются в том, что данная среда анализирует время задержки, сдвиг фазы сигнала, рабочий диапазон данной линии, эффект связанных линий (модели линий, разработанные для анализа сигналов в печатных платах) и искажения. Короче говоря, яркой отличительной особенностью является то, что у используемого программного пакета есть возможность исследовать параметры целостности сигнала (Signal Integrity) в зависимости от конфигурации топологии на основе анализа по методу Монте-Карло (Monte Carlo Analysis) статистика, основанная на проведении многократного расчета схемы с вариацией одного или нескольких параметров (по заранее известному алгоритму или случайным образом) заданных элементов, в результате чего определяются значения для наихудшего случая.
Сигнальная линия (трасса) это проводник с четко и точно выраженной геометрией, где также учитывается материал печатной платы (PCB) и толщина межслойного диэлектрика, в результате чего данное "определение" очень удобно рассматривать с позиции моделирования. При моделировании шинных структур, в HSPICE заменили идеальные проводники линиями передачи с потерями, что дает возможность наблюдать искажения сигнала, максимально приближенные к реальности, и, изменяя реальные параметры параметрами моделируемых линий, можно взаимно располагать проводники и изменять их геометрию, чтобы добиться наименьшего значения влияния эффектов перекрестных помех и межсимвольной интерференции.
Основной упор делается на моделировании влияния на параметры сигнала собственно параметров проводников шины, перехода с проводника на вывод внутри корпуса микросхемы, и внешнего вывода все описано соответствующими моделями. Это необходимо, поскольку огромные частоты порождают целую серию отрицательных эффектов (таких, как рассматриваемые здесь Crosstalk и ISI, но это лишь небольшая часть), влияние которых стараются уменьшать, варьируя параметры сигнальной линии.
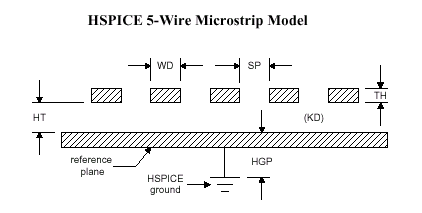
"Физически" используется модель пятивыводной микрополосковой линии (5-Wire Microstrip Model), где проводник печатной платы рассматривается как микрополосковая линия с отсутствующим верхним диэлектрическим слоем, присутствующим только между экранирующим слоем и проводником. "Опорный" слой (Reference Plane), использующийся при моделировании двухслойной печатной платы, является и экранирующим (Shield Plane), и заземляющим (Ground Plane).
Данная планарная геометрическая модель (HSPICE Five-Wire Planar Geometric Model) описывается в среде HSPICE как "секция" (определенный отрезок сигнальной линии фиксированной длины, элемент), характеризующая моделируемый участок и учитывающая все основные параметры микрополосковой линии: количество слоев (NLAY), длину "секции" (L), расстояние между соседними проводниками, (SP), ширину (WD) и толщину отдельного проводника (TH), сопротивление материала проводника (RHO), толщину диэлектрического слоя (HT), относительную диэлектрическую проницаемость (KD) и т.д. всего 16 параметров.
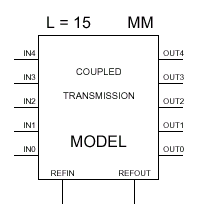
Используемые выводы опорной поверхности REFIN и REFOUT с физической точки зрения являются одним и тем же это как бы выводы заземляющего слоя на микрополосковой плате со стороны входа и выхода, однако поскольку рассматривается сечение печатной платы, то рассматриваемые выводы оказываются задействованы не всегда и могут подключаться или не подключаться к общему интерфейсу всей схемы в зависимости от необходимости применения.
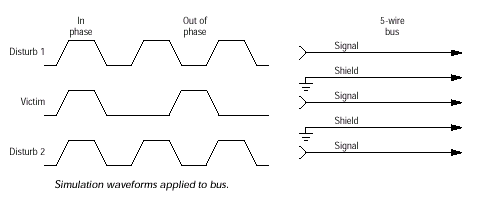
При моделировании эффектов связанных линий (а именно переходные процессы при нарастании амплитуды и переходные процессы при спаде, а также случайные выбросы Jitter-effect) пятивыводную репродукцию "разделяют" на два сигнальных провода-"возбудителя" (Disturb или упоминавшийся ранее Aggressor), два экранирующих провода (Shield) и один провод-"жертву" (Victim), на котором и наблюдают искажения сигнала постоянной длительности все как в ранее описываемой теории. Математически это можно представить в виде следующей формулы: V1=L11(dI1/dt)+L12(dI2/dt)+L13(dI3/dt), где V1 погонное напряжение линии 1; L12, L13 взаимные индуктивности между линиями 1-2 и 1-3; L11 погонная индуктивность линии 1; I1, I2, I3 токи в соответствующих линиях (экранирующая линия это та же сигнальная линия в которой соотношение dI/dt=0). Причем, сигнальная линия 1 находится между линиями 2 и 3 таким образом достигается максимальный эффект взаимодействия соседних трасс и упрощается расчет суперпозиции, достаточный для моделирования.
При моделировании эффекта межсимвольной интерференции (искажение сигнала при разном времени взаимодействия) длительность импульсов в проводниках-"возбудителях" одинакова, а в проводнике-"жертве" меняется согласно используемому подготовленному заранее "шаблону" (Bit-pattern), создавая такими задержками синфазное или противофазное возбуждения. При этом на проводнике Victim наблюдают искажения сигнала при различных длительностях (Long and Short Data Periods), т.е. насколько сильны искажения в зависимости от времени взаимодействия. Воссоздание подобных процессов избегает традиционного представления сосредоточенного LC-контура (Lumped LC) при моделировании корпусных выводов микросхемы (IC Package Lead) на высоких и сверхвысоких частотах функционирования из-за того, что характеристики короткого контура уменьшают моделируемую полосу пропускания по сравнению с моделью рассредоточенных выводов это обстоятельство также отражается на нагрузочных характеристиках и задержке распространения сигнала (Propagation Delay). Для максимального реализма используются исключительно модели связанной линии передачи, что дает возможность представить даже такие эффекты, как искажение по фронтам (Edge Jitter), шумы коммутации (Switching Noise) и взаимозависимости шаблонов (Bit-pattern Dependencies), особенно актуальных при моделировании эффекта межсимвольной интерференции (ISI).
Исходя из имеющейся документации была проведена небольшая оптимизация трассировки сигнальных линий по базовой плате и модулю памяти с целью идеализирования модели и оптимизации репродукций на максимальную производительность действительная и рекомендуемая конфигурация подсистем памяти могут несколько различаться с рассматриваемыми схемами RAMBus и SLBus. Так, активные компоненты не использовались (сугубо линейная схема, описывающая исключительно топологию шины), источник CMOS-сигнала SLDRAM представлен, как идеальный источник напряжения с последовательным сопротивлением и емкостной нагрузкой 2pF на вывод, а источник сигнала DRDRAM представлен, как идеальный источник тока с емкостным ограничением 2pF на вывод. Монтажные отверстия в печатной плате и контактные площадки для пайки представлены идеальными емкостями между сигнальной линией и "землей" (эти емкости по 0.5pF показаны на схеме в виде маленьких ромбиков с точкой подсоединения в центре). В процессе исследования было обнаружено, что наличие малой сосредоточенной емкости, распределенной вдоль шин, оказывает малое влияние на результаты моделирования. Характеристики каждой моделируемой шины зависят главным образом от длины отрезков линий и емкости, образованной контактной площадкой в конце трассы.
HSPICE обеспечивает точное моделирование для всех видов соединений в схемах, включая как идеальные проводники, так и линии передач с потерями. При этом линия с потерями представляется сосредоточенным низкочастотным фильтром, а потери за счет скин-эффекта (поле начинает концентрироваться в тонком слое на поверхности проводника) и потери в экранирующем слое могут быть учтены с заданной точностью. Специализированная U-модель, принятая в HSPICE для описания соответствующей секции, имеет универсальные форматы, поддерживающие задание геометрических и физических параметров, заранее вычисленные данные от Field Solver ("калькулятор" электромагнитных полей), и электрические параметры, такие как различные задержки и полное сопротивление (Zo).
Значение времени нарастания (Rise Time) указывается в задании и определяет наименьшее время изменения сигнала, используемое в моделировании. HSPICE оценивает максимальную частоту, на которой проявляется скин-эффект, именно из этого параметра. Также, из времени нарастания и длин линий HSPICE вычисляет число сосредоточенных элементов, которые необходимо использовать в модели линии передачи эта опция оказывает большое влияние на точность и время моделирования. Как правило, значение RISETIME выбирается намного меньше времени нарастания сигнала от источника (Stimulus Ramp Time) предпочтительнее его сначала установить равным 1/3 от самого наименьшего (по времени) изменения сигнала. В дальнейшем целесообразно уменьшать значение времени нарастания от первоначального до тех пор, пока последующее изменение не будет оказывать влияния на результаты моделирования.
Данное описание предлагается как готовое руководство для читателей, желающих провести свое собственное моделирование шин в HSPICE. Надо заметить, что многие разработчики высокоскоростных интерфейсов используют приведенную здесь методику для оценки сигнальных характеристик высокоспециализированных DUT-карт, разработанных непосредственно для тестирования интерфейсов DRDRAM и SLDRAM.
Характеристики подсистем памяти DRDRAM и SLDRAM
Неким "ключевым" моментом в рассматриваемых подсистемах DRDRAM и SLDRAM является то, что их микросхемы памяти имеют разрядность шин команд, адреса, данных, равную ширине этих шин самих структур и соответственно аналогичных интерфейсов управляющего устройства. Так, например, интерфейс стандартного синхронного ДОЗУ (SDRAM, DDR SDRAM) предусматривает параллельное соединение нескольких микросхем в составе одного модуля памяти, чтобы заполнить шину данных контроллера. В противоположность этой схеме, одна микросхема DRDRAM/SLDRAM полностью "перекрывает" всю структуру RAMBus/SLBus соответственно и рассматривается как полная нагрузка разница заключается в подходе, речь о котором пойдет далее.
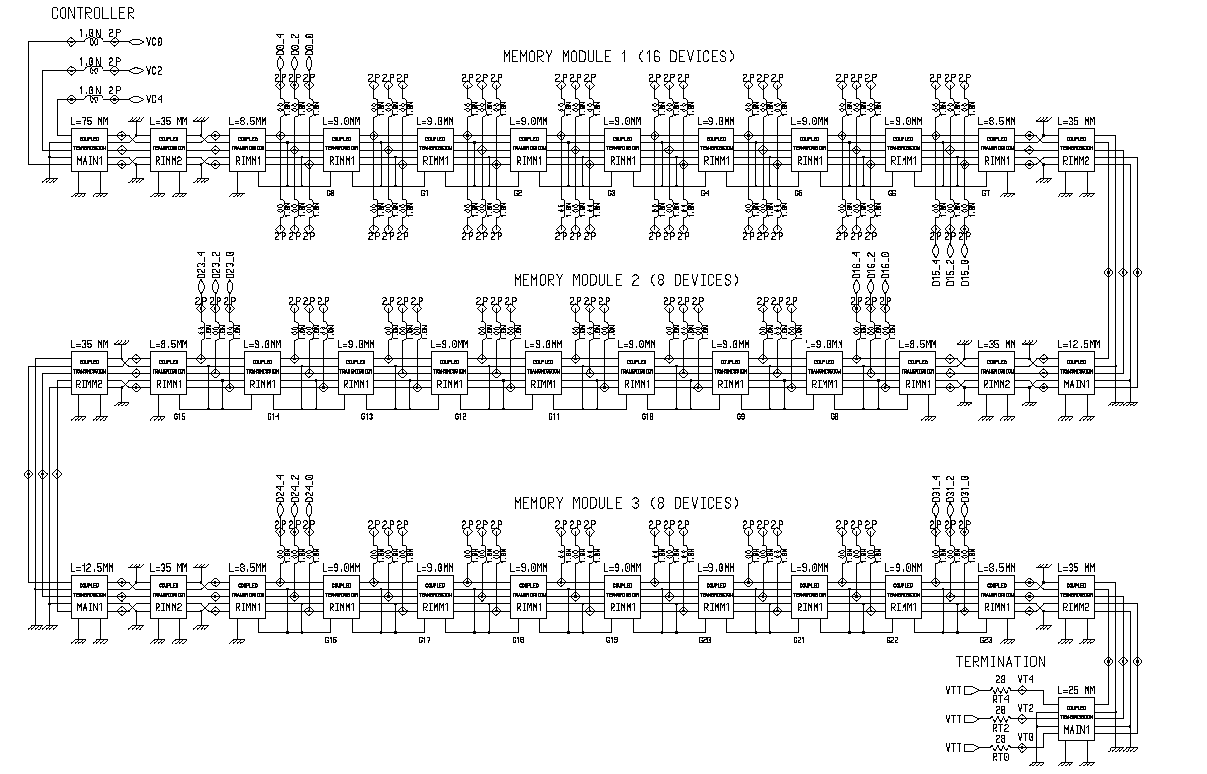
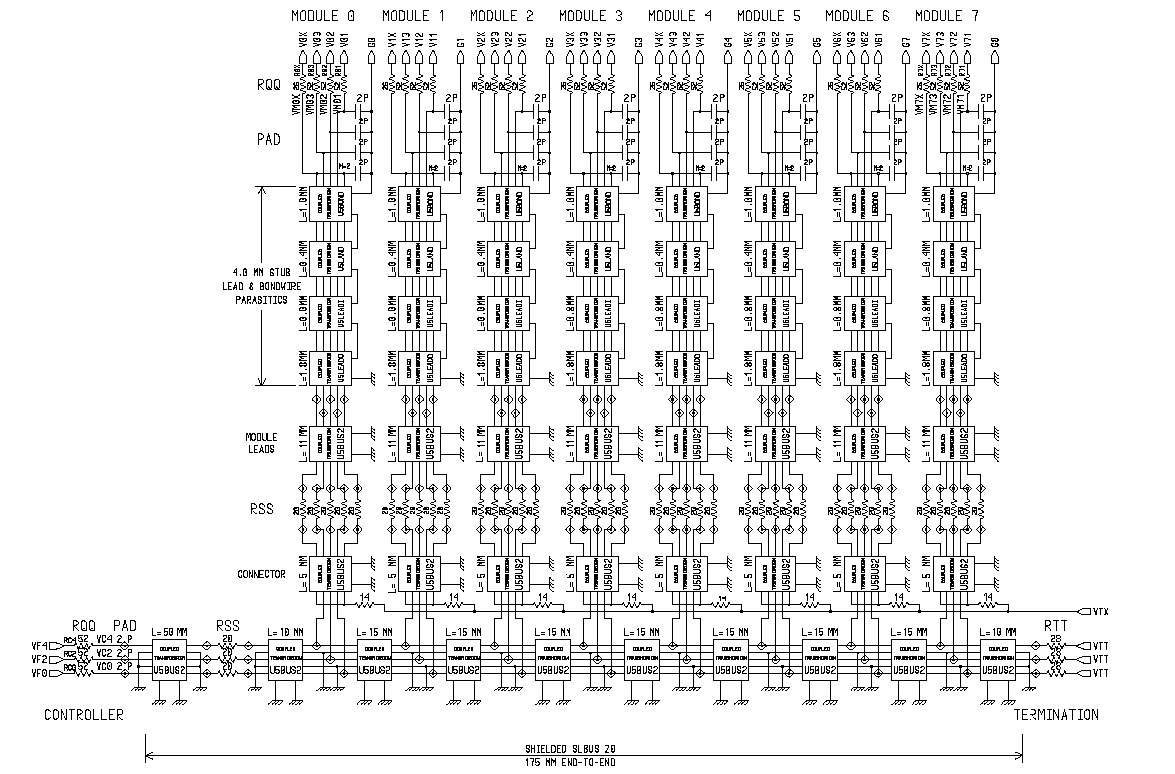
Структура SLDRAM, именуемая SLBus, может быть охарактеризована как короткая с параллельным интерфейсом (если не считать последовательную цепь инициализации микросхем памяти) и состоящая из небольших последовательных "связующих отрезков" шина. В общем представлении, весьма помехозащищенная структура SyncLink общей продолжительностью сигнальной линии в 175mm берет начало от специализированного контроллера памяти (SLC SyncLink Controller) и заканчивается группой нагрузочных сопротивлений (RTERM).
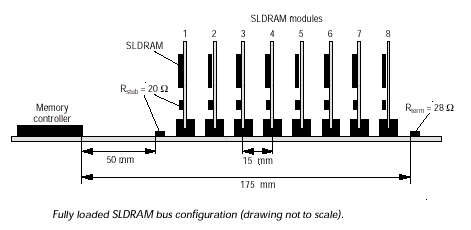
На данном промежутке возможна установка восьми нагрузок (отдельной микросхемы, если используется нерасширяемая система, или групп микросхем в составе буферизируемого по специальным правилам модуля) в специальные разъемы (SLMC SLDRAM Module Connector) с 15mm интервалом, берущих начало на расстоянии 60mm от корпуса контроллера и заканчивающихся за 10mm до группы терминирующих резисторов. "Стартовая" секция шины (50-mm интервал) ограничивается серией 20W последовательных сопротивлений (RSTUB) за 10mm до первого соединительного ответвления, чтобы получить делитель (подробнее об этом далее).
Модули (SLM SLDRAM Module) содержат от одного до восьми чипов памяти (SLDRAM Sync-Link DRAM), причем модуль, содержащий две и более микросхемы, должен буферизироваться, поскольку по правилам SLBus один модуль не может быть представлен двойной и более нагрузкой. Вывод разъема, сигнальная трасса на модуле и вывод на микросхемы SLDRAM представляют единичный отрезок, именуемый Stub. Длина этого отрезка составляет приблизительно 20mm: около 5mm длина вывода разъема, 11mm составляет длина сигнальной линии от начала контактной площадки модуля до начала внешнего вывода на корпусе самой микросхемы памяти или вывода буферизирующего чипа, и оставшиеся 4mm это общая продолжительность (End-to-End) вывода микросхемы, включая внешний отрезок от корпуса и связующий с чипом внутренний. Основная часть этих отрезков проходит над экранирующим слоем (Ground Plane) это делается потому, что одинаковые по длине отрезки не имеют собственной "экранирующей пары" (зато это делается в структуре DRDRAM), использование которой в незначительной степени улучшает качество сигнала, что упрощает разводку сигнальных трасс и делает модуль SLDRAM значительно дешевле. За счет того, что сигнальные линии короткие, экранирующие пары между трассами не нужны, поскольку мала длина взаимодействия между соседними проводниками.
Шина Direct RDRAM, именуемая RAMBus, является достаточно длинной, с единой неделимой структурой (Stubless), имеющей последовательный интерфейс. Типичная продолжительность сигнальной линии канала составляет 575mm, начинаясь от специализированного контроллера (RMC Rambus Memory Controller), проходя через все микросхемы памяти (DRDRAM Direct Rambus DRAM) на модулях расширения (RIMM Rambus In-line Memory Module), устанавливающихся в три разъема (RC RIMM Connector), и заканчиваясь на цепи терминирующих резисторов (RTERM) и специализированного задающего генератора дифференциальных синхроимпульсов (DRCG Direct Rambus Clock Generator).
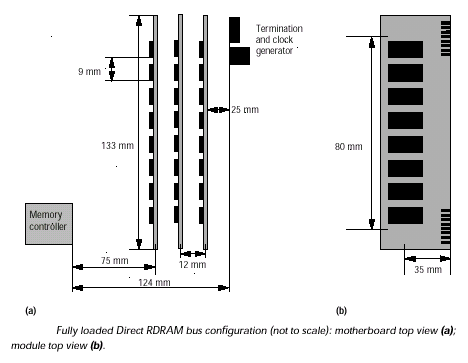
Три разъема, разделенные между собой 12-mm интервалом, берут начало от 75-mm "стартовой" секции, разделяющий контроллер и первый разъем, и заканчиваются перед 25-mm промежутком, отделяющим последний разъем от группы оконечных резисторов и формирователя синхросигналов. Основной особенностью является то, что данная структура свободна от применения последовательной нагрузки No Stub Series Resistors. Однако, если в случае параллельной шины SLDRAM разрешается использование пустых разъемов (цепь инициализации для этого включает в цепь каждого слота расширения 1 кОм согласующий резистор, который является мостом последовательной цепочки), то в последовательной структуре RAMBus для решения проблемы распространения сигнала используются специальные продолжители канала (D-RIMM-CONT, называемые еще Dummy Module), представляющие собой печатную плату, не содержащую активных компонентов, которая должна заполнять пустой разъем и продолжать канал, не допуская разрыва в электрической цепи последствия ставки на "неделимую" шину с последовательным интерфейсом.
Один модуль памяти DRDRAM RIMM может содержать от 1 до 16 микросхем памяти, при ограничении максимум 32 подчиненными устройствами (Memory Slave микросхема памяти на инженерном жаргоне) в пределах одного канала. Для моделирования ограничились "нетипичной" конфигурацией, предусматривающей максимальную нагрузку на канал 16 микросхем памяти в первом модуле памяти и по 8 устройств в двух остальных. Чип памяти DRDRAM упакован в специализированный корпус CSP (Chip Scale Package) типа микроматрицы шариковидных выводов (µBGA micro Ball Grid Array), особенность которого в очень короткой длине сигнального вывода: 2-3 mm (в противовес 20mm в SLDRAM), включая внутреннюю связь с кристаллом. Принимая во внимание особенность упаковки BGA, можно сказать, что сами чипы памяти в буквальном смысле напрямую соединены с каналом и расположены на четко рассчитанном интервале друг от друга, что позволяет поддерживать максимально точно номинальные значения импеданса и емкостной нагрузки.
Для более наглядного представления различий данных шин рассмотрим используемую схему включения и сигнальный протокол каждой структуры: различия в представлении логических уровней сигнала, полного сопротивления и рассеиваемой мощности.
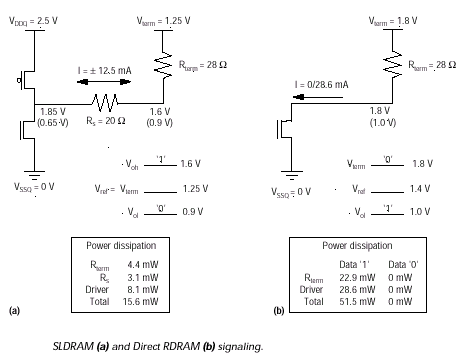
Протокол SLDRAM определяет прямую логику, в основу которой положен сигнальный интерфейс SLIO (Sync-Link I/O), предусматривающий высокий 1.6V (VOH) и низкий 0.9V выходные (VOL) уровни с разностью 700mV. Напряжение функционирования интерфейсных схем (выходные цепи питания контроллера и микросхем памяти) составляет 2.5V. Шины команд и данных терминированы в один конец (Single-End Termination), к средней точке опорного напряжения (VTERM=1.25V).
Структура SLBus использует терминирование к средней точке (Center-Tap-Terminated) уровню опорного напряжения (VTERM=VREF), характеризующее последовательно-параллельную схему нагрузки, применяемую в сигнальном протоколе SLIO. Подтягивание к средней точке (высокоимпедансное Hi-Z состояние линии, характеризующееся низким потреблением, при котором ток не протекает) обуславливается специализацией протокола, используемого в SLDRAM, и применяется, в частности, для того, чтобы уменьшить длительность переключения между логическими уровнями и шум коммутации сигнала (третье состояние является нормальным исходным для входных и выходных буферов SLDRAM). Данная логика основана на сигнальном протоколе SSTL_2, применяемом в DDR SDRAM-базируемых системах, кроме чего в SLIO предъявляются более жесткие требования к переключениям между логическими уровнями (порог срабатываниям приемников сигнала), определяемые самой схемой. Уровень сигнала и синфазность контролируются системой самокалибровки, которая производится контроллером SLC, учитывая возможные девиации напряжения, температуры и частоты, сначала в фазе жесткого сброса (Hard Reset), а затем при необходимости, во время работы. Источник формирования сигнала SLIO поддерживает 0.7V размах между активными уровнями через последовательный 20 Ом резистор. Шина нагружена на 28 Ом параллельную нагрузку и терминирована к напряжению VTERM (0.5 от уровня VDD). Последовательный резистор RSTUB реализует делитель, задающий терминирующее напряжение VTERM (напряжение на оконечной нагрузке), а в зависимости от направления тока через этот резистор устанавливаются соответственно логические "0" и "1" их уровни симметричны относительно VTERM (при входных и выходных токах ±12.5mA), которое и определяет соотношение между RSTUB и RTERM. Общая мощность сигнала по SLIO составляет 15.6mW на одну сигнальную линию для схемы с 18 линиями она составляет около 0.28 W, однако лишь 0.15W рассеивается в микросхеме SLDRAM.
В основе сигнальных уровней DRDRAM лежит инверсная логика, основанная на специализированном высокоскоростном протоколе RSL (Rambus Signaling Levels), использующая низковольтный размах 800mV (VCOS=VOH-VOL) между логическим "0" (VOH=1.8V) и логической "1" (VOL=1.0V) при внешнем опорном напряжении VREF=1.4V. Командно-адресный интерфейс и шина данных терминируются в один конец, к высокому уровню (VTERM=1.8V). Напряжения питания интерфейсных схем подсистемы Rambus составляет 2.5V. Процедура самокалибровки и ре-калибровки уровней RSL выполняется, учитывая влияние температуры, 3-sigma-вариации, а также возможные девиации напряжения и частоты, контроллером RMC в периоды проведения текущего теста системы по выходу из состояний "дремоты" (NAP) и деактивации (PDN).
В схеме RAMBus применяется 28 Ом нагрузка, подтягивающая уровень напряжения на к VTERM (1.8V) в отсутствие сигнала для обеспечения логического "0". Любое устройство на шине может установить логическую "1", подключив источник тока 28.6mA, используя n-канальную структуру, основанную на МДП-транзисторе с открытым ненагруженным стоком (Open-Drain NMOS Structure). Каждое такое устройство на шине может подстраивать величину этого тока для удержания логической разности между логическими уровнями в 0.8V, поэтому при низком уровне сигнала на каждой линии рассеивается 51.5mW, а максимальная потребляемая мощность (при условии передачи всех "1") в 18bit шине составляет 0.93W. Так, максимальная выходная мощность одной микросхемы составляет 0.51W, и абсолютно не потребляется, когда на шине установлен уровень VTERM (передача всех "0"). Для случая средней нагрузки (типичный набор данных с соотношением "0" и "1" пополам) потребляемая мощность составляет 0.46W, из которых 0.26W потребляется только микросхемой.
При обычных условиях интерфейс DRDRAM потребляет на 73% мощности больше при расчете на один корпус, чем SLBus. И хотя DRDRAM работает на частоте вдвое большей, на энергетику это никакого влияния не оказывает потребляемая мощность должна быть одинаковой как при скорости 1bps, так и при 1Gbps. Такое различие в интерфейсах возникает из-за разных схем включения, применяемых в рассматриваемых структурах: схема с открытым стоком, используемая в RAMBus, в противовес двухтактному выходному каскаду (Push-Pull Drivers), применяемом в SLBus. Скорость передачи данных обеих схем определяется топологией шин, но никак не схемой ввода/вывода.
Условия, критерии и результаты моделирования
В подсистемах памяти, использующих высокоскоростную шину, эффект искажения при передаче информации является первопричиной ограничения пропускной способности, а не полоса пропускания по переменному току используемых элементов в схеме. Например, в фазе чтения предполагается 200ps дисперсия данных и 200ps точность синхронизации системных таймингов (Timing, временной параметр) таким образом, искажение непосредственно для чипов памяти в данном случае составляет 400ps. Также дисперсия данных к контроллеру памяти, обусловленная временем установки (Setup Time) и удержания (Hold Time), составляет 200ps, плюс 200ps точность формирования синхросигнала в результате искажение синхронизации чтения данных контроллером от разных чипов памяти равняется 400ps. Принимая во внимание дополнительные 200ps, учитывающие влияние шума, эффектов "выбросов" в связанных линиях (Crosstalk Jitter Effects искажение фронтов/срезов импульсов, обусловленное разными эффектами индуктивности, емкости, плюс погонные миллиметры играют роль линии задержки), полное искажение (Skew) при передаче данных составляет 400ps+400ps+200ps=1000ps. Если учесть еще и информационно-зависимый сдвиг сигнала в зависимости от идущего набора данных (Data-Pattern-Dependent Skew), то можно вычислить максимально возможную скорость передачи информации в фазе чтения для конкретно рассчитываемой подсистемы памяти.
Сами искажения являются комплексной величиной, включающей две составляющие. Статический перекос (Static Skew) постоянен для конкретной системы и зависит от разводки сигнальных линий на печатной плате (трассировка), исполнения выводов и нагрузочного дисбаланса (разбалансировка нагрузочных сопротивлений). Динамический сдвиг (Dynamic Skew) включает в себя абсолютно все действующие временные параметры, такие как искажение фронта/среза импульса, вызванное влиянием шума, эффекты связанных линий и эффекты информационно-зависимого сдвига их множество.
Наиболее интересным аспектом информационно-зависимого сдвига является то, что он как бы перестает существовать на скоростях передачи, больших некоторой критической (виртуальное ограничение критического уровня передачи данных) сдвиг уменьшается с почти постоянной скоростью по мере того как скорость передачи увеличивается. Влияние зависимости сдвига увеличивается в основном от скорости установки логических уровней на шине и набора данных, передаваемого до и после этой установки. Например, если время установки уровня 2ns, то информационно-зависимый сдвиг проявится на скоростях близких к 500Mbps (0.5ns период). На скоростях передачи, близких к реальной пропускной способности, сдвиг резко увеличивается по мере того, как сигнал начинает искажаться из-за конечной скорости установки напряжения на шине и конечного значения полосы пропускания (AC Bandwidth). Когда общая дисперсия сигнала или сдвиг превысит период следования данных, значение задержки передаваемой информации станет неопределенной и возникнет затор, в результате чего поток прервется. Другими словами, сдвиг по шине, превышающий период следования данных, перекрывает набор целиком и делает их восстановление невозможным по-другому определяя предельную частоту функционирования конкретной структуры.
В процессе моделирования был составлен специальный список связей (NetList), который описывает используемую конфигурацию исследуемых структур RAMBus и SLBus в упрощенной форме (как уже говорилось, ограничились пятивыводной репродукцией для каждой моделируемой шины без активных компонентов). Источник сигнала SLDRAM смоделирован как идеальный источник напряжения с последовательно включенными сопротивлениями и емкостной нагрузкой 2pF на вывод, а источник сигнала DRDRAM представлен, как идеальный источник тока с емкостным ограничением 2pF на вывод. Использовалась модель идеального конденсатора: в текущих спецификациях на исследуемые структуры емкость I/O вывода составляет 3.0pF для микросхемы SLDRAM и 2.0-2.4 pF для прибора DRDRAM. Однако принимая во внимание современную норму производства чипов памяти (0.25/0.18 µm), было выбрано значение 2.0pF для обеих структур в качестве эталона моделирования емкостной нагрузки вывода использовались данные 64Mbit микросхем DRDRAM и SLDRAM.
Так, проведенные измерения показали, что емкость I/O вывода микросхемы SLDRAM составляет порядка 1.9pF и включает в себя 0.3pF для структуры контактной площадки (Pad Metal Structure), 0.5pF для структуры защитного диода для предотвращения пробоев зарядом статического электричества (Electrostatic Discharge Diode Structure), 0.1pF запирающей емкости (Gate Capacitance) для входных буферов SLIO-интерфейса и 1.0pF емкости перехода (Junction Capacitance) для выходных буферов, находящихся в третьем состоянии. Емкость рамки выводов не учитывается, хотя было проведено моделирование ее электрических характеристик: длинные выводы представлены линиями передачи, короткие выводы индуктивностью. Модель рамки микросхемы DRDRAM, согласно спецификации, представлена как идеальная индуктивность 1.0nH.
| Используемые условия моделирования структур | ||
| Параметр | SLDRAM | Direct RDRAM |
| Полная длина шины (Total Bus Length) | 175mm | 575mm |
| Единичная нагрузка (Loads) | 8 | 32 |
| Длина соединительных отрезков (Stub Length) | 20mm | <= 3mm |
| Межсигнальная защита на основной плате (Board Intersignal Shielding) | Да | Да |
| Межсигнальная защита на модуле (Module Intersignal Shielding) | Нет | 70% |
| Емкость вывода (Pad Capacitance), CP | 2.0pF | 2.0pF |
| Емкость межслойного перехода (Bus Vias), CV | 0.5pF | 0.5pF |
| Емкость контактной площадки под пайку (Solder Lands), CL | 0.5pF | 0.5pF |
| Модель рамки вывода ИС (Lead Frame Model) | U-модель | 1.0nH |
| Тип источника сигнала (Driver Source Type) | напряжение | ток |
| Сопротивление источника сигнала (Driver Source Resistance), RQ | 52 Ом | бесконечное |
| Сопротивление соединительного отрезка (Series Stub Resistance), RS | 20 Ом | Нет |
| Нагрузочное сопротивление (Terminating Resistance), RT | 28 Ом | 28 Ом |
| Напряжение на терминаторах (Terminating Voltage), VTERM | 1.25V | 1.8V |
| Опорное напряжение (Reference Voltage), VREF | 1.25V | 1.4V |
| Высокий уровень напряжения на входе (High Level), VIH | 1.6V | 1.8V |
| Низкий уровень напряжения на входе (Low Level), VIL | 0.9V | 1.0V |
| Ток на выходе (Driver Source Current), IOH | 12.5mA | 0 |
| Ток утечки (Driver Sink Current), IOL | 12.5mA | 28.6mA |
| Время нарастания сигнала от источника (HSPICE Stimulus Ramp Time) | 500ps | 500ps |
Следует также учесть, что времени нарастания 500ps в HSPICE (Ramp Time) с уровня 0 до 1.0 соответствует 300ps длительность фронта/среза импульса (взято из спецификации) по уровню 0.2-0.8, что увеличивает крутизну (Slew).
| Геометрические параметры МПЛ моделируемых структур | |||
| Параметр | SLDRAM | Direct RDRAM | |
| Нагруженная шина модуля (Loaded Module Bus) | |||
| Ширина сигнальной линии (Track Width), WD | N/A | 5.0mils | |
| Протяженность сигнальной линии (Track Spacing), SP | N/A | 11.0mils | |
| Толщина сигнальной линии (Track Thickness), TH | N/A | 2.7mils | |
| Толщина слоя диэлектрика (Track Height Above Plane), HT | N/A | 8.0mils | |
| Ненагруженная шина модуля (Unloaded Module Bus) | |||
| Ширина сигнальной линии (Track Width), WD | 5.0mils | 26.0mils | |
| Протяженность сигнальной линии (Track Spacing), SP | 15.0mils | 53.0mils | |
| Толщина сигнальной линии (Track Thickness), TH | 1.4mils | 2.7mils | |
| Толщина слоя диэлектрика (Track Height Above Plane), HT | 5.0mils | 8.0mils | |
| Основная монтажная плата (Main Board) | |||
| Ширина сигнальной линии (Track Width), WD | 5.0mils | 16.5mils | |
| Протяженность сигнальной линии (Track Spacing), SP | 15.0mils | 22.5mils | |
| Толщина сигнальной линии (Track Thickness), TH | 1.4mils | 2.7mils | |
| Толщина слоя диэлектрика (Track Height Above Plane), HT | 5.0mils | 5.0mils | |
| Примечание: | 1 mil = 0.0025cm | ||
Для оценки влияния перекрестных помех и межсимвольной интерференции использовались временные диаграммы сигналов пятивыводной базовой модели. По трем из пяти линий шины передается информация, а две остальные выполняют функцию "экрана". По центральной линии передается сигнал-"жертва", а сигналы-"агрессоры" первоначально распространяются в фазе с сигналом-"жертвой", затем в противофазе. В результате проводятся измерения временных характеристик сигналов в разных точках шины с данным набором сигналов исследуется изменение времени нарастания и времени спада сигнала-"жертвы" при синфазном и противофазном воздействии на него сигналов-"агрессоров". Также, при моделировании с полностью нагруженной шиной для коротких и длинных периодов следования сигнала-"жертвы" можно наблюдать эффекты межсимвольной интерференции.
Большой интерес представляет используемая методика измерения реальной пропускной способности (ABW Available BandWidth), используя наибольшие длительности фронта/среза импульса, полученные при моделировании полосы пропускания конкретной структуры на заданном отрезке времени. Так, рекомендуется использовать следующую формулу расчета ABW по измерению длительности фронта/среза импульса: ABW=1/(1.2*(TRISE[25/75] + TFALL[75/25])), где TRISE длительность фронта (время нарастания), а TFALL длительность среза (время спада).
Измерения времени нарастания/спада сигнала в структурах проводились в диапазоне 0.25-0.75 от размаха между логическими уровнями, что позволило не учитывать ложные результаты, связанные с затуханием и выбросами напряжения в результате переходного процесса, превышающих 15% от номинального уровня. Форма сигнала на ABW с прямолинейными фронтами между уровнями 0.0-1.0 от номинального остается неизменной на 20% временного участка. С другой стороны, при передаче синусоидального сигнала с пиковыми уровнями 0.1 и 0.9 реальная полоса пропускания будет равна удвоенной частоте этого синусоидального сигнала. Формула для вычисления ABW предполагает, что предельного значения полоса пропускания достигает тогда, когда искажения передаваемого сигнала становятся значительными (недопустимыми), из чего можно заключить, что величина полосы пропускания строго определяет пропускную способность шины.
Измеряя такой параметр, как перекос, ограничились лишь его динамической составляющей, получая сдвиг данных из общего числа измерений задержек распространения сигнала по шине. Измерялась задержка распространения между всеми перемещениями сигнала в проводе-"жертве" по фронту/срезу импульса на уровне пересечения в средней точке (уровень опорного напряжения). Если смещения не наблюдалось, то все измерения задержки распространения принимались одинаковой длительности. Если сдвиг наблюдался, то измерения задержки распространения проводились в диапазоне значений минимума и максимума. Значение перекоса для любого моделирования вычисляется как разность между измерениями максимальной и минимальной задержек распространения.
Конечными результатами данного исследования являются получение значений перекоса данных на шине и действительной пропускной способности самых важных характеристик эффективности любой шинной структуры. Как уже говорилось, проводимое моделирование не допускает влияние цепей управления таймингами или рассогласования по амплитуде; паразитного всплеска синхросигнала в приемнике или передатчике; вариации от трассы к трассе на основной плате, разъемах, контактных площадках и модулях; терминирующего рассогласования, а также VREF и VTERM ошибок протокола или шума никаких подобных специальных дисбалансных параметров или предискажений сигнала не вводилось. Данные результаты характеризуют исключительно саму структуру в лучших из возможных условий с идеальными компонентами и полностью помехозащищенной средой.
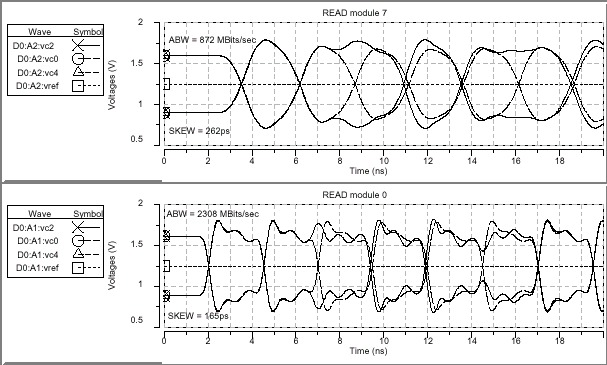
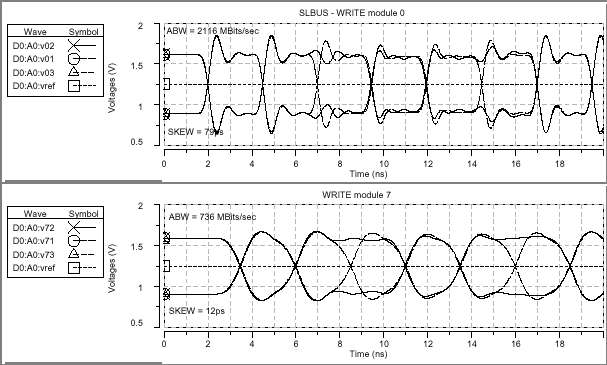
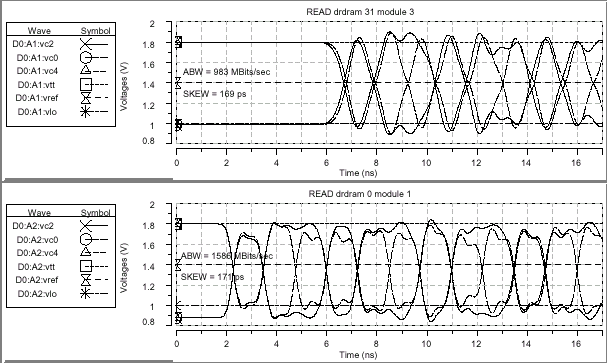
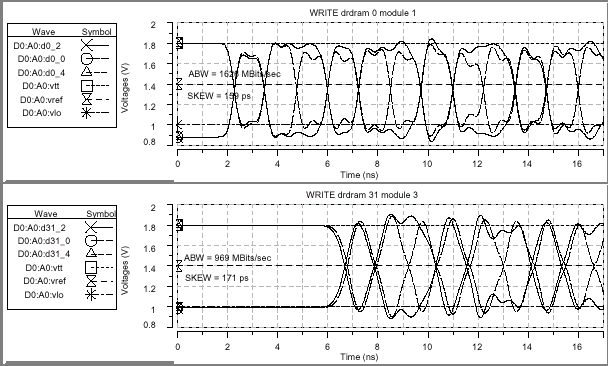
| Итоговые параметры целостности сигнала в моделируемых структурах | ||||
| Параметр | SLDRAM | Direct RDRAM | ||
| Модуль 0 | Модуль 7 | Модуль 1, DRDRAM 0 | Модуль 3, DRDRAM 31 | |
| Пропускная способность при записи (Write ABW) | 2116Mbps | 736Mbps | 1626Mbps | 969Mbps |
| Пропускная способность при чтении (Read ABW) | 2308Mbps | 872Mbps | 1586Mbps | 983Mbps |
| Перекос при записи (Write Skew) | 79ps | 12ps | 159ps | 171ps |
| Перекос при чтении (Read Skew) | 165ps | 262ps | 171ps | 169ps |
Полученные результаты демонстрируют, что конфигурация RAMBus при идеальных условиях достигает уровня передачи данных около 1000Mbps, в то время как SLBus в аналогичной ситуации может предоставить лишь приблизительно 800Mbps, если не рассматривать влияние статического перекоса. Тайминговый сдвиг (динамический перекос) составляет приблизительно 14% от номинального периода передачи данных в DRDRAM и 10% в SLDRAM.
Кроме всего прочего были сняты группы временных диаграмм проводимого моделирования, которые наглядно демонстрируют ожидаемую производительность устройства SLDRAM при 400Mbps чтении и записи, и DRDRAM при 800Mbps чтении и записи в самой ближней и дальней точках структуры относительно контроллера памяти. Принимая по внимание возможные решения при проектировании печатной платы, сопротивление по постоянному току относительно длинной структуры DRDRAM должно быть менее 5 Ом, поскольку при 28 Ом полном сопротивлении 5 Ом могут дать смещение уровня сигнала на 143mV при токе 28.6mA. На первой и последней диаграммах для DRDRAM низкий логический уровень на 100mV меньше, чем уровень логической "1" на двух других диаграммах.
Рассматриваемые диаграммы демонстрируют 3ns промежуток времени на передачу данных и подтверждение приема устройством (tRT Round-Trip time) для структуры SLBus, и приблизительно 10ns период обращения (Bus Turnaround) шины RAMBus. Сравнительно большой промежуток tRT не только вводит цикл задержки чтения (Read Data Latency) в подсистему памяти, но и увеличивает цикл переключения шины между операциями чтения/записи.
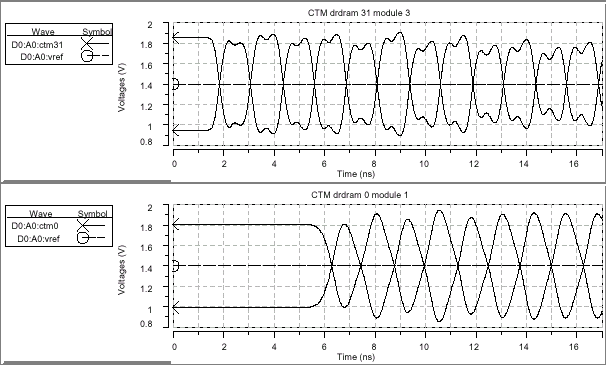
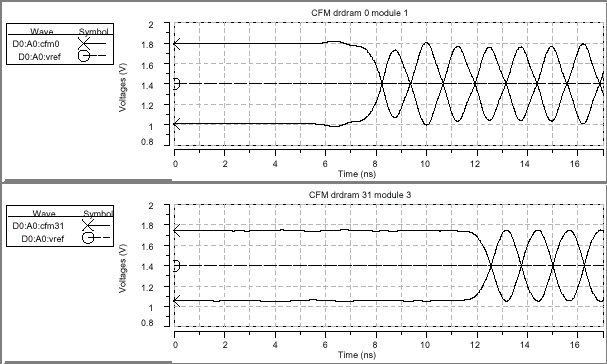
В структуре SLDRAM синхросигнал и данные четко согласованы, поскольку они берут начало от одного источника формирования и проходят абсолютно одинаковую дистанцию. В отличие от шины SLBus, синхросигналы структуры RAMBus проходят в два раза большее расстояние, нежели данные, в результате чего возникает необходимость проведения дополнительного моделирования. Поэтому была введена еще одна группа диаграмм, показывающая поведение дифференциальных тактовых сигналов в схеме синхронизации узлов DRDRAM при движении их к концу шины и возвращению назад: первая диаграмма демонстрирует "прямой" сигнал (CTM Clock To Master) на последнем устройстве в канале (последняя микросхема) возле терминатора и формирователя синхросигнала; вторая диаграмма показывает поведение CTM на первой микросхеме в канале, возле контроллера, в конце шины; третья диаграмма демонстрирует обратный ход синхросигнала (CFM Clock From Master) на первом приборе в конце шины; и последняя диаграмма отражает CFM на последней микросхеме, возле терминатора.
Интересной особенностью является уменьшение амплитуды и полосы пропускания синхросигнала по всей длине структуры RAMBus, что связано с 30% затуханием сигнала (что неудивительно, принимая во внимание общую протяженность сигнальной линии) и 10ns периодом обращения. Поскольку форма тактового сигнала на котроллере отличается от формы сигнала записываемых данных, сдвиг между ними (Clock-to-Data Skew) закладывается как распространение основных сигналов на дальнем конце шины. Идеально четкое пересечение дифференциальных сигналов по уровню опорного напряжения для записываемых данных у контроллера сменяется 80ps отставанием (Reference-Level Crossing Lag) на дальнем конце шины (последнее устройство), в то время как считываемые данные на контроллере имеют 40ps опережение по опорному уровню (Reference-Level Crossing Lead). Эти маленькие перекосы кажутся незначительными, однако не могут быть проигнорированы в силу того, что в сумме составляют около 6% от номинального периода передачи данных таким образом, они введены в общий временной сдвиг по RAMBus в таблице итоговых параметров сигнала.
Заключение
Конечно, многие вопросы остались за кадром данного моделирования. Тем не менее, необходимо коротко охарактеризовать результаты проведенных исследований. Так, шина SLBus, использующая достаточно короткие соединительные отрезки, имеет действительную пропускную способность чтения/записи около 800Mbps и соответственно 400Mbps запас для функционирования при использовании 200MHz синхронизации. Серии изолирующих резисторов на модуле обеспечивают необходимый дампинг (сглаживание "выбросов", обуславливаемых влияниями паразитных емкостей и индуктивностей) для регулирования эффектов отражения сигнала и обеспечения его четкого уровня. Безо всяких улучшений в текущей структуре, существующая конфигурация SLBus может поднять общий уровень функционирования до 600Mbps. А небольшое уменьшение длины отрезков и/или количество единичных нагрузок может поднять планку текущего ABW за пределы 1Gbps, рассчитанную на приборы SLDRAM следующих поколений. Полученные результаты указывают на то, что общепринятые методы упаковки микросхем и технология изготовления недорогих модулей памяти с определенными оговорками еще может применяться в будущих высокоскоростных архитектурах памяти. Производительность настоящей шины SLBus очень хорошая, однако думается, что переход на более совершенный тип упаковки (например, CSP) позволит улучшить степень помехозащищенности и перейти на более высокие частоты синхронизации (частично за счет уменьшения длины выводов), увеличивая общую производительность.![]()
Шина RAMBus достигает реальной пропускной способности чтения/записи около 1000Mbps, достаточной для 800Mbps функционирования при 400MHz синхросигнале, однако остаток запаса "расходуется" на рассогласование компонентов и шумы. Текущая реальная пропускная способность структуры RAMBus просто поражает, учитывая почти двухфутовую (приблизительно 20 дюймов) общую длину сигнальных трасс и 32 единичные нагрузки на шину. Такая пропускная способность достигается благодаря трем факторам: "безвыводной" топологии (чип памяти практически напрямую соединяется с шиной) с применением корпуса CSP, непрерывной "сквозной" шине и пустым модулям, поддерживающим соединение в системах с частичным заполнением разъемов в канале. Основные улучшения в архитектуре Direct RDRAM, думается, должны состоять в адаптации к двухтактному выходному каскаду для уменьшения потребляемой мощности, ограничения падения напряжения (IR drop) по всей длине шины и затухания сигнала. Дополнительно введенный в чип механизм подготовки формирования синхросигнала (On-chip Clock Trimming) для минимизации эффекта ограничения пропускной способности, обуславливаемого статическими перекосами, может значительно расширить полосу пропускания шины DRDRAM далеко за пределы полученных "идеальных" 1000Mbps.
Список использованных и рекомендуемых источников
- JESD8-9, Stub Series Terminated Logic For 2.5 Volts (SSTL_2)
- JEDEC Std JESD-21-C, Configuration of Solid-State Memories, DDR SDRAM Explained
- JESD79, Double Data Rate (DDR) SDRAM Specification
- JESD100-B, Terms, Definitions, and Letter Symbols for Microcomputers, Microprocessors, and Memory Integrated Circuits
- EIA/JESD65, Definition of Skew Specification for Standard Logic Devices
- JESD625-A, Requirements for Handling Electrostatic-Discharge-Sensitive (ESDS) Devices
- Two High-Bandwidth Memory Bus Structures, "IEEE Design & Test of Computers"
- Two High-Bandwidth Memory Bus Structures, Appendix A HSPICE Models
- Interconnect Characterization and Design Optimization for High Speed Digital Applications
- Controlled Impedance Design and Test
- Direct Rambus Long Channel Design Guide
- Printed Circuit Board (PCB) Test Methodology
- Test and Measurements
- CSP Die Shrink Solution for Memory Devices
- Performance Characteristics of IC Packages
- Physical Constants of IC Package Materials
- International Packaging Specifications
- Knowledge Based Reliability Evaluation of New Package Technologies Utilizing Use Conditions
- Package/Module/PC Card Outlines and Dimensions
- New Signaling Meets Tomorrow's Bandwidth Requirements
- The Rambus Systems Test and Measurement Guide: Verifying, Characterizing, and Debugging your Rambus Design
- How to Measure RDRAM System Clock Jitter
- Rambus RIMM Module Propagation Delay Measurement and Optimization
- Direct Rambus System and Board Design Considerations
- Base/Concurrent Rambus Layout Guide
- Rambus Channel Layout Helper (Excel Format)
- Package for Direct Rambus DRAM
- Direct RDRAM 64/72-Mbit (256Kx16/18x16d)
- SLD4M18DR400, 400 Mb/s/pin 4Mx18 SLDRAM
- Applications for Rambus Interface Technology
- IEEE 1596.7-199x, Standard for A High-Speed Memory Interface (SyncLink)
- SLDRAM: High-Performance Open Standard Memory
- SLDRAM Architectural and Functional Overview
- Source Synchronization and Timing Vernier Techniques for 1.2GBps SLDRAM Interface
- Outline Background SLDRAM Interface Evaluation System Demonstration Chip Experimental Results Conclusion
- Intel Xeon Processor and Intel 860 Chipset Platform Design Guide
- Intel Pentium 4 Processor and Intel 850 Chipset Platform Design Guide
- 100MHz 2-Way SMP Pentium III Xeon Processor/Intel 440GX AGPset AGTL+ Layout Guidelines
- Pentium III Xeon Processor/Intel 450NX PCIset AGTL+ Layout Guidelines
- HSPICE User's Manual, Meta-Software Inc.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}