— Дамы и господа! На борту нашего сверхсовременного
авиалайнера к вашим услугам зимний сад, два бара, сауна, бассейн,
ресторан, биллиардный и кино-залы. А теперь пристегнитесь,
вдохните поглубже, и пожелайте нам всем удачи: сейчас я и мой
экипаж попытаемся поднять это чудо в воздух…
(довольно старый анекдот)
Эта статья наверняка многим покажется «смутно знакомой». Помните то самое непередаваемое словами ощущение из серии «где-то я что-то такое уже…»? Скорее всего — оно возникнет. Кому-то она, быть может, покажется bugfix-пакетом к «Боже, храни писишников…» — и, наверное, они будут правы. Кто-то обнаружит здесь знакомые темы из «Какой русский не любит быстрой езды?…» — и тоже будет по-своему прав. Но «правее» всех все-таки окажутся те, кто вспомнит давнее авторское обещание написать когда-нибудь про «идеальный компьютер» — каюсь, так и не сдержанное. Фактически, то, что вы сейчас прочитаете — это «похороны» этой статьи. Осколки и фрагменты, которые так и не смогли превратиться в единое целое, как я ни старался. Кто-то скажет: «Квалификации вам, батенька, не хватило, не на то замахнулись», — и, может быть, тоже будет прав. Однако фрагменты остались, и, честно говоря, просто жаль потраченного на них времени. Поэтому я написал эти «записки» — standalone отрывки, связанные между собой, пожалуй, только двумя вещами — тем, что речь в них идет о компьютерном железе, и тем, что всем им присущ оттенок грусти. Виктор Картунов (aka matik) не так давно изобрел жанр «технического ворчания», я же предлагаю вам «техническую грусть». Чем не жанр? :)
Процессоры
Сейчас, естественно, вспомнив заголовок, все подумают, что автор начнет последовательно критиковать Pentium 4. Это так… и не так. Вообще, мне не хотелось бы (и к этому были приложены усилия), чтобы данный editorial воспринимали как критический. Скорее он несколько печальный — ибо приходится констатировать, что по многим признакам мы «идем куда-то не туда». Однако, с другой стороны, успех того же пресловутого Pentium 4 воочию демонстрирует, что с тактической точки зрения (если ориентироваться на ближайшее будущее) Intel избрал совершенно верную маркетинговую позицию. Если смотреть фактам в лицо, то Pentium 4 с его концепцией больших мегагерцев («против лома нет приема») реально побил ближайшую альтернативу в лице AMD Athlon XP по производительности, и тенденций к пропаданию разрыва между ними что-то не видно — он то сокращается, то становится шире, но присутствует всегда. Будущий Hammer выглядит на бумаге очень неплохо, и, вполне возможно, таковым и окажется, однако сейчас говорить о нем как о конкуренте Pentium 4 не имеет никакого смысла. Ибо не может то, чего нет, «конкурировать» с тем, что уже есть и успешно продается.
Но тем не менее, тем не менее… Недаром ведь практически в любом серьезном противостоянии процессорных архитектур всегда участвуют воплощения двух принципиально различных подходов — наращивания тактовой частоты, и попыток исполнить максимальное количество инструкций за один такт. Думаю, не нужно быть семи пядей во лбу, чтобы разделить эти подходы по основному признаку на технологический и интеллектуальный (экстенсивный и интенсивный, эволюционный и революционный, и т. п.). В первом случае разработчик ориентируется на единственную задачу — заставить ядро CPU работать на как можно более высокой частоте. Конечно, и тут есть где разгуляться полету творческой мысли. В Pentium 4 довольно много интересных решений — хитрые приемы синхронизации, быстрая процессорная шина, 256-битовая шина L2 cache, высокоинтеллектуальный механизм предсказания ветвлений, удвоенная частота ALU, trace cache, и т. д. и т. п. Однако эти ноу-хау по большому счету можно отнести именно к хитростям т. е. небольшим, изящным инженерным решениям некой частной проблемы. Так сказать, «максимальным подслащиванием имеющегося в наличии материала с целью изготовления из него конфеты» :).
Введение «глубокой» (т. е. многоступенчатой, с большой предвыборкой) out-of-order execution, совершенствование механизмов распараллеливания выполнения инструкций, оснащение CPU другими интеллектуальными функциями, позволяющими, «выкусывать» из кода большие куски, пригодные для одновременного исполнения — это, по сути, задача больше научная, чем прикладная. Поэтому критиковать получается по сути и нечего: ни одна попытка создания массового высокопроизводительного CPU, чьей идеологией была бы не тактовая частота, а одновременное исполнение большого количества инструкций за такт, пока что не смогла «побить» подход сугубо технологический — наращивание частоты за счет удлинения конвейера и освоения новых xx-микронных техпроцессов.
Не удались эти попытки (автор заранее оговаривается, что это его личная точка зрения, базирующаяся на анализе известных ему фактов) именно из-за того, что задачи оптимизации архитектуры и кода для такого случая пока что не решены даже на теоретическом уровне. Да что там «не решены» — даже четкой постановки самого вопроса нет! Правда, «постарались» тут еще и программисты — параллельные алгоритмы, так широко применяющиеся, к примеру, в природе, в программном обеспечении встречаются очень редко, а хорошие их реализации — и того реже. Вспомним Itanium от Intel с его VLIW архитектурой и необходимостью «умного» компилятора: все его преимущества проявляются только на весьма узкоспециализированном, исключительно под него писаном software, и даже сама компания-производитель признает, что для массовых задач он сейчас малоприменим. Хотя, с другой стороны, продолжение работ над VLIW-процессорами и настойчивость Intel дают надежду на то, что рано или поздно в этой области произойдет некий прорыв.
Оптимисты, кстати, могут предположить, что он уже начался — по имеющимся данным (автор поплевал через плечо чтобы не сглазить), производительность Itanium 2 уже находится на уровне таких ранее недостижимых монстров RISC-мира как IBM Power 4. Есть правда во всей этой бочке меда одна немаловажная ложка дегтя: мы говорим о решениях массовых, вывести же сейчас в массы мощный VLIW (Itanium 2) или же мощный RISC (IBM Power 4) практически нереально. Причина проста — он действительно очень дорог. Другими словами, не «дорого продается», а имеет реально очень высокую себестоимость производства.
Вторая надежда (после VLIW) — это все чаще раздающиеся голоса о «закате эпохи RISC». Здесь нужно сделать сноску: под самой аббревиатурой в данном случае понимается скорее не то, что мы привыкли понимать под RISC CPU «целиком», а символ процессора с простым набором команд. Очень симптоматичными с этой точки зрения автору видятся не так давно появившиеся разработки компании Ajile — AJ-80 и AJ-100 — процессоры, для которых ассемблером является… байт-код Java-машины! Не секрет, что история развивается циклично, поэтому вполне логичным выглядит предположение, что победное шествие высокоскоростных «туповатых» CPU рано или поздно должно завершиться, и на смену им (по закону шараханья эволюции из стороны в сторону) придут процессоры, которым ни высокая частота, ни даже большое количество инструкций, выполняемых за такт, будут не нужны по простой причине — потому что одна инструкция такого процессора будет намного более емкой, чем «A сложить с B и поместить результат в C».
Наконец-таки, третий вариант (который, кстати, вполне можно совместить с любым из перечисленных выше) — это своеобразный «back to the future» в подходе к конструированию самого CPU. Сейчас мы уже привыкли, что ALU, FPU, MMU, L1/L2 cache — все это сосредоточено в одном корпусе. Однако появление таких процессоров как VIA Cyrix III (C3) показывает, что некоторые из блоков при условии ориентации компьютера на определенный круг задач… фактически не нужны! Я, конечно, понимаю, что это весьма смелое сравнение, но все же с известной долей иронии позволю себе назвать VIA C3 «процессором без FPU» (если кому-то это кажется некорректной гиперболой, предлагается формулировка «с номинальным наличием FPU»). Ну и что — сильно это ему мешает? Зато (кстати!) если бы у нас была возможность взять дешевый как пирожок с повидлом «ALU от VIA», да совместить его с FPU от того же Intel… Кто знает, кто знает…
Лирическое отступление авторского альтер-эго
Понятно, что зачастую у многих приводимых здесь решений имеется минусов едва ли не больше, чем плюсов. Авторская задача в данном случае состоит не в том, чтобы предложить схему выхода из кризиса (кому не нравится слово «кризис», может читать в оптимистическом ключе: «схему нового прорыва» :). Скорее речь идет о том, чтобы попытаться понять, какие решения из уже известных, но [незаслуженно] забытых все еще «в строю» и могут быть использованы.
Ну а если совсем с головой уходить в мечтания, то можно дойти даже до такой крамольной мысли как ненужность FPU в принципе! Действительно — а почему именно «floating point»? Нет, в общем-то оно понятно — чаще всего дополнительно к арифметике целочисленной нужна именно вещественная. Но, с другой стороны, ограниченность этого «дополнительного» блока процессора строго заданным набором команд, и породила в конечном итоге кучу других дополнительных блоков (все эти MMX / 3DNow! / SSE / SSE2…). Может быть, начиная все с нуля, стоит не выбирать наилучший набор из существующих, не разрабатывать собственный, а просто сесть и немного подумать над сутью проблемы? Решение ведь напрашивается элементарнейшее: раз инструкции нам могут быть нужны самые разные, и даже иногда невозможно предсказать, какие понадобятся завтра, то блок, дополняющий ALU, нужно просто сделать перепрограммируемым! Вначале (после включения питания) пусть он будет запрограммирован как классический FPU, а потом — все отдается на усмотрение конкретного программиста. Конечно, необходимо будет предусмотреть ситуацию, когда перепрошивка процессора на лету какой-то одной программой приведет к конфликту с другой. Однако если такую возможность изначально предусмотреть (мы же договорились изобретать все «с нуля»), то ввести в ОС способы разрешения этого конфликта особого труда не составит. В конце концов, программы, прошивающие в этот «универсальный вспомогательный процессор» свой собственный код, можно заставить исполняться исключительно поодиночке и в эксклюзивном («однозадачном») режиме. Все-таки, как правило, хитрые приемы типа изобретения собственных наборов команд, используются исключительно для увеличения быстродействия, так что многозадачность во время исполнения вряд ли понадобится.
Лирическое отступление авторского альтер-эго
Остапа явно несло :) — последняя идея по своей сути, противоречит некоторым основополагающим принципам, которые изложены в других частях этой же статьи! Ну да ладно, отнесем к особенностям жанра «записок». Да и сама по себе идейка не то что бы новая но довольно забавная…
Чипсеты
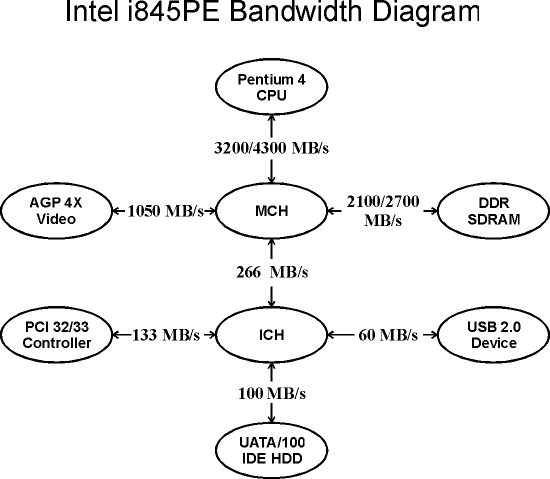
Против обыкновения, приведу здесь один маленький рисунок. Я его назвал конкурсом «Найди одинаковый bandwidth» :). Итак, в чем же основная беда всех современных чипсетов? В узких местах? В медленных шинах? Да ничего подобного! Беда как раз в том, что некоторые из них слишком быстрые :). Вторая же — этих самых шин совершенно невозможное количество. Давайте посчитаем:
- между процессором и северным мостом — раз;
- между северным мостом и южным — два;
- шина памяти — три;
- AGP и PCI — четыре, пять;
- …
Уже, imho, достаточно потому что уже «перебор». Работает весь этот дивный зоопарк на куче различных частот (пусть и базирующихся на одной опорной, однако отнюдь не всегда «четных» по коэффициенту умножения), с разными «иксовыми» коэффициентами уплотнения потока, что приводит нас к необходимости сквозной буферизации всех и вся, потому что иначе никак не получится — скорости-то разные! Теперь давайте вспомним что такое буфер, как он работает, и как его наличие сказывается на результативной пропускной способности канала в условиях неравномерной загрузки. А ведь плохо получается… Даже если просто попытаться представить сколько скоростей, частот и буферов, должна пройди одна немудрящая текстурка чтобы попасть из ОЗУ в видеопамять — сразу же становится понятно, что все эти AGP8X, DDR400 и 533 MHz FSB, делая вид что они ужасно быстрые, на самом деле таковыми «в сборе» совершенно не являются — исключительно по причине неизбежных потерь на синхронизацию.
Лирическое отступление авторского альтер-эго
Тут кстати очень хочется «пнуть» одну широко известную компанию — изобретателя шины AGP. Нет, даже не так — сначала похвалить, но потом все же пнуть. Потому что хваленая концепция Direct in Memory Execution (DiME, она же в просторечии AGP Texturing) при нынешней копеечной стоимости памяти нужна в общем-то как зайцу пятая нога. По крайней мере одно можно утверждать точно — если бы DiME не было, то обходиться без него как-нибудь смогли бы, и не думаю, что это привело бы к значительному снижению качества графики или скорости. Сейчас же мы имеем еще одно устройство (AGP-видеокарту), которое имеет право по своим нуждам вести тревожащий огонь командами по контроллеру памяти, что безусловно только прибавляет бардака… Сделали бы «честную» 2X (4X, 8X) шину без этих наворотов с отшариванием основного ОЗУ — и было бы все намного проще.
Итак, первый вот бич современных чипсетов — асинхронность. Второй же — введение в состав большого количества разномастных примитивных контроллеров, к которым подключаются столь же примитивные устройства. Сколько у нас внешних шин, а точнее сказать, «разно-спецификационных» контроллеров, организующих каналы поступления и выдачи цифровой информации? USB, COM, PS/2, LPT. Уже четыре. Плюс практически обязательный Ethernet, плюс довольно часто встречающаяся FireWire — итого шесть. Внутренние шины мы уже посчитали выше. Автор предлагает всем отбросить синдром «на привычное внимания не обращаем», и попытаться ответить на очень простой вопрос: А ЗАЧЕМ? Зачем нам более десятка шин в таком достаточно в примитивном с точки зрения выполняемых задач устройстве как средней руки современный ПК? Идеальный чипсет? Да пожалуйста — сквозная шина общего назначения, разведенная на плате, со слотами для подключения устройств. Или даже топология «звезда», чего уж скромничать :). Нужна асинхронность? Без проблем — пусть ее реализует разработчик конкретного устройства внутри самого этого устройства. Банально? Примитивно? А не тут сложности вводить нужно, ой не тут… Впрочем, об этом — ниже.
Лирическое отступление авторского альтер-эго
Если уж совсем отрываться от имеющегося, то «идеальный чипсет» выглядеть будет по мысли автора примерно так:
- Центральный коммутатор для высокоскоростных устройств. Кстати, можно поступить как сделали в Hammer — интегрировать его в процессор, вместе с контроллером памяти;
- Вспомогательный коммутатор, подсоединяющийся к одному каналу центрального;
- Все устройства подсоединяются к каналам одного из коммутаторов, при необходимости реализуя все необходимые им внутренние шины внутри себя. Конечно, кому-то может тогда прийти в голову, что проще этого не делать. И действительно — намного проще :).
Видеочипы
Как уже говорилось выше, основной принцип в рамках данного материала — не отягощать себя излишними усилиями в тех случаях когда что-то довольно неплохое в рассматриваемой области уже сделано или изобретено. Именно таким, полностью «краденым» :) и будет видеораздел.
Начнем, пожалуй, со штуки, про существование которой почти все уже полностью забыли, несмотря на то, что сделана она в современных x86-системах не то что бы «неважно», а прямо скажем — абсолютно безобразно. Штука эта называется 2D, а ее ближайшее видимое практическое применение — GUI. Итак, в чем же, собственно, безобразие? Да в том что и 2D и GUI у нас до сих пор растровые! И это после того, как уже в лохматой давности 80-х годах прошлого века существовал компьютер NeXT с его замечательным интерфейсом на основе Display Postscript — языка высокого уровня, специально предназначенного для описания изображений (знакомые с компьютерной версткой наверняка увидев знакомое слово Postscript, «врубились в тему» сходу). Обрабатывался этот язык в NeXT аппаратно (!) — отдельным, специально для этого предназначенным DSP, который фактически исполнял ту же роль, которую нынче с трудом осиливает какая-нибудь GeForce4 Ti4600 :). Причем, скажу я вам, как человек видевший NeXT в работе — справлялся этот DSP со своей задачей не хуже GeForce4. Даже скорее лучше, потому что к примеру аппаратный антиалиасинг шрифтов мы до сих пор увидели только в Matrox Parhelia, а в NeXT он был еще тогда. И, кстати — то, что называет сглаженными шрифтами Windows, после NeXT ничего кроме печальной улыбки вызвать не способно…
Так вот, возвращаясь к Display Postscript. Как уже было сказано выше, это — язык. Если не вдаваться в сложности — один из многих языков описания изображений. В частности — векторных, но возможны растровые «вставки». Самая же замечательная особенность при таком подходе к организации GUI состоит в том, что, мы сразу же безжалостно расправляемся с одним из самых сильных источников «глюков» — мы закрываем программам доступ в видеопамять. Нет видеопамяти! Вообще нет, ни для кого кроме этого самого DSP! Все что может программа (и ОС как частный ее случай) — это посылать на вход «запрограммированные» изображения, и ожидать их появления на экране в указанном месте. При этом, строго говоря, даже узнать появились они там или нет, программа не может (по крайней мере если данную аппаратную подсистему организовывать «канонически»). Ну и второе, не менее приятное следствие — у нас сразу же пропадает проблема драйверов, причем полностью и навсегда. «2D-чипы» могут производиться хоть сотней компаний, быть сложными или простыми, быстрыми или медленными, но язык они все должны понимать один и тот же. Кстати, недаром про Display Postscript не так давно вспомнили в Apple, построив на его основе весь интерфейс MacOS X. А вот что Apple сделала в корне неправильно, фактически загубив всю прелесть идеи (на нынешнем этапе по крайней мере) — она сделала Display Postscript в MacOS X программным. Будем надеяться, что это они от спешки.
Что же касается 3D-части, то ее давным-давно пора вчистую отгородить от 2D, вынеся в отдельный чип. Энное количество неприятностей и сложностей это, конечно, принесет — необходимость как-то делить между двумя чипами доступ к общему frame buffer, разборки «кто на экране сейчас хозяин» :) и т. д. и т. п. Однако на все эти простые и очевидные вопросы есть не менее простые и очевидные ответы — два устройства на одной шине ни для кого уже давно не в диковинку, а механизмы арбитража применительно к такой простой штуке как экран X на Y точек может набросать на коленке любой третьекурсник. Что же касается самого 3D-чипа, то должен он быть… ну конечно же, тоже «языковым»! Вот здесь кстати автор будет довольно краток, ибо в современном 3D профессионалом себя отнюдь не считает. Очень симпатично в качестве основы для такого языка выглядит RenderMan от Pixar. По крайней мере автору такой подход кажется более идеологически выверенным чем слишком уж «низкоуровневые» Direct3D и OpenGL. Их-то реализовать полностью в железе можно хоть сейчас (собственно, последние 3D-акселераторы от этого стоят в двух шагах), да вот только вряд ли это что-то изменит в лучшую сторону…
Лирическое отступление авторского альтер-эго
Вообще-то, раз уж мы разделили 2D и 3D по разным чипам, напрашивается мысль об установке их в соответствующие сокеты на плате т. е. об организации возможности замены. Причем автору кажется, что платы сразу же поделятся на две категории — «продвинутые» с двумя сокетами под 2D и 3D чипы, и обычные, с впаянным 2D и сокетом под 3D (можно еще предположить появление супердешевых плат вообще без возможности установки 3D-чипа). Далее, нам скорее всего все-таки понадобится выделенный интерфейс между 2D и 3D чипом, ибо возможность работы с frame buffer и наличие RAMDAC логично полностью отдать на откуп 2D-чипу, а 3D-акселератору просто предоставить возможность управлять содержимым некоего окна на экране (или, как частный случай, содержимым всего экрана). А вот текстуры вполне можно размещать и в основном ОЗУ, раз уж акселератор будет «сидеть на сокете» т. е. на одном из каналов центрального коммутатора. Одна из основных проблем при такой архитектуре — обеспечить возможность быстрой отрисовки картинок с большим разрешением и цветностью, ведь в случае с 3D работать придется не напрямую с frame buffer, а через 2D-чип. Однако все не так уж смертельно — 1920×1080×32 (качество HDTV) при частоте 100 кадров/с дают нам не такой уж большой по современным меркам поток — ~770 MB/sec. А если передавать еще и не все изображение, а только изменившиеся его части — получится и того меньше.
Накопители
В последнем разделе этих «записок» я осознанно не буду делать длинных вступлений, а сразу возьму быка за рога: вещь, которая меня в современных накопителях (в частности, в самом распространенном их классе — IDE-винчестерах) более всего раздражает — это их непроходимая тупость. Причем относится это сразу ко всей связке — и к собственно накопителю, и к контроллеру. SCSI-устройства производят более благоприятное впечатление — там хоть контроллер по степени «разумности» вполне может сравниться со специализированным и довольно сложным процессором, но дело в том, что… именно SCSI-накопители, и именно по этой причине и являются дополнительным фактором, тормозящим развитие отрасли в целом! Да, они «более умны». Но без приставки «более» это слово использовать все равно нельзя, потому что «разумными» их можно называть разве что по отношению к еще более тупым IDE :). Однако почему-то очень часто встречается мнение, что дескать венец творения (SCSI) у нас уже имеется, и все что нужно — сделать его доступнее страждущим массам. Imho — не стоит. Потому что идея, бывшая венцом творения не один десяток лет, да еще и в такой динамичной отрасли как компьютерная, явно не может являться им сейчас. Попробую доказать…
Во-первых (и в основных) — c чего это все вдруг решили, что нам вот так позарез необходим доступ к хранилищу информации как к физическому устройству? Автор довольно немало проработал с различными ОС и программами, и на данном этапе своего развития искренне считает, что прямой доступ к устройству хранения информации, позволяющий прочитать к примеру «такой-то сектор на такой-то дорожке такой-то пластины» — нужен по-хорошему только для того, чтобы наживать себе известное заболевание прямой кишки да плодить глюкавые программы и вирусы :). Чем же его заменить? Одно из решений более всего милых моему сердцу не то что лежит на поверхности, а даже подпрыгивает на ней и привлекает внимание любого интересующегося с помощью флагов, транспарантов, и всех иных возможных средств. Давайте-ка представим себе… аппаратный FTP-сервер!
Предупреждая возмущенные возгласы: понятно, что протокол FTP взят просто в качестве наиболее близко лежащего примера. Речь идет, в общем случае, об управляемом с помощью языка высокого уровня накопителе, обеспечивающем выполнение команд доступа к файловой структуре. Так… Кто сказал «дорого»? Я даже не буду приводить цены на MIPS-совместимые процессоры и современные DSP, быстродействия которых будет достаточно для требуемой функциональности — пусть желающие найдут их сами, так оно лучше запомнится :). Что же касается памяти под интерпретатор языка, который будет исполняться этим процессором, то по-моему повальное оснащение даже low-end моделей кэш-буфером размеров 2 MB, дает вполне четкий ответ на этот вопрос. Размер… Автор берется с уверенностью утверждать, что по размеру данное устройство даже сейчас вполне реально сделать ни на миллиметр ни по какой оси не отличающимся от обычного винчестера. Преимущества же такой концепции громадны! Перечислю самые основные:
1) «Программное» нарушение целостности данных на накопителе становится в условиях нормальной работы железа просто-напросто принципиально невозможным — даже ОС физически не способна это сделать. Все, что позволено -работать с накопителем на уровне языка, для которого адресуемыми объектами являются либо фиксированные элементы логической структуры (логический диск, каталог, файл), либо их части (некий фрагмент внутри файла, задаваемый, к примеру, смещением от его начала и длиной).
2) Обнаружение устройства и последующая работа с ним совершенно отвязывается от конкретного типа подключения. Все, что нужно системе — это уметь работать с физическим каналом данных, на другом конце которого расположено «что-нибудь». При инициализации формируется стандартный запрос этому «что-нибудь»: «ты кто?». Стандартный ответ: «я — накопитель» — значит, понимает стандартизованные языковые команды. Поздоровались, работаем. Нет ответа? Значит, не накопитель :).
3) На уровне абстракции ниже чем структура логических устройств хранения, каталогов и файлов — организация размещения информации (сиречь файловая система) может быть любой — просто потому, что это никого не касается кроме производителя конкретного устройства. Нравится ему иметь внутри NTFS — никаких проблем, нравится FAT32 или ext2 — а не все ли нам равно? Алгоритмы кэширования (на уровне устройства), оптимизация запросов, внеочередное исполнение, буферизация — обо всем этом пусть болит голова у производителя и его разработчиков firmware. Нас же интересует только одно — способность устройства адекватно реагировать на посылаемые ему запросы.
4) Отказ от понятия драйверов контроллера или, Боже упаси, самого накопителя. А зачем? Высокоуровневый коммуникационный протокол — он и в Африке таковым остается. Все что требуется — определить канал, по которому должны «бегать» команды и данные, обеспечить их прием и передачу, и контроль ошибок на линии.
Лирическое отступление авторского альтер-эго
Драйверы... Как правило, я не люблю выступать от лица всех, предпочитая ограничиваться рамками IMHO, но сейчас все же рискну. «Драйвер» — слово для любого железячника матерное. Это замечательная во всех отношениях прослойка между железом и ОС, «одной ногой» стоящая в hardware, а другой в software... вот только почему-то первой в голову приходит ассоциация не с ногами, а с, мильпардон, немного другой частью тела. Которая традиционно пытается сидеть на двух стульях сразу, и столь же традиционно с одного из них периодически слетает, с грохотом падая. Милые вы мои глюкодромы, любимые BSOD-генераторы... Так иногда хочется подержать за шею тех, кто вас пишет... Приподнять сантиметров на 50 над уровнем земли, заглянуть в глаза, и ловя остатки затухающего от недостатка кислорода взгляда, нежно и ласково спросить: «За что, любезный? Почему ты меня так не любишь, чего я тебе плохого сделал?» Драйверы must die...
К слову — разработки в области «интеллектуализации» устройств хранения информации в принципе тоже ведутся, нельзя сказать что все стоит на месте. Но ведутся они с точки зрения автора как-то очень «вяло» и «невнятно». Если автору не изменяет память, в «Fiber Channel — Arbitration Loop» (FC-AL), оконечное устройство наделено уже довольно большим интеллектом по сравнению с всеми предшественниками, включая SCSI-винчестеры. Интересующиеся подробностями могут прочитать про особенности этой архитектуры у нас на сайте: «Fibre Channel: первое знакомство», «Fibre Channel: архитектура», «Fibre Channel: топология и оборудование». Однако производители данных устройств почему-то вообразили, что стоить они должны бешеных денег, в результате чего популярность им, мягко говоря, не грозит.
Кроме того, во всех материалах по FC-AL упор делается на сверхвысокий bandwidth, что в обсуждаемом выше устройстве обязательным в общем-то не является, ибо не в bandwidth в данном случае суть. Между прочим, ситуация с FC-AL является еще и замечательным примером весьма распространенного в IT-индустрии явления, когда хорошую в принципе идею «насилуют», стремясь выколотить из нее сверхприбыли «именно сейчас и любой ценой» вместо того чтобы поставить на массовость и сделать денег в десятки раз больше, всего лишь немного подождав.
«Незаконченная пьеса для механического пианино»
Ну, вот он как-то и получился, «идеальный компьютер». Процессор с достаточно низкой частотой и сложной системой команд («архи-CISC», так сказать). Чипсет, фактически являющийся функциональным аналогом коммутируемой сети (только, Боже упаси, не Ethernet! :). Преимущественно высокоуровневые протоколы (скорее даже «языки») для общения со всеми основными трафикообразующими устройствами. «Бездрайверная» ОС, использующая для общения с устройствами жестко стандартизованные (очень желательно еще и открытые) протоколы. «Умные» устройства, обладающие свойством самоуправления без участия / вмешательства пользователя и даже операционной системы (впрочем, умеющие сообщать о своем состоянии по запросу).
Окончательное признание страшнейшим злом концепции прямого доступа одного устройства к ресурсам другого, и, соответственно, избежание ее применения во всех возможных случаях. Отказ от противопоставления 2D и 3D (но в то же самое время отделение одного от другого) и постепенный приход к нормальной практике формирования любого изображения аппаратными средствами ответственных за это процессоров, воспринимающих команды высокого уровня. «Псевдоасинхронность» в случаях когда ее невозможно избежать, переложенная с плеч аппаратного обеспечения на программное, или «спрятанная» внутри устройства, видимого всеми остальными в качестве единого целого. Общие довольно-таки фразы, не так ли? Ну а что поделать — я же предупреждал…
Если честно, то основная причина столь общего подхода — это прежде всего то, что с детства воспитанный в x86-традициях автор, оценивая по прошествии времени свои же опусы, обнаружил в себе некоторую даже неспособность зримо и явно представить себе во всех деталях тот «прекрасный новый мир», к которому его так тянет вечная человеческая страсть к поискам идеала. Все время безудержный полет фантазии скатывается либо к чему-нибудь вроде Pentium 8 10'000 GHz + AGP 128X + GeRadeon 64000 512 MB :), либо к желанию для начала взять большую кувалду и повторить подвиги луддитов, а потом уже «главное что место чистое, а как заполнить — что-нибудь придумаем». Что поделать — мы везде ищем привычное и все стремимся свести к знакомым стереотипам, так уж устроена человеческая психика. Однако иногда хочется просто помечтать. Пусть даже и с налетом грусти…
P.S. или «…И все же попытаемся!» :)
Несмотря на то, что автор вроде бы зарекся разрабатывать полномасштабную спецификацию «Идеального ПК» или даже хотя бы общую его схему, в процессе обсуждения статьи стало ясно, что обойтись без нее в некоторых случаях чрезвычайно сложно. Хотя бы потому, что объяснять даже самые общие принципы «на пальцах» зачастую не получается, а исходя из текста статьи трактовать их можно иногда совершенно неоднозначно, в том числе и не так, как подразумевалось автором материала. Поэтому было решено некую блок-схему с минимальными разъяснениями в статью все же включить. Однако мы заранее предупреждаем, что полной и даже непротиворечивой ее назвать сейчас нельзя — и в первую очередь потому, что изначально ее существование совершенно не предполагалось. С точки зрения автора, данная блок-схема более всего близка к понятию «альфа-версия» т. е. до Release Candidate ей еще очень и очень далеко :). Итак, как же работает наш «Идеальный ПК»? Для начала приведем собственно блок-схему.
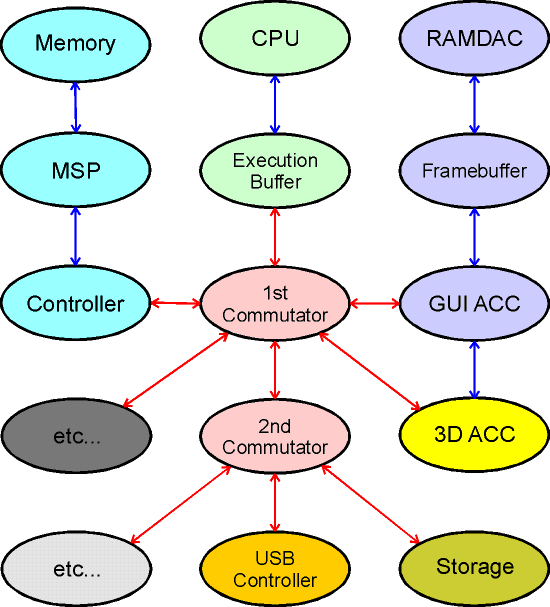
Коммутаторы первого и второго уровня заменяют привычный нам чипсет. Один из них высокоскоростной (первого уровня), предназначен для работы с основными «трафикообразующими» устройствами — процессором, памятью, графическими чипами, etc. Второй, подключенный к одному из портов первого — относительно «низкоскоростной», предназначен в основном для подключения контроллеров универсальных периферийных шин (на схеме в качестве примера приведен контроллер USB) или же устройств, не генерирующих трафика более 100-150 MB/sec.
Стрелки красного цвета обозначают единую (но не обязательно одинаковой ширины и пропускной способности) коммутируемую пакетную шину, по которой все подключаемые к коммутаторам устройства могут независимо (соединения «точка-точка») обмениваться информацией между собой на основании общего открытого протокола. Синим цветом обозначены соединения, которые могут быть реализованы на других принципах, причем в качестве одного из вариантов выбор этих самых принципов (шин, протоколов…) может быть «отдан на откуп» разработчикам конкретных устройств.
Одинаковым цветом обозначены группы устройств, которые с точки зрения коммутатора представляют из себя единое целое, и, в принципе, потенциально даже могут быть реализованы в рамках одного чипа.
Как видно, наш «идеальный процессор» :) снабжен собственным «буфером исполняемых инструкций и данных», только в рамках которого он и работает т. е. единственные доступные ему операции по отношению к основному ОЗУ — это копирование участка памяти в этот буфер или же наоборот копирование участка буфера в память. Предполагается, что буфер представляет из себя около 4 MB быстрой статической памяти (то есть фактически в старой терминологии x86 это будет наш «кэш первого уровня») и размещается на той же микросхеме что и сам CPU.
Дополнительно мы вводим чип, который авторы решили назвать «MSP» — Memory Streaming Processor. Он берет на себя часть работы CPU, выполняя независимо от последнего (но в соответствии с поступающими от CPU управляющими командами) операции по копированию данных из одной области ОЗУ в другую, а также различные потоковые операции (из самых примитивных примеров — «взять массив двойных слов с адреса X по адрес Y и умножить каждый элемент массива на Z»). Фактически, это будет некий гибрид ALU/MMU/SIMD-блоков с ограниченной функциональностью, сведенной к выполнению наиболее часто встречающихся операций. Потенциально — с возможностью перепрограммирования части микрокода под исполнение «уникальных» команд (правда, это скорее в будущем…).
«Умные» устройства общаются между собой без участия центрального процессора, что, с одной стороны приводит к возрастанию трафика «внутри чипсета» (на коммутаторах), генерируемого периферией. Однако с другой стороны, канал «процессор-память» уже не является настолько большим генератором трафика как ранее, особенно учитывая существование относительно большого буфера исполняемых инструкций и специального MSP, работающего с памятью напрямую и параллельно с CPU, следовательно, задержек и трафика не генерирующего вообще. В результате по мысли авторов общего роста трафика не будет, просто несколько изменится его баланс — от «процессорно-ориентированного» сегодняшнего к более «размазанному» по устройствам.
На этом, собственно, пока что все. При наличии времени а также дальнейшем появлении каких-либо уточняющих и дополняющих данную блок-схему идей (не обязательно своих :), автор предполагает вносить изменения в данный post scriptum динамически. Кто знает — быть может, общими усилиями нам удастся действительно разработать полную спецификацию этого чуда?! :)
из переписки с которым были почерпнуты многие идеи, легшие в основу статьи,
и Виктору Картунову aka matik (kartunov@sky.od.ua), чья беспристрастная критика сделала ее гораздо полнее и глубже


