Часть 8 — процессоры Intel Pentium 4 и Pentium 4 Extreme Edition с новой ревизией ядра Prescott
21 февраля ожидается анонс двух новых моделей процессоров Pentium 4 крупнейшего процессорного гиганта Intel. Первая из них — это долгожданная «600-я» серия процессоров Pentium 4 (630, 640, 650 и 660), функционирующих на частотах от 3.0 до 3.6 ГГц с 200-МГц частотой системной шины (800 МГц Quad Pumped Bus). Они основаны на новой ревизии ядра Prescott, поддерживающей технологии Extended Memory 64-bit Technology (EM64T, аналог AMD x86-64) и Enhanced Intel SpeedStep. Вторая модель пока что представлена в единственном экземпляре — в виде «экстремального» Pentium 4 Extreme Edition с частотой ядра 3.73 ГГц, рассчитанного на 266-МГц частоту системной шины (1066 МГц Quad Pumped Bus). Отметим, что это, фактически, первый представленный компанией «экстремальный» процессор, основанный на ядре Prescott. Обе модели оснащены 2 МБ кэша данных второго уровня. В настоящей статье рассмотрены основные характеристики новых ревизий процессорного ядра Prescott, реализованного в обоих процессорах, в сопоставлении с предыдущими ревизиями ядер Prescott и Nocona, рассмотренными в статье «Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer. Часть 6 — Платформа Intel Xeon (Nocona)».
Конфигурации тестовых стендов и ПО
Тестовый стенд №1
- Процессор: Intel Pentium 4 3,6 ГГц (ядро Prescott, Socket 775, FSB 200 МГц, 2 МБ L2)
- Материнская плата: Gigabyte 8AENXP-D на чипсете Intel 925XE, версия BIOS F2 от 01/04/2005
- Память: 2x512 МБ PC2-4300 DDR2-533 Corsair XMS Pro (тайминги 4-3-3-8)
Тестовый стенд №2
- Процессор: Intel Pentium 4 Extreme Edition 3,73 ГГц (ядро Prescott, Socket 775, FSB 266 МГц, 2 МБ L2)
- Материнская плата: Gigabyte 8AENXP-D на чипсете Intel 925XE, версия BIOS F2 от 01/04/2005
- Память: 2x512 МБ PC2-4300 DDR2-533 Corsair XMS Pro (тайминги 4-3-3-8)
Программное обеспечение
- Windows XP Professional SP2
- Intel Chipset Installation Utility 6.2.1.1001
- DirectX 9.0c
- RightMark Memory Analyzer 3.47 pre-release
Характеристики CPUID
Исследование новой ревизии процессорного ядра Prescott начнем с анализа избранных характеристик, выдаваемых инструкцией CPUID процессоров.
Pentium 4 660
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0F43h | Семейство 15, модель 4, степпинг 3 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | 50h 5Bh 60h 40h 70h 7Dh | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12K-uops, 8-ассоциативный L2-кэш: 2 МБ, 8-ассоц., 64-байтн. строка |
| Basic Features, ECX (наиболее значимые характеристики) | 0000659Dh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 7: Поддержка Enhanced Intel SpeedStep Bit 8: Поддержка Thermal Monitor 2 Bit 2: Неизвестно Bit 13: Неизвестно |
| Extended Features, EDX | 20100000h | Bit 20: Поддержка Execute Disable bit Bit 29: Поддержка Intel (R) EM64T (x86-64) |
Среди важнейших отличий новой ревизии ядра Prescott, реализованной в 600-й серии процессоров Pentium 4 от предыдущей можно отметить, прежде всего, увеличение номера степпинга ядра до 3 (новые ядра имеют сигнатуру 0F43h, последняя ревизия E0 характеризовалась сигнатурой 0F41h). Учитывая, что каждой последующей ревизии ядра Prescott в ее буквенно-цифровом обозначении производителем назначалась более «старшая» буква алфавита без изменения цифрового индекса (переход от ревизии C0 к D0 и затем к E0), новой ревизии можно предположительно присвоить обозначение «F0», которое и будет фигурировать в настоящей статье. Интересно будет посмотреть, так ли оно окажется на самом деле.
Среди дескрипторов кэшей/TLB внимание заслуживает изменение значения одного из них с 7Ch на 7Dh, что означает переход от 1-МБ к 2-МБ кэшу второго уровня без изменения его прочих характеристик (ассоциативности и длины строки).
Тем не менее, наиболее интересны, на наш взгляд, характеристики основных «фич» новой ревизии ядра. Помимо наличия поддержки Thermal Monitor 2 и Execute Disable bit (уже присущих ревизии E0 ядра Prescott, т.е. «серии J» процессоров Pentium 4), в новую ревизию ядра встроена поддержка технологий Enhanced Intel SpeedStep и EM64T, изначально присущих серверным ядрам Nocona. Любопытно отметить присутствие двух пока «неизвестных» (т.е. отсутствующих в официальной документации) технологий, обозначенных битами 2 и 13 регистра ECX. Быть может, так будут обозначаться те самые, пока что «скрытые» от глаз рядового пользователя технологии LaGrande и VanderPool? Надеемся, это станет ясно с выходом новой ревизии документа Intel(R) Processor Identification and the CPUID Instruction, Application Note 485, последняя ревизия 027 которого датирована июлем 2004 года.
Итак, по всем перечисленным параметрам новую ревизию ядра Prescott можно, фактически, считать «десктопным» воплощением последней ревизии E0 серверного ядра Nocona, к тому же, оснащенного двумя мегабайтами кэша второго уровня. Переходим к новой «экстремальной» серии процессоров Pentium 4.
Pentium 4 Extreme Edition 3.73 ГГц
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0F43h | Семейство 15, модель 4, степпинг 3 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | 50h 5Bh 60h 40h 70h 7Dh | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12K-uops, 8-ассоциативный L2-кэш: 2 МБ, 8-ассоц., 64-байтн. строка |
| Basic Features, ECX (наиболее значимые характеристики) | 0000641Dh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 2: Неизвестно Bit 13: Неизвестно |
| Extended Features, EDX | 20100000h | Bit 20: Поддержка Execute Disable bit Bit 29: Поддержка Intel (R) EM64T (x86-64) |
В чем же заключается ее «экстремальность»? Ответ на этот вопрос совершенно не очевиден. Традиционный компонент «экстремальной» серии — кэш данных третьего уровня, в данном процессоре отсутствует. Впрочем, никто и не обещал, что «экстремальность» заключается в наличии именно L3-кэша. Более того, это не столь неожиданно, учитывая, что толку от 2 МБ кэша L3 при наличии 2 МБ кэша L2 и инклюзивной организации кэша данных будет… ровно ноль! (напомним, что эффективный объем кэшируемого пространства при инклюзивной организации кэша равен объему наибольшего из кэшей, но не сумме объемов всех уровней кэша). Вполне возможно, под «экстремальностью» имеется в виду способность ядра функционировать с 266-МГц частотой системной шины (которую, заметим, нам не удалось достичь с первым «подопытным» экземпляром), ибо… других вариантов просто нет.
Смотрим далее: сигнатура CPUID данной модели — вновь 0F43h, т.е. это как бы та же самая, новая ревизия «F0» ядра Prescott, реализованная в 600-й серии процессоров Pentium 4. Тем не менее, по «фичам» имеются явные отличия между этими двумя, казалось бы одинаковыми, ядрами. Так, у «экстремальной» реализации… отсутствуют технологии Thermal Monitor 2 и Enhanced Intel SpeedStep. В ней, тем не менее, присутствуют XD bit и EM64T, а также две «неизвестные» технологии, о которых мы упоминали выше.
Таким образом, по характеристикам CPUID первая «экстремальная» серия процессорных ядер Prescott — весьма неоднозначное явление. При ее реализации часть технологий была явно позаимствована у предыдущей ревизии E0 «неэкстремального» ядра Prescott (XD bit), а часть — у серверного ядра Nocona (EM64T). Но в том-то и дело, что только часть — новому «экстремальному» ядру почему-то «не достались» технологии TM2 (от Prescott E0) и Enhanced Intel SpeedStep (от Nocona), которые имеются у той же самой ревизии «неэкстремального» ядра Prescott (см. выше). Зачем так было поступать — понятно, наверное, лишь производителю процессоров, но запутать пользователей ему явно удалось очень хорошо…
Реальная пропускная способность кэша данных/памяти
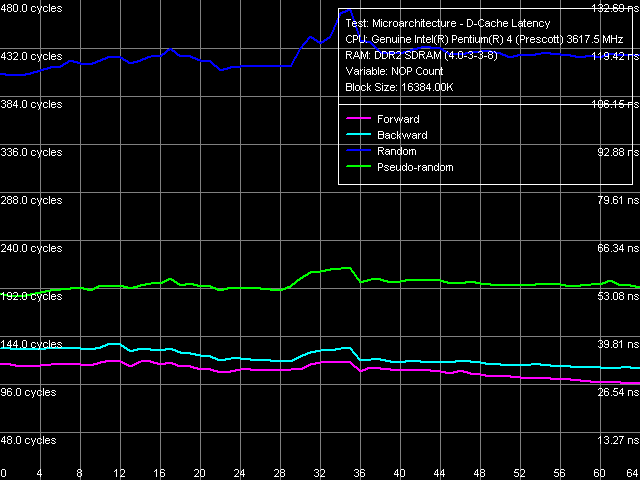
Переходим к результатам тестов новых процессоров, полученных в тестовом пакете RMMA. Общая картина реальной пропускной способности уровней подсистемы памяти (L1/L2/RAM) на Pentium 4 660 и Pentium 4 EE 3.73 выглядит одинаково.
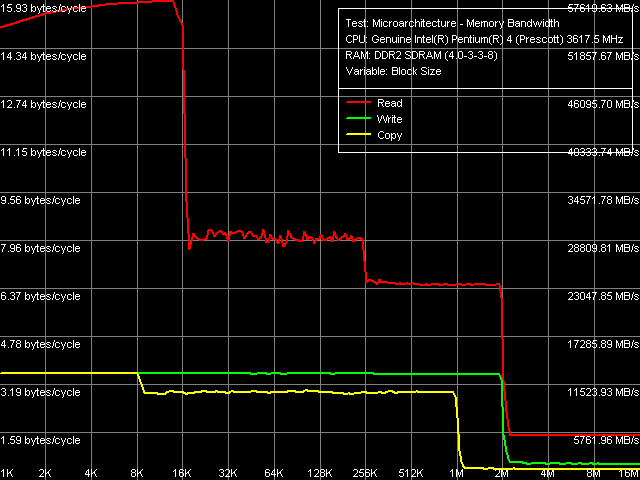 Реальная пропускная способность кэша данных и оперативной памяти,
Реальная пропускная способность кэша данных и оперативной памяти,Pentium 4 660 и Pentium 4 EE 3.73
Основные черты, которые можно отметить на графике, следующие: объем L2-кэша данных действительно увеличен до 2 МБ, однако уже при обращении к 256-КБ блокам данных ПС этого уровня подсистемы памяти заметно «проседает». Напомним, что это связано с исчерпанием ресурса буфера D-TLB, размер которого в новой ревизии ядра остался без изменений — 64 записи, т.е. 256 КБ «покрываемого» им виртуального адресного пространства. Отсутствие различий в эффективности L1 и L2 кэша на запись (т.е. отсутствие характерного перегиба в области 16 КБ) свидетельствует о «сквозной» организации записи данных (Write-Through), при которой данные всегда записываются только в L2-кэш, тем самым, увеличивая эффективность малого L1-кэша на чтение.
| Уровень | Средняя пропускная способность, байт/такт (МБ/с) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.98 15.93 2.91 3.56 | 7.96 15.93 2.90 3.54 | 7.98 15.93 2.91 3.56 | 7.98 15.93 2.91 3.56 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.41 8.02 2.91 3.56 | 4.39 7.84 2.89 3.54 | 4.53 8.13 2.91 3.56 | 4.57 8.20 2.91 3.56 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 3901.4 МБ/с 4457.4 МБ/с 1750.0 МБ/с 1760.6 МБ/с | 3215.2 МБ/с 3620.1 МБ/с 1863.0 МБ/с 1855.0 МБ/с | 5187.3 МБ/с 5490.6 МБ/с 2061.8 МБ/с 2057.8 МБ/с | 6002.8 МБ/с 6540.3 МБ/с 2216.9 МБ/с 2218.1 МБ/с |
Количественные характеристики ПС L1-кэша данных остались без изменений — они совпадают с полученными ранее на ядрах Prescott и Nocona ревизии D0. Характеристики ПС L2-кэша несколько отличаются — в частности, можно видеть несколько более высокую эффективность этого уровня кэша на чтение у обоих процессоров (полученную усреднением ПС L2 в интервале 20 — 240 КБ). Тем не менее, учитывая значительный разброс величины в указанном интервале, это вряд ли следует считать признаком серьезной доработки ядра — скорее, это следует считать просто погрешностью измерения :).
Тем не менее, в величинах ПС оперативной памяти наблюдаются заметные изменения — реальная ПС этого уровня подсистемы памяти на чтение заметно возросла. С одной стороны, это может быть следствием дальнейшего улучшения эффективности алгоритма аппаратной предвыборки данных, с другой — следствием использования нового чипсета i925XE, в котором, возможно, производителю удалось реализовать более эффективный контроллер памяти. Более высокие значения ПСП на Pentium 4 EE 3.73 объясняются 266-МГц частотой системной шины (увеличивающей ее пиковую ПС до 8.53 ГБ/с) и функционированием оперативной памяти в режиме, синхронном с процессорной шиной (соотношение частот FSB:DRAM 1:1).
Предельная реальная пропускная способность памяти
Как обычно (для процессоров Pentium 4), метод Software Prefetch позволяет достичь наибольших значений ПСП, в то время как остальные методы не обладают столь высокой эффективностью.
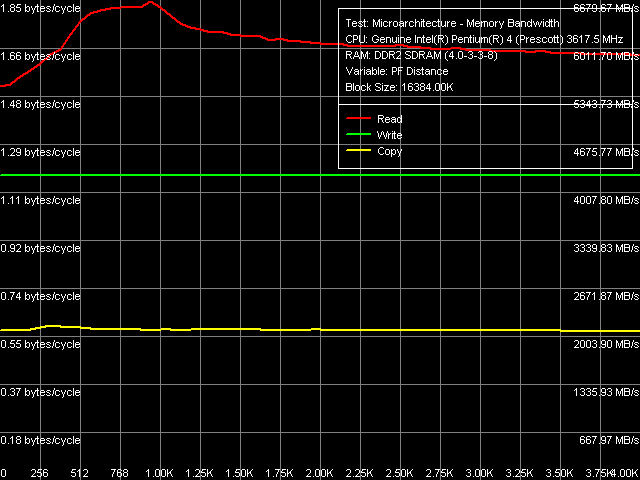 Максимальная реальная ПСП, Software Prefetch, Pentium 4 660
Максимальная реальная ПСП, Software Prefetch, Pentium 4 660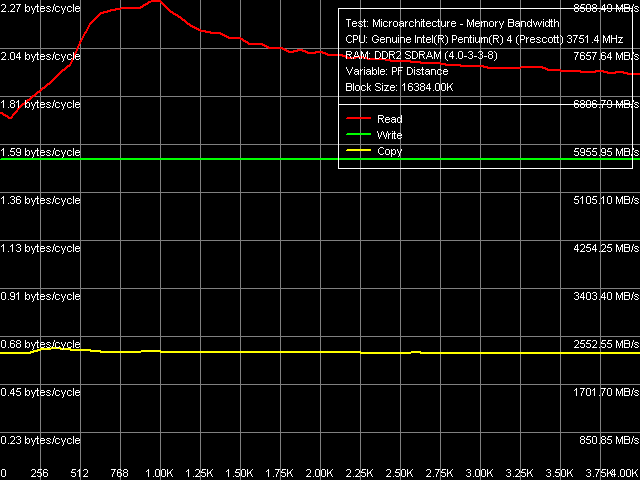 Максимальная реальная ПСП, Software Prefetch, Pentium 4 EE 3.73
Максимальная реальная ПСП, Software Prefetch, Pentium 4 EE 3.73 Кривые зависимости реальной ПСП от дистанции программной предвыборки на Pentium 4 660 и Pentium 4 EE 3.73 на качественном уровне совпадают — отличаются лишь количественные показатели, связанные с различием в частотах FSB (200 МГц на платформе Pentium 4 660 против 266 МГц на Pentium 4 EE 3.73). Полученные кривые префетча характерны для ядер Prescott (внешне они совпадают с теми, которые мы получили ранее, на предыдущих ревизиях этого ядра), кроме того, они указывают на отсутствие различий в реализации алгоритма программной предвыборки в «неэкстремальной» и «экстремальной» версиях новой ревизии ядра Prescott «F0».
| Режим доступа | Предельная ПСП на чтение, МБ/с* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 3901.4 (61.0%) 4457.4 (69.6%) 6311.3 (98.6%) 6334.2 (99.0%) 4191.0 (65.5%) 4614.8 (72.1%) 3948.3 (61.7%) 4517.2 (70.6%) 5180.9 (81.0%) 5178.7 (80.9%) | 3215.2 (50.2%) 3620.1 (56.6%) 5334.2 (83.3%) 5329.9 (83.3%) 3302.2 (51.6%) 3524.3 (55.1%) 3392.3 (53.0%) 3784.5 (59.1%) 3313.5 (51.8%) 3315.8 (51.8%) | 5187.3 (81.1%) 5490.6 (85.8%) 6521.3 (101.9%) 6679.7 (104.4%) 4630.6 (72.4%) 5046.4 (78.9%) 5146.9 (80.4%) 5492.2 (85.8%) 5968.8 (93.3%) 5957.7 (93.1%) | 6002.8 (70.3%) 6540.3 (76.6%) 8314.7 (97.4%) 8508.5 (99.7%) 5490.0 (64.3%) 6069.2 (71.1%) 5936.4 (69.6%) 6557.0 (76.8%) 7623.3 (89.3%) 7613.2 (89.2%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с для 200-МГц FSB, 8.53 ГБ/с для 266-МГц FSB)
По количественным показателям видно, что Software Prefetch «помогает» Pentium 4 EE 3.73 несколько в большей степени (выигрыш от его использования на этой платформе больше), нежели Pentium 4 660. Причина этого явления достаточно очевидна — эффективность программной предвыборки, на самом деле, одинаково высока у обоих процессоров, однако Pentium 4 660 намного быстрее «упирается» в теоретический предел ПС процессорной шины, по сравнению с Pentium 4 EE 3.73. Тем не менее, оба процессора достигают почти максимальной эффективности чтения данных из памяти (100% и даже выше :)) в области максимальной эффективности действия Software Prefetch — при предвыборке данных, находящихся на расстоянии от 768 до 1024 байта относительно запрашиваемых.
| Режим доступа | Предельная ПСП на запись, МБ/с* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 1750.0 (27.3%) 1760.6 (27.5%) 4265.9 (66.7%) 4266.0 (66.7%) 2283.9 (35.7%) 2254.2 (35.2%) | 1863.0 (29.1%) 1855.0 (29.0%) 4236.2 (66.2%) 4235.9 (66.2%) 2380.2 (37.2%) 2386.1 (37.3%) | 2061.8 (32.2%) 2057.8 (32.2%) 4255.0 (66.5%) 4254.9 (66.5%) 2527.7 (39.5%) 2435.0 (38.0%) | 2216.9 (26.0%) 2218.1 (26.0%) 5704.7 (66.9%) 5706.7 (66.9%) 2759.7 (32.3%) 2702.9 (31.7%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с для 200-МГц FSB, 8.53 ГБ/с для 266-МГц FSB)
Что касается показателей максимальной реальной ПСП на запись, легко видеть, что здесь мало что изменилось — использование метода прямого сохранения данных во всех случаях позволяет достичь 2/3 от максимальной теоретической ПС процессорной шины. Эффективность метода записи строк кэша можно также считать практически одинаковой для всех случаев: прирост по сравнению со средней ПСП на запись составляет в среднем 500 МБ/с.
Латентность кэша данных/памяти
Общая картина латентности, как и ПСП, у обоих исследуемых процессоров внешне выглядит одинаково.
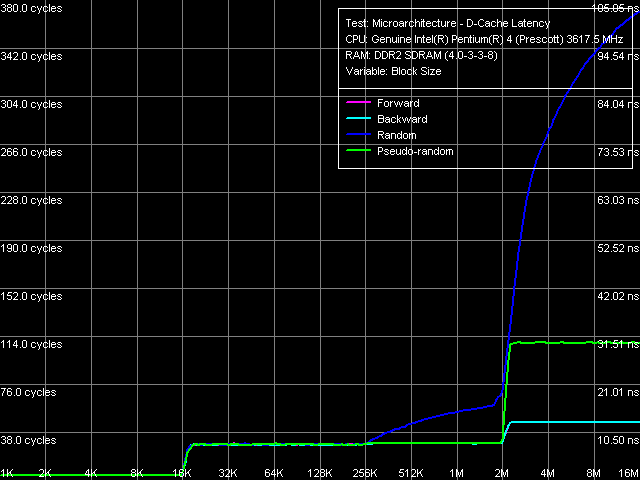 Латентность кэша данных/памяти, Pentium 4 660 и Pentium 4 EE 3.73
Латентность кэша данных/памяти, Pentium 4 660 и Pentium 4 EE 3.73 Характерные черты организации кэшей данных и D-TLB проявляются в этом тесте не менее отчетливо: перегибы в области 16 КБ и 2 МБ, соответствующие размерам L1 и L2 кэшей, а также плавное возрастание латентности случайного доступа в L2-кэш при размере блока от 256 КБ.
| Уровень, доступ | Средняя латентность, тактов (нс) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| L1 | 4.0 | 4.0 | 4.0 | 4.0 |
| L2 | ~28.5 | ~28.5 | ~28.5 | ~28.5 |
| RAM*, прямой RAM, обратный RAM, случайный** RAM, псевдослучайный | 37.3 нс 41.1 нс 126.0 нс 56.1 нс | 50.3 нс 52.6 нс 134.1 нс 75.8 нс | 32.5 нс (80.4 нс) 36.8 нс (77.2 нс) 106.1 нс (111.0 нс) 52.0 нс (80.4 нс) | 30.3 нс (76.6 нс) 33.9 нс (73.8 нс) 101.4 нс (106.2 нс) 49.4 нс (76.6 нс) |
*В скобках указаны значения, полученные при отключении Hardware Prefetch
**Размер блока 4 МБ
Количественные характеристики латентности первого и второго уровней кэша одинаковы для всех рассмотренных в таблице процессоров. Кстати, латентность L1 в 4 такта на Pentium 4 EE 3.73 можно считать первым экспериментальным подтверждением того факта, что этот процессор действительно основан на ядре Prescott (все предыдущие Pentium 4 Extreme Edition, как известно, были основаны на ядре Gallatin, латентность L1 кэша которого составляла 2 такта).
Относительно латентности памяти отметим, что приведенные в таблице величины получены в отдельном тесте, в котором осуществляется обход цепочки данных с шагом 128 байт, т.е. «эффективной» длиной строки L2-кэша. Кроме того, для новых процессоров впервые приведены данные, полученные при отключении алгоритма Hardware Prefetch, что наглядно позволяет оценить его эффективность (последняя методика измерения латентности памяти на платформе Pentium 4 подробно описана в нашей недавней статье «Две методики измерения латентности памяти на платформе Intel Pentium 4 с помощью тестового пакета RightMark Memory Analyzer — как выбрать подходящую?»).
Итак, латентность памяти при всех режимах обхода несколько снизилась по сравнению с ранее тестируемой платформой Pentium 4 (Prescott D0) — наиболее заметно снижение латентности случайного обхода (порядка 20 нс), очевидно — за счет нового чипсета i925XE (ибо Hardware Prefetch при случайном обходе, как мы показывали ранее и увидим ниже, практически бездействует). Отметим также, что латентность памяти на Pentium 4 EE 3.73 несколько ниже — наиболее очевидное объяснение заключается в синхронности функционирования подсистемы памяти на этой платформе.
Отключение Hardware Prefetch в обоих случаях приводит почти к 2.5-кратному возрастанию латентности прямого и обратного обхода, оно несколько ниже (примерно в 1.5 раза) в случае псевдослучайного обхода и практически незаметно при случайном обходе. Полученные цифры можно считать прямой оценкой эффективности алгоритма Hardware Prefetch при различных режимах доступа в оперативную память — она максимальна в случае прямого и обратного обхода цепочки, несколько ниже при псевдослучайном обходе (в этом случае, как мы предположили, работает предвыборка на уровне целых страниц памяти); наконец, этот алгоритм практически бездействует при истинно случайном обходе. К сожалению, сопоставить полученные данные по эффективности алгоритма аппаратной предвыборки на новой ревизии ядер Prescott с предыдущими ревизиями на данный момент невозможно — измерение латентности памяти без аппаратного префетча является новым, развивающимся направлением наших исследований. С количественных позиций, «истинная» средняя латентность используемой в тестах памяти Corsair DDR2-533 равняется 80.4 нс при асинхронном режиме работы и 76.6 нс в синхронном режиме. Несколько меньшие величины латентности обратного режима обхода при отключенном Hardware Prefetch являются интересным, но пока необъяснимым фактом.
Минимальная латентность кэша данных/памяти
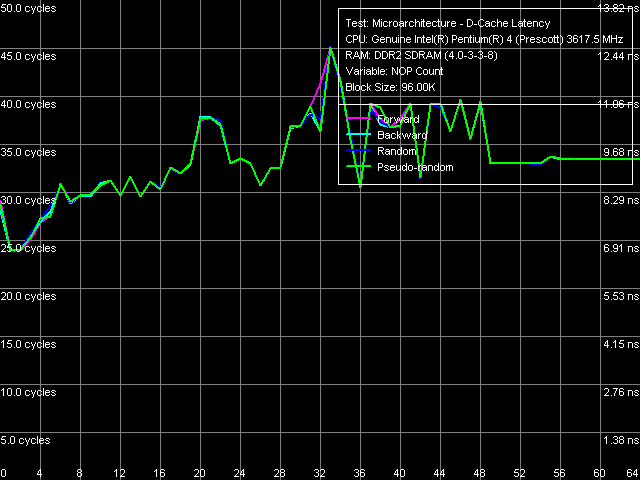 Минимальная латентность L2 кэша, Pentium 4 660 и Pentium 4 EE 3.73, метод 1
Минимальная латентность L2 кэша, Pentium 4 660 и Pentium 4 EE 3.73, метод 1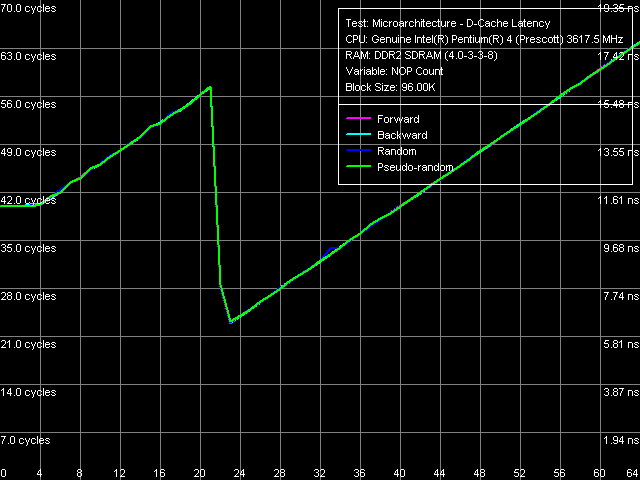 Минимальная латентность L2 кэша, Pentium 4 660 и Pentium 4 EE 3.73, метод 2
Минимальная латентность L2 кэша, Pentium 4 660 и Pentium 4 EE 3.73, метод 2 Кривые разгрузки шины L1-L2, т.е. достижения минимальной латентности L2, выглядят одинаково у обоих процессоров и вполне типично для процессорных ядер Prescott: латентность этого уровня не достигает минимума при «стандартной» разгрузке шины L1-L2 вставкой «пустых» операций (метод 1), и снижается до 22 тактов при «нестандартной» разгрузке, разработанной специально для процессоров с выраженной спекулятивной загрузкой данных (метод 2).
 Минимальная латентность памяти, Pentium 4 660 и Pentium 4 EE 3.73
Минимальная латентность памяти, Pentium 4 660 и Pentium 4 EE 3.73 Кривые «стандартной» разгрузки шины L2-RAM обоих процессоров внешне также ничем не отличаются от тех, которые мы получили ранее на ядрах Prescott и Nocona ревизии D0.
| Уровень, доступ | Минимальная латентность, тактов (нс) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| L1 | 4.0 | 4.0 | 4.0 | 4.0 |
| L2* | 24.0 (22.0) | 24.0 (22.0) | 24.0 (22.0) | 24.0 (22.0) |
| RAM**, прямой RAM, обратный RAM, случайный*** RAM, псевдослучайный | 28.7 нс 31.1 нс 125.2 нс 55.0 нс | 38.4 нс 41.2 нс 134.0 нс 74.5 нс | 27.0 нс (79.6 нс) 31.1 нс (77.9 нс) 105.4 нс (109.9 нс) 50.9 нс (79.4 нс) | 23.5 нс (75.9 нс) 27.6 нс (74.1 нс) 100.6 нс (105.3 нс) 48.5 нс (75.9 нс) |
*В скобках указаны значения, полученные методом 2
**В скобках указаны значения, полученные при отключении Hardware Prefetch
***Размер блока 4 МБ
Следует вновь отметить снижение латентности доступа в оперативную память (по сравнению с исследованной ранее платформой Pentium 4), практически незаметную при прямом и обратном обходе, и максимальную (20-25 нс) — при случайном обходе. Заметим, что величины минимальной латентности доступа в память практически не отличаются от «средних» величин, полученных в предыдущем тесте, за исключением разве что прямого и обратного режимов обхода, в которых алгоритм аппаратной предвыборки получает дополнительное преимущество от разгрузки шины L2-RAM (BIU). Разумеется, подобное утверждение не распространяется на случай измерений при отключенном алгоритме Hardware Prefetch.
Ассоциативность кэша данных
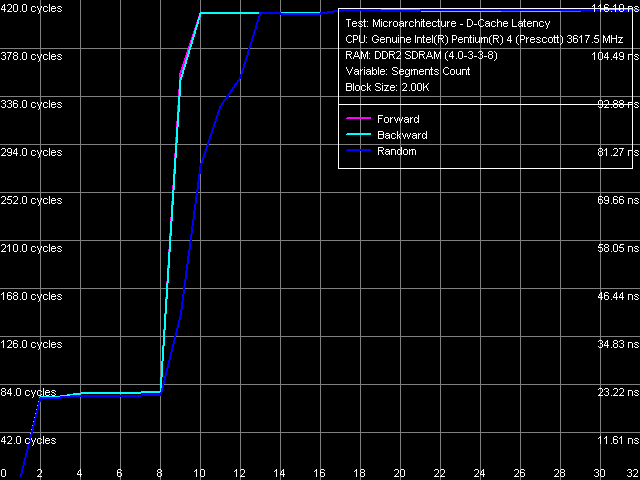 Ассоциативность кэша данных, Pentium 4 660 и Pentium 4 EE 3.73
Ассоциативность кэша данных, Pentium 4 660 и Pentium 4 EE 3.73Тест ассоциативности L1/L2 кэша данных обоих процессоров, результат которого приведен на рисунке, указывает на отсутствие каких-либо изменений по данному параметру. Как и у всех остальных исследованных нами процессоров семейства Pentium 4/Xeon, «эффективная» ассоциативность L1-кэша данных получается равной единице, ассоциативность объединенного L2-кэша инструкций/данных — восьми.
Реальная пропускная способность шины L1-L2 кэша
| Режим доступа | Пропускная способность, байт/такт* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 16.42 (51.3%) 16.40 (51.3%) 4.76 (14.9%) 4.75 (14.9%) | 16.42 (51.3%) 16.42 (51.3%) 4.79 (15.0%) 4.78 (14.9%) | 14.50 (45.3%) 14.53 (45.4%) 3.99 (12.5%) 4.00 (12.5%) | 14.66 (45.8%) 14.60 (45.6%) 4.10 (12.8%) 4.10 (12.8%) |
*в скобках указаны значения относительно теоретического предела
Несмотря на то, что полученные выше количественные характеристики (ПС, латентность) L1 и L2 кэшей данных рассматриваемых процессоров практически совпадали с результатами тестирования предыдущих ревизий ядер Prescott и Nocona, результаты настоящего теста вскрывают новые, весьма неожиданные подробности реализации шины L1-L2. А именно, нельзя не заметить дальнейшее снижение ее эффективности до 45.3-45.8% при операциях чтения и до 12.5-12.8% при операциях записи (напомним, что эффективность утилизации этой шины при операциях чтения в старые добрые времена — т.е. во времена ядра Northwood, была близка к теоретическому пределу).
Trace Cache, эффективность декодирования/исполнения
Займемся изучением еще одной, наиболее интересной детали микроархитектуры NetBurst — его специализированного кэша микроопераций, поставляемых ему предекодером, именуемый Execution Trace Cache. Появившиеся еще во времена выхода серверных ядер Nocona предположения об увеличении его объема до 16000 микроопераций, и введением вместе с этим «четверной» выборки микроопераций за такт, в очередной раз не оправдались.
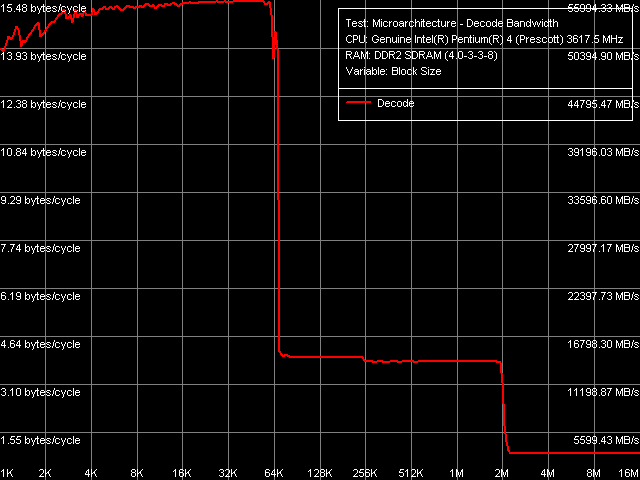 Эффективность декодирования/исполнения, Pentium 4 660 и Pentium 4 EE 3.73
Эффективность декодирования/исполнения, Pentium 4 660 и Pentium 4 EE 3.73Общая картина скорости декодирования/исполнения «крупных» 6-байтных инструкций CMP, как всегда, наиболее показательна. В этом тесте, как и во всех других тестах этого типа, качественных отличий в поведении изучаемых ядер Prescott не наблюдается. Переходим к количественным оценкам.
Эффективность декодирования/исполнения, Xeon (Nocona D0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.5 (10.5) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.85 (2.85) 5.70 (2.85) 3.97 (1.98) 3.64 (1.82) 5.70 (2.85) 5.40 (2.70) 10.29 (2.57) 15.50 (2.58) 15.50 (2.58) 15.50 (2.58) 8.62 (1.44) 20.66 (2.58) 20.66 (2.58) 20.66 (2.58) 11.53 (1.44) | 0.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.98 (0.99) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Для отслеживания общей тенденции изменений, приведем в качестве опорной точки данные, полученные ранее на платформе Xeon (ядро Nocona ревизии D0). Напомним, что в этом процессорном ядре, оснащенном технологией EM64T, впервые наметилась тенденция ухудшения эффективности декодирования/исполнения некоторых команд — в частности, простейших операций типа TEST (test eax, eax) и CMP 1 (cmp eax, eax). Посмотрим, какие изменения претерпела эта микроархитектурная деталь при переходе к новой ревизии ядер Prescott, также поддерживающей технологию EM64T.
Эффективность декодирования/исполнения, Pentium 4 660 и Pentium 4 EE 3.73 (Prescott F0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.5 (10.5) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.87 (2.87) 5.73 (2.87) 3.99 (2.00) 3.42 (1.71) 5.73 (2.87) 5.16 (2.58) 10.32 (2.58) 15.48 (2.58) 15.48 (2.58) 15.48 (2.58) 8.67 (1.45) 20.62 (2.58) 20.60 (2.58) 20.60 (2.58) 11.56 (1.45) | 1.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 3.99 (1.00) 4.00 (0.67) 4.00 (0.67) 4.00 (0.67) 4.00 (0.67) 4.14 (0.52) 4.14 (0.52) 4.14 (0.52) 4.14 (0.52) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Различия между двумя процессорами столь незаметны, что мы решили привести «усредненные» данные по ним в одной таблице. Увы, намеченная тенденция ухудшения производительности процессоров (исполнения ряда команд) здесь активно продолжается — т.е. внедрение EM64T явно дается не легкой ценой. Прежде всего, заметно дальнейшее снижение эффективности исполнения команд TEST и CMP 1 — скорость исполнения первой снизилась до 1.71 инструкций/такт, второй — до 2.58 инструкций/такт, т.е. можно сказать, последняя сравнялась с эффективностью исполнения остальных команд CMP (2-5). Второе значимое изменение, вновь характеризующее новую ревизию ядер не лучшим образом — это снижение максимальной скорости декодирования/исполнения всех операций CMP из L2-кэша до 4.0 байт/такт (1.0 или 0.67 инструкций/такт, в зависимости от длины команды), а также — «префиксных» CMP до 4.14 байт/такт (0.52 операций/такт).
Второе значимое ухудшение эффективности декодера/конвейера ядра Nocona с EM64T заключалось в снижении эффективности отбрасывания «бессмысленных» префиксов в тесте исполнения инструкций вида [0x66]nNOP, n = 0..14.
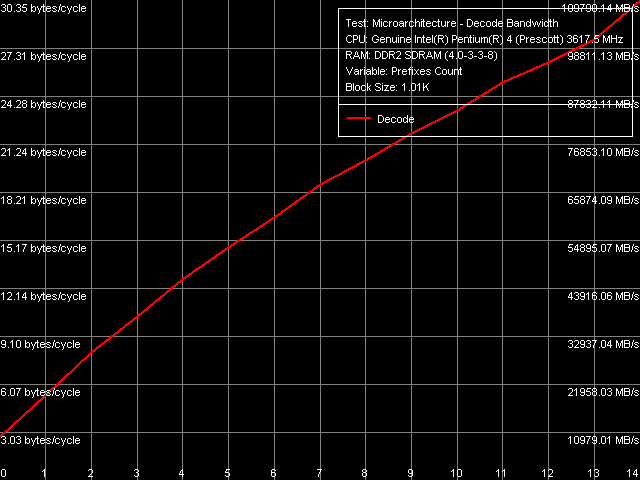 Эффективность декодирования/исполнения префиксных инструкций, Pentium 4 660 и Pentium 4 EE 3.73
Эффективность декодирования/исполнения префиксных инструкций, Pentium 4 660 и Pentium 4 EE 3.73| Количество префиксов | Эффективность декодирования/исполнения, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott F0) | Pentium 4 EE (Prescott F0) | |
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 2.84 (2.84) 5.68 (2.84) 8.52 (2.84) 11.34 (2.84) 14.09 (2.82) 16.89 (2.82) 19.51 (2.79) 22.30 (2.79) 24.87 (2.76) 27.54 (2.75) 30.76 (2.80) 33.24 (2.77) 35.86 (2.76) 38.18 (2.73) 40.85 (2.72) | 2.79 (2.79) 5.41 (2.71) 8.16 (2.72) 10.48 (2.62) 12.73 (2.55) 14.73 (2.46) 16.63 (2.38) 18.75 (2.34) 20.63 (2.29) 21.93 (2.19) 23.44 (2.13) 25.78 (2.15) 27.14 (2.09) 28.64 (2.05) 30.33 (2.02) | 2.80 (2.80) 5.43 (2.72) 8.13 (2.71) 10.42 (2.61) 12.74 (2.55) 14.74 (2.46) 16.64 (2.38) 18.76 (2.35) 20.23 (2.25) 21.96 (2.20) 23.45 (2.13) 25.17 (2.10) 26.46 (2.04) 27.89 (1.99) 30.35 (2.02) | 2.80 (2.80) 5.43 (2.72) 8.13 (2.71) 10.42 (2.61) 12.74 (2.55) 14.74 (2.46) 16.64 (2.38) 18.76 (2.35) 20.23 (2.25) 21.96 (2.20) 23.45 (2.13) 25.17 (2.10) 26.46 (2.04) 27.89 (1.99) 30.35 (2.02) |
В этом плане, в новой ревизии ядер Prescott с EM64T если что-то и изменилось, то весьма незначительно: снижение темпа исполнения «префиксных» NOP-ов по мере увеличения количества префиксов, наблюдающееся на новых Prescott, практически совпадает с наблюдаемым ранее на ядре Nocona (за исключением одной дополнительной, хорошо воспроизводимой «просадки» при наличии 13 префиксов перед инструкцией NOP). Таким образом, вывод, сделанный ранее относительно первого «64-разрядного» ядра Nocona, распространяется и на случай новой «64-разрядной» ревизии ядра Prescott: отбрасывание лишних префиксов, что является функцией декодера x86-инструкций, находящегося перед Trace Cache, отныне протекает менее эффективно. Разумно предположить, что это касается не только префиксов, но и эффективности функционирования декодера в целом.
Характеристики TLB
На изучении характеристик D-TLB и I-TLB подробно останавливаться не будем, учитывая, что они (по значениям дескрипторов CPUID) совпадают у всех рассматриваемых процессоров.
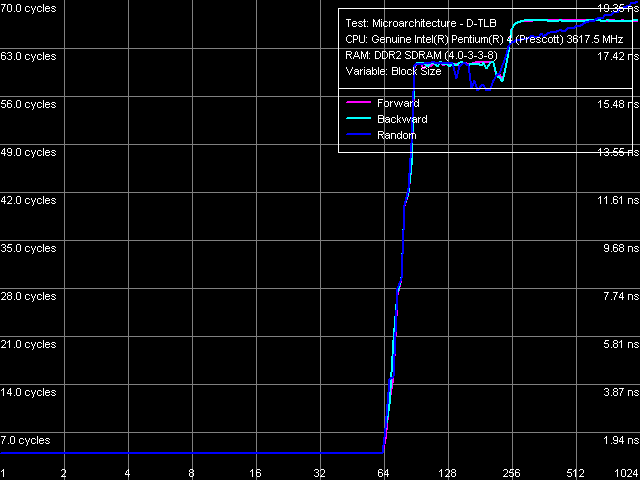 Объем D-TLB, Pentium 4 660 и Pentium 4 EE 3.73
Объем D-TLB, Pentium 4 660 и Pentium 4 EE 3.73 Ассоциативность D-TLB, Pentium 4 660 и Pentium 4 EE 3.73
Ассоциативность D-TLB, Pentium 4 660 и Pentium 4 EE 3.73 Объем D-TLB составляет 64 записи страниц (что мы уже видели по результатам других тестов), его промах при исчерпании объема «обходится» процессору минимум в 57 тактов. Ассоциативность — полная.
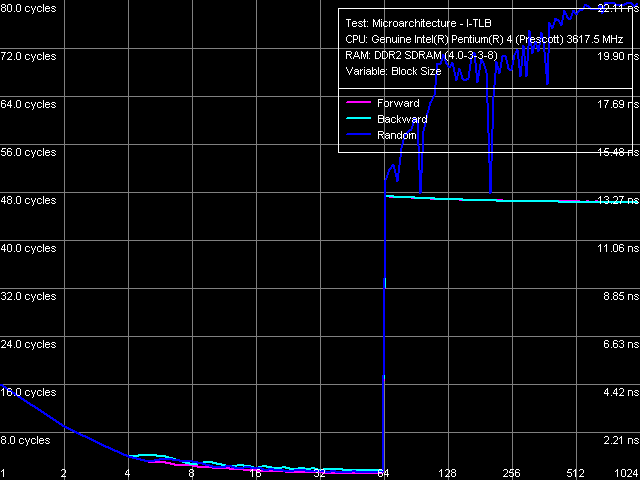 Объем I-TLB, Pentium 4 660 и Pentium 4 EE 3.73
Объем I-TLB, Pentium 4 660 и Pentium 4 EE 3.73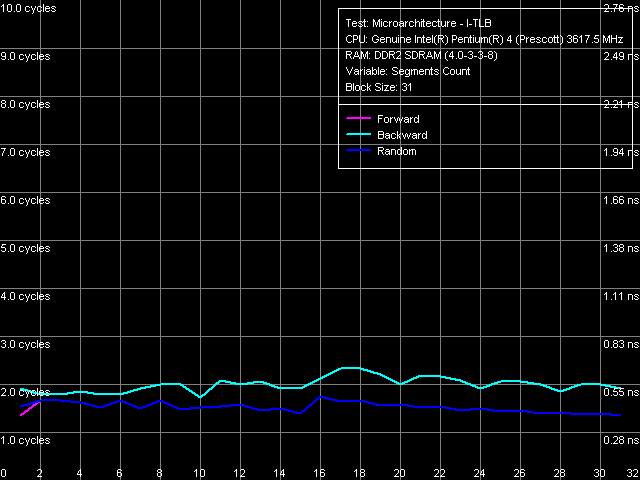 Ассоциативность I-TLB, Pentium 4 660 и Pentium 4 EE 3.73
Ассоциативность I-TLB, Pentium 4 660 и Pentium 4 EE 3.73Объем I-TLB — 64 записи (напомним, что этот ресурс при включении технологии Hyper-Threading разделяется пополам между логическими процессорами), штраф промаха буфера — 45 тактов (прямой, обратный обход) и более (случайный обход), ассоциативность — полная.
Заключение
В нашем предыдущем исследовании микроархитектуры NetBurst мы наметили одну интересную, но далеко не столь радостную — как для производителя, так и для конечных пользователей, тенденцию развития этой микроархитектуры с воплощением ее каждой последующей реализации. А заключается эта тенденция… в постепенном ухудшении низкоуровневых характеристик рассматриваемой микроархитектуры по мере ее «развития», т.е. введения в нее все большего и большего числа «наворотов». Вспомним, что при переходе от Northwood к Prescott вместе с SSE3 нам «достались» значительно увеличенные латентности кэшей данных, весьма ощутимое снижение эффективной пропускной способности шины L1-L2, наконец, некоторое снижение эффективности исполнения кода. А переход к серверному варианту Prescott — первому x86-64-совместимому ядру Nocona привел к дополнительному снижению скорости исполнения ряда команд, вместе со снижением эффективности функционирования декодера в целом.
Вывод, который можно сделать по результатам наших сегодняшних исследований, увы, будет весьма пессимистичным: описанная выше тенденция… продолжается. Новая «64-разрядная» ревизия ядра Prescott характеризуется дальнейшим снижением пропускной способности шины L1-L2 кэша данных и скорости исполнения операций сравнения.
Что касается сопоставления «неэкстремальной» и «экстремальной» версий новой ревизии ядра Prescott между собой — проведенные тесты показывают полную идентичность реализации их микроархитектуры. Таким образом, присвоение одинаковой сигнатуры CPUID (0F43h) обоим процессорам, несмотря на имеющиеся различия по «фичам», отчасти можно считать оправданным — это действительно одно и то же ядро. Просто в первом случае (600-я серия Pentium 4) оно функционирует с 200-МГц частотой системной шины, и в нем «открыты» (можно сказать, «выставлены напоказ») технологии TM2 и EIST. А во втором случае (Pentium 4 Extreme Edition 3.73 ГГц — процессора, пока что не получившего своего номера) ядро способно функционировать при 266-МГц частоте системной шины, а технологии TM2 и EIST, которые в нем, несомненно, также присутствуют, надежно спрятаны каким-нибудь хитрым аппаратным способом.
Отметим, что Pentium 4 Extreme Edition 3.73 ГГц — первый случай (но наверняка не единственный, в дальнейшем), когда «экстремальность» процессора задается не наличием огромного кэша данных третьего уровня, а именно увеличенной частотой системной шины. Правда, в таком случае понятие «экстремальности» становится куда более условным — ибо ничего не мешает найти более удачный (чем в нашем случае) экземпляр «неэкстремального» Pentium 4 600-й серии и заставить его работать с 266-МГц частотой FSB. Напоследок, нельзя не отметить, что такой подход к «экстремальности» может также означать отмену разработки и/или выпуска процессорного ядра Potomac (аналога ядра Prescott с кэшем данных третьего уровня) — по крайней мере, в десктопном секторе (оставляя место лишь серверным вариантам с очень большим объемом кэша L3, значительно превышающим текущий 2-МБ объем кэша L2).


