Часть 6 — Платформа Intel Xeon (Nocona)
29 июня 2004 г. состоялся официальный анонс новой серии серверных процессоров Intel Xeon с частотой процессорной шины 800 МГц, основанных на новом ядре под кодовым названием Nocona. С микроархитектурной точки зрения ядро Nocona является продолжением микроархитектурной линии Intel NetBurst с поддержкой технологии Hyper-Threading. Наиболее значимым новшеством этого ядра (в сравнении с предыдущим — Prescott) является поддержка технологии EM64T (полное название — Intel(R) Extended Memory 64 Technology), аналога давно существующей в мире процессоров технологии AMD64, введенного, прежде всего, для поддержки будущих 64-разрядных операционных систем. Технология EM64T как таковая, и вопросы ее совместимости с 64-разрядным кодом, разработанным под AMD64 — предмет отдельного исследования, которым мы займемся в дальнейшем. Пока же остановимся на изучении микроархитектурных аспектов нового процессорного ядра — ведь резонно предположить, что расширение NetBurst введением «64-разрядности» могло определенным образом сказаться на некоторых низкоуровневых характеристиках ядра (причем не исключено, что как в лучшую, так и в худшую сторону). Эти характеристики мы сравним с таковыми для предыдущего воплощения микроархитектуры NetBurst — ядра процессора Intel Pentium 4 Prescott.
Конфигурации тестовых стендов и ПО
Тестовый стенд №1
- Процессор: Intel Pentium 4 3,4 ГГц (ядро Prescott, Socket 775, FSB 800/HT, 1 МБ L2) на частоте 2.8 ГГц
- Материнская плата: Intel D915PCY на чипсете Intel 915
- Память: 2x512 МБ PC2-4300 DDR2-533 SDRAM DIMM Samsung (тайминги 4-4-4-11)
Тестовый стенд №2
- Процессоры: Intel Xeon 3,0 ГГц (ядро Nocona, FC-mPGA604, FSB 800, 1 МБ L2)
- Материнская плата: Supermicro X6DA8-G на чипсете Intel E7525
- Память: 2x512 МБ Registered PC2-3200 DDR2-400 SDRAM DIMM Crucial
(тайминги 3-3-3-9)
Программное обеспечение
- Windows XP Professional SP1
- Intel Chipset Installation Utility 6.0.1.1002
- DirectX 9.0b
- RightMark Memory Analyzer 3.2 (тестирование Prescott)
- RightMark Memory Analyzer 3.3 (тестирование Nocona)
Характеристики CPUID
Исследование нового процессорного ядра мы начнем с анализа наиболее значимых величин, выдаваемых инструкцией CPUID с различными входными параметрами. Для начала посмотрим на значения, полученные на процессоре Pentium 4 Prescott.
Pentium 4 (Prescott)
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0xF34 | Семейство 15, модель 3, степпинг 4 |
| Brand ID | 0x00 | Не поддерживается |
| Дескрипторы кэшей/TLB | 0x50 0x5B 0x60 0x40 0x70 0x7C | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12K-uops, 8-ассоциативный L2-кэш: 1 МБ, 8-ассоц., 64-байтн. строка |
| Extended Features, EDX bit 29 | 0 | Не поддерживает Intel (R) EM64T |
Важно отметить, что данный процессор имеет нулевой Brand ID, что, согласно документации Intel, означает, что данная функция не поддерживается процессором. По всей видимости, это означает, что наш тестируемый процессор является инженерным сэмплом.
Новый Xeon Nocona с точки зрения его идентификации проявил себя неожиданным образом с самого начала — даже последняя версия RMMA 3.3 опознала его как... все тот же Pentium 4 Prescott! Давайте посмотрим, почему так могло произойти.
Xeon (Nocona)
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0xF34 | Семейство 15, модель 3, степпинг 4 |
| Brand ID | 0x00 | Не поддерживается |
| Дескрипторы кэшей/TLB | 0x51 0x5B 0x60 0x40 0x70 0x7C | I-TLB: полноассоциативный, 128 записей D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12K-uops, 8-ассоциативный L2-кэш: 1 МБ, 8-ассоц., 64-байтн. строка |
| Extended Features, EDX bit 29 | 1 | Поддерживает Intel (R) EM64T |
Ответом является все тот же Brand ID, который у Xeon Nocona также оказался нулевым! Будем надеяться, что подобное присуще лишь инженерным образцам, потому что определить этот процессор как-то иначе, что это Xeon, а не Pentium 4, просто невозможно. По той простой причине, что по всем остальным важнейшим параметрам CPUID он совпадает с Pentium 4 Prescott. Отличия всего два: первое — вдвое больший размер I-TLB за счет того, что в тестируемой платформе выключен Hyper-Threading (почему это так, можно подробнее узнать из нашего отдельного небольшого исследования); второе — наличие флага, соответствующего поддержке EM64T (надо заметить, что он находится абсолютно на той же позиции, что и флаг Long Mode у 64-разрядных процессоров AMD, причем ранее этот регистр, который давно использовался AMD для указания наличия в процессоре фич вроде поддержки наборов инструкций 3DNow!/Extended 3DNow!, в документации Intel обозначался «зарезервированным»). Тем не менее, обоих отличий недостаточно для того, чтобы однозначно считать новый процессор Xeon-ом. Первое нивелируется при включении технологии Hyper-Threading, второе — с выходом процессоров Pentium 4 Prescott с поддержкой EM64T.
В связи со всем вышесказанным важно отметить следующее: по идентификационной информации процессоров получается, что новое ядро Nocona почти ничем не отличается от ядра Prescott. Даже значения степпингов у обоих процессоров совпадают, не говоря уж об архитектурных деталях (одинаковые тип/размер кэшей и TLB). Нет, повторим, от нынешнего поколения Prescott-ов он отличается наличием технологии EM64T, а вот от будущих, где она также будет реализована — формально, уже ничем. Что ж, нам остается лишь попытаться найти отличия «вручную» — с помощью наших низкоуровневых тестов.
Реальная пропускная способность кэша данных/памяти
Первая серия тестов — реальной пропускной способности L1/L2 кэша данных/оперативной памяти (подтест Memory Bandwidth). Все оптимизации чтения/записи выключены, соответственно и получаемые значения мы условно называем «средними».
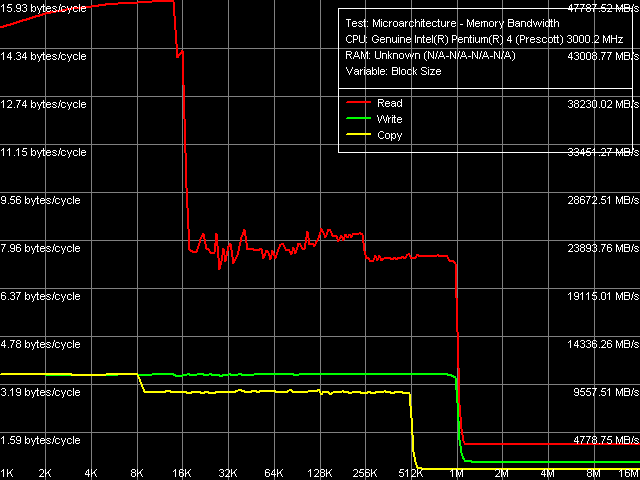 Реальная пропускная способность кэша/памяти, Xeon (Nocona)
Реальная пропускная способность кэша/памяти, Xeon (Nocona)Результат теста в графическом виде (с использованием регистров SSE/SSE2) совпадает с тем, что мы получили ранее на процессоре Prescott. По кривой чтения четко заметно 3 области, соответствующие 16-КБ L1-кэшу данных, 1-МБ инклюзивному L2-кэшу и оперативной памяти. Интересно отметить нестабильность значений ПС чтения из L2-кэша в области 16-256 КБ, которые выходят на более-менее постоянный уровень в области 256-1024 КБ, что связано с исчерпанием D-TLB, размер которого, как и у предыдущих ядер семейства NetBurst — 64 записи соответствия страниц физической и виртуальной памяти. По кривой ПС записи различий между L1 и L2 незаметно, что связано с режимом работы L1-кэша данных процессора по принципу сквозной записи (Write-Through), при котором данные всегда записываются только в L2-кэш, тем самым, увеличивая эффективность L1-кэша на чтение.
Близкими можно считать и количественные характеристики L1 и L2 кэшей рассматриваемых процессоров.
| Уровень | Средняя пропускная способность, байт/такт (МБ/с) | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.98 15.93 2.91 3.56 | 7.96 15.93 2.90 3.54 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.41 8.02 2.91 3.56 | 4.39 7.84 2.89 3.54 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 3901.4 МБ/с 4457.4 МБ/с 1750.0 МБ/с 1760.6 МБ/с | 3215.2 МБ/с 3620.1 МБ/с 1863.0 МБ/с 1855.0 МБ/с |
Напротив, в величинах ПС оперативной памяти наблюдаются значительные различия, причем явно не в пользу Xeon Nocona. Разумеется, списывать это на счет процессора никак нельзя — используются разные чипсеты, разные типы памяти (нерегистровая и регистровая на платформах Prescott и Nocona, соответственно). Кстати, сразу ответим на возможное замечание в наш адрес по поводу прямого сравнения скоростных характеристик разных типов памяти, обладающих разной теоретической ПСП (8.6 ГБ/с для двухканальной DDR2-533, 6.4 ГБ/с для двухканальной DDR2-400). В нашем случае, когда предел реальной ПСП задается теоретическим пределом скорости I/O по процессорной шине — 6.4 ГБ/с, использование DDR2-533 не дает никаких преимуществ по сравнению с DDR/DDR2-400 в плане ее пропускной способности, о чем мы уже писали.
Предельная реальная пропускная способность памяти
Учитывая сделанную выше оговорку, будем считать теоретическим пределом ПСП на обоих платформах величину в 6.4 ГБ/с, относительно которой приведены процентные величины в таблицах. Для достижения предельной реальной ПСП используем тесты, реализующие методы Software Prefetch, Block Prefetch 1 и 2, считывания целых строк кэша из памяти.
Поскольку метод Software Prefetch позволяет достичь наибольших значений ПСП, рассмотрим его в первую очередь. Графические зависимости ПСП от длины дистанции префетча на Prescott и Nocona выглядят следующим образом.
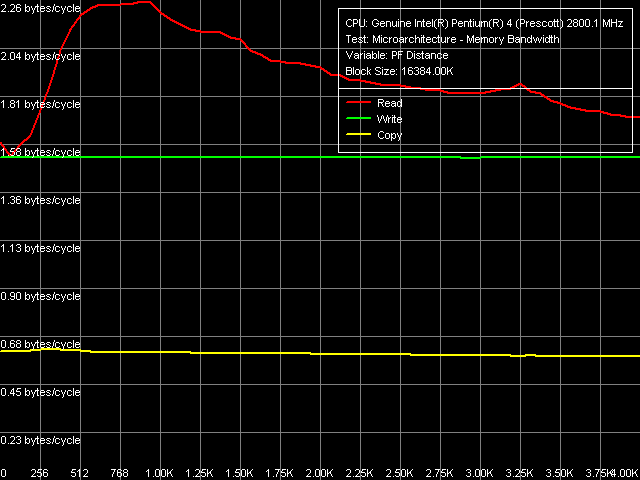 Максимальная реальная ПСП, Software Prefetch, Pentium 4 (Prescott)
Максимальная реальная ПСП, Software Prefetch, Pentium 4 (Prescott)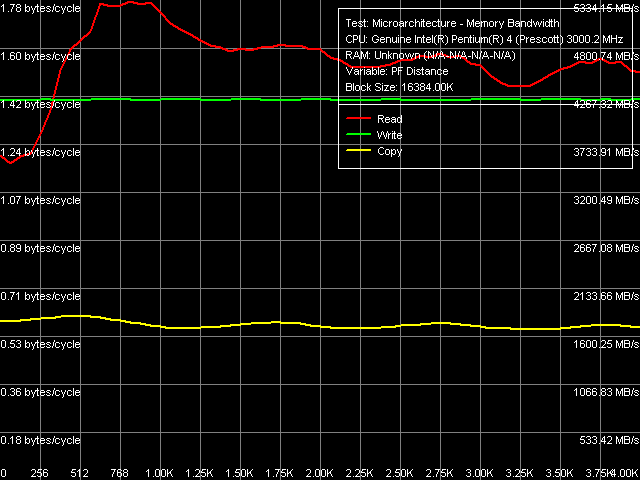 Максимальная реальная ПСП, Software Prefetch, Xeon (Nocona)
Максимальная реальная ПСП, Software Prefetch, Xeon (Nocona) По кривым чтения заметно первое значимое различие между Prescott и Nocona: Software Prefetch ведет себя немного по-разному. Максимум эффективности, можно считать, совпадает — область 512-1024 байт, но за пределами этой области наблюдаются различия: у Prescott эффективность спадает плавно, у Nocona — волнообразно (что также заметно на кривой копирования). Различаются и абсолютные значения достигаемой ПСП: у Prescott это почти теоретический максимум (99%), Nocona показывает лишь 83.3% от теоретического предела. Интересно, что больший выигрыш от использования Software Prefetch наблюдается, напротив, у Nocona (прирост 47%) против Prescott (прирост 42%). Видимо, последнему просто уже «негде развернуться» — когда абсолютное значение ПСП и так является предельным, тогда как первому еще есть куда стремиться.
| Режим доступа | Предельная ПСП на чтение, МБ/с* | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 3901.4 (61.0%) 4457.4 (69.6%) 6311.3 (98.6%) 6334.2 (99.0%) 4191.0 (65.5%) 4614.8 (72.1%) 3948.3 (61.7%) 4517.2 (70.6%) 5180.9 (81.0%) 5178.7 (80.9%) | 3215.2 (50.2%) 3620.1 (56.6%) 5334.2 (83.3%) 5329.9 (83.3%) 3302.2 (51.6%) 3524.3 (55.1%) 3392.3 (53.0%) 3784.5 (59.1%) 3313.5 (51.8%) 3315.8 (51.8%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с)
Остальные методы не заслуживают большого внимания, лишь в очередной раз доказывая неприменимость AMD-шных методик (Block Prefetch 1 и 2) для Intel-овских процессоров. Интереснее упомянуть про методы чтения строк кэша — тогда как на Pentium 4 Prescott при этом достигается некоторый выигрыш в ПСП (5185 МБ/с против 4457 МБ/с), Xeon Nocona не то что не выигрывает, а даже проигрывает в скорости (3316 МБ/с против 3620 МБ/с). Этот факт никак нельзя объяснить различиями в используемых чипсетах и памяти, поэтому будем считать его исключительно «заслугой» процессора.
Исследуем теперь максимальную реальную ПСП на запись, используя методы прямого сохранения (минуя кэш данных) и «построчной» записи в память. Прежде всего, надо сказать, что Nocona, проявляя себя намного хуже при чтении данных, при записи в память ведет себя чуть лучше Prescott уже в обычном режиме (без оптимизаций). То же самое можно сказать и о записи строк кэша — прирост почти одинаковый (28-29%), абсолютный результат немного выше у Nocona (37.2% от максимальной теоретической ПСП). А вот метод Non-Temporal store практически выравнивает сравниваемые процессоры, на этот раз — с небольшим перевесом Prescott (66.7%) над Nocona (66.2%). Кстати, подобные цифры в 2/3 от теоретического максимума ПСП нам уже весьма привычны по предыдущим исследованиям микроархитектуры NetBurst, явно указывая на существование загадочного предела в скорости функционирования процессорной шины на запись данных, и его отсутствие — при чтении.
| Режим доступа | Предельная ПСП на запись, МБ/с* | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 1750.0 (27.3%) 1760.6 (27.5%) 4265.9 (66.7%) 4266.0 (66.7%) 2283.9 (35.7%) 2254.2 (35.2%) | 1863.0 (29.1%) 1855.0 (29.0%) 4236.2 (66.2%) 4235.9 (66.2%) 2380.2 (37.2%) 2386.1 (37.3%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с)
Латентность кэша данных/памяти
Следующая серия тестов — тесты латентности L1/L2 кэша данных и оперативной памяти (подтест D-Cache Latency). Напомним, что под «средними» величинами латентности мы понимаем время поиска элемента (строки кэша) в данном уровне подсистемы памяти без какой-либо «разгрузки» шины данных.
Общая картина латентности, как и ПСП, у обоих процессоров внешне выглядит одинаково.
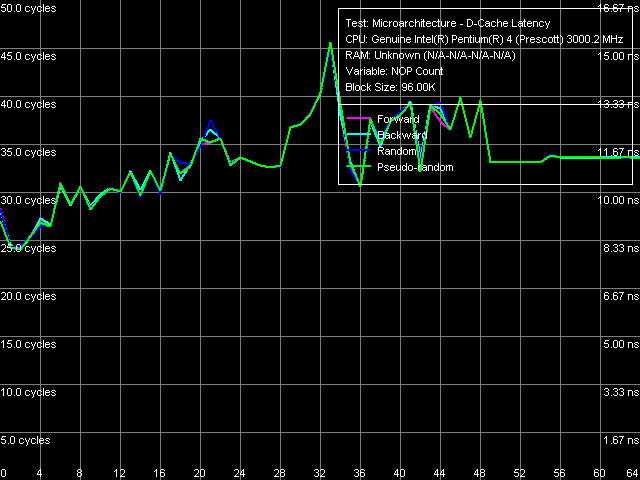
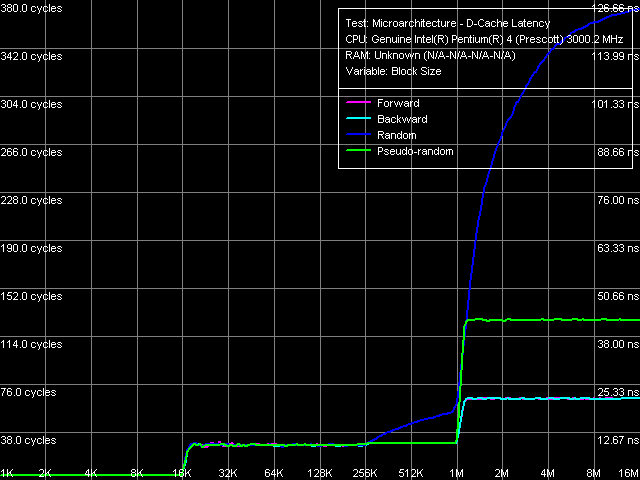 Латентность кэша/памяти, Xeon (Nocona)
Латентность кэша/памяти, Xeon (Nocona) Характерные перегибы наблюдаются в тех же областях, что и в первой серии тестов — 16 и 1024 КБ, что соответствует истинным размерам L1 и L2 кэшей данных. Для случайного доступа добавляется дополнительная ступень при 256 КБ, причина которой, как мы отмечали выше, связанна с исчерпанием размера D-TLB. Легко видеть, что псевдослучайный доступ подобным «недостатком» не страдает, что оправдывает его применение для объективного измерения латентности в области больших объемов данных, т.е. латентности RAM.
| Уровень, доступ | Средняя латентность, тактов (нс) | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| L1 | 4.0 | 4.0 |
| L2 | ~28.5 | ~28.5 |
| RAM, прямой RAM, обратный RAM, случайный* RAM, псевдослучайный* | 37.3 нс 41.1 нс 126.0 нс 56.1 нс | 50.3 нс 52.6 нс 134.1 нс 75.8 нс |
*размер блока 4 МБ
Количественные характеристики первого и второго уровней кэша одинаковы для обоих процессоров. Касательно латентности памяти отметим, что приведенные в таблице величины получены в отдельном тесте, в котором осуществляется обход цепочки данных с шагом 128 байт, т.е. «эффективной» длиной строки L2-кэша (подробнее о методике измерения латентности оперативной памяти на платформе Pentium 4 мы писали ранее). О латентности памяти в целом можно сказать следующее: она значительно выше (до 35%) на платформе Xeon Nocona. С одной стороны, использование DDR2-400 на первой платформе (Prescott), возможно, привело бы к еще более низким величинам латентности (т.к. собственная латентность DDR2-533 несколько выше, чем DDR2-400). С другой стороны, на второй платформе (Nocona) используется регистровая память, хотя увеличение латентности за счет «регистровости», по нашим оценкам, составляет, как правило, не более 5%. Таким образом, здесь «виноваты» либо чипсет, вносящий дополнительные задержки, либо сам процессор. Попробуем оценить это из тестов минимальной латентности.
Минимальная латентность кэша данных/памяти
Для начала, сравним минимальную латентность кэша данных. С L1-кэшем все понятно, как было 4 такта (сейчас уже вполне привычные нам), так и остается. Да и L2 кэш Prescott и Nocona ведет себя одинаково.
 Минимальная латентность L2-кэша, Xeon (Nocona), метод 1
Минимальная латентность L2-кэша, Xeon (Nocona), метод 1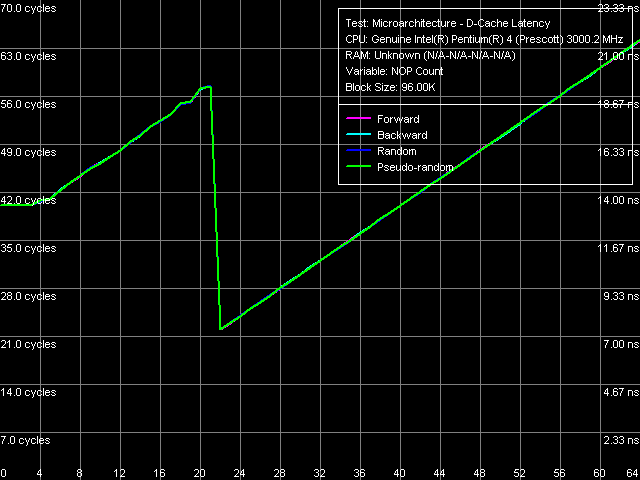 Минимальная латентность L2-кэша, Xeon (Nocona), метод 2
Минимальная латентность L2-кэша, Xeon (Nocona), метод 2 А именно — его латентность явно не достигает минимума при «стандартной» разгрузке шины L1-L2 вставкой «пустых» операций (метод 1), и снижается до 22 тактов при «нестандартной» разгрузке, разработанной специально для процессоров с выраженной спекулятивной загрузкой данных (метод 2). Причем на второй серии кривых минимум наблюдается при вставке 22 «пустых» операций (or eax, edx), а значит, время исполнения такой операции не изменилось со времен Prescott — это по-прежнему 1 такт, а не 0.5-такта, как в прежних воплощениях NetBurst.
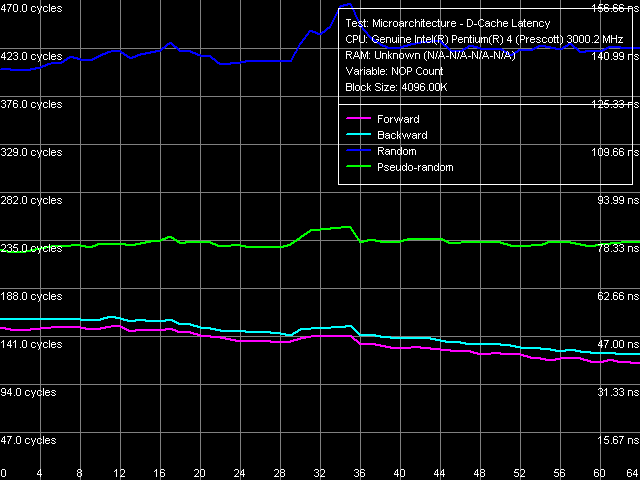 Минимальная латентность памяти, Xeon (Nocona)
Минимальная латентность памяти, Xeon (Nocona) Кривые «стандартной» разгрузки шины L2-RAM на Xeon Nocona также внешне ничем не отличаются от тех, которые мы получили на Prescott (в связи с чем здесь они не показаны). Различия, как всегда, кроются в количественных характеристиках.
| Уровень, доступ | Минимальная латентность, тактов (нс) | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| L1 | 4.0 | 4.0 |
| L2* | 24.0 (22.0) | 24.0 (22.0) |
| RAM, прямой RAM, обратный RAM, случайный** RAM, псевдослучайный** | 28.7 нс 31.1 нс 125.2 нс 55.0 нс | 38.4 нс 41.2 нс 134.0 нс 74.5 нс |
*в скобках указаны значения, полученные методом 2
**размер блока 4 МБ
По этим тестам можно с высокой вероятностью утверждать, что сам процессор все-таки непричастен к факту увеличенной латентности памяти на платформе Xeon Nocona. Во-первых, кривые разгрузки шины выглядят похоже, во-вторых — относительные минимальные латентности прямого и обратного обхода попадают в интервал 76-78% (от средних значений) у обоих Prescott и Nocona. Значит, Hardware Prefetch у этих процессоров работает одинаково. Также отметим, что минимальные латентности случайного и псевдослучайного доступа практически равны средним величинам на обоих платформах.
Ассоциативность кэша данных
Учитывая, что значения дескрипторов кэшей процессоров Pentium 4 (Prescott) и Xeon (Nocona) совпадают, вполне естественно ожидать, что различий в ассоциативности кэшей между этими процессорами быть не должно.
 Ассоциативность кэша данных, Xeon (Nocona)
Ассоциативность кэша данных, Xeon (Nocona)Тест ассоциативности L1/L2 кэша данных, результат которого приведен на рисунке, подтверждает это. Как и у всех остальных исследованных нами процессорах семейства Pentium 4, «эффективная» ассоциативность L1-кэша данных получается равной единице, ассоциативность объединенного L2-кэша инструкций/данных — восьми. Заметим, что на Nocona кривые ассоциативности выглядят не менее четко, чем на Prescott, т.е. гораздо отчетливее, чем на предыдущих моделях Pentium 4 (Northwood).
Пропускная способность шины L1-L2 кэша
Приведенные выше тесты средней/минимальной латентности L2 кэша данных показали их идентичность на Prescott и Nocona, в связи с чем логично предположить, что организация шины L1-L2 не претерпела каких-либо изменений. Проверим это предположение с помощью подтеста D-Cache Bandwidth.
| Режим доступа | Пропускная способность, байт/такт* | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 16.42 (51.3%) 16.40 (51.3%) 4.76 (14.9%) 4.75 (14.9%) | 16.42 (51.3%) 16.42 (51.3%) 4.79 (15.0%) 4.78 (14.9%) |
*в скобках указаны значения относительно теоретического предела
Действительно, оба процессора показывают одинаково низкую эффективность утилизации «продвинутой» шины данных L1-L2 (256-bit Advanced Transfer Cache with ECC) — всего порядка 51%, против почти 99% у предыдущей модели Northwood. Несмотря на то, что с тех пор в названии этой шины вроде бы ничего не поменялось. Ее эффективность на запись и того меньше — всего 15%, хотя, надо заметить, по этому показателю Northwood также особо не выделяется.
Trace Cache, эффективность декодирования/исполнения
Пришло время изучить другую важнейшую деталь микроархитектуры NetBurst (помимо Advanced Transfer Cache) — его особый кэш инструкций (точнее, микроопераций, поставляемых ему декодером), именуемый Execution Trace Cache. Несмотря на ряд появившихся предположений об увеличении его объема до 16000 микроопераций, и введением вместе с этим «четверной» выборки микроопераций за такт, ничего подобного не произошло. По крайней мере, в рассматриваемом нами образце. Хотя, надо сказать, возможность существования Trace Cache объемом 16k и даже 32k uops Intel зарезервировала (в дескрипторах кэшей/TLB) уже довольно давно. Возможно, появление таких процессоров следует ожидать в будущем, а нам пока ничего не остается, как вернуться к нашим «подопытным» образцам процессоров.
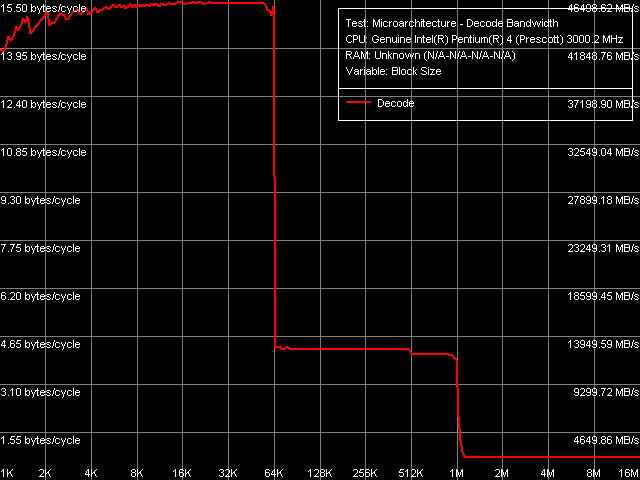 Эффективность декодирования/исполнения, Xeon (Nocona)
Эффективность декодирования/исполнения, Xeon (Nocona)Общая картина скорости декодирования/исполнения «крупных» 6-байтных инструкций CMP, как всегда, наиболее показательна. В этом тесте, равно как и во всех других, качественных различий между Prescott и Nocona не наблюдается. Эффективный объем Trace Cache, в пересчете на количество микроопераций, достигает 11k uops (ввиду необходимости резервирования его части под «служебные» нужды, связанные с особенностью его строения). Учитывая, что такая же картина наблюдалась еще и у более ранней модели Pentium 4 (Northwood), можно считать, что организация Trace Cache с тех времен не изменилась.
Что касается количественных оценок, характеризующих эффективность исполнительных блоков процессора — различия имеются, причем не в пользу Nocona. Для удобства мы выделили их в приведенных ниже таблицах цветом.
Эффективность декодирования/исполнения, Pentium 4 (Prescott)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.0 (10.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.85 (2.85) 5.70 (2.85) 3.97 (1.98) 3.97 (1.98) 5.70 (2.85) 5.70 (2.85) 10.29 (2.57) 15.50 (2.58) 15.50 (2.58) 15.50 (2.58) 8.62 (1.44) 20.66 (2.58) 20.66 (2.58) 20.66 (2.58) 11.53 (1.44) | 0.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.98 (0.99) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Эффективность декодирования/исполнения, Xeon (Nocona)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.0 (10.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.85 (2.85) 5.70 (2.85) 3.97 (1.98) 3.64 (1.82) 5.70 (2.85) 5.40 (2.70) 10.29 (2.57) 15.50 (2.58) 15.50 (2.58) 15.50 (2.58) 8.62 (1.44) 20.66 (2.58) 20.66 (2.58) 20.66 (2.58) 11.53 (1.44) | 0.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.98 (0.99) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Итак, различия наблюдаются в довольно неожиданных местах — они касаются простейших инструкций TEST (test eax, eax) и CMP 1 (cmp eax, eax), которые, надо заметить, большинство современных процессоров умеет исполнять со скоростью NOP-ов. По всем остальным величинам процессоры Prescott и Nocona весьма близки. Так, предельная скорость исполнения независимых микроопераций — 2.85/такт, зависимых арифметическо-логических операций — 1.0/такт. Скорость исполнения сдвиговых операций (SHL, ROL), которая, как мы помним, значительно возросла в ядре Prescott, естественно, осталась такой же и в Nocona.
Различие в поведении инструкций TEST и CMP — не единственное обнаруженное нами среди рассматриваемых процессоров. Второе заключается в эффективности отбрасывания «бессмысленных» префиксов в тесте исполнения инструкций вида [0x66]nNOP, n = 0..14.
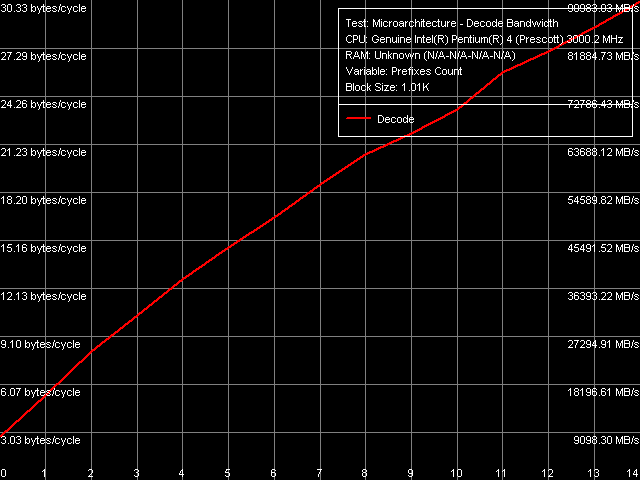 Эффективность декодирования/исполнения префиксных инструкций, Xeon (Nocona)
Эффективность декодирования/исполнения префиксных инструкций, Xeon (Nocona)| Количество префиксов | Эффективность декодирования/исполнения, байт/такт (инструкций/такт) | |
|---|---|---|
| Pentium 4 (Prescott) | Xeon (Nocona) | |
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 2.84 (2.84) 5.68 (2.84) 8.52 (2.84) 11.34 (2.84) 14.09 (2.82) 16.89 (2.82) 19.51 (2.79) 22.30 (2.79) 24.87 (2.76) 27.54 (2.75) 30.76 (2.80) 33.24 (2.77) 35.86 (2.76) 38.18 (2.73) 40.85 (2.72) | 2.79 (2.79) 5.41 (2.71) 8.16 (2.72) 10.48 (2.62) 12.73 (2.55) 14.73 (2.46) 16.63 (2.38) 18.75 (2.34) 20.63 (2.29) 21.93 (2.19) 23.44 (2.13) 25.78 (2.15) 27.14 (2.09) 28.64 (2.05) 30.33 (2.02) |
Скорость исполнения микроопераций, соответствующих «префиксным» NOP-ам, из Trace Cache процессора Prescott практически не зависит от количества префиксов (плавно снижаясь от 2.84 до 2.72 микроопераций/такт), тогда как темп их исполнения на Nocona значительно снижается с ростом числа префиксов. Значит, отбрасывание лишних префиксов, что является функцией декодера x86-инструкций, находящегося перед Trace Cache, на последнем протекает менее эффективно. Вполне логично предположить, что это касается не только префиксов, но и эффективности функционирования декодера в целом.
Характеристики TLB
На изучении характеристик D-TLB и I-TLB подробно останавливаться не будем, учитывая, что они, в общем-то, совпадают у обоих Prescott и Nocona (по значениям дескрипторов, выдаваемых CPUID).
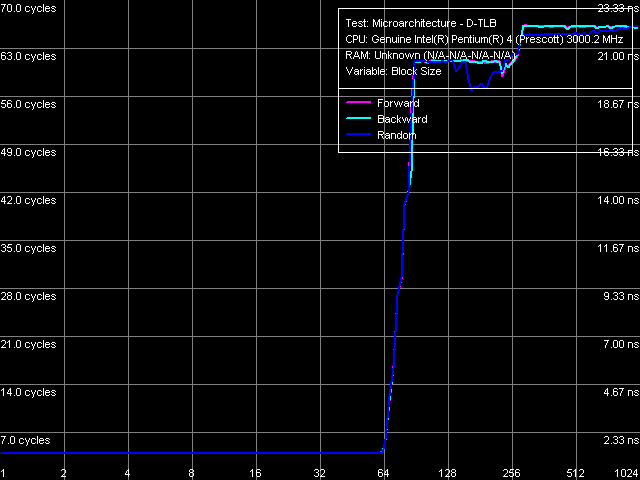 Объем D-TLB, Xeon (Nocona)
Объем D-TLB, Xeon (Nocona) Ассоциативность D-TLB, Xeon (Nocona)
Ассоциативность D-TLB, Xeon (Nocona) Итак, D-TLB: его объем — 64 записи страниц (что мы уже видели и по результатам других тестов), его промах при исчерпании объема «обходится» процессору минимум в 57 тактов. Ассоциативность — полная.
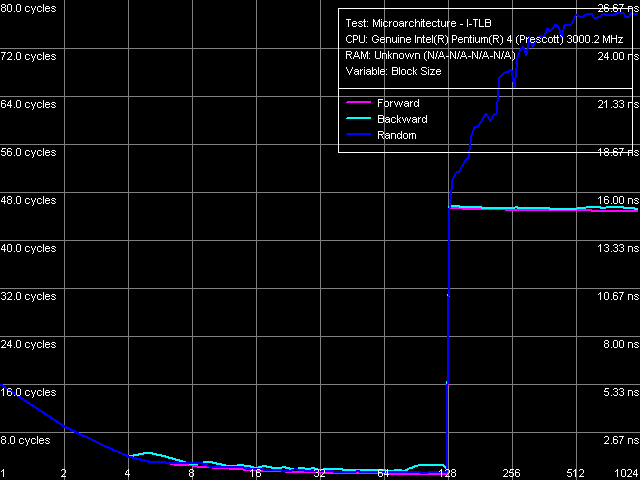 Объем I-TLB, Xeon (Nocona)
Объем I-TLB, Xeon (Nocona) Ассоциативность I-TLB, Xeon (Nocona)
Ассоциативность I-TLB, Xeon (Nocona)I-TLB: объем 128 записей (с учетом того, что Hyper-Threading на рассматриваемой платформе отключен), штраф промаха буфера — 45 тактов (прямой, обратный обход) и более (случайный обход), ассоциативность — полная.
Латентность/ассоциативность кэша инструкций
Напоследок сделаем небольшое дополнение к рассмотрению уже привычных по нашему циклу статей микроархитектурных характеристик процессорных ядер, и познакомим читателей с рядом новых возможностей тестов, которые были реализованы в тестовом пакете RMMA, начиная с версии 3.1, а заодно оценим их применимость по отношению к изучению микроархитектуры NetBurst. Отметим, что результаты, полученные на процессорах Prescott и Nocona в этих тестах, как и многие другие, практически одинаковы, в связи с чем представленные ниже данные можно считать характерными для микроархитектуры NetBurst в целом.
Для начала, остановимся на результатах подтеста под названием I-Cache Latency. В нем измеряется время исполнения операций безусловного перехода (одного из перечисленных типов) по области памяти заданного размера.
- Ближний переход (near jump):
jmp +(32-битное относительное смещение)
- Дальний переход (far jump):
mov ecx, (32-битное абсолютное смещение)
jmp ecx
В зависимости от расположения смещений, этот тест дает либо общую картину «латентности» кэша инструкций, либо картину его ассоциативности (для чего в данном подтесте реализованы соответствующие пресеты).
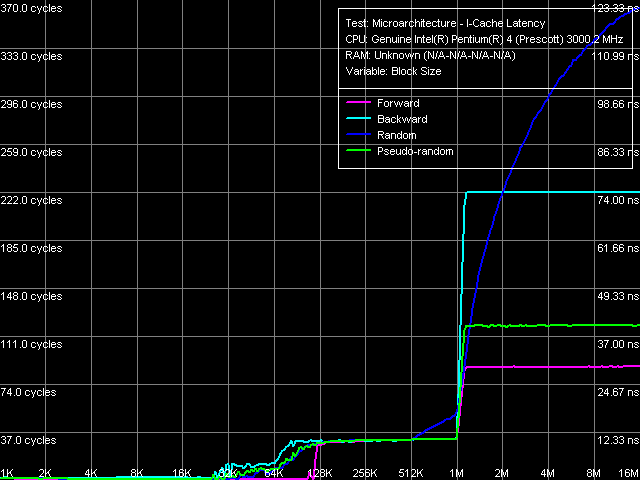 Латентность кэша инструкций, ближний переход, Xeon (Nocona)
Латентность кэша инструкций, ближний переход, Xeon (Nocona) Картина исполнения цепочек инструкций ближнего перехода, на первый взгляд, раскрывает воистину огромный потенциал Trace Cache (эффективный объем кэширования — до 110 КБ «кода»). Разумеется, не стоит понимать это слишком буквально. Проведем более точную количественную оценку: поскольку «прыжки» расположены в этом тесте на расстоянии 64 байта относительно друг друга, реальное их количество, помещающееся в этот объем, составляет порядка 1760 шт. (110K / 64). Иными словами, именно такое количество инструкций перехода способен «развернуть» Trace Cache, превращая, тем самым, данный фрагмент кода в линейную последовательность участок. В нашем случае, поскольку кроме инструкций jmp ничего не используется, можно считать, что такой код превращается в последовательность простых «микроопераций перехода», причем скорость их исполнения составляет 1 шт./такт. Кстати, заметим, что стоит только нам организовать обход цепочки иным образом, как эффективность такого режима работы Trace Cache заметно падает, причем провести четкую границу уже весьма затруднительно. Вторая граница в области 1 МБ, во всех случаях, выглядит достаточно четко, учитывая, что L2 кэш процессора является вполне «обычным» объединенным кэшем кода/данных.
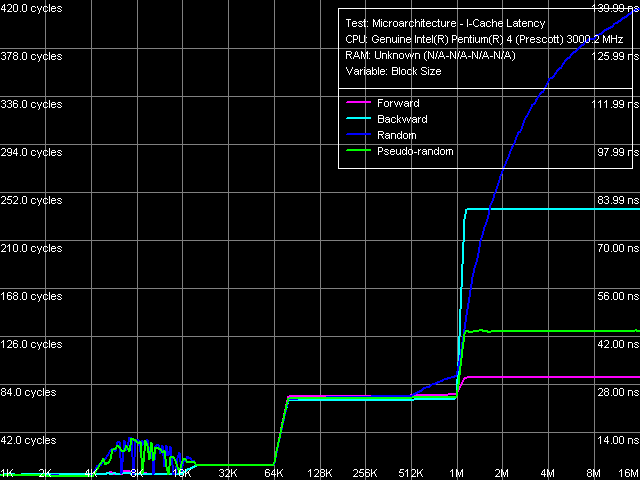 Латентность кэша инструкций, дальний переход, Xeon (Nocona)
Латентность кэша инструкций, дальний переход, Xeon (Nocona) Аналогичный тест, но уже с использованием инструкций дальнего перехода. Картина выглядит заметно иначе — прежде всего, отметим четкий перегиб в области 64 КБ во всех режимах обхода (в связи с чем по данному рисунку совершенно невозможно определить, какой тип кэша инструкций имеет изучаемый процессор — Trace Cache, или обычный L1 кэш инструкций объемом 64 КБ). Оценим эффективный объем Trace Cache и для этого случая: он составляет 1024 операции (64K / 64). Таким образом, в этом случае Trace Cache процессора способен вместить 2048 микроопераций MOV (каждая такая инструкция с 32-битным значением immediate составляет 2 микрооперации) и 1024 «микроопераций перехода». Кроме того, время исполнения одного «прыжка» в такой цепочке несколько выше — порядка 4-5 тактов, хотя точная оценка, почему это именно так, здесь вряд ли возможна. Интересно также отметить область 4-16 КБ, в которой на кривых случайного и псевдослучайного обходов заметен определенный «всплеск». Очевидно, что это связано с особенностью функционирования Trace Cache BTB (branch target buffer), однако и здесь весьма затруднительно провести точную количественную оценку этого явления (почему оно наблюдается именно в этой области, и почему «латентности» возрастают на столько-то тактов).
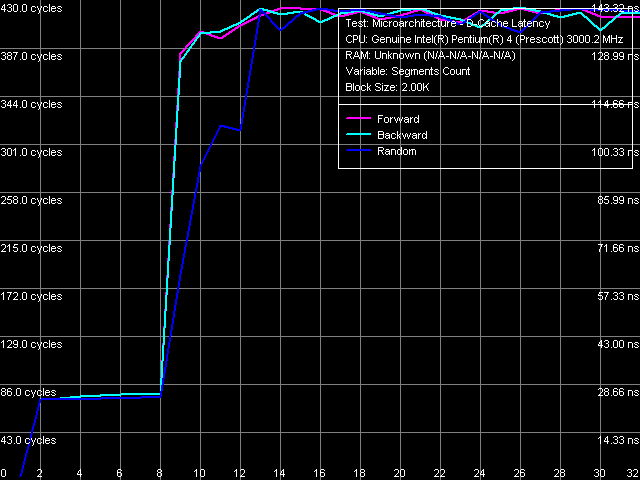
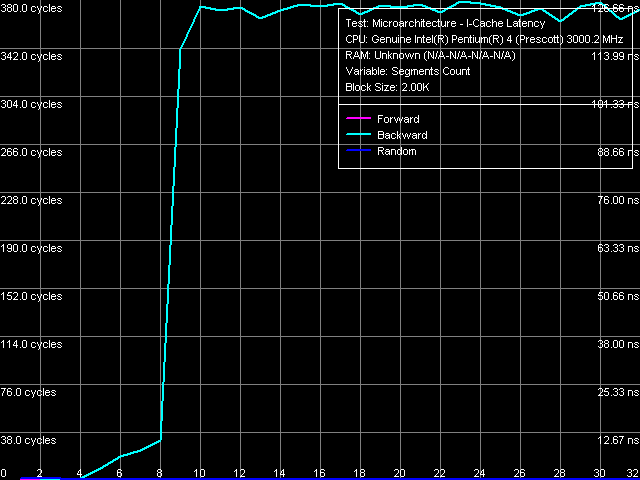 Ассоциативность кэша инструкций, ближний переход, Xeon (Nocona)
Ассоциативность кэша инструкций, ближний переход, Xeon (Nocona)Первый тест ассоциативности кэша инструкций, с использованием операций ближнего перехода. Результат весьма интересный — Trace Cache проявляет «полную ассоциативность» при прямом и случайном(!) обходе. Это означает следующее: при прямом и случайном режимах обхода малой последовательности ближних переходов по большим расстояниям она полностью «разворачивается» в линейную последовательность в Trace Cache процессора, после чего ее исполнение идет только из этого кэша, не требуя «подкачки» из L2 кэша или RAM.
Достаточно неожиданным является случай обратного обхода — по первому перегибу на кривой можно сказать, что в этом случае кэшируется только первые 4 операции перехода, а каждая последующая подзагружается из L2-кэша. Второй перегиб на этой кривой при обходе 8 и более одномегабайтных сегментов соответствует ассоциативности L2-кэша. В связи с этим можно предположить, что Trace Cache не умеет эффективно осуществлять «развертку» ближних безусловных переходов, расположенных в обратном порядке (от большего значения адреса виртуальной памяти к меньшему). Фактическая ассоциативность Trace Cache для такого случая равна 4. Это объясняет, почему при случайном обходе наблюдается как бы полная ассоциативность Trace Cache: все дело в том, что в случайном обходе, по статистике, на один прямой переход должен приходиться один обратный, а вероятность нахождения четырех обратных перехода подряд гораздо ниже.
Посмотрим, как обстоят дела с дальними переходами.
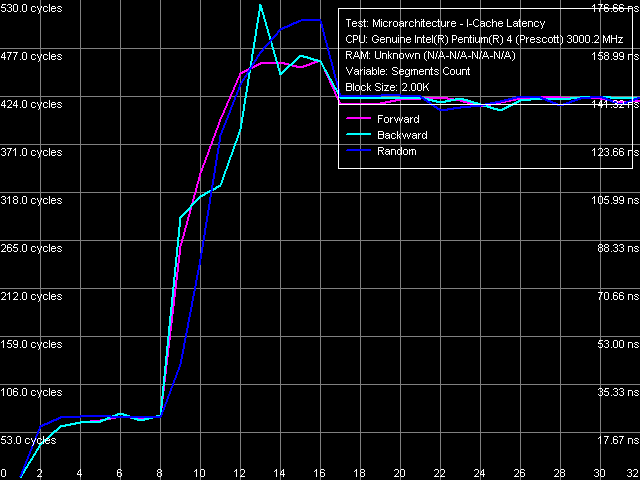 Ассоциативность кэша инструкций, дальний переход, Xeon (Nocona)
Ассоциативность кэша инструкций, дальний переход, Xeon (Nocona)Результат вновь достаточно интересный — в этом случае Trace Cache процессора проявляет себя как одноассоциативный кэш инструкций. Иными словами, получается, что при исполнении дальних переходов, расположенных на очень большом расстоянии друг от друга, они не кэшируются Trace Cache процессора вовсе, а исполняются из L2-кэша, который и в этом тесте проявляет свою степень ассоциативности 8.
Подводя итог этого небольшого исследования, можно сделать следующие качественные выводы относительно взаимодействия Trace Cache процессоров микроархитектуры NetBurst с командами безусловного перехода:
1. Операции ближнего перехода по близкорасположенным адресам (порядка длины строки кэша), располагающиеся в цепочке кода в любой последовательности, эффективно «разворачиваются» в Trace Cache в линейную последовательность кода, причем текущая реализация Trace Cache способна вместить 1000 и более таких операций, идущих подряд (если это позволяет объем остального кода, который в данных тестах равен нулю).
2. Операции дальнего перехода по близкорасположенным адресам, располагающиеся в цепочке кода в любой последовательности (до 1024 операций при отсутствии иного кода), также способны «разворачиваться» в Trace Cache в линейную последовательность кода.
3. Операции ближнего перехода по дальним адресам (порядка размера сегмента кэша), располагающиеся в прямом или случайном порядке, полностью «разворачиваются» Trace Cache в линейную последовательность кода. При этом Trace Cache проявляет полную «ассоциативность».
4. Если операции ближнего перехода (jmp near) по дальним адресам (порядка размера сегмента кэша) располагаются в обратном порядке, Trace Cache способен полностью «развернуть» не более четырех таких операций, проявляя эффективную степень «ассоциативности», равную 4.
5. Операции дальнего перехода по дальним адресам, располагающиеся в любой последовательности, не «разворачиваются» в Trace Cache вовсе, т.е. эффективная степень ассоциативности Trace Cache в этом случае равна 1.
Буфер переупорядочивания инструкций (I-ROB)
Еще один новый подтест (под названием I-ROB), реализованный в тестовом пакете RMMA версии 3.1 и выше, позволяет оценить глубину буфера переупорядочивания инструкций (ROB, I-ROB). Методология этого теста проста — запускается одна простая, но очень долго исполняемая инструкция (в качестве такой используется операция зависимой загрузки последующей строки из памяти, mov eax, [eax]), а сразу вслед за ней — серия предельно простых, не зависящих от нее операций (nop). Тогда, в идеализированном случае, как только время исполнения такой связки начинает зависеть от количества NOP-ов, можно считать, что глубина ROB исчерпана.
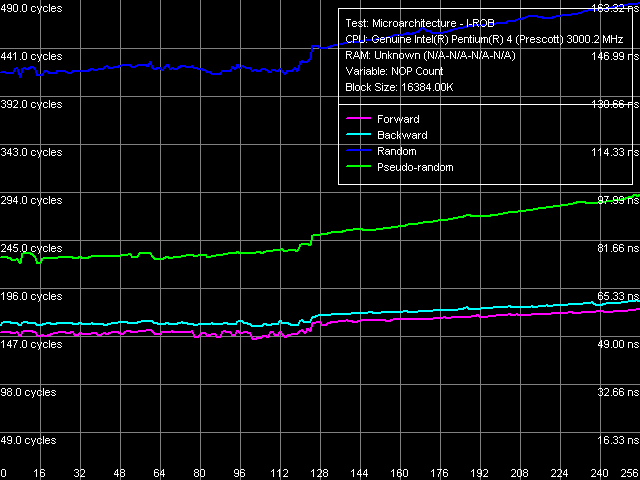 Глубина буфера переупорядочивания инструкций, Xeon (Nocona)
Глубина буфера переупорядочивания инструкций, Xeon (Nocona)Результат теста на Xeon Nocona. Легко заметить, на этом процессоре (равно как и на всех остальных Pentium 4, характеризующихся высокой степенью «асинхронности») достигается почти описанный выше идеализированный случай. Перегиб наблюдается в области 120 пустых операций, что и дает нам «среднюю» глубину этого буфера, весьма близкую к подлинному значению, заявленному в документации Pentium 4 Prescott (126).
Заключение
Подведем итог. По имеющимся результатам исследования нового ядра Nocona можно сделать вывод о том, что введение технологии EM64T не прошло «даром» , а привело к явному ухудшению некоторых низкоуровневых характеристик микроархитектуры NetBurst. Разумеется, в первую очередь это коснулось декодера x86-инструкций, располагающегося в архитектурной схеме процессора перед Trace Cache. Что, с одной стороны, выглядит естественно — ведь в существующую архитектуру (старую добрую IA-32) с введением EM64T добавились новые режимы адресации, новая ширина регистров, наконец, новые регистры как таковые. С другой стороны, Intel могла бы постараться сделать это получше. Потому что пока мы получаем довольно печальную тенденцию: введение какой-либо новой технологии в архитектуру NetBurst неизбежно «выходит боком» в каких-либо ее модулях. Так, сначала появились новые SIMD-расширения SSE3 (а вместе с ними, по некоторым данным, пока что «скрытые» фирменные технологии Intel LaGrande и VanderPool). И что мы получили в результате перехода от Northwood к Prescott? Увеличение вдвое латентности L1, и даже более чем вдвое — латентности L2, снижение эффективной пропускной способности шины L1-L2, снижение эффективности исполнения кода... Список можно продолжать. Сейчас мы имеем очередной этап «эволюции» NetBurst — попытку не сильно отстать от AMD в плане предложения на рынок процессоров своего варианта «64-разрядных решений», который «вылился» в дополнительное снижение эффективности декодера/конвейера. Так что же следует ожидать дальше? Введение «многоядерности» с очередным ущемлением потенциала NetBurst? Как говорится, поживем — увидим... в смысле, проанализируем.


